ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее изобретение, в целом, относится к области обработки речи и, в частности, к решению относительно наличия/отсутствия вокализации для обработки речи.
УРОВЕНЬ ТЕХНИКИ
[0002] Кодирование речи означает процесс, который снижает битовую скорость речевого файла. Кодирование речи это применение сжатия данных цифровых аудиосигналов, содержащих речь. Кодирование речи использует оценивание речевого параметра с использованием методов обработки аудиосигнала для моделирования речевого сигнала, объединенное с алгоритмами общего сжатия данных, для представления полученных смоделированных параметров в компактном битовом потоке. Задачей кодирования речи является достижение экономии необходимого объема памяти, полосы передачи и мощности передачи путем уменьшения количества битов для каждой выборки, чтобы декодированную (восстановленную после сжатия) речь невозможно было отличить на слух от исходной речи.
[0003] Однако речевые кодеры являются кодерами с потерями, т.е. декодированный сигнал отличается от исходного. Таким образом, одной из целей кодирования речи является минимизация искажений (или воспринимаемых потерь) при данной битовой скорости или минимизация битовой скорости для достижения данного уровня искажений.
[0004] Кодирование речи отличается от других форм аудиокодирования тем, что речь является значительно более простым сигналом, чем большинство других аудиосигналов, и доступно гораздо больше статистической информации о свойствах речи. В результате, некоторая звуковая информация, значимая в аудиокодировании, может быть не нужна в контексте кодирования речи. В кодировании речи, наиболее важным критерием является сохранение разборчивости и "приятности" речи при ограниченном объеме передаваемых данных.
[0005] Разборчивость речи включает в себя, помимо фактического буквального содержания, также личность, эмоции, интонацию, тембр и т.д. говорящего, которые все важны для высокой разборчивости. Более абстрактное понятие приятности искаженного речевого сигнала является другим свойством, чем разборчивость, поскольку возможно, что искаженный речевой сигнал полностью разборчив, но субъективно раздражает слушателя.
[0006] Избыточность форм волны речи можно рассматривать в отношении нескольких разных типов речевого сигнала, например, вокализованного и невокализованного речевых сигналов. Вокализованные звуки, например, ‘а’, ‘б’, по существу, обусловлены вибрациями голосовых связок и являются колебательными. Таким образом, в течение коротких периодов времени, они успешно моделируются суммами периодических сигналов, например синусоид. Другими словами, для вокализованной речи, речевой сигнал является, по существу, периодическим. Однако эта периодичность может изменяться в течение длительности речевого сегмента, и форма периодической волны обычно изменяется постепенно от сегмента к сегменту. Кодирование речи с низкой битовой скоростью может извлекать большое преимущество из исследования такой периодичности. Период вокализованной речи также называется основным тоном, и прогнозирование основного тона часто именуется долгосрочным прогнозированием (LTP). Напротив, невокализованные звуки, например, ‘с’, ‘ш’, являются более шумоподобными. Дело в том, что невокализованный речевой сигнал, более вероятно, является случайным шумом и имеет меньшую степень прогнозируемости.
[0007] Традиционно, все способы параметрического кодирования речи используют избыточность, присущую речевому сигналу для снижения объема информации, которую нужно отправлять, и для оценивания параметров речевых выборок сигнала с короткими интервалами. Эта избыточность, в основном, обусловлена повторением форм волны речи с квазипериодической частотой, и медленным изменением спектральной огибающей речевого сигнала.
[0008] Избыточность форм волны речи можно рассматривать в отношении нескольких разных типов речевого сигнала, например, вокализованного и невокализованного. Хотя речевой сигнал является, по существу, периодическим для вокализованной речи, эта периодичность может изменяться в течение длительности речевого сегмента, и форма периодической волны обычно изменяется постепенно от сегмента к сегменту. Кодирование речи с низкой битовой скоростью может извлекать большое преимущество из исследования такой периодичности. Период вокализованной речи также называется основным тоном, и прогнозирование основного тона часто именуется долгосрочным прогнозированием (LTP). Что касается невокализованной речи, сигнал, более вероятно, является случайным шумом и имеет меньшую степень прогнозируемости.
[0009] В любом случае, параметрическое кодирование может использоваться для снижения избыточности речевых сегментов путем отделения компоненты возбуждения речевого сигнала от компоненты спектральной огибающей. Медленно изменяющуюся спектральную огибающую можно представить посредством кодирования с линейным прогнозированием (LPC), также именуемого краткосрочным прогнозированием (STP). Кодирование речи с низкой битовой скоростью также может пользоваться большим преимуществом исследования такого краткосрочного прогнозирования. Преимущество кодирования обусловлено низкой скоростью изменения параметров. Кроме того, параметры редко значительно отличаются от значений, поддерживаемых в течение нескольких миллисекунд. Соответственно, при частоте дискретизации 8 кГц, 12.8 кГц или 16 кГц, алгоритм кодирования речи предусматривает номинальную длительность кадра в пределах от десяти до тридцати миллисекунд. Чаще всего, длительность кадра составляет двадцать миллисекунд.
[0010] В более недавних общеизвестных стандартах применяются, например, G.723.1, G.729, G.718, Enhanced Full Rate (EFR), Selectable Mode Vocoder (SMV), Adaptive Multi-Rate (AMR), Variable-Rate Multimode Wideband (VMR-WB) или Adaptive Multi-Rate Wideband (AMR-WB), Code Excited Linear Prediction Technique ("CELP"). Под CELP обычно понимают техническую комбинацию кодированного возбуждения, долгосрочного прогнозирования и краткосрочного прогнозирования. CELP в основном, используется для кодирования речевого сигнала на основе конкретных характеристик человеческого голоса или модели генерации человеческого голоса. Кодирование речи CELP является очень популярным алгоритмом в области сжатия речи, хотя детали CELP для разных кодеков могут значительно отличаться. Благодаря своей популярности, алгоритм CELP использовался в различных стандартах ITU-T, MPEG, 3GPP и 3GPP2. Варианты CELP включают в себя алгебраическое CELP, ослабленное CELP, CELP низкой задержки и линейное прогнозирование с возбуждением векторной суммой и пр.. CELP является общим термином для класса алгоритмов, но не для конкретного кодека.
