Настоящее изобретение относится к реализуемому компьютером способу ввода данных. Изобретение также относится к способу представления информации, указывающей количество удерживаемых данных, относящихся к объекту данных.
Теперь компьютеры являются вездесущими в современном обществе. Они используются во многих разных применениях, в том числе индивидуумами в своих домах и на их местах работы. Во многих коммерческих приложениях существует необходимость в компьютерных системах, которые эффективно принимают, обрабатывают и хранят данные. Во многих применениях важно, чтобы данные управлялись гибко, надежно и безопасно. Требования безопасности многих применений требуют не только, чтобы тщательно контролировался доступ к данным, но также чтобы данные обрабатывались таким образом, чтобы избежать нарушения целостности данных.
В последние годы много внимания было сфокусировано на способе, которым люди взаимодействуют с компьютерами. Действительно, было выполнено много исследовательской работы в области, известной как человекомашинное взаимодействие. Когда компьютеры впервые становились популярными, они предусматривали интерфейсы, которые были преимущественно или исключительно текстовыми. Позднее стали широко использоваться графические интерфейсы пользователя. Значительная исследовательская работа продолжает выполняться с тем, чтобы разрабатывать пользовательские интерфейсы, которые предоставляют пользователям возможность более эффективно взаимодействовать с компьютерами.
Согласно первому аспекту настоящего изобретения предложен реализуемый компьютером способ представления информации, указывающей количество удерживаемых данных, относящихся к объекту данных, способ содержит: обработку данных, ассоциативно связанных с упомянутым объектом данных для генерирования данных, указывающих один из предопределенного набора классов, каждый класс представляет диапазон предопределенных количеств данных и отображение данных, указывающих упомянутый класс.
