УРОВЕНЬ ТЕХНИКИ
Блочное основанное на преобразовании кодирование
Кодирование на основе преобразования - это методика сжатия, используемая во многих системах сжатия звука, изображений и видео. Несжатое цифровое изображение и видео типично представляется или захватывается в виде дискретных выборок элементов или цветов картинки на позициях в кадре изображения или видео, скомпонованном в двумерной (2D) сетке. Это называется представлением изображения или видео в пространственной области. Например, типичный формат для изображений состоит из потока 24-битных дискретных выборок элементов цветной картинки, скомпонованных в виде сетки. Каждая дискретная выборка, среди прочего, является числом, представляющим цветовые компоненты на позиции пикселя в сетке в пределах цветового пространства, такого как RGB или YIQ. Различные системы изображения и видео могут использовать различные цветовые, пространственные и временные разрешения дискретизации. Так же цифровое аудио типично представляется как выбираемый по времени поток звуковых сигналов. Например, типичный звуковой формат состоит из потока 16-битных амплитудных дискретных выборок звукового сигнала, взятых с постоянными временными интервалами.
Несжатые цифровые сигналы звука, изображения и видео могут использовать значительную емкость запоминающего устройства и передачи. Кодирование с преобразованием уменьшает размер цифрового звука, изображений и видео посредством преобразования представления сигнала в пространственной области в представление в частотной области (или другой аналогичной области преобразования), а затем уменьшения разрешения некоторых, в целом менее воспринимаемых, частотных компонентов представления в области преобразования. Это, как правило, производит гораздо менее воспринимаемое ухудшение цифрового сигнала в сравнении с уменьшением цветового или пространственного разрешения изображений или видео в пространственной области, или звука - во временной области.
Более конкретно, типичный блочный, основанный на преобразовании, кодек 100, показанный на фиг.1, делит пиксели несжатого цифрового изображения на двумерные блоки фиксированного размера (X1,…, Xn), каждый блок, возможно, перекрывается с другими блоками. Линейное преобразование 120-121, которое производит анализ пространственных частот, применяется к каждому блоку, который конвертирует разнесенные дискретные выборки в пределах блока в набор коэффициентов частот (или преобразования), обычно представляющих мощность цифрового сигнала в соответствующих полосах частот по блочному интервалу. Для сжатия коэффициенты преобразования могут быть избирательно квантованы 130 (т.е. уменьшены в разрешении, например, отбрасыванием младших значащих битов значений коэффициентов или, в ином случае, преобразованием значений в числовом множестве с более высоким разрешением в более низкое разрешение), а также статистически закодированы 130 или с переменной длиной в сжатый поток данных. При декодировании коэффициенты преобразования обратно преобразуются 170-171, чтобы приблизительно восстановить исходный, выбираемый по цвету/пространству, сигнал изображения/видео (восстановленные блоки 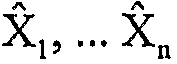 ).
).
Блочное преобразование 120-121 может быть задано как математическая операция над вектором x размера N. Более часто операцией является линейное умножение, генерирующее выходной результат y=Mx, области преобразования M, являющийся матрицей преобразования. Когда входные данные имеют произвольную длину, они сегментируются на N-мерные векторы, а блочное преобразование применяется к каждому сегменту. В целях сжатия данных выбраны обратимые блочные преобразования. Другими словами, матрица M является обратимой. В многочисленных измерениях (например, для изображения и видео) блочные преобразования типично реализованы как раздельные операции. Матричное умножение раздельно применяется вдоль каждого измерения данных (т.е. как строк, так и столбцов).
Для сжатия коэффициенты преобразования (компоненты вектора y) могут быть выборочно квантованы (т.е. уменьшены по разрешению, например, отбрасыванием младших значащих битов значений коэффициентов или, в ином случае, преобразованием значений в наборе с более высоким разрешением в более низкое разрешение), а также статистически закодированы или с переменной длиной в сжатый поток данных.
При декодировании в декодере 150 инверсия этих операций (декодирование 160 по деквантованию/статистическое и обратное блочное преобразование 170-171) применяется на стороне декодера 150, как показано на фиг.1. При восстановлении данных обратная матрица M-1 (обратное преобразование 170-171) применяется в качестве множителя к данным области преобразования. Когда применено к данным области преобразования, обратное преобразование приближенно восстанавливает исходные цифровые аудиовизуальные данные временной области или пространственной области.
Во многих приложениях кодирования на основе блочного преобразования преобразование желательно обратимое, чтобы поддерживать кодирование как с потерями, так и без потерь, в зависимости от коэффициента квантования. При отсутствии квантования (обычно представляемого как коэффициент квантования 1), например, кодек, использующий обратимое преобразование, может точно воспроизводить входные данные при декодировании. Тем не менее, требование обратимости в этих приложениях ограничивает выбор преобразований, на основе которых может быть разработан кодек.
Многие системы сжатия изображений и видео, такие как MPEG и Windows Media, помимо прочих, используют преобразования на основе дискретного косинусного преобразования (DCT). DCT, как известно, имеет подходящие свойства энергетического сжатия, что приводит к практически оптимальному сжатию данных. В этих системах сжатия обратное DCT (IDCT) используется в циклах восстановления как в кодере, так и в декодере системы сжатия для восстановления отдельных блоков изображений.
Статистическое кодирование коэффициентов преобразования с большим диапазоном
Входные данные с большим динамическим диапазоном приводят к коэффициентам преобразования с еще более большим динамическим диапазоном, сформированным в процессе кодирования изображения. Например, коэффициенты преобразования, сформированные посредством DCT-операции N на N, имеют динамический диапазон, превышающий более чем в N раз динамический диапазон исходных данных. При небольших или единичных коэффициентах квантования (используемых для того, чтобы реализовать сжатие с малыми потерями или без потерь) диапазон квантованных коэффициентов преобразования также большой. Статистически, эти коэффициенты имеют большое распределение Лапласа, как показано на фиг.2 и 3. Фиг.2 иллюстрирует распределение Лапласа для коэффициентов с большим динамическим диапазоном. Фиг.3 иллюстрирует распределение Лапласа для типичных коэффициентов с узким динамическим диапазоном.
Традиционное кодирование с преобразованием настроено для небольшого динамического диапазона входных данных (типично 8 битов) и относительно больших квантователей (таких как числовые значения в 4 и выше). Следовательно, фиг.3 иллюстрирует распределение коэффициентов преобразования в этом традиционном кодировании с преобразованием. Дополнительно, статистическое кодирование, используемое с этим традиционным кодированием с преобразованием, может быть вариантом кодирования уровня серии, где последовательность нулей кодируется вместе с ненулевым символом. Это может быть эффективным средством того, чтобы представлять серии нулей (которые возникают с высокой вероятностью), а также фиксирования межсимвольных корреляций.
С другой стороны, традиционное кодирование с преобразованием менее подходит для сжатия распределений с большим динамическим диапазоном, таких как показанное на фиг.2. Хотя символы являются нулями с более высокой вероятностью, чем любое другое значение (т.е. распределение имеет максимум на нуле), вероятность того, что коэффициент является точно нулем, очень мала для распределения с большим динамическим диапазоном. Следовательно, нули не возникают часто, и методики статистического кодирования на основе длин серий, которые базируются на числе нулей между последовательными ненулевыми коэффициентами, очень неэффективны для входных данных с большим динамическим диапазоном.
Распределение с большим динамическим диапазоном также имеет расширенный символьный алфавит в сравнении с распределением с узким диапазоном. Вследствие этого расширенного символьного алфавита таблица(ы) энтропии, используемая для того, чтобы кодировать символы, должна быть большой. В противном случае, многие в итоге кодируются переходом, что является неэффективным. Таблицы большего размера требуют больше памяти и могут также приводить к большей сложности.
Следовательно, традиционное кодирование с преобразованием не имеет гибкости, работая хорошо для входных данных с распределением с небольшим динамическим диапазоном, но не оптимально для распределения с большим динамическим диапазоном.
Тем не менее, для данных с небольшим диапазоном нахождение эффективного статистического кодирования квантованных коэффициентов преобразования является важнейшим процессом. Любой прирост производительности, который может быть достигнут на этом этапе (прирост и в отношении эффективности сжатия, и в отношении скорости кодирования/декодирования), превращается в общее повышение качества.
Различные схемы статистического кодирования помечены посредством их возможности успешно использовать преимущество таких раздельных критериев эффективности, как: применение контекстной информации, более сильное сжатие (например, арифметическое кодирование), меньшие вычислительные требования (такие, которые приводятся в методиках кодирования Хаффмана) и использование лаконичного набора кодовых таблиц, чтобы минимизировать использование дополнительной памяти кодера/декодера. Традиционные способы статистического кодирования, которые не удовлетворяют всем этим признакам, не демонстрируют полной эффективности кодирования коэффициентов преобразования.
Сущность изобретения
Методика кодирования и декодирования цифрового мультимедиа и реализация методики в цифровом мультимедийном кодеке, описываемом в данном документе, достигает более эффективного сжатия коэффициентов преобразования. Например, один примерный, основанный на блочном преобразовании, цифровой мультимедийный кодек, проиллюстрированный в данном документе, более эффективно кодирует коэффициенты преобразования посредством совместного кодирования ненулевых коэффициентов с последующими сериями коэффициентов с нулевыми значениями. Когда ненулевые коэффициенты являются последними в своем блоке, последний индикатор заменяется на значение серии в символе этого коэффициента. Начальные ненулевые коэффициенты указываются в специальном символе, который совместно кодирует ненулевой коэффициент вместе с начальными и последующими сериями нулей.
Примерный кодек допускает множество контекстов кодирования посредством обнаружения разрывов в сериях ненулевых коэффициентов и кодирования ненулевых коэффициентов на какой-либо стороне этого разрыва отдельно. Дополнительные контексты предоставляются посредством переключения контекста на основе внутренних, промежуточных и внешних преобразований, а также посредством переключения контекста на основе того, соответствуют ли преобразования каналам яркости или цветности. Это дает возможность кодовым таблицам иметь меньшую энтропию без создания такого большого числа контекстов, чтобы снижать их полезность.
Примерный кодек также уменьшает размер кодовой таблицы посредством указания в каждом символе того, имеет ли ненулевой коэффициент абсолютное значение больше 1, и имеют ли серии нулей положительные значения, и отдельно кодирует уровень коэффициентов и длину серий вне символов. Кодек может использовать преимущество переключения контекста для этих отдельно закодированных серий и уровней.
Различные методики и средства могут быть использованы в комбинации или независимо.
Данный раздел предусмотрен для того, чтобы в упрощенной форме представить набор идей, которые дополнительно описываются ниже в подробном описании. Этот раздел не предназначен для того, чтобы идентифицировать ключевые признаки или важнейшие признаки заявляемого предмета изобретения, а также не предназначен для того, чтобы быть использованным в качестве помощи при определении области применения заявляемого предмета изобретения.
Дополнительные признаки и преимущества должны стать очевидными из последующего подробного описания вариантов осуществления, которое осуществляется со ссылками на прилагаемые чертежи.
Краткое описание чертежей
Фиг.1 - это блок-схема традиционного, основанного на блочном преобразовании, кодека в предшествующем уровне техники.
Фиг.2 - это гистограмма, показывающая распределение коэффициентов преобразования, имеющих большой динамический диапазон.
Фиг.3 - это гистограмма, показывающая распределение коэффициентов преобразования с небольшим диапазоном.
Фиг.4 - это блок-схема типичного кодера, содержащего адаптивное кодирование коэффициентов с большим диапазоном.
Фиг.5 - это блок-схема типичного декодера, содержащего декодирование адаптивно кодированных коэффициентов с большим диапазоном.
Фиг.6 - это блок-схема, иллюстрирующая группировку и разбиение на уровни коэффициента преобразования при адаптивном кодировании коэффициентов с большим диапазоном, как, например, в кодере согласно фиг.4.
Фиг.7 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством кодера, согласно фиг.4, для того, чтобы кодировать коэффициент преобразования для выбранной группировки коэффициентов преобразования в контейнерах.
Фиг.8 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством кодера, согласно фиг.5, для того, чтобы восстановить коэффициент преобразования, закодированный посредством процесса согласно фиг.7.
Фиг.9 - это блок-схема последовательности операций способа, иллюстрирующая процесс адаптации для адаптивного варьирования группировки, согласно фиг.6, чтобы сформировать более оптимальное распределение для статистического кодирования коэффициентов.
Фиг.10 и 11 - это распечатка псевдокода процесса адаптации по фиг.9.
Фиг.12 иллюстрирует примеры кодированных коэффициентов преобразования в предшествующем уровне техники.
Фиг.13 иллюстрирует один пример коэффициентов преобразования, кодированных согласно методикам кодирования, описанным в данном документе.
Фиг.14 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством кодера, согласно фиг.4, чтобы кодировать коэффициенты преобразования.
Фиг.15 иллюстрирует примеры различных контекстов кодовых таблиц, используемых для того, чтобы кодировать коэффициенты преобразования согласно методикам, описанным в данном документе.
Фиг.16 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством кодера, согласно фиг.4, чтобы определять контексты кодирования, которые должны быть использованы при кодировании коэффициентов преобразования.
Фиг.17 иллюстрирует пример сокращенных коэффициентов преобразования, кодированных согласно методикам кодирования, описанным в данном документе.
Фиг.18 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством кодера, согласно фиг.4, чтобы кодировать и отправлять начальные коэффициенты преобразования в сокращенной форме.
