Связанные заявки
Данная заявка испрашивает приоритет предварительной заявки на патент США № 60/828,414, номер в реестре поверенного 061680P1, поданной 6 октября 2006 и названной "SYSTEMS, METHODS, AND APPARATUS FOR FRAME ERASURE RECOVERY."
Область техники
Настоящее изобретение имеет отношение к обработке речевых сигналов.
Уровень техники
Передача аудиоданных, например, голоса и музыки, с помощью цифровых методов стала широко распространенной, особенно в междугородной телефонии, телефонной связи с пакетной коммутацией, такой как передача Голос-по-IP (также названной VoIP, где IP обозначает Интернет протокол), и цифровой радиотелефонной связи, такая как сотовая телефонная связь. Такое быстрое увеличение создало интерес к сокращению объема информации, используемой для передачи речевых данных по каналу передачи, в то же время поддерживая воспринимаемое качество восстановленной речи. Например, желательно лучше использовать доступную полосу частот беспроводной системы. Один способ использовать полосу частот системы эффективным образом состоит в том, чтобы использовать методики сжатия сигнала. Для беспроводных систем, которые передают речевые сигналы, способы сжатия речи (или "кодирование речи") обычно используются с этой целью.
Устройства, которые конфигурируются для сжатия речи посредством извлечения параметров, которые относятся к модели генерации человеческой речи, часто называют вокодерами, "аудиокодерами" или "речевыми кодерами". Аудиокодер обычно включает в себя кодер и декодер. Кодер обычно разделяет входящий речевой сигнал (цифровой сигнал, представляющий аудиоинформацию) на сегменты времени, называемые "кадрами", анализирует каждый кадр, чтобы извлечь некоторые релевантные параметры, и квантует эти параметры в кодированный кадр. Кодированные кадры передаются по каналу передачи (то есть, проводному или беспроводному сетевому соединению) на приемник, который включает в себя декодер. Декодер принимает и обрабатывает кодированные кадры, деквантует их для получения этих параметров, и воссоздает речевые кадры, используя деквантованные параметры.
В типичном сеансе разговора каждый говорящий молчит в течение приблизительно шестидесяти процентов времени. Речевые кодеры обычно конфигурируются так, чтобы отличить кадры речевого сигнала, которые содержат речь ("активные кадры"), от кадров речевого сигнала, которые содержат только тишину (молчание) или фоновый шум ("неактивные кадры"). Такой кодер может быть конфигурирован так, чтобы использовать различные режимы кодирования и/или скорости для кодирования активных и неактивных кадров. Например, речевые кодеры обычно конфигурируются так, чтобы использовать меньше битов для кодирования неактивного кадра, чем для кодирования активного кадра. Речевой кодер может использовать более низкую скорость передачи в битах для неактивных кадров, чтобы поддерживать передачу речевого сигнала с более низкой средней скоростью передачи в битах в диапазоне от малой до почти не воспринимаемой потери качества.
Примеры скоростей передачи в битах, используемых для кодирования активных кадров, включают в себя 171 бит на кадр, восемьдесят битов на кадр, и сорок битов на кадр. Примеры скоростей передачи в битах, используемых для кодирования неактивных кадров, включают в себя шестнадцать битов на кадр. В контексте сотовых систем телефонной связи (особенно систем, которые совместимы с Временным Стандартом (IS)-95, который провозглашен Ассоциацией Промышленности Телекоммуникаций, (Telecommunication Industry Association) Arlington, Вирджиния, или аналогичным отраслевым стандартом) эти четыре скорости передачи в битах также называются "как полная скорость", "половинная скорость", "четверная скорость" и "одна восьмая скорости", соответственно.
Многие системы связи, которые используют речевые кодеры, такие как сотовые телефоны и системы спутниковой связи, полагаются на беспроводные каналы для передачи информации. В ходе такой передачи информации беспроводный канал передачи может страдать от нескольких источников ошибки, таких как многолучевое замирание. Ошибки в передаче могут привести к неисправимому искажению кадра, также называемому "стирание кадра." В типичной сотовой системе стирание (разрушение) кадра происходит с частотой один - три процента и может даже достигнуть или превысить пять процентов.
Проблема потери пакетов в сетях с пакетной коммутацией, которые используют устройства аудиокодирования (например, Голос-по-Интернет протоколу или "VoIP"), очень похожа на стирание кадра в беспроводном контексте. Таким образом, из-за потери пакета аудиодекодер может быть не в состоянии принимать кадр или может принять кадр, имеющий значительное количество битовых ошибок. В любом случае аудиодекодер встречается с той же проблемой - потребность сформировать декодированный аудиокадр, несмотря на потерю сжатой речевой информации. В целях настоящего описания можно считать, что термин "стирание кадра" включает в себя "потерю пакета".
Стирание кадра может быть обнаружено в декодере согласно неудачному результату функции проверки, такой как функция CRC (проверка при помощи циклического избыточного кода) или другая функция обнаружения ошибок, которая использует, например, одну или более контрольных сумм и/или разрядов проверки на четность. Такая функция обычно выполняется декодером канала (например, в подуровне мультиплексирования), который может также выполнить задачи, такие как сверточное декодирование и/или обращенное перемежение. В типичном декодере детектор ошибочного кадра устанавливает флаг стирания кадра после приема индикации относительно неисправляемой ошибки в кадре. Декодер может быть конфигурирован для выбора модуля восстановления при стирании кадра, чтобы обработать кадр, для которого установлен флаг стирания кадра.
Сущность изобретения
Способ декодирования речи согласно одной конфигурации включает в себя обнаружение в кодированном речевом сигнале стирание второго кадра длительного голосового сегмента. Способ также включает в себя вычисление, на основании первого кадра длительного голосового сегмента, кадра замены для второго кадра. В этом способе вычисление кадра замены включает в себя получение значения усиления, которое выше, чем соответствующее значение усиления первого кадра.
Способ получения кадров декодированного речевого сигнала согласно другой конфигурации включает в себя вычисление, на основании информации из первого кодированного кадра кодированного речевого сообщения и первого сигнала возбуждения, первого кадра декодированного речевого сигнала. Этот способ также включает в себя вычисление, в ответ на индикацию стирания кадра упомянутого кодированного речевого сигнала, который непосредственно следует за упомянутым первым кодированным кадром, и на основании второго сигнала возбуждения, второго кадра упомянутого декодированного речевого сигнала, который непосредственно следует за упомянутым первым кадром. Этот способ также включает в себя вычисление, на основании третьего сигнала возбуждения, третьего кадра, который предшествует упомянутому первому кадру декодированного речевого сигнала. В этом способе первый сигнал возбуждения основан на произведении (A) первой последовательности значений, которая основана на информации из третьего сигнала возбуждения, и (B) первого коэффициента усиления. В этом способе вычисление второго кадра включает в себя формирование второго сигнала возбуждения согласно соотношению между пороговым значением и значением, основанным на первом коэффициенте усиления, таким образом, что второй сигнал возбуждения основан на произведении (A) второй последовательности значений, которая основана на информации из упомянутого первого сигнала возбуждения, и (B) второго коэффициента усиления, большего чем первый коэффициент усиления.
Способ получения кадров декодированного речевого сигнала согласно другому варианту включает в себя генерирование первого сигнала возбуждения, который основан на произведении первого коэффициента усиления и первой последовательности значений. Этот способ также включает в себя вычисление, на основании первого сигнала возбуждения и информации из первого закодированного кадра кодированного речевого сигнала, первого кадра декодированного речевого сигнала. Этот способ также включает в себя генерирование, в ответ на индикацию стирания кадра упомянутого кодированного речевого сигнала, который непосредственно следует за упомянутым первым кодированным кадром, и согласно соотношению между пороговым значением и значением, основанным на первом коэффициенте усиления, второго сигнала возбуждения на основании произведения (A) второго коэффициента усиления, который больше, чем первый коэффициент усиления, и (B) второй последовательности значений. Этот способ также включает в себя вычисление, на основании второго сигнала возбуждения, второго кадра, который непосредственно следует за упомянутым первым кадром декодированного речевого сигнала. Этот способ также включает в себя вычисление, на основании третьего сигнала возбуждения, третьего кадра, который предшествует упомянутому первому кадру декодированного речевого сигнала. В этом способе первая последовательность основана на информации из третьего сигнала возбуждения, и вторая последовательность основана на информации из первого сигнала возбуждения.
Устройство для получения кадров декодированного речевого сигнала согласно другому варианту включает в себя генератор сигнала возбуждения, выполненный с возможностью генерировать первый, второй и третий сигналы возбуждения. Это устройство также включает в себя спектральный формирователь, конфигурированный, чтобы (A) вычислять, на основании первого сигнала возбуждения и информации из первого закодированного кадра кодированного речевого сигнала, первый кадр декодированного речевого сигнала, (B) вычислять, на основании второго сигнала возбуждения, второй кадр, который непосредственно следует за упомянутым первым кадром декодированного речевого сигнала, и (C), вычислять, на основании третьего сигнала возбуждения, третий кадр, который предшествует упомянутому первому кадру декодированного речевого сигнала. Это устройство также включает в себя логический модуль, конфигурированный, чтобы (A) оценить соотношение между пороговым значением и значением, основанным на первом коэффициенте усиления, и (B) выполнять прием индикации относительно стирания кадра кодированного речевого сигнала, который непосредственно следует за упомянутым первым кодированным кадром. В этом устройстве генератор сигнала возбуждения конфигурируется, чтобы генерировать первый сигнал возбуждения, на основании произведения (A) первого коэффициента усиления и (B) первой последовательности значений, которая основана на информации из третьего сигнала возбуждения. В этом устройстве логический модуль конфигурируется, в ответ на индикацию стирания и согласно оцененному отношению, чтобы вынудить генератор сигнала возбуждения генерировать второй сигнал возбуждения, основанный на произведении (A) второго коэффициента усиления, который больше, чем первый коэффициент усиления, и (B) второй последовательности значений, которая основана на информации из первого сигнала возбуждения.
Устройство для получения кадров декодированного речевого сигнала согласно другой конфигурации включает в себя средство для генерирования первого сигнала возбуждения, который основан на произведении первого коэффициента усиления и первой последовательности значений. Это устройство также включает в себя средство для вычисления, на основании первого сигнала возбуждения и информации из первого закодированного кадра кодированного речевого сигнала, первого кадра декодированного речевого сигнала. Это устройство также включает в себя средство для генерирования, в ответ на индикацию стирания кадра упомянутого кодированного речевого сигнала, который непосредственно следует за упомянутым первым кодированным кадром, и согласно отношению между пороговым значением и значением, основанным на первом коэффициенте усиления, второго сигнала возбуждения на основании произведения (A) второго коэффициента усиления, который больше, чем первый коэффициент усиления, и (B) второй последовательности значений. Это устройство также включает в себя средство для вычисления, на основании второго сигнала возбуждения, второго кадра, который непосредственно следует за упомянутым первым кадром декодированного речевого сигнала. Это устройство также включает в себя средство для вычисления, на основании третьего сигнала возбуждения, третьего кадра, который предшествует упомянутому первому кадру декодированного речевого сигнала. В этом устройстве первая последовательность основана на информации из третьего сигнала возбуждения, и вторая последовательность основана на информации из первого сигнала возбуждения.
Компьютерный программный продукт согласно другому варианту включает в себя считываемый компьютером носитель, который включает в себя (программный) код для того, чтобы заставить по меньшей мере один компьютер генерировать первый сигнал возбуждения, который основан на произведении первого коэффициента усиления и первой последовательности значений. Этот носитель также включает в себя (программный) код для того, чтобы заставить по меньшей мере один компьютер вычислять, на основании первого сигнала возбуждения и информации из первого закодированного кадра кодированного речевого сигнала, первый кадр декодированного речевого сигнала. Этот носитель также включает в себя код для того, чтобы заставить по меньшей мере один компьютер генерировать, в ответ на индикацию стирания кадра упомянутого кодированного речевого сигнала, который непосредственно следует за упомянутым первым кодированным кадром, и согласно соотношению между пороговым значением и значением, основанным на первом коэффициенте усиления, второй сигнал возбуждения, на основании произведения (A) второго коэффициента усиления, который больше, чем первый коэффициент усиления, и (B) второй последовательности значений. Этот носитель также включает в себя код для того, чтобы заставить по меньшей мере один компьютер вычислять, на основании второго сигнала возбуждения, второй кадр, который непосредственно следует за упомянутым первым кадром декодированного речевого сигнала. Этот носитель также включает в себя код для того, чтобы заставить по меньшей мере один компьютер вычислять, на основании третьего сигнала возбуждения, третий кадр, который предшествует упомянутому первому кадру декодированного речевого сигнала. В этом произведении первая последовательность основана на информации из третьего сигнала возбуждения, и вторая последовательность основана на информации из первого сигнала возбуждения.
Краткое описание чертежей
Фиг.1 - блок-схема универсального речевого декодера, основанного на фильтре синтеза с возбуждением.
Фиг.2 - диаграмма, представляющая амплитуду голосового сегмента речи во времени.
Фиг.3 - блок-схема декодера CELP, имеющего фиксированную и адаптивную кодовые книги.
Фиг.4 иллюстрирует зависимости по данным в процессе декодирования последовательности кадров, кодированных в формате CELP.
Фиг.5 показывает блок-схему примера многорежимного декодера речи с переменной скоростью.
Фиг.6 иллюстрирует зависимости по данным в процессе декодирования последовательности кадра NELP (например, кадр молчания или не голосовой речевой кадр), за которым следует кадр CELP.
Фиг.7 иллюстрирует зависимости по данным в процессе обработки стирания кадра, который следует за кадром, кодированным в формате CELP.
Фиг.8 показывает последовательность операций для способа стирания кадра, совместимого с EVRC Service Option 3.
Фиг.9 показывает последовательность кадров во времени, которая включает в себя начало длительного голосового сегмента.
Фиг. 10a, 10b, 10c и 10d показывают последовательности операций для способов M110, M120, M130 и M140 соответственно, согласно вариантам настоящего описания.
Фиг.11 показывает последовательность операций для реализации M180 способа M120.
Фиг.12 показывает блок-схему примера речевого декодера согласно варианту осуществления.
Фиг.13A показывает последовательность операций способа M200 получения кадров декодированного речевого сигнала согласно общей конфигурации.
Фиг.13B показывает блок-схему устройства F200 для получения кадров декодированного речевого сигнала согласно общей конфигурации.
Фиг.14 иллюстрирует зависимости по данным в применении реализации способа M200.
Фиг.15A показывает последовательность операций способа реализации M201 способа M200.
Фиг.15B показывает блок-схему устройства F201, соответствующего способу M201 согласно Фиг.15A.
Фиг.16 иллюстрирует некоторые зависимости по данным в типичном применении способа M201.
Фиг.17 иллюстрирует зависимости по данным в применении реализации способа M201.
Фиг.18 показывает последовательность операций способа M203 реализации способа M200.
Фиг.19 иллюстрирует некоторые зависимости по данным в типичном применении способа M203 согласно Фиг.18.
Фиг.20 иллюстрирует некоторые зависимости по данным для применения способа M203 согласно Фиг. 18.
Фиг.21A показывают блок-схему устройства A100 для получения кадров декодированного речевого сигнала согласно общей конфигурации.
Фиг.21B иллюстрирует типичное применение устройства A100.
Фиг.22 показывает логическую схему, которая описывает работу реализации 112 логического модуля 110.
Фиг.23 показывает последовательность операций работы реализации 114 логического модуля 110.
Фиг.24 показывает описание работы другой реализации 116 логического модуля 110.
Фиг.25 показывает описание работы реализации 118 логического модуля 116.
Фиг.26A показывает блок-схему реализации A100A устройства A100.
Фиг.26B показывает блок-схему реализации A100B устройства A100.
Фиг.26C показывает блок-схему реализации A100C устройства A100.
Фиг.27A показывает блок-схему реализации 122 генератора 120 сигнала возбуждения.
Фиг.27B показывает блок-схему реализации 124 генератора 122 сигнала возбуждения.
Фиг.28 показывает блок-схему реализации 232 вычислителя 230 параметров речи.
Фиг.29A показывает блок-схему примера системы, которая включает в себя реализации блока 210 обнаружения стирания, детектор 220 формата, вычислитель 230 параметров речи и устройства A100.
Фиг.29B показывает блок-схему системы, которая включает в себя реализацию 222 блока 220 определения формата.
Подробное описание
Варианты осуществления, описанные здесь, включают в себя системы, способы и устройство для восстановления при стирании кадра, которое может быть использовано для обеспечения повышенной производительности для случаев, в которых стирается существенный (значимый) кадр длительного голосового сегмента. Альтернативно, значимый кадр длительного голосового сегмента может быть обозначен как ключевой кадр. Явно рассматривается и тем самым раскрывается, что такие варианты осуществления могут быть адаптированы для использования в сетях, которые являются сетями с пакетной коммутацией (например, проводные и/или беспроводные сети с возможностью передачи согласно протоколам передачи голоса, таким как VoIP) и/или с коммутацией каналов. Также явно рассматривается и тем самым раскрывается, что такие варианты осуществления могут быть адаптированы для использования в узкополосных системах кодирования (например, системах, которые кодируют диапазон звуковой частоты приблизительно четыре или пять килогерц), а также в широкополосных системах кодирования (например, системах, которые кодируют звуковые частоты более пяти килогерц), включая системы кодирования всего диапазона и системы кодирования с разбиением диапазона.
Если явно не ограничено контекстом, термин "генерирование" используется здесь, чтобы указать любое из его обычных значений, таких как вычисление или иное формирование. Если явно не ограничен своим контекстом, термин "вычисление" используется здесь, чтобы указать любое из его обычных значений, таких как вычисление, оценка и/или выбор из ряда значений. Если явно не ограничен своим контекстом, термин "получение" используется для указания любого из его обычных значений, таких как вычисление, выведение, прием (например, от внешнего устройства) и/или извлечение (например, из массива элементов памяти). Там, где термин "содержащий" используется в настоящем описании и формуле изобретения, он не исключает другие элементы или операции. Термин "основанный на" (как в "A основано на B") используется для указания любого из его обычных значений, включая случаи (i) "основанный на по меньшей мере" (например, "A основано на по меньшей мере B") и, если является подходящим в конкретном контексте, (ii) "равный" (например, "A равно B").
Если не указано иначе, любое раскрытие речевого декодера, имеющего конкретный признак, также явно предназначается для раскрытия способа декодирования речи, имеющего аналогичный признак (и наоборот), и любое раскрытие речевого декодера согласно конкретной конфигурации также явно предназначается, чтобы раскрыть способ декодирования речи согласно аналогичной конфигурации (и наоборот).
Для целей кодирования речи речевой сигнал обычно оцифровывается (или квантуется) для получения потока выборок. Процесс оцифровывания может быть выполнен в соответствии с любым из различных способов, известных в технике, включая, например, импульсно-кодовую модуляцию (ИКМ, PCM), ИКМ с компандированием согласно mu-закону, и ИКМ с компандированием согласно A-закону. Узкополосные речевые кодеры обычно используют частоту дискретизации 8 кГц, в то время как широкополосные речевые кодеры обычно используют более высокую частоту дискретизации (например, 12 или 16 кГц).
Оцифрованный речевой сигнал обрабатывается как последовательность кадров. Эта последовательность обычно реализуется как неперекрывающаяся последовательность, хотя операция обработки кадра или сегмента кадра (также называемого подкадром) может также включать в себя сегменты одного или более соседних кадров при его вводе. Кадры речевого сигнала обычно являются короткими, такими что спектральная огибающая сигнала, как можно ожидать, остается относительно постоянной по кадру. Кадр обычно соответствует от пяти до тридцати пяти миллисекундам речевого сигнала (или приблизительно от сорока до 200 выборок), с размера всего кадра десять, двадцать и тридцать миллисекунд. Реальный размер кодированного кадра может изменяться от кадра к кадру со скоростью передачи в битах кодирования.
Длина кадра в двадцать миллисекунд соответствует 140 выборкам при частоте дискретизации семь килогерц (кГц), но могут использоваться 160 выборок при частоте дискретизации восемь кГц, и 320 выборок при частоте дискретизации 16 кГц, хотя любая частота дискретизации считается подходящей для конкретного применения. Другой пример частоты дискретизации, которая может использоваться для кодирования речи, составляет 12,8 кГц, и другие примеры включают в себя другие скорости в диапазоне от 12,8 до 38,4 кГц.
Обычно все кадры имеют одну и ту же длину, и одинаковая длина кадра предполагается в конкретных примерах, описанных здесь. Однако также явно рассматривается и тем самым раскрывается, что могут использоваться неодинаковые длины кадра. Например, реализации способа M100 и M200 могут также использоваться в применениях, которые используют отличные длины кадра для активных и неактивных кадров и/или для голосовых и неголосовых кадров.
Кодированный кадр обычно содержит значения, из которых может быть восстановлен соответствующий кадр речевого сигнала. Например, кодированный кадр может включать в себя описание распределения энергии в кадре по частотному спектру. Такое распределение энергии также называют "частотной огибающей" или "спектральной огибающей" кадра. Кодированный кадр обычно включает в себя упорядоченную последовательность значений, которая описывает спектральную огибающую кадра. В некоторых случаях каждое значение упорядоченной последовательности указывает амплитуду или величину сигнала на соответствующей частоте или по соответствующему спектральному диапазону. Примером такого описания является упорядоченная последовательность коэффициентов преобразования Фурье.