Согласно дополнительному аспекту настоящего изобретения предложен реализуемый компьютером способ ввода данных, содержащий: прием текстовых входных данных, обработку упомянутых текстовых входных данных для идентификации одной из предопределенного множества категорий данных, выбор элемента данных, ассоциативно связанного с упомянутой идентифицированной категорией данных, и сохранение упомянутого выбранного элемента данных.
Согласно дополнительному аспекту настоящего изобретения предложен реализуемый компьютером способ ввода данных, содержащий: прием текстовых входных данных, содержащих первые текстовые входные данные и вторые текстовые входные данные, обработку упомянутых первых текстовых входных данных и сохранение упомянутых вторых текстовых входных данных некоторым образом, основанным на упомянутой обработке.
Варианты осуществления настоящего изобретения далее будут описаны только в качестве примера со ссылкой на прилагаемые чертежи, на которых:
фиг.1 - общий вид сети компьютеров, используемых для реализации вариантов осуществления настоящего изобретения;
фиг.2 - схематическая иллюстрация, показывающая сервер по фиг.1 более подробно;
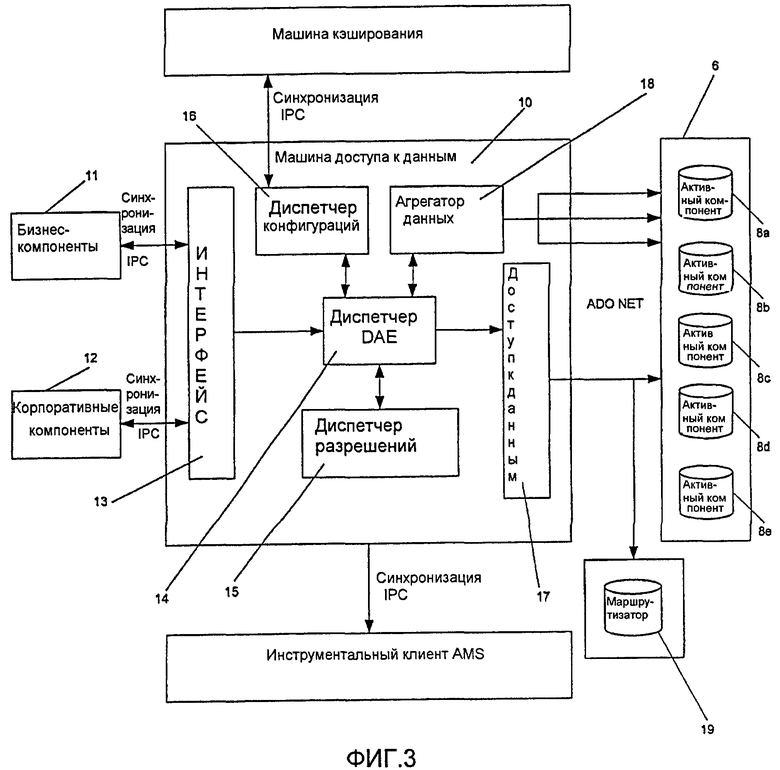
фиг.3 - схематичная иллюстрация архитектуры управления доступом к базе данных, используемой в вариантах осуществления настоящего изобретения;
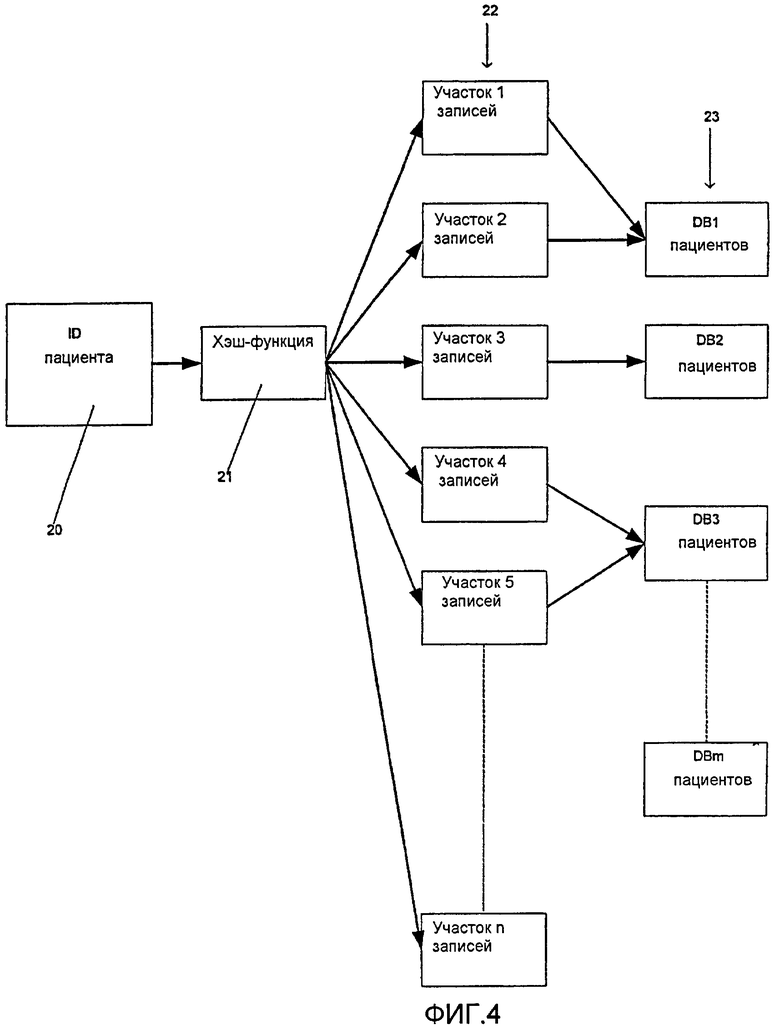
фиг.4 - схематическая иллюстрация алгоритма хэширования, используемого в архитектуре по фиг.3;
фиг.5 - частичная иллюстрация схемы базы данных;
фиг.6 - схематическая иллюстрация графического интерфейса пользователя (GUI), используемого в вариантах осуществления настоящего изобретения для отображения данных, указывающих количество данных, относящихся к объекту данных;
фиг.7 - схематическая иллюстрация GUI, используемого в вариантах осуществления настоящего изобретения для управления отображением по фиг.3;
фиг.8 - снимок экрана текстового ввода, предусмотренного в вариантах осуществления изобретения;
фиг.9 и 10 - снимки экрана, показывающие, каким образом рубрики могут использоваться на экране ввода текстовых данных по фиг.8, и
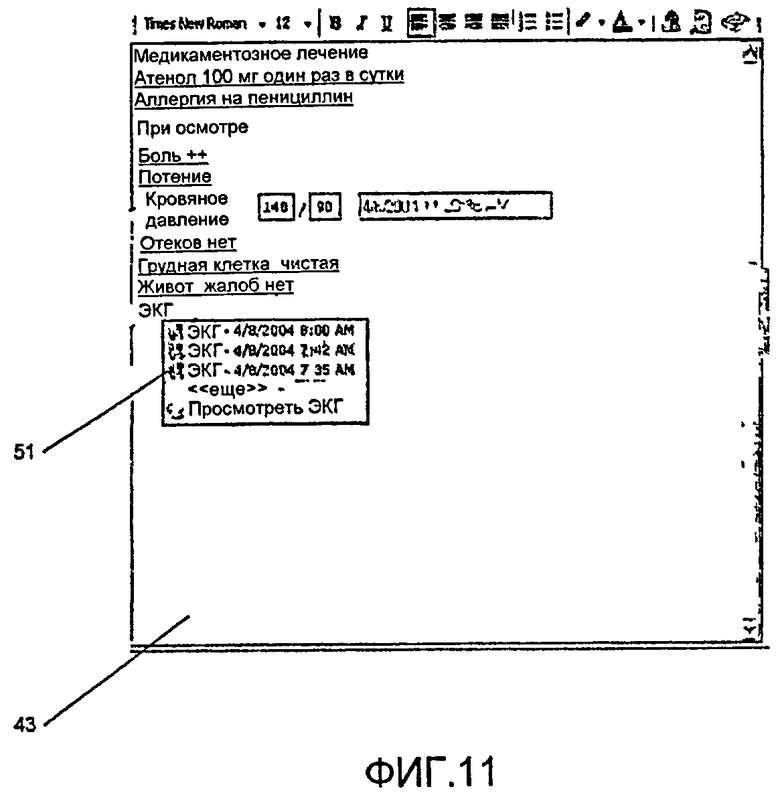
фиг.11 - снимок экрана, показывающий, каким образом могут использоваться команды форматирования для содействия вводу данных.
