Заявление об авторских правах
Часть раскрытия этого патентного документа содержит материал, подлежащий защите авторских прав. Владелец авторских прав не возражает против факсимильного воспроизведения патентного документа или раскрытия патента в том виде, в каком они представлены в файле или записях патента, хранящихся в ведомстве по патентам и торговым маркам, но в остальном сохраняет за собой все авторские права.
Предпосылки изобретения
Кодирование на основе блочного преобразования
Кодирование с преобразованием - это метод сжатия, используемый во многих системах сжатия аудиосигнала, изображений и видеосигнала. Несжатое цифровое изображение и видео обычно представляют или захватывают в виде выборок элементов изображения или цветов в местах изображения или кадра видео, которые образуют двухмерную (2D) сетку. Это называют пространственным представлением изображения или видео. Например, типичный формат изображений состоит из потока выборок элементов изображения с 24-битовым цветом, размещенных в виде сетки. Каждая выборка является числом, представляющим цветовые компоненты в месте расположения пикселя в сетке в цветовом пространстве, например RGB или YIQ, помимо прочих. Различные системы изображений и видео могут использовать различные другие цветовые, пространственные и временные разрешения дискретизации. Аналогично, цифровой аудиосигнал обычно представляют в виде потока аудиосигнала, дискретизированного по времени. Например, типичный формат аудио состоит из потока выборок с 16-битовой амплитудой аудиосигнала, взятых с регулярными временными интервалами.
Несжатые цифровые аудиосигналы, сигналы изображения и видеосигналы могут потреблять значительный объем памяти и пропускной способности. Кодирование с преобразованием уменьшает размер цифровых аудиосигналов, сигналов изображения и видеосигналов за счет преобразования пространственного представления сигнала к частотному представлению (или какой-либо другой области представления преобразования) и последующего снижения разрешения некоторых, обычно менее важных для восприятия, частотных компонентов преобразованного представления. Это в общем случае приводит к значительно меньшему воспринимаемому ухудшению цифрового сигнала по сравнению со снижением цветового или пространственного разрешения изображений или видео в пространственной области определения или аудио во временной области определения.
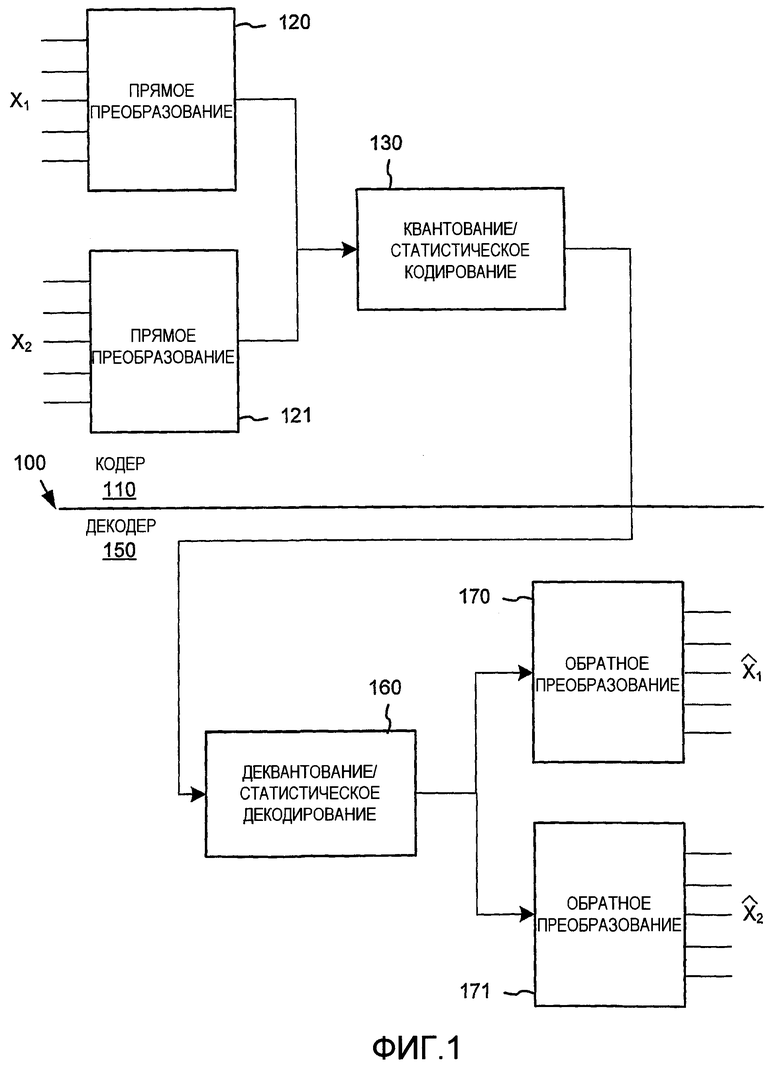
В частности, типичный кодек на основе блочного преобразования 100, показанный на фиг.1, делит пиксели несжатого цифрового изображения на двухмерные блоки фиксированного размера (X1,..., Xn), причем каждый блок может перекрываться с другими блоками. Линейное преобразование 120-121, осуществляющее пространственно-частотный анализ, применяется к каждому блоку, который преобразует разнесенные выборки в блоке в набор частотных коэффициентов (или коэффициентов преобразования), в общем случае выражающих интенсивность цифрового сигнала в соответствующих полосах частот по интервалу блока. Для сжатия коэффициенты преобразования можно избирательно квантовать 130 (т.е. понижать разрешение, например путем отбрасывания младших битов в значениях коэффициентов или иного отображения (преобразования) значений в наборе чисел с более высоким разрешением в более низкое разрешение), а также подвергать статистическому кодированию или кодированию с переменной длиной 130 в поток сжатых данных. При декодировании коэффициенты преобразования подвергаются обратному преобразованию 170-171 для приближенной реконструкции исходного сигнала изображения/видео, дискретизированного по цвету/пространственным координатам (реконструированные блоки  ).
).
Блочное преобразование 120-121 можно задать в виде математической операции над вектором x размера N. Чаще всего операция является линейным умножением, порождающим выходной результат y=Mx в области преобразования, где M - матрица преобразования. Когда входные данные имеют произвольную длину, они сегментируются на векторы размера N, и блочное преобразование применяется к каждому сегменту. В целях сжатия данных выбирают обратимые блочные преобразования. Иными словами, матрица M является обратимой. В многомерных пространствах (например, для изображений и видео) блочные преобразования обычно реализуют в виде раздельных операций. Матричное умножение применяется раздельно в каждом измерении данных (т.е. по строкам и столбцам).
Для сжатия коэффициенты преобразования (компоненты вектора y) можно избирательно квантовать (т.е. понижать разрешение, например путем отбрасывания младших битов в значениях коэффициентов или иного преобразования значений в наборе чисел с более высоким разрешением в более низкое разрешение), а также подвергать статистическому кодированию или кодированию с переменной длиной в поток сжатых данных.
При декодировании на декодере 150 на стороне декодера 150 применяются обратные операции (деквантование/статистическое декодирование 160 и обратное блочное преобразование 170-171), что показано на фиг.1. При реконструкции данных обратная матрица M-1 (обратное преобразование 170-171) применяется в качестве множителя к данным области преобразования. При применении к данным области преобразования обратное преобразование примерно реконструирует исходный цифровой медиасигнал во временной области или пространственной области.
Во многих приложениях кодирования на основе блочного преобразования желательно, чтобы преобразование было обратимым, для обеспечения поддержки сжатия с потерями и без потерь в зависимости от коэффициента квантования. Например, в отсутствие квантования (что обычно выражается коэффициентом квантования 1) кодек, использующий обратимое преобразование, может точно воспроизводить входные данные при декодировании. Однако требование обратимости в этих приложениях ограничивает выбор преобразований, лежащих в основе кодека.
Многие системы сжатия изображения и видео, например MPEG и Windows Media, помимо прочих, используют преобразования на основе дискретного косинусного преобразования (ДКП). ДКП, как известно, имеет хорошие характеристики сжатия энергетического спектра, что обеспечивает сжатие данных, близкое к оптимальному. В этих системах сжатия обратное ДКП (ОДКП) применяется в циклах реконструкции на кодере и декодере системы сжатия для реконструкции отдельных блоков изображения.