В других случаях упорядоченная последовательность включает в себя значения параметров модели кодирования. Типичный пример такой упорядоченной последовательности - набор значений коэффициентов в анализе кодирования с линейным предсказанием (LPC). Эти коэффициенты кодируют резонансы кодированной речи (также называемые "форманты") и могут быть конфигурированы как коэффициенты фильтра или как коэффициенты отражения. Кодирующая часть большинства современных речевых кодеров включает в себя фильтр анализа, который извлекает набор значений коэффициентов LPC для каждого кадра. Количество значений коэффициентов в наборе (которые обычно упорядочиваются как один или более векторов) также называется "порядком" LPC анализа. Примеры типичного порядка LPC анализа, который выполняется речевым кодером устройства связи (таким как мобильный телефон), включают в себя 4, 6, 8, 10, 12, 16, 20, 24, 28, и 32.
Описание спектральной огибающей обычно появляется в пределах кодированного кадра в квантованной форме (например, как один или более индексов в соответствующих поисковых таблицах или "кодовых книгах"). Соответственно, общепринято для декодера принимать ряд значений коэффициентов LPC в форме, которая является более эффективной для квантования, например, как набор значений пар спектральных линий (LSP), линейных спектральных частот (LSF), иммиттансных спектральных пар (ISP), иммиттансных спектральных частот (ISF), кепстральных коэффициентов или соотношений в логарифмической области. Речевой декодер обычно конфигурируется, чтобы преобразовать такой набор в соответствующий набор значений коэффициентов LPC.
Фиг.1 показывает общий пример речевого декодера, который включает в себя фильтр синтеза с возбуждением. Чтобы декодировать кодированный кадр, деквантованные значения коэффициентов LPC используют для конфигурирования фильтра синтеза в декодере. Закодированный кадр может также включать в себя временную информацию или информацию, которая описывает распределение энергии во времени в пределах периода кадра. Например, временная информация может описывать сигнал возбуждения, который используется для возбуждения фильтра синтеза, чтобы воспроизвести речевой сигнал.
Активный кадр речевого сигнала может быть классифицирован как один из двух или более различных типов, такой как голосовой (например, представляющий гласный звук), неголосовой (например, представляющий фрикативный звук) или переходный (например, представляющий начало или конец слова). Кадры голосовой речи имеют тенденцию иметь периодическую структуру, которая является долговременной (то есть, которая продолжается более одного периода кадра) и относится к основному тону, и обычно более эффективно кодировать голосовой кадр (или последовательность голосовых кадров) с использованием режима кодирования, который кодирует описание этой долговременной спектральной особенности. Примеры таких режимов кодирования включают в себя линейное предсказание с кодовым возбуждением (CELP), период основного тона прототипа (PPP) и интерполяцию волновым (vaweform) прототипом (PWI). Неголосовые кадры и неактивные кадры, с другой стороны, обычно испытывают недостаток в какой-либо значительной долговременной спектральной особенности, и речевой кодер может быть конфигурирован для кодирования этих кадров, используя режим кодирования, который не пытается описать такую особенность. Линейное предсказание с возбуждением шумом (NELP) является одним примером такого режима кодирования.
Фиг.2 показывает один пример амплитуды голосового речевого сегмента (такого как гласный) во времени. Для голосового кадра сигнал возбуждения обычно напоминает последовательность импульсов, которая является периодической на частоте основного тона, в то время как для неголосового кадра сигнал возбуждения обычно аналогичен белому Гауссову шуму. Кодер CELP может использовать более высокую периодичность, которая является характеристикой голосовых речевых сегментов, чтобы достигнуть лучшей эффективности кодирования.
Кодер CELP является речевым кодером анализа через синтез, который использует одну или более кодовых книг, чтобы кодировать сигнал возбуждения. В этом кодере выбираются одна или более записей кодовой книги. Декодер принимает индексы кодовой книги этих записей наряду с соответствующими значениями коэффициентов усиления (которые могут быть также индексами в одной или более кодовых книгах усиления). Декодер масштабирует эти записи кодовой книги (или сигнализирует на основе нее) посредством коэффициентов усиления, чтобы получить сигнал возбуждения, который используется для возбуждения фильтра синтеза и получения декодированного речевого сигнала.
Некоторые системы CELP моделируют периодичность, используя фильтр, прогнозирующий основной тон. Другие системы CELP используют адаптивную кодовую книгу (или ACB, также называемую "кодовая книга основного тона"), чтобы моделировать периодический или связанный с основным тоном компонент сигнала возбуждения, с фиксированной кодовой книгой (также называемой "инновационной кодовой книгой"), обычно используемой для моделирования непериодического компонента, как, например, последовательность позиций импульсов. Обычно, «сильно» голосовые сегменты являются наиболее перцепционно релевантными. Для «сильно» голосового речевого кадра, который кодирован, используя схему адаптивного CELP, большая часть сигнала возбуждения моделируется посредством ACB, которая является обычно строго периодической с доминирующим частотным компонентом, соответствующим задержке (шагу) основного тона.
Вклад ACB в сигнал возбуждения представляет корреляцию между остатком текущего кадра и информацией из одного или более прошлых кадров. ACB обычно реализуется как память, которая хранит выборки прошлых речевых сигналов, или их производные, такие как остаточные сигналы или сигналы возбуждения. Например, ACB может содержать копии предыдущего остатка, задержанного на различные величины. В одном примере ACB включает в себя набор различных периодов основного тона ранее синтезированного сигнала возбуждения речи.
Один параметр адаптивно кодированного кадра - запаздывание основного тона (также называемая задержкой или задержкой основного тона). Этот параметр обычно выражается как количество речевых выборок, которое максимизирует автокорреляционную функцию кадра и может включать в себя дробный компонент. Частота основного тона человеческого голоса находится обычно в диапазоне от 40 до 500 Гц, что соответствует приблизительно от 200 до 16 выборок. Один пример адаптивного декодера CELP преобразовывает выбранную запись ACB посредством одного запаздывания основного тона. Декодер может также интерполировать транслируемую запись (например, используя фильтр с конечно импульсной характеристикой, FIR). В некоторых случаях запаздывание основного тона может служить индексом ACB. Другой пример адаптивного декодера CELP конфигурируется, чтобы сгладить (или "изменить шкалу времени") сегмент адаптивной кодовой книги согласно соответствующим последовательным, но различным значениям параметра запаздывания основного тона.
Другой параметр адаптивно кодированного кадра - усиление ACB (или усиление основного тона), который указывает уровень долговременной периодичности и обычно оценивается для каждого подкадра. Чтобы получить вклад ACB в сигнал возбуждения для конкретного подкадра, декодер умножает интерполированный сигнал (или его соответствующую часть) на соответствующее значение усиления ACB. Фиг.3 показывает блок-схему одного примера декодера CELP, имеющего ACB, где gc и gp обозначают усиление кодовой книги и усиление основного тона соответственно. Другой обычный параметр ACB - дельта-задержка, которая указывает разность в задержке между текущим и предыдущим кадрами и может быть использована для вычисления запаздывания основного тона для стертых или поврежденных кадров.
Известный кодер речи временной области - прогнозирующий кодер с линейным кодовым возбуждением (CELP), описанный в B. Rabiner & R.W. Schafer, Digital Processing of Speech Signals, стр 396-453 (1978). Примерный кодер CELP с переменной скоростью кодирования описан в патенте US 5,414,796, который передан заявителю настоящего изобретения и полностью включен в настоящее описание по ссылке. Есть много вариантов CELP. Представительные примеры включают в себя следующее: AMR Speech Codec (Adaptive Multi-Rate, Third Generation Partnership Project (3GPP) Technical Specification (TS) 26.090, части 4, 5 и 6, декабрь 2004); AMR-WB Speech Codec (AMR-Wideband, International Telecommunications Union (ITU)-T Recommendation 722.2, части 5 и 6, июль 2003); и EVRC (Enhanced Variable Rate Codec), внутренний стандарт IS-127 Ассоциации электронной промышленности США (EIA)/ Ассоциации Промышленности Средств связи (TIA), часть 4 и часть 5, январь 1997).
Фиг.4 иллюстрирует зависимости по данным в процессе декодирования последовательности кадров CELP. Кодированный кадр B обеспечивает адаптивный коэффициент усиления B, и адаптивная кодовая книга обеспечивает последовательность А, основанную на информации от предыдущего сигнала возбуждения A. Процесс декодирования генерирует сигнал возбуждения B на основании адаптивного коэффициента усиления B и последовательности A, который спектрально формируется согласно спектральной информации из закодированного кадра B, чтобы получить декодированный кадр B. Процесс декодирования также обновляет адаптивную кодовую книгу на основании сигнала возбуждения B. Следующий кодированный кадр C обеспечивает адаптивный коэффициент усиления C, и адаптивная кодовая книга обеспечивает последовательность B на основании сигнала возбуждения B. Процесс декодирования генерирует сигнал возбуждения C на основании адаптивного коэффициента усиления C и последовательности B, который спектрально формируется согласно спектральной информации из закодированного кадра C, для получения декодированного кадра C. Процесс декодирования также обновляет адаптивную кодовую книгу на основании сигнала возбуждения C и так далее, пока не встретится кадр, закодированный в другом режиме кодирования (например, NELP).
Может быть желательно использовать схему кодирования с переменной скоростью (например, чтобы сбалансировать сетевые требования и емкость). Может быть также желательно использовать многорежимную схему кодирования, в которой кадры кодируют, используя различные режимы согласно классификации, основанной на, например, периодичности или озвучивании. Например, может быть желательно для речевого кодера использовать различные режимы кодирования и/или скорости передачи в битах для активных кадров и неактивных кадров. Может быть также желательно для речевого кодера использовать различные комбинации скоростей передачи в битах и режимов кодирования (также называемые "схемами кодирования") для различных типов активных кадров. Один пример такого речевого кодера использует полноскоростную схему CELP для кадров, содержащих голосовые речевые и переходные кадры, полускоростную схему NELP для кадров, содержащих неголосовую (неозвученную) речь, и схему NELP со скоростью кодирования одна восьмая для неактивных кадров. Другие примеры такого речевого кодера поддерживают множество скоростей кодирования для одной или более схем кодирования, таких как полноскоростная и полускоростная схемы CELP и/или полноскоростная и четвертьскоростная схемы PPP.
Фиг.5 показывает блок-схему примера многорежимного декодера с переменной скоростью, который принимает пакеты и соответствующие индикаторы типа пакета (например, от подуровня мультиплексирования). В этом примере детектор сигнала ошибки кадра выбирает соответствующую скорость (или восстановление при стирании) согласно индикатору типа пакета, и блок распаковки разбирает пакет и выбирает соответствующий режим. Альтернативно, детектор стирания кадра может быть конфигурирован для выбора корректной схемы кодирования. Доступные режимы в этом примере включают в себя полно- и полускоростную CELP, полно- и четвертьскоростную PPP (период основного тона прототипа, используемую для строго голосовых кадров), NELP (используемую для неголосовых кадров) и молчание. Декодер обычно включает в себя постфильтр, который конфигурируется, чтобы уменьшить шум квантования (например, посредством подчеркивания частот форманты и/или посредством уменьшения точек спектрального минимума), и может также включать в себя адаптивный регулятор усиления.
Фиг.6 иллюстрирует зависимости по данным в процессе декодирования кадра NELP с последующим кадром CELP. Чтобы декодировать закодированный NELP-кадр N, процесс декодирования генерирует сигнал шума в качестве сигнала N возбуждения, который является спектрально сформированным согласно спектральной информации из кодированного кадра N, чтобы сформировать декодированный кадр N. В этом примере процесс декодирования также обновляет адаптивную кодовую книгу на основании сигнала N возбуждения. Кодированный CELP кадр C обеспечивает адаптивный коэффициент усиления C, и адаптивная кодовая книга обеспечивает последовательность N на основании сигнала возбуждения N. Корреляция между сигналами возбуждения NELP кадра N и CELP кадра C, вероятно, будет очень низка, так что корреляция между последовательностью N и сигналом возбуждения кадра C также вероятно будет очень низка. Следовательно, адаптивный коэффициент усиления C, вероятно, будет иметь значение, близкое к нулю. Процесс декодирования генерирует сигнал возбуждения C, который номинально основан на адаптивном коэффициенте усиления C и последовательности N, но, вероятно, будет в более значительной степени основан на информации фиксированной кодовой книги из кодированного кадра C, и сигнал возбуждения C является спектрально сформированным согласно спектральной информации из кодированного кадра C для формирования декодированного кадра C. Процесс декодирования также обновляет адаптивную кодовую книгу на основании сигнала C возбуждения.
В некоторых CELP кодерах коэффициенты LPC обновляются для каждого кадра, в то время как параметры возбуждения, такие как запаздывание основного тона и/или усиление ACB, обновляются для каждого подкадра. В AMR-WB, например, параметры возбуждения CELP, такие как запаздывание основного тона и усиление ACB, обновляются однажды для каждого из четырех подкадров. В CELP режиме для EVRC каждый из этих трех подкадров (длиной 53, 53 и 54 выборки соответственно) кадра с 160 выборками имеет соответствующие значения ACB и усиления FCB и соответствующий индекс FCB. Различные режимы в одном кодеке могут также обрабатывать кадры по-другому. В кодеке EVRC, например, режим CELP обрабатывает сигнал возбуждения согласно кадрам, имеющим три подкадра, в то время как режим NELP обрабатывает сигнал возбуждения согласно кадрам, имеющим четыре подкадра. Также существуют режимы, которые обрабатывают сигнал возбуждения согласно кадрам, имеющим два подкадра.
Декодер речи с переменной скоростью может быть конфигурирован, чтобы определить скорость передачи в битах кодированного кадра из одного или более параметров, таких как энергия кадра. В некоторых применениях система кодирования конфигурируется для использования только одного режима кодирования для конкретной скорости передачи в битах, так что скорость передачи в битах закодированного кадра также указывает режим кодирования. В других случаях кодированный кадр может включать в себя информацию, такую как набор из одного или более битов, которая идентифицирует режим кодирования, согласно которому кодирован кадр. Такой набор битов также называют "индексом кодирования". В некоторых случаях индекс кодирования может явно указывать режим кодирования. В других случаях индекс кодирования может неявно указывать режим кодирования, например посредством указания значения, которое может быть недействительным для другого режима кодирования. В этом описании и прилагаемой формуле изобретения термин "формат" или "формат кадра" используется для указания одного или более аспектов кодированного кадра, из которых может быть определен режим кодирования, причем аспекты могут включать в себя скорость передачи в битах и/или индекс кодирования, как описано выше.
Фиг.7 иллюстрирует зависимости по данным в процессе обработки стирания кадра, который следует за кадром CELP. Как и на Фиг.4, кодированный кадр B обеспечивает адаптивный коэффициент усиления B, и адаптивная кодовая книга обеспечивает последовательность А на основании информации от предыдущего сигнала A возбуждения. Процесс декодирования генерирует сигнал возбуждения B на основании адаптивного коэффициента усиления B и последовательности A, которая является спектрально сформированной согласно спектральной информации из закодированного кадра B, чтобы сформировать декодированный кадр B. Процесс декодирования также обновляет адаптивную кодовую книгу на основании сигнала возбуждения B. В ответ на индикацию, что следующий закодированный кадр стирается, процесс декодирования продолжает работать в предыдущем режиме кодирования (то есть, CELP) таким образом, что адаптивная кодовая книга обеспечивает последовательность B на основании сигнала возбуждения B. В этом случае процесс декодирования генерирует сигнал возбуждения X на основании адаптивного коэффициента усиления B и последовательности B, которая является спектрально сформированной согласно спектральной информации из закодированного кадра B, чтобы сформировать декодированный кадр X.
Фиг.8 показывает последовательность операций для способа восстановления при стирании кадра, которое совместимо с стандартом C.S0014-A v1.0 3GPP2 (EVRC Service Option 3), часть 5, апрель 2004. Патент США № 2002/0123887 (Unno) описывает аналогичный процесс согласно рекомендации G.729 ITU-T. Такой способ может быть выполнен, например, модулем устранения ошибок кадра, как показано на Фиг.5. Способ инициируется обнаружением, что текущий кадр недоступен (например, так что значение флага стирания кадра для текущего кадра [FER(m)] имеет значение ИСТИНА). Задача T110 определяет, был ли предыдущий кадр также недоступен. В этой реализации задача T110 определяет, является ли значение флага стирания кадра для предыдущего кадра [FER ("m-1")] также значением ИСТИНА.
Если предыдущий кадр не был стерт, задача T120 устанавливает значение среднего усиления адаптивной кодовой книги для текущего кадра [gpavg(m)] равным значению среднего усиления адаптивной кодовой книги для предыдущего кадра [gpavg ("m-1")]. Иначе (то есть, если предыдущий кадр также был стерт), то задача T130 устанавливает значение среднего усиления ACB для текущего кадра [gpavg(m)] равным уменьшенной версии среднего усиления ACB для предыдущего кадра [gpavg("m-1")]. В этом примере задача T130 устанавливает среднее усиление ACB равным 0,75, умноженному на gpavg("m -1"). Задача T140 затем устанавливает значения усиления ACB для подкадров текущего кадра [gp(m.i) для i=0,1,2] равными значению gpavg(m). Обычно коэффициенты усиления FCB устанавливаются равными нулю для стертого кадра. Секция 5.2.3.5 стандарта C.S0014-C v1.0 3GPP2 описывает вариант этого способа для EVRC Service Option 68, в котором значения ACB для подкадров текущего кадра [gp(m.i) для i=0,1,2] установлены равными нулю, если предыдущий кадр был стерт или был обработан как молчание или кадр NELP.
Кадр, который следует за стиранием кадра, может быть декодирован без ошибок только в системе или режиме кодирования без запоминания. Для режимов, которые используют корреляцию с одним или более прошлыми кадрами, стирание кадра может вызывать ошибки для распространения в последующие кадры. Например, переменные состояния адаптивного декодера, возможно, нуждаются в некотором времени для восстановления из стирания кадра. Для кодера CELP адаптивная кодовая книга вводит сильную межкадровую зависимость и является обычно основной причиной такого распространения ошибок. Следовательно, типичным является использование усиления ACB, которое не выше, чем предыдущее среднее число, как в задаче T120, или даже уменьшение усиления ACB, как в задаче T130. В некоторых случаях, однако, такая практика может неблагоприятно влиять на воспроизведение последующих кадров.
Фиг.9 иллюстрирует пример последовательности кадров, которая включает в себя не голосовой сегмент, с последующим длительным голосовым сегментом. Такой длительный голосовой сегмент может произойти в слове, таком как “crazy” ("сумасшедший") или “feel” ("чувство"). Как указано на этом чертеже, первый кадр длительного голосового сегмента имеет низкую зависимость от прошлого. В частности, если кадр должен быть кодирован, используя адаптивную кодовую книгу, то значения усиления адаптивной кодовой книги для кадра будут низкими. Для остальной части кадров в длительном голосовом сегменте значения усиления ACB обычно будут высокими, как следствие, сильной корреляции между смежными кадрами.
В такой ситуации может возникнуть проблема, если второй кадр длительного голосового сегмента стирается. Поскольку этот кадр имеет высокую зависимость от предыдущего кадра, его значения усиления адаптивной кодовой книги должны быть высокими, усиливая периодический компонент. Поскольку восстановление при стирании кадра будет обычно восстанавливать стертый кадр от предыдущего кадра, однако, восстановленный кадр будет иметь низкие значения усиления адаптивной кодовой книги так, что вклад от предыдущего голосового кадра будет неприемлемо низким. Эта ошибка может быть распространена на следующие несколько кадров. По таким причинам второй кадр длительного голосового сегмента также называют значимым кадром. Альтернативно, второй кадр длительного голосового сегмента можно также назвать ключевым кадром.
Фиг.10a, 10b, 10c и 10d показывают последовательности операций для способов M110, M120, M130 и M140 согласно соответствующим вариантам осуществления настоящего описания. Первая задача в этих способах (задачи T11, T12 и T13) обнаруживает одну или более конкретных последовательностей режимов в этих двух кадрах, предшествующих стиранию кадра, или (задача T14) обнаруживает стирание значимого кадра длительного голосового сегмента. В задачах T11, T12 и T13 конкретная последовательность или последовательности обычно определяются со ссылками на режимы, согласно которым закодированы эти кадры.
В способе M110 задача T11 обнаруживает последовательность (не голосовой кадр, голосовой кадр, стирание кадра). Категория "не голосовые кадры" может включать в себя кадры молчания (то есть, фоновый шум), а также не голосовые кадры, такие как фрикативные звуки. Например, категория "не голосовые кадры" может быть реализована, чтобы включать в себя кадры, которые закодированы или в режиме NELP, или в режиме молчания (что является обычно также режимом NELP). Как показано на Фиг.10b, категория "голосовые кадры" может быть ограничена в задаче T12 кадрами, закодированным с использованием режима CELP (например, в декодере, который также имеет один или более режимов PPP). Эта категория может быть также дополнительно ограничена кадрами, закодированными при использовании режима CELP, который имеет адаптивную кодовую книгу (например, в декодере, который также поддерживает режим CELP, имеющий только фиксированную кодовую книгу).
