Настоящее изобретение относится к области извлечения сводки содержимого множества изображений, например видеопоследовательности. Более конкретно, изобретение направлено на способ и устройство для автоматического генерирования сводки множества изображений, в которой сохраняется основная сюжетная линия или логическая линия.
Формирование сводки стало чрезвычайно востребованным инструментом при броузинге и поиске в домашних видеоколлекциях и в производимых видеоархивах или фотоархивах, что позволяет пользователям экономить время и предоставляет значительную степень управления и обзорности. Различные типы способов формирования сводки были предложены в литературе: визуальная таблица содержания, поверхностное ознакомление и мультимедийные сводки. Кроме того, использовались различные области, такие как формирование структурированной видеосводки для новостей, музыкальных видеоизображений и спортивных событий.
Пользователи хотят смотреть фильмы за более короткое время, чем изначальная длительность, понимая при этом логическую линию, то есть существует требование, чтобы общая сюжетная линия фильма была сохранена. Были предложены алгоритмы быстрой прокрутки и сжатия звука, которые позволяют ускорить скорость просмотра в 1,5-2 раза. Одна из возможностей состоит в увеличении скорости воспроизведения, однако быстрое воспроизведение требует очень высокого уровня внимания от зрителя и может показаться забавным и непонятным.
Таким образом, все еще остается задача формирования описательной видеосводки, что включает в себя способы формирования сводки описательного содержимого видеопоследовательности, такой как кинофильмы, документальные фильмы и домашнее видео. Формирование сводки для повествовательного мультимедийного контента, такого как фильм, представляет собой задачу активных исследований, однако обычно цель состоит в создании материала для предварительного просмотра, который не передает всю информацию о сюжете исходного фильма.
В публикации WO 03/090444 раскрыты способы выбора последовательности видеокадров из видеопоследовательности. В последовательности видеокадров задают функцию расстояния, связывающую два видеокадра друг с другом, например расстояние между RGB-гистограммами кадров. Для выражения характерной черты множества подпоследовательностей видеокадров, выбранных из последовательности видеокадров, задают критерий оптимизации. Затем определяют подпоследовательность видеокадров путем оптимизации значений функции критерия оптимизации, заданной по всем подпоследовательностям, например, функции энергии. В WO 03/090444 функция расстояния, связывающая кадры друг с другом, основана на визуальном расстоянии между кадрами. Таким образом, выбранная подпоследовательность кадров будет набором ключевых кадров, которые представляют собой наиболее отличающиеся кадры относительно визуального контента и, таким образом, в некотором смысле, являются репрезентативными для видеопоследовательности. Однако, поскольку два кадра взаимосвязаны между собой только визуальным расстоянием, выбранная подпоследовательность не обязательно будет представлять связку, отображающую сюжетную линию и действительный смысл видеопоследовательности.
Следовательно, задача состоит в создании способа и системы формирования сводки, позволяющих предоставлять последовательность-сводку, отражающую логическую сюжетную линию множества изображений, например, видеопоследовательности, при этом имеющую ту же скорость воспроизведения, что и исходная видеопоследовательность.
Эта задача и некоторые другие задачи решаются в первом аспекте изобретения посредством предоставления способа формирования сводки множества изображений, содержащего этапы, на которых:
a) разделяют упомянутое множество изображений на множество сегментов, причем каждый сегмент содержит по меньшей мере одно изображение,
b) анализируют каждый сегмент в отношении содержимого и ассоциируют набор дескрипторов (описателей) содержимого по результату анализа упомянутого сегмента,
c) устанавливают взаимосвязи между сегментами на основе дескрипторов содержимого, причем каждая взаимосвязь между первым и вторым сегментами имеет один или больше весовых коэффициентов, ассоциированных с нею, причем эти один или больше весовых коэффициентов представляют меру взаимосвязи между первым и вторым сегментами,
d) определяют для каждого сегмента меру релевантности на основе весовых коэффициентов, ассоциированных с взаимосвязями с упомянутым сегментом,
e) генерируют краткое содержание путем выбора поднабора сегментов из упомянутого множества сегментов на основе параметров релевантности, ассоциированных с сегментами.
Под "множеством изображений" понимают набор изображений, такой как архив фотографий или видеопоследовательность кадров изображения. Под "мерой взаимосвязи" следует понимать меру, представляющую степень взаимосвязи между двумя сегментами. Например, "мера взаимосвязи" может представлять собой меру, представляющую логическую корреляцию между сегментами, либо она может просто представлять собой меру того, насколько аналогичны сегменты, в отношении конкретного дескриптора содержимого.
Изобретение частично, но не исключительно, является преимущественным для автоматического генерирования краткого содержания фильма или домашнего видео и т.д. В предпочтительных вариантах воплощения можно автоматически генерировать сводку, которая будет включать в себя квинтэссенцию исходной видеопоследовательности, и, поскольку эту сводку генерируют из выбранных сегментов или сцен исходной видеопоследовательности, сводка будет иметь естественную скорость воспроизведения, то есть без принудительного ввода неестественно высокой скорости.
Способ также можно использовать для генерирования сводки архива фотографий, например, архива фотографий с праздника и т.д., когда требуется получить краткое содержание, представляющее содержимое фотографий. В случае фотографий, сегмент может представлять собой либо одну фотографию, либо набор фотографий.
В случае, например, видеопоследовательности, которая уже была разделена на сегменты, например один раздел выделен для каждой сцены видеопоследовательности, следует понимать, что этап a) может быть исключен. В противном случае, этап a) может включать в себя сегментирование по времени, например, на основе обнаружения границ сегментов, используя способ обнаружения различий между кадрами, как известно в данной области техники.
На этапе c) устанавливают очень компактное представление упомянутого множества изображений, используя очень ограниченное количество данных. Например, полуторачасовой фильм может быть представлен с использованием 5-10 дескрипторов содержимого, и обычно его разделяют на 700-1000 сегментов.
Предпочтительно, этап e) включает в себя выбор сегментов с наибольшей мерой значения релевантности. Другими словами, вначале исключают один или больше сегментов с наименьшей степенью взаимосвязи с остальными сегментами из упомянутого множества изображений, и, таким образом, их исключают из краткого содержания. В результате эффективно гарантируется то, что сводка будет основана на сегментах с максимально возможным семантическим содержимым упомянутого множества изображений, и, таким образом, сводка будет в наилучшей степени отражать суть смыслового значения упомянутого множества изображений.
