ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к обработке сигналов звукозаписи. Более точно, изобретение относится к обработке звукозаписи развлекательных программ, таких как звукозапись телевизионных программ, для улучшения ясности и разборчивости речи, такой как диалог, и повествовательной речи. Изобретение относится к способам, устройству для выполнения таких способов и к программному обеспечению, хранимому на машиночитаемом носителе, для побуждения компьютера выполнять такие способы.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Аудиовизуальные развлекательные программы превращаются в имеющую быстрый темп последовательность диалога, повествовательной речи, музыки и эффектов. Высокий реализм, достигаемый современными технологиями развлекательных программ и способами их производства, поощряет использование разговорных стилей беседы на телевидении, которые существенно отличаются от ясно произносимых аналогичных театральному представлению в прошлом. Эта ситуация представляет собой проблему не только для растущей численности пожилых зрителей, которые имеют проблемы, связанные с ослабленными сенсорными возможностями и возможностями языкового понимания, которые должны напрячься, чтобы понять программу, но также и для людей с нормальным слухом, например, при прослушивании на низких акустических частотах.
Насколько хорошо может быть понятна речь, зависит от нескольких факторов. Примерами являются тщательность речеобразования (ясной или разговорной речи), скорость речи и внятность речи. Разговорный язык является достаточно ясным и может пониматься в менее чем идеальных условиях. Например, слушатели с нарушенным слухом обычно могут понимать ясную речь, даже когда они не могут услышать часть речи вследствие пониженной остроты слуха. Однако по мере того, как скорость произнесения речи увеличивается, а речеобразование становится менее аккуратным, прослушивание и осмысление требуют возрастающих усилий, особенно, если неслышимы части речевого спектра.
Телезрители ничего не могут сделать, чтобы повлиять на ясность прослушиваемой речи, но слушатели с нарушенным слухом могут пытаться компенсировать недостаточную внятность увеличением громкости прослушивания. Помимо неудобства, доставляемого людям с нормальным слухом в том же самом помещении или соседям, этот подход эффективен всего лишь отчасти. Это так, потому что в большинстве случаев потери слуха являются неравномерными по частоте, потери на высоких частотах больше, чем на низких и средних частотах. Например, типичная способность 70-летнего мужчины слышать звуки на частоте 6 кГц и 50 дБ хуже, чем у молодого человека, при этом на частотах ниже 1 кГц потери слуха старшего человека меньше, чем 10 дБ (ISO 7029. Акустика - Статистическое распределение порогов слышимости как функции возраста). Увеличение громкости делает низко- и среднечастотные звуки громче без значительного увеличения понятия речи, так как на таких частотах слышимость уже достаточна. Увеличение уровня громкости также мало влияет на преодоление значительной потери слуха на высоких частотах. Более уместной коррекцией является регулировка тембра, обеспечиваемая, например, графическим эквалайзером.
Регулировка тембра по-прежнему недостаточна для большинства потерь слуха, хотя и является лучшим выбором, чем простое увеличение регулировки громкости. Большой коэффициент усиления высокой частоты, требуемый, чтобы сделать слышимым приглушенный разговор слушателю с нарушением слуха, вероятно, был бы некомфортным увеличением громкости во время разговорных эпизодов на высоком уровне звука и даже может перегружать цепи воспроизведения звуков. Лучшее решение состоит в том, чтобы осуществлять усиление в зависимости от уровня сигнала, обеспечивая большие коэффициенты усиления для низкоуровневых участков сигнала и меньшие коэффициенты усиления (или вообще никакого усиления) для высокоуровневых участков. Такие системы, известные в качестве автоматической регулировки усиления (АРУ, AGC) или компрессоров динамического диапазона (DRC), используются в целях прослушивания и были предложены для использования в телекоммуникационных системах для улучшения разборчивости речи для людей с нарушенным слухом (например, патент США 5388185, патент США 5539806 и патент США 6061431).