Задача T13 способа M130 характеризует целевую последовательность в терминах сигнала возбуждения, используемого в кадрах, где первый кадр имеет непериодическое возбуждение (например, случайное возбуждение, как используется в кодировании NELP или молчании), и второй кадр имеет адаптивное и периодическое возбуждение (например, как используется в режиме CELP, имеющем адаптивную кодовую книгу). В другом примере задача T13 реализуется таким образом, что обнаруженная последовательность также включает в себя первые кадры, не имеющие сигнала возбуждения. Задача T14 способа M140, который обнаруживает стирание значимого кадра длительного голосового сегмента, может быть реализована, чтобы обнаружить стирание кадра немедленно после последовательности (кадр NELP или молчания, кадр CELP).
Задача T20 получает значение усиления на основании, меньшей мере частично, кадра перед стиранием. Например, полученное значение усиления может быть значением усиления, которое предсказано для стертого кадра (например, модулем восстановления при стирании кадра). В конкретном примере значение усиления является значением усиления возбуждения (таким, как значение усиления ACB), предсказанным для стертого кадра посредством модуля восстановления при стирании кадра. Задачи T110-T140 на Фиг. 8 показывают один пример, в котором несколько значений ACB предсказываются на основании кадра, который предшествует стиранию.
Если указанная последовательность (или одна из указанных последовательностей) обнаруживается, то задача T30 сравнивает полученное значение усиления с пороговым значением. Если полученное значение усиления меньше, чем (альтернативно, не больше чем) пороговое значение, задача T40 увеличивает полученное значение усиления. Например, задача T40 может быть конфигурирована так, чтобы суммировать положительное значение с полученным значением усиления или умножать полученное значение усиления на коэффициент, больший единицы. Альтернативно, задача T40 может быть конфигурирована так, чтобы заменить полученное значение усиления одним или больше более высокими значениями.
Фиг.11 показывает последовательность операций конфигурации M180 способа M120. Задачи T100, T120, T130 и T140 являются такими, как описано выше. После того, как значение gpavg(m) было установлено (задача T120 или T130), задачи N210, N220 и N230 проверяют некоторые условия, относящиеся к текущему кадру и недавней истории. Задача N210 определяет, был ли предыдущий кадр закодирован как кадр CELP. Задача N220 определяет, был ли кадр перед предыдущим закодирован как не голосовой кадр (например, как NELP или молчание). Задача N230 определяет, является ли значение gpavg(m) меньше, чем значение Tmax порога. Если результат любой из задач N210, N220 и N230 является отрицательным, то задача T140 выполняется, как описано выше. Иначе, задача N240 назначает новый профиль усиления на текущий кадр.
В конкретном примере, показанном на Фиг.11, задача N240 назначает значениям T1, T2 и T3, соответственно, значения gp(m.i) для i=0,1,2. Эти значения могут быть упорядочены таким образом, что T1≥T2≥T3, приводя к профилю усиления, который является или постоянным, или уменьшается, когда T1 близко к (или равно) Tmax.
Другие реализации задачи N240 могут быть конфигурированы так, чтобы умножить одно или более значений gp(m.i) на соответствующие коэффициенты усиления (по меньшей мере один больший, чем единица) или на общий коэффициент усиления, или суммировать положительное смещение с одним или более значениями gp(m.i). В таких случаях может быть желательно наложить верхнюю границу (например, Tmax) на каждое значение gp(m.i). Задачи N210-N240 могут быть реализованы как аппаратное обеспечение, программно-аппаратное обеспечение и/или программные подпрограммы в модуле восстановления при стирании кадра.
В некоторых способах стертый кадр экстраполируется из информации, принятой во время одного или более предыдущих кадров, и возможно одного или более последующих кадров. В некоторых конфигурациях речевые параметры и в предыдущих и в будущих кадрах используются для реконструкции стертого кадра. В этом случае задача T20 может быть конфигурирована, чтобы вычислять полученное значение усиления на основании и кадра перед стиранием, и кадра после стирания. Дополнительно или альтернативно, реализация задачи T40 (например, задача N240) может использовать информацию из будущего кадра, чтобы выбрать профиль усиления (например, посредством интерполяции значений усиления). Например, такая реализация задачи T40 может выбрать уровень или профиль увеличивающегося усиления вместо уменьшающегося, или профиль увеличивающегося усиления вместо профиля с постоянным уровнем. Конфигурация этого вида может использовать буфер дрожания (флуктуации во времени), чтобы указать, доступен ли будущий кадр для такого использования.
Фиг.12 показывает блок-схему речевого декодера, включающего в себя модуль 100 восстановления при стирании кадра согласно варианту осуществления. Такой модуль 100 может быть конфигурирован для выполнения способа M110, M120, M130 или M180, как описано здесь.
Фиг.13A показывает последовательность операций способа M200 получения кадров декодированного речевого сигнала согласно общей конфигурации, которая включает в себя задачи T210, T220, T230, T240, T245 и T250. Задача T210 генерирует первый сигнал возбуждения. На основании первого сигнала возбуждения задача T220 вычисляет первый кадр декодированного речевого сигнала. Задача T230 генерирует второй сигнал возбуждения. На основании второго сигнала возбуждения задача T240 вычисляет второй кадр, который непосредственно следует за первым кадром декодированного речевого сигнала. Задача T245 генерирует третий сигнал возбуждения. В зависимости от конкретного применения задача T245 может быть конфигурирована, чтобы генерировать третий сигнал возбуждения на основании сгенерированного сигнала шума и/или на основании информации из адаптивной кодовой книги (например, на основании информации от одного или более предыдущих сигналов возбуждения). На основании третьего сигнала возбуждения задача T250 вычисляет третий кадр, который непосредственно предшествует первому кадру декодированного речевого сигнала. Фиг.14 иллюстрирует некоторые из зависимостей по данным в типичном применении способа M200.
Задача T210 выполняется в ответ на индикацию, что первый закодированный кадр кодированного речевого сигнала имеет первый формат. Первый формат указывает, что кадр должен быть декодирован, используя сигнал возбуждения, который основан на памяти о прошлой информации возбуждения (например, используя режим кодирования CELP). Для системы кодирования, которая использует только один режим кодирования при скорости передачи в битах первого закодированного кадра, определение скорости передачи в битах может быть достаточным, чтобы определить режим кодирования таким образом, что индикация относительно скорости передачи в битах может служить также для указания формата кадра.
Для системы кодирования, которая использует более одного режима кодирования при скорости передачи в битах первого закодированного кадра, закодированный кадр может включать в себя индекс кодирования, например, набор из одного или более битов, который идентифицирует режим кодирования. В этом случае индикация формата может быть основана на определении индекса кодирования. В некоторых случаях индекс кодирования может явно указывать режим кодирования. В других случаях индекс кодирования может неявно указать режим кодирования, например, посредством индикации значения, которое может быть недействительным для другого режима кодирования.
В ответ на индикацию формата задача T210 генерирует первый сигнал возбуждения на основании первой последовательности значений. Первая последовательность значений основана на информации из третьего сигнала возбуждения, такой как сегмент третьего сигнала возбуждения. Это соотношение между первой последовательностью и третьим сигналом возбуждения обозначено пунктиром на Фиг.13A. В типичном примере первая последовательность основана на последнем подкадре третьего сигнала возбуждения. Задача T210 может включать в себя извлечение первой последовательности из адаптивной кодовой книги.
Фиг.13B показывает блок-схему устройства F200 для получения кадров декодированного речевого сигнала согласно общей конфигурации. Устройство F200 включает в себя средство для выполнения различных задач способа M200 согласно Фиг.13A. Средство F210 генерирует первый сигнал возбуждения. На основании первого сигнала возбуждения средство F220 вычисляет первый кадр декодированного речевого сигнала. Средство F230 генерирует второй сигнал возбуждения. На основании второго сигнала возбуждения средство F240 вычисляет второй кадр, который непосредственно следует за первым кадром декодированного речевого сигнала. Средство F245 генерирует третий сигнал возбуждения. В зависимости от конкретного применения средство F245 может быть сконфигурировано, чтобы генерировать третий сигнал возбуждения, на основании сгенерированного сигнала шума и/или на информации из адаптивной кодовой книги (например, на основании информации от одного или более предыдущих сигналов возбуждения). На основании третьего сигнала возбуждения средство F250 вычисляет третий кадр, который непосредственно предшествует первому кадру декодированного речевого сигнала.
Фиг.14 показывает пример, в котором задача T210 генерирует первый сигнал возбуждения на основании первого коэффициента усиления и первой последовательности. В таком случае задача T210 может быть конфигурирована так, чтобы генерировать первый сигнал возбуждения на основании произведения первого коэффициента усиления и первой последовательности. Первый коэффициент усиления может быть основан на информации из первого кодированного кадра, такой как индекс адаптивной кодовой книги усиления. Задача T210 может быть конфигурирована так, чтобы генерировать первый сигнал возбуждения на основании другой информации из первого закодированного кадра, такой как информация, которая определяет вклад фиксированной кодовой книги в первый сигнал возбуждения (например, один или более индексов кодовой книги и соответствующие значения коэффициента усиления или индексов кодовой книги).
На основании первого сигнала возбуждения и информации из первого закодированного кадра задача T220 вычисляет первый кадр декодированного речевого сигнала. Обычно информация из первого закодированного кадра включает в себя набор значений спектральных параметров (например, один или более векторов коэффициентов LSF или LPC) таким образом, что задача T220 конфигурируется, чтобы сформировать спектр первого сигнала возбуждения согласно значениям спектральных параметров. Задача T220 может также включать в себя выполнение одной или более других операций по обработке (например, фильтрование, сглаживание, интерполяция) в отношении первого сигнала возбуждения, информации из первого закодированного кадра, и/или вычисленного первого кадра.
Задача T230 выполняется в ответ на индикацию стирания закодированного кадра, который непосредственно следует за первым закодированным кадром в кодированном речевом сигнале. Индикация стирания может быть основана на одном или более следующих условий: (1) кадр содержит слишком много битовых ошибок, которые должны быть восстановлены; (2) скорость передачи в битах, указанная для кадра, является недействительной или неподдерживаемой; (3) все биты кадра равны нулю; (4) скорость передачи в битах, указанная для кадра, является одной восьмой скорости и все биты кадра равны единице; (5) кадр является пустым, и последняя действительная скорость передачи в битах не была равна одной восьмой скорости.
Задача T230 также выполняется согласно соотношению между пороговым значением и значением, основанным на первом коэффициенте усиления (также названном "базовым значением коэффициента усиления"). Например, задача T230 может быть конфигурирована для выполнения, если базовое значение коэффициента усиления меньше, чем (альтернативно, не более чем) пороговое значение. Базовое значение коэффициента усиления может быть просто значением первого коэффициента усиления, особенно для применения, в котором первый кодированный кадр включает в себя только один коэффициент усиления адаптивной кодовой книги. Для применения, в котором первый закодированный кадр включает в себя несколько коэффициентов усиления адаптивной кодовой книги (например, различный коэффициент для каждого подкадра), базовое значение коэффициента усиления может быть также основано на одном или более других коэффициентов усиления адаптивной кодовой книги. В таком случае, например, базовое значение коэффициента усиления может быть средним числом коэффициентов усиления адаптивной кодовой книги первого закодированного кадра, как в значении gpavg(m), описанном со ссылками на Фиг.11.
Задача T230 может также выполняться в ответ на индикацию, что первый кодированный кадр имеет первый формат и что кодированный кадр, предшествующий первому закодированному кадру ("предыдущий кадр"), имеет второй формат, отличный от первого формата. Второй формат указывает, что кадр должен быть декодирован, используя сигнал возбуждения, который основан на сигнале шума (например, используя режим кодирования NELP). Для системы кодирования, которая использует только один режим кодирования при скорости передачи в битах предыдущего кадра, определение скорости передачи в битах может быть достаточным, чтобы определить режим кодирования таким образом, что индикация скорости передачи в битах может также служить для указания формата кадра. Альтернативно, предыдущий кадр может включать в себя индекс кодирования, который указывает режим кодирования таким образом, что индикация формата может быть основана на определении индекса кодирования.
Задача T230 генерирует второй сигнал возбуждения на основании второго коэффициента усиления, который больше, чем первый коэффициент усиления. Второй коэффициент усиления может быть также больше, чем базовое значение коэффициента усиления. Например, второй коэффициент усиления может быть равным или даже больше, чем пороговое значение. Для случая, в котором задача T230 конфигурируется для генерирования второго сигнала возбуждения в качестве последовательности сигналов возбуждения подкадра, отличающееся значение второго коэффициента усиления может использоваться для каждого сигнала возбуждения подкадра, где по меньшей мере одно из значений больше, чем базовое значение коэффициента усиления. В таком случае может быть желательно, чтобы различные значения второго коэффициента усиления были упорядочены так, чтобы увеличиваться или уменьшаться в течение периода кадра.
Задача T230 обычно конфигурируется так, чтобы генерировать второй сигнал возбуждения на основании произведения второго коэффициента усиления и второй последовательности значений. Как показано на Фиг.14, вторая последовательность основана на информации из первого сигнала возбуждения, такой как сегмент первого сигнала возбуждения. В типичном примере вторая последовательность основана на последнем подкадре первого сигнала возбуждения. Соответственно, задача T210 может быть конфигурирована, чтобы обновлять адаптивную кодовую книгу на основании информации из первого сигнала возбуждения. Для применения способа M200 к системе кодирования, которая поддерживает упрощенный режим кодирования CELP (RCELP), такая реализации задачи T210 может быть конфигурирована для подвергания сегмента изменению шкалы времени согласно соответствующему значению параметра запаздывания основного тона. Пример такой операции изменения шкалы времени описан в Секции 5.2.2 (со ссылками на Секцию 4.11.5) документа C.S0014-C v1.0 3GPP2, цитированного выше. Другие реализации задачи T230 могут включать в себя один или более способов M110, M120, M130, M140 и M180, как описано выше.
На основании второго сигнала возбуждения задача T240 вычисляет второй кадр, который непосредственно следует за первым кадром декодированного речевого сигнала. Как показано на Фиг. 14, задача T240 может быть также конфигурирована, чтобы вычислять второй кадр на основании информации из первого закодированного кадра, такой как набор значений спектральных параметров, как описано выше. Например, задача T240 может быть конфигурирована, чтобы сформировать спектр второго сигнала возбуждения согласно набору значений спектральных параметров.
Альтернативно, задача T240 может быть конфигурирована, чтобы сформировать спектр второго сигнала возбуждения согласно второму набору значений спектральных параметров, который основан на наборе значений спектральных параметров. Например, задача T240 может быть конфигурирована, чтобы вычислять второй набор значений спектральных параметров как среднее число набора значений спектральных параметров из первого закодированного кадра и начального набора значений спектральных параметров. Пример такого вычисления как взвешенного среднего описывается в Секции 5.2.1 документа C.S0014-C v1.0 3GPP2, процитированного выше. Задача T240 может также включать в себя выполнение одной или более других операций по обработке (например, фильтрование, сглаживание, интерполяция) в отношении одного или более из: второго сигнала возбуждения, информации из первого закодированного кадра и вычисленного второго кадра.
На основании третьего сигнала возбуждения задача T250 вычисляет третий кадр, который предшествует первому кадру в декодированном речевом сигнале. Задача T250 может также включать в себя обновление адаптивной кодовой книги посредством сохранения первой последовательности, где первая последовательность основана на по меньшей мере сегменте третьего сигнала возбуждения. Для применения способа M200 к системе кодирования, которая поддерживает упрощенный режим кодирования CELP (RCELP), задача T250 может быть конфигурирована для применения к сегменту изменения шкалы времени согласно соответствующему значению параметра запаздывания основного тона. Пример такой операции изменения шкалы времени описывается в Секции 5.2.2 (со ссылками на Секцию 4.11.5) документа C.S0014-C v 1.0 3GPP2, цитированного выше.
По меньшей мере некоторые из параметров закодированного кадра могут быть скомпонованы для описания аспекта декодированного кадра передачи как последовательности подкадров. Например, для закодированного кадра, форматированного согласно режиму кодирования CELP, характерно включать в себя набор значений спектральных параметров для кадра и отдельный набор временных параметров (например, индексы кодовой книги и значения коэффициента усиления) для каждого из подкадров. Соответствующий декодер может быть конфигурирован, чтобы вычислять декодированный кадр с приращением подкадрами. В таком случае задача T210 может быть конфигурирована, чтобы генерировать первый сигнал возбуждения как последовательность сигналов возбуждения подкадра, так что каждый из сигналов возбуждения подкадра может быть основан на различных коэффициентах усиления и/или последовательностях. Задача T210 может быть также конфигурирована, чтобы обновить адаптивную кодовую книгу последовательно с информацией от каждого из сигналов возбуждения подкадра. Аналогично, задача T220 может быть конфигурирована, чтобы вычислять каждый подкадр первого декодированного кадра на основании отличного подкадра первого сигнала возбуждения. Задача T220 может быть также конфигурирована, чтобы интерполировать или иначе сглаживать между кадрами набор спектральных параметров по подкадрам.
Фиг.15A показывает, что декодер может быть конфигурирован, чтобы использовать информацию от сигнала возбуждения, который основан на сигнале шума (например, сигнале возбуждения, сгенерированном в ответ на индикацию формата NELP), чтобы обновить адаптивную кодовую книгу. В частности, Фиг.15A показывает последовательность операций такой реализации M201 способа M200 (из Фиг.13A и описано выше), которая включает в себя задачи T260 и T270. Задача T260 генерирует сигнал шума (например, псевдослучайный сигнал, аппроксимирующий белый Гауссов шум), и задача T270 генерирует третий сигнал возбуждения на основании сгенерированного сигнала шума. Снова, отношение между первой последовательностью и третьим сигналом возбуждения обозначается пунктиром на Фиг.15A. Для задачи T260 может быть желательно генерировать сигнал шума, используя начальное значение, которое основано на другой информации из соответствующего кадра передачи (например, спектральной информации), когда такая методика может быть использована для генерации поддержки того же самого сигнала шума, который использовался в кодере. Способ M201 также включает в себя реализацию T252 задачи T250 (из Фиг. 13A и описана выше), которая вычисляет третий кадр на основании третьего сигнала возбуждения. Задача T252 также конфигурируется, чтобы вычислять третий кадр на основании информации из закодированного кадра, который непосредственно предшествует первому закодированному кадру ("предыдущий кадр") и имеет второй формат. В таких случаях задача T230 может быть основана на индикации, что (A) предыдущий кадр имеет второй формат и (B) первый кодированный кадр имеет первый формат.
Фиг.15B показывает блок-схему устройства F201, соответствующего способу M201, описанному выше со ссылками на фиг.15A. Устройство F201 включает в себя средство для выполнения различных задач способа M201. Различные элементы могут быть реализованы согласно любым структурам, способным выполнять такие задачи, включая любую из структур для выполнения таких задач, которые раскрыты в настоящем описании (например, как один или более наборов команд, один или более наборов логических элементов, и т.д.). Фиг.15B показывает, что декодер может быть конфигурирован, чтобы использовать информацию из сигнала возбуждения, которая основана на сигнале шума (например, сигнале возбуждения, сгенерированном в ответ на индикацию формата NELP), чтобы обновить адаптивную кодовую книгу. Устройство F201 согласно Фиг.15B аналогично устройству F200 на Фиг.13B с добавлением средств F260, F270 и F252. Средство F260 генерирует сигнал шума (например, псевдослучайный сигнал, аппроксимирующий белый Гауссов шум), и средство F270 генерирует третий сигнал возбуждения на основании сгенерированного сигнала шума. Снова, соотношение между первой последовательностью и третьим сигналом возбуждения обозначается иллюстрированной пунктирной линией. Для средства F260 может быть желательно генерировать сигнал шума, используя начальное значение, которое основано на другой информации от закодированного кадра передачи (например, спектральной информации), когда такая методика может быть использована для генерирования поддержки того же самого сигнала шума, который использовался в кодере. Устройство F201 также включает в себя средство F252, которое соответствует средству F250 (на Фиг.13A и описанному выше). Средство F252 вычисляет третий кадр на основании третьего сигнала возбуждения. Средство F252 также конфигурируется, чтобы вычислять третий кадр на основании информации из закодированного кадра, который непосредственно предшествует первому закодированному кадру ("предыдущий кадр") и имеет второй формат. В таких случаях средство F230 может быть основано на индикации того, что (A) предыдущий кадр имеет второй формат и (B) первый кодированный кадр имеет первый формат.
Фиг.16 иллюстрирует некоторые зависимости по данным в типичном применении способа M201. В этом применении кодированный кадр, который непосредственно предшествует первому закодированному кадру (обозначенный в этом чертеже как "второй закодированный кадр"), имеет второй формат (например, формат NELP). Как показано на Фиг.16, задача T252 конфигурируется, чтобы вычислять третий кадр на основании информации из второго закодированного кадра. Например, задача T252 может быть конфигурирована, чтобы формировать спектр третьего сигнала возбуждения согласно набору значений спектральных параметров, которые основаны на информации из второго закодированного кадра. Задача T252 может также включать в себя выполнение одной или более других операций по обработке (например, фильтрование, сглаживание, интерполяция) в отношении одного или более из: третьего сигнала возбуждения, информации от второго закодированного кадра и вычисленного третьего кадра. Задача T252 может быть также конфигурирована, чтобы обновить адаптивную кодовую книгу на основании информации из третьего сигнала возбуждения (например, сегмента третьего сигнала возбуждения).