Статистическое кодирование коэффициентов преобразования с широким диапазоном
Широкий динамический диапазон входных данных приводит к расширению динамического диапазона коэффициентов преобразования, генерируемых в процессе кодирования изображения. Например, коэффициенты преобразования, генерируемые операцией ДКП N×N, имеют динамический диапазон, более чем в N раз превышающий динамический диапазон исходных данных. При малом или единичном факторе квантования (используемом для реализации сжатия с малыми потерями или без потерь) диапазон квантованных коэффициентов преобразования также велик. Статистически эти коэффициенты имеют распределение Лапласа, что показано на фиг.2 и 3. На фиг.2 показано распределение Лапласа для коэффициентов с широким динамическим диапазоном. На фиг.3 показано распределение Лапласа для обычных коэффициентов с узким динамическим диапазоном.
Традиционное кодирование с преобразованием настроено на малый динамический диапазон входных данных (обычно 8 битов) и относительно большие факторы квантования (например, численные значения от 4 и выше). На фиг.3 представлено распределение коэффициентов преобразования в таком традиционном преобразовательном кодировании. Кроме того, статистическое кодирование, применяемое с таким традиционным преобразовательным кодированием, может быть разновидностью кодирования «последовательность-уровень», где последовательность нулей кодируется в ненулевой символ. Это может быть эффективным средством представления серий нулей (которые появляются с высокой вероятностью), а также захвата межсимвольных корреляций.
С другой стороны, традиционное кодирование с преобразованием менее пригодно для сжатия распределений в широком динамическом диапазоне, например, показанного на фиг.2. Хотя символы равны нулю с более высокой вероятностью, чем какому-либо другому значению (т.е. распределение имеет пик в нуле), вероятность того, что коэффициент в точности равен нулю, очень мала для распределения в широком динамическом диапазоне. Поэтому нули не появляются часто, и методы статистического кодирования по длине серии, основанные на количестве нулей между последовательными ненулевыми коэффициентами, весьма неэффективны для входных данных с широким динамическим диапазоном.
Распределение в широком динамическом диапазоне также имеет расширенный алфавит символов по сравнению с распределением в узком диапазоне. Из-за этого расширенного алфавита символов для кодирования символов приходится использовать большую(ие) статистическую(ие) таблицу(ы). В противном случае многие символы будут отбрасываться, избегая кодирования, что неэффективно. Большие таблицы требуют больше памяти, а также могут приводить к усложнению.
Таким образом, традиционному кодированию с преобразованием недостает универсальности - оно хорошо работает на входных данных с распределением в узком динамическом диапазоне, но не с распределением в широком динамическом диапазоне.
Сущность изобретения
Описанные здесь способы кодирования и декодирования цифрового медиасигнала и цифровой медиакодек, реализующий эти способы, позволяют добиться более эффективного сжатия коэффициентов преобразования с широким динамическим диапазоном. Например, один иллюстративный цифровой медиакодек на основе блочного преобразования представляет коэффициенты преобразования с широким динамическим диапазоном в двух частях: нормализованный коэффициент и адрес контейнера. Нормализованный коэффициент относится к группированию значений коэффициентов с широким динамическим диапазоном в контейнеры, тогда как адрес контейнера - это индекс значения коэффициента в контейнере. При тщательном выборе размера контейнера часть нормализованного коэффициента для коэффициентов преобразования имеет примерно такое же распределение вероятностей, как и для коэффициентов преобразования с узким диапазоном, которое лучше поддается статистическому кодированию с переменной длиной.
Иллюстративный кодек использует статистическое кодирование с переменной длиной для кодирования нормализованных коэффициентов в "базе" сжатого битового потока и кодирование с фиксированной длиной для кодирования адреса контейнера в качестве отдельного дополнительного уровня, которое можно не выполнять. Даже в отсутствие уровня адреса контейнера кодек может декодировать битовый поток и приближенно реконструировать входные цифровые медиаданные. Группирование коэффициентов преобразования в контейнеры примерно такой же эффект, как квантование коэффициентов преобразования в более узкий динамический диапазон.
Кроме того, кодек адаптивно изменяет размер контейнера группирования на основании процесса обратной адаптации для подгонки нормализованных коэффициентов к распределению вероятностей, допускающему эффективное статистическое кодирование с переменной длиной. В иллюстративном кодеке адаптация опирается на счетчик ненулевых нормализованных коэффициентов в предыдущих блоках. Таким образом, адаптация зависит только от информации в базовом битовом потоке, что не противоречит ограничению, согласно которому уровень, содержащий адрес контейнера, можно избирательно игнорировать.
Эта сущность изобретения приведена здесь для ознакомления с рядом концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Эта сущность изобретения не призвана выявлять ключевые признаки или существенные признаки заявленного изобретения, а также не призвана помогать в определении объема заявленного изобретения.
Краткое описание чертежей
Фиг.1 - блок-схема традиционного кодека на основе блочного преобразования согласно уровню техники.
Фиг.2 - гистограмма, демонстрирующая распределение коэффициентов преобразования, имеющих широкий динамический диапазон.
Фиг.3 - гистограмма, демонстрирующая распределение коэффициентов с узким диапазоном.
Фиг.4 - схема операций иллюстративного кодера, обеспечивающего адаптивное кодирование коэффициентов с широким диапазоном.
Фиг.5 - схема операций декодера, обеспечивающего декодирование адаптивно кодированных коэффициентов с широким диапазоном.
Фиг.6 - схема операций, демонстрирующая группирование и «расслоение» коэффициента преобразования при адаптивном кодировании коэффициентов с широким диапазоном, например в кодере, показанном на фиг.4.
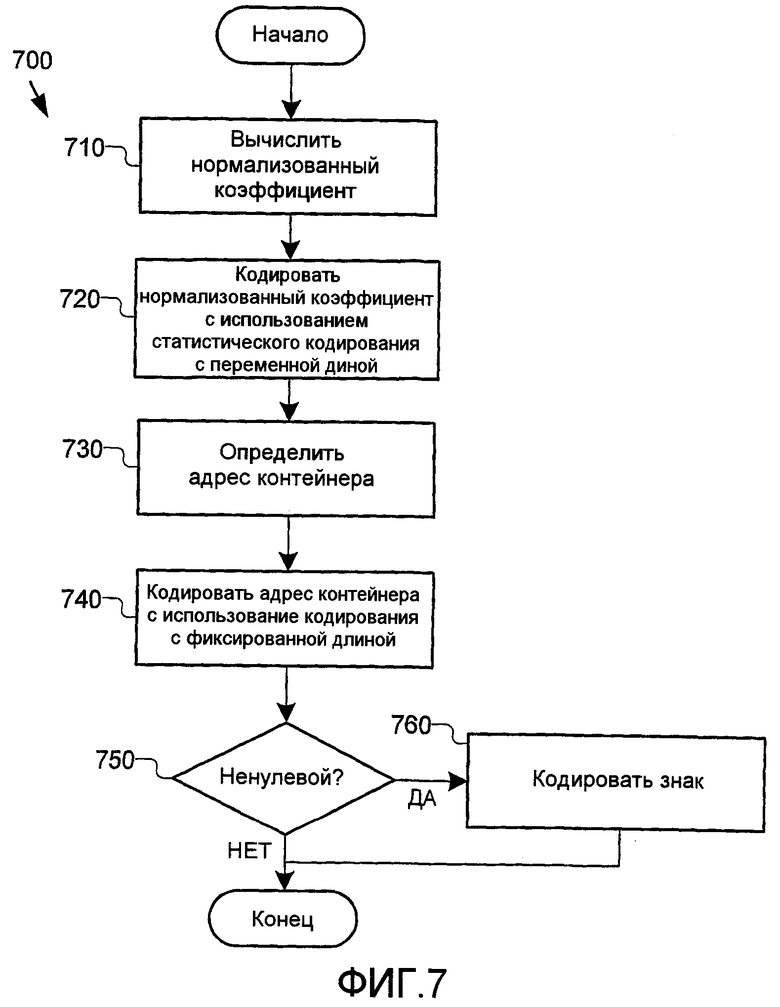
Фиг.7 - блок-схема операций процесса, выполняемого кодером, показанным на фиг.4, для кодирования коэффициента преобразования при выбранном группировании коэффициентов преобразования в контейнеры.