Так как потеря слуха обычно развивается постепенно, большинство слушателей с недостатками слуха привыкают к потерям случа. Как результат, они часто неодобрительно относятся к качеству звукозаписи развлекательных программ, когда программы обрабатываются для компенсации нарушения слуха. Аудитория с нарушенным слухом более вероятно должна принять качество звука компенсированных звукозаписей, когда имеется ощутимая выгода, например повышается разборчивость речи при прослушивании диалога и уменьшается умственное напряжение, требуемое для понимания. Поэтому полезно ограничивать применение компенсации при потерях слуха для тех частей звукозаписи программы, в которых доминирует речь. Это, таким образом, оптимизирует компромисс между потенциально неприятными модификациями качества музыкального и звукового сопровождения, с одной стороны, и желательными преимуществами в повышении разборчивости речи, с другой.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Согласно одному аспекту изобретения можно улучшить речь в звукозаписи развлекательных программ посредством обработки в ответ на одно или более управляющих воздействий звукозаписи развлекательной программы для улучшения ясности и разборчивости участков речи в звукозаписи развлекательных программ и формирования управляющего сигнала для обработки, при этом формирование включает в себя характеризацию временных сегментов в звукозаписи развлекательной программы: (a) как речевых или неречевых либо (b) как возможно являющихся речевыми или неречевыми, и реагирование на изменения уровня звука в звукозаписи развлекательной программы для формирования управляющего сигнала для обработки, при этом такие изменения подвергаются реагированию в пределах периода времени, более короткого, чем временные сегменты, а критерий решения реагирования управляется характеризацией. Обработка и реагирование - каждое может работать в соответствующих многочисленных полосах частот, при этом реагирование обеспечивает управляющее воздействие для обработки по каждой из многочисленных полос частот.
Аспекты изобретения могут работать «упреждающим» образом, так что, когда имеется доступ к временной эволюции звукозаписи развлекательной программы до и после момента обработки, формирование управляющего воздействия реагирует на, по меньшей мере, некоторую звукозапись после момента обработки.
Аспекты изобретения могут применять временное и/или пространственное разделение, так чтобы один из шагов из обработки, характеризации и реагирования выполнялись в разные моменты времени или в разных местах. Например, характеризация может выполняться в первый момент времени или на первом месте, обработка и реагирование могут выполняться во второй момент времени или на втором месте, и информация о характеризации отрезков времени может сохраняться или передаваться для управления критерием решения реагирования.
Аспекты изобретения также могут включать в себя кодирование звукозаписи развлекательной программы в соответствии со схемой перцепционного (относящегося к восприятию) кодирования или схемой кодирования без потерь и декодирование звукозаписи развлекательной программы в соответствии с такой же схемой декодирования, применяемой при кодировании, при этом одни из шагов обработки, характеризации и реагирования выполняются вместе с кодированием или декодированием. Характеризация может выполняться вместе с кодированием и обработкой, и/или реагирование может выполняться вместе с декодированием.
Согласно вышеупомянутым аспектам изобретения обработка может осуществляться в соответствии с одним или более параметрами обработки. Настройка одного или более параметров может реагировать на звукозапись развлекательной программы, так чтобы показатель разборчивости речи обработанной звукозаписи был либо максимизирован, либо стал выше требуемого порогового уровня. Согласно аспектам изобретения звукозапись развлекательной программы может содержать множество каналов звукозаписи, в которых один канал является преимущественно речевым, а один или более других каналов являются в основном неречевыми, при этом показатель разборчивости речи основан на уровне речевого канала и уровне в одном или более других каналах. Показатель разборчивости речи также может быть основан на уровне шума в среде прослушивания, в которой воспроизводится обработанная звукозапись. Настройка одного или более параметров может реагировать на один или более долгосрочных дескрипторов звукозаписи развлекательной программы. Примеры долгосрочных дескрипторов включают в себя средний уровень диалога звукозаписи развлекательной программы и оценку обработки, уже примененной к звукозаписи развлекательной программы. Настройка одного или более параметров может быть в соответствии с предписывающей формулой, при этом предписывающая формула соотносит остроту слуха слушателя или группы слушателей с одним или более параметров. В качестве альтернативы или в дополнение, настройка одного или более параметров может быть в соответствии с предпочтениями одного или более слушателей.
Согласно вышеупомянутым аспектам изобретения обработка может включать в себя многочисленные функции, действующие параллельно. Каждая из многочисленных функций может осуществляться в одной из многочисленных полос частот. Каждая из многочисленных функций может по отдельности или вместе обеспечивать регулирование динамического диапазона, динамическую коррекцию, спектральное обострение, перестановку частот, выделение речи, шумоподавление или другие действия по повышению разборчивости речи. Например, регулирование динамического диапазона может обеспечиваться многочисленными функциями или устройствами сжатия/расширения, при этом каждое обрабатывает диапазон частот сигнала звукозаписи.
Независимо от того, включает в себя или нет обработка многочисленные функции, действующие параллельно, обработка может включать управление динамическим диапазоном, динамическое выравнивание, спектральное уточнение, смещение частот, выделение речи, шумоподавление или другие действия по повышению разборчивости речи. Например, управление динамическим диапазоном может обеспечиваться функцией или устройством сжатия/расширения динамического диапазона.
Согласно еще одному аспекту изобретения управляют повышением разборчивости речи, обеспечивая компенсацию потери слуха, так чтобы идеально оно действовало только на участки речи программы звукозаписи и не действовало на оставшиеся (неречевые) участки программы, тем самым не изменяя тембра (спектральное распределение) или воспринимаемую громкость оставшихся (неречевых) участков программы.
