Связанные заявки
Настоящая заявка испрашивает приоритет предварительной заявки на патент США №60/834,683, поданной 31 июля 2006 и названной "DIM AND BURST SIGNALLING FOR 4GV WIDEBAND". Настоящая заявка также относится к заявке на патент США №11/830,842, номер в реестре поверенного 061658, поданной 30 июля 2007 и названной "SYSTEMS, METHODS, AND APPARATUS FOR WIDEBAND ENCODING AND DECODING OF INACTIVE FRAMES".
Область техники
Настоящая заявка относится к обработке речевых сигналов.
Уровень техники
Передача голоса цифровыми методиками стала широко распространенной, особенно в междугородной телефонии, телефонии с пакетной коммутацией, такой как речь по IP (также названной VoIP, где IP обозначает Интернет-протокол), и цифровой радиотелефонной связи, такой как сотовая телефонная связь. Такой быстрый рост вызвал интерес к сокращению объема информации, используемой для передачи речевой связи по каналу передачи, в то же время поддерживая воспринимаемое качество восстановленной речи.
Устройства, которые конфигурируются для сжатия речи посредством извлечения параметров, которые относятся к модели генерации человеческой речи, называют «речевыми кодерами». Речевой кодер (также называемый речевым кодеком или вокодером) обычно включает в себя речевой кодер и речевой декодер. Речевой кодер обычно разделяет входящий речевой сигнал (цифровой сигнал, представляющий аудиоинформацию) на сегменты времени, названные "кадрами", анализирует каждый кадр, чтобы извлечь некоторые релевантные параметры, и квантует параметры в закодированный кадр. Кодированные кадры передаются по каналу передачи (то есть проводному или беспроводному сетевому соединению) на приемник, который включает в себя речевой декодер. Речевой декодер принимает и обрабатывает кодированные кадры, деквантует их, чтобы получить параметры, и заново создает речевые кадры, используя эти деквантованные параметры.
Речевые кодеры обычно конфигурируются так, чтобы отличать кадры речевого сигнала, которые содержат речь ("активные кадры") от кадров речевого сигнала, которые содержат только тишину (молчание) или фоновый шум ("неактивные кадры"). Речевой кодер может быть конфигурирован так, чтобы использовать различные режимы и/или скорости кодирования, чтобы кодировать активные и неактивные кадры. Например, речевые кодеры обычно конфигурируются для использования меньше битов для кодирования неактивного кадра, чем кодирования активного кадра. Речевой кодер может использовать более низкую скорость передачи в битах для неактивных кадров, и/или различные скорости передачи в битах для различных типов активных кадров, чтобы поддерживать передачу речевого сигнала с более низкой средней скоростью передачи в битах с от малой до не воспринимаемой потерей качества.
Речевая связь по коммутируемой телефонной сети общего пользования (PSTN) была традиционно ограничена по ширине полосы частот частотными диапазонами 300-3400 килогерц (кГц). Более недавние сети для речевой связи, такие как сети, которые используют сотовую телефонную связь и/или VoIP, могут не иметь тех же самых пределов ширины полосы частот, и может быть желательно для устройства, использующего такие сети, иметь способность передавать и принимать речевые сигналы, которые включают в себя широкополосный частотный диапазон. Например, для такого устройства может быть желательно поддерживать диапазон аудиочастот, который опускается вниз до 50 Гц и/или до 7 или 8 кГц. Может также быть желательно для такого устройства поддерживать другие приложения, такие как высококачественное аудио или аудио/видео конференцию, доставка мультимедийных услуг, таких как музыка и/или телевидение, и т.д., которые могут иметь речевой аудио контент в диапазонах вне традиционных пределов PSTN.
Расширение диапазона, поддерживаемого речевым кодером, до более высоких частот, может улучшить разборчивость (речи). Например, информация в речевом сигнале, которая дифференцирует фрикативные звуки, такие как 's' и 'f', находится в значительной степени в высоких частотах. Расширение в более высокие частоты может также улучшить другие качества декодированного речевого сигнала, такие как присутствие. Например, даже произнесенная гласная может иметь спектральную энергию намного выше частотного диапазона PSTN.
Сущность изобретения
Способ обработки речевого сигнала согласно конфигурации включает в себя формирование, на основании первого активного кадра речевого сигнала, первого речевого пакета, который включает в себя описание спектральной огибающей по (A) первому диапазону частот и (B) второму диапазону частот, который располагается выше первого диапазона частот, части речевого сигнала, которая включает в себя первый активный кадр. Этот способ также включает в себя формирование, на основании второго активного кадра речевого сигнала, второго речевого пакета, который включает в себя описание спектральной огибающей, по первому диапазону частот, части речевого сигнала, которая включает в себя второй активный кадр. В этом способе второй речевой пакет не включает в себя описание спектральной огибающей по второму диапазону частот.
Речевой кодер согласно другой конфигурации включает в себя кодер пакетов и форматер (средство форматирования) кадра. Кодер пакетов конфигурируется для формирования, на основании первого активного кадра речевого сигнала и в ответ на первое состояние сигнала управления скоростью передачи, первого речевого пакета, который включает в себя описание спектральной огибающей по (1) первому диапазону частот и (2) второму диапазону частот, который располагается выше первого диапазона частот. Кодер пакетов также конфигурируется для формирования, на основании второго активного кадра речевого сигнала и в ответ на второе состояние сигнала управления скоростью передачи, отличное от первого состояния, второго речевого пакета, который включает в себя описание спектральной огибающей по первому диапазону частот. Форматер кадра выполнен с возможностью принимать первый и второй речевые пакеты. Форматер кадра конфигурируется для формирования, в ответ на первое состояние сигнала управления «понижением», первого кодированного кадра, который содержит этот первый речевой пакет. Форматер кадра также конфигурируется, чтобы сформировать, в ответ на второе состояние сигнала управления «понижением», отличное от первого состояния, второй закодированный кадр, который содержит второй речевой пакет и пачку информационного сигнала, который является отдельным от речевого сигнала. В этом кодере первый и второй кодированные кадры имеют одинаковую длину, при этом первый речевой пакет занимает по меньшей мере восемьдесят процентов первого закодированного кадра, второй речевой пакет занимает не больше чем половину второго кодированного кадра, и второй активный кадр начинается сразу после первого активного кадра в речевом сигнале.
Способ обработки речевых пакетов согласно другой конфигурации включает в себя получение, на основании информации из первого речевого пакета из кодированного речевого сигнала, описания спектральной огибающей первого кадра речевого сигнала по (A) первому диапазону частот и (B) второму диапазону частот, отличному от первого диапазона частот. Этот способ также включает в себя получение, на основании информации из второго речевого пакета из кодируемого речевого сигнала, описания спектральной огибающей второго кадра речевого сигнала по первому диапазону частот. Этот способ также включает в себя получение, на основании информации от первого речевого пакета, описания спектральной огибающей второго кадра по второму диапазону частот. Этот способ также включает в себя получение, на основании информации из второго речевого пакета, информации, относящейся к компоненту основного тона второго кадра для первого диапазона частот.
Речевой декодер согласно другой конфигурации конфигурируется так, чтобы вычислять декодированный речевой сигнал, основанный на кодируемом речевом сообщении. Этот речевой декодер включает в себя логику управления и декодер пакетов. Логика управления конфигурируется, чтобы сгенерировать сигнал управления, содержащий последовательность значений, которая основана на кодировании индексов речевых пакетов из кодированного речевого сигнала, причем каждое значение последовательности соответствует периоду кадра декодированного речевого сигнала. Декодер пакетов конфигурируется, чтобы вычислять, в ответ на значение сигнала управления, имеющего первое состояние, соответствующего декодированного кадра на основании описания спектральной огибающей декодированного кадра по (1) первому диапазону частот и (2) второму диапазону частот, который располагается выше первого диапазона частот, причем описание основано на информации из речевого пакета из кодированного речевого сигнала. Декодер пакетов также конфигурируется, чтобы вычислять, в ответ на значение сигнала управления, имеющего второе состояние, отличное от первого состояния, соответствующего декодированного кадра, на основании (1) описания спектральной огибающей декодированного кадра по первому диапазону частот, причем это описание основано на информации из речевого пакета из кодируемого речевого сигнала, и (2) описания спектральной огибающей декодированного кадра по второму диапазону частот, причем это описание основано на информации по меньшей мере из одного речевого пакета, который имеется в кодируемом речевом сообщении перед этим речевым пакетом.
Краткое описание чертежей
Фиг.1 показывает схему системы беспроводного телефона, которая сопряжена с PSTN.
Фиг.2 иллюстрирует диаграмму системы беспроводного телефона, которая сопряжена с Интернетом.
Фиг.3 иллюстрирует блок-схему двух пар кодера/декодера речи.
Фиг.4 иллюстрирует один пример дерева решений, которое речевой кодер или способ кодирования речи могут использовать для выбора скорости передачи в битах.
Фиг.5А иллюстрирует график трапециевидной функции вырезания окна, которая может быть использована для вычисления значения формы (сигнала) усиления.
Фиг.5B показывает применение функции вырезания окна согласно Фиг.6A к каждому из пяти подкадров кадра.
Фиг.6A показывает один пример схемы неперекрывающихся диапазонов частот, которая может использоваться кодером с разбиением диапазона, чтобы закодировать широкополосный речевой контент.
Фиг.6B показывает один пример схемы перекрывающихся диапазонов частот, которая может использоваться кодером с разбиением диапазона, чтобы закодировать широкополосный речевой контент.
Фиг.7A-7C показывают три различных формата для 192-битного кодированного кадра.
Фиг.8A иллюстрирует блок-схему для способа M110 согласно общей конфигурации.
Фиг.8B иллюстрирует блок-схему для реализации M110 способа M100.
Фиг.9 иллюстрирует операцию кодирования двух последовательных активных кадров речевого сигнала, используя реализацию способа M100.
Фиг.10 иллюстрирует работу задач T100 и T120 способа M100.
Фиг.11 иллюстрирует операции по реализации задачи T112 и задачи T120 способа M110.
Фиг.12 иллюстрирует таблицу, которая показывает один набор из четырех различных схем кодирования, который может использовать речевой кодер, сконфигурированный для выполнения реализации способа M100.
Фиг.13 - таблица, описывающая распределения битов 171-битового широкополосного пакета FCELP.
Фиг.14 - таблица, описывающая распределения битов 80-битового узкополосного пакета HCELP.
Фиг.15A показывает блок-схему речевого кодера 100 согласно общей конфигурации.
Фиг.15B показывает блок-схему реализации 122 кодера 120 пакетов.
Фиг.15C показывает блок-схему реализации 142 вычислителя 140 описания спектральной огибающей.
Фиг.16A показывает блок-схему реализации 124 кодера 122 пакетов.
Фиг.16B показывает блок-схему реализации 154 вычислителя 152 описания временной информации.
Фиг.17A показывает блок-схему реализации 102 речевого кодера 100, который конфигурируется, чтобы кодировать широкополосный речевой сигнал согласно схеме кодирования с разбиением диапазона.
Фиг.17B показывает блок-схему реализации 128 кодера 126 пакетов.
Фиг.18A показывает блок-схему реализации 129 кодера 126 пакетов.
Фиг.18B показывает блок-схему реализации 158 вычислителя 156 временного описания.
Фиг.19A показывает блок-схему способа M200 согласно общей конфигурации.
Фиг.19B показывает блок-схему реализации M220 способа M200.
Фиг.19C показывает блок-схему реализации M230 способа M200.
Фиг.20 иллюстрирует применение способа M200.
Фиг.21 иллюстрирует соотношение между способами M100 и M200.
Фиг.22 иллюстрирует применение реализации M210 способа M200.
Фиг.23 иллюстрирует применение способа M220.
Фиг.24 иллюстрирует применение способа M230.
Фиг.25 иллюстрирует применение реализации M240 способа M200.
Фиг.26A показывает блок-схему речевого декодера 200 согласно общей конфигурации.
Фиг.26B показывает блок-схему реализации 202 речевого декодера 200.
Фиг.26C показывает блок-схему реализации 204 речевого декодера 200.
Фиг.27A показывает блок-схему реализации 232 первого модуля 230.
Фиг.27B показывает блок-схему реализации 272 декодера 270 описания спектральной огибающей.
Фиг.28A показывает блок-схему реализации 242 второго модуля 240.
Фиг.28B показывает блок-схему реализации 244 второго модуля 240.
Фиг.28C показывает блок-схему реализации 246 второго модуля 242.
В чертежах и сопроводительном описании одни и те же ссылочные позиции относятся к одним и тем же или аналогичным элементам или сигналам.
Подробное описание
Конфигурации, описанные ниже, принадлежат системе радиотелефонной связи, сконфигурированной для использования эфирного интерфейса CDMA. Однако специалистам в данной области техники понятно, что способ и устройство, имеющие признаки, которые описаны в настоящем описании, могут принадлежать любой из различных систем связи, использующих широкий диапазон технологий, известных специалистам, например, системы, использующие (протокол) Речь по IP (VoIP) по проводному и/или беспроводному (например, CDMA, TDMA, FDMA, и/или TD-SCDMA) каналам передачи. Явно рассматривается и тем самым раскрыто, что такие конфигурации могут быть адаптированы для использования в сетях с пакетной коммутацией (например, проводных и/или беспроводных сетях, способных передавать сигналы речи согласно протоколам, таким как VoIP) и/или с коммутацией каналов.
Конфигурации, описанные здесь, могут быть применены в широкополосной системе кодирования речи, чтобы поддержать понижение активных кадров. Например, такие конфигурации могут быть применены для поддержки использования методик понизить-и-пакетировать для того, чтобы передать сигнализацию и/или трафик вторичной информации в широкополосной системе кодирования речи.
Если явно не ограничен своим контекстом, термин "вычисление" используется здесь, чтобы указать любое из его обычных значений, таких как вычисление, оценка, формирование и/или выбор из ряда значений. Если явно не ограничен своим контекстом, термин "получение" используется для указания любого из его обычных значений, таких как вычисление, выведение, прием (например, от внешнего устройства) и/или извлечение (например, из массива элементов памяти). Где термин "содержащий" используется в настоящем описании и формуле изобретения, он не исключает другие элементы или операции. Термин "A основан на В" используется для указания любого из его обычных значений, включая случаи (i) "A основано на по меньшей мере В", и (ii) "A равно В" (если приемлемо в конкретном контексте).
Если не указано иначе, любое раскрытие речевого кодера, имеющее конкретный признак, также явно предназначено для раскрытия способа кодирования речи, имеющего аналогичный признак (и наоборот), и любое раскрытие речевого кодера согласно конкретной конфигурации также явно предназначено для раскрытия способа кодирования речи согласно аналогичной конфигурации (и наоборот). Если не указано иначе, любое раскрытие речевого декодера, имеющего конкретный признак, также явно предназначено для раскрытия способа декодирования речи, имеющего аналогичный признак (и наоборот), и любое раскрытие речевого декодера согласно конкретной конфигурации также явно предназначено для раскрытия способа декодирования речи согласно аналогичной конфигурации (и наоборот).
Как проиллюстрировано на Фиг.1, система беспроводного телефона CDMA обычно включает в себя множество модулей 10 мобильного абонента, сконфигурированных, чтобы обмениваться беспроводным образом с сетью радиодоступа, которая включает в себя множество базовых станций 12 и один или более контроллеров 14 базовых станций (BSC, КБС). Такая система также обычно включает в себя центр коммутации мобильной связи (MSC, ЦКМС) 16, подсоединенный к контроллерам 14 базовых станций, и который сконфигурирован, чтобы связать с помощью интерфейса сеть радиодоступа с обычной коммутируемой телефонной сетью общего пользования (PSTN) 18 (возможно через медиа-шлюз). Контроллеры BSC 14 базовых станций подсоединяются к базовым станциям 12 через линии с обратным соединением. Линии с обратным соединением могут быть конфигурированы, чтобы поддерживать любой из нескольких известных интерфейсов, включая, например, El/Tl, ATM, IP, PPP, Frame Relay, HDSL, ADSL, или xDSL.
Каждая базовая станция 12 предпочтительно включает в себя по меньшей мере один сектор (не показан), причем каждый сектор содержит всенаправленную антенну или антенну, направленную в конкретном направлении радиально от базовой станции 12. Альтернативно, каждый сектор может содержать две антенны для разнесенного приема. Каждая базовая станция 12 может быть предпочтительно предназначена, чтобы поддерживать множество назначений частот. Пересечение сектора и назначения частот может быть названо как канал CDMA. Базовые станции 12 могут быть также известны как подсистемы приемопередатчика базовой станции (BTS, ППБС) 12. Альтернативно, "базовая станция" может использоваться в промышленности, чтобы ссылаться вместе на BSC 14 и одну или более BTS 12. BTS 12 могут быть также обозначены как "ячейки" 12. Альтернативно, индивидуальные сектора данной BTS 12 могут называться как ячейки. Модули 10 мобильного абонента обычно являются сотовыми телефонами или телефонами системы 10 персональной мобильной связи. Такая система может быть конфигурирована для использования в соответствии с одной или более версиями стандарта IS-95 (например, IS-95, IS-95A, IS-95B, cdma2000; как опубликовано Telecommunications Industry Alliance, Arlington, VA).
Во время обычной работы системы мобильных телефонов базовые станции 12 принимают наборы сигналов обратной линии связи от наборов модулей 10 мобильного абонента. Модули 10 мобильного абонента передают телефонные вызовы или другие сигналы. Каждый сигнал обратной линии связи, принятый данной базовой станцией 12, обрабатывается в этой базовой станции 12. Результирующие данные направляются к контроллерам BSC 14. Контроллеры BSC 14 обеспечивают распределение ресурсов вызова и функциональные возможности управления мобильностью, включая гармоничное сочетание мягких передач обслуживания между базовыми станциями 12. Контроллеры BSC 14 также маршрутизируют принятые данные к MSC 16, который оказывает дополнительные услуги маршрутизации для интерфейса с PSTN 18. Точно так же PSTN 18 сопрягается с MSC 16, и MSC 16 сопрягается с контроллерами BSC 14, которые в свою очередь управляют базовыми станциями 12 для передачи наборов сигналов прямой линии связи к наборам модулей 10 мобильного абонента.
Элементы сотовой системы телефонной связи, как показано на Фиг.1, могут также быть конфигурированы, чтобы поддерживать передачи данных с коммутацией пакетов. Как показано на Фиг.2, трафик пакетных данных обычно маршрутизируется между модулями 10 мобильного абонента и внешней сетью передачи данных (например, сетью общего пользования, такой как Интернет), используя узел обслуживания пакетных данных (PDSN), который соединяется с маршрутизатором шлюза, соединенным с сетью передачи данных. PDSN в свою очередь маршрутизирует данные к одному или более функциональным блокам управления пакетами (БУП, PCF), каждый из которых обслуживает один или более BSC и действует как линия связи между сетью передачи данных и сетью радиодоступа. Такая система может быть конфигурирована, чтобы передавать телефонный вызов или другую коммуникационную информацию в качестве трафика пакетных данных между модулями мобильного абонента по различным сетям радиодоступа (например, посредством одного или более протоколов, таких как VoIP), даже без входа в PSTN.
Фиг.3A показывает первый речевой кодер 30a, который выполнен с возможностью принимать оцифрованный речевой сигнал s1(n) и кодировать сигнал для передачи по коммуникационному каналу 50 (например, по среде передачи) на первый речевой декодер 40a. Первый речевой декодер 40a выполнен с возможностью декодировать кодированный речевой сигнал и синтезировать выходной речевой сигнал ssynth1(n) Фиг.3B показывает второй речевой кодер 30b, выполненный с возможностью кодировать оцифрованный речевой сигнал s2(n) для передачи в противоположном направлении по коммуникационному каналу 60 (например, по той же самой или отличной среде передачи) на второй речевой декодер 40b. Речевой декодер 40b выполнен с возможностью декодировать этот кодированный речевой сигнал, генерируя синтезированный выходной речевой сигнал ssynth2(n). Первый речевой кодер 30a и второй речевой декодер 40b (точно так же второй речевой кодер 30b и первый речевой декодер 40a) могут использоваться вместе в любом устройстве связи для передачи и приема речевых сигналов, включая, например, абонентские блоки, BTS или BSC, описанные выше со ссылками на Фиг.1 и 2.
Речевые сигналы s1(n), и s2(n) представляют аналоговые сигналы, которые были оцифрованы и квантованы в соответствии с любым из различных способов, известных в технике, таким как импульсно-кодовая модуляция (ИКМ), компандированный mu-закон, или A-закон. Как известно в уровне техники, речевой кодер принимает цифровые выборки речевого сигнала в качестве кадров входных данных, причем каждый кадр содержит заранее определенное количество выборок. Кадры речевого сигнала обычно являются короткими, достаточными для того, что спектральная огибающая сигнала, как можно ожидать, останется относительно постоянной по кадру. Одна типичная длина кадра составляет двадцать миллисекунд, хотя может использоваться любая длина кадра, которую считают подходящей для конкретного применения. Длина кадра в двадцать миллисекунд соответствует 140 выборкам при частоте дискретизации семь килогерц (кГц), 160 выборок при частоте дискретизации восемь кГц, и 320 выборок при частоте дискретизации 16 кГц, хотя может использоваться любая частота дискретизации считала, подходящая для конкретного применения. Другой пример частоты дискретизации, которая может использоваться для кодирования речи, составляет 12,8 кГц, и другие примеры включают в себя другие скорости в диапазоне от 12,8 кГц до 38,4 кГц.
Обычно все кадры речевого сигнала имеют одну и ту же длину, и одинаковая длина кадра предполагается в конкретных примерах, описанных в настоящем описании. Однако также явно рассматривается и тем самым раскрыто, что могут использоваться неодинаковые длины кадра. В некоторых применениях кадры не перекрываются, в то время как в других применениях используется схема перекрывающихся кадров. Например, для речевого кодера обычно использовать схему перекрывающихся кадров в кодере и схему не перекрывающихся кадров в декодере. Также можно для кодера использовать различные схемы кадра для различных задач. Например, речевой кодер или способ кодирования речи могут использовать одну схему перекрывающихся кадров для кодирования описания спектральной огибающей кадра и отличную схему перекрывающихся кадров для кодирования описания временной информации этого кадра.
Может быть желательно конфигурировать речевой кодер, чтобы использовать различные скорости передачи в битах для кодирования активных кадров и неактивных кадров. Может быть также желательно для речевого кодера использовать различные скорости передачи в битах для кодирования различных типов активных кадров. В таких случаях более низкие скорости передачи в битах могут выборочно использоваться для кадров, содержащих относительно меньше речевой информации. Примеры скоростей передачи в битах, обычно используемых для кодирования активных кадров, включают в себя 171 бит на кадр, восемьдесят битов на кадр и сорок битов на кадр; и примеры скоростей передачи в битах, обычно используемых для кодирования неактивных кадров, включают в себя шестнадцать битов на кадр. В контексте сотовых систем телефонной связи (особенно системы, которые совместимы с Промежуточным Стандартом (IS)-95, как провозглашено Telecommunications Industry Association, Arlington, VA, или аналогичным отраслевым стандартом), эти четыре скорости передачи в битах также называют "полная скорость", "половинная скорость", "чертвертная скорость" и "одна восьмая скорости" соответственно.
Может быть желательно классифицировать каждый из активных кадров речевого сигнала как один из нескольких различных типов. Эти различные типы могут включать в себя кадры произнесенной (озвученной) речи (например, речь, представляющая гласный звук), переходные кадры (например, кадры, которые представляют начало или конец слова), и кадры непроизнесенной (неозвученной) речи (например, речь, представляющая фрикативный звук). Может быть желательно конфигурировать речевой кодер, чтобы использовать различные режимы кодирования для кодирования различных типов речевых кадров. Например, кадры озвученной речи имеют тенденцию иметь периодическую структуру, которая является долговременной (то есть, который продолжается больше одного периода кадра), и относится к основному тону, и обычно более эффективно кодировать озвученный кадр (или последовательность озвученных кадров), используя режим кодирования, который кодирует описание этой долговременной спектральной особенности. Примеры таких режимов кодирования включают в себя линейное предсказание с кодовым возбуждением (CELP) и период основного тона прототипа (PPP). Неозвученные кадры и неактивные кадры, с другой стороны, обычно испытывают недостаток в любой существенной долговременной спектральной особенности, и речевой кодер может быть конфигурирован так, чтобы кодировать эти кадры, используя режим кодирования, который не пытается описать такую особенность. Линейное предсказание с возбуждением шумом (NELP) является одним примером такого режима кодирования.
Речевой кодер или способ речевого кодирования могут быть сконфигурированы так, чтобы осуществлять выбор среди различных комбинаций скоростей передачи в битах и режимов кодирования (также называемых "схемами кодирования"). Например, речевой кодер может быть сконфигурирован, чтобы использовать полноскоростную схему CELP для кадров, содержащих озвученную речь и для переходных кадров, полускоростную схему NELP для кадров, содержащих неозвученную речь, и схему с одной восьмой скоростью NELP для неактивных кадров. Альтернативно, такой речевой кодер может быть конфигурирован для использования полноскоростной схемы PPP для кадров, содержащих озвученную речь.
Речевой кодер может также быть конфигурирован, чтобы поддерживать множественные скорости кодирования для одной или более схем кодирования, такие как полноскоростная и полускоростная схемы CELP и/или полноскоростная и четвертьскоростная схема PPP. Кадры в последовательности, которая включает в себя период стабильной озвученной речи, имеют тенденцию быть в значительной степени избыточными, например, так что по меньшей мере некоторые из них могут быть закодированы при меньшей, чем полная, скорости без значимой потери перцепционного качества.
Многосхемные кодеры речи (включая речевые кодеры, которые поддерживают множественные скорости кодирования и/или режимы кодирования) обычно обеспечивают эффективное кодирование речи при низких скоростях передачи в битах. Специалистам понятно, что увеличение числа схем кодирования допускает большую гибкость при выборе схемы кодирования, которая может привести к более низкой средней скорости передачи в битах. Однако увеличение количества схем кодирования соответственно может увеличивать сложность во всей системе. Конкретную комбинацию доступных схем, используемых в любой данной системе, будут диктовать доступные системные ресурсы и конкретная сигнальная среда. Примеры многосхемных способов кодирования описаны, например, в патенте US6,691,084, названном "VARIABLE RATE SPEECH CODING," и в заявке на патент 11/625,788 (Manjunath и другие), названной "ARBITRARY AVERAGE DATA RATES FOR VARIABLE RATE CODERS".