Со ссылкой на фиг.1 проиллюстрирована сеть компьютеров, пригодных для реализации вариантов осуществления настоящего изобретения. Может быть видно, что три клиентских компьютера 1, 2, 3 осуществляют доступ к службам, предоставляемым сервером 4, через сеть 5.
Клиентские компьютеры 1, 2, 3 могут принимать любую удобную форму. Например, в некоторых вариантах осуществления некоторые клиентские компьютеры 1, 2, 3 принимают форму настольных компьютеров, иные принимают форму дорожных компьютеров наряду с тем, что другие принимают форму планшетных ПК (персональных компьютеров, PC). Однако клиентские компьютеры также могут принимать форму мобильных устройств, таких как устройства мобильной телефонии или PDA (персональные цифровые ассистенты).
Сеть 5 может быть любой подходящей сетью, которая обеспечивает эффективную связь между клиентскими компьютерами 1, 2, 3 и сервером 4. Например, сеть 5 может быть проводной или беспроводной локальной сетью (LAN). В качестве альтернативы сеть 5 может содержать глобальную сеть, такую как сеть Интернет. В таком случае сеть 5 дополнительно может содержать множество LAN, соединенных с глобальной сетью, клиентские компьютеры 1, 2, 3, в свою очередь, являющиеся присоединенными к LAN и через LAN являющиеся способными поддерживать связь по глобальной сети.
Сервер 4 может быть одиночным компьютером или, типичнее, множеством компьютеров. Будет приниматься во внимание, что в тех случаях, когда множество компьютеров предусмотрено для генерирования сервера 4, службы, предоставляемые сервером 4, могут быть распределены между компьютерами любым удобным образом.
Клиентские компьютеры 1, 2, 3 выполняют клиентские приложения, которые поддерживают связь с сервером 4. Например, сервер 4 может предусматривать логический склад 6 данных. Доступ к логическому складу 6 данных может контролироваться сервером 4 из условия, чтобы посредством связи с программами, работающими на сервере 4, клиентские компьютеры 1, 2, 3 были способны осуществлять доступ к логическому складу 6 данных. Фиг. 2 иллюстрирует примерную архитектуру для сервера 4.
Со ссылкой на фиг.2 может быть видно, что серверный компьютер 7 поддерживает связь и управляет доступом к логическому складу 6 данных. Можно видеть, что логический склад 6 данных снаряжен тремя складами 8a, 8b, 8c данных, каждый из которых присоединен к соответственному серверу 9a, 9b, 9c базы данных. Серверный компьютер 7 поддерживает связь с серверами 9a, 9b, 9c баз данных, чтобы осуществлять доступ и изменять данные, хранимые в складах 8a, 8b, 8c данных.
Описанные варианты осуществления имеют конкретную применимость в средах здравоохранения. В таких средах (как и во многих других) защита данных очень важна как с точки зрения управления доступом к данным, так и с точки зрения гарантирования, что данные не теряются и не искажаются. Архитектура, пригодная для администрирования доступа к данным здравоохранения, описана далее со ссылкой на фиг.3.
Со ссылкой на фиг.3 может быть видно, что логический склад 6 данных здесь содержит пять отдельных складов 8a, 8b, 8c, 8d, 8e данных. Эти склады данных скомпонованы с тем, чтобы обеспечивать эффективный и рациональный доступ к данным, хранимым в логическом складе 6 данных. Например, в тех случаях, когда хранятся данные пациентов, предпочтительно, чтобы все данные, относящиеся к конкретному пациенту, хранились в пределах одного из складов с 8a по 8e данных. Может быть видно, что предусмотрена машина 10 доступа к данным (DAE), чтобы управлять доступом к складам с 8a по 8e данных. Клиентские приложения, желающие осуществить доступ к данным, хранимым в складах с 8a по 8e данных, используют DAE 10 для успешного выполнения такого доступа. Такие клиентские приложения могут выполняться на клиентских компьютерах 1, 2, 3 по фиг.1. Может быть видно, что клиентские приложения могут включать в себя бизнес-компоненты 11 и корпоративные компоненты 12, и те, и другие из которых осуществляют доступ к данным с использованием машины 10 доступа к данным.
Далее описаны компоненты машины 10 доступа к данным. В предпочтительном варианте осуществления DAE реализована с использованием каркаса Microsoft®.NET. Каркас.NET предусматривает набор классов, указываемых ссылкой как ADO.NET, которые предоставляют удобные функциональные возможности для доступа к базам данных. DAE 10 осуществляет доступ к складам с 8a по 8e данных с использованием функциональных возможностей, предусмотренных классами ADO.NET. DAE 10 абстрагирует постоянство существования данных и механизмы извлечения данных ADO.NET. Для достижения этого групповые методы доступа к данным ADO.NET инкапсулируются с тем, чтобы как следует инкапсулировать функциональные возможности выполнения программ для баз данных Oracle и баз данных SQL Server. Будет приниматься во внимание, что также могли бы использоваться другие базы данных.
