Описание
Настоящее изобретение относится к области передачи кодированных аудиосигналов, более конкретно - к способу и устройству для получения спектральных коэффициентов для заменяющего кадра аудиосигнала, декодеру аудио, приемнику аудио и системе для передачи аудиосигналов. Варианты осуществления относятся к подходу для создания спектра для заменяющего кадра на основе ранее принятых кадров.
В известном уровне техники описаны некоторые подходы, рассматривающие вопросы потери кадра в приемнике аудио. Например, когда кадр теряется на стороне приемника аудиокодека или речевого кодека, могут использоваться простые способы маскирования потери кадра, как описано в ссылке [1], такие как:
- повторение последнего принятого кадра,
- подавление потерянного кадра или
- скремблирование со знаком.
Кроме того, в ссылке [1] представлен усовершенствованный способ, использующий блоки предсказания (экстраполяторы) в поддиапазонах. Методика блока предсказания затем объединяется со «скремблированием со знаком», и коэффициент усиления по предсказанию используется в качестве критерия принятия решения на основе поддиапазона, чтобы определять способ, который будет использоваться для спектральных коэффициентов этого поддиапазона.
В ссылке [2] экстраполяция аналогового сигнала (волновой формы) во временной области используется для кодека области модифицированного дискретного косинусного преобразования (MDCT). Этот вид подхода может быть хорошим для монофонических сигналов, включая речь.
Если допускается задержка в один кадр, может использоваться интерполяция кадров окружения для создания потерянного кадра. Такой подход описан в ссылке [3], где амплитуды тональных компонентов в потерянном кадре с индексом m интерполируют, используя соседние кадры с индексами m-1 и m+1. Вспомогательная информация, которая задает знаки коэффициентов MDCT для тональных компонентов, передается в потоке битов. Скремблирование со знаком используется для других нетональных коэффициентов MDCT. Тональные компоненты определяют как предварительно определенное фиксированное число спектральных коэффициентов с наибольшими амплитудами. Этот подход выбирает n спектральных коэффициентов с наибольшими амплитудами в качестве тональных компонентов.
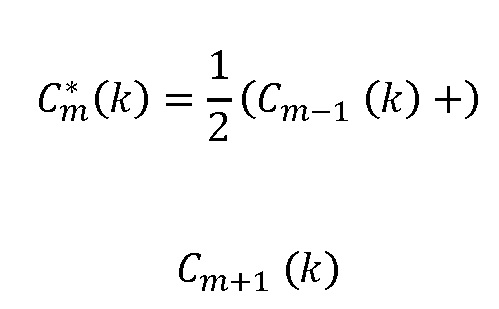
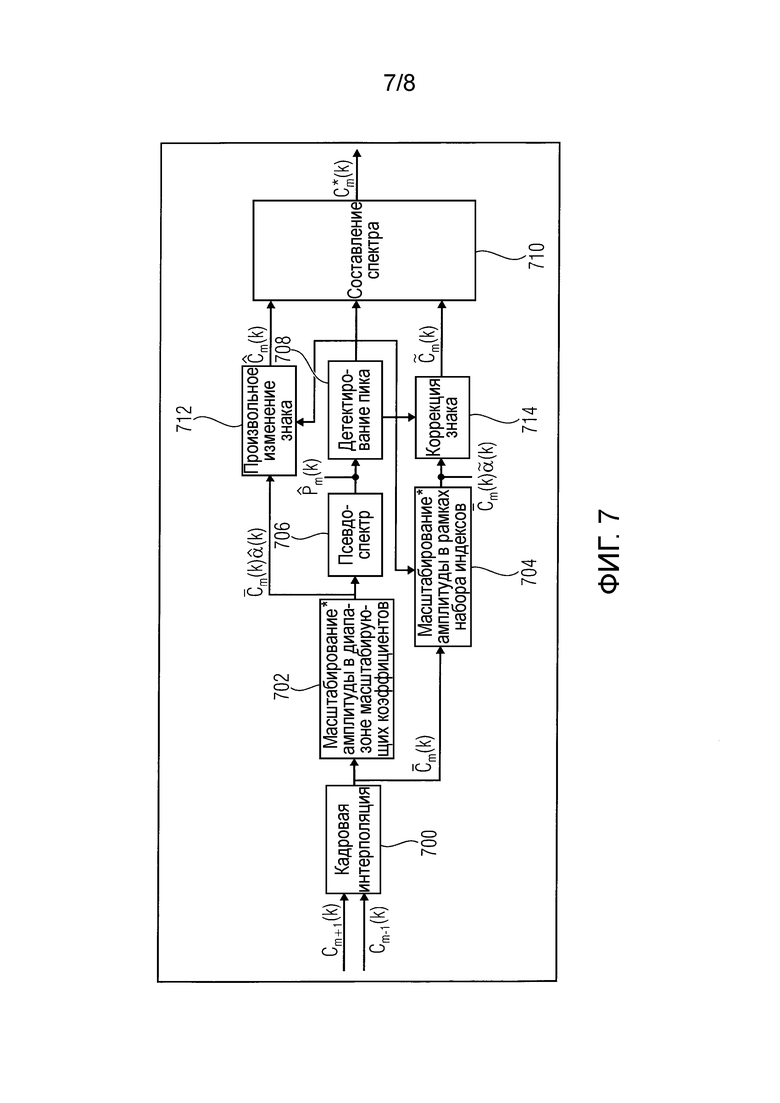
Фиг.7 показывает блок-схему, представляющую интерполяционный подход без передаваемой вспомогательной информации, как это, например, описано в ссылке [4]. Интерполяционный подход работает на основе аудио кадров, кодированных в частотной области, с использованием MDCT (модифицированное дискретное косинусное преобразование). Блок 700 кадровой интерполяции принимает коэффициенты MDCT для кадра, предшествующего потерянному кадру, и кадра, следующего после потерянного кадра, более конкретно в подходе, описанном в отношении Фиг.7, MDCT-коэффициенты 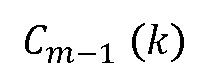 предыдущего кадра и MDCT-коэффициенты
предыдущего кадра и MDCT-коэффициенты 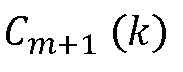 последующего кадра принимают на этапе 700 кадровой интерполяции. Блок 700 кадровой интерполяции генерирует интерполированный MDCT коэффициент
последующего кадра принимают на этапе 700 кадровой интерполяции. Блок 700 кадровой интерполяции генерирует интерполированный MDCT коэффициент 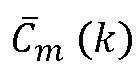 для текущего кадра, который либо был потерян в приемнике, либо не может быть обработан в приемнике по другим причинам, например, из-за ошибок в принятых данных и т.п. Интерполированный MDCT-коэффициент, выводимый блоком 700 кадровой интерполяции, подается на блок 702, вынуждая масштабирование амплитуды в диапазоне масштабирующих коэффициентов, и на блок 704, вынуждая масштабирование амплитуды в рамках набора индексов, и соответственные блоки 702 и 704 выводят MDCT-коэффициент, масштабированный множителем
для текущего кадра, который либо был потерян в приемнике, либо не может быть обработан в приемнике по другим причинам, например, из-за ошибок в принятых данных и т.п. Интерполированный MDCT-коэффициент, выводимый блоком 700 кадровой интерполяции, подается на блок 702, вынуждая масштабирование амплитуды в диапазоне масштабирующих коэффициентов, и на блок 704, вынуждая масштабирование амплитуды в рамках набора индексов, и соответственные блоки 702 и 704 выводят MDCT-коэффициент, масштабированный множителем 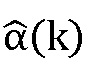 и
и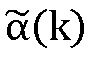 , соответственно. Выходной сигнал блока 702 вводится на блок 706 псевдоспектра, генерирующий на основе принятого входного сигнала псевдо спектр
, соответственно. Выходной сигнал блока 702 вводится на блок 706 псевдоспектра, генерирующий на основе принятого входного сигнала псевдо спектр 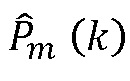 , который вводится на блок 708 детектирования пика, генерирующий сигнал, указывающий детектированные пики. Сигнал, обеспечиваемый блоком 702, также подается на блок 712 произвольного изменения знака, который, в ответ на сигнал детектирования пика, сгенерированный блоком 708, вызывает изменение знака принятого сигнала и выводит измененный MDCT-коэффициент
, который вводится на блок 708 детектирования пика, генерирующий сигнал, указывающий детектированные пики. Сигнал, обеспечиваемый блоком 702, также подается на блок 712 произвольного изменения знака, который, в ответ на сигнал детектирования пика, сгенерированный блоком 708, вызывает изменение знака принятого сигнала и выводит измененный MDCT-коэффициент 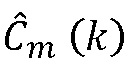 на блок 710 составления спектра. Масштабированный сигнал, обеспечиваемый блоком 704, подается на блок 714 коррекции знака, вынуждая в ответ на сигнал детектирования пика, обеспечиваемый блоком 708, коррекцию знака масштабированного сигнала, обеспечиваемого блоком 704, и вывод модифицированного MDCT-коэффициента
на блок 710 составления спектра. Масштабированный сигнал, обеспечиваемый блоком 704, подается на блок 714 коррекции знака, вынуждая в ответ на сигнал детектирования пика, обеспечиваемый блоком 708, коррекцию знака масштабированного сигнала, обеспечиваемого блоком 704, и вывод модифицированного MDCT-коэффициента 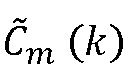 на блок 710 составления спектра, который на основе принятых сигналов генерирует интерполированный MDCT-коэффициент
на блок 710 составления спектра, который на основе принятых сигналов генерирует интерполированный MDCT-коэффициент 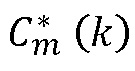 , который выводится блоком 710 составления спектра. Как показано на Фиг.7, сигнал детектирования пика, обеспечиваемый блоком 708, также предоставляется на блок 704, генерирующий масштабированный MDCT-коэффициент.
, который выводится блоком 710 составления спектра. Как показано на Фиг.7, сигнал детектирования пика, обеспечиваемый блоком 708, также предоставляется на блок 704, генерирующий масштабированный MDCT-коэффициент.
Фиг.7 показывает формирование на выходе блока 714 спектральных коэффициентов 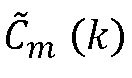 для потерянного кадра, связанных с тональными компонентами, и на выходе блока 712 спектральные коэффициенты
для потерянного кадра, связанных с тональными компонентами, и на выходе блока 712 спектральные коэффициенты 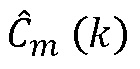 для нетональных компонентов обеспечиваются с тем результатом, что на этапе 710 составления спектра на основе спектральных коэффициентов, принятых для тональных и нетональных компонентов, обеспечиваются спектральные коэффициенты для спектра, связанного с потерянным кадром.
для нетональных компонентов обеспечиваются с тем результатом, что на этапе 710 составления спектра на основе спектральных коэффициентов, принятых для тональных и нетональных компонентов, обеспечиваются спектральные коэффициенты для спектра, связанного с потерянным кадром.
Действие способа FLC (маскирование потери кадра), описанного на блок-схеме по Фиг.7, теперь будет описана более подробно.
На Фиг.7, в основном могут быть выделены четыре модуля:
модуль вставки формируемого шума (включая интерполяцию кадра 700, масштабирование амплитуды в рамках диапазона 702 масштабирующих коэффициентов и произвольное изменение 712 знака),
модуль классификации элемента выборки MDCT (включая псевдоспектр 706 и детектирование 708 пиков),
модуль операций тонального маскирования (включая масштабирование амплитуды в рамках набора индексов 704 и коррекцию 714 знака), и
модуль 710 составления спектра.
Подход основывается на следующей общей формуле:
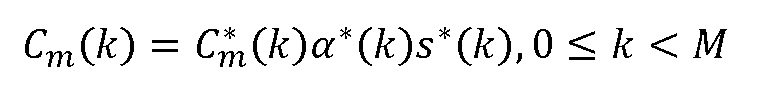
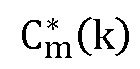 выводят путем интерполяции по элементам выборки (см. блок 700 “Кадровая интерполяция”),
выводят путем интерполяции по элементам выборки (см. блок 700 “Кадровая интерполяция”),
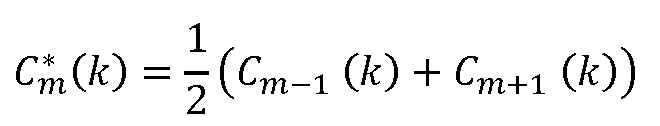
Значение 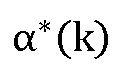 получают путем интерполяции значений энергии, используя среднее геометрическое:
получают путем интерполяции значений энергии, используя среднее геометрическое:
на основе диапазона масштабирующих коэффициентов для всех компонентов, (см. блок 702 “Масштабирование амплитуды в диапазоне масштабирующих коэффициентов”), и
на основе поднабора индексов для тональных компонентов (см. этап, 704 “Масштабирование амплитуды в рамках набора индексов”):
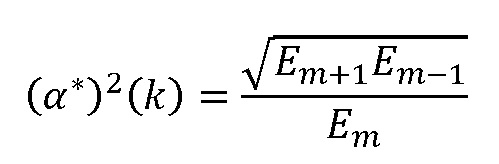
для тональных компонентов можно показать что 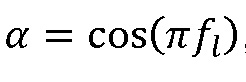 , при
, при 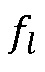 , являющейся частотой тонального компонента.
