ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к обработке цифровых изображений с помощью компьютера и, в частности, относится к новому способу и устройству распознавания категории объекта изображения.
УРОВЕНЬ ТЕХНИКИ
С развитием цифровых мультимедиа количество цифровых изображений экспоненциально возросло; в частности, в электронном Интернете все подробные сведения о товарах для продажи показываются с изображениями товаров, причем изображения с богатым семантическим содержанием заменяют описания подробных сведений о товарах. Таким образом, количество изображений растет. И насущной проблемой становится то, каким образом категоризировать крупномасштабные данные изображений в соответствии с товарами, описанными в изображениях.
Существующие способы распознавания категории объекта изображения главным образом используют способы машинного обучения. На практике параметры в большинстве моделей обучения получаются через обучающие выборки и имеют неопределенности. В то же время, вследствие различий в обучающих выборках модели классификации будут производить ошибки, и ошибки и частоты возникновения ошибок присутствуют при установлении категории объекта. Кроме того, хотя часть инфраструктуры для распознавания объектов, использующая многоуровневую структуру, улучшает точность распознавания, она требует большого количества ресурсов и тратит много времени при распознавании категории.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение обеспечивает новые способ и устройство распознавания категории объекта изображения, разработанные для решения следующих проблем в существующих способах распознавания категории изображения: 1) в существующем способе распознавания категории объекта изображения посредством оценки параметров модели классификации параметры получаются через обучающие выборки и имеют неопределенность; 2) вследствие различий в обучающих выборках модели классификации произведут ошибки, и ошибки и частоты появления ошибок присутствуют при установлении категории объекта, будучи не в состоянии реализовать точное распознавание категории объекта изображения; 3) распознавание категории объекта изображения имеет низкую точность и медленную скорость.
Способ и устройство настоящего изобретения начинаются с визуальных признаков низкого уровня изображений. Построенные модули обучения могут обнаружить главную общность среди изображений для каждой категории объектов, и между тем могут в основном отличать разные категории, чтобы реализовать точное распознавание категории объекта изображения, увеличивая точность и скорость распознавания категории объекта изображения.
Настоящее изобретение сначала извлекает ключевые точки признаков из всех образцовых изображений, значительно уменьшая количество вычислений посредством алгоритма кластеризации, алгоритма поиска и т.д. Дополнительное использование способа извлечения общности признаков изображения уменьшает количество вычислений, увеличивая точность распознавания изображения.
Техническое решение настоящего изобретения представляет собой следующее.
Настоящее изобретение включает в себя способ распознавания категории объекта изображения, содержащий следующие этапы:
этап (S1) извлечения признаков изображения, на котором извлекают точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков и создают соответствие "известная категория - образцовое изображение - точка признака", где N - натуральное число больше 1, каждая категория содержит по меньшей мере одно образцовое изображение;
этап (S2) кластерного анализа, на котором выполняют кластерный анализ всех извлеченных точек признаков с использованием алгоритма кластеризации и разделяют точки признаков на N подмножеств;
этап (S3) определения категории объекта, на котором определяют категорию Sn объектов для каждого из подмножеств; и
этап (S4) сбора общих признаков, на котором собирают общие признаки среди изображений в каждой категории Sn объектов с помощью алгоритма поиска, где Sn - n-ая категория объектов, и n - положительное целое число не больше N.
После этапа S4 способ может дополнительно содержать этап S5 онлайнового распознавания и категоризации изображения, на котором распознают и автоматически категоризируют изображение, которое должно быть категоризировано, этап S5 онлайнового распознавания и категоризации изображения содержит этапы:
S502, на котором выполняют такую же обработку извлечения признаков изображения над изображением, которое должно быть категоризировано, как на этапе S1, чтобы извлечь точки признаков изображения, которое должно быть категоризировано;
S503, на котором сравнивают точки признаков, извлеченные из изображения, которое должно быть категоризировано, с каждым из общих признаков каждой категории Cn объектов среди n категорий объектов, чтобы вычислить подобие между изображением, которое должно быть категоризировано, и каждой категорией объектов соответственно;
S504, на котором приписывают изображение, которое должно быть категоризировано, к категории Cn объектов, имеющей наибольшее подобие.
Настоящее изобретение дополнительно содержит устройство распознавания категории объекта изображения, устройство содержит:
блок извлечения признаков изображения, выполненный с возможностью извлекать точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков и создавать соответствие "известная категория - образцовое изображение - точка признака", где N - натуральное число больше 1, каждая категория содержит по меньшей мере одно образцовое изображение
блок кластерного анализа, выполненный с возможностью выполнять кластерный анализ всех извлеченных точек признаков с использованием алгоритма кластеризации и разделять точки признаков на N подмножеств;
блок определения для определения категории Cn объектов для каждого из подмножеств; и
блок сбора данных для сбора общих признаков среди изображений в каждой категории Cn объектов с помощью алгоритма поиска, где Cn - n-ая категория объектов, и n - положительное целое число не больше N.
Настоящее изобретение также относится к способу автоматической категоризации изображения, которое должно быть категоризировано, с помощью способа распознавания категории объекта изображения по пункту 1 формулы изобретения, содержащему следующие этапы:
этап извлечения на котором выполняют такую же обработку извлечения признаков изображения над изображением, которое должно быть категоризировано, как на этапе S1, чтобы извлечь визуальные признаки низкого уровня из изображения, которое должно быть категоризировано;
этап сравнения и вычисления, на котором сравнивают каждую точку признака, извлеченную из изображения, которое должно быть категоризировано, с каждой точкой признака в множестве общих точек признака для каждой категории объектов или в усредненных изображениях каждой категории объектов друг за другом с помощью алгоритма измерения подобия изображений, чтобы вычислить подобие между точками признаков изображения, которое должно быть категоризировано, и точками признаков каждой категории объектов; и
этап приписывания, на котором приписывают изображение, которое должно быть категоризировано, к категории объектов, имеющей наибольшее подобие.
Настоящее изобретение дополнительно относится к системе распознавания изображений, содержащей по меньшей мере процессор, выполненный с возможностью содержать по меньшей мере следующие функциональные блоки:
блок извлечения признаков изображения, выполненный с возможностью извлекать точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков, где N - натуральное число больше 1, каждая категория содержит по меньшей мере одно образцовое изображение, и создано соответствие "известная категория - образцовое изображение - точка признака;
блок кластерного анализа, выполненный с возможностью выполнять кластерный анализ всех точек признаков, извлеченных с использованием алгоритма кластеризации и разделять точки признаков на N подмножеств;
блок определения для определения категории Cn объектов для каждого из подмножеств; и
блок сбора данных для поиска общих признаков среди изображений в каждой категории Cn объектов с помощью алгоритма поиска, где Cn - n-ая категория объектов, и n - положительное целое число не больше N.
Варианты осуществления настоящего изобретения получили следующие положительные эффекты:
1. Компьютер извлекает и автоматически анализирует признаки категории объектов образцовых изображений, автономно изучает и категоризирует образцовые изображения, автоматически распознает категорию изображения, которое должно быть распознано, на основе результата автономного обучения и классификации.
2. Отбор репрезентативных изображений категории объектов сокращает воздействие конкретного изображения с относительно большим отличием в категории объектов на распознавание всей категории объектов, улучшая извлечение общих признаков из общих изображений в категории объектов. Концепция построения k-дерева в большой степени гарантирует пространственную релевантность среди категорий объектов с подобной общностью.
3. Посредством изучения усредненных изображений категории объектов увеличивается скорость распознавания. Кроме того, в процессе распознавания объекта определение порогов для разных категорий объектов в соответствии с характеристиками разных категорий объектов в значительной степени устраняет влияние использования однородных критериев со стороны категорий объектов, уменьшает ошибки при распознавании и увеличивает точность распознавания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
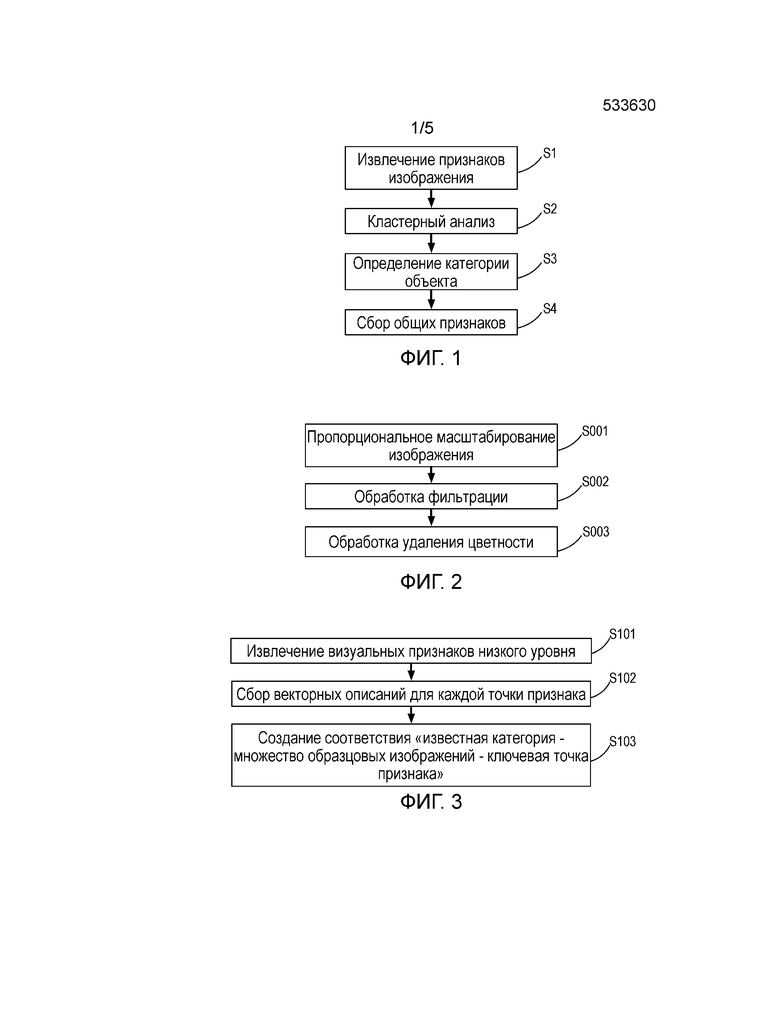
Фиг. 1 - основная блок-схема последовательности операций способа распознавания категории объекта изображения на основе офлайновой (первая часть) модели автономного обучения компьютера настоящего изобретения.