Поскольку весовые коэффициенты обозначают, в какой степени два сегмента взаимосвязаны (высокое значение весового коэффициента отражает высокую степень взаимосвязи; весовой коэффициент может быть, например, определен как коэффициент корреляции между наборами параметров двух сегментов, причем эти наборы содержат по меньшей мере один параметр), меру релевантности предпочтительно рассчитывают на основе суммы всех весовых коэффициентов, ассоциированных с взаимосвязями с конкретным сегментом. Мера релевантности может, в частности, быть равна сумме всех весовых коэффициентов, ассоциированных с взаимосвязями с этим конкретным сегментом.
В предпочтительных вариантах воплощения дополнительную текстовую информацию, ассоциированную с сегментом, учитывают при анализе содержимого упомянутого сегмента, например, на этапе b), и предпочтительно также при установлении взаимосвязи между упомянутым сегментом и другими сегментами. Текстовая информация может быть внедрена в видеоконтент, например в форме субтитров, или может быть сохранена на том же физическом или логическом носителе с видеопоследовательностью, например в виде субтитров на дисках DVD или субтитров, передаваемых вместе с телевизионным вещанием.
Таким образом, такая дополнительная текстовая информация может использоваться для поддержки анализа содержимого, который в противном случае может быть основан исключительно на автоматическом алгоритме, применяемом к множеству изображений самих по себе. В случае, когда дополнительная текстовая информация внедрена в упомянутое множество изображений самих по себе, например в виде субтитров, предпочтительный дополнительный этап включает в себя этап, на котором извлекают такую дополнительную текстовую информацию из упомянутого множества сегментов для обеспечения возможности ее учета для дополнительного анализа. Извлечение дополнительной текстовой информации может включать в себя распознавание речи в случае, когда должна быть выделена дополнительная текстовая информация, например, из повествовательной речи, внедренной в аудиочасть, связанную с упомянутым множеством изображений.
Может быть предпочтительным включить в сводку релевантную часть дополнительной текстовой информации. Это может быть выполнено в виде субтитров в видеочасти сводки и/или путем преобразования дополнительной текстовой информации в речь, используя метод синтеза речи.
Упомянутое множество изображений может состоять только из изображений или кадров изображения, либо дополнительно содержать звуковую часть, ассоциированную с упомянутым множеством изображений, например звуковую дорожку фильма. Дополнительная текстовая информация может включать в себя краткий текст, который описывает сцену фильма, например с информацией, включающей в себя "кто", "где" и "когда". Обычно дополнительная текстовая информация может включать в себя, например: субтитры (например, введенные вручную и синхронизированные людьми), сценарий фильма (например, написанный людьми и автоматически совмещенный с видеопоследовательностью), транскрипцию речи (например, написанную человеком или сгенерированную с помощью автоматического распознавания речи). Дополнительная текстовая информация может быть предусмотрена как отдельная услуга для предоставления выполненных вручную аннотаций, синхронизированных с видеопоследовательностью, для того, чтобы помочь составить персонализированный дайджест читателя, например метаданные о том, "кто находится в этой сцене", "что представлено в этой сцене", "где эта сцена", "почему что-то происходит или показано" и т.д.
В случае, когда указанное множество изображений включает в себя как видеочасть, так и звуковую часть, предпочтительно включать дескрипторы содержимого, учитывающие как видеочасть, так и звуковую часть. Например, как изображения, так и голосовой сигнал могут быть проанализированы и могут использоваться для извлечения информации, относящейся к индивидууму (индивидуумам) или герою (героям) фильма, которые присутствуют в некотором сегменте видеопоследовательности. Предпочтительно, взаимосвязи включают в себя по меньшей мере одну взаимосвязь, основанную на аудиочасти, и одну взаимосвязь, основанную на видеочасти. Таким образом, обеспечивается наилучшее использование доступных данных в связи с упомянутым множеством изображений, например, как с видеоданными, так и с аудиоданными.
Предпочтительно, взаимосвязи включают в себя по меньшей мере одну взаимосвязь, основывающуюся на одном или больше из:
1) расстояния во времени между первым и вторым сегментами,
2) одновременного появления ключевых слов в текстовой информации, ассоциированной с соответствующими первым и вторым сегментами,
3) одновременного появления индивидуума в первом и втором сегментах,
4) поля зрения в видеочасти сегментов.
Что касается 1), сегментам, расположенным на большом расстоянии во времени друг от друга, должно быть назначено большое расстояние, и поэтому весовой коэффициент между двумя сегментами, визуально аналогичными, но расположенными на большом расстоянии во времени друг от друга, не должен быть таким же большим, как в случае, когда сегменты также расположены рядом друг с другом во времени, например, когда они фактически принадлежат одной и той же сцене или разделу.
Что касается 3), идентификация индивидуума на основе, например, обнаружения и распознавания лица и/или распознавания голоса, должна быть включена в этап b).
Что касается 4), поле зрения следует понимать как расстояние камеры до субъекта и фокусное расстояние объектива, используемое в конкретном сегменте, например съемка с близкого расстояния, съемка с дальнего расстояния, съемка со среднего расстояния и т.д.
Предпочтительно, этапы c)-e) повторяются для того, чтобы уменьшить количество сегментов, например один за другим, до тех пор, пока выбранный поднабор сегментов не удовлетворит заранее заданному критерию останова. Такой критерий останова может представлять собой заранее заданное максимальное время воспроизведения выбранного поднабора сегментов. Например, пользователь желает просмотреть 45-минутную сокращенную версию полуторачасового фильма. Затем сегменты удаляются до тех пор, пока общее время воспроизведения оставшихся сегментов не будет равно или меньше, чем 45 минут.
В общем, сводка может быть сгенерирована с учетом предпочтений, введенных пользователем, например, в отношении времени воспроизведения, как упомянуто выше. Однако предпочтения пользователя, относящиеся к определенным темам или героям фильма, могут быть введены пользователем и могут учитываться на любом из одного или больше из этапов c), d) и e) таким образом, чтобы сводка отражала специальные предпочтения пользователя. Например, пользователь может заинтересоваться сценами охоты на автомобилях, и, таким образом, сегменты, включающие в себя охоту на автомобилях, будут удалены позже других сегментов, например, путем манипуляции с мерой релевантности, которая должна быть высока в сегментах со сценами охоты на автомобилях. В частности, весовые коэффициенты по этапу c) могут быть рассчитаны как функция предпочтений, введенных пользователем.