Речевой сигнал обычно включает в себя периоды, во время которых говорящий молчит. Может быть желательно для кодера передать закодированные кадры в меньшем количестве, чем все неактивные кадры, во время такого периода. Такую операцию также называют прерывистой передачей (DTX). В одном примере речевой кодер выполняет прерывистую передачу DTX посредством передачи одного кодированного неактивного кадра (также называемого "дескриптором молчания", "описанием молчания" или SID) для каждой строки из 32 последовательных неактивных кадров. В других примерах речевой кодер выполняет DTX посредством передачи одного SID для каждой строки с различным количеством последовательных неактивных кадров (например, 8 или 16) и/или посредством передачи SID при некотором другом событии, например, изменении энергии кадра или спектрального наклона. Соответствующий декодер использует информацию в SID (обычно, значения спектральных параметров и профиль усиления), чтобы синтезировать неактивные кадры в течение последующих периодов кадра, в течение которых не было принято закодированного кадра.
Может быть желательно использовать способ M200 в системе кодирования, которая также поддерживает передачу DTX. Фиг.17 иллюстрирует некоторые зависимости по данным для такого применения способа M201, в котором второй закодированный кадр является кадром SID, и эти кадры между этим кадром и первым закодированным кадром являются пустыми (обозначенными здесь как "интервал DTX"). Линия, соединяющая второй закодированный кадр с задачей T252, указана штриховой линией, чтобы указать, что информация от второго закодированного кадра (например, значения спектральных параметров) используется для вычисления более чем одного кадра декодированного речевого сигнала.
Как отмечено выше, задача T230 может выполняться в ответ на индикацию, что кодированный кадр, предшествующий первому закодированному кадру, имеет второй формат. Для применения, показанного на Фиг. 17, эта индикация второго формата может быть индикацией, что кадр, непосредственно предшествующий первому кодированному кадру, является пустым, для DTX, или индикацией, что режим кодирования NELP используется для вычисления соответствующего кадра декодированного речевого сигнала. Альтернативно, эта индикация второго формата может быть индикацией формата второго кодированного кадра (то есть, индикацией формата последнего кадра SID до первого кодированного кадра).
Фиг.17 показывает конкретный пример, в котором третий кадр непосредственно предшествует первому кадру в декодированном речевом сигнале и соответствует последнему периоду кадра в интервале DTX. В других примерах третий кадр соответствует другому периоду кадра в интервале DTX, так что один или более кадров отделяют третий кадр от первого кадра в декодированном речевом сигнале. Фиг.17 также показывает пример, в котором адаптивная кодовая книга не обновляется во время интервала DTX. В других примерах один или более сигналов возбуждения, сгенерированных во время интервала DTX, используются для обновления адаптивной кодовой книги.
Память об основанном на шуме сигнале возбуждения может не быть полезной для генерирования сигналов возбуждения для последующих кадров. Следовательно, может быть желательно для декодера не использовать информацию от основанных на шуме сигналов возбуждения для обновления адаптивной кодовой книги. Например, такой декодер может быть конфигурирован, чтобы обновить адаптивную кодовую книгу только при декодировании кадра CELP; или только при декодировании кадра CELP, PPP или PWI; а не при декодировании кадра NELP.
Фиг.18 показывает последовательность операций такого способа M203 реализации способа M200 (Фиг.13A), который включает в себя задачи T260, T280 и T290. Задача T280 генерирует четвертый сигнал возбуждения на основании сигнала шума, сгенерированного задачей T260. В этом конкретном примере задачи T210 и T280 конфигурируются для выполнения согласно индикации, что второй кодированный кадр имеет второй формат, как обозначено сплошной линией. На основании четвертого сигнала возбуждения задача T290 вычисляет четвертый кадр декодированного речевого сигнала, который непосредственно предшествует третьему кадру. Способ M203 также включает в себя реализацию T254 задачи T250 (Фиг.13A), которая вычисляет третий кадр декодированного речевого сигнала на основании третьего сигнала возбуждения от задачи T245.
Задача T290 вычисляет четвертый кадр на основании информации, такой как набор значений спектральных параметров, из второго кодированного кадра, который предшествует первому кодированному кадру. Например, задача T290 может быть конфигурирована, чтобы сформировать спектр четвертого сигнала возбуждения согласно набору значений спектральных параметров. Задача T254 вычисляет третий кадр на основании информации, такой как набор значений спектральных параметров, из третьего кодированного кадра, который предшествует второму закодированному кадру. Например, задача T254 может быть конфигурирована, чтобы сформировать спектр третьего сигнала возбуждения согласно набору значений спектральных параметров. Задача T254 может быть также конфигурирована для выполнения в ответ на индикацию, что третий кодированный кадр имеет первый формат.
Фиг.19 иллюстрирует некоторые зависимости по данным в типичном применении способа M203 (Фиг.18). В этом применении третий кодированный кадр может быть отделен от второго кодированного кадра одним или более кодированными кадрами, сигналы возбуждения которых не используются для обновления адаптивной кодовой книги (например, кодированными кадрами, имеющими формат NELP). В таком случае третий и четвертый декодированные кадры обычно могут отделяться на то же самое количество кадров, что отделяют второй и третий кодированные кадры.
Как отмечено выше, может быть желательно использовать способ M200 в системе кодирования, которая также поддерживает DTX. Фиг.20 иллюстрирует некоторые зависимости по данным для такого применения способа M203 (Фиг.18), в котором второй закодированный кадр является кадром SID и кадры между этим кадром и первым закодированным кадром являются пустыми. Линия, соединяющая второй закодированный кадр с задачей T290, является пунктирной, чтобы указать, что информация от второго кодированного кадра (например, значения спектральных параметров) используется для вычисления более чем одного кадра декодированного речевого сигнала.
Как отмечено выше, задача T230 может выполняться в ответ на индикацию, что кодированный кадр, предшествующий первому закодированному кадру, имеет второй формат. Для применения, которое показано на Фиг.20, эта индикация второго формата может быть индикацией, что кадр, непосредственно предшествующий первому закодированному кадру, является пустым для DTX, или индикацией, что режим кодирования NELP используется для вычисления соответствующего кадра декодированного речевого сигнала. Альтернативно, эта индикация второго формата может быть индикацией о формате второго кодированного кадра (то есть, индикацией о формате последнего кадра SID до первого кодированного кадра).
Фиг.20 показывает конкретный пример, в котором четвертый кадр непосредственно предшествует первому кадру в декодированном речевом сигнале и соответствует последнему периоду кадра в интервале DTX. В других примерах четвертый кадр соответствует другому периоду кадра в интервале DTX так, что один или более кадров отделяют четвертый кадр от первого кадра в декодированном речевом сигнале.
В типичном применении реализации способа M200 (Фиг.13A) набор логических элементов (например, логические вентили) конфигурируется для выполнения одной, более одной, или даже всех различных задач способа. Одна или более (возможно все) задачи могут быть также реализованы как код (например, один или более наборов команд), воплощены в компьютерном программном продукте (например, одном или более носителях хранения данных, таких как диски, перепрограммируемые или другие платы энергонезависимой памяти, микросхемы полупроводниковой памяти, и т.д.), который является считываемым и/или выполняемым машиной (например, компьютером), включая набор логических элементов (например, процессор, микропроцессор, микроконтроллер или другой конечный автомат). Задачи реализации способа M200 (Фиг.13A) могут также быть выполнены более чем одним таким набором или машиной. В этих или других реализациях задачи могут быть выполнены в устройстве для беспроводной связи, таком как мобильный телефон или другое устройство, имеющем такую возможность связи. Такое устройство может быть сконфигурировано для выполнения обмена с сетью с коммутацией каналов и/или с пакетной коммутацией (например, используя один или более протоколов, таких как VoIP). Например, такое устройство может включать в себя РЧ схему, конфигурированную для приема кодированных кадров.
Фиг.21A показывают блок-схему устройства A100 для получения кадров декодированного речевого сигнала согласно общей конфигурации. Например, устройство A100 может быть конфигурировано для выполнения способа декодирования речи, который включает в себя реализацию способа M100 или M200, как описано в настоящем описании. Фиг.21B иллюстрирует типичное применение устройства A100, которое конфигурируется для вычисления последовательных первого и второго кадров декодированного речевого сигнала, на основании (A) первого кодированного кадра кодированного речевого сигнала и (B) индикации о стирании кадра, который непосредственно следует за первым кодированным кадром в кодированном речевом сигнале. Устройство A100 включает в себя логический модуль 110, конфигурированный для приема индикации стирания; генератор 120 сигнала возбуждения, выполненный с возможностью генерировать первый, второй и третий сигналы возбуждения, как описано выше; и спектральный формирователь 130, конфигурированный для вычисления первого и второго кадров декодированного речевого сигнала.
Устройство связи, которое включает в себя устройство A100, такое как мобильный телефон, может быть конфигурировано, чтобы принимать передачу, включающую в себя кодированное речевое сообщение, из проводного, беспроводного или оптического канала передачи. Такое устройство может быть конфигурировано, чтобы демодулировать несущий сигнал и/или выполнять операции предварительной обработки в отношении передачи, чтобы обеспечить кодированную речевую связь, такие как обращенное перемежение и/или декодирование кодов коррекции ошибок. Такое устройство может также включать в себя реализации обоих из устройства A100 и устройства для кодирования и/или передачи другого речевого сигнала дуплексного сеанса связи (например, как в приемопередатчике).
Логический модуль 110 конфигурируется и компонуется, чтобы вынудить генератор 120 сигнала возбуждения выводить второй сигнал возбуждения. Второй сигнал возбуждения основан на втором коэффициенте усиления, который больше, чем базовое значение коэффициента усиления. Например, комбинация логического модуля 110 и генератора 120 сигнала возбуждения может быть конфигурирована, чтобы выполнить задачу T230 так, как описано выше.
Логический модуль 110 может быть конфигурирован для выбора второго коэффициента усиления из двух или более опций согласно нескольким условиям. Эти условия включают в себя (A) что наиболее недавний кодированный кадр имел первый формат (например, формат CELP), (B) что кодированный кадр, предшествующий наиболее недавнему кодированному кадру, имел второй формат (например, формат NELP), (C) что текущий кодированный кадр стирается, и (D) что соотношение между пороговым значением и базовым значением коэффициента усиления имеет конкретное состояние (например, что пороговое значение больше, чем базовое значение коэффициента усиления). Фиг.22 показывает логическую схему, которая описывает работу такой реализации 112 логического модуля 110, используя вентиль И 140 и селектор 150. Если все условия имеют значение ИСТИНА, логический модуль 112 выбирает второй коэффициент усиления. Иначе, логический модуль 112 выбирает базовое значение коэффициента усиления.
Фиг.23 показывает последовательность операций работы другой реализации 114 логического модуля 110. В этом примере логический модуль 114 конфигурируется, чтобы выполнять задачи N210, N220 и N230, как показано на Фиг.8. Реализация логического модуля 114 может быть также конфигурирована для выполнения одной или более (возможно всех) задач T110-T140, как показано на Фиг.8.
Фиг.24 показывает описание работы другой реализации 116 логического модуля 110, которая включает в себя конечный автомат. Для каждого кодированного кадра конечный автомат обновляет свое состояние (где состояние 1 является начальным состоянием) согласно индикации формата или стиранию текущего кодированного кадра. Если конечный автомат находится в состоянии 3, когда он принимает индикацию, что текущий кадр стирается, то логический модуль 116 определяет, является ли базовое значение коэффициента усиления меньше, чем (альтернативно, не больше чем) пороговое значение. В зависимости от результата этого сравнения логический модуль 116 выбирает один из базового значения коэффициента усиления или второго коэффициента усиления.
Генератор 120 сигнала возбуждения может быть конфигурирован для генерирования второго сигнала возбуждения как последовательности сигналов возбуждения подкадра. Соответствующая реализация логического модуля 110 может быть конфигурирована для выбора или иным образом формирования отличного значения второго коэффициента усиления для каждого сигнала возбуждения подкадра, причем по меньшей мере одно из значений является большим, чем базовое значение коэффициента усиления. Например, Фиг.25 показывает описание работы такой реализации 118 логического модуля 116, которая сконфигурирована для выполнения задач T140, T230 и T240, как показано на Фиг.8.
Логический модуль 120 может быть скомпонован так, чтобы принять индикацию стирания от блока 210 обнаружения стирания, который встроен в устройство A100 или является внешним к устройству A100 (например, в устройстве, которое включает в себя устройство A100, такой как мобильный телефон). Блок 210 обнаружения стирания может быть конфигурирован, чтобы сформировать индикацию стирания для кадра после обнаружения любого одного или более следующих условий: (1) кадр содержит слишком много битовых ошибок, которые должны быть восстановлены; (2) скорость передачи в битах, указанная для кадра, является недействительной или неподдерживаемой; (3) все биты кадра равны нулю; (4) скорость передачи в битах, указанная для кадра, является скоростью одной восьмой, и все биты кадра равны единице; (5) кадр является пустым, и последняя действительная скорость передачи в битах не была равна одной восьмой.
Другие реализации логического модуля 110 могут быть конфигурированы так, чтобы выполнять дополнительные аспекты обработки стирания, такие как выполняемые модулем 100 восстановления при стирании кадра, как описано выше. Например, такая реализация логического модуля 110 может быть конфигурирована, чтобы выполнять такие задачи, как вычисление базового значения коэффициента усиления и/или вычисление набора значений спектральных параметров для фильтрации второго сигнала возбуждения. Для применения, в котором первый закодированный кадр включает в себя только один коэффициент усиления адаптивной кодовой книги, базовое значение коэффициента усиления может быть просто значением первого коэффициента усиления. Для применения, в котором первый закодированный кадр включает в себя несколько коэффициентов усиления адаптивной кодовой книги (например, отличный коэффициент для каждого подкадра), базовое значение коэффициента усиления может быть основано также на одном или более других коэффициентах усиления адаптивной кодовой книги. В таком случае, например, логический модуль 110 может быть конфигурирован, чтобы вычислять базовое значение коэффициента усиления как среднее число коэффициентов усиления адаптивной кодовой книги первого закодированного кадра.
Реализации логического модуля 110 могут быть классифицированы согласно способу, которым они заставляют генератор 120 сигнала возбуждения выводить второй сигнал возбуждения. Один класс 110А логического модуля 110 включает в себя реализации, которые конфигурируются, чтобы выдать второй коэффициент усиления к генератору 120 сигнала возбуждения. Фиг.26A показывает блок-схему реализации A100A устройства A100, которая включает в себя такую реализацию логического модуля 110 и соответствующую реализацию 120A генератора 120 сигнала возбуждения.
Другой класс 110В логического модуля 110 включает в себя реализации, которые конфигурируются, чтобы заставить генератор сигнала возбуждения 110 выбирать второй коэффициент усиления из двух или более возможных (например, в качестве ввода). Фиг.26B показывает блок-схему реализации A100B устройства A100, которая включает в себя такую реализацию логического модуля 110 и соответствующую реализацию 120B генератора 120 сигнала возбуждения. В этом случае селектор 150, который показан в логическом модуле 112 на Фиг.22, располагается в генераторе 120B сигнала возбуждения вместо этого. Явно рассматривается и тем самым раскрывается, что любая из реализаций 112, 114, 116 118 логического модуля 110 может быть конфигурирована и скомпонована согласно классу 110А или классу 110В.
Фиг.26C показывает блок-схему реализации A100C устройства A100. Устройство A100C включает в себя реализацию класса 110В логического модуля 110, которая выполнена с возможностью заставить генератор 120 сигнала возбуждения выбирать второй сигнал возбуждения из двух или более сигналов возбуждения. Генератор 120C сигнала возбуждения включает в себя две подреализации 120C1, 120C2 генератора 120 сигнала возбуждения, одна сконфигурирована для генерирования сигнала возбуждения на основании второго коэффициента усиления и другая сконфигурирована для генерирования сигнала возбуждения на основании другого значения коэффициента усиления (например, базового значения коэффициента усиления). Генератор 120C сигнала возбуждения конфигурируется, чтобы сгенерировать второй сигнал возбуждения согласно управляющему сигналу от логического модуля 110B к селектору 150, посредством выбора сигнала возбуждения, который основан на втором коэффициенте усиления. Следует заметить, что конфигурация класса 120C генератора 120 сигнала возбуждения может требовать больше циклов обработки, мощности и/или памяти, чем соответствующая реализация класса 120A или 120B.
Генератор 120 сигнала возбуждения конфигурируется, чтобы сгенерировать первый сигнал возбуждения на основании первого коэффициента усиления и первой последовательности значений. Например, генератор 120 сигнала возбуждения может быть конфигурирован для выполнения задачи T210, как описано выше. Первая последовательность значений основана на информации из третьего сигнала возбуждения, такой как сегмент третьего сигнала возбуждения. В типичном примере первая последовательность основана на последнем подкадре третьего сигнала возбуждения.
Типичная реализация генератора 120 сигнала возбуждения включает в себя память (например, адаптивную кодовую книгу), сконфигурированную для приема и хранения первой последовательности. Фиг.27A показывают блок-схему реализации 122 генератора 120 сигнала возбуждения, которая включает в себя такую память 160. Альтернативно, по меньшей мере часть адаптивной кодовой книги может быть расположена в памяти в другом месте в пределах или вне устройства A100 таким образом, что часть (возможно вся) первой последовательности подается как входные данные к генератору 120 сигнала возбуждения.
Как показано на Фиг.27A, генератор 120 сигнала возбуждения может включать в себя умножитель 170, который конфигурируется для вычисления произведения текущего коэффициента усиления и последовательности. Первый коэффициент усиления может быть основан на информации из первого закодированного кадра, такой как индекс кодовой книги усиления. В таком случае генератор 120 сигнала возбуждения может включать в себя кодовую книгу усиления, вместе с логикой, сконфигурированной для извлечения первого коэффициента усиления в качестве значения, которое соответствует этому индексу. Генератор 120 сигнала возбуждения может быть также конфигурирован, чтобы принять индекс адаптивной кодовой книги, который указывает местоположение первой последовательности в пределах адаптивной кодовой книги.
Генератор 120 сигнала возбуждения может быть сконфигурирован для генерирования первого сигнала возбуждения на основании дополнительной информации из первого закодированного кадра. Такая информация может включать в себя один или более индексов фиксированной кодовой книги и соответствующие значения коэффициента усиления или индексы кодовой книги, которые определяют вклад фиксированной кодовой книги в первый сигнал возбуждения. Фиг.27B показывает блок-схему реализации 124 генератора 122 сигнала возбуждения, которая включает в себя кодовую книгу 180 (например, фиксированную кодовую книгу), конфигурированную, чтобы хранить другую информацию, на которой сгенерированный сигнал возбуждения может быть основан, умножитель 190, сконфигурированный для вычисления произведения последовательности фиксированной кодовой книги и коэффициента усиления фиксированной кодовой книги, и сумматор 195, сконфигурированный для вычисления сигнала возбуждения как суммы вкладов фиксированной и адаптивной кодовых книг. Генератор 124 сигнала возбуждения может также включать в себя логику, конфигурированную для извлечения последовательности и коэффициентов усиления из соответствующих кодовых книг согласно соответствующим индексам.
Генератор 120 сигнала возбуждения также конфигурируется, чтобы генерировать второй сигнал возбуждения на основании второго коэффициента усиления и второй последовательности значений. Второй коэффициент усиления больше, чем первый коэффициент усиления, и может быть больше, чем базовое значение коэффициента усиления. Второй коэффициент усиления может быть также равным или даже большим, чем пороговое значение. Для случая, в котором генератор 120 сигнала возбуждения конфигурируется, чтобы сгенерировать второй сигнал возбуждения как последовательность сигналов возбуждения подкадра, различное значение второго коэффициента усиления может использоваться для каждого сигнала возбуждения подкадра, причем по меньшей мере одно из значений является большим, чем базовое значение коэффициента усиления. В таком случае может быть желательно, чтобы различные значения второго коэффициента усиления увеличивались или уменьшались в течение периода кадра.
Вторая последовательность значений основана на информации из первого сигнала возбуждения, такой как сегмент первого сигнала возбуждения. В типичном примере вторая последовательность основана на последнем подкадре первого сигнала возбуждения. Соответственно, генератор 120 сигнала возбуждения может быть конфигурирован, чтобы обновлять адаптивную кодовую книгу на основании информации из первого сигнала возбуждения. Для применения устройства A100 к системе кодирования, которая поддерживает упрощенный режим кодирования CELP (RCELP), такая реализация генератора 120 сигнала возбуждения может быть сконфигурирована подвергать сегмент изменению шкалы времени согласно соответствующему значению параметра запаздывания основного тона. Пример такой операции по изменению шкалы времени описан в Секции 5.2.2 (со ссылками на Секцию 4.11.5) документа C.S0014-C v1.0 3GPP2, процитированного выше.
Генератор 120 сигнала возбуждения также конфигурируется, чтобы сгенерировать третий сигнал возбуждения. В некоторых применениях генератор 120 сигнала возбуждения конфигурируется, чтобы генерировать третий сигнал возбуждения на основании информации из адаптивной кодовой книги (например, памяти 160).