, являющейся частотой тонального компонента.
Значения 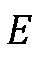 энергии получают на основании энергетического псевдоспектра, получаемого простой операцией сглаживания:
энергии получают на основании энергетического псевдоспектра, получаемого простой операцией сглаживания:
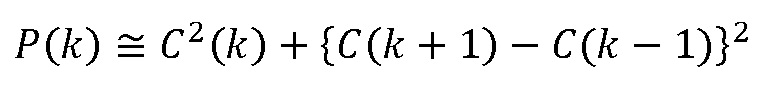
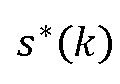 устанавливают произвольным образом в ±1 для нетональных компонентов (см. блок 712 “Произвольное изменение знака”), и либо в +1 или -1 для тональных компонентов (см. блок 714 “коррекция знака”).
устанавливают произвольным образом в ±1 для нетональных компонентов (см. блок 712 “Произвольное изменение знака”), и либо в +1 или -1 для тональных компонентов (см. блок 714 “коррекция знака”).
Детектирование пиков выполняется в виде поиска локальных максимумов в энергетическом псевдоспектре, чтобы детектировать точные местоположения спектральных пиков, соответствующих нижележащим синусоидам. Это основывается на процессе идентификации тона, принятом в предложенной Экспертной группой по вопросам движущегося изображения психоакустической модели MPEG 1, описанной в ссылке [5]. Из этого, поднабор индексов задается имеющим ширину спектра, соответствующую основному лепестку окна анализа в терминах элементов выборки MDCT и детектированным пиком в его центре. Эти элементы выборки обрабатывают как тональные доминантные элементы выборки MDCT для синусоиды, и поднабор индексов обрабатывается как отдельный тональный компонент.
Коррекция знака 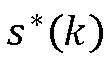 переключает либо знаки всех элементов выборки некоторого тонального компонента, либо ни одного. Определение выполняют, используя метод анализа через синтез, то есть, SFM получают выводом для обеих версий и выбирают версии с более низким SFM. Для вывода SFM требуется энергетический спектр, которому в свою очередь требуются коэффициенты модифицированного дискретного синусного преобразования (MDST). Для поддержания поддающейся управлению сложности, выводят только коэффициенты MDST для тонального компонента, используя также только коэффициенты MDCT этого тонального компонента.
переключает либо знаки всех элементов выборки некоторого тонального компонента, либо ни одного. Определение выполняют, используя метод анализа через синтез, то есть, SFM получают выводом для обеих версий и выбирают версии с более низким SFM. Для вывода SFM требуется энергетический спектр, которому в свою очередь требуются коэффициенты модифицированного дискретного синусного преобразования (MDST). Для поддержания поддающейся управлению сложности, выводят только коэффициенты MDST для тонального компонента, используя также только коэффициенты MDCT этого тонального компонента.
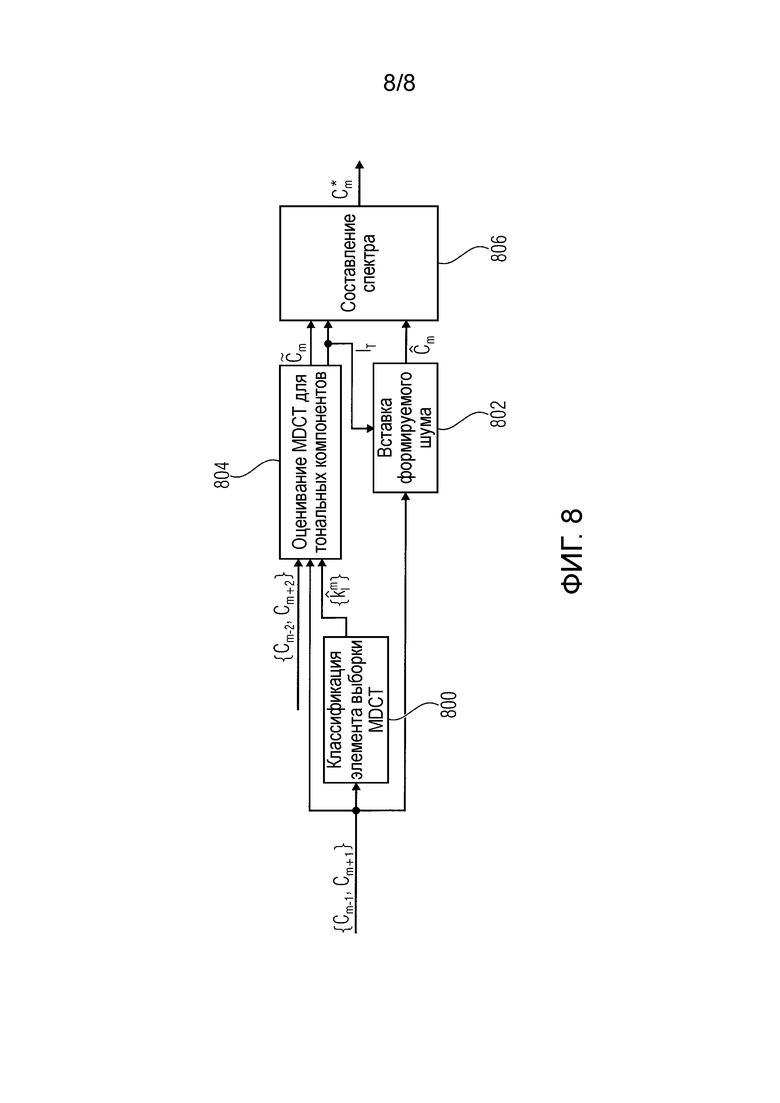
Фиг.8 иллюстрирует блок-схему общего способа FLC, который уточнен по сравнению с подходом по Фиг.7, и который описан в ссылке [6]. На Фиг.8 MDCT-коэффициенты 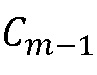 и
и 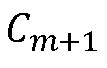 последнего кадра, предшествующего потерянному кадру, и первого кадра после потерянного кадра, принимают на этапе 800 классификации элемента выборки MDCT. Эти коэффициенты также предоставляются на этап 802 вставки формируемого шума и на этап 804 оценивания MDCT для тональных компонентов. На этапе 804 кроме того принимают выходной сигнал, обеспечиваемый этапом 800 классификации, а также принимают MDCT-коэффициенты
последнего кадра, предшествующего потерянному кадру, и первого кадра после потерянного кадра, принимают на этапе 800 классификации элемента выборки MDCT. Эти коэффициенты также предоставляются на этап 802 вставки формируемого шума и на этап 804 оценивания MDCT для тональных компонентов. На этапе 804 кроме того принимают выходной сигнал, обеспечиваемый этапом 800 классификации, а также принимают MDCT-коэффициенты 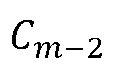 и
и 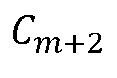 предпоследнего кадра, предшествующего потерянному кадру, и второго кадра после потерянного кадра, соответственно. Этап 804 формирует MDCT коэффициенты
предпоследнего кадра, предшествующего потерянному кадру, и второго кадра после потерянного кадра, соответственно. Этап 804 формирует MDCT коэффициенты 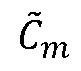 потерянного кадра для тональных компонентов, и этап 802 вставки формируемого шума формирует спектральные MDCT-коэффициенты
потерянного кадра для тональных компонентов, и этап 802 вставки формируемого шума формирует спектральные MDCT-коэффициенты 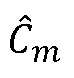 потерянного кадра для нетональных компонентов. Эти коэффициенты подаются на этап 806 составления спектра, генерирующий на выходе спектральные коэффициенты
потерянного кадра для нетональных компонентов. Эти коэффициенты подаются на этап 806 составления спектра, генерирующий на выходе спектральные коэффициенты 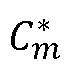 для потерянного кадра. Этап 802 вставки формируемого шума работает в ответ на системный
для потерянного кадра. Этап 802 вставки формируемого шума работает в ответ на системный 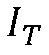 , сформированный этапом 804 оценивания.
, сформированный этапом 804 оценивания.
Последующие модификации представляют интерес относительно ссылки [4]:
Энергетический псевдоспектр, используемый для детектирования пика, выводят в виде
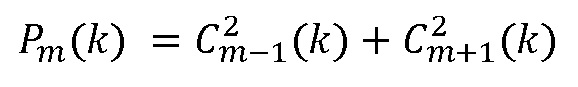
Для устранения по восприятию нерелевантных или паразитных пиков, детектирование пиков применяют только к ограниченному спектральному диапазону и рассматриваются только локальные максимумы, которые превышают относительное пороговое значение по отношению к абсолютному максимуму энергетического псевдоспектра. Остающиеся пики сортируют в порядке убывания их величины (высоты), и предварительно-указанное число высоко ранжированных максимумов классифицируют как тональные пики.
Подход основывается на следующей общей формуле (при 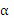 со знаком в этот момент):
со знаком в этот момент):
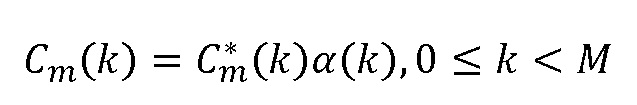
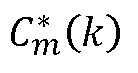 выводят, как указано выше, но вывод становится более усовершенствованным, следуя подходу
выводят, как указано выше, но вывод становится более усовершенствованным, следуя подходу
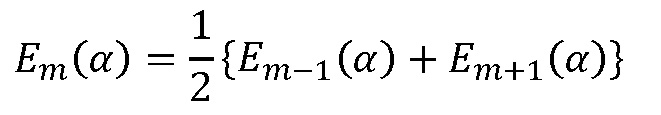
Замена 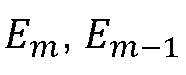 и
и 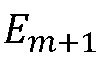 на
на
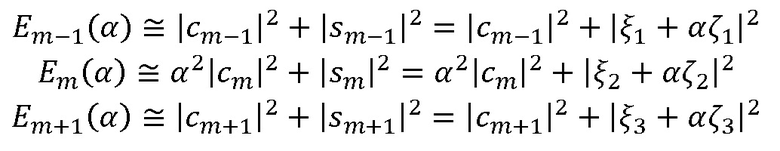
тогда как
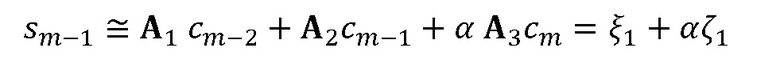
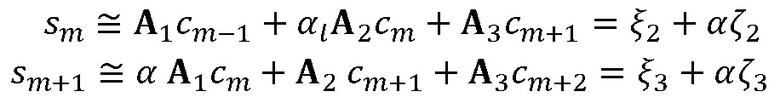
дает выражение, которое является квадратичным относительно α. Следовательно, для данной оценки MDCT имеются два кандидата (с противоположными знаками) для мультипликативного поправочного коэффициента (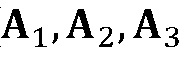 являются матрицами преобразования). Выбор лучшей оценки выполняют подобно тому, как описано в ссылке [4].
являются матрицами преобразования). Выбор лучшей оценки выполняют подобно тому, как описано в ссылке [4].
Этот усовершенствованный подход требует двух кадров до и после потери кадра для того, чтобы вывести коэффициенты MDST для предыдущего и последующего кадра.
Не имеющая задержку версия подхода предложена в ссылке [7]:
В качестве начальной точки, повторно используется интерполяционная формула 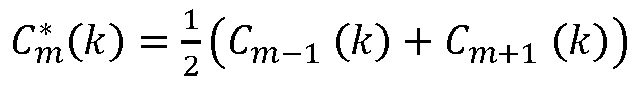 , но применяется для кадра m-1, приводя к:
, но применяется для кадра m-1, приводя к:
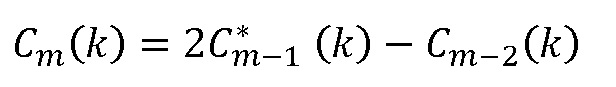
Затем результат 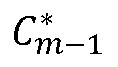 интерполяции заменяют истинной оценкой (здесь, множитель 2 становится частью поправочного коэффициента:
интерполяции заменяют истинной оценкой (здесь, множитель 2 становится частью поправочного коэффициента: 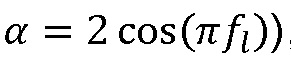 , каковое приводит к
, каковое приводит к
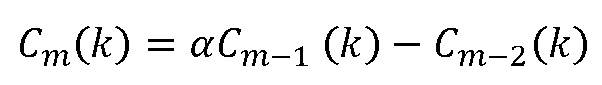
Поправочный коэффициент определяют путем ведения наблюдения энергии двух предыдущих кадров. Исходя из вычисления энергии коэффициенты MDST предыдущего кадра аппроксимируют в виде
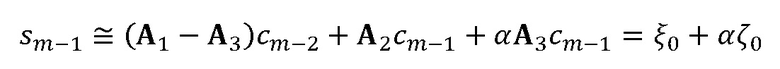
Затем вычисляют синусоидальную энергию в виде
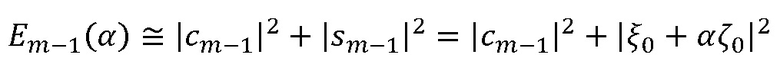
Подобным образом вычисляют синусоидальную энергию для кадра m-2 и обозначают 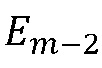 , которая не зависит от α.