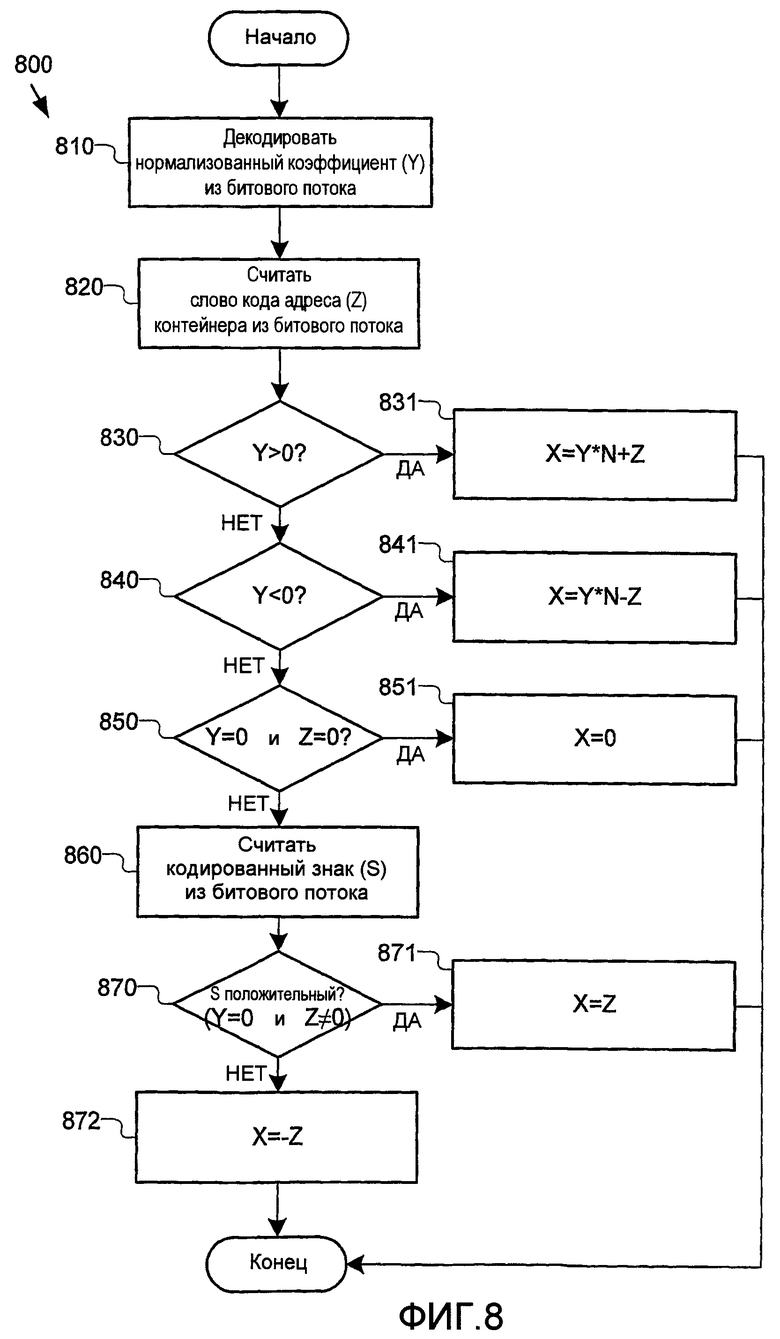
Фиг.8 - блок-схема этапов процесса, выполняемого декодером, показанным на фиг.5, для реконструкции коэффициента преобразования, закодированного в процессе, показанном на фиг.7.
Фиг.9 - блок-схема этапов процесса адаптации для адаптивного изменения группирования, показанного на фиг.6, для создания более оптимального распределения для статистического кодирования коэффициентов.
Фиг.10 и 11 - листинг псевдокода процесса адаптации, показанного на фиг.9.
Фиг.12 - блок-схема вычислительной среды, пригодной для реализации адаптивного кодирования коэффициентов с широким диапазоном, показанного на фиг.6.
Подробное описание
Нижеследующее описание посвящено способам кодирования и декодирования, которые адаптивно регулируются для более эффективного статистического кодирования коэффициентов преобразования с широким диапазоном. В нижеследующем описании раскрыта иллюстративная реализация способа применительно к системе сжатия цифрового медиасигнала или кодеку. Цифровая медиасистема кодирует цифровые медиаданные в сжатом виде для передачи или хранения и декодирует данные для воспроизведения или иной обработки. В целях иллюстрации эта иллюстративная система сжатия, предусматривающая это адаптивное кодирование коэффициентов с широким диапазоном, представляет собой систему сжатия изображения или видео. Альтернативно способ также можно использовать в системах сжатия или кодеках для других 2D-данных. Способ адаптивного кодирования коэффициентов с широким диапазоном не требует, чтобы система сжатия цифрового медиасигнала кодировала сжатые цифровые медиаданные в конкретном формате кодирования.
1. Кодер/декодер
На фиг.4 и 5 показаны общие схемы процессов, осуществляемых в иллюстративных кодере 400 и декодере 500 2-мерных (2D) данных. Схемы представляют обобщенную или упрощенную иллюстрацию системы сжатия, включающей в себя кодер и декодер 2D-данных, которые осуществляют адаптивное кодирование коэффициентов с широким диапазоном. В альтернативных системах сжатия с использованием адаптивного кодирования коэффициентов с широким диапазоном для сжатия 2D-данных можно использовать больше или меньше процессов, чем показано в этих иллюстративных кодере и декодере. Например, некоторые кодеры/декодеры также могут включать в себя преобразование цветов, цветовые форматы, масштабируемое кодирование, кодирование без потерь, режимы макроблоков и т.д. Система сжатия (кодер и декодер) могут обеспечивать сжатие без потерь и/или с потерями 2D-данных, в зависимости от квантования, т.е. на основании параметра квантование, изменяющегося от значения «без потерь» к значению «с потерями».
Кодер 2D-данных 400 создает сжатый битовый поток 420, который является более компактным представлением (для обычного ввода) 2D-данных 410, поданных в качестве ввода в кодер. Например, входные 2D-данные могут представлять собой изображение, кадр видеопоследовательности или другие данные, имеющие два измерения. Кодер 2D-данных разбивает 430 входные данные на макроблоки, каждый из которых имеет размер 16×16 пикселей в этом иллюстративном кодере. Кодер 2D-данных дополнительно разбивает каждый макроблок на блоки 4×4. Оператор 440 "прямого перекрытия" применяется к каждой границе между блоками, после чего каждый блок 4×4 преобразуется с использованием блочного преобразования 450. Это блочное преобразование 450 может быть обратимым, немасштабируемым 2D преобразованием, описанным Шринивасаном (Srinivasan) в патентной заявке США №11/015707 под названием "Reversible Transform For Lossy And Lossless 2-D Data Compression", поданной 17 декабря 2004 года. Оператор перекрытия 440 может представлять собой обратимый оператор перекрытия, описанный Ту (Tu) и др. в патентной заявке США №11/015148 под названием "Reversible Overlap Operator for Efficient Lossless Data Compression", поданной 17 декабря 2004 года; и Ту (Tu) и др. в патентной заявке США №11/035991 под названием "Reversible 2-Dimensional Pre-/Post-Filtering For Lapped Biorthogonal Transform", поданной 14 января 2005 года. Альтернативно можно использовать дискретное косинусное преобразование или другие блочные преобразования и операторы перекрытия. После преобразования DC коэффициент 460 каждого блока 4×4 преобразования подвергается аналогичной цепочке обработки (разбиению, прямому перекрытию и затем блочному 4×4 преобразованию). Полученные DC коэффициенты преобразования и AC коэффициенты преобразования квантуются 470, статистически кодируются 480 и пакетизируются 490.
Декодер осуществляет обратный процесс. На стороне декодера из соответствующих пакетов извлекаются 510 биты коэффициентов преобразования, из которых декодируются 520 и деквантуются 530 собственно коэффициенты. DC коэффициенты 540 регенерируются путем применения обратного преобразования, и плоскость DC коэффициентов подвергается "обратному перекрытию" с использованием подходящего оператора сглаживания, применяемого по краям DC блоков. Затем все данные регенерируются с применением обратного 4×4 преобразования 550 к DC коэффициентам и AC коэффициентам 542, декодированным из битового потока. Наконец, края блоков в результирующих плоскостях изображения подвергаются фильтрации с обратным перекрытием 560. В результате на выходе получаются реконструированные 2D-данные.