[0011] Алгоритм CELP базируется на четырех основных принципах. Во-первых, используется модель источника-фильтра генерации речи посредством линейного прогнозирования (LP). Модель источника-фильтра генерации речи моделирует речь в виде комбинации источника звука, например, голосовых связок, и линейного акустического фильтра, речевого тракта (и характеристики излучения). В реализации модели источника-фильтра генерации речи, источник звука, или сигнал возбуждения, часто моделируется как периодическая последовательность импульсов, для вокализованной речи, или белый шум для невокализованной речи. Во-вторых, адаптивная и фиксированная кодовая книга используется в качестве входа (возбуждения) модели LP. В-третьих, поиск осуществляется с обратной связью в “перцепционно взвешенной области”. В-четвертых, применяется векторное квантование (VQ).
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0012] В соответствии с вариантом осуществления настоящего изобретения, способ обработки речи содержит определение параметра наличия/отсутствия вокализации, отражающего характеристику невокализованной/вокализованной речи в текущем кадре речевого сигнала, содержащего множество кадров. Сглаженный параметр наличия/отсутствия вокализации определяется для включения информации параметра наличия/отсутствия вокализации в кадр, предшествующий текущему кадру речевого сигнала. Вычисляется разность между параметром наличия/отсутствия вокализации и сглаженным параметром наличия/отсутствия вокализации. Способ дополнительно включает в себя генерацию точки принятия решения относительно наличия/отсутствия вокализации для определения, содержит ли текущий кадр невокализованную речь или вокализованную речь, с использованием вычисленной разности в качестве параметра принятия решения.
[0013] В альтернативном варианте осуществления, устройство обработки речи содержит процессор и компьютерно-считываемый носитель данных, где хранится программное обеспечение, исполняемое процессором. Программное обеспечение включает в себя инструкции для определения параметра наличия/отсутствия вокализации, отражающего характеристику невокализованной/вокализованной речи в текущем кадре речевого сигнала, содержащего множество кадров, и определения сглаженного параметра наличия/отсутствия вокализации для включения информации параметра наличия/отсутствия вокализации в кадр, предшествующий текущему кадру речевого сигнала. Программное обеспечение дополнительно включает в себя инструкции для вычисления разности между параметром наличия/отсутствия вокализации и сглаженным параметром наличия/отсутствия вокализации, и генерации точки принятия решения относительно наличия/отсутствия вокализации для определения, содержит ли текущий кадр невокализованную речь или вокализованную речь, с использованием вычисленной разности в качестве параметра принятия решения.
[0014] В альтернативном варианте осуществления, способ обработки речи содержит обеспечение множества кадров речевого сигнала и определение, для текущего кадра, первого параметра для первого частотного диапазона из первой энергетической огибающей речевого сигнала во временной области и второго параметра для второго частотного диапазона из второй энергетической огибающей речевого сигнала во временной области. Сглаженный первый параметр и сглаженный второй параметр определяются из предыдущих кадров речевого сигнала. Первый параметр сравнивается со сглаженным первым параметром, и второй параметр сравнивается со сглаженным вторым параметром. Точка принятия решения относительно наличия/отсутствия вокализации генерируется для определения, содержит ли текущий кадр невокализованную речь или вокализованную речь, с использованием сравнения в качестве параметра принятия решения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0015] Для более полного понимания настоящего изобретения и его преимуществ, ниже приведены описания совместно с прилагаемыми чертежами, в которых:
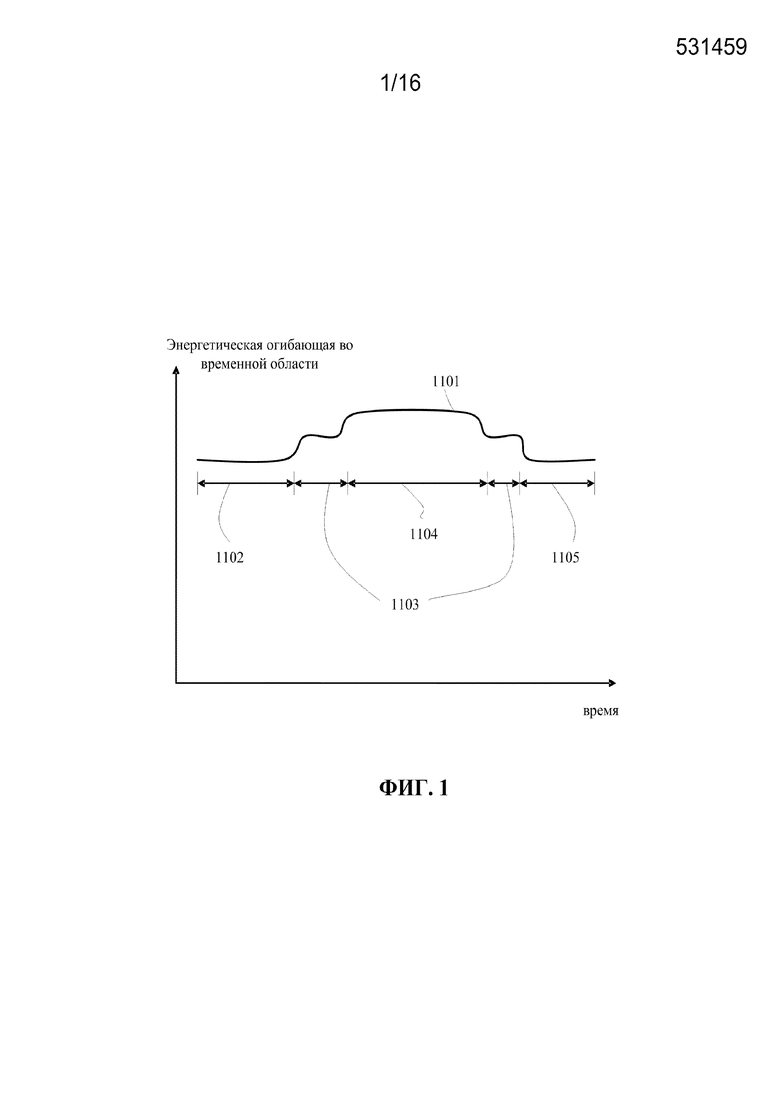
[0016] фиг. 1 иллюстрирует оценивание энергии во временной области речевого сигнала низкочастотного диапазона в соответствии с вариантами осуществления настоящего изобретения;
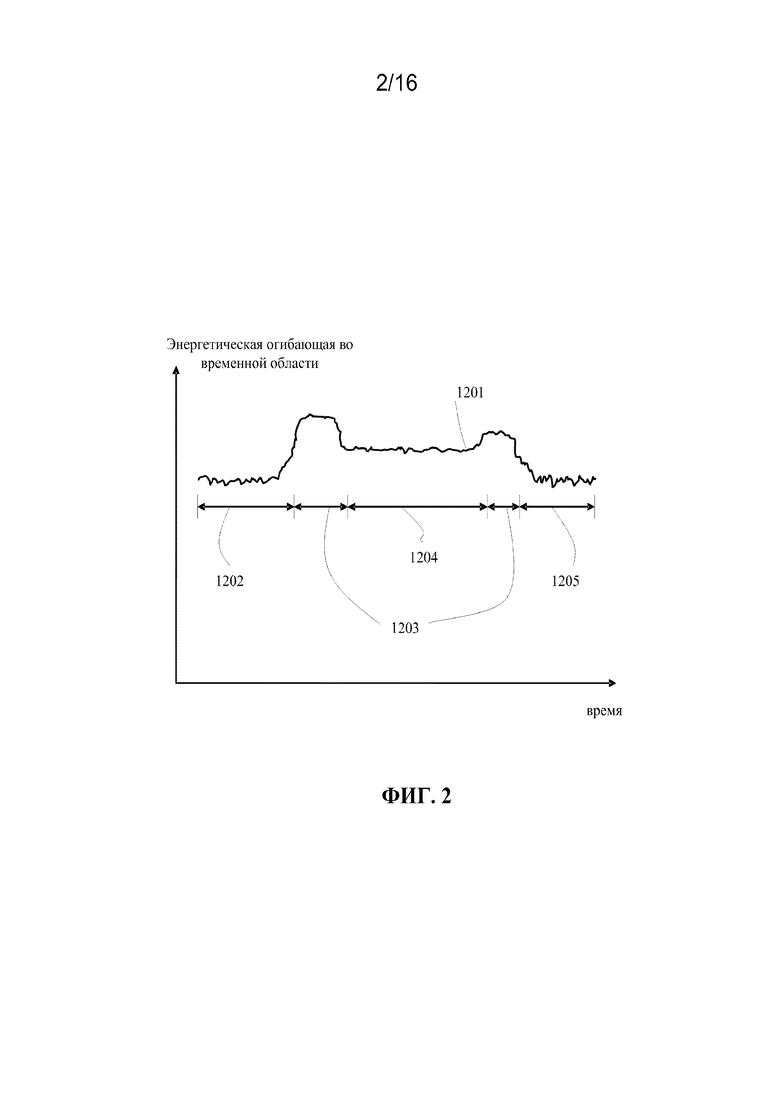
[0017] фиг. 2 иллюстрирует оценивание энергии во временной области речевого сигнала высокочастотного диапазона в соответствии с вариантами осуществления настоящего изобретения;
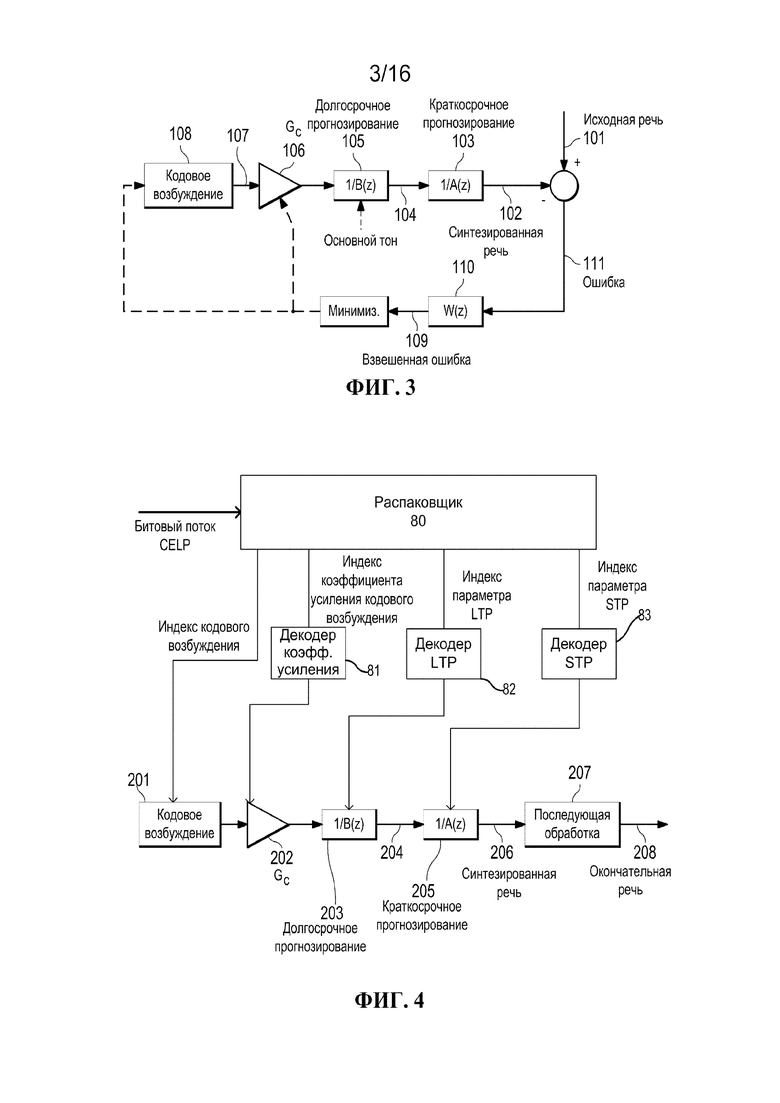
[0018] фиг. 3 иллюстрирует операции, осуществляемые в ходе кодирования исходной речи с использованием традиционного кодера CELP, реализующего вариант осуществления настоящего изобретения.
[0019] фиг. 4 иллюстрирует операции, осуществляемые в ходе декодирования исходной речи с использованием традиционного декодера CELP, реализующего вариант осуществления настоящего изобретения;
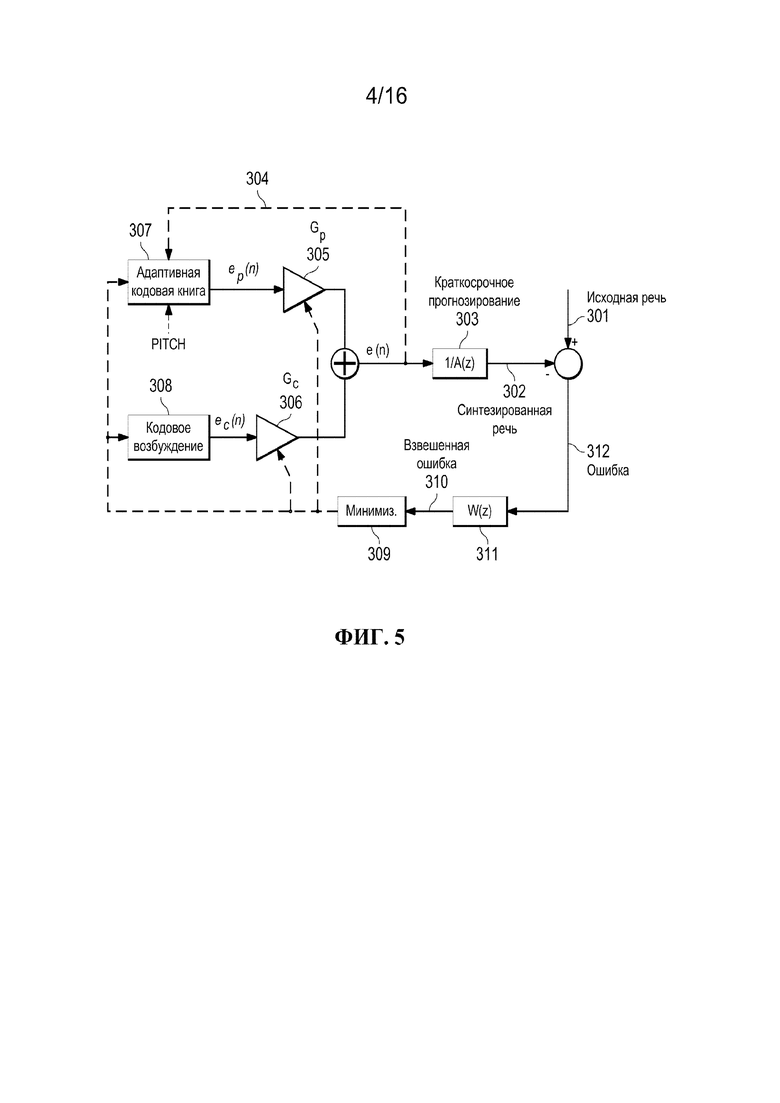
[0020] фиг. 5 иллюстрирует традиционный кодер CELP, используемый в реализации вариантов осуществления настоящего изобретения;
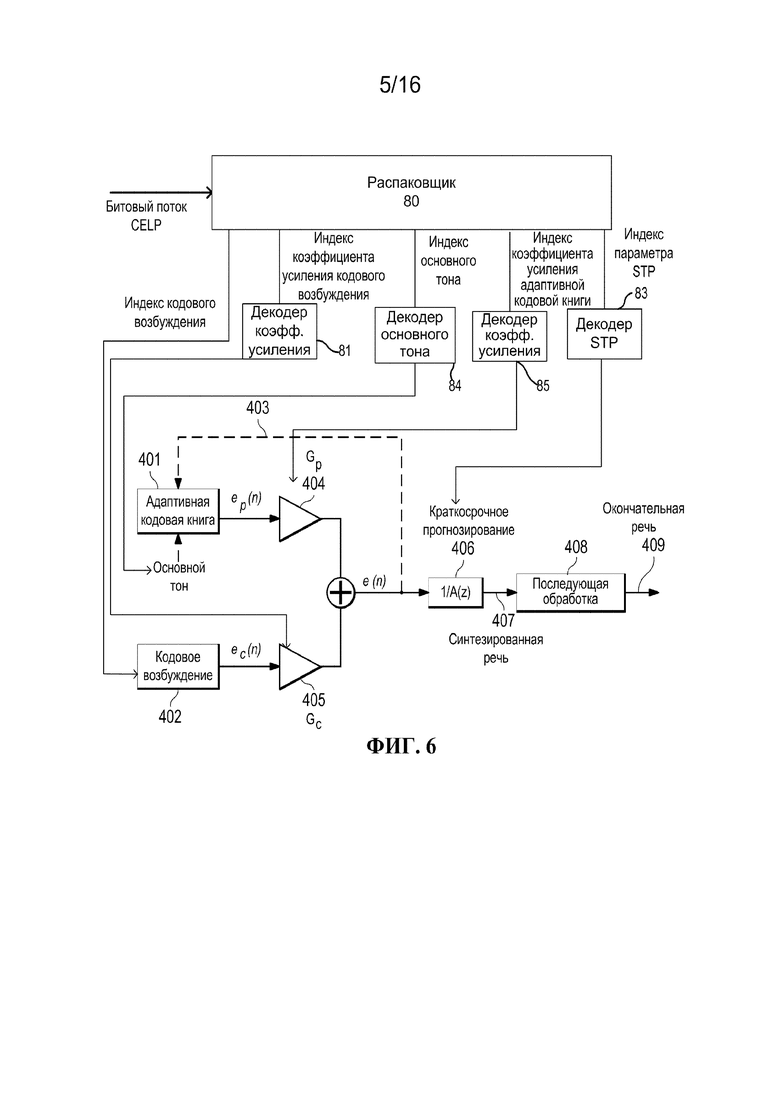
[0021] фиг. 6 иллюстрирует базовый декодер CELP, соответствующий кодеру, показанному на фиг. 5, в соответствии с вариантом осуществления настоящего изобретения;
[0022] фиг. 7 иллюстрирует шумоподобные векторы-кандидаты для построения кодовой книги кодированного возбуждения или фиксированной кодовой книги кодирования речи CELP;
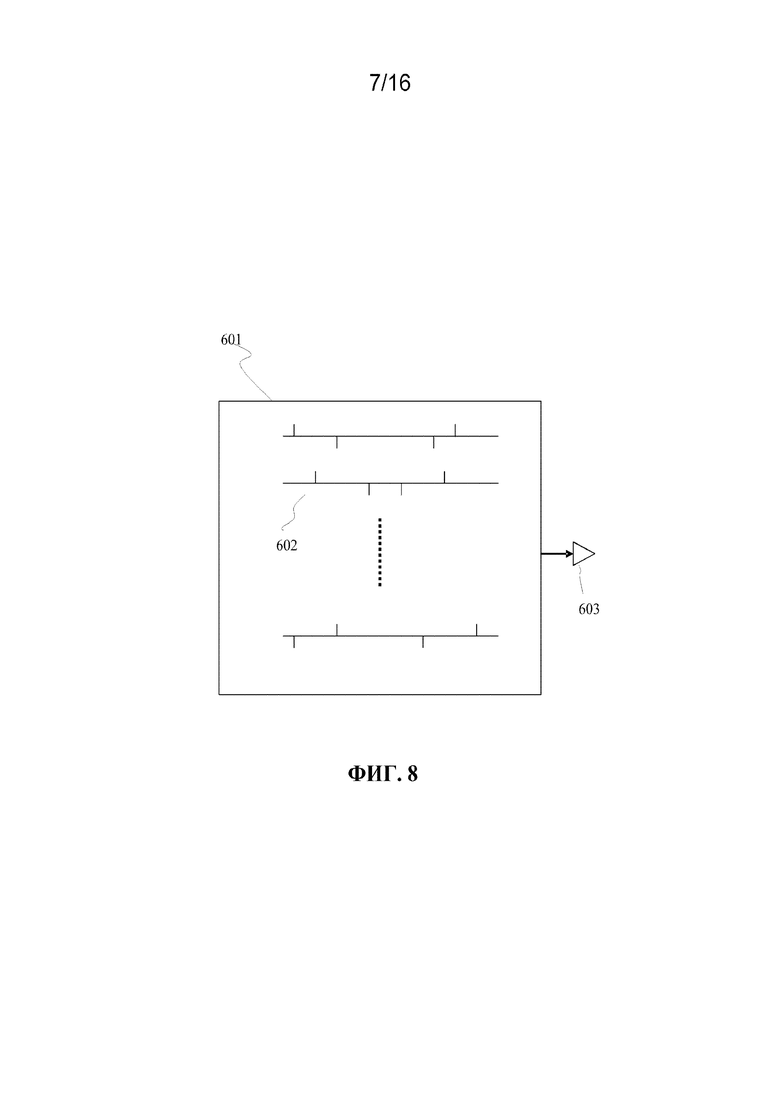
[0023] фиг. 8 иллюстрирует импульсоподобные векторы-кандидаты для построения кодовой книги кодированного возбуждения или фиксированной кодовой книги кодирования речи CELP;
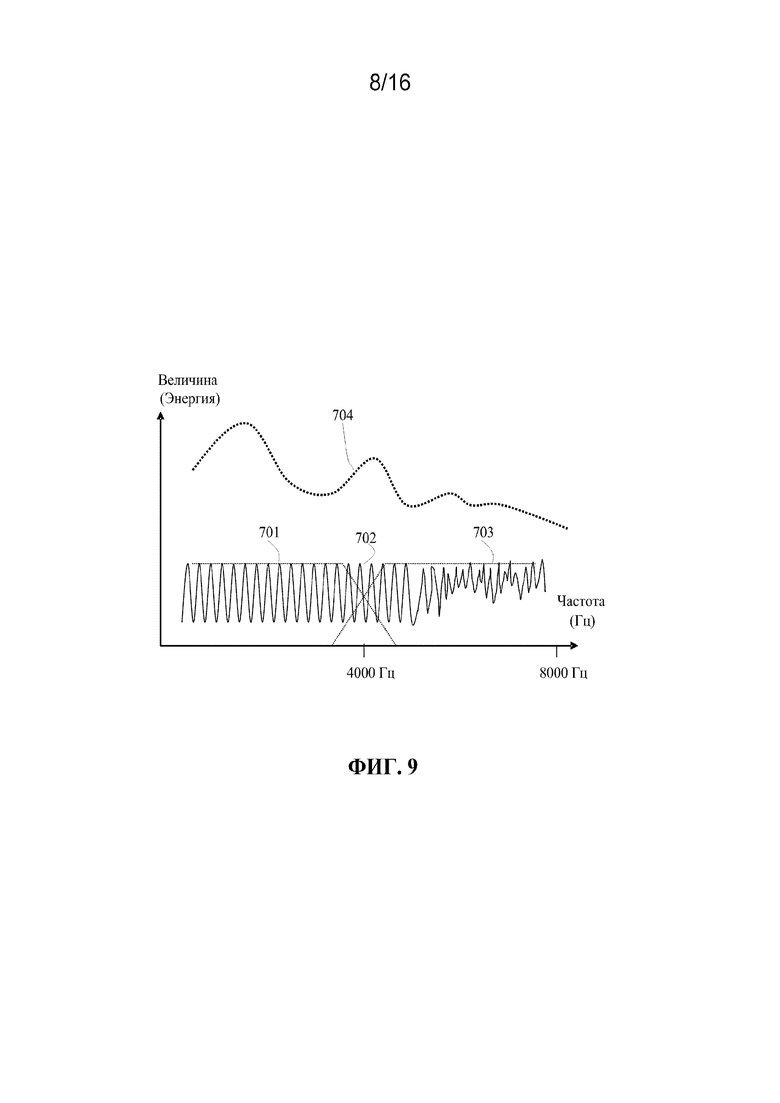
[0024] фиг. 9 иллюстрирует пример спектра возбуждения для вокализованной речи;
[0025] фиг. 10 иллюстрирует пример спектра возбуждения для невокализованной речи;
[0026] фиг. 11 иллюстрирует пример спектра возбуждения для сигнала фонового шума;
[0027] фиг. 12A и 12B иллюстрируют примеры кодирования/декодирования в частотной области с расширением полосы, в которых фиг. 12A иллюстрирует кодер с информацией стороны BWE, тогда как фиг. 12B иллюстрирует декодер с BWE;