Фиг.19 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством кодера, согласно фиг.4, чтобы кодировать и отправлять последующие коэффициенты в сокращенной форме.
Фиг.20 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством декодера, согласно фиг.5, чтобы декодировать кодированные коэффициенты преобразования.
Фиг.21 - это блок-схема последовательности операций способа, иллюстрирующая процесс посредством декодера, согласно фиг.5, чтобы декодировать кодированные коэффициенты преобразования.
Фиг.22 - это блок-схема подходящего вычислительного окружения для реализации адаптивного кодирования коэффициентов с большим диапазоном согласно фиг.6.
Подробное описание изобретения
Нижеприведенное описание относится к методикам кодирования и декодирования, которые адаптивно приспособлены для более эффективного статистического кодирования коэффициентов преобразования с большим диапазоном, а также для более эффективного кодирования коэффициентов преобразования в общем. Нижеприведенное описание поясняет примерную реализацию методики в контексте системы или кодека сжатия цифрового мультимедиа. Цифровая мультимедийная система кодирует цифровые мультимедийные данные в сжатую форму для передачи или хранения и декодирует данные для воспроизведения или другой обработки. В целях иллюстрации, эта примерная система сжатия, содержащая данное адаптивное кодирование коэффициентов с большим диапазоном, является системой сжатия изображений или видео. Альтернативно, методика также может быть включена в системы сжатия или кодеки для других двухмерных данных. Адаптивное кодирование коэффициентов с большим диапазоном не требует того, чтобы система сжатия цифрового мультимедиа кодировала сжатые цифровые мультимедийные данные в конкретном формате кодирования.
1. Кодер/декодер
Фиг.4 и 5 - это обобщенные схемы процессов, используемых в типичном двумерном (2D) кодере 400 и декодере 500 данных. Схемы представляют обобщенную или упрощенную иллюстрацию системы сжатия, включающей кодер и декодер двумерных данных, которые реализуют адаптивное кодирование на основе коэффициентов с большим диапазоном. В альтернативных системах сжатия, использующих адаптивное кодирование на основе коэффициентов с большим диапазоном, дополнительное или меньшее число процессов, чем проиллюстрировано в типичном кодере и декодере, может быть использовано для сжатия двумерных данных. Например, некоторые кодировщики/декодеры также могут включать в себя цветовое преобразование, цветовые форматирования, масштабируемое кодирование, кодирование без потерь, режимы макроблока и т.д. Система сжатия (кодировщик и декодер) может обеспечивать кодирование без потерь и/или с потерями 2D-данных, в зависимости от квантования, которое может быть основано на параметре квантования, изменяющемся от «без потерь» до «с потерями».
Кодер 400 2D-данных вырабатывает сжатый битовый поток 420, который является более компактным представлением (для типичного ввода) 2D-данных 410, представленных в качестве входных данных кодировщику. Например, входным сигналом 2D-данных может быть изображение, кадр видеопоследовательности или другие данные, имеющие два измерения. Кодировщик 2D-данных фрагментирует 430 входные данные на макроблоки, которые имеют размер 16×16 пикселей в этом иллюстративном кодировщике. Кодер 2D-данных дополнительно фрагментирует макроблок на блоки 4×4. Оператор 440 "прямого перекрытия" применяется к каждому краю между блоками, после чего каждый блок 4×4 преобразуется с помощью блочного преобразования 450. Этим блочным преобразованием 450 может быть обратимое безразмерное двумерное преобразование, описанное в Патентной заявке номер 11/015707 (США) Srinivasan, озаглавленной "Reversible Transform For Lossy And Lossless 2-D Data Compression", зарегистрированной 17 декабря 2004 года. Оператор перекрытия 440 может быть оператором обратимого перекрытия, который подробно описан Tu et al. Патентная заявка (США) номер 11/015148, озаглавленная "Reversible Overlap Operator for Efficient Lossless Data Compression", зарегистрированная 17 декабря 2004 года; и Tu et al., Патентная заявка (США) номер 11/035991, озаглавленная "Reversible 2-Dimensional Pre-/Post-Filtering For Lapped Biorthogonal Transform", зарегистрированная 14 января 2005 года. В качестве альтернативы, могут быть использованы дискретное косинусное преобразование или другие блочные преобразования и операторы перекрытия. Вслед за преобразованием, DC-коэффициент 460 каждого блока 4×4 преобразования подвергается аналогичной цепочке обработки (разбиению, прямому перекрытию, сопровождаемому блочным преобразованием 4×4). Результирующие DC-коэффициенты преобразования и AC-коэффициенты квантуются 470, статистически кодируются 480 и пакетируются 490.
Декодер выполняет обратную последовательность операций. На стороне декодера биты коэффициентов преобразования извлекаются 510 из их соответствующих пакетов, из которых декодируются 520 и деквантуются 530 сами коэффициенты. DC-коэффициенты 540 регенерируются посредством применения обратного преобразования, и плоскость DC-коэффициентов «инверсно перекрывается» с использованием подходящего сглаживающего оператора, применяемого по границам DC-блоков. В дальнейшем все данные регенерируются посредством применения обратного преобразования 550 4×4 к DC-коэффициентам, и AC-коэффициенты 542 декодируются из потока битов. В заключение, границы блока в плоскостях результирующего изображения фильтруются 560 с обратным перекрытием. Это вырабатывает выходной сигнал восстановленных 2D-данных.
В примерной реализации кодер 400 (фиг.4) сжимает входное изображение в сжатый поток 420 битов (к примеру, файл), а декодер 500 (фиг.5) восстанавливает исходные входные данные или их приближение на основе того, какое кодирование (с потерями или без потерь) используется. Процесс кодирования влечет за собой применение прямого перекрывающегося преобразования (LT), описанного ниже, которое реализовано с помощью обратимой двумерной предварительной/пост-фильтрации, также более подробно описанной ниже. Процесс декодирования влечет за собой применение обратного перекрывающегося преобразования (ILT) с использованием обратимой двумерной предварительной/пост-фильтрации.
Проиллюстрированные LT и ILT являются инверсиями друг друга, в точном смысле, и поэтому вместе могут быть названы как обратимое перекрывающееся преобразование. В качестве обратимого преобразования пара LT/ILT может быть использована для сжатия изображений без потерь.
Входными данными 410, сжатыми проиллюстрированным кодером 400/декодером 500, могут быть изображения различных форматов цветов (к примеру, форматы цветных изображений RGB/YUV4:4:4, YUV4:2:2 или YUV4:2:0). Типично, входное изображение всегда имеет компонент яркости (Y). Если оно является изображением RGB/YUV4:4:4, YUV4:2:2 или YUV4:2:0, изображение также имеет компоненты цветности, такие как компонент U и компонент V. Отдельные цветовые плоскости или компоненты изображения могут иметь различные пространственные разрешения. В случае входного изображения, например, в формате цвета YUV 4:2:0, компоненты U и V имеют половину ширины и высоты компонента Y.
Как описано выше, кодер 400 разбивает входное изображение или рисунок на макроблоки. В примерной реализации кодер 400 разбивает входное изображение на макроблоки 16×16 в канале Y (которыми могут быть области 16×16, 16×8 или 8×8 в каналах U и V, в зависимости от формата цвета). Цветовая плоскость каждого макроблока разбита на зоны или блоки 4×4. Поэтому макроблок составляется для различных форматов цвета следующим образом для этой примерной реализации кодера:
1. Для изображения по шкале серого каждый макроблок содержит 16 блоков яркости (Y) 4×4.
2. Для изображения формата цвета YUV4:2:0 каждый макроблок содержит 16 блоков Y 4×4 и по 4 блока цветности (U и V) 4×4.
3. Для изображения формата цвета YUV4:2:2 каждый макроблок содержит 16 блоков Y 4×4 и по 8 блоков цветности (U и V) 4×4.
4. Для цветного изображения RGB или YUV4:4 каждый макроблок содержит 16 блоков каждого из каналов Y, U и V.
2. Адаптивное кодирование коэффициентов с большим диапазоном
В случае данных с большим динамическим диапазоном, в частности, декоррелированных данных преобразования (таких как коэффициенты 460, 462 в кодере по фиг.4) значительное количество битов младшего порядка являются непрогнозируемыми и "шумовыми". Другими словами, есть немного корреляции в битах младшего порядка, которые могут быть использованы для эффективного статистического кодирования. Эти биты имеют высокую энтропию, достигающую 1 бита для каждого кодированного бита.
2.1. Группировка
Дополнительно, функция Лапласа распределения вероятностей коэффициентов преобразования с большим диапазоном, показанных на фиг.3, задается посредством:
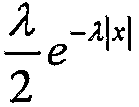
(для удобства произвольная переменная, соответствующая коэффициентам преобразования, трактуется как непрерывное значение). Для данных с большим динамическим диапазоном λ является небольшим, а абсолютное среднее 1/λ является большим. Кривая этого распределения ограничена рамками ±Ѕ(λ2), что является очень небольшим. Это означает, что вероятность равенства коэффициента преобразования x очень близка к вероятности x+ξ для небольшого сдвига ξ. В дискретной области значений это преобразуется в утверждение "вероятность принятия коэффициентами преобразования соседних значений j и (j+1) является практически идентичной".
Со ссылкой теперь на фиг.6, адаптивное кодирование коэффициентов с большим диапазоном осуществляет группировку 610 последовательных символов алфавита в "контейнеры" по N символов. Числом символов на контейнер может быть любое число N. Тем не менее, для практичности число N желательно является степенью 2 (т.е. N=2k), так чтобы индекс или адрес коэффициента в контейнере могли быть закодированы эффективно как код фиксированной длины. Например, символы могут быть сгруппированы в пары, так чтобы символ мог быть идентифицирован как индекс пары, наряду с индексом символа в паре.
Данная группировка имеет преимущество в том, что при надлежащем выборе N распределение вероятностей индекса контейнера для коэффициентов с большим диапазоном в большей степени напоминает распределение вероятностей данных с небольшим диапазоном, к примеру, показанных на фиг.3. Эта группировка математически аналогична операции квантования. Это означает то, что индекс контейнера может быть эффективно кодирован с помощью методик статистического кодирования переменной длины, которые лучше всего работают с распределением вероятностей с узким диапазоном.
На основе группировки коэффициентов в контейнеры кодер затем может закодировать коэффициент 615 преобразования с помощью индекса его контейнера (также упоминаемого в данном документе как нормализованный коэффициент 620) и его адреса внутри контейнера (также упоминаемого в данном документе как адрес 625 контейнера). Нормализованный коэффициент кодируется с помощью статистического кодирования переменной длины, при этом адрес контейнера кодируется посредством кода фиксированной длины.
Выбор N (или эквивалентно, число битов k для кодирования фиксированной длины адреса контейнера) определяет детальность группировки. В общем, чем больше диапазон коэффициентов преобразования, тем больше значение k должно быть выбрано. Когда k тщательно подобрано, нормализованный коэффициент Y равен нулю с высокой вероятностью, что соответствует схеме статистического кодирования для Y.
Как описано ниже, значение k может варьироваться адаптивно (обратно адаптивным способом) в кодере и декодере. Более конкретно, значение k в кодере и декодере варьируется только на основе ранее кодированных/декодированных данных.
В одном конкретном примере данного кодирования, показанном на фиг.7, кодер кодирует коэффициент преобразования X следующим образом. На начальном этапе 710 кодер вычисляет нормализованный коэффициент Y для коэффициента преобразования. В этой примерной реализации нормализованный коэффициент Y задается как Y=sign(X)*floor(abs(X)/N) для некоторого варианта размера контейнера N=2k. Кодер кодирует символ Y с помощью статистического кода (этап 720) либо отдельно, либо вместе с другими символами. Далее на этапе 730 кодер определяет адрес контейнера (Z) коэффициента преобразования X. В этой примерной реализации адрес контейнера является остатком от деления нацело abs(X) на размер N, или Z=abs(X)%N. Кодер кодирует это значение как код фиксированной длины из k на этапе 740. Дополнительно, в случае ненулевого коэффициента преобразования кодер также кодирует знак. Более конкретно, как указано на этапах 750-760, кодер кодирует знак нормализованного коэффициента (Y), когда нормализованный коэффициент является ненулевым. Дополнительно, в случае если нормализованный коэффициент является нулевым, а коэффициент преобразования является нулевым, кодер кодирует знак коэффициента преобразования (X). Поскольку нормализованный коэффициент кодируется с помощью статистического кода переменной длины, он также упоминается в данном документе как часть переменной длины, а адрес контейнера (Z) также упоминается в данном документе как часть фиксированной длины. В других альтернативных реализациях математические определения нормализованного коэффициента, адреса контейнера и знака коэффициента преобразования могут варьироваться.
Продолжая этот пример, фиг.8 иллюстрирует примерный процесс 800 посредством декодера 500 (фиг.5), чтобы восстановить коэффициент преобразования, который кодирован посредством процесса 700 (фиг.7). На этапе 810 декодер декодирует нормализованный коэффициент (Y) из сжатого потока 420 битов 420 (фиг.5) либо отдельно, либо вместе с другими символами, как задано в процессе блочного кодирования. Декодер дополнительно считывает k-битовое кодовое слово для адреса контейнера и знак (когда кодирован) из сжатого потока битов на этапе 820. На этапах 830-872 декодер после этого восстанавливает коэффициент преобразования следующим образом:
1. Когда Y>0 (этап 830), то коэффициент преобразования восстанавливается как X=Y*N+Z (этап 831).
2. Когда Y<0 (этап 840), то коэффициент преобразования восстанавливается как X=Y*N-Z (этап 841).