Фиг. 2 - блок-схема последовательности операций выполнения предварительной обработки изображения в соответствии с настоящим изобретением.
Фиг. 3 - подробная блок-схема последовательности операций способа извлечения визуального признака низкого уровня изображения в соответствии с одним вариантом осуществления настоящего изобретения.
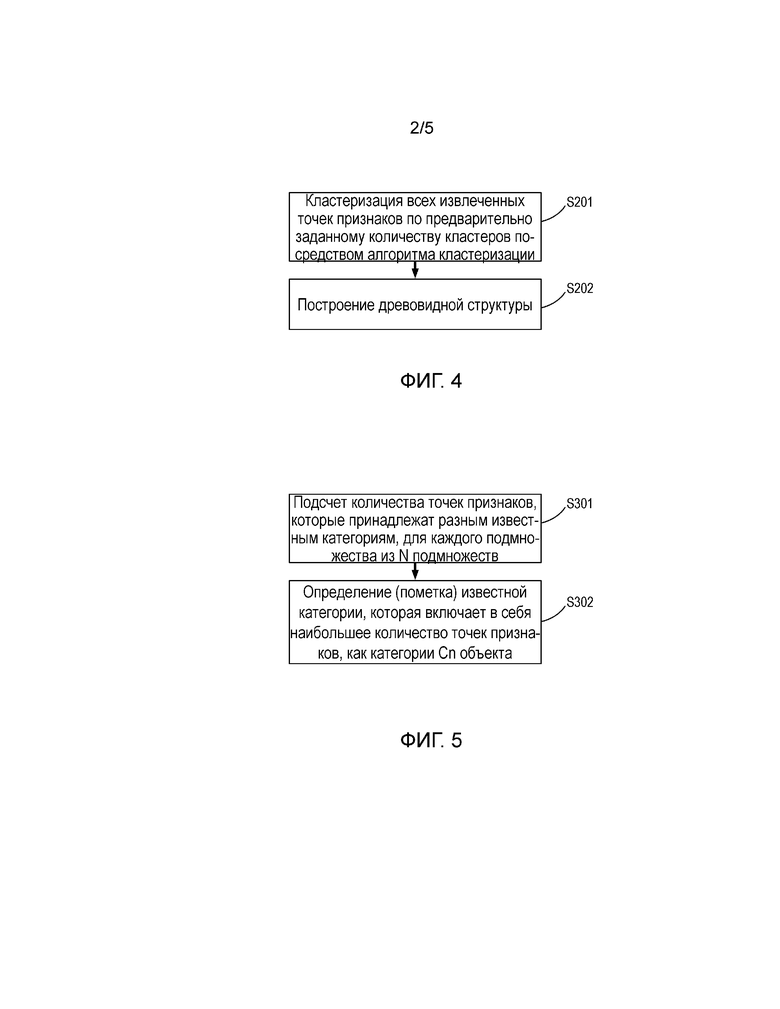
Фиг. 4 - подробная блок-схема последовательности операций способа кластерного анализа в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 5 - подробная блок-схема последовательности операций этапа S3 в соответствии с одним вариантом осуществления настоящего изобретения.
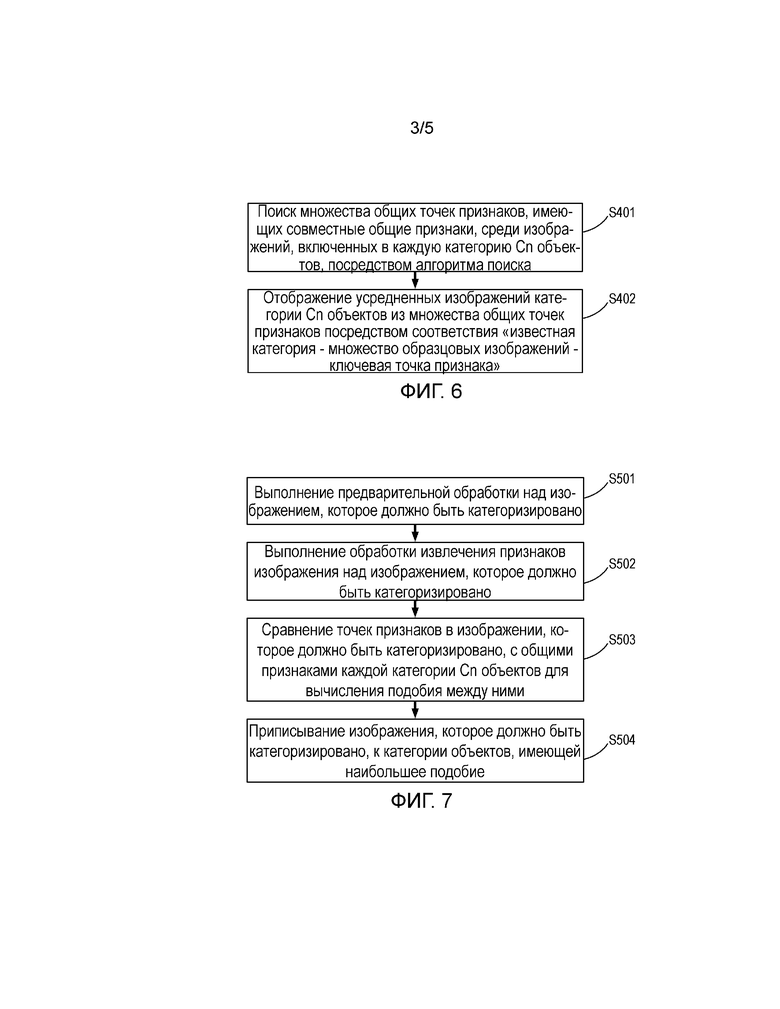
Фиг. 6 - подробная блок-схема последовательности операций этапа S4 в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 7 - основная блок-схема последовательности операций онлайнового (вторая часть) способ распознавания категории изображения настоящего изобретения.
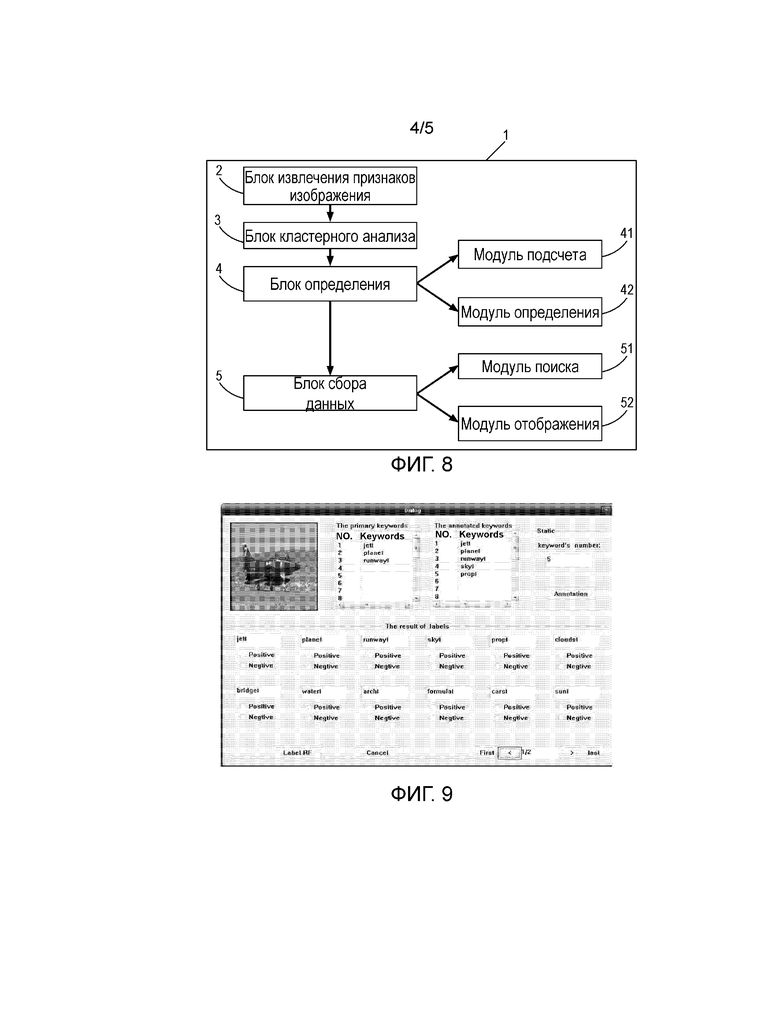
Фиг. 8 - блок-схема устройства распознавания категории объекта изображения настоящего изобретения.
Фиг. 9 - Конкретный пример офлайнового автоматического распознавания образов с помощью компьютера.
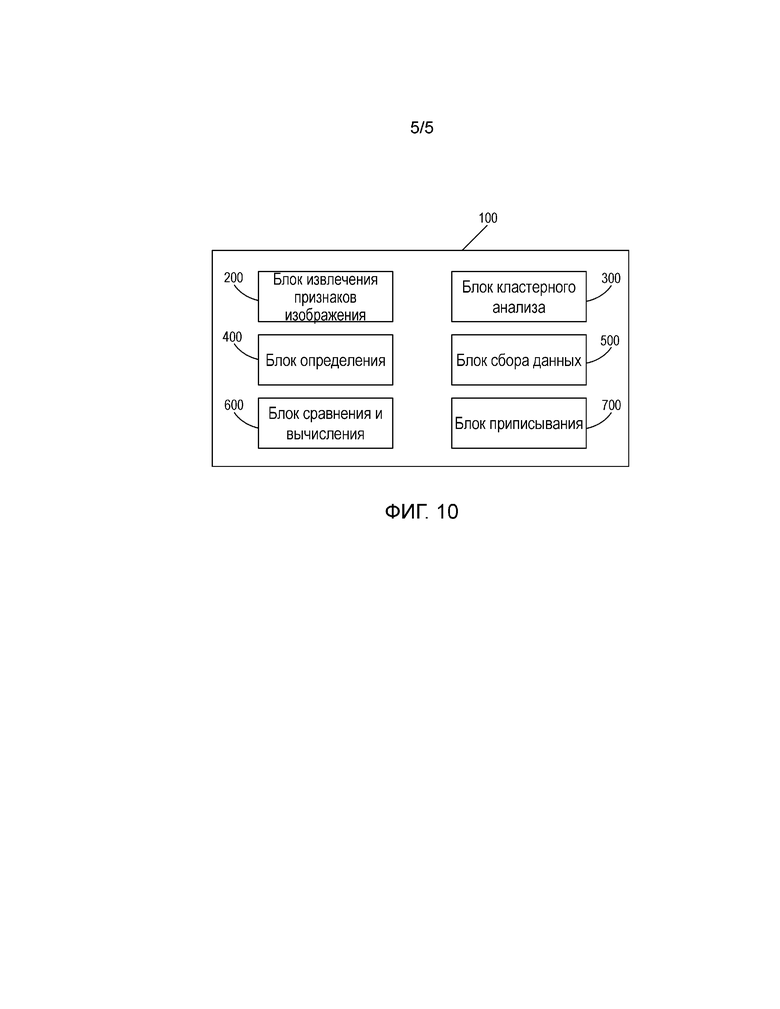
Фиг. 10 - блок-схема системы распознавания изображений, содержащей устройство распознавания категории объекта изображения настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Чтобы разъяснить задачу, техническое решение и преимущества, настоящее изобретение будет далее подробно описано со следующими прилагаемыми чертежами и конкретными вариантами осуществления. Чертежи иллюстрируют только типичные варианты реализации настоящего изобретения. Настоящее изобретение может быть реализовано в различных формах и не должно быть истолковано, как ограниченное конкретными вариантами реализации, описанными или проиллюстрированными здесь. Эти варианты осуществления обеспечены только для того, чтобы сделать раскрытие достаточным и всесторонним. Всюду по тексту одинаковые ссылочные позиции соответствуют одинаковым элементам. Для одинаковых элементов на каждом из чертежей разъяснения не будут повторяться. Использование в настоящем документе фраз "включает в себя", "содержит" и их вариантов означает включение перечисленных после этого элементов и их эквивалентов, а также дополнительных элементов.
