Притязание на приоритет
Настоящая патентная заявка притязает на приоритет предварительной заявки №60/787,915 под названием "High Speed Media Access Control", поданной 31 марта 2006 г., права на которую принадлежат заявителю настоящей заявки и, таким образом, непосредственно включенной сюда посредством ссылки.
Область техники, к которой относится изобретение
Настоящее раскрытие относится, в целом, к беспроводной связи и к высокоскоростному управлению доступом к среде.
Уровень техники
Системы беспроводной связи широко используются для обеспечения различных типов связи, например передачи голоса и данных. Типичная система или сеть беспроводной передачи данных обеспечивает множеству пользователей доступ к одному или нескольким ресурсам общего пользования. Система может использовать различные методы множественного доступа, например мультиплексирование с частотным разделением (FDM), мультиплексирование с временным разделением (TDM), мультиплексирование с кодовым разделением (CDM), мультиплексирование с ортогональным частотным разделением (OFDM) и др.
Примерные беспроводные сети включают в себя системы передачи данных на базе сотовых технологий. Ниже приведено несколько таких примеров: (1) "TIA/EIA-95-B Mobile Station-Base Station Compatibility Standard for Dual-Mode Wideband Spread Spectrum Cellular System" (стандарт IS-95), (2) стандарт, предложенный консорциумом под названием "3rd Generation Partnership Project" (3GPP) и воплощенный в пакете документов, включающем в себя документы №№3G TS 25.211, 3G TS 25.212, 3G TS 25.213 и 3G TS 25.214 (стандарт W-CDMA), (3) стандарт, предложенный консорциумом под названием "3rd Generation Partnership Project 2" (3GPP2) и реализованный как "TR-45.5 Physical Layer Standard for cdma2000 Spread Spectrum Systems" (стандарт IS-2000), и (4) система высокоскоростной передачи данных (HDR), отвечающая стандарту TIA/EIA/IS-856 (стандарт IS-856).
Другие примеры беспроводных систем включают в себя беспроводные локальные сети (WLAN), например IEEE 802.11 (т.е. 802.11 (a), (b) или (g)). Эти сети допускают усовершенствования, которые достигаются с применением WLAN со многими входами и многими выходами (MIMO), содержащей методы модуляции мультиплексирования с ортогональным частотным разделением (OFDM). Стандарт IEEE 802.11(e) был введен для повышения качества обслуживания (QoS) по сравнению с предыдущими стандартами 802.11.
Сейчас вводятся спецификации 802.11(n), которые определяют высокоскоростные беспроводные сети и протоколы MAC для работы с ними. Предыдущие 802.11 стандарты связаны, в основном, с приложениями передачи данных, навигации и электронной почты. Стандарт 802.11(n) призван обслуживать приложения распространения мультимедиа, для которых требуются высокие пропускная способность, стабильность характеристик и качества обслуживания. Эти требования сопряжены с необходимостью в эффективных реализациях и методах обеспечения качества обслуживания и высокого быстродействия. Таким образом, в технике существует необходимость в эффективном высокоскоростном управлении доступом к среде.
Сущность изобретения
Раскрытые здесь аспекты удовлетворяют необходимость в эффективном высокоскоростном управлении доступом к среде.
Согласно одному аспекту описано устройство, которое включает в себя первую структуру данных, ассоциированную с пакетом, вторую структуру данных, содержащую данные из ассоциированного пакета, и в котором первая структура данных содержит поле длины, указывающее длину ассоциированного пакета, поле порядкового номера, указывающее порядковый номер ассоциированного пакета, поле указателя второй структуры данных, указывающее местоположение второй структуры данных в буфере пакетов.
Согласно еще одному аспекту описана первая структура данных, которая способна работать со второй структурой данных, содержащая данные из ассоциированного пакета, и которая включает в себя поле длины, указывающее длину ассоциированного пакета, поле порядкового номера, указывающее порядковый номер ассоциированного пакета, и поле указателя, в котором хранится местоположение второй структуры данных в памяти.
Согласно еще одному аспекту раскрыт способ, содержащий этапы, на которых сохраняют в первой структуре данных в буфере пакетов длину первого пакета, порядковый номер пакета и второе местоположение в буфере пакетов второй структуры данных в буфере пакетов и сохраняют данные из первого пакета во второй структуре данных, идентифицируемой сохраненным вторым местоположением в буфере пакетов.
Согласно еще одному аспекту раскрыт способ, содержащий этапы, на которых сохраняют совокупность пакетов в буфере пакетов, причем каждый пакет сохраняется с ассоциированной первой структурой данных и одной или несколькими ассоциированными вторыми структурами данных, причем одна или несколько вторых структур данных образуют связанный список; в котором каждая первая структура данных содержит поле длины, указывающее длину ассоциированного пакета, поле порядкового номера, указывающее порядковый номер ассоциированного пакета, и поле указателя второй структуры данных, указывающее местоположение в буфере пакетов первой из одной или нескольких вторых структур данных; и в котором каждая вторая структура данных содержит данные из ассоциированного пакета и поле указателя следующей второй структуры данных, указывающего следующую вторую структуру в соответствующем связанном списке, если таковая существует.
Согласно еще одному аспекту описано устройство, которое включает в себя средства хранения в первой структуре данных в буфере пакетов длины первого пакета, порядкового номера пакета, и второго местоположения в буфере пакетов второй структуры данных в буфере пакетов, и средства хранения данных из первого пакета во второй структуре данных, идентифицируемой сохраненным вторым местоположением в буфере пакетов.
Согласно еще одному аспекту описано устройство, которое включает в себя первую структуру данных, ассоциированную с пакетом, и одну или несколько вторых структур данных, содержащих данные из ассоциированного пакета; и в котором первая структура данных содержит поле длины, указывающее длину ассоциированного пакета, поле порядкового номера, указывающее порядковый номер ассоциированного пакета, и поле указателя второй структуры данных, указывающее местоположение в буфере пакетов одной из вторых структур данных; и средства хранения пакета в одной или нескольких вторых структур данных.
Согласно еще одному аспекту описано устройство, которое включает в себя первую память, сконфигурированную в первом режиме для хранения одного или нескольких параметров для каждого из совокупности коммуникационных потоков и сконфигурированную во втором режиме для хранения указателя для каждого из совокупности коммуникационных потоков, причем каждый указатель указывает местоположение, ассоциированное коммуникацией с соответствующим потоком; вторую память, сконфигурированную в первом режиме для хранения пакетов для каждого из совокупности коммуникационных потоков и сконфигурированную во втором режиме для хранения совокупности множеств из одного или нескольких параметров для каждого из совокупности коммуникационных потоков, причем каждое множество из одного или нескольких параметров хранится в местоположении, указанном указателем, ассоциированным с соответствующим коммуникационным потоком; интерфейс памяти, способный работать с третьей памятью, сконфигурированной во втором режиме с возможностью хранить пакеты для каждого из совокупности коммуникационных потоков; и процессор, выбирающий выбранный режим в качестве первого режима или второго режима, конфигурирующий первую память согласно выбранному режиму, конфигурирующий вторую память согласно выбранному режиму и конфигурирующий интерфейс памяти согласно выбранному режиму.
Согласно еще одному аспекту описано устройство беспроводной связи, которое включает в себя первую интегральную схему, содержащую первую память, сконфигурированную в первом режиме для хранения одного или нескольких параметров для каждого из совокупности коммуникационных потоков и сконфигурированную во втором режиме для хранения указателя для каждого из совокупности коммуникационных потоков, причем каждый указатель указывает местоположение, ассоциированное с соответствующим коммуникационным потоком; вторую память, сконфигурированную в первом режиме для хранения пакетов для каждого из совокупности коммуникационных потоков и сконфигурированную во втором режиме для хранения совокупности множеств из одного или нескольких параметров для каждого из совокупности коммуникационных потоков, причем каждое множество из одного или нескольких параметров хранится в местоположении, указанном указателем, ассоциированным с соответствующим коммуникационным потоком; интерфейс памяти, способный работать с третьей памятью, сконфигурированной во втором режиме с возможностью хранения пакетов для каждого из совокупности коммуникационных потоков; и процессор, выбирающий выбранный режим в качестве первого режима или второго режима, конфигурирующий первую память согласно выбранному режиму, конфигурирующий вторую память согласно выбранному режиму и конфигурирующий интерфейс памяти согласно выбранному режиму; и вторую интегральную схему, содержащую третью память, в которой хранятся пакеты для каждого из совокупности коммуникационных потоков, подключенную к интерфейсу памяти первой интегральной схемы.
Согласно еще одному аспекту описано устройство беспроводной связи, которое включает в себя первую память, в которой хранятся один или несколько параметров для каждого из совокупности коммуникационных потоков; и вторую память, в которой хранятся пакеты для каждого из совокупности коммуникационных потоков, содержащую первую структуру данных, ассоциированную с пакетом; и вторую структуру данных, содержащую данные из ассоциированного пакета; и в котором первая структура данных содержит поле длины, указывающее длину ассоциированного пакета, поле порядкового номера, указывающее порядковый номер ассоциированного пакета, и поле указателя второй структуры данных, указывающее местоположение во второй памяти второй структуры данных.
Согласно еще одному аспекту описано устройство беспроводной связи, которое включает в себя первую память, в которой хранится указатель для каждого из совокупности коммуникационных потоков, причем каждый указатель указывает местоположение, ассоциированное с соответствующим потоком связи; и вторую память, в которой хранится совокупность множеств из одного или нескольких параметров для каждого из совокупности коммуникационных потоков, причем каждое множество из одного или нескольких параметров хранится в местоположении, указанном указателем, ассоциированным с соответствующим коммуникационным потоком; и третью память, в которой хранятся пакеты для каждого из совокупности коммуникационных потоков.
Согласно еще одному аспекту описано устройство, которое включает в себя средства выбора первого или второго режима, средства конфигурирования первой памяти в первом режиме для хранения одного или нескольких параметров для каждого из совокупности коммуникационных потоков, средства конфигурирования первой памяти во втором режиме для хранения указателя для каждого из совокупности коммуникационных потоков, причем каждый указатель указывает местоположение, ассоциированное с соответствующим коммуникационным потоком, средства конфигурирования второй памяти в первом режиме для хранения пакетов для каждого из совокупности коммуникационных потоков, средства конфигурирования второй памяти во втором режиме для хранения совокупности множеств из одного или нескольких параметров для каждого из совокупности коммуникационных потоков, причем каждое множество из одного или нескольких параметров хранится в местоположении, указанном указателем, ассоциированным с соответствующим коммуникационным потоком, и средства конфигурирования интерфейса памяти, способного работать с третьей памятью во втором режиме с возможностью хранения пакетов для каждого из совокупности коммуникационных потоков.
Согласно еще одному аспекту описан машиночитаемый носитель с возможностью выполнения выбора первого или второго режима, конфигурирования первой памяти в первом режиме для хранения одного или нескольких параметров для каждого из совокупности коммуникационных потоков, конфигурирования первой памяти во втором режиме для хранения указателя для каждого из совокупности коммуникационных потоков, причем каждый указатель указывает местоположение, ассоциированное с соответствующим коммуникационным потоком, конфигурирования второй памяти в первом режиме для хранения пакетов для каждого из совокупности коммуникационных потоков, конфигурирования второй памяти во втором режиме для хранения совокупности множеств из одного или нескольких параметров для каждого из совокупности коммуникационных потоков, причем каждый набор из одного или нескольких параметров хранится в местоположении, указанном указателем, ассоциированным с соответствующим коммуникационным потоком, и конфигурирования интерфейса памяти, способного работать с третьей памятью во втором режиме, с возможностью хранения пакетов для каждого из совокупности коммуникационных потоков.
Краткое описание чертежей
Фиг.1 - общая блок-схема системы беспроводной связи, способной поддерживать множество пользователей.
Фиг.2 - аспекты устройства беспроводной связи, которое может быть сконфигурировано как точка доступа или пользовательский терминал.
Фиг.3 - вариант осуществления процессора MAC, сконфигурированного для пользовательского терминала.
Фиг.4 - вариант осуществления процессора MAC, сконфигурированного для точки доступа.
Фиг.5 - более подробный примерный вариант осуществления устройства беспроводной связи.
Фиг.6 - примерный вариант осуществления буфера пакетов.
Фиг.7 - дополнительный пример буфера пакетов.
Фиг.8 - дополнительные компоненты, которые могут быть внедрены в процессоре MAC.
Фиг.9 - примерный вариант осуществления способа для записи пакетов в буфер пакетов и создания очередей.
Фиг.10 - примерный вариант осуществления хоста подсистемы WLAN.
Фиг.11 - примерный вариант осуществления содержимого таблицы состояний ТХ-потока.
Фиг.12 - примерный вариант осуществления способа выполнения политики входа.
Фиг.13 - примерный вариант осуществления способа политики входа.
Фиг.14 - примерный вариант осуществления FIFO.
Фиг.15 - примерный процесс разбиения MSDU на один или несколько фрагментов.
Фиг.16 - принципиальная конфигурация арбитра совместно с двумя или более блоками записи в память.
Фиг.17 - примерный вариант осуществления части устройства беспроводной связи, сконфигурированного для поддержки относительно большой совокупности очередей EDCA с использованием меньшего, фиксированного множества стандартных очередей EDCA.
Фиг.18 - примерный вариант осуществления, демонстрирующий различные компоненты нижнего ядра MAC.
Фиг.19 - подробно описанный примерный вариант осуществления секции процессора нижнего ядра MAC.
Фиг.20 - примерная блокировка.
Фиг.21 - примерный вариант осуществления ID линии связи.
Фиг.22 - дополнительные компоненты примерного варианта осуществления нижнего ядра MAC.
Фиг.23 - примерный вариант осуществления FSM скорости.
Фиг.24 - примерный механизм традиционного протокола.
Фиг.25 - примерный механизм традиционного протокола, соединенный принципиальными линиями связи к PHY.
Фиг.26 - примерный механизм осуществления, дополнительно детализирующий MAC обработку пакетов передачи.
Фиг.27 - примерный формат A-MPDU.
Фиг.28 - примерный вариант осуществления компонентов приема нижнего ядра MAC.
Фиг.29 - примерный вариант осуществления аппаратной таблицы, сконфигурированной для пользовательского терминала.
Фиг.30 - примерный вариант осуществления аппаратной таблицы, сконфигурированный для использования в точке доступа или суперстанции.
Фиг.31 - примерный вариант осуществления таблицы состояний RX-потока.
Фиг.32 - примерный вариант осуществления способа конфигурирования аппаратных таблиц и памяти в различных конфигурациях.
Фиг.33 - альтернативная конфигурация части буфера пакетов, сконфигурированного для поддержки массивов пакетов RX.
Фиг.34 - примерная сквозная схема приоритетов для беспроводных сетей, включающая в себя политику входа и хэндовер на основе приоритета.
Фиг.35 - примерный вариант осуществления способа, демонстрирующий работу блока решений хэндовера и механизма хэндовера.
Фиг.36 - примерный вариант осуществления способа выполнения принятия решения хэндовера.
Фиг.37 - примерный вариант осуществления способа обработки принятого пакета.
Фиг.38 - примерный вариант осуществления способа обработки одной или нескольких очередей хэндовера.
Фиг.39 - примерный вариант осуществления способа определения потоков, доступных для хэндовера.
Фиг.40 - примерная таблица состояний решений.
Фиг.41 - примерный вариант осуществления очереди хэндовера.
Фиг.42 - примерный вариант осуществления способа выполнения хэндовера.
Фиг.43 - примерные переменные, используемые для индексирования буфера пакетов в таблице состояний хэндовера.
Фиг.44 - примерный вариант осуществления способа для ответа на запрос немедленного квитирования блока.
Фиг.45 - иллюстративный вариант осуществления способа для ответа на квитирование блока.
Фиг.46 - примерный вариант осуществления способа использования пинг-понгового кэша массива узлов в процессе повторной передачи.
Фиг.47 - примерный вариант осуществления способа выполнения доставки незапланированного автоматического энергосбережения.
Фиг.48 - альтернативный вариант осуществления, предусматривающий более одного процессора MAC.
Фиг.49 - примерный вариант осуществления устройства беспроводной связи, включающего в себя два процессора MAC, включая первый процессор MAC и второй процессор MAC, реализованные в микропроцессоре.
Фиг.50 - аспекты многопоточной буферизации и очередизации пакетов.
Фиг.51 - аспекты многопоточной буферизации и очередизации пакетов.
Фиг.52 - аспекты управления памятью для высокоскоростного управления доступом к среде.
Фиг.53 - аспекты многопоточного управления доступом к среде.
Фиг.54 - аспекты многопоточного управления доступом к среде.
Фиг.55 - аспекты мультиплексирования множества потоков для высокоскоростного управления доступом к среде.
Фиг.56 - аспекты агрегации в высокоскоростной системе связи.
Фиг.57 - аспекты теневых кэшей, выступающих в качестве обслуживаемых очередей и ожидающих очередей.
Фиг.58 - аспекты политики входа.
Фиг.59 - аспекты политики входа.
Фиг.60 - аспекты политики входа.
Фиг.61 - аспекты управления доступом к среде для ответа с низкой задержкой.
Подробное описание
Ниже будут подробно описаны различные аспекты, один или несколько из которых можно комбинировать в любом данном варианте осуществления. Раскрытые здесь аспекты поддерживают высокоэффективную работу WLAN с очень высокой скоростью передачи битов на физических уровнях (или аналогичные приложения с использованием новых технологий передачи). Примерная WLAN способна работать в двух частотных диапазонах, 20 МГц и 40 МГц. Она поддерживает скорости передачи битов свыше 100 Мбит/с (миллионов бит в секунду), в том числе до 300 Мбит/с на канале с полосой 20 МГц и до 600 Мбит/с на канале с полосой 40 МГц. Также поддерживаются различные альтернативные WLAN, включая имеющие более двух частотных диапазонов, и любое количество скоростей передачи битов.
Различные аспекты сохраняют простоту и устойчивость работы распределенной координации традиционных систем WLAN, примеры которых приведены в 802.11 (a-g). Преимущества различных вариантов осуществления сочетаются с поддержанием обратной совместимости с такими традиционными системами. (Заметим, что в нижеприведенном описании 802.11 системы можно описывать как примерные традиционные системы. Специалистам в данной области техники очевидно, усовершенствования также могут быть совместимы с альтернативными системами и стандартами.)
Один или несколько описанных здесь примерных аспектов изложены применительно к системе беспроводной передачи данных. Хотя использование в этом контексте является преимущественным, другие варианты осуществления раскрытия могут быть включены в другие окружения или конфигурации. В общем случае, различные системы, описанные здесь, можно формировать с использованием процессоров с программным управлением, интегральных схем или дискретной логики. Данные, инструкции, команды, информация, сигналы, биты, символы и чипы, которые могут упоминаться на протяжении заявки, предпочтительно представлять напряжениями, токами, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами, или их комбинацией. Кроме того, блоки, показанные в каждой блок-схеме, могут представлять оборудование или этапы способа. Этапы способа можно менять местами, не выходя за рамки объема настоящего раскрытия. Слово "примерный" используется здесь в смысле "служащий примером, вариантом или иллюстрацией". Любой вариант осуществления, описанный здесь как "примерный", не обязательно рассматривать как предпочтительный или преимущественный над другими вариантами осуществления.
На фиг.1 показаны примерные варианты осуществления системы 100, содержащей точку 104 доступа (AP), подключенную к одному или нескольким пользовательским терминалам (UT) 106A-N. В соответствии с терминологией 802.11 в этом документе AP и UT также именуются станциями или STA. Описанные здесь методы и аспекты также применимы к другим типам систем (примеры включают в себя стандарты сотовой связи, подробно описанные выше). Используемый здесь термин «базовая станция» можно использовать взаимозаменяемо с термином «точка доступа». Термин «пользовательский терминал» можно использовать взаимозаменяемо с терминами «пользовательское оборудование» (UE), «абонентский блок», «абонентская станция», «терминал доступа», «удаленный терминал», «мобильная станция» или другие соответствующие термины, известные в технике. Термин «мобильная станция» охватывает стационарные беспроводные применения.
Заметим также, что пользовательские терминалы 106 могут осуществлять связь непосредственно друг с другом. Direct Link Protocol (DLP), заданный в 802.11(e), позволяет STA передавать кадры непосредственно на другую STA назначения с помощью Basic Service Set [базового набора услуг] (BSS) (управляемого той же AP). В различных вариантах осуществления, как известно в технике, точка доступа не требуется. Например, Independent [независимый] BSS (IBSS) можно формировать с помощью любой комбинации STA. Можно формировать специализированные сети пользовательских терминалов, которые осуществляют связь друг с другом по беспроводной сети 120 с использованием любого из многочисленных форматов связи, известных в технике.
AP и UT осуществляют связь по беспроводной локальной сети (WLAN) 120. Согласно вариантам осуществления, подробно описанным ниже, WLAN 120 представляет собой высокоскоростную систему MIMO OFDM. Однако WLAN 120 может быть любой беспроводной LAN. В необязательном порядке, точка 104 доступа осуществляет связь с любым количеством внешних устройств или процессов по сети 102. Сетью 102 может быть Интернет, интрасеть или любая другая проводная, беспроводная или оптическая сеть. Соединение 110 переносит сигналы физического уровня из сети на точку доступа 104. Устройства или процессы могут быть подключены к сети 102 или как UT (или через соединения с ними) в WLAN 120. Примеры устройств, которые могут быть подключены либо к сети 102, либо к WLAN 120, включают в себя телефоны, карманные персональные компьютеры (PDA), компьютеры различных типов (портативные компьютеры, персональные компьютеры, рабочие станции, терминалы любого типа), видеоустройства, например фотоаппараты, видеокамеры, веб-камеры и, в принципе, устройство обработки данных любого другого типа. Процессы могут включать в себя передачу речи, видео, данных и т.д. Различные потоки данных могут иметь изменяющиеся требования к передаче, которые могут удовлетворяться с использованием различных методов качества обслуживания (QoS).
Система 100 может быть обеспечена централизованной AP 104. В одном варианте осуществления все UT 106 осуществляют связь с AP. В альтернативном варианте осуществления может быть обеспечена непосредственная равноправная связь для двух UT благодаря модификациям системы, которые очевидны специалистам в данной области техники, примеры которых проиллюстрированы ниже. Любую станцию можно настроить в качестве обозначенной AP согласно вариантам осуществления, поддерживающим обозначенные точки доступа. Управление доступом может осуществляться посредством AP или специально (т.е. на конкурсной основе).
В одном варианте осуществления AP 104 обеспечивает адаптацию к Ethernet. В этом случае можно обеспечить IP-маршрутизатор помимо AP для обеспечения соединения с сетью 102 (детали не показаны). Кадры Ethernet можно переносить между маршрутизатором и UT 106 по подсети WLAN (подробно описанной ниже). Адаптация и возможность подключения к Ethernet хорошо известны в технике.
В альтернативном варианте осуществления AP 104 обеспечивает адаптацию к IP. В этом случае AP выступает в роли шлюзового маршрутизатора для множества подключенных UT (детали не показаны). В этом случае AP 104 может маршрутизировать датаграммы IP на UT 106 и от них. Адаптация и возможность подключения к IP хорошо известны в технике.
На фиг.2 показаны аспекты устройства беспроводной связи, которое можно сконфигурировать как точку доступа 104 или пользовательский терминал 106. Устройство беспроводной связи является примером STA, пригодной для внедрения в системе 100.
Процессор 210 обеспечен для осуществления различных задач для устройства беспроводной связи, включающих в себя задачи осуществления связи. В этом примере процессор 210 выполняет задачи, которые называются здесь заданиями "программно-аппаратного обеспечения". Для простоты, согласно вариантам осуществления, подробно описанным ниже, ссылка на программно-аппаратное обеспечение включает в себя такие задачи, осуществляемые процессором 210, а также задачи, осуществляемые совместно с различными другими компонентами или блоками. Процессор 210 может представлять собой микропроцессор общего назначения, цифровой сигнальный процессор (DSP) или процессор специального назначения. Процессор 210 может быть соединен со специальным оборудованием для помощи в различных задачах (детали не показаны). Различные приложения могут выполняться на внешне подключенных процессорах, например внешне подключенном компьютере или по сетевому соединению, могут выполняться на дополнительном процессоре (не показан) в устройстве беспроводной связи 104 или 106, или могут выполняться на самом процессоре 210.
Показано, что процессор 210 соединен с памятью 220, которую можно использовать для хранения данных, а также инструкций для выполнения различных описанных здесь процедур и методов, и многого другого. Специалистам в данной области техники очевидно, что память 220 может состоять из одного или нескольких компонентов памяти различных типов, которые, полностью или частично, могут быть встроены в процессор 210. Показано, что к процессору 210 подключен блок ввода/вывода 230, который может содержать один или несколько функций ввода и/или вывода, примеры которых хорошо известны в технике.
Процессор 240 управления доступом к среде (MAC) подключен к процессору 210. Во многих вариантах осуществления, подробно описанных ниже, процессор 240 MAC осуществляет высокоскоростную обработку пакетов, т.е. на скорости линии. В общем случае, обработка на более низкой скорости, или "программно-аппаратные" задачи, будут осуществляться процессором 210 совместно с обработкой "на скорости линии", обычно производимой процессором 240 MAC. Процессор 240 MAC доставляет данные для передачи на физический уровень (PHY) 260 для передачи по WLAN 120, и обрабатывает данные из PHY 260, принятые на WLAN 120. Процессор 210 также может принимать данные физического уровня и обрабатывать данные для формирования пакетов для исходящих потоков (в целом, совместно с процессором 240 MAC, в примерах, подробно описанных ниже). Формат данных, поступающих на PHY 260 и принимаемых оттуда, будет соответствовать техническому описанию системы связи или систем, поддерживаемых устройством 104 или 106 беспроводной связи.
Процессор 240 MAC принимает и передает данные через соединение 110 согласно требованиям физического уровня сети 102. Необязательный сетевой процессор 280 можно обеспечить для приема и передачи согласно физическому уровню сети 102 на необязательном сетевом соединении 110. Сетевой процессор может принимать и передавать данные на процессор 240 MAC с использованием любого типа формата данных. Примерные пакеты данных дополнительно подробно описаны ниже (эти и альтернативные форматы данных хорошо известны специалистам в данной области техники). Эти данные можно называть здесь потоками. Потоки могут иметь разные характеристики и могут требовать различной обработки на основании типа приложения, связанного с потоком. Например, видео или голос можно охарактеризовать как потоки с низкой задержкой (видео, в целом, отличается более высокими требованиями к пропускной способности, чем голос). Многие приложения передачи данных менее чувствительны к задержке, но могут иметь более высокие требования к целостности данных (т.е. при передаче голоса может быть допустима некоторая потеря пакетов, а при передаче файлов потеря пакетов, в целом, недопустима).
Процессор 240 MAC принимает данные потока, и этот процесс мы будем называть входом, и сохраняет пакеты данных потока в буфере 250 пакетов. Процессор 240 MAC извлекает пакеты для передачи по WLAN 120, именуемые пакетами передачи или TX, и доставляет их на PHY 260. Пакеты, принятые по WLAN 120, именуемые пакетами приема или RX, поступают из PHY 260 на процессор 240 MAC, который сохраняет их в буфере 250 пакетов. Процессор 240 MAC извлекает пакеты приема из буфера 250 пакетов для доставки по сетевому соединению 110 (или на необязательный сетевой процессор 280), и этот процесс будем называть выходом. Примерные варианты осуществления буфера 250 пакетов подробно описаны ниже. Различные варианты осуществления, подробно описанные ниже, раскрывают аспекты осуществления высокоскоростной обработки пакетов для входа, передачи, приема и выхода.
Хотя в показанном примере позиция 110 идентифицирует вход и выход, и WLAN 120 идентифицирует RX и ТХ, процессор 240 MAC можно надлежащим образом применять для работы с любой функцией выхода или входа, а также с любым типом функции приема или передачи. Классификацию потока может выполнять драйвер, который может быть включен в процессор 210 или сетевой процессор 280, или в любой другой пригодный компонент, что хорошо известно в технике. Можно обеспечить различные драйверы для обработки MAC различных типов данных, форматов, классов потока и т.д.
Управление и сигнализация, связанные с WLAN (т.е. 802.11 или другие стандарты), также могут передаваться между АР и различными UT. Протокольные блоки данных MAC (MPDU), инкапсулированные в протокольные блоки данных физического уровня (PHY) (PPDU), передаются на PHY 260 и принимаются оттуда. MPDU также можно называть кадром. Когда один MPDU инкапсулирован в один PPDU, кадром иногда называют PPDU. Альтернативные варианты осуществления предусматривают использование любого метода преобразования, и терминология может варьироваться в альтернативных вариантах осуществления. Обратная связь, соответствующая различным ID MAC, может возвращаться с PHY 260 в различных целях. Обратная связь может содержать любую информацию физического уровня, включающую в себя поддерживаемые скорости для каналов (включающих в себя многоадресные, а также одноадресные трафик/пакеты), формат модуляции и различные другие параметры.
PHY 260 может представлять собой любой тип приемопередатчика (и может включать в себя приемник и передатчик, но также может быть внедрен в альтернативном варианте осуществления). В одном варианте осуществления PHY 260 включает в себя приемопередатчик мультиплексирования с ортогональным частотным разделением (OFDM), который можно использовать с интерфейсом со многими входами и многими выходами (MIMO) или со многими входами и одним выходом (MISO).
MIMO и MISO известны специалистам в данной области техники. Различные иллюстративные приемопередатчики OFDM, MIMO и MISO подробно описаны в совместно рассматриваемой патентной заявке США №10/650,295, под названием "FREQUENCY-INDEPENDENT SPATIAL-PROCESSING FOR WIDEBAND MISO AND MIMO SYSTEMS", поданной 27 августа 2003 г., присвоенной правообладателю настоящей заявки и включенной сюда посредством ссылки. Альтернативные варианты осуществления могут включать в себя системы с одним входом и многими выходами (SIMO) или с одним входом и одним выходом (SISO).
Показано, что PHY 260 соединен с антеннами 270 A-N. В различных вариантах осуществления может поддерживаться любое количество антенн. Антенны 270 можно использовать для передачи и приема по WLAN 120.
PHY 260 может содержать пространственный процессор, в связи с каждой из одной или нескольких антенн 270. Пространственный процессор может обрабатывать данные для передачи независимо для каждой антенны или совместно обрабатывать принятые сигналы на всех антеннах. Примеры независимой обработки могут основываться на оценках канала, обратной связи от UT, инверсии канала или различных других методов, известных в технике. Обработка осуществляется с использованием любого из различных методов пространственной обработки. Различные приемопередатчики этого типа могут передавать с использованием метода формирования пучка, управления положением пучка, управления собственным вектором, или других методов пространственной обработки для повышения пропускной способности на и от данного пользовательского терминала. В некоторых вариантах осуществления, в которых передаются символы OFDM, пространственный процессор может содержать пространственные подпроцессоры для обработки каждой из поднесущих OFDM (также именуемых тонами), или бинов.
В примерной системе AP (или любая STA, например UT) может иметь N антенн, а примерный UT может иметь M антенн. Таким образом, существует M x N путей между антеннами AP и UT. В технике известны различные методы пространственной обработки для повышения пропускной способности с использованием этого множества путей. В системе с пространственно-временным разнесением передачи (STTD) (также именуемой здесь "разнесением") данные передачи форматируются и кодируются и передаются через все антенны как единый поток данных. При наличии M передающих антенн и N приемных антенн может существовать MIN(M,N) независимых каналов, которые можно формировать. Пространственное мультиплексирование позволяет использовать эти независимые пути и передавать разные данные по каждому из этих независимых путей для повышения скорости передачи.
Известны различные методы для изучения или адаптации к характеристикам канала между AP и UT. С каждой передающей антенны можно передавать уникальные пилот-сигналы. В этом случае пилот-сигналы принимаются на каждой приемной антенне и измеряются. Затем информация обратной связи по состоянию канала может возвращаться на передающее устройство для использования в передаче. Разложение измеренной матрицы канала по собственным векторам можно осуществлять для определения собственных состояний канала. Альтернативный метод во избежание разложения измеренной матрицы канала по собственным векторам на приемнике предусматривает использование управления собственным вектором пилот-канала и канала данных для упрощения пространственной обработки на приемнике.
Таким образом, в зависимости от текущих канальных условий изменяющиеся скорости передачи данных могут быть доступны для передачи на различные пользовательские терминалы в системе. PHY 260 может определять поддерживаемую скорость на основании того, какая пространственная обработка используется на физической линии связи между AP и UT. Эта информация может передаваться обратно для использования при обработке MAC.
Согласно одному аспекту единая специализированная интегральная схема (ASIC) предусмотрена для поддержки обработки MAC на устройствах беспроводной связи, включающих в себя как точки доступа, так и пользовательские терминалы. На фиг.3 и 4 показана в общем виде такая ASIC 310, сконфигурированная для использования на пользовательском терминале 106 и точке доступа 104 соответственно.
На фиг.3 показана примерная конфигурация ASIC процессора MAC 310 для пользовательского терминала 106. В этой конфигурации процессор 240 MAC, описанный выше, подключен к аппаратной таблице 320. Аппаратная таблица 320 содержит, помимо прочего, параметры для каждого потока, который активен на станции. Таким образом, при осуществлении различных функций обработки MAC, примеры которых подробно описаны ниже, процессор 240 MAC обращается к аппаратной таблице 320 для извлечения параметров для каждого потока 325. Процессор 240 MAC также подключен к SRAM 330. В этой конфигурации SRAM 330 адаптирована для осуществления функции буфера 250 пакетов. ASIC 310 процессора MAC может содержать различные другие компоненты, примеры которых подробно описаны ниже. Заметим, что в этом варианте осуществления буфер 250 пакетов размещен в ASIC 310 процессора MAC. Заметим, что аппаратная таблица 320 показана как отдельный блок лишь для ясности. В различных вариантах осуществления аппаратная таблица 320 и SRAM 330 могут обе входить в состав процессора 240 MAC.
На фиг.4 показана ASIC процессора 310 MAC, сконфигурированная для использования в качестве точки доступа. Эту конфигурацию также можно использовать для станции, способной поддерживать большее количество потоков и/или более высокую пропускную способность, так называемой суперстанции. В примерах, подробно описанных ниже, суперстанцию и конфигурацию точки доступа можно просто именовать точкой доступа или конфигурацией точки доступа. В этом варианте осуществления ASIC 310 процессора MAC 310 содержит процессор 240 MAC, аппаратную таблицу 320 и SRAM 330, как показано на фиг.3. Опять же, эти компоненты показаны отдельно лишь в целях иллюстрации, и один или несколько из них могут быть включены в процессор 240 MAC. В этой конфигурации аппаратная таблица 320 уже не содержит все параметры для каждого потока, используемые для обработки MAC. В этом случае указатели 335 для каждого потока содержатся в аппаратной таблице 320, причем каждый из них указывает на соответствующие параметры для каждого потока 325, которые сохраняются в SRAM 330. Заметим, что некоторые параметры для каждого потока по желанию также можно сохранять в аппаратной таблице 320. Заметим, что ту же самую ASIC 310 процессора, содержащую те же аппаратные компоненты, которые показаны, можно адаптировать к любой конфигурации для поддержки разных требований. В этом примере SRAM 330 меняет свое назначение с буфера 250 пакетов в режиме STA на хранилище параметров 325 для каждого потока в режиме точки доступа. Таким образом, процессор MAC 240 обращается к аппаратной таблице 320 на предмет параметров и в зависимости от конфигурации будет извлекать эти параметры или следовать уровню косвенной адресации для извлечения их из SRAM 330. Программно-аппаратное обеспечение (выполняемое, например, процессором 210) может конфигурировать различные компоненты ASIC 310 процессора MAC для осуществления в первом режиме (режим станции) или во втором режиме (режиме точки доступа). Различные методы для выбора режимов хорошо известны в технике. Например, настройки регистров, сигналы выбора режима и пр. можно использовать для указания одному или нескольким компонентам текущего состояния конфигурации. Кроме того, программно-аппаратное обеспечение может заполнять аппаратную таблицу 320 и SRAM 330 по-разному, в зависимости от выбранной конфигурации.
Согласно фиг.4 внешняя память, в этом примере SDRAM 340, предусмотрена для осуществления функции буфера 250 пакетов. Таким образом, в режиме точки доступа использование SRAM 330 для сохранения параметров для каждого потока позволяет поддерживать большее количество потоков, чем можно было бы поддерживать с использованием только аппаратной таблицы 320 (предполагая, что аппаратная таблица 320 меньше, чем SRAM 330). Размер SRAM 330 можно выбирать для удовлетворения требований буфера пакетов для устройства беспроводной связи в режиме станции. В одном варианте осуществления этот размер также пригоден для хранения всех параметров для каждого потока, необходимых для количества потоков, поддерживаемого точкой доступа. В альтернативном варианте осуществления SRAM 330 может иметь размер для поддержки большего количества потоков, для чего может потребоваться SRAM большего размера, чем в противном случае было бы необходимо для буфера пакетов. SDRAM 340 можно выбирать для согласования количества потоков, поддерживаемого точкой доступа. Специалистам в данной области техники очевидно, как выбирать пригодные размеры для аппаратной таблицы 320, SRAM 330 и SDRAM 340.
Таким образом, единая ASIC 310 процессора MAC может быть предназначена для поддержки множества режимов. Аппаратные компоненты можно повторно использовать в каждом режиме для обеспечения разных функций. Более подробно описанные примеры использования аппаратных таблиц и буферов пакетов проиллюстрированы ниже. Применение единой ASIC 310 процессора MAC, которую можно конфигурировать, как показано на фиг.3, позволяет уменьшить размер и снизить стоимость. Ту же ASIC 310 процессора MAC также можно использовать в более производительных устройствах, например на точке доступа или суперстанции, добавив внешнюю SDRAM 340 и переконфигурировав ASIC 310 процессора MAC. Различные другие размеры SDRAM 340 можно выбирать в зависимости от требований к производительности для данной конфигурации.
На фиг.5 показан более подробный иллюстративный вариант осуществления устройства беспроводной связи, например STA 104 или AP 106. В этом примере будет описана обработка MAC для самых разнообразных примерных признаков пакета с использованием одного процессора MAC (описана в широком смысле). В альтернативном варианте осуществления функции обработки MAC для разных типов пакетов можно распределить по двум или более процессорам MAC (примерные альтернативные варианты осуществления подробно описаны ниже со ссылкой на фиг.48 и 49).
Как и раньше, процессор 210 предусмотрен для выполнения программно-аппаратных задач. Показано примерное множество функций поддержки, которое может быть типичным в такой конфигурации. Различные альтернативные варианты осуществления очевидны специалистам в данной области техники. Процессор 210 осуществляет связь с SRAM 502 инструкций и загрузочным ROM 504 через шину 506 инструкций. Эти блоки памяти можно использовать для выполнения общеизвестного хранения и извлечения инструкций для использования в программно-аппаратной обработке на процессоре 210. Иллюстративные функции ввода/вывода и функции поддержки представлены компонентами, подключенными к шине 514. В этом примере можно обеспечить таймеры 508 для выполнения различных функций отсчета времени. Можно обеспечить универсальный асинхронный приемник-передатчик (UART) 510. Другим примером ввода/вывода является интерфейс I2C 512. В этом примере различные вспомогательные компоненты подключены через шину 514 к контроллеру векторов прерывания (VIC) 516, который подключен к процессору 210. Таким образом, прерывания хронирования, прерывания ввода/вывода и соответствующую обработку может осуществлять процессор 210 в соответствии с соответствующими предусмотренными функциями. В технике хорошо известны различные альтернативные функции для соединения с процессорами различных типов, что очевидно специалистам в данной области техники. Мост 518 соединяет компоненты, подключенные к шине 514, с другими компонентами, подключенными к шине 520. Таким образом, различные компоненты, подключенные к шине 520, включающие в себя процессор 210, могут передавать данные в шину 514 для доставки на соответствующие компоненты или их приема оттуда. В этом примере арбитр 522 шины обеспечен для управления доступом к шине 520 контроллера DMA, дополнительные компоненты, подключенные к шине 520, включают в себя контроллер 524 прямого доступа к памяти (DMA), SRAM 526 данных и ведомый интерфейс 528 шины. Ведомый интерфейс 528 шины обеспечивает канал между шиной 520 и логикой и мультиплексорами форматирования 570, которые будут более подробно описаны ниже. Компоненты, описанные таким образом, могут принципиально идентифицироваться различными компонентами, например процессором 210, памятью 220 и блоком ввода/вывода 230, описанными выше со ссылкой на фиг.2.
Компоненты, показанные на фиг.5, за исключением SDRAM 340, образуют части одного примерного варианта осуществления ASIC 310 процессора MAC, например, описанного выше на фиг.3 и 4. Эти компоненты можно сконфигурировать для использования в качестве конфигурации STA 106, подробно описанной на фиг.3, или точки доступа или конфигурации суперстанции, подробно описанной на фиг.4. В свете предыдущего рассмотрения можно видеть, что различные компоненты, подробно описанные на фиг.5, могут образовывать участки процессора 240 MAC и аппаратной таблицы 320. Различные описанные компоненты можно конфигурировать в разных режимах для осуществления разных функций. Различные компоненты, например процессор 210 и примерные вспомогательные компоненты 502-528, могут быть включены или не включены в иллюстративном варианте осуществления ASIC 310 процессора MAC.
Заметим, что процессор 210 и различные другие показанные компоненты могут осуществлять связь с компонентами процессора MAC через шину 520. В этом примере процессор MAC содержит две главные функции, включающие в себя нижнее ядро MAC 540 и подсистему «хоста - WLAN», обозначенную как процессор 530 H2W. Иллюстративные варианты осуществления этих компонентов дополнительно подробно описаны ниже. Это разделение компонентов на различные части является лишь одним примером, и специалисты в данной области техники могут легко разместить различные описанные процессы и функции в альтернативных конфигурациях, которые очевидны в свете идей настоящего изобретения.
Доступ к SRAM 560 можно осуществлять через интерфейс 558 SRAM, который подключен к MUX 554. Мультиплексор 554 выбирает в качестве входа в интерфейс SRAM 558 соединение с арбитром 556 памяти или соединение с арбитром 552 памяти. Арбитр 552 памяти принимает запросы и принимает решение в отношении доступа к SRAM 560 из различных источников, включающих в себя компоненты на шине 520, а также шине 550. В этом примере шина 550 обеспечивает прямое соединение между нижним ядром 540 MAC и памятью (SRAM) 560. Заметим, что также существует путь между этими компонентами через шину 520. В этом примере предусмотрена дополнительная шина 550, чтобы гарантировать производительность доступа с SRAM 560 для извлечения и сохранения данных, чувствительных к времени, в и из нижнего ядра 540 MAC. Заметим, что согласно фиг.3 и 4 SRAM 560 может выступать в роли буфера пакетов в одной конфигурации и в качестве хранилища параметров для каждого потока в другой конфигурации.
Нижнее ядро MAC 540 подключено к интерфейсу MAC/PHY 545, который можно использовать для доставки пакетов для передачи на PHY 260 и для обработки принятых пакетов от PHY 260. Примерные варианты осуществления компонентов в нижнем ядре 540 MAC дополнительно подробно описаны ниже.
Процессор 530 H2W обрабатывает пакеты входа, примерные варианты осуществления будут более подробно описаны ниже. В одном варианте осуществления вход можно отключать от обработки входящих пакетов. В этом случае пакеты входа можно записывать в буфер пакетов на скорости линии (т.е. на скорости входа). Обработка этих пакетов может осуществляться позже, путем чтения их из буфера пакетов. Это отключение позволяет осуществлять обработку на скорости, отличающейся от скорости линии входа. Недостаток этого подхода состоит в наличии дополнительных операций чтения и записи в буфер пакетов, поскольку пакеты нужно считывать, обрабатывать и помещать обратно в буфер пакетов для ожидания передачи. В некоторых вариантах осуществления это вынужденное снижение пропускной способности памяти может быть приемлемым. Альтернативный вариант осуществления, проиллюстрированный в нижеприведенных примерах, обеспечивает оперативную обработку пакетов входа. В этих иллюстративных вариантах осуществления обработка MAC нужна для того, чтобы каждый пакет входа можно было форматировать для передачи на скорости линии, с единичной операцией записи в буфер пакетов (после которой следует операция чтения, когда наступает время для передачи пакета). Во втором случае нагрузка на пропускную способность памяти снижается по сравнению с первым случаем. Специалисты в данной области техники могут легко адаптировать каждый подход к различным предусмотренным здесь аспектам в различных вариантах осуществления.
SDRAM 340 показана как компонент внешний по отношению к ASIC 310 процессора MAC в этом варианте осуществления. Это соответствует рассмотрению, приведенному выше со ссылкой на фиг.3 и 4, в котором устройства беспроводной связи, нуждающиеся в поддержке большего количества потоков (что приводит к необходимости в увеличении размера буфера пакетов, например, на точке доступа или суперстанции), можно согласовать с единой недорогой ASIC 310 процессора MAC и необязательной внешней памятью, например SDRAM 340. К SDRAM 340 можно обращаться через интерфейс SDRAM 562, который подключен к арбитру 556 памяти. В альтернативном варианте осуществления SDRAM 340 также может входить в состав ASIC 310 процессора MAC. Выделение компонентов, представленное на фиг.5, является лишь одним примером. Любой из показанных компонентов может быть включен в единую ASIC или может быть включен в одно или несколько внешних устройств, в зависимости от требований к площади каждой ASIC и желательной производительности.
В этом примере вход и выход пакетов осуществляется через один из двух примерных внешних интерфейсов. Специалистам в данной области техники очевидно, что помимо или вместо этих интерфейсов можно обеспечить альтернативные интерфейсы. В этом примере интерфейс SDIO 582 и интерфейс PCI 584 предусмотрены для приема и хэндовера пакетов на внешние (или внутренние) устройства, осуществляющие связь с одним или несколькими из этих интерфейсов. Интерфейс SDIO 582 и интерфейс PCI 584 выбираются через MUX 580.