Может быть видно, что DAE 10 содержит интерфейс 13, и это тот интерфейс, через который и те, и другие бизнес-компоненты 11 и корпоративные компоненты 12 поддерживают связь с DAE, чтобы осуществлять доступ к данным. Интерфейс 13 определяет константы и снабжает бизнес-компоненты 11 и корпоративные компоненты 12 доступом к диспетчеру 14 DAE.
Диспетчер 14 DAE ответственен за диспетчеризацию операций доступа к данным. Диспетчер 14 DAE взаимодействует с компонентом 15 диспетчера разрешений, компонентом 16 диспетчера конфигураций, компонентом 17 доступа к данным и компонентом 18 агрегатора данных. Далее описано назначение этих компонентов.
Компонент 16 диспетчера конфигураций ответственен за предоставление конфигурационной информации. Диспетчер конфигураций является одноэкземплярным классом, который является классом, имеющим единственный экземпляр для конкретного физического сервера. Компонент 16 диспетчера конфигураций принимает в качестве входных данных два файла расширяемого языка разметки (XML), содержащих конфигурационную информацию.
Компонент 15 диспетчера разрешений вызывается для получения подробностей о сервере базы данных, на котором должен выполняться конкретный запрос. Эта последовательность операций может выполняться некоторым количеством способов. Например, конфигурационные файлы, поставляемые в компонент 16 диспетчера конфигураций, могут задавать сервер базы данных, который должен быть ассоциативно связан с каждым классом. Посредством получения идентификатора класса, ассоциативно связанного с конкретным запросом, диспетчер конфигураций может использоваться компонентом 15 диспетчера разрешений для определения, какой сервер базы данных должен подвергаться доступу.
В качестве альтернативы база 19 данных маршрутизатора может использоваться в качестве указателя на склады с 8a по 8e данных. В тех случаях, когда данные хранятся сосредоточенным на пациенте образом (то есть образом, ассоциативно связанным с конкретным пациентом), база 19 данных маршрутизатора будет использовать данные, ассоциативно связанные с конкретным пациентом для идентификации одного или более из складов с 8a по 8e данных, в которых хранятся существенные данные. Таким образом, компонент 15 диспетчера разрешений использует базу 19 данных маршрутизатора для определения, какие из складов данных должны использоваться для получения необходимой информации.
База 19 данных маршрутизатора может хорошо работать в тех случаях, когда данные, которые должны быть извлечены, являются сосредоточенными на пациенте данными. При условии, что некоторая информация в системах здравоохранения не является сосредоточенной на пациенте (например, информация, относящаяся к учреждению здравоохранения), данные могут иметь ассоциативно связанный атрибут, служащий признаком, являются ли они сосредоточенными на пациенте данными. Этот атрибут указывается как спецификатор раздела. Используя спецификатор раздела, компонент 15 диспетчера разрешений способен, прежде всего, определять, являются ли требуемые данные сосредоточенными на пациенте данными. Если это неверно, запрашиваются один или более складов данных, удерживающих не сосредоточенные на пациенте данные. Однако, если данные являются сосредоточенными на пациенте данными, база 19 данных маршрутизатора может использоваться образом, описанным выше, для идентификации надлежащих складов данных, которые должны запрашиваться.
Хотя использование базы 19 данных маршрутизатора способом, описанным выше, обеспечивает эффективный доступ к данным, хранимым в пределах логического склада 6 данных, будет приниматься во внимание, что повторяемый доступ к базе 19 данных маршрутизатора может быть источником неэффективности. Диспетчер 15 разрешений поэтому может использовать кэш для предотвращения чрезмерно частого доступа базы 19 данных маршрутизатора. Кэш используется для хранения связывающих строк для каждого интересующего склада данных. Кэш хранит схему, которая отображает идентификаторы участков записей, сформированных алгоритмом хэширования (описанным ниже) в связывающие строки. Надлежащая связывающая строка идентифицируется с использованием идентификатора участков записей, сформированного алгоритмом хэширования, как описано ниже со ссылкой на фиг.4.
Со ссылкой на фиг.4 может быть видно, что идентификатор 20 пациента вводится в алгоритм 21 хэширования. Выходными данными алгоритма 21 хэширования является идентификатор 22 участков записей. Кэш, описанный выше, хранит схему, отображающую идентификаторы 22 участков записей в связывающие строки 23, каждая связывающая строка 23 является сконфигурированной с возможностью подключения к конкретному складу данных. Каждый идентификатор участков записей ассоциативно связан с единственным складом данных, хотя более чем один участок записей может быть ассоциативно связан с любым одним складом данных.