Кроме того, следует понимать, что варианты осуществления настоящего изобретения, включающие в себя аппаратные средства, программное обеспечение, программно-аппаратное обеспечение и электронные компоненты или модули и т.д., могут быть проиллюстрированы и описаны таким образом, что большинство частей реализовано исключительно в аппаратных средствах в целях описания. Однако на основе приведенных в настоящем документе подробных описаний специалисты в области техники поймут, что по меньшей мере в одном варианте осуществления один аспект настоящего изобретения, основанный на электронном устройстве, может быть реализован посредством программного обеспечения или программно-аппаратного обеспечения. Также следует отметить, что множество устройств, основанных на аппаратных средствах, программном обеспечении и программно-аппаратном обеспечении, и множество различных структурных компонентов могут использоваться в реализации настоящего изобретения. Кроме того, как описано в нижеследующих абзацах, конкретная механическая конфигурация, проиллюстрированная на чертежах, приведена в качестве примера вариантов осуществления настоящего изобретения, и также возможны другие альтернативные конфигурации.
Специалисты в области техники могут с легкостью обеспечить подходящую программную среду для помощи в реализации настоящего изобретения посредством использования представленной здесь идеи и языков и инструментов программирования, таких как Java, Pascal, C++, C, язык для работы с базами данных, API, SDK, компилятор, программно-аппаратное обеспечение, микрокод и т.п.
Предпочтительные варианты осуществления в соответствии с настоящим изобретением теперь будут описаны со ссылкой на варианты реализации обработки изображений. На практике настоящее изобретение может обрабатывать различные изображения, например, цветные, черно-белые или полутоновые и т.д.
Способ в соответствии с заявкой может быть разделен на две части. Первая часть представляет процесс автономной тренировки и обучения компьютера, и вторая часть представляет автоматический процесс распознавания категории. Обе эти части могут быть исполнены или реализованы офлайновым или онлайновым методом. Офлайновый метод относится к процессу, в котором независимо от сетевой системы компьютер выполняет автономное приобретение знаний о категории объекта для изображения; и онлайновый метод означает процесс, в котором автоматическое распознавание категории объекта для категоризируемого изображения, которое было получено, выполняется в практическом применении, особенно в сетевой среде. Эти две части могут быть выполнены независимо друг от друга.
В первой части сначала репрезентативное множество образцовых изображений для каждой категории выбирается соответственно из множества известных образцовых изображений (продуктов или товаров и т.д.), которые были явным образом категоризированы по известным категориям (например, N известных категорий), каждое множество образцовых изображений включает в себя по меньшей мере одно образцовое изображение, содержащее типичные признаки известной категории. Посредством соответствующего анализа этих репрезентативных множеств образцовых изображений с помощью компьютера из них извлекается общность признаков каждого множества образцовых изображений для каждой известной категории, чтобы установить соответствие среди известной категории, образцового изображения и точки признака, и компьютер побуждают автономно извлекать (вычислять) общие признаки или усредненные изображения среди множества образцовых изображений для каждой категории объектов на основе соответствия.
Во второй части с использованием общих признаков или усредненных изображений каждой категории объектов, полученных в первой части, в качестве эталона для сравнения, используемого при участии в онлайновом процессе распознавания категории объекта для выполнения автоматического распознавания категории для изображений, которые должны быть категоризированы. Если общие признаки образцовых изображений для каждой категории объектов были получены при помощи других способов, автоматический процесс распознавания второй части может быть выполнен непосредственно, с исключением первой части.
Конкретные варианты реализации для каждой части будут описаны более подробно.
Фиг. 1 является основной блок-схемой последовательности операций первой части способа распознавания категории объекта изображения.
В первой части основная цель состоит в том, чтобы побудить компьютер автономно учиться извлекать общие признаки из известного множества образцовых изображений для каждой известной категории. Первая часть в основном включает в себя, но без ограничения, следующие этапы: этап извлечения признака изображения; этап кластерного анализа; и этап определения категории объекта и поиска множества общих точек признаков и т.д. (см. фиг. 1).
Сначала каждая конкретная категория (такая как телевизор, холодильник и т.д.) в множествах изображений для N (N - натуральное число больше 1) известных категорий была определена вручную или другими средствами, и каждая категория имеет свое собственное множество изображений. Каждое множество изображений включает в себя по меньшей мере одно образцовое изображение, посредством чего может быть установлено соответствие между каждой известной категорией и каждым множеством образцовых изображений или даже каждым изображением (в дальнейшем таблица соответствия "известная категория - множество образцовых изображений”).
Поскольку процесс субъективного суждения и распознавания для некоторого изображения человеческим глазом абсолютно отличается от принципа суждения и распознавания относительно того же самого изображения с помощью компьютера, результаты распознавания могут быть далекими друг от друга. Чтобы разрешить компьютеру получить результат распознавания, сходный с человеческим глазом, необходимо сначала "натренировать" компьютер и заставить его "учиться" автономно категоризировать и распознавать изображения.
Чтобы натренировать компьютер автономно изучать общие признаки множества изображений для каждой известной категории и получать точные описания для каждой известной категории, настоящее изобретение анализирует множество образцовых изображений для каждой категории с помощью компьютера сначала, чтобы извлечь (вычислить) описания признаков каждого изображения в множестве образцовых изображений для каждой категории. С этой целью первая часть настоящего изобретения может включать в себя, но без ограничения, следующие этапы:
ЭТАП ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ
Перед анализом изображения, чтобы уменьшить количество вычислений и/или удалить шум из изображения, часто требуется необходимая предварительная обработка изображения. Однако этап предварительной обработки не является обязательным и может быть опущен при условии, что изображение, которое будет проанализировано, может удовлетворять требованиям для извлечения признаков. Согласно фиг. 2, для цветного изображения, например, этап предварительной обработки изображения настоящего варианта осуществления включает в себя, но без ограничения: пропорциональное масштабирование изображения для уменьшения количества вычислений; удаление части или всего шума с помощью средства фильтрации; обработка удаления цветности и т.д. С черно-белыми изображениями обработка удаления цветности и т.д. может быть опущена.
Конкретный этап предварительной обработки может быть реализован с помощью следующих подэтапов.
Этап S001: пропорциональное масштабирование цветного изображения в соответствии с формулой (1.1):
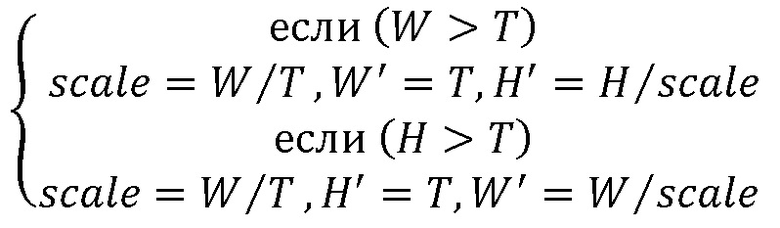 (1.1),
(1.1),
где W, H представляют ширину и высоту исходного изображения перед масштабированием, W', H' представляют ширину и высоту пропорционально масштабированного изображения, scale представляет коэффициент масштабирования, и T - порог для пропорционального масштабирования. В настоящем изобретении в пикселях в качестве единицы измерения можно установить порог T ∈ [500, 800]. Посредством многократных экспериментов автор изобретения обнаружил, что когда порог находится в пределах этого диапазона, результат является оптимальным; особенно, когда T=600, изображение может быть масштабировано до подходящего размера, и не производится какое-либо влияние на дальнейшую обработку и распознавание изображения с улучшенной эффективностью вычисления.
Затем в соответствии с формулой (1.2) линейная интерполяция в направлении X применяется к исходному изображению, и затем выполняется линейная интерполяция в направлении Y в соответствии с формулой (1.3) для получения пропорционально масштабированного изображения:
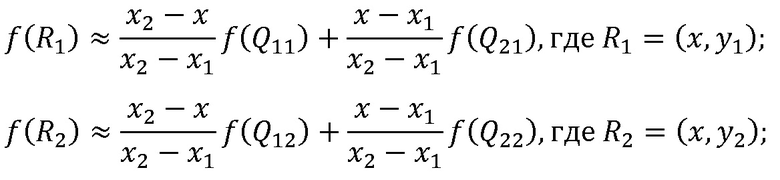 (1.2)
(1.2)
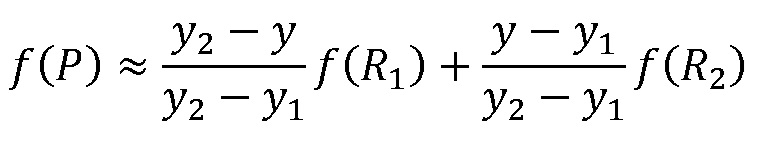 (1.3),
(1.3),
где R1 и R2 представляют линейно интерполированные в направлении X пиксели, x, y, x1, y1, x2, y2 являются координатами пикселей в изображении, f(*, *) представляет значение цвета пикселей, Q11=(x1, y1), Q12=(x1, y2), Q21=(x2, y1), Q22=(x2, y2) представляют четыре точки в исходном изображении, которые участвуют в вычислении масштабирования, и P представляет линейно интерполированную в направлении Y точку. В настоящем варианте осуществления после линейной интерполяции в направлении Y получено пропорционально масштабированное изображение.