, которая не зависит от α.
Применение требования к энергии
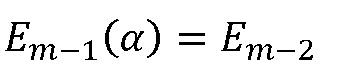
снова дает выражение, которое является квадратичным относительно α.
Процесс выбора для вычисленных кандидатов выполняют, как и ранее, но правило принятия решения учитывает только энергетический спектр предыдущего кадра.
Другое маскирование потери кадра без задержки в частотной области описано в ссылке [8]. Указания по ссылке [8] могут быть упрощены без потери общности в виде:
Предсказание с использованием дискретного преобразования Фурье (DFT) для сигнала (отметки) времени:
(a) Получить спектр DFT из декодированного сигнала во временной области, который соответствует принятым кодированным коэффициентам 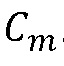 частотной области.
частотной области.
(b) Модулировать амплитуды DFT, полагая линейное изменение фазы, чтобы предсказать недостающие коэффициенты 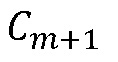 частотной области в следующем кадре
частотной области в следующем кадре
Предсказание с использованием оценивания амплитуды из принятого частотного спектра:
(a) Найти 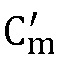 и
и 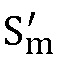 , используя
, используя 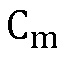 в качестве входа, так что
в качестве входа, так что
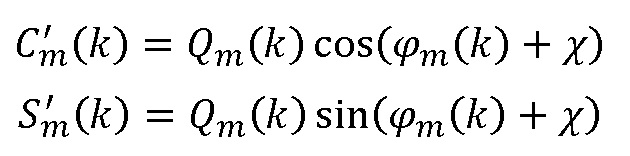
где 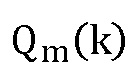 - амплитуда коэффициента DFT, который соответствует
- амплитуда коэффициента DFT, который соответствует 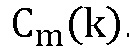 .
.
(b) Вычислить:
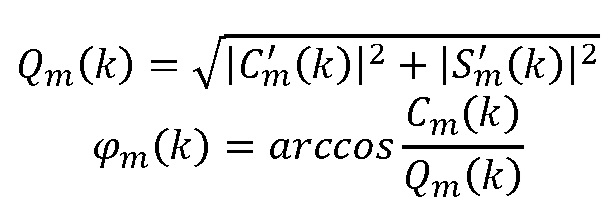
(c) Выполнить линейную экстраполяцию амплитуды и фазы:
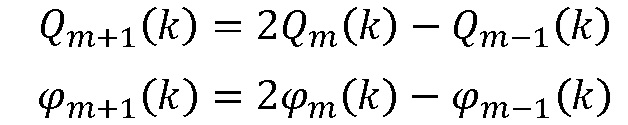
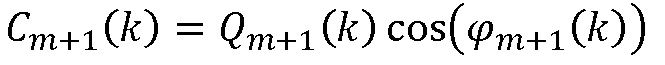
Использовать фильтры, чтобы вычислить 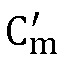 и
и 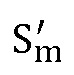 из
из 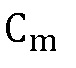 и затем продолжить, как указано выше, чтобы получить
и затем продолжить, как указано выше, чтобы получить 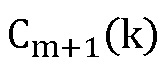
Использовать адаптивный фильтр для вычисления 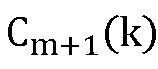 :
:
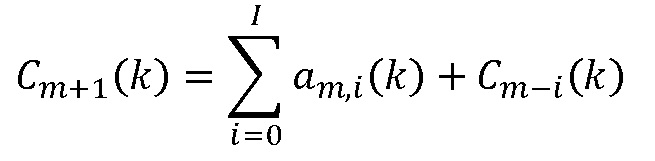
Выбор спектральных коэффициентов, подлежащих предсказанию, упоминается в ссылке [8], но не описан подробно.
В ссылке [9] было выявлено, что для квазистационарных сигналов разность фаз между последовательными кадрами является почти постоянной и зависит только от дробной частоты. Однако используется только линейная экстраполяция из последних двух комплексных спектров.
В адаптивном многоскоростном широкополосном (AMR-WB+) кодере (см. ссылку [10]) используется способ, описанный в ссылке [11]. Способ в ссылке [11] является расширением способа, описанного в ссылке [8] в том смысле, что использует также доступные спектральные коэффициенты текущего кадра, полагая, что потеряна только часть текущего кадра. Однако ситуация полной потери кадра не рассматривается в ссылке [11].
Другое маскирование потери кадра без задержки в области MDCT описывается в ссылке [12]. В ссылке [12] сначала определяют, является ли потерянный P-й кадр кратно-гармоническим кадром. Потерянный P-й кадр является кратно-гармоническим кадром, если более чем K0 кадров из числа K кадров перед P-м кадром имеют сглаженность спектра меньше чем пороговое значение. Если потерянный P-й кадр является кратно-гармоническим кадром то кадры от (P−K)-го до (P−2)-го кадров в области MDCT-MDST используются для предсказания потерянного P-ого кадра. Спектральный коэффициент является пиком, если его энергетический спектр больше чем два соседних коэффициента энергетического спектра. Псевдо спектр как описан в ссылке [13] используется для (P−1)-ого кадра.
Множество спектральных коэффициентов Sc строится из L1 кадров энергетического спектра, как изложено ниже:
Получение L1 множеств S1..., SL1, составленных из пиков в каждом из L1 кадров, числом пиков в каждом множестве является N1..., NL1 соответственно. Выбор множества Si из L1 множеств S1...,SL1. Для каждого коэффициента mj, j=1...Ni, пика в множестве S1, принятие решения, имеется ли какой-либо частотный коэффициент среди mj, mj±1..., mj±k, принадлежащий всем другим множествам пиков. Если какой-либо коэффициент имеется, помещение всех частот mj, mj±1..., mj±k в множество SC частот. Если не имеется частотного коэффициента, принадлежащего всем другим множествам пиков, непосредственное помещение всех частотных коэффициентов в кадре в множество SC частот. Упомянутый k является неотрицательным целым числом. Для всех спектральных коэффициентов в множестве SC фазу предсказывают, используя L2 кадров среди кадров MDCT-MDST от (P−K)-ого до (P−2)-ого. Предсказание делают, используя линейную экстраполяцию (когда L2=2) или линейное приближение (когда L2>2). Для линейной экстраполяции:
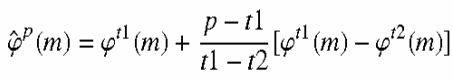
где p, t1 и t2 являются индексами кадров.
Спектральные коэффициенты, не находящиеся в множестве SC, получают, используя множество кадров до (P−1)-ого кадра, без конкретного пояснения каким образом.
Объект настоящего изобретения состоит в обеспечении улучшенного подхода для получения спектральных коэффициентов для заменяющего кадра аудиосигнала.
Этот объект достигается посредством способа по п.1, некратковременного компьютерного программного продукта по п.34, устройства по п.35 или по п.36, кодера аудио по п.37, приемника аудио по п.38 и системы для передачи аудиосигналов по п.39.
Настоящее изобретение обеспечивает способ получения спектральных коэффициентов для заменяющего кадра аудиосигнала, способ содержит:
детектирование тонального компонента спектра аудиосигнала на основании пика, который присутствует в спектрах кадров, предшествующих заменяющему кадру;
для тонального компонента спектра, предсказание спектральных коэффициентов для пика и его окружения в спектре заменяющего кадра; и
для нетонального компонента спектра, использование непредсказываемого спектрального коэффициента для заменяющего кадра или соответствующего спектрального коэффициента для кадра, предшествующего заменяющему кадру.
Настоящее изобретение обеспечивает устройство для получения спектральных коэффициентов для заменяющего кадра аудиосигнала, устройство содержит:
детектор, сконфигурированный для детектирования тонального компонента спектра аудиосигнала на основании пика, который присутствует в спектрах кадров, предшествующих заменяющему кадру; и
блок предсказания, сконфигурированный для предсказания для тонального компонента спектра спектральных коэффициентов для пика и его окружения в спектре заменяющего кадра;
при этом для нетонального компонента спектра используется непредсказываемый спектральный коэффициент для заменяющего кадра или соответствующий спектральный коэффициент кадра, предшествующего заменяющему кадру.
Настоящее изобретение обеспечивает устройство для получения спектральных коэффициентов для заменяющего кадра аудиосигнала, устройство, конфигурируемое для действия по новому способу получения спектральных коэффициентов для заменяющего кадра аудиосигнала.
Настоящее изобретение обеспечивает декодер аудио, содержащий новое устройство для получения спектральных коэффициентов для заменяющего кадра аудиосигнала.
Настоящее изобретение обеспечивает приемник аудио, содержащий новый декодер аудио.
Настоящее изобретение обеспечивает систему для передачи аудиосигналов, система содержит:
кодер, сконфигурированный для генерирования кодированного аудиосигнала; и
новый декодер, сконфигурированный для приема кодированного аудиосигнала и декодирования кодированного аудиосигнала.
Настоящее изобретение обеспечивает невременный компьютерный программный продукт, содержащий компьютерно-читаемый носитель, сохраняющий инструкции, которые при исполнении на компьютере выполняют новый способ получения спектральных коэффициентов для заменяющего кадра аудиосигнала.
Новый подход является полезным, поскольку он обеспечивает хорошее маскирование потери кадра для тональных сигналов с хорошим качеством и без внесения дополнительной задержки. Новый кодек с малой задержкой является полезным, поскольку он работает хорошо и на речевых, и на звуковых сигналах и извлекает преимущество, например, в предрасположенной к ошибкам среде, из хорошего маскирования потери кадра, которое достигается конкретно для стационарных тональных сигналов. Предложено маскирование потери кадра без задержки для монофонических и полифонических сигналов, которое дает хорошие результаты для тональных сигналов без ухудшения качества нетональных сигналов.
В соответствии с вариантами осуществления настоящего изобретения, обеспечивается улучшенное маскирование тональных компонентов в области MDCT. Варианты осуществления относятся к кодированию аудио и речи, которое включает в себя кодек частотной области или коммутируемый кодек речи/частотной области, в частности к маскированию потери кадра в области MDCT (модифицированное дискретное косинусное преобразование). Изобретение, в соответствии с вариантами осуществления, предлагает не имеющий задержки способ создания спектра MDCT для потерянного кадра на основании ранее принятых кадров, где последний принятый кадр кодирован в частотной области с использованием MDCT.
В соответствии с предпочтительными вариантами осуществления, новый подход включает в себя детектирование частей спектра, которые являются тональными, например, с использованием предпоследнего комплексного спектра, чтобы получить корректное местоположение или место пика, с использованием последнего действительного спектра для уточнения решения, если элемент сигнала является тональным, и с использованием информации основного тона для лучшего детектирования либо начала, либо смещения тона, причем информация основного тона является либо уже присутствующей в потоке битов, или выводимой на стороне декодера. Кроме того, новый подход включает в себя предоставление адаптивной к сигналу ширины гармоники, подлежащей маскированию. Вычисление фазового сдвига или разности фаз между кадрами каждого спектрального коэффициента, являющегося частью гармоники, также обеспечивается, причем это вычисление основано на последнем доступном спектре, например, спектре Комплексного модифицированного дискретного косинусного преобразования (CMDCT), без предпоследнего CMDCT. В соответствии с вариантами осуществления, разность фаз уточняют, используя последний принятый спектр MDCT, и уточнение может быть адаптируемым, зависеть от числа последовательно потерянных кадров. Спектр CMDCT может строиться из декодированного сигнала во временной области, каковое является полезным, поскольку устраняет потребность какой-либо синхронизации с кадрированием кодека, и это позволяет создание комплексного спектра насколько возможно близким к потерянному кадру путем применения характеристик окон с малым перекрытием. Варианты осуществления изобретения обеспечивают покадровое принятие решения относительно использования маскирования или во временной области, или в частотной области.
Подход согласно настоящему изобретению является полезным, поскольку он работает полностью на основе информации, уже доступной на стороне приемника, при определении, что кадр был потерян или подлежит замене, и нет необходимости в дополнительной вспомогательной информации, которая должна быть получена так, чтобы не было также какого-либо источника для дополнительных задержек, которые имеют место в подходах предшествующего уровня техники, при условии необходимости или принимать дополнительную вспомогательную информацию, или выводить дополнительную вспомогательную из имеющейся в распоряжении информации.
Новый подход является полезным в сравнении с вышеописанными подходами известного уровня техники, поскольку изложенные далее в общих чертах недостатки таких подходов, которые были выявлены авторами настоящего изобретения, устраняются путем применения нового подхода.
Способы маскирования потери кадра, описанные в ссылке [1], не являются достаточно устойчивыми и не дают достаточно хорошие результаты для тональных сигналов.
Экстраполяция формы волны сигнала во временной области, как описано в ссылке [2], не может обрабатывать полифонические сигналы и требует повышенной сложности для маскирования весьма стационарных тональных сигналов, поскольку должен быть определен точный интервал запаздывания основного тона.