Для согласования интерфейсов с переменными скоростями, а также для предъявления изменяющихся требований к сохранению и обработке входящих и исходящих пакетов можно обеспечить FIFO, мультиплексоры и логику форматирования для осуществления согласования по скорости и очереди для ослабления перегрузки при обращении к блокам памяти, например SRAM 560 и SDRAM 340, и функции обработки MAC, например процессор 530 H2W и нижнее ядро 540 MAC. Например, интерфейсы входа и выхода могут работать на более высоких скоростях относительно пропускной способности WLAN. Входящие потоки могут быть импульсными и высокоскоростными. Информация от процессора 210 или любого другого компонента, подключенного к шине 520, может поступать на другой скорости. Процессор 530 H2W и нижнее ядро 540 H2W будут генерировать запросы доступа и извлекать или сохранять данные, результирующие из этих запросов, по завершении обработки для различных задач, как дополнительно описано ниже. Таким образом, в этом примере можно обеспечить FIFO 572 между логикой и мультиплексорами форматирования 570 и логикой и мультиплексорами форматирования 574. В одном примере множество FIFO 572, один для буферизации данных из логики и мультиплексоров форматирования 570 в логику и мультиплексоры форматирования 574, и другой для буферизации данных в противоположном направлении, можно обеспечить для сопряжения с функциями входа и выхода (например, интерфейсом SDIO 582 или интерфейсом PCI 584). Другое множество FIFO 572, по одному в каждом направлении, можно обеспечить для поддержки данных на и из процессора 530 H2W. Еще одно аналогичное множество можно обеспечить для использования совместно с нижним ядром 540 MAC. Еще одно аналогичное множество можно обеспечить для сопряжения между компонентами на шине 520, доступ к которым осуществляется через ведомый интерфейс 528 шины. Специалистам в данной области техники очевидно, что эта конфигурация является всего лишь одним примером. Можно обеспечить различные альтернативные варианты осуществления, что очевидно специалистам в данной области техники в свете идей настоящего изобретения. Таким образом, примерный вариант осуществления устройства 104 или 106 беспроводной связи, показанного на фиг.5, служит для иллюстрации одного возможного межсоединения различных компонентов, детали которого описаны ниже. В рамках объема изобретения можно обеспечить многочисленные альтернативные конфигурации с использованием подмножеств этих компонентов и/или дополнительных компонентов (не показаны).
Буфер пакетов и управление памятью
На фиг.6 показан примерный вариант осуществления буфера 250 пакетов. В различных подробно описанных здесь иллюстративных вариантах осуществления буфер 250 пакетов, показанный на фиг.6, иллюстрирует структуры данных и соответствующие связные списки, которые полезны для выполнения различных функций для обработки пакетов в процессоре 240 MAC. Хотя различные варианты осуществления, подробно описанные здесь, не требуют такой структуры, и в альтернативных вариантах осуществления можно обеспечить альтернативные буферы пакетов, варианты осуществления, подробно описанные в этом описании изобретения, будут использовать эти связные списки и структуры данных для иллюстрации их использования в этих различных функциях. Кроме того, буфер пакетов, например, описанный на фиг.6, можно обеспечить для использования в различных альтернативных функциях, помимо подробно описанных здесь. Специалисты в данной области техники могут легко адаптировать этот буфер пакетов и компоненты и их подкомпоненты в различных вариантах осуществления, включающие в себя те, для которых требуется относительно высокоскоростная обработка пакетов. Примерный буфер 250 пакетов может включать в себя дополнительные структуры данных, не показанные на фиг.6, которые дополнительно подробно описаны на фиг.7, описанной ниже.
В этом примере каждый пакет сохраняется в буфере 250 пакетов с использованием двух типов структур данных, причем первая структура данных называется здесь узлом 610, и вторая структура данных называется здесь куском 620. Каждый пакет или фрагмент пакета (если обеспечена фрагментация, например описанная в 802.11(g) и (e)), включает в себя один узел 610 и один или несколько кусков 620. Количество кусков, необходимое для сохранения пакетных данных, будет варьироваться в зависимости от размера пакета или фрагмента. Таким образом, пакет располагается в буфере 250 пакетов в виде структуры связного списка, содержащей узел, указывающий на первый кусок, и, когда необходимы дополнительные куски, связный список содержит дополнительные куски, причем каждый кусок указывает на следующий кусок (за исключением последнего куска).
Одно преимущество такого разделения между узлами и кусками состоит в том, что информация, критическая для решений по управлению, может поддерживаться в узле, в то время как сами данные поддерживаются в относительно более крупных кусках. Это позволяет использовать узлы, представляющие соответствующие пакеты, для обработки управления без необходимости доступа ко всему пакету.
Дополнительно, поступающие пакеты ввода, а также пакеты, ожидающие вывода, в целом, будут связаны с одним или несколькими потоками. Описанная структура узлов и кусков также облегчает эффективное формирование очередей пакетов в буфере пакетов, причем с каждой очередью связан соответствующий поток. Эта общая структура показана на фиг.6 в порядке примера единой очереди, содержащей различные узлы и куски. В этом примере узлы 610A-N образуют связный список, ассоциированный с очередью для потока. Очередь имеет голову, идентифицируемую указателем 630 головы очереди, и указатель 640 хвоста очереди идентифицирует последний узел в очереди. В этом примере в очереди существует N пакетов, с каждым из которых ассоциирован узел 610. Показано, что каждый узел 610 содержит ряд кусков 620A-M. С одним узлом может быть связано любое количество кусков. Остальные куски, показанные на этой фигуре, просто обозначены 620. Специалистам в данной области техники очевидно, что можно обеспечить узлы различных размеров, а также куски различных размеров. В примерном варианте осуществления кусок имеет размер 512 байтов. Таким образом, поскольку примерные пакеты обычно имеют размер менее 2 кбайт, самое большее 4 куска потребуется для каждого пакета (обычно меньше), включающего в себя заголовок пакета и другую ассоциированную с ним информацию. В альтернативных вариантах осуществления можно обеспечить любой размер куска в соответствии с любым размером пакета.
В этом примерном варианте осуществления управление и данные разделены в памяти. Для передачи и приема могут потребоваться ряд манипуляций со структурами управления. Однако для полезных данных осуществляется только одна операция записи в память (после входа или приема из WLAN) и одна операция чтения из этой памяти (после передачи по WLAN или выхода через внешний интерфейс). Таким образом, можно снизить требования к пропускной способности памяти, поскольку перенос в и из памяти относительно эффективны.
На фиг.6 показан примерный узел 610. Узел 610 содержит указатель 612 следующего узла, который используется для указания следующего узла в очереди. Включены поле 614 длины и порядковый номер 616. Эти поля полезны при обработке пакетов, которая дополнительно описана ниже, и позволяют осуществлять обработку MAC без обращения к данным или перемещения данных, содержащихся в кусках 620. Например, поле длины полезно для агрегации, при агрегации пакетов в TXOP. Порядковый номер полезен при отправке запроса квитирования блока. В общем случае, любую информацию пакета, полезную для обработки, можно добавлять к альтернативным вариантам осуществления узла. Узел 610 также включает в себя указатель 618 куска, который указывает на первый кусок, содержащий пакетные данные.
Эта структура позволяет гибко генерировать очереди любой длины, ограничиваясь только общим размером памяти буфера пакетов. Таким образом, могут поддерживаться различные другие типы потока, и поддерживаемое количество потоков не должно быть фиксировано. Например, несколько потоков, требующих малого количества пакетов, могут быть выделенным хранилищем, для которого потоки требуют большего количества пакетов, и, таким образом, буфер пакетов меньшего размера можно обеспечить для поддержки данного количества потоков. Альтернативно, можно обеспечить переменное количество потоков для любого данного размера памяти. Как можно видеть, очереди могут расти и сокращаться независимо, и, поскольку узлы и куски могут повторно использоваться любым потоком или пакетом, соответственно, структура предоставляет большую гибкость при очень эффективном управлении памятью.
Также показан примерный кусок 620. Данные 622 куска содержат пакет, включающий в себя любые поля заголовка, последовательности проверки кадров и пр. Указатель 624 следующего куска включен в кусок для указания на следующий кусок в связанном списке, если таковой существует.
В одном варианте осуществления куски имеют фиксированный размер. Благодаря этому память буфера пакетов может содержать фиксированный участок памяти, выделенный кускам. Структура связного списка позволяет использовать любой кусок в любом связном списке пакетов. По мере прихода и ухода пакетов куски можно с легкостью повторно использовать, без необходимости в дополнительной служебной нагрузке для управления памятью (например, повторного выделения места для пакетов другого размера и пр.). Эта структура также позволяет эффективно осуществлять обработку, благодаря чему, в общем случае, куски можно один раз записывать в буфер пакетов, где они остаются, пока не будут готовы к передаче по WLAN или к хэндоверу на пункт назначения вывода. Пакеты также можно перемещать в очереди или перемещать в новые очереди, просто переписывая указатели (т.е. изменяя связный список). Это полезно при обработке пакетов для повторной передачи. Использование этих структур обеспечивает дополнительные эффективности, что будет дополнительно подробно описано ниже. Каждый связный список может использовать любой из различных терминаторов списка для последнего узла в очереди или последнего куска в пакете. В примерном варианте осуществления первый и последний узлы в связном списке указываются заголовком и указателем хвоста, тогда как указатели куска сцепляются для указания последнего куска в пакете. В альтернативном варианте осуществления может быть желательно добавлять количество кусков в заголовок узла совместно с длиной пакета и порядковым номером пакета. Также можно предусмотреть альтернативные варианты осуществления, включающие в себя переменные размеры куска.
На фиг.7 показана дополнительная иллюстрация буфера 250 пакетов. Различным типам структур данных можно выделять непрерывные куски памяти, хотя это не является обязательным требованием. Как описано выше, часть сегмента 730 можно выделить для узлов, и сегмент 740 можно выделить для кусков. В примерном варианте осуществления каждый из этих сегментов является непрерывным пространством памяти, включающим в себя узлы и куски фиксированного размера, повторно используемые для любого пакета и/или потока, как описано выше. Кроме того, поддерживаются список 710 свободных указателей узла и список 720 свободных указателей куска. Различные структуры данных можно обеспечивать для списков свободных указателей, что очевидно специалистам в данной области техники. В одном примере указатели узлов и указатели кусков можно проталкивать и выталкивать в соответствующие им списки указателей 710 или 720. Эти списки могут представлять собой, например, кольцевые буферы. После выталкивания указателя для формирования нового узла или куска этот указатель будет продолжать использоваться, пока узел или кусок не освободится, после чего указатель снова можно будет протолкнуть для использования в будущем.
На фиг.8 показаны дополнительные компоненты, которые можно обеспечить в процессоре MAC, например в подробно описанных здесь иллюстративных вариантах осуществления. Эти компоненты не являются обязательными, но могут обеспечивать преимущества в определенных ситуациях в силу конкретных свойств используемого типа памяти. Например, в целом, имеет место задержка, связанная с доступом к SDRAM. Также могут иметь место неэффективности при осуществлении малых переносов (т.е. при извлечении или сохранении одного указателя узла или куска). С использованием определенных типов SDRAM, при выделении доступа к строке, доступа к столбцу и т.д. циклы служебной нагрузки могут превосходить циклы переноса фактических данных. Во избежание больших задержек можно обеспечить различные кэши для извлечения сразу нескольких указателей для использования при обработке MAC. На фиг.8 приведены примеры нескольких из этих кэшей. Некоторые или все из этих кэшей можно обеспечить в различных альтернативных вариантах осуществления. Иллюстративные кэши, используемые в подробно описанных здесь вариантах осуществления, включают в себя кэш 810 указателей свободных узлов ТХ, кэш 820 указателей свободных кусков ТХ, кэш 830 указателей свободных узлов RX и кэш 840 указателей свободных кусков RX. Структуру данных, проиллюстрированную выше для пакетов, можно упростить для использования с пакетами приема, примерный вариант осуществления которой дополнительно подробно описан ниже со ссылкой на фиг.33. В общем случае, каждый из этих кэшей 810-840 принимает один или несколько указателей из соответствующих списков указателей узлов в буфере 250 пакетов для создания эффективностей. Совокупность указателей каждого типа можно одновременно извлекать из буфера пакетов. В этом примере совокупность указателей можно выталкивать из соответствующего списка. Затем эти указатели заполняют соответствующий кэш, и единичные указатели можно выталкивать из соответствующего кэша для использования в различных компонентах обработки MAC. Использование указателей и соответствующих им кэшей будет дополнительно проиллюстрировано посредством различных подробно описанных ниже иллюстративных вариантов осуществления.
На фиг.9 представлен иллюстративный вариант осуществления способа 900 для записи пакетов в буфер пакетов и создания очередей. Очередь можно формировать с использованием структуры данных, в этом примере связанного списка. Очереди также можно формировать в виде массивов (приведен пример массива узлов 3330, подробно описанного ниже). Этот способ пригоден для реализации совместно с буфером пакетов, например, описанным выше со ссылкой на фиг.6 и 7. Способ 900 иллюстрирует методы, которые можно использовать для записи пакетов входа в буфер пакетов. Аналогичные методы можно использовать для записи принятых пакетов в буфер пакетов для ожидания обработки хэндовера для выхода. Ниже будут дополнительно подробно описаны примерные варианты осуществления хэндовера. В необязательном порядке, также можно обеспечить кэши указателей (т.е. 810-840, представленные на фиг.8) и они также могут быть первичным источником новых указателей. Различные варианты осуществления можно обеспечить с кэшами или без них, и этот способ можно использовать с любой подобной конфигурацией, что очевидно специалистам в данной области техники.
На этапе 910 пакет принимается. На этапе 912 узел выталкивается для ассоциирования с пакетом. На блоке принятия решения 914, если этот пакет является первым пакетом в соответствующей очереди, происходит переход к этапу 916 и обновление указателя головы очереди для указания на узел, связанный с новым пакетом (например, указатель головы очереди 630, проиллюстрированный на фиг.6). Затем происходит переход к 918. На блоке принятия решения 914, если этот пакет не является первым пакетом в соответствующей очереди, происходит переход к этапу 918.
На этапе 918 производится выталкивание указателя куска. Опять же, выталкивание узлов и кусков (условное обозначение для выталкивания соответствующего указателя) можно осуществлять непосредственно из буфера пакетов и, в частности, из списка свободных указателей узла или списка свободных указателей куска соответственно. В иллюстративном варианте осуществления указатели выталкиваются из кэша 810 свободных указателей узла передачи и кэша 820 указателей свободных кусков передачи (который может потребоваться пополнять по мере их истощения). На этапе 920 производится наполнение узла порядковым номером и длиной пакета и вставка указателя куска, извлеченного на этапе 918, в поле указателя куска узла (т.е. с использованием формата узла, например узла 610, проиллюстрированного на фиг.6). На этапе 922 производится наполнение куска пакетными данными. Кусок 620, показанный на фиг.6, можно обеспечить в одном примере.
На блоке принятия решения 924, если определено, что требуется еще один кусок, потому что пакет больше, чем может поместиться в первый кусок, происходит переход к этапу 926. В противном случае, происходит переход к этапу 932. На этапе 926 производится выталкивание нового указателя куска. На этапе 928 производится запись нового указателя куска в поле указателя следующего куска предыдущего куска. На этапе 930 производится заполнение нового куска пакетными данными. В иллюстративном варианте осуществления пакетные данные будут последовательно записываться в ряд кусков. Затем происходит возврат к блоку принятия решения 924 для определения, требуется ли еще один кусок. Этот цикл может повторяться, пока пакет не будет полностью записан в один или несколько кусков.
На этапе 932 процесс записи пакета завершается. Узел, связанный с пакетом, ставится в надлежащую очередь. Например, это можно осуществлять путем записи адреса узла, т.е. указателя, извлеченного на этапе 912, в указатель следующего узла хвостового узла. В этом примере хвостовой узел идентифицируется указателем хвоста очереди (например, указателем хвоста очереди 640, представленного на фиг.6). На этапе 934 производится обновление указателя хвоста для указания на текущий узел, который станет хвостовым узлом.
На блоке принятия решения 936, если принимается еще один пакет, цикл возвращается к этапу 912, и процесс может повториться. Если еще один пакет не готов для записи в буфер пакетов, процесс может остановиться. Для ясности, детали ассоциирования пакета с ассоциированным с ним потоком, из которого будут извлечены соответствующая очередь и ассоциированные с ней указатели головы и хвоста, опущены. Примерные варианты осуществления ассоциирования пакетов с потоками более подробно показаны ниже.
Процессор H2W и политика входа
На фиг.10 показан примерный вариант осуществления подсистемы хост-WLAN, например, процессора 530 H2W. Пакет можно принимать из различных источников. В этом примере в порядке иллюстрации, показаны два источника. Этот примерный вариант осуществления демонстрирует подмножество компонентов, которые могут содержаться в процессоре 530 H2W. Некоторые из компонентов, показанных на фиг.10, могут соответствовать компонентам, показанным на фиг.5, не включенным в процессор 530 H2W, и показаны для упрощения рассмотрения. Специалистам в данной области техники очевидно, что показанные компоненты и их разделение носят исключительно иллюстративный характер. Типичные пакеты входа в этом примере поступают из внешнего интерфейса, например интерфейса SDIO 582 или интерфейса PCI 584, представленных на фиг.5. Другой примерный пакет может поступать из процессора 210 или любого другого компонента, подключенного к шине 520, как показано на фиг.5. Пакеты внешнего интерфейса поступают в процессор 530 H2W через внешний интерфейс 1006. Пакеты из шины 520, например, могут поступать через интерфейс процессора 1002. Можно обеспечивать FIFO для временного хранения одного или нескольких пакетов для обработки. Например, можно обеспечить FIFO 1004 и 1008 для временного хранения пакетов, принятых от интерфейса процессора 1002 или внешнего интерфейса 1006 соответственно. Блок 1004 можно обеспечить для временного хранения пакетов администрирования и управления, поступающих от процессора, которые необходимо передавать по WLAN. В альтернативном варианте осуществления, подробно описанном ниже со ссылкой на фиг.48, интерфейс процессора 1002 и соответствующие компоненты можно опустить, поскольку традиционные пакеты и другие пакеты более низкой пропускной способности (например) обрабатываются на процессоре 210 (или другом альтернативном процессоре MAC), и поэтому этот интерфейс может быть не нужен.
В этом примере MAC-адрес назначения совместно с идентификатором потока трафика [Traffic Stream Identifier] (TSID) используются для уникальной идентификации потока. В альтернативных вариантах осуществления можно обеспечить другие механизмы для отображения потока. Как упомянуто выше, обычно имеется драйвер для выполнения классификации потоков, который может действовать на уровне программно-аппаратного обеспечения, или на некотором другом внешнем процессоре. Драйвер может генерировать MAC-адрес с адресом назначения (DA), TSID, и адресом источника. В этом примере DA и TSID можно использовать для идентификации потока. DMAC-TSID поступает на блок 1020 отображения потока, из которого возвращается ID потока, соответствующий DMAC-TSID.
Примерные варианты осуществления блока 1020 отображения потока могут использовать любой тип поисковой или другой функции для определения ID потока из данной информации идентификации. Один пример показан на фиг.10B. В примерном варианте осуществления желательно отключать взаимодействие на уровне программно-аппаратного обеспечения от обработки на скорости линии, как описано выше. Однако может случиться так, что программно-аппаратное обеспечение пригодно для создания таблиц для отображения потока. Для отключения взаимодействия на уровне программно-аппаратного обеспечения предусмотрены две теневые таблицы потока, таблица 1 1092 и таблица 2 1096. Процессор 530 H2W использует одну теневую таблицу, выбранную коммутатором 1090, тогда как программно-аппаратное обеспечение может обновлять другую теневую таблицу, выбранную коммутатором 1099. Таким образом, можно обеспечить пинг-понговый метод, благодаря чему программно-аппаратное обеспечение обновляет одну таблицу, тогда как другая используется для обработки MAC. Каждая теневая таблица 1092 или 1096 потока содержит элементы списка DMAC-TSID с соответствующими ID потоками. Теневая таблица потока 1 1092 содержит DMAC-TSID 1093A-N, ассоциированные с ID потока 1094A-N. Теневая таблица потока 2 1096 содержит DMAC-TSID 1097A-N, ассоциированные с ID потока 1098A-N. Таким образом, блок 1020 отображения потока доставляет DMAC-TSID в активную выбранную теневую таблицу потока, и ID потока возвращается. В примерном варианте осуществления для выполнения быстрого поиска ID потока выполняется двоичный поиск. Программно-аппаратное обеспечение хорошо подходит для упорядочения полей DMAC-TSID для облегчения двоичного поиска. Специалистам в данной области техники очевидны альтернативные процедуры отображения потока, которые можно заменить в альтернативных вариантах осуществления.
Согласно фиг.10A ID потока поступает в таблицу 1030 состояний потока ТХ, примерный вариант осуществления которой подробно описан ниже со ссылкой на фиг.11. Таблица 1030 состояний потока ТХ содержит различные параметры для каждого потока. Физическое местоположение таблицы 1030 состояний потока ТХ может варьироваться, как описано выше со ссылкой на фиг.3 и 4. Например, в одной конфигурации таблица состояний потока ТХ может храниться в виде аппаратной таблицы в процессоре 530 H2W. В альтернативном варианте осуществления аппаратная таблица может размещаться в нижнем ядре 540 MAC, детали не показаны, и оба блока 530 и 540 могут совместно использовать одну и ту же аппаратную таблицу. Альтернативно, каждый из блоков 530 и 540 может поддерживать части аппаратной таблицы, что в общем виде представлено на фиг.3 и 4. Из доставленного ID потока можно выбирать участок таблицы 1030 состояний потока ТХ, соответствующий ID потока, и извлекать различные параметры. Примерные параметры будут описаны в этих вариантах осуществления.
Некоторые параметры могут поступать на блок 1010 политики. Примерные варианты осуществления блока политики дополнительно подробно описаны ниже. Если предусмотрено шифрование, блок шифрования, в этом примере код целостности сообщения [Message Integrity Code] (MIC), 1025, может иметь ключи, доставляемые для использования при шифровании.
На блоке 1025 MIC из поступающих ключей и данных в части полезной нагрузки пакета может генерироваться вычисление MIC. В этом варианте осуществления отдельный компонент используется для осуществления шифрования полезной нагрузки (см. механизм 2210 традиционного протокола, подробно описанный ниже). Альтернативные методы шифрования хорошо известны в технике и могут использоваться вместо описанных выше.
Другие параметры можно доставлять на блок 1035 присоединения заголовка для создания заголовка. Сгенерированный заголовок может включать в себя поля для использования в самом заголовке пакета, а также значения управления для использования, в то время как пакет проходит через функции обработки MAC. Эти значения управления можно удалять до того, как пакет поступит для передачи. Это один примерный метод поддержания информации состояния для пакета во время выполнения обработки MAC. Специалистам в данной области техники очевидны альтернативные методы поддержания состояния пакетов при выполнении на них различных функций MAC.
Блок 1010 политики совместно с параметрами, поступающими из таблицы 1030 состояний потока, может отвергнуть пакет, и в этом случае функции шифрования, например вычисление MIC, не будут осуществляться, и пакет может удаляться из FIFO. Примерные варианты осуществления политики входа дополнительно подробно описаны ниже. Если блок 1010 политики разрешает пакет, то полезная нагрузка совместно с частью MIC, сгенерированной в MIC 1025, если он предусмотрен, и соответствующий заголовок поступают для хранения в FIFO 1050.
На фиг.11 показан примерный вариант осуществления содержимого таблицы 1030 состояний потока ТХ. Множества параметров поддерживаются для каждого потока. Проиллюстрированы параметры одного потока. Тип 1102 пакета указывает, какого типа пакет принимается. Например, пакет может представлять собой пакет 802.11(g), (e) или (n). Другие типы пакетов могут поддерживаться и могут указываться в поле 1102 типа пакета.
Политика безопасности 1104 указывает, будут ли использоваться методы защиты (например, шифрование). Примерный вариант осуществления поддерживает AES-CCMP (Advanced Encryption Standard - Counter Mode Cipher Block Chaining Message Authentication MAC Protocol) и RC4-TKIP (Rivest's Cipher-4 - Temporal Key Integration Protocol). Адрес 1106 приемника указывает MAC-адрес приемника, для которого предназначен пакет. Порядковый номер 1108 указывает порядковый номер пакета. Ключ 1110 MIC идентифицирует ключ MIC, если предусмотрен TKIP. Контроль 1112 кадра включает в себя информацию для построения соответствующего заголовка.
Контроль 1114 качества обслуживания (QoS) можно использовать для указания уровня QoS. В примерном варианте осуществления поддерживается четыре уровня QoS. Примеры обработки очередей для различных значений QoS дополнительно проиллюстрированы ниже.
Поле 1116 «время жизни» можно использовать для указания, как долго пакет может оставаться в буфере. По истечении времени жизни пакет, например, можно очистить. Максимальная загруженность 1118 буфера, максимальное количество 1120 пакетов на поток и совокупное количество 1122 пакетов на поток используются в примерном варианте осуществления для политики входа, например на блоке 1010 политики, примеры которого дополнительно подробно описаны ниже со ссылкой на фиг.12 и 13. Заметим, что глобальная переменная «Текущая загруженность буфера» можно использовать совместно с этими тремя параметрами для осуществления различных методов политики входа. Указатель 1124 хвоста очереди используется для идентификации хвостового узла, как описано выше, со ссылкой на фиг.6 и 9.
Эти переменные или параметры таблицы состояний потока ТХ приведены исключительно в целях иллюстрации. Специалистам в данной области техники очевидно, что дополнительные переменные или параметры могут быть полезны для поддержания для каждого потока и также могут быть включены. Кроме того, не все признаки необходимо поддерживать во всех вариантах осуществления, и, таким образом, можно обеспечить подмножество этих параметров.
На фиг.12 показан примерный вариант осуществления способа 1200 выполнения политики входа. Более подробное рассмотрение преимуществ политики входа приведено ниже со ссылкой на фиг.34, применительно к хэндоверу выхода и общему QoS WLAN. Как описано выше в отношении примерной таблицы 1030 состояний потока ТХ, показанной на фиг.11, различные параметры могут поддерживаться для каждого потока. Эти параметры можно регулировать на основании уровня QoS для более легкого одобрения или отвержения пакетов функцией политики.
В отношении QoS WLAN - это дополнительный метод, позволяющий распознавать, что при согласовании с высокоскоростным входом (который может быть импульсным и содержать смесь потоков с высоким и низким QoS) на блоке обработки MAC может формироваться узкое место помимо перегрузки на самой WLAN. Например, возможно, что функции обработки MAC могут заполняться пакетами более низкого QoS. Без правильной политики пакеты более низкого QoS могут вводиться в конвейер в периоды времени относительно низкой перегрузки, и узкое место может формироваться при ухудшении условий на WLAN и снижении пропускной способности. Таким образом, блок 1010 политики можно сконфигурировать так, чтобы пакеты более высокого QoS могли поддерживать свой приоритет в периоды времени относительной перегрузки, и чтобы можно было более свободно обрабатывать пакеты более низкого QoS при снижении перегрузки. Стандарты 802.11 (например, b, g, e и n) обращают внимание на контроль QoS на WLAN, однако без должного внимания к входу. Поэтому, если приложение низкого QoS занимает все буферы на станции, то пакет более высокого приоритета не может получить доступ к системе. Политика входа, как описано здесь, может предотвращать подобные сценарии и обеспечивать сквозное QoS, не только QoS на WLAN. Специалистам в данной области техники очевидны различные альтернативные варианты осуществления для функций политики в свете идей настоящего изобретения.
Согласно фиг.12, на этапе 1210 осуществляется прием пакета для передачи. Например, пакет может поступать в процессор 530 H2W, и блок 1010 политики может определять, принять или отвергнуть пакет для дальнейшей обработки MAC. На этапе 1220, производится определение ID принятого пакета. Например, можно использовать блок 1020 отображения потока. На этапе 1230 осуществляется доступ к параметрам политики и/или функции политики, ассоциированной с ID потока. В примерном варианте осуществления эти параметры можно сохранять в таблице 1030 состояний потока ТХ, и они могут включать в себя максимальную загруженность 1118 буфера, максимальное количество 1120 пакетов на поток и совокупное количество 1122 пакетов на поток. В примерной таблице 1030 состояний потока ТХ, представленной на фиг.11, не показана возможность того, что можно задать совокупность функций политики (и, возможно, ассоциированные с ними альтернативные параметры), причем разные функции политики подлежат использованию для разных потоков. На блоке 1240 принятия решения, если одобрение принятого пакета удовлетворяет соответствующей функции политики, заданной для потока, согласно параметрам, специфическим для потока, и любым глобальным переменным, ассоциированным с текущей перегрузкой или другими системными условиями, происходит переход к этапу 1250 и допуск пакета. В противном случае, происходит переход к этапу 1260, и пакет отвергается. После этого процесс может остановиться.
На фиг.13 представлен один примерный вариант осуществления способа 1300 выполнения функции политики, пригодного для реализации на этапе 1240, показанном на фиг.12. Как описано выше, параметры «максимальная загруженность буфера» и «максимальное количество пакетов на поток» можно регулировать для каждого отдельного потока. Это может быть ассоциировано с уровнями QoS потока. Заметим, что в примерном варианте осуществления предусмотрено четыре уровня QoS. Однако эти параметры можно регулировать по размеру для согласования более значительного изменения, чем заранее заданные уровни QoS. Таким образом, в некоторых вариантах осуществления функцию политики можно реализовать с более высокой детализацией, чем в примерной настройке QoS. В этом примере блок 1240 принятия решения, который может получать информацию с этапа 1230 в конфигурации, показанной на фиг.12, определяет, одобрять ли пакет (после чего происходит переход к блоку 1250 или 1260, соответственно, в конфигурации, показанной на фиг.12).
Примерная проверка, осуществляемая в блоке 1240 принятия решения, содержит два условия. Для одобрения пакета должно быть выполнено одно из условий. Если не выполнено ни одно из условий, пакет отвергается.
Первое условие можно рассматривать как индикатор перегрузки на блоке обработки MAC. Когда блок обработки MAC относительно недогружен, первое условие будет выполняться с более высокой вероятностью, даже для более низкоприоритетных пакетов, и поэтому пакеты будут одобрены с большей вероятностью. В показанном примере первое условие выполняется, когда текущая загруженность буфера меньше максимальной загруженности буфера. В данном случае текущая загруженность буфера является глобальной переменной, доступной процессу, которая указывает общую загруженность буфера пакетов. Заметим, что максимальную загруженность буфера можно регулировать по-разному для разных потоков, в результате чего первое условие оператора ИЛИ становится более или менее строгим, по желанию. Например, поток с высоким QoS может иметь более высокую настройку максимальной загруженности буфера, таким образом, допуск становится более вероятным. Напротив, более низкая настройка максимальной загруженности буфера приведет к снижению вероятности допуска. Иными словами, максимальную загруженность буфера можно задавать по-разному для каждого потока, что позволяет по-разному определять, что означает перегрузка, на основании типа потока.
Второе условие, в целом, определяет, когда имеет место относительная перегрузка. В этом случае преобладает информация для каждого потока. В показанном примере второе условие выполняется, если текущее количество пакетов на поток для данного потока меньше заданного максимального количества пакетов на поток. В частности, максимальное количество пакетов на поток можно задать для потока так, чтобы потокам более высокого приоритета присваивалось большее значение и потокам более низкого приоритета присваивалось меньшее значение. Таким образом, когда текущая загруженность буфера относительно велика (таким образом, первое условие не выполняется), более высокоприоритетные пакеты, имеющие большее максимальное количество пакетов на поток, будут допущены с более высокой вероятностью. Максимальное количество пакетов на поток для более низкого приоритета можно понижать. Таким образом, вместо того, чтобы фактически ограничивать их все, можно допускать относительно небольшое количество более низкоприоритетных пакетов. В альтернативном варианте осуществления совокупное количество пакетов на поток можно вычислять с помощью значения времени (значение времени может разниться от потока к потоку) для генерации пакетной скорости для потока. Затем максимальное количество пакетов на поток можно аналогично задать равным пакетной скорости для каждого потока. Можно предусмотреть различные альтернативные параметры и связанные с ними условия допуска и отвержения пакетов, что очевидно специалистам в данной области техники в свете идей настоящего изобретения.
Заметим, что эти параметры не обязаны оставаться статическими, и могут обновляться на основании других условий системы (например, качества линии связи и ассоциированных скоростей, которые указаны в обратной связи по скорости от PHY). Специалисты в данной области техники могут предложить многочисленные настройки для каждой из переменных и хорошо понимают, что эти настройки могут изменяться по-разному в ответ на изменение системных условий.
Чистый результат состоит в том, что эффективную функцию политики можно эффективно обеспечить на скорости линии, просто извлекая параметры для каждого потока из таблицы 1030 состояний потока ТХ, и решение можно быстро принимать для каждого входящего пакета. Заметим, что допуск и отвержение пакетов согласно функции политики входа можно комбинировать с любым методом контроля потока, примеры которого хорошо известны в технике, благодаря чему различные скорости обработки пакетов можно реализовать без потери пакетов. В одном варианте осуществления идентификатор потока можно принимать до приема всего пакета на внешнем интерфейсе, чтобы можно было принимать решение относительно политики входа, во избежание использования полосы интерфейса для приема пакета, когда пакет отвергается.
В итоге, этот пример подчеркивает несколько возможностей для политики. При высокой нагрузке можно препятствовать преобладающему использованию ресурсов одним потоком (даже высокоприоритетным потоком), в то же время предоставляя более обширный доступ потокам более высокого приоритета. При более высокой нагрузке менее ограничительные решения могут позволять низкоприоритетным потокам использовать ресурсы, поскольку они не потребляются в это время. Политика входа может представлять собой любую функцию описанных четырех переменных (и альтернативные варианты осуществления могут использовать другие переменные или параметры). Политику можно использовать для равноправия, чтобы предоставлять, по меньшей мере, некоторый доступ всем типам потока, даже если другие являются предпочтительными до любой желаемой степени. Политику также можно использовать для управления линиями связи низкого качества. Независимо от того, желательно ли регулировать качество линии связи или перегрузку, или их комбинацию, можно использовать те же (или аналогичные) параметры.
Согласно фиг.10A вывод FIFO 1050 поступает на блок 1060 фрагментации. Напомним, что FIFO 1050 может включать в себя один или несколько пакетов, которые были одобрены, совместно с их соответствующими заголовками, и вычисление MIC, если применимо. Фрагментацию можно осуществлять в зависимости от типа пакета. Например, фрагментация может быть разрешена для 802.11(e) или (g) или для любого другого типа пакета, для которого желательна фрагментация. В примерном варианте осуществления глобальная переменная, порог фрагментации (FT), задается посредством функции управления AP (это функциональный элемент, заданный в кадре маяка). Он, в целом, не изменяется в течение коротких периодов времени. Программно-аппаратное обеспечение может устанавливать порог фрагментации в регистре. Если пакет превышает порог фрагментации, пакет разбивается на фрагменты размером FT с возможным остаточным частичным фрагментом.
Заметим, что фрагментация не требуется. В альтернативном варианте осуществления блок 1060 фрагментации и все связанные с ним функции можно опустить. В другом альтернативном варианте осуществления, дополнительно подробно описанном ниже со ссылкой на фиг.48, можно обеспечить более одного блока обработки MAC. В таком варианте осуществления один блок обработки MAC можно приспособить для осуществления фрагментации, тогда как другой блок обработки MAC не будет приспособлен для этого. В одном случае высокоскоростные пакеты могут не требовать или не поддерживать фрагментации, и могут обрабатываться на процессоре 530 H2W без помощи блока 1060 фрагментации, тогда как поддержка для других типов пакетов, включающих в себя фрагментацию (например, традиционные 802.11 пакеты), может обеспечиваться на дополнительном процессоре MAC, например процессоре MAC 4810, подробно описанном ниже. Специалисты в данной области техники легко могут предложить компромиссы при обеспечении варианта осуществления, включающего в себя один процессор, способный обрабатывать все функции различных типов пакетов, и другого варианта осуществления, содержащего два или более процессоров MAC, каждый из которых способен обеспечивать любое подмножество функций. Конечно, можно также обеспечить единый процессор MAC, способный обрабатывать пакеты, требующие единого набора функций.
Блок 1060 фрагментации определяет количество фрагментов на основании порога фрагментации и длины пакета. Количество фрагментов поступает на блок 1065 функций списка, который возвращает указатели на блок 1060 фрагментации. Когда фрагментация не разрешена, или порог фрагментации не превышен, количество фрагментов будет равно одному, и будет возвращаться один указатель узла и ассоциированные с ним один или несколько указателей куска. Блок 1065 функций списка выполняет различные процедуры связного списка, применимые для используемой структуры памяти (например, описанной выше на фиг.6). Заметим, что, как показано, кэш 810 указателей узлов и кэш 820 указателей кусков располагаются в блоке функции списка, в порядке примера. Таким образом, пул доступных указателей можно брать из доступного пула в каждом кэше. Подробности того, как обновлять и пополнять эти кэши, не показаны, но очевидны специалистам в данной области техники в свете идей настоящего изобретения. В принципе, как показано на фиг.10A, количество фрагментов может передаваться функциям 1065 списка, и может возвращаться группа указателей для этого количества фрагментов. В отсутствие фрагментации количество фрагментов равно одному, и могут возвращаться один указатель узла и ассоциированный/ые с ним указатель или указатели куска. В альтернативном варианте осуществления аналогичная функция может выполняться блоком 1060 фрагментации, в котором повторные вызовы функции 1065 списка производятся для каждого фрагмента, пока не будет фрагментирован весь пакет. Поскольку возвращается каждый указатель, глобальная переменная «загруженность буфера» увеличивается согласно количеству кусков или пакетов. Загруженность буфера можно измерять в примерном варианте осуществления, и альтернативные варианты осуществления могут использовать альтернативные измерения.
На фиг.14 показан примерный вариант осуществления FIFO 1050. FIFO 1050 включает в себя один или несколько блоков служебных данных MAC (MSDU) 1410A-N. Каждый MSDU содержит заголовок 1430, полезную нагрузку 1440 и вычисление 1450 MIC (если используется TKIP), как описано выше. В одном варианте осуществления данные управления можно добавлять в каждый MSDU в FIFO 1050, которые могут поступать обратно из блока 1060 фрагментации, как описано выше. В альтернативном варианте осуществления информация управления не поддерживается в FIFO 1050. Заметим, что информация управления, добавленная для использования в процессоре 530 H2W, будет удалена до записи пакета в память буфера пакетов.
Если фрагментация не нужна, MSDU можно сохранять непосредственно в буфере 1062. Его можно сохранять с указателем узла и указателями куска, извлеченными из функций 1065 списка. Функции списка обеспечивают количество и адреса кусков для каждого пакета, полезная нагрузка пакета (и, следовательно, полезная нагрузка кусков) записывается в память по соответствующим адресам. Если фрагментация нужна, то каждый создаваемый фрагмент также сохраняется в буфере 1062.
Содержимое буфера 1062 поступает в блок 1070 записи в память. Блок 1070 записи в память взаимодействует с арбитром 1080 памяти, который борется за доступ к памяти буфера пакетов, чтобы фактически ввести пакет и/или фрагменты в буфер пакетов. Заметим, что арбитр 1080 памяти можно реализовать в виде одного из арбитров 556 или 552 памяти, как показано на фиг.5, в зависимости от конфигурации ASIC процессора 310 MAC.
Показано, что арбитр 1080 памяти принимает запрос от блока 1070 записи в память и может принимать другие запросы от других компонентов, борющихся за доступ к памяти буфера пакетов. Когда доступ предоставляется, предоставление будет возвращаться на блок 1070 записи в память, и пакет и/или фрагменты записываются в память буфера пакетов. Способ, аналогичный описанному со ссылкой на фиг.9, можно использовать для осуществления блока записи в память. Например, узел создается и заполняется текущими данными, включающими в себя длину и указатели кусков, и т.д., согласно вышеприведенному описанию. Затем куски записываются посредством 64-байтовых актов доступа в примерном варианте осуществления, пока не будет заполнен каждый 512-байтовый кусок. Блок 1070 записи в память продолжает делать запросы, пока весь пакет, включающий в себя все фрагменты, если таковые существуют, не будет записан в RAM. Указатели, используемые для помещения пакета в соответствующую очередь, извлекаются в качестве указателя узла для пакета (или указателей узла для каждого фрагмента), а также указателя хвоста очереди для идентификации последнего узла в очереди (места, где будут присоединены последующие новые пакеты и/или фрагменты).
В одном варианте осуществления арбитр памяти принимает запросы от автомата входа, автомата ТХ WLAN, автомата RX WLAN и машины состояний выхода. Он может упорядочивать эти запросы по их приоритетам, например, в следующем порядке приоритетов: RX WLAN, ТХ WLAN, выход и вход. Автоматам может потребоваться весь пакет, подлежащий чтению или записи. В другие моменты автоматы могут лишь искать указатель узла, указатель куска и/или другую информацию управления для выполнения планирования или других функций. Можно установить систему приоритетов, охватывающую акты чтения и записи управления и пакетов в целях RX/ТХ WLAN и выхода/входа.
Потоки настраиваются, когда станция производит спецификацию потока (т.е. TSPEC). В этот момент программно-аппаратное обеспечение может задавать элемент во всех таблицах, связанных с потоком. Оно также может наполнять указатель головы (и, значит, первого пакета) для этого потока. Специалистам в данной области техники известны различные способы отслеживания новых очередей и обновления ассоциированных указателей головы очереди.
В примерном варианте осуществления арбитр памяти ограничивает доступ к памяти определенным числом байтов (т.е. 64), чтобы другие компоненты могли беспрепятственно обращаться к памяти буфера пакетов. В примерном варианте осуществления предусмотрен циклический доступ к памяти, распределенный между запросами записи входа, актами записи RX WLAN и выходом ТХ WLAN (т.е. хэндовером, дополнительно подробно описанным ниже). Например, MPDU размером 1500 байтов будет вносить большую задержку в отношении других, ожидающих доступа, если весь MPDU был записан в прерывистом потоке. Планирование, например, циклическое препятствует остановке других процессов.
На фиг.15 показан процесс разбиения MSDU 1410 на один или несколько фрагментов (размер каждого из которых не превышает порог фрагментации), плюс возможный остаточный фрагмент. В этом примере управление 1420 исключено. В одном альтернативном варианте осуществления управление 1420 можно просто присоединять спереди к первому заголовку 1510, как показано. Информация управления может включать в себя указатели или любую другую информацию управления, которую можно присоединять спереди к каждому заголовку 1510 и можно удалять до завершения записи в память. Согласно фиг.15 каждый фрагмент 1530A-N присоединяется спереди к заголовку 1510, и каждый фрагмент идентифицируется как полезная нагрузка 1520, которая является частью полезной нагрузки 1440 из MSDU. Каждый заголовок 1510 включает в себя порядковый номер 1540, который является порядковым номером пакета, и номер фрагмента 1550, который является номером, ассоциированным с каждым отдельным фрагментом.
В иллюстративном варианте осуществления после выполнения фрагментации каждый фрагмент последовательно обрабатывается как пакет. Это позволяет эффективно обрабатывать пакеты и фрагменты посредством различных методов обработки MAC, которые подробно описаны здесь. Альтернативные варианты осуществления не нуждаются в совместном использовании этого требования. Концевой фрагмент 1530N включает в себя MIC 1450, если используется TKIP. Напомним, что в примерном варианте осуществления MIC вычисляется в пределах пакета до фрагментации посредством MIC 1025.
На фиг.16 показана принципиальная конфигурация арбитра 556 совместно с двумя или более блоками 1610A-1610N записи в память. Блок 1610 записи в память может представлять собой вышеописанный блок 1070 записи в память или один из различных других, подробно описанных ниже. Каждый блок записи в память посылает запрос 1630 в арбитр 556. Арбитр 556 передает линию 1640 предоставления в каждый блок записи в память, указывающую, когда начинается запись в память. Арбитр 556 также может управлять MUX 1620 для выбора вывода предоставленного компонента записи в память для доставки на контроллер 1650 SDRAM. Например, контроллер 1650 SDRAM может представлять собой интерфейс 562 SDRAM в примере, показанном на фиг.5, или может включать в себя любые другие компоненты, подключенные к SDRAM 340. Заметим, что аналогичную схему арбитража можно обеспечить для арбитра 552 памяти для записи пакетов в память пакетов в соответствии с выбранными режимами конфигурации. В технике хорошо известны различные схемы арбитража памяти, любую из которых можно обеспечить здесь в различных вариантах осуществления. В примерном варианте осуществления, в целом, за контроллером следует интерфейс. Контроллер может управлять логикой чтения и записи в память, тогда как интерфейс обеспечивает физическое соединение. На фиг.16 показан только один иллюстративный пример.
Обработка передачи
В предыдущем разделе были описаны различные варианты осуществления, иллюстрирующие аспекты эффективной обработки MAC пакетов входа, приводящие к обработке пакетов в буфер пакетов, с использованием различных структур данных, для ожидания передачи. В этом разделе «обработка передачи» будут рассмотрены дополнительные эффективности, предоставляемые за счет использования представленных выше структур данных. Кроме того, будут рассмотрены другие аспекты, которые повышают эффективность высокоскоростной обработки MAC.
В общем случае, точка доступа, способная поддерживать большое количество потоков для множества STA, обеспечивает более сложный анализ, чем относительно простая STA, поддерживающая 16 потоков. Таким образом, во многих вариантах осуществления, подробно описанных ниже, более сложная точка доступа будет использоваться как эталон. При необходимости, будут подчеркнуты различия между STA и точкой доступа. В целом, при обработке передачи желательно иметь возможность работать с большим количеством потоков, и по-прежнему быстро реагировать, когда возможности передачи становятся доступными. Кроме того, поддержка традиционных спецификаций передачи может играть важную роль. Некоторые аспекты предпочтительны ввиду сокращения площади схемы, более эффективного использования схем, простоты конструкции и/или возможности согласования с традиционными протоколами и компонентами.
Один пример, иллюстрирующий необходимость в быстром ответе, когда возникает возможность передачи, включает в себя протокол доставки незапланированного автоматического энергосбережения [Unscheduled Automatic Power Save Delivery] (UAPSD). Другим примером является немедленное квитирование блока. Варианты осуществления, подробно описанные ниже, предусматривают эффективную поддержку множества потоков за счет поддержания подмножества пакетов в готовности к быстрому ответу. Это позволяет поддерживать UAPSD, немедленное квитирование блока и доставку приглашения, когда TXOP заработан. Это будет, в большинстве случаев, избавлять от необходимости в ранее использовавшихся методах резервирования полосы, например отправки CTS самому себе и т.д. В одном примере, если перегрузка при обращении к памяти препятствует подготовке более крупного агрегата, малое множество пакетов можно быстро передавать в ходе TXOP. После приема квитанции для этого множество пакетов, если в TXOP остается емкость, можно передавать дополнительные пакеты. Как указано выше, удаление программно-аппаратного обеспечения из высокоскоростных участков обработки пакетов повышает эффективность. В примерных вариантах осуществления можно обеспечить различные кэши и очереди для отключения программно-аппаратной обработки (и ее относительно сниженной скорости) от обработки MAC. Эти и другие аспекты будут проиллюстрированы ниже в различных вариантах осуществления.