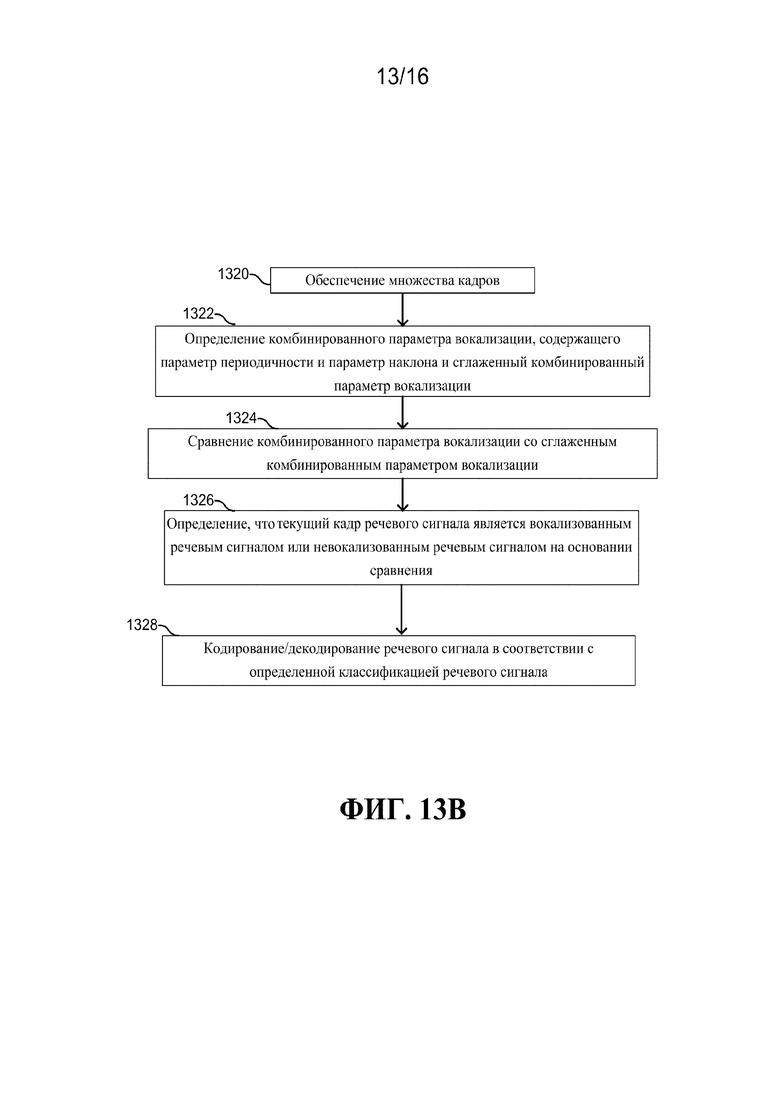
[0028] фиг. 13A-13C описывают операции обработки речи в соответствии с различными вышеописанными вариантами осуществления;
[0029] фиг. 14 иллюстрирует систему 10 связи согласно варианту осуществления настоящего изобретения; и
[0030] фиг. 15 демонстрирует блок-схему системы обработки, которая может использоваться для реализации раскрытых здесь устройств и способов.
ПОДРОБНОЕ ОПИСАНИЕ ИЛЛЮСТРАТИВНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0031] В современной системе передачи цифрового аудио/речевого сигнала, цифровой сигнал сжимается на кодере, и сжатая информация или битовый поток может покадрово пакетизироваться и отправляться на декодер по каналу связи. Декодер принимает и декодирует сжатую информацию для получения цифрового аудио/речевого сигнала.
[0032] Для более эффективного кодирования речевого сигнала, речевой сигнал можно классифицировать на разные классы, и каждый класс кодируется по-разному. Например, в некоторых стандартах, например, G.718, VMR-WB или AMR-WB, речевой сигнал подразделяется на невокализованный, переходный, общий, вокализованный и шумовой.
[0033] Вокализованный речевой сигнал является сигнальном квазипериодического типа, который обычно имеет более высокую энергию в низкочастотной области, чем в высокочастотной области. Напротив, невокализованный речевой сигнал является шумоподобным сигналом, который обычно имеет более высокую энергию в высокочастотной области, чем в низкочастотной области. Классификация по наличию/отсутствию вокализации или решение относительно отсутствия вокализации широко используется в области кодирования речевого сигнала, расширения полосы речевого сигнала (BWE), улучшения речевого сигнала и снижения фонового шума речевого сигнала (NR).
[0034] В кодировании речи, невокализованный речевой сигнал и вокализованный речевой сигнал могут кодироваться/декодироваться по-разному. В расширении полосы речевого сигнала, энергия расширенного высокополосного сигнала невокализованного речевого сигнала может управляться иначе, чем энергия вокализованного речевого сигнала. В снижении фонового шума речевого сигнала, алгоритм NR может различаться для невокализованного речевого сигнала и вокализованного речевого сигнала. Поэтому достоверное решение относительно отсутствия вокализации важно для вышеупомянутых видов применений.
[0035] Варианты осуществления настоящего изобретения повышают точность классификации аудиосигнала как вокализованного сигнала или невокализованного сигнала до операций кодирования речи, расширения полосы и/или улучшения речи. Таким образом, варианты осуществления настоящего изобретения могут применяться к кодированию речевого сигнала, расширению полосы речевого сигнала, улучшению речевого сигнала и снижению фонового шума речевого сигнала. В частности, варианты осуществления настоящего изобретения могут использоваться для улучшения стандарта речевого кодера AMR-WB ITU-T в расширении полосы.
[0036] Иллюстрация характеристик речевого сигнала, используемых для повышения точности классификации аудиосигнала на вокализованный сигнал или невокализованный сигнал в соответствии с вариантами осуществления настоящего изобретения будет проиллюстрирована с использованием фиг. 1 и 2. Речевой сигнал оценивается в двух режимах: низкочастотном диапазоне и высокочастотном диапазоне в нижеследующих иллюстрациях.
[0037] Фиг. 1 иллюстрирует оценивание энергии во временной области речевого сигнала низкочастотного диапазона в соответствии с вариантами осуществления настоящего изобретения.
[0038] Энергетическая огибающая 1101 во временной области речь низкочастотного диапазона является сглаженной по времени энергетической огибающей и включает в себя первую область 1102 фонового шума и вторую область 1105 фонового шума, разделенные областями 1103 невокализованной речи и областью 1104 вокализованной речи. Низкочастотный вокализованный речевой сигнал области 1104 вокализованной речи имеет более высокую энергию, чем низкочастотный невокализованный речевой сигнал в областях 1103 невокализованной речи. Дополнительно, низкочастотный невокализованный речевой сигнал имеет более высокую или более близкую энергию по сравнению с низкочастотным сигналом фонового шума.
[0039] Фиг. 2 иллюстрирует оценивание энергии во временной области речевого сигнала высокочастотного диапазона в соответствии с вариантами осуществления настоящего изобретения.
[0040] В отличие от фиг. 1, высокочастотный речевой сигнал имеет другие характеристики. Энергетическая огибающая во временной области высокополосного речевого сигнала 1201, которая является сглаженной по времени энергетической огибающей, включает в себя первую область 1202 фонового шума и вторую область 1205 фонового шума, разделенные областями 1203 невокализованной речи и областью 1204 вокализованной речи. Высокочастотный вокализованный речевой сигнал имеет более низкую энергию, чем высокочастотный невокализованный речевой сигнал. Высокочастотный невокализованный речевой сигнал имеет значительно более высокую энергию по сравнению с высокочастотным сигналом фонового шума. Однако высокочастотный невокализованный речевой сигнал 1203 имеет сравнительно меньшую длительность, чем вокализованная речь 1204.
[0041] Варианты осуществления настоящего изобретения опираются на это различие в характеристики между вокализованной и невокализованной речью в разных частотных диапазонах во временной области. Например, сигнал в текущем кадре можно идентифицировать как вокализованный сигнал путем определения, что энергия сигнала выше, чем у соответствующего невокализованного сигнала в полосе низких частот, но не в полосе высоких частот. Аналогично, сигнал в текущем кадре можно идентифицировать как невокализованный сигнал путем идентификации, что энергия сигнала ниже, чем у соответствующего вокализованного сигнала в полосе низких частот, но выше, чем у соответствующего вокализованного сигнала в полосе высоких частот.
[0042] Традиционно, для обнаружения невокализованного/вокализованного речевого сигнала используются два главных параметра. Один параметр представляет периодичность сигнала, и другой параметр указывает спектральный наклон, который выражает, насколько падает интенсивность с ростом частота.
[0043] Популярный параметр периодичности сигнала обеспечен ниже в уравнении (1).