В ссылке [3] вносится дополнительная задержка и требуется значительная вспомогательная информация. Выбор тонального компонента является очень простым и будет выбирать многие пики из числа нетональных компонентов.
Способ, описанный в ссылке [4], требует упреждения на стороне декодера и, следовательно, вносит дополнительную задержку в один кадр. Использование сглаженного энергетического псевдоспектра для детектирования пика снижает точность определения позиции пиков. Это также снижает надежность детектирования, поскольку будет обнаруживать из шума пики, которые появляются только в одном кадре.
Способ, описанный в ссылке [6], требует упреждения на стороне декодера и, следовательно, вносит дополнительную задержку в два кадра. Выбор тонального компонента не проверяет тональные компоненты в двух кадрах отдельно, а основывается на усредненном спектре, и таким образом будет иметь или слишком много ложных утверждений или ложных отрицаний, делая невозможным подстройку пороговых значений детектирования пиков. Определение местоположения пиков не будет точным, поскольку используется энергетический псевдоспектр. Ограниченный спектральный диапазон для поиска пиков похож на прием с обходом для описываемых проблем, которые возникают, поскольку используется энергетический псевдоспектр.
Способ, описанный в ссылке [7], основан на способе, описанном в ссылке [6], и, следовательно, имеет такие же недостатки; он лишь устраняет дополнительную задержку.
В ссылке [8] нет подробного описания решения относительно принадлежности спектрального коэффициента тональной части сигнала. Однако синергическая связь между детектированием тональных спектральных коэффициентов и маскированием является важной, и таким образом важно хорошее детектирование тональных компонентов. Кроме того, не было выявлено использование фильтров, зависимых от и 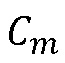 , и
, и 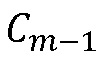 (то есть
(то есть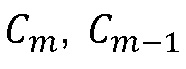 , и
, и 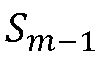 , поскольку
, поскольку 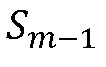 можно вычислить, если доступны
можно вычислить, если доступны 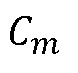 и
и 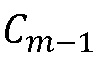 ) для вычисления
) для вычисления 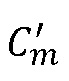 и
и 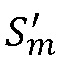 . Кроме того, не было выявлено использование возможности вычислять комплексный спектр, который не синхронизирован с кадрированием кодированного сигнала, которое дается при окнах с малым перекрытием. Кроме того, не было выявлено использование возможности вычислять разность фаз между кадрами только на основании предпоследнего комплексного спектра.
. Кроме того, не было выявлено использование возможности вычислять комплексный спектр, который не синхронизирован с кадрированием кодированного сигнала, которое дается при окнах с малым перекрытием. Кроме того, не было выявлено использование возможности вычислять разность фаз между кадрами только на основании предпоследнего комплексного спектра.
В ссылке [12], по меньшей мере, три предшествующих кадра должны сохраняться в памяти, тем самым значительно повышая требования к памяти. Решение, использовать ли тональное маскирование, может быть ошибочным, и кадр с одной или большим числом гармоник может быть классифицирован как кадр без кратных гармоник. Последний принятый кадр MDCT напрямую не используется для улучшения предсказания потерянного спектра MDCT, а только в поиске тональных компонентов. Число коэффициентов MDCT, подлежащих маскированию для гармоники, является фиксированным, однако, в зависимости от уровня шума, желательно иметь переменное число коэффициентов MDCT, которые составляют одну гармонику.
В последующем варианты осуществления настоящего изобретения будут описаны с дополнительными подробностями со ссылкой на сопроводительные чертежи, на которых:
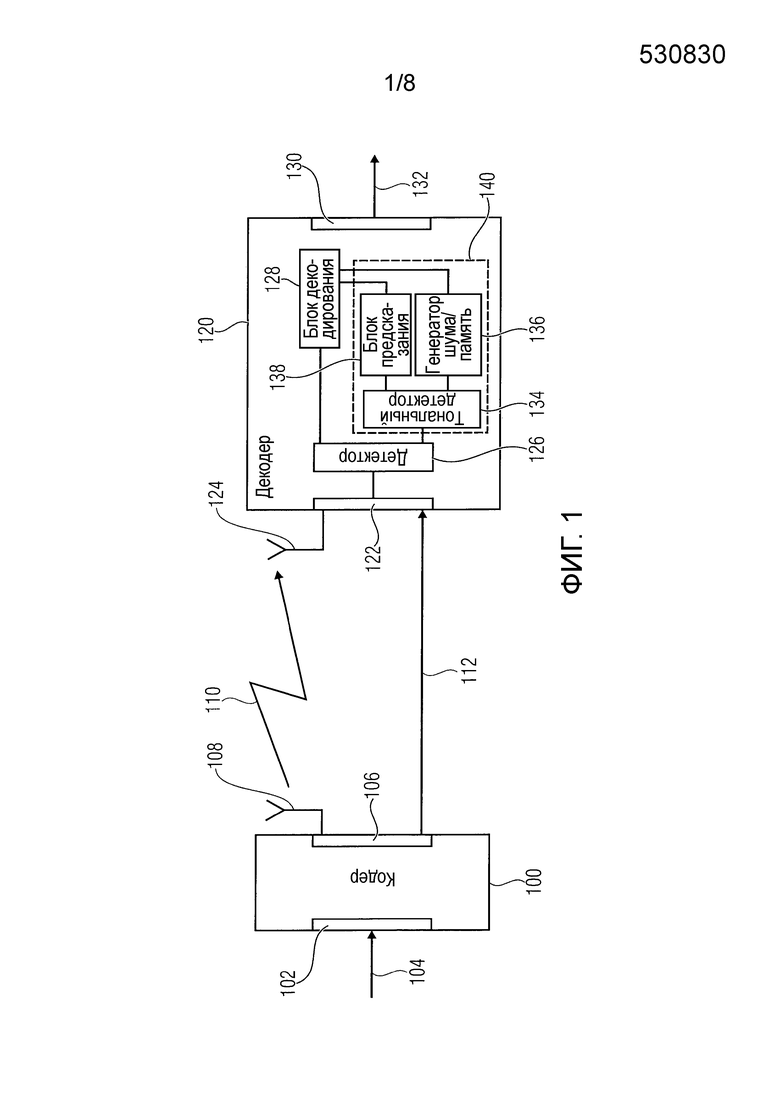
Фиг.1 - иллюстрация упрощенной блок-схемы системы для передачи аудиосигналов, реализующей новый подход на стороне декодера,
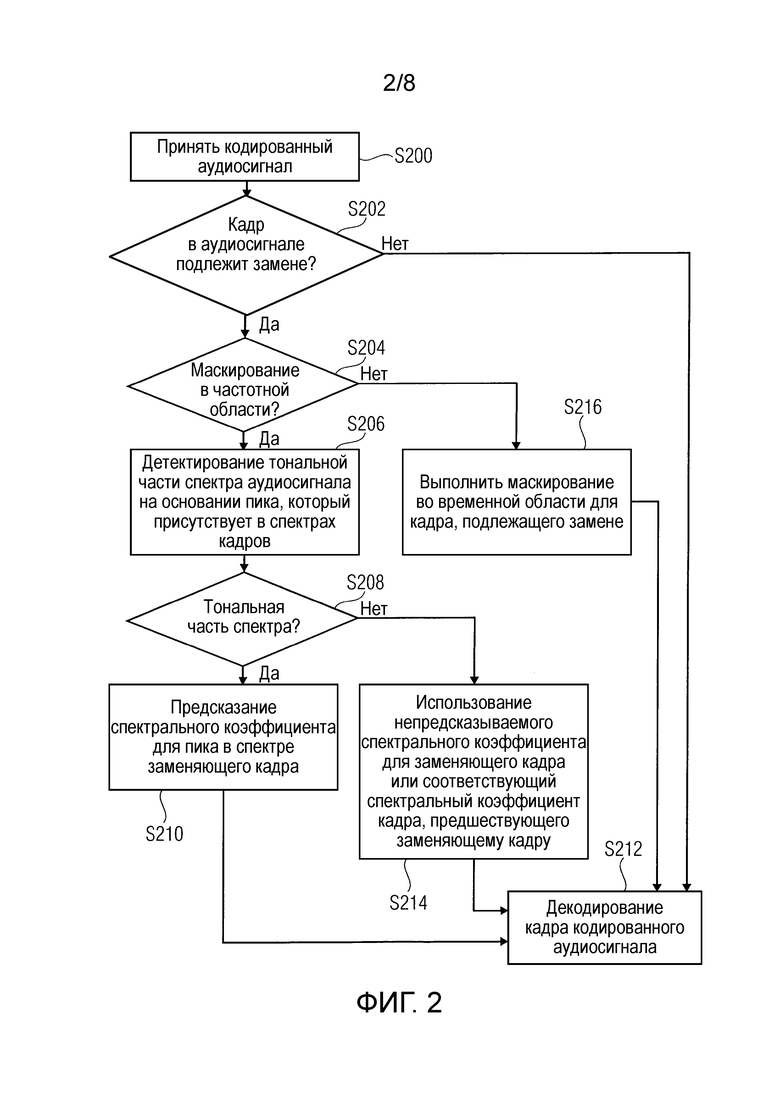
Фиг.2 - иллюстрация структурной схемы нового подхода в соответствии с вариантом осуществления воплощением,
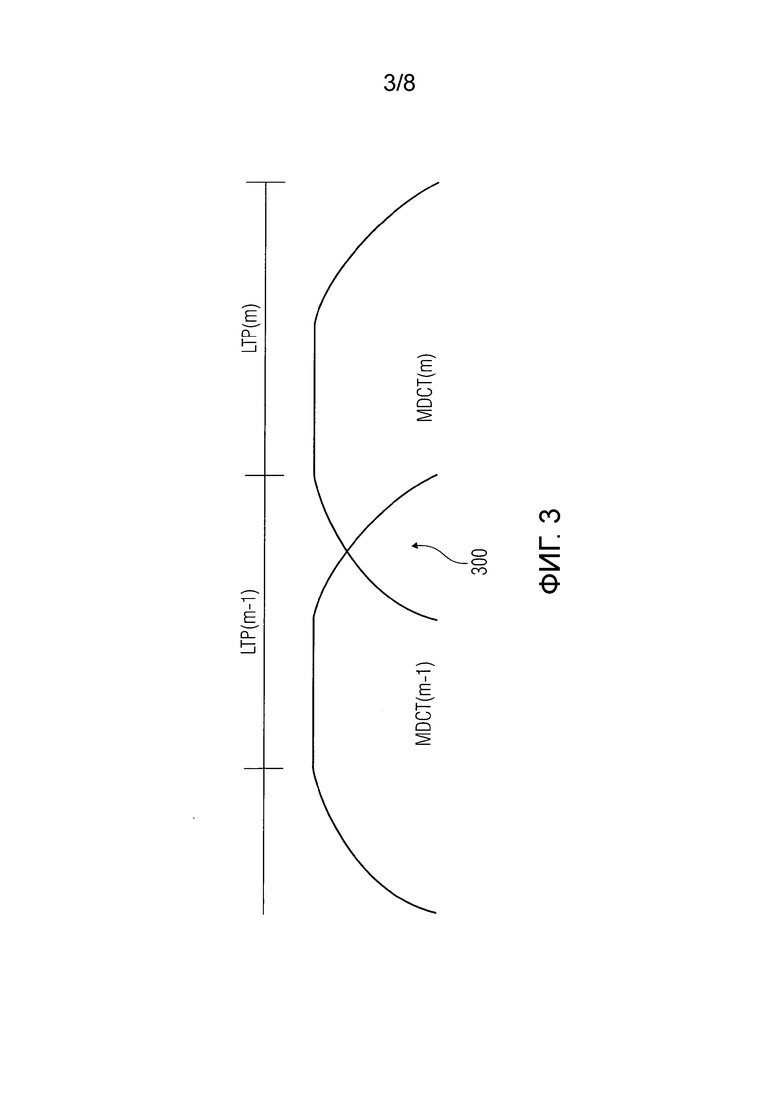
Фиг.3 - схематичное представление перекрывающихся окон MDCT для соседних кадров,
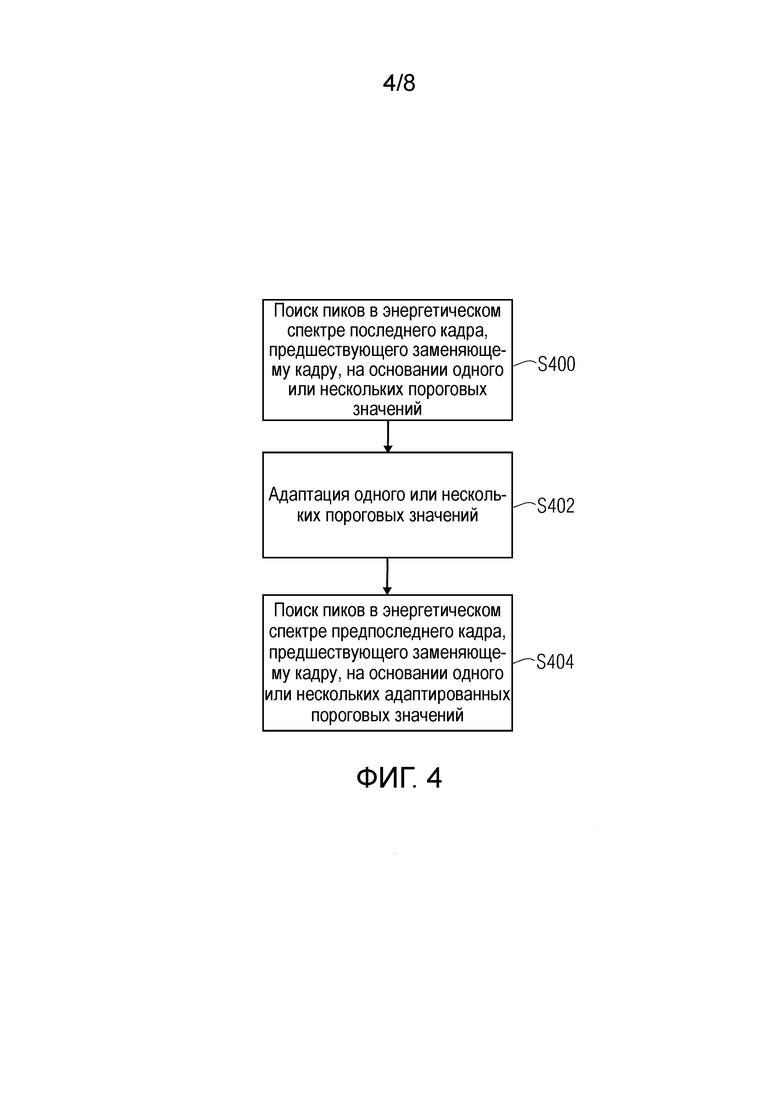
Фиг.4 - иллюстрация структурной схемы, представляющей этапы для отбора пика в соответствии с вариантом осуществления,
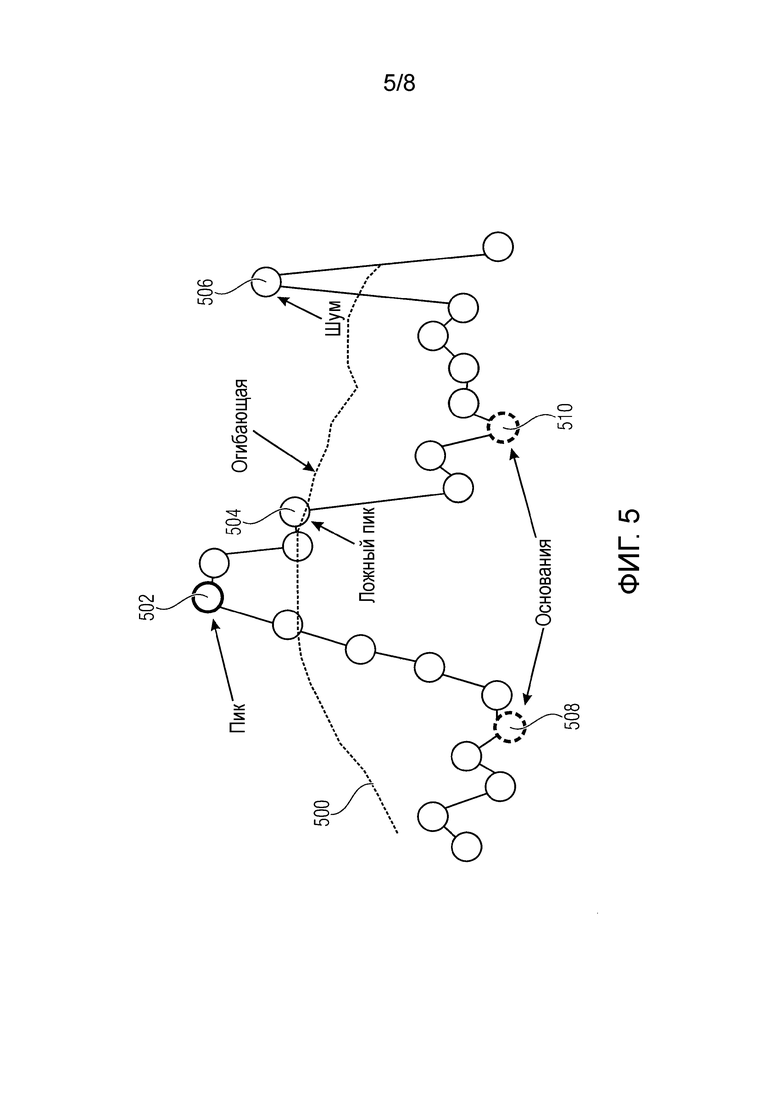
Фиг.5 - схематичное представление энергетического спектра кадра, из которого детектируют один или несколько пиков,
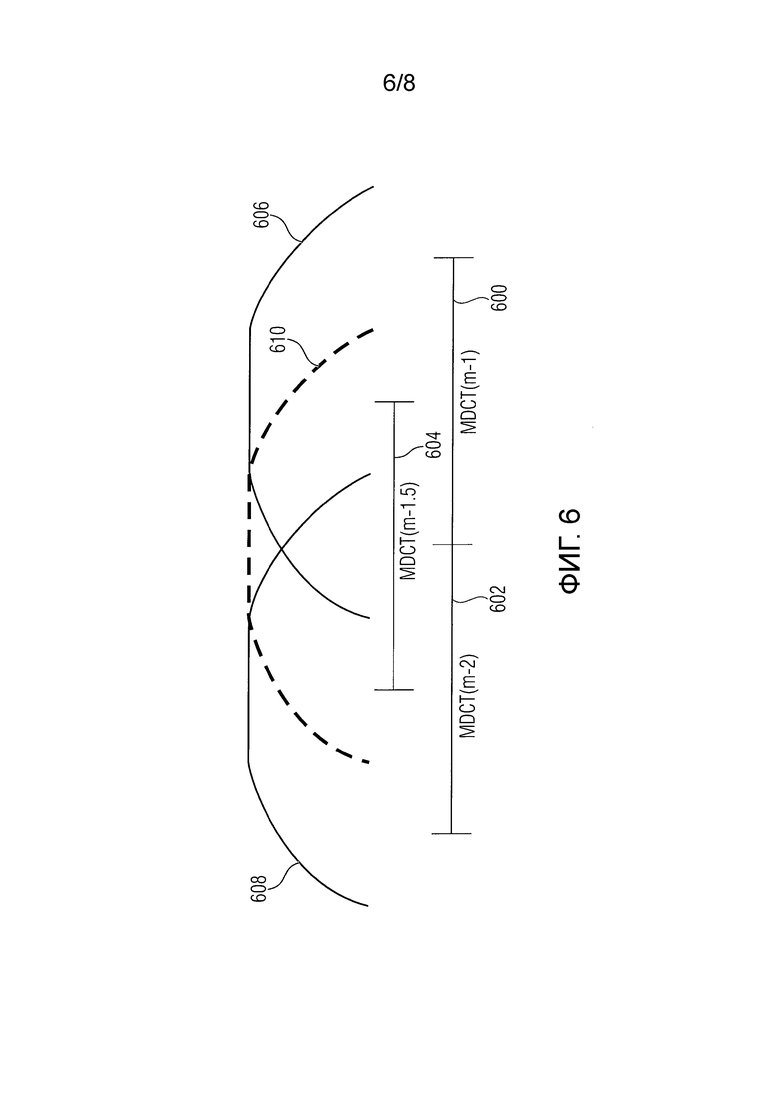
Фиг.6 - иллюстрация примера для “промежуточного кадра”,
Фиг.7 - иллюстрация блок-схемы, представляющей интерполяционный подход без передаваемой вспомогательной информации, и
Фиг.8 - иллюстрация блок-схемы общего способа FLC, уточненного по сравнению с Фиг.7.