Генератор 120 сигнала возбуждения может быть конфигурирован, чтобы генерировать сигнал возбуждения, который основан на сигнале шума (например, сигнале возбуждения, сгенерированном в ответ на индикацию формата NELP). В таких случаях генератор 120 сигнала возбуждения может быть конфигурирован, чтобы включать в себя генератор шума, конфигурированный для выполнения задачи T260. Может быть желательно, чтобы генератор шума использовал значение начального числа, которое основано на другой информации от соответствующего кодированного кадра (такой как спектральная информация), также способ может быть использован для генерирования поддержки того же самого сигнала шума, который использовался в кодере. Альтернативно, генератор 120 сигнала возбуждения может быть конфигурирован, чтобы принять сгенерированный сигнал шума. В зависимости от конкретного применения генератор 120 сигнала возбуждения может быть сконфигурирован для генерирования третьего сигнала возбуждения на основании сгенерированного сигнала шума (например, для выполнения задачи T270) или генерирования четвертого сигнала возбуждения, на основании сгенерированного сигнала шума (например, для выполнения задачи T280).
Генератор 120 сигнала возбуждения может быть сконфигурирован для генерирования сигнала возбуждения на основании последовательности из адаптивной кодовой книги или генерирования сигнала возбуждения на основании сгенерированного сигнала шума согласно индикации формата кадра. В таком случае генератор 120 сигнала возбуждения обычно конфигурируется, чтобы продолжить работать согласно режиму кодирования последнего действительного кадра в случае, когда текущий кадр стирается.
Генератор 122 сигнала возбуждения обычно реализуется, чтобы обновлять адаптивную кодовую книгу таким образом, что последовательность, сохраненная в памяти 160, была основана на сигнале возбуждения для предыдущего кадра. Как отмечено выше, обновление адаптивной кодовой книги может включать в себя выполнение операции изменения шкалы времени согласно значению параметра запаздывания основного тона. Генератор 122 сигнала возбуждения может быть конфигурирован, чтобы обновлять память 160 в каждом кадре (или даже в каждом подкадре). Альтернативно, генератор 122 сигнала возбуждения может быть реализован, чтобы обновлять память 160 только в кадрах, которые декодируются, используя сигнал возбуждения, на основании информации из памяти. Например, генератор 122 сигнала возбуждения может быть реализован, чтобы обновлять память 160 на основании информации из сигналов возбуждения для кадров CELP, но не на информации из сигналов возбуждения для кадров NELP. В течение периодов кадра, в которых память 160 не обновляется, содержимое памяти 160 может оставаться неизменным или даже может быть возвращено в начальное состояние (например, установлено в нуль).
Спектральный формирователь 130 конфигурируется для вычисления первого кадра декодированного речевого сигнала на основании первого сигнала возбуждения и информации из первого закодированного кадра кодированного речевого сигнала. Например, спектральный формирователь 130 может быть конфигурирован для выполнения задачи T220. Спектральный формирователь 130 также конфигурируется для вычисления, на основании второго сигнала возбуждения, второго кадра декодированного речевого сигнала, который непосредственно следует за первым кадром. Например, спектральный формирователь 130 может быть конфигурирован для выполнения задачи T240. Спектральный формирователь 130 также конфигурируется для вычисления, на основании третьего сигнала возбуждения, третьего кадра декодированного речевого сигнала, который предшествует первому кадру. Например, спектральный формирователь 130 может быть конфигурирован для выполнения задачи T250. В зависимости от применения спектральный формирователь 130 может быть также конфигурирован, чтобы вычислять четвертый кадр декодированного речевого сигнала, на основании четвертого сигнала возбуждения (например, для выполнения задачи T290).
Типичная реализация спектрального формирователя 130 включает в себя фильтр синтеза, который конфигурируется согласно набору значений спектральных параметров для кадра, такому как набор значений коэффициентов LPC. Спектральный формирователь 130 может быть скомпонован, чтобы принимать набор значений спектральных параметров от вычислителя параметра речи, как описано в настоящем описании, и/или от логического модуля 110 (например, в случаях стирания кадра). Спектральный формирователь 130 может быть также конфигурирован, чтобы вычислять декодированный кадр согласно последовательности различных подкадров сигнала возбуждения и/или последовательности различных наборов значений спектральных параметров. Спектральный формирователь 130 может быть также конфигурирован для выполнения одной или более других операций по обработке в отношении сигнала возбуждения в отношении сформированного сигнала возбуждения и/или в отношении значений спектральных параметров, таких как другие операции фильтрования.
Детектор 220 формата, который встроен в устройство A100 или является внешним устройству A100 (например, в устройство, которое включает в себя устройство A100, такое как мобильный телефон), может быть скомпонован, чтобы выдать индикации формата кадра для первого и других кодированных кадров к одному или более из: логического модуля 110, генератора 120 сигнала возбуждения и спектрального формирователя 130. Детектор 220 формата может содержать блок 210 обнаружения стирания, или эти два элемента могут быть реализованы отдельно. В некоторых применениях система кодирования конфигурируется, чтобы использовать только один режим кодирования для конкретной скорости передачи в битах. Для этих случаев скорость передачи в битах кодированного кадра (которая определена, например, из одного или более параметров, таких как энергия кадра) также указывает формат кадра. Для системы кодирования, которая использует более одного режима кодирования при скорости передачи в битах закодированного кадра, детектор 220 формата может быть конфигурирован, чтобы определять формат из индекса кодирования, такого как набор из одного или более битов в кодированном кадре, который идентифицирует режим кодирования. В этом случае индикация формата может быть основана на определении индекса кодирования. В некоторых случаях индекс кодирования может явно указать режим кодирования. В других случаях индекс кодирования может неявно указать режим кодирования, например, посредством индикации значения, которое может быть недействительным для другого режима кодирования.
Устройство A100 может быть скомпоновано, чтобы принимать речевые параметры кодированного кадра (например, значения спектральных параметров, индексы адаптивной и/или фиксированной кодовой книги, значения коэффициента усиления и/или индексы кодовой книги) от вычислителя 230 параметров речи, который включен в устройство A100 или является внешним устройству A100 (например, в устройство, которое включает в себя устройство A100, такое как мобильный телефон). Фиг. 28 показывает блок-схему реализации 232 вычислителя 230 параметров речи, которая включает в себя синтаксический анализатор 310 (также называемый "обратный формирователь пакетов"), деквантователь 320 и 330 и преобразователь 340. Синтаксический анализатор 310 конфигурируется, чтобы анализировать (выполнять синтаксический разбор) кодированный кадр согласно его формату. Например, синтаксический анализатор 310 может быть конфигурирован, чтобы отличать различные типы информации в кадре согласно их позициям битов в кадре, как обозначено форматом.
Деквантователь 320 конфигурируется, чтобы деквантовать спектральную информацию. Например, деквантователь 320 обычно конфигурируется, чтобы применить спектральную информацию, полученную в результате синтаксического разбора кодированного кадра, в качестве индексов к одной или более кодовым книгам, чтобы получить набор значений спектральных параметров. Деквантователь 330 конфигурируется, чтобы деквантовать временную информацию. Например, деквантователь 330 также обычно конфигурируется, чтобы применить временную информацию, полученную в результате синтаксического разбора кодированного кадра, в качестве индексов к одной или более кодовым книгам, чтобы получить временные значения параметра (например, значения коэффициента усиления). Альтернативно, генератор 120 сигнала возбуждения может быть конфигурирован для выполнения деквантования некоторой или всей временной информации (например, индексы адаптивной и/или фиксированной кодовой книги). Как показано на Фиг.28, один или оба из деквантователей 320 и 330 могут быть конфигурированы, чтобы деквантовать соответствующую информацию кадра согласно конкретному формату кадра, поскольку различные режимы кодирования могут использовать различные таблицы или схемы квантования.
Как отмечено выше, значения коэффициентов LPC обычно преобразуются в другую форму (например, значения LSP, LSF, ISP и/или ISF) перед квантованием. Преобразователь 340 конфигурируется, чтобы преобразовывать деквантованную спектральную информацию в значения коэффициентов LPC. Для стертого кадра выходные значения вычислителя 230 параметров речи могут быть нулевыми, неопределенными или неизменяемыми, в зависимости от конкретного выбора варианта осуществления. Фиг. 29A показывает блок-схему примера системы, которая включает в себя реализации блока 210 обнаружения стирания, блока 220 определения формата, вычислителя 230 параметров речи и устройства A100. Фиг.29B показывает блок-схему аналогичной системы, которая включает в себя реализацию 222 блока 220 определения формата, который также выполняет обнаружение стирания.
Различные элементы реализации устройства A100 (например, логический модуль 110, генератор 120 сигнала возбуждения и спектральный формирователь 130) могут быть воплощены в любой комбинации аппаратного обеспечения, программного обеспечения и/или программно-аппаратного обеспечения, которую считают подходящей для намеченного применения. Например, такие элементы могут быть изготовлены как электронное и/или оптическое устройства, например, на одной и той же микросхеме или на двух или более кристаллах в наборе микросхем. Один пример такого устройства - фиксированный или программируемый набор логических элементов, таких как транзисторы или логические вентили, и любой из этих элементов может быть реализован как один или более таких массивов. Любые два или более, или даже все, из этих элементов могут быть реализованы в одном и том же наборе или наборах. Такой набор или наборы могут быть реализованы в одной или более микросхемах (например, в наборе микросхем, включающем в себя две или более микросхем).
Один или более элементов различных реализаций устройства A100, как описано в настоящем описании (например, логический модуль 110, генератор 120 сигнала возбуждения и спектральный формирователь 130), могут также быть реализованы полностью или частично как один или более наборов команд, предназначенных для выполнения на одном или более фиксированном или программируемом наборе логических элементов, таких как микропроцессоры, встроенные процессоры, ядра IP, цифровые процессоры сигналов, FPGA (программируемые пользователем вентильные матрицы), ASSP (специализированные для применения стандартные продукты), и ASICs (специализированные для приложения интегральные схемы). Любой из различных элементов реализации устройства A100 может быть также воплощен как один или более компьютеров (например, машины, включающие в себя один или более массивов, запрограммированных для выполнения одного или более наборов или последовательностей команд, также названных "процессорами"), и любые два или более, или даже все, из этих элементов могут быть реализованы в пределах одного и того же такого компьютера или компьютеров.
Различные элементы реализации устройства A100 могут быть включены в устройство для беспроводной связи, такое как мобильный телефон или другое устройство, имеющее такую возможность связи. Такое устройство может быть конфигурировано, чтобы общаться с сетью с коммутацией каналов и/или с пакетной коммутацией (например, используя один или более протоколов, таких как VoIP). Такое устройство может быть конфигурировано, чтобы выполнить операции в отношении сигнала, несущего кодированные кадры, такие как обращенное перемежение, обратное «прокалывание», декодирование одного или более сверточных кодов, декодирование одного или более кодов с исправлением ошибок, декодирование одного или более уровней протокола сети (например, Ethernet, TCP/IP, cdma2000), радиочастотной (RF) демодуляции и/или РЧ приема.
Возможно использовать один или более элементов реализации устройства A100 для выполнения задач или выполнения других наборов команд, которые непосредственно не относятся к работе устройства, таких как задача, относящаяся к другой работе устройства или системы, в которую внедрено устройство. Также возможно, что один или более элементов реализации устройства A100 имеют общую структуру (например, процессор, используемый для выполнения части кода, соответствующего различным элементам в разные моменты времени, набора команд, исполняемых для выполнения задач, соответствующих различным элементам в разные моменты времени, или компоновки электронных и/или оптических устройств, выполняющих операции для различных элементов в разные моменты времени). В одном таком примере логический модуль 110, генератор 120 сигнала возбуждения и спектральный формирователь 130 реализуются как наборы команд, предназначенных для выполнения на одном и том же процессоре. В другом таком примере эти элементы и один или более (возможно все) из блока 210 обнаружения стирания, блока 220 определения формата и вычислителя 230 параметров речи реализуются как наборы команд, предназначенных для выполнения на одном и том же процессоре. В другом примере генераторы 120C1 и 120C2 сигнала возбуждения реализуются как один и тот же набор команд, выполняющихся в различные моменты времени. В другом примере деквантователи 320 и 330 реализуются как один и тот же набор команд, выполняющихся в различные моменты времени.
Устройство для беспроводной связи, такое как мобильный телефон или другое устройство, имеющее такую возможность связи, может быть конфигурировано, чтобы включать в себя реализации обоих из устройства A100 и речевого кодера. В таком случае возможно, что устройство A100 и речевой кодер имеют общую структуру. В одном таком примере устройство A100 и речевой кодер реализуются, чтобы включать в себя наборы команд, которые предназначены для выполнения на одном и том же процессоре.
Предшествующее представление описанных конфигураций обеспечивается, чтобы позволить любому специалисту в области техники сделать или использовать способы и другие структуры, раскрытые здесь. Последовательности операций, блок-схемы, диаграммы состояний и другие структуры, показанные и описанные здесь, являются только примерами, и другие варианты этих структур также включаются в рамки настоящего описания. Возможны различные модификации этих конфигураций, и универсальные принципы, представленные здесь, могут быть применены также к другим конфигурациям. Например, хотя примеры преимущественно описывают применение к стертому кадру, следующему после кадра CELP, явно рассматривается и тем самым раскрывается, что такие способы, устройство и системы могут также быть применены к случаям, в которых стертый кадр следует за кадром, кодированным согласно другому режиму кодирования, который использует сигнал возбуждения на основании памяти о прошлой информации возбуждения, такой как PPP или другой PWI режим кодирования. Таким образом, настоящее описание не предназначается, чтобы быть ограниченным конкретными примерами или конфигурациями, показанными выше, а скорее должно получить самый широкий объем, совместимый с принципами и новыми признаками, раскрытыми в любом виде здесь, включенными в прилагаемую формулу изобретения как она подана, которые являются частью первоначального описания.
Примеры кодеков, которые могут быть использованы или адаптированы для использования с речевыми декодерами и/или способами декодирования речи, как описаны здесь, включают в себя усовершенствованный кодек с переменной скоростью (EVRC), как описано в документе C.S0014-C 3GPP2 версии 1.0, "Enhanced Variable Rate Codec, Speech Service Options 3, 68, and 70 for Wideband Spread Spectrum Digital Systems," Часть 5, январь 2007; адаптивный речевой кодек с множеством скоростей передачи (AMR), как описано в документе ETSI TS 126 092 V6.0.0, часть 6, декабрь 2004; и широкополосный речевой кодек AMR, как описано в документе document ETSI TS 126 192 V6.0.0, часть 6, декабрь 2004.
Специалистам в области техники понятно, что информация и сигналы могут быть представлены, используя любую из множества различных технологий и методик. Например, данные, инструкции, команды, информация, сигналы, биты и символы, на которые можно сделать ссылки в вышеупомянутом описании, могут быть представлены напряжениями, токами, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами, или любой их комбинацией. Хотя сигнал, из которого закодированные кадры получают, и сигнал, который декодирован, называют "речевыми сигналами", также рассматривается и тем самым раскрывается, что эти сигналы могут передавать музыку или другой неречевой информационный контент во время активных кадров.
Специалисты также могут оценить, что различные иллюстративные логические блоки, модули, схемы и операции, описанные совместно с конфигурациями, раскрытыми здесь, могут быть реализованы как электронное аппаратное обеспечение, программное обеспечение, или комбинации обоих. Такие логические блоки, модули, схемы и операции могут быть реализованы или выполнены процессором общего назначения, цифровым процессором сигналов (DSP), специализированными интегральными схемами, FPGA или другим программируемым логическим устройством, дискретной вентильной или транзисторной логикой, дискретными компонентами аппаратного обеспечения или любой их комбинацией, предназначенной для выполнения функций, описанных здесь. Процессор общего назначения может быть микропроцессором, но альтернативно, процессор может быть любым обычным процессором, контроллером, микроконтроллером или конечным автоматом. Процессор может быть также реализован как комбинация вычислительных устройств, например как комбинация DSP и микропроцессора, множества микропроцессоров, одного или более микропроцессоров вместе с ядром DSP, или любая другая такая конфигурация.
Задачи способов и алгоритмов, описанных здесь, могут быть воплощены непосредственно в аппаратном обеспечении, в программном модуле, выполняемом процессором, или их комбинации. Программный модуль может постоянно находиться в памяти оперативной памяти (RAM), флэш-памяти, памяти ПЗУ, памяти программируемого ПЗУ, памяти СППЗУ, регистрах, жестком диске, сменном диске, CD-ROM, или любой другой форме носителя данных, известного в технике. Иллюстративный носитель данных подсоединяется к процессору так, что процессор может считывать информацию с и записывать информацию на носитель данных. В альтернативе, носитель данных может быть встроен в процессор. Процессор и носитель данных могут постоянно находиться в специализированных интегральных схемах. Специализированные интегральные схемы могут постоянно находиться в пользовательском терминале. В альтернативе, процессор и носитель данных могут постоянно находиться как дискретные компоненты в пользовательском терминале.
Каждая из конфигураций, описанных здесь, может быть реализована, по меньшей мере частично, как аппаратная схема, как схемная структура, изготовленная в виде специфической для приложения интегральной схемы, или как программа программно-аппаратного обеспечения, загруженная в энергонезависимую память, или программа, загруженная из или на носитель хранения данных в качестве машиносчитываемого кода, такой код выполняется набором логических элементов, таких как микропроцессор или другой модуль обработки цифровых сигналов. Носитель хранения данных может быть массивом элементов памяти, таких как полупроводниковая память (которая может включать в себя без ограничения динамическую или статическую оперативную память (RAM), ПЗУ (ROM) и/или перепрограммируемую оперативную память), или сегнетоэлектрическую, магниторезистивную память, память на аморфных полупроводниках, полимерную или память с изменением фазы; или дисковый носитель, такой как магнитный или оптический диск. Термин "программное обеспечение" следует понимать как включающий в себя исходный текст, код на языке ассемблера, машинный код, двоичный код, программно-аппаратное обеспечение, макрокоманду, микрокод, любой один или более наборов или последовательностей инструкций, выполняемых набором логических элементов, и любую комбинацию таких примеров.