Согласно еще одному аспекту изобретения повышение разборчивости речи развлекательной программы содержит анализ звукозаписи развлекательной программы для классификации отрезков времени звукозаписи, которые являются либо речевыми или другой звукозаписью, и применение сжатия динамического диапазона к одной или многочисленным полосам частот звукозаписи развлекательной программы в течение отрезков времени, классифицированных как речевые.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
В дальнейшем изобретении поясняется описанием предпочтительного варианта воплощения со ссылками на сопроводительные чертежи, на которых:
Фиг.1a представляет функциональную структурную схему, иллюстрирующую примерную реализацию аспектов изобретения;
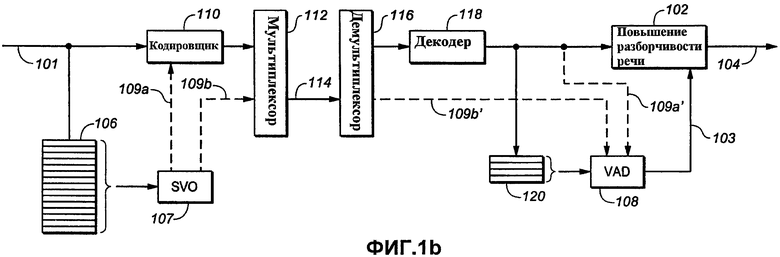
Фиг.1b представляет функциональную структурную схему, показывающую пример реализации модифицированного варианта по фиг.1a, в котором устройства и/или функции могут быть разделены временным и/или пространственным образом;
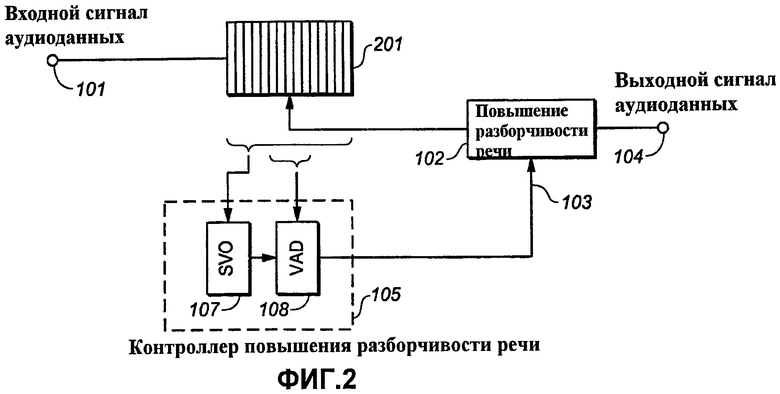
Фиг.2 представляет функциональную структурную схему, показывающую вариант реализации модифицированного варианта по фиг.1a, в котором управление разборчивостью речи осуществляют «упреждающим» образом;
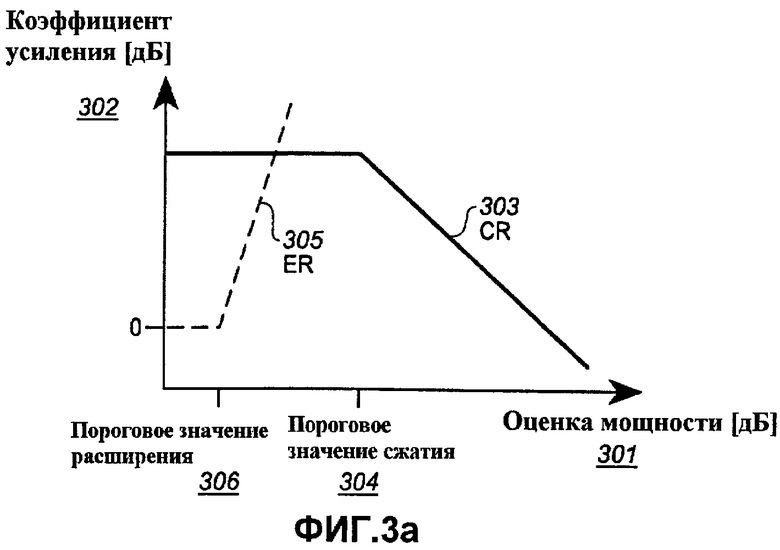
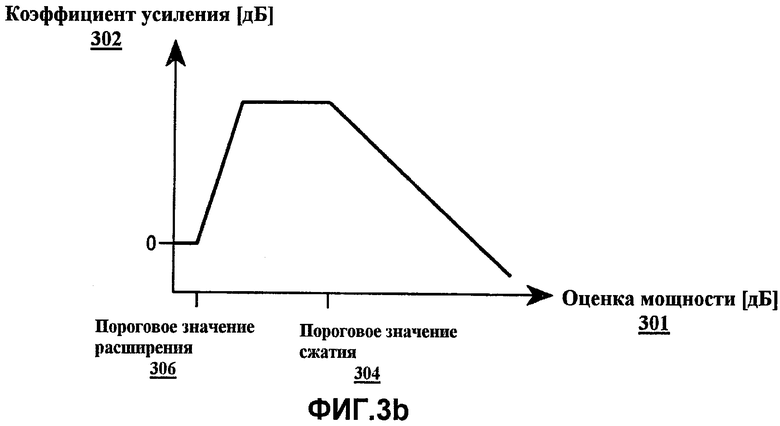
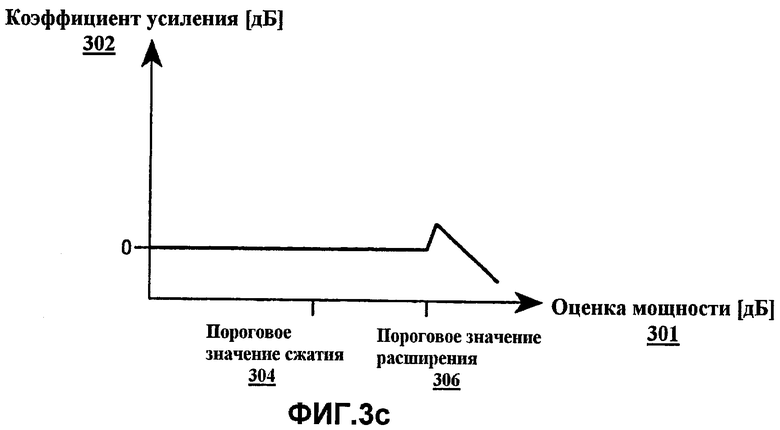
Фиг.3а-c представляют примеры диаграмм преобразований мощности в коэффициент усиления, полезные для понимания примера по фиг.4.
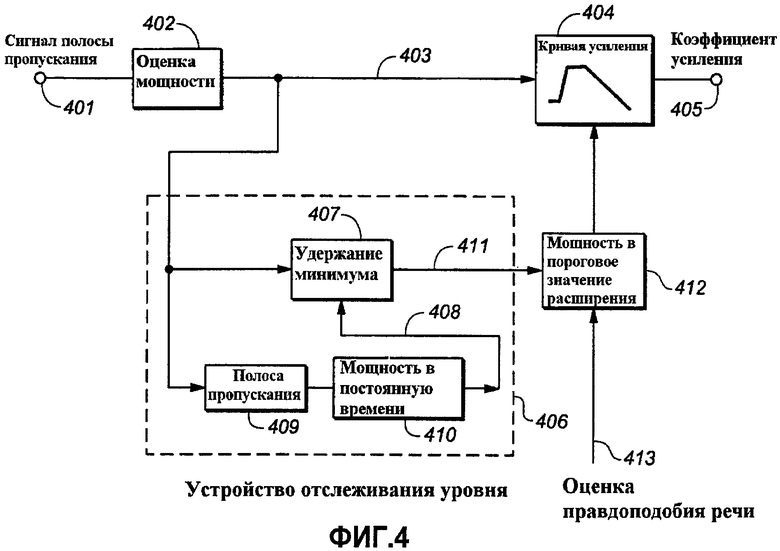
Фиг.4 представляет функциональную структурную схему, показывающую, каким образом коэффициент усиления разборчивости речи в полосе частот может выводиться из оценки мощности сигнала этой полосы в соответствии с аспектами изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНОГО ВАРИАНТА ВОПЛОЩЕНИЯ ИЗОБРЕТЕНИЯ