В иллюстративной реализации кодер 400 (фиг.2) сжимает входное изображение в сжатый битовый поток 420 (например, файл) и декодер 500 (фиг.5) реконструирует исходный входной сигнал или его приближение на основании того, применяется ли кодирование без потерь или с потерями. Процесс кодирования предусматривает применение прямого преобразования с перекрытием (LT), рассмотренного ниже, которое реализуется путем обратимой 2-мерной пре-/пост-фильтрации, которая также описана более подробно ниже. Процесс декодирования предусматривает применение обратного преобразования с перекрытием (ILT) с использованием обратимой 2-мерной пре-/пост-фильтрации.
Проиллюстрированные LT и ILT обратны друг другу в прямом смысле, и потому их можно в совокупности называть обратимым преобразованием с перекрытием. В качестве обратимого преобразования пару LT/ILT можно использовать для сжатия изображения без потерь.
Входные данные 410, сжимаемые иллюстрируемым кодером 400/декодером 500, могут представлять собой изображения в различных цветовых форматах (например, форматах цветного изображения RGB/YUV 4:4:4 или YUV 4:2:0). Обычно входное изображение всегда имеет компонент яркости (Y). Если это изображение RGB/YUV 4:4:4 или YUV 4:2:0, то изображение также имеет компоненты цветности, например компонент U и компонент V. Отдельные цветовые плоскости или компоненты изображения могут иметь разные пространственные разрешения. В случае входного изображения в цветовом формате YUV 4:2:0, например, компоненты U и V имеют половину ширины и высоты компонента Y.
Как рассмотрено выше, кодер 400 разбивает входное изображение на макроблоки. В иллюстративной реализации кодер 400 разбивает входное изображение на макроблоки 16×16 в канале Y (которые могут представлять собой области 16×16 или 8×8 в каналах U и V в зависимости от цветового формата). Цветовая плоскость каждого макроблока разбивается на участки или блоки 4×4. Поэтому макроблок для этой иллюстративной реализации кодера формируется для различных цветовых форматов следующим образом:
1. Для серого изображения каждый макроблок содержит 16 блоков яркости (Y) 4×4.
2. Для цветного изображения в формате YUV 4:2:0 каждый макроблок содержит 16 блоков Y 4×4, и 4 блока цветности (U и V) каждый размером 4×4.
3. Для цветного изображения RGB или YUV 4:4:4 каждый макроблок содержит 16 блоков каждого из каналов Y, U и V.
2. Адаптивное кодирование коэффициентов с широким диапазоном
В случае данных с широким динамическим диапазоном, особенно декоррелированных данных преобразования (например, коэффициентов 460, 462 в кодере, показанном на фиг.4), значительное количество младших битов непредсказуемы и создают "шум". Иными словами, в младших битах нет достаточной корреляции, которую можно использовать для эффективного статистического кодирования. Биты имеют высокую энтропию, достигающую 1 бита для каждого кодированного бита.
2.1 Группирование
Кроме того, функция лапласова распределения вероятностей коэффициентов преобразования с широким диапазоном, показанная на фиг.3, выражается как

(для удобства случайная переменная, соответствующая коэффициентам преобразования, рассматривается как непрерывная величина). Для данных с широким динамическим диапазоном λ мала и абсолютное значение 1/λ велико. Наклон этого распределения заключен в пределах ±1/2(λ2), т.е. очень мал. Это значит, что вероятность того, что коэффициент преобразования равен x, очень близка к вероятности для x+ξ, для малого сдвига ξ. В дискретной области определения это сводится к утверждению: "вероятность того, что коэффициент преобразования принимает соседние значения j и (j+1), почти одинакова".
Согласно фиг.6 при адаптивном кодировании коэффициентов с широким диапазоном осуществляется группирование 610 последовательных символов алфавита в "контейнеры" из N символов. Количество символов на контейнер может быть любым числом N. Однако для практического использования желательно, чтобы количество N было степенью 2 (т.е. N=2k), с тем чтобы индекс или адрес коэффициента в контейнере можно было эффективно кодировать в виде кода с фиксированной длиной. Например, символы можно группировать в пары, с тем чтобы символ можно было идентифицировать по индексу пары, совместно с индексом символа в паре.
Это группирование имеет преимущество в том, что при надлежащем выборе N распределение вероятностей индекса контейнера для коэффициентов с широким диапазоном больше напоминает распределение вероятностей для данных с узким диапазоном, например, показанное на фиг.3. Группирование математически сходно операции квантования. Это значит, что индекс контейнера можно эффективно кодировать с использованием методов статистического кодирования с переменной длиной, которое наиболее применимо к данным, имеющим распределение вероятностей в узком диапазоне.
На основании группирования коэффициентов в контейнеры кодер может затем кодировать коэффициент преобразования 615 с использованием индекса этого контейнера (также именуемого здесь нормализованным коэффициентом 620) и его адреса в контейнере (именуемого здесь адресом 625 контейнера). Нормализованный коэффициент кодируется с использованием статистического кодирования с переменной длиной, а адрес контейнера кодируется посредством кода с фиксированной длиной.
Выбор N (или, что одно и то же, количества битов k для кодирования адреса контейнера с фиксированной длиной) определяет степень детализации группирования. В общем случае чем шире диапазон коэффициентов преобразования, тем большее значение k следует выбирать. При надлежащем выборе k нормализованный коэффициент Y равен нулю с высокой вероятностью, что отвечает схеме статистического кодирования для Y.
Как описано ниже, значение k может адаптивно изменяться (в режиме обратной адаптации) в кодере и декодере. В частности, значение k на кодере и декодере изменяется только на основании ранее кодированных/декодированных данных.
В одном конкретном примере этого кодирования, показанном на фиг.7, кодер кодирует коэффициент преобразования X следующим образом. На начальном этапе 710 кодер вычисляет нормализованный коэффициент Y для коэффициента преобразования. В этой иллюстративной реализации нормализованный коэффициент Y задается как Y=sign(X)*floor(abs(X)/N) для некоторого выбора размера контейнера N=2k. Кодер кодирует символ Y с использованием статистического кода (этап 720) либо отдельно, либо совместно с другими символами. Затем, на этапе 730, кодер определяет адрес (Z) контейнера коэффициента преобразования X. В этой иллюстративной реализации адрес контейнера является остатком от целочисленного деления abs(X) на размер контейнера N, или Z=abs(X)%N. Кодер кодирует это значение в виде кода с фиксированной длиной k битов на этапе 740. Кроме того, в случае ненулевого коэффициента преобразования кодер также кодирует знак. В частности, как указано на этапах 750-760, кодер кодирует знак нормализованного коэффициента (Y), когда нормализованный коэффициент не равен нулю. Кроме того, в случае, когда нормализованный коэффициент равен нулю и коэффициент преобразования не равен нулю, кодер кодирует знак коэффициента преобразования (X). Поскольку нормализованный коэффициент кодируется с использованием статистического кода переменной длины, он также называется здесь частью переменной длины, и адрес (Z) контейнера также называется частью фиксированной длины. В других альтернативных реализациях математические определения нормализованного коэффициента, адреса контейнера и знака коэффициента преобразования могут отличаться.
Согласно этому же примеру на фиг.8 показан процесс 800, осуществляемый декодером 500 (фиг.5) для реконструкции коэффициента преобразования, закодированного в процессе 700 (фиг.7). На этапе 810 декодер декодирует нормализованный коэффициент (Y) из сжатого битового потока 420 (фиг.5) либо отдельно, либо совместно с другими символами, в соответствии с процессом блочного кодирования. Декодер дополнительно считывает k-битовое слово кода для адреса контейнера и знак (когда он кодируется) из сжатого битового потока на этапе 820. На этапах 830-872, декодер реконструирует коэффициент преобразования следующим образом:
1. Если Y>0 (этап 830), то коэффициент преобразования реконструируется как X=Y*N+Z (этап (831)).
2. Если Y<0 (этап 840), то коэффициент преобразования реконструируется как X=Y*N-Z (этап 841).
3. Если Y=0 и Z=0 (этап 850), то коэффициент преобразования реконструируется как X=0 (этап 851).
4. Если Y=0 и Z≠0, то декодер дополнительно считывает кодированный знак (S) из сжатого битового потока (этап 860). Если знак положительный (S=0) (этап 870), то коэффициент преобразования реконструируется как X=Z (этап 871). Если знак отрицательный (S=1), то коэффициент преобразования реконструируется как X=-Z (этап 872).