Согласно второму аспекту изобретение относится к исполняемому компьютерному программному коду, приспособленному для обеспечения компьютеру возможности выполнять способ в соответствии с первым аспектом. Программный код может представлять собой типичный программный код или программный код, специфичный для конкретного процессора. Программный код может быть адаптирован для исполнения на персональном компьютере или в любом устройстве, включающем в себя процессор данных. Этот аспект изобретения является, в частности, но не исключительно, преимущественным в том, что настоящее изобретение может быть реализовано в виде компьютерного программного продукта, обеспечивающего компьютерной системе возможность выполнять операции в соответствии с первым аспектом изобретения. Таким образом, предусматривается, что некоторое известное устройство может быть изменено так, что оно будет работать в соответствии с настоящим изобретением путем установки компьютерного программного продукта в этом устройстве и, таким образом, обеспечения данному устройству возможности выполнять способ в соответствии с первым аспектом.
В третьем аспекте изобретение относится к носителю данных, включающему в себя исполняемый компьютерный программный код в соответствии со вторым аспектом. Носитель данных представляет собой считываемый компьютером носитель любого типа, например, носитель, основанный на магнитном или оптическом принципе, либо через вычислительную сеть, например Интернет.
В четвертом аспекте изобретение направлено на устройство, содержащее средство обработки, выполненное с возможностью осуществления способа в соответствии с первым аспектом. Устройство может включать в себя средство хранения для сохранения сгенерированной сводки и/или средство отображения, выполненное с возможностью представления этой сводки. Устройство может быть таким, как устройство персональной видеозаписи, устройство записи на основе жесткого диска, проигрыватель DVD, видеокамера, домашний мультимедийный сервер, персональный компьютер (ПК), устройство-электронный концентратор (e-hub), система видео по запросу и т.д.
Согласно пятому аспекту изобретение относится к системе, включающей в себя устройство в соответствии с четвертым аспектом и средство отображения, выполненное с возможностью отображения видеочасти сводки. Система также может включать в себя громкоговоритель для обеспечения возможности также представлять звуковую часть сводки, сгенерированной устройством. Система может быть интегрирована с упомянутым устройством, например, телевизионным приемником, включающим в себя накопитель на жестких дисках и средство обработки, выполненное с возможностью генерировать сводку и либо представлять ее на телевизионном экране, либо сохранять ее на жестком диске. В качестве альтернативы, система может быть сформирована из отдельных компонентов, например, в случае, когда устройство, выполненное с возможностью генерировать краткое содержание, представляет собой отдельное устройство, и другие части системы включают в себя, например, средство отображения и средство хранения. В качестве примера, система может представлять собой ПК с программным обеспечением, выполненным с возможностью генерировать сводку на основе видеопоследовательностей или фотографий, сохраненных в удаленном сервере, подключенном к ПК через Интернет.
Следует понимать, что преимущества и варианты воплощения, упомянутые для первого аспекта, также применимы ко второму, третьему и четвертому аспектам изобретения. Таким образом, каждый любой аспект настоящего изобретения может быть скомбинирован с любым из других аспектов.
Перечень чертежей
Настоящее изобретение поясняется ниже только на примере, со ссылкой на прилагаемые чертежи, на которых
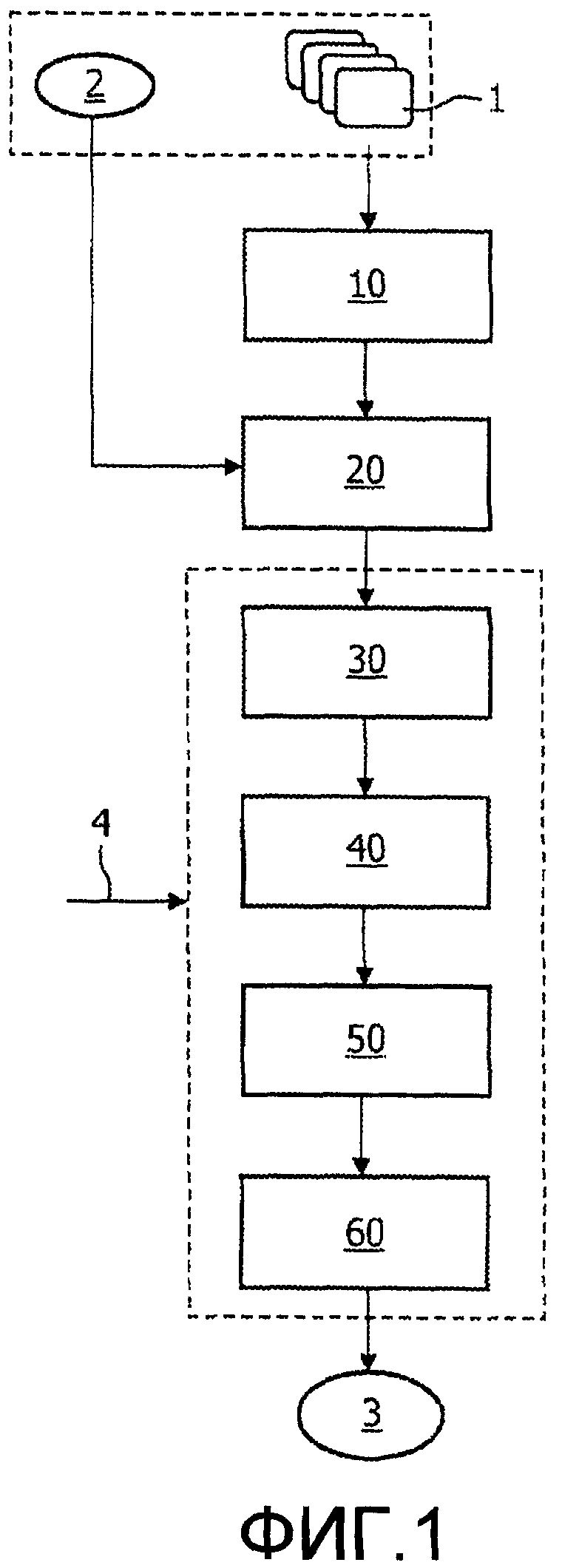
на фиг.1 иллюстрируется блок-схема последовательности операций предпочтительного варианта воплощения способа в соответствии с изобретением,
на фиг.2 иллюстрируется принцип удаления сегментов из исходной видеопоследовательности сегментов для того, чтобы получить сводку, представляющую собой поднабор сегментов исходных сегментов, и
на фиг.3 иллюстрируется эскиз предпочтительного устройства в соответствии с изобретением.