Многосхемный кодер речи обычно включает в себя модуль принятия решения с разомкнутым контуром, который проверяет входной кадр речи и принимает решение относительно того, какую схему кодировании применить к кадру. Этот модуль обычно конфигурируется, чтобы классифицировать кадры как активные или неактивные и может также быть конфигурирован, чтобы классифицировать активный кадр как один из двух или более различных типов, таких как озвученный, не озвученный или переходный. Классификация кадров может быть основана на одной или более особенностях текущего кадра, и/или одном или более предыдущих кадров, таких как полная энергия кадра, энергия кадра в каждом из двух или более различных диапазонов частот, отношение сигнал-шум (SNR), периодичность, и частота пересечения нуля. Такая классификация может включать в себя сравнение значения или величины такого фактора с пороговым значением и/или сравнение величины изменения в таком факторе с пороговым значением.
Фиг.4 иллюстрирует один пример дерева решений, которое модуль принятия решения с разомкнутым контуром может использовать для выбора скорости передачи в битах для кодирования конкретного кадра согласно типу речи, который содержит кадр. В других случаях скорость передачи в битах, выбранная для конкретного кадра, может также зависеть от таких критериев, как требуемая средняя скорость передачи в битах, требуемый шаблон скоростей передачи в битах по последовательности кадров (который может быть использован для поддержки требуемой средней скорости передачи в битах), и/или скорость передачи в битах, выбранная для предыдущего кадра.
Мультисхемный кодер речи может также выполнить решение кодирования с замкнутым контуром, в котором одно или более измерений производительности кодирования получают после полного или частичного кодирования, используя выбранную скорость передачи в битах с разомкнутым контуром. Измерения производительности, которые могут быть рассмотрены в тесте с замкнутым контуром, включают в себя, например, SNR, предсказание с SNR в схемах кодирования, таких как кодер речи PPP, SNR квантования с предсказанием ошибок, SNR фазового квантования, SNR квантования по амплитуде, перцепционный SNR, и нормализованная кросс-корреляция между текущим и прошлым кадрами как мера стационарности. Если измерение производительности падает ниже порогового значения, скорость кодирования и/или режим могут быть изменены на тот, который, как ожидают, даст лучшее качество. Примеры схем классификации с замкнутым контуром, которые могут быть использованы для подтверждения качества кодера речи с переменной скоростью передачи в битах, описаны в заявке на патент США № 09/191,643, «CLOSED-LOOP VARIABLE-RATE MULTIMODE PREDICTIVE SPEECH CODER», поданной 13 ноября 1998, и в патенте US 6330532.
Речевой кодер обычно конфигурируется для кодирования кадра речевого сигнала как речевого пакета, где размер и формат речевого пакета соответствуют конкретной схеме кодирования, выбранной для этого кадра. Речевой пакет обычно содержит набор параметров речи, из которых может быть восстановлен соответствующий кадр речевого сигнала. Этот набор параметров речи обычно включает в себя спектральную информацию, такую как описание распределения энергии в кадре по частотному спектру. Такое распределение энергии также называют "частотной огибающей" или "спектральной огибающей" кадра. Описание спектральной огибающей кадра может иметь различную форму и/или длину в зависимости от конкретной схемы кодирования, используемой для кодирования соответствующего кадра.
Речевой кодер обычно конфигурируется для вычисления описания спектральной огибающей кадра как упорядоченная последовательность значений. В некоторых случаях речевой кодер конфигурируется для вычисления упорядоченной последовательности таким образом, что каждое значение указывает амплитуду или величину сигнала на соответствующей частоте или по соответствующей спектральной области. Один пример такого описания есть упорядоченная последовательность коэффициентов преобразования Фурье.
В других случаях речевой кодер конфигурируется для вычисления описания спектральной огибающей как упорядоченная последовательность значений параметров модели кодирования, например, набор значений коэффициентов анализа кодирования с линейным предсказанием (LPC). Упорядоченная последовательность значений коэффициентов LPC обычно компонуется как один или более векторов, и речевой кодер может быть реализован для вычисления этих значений как коэффициентов фильтра или как коэффициентов отражения. Количество значений коэффициентов в наборе также называют "порядком" анализа LPC, и примеры типичного порядка анализа LPC, который выполняется речевым кодером коммуникационного устройства (такого как мобильный телефон), включают в себя четыре, шесть, восемь, десять, 12, 16, 20, 24, 28, и 32.
Речевой кодер обычно конфигурируется для передачи описания спектральной огибающей через канал передачи в квантованной форме (например, как один или более индексов в соответствующих поисковых таблицах или "кодовых книгах"). Соответственно, может быть желательно для речевого кодера вычислить ряд значений коэффициентов LPC в форме, которая может быть эффективно квантована, например набор значений пар спектральных линий (LSP), линейные спектральные частоты (LSF), иммиттансные спектральные пары (ISP), иммиттансные спектральные частоты (ISF), коэффициенты косинусного преобразования Фурье или области логарифмических соотношений. Речевой кодер может также быть конфигурирован для выполнения других операций, таких как перцепционное взвешивание, в отношении упорядоченной последовательности значений перед преобразованием и/или квантованием.
В некоторых случаях описание спектральной огибающей кадра также включает в себя описание временной информации кадра (например, как в упорядоченной последовательности коэффициентов преобразования Фурье). В других случаях набор параметров речи речевого пакета может также включать в себя описание временной информации кадра. Форма описания временной информации может зависеть от конкретного режима кодирования, используемого для кодирования кадра. Для некоторых режимов кодирования (например, для режима кодирования CELP) описание временной информации может включать в себя описание сигнала возбуждения, который должен быть использован речевым декодером для возбуждения модели LPC (например, как определено в соответствии с описанием спектральной огибающей). Описание сигнала возбуждения обычно проявляется в речевом пакете в квантованной форме (например, как один или более индексов в соответствующих кодовых книгах). Описание временной информации может также включать в себя информацию, относящуюся к по меньшей мере одному компоненту основного тона сигнала возбуждения. Для режима кодирования PPP, например, кодированная временная информация может включать в себя описание прототипа, который должен использоваться речевым декодером, чтобы воспроизвести компонент основного тона сигнала возбуждения. Описание информации, относящейся к компоненту основного тона, обычно проявляется в речевом пакете в квантованной форме (например, как один или более индексов в соответствующих кодовых книгах).
Для других режимов кодирования (например, для режима кодирования NELP) описание временной информации может включать в себя описание временной огибающей кадра (также названной "огибающей энергии" или "огибающей усиления" кадра). Описание временной огибающей может включать в себя значение, которое основано на средней энергии кадра. Такое значение обычно представляется как значение усиления, которое должно быть применено к кадру во время декодирования, и также называется "кадром усиления». В некоторых случаях кадр усиления является коэффициентом нормализации, основанным на соотношении между (A) энергией Eorig первоначального кадра и (B) энергией Esynth кадра, синтезированного из других параметров речевого пакета (например, включающих в себя описание спектральной огибающей). Например, кадр усиления может быть выражен как Eorig/Esynth или как квадратный корень из Eorig/Esynth. Кадры усиления и другие аспекты временных огибающих описываются более подробно, например, в заявке на патент США US 2006/0282262 (Vos и другие), "SYSTEMS, METHODS, AND APPARATUS FOR GAIN FACTOR ATTENUATION", поданной 14 декабря 2006.
Альтернативно или дополнительно, описание временной огибающей может включать в себя относительные значения энергии для каждого из ряда подкадров кадра. Такие значения обычно представляются как значения усиления, подлежащие применению к соответствующим подкадрам во время декодирования, и все вместе называется "профилем усиления" или "формой усиления”. В некоторых случаях значениями формы усиления являются коэффициенты нормализации, каждый основан на отношении между (A) энергией Eorig.i первоначального подкадра i и (B) энергией соответствующего подкадра i кадра, синтезированного из других параметров кодированного кадра (например, включающих в себя описание спектральной огибающей) Esynth.i. В таких случаях энергия Esynth.i может быть использована для нормализации энергии Eorig.i. Например, значение формы усиления может быть выражено как Eorig.i/Esynth.i или как квадратный корень Eorig.i/Esynth.i. Один пример описания временной огибающей включает в себя кадр усиления и форму усиления, где форма усиления включает в себя значение для каждого из пяти четырехмиллисекундных подкадров двадцатимиллисекундного кадра. Значения усиления могут быть выражены в линейном масштабе или в логарифмическом (например, децибелах) масштабе. Такие признаки описаны более подробно, например, в заявке на патент США US2006/0282262, процитированной выше.
При вычислении значения кадра усиления (или значений формы усиления), может быть желательно применить функцию вырезания окна, которая перекрывает смежные кадры (или подкадры). Значения усиления, сформированные таким способом, обычно применяются способом добавления наложения в речевом декодере, что может помочь уменьшить или избежать разрывов между кадрами или подкадрами. Фиг.5A показывает график трапециевидной функции вырезания окна, которая может быть использована для вычисления каждого из значений формы усиления. В этом примере окно перекрывает каждый из двух смежных подкадров на одну миллисекунду. Фиг.5B показывает применение этой функции вырезания окна к каждому из пяти подкадров двадцатимиллисекундного кадра. Другие примеры функций вырезания окна включают в себя функции, имеющие отличные периоды перекрытия (наложения) и/или отличные формы окна (например, прямоугольный или Хемминга), которые могут быть симметричными или асимметричными. Также возможно вычислять значения формы усиления при применении различных функций вырезания окна к различным подкадрам и/или при вычислении различных значений формы усиления по подкадрам различных длин.
Речевой пакет, который включает в себя описание временной огибающей, обычно включает в себя такое описание в квантованной форме как один или более индексов в соответствующих кодовых книгах, хотя в некоторых случаях алгоритм может быть использован для квантования и/или деквантования формы кадра и/или формы усиления, не используя кодовую книгу. Один пример описания временной огибающей включает в себя квантованный индекс из восьми - двенадцати битов, который задает пять значений формы усиления для этого кадра (например, один для каждого из пяти последовательных подкадров). Такое описание может также включать в себя другой квантованный индекс, который определяет значение кадра усиления для этого кадра.
Как отмечено выше, может быть желательно передавать и принимать речевой сигнал, имеющий частотный диапазон, который превышает частотный диапазон PSTN 300-3400 кГц. Один подход к кодированию такого сигнала заключается в кодировании всего расширенного частотного диапазона как одного диапазона частот. Такой подход может быть реализован посредством масштабирования методики узкополосного кодирования речи (например, конфигурированной для кодирования частотного диапазона с PSTN качеством, такой как 0-4 кГц или 300-3400 Гц), чтобы охватить широкополосный частотный диапазон, такой как 0-8 кГц. Например, такой подход может включать в себя (A) дискретизацию речевого сигнала с более высокой скоростью для включения в себя компонентов на высоких частотах и (B) реконфигурации узкополосного способа кодирования, чтобы представить этот широкополосный сигнал с требуемой степенью точности. Один такой способ реконфигурирования узкополосного способа кодирования должен использовать анализ LPC более высокого порядка (то есть сформировать вектор коэффициентов, имеющий больше значений). Широкополосный речевой кодер, который кодирует широкополосное сообщение как один диапазон частот, также называют "полнодиапазонным" кодером.
Может быть желательно реализовать широкополосный речевой кодер таким образом, что по меньшей мере узкополосную часть кодированного сигнала можно послать через узкополосный канал (такой как канал PSTN) без необходимости транскодировать или иным образом значительно модифицировать кодированный сигнал. Такая особенность может облегчить обратную совместимость с сетями и/или устройством, которые распознают только узкополосные сигналы. Может быть также желательно реализовать широкополосный речевой кодер, который использует различные режимы и/или скорости кодирования для различных диапазонов частот речевого сигнала. Такая особенность может быть использована для поддержки повышения эффективности кодирования и/или перцепционного качества. Широкополосный речевой кодер, который конфигурируется, чтобы формировать речевые пакеты, имеющие части, которые представляют различные диапазоны частот широкополосного речевого сигнала (например, отдельные наборы параметров речи, причем каждый набор представляет отличный диапазон частот широкополосного речевого сигнала), также называют кодером "с разбиением диапазона".
Фиг.6A показывает один пример схемы с неперекрывающимися диапазонами частот, которая может использоваться речевым кодером с разбиением диапазонов, чтобы закодировать широкополосный речевой контент по диапазону от 0 Гц до 8 кГц. Эта схема включает в себя первый диапазон частот, который располагается от 0 Гц до 4 кГц (также названный узкополосным диапазоном), и второй диапазон частот, который располагается от 4 до 8 кГц (также названный расширенным, верхним, или диапазоном более высокой частоты). Фиг.6B показывает один пример схемы с перекрывающимися диапазонами частот, которая может использоваться речевым кодером с разбиением диапазона, чтобы закодировать широкополосный речевой контент в диапазоне от 0 Гц до 7 кГц. Эта схема включает в себя первый диапазон частот, который располагается от 0 Гц до 4 кГц (узкополосный диапазон) и второй диапазон частот, который располагается от 3,5 до 7 кГц (расширенный, верхний, или диапазон более высокой частоты).
Другие примеры схем диапазонов частот включают в себя те, в которых узкополосный диапазон располагается вниз только до приблизительно 300 Гц. Такая схема может также включать в себя другой диапазон частот, который охватывает низкочастотный диапазон от приблизительно 0 или 50 Гц до приблизительно 300 или 350 Гц. Один конкретный пример кодера речи с разбиением диапазона конфигурируется для выполнения анализа LPC десятого порядка для узкополосного диапазона и анализ LPC шестого порядка для диапазона более высокой частоты.
Кодированный речевой пакет, использующий схему кодирования полного диапазона, содержит описание одной спектральной огибающей, которая распределена по всему широкополосному частотному диапазону, в то время как у кодированного речевого пакета, использующего схему кодирования с разбиением диапазона, есть две или более отдельных части, которые представляют информацию в различных диапазонах частот (например, узкополосный диапазон и диапазон более высокой частоты) широкополосного речевого сигнала. Например, обычно каждая из этих отдельных частей закодированного с разбиением диапазона речевого пакета содержит описание спектральной огибающей речевого сигнала по соответствующему диапазону частот. Закодированный с разбиением диапазона речевой пакет может содержать одно описание временной информации кадра для всего широкополосного частотного диапазона, или каждая из отдельных частей закодированного с разбиением диапазона речевого пакета может содержать описание временной информации речевого сигнала для соответствующего диапазона частот.
Речевой кодер обычно конфигурируется для формирования последовательности закодированных кадров, где каждый кодированный кадр включает в себя речевой пакет и возможно один или более ассоциированных битов. Фиг.7A иллюстрирует один пример формата для кодированного кадра, имеющего длину 192 битов. В этом примере закодированный кадр включает в себя 171-битовый полноскоростной речевой пакет, который представляет кадр речевого сигнала (то есть, первичный трафик). Кодированный кадр может также включать в себя один или более битов проверки. В этом примере кодированный кадр включает в себя двенадцатибитовый индикатор F качества кадра, который может включать в себя биты проверки на четность или биты проверки при помощи циклического кода (CRC), и восьмиразрядный набор хвостовых битов T, который может быть использован для завершения и инициализации сверточного кода, который генерирует эти биты CRC. Кодированный кадр может также включать в себя один или более битов, которые указывают присутствие данных, отличных от речевого пакета (например, пакет информации). В этом примере кодированный кадр включает в себя бит MM смешанного режима, который в этом случае сброшен (то есть имеет значение, равное нулю).
Может быть желательно иногда или периодически включать в закодированный кадр информацию, которая не является частью речевого сигнала. Например, может быть желательно для кодированного кадра иметь пачку информации сигнализации между мобильной станцией и другим объектом в сети, таким как BTS, BSC, MSC, PCF, или PDSN. Пачка информации сигнализации может иметь по меньшей мере часть запроса на выполнение действия, например, увеличить мощность передачи или измерить параметр (например, уровень пилот-сигнала), или ответ на такой запрос (например, измеренное значение параметра). Пачка информации сигнализации, относящаяся к передаче обслуживания в пределах сети радиодоступа или от одной сети радиодоступа к другой, может включать в себя обновленную информацию сети, такую как значения для идентификатора сети (NID), системный идентификатор (SID), и/или идентификатор зоны пакета (PZID). В некоторых случаях пачка информации сигнализации включает в себя по меньшей мере часть сообщения внутри системных параметров трафика, которое содержит одно или более этих значений параметра передачи обслуживания.
Альтернативно, может быть желательно для закодированного кадра иметь пакет вторичного трафика. Пакет вторичного трафика может включать в себя информацию, которая иногда обновляется, такую как обновление по меньшей мере части информации о географической позиции (например, информация Глобальной системы определения местоположения, или GPS). В другом случае пакет вторичного трафика может включать в себя по меньшей мере часть передачи данных с низкой скоростью передачи в битах, такую как пейджинговое сообщение, сообщение службы обмена краткими сообщениями (SMS) или почтовое сообщение.
В таких случаях может быть желательно для речевого кодера конфигурировать кодированный кадр таким образом, чтобы некоторые биты были доступны для передачи другой информации. Например, может быть желательно для речевого кодера кодировать кадр в меньший речевой пакет при использовании более низкой скорости передачи в битах чем тот, что указан механизмом выбора скорости. Такую операцию называют "понижение" или "понижение исходного уровня”. В одном типичном примере понижения исходного уровня речевой кодер принуждается использовать полускоростную схему, чтобы кодировать кадр, для которого была иначе выбрана полноскоростная схема, хотя понижение исходного уровня вообще может включать в себя любое снижение скорости. Кодер речи с переменной скоростью может быть сконфигурирован для выполнения способа понизить-и-пакетировать, чтобы сформировать кодированный кадр, который включает в себя речевой пакет с пониженной скоростью и пакет другой информации. Описание таких способов может быть найдено, например, в патенте US 5,504,773 (Padovani и другие).
Закодированный кадр, использующий способ понизить-и-пакетировать, может включать в себя один или более битов, которые указывают, включает он в себя информацию сигнализации или вторичный трафик. Фиг.7B показывает формат кодированного кадра, который может использовать способ понизить-и-пакетировать, чтобы включать в себя полускоростной речевой пакет (80 битов) первичного трафика и 86-битовую пачку сигнализации об информации. Этот кадр включает в себя бит BF формата пакета, который указывает, используется ли формат понизить-и-пакетировать или формат сделать_пустым-и-пакетировать, бит TT типа трафика, который указывает, содержит ли пакет трафик сигнализации или вторичный трафик, и два бита TM режима трафика, которые могут быть использованы для указания различного количества битов для первичного трафика и/или для сигнализации или вторичного трафика, все из которых являются очищенными в этом случае. Кадр также включает в себя бит SOM начала сообщения, который указывает, является ли следующий бит первым битом сообщения сигнализации. Фиг.7C показывает формат кодированного кадра, в котором способ понизить-и-пакетировать может использоваться, чтобы включать в себя полускоростной пакет речевого сигнала и 87-битовый пакет вторичного трафика. В этом случае формат кадра не включает в себя бит начала сообщения, и бит TT типа трафика является установленным.
Чрезмерное использование понижения может вызвать ухудшение качества кодируемого речевого сигнала. Обычно использование понижения ограничивается не больше чем пятью процентами полноскоростных кадров, хотя более обычно понижают уровень не больше чем одного или возможно двух процентов таких кадров. В некоторых случаях речевой кодер конфигурируется для выбора кадров, подлежащих понижению уровня, согласно двоичному файлу маски, где каждый бит файла маски соответствует кадру, и состояние этого бита указывает, должен ли быть понижен уровень этого кадра. В других случаях речевой кодер конфигурируется, чтобы избежать понижения уровня, если возможно, в то же время ожидая, пока не будет запланирован полускоростной кадр.
Может быть желательно реализовать широкополосную систему кодирования как обновление к существующей узкополосной системе кодирования. Например, может быть желательно минимизировать изменения в сети посредством использования одних и тех же скоростей передачи в битах и размеров пакета, с дополнительными форматами пакета, чтобы поддерживать дополнительные широкополосные схемы кодирования. Один существующий тип узкополосного кодека для разговорных сигналов, который использует IS-95 - совместимые форматы кадра, как показано на Фиг.7A-7C, является Усовершенствованным Кодеком с Переменной Скоростью, версия В (EVRC-B), как описано в документе C.S0014-В v1.0 Проекта партнерства третьего поколения 2 (3GPP2) (май 2006), доступный в режиме онлайн по адресу 3gpp2.org. Может быть желательно модернизировать систему, которая поддерживает EVRC-B, чтобы также поддерживать Усовершенствованный Кодек с Переменной Скоростью, версия C (EVRC-C, также названный EVRC-WB), как описано в 3GPP2 документе C.S0014-C v1.0 (январь 2007), также доступно онлайн по адресу 3gpp2.org.
Как отмечено выше, существующие узкополосные системы кодирования поддерживают использование способов понизить-и-пакетировать. Может быть желательно поддерживать методики понизить-и-пакетировать в широкополосной системе кодирования. Один подход к понижению широкополосного кадра использует создание и реализацию более низкой скорости передачи в битах (например, полускоростной) широкополосной схемы кодирования для использования с пониженными кадрами. Широкополосный речевой кодер может быть конфигурирован для кодирования пониженных кадров согласно такой схеме или, альтернативно, для создания речевого пакета, имеющего формат такой схемы, посредством использования выбранных битов речевого пакета, кодированного с использованием широкополосной схемы кодирования с более высокой скоростью передачи в битах. В любом случае, однако, создание широкополосной схемы кодирования с более низкой скоростью передачи в битах так, чтобы иметь приемлемое перцепционное (воспринимаемое) качество, может быть дорого. Реализация такой схемы кодирования также, вероятно, может потреблять больше ресурсов речевого кодера, например, циклов обработки и памяти. Реализация дополнительной схемы кодирования также может увеличить сложность системы.
Другой подход к понижению широкополосного кадра должен использовать узкополосную схему кодирования с более низкой скоростью передачи в битах для кодирования пониженного широкополосного кадра. Хотя такой подход вовлекает потерю информации более высокого диапазона, он может быть проще реализован в широкополосном обновлении к существующей узкополосной инсталляции, поскольку он может быть сконфигурирован для использования существующей узкополосной схемы кодирования (например, полускоростной CELP). Соответствующий речевой декодер может быть конфигурирован для восстановления отсутствующей информации более высокого диапазона из информации более высокого диапазона одного или более предыдущих кадров.
Фиг.8 иллюстрирует блок-схему операций способа M100 согласно общей конфигурации, которая включает в себя задачи T110, T120, T130 и T140. Задача T110 конфигурируется для формирования первого речевого пакета на основании первого активного кадра речевого сигнала. Первый речевой пакет включает в себя описание спектральной огибающей по (A) первому диапазону частот и (B) второму диапазону частот, который располагается выше первого диапазона частот. Это описание может быть единым описанием, которое распространяется по обоим диапазонам частот, или оно может включать в себя отдельные описания, каждое из которых распространено по соответствующему одному из диапазонов частот. Задача T110 может также быть конфигурирована для формирования первого речевого пакета так, чтобы он содержал описание временной огибающей по первому и второму диапазонам частот. Это описание может быть единственным описанием, которое распространяется по обоим диапазонам частот, или оно может включать в себя отдельные описания, из которых каждый распространяется по соответствующему одному из диапазонов частот. Следует явно отметить, что диапазон реализаций способа M100 также включает в себя реализации, в которых задача T110 конфигурируется для формирования первого речевого пакета на основании неактивного кадра речевого сигнала.
Задача T120 конфигурируется для формирования второго речевого пакета на основании второго активного кадра речевого сигнала, который имеет место в речевом сигнале после первого активного кадра (например, активного кадра, который сразу следует за первым активным кадром, или активным кадром, который отделен от первого активного кадра одним или более другими активными кадрами). Второй речевой пакет включает в себя описание спектральной огибающей по первому диапазону частот. Задача T120 может также быть конфигурирована для формирования второго речевого пакета, содержащего описание временной информации для первого диапазона частот. Задача T130 конфигурируется для формирования первого кодированного кадра, который содержит первый речевой пакет, и задача T140 конфигурируется для формирования второго кодированного кадра, который содержит второй речевой пакет и пачку информационного сигнала, который является отдельным от речевого сигнала. Первый и второй речевые пакеты могут также включать в себя описания временной информации, основанной на соответствующих кадрах. Фиг.9 иллюстрирует применение способа M100.
Задачи T130 и T140 конфигурируются для формирования первого и второго кодированных кадров, имеющих один и тот же размер (например, 192 бита). Задача T110 может быть конфигурирована для формирования первого речевого пакета, чтобы он имел длину, которая больше половины длины первого кодированного кадра. Например, задача T110 может быть конфигурирована для формирования первого речевого пакета, чтобы он имел длину, которая составляет по меньшей мере шестьдесят, семьдесят, семьдесят пять, восемьдесят или восемьдесят пять процентов длины первого кодированного кадра. В одном конкретном таком примере задача T110 конфигурируется для формирования первого речевого пакета, чтобы он имел длину 171 бита. Альтернативно, задача T110 может быть конфигурирована для формирования первого речевого пакета, чтобы он имел длину, которая составляет не больше чем пятьдесят, сорок пять или сорок два процента длины первого кодированного кадра. В одном конкретном таком примере задача T110 конфигурируется для формирования первого речевого пакета, чтобы он имел длину восемьдесят битов.
Задача T120 конфигурируется для формирования второго речевого пакета, чтобы он имел длину, которая не больше чем шестьдесят процентов длины второго кодированного кадра. Например, задача T120 может быть конфигурирована для формирования второго речевого пакета, чтобы он имел длину, которая составляет не больше чем пятьдесят, сорок пять, или сорок два процента длины второго кодированного кадра. В одном конкретном примере задача T120 конфигурируется для формирования второго речевого пакета, чтобы он имел длину восемьдесят битов. Задача T120 может также быть конфигурирована таким образом, что второй речевой пакет не включает в себя описание спектральной огибающей по второму диапазону частот и/или описание временной информации для второго диапазона частот.