Устройства классификации звукозаписи на речевую и неречевую (такую, как музыка) известны в данной области техники и в некоторых случаях известны как дискриминатор речевого сигнала/неречевого сигнала («SVO»), см., например, патенты США, 6785645 и 6570991, а также опубликованную заявку 2004/0044525 на патент США, и ссылки, содержащиеся в них. Дискриминаторы речевого сигнала/неречевого сигнала анализируют отрезки времени сигнала звукозаписи и выделяют один или более дескрипторов (признаков) сигналов из каждого отрезка времени. Такие признаки пересылаются в процессор, который формирует оценку вероятности отрезка времени, являющегося речевым, либо принимает жесткое решение речь/не речь. Большинство признаков отражают эволюцию сигнала со временем. Типичными примерами признаков являются скорость, с которой спектр сигнала изменяется со временем, или наклон распределения скорости, с которой меняется полярность сигнала. Для достоверного отражения отдельных характеристик речи отрезки времени должны быть достаточной длины. Так как многие признаки основаны на характеристиках сигнала, которые отражают переходы между соседними слогами, отрезки времени типично покрывают, по меньшей мере, длительность двух слогов (то есть около 250 мс), чтобы захватывать один такой переход. Однако для получения более достоверных оценок отрезки времени часто бывают длиннее (например, с коэффициентом приблизительно в 10). Хотя SVO относительно медленны в работе, они достаточно надежны и точны при классификации звукозаписи речь и не речь. Однако, чтобы избирательно повышать разборчивость речи в звукозаписи программы в соответствии с аспектами настоящего изобретения, желательно управлять повышением разборчивости речи в масштабе времени, более мелком, чем длительность отрезков времени, анализируемых дискриминатором речевого сигнала/неречевого сигнала.