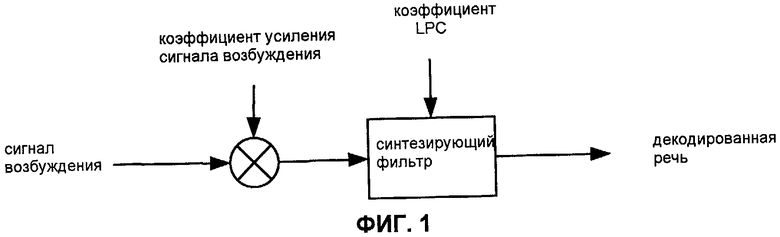
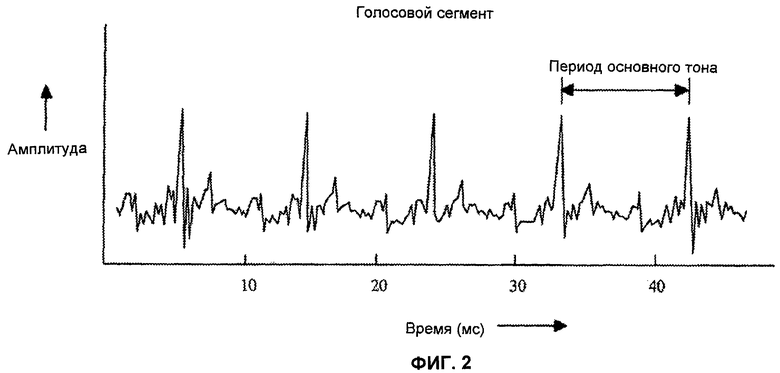
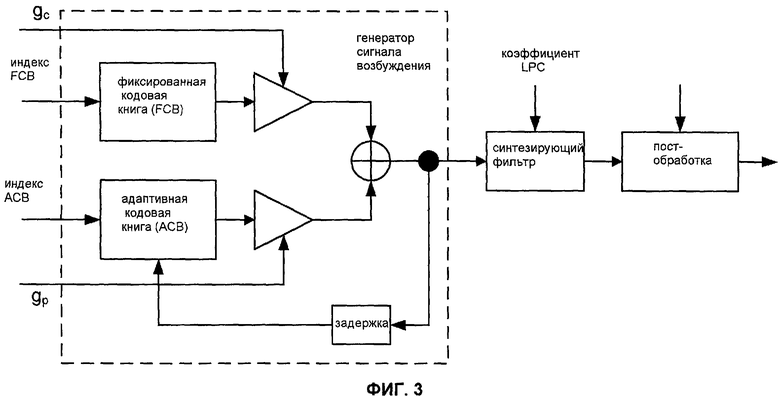
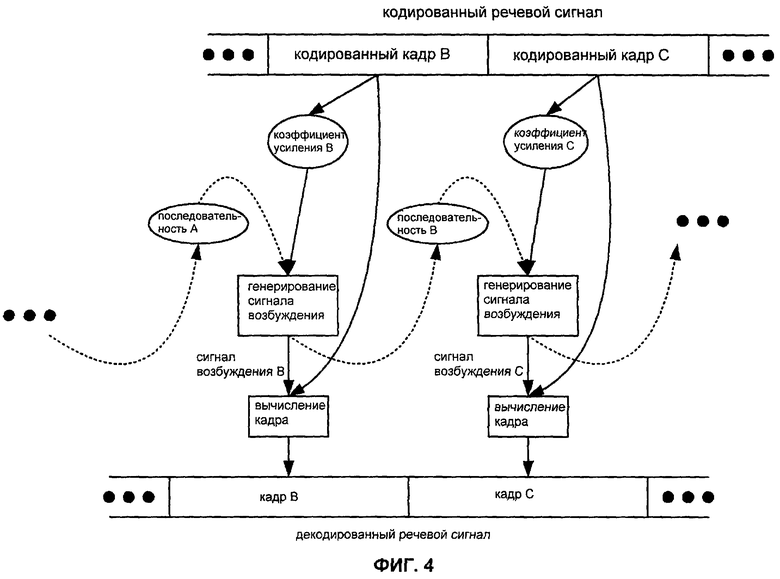
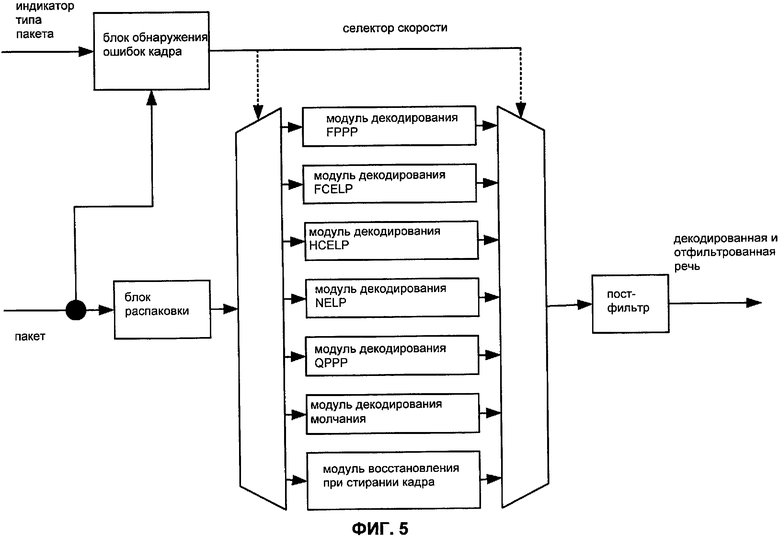
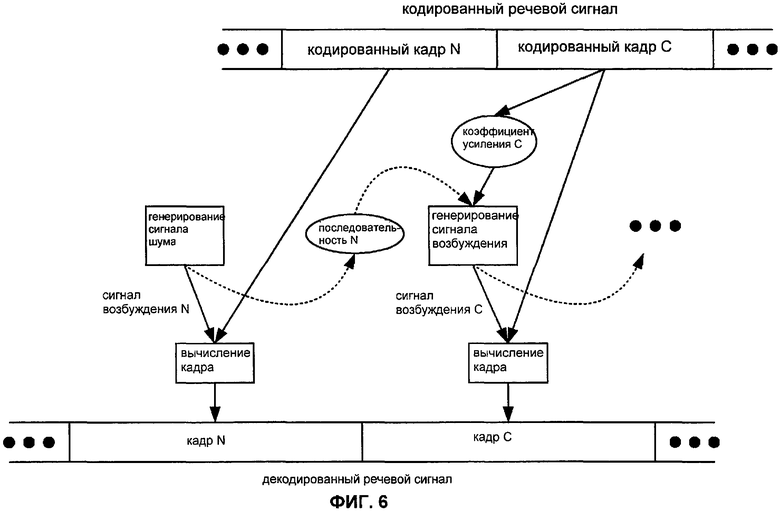
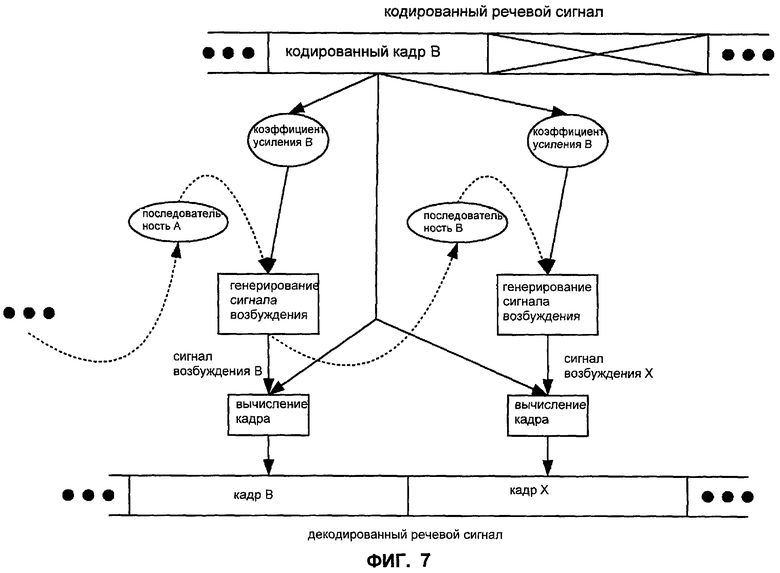
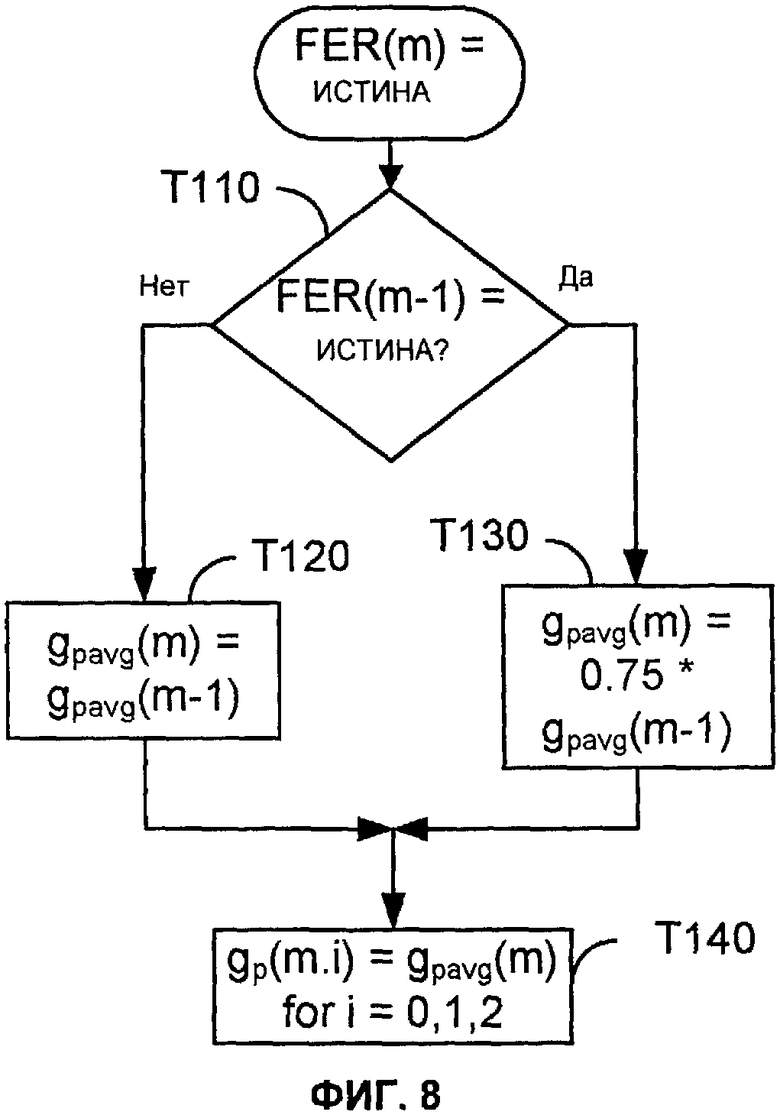
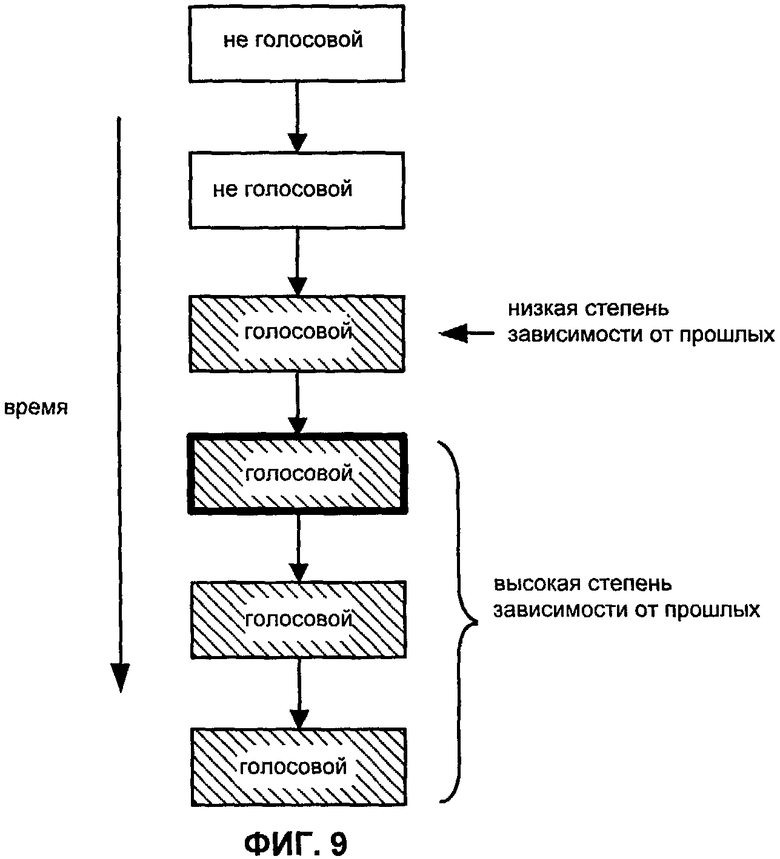
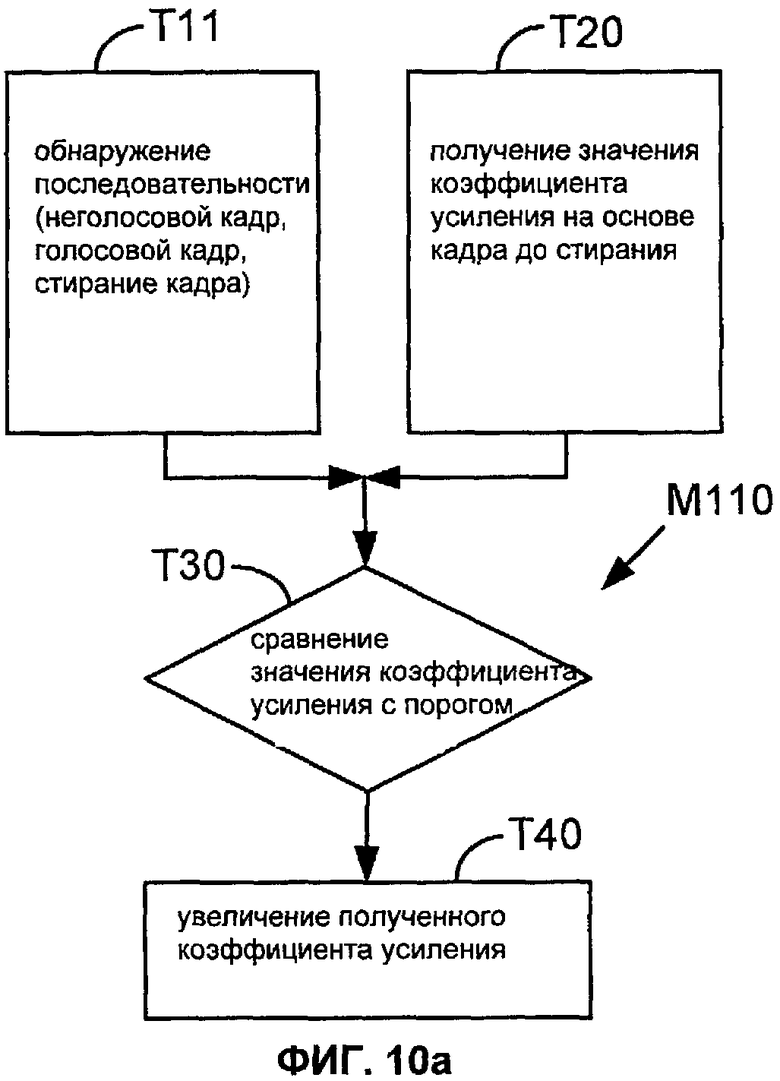
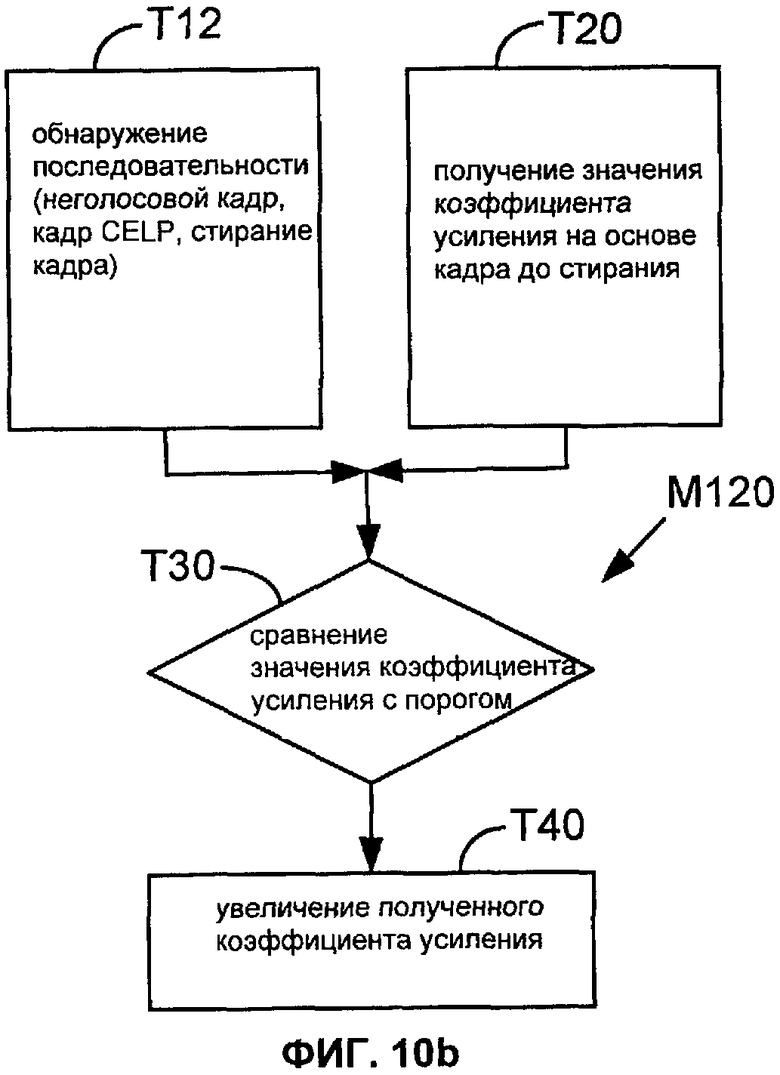
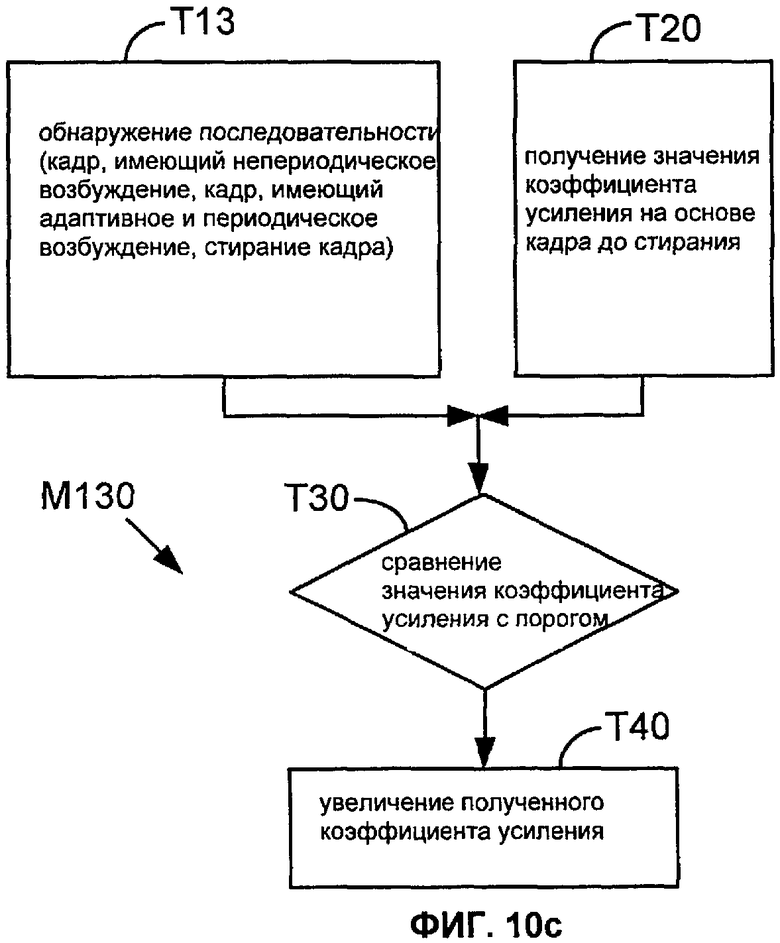
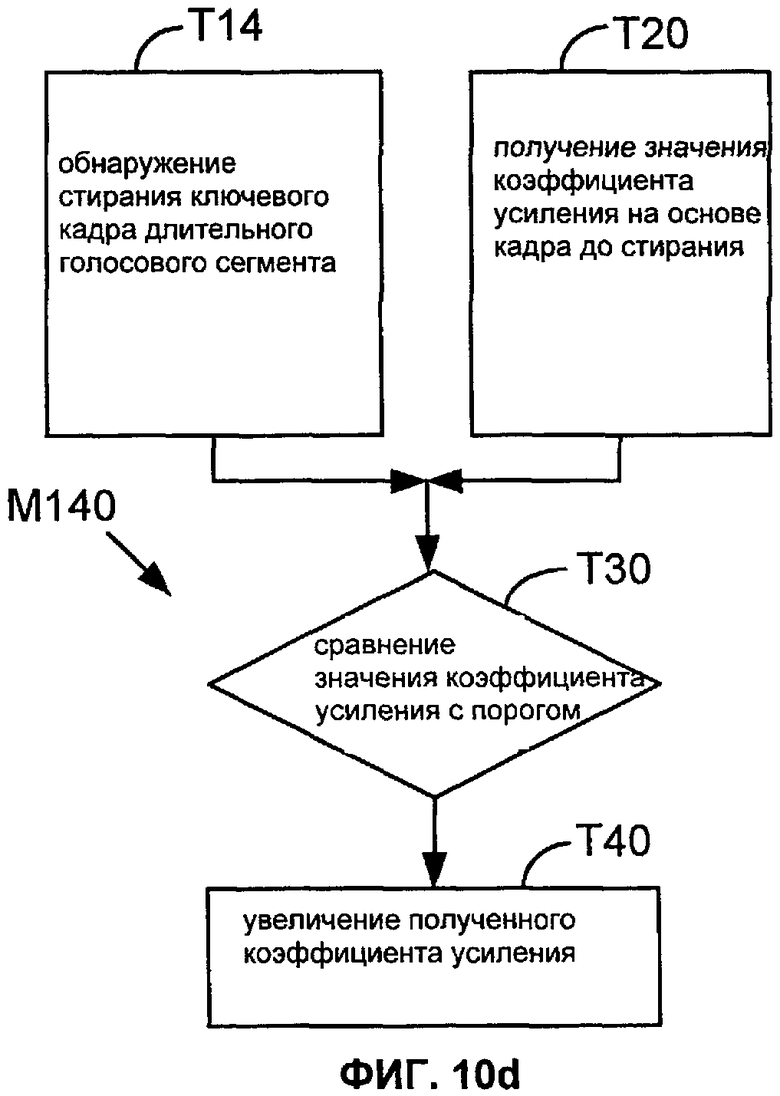
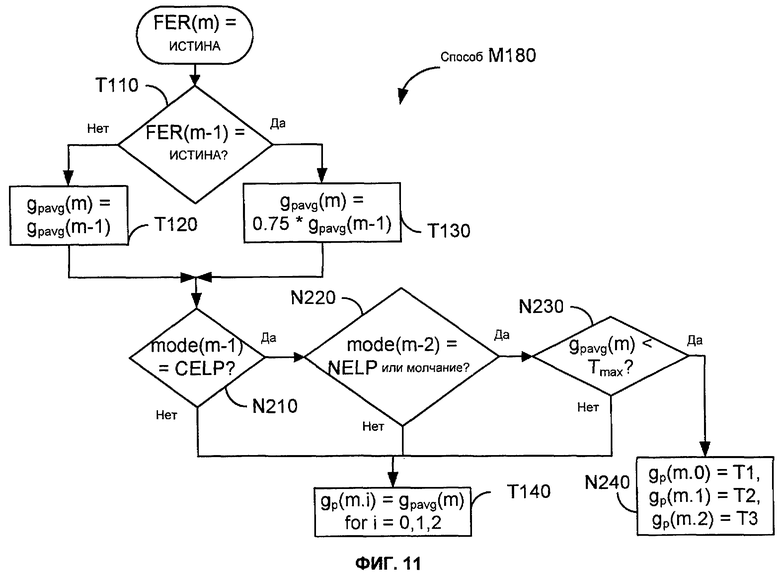
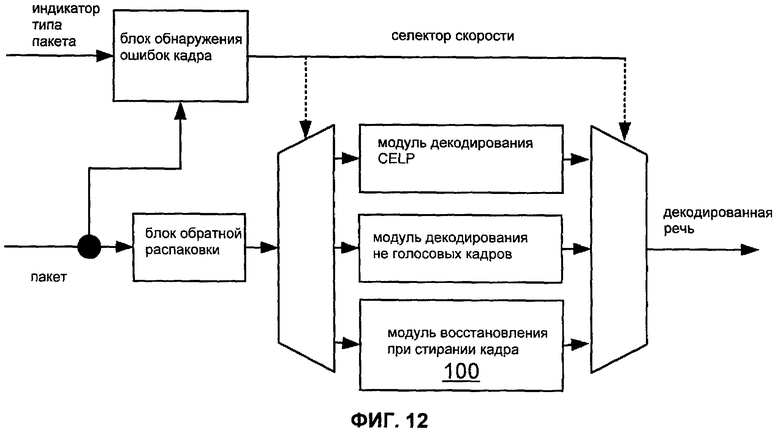
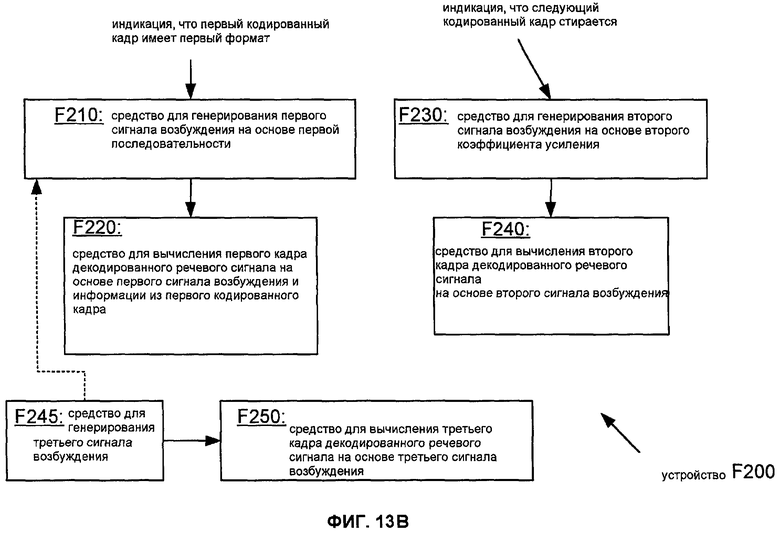
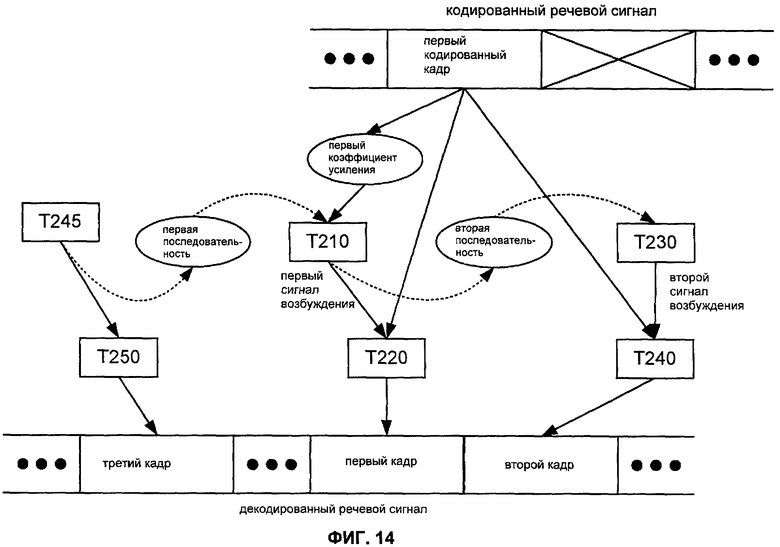
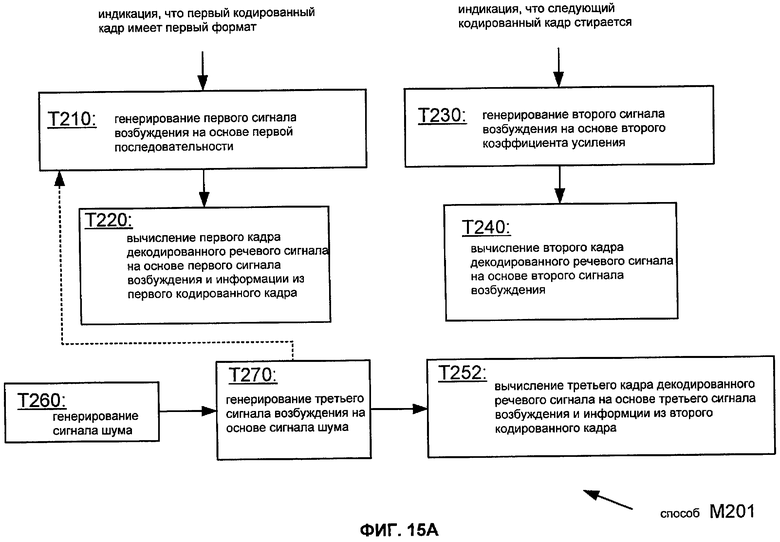
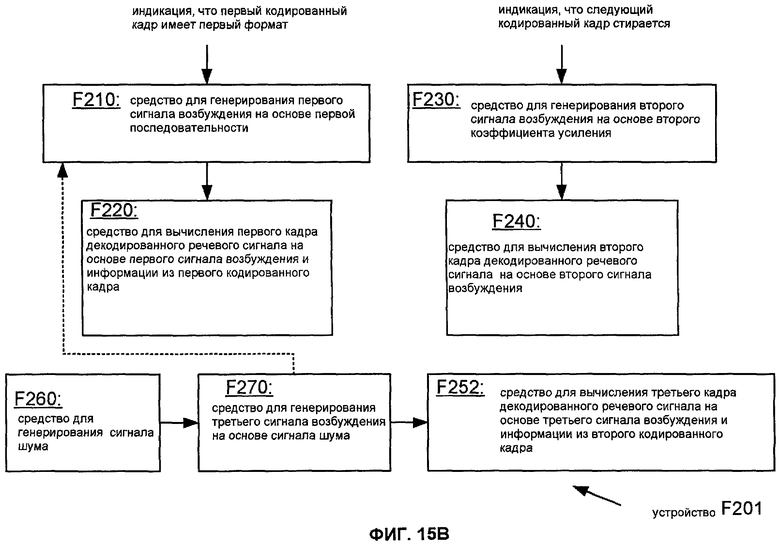
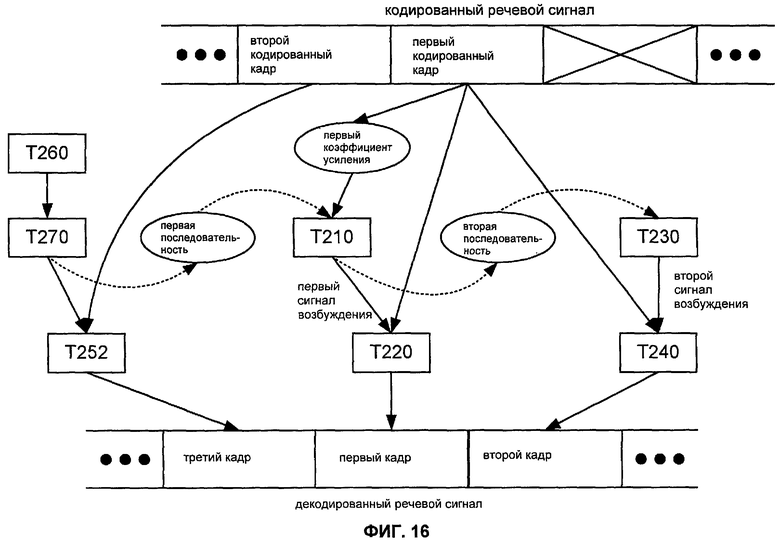
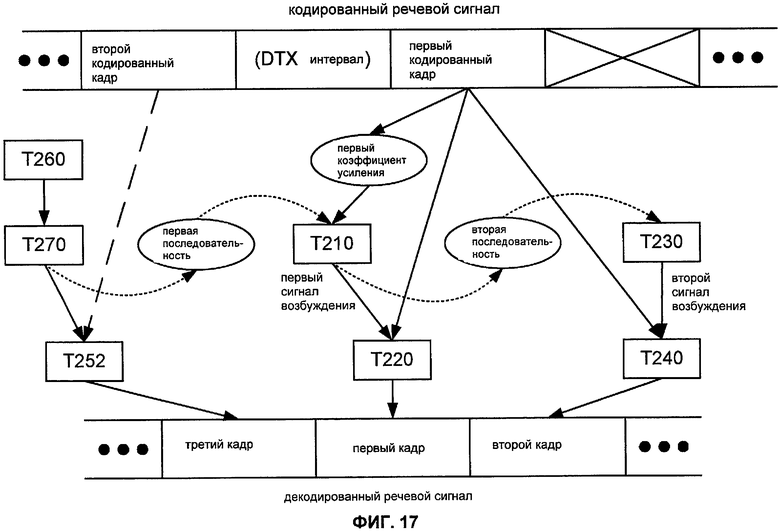
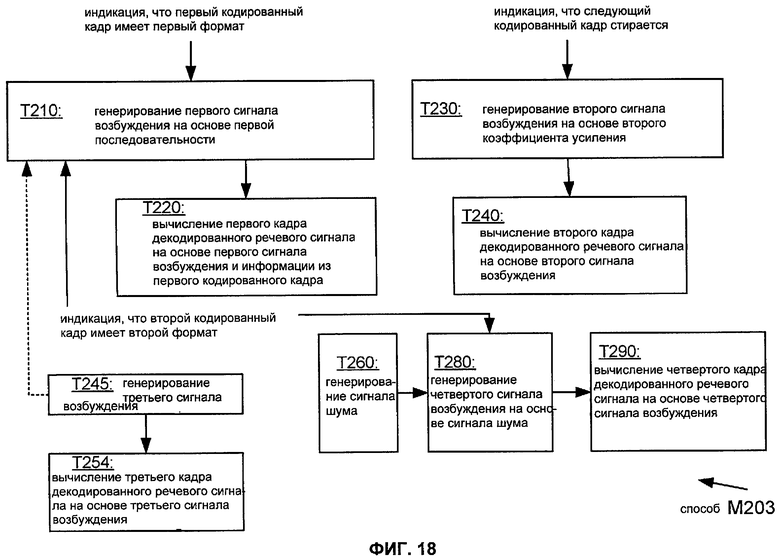
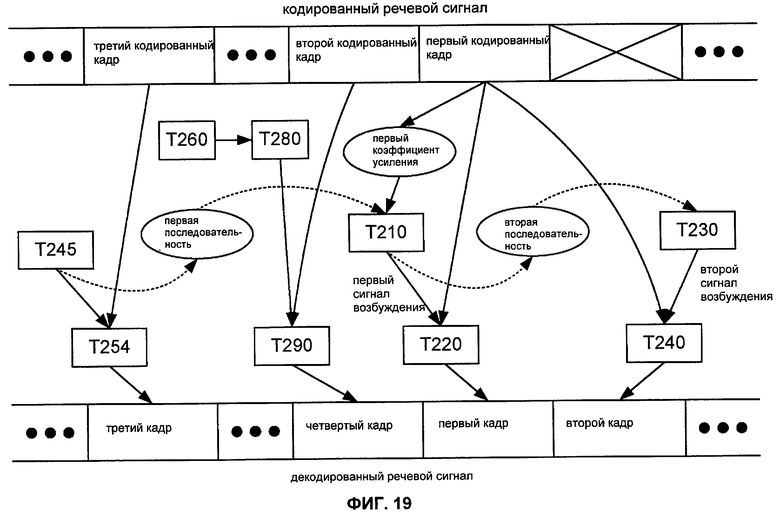
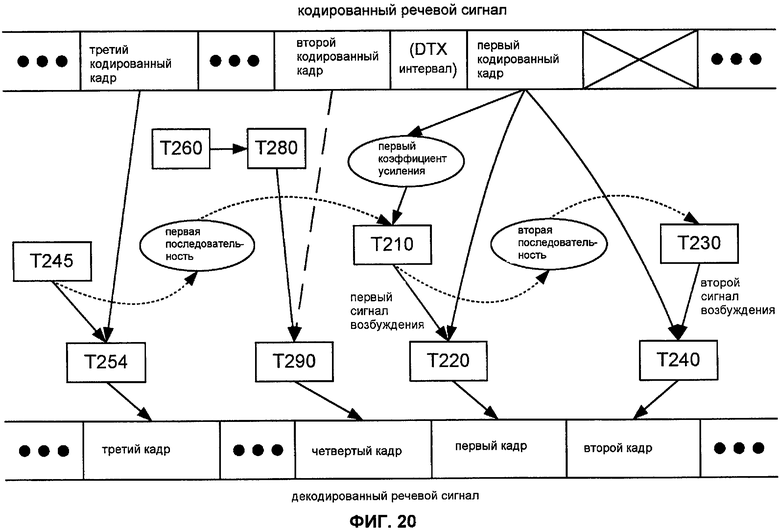
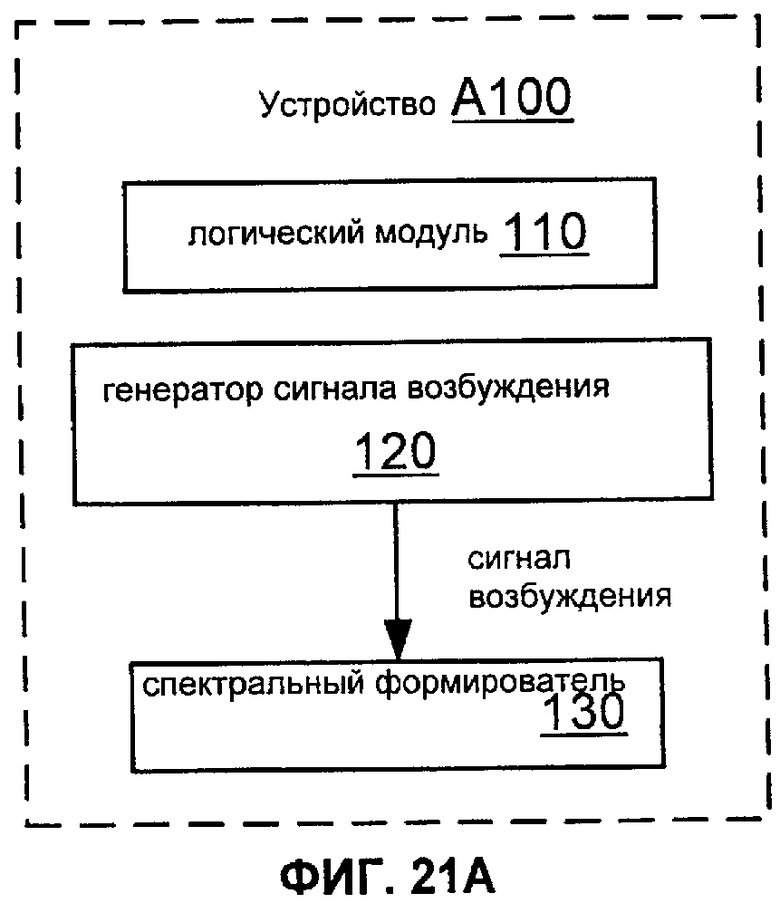
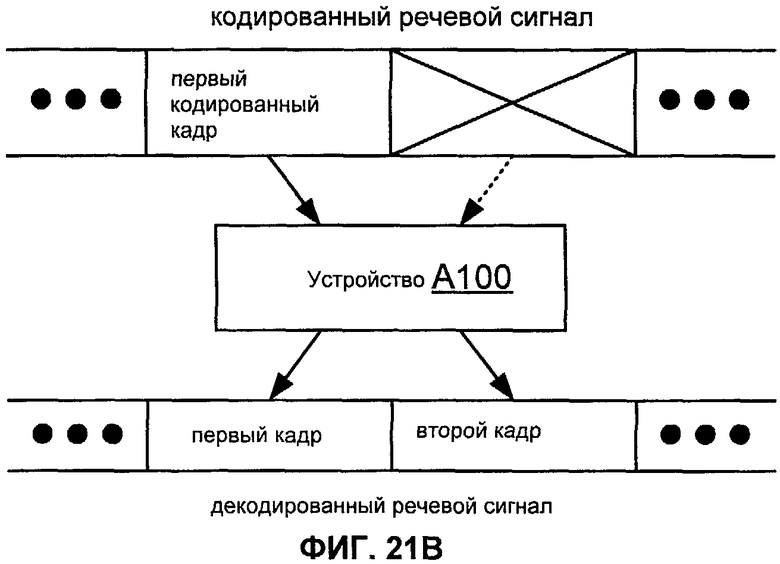
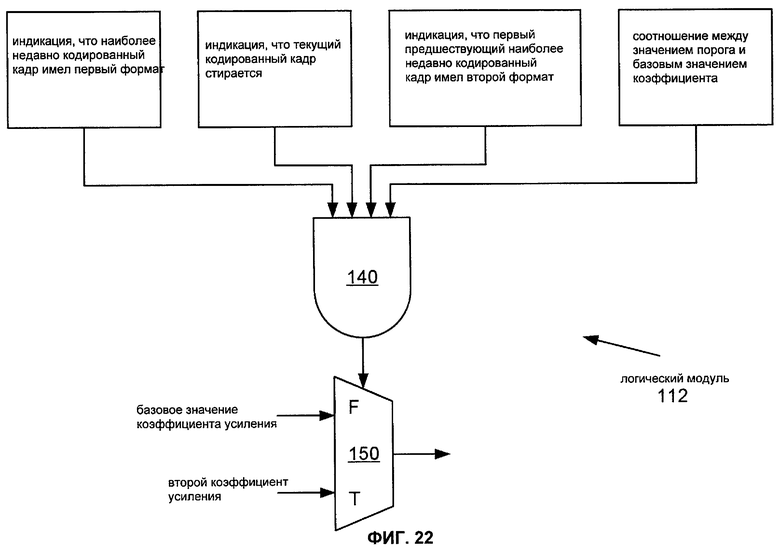
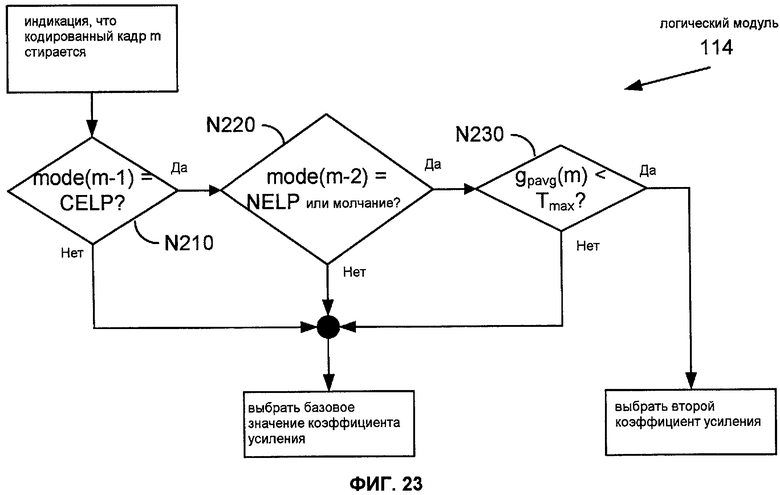
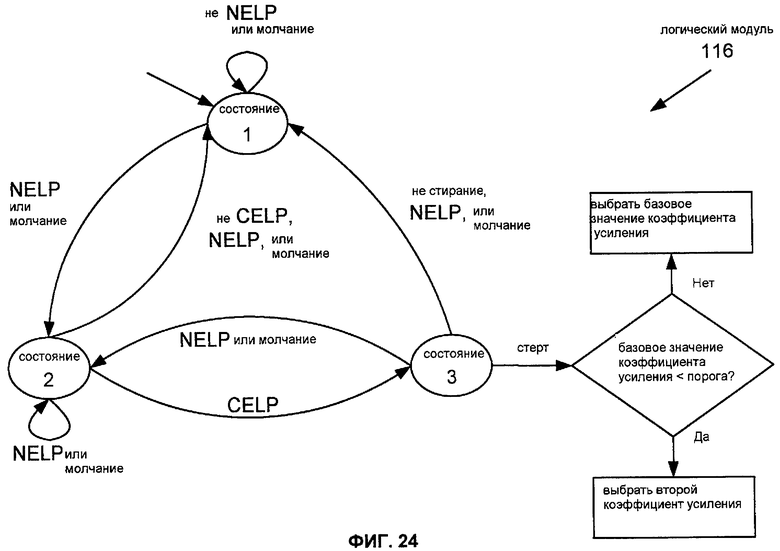
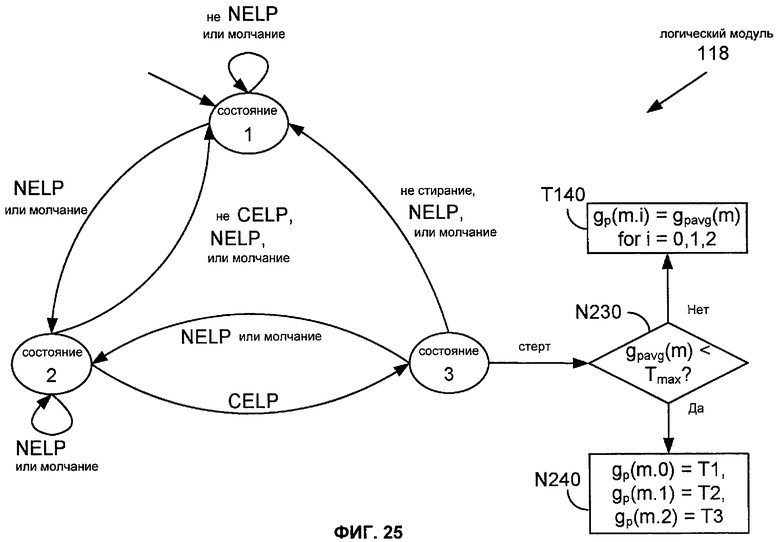
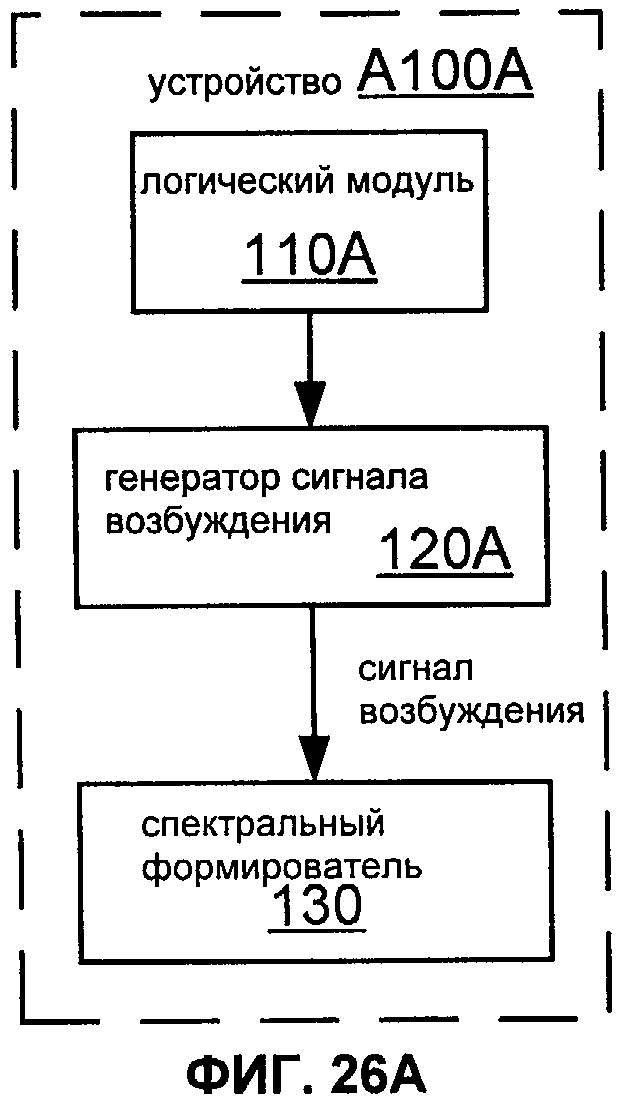
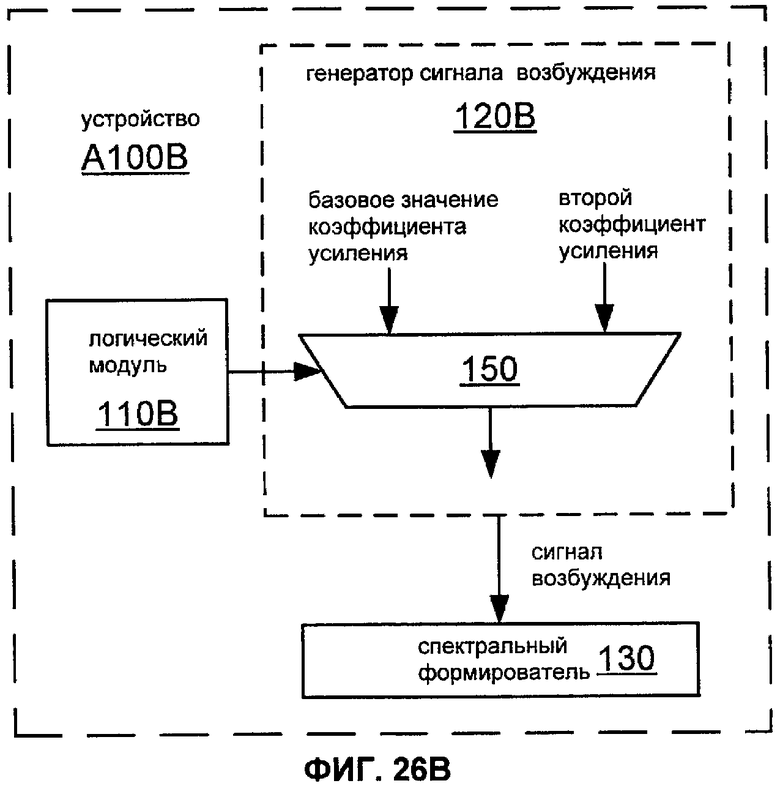
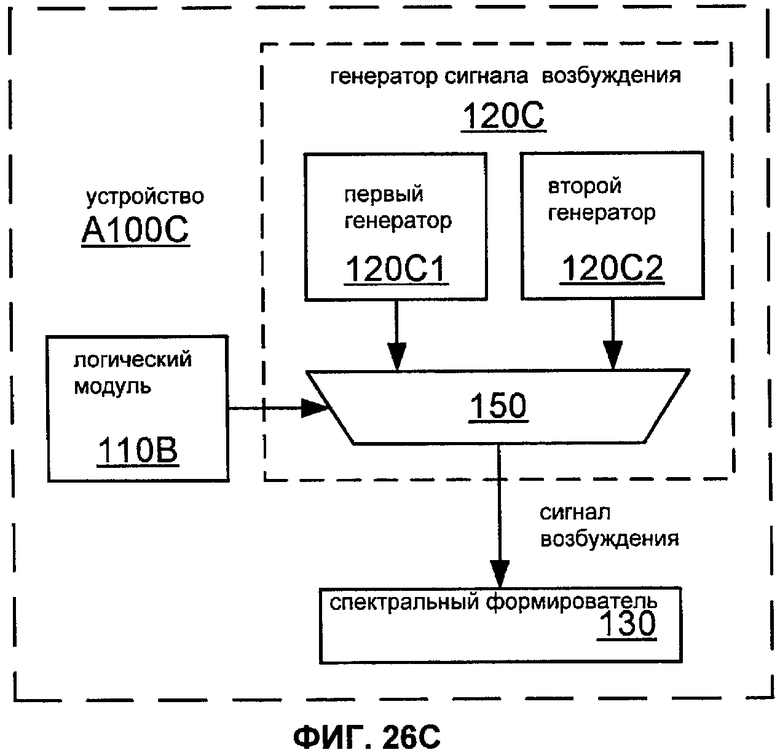
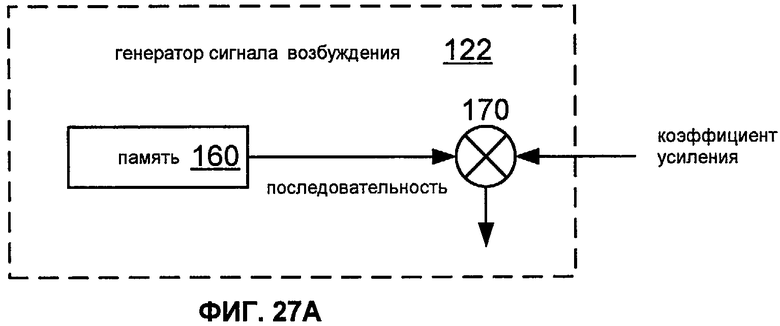
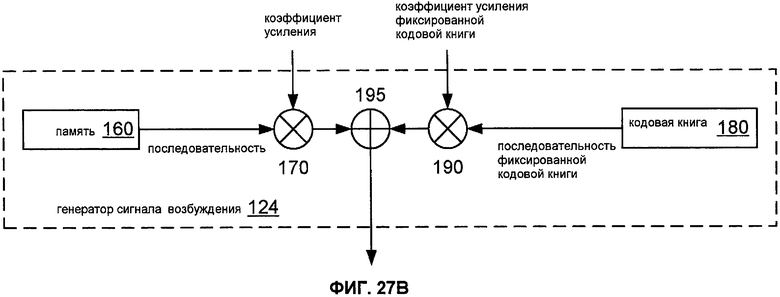
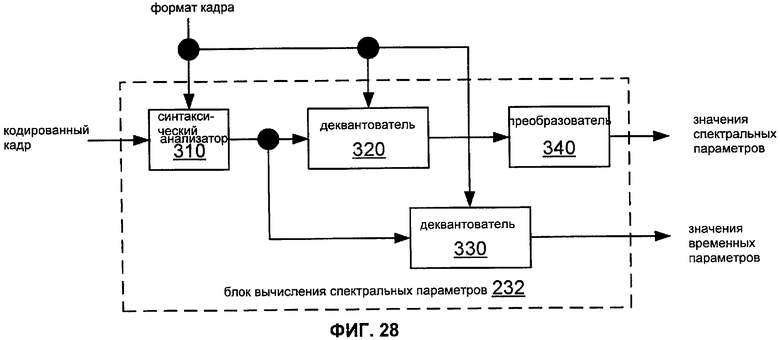
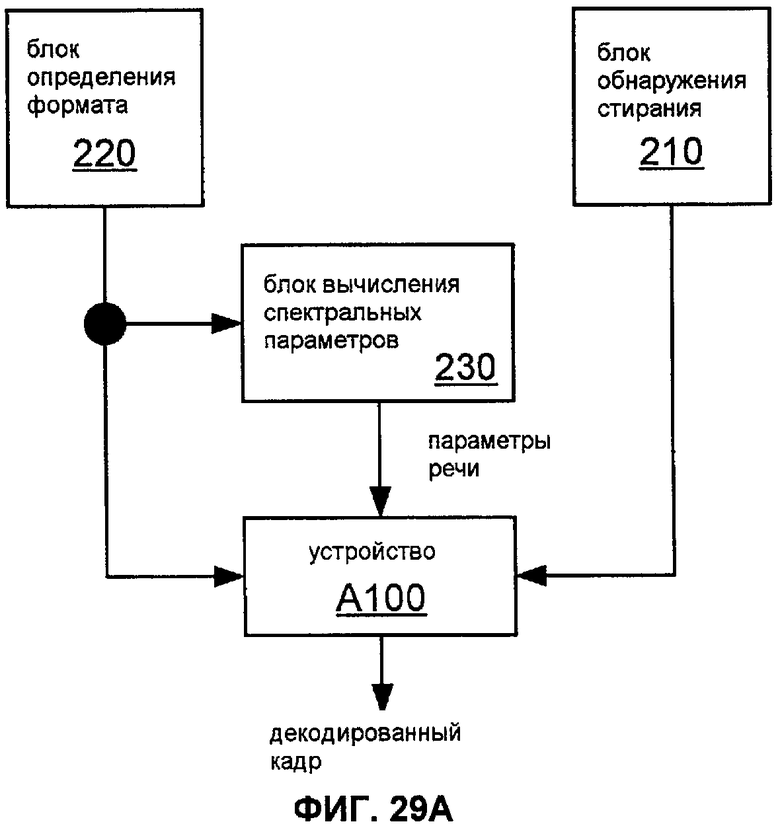
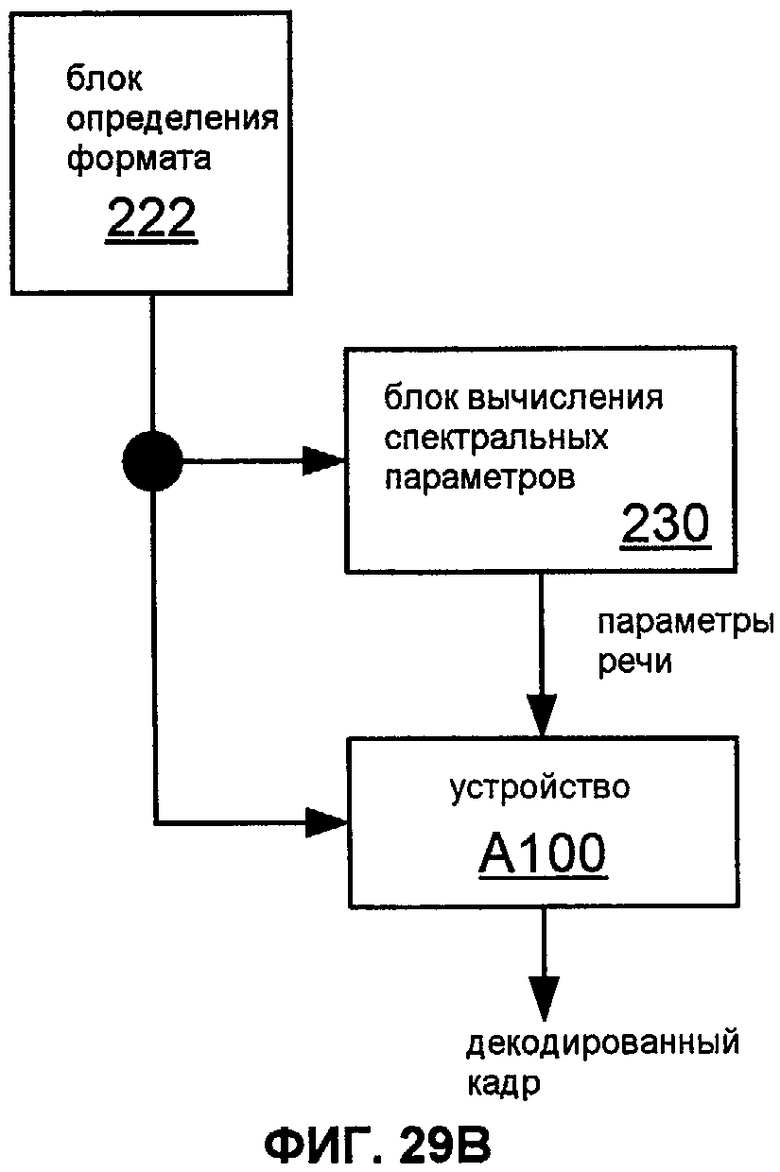
Изобретение относится к обработке речевых сигналов. В одном варианте осуществления обнаруживают стирание значимого кадра длительного голосового сегмента. Значение усиления адаптивной кодовой книги для стертого кадра вычисляют на основании предыдущего кадра. Если вычисленное значение меньше чем (альтернативно, не больше чем) пороговое значение, более высокое значение усиления адаптивной кодовой книги используется для стертого кадра. Большее значение может быть выведено из вычисленного значения или выбрано из одного или более заранее определенных значений. Технический результат - обеспечение формирования декодированного аудиокадра при потере сжатой речевой информации. 3 н. и 12 з.п. ф-лы, 29 ил.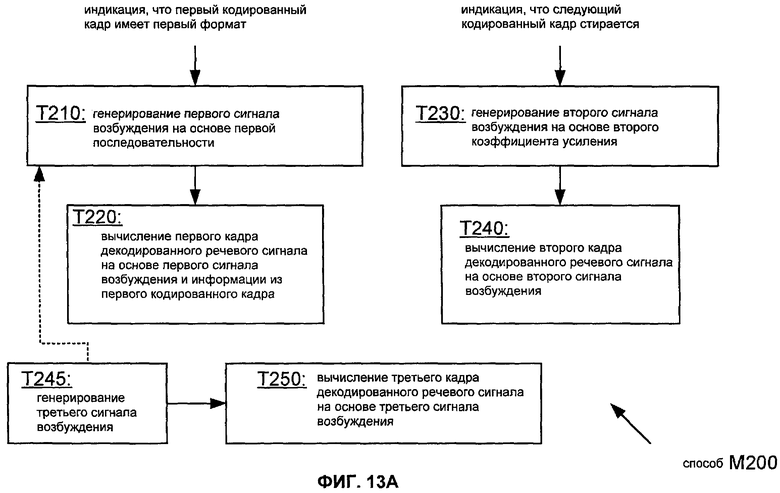
1. Способ обработки кодированного речевого сигнала, причем упомянутый способ содержит этапы:
обнаружение, по меньшей мере, одной конкретной последовательности режимов в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра;
получение значения усиления на основании, по меньшей мере, частично кадра кодированного речевого сигнала перед упомянутым стиранием,
в ответ на обнаружение сравнение полученного значения усиления с пороговым значением,
в ответ на результат сравнения увеличение полученного значения усиления, и
на основании увеличенного значения усиления генерирование сигнала возбуждения для стертого кадра.
2. Способ по п.1, в котором обнаружение содержит обнаружение последовательности «не голосовой кадр, голосовой кадр» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
3. Способ по п.1, в котором обнаружение содержит обнаружение последовательности «кадр, имеющий непериодическое возбуждение, кадр, имеющий адаптивное и периодическое возбуждение» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
4. Способ по п.1, в котором обнаружение содержит обнаружение последовательности «кадр, кодированный с использованием линейного предсказания с шумовым возбуждением, кадр, кодированный с использованием линейного предсказания с кодовым возбуждением» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
5. Способ по п.1, в котором обнаружение содержит обнаружение последовательности «кадр дескриптора тишины, голосовой кадр» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
6. Способ по любому одному из пп.1-5, в котором полученное значение усиления является значением усиления адаптивной кодовой книги, предсказанным для стертого кадра.
7. Способ по любому одному из пп.1-5, в котором вычисление сигнала возбуждения для стертого кадра включает в себя умножение последовательности значений, которая основана на кадре кодированного речевого сигнала, который предшествует стиранию кадра, на увеличенное значение усиления.
8. Считываемый компьютером носитель, содержащий команды, которые при выполнении набором логических элементов вынуждают этот набор выполнять способ по одному из пп.1-7.
9. Устройство обработки кодированного речевого сигнала, содержащее:
средство для обнаружения, по меньшей мере, одной конкретной последовательности режимов в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра,
средство для получения значения усиления на основании, по меньшей мере, частично кадра кодированного речевого сигнала перед упомянутым стиранием,