3. Когда Y=0 и Z=0 (этап 850), то коэффициент преобразования восстанавливается как X=0 (этап 851).
4. Когда Y=0 и Z≠0, декодер дополнительно считывает кодированный знак (S) из сжатого потока битов (этап 860). Если знак положительный (S=0) (этап 870), то коэффициент преобразования восстанавливается как X=Z (этап 871). Иначе, если знак отрицательный (S=1), коэффициент преобразования восстанавливается как X=-Z (этап 872).
2.2. Разбиение на уровни
Со ссылкой снова на фиг.6, кодер и декодер желательно абстрагируют адреса 625 контейнеров с кодированием с фиксированной длиной и знак в отдельный кодированный уровень (называемый в данном документе как уровень 645 Flexbits) в сжатый поток битов 420 (фиг.4). Нормализованные коэффициенты 620 кодируются на уровне базового потока 640 битов. Это предоставляет кодеру и/или декодеру возможность понижать уровень или полностью отбрасывать эту часть Flexbits кодирования, как требуется, чтобы удовлетворить скорости передачи битов или другим ограничениям. Даже при полном отбрасывании кодером уровня Flexbits сжатый поток битов по-прежнему должен декодироваться, хотя и при сниженном качестве. Декодер по-прежнему может восстановить сигнал только из части нормализованных коэффициентов. Это фактически аналогично применению большей степени квантования 470 (фиг.4) в кодере. Кодирование адресов контейнеров и знака как отдельного уровня Flexbits также имеет потенциальное преимущество в том, что в некоторых реализациях кодера/декодера дополнительное кодирование с переменной длиной (к примеру, арифметическое кодирование, Lempel-Ziv, Burrows-Wheeler и т.д.) может быть применено к данным на этом уровне для дополнительного улучшенного сжатия.
Для разбиения на уровни секции сжатого потока битов, содержащие часть Flexbits, передаются посредством отдельного заголовка уровня или другого индикатора в потоке битов, с тем чтобы декодер мог идентифицировать и отделить (т.е. проанализировать) уровень 645 Flexbits (когда не опущен) от базового потока битов 640.
Разбиение на уровни представляет дополнительную сложную задачу при проектировании обратно совместимой группировки (описанной в следующем разделе). Поскольку уровень Flexbits может присутствовать или отсутствовать в данном потоке битов, модель обратно адаптивной группировки не может надежно ссылаться на какую-либо информацию в уровне Flexbits. Вся информация, требуемая для того, чтобы определять число битов кода фиксированной длины k (соответствующих размеру контейнера N=2k), должна размещаться в причинном базовом потоке битов.
2.3. Адаптация
Кодер и декодер дополнительно предоставляют процесс обратной адаптации, чтобы адаптивно регулировать выбор числа k битов кода фиксированной длины, и соответственно, размер контейнера N группировки, описанной выше, в ходе кодирования и декодирования. В одной реализации процесс адаптации может быть основан на моделировании коэффициентов преобразования как распределения Лапласа, с тем чтобы значение k извлекалось из параметра λ Лапласиана. Тем не менее, такая усложненная модель должна потребовать, чтобы декодер выполнил инверсию группировки 610 (восстановление коэффициентов преобразования из нормализованных коэффициентов в базовом потоке 640 битов и адреса контейнера/знака в уровне 645 Flexbits) по фиг.6 для моделирования распределения для будущих блоков. Это требование должно нарушить ограничение разбиения на уровни в том, что декодер должен разрешить отбрасывание уровня Flexbits из сжатого потока 420 битов.
В примерной реализации, показанной на фиг.9, процесс 900 адаптации вместо этого базируется на наблюдении того, что более оптимальное кодирование длин серий коэффициентов преобразования достигается, когда примерно одна четверть коэффициентов являются ненулевыми. Таким образом, параметр адаптации, который может быть использован для того, чтобы подстроить группировку под ситуацию "зоны наилучшего восприятия", где примерно три четвери нормализованных коэффициентов равны нулю, предоставляет оптимальную производительность статистического кодирования. Соответственно, число ненулевых нормализованных коэффициентов в блоке используется в качестве параметра адаптации в примерной реализации. Данный параметр адаптации имеет преимущество в том, что он зависит только от информации, содержащейся в базовом потоке битов, который удовлетворяет ограничению разбиения на уровни в том, что коэффициенты преобразования по-прежнему могут быть декодированы с пропущенным уровнем Flexbits. Данный процесс является обратной адаптацией в том смысле, что модель адаптации, применяемая при кодировании/декодировании текущего блока, основана на информации из предыдущего блока(ов).
В своем процессе адаптации примерный кодер и декодер выполняет адаптацию на основе обратной адаптации. Т.е. текущая итерация адаптации основана на информации, ранее обнаруженной в процессе кодирования или декодирования, например, в предыдущем блоке или макроблоке. В примерном кодере и декодере обновление адаптации осуществляется один раз на макроблок для данной полосы преобразования, что предназначено для того, чтобы минимизировать запаздывание и перекрестную зависимость. Альтернативные реализации кодека могут выполнять адаптацию с различными интервалами, например, после каждого блока преобразования.
В примерном кодере и декодере процесс 900 адаптации обновляет значение k. Если число ненулевого нормализованного коэффициента слишком большое, то k повышается так, что это число зачастую отбрасывается в будущих блоках. Если число ненулевых нормализованных коэффициентов слишком мало, то k снижается с ожиданием того, что будущие блоки затем сформируют больше ненулевых нормализованных коэффициентов, поскольку размер контейнера N меньше. Примерный процесс адаптации ограничивает значение k так, чтобы быть в наборе чисел (0, 1,…, 16), но альтернативные реализации могут использовать другие диапазоны значений k. При каждом обновлении адаптации кодер и декодер увеличивает, уменьшает или оставляет неизменным k. Примерный кодер и декодер увеличивает или уменьшает k на единицу, но альтернативные реализации могут использовать другие размеры шагов.
Процесс 900 адаптации в примерном кодере и декодере дополнительно использует внутренний параметр модели или переменную состояния (M), чтобы управлять обновлением параметра группировки k с эффектом гистерезиса. Этот параметр модели предоставляет задержку до обновления параметра группировки k, с тем чтобы не допустить вызывания быстрого колебания параметра группировки. Параметр модели в этом примерном процессе адаптации имеет 17 целых шагов, от -8 до 8.
Со ссылкой теперь на фиг.9, примерный процесс 900 адаптации продолжается следующим образом. Этот примерный процесс адаптации подробнее показан в распечатке псевдокода по фиг.10 и 11. Как указано на этапах 910, 990, процесс адаптации в примерном кодере и декодере выполняется отдельно в каждом диапазоне преобразования, представляемом в сжатом потоке битов, включающем в себя диапазон яркости и диапазон цветности, AC- и DC-коэффициенты и т.д. Альтернативные кодеки могут варьироваться по числу полос преобразования и дополнительно могут применять адаптацию отдельно или совместно к диапазонам преобразования.
На этапе 920 процесс адаптации затем подсчитывает число ненулевых нормализованных коэффициентов диапазона преобразования в рамках непосредственно перед этим кодированным/декодированным макроблоком. На этапе 930 этот необработанный показатель нормализуется так, чтобы отражать округленное до целого число ненулевых коэффициентов в зоне с обычным размером. Процесс адаптации далее вычисляет (этап 940) отклонение показателя от требуемой модели (т.е. "зону наилучшего восприятия" одной четверти коэффициентов, являющихся ненулевыми). Например, макроблок AC-коэффициентов в примерном кодере, показанном на фиг.4, имеет 240 коэффициентов. Таким образом, требуемая модель служит для 70 из 240 коэффициентов, которые должны быть ненулевыми. Отклонение дополнительно масштабируется, ограничивается порогами и используется для того, чтобы обновлять внутренний параметр модели.
На следующих этапах 960, 965, 970, 975 процесс адаптации затем адаптирует значение k согласно любому изменению во внутреннем параметре модели. Если параметр модели меньше отрицательного порога, значение k уменьшается (в рамках допустимых пределов). Эта адаптация должна формировать больше ненулевых коэффициентов. С другой стороны, если параметр модели превышает положительный порог, значение k увеличивается (в рамках допустимых пределов). Такая адаптация должна формировать меньше ненулевых коэффициентов. В противном случае значение k остается неизмененным.
Помимо этого, как указано на этапах 910, 980, процесс адаптации повторяется отдельно для каждого канала и субполосы данных, например, отдельно для каналов цветности и яркости.
Примерный процесс 900 адаптации подробнее показан в распечатке 1000 псевдокода, проиллюстрированной на фиг.10 и 11.
3. Эффективное статистическое кодирование
3.1. Способы предшествующего уровня техники
В различных стандартах кодирования процесс кодирования блоков преобразования сводится к кодированию строки коэффициентов. Один пример такой строки предоставлен на фиг.12 как пример 1200 коэффициентов преобразования. В примере 1200 коэффициенты C0, C1, C2, C3 и C4 представляют четыре ненулевых значения коэффициентов (с положительным или отрицательным знаком), тогда как другие коэффициенты в последовательности имеют значение нуль.
Некоторые свойства традиционно предназначены для такой строки коэффициентов преобразования:
- общее число коэффициентов типично является детерминированным и задается посредством размера преобразования;
- в вероятностном смысле большое число коэффициентов равно нулю;
- по меньшей мере, один коэффициент является ненулевым; в случае, когда все коэффициенты являются ненулевыми, этот случай типично сообщается посредством шаблона кодированных блоков, таких как описанные в Srinivasan, Патентная заявка (США) номер TBD, "Non-Zero Coefficient Block Pattern Coding", зарегистрированная 12 августа 2005 года;
- в вероятностном смысле ненулевые коэффициенты и коэффициенты с большими значениями появляются в начале строки, а нули и коэффициенты с меньшими значениями появляются к концу;
- ненулевые коэффициенты принимают целевые значения с известным минимумом/максимумом.
Различные методики кодирования используют преимущество того факта, что коэффициенты с нулевыми значениями, которые типично появляются достаточно часто, могут быть кодированы с помощью кодов на основе длин серий. Тем не менее, когда кодируемое входное изображение является данными с высоким динамическим диапазоном (к примеру, более 8 битов) или когда параметр квантования является единичным либо небольшим, меньше коэффициентов преобразования равно нулю, как описано выше. В этой ситуации методики адаптивного кодирования и декодирования, описанные выше, могут быть использованы для того, чтобы приводить в требуемое состояние данные так, чтобы приведенные в требуемое состояние данные имели эти характеристики. Другие методики также могут формировать наборы коэффициентов преобразования, аналогичные наборам примера 1200 коэффициентов преобразования, другим способом, например посредством задания высокого уровня квантования.
Фиг.12 также иллюстрирует два способа кодирования коэффициентов преобразования, например, в примере 1200 коэффициентов преобразования. Эти способы используют преимущество совместного кодирования серии нулей вместе с последующим ненулевым коэффициентом, чтобы предоставить преимущество кодирования. Пример 1220 двухмерного кодирования демонстрирует одну методику для такой схемы кодирования уровня серий. Пример 1220 иллюстрирует то, что при двухмерном кодировании серия коэффициентов с нулевыми значениями (серия имеет либо длину нуль, либо положительную длину) кодируется вместе как символ 1225 с последующим ненулевым коэффициентом в последовательности коэффициентов преобразования; в проиллюстрированном случае символ <0, C0> указывает то, что нули предшествуют ненулевому коэффициенту C0. Специальный символ 1235, называемый "окончанием блока", или EOB, используется для того, чтобы передать последнюю серию нулей. Это типично называется двухмерным кодированием, поскольку каждый символ совместно кодирует серию (серию коэффициентов с нулевым значением) и уровень (значение ненулевого коэффициента), а следовательно, имеет два значения и может считаться кодированием двух измерений данных коэффициентов преобразования. Эти символы затем могут быть статистически кодированы с помощью кодов Хаффмана или арифметического кодирования и отправлены в сжатый поток 420 битов по фиг.4.
Другой альтернативной схемой кодирования является трехмерное кодирование, пример которого проиллюстрирован в примере 1240. При трехмерном кодировании серия нулей типично кодируется совместно с последующим ненулевым коэффициентом, как в двухмерном кодировании. Дополнительно, элемент булевых данных, "last", указывающий то, является ли данный ненулевой коэффициент последним ненулевым коэффициентом в блоке, кодируется. Следовательно, символ 1245 совместно кодирует серию, уровень и последний; в проиллюстрированном случае символ <2, C1, not last> указывает то, что два нуля предшествуют ненулевому коэффициенту C1, а также то, что он не последний ненулевой коэффициент в последовательности. Поскольку каждый из этих элементов свободно может принимать все значения, символ кодирует три независимых изменения, приводя к названию "трехмерное кодирование".
Каждая из этих методик имеет несколько преимуществ. Каждый символ в методике двухмерного кодирования имеет меньшую энтропию, чем символ, используемый в трехмерном кодировании, поскольку первое переносит меньше информации, чем второе. Таким образом, число положительных символов в данной схеме трехмерного кодирования в два раза превышает сравнимую схему двухмерного кодирования. Это увеличивает размер кодовой таблицы и может замедлять кодирование и декодирование для схемы трехмерного кодирования. Тем не менее, при двухмерном кодировании дополнительный символ отправляется для того, чтобы сообщить окончание блока, и необходимость отправки целого дополнительного символа является затратной с точки зрения размера потока битов. Фактически, на практике трехмерное кодирование является более эффективным, чем двухмерное кодирование, несмотря на больший размер кодовых таблиц.