Другой класс технологий, иногда известных в качестве детекторов активности голоса (VAD), указывает наличие или отсутствие речи на фоне относительно постоянного шума. VAD широко используются в качестве части схем шумоподавления в приложениях речевой связи. В отличие от дискриминаторов речевого сигнала/неречевого сигнала VAD обычно имеют временное разрешение, которое достаточно для управления повышением разборчивости речи в соответствии с аспектами настоящего изобретения. VAD интерпретируют резкое увеличение мощности сигнала в качестве начала звука речи, а резкое уменьшение мощности сигнала в качестве окончания звука речи. Поступая таким образом, они сигнализируют о разграничении между речью и фоном почти мгновенно (то есть в пределах окна интегрирования по времени для измерения мощности сигнала, например, около 10 мс). Однако, так как VAD реагируют на любое резкое изменение мощности сигнала, они не могут проводить различия между речевыми и другими доминирующими сигналами, такими как музыка. Поэтому, если используются в одиночку, VAD не пригодны для управления повышением разборчивости речи, чтобы избирательно повышать разборчивость речи в соответствии с настоящим изобретением.
Еще одним аспектом настоящего изобретения является комбинирование специфичности речь/не речь дискриминаторов речевого сигнала/неречевого сигнала (SVO) с временной остротой детекторов активности голоса (VAD) для содействия повышению разборчивости речи, которое избирательно реагирует на речь в сигнале звукозаписи с временным разрешением, которое мельче, чем обнаруживаемое в дискриминаторах речевого сигнала/неречевого сигнала.
Хотя, в принципе, аспекты изобретения могут быть реализованы в аналоговой и/или цифровой форме, насколько можно ожидать, практическое воплощение должно быть реализовано в цифровой области, в которой каждый из звуковых сигналов представлен отдельными сэмплами или сэмплами внутри блоков данных.
Далее, со ссылкой на фиг.1a показана функциональная структурная схема, иллюстрирующая аспекты изобретения, на которой сигнал 101 ввода звукозаписи передается в функцию или устройство 102 увеличения разборчивости речи («Повышение разборчивости речи»), которое, когда задействовано сигналом 103 управления, вырабатывает выходной сигнал 104 звукозаписи с повышенной разборчивостью речи. Сигнал управления формируется функцией или устройством 105 управления («Контроллером повышения разборчивости речи»), которое оперирует буферизированными отрезками времени сигнала 101 ввода звукозаписи. Контроллер 105 повышения разборчивости речи включает в себя функцию или устройство 107 дискриминатора речевого сигнала/неречевого сигнала («SVO») и набор из одной или более функций или устройства 108 детектора активности голоса («VAD»). SVO 107 анализирует сигнал на промежутке времени, который больше, чем анализируемый посредством VAD. То обстоятельство, что SVO 107 и VAD 108 действуют на промежутках времени разных продолжительностей, графически проиллюстрировано скобкой, охватывающей широкую область (связанную с SVO 107) и другой скобкой, охватывающей более узкую область (связанную с VAD 108) функции или устройства 106 буфера сигнала («Буфер»). Широкая область и более узкая область являются схематическими и не должны определять масштаб. В случае цифровой реализации, в которой данные звукозаписи переносятся в блоках, каждая часть буфера 106 может хранить блок данных звукозаписи. Область, доступная VAD, включает в себя новые участки хранения сигнала в буфере 106. Правдоподобие текущего сегмента сигнала, являющегося речевым, как определяется посредством SVO 107, служит для управления 109 VAD 108. Например, оно может управлять критерием решения VAD 108, тем самым смещая решения VAD.
Буфер 106 символизирует память, необходимую при обработке, и может быть или может не быть непосредственно реализованным. Например, если обработка выполняется над сигналом звукозаписи, который хранится на носителе с произвольным доступом к памяти, то такой носитель может служить в качестве буфера. Подобным образом предыстория входных данных звукозаписи может отражаться на внутреннем состоянии дискриминатора 107 речевого сигнала/неречевого сигнала и внутреннем состоянии детектора активности голоса, в этом случае, отдельные буферы не нужны.