Этап S002: выполнение следующей обработки двусторонней фильтрации в соответствии с формулой (1.4) над пропорционально масштабированным на этапе S001 изображением:
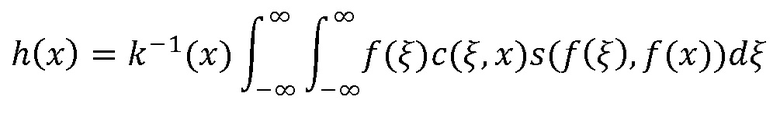 (1.4),
(1.4),
где f(x) - входное изображение, h(x) - выходное изображение, с(ξ, x) измеряет степень геометрической близости между пороговым центром x и его смежной точкой ξ, s(f(ξ), f(x)) измеряет подобие яркости пикселей между пороговым центром x и его смежной точкой ξ, и k - нормализованный параметр. В гладкой области двусторонний фильтр воплощен как стандартный фильтр сетевой области, который отфильтровывает шум посредством процесса сглаживания, такого как удаление заметных изменчивых изолированных пикселей и т.д.
Затем выполняется операция удаления цветности над входным цветным изображением в соответствии с формулой (1.5). Этот этап может быть опущен, когда не используется алгоритм SIFT.
Y=0,299*R+0,587*G+0,114*B (1.5),
где Y представляет пиксельное значение текущего пикселя после преобразования, R представляет значение красного цвета текущего пикселя, G представляет значение зеленого цвета текущего пикселя, и B представляет значение синего цвета текущего пикселя.
Способы и устройства предварительной обработки, которые могут удовлетворять требованиям извлечения признаков изображения на предшествующем уровне техники, могут использоваться в любой форме для предварительной обработки изображения.
ЭТАП S1 ИЗВЛЕЧЕНИЯ ПРИЗНАКА
После выборочной предварительной обработки изображения наступает этап S1 (см. фиг. 1 и фиг. 3): извлечение соответствующего описания признака каждого изображения в известном множестве образцовых изображений для каждой категории.
Конкретно для вариантов осуществления настоящего изобретения способ извлечения визуального признака низкого уровня (см. фиг. 3) может использоваться для извлечения каждой ключевой точки признака из каждого изображения в каждом множестве образцовых изображений (этап S101) и вычисления (получения) векторного описания, т.е. дескриптора каждой ключевой точки признака (этап S102). В варианте осуществления процесс извлечения визуального признака низкого уровня из изображения описан с использованием алгоритма SIFT в качестве примера.
Этап извлечения визуального признака низкого уровня может быть реализован через следующие подэтапы.
Этап S101: извлечение визуальных признаков низкого уровня из предварительно обработанного изображения. Например, извлечение визуальных признаков низкого уровня может быть выполнено с использованием алгоритма SIFT (масштабно-инвариантная трансформация признаков). Алгоритм SIFT выдвинут Д. Г. Лоу (D. G. Lowe) в 1999 году и усовершенствован и заключительно сформулирован в 2004 году. Работа была опубликована в IJCV: David G. Lowe, "Distinctive image features from scale-invariant key points", International Journal of Computer Vision, 60, 2 (2004), pp.91-110. Содержания этого документа полностью включено в настоящий документ посредством цитирования и ссылки.
В SIFT ключевые точки признаков и дескрипторы (т.е. векторные выражения точек признаков) ключевых точек признаков могут быть вычислены с помощью хорошо известного и используемого способа. И этапы S101 и S102 могут быть выполнены на одном вычислительном этапе или в одном функциональном блоке.
Через извлечение визуальных признаков низкого уровня компьютер может извлечь (т.е. вычислить) каждую ключевую точку признака, имеющую известную характеристику, в каждом изображении и ее соответствующий дескриптор. Затем создается соответствие (см. таблицу 1) “известная категория - множество образцовых изображений - ключевая точка признака (т.е. дескриптор)” (этап S103) на основе ранее созданной таблицы соответствия “известная категория - множество образцовых изображений”. На основе соответствия (таблицы) компьютер может идентифицировать количества ключевых точек признаков, включенных в каждую категорию и даже в каждое образцовое изображение, и дескрипторы и соответствия между ними. Таблица соответствия также может создаваться одновременно с тем или после того, как вычислена каждая ключевая точка признака. Таким образом, этап S103 может быть выполнен параллельно с этапами S101 и/или этапом S102 или последовательно после них, и таблица соответствия может быть сохранена в соответствующей памяти согласно необходимости.
где Cn представляет n-ю категорию объектов, C1, ..., Cn (n≤N); In1, ..., Inj представляет j-ое изображение в n-й категории объектов (j - количество изображений в категории Cn объектов); Fnj1, ..., Fnjf представляет f-ую ключевую точку признака SIFT в каждом изображении Inj, причем f - натуральное число не меньше 1.
При этом другие способы извлечения признаков изображения могут использоваться в качестве схем, альтернативных алгоритму SIFT, например, алгоритм SURF или алгоритм PCA (анализ основных составляющих)-SIFT и т.д., и эти алгоритмы применимы к настоящему изобретению.
ЭТАП S2 КЛАСТЕРНОГО АНАЛИЗА
После извлечения признака каждого образцового изображения, т.е. визуального признака низкого уровня, наступает этап S2 кластерного анализа (см. фиг. 1). Все ключевые точки признаков (т.е. дескрипторы), извлеченные из всех множеств образцовых изображений для всех категорий подвергаются кластерному анализу, и строится древоподобная структура. Древоподобная структура может быть истолкована с использованием структуры k-дерева. Этап S2 может быть реализован с помощью следующего конкретного способа (см. фиг. 4).
Все ключевые точки признаков SIFT, включенные во все образцовые изображения для всех полученных категорий объектов, кластеризируются по предварительно заданному количеству кластеров (этап S201) с помощью алгоритма кластеризации. Процесс кластеризации извлекает главную общность среди каждой категории самонастраивающимся образом, в основном отличая различные категории. Может использоваться хорошо известный и используемый алгоритм кластеризации, например, метод k-средних (k-means). Информацию об алгоритме кластеризации k-средних можно найти в следующих документах: MacQueen, J. B., Some methods for classification and analysis of multivariate observations, in Proc. 5th Berkeley Symp. Mathematical Statistics and Probability, 1967, pp. 281-297. Подробное введение можно дополнительно найти на следующих веб-сайтах, и их содержание включено в настоящий документ посредством цитирования.
1. http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
2. http://wenku.baidu.com/view/179d21a4f524ccbff1218482.html
Другие способы кластеризации также могут быть применены к настоящему изобретению при условии, что они могут категоризировать пространственно смежные данные в одну и ту же категорию. Альтернативные алгоритмы кластеризации включают в себя, но без ограничения: алгоритм k-modes, алгоритм k-Prototype, иерархический способ кластеризации, способ выборки с максимальным расстоянием, муравьиный алгоритм кластеризации, алгоритм нечеткой кластеризации и т.д.
В этом случае настоящее изобретение описывает процесс кластеризации с использованием алгоритма k-средних в качестве примера. Алгоритм k-средних категоризирует n объектов данных по k кластерам на основе предварительно установленного значения k. Объекты в одном и том же кластере имеют высокое подобие, тогда как объекты в разных кластерах имеют низкое подобие. Подобие кластеров вычисляется посредством "центрального объекта" (центра тяжести), полученное посредством средннго из объектов данных в каждом кластере. Например, в настоящем изобретении, когда известное и предварительно установленное количество категорий объектов равно N, диапазон k представляет собой k ∈ (1, N), или k меньше общего количества точек признаков, которые участвуют в кластеризации. В настоящем варианте осуществления выбрано, что k ∈ (1,10), и обычно k не больше 10. Выбор k может быть определен на основе оптимального значения, полученного опытным путем или через тесты в соответствии с фактическими потребностями.
Рабочий процесс алгоритма k-средних представляет собой следующее: сначала случайно выбираются k объектов в качестве начальных центров кластеризации из x объектов данных; остальные объекты данных распределяются по центрам кластеризации, наиболее подобным с ними (ближайшим в пространственном расстоянии), соответственно на основе их подобия (пространственных расстояний) с центрами кластеризации.
Конкретно для варианта осуществления настоящего изобретения множество дескрипторов всех ключевых точек признаков, извлеченных из всех изображений, подвергается кластерному анализу. При этом на начальной стадии кластеризации k-средних центры кластеризации сначала могут быть определены случайным образом. Например, когда выбрано, что k=2, случайным образом выбираются дескрипторы двух ключевых точек признаков в качестве начальных центров кластеризации. Посредством вычисления евклидова расстояния между дескрипторами ключевых точек признаков, которые недавно присоединились, и предварительно выбранными двумя начальными центрами кластеризации, дескрипторы ключевых точек признаков, которые недавно присоединились, приписываются к категории (т.е. к кластеру), которая имеет минимальное евклидово расстояние. Таким образом, например, через итерационный подход осуществляется обход всех точек признаков, пока все точки признаков или дескрипторы не будут вовлечены в кластеризацию, и в конечном счете все извлеченные ключевые признаки кластеризируются в два кластера вокруг двух начальных центров кластеризации. Затем средние значения (средние значения векторов дескрипторов) всех дескрипторов в каждом кластере повторно вычислены для этих двух кластеров, чтобы получить новый центр кластеризации. Затем вновь полученный центр кластеризации и предыдущий (смежный предыдущий) центр кластеризации сравниваются, чтобы вычислить разность (например, дисперсию) между ними. Когда разность равна нулю или достигает предварительно заданного порога, процесс кластеризации может быть закончен. Иначе новый центр кластеризации, определенный посредством текущей итерации, может использоваться в качестве начального центра кластеризации для следующей итерации, чтобы постоянно корректировать центр кластеризации. Упомянутый выше процесс итерации или кластеризации может повторяться, пока центр кластеризации не перестает изменяться или изменяется мало (т.е. удовлетворяет предварительно установленному порогу).