В подробно описанных ниже примерных вариантах осуществления представлено несколько аспектов. Согласно одному аспекту предусмотрена совокупность кэшей, каждый из которых используется для сохранения элементов, связанных с пакетами потока. Эти кэши (проиллюстрированные ниже узловыми кэшами 1810) обеспечивают ответ с низкой задержкой по времени в различных приложениях. Ответ с низкой задержкой позволяет станции или AP эффективно использовать возможности передачи различных типов, например предоставления в обратном направлении, UAPSD и аналогичные запросы, и позволяет захватывать оставшуюся возможность передачи, следующую за передачей. Ответ с низкой задержкой позволяет легче избегать конфликтов (например, успешный быстрый ответ в ранней возможности передачи позволяет избегать конфликтов, обусловленных конкуренцией, которая может возникать при попытке более позднего ответа). Ответ с низкой задержкой может облегчать энергосбережение.
Согласно еще одному аспекту теневые очереди (именуемые ниже пинг-понговыми очередями, и образованные ожидающей очередью и обслуживаемой очередью) позволяют упорядочивать элементы потока до возможности передачи (даже если другой поток обрабатывается для передачи). Таким образом, поток ожидает, будучи готовым к обработке. Это облегчает откладывание обработки так надолго, как это возможно. Откладывание часто бывает желательно, чтобы можно было отложить принятие решения по скорости для потока, поскольку принятие решения по скорости оказывается максимально поздним и свежим, что позволяет выбирать соответствующую скорость для максимизации пропускной способности и/или минимизации ошибок.
Согласно еще одному аспекту заполнение очереди (представленной ниже как очереди 1842, 1850 и 1855) элементами, связанными с пакетами для потока, облегчает быстрое определение длины для формирования пакета (полезное при отложенном определении скорости), а также облегчает быструю агрегацию пакетов. Помимо агрегации, в общем случае, проиллюстрированные аспекты облегчают повторную передачу (т.е. в ответ на квитирование принятого блока). Эти аспекты по отдельности желательны во многих контекстах, и их также можно комбинировать.
В традиционных системах 802.11 обычно обеспечивается поддержка четырех очередей EDCA. Напомним, что очереди EDCA борются за доступ в течение незапланированных периодов в среде и, после того как TXOP заработан, передают как можно больше данных, вплоть до максимума, заданного в TXOP. Для согласования соревнующихся очередей EDCA предусмотрены различные схемы отсрочки во избежание непрерывных, одновременных попыток заработать TXOP со стороны соревнующихся очередей EDCA. Таким образом, каждая очередь EDCA может быть связана с каналом, для которого поддерживаются различные таймеры, производится оценка чистого канала (CCA), и осуществляются другие процедуры предоставления доступа. Некоторые из этих функций могут совместно использоваться по каналам или очередями, и некоторые могут различаться. В устройстве беспроводной связи, например точке доступа, желающем поддерживать одновременно большое количество потоков (т.е. 256 потоков в примерном варианте осуществления), поддержка таймеров отсрочки и осуществление различной служебной нагрузки, связанной с зарабатыванием TXOP, для каждого из большого количества потоков могут быть не желательными. Разные настройки для различных параметров типа канала могут приводить к обеспечению различных уровней качества обслуживания.
На фиг.17 показан примерный вариант осуществления части устройства беспроводной связи, сконфигурированного для поддержки относительно большой совокупности очередей 1710 EDCA с использованием меньшего, фиксированного набора стандартных очередей 1730 EDCA. В одном применении можно предусмотреть совокупность очередей EDCA, каждая из которых обеспечивает отдельный уровень качества обслуживания. В этом примере поддерживается совокупность из N очередей EDCA для каждой станции 1770A-N. В примерном варианте осуществления может поддерживаться 256 таких очередей для каждого из 256 поддерживаемых потоков. Циклический селектор 1720 принимает решение относительно очередей EDCA для каждой станции и выбирает данные, подлежащие постановке в очередь, в одной из 4 стандартных очередей ECDA 1730A-D. В альтернативном варианте осуществления селектор 1720 может выполнять альтернативный алгоритм планирования, помимо циклического. Селектор можно обеспечить различными путями, например, как подробно описано ниже со ссылкой на фиг.18. В примерном варианте осуществления программно-аппаратное обеспечение включает в себя функцию планирования, которая обеспечивает критерии выбора для выбора очередей EDCA для каждой станции для доставки с использованием одной из стандартных очередей EDCA. В альтернативных вариантах осуществления, естественно, может поддерживаться любое количество очередей EDCA. Четыре очереди предусмотрены в одном варианте осуществления по причине наличия существующих традиционных компонентов обработки с необходимыми таймерами и компонентами оценки канала, необходимыми для борьбы за доступ и для получения доступа к совместно используемому каналу. Специалистам в данной области техники хорошо известны многочисленные традиционные ядра и компоненты 802.11, которые могут быть включены здесь в различных вариантах осуществления, или модифицироваться для поддержки нужных дополнительных признаков. Примерные варианты осуществления, предусматривающие использование традиционных ядер и/или компонентов в соответствии с раскрытыми здесь принципами, дополнительно подробно описаны ниже. Пакеты, запланированные в очередях EDCA 1730A-D, можно передавать с использованием стандартных процедур EDCA. Программно-аппаратный планировщик может осуществлять дополнительное планирование помимо EDCA, например, опрошенные TXOP (пример которых известен в протоколе HCCA). Можно предусмотреть различные другие протоколы, для которых можно адаптировать планировщик, что очевидно специалистам в данной области техники. Помимо циклического выбора очередей 1710 EDCA для передачи со стандартными очередями, в целом, эффективнее агрегировать пакеты для каждой STA и производить управление собственным вектором (или другую пространственную обработку) для всех пакетов от этой станции. Управление собственным вектором обеспечивает наибольшие преимущества, когда передачи направляются на конкретную станцию (или группу близко расположенных станций). Таким образом, может иметь смысл поместить все пакеты, адресованные данной станции, в один буфер, чтобы их можно было агрегировать и передавать на эту станцию. В альтернативном варианте осуществления можно иметь единый буфер для всех пакетов EDCA. Однако в этом случае, когда пакеты перемежаются с пакетами, адресованными другим станциям (с другими значениями управления собственным вектором), агрегация может быть затруднена или невозможна.
Использование очередей EDCA носит исключительно иллюстративный характер. В общем случае, можно обеспечить выбор очередей, ассоциированных с каналами различных типов. Типы канала могут варьироваться на основании уровня качества обслуживания и/или типа передачи, например запланированного доступа или доступа на конкурсной основе.
На фиг.18 показан примерный вариант осуществления, демонстрирующий различные компоненты нижнего ядра 540 MAC. Различные аспекты, обеспечивающие эффективности использования узлов для обработки пакетов, очередей и кэшей для отключения программно-аппаратного обеспечения от скорости обработки пакетов, и другие аспекты будут проиллюстрированы в следующем примере. Специалистам в данной области техники очевидно, что можно обеспечить дополнительные компоненты (не показаны), и не каждый проиллюстрированный аспект или признак требуется в любом конкретном варианте осуществления для извлечения пользы из других аспектов или признаков. На фиг.18 подробно показаны планирование потоков и идентификация различных пакетов, запланированных для окончательной передачи. Результаты приводят к доставке идентификаторов, ассоциированных с запланированными пакетами, соответствующих параметров и сигнала готовности для каждого типа канала на механизм 1880 передачи (TX). В этом варианте осуществления идентификация пакета осуществляется с использованием узлов, что подробно описано выше. В этом примере традиционные каналы типа 802.11 используются в целях иллюстрации. Специалистам в данной области техники очевидно, что с использованием аналогичных компонентов, подробно описанных на фиг.18, можно работать с каналом любого типа. В этом примере поддерживаются четыре очереди EDCA, EDCA 0-3 1850A-D. Также обеспечена очередь 1855 HCCA совместно с широковещательным каналом 1860 управления. Структура EDCA 0 проиллюстрирована подробно, тогда как для других каналов детали опущены, поскольку они могут быть идентичными или аналогичными в различных вариантах осуществления.
Планирование передачи начинается с программно-аппаратного заполнения одного или нескольких списков 1815 команд, ассоциированных с каждым каналом (например, 1850 или 1855). Списки команд заполняются ID потока, подлежащими планированию. Список команд может содержать ID потока совместно с TXOP. Очереди EDCA могут бороться за TXOP, и, таким образом, время передачи может быть заранее неизвестно. Однако максимальный размер TXOP может быть включен совместно с ID потока. Для планирования HCCA могут быть известны размер TXOP, а также запланированное время доставки, и эта информация TXOP может быть включена совместно с ID потока в соответствующий список 1815 команд. Для каждого канала контроллер 1840 массива может управлять планированием пакетов для канала. Контроллер массива выталкивает ID потока из списка 1815 команд для определения следующего запланированного потока для передачи. Поддержание нескольких из этих списков команд позволяет программно-аппаратному планировщику сразу создавать пакет решений и помещать их в соответствующие списки, что может осуществляться с течением времени. Это позволяет различным контроллерам 1840 массива обрабатывать ID потока из списков, что снижает необходимость во взаимодействии на уровне программно-аппаратного обеспечения. Это позволяет сократить или исключить прерывания на программно-аппаратное обеспечение и отключить программно-аппаратное планирование от обработки MAC, как описано выше. Специалисты в данной области техники легко могут предложить альтернативные методы планирования потоков для обслуживания в поддерживаемом наборе каналов, включающем в себя каналы типа EDCA на конкурсной основе или опрашиваемые или запланированные каналы типа HCCA.
В этом примере кэш 1810 узлов ТХ поддерживается для каждого из поддерживаемой совокупности потоков. Кэши 1810 узлов ТХ служат примерами общих кэшей для каждого потока и пригодны для реализации в качестве очередей 1710, проиллюстрированных выше. В примерном варианте осуществления поддерживается 256 таких потоков. Каждый кэш потока содержит место для совокупности узлов (которые представляют соответствующие пакеты для потока). В иллюстративном варианте осуществления в каждом кэше 1810 узлов ТХ поддерживается четыре узла для каждого потока. Таким образом, по меньшей мере, 4 пакета идентифицируются как следующие пакеты, подлежащие передаче, для каждого из 256 потоков. Любая непосредственная передача, необходимая для этих потоков, может быть удовлетворена, по меньшей мере, этими четырьмя узлами. В альтернативных вариантах осуществления, по желанию, могут поддерживаться дополнительные узлы.
Хотя узлы используются в этом примерном варианте осуществления для иллюстрации одного аспекта, существует ряд эквивалентных методов, которые можно обеспечить. Например, можно кэшировать альтернативные структуры данных. В другом примере можно кэшировать сам пакет. В общем случае, кэши, проиллюстрированные как совокупность кэшей 1810, будут использоваться для сохранения одного или нескольких элементов, из которых соответствующий один или несколько пакетов можно идентифицировать и извлекать после обработки кэшированных элементов.
Блок 1835 обновления кэша узлов ТХ взаимодействует с кэшами 1810 для поддержания их заполнения и обновления. Блок 1835 обновления кэша узлов ТХ может взаимодействовать с арбитром памяти, например, арбитром 1080 памяти, подробно описанным выше. В одном варианте осуществления, делается запрос для извлечения одного или нескольких узлов для потоков, и, когда предоставляется доступ к буферу пакетов, извлеченные узлы можно помещать в соответствующий кэш 1810 узлов ТХ. Блок обновления кэша узлов ТХ может действовать относительно независимо от остальной обработки, показанной на фиг.18.
Контроллеры 1840 массива для каждого канала определяют следующий ID потока для передачи из списка 1815 команд. На основании ID потока контроллер 1840 массива обращается к таблице 1830 состояний массива ТХ для извлечения различных параметров и/или сохранения состояния, ассоциированного с этим ID потока. Таким образом, таблица 1830 состояний массива ТХ поддерживает информацию состояния для каждого потока для поддерживаемых потоков. (Заметим, что в альтернативном варианте осуществления таблица 1830 состояний массива ТХ может быть объединена с любой другой таблицей состояний для каждого потока, например таблицей 1030 состояний потока ТХ, подробно описанной выше.) Заметим, что блок 1835 обновления кэша узлов ТХ также взаимодействует с таблицей 1830 состояний массива ТХ для обновления определенных параметров, связанных с обновлением кэша, дополнительно проиллюстрированных ниже. Например, блок 1835 обновления кэша узлов ТХ извлекает узлы для потока на основании очереди передачи соответствующего узла.
Контроллер массива 1840 использует состояние для каждого потока для запланированного потока для заполнения своего соответствующего массива 1842 узлов ТХ (иллюстрация очереди). Массив 1842 узлов передачи - это массив узлов для потока, выстроенных в последовательности ТХ для доставки на 1880 механизм ТХ. Как показано, набор узлов, хранящихся в кэше 1810 узлов ТХ для текущего запланированного потока, идентифицируемого списком 1815 команд, поступает в массив 1842 узлов ТХ для канала, по которому планируется передавать поток. Это позволяет планировать набор известных узлов сразу же, когда передача становится доступной. В примерном варианте осуществления четыре узла доступно для каждого потока для помещения в массив 1842 узлов ТХ. Остаток массива 1842 узлов передачи можно заполнять дополнительными узлами для потока. В иллюстративном варианте осуществления массивы 1842 узлов ТХ поддерживают 64 идентификатора пакета, т.е. узлов, на момент запланированной доставки через механизм 1880 ТХ. Первые четыре извлекаются из кэша узлов ТХ потока, и остальные пакеты извлекаются из памяти буфера пакетов. По аналогии с другими обращениями к памяти буфера пакетов можно делать запросы для излечения узлов для потока из памяти буфера пакетов (детали не показаны). В альтернативном варианте осуществления массив узлов можно заполнять непосредственно из буфера пакетов без первоначального извлечения элементов из кэша, например кэша 1810. Согласно еще одному варианту осуществления кэши 1810 вовсе не нужно обеспечивать, и, тем не менее, можно пользоваться аспектами, иллюстрируемыми массивами 1842 узлов.
Контроллер 1840 массива, списки 1815 команд и соответствующие компоненты являются примерами компонентов, которые могут быть включены в селектор (например, описанный выше со ссылкой на фиг.17) для выбора элементов из совокупности кэшей (т.е. 1810) и их сохранения в одной из совокупности очередей (например, проиллюстрированных очередью 1842 и очередями 1850 и 1855 EDCA и НССА соответственно). В общем случае, селектор может выбирать любое количество кэшей для каждого потока или очередей для каждого потока (т.е. очередь передачи в буфере пакетов) для сохранения элементов в очереди, например массиве 1842 узлов, или в одной из совокупности таких очередей, на основании любых факторов по желанию (например, качества обслуживания, типа канала и пр.).
В примерном варианте осуществления, как указано выше, желательно, чтобы блок 1835 обновления кэша узлов ТХ работал автономно, отдельно от различных контроллеров 1840 массива, заполняющих массивы 1842 узлов ТХ для доставки в механизм 1880 ТХ. Однако время от времени может существовать возможность, что может потребоваться обновление кэша узлов ТХ для соответствующего потока примерно тогда же, когда контроллер 1840 массива обращается к пакетам из очереди для этого потока из памяти буфера пакетов. Таким образом, можно задать функцию блокировки, не позволяющую ни контроллеру 1840 массива, ни блоку 1835 обновления кэша узлов ТХ повреждать очередь передачи, что препятствует дублированию и выпадению пакетов из этой очереди. Различные методы блокировки хорошо известны специалистам в данной области техники, и примерный вариант осуществления дополнительно подробно описан ниже со ссылкой на фиг.20.
Дополнительный аспект может быть включен в различные каналы, например каналы 1850 EDCA, канал 1855 HCCA или широковещательное 1860 управление. В примерном варианте осуществления массив 1842 узлов ТХ реализован в виде двух теневых массивов узлов. Таким образом, первый теневой массив узлов ТХ можно заполнять узлами для запланированного потока и сигнал готовности можно утверждать на механизм 1880 ТХ. Затем контроллер 1840 массива может переходить к выталкиванию ID следующего потока из своего списка 1815 команд и осуществлению обработки, необходимой для загрузки второго теневого массива узлов ТХ с пакетами для следующего потока. Таким образом, один массив узлов ТХ можно обрабатывать для передачи, в то же время заполняя другой, что снижает возможную задержку, связанную с ожиданием завершения передачи до начала процесса заполнения нового массива узлов. ID 1844 линии связи связан с массивом 1842 узлов ТХ, благодаря чему механизм 1880 ТХ может извлекать надлежащие параметры и состояние линии связи для использования при передаче потока по фактической физической линии связи между двумя станциями. Когда пинг-понговый или теневой кэш обеспечен, как описано выше, в ID 1844 линии связи хранится ID линии связи A для потока, содержащегося в одном теневом массиве узлов ТХ, и ID линии связи B содержит ID линии связи для потока во втором теневом массиве узлов ТХ. Другие параметры также могут храниться совместно с ID линии связи в 1844, ассоциированным с каждым соответствующим потоком, в альтернативном варианте осуществления.
Два теневых массива узлов иллюстрируют общий аспект теневых или пинг-понговых очередей. В общем случае, очередь может соответствовать конкретному типу канала, например каналу EDCA или HCCA. С каждым каналом может быть связан уровень качества обслуживания, выбранный из совокупности уровней качества обслуживания. Очередь в этом примере содержит две теневые очереди. Очередь также можно описать как содержащую обслуживаемую очередь и ожидающую очередь. Физические теневые очереди поочередно назначаются как обслуживаемые очереди и ожидающие очереди. Таким образом, как описано выше, ожидающую очередь можно заполнять, не мешая обработке обслуживаемой очереди. По окончании обработки обслуживаемой очереди соответствующую ей теневую очередь можно повторно выбрать в качестве ожидающей очереди, и можно начать заполнять другим потоком в любое время. Теневая очередь, которая была ожидающей очередью, затем повторно выбирается как обслуживаемая очередь, после чего может начаться обработка для передачи. Таким образом, относительно большое количество потоков, с которыми могут быть ассоциированы различные уровни качества обслуживания, можно выбирать для сохранения в соответствующей очереди (согласно уровню качества обслуживания, а также запланированному доступу или доступу на конкурсной основе, и т.д.). Выбор можно производить на циклической основе, как описано выше, или на основании критериев выбора любого другого типа.
Как указано выше в отношении кэшей 1810, хотя узлы используются в этом примерном варианте осуществления для иллюстрации одного аспекта, существует ряд эквивалентных методов, которые можно обеспечить. Например, альтернативные структуры данных могут храниться в очередях, например 1842 (или 1850 и 1855). В другом примере может хранится сам пакет. В общем случае, очереди, проиллюстрированные очередью 1842, будут использоваться для сохранения одного или нескольких элементов, из которых соответствующий один или несколько пакетов можно идентифицировать и извлекать после обработки элементов, поставленных в очередь.
При заполнении одной стороны "пинг-понгового" буфера 1842, например, четырьмя узлами из кэша 1810 массива узлов, в ходе передачи может быть время для продолжения заполнения этого массива. Как упомянуто выше и дополнительно подробно описано ниже, существует режим U-APSD, который позволяет непосредственно использовать первые четыре пакета. В режиме U-APSD индикатор например, бит "more" можно передавать с первыми четырьмя пакетами. После передачи пакетов и в ожидании квитирования первых четырех пакетов (с любым необходимым межкадровым интервалом) передатчик должен быть готов к дополнительной передаче. В течение этого времени доступ к дополнительным узлам из потока можно осуществлять из кэша узлов ТХ или буфера пакетов в соответствии с тем, что предусматривает данный вариант осуществления. Для других типов передачи могут существовать аналогичные возможности для поддержания массива узлов ТХ полным, для передачи всех пакетов, обеспеченных имеющейся возможностью передачи.
Можно обеспечить широковещательное 1860 управление с функциями, аналогичными функциям контроллера 1840 массива в любом данном варианте осуществления. Однако может потребоваться сокращенный или альтернативный набор функций. В этом примере обеспечен блок 1862 маяка, который содержит указатель 1863, указывающий пакет маяка. Программно-аппаратное обеспечение может генерировать пакет маяка, включающий в себя любую информацию заголовка, необходимые параметры и т.д., что хорошо известно в технике. Маяк 1862 может извлекать созданный пакет для передачи в соответствующее время. Например, программно-аппаратный планировщик может генерировать значение метки времени для создаваемого маяка и доставлять его на блок 1862 маяка. Таким образом, маяк можно передавать с соответствующей периодичностью или близко к ней (т.е. TBTT в вариантах осуществления 802.11). В таком примере маяк 1862 генерирует через широковещательное управление 1860 сигнал готовности на механизм 1880 ТХ. Осуществляется борьба за среду, и маяк будет передаваться в соответствующее время с поправкой на любую задержку, связанную с ожиданием освобождения канала. Специалисты в данной области техники могут легко адаптировать фиг.18 для работы с маяками или другими сообщениями системной сигнализации в свете идей настоящего изобретения. В альтернативном варианте осуществления маяк 1862 может фактически хранить непосредственно пакет маяка, вместо того, чтобы использовать косвенный указатель 1863.
Аналогичным образом можно также генерировать широковещательный или многоадресный канал. Широковещательные и/или многоадресные каналы, по существу, представляют собой ID потока специального назначения. Широковещательный канал не требуется планировать с множественными ID наподобие вышеописанного списка 1815 команд. Однако если нужны множественные широковещательные каналы и/или различные многоадресные каналы, также можно обеспечить аналогичные процедуры планирования (детали не показаны). Широковещательный или многоадресный пакет можно идентифицировать указателем 1865 в широковещательном многоадресном блоке 1864 для передачи на механизм 1880 ТХ (через широковещательное управление 1860). Альтернативно, можно сохранять сам пакет в 1864. Заметим, что из фиг.18 можно видеть, что ссылку на пакет можно использовать вместо ссылки на узел, когда обеспечена схема памяти буфера пакетов, например, подробно описанная выше со ссылкой на фиг.6. Таким образом, очевидно, что, когда узлы и куски используются для хранения пакетов, поддержание очередей можно эффективно и легко осуществлять в самой памяти буфера пакетов. Кроме того, кэши для планирования различных потоков, как показано на фиг.18, могут поддерживаться просто за счет извлечения и сохранения узлов (вместо перемещения пакетов совместно с узлами). Как будет дополнительно подробно описано ниже, фактические пакетные данные удаляются из буфера пакетов только в момент времени передачи пакета. При этом обработка и планирование пакетов осуществляется просто с использованием узла. Дополнительные аспекты, иллюстрирующие преимущества узлов, дополнительно подробно описаны ниже в описании движка передачи 1880. Аналогичные преимущества также имеют место на стороне обработки приема.
Заметим, что, как дополнительно подробно описано ниже со ссылкой на фиг.48 и 49, в альтернативном варианте осуществления могут существовать пакеты для доставки на механизм ТХ, которые поступают из других источников помимо буфера пакетов. Например, традиционные пакеты или пакеты низкой пропускной способности можно форматировать на процессоре с использованием программно-аппаратного процессора MAC, и эти пакеты можно обеспечивать для передачи. Заметим, что структуры, подробные описанным выше, можно адаптировать к такому варианту осуществления. Например, списки 1815 команд можно использовать для планирования передачи также из альтернативных источников. Например, ID потока, количество пакетов, подлежащих передаче, и индикатор того, имеет ли пакет высокую или низкую пропускную способность (или, более общо, из буфера пакетов или внешних источников пакетов). Если планируется пакет низкой пропускной способности, его можно извлечь из FIFO памяти процессора передачи (т.е. 4950) или, альтернативно, из памяти процессора (например, через DMA), как описано ниже. Заметим, что в таком варианте осуществления сообщения, генерируемые для широковещательного управления 1860, например маяк и любые широковещательные или многоадресные сообщения, можно альтернативно формировать в программно-аппаратном обеспечении. Таким образом, компоненты 1862, 1864 и 1860 можно упразднить.
На фиг.19 подробно описан примерный вариант осуществления секции процессора нижнего ядра 540 MAC. Согласно фиг.19 селектор 1930 доставляет ID потока, извлеченные из списка 1815 команд. Это принципиальная схема, в которой не важно, к каналу какого типа осуществляется доступ. Любое количество списков команд можно выбирать и подключать к таблице 1830 состояний массива ТХ. Когда ID потока из выбранного канала представляется таблице 1830 состояний массива ТХ, соответствующее состояние 1902 массива для каждого потока извлекается и доставляется на один или несколько компонентов, нуждающихся в различных компонентах этого состояния. Селектор 1930 является примером, иллюстрирующим селектор, избирательно извлекающий параметры для каждого потока (т.е. сохраненные в состоянии массив 1902) на основании идентификатора потока. В общем случае, таблицы состояний потока (или любой другой набор параметров для каждого потока) можно извлекать по идентификатору потока или можно извлекать косвенно, выбирая индекс потока в соответствии с идентификатором потока и используя индекс потока для определения местоположения параметров для каждого потока (возможно, хранящихся в одном или нескольких блоках памяти). Представленные здесь примеры демонстрируют различные параметры приема и передачи для каждого потока, которые можно сохранять и/или к которым можно обращаться с использованием любого из этих методов. Как показано в целом на фиг.3 и 4, можно обеспечить интегральную схему (в порядке примера) для использования любого типа хранилища параметров для каждого потока, в зависимости от того, в каком режиме сконфигурирована интегральная схема. Это позволяет эффективно поддерживать переменное количество потоков, большое или малое, в доступных блоках памяти.
Проиллюстрирован пример состояния 1902 массива для каждого потока. При извлечении узлов из буфера пакетов для соответствующего потока количество узлов для извлечения составляет минимальное значение из размера окна и количества доступных пакетов. Таким образом, для суммарного количества доступных пакетов или размера 1910 окна передачи массивы узлов ТХ можно заполнять последовательностью до 64 узлов (в примерном варианте осуществления). Как описано выше, каждый последующий узел в очереди ТХ соответствующего потока определяется путем считывания следующего указателя очереди в каждом узле, извлечения следующего узла, помещения узла в массив ТХ и т.д., пока не кончатся пакеты, доступные для потока, или пока не заполнится окно.
Указатель 1912 головы очереди указывает на указатель на узел в голове очереди для очереди передачи соответствующего потока (например, структуры данных в виде связного списка). Указатель головы очереди - это первый узел, подлежащий последовательному извлечению, когда пакеты из потока подлежат передаче. Количество пакетов в очереди сохраняется в поле 1914. Это количество будет увеличиваться, когда пакеты ввода принимаются для потока и уменьшается, когда они передаются. Количество пакетов в кэше, хранящееся в поле 1916, которое можно использовать в связи с блоком 1835 обновления кэша узлов ТХ для пополнения кэша 1810 узлов ТХ и для наполнения массива 1842 узлов ТХ узлами из него. ID 1918 линии связи извлекается для данного потока и может сохраняться в ID 1844 линии связи для использования на передатчике для извлечения состояния и/или параметров конкретной линии связи. В некоторых вариантах осуществления связный список узлов может состоять из большого количества пакетов. Размер окна можно использовать, чтобы гарантировать, что только пакеты в окне обрабатываются для передачи. Указатель 1920 конца окна может использоваться для управления окном. Альтернативные варианты осуществления могут включать в себя дополнительные поля и могут не включать в себя некоторые из описанных. Иллюстративные дополнительные поля включают в себя поле плотности AMPDU и указатель хвоста очереди передачи.
На фиг.20 показана примерная блокировка, которую можно обеспечить для использования, как показано на фиг.18. В этом примере блок 1835 обновления кэша узлов ТХ генерирует сигнал «занято», когда он находится в процессе извлечения информации из памяти буфера пакетов. При этом он также указывает ID потока кэша узлов ТХ, который он обновляет. В этом случае контроллер 1840 массива знает, обращается ли ID потока, который он может обрабатывать, к узлам из буфера пакетов (заметим, что может быть несколько контроллеров 1840 массива, каждый из которых извлекает эти сигналы, по одному на каждый канал). Таким образом, контроллер 1840 массива может откладывать обращение к RAM буфера пакетов для этого ID потока, поскольку некоторые пакеты из этого ID потока могут находиться на пути в кэш массива узлов. Это не позволяет контроллеру 1840 массива мешать работе блока обновления кэша узлов ТХ для потока.
Кроме того, некоторое количество блоков 2010 сравнения предусмотрено для приема ID потока из блока обновления кэша узлов ТХ. Каждый блок сравнения принимает ID потока из канала (т.е. EDCA 0-3 1850A-D, детали не показаны), указывающий, что контроллер 1840 массива соответствующего канала обращается к буферу пакетов для извлечения узлов для заполнения дополнительных свободных мест в соответствующем массиве 1842 узлов ТХ. Если какие-либо из этих ID потока совпадают, будет назначена соответствующая линия. Вентиль 2020 ИЛИ обеспечивает логическую операцию ИЛИ для всех выводов сравнения генерирует сигнал «занято». Блок 1835 обновления кэша узлов ТХ может ожидать продолжения обновления, пока не прекратится сигнал «занято». Альтернативно, он может изменить ID потока в попытке обновить кэш другого потока. Если изменение ID потока приводит к отмене сигнала «занято», блок 1835 обновления кэша узлов ТХ знает, что он не будет мешать работе ни одного контроллера 1840 массива. Специалистам в данной области техники очевидны различные модификации этой схемы блокировки, а также другие схемы блокировки, которые можно обеспечить в рамках объема настоящего изобретения.
В альтернативном варианте осуществления (детали не показаны) кэш 1810 узла четырех пакетов [Four Packet Node Cache] (FPNC) поддерживается для каждого потока, как и раньше. Каждый кэш содержит указатели узла (12 байтов). Как и раньше, это первые четыре пакета, которые будут переданы по WLAN, когда соответствующий поток получит возможность передачи. В этом варианте осуществления, когда пакет принимается при входе, он помещается в SDRAM, о чем извещается конечный автомат (FSM) кэша узлов (который может быть аналогичным блоку 1835 обновления кэша узлов ТХ или обеспечен вместо него). Если в кэше узла четырех пакетов имеется свободное место, соответствующее принятому пакету, информация узла добавляется в соответствующую кэш-память. Когда информация узла поступает в SDRAM для помещения в связанный список, она также поступает в FPNC. Если в FPNC имеется свободное место и если FPNC не используется (в течение возможности передачи WLAN для соответствующего потока), то информация узла помещается в FPNC. Контроллер 1840 массива может задавать бит «обслуживание», указывающий FSM, что поток обслуживается. Это обеспечивает эффект, аналогичный блокировке, подробно описанной выше.
Автомат FPNC действует по принципу «первым пришел - первым обслужен» для обновления FPNC. FPNC особенно полезен для обслуживания пакетов для станций с возможностью U-APSD, которые дополнительно подробно описаны ниже. При получении триггера нижнее ядро 540 MAC квитирует триггер и может сразу же ответить агрегатом до 4 пакетов, как описано выше. Автомат FPNC должен пополнить FPNC после его опустошения вследствие возможности передачи. Автомат FPNC может действовать, используя очередь, идентифицирующую потоки, которые нуждаются в пополнении. Очередь может состоять из потоков в порядке приоритета для обслуживания со стороны FPNC - приоритет определяется из таких соображений, как, например, работает ли станция в режиме U-APSD, является ли поток потоком на основе HCCA или EDCA, и пр.
Эффект этого альтернативного варианта осуществления может быть аналогичен блоку 1835 обновления кэша узлов ТХ с использованием блокировки, подробно описанному выше. В общем случае, может потребоваться обновление кэшей массива узлов на основании триггера от входа и/или периодического обновления. Мгновенный (или близкий к этому) триггер из входа может быть желателен для приложений, чувствительных к времени, например речевых приложений. Периодическое обновление можно использовать для пополнения кэшей узлов ТХ пакетами, которые находятся в буфере пакетов (т.е. после того, как один или несколько пакетов для потока были отправлены для передачи и уже не находятся в кэше 1810 узлов). (Например, если пакет поступил при входе, и кэш узла полон, пакет просто направляется в буфер пакетов, что, в целом, желательно для поддержания кэшей полными.) В иллюстративном варианте осуществления периодическое обновление может быть фоновым процессом, который выполняется автономно. Специалистам в данной области техники очевидно, что автоматы, биты «обслуживание», блокировки и различные другие методы можно использовать для поддержания кэшей полными, и для заполнения их в соответствии с необходимостью, возникающей при поступлении пакетов входа, а также отправке пакетов передачи.
На фиг.21 показан примерный вариант осуществления ID 1844 линии, подробно описанный выше со ссылкой на фиг.18. Как показано, сохраняется ID линии A 2110, идентифицирующий ID линии потоком в одном из теневых массивов узлов ТХ, включенном в массив 1842 узлов ТХ. Поле 2120 идентифицирует количество пакетов (т.е. узлов), которые включены посредством этого ID линии. Заметим, что в этом варианте осуществления агрегация по прежнему осуществляется на основании ID потока, поскольку ID линии используется для идентификации параметров физического уровня (например, скоростей PHY) и ключей безопасности. Индексом к этой таблице является ID потока.
Аналогично, ID линии B 2130 сохраняется для идентификации ID линии потока в другом теневом массиве узлов ТХ, включенном в массив 1842 узлов ТХ. Количество пакетов, связанных с этим ID линии, сохраняется в поле 2140. Заметим, что, при желании, различные другие параметры и/или переменные состояния можно сохранять совместно с этими, связанными с соответствующими потоками, для использования в альтернативных вариантах осуществления.
На фиг.22 показаны дополнительные компоненты примерного варианта осуществления нижнего ядра 540 MAC. Как описано выше со ссылкой на фиг.18, совокупность каналов может быть подключена к механизму 1880 ТХ, причем каждый из них устанавливает индикатор готовности, сообщающий механизму 1880 ТХ о том, что один или несколько пакетов готовы к отправке. Узлы, идентифицирующие пакеты, будут ожидать в массивах 1842 узлов ТХ, и соответствующий ID линии для этих пакетов будет храниться в ID 1844 линии. Набор всех этих компонентов может присутствовать для каждого канала. На фиг.22 проиллюстрирована дополнительная обработка этих пакетов по мере того, как они перемещаются по тракту передачи.
Механизм 1880 ТХ принимает различные сигналы готовности и производит выбор между ними для осуществления различных процессов и заданий. Когда механизм 1880 ТХ готов к подготовке пакетов для передачи, он знает размер ТХОР, который указывает продолжительность времени, доступную для использования среды общего пользования. Однако поскольку скорости передачи данных изменяются на основании условий линии, количество пакетов, подлежащих передаче в ТХОР, также изменяется. В примерном варианте осуществления, конечный автомат 2211 (FSM) скорости обеспечен для использования при определении количества символов OFDM, которые будет использовать конкретный пакет. Механизм 1880 ТХ доставляет на FSM 2211 скорости длину ТХ, указывающую длину пакета в байтах (которая предпочтительно располагается в поле длины узла). Доставляется ID линии (из ID 1844 линии), и сигнал начала для указания, что FSM 2211 скорости должна начать свой процесс. FSM 2211 скорости возвращает количество символов, которое будет использовать пакет. Эту информацию можно использовать для определения количества символов для каждого пакета, которое можно накапливать при осуществлении агрегации, дополнительно подробно описанной ниже. Заметим, что можно обеспечить различные альтернативные методы для определения количество символов, скорости и пр. Использование внешнего FSM, который осуществляет вычисление символов для каждого пакета, является лишь одним из многих примеров, пригодных для реализации. Примерный вариант осуществления FSM 2211 скорости подробно описан ниже.
Механизм 1880 ТХ также подключен к арбитру памяти, например арбитру 1080 памяти, описанному выше. Для каждого из пакетов, готовых к передаче, механизм 1880 ТХ извлекает куски из буфера пакетов согласно информации в соответствующем узле, и любые связные куски, идентифицируемые указателем следующего куска. Данные куска возвращаются на механизм 1880 ТХ, где он поступает на один или несколько FIFO 2220. В этом примере FIFO 2220 содержатся в механизме 2210 традиционного протокола. Заметим, что запись данных в один или несколько FIFO может регулироваться сигналом готовности FIFO или любым другим механизмом управления потоков. Как описано выше и дополнительно подробно описано ниже со ссылкой на фиг.48 и 49, в альтернативном варианте осуществления могут существовать дополнительные вводы механизма 1880 ТХ для взаимодействия с более чем одним процессором MAC. В альтернативном примерном варианте осуществления процессор 210 и программно-аппаратное обеспечение реализуют процессор MAC для обработки пакетов низкой пропускной способности. Эти пакеты могут поступать на механизм 1880 ТХ из FIFO 4950 памяти процессора (или непосредственно из памяти процессора в другом альтернативном варианте осуществления).
Как описано выше, может быть удобно использовать существующие компоненты традиционных протоколов для выполнения различных функций для поддержки обработки MAC 802.11. Можно также обеспечить другие стандартные механизмы протокола, и механизм 2210 традиционного протокола можно модифицировать для обеспечения различных желаемых признаков. В иллюстративном варианте осуществления механизма традиционного протокола существует четыре FIFO 2220 A-D, по одному на каждые четыре очереди EDCA. Существует дополнительный FIFO 2220 E для канала НССА, и FIFO 2220 F-G обеспечены для маяка и широковещательного/многоадресного канала. Заметим, что FIFO можно обеспечить как единый буфер (т.е. для хранения сигнала маяка). Для приема пакетов для передачи можно обеспечить любое количество FIFO или буферов других типов.
Приняв извещение о готовности, механизм 1880 ТХ помещает первый кусок пакета в соответствующий FIFO ядра, указанный в первом узле. Как описано выше, это может продолжаться для дополнительных кусков, если таковые существуют, пока первый пакет не будет завершен. Одновременно, суммарное количество пакетов, которые можно передавать, можно определить с использованием FSM 2211 скорости. Отслеживая готовность FIFO, механизм 1880 ТХ может продолжать процедуру, помещая остаток пакетов в соответствующий FIFO. В примерном варианте осуществления помещение пакетов в FIFO побуждает механизм 2210 традиционного протокола бороться за доступ (доступ типа EDCA) и начинать передачу (когда доступ заработан, или в ходе запланированного ТХОР).
На фиг.23 показан примерный вариант осуществления FSM 2211 скорости. Принятый ID линии используется как индекс таблицы 2310 скоростей. Таблица 2310 сохраняется на основе ID линии и содержит одну или несколько скоростей, связанных с линией, а также значение 2311 метки времени (TSV). Таблицу 2310 скоростей можно обновлять любым из различных способов. Программно-аппаратное обеспечение может обеспечивать обновленные скорости. Принятый пакет векторной обратной связи по скорости передачи данных может включать в себя информацию скорости, и его можно использовать для обновления различных скоростей. TSV 2311 можно использовать для указания метки времени, указывающей, когда принимается пакет, содержащий обратную связь по скорости, таким образом, обеспечивая указание, является ли информация скорости свежей или устаревшей. Например, если скорость не была обновлена в течение некоторого времени, консервативный подход может состоять в снижении скорости в случае ухудшения канала в промежуточном временном кадре. Программно-аппаратное обеспечение может определять, имеет ли место устаревание, и стоит ли откатить скорости и обновить таблицу скоростей. В примерном варианте осуществления существует четыре скорости R1-R4 2312-2315, соответствующие каждой из четырех антенн. Для вычисления скорости можно использовать и другую информацию, например используется ли режим управления собственным вектором или другой режим разнесения. Информация скорости из таблицы 2310 поступает на FSM 2320 вычисления скорости.
Для каждой скорости таблица 2330 выбора скорости содержит таблицу, обновляемую программно-аппаратным обеспечением, с числом байтов на символ, доступным для каждой из скоростей. В примерном варианте осуществления существует N=16 скоростей 2332, каждая из которых имеет соответствующее число байтов на символ, таким образом, каждое значение выбора скорости имеет 4 бита. Число байтов на символ поступает на сумматор 2335, вывод которого подключен к накопителю 2340 агрегатной скорости.
Накопитель 2340 агрегатной скорости используется для накопления агрегатной скорости, и выход поступает обратно на сумматор 2335. Накопитель 2340 можно очищать с помощью сигнала очистки от FSM 2320 вычисления скорости. Для каждой из доступных скоростей число байтов на символ прибавляется для накопления суммарной агрегатной скорости, из которой определенное количество символов NS 2360 можно использовать для указания количества потоков. NS 2360 вычитается в 2345 для обеспечения агрегатной скорости. NS 2360 можно обновлять посредством программно-аппаратного обеспечения. Длина доставленного пакета в байтах в иллюстративном варианте осуществления прибавляется в 2350 к константе 2365 (также обновляемой программно-аппаратным обеспечением) для генерации истинной длины. CONST 2365 может указывать необязательное ограничение. Например, можно предусмотреть плотность AMPDU, обеспечивающую минимальное разделение между последовательными заголовками MPDU. Делитель 2355 делит истинную длину A на агрегатную скорость, нормализованную по NS, и генерирует частное и остаток. Частное поступает на сумматор 2375 для создания, в принципе, функции потолка, где при наличии какого-либо остатка в 2370 нужно использовать один дополнительный символ (т.е. заполняется часть символа, но нужно обеспечить символ целиком). FSM 2320 вычисления скорости выделяет регистр N SYM 2375 для сохранения результирующего количества символов для доставки и использования механизмом 1880 ТХ.
На фиг.24 показан, в общем виде, механизм 2210 традиционного протокола. Сигнал выбора режима можно использовать для указания одного из различных режимов, в которых функционирует механизм протокола. В общем случае, доставляются MPDU совместно с сигналом готовности для указания того, что передача должна начаться. Механизм традиционного протокола может генерировать шифрованный вывод из вводных MPDU. В примерном варианте осуществления используются признаки шифрования механизма традиционного протокола (обычно предусмотренные в типичном ядре 802.11). В альтернативном варианте осуществления может быть включено устройство шифрования любого типа, что хорошо известно в технике. На фиг.24 также показан шифрованный ввод (например, принятый от WLAN 120), поступающий в механизм 2210 традиционного протокола для создания незашифрованных выводных MPDU.
На фиг.25 показан типичный механизм традиционного протокола, соединенный посредством принципиальных линий с PHY 260. Показано, что вектор RX поступает из PHY 260 в механизм 2210 традиционного протокола совместно с принятыми данными и сигналом оценки чистого канала (ССА). Вектор приема может содержать различную информацию, например тип модуляции, длину принятых данных и другие параметры. В частности, может возвращаться обратная связь по скорости передачи данных, полезная для определения скорости, например на FSM 2211 скорости, описанной выше. Оценку чистого канала можно использовать совместно с таймерами 2510, связанными с различными каналами, для борьбы за доступ к среде, когда используются протоколы на основе конкуренции (например, EDCA). Шифрование и дешифрование можно осуществлять в блоке 2520. FIFO 2220 может быть аналогичен описанным выше. Для НССА, конечно, передача планируется, и может начинаться в заранее определенное время. Шифрованные данные поступают на PHY 260 с сигналом запроса ТХ, указывающим, что ТХ должна начаться. Вектор передачи, поступающий на PHY 260, указывает различные параметры, генерируемые традиционными функциями. Заметим, что в примерном варианте осуществления при работе в традиционном режиме вывод механизма традиционного протокола может быть достаточен для передачи по PHY 260.
На фиг.26 показан примерный вариант осуществления, дополнительно детализирующий обработку MAC пакетов передачи. В примерном варианте осуществления вывод механизма традиционного протокола, MPDU (шифрованные, когда применимо) поступают на модуль 2610 агрегации. В отличие от варианта осуществления, подробно описанного на фиг.25, шифрованные данные, выводимые из механизма 2210 традиционного протокола, не поступают непосредственно на PHY. В примерном варианте осуществления могут быть предусмотрены модификации механизма 2210 традиционного протокола, благодаря чему хронированный устойчивый поток шифрованных MPDU поступает в модуль агрегации, а затем на PHY для доставки. Модификации могут предусматривать удаление межкадровых промежутков (например, SIFS) или любых других признаков MPDU, которые не требуются для создания агрегированного кадра. В различных вариантах осуществления агрегированные кадры могут иметь различные формы и могут содержать различные типы пакетов или MPDU. Выше были подробно описаны различные методы хронирования пакетов, например метки времени, борьба за доступ и пр., которые хорошо известны в технике.
Количество пакетов для агрегации может вычисляться на механизме 1880 ТХ. Вызов FSM 2211 скорости можно делать для каждого пакета и, для количества символов, возвращаемого для каждого пакета, TXOP можно сокращать на это количество символов. Счетчик агрегатного пакета может увеличиваться для каждого агрегатного пакета, пока не будет определено суммарное количество пакетов, которое поместится в TXOP. Эта информация может поступать на модуль 2610 агрегации.
В различных вариантах осуществления можно обеспечить любое количество форматов и/или схем агрегации. В примерном варианте осуществления агрегированная MPDU (A-MPDU) выводится из модуля 2610 агрегации. Формат A-MPDU 2710 представлен на фиг.27. Показано, что разделитель 2720 MPDU помещен между каждыми двумя соседними MPDU 2722 в агрегированной MPDU 2710. Один или несколько символов 2724 заполнения можно вставлять в конец MPDU 2722, чтобы длина подкадра A-MPDU была кратной 4 байтам. Каждая MPDU 2722 содержит заголовок 2732 MPDU, полезную нагрузку 2734 MPDU и последовательность 2736 проверки кадров. В этом примере разделителем 2720 MPDU является поле CRC длины, содержащее резервные биты, заданные равными нулю, длину MPDU, CRC резервных битов и длины и уникальный шаблон, который можно использовать для сканирования и обнаружения MPDU. В примерном варианте осуществления уникальный шаблон задается равным значению ASCII для символа 'N'.
Согласно фиг.26 агрегатные MPDU можно сохранять в FIFO 2620 согласования скорости (в альтернативных вариантах осуществления FIFO согласования скорости может быть не нужен в зависимости от обеспеченного типа PHY и его характеристик). FIFO 2620 согласования скорости подключен к интерфейсу 545 MAC/PHY для окончательной доставки пакетов для передачи по PHY 260.