3.2. 3-2-мерное кодирование
Хотя методики предшествующего уровня техники, проиллюстрированные на фиг.12, используют совместное кодирование уровней ненулевых коэффициентов наряду с предшествующими сериями нулей, может быть продемонстрировано то, что серия нулей, следующая после ненулевого коэффициента, показывает сильную корреляцию с величиной ненулевого коэффициента. Это свойство предоставляет полезность совместного кодирования уровня и последующей серии.
Фиг.13 демонстрирует одну такую альтернативную методику кодирования, которая улучшается для методик двухмерного или трехмерного кодирования, проиллюстрированных на фиг.12. Фиг.13 иллюстрирует пример 1340 схемы кодирования, использующей идею кодирования последующих серий нулей для того, чтобы создать символы для примерных последовательностей коэффициентов 1300 преобразования. Фиг.13 иллюстрирует то, что коэффициенты совместно кодируются в символы 1355, которые содержат значение ненулевого коэффициента наряду с длиной серии нулей, которая следует за ненулевым коэффициентом (если такой имеется) как пара: <уровень, серия>. Таким образом, проиллюстрированный символ 1355, <C1, 4>, совместно кодирует ненулевой коэффициент C1 и четыре коэффициента с нулевым значением, которые идут после него.
Помимо этого, используя преимущество сильной корреляции между ненулевыми коэффициентами и сериями последующих нулей, этот способ предоставляет дополнительное преимущество, когда ненулевой коэффициент является последним ненулевым коэффициентом в блоке, посредством использования специального значения серии, чтобы сообщить о том, что ненулевой коэффициент является последним в последовательности. Таким образом, при совместном кодировании символа посылаемой информацией является значение уровня и еще одно значение, указывающее либо длину серии нулей, либо значение "last". Это проиллюстрировано на фиг.13 посредством символа 1365, <C4, last>, который содержит значение уровня и значение "last" вместо длины серии. Поскольку эти различные ситуации кодируются в одном месте в символы, серия и "last" не являются независимыми; только одно отправляется для каждого символа. Таким образом, размерность символа составляет не 2 и не 3, а нечто среднее между ними. Это кодирование названо как "2-мерное кодирование".
Этот признак 2-мерного кодирования не обязательно требуется для схемы совместного кодирования, которая комбинирует уровни и последующие серии; в альтернативной реализации конечный передаваемый символ может просто кодировать длину конечной серии нулей, хотя это должно быть нежелательным, поскольку это может существенно увеличить размер кодированного потока битов. В другой альтернативе может быть использован EOB-символ, аналогичный используемому в двухмерном кодировании. Тем не менее, как и в трехмерном кодировании, использование в 2-мерном кодировании значения "last" содержит преимущество над двухмерным кодированием в том, что нет необходимости кодировать дополнительный символ, обозначающий окончание блока. Дополнительно, 2-мерное кодирование имеет преимущество над трехмерным кодированием в том, что (1) энтропия каждого символа меньше, чем энтропия последнего, и (2) структура кодовой таблицы первого проще структуры кодовой таблицы последнего. Оба этих преимущества являются результатом того, что 2-мерный код имеет меньше возможностей, чем трехмерный код.
Тем не менее, только 2-мерное кодирование не может описать всю серию коэффициентов преобразования, поскольку оно не предоставляет способ посылать длину серии до первого ненулевого коэффициента. Как проиллюстрировано на фиг.13, для этой цели используется специальный символ 1375, который дополнительно кодирует длину первой серии нулей. Это делает первый символ совместным кодированием first_run, уровня и (серия OR last). На фиг.13 первый символ 1375, <0, C0, 2>, отправляет первую серию (которая равна нулю), уровень первого ненулевого коэффициента и вторую серию (которая равна 2, а первый ненулевой коэффициент не является последним ненулевым коэффициентом в блоке). Поскольку этот символ содержит дополнительную размерность, его кодирование упоминается как "3-мерное кодирование".
Хотя дополнительная информация в 3-мерном кодировании может показаться на первый взгляд как опровергающая некоторые преимущества 2-мерного кодирования, другая обработка первого символа фактически является преимущественной с точки зрения эффективности кодирования. 3-мерный символ обязательно имеет отличный от других алфавит (2-мерных символов), что означает то, что он кодируется отдельно от других символов и не повышает 2-мерную энтропию.
Фиг.14 иллюстрирует примерный процесс 1400 кодера 400 (фиг.4) для того, чтобы кодировать коэффициенты преобразования согласно 2-3-мерному кодированию. В одном окружении процесс 1400 может быт включен как часть процесса 720 по фиг.7 для кодирования нормализованных коэффициентов. В другом процесс 1400 может быть использован для того, чтобы кодировать коэффициенты, которые квантованы посредством традиционных методик. В различных реализациях процесса 1400 этапы могут быть удалены, комбинированы или разбиты на подэтапы.
Процесс начинается на этапе 1420, на котором идентифицируется первый ненулевой коэффициент преобразования. Затем на этапе 1430 3-мерный символ создается с помощью длины начальной серии нулей (которая может быть либо длиной 0, либо положительной длиной) и первого ненулевого коэффициента. В этой точке 3-мерный символ является неполным. Далее процесс переходит к этапу 1435 принятия решения, на котором он определяет то, является ли ненулевой коэффициент, который идентифицирован в данный момент, последним ненулевым коэффициентом в серии коэффициентов преобразования. Если это последний ненулевой коэффициент, процесс переходит к этапу 1480, на котором индикатор "last" вставляется в символ вместо серии последующих нулей. Далее процесс кодирует символ с помощью статистического кодирования на этапе 1490 и процесс завершается. Один пример такого процесса кодирования символов приведен ниже со ссылкой на фиг.16.
Тем не менее, если процесс определяет на этапе 1435 принятия решения то, что это не последний ненулевой коэффициент, то на этапе 1440 длина последующий серии нулей (которая может быть либо 0, либо положительным числом) вставляется в символ, и символ кодируется на этапе 1450. Один пример такого процесса кодирования символов представлен ниже со ссылкой на фиг.16. Процесс далее идентифицирует следующий ненулевой коэффициент на этапе 1460, который, как известно, существует, поскольку определено, что предыдущий ненулевой коэффициент не является последним. На этапе 1470 2-мерный символ далее создается с помощью этого ненулевого коэффициента. В этой точке, аналогично 3-мерному символу выше, символ еще не завершен. Затем на этапе 1475 принятия решения процесс определяет то, является ли текущий ненулевой коэффициент последним в последовательности. Если да, процесс переходит к этапу 1480, на котором включается индикатор "last", и символ кодируется. Если нет, процесс возвращается обратно к этапу 1440, на котором следующая серия нулей включается, символ кодируется и процесс продолжается со следующим ненулевым коэффициентом.
3.3. Контекстная информация
Помимо кодирования символов, согласно 2-мерному и 3-мерному кодированию, несколько фрагментов причинно-следственной информации могут быть использованы для того, чтобы сформировать контекст для кодируемого символа. Этот контекст может быть использован посредством кодера 400 (фиг.4) или декодера 500 (фиг.5) для того, чтобы индексировать в одну из набора таблиц статистического кодирования, чтобы кодировать и декодировать символ. Увеличение числа контекстов предоставляет большую гибкость кодека, чтобы приспосабливать или использовать таблицы, подстроенные под каждый конкретный контекст. Тем не менее, обратной стороной задания большого числа контекстов является то, что (1) есть размывание контекста (при котором каждый контекст применяется только к небольшому числу символов, тем самым снижая эффективность адаптации), и (2) большее число кодовых таблиц означает большую сложность и повышенные требования к памяти.
С учетом этого контекстная модель, описанная в данном документе, выбирается так, чтобы принимать во внимание три фактора для того, чтобы определять то, какой контекст выбирается для каждого символа. В одной реализации этими факторами является (1) уровень преобразования, т.е. то, является ли преобразование внутренним, промежуточным или внешним преобразованием, (2) являются ли коэффициенты для каналов яркости или цветности, и (3) был ли какой-либо разрыв в серии ненулевых коэффициентов в последовательностях коэффициентов. В альтернативных реализациях один или более из этих факторов может не использоваться для определения контекста кодирования и/или могут учитываться другие факторы.
Таким образом, посредством (1) внутреннее преобразование использует набор таблиц, отличный от промежуточного преобразования, которое использует набор таблиц, отличный от внешнего преобразования. В других реализациях контекстные модели могут отличаться только между двумя уровнями преобразования. Аналогично, посредством (2) коэффициенты яркости используют набор таблиц, отличный от коэффициентов цветности. Оба этих фактора контекста не изменяются в данном наборе коэффициентов преобразования.
Тем не менее, фактор (3) изменяется в наборе коэффициентов преобразования. Фиг.15 иллюстрирует три примерные серии коэффициентов преобразования, которые лучше иллюстрируют это переключение контекста. Во всех трех сериях 1500, 1520 и 1540 ненулевые коэффициенты представляются посредством букв.
Как иллюстрируют все три примера, первый символ в блоке, являющийся 3-мерным символом, обязательно кодируется с помощью таблицы, отличной от других символов, поскольку алфавит отличается от других. Это формирует "естественный" контекст для первого символа. Таким образом, коэффициент A, являющийся первым ненулевым коэффициентом во всех трех примерах, кодируется с помощью 3-мерного кода. Дополнительно, поскольку 3-мерный символ кодирует предшествующие и последующие серии нулей вокруг первого ненулевого коэффициента, первые два коэффициента примера 1520 (A, 0) и первые два коэффициента примера 1540 (0, A) совместно кодируются в 3-мерном символе. Благодаря этому в одной реализации фактор (3) не применяется для того, чтобы определять контекст 3-мерных символов.
2-мерные символы, в отличие от этого, кодируются по-другому в зависимости от фактора (3). Таким образом, в примере 1500 можно видеть, что поскольку нет разрыва в серии ненулевых коэффициентов до элемента после коэффициента D, коэффициенты B, C и D (а также все нули, следующие D) кодируются с помощью первой контекстной модели. Тем не менее, нули после D составляют разрыв в серии ненулевых коэффициентов. Следовательно, оставшиеся коэффициенты E, F, G, H (и все последующие)... кодируются с помощью второй контекстной модели. Это означает, что хотя каждый ненулевой коэффициент, отличный от A, кодируется с помощью 2-мерного символа, другие кодовые таблицы должны быть использованы для коэффициентов B, C и D (и всех ассоциативно связанных серий нулевых значений), отличные от используемых для коэффициентов E, F, G и H.
В отличие этого, в примере 1520 есть разрыв между A и B. Он составляет разрыв в серии ненулевых коэффициентов, а следовательно, коэффициент B и все последующие ненулевые коэффициенты кодируются с помощью второй контекстной модели. Аналогично, в примере 1540 есть разрыв перед A. Таким образом, как и в примере 1520, коэффициенты B, C, D,... кодируются с помощью второй контекстной модели.
Фиг.16 иллюстрирует примерный процесс 1600 посредством кодера 400 (фиг.4) для того, чтобы кодировать символ. В одной реализации процесс 1600 осуществляет процесс этапов 1450-1490 процесса 1400 (фиг.14). В различных реализациях процесса 1600 этапы могут быть удалены, комбинированы или разбиты на подэтапы. Процесс начинается на этапе 1605 принятия решения, где кодер определяет то, является ли символ 3-мерным символом. Если да, процесс переходит к этапу 1610, на котором символ кодируется с помощью 3-мерных таблиц, и процесс завершается. В различных реализациях символ может быть кодирован с помощью статистического кодирования, такого как кодирование Хаффмана или арифметическое кодирование. Альтернативно, могут быть использованы другие схемы кодирования.
Если символ не является 3-мерным символом, процесс переходит к этапу 1615 принятия решения, на котором кодер определяет то, предшествовал ли, по меньшей мере, один нуль ненулевому коэффициенту, который совместно кодирован в символе. Если нет, процесс переходит к этапу 1620, на котором символ кодируется с помощью 2-мерных кодовых таблиц из первой контекстной модели, и процесс завершается. Если был разрыв, процесс переходит к этапу 1630, на котором символ кодируется с помощью 2-мерных кодовых таблиц из второй контекстной модели, и процесс завершается.
3.4. Уменьшение размера кодовых таблиц
Хотя вышеописанные методики предоставляют эффективность в сравнении с традиционными методиками, они по-прежнему не могут по собственной инициативе значительно снижать размер кодовых таблиц. Кодовые таблицы, создаваемые для этих методик, должны иметь возможность передавать все комбинации (max_level x (max_run + 2)) для 2-мерных символов и (max_level x (max_run + 1) x (max_run + 2)) для 3-мерных символов, где max_level - это максимальное (абсолютное) значение ненулевого коэффициента, а max_run - это максимальная возможная длина серии нулей. Значение (max_run + 1) извлекается из начальной серии 3-мерного символа, поскольку возможные значения для серии нулей идут от 0 до max_run из общего количества (max_run + 1). Аналогично, каждый символ кодирует последующую серию нулей длины между 0 и max_run, а также символ "last" из общего количества (max_run + 2) значений. Даже при кодировании с переходом (где редко встречающиеся символы сгруппированы в один или несколько метасимволов, сообщаемых посредством кодов перехода) размеры кодовых таблиц могут быть огромными.