Блок повышения 102 разборчивости речи может состоять из множества устройств или функций обработки звукозаписи, которые работают параллельно, чтобы повышать разборчивость речи. Каждое устройство или функция могут работать в диапазоне частот сигнала звукозаписи, в котором должна повышаться разборчивость речи. Например, устройства и функции могут, по отдельности или как единое целое, обеспечивать управление динамическим диапазоном, динамическое выравнивание, спектральное уточнение, смещение частот, выделение речи, шумоподавление или другие действия по повышению разборчивости речи. В подробных примерах аспектов изобретения управление динамическим диапазоном обеспечивает сжатие и/или расширение полос частот сигнала звукозаписи. Таким образом, например, блок повышения 102 разборчивости речи может быть группой компрессоров/расширителей или функций сжатия/расширения, при этом каждая обрабатывает диапазон частот сигнала звукозаписи (многополосные компрессор/расширитель или функция сжатия/расширения). Частотная специфичность, выдаваемая многополосным сжатием/расширением, полезна не только потому, что она предоставляет возможность приспосабливаться модели повышения разборчивости речи к модели заданной потери слуха, но также потому, что она предоставляет возможность реагирования на то обстоятельство, что в любой данный момент речь может присутствовать в одном диапазоне частот, но отсутствовать в другом.
Чтобы полностью воспользоваться преимуществом частотной специфичности, предложенной многополосным сжатием, каждая полоса сжатия/расширения может управляться своими собственными детектором или функцией детектирования активности голоса. В таком случае каждые детектор или функция детектирования активности голоса могут сигнализировать об активности голоса в диапазоне частот, связанном с той полосой сжатия/расширения, которой они управляют. Хотя есть преимущества в блоке повышения 102 разборчивости речи, состоящем из нескольких устройств или функций обработки аудиоданных, которые работают параллельно, при этом простые варианты осуществления аспектов изобретения могут использовать блок 102 повышения разборчивости речи, который состоит всего лишь из одного устройства или функции обработки звукозаписи.
Даже когда есть много детекторов активности голоса, может быть только один дискриминатор 107 речи, вырабатывающий одиночный выходной сигнал 109 для управления всеми детекторами активности голоса, которые присутствуют. Предпочтение использовать только один дискриминатор речевого сигнала/неречевого сигнала отражает два наблюдения. Одно состоит в том, что частота, с которой чересполосная модель активности голоса изменяется со временем, типично является гораздо большей, чем временное разрешение дискриминатора речевого сигнала/неречевого сигнала. Другое наблюдение состоит в том, что признаки, используемые дискриминатором речевого сигнала/неречевого сигнала, типично выводятся из спектральных характеристик, которые могут лучше всего экспериментально обнаруживаться в широкополосном сигнале. Оба наблюдения делают непрактичным использование специфичных полосе дискриминаторов речевого сигнала/неречевого сигнала.
Комбинация SVO 107 и VAD 108, которая проиллюстрирована в контроллере 105 повышения разборчивости речи, также может использоваться для целей, иных, чем для повышения разборчивости речи, например для оценки громкости речи в программе звукозаписи или для измерения скорости речи.
Схема повышения разборчивости речи, описанная выше, может применяться различным образом. Например, полная схема может быть реализована внутри телевизора или телевизионной абонентской приставки, чтобы оперировать принятым сигналом звукозаписи телевизионного вещания. В качестве альтернативы, она может быть объединена с перцепционным кодировщиком звукозаписи (например, AC-3 или AAC) или она может быть объединена с кодировщиком звукозаписи без потерь.
Повышение разборчивости речи в соответствии с аспектами настоящего изобретения может выполняться в разные моменты времени или в разных местах. Рассмотрим пример, в котором повышение разборчивости речи объединено или связано с кодировщиком или последовательностью операций кодирования звукозаписи. В таком случае часть дискриминатора 107 речи в сравнении с прочим (SVO) из контроллера 105 повышения разборчивости речи, который часто бывает дорогостоящим, может быть объединена или связана с кодировщиком или последовательностью операций кодирования звукозаписи. Выходной сигнал 109 SVO, например флаг, указывающий наличие речи, может быть встроен в кодированный аудиопоток. Такая информация, встроенная в кодированный аудиопоток, часто указывается ссылкой как метаданные. Повышение 102 разборчивости речи и VAD 108 из контроллера 105 повышения разборчивости речи могут быть объединены или связаны с декодером звукозаписи и оперировать ранее кодированной звукозаписью. Набор из одного или более детекторов 108 активности голоса (VAD) также использует выходной сигнал 109 дискриминатора 107 речевого сигнала/неречевого сигнала (SVO) 107, который он извлекает из кодированного аудиопотока.