Обработка приема
На фиг.28 показан примерный вариант осуществления компонентов приема нижнего ядра 540 MAC. Компоненты приема, описанные в нижнем ядре 540 MAC, или их подмножество может содержать часть механизма приема, как описано ниже в отношении альтернативного варианта осуществления, показанного на фиг.49. Информационные данные, включающие в себя пакеты, принятые от WLAN 120, поступают на интерфейс 545 MAC/PHY и поступают на блок 2802 дезагрегации. Как описано выше, в отношении агрегации, показанной на фиг.26 и 27, примерная A-MPDU содержит разделитель 2720 MPDU, который можно использовать для разделения входящего потока данных на составляющие его пакеты на блоке 2802 дезагрегации.
Результирующий поток MPDU поступает на блок 2804 FCS фильтрации. На этом блоке функция фильтрации определяет, адресован ли какой-либо из принятых пакетов текущему устройству, включая широковещательные или многоадресные пакеты. Также проверяется последовательность проверки кадров. Пакеты, адресованные приемнику, прошедшие проверку кадров, поступают в FIFO 2812.
В примерном варианте осуществления пакеты сохраняются в FIFO по мере их приема, исходя из того, что они адресованы надлежащим образом и являются хорошими пакетами. Затем пакет легко удалить из FIFO, если он идентифицируется как неправильный пакет, или не адресован текущему приемнику. (Один простой механизм управления предусматривает возвращение предыдущего указателя FIFO и восстановление этого указатель, если недавно сохраненный пакет подлежит удалению.) Пакеты (не удаленные) из FIFO 2812 поступают на интерфейс 2860 ядра.
FSM 2806 контроллера RX обеспечивается для управления любым из различных блоков, подробно описанных на фиг.28. В частности, FSM 2806 контроллера RX может инициировать обработку после приема пакета и обеспечивать различные сигналы управления для активации и сохранения промежуточных результатов по мере того, как пакеты проходят по тракту приема.
В этом примере заголовок принимается и поступает на анализатор 2810 пакетов для обработки. Из заголовка пакета известна длина передачи, а также где начинается пакет и где в пакете найти байты данных и/или управления. Заголовок также указывает тип пакета (т.е. 802.11(a)(b)(g)(e)(n), или любой другой поддерживаемый тип пакета).
Анализатор 2810 пакетов знает, был ли пакет принят путем доступа опросного типа (например, опроса, свободного от конкуренции) из ID потока. Анализатор 2810 пакетов, таким образом, будет передавать сигнал на передатчик, чтобы инициировать ответ, когда ответ необходим в течение заранее определенного периода (например, в SIFS). Анализатор пакетов 2810 может доставлять ID потока и информацию TXOP, чтобы передатчик мог отвечать. При приеме запроса квитирования блока принятая битовая карта также может поступать на передатчик для осуществления квитирования блока в течение заранее определенного временного кадра, при необходимости (например, немедленного квитирования блока). Квитирование блока и другая обработка быстрого ответа, например U-APSD, дополнительно подробно описаны ниже.
Анализатор 2810 пакетов доставляет длину пакета на FSM 2850 указателей кусков, который определяет количество указателей куска, необходимых для сохранения входящего пакета. FSM указателей куска будет извлекать указатели куска из кэша 840 указателей куска RX, описанного выше. В этом примерном варианте осуществления куски идентичны описанным выше, но пакетам приема не нужны сложность и дополнительные требования к памяти, характерные для истинной очереди связного списка. Вместо этого можно обеспечить более простой массив. Этот вариант осуществления дополнительно подробно описан ниже со ссылкой на фиг.33. В альтернативном варианте осуществления пакеты RX, по желанию, также могут использовать структуру связного списка, идентичные тем, которые используются при обработке передачи. FSM 2850 указателей куска взаимодействует с буфером 250 пакетов (т.е. через арбитр 1080 памяти), когда это необходимо для извлечения дополнительных кусков либо для использования с пакетом, либо при обновлении кэша 2840 указателей куска RX. В примерном варианте осуществления может быть необходимо до четырех указателей куска на пакет, при данных выбранном размере куска и типичной длине пакета. Эти указатели куска сохраняются в заголовке пакета по мере того, как он проходит остаток тракта обработки приема, и используются для окончательной записи пакета в буфер пакетов.
Интерфейс 2860 ядра извлекает указатели куска и параметры, включенные в расширенный вектор RX (из аппаратной таблицы 2820) и добавляет их в заголовок пакетов, принятых из FIFO 2812. Затем пакеты поступают в механизм 2210 традиционного протокола, который используется, в основном, для дешифрования в вышеописанном примерном варианте осуществления. Заметим, что в примерном варианте осуществления и в типичных доступных механизмах традиционного протокола заголовок будет игнорироваться. Таким образом, различные механизмы управления могут осуществляться за счет сохранения информации управления в заголовке, как описано в этом примере. Дешифрованные пакеты из механизма 2210 традиционного протокола поступают в FIFO 2870 RX. В примерном варианте осуществления FIFO 2870 RX может совместно использоваться со сравнимым FIFO 572, показанным на фиг.5, или может быть идентичен ему.
Хотя хэндовер и выход дополнительно подробно описаны ниже, их основная структура проиллюстрирована на фиг.28. Один аспект этой структуры состоит в том, что принятие решения на хэндовер отключается от фактического процесса хэндовера самого по себе, что позволяет принимать и обрабатывать пакеты без ожидания узких мест, которые могут образовываться, когда другие пакеты ожидают хэндовер выхода. Узкие места могут образовываться, когда порядок доставки пакетов предписан, и требуется повторная передача для одного или нескольких пакетов. Это дополнительно подробно описано ниже.
Пакеты из FIFO 2870 RX поступают в блок 2875 записи в память, который делает запросы для доступа к памяти буфера 250 пакетов через арбитр 1080 памяти, как описано выше. В то время как пакет ожидает записи в буфер пакетов, параметры этого пакета поступают на блок 2880 принятия решения на хэндовер для начала принятия решения на хэндовер. Во избежание осуществления процедуры быстрого хэндовера до того, как пакет будет полностью записан в буфер пакетов, сигнал «запись произведена» передается из блока 2875 записи в память на блок 2880 принятия решения на хэндовер.
Механизм 2890 хэндовера подключен к блоку 2880 принятия решения на хэндовер. Показаны различные иллюстративные сигналы для взаимодействия между блоком 2880 принятия решения на хэндовер и механизмом 2890 хэндовера, которые будут дополнительно подробно описаны ниже. Механизм 2890 хэндовера извлекает пакеты из буфера пакетов через арбитр 1080 памяти и, в конце концов, доставляет пакеты на выход. Механизм 2890 хэндовера в зависимости от типа пакета может использовать блок 2892 дефрагментации для удаления заголовков и т.д. из фрагментов пакета и преобразования нефрагментированного пакета для доставки пакета на выход. Как подробно описано ниже со ссылкой на фиг.48, фрагментация может быть необязательной, и соответствующие компоненты можно опустить. Время от времени могут возникать ситуации, в которых один или несколько пакетов необходимо отбросить. Блок 2894 очистки подключен к механизму 2890 хэндовера для осуществления этих заданий. На этих блоках также могут выполняться различные другие функции управления памятью, связанные с поддержанием структур связного списка для очередей, указателей, узлов и кусков.
Контроллер 2814 поиска RX отслеживает пакеты, поступающие в FIFO 2812. Контроллер поиска RX определяет ID потока для пакета. В примерном варианте осуществления можно обеспечить таблицы поиска TA и TID, как описано выше для обработки пакетов входа, например, на фиг.10. Аппаратная таблица 2820 обеспечивается для поддержания состояния и параметров для потоков и линий связи. Аппаратная таблица 2820 дополнительно подробно описана ниже и включает в себя примерные варианты осуществления двух конфигураций, подробно описанных выше со ссылкой на фиг.3 и 4. В этом контексте аппаратная таблица 2820 может быть компонентом аппаратной таблицы 320.
В одном варианте осуществления поддерживаются отдельные аппаратные таблицы для входа и выхода (и, возможно, обработки передачи). В альтернативном варианте осуществления одна или несколько функций могут совместно использовать аппаратную таблицу. В этом случае аппаратная таблица 2820 может, в принципе, быть идентичной аппаратной таблице 320, которая подробно описана на фиг.3 и 4. Специалистам в данной области техники очевидно, что совместное использование таблиц может вносить усложнение, связанное с арбитражем множественных запросов и необходимостью обеспечивать достаточную полосу для ряда необходимых актов доступа. С другой стороны, совместное использование таблиц может приводить к сокращению общей площади, и может приводить к сокращению количества обновлений параметрами, которые могут быть общими для обеих, по множеству таблиц. Например, рассмотрим AP с объединенной аппаратной таблицей приема и входа. TSID и TID такие же, когда AP принимает от STA, на которую AP ранее передавала. Хотя не всегда справедливо, что MAC-адрес назначения и MAC-адрес передачи одинаковы (могут быть подключены дополнительные устройства помимо устройства назначения), бывают ситуации, когда они одинаковы. В этих ситуациях можно извлечь преимущество из совместного использования таблицы. Таким образом, объединенную таблицу можно сделать больше, чем любая из таблиц, с которой можно было бы работать по отдельности, в случаях, когда адреса не одинаковы. Тем не менее, совместное использование может обеспечивать выигрыш в площади.
Как описано выше, в примерном варианте осуществления можно обеспечить пинг-понговый кэш, позволяющий программно-аппаратному обеспечению переупорядочить список, одновременно обновляя его, и позволяющий контроллеру поиска одновременно осуществлять доступ к теневому списку. Двоичный поиск осуществляется для получения ID потока, который используется для индексирования аппаратной таблицы 2820.
На фиг.29 показан примерный вариант осуществления аппаратной таблицы 2920, сконфигурированной как STA, аналогично конфигурации, описанной выше со ссылкой на фиг.3. Таким образом, в этом случае все различные параметры, ассоциированные с потоками и линиями, поддерживаются в аппаратной таблице, поскольку STA поддерживает только 16 потоков (в этом примере). В аппаратной таблице 2820 являются списком адресов 2912 передачи, TID 2914 и ID потока 2916, для каждого поддерживаемого потока. Таким образом, ID потока можно извлекать из TA плюс TID и использовать в качестве индекса для соответствующей таблицы 2920 состояний потока RX. В примерном варианте осуществления программно-аппаратное обеспечение создает упорядоченную таблицу, направляет HW на работу с одной таблицей или другой. Двоичный поиск производится в HW на текущей таблице. Когда необходимо добавить новый поток, программно-аппаратное обеспечение добавляет поток в таблицу дежурного режима, упорядочивает ее и затем переключает текущую таблицу оборудования на таблицу дежурного режима. Затем исходная таблица становится новой таблицей дежурного режима. Примерная таблица 2920 состояний потока RX описана ниже со ссылкой на фиг.31.
Дополнительные параметры, зависящие от линии, также могут быть включены в аппаратную таблицу 2920. Эти параметры могут быть адресованы посредством ID линии, который можно сохранять в аппаратной таблице 2920 RX. Примеры включают в себя векторную обратную связь 2930 по скорости передачи данных, описанную выше для использования в отношении определения скорости и определения скорости, формирования пакета и агрегации. Процессор приема может иметь доступ к этой информации из сообщений, доставляемых от удаленных устройств, и может сохранять эту информацию в аппаратной таблице 2920. Как описано выше, ключ 2940 безопасности для каждой линии можно использовать для различных типов шифрования. Различные типы ключей безопасности можно сохранять для поддержки изменяющихся протоколов шифрования. Блок 2950 обнаружения традиционного дублирования сохраняет порядковый номер последнего правильно принятого пакета, и порядковый номер текущего пакета можно сравнивать с этим значением в целях обнаружения дублирования.
На фиг.30 показан примерный вариант осуществления аппаратной таблицы 2820, сконфигурированный для использования в точке доступа или суперстанции, что подробно описано выше со ссылкой на фиг.4. В этом примере различные указатели 3002 связаны с MAC-индексами 3004 в аппаратной таблице 2820. Заметим, что в этом примере ID 3006 линии также сохраняется совместно с каждым ID MAC. Заметим, что ID 3006 линии, альтернативно, может сохраняться совместно с другими параметрами в альтернативном местоположении, например SRAM 330. В отличие от аппаратной таблицы 2820, проиллюстрированной на фиг.29 (в которой различные параметры для линий и потоков хранились в аппаратной таблице), помимо ID 3006 линии, все параметры сохраняются в альтернативной памяти, например SRAM 330.
SRAM 330 содержит общие таблицы скоростей 3010A-N, каждая из которых содержит указатели для каждого MAC-адреса (т.е. каждой линии, для которой могут поддерживаться до 16 потоков). Параметры для различных потоков сохраняются в таблице параметров, индексируемой индексами 3020 потока. Это обеспечивает уровень косвенности для фактических параметров. В примерном варианте осуществления SRAM 330 также используется для сохранения таблицы, например таблиц 2920 состояний RX, пример которых дополнительно подробно описан ниже. Таким образом, для каждой линии поддержка максимального количества потоков включена в схему индексирования, как показано в общих таблицах 3010 скоростей. Однако использование памяти может расти по мере добавления потоков. Память не требуется выделять для сохранения параметров прежде, чем поток станет активным. Таким образом, для данной линии, если активен/активны только один или два потока, нужно создавать и наполнять только одну или две таблицы 2920 состояний потока RX.
На фиг.30 также показана альтернативная таблица 3042, которая просто включает в себя ключ 3044 безопасности и битовую карту 3046. Этот пример демонстрирует сокращенный набор параметров, пригодный для использования с пакетами 802.11 (g). В таком альтернативном варианте осуществления использование сокращенной таблицы состояний позволяет экономить память и время, связанное с дополнительными обращениями к памяти. Однако общую структуру также можно использовать для всех типов пакетов согласно варианту осуществления.
Детали примерной таблицы 2920 состояний потока RX будут представлены ниже со ссылкой на фиг.31. Однако здесь показан один компонент, битовая карта 3130. Представлен указатель 3050 битовой карты, указывающий битовую карту 3130. В примерном варианте осуществления битовые карты 3130 также хранятся в SRAM 330. Этот уровень косвенности допускает простой общий формат для осуществления доступа к битовой карте, в то же время позволяя увеличивать использование памяти в случае необходимости, в отличие от предварительного выделения максимальной памяти, которая может потребоваться. Таким образом, аналогично возможности увеличения таблиц состояний потока RX по мере необходимости могут поддерживаться изменяющиеся типы битовых карт без необходимости в предварительном выделении памяти для них. Например, когда поддерживается фрагментация, битовая карта может содержать 64 пакета, каждый из которых имеет 16 фрагментов. Это гораздо большая битовая карта, чем потребовалась бы простой битовой карте квитирования блока с одним битом для каждого пакета в 64-пакетном окне. Таким образом, для потоков, требующих фрагментации, можно создавать более крупные битовые карты квитирования блока, тогда как требующие меньшей памяти могут создаваться с меньшей битовой картой.
На этой фигуре проиллюстрированы различные аспекты конфигурации памяти, включающие в себя обеспечение повышенной гибкости и более эффективного использования памяти. Дополнительные аспекты обработки квитирования блока дополнительно подробно описаны ниже.
На фиг.31 показан примерный вариант осуществления таблицы 2920 состояний потока RX. Проиллюстрированы различные поля. В альтернативных вариантах осуществления можно ввести дополнительные поля, или некоторые из показанных полей можно опустить. Заметим, что, в общем случае, любая из показанных здесь таблиц состояний потока, включающих в себя таблицу 2920 состояний потока RX, массив 1902 состояний для каждого потока, таблица 1030 состояний потока ТХ и аналогичные таблицы для каждого потока можно объединять или разделять на любое количество таблиц для каждого потока, что очевидно специалистам в данной области техники.
Начальный порядковый номер 3102 можно использовать для указания порядкового номера начального пакета при передаче блока. Начальный порядковый номер можно обновлять при приеме переданных пакетов (т.е. окно перемещается вперед). В одном варианте осуществления существующий начальный порядковый номер плюс размер 3104 окна может определять порядковые номера предполагаемых входящих пакетов. Однако передатчику позволено отправлять пакеты, которые превышают этот предел в порядковых номерах, и, в таком случае, начальный порядковый номер можно вычислить, взяв наибольший принятый порядковый номер и вычтя (Размер окна - 1). Начальный порядковый номер также можно непосредственно обновлять входящим BAR (Запросом Block_Ack). Различные методы обработки квитирования блока дополнительно подробно описаны ниже. В одном примере размер окна может указывать буфер, выделенный (в единицах пакетов) данному передатчику на приемнике. В этом случае передатчик не должен отправлять неквитированные пакеты, которые превышают размер окна на приемнике.
Поле 3106 немедленного квитирования блока можно использовать для указания приемнику, ожидает ли передатчик немедленного или отложенного квитирования блока. Поддержка немедленного квитирования блока обязательна в текущем проекте стандарта 802.11n.
Битовая карта 3130 может быть фактической битовой картой квитирования блока, т.е. когда аппаратная таблица 2820 сконфигурирована как STA, как описано выше со ссылкой на фиг.29. В альтернативной конфигурации битовая карта 3130 может быть указателем на фактическую битовую карту, как описано выше со ссылкой на фиг.30. Ethernet-заголовок 3132 сохраняется для замены MAC-заголовка соответствующим Ethernet-заголовком при подготовке пакетов к выходу. Указатель 3134 окна - это указатель на структуру данных, которая поддерживает физические адреса пакетов, сохраненных приемником, которые, в конце концов, требуется перевести на более высокий уровень (см. примерные методы хэндовера, дополнительно подробно описанные ниже). В одном примере эти пакеты сохраняются в буферах, подлежащие последовательному хэндоверу на более высокий уровень. При наличии дырки (потерянного пакета) в голове этой структуры данных передатчик должен ждать, пока эта дырка не заполнится, для последовательного перевода пакетов на более высокий уровень по порядку. Заметим, что указатель 3320 окна, подробно описанный ниже, является одним примером указателя, пригодного для использования в этом поле.
В одном примере старый начальный порядковый номер 3138 можно задать равным начальному порядковому номеру, чтобы начать с него. Когда входящий пакет приводит к изменению начального порядкового номера, приемник может переводить на более высокий уровень все пакеты, начиная со старого начального порядкового номера и до текущего начального порядкового номера. После осуществления этой операции старый начальный порядковый номер можно задать равным текущему начальному порядковому номеру. ID 3140 линии указывает линию, связанную с потоком. Это можно использовать для извлечения параметров, зависящих от линии, для использования при приеме и передаче по WLAN 120. Различные примеры были подробно описаны выше. Можно обеспечить поле 3136, указывающее, что больше нет фрагментов, подлежащих приему. В различных вариантах осуществления, в которых фрагментация не выполняется или когда она выполняется в альтернативном блоке обработки MAC, это поле можно опустить.
На фиг.32 представлен примерный вариант осуществления способа конфигурирования аппаратных таблиц и памяти в различных конфигурациях. Заметим, что методы, рассмотренные со ссылкой на фиг.29-31, можно применять по аналогии с другими аппаратными таблицами, например таблицей 1030 состояний потока передачи, подробно описанной выше. Детали конфигурирования таблиц передачи для краткости опущены. Напомним, что аппаратные таблицы можно комбинировать для поддержки различных компонентов (т.е. приема, передачи, входа, выхода и т.д.). Принципы, идентифицируемые уровнями косвенности для приемного оборудования, таблиц состояний потока, RAM и/или буферов пакетов, можно в равной степени применять к другим описанным здесь таблицам состояний или их комбинациям.
Общий процесс 3200 описан на фиг.32. В этом примере описаны первый, второй и третий блоки памяти. Заметим, что, как подробно описано здесь, можно обеспечить любое количество блоков памяти различных типов. В примерном варианте осуществления память 1 представляет собой аппаратную таблицу, например аппаратную таблицу 2820 или 320. Память 2 является памятью большего объема, например SRAM 330. Память 3 является в этом случае внешней памятью, хотя возможны также внутренние третьи блоки памяти. В этом примере память 3 может быть SDRAM 340.
Если на блоке 3210 принятия решения определено, что третья память подлежит использованию для буфера пакетов, происходит переход к 3216 для конфигурирования различных компонентов устройства беспроводной связи в первом режиме (т.е. компонентов в ASIC 310 процессора MAC или различных других). В примерном варианте осуществления первый режим использует внешний буфер пакетов, хранящийся во внешнем RAM, например SDRAM 340.
Если на блоке 3210 принятия решения определено, что третья память не подлежит использованию для буфера пакетов, происходит переход к 3212 для конфигурирования различных компонентов устройства беспроводной связи во втором режиме. В примерном варианте осуществления второй режим является вышеописанным режимом типа STA (в котором SRAM используется для буфера пакетов), и параметры сохраняются в аппаратной таблице.
На этапе 3216 осуществляется конфигурирование первой памяти (которая может представлять собой аппаратную таблицу) с указателями типа MAC-адреса на структуры данных во второй памяти. На этапе 3218 осуществляется конфигурирование второй памяти со структурами данных. Эти структуры данных могут включать в себя изменяющиеся дополнительные уровни косвенности, например, описанные выше со ссылкой на фиг.30. Например, первая структура данных может идентифицировать потоки, связанные с MAC-адресами. ID потока можно использовать для индексирования дополнительных таблиц, например таблицы состояний потока RX или таблицы состояний потока TX. Кроме того, одна или несколько таблиц, например таблица состояний потока RX, может иметь указатели на дополнительные структуры данных, связанные с потоком (например, указатель битовой карты, указывающий на местоположение битовой карты квитирования блока). На этапе 3220 осуществляется конфигурирование буфера пакетов в третьей памяти. В одном примере конфигурирование буфера пакетов может включать в себя задание различных списков свободных указателей, например списка 710 свободных указателей узла и списка 720 свободных указателей куска, и выделение места под узлы 730 и куски 740. Дополнительно, можно выделять массивы (например, используемые для обработки приема пакетов) со списками свободных указателей окна, связанными с этими массивами.
Программно-аппаратное обеспечение может осуществлять многие этапы, необходимые для форматирования различных блоков памяти с соответствующими структурами данных. При необходимости различные настройки регистров или другие методы задания переменных можно использовать для указания режима компонентам в устройстве. Эти методы очевидны специалистам в данной области техники. Таким образом, конфигурируется первый режим, и процесс может остановиться.
На этапе 3212 производится конфигурирование первой памяти с различными структурами данных, например, описанными выше. В этом случае память 1 может быть аппаратной таблицей, и доступ к структурам данных не обязательно производить косвенно, но это можно делать, как описано на фиг.29 (например, таблицы состояний потока RX, индексированные для каждого потока в аппаратной таблице). На этапе 3214 производится конфигурирование второй памяти как буфера пакетов практически таким же образом, как описано выше для памяти 3 на этапе 3220. Таким образом, конфигурируется второй режим. После этого процесс может остановиться. Обработка MAC, подробная описанной здесь, может продолжиться.
На фиг.33 показана альтернативная конфигурация части буфера 250 пакетов, сконфигурированного для поддержки массивов пакетов RX. Этот вариант осуществления аналогичен буферу 250 пакетов, описанному на фиг.6. Однако в этой конфигурации структура данных очереди связного списка, показанная на фиг.6, заменена массивом узлов 3330. Использование структуры данных массива допускает ряд упрощений. В этом примере узлы в массиве узлов следуют друг за другом, поэтому указатель следующего узла 612 не требуется. Таким образом, узел 610 заменяется сокращенным узлом 3310. Поля, оставшиеся в узле 3310, длина 614, порядковый номер 616 и указатель 618 куска такие же, как описаны со ссылкой на фиг.6. Меньшие узлы приводят к снижению использования памяти.
Как и раньше, куски 620 используются для сохранения пакетов различных длин. Разница состоит в том, что структура массива не требует упорядочения узлов с образованием очереди. Таким образом, как упомянуто выше, указатель следующего узла не требуется для определения положения узлов. Указатель 640 хвоста очереди и указатель 630 головы очереди заменены единым указателем, указателем 3320 окна, который указывает, где в буфере пакетов располагается нужный массив 3330 узлов. Использование этой модифицированной структуры узла/куска будет понятно специалистам в данной области техники в свете идей настоящего изобретения. Опять же, вышеописанная структура массива не требуется для обработки RX, поскольку структура, показанная на фиг.6, полностью пригодна и для этого контекста. Однако в конфигурации, представленной на фиг.33, массив 3330 узлов может накапливаться до полного окна за счет местоположений адресов пакетов. Его можно индексировать смещением окна относительно текущего начального порядкового номера. В этом случае массив 3330 узлов можно использовать как циклический буфер местоположений пакета.
Обработка хэндовера
В этом разделе будет более подробно описана обработка хэндовера. Блок 2880 принятия решения на хэндовер и механизм хэндовера 2890 совместно с соответствующими сигналами и другими взаимосвязанными блоками представлены выше со ссылкой на фиг.28. Несколько аспектов, относящиеся к хэндоверу, будут проиллюстрированы ниже.
Согласно одному аспекту принятие решения на хэндовер отделено от самого процесса хэндовера. Процесс принятия решения можно осуществлять на скорости линии, тогда как механизм хэндовера автономно выполняется в фоновом режиме. Один примерный контекст, в котором этот аспект может быть полезен, проиллюстрирован путем поддержки квитирования блока. В ранних системах беспроводной пакетной связи, например 802.11(g) и (b), не было поддержки квитирования блока. При поступлении пакета он либо будет квитирован, либо не будет квитирован. Если пакет квитирован, он будет подвергнут хэндоверу, и передача последующих пакетов возобновится. Если пакет не квитирован, передатчик будет повторно передавать пакет, пока он не будет правильно принят (или пакет не будет отброшен вследствие того, что процесс превышает заранее определенные пределы). Поэтому естественно выполнять хэндовер пакетов в порядке их поступления.
В системах, поддерживающих квитирование блока, можно принимать пакеты вне порядка. В случае правильного приема пакетов соответствующий бит задается в битовой карте окна. Для пакетов, которые не квитированы, соответствующие биты можно задать равными нулю. В дальнейшем можно попытаться повторно передать пакеты. Тем временем, последующие пакеты можно принимать и сохранять для хэндовера. В системах, где предусмотрено осуществление хэндовера пакетов по порядку, неквитированный пакет создает дырку, которая останавливает хэндовер последовательно принимаемых пакетов в ожидании, пока неквитированный пакет не будет правильно принят. Затем после повторной передачи можно принять один пакет, который заполнит дырку, и после приема нескольких пакетов подряд группа пакетов становится непосредственно доступной для хэндовера. Таким образом, можно задать очередь пакетов, ожидающих хэндовера, и можно гарантировать задержку хэндовера. Отделение принятия решения на хэндовер от обработки механизма хэндовера позволяет блоку принятия решения на хэндовер работать на скорости линии, в то время как очередь пакетов обрабатывается для хэндовера. Механизм хэндовера может действовать автономно, и, предполагая, что интерфейс к памяти хэндовера имеет высокую скорость по отношению к принятой скорости, механизм хэндовера будет способен к подхвату. Таким образом, очередь пакетов не ограничивается общей пропускной способностью приемника.
Согласно еще одному аспекту разделение принятия решения на хэндовер и обработки позволяет назначать приоритет хэндоверу потока. Например, информация, чувствительная к задержке, например речь, видео или другие приоритетные данные, можно обрабатывать иначе, чем низкоприоритетные данные.
На фиг.34 показана сквозная схема приоритетов для беспроводных сетей, включающая в себя политику входа и хэндовер на основе приоритета. На фиг.34 система 100 включает в себя функцию 3410 политики входа для приема пакетов входа. Как подробно описано выше, различные функции политики входа позволяют назначать приоритеты входящих пакетов выхода. Беспроводная LAN 120 соединяет блок 3410 политики входа с блоком 3420 хэндовера на основе приоритета. WLAN QoS (хорошо известные в технике) позволяют назначать идентифицируемым пакетам и/или потокам более высокий приоритет, чем другим типам пакетов или потоков. Однако традиционная обработка QoS осуществляется только для двухточечной связи от приемника и передатчика на WLAN 120. Блок 3420 хэндовера на основе приоритета осуществляет принятие решения на хэндовер с учетом приоритета. В этом случае пакеты уже были переданы и приняты, возможно, согласно приоритету или QoS. Хэндовер на основе приоритета находится выше и за пределами концепции QoS в WLAN, например WLAN 120. Таким образом, более высокоприоритетные пакеты можно подвергать хэндоверу для выхода раньше пакетов более низкого приоритета.
Таким образом, QoS могут поддерживаться от входа на стороне передатчика всю дорогу к выходу, после приема на приемнике. Политика 3410 входа может назначать приоритеты пакетов на стороне входа, где они будут передаваться с приоритетом на WLAN QoS 120 (если QoS поддерживается), и при наличии какой-либо задержки в хэндовере на приемнике пакетам более высокого приоритета можно назначать первый приоритет. Заметим, что политика входа либо хэндовер на основе приоритета можно обеспечить с или без WLAN QoS и также можно обеспечить отдельно друг от друга. Таким образом, хэндовер на основе приоритета можно использовать в схеме с одним или несколькими другими методами QoS. Эти аспекты также могут быть желательны в приложениях, которые не опираются на хост-процессор. Например, приложения более высокого уровня могут иметь некоторую возможность назначения приоритетов для определения порядка, в котором пакеты поступают на процессор MAC. По мере того как все больше устройств получает возможность беспроводного подключения, например фотоаппараты, цифровые музыкальные устройства и пр., такие устройства могут иметь ограниченные собственные возможности обработки (или вовсе не иметь их). В этом случае было бы полезно обеспечить политику входа, чтобы гарантировать эффективные передачу и прием множественных потоков.
Политика входа и хэндовер на основе приоритета, подробно описанные здесь, можно успешно комбинировать со структурой связанного списка для управления пакетами (т.е. с использованием связанных списков для узлов, кусков и очередей), хотя их комбинация не требуется ни в одном описанном варианте осуществления. В частности, динамическое выделение пакетов по мере их поступления (через вход или посредством приемника) позволяет гибко распределять память между пакетами или потоками высокого и низкого приоритета. Структуры связного списка допускают гибкость в эффективном изменении порядка обслуживания, когда уровни перегрузки требуют, чтобы обслуживались более высокоприоритетные пакеты, и простой возврат к обслуживанию всех классов пакетов, когда перегрузка снижается.
На фиг.35 представлен примерный вариант осуществления способа 3500, демонстрирующий работу блока 2880 принятия решения на хэндовер и механизма 2890
хэндовера. На этапе 3510 блок 2880 принятия решения на хэндовер будет принимать триггер, указывающий, что пакет принят. В примерном варианте осуществления сигнал «запись произведена» будет указывать, когда пакет полностью записан в буфер пакетов, во избежание случайного хэндовера частично записанного пакета. Информация, необходимая для принятия решения на хэндовер, как дополнительно подробно описано ниже, поступает на блок 2880 принятия решения на хэндовер от FIFO 2870 RX.
На этапе 3520 блок 2880 принятия решения на хэндовер определяет, доступны ли пакеты для хэндовера. В общем случае, можно использовать любой способ или метод назначения приоритетов пакетам для хэндовера. В одном примере, как описано выше, приоритеты, назначаемые потокам, позволяют переупорядочивать потоки на основе хэндовера в соответствии с приоритетом, а не только с порядком поступления. Заметим, что назначение приоритетов не требуется. Потоки можно подвергать хэндоверу в том порядке, в котором пакеты оказываются доступными. Если пакеты доступны для хэндовера, то на этапе 3530 очередь хэндовера обновляется для указания ID потока, ассоциированного с одним или несколькими пакетами, доступными для хэндовера. На этапе 3540 механизм 2890 хэндовера будет автономно осуществлять хэндовер доступных пакетов, позволяя блоку 2880 принятия решения на хэндовер ожидать следующего принятого пакета и осуществлять принятие решения на хэндовер для этого пакета.
Общие концепции, проиллюстрированные выше, можно лучше понять, обратившись к нижеследующему примерному варианту осуществления. В нижеследующем примере блок 2880 принятия решения на хэндовер будет принимать решения на хэндовер, обновлять очереди, связанные с пакетами для хэндовера, и выдавать инструкции механизму 2890 хэндовера для автономной обработки хэндовера. Как показано на фиг.28, блок 2880 принятия решения на хэндовер доставляет ID потока и соответствующие параметры для инициирования хэндовера. В примерном варианте осуществления счетчик хэндовера, указывающий количество пакетов, доступных для хэндовера, ID потока, связанный с этими пакетами, и тип потока поступают в механизм 2890 хэндовера из блока 2880 принятия решения на хэндовер.
Кроме того, можно обеспечить сигнал прерывания. Это необязательное прерывание можно использовать в случае приема пакета более высокого приоритета, когда блок 2880 принятия решения на хэндовер желает переместить пакет более высокого приоритета и его поток вперед тех, над которыми в данный момент осуществляется хэндовер. Методы прерывания хорошо известны в технике и могут включать в себя прерывания опросного типа, а также прерывания, инициируемые вектором, и различные другие, в зависимости от типа используемых блока принятия решения на хэндовер и механизма хэндовера. Специалистам в данной области техники очевидно, что блок 2880 принятия решения на хэндовер и/или механизм хэндовера 2890 можно обеспечить с использованием автоматов, программных или программно-аппаратных процессов, в процессорах общего или специального назначения, специальном оборудовании или любой их комбинации. В этом примере механизм 2890 хэндовера будет возвращать сигнал «хэндовер произведен» для указания, что хэндовер выполнен, совместно с количеством пакетов, подвергнутых хэндоверу. Этот примерный вариант осуществления дополнительно подробно описан ниже.
Выше было описано разделение задач между блоком 2880 принятия решения на хэндовер и механизмом 2890 хэндовера, и были описаны некоторые преимущества, включающие в себя назначение приоритетов потоков и управление потенциальными узкими местами. В этом примерном варианте осуществления общий интерфейс между блоком принятия решения на хэндовер и движком хэндовера предназначен для поддержания параметра счетчика хэндовера для каждого потока. Блок принятия решения на хэндовер, по существу, указывает необходимость в хэндовере потока путем увеличения счетчика хэндовера. Механизм хэндовера по мере того, как он осуществляет хэндовер пакетов, уменьшает счетчик хэндовера. Таким образом, этот параметр можно, в целом, использовать между любым вариантом осуществления блока принятия решения на хэндовер и любыми данными механизмами хэндовера.
Заметим, что этот метод может контрастировать с альтернативным использованием FIFO. Можно также обеспечить FIFO для хэндовера совместно с подробно описанными здесь различными вариантами осуществления. Однако в силу большой изменчивости количества пакетов, которые могут ожидать хэндовера, в ряде случаев может потребоваться весьма глубокий FIFO. Также заметим, что без добавления дополнительной сложности к FIFO переупорядочение пакетов для согласования с приоритетом может быть затруднено. В примерном варианте осуществления очередь «первым пришел - первым обслужен» поддерживается для каждого из совокупности уровней приоритета. В примерном варианте осуществления поддерживается четыре приоритета. Специалистам в данной области техники очевидно, что может поддерживаться любое количество очередей и/или приоритетов.
В альтернативном варианте осуществления блок 2880 принятия решения на хэндовер может принимать решения на хэндовер и наполнять одну или несколько очередей и/или таблиц состояний для указания статуса очередей и пакетов, ожидающих хэндовера, в них. Можно обеспечить механизм 2890 хэндовера, который не требует непосредственного инициирования от блока 2880 принятия решения на хэндовер, как показано, но самостоятельно отслеживает состояние различных очередей и таблиц состояний для определения, какие пакеты доступны для хэндовера, и для назначения приоритетов порядку, в котором они подвергаются хэндоверу. Специалисты в данной области техники могут легко обеспечить эти и другие альтернативные варианты осуществления в рамках объема настоящего изобретения. Детали этого альтернативного варианта осуществления опущены.
На фиг.36 показан примерный вариант осуществления способа 3600 для осуществления принятия решения на хэндовер, пригодный для реализации на блоке 2880 принятия решения на хэндовер, проиллюстрированном выше. На этапе 3610 при приеме пакета происходит переход к этапу 3620 для обработки потока для принятого пакета. Примерный процесс дополнительно подробно описан ниже. В общем случае, при поддержке квитирования блока обработка пакета включает в себя определение, заполнена ли дырка (т.е. были ли один или несколько пакетов с более высокими порядковыми номера правильно приняты и ожидают хэндовера, пока не будет принят пакет с предыдущим порядковым номером после повторной передачи). Естественно, пакеты правильно принятые по порядку, могут быть доступны для хэндовера без заполнения дырки (т.е. отсутствие пакетов с более высокими порядковыми номерами, ожидающих хэндовера). Прием пакета может инициировать доступность одного или нескольких пакетов для хэндовера, или сам пакет может быть единственным пакетом, готовым для хэндовера. Если принятый пакет не заполняет существующую дырку, может не существовать хэндовера, доступного для этого потока. Затем процесс возвращается к блоку 3610 принятия решения.
В этом примере поток перемежается между блоком 3630 обработки пакета и блоком 3630 обработки очереди (дополнительно подробно описанным ниже). Специалистам в данной области техники очевидно, что способ 3600 иллюстрирует два одновременно выполняющихся процесса, один для обработки очереди хэндовера и другой для приема пакетов по мере их поступления. Специалистам в данной области техники известны многочисленные методы для осуществления такой параллельной обработки, и примерный вариант осуществления служит лишь примером.
На фиг.37 показан примерный вариант осуществления способа обработки принятого пакета, пригодный для реализации в качестве блока 3620, представленного выше. На этапе 3710 происходит прием пакета. Производится определение, был ли поток, связанный с этим пакетом, введен в таблицу состояний принятия решения. Примерная таблица состояний принятия решения представлена на фиг.40. В примерной таблице 4000 состояний принятия решения, показанной на фиг.40, существует N поддерживаемых ID потока в любой момент времени. В примерном варианте осуществления могут поддерживаться до 256 потоков. Таблица 4000 состояний принятия решения включает в себя для каждого ID потока набор параметров 4010. В примерном варианте осуществления таблица 4000 состояний принятия решения включает в себя для каждого ID потока смещение 4012 решения, счетчик 4014 хэндовера, поле 4016 следующего указателя, бит 4018 «в очереди» и поле 4020 приоритета.
Согласно фиг.37 на этапе 3710, если поток не включен в таблицу 4000 состояний принятия решения, происходит переход к этапу 3715 для добавления потока в таблицу состояний принятия решения. Когда определено, что поток включен в таблицу состояний принятия решения, происходит переход к этапу 3720 для определения, доступен ли пакет для хэндовера. Поле смещения решения 4012 используется для определения следующего потенциального пакета в потоке, который можно подвергать хэндоверу. Для поддержания этой информации можно использовать различные методы. Например, можно обеспечить битовую карту с соответствующим битом для каждого пакета и/или фрагментом в окне. Когда пакет принят правильно, битовая карта обновляется для указания успешного приема пакета. Таким образом, В этом примере если пакет, связанный с позицией, указанной полем смещения решения, задан (т.е. единица), то пакет доступен для хэндовера. Если эта позиция в битовой карте отменена (т.е. задана равной нулю), обозначается дырка, и ни один из последующих пакетов для этого потока (если таковые существуют) не будет доступен для хэндовера.
В этом примере процесс 3600 принятия решения на хэндовер циклически повторяется. Если пакет доступен для хэндовера, происходит переход к блоку принятия решения 3730 для определения, включен ли ID потока в очередь хэндовера. Примерный вариант осуществления очереди хэндовера проиллюстрирован в виде таблицы 4100 Q состояний массива, показанной на фиг.41. В этом примере очереди поддерживаются до M приоритетов, каждый из которых имеет элементы 4110 в таблице 4100 Q состояний массива. В этом примере элемент 4110 включает в себя переменную 4112 счетчика Q, указатель головы 4114 и указатель хвоста 4116. Очереди поддерживаются с использованием структуры связного списка. В альтернативных вариантах осуществления можно обеспечить другие типы очередей. В примерном варианте осуществления M задано равным 4, и, таким образом, поддерживается 4 уровня приоритета. Уровень приоритета для потока можно определить из поля 4020 приоритета таблицы 4000 состояний принятия решения. Бит 4018 «в очереди» можно использовать для определения, вставлен ли поток в таблицу Q состояний массива. В альтернативном варианте осуществления счетчик 4014 хэндовера можно использовать в помощь логике принятия решения для определения, имеет ли уже данный поток пакеты, ожидающие хэндовера, или нужно ли добавить его в очередь. Счетчик хэндовера может быть не равным нулю, но может быть неясно, уходит ли он от нулевого значения или приближается к нулю. В этом примере пакеты могут обрабатываться по одному. В различных вариантах осуществления этот бит может быть необязательным или может использоваться по желанию.
Если ID потока не включен в очередь хэндовера, происходит переход к этапу 3735 для добавления в поток. Как показано на фиг.41, для каждой приоритетной очереди поддерживаются указатель 4114 головы и указатель 4116 хвоста. Указатель 4114 головы включает в себя ID потока, который можно использовать для индексирования таблицы 4000 состояний принятия решения для определения первого потока в очереди. В этом примере напомним, что при равном приоритете потоки обслуживаются по принципу «первым пришел - первым обслужен». Таким образом, указатель 4114 головы является индексом ID потока для первого потока, подлежащего обслуживанию в очереди. Заметим, что после обращения к ID потока, указанному указателем 4114 головы, следующий поток в этой очереди, если таковой существует, указан полем 4016 следующего указателя. Указатель 4116 хвоста в таблице 4100 Q состояний массива указывает последний поток в приоритетной очереди. При добавлении нового потока в очередь хэндовера процесс можно осуществлять путем обновления поля следующего указателя для ID потока, идентифицируемого указателем хвоста 4116. Это поле будет заменено указателем на добавляемый поток. Затем поле 4116 указателя хвоста обновляется для указания на вновь поступающий поток, который становится новым хвостом очереди (т.е. последним в линии). Кроме того, поле 4112 счетчика очереди поддерживает полное количество потоков в приоритетной очереди. Таким образом, считывая значения счетчика очереди для уровня приоритета, можно быстро определить, существуют ли какие-либо пакеты этого приоритета, ожидающие хэндовера. Эта процедура выполняется для поддержания очередей для каждой из M приоритетных очередей, и состояние легко поддерживается в таблице 4100 Q состояний массива.
Когда определено, что поток находится в очереди хэндовера или был добавлен, происходит переход к этапу 3740 для увеличения счетчика хэндовера 4014. Напомним, что счетчик хэндовера - это параметр, используемый для определения количества пакетов, ожидающих хэндовера для конкретного потока, и поддерживается в таблице 4000 состояний принятия решения. На этапе 3750 производится определение, имеются ли дополнительные пакеты, подлежащие хэндоверу, для потока. Когда определено, что первый пакет готов для хэндовера и счетчик хэндовера увеличен, смещение решения можно продвинуть вперед в битовой карте (т.е. смещение решения ++). Если обновленное смещение решения также показывает пакет, доступный для хэндовера, производится возврат к этапу 3740, увеличение счетчика хэндовера, и процесс продолжается, пока не будут проверены все пакеты в окне или не будет достигнута дырка. Заметим, что после этого смещение решения будет указывать на следующую дырку. В последующих итерациях способа 3620 каждый поток будет проверяться на предмет доступных пакетов хэндовера, по мере поступления пакетов для этого потока.
После достижения дырки и в отсутствие дополнительных пакетов для хэндовера происходит переход к этапу 3760. Блок принятия решения 3760 иллюстрирует необязательный пример процедуры прерывания, которую можно обеспечить. Специалисты в данной области техники могут легко обеспечить любое количество процедур прерывания. На этапе 3760 производится определение, осуществляется ли в данный момент хэндовер. Если хэндовер не осуществляется, процесс может остановиться. Если хэндовер осуществляется, и если это необязательное повторное назначение приоритетов обеспечивается, происходит переход к 3770. На этапе 3770 производится определение, имеет ли поток вновь поступающего пакета более высокий приоритет и следует ли его переместить вперед любых пакетов, участвующих в данный момент в хэндовере. Производится сравнение приоритета текущего потока с приоритетом потока, который обрабатывается механизмом 2890 хэндовера. Если приоритет текущего потока больше, чем у обрабатываемого, происходит переход к этапу 3775 и задается флаг прерывания. В этом примере флаг прерывания будет распознаваться в ходе обработки очереди хэндовера, которая обозначена выше блоком 3630 и проиллюстрирована более подробно ниже. Если приоритет текущего потока меньше, чем у потока, обрабатываемого механизмом 2890 хэндовера, реализовывать приоритет не требуется, и процесс может остановиться.
На фиг.38 показан примерный вариант осуществления способа обработки одной или нескольких очередей хэндовера, пригодный для реализации в качестве блока 3630, представленного выше. Процесс начинается на блоке 3810 принятия решения. Если хэндовер, обрабатываемый механизмом 2890 хэндовера, выполняется в данный момент (т.е. предыдущая итерация способа 3630, инициированная таким хэндовером), то происходит переход к блоку 3815 принятия решения для определения, завершен ли хэндовер. Если он завершен, то на этапе 3820 счетчик хэндовера обновляется. В примерном варианте осуществления количество пакетов, подвергнутых хэндоверу, будет возвращаться механизмом 2890 хэндовера и может вычитаться из счетчика хэндовера. Сигнал «хэндовер произведен», изображенный на фиг.28, можно использовать для определения, завершен ли хэндовер. Заметим, что при обнулении счетчика хэндовера ID потока можно удалить из соответствующей приоритетной очереди с использованием полей, проиллюстрированных на фиг.41. Кроме того, при удалении потока из очереди соответствующий счетчик Q также уменьшается. На этапе 3825 флаг ожидания, используемый для определения, осуществляется ли хэндовер, сбрасывается. Этот флаг полезен для определения ожидания хэндовера в блоке 3810 принятия решения, и его также можно использовать на вышеописанном блоке 3760 принятия решения в отношении обработки пакетов.