Идентификатор 20 пациента, введенный в алгоритм 21 хэширования, а в более общем смысле, идентификатор пациента, используемый для обработки сосредоточенных на пациенте запросов, может приобретать любую удобную форму. Например, цифровой или алфавитно-цифровой идентификатор, уникально выделенный каждому пациенту учреждением здравоохранения или службой здравоохранения (такой, как Государственная служба здравоохранения в Соединенном Королевстве), может использоваться соответствующим образом. Определив идентификатор, который должен использоваться в качестве идентификатора 20 пациента, алгоритм хэширования сконфигурирован с возможностью работы с этим идентификатором.
Возвращаясь к фиг.3, компонент 18 агрегатора данных у DAE 10 является необязательным компонентом. Когда клиентское приложение создает запрос данных, который запрашивает данные, которые должны извлекаться из множества складов данных, диспетчер 14 DAE взаимодействует с компонентом 18 агрегатора данных, чтобы гарантировать, что надлежащие запросы данных производятся в надлежащие склады данных. Компонент агрегатора данных является многопоточным компонентом с конфигурируемым пользователем количеством потоков.
Компонент 17 доступа к данным ответственен за все связи со складами данных и надлежащим образом обертывает методы выполнения ADO.NET. Компонент 117 доступа к данным реализован с использованием абстрактного шаблона фабрики. Реализованы экземпляры помощника, которые специфичны базам данных, которые должны подвергаться доступу. Экземпляры помощника могут выполнять хранимые процедуры или узкоспециализированные запросы для операций базы данных обновления, выборки и удаления.
Может быть видно, что DAE 10, кроме того, поддерживает связь с машиной 24 кэширования и инструментальным клиентом 25 службы контроля приложений (AMS). Машина 24 кэширования предусматривает кэш для использования компонентом 16 диспетчера конфигураций. Инструментальный клиент 25 AMS предоставляет возможности для оснащения инструментами операций для различных вещей, которые заданы требованиями.
Будет приниматься во внимание, что сосредоточенные на пациенте данные, хранимые в складах с 8a по 8e данных, хранят широкое многообразие данных, относящихся к пациентам, чьи данные должны обрабатываться. Данные хранятся в таблицах баз данных некоторым образом, который будет хорошо известен специалистам в данной области техники. Фиг.5 показывает часть схемы базы данных, сосредоточенной вокруг таблицы 26 пациентов. Может быть видно, что проиллюстрированы отношения между таблицей 26 пациентов и различными другими таблицами, которые хранят демографические данные пациента. Таблица 26 пациентов хранит данные, относящиеся к конкретным пациентам, такие как данные имени, данные о дне рождения и данные пола.
Другие таблицы базы данных (некоторые из которых проиллюстрированы на фиг.5) также хранят данные, относящиеся к конкретным пациентам. Эти таблицы соотносят свои данные с конкретным пациентом, имея поле внешнего ключа, которое нацеливает первичный ключ таблицы пациентов.
Когда данные пациента хранятся электронным образом, медицинскому практикующему специалисту трудно получать быстрый признак количества хранимых данных, относящихся к конкретному пациенту. Этот признак часто может быть полезным при условии, что пациенты, по которым сохранено много данных, вероятно, должны иметь более длительную и/или более сложную историю болезни, чем те, по которым сохранено относительно мало данных. Этот признак поэтому может быть полезным начальным указателем на медицинского практикующего специалиста.
В предпочтительных вариантах осуществления все истории болезней пациентов (где история болезни пациента содержит в себе все хранимые данные, которые относятся к конкретному пациенту) имеют ассоциативно связанную классификацию как небольшие, средние и большие на основании количества хранимых данных, относящихся к пациенту.
Выше было описано, что база данных включает в себя таблицу 26 пациентов, которая имеет, в качестве своего первичного ключа, уникальный идентификатор пациента. Также было пояснено, что этот ключ используется для идентификации данных в других таблицах, которые относятся к конкретной таблице. Этим способом можно определять, сколько данных хранится о конкретном пациенте, простым подсчетом записей во множестве таблиц базы данных, которые указывают на идентификатор пациента. То есть все надлежащие таблицы базы данных имеют поле пациента, хранящее данные, которые указывают конкретного пациента с использованием идентификатора пациента. Посредством запрашивания всех таблиц для идентификации записей, имеющих поле пациента, установленное в предопределенный идентификатор пациента, могут идентифицироваться все записи, ассоциативно связанные с предопределенным идентификатором пациента, и может выполняться подсчет таких записей по всем надлежащим таблицам.
В некоторых вариантах осуществления надлежащие таблицы базы данных, в которых записи подсчитываются с использованием способа, описанного выше, показаны в таблице 1, приведенной ниже.
Будет приниматься во внимание, что подсчетом записей, относящихся к конкретному пациенту во всех таблицах, показанных в таблице 1, приведенной выше, получается хороший признак количества хранимых данных, которые ассоциативно связаны с конкретным пациентом. Это приблизительно устанавливает равенство вероятной толщиной папки с бумагами, ассоциативно связанной с пациентом.