На фиг.1 показан предпочтительный способ генерирования сводки 3 видеоизображения для видеопоследовательности 1, например фильма с аудиовизуальным контентом. Предпочтительно, дополнительная текстовая информация 2 доступна в дополнение к видеопоследовательности 1. Такая дополнительная текстовая информация 2 может включать в себя субтитры, скрытые субтитры, транскрипцию речи, сценарий кинофильма и т.д. В частности, дополнительная текстовая информация 2 речи может быть извлечена из звуковой части видеопоследовательности 1, используя распознавание речи для предоставления текста, представляющего разговорный язык. См., например, публикацию WO 05/055196 A2, относящуюся к идентификации героев фильма, используя сценарий, транскрипцию, характерные черты Web и аудио.
Вначале выполняют автоматическое временное сегментирование 10 видеопоследовательности 1. При этом видеопоследовательность 1 разделяют на логические когерентные сегменты, где каждый сегмент представляет собой снимок или сцену фильма. Временное сегментирование может быть основано на обнаружении границ снимков, как известно в уровне техники, то есть включая различные низкоуровневые дескрипторы, которые используются для того, чтобы обнаруживать различие между отдельными кадрами видеопоследовательности 1. Следует понимать, что этап 10 временного сегментирования может быть исключен в случае, когда видеопоследовательность 1 уже разделена на временные сегменты, например разделы, представляющие снимки или сцены.
Затем анализ 20 содержимого выполняют в отношении сегментов для того, чтобы обеспечить возможность представить их содержимое путем вычисления для каждого сегмента набора различных дескрипторов содержимого. Могут быть включены дескрипторы содержимого на довольно низком уровне, а также могут использоваться дескрипторы содержимого на достаточно высоком уровне абстракции. Если она доступна, для анализа 20 содержимого предпочтительно используют дополнительную текстовую информацию 2, ассоциированную с каждым сегментом, например информацию о том, какие персонажи присутствуют в сцене и т.д.
Как аудио-, так и видеочасть сегментов можно использовать для вычисления дескрипторов содержимого либо по отдельности, либо в комбинации. Не исчерпывающий список дескрипторов содержимого представляет собой:
- распределение цвета, например, путем расчета гистограммы цвета,
- аудиокласс, анализ аудиочасти сегментов и разделение по категориям их содержимого, таким как, например, речь, тишина, музыка и т.д.,
- расположение и присутствие лиц,
- идентификацию индивидуума, например, используя распознавание лица и/или речи,
- поле зрения сцены, например съемка крупным планом, средним планом, на большом расстоянии, на очень большом расстоянии и т.д.
В случае, когда доступна дополнительная текстовая информация 2, такая как скрытые субтитры или сценарий кинофильма, такую информацию анализируют для извлечения текстовых дескрипторов в форме ключевых слов о том, какие индивидуумы присутствуют в сегменте, что происходит, где и когда (по времени повествования) происходит событие. См., например, публикацию WO 05/055196 A2, которая относится к идентификации героев фильма, используя киносценарий, транскрипт, характерные черты Web и аудио.
После того как ряд дескрипторов содержимого будет ассоциирован с сегментами, устанавливают 30 взаимосвязи между сегментами и, таким образом, формируют очень компактное представление видеопоследовательности. Что касается взаимосвязей, применяют весовые коэффициенты с целью отражения, являются ли два сегмента логически взаимосвязанными (высокое значение весового коэффициента) или логически несвязанными (низкое значение весового коэффициента). В частности, такие весовые коэффициенты для взаимосвязи между двумя сегментами могут представлять собой векторы весовых коэффициентов, где каждый весовой коэффициент представляет меру подобия в отношении одного дескриптора содержания. Таким образом, для каждой взаимосвязи между двумя сегментами существует набор из весовых коэффициентов, который описывает логическую взаимосвязь между сегментами в различных отношениях.
После того как весовые коэффициенты будут применены к взаимосвязям, для каждого сегмента выполняют этап определения степени релевантности 40. Степень релевантности предпочтительно определяют как сумму всех весовых коэффициентов, ассоциированных со взаимосвязями, относящимися к конкретному сегменту. Таким образом, если сумма всех весовых коэффициентов высока, сегмент считается релевантным, в то время как сегмент считается нерелевантным, если сумма всех весовых коэффициентов мала.
Следующий этап включает в себя выбор поднабора сегментов 50. Такой выбор может быть выполнен шаг за шагом путем выбора сперва сегментов с наибольшей мерой значений релевантности, например, исключая их один за другим с промежуточным пересчетом весовых коэффициентов и мер релевантности, или просто с помощью выбора путем исключения большего количества сегментов за раз, то есть исключая сегменты с самыми малыми значениями меры релевантности.
Конечный этап 60, таким образом, состоит в генерировании сводки 3 путем взятия выбранных сегментов видеопоследовательности, то есть сегментов, которые были выбраны на этапе 50. В простом варианте воплощения сводку 3 просто генерируют с помощью сцепления выбранных сегментов в хронологическом порядке.
Следует понимать, что сводка 3 может быть предусмотрена в любой форме как аналоговый или цифровой сигнал, либо в виде любого типа представления данных, пригодного для непосредственного воспроизведения и/или сохранения на носителе информации. Таким образом, способ можно применять для онлайнового генерирования сводки 3 в случае, когда доступна необходимая мощность обработки данных, либо сводки видеопоследовательностей всего видеоархива могут быть сгенерированы в режиме офлайн.