Если на блоке 3815 принятия решения определено, что хэндовер не завершен и признак прерывания обеспечен, как описано выше, происходит переход к блоку 3830 принятия решения для определения, задан ли флаг прерывания. Например, такой флаг можно задать, как описано на вышеупомянутом блоке 3775. Если нет, процесс может остановиться. Механизм 2890 хэндовера может продолжать свою работу для осуществления своих текущих операций хэндовера, и последовательность обработки, показанная на фиг.36, может возвращаться к блоку 3610 принятия решения в ожидании поступления дополнительных пакетов или изменения статуса очереди обработки хэндовера. Если в блоке 3830 принятия решения определено, что флаг прерывания задан, то в блоке 3835 механизму хэндовера назначается прерывание. Примерный вариант осуществления обработки механизмом хэндовера сигнала прерывания дополнительно подробно описан ниже.
В блоке 3840 принятия решения механизм хэндовера завершает любую предыдущую обработку, и могут генерироваться дополнительные инструкции хэндовера. В блоке 3840 принятия решения производится определение, доступен ли поток для хэндовера в очереди хэндовера. Примерный вариант осуществления дополнительно подробно описан ниже. Если нет, процесс может остановиться и продолжать итерацию, как описано выше. Если поток доступен, на этапе 3845 движку хэндовера предписывается произвести хэндовер. Как описано выше, ID потока и соответствующие параметры могут поступать в механизм хэндовера. В примерном варианте осуществления счетчик хэндовера может быть любым числом. Если счетчик хэндовера больше единицы, механизм хэндовера может осуществлять хэндовер каждого пакета, пока они не кончатся, если не будет остановлен. В альтернативном варианте осуществления механизм хэндовера может обрабатывать один пакет каждый раз при инициировании хэндовера. В этом альтернативном варианте осуществления прерывание может не требоваться. На этапе 3850 флаг ожидания задается для указания, что процесс хэндовера ожидается. Затем текущая итерация процесса может остановиться.
На фиг.39 представлен примерный вариант осуществления способа определения потоков, доступных для хэндовера, пригодный для реализации в качестве вышеописанного блока 3840. Заметим, что в этом примере предполагается, что потокам более высокого приоритета назначается меньшее численное значение приоритета. Таким образом, приоритет 0 означает наивысший приоритет. Специалисты в данной области техники могут легко адаптировать любой тип схемы приоритетов к объему настоящего изобретения. На этапе 3910 индекс приоритета задается равным 0. Это первый и наивысший приоритет для проверки. Если в блоке 3920 принятия решения определено наличие потока в очереди, идентифицируемого индексом приоритета (т.е. его счетчик Q больше 0), то способ 3840 заканчивается, и поток возвращается. Опять же, в примерном варианте осуществления первый поток в очереди (идентифицируемый указателем головы) идентифицируемого приоритета будет подвергнут хэндоверу.
Если идентифицируемая приоритетная очередь не содержит никаких потоков, индекс приоритета увеличивается на этапе 3930. Если на этапе 3940 определено, что индекс приоритета больше N, т.е. количества поддерживаемых приоритетов (в примерном варианте осуществления N=4), дополнительные очереди, подлежащие проверке, отсутствуют. В этом случае все очереди пусты. При наличии дополнительных очередей, подлежащих проверке (т.е. индекс приоритета меньше N), производится возврат для проверки следующей очереди на этапе 3920. Процесс продолжается, пока поток не будет найден или не закончатся очереди. Опять же, на этапе 3840 можно использовать любой метод выбора потока.
На фиг.42 представлен примерный вариант осуществления способа 4200 для выполнения хэндовера, пригодный для реализации в механизме 2890 хэндовера. В этом примерном варианте осуществления блок 2880 принятия решения на хэндовер доставляет в механизм хэндовера 2890 количество пакетов, подлежащих хэндоверу, счетчик хэндовера, тип потока (который можно использовать, если обеспечивается поддержка для множества типов пакетов, например 802.11 (b), (g), (n) и т.д.) и прерывание. Механизм хэндовера доставляет пакеты для выхода, которые извлекаются из буфера пакетов через арбитр 680 памяти, что проиллюстрировано выше со ссылкой на фиг.28. Количество пакетов, подвергнутых хэндоверу, совместно с сигналом «хэндовер произведен», возвращаются в блок 2880 принятия решения для вышеописанной обработки.
На этапе 4210 механизм 2890 хэндовера извлекает один или несколько узлов из буфера пакетов, вплоть до количества, указанного счетчиком хэндовера. Узлы будут располагаться в буфере пакетов в ячейке, идентифицируемой указателем окна плюс смещение хэндовера, которые устанавливаются в соответствии с ID потока. Напомним, что примерный буфер принятых пакетов может быть таким, как показано на фиг.33, где массив 3330 узлов содержит узлы 3310, каждый из которых соответствует пакету, связанные в формате массива, причем связные списки кусков содержат ассоциированные с ними пакетные данные. Переменные, используемые для индексирования буфера пакетов, поддерживаются для механизма хэндовера в таблице 4300 состояний хэндовера, проиллюстрированной на фиг.43. Опять же, поддерживается N ID потока, и для каждого ID потока поддерживается элемент 4310 в таблице 4300 состояний хэндовера. В примерном варианте осуществления поддерживается до 256 потоков. Программно-аппаратное обеспечение поддерживает местоположение массива узлов в буфере пакетов для каждого потока. Она идентифицируется в таблице 4300 состояний хэндовера указателем окна 4314. Размер окна для потоков указан в размере окна 4316. Смещение хэндовера 4312 - это состояние, поддерживаемое механизмом хэндовера для определения, где будет найден следующий пакет, подлежащий хэндоверу. Таким образом, узлы, соответствующие пакетам, подлежащим хэндоверу, идентифицируются, как описано выше, путем сложения смещения хэндовера 4312 с указателем окна 4314. Для более эффективного доступа к SDRAM может быть желательно извлекать каждый раз более одного узла, хотя это не обязательно.
Размер окна 4316 можно использовать с начальным порядковым номером и смещением хэндовера для указания механизму хэндовера пакета, который нужно обрабатывать для хэндовера. В этом примере смещение хэндовера указывает начальный порядковый номер в структуре данных окна (т.е. массиве узлов) и порядковый номер, подлежащий хэндоверу, идентифицируется по отношению к начальному порядковому номеру.
На этапе 4215 производится выбор первого узла, соответствующего смещению 4312 хэндовера. На этапе 4220 производится извлечение кусков, соответствующих этому узлу из буфера пакетов. На этапе 4225, при необходимости, производится дефрагментация пакета на основании типа потока. Для этого можно извлекать несколько фрагментов из буфера пакетов, удалять заголовки фрагмента из каждого фрагмента, уплотнять куски в единый пакет и создавать соответствующий заголовок. Это можно осуществлять на соответствующем блоке 2892 дефрагментации, проиллюстрированном на фиг.28. Тип потока можно использовать для указания, когда необходима фрагментация. Например, в некоторых вариантах осуществления могут поддерживаться пакеты 802.11 (e) и (g), и можно использовать фрагментацию. Заметим, что в альтернативном варианте осуществления, дополнительно подробно описанном ниже, типы пакетов, требующие фрагментации, обрабатываются программно-аппаратными средствами для уменьшения сложности. В таком варианте осуществления блок 2892 дефрагментации обеспечивать не нужно.
На этапе 4230 после извлечения каждого из кусков, ассоциированных с пакетом, и реконструкции пакета (включающей в себя любую необходимую дефрагментацию) пакет доставляется для выхода. Как описано выше, выход можно выполнять через различные интерфейсы, примеры которых приведены выше.
После осуществления хэндовера пакета (или набора фрагментов) смещение 4312 хэндовера обновляется для идентификации следующего пакета для хэндовера. На этапе 4240 переменная, «количество пакетов, подвергнутых хэндоверу», позволяющая отслеживать количество пакетов, подвергнутых хэндоверу, соответственно увеличивается. Если на этапе 4245 определено, что прерывания поддерживаются и сигнал прерывания выдан, происходит переход к этапу 4255. На этапе 4255 хэндовер останавливается, выдается сигнал «хэндовер произведен», и возвращается «количество пакетов, подвергнутых хэндоверу». В этом варианте осуществления прерывание осуществляется по окончании хэндовера каждого пакета. Можно обеспечить альтернативные схемы прерывания, которые хорошо известны специалистам в данной области техники. После прерывания процесс хэндовера останавливается. В этом примере блок 2880 принятия решения на хэндовер может позже выдавать команду «новый хэндовер» в механизм 2890 хэндовера для продолжения хэндовера пакетов для прерванного потока. Если на этапе 4245 определено, что ни одного прерывания не принято, происходит переход к блоку 4250 принятия решения. Если на этапе 4250 определено, что не существует дополнительных пакетов, подлежащих хэндоверу, что можно определить путем сравнения количества пакетов, подвергнутых хэндоверу, со счетчиком хэндовера, хэндовер завершается. Происходит переход к этапу 4255, на котором выдается сигнал «хэндовер произведен», и возвращается количество пакетов, подвергнутых хэндоверу.
При наличии дополнительных пакетов, подлежащих хэндоверу, происходит переход к этапу 4260. Осуществляется обработка следующего узла, и возврат к 4220 для извлечения кусков, которые соответствуют этому узлу, после чего вышеописанный процесс возобновляется.
Блок 2894 очистки осуществляет различные функции при перемещении окна ARQ. Например, удаляются частично фрагментированные пакеты. Завершенные пакеты подвергаются хэндоверу независимо от наличия дырок. Буферы освобождаются, и, таким образом, указатели куска помещаются обратно в список свободных указателей куска, и окна перемещаются.
Специалисты в данной области техники могут легко адаптировать различные схемы, компоненты и методы к альтернативным вариантам осуществления. В одном альтернативном обобщенном варианте осуществления (и совместимом с альтернативным вариантом 4900 осуществления, представленным на фиг.49, который подробно описан ниже) автомат входа (ISM) обрабатывает входящие пакеты и обновляет информацию, используемую автоматом управления (CSM). Эти обновления могут приводить к увеличению количества пакетов в памяти, а также к обновлению порядка, в котором CSM должен обрабатывать Flow_ID. CSM может обновлять кэш узлов четырех пакетов на передатчике, что подробно описано выше. Этот автомат действует на основании информации в Flow_Packet_Table. A указатель головы и указатель хвоста, а также указатель следующего потока в таблице позволяют CSM выбирать следующий Flow_ID, подлежащий обработке. В таблице может существовать бит «обслуживание» (для каждого Flow_ID), из которого CSM узнает, передаются ли в данный момент пакеты из этого Flow_ID. Механизм ТХ может задать этот бит равным 1 прежде, чем начать передачу, и равным 0 по завершении передачи. Автомат передачи использует информацию из очереди команд для передачи пакетов по WLAN (аналогично тому, что описано выше со ссылкой на фиг.18). Автомат очистки (FSM), который можно использовать в качестве блока 2894 очистки, удаляет из SDRAM пакеты, которые правильно приняты и квитированы соответствующим приемником. Затем FSM уменьшает счетчик пакетов в памяти в Flow_Packet_Table.
Flow_Packet_Table может иметь один или несколько из следующих элементов: Flow_ID (1 байт), «количество пакетов в памяти» (2 байта), «количество пакетов в кэше» (2 бита), бит «обслуживание» (1 бит), Next_Flow_ID (1 байт) и 2-битовое поле приоритета. Когда пакет поступает на вход, ISM обновляет «количество пакетов в памяти», обновляет Next_Flow_ID, а также Tail_Pointer. Автомат передачи при передаче пакетов из конкретного Flow_ID задает соответствующий бит «обслуживание». После задания CSM не будет обновлять кэш узлов четырех пакетов. После передачи пакетов автомат передачи обновляет «количество пакетов в кэше», а также сбрасывает бит «обслуживание». CSM будет действовать только, когда бит «обслуживание» сброшен. Порядок, в котором он обрабатывает Flow_ID, определяется Next_Flow_ID. По желанию, в таблицу можно добавить 2-битовое поле приоритета. В этом случае CSM будет сначала обрабатывать потоки наивысшего приоритета, затем более низкого приоритета и т.д. Примерный размер этой таблицы составляет приблизительно 4 байта, умноженные на количество потоков, т.е. приблизительно 1 кбайт для 256 потоков. CSM использует указатель заголовка для Flow_ID (первый пакет в Linked_list) для указания адресов узла для пакетов, которые должны быть включены в кэш узлов четырех пакетов.
Таким образом, в примерном варианте осуществления примерный механизм очистки или блок 2894 очистки может удалять из буфера пакетов все пакеты, которые успешно приняты и квитированы. При приеме битовой карты квитирования блока автомат передачи сначала обрабатывает ее и может сразу же осуществлять повторные передачи в отношении определенных неквитированных пакетов. (Квитирование блока дополнительно подробно описано ниже.) Затем битовая карта поступает в автомат механизма очистки в механизме очистки или блоке 2894 очистки, который извлекает Head_Pointer структуры данных в виде связного списка для соответствующего Flow_ID - Head_Ptr доступен в RAM состояний потока. Head_Ptr содержит адрес узла первого пакета для данного Flow_ID, а также порядковый номер этого пакета. Автомат механизма очистки обрабатывает битовую карту и ставит ее в очередь для последовательного удаления пакетов, которые были квитированы. Эта логика может быть аналогичной логике, которую использует автомат выхода, где пакеты, последовательно принятые, передаются на хост. После того как автомат механизма очистки идентифицирует количество пакетов, подлежащих удалению, и их порядковые номера, их можно поместить в очередь на удаление. Head_Ptr дает адрес узла первого пакета в связном списке. Адреса узла для пакетов, подлежащих удалению, получаются путем обращения к адресам узлов соответствующих пакетов из связного списка. В примерном варианте осуществления память выделяется для обеспечения достаточного количества местоположений пакета, кусков и узлов. Таким образом, удаление можно производить в фоне, поскольку оно, в целом, не сопряжено со строгим ограничением по времени. Арбитр памяти может обеспечивать обращения к функциям очистки как задачу низкого приоритета.
Квитирование блока
Различные аспекты, представленные примерными вариантами осуществления, подробно описанными выше, хорошо подходят для осуществления квитирования блока для высокоскоростного управления доступом к среде. В типичном протоколе квитирования блока передатчик передает пакеты на приемник в течение периода времени, без необходимости принимать квитирование какого-либо из пакетов. Затем квитирование блока возвращается с приемника на передатчик, указывающий, какие из ранее переданных пакетов приняты правильно. Квитирование блока можно передавать в ответ на запрос квитирования блока, или можно обеспечить альтернативные механизмы планирования, например ответ после приема заранее определенного количества пакетов. Запрос квитирования блока, при желании, может быть особым сообщением, передаваемым для указания квитирования блока, или квитирование блока может быть свойственно другому типу сигнала или сообщения.
Один механизм для поддержания состояние квитированных или неквитированных пакетов состоит в поддержании битовой карты, в которой позиция каждого бита соответствует пакету или фрагменту пакета, как описано выше со ссылкой на фиг.30 и 31. Примерная битовая карта 3130 описана выше.
В системе с высокой пропускной способностью может быть желательно возвращать запрос квитирования блока в течение относительно короткого промежутка времени после инициирующего события, например явный или собственный запрос квитирования блока или другой индикатор запроса квитирования блока. В примерном варианте осуществления 802.11 может быть необходимо, чтобы запрос квитирования блока возвращался в течение периода SIFS после запроса квитирования блока (т.е. немедленное квитирование блока). Таким образом, может быть желательно поддерживать информацию состояния для множества потоков, что допускает быстрый ответ квитирования блока для любого из текущих ожидающих потоков и позволяет обрабатывать квитирования блоков после запроса квитирования блока для повторной передачи любых пакетов, нуждающихся в повторной передаче. Могут поддерживаться различные типы квитирования блока. Например, может быть желательно квитирование частичного или полного состояния. В общем случае, квитирование частичного состояния может требовать меньшей вычислительной нагрузки или меньшей задержки. Описанные здесь примерные варианты осуществления можно легко адаптировать к квитированию блока в частичном или полном состоянии или их комбинации. Аспекты описаны далее посредством нижеследующих примерных вариантов осуществления.
Квитирование блока на приемнике
В примерном варианте осуществления принимается пакет, который может являться агрегатным пакетом. По мере того как пакеты принимаются на приемнике, они тестируются для определения, правильно ли был принят пакет, например, можно использовать последовательность проверки кадров и т.п. Вне зависимости от способа определения правильного приема пакета можно сохранять индикатор для каждого пакета (или фрагмент, при необходимости). В примерном варианте осуществления эти индикаторы квитирования сохраняются в битовой карте, связанной с каждым потоком. Различные методы хранения битовых карт для потоков подробно описаны выше со ссылкой на фиг.30.
На фиг.44 представлен примерный вариант осуществления способа 4400 для ответа на запрос непосредственного квитирования блока. Этот способ пригоден для быстрого ответа на запрос квитирования блока.
На этапе 4410 информация заголовка пакета поддерживается для любого потока, для которого может быть необходимо генерировать квитирование блока. Эта информация заголовка может поддерживаться в любых форматах, примеры которых хорошо известны в технике. Информация заголовка (или в альтернативных вариантах осуществления любая информация, которая может быть заранее определена для использования при подготовке ответа квитирования блока) сохраняется для построения пакета до потенциальной передачи квитирования блока. Другими словами, пакет находится в той или иной разновидности памяти, надлежащим образом отформатированной всеми значениями для отправки (которые могут быть заранее заданы). Пропущенный фрагмент - это информация битовой карты, указывающая положительное квитирование или отрицательное квитирование каждого отдельного пакета или фрагмента (или любая другая информация, которую нельзя установить раньше). Битовая карта (и вся оставшаяся информация) просто вставляется в ожидающий пакет и передается.
Напомним, что в примерном варианте осуществления, описанном выше, можно обеспечить три уровня памяти для обеспечения различных уровней косвенной адресации. В одном примере, первый уровень памяти - это аппаратные таблицы, например, аппаратная таблица 2820. Второй уровень памяти может включать в себя SRAM 330. В необязательной конфигурации можно обеспечить третий уровень, например, SDRAM 340. Информацию заголовка пакета можно сохранять в памяти любого уровня, к которой можно надлежащим образом обращаться.
На этапе 4420 принимается запрос квитирования блока, который может быть косвенным или прямым. На этапе 4430 извлекается битовая карта, связанная с потоком. Для извлечения битовой карты можно использовать любой идентификатор потока. Например, как описано выше на фиг.30, MAC-индекс 3004 используется для идентификации ID 3006 линии, с которым ассоциирован указатель 3002. Указатель 3002 может указывать непосредственно на таблицу 3042, включающую в себя битовую карту 3046, или же указатель 3002 может указывать на таблицу 3010 скоростей, которая на основании ID 3020 передачи указывают на таблицу 2920 состояний RX. Как описано выше, таблица 2920 состояний может включать в себя указатель 3050 битовой карты для указания на фактическую битовую карту 3130. Специалистам в данной области техники очевидно, что любой можно обеспечить тип косвенного или прямого хранения битовых карт. В соответствии с используемым методом извлекается надлежащая битовая карта, связанная с ID потока, с помощью запроса квитирования блока.
На этапе 4440 извлеченная битовая карта помещается в поддерживаемый пакет, и на этапе 4450 передается только что построенное квитирование блока. Таким образом, в этом варианте осуществления заранее строится как можно больше пакета квитирование блока. Информация битовой карты или другие данные квитирования в альтернативном варианте осуществления поддерживается в легкодоступном участке памяти для быстрого извлечения. Затем комбинация этих двух фрагментов быстро передается для обеспечения немедленного квитирования блока в частичном или полном состоянии в ответ на запросы непосредственного квитирования блока.
Вышеприведенные варианты осуществления поддерживают немедленное квитирование блока в полном состоянии или частичном состоянии. В примерном варианте осуществления можно обеспечить поддержку частичного состояния, полного состояния или любой их комбинации. Однако в других вариантах осуществления может быть необходимо поддерживать только квитирование блока частичного состояния, что, наиболее вероятно, будет отвечать стандарту для 802,11(n). В этом случае квитирование блока передается только в ответ прием агрегата, и статус передается только для принятых пакетов.
Для квитирования блока частичного состояния нужно поддерживать только одну память на приемнике. Нет нужды включать полное состояние (т.е. память для 256 потоков). Частичное состояние битовой карты, поддерживаемой на приемнике, может перезаписываться при получении передачи от другого отправителя. Заметим, что если состояние случайно перезаписывается, то в дальнейшем запрос на квитирование блока будет невозможен. В одном примере в этом случае можно передавать битовую карту со всеми нулями. Данный вариант осуществления можно обеспечить, по желанию, для поддержания более чем минимального объема состояния.
Квитирование блока на передатчике
Как описано выше, передатчик может передавать некоторое количество пакетов и затем статус приема запроса через прямой или косвенный запрос квитирования блока. Для поддержания высокой пропускной способности желательно, чтобы передатчик был готов продолжать передачу или, при необходимости, выполнить повторную передачу, быстро, когда принимается соответствующее квитирование блока. Различные варианты осуществления легко приспособить для извлечения выгоды из различных аспектов, подробно описанных в этом описании изобретения, для эффективного и быстрого осуществления повторной передачи в ответ на квитирование блока.
На фиг.45 представлен примерный вариант осуществления способа 4500 для ответа на квитирование блока. Этот способ соответствует вариантам осуществления, предусматривающим массивы узлов, например, хранящиеся в кэшах 1810 массива узлов, подробно описанных выше. Кроме того, вышеописанные очереди, которые могут изменяться и поддерживаться связными списками узлов, также весьма пригодны для адаптации к способу 4500.
Чтобы подытожить процедуру, напомним, что квитирование блока соответствует размеру окна (который в примерном варианте осуществления достигает размера 64). Начальный порядковый номер задается равным наименьшему порядковому номеру, представленному окном (в принципе, самой левой точкой окна). Передатчик знает, сколько пакетов было передано, таким образом он знает, где находится последний пакет в окне. Начиная с последнего переданного пакета, передатчик может затем переходить от пакета к пакету по битовой карте от наиболее недавно переданного к переданному раньше всех. Если идентифицируется отрицательное квитирование (нуль в примерном варианте осуществления), то указатель узла для этого пакета повторно привязывается к очереди передачи (которая повторно ставит пакет в очередь для повторной передачи). Передатчик проходит по битовой карте, реконструируя очередь передачи в виде связного списка, прежде чем достигнет начала битовой карты (идентифицируемого предыдущей начальной последовательностью). Способ 4500 представляет собой один такой метод, который можно обеспечить, хотя любой метод для определения необходимых параметров повторной передачи можно использовать совместно с вариантами осуществления, подробно описанными здесь.
Нижеприведенный пример иллюстрирует использование битовой карты квитирования блока для обработки очереди передачи в буфере пакетов. Те же или аналогичные методы в равной степени применимы к обеспечению повторной передачи с низкой задержкой в ответ на квитирование блока. Например, очередь, например, массив 1842 узлов может загружаться узлами потока, которые затем передаются, как описано выше. Эти узлы могут оставаться, пока квитирование блока не будет принято и обработано. Битовую карту квитирования блока можно использовать для указания, какие узлы необходимо повторно передавать. В одном варианте осуществления позиции узлов в массиве узлов будут соответствовать позициям в битовом поле квитирования блока. После приема квитирования блока пакеты, которые не были квитированы, можно быстро агрегировать и повторно передавать (предполагая, что возможность передачи доступна) с использованием методов агрегации, подробно описанных выше. Это один пример методов ответа с низкой задержкой, который позволяет эффективно использовать оставшуюся возможность передачи. Узлы в массиве узлов могут перемещаться при перемещении окна аналогично тому, как описано ниже. Заметим, что использование массивов узлов или же буферов передачи для обработки квитирования блока и повторной передачи, когда пакеты сохраняются в буфере пакетов с использованием структур данных, например узлов и кусков, подробно описанных выше, устраняет необходимость в перемещении пакетных данных в буфере пакетов. Они могут оставаться в одном местоположении на протяжении первой передачи и любых последующих повторных передач (хотя к ней можно повторно обращаться в течение каждой передачи), пока пакет не будет успешно принят или не превысит заранее определенные пределы и не будет удален.
На этапе 4510 принимается квитирование блока. На этапе 4515 начальный порядковый номер задается для указания на первый непереданный пакет. Таким образом, в примере, где принимается квитирование блока, указывающее, что все переданные пакеты были приняты правильно, окно будет перемещаться. Следующий пакет для передачи будет первым пакетом в новом окне, поэтому начальный порядковый номер должен быть ассоциирован с этим пакетом. В следующих этапах подробно описано, как изменять начальный порядковый номер и обновлять очередь передачи, чтобы иметь дело с любыми необходимыми повторными передачами, если они понадобятся. По окончании процесса начальный порядковый номер будет автоматически обновлен для надлежащего перемещения окна вперед (если возможно). Очередь передачи будет обновлена, что позволит немедленно начать передачу или повторную передачу.
На этапе 4520 производится проверка битовой карты квитирования блока, начиная с наиболее недавно переданного пакета. На этапе 4525 при обнаружении нуля (или в альтернативном варианте осуществления регистрируется индикатор отрицательного квитирования) этот пакет необходимо повторно передать. Происходит переход к этапу 4530 и указатель следующей передачи привязывается к пакету, связанному с этой позицией битовой карты. Например, когда обеспечена очередь передачи, например, подробно описанная выше со ссылкой на фиг.6, указатель 630 головы очереди может быть предназначен для указания узла, связанного с пакетом, для которого обнаружен нуль. Затем поле 612 указателя следующего узла, содержащееся в этом узле, можно обновлять для указания предыдущего указателя головы. В альтернативных вариантах осуществления можно использовать альтернативные методы обновления очереди передачи.
На этапе 4535 начальный порядковый номер обновляется для указания текущего пакета. Таким образом, для каждого принятого нуля начальный порядковый номер будет перемещен в предыдущее местоположение. Как описано выше, если все пакеты приняты правильно, окно будет перемещаться на следующий пакет, ожидающий передачи. Однако это перемещение вперед затем обращается, пока не будет обнаружен первый нуль. После осуществления всего способа 4500, если пакет, ассоциированный с начальным порядковым номером в квитировании блока, не был принят правильно, естественно, окно вообще не переместится вперед.
На этапе 4540 осуществляется перемещение назад по битовой карте к следующему предыдущему пакету. Если на этапе 4545 определено, что существуют другие позиции битовой карты, подлежащие проверке, происходит возврат к блоку принятия решения 4525 для следующего квитирования. Если на этапе 4525 нуль не обнаружен, то процесс переходит к этапу 4540, на котором осуществляется перемещение назад по битовой карте и проверка, завершена ли битовая карта. Когда все пакеты в битовой карте проверены, происходит переход от блока 4545 принятия решения к этапу 4550, на котором начинается передача с использованием обновленной очереди передачи. На этапе 4560 пакеты, которые были квитированы, можно удалять и освобождать связанные с ними указатели для последующего использования. Заметим, что этот этап может выполняться параллельно (или в фоновом режиме), как показано. После этого процесс может остановиться.
В итоге, когда битовая карта принимается для квитирования блока, нули в битовой карте повторно связываются с существующей очередью передачи для формирования новой очереди передачи. Соответствующие указатели узла для этих пакетов перезаписываются в памяти. Заметим, однако, что это не относится к самим пакетам (идентифицируемым указателями куска и содержащимся в кусках 620). Только, когда пакеты были успешно приняты и квитированы (или происходит другое событие, например тайм-аут), узел и кусок удаляются, и указатели возвращаются в список свободных указателей. Этот процесс управления памятью можно осуществлять параллельно, может отставать от обработки квитирования блока, можно осуществлять в фоновом режиме и т.д. В случае, когда, например, у передатчика остается время в его TXOP, очередь повторной передачи генерируется быстро, и передача может переходить к использованию любого оставшегося TXOP. Если передатчик не имеет разрешения на немедленную повторную передачу (т.е. больше не осталось TXOP), можно осуществлять тот же способ, но передача не происходит немедленно.
Напомним, что, как описано выше со ссылкой на фиг.18, можно обеспечить кэш пинг-понгового типа, чтобы массивы 1842 узлов можно было обновлять, не мешая действующей передаче. Этот метод можно также обеспечить в схеме повторной передачи квитирования блока. На фиг.46 представлен примерный вариант осуществления способа 4600, который можно обеспечить для использования пинг-понгового кэша массива узлов в процессе повторной передачи. Например, способ 4600 может быть включен в вышеописанный блок 4550. На этапе 4610 задается первый пинг-понговый массив 1842 узлов с использованием указателей узла из очереди передачи, потенциально обновленной в ответ на информацию повторной передачи в запросе квитирования блока. При необходимости, производится обновление ID линии в 1844, что подробно описано выше. На этапе 4620 производится переход к этому первому массиву узлов, чтобы можно было перейти к передаче. На этапе 4630, при необходимости, структуру памяти можно очистить (т.е. удалить пакеты, очистить указатели и пр.).
Квитирование блока с множеством TID
На данной станции возможна поддержка различных потоков (например, до 16 потоков), где каждый поток соответствует идентификатору трафика [Traffic Identifier] (TID). Напомним, что TID отображает поток со станции. В одном агрегате можно найти пакеты, соответствующие множеству TID, например, агрегируя пакеты для каждой линии связи. Это позволяет возвращать квитирование блока, соответствующее множеству TID (или квитирование блока с множеством TID). В одном варианте осуществления квитирование блока с множеством TID содержит TID, затем битовую карту, затем другой TID, затем еще одну битовую карту и т.д. Одна проблема состоит в том, что пакеты в агрегате не обязательно организованы в последовательном порядке (т.е. в ходе повторных передач). Поэтому для данного TID квитирование блока может начинаться с начального порядкового номера, который задает наименьший порядковый номер, принятый в этом агрегате для этого TID. Затем обеспечивается битовая карта TID в качестве смещения относительно начального порядкового номера. Ниже подробно описано несколько вариантов осуществления для подготовки квитирования блока с множеством TID.
В одном варианте осуществления по мере поступления пакетов сравнивают каждый порядковый номер и сохраняют наименьший. Процесс может начинаться с сохранения первого принятого порядкового номера для каждого TID. Затем для каждого входящего пакета сравнивают сохраненный порядковый номер для TID с порядковым номером нового пакета и сохраняют меньший из них. На конце агрегата получаем наименьший начальный порядковый номер для каждого TID. Найдя наименьший представленный порядковый номер, вычитают этот порядковый номер из порядкового номера каждого пакета, для которого обеспечивается ответ (который можно сохранять по мере их поступления), чтобы найти смещение этого пакета в битовой карте. Наименьший начальный порядковый номер - это начальный порядковый номер для TID. На скорости линии определение, пригоден ли пакет, может происходить на скорости линии, и можно просто сохранять каждый бит для ACK или NAK совместно с абсолютными порядковыми номерами. На конце агрегата обходят последовательность сохраненных порядковых номеров пакета, используют вычтенное значение в качестве смещения или индекса в битовой карте, и помещают сохраненное ACK или NAK в битовую карту.
В альтернативном варианте осуществления производится сохранение битовой карты относительно наименьшего порядкового номера, принятого в данный момент. Затем можно произвести сдвиг влево и вправо (в зависимости от порядка сохранения) для обновления местоположения. Например, при сохранении битовой карты, если порядковый номер входящего пакета больше текущего наименьшего порядкового номера, просто осуществляется пометка бита квитирования в соответствующем месте (определяемом разностью между наименьшем принятым порядковым номером и принятым в данный момент порядковым номером). Если входящий порядковый номер меньше, чем наименьший из ранее принятых порядковых номеров, то производится сдвиг битовой карты (и новое ACK или NAK помещается в самую нижнюю точку). Сдвиг можно определить как разность между старым начальным порядковым номером (т.е. наименьшим ранее принятым начальным порядковым номером) и новым начальным порядковым номером (т.е. номером принятого в данный момент пакета, который будет новым наименьшим). В отличие от первого варианта осуществления, подробно описанного выше, в котором осуществлялся обход по сохраненным порядковым номерам, в этом варианте осуществления необходимо только сохранять битовую карту и наименьший начальный порядковый номер. Никакие другие порядковые номера в битовой карте сохранять не нужно.
Вышеприведенные описания вариантов осуществления применимы к немедленному квитированию блока частичного состояния. Для распространения на полное состояние нужно просто сначала извлечь сохраненную историю для каждого потока, а затем добавить к нему. Любой вариант осуществления можно обеспечить для случая одного TID и можно повторять для каждого TID для поддержки множества TID.
Незапланированный U-APSD
Подробно описанные здесь примерные варианты осуществления также пригодны для адаптации для обеспечения незапланированной доставки с автоматическим энергосбережением (U-APSD). U-APSD - это метод, используемый для экономии энергии. Существует много вариантов, включая запланированный и незапланированный методы. На фиг.47 представлен примерный вариант осуществления способа 4700 для осуществления незапланированной доставки с автоматическим энергосбережением. На этапе 4710 в типичной схеме U-APSD пользовательский терминал включается самостоятельно. На этапе 4720 пользовательский терминал передает пакет-триггер на точку доступа. На этапе 4730 точка доступа определяет ID потока из принятого пакета. Если в блоке 4740 принятия решения определено, что существуют пакеты, ожидающие передачи на пользовательский терминал, связанный с ID потока, происходит переход к этапу 4750. В противном случае, происходит переход к этапу 4790, на котором индикатор "отправить еще" отменяется, что указывает отсутствие пакетов для передачи (например, бит «конец периода обслуживания» [End Of Service Period] (EOSP)). На этапе 4795 пользовательский терминал может вернуться в режим ожидания, и процесс может остановиться. Если на блоке 4740 принятия решения определено, что существуют пакеты для передачи на пользовательский терминал, происходит переход к этапу 4750.
На этапе 4750 немедленно осуществляется передача одного или несколько пакетов из кэша массива узлов ТХ. Например, можно обращаться к кэшу 1810 массива узлов ТХ, например, описанному выше на фиг.18. С использованием методов, проиллюстрированных на фиг.18, передатчик может немедленно отвечать включившемуся пользовательскому терминалу. Это позволяет избавиться от необходимости применять альтернативный метод сохранения пользовательского терминала в активном состоянии, например отправки пакета без данных. Это позволяет избегать растрачивания полосы, а также энергии, поскольку пользовательскому терминалу не нужно оставаться в активном состоянии более чем необходимо. Поскольку пакеты упорядочены и легко доступны, как описано выше, весьма вероятно, что с использованием этого метода можно создавать ответ пользовательскому терминалу, включающий в себя данные. Заметим, что в некоторых примерных системах, например в типичной системе передачи голоса по интернет-протоколу (VOIP), только один или два пакета могут понадобиться для поддержки голосовой связи. Таким образом, пользовательский терминал, использующий U-APSD, может включаться незапланированным образом, быстро извлекать пакет или два с относительно небольшой задержкой и переходить к возврату в ждущий режим сохранения энергии.
Если в блоке 4760 принятия решения определено, что существуют пакеты для отправки помимо тех, которые включены в пакет ответа, переданный на этапе 4750, происходит переход к этапу 4770. На этапе 4770 назначается индикатор "отправить еще", который может быть включен в пакет, передаваемый на пользовательский терминал. Это назначение "отправить еще" будет указывать пользовательскому терминалу, что следует оставаться активным для приема дополнительных пакетов. На этапе 4780 извлекаются дополнительные узлы и передаются соответствующие дополнительные пакеты, как описано выше. Происходит возврат к этапу 4760 для определения, имеются ли дополнительные пакеты для отправки. После передачи всех пакетов, адресованных этому пользовательскому терминалу, как описано выше, на этапе 4790 "отправить еще" отменяется, и на этапе 4795 пользовательский терминал может вернуться в ждущий режим.
Таким образом, согласно примерному варианту осуществления U-APSD, подробно описанному выше, до четырех пакетов можно передавать на любой пользовательский терминал сразу же, как они станут доступны в кэше массива узлов. Эти четыре пакета можно быстро передавать, и если существуют другие пакеты, можно задать индикатор. Затем после SIFS, квитирования блока и пр. дополнительные пакеты будут готовы к передаче. В этом примере переменная поддерживается в таблице состояний потока ТХ (например, 1030) для указания AP активен ли UT или он находится в состоянии ожидания. Этот вариант осуществления описывает использование кэширования, которое проиллюстрировано в передатчике, показанном на фиг.18 (кэши 1810 массива узлов). Заметим, что можно использовать альтернативные или иначе разделенные объемы кэширования, если для конкретных потоков требуется увеличенная емкость памяти (т.е. повторное разделение, допускающее более 4 пакетов в ответе).
Power Save Multi Poll (PSMP)
Power Save Multi Poll [энергосбережение с множественными опросами] (PSMP) - это еще одна область, где схема кэширования узлов, подробно описанная выше, обеспечивает преимущества. Существует два варианта PSMP: незапланированный и запланированный.
Незапланированный PSMP (U-PSMP) аналогичен незапланированному APSD. Когда станция включается, она использует процедуры EDCA для отправки сообщения-триггера, которое может представлять собой сообщение QoS_Data или QoS_Null для Access Class (класс доступа), который сконфигурирован в состояние («триггер включен») Trigger Enabled (через сообщения установки). Получив этот пакет, AP передает пакеты, хранящиеся для этой станции, которые предпочтительно хранятся в кэше 1810 массива узлов. В последнем пакете AP устанавливает EOSP на 1 для указания, что пакетов больше нет. Получив этот пакет, станция возвращается в ждущее состояние. Когда станция сконфигурирована на включение U-PSMP для конкретного Access Class, соответствующий поток указывается как имеющий U-PSMP в таблице отображения потока TA/TID (например, 1030). Кроме того, переменная состояния, указывающая, находится ли поток в ждущем или активном режиме, также поддерживается в таблице отображения потока TA/TID.
Таким образом, вышеприведенные варианты осуществления пригодны для поддержки U-PSMP. В примерном варианте осуществления могут поддерживаться первая переменная, указывающая, является ли поток потоком PSMP, и вторая переменная, указывающая, находится ли конкретная станция в активном или ждущем режиме, и эти переменные добавляются к другим переменным, как описано выше. Получив данные (или триггер), AP удостоверяется, что этот триггер является законным потоком U-PSMP (в соответствии с первой переменной), и устанавливает вторую переменную из "asleep" в "awake". AP передает пакеты, хранящиеся для этой STA, которые легко доступны, затем предписывает станции перейти в режим ожидания и задает вторую переменную обратно в "asleep". Бит активации также можно использовать при наличии оставшегося TXOP. В этом случае проверяется бит активации, и TXOP используется только для STA, когда она активна. AP имеет возможность поддерживать станцию в активном состоянии для осуществления передач и т.д. Переменные можно добавлять в таблицу 1830 состояний массива ТХ.
В запланированном PSMP (S-PSMP) разрабатывается шаблон и затем публикуется расписание восходящей и нисходящей линии (например, эту функцию может осуществлять программно-аппаратное обеспечение в AP, а также любое другое устройство). Устройства беспроводной связи в WLAN могут использовать один и тот же шаблон, пока не будет добавлен новый вызов или пока вызов не закончится. Затем можно создать новый шаблон.
В одном варианте осуществления AP действует под управлением запланированного PSMP. Один способ можно осуществлять следующим образом:
1) AP сама посылает Clear to Send (CTS) для очистки среды. CTS задает интервал NAV равной возможности передачи «ниже по течению» плюс «выше по течению».
2) AP передает кадр PSMP, который детализирует расписание восходящей и нисходящей линий (для каждой станции, с точностью микросекунды).
3) Затем начинается передача по нисходящей линии.
4) Передача по восходящей линии следует за передачей по нисходящей линии.
5) Этот формат хорошо запланирован, и AP избегает выхода за пределы запланированного конечного времени для устранения дрожания. Для этого можно ограничить доступ к среде вблизи конца интервала NAV. Важно избегать дрожания, поэтому пользовательские терминалы не активируются для проверки своего статуса, пропускают свои сообщения вследствие смещения, внесенного дрожанием, и переходят обратно в ждущий режим, пропуская свои возможности передачи.
В примерном варианте осуществления структура данных, используемая для генерации расписания, будет поддерживаться в пинг-понговой структуре данных, как описано выше. Структура данных содержит шаблон, используемый для расписания восходящей и нисходящей линий, используемого для запланированного PSMP. Текущее расписание поддерживается в одной половине пинг-понговой структуры данных. Это можно передавать на станции по WLAN. Затем AP может вносить изменение в шаблон в другой половине пинг-понговой структуры данных. Можно обеспечить селектор для переключения между первым шаблоном и вторым шаблоном. AP способна работать на любом неактивном шаблоне, не мешая активному шаблону. Этот метод аналогичен использованию массивов 1842 узлов или теневых таблиц (1092 и 1096) потока.
Альтернативный вариант осуществления: Разветвление высокой и низкой пропускной способности
Как описано выше со ссылкой на фиг.10A, различные функции, например фрагментация, могут не требоваться для высокоскоростной обработки пакетов, тогда как поддержка других типов пакетов или традиционных пакетов 802.11 все же может быть нужна. На фиг.48 показан альтернативный вариант осуществления, предусматривающий более одного процессора MAC. Высокоскоростной процессор MAC, например, подробно описанный процессор H2W 530 и нижний MAC 540 (реализованный в процессоре MAC, например, 240, подробно описанном выше), можно обеспечить (возможно, с упрощенными функциями) для эффективной высокоскоростной обработки, тогда как альтернативный процессор 4810 MAC параллельно обеспечивается для обработки других типов пакетов (или традиционных пакетов, например различных типов пакетов 802.11).
В одном примерном варианте осуществления процессор 4810 MAC более низкой пропускной способности реализован в виде процессора 210 (и также может включать в себя другие компоненты, например компоненты, предусмотренные, по желанию, для традиционной обработки пакетов). Процессор 210 в примерном варианте осуществления успешно инициируется для обработки пакетов низкой пропускной способности и традиционных пакетов, что позволяет компонентам более высокой пропускной способности, например процессору 530 H2W, эффективно поддерживать пакеты высокой пропускной способности. Другие варианты осуществления могут включать в себя дополнительные процессоры MAC, как описано ниже.
В этом примере, поскольку пакеты 802,11(n) не поддерживают фрагментацию, варианты осуществления, подробно описанные выше, можно упростить путем удаления поддержки фрагментации из оборудования и ее реализации в программно-аппаратном обеспечении. Различные примерные описания приведены выше. Тот факт, что программно-аппаратное обеспечение обрабатывает все традиционные пакеты, позволяет удалять поддержку фрагментации, упростить механизмы передачи и приема и упростить управление узлами и кусками (поскольку порог фрагментации может отличаться от размеров кусков). Специалисты в данной области техники могут легко адаптировать варианты осуществления, подробно описанные здесь, для включения или упразднения различных блоков обработки в зависимости от того, какие признаки поддерживаются.
Специалисты в данной области техники легко могут предложить компромиссы при обеспечении варианта осуществления, включающего в себя один процессор, способный обрабатывать все функции различных типов пакетов, и другого варианта осуществления, содержащего два или более процессоров MAC, каждый из которых способен обеспечивать любое подмножество функций. Конечно, можно также обеспечить единый процессор MAC, способный обрабатывать пакеты, требующие единого набора функций.
Разветвление высокой и низкой пропускной способности является всего лишь одним примером разделения функций между несколькими процессорами MAC. В общем случае, любой набор функций можно обеспечить в различных процессорах MAC. Например, может быть желательно обрабатывать два типа пакетов одинаково высокой скорости (или любой скорости) на раздельных процессорах, когда требования к обработке для разных типов пакетов не используют совместно достаточные аналогии для достижения эффективности за счет совместного использования компонентов, или если соображения относительно конструкции схем в достаточной степени различаются между конструкциями для поддержки различных типов пакетов.
На фиг.49 показан примерный вариант осуществления устройства 4900 беспроводной связи (например, точки 104 доступа или пользовательского терминала 106), включающего в себя два процессора MAC, включающих в себя первый процессор MAC, как описано выше, и второй процессор MAC, реализованные в микропроцессоре. Этот пример является более подробно описанным примером, аналогичным обобщенному варианту осуществления на фиг.48.
Специалисты в данной области техники могут легко адаптировать вариант осуществления, показанный выше на фиг.5, к альтернативному варианту осуществления, представленному на фиг.49. В этом примере пакеты входа и выхода поступают на внешний интерфейс и уходят оттуда по шине 4980. Примерные внешние интерфейсы включают в себя интерфейс 582 SDIO, интерфейс 584 PCI, интерфейс USB или интерфейс любого другого типа. Интерфейс может включать в себя схему для арбитража и/или мультиплексирования между одним или несколькими интерфейсами. Входящие пакеты обрабатываются блоком 4910 входа и сохраняются в памяти через интерфейс 4920 памяти с использованием любого из вышеописанных методов управления входом и памятью. Интерфейс 4920 памяти может включать в себя, например, арбитр 552 памяти и/или 556, мультиплексор 554, интерфейс 558 SRAM, интерфейс 562 SDRAM или различные другие компоненты. Специалисты в данной области техники также смогут адаптировать другие интерфейсы памяти.
В отличие от варианта осуществления, представленного на фиг.5, определенные типы пакетов обрабатываются на процессоре (например, процессоре 210). В этом примере пакеты входа, которые подлежат форматированию процессором, поступают из интерфейса 4920 памяти на процессор через шину 520 процессора (к шине 520 процессора также могут быть подключены различные другие компоненты, примеры которых показаны на фиг.5). Можно обеспечить интерфейс процессора между интерфейсом 4920 памяти и шиной 520. В этом примере предусмотрены один или несколько FIFO 4950 памяти процессора (любой другой интерфейс для доставки принятых пакетов). Это позволяет сохранять пакеты (а также структуры данных, например узлы, куски и т.д.) для использования процессором 210. Принятые пакеты низкой пропускной способности также обрабатываются процессором 210 и могут переноситься из интерфейса 4920 памяти на шину 520 процессора через FIFO 4950 памяти процессора.
В альтернативном варианте осуществления FIFO памяти процессора могут быть заменены прямым соединением с памятью процессора. Например, DMA можно использовать для помещения низкоскоростных пакетов в память для обработки процессором 210. В одном варианте осуществления интерфейс 4920 памяти может записывать низкоскоростные пакеты непосредственно в память 4950 процессора (не FIFO) без сохранения пакета в RAM высокоскоростных пакетов.
В этом примере пакеты также можно размещать в памяти (через интерфейс 4920 памяти) с помощью процессора 210. Например, процессор может перенаправить принятый пакет обратно по WLAN, не посылая пакет на внешний интерфейс. Заметим, что все варианты осуществления, подробно описанные здесь, можно адаптировать к перенаправлению принятых пакетов обратно для передачи. Пакеты, доставленные в шину 520, можно форматировать с использованием любого из вышеописанных методов.