Фиг.6 - снимок экрана, взятый из варианта осуществления изобретения. Может быть видно, что область 30 включает в себя три пиктограммы. Эти пиктограммы представляют малую, среднюю и большую классификации для историй болезней пациентов, описанных выше. Может быть видно, что в случае, проиллюстрированном на фиг.6, первая пиктограмма 31, представляющая малую классификацию, показана в первом подсвеченном состоянии, тогда как вторые пиктограммы 32, 33 показаны во вторых обесцвеченных состояниях. Таким образом, хотя все три пиктограммы отображаются всегда, одна из трех пиктограмм подсвечивается, чтобы показать признак размера, ассоциативно связанный с конкретным пациентом.
Было описано, что способ выбора одной из малой, средней и большой классификации влечет за собой подсчет количества записей, относящихся к конкретному пациенту, в различных таблицах базы данных. Будет приниматься во внимание, что, выполнив этот подсчет, необходимо интерпретировать абсолютное количество записей в одну из трех классификаций. Это может выполняться заданием диапазонов количеств записей, которые соответствуют малой, средней и большой классификациям соответственно.
Фиг.7 - снимок экрана, взятый из варианта осуществления изобретения, в котором пользователь вводит диапазоны количеств записей, ассоциативно связанных с каждой из трех классификаций. Должно быть отмечено, что пользовательский ввод может задаваться на различных уровнях организации здравоохранения.
Следует отметить, что минимальным значением для количества записей в истории болезни пациента, которое должно классифицироваться как малое, неизменно является ноль наряду с тем, что максимальное количество записей в историях болезней пациентов, которое должно классифицироваться как большое, всегда бесконечно. Другие границы диапазонов могут задаваться пользователем, хотя должно быть отмечено, что ограничения накладываются из условия, чтобы минимальное количество записей в пределах истории болезни пациента, которое должно классифицироваться как среднее, всегда является бóльшим, чем максимальное количество записей в пределах истории болезни пациента, которое должно классифицироваться как малое. Подобные ограничения применяются в отношениях между средней и большой классификациями. Таким образом, может быть видно, что определен непрерывный диапазон, так что все записи будут попадать точно в одну классификацию.
Далее описаны пригодные механизмы для приема и обработки входных данных. Сначала со ссылкой на фиг.8 проиллюстрирован графический интерфейс пользователя (GUI), сконфигурированный с возможностью приема входных данных в средах здравоохранения. Может быть видно, что GUI содержит три панели 40, 41, 42 инструментов, которые используются для назначения ввода данных на три части 43 свободного ввода текстовых данных. Панели 40, 41 инструментов содержат различные кнопки, которые управляют такими вещами, как шрифт, размер шрифта, начертание шрифта, (например, полужирное, наклонное, подчеркнутое), выравнивание текста и проверка орфографии. Панель 42 инструментов предусматривает функцию поиска для поиска текста в пределах части 43 ввода текстовых данных.
Может быть видно, что часть 43 ввода текстовых данных, в общих чертах, сконфигурирована с возможностью приема свободного текстового ввода. Также может быть видно, что часть ввода текстовых данных дополнительно может допускать изображения в качестве входных данных, как показано изображением 44 на фиг.8.
Ввод текстовых данных с использованием части 43 ввода текстовых данных может компоноваться с использованием рубрик традиционным образом. Однако в предпочтительных вариантах осуществления изобретения рубрики обрабатываются с тем, чтобы определять, каким образом обрабатывать введенные текстовые данные как одно целое. Например, со ссылкой на фиг.9 может быть видно, что пользователь ввел входные текстовые данные «пж». Эти текстовые входные данные были автоматически преобразованы в текст «предъявляемые жалобы». Дополнительные текстовые данные, введенные впоследствии под рубрикой «предъявляемые жалобы», могут сохраняться в базе данных типа, описанного выше, таким образом, чтобы указывать жалобы, которые предъявлял пациент. То есть рубрика «предъявляемые жалобы» используется для определения, каким образом и где в базе данных должны сохраняться введенные впоследствии текстовые данные.
Пояснялось, что рубрика «предъявляемые жалобы» формировалась посредством ввода текстовых данных «пж». Фиг.10 показывает альтернативный вариант осуществления. Здесь список рубрик 50 представляется пользователю. Пользователь может выбирать рубрики из списка 50 для включения в часть 43 ввода текстовых данных. Это может достигаться любым удобным образом, например с использованием функциональных возможностей «переноса с фиксацией по новому месту». Рубрики, введенные этим способом, могут обрабатываться описанным выше образом.
Фиг.11 показывает команды форматирования, используемые для содействия вводу данных. В проиллюстрированном примере, пользователь ввел текст «экг» с последующим отображением списка 51, представляющего данные ЭКГ (электрокардиограммы, ECG) для пациента, для которого данные вводятся в текущий момент. Пользователь может выбирать один из элементов данных из списка 51, которые должны быть включены в часть 43 ввода текстовых данных либо непосредственно, или посредством ссылки.
Текстовый ввод «экг» и список 51 являются одним из примеров способа, которым ввод данных значительно автоматизируется. Более точно, посредством обработки входных данных (в этом случае «экг») для идентификации класса данных (в этом случае результатов исследования ЭКГ) медицинский практикующий специалист может быстрее вводить данные, относящиеся к пациенту, получая другие связанные данные быстрым и удобным образом по мере того, как продвигается ввод данных.