На любом из этапов 30, 40, 50, 60 пользовательский ввод 4 может быть учтен для того, чтобы приспособить конечную сводку 3 к предпочтениям пользователя и, таким образом, обеспечить возможность персонализации информации, представляемой в сводке, на основе предпочтений 4, введенных пользователем. Этот ввод 4 может быть сохранен заранее. На основе персональных предпочтений сводка может включать в себя разные элементы. Если индивидуум заинтересован в большей степени в некоторых частях фильма или кинофильма, тогда сегменты, относящиеся к этим частям, выбирают относительно сегментов, включающих другие элементы повествования, и т.д. Для достижения такого типа персонализации пользовательский ввод 4 может включать в себя профиль пользователя, например ключевые слова с соответствующими весовыми коэффициентами важности, которые добавлены к согласующимся сегментам во время построения краткого содержания, то есть на одном или больше из этапов 30, 40, 50 и 60.
В случае, когда входные команды 4 пользователя обозначают очень специфичные предпочтения, это также может быть учтено уже на этапе 10 или 20, и эти этапы затем могут быть расположены так, чтобы они, например, фокусировались на аспектах, которые интересуют пользователя, и, возможно, другие аспекты могут быть исключены, ограничивая, таким образом, количество требуемой вычислительной мощности для выполнения этапа 20, и также, возможно, для последующих этапов, поскольку определенные характерные черты сегментов могут быть нерелевантны для пользователя.
В некоторых вариантах воплощения сводка также может представлять собой многоуровневое краткое содержание, например сводка с иерархической структурой. Таким образом, для пользователя становится возможным выбирать между набором сегментов с более высоким уровнем. В любое время пользователь может перейти "глубже" по дереву и получить большее количество сегментов, относящихся к сегменту, который он просматривает. И аналогично, пользователь может "подняться" для того, чтобы перейти на более высокий уровень. Представление данных и обработка, которые будут описаны ниже, соответствуют такому иерархическому выбору частей сегментов.
На фиг.2 более подробно иллюстрируются с примерными эскизами этапы 30, 40 и 50. Простой случай видеопоследовательности, разделенной на четыре сегмента s1, s2, s3, s4, иллюстрируется в позиции 110 и, таким образом, представляет вариант воплощения этапа 30. Линии, соединяющие сегменты s1, s2, s3, s4, обозначают взаимосвязи между сегментами s1, s2, s3, s4. Векторы w12, w13, w14, w23, w24, w34 представляют наборы весовых коэффициентов, причем каждый весовой коэффициент представляет значение, отражающее меру взаимосвязи, например, подобие или логическую корреляцию между двумя сегментами, к которым относится взаимосвязь. Вектор, предпочтительно, включает в себя отдельные весовые коэффициенты для каждого из дескрипторов содержимого, извлеченных на этапе 20 анализа сегмента. Таким образом, вектор w12 включает в себя набор весовых коэффициентов, обозначающих подобие набора дескрипторов содержимого, ассоциированных с сегментами s1 и s2. Как можно видеть в позиции 110, все данные представлены на графе.
Весовые коэффициенты, примененные к взаимосвязи между двумя сегментами, могут быть основаны на большом разнообразии дескрипторов содержимого. Ниже приведено несколько примеров типа взаимосвязей и того, как применяют весовые коэффициенты на основе дескрипторов содержимого, ассоциированных с каждым из двух сегментов:
- последовательность, то есть весовой коэффициент обозначает, являются ли два сегмента последовательными сегментами,
- совпадение ключевых слов, то есть сегменты с одинаковыми или аналогичными ключевыми словами имеют весовой коэффициент, заданный по количеству совпадений,
- появление индивидуума или героя, то есть весовой коэффициент задают по общему относительному количеству накладывающихся моментов времени, когда один и тот же индивидуум или герой появляется в двух сегментах,
- подобие содержимого на основе свойств сигнала, то есть весовые коэффициенты задают по фактической функции подобия,
- подобие содержимого на основе аудиокласса, то есть высокий весовой коэффициент обозначает присутствие того же аудиокласса (речь, музыка и т.д.) в течение некоторого периода времени в двух сегментах,
- подобие содержания на основе поля зрения, то есть большое значение весового коэффициента обозначает присутствие одного и того же поля зрения (например, крупный план, съемка с общим планом, со среднего расстояния и т.д.) в некоторый период времени в двух сегментах.
Совпадение ключевых слов и появление индивидуума или героя, вероятно, представляют собой особенно важные характерные черты для установления взаимосвязи между сегментами, в результате чего получают сводку 130, отражающую логическую сюжетную линию входных сегментов s1, s2, s3, s4.
Граф 110 представляет собой очень компактное представление видеопоследовательности только с ограниченным количеством одиночных значений данных. Его структура основывается на относительной важности содержимого сегментов, и граф 110 является полезным представлением для последующих этапов 40, 50 и 60.
На этапе 40 каждому из сегментов s1, s2, s3, s4 назначают меру релевантности на основе векторов w12, w13, w14, w23, w24, w34. Предпочтительно, мера релевантности для сегмента основана на сумме всех весовых коэффициентов, применяемых к взаимосвязям с этим сегментом. Например, мера релевантности для сегмента s1 может быть выражена как векторная сумма w12, w13 и w14. В случае, когда пользовательский ввод 4 обозначает, например, предпочтение на предмет конкретного героя фильма, это предпочтение может повлиять на меру релевантности, например, путем применения дополнительного весового коэффициента к весовому коэффициенту векторов w12, w13, w14, обозначая присутствие этого героя, когда рассчитывают сумму весовых коэффициентов. Таким образом, окончательная сводка 3 может быть сконфигурирована в смысле того, что пользователь может указать минимальную версию сводки 3, которая отражает сущность истории и ее разрешение, или оптимальную версию, которая включает в себя больше информации. Это возможно, ввиду количества информации и метаданных, которые были извлечены для видеопоследовательности и представления 110 данных в виде графа.
На этапе 50 выполняют "обрезку графа" на основе меры релевантности. Предпочтительно, выбор сегментов и решения касаемо того, какие сегменты следует включить в сводку, основан на весовых коэффициентах всего графа.