В последующем варианты осуществления нового подхода будут описаны с дополнительными подробностями, и отмечается, что на сопроводительных чертежах элементы, имеющие одинаковую или сходную функциональность, обозначаются одинаковыми ссылочными знаками. В последующих вариантах осуществления нового подхода будет описано, в соответствии с каковым маскирование выполняют в частотной области, только если последние два принятых кадра кодированы с использованием MDCT. Подробности принятия решения об использовании маскирования во временной или частотной области относительно потери кадра после приема двух кадров MDCT также будут описаны. Относительно вариантов осуществления, описанных в последующем, отмечается, что требование кодирования последних двух кадров в частотной области не снижает применимость нового подхода поскольку в коммутируемом кодеке частотная область будет использоваться для стационарных тональных сигналов.
Фиг.1 иллюстрирует упрощенную блок-схему системы для передачи аудиосигналов, реализующей новый подход на стороне декодера. Система содержит кодер 100, принимающий на входе 102 аудиосигнал 104. Кодер сконфигурирован, чтобы формировать на основе принятого аудиосигнала 104 кодированный аудиосигнал, который обеспечивается на выходе 106 кодера 100. Кодер может обеспечивать кодированный аудиосигнал таким образом, что кадры аудиосигнала кодированы с использованием MDCT. В соответствии с вариантом осуществления кодер 100 содержит антенну 108, чтобы позволять беспроводную передачу аудиосигнала, как указано в ссылочном знаке 110. В других вариантах осуществления кодер может выводить кодированный аудиосигнал, обеспечиваемый на выходе 106, через линию проводного соединения, как это, например, указано в ссылочном знаке 112.
Система дополнительно содержит декодер 120, имеющий вход 122, на котором принимают кодированный аудиосигнал, обеспечиваемый кодером 106. Кодер 120 может содержать, в соответствии с вариантом осуществления, антенну 124 для приема беспроводной передачи 110 от кодера 100. В другом варианте осуществления вход 122 может обеспечивать соединение с проводной передачей 112 для приема кодированного аудиосигнала. Аудиосигнал, принятый на входе 122 декодера 120, подается на детектор 126, который определяет, нуждается ли в замене кодированный кадр принятого аудиосигнала, подлежащий декодированию декодером 120. Например, в соответствии с вариантами осуществления, это может быть случаем, когда детектор 126 определяет, что кадр, который должен следовать за предшествующим кадром, не принят в декодере, или когда определяют, что принятый кадр имеет ошибки, каковое препятствует его декодированию на стороне декодера 120. В случае если в детекторе 126 определено, что кадр, представленный для декодирования, является пригодным, кадр будет пересылаться на блок 128 декодирования, где декодирование кодированного кадра выполняется с тем результатом, что на выходе декодера 130 может выводиться поток декодированных аудио кадров или декодированного аудиосигнала 132.
В случае если в блоке 126 определено, что кадр, который в настоящий момент подлежит обработке, нуждается в замене, кадры, предшествующие текущему кадру, требующему замены, и которые могут буферизоваться в схеме 126 детектора, предоставляются на тональный детектор 134, определяющий, включает или не включает спектр замены тональные компоненты. В случае если тональные компоненты обеспечены, это указывается на блок 136 памяти/генератора шума, который формирует спектральные коэффициенты, являющиеся непредсказываемыми коэффициентами, которые могут формироваться с использованием генератора шума или другого традиционного способа генерирования шума, например, скремблирования со знаком и т.п. Альтернативно, также предварительно определенные спектральные коэффициенты для нетональных компонентов спектра могут быть получены из памяти, например, из таблицы поиска. Альтернативно, когда определяют, что спектр не содержит тональные компоненты, вместо генерирования непредсказываемых спектральных коэффициентов, могут быть выбраны соответствующие спектральные характеристики одного из кадров, предшествующих замене.
В случае если тональный детектор 134 обнаруживает, что спектр включает в себя тональные компоненты, соответственный сигнал указывается блоку 138 предсказания, предсказывающему, в соответствии с вариантами осуществления настоящего изобретения, описанными далее, спектральные коэффициенты для заменяющего кадра. Соответственные коэффициенты, определенные для заменяющего кадра, предоставляются на блок 128 декодирования, где на основе этих спектральных коэффициентов выполняется декодирование потерянного или заменяющего кадра.
Как показано на Фиг.1, тональный детектор 134, генератор 136 шума и блок 138 предсказания определяют устройство 140 для получения спектральных коэффициентов для заменяющего кадра в декодере 120. Изображенные элементы могут быть реализованы с использованием аппаратных и/или программных компонентов, например, надлежаще запрограммированных устройств обработки.
Фиг.2 иллюстрирует структурную схему нового подхода в соответствии с вариантом осуществления. На первом этапе S200 принимают кодированный аудиосигнал, например, в декодере 120, как изображено на Фиг.1. Принятый аудиосигнал может быть в форме соответственных аудио кадров, которые кодированы с использованием MDCT.
На этапе S202 определяют, требует ли замены текущий кадр, подлежащий обработке декодером 120ь. Заменяющий кадр может быть необходимым на стороне декодера, например, в случае, если кадр не может быть обработан из-за ошибки в принятых данных или подобного, или в случае, если кадр был потерян в ходе передачи на приемник/декодер 120, или в случае, если кадр не был принят вовремя в приемнике 120 аудиосигнала, например, из-за задержки в ходе передачи кадра со стороны кодера на сторону декодера.