2.2 Расслоение
Согласно фиг.6 желательно, чтобы кодер и декодер выводили адреса 625 контейнера и знак, кодированные с фиксированной длиной, в отдельный кодовый слой (уровень) (именуемый здесь слоем 645 «флексбитов») в сжатом битовом потоке 420 (фиг.4). Нормализованные коэффициенты 620 кодируются в слое базового битового потока 640. Это дает кодеру и/или декодеру возможность при желании понижать или полностью отбрасывать эту флексбитовую часть кодирования, чтобы соответствовать ограничениям битовой скорости и пр. Даже когда кодер полностью отбрасывает слой флексбитов, сжатый битовый поток все же можно декодировать, хотя и с пониженным качеством. Декодер все же может реконструировать сигнал из одной лишь части нормализованных коэффициентов. Это, в сущности, аналогично применению более высокой степени квантования 470 (фиг.4) в кодере. Кодирование адресов контейнеров и знака в качестве отдельного слоя флексбитов также имеет потенциальное преимущество в том, что в ряде реализаций кодера/декодера для дополнительного улучшения сжатия к данным в этом слое (уровне) можно применять дополнительное статистическое кодирование с переменной длиной (например, арифметическое кодирование, кодирование Лемпела-Цива, Барроуза-Уилера и т.д.).
Для расслоения (разбиения на уровни) участки сжатого битового потока, содержащие флексбитовую часть, помечаются отдельным заголовком слоя (уровня) или другой индикацией в битовом потоке, чтобы декодер мог идентифицировать и отделять (т.е. анализировать) слой флексбитов 645 (когда он не отброшен) от базового битового потока 640.
Расслоение создает дополнительную трудность в построении группирования с обратной адаптацией (описанного в нижеследующем разделе). Поскольку слой (уровень) флексбитов может присутствовать или отсутствовать в данном битовом потоке, модель группирования с обратной адаптацией не может просто обращаться к любой информации в слое флексбитов. Вся информация, необходимая для определения количества k битов кода с фиксированной длиной (соответствующего размеру контейнера N=2k), должна находиться в каузальном, базовом битовом потоке.
2.3 Адаптация
Кодер и декодер дополнительно обеспечивают процесс обратной адаптации для адаптивной коррекции выбора вышеописанного количества k битов кода с фиксированной длиной и, соответственно, размера контейнера N для группирования в ходе кодирования и декодирования. В одной реализации процесс адаптации может основываться на моделировании коэффициентов преобразования в соответствии с распределением Лапласа, что позволяет выводить значение k из параметра λ распределения Лапласа. Однако такая изощренная модель требует, чтобы декодер осуществлял операцию, обратную группированию 610 (реконструировал коэффициенты преобразования из нормализованных коэффициентов в базовом битовом потоке 640 и адреса контейнера/знака в слое флексбитов 645), показанному на фиг.6, до моделирования распределения для будущих блоков. Это требование нарушает ограничение по расслоению, состоящее в том, что декодер должен разрешать выбрасывать слой флексбитов из сжатого битового потока 420.
В иллюстративной реализации, показанной на фиг.9, процесс адаптации 900, напротив, основан на том наблюдении, что более оптимальное кодирование по длине серии коэффициентов преобразования достигается, когда примерно четверть коэффициентов не равна нулю. Таким образом, параметр адаптации, который можно использовать для настройки группирования на случай "зоны наилучшего восприятия", где примерно три четверти нормализованных коэффициентов равны нулю, будет обеспечивать хорошую эффективность статистического кодирования. Соответственно, количество ненулевых нормализованных коэффициентов в блоке используется в качестве параметра адаптации в иллюстративной реализации. Этот параметр адаптации имеет преимущество в том, что он зависит только от информации, содержащейся в базовом битовом потоке, что отвечает ограничению по расслоению, согласно которому коэффициенты преобразования все же можно декодировать без использования слоя флексбитов. Процесс является обратной адаптацией в том смысле, что модель адаптации, применяемая при кодировании/декодировании текущего блока, основана на информации из предыдущего(их) блока(ов).
В этом процессе адаптации иллюстративные кодер и декодер осуществляют адаптацию по принципу обратной адаптации. Иными словами, текущая итерация адаптации опирается на информацию, известную ранее в процессе кодирования или декодирования, например, в предыдущем блоке или макроблоке. В иллюстративных кодере и декодере обновление адаптации происходит один раз для каждого макроблока для данной полосы преобразования, что призвано минимизировать латентность и взаимозависимость. Альтернативные реализации кодека могут осуществлять адаптацию с другими интервалами, например после преобразования каждого блока.
В иллюстративных кодере и декодере процесс адаптации 900 обновляет значение k. Если количество ненулевых нормализованных коэффициентов слишком велико, то k повышается, в результате чего это число имеет тенденцию к снижению в будущих блоках. Если количество ненулевых нормализованных коэффициентов слишком мало, то k понижается в ожидании, что будущие блоки создадут больше ненулевых нормализованных коэффициентов, поскольку размер контейнера N меньше. Иллюстративный процесс адаптации ограничивает значение k в пределах множества чисел {0, 1,..., 16}, но альтернативные реализации могут использовать другие диапазоны значений k. При каждом обновлении адаптации кодер и декодер увеличивают, уменьшают или оставляют значение k неизменным. Иллюстративные кодер и декодер увеличивают или уменьшают k на единицу, но альтернативные реализации могут использовать другие размеры шага.
Процесс адаптации 900 в иллюстративных кодере и декодере дополнительно использует внутренний параметр модели или переменную состояния (M) для управления обновлением параметра группирования k с эффектом гистерезиса. Этот параметр модели обеспечивает запаздывание перед обновлением параметра группирования k во избежание быстрых флуктуаций параметра группирования. Параметр модели в иллюстративном процессе адаптации имеет 16 фиксированных целочисленных значений от -8 до +8.
На фиг.9 показан иллюстративный процесс адаптации 900. Этот иллюстративный процесс адаптации дополнительно детализирован в псевдокоде, представленном на фиг.10 и 11. Как указано на этапах 910, 990, процесс адаптации в иллюстративных кодере и декодере осуществляется отдельно в отношении каждой полосы преобразования, представленной в сжатом битовом потоке, включая полосу яркости и полосы цветности, AC и DC коэффициенты и т.д. Альтернативные кодеки могут отличаться количеством полос преобразования и дополнительно могут применять адаптацию к полосам преобразования по отдельности или совместно.
На этапе 920 процесс адаптации подсчитывает количество ненулевых нормализованных коэффициентов полосы преобразования в непосредственно предшествующем кодированном/декодированном макроблоке. На этапе 930 этот необработанный счетчик нормализуется так, чтобы он отражал количество ненулевых коэффициентов, приведенное к целочисленному виду, в области заданного размера. Затем процесс адаптации вычисляет (этап 940) отклонение счетчика от нужной модели (т.е. "зоны наилучшего восприятия", где четверть коэффициентов не равна нулю). Например, макроблок AC коэффициентов в иллюстративном кодере, показанном на фиг.4, имеет 240 коэффициентов. Согласно нужной модели, 70 из 240 коэффициентов не равно нулю. Отклонение дополнительно масштабируется, сравнивается с порогом и используется для обновления внутреннего параметра модели.
На следующих этапах 960, 965, 970, 975 процесс адаптации адаптирует значение k согласно любому изменению внутреннего параметра модели. Если параметр модели меньше отрицательного порога, значение k уменьшается (в допустимых пределах). Эта адаптация порождает больше ненулевых коэффициентов. С другой стороны, если параметр модели превышает положительный порог, значение k увеличивается (в допустимых пределах). Такая адаптация порождает меньше ненулевых коэффициентов. В противном случае значение k остается неизменным.
Опять же, как указано на этапах 910, 980, процесс адаптации повторяется отдельно для каждого канала и поддиапазона данных, например отдельно для каналов цветности и яркости.
Иллюстративный процесс адаптации 900 дополнительно детализирован в псевдокоде 1000, показанном на фиг.10 и 11.
3. Вычислительная среда
Вышеописанные кодер 400 (фиг.4) и декодер 500 (фиг.5) и методы адаптивного кодирования/декодирования коэффициентов с широким диапазоном можно осуществлять на самых разнообразных устройствах, в которых осуществляется обработка цифрового медиасигнала, включая, помимо прочего, компьютеры; оборудование для записи, передачи и приема изображений и видео; портативные видеопроигрыватели; оборудование для видеоконференций; и т.д. Методы кодирования цифрового медиасигнала можно реализовать в электронном оборудовании, а также в программном обеспечении обработки цифрового медиасигнала, выполняющемся на компьютере или в другой вычислительной среде, например, показанной на фиг.12.