Чтобы уменьшить размер кодовых таблиц, вышеописанные методики могут быть дополнительно усовершенствованы. Во-первых, каждая серия и каждый уровень попадают в каждую пару символов:
run = nonZero_run (+ run1)
level = nonOne_level (+ level1)
В этой паре символов символы nonZero_run и nonOne_level являются булевыми, указывая, соответственно, является ли серия больше нуля, а абсолютный уровень больше 1. Значения run1 и level1 используются тогда, когда булевые значения равны истине и указывают серию (между 1 и max_run) и уровень (между 2 и max_level). Тем не менее, поскольку случай "last" также должен быть кодирован, значение (run OR last) любой последующей серии нулей в совместно кодированном символе отправляется как троичный символ nonZero_run_last, который принимает значение 0 - когда серия имеет нулевую длину, 1 - когда серия имеет ненулевую длину, и 2 - когда ненулевой коэффициент символа является последним в последовательности.
Следовательно, чтобы использовать это сокращенное кодирование, первый 3-мерный символ принимает форму <nonZero_run, nonOne_level, nonZero_run_last>. Это создает алфавит размера 2x2x3=12. Последующие 2-мерные символы принимают форму <nonOne_level, nonZero_run_last>, создавая алфавит размера 2x3=6. В одной реализации эти символы упоминаются как "индекс". В некоторых реализациях run1 также называется NonzeroRun, а level1 называется SignificantLevel.
Поскольку индекс содержит только информацию о том, являются ли уровни и серии значительными, может потребоваться отправить дополнительную информацию вместе с символами, чтобы предоставить возможность декодеру точно воссоздать последовательность коэффициентов преобразования. Таким образом, после каждого символа из индекса, если уровень является значительным, значение уровня отдельно кодируется и отправляется после символа. Аналогично, если символ указывает то, что серия нулей имеет ненулевую (положительную) длину, то длина отдельно кодируется и отправляется после символа.
Фиг.17 иллюстрирует пример сокращенного 3-2-мерного кодирования 1740, которое представляет примерную последовательность 1700 абсолютных значений коэффициентов преобразования. Знаки коэффициентов преобразования могут быть кодированы где-либо еще. Как иллюстрирует фиг.17, примерная последовательность коэффициентов 1700 начинается с "5, 0, 0". В несокращенном 3-2-мерном кодировании, как, например, проиллюстрировано выше, первый символ в таком случае должен быть <0, 5, 2>. Тем не менее, в сокращенном кодировании фиг.17 иллюстрирует первый символ 1745 из индекса: <0, 1, 1>. Этот символ указывает то, что нет нулей до первого ненулевого коэффициента, что первый ненулевой коэффициент имеет абсолютное значение 1 и что есть, по меньшей мере, один нуль после этого ненулевого коэффициента. После этого символа далее следует значение SignificantLevel "level_5" (1755), указывающее то, что абсолютное значение ненулевого коэффициента равно 5, и значение NonzeroRun "run_2" (1765), которое указывает то, что два нуля следуют после коэффициента. В отличие от этого символ 1775, <0, 0>, который указывает нулевой коэффициент с абсолютным значением 1, после которого не следуют нули, не требует, чтобы другие значения после него предоставляли информацию.
Поскольку некоторые символы требуют, чтобы дополнительная информация была отправлена после них, символы из индекса должны быть проанализированы, чтобы определить то, должна ли быть отправлена дополнительная информация вместе с ними. Фиг.18 иллюстрирует примерный процесс 1800 посредством кодера 400 (фиг.4) для того, чтобы определять то, какая информация содержится в 3-мерном символе индекса, и отправлять дополнительную информацию при необходимости. В различных реализациях процесса 1800 этапы могут быть удалены, комбинированы или разбиты на подэтапы. В описаниях символов для фиг.18 значение "x" - это заполнитель, представляющий любое возможное значение для этой конкретной части символа. Процесс начинается на этапе 1810, на котором отправляется первый кодированный символ. Далее на этапе 1820 принятия решения кодер определяет то, имеет ли символ форму <x, 1, x>. Это эквивалентно запрашиванию того, имеет ли ненулевой коэффициент, представляемый посредством символа, абсолютное значение больше 1. Если кодер определяет то, что это так, значение ненулевого коэффициента кодируется и отправляется на этапе 1830. Важно отметить то, что хотя фиг.18 не поясняет в явном виде кодирование знака ненулевого коэффициента, этот знак может быть включен в различных точках процесса 1800. В различных реализациях это может повлечь за собой отправку знака сразу после совместно кодированного символа, внутри совместно кодированного символа и/или вместе с абсолютным значением уровня.
Вне зависимости от определения на этапе 1820, на этапе 1840 принятия решения кодер определяет то, имеет ли символ форму <1, x, x>. Данное определение эквивалентно запрашиванию того, имеет ли ненулевой коэффициент, представленный посредством символа, какие-либо предшествующие нули. Если да, на этапе 1850 кодер кодирует длину серии нулей, предшествующих ненулевому коэффициенту, и отправляет это значение.
Затем на этапе 1860 принятия решения кодер рассматривает значение t, где символ - это <x, x, t>. Данное определение эквивалентно запрашиванию того, имеет ли ненулевой коэффициент, представленный посредством символа, какие-либо нули после него. Если t=0, то кодер знает то, что нет последующих нулей, и продолжает отправлять еще символы на этапе 1880, и процесс 1800 завершается. В одной реализации процесс 1900 по фиг.19 после этого начинается для следующего символа. Если t=1, кодер затем кодирует и отправляет длину серии нулей после ненулевого коэффициента на этапе 1870, а после этого продолжает отправлять символы на этапе 1880, и процесс 1800 завершается. Тем не менее, если t=2, кодер знает то, что ненулевой коэффициент, представленный посредством символа, является последним (и единственным) в последовательности, и таким образом, блок, представленный посредством коэффициентов преобразования, завершен. Таким образом, процесс 1800 завершается, и следующий блок может быть преобразован и кодирован, если применимо.
Фиг.19 иллюстрирует примерный процесс 1900 кодера 400 (фиг.4) для того, чтобы определять то, какая информация содержится в 2-мерном символе индекса, и отправлять дополнительную информацию при необходимости. В различных реализациях процесса 1900 этапы могут быть удалены, комбинированы или разбиты на подэтапы. Как и на фиг.18, на фиг.18 значение "x" - это заполнитель, представляющий любое возможное значение для этой конкретной части символа. Процесс начинается на этапе 1910, на котором отправляется следующий кодированный символ. Далее на этапе 1920 принятия решения кодер определяет то, имеет ли символ форму <1, x>. Это эквивалентно запрашиванию того, имеет ли ненулевой коэффициент, представленный посредством символа, абсолютное значение больше 1. Если кодер определяет то, что это так, значение ненулевого коэффициента кодируется и отправляется на этапе 1930. Как и в процессе 1800, важно отметить то, что хотя фиг.19 не поясняет в явном виде кодирование знака ненулевого коэффициента, этот знак может быть включен в различных точках процесса 1900.
Затем на этапе 1940 принятия решения кодер рассматривает значение t, где символ - это <x, t>. Данное определение эквивалентно запрашиванию того, имеет ли ненулевой коэффициент, представленный посредством символа, какие-либо нули после него. Если t=0, то кодер знает то, что нет последующих нулей, и продолжает отправлять еще символы на этапе 1960, и процесс 1900 завершается. В одной реализации процесс 1900 по фиг.19 после этого повторяется для следующего символа. Если t=1, кодер затем кодирует и отправляет длину серии нулей после ненулевого коэффициента на этапе 1950, а после этого продолжает отправлять символы на этапе 1960, и процесс 1900 завершается. Тем не менее, если t=2, кодер знает то, что ненулевой коэффициент, представленный посредством символа, является последним в последовательности, и таким образом, блок, представленный посредством коэффициентов преобразования, завершен. Таким образом, процесс 1900 завершается, и следующий блок может быть преобразован и кодирован, если применимо.
3.5. Дополнительные преимущества
Помимо вышеописанного уменьшения размера кодовой таблицы одно преимущество разбивки символов серии и уровня заключается в том, что после передачи 3-мерного совместного символа декодер может определять, есть или нет какие-либо ведущие (начальные) нули в блоке. Это означает то, что контекстная информация описывает, известно ли то, что содержит первая или вторая контекстная модель, на стороне декодера, и составляет ли допустимый контекст для кодирования значения level1 первого ненулевого коэффициента. Это означает то, что контексты, которые применяются к значениям 2-мерных символов, могут в равной степени применяться к значениям 3-мерных символов, даже если совместно кодированные символы индекса используют другие алфавиты.
Более того, поскольку общее число коэффициентов преобразования в блоке постоянно, каждая последующая серия привязывается посредством монотонного уменьшения последовательности. В предпочтительной реализации эта информация используется при кодировании значений серии. Например, кодовая таблица может включать в себя набор кодов значений серии для серий, начинающихся в первой половине набора коэффициентов, и другой набор для серий, начинающихся во второй половине. Поскольку длина любой возможной серии, начинающейся во второй половине, обязательно меньше, чем возможная длина серий, начинающихся в первой половине, второй набор кодов не обязательно должен быть настолько большим, понижая энтропию и повышая производительность кодирования.
Другая информация может быть собрана посредством тщательного анализа размещения коэффициентов. Например, если ненулевой коэффициент, представленный посредством символа, появляется в первой позиции последовательности коэффициентов, то "last" всегда истинно. Аналогично, если ненулевой коэффициент, представленный посредством символа, появляется в предпоследней позиции массива, то либо "last" истинно, либо последующая серия нулевая. Каждое из этих наблюдений предоставляет возможность кодирования посредством более коротких таблиц.
3.6. Пример реализации индекса
Первый индекс имеет размер алфавита в 12. В одной реализации пять таблиц Хаффмана доступно для этого символа, что задается как FirstIndex=a+2b+4c, где символ 0 - это <a, b, c>, а a и b - это 0 или 1 и c может принимать значения 0, 1 или 2. Одна реализация длины кодового слова для двенадцати символов в каждой из таблиц представлена ниже. Стандартные процедуры составления кодов Хаффмана в одной реализации могут быть применены для того, чтобы извлекать эти наборы кодовых слов префикса:
Последующие символы индекса имеют размер алфавита в 6. В одной реализации индекс задается как индекс = a+2b, где символ - это <a, b>, а a - это булевой параметр и b может принимать значения 0, 1 или 2. Четыре таблицы Хаффмана задаются для индекса, как показано ниже:
Дополнительно, в одной реализации для того, чтобы использовать преимущество некоторой информации, описанной в разделе 3.5 выше, когда коэффициент размещен в последней позиции массива, однобитовый код (заданный посредством a) используется (b уникально равно 2 в этом случае). В одной реализации, когда коэффициент находится в предпоследней позиции, двухбитовый код используется, поскольку известно, что b≠1.
Одна реализация SignificantLevel кодирует уровень с помощью процедуры связывания, которая сворачивает диапазон уровней в семь контейнеров. Уровни в контейнере кодируются с помощью кодов фиксированной длины, а сами контейнеры кодируются с помощью кодов Хаффмана. Это может быть осуществлено в одной реализации посредством методик группировки, описанных выше. Аналогично, в одной реализации NonzeroRun кодируется с помощью процедуры связывания, которая индексируется в пять контейнеров на основе позиции текущего символа.
3.7. Декодирование 3-2-мерных символов
Фиг.20 иллюстрирует примерный процесс 2000 посредством декодера 500 (фиг.5) для того, чтобы декодировать последовательность символов в коэффициенты преобразования. В различных реализациях процесса 2000 этапы могут быть удалены, комбинированы или разбиты на подэтапы. Дополнительно, могут быть заданы этапы для того, чтобы обрабатывать состояния ошибки, такие как инициируемые посредством поврежденных потоков битов. Процесс начинается на этапе 2010, на котором декодер принимает первый совместно кодированный символ и декодирует его с помощью 3-мерной кодовой таблицы. Затем на этапе 2020 коэффициенты преобразования заполняются на основе декодированного символа (включая любую информацию серии или уровня, также присутствующую в сжатом потоке битов). Одна реализация этого этапа подробнее описана ниже в отношении фиг.21. Процесс затем переходит к этапу 2030 принятия решения, на котором декодер определяет, указывает ли символ то, что он предназначен для последнего ненулевого коэффициента. Если да - процесс переходит к этапу 2090, на котором все оставшиеся незаполненные коэффициенты заполняются нулями, и процесс 2000 завершается.
Если символ не предназначен для последнего ненулевого коэффициента, процесс переходит к этапу 2040 принятия решения, на котором декодер определяет то, указаны ли какие-либо нулевые коэффициенты посредством символа к этому времени. Если нет - процесс переходит к этапу 2050, на котором следующий символ принимается и декодируется с помощью 2-мерных кодовых таблиц, следующих первой контекстной модели. Если, наоборот, нулевые коэффициенты указаны на этапе 2040 принятия решения, то на этапе 2060 декодер принимает и декодирует следующий символ с помощью 2-мерных кодовых таблиц, следующих второй контекстной модели. Вне зависимости от того, какая контекстная модель использована, процесс после этого переходит к этапу 2070, на котором коэффициенты преобразования заполняются на основе декодированного символа (включая любую информацию серии или уровня, также присутствующую в сжатом потоке битов). Как и на этапе 2020, одна реализация этого этапа подробнее описана ниже в отношении фиг.21. Процесс затем переходит к этапу 2030 принятия решения, на котором декодер определяет то, указывает ли символ то, что он предназначен для последнего ненулевого коэффициента. Если нет, процесс возвращается к этапу 2040 принятия решения и повторяется. Если да - процесс переходит к этапу 2090, на котором все оставшиеся незаполненные коэффициенты заполняются нулями, и процесс 2000 завершается.