Более конкретно может использоваться стандартный показатель для определения, удовлетворяет ли итерационный процесс условию сходимости, чтобы определить, может ли итерационный процесс быть закончен. В варианте осуществления настоящего изобретения, когда k=2, стандартный показатель может быть определен как сумма абсолютных значений разности между каждым компонентом дескриптора SIFT и соответствующим компонентом полученного дескриптора центра кластеризации. Когда сумма больше некоторого значения или количество повторений больше предварительно заданного числа, итерационный процесс кластеризации заканчивается.
Чтобы сократить временную сложность вычисления, в качестве стандартного показателя также можно выбрать следующее: вычисление абсолютного значения разности между текущим центром кластеризации и предыдущим центром кластеризации для каждой категории и затем вычисление суммы абсолютных значений всех категорий. Когда сумма меньше определенного порога, итерации заканчиваются.
Древоподобная структура ключевых точек признаков (или дескрипторов), т.е. k-дерево, может строиться (этап S202) одновременно с выполнением алгоритма кластеризации или после него. Таким образом, функция кластерного анализа на этапе S2 может быть реализована посредством объединения этапов S201 и S202 в один этап или в один функциональный модуль в конкретном варианте осуществления.
Конкретно для одного варианта осуществления при k=2 (т.е. двоичное дерево) в качестве примера все визуальные признаки низкого уровня всех образцовых изображений категории объектов, т.е. из ключевых точек признаков SIFT в упомянутом выше варианте осуществления строится корневой узел n1 двоичного дерева, и упомянутый выше кластерный анализ выполняется над всеми ключевыми точками признаков в узле n1.
Множество кластеров, имеющее относительно большее количество ключевых точек признаков в узле n1 после кластеризации, служит в качестве левого дочернего узла n2 корневого узла n1, тогда как множество кластеров, имеющее относительно меньшее количество ключевых точек признаков в узле, служит в качестве правого дочернего узла n3 корневого узла n1. Остальное выполняется таким же образом, последующий кластерный анализ выполняется над узлами n2 и n3 соответственно, пока количество концевых узлов двоичного дерева не станет равно известному и предварительно установленному общему количеству N категорий объектов, т.е. заключительное количество концевых узлов должно быть равно N. Другими словами, все ключевые точки признаков всех изображений во всех категориях объектов разделены на N подмножеств.
При k=2, например, структурная диаграмма окончательно построенного двоичного дерева следующая:
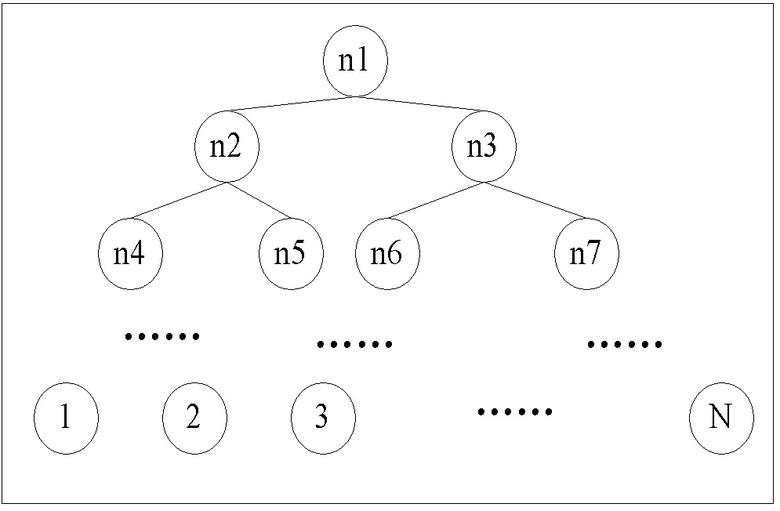
В предположении, что каждый узел k-дерева, построенного на этапе S2, выражен следующим образом:
ni(C1, I11, F111, ..., F11f, f11, ..., I1j, F1j1, ..., F1jf, f1j; ...;Cn, In1, Fn11, ..., Fn1f, fn1, ..., Inj, Fnj1, ..., Fnjf, fnj)
где ni обозначает i-ый концевой узел k-дерева, категории объектов, обозначенные ключевыми точками признаков SIFT, сохраненными в узле, представляют собой C1, ..., Cn (n≤N), изображения в каждой категории объектов обозначены как In1, ..., Inj (j - количество изображений в категории Cn объектов), ключевые точки признаков SIFT, кластеризированные как узел ni в каждом изображении Inj, представляют собой Fnj1, ..., Fnjf, fnj - количество ключевых точек признаков SIFT, кластеризированных как ni-ый концевой узел в j-ом изображение n-ой (1n≤N) категории объектов (т.е. Cn).
Таким образом, все ключевые точки признаков во всех образцовых изображениях распределены или разделены на N концевых узлов или подмножеств. Повторяющиеся ключевые точки признаков не включены в N концевых узлов, т.е. между каждыми двумя концевыми узлами нет никаких пересечений, но ключевые точки признаков изображений другой категории могут смешиваться или включаться в каждый концевой узел.
ЭТАП S3 ОПРЕДЕЛЕНИЯ КАТЕГОРИИ ОБЪЕКТА И ПОИСКА МНОЖЕСТВА ОБЩИХ ТОЧЕК ПРИЗНАКОВ
Для удаления изображений, которые не принадлежат категории из каждого узла ni, чтобы точно ограничить категорию, которой принадлежит образцовое изображение, настоящее изобретение дополнительно содержит этап S3 определения категории объекта и поиска общих признаков для каждого изображения, включенного в каждую категорию объектов (см. фиг. 1).
Конкретные способы реализации или этапы для этапа S3 описаны ниже со ссылкой на фиг. 5.
Этап S3 (для определения категории объекта): анализ каждого концевого узла или подмножества древоподобной структуры, полученной на предыдущем этапе S2, со ссылкой на таблицу соответствия “известная категория - множество образцовых изображений - ключевая точка признака и дескриптор”, полученную на предыдущем этапе, для определения категории, которой должен принадлежать каждый концевой узел, чтобы удалить те изображения, которые не принадлежат категории объектов.
Конкретный процесс реализации представляет собой следующее: вычисление или подсчет общего количества ключевых точек признаков SIFT, распределенных для ni-го концевого узла и принадлежащих разным известным категориям, на основе таблицы соответствия “известная категория - множество образцовых изображений - ключевая точка признака и дескриптор”, полученной на предыдущем этапе (S301):
class_number_SIFT(Cn)=fn1+fn2+...+fnj.
Категория, имеющая самое большое количество ключевых точек признаков SIFT в каждом концевом узле, полученное со ссылкой на соответствие “известная категория - множество образцовых изображений - ключевая точка признака и дескриптор":
node_class_label(ni)=max(class_number_SIFT(Cn)).
Категория Cn объектов помечена или идентифицирована как категория, имеющая самое большое общее количество ключевых точек признаков в концевом узле (S302). Если до этого категория была помечена или распределена другому концевому узлу, для пометки выбирается категория, имеющая меньшее общее количество ключевых точек признаков SIFT. Остальное делается таким же образом, чтобы пометить категорию для каждого концевого узла. Например, в предположении, что некоторый концевой узел включает в себя известные категории, пронумерованные как 1.5.8.9, и общие количества точек признаков изображений SIFT, включенных в соответствующие категории, составляют 10.25.15.35 соответственно, порядок в соответствии с общим количеством точек признаков SIFT представляет собой 9(35).5(25).8(15).1(10). В соответствии с этим номер категории (т.е. 9), имеющей наибольшее количество точек признаков, распределяется или помечается для концевого узла. Однако если категория номер 9 до этого была распределена другому концевому узлу, категория номер 5 (т.е. имеющая меньшее общее количество ключевых точек признаков) последовательно распределяется текущему концевому узлу. В предположении, что номер 5 также был распределен другому концевому узлу, номер 8 выбирается для пометки концевого узла. Остальное делается таким же образом, пока не будут помечены все концевые узлы.
Теперь для каждой категории Cn объектов категория, которой она принадлежит, была помечена или идентифицирована. Однако на практике подмножество изображений в категории объектов включает в себя более одного изображения, и некоторое образцовое изображение включает в себя некоторые избыточные элементы признаков. Например, в множестве "похожих на компьютер" образцовых изображений, полученных при тренировке, в отличие от других "похожих на компьютер" образцовых изображений одно из "похожих на компьютер" изображений дополнительно включает в себя избыточный элемент признака "звукового проигрывателя". Таким образом, посредством процесса кластерного анализа некоторые избыточные точки признаков или элементы, которые не могут представлять основные признаки категории объектов, неизбежно примешиваются в каждой категории объектов. Кроме того, даже для изображений в одной и той же категории вследствие вмешательства угла съемки, освещения и подобных факторов описания одной и той же точки признака различаются, и эти элементы будут влиять на корректную категоризацию и автоматическое распознавание изображений посредством компьютера.
С этой целью компьютер должен прояснить общие признаки среди изображений для каждой категории, чтобы как можно больше устранить влияние этих оказывающих помехи факторов.
С этой целью настоящее изобретение дополнительно содержит этап S4 сбора общих признаков среди каждого изображения, включенного в каждую категорию Cn объектов.
Этап S4 описан со ссылкой на фиг. 6. Более конкретно этап S4 по меньшей мере содержит: извлечение множества общих точек признаков (в дальнейшем: множество общих точек признаков) среди каждого изображения для каждой категории Cn объектов (этап S401) и/или дополнительное отображение репрезентативных типичных изображений, соответствующих этим общим признакам, посредством таблицы соответствия "известная категория - множество образцовых изображений - ключевая точка признака и дескриптор" (S402), тем самым не только заставляя компьютер прояснить общие признаки каждой категории Cn объектов, обеспечивая вручную основание для подтверждения, является ли корректным автономное распознавание с помощью компьютера относительно категории Cn объектов, но также обеспечивая точный и оптимальный эталон для сравнения для последующего точного онлайнового распознавания категории объектов, значительно уменьшая количество вычислений.