Способ M100 обычно выполняется как часть большего способа кодирования речи, и речевые кодеры и способы кодирования речи, которые конфигурируются для выполнения способа M100, явно рассматривается и тем самым раскрывается. Такой кодер или способ могут быть конфигурированы, чтобы кодировать активный кадр в речевом сигнале, который следует за вторым кадром (например, активный кадр, который сразу следует за вторым кадром, или активный кадр, который отделяется от второго кадра одним или более другими активными кадрами), используя тот же самый формат, что и первый кодированный кадр, или используя тот же самый формат, что и второй кодированный кадр. Альтернативно, такой кодер или способ могут быть конфигурированы, чтобы кодировать неозвученный или неактивный кадр, следующий после второго кадра, используя отличную схему кодирования. Соответствующий речевой декодер может быть конфигурирован для использования информации, которая была декодирована из первого кодированного кадра, чтобы дополнить декодирование активного кадра из другого кодированного кадра, который имеет место в кодируемом речевом сигнале после первого закодированного кадра. В другом месте в этом описании раскрываются речевые декодеры и способы декодирования кадров речевого сигнала, которые используют информацию, которая была декодирована из первого закодированного кадра при декодировании одного или более последующих активных кадров.
Одна или обе из задач T110 и T120 могут быть конфигурированы, чтобы вычислять соответствующие описания спектральной огибающей. Фиг.10 иллюстрирует применение подзадачи T112 такой реализации задачи T110, которая сконфигурирована для вычисления, на основании первого кадра, описания спектральной огибающей по первому и второму диапазонам частот. Фиг.10 также иллюстрирует применение подзадачи T122 такой реализации задачи T120, которая конфигурируется для вычисления, на основании второго кадра, описания спектральной огибающей по первому диапазону частот. Задачи T110 и T120 могут быть также конфигурированы, чтобы вычислить описания временной информации на основании соответствующих кадров, причем эти описания могут быть включены в соответствующие речевые пакеты.
Задачи T110 и T120 могут быть конфигурированы таким образом, что второй речевой пакет включает в себя описание спектральной огибающей по первому диапазону частот, где длина описания составляет не меньше половины длины описания спектральной огибающей по первому и второму диапазонам частот, которая включена в первый речевой пакет. Например, задачи T110 и T120 могут быть конфигурированы таким образом, что длина описания спектральной огибающей по первому диапазону частот во втором речевом пакете составляет по меньшей мере пятьдесят пять или шестьдесят процентов длины описания спектральной огибающей по первому и второму диапазонам частот, которая включена в первый речевой пакет. В одном конкретном примере длина описания спектральной огибающей по первому диапазону частот во втором речевом пакете составляет двадцать два бита, и длина описания спектральной огибающей по первому и второму диапазонам частот, которая включена в первый речевой пакет, равна тридцати шести битам.
Второй диапазон частот является отличным от первого диапазона частот, хотя способ M110 может быть конфигурирован таким образом, что эти два диапазона частот перекрываются. Примеры нижней границы для первого диапазона частот включают в себя нуль, пятьдесят, 100, 300 и 500 Гц, и примеры верхней границы для первого диапазона частот включают в себя три, 3,5, четыре, 4,5 и 5 кГц. Примеры нижней границы для второго диапазона частот включают в себя 2,5, 3, 3,5, 4 и 4,5 кГц, и примеры верхней границы для второго диапазона частот включают в себя 7, 7,5, 8 и 8,5 кГц. Все пятьсот возможных комбинаций вышеупомянутых границ явно рассматриваются и тем самым раскрываются, и применение любой такой комбинации к любой реализации способа M110 также явно рассматривается и тем самым раскрывается (в настоящем описании). В одном конкретном примере первый диапазон частот включает в себя диапазон от приблизительно пятидесяти герц до приблизительно четырех килогерц, и второй диапазон частот включает в себя диапазон от приблизительно четырех до приблизительно семи килогерц. В другом конкретном примере первый диапазон частот включает в себя диапазон от приблизительно 100 Гц до приблизительно четырех килогерц, и второй диапазон частот включает в себя диапазон от приблизительно 3,5 до приблизительно семи килогерц. В другом конкретном примере первый диапазон частот включает в себя диапазон от приблизительно 300 Гц до приблизительно четырех килогерц, и второй диапазон частот включает в себя диапазон от приблизительно 3,5 до приблизительно семи килогерц. В этих примерах термин "приблизительно" указывает плюс или минус пять процентов, с границами различных диапазонов частот, обозначаемых соответствующими 3 дБ точками.
Как отмечено выше, для широкополосных применений схема кодирования с разбиением диапазона может иметь преимущества перед схемой кодирования полного диапазона, такие как повышенная эффективность кодирования и поддержка обратной совместимости. Может быть желательно реализовать способ M100, чтобы сформировать первый кодированный кадр, используя схему кодирования с разбиением диапазона, а не схему кодирования полного диапазона. Фиг.8B показывает блок-схему реализации M110 способа M100, которая включает в себя реализацию T114 задачи T110. В качестве реализации задачи T110, задача T114 конфигурируется для формирования первого речевого пакета, который включает в себя описание спектральной огибающей по первому и второму диапазонам частот. В этом случае задача T114 конфигурируется для формирования первого речевого пакета, который включает в себя описание спектральной огибающей по первому диапазону частот и описание спектральной огибающей по второму диапазону частот, таким образом, что эти два описания являются отдельными друг от друга (хотя возможно смежными друг с другом в речевом пакете).
Задача T114 может быть конфигурирована для вычисления описания спектральной огибающей, используя схему кодирования с разбиением диапазона. Фиг.11 иллюстрирует применение подзадачи T116 такой реализации задачи T114, где подзадача T116 является реализацией с разбиением диапазона для подзадачи T112. Подзадача T116 включает в себя подзадачу T118a, которая конфигурируется для вычисления, на основании первого кадра, описания спектральной огибающей по первому диапазону частот. Подзадача T116 также включает в себя подзадачу T118b, которая конфигурируется для вычисления, на основании первого кадра, описания спектральной огибающей по второму диапазону частот. Задачи T118a и T118b могут быть также конфигурированы, чтобы вычислить отдельные описания временной информации по этим двум диапазонам частот.
Вычисление описаний спектральной и/или временной информации для кадра может быть основано на информации от одного или более предыдущих кадров. В таком случае использование узкополосной схемы кодирования для кодирования второго кадра может снизить производительность кодирования для одного или более последующих кадров. Задача T120 может включать в себя подзадачу T124 (не показана), которая конфигурируется для вычисления, на основании второго кадра, описания спектральной огибающей по второму диапазону частот и/или описания временной информации для второго диапазона частот. Например, задача T120 может быть конфигурирована для кодирования второго кадра, используя широкополосную схему кодирования. Как отмечено выше, задача T120 может быть конфигурирована таким образом, что второй речевой пакет не включает в себя описание спектральной огибающей по второму диапазону частот или описание временной информации для второго диапазона частот. Даже в этом случае, однако, вычисление такой информации для второго диапазона частот так, чтобы она могла быть доступна в кодере для использования при кодировании одного или более последующих кадров на основе такой хронологической информации, может обеспечить лучшее перцепционное качество по этим кадрам, чем их кодирование без такой информации. Альтернативно, задача T120 может быть конфигурирована для использования узкополосной схемы кодирования, чтобы кодировать первый диапазон частот второго кадра и инициализировать хронологии для второго диапазона частот следующего кадра (например, посредством сброса памяти, которая хранит прошлую спектральную и/или временную информацию). В другой альтернативе задача T120 конфигурируется для использования узкополосной схемы кодирования, чтобы кодировать первый диапазон частот второго кадра и оценить описание спектральной огибающей по второму диапазону частот (и/или описание временной информации для второго диапазона частот) для второго кадра, используя подпрограмму обработки стирания. Например, такая реализация задачи T120 может быть конфигурирована, чтобы оценивать описание спектральной огибающей по второму диапазону частот (и/или описание временной информации для второго диапазона частот) для второго кадра, на основании информации из первого кадра и, возможно, от одного или более предыдущих кадров.
Задачи T118a и T118b могут быть конфигурированы для вычисления описаний спектральных огибающих по двум диапазонам частот, которые имеют одинаковую длину, или одна из задач T118a и T118b может быть конфигурирована для вычисления описания, которое является более длинным, чем описание, вычисленное другой задачей. Например, задачи T118a и T118b могут быть конфигурированы таким образом, что длина описания спектральной огибающей по второму диапазону частот в первом речевом пакете, которая вычислена задачей T118b, составляет не больше, чем пятьдесят, сорок или тридцать процентов от длины описания спектральной огибающей по первому диапазону частот в первом речевом пакете, которая вычислена задачей T118a. В одном конкретном примере длина описания спектральной огибающей по первому диапазону частот в первом речевом пакете составляет двадцать восемь битов, и длина описания спектральной огибающей по второму диапазону частот в первом речевом пакете составляет восемь битов. Задачи T118a и T118b могут быть также конфигурированы для вычисления отдельных описаний временной информации для этих двух диапазонов частот.
Задачи T118a и T122 могут быть конфигурированы для вычисления описания спектральных огибающих по первому диапазону частот, которые имеют одинаковую длину, или одна из задач T118a и T122 может быть конфигурирована для вычисления описания, которое является более длинным, чем описание, вычисленное другой задачей. Например, задачи T118a и T122 могут быть конфигурированы таким образом, что длина описания спектральной огибающей по первому диапазону частот во втором речевом пакете, которая вычислена задачей T122, составляет по меньшей мере пятьдесят, шестьдесят, семьдесят или семьдесят пять процентов длины описания спектральной огибающей по первому диапазону частот в первом речевом пакете, которая вычислена задачей T118a. В одном конкретном примере длина описания спектральной огибающей по первому диапазону частот в первом речевом пакете составляет двадцать восемь битов, и длина описания спектральной огибающей по первому диапазону частот во втором речевом пакете составляет двадцать два бита.
Таблица на Фиг.13 иллюстрирует один набор из четырех различных схем кодирования, которые может использовать речевой кодер, чтобы выполнить способ кодирования речи, который включает в себя реализацию способа M100. В этом примере полноскоростная широкополосная схема кодирования CELP ("схема 1 кодирования") используется для кодирования озвученных кадров. Эта схема кодирования использует 153 бита, чтобы закодировать узкополосную часть кадра, и 16 битов, чтобы закодировать часть более высокого диапазона. Для узкополосного случая схема 1 кодирования использует 28 битов, чтобы закодировать описание спектральной огибающей (например, как один или более квантованных векторов LSP), и 125 битов, чтобы закодировать описание сигнала возбуждения. Для случая более высокого диапазона схема 1 кодирования использует 8 битов, чтобы закодировать спектральную огибающую (например, как один или более квантованных векторов LSP), и 8 битов, чтобы закодировать описание временной огибающей.
Может быть желательно конфигурировать схему 1 кодирования для получения сигнала возбуждения для более высокого диапазона из узкополосного сигнала возбуждения таким образом, что никакие биты закодированного кадра не являются необходимыми, чтобы передавать сигнал возбуждения для более высокого диапазона. Может также быть желательно конфигурировать схему 1 кодирования вычислять временную огибающую более высокого диапазона относительно временной огибающей сигнала более высокого диапазона, которая синтезируется из других параметров закодированного кадра (например, включая описание спектральной огибающей по второму диапазону частот). Такие признаки описаны более подробно, например, заявке US 2006/0282262, упомянутой выше.
В примере согласно таблице Фиг.12 полускоростная узкополосная схема кодирования CELP ("схема 2 кодирования") используется для кодирования «пониженных» кадров. Эта схема кодирования использует 80 битов, чтобы закодировать узкополосную часть кадра (и не использует битов для кодирования части более высокого диапазона). Схема 2 кодирования использует 22 бита для кодирования описания спектральной огибающей (например, как один или более квантованных векторов LSP) и 58 битов для кодирования описания сигнала возбуждения.
По сравнению с озвученным речевым сигналом неозвученный речевой сигнал обычно содержит больше информации, которая важна для понимания речи в более высоком диапазоне. Таким образом, может быть желательно использовать больше битов для кодирования части в более высоком диапазоне неозвученного кадра, чем кодировать часть в более высоком диапазоне озвученного кадра, даже для случая, в котором озвученный кадр кодирован, используя более высокую общую скорость передачи в битах. В примере согласно таблице Фиг.12 полускоростная широкополосная схема кодирования NELP ("схема 3 кодирования") используется для кодирования неозвученных кадров. Вместо 16 битов, используемых схемой 1 кодирования для кодирования части в более высоком диапазоне для озвученного кадра, эта схема кодирования использует 27 битов для кодирования части в более высоком диапазоне кадра: 12 битов для кодирования описания спектральной огибающей (например, как один или более квантованных векторов LSP) и 15 битов для кодирования описания временной огибающей (например, как квантованный кадр формы и/или форма усиления). Для кодирования узкополосной части схема 3 кодирования использует 47 битов: 28 битов для кодирования описания спектральной огибающей (например, как один или более квантованных векторов LSP) и 19 битов для кодирования описания временной огибающей (например, как квантованный кадр формы и/или форма усиления).
В примере согласно таблице Фиг.12 узкополосная схема кодирования NELP со скоростью кодирования одна восьмая ("схема 4 кодирования") используется для кодирования неактивных кадров со скоростью 16 битов на кадр, с 10 битами для кодирования описания спектральной огибающей (например, как один или более квантованных векторов LSP) и 5 битами для кодирования описания временной огибающей (например, как квантованный кадр формы и/или форма усиления). Другой пример схемы 4 кодирования использует 8 битов для кодирования описания спектральной огибающей и 6 битов для кодирования описания временной огибающей.
В примере согласно Фиг.12 схема 2 кодирования и/или схема 4 кодирования может наследовать схему кодирования от лежащей в основе узкополосной инсталляции. Такой речевой кодер или способ речевого кодирования могут быть также конфигурированы, чтобы поддерживать другие унаследованные схемы кодирования и/или новые схемы кодирования. Таблица Фиг.13 иллюстрирует набор распределения битов для полноскоростного пакета (171 бит), сформированный примерной широкополосной схемой 1 кодирования CELP. Таблица Фиг.14 иллюстрирует набор распределения битов для полускоростного пакета (восемьдесят битов), сформированный примерной узкополосной схемой 2 кодирования CELP. Один конкретный пример задачи T110 использует полноскоростную схему кодирования CELP (например, согласно схеме 1 кодирования в таблице Фиг.12), чтобы сформировать первый речевой пакет на основании озвученного или переходного кадра речевого сигнала. Другой конкретный пример задачи T110 использует полускоростную схему кодирования NELP (например, согласно схеме 3 кодирования в таблице Фиг.12), чтобы сформировать первый речевой пакет на основании неозвученного кадра речевого сигнала. Другой конкретный пример задачи T110 использует схему кодирования NELP со скоростью кодирования одна восьмая (например, согласно схеме 4 кодирования в таблице Фиг.12), чтобы сформировать первый речевой пакет на основании неактивного кадра речевого сигнала.
В типичном применении реализации способа M100 массив логических элементов (например, логические вентили) конфигурируется для выполнения одной, более одной или даже всех различных задач способа. Одна или более (возможно все) задач могут также быть реализованы как (программный) код (например, один или более наборов команд), воплощенных в компьютерном программном продукте (например, один или более носителей хранения данных, таких как диски, платы флэш- или другой энергонезависимой памяти, микросхемы полупроводниковой памяти, и т.д.), которые являются считываемыми и/или выполняемыми машиной (например, компьютером), включая массив логических элементов (например, процессор, микропроцессор, микроконтроллер или другой конечный автомат). Задачи реализации способа M100 могут быть также выполнены более чем одним таким массивом или машиной. В этих или других реализациях задачи могут быть выполнены в устройстве для беспроводных обменов, таких как мобильный телефон или другое устройство, имеющее такую возможность обмена. Такое устройство может быть сконфигурировано для связи с сетью с коммутацией каналов и/или с пакетной коммутацией (например, используя один или более протоколов, таких как VoIP). Например, такое устройство может включать в себя РЧ схему, сконфигурированную для передачи кодированных кадров.
Другой подход к использованию способа понизить-и-пакетировать в широкополосном контексте заключается в использовании части в более высоком диапазоне пониженного пакета для передачи информационного пачки. В этом случае широкополосная схема кодирования с более высокой скоростью передачи данных (например, полноскоростная) может быть модифицирована таким образом, что каждый речевой пакет, который она формирует, включает в себя биты, зарезервированные для использования в качестве индикатора смешанного режима, и речевой кодер может быть конфигурирован, чтобы установить бит смешанного режима для указания, что часть в более высоком диапазоне речевого пакета содержит информацию сигнализации или вторичный трафик вместо обычной речевой информации в более высоком диапазоне.
Фиг.15A показывает блок-схему речевого кодера 100 согласно общей конфигурации. Речевой кодер 100 включает в себя кодер 120 пакетов, выполненный с возможностью принимать кадры речевого сигнала и сигнал управления скоростью передачи. Кодер 120 пакетов конфигурируется для формирования речевых пакетов согласно скорости, указанной сигналом управления скоростью передачи. Речевой кодер 100 также включает в себя форматер 130 кадра, выполненный с возможностью принимать речевые пакеты, информационный пакет, и сигнал управления понижением. Форматер 130 кадра конфигурируется для формирования кодированных кадров согласно состоянию сигнала управления понижением. Коммуникационное устройство, которое включает в себя речевой кодер 100, такой как сотовый телефон, может быть конфигурировано для выполнения других операций обработки в отношении закодированных кадров, например, кодирование с исправлением ошибок и/или избыточное, прежде, чем передать их в проводной, беспроводный или оптический канал передачи.
В этом примере речевой кодер 100 принимает сигнал управления скоростью передачи от другого модуля. Речевой кодер 100 может также быть реализован, чтобы включать в себя модуль выбора скорости передачи, который конфигурируется для формирования сигнала управления скоростью передачи (например, согласно алгоритму выбора скорости передачи с разомкнутым или разомкнутым и замкнутым контуром, как описано выше). В таком случае модуль выбора скорости передачи может быть конфигурирован, чтобы управлять операцией понижения (например, согласно двоичному файлу маски как описано выше) и сгенерировать сигнал управления понижением. Альтернативно, модуль выбора скорости передачи может быть конфигурирован для приема сигнала отмены, связанного с сигналом управления понижением, от другого модуля, который находится или внутри или является внешним к речевому кодеру. Речевой кодер 100 может также быть конфигурирован для выполнения одной или более операций предварительной обработки в отношении принятых кадров, таких как перцепционное взвешивание или другой операции фильтрования.
Кодер 120 пакетов конфигурируется для формирования, на основании первого активного кадра речевого сигнала и в ответ на первое состояние сигнала управления скоростью передачи, первого речевого пакета, как описано выше, который включает в себя описание спектральной огибающей по первому и второму диапазонам частот. Например, первое состояние сигнала управления скоростью передачи может указывать широкополосную схему 1 кодирования согласно примеру согласно Фиг.12. Кодер 120 пакетов также конфигурируется для формирования, на основании второго активного кадра речевого сигнала и в ответ на второе состояние сигнала управления скоростью передачи, отличное от первого состояния, второго речевого пакета, как описано выше, который включает в себя описание спектральной огибающей по первому диапазону частот. Например, второе состояние сигнала управления скоростью передачи может указать узкополосную схему 2 кодирования согласно примеру Фиг.12.
Фиг.15B показывает блок-схему реализации 122 кодера 120 пакетов, который включает в себя вычислитель 140 описания спектральной огибающей, вычислитель 150 описания временной информации и форматер 160 пакета. Вычислитель 140 описания спектральной огибающей конфигурируется для вычисления описания спектральной огибающей для каждого кадра, который должен быть закодирован. Вычислитель 150 описания временной информации конфигурируется для вычисления описания временной информации для каждого кадра, который должен быть кодирован. Форматер 160 пакета конфигурируется для формирования речевого пакета, который включает в себя вычисленное описание спектральной огибающей и вычисленное описание временной информации. Форматер 160 пакета может быть конфигурирован для формирования речевого пакета согласно требуемому формату пакета (например, как указано состоянием сигнала управления скоростью передачи), возможно используя различные форматы для различных схем кодирования. Форматер 160 пакета может быть конфигурирован для формирования речевого пакета так, чтобы он включал в себя дополнительную информацию, такую как набор из одного или более битов, которые идентифицируют схему кодирования, или скорость, или режим кодирования, согласно которому кодируется кадр (также называемые "индексом кодирования").
Вычислитель 140 описания спектральной огибающей конфигурируется для вычисления, согласно состоянию сигнала управления скоростью передачи, описания спектральной огибающей для каждого кадра, который должен быть закодирован. Описание основано на текущем кадре и может также быть основано на по меньшей мере части одного или более других кадров. Например, вычислитель 140 может быть конфигурирован, чтобы применить окно, которое располагается в одном или более смежных кадров и/или вычислять среднее описаний (например, среднее число векторов LSP) двух или более кадров.
Вычислитель 140 может быть конфигурирован для вычисления описания спектральной огибающей для кадра посредством выполнения спектрального анализа, такого как LPC анализ. Фиг.15C показывает блок-схему реализации 142 вычислителя 140 описания спектральной огибающей, который включает в себя модуль 170 анализа LPC, блок 180 преобразования и квантователь 190. Модуль 170 анализа конфигурируется для выполнения LPC анализа кадра и формирования соответствующего набора параметров модели. Например, модуль 170 анализа может быть конфигурирован для формирования вектора коэффициентов LPC, таких как коэффициенты фильтра или коэффициенты отражения. Модуль 170 анализа может быть конфигурирован для выполнения анализа по окну, которое включает в себя части одного или более смежных кадров. В некоторых случаях модуль 170 анализа конфигурируется таким образом, что порядок анализа (например, количество элементов в векторе коэффициентов), выбирается согласно схеме кодирования, указанной посредством блока 120 выбора схемы кодирования.
Блок 180 преобразования конфигурируется для преобразования набора параметров модели в форму, которая более эффективна для квантования. Например, блок 180 преобразования может быть конфигурирован для преобразования вектора коэффициентов LPC в набор LSP. В некоторых случаях блок 180 преобразования конфигурируется для преобразования набора коэффициентов LPC в конкретную форму согласно схеме кодирования, указанной посредством блока 120 выбора схемы кодирования.
Квантователь 190 конфигурируется для формирования описания спектральной огибающей в квантованной форме посредством квантования преобразованного набора параметров модели. Квантователь 190 может быть конфигурирован для квантования преобразованного набора посредством отсечения элементов преобразованного набора и/или посредством выбора одного или более индексов таблицы квантования для представления преобразованного набора. Может быть желательно конфигурировать квантователь 190, чтобы квантовать преобразованный набор в конкретную форму и/или длину согласно состоянию сигнала управления скоростью передачи. Например, квантователь 190 может быть реализован так, чтобы сформировать квантованное описание, как описано на Фиг.13, в ответ на первое состояние сигнала управления скоростью передачи и сформировать квантованное описание, как описано на Фиг.14, в ответ на второе состояние сигнала управления скоростью передачи.
Вычислитель 150 описания временной информации конфигурируется для вычисления описания временной информации кадра. Описание может быть основано также на временной информации по меньшей мере части одного или более других кадров. Например, вычислитель 150 может быть конфигурирован для вычисления описания по окну, которое занимает один или более смежных кадров и/или вычисления среднего значения описаний двух или более кадров.
Вычислитель 150 описания временной информации может быть конфигурирован для вычисления описания временной информации, которая имеет конкретную форму и/или длину согласно состоянию сигнала управления скоростью передачи. Например, вычислитель 150 может быть конфигурирован для вычисления, согласно состоянию сигнала управления скоростью передачи, описания временной информации, которая включает в себя одно или оба из (A) временной огибающей кадра и (B) сигнала возбуждения кадра, которая может включать в себя описание по меньшей мере одного компонента основного тона (например, задержка или отставание основного тона, усиление основного тона, и/или описание прототипа). В кодере LPC отставание основного тона обычно вычисляется как значение задержки, которое максимизирует автокорреляционную функцию LPC остатка кадра. Сигнал возбуждения может также быть основан на другой информации, такой как значения из адаптивной кодовой книги (также названный кодовой книгой основного тона) и/или значения из фиксированной кодовой книги (также названный кодовой книгой новаций и возможно указывающей местоположения импульсов).
Вычислитель 150 может быть конфигурирован для вычисления описания временной информации, которая включает в себя временную огибающую кадра (например, значение кадра усиления и/или значения формы усиления). Например, вычислитель 150 может быть конфигурирован, чтобы выдавать такое описание в ответ на указание схемы кодирования NELP. Как описано в настоящем описании, вычисление такого описания может включать в себя вычисление энергии сигнала по кадру или подкадру как сумму квадратов сигнальных выборок, вычисление энергии сигнала по окну, которое включает в себя части других кадров и/или подкадров, и/или квантование вычисленной временной огибающей.
Вычислитель 150 может быть конфигурирован для вычисления описания временной информации кадра, которая включает в себя информацию, относящуюся к основному тону или периодичности кадра. Например, вычислитель 150 может быть конфигурирован, чтобы выдавать описание, которое включает в себя информацию основного тона кадра, такую как отставание или задержка основного тона и/или усиление основного тона, в ответ на указание о схеме кодирования CELP. В некоторых случаях информация, относящаяся к компоненту основного тона для кадра, такого как сигнал возбуждения или параметр, такой как отставание основного тона, может быть получена из соответствующего речевого пакета, а также из предыдущего речевого пакета. Альтернативно или дополнительно, вычислитель 150 может быть конфигурирован для вывода описания формы волны (сигнала) (также называемой "прототипом") в ответ на указание схемы кодирования PPP. Вычисление шага и/или информации прототипа обычно включает в себя извлечение такой информации из LPC остатка и может также включать в себя комбинирование информации основного тона и/или прототипа из текущего кадра с такой информацией от одного или более прошлых кадров. Вычислитель 150 может также быть конфигурирован для квантования такого описания временной информации (например, в качестве одного или более индексов таблицы).
Вычислитель 150 может быть конфигурирован для вычисления описания временной информации кадра, которая включает в себя сигнал возбуждения. Например, вычислитель 150 может быть конфигурирован для вывода описания, которое включает в себя сигнал возбуждения, в ответ на указание схемы кодирования CELP. Сигнал возбуждения может также включать в себя описание компонента основного тона (например, отставание или задержка основного тона, усиление основного тона и/или описание прототипа). Вычисление сигнала возбуждения обычно включает в себя получение такого сигнала из LPC остатка и может также включать в себя комбинирование информации возбуждения из текущего кадра с такой информацией из одного или более прошлых кадров. Вычислитель 150 может также быть конфигурирован для квантования такого описания временной информации (например, в качестве одного или более индексов таблицы). Для случаев, в которых речевой кодер 132 поддерживает упрощенную схему кодирования CELP (RCELP), вычислитель 150 может быть конфигурирован, чтобы приводить сигнал возбуждения в надлежащее состояние.