Фиг.21 иллюстрирует примерный процесс 2100 посредством декодера 500 (фиг.5) для того, чтобы заполнять коэффициенты преобразования. В различных реализациях процесса 2100 этапы могут быть удалены, комбинированы или разбиты на подэтапы. Хотя процесс 2100 выполнен с возможностью декодировать символы, кодированные согласно методикам раздела 3.4 выше, в альтернативных реализациях значения уровней и длины серий могут быть включены в 2-мерные и 3-мерные символы, что должно позволить упростить процесс 2100. Процесс начинается на этапе 2110 принятия решения, где декодер определяет то, является ли символ 3-мерным символом. Если нет - процесс переходит к этапу 2140 принятия решения, который описан ниже. Тем не менее, если символ является 3-мерным символом - декодер определяет на этапе 2120 принятия решения то, указывает ли символ начальную серию положительной длины нулевых коэффициентов. Это может быть сделано посредством определения того, равно ли значение nonZero_run в 3-мерном символе 1, указывая серию положительной длины, или 0, указывая серию нулевой длины. Если символ указывает серию положительной длины нулевых коэффициентов, то процесс переходит к этапу 2130, на котором длина серии декодируется на основе кодированного level1, следующего 3-мерному символу, и начальные коэффициенты преобразования заполняются нулями согласно длине серии.
Затем процесс переходит к этапу 2140 принятия решения, на котором декодер определяет то, указывает ли символ то, что его ненулевой коэффициент имеет абсолютное значение больше 1. Это может быть выполнено посредством определения того, равно ли значение nonOne_level в символе 1, указывая то, что уровень имеет абсолютное значение больше 1, или 0, указывая то, что ненулевой коэффициент равен либо -1, либо 1. Если символ не указывает коэффициент с абсолютным значением больше 1, процесс переходит к этапу 2150, на котором следующий коэффициент заполняется -1 или 1 в зависимости от знака ненулевого коэффициента. Если символ указывает коэффициент с абсолютным значением больше 1, процесс вместо этого переходит к этапу 2160, на котором уровень коэффициента декодируется, и коэффициент заполняется значением уровня вместе с его знаком. Как описано выше, знак может быть указан различными способами, таким образом, декодирование знака коэффициента явно не поясняется на этапах 2150 или 2160.
Далее на этапе 2170 принятия решения декодер определяет то, указывает ли символ последующую серию положительной длины нулевых коэффициентов. Это может быть сделано посредством определения того, равно ли значение nonZero_run_last в 3-мерном символе 1, указывая серию положительной длины, или 0, указывая серию нулевой длины. (Случай равенства nonZero_run_last 2 не показан, поскольку этот случай пояснен в процессе 2000.) Если символ указывает серию положительной длины нулевых коэффициентов, то процесс переходит к этапу 2180, на котором длина серии декодируется на основе кодированного run1, следующего символу, и последующие коэффициенты преобразования заполняются нулями согласно длине серии, и процесс 2100 завершается.
4. Вычислительное окружение
Вышеописанный кодер 400 (фиг.4) и декодер 500 (фиг.5) и методики эффективного кодирования и декодирования на основе коэффициентов преобразования могут быть выполнены на любом из множества устройств, в которых выполняется обработка цифровых мультимедийных сигналов, в том числе, среди прочих примеров, на компьютерах, оборудовании для записи, передачи и приема изображений и видео, портативных видеопроигрывателях, средствах проведения видеоконференций и т.д. Методики кодирования цифровых мультимедийных данных могут быть реализованы в схемах аппаратных средств, а также в программном обеспечении обработки цифровых мультимедийных данных, исполняемом в пределах компьютера или другого вычислительного окружения, такой как показанная на фиг.22.
Фиг.22 иллюстрирует обобщенный пример подходящего вычислительного окружения (2200), в котором описанные варианты осуществления могут быть реализованы. Вычислительное окружение 2200 не предназначено для того, чтобы накладывать какое-либо ограничение на область использования или функциональность изобретения, поскольку настоящее изобретение может быть реализовано в различных вычислительных окружениях общего или специального назначения.
Ссылаясь на фиг.22, вычислительное окружение (2200) включает в себя, по меньшей мере, один процессор (2210) и память (2220). На фиг.22 эта самая базовая конфигурация (2230) показана пунктирной линией. Процессор (2210) приводит в исполнение машиноисполняемые инструкции и может быть реальным или виртуальным процессором. В многопроцессорной системе несколько процессоров приводят в исполнение машиноисполняемые инструкции, чтобы повысить вычислительную мощность. Памятью (2220) может быть энергозависимая память (например, регистры, кэш, ОЗУ (оперативное запоминающее устройство, RAM), энергонезависимая память (например, ПЗУ (постоянное запоминающее устройство, ROM), ЭСППЗУ (электрически стираемое и программируемое ПЗУ, EEPROM), флэш-память и т.д.) или некоторое сочетание этих двух. Запоминающее устройство (2220) сохраняет программное обеспечение (1280), реализующее описанный кодер/декодер и эффективные методики кодирования/декодирования на основе коэффициентов преобразования.
Вычислительное окружение может обладать дополнительными признаками. Например, вычислительное окружение (2200) включает в себя хранилище (2240), устройства (2250) ввода, одно или более устройств (2260) вывода и одно или более соединений (2270) связи. Механизм межкомпонентного соединения (не показан), такой как шина, контроллер или сеть соединяет между собой компоненты вычислительного окружения (2200). В типичном варианте программное обеспечение операционной системы (не показано) предоставляет операционное окружение для другого программного обеспечения, приводимого в исполнение в вычислительном окружении (2200), и координирует действия компонентов вычислительного окружения (2200).
Запоминающее устройство (2240) может быть съемным или несъемным и включает в себя магнитные диски, магнитные ленты или кассеты, CD-ROM, CD-RW, DVD или любой другой носитель, который может быть использован, чтобы сохранять информацию, и к которому можно осуществлять доступ в пределах вычислительного окружения (2200). Хранилище (2240) сохраняет инструкции для программного обеспечения (2280), реализующего описанные кодер/декодер и эффективные методики кодирования/декодирования на основе коэффициентов преобразования.