В примерном варианте осуществления пакеты 802,11 (b), (g) и (e) направляются на процессор для форматирования (включающего в себя любую фрагментацию, которая может потребоваться). Другие типы пакетов также могут быть пригодны для процессорного форматирования. Например, в 802.11 (n) задан агрегированный блок служебных данных MAC (A-MSDU), который также надлежащим образом форматируется процессором. Можно обеспечить различные методы перенаправления. В этом примере, когда пакет принимается для процессорного форматирования, пакет сохраняется в памяти, и прерывание задается процессору для инициирования форматирования для передачи (детали не показаны).
Форматированные пакеты низкой пропускной способности или традиционные пакеты после обработки процессором 210 можно сохранять для передачи в FIFO 4960 передачи процессора WLAN. На FIFO 4960 передачи процессора WLAN может поступать обратная связь, например сигнал готовности, сигналы для обеспечения дросселирования и пр. Эти пакеты также можно доставлять в механизм 1880 ТХ для постановки в очередь и возможной дополнительной обработки (например, с помощью механизма 2210 традиционного протокола) и, в конце концов, для передачи по PHY 260. Их можно доставлять непосредственно на механизм 1880 ТХ, или их можно включать в очереди 1850 (как описано на фиг.18) под управлением контроллера 1840 массива и т.д. Заметим, что в примерном варианте осуществления модуль 2610 агрегации можно обойти для традиционных пакетов и пакетов A-MSDU.
Высокоскоростные пакеты, например 802.11(n) агрегированные протокольные блоки данных Mac (A-MPDU), также принимаются блоком 4910 входа и сохраняются в памяти через интерфейс 4920 памяти. В этом случае пакеты передаются механизм 1880 ТХ с использованием методов, подробно описанных выше (например, со ссылкой на фиг.18). В этом примере аппаратная обработка высокоскоростных пакетов позволяет осуществлять высокоскоростную передачу, тогда как низкоскоростные пакеты, например традиционные пакеты, описанные выше, могут выполняться в программно-аппаратном обеспечении процессора 210, не создавая узкое место в пропускной способности. Это позволяет не включать традиционные детали различных традиционных пакетов в оборудование высокоскоростной обработки MAC, что позволяет более эффективно конструировать его, в то же время обеспечивая традиционную поддержку посредством процессора MAC, реализованного в программно-аппаратном обеспечении. Высокоскоростные пакеты, в конце концов, передаются по WLAN через PHY. Можно использовать заголовок для указания высокоскоростной или низкоскоростной физической передачи.
Пакеты, принятые от WLAN, поступают на подключенный механизм 4970 RX и, в конце концов, сохраняются в памяти через интерфейс 4920 памяти. Низкоскоростные пакеты могут поступать на процессор 210 для обработки (т.е. традиционные пакеты, или для пакетов с использованием признаков, не поддерживаемых в аппаратном процессоре MAC, например фрагментации, и т.д.). В альтернативном варианте осуществления пакеты могут поступать непосредственно на процессор 210 (без сохранения в памяти) или могут поступать на любой другой альтернативный процессор MAC (напомним, что можно обеспечить любое количество процессоров MAC для поддержки любого количества наборов признаков пакета). В этом примере пакеты низкой пропускной способности или традиционные пакеты поступают на процессор из интерфейсов 4920 памяти через FIFO 4950 памяти процессора, как описано выше. Они могут или не могут частично обрабатываться механизмом 2210 традиционного протокола. Заметим, что блок 2802 дезагрегации можно обойти для неагрегированных блоков данных (например, традиционных пакетов).
Механизм 4970 RX (а также другие компоненты, например традиционный механизм 2210, если предусмотрен) обрабатывает дезагрегированные пакеты, как подробно описано выше, в нижнем ядре 540 MAC. В этом примере высокоскоростные пакеты представляют собой только пакеты, обрабатываемые на аппаратном процессоре MAC, но в альтернативных вариантах осуществления можно обрабатывать любой тип пакетов.
Механизм 4970 RX может дешифровать любой тип пакета с использованием традиционного механизма 2210, что подробно описано выше. Заметим, что принятые пакеты можно маркировать посредством интерфейса MAC/PHY (например, интерфейса MAC/PHY 545, подробно описанного выше) для указания типа пакета. Например, пакеты можно идентифицировать как 802.11 (a), (b) (e), (g), (n), и т.д. Пакеты можно идентифицировать как A-MSDU или A-MPDU. В общем случае, можно применять любой маркер для указания маршрутизации пакета на один из любого количества процессоров MAC.
Заметим, что в вышеописанном примерном варианте осуществления агрегация и дезагрегация применяются только к высокоскоростным пакетам (агрегация необязательна для высокоскоростных пакетов, как описано выше). Низкоскоростные пакеты проходят через блоки агрегации и дезагрегации. Фрагментация поддерживается только для традиционных или низкоскоростных пакетов, но не для высокоскоростных пакетов. Процессор (т.е. 210) является первым процессором MAC, и второй процессор MAC содержит различные компоненты, подробно описанные выше (т.е. на фиг.5). Как описано выше, это лишь примеры. В общем случае, на первом процессоре MAC может поддерживаться любой набор признаков, и тот же набор или другой набор признаков во втором процессоре MAC (любой из которых или ни один из которых можно осуществлять с использованием процессора, например процессора 210).
Блок 4930 выхода может принимать и подвергать хэндоверу высокоскоростные пакеты из буфера пакетов через интерфейс 4920 памяти. Блок 4930 выхода также может осуществлять арбитраж между низкоскоростными пакетами, поступающими из FIFO 4940 выхода процессора, и высокоскоростными пакетами. В примерном варианте осуществления процессор доставляет обработанные пакеты, готовые к хэндоверу в порядке приоритета, на FIFO 4940 выхода процессора. В альтернативном варианте осуществления, по желанию, альтернативная память может заменять FIFO 4940 выхода процессора, чтобы блок 4930 выхода мог выбирать пакеты для назначения приоритетов в блоке 4930 выхода. В еще одном альтернативном варианте осуществления FIFO 4940 выхода процессора можно исключить, и блок 4930 выхода может подвергать низкоскоростные пакеты хэндоверу посредством прямого доступа к памяти процессора (например, с помощью DMA или любого другого способа доступа). В еще одном варианте осуществления FIFO 4940 выхода процессора может иметь множественные приоритетные очереди, среди которых блок 4930 выхода может выбирать для реализации схемы приоритетов.
Специалисты в данной области техники могут предложить многочисленные альтернативные конфигурации в соответствии с принципами, воплощенными в устройстве 4900 беспроводной связи.
На фиг.50 показаны аспекты многопоточной буферизации и упорядочения пакетов. Фиг.50 содержит средства 5010 сохранения в первой структуре 5040 данных в буфере 5030 пакетов длины 5050 первого пакета, порядкового номера 5060 пакета и второго местоположения 5070 буфера пакетов второй структуры 5080 данных в буфере пакетов; средства 5020 сохранения данных из первого пакета во второй структуре 5080 данных идентифицируем сохраненным вторым местоположением 5070 буфера пакетов.
На фиг.51 показаны аспекты многопоточной буферизации и упорядочения пакетов. Фиг.51 содержит первую структуру 5140 данных, ассоциированную с пакетом; и одну или несколько вторых структур 5180 данных, содержащих данные из ассоциированного пакета; причем первая структура данных содержит поле 5150 длины, указывающее длину ассоциированного пакета; поле 5160 порядкового номера, указывающее порядковый номер ассоциированного пакета; и поле 5170 указателя второй структуры данных, указывающее ячейку в буфере пакетов 5130 одной из вторых структур данных 5180; и средства 5120 сохранения пакета в одной или нескольких вторых структур 5180 данных.
На фиг.52 показаны аспекты управления памятью для высокоскоростного управления доступом к среде. Фиг.52 содержит средства 5290 выбора первого или второго режима; средства 5210 конфигурирования первой памяти 5230 в первом режиме для сохранения одного или несколько параметров для каждого из совокупности коммуникационных потоков; средства 5260 конфигурирования первой памяти во втором режиме для сохранения указателя для каждого из совокупности коммуникационных потоков, причем каждый указатель указывает местоположение, ассоциированное с соответствующим коммуникационным потоком; средства 5220 конфигурирования второй памяти 5240 в первом режиме для сохранения пакетов для каждого из совокупности коммуникационных потоков; средства 5270 конфигурирования второй памяти во втором режиме для сохранения совокупности множеств из одного или нескольких параметров для каждого из совокупности коммуникационных потоков, причем каждое множество из одного или нескольких параметров хранится в местоположении, указанном указателем, ассоциированным с соответствующим коммуникационным потоком; и средства 5280 конфигурирования интерфейса 5250 памяти, способного работать с третьей памятью во втором режиме, чтобы ее можно было использовать для сохранения пакетов для каждого из совокупности коммуникационных потоков.
На фиг.53 показаны аспекты многопоточного управления доступом к среде. Фиг.53 содержит средства 5320 задания индекса идентификатора потока равным одному из совокупности значений индексов идентификатора потока, причем каждый индекс идентификатора потока связан с соответствующим одним из совокупности потоков; средства 5310 сохранения совокупности множеств 5340 параметров в первой памяти 5330 в совокупности местоположений первой памяти, причем каждое множество параметров содержит один или несколько параметров для соответствующего одного из совокупности потоков, причем местоположение в первой памяти для каждого множества параметров идентифицируется соответствующим значением индекса идентификатора потока, заданным в индексе идентификатора потока; и средства 5350 извлечения одного или нескольких параметров из одного из совокупности наборов параметров из первой памяти в соответствии с индексом идентификатора потока.