Фиг.16A показывает блок-схему реализации 124 кодера 122 пакетов, которая включает в себя реализацию 152 вычислителя 150 описания временной информации. Вычислитель 152 конфигурируется для вычисления описания временной информации для кадра (например, сигнала возбуждения, информации основного тона и/или прототипа), которая основана на описании спектральной огибающей кадра, которое вычислено вычислителем 140 описания временной информации.
Фиг.16B показывает блок-схему реализации 154 вычислителя 152 описания временной информации, который конфигурируется для вычисления описания временной информации, основанной на LPC остатке для кадра. В этом примере вычислитель 154 выполнен с возможностью принимать описание спектральной огибающей кадра, которое вычислено вычислителем 142 описания временной информации. Деквантователь А10 конфигурируется для деквантования описания, и блок A20 обратного преобразования конфигурируется, чтобы применить обратное преобразование к деквантованному описанию, чтобы получить набор LPC коэффициентов. Забеливающий фильтр A30 конфигурируется согласно набору коэффициентов LPC и выполнен с возможностью фильтровать речевой сигнал, чтобы сформировать LPC остаток. Блок квантования A40 конфигурируется для квантования описания временной информации для этого кадра (например, в качестве одного или более индексов таблицы), которая основана на LPC остатке и возможно также основана на информации основного тона для кадра и/или временной информации от одного или более прошлых кадров.
Может быть желательно использовать реализацию кодера 122 пакетов для кодирования кадров широкополосного речевого сигнала согласно схеме кодирования с разбиением диапазона. В таком случае вычислитель 140 описания спектральной огибающей может быть конфигурирован для вычисления различных описаний спектральных огибающих кадра по соответствующим диапазонам частот последовательно и/или параллельно и возможно согласно различным режимам и/или скоростям кодирования. Вычислитель 150 описания временной информации может также быть конфигурирован для вычисления описаний временной информации кадра по различным диапазонам частот последовательно и/или параллельно и возможно согласно различным режимам и/или скоростям кодирования.
Фиг.17A показывает блок-схему реализации 102 речевого кодера 100, который конфигурирован для кодирования широкополосного речевого сигнала согласно схеме кодирования с разбиением диапазона. Речевой кодер 102 включает в себя банк A50 фильтров, который конфигурируется для фильтрации речевого сигнала, чтобы сформировать сигнал поддиапазона, содержащий контент речевого сигнала по первому диапазону частот (например, узкополосного сигнала), и сигнал поддиапазона, содержащий контент речевого сигнала по второму диапазону частот (например, сигнала более высокого диапазона). Конкретные примеры таких банков фильтров описаны, например, в заявке на патент US 2007/088558 (Vos и другие), "SYSTEMS, METHODS, AND APPARATUS FOR SPEECH SIGNAL FILTERING," поданной 19 апреля 2007. Например, банк A50 фильтров может включать в себя фильтр низких частот, конфигурированный для фильтрации речевого сигнала, чтобы сформировать узкополосный сигнал, и фильтр верхних частот, конфигурированный для фильтрации речевого сигнала, чтобы сформировать сигнал более высокого диапазона. Банк A50 фильтров может также включать в себя блок квантования с понижением частоты, конфигурированный для снижения частоты дискретизации узкополосного сигнала и/или сигнала более высокого диапазона согласно требуемому соответствующему коэффициенту прореживания, как описано, например, в заявке на патент США US2007/088558 (Vos и др.). Речевой кодер 102 может быть также конфигурирован для выполнения операции подавления шумов в отношении по меньшей мере сигнала более высокого диапазона, такой как операции подавления всплесков более высокого диапазона, как описано в заявке на патент США US 2007/088541 (Vos и др.), "SYSTEMS, METHODS, AND APPARATUS FOR HIGHBAND BURST SUPPRESSION," поданной 19 апреля 2007.
Речевой кодер 102 также включает в себя реализацию 126 кодера 120 пакета, который конфигурирован для кодирования отдельных сигналов поддиапазона согласно состоянию сигнала управления скоростью передачи. Фиг.17B показывает блок-схему реализации 128 кодера 126 пакета. Кодер 128 пакета включает в себя вычислитель 140a спектральной огибающей (например, экземпляр вычислителя 142) и вычислитель 150a временной информации (например, экземпляр вычислителя 152 или 154), которые конфигурируются для вычисления описаний спектральных огибающих и временной информации, соответственно, на основании узкополосного сигнала, сформированного банком A50 фильтров, и согласно схеме кодирования, как указано состоянием сигнала управления скоростью передачи. Кодер 128 пакета также включает в себя вычислитель 140b спектральной огибающей (например, экземпляр вычислителя 142) и вычислитель 150b временной информации (например, экземпляр вычислителя 152 или 154), которые конфигурируются для формирования вычисленных описаний спектральных огибающих и временной информации, соответственно, на основании сигнала более высокого диапазона, сформированного банком A50 фильтров, и согласно схеме кодирования, как указано состоянием сигнала управления скоростью передачи. Кодер 128 пакета также включает в себя реализацию 162 форматера 160 пакетов, конфигурированного для формирования речевого пакета, который включает в себя вычисленные описания спектральной огибающей и временной информации для одного или обоих из узкополосного сигнала и сигнала более высокого диапазона, как указано состоянием сигнала управления скоростью передачи.
Как отмечено выше, описание временной информации для части в более высоком диапазоне широкополосного речевого сигнала может быть основано на описании временной информации для узкополосной части этого сигнала. Фиг.18A показывает блок-схему соответствующей реализации 129 кодера 126 пакета. Как кодер 128 пакета, описанный выше, кодер 129 пакета включает в себя вычислители 140a и 140b описания спектральной огибающей, которые выполнены с возможностью вычислять соответствующие описания спектральной огибающей. Кодер 129 пакета также включает в себя экземпляр 152a вычислителя 152 описания временной информации (например, вычислитель 154), который выполнен с возможностью вычислять описание временной информации на основании вычисленного описания спектральной огибающей для узкополосного сигнала. Кодер 129 пакета также включает в себя реализацию 156 вычислителя описания 150 временной информации. Вычислитель 156 конфигурируется для вычисления описания временной информации для сигнала более высокого диапазона, которое основано на описании временной информации для узкополосного сигнала.
Фиг.18B показывает блок-схему реализации 158 вычислителя 156 временного описания. Вычислитель 158 включает в себя генератор A60 сигнала возбуждения более высокого диапазона, который конфигурируется для формирования сигнала возбуждения более высокого диапазона на основании узкополосного сигнала возбуждения, сформированного вычислителем 152a. Например, генератор A60 может быть конфигурирован для выполнения операции, такой как спектральное расширение, гармоническое расширение, нелинейное расширение, спектральная свертка и/или спектральное преобразование, в отношении узкополосного сигнала возбуждения (или одного или более его компонентов), чтобы сгенерировать сигнал возбуждения более высокого диапазона. Дополнительно или альтернативно, генератор A60 может быть конфигурирован для выполнения спектрального и/или амплитудного формирования случайного шума (например, сигнал псевдослучайного Гауссова шума), чтобы сгенерировать сигнал возбуждения более высокого диапазона. Для случая, когда генератор A60 использует псевдослучайный шумовой сигнал, может быть желательно синхронизировать генерирование этого сигнала кодером и декодером. Такие способы и устройство для генерирования сигнала возбуждения более высокого диапазона описаны более подробно, например, в заявке на патент США US2007/0088542 (Vos и другие), "SYSTEMS, METHODS, AND APPARATUS FOR WIDEBAND SPEECH CODING," поданной 19 апреля 2007. В примере на Фиг.18B генератор A60 выполнен с возможностью принимать квантованный узкополосный сигнал возбуждения. В другом примере генератор A60 выполнен с возможностью принимать узкополосный сигнал возбуждения в другой форме (например, в предварительно квантованной или деквантованной форме).
Вычислитель 158 также включает в себя синтезирующий фильтр A70, конфигурированный, чтобы генерировать синтезированный сигнал более высокого диапазона, который основан на сигнале возбуждения более высокого диапазона и описании спектральной огибающей сигнала более высокого диапазона (например, сформированном вычислителем 140b). Фильтр A70 обычно конфигурируется согласно набору значений в описании спектральной огибающей сигнала более высокого диапазона (например, одному или более векторам коэффициентов LSP или LPC), чтобы сформировать синтезированный сигнал более высокого диапазона в ответ на сигнал возбуждения более высокого диапазона. В примере на Фиг.18B фильтр A70 синтеза выполнен с возможностью принимать квантованное описание спектральной огибающей сигнала более высокого диапазона и может быть конфигурирован соответственно, чтобы включать в себя деквантователь, и возможно блок обратного преобразования. В другом примере A70 фильтр выполнен с возможностью принимать описание спектральной огибающей сигнала более высокого диапазона в другой форме (например, в предварительно квантованной или деквантованной форме).
Вычислитель 158 также включает в себя вычислитель A80 коэффициента усиления более высокого диапазона, который конфигурируется для вычисления описания временной огибающей сигнала более высокого диапазона на основании временной огибающей синтезированного сигнала более высокого диапазона. Вычислитель A80 может быть конфигурирован для вычисления этого описания, включающего в себя одно или более расстояний между временной огибающей сигнала более высокого диапазона и временной огибающей синтезированного сигнала более высокого диапазона. Например, вычислитель A80 может быть конфигурирован для вычисления такого расстояния как значение кадра усиления (например, как отношение между измерениями энергии соответствующих кадров двух сигналов, или как квадратный корень такого отношения). Дополнительно или альтернативно, вычислитель A80 может быть конфигурирован для вычисления ряда таких расстояний как значения формы усиления (например, как отношения между измерениями энергии соответствующих подкадров двух сигналов, или как квадратные корни таких отношений). В примере на Фиг.18B, вычислитель 158 также включает в себя квантователь A90, конфигурированный для квантования вычисленного описания временной огибающей (например, как один или более индексов кодовой книги). Различные признаки и реализации элементов вычислителя 158 описываются, например, в заявке на патент США US 2007/0088542 (Vos и др.), которая упомянута выше.
Различные элементы реализации речевого кодера 100 могут быть воплощены в любой комбинации аппаратного обеспечения, программного обеспечения и/или программно-аппаратного обеспечения, которая является подходящей для намеченного применения. Например, такие элементы могут быть изготовлены как электронные и/или оптические устройства, например, в одной микросхеме или на двух или более микросхемах из набора микросхем. Один пример такого устройства является прошитым или программируемым массивом логических элементов, таких как транзисторы или логические вентили, и любой из этих элементов может быть реализован как один или более таких массивов. Любые два или более или даже все из этих элементов могут быть реализованы в одном массиве или массивах. Такой массив или массивы могут быть реализованы в одной или более микросхемах (например, в наборе микросхем, включающем в себя две или более микросхем).
Один или более элементов различных реализаций речевого кодера 100, который описан здесь, могут быть также реализованы полностью или частично как один или более наборов команд, выполненных с возможностью выполнения на одном или более прошитом или программируемом массиве логических элементов, таких как микропроцессоры, встроенные процессоры, IP ядра, цифровые процессоры сигналов, FPGA (программируемые пользователем вентильные матрицы), ASSP (специализированные стандартные продукты), и ASIC (специализированные интегральные схемы). Любой из различных элементов реализации речевого кодера 100 может также быть воплощен как один или более компьютеров (например, машины, включающие в себя один или более массивов, запрограммированных для выполнения одного или более наборов или последовательностей команд, также называемых "процессорами"), и любые два или более, или даже все, из этих элементов могут быть реализованы в одном и том же таком компьютере или компьютерах.
Различные элементы реализации речевого кодера 100 могут быть включены в устройство для беспроводных обменов, таких как мобильный телефон или другое устройство, имеющее такую возможность обмена. Такое устройство может быть сконфигурировано, чтобы общаться с сетью с коммутацией каналов и/или с пакетной коммутацией (например, используя один или более протоколов, таких как VoIP). Такое устройство может быть конфигурировано для выполнения операции в отношении сигнала, передающем кодированные кадры, таких как перемежение, прокалывание (исключение), сверточное кодирование, кодирование с исправлением ошибок, кодирование одного или более уровней сетевого протокола (например, Ethernet, TCP/IP, cdma2000), радиочастотная (РЧ) модуляция, и/или РЧ передача.
Возможно использовать один или более элементов реализации речевого кодера 100 для выполнения задачи или выполнения других наборов команд, которые непосредственно не относятся к работе устройства, такой как задача, относящаяся к работе другого устройства или системы, в которую внедрено это устройство. Также возможно для одного или более элементов реализации речевого кодера 100 иметь общую структуру (например, процессор, используемый для выполнения части кода, соответствующей различным элементам в различные моменты времени, набор команд, исполняемых для выполнения задач, соответствующих различным элементам в различные моменты времени, или компоновка электронных и/или оптических устройств для различных элементов в различные моменты времени). В одном таком примере кодер 120 пакетов и форматер 130 кадра реализуется как наборы команд, выполненные с возможностью выполняться в одном и том же процессоре. В другом таком примере вычислители 140a и 140b описания спектральной огибающей реализуются как один и тот же набор команд, выполняющийся в различные моменты времени.
Фиг.19A показывает блок-схему способа M200 обработки речевых пакетов из кодированного речевого сигнала согласно общей конфигурации. Способ M200 конфигурируется для приема информации от двух речевых пакетов (например, от последовательных кодированных кадров кодированного речевого сигнала) и формирования описания спектральных огибающих двух соответствующих кадров речевого сигнала. На основании информации из первого речевого пакета (также названного "опорным" (эталонным) речевым пакетом) задача T210 получает описание спектральной огибающей первого кадра речевого сигнала по первому и второму диапазонам частот. Это описание может быть единым описанием, которое распространяется по обоим диапазонам частот, или оно может включать в себя отдельные описания, каждое из которых распространяется по соответствующему одному из диапазонов частот. На основании информации из второго речевого пакета задача T220 получает описание спектральной огибающей второго кадра речевого сигнала (также названного "целевым" кадром) по первому диапазону частот. На основании информации из опорного речевого пакета задача T230 получает описание спектральной огибающей целевого кадра по второму диапазону частот. На основании информации из второго речевого пакета задача T240 получает описание информации основного тона целевого кадра для первого диапазона частот.
Фиг.20 иллюстрирует применение способа M200. В этом примере описания спектральных огибающих имеют порядки LPC, и этот порядок LPC описания спектральной огибающей целевого кадра по второму диапазону частот является меньшим, чем порядок LPC для описания спектральной огибающей целевого кадра по первому диапазону частот. В конкретном примере LPC-порядки описаний спектральной огибающей целевого кадра по первому и второму диапазонам частот равны соответственно десяти и шести. Другие примеры включают в себя случаи, в которых LPC-порядок описания спектральной огибающей целевого кадра по второму диапазону частот составляет по меньшей мере пятьдесят процентов, по меньшей мере шестьдесят процентов, не больше чем семьдесят пять процентов, не больше чем восемьдесят процентов, равный и больший, чем LPC порядок описания спектральной огибающей целевого кадра по первому диапазону частот.
Фиг.20 также иллюстрирует пример, в котором LPC порядок описания спектральной огибающей первого кадра по первому и второму диапазонам частот равен сумме порядков LPC описаний спектральной огибающей целевого кадра по первому и второму диапазонам частот. В другом примере LPC порядок описания спектральной огибающей первого кадра по первому и второму диапазонам частот может быть больше или меньше, чем сумма порядков LPC описаний спектральных огибающих целевого кадра по первому и второму диапазонам частот.
Опорный речевой пакет может включать в себя квантованное описание спектральной огибающей по первому и второму диапазонам частот, и второй речевой пакет может включать в себя квантованное описание спектральной огибающей по первому диапазону частот. В одном конкретном примере квантованное описание спектральной огибающей по первому и второму диапазонам частот, включенное в опорный речевой пакет, имеет длину из тридцати шести битов, и квантованное описание спектральной огибающей по первому диапазону частот, включенное во второй речевой пакет, имеет длину из двадцати двух битов. В других примерах длина квантованного описания спектральной огибающей по первому диапазону частот, включенное во второй речевой пакет, не больше чем шестьдесят пять, семьдесят, семьдесят пять или восемьдесят процентов длины квантованного описания спектральной огибающей по первому и второму диапазонам частот, включенной в опорный речевой пакет.
Каждая из задач T210 и T220 может быть конфигурирована так, что включает в себя одну или обе из следующих двух операций: синтаксический разбор речевого пакета для извлечения квантованного описания спектральной огибающей, и деквантование квантованного описания спектральной огибающей, чтобы получить ряд параметров модели кодирования для этого кадра. Типичные реализации задач T210 и T220 включают в себя обе из этих операций таким образом, что каждая задача обрабатывает соответствующий речевой пакет, чтобы сформировать описание спектральной огибающей в форме ряда параметров модели (например, один или более из векторов коэффициентов LSF, LSP, ISF, ISP и/или LPC). В одном конкретном примере опорный речевой пакет имеет длину 171 бит, и второй речевой пакет имеет длину восемьдесят битов. В других примерах длина второго речевого пакета составляет не больше чем пятьдесят, шестьдесят, семьдесят, или семьдесят пять процентов длины опорного речевого пакета.
Опорный речевой пакет может включать в себя квантованное описание временной информации для первого и второго диапазонов частот, и второй речевой пакет может включать в себя квантованное описание временной информации для первого диапазона частот. В одном конкретном примере квантованное описание временной информации для первого и второго диапазонов частот, включенной в опорный речевой пакет, имеет длину 133 бита, и квантованное описание временной информации для первого диапазона частот, включенной во второй речевой пакет, имеет длину пятьдесят восемь битов. В других примерах длина квантованного описания временной информации для первого диапазона частот, включенного во второй речевой пакет, составляет не больше чем сорок пять, пятьдесят, или шестьдесят процентов, или составляет не меньше чем сорок процентов от длины квантованного описания временной информации для первого и второго диапазонов частот, включенного в опорный речевой пакет.
Задачи T210 и T220 могут быть также реализованы, чтобы сформировать описания временной информации из соответствующих речевых пакетов. Например, одна или обе из этих задач могут быть сконфигурированы так, чтобы получить, на основании информации от соответствующего речевого пакета, описание временной огибающей, описание сигнала возбуждения, описание информации основного тона или описание прототипа. Как и при получении описания спектральной огибающей, такая задача может включать в себя синтаксический разбор квантованного описания временной информации из речевого пакета и/или деквантование квантованного описания временной информации. Реализации способа M200 могут также быть конфигурированы таким образом, что задача T210 и/или задача T220 также получает описание спектральной огибающей и/или описание временной информации на основании информации от одного или более других речевых пакетов, такой как информация из речевых пакетов от одного или более предыдущих кодированных кадров. Например, описания сигналов возбуждения, описания информации основного тона и описания прототипов обычно основаны на информации от предыдущих кадров.
Задача T240 конфигурируется для получения описания информации основного тона целевого кадра для первого диапазона частот на основании информации из второго речевого пакета. Описание информации основного тона может включать в себя описание одного или более из следующего: отставание основного тона, усиление основного тона, прототип и сигнал возбуждения. Задача T240 может включать в себя синтаксический разбор квантованного описания информации основного тона из второго речевого пакета и/или деквантования квантованного описания информации основного тона. Например, второй речевой пакет может включать в себя квантованное описание информации основного тона для первого диапазона частот, длина которого составляет по меньшей мере пять процентов и/или самое большее десять процентов от длины второго речевого пакета. В одном конкретном примере второй речевой пакет имеет длину восемьдесят битов, и квантованное описание информации основного тона для первого диапазона частот (например, индекс отставания шага), включенное во второй речевой пакет, имеет длину семь битов. Задача T240 может также быть сконфигурирована для вычисления сигнала возбуждения целевого кадра для первого диапазона частот на основании информации основного тона от второго речевого пакета. Может также быть желательно конфигурировать задачу T240 для вычисления сигнала возбуждения целевого кадра для второго диапазона частот на основании сигнала возбуждения целевого кадра для первого диапазона частот, как описано в настоящем описании (например, со ссылками на генераторы A60 и 330 возбуждения более высокого диапазона).
Реализации способа M200 могут быть также конфигурированы таким образом, что задача T240 также получает описание информации основного тона на основании информации от одного или более других речевых пакетов, такой как информация из речевых пакетов от одного или более предыдущих закодированных кадров. Фиг.22 иллюстрирует применение такой реализации M210 способа M200. Способ M210 включает в себя реализацию T242 задачи T240, которая конфигурируется для получения описания информации основного тона целевого кадра для первого диапазона частот на основании информации от каждого из опорного и второго речевых пакетов. Например, задача T242 может быть конфигурирована для интерполяции контура задержки целевого кадра для первого диапазона частот на основании первого значения задержки основного тона, на основании информации из второго речевого пакета, и второго значения задержки основного тона, на основании информации от опорного речевого пакета. Задача T242 может также быть конфигурирована для вычисления сигнала возбуждения целевого кадра для первого диапазона частот на основании информации основного тона от каждого из опорного и второго речевых пакетов.
Способ M200 обычно выполняется как часть большего способа декодирования речи, и речевые декодеры и способы декодирования речи, которые конфигурируются для выполнения способа M200, явно рассматривается и тем самым раскрывается. Речевой кодер может быть конфигурирован для выполнения реализации способа M100 в кодере и выполнения реализации способа M200 в декодере. В этом случае "первый речевой пакет", как кодирован задачей T110, соответствует опорному речевому пакету, который выдает информацию к задачам T210 и T230, и "второй речевой пакет", как закодирован задачей T120, соответствует речевому пакету, который выдает информацию к задачам T220 и T240. Фиг.21 иллюстрирует это отношение между способами M100 и M200, используя пример пары последовательных кадров, кодированных с использованием способа M100, и декодированных с использованием способа M200. Способ M200 может также быть реализован так, что включает в себя операции, которые выполняют синтаксический разбор или иначе получают опорный речевой пакет и второй речевой пакет из соответствующих кодированных кадров (например, сформированных задачами T130 и T140).
Несмотря на конкретный пример Фиг.21, явно отмечается, что обычно применения способа M100 и применения способа M200 не ограничиваются обработкой пар последовательных кадров. В одном таком другом применении способа M200, например, кодированный кадр, который подает речевой пакет, обработанный задачами T210 и T230, может быть отделен от закодированного кадра, который подает речевой пакет, обработанный задачами T220 и T240, одним или более прошедшими кадрами, которые были потеряны при передаче (то есть стертыми кадрами).
Задача T220 конфигурируется для получения описания спектральной огибающей целевого кадра по первому диапазону частот на основании, по меньшей мере в первую очередь, информации из второго речевого пакета. Например, задача T220 может быть конфигурирована для получения описания спектральной огибающей целевого кадра по первому диапазону частот на основании целиком информации из второго речевого пакета. Альтернативно, задача T220 может быть конфигурирована для получения описания спектральной огибающей целевого кадра по первому диапазону частот на основании также другой информации, такой как информация из речевых пакетов из одного или более предыдущих закодированных кадров. В таком случае задача T220 конфигурируется для присвоения большего веса информации из второго речевого пакета, чем другой информации. Например, такая реализация задачи T220 может быть сконфигурирована для вычисления описания спектральной огибающей целевого кадра по первому диапазону частот как среднего числа информации из второго речевого пакета и информации из речевого пакета из предыдущего закодированного кадра (например, опорного кодированного кадра), в котором информации из второго речевого пакета присвоен больший вес, чем информации из другого речевого пакета. Аналогично, задача T220 может быть конфигурирована для получения описания временной информации целевого кадра для первого диапазона частот на основании, по меньшей мере в первую очередь, информации из второго речевого пакета.
На основании информации от опорного речевого пакета (также названной здесь "опорной спектральной информацией") задача T230 получает описание спектральной огибающей целевого кадра по второму диапазону частот. Фиг.19B показывает блок-схему реализации M220 способа M200, который включает в себя реализацию T232 задачи T230. Как реализация задачи T230, задача T232 получает описание спектральной огибающей целевого кадра по второму диапазону частот на основании опорной спектральной информации. В этом случае опорная спектральная информация включается в описание спектральной огибающей первого кадра речевого сигнала. Фиг.23 иллюстрирует пример применения способа M220.
Задача T230 конфигурируется для получения описания спектральной огибающей целевого кадра по второму диапазону частот, на основании, по меньшей мере в первую очередь, опорной спектральной информации. Например, задача T230 может быть конфигурирована для получения описания спектральной огибающей целевого кадра по второму диапазону частот, на основании целиком опорной спектральной информации. Альтернативно, задача T230 может быть сконфигурирована для получения описания спектральной огибающей целевого кадра по второму диапазону частот, на основании (A) описания спектральной огибающей по второму диапазону частот, которое основано на опорной спектральной информации, и (B) описания спектральной огибающей по второму диапазону частот, которое основано на информации из второго речевого пакета.
В таком случае задача T230 может быть конфигурирована для назначения большего веса описанию на основании опорной спектральной информации, чем описанию на основании информации из второго речевого пакета. Например, такая реализация задачи T230 может быть конфигурирована для вычисления описания спектральной огибающей целевого кадра по второму диапазону частот как среднего числа описаний на основании опорной спектральной информации и информации из второго речевого пакета, в котором описание, основанное на опорной спектральной информации, имеет больший вес, чем описание, основанное на информации из второго речевого пакета. В другом случае LPC-порядок описания, основанного на опорной спектральной информации, может быть больше чем LPC порядок описания, основанного на информации из второго речевого пакета. Например, LPC-порядок описания, основанного на информации из второго речевого пакета, может быть единицей (например, описание может быть спектральным значением наклона, таким как значение первого коэффициента отражения). Аналогично, задача T230 может быть конфигурирована для получения описания временной информации целевого кадра для второго диапазона частот, на основании, по меньшей мере в первую очередь, опорной временной информации (например, основанной полностью на опорной временной информации или основанной также и в меньшей части на информации из второго речевого пакета).