В случае если на этапе S202 определяют, например, посредством детектора 126 в декодере 120, что кадр, который в настоящий момент подлежит обработке декодером 120, должен быть заменен, способ переходит на этап S204, на котором делают дополнительное определение, требуется ли маскирование в частотной области. В соответствии с вариантом осуществления, если информация основного тона имеется для последних двух принятых кадров, и если основной тон не изменяется, на этапе S204 определяют, что требуется маскирование в частотной области. Иначе, определяют, что следует применить маскирование во временной области. В альтернативном варианте осуществления основной тон можно вычислять на основе подкадра с использованием декодированного сигнала, и вновь с использованием решения, что в случае, если основной тон присутствует, и в случае, если он является постоянным в подкадрах, используется маскирование в частотной области, иначе применяется маскирование во временной области.
В еще одном варианте осуществления настоящего изобретения может обеспечиваться детектор, например, детектор 126 в декодере 120, и может быть сконфигурирован таким образом, что он дополнительно анализирует спектр предпоследнего кадра, или последнего кадра или обоих этих кадров, предшествующих заменяющему кадру, и решает на основании найденных пиков, является ли сигнал монофоническим или полифоническим. В случае если сигнал является полифоническим, маскирование в частотной области должно использоваться независимо от присутствия информации основного тона. Альтернативно, детектор 126 в декодере 120 может быть сконфигурирован таким образом, что он дополнительно анализирует один или большее число кадров, предшествующих заменяющему кадру, чтобы указать, превышает ли число тональных компонентов в сигнале предварительно определенное пороговое значение или нет. В случае если число тональных компонентов в сигнале превышает пороговое значение, будет использоваться маскирование в частотной области.
В случае если на этапе S204 определяют, что должно использоваться маскирование в частотной области, например, путем применения вышеупомянутых критериев, способ переходит на этап S206, где тональная часть или тональный компонент спектра аудиосигнала детектируют на основании одного или большего числа пиков, которые присутствуют в спектрах предшествующих кадров, а именно, одного или большего числа пиков, которые присутствуют по существу в той же позиции в спектре предпоследнего кадра и спектре последнего кадра, предшествующих заменяющему кадру. На этапе S208 определяют, имеется ли тональная часть спектра. В случае если имеется тональная часть спектра, способ переходит на этап S210, где один или большее число спектральных коэффициентов для одного или большего числа пиков и их окружений в спектре заменяющего кадра предсказывают, например, на основе информации, получаемой из предшествующих кадров, а именно, предпоследнего кадра и последнего кадра. Спектральный(е) коэффициент(ы), предсказанный на этапе S210, передают, например, на блок 128 декодирования, показанный на Фиг.1, так что, как показано на этапе 212, может выполняться декодирование кадра кодированного аудиосигнала на основе спектральных коэффициентов от этапа 210.
В случае если на этапе S208 определяют, что не имеется тональной части спектра, способ переходит на этап S214, используя непредсказываемый спектральный коэффициент для заменяющего кадра или соответствующий спектральный коэффициент кадра, предшествующего заменяющему кадру, которые предоставляются на этап S212 для декодирования кадра.
В случае если на этапе S204 определяют, что маскирование в частотной области не требуется, способ переходит на этап S216, где выполняется традиционное маскирование во временной области для кадра, который подлежит замене, и на основе спектральных коэффициентов, сформированных процессом на этапе S216, кадр кодированного сигнала декодируется на этапе S212.
В случае если на этапе S202 определяют, что нет заменяющего кадра в текущем обрабатываемом аудиосигнале, то есть обрабатываемый в текущий момент кадр может быть полностью декодирован с использованием традиционных подходов, способ непосредственно переходит на этап S212 для декодирования кадра кодированного аудиосигнала.
В последующем будет описана более подробная информация в соответствии с вариантами осуществления настоящего изобретения.
Вычисление энергетического спектра
Для предпоследнего кадра, индексированного 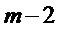
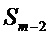
Для последнего кадра используется оценка спектра MDST, которую вычисляют их MDCT коэффициентов 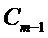
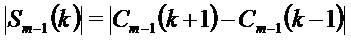
Энергетические спектры для кадров 
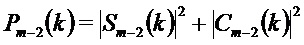
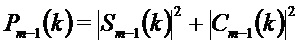
причем:
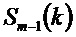
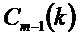
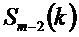
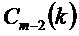
Полученные энергетические спектры сглаживают, как изложено ниже:
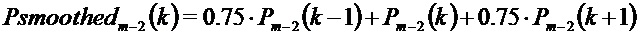
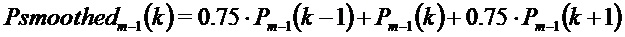
Детектирование тональных компонентов
Пики, присутствующие в последних двух кадрах (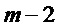
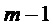
Информация основного тона
Полагают, что информация основного тона является доступной:
вычисленной на стороне кодера и доступной в потоке битов, или
вычисленной на стороне декодера.
Информация основного тона используется, только если удовлетворяются все следующие условия:
коэффициент усиления основного тона больше чем нуль;
задержка основного тона является постоянной в последних двух кадрах;
основная частота больше чем 100 Гц.
Основную частоту вычисляют из запаздывания основного тона:

Если имеется 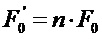
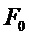
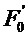
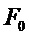
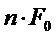
В соответствии с вариантом осуществления, информацию основного тона вычисляют на основе кадрирования, синхронизированного по правой границе окна MDCT, показанного на Фиг.3. Такое совмещение является полезным для экстраполяции тональных частей сигнала, поскольку область 300 перекрытия, являясь частью, которая требует маскирования, также используется для вычисления запаздывания основного тона.
В другом варианте осуществления информация основного тона может передаваться в потоке битов и использоваться кодеком в «чистом» канале и таким образом происходит без дополнительных затрат на маскирование.
Огибающая
В последующем описывается процедура для получения огибающей спектра, которая необходима для описанного далее отбора пика.
Огибающую каждого энергетического спектра в последних двух кадрах вычисляют, используя фильтр скользящего среднего, имеющего длину 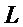
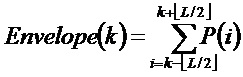
Длина фильтра зависит от основной частоты (и может быть ограничена интервалом [7,23]):
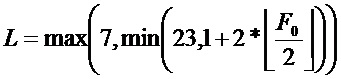
Эта связь между 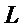
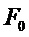
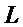
Таким образом, в соответствии с вариантами осуществления, основная частота предназначена для сигнала, включающего в себя последний кадр (m-1), предшествующий заменяющему кадру (m), и упреждения последнего кадра (m-1), предшествующего заменяющему кадру (m). Упреждение последнего кадра (m-1), предшествующего заменяющему кадру (m), может вычисляться на стороне кодера, используя упреждение.
Отбор пика
Сначала осуществляют поиск пиков в энергетическом спектре кадра 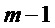
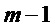
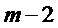
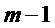
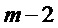
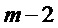
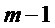
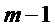
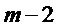
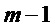
Фиг.5 является схематичным представлением энергетического спектра кадра, из которого детектируют один или большее число пиков. На Фиг.5 показана огибающая 500, которая может быть определена, как в общих чертах изложено выше, или которая может быть определена согласно другим известным подходам. Показан ряд пиков-кандидатов, которые представлены окружностями на Фиг.5. Нахождение пика, среди пиков-кандидатов, будет описано ниже с дополнительными подробностями. Фиг.5 иллюстрирует пик 502, который был найден, а также ложный пик 504 и пик 506, представляющий шум. Кроме того, показываются левое основание 508 и правое основание 510 спектрального коэффициента.
В соответствии с вариантом осуществления, нахождение пиков в энергетическом спектре 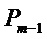
спектральный коэффициент классифицируют как тональный пик-кандидат, если удовлетворены все следующие критерии:
- отношение между сглаженным энергетическим спектром и огибающей 500 больше, чем некоторое пороговое значение:
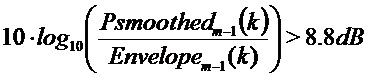
- отношение между сглаженным энергетическим спектром и огибающей 500 больше, чем ее окружающих соседей, означая, что это является локальным максимумом,
локальные максимумы определяют путем нахождения левого основания 508 и правого основание 510 спектрального коэффициента k и нахождения максимума между левым основанием 508 и правым основанием 510. Этот этап, как может быть видно на Фиг.4, требуется там, где ложный пик 504 может быть обусловлен боковым лепестком или шумом квантования.
Пороговые значения для поиска пика в энергетическом спектре 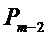
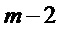
в коэффициентах 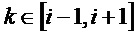
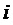
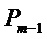
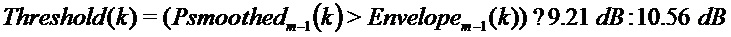
если 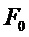
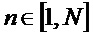
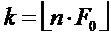
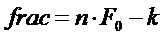
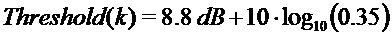
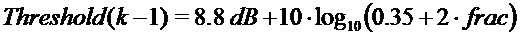
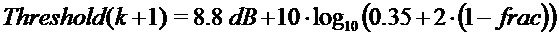
если 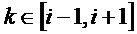
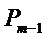
для всех других индексов:
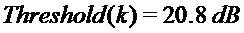
Тональные пики находят в энергетическом спектре
спектральный коэффициент классифицируют как тональный пик, если:
- отношение энергетического спектра и огибающей больше, чем пороговое значение:
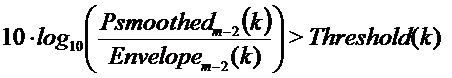
- отношение энергетического спектра и огибающей больше, чем у его соседей окружения, означая, что он является локальным максимумом,
локальные максимумы определяют путем нахождения левого основания 508 и правого основания 510 спектрального коэффициента k и нахождения максимума между левым основанием 508 и правым основанием 510,
Левое основание 508 и правое основание 510 также задают окружение тональных пиков 502, то есть, спектральные элементы- выборки тонального компонента, где будет использоваться способ тонального маскирования.
Использование вышеописанного способа показывает, что правый пик 506 на Фиг.4 присутствуют только в одном из кадров, то есть, он не присутствует в обоих из кадров 
Извлечение синусоидального параметра
Для синусоидального сигнала 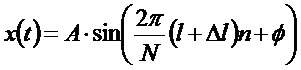
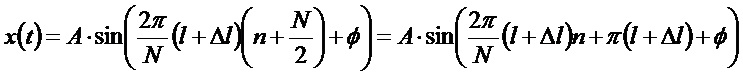
Таким образом, имеется фазовый сдвиг 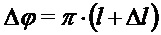
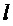
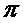
Дробная часть частоты 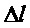
при условии, что амплитуда сигнала в поддиапазоне 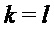
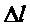
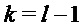
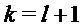
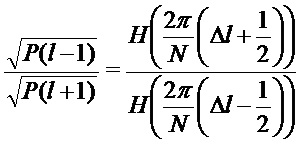
где используется приближение характеристики величины окна:
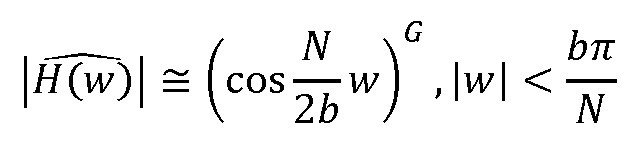
где b - ширина основного лепестка. Константа G в этом выражении была установлена в 27,4/20,0 для того, чтобы минимизировать максимальную абсолютную погрешность оценки,
подстановка приближенной частотной характеристики и допущение
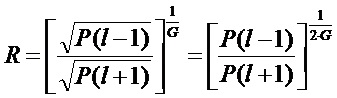
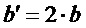
приводит к:
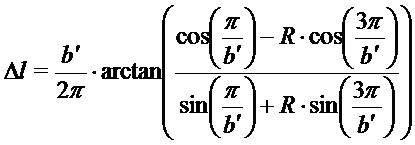
Предсказание MDCT
Для всех найденных пиков спектра и их окружений, используется предсказание MDCT. Для всех других спектральных коэффициентов может использоваться скремблирование со знаком или подобный способ генерирования шума.
Все спектральные коэффициенты, принадлежащие найденным пикам и их окружениям, принадлежат множеству, которое обозначено как  . Например, на Фиг.5 пик 502 был идентифицирован как пик, представляющий тональный компонент. Окружение пика 502 может быть представлено предварительно определенным числом соседних спектральных коэффициентов, например, спектральными коэффициентами между левым основанием 508 и правым основанием 510 плюс коэффициенты оснований 508, 510.
. Например, на Фиг.5 пик 502 был идентифицирован как пик, представляющий тональный компонент. Окружение пика 502 может быть представлено предварительно определенным числом соседних спектральных коэффициентов, например, спектральными коэффициентами между левым основанием 508 и правым основанием 510 плюс коэффициенты оснований 508, 510.
В соответствии с вариантами осуществления, окружение пика задают предварительно определенным числом коэффициентов вблизи пика 502. Окружение пика может содержать первое число коэффициентов слева от пика 502 и второе число коэффициентов справа от пика 502. Первое число коэффициентов слева от пика 502 и второе числа коэффициентов справа от пика 502 могут быть равными или различными.