В уравнении (1), 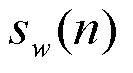 - взвешенный речевой сигнал, числитель выражает корреляцию, и знаменатель - коэффициент нормализации энергии. Параметр периодичности также называется “корреляцией основного тона” или “вокализацией”. Другой пример параметр вокализации обеспечен ниже в уравнении (2).
- взвешенный речевой сигнал, числитель выражает корреляцию, и знаменатель - коэффициент нормализации энергии. Параметр периодичности также называется “корреляцией основного тона” или “вокализацией”. Другой пример параметр вокализации обеспечен ниже в уравнении (2).
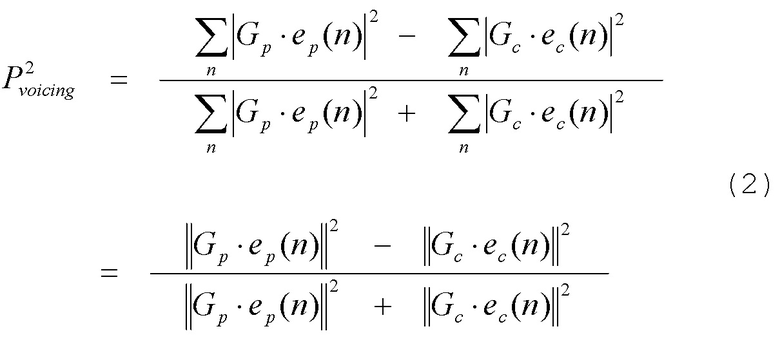
В (2), 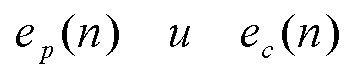 - сигналы компонент возбуждения и будут дополнительно описаны ниже. В различных применениях, можно использовать некоторые варианты уравнений (1) и (2), но все же они могут представлять периодичность сигнала.
- сигналы компонент возбуждения и будут дополнительно описаны ниже. В различных применениях, можно использовать некоторые варианты уравнений (1) и (2), но все же они могут представлять периодичность сигнала.
[0044] Наиболее популярный параметр спектрального наклона обеспечен ниже в уравнении (3).
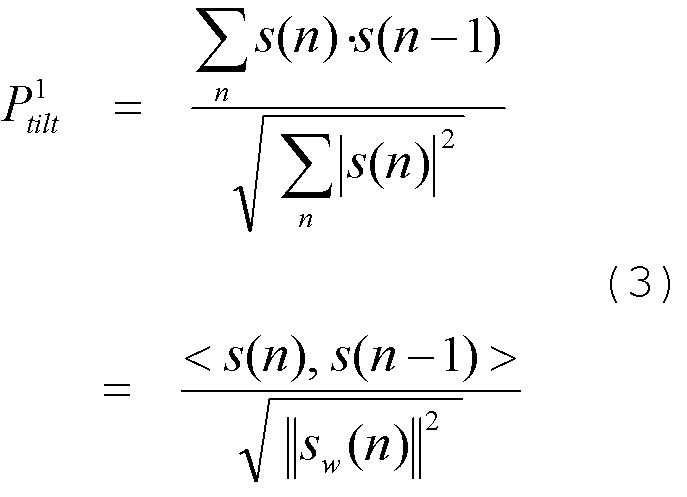
В уравнении (3), s(n) - речевой сигнал. Если доступна энергия в частотной области, параметр спектрального наклона можно выразить в уравнении (4).
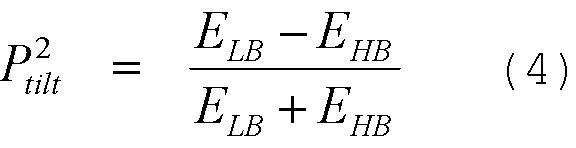
В уравнении (4), ELB - энергия низкочастотного диапазона, и EHB - энергия высокочастотного диапазона.
[0045] Другой параметр, который может отражать спектральный наклон, называется частота прохождения через нуль (ZCR). ZCR показывает, сколько раз сигнал меняет знак на протяжении кадра или подкадра. Обычно, когда энергия высокочастотного диапазона высока относительно энергии низкочастотного диапазона, ZCR также высока. В противном случае, когда энергия высокочастотного диапазона низка относительно энергии низкочастотного диапазона, ZCR также низка. В реальных применениях могут использоваться некоторые варианты уравнений (3) и (4), но все же они могут представлять спектральный наклон.
[0046] Как упомянуто ранее, классификация по наличию/отсутствию вокализации или решение относительно наличия/отсутствия вокализации широко используется в области кодирования речевого сигнала, расширения полосы речевого сигнала (BWE), улучшения речевого сигнала и снижения фонового шума речевого сигнала (NR).
[0047] В кодировании речи, невокализованный речевой сигнал можно кодировать с использованием шумоподобного возбуждения, и вокализованный речевой сигнал можно кодировать с использованием импульсоподобного возбуждения, как будет проиллюстрировано ниже. В расширении полосы речевого сигнала, энергия расширенного высокополосного сигнала невокализованного речевого сигнала может увеличиваться, тогда как энергия расширенного высокополосного сигнала вокализованного речевого сигнала может снижаться. В снижении фонового шума речевого сигнала (NR), алгоритм NR может быть менее агрессивным для невокализованного речевого сигнала и более агрессивным для вокализованного речевого сигнала. Поэтому достоверное решение о наличии/отсутствии вокализации важно для вышеупомянутых видов применений. На основании характеристик невокализованной речи и вокализованной речи, параметр периодичности Pvoicing и параметр спектрального наклона Ptilt или их варианты по большей части используются для обнаружения невокализованных/вокализованных классов. Однако авторы данной заявки установили, что “абсолютные” значения параметра периодичности Pvoicing и параметра спектрального наклона Ptilt или их вариантов зависят от оборудования записи речевого сигнала, уровня фонового шума и/или громкоговорителей. Эти зависимости, которые трудно заранее определить, возможно, приводят к недостоверному обнаружению невокализованной/вокализованной речи.
[0048] Варианты осуществления настоящего изобретения описывают усовершенствованное обнаружение невокализованной/вокализованной речи, при котором используются “относительные” значения параметра периодичности Pvoicing и параметра спектрального наклона Ptilt или их вариантов вместо “абсолютных” значений. “Относительные” значения гораздо меньше, чем “абсолютные” значения, зависят от оборудования записи речевого сигнала, уровня фонового шума и/или громкоговорителей, что приводит к более достоверному обнаружению невокализованной/вокализованной речи.
[0049] Например, комбинированный параметр отсутствия вокализации можно задать согласно нижеприведенному уравнению (5).
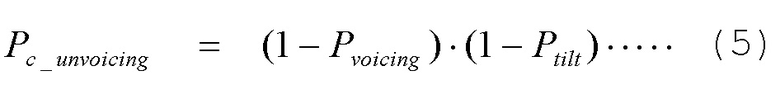
Точки в конце уравнения (5) указывают, что можно добавить другие параметры. При увеличении “абсолютного” значения 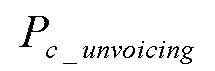 , он, вероятно, является невокализованным речевым сигналом. комбинированный параметр вокализации можно описать согласно нижеприведенному уравнению (6).
, он, вероятно, является невокализованным речевым сигналом. комбинированный параметр вокализации можно описать согласно нижеприведенному уравнению (6).
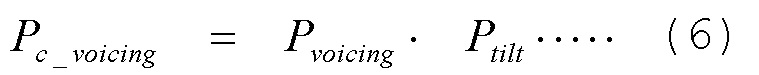
Точки в конце уравнения (6) аналогично указывают, что можно добавить другие параметры. При увеличении “абсолютного” значения  , он, вероятно, является вокализованным речевым сигналом. До задания “относительных” значений или , сильно сглаженный параметр или задается. Например, параметр для текущего кадра можно сглаживать из предыдущего кадра, как описано неравенством, приведенным ниже в уравнении (7).
, он, вероятно, является вокализованным речевым сигналом. До задания “относительных” значений или , сильно сглаженный параметр или задается. Например, параметр для текущего кадра можно сглаживать из предыдущего кадра, как описано неравенством, приведенным ниже в уравнении (7).

в уравнении (7), 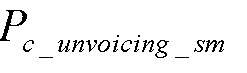 - сильно сглаженное значение
- сильно сглаженное значение 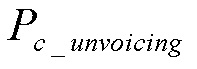 .
.
[0050] Аналогично, сглаженный комбинированный параметр вокализации 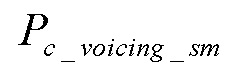 можно определить с использованием неравенства, приведенного ниже уравнении (8).
можно определить с использованием неравенства, приведенного ниже уравнении (8).

Здесь, в уравнении (8), - сильно сглаженное значение .
[0051] Статистическое поведение вокализованной речи отличается от статистического поведения невокализованной речи, и, таким образом в различных вариантах осуществления, можно находить параметры, удовлетворяющие вышеприведенному неравенству (например, 0.9, 0.99, 7/8, 255/256), и дополнительно уточнять их, при необходимости, на основании экспериментов.
[0052] “Относительные” значения или можно задавать согласно нижеприведенным уравнениям (9) и (10).

[0053] Нижеприведенное неравенство является иллюстративным вариантом осуществления применения обнаружения невокализованной речи. В этом иллюстративном варианте осуществления, установление флага Unvoiced_flag равным истина указывает, что речевой сигнал является невокализованной речью, тогда как установление флага Unvoiced_flag равным ложь указывает, что речевой сигнал не является невокализованной речью.

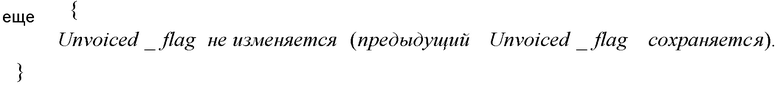
[0054] Нижеприведенное неравенство является альтернативным иллюстративным вариантом осуществления применения обнаружение вокализованной речи. В этом иллюстративном варианте осуществления, установление Voiced_flag равным истина указывает, что речевой сигнал является вокализованной речью, тогда как установление Voiced_flag равным ложь указывает, что речевой сигнал не является вокализованной речью.


[0055] После идентификации принадлежности речевого сигнала к вокализованному классы, речевой сигнал можно кодировать согласно подходу кодирования во временной области, например CELP. Варианты осуществления настоящего изобретения также можно применять для переклассификации невокализованного сигнала в вокализованный сигнал до кодирования.
[0056] В различных вариантах осуществления, вышеописанный усовершенствованный алгоритм обнаружение невокализованной/вокализованной речи может использоваться для улучшения AMR-WB-BWE и NR.
[0057] Фиг. 3 иллюстрирует операции, осуществляемые в ходе кодирования исходной речи с использованием традиционного кодера CELP, реализующего вариант осуществления настоящего изобретения.
[0058] Фиг. 3 иллюстрирует традиционный первоначальный кодер CELP, где взвешенная ошибка 109 между синтезированной речью 102 и исходной речью 101 минимизируется часто с использованием подхода анализа через синтез, и это означает, что кодирование (анализ) осуществляется путем перцепционной оптимизации декодированного (синтезированного) сигнала с обратной связью.
[0059] Базовый принцип, который используют все речевые кодеры, состоит в том, что речевые сигналы являются сильно коррелирующими формами волны. В порядке иллюстрации, речь можно представить с использованием авторегрессионной (AR) модели согласно нижеприведенному уравнению (11).
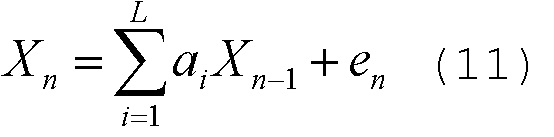
[0060] В уравнении (11), каждая выборка представлена в виде линейной комбинации предыдущих L выборок плюс белый шум. Весовые коэффициенты a1, a2,... aL называются коэффициентами линейного прогнозирования (LPC). Для каждого кадра, весовые коэффициенты a1, a2,... aL, выбираются таким образом, чтобы спектр {X1, X2, ..., XN}, генерируемый с использованием вышеописанной модели, был максимально близок к спектру входного речевого кадра.
[0061] Альтернативно, речевые сигналы также могут быть представлены комбинацией модели гармоник и модели шума. Гармоническая часть модели, по существу, является представлением периодической компоненты сигнала в виде ряда Фурье. В общем случае, для вокализованных сигналов, гармонико-шумовая модель речи состоит из смеси гармоник и шума. Соотношение гармоник и шума в вокализованной речи зависит от ряда факторов, включающих в себя характеристики говорящего (например, до какой степени голос говорящего является нормальным или хриплым); характер речевого сегмента (например, до какой степени речевой сегмент является периодическим) и от частоты. Более высокие частоты вокализованной речи имеют более высокое содержание шумоподобных компонентов.
[0062] Модель линейного прогнозирования и модель гармоник/шума являются двумя основными способами моделирования и кодирования речевых сигналов. Модель линейного прогнозирования особенно полезна при моделировании спектральной огибающей речи, тогда как модель гармоник/шума полезна при моделировании тонкой структуры речи. Два способа можно комбинировать, чтобы извлечь преимущество их относительных сил.