Задача T210 может быть реализована для получения, из опорного речевого пакета, описания спектральной огибающей, которое является единым представлением всего диапазона по обоим из первого и второго диапазонов частот. Более типично, однако, реализовать задачу T210 для получения этого описания как отдельных описаний спектральной огибающей по первому диапазону частот и по второму диапазону частот. Например, задача T210 может быть конфигурирована для получения отдельных описаний из опорного речевого пакета, который был закодирован, используя схему кодирования с разбиением диапазона, как описано в настоящем описании (например, схема 1 кодирования в примере на Фиг.12).
Фиг.19C показывает блок-схему реализации M230 способа M220, в которой задача T210 реализована как две подзадачи T212a и T212b. На основании информации из опорного речевого пакета задача T212a получает описание спектральной огибающей первого кадра по первому диапазону частот. На основании информации из опорного речевого пакета задача T212b получает описание спектральной огибающей первого кадра по второму диапазону частот. Задача T212a и/или T212b может включать в себя синтаксический разбор квантованного описания спектральной огибающей из соответствующего речевого пакета и/или деквантование квантованного описания спектральной огибающей.
Задача T212a и/или T212b может также быть реализована для формирования описания временной информации на основании информации из соответствующего речевого пакета. Например, одна или обе из этих задач могут быть конфигурированы для получения, на основании информации из соответствующего речевого пакета описания временной огибающей, описания сигнала возбуждения и/или описания информации основного тона. Как и при получении описания спектральной огибающей такая задача может включать в себя синтаксический разбор квантованного описания временной информации из речевого пакета и/или деквантование квантованного описания временной информации.
Способ M230 также включает в себя реализацию T234 задачи T232. В качестве реализации задачи T230, задача T234 получает описание спектральной огибающей целевого кадра по второму диапазону частот, которое основано на опорной спектральной информации. Как в задаче T232, опорная спектральная информация включается в описание спектральной огибающей первого кадра речевого сигнала. В конкретном случае задачи T234 опорная спектральная информация включается в (и является возможно тем же самым что) описание спектральной огибающей первого кадра по второму диапазону частот. Задача T234 может также быть конфигурирована для получения описания временной информации целевого кадра для второго диапазона частот, которое основано на информации, включенной в (и является возможно тем же самым что) описание временной информации первого кадра для второго диапазона частот.
Фиг.24 иллюстрирует применение способа M230, в котором принимают информацию от двух речевых пакетов и формируют описания спектральных огибающих двух соответствующих кадров речевого сигнала. В этом примере описания спектральных огибающих имеют LPC порядки, и LPC порядки описаний спектральных огибающих первого кадра по первому и второму диапазонам частот равны LPC порядкам описаний спектральных огибающих целевого кадра по соответствующим диапазонам частот. Другие примеры включают в себя случаи, в которых одно или оба из описаний спектральных огибающих первого кадра по первому и второму диапазонам частот являются большими, чем соответствующее описание спектральной огибающей целевого кадра по соответствующему диапазону частот.
Опорный речевой пакет может включать в себя квантованное описание спектральной огибающей по первому диапазону частот и квантованное описание спектральной огибающей по второму диапазону частот. В одном конкретном примере квантованное описание спектральной огибающей по первому диапазону частот, включенное в опорный речевой пакет, имеет длину двадцать восемь битов, и квантованное описание спектральной огибающей по второму диапазону частот, включенное в опорный речевой пакет, имеет длину восемь битов. В других примерах длина квантованного описания спектральной огибающей по второму диапазону частот, включенной в опорный речевой пакет, составляет не больше чем тридцать, сорок, пятьдесят или шестьдесят процентов длины квантованного описания спектральной огибающей по первому диапазону частот, включенного в опорный речевой пакет.
Опорный речевой пакет может включать в себя квантованное описание временной информации для первого диапазона частот и квантованное описание временной информации для второго диапазона частот. В одном конкретном примере квантованное описание временной информации для первого диапазона частот, включенное в опорный речевой пакет, имеет длину 125 битов, и квантованное описание временной информации для второго диапазона частот, включенное в опорный речевой пакет, имеет длину восемь битов. В других примерах длина квантованного описания временной информации для второго диапазона частот, включенного в опорный речевой пакет, не больше чем десять, двадцать, двадцать пять или тридцать процентов длины квантованного описания временной информации для первого диапазона частот, включенного в опорный речевой пакет.
Второй речевой пакет может включать в себя квантованное описание спектральной огибающей по первому диапазону частот и/или квантованное описание временной информации для первого диапазона частот. В одном конкретном примере квантованное описание спектральной огибающей по первому диапазону частот, включенное во второй кодированный кадр, имеет длину двадцать два бита. В других примерах длина квантованного описания спектральной огибающей по первому диапазону частот, включенного во второй речевой пакет, составляет не меньше чем сорок, пятьдесят, шестьдесят, семьдесят или семьдесят пять процентов длины квантованного описания спектральной огибающей по первому диапазону частот, включенного в опорный речевой пакет. В одном конкретном примере квантованное описание временной информации для первого диапазона частот, включенное во второй речевой пакет, имеет длину пятьдесят восемь битов. В других примерах длина квантованного описания временной информации для первого диапазона частот, включенного во второй речевой пакет, составляет по меньшей мере двадцать пять, тридцать, сорок или сорок пять процентов и/или самое большее пятьдесят, шестьдесят или семьдесят процентов длины квантованного описания спектральной огибающей по первому диапазону частот, включенного в опорный речевой пакет.
В типичной реализации способа M200 опорная спектральная информация - это описание спектральной огибающей по второму диапазону частот. Это описание может включать в себя ряд параметров модели, таких как один или более векторов коэффициентов LSP, LSF, ISP, ISF, или LPC. Обычно это описание есть описание спектральной огибающей первого кадра по второму диапазону частот, которое получено из опорного речевого пакета задачей T210. Также возможно, что опорная спектральная информация включает в себя описание спектральной огибающей (например, первого кадра) по первому диапазону частот и/или по другому диапазону частот.
Фиг.25 иллюстрирует применение реализации M240 способа M200, который включает в себя задачу T260. Задача T260 конфигурируется для формирования, на основании информации из кодированного кадра, который включает в себя второй речевой пакет, пачки информационного сигнала, которая является отдельной от речевого сигнала. Например, задача T260 может быть конфигурирована для выдачи конкретной части кодированного кадра в качестве пачки сигнализации или вторичного сигнала трафика, как описано выше. Такая пачка может иметь длину в битах, которая составляет по меньшей мере сорок, сорок пять или пятьдесят процентов длины закодированного кадра. Альтернативно или дополнительно, такая пачка может иметь длину в битах, которая составляет по меньшей мере девяносто процентов длины второго речевого пакета, или такая пачка может иметь длину, которая равна или больше, чем длина второго речевого пакета. В одном конкретном примере пачка имеет длину 86 битов (в другом примере, 87 битов), второй речевой пакет имеет длину 80 битов и кодированный кадр имеет длину 171 бит. Способы M210, M220 и M230 могут быть также реализованы так, чтобы включать в себя задачу T260.
Задача T230 обычно включает в себя операцию извлечения опорной спектральной информации из массива элементов памяти, таких как полупроводниковая память (также называемую здесь "буфер"). Для случая, когда опорная спектральная информация включает в себя описание спектральной огибающей по второму диапазону частот, действие по извлечению опорной спектральной информации может быть достаточным, чтобы завершить задачу T230. Альтернативно, может быть желательно конфигурировать задачу T230, чтобы вычислять описание спектральной огибающей целевого кадра по второму диапазону частот (также называемое здесь "целевым спектральным описанием"), а не просто извлекать его. Например, задача T230 может быть конфигурирована для вычисления целевого спектрального описания посредством суммирования случайного шума с опорной спектральной информацией и/или вычисления целевого спектрального описания на основании спектральной информации по меньшей мере от одного дополнительного речевого пакета (например, на основании информации от более чем одного опорного речевого пакета). Например, задача T230 может быть конфигурирована для вычисления целевого спектрального описания как среднего числа описаний спектральных огибающих по второму диапазону частот от двух или более опорных речевых пакетов, и такое вычисление может включать в себя суммирование случайного шума с вычисленным средним.
Задача T230 может быть конфигурирована для вычисления целевого спектрального описания посредством экстраполирования во времени из опорной спектральной информации или посредством интерполяции во времени между описаниями спектральных огибающих по второму диапазону частот от двух или более опорных речевых пакетов. Альтернативно или дополнительно, задача T230 может быть конфигурирована для вычисления целевого спектрального описания посредством экстраполирования по частоте из описания спектральной огибающей целевого кадра по другому диапазону частот (например, по первому диапазону частот) и/или посредством интерполяции по частоте между описаниями спектральных огибающих по другим диапазонам частот.
Обычно опорная спектральная информация и целевое спектральное описание являются векторами значений спектральных параметров (или "спектральными векторами"). В одном таком примере оба из целевого и опорного спектральных векторов являются векторами LSP. В другом примере оба из целевого и опорного спектральных векторов являются векторами коэффициентов LPC. В другом примере оба из целевого и опорного спектральных векторов являются векторами коэффициентов отражения. Задача T230 может быть конфигурирована для копирования целевого спектрального описания с опорной спектральной информации согласно выражению, такому как sti = sri 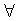 i
i 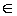 {1,2,…n}, где st - целевой спектральный вектор, sr является опорным спектральным вектором (чьи значения обычно находятся в диапазоне от -1 до +1), i - индекс элемента вектора, и n - длина вектора st. В другой разновидности этой операции задача T230 конфигурируется, чтобы применять коэффициент взвешивания (или вектор коэффициентов взвешивания) к опорному спектральному вектору. В другой разновидности этой операции задача T230 конфигурируется для вычисления целевого спектрального вектора посредством суммирования случайного шума с опорным спектральным вектором согласно выражению, такому как sti=sri+zi, i {1,2,…n}, где z - вектор случайных значений. В таком случае каждый элемент z может быть случайной переменной, значения которой распределены (например, однородно) по требуемому диапазону.
{1,2,…n}, где st - целевой спектральный вектор, sr является опорным спектральным вектором (чьи значения обычно находятся в диапазоне от -1 до +1), i - индекс элемента вектора, и n - длина вектора st. В другой разновидности этой операции задача T230 конфигурируется, чтобы применять коэффициент взвешивания (или вектор коэффициентов взвешивания) к опорному спектральному вектору. В другой разновидности этой операции задача T230 конфигурируется для вычисления целевого спектрального вектора посредством суммирования случайного шума с опорным спектральным вектором согласно выражению, такому как sti=sri+zi, i {1,2,…n}, где z - вектор случайных значений. В таком случае каждый элемент z может быть случайной переменной, значения которой распределены (например, однородно) по требуемому диапазону.
Может быть желательно гарантировать, что значения целевого спектрального описания являются ограниченными (например, в диапазоне от -1 до +1). В таком случае задача T230 может быть конфигурирована для вычисления целевого спектрального описания согласно выражению, такому как sti=wsri+zi, i {1,2,…n}, где w имеет значение между нулем и единицей (например, в диапазоне от 0,3 до 0,9), и значения каждого элемента z распределены (например, однородно) по диапазону от -(1-w) до +(1-w).
В другом примере задача T230 конфигурируется для вычисления целевого спектрального описания на основании описания спектральной огибающей по второму диапазону частот от каждого из более чем одного опорного речевого пакета (например, как среднее число описаний спектральных огибающих по второму диапазону частот от каждого из двух наиболее недавних опорных речевых пакетов). В таком случае может быть желательно назначать веса опорным векторам отличным друг от друга способом (например, вектору из более недавнего опорного речевого пакета может быть назначен больший вес).
Может быть желательно выполнить задачу T230 как вариант более общей операции для обработки стирания части более высокого диапазона для речевого пакета, кодированного с разбиением диапазона. Например, речевой декодер или способ речевого декодирования могут быть конфигурированы, чтобы выполнить такую операцию после приема речевого пакета, в которой по меньшей мере часть более высокого диапазона стирается (то есть отсутствует или определяется как имеющая слишком много ошибок, которые должны быть надежно восстановлены).
В типичном примере задача T230 конфигурируется для вычисления целевого спектрального описания на основании взвешенной версии опорной спектральной информации. Вес w может быть скаляром, как в следующем выражении: sti=wsri, i {1,2,…n}. Альтернативно, вес w может быть вектором элементов, которые имеют, возможно, различные значения, как в следующем выражении: sti=wi sri, i {1,2,…n}.
Для случая, в котором задача T230 является вариантом более общей операции для обработки стирания, может быть желательно реализовать вес как коэффициент α ослабления. Может также быть желательно реализовать эту операцию таким образом, что значение (или значения) коэффициента α ослабления уменьшаются с каждым в последовательной последовательности стираний более высокого диапазона. Например, коэффициент α ослабления может быть значением 0,9 для первого пакета в последовательности, 0,7 для второго пакета в последовательности, и 0,5 для последующих пакетов в последовательности. (В этом случае может быть желательно использовать один и тот же опорный спектральный вектор для каждого пакета в последовательности стираний). В другом таком примере задача T230 конфигурируется для вычисления целевого спектрального описания на основании аддитивной константы v, которая может быть скаляром, как в выражении sti=αsri+v, i {1,2,…n}, или вектором, как в выражении sti=αsri+vi, i {1,2,…n}. Эта константа v может быть реализована как начальный спектральный вектор s0, как в выражении sti=αsri+s0i, i {1,2,…n}. В таком случае значения элементов начального спектрального вектора могут быть функцией i (например, s0i = bi, где b - константа). В одном конкретном примере s0i =0,048i i {1,2,…n}.
Задача T230 может также быть реализована для вычисления целевого спектрального описания на основании, в дополнение к опорной спектральной информации, спектральной огибающей одного или более кадров по другому диапазону частот. Например, такая реализация задачи T230 может быть конфигурирована для вычисления целевого спектрального описания посредством экстраполирования по частоте из спектральной огибающей текущего кадра и/или одного или более предыдущих кадров по другому диапазону частот (например, первому диапазону частот).
Задача T230 может быть конфигурирована для получения описания временной информации целевого кадра по второму диапазону частот на основании информации из опорного речевого пакета (также названной здесь "опорной временной информацией"). Опорная временная информация обычно является описанием временной информации по второму диапазону частот. Это описание может включать в себя одно или более значений кадра усиления, значений профиля усиления, значений параметра основного тона и/или индексов кодовой книги. Обычно это описание является описанием временной информации первого кадра по второму диапазону частот, который получен из опорного речевого пакета с помощью задачи T210. Также возможно, что опорная временная информация включает в себя описание временной информации (например, первого кадра) по первому диапазону частот и/или по другому диапазону частот.
Задача T230 может быть конфигурирована для получения описания временной информации целевого кадра по второму диапазону частот (также названной здесь "целевым временным описанием") посредством копирования опорной временной информации. Альтернативно, может быть желательно конфигурировать задачу T230 для получения целевого временного описания посредством вычисления его на основании опорной временной информации. Например, задача T230 может быть конфигурирована для вычисления целевого временного описания посредством суммирования случайного шума с опорной временной информацией. Задача T230 может также быть конфигурирована для вычисления целевого временного описания на основании информации от более чем одного опорного речевого пакета. Например, задача T230 может быть конфигурирована для вычисления целевого временного описания как среднего числа описаний временной информации по второму диапазону частот из двух или более опорных речевых пакетов, и такое вычисление может включать в себя суммирование случайного шума с вычисленным средним числом. Для задачи T230 может быть желательно получить описание временной информации целевого кадра по второму диапазону частот в качестве части варианта более общей операции для того, чтобы обработать стирание части более высокого диапазона речевого пакета, кодированного с разбиением диапазона, как описано выше.
Целевое временное описание и опорная временная информация могут каждая включать в себя описание временной огибающей. Как отмечено выше, описание временной огибающей может включать в себя значение кадра усиления и/или ряд значений формы усиления. Альтернативно или дополнительно, целевое временное описание и опорная временная информация могут каждая включать в себя описание сигнала возбуждения. Описание сигнала возбуждения может включать в себя описание компонента основного тона (например, отставание или задержка основного тона, усиление основного тона, и/или описание прототипа).
Задача T230 обычно конфигурируется, чтобы установить форму усиления целевого временного описания как плоскую. Например, задача T230 может быть конфигурирована, чтобы установить значения формы усиления целевого временного описания равными друг другу. Одна такая реализация задачи T230 конфигурируется, чтобы установить все значения формы усиления равными коэффициенту один (например, ноль дБ). Другая такая реализация задачи T230 конфигурируется, чтобы установить все значения формы усиления равным коэффициенту 1/n, где n - количество значений формы усиления в целевом временном описании.
Задача T230 может быть конфигурирована для вычисления значения gt кадра усиления целевого временного описания согласно выражению, такому как gt=zgr или gt=wgr+(1-w)z, где gr - значение кадра усиления из опорной временной информации, z - случайное значение, и w - коэффициент взвешивания. Типичные диапазоны для значений z включают в себя от 0 до 1 и от -1 до +1. Типичные диапазоны значений для w включают в себя 0,5 (или 0,6) до 0,9 (или 1,0).
В типичном примере задача T230 конфигурируется для вычисления значения кадра усиления целевого временного описания на основании взвешенной версии значения кадра усиления опорной временной информации, как в выражении gt = wgr. Для случая, в котором задача T230 является вариантом более общей операции для обработки стирания, может быть желательно реализовать вес как коэффициент β ослабления. Может также быть желательно реализовать эту операцию таким образом, что значение коэффициента β ослабления уменьшается с каждым значением в последовательной последовательности стираний более высокого диапазона. Например, коэффициент β ослабления может иметь значение 0,9 для первого пакета в последовательности, 0,7 для второго пакета в последовательности, и 0,5 для последующих пакетов в последовательности. (В таком случае может быть желательно использовать одно и то же опорное значение кадра усиления для каждого пакета в последовательности стираний). В другом таком примере задача T230 конфигурируется для вычисления значения кадра усиления целевого временного описания на основании одного или более значений hri формы усиления из опорной временной информации, как в выражении gt = β gr × 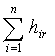 , где n - количество значений формы усиления в опорном речевом пакете.
, где n - количество значений формы усиления в опорном речевом пакете.
Задача T230 может быть конфигурирована для вычисления значения кадра усиления для целевого кадра на основании значений кадра усиления из двух или трех наиболее недавних опорных речевых пакетов. В одном таком примере задача T230 конфигурируется для вычисления значения кадра усиления целевого временного описания как среднего числа согласно выражению, такому как gt =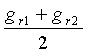 , где gr1 - значение кадра усиления наиболее недавнего опорного речевого пакета, и gr2 - значение кадра усиления из следующего наиболее недавнего опорного речевого пакета. В соответствующем примере опорные значения кадра усиления взвешиваются различным образом друг относительно друга (например, более новое значение может иметь больший вес). В другом примере задача T230 конфигурируется, чтобы применять коэффициент β ослабления к вычисленному среднему числу и/или включать в себя коэффициент, основанный на одном или более значениях формы усиления из опорной временной информации.
, где gr1 - значение кадра усиления наиболее недавнего опорного речевого пакета, и gr2 - значение кадра усиления из следующего наиболее недавнего опорного речевого пакета. В соответствующем примере опорные значения кадра усиления взвешиваются различным образом друг относительно друга (например, более новое значение может иметь больший вес). В другом примере задача T230 конфигурируется, чтобы применять коэффициент β ослабления к вычисленному среднему числу и/или включать в себя коэффициент, основанный на одном или более значениях формы усиления из опорной временной информации.
Реализации способа M200 (включая способы M210, M220 и M230) обычно конфигурируются так, чтобы включать в себя операцию, которая сохраняет опорную спектральную информацию в буфер. Такая реализация способа M200 может также включать в себя операцию, которая сохраняет опорную временную информацию в буфер. Альтернативно, такая реализация способа M200 может включать в себя операцию, которая сохраняет обе из опорной спектральной информации и опорной временной информации в буфер.
Реализация способа M200 может быть конфигурирована, чтобы сохранять информацию, основанную на текущем речевом пакете, как опорную спектральную информацию, если речевой пакет содержит описание спектральной огибающей по второму диапазону частот. В контексте набора схем кодирования, как показано на Фиг.12, например, такая реализация способа M200 может быть конфигурирована, чтобы сохранять опорную спектральную информацию, если индекс кодирования речевого пакета указывает любую из схем кодирования 1 и 3 (то есть вместо схем кодирования 2 или 4). В более общем случае такая реализация способа M200 может быть конфигурирована, чтобы сохранять опорную спектральную информацию, если индекс кодирования речевого пакета указывает широкополосную схему кодирования, а не узкополосную схему кодирования. Такие реализации способа M200 могут быть конфигурированы, чтобы сохранять опорную временную информацию согласно тем же самым критериям.
Может быть желательно реализовать способ M200 таким образом, что сохраненная опорная спектральная информация доступна для более чем одного опорного речевого пакета одновременно. Например, задача T230 может быть конфигурирована для вычисления целевого спектрального описания, которое основано на информации от более чем одного опорного речевого пакета. В таких случаях способ M200 может быть конфигурирован, чтобы поддерживать в памяти в любой момент времени опорную спектральную информацию из наиболее недавнего опорного речевого пакета, информацию из второго наиболее недавнего опорного речевого пакета и возможно также информацию от одного или более старых опорных речевых пакетов. Такой способ может также быть конфигурирован, чтобы поддерживать одну и ту же хронологию, или отличную хронологию, для опорной временной информации. Например, способ M200 может быть конфигурирован, чтобы сохранить описание спектральной огибающей из каждого из двух новых опорных речевых пакетов и описание временной информации от наиболее недавнего опорного речевого пакета.
В типичном применении реализации способа M200 массив логических элементов (например, логические вентили) конфигурируется, чтобы выполнять одну, более одной или даже все различные задачи этого способа. Одна или более (возможно все) задачи могут быть также реализованы как код (например, один или более наборов команд), воплощенных в компьютерном программном продукте (например, одном или более носителях хранения данных, таких как диски, платы флэш- или другой энергонезависимой памяти, микросхемы полупроводниковой памяти и т.д.), которые являются считываемыми и/или выполнимыми машиной (например, компьютером), включая массив логических элементов (например, процессор, микропроцессор, микроконтроллер или другой конечный автомат). Задачи реализации способа M200 могут быть также выполнены более чем одним таким массивом или машиной. В этих или других реализациях задачи могут быть выполнены в устройстве для беспроводного обмена, таких как мобильный телефон или другое устройство, имеющее такую возможность обмена. Такое устройство может быть конфигурировано, чтобы обмениваться с сетями с коммутацией каналов и/или с пакетной коммутацией (например, используя один или более протоколов, таких как VoIP). Например, такое устройство может включать в себя РЧ схему, конфигурированную для приема кодированных кадров.
Фиг.26A показывает блок-схему речевого декодера 200 для обработки кодированного речевого сигнала согласно общей конфигурации. Например, речевой декодер 200 может быть конфигурирован для выполнения способа декодирования речи, который включает в себя реализацию способа M200, как описано в настоящем описании. Речевой декодер 200 включает в себя логику 210 управления, которая конфигурируется для формирования сигнала управления, имеющего последовательность значений. Речевой декодер 200 также включает в себя декодер 220 пакетов, который конфигурируется для вычисления декодированных кадров речевого сигнала на основании значений сигнала управления и соответствующих речевых пакетах кодированного речевого сигнала.
Коммуникационное устройство, которое включает в себя речевой декодер 200, такой как мобильный телефон, может быть конфигурировано, чтобы принимать кодированный речевой сигнал из проводного, беспроводного или оптического канала передачи. Такое устройство может быть конфигурировано для выполнения операции предварительной обработки в отношении кодированного речевого сигнала, такой как декодирование с исправлением ошибок и/или кодами избыточности. Такое устройство может также включать в себя реализации как речевого кодера 100 так и речевого декодера 200 (например, в приемопередатчике).
Логика 210 управления конфигурируется для формирования сигнала управления, включающего в себя последовательность значений, которая основана на индексах кодирования речевых пакетов кодированного речевого сигнала. Каждое значение последовательности соответствует речевому пакету кодированного речевого сигнала (за исключением случая стертого кадра, как описано ниже) и имеет одно из множества состояний. В некоторых реализациях речевого декодера 200, как описано ниже, последовательность является двоичной (то есть последовательность высоких и низких значений). В других реализациях речевого декодера 200, как описано ниже, значения последовательности могут быть более двух состояний.
Логика 210 управления может быть конфигурирована для определения индекса кодирования для каждого речевого пакета. Например, логика 210 управления может быть конфигурирована, чтобы считывать по меньшей мере часть индекса кодирования из речевого пакета, чтобы определить скорость передачи в битах речевого пакета из одного или более параметров, таких как энергия кадра, и/или чтобы определить соответствующий режим кодирования из формата речевого пакета. Альтернативно, речевой декодер 200 может быть реализован так, чтобы включать в себя другой элемент, который конфигурируется для определения индекса кодирования для каждого речевого пакета и выдачи его логике 210 управления, или речевой декодер 200 может быть конфигурирован для приема индекса кодирования от другого модуля устройства, которое включает в себя речевой декодер 200.
Речевой пакет, который не принят так, как ожидается, или принят имеющим слишком много ошибок, которые должны быть восстановлены, называют стиранием кадра. Речевой декодер 200 может быть конфигурирован таким образом, что одно или более состояний индекса кодирования используются для указания стирания кадра или частичного стирания кадра, например, отсутствие части речевого пакета, который несет спектральную и временную информацию для второго диапазона частот. Например, речевой декодер 200 может быть конфигурирован таким образом, что индекс кодирования для речевого пакета, который был закодирован, используя схему 2 кодирования (как на Фиг.12), указывает стирание части кадра более высокого диапазона. В таком случае речевой декодер 200 может быть конфигурирован для выполнения реализации способа M200 в качестве случая общего способа обработки стирания. Речевой декодер 200 может также быть конфигурирован таким образом, что индекс кодирования для речевого пакета, который был закодирован, используя любую из схем 2 и 4 кодирования (как на Фиг.12), указывает стирание части кадра более высокого диапазона.
Декодер 220 пакетов конфигурируется для вычисления декодированных кадров, на основании значений сигнала управления и соответствующих речевых пакетах кодированного речевого сигнала. Когда значение сигнала управления имеет первое состояние, декодер 220 пакетов вычисляет декодированный кадр на основании описания спектральной огибающей по первому и второму диапазонам частот, где описание основано на информации из соответствующего речевого пакета. Когда значение сигнала управления имеет второе состояние, декодер 220 пакетов извлекает описание спектральной огибающей по второму диапазону частот и вычисляет декодированный кадр на основании извлеченного описания и описания спектральной огибающей по первому диапазону частот, где описание по первому диапазону частот основано на информации из соответствующего речевого пакета.