Устройством(ами) (2250) ввода может быть устройство сенсорного ввода, такое как клавиатура, мышь, перо или шаровой манипулятор, устройство голосового ввода, устройство сканирования или другое устройство, которое обеспечивает ввод в вычислительное окружение (2200). Для звука устройством(ами) (2250) ввода может быть звуковая плата или аналогичное устройство, которое принимает звуковой входной сигнал в аналоговой или цифровой форме, либо считыватель CD-ROM, который поставляет звуковые выборки в вычислительное окружение. Устройством(ами) (2260) вывода может быть дисплей, принтер, динамик, устройство для записи CD-RW или другое устройство, которое обеспечивает вывод из вычислительного окружения (2200).
Соединения (2270) связи обеспечивают обмен данными по среде обмена данными с другим вычислительным объектом. Среда передачи данных транспортирует информацию, такую как машиноисполняемые инструкции, сжатую звуковую и видеоинформацию или другие данные в модулированном информационном сигнале. Модулированный сигнал данных - это сигнал, который имеет одну или более характеристик, установленных или изменяемых таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения - среда обмена данными включает в себя проводные или беспроводные методики, реализованные с помощью электрического, оптического, радиочастотного, инфракрасного, акустического или другого оборудования связи.
Методики обработки цифровых аудиовизуальных данных в материалах настоящей заявки могут быть описаны в общем контексте машиночитаемых носителей. Машиночитаемые носители - это любые доступные носители, к которым можно осуществлять доступ в вычислительном окружении. В качестве примера, а не ограничения - в вычислительном окружении (2200) машиночитаемые носители включают в себя память (2220), устройство (2240) хранения, среду обмена данными и комбинации любых вышеозначенных элементов.
Методики обработки цифровых аудиовизуальных данных в материалах настоящей заявки могут быть описаны в общем контексте машиноисполняемых инструкций, таких как включенные в программные модули, являющиеся исполняемыми в вычислительном окружении на целевом реальном или виртуальном процессоре. В общем, программные модули включают в себя процедуры, программы, библиотеки, объекты, классы, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Функциональность программных модулей может быть комбинирована или разделена между программными модулями, как требуется в различных вариантах осуществления. Машиноисполняемые инструкции для программных модулей могут быть приводимы в исполнение в локальном или распределенном вычислительном окружении.
Для целей представления подробное описание использует такие термины, как "определить", "сформировать", "настроить" и "применить", чтобы описывать операции компьютера в вычислительном окружении. Эти термины являются высокоуровневыми абстракциями для операций, выполняемых компьютером, и не должны путаться с действиями, выполняемыми человеком. Фактические операции компьютера, соответствующие этим терминам, различаются в зависимости от реализации.
В свете множества возможных вариаций описываемого в данном документе предмета изобретения, мы заявляем в качестве изобретения все подобные варианты осуществления, которые могут подпадать под область применения нижеследующей формулы изобретения и ее эквивалентов.
| название | год | авторы | номер документа |
|---|---|---|---|
| АДАПТИВНОЕ КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ КОЭФФИЦИЕНТОВ С ШИРОКИМ ДИАПАЗОНОМ | 2006 |
|
RU2433479C2 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ В КОДЕРАХ И/ИЛИ ДЕКОДЕРАХ ИЗОБРАЖЕНИЯ И ВИДЕОДАННЫХ | 2003 |
|
RU2354073C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ КОДИРОВАНИЯ ЗНАЧИМЫХ КОЭФФИЦИЕНТОВ ПРИ ВИДЕОСЖАТИИ | 2007 |
|
RU2406256C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ КОДИРОВАНИЯ УТОЧНЯЮЩИХ КОЭФФИЦИЕНТОВ ПРИ СЖАТИИ ВИДЕОДАННЫХ | 2007 |
|
RU2406259C2 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ В КОДЕРАХ И/ИЛИ ДЕКОДЕРАХ ИЗОБРАЖЕНИЯ/ВИДЕОСИГНАЛА | 2003 |
|
RU2335845C2 |
| СЖАТИЕ ВИДЕОИЗОБРАЖЕНИЙ С ПОМОЩЬЮ АДАПТИВНЫХ КОДОВ С ПЕРЕМЕННОЙ ДЛИНОЙ | 2007 |
|
RU2407219C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2018 |
|
RU2699677C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2642373C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |



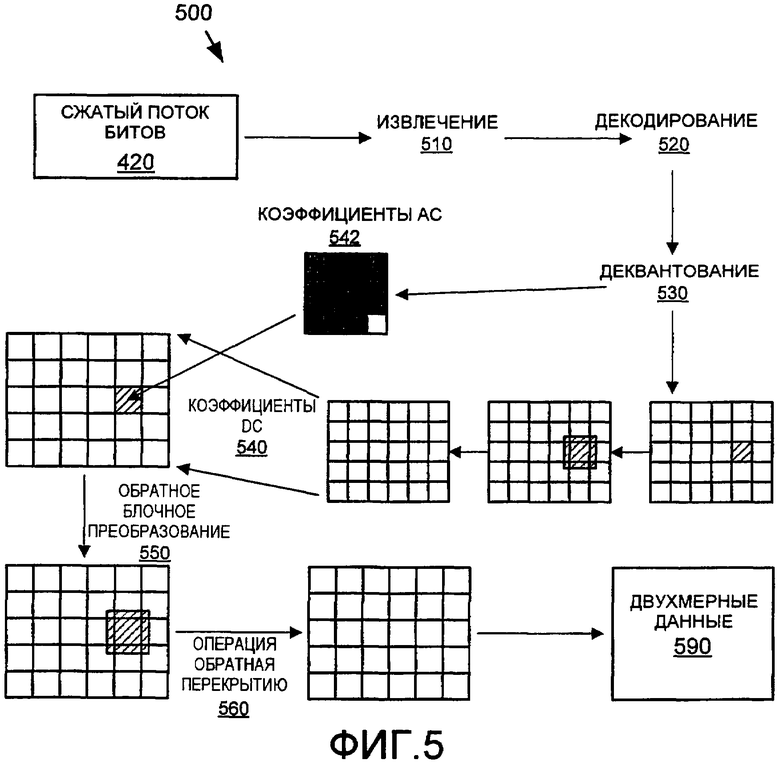
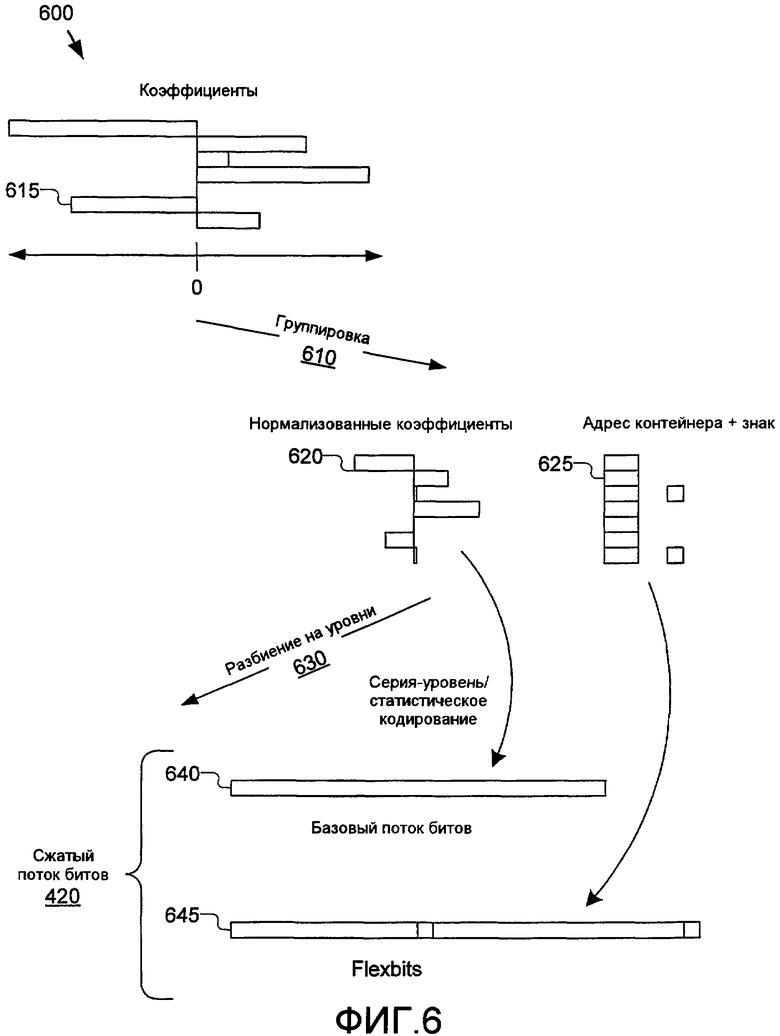
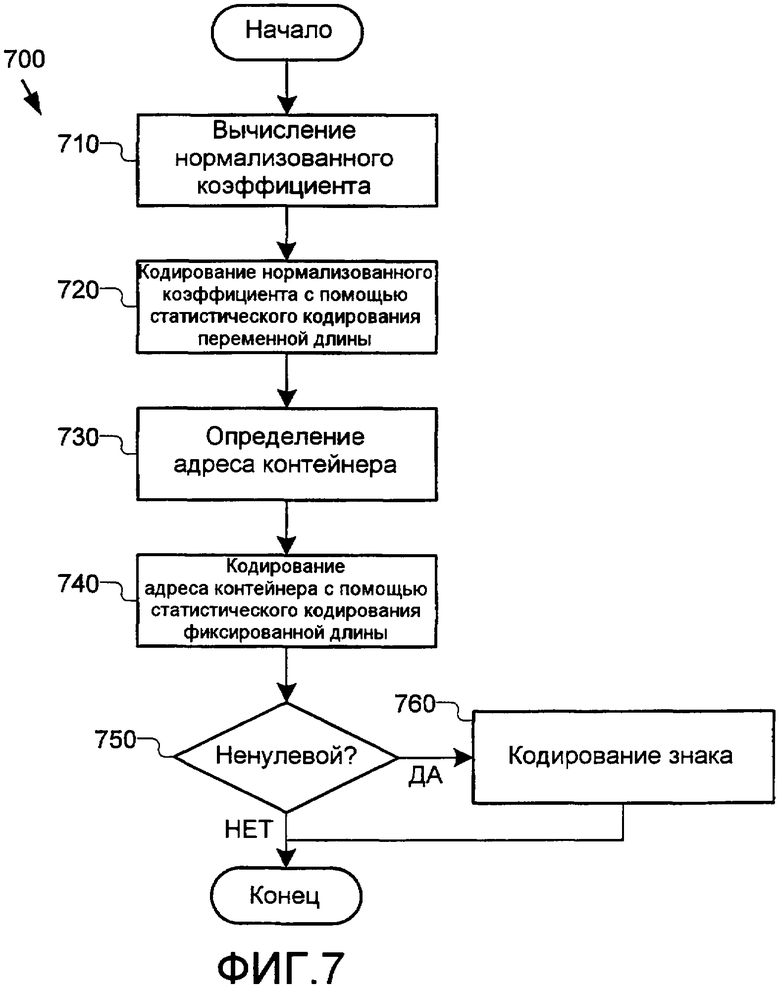
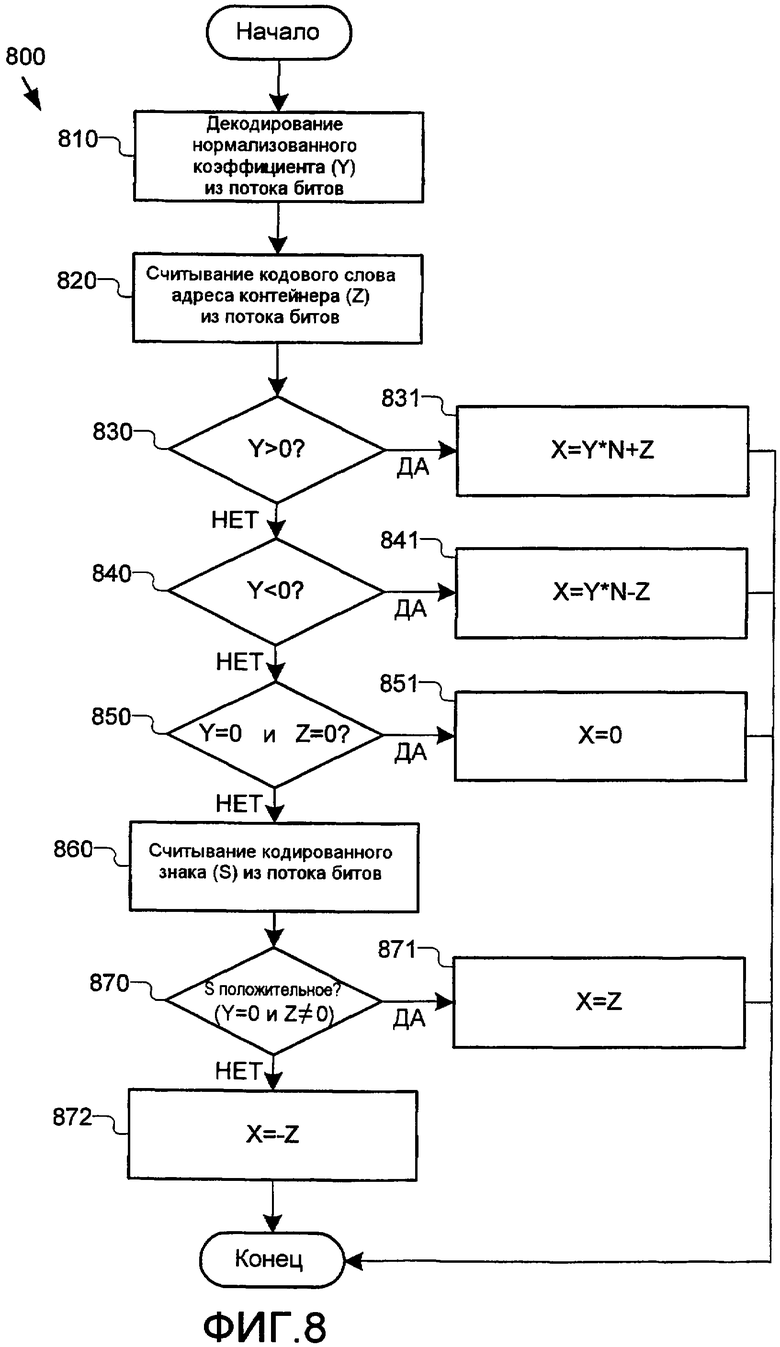



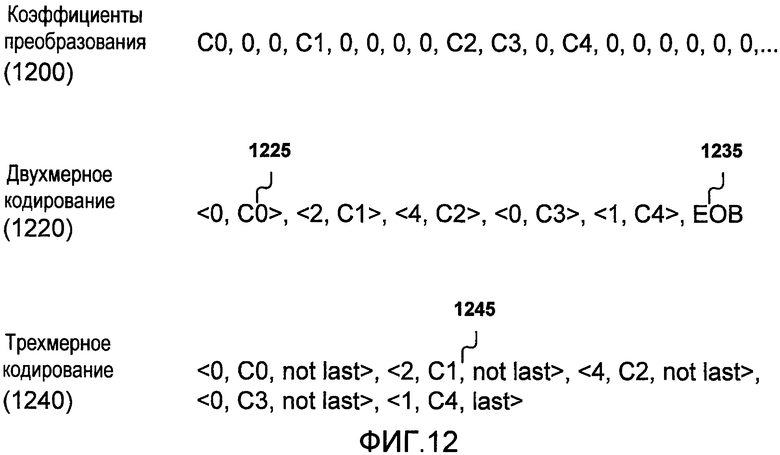
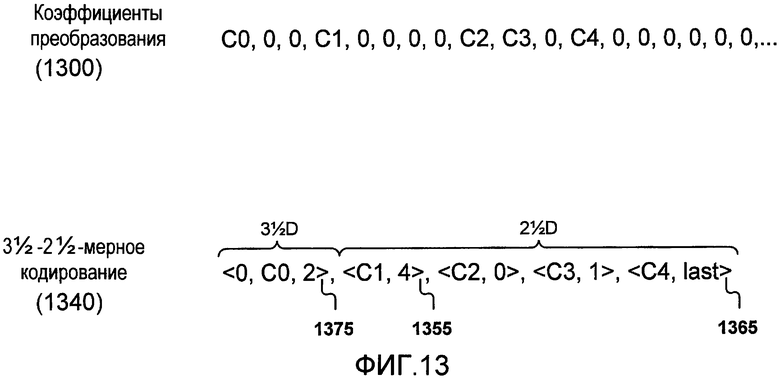

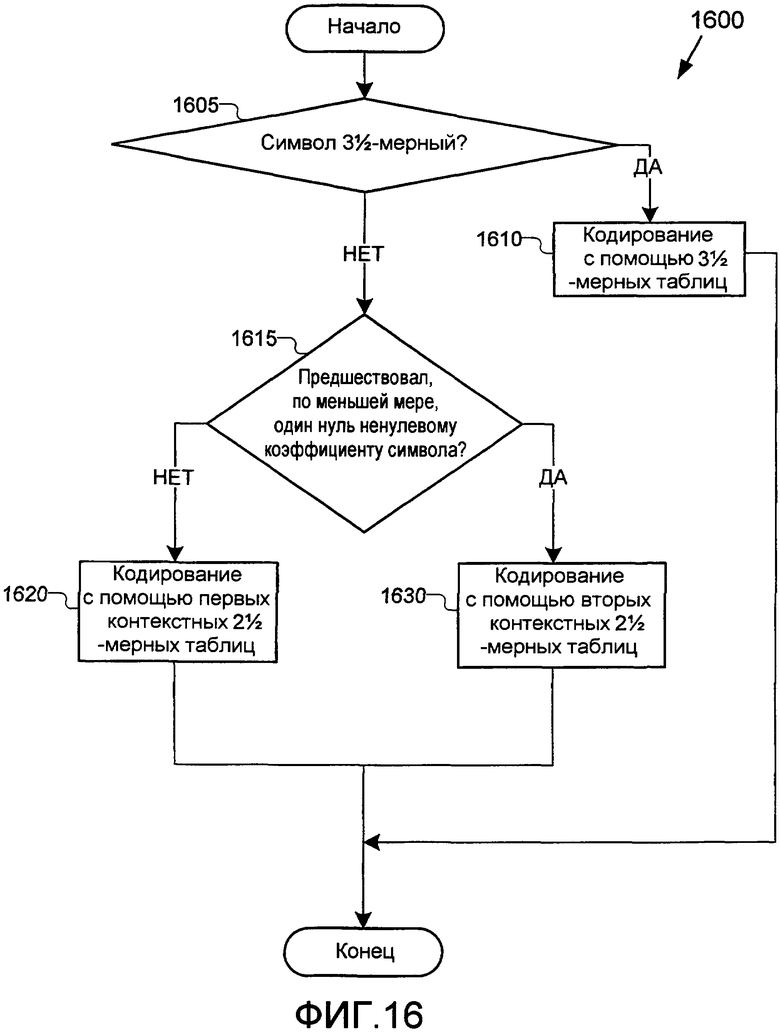
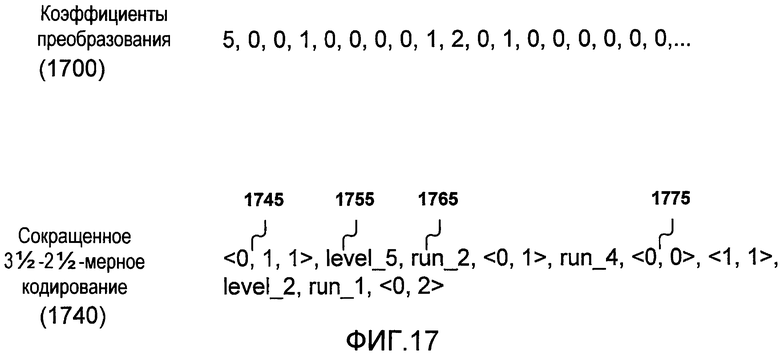

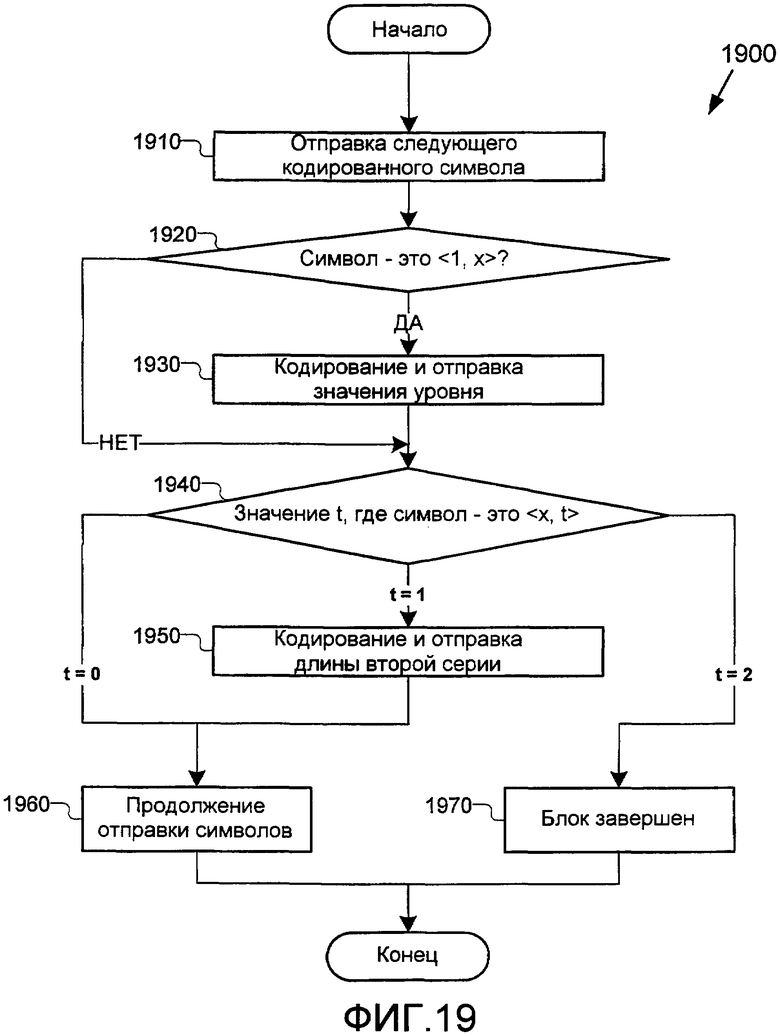



Изобретение относится к методам кодирования/декодирования цифрового мультимедиа, в частности к основанному на блочном преобразовании цифровому мультимедийному кодеку. Техническим результатом является повышение эффективности сжатия коэффициентов преобразования и скорости кодирования/декодирования. Указанный технический результат достигается тем, что кодек кодирует коэффициенты преобразования посредством совместного кодирования ненулевых коэффициентов с последующими сериями коэффициентов с нулевыми значениями. Когда ненулевые коэффициенты являются последними в своем блоке, последний индикатор заменяется для значения серии в символе этого коэффициента (1435). Начальные ненулевые коэффициенты указываются в специальном символе, который совместно кодирует ненулевой коэффициент вместе с начальными и последующими сериями нулей (1440). Кодек предоставляет возможность нескольких контекстов кодирования посредством обнаружения разрывов в сериях ненулевых коэффициентов и кодирования ненулевых коэффициентов на какой-либо стороне этого разрыва отдельно (1460). Кодек также уменьшает размер кодовой таблицы посредством указания в каждом символе того, имеет ли ненулевой коэффициент абсолютное значение больше 1, и имеют ли серии нулей положительные значения (1475), и отдельно кодирует уровень коэффициентов и длину серий вне символов (1490). 4 н. и 21 з.п. ф-лы, 22 ил.