Это представлено в позиции 120, где сегмент s3 был удален, поскольку предполагается, что s3 представлял собой сегмент с наименьшей мерой релевантности из четырех сегментов s1, s2, s3, s4, и, таким образом, это сегмент, в отношении которого можно предполагать, что он имеет содержимое, наименее релевантное для представления семантической сущности видеопоследовательности 1. Дальнейшую обрезку выполняют между позициями 120 и 130, где был удален сегмент s1, поскольку определено, что он представляет собой наименее релевантный сегмент из трех оставшихся сегментов s1, s2, s4. Вообще, обрезку сегментов продолжают до тех пор, пока не будет достигнут критерий останова. Например, критерий останова основан на пользовательском вводе 4, обозначающем предпочтительное максимальное время воспроизведения сводки, и, таким образом, обрезку продолжают до тех пор, пока оставшиеся сегменты не будет иметь суммарное время воспроизведения, равное или меньшее, чем время воспроизведения, обозначенное в пользовательском вводе 4. В качестве альтернативы, критерий останова может представлять собой процент от времени воспроизведения всей видеопоследовательности 1, например сводку можно выбирать так, чтобы она приблизительно составляло 70% от времени воспроизведения исходной видеопоследовательности.
Наконец, когда будет удовлетворен критерий останова, может быть выполнен этап генерирования сводки 60. В простом варианте воплощения сводка представляет собой сцепление оставшихся сегментов, например на фиг.2 сводка 130 включает в себя сегменты s2 и s4, и сводка 130 может представлять собой просто аудиовидеоконтент этих сегментов s2, s4, предпочтительно воспроизводимых в хронологическом порядке таким образом, чтобы в наилучшей степени отражать хронологическое воспроизведение видеопоследовательности 1.
Для формирования краткого содержания узлы с наименьшими весовыми коэффициентами удаляют один за другим до тех пор, пока не будет достигнута требуемая длительность. Весовой коэффициент узла представляет собой сумму весовых коэффициентов ребер, которые соединены с узлом.
На фиг.3 представлена система, включающая в себя устройство 210 с процессором 211, выполненным с возможностью осуществления способа в соответствии с первым аспектом изобретения, то есть устройство 210 включает в себя средство 211a разделения, средство 211b анализа, средство 211c анализа взаимосвязей, средство 211d определения релевантности и генератор 211e сводки. Устройство 210 может представлять собой персональное устройство видеозаписи, домашний мультимедийный сервер, мультимедийный центр на основе ПК, устройство типа электронного концентратора e-hub, систему типа "видео по запросу" и т.д. Устройство принимает сигнал, включающий в себя видеопоследовательность 201, например видеоизображение, совместимое со стандартом MPEG (Экспертной группы по кинематографии), и аудиосигнал, принимаемый из проигрывателя DVD, который представляет собой либо интегрированное устройство 210, или внешний DVD проигрыватель, соединенный с устройством 210. Кроме видеопоследовательности устройство 210 также принимает дополнительную текстовую информацию 202, ассоциированную с видеопоследовательностью 201. Устройство обрабатывает входной сигнал 201, 202 в процессоре 211 и генерирует в ответ сводку 220. Как обозначено пунктирными линиями, устройство может сохранять входной сигнал 201, 202 во встроенном средстве 212 хранения информации, например, на жестком диске 212 и затем генерировать сводку 220 по запросу. В качестве альтернативы, сводку 220 генерируют немедленно и выводят, или сводку 220 генерируют и хранят в средстве 212 хранения информации до тех пор, пока не поступит запрос в отношении сводки 220.
В системе по фиг.3 также представлено средство 230 представления краткого содержания, выполненное с возможностью представления видеочасти 221 и аудиочасти 222 сводки 220. Видеочасть 221 представлена на экране 231 дисплея, например, на LCD-дисплее (жидкокристаллическом дисплее), в то время как аудиочасть 222 представляют с использованием громкоговорителя 232. В случае необходимости сводка 220 может включать в себя части дополнительной текстовой информации 202. Эти части дополнительной текстовой информации 202 могут отображаться на экране 231 дисплея или на дополнительном интерфейсе/дисплее пользователя, и/или части дополнительной текстовой информации 202 могут быть представлены через громкоговоритель 232 в случае, когда текст преобразуют в искусственную речь с помощью средства синтеза речи. Средство 230 представления сводки может представлять собой телевизионный приемник со встроенным громкоговорителем и т.д.
Изобретение может быть воплощено в любой соответствующей форме, включая аппаратные средства, программное обеспечение, программно-аппаратное обеспечение или любую их комбинацию. Изобретение или некоторые свойства изобретения могут быть воплощены как компьютерное программное обеспечение, работающее с одним или больше процессорами данных и/или процессорами цифровых сигналов. Элементы и компоненты варианта воплощения изобретения могут быть физически, функционально и логически воплощены любым соответствующим способом. Действительно, функциональность может быть воплощена в виде единого модуля, в виде множества модулей или как часть других функциональных модулей. При этом изобретение может быть воплощено как один модуль, или может быть физически и функционально распределено между разными модулями и процессорами.
Хотя настоящее изобретение было описано совместно с конкретными вариантами воплощения, не предполагается его ограничение конкретной формой, представленной здесь. Вместо этого, объем настоящего изобретения ограничен только приложенной формулой изобретения. В формуле изобретения термин "содержащий" не исключает присутствие других элементов или этапов. Кроме того, хотя отдельные признаки могут быть включены в разные пункты формулы изобретения, они могут быть скомбинированы выгодным образом, и включение в различные пункты формулы изобретения не подразумевает, что комбинация признаков невозможна и/или не является предпочтительной. Кроме того, упоминание в единственном числе не исключает множественного числа. Таким образом, числительные "первый", "второй" и т.д. не исключают множественности. Кроме того, номера ссылочных позиций в представленной формуле изобретения не следует рассматривать как ограничение объема.
Кроме того, изобретение также может быть воплощено с меньшим количеством компонентов, чем предоставлено в описанных здесь вариантах воплощения, в котором один компонент осуществляет множество функций. В той же степени изобретение может быть воплощено, используя большее количество элементов, чем показано на фиг.2, при этом функции, осуществляемые одним компонентом в предоставленном варианте воплощения, распределены среди множества компонентов.
Для специалиста в данной области техники будет совершенно понятно, что различные параметры, раскрытые в описании, могут быть модифицированы и что различные раскрытые и/или заявленные варианты воплощения могут быть скомбинированы без выхода за пределы объема настоящего изобретения.