Сначала в каждом концевом узле выбирается соответствующее множество изображений, помеченных как категория Cn, и множество изображений выражено следующим образом:
I(Cn)={In1, In2, ..., Inj}
Этап S401: извлечение общих признаков для каждой категории Cn объектов. Когда визуальные признаки низкого уровня изображения служат в качестве описаний изображения, в каждой категории Cn объектов может быть выбрано множество ключевых точек признаков среди каждого изображения, чтобы выражать общие признаки категории объектов. Чтобы уменьшить количество вычислений или поиска, наименьшее количество общих точек признаков, которые должны быть извлечены в каждой категории Cn объектов, может быть определено посредством следующих этапов
Количество соответствующих ключевых точек признаков SIFT и количество точек признаков каждого изображения выражены следующим образом:
I(Cn)={In1, Fn11, ..., Fn1f, fn1, ..., Inj, Fnj1, ..., Fnjf, fnj},
где fnj - количество ключевых точек признаков SIFT, помеченных как Cn, в изображении Inj.
Поскольку количество общих точек признаков среди каждого изображения для каждой категории Cn объектов неизбежно не больше, чем количество точек признаков в изображении, имеющем наименьшее количество точек признаков, минимальное количество K(Cn) общих точек признаков может быть определено следующим упрощенным методом. Например, со ссылкой на соответствие "известная категория - множество образцовых изображений - ключевая точка признака и дескриптор" может быть подсчитано количество ключевых точек признаков SIFT, помеченных как категория Cn в каждом изображении в каждой категории Cn объектов, и среди них может быть выбран минимум:
K(Cn)={fn1, fn2, ..., fnj}
В соответствии с этим диапазон количества ключевых точек признаков, имеющих совместные общие признаки в категории объектов (или в множестве изображений I(Cn)), может быть сначала определен численно. Однако упомянутые выше этапы могут прояснить только количество общих точек признаков, включенных в каждую категорию Cn объектов, эти точки признаков и изображения, которым они соответственно принадлежат, не могут быть определены.
Алгоритм поиска, такой как KNN (алгоритм k ближайших соседей) (документ Hastie, T.and Tibshirani, R.1996. Discriminant Adaptive Nearest Neighbor Classification. IEEE Trans. Pattern Anal.Mach. Intell. (TPAMI) .18,6 (Jun.1996), 607-616., который включен в настоящий документ посредством ссылки) может использоваться, чтобы найти множество общих точек признаков, имеющих совместные общие признаки в каждом изображении, включенном в каждую категорию Cn объектов, и соответствующее множество изображений этих общих точек признаков.
В примере использования алгоритма поиска KNN конкретные этапы являются следующими: в предположении, что векторный центр всех множеств точек признаков SIFT, включенных в категорию, помеченную как Cn, в множестве репрезентативных изображений I(Cn)={In1, In2, ..., Inj}, полученном на предыдущем этапе, обозначен как centre(Cn), векторный центр может быть получен посредством вычисления среднего вектора дескрипторов всех точек признаков SIFT, помеченных в множестве репрезентативных изображений:
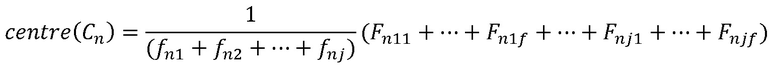
Вычисляется евклидово расстояние Dis(Fnjf, centre(Cn)) между дескриптором ключевой точки признака SIFT, помеченной в множестве репрезентативных изображений категории объектов, и векторным центром centre(Cn) (этап S401).
Хорошо известный и используемый алгоритм поиска ближайших соседей KNN или другие общие алгоритмы сортировки могут использоваться для получения K(Cn) ключевых точек признаков SIFT, самых близких к векторному центру centre(Cn), и обозначенных KNN(F), чтобы извлечь K(Cn) точек признаков, самых близких к векторному центру centre(Cn). K(Cn) ключевых точек признаков и их соответствующие образцовые изображения, к которым они принадлежат, могут быть определены и извлечены посредством полученного ранее соответствия "известная категория - множество образцовых изображений - ключевая точка признака и дескриптор".
Таким образом, с помощью упомянутого выше алгоритма множество общих точек признаков, имеющих совместные общие признаки среди каждого изображения в каждой категории Cn объектов (или называемый множеством общих точек признаков в категории Cn объектов) может быть получено и использовано непосредственно в качестве основания для сравнения на последующем этапе S5.
Однако в целях проверки правильности автономного обучения компьютера или визуального сравнения изображений иногда необходимо найти множество образцовых изображений, соответствующих K(Cn) ключевым точкам признаков, или его наибольшее подмножество. С этой целью настоящее изобретение дополнительно содержит этап S402: дополнительный поиск множества изображений, включающего в себя K(Cn) точек признаков из множества изображений категории Cn объектов, или его наибольшее подмножество на основе K(Cn) точек признаков, найденных на предыдущем этапе, и соответствия "известная категория - образцовое изображение - точка признака", чтобы использовать самое большое подмножество образцовых изображений, включающее в себя K(Cn) точек признаков, как усредненные изображения или множество изображений категории объектов, полученное через машинное автономное обучение.
Дополнительно, но не обязательно, минимальное расстояние (min_dis(Cn)) K(Cn) общих точек признаков до векторного центра centre(Cn) категории объектов может быть получено и использовано в качестве основания для ограничения порогового диапазона подобия сравниваемых изображений на последующем этапе S5, причем расстояние обозначает подобие среди точек в пространстве, и минимальное расстояние означает, что изображение может наилучшим образом изобразить главную общность категории объектов. Минимальное расстояние выражено как:
min_dis(Cn)=min(Dis(Fnjf, centre(ni))).
Через описанную выше офлайновую обработку в первой части посредством офлайновой тренировки на определенном количестве известных образцовых изображений компьютер завершил процесс автономного распознавания категории объектов и извлек множество общих точек признаков, имеющих совместные общие признаки, среди каждого изображения, включенного в каждую категорию Cn объектов, и соответствующие усредненные изображения или множество изображений из всех образцовых изображений. Усредненные изображения или множество изображений используются в качестве основания в последующем онлайновом процессе распознавания категорий объектов (т.е. во второй части).
Вторая часть: онлайновое распознавание и категоризация изображений. Фиг. 7 иллюстрирует один метод реализации этапа S5.
После получения множества общих точек признаков среди изображений, включенных в каждую категорию Cn объектов, или соответствующих усредненных изображений или множества изображений, множество общих точек признаков или усредненных изображений может быть соединено с соответствующей сетью или помещено в любую платформу или местоположение, желаемое для последующей реализации автоматического распознавания изображения, которое должно быть категоризировано.
Например, в предположении, что новое изображение, которое должно быть категоризировано, получено через сеть или другими средствами, новое изображение не категоризировано, или категория, которой оно принадлежит, не идентифицирована, и желательно, чтобы изображение, которое должно быть категоризировано, было категоризировано автономно по упомянутым выше известным N изображениям (или N типам товаров).
С этой целью настоящее изобретение выполняет такую же обработку над новым изображением, которое должно быть категоризировано, как на этапе предварительной обработки и на этапе S1 извлечения признака изображения в первой части. Более конкретно со ссылкой на фиг. 7, факультативно выполняется этап S501. Когда необходимо, такая же предварительная обработка, как на предыдущих этапах S001-S003, выполняется над новым изображением.
Этап S502: извлечение визуальных признаков низкого уровня из изображения, которое должно быть категоризировано, с использованием такого же способа извлечения признака изображения, который используется на этапе S1 в первой части, т.е. извлечение ключевых точек признаков и дескрипторов изображения, которое должно быть категоризировано.
Этап S503: сравнение изображения, которое должно быть категоризировано, с общими признаками каждой категории объектов, полученными в первой части, чтобы определить (вычислить) подобие между ними. Затем изображение, которое должно быть категоризировано, распределяется (приписывается) в категорию объектов, имеющей наибольшее подобие (этап S504).
Более конкретно, ключевые точки признаков и дескрипторы, извлеченные из изображения, которое должно быть категоризировано, сравниваются непосредственно с множеством общих точек признаков для каждой категории объектов, полученным ранее, или с ключевыми точками признаков в усредненных изображениях в каждой категории объектов, чтобы измерить подобие между изображением, которое должно быть категоризировано, и каждым образцовым изображением, и изображение, которое должно быть категоризировано, распределяется в категорию с наибольшим подобием.
Конкретно для настоящего изобретения, если подобие измерено с помощью алгоритма SIFT и с использованием евклидова расстояния, и множество общих точек признаков для каждой категории объектов выбрано как основание для сравнения, все ключевые точки признаков SIFT, извлеченные из изображения, которое должно быть категоризировано, сравниваются с каждой ключевой точкой признака SIFT, включенной в множество общих точек признаков, друг за другом для каждой категории объектов, чтобы вычислить евклидово расстояние Dis(FRi , FAi) между ними, где FRi - i-ая ключевая точка признака SIFT в изображении, которое должно быть распознано, FAi - i-ая ключевая точка признака SIFT в множестве общих точек признаков категории объектов.
Преимущество прямого выбора множества общих точек признаков для каждой категории объектов в качестве основания для сравнения заключается в значительном сокращении количества вычислений и в сокращении времени для вычисления. Однако проблема состоит в том, что поскольку множество общих точек признаков представляет собой улучшенное описание общих признаков категории объектов, возможно удалено большое количество точек признаков, которые должны принадлежать категории. Например, вследствие вмешательства угла съемки, освещения и подобных факторов описания точек признаков, которые должны были принадлежать одному и тому же признаку, отличаются, и точки признаков не приписаны к множеству общих точек признаков, и это влияет на корректную классификацию и распознавание изображения, которое должно быть категоризировано, с помощью компьютера.
Таким образом, в настоящем изобретении предпочтительно, чтобы изображение, которое должно быть категоризировано, сравнивалось с усредненными изображениями или множеством изображений каждой категории объектов, вместо того, чтобы использовать множество точек признаков для каждой категории объектов в качестве основания для сравнения. В это время все ключевые точки признаков SIFT, извлеченные из изображения, которое должно быть категоризировано, сравниваются со всеми ключевыми точками признаков SIFT (т.е. полным множеством ключевых точек признаков в каждом изображении) в каждом изображении среди усредненных изображений в каждой категории объектов друг за другом, и вычисляется евклидово расстояние Dis(FRi , FAi) между ними, где FRi - i-я ключевая точка признака SIFT в изображении, которое должно быть идентифицировано, и FAi - i-я точка признака SIFT в усредненных изображениях категории объектов.
Затем подсчитывается количество ключевых точек признаков, которые удовлетворяют пороговым условиям, и категория, имеющая наибольшее количество точек признаков, которое удовлетворяет предварительно заданным условиям, может быть определена как категория, которой принадлежит изображение, которое должно быть категоризировано.