1. Способ кодирования последовательностей коэффициентов преобразования (1300), представляющих цифровые мультимедийные данные, содержащий этапы, на которых:
- представляют (1400) последовательность коэффициентов преобразования как последовательность символов (1340), в которой каждый символ (1355) содержит индикатор ненулевого коэффициента из последовательности коэффициентов преобразования и индикатор длины последующей серии коэффициентов с нулевыми значениями;
- для каждого символа в упомянутой последовательности символов отправляют (1600) символ, который должен быть кодирован, в сжатом потоке (420) битов; и
- при этом последний ненулевой коэффициент в последовательности коэффициентов преобразования представляется посредством символа (1365), причем индикатор длины последующей серии коэффициентов с нулевыми значениями содержит индикатор того, что коэффициент является последним ненулевым коэффициентом.
2. Способ по п.1, в котором первый символ в последовательности символов дополнительно содержит индикатор длины серии коэффициентов с нулевым значением, предшествующей первому ненулевому коэффициенту в последовательности коэффициентов преобразования.
3. Способ по п.2, в котором последовательность коэффициентов преобразования возникает в результате определения нормализованной части последовательности коэффициентов преобразования с большим диапазоном.
4. Способ по п.2, в котором один набор кодовых таблиц используется для того, чтобы кодировать первый символ в последовательности символов, и другой набор кодовых таблиц используется для того, чтобы кодировать другие символы в последовательности символов.
5. Способ по п.2, в котором каждый символ в последовательности символов имеет ассоциативно связанный контекст.
6. Способ по п.5, в котором контекст для символа базируется, по меньшей мере частично, на основе того, появляется ли ненулевой коэффициент, представленный посредством символа, до или после первого коэффициента с нулевым значением в последовательности коэффициентов.
7. Способ по п.5, в котором контекст для символа базируется, по меньшей мере частично, на основе того, служит ли последовательность коэффициентов преобразования для каналов яркости или цветности.
8. Способ по п.5, в котором контекст для символа базируется, по меньшей мере частично, на основе того, служит ли последовательность коэффициентов преобразования для внутреннего преобразования, промежуточного преобразования или внешнего преобразования.
9. Способ по п.2, в котором для каждого символа индикатор в этом символе длины серии последующих ненулевых коэффициентов содержит троичный символ, указывающий одно из следующих условий для символа:
- серия коэффициентов с нулевым значением имеет нулевую длину;
- серия коэффициентов с нулевым значением имеет положительную длину;
- коэффициент, указанный посредством символа, является последним коэффициентом в последовательности коэффициентов преобразования.
10. Способ по п.9, в котором индикатор длины серии коэффициентов с нулевыми значениями, предшествующих первому коэффициенту с ненулевым значением в первом символе в последовательности символов, содержит булеву переменную, указывающую то, имеет ли серия коэффициентов с нулевыми значениями, предшествующая первому ненулевому коэффициенту, длину нуль или положительную длину.
11. Способ по п.9, дополнительно содержащий, когда символ содержит индикатор того, что серия коэффициентов с нулевым значением имеет положительную длину, этап, на котором отправляют длину серии коэффициентов с нулевыми значениями, которые должны быть кодированы в сжатом потоке битов.
12. Способ по п.1, в котором для каждого символа индикатор в этом символе ненулевого коэффициента из последовательности коэффициентов преобразования содержит булеву переменную, указывающую то, больше 1 или нет абсолютное значение ненулевого коэффициента.
13. Способ по п.12, дополнительно содержащий, когда символ содержит индикатор того, что серия ненулевого коэффициента имеет абсолютное значение больше 1, этап, на котором отправляют абсолютное значение ненулевого коэффициента, который должен быть кодирован в сжатом потоке битов.
14. Цифровой мультимедийный декодер, содержащий:
- буфер (2280) хранения данных для сохранения кодированных цифровых мультимедийных данных; и
- процессор (2210), выполненный с возможностью:
- принимать набор сжатых символов (420), описывающих последовательность коэффициентов преобразования;
- распаковывать символы (510); и
- восстанавливать (520) последовательность коэффициентов преобразования посредством анализа набора несжатых символов;
- и при этом:
- набор несжатых символов содержит совместно кодированные символы (1340), закодированные (1600) из набора кодовых таблиц согласно контекстной модели;
- каждый совместно кодированный символ (1355) описывает ненулевой уровень из последовательности коэффициентов преобразования, а также то, имеются ли коэффициенты с нулевыми значениями после ненулевого уровня.
15. Цифровой мультимедийный декодер по п.14, в котором:
- каждый совместно кодированный символ описывает ненулевой уровень посредством указания того, больше ли 1 абсолютное значение ненулевого уровня;
- набор сжатых символов дополнительно содержит символы уровня, описывающие значение каждого ненулевого уровня и индикаторы знаков уровня; и
- процессор дополнительно выполнен с возможностью при анализе совместно кодированного символа, который указывает ненулевое значение, абсолютное значение которого больше 1, восстанавливать ненулевой уровень посредством нахождения символа уровня, который описывает значение ненулевого уровня.
16. Цифровой мультимедийный декодер по п.14, в котором первый символ в наборе сжатых символов дополнительно описывает то, есть ли коэффициенты с нулевыми значениями, предшествующие ненулевому уровню, в последовательности коэффициентов преобразования.
17. Цифровой мультимедийный декодер по п.14, в котором:
- каждый совместно кодированный символ описывает серию коэффициентов с нулевыми значениями посредством указания того, больше ли 0 длина серии коэффициентов с нулевыми значениями;
- набор сжатых символов дополнительно содержит символы серии, описывающие длину каждой серии коэффициентов с нулевыми значениями, длина которой превышает 0.
18. Цифровой мультимедийный декодер по п.14, в котором последний символ в наборе сжатых символов включает в себя индикацию ненулевого уровня для соответствующего коэффициента преобразования и индикацию, что соответствующий коэффициент преобразования является последним ненулевым коэффициентом преобразования.
19. Цифровой мультимедийный декодер по п.18, в котором последний символ в наборе сжатых символов не включает в себя индикацию длины серии с нулевыми значениями.
20. Машиночитаемый носитель, хранящий инструкции, которые описывают программу декодирования цифрового мультимедиа для осуществления способа декодирования сжатых цифровых мультимедийных данных, при этом способ содержит этапы, на которых:
- принимают (2000) поток (420) битов, содержащий сжатые совместно кодированные символы (1340), кодированные из набора кодовых таблиц согласно контекстной модели;
- декодируют (2000) совместно кодированные символы, чтобы определить для по меньшей мере некоторых из символов уровень коэффициента преобразования и серию последующих нулей коэффициентов преобразования; и
- восстанавливают (2100) набор коэффициентов преобразования из определенных уровней и серий нулей коэффициентов преобразования.
21. Машиночитаемый носитель по п.20, в котором поток битов дополнительно содержит начальный совместно кодированный символ, а способ дополнительно содержит этап, на котором декодируют начальный совместно кодированный символ, чтобы определить серию начальных нулей коэффициентов преобразования, уровень коэффициентов преобразования и серию последующих нулей коэффициентов преобразования.
22. Машиночитаемый носитель по п.20, в котором:
- совместно кодированные символы указывают для каждого уровня коэффициентов преобразования то, имеет ли данный уровень абсолютное значение больше 1;
- совместно кодированные символы указывают для каждой серии нулей коэффициентов преобразования, имеет ли эта серия длину больше 0;
- поток битов дополнительно содержит сжатые символы, описывающие длину серии нулей коэффициентов преобразования, и знак и величину уровней коэффициентов преобразования; и
- декодирование совместно кодированных символов содержит этапы, на которых:
- при декодировании совместно кодированного символа, который указывает то, что уровень коэффициента преобразования имеет абсолютное значение больше 1, определяют этот уровень коэффициентов преобразования посредством декодирования одного или более символов в потоке битов, которые указывают знак и значение уровня коэффициентов преобразования; и
- при декодировании совместно кодированного символа, который указывает то, что серия нулей коэффициента преобразования больше 0, определяют длину серии нулей коэффициента преобразования посредством декодирования символа в потоке битов, который указывает длину серии.
23. Способ декодирования сжатых данных цифрового мультимедиа, содержащий этапы, на которых:
- принимают поток битов, содержащий сжатые совместно кодированные символы, кодированные из набора кодовых таблиц согласно контекстной модели;
- декодируют совместно кодированные символы, чтобы определить для по меньшей мере некоторых из символов уровень коэффициента преобразования и серию последующих нулей коэффициентов преобразования; и
- восстанавливают набор коэффициентов преобразования из определенных уровней и серий нулей коэффициентов преобразования.
24. Способ по п.23, в котором поток битов дополнительно содержит начальный совместно кодированный символ, а способ дополнительно содержит этап, на котором декодируют начальный совместно кодированный символ, чтобы определить серию начальных нулей коэффициентов преобразования, уровень коэффициентов преобразования и серию последующих нулей коэффициентов преобразования.
25. Способ по п.23, в котором:
- совместно кодированные символы указывают для каждого уровня коэффициентов преобразования то, имеет ли данный уровень абсолютное значение больше 1;
- совместно кодированные символы указывают для каждой серии нулей коэффициентов преобразования, имеет ли эта серия длину больше 0;
- поток битов дополнительно содержит сжатые символы, описывающие длину серии нулей коэффициентов преобразования, и знак и величину уровней коэффициентов преобразования; и
- декодирование совместно кодированных символов содержит этапы, на которых:
- при декодировании совместно кодированного символа, который указывает то, что уровень коэффициента преобразования имеет абсолютное значение больше 1, определяют этот уровень коэффициентов преобразования посредством декодирования одного или более символов в потоке битов, которые указывают знак и значение уровня коэффициентов преобразования; и
- при декодировании совместно кодированного символа, который указывает то, что серия нулей коэффициента преобразования больше 0, определяют длину серии нулей коэффициента преобразования посредством декодирования символа в потоке битов, который указывает длину серии.
| US 6690307 В2, 10.02.2004 | |||
| US 6600872 B1, 29.07.2003 | |||
| US 5706001 A, 06.01.1998 | |||
| US 2003202601 A1, 30.10.2003 | |||
| US 5045938 A, 03.09.1991 | |||
| СПОСОБ КОДИРОВАНИЯ СИГНАЛОВ | 1992 |
|
RU2090973C1 |
| RU 92016549 A, 20.12.1997. | |||