[0063] Как указано выше, до кодирования CELP, входной сигнал микрофона телефонной трубки фильтруется и дискретизируется, например, на скорости 8000 выборок в секунду. Затем каждая выборка квантуется, например, 13 битами для каждой выборки. Дискретизированная речь сегментируется на сегменты или кадры 20 мс (например, в этом случае 160 выборок).
[0064] Речевой сигнал анализируется, и его модель LP, сигналы возбуждения и основной тон извлекаются. Модель LP представляет спектральную огибающую речи. Он преобразуется в набор коэффициентов линейных спектральных частот (LSF), который является альтернативным представлением параметров линейного прогнозирования, поскольку коэффициенты LSF обладают хорошие свойства квантования. Коэффициенты LSF можно подвергать скалярному квантованию или, более эффективно, векторному квантованию с использованием ранее обученных кодовых книг векторов LSF.
[0065] Кодовое возбуждение включает в себя кодовую книгу, содержащую кодовые векторы, все компоненты которых независимо выбираются таким образом, что каждый кодовый вектор может иметь приблизительно ‘белый’ спектр. Для каждого подкадра входной речи, каждый из кодовых векторов фильтруется посредством фильтра 103 краткосрочного линейного прогнозирования и фильтра 105 долгосрочного прогнозирования, и выходной сигнал сравнивается с речевыми выборками. В каждом подкадре, кодовый вектор, выход которого наилучшим образом совпадает с входной речью (минимизированная ошибка), выбирается для представления этого подкадра.
[0066] Кодированное возбуждение 108 обычно содержит импульсоподобный сигнал или шумоподобный сигнал, которые математически построены или сохранены в кодовой книге. Кодовая книга доступна как кодеру, так и принимающему декодеру. Кодированное возбуждение 108, которое может быть стохастической или фиксированной кодовой книгой, может быть словарем векторного квантования, который (неявно или явно) зашит в кодек. Такая фиксированная кодовая книга может быть алгебраическим линейным прогнозированием с кодовым возбуждением или храниться явно.
[0067] Кодовый вектор из кодовой книги масштабируется надлежащим коэффициентом усиления, чтобы энергия была равна энергии входной речи. Соответственно, выходной сигнал кодированного возбуждения 108 масштабируется коэффициентом усиления Gc 107 до прохождения через линейные фильтры.
[0068] Фильтр 103 краткосрочного линейного прогнозирования формирует ‘белый’ спектр кодового вектора, напоминающий спектр входной речи. Эквивалентно, во временной области, фильтр 103 краткосрочного линейного прогнозирования включает краткосрочные корреляции (корреляцию с предыдущими выборками) в белой последовательности. Фильтр, который формирует возбуждение, имеет модель с одними полюсами в форме 1/A(z) (фильтр 103 краткосрочного линейного прогнозирования), где A(z) называется прогнозирующим фильтром и может быть получена с использованием линейного прогнозирования (например, алгоритма Левинсона-Дурбина). В одном или более вариантах осуществления, может использоваться фильтр с одними полюсами, поскольку он является хорошим представлением человеческого речевого тракта и поскольку его легко вычислять.
[0069] Фильтр 103 краткосрочного линейного прогнозирования получается путем анализа исходного сигнала 101 и представляется набором коэффициентов:
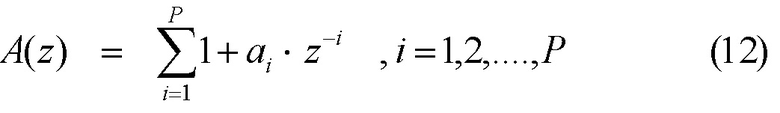
[0070] Как описано ранее, области вокализованной речи демонстрируют долгосрочную периодичность. Этот период, известный как основной тон, вносится в синтезированный спектр фильтром основного тона 1/(B(z)). Выходной сигнал фильтра 105 долгосрочного прогнозирования зависит от основного тона и коэффициента усиления основного тона. В одном или более вариантах осуществления, основной тон можно оценивать на основании исходного сигнала, остаточного сигнала или взвешенного исходного сигнала. В одном варианте осуществления, функцию долгосрочного прогнозирования (B(z)) можно выразить с использованием уравнения (13) следующим образом.
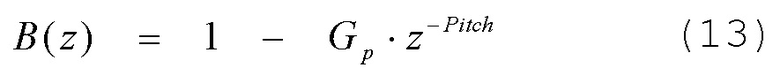
[0071] Взвешивающий фильтр 110 связан с вышеупомянутым фильтром краткосрочного прогнозирования. Один из типичных взвешивающих фильтров можно представить, как описано в уравнении (14).

[0072] В другом варианте осуществления, взвешивающий фильтр W(z) можно вывести из фильтра LPC с использованием расширения полосы как показано в одном варианте осуществления в нижеследующем уравнении (15).

В уравнении (15), γ1>γ2, которые являются коэффициентами, с которыми полюсы перемещаются к началу отсчета.
[0073] Соответственно, для каждого кадра речи, LPC и основной тон вычисляются, и фильтры обновляются. Для каждого подкадра речи, кодовый вектор, который формирует ‘наилучший’ фильтрованный выходной сигнал, выбирается для представления подкадра. Соответствующее квантованное значение коэффициента усиления подлежит передаче на декодер для надлежащего декодирования. LPC и значения основного тона также подлежат квантованию и отправке в каждом кадре для реконструкции фильтров на декодере. Соответственно, индекс кодированного возбуждения, квантованный индекс коэффициента усиления, квантованный индекс параметра долгосрочного прогнозирования и квантованный индекс параметра краткосрочного прогнозирования передаются на декодер.
[0074] Фиг. 4 иллюстрирует операции, осуществляемые в ходе декодирования исходной речи с использованием декодера CELP в соответствии с вариантом осуществления настоящего изобретения.
[0075] Речевой сигнал реконструируется на декодере путем пропускания принятых кодовых векторов через соответствующие фильтры. В результате, каждый блок, за исключением последующей обработки, имеет такое же определение, как описано в кодере, показанном на фиг. 3.
[0076] Кодированный битовый поток CELP принимается и распаковывается 80 на принимающем устройстве. Для каждого принятого подкадра, принятый индекс кодированного возбуждения, квантованный индекс коэффициента усиления, квантованный индекс параметра долгосрочного прогнозирования и квантованный индекс параметра краткосрочного прогнозирования, используются для нахождения соответствующих параметров с использованием соответствующих декодеров, например, декодера 81 коэффициента усиления, декодера 82 с долгосрочным прогнозированием и декодера 83 с краткосрочным прогнозированием. Например, из принятого индекса кодированного возбуждения можно определить позиции и знаки амплитуды импульсов возбуждения и алгебраический кодовый вектор кодового возбуждения 402.
[0077] Согласно фиг. 4, декодер является комбинацией нескольких блоков, которые включают в себя кодированное возбуждение 201, долгосрочное прогнозирование 203, краткосрочное прогнозирование 205. Первоначальный декодер дополнительно включает в себя блок 207 последующей обработки после синтезированной речи 206. Последующая обработка может дополнительно содержать краткосрочную последующую обработку и долгосрочную последующую обработку.
[0078] Фиг. 5 иллюстрирует традиционный кодер CELP, используемый в реализации вариантов осуществления настоящего изобретения.
[0079] Фиг. 5 иллюстрирует базовый кодер CELP, использующий дополнительную адаптивную кодовую книгу для улучшения долгосрочного линейного прогнозирования. Возбуждение генерируется путем суммирования вкладов от адаптивной кодовой книги 307 и кодового возбуждения 308, которое может быть стохастической или фиксированной кодовой книгой, как описано ранее. Записи в адаптивной кодовой книге содержат задержанные версии возбуждения. Это позволяет эффективно кодировать периодические сигналы, например, вокализованные звуки.
[0080] Согласно фиг. 5, адаптивная кодовая книга 307 содержит прошлое синтезированное возбуждение 304 или цикл повторения основного тона прошлого возбуждения с периодом основного тона. Отставание основного тона можно кодировать в целочисленном значении, когда оно большое или длинное. Отставание основного тона часто кодируется в более точном дробном значении, когда оно малое или короткое. Периодическая информация основного тона используется для генерации адаптивной компоненты возбуждения. Затем эта компонента возбуждения масштабируется коэффициентом усиления Gp 305 (также именуемым коэффициентом усиления основного тона).
[0081] Долгосрочное прогнозирование играет очень важную роль для кодирования вокализованной речи, поскольку вокализованная речь имеет сильную периодичность. Соседние циклы основного тона вокализованной речи аналогичны друг другу, в том смысле, что математически коэффициент усиления основного тона Gp в нижеследующем выражении возбуждения высок или близок к 1. Результирующее возбуждение можно выразить согласно уравнению (16) как комбинацию отдельных возбуждений.
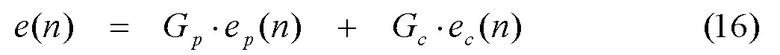
где ep(n) - один подкадр последовательности выборок, индексированной n, поступающий из адаптивной кодовой книги 307, которая содержит прошлое возбуждение 304, через контур обратной связи (фиг. 5). ep(n) можно адаптивно фильтровать по низким частотам, поскольку низкочастотная область часто является более периодической или более гармонической, чем высокочастотная область. ec(n) поступает из кодовой книги 308 кодированного возбуждения (также именуемой фиксированной кодовой книгой), которая является текущим вкладом в возбуждение. Дополнительно, ec(n) также можно улучшать, например, с использованием улучшения высокочастотной фильтрации, улучшения основного тона, дисперсионного улучшения, формантного улучшения и пр..
[0082] Для вокализованной речи вклад ep(n) из адаптивной кодовой книги 307 может преобладать, и коэффициент усиления основного тона Gp 305 близок к значению 1. Возбуждение обычно обновляется для каждого подкадра. Типичный размер кадра равен 20 миллисекундам, и типичный размер подкадра равен 5 миллисекундам.
[0083] Как описано на фиг. 3, фиксированное кодированное возбуждение 308 масштабируется коэффициентом усиления Gc 306 до прохождения через линейные фильтры. Две масштабированные компоненты возбуждения из фиксированного кодированного возбуждения 108 и адаптивной кодовой книги 307 суммируются до фильтрации посредством фильтра 303 краткосрочного линейного прогнозирования. Два коэффициента усиления (Gp и Gc) квантуются и передаются на декодер. Соответственно, индекс кодированного возбуждения, индекс адаптивной кодовой книги, квантованные индексы коэффициента усиления и квантованный индекс параметра краткосрочного прогнозирования передаются на принимающее аудио-устройство.
[0084] Битовый поток CELP, кодированный с использованием устройства, проиллюстрированного на фиг. 5, принимается на принимающем устройстве. Фиг. 6 иллюстрируют соответствующий декодер принимающего устройства.
[0085] Фиг. 6 иллюстрирует базовый декодер CELP, соответствующий кодеру, показанному на фиг. 5, в соответствии с вариантом осуществления настоящего изобретения. Фиг. 6 включает в себя блок 408 последующей обработки, принимающий синтезированную речь 407 от основного декодера. Этот декодер аналогичен показанному на фиг. 2, за исключением адаптивной кодовой книги 307.
[0086] Для каждого принятого подкадра, принятый индекс кодированного возбуждения, квантованный индекс коэффициента усиления кодированного возбуждения, квантованный индекс основного тона, квантованный индекс коэффициента усиления адаптивной кодовой книги и квантованный индекс параметра краткосрочного прогнозирования, используются для нахождения соответствующих параметров с использованием соответствующих декодеров, например, декодера 81 коэффициента усиления, декодера 84 основного тона, декодера 85 коэффициента усиления адаптивной кодовой книги и декодера 83 с краткосрочным прогнозированием.
[0087] В различных вариантах осуществления, декодер CELP является комбинацией нескольких блоков и содержит кодированное возбуждение 402, адаптивную кодовую книгу 401, краткосрочное прогнозирование 406 и последующую обработку 408. Каждый блок, за исключением последующей обработки, имеет такое же определение, как описано в кодере, показанном на фиг. 5. Последующая обработка может дополнительно включать в себя краткосрочную последующую обработку и долгосрочную последующую обработку.
[0088] Как упомянуто выше, CELP в основном, используется для кодирования речевого сигнала на основе конкретных характеристик человеческого голоса или модели генерации человеческого голоса. Для более эффективного кодирования речевого сигнала, речевой сигнал можно классифицировать на разные классы, и каждый класс кодируется по-разному. Классификация "вокализованный/невокализованный" или решение относительно отсутствия вокализации может быть важной и базовой классификацией из всех классификаций разных классов. Для каждого класса, фильтр LPC или STP всегда используется для представления спектральной огибающей. Однако возбуждение фильтра LPC может различаться. Невокализованные сигналы можно кодировать шумоподобным возбуждением. С другой стороны, вокализованные сигналы можно кодировать импульсоподобным возбуждением.
[0089] Блок кодового возбуждения (обозначенный ссылочной позицией 308 на фиг. 5 и 402 на фиг. 6) иллюстрирует местоположение фиксированной кодовой книги (FCB) для общего кодирования CELP. Выбранный кодовый вектор из FCB масштабируется коэффициентом усиления, часто обозначаемым Gc 306.