На фиг.54 показаны аспекты многопоточного управления доступом к среде. Фиг.54 содержит средство 5410 сохранения совокупности множеств 5420 параметров в первой памяти 5430, причем каждое множество параметров хранится в соответствующей одной из совокупности местоположений множеств параметров, причем каждое множество параметров содержит один или несколько параметров для соответствующего одного из совокупности потоков, причем каждый из совокупности потоков идентифицируется одним из совокупности идентификаторов потока; средства 5440 сохранения совокупности указателей множества 5450 параметров во второй памяти, причем каждый указатель множества параметров идентифицирует одну из совокупности местоположений множества параметров в первой памяти, причем каждый указатель набора параметров ассоциирован с одним из совокупности потоков; средства 5470 извлечения указателя набора параметров из второй памяти в соответствии с идентификатором потока; средства 5480 извлечения одного или нескольких параметров из первой памяти путем доступа к множеству параметров в соответствии с извлеченным указателем набора параметров.
На фиг.55 показаны аспекты мультиплексирования множества потоков для высокоскоростного управления доступом к среде. Фиг.55 содержит средства 5510 сохранения одного или нескольких элементов 5520 пакета, ассоциированных с одним из совокупности потоков в каждой из второй совокупности очередей 5530; средства 5540 выбора элемента из одной из второй совокупности очередей; и средства 5550 сохранения выбранного элемента 5560 в одной из первой совокупности очередей 5570, причем каждая очередь ассоциирована с одним из совокупности каналов.
На фиг.56 показаны аспекты агрегации в высокоскоростной системе связи. Фиг.56 содержит средства 5610 сохранения одной или нескольких первых структур 5620 данных в очереди 5630, причем каждая первая структура данных содержит поле 5635 длины соответствующего пакета и указатель 5640 на вторую структуру 5650 данных, причем вторая структура данных содержит, по меньшей мере, участок соответствующих пакетных данных; средства 5660 определения объема передаваемых данных; средства 5670 извлечения одного или нескольких значений длины из поля длины одной или нескольких первых структур данных в очереди; средства 5680 выбора набора из одной или нескольких первых структур данных, так чтобы сумма извлеченных значений длины из набора первых структур данных была меньше или равна объему передаваемых данных; и средства 5690 агрегации пакетов в агрегатный протокольный блок данных, причем каждый агрегированный пакет идентифицируется указателем на вторую структуру данных в выбранном наборе первых структур данных.
На фиг.57 показаны аспекты теневых кэшей, выступающих в качестве обслуживаемых очередей и ожидающих очередей. Фиг.57 содержит средства 5720 выбора первой очереди 5710 в качестве обслуживаемой очереди; средства 5740 выбора второй очереди 5730 в качестве ожидающей очереди; средства 5750 планирования первого потока; средства 5760 планирования второго потока; средства 5770 сохранения одного или нескольких элементов, ассоциированных с первым запланированным потоком в обслуживаемой очереди; средства 5780 обработки обслуживаемой очереди для передачи в течение первой возможности передачи; и средства 5790 сохранения одного или нескольких элементов, связанных со вторым запланированным потоком в ожидающей очереди, причем сохранение может осуществляться одновременно с обработкой обслуживаемой очереди.
На фиг.58 показаны аспекты политики входа. Фиг.58 содержит средства 5810 приема идентификатора потока, связанного с пакетом, для одного из совокупности потоков; средства 5820 извлечения одного или нескольких параметров, ассоциированных с идентификатором потока; средства 5830 допуска пакета, когда заранее определенное условие выполняется в соответствии с одним или несколькими извлеченными параметрами, связанными с идентификатором потока; и средства 5840 отвержения пакета, когда заранее определенное условие не выполняется в соответствии с одним или несколькими извлеченными параметрами, ассоциированными с идентификатором потока.
На фиг.59 показаны аспекты политики входа. Фиг.59 содержит средства 5910 приема идентификатора потока, ассоциированного с пакетом, для одного из совокупности потоков; средства 5920 извлечения текущей загруженности буфера пакетов; средства 5930 извлечения максимальной загруженности буфера, ассоциированной с идентификатором потока; средства 5940 извлечения совокупного количества пакетов, ассоциированного с идентификатором потока; средства 5950 извлечения максимального количества пакетов, ассоциированного с идентификатором потока; и средства 5960 допуска пакета, когда текущая загруженность буфера пакетов меньше максимальной загруженности буфера, ассоциированной с идентификатором потока, или совокупное количество пакетов, ассоциированное с идентификатором потока, меньше максимального количества пакетов, ассоциированного с идентификатором потока.
На фиг.60 показаны аспекты политики входа. Фиг.60 содержит буфер 6010 пакетов; средства 6020 извлечения одного или нескольких параметров для каждого из совокупности потоков; и средства 6030 условного сохранения пакета, ассоциированного с одним из совокупности потоков, в буфере пакетов в соответствии с одним или несколькими извлеченными параметрами.
На фиг.61 показаны аспекты управления доступа к среде для ответа с низкой задержкой. Фиг.61 содержит средства 6110 сохранения одной или нескольких первых структур 6120 данных в очереди 6130, причем каждая первая структура данных содержит поле 6135 длины соответствующего пакета и указатель 6140 на вторую структуру 6150 данных, причем вторая структура данных содержит, по меньшей мере, участок соответствующих пакетных данных; средства 6160 извлечения одного или нескольких значений длины из поля длины одной или нескольких первых структур данных в очереди в ответ на возможность передачи, требующую ответной передачи в течение заранее определенного интервала времени; и средства 6170 формирования ответного протокольного блока данных в течение заранее определенного интервала времени, причем протокольный блок данных содержит значение длины протокольного блока данных, определяемое в соответствии с, по меньшей мере, одним значением длины в течение заранее определенного интервала времени.
Специалисту в данной области также очевидно, что информация и сигналы могут быть представлены с использованием разнообразных технологий и методов. Например, данные, инструкции, команды, информация, сигналы, биты, символы и элементы данных, упомянутые в вышеприведенном описании, могут быть представлены напряжениями, токами, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами или любой их комбинацией.
Специалисту в данной области очевидно, что различные примерные логические блоки, модули, схемы и этапы способа, описанные в связи с раскрытыми здесь вариантами осуществления, могут быть реализованы в виде электронного оборудования, компьютерного программного обеспечения или их комбинации. Чтобы отчетливо проиллюстрировать эту взаимозаменяемость оборудования и программного обеспечения, различные примерные компоненты, блоки, модули и этапы были описаны выше, в целом, применительно к их функциональным возможностям. Будут ли эти функциональные возможности реализованы аппаратными или программными средствами, зависит от конкретного применения и конструктивных ограничений, наложенных на систему в целом. Специалисты в данной области могут реализовать описанные функциональные возможности разными способами для каждой конкретной области применения, но такие решения по реализации не следует интерпретировать как отход от объема настоящего изобретения.
Различные примерные логические блоки, модули и схемы, описанные в связи с раскрытыми здесь вариантами осуществления, можно реализовать или осуществлять посредством процессора общего назначения, цифрового сигнального процессора (DSP), специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA) или другого программируемого логического устройства, дискретной вентильной или транзисторной логики, дискретных аппаратных компонентов или любой их комбинации, предназначенных для осуществления описанных здесь функций. Процессор общего назначения может представлять собой микропроцессор, но, альтернативно, процессор может представлять собой любой традиционный процессор, контроллер, микроконтроллер или автомат. Процессор также может быть реализован как комбинация вычислительных устройств, например комбинация DSP и микропроцессора, совокупность микропроцессоров, один или несколько микропроцессоров в сочетании с ядром DSP или любая другая подобная конфигурация.
Этапы способа или алгоритма, описанные в связи с раскрытыми здесь вариантами осуществления, могут быть реализованы непосредственно в оборудовании, в программном модуле, выполняемом процессором или в их комбинации. Программный модуль может размещаться в RAM, флэш-памяти, ROM, EPROM, EEPROM, на жестком диске, сменном диске, CD-ROM или носителе данных любого другого типа, известного в технике. Примерный носитель данных подключен к процессору, в результате чего процессор может считывать с него информацию и записывать на него информацию. Альтернативно, носитель данных может образовывать с процессором единое целое. Процессор и носитель данных могут размещаться в ASIC. ASIC может находиться на пользовательском терминале. Альтернативно, процессор и носитель данных могут размещаться на пользовательском терминале как дискретные компоненты.
Вышеприведенное описание раскрытых вариантов осуществления предоставлено, чтобы специалист в данной области техники мог использовать настоящее изобретение. Специалисту в данной области техники должны быть очевидны различные модификации этих вариантов осуществления, и раскрытые здесь общие принципы можно применять к другим вариантам осуществления, не выходя за рамки сущности и объема изобретения. Таким образом, настоящее изобретение не ограничивается показанными здесь вариантами осуществления, но подлежит рассмотрению в широчайшем объеме, согласующемся с раскрытыми здесь принципами и признаками новизны.
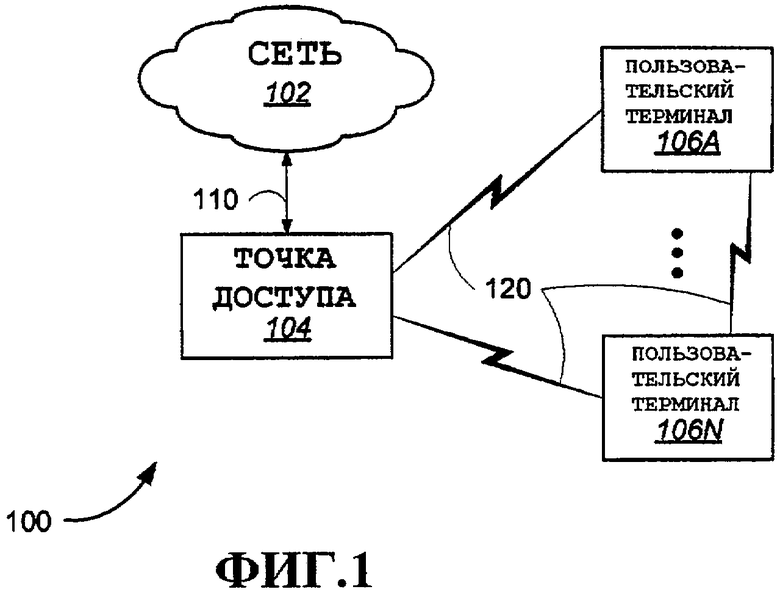
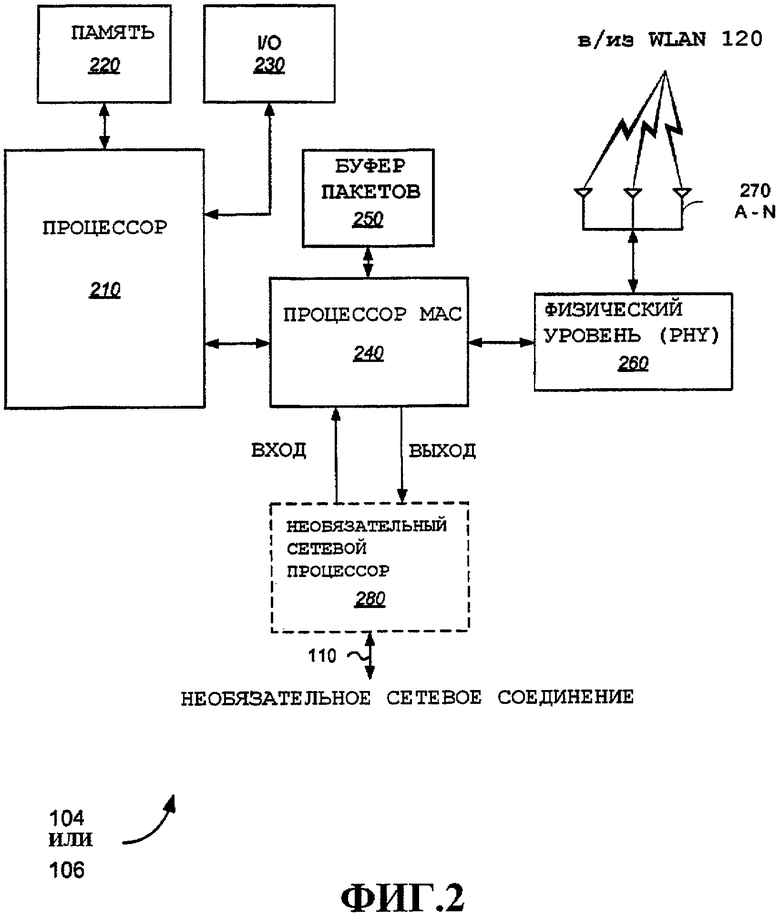
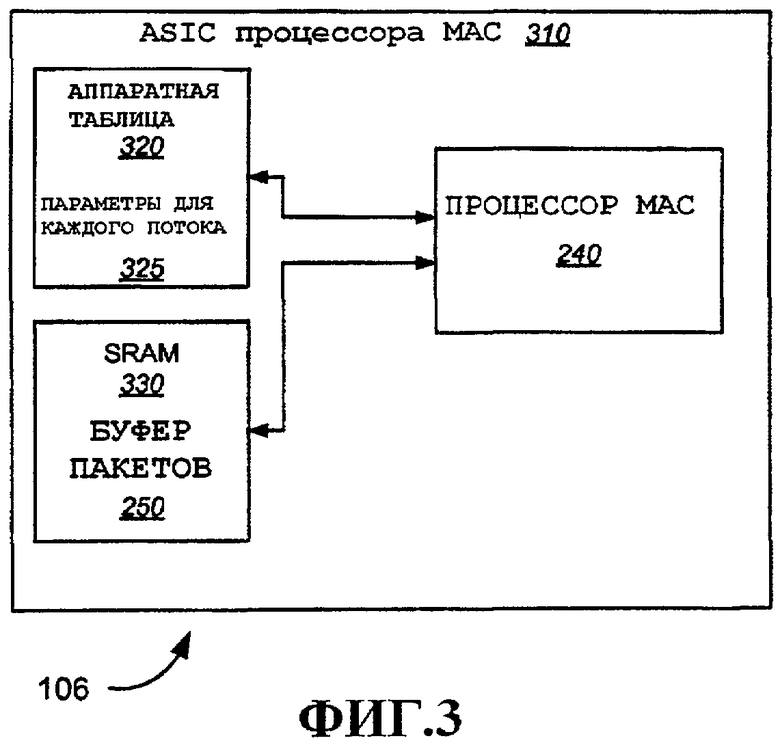
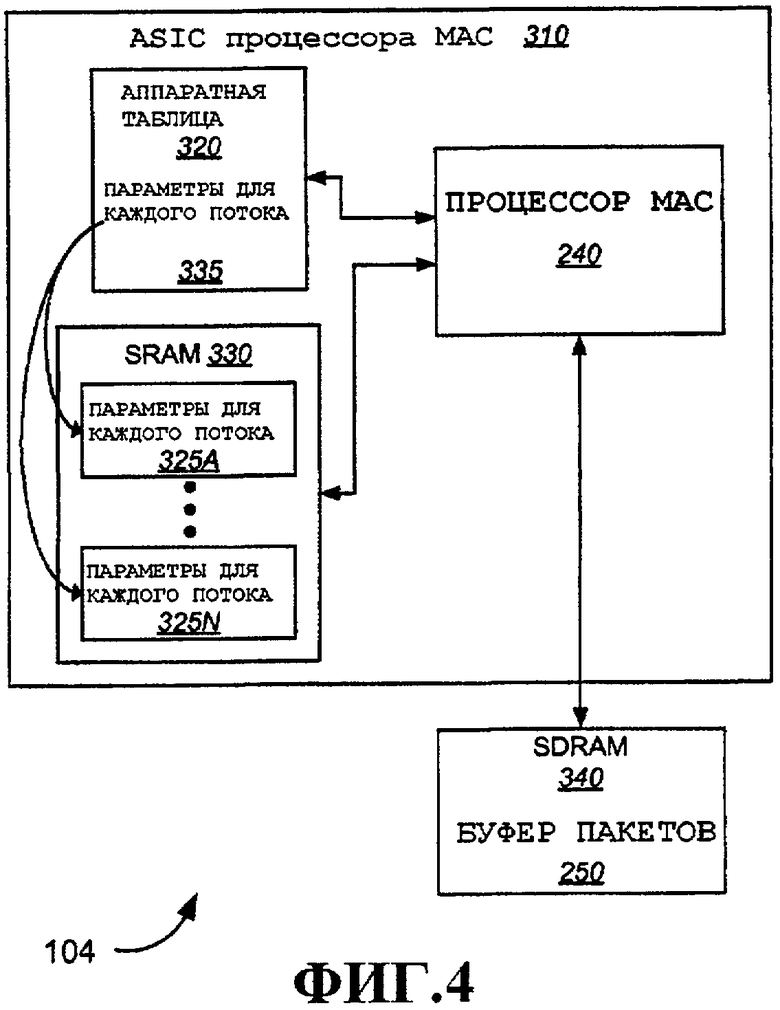
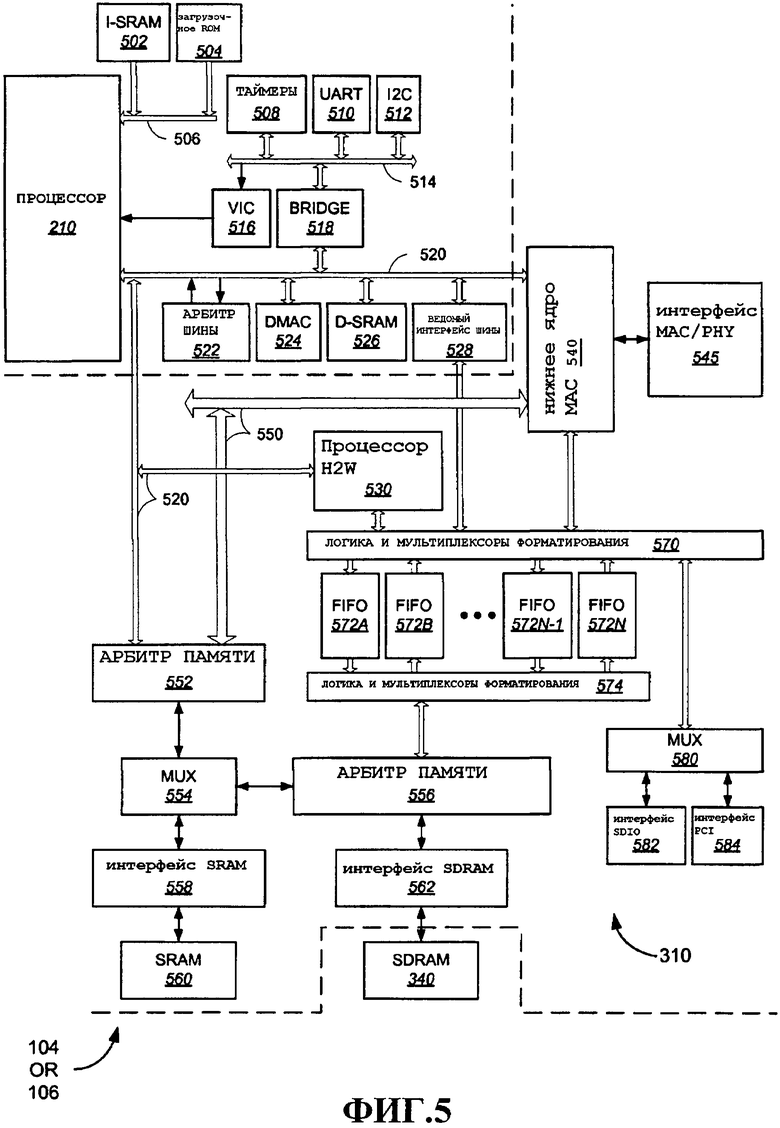
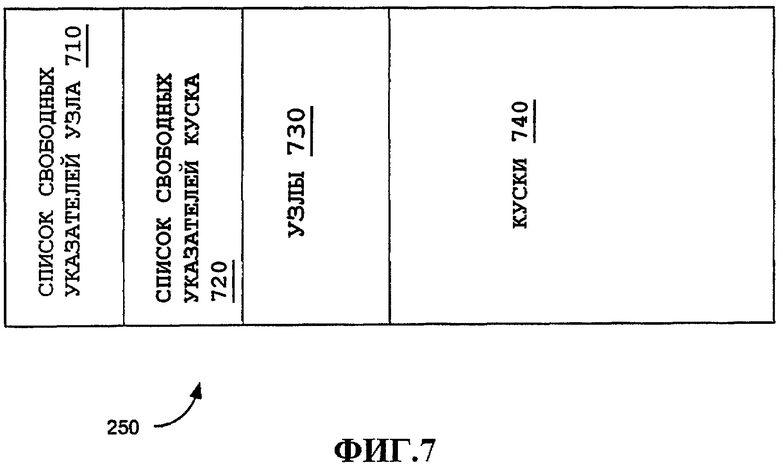
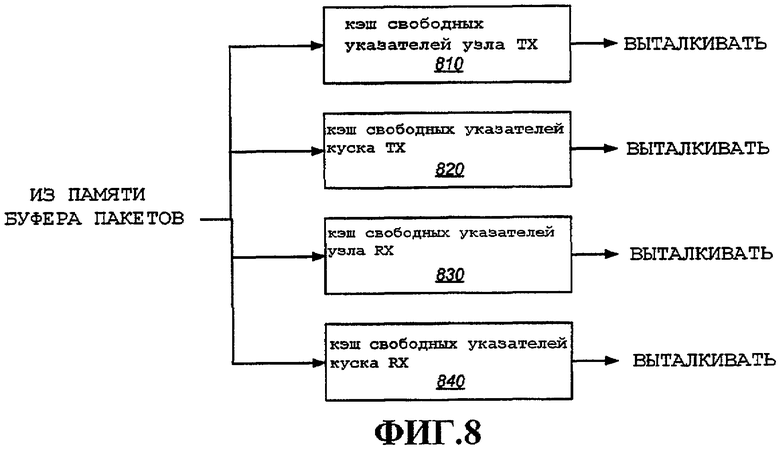
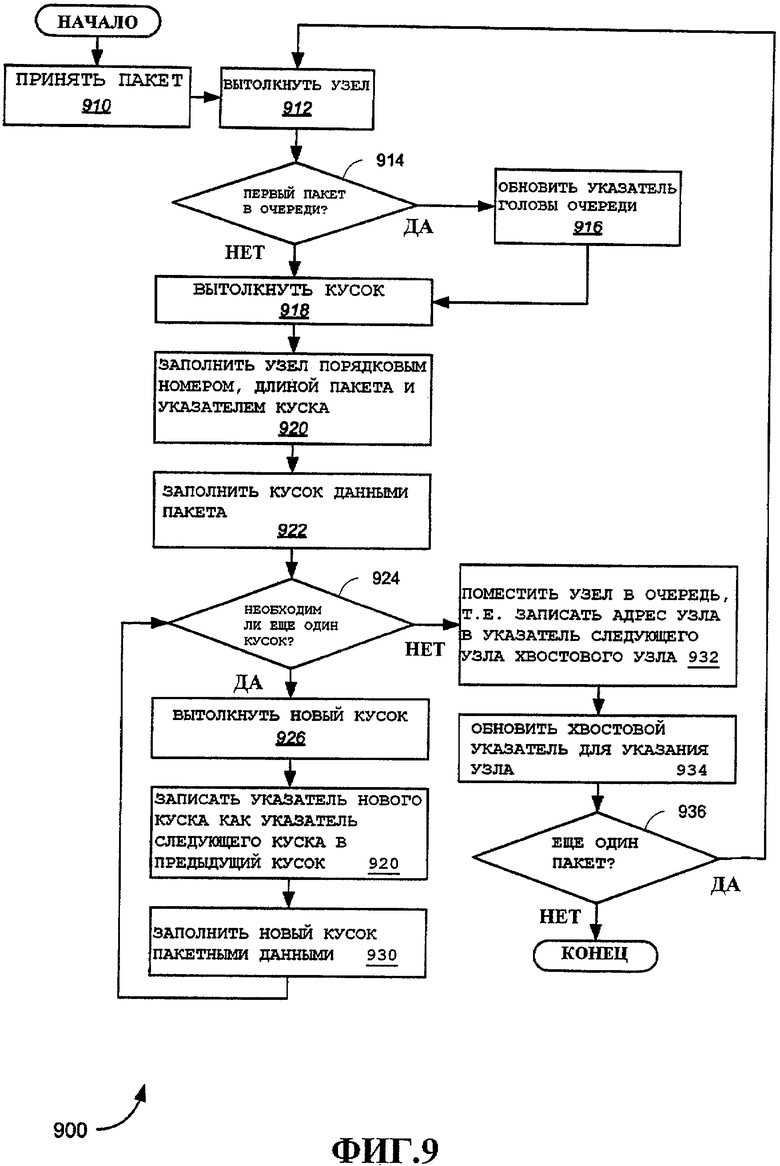
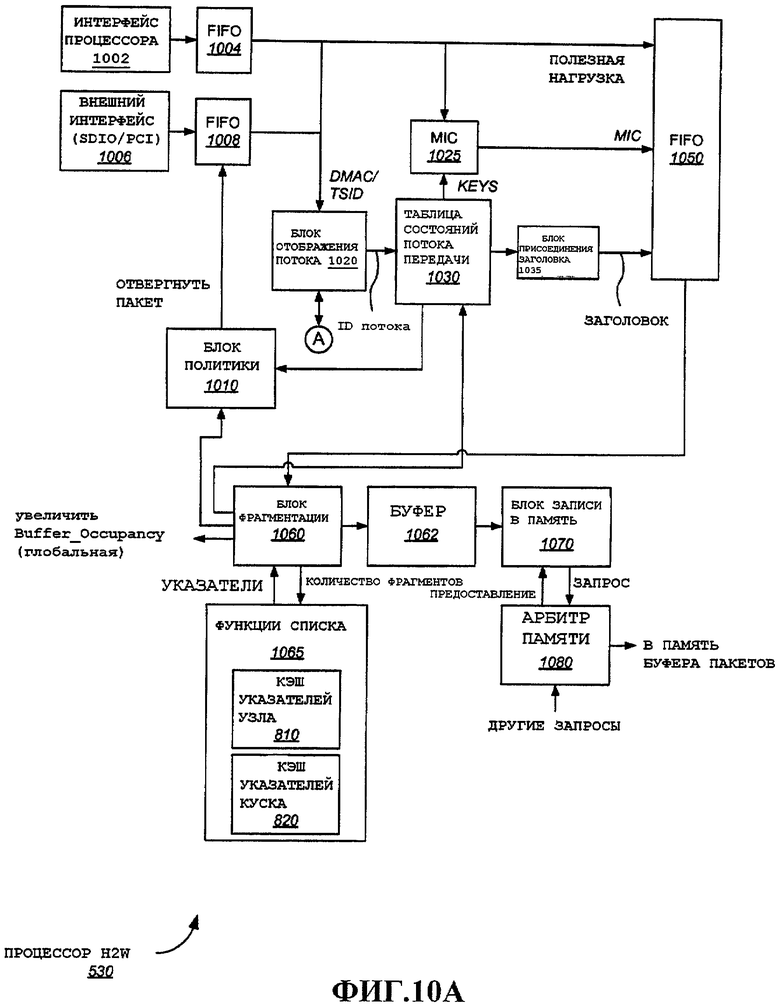
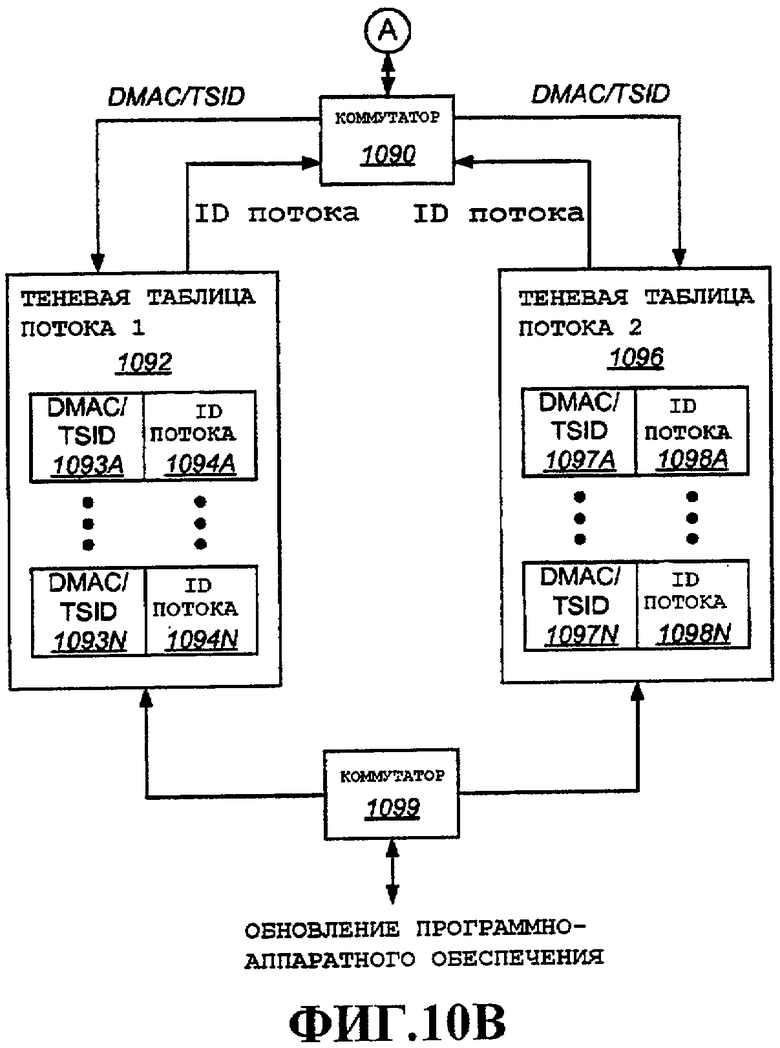

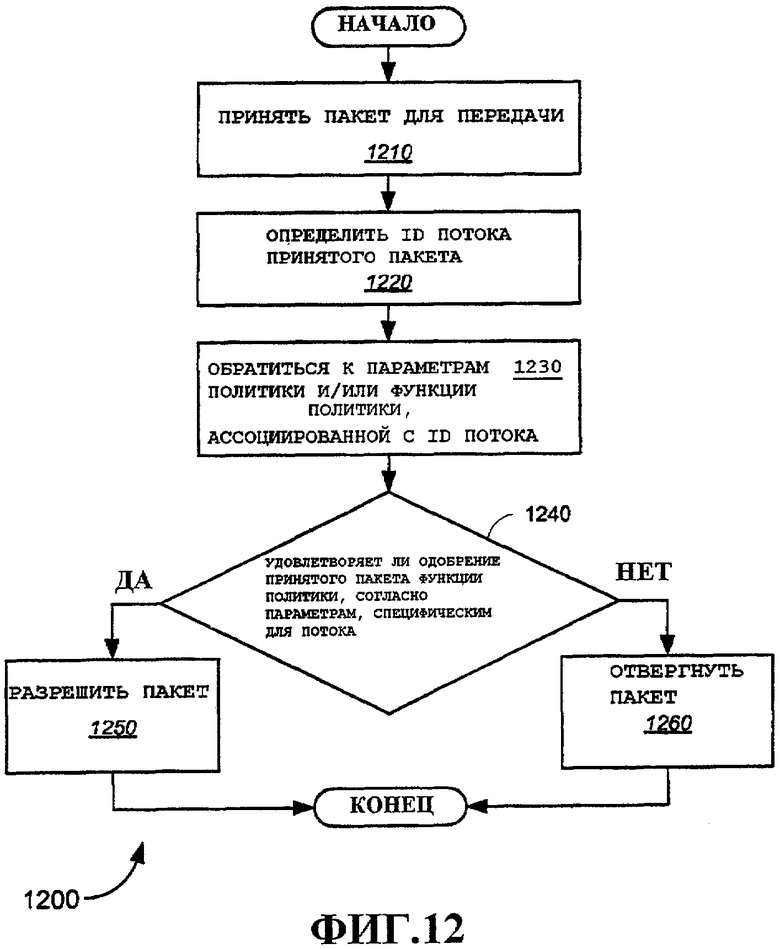
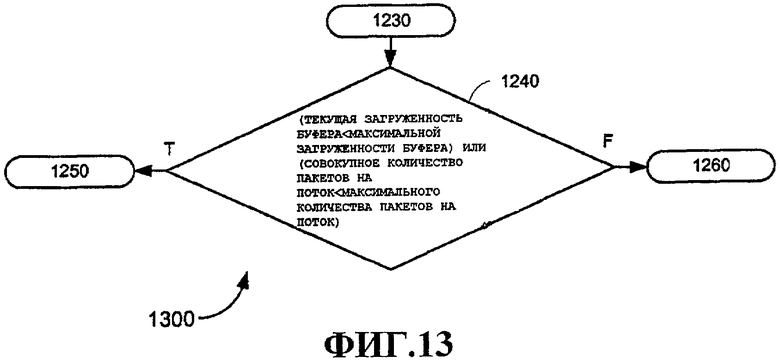
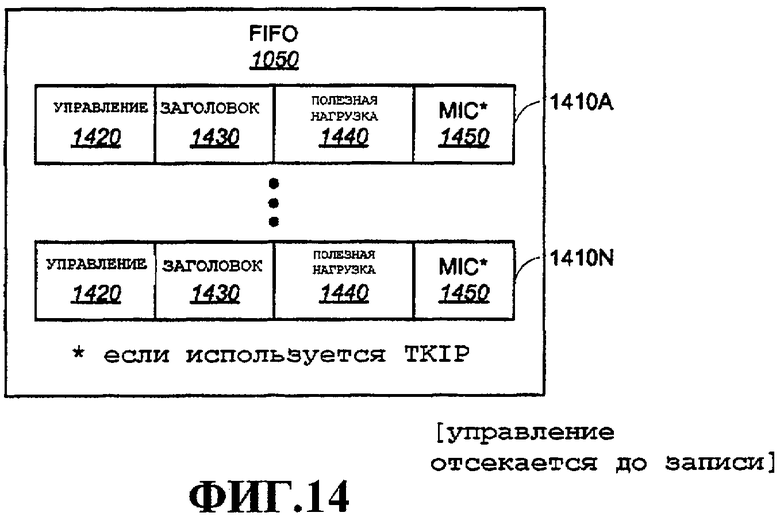
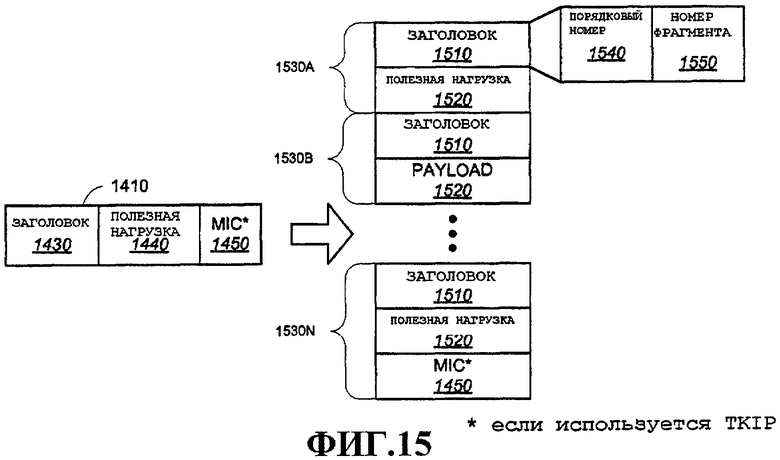
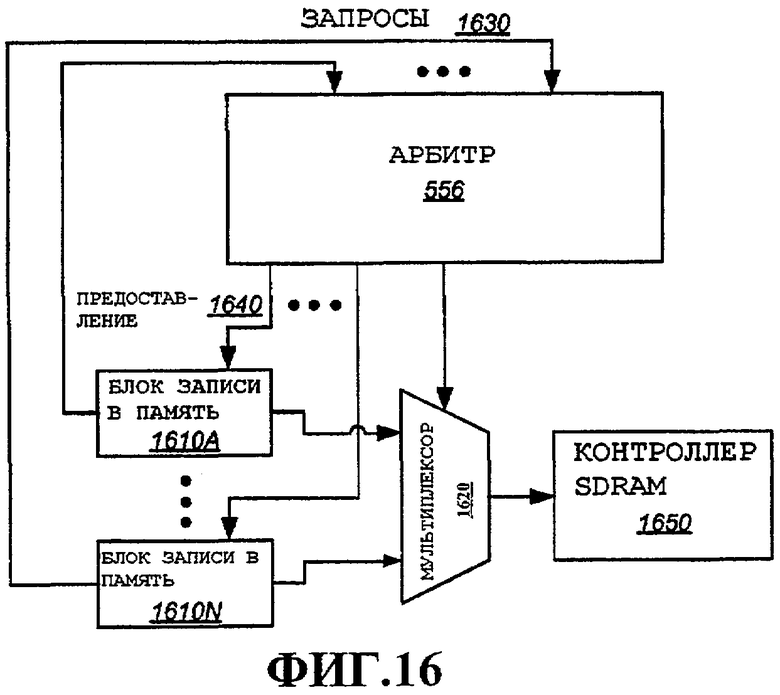
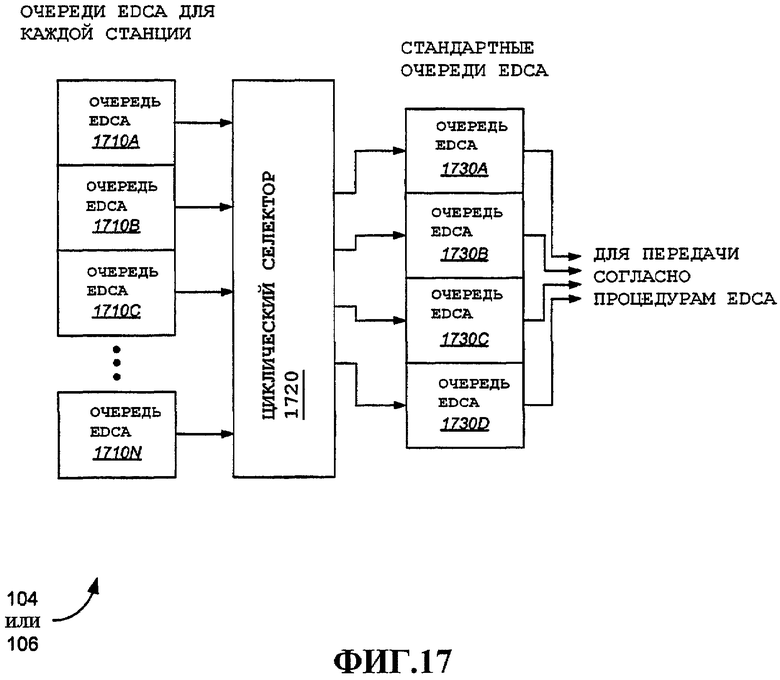
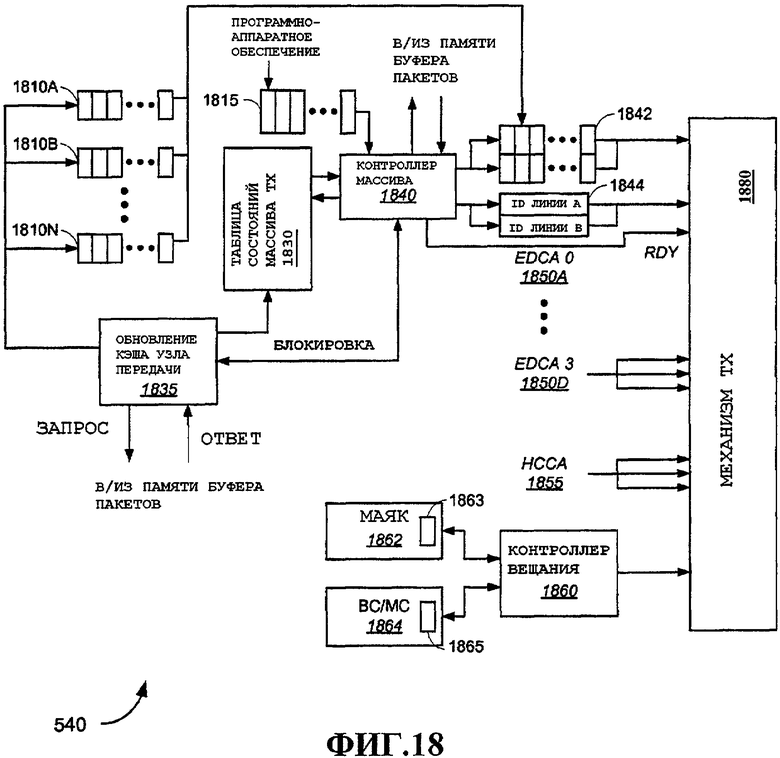
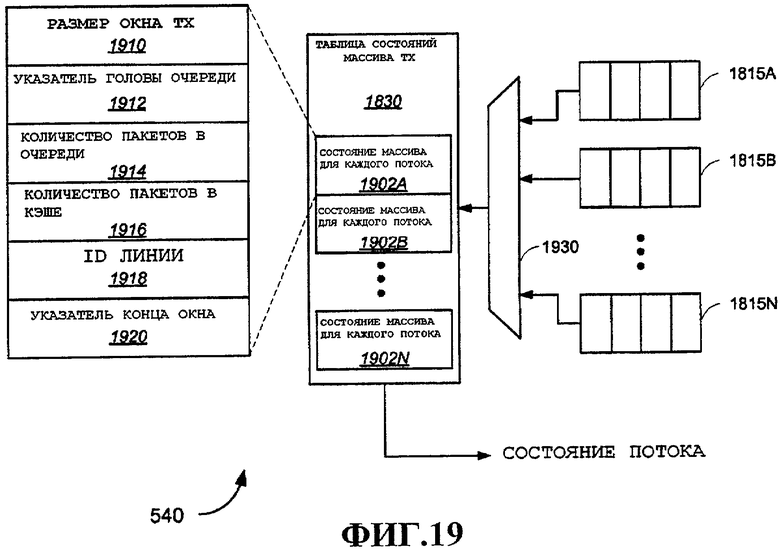
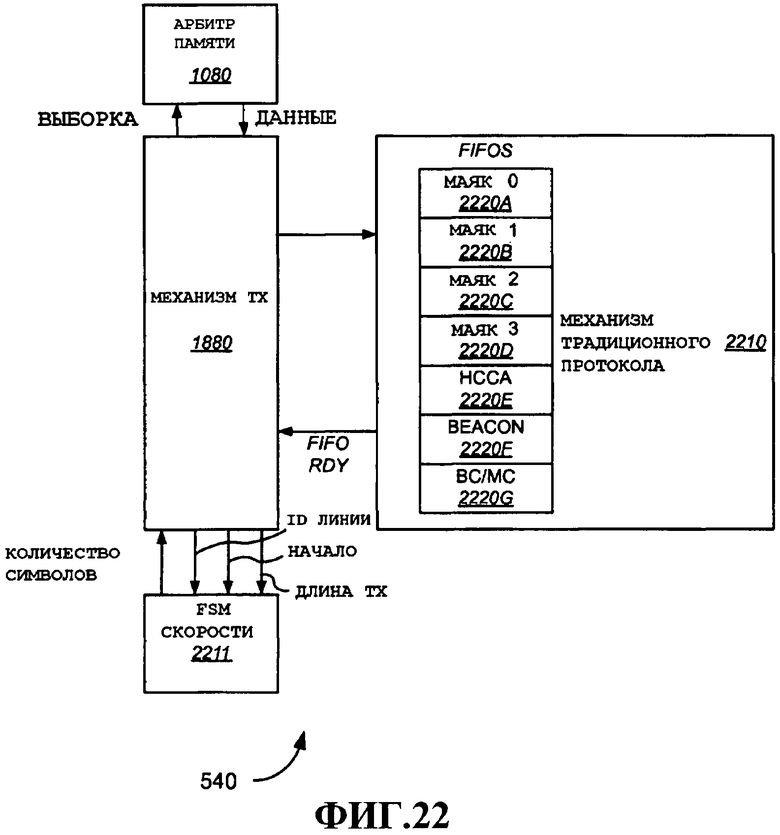
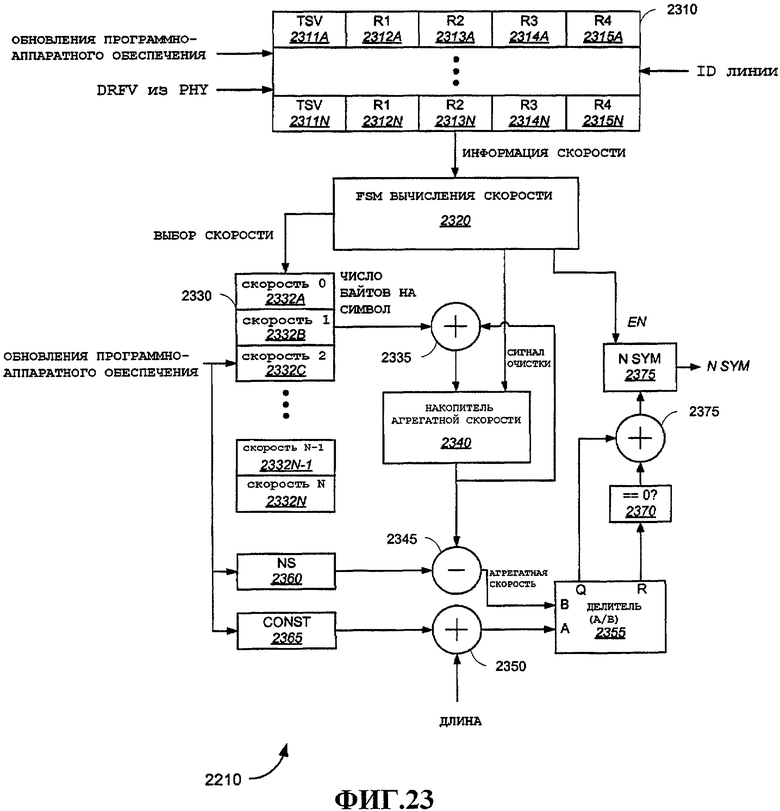
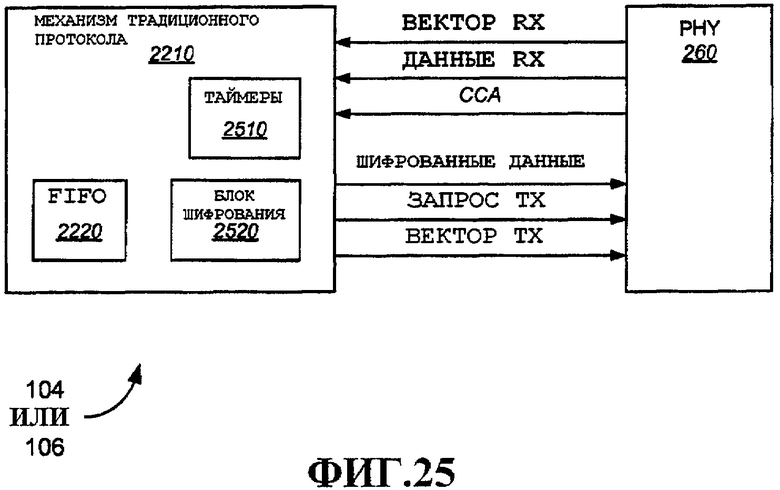
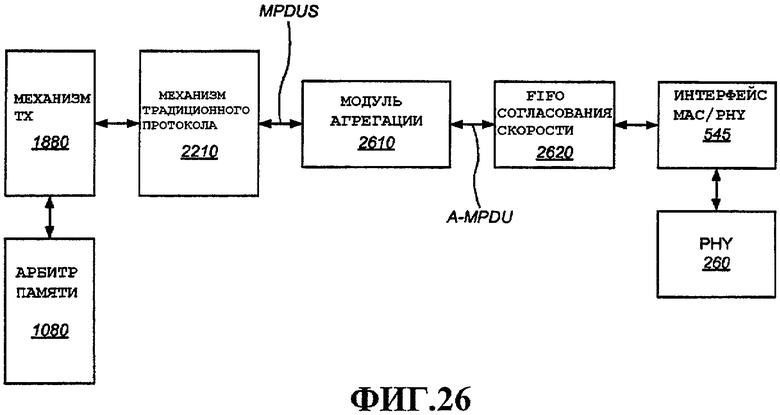
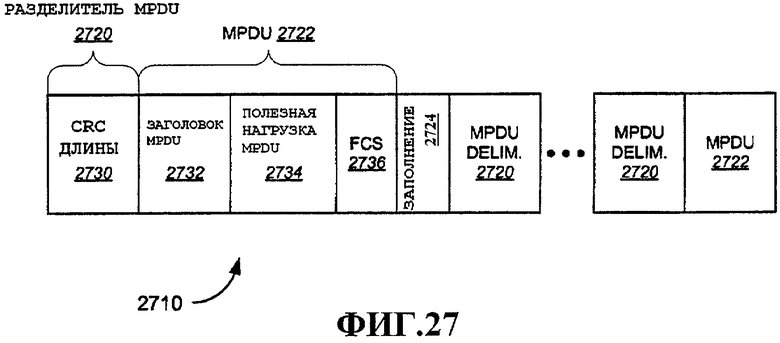
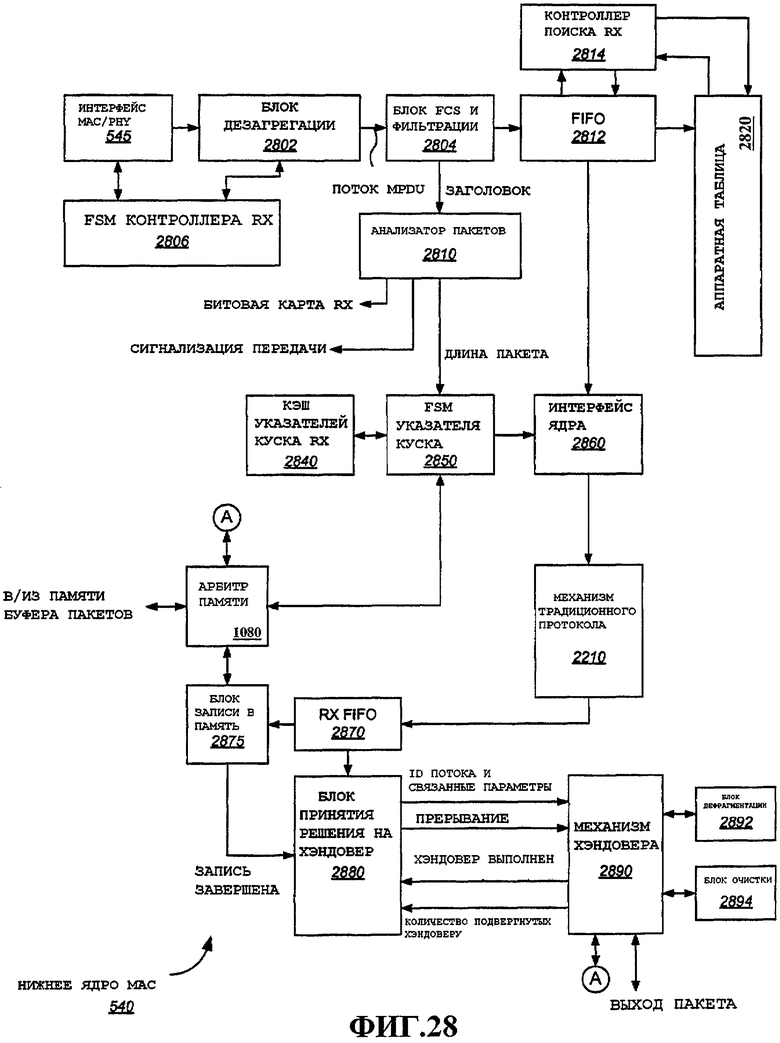
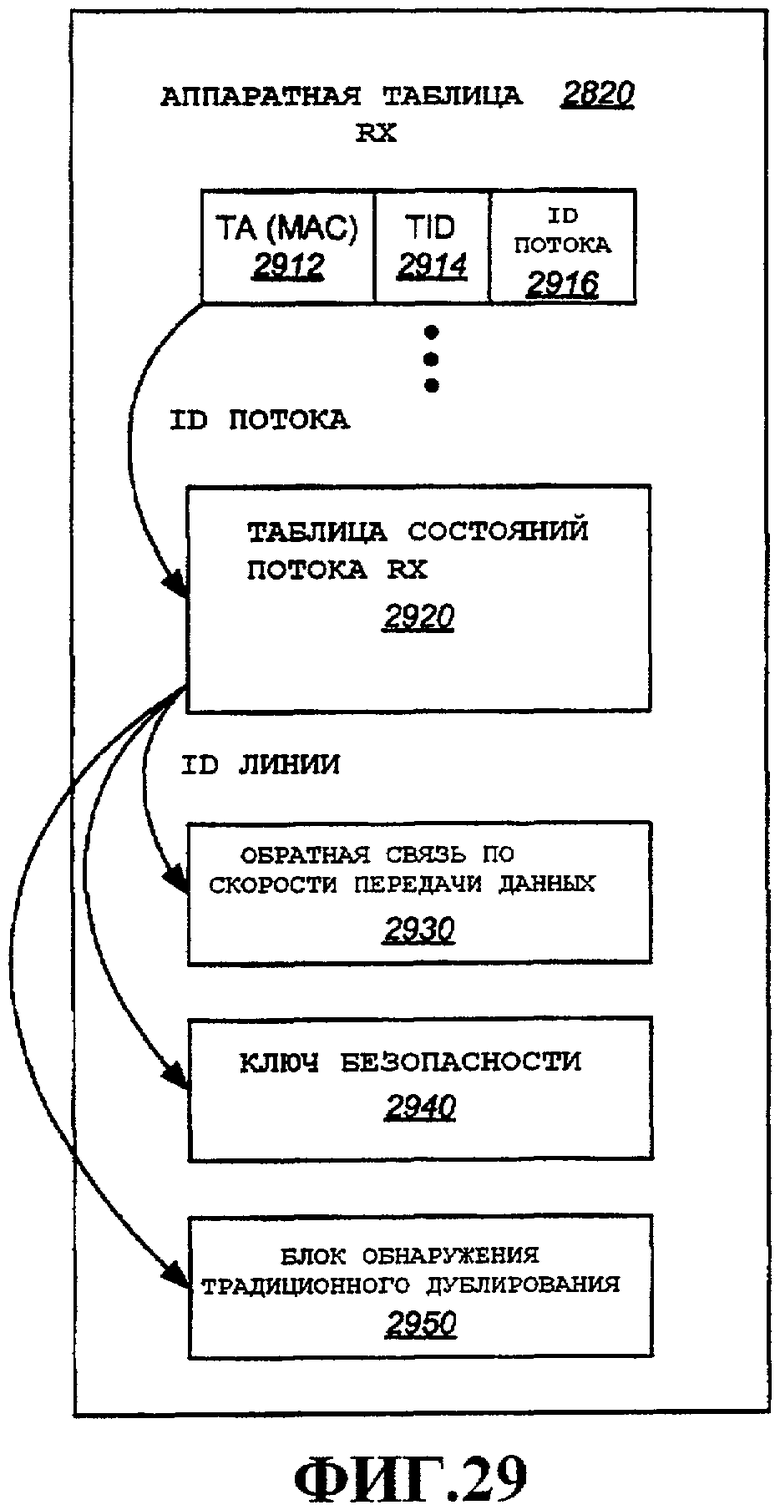
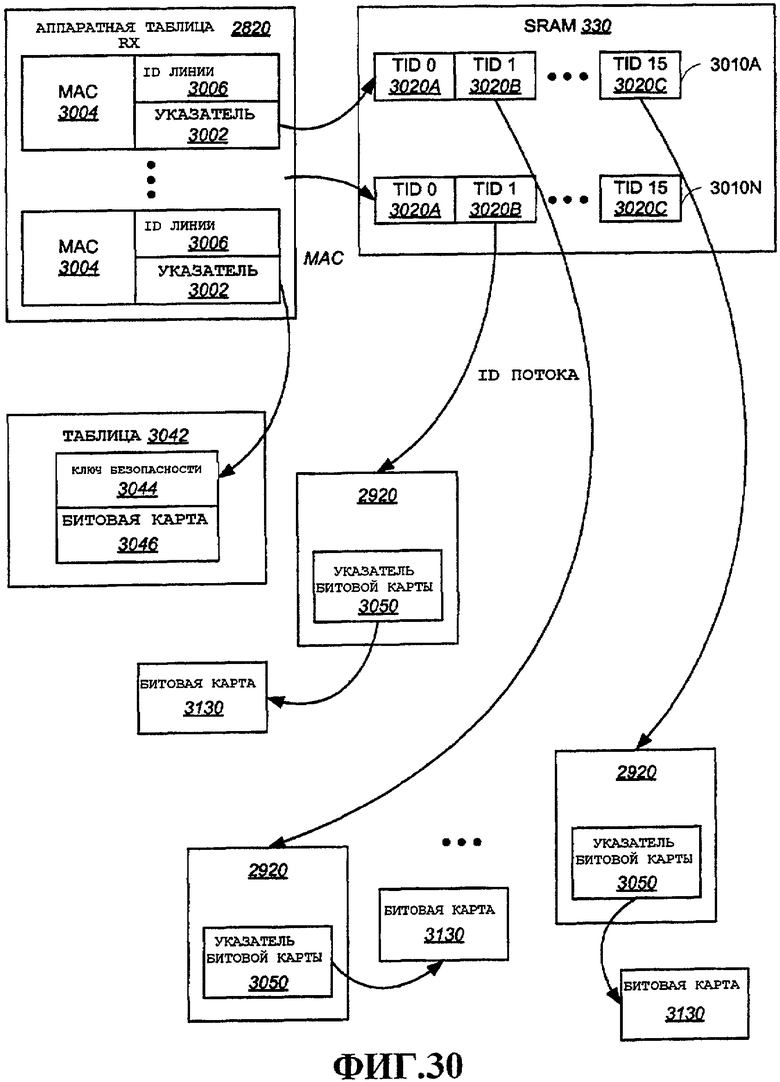