Фиг.26B показывает блок-схему реализации 202 речевого декодера 200. Речевой декодер 202 включает в себя реализацию 222 декодера 220 пакетов, который включает в себя первый модуль 230 и второй модуль 240. Модули 230 и 240 конфигурируются для вычисления соответствующих частей поддиапазона декодированных кадров. В частности, первый модуль 230 конфигурируется для вычисления декодированной части кадра по первому диапазону частот (например, узкополосный сигнал), и второй модуль 240 конфигурируется для вычисления, на основании значения сигнала управления, декодированной части кадра по второму диапазону частот (например, сигнал более высокого диапазона).
Фиг.26C показывает блок-схему реализации 204 речевого декодера 200. Синтаксический анализатор 250 конфигурируется для анализа битов речевого пакета, чтобы выдать индекс кодирования на логику 210 управления и по меньшей мере одно описание спектральной огибающей на декодер 220 пакетов. В этом примере речевой декодер 204 является также реализацией речевого декодера 202 таким образом, что синтаксический анализатор 250 конфигурируется для выдачи описания спектральных огибающих по соответствующим диапазонам частот (когда доступны) на модули 230 и 240. Синтаксический анализатор 250 может также быть конфигурирован для выдачи по меньшей мере одного описания временной информации на речевой декодер 220. Например, синтаксический анализатор 250 может быть реализован для выдачи описания временной информации для соответствующих диапазонов частот (когда доступны) на модули 230 и 240.
Синтаксический анализатор 250 может быть также конфигурирован так, чтобы анализировать биты закодированного кадра, который содержит речевой пакет, чтобы сформировать пачку информационного сигнала, которая является отдельной от речевого сигнала (например, пакет сигнализации или вторичного трафика, как описано выше). Альтернативно, речевой декодер 204 или устройство, содержащее речевой декодер 204, может быть в ином случае конфигурировано для анализа кодированного кадра, чтобы сформировать речевой пакет (например, в качестве входного сигнала к синтаксическому анализатору 250) и пачку.
Декодер пакетов 222 также включает в себя банк фильтров 260, который конфигурируется, чтобы комбинировать декодированные части кадров по первому и второму диапазонам частот, чтобы сформировать широкополосный речевой сигнал. Конкретные примеры таких банков фильтров описываются, например, в заявке на патент США US 2007/088558 (Vos и другие), "SYSTEMS, METHODS, AND APPARATUS FOR SPEECH SIGNAL FILTERING", поданной 19 апреля 2007. Например, банк фильтров 260 может включать в себя фильтр низких частот, конфигурированный для фильтрации узкополосного сигнала, чтобы сформировать сигнал первой полосы пропускания, и фильтр верхних частот, конфигурированный для фильтрации сигнала более высокого диапазона, чтобы сформировать сигнал второй полосы пропускания. Банк фильтров 260 может также включать в себя дискретизатор с повышением частоты, конфигурированный для увеличения частоты дискретизации узкополосного сигнала и/или сигнала более высокого диапазона, согласно требуемому соответствующему коэффициенту интерполяции, как описано в, например, заявке на патент США US 2007/088558 (Vos и др.).
Фиг.27A показывает блок-схему реализации 232 первого модуля 230, который включает в себя экземпляр 270a декодера 270 описания спектральной огибающей и экземпляр 280a декодера 280 описания временной информации. Декодер 270a описания спектральной огибающей конфигурируется для декодирования описания спектральной огибающей по первому диапазону частот (например, как принято от синтаксического анализатора 250). Декодер 280a описания временной информации конфигурируется для декодирования описания временной информации для первого диапазона частот (например, которая принята от синтаксического анализатора 250). Например, декодер 280a описания временной информации может быть конфигурирован для декодирования информации основного тона для первого диапазона частот. Декодер 280a описания временной информации может также быть конфигурирован для вычисления сигнала возбуждения для первого диапазона частот на основании декодированного описания (и возможно на временной информации от одного или более предыдущих кадров). Экземпляр 290a синтезирующего фильтра 290 конфигурируется для формирования декодированной части кадра по первому диапазону частот (например, узкополосного сигнала), которая основана на декодированных описаниях спектральной огибающей и временной информации. Например, синтезирующий фильтр 290a может быть конфигурирован согласно набору значений в описании спектральной огибающей по первому диапазону частот (например, одном или более векторов коэффициентов LSP или LPC), чтобы сформировать декодированную часть в ответ на сигнал возбуждения для первого диапазона частот.
Фиг.27B показывает блок-схему реализации 272 декодера 270 описания спектральной огибающей. Деквантователь 310 конфигурируется для деквантования описания, и блок 320 обратного преобразования конфигурируется для применения обратного преобразования к деквантованному описанию, чтобы получить набор коэффициентов LPC. Декодер 280 описания временной информации также обычно конфигурируется так, чтобы включать в себя деквантователь.
Фиг.28A показывает блок-схему реализации 242 второго модуля 240. Второй модуль 242 включает в себя экземпляр 270b декодера 270 описания спектральной огибающей, буфер 300 и селектор 340. Декодер 270b описания спектральной огибающей конфигурируется для декодирования описания спектральной огибающей по второму диапазону частот (например, как принято от синтаксического анализатора 250). Буфер 300 конфигурируется для сохранения одного или более описаний спектральной огибающей по второму диапазону частот в качестве опорной спектральной информации, и селектор 340 конфигурируется для выбора, согласно состоянию соответствующего значения сигнала управления, сгенерированного логикой 210 управления, декодированного описания спектральной огибающей или из (A) буфера 300 или из (B) декодера 270b.
Второй модуль 242 также включает в себя генератор 330 сигнала возбуждения более высокого диапазона и экземпляр 290b синтезирующего фильтра 290, который конфигурируется для формирования декодированной части кадра по второму диапазону частот (например, сигнала более высокого диапазона) на основании декодированного описания спектральной огибающей, принятой посредством селектора 340. Генератор 330 сигнала возбуждения более высокого диапазона конфигурируется для формирования сигнала возбуждения для второго диапазона частот, на основании сигнала возбуждения для первого диапазона частот (например, сформированного декодером 280a описания временной информации). Дополнительно или альтернативно, генератор 330 может быть конфигурирован для выполнения спектральной и/или амплитудной формы случайного шума, чтобы сгенерировать сигнал возбуждения более высокого диапазона. Генератор 330 может быть реализован как экземпляр генератора A60 сигнала возбуждения более высокого диапазона, как описано выше. Фильтр 290b синтеза конфигурируется согласно набору значений в описании спектральной огибающей по второму диапазону частот (например, одному или более из векторов коэффициентов LSP или LPC), чтобы сформировать декодированную часть кадра по второму диапазону частот в ответ на сигнал возбуждения более высокого диапазона.
В одном примере реализации речевого декодера 202, который включает в себя реализацию 242 второго модуля 240, логика 210 управления конфигурируется для вывода бинарного сигнала на селектор 340 таким образом, что каждое значение последовательности имеет состояние A или состояние В. В этом случае, если индекс кодирования текущего кадра указывает, что он неактивен, логика 210 управления генерирует значение, имеющее состояние A, которое заставляет селектор 340 выбирать выходной сигнал буфера 300 (то есть выбор A). Иначе, логика 210 управления генерирует значение, имеющее состояние В, которое заставляет селектор 340 выбирать выходной сигнал 270b (то есть выбор B).
Речевой декодер 202 может быть скомпонован таким образом, что логика 210 управления управляет работой буфера 300. Например, буфер 300 может быть скомпонован таким образом, что значение сигнала управления, который имеет состояние В, вынуждает буфер 300 сохранять выходной сигнал декодера 270b. Такое управление может быть реализовано посредством подачи сигнала управления на вход разрешения записи буфера 300, где этот вход конфигурируется таким образом, что состояние В соответствует своему активному состоянию. Альтернативно, логика 210 управления может быть реализована так, чтобы генерировать второй сигнал управления, также включающий в себя последовательность значений, которая основана на кодировании индексов речевых пакетов кодированного речевого сигнала, для управления работой буфера 300.
Фиг.28B показывает блок-схему реализации 244 второго модуля 240. Второй модуль 244 включает в себя декодер 270b описания спектральной огибающей и экземпляр 280b декодера 280 описания временной информации, который конфигурируется для декодирования описания временной информации для второго диапазона частот (например, как принято от синтаксического анализатора 250). Второй модуль 244 также включает в себя реализацию 302 буфера 300, который также конфигурируется для сохранения одного или более описаний временной информации по второму диапазону частот в качестве опорной временной информации.
Второй модуль 244 включает в себя реализацию 342 селектора 340, который конфигурируется для выбора, согласно состоянию соответствующего значения сигнала управления, сгенерированного логикой 210 управления, декодированного описания спектральной огибающей и декодированного описания временной информации или от (A) буфера 302 или от (B) декодеров 270b, 280b. Экземпляр 290b синтезирующего фильтра 290 конфигурируется для формирования декодированной части кадра по второму диапазону частот (например, сигнал более высокого диапазона), которая основана на декодированных описаниях спектральной огибающей и временной информации, принятых посредством селектора 342. В типичной реализации речевого декодера 202, которая включает в себя второй модуль 244, декодер 280b описания временной информации конфигурируется для формирования декодированного описания временной информации, которое включает в себя сигнал возбуждения для второго диапазона частот, и синтезирующий фильтр 290b конфигурируется согласно набору значений в описании спектральной огибающей по второму диапазону частот (например, один или более векторов коэффициентов LSP или LPC), чтобы сформировать декодированную часть кадра по второму диапазону частот в ответ на сигнал возбуждения.
Фиг.28C показывает блок-схему реализации 246 второго модуля 242, который включает в себя буфер 302 и селектор 342. Второй модуль 246 также включает в себя экземпляр 280c декодера 280 описания временной информации, который конфигурируется для декодирования описания временной огибающей для второго диапазона частот, и элемент 350 регулировки усиления (например, множитель или усилитель), который конфигурируется так, чтобы применять описание временной огибающей, принятой посредством селектора 342, к декодированной части кадра по второму диапазону частот. Для случая, в котором декодированное описание временной огибающей включает в себя значения формы усиления, элемент 350 регулировки усиления может включать в себя логику, конфигурированную для применения значений формы усиления к соответствующим подкадрам декодированной части.
Фиг.28A-28C показывают реализации второго модуля 240, в котором буфер 300 принимает полностью декодированные описания спектральных огибающих (и, в некоторых случаях, временной информации). Аналогичные реализации могут быть скомпонованы таким образом, что буфер 300 принимает описания, которые не полностью декодированы. Например, может быть желательно уменьшить требования к памяти посредством сохранения описания в квантованной форме (например, как принято от синтаксического анализатора 250). В таких случаях путь передачи сигналов от буфера 300 к селектору 340 может быть конфигурирован так, чтобы включать в себя логику декодирования, такую как деквантователь и/или блок инверсного преобразования.
Логика 210 управления может быть реализована для формирования единственного сигнала управления для управления работой селектора 340 и буфера 300. Альтернативно, логика 210 управления может быть реализована для формирования (1) сигнала управления, значениями которого являются по меньшей мере два возможных состояния, для управления работой селектора 340, и (2) второго сигнала управления, включающего в себя последовательность значений, которая основана на кодировании индексов закодированных кадров кодированного речевого сигнала, и значения которого имеют по меньшей мере два возможных состояния для управления работой буфера 300.
Может быть желательно реализовать речевой декодер 200 так, чтобы поддерживать декодирование как узкополосных, так и широкополосных речевых сигналов. Как отмечено выше, может быть желательно для кодера использовать узкополосную схему кодирования (например, схему кодирования 2 в примере на Фиг.12) для пониженных кадров. В таком случае только один индекс кодирования из такого речевого пакета может быть не достаточным, чтобы указать, должен ли речевой пакет быть декодирован как узкополосная речь или как широкополосная речь. Если кодер конфигурируется также для использования способа понизить-и-пакетировать в отношении кодированных кадров узкополосного канала, то даже присутствие пакета в том же самом кодированном кадре также может не помочь указать, должен ли речевой пакет быть декодирован как узкополосная речь или как широкополосная речь.
Поэтому может быть желательно конфигурировать элемент речевого декодера 200 (например, логику 210 управления или дополнительный управляющий элемент), чтобы поддерживать операционное значение, которое имеет по меньшей мере два состояния, соответствующих соответственно, узкополосной операции и широкополосной операции. Такой элемент может быть конфигурирован, чтобы разрешать или запрещать второй модуль 240, или разрешать или запрещать выходной сигнал части декодированного сигнала более высокого диапазона от второго модуля 240, на основании текущего состояния операционного значения. Элемент может быть конфигурирован для вычисления состояния операционного значения на основании такой информации как присутствие информационной пачки в речевом пакете, индексы кодирования одного или более наиболее недавних речевых пакетов из кодированного речевого сигнала, и/или индексы кодирования одного или более последующих речевых пакетов из кодированного речевого сигнала.
Например, такой элемент может быть конфигурирован так, чтобы заставить текущее состояние операционного значения указывать широкополосную операцию, если схема кодирования наиболее недавнего речевого пакета указывает широкополосную схему кодирования. В другом примере такой элемент может быть конфигурирован так, чтобы заставить текущее состояние операционного значения указывать широкополосную операцию, если индекс кодирования текущего речевого пакета указывает схему кодирования, которая используется для широкополосного понижения. В другом примере такой элемент может быть конфигурирован, чтобы устанавливать текущее состояние операционного значения для указания широкополосной операции, если (A) индекс кодирования текущего речевого пакета указывает широкополосную схему кодирования, или (B) индекс кодирования текущего речевого пакета указывает схему кодирования, которая может использоваться для широкополосного понижения, текущий кодированный кадр включает в себя информационный пакет, и схема кодирования наиболее недавнего речевого пакета (альтернативно, по меньшей мере один из двух наиболее недавних речевых пакетов) указывает широкополосную схему кодирования. В другом примере такой элемент также может быть конфигурирован, чтобы устанавливать текущее состояние операционного значения для указания широкополосной операции, если (C) индекс кодирования текущего речевого пакета указывает схему кодирования, которая может использоваться для широкополосного понижения, текущий кодированный кадр включает в себя информационную пачку, схема кодирования наиболее недавнего речевого пакета указывает стирание кадра, и схема кодирования второго наиболее недавнего речевого пакета указывает широкополосную схему кодирования.
Различные элементы реализации речевого декодера 200 могут быть воплощены в любой комбинации аппаратного обеспечения, программного обеспечения и/или программно-аппаратного обеспечения, которая как считается, является подходящей для намеченного применения. Например, такие элементы могут быть изготовлены как электронные и/или оптические устройства, например, на одной и той же микросхеме или на двух или более микросхемах из набора микросхем. Одним примером такого устройства является прошитый или программируемый массив логических элементов, таких как транзисторы или логические вентили, и любой из этих элементов может быть реализован как один или более таких массивов. Любые два или более, или даже все, этих элементов могут быть реализованы в одном и том же массиве или массивах. Такие массив или массивы могут быть реализованы в одной или более микросхемах (например, в наборе микросхем, включающем в себя две или более микросхем).
Один или более элементов различных реализаций речевого декодера 200, который описан здесь, могут быть также реализованы полностью или частично как один или более наборов команд, выполненных с возможностью выполняться на одном или более прошитых или программируемых массивах логических элементов, таких как микропроцессоры, встроенные процессоры, IP-ядра, цифровые процессоры сигналов, FPGA (программируемые пользователем вентильные матрицы), ASSP (специфические для приложения стандартные продукты), и ASIC (специализированные интегральные схемы). Любой из различных элементов реализации речевого декодера 200 может также быть воплощен как один или более компьютеров (например, машины, включающие один или более массивов, запрограммированных для выполнения одного или более наборов или последовательностей команд, также называемых "процессорами"), и любые два или более, или даже все, этих элементов могут быть реализованы в одном и том же компьютере или компьютерах.
Различные элементы реализации речевого декодера 200 могут быть включены в устройство для беспроводной связи, такое как мобильный телефон или другое устройство, имеющее такую возможность обмена. Такое устройство может быть конфигурировано для обмена с сетями с коммутацией каналов и/или с пакетной коммутацией (например, используя один или более протоколов, таких как VoIP). Такое устройство может быть конфигурировано для выполнения операций в отношении сигнала, несущего кодированные кадры, таких как обратное перемежение, обратное прокалывание, декодирование одного или более сверточных кодов, декодирование одного или более кодов с исправлением ошибок, декодирование одного или более уровней сетевого протокола (например, Ethernet, TCP/IP, cdma2000), радиочастотную (РЧ) демодуляцию и/или РЧ прием.
Возможно, что один или более элементов реализации речевого декодера 200 используются для выполнения задачи или выполнения других наборов команд, которые непосредственно не относятся к работе речевого декодера, такой как задача, относящаяся к работе другого устройства или системы, в которую внедрен речевой декодер. Также возможно, что один или более элементов реализации речевого декодера 200 будут иметь общую структуру (например, процессор, используемый для выполнения части кода, соответствующего различным элементам в различные моменты времени, набор команд, выполняемых для выполнения задач, соответствующих различным элементам в разное время, или конструкция из электронных и/или оптических устройств для различных элементов в разное время). В одном таком примере логика 210 управления, первый модуль 230 и второй модуль 240 реализуются как наборы команд, выполненные с возможностью выполнения на одном и том же процессоре. В другом таком примере декодеры 270a и 270b описания спектральной огибающей реализуются как один и тот же набор команд, выполняющийся в разное время.
Устройство для беспроводной связи, такое как мобильный телефон или другое устройство, имеющее возможность такой связи, может быть конфигурировано, чтобы включать в себя реализации как речевого кодера 100, так и речевого декодера 200. В таком случае возможно, что речевой кодер 100 и речевой декодер 200 будут иметь общую структуру. В одном таком примере речевой кодер 100 и речевой декодер 200 реализуются так, чтобы включать в себя наборы команд, которые выполнены с возможностью выполнения на одном и том же процессоре.
Предшествующее представление описанных конфигураций предоставлено, чтобы позволить любому человеку, квалифицированному в технике, изготовить или использовать способы и другие структуры, раскрытые здесь. Последовательности операций, блок-схемы, диаграммы состояний и другие структуры, показанные и описанные здесь, являются только примерами, и другие варианты этих структур также находятся в рамках настоящего раскрытия. Различные модификации к этим конфигурациям возможны, и универсальные принципы, представленные здесь, также могут быть применены к другим конфигурациям. Например, различные элементы и задачи, описанные здесь, для обработки части более высокого диапазона речевого сигнала, которая включает в себя частоты выше диапазона узкополосной части речевого сигнала, могут быть применены альтернативно или дополнительно, и аналогичным способом, для обработки части более низкого диапазона речевого сигнала, которая включает в себя частоты ниже диапазона узкополосной части речевого сигнала. В таком случае раскрытые методики и структуры для получения сигнала возбуждения более высокого диапазона из узкополосного сигнала возбуждения могут быть использованы для получения сигнала возбуждения более низкого диапазона из узкополосного сигнала возбуждения. Таким образом, настоящее раскрытие не предназначено быть ограниченным конфигурациями, показанными выше, а скорее должно иметь самый широкий объем, совместимый с принципами и новыми признаками, раскрытыми здесь в любом виде, включая прилагаемые пункты формулы, как поданы, которые являются частью первоначального раскрытия.
Примеры кодеков, которые могут использоваться с, или адаптированы для использования с, речевыми кодерами, способами кодирования речи, речевыми декодерами, и/или способами декодирования речи, как описано здесь, включают в себя Усовершенствованный Кодек с Переменной Скоростью (EVRCB), как описано в документе 3GPP2 версии 1.0 C.S0014-C, "Enhanced Variable Rate Codec, Speech Service Options 3, 68, and 70 for Wideband Spread Spectrum Digital Systems" (Проект Партнерства Третьего поколения 2, Arlington, Вирджиния, январь 2007); Адаптивный речевой кодек с множеством скоростей передачи (AMR), как описано в документе ETSI TS 126 092 V6.0.0 (Европейский институт стандартизации электросвязи (ETSI), София Antipolis Cedex, FR, декабрь 2004); и AMR широкополосный речевой кодек, как описано в документе ETSI TS 126 192 V6.0.0 (ETSI, декабрь 2004).
Специалисты поймут, что информация и сигналы могут быть представлены, используя любое множество различных технологий и способов. Например, данные, инструкции, команды, информация, сигналы, биты и символы, на которые имеются ссылки по вышеупомянутому описанию, могут быть представлены напряжениями, токами, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами или любой их комбинацией. Хотя сигнал, из которого получают речевые пакеты, называют "речевым сигналом", и хотя эти пакеты называют "речевыми пакетами", также рассматривается и тем самым раскрыто, что этот сигнал может передавать музыку или другой неречевой информационный контент во время активных кадров.
Специалисты поймут, что различные иллюстративные логические блоки, модули, схемы и операции, описанные совместно с конфигурациями, раскрытыми здесь, могут быть реализованы как электронное аппаратное обеспечение, программное обеспечение или их комбинация. Такие логические блоки, модули, схемы и операции могут быть реализованы или выполнены процессором общего назначения, цифровым процессором сигналов (DSP), специализированными интегральными схемами, FPGA или другим программируемым логическим устройством, дискретным логическим элементом или транзисторной логикой, дискретными компонентами аппаратного обеспечения или любой из комбинаций, предназначенной для выполнения функций, описанных здесь. Процессор общего назначения может быть микропроцессором, но альтернативно, процессор может быть любым обычным процессором, контроллером, микроконтроллером или конечным автоматом. Процессор может также быть реализован как комбинация вычислительных устройств, например комбинация DSP и микропроцессора, множество микропроцессоров, один или более микропроцессоров вместе с ядром DSP или любая другая такая конфигурация.
Задачи способов и алгоритмов, описанных в настоящем описании, могут быть воплощены непосредственно в аппаратном обеспечении, в программном модуле, выполняемом процессором, или их комбинации. Программный модуль может постоянно находиться в памяти RAM, флэш-памяти, памяти ROM, памяти EPROM, памяти EEPROM, регистрах, на жестком диске, сменном диске, CD-ROM, или любой другой форме носителя данных, известного в технике. Иллюстративный носитель данных подсоединяется к процессору, так что процессор может считывать информацию с, и записывать информацию на носитель данных. Альтернативно носитель данных может являться неотъемлемой частью процессора. Процессор и носитель данных могут постоянно находиться в специализированных интегральных схемах. Специализированные интегральные схемы могут постоянно находиться в пользовательском терминале. Альтернативно процессор и носитель данных могут постоянно находиться в качестве дискретных компонентов в пользовательском терминале.
Каждая из конфигураций, описанных в настоящем описании, может быть реализована, по меньшей мере частично, как аппаратная схема, как схемная конфигурация, изготовленная в виде ориентированной на приложение интегральной схеме, или как программа программно-аппаратного обеспечения, загруженная в энергонезависимую память, или программа, загруженная из или в среду хранения данных в виде машино-считываемого кода, причем такой код может быть командами, выполняемыми массивом логических элементов, таких как микропроцессор или другой цифровой модуль обработки сигналов. Среда хранения данных может быть массивом элементов памяти, таких как полупроводниковая память (которая может включать в себя без ограничения динамическую или статическую RAM (ОЗУ), ROM (ПЗУ), и/или перепрограммируемую RAM), или сегнетоэлектрик, магниторезистивную, память на аморфных полупроводниках, полимерную или с изменением фазы; или дисковый носитель, такой как магнитный или оптический диск. Термин "программное обеспечение" должен пониматься как включающий в себя исходный код, код на языке ассемблера, машинный код, двоичный код, программно-аппаратное обеспечение, макрокоманду, микрокод, любой один или более наборов или последовательностей команд, выполняемых массивом логических элементов, и любую комбинацию таких примеров.