средство для сравнения полученного значения усиления с пороговым значением, в ответ на обнаружение, по меньшей мере, одной конкретной последовательности режимов упомянутым средством для обнаружения,
средство для увеличения полученного значения усиления в ответ на результат сравнения упомянутым средством сравнения, и
средство для вычисления сигнала возбуждения для стертого кадра на основании увеличенного значения усиления.
10. Устройство по п.9, в котором упомянутое средство для обнаружения сконфигурировано для обнаружения последовательности «не голосовой кадр, голосовой кадр» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
11. Устройство по п.9, в котором упомянутое средство для обнаружения сконфигурировано для обнаружения последовательности «кадр, имеющий непериодическое возбуждение, кадр, имеющий адаптивное и периодическое возбуждение» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
12. Устройство по п.9, в котором упомянутое средство для обнаружения сконфигурировано для обнаружения последовательности «кадр, кодированный с использованием линейного предсказания с шумовым возбуждением, кадр, кодированный с использованием линейного предсказания с кодовым возбуждением» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
13. Устройство по п.9, в котором упомянутое средство для обнаружения сконфигурировано для обнаружения последовательности «кадр дескриптора тишины, голосовой кадр» в двух кадрах кодированного речевого сигнала, которые предшествуют стиранию кадра.
14. Устройство по любому одному из пп.9-13, в котором полученное значение усиления является значением усиления адаптивной кодовой книги, предсказанным для стертого кадра.
15. Устройство по любому одному из пп.9-13, в котором упомянутое средство для вычисления сигнала возбуждения для стертого кадра сконфигурировано для умножения последовательности значений, которая основана на кадре кодированного речевого сигнала, который предшествует стиранию кадра, на увеличенное значение усиления.
| Грохот | 1988 |
|
SU1577881A1 |
| US 6810377 B1, 26.10.2004 | |||
| СПОСОБ ПОВЫШЕНИЯ КАЧЕСТВА ТЕКУЩЕГО РЕЧЕВОГО КАДРА В РАДИОСИСТЕМЕ МНОГОСТАНЦИОННОГО ДОСТУПА С ВРЕМЕННЫМ РАЗДЕЛЕНИЕМ КАНАЛОВ И СИСТЕМА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 1994 |
|
RU2130693C1 |
| US 2003036901 A1, 20.02.2003 | |||
| US 2002123887 A1, 05.09.2002. | |||