[0090] Фиг. 7 иллюстрирует шумоподобные векторы-кандидаты для построения кодовой книги кодированного возбуждения или фиксированной кодовой книги кодирования речи CELP.
[0091] FCB, содержащая шумоподобные векторы, может быть наилучшей структурой для невокализованных сигналов с точки зрения воспринимаемого качества. Дело в том, что вклад адаптивной кодовой книги или вклад LTP будет малым или несущественным, и основной вклад в возбуждение опирается на компоненту FCB для сигнала невокализованного класса. В этом случае, если используется импульсоподобная FCB, выходной синтезированный речевой сигнал будет звучать колюче, ввиду большого количества нулей в кодовом векторе, выбранном из импульсоподобной FCB, предназначенной для кодирования с низкими битовыми скоростями.
[0092] Согласно фиг. 7, структура FCB включает в себя шумоподобные векторы-кандидаты для построения кодированного возбуждения. Шумоподобная FCB 501 выбирает конкретный шумоподобный кодовый вектор 502, который масштабируется коэффициентом усиления 503.
[0093] Фиг. 8 иллюстрирует импульсоподобные векторы-кандидаты для построения кодовой книги кодированного возбуждения или фиксированной кодовой книги кодирования речи CELP.
[0094] Импульсоподобная FCB обеспечивает более высокое качество, чем шумоподобная FCB для сигнала вокализованного класса с точки зрения восприятия. Дело в том, что вклад адаптивной кодовой книги или вклад LTP будет преобладать для высокопериодического сигнала вокализованного класса, и основной вклад в возбуждение не опирается на компоненту FCB для сигнала вокализованного класса. Если используется шумоподобная FCB, выходной синтезированный речевой сигнал может звучать зашумленно или менее периодически, поскольку труднее обеспечить хорошее совпадение формы волны с использованием кодового вектора, выбранного из шумоподобной FCB, предназначенной для кодирования с низкими битовыми скоростями.
[0095] Согласно фиг. 8, структура FCB может включать в себя множество импульсоподобных векторов-кандидатов для построения кодированного возбуждения. Импульсоподобный кодовый вектор 602 выбирается из импульсоподобной FCB 601 и масштабируется коэффициентом усиления 603.
[0096] Фиг. 9 иллюстрирует пример спектра возбуждения для вокализованной речи. После удаления спектральной огибающей 704 LPC, спектр 702 возбуждения является почти плоским. Низкополосный спектр 701 возбуждения обычно является более гармоническим, чем высокополосный спектр 703. Теоретически, идеальный или неквантованный высокополосный спектр возбуждения может иметь почти такой же уровень энергии, как низкополосный спектр возбуждения. На практике, если полоса низких частот и полоса высоких частот кодируются посредством технологии CELP, синтезированный или квантованный высокополосный спектр может иметь более низкий уровень энергии, чем синтезированный или квантованный низкополосный спектр, по меньшей мере, по двум причинам. Во-первых, кодирование CELP с обратной связью больше сосредотачивается на полосе низких частот, чем на полосе высоких частот. Во-вторых, совпадения формы волны для низкополосного сигнала легче добиться, чем для высокополосного сигнала, не только вследствие более быстрого изменения высокополосного сигнала, но и вследствие более шумоподобной характеристики высокополосного сигнала.
[0097] При кодировании CELP с низкой битовой скоростью, например AMR-WB, полоса высоких частот обычно не кодируется, но генерируется на декодере посредством технологии расширения полосы (BWE). В этом случае, высокополосный спектр возбуждения может просто копироваться с низкополосного спектра возбуждения при добавлении некоторого случайного шума. Огибающую высокополосной спектральной энергии можно прогнозировать или оценивать из огибающей низкополосной спектральной энергии. Надлежащее управление энергией высокополосного сигнала приобретает важность при использовании BWE. В отличие от невокализованного речевого сигнала, энергию генерируемого высокополосного вокализованного речевого сигнала нужно надлежащим образом снижать для достижения наилучшего воспринимаемого качества.
[0098] Фиг. 10 иллюстрирует пример спектра возбуждения для невокализованной речи.
[0099] В случае невокализованной речи, спектр 802 возбуждения является почти плоским после удаления спектральной огибающей 804 LPC. Низкополосный спектр 801 возбуждения и высокополосный спектр 803 являются шумоподобными. Теоретически, идеальный или неквантованный высокополосный спектр возбуждения может иметь почти такой же уровень энергии, как низкополосный спектр возбуждения. На практике, если полоса низких частот и полоса высоких частот кодируются посредством технологии CELP, синтезированный или квантованный высокополосный спектр может иметь такой же или немного более высокий уровень энергии, чем синтезированный или квантованный низкополосный спектр по двум причинам. Во-первых, кодирование CELP с обратной связью больше сосредотачивается на области более высокой энергии. Во-вторых, хотя совпадения формы волны для низкополосного сигнала легче добиться, чем для высокополосного сигнала, всегда трудно иметь хорошее совпадение формы волны для шумоподобных сигналов.
[00100] Аналогично кодированию вокализованной речи, для невокализованного кодирования CELP с низкой битовой скоростью, например AMR-WB, полоса высоких частот обычно не кодируется, но генерируется на декодере посредством технологии BWE. В этом случае, невокализованный высокополосный спектр возбуждения может просто копироваться с невокализованного низкополосного спектра возбуждения при добавлении некоторого случайного шума. Огибающую высокополосной спектральной энергии невокализованного речевого сигнала можно прогнозировать или оценивать из огибающей низкополосной спектральной энергии. Надлежащее управление энергией невокализованного высокополосного сигнала особенно важно при использовании BWE. В отличие от вокализованного речевого сигнала, энергию генерируемого высокополосного невокализованного речевого сигнала предпочтительно надлежащим образом повышать для достижения наилучшего воспринимаемого качества.
[00101] Фиг. 11 иллюстрирует пример спектра возбуждения для сигнала фонового шума.
[00102] Спектр 902 возбуждения является почти плоским после удаления спектральной огибающей 904 LPC. Низкополосный спектр 901 возбуждения, обычно является шумоподобным, как и высокополосный спектр 903. Теоретически, идеальный или неквантованный высокополосный спектр возбуждения сигнала фонового шума может иметь почти такой же уровень энергии, как низкополосный спектр возбуждения. На практике, если полоса низких частот и полоса высоких частот кодируются посредством технологии CELP, синтезированный или квантованный высокополосный спектр сигнала фонового шума может иметь более низкий уровень энергии, чем синтезированный или квантованный низкополосный спектр по двум причинам. Во-первых, кодирование CELP с обратной связью больше сосредотачивается на полосе низких частот, которая имеет более высокую энергию, чем полоса высоких частот. Во-вторых, совпадения формы волны для низкополосного сигнала легче добиться, чем для высокополосного сигнала. Аналогично кодирование речи, для кодирования CELP с низкой битовой скоростью сигнала фонового шума, полоса высоких частот обычно не кодируется, но генерируется на декодере посредством технологии BWE. В этом случае, высокополосный спектр возбуждения сигнала фонового шума может просто копироваться с низкополосного спектра возбуждения при добавлении некоторого случайного шума; огибающая высокополосной спектральной энергии сигнала фонового шума можно прогнозировать или оценивать из огибающей низкополосной спектральной энергии. Управление высокополосного сигнала фонового шума может отличаться от речевого сигнала при использовании BWE. В отличие от речевого сигнала, предпочтительно, чтобы энергия генерируемого речевого сигнала с высокополосным фоновым шумом не изменялась со временем, для достижения наилучшего воспринимаемого качества.
[00103] Фиг. 12A и 12B иллюстрируют примеры кодирования/декодирования в частотной области с расширением полосы. Фиг. 12A иллюстрирует кодер с информацией стороны BWE, тогда как фиг. 12B иллюстрирует декодер с BWE.
[00104] Согласно фиг. 12A, низкополосный сигнал 1001 кодируется в частотной области с использованием низкополосных параметров 1002. Низкополосные параметры 1002 квантуются, и индекс квантования передается на принимающее устройство аудиодоступа по каналу 1003 битового потока. Высокополосный сигнал, извлеченный из аудиосигнала 1004, кодируется малым количеством битов с использованием параметров высокополосной стороны 1005. Квантованные параметры высокополосной стороны (индекс информации HB стороны) передаются на принимающее устройство аудиодоступа по каналу 1006 битового потока.
[00105] Согласно фиг. 12B, на декодере, низкополосный битовый поток 1007 используется для генерации декодированного низкополосного сигнала 1008. Битовый поток 1010 высокополосной стороны используется для декодирования и генерации параметров 1011 высокополосной стороны. Высокополосный сигнал 1012 генерируется из низкополосного сигнала 1008 с помощью параметров 1011 высокополосной стороны. Окончательный аудиосигнал 1009 генерируется путем объединения низкополосного сигнала и высокополосного сигнала. BWE частотной области также нуждается в надлежащей регулировке энергии генерируемого высокополосного сигнала. Уровни энергии можно устанавливать по-разному для невокализованных, вокализованных и шумовых сигналов. Таким образом, высококачественная классификация речевого сигнала также необходима для BWE частотной области.
[00106] Ниже описаны значимые детали алгоритма снижения фонового шума. В общем случае, поскольку невокализованный речевой сигнал является шумоподобным, снижение фонового шума (NR) в невокализованной области должно быть менее агрессивным, чем в вокализованной области, на основании эффекта маскировки шума. Другими словами, фоновый шум одного и того же уровня является более слышимым в вокализованной области, чем в невокализованной области, благодаря чему, NR должно быть более агрессивным в вокализованной области, чем в невокализованной области. В таком случае, необходимо высококачественное решение относительно наличия/отсутствия вокализации.
[00107] В общем случае, невокализованный речевой сигнал является шумоподобным сигналом, который не имеет периодичности. Дополнительно, невокализованный речевой сигнал имеет более высокую энергию в высокочастотной области, чем в низкочастотной области. Напротив, вокализованный речевой сигнал имеет противоположные характеристики. Например, вокализованный речевой сигнал является сигнальном квазипериодического типа, который обычно имеет более высокую энергию в низкочастотной области, чем в высокочастотной области (см. также фиг. 9 и 10).
[00108] На фиг. 13A-13C схематически проиллюстрирована обработка речи с использованием различных вышеописанных вариантов осуществления обработки речи.
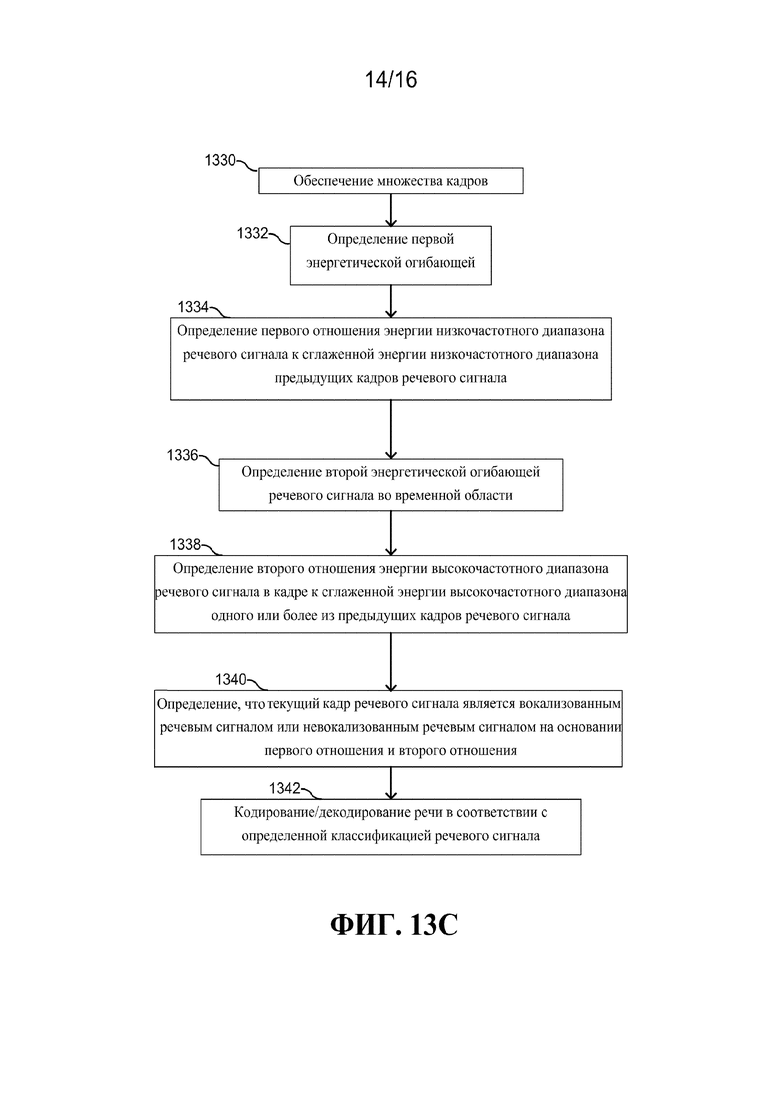
[00109] Согласно фиг. 13A, способ обработки речи включает в себя прием множества кадров речевого сигнала, подлежащих обработке (блок 1310). В различных вариантах осуществления, множество кадров речевого сигнала может генерироваться в одном и том же аудио-устройстве, например, содержащем микрофон. В альтернативном варианте осуществления, речевой сигнал может приниматься на аудио-устройстве в порядке примера. Затем, например, речевой сигнал может кодироваться или декодироваться. Для каждого кадра, определяется параметр наличия/отсутствия вокализации, отражающий характеристику невокализованной/вокализованной речи в текущем кадре (блок 1312). В различных вариантах осуществления, параметр наличия/отсутствия вокализации может включать в себя параметр периодичности, параметр спектрального наклона или другие варианты. Способ дополнительно включает в себя определение сглаженного параметра отсутствия вокализации для включения информации параметра наличия/отсутствия вокализации в предыдущие кадры речевого сигнала (блок 1314). Получается разность между параметром наличия/отсутствия вокализации и сглаженным параметром наличия/отсутствия вокализации (блок 1316). Альтернативно, может быть получено относительное значение (например, отношение) между параметром наличия/отсутствия вокализации и сглаженным параметром наличия/отсутствия вокализации. При определении, более ли текущий кадр пригоден для обработки в качестве невокализованной/вокализованной речи, решение относительно наличия/отсутствия вокализации принимается с использованием определенной разности в качестве параметра принятия решения (блок 1318).