На фиг.1b показан пример реализации такого модифицированного варианта фиг.1a. Устройства и функции на фиг.1b, которые соответствуют таковым на фиг.1, имеют такие же номера. Сигнал 101 ввода звукозаписи передается в кодировщик или функцию 110 кодирования («Кодировщик») и в буфер 106, которые покрывают промежуток времени, требуемый SVO 107. Кодировщик 110 может быть частью системы перцепционного кодирования или кодирования без потерь. Выходной сигнал кодировщика 110 пересылается в мультиплексор или функцию 112 мультиплексирования («Мультиплексор»). Выходной сигнал SVO (109 на фиг. 1a) показан в качестве подаваемого 109a в кодировщик 110 или, в качестве альтернативы, подаваемого 109b в мультиплексор 112, который также принимает выходной сигнал кодировщика 110. Выходной сигнал SVO, такой как флаг на фиг.1a, переносится в выходных данных (например, метаданных) битового потока кодировщика 110 или мультиплексируется с выходным сигналом кодировщика 110, чтобы выдавать пакет и сборный битовый поток 114 для сохранения или передачи в демультиплексор или функцию 116 демультиплексирования («Демультиплексор»), которые распаковывают битовый поток 114 для пересылки в декодер или функцию 118 декодирования. Если выходной сигнал SVO 107 передавался 109b на мультиплексор 112, то он принимается 109b' из демультиплексора 116 и пересылается в VAD 108. В качестве альтернативы, если выходной сигнал SVO 107 передавался 109a в кодировщик 110, то он принимается 109a' из декодера 118. Как в примере фиг.1а, VAD 108 может содержать многочисленные функции или устройства активности голоса. Функция или устройство 120 буфера сигнала («Буфер»), поданные декодером 118, который покрывает промежуток времени, требуемый от VAD 108, предусматривают еще одну подачу в VAD 108. Выходной сигнал 103 VAD передается на повышение 102 разборчивости речи, которое выдает выходной сигнал звукозаписи с повышенной разборчивостью речи, как на фиг.1a. Хотя раскрыты отдельно для ясности, SVO 107 и/или буфер 106 могут быть объединены с кодировщиком 110. Аналогично, хотя показаны отдельно для ясности, VAD 108 и/или буфер 120 могут быть объединены с декодером 118 или блоком 102 повышения разборчивости речи.
Если сигнал звукозаписи, который должен обрабатываться, был предварительно записан, например, при воспроизведении с DVD в доме потребителя или при обработке в автономном режиме в вещательной среде, дискриминатор речевого сигнала/неречевого сигнала и/или детектор активности голоса могут оперировать сегментами сигнала, которые во время воспроизведения возникают после текущего отсчета сигнала или сигнального блока. Это проиллюстрировано на фиг.2, где символический буфер 201 сигнала содержит сегменты сигнала, которые во время воспроизведения возникают после текущего отсчета сигнала или сигнального блока («с упреждением»). Даже если сигнал не был предварительно закодирован, упреждение по-прежнему может использоваться, когда кодировщик звукозаписи имеет существенную присущую задержку обработки.
Параметры обработки блока 102 повышения разборчивости речи могут обновляться в ответ на обработанный сигнал звукозаписи с частотой, которая ниже, чем частота динамической характеристики компрессора. Есть несколько целей, которые можно было преследовать при обновлении параметров процессора. Например, параметр обработки функции усиления процессора повышения разборчивости речи может настраиваться в ответ на средний уровень речи программы, чтобы гарантировать, что изменение долгосрочного среднего спектра речи является зависящим от уровня речи. Чтобы понять эффект и необходимость в такой настройке, рассмотрим следующий пример. Повышение разборчивости речи применяется только к высокочастотной части сигнала. На заданном среднем уровне речи оценка 301 мощности высокочастотной части сигнала вводит среднее значение P1, где P1 является большим, чем пороговая мощность 304 сжатия. Коэффициентом усиления, связанным с этой оценкой мощности, является G1, который является средним коэффициентом усиления, применяемым к высокочастотной части сигнала. Так как низкочастотная часть не получает усиления, средний спектр речи формируется, чтобы быть на G1 дБ выше на высоких частотах, чем на низких частотах. Далее рассмотрим, что происходит, когда средний уровень речи увеличивается на некоторую величину ΔL. Увеличение среднего уровня речи на ΔL дБ увеличивает оценку 301 средней мощности высокочастотной части сигнал до P2=P1+ΔL. Как видно из фиг.3a, более высокая оценка P2 мощности дает подъем коэффициенту усиления G2, который является меньшим, чем G1. Следовательно, средний спектр речи обработанного сигнала показывает меньший высокочастотный акцент, когда средний уровень входного сигнала высок, чем когда он низок. Так как слушатели компенсируют различия в среднем уровне речи своей регулировкой уровня громкости, зависимость уровня от среднего высокочастотного предыскажения является нежелательной. Она может устраняться модифицированием амплитудной характеристики по фиг.3a-c в ответ на средний уровень речи. Фиг.3а-c обсуждены ниже.