Конкретный процесс реализации представляет собой следующее.
(1) Для n-ой категория Cn объектов, если Dis(FRi, FAi)<T1, где T1 - предварительно установленный порог, количественный показатель категории равен score(Cn) плюс 1, причем T1=ε*min_dis(Cn). Здесь ε обозначает весовой коэффициент, который установлен в основном для сокращения количества вычислений и, таким образом, не является необходимым. При условии, что количество вычисления не является большим, ε может быть опущен. И min_dis(Cn) представляет собой минимальное расстояние до векторного центра centre(Cn), полученного ранее после этапа S402. В настоящем изобретении оптимальное значение для весового коэффициента ε получено в соответствии с тестами. В процессе тестирования было обнаружено, что когда ε ∈ [1,5; 2,3], был достигнут более хороший эффект. В более предпочтительном варианте осуществления настоящего изобретения, когда было выбрано, что ε=1,8, может быть получена более высокая точность распознавания.
(2) Затем для каждой категории объектов, если score(Cn)>K(Cn), категория используется в качестве потенциальной распознанной категории изображения, которой должно быть распознано. Наконец, score(Cn) сортируется в порядке убывания, и категория объектов, отсортированная как первая, представляет собой категорию объекта в изображении, которое должно быть распознано.
Другие минимальные расстояния, предварительно установленные или полученные другими средствами, могут быть выбраны для замены min_dis(Cn) до векторного центра center(Cn), чтобы они служил в качестве основания для сравнения расстояния. Например, минимальное евклидово расстояние Dis(FRi , FAi) между каждой точкой признака в изображении, которое должно быть категоризировано, и каждой точкой признака в множестве общих точек признаков или каждой точкой признака в усредненных изображениях может быть выбрано для замены min_dis(Cn) и может быть равно 0 или иметь ненулевое значение.
При условии, что подобие среди изображений может быть измерено точно, могут использоваться другие способы для измерения подобия изображений. Например, расстояние Махаланобиса, расстояние городских кварталов и т.д. может быть выбрано для замены упомянутого выше вычислительного способа с евклидовым расстоянием.
Фиг. 8 показывает один вариант осуществления устройства распознавания категории объекта изображения в соответствии с настоящим изобретением.
Устройство 1 распознавания категории объекта изображения содержит:
блок 2 извлечения признака изображения, выполненный с возможностью извлекать точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков, где N - натуральное число больше 1, каждая категория содержит по меньшей мере одно образцовое изображение, и создано соответствие "известная категория - образцовое изображение - точка признака";
блок 3 кластерного анализа, выполненный с возможностью выполнять кластерный анализ всех точек признаков, извлеченных с использованием алгоритма кластеризации и разделять точки признаков на N подмножеств;
блок 4 определения для определения категории Cn объектов для каждого из подмножеств;
блок 5 сбора данных для сбора общих признаков среди изображений, включенных в каждую категорию Cn объектов с помощью алгоритма поиска, где Cn - n-я категория объектов, и n - положительное целое число не больше N.
Кроме того, блок 4 определения выполнен с возможностью включать в себя по меньшей мере следующие модули: модуль 41 подсчета для подсчета количества точек признаков, которые принадлежат разным известным категориям, для каждого подмножества из N подмножеств; и модуль 42 определения для определения известной категории, которая включает в себя наибольшее количество точек признаков, как категории Cn объектов.
Блок 5 сбора данных выполнен с возможностью включить в себя по меньшей мере следующий модуль: модуль 51 поиска для поиска множества общих точек признаков, имеющих совместные общие признаки, среди изображений, включенных в каждую категорию Cn объектов посредством алгоритма поиска. Чтобы удалить избыточные точки признаков, которые не принадлежат категории Cn объектов.
Предпочтительно, блок 5 сбора данных дополнительно выполнен с возможностью включать в себя: модуль 52 отображения для дополнительного отображения образцовых изображений, имеющих наибольшее количество общих точек признаков среди множества общих точек признаков, из каждой категории Cn объектов посредством соответствия "известная категория - образцовое изображение - точка признака", и с использованием образцовых изображений в качестве усредненных изображений категории Cn объектов.
Фиг. 9 показывает конкретный схематический результат сравнения при распознавании изображения, который включает в себя результаты ручного и компьютерного распознавания. Процесс распознавания категории объекта изображения в первой части настоящего изобретения подобен этому. Три блока слева направо сверху представляют соответственно следующие области: 1. изображения для компьютера для выполнения автономного распознавания категории объектов (в том числе плоскость на фоне); 2. категория изображения, распознанная вручную, и результат извлечения признаков (ключевые слова); 3. категория объектов, распознанная через компьютерный алгоритм автономного обучения, и соответствующий результат извлечения признаков (ключевые слова).
Фиг. 10 показывает блок-схему иллюстративного варианта осуществления системы 100 распознавания изображений, содержащую упомянутое выше устройство распознавания категории объекта изображения. Система 100 по меньшей мере содержит: блок 200 извлечения признаков изображения, блок 300 кластерного анализа, блок 400 определения и блок 500 сбора данных, причем блок 400 определения может содержать по меньшей мере следующие функциональные модули: модуль подсчета и модуль определения. Блок сбора данных может содержать по меньшей мере: модуль поиска и/или модуль отображения и т.д. Эти блоки или модули соответственно реализуют функции блоков, показанных на фиг. 8, которые здесь не повторяются.
Кроме того, чтобы достигнуть функции автоматического распознавания категории во второй части настоящего изобретения, упомянутая система 100 распознавания изображения может дополнительно содержать блок 600 сравнения и вычисления для сравнения каждой точки признака, извлеченной блоком 200 извлечения признаков изображения из изображения, которое должно быть категоризировано, с каждой точкой признака в множестве общих точек признаков для каждой категории объектов или в усредненных изображениях каждой категории объектов друг за другом с помощью алгоритма измерения подобия изображений, чтобы вычислить подобие между точкой признака изображения, которое должно быть категоризировано, и точкой признака каждой категории объектов; и блок 700 приписывания для приписывания изображения, которое должно быть категоризировано, к категории Cn объектов, имеющей наибольшее подобие.
Система 100 включает в себя по меньшей мере один процессор, который может быть запрограммирован для выполнения упомянутого выше способа распознавания категории объекта изображения. Или процессор может содержать программное обеспечение, микропрограммные или аппаратные средства и/или их комбинацию для реализации упомянутых выше функциональных модулей и/или их комбинации.
Варианты осуществления настоящего изобретения были полностью реализованы на платформе компиляции Visual Studio 2010, предоставляемой Windows, и применимы к приложениям для сетевого маркетинга и т.д. или другим приложениям, которым требуется категоризировать изображения.
Выше были описаны только предпочтительные варианты осуществления настоящего изобретения, и описание не предназначено для ограничения настоящего изобретения. Любые модификации, эквивалентные замены, улучшения и т.д. в пределах сущности и принципов настоящего изобретения должны быть включены в объем защиты настоящего изобретения.
Изобретение относится к области обработки изображений, а именно к распознаванию категории объекта изображения. Технический результат – повышение скорости и точности распознавания категории объекта изображения. Способ распознавания категории объекта изображения содержит: этап извлечения признаков изображения, на котором извлекают точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков и создают соответствие "известная категория - образцовое изображение - точка признака", где N - натуральное число больше 1, и каждая категория содержит по меньшей мере одно образцовое изображение; этап кластерного анализа, на котором выполняют кластерный анализ всех точек признаков, извлеченных с использованием алгоритма кластеризации, и разделяют точки признаков на N подмножеств; этап определения категории объектов, на котором определяют категорию Cn объекта для каждого из подмножеств; и этап сбора общих признаков, на котором собирают общие признаки среди изображений в каждой категории Cn объектов с помощью алгоритма поиска, где Cn - n-я категория объектов, и n - положительное целое число не больше N. 4 н. и 11 з.п. ф-лы, 10 ил., 1 табл.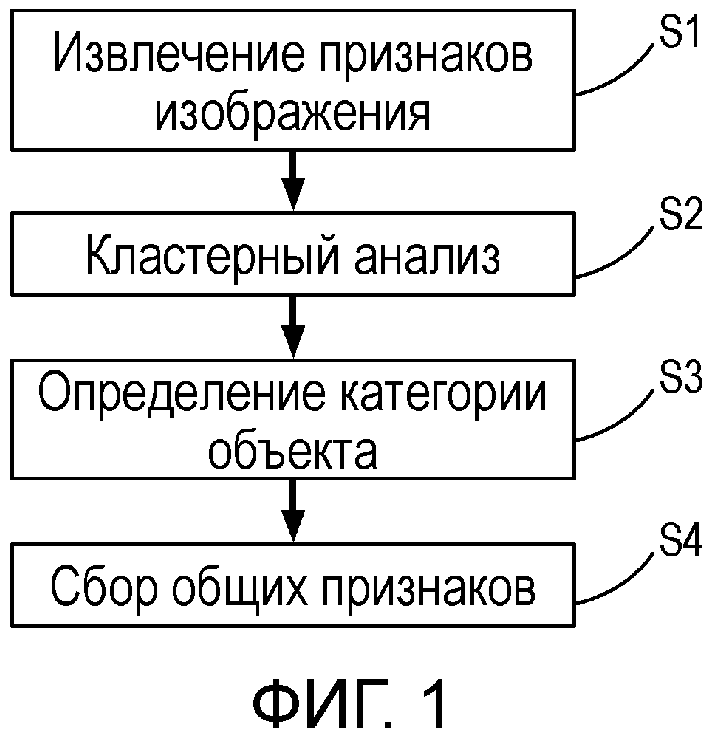
1. Способ распознавания категории объекта изображения, содержащий следующие этапы:
этап (S1) извлечения признаков изображения, на котором извлекают точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков и создают соответствие "известная категория - образцовое изображение - точка признака", где N - натуральное число больше 1, и каждая категория содержит по меньшей мере одно образцовое изображение;
этап (S2) кластерного анализа, на котором выполняют кластерный анализ всех точек признаков, извлеченных с использованием алгоритма кластеризации, и разделяют точки признаков на N подмножеств;
этап (S3) определения категории объектов, на котором определяют категорию Cn объекта для каждого из подмножеств; и
этап (S4) сбора общих признаков, на котором собирают общие признаки среди изображений в каждой категории Cn объектов с помощью алгоритма поиска, где Cn - n-я категория объектов, и n - положительное целое число не больше N;
причем этап S4 содержит по меньшей мере следующий подэтап:
S401, на котором выполняют поиск множества общих точек признаков, имеющих совместные общие признаки, среди изображений, включенных в каждую категорию Cn объектов, посредством алгоритма поиска;
причем после подэтапа S401, дополнительно содержит этап:
S402, на котором дополнительно отображают образцовые изображения, имеющие наибольшее количество общих точек признаков среди множества общих точек признаков из каждой категории Cn объектов, на основе множества общих точек признаков, найденных посредством соответствия "известная категория - образцовое изображение - точка признака", и используют образцовые изображения в качестве усредненных изображений категории Cn объектов.