Изобретение относится к области извлечения сводки содержимого множества изображений. Техническим результатом является автоматическое формирование видеопоследовательности, представляющей собой всю логическую сюжетную линию исходной видеопоследовательности, но имеющей меньшую длительность, сохраняя при этом исходную скорость воспроизведения. Сущность изобретения заключается в том, что разделяют видеопоследовательность на множество сегментов. Сегменты анализируют в отношении содержимого, и набор дескрипторов содержимого ассоциируют с сегментами. Предпочтительно, дополнительную текстовую информацию о сегментах, киносценарии и т.д. используют для определения дескрипторов содержимого. Строят граф, представляющий взаимосвязи между сегментами, который обозначает взаимосвязи между сегментами. Весовые коэффициенты ассоциируют со взаимосвязями таким образом, чтобы представить меру взаимосвязи, например логическую корреляцию между сегментами. Весовые коэффициенты основаны на рассчитанных дескрипторах содержимого. Меру релевантности для сегмента определяют на основе всех весовых коэффициентов, ассоциированных со взаимосвязями упомянутого сегмента. Наконец, сводку генерируют путем выбора наиболее релевантных сегментов. 4 н. и 13 з.п. ф-лы, 3 ил.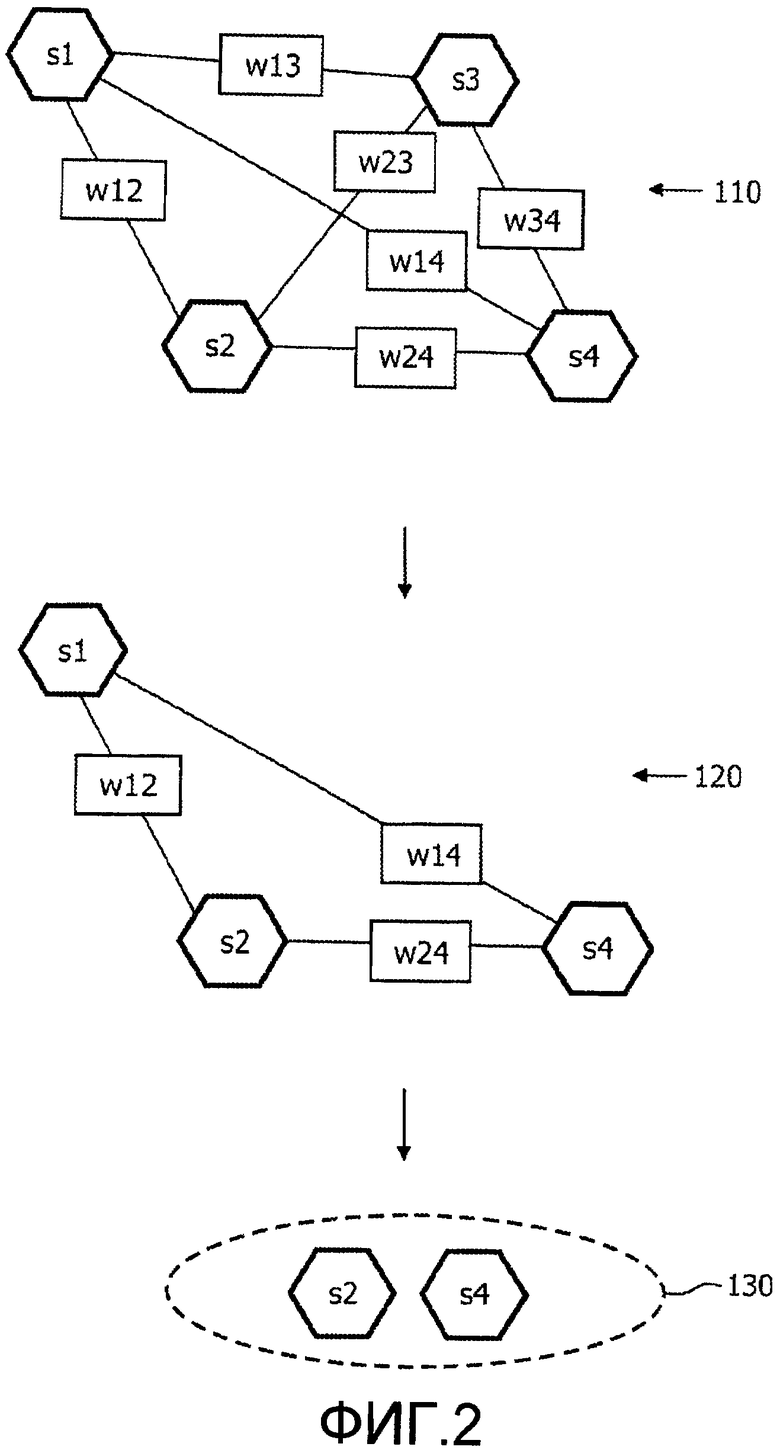
1. Способ формирования сводки видеопоследовательности, содержащей множество изображений (1), содержащий этапы, на которых
a) разделяют упомянутое множество изображений (1) на множество сегментов (s1, s2, s3, s4), причем каждый сегмент (s1, s2, s3, s4) содержит, по меньшей мере, одно изображение,
b) анализируют каждый сегмент (s1, s2, s3, s4) в отношении содержимого и ассоциируют с ним набор дескрипторов содержимого, полученный в результате анализа упомянутого сегмента (s1, s2, s3, s4),
c) устанавливают взаимосвязи между сегментами (s1, s2, s3, s4) на основе дескрипторов содержимого, при этом каждая взаимосвязь между первым и вторым сегментами (s1, s2) имеет один или больше весовых коэффициентов (w12), ассоциированных с нею, причем эти один или больше весовых коэффициентов (w12) представляют меру взаимосвязи между первым и вторым сегментами (s1, s2),
d) определяют для каждого сегмента (s1) меру релевантности на основе весовых коэффициентов (w12, w13, w14), ассоциированных с взаимосвязями с упомянутым сегментом (s1),
e) генерируют сводку (130) путем выбора поднабора сегментов (s2, s4) из упомянутого множества сегментов (s1, s2, s3, s4) на основе параметров релевантности, ассоциированных с сегментами (s1, s2, s3, s4),
при этом доступную дополнительную текстовую информацию (2), ассоциированную с сегментом (s1, s2, s3, s4), учитывают при анализе содержимого упомянутого сегмента и при установлении взаимосвязи между упомянутым сегментом и другими сегментами, и
при этом упомянутую текстовую информацию внедряют в видеопоследовательность или предоставляют как отдельную услугу.