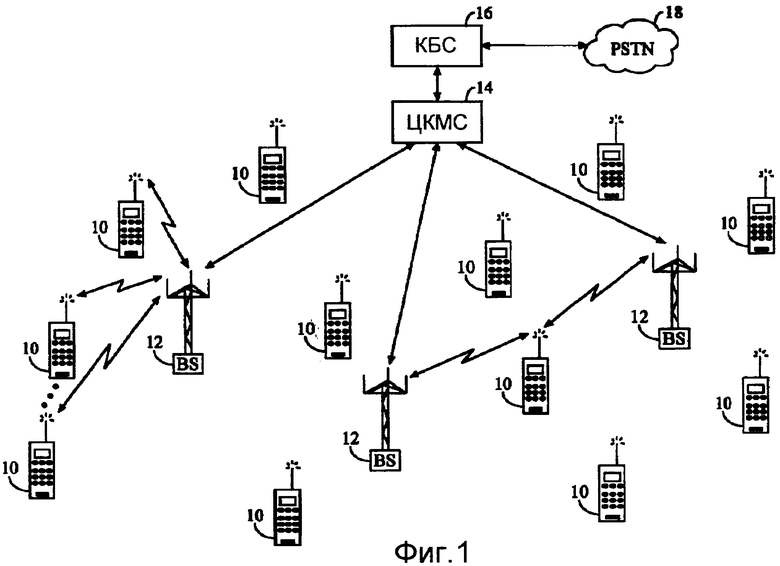
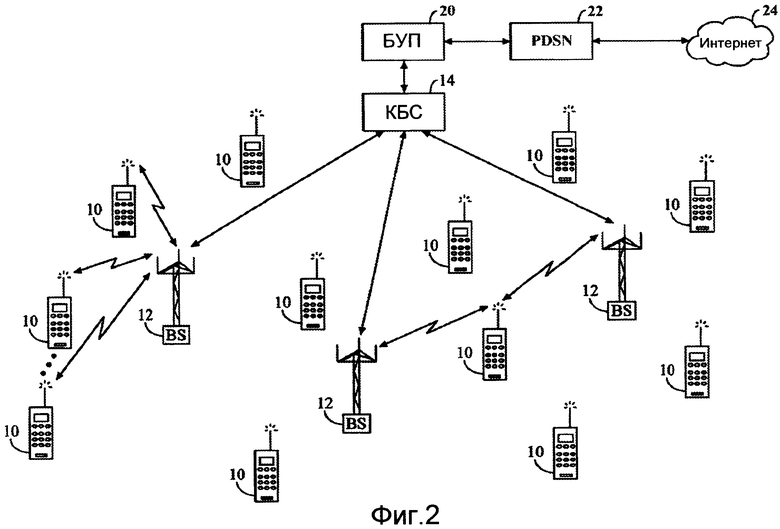


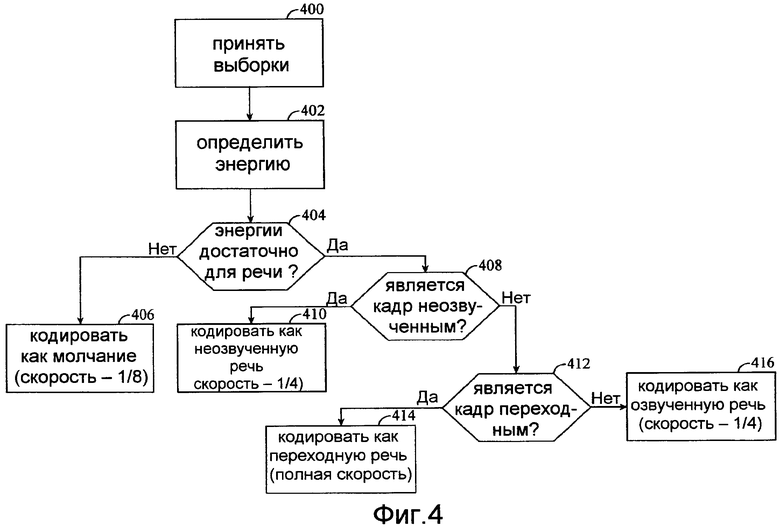
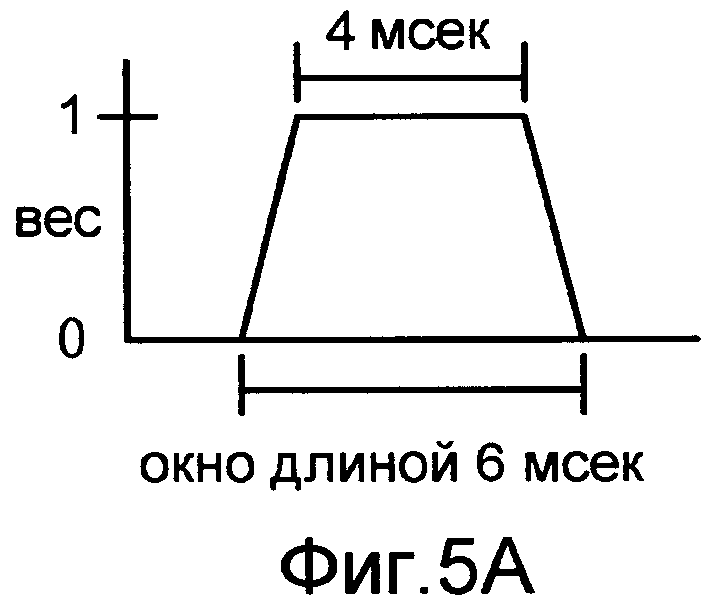
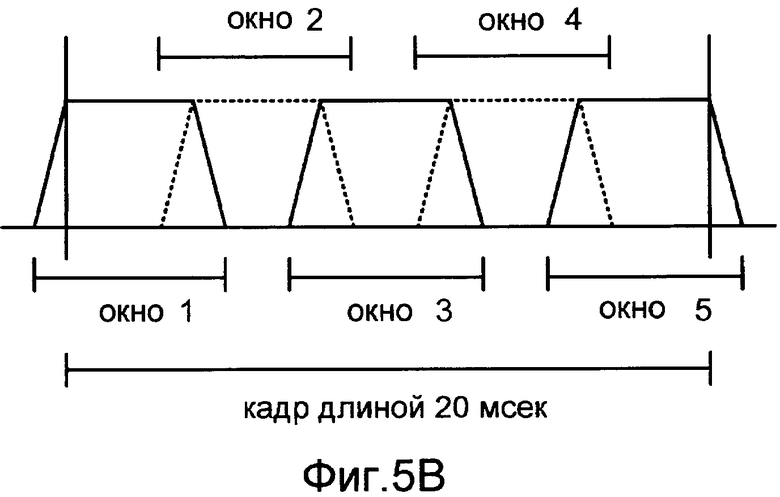
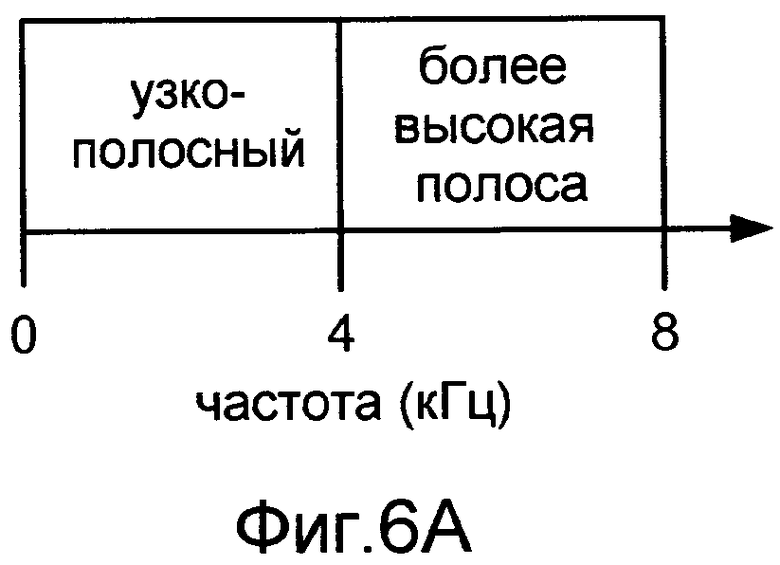
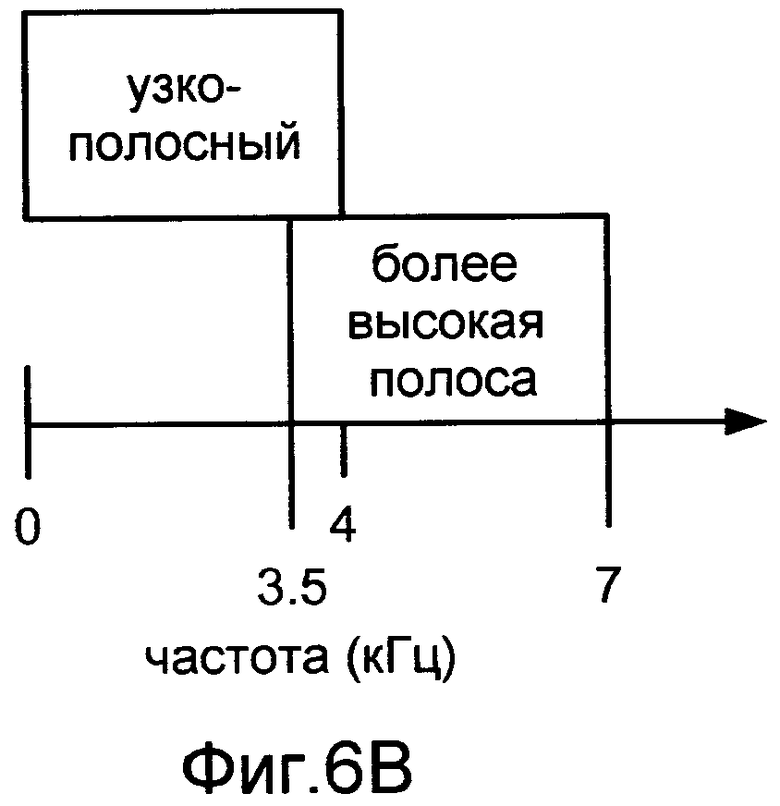
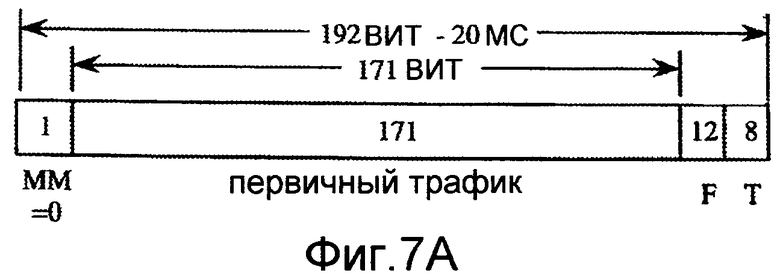
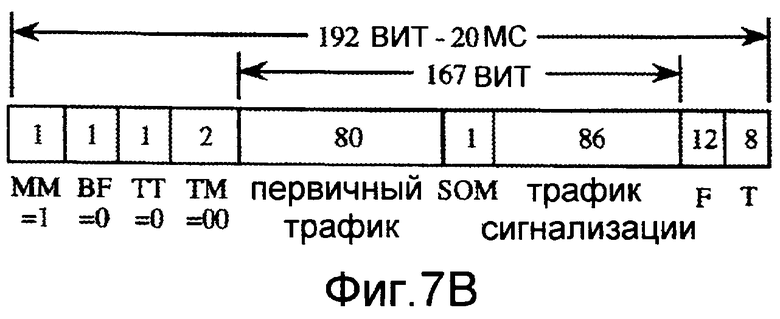
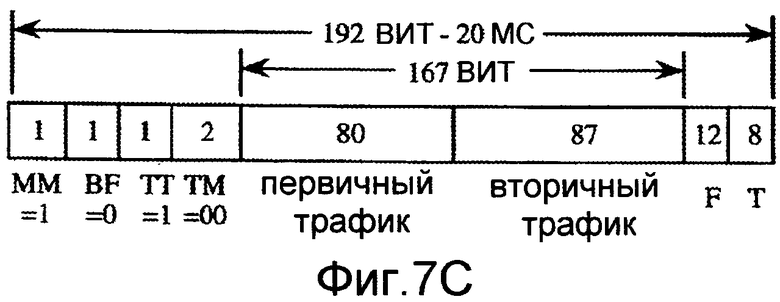
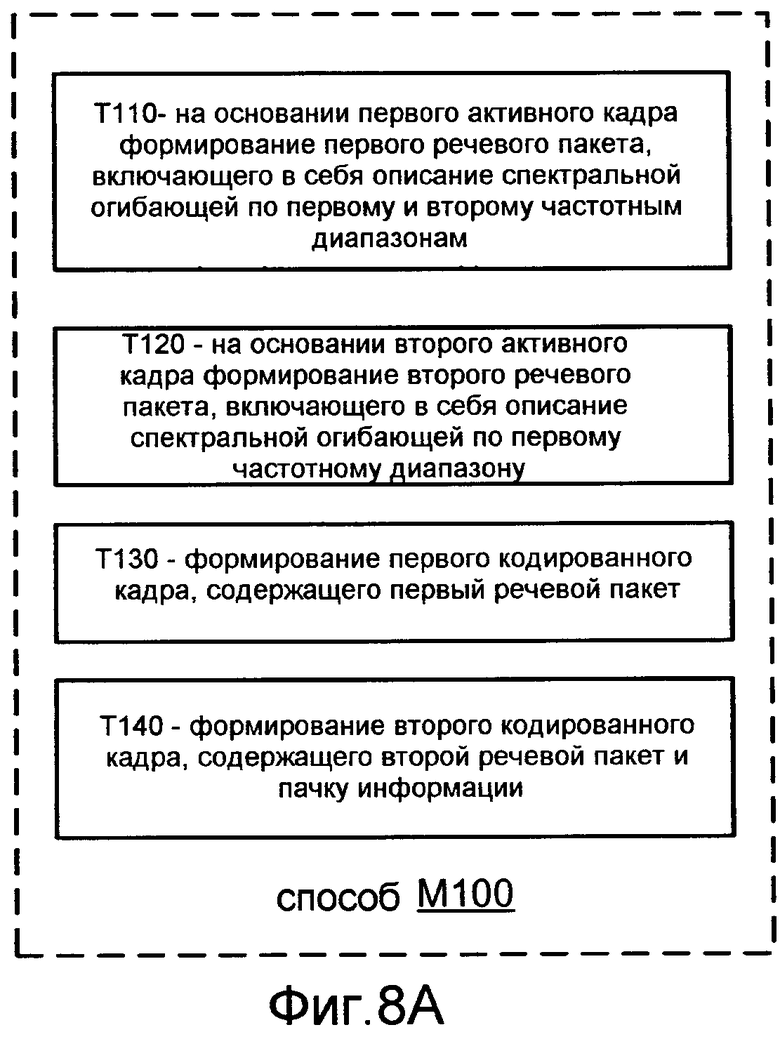


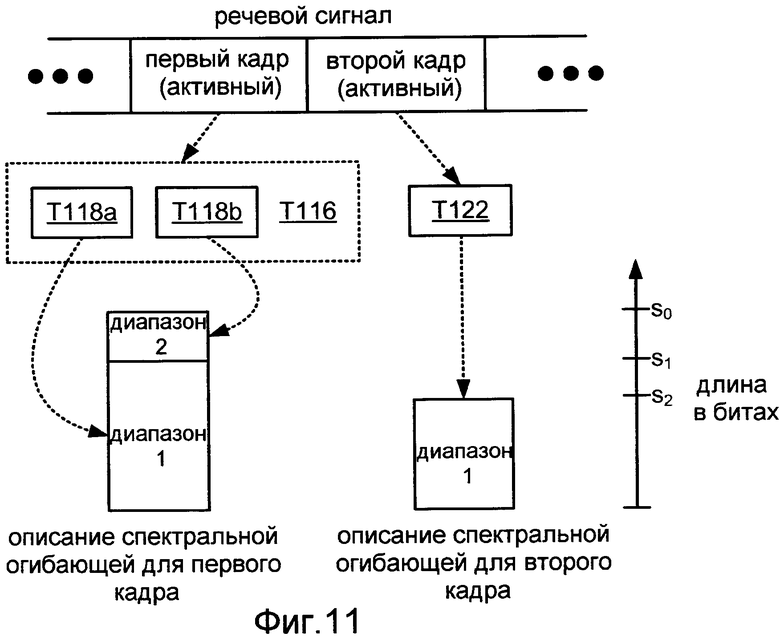

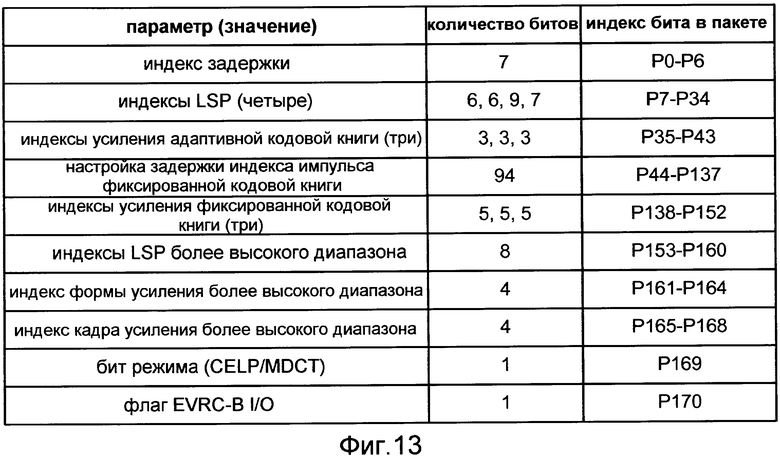
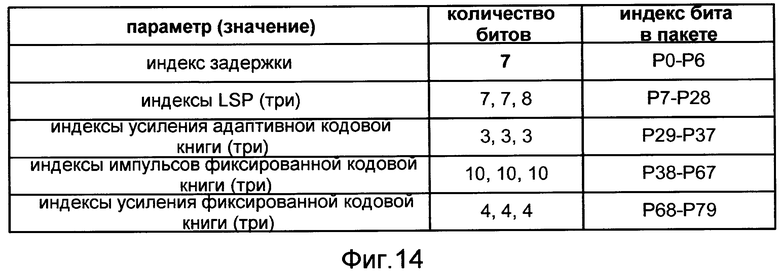
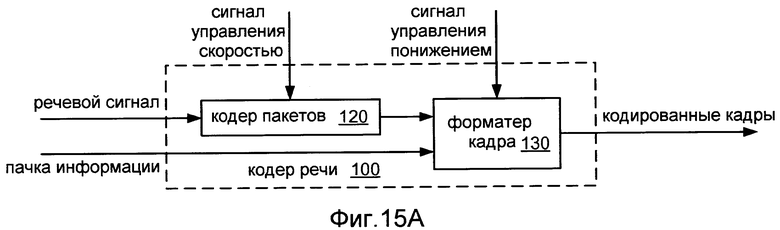


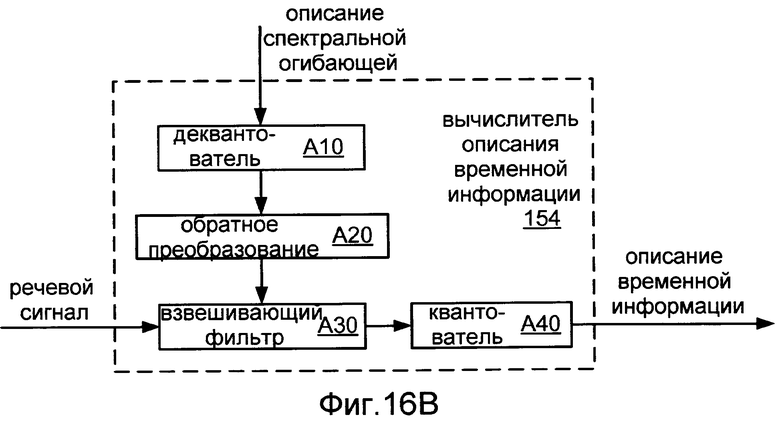
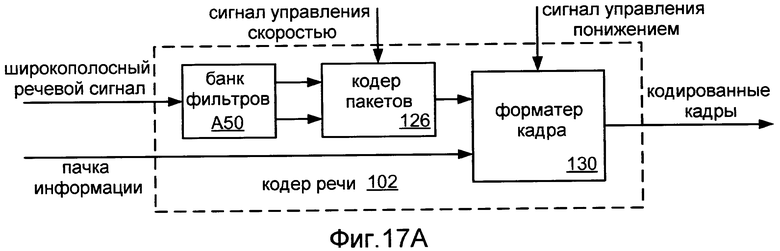

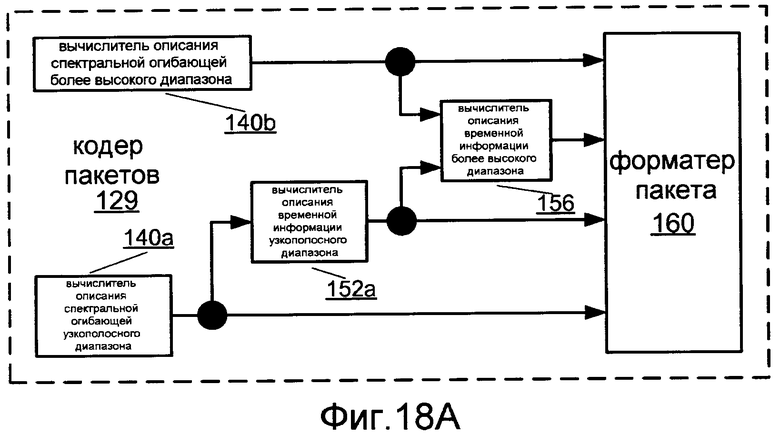
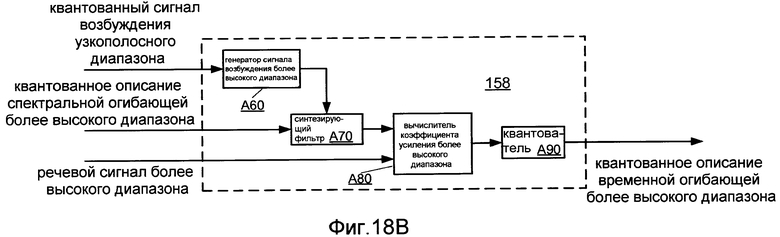
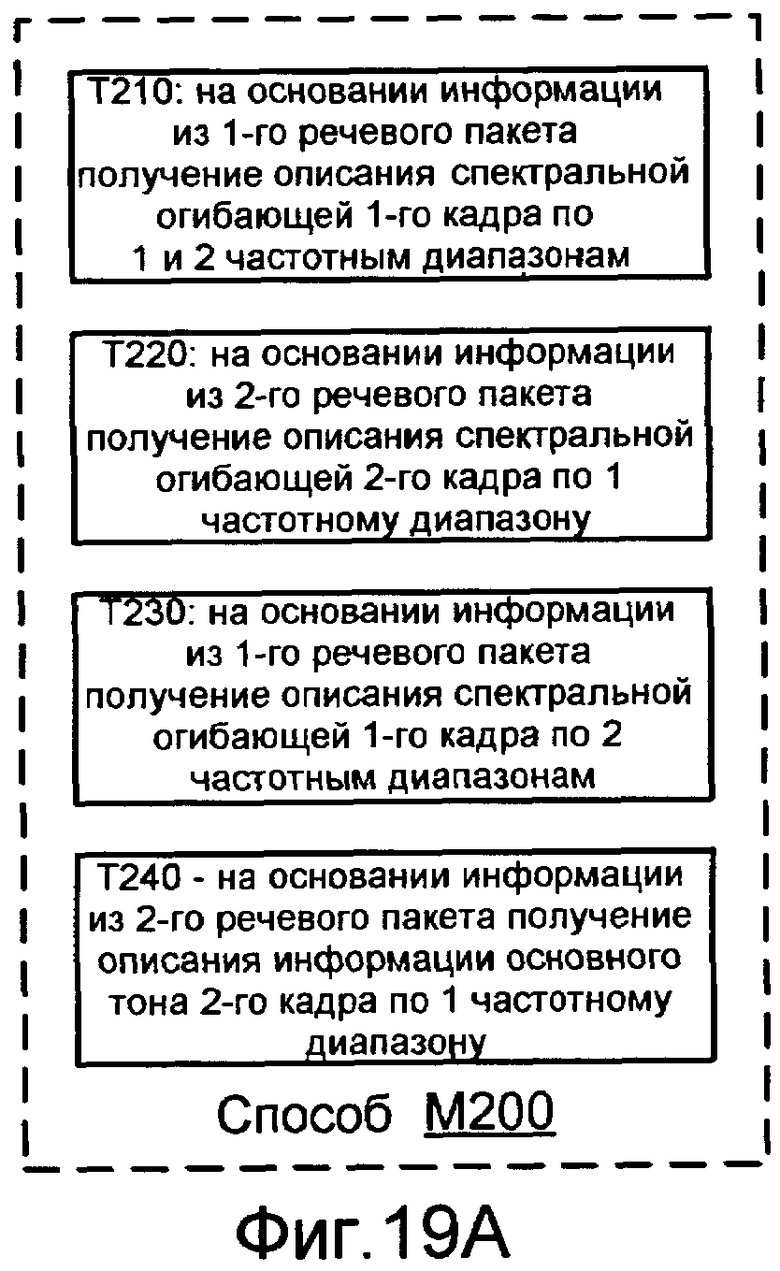

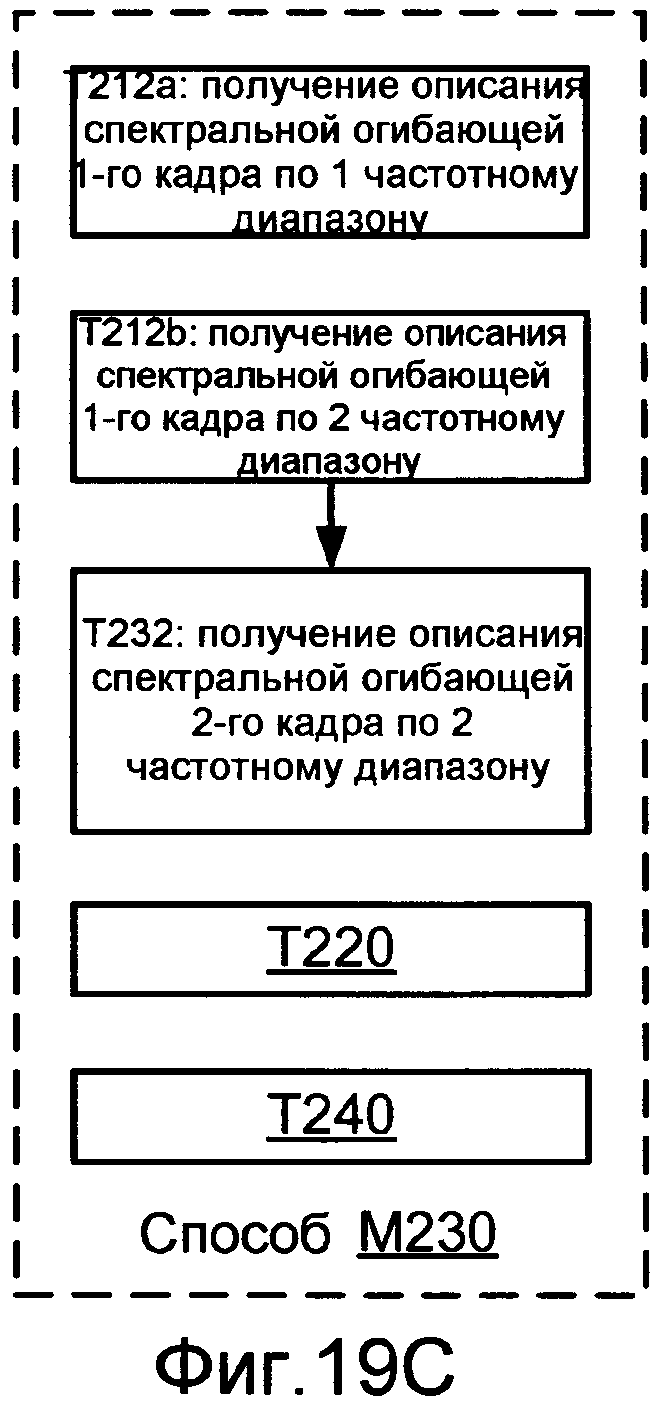
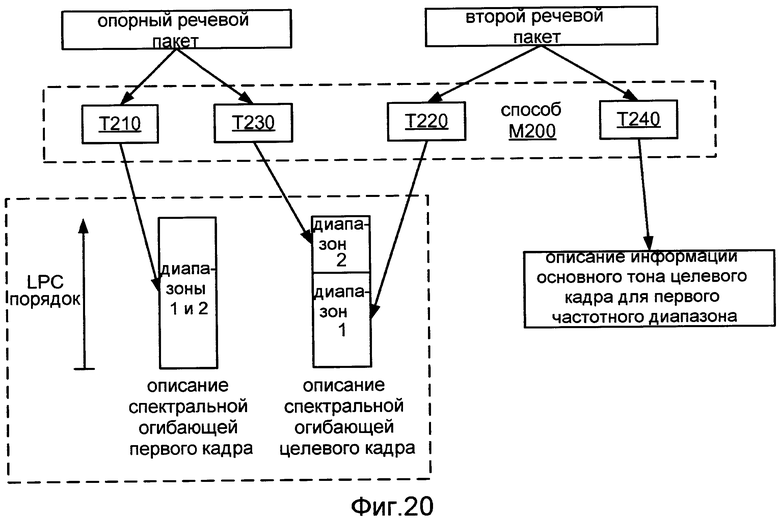
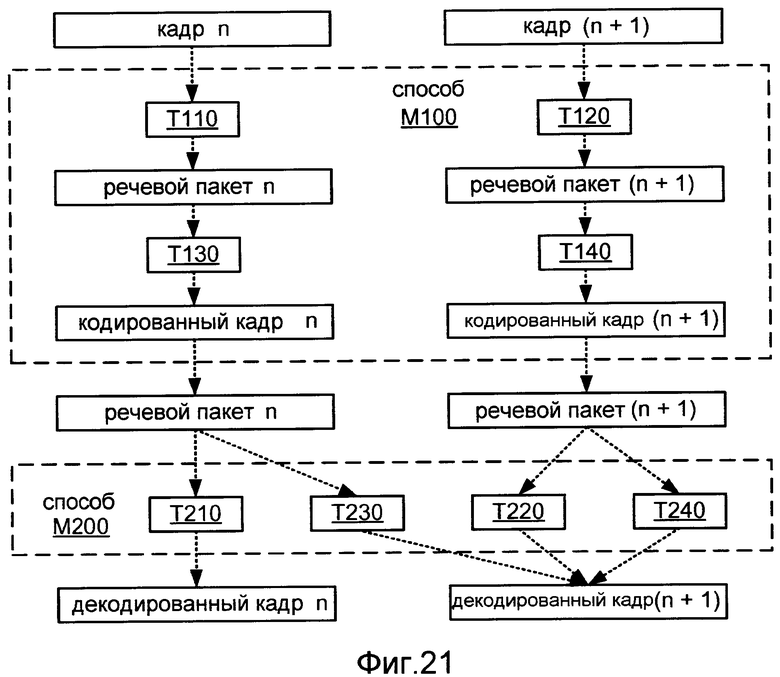
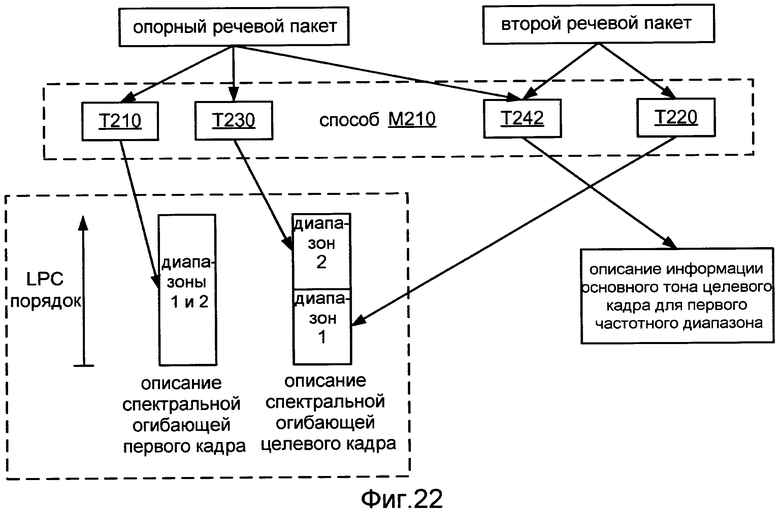
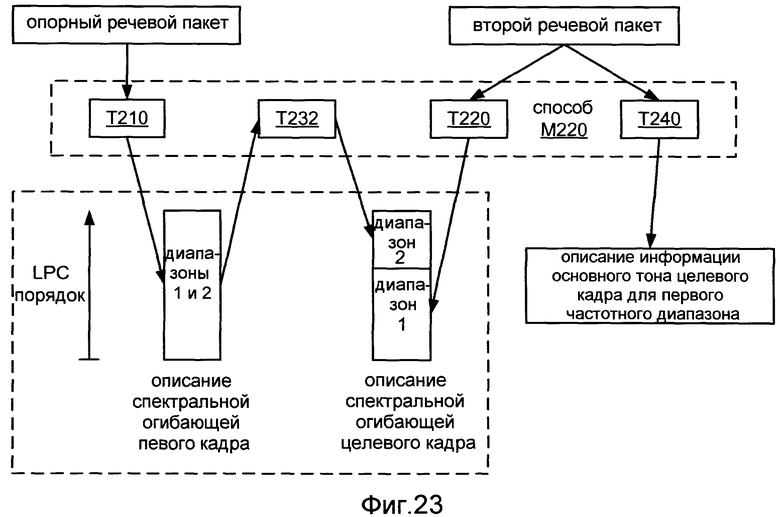
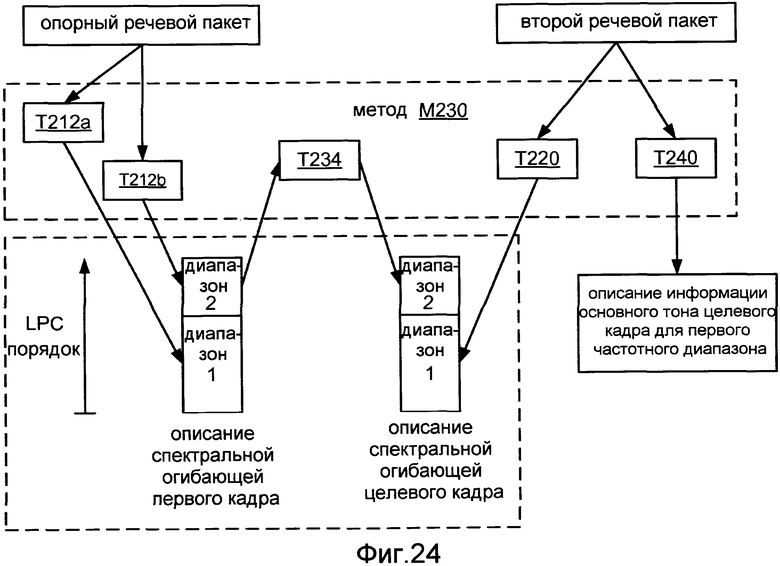
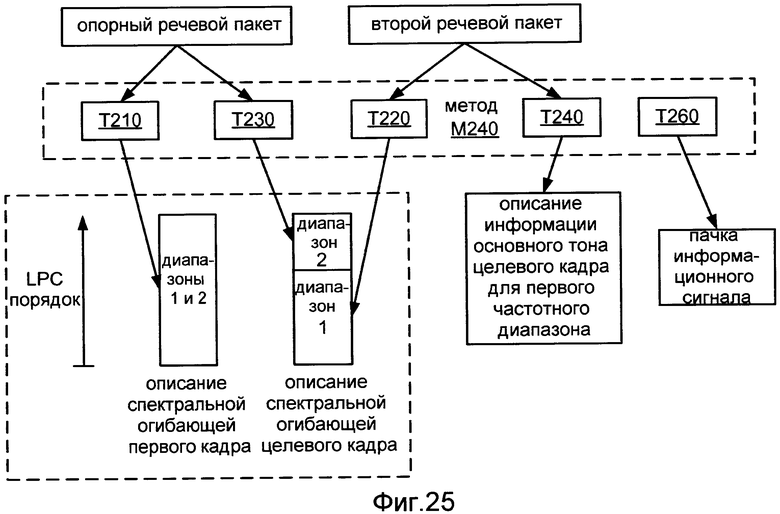
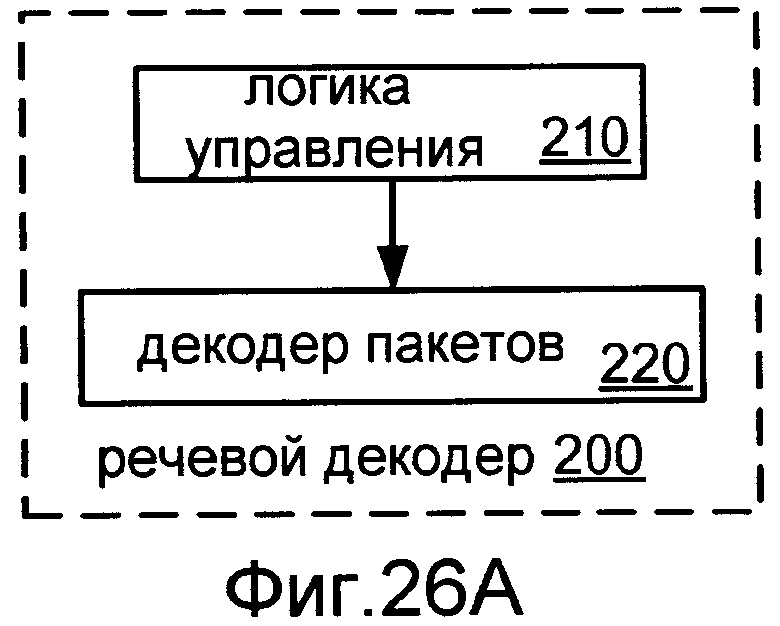
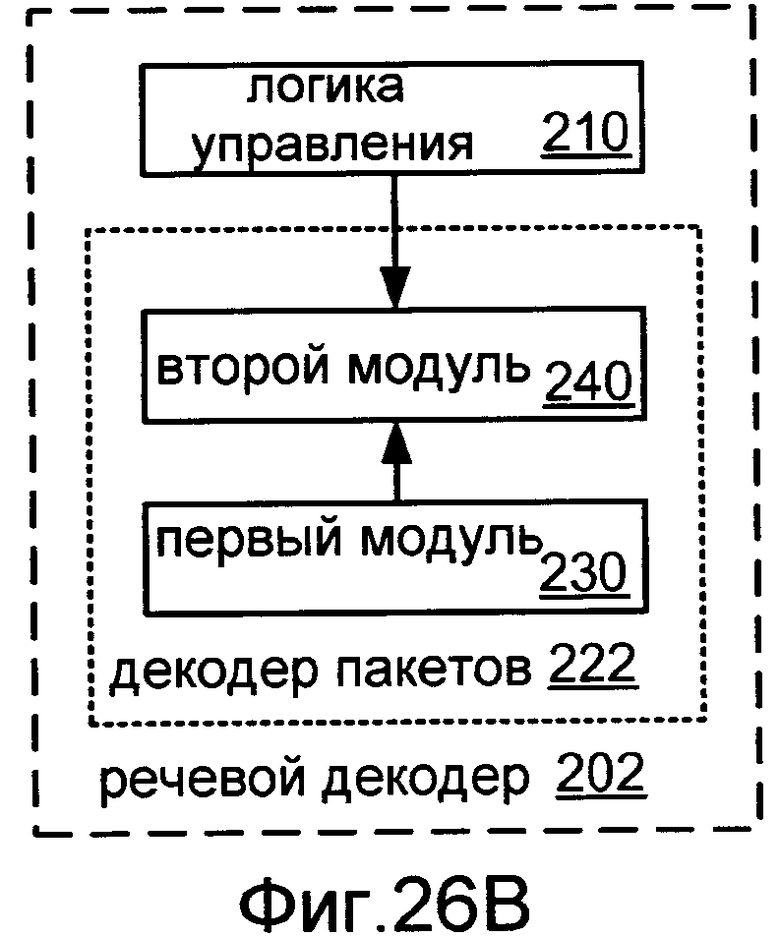
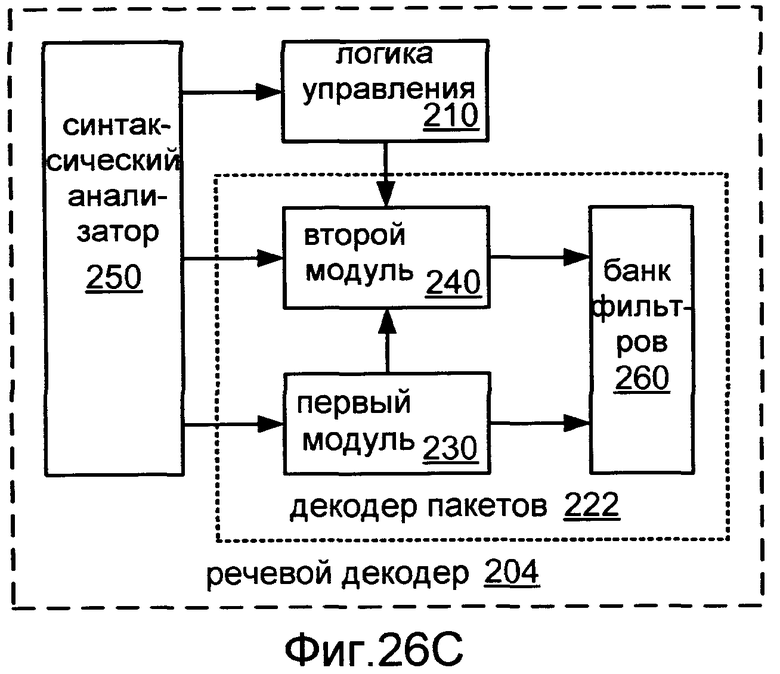
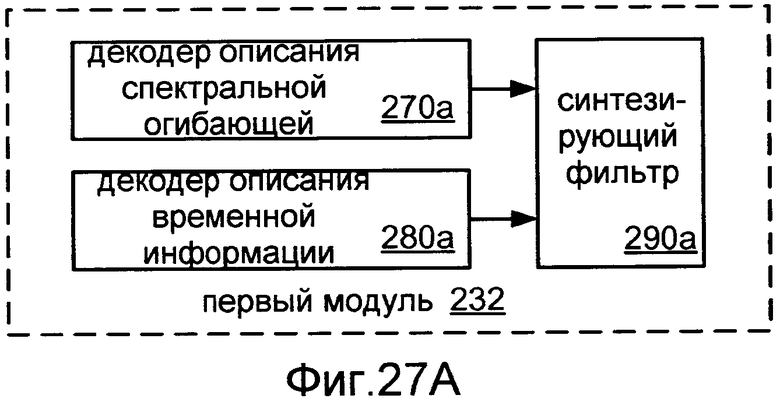
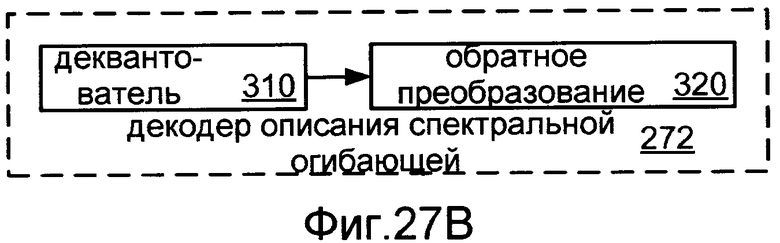
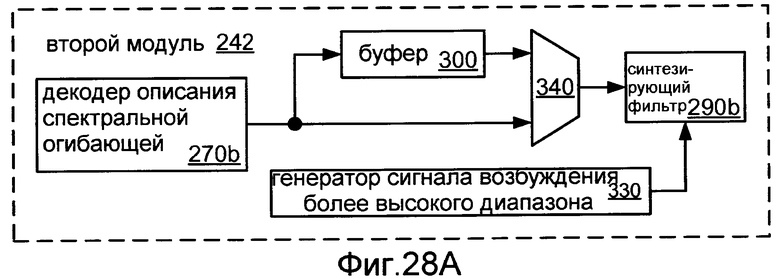
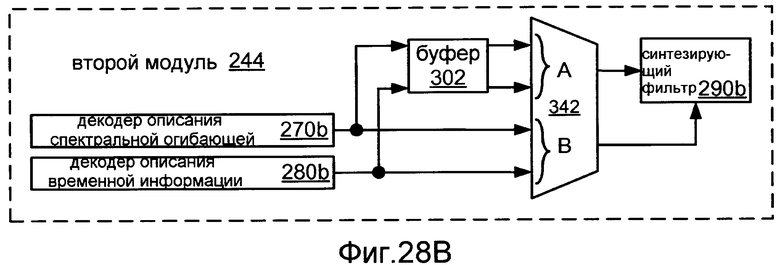
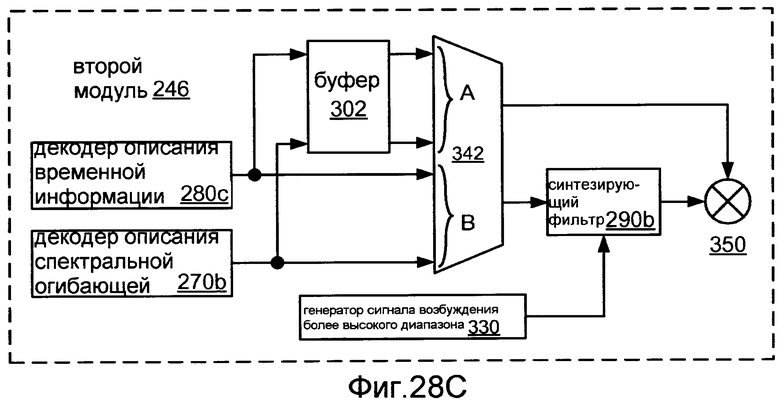
Изобретение относится к обработке речевых сигналов. Описаны применения методик понизить-и-пакетировать к кодированию широкополосных речевых сигналов. Также описывается реконструкция части кадра более высокого диапазона широкополосного речевого сигнала, используя информацию от предыдущего кадра. Технический результат - улучшение разборчивости речи путем расширения диапазона, поддерживаемого речевым кодером, до более высоких частот. 4 н. и 8 з.п. ф-лы, 46 ил.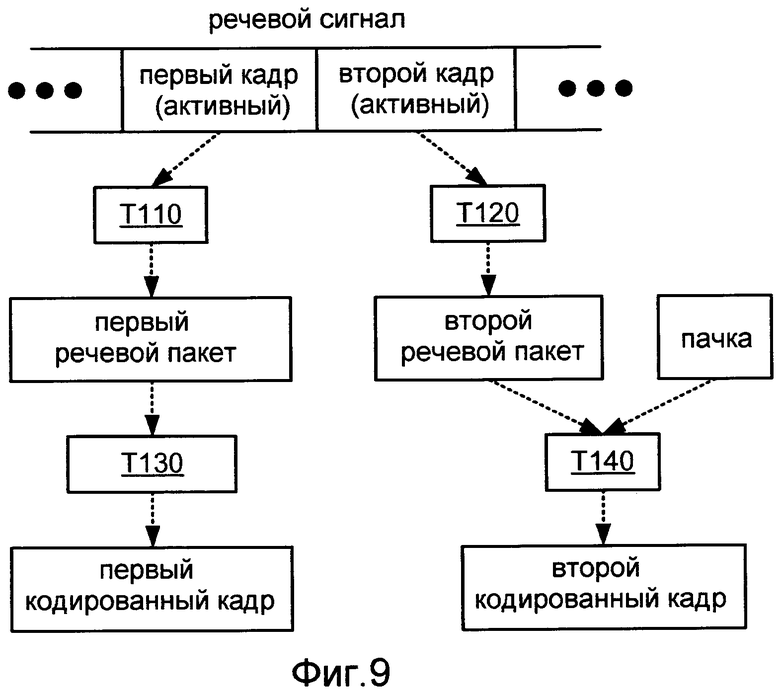
1. Способ обработки речевого сигнала, упомянутый способ содержит этапы:
на основании первого активного кадра речевого сигнала формируют первый речевой пакет, который включает в себя описание спектральной огибающей по (А) первому диапазону частот и (В) второму диапазону частот, который располагается выше первого диапазона частот, части речевого сигнала, который включает в себя первый активный кадр; и
на основании второго активного кадра речевого сигнала формируют второй речевой пакет, который включает в себя описание спектральной огибающей, по первому диапазону частот, части речевого сигнала, который включает в себя второй активный кадр,
при этом второй речевой пакет не включает в себя описание спектральной огибающей по второму диапазону частот,
при этом упомянутый способ содержит формирование кодированного кадра, который содержит (А) второй речевой пакет и (В) пачку информационного сигнала, которая является отдельной от речевого сигнала.
2. Способ по п.1, в котором длина пачки меньше, чем длина второго речевого пакета.
3. Способ по п.1, в котором длина пачки равна длине второго речевого пакета.
4. Способ по п.1, в котором длина пачки больше, чем длина второго речевого пакета.
5. Способ по любому одному из пп.1-4, в котором упомянутый второй активный кадр находится в речевом сигнале непосредственно после упомянутого первого активного кадра.
6. Способ по любому одному из пп.1-4, в котором описание спектральной огибающей части речевого сигнала, который включает в себя первый активный кадр, включает в себя отдельные первое и второе описания, при этом первое описание есть описание спектральной огибающей, по первому диапазону частот, части речевого сигнала, который включает в себя первый активный кадр, и в котором второе описание есть описание спектральной огибающей, по второму диапазону частот, части речевого сигнала, который включает в себя первый активный кадр.
7. Способ по любому одному из пп.1-4, в котором первый и второй диапазоны частот перекрываются, по меньшей мере, на двести герц.
8. Способ по любому одному из пп.1-4, в котором второй диапазон частот имеет нижнюю границу не менее чем 3 килогерц.
9. Способ по любому одному из пп.1-4, в котором упомянутый способ содержит этапы:
на основании информации из первого активного кадра генерирование первого сигнала выбора скорости передачи, который указывает широкополосную схему кодирования:
на основании информации из второго активного кадра генерирование второго сигнала выбора скорости передачи, который указывает широкополосную схему кодирования:
на основании информации из файла маски генерирование сигнала управления понижением;
на основании состояния сигнала управления понижением, который соответствует второму активному кадру, выбор узкополосной схемы кодирования;