Подобным образом может быть видно, что отображенный текст включает в себя показание кровяного давления. Это вновь может вводиться печатанием на клавиатуре «кровяное давление» или другой подходящей текстовой строки, представленной показаниями кровяного давления, и побуждением таковых вставляться в часть 43 текстового ввода.
Хотя варианты осуществления настоящего изобретения были описаны выше, будет приниматься во внимание, что различные модификации могут быть произведены в отношении описанных вариантов осуществления, не выходя за рамки сущности и объема прилагаемой формулы изобретения. В частности, в тех случаях, когда варианты осуществления изобретения были описаны в качестве имеющих конкретную применимость в здравоохранении, изобретение не ограничено такими применениями, а взамен является широко применимым.
| название | год | авторы | номер документа |
|---|---|---|---|
| СЧЕТА ПРЕДОПЛАТЫ ЗА ПРИЛОЖЕНИЯ, УСЛУГИ И КОНТЕНТ ДЛЯ УСТРОЙСТВ СВЯЗИ | 2007 |
|
RU2542670C2 |
| СЧЕТА ПРЕДОПЛАТЫ ЗА ПРИЛОЖЕНИЯ, УСЛУГИ И КОНТЕНТ ДЛЯ УСТРОЙСТВ СВЯЗИ | 2014 |
|
RU2614579C2 |
| ТЕХНОЛОГИИ АВТОМАТИЧЕСКОГО ДИАЛОГА | 2009 |
|
RU2523165C2 |
| Способ для разграничения доступа к данным в базе данных | 2018 |
|
RU2682010C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ КОНТЕНТА | 2007 |
|
RU2413980C2 |
| СПОСОБ, СИСТЕМА И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ПОДАЧИ АНОНИМНЫХ КОРПОРАТИВНЫХ ЖАЛОБ | 2022 |
|
RU2791954C1 |
| АВТОМАТИЗИРОВАННОЕ ПРЕОБРАЗОВАНИЕ ОБЪЕКТА ИНТЕРФЕЙСА ПОЛЬЗОВАТЕЛЯ И ГЕНЕРАЦИЯ КОДА | 2012 |
|
RU2604431C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБРАБОТКИ ВХОДНЫХ ПОТОКОВ КАЛЕНДАРНЫХ ПРИЛОЖЕНИЙ | 2013 |
|
RU2636691C2 |
| ИНФОРМАЦИОННАЯ СИСТЕМА КЛИЕНТ - СЕРВЕР И СПОСОБ ПРЕДОСТАВЛЕНИЯ ГРАФИЧЕСКОГО ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА | 2005 |
|
RU2313824C2 |
| РАСЩЕПЛЕННАЯ ЗАГРУЗКА ДЛЯ ЭЛЕКТРОННЫХ ЗАГРУЗОК ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2006 |
|
RU2424552C2 |







Изобретение относится к области ввода, обработки и сохранения данных в базах данных, например данных, касающихся истории болезни пациентов. Технический результат заключается в ускорении и упрощении ввода данных в хранилище данных, а также в обеспечении структурного единообразия вводимых данных. Для этого реализуемый компьютером способ ввода данных содержит этапы, на которых принимают текстовые входные данные и обрабатывают упомянутые текстовые входные данные для идентификации одной из предопределенного множества категорий данных. Затем получают множество элементов данных, ассоциативно связанных с упомянутой идентифицированной категорией данных и представляют упомянутое множество элементов данных пользователю для выбора. Далее выбирают элемент данных, ассоциативно связанный с упомянутой идентифицированной категорией данных и сохраняют упомянутый выбранный элемент данных. 4 н. и 14 з.п. ф-лы, 1 табл., 11 ил.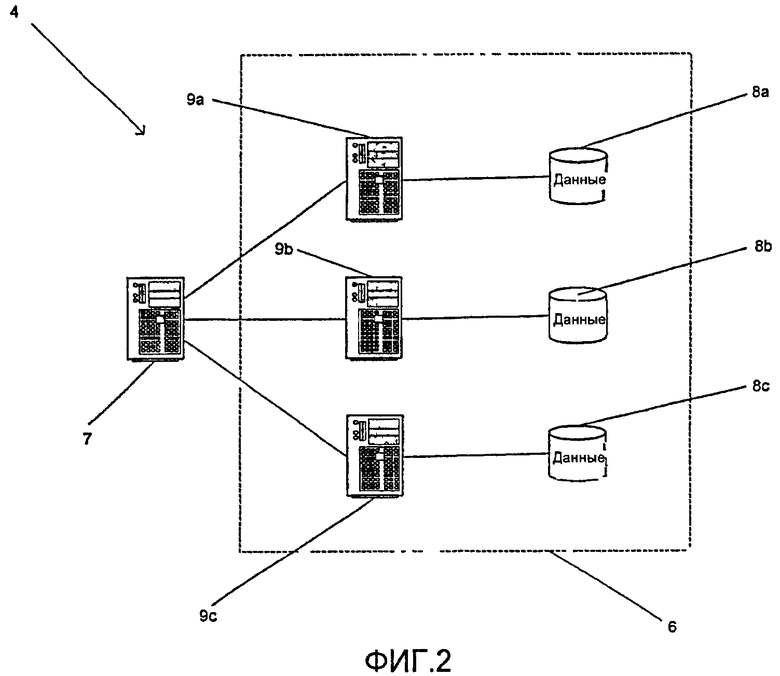
1. Реализуемый компьютером способ ввода данных, содержащий этапы, на которых:
принимают текстовые входные данные;
обрабатывают упомянутые текстовые входные данные для идентификации одной из предопределенного множества категорий данных;
выбирают элемент данных, ассоциативно связанный с упомянутой идентифицированной категорией данных; и
сохраняют упомянутый выбранный элемент данных.