[00110] Согласно фиг. 13B способ обработки речи включает в себя прием множества кадров речевого сигнала (блок 1320). Вариант осуществления описан с использованием параметра вокализации, но в равной степени применяется к использованию параметра отсутствия вокализации. Комбинированный параметр вокализации определяется для каждого кадра (блок 1322). В одном или более вариантах осуществления, комбинированный параметр вокализации может представлять собой параметр периодичности и параметр наклона и сглаженный комбинированный параметр вокализации. Сглаженный комбинированный параметр вокализации может быть получен сглаживанием комбинированного параметра вокализации по одному или более предыдущим кадрам речевого сигнала. Комбинированный параметр вокализации сравнивается со сглаженным комбинированным параметром вокализации (блок 1324). Текущий кадр классифицируется как вокализованный речевой сигнал или невокализованный речевой сигнал с использованием сравнения при принятии решения (блок 1326). Речевой сигнал может обрабатываться, например, кодироваться или декодироваться, в соответствии с определенной классификацией речевого сигнала (блок 1328).
[00111] В другом иллюстративном варианте осуществления, согласно фиг. 13C, способ обработки речи содержит прием множества кадров речевого сигнала (блок 1330). Определяется первая энергетическая огибающая речевого сигнала во временной области (блок 1332). Первую энергетическую огибающую можно определять в первом частотном диапазоне, например, низкочастотном диапазоне, например, до 4000 Гц. Сглаженную энергию низкочастотного диапазона можно определять из первой энергетической огибающей с использованием предыдущих кадров. Вычисляется разность или первое отношение энергии низкочастотного диапазона речевого сигнала к сглаженной энергии низкочастотного диапазона (блок 1334). Определяется вторая энергетическая огибающая речевого сигнала во временной области (блок 1336). Вторая энергетическая огибающая определяется во втором частотном диапазоне. Второй частотный диапазон является другим частотным диапазоном, чем первый частотный диапазон. Например, вторая частота может быть высокочастотным диапазоном. В одном примере, второй частотный диапазон может составлять от 4000 Гц до 8000 Гц. Вычисляется сглаженная энергия высокочастотного диапазона по одному или более из предыдущих кадров речевого сигнала. Разность или второе отношение определяется с использованием второй энергетической огибающей для каждого кадра (блок 1338). Второе отношение можно вычислять как отношение энергии высокочастотного диапазона речевого сигнала в текущем кадре к сглаженной энергии высокочастотного диапазона. Текущий кадр классифицируется как вокализованный речевой сигнал или невокализованный речевой сигнал с использованием первого отношения и второго отношения при принятии решения (блок 1340). Классифицированный речевого сигнала обрабатывается, например, кодируется, декодируется и пр., в соответствии с определенной классификацией речевого сигнала (блок 1342).
[00112] В одном или более вариантах осуществления, речевой сигнал могут кодироваться/декодироваться с использованием шумоподобного возбуждения, когда речевой сигнал определяется как невокализованный речевой сигнал, и при этом речевой сигнал кодируется/декодируется импульсоподобным возбуждением, когда речевой сигнал определяется как вокализованный сигнал.
[00113] В дополнительных вариантах осуществления, речевой сигнал могут кодироваться/декодироваться в частотной области, когда речевой сигнал определяется как невокализованный сигнал, и при этом речевой сигнал кодируется/декодируется во временной области, когда речевой сигнал определяется как вокализованный сигнал.
[00114] Соответственно, варианты осуществления настоящего изобретения могут использоваться для улучшения решения относительно наличия/отсутствия вокализации для кодирования речи, расширения полосы и/или улучшения речи.
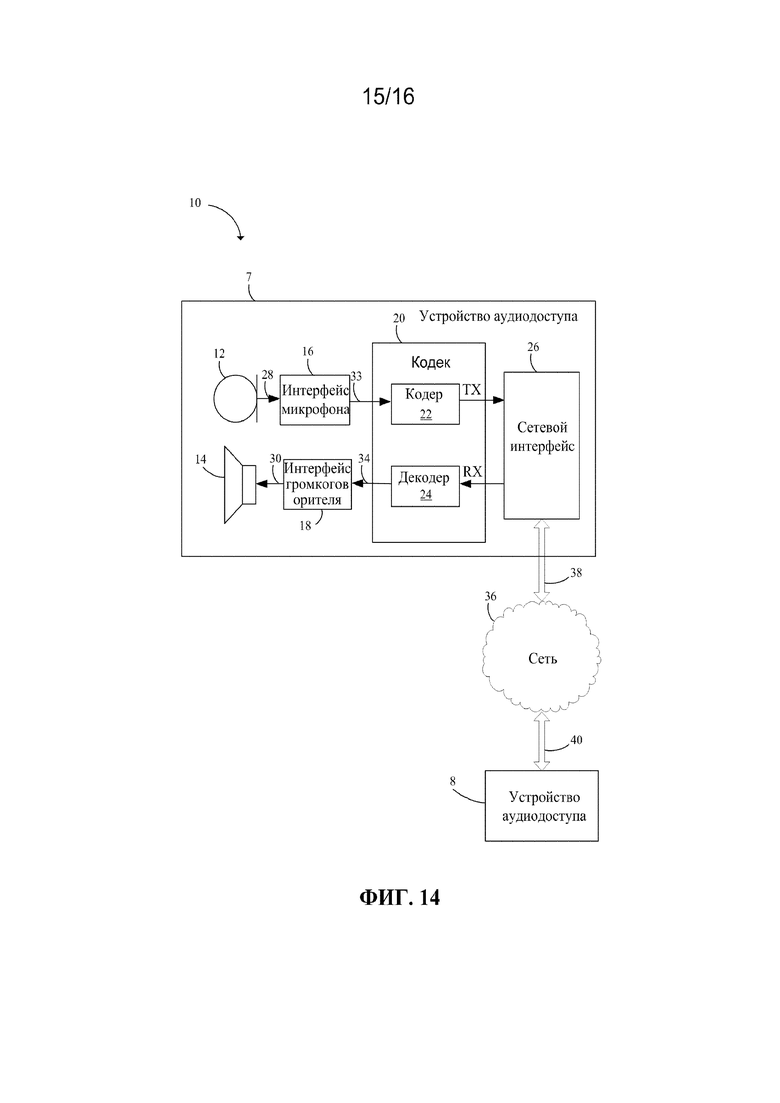
[00115] Фиг. 14 иллюстрирует систему 10 связи согласно варианту осуществления настоящего изобретения.
[00116] Система 10 связи имеет устройства 7 и 8 аудиодоступа, подключенные к сети 36 по линиям 38 и 40 связи. В одном варианте осуществления, устройства 7 и 8 аудиодоступа являются устройствами передачи голоса по интернет-протоколу (VOIP), и сеть 36 является глобальной сетью (WAN), коммутируемой телефонной сетью общего пользования (PTSN) и/или интернетом. В другом варианте осуществления, линии 38 и 40 связи являются проводными и/или беспроводными широкополосными соединениями. В альтернативном варианте осуществления, устройства 7 и 8 аудиодоступа являются сотовыми или мобильными телефонами, линии 38 и 40 связи являются беспроводными каналами мобильной телефонии, и сеть 36 представляет собой мобильную телефонную сеть.
[00117] Устройство 7 аудиодоступа использует микрофон 12 для преобразования звука, например, музыки или человеческого голоса в аналоговый входной аудиосигнал 28. Интерфейс 16 микрофона преобразует аналоговый входной аудиосигнал 28 в цифровой аудиосигнал 33, поступающий на кодер 22 кодека 20. Кодер 22 формирует кодированный аудиосигнал TX для передачи в сеть 26 через сетевой интерфейс 26 согласно вариантам осуществления настоящего изобретения. Декодер 24 в кодеке 20 принимает кодированный аудиосигнал RX из сети 36 через сетевой интерфейс 26 и преобразует кодированный аудиосигнал RX в цифровой аудиосигнал 34. Интерфейс 18 громкоговорителя преобразует цифровой аудиосигнал 34 в аудиосигнал 30 пригодный для возбуждения громкоговорителя 14.
[00118] В вариантах осуществления настоящего изобретения, где устройство 7 аудиодоступа является устройством VOIP, некоторые или все компоненты в устройстве 7 аудиодоступа реализуются в телефонной трубке. Однако, в некоторых вариантах осуществления, микрофон 12 и громкоговоритель 14 являются отдельными блоками, и интерфейс 16 микрофона, интерфейс 18 громкоговорителя, кодек 20 и сетевой интерфейс 26 реализуются в персональном компьютере. Кодек 20 можно реализовать либо в программном обеспечении, выполняющемся на компьютере или специализированном процессоре, либо посредством специализированного оборудования, например, на специализированной интегральной схеме (ASIC). Интерфейс 16 микрофона реализуется посредством аналого-цифрового (A/D) преобразователя, а также другой схемы интерфейса, находящейся в телефонной трубке и/или в компьютере. Аналогично, интерфейс 18 громкоговорителя реализуется посредством цифроаналогового преобразователя и другой схемы интерфейса, находящейся в телефонной трубке и/или в компьютере. В дополнительных вариантах осуществления, устройство 7 аудиодоступа может быть реализовано и разделено другими способами, известными в технике.
[00119] В вариантах осуществления настоящего изобретения, где устройство 7 аудиодоступа является сотовым или мобильным телефоном, элементы в устройстве 7 аудиодоступа реализуются в сотовой телефонной трубке. Кодек 20 реализуется посредством программного обеспечения, выполняющегося на процессоре в телефонной трубке, или посредством специализированного оборудования. В дополнительных вариантах осуществления настоящего изобретения, устройство аудиодоступа может быть реализовано в других устройствах, например, проводных и беспроводных цифровых системах связи между равноправными устройствами, например, селекторами и портативными радиостанциями. Например, применительно к бытовым аудиоустройствам, устройство аудиодоступа может содержать кодек только с кодером 22 или декодером 24, например, в цифровой микрофонной системе или устройстве воспроизведения музыки. В других вариантах осуществления настоящего изобретения, кодек 20 может использоваться без микрофона 12 и громкоговорителя 14, например, в базовых станциях сотовой связи, которые осуществляют доступ к PTSN.
[00120] Обработка речи для улучшения классификации по наличию/отсутствию вокализации, описанная в различных вариантах осуществления настоящего изобретения, может быть реализована, например, в кодере 22 или декодере 24. Обработка речи для улучшения классификации по наличию/отсутствию вокализации может быть реализована в оборудовании или программном обеспечении в различных вариантах осуществления. Например, кодер 22 или декодер 24 может входить в состав микросхемы обработки цифровых сигналов (DSP).
[00121] Фиг. 15 демонстрирует блок-схему системы обработки, которая может использоваться для реализации раскрытых здесь устройств и способов. Конкретные устройства могут использовать все показанные компоненты или только часть компонентов, и уровни интеграции могут изменяться от устройства к устройству. Кроме того, устройство может содержать множественные экземпляры компонента, например множественные блоки обработки, процессоры, блоки памяти, передатчики, приемники и т.д. Система обработки может содержать блок обработки, снабженный одним или более устройствами ввода/вывода, например, громкоговорителем, микрофоном, мышью, сенсорным экраном, клавишной панелью, клавиатурой, принтером, дисплеем и пр. Блок обработки может включать в себя центральный процессор (CPU), память, запоминающее устройство большой емкости, видеоадаптер и интерфейс ввода-вывода, подключенный к шине.
[00122] Шина может относиться к одной или более из нескольких шинных архитектур любого типа, включающих в себя шину памяти или контроллер памяти, периферийную шину, шину видео и т.п. CPU может содержать процессор электронных данных любого типа. Память может содержать системную память любого типа, например, статическую оперативную память (SRAM), динамическую оперативную память (DRAM), синхронную DRAM (SDRAM), постоянную память (ROM), их комбинацию и т.п. Согласно варианту осуществления, память может включать в себя ROM для использования при запуске, DRAM для хранения программ и данных для использования при выполнении программ.