На фиг.12 показан обобщенный пример подходящей вычислительной среды (1200), в которой можно реализовать описанные варианты осуществления. Вычислительная среда (1200) не призвана налагать каких-либо ограничений на сферу применимости или функциональные возможности изобретения, так как настоящее изобретение можно реализовать в различных вычислительных средах общего или специального назначения.
Согласно фиг.12 вычислительная среда (1200) включает в себя, по меньшей мере, один процессор (1210) и память (1220). На фиг.12 эта наиболее базовая конфигурация (1230) ограничена пунктирной линией. Процессор (1210) выполняет компьютерно-выполняемые команды и может представлять собой реальный или виртуальный процессор. В многопроцессорной системе несколько процессоров выполняют компьютерно-выполняемые команды для повышения вычислительной мощности. Память (1220) может представлять собой энергозависимую память (например, регистры, кэш, ОЗУ), энергонезависимую память (например, ПЗУ, ЭСППЗУ, флэш-память и т.д.) или какую-либо их комбинацию. В памяти (1220) хранится программное обеспечение (1280), реализующее описанные кодер/декодер и способы кодирования/декодирования коэффициентов с широким диапазоном.
Вычислительная среда может иметь дополнительные особенности. Например, вычислительная среда (1200) включает в себя память (1240), одно или несколько устройств ввода (1250), одно или несколько устройств вывода (1260) и одно или несколько коммуникационных соединений (1270). Механизм внутреннего соединения (не показан), например шина, контроллер или сеть, соединяет между собой компоненты вычислительной среды (1200). Обычно программное обеспечение операционной системы (не показано) обеспечивает операционную среду для другого программного обеспечения, выполняющегося в вычислительной среде (1200), и координирует действия компонентов вычислительной среды (1200).
Память (1240) может быть сменной или стационарной и включает в себя магнитные диски, магнитные ленты или кассеты, CD-ROM, CD-RW, DVD или любой другой носитель, который можно использовать для хранения информации и к которому можно осуществлять доступ в вычислительной среде (1200). В памяти (1240) хранятся команды программного обеспечения (1280), реализующие описанные кодер/декодер и методы кодирования/декодирования коэффициентов с широким диапазоном.
Устройство(а) ввода (1250) может/могут представлять собой устройства ручного ввода, например клавиатуру, мышь, перо или шаровой манипулятор, устройство речевого ввода, сканирующее устройство или другое устройство, которое обеспечивает ввод в вычислительную среду (1200). Для аудиосигнала устройство(а) ввода (1250) может/могут представлять собой звуковую карту или аналогичное устройство, которое принимает аудиоввод в аналоговой или цифровой форме, или устройство чтения CD-ROM, которое выдает дискретизированный аудиосигнал в вычислительную среду. Устройство(а) вывода (1260) может/могут представлять собой дисплей, принтер, громкоговоритель, устройство записи CD или другое устройство, которое обеспечивает вывод из вычислительной среды (1200).
Коммуникационное(ые) соединение(я) (1270) обеспечивают связь по среде связи с другой вычислительной сущностью. Среда связи переносит информацию, например компьютерно-выполняемые команды, сжатую аудио или видео информацию или другие данные в сигнале, модулированном данными. Сигнал, модулированный данными, - это сигнал, одна или несколько характеристик которого изменяются таким образом, чтобы кодировать информацию в сигнале. В порядке примера, но не ограничения, среды связи включают в себя проводные или беспроводные методы, реализуемые посредством электрического, оптического, РЧ, инфракрасного, акустического или иного носителя.
Способы обработки цифрового медиасигнала можно описывать в общем контексте компьютерно-считываемых носителей. Компьютерно-считываемые носители представляют собой любые доступные носители, к которым можно осуществлять доступ в вычислительной среде. В порядке примера, но не ограничения, в вычислительной среде (1200) компьютерно-считываемые носители включают в себя запоминающее устройство (1220), память (1240), среды связи и комбинации вышеперечисленных примеров.
Способы обработки цифрового медиасигнала можно описывать в общем контексте компьютерно-выполняемых команд, например, входящих в состав программных модулей, выполняемых в вычислительной среде на реальном или виртуальном процессоре. В общем случае программные модули включают в себя процедуры, программы, библиотеки, объекты, классы, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют определенные абстрактные типы данных. Функциональные возможности программных модулей могут объединяться или разделяться между программными модулями, что описано в различных вариантах осуществления. Компьютерно-выполняемые команды для программных модулей могут выполняться в локальной или распределенной вычислительной среде.
В целях представления в подробном описании используются такие термины, как “определяет”, “генерирует”, “регулирует” и “применяет”, для описания компьютерных операций в вычислительной среде. Эти термины являются абстракциями высокого уровня для операций, осуществляемых компьютером, и их не следует путать с действиями, производимыми человеком. Фактические компьютерные операции, соответствующие этим терминам, варьируются в зависимости от реализации.
В виду большого количества возможных вариаций описанного здесь изобретения в качестве изобретения заявлены все подобные варианты осуществления в той мере, в какой они отвечают объему нижеследующей формулы изобретения и ее эквивалентов.








Изобретение относится к системам сжатия аудиосигнала, изображений и видеосигнала. Техническим результатом является повышение эффективности сжатия коэффициентов преобразования с широким диапазоном. Цифровой медиакодек на основе блочного преобразования более эффективно кодирует коэффициенты преобразования с широким динамическим диапазоном в две части, нормализованный коэффициент и адрес контейнера. Нормализованный коэффициент относится к группированию значений коэффициентов с широким динамическим диапазоном в контейнеры, тогда как адрес контейнера - это индекс значения коэффициента в контейнере. При тщательном выборе размера контейнера нормализованные коэффициенты имеют примерно такое же распределение вероятностей, как для коэффициентов преобразования с узким диапазоном, которое лучше поддается статистическому кодированию с переменной длиной. Кодек использует статистическое кодирование с переменной длиной для кодирования нормализованных коэффициентов в «базе» сжатого битового потока и кодирование с фиксированной длиной для кодирования адреса контейнера в качестве отдельного необязательного слоя, которое можно не выполнять. Кроме того, кодек адаптивно изменяет размер контейнера группирования на основании процесса обратной адаптации для подгонки нормализованных коэффициентов к распределению вероятностей, допускающему эффективное статистическое кодирование с переменной длиной. 11 н. и 18 з.п. ф-лы, 12 ил.
1. Способ кодирования цифровых медиаданных в вычислительной среде, содержащей процессор и память, содержащий этапы, на которых применяют преобразование к блокам цифровых медиаданных для создания набора коэффициентов преобразования для соответствующих блоков, для группирования множества значений коэффициентов определяют нормализованную часть и адресную часть коэффициентов преобразования блока, где нормализованная часть указывает группу, содержащую значение соответствующего коэффициента преобразования, и адресная часть указывает адрес значения соответствующего коэффициента преобразования в группе, и при этом нормализованная часть и адресная часть являются отдельными частями,
кодируют нормализованную часть коэффициента преобразования с использованием статистического кодирования с переменной длиной в сжатом битовом потоке, и
кодируют адресную часть коэффициента преобразования с использованием кодирования с фиксированной длиной в сжатом битовом потоке.
2. Способ по п.1, дополнительно содержащий этап, на котором выбирают группирование блока таким образом, чтобы множество групп коэффициентов содержали количество значений коэффициентов, равное степени двойки.
3. Способ по п.2, в котором определение
нормализованной части и адресной части коэффициентов преобразования содержит этапы, на которых
определяют нормализованную часть (У) коэффициента преобразования (X) согласно первому соотношению Y=sign(X)·floor(abs(X)/N), где N - количество значений коэффициентов на группу, и
определяют адресную часть (2) коэффициента преобразования согласно второму соотношению Z=abs(X)%N.
4. Способ по п.3, дополнительно содержащий этап, на котором в случае, когда нормализованная часть равна нулю и адресная часть не равна нулю, кодируют знак коэффициента преобразования в сжатом битовом потоке, иначе опускают кодирование знака в сжатом битовом потоке.