В соответствии с вариантами осуществления, применяющими стандарт EVS, предварительно определенное число соседних коэффициентов может быть установлено или зафиксировано на первом этапе, например, до детектирования тонального компонента. В стандарте EVS могут использоваться три коэффициента слева от пика 502, три коэффициента справа и пик 502, то есть, всего в совокупности семь коэффициентов (это число было выбрано по причинам сложности, однако, любое другое число также будет работать). Таким образом, в соответствии с вариантами осуществления, предварительно определенное число коэффициентов вблизи пика 502 задается до этапа детектирования тонального компонента.
В соответствии с вариантами осуществления, размер окружения пика является адаптируемым. Окружения пиков, идентифицированные в качестве представляющих тональный компонент, может быть модифицировано так, что окружения вблизи двух пиков не перекрываются. В соответствии с вариантами осуществления, пик всегда рассматривается только со своим окружением, и они вместе задают тональный компонент.
Для предсказания коэффициентов MDCT в потерянном кадре используется энергетический спектр (амплитуда комплексного спектра) в предпоследнем кадре:
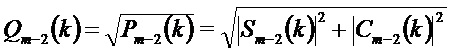
Потерянный MDCT-коэффициент в заменяющем кадре оценивают как:
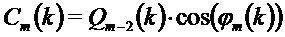
В последующем будет описан способ вычисления фазы 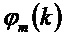
Предсказание фазы
Для каждого найденного пика спектра дробную частоту 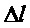
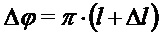
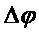
Фазу для каждого спектрального коэффициента в позиции пика и окружениях 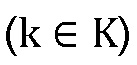 вычисляют в предпоследнем принятом кадре, используя выражение:
вычисляют в предпоследнем принятом кадре, используя выражение:

Фазу в потерянном кадре предсказывают в виде:
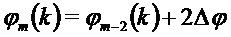
В соответствии с вариантом осуществления, может использоваться уточненный фазовый сдвиг. Использование вычисленной фазы 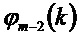
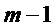
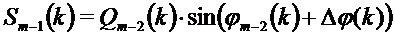
при:
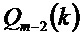
Исходя из этой оценки MDST и из принятого MDCT получают оценку фазы в кадре 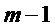

Оцененная фаза используется для уточнения фазового сдвига:
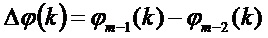
причем:
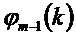
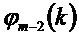
Фазу в потерянном кадре предсказывают в виде:
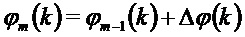
Уточнение фазового сдвига в соответствии с этим вариантом осуществления улучшает предсказание синусоид в присутствии фонового шума или если изменяется частота синусоиды. Для неперекрывающихся синусоид с постоянной частотой и без фонового шума фазовый сдвиг является одинаковым для всех коэффициентов MDCT, которые окружают пик.
Маскирование, которое используется, может иметь различные скорости замирания для тональной части и для шумовой части. Если скорость замирания для тональной части сигнала снижается после множественных потерь кадров, то тональная часть становится доминирующей. Флуктуации в синусоиде, которые происходят из-за различных фазовых сдвигов синусоидальных компонентов, создают неприятные артефакты.
Чтобы решить эту проблему, в соответствии с вариантами осуществления, начиная с третьего потерянного кадра, разность фаз для пика (с индексом k) используется для всех спектральных коэффициентов его окружения (
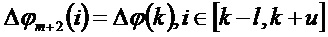
В соответствии с дополнительными вариантами осуществления обеспечивается преобразование. Спектральные коэффициенты во втором потерянном кадре с высоким затуханием используют разность фаз из пика, и коэффициенты с малым затуханием используют скорректированную разность фаз:
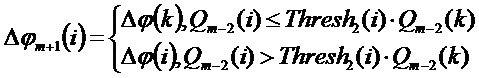
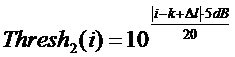
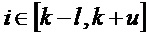
Уточнение амплитуды
В соответствии с другими вариантами осуществления, вместо применения вышеописанного уточнения фазового сдвига, может быть применен другой подход, который использует уточнение амплитуды:
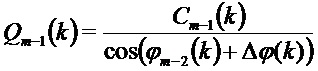
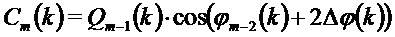
где 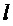
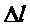
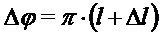
Чтобы избежать повышения энергии, уточненная амплитуда, в соответствии с дополнительными вариантами осуществления, может ограничиваться амплитудой из предпоследнего кадра:
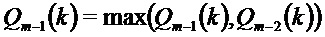
Кроме того, в соответствии с еще дополнительными вариантами осуществления, уменьшение амплитуды может использоваться для его затухания:
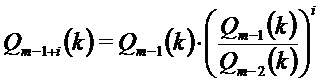
Предсказание фазы с использованием “промежуточного кадра”
Вместо базирования предсказания спектральных коэффициентов на кадрах, предшествующих заменяющему кадру, в соответствии с другими вариантами осуществления, предсказание фазы может использовать “кадр-посредник” (также называемый "прмежуточным" кадром). Фиг.6 иллюстрирует пример для “кадра-посредника”. На Фиг.6 последний кадр 600 (
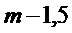
Если перекрытие окна MDCT составляет менее чем 50%, является возможным получить спектр CMDCT более близким к потерянному кадру. На Фиг.6 изображен пример с перекрытием окна MDCT в 25%. Это позволяет получать спектр CMDCT для кадра-посредника 604 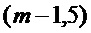
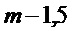
В этом варианте осуществления вычисление и MDST коэффициентов 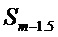
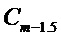
Вычисление энергетического спектра выполняют, как описано выше, и детектирование тональных компонентов выполняют, как описано выше, при m-2-ом кадре, заменяемым кадром m-1,5.
Для синусоидального сигнала 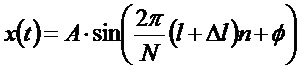
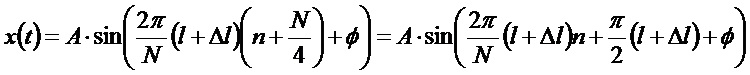
Это приводит к фазовому сдвигу 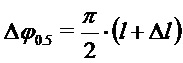
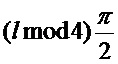
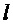
Для предсказания коэффициентов MDCT в потерянном кадре используется амплитуда из кадра m-1,5:
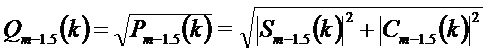
Потерянный коэффициент MDCT оценивают как:
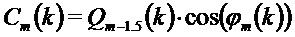
Фаза 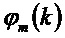
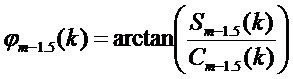
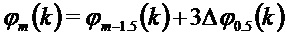
Кроме того, в соответствии с вариантами осуществления, может применяться уточнение фазового сдвига, описанное выше:
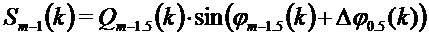

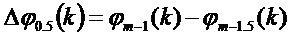
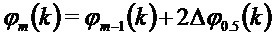
Кроме того сходимость фазового сдвига для всех спектральных коэффициентов, окружающих пик, к фазовому сдвигу пика, может использоваться, как описано выше.
Хотя некоторые аспекты описанной идеи были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или функции этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или функции соответствующего устройства.
В зависимости от некоторых требований к реализации, варианты осуществления изобретения могут быть реализованы аппаратно или программно. Реализацию можно выполнить, используя цифровой носитель данных, например, гибкий диск, цифровой многофункциональный диск (DVD), диск по технологии Blue-Ray, компакт-диск (CD), постоянное запоминающее устройство (ROM), PROM, EPROM, EEPROM или флэш-память, с наличием хранимых там электронно-читаемых управляющих сигналов, которые действуют совместно (или способны к совместному действию) с программируемой компьютерной системой таким образом, что выполняется соответственный способ. Следовательно, цифровой носитель данных может быть компьютерно-читаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель информации с наличием электронно-читаемых управляющих сигналов, которые способны к совместному действию с программируемой компьютерной системой таким образом, что выполняется соответственный способ.
Обычно, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с кодом программы, код программы является рабочим для выполнения одного из способов при исполнении компьютерного программного продукта на компьютере. Код программы может, например, сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в данном документе способов, сохраненную на машиночитаемом носителе.
Другими словами, вариантом осуществления нового способа является, следовательно, компьютерная программа, имеющая код программы для выполнения одного из описанных в данном документе способов, когда компьютерная программа работает на компьютере.
Дополнительным вариантом осуществления способов по изобретению является, следовательно, носитель информации (или цифровой носитель данных, или компьютерно-читаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в данном документе.
Дополнительным вариантом осуществления нового способа является, следовательно, поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в данном документе. Поток данных или последовательность сигналов могут, например, быть сконфигурированы, чтобы передаваться через соединение для передачи данных, например, через сеть Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер с установленной в нем компьютерной программой для выполнения одного из способов, описанных в данном документе.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая вентильная матрица) может использоваться для выполнения некоторых или всех из функциональных возможностей способов, описанных в данном документе. В некоторых вариантах осуществления программируемая вентильная матрица может действовать вместе с микропроцессором, чтобы выполнять один из способов, описанных в данном документе. Обычно, способы предпочтительно выполняются любым аппаратно-реализованным устройством.
Вышеописанные варианты осуществления являются просто пояснительными для принципов настоящего изобретения. Следует понимать, что модификации и разновидности конфигураций и деталей, описанных в данном документе, будут очевидны специалистам в данной области техники. Следовательно, ограничиваться следует только объемом прилагаемой формулы изобретения, а не конкретными подробностями, представленными посредством описания и пояснения вариантов осуществления в этом документе.
Ссылки на известный уровень техники
[1] P. Lauber and R. Sperschneider, "Error Concealment for Compressed Digital Audio," in AES 111th Convention, New York, USA, 2001.
[2] C. J. Hwey, "Low-complexity, low-delay, scalable and embedded speech and audio coding with adaptive frame loss concealment". Патент US 6351730 B2, 2002.
[3] S. K. Gupta, E. Choy and S.-U. Ryu, "Encoder-assisted frame loss concealment techniques for audio coding". Патентная заявка US 2007/094009 A1.
[4] S.-U. Ryu and K. Rose, "A Frame Loss Concealment Technique for MPEG-AAC," in 120th AES Convention, Paris, France, 2006.
[5] ISO/IEC JTC1/SC29/WG11, Information technology - Coding of moving pictures and associated, International Organization for Standardization, 1993.
[6] S.-U. Ryu and R. Kenneth, An MDCT domain frame-loss concealment technique for MPEG Advanced Audio Coding, Department od Electrical and Computer Engineering, University of California, 2007.
[7] S.-U. Ryu, Source Modeling Approaches to Enhanced Decoding in Lossy Audio Compression and Communication, UNIVERSITY of CALIFORNIA Santa Barbara, 2006.
[8] M. Yannick, "Method and apparatus for transmission error concealment of frequency transform coded digital audio signals". Патент EP 0574288 B1, 1993.
[9] Y. Mahieux, J.-P. Petit and A. Charbonnier, "Transform coding of audio signals using correlation between successive transform blocks," in Acoustics, Speech, and Signal Processing, 1989. ICASSP-89., 1989.
[10] 3GPP; Technical Specification Group Services and System Aspects, Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec, 2009.
[11] A. Taleb, "Partial Spectral Loss Concealment in Transform Codecs". Патент US 7356748 B2.
[12] C. Guoming, D. Zheng, H. Yuan, J. Li, J. Lu, K. Liu, K. Peng, L. Zhibin, M. Wu and Q. Xiaojun, "Compensator and Compensation Method for Audio Frame Loss in Modified Discrete Cosine Transform Domain". Патентная заявка US 2012/109659 A1.
[13] L. S. M. Dauder, "MDCT Analysis of Sinusoids: Exact Results and Applications to Coding Artifacts Reduction," IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, pp. 302-312, 2004.
[14] D. B. Paul, "The Spectral Envelope Estimation Vocoder," IEEE Transactions on Acoustics, Speech, and Signal Processing, pp. 786-794, 1981.
[15] A. Ferreira, "Accurate estimation in the ODFT domain of the frequency, phase and magnitude of stationary sinusoids," 2001 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, pp. 47-50, 2001.