2. Способ по п.1, в котором дополнительную текстовую информацию (2) извлекают из упомянутого множества изображений (1).
3. Способ по п.1, в котором упомянутое множество изображений (1) включает в себя видеочасть и аудиочасть, при этом дескрипторы содержимого включены с учетом как видеочасти, так и аудиочасти.
4. Способ по п.3, в котором взаимосвязи включают в себя, по меньшей мере, одну взаимосвязь на основе аудиочасти и одну взаимосвязь на основе видеочасти.
5. Способ по п.1, в котором взаимосвязи включают в себя, по меньшей мере, одну взаимосвязь на основе расстояния во времени между первым и вторым сегментами.
6. Способ по п.1, в котором взаимосвязи включают в себя, по меньшей мере, одну взаимосвязь, основанную на совпадении ключевых слов в первой и второй текстовой информации, ассоциированной с соответствующими первым и вторым сегментами.
7. Способ по п.1, в котором взаимосвязи включают в себя, по меньшей мере, одну взаимосвязь, основанную на совпадении появления индивидуума в первом и втором сегментах.
8. Способ по п.1, в котором взаимосвязи включают в себя, по меньшей мере, одну взаимосвязь, основанную на поле зрения видеочасти сегментов.
9. Способ по п.1, в котором этап е) включает в себя этап, на котором
удаляют сегмент с наименьшей мерой значения релевантности.
10. Способ по п.9, в котором мера релевантности для каждого сегмента (s1) основана на сумме всех весовых коэффициентов (w12, w13, w14), ассоциированных со взаимосвязями упомянутого сегмента (s1).
11. Способ по п.1, в котором этапы с)-е) повторяют для уменьшения количества сегментов до тех пор, пока выбранный поднабор сегментов (s2, s4) не станет удовлетворять заранее заданному критерию останова.
12. Способ по п.11, в котором критерий останова включает в себя заранее заданное максимальное время воспроизведения выбранного поднабора сегментов (s2, s4).
13. Способ по п.1, в котором сводку генерируют, учитывая предпочтения (4), введенные пользователем.
14. Способ по п.13, в котором весовые коэффициенты по этапу с) рассчитывают в зависимости предпочтений (4), введенных пользователем.
15. Устройство (210) для формирования сводки (220) видеопоследовательности, содержащей множество изображений (201), содержащее средство (211) обработки, включающее в себя
средство (211а) разделения, выполненное с возможностью разделить упомянутое множество изображений (201) на множество сегментов, причем каждый сегмент содержит, по меньшей мере, одно изображение,
средство (211b) анализа, выполненное с возможностью анализировать каждый сегмент в отношении содержимого и ассоциировать с ним набор дескрипторов содержимого, полученных в результате анализа упомянутого сегмента,
средство (211с) анализа взаимосвязей, выполненное с возможностью устанавливать взаимосвязи между сегментами, при этом каждая взаимосвязь между первым и вторым сегментами имеет один или больше весовых коэффициентов, основанных на дескрипторах содержимого, ассоциированных с ними, причем эти один или больше весовых коэффициентов представляют меру взаимосвязи между первым и вторым сегментами,
средство (211d) определения релевантности, выполненное с возможностью определить для каждого сегмента меру релевантности на основе весовых коэффициентов, ассоциированных со взаимосвязями с упомянутым сегментом,
генератор (211е) сводки, выполненный с возможностью генерировать сводку (220) путем выбора поднабора сегментов из упомянутого множества сегментов на основе параметров релевантности, ассоциированных с сегментами,
при этом доступная дополнительная текстовая информация (2), ассоциированная с сегментом (s1, s2, s3, s4), учитывается при анализе содержимого упомянутого сегмента и при установлении взаимосвязи между упомянутым сегментом и другими сегментами, и
при этом упомянутая текстовая информация внедряется в видеопоследовательность или предоставляется как отдельная услуга.
16. Система формирования сводки множества изображений, содержащая устройство (210) по п.15 и средство (231) отображения, выполненное с возможностью отображения видеочасти (221) сводки (220).
17. Машиночитаемый носитель данных, на котором записан машиноисполняемый программный код, который при его исполнении компьютером предписывает компьютеру выполнять способ формирования сводки видеопоследовательности, содержащей множество изображений (1), содержащий этапы, на которых:
а) разделяют упомянутое множество изображений (1) на множество сегментов (s1, s2, s3, s4), причем каждый сегмент (s1, s2, s3, s4) содержит, по меньшей мере, одно изображение,
b) анализируют каждый сегмент (s1, s2, s3, s4) в отношении содержимого и ассоциируют с ним набор дескрипторов содержимого, полученный в результате анализа упомянутого сегмента (s1, s2, s3, s4),
c) устанавливают взаимосвязи между сегментами (s1, s2, s3, s4) на основе дескрипторов содержимого, при этом каждая взаимосвязь между первым и вторым сегментами (s1, s2) имеет один или больше весовых коэффициентов (w12), ассоциированных с нею, причем эти один или больше весовых коэффициентов (w12) представляют меру взаимосвязи между первым и вторым сегментами (s1, s2),
d) определяют для каждого сегмента (s1) меру релевантности на основе весовых коэффициентов (w12, w13, w14), ассоциированных с взаимосвязями с упомянутым сегментом (s1),
e) генерируют сводку (130) путем выбора поднабора сегментов (s2, s4) из упомянутого множества сегментов (s1, s2, s3, s4) на основе параметров релевантности, ассоциированных с сегментами (s1, s2, s3, s4),
при этом доступную дополнительную текстовую информацию (2), ассоциированную с сегментом (s1, s2, s3, s4), учитывают при анализе содержимого упомянутого сегмента и при установлении взаимосвязи между упомянутым сегментом и другими сегментами, и
при этом упомянутую текстовую информацию внедряют в видеопоследовательность или предоставляют как отдельную услугу.
| XIAODI HUANG ET AL | |||
| NODERRANK: A NEW STRUCTURE BASED APPROACH TO INFORMATION FILTERING, PROCEEDINGS OF THE INTERNATIONAL CONFERENCE ON INTERNET COMPUTING, 2003 | |||
| EP 1067800 A1, 10.01.2001 | |||
| Способ анализа и синтеза телевизионного изображения | 1957 |
|
SU120534A1 |