5. По меньшей мере один считываемый компьютером носитель записи, хранящий сжатый битовый поток, закодированный согласно способу кодирования цифровых медиаданных, причем способ содержит этапы, на которых
применяют преобразование к блокам цифровых медиаданных для создания набора коэффициентов преобразования для соответствующих блоков,
для группирования множества значений коэффициентов определяют нормализованную часть и адресную часть коэффициентов преобразования блока, где нормализованная часть указывает группу, содержащую значение соответствующего коэффициента преобразования, и адресная часть указывает адрес значения соответствующего коэффициента преобразования в группе, и при этом нормализованная часть и адресная часть являются отдельными частями,
кодируют нормализованную часть коэффициента преобразования с использованием статистического кодирования с переменной длиной в сжатом битовом потоке, и
кодируют адресную часть коэффициента преобразования с использованием кодирования с фиксированной длиной в сжатом битовом потоке,
в случае, когда нормализованная часть равна нулю и адресная часть не равна нулю, кодируют знак коэффициента преобразования в сжатом битовом потоке, иначе опускают кодирование знака в сжатом битовом потоке.
6. Способ по п.1, дополнительно содержащий этап, на котором кодируют с помощью процессора сжатый битовый поток в
соответствии с многослойной синтаксической структурой битового потока, причем синтаксическая структура содержит базовую часть и дополнительный слой, где базовая часть содержит достаточную информацию, чтобы представление цифровых медиаданных можно было декодировать и реконструировать, не обращаясь к дополнительному слою, на основании исключительно базовой части сжатого битового потока;
кодируют с помощью процессора нормализованные части коэффициентов преобразования в базовую часть сжатого битового потока, и
кодируют с помощью процессора адресные части коэффициентов преобразования в дополнительный слой сжатого битового потока.
7. Способ по п.6, дополнительно содержащий этап, на котором осуществляют дополнительное статистическое кодирование кодированных с фиксированной длиной адресных частей коэффициентов преобразования.
8. Способ по п.6, дополнительно содержащий этап, на котором адаптивно изменяют группирование, применяемое к текущему блоку, на основании наблюдаемой характеристики распределения вероятностей значений коэффициента преобразования по меньшей мере одного предыдущего блока.
9. Способ по п.8, в котором при осуществлении адаптивного изменения группирования основано исключительно на информации, содержащейся в базовой части сжатого битового потока.
10. Способ по п.1, дополнительно содержащий этап, на котором адаптивно изменяют группирование, применяемое к текущему блоку, на основании наблюдаемой характеристики распределения вероятностей значений коэффициента преобразования по меньшей мере одного предыдущего блока.
11. Способ по п.10, в котором адаптивное изменение группирования содержит этапы, на которых
подсчитывают случаи появления ненулевых коэффициентов преобразования в по меньшей мере одном предыдущем блоке, и
регулируют размер групп коэффициентов в группировании, применяемом к текущему блоку, на основании значения подсчета коэффициентов преобразования, имеющих ненулевую нормализованную часть в по меньшей мере одном предыдущем блоке, чтобы таким образом с большей вероятностью создать распределение вероятностей нормализованной части коэффициентов преобразования в текущем блоке, пригодное для более эффективного сжатия нормализованной части коэффициентов преобразования с использованием кодирования с переменной длиной.
12. Способ по п.11, в котором адаптивное изменение группирования содержит этапы, на которых
определив, что тенденция в значении подсчета ненулевой нормализованной части коэффициентов преобразования ниже порога, уменьшают размер групп коэффициентов, чтобы распределение вероятностей нормализованной части коэффициентов преобразования в текущем блоке с большей вероятностью содержало больше ненулевых нормализованных частей, и
определив, что тенденция в значении подсчета ненулевой нормализованной части коэффициентов преобразования выше порога, увеличивают размер групп коэффициентов, чтобы распределение вероятностей нормализованной части коэффициентов преобразования в текущем блоке с большей вероятностью содержало меньше ненулевых нормализованных частей.
13. Способ декодирования цифровых медиаданных в компьютерной среде, содержащий процессор и память, способ содержит этапы, на которых
декодируют нормализованную часть Y и адресную часть Z для коэффициента преобразования Х из сжатого битового потока, при этом нормализованная часть Y и адресная часть Z являются отдельными частями, нормализованная часть Y кодирована с переменной длиной и адресная часть Z кодирована с фиксированной длиной, где нормализованная часть указывает группу для коэффициента преобразования X, где адресная часть Z указывает адрес коэффициента преобразования Х внутри группы и где N указывает число возможных значений коэффициента на группу; и
в случае, когда нормализованная часть Y больше нуля, реконструируют коэффициент Х преобразования согласно соотношению X=Y·N+Z,
в случае, когда нормализованная часть Y меньше нуля, реконструируют коэффициент Х преобразования согласно соотношению X=Y·N-Z, и
в случае, когда нормализованная часть Y и адресная часть Z обе равны нулю, реконструируют коэффициент преобразования X, чтобы он также был равен нулю, и
в случае, когда нормализованная часть Y равна нулю и адресная часть Z не равна нулю, считывают знак из сжатого битового потока и реконструируют коэффициент преобразования как функцию адресной части Z и знака.
14. По меньшей мере один считываемый компьютером носитель записи, несущий сжатый битовый поток, закодированный согласно способу кодирования цифровых медиаданных, содержащий этапы, на которых применяют преобразование к блокам цифровых медиаданных для создания набора коэффициентов преобразования для соответствующих блоков, для группирования множества значений коэффициентов во множество групп коэффициентов, определяют нормализованную часть и адресную часть коэффициентов преобразования блока, где нормализованная часть указывает группу, содержащую значение соответствующего коэффициента преобразования, и адресная часть указывает адрес значения соответствующего коэффициента преобразования в группе, и при этом нормализованная часть и адресная часть являются отдельными частями,
кодируют нормализованную часть коэффициента преобразования с использованием статистического кодирования с переменной длиной в сжатом битовом потоке, и
кодируют адресную часть коэффициента преобразования с использованием кодирования с фиксированной длиной в сжатом битовом потоке,
кодируют сжатый битовый поток в соответствии с многослойной синтаксической структурой битового потока, причем синтаксическая структура содержит базовую часть и дополнительный слой, где базовая часть содержит достаточную информацию, чтобы представление цифровых медиаданных можно было декодировать и реконструировать, не обращаясь к дополнительному слою, на основании исключительно базовой части сжатого битового потока;
кодируют нормализованные части коэффициентов преобразования в базовую часть сжатого битового потока, и
кодируют адресные части коэффициентов преобразования в дополнительный слой сжатого битового потока.
15. Цифровой медиакодер, содержащий
буфер данных для хранения цифровых медиаданных, подлежащих кодированию,
процессор, запрограммированный
адаптивно изменять группирование значений коэффициентов преобразования в множество групп коэффициентов для текущего блока цифровых медиаданных на основании наблюдаемой характеристики распределения вероятностей предыдущих коэффициентов преобразования, определять нормализованную часть и адресную часть коэффициентов преобразования текущего блока, где нормализованная часть указывает группу коэффициентов, содержащую значение соответствующего коэффициента преобразования, и адресная часть дифференцирует значение коэффициента преобразования в группе коэффициентов, причем нормализованная часть и адресная часть являются раздельными частями, кодировать нормализованную часть с использованием кодирования с переменной длиной, и
кодировать адресную часть с использованием кодирования с фиксированной длиной.
16. Цифровой медиакодер по п.15, в котором процессор дополнительно запрограммирован кодировать нормализованные части коэффициентов преобразования в базовой части сжатого битового потока в соответствии с многослойной синтаксической структурой битового потока, имеющей базовую часть и необязательный слой, где базовая часть содержит достаточную информацию для кодирования и по меньшей мере приближенной реконструкции цифровых медиаданных без обращения к информации в необязательном слое, и
кодировать адресные части коэффициентов преобразования в необязательном слое.
17. Цифровой медиакодер по п.15, в котором группирование значений коэффициентов осуществляется группами коэффициентов, имеющими размер, исчисляемый количеством коэффициентов, равным степени двойки, и в котором программирование процессора на определение нормализованной части и адресной части содержит квантование процессором коэффициента преобразования на степень двойки для определения нормализованной части, и взятие остатка от целочисленного деления коэффициента преобразования на степень двойки в качестве адресной части.
18. Цифровой медиакодер по п.15, в котором процессор дополнительно запрограммирован кодировать знак коэффициента преобразования, только когда нормализованная часть равна нулю и адресная часть не равна нулю.