2. Способ по п.1, в котором выбор элемента данных, ассоциативно связанного с упомянутой идентифицированной категорией, содержит этапы, на которых:
получают множество элементов данных, ассоциативно связанных с упомянутой идентифицированной категорией данных;
представляют упомянутое множество элементов данных пользователю для выбора; и
принимают данные, выбирающие один из упомянутого множества элементов данных;
при этом упомянутое сохранение содержит этап, на котором сохраняют упомянутый элемент данных, выбранный посредством упомянутых данных, выбирающих один из упомянутого множества элементов данных.
3. Способ по любому из пп.1 или 2, в котором получение множества элементов данных, ассоциативно связанных с упомянутой идентифицированной категорией данных, содержит этап, на котором:
извлекают элементы данных, ассоциативно связанные с упомянутой идентифицированной категорией данных и удовлетворяющие, по меньшей мере, одному предопределенному критерию.
4. Способ по п.3, в котором упомянутый, по меньшей мере, один предопределенный критерий основан на контексте, в котором принимаются упомянутые текстовые входные данные.
5. Способ по п.3, в котором упомянутый, по меньшей мере, один предопределенный критерий определен со ссылкой на объект данных.
6. Способ по п.5, в котором упомянутым объектом данных является пациент.
7. Способ по п.6, в котором каждая из упомянутых категорий данных ассоциативно связана с соответственным событием.
8. Способ по п.7, в котором упомянутое соответственное событие выбирают из группы, содержащей: предопределенный результат исследования, значение клинического наблюдения, консультацию и предписание, результат диагностического исследования.
9. Способ по п.7 или 8 в качестве зависимых от п.2, в котором получение множества элементов данных, ассоциативно связанных с упомянутой идентифицированной категорией данных, содержит этап, на котором получают элементы данных, ассоциативно связанные с каждым появлением события, представленного идентифицированной категорией данных.
10. Способ по п.1, в котором прием текстовых входных данных содержит этап, на котором принимают текстовые входные данные через графический интерфейс пользователя, сконфигурированный с возможностью приема свободного текстового ввода.
11. Способ по п.10, в котором обработка упомянутых текстовых входных данных содержит этап, на котором обрабатывают упомянутые текстовые входные данные в ответ на пользовательский ввод.
12. Способ по п.11, в котором упомянутый пользовательский ввод содержит сочетание нажатий клавиш.
13. Программоноситель, несущий компьютерочитаемый программный код, сконфигурированный с возможностью побуждения компьютера выполнять способ по любому из пп.1-12.
14. Компьютерное устройство для приема входных данных, причем устройство содержит:
программную память, хранящую читаемые процессором команды; и
процессор, сконфигурированный с возможностью считывания и выполнения команд, хранимых в упомянутой программной памяти;
при этом читаемые процессором команды содержат команды, сконфигурированные с возможностью побуждения процессора выполнять способ по любому из пп.1-12.
15. Реализуемый компьютером способ ввода данных, содержащий этапы, на которых:
принимают текстовые входные данные, содержащие первые текстовые входные данные и вторые текстовые входные данные;
обрабатывают упомянутые первые текстовые входные данные; и
сохраняют упомянутые вторые текстовые входные данные некоторым образом, основанным на упомянутой обработке.
16. Способ по п.15, в котором упомянутые первые и вторые текстовые входные данные принимают через графический интерфейс пользователя, сконфигурированный для приема свободного текстового ввода.
17. Способ по п.15 или 16, в котором упомянутые первые текстовые входные данные выбирают из предопределенного набора элементов первых текстовых входных данных.
18. Способ по п.17, в котором упомянутые первые текстовые входные данные вводят через клавиатуру.
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Сопло | 1929 |
|
SU15140A1 |
| JP 2003141107 A, 16.05.2003 | |||
| СПОСОБ, ПОБУЖДАЮЩИЙ ЖИВОТНЫХ К ДВИЖЕНИЮ | 2007 |
|
RU2376760C2 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| WO 00/65522 A2, 02.11.2000 | |||
| JP 2004227218 A, 12.08.2004. | |||