[00123] Запоминающее устройство большой емкости может содержать запоминающее устройство любого типа, выполненное с возможностью хранения данных, программ и другой информации и обеспечения доступа к данным, программам и другой информации через шину. Запоминающее устройство большой емкости может содержать, например, один или более из твердотельного диска, жесткого диска, привода магнитных дисков, привода оптических дисков и т.п.
[00124] Видеоадаптер и интерфейс ввода-вывода обеспечивают интерфейсы для подключения внешних устройств ввода и вывода к блоку обработки. Как показано, примеры устройств ввода и вывода включают в себя дисплей, подключенный к видеоадаптеру, и мышь/клавиатура/принтер, подключенный к интерфейсу ввода-вывода. Другие устройства могут быть подключены к блоку обработки, и можно использовать больше или меньше карт интерфейса. Например, последовательный интерфейс, например, универсальная последовательная шина (USB) (не показана) может использоваться для обеспечения интерфейса для принтера.
[00125] Блок обработки также включает в себя один или более сетевых интерфейсов, которые могут содержать проводные линии связи, например, кабель Ethernet и т.п., и/или беспроводные линии связи с узлами доступа или другими сетями. Сетевой интерфейс позволяет блоку обработки осуществлять связь с удаленными блоками через сети. Например, сетевой интерфейс может обеспечивать беспроводную связь через один или более передатчиков/передающих антенн и один или более приемников/приемных антенн. Согласно варианту осуществления, блок обработки подключается к локальной сети или глобальной сети для обработки данных и связи с удаленными устройствами, например, другими блоками обработки, интернетом, служб удаленного хранения и т.п.
[00126] Хотя это изобретение описано со ссылкой на иллюстративные варианты осуществления, это описание не следует рассматривать в ограничительном смысле. Различные модификации и комбинации иллюстративных вариантов осуществления, а также другие варианты осуществления изобретения, специалисты в данной области техники смогут вывести из описания. Например, различные вышеописанные варианты осуществления можно объединять друг с другом.
[00127] Хотя настоящее изобретение и его преимущества были подробно описаны, следует понимать, что оно допускает различные изменения, замены и изменения без выхода за рамки сущности и объема изобретения, заданных нижеследующей формулой изобретения. Например, многие рассмотренные выше признаки и функции можно реализовать в программном обеспечении, аппаратном обеспечении или программно-аппаратном обеспечении или их комбинации. Кроме того, объем настоящей заявки не подлежит ограничению конкретными вариантами осуществления процесса, устройства, производства, состава вещества, средств, способов и этапов, описанных в описании изобретения. Из раскрытия настоящего изобретения специалист в данной области техники сможет понять процессы, устройства, производство, составы вещества, средства, способы или этапы, существующие в настоящее время или подлежащие разработке в дальнейшем, которые осуществляют, по существу, такую же функцию или достигают, по существу, того же результата, поскольку соответствующие описанные здесь варианты осуществления можно использовать согласно настоящему изобретению. Соответственно, такие процессы, устройства, производство, составы вещества, средства, способы или этапы подлежат включению в объем нижеследующей формулы изобретения.





Изобретение относится к решению относительно наличия/отсутствия вокализации для обработки речи. Технический результат заключается в усовершенствованном и более надежном обнаружении невокализованной/вокализованной речи. Способ обработки речи включает этапы: определение параметра наличия/отсутствия вокализации в текущем кадре речевого сигнала, который является комбинированным параметром, отражающим произведение параметра периодичности и параметра спектрального наклона; определение сглаженного параметра наличия/отсутствия вокализации для включения информации параметра наличия/отсутствия вокализации в предшествующий кадр; вычисление разности между параметром наличия/отсутствия вокализации в текущем кадре и сглаженным параметром и определение, содержит ли текущий кадр невокализованную речь или вокализованную речь, с использованием вычисленной разности в качестве параметра принятия решения. 2 н. и 18 з.п. ф-лы, 15 ил.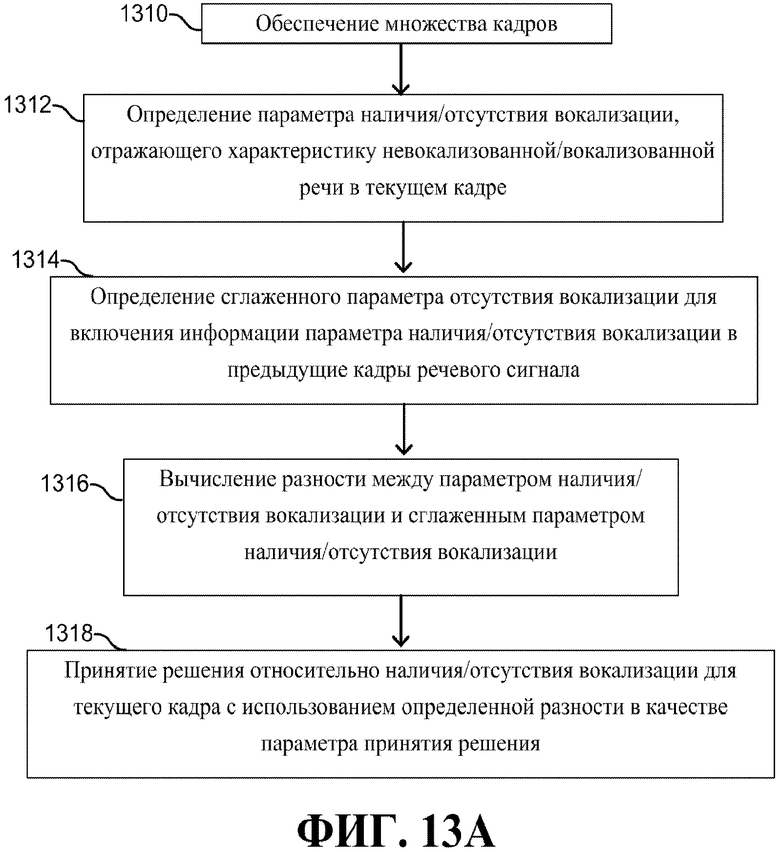
ИЗМЕНЕННАЯ ФОРМУЛА ИЗОБРЕТЕНИЯ,
ПРЕДЛОЖЕННАЯ ЗАЯВИТЕЛЕМ ДЛЯ РАССМОТРЕНИЯ
1. Способ обработки речи, причем способ содержит этапы, на которых:
определяют параметр наличия/отсутствия вокализации в текущем кадре речевого сигнала, содержащего множество кадров;
при этом параметр наличия/отсутствия вокализации является комбинированным параметром, отражающим произведение параметра периодичности и параметра спектрального наклона;
определяют сглаженный параметр наличия/отсутствия вокализации для включения информации параметра наличия/отсутствия вокализации в кадр, предшествующий текущему кадру речевого сигнала;
вычисляют разность между параметром наличия/отсутствия вокализации в текущем кадре и сглаженным параметром наличия/отсутствия вокализации; и
определяют, содержит ли текущий кадр невокализованную речь или вокализованную речь, с использованием вычисленной разности в качестве параметра принятия решения.
2. Способ по п. 1, в котором параметр наличия/отсутствия вокализации является комбинированным параметром отсутствия вокализации, при этом произведение представляет собой 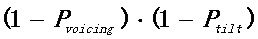

3. Способ по п. 1, в котором параметр наличия/отсутствия вокализации является параметром отсутствия вокализации (Punvoicing), отражающим характеристику невокализованной речи, причем сглаженный параметр наличия/отсутствия вокализации является сглаженным параметром отсутствия вокализации (Punvoicing_sm).
4. Способ по п. 3, в котором, когда разность между параметром отсутствия вокализации и сглаженным параметром отсутствия вокализации больше 0.1, определяют, что текущий кадр речевого сигнала является невокализованной речью, при этом, когда разность между параметром отсутствия вокализации и сглаженным параметром отсутствия вокализации меньше 0.05, определяют, что текущий кадр речевого сигнала не является невокализованной речью.
5. Способ по п. 4, в котором, когда разность между параметром отсутствия вокализации и сглаженным параметром отсутствия вокализации составляет от 0.05 до 0.1, определяют, что текущий кадр речевого сигнала имеет тот же тип речи, что и кадр, предшествующий текущему кадру.
6. Способ по п. 3, в котором сглаженный параметр отсутствия вокализации вычисляется из параметра отсутствия вокализации следующим образом:
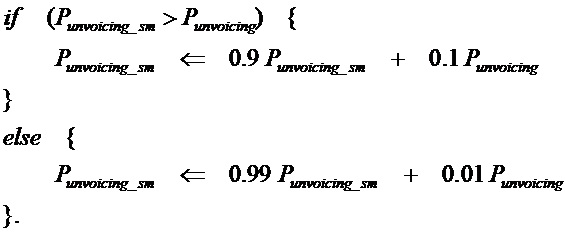
7. Способ по п. 1, в котором параметром наличия/отсутствия вокализации является параметр вокализации (Pvoicing), отражающий характеристику вокализованной речи, и при этом сглаженный параметр наличия/отсутствия вокализации является сглаженным параметром вокализации (Pvoicing_sm).
8. Способ по п. 7, в котором, когда разность между параметром вокализации и сглаженным параметром вокализации больше 0.1, определяют, что текущий кадр речевого сигнала является вокализованным сигналом, и при этом, когда разность между параметром вокализации и сглаженным параметром вокализации меньше 0.05, определяют, что текущий кадр речевого сигнала не является вокализованной речью.
9. Способ по п. 7, в котором сглаженный параметр вокализации вычисляется из параметра вокализации следующим образом:

10. Способ по п. 1, в котором кадр содержит подкадр.
11. Устройство обработки речи, содержащее:
процессор; и
компьютерно-считываемый носитель данных, хранящий программное обеспечение для исполнения процессором, причем программное обеспечение включает в себя инструкции для:
определения параметра наличия/отсутствия вокализации в текущем кадре речевого сигнала, содержащего множество кадров, при этом параметр наличия/отсутствия вокализации является комбинированным параметром, отражающим произведение параметра периодичности и параметра спектрального наклона;
определения сглаженного параметра наличия/отсутствия вокализации для включения информации параметра наличия/отсутствия вокализации в кадр, предшествующий текущему кадру речевого сигнала,
вычисления разности между параметром наличия/отсутствия вокализации в текущем кадре и сглаженным параметром наличия/отсутствия вокализации, и
определения, содержит ли текущий кадр невокализованную речь или вокализованную речь, с использованием вычисленной разности в качестве параметра принятия решения.
12. Устройство по п. 11, в котором параметр наличия/отсутствия вокализации является комбинированным параметром отсутствия вокализации, при этом произведение представляет собой
13. Устройство по п. 11, в котором параметр наличия/отсутствия вокализации является параметром отсутствия вокализации (Punvoicing), отражающим характеристику невокализованной речи, причем сглаженный параметр наличия/отсутствия вокализации является сглаженным параметром отсутствия вокализации (Punvoicing_sm).
14. Устройство по п. 13, в котором, когда разность между параметром отсутствия вокализации и сглаженным параметром отсутствия вокализации больше 0.1, осуществляется определение, что текущий кадр речевого сигнала является невокализованной речью, при этом, когда разность между параметром отсутствия вокализации и сглаженным параметром отсутствия вокализации меньше 0.05, осуществляется определение, что текущий кадр речевого сигнала не является невокализованной речью.
15. Устройство по п. 14, в котором, когда разность между параметром отсутствия вокализации и сглаженным параметром отсутствия вокализации составляет от 0.05 до 0.1, осуществляется определение, что текущий кадр речевого сигнала имеет тот же тип речи, что и кадр, предшествующий текущему кадру.
16. Устройство по п. 13, в котором сглаженный параметр отсутствия вокализации вычисляется из параметра отсутствия вокализации следующим образом:
17. Устройство по п. 11, в котором параметр наличия/отсутствия вокализации является параметром вокализации, отражающим характеристику вокализованной речи, и при этом сглаженный параметр наличия/отсутствия вокализации является сглаженным параметром вокализации.
18. Устройство по п. 17, в котором, когда разность между параметром наличия вокализации и сглаженным параметром наличия вокализации больше 0.1, осуществляется определение, что текущий кадр речевого сигнала является вокализованной речью, при этом, когда разность между параметром наличия вокализации и сглаженным параметром наличия вокализации меньше 0.05, осуществляется определение, что текущий кадр речевого сигнала не является вокализованной речью.
19. Устройство по п. 17, в котором сглаженный параметр наличия вокализации вычисляется из параметра наличия вокализации следующим образом:
20. Устройство по п. 11, в котором кадр содержит подкадр.
По доверенности
| СПОСОБ И УСТРОЙСТВО ЭФФЕКТИВНОЙ МАСКИРОВКИ СТИРАНИЯ КАДРОВ В РЕЧЕВЫХ КОДЕКАХ | 2006 |
|
RU2419891C2 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6453285 B1, 17.09.2002 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 5216747 A1, 01.06.1993 | |||
| US 5960388 A1, 28.09.1999 | |||
| US 6640208 B1, 28.10.2003. | |||