19. По меньшей мере один считываемый компьютером носитель записи, несущий выполняемую компьютером программу обработки цифровых медиаданных для вынуждения одного или более процессоров выполнять способ обработки цифровых медиаданных, способ содержит этапы, на которых
адаптивно изменяют группирование значений коэффициента преобразования во множество групп коэффициентов для текущего блока цифровых медиаданных на основании наблюдаемой характеристики распределения вероятностей предыдущих коэффициентов преобразования, определяют нормализованную часть и адресную часть коэффициентов преобразования текущего блока, где нормализованная часть указывает группу коэффициентов, содержащую значение соответствующего коэффициента преобразования, и адресная часть дифференцирует значение коэффициента преобразования в группе коэффициентов, причем нормализованная часть и адресная часть являются отдельными частями, кодируют нормализованную часть с использованием кодирования с переменной длиной, и
кодируют адресную часть с использованием кодирования с фиксированной длиной.
20. По меньшей мере один считываемый компьютером носитель записи по п.19, в котором способ дополнительно содержит этапы, на которых
кодируют нормализованные части коэффициентов преобразования в базовой части сжатого битового потока в соответствии с многослойной синтаксической структурой битового потока, имеющей базовую часть и необязательный слой, где базовая часть содержит достаточную информацию для декодирования и, по меньшей мере, приближенной реконструкции цифровых медиаданных без обращения к информации в необязательном слое, и кодируют адресные части коэффициентов преобразования в необязательном слое.
21. По меньшей мере один считываемый компьютером носитель записи, содержащий инструкции для вынуждения одного или более процессоров выполнять способ кодирования цифровых медиаданных, причем способ содержит этапы, на которых
применяют преобразование к блокам цифровых медиаданных для создания набора коэффициентов преобразования для соответствующих блоков,
для группирования множества значений коэффициентов определяют нормализованную часть и адресную часть коэффициентов преобразования блока, где нормализованная часть указывает группу, содержащую значение соответствующего коэффициента преобразования, и адресная часть указывает адрес значения соответствующего коэффициента преобразования в группе, и при этом нормализованная часть и адресная часть являются отдельными значениями,
адаптивно изменяют группирование, применяемое к текущему блоку, на основании наблюдаемой характеристики распределения вероятностей значений коэффициента преобразования по меньшей мере одного предыдущего блока посредством подсчета появлений ненулевых коэффициентов преобразования в по меньшей мере одном предыдущем блоке и регулируют размер групп коэффициентов в группировании, применяемом к текущему блоку, на основании значения подсчета коэффициентов преобразования, имеющих ненулевую нормализованную часть в по меньшей мере одном предыдущем блоке, чтобы таким образом с большей вероятностью создать распределение вероятностей нормализованной части коэффициентов преобразования в текущем блоке, пригодное для более эффективного сжатия нормализованной части коэффициентов преобразования с использованием кодирования с переменной длиной, причем
кодируют нормализованную часть коэффициента преобразования с использованием статистического кодирования с переменной длиной в сжатом битовом потоке, и
кодируют адресную часть коэффициента преобразования с использованием кодирования с фиксированной длиной в сжатом битовом потоке.
22. Способ декодирования сжатого битового потока в цифровые медиаданные, способ содержит этапы, на которых:
для каждого коэффициента преобразования набора коэффициентов преобразования, декодируют нормализованную часть коэффициента преобразования из сжатого битового потока, используя статическое декодирование с переменной длиной, нормализованную часть, указывающая группу, содержащую значение коэффициента преобразования;
для каждого коэффициента преобразования набора коэффициентов преобразования, декодируют адресную часть коэффициента преобразования из сжатого битового потока, используя фиксированную длину декодирования, адресную часть, указывающую адрес значения коэффициента преобразования в группе, адресную часть, являющуюся отдельной от нормализованной части, при этом коэффициент преобразования реконструируют на основании по меньшей мере частично нормализованной части коэффициента преобразования и адресной части коэффициента преобразования; и
применяют обратное преобразование к набору коэффициентов преобразования, таким образом, создавая блок цифровых медиаданных.
23. По меньшей мере один считываемый компьютером носитель записи, хранящий на нем компьютероисполняемую программу обработки цифровых медиаданных, для выполнения способа, содержащего этапы, на которых:
для каждого коэффициента преобразования набора коэффициентов преобразования, декодируют нормализованную часть коэффициента преобразования из сжатого битового потока, используя статическое декодирование с переменной длиной, нормализованную часть, указывающая группу, содержащую значение коэффициента преобразования;
для каждого коэффициента преобразования набора коэффициентов преобразования, декодируют адресную часть коэффициента преобразования из сжатого битового потока, используя фиксированную длину декодирования, адресную часть, указывающую адрес значения коэффициента преобразования в группе адресную часть, являющуюся отдельной от нормализованной части, при этом, коэффициент преобразования реконструируют на основании, по меньшей мере, частично нормализованной части коэффициента преобразования и адресной части коэффициента преобразования; и
применяют обратное преобразование к набору коэффициентов преобразования, таким образом, создавая блок цифровых медиаданных.
24. Цифровой медиадекодер, содержащий буфер данных для хранения сжатого битового потока, подлежащего декодированию;
процессор, запрограммированный
адаптивно изменять группирование значений коэффициентов преобразования в множество групп коэффициентов для текущего блока цифровых медиаданных на основании наблюдаемой характеристики распределения вероятностей предыдущих декодированных коэффициентов преобразования;
для каждого коэффициента преобразования текущего блока декодировать нормализованную часть коэффициента преобразования, используя декодирование с переменной длиной, нормализованную часть, указывающую группу коэффициентов, содержащих значение коэффициента преобразования; и
для каждого коэффициента преобразования текущего блока декодировать адресную часть коэффициента преобразования, используя декодирование с фиксированной длиной, адресная часть, дифференцирующая значение коэффициента пребразования внутри группы коэффициентов, адресная часть является отдельной частью от нормализованной части.
25. Цифровой медиадекодер по п.24, в котором процессор дополнительно запрограммирован для:
декодирования нормализованной части коэффициента преобразования от базовой части сжатого потока в соответствии с многослойной синтаксической структурой битового потока, имеющей базовую часть и дополнительный слой, где базовая часть содержит достаточную информацию для декодирования и по меньшей мере приближенной реконструкции цифровых медиаданных без обращения к информации в необязательном слое; и
декодирования адресных частей коэффициентов преобразования в необязательном слое.
26. Цифровой медиадекодер по п.24 в котором группирование значений коэффициентов осуществляется группами коэффициентов, имеющими размер, исчисляемый количеством коэффициентов, равным степени двойки.
27. Цифровой медиадекодер по п.24, в котором процессор дополнительно запрограммирован для каждого коэффициента преобразования текущего блока декодировать знак коэффициента преобразования, только когда нормализованная часть равна нулю и адресная часть не равна нулю.
28. По меньшей мере один компьютерочитаемый носитель, хранящий компьютероисполняемую программу обработки цифровых медиаданных для выполнения способа обработки цифровых медиаданных, при этом способ содержит этапы, на которых:
адаптивно изменяют группирование значений коэффициентов преобразования в множество групп коэффициентов для текущего блока цифровых медиаданных на основании наблюдаемой характеристики распределения вероятностей предыдущих декодированных коэффициентов преобразования,
для каждого коэффициента преобразования текущего блока декодируют нормализованную часть коэффициента преобразования, используя декодирование с переменной длиной, нормализованную часть, указывающую группу коэффициентов, содержащих значение коэффициента преобразования; и
для каждого коэффициента преобразования текущего блока декодируют адресную часть коэффициента преобразования, используя декодирование с фиксированной длиной, адресная часть дифференцирующая значение коэффициента пребразования внутри группы коэффициентов, адресная часть является отдельной частью нормализованной части.
29. По меньшей мере один компьютерочитаемый носитель по п.28, в котором способ дополнительно содержит этапы:
декодирования нормализованной части коэффициента преобразования от базовой части сжатого потока в соответствии с многослойной синтаксической структурой битового потока, имеющей базовую часть и дополнительный слой, где базовая часть содержит достаточную информацию для декодирования и по меньшей мере приближенной реконструкции цифровых медиаданных без обращения к информации в необязательном слое; и
декодирования адресной части коэффициентов преобразования в необязательном слое.
| US 5825979 А, 20.10.1998 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 5109451 A, 28.04.1992 | |||
| US 6650784 B2, 18.11.2003 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ В ЦИФРОВОЙ ФОРМЕ | 1998 |
|
RU2196391C2 |