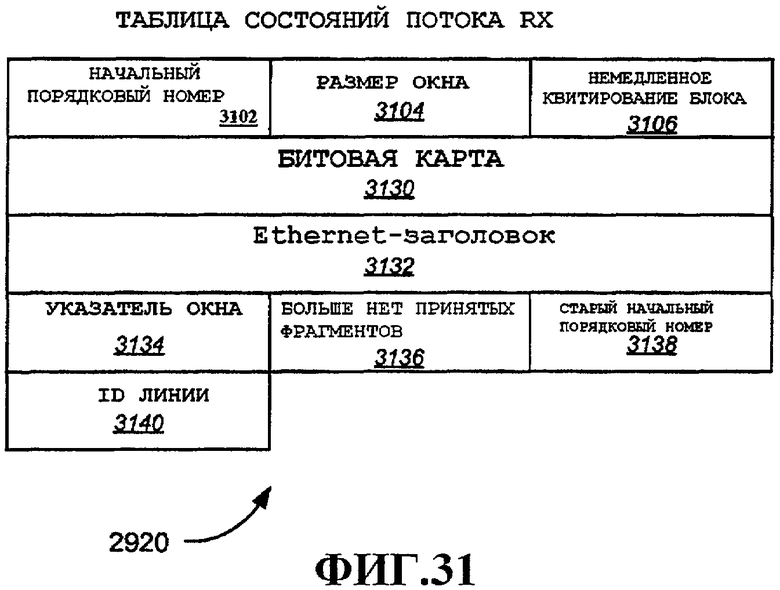
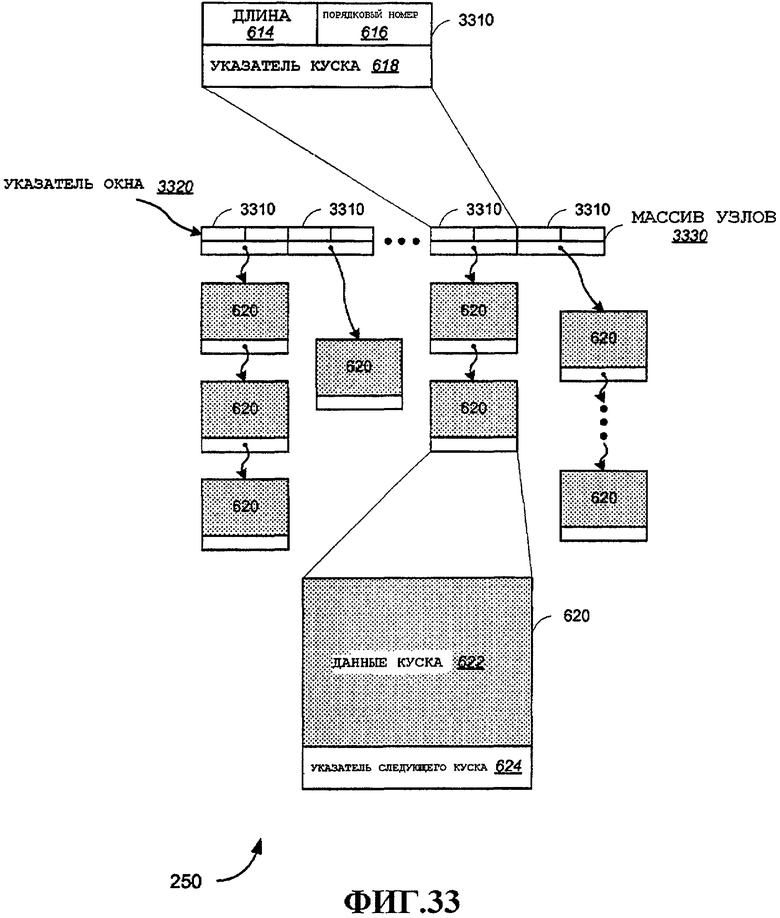
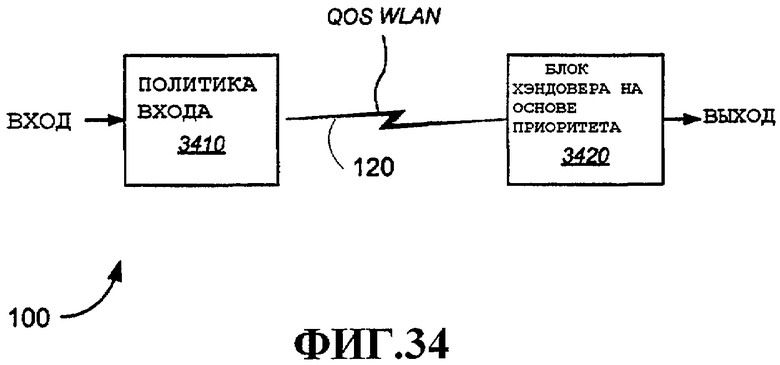
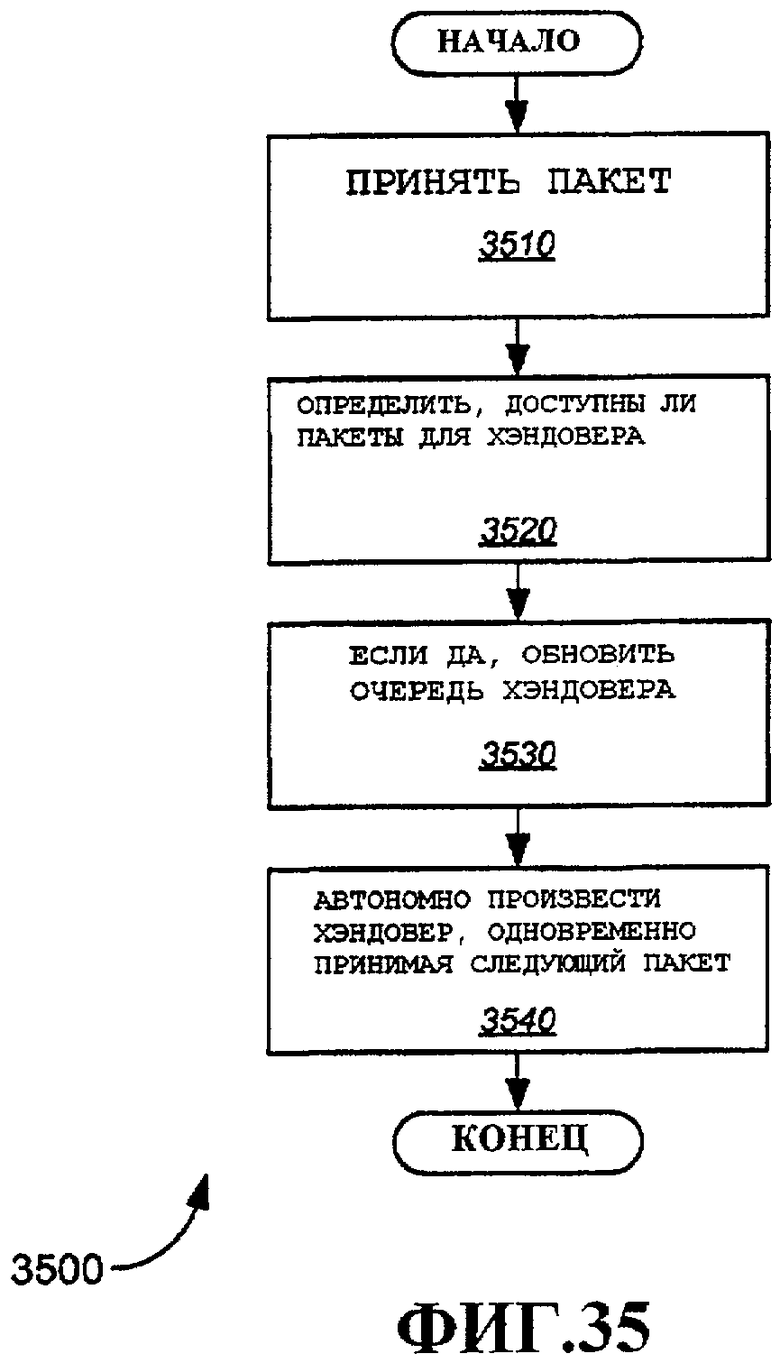
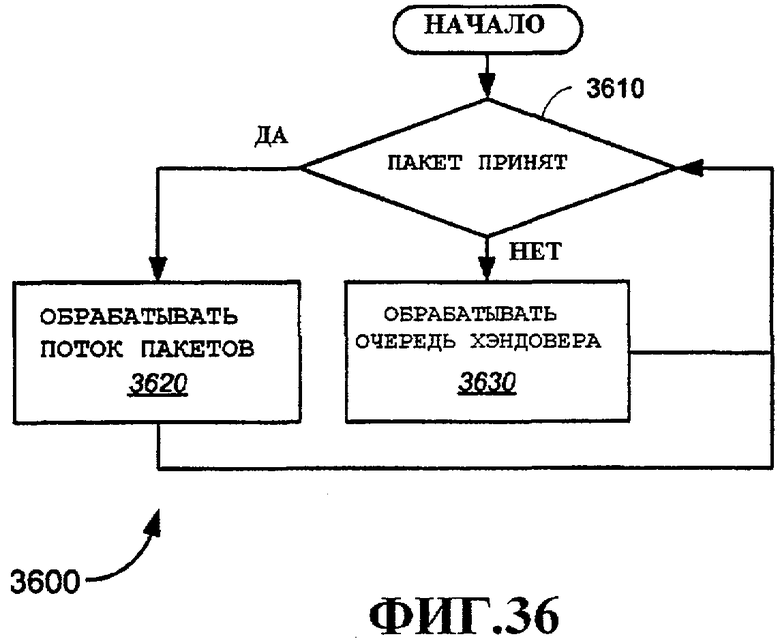
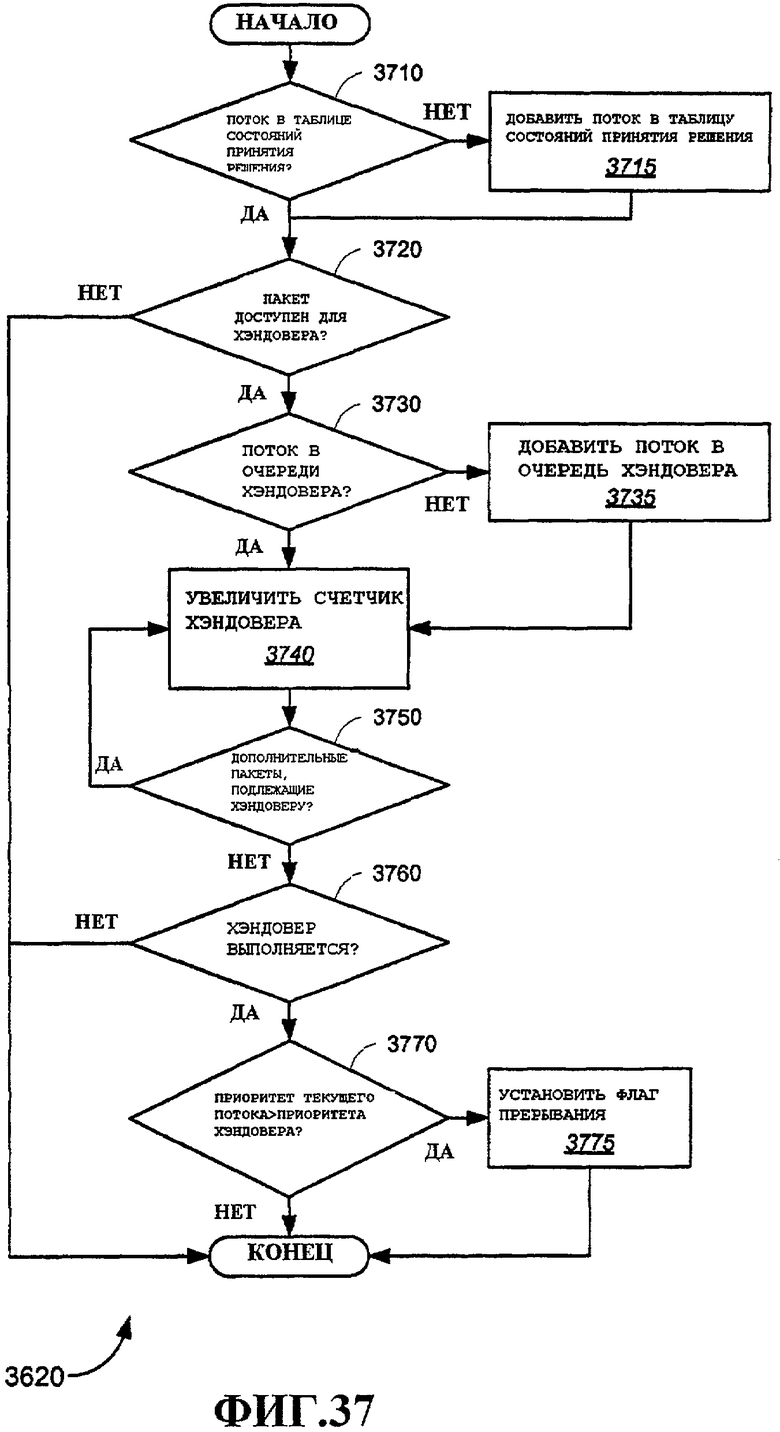
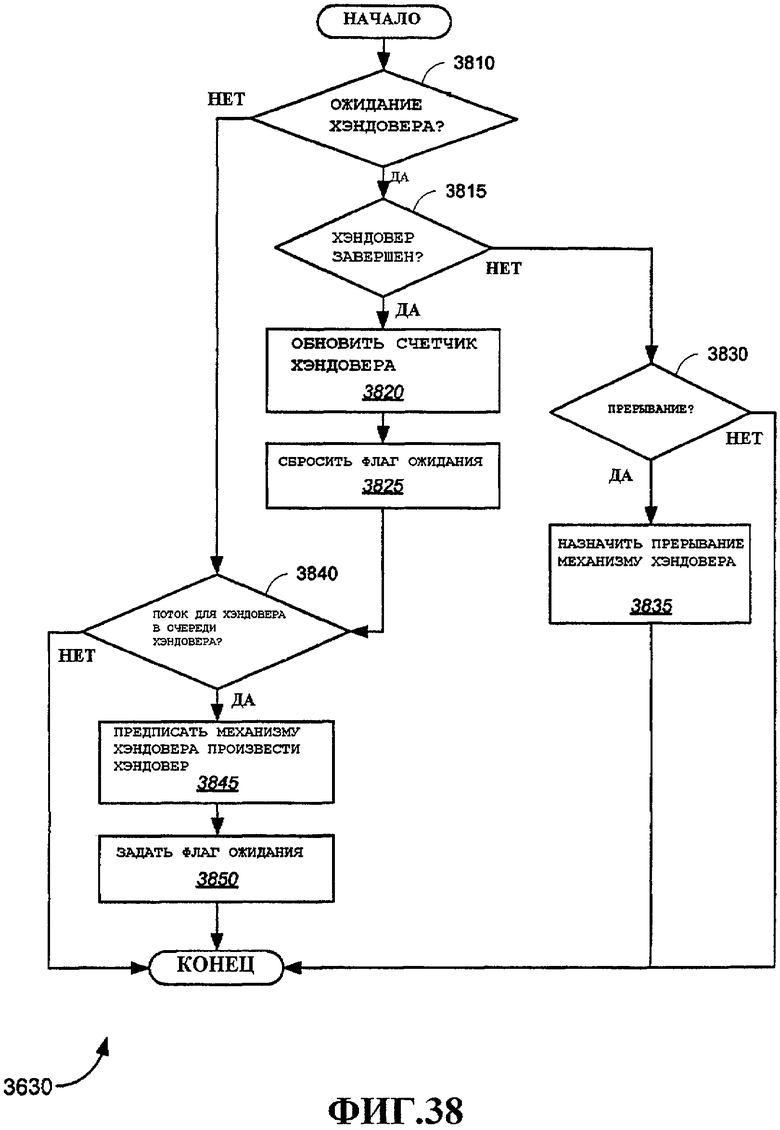
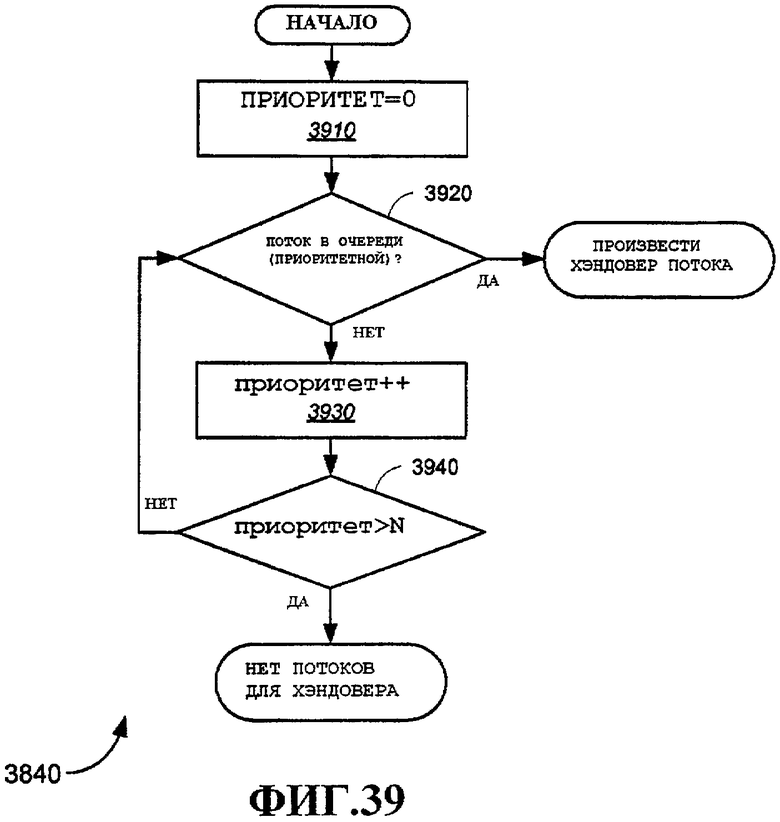

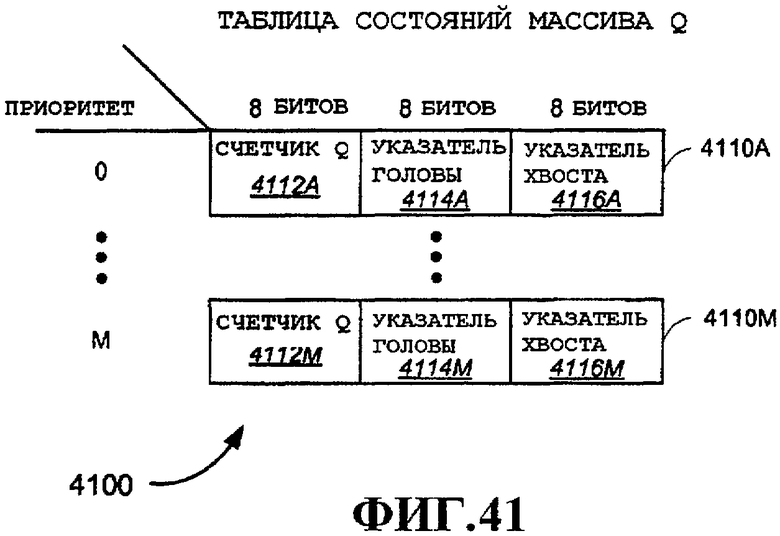
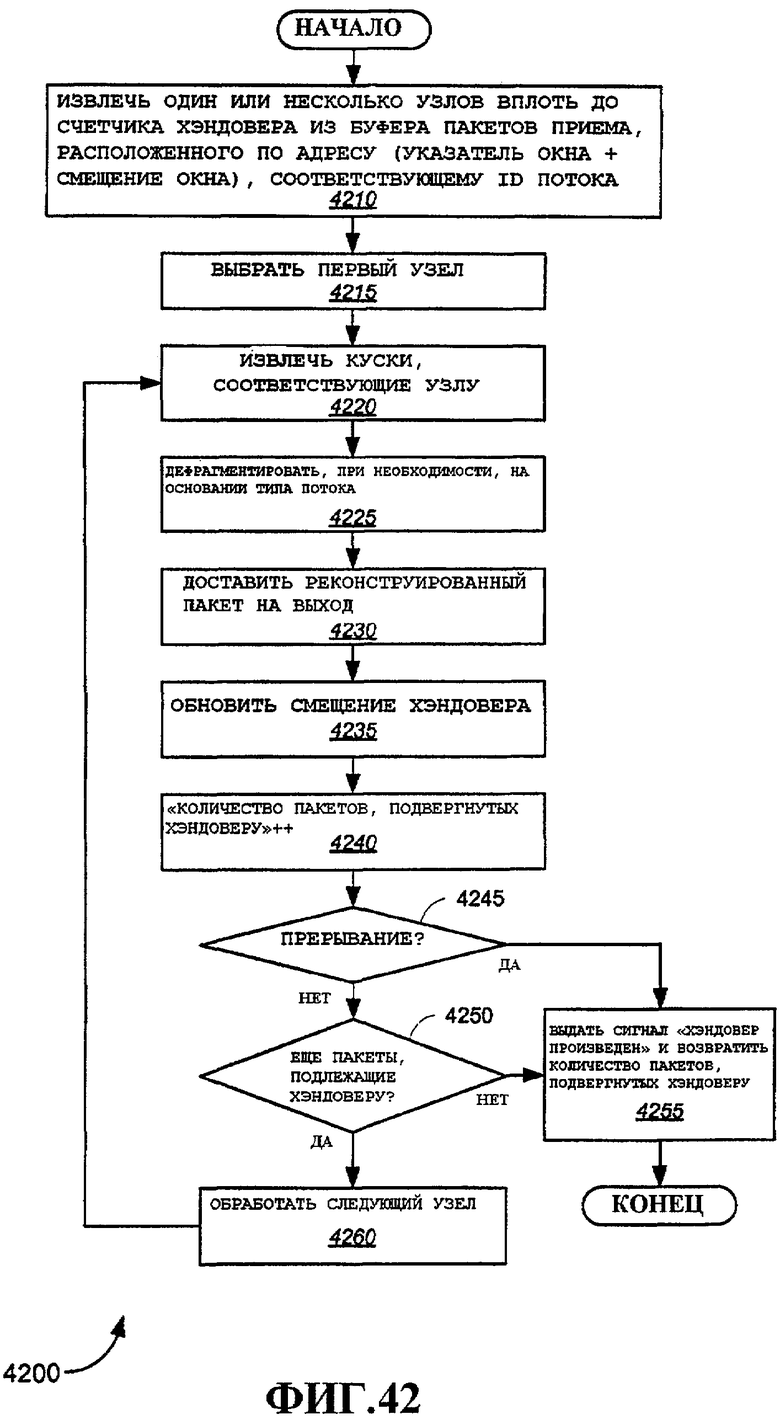
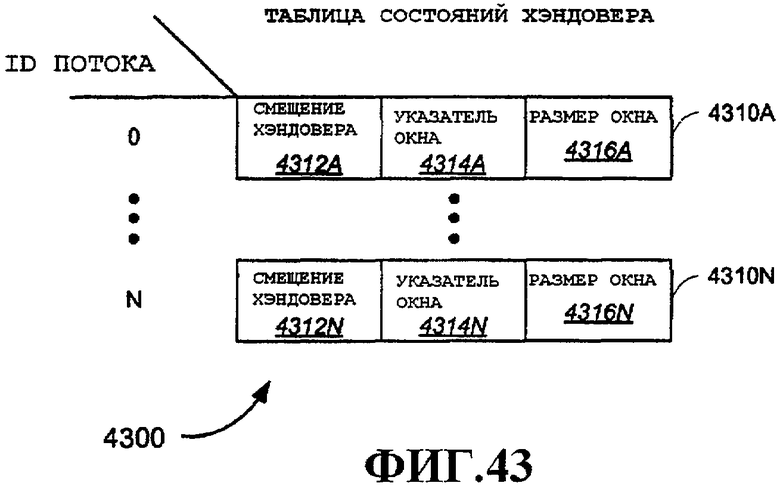
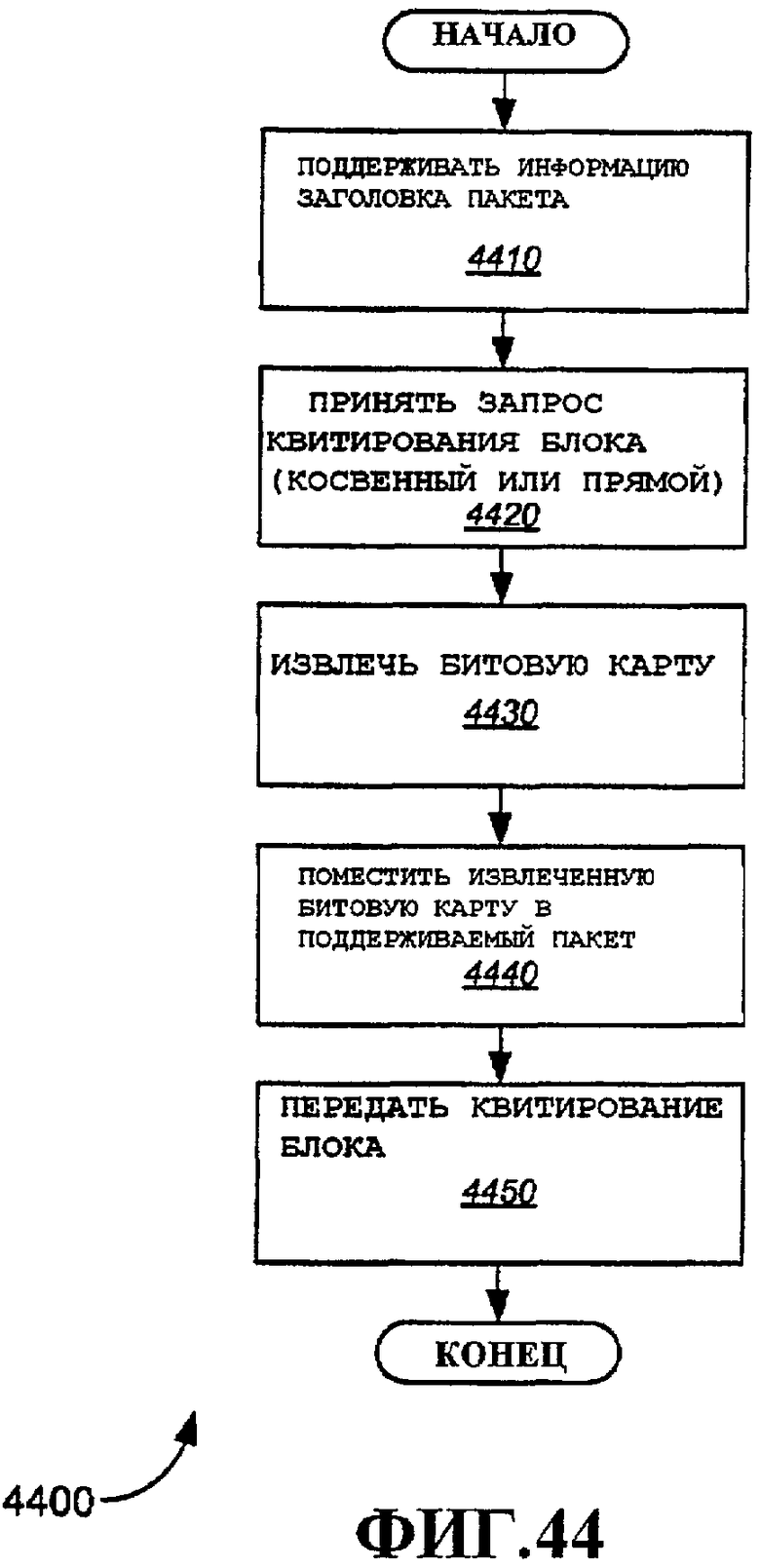
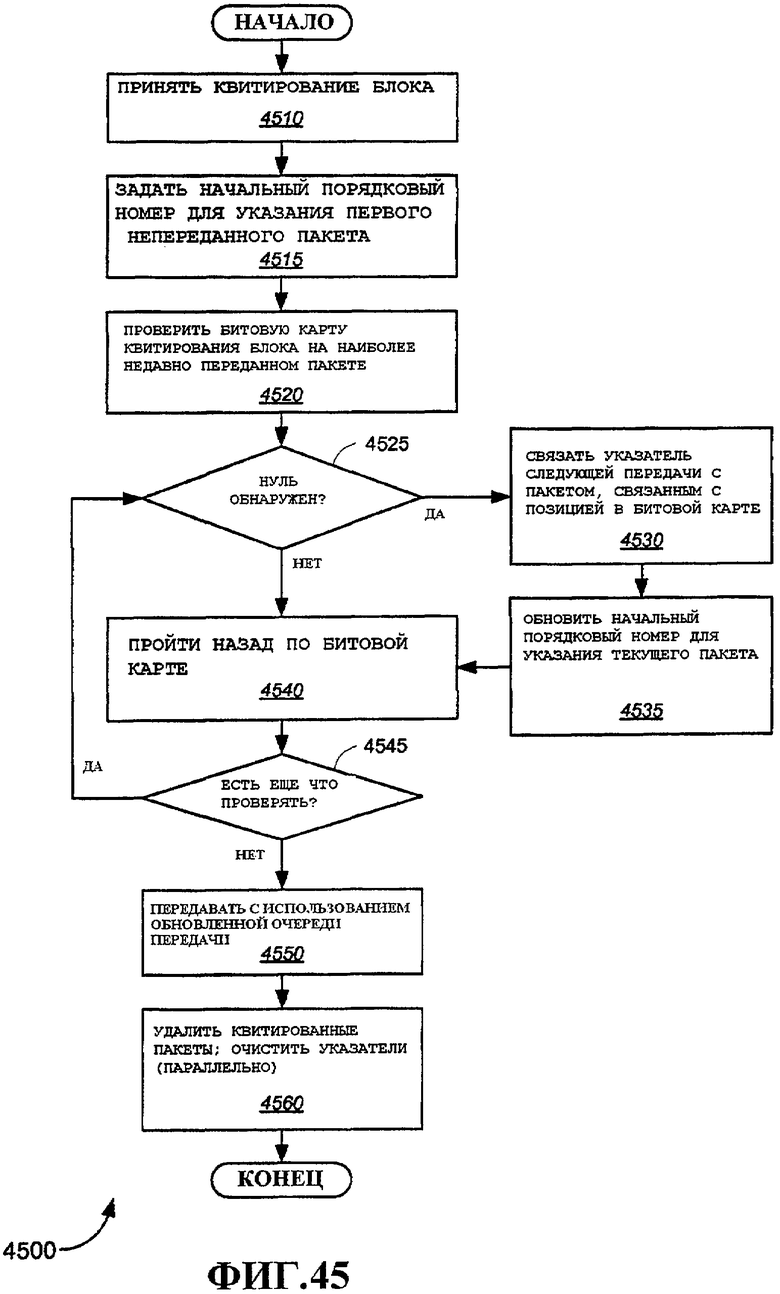
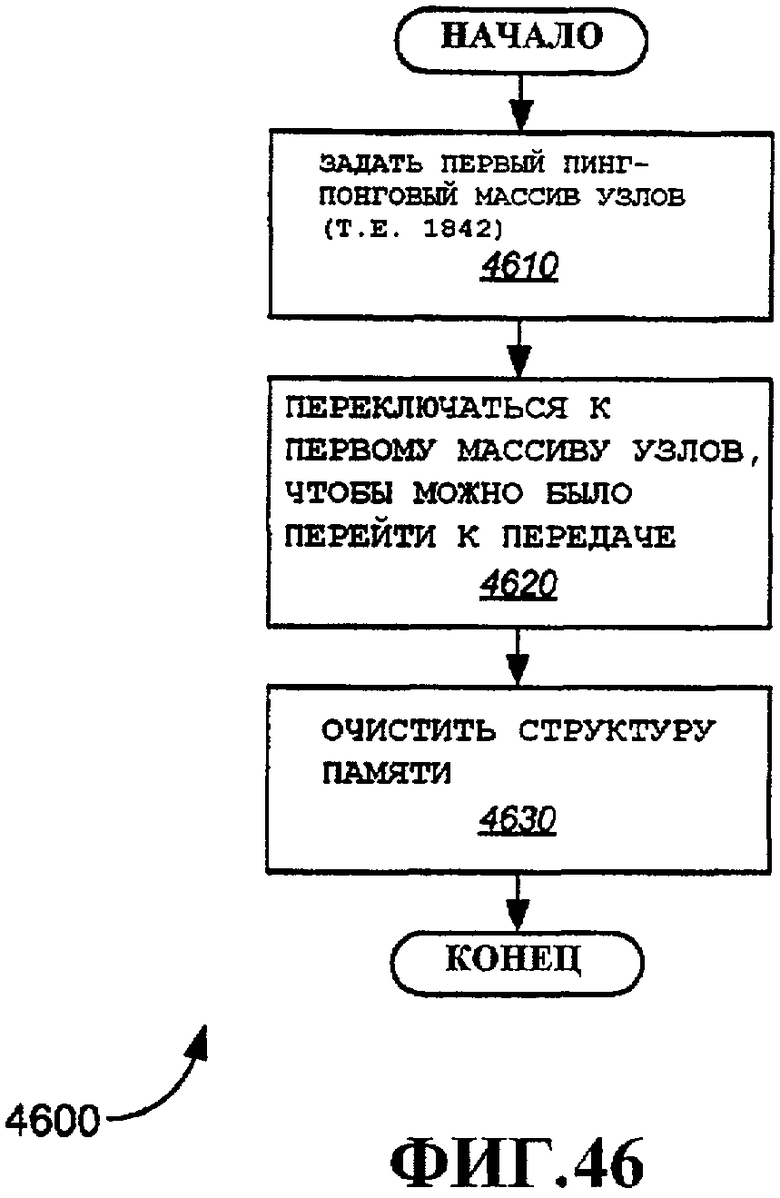
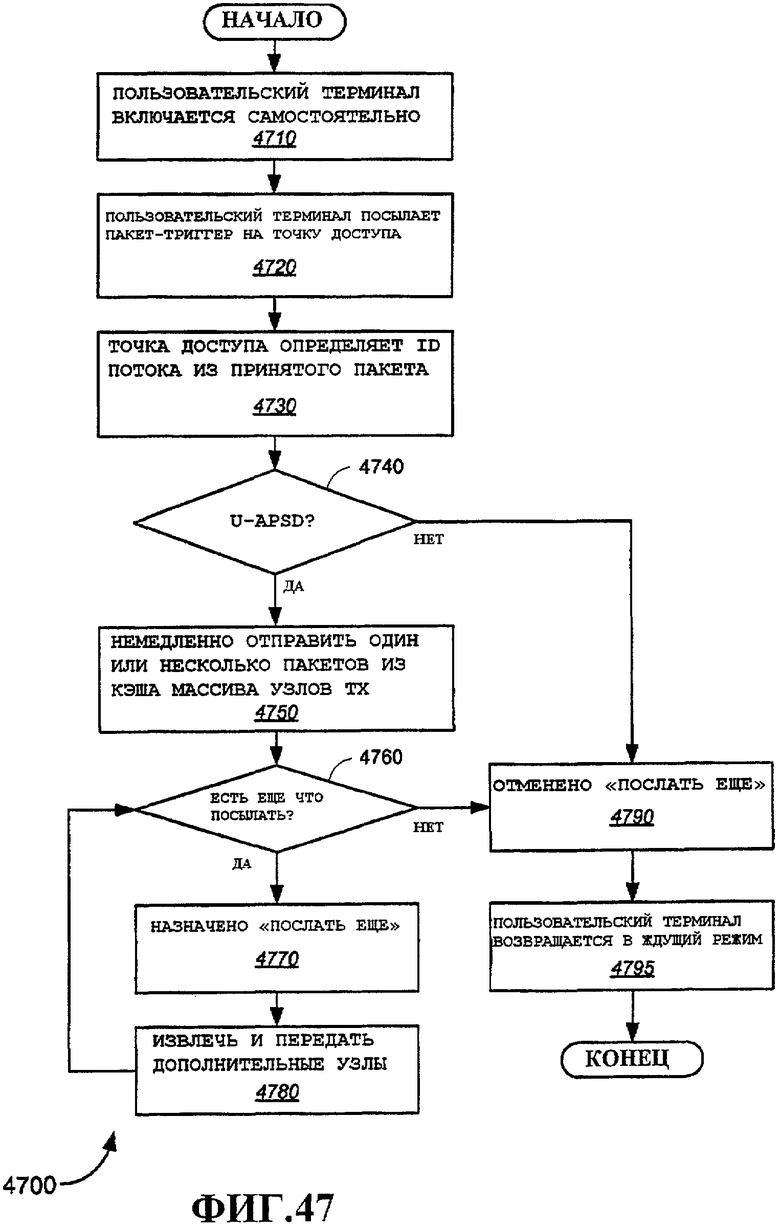
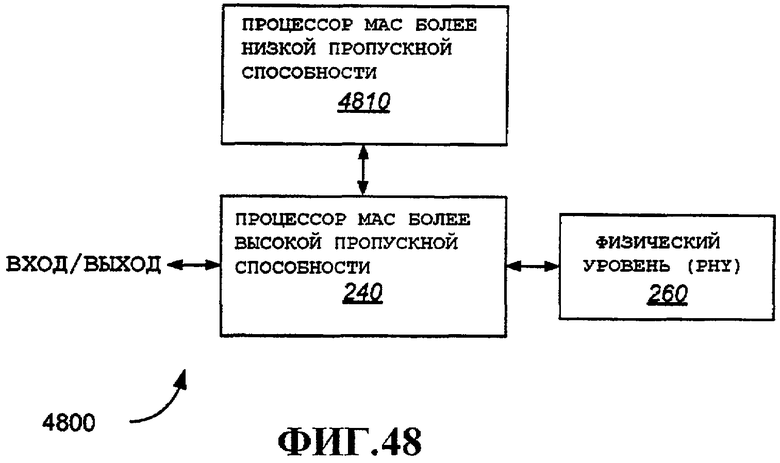
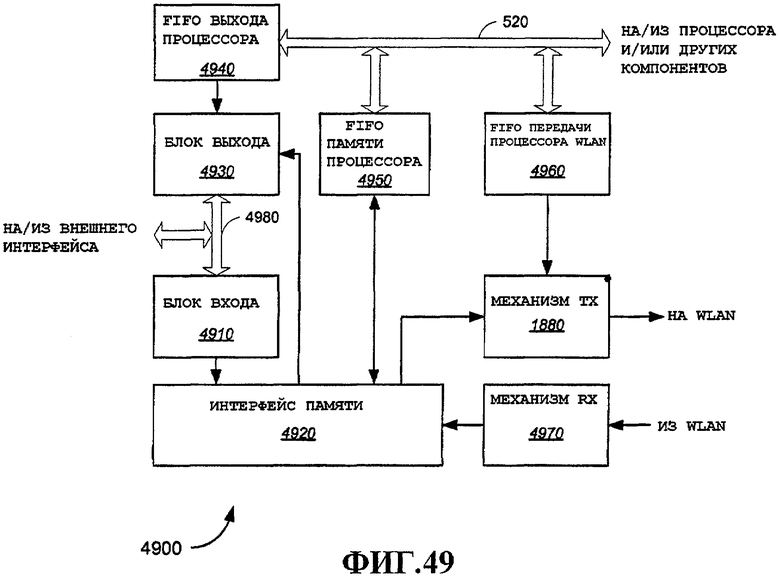
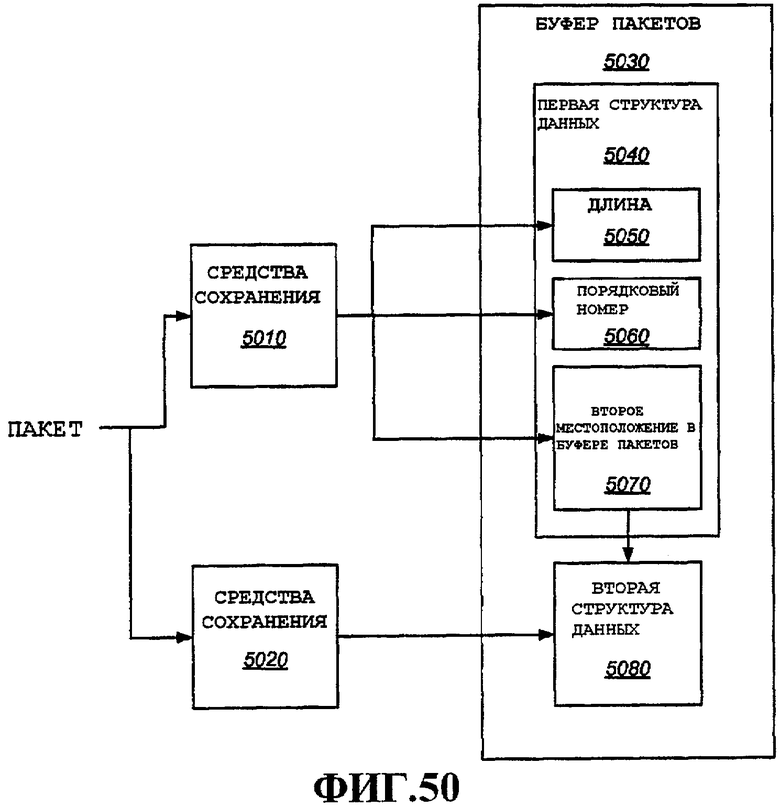
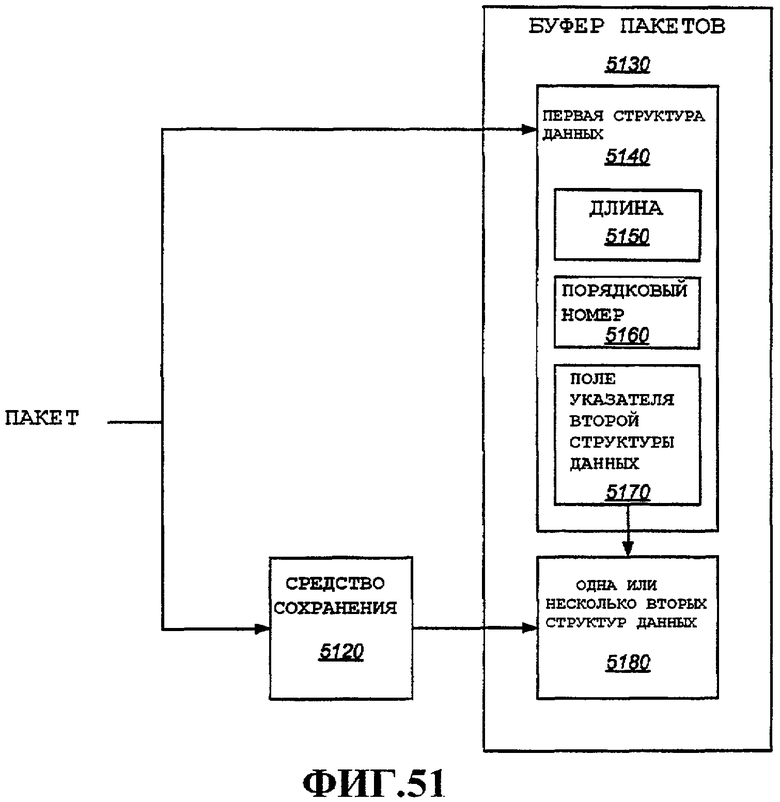
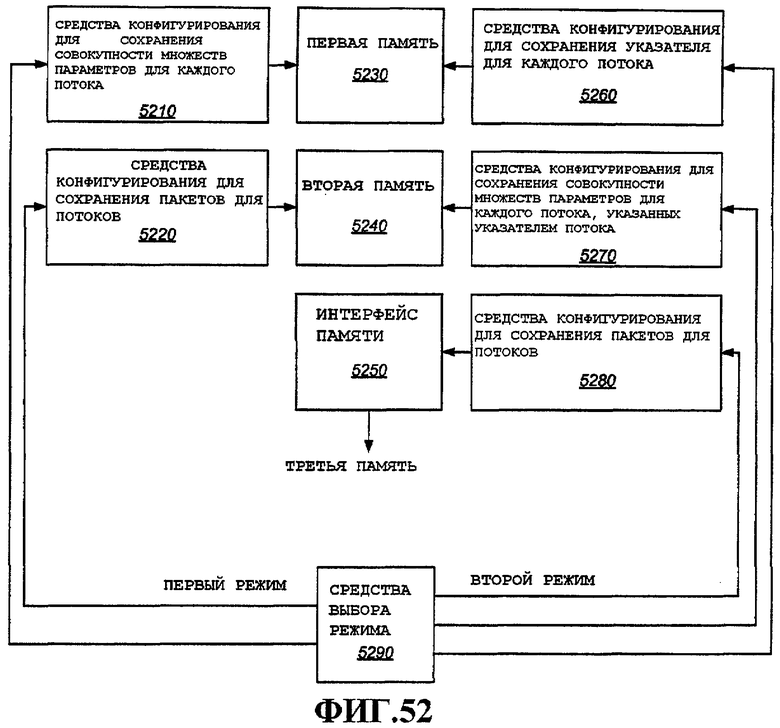
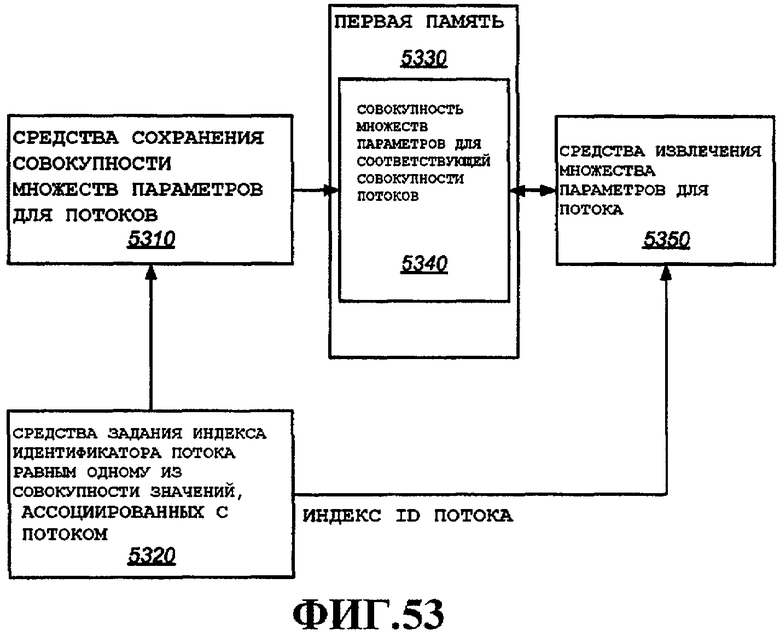
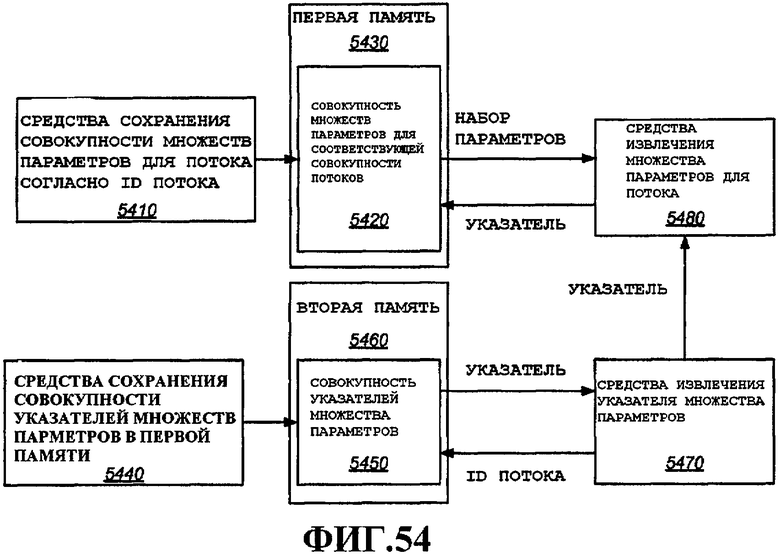
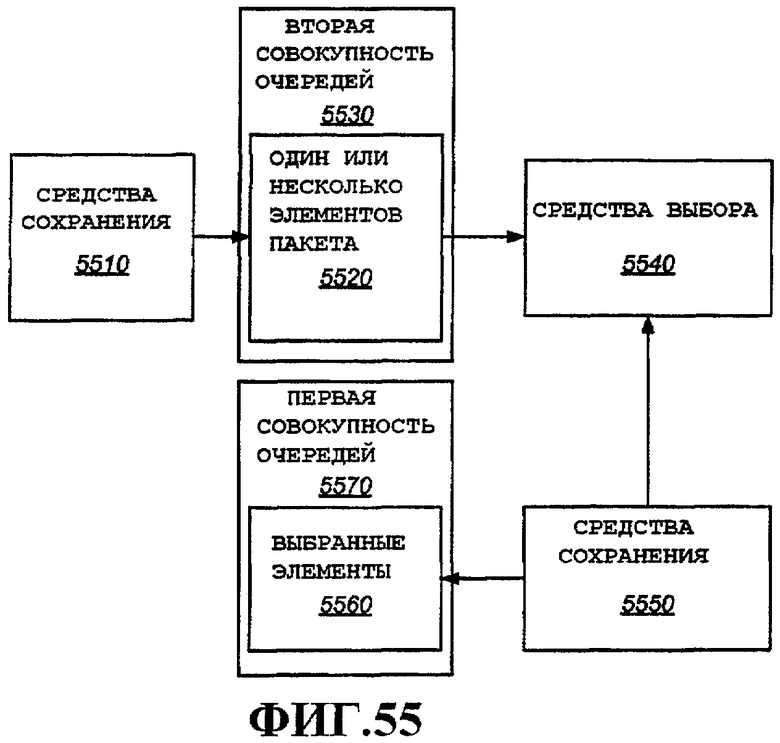
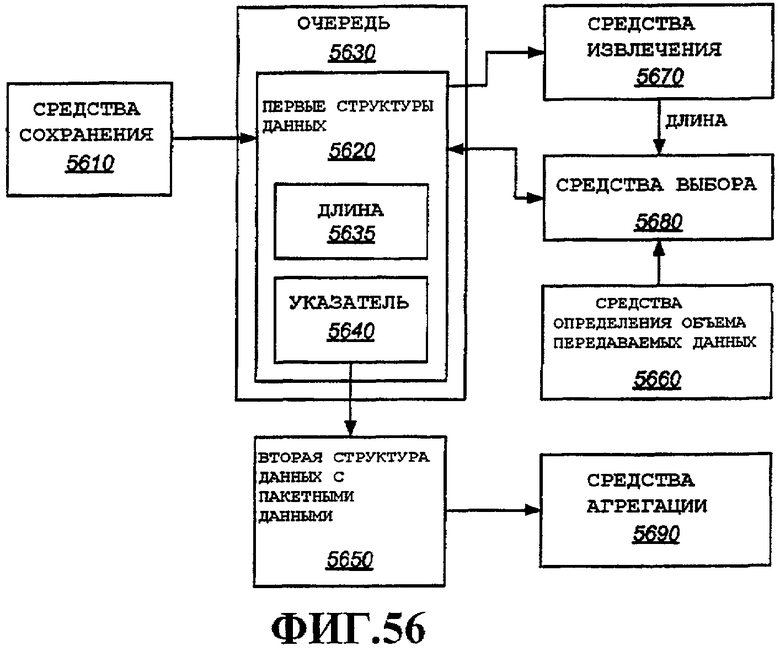
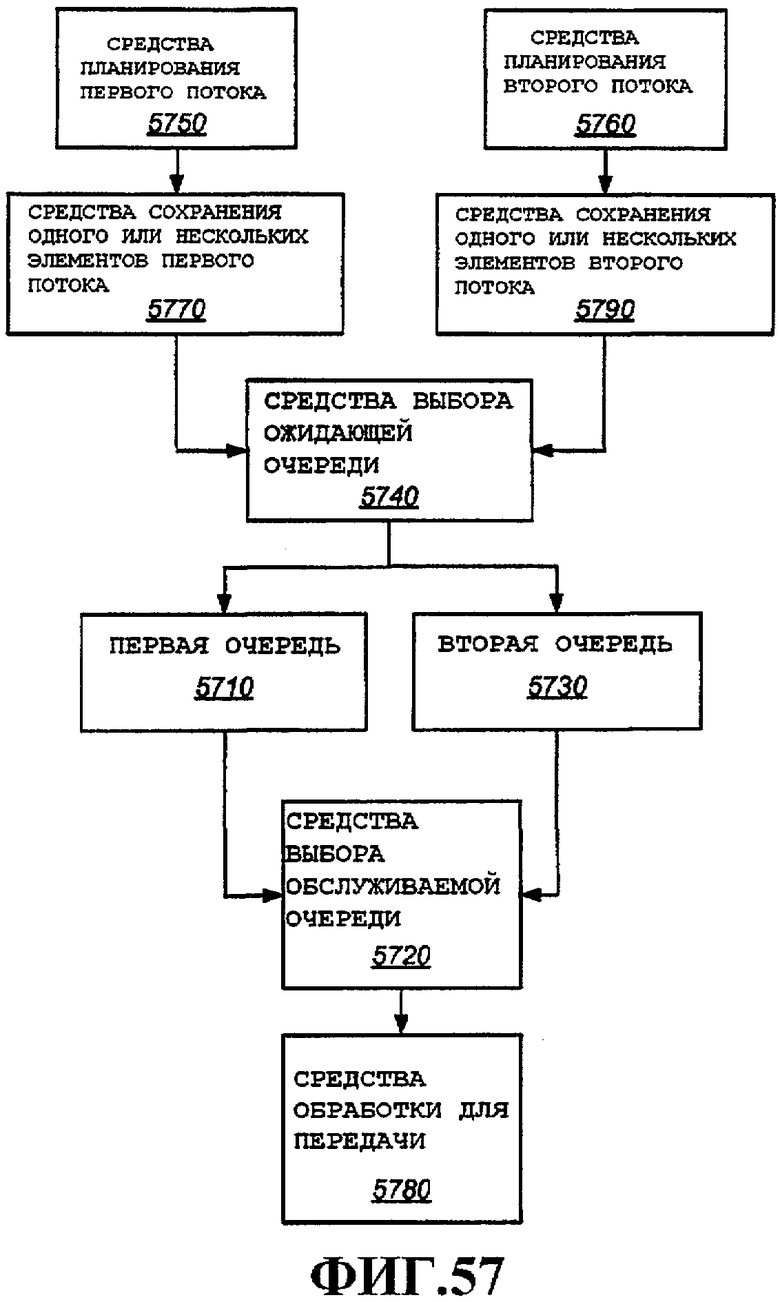
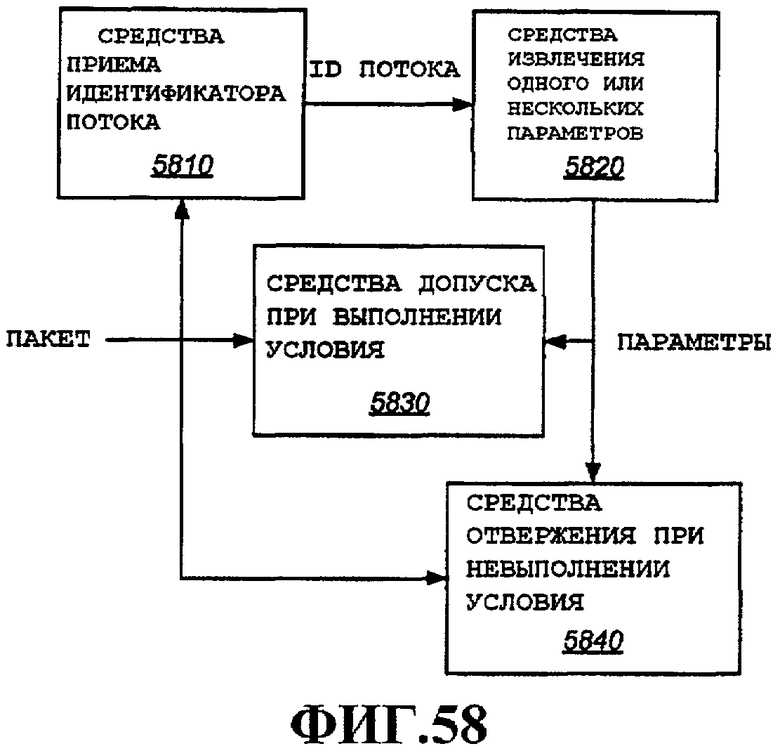
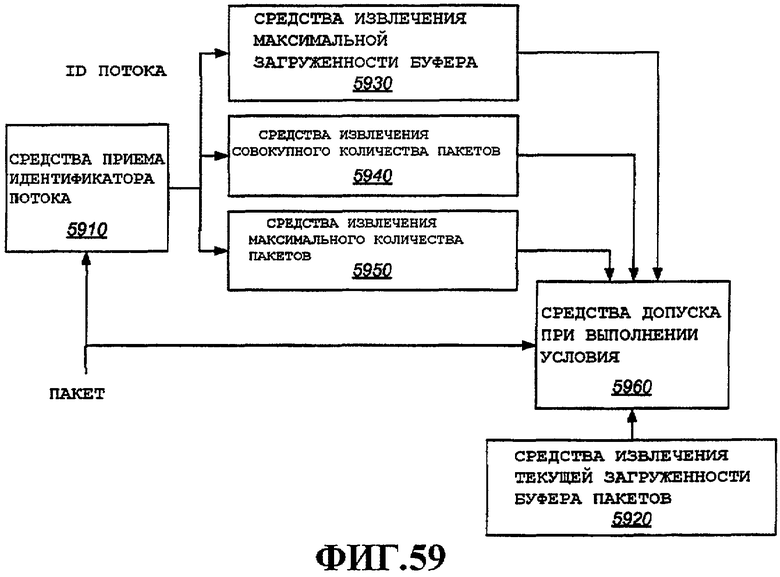
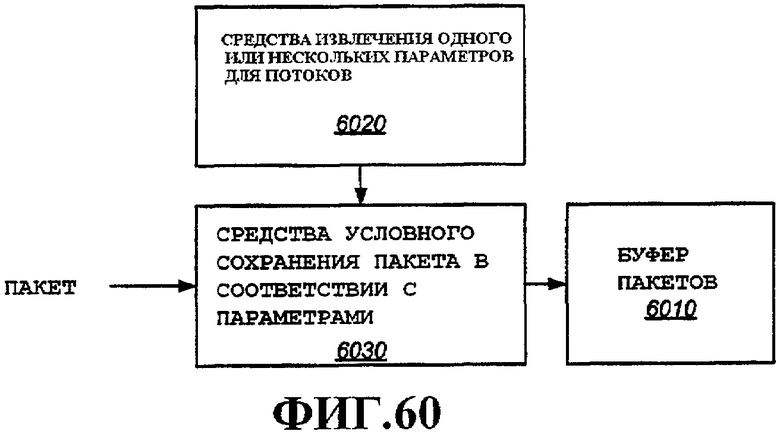
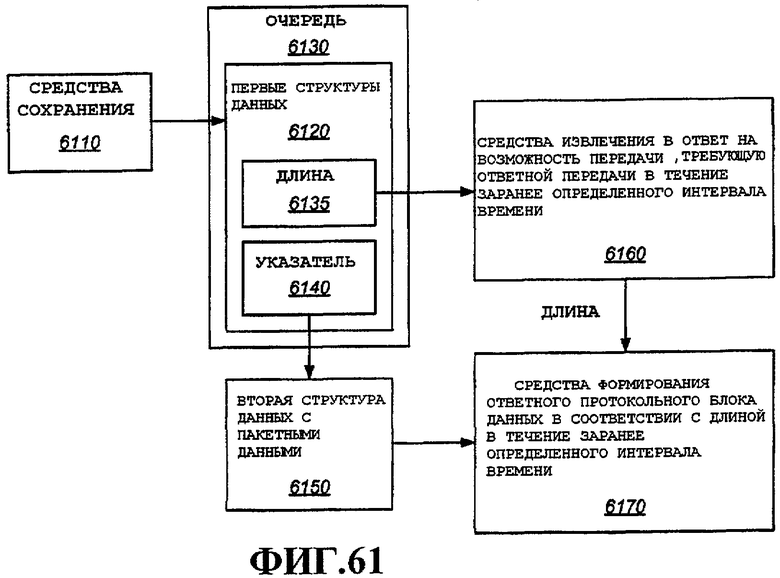
Заявленное изобретение относится к беспроводной связи. Технический результат заключается в эффективном высокоскоростном управлении доступом к среде. Для этого в буфере пакетов могут храниться пакеты с первой структурой данных, содержащей длину пакета, порядковый номер и указатель на вторую структуру данных. Пакетные данные можно сохранять в связном списке из одной или нескольких вторых структур данных. Очереди передачи и приема можно формировать с использованием связных списков или массивов первых структур данных. Местоположения в памяти для хранения первых и вторых структур данных могут поддерживаться в списках, указывающих свободные местоположения для соответствующих типов структур данных. Раскрыта гибкая архитектура памяти, в которой можно выбирать две конфигурации. В первой конфигурации первая память содержит параметры каждого потока для множества потоков, и вторая память содержит буфер пакетов. Во второй конфигурации первая память содержит указатели для каждого потока на параметры для каждого потока во второй памяти. Буфер пакетов располагается в третьей памяти. Также представлены различные другие аспекты. 5 н. и 16 з.п. ф-лы, 61 ил.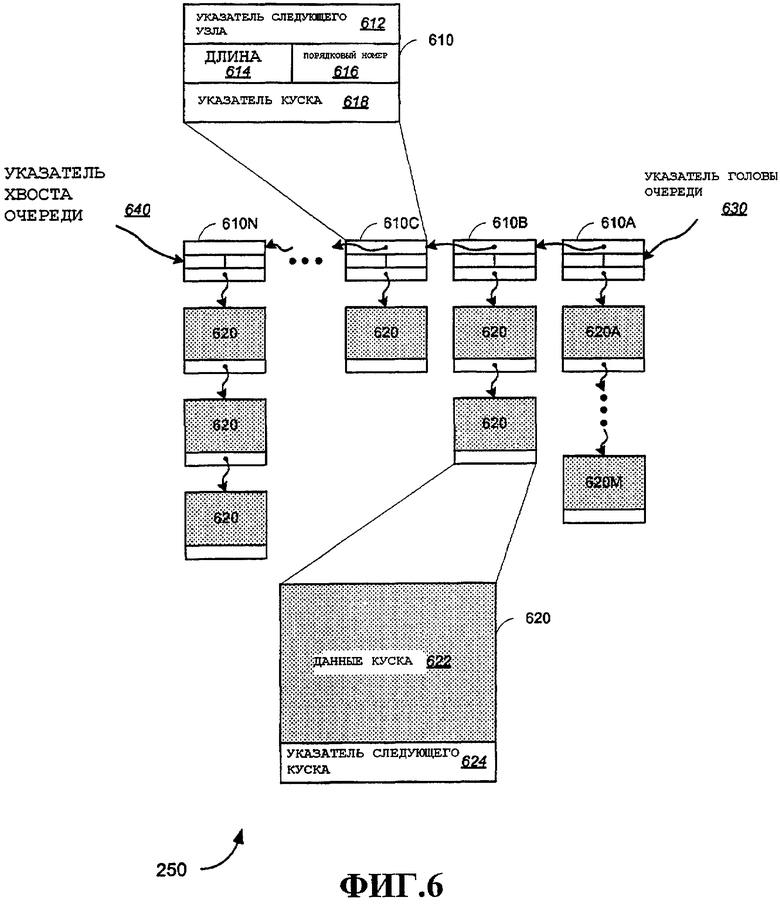
1. Способ управления памятью для высокоскоростного доступа к среде, содержащий этапы, на которых
сохраняют в первой структуре данных в буфере пакетов длину первого пакета, порядковый номер упомянутого пакета и местоположение второго пакета в буфере пакетов для второй структуры данных в буфере пакетов; и
сохраняют данные из первого пакета во второй структуре данных, идентифицируемой сохраненным местоположением второго пакета в буфере пакетов.
2. Способ по п.1, дополнительно содержащий этапы, на которых
сохраняют в третьей структуре данных в буфере пакетов длину второго пакета, порядковый номер второго пакета и местоположение четвертого пакета в буфере пакетов для четвертой структуры данных в буфере пакетов,
сохраняют данные из второго пакета в четвертой структуре данных, идентифицируемой сохраненным местоположением четвертого пакета в буфере пакетов, и
сохраняют местоположение третьей структуры данных в первой структуре данных.
3. Способ по п.1, дополнительно содержащий этап, на котором формируют очередь пакетов путем сохранения связного списка совокупности первых структур данных, причем каждая первая структура данных ассоциирована с одним из совокупности пакетов.
4. Способ по п.1, дополнительно содержащий этап, на котором формируют массив первых структур данных, причем каждая первая структура данных ассоциирована с одним из совокупности пакетов.
5. Способ по п.1, дополнительно содержащий этап, на котором формируют список свободных указателей первой структуры данных, причем список свободных указателей первой структуры данных содержит один или несколько указателей первой структуры данных для ассоциирования с первой структурой данных.
6. Способ по п.5, дополнительно содержащий этапы, на которых
извлекают указатель первой структуры данных из списка свободных указателей первой структуры данных,
удаляют извлеченный указатель первой структуры данных из списка свободных указателей первой структуры данных, и
сохраняют первую структуру данных в буфере пакетов в местоположении, идентифицируемом извлеченным указателем первой структуры данных.
7. Способ по п.5, дополнительно содержащий этап, на котором добавляют ранее удаленный указатель первой структуры данных к списку свободных указателей первой структуры данных для удаления первой структуры данных из буфера пакетов.
8. Способ по п.1, дополнительно содержащий этап, на котором формируют список свободных указателей второй структуры данных, причем список свободных указателей второй структуры данных содержит один или несколько указателей для ассоциирования со второй структурой данных.
9. Способ по п.8, дополнительно содержащий этапы, на которых
извлекают указатель второй структуры данных из списка свободных указателей второй структуры данных, удаляют извлеченный указатель второй структуры данных из списка свободных указателей второй структуры данных, и
сохраняют извлеченный указатель второй структуры данных во втором местоположении в буфере пакетов первой структуры данных.
10. Способ по п.9, дополнительно содержащий этап, на котором сохраняют вторую структуру данных в буфере пакетов в местоположении, идентифицируемом извлеченным указателем второй структуры данных.
11. Способ по п.8, дополнительно содержащий этап, на котором добавляют ранее удаленный указатель второй структуры данных в список свободных указателей второй структуры данных для удаления второй структуры данных из буфера пакетов.
12. Способ по п.11, в котором второе местоположение в буфере пакетов второй структуры данных в буфере пакетов сохраняют в поле указателя второй структуры данных первой структуры данных, и дополнительно содержащий этап, на котором извлекают вторую структуру данных из буфера пакетов, причем вторая структура данных идентифицируется полем указателя второй структуры данных первой структуры данных.
13. Устройство управления памятью для высокоскоростного доступа к среде, содержащее
средства сохранения в первой структуре данных в буфере пакетов длины первого пакета, порядкового номера упомянутого пакета и местоположения второго пакета в буфере пакетов для второй структуры данных в буфере пакетов, и
средства сохранения данных из первого пакета во второй структуре данных, идентифицируемой сохраненным местоположением второго пакета в буфере пакетов.
14. Устройство по п.13, дополнительно содержащее
средства сохранения в третьей структуре данных в буфере пакетов длины второго пакета, порядкового номера второго пакета и местоположения четвертого пакета в буфере для четвертой структуры данных в буфере пакетов,
средства сохранения данных из второго пакета в четвертой структуре данных, идентифицируемой сохраненным местоположением четвертого пакета в буфере, и
средства сохранения местоположения третьей структуры данных в первой структуре данных.
15. Устройство по п.13, дополнительно содержащее средства формирования очереди пакетов путем сохранения связного списка совокупности первых структур данных, причем каждая первая структура данных ассоциирована с одним из совокупности пакетов.
16. Устройство по п.13, дополнительно содержащее средства формирования массива первых структур данных, причем каждая первая структура данных ассоциирована с одним из совокупности пакетов.
17. Устройство беспроводной связи для управления памятью для высокоскоростного доступа к среде, содержащее
первую память, в которой хранятся один или несколько параметров для каждого из совокупности коммуникационных потоков, и
вторую память, в которой хранятся пакеты для каждого из совокупности коммуникационных потоков, содержащую
первую структуру данных, ассоциированную с пакетом, и вторую структуру данных, содержащую данные из ассоциированного пакета, и
в котором первая структура данных содержит поле длины, указывающее длину ассоциированного пакета,
поле порядкового номера, указывающее порядковый номер ассоциированного пакета, и
поле указателя второй структуры данных, указывающее местоположение во второй памяти второй структуры данных.
18. Устройство беспроводной связи по п.17, в котором первая структура данных дополнительно содержит поле указателя следующих первых данных, указывающее местоположение во второй памяти второй первой структуры данных.
19. Устройство беспроводной связи по п.18, дополнительно содержащее очередь пакетов совокупности пакетов, причем очередь формируется связным списком совокупности первых структур данных, причем каждая первая структура данных ассоциирована с одним из совокупности пакетов, причем порядок очереди определяется связыванием каждой из совокупности первых структур данных в связном списке в соответствии с полем указателя следующих первых данных каждой соответствующей первой структуры данных.
20. Компьютерно-считываемый носитель, включающий в себя инструкции, которые при исполнении процессором предписывают процессору выполнять следующее:
сохранение в первой структуре данных в буфере пакетов длины первого пакета, порядкового номера упомянутого пакета и местоположения второго пакета в буфере пакетов для второй структуры данных в буфере пакетов; и
сохранение данных из первого пакета во второй структуре данных, идентифицируемой сохраненным местоположением второго пакета в буфере пакетов.
21. Устройство беспроводной связи для управления памятью для высокоскоростного доступа к среде, содержащее
первую память, в которой хранятся в первой структуре данных в буфере пакетов длина первого пакета, порядковый номер упомянутого пакета и местоположение второго пакета в буфере пакетов для второй структуры данных в буфере пакетов; и
вторую память, в которой хранятся во второй структуре данных заголовок и данные из первого пакета, причем местоположение заголовка и данных, ассоциированных с первым пакетом, устанавливается с помощью указателя данных, и при этом первая и вторая структуры данных различны.
| US 6426943 B1, 30.07.2002 | |||
| УПРАВЛЕНИЕ ПАКЕТНОЙ ПЕРЕДАЧЕЙ МЕЖДУ КОНТРОЛЛЕРОМ БАЗОВОЙ СТАНЦИИ И БАЗОВОЙ СТАНЦИЕЙ | 2002 |
|
RU2254686C1 |
| УСТРОЙСТВО ПРЕДОТВРАЩЕНИЯ ОШИБОК ДЛЯ МУЛЬТИМЕДИЙНОЙ СИСТЕМЫ | 1998 |
|
RU2234806C2 |
| US 6832261 B1, 14.12.2004 | |||
| Приспособление в пере для письма с целью увеличения на нем запаса чернил и уменьшения скорости их высыхания | 1917 |
|
SU96A1 |
| Прибор для очистки паром от сажи дымогарных трубок в паровозных котлах | 1913 |
|
SU95A1 |