причем упомянутое генерирование первого речевого пакета содержит генерирование первого речевого пакета в ответ на упомянутый первый сигнал выбора скорости передачи, и
причем упомянутое генерирование второго речевого пакета содержит генерирование второго речевого пакета в ответ на упомянутый выбор узкополосной схемы кодирования.
10. Устройство для обработки речевого сигнала, причем упомянутое устройство содержит:
средство для формирования, на основании первого активного кадра речевого сигнала, первого речевого пакета, который включает в себя описание спектральной огибающей, по (А) первому диапазону частот и (В) второму диапазону частот, который располагается выше первого диапазона частот, части речевого сигнала, который включает в себя первый активный кадр; и
средство для формирования, на основании второго активного кадра речевого сигнала, второго речевого пакета, который включает в себя описание спектральной огибающей, по первому диапазону частот, части речевого сигнала, который включает в себя второй активный кадр,
при этом второй речевой пакет не включает в себя описание спектральной огибающей по второму диапазону частот, и
при этом упомянутое устройство содержит средство для формирования кодированного кадра, который содержит (А) второй речевой пакет и (В) пачку информационного сигнала, которая является отдельной от речевого сигнала.
11. Считываемый компьютером носитель, при этом упомянутый носитель содержит:
программный код для вынуждения, по меньшей мере, одного компьютера сформировать, на основании первого активного кадра речевого сигнала, первый речевой пакет, который включает в себя описание спектральной огибающей, по (А) первому диапазону частот и (В) второму диапазону частот, который располагается выше первого диапазона частот, части речевого сигнала, который включает в себя первый активный кадр; и
программный код для вынуждения, по меньшей мере, одного компьютера сформировать, на основании второго активного кадра речевого сигнала, второй речевой пакет, который включает в себя описание спектральной огибающей, по первому диапазону частот, части речевого сигнала, который включает в себя второй активный кадр,
программный код для вынуждения, по меньшей мере, одного компьютера сформировать кодированный кадр, который содержит (А) второй речевой пакет и (В) пачку информационного сигнала, которая является отдельной от речевого сигнала,
при этом второй речевой пакет не включает в себя описание спектральной огибающей по второму диапазону частот.
12. Речевой кодер, причем упомянутый речевой кодер содержит:
кодер пакетов, конфигурированный для формирования (А) на основании первого активного кадра речевого сигнала и в ответ на первое состояние сигнала управления скоростью передачи, первого речевого пакета, который включает в себя описание спектральной огибающей по (1) первому диапазону частот и (2) второму диапазону частот, который располагается выше первого диапазона частот, и (В) на основании второго активного кадра речевого сигнала и в ответ на второе состояние сигнала управления скоростью передачи, отличное от первого состояния, второго речевого пакета, который включает в себя описание спектральной огибающей по первому диапазону частот; и
форматер кадра, выполненный с возможностью принимать первой и второй речевые пакеты и конфигурированный для формирования (А) в ответ на первое состояние сигнала управления понижением, первого кодированного кадра, который содержит первый речевой пакет, и (В) в ответ на второе состояние сигнала управления понижением, отличное от первого состояния, второго кодированного кадра, который содержит второй речевой пакет и пачку информационного сигнала, которая является отдельной от речевого сигнала,
причем первый и второй кодированные кадры имеют одну и ту же длину, первый речевой пакет занимает, по меньшей мере, восемьдесят процентов первого кодированного кадра, и второй речевой пакет занимает не больше, чем половину второго кодированного кадра, и
причем упомянутый второй активный кадр следует непосредственно после упомянутого первого активного кадра в речевом сигнале.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| АДАПТИВНЫЙ КРИТЕРИЙ КОДИРОВАНИЯ РЕЧИ | 1999 |
|
RU2223555C2 |
| US 6738391 B1, 18.05.2004 | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ МАСШТАБИРУЕМОГО КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ АУДИОСИГНАЛОВ | 1997 |
|
RU2214047C2 |
| СПОСОБ И УСТРОЙСТВО МАСШТАБИРУЕМОГО КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ СТЕРЕОФОНИЧЕСКОГО ЗВУКОВОГО СИГНАЛА (ВАРИАНТЫ) | 1998 |
|
RU2197776C2 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