Изобретение относится к акустике, в частности, к способам обработки аудиоинформации. Способ получения спектральных коэффициентов для заменяющего кадра аудиосигнала осуществляется следующим образом: детектируют тональные компоненты спектра аудиосигнала на основании пика, который присутствует в спектрах кадров, предшествующих заменяющему кадру, для тонального компонента спектра осуществляют предсказание спектральных коэффициентов для пика и его окружения в спектре заменяющего кадра и для нетонального компонента спектра используют непредсказываемый спектральный коэффициент для заменяющего кадра или соответствующего спектрального коэффициента кадра, предшествующего заменяющему кадру. Спектральные коэффициенты для пика и его окружения в спектре заменяющего кадра предсказывают на основании амплитуды комплексного спектра кадра, предшествующего заменяющему кадру, и предсказанной фазы комплексного спектра заменяющего кадра, и фазу комплексного спектра заменяющего кадра предсказывают на основании фазы комплексного спектра кадра , предшествующего заменяющему кадру, и фазового сдвига между кадрами, предшествующими заменяющему кадру. Технический результат – повышение точности декодирования. 7 н. и 32 з.п. ф-лы, 8 ил.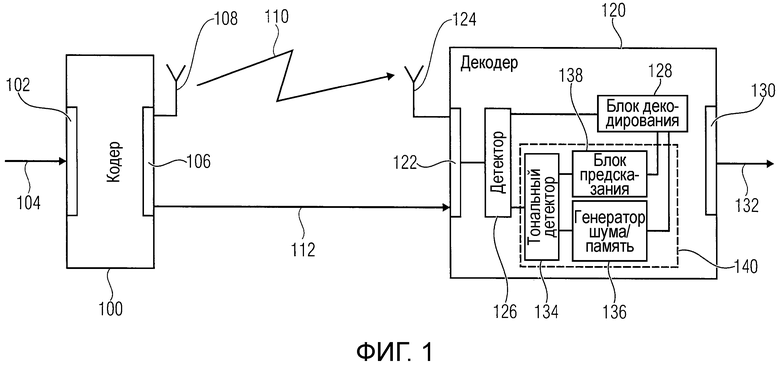
1. Способ получения спектральных коэффициентов для заменяющего кадра аудиосигнала, причем способ содержит:
детектирование (S206) тонального компонента спектра аудиосигнала на основании пика (502), который присутствует в спектрах кадров (m-1, m-2), предшествующих заменяющему кадру (m);
для тонального компонента спектра, предсказание (S210) спектральных коэффициентов для пика (502) и его окружения в спектре заменяющего кадра (m); и
для нетонального компонента спектра, использование (S214) непредсказываемого спектрального коэффициента для заменяющего кадра (m) или соответствующего спектрального коэффициента кадра, предшествующего заменяющему кадру (m).
2. Способ по п.1, в котором
спектральные коэффициенты для пика (502) и его окружения в спектре заменяющего кадра (m) предсказывают на основании амплитуды комплексного спектра кадра (m-2), предшествующего заменяющему кадру (m), и предсказанной фазы комплексного спектра заменяющего кадра (m), и
фазу комплексного спектра заменяющего кадра (m) предсказывают на основании фазы комплексного спектра кадра (m-2), предшествующего заменяющему кадру (m), и фазового сдвига между кадрами (m-1, m-2), предшествующими заменяющему кадру (m).
3. Способ по п.2, в котором
спектральные коэффициенты для пика (502) и его окружения в спектре заменяющего кадра (m) предсказывают на основании амплитуды комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m), и предсказанной фазы комплексного спектра заменяющего кадра (m), и
фазу комплексного спектра заменяющего кадра (m) предсказывают на основании комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m).
4. Способ по п.2, в котором фазу комплексного спектра заменяющего кадра (m) предсказывают на основании фазы для каждого спектрального коэффициента в пике и его окружении в кадре (m-2), предшествующем заменяющему кадру (m).
5. Способ по п.2, в котором фазовый сдвиг между кадрами (m-1, m-2), предшествующими заменяющему кадру (m), является одинаковым для каждого спектрального коэффициента на пике и в его окружении в соответственных кадрах.
6. Способ по п.1, в котором тональный компонент задается пиком и его окружением.
7. Способ по п.1, в котором окружение пика задается предварительно определенным числом коэффициентов вблизи пика (502).
8. Способ по п.1, в котором окружение пика содержит первое число коэффициентов слева от пика (502) и второе число коэффициентов справа от пика (502).
9. Способ по п.8, в котором первое число коэффициентов содержит коэффициенты между левым основанием (508) и пиком (502) плюс коэффициент левого основания (508), и при этом второе число коэффициентов содержит коэффициенты между правым основанием (510) и пиком (502) плюс коэффициент правого основания (510).
10. Способ по п.8, в котором первое число коэффициентов слева от пика (502) и второе число коэффициентов справа от пика (502) являются одинаковыми или различными.
11. Способ по п.10, в котором первым числом коэффициентов слева от пика (502) является три, и вторым числом коэффициентов справа от пика (502) является три.
12. Способ по п.6, в котором предварительно определенное число коэффициентов вблизи пика (502) задают до этапа детектирования тонального компонента.
13. Способ по п.1, в котором размер окружения пика является адаптируемым.
14. Способ по п.13, в котором окружение пика выбирают так, что окружения вблизи двух пиков не перекрываются.
15. Способ по п.2, в котором
спектральный коэффициент для пика (502) и его окружения в спектре заменяющего кадра (m) предсказывают на основании амплитуды комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m), и предсказанной фазы комплексного спектра заменяющего кадра (m),
фазу комплексного спектра заменяющего кадра (m) предсказывают на основании фазы комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), и уточненного фазового сдвига между последним кадром (m-1) и предпоследним кадром (m-2), предшествующим заменяющему кадру (m),
фазу комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), определяют на основании амплитуды комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m), фазы комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m), фазового сдвига между последним кадром (m-1) и предпоследним кадром (m-2), предшествующим заменяющему кадру (m), и действительного спектра последнего кадра (m-1), и
уточненный фазовый сдвиг определяют на основании фазы комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), и фазы комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m).
16. Способ по п.15, в котором уточнение фазового сдвига является адаптируемым на основании числа последовательно потерянных кадров.
17. Способ по п.16, в котором, начиная с третьего потерянного кадра, фазовый сдвиг, определенный для пика, используется для предсказания спектральных коэффициентов, окружающих пик (502).
18. Способ по п.17, в котором для предсказания спектральных коэффициентов во втором потерянном кадре фазовый сдвиг, определенный для пика (502), используется для предсказания спектральных коэффициентов для спектральных коэффициентов окружения, когда фазовый сдвиг в последнем кадре (m-1), предшествующем заменяющему кадру (m), равен или ниже предварительно определенного порогового значения, и фазовый сдвиг, определенный для соответственных спектральных коэффициентов окружения, используется для предсказания спектральных коэффициентов для спектральных коэффициентов окружения, когда фазовый сдвиг в последнем кадре (m-1), предшествующем заменяющему кадру (m), выше предварительно определенного порогового значения.
19. Способ по п.2, в котором
спектральный коэффициент для пика (502) и его окружения в спектре заменяющего кадра (m) предсказывают на основании уточненной амплитуды комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), и предсказанной фазы комплексного спектра заменяющего кадра (m), и
фазу комплексного спектра заменяющего кадра (m) предсказывают на основании фазы комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m), и удвоенного фазового сдвига между последним кадром (m-1) и предпоследним кадром (m-2), предшествующим заменяющему кадру (m).
20. Способ по п.19, в котором уточненную амплитуду комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), определяют на основании коэффициента действительного спектра для действительного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), фазы комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m), и фазового сдвига между последним кадром (m-1) и предпоследним кадром (m-2), предшествующим заменяющему кадру (m).
21. Способ по п.19, в котором уточненная амплитуда комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), ограничена амплитудой комплексного спектра предпоследнего кадра (m-2), предшествующего заменяющему кадру (m).
22. Способ по п.2, в котором
спектральный коэффициент для пика (502) и его окружения в спектре заменяющего кадра (m) предсказывают на основании амплитуды комплексного спектра промежуточного кадра между последним кадром (m-1) и предпоследним кадром (m-2), предшествующим заменяющему кадру (m), и предсказанной фазы комплексного спектра заменяющего кадра (m).
23. Способ по п.22, в котором
фазу комплексного спектра заменяющего кадра (m) предсказывают на основании фазы комплексного спектра промежуточного кадра, предшествующего заменяющему кадру (m), и фазового сдвига между промежуточными кадрами, предшествующими заменяющему кадру (m), или
фазу комплексного спектра заменяющего кадра (m) предсказывают на основании фазы комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), и уточненного фазового сдвига между промежуточными кадрами, предшествующими заменяющему кадру (m), причем уточненный фазовый сдвиг определяют на основании фазы комплексного спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), и фазы комплексного спектра промежуточного кадра, предшествующего заменяющему кадру (m).
24. Способ по п.1, в котором детектирование тонального компонента спектра аудиосигнала содержит:
поиск (S400) пиков в спектре последнего кадра (m-1), предшествующего заменяющему кадру (m), на основании одного или более предварительно определенных пороговых значений;
адаптацию (S402) одного или более пороговых значений; и
поиск (S404) пиков в спектре предпоследнего кадра (m-2), предшествующего заменяющему кадру (m), на основании одного или более адаптированных пороговых значений.
25. Способ по п.24, в котором адаптация одного или более пороговых значений содержит установку одного или более пороговых значений для поиска пика в предпоследнем кадре (m-2), предшествующем заменяющему кадру (m), в области вблизи пика, найденного в последнем кадре (m-1), предшествующем заменяющему кадру (m), на основании спектра и огибающей спектра последнего кадра (m-1), предшествующего заменяющему кадру (m), или на основании основной частоты.
26. Способ по п.25, в котором основная частота предназначена для сигнала, включающего в себя последний кадр (m-1), предшествующий заменяющему кадру (m), и упреждения последнего кадра (m-1), предшествующего заменяющему кадру (m).
27. Способ по п.26, в котором упреждение последнего кадра (m-1), предшествующего заменяющему кадру (m), вычисляют на стороне кодера, используя упреждение.
28. Способ по п.24, в котором адаптация (S402) одного или более пороговых значений содержит установку одного или более пороговых значений для поиска пика в предпоследнем кадре (m-2), предшествующем заменяющему кадру (m), в области не вблизи пика, найденного в последнем кадре (m-1), предшествующем заменяющему кадру (m), в предварительно определенное пороговое значение.
29. Способ по п.1, содержащий:
определение (S204) для заменяющего кадра (m), применять ли маскирование во временной области или маскирование в частотной области, с использованием предсказания спектральных коэффициентов для тональных компонентов аудиосигнала.
30. Способ по п.29, в котором маскирование в частотной области применяют в случае, если последний кадр (m-1), предшествующий заменяющему кадру (m), и предпоследний кадр (m-2), предшествующий заменяющему кадру (m), имеют постоянный основной тон, или анализ одного или нескольких кадров, предшествующих заменяющему кадру (m), указывает, что ряд тональных компонентов в сигнале превышает предварительно определенное пороговое значение.
31. Способ по п.1, в котором кадры аудиосигнала кодированы с использованием MDCT.
32. Способ по п.1, в котором заменяющий кадр (m) содержит кадр, который не может быть обработан в приемнике аудио, например, из-за ошибки в принятых данных, или кадр, который был потерян в ходе передачи на приемник аудио, или кадр, не принятый вовремя в приемнике аудио.
33. Способ по п.1, в котором непредсказываемый спектральный коэффициент формируют с использованием способа генерации шума, например, скремблирования со знаком, или с использованием предварительно определенного спектрального коэффициента из памяти, например, таблицы поиска.
34. Компьютерно-читаемый носитель, сохраняющий инструкции, которые, при исполнении на компьютере, выполняют способ по одному из п.п.1-33.
35. Устройство для получения спектральных коэффициентов для заменяющего кадра (m) аудиосигнала, причем устройство содержит:
детектор (134), сконфигурированный для детектирования тонального компонента спектра аудиосигнала на основании пика, который присутствует в спектрах кадров, предшествующих заменяющему кадру (m); и
блок (138) предсказания, сконфигурированный, чтобы предсказывать для тонального компонента спектра спектральные коэффициенты для пика (502) и его окружения в спектре заменяющего кадра (m);
при этом для нетонального компонента спектра используется непредсказываемый спектральный коэффициент для заменяющего кадра (m) или соответствующий спектральный коэффициент кадра, предшествующего заменяющему кадру (m).
36. Устройство для получения спектральных коэффициентов для заменяющего кадра (m) аудиосигнала, причем устройство сконфигурировано функционировать согласно способу по одному из пп.1-33.
37. Декодер аудио, содержащий устройство по п.35 или 36.
38. Приемник аудио, содержащий декодер аудио по п.37.
39. Система передачи аудиосигналов, содержащая:
кодер (100), сконфигурированный, чтобы генерировать кодированный аудиосигнал; и
декодер (120) по п.37, сконфигурированный, чтобы принимать кодированный аудиосигнал и декодировать кодированный аудиосигнал.
| S.-U | |||
| Ryu and R | |||
| Kenneth, An MDCT domain frame-loss concealment technique for MPEG Advanced Audio Coding, Department od Electrical and Computer Engineering, University of California, 2007 | |||
| US 20120109659 A1, 03.05.2012 | |||
| US 20070094009 A1, 26.04.2007 | |||
| US 6138101 A, 24.10.2000 | |||
| WO 2002059875 A2, 01.08.2002 | |||
| СПОСОБ И УСТРОЙСТВО ЭФФЕКТИВНОЙ МАСКИРОВКИ СТИРАНИЯ КАДРОВ В РЕЧЕВЫХ КОДЕКАХ | 2006 |
|
RU2419891C2 |