2. Способ по п. 1, в котором этап S1 содержит по меньшей мере следующие подэтапы:
S101, на котором извлекают точки признаков среди визуальных признаков низкого уровня каждого из образцовых изображений;
S102, на котором собирают векторное описание для каждой из точек признаков; и
S103, на котором создают соответствие "известная категория - образцовое изображение - точка признака".
3. Способ по п. 2, в котором этап S2 содержит по меньшей мере следующие подэтапы:
S201, на котором подвергают кластеризации все извлеченные точки признаков на предварительно заданное количество кластеров посредством алгоритма кластеризации; и
S202, на котором из кластеров строят структуру k-дерева, где k - положительное целое число, и k ∈ (1, N).
4. Способ по п. 3, в котором этап S3 содержит по меньшей мере следующие подэтапы:
S301, на котором подсчитывают количество точек признаков, которые принадлежат разным известным категориям, для каждого подмножества из N подмножеств; и
S302, на котором определяют известную категорию, которая включает в себя наибольшее количество точек признаков, как категорию Cn объекта.
5. Способ по п. 1, в котором количество общих точек признаков (K(Cn)) в множестве общих точек признаков определяется на основе количества точек признаков изображения, имеющего наименьшее количество точек признаков в категории Cn объектов.
6. Способ по одному из пп. 1-5, который после этапа S4 дополнительно содержит этап S5 онлайнового распознавания и категоризации изображения, на котором распознают и автоматически категоризируют изображение, которое должно быть категоризировано, причем этап S5 онлайнового распознавания и категоризации содержит этапы:
S502, на котором выполняют такую же обработку извлечения признаков изображения над изображением, которое должно быть категоризировано, как на этапе S1, чтобы извлечь точки признаков изображения, которое должно быть категоризировано;
S503, на котором сравнивают точки признаков, извлеченные из изображения, которое должно быть категоризировано, с каждым из общих признаков каждой категории Cn объектов среди n категорий объектов, чтобы вычислить подобие между изображением, которое должно быть категоризировано, и каждой категорией объектов соответственно; и
S504, на котором приписывают изображение, которое должно быть категоризировано, к категории Cn объектов, имеющей наибольшее подобие.
7. Способ по одному из пп. 1-5, который после этапа S4 дополнительно содержит этап S5 онлайнового распознавания и категоризации изображения, на котором распознают и автоматически категоризируют изображение, которое должно быть категоризировано, причем этап S5 онлайнового распознавания и категоризации содержит этапы:
S502, на котором выполняют такую же обработку извлечения признаков изображения над изображением, которое должно быть категоризировано, как на этапе S1, чтобы извлечь точки признаков изображения, которое должно быть категоризировано;
S503, на котором сравнивают каждую из точек признаков, извлеченных из изображения, которое должно быть категоризировано, с каждой точкой признака в усредненных изображениях категории объектов друг за другом, чтобы вычислить подобие между изображением, которое должно быть категоризировано, и каждым усредненным изображением категории объектов соответственно; и
S504, на котором приписывают изображение, которое должно быть категоризировано, к категории Cn объектов, имеющей наибольшее подобие.
8. Способ по одному из пп. 1-5, который до этапа S1 дополнительно содержит этап предварительной обработки изображения для каждого изображения, причем этап предварительной обработки изображения содержит этапы:
S001, на котором пропорционально масштабируют изображение;
S002, на котором выполняют обработку фильтрации над пропорционально масштабированном изображением для удаления шума; и
S003, на котором выполняют обработку удаления цветности над изображением, подвергнутым обработке фильтрации.
9. Способ по одному из пп. 1-5, в котором:
способ извлечения точек признаков представляет собой алгоритм масштабно-инвариантной трансформации признаков (SIFT), с помощью которого извлекаются ключевые точки признаков SIFT каждого изображения и дескрипторы SIFT каждой ключевой точки признака;
алгоритм кластеризации представляет собой алгоритм k-средних, и ключевые точки признаков разделяются на N подмножеств посредством построения k-дерева, где k - положительное целое число, и k ∈ (1, N); и
алгоритм поиска представляет собой алгоритм поиска k ближайших соседей (KNN).
10. Устройство распознавания категории объекта изображения, содержащее:
блок извлечения признаков изображения, выполненный с возможностью извлекать точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков и создавать соответствие "известная категория - образцовое изображение - точка признака", где N - натуральное число больше 1, причем каждая категория содержит по меньшей мере одно образцовое изображение;
блок кластерного анализа, выполненный с возможностью выполнять кластерный анализ всех извлеченных точек признаков с использованием алгоритма кластеризации и разделять точки признаков на N подмножеств;
блок определения для определения категории Cn объектов для каждого из подмножеств; и
блок сбора данных для сбора общих признаков среди изображений, включенных в каждую категорию Cn объектов, с помощью алгоритма поиска, где Cn - n-я категория объектов и n - положительное целое число не больше N;
причем блок сбора данных включает в себя по меньшей мере следующий подмодуль:
модуль поиска для поиска множества общих точек признаков, имеющих совместные общие признаки, среди изображений, включенных в каждую категорию объектов Cn посредством алгоритма поиска;
причем блок сбора данных дополнительно содержит:
модуль отображения для отображения образцовых изображений, имеющих наибольшее количество общих точек признаков среди множества общих точек признаков из каждой категории Cn объектов, посредством соответствия "известная категория - образцовое изображение - точка признака" и с использованием образцовых изображений в качестве усредненных изображений категории Cn объектов.
11. Устройство по п. 10, в котором блок определения содержит по меньшей мере следующие подмодули:
модуль подсчета для подсчета количества точек признаков, которые принадлежат разным известным категориям, для каждого подмножества из N подмножеств; и
модуль определения для определения известной категории, которая включает в себя наибольшее количество точек признаков, как категории Cn объекта.
12. Способ автоматической категоризации изображения, которое должно быть категоризировано, с помощью способа распознавания категории объекта изображения по п. 1, содержащий следующие этапы:
этап извлечения, на котором выполняют такую же обработку извлечения признаков изображения над изображением, которое должно быть категоризировано, как на этапе S1, чтобы извлечь визуальные признаки низкого уровня из изображения, которое должно быть категоризировано;
этап сравнения и вычисления, на котором сравнивают каждую точку признака, извлеченную из изображения, которое должно быть категоризировано, с каждой точкой признака в множестве общих точек признака для каждой категории объектов или в усредненных изображениях каждой категории объектов друг за другом с помощью алгоритма измерения подобия изображений, чтобы вычислить подобие между точками признаков изображения, которое должно быть категоризировано, и точками признаков каждой категории объектов; и
этап приписывания, на котором приписывают изображение, которое должно быть категоризировано, к категории объектов, имеющей наибольшее подобие.
13. Система распознавания изображений, содержащая по меньшей мере процессор, выполненный с возможностью содержать по меньшей мере следующие функциональные блоки:
блок извлечения признаков изображения, выполненный с возможностью извлекать точки признаков всех образцовых изображений в N известных категориях с помощью способа извлечения точек признаков и создавать соответствие "известная категория - образцовое изображение - точка признака", где N - натуральное число больше 1, причем каждая категория содержит по меньшей мере одно образцовое изображение;
блок кластерного анализа, выполненный с возможностью выполнять кластерный анализ всех извлеченных точек признаков с использованием алгоритма кластеризации и разделять точки признаков на N подмножеств;
блок определения для определения категории Cn объектов для каждого из подмножеств; и
блок сбора данных для сбора общих признаков среди изображений, включенных в каждую категорию Cn объектов, с помощью алгоритма поиска, где Cn - n-я категория объектов и n - положительное целое число не больше N;
причем блок сбора данных выполнен с возможностью содержать по меньшей мере следующий модуль:
модуль поиска для поиска множества общих точек признаков, имеющих совместные общие признаки среди изображений, включенных в каждую категорию Cn объектов, посредством алгоритма поиска;
причем блок сбора данных дополнительно выполнен с возможностью по меньшей мере содержать:
модуль отображения для дополнительного отображения образцовых изображений, имеющих наибольшее количество общих точек признаков среди множества общих точек признаков из каждой категории Cn объектов, на основе множества общих точек признаков, найденных посредством соответствия "известная категория - образцовое изображение - точка признака", и используют образцовые изображения в качестве усредненных изображений категории Cn объектов.
14. Система по п. 13, в которой блок определения выполнен с возможностью содержать по меньшей мере следующие модули:
модуль подсчета для подсчета количества точек признаков, которые принадлежат разным категориям Cn объектов, для каждого подмножества из N подмножеств; и
модуль определения для пометки категории Cn объектов категорией, которая включает в себя наибольшее количество точек признака.
15. Система по одному из пп. 13 и 14, в которой блок извлечения признаков изображения дополнительно используется для извлечения точек признаков из изображения, которое должно быть категоризировано; и
процессор выполнен с возможностью дополнительно содержать:
блок сравнения и вычисления для сравнения каждой точки признака, извлеченной из изображения, которое должно быть категоризировано, с каждой точкой признака в множестве общих точек признаков для каждой категории объектов или в усредненных изображениях каждой категории объектов друг за другом с помощью алгоритма измерения подобия изображений, чтобы вычислить подобие между точками признаков изображения, которое должно быть категоризировано, и точками признаков каждой категории объектов; и
блок приписывания для приписывания изображения, которое должно быть категоризировано, к категории Cn объектов, имеющей наибольшее подобие.
| CN 102609719 A, 25.07.2012 | |||
| CN 102930296 A, 13.02.2013 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СИСТЕМА ИДЕНТИФИКАЦИИ ИЗОБРАЖЕНИЙ | 2002 |
|
RU2302656C2 |
| УСТРОЙСТВО И СПОСОБ УПРАВЛЕНИЯ ОТОБРАЖЕНИЕМ | 2010 |
|
RU2494566C2 |