Параметры обработки блока 102 повышения разборчивости речи также могут настраиваться, чтобы гарантировать, что метрика разборчивости речи либо максимизирована, либо выше требуемого порогового уровня. Метрика разборчивости речи может вычисляться по относительным уровням сигнала звукозаписи и конкурирующего звука в среде прослушивания (такого, как шум в кабине летательного аппарата). Когда сигнал звукозаписи является многоканальным звуковым сигналом с речью в одном канале и неречевыми сигналами в остальных каналах, метрика разборчивости речи, например, может вычисляться из относительных уровней всех каналов и распределения спектральной энергии в них. Подходящие метрики разборчивости широко известны [например, ANSI S3.5-1997, «Способ для расчета показателя разборчивости речи» («Method for Calculation of the Speech Intelligibility Index»), Национальный институт стандартизации США, 1997; или Муч и Бьюус. «Использование теории статистического решения для предсказания разборчивости речи. Структура внутренней модели» («Using statistical decision theory to predict speech intelligibility. I Model Structure»). Журнал акустического общества США, (2001) 109, стр. 2896 - 2909].
Аспекты изобретения, показанные на функциональных структурных схемах (фиг.1a и 1b) и описанные в материалах настоящей заявки, могут быть реализованы, как показано в примере на фиг.3а-c и 4. В этом примере усиление с формирующим частоту сжатием речевых составляющих и освобождение от обработки для неречевых составляющих могут быть реализованы благодаря многополосному процессору динамического диапазона (не показан), который реализует как сжимающую, так и расширяющую характеристики. Такой процессор может характеризоваться набором функций усиления. Каждая функция усиления определяет отношение мощности входного сигнала в полосе частот к соответствующему коэффициенту усиления полосы, который может применяться к составляющим сигнала в этой полосе. Одно из таких отношений проиллюстрировано на фиг.3a-c.
Со ссылкой на фиг.3a оценка мощности 301 входного сигнала полосы отнесена к требуемому коэффициенту 302 усиления полосы посредством амплитудной характеристики. Амплитудная характеристика берется в качестве минимума двух составляющих кривых. Одна составляющая кривая, показанная сплошной линией, имеет сжимающую характеристику с надлежащим образом, выбранным коэффициентом 303 сжатия («CR») для оценок 301 мощности выше порогового значения 304 сжатия и постоянным коэффициентом усиления для оценок мощности ниже порогового значения сжатия. Другая составляющая кривая, показанная пунктирной линией, имеет расширяющую характеристику с надлежащим образом, выбранным коэффициентом 305 расширения («ER») для оценок мощности выше порогового значения 306 расширения, и нулевой коэффициент усиления для оценок мощности ниже. Окончательная амплитудная характеристика берется в качестве минимума этих двух составляющих кривых.
Пороговое значение 304 сжатия, коэффициент 303 сжатия и коэффициент усиления при пороговом значении сжатия являются фиксированными параметрами. Их выбор определяет, каким образом огибающая и спектр речевого сигнала обрабатываются в конкретной полосе. Идеально они выбираются согласно предписывающей формуле, которая определяет надлежащие коэффициенты усиления и коэффициенты сжатия в соответственных полосах для группы слушателей с присущей им остротой слуха. Примером такой предписывающей формулы является NAL-NL1, которая была разработана Национальной акустической лабораторией в Австралии и описана Х. Диллоном в «Предписание рабочих характеристик слухового аппарата» («Prescribing hearing aid performance») [Х. Диллон (под редакцией). Слуховые аппараты (стр. 249-261); Сидней; Boomerang Press, 2001 год.] Однако они также могут быть основаны просто на предпочтении слушателя. Пороговое значение 304 сжатия и коэффициент 303 сжатия в конкретной полосе, кроме того, могут зависеть от параметров, специфичных данной программе звукозаписи, таких как средний уровень диалога в звуковой дорожке фильма.
Тогда как пороговое значение может быть постоянным, пороговое значение 306 расширения предпочтительно является адаптивным и меняется в ответ на входной сигнал. Пороговое значение расширения может допускать любое значение в пределах динамического диапазона системы, в том числе значения, большие, чем пороговое значение сжатия. Когда во входном сигнале доминирует речь, сигнал управления, описанный ниже, приводит пороговое значение расширения на низкие уровни, так что уровень входного сигнала выше, чем диапазон оценок мощности, к которому применяется расширение (смотрите фиг.3a и 3b). В таком состоянии коэффициенты усиления, применяемые к сигналу, подчинены сжимающей характеристике процессора. Фиг.3b изображает пример функции усиления, представляющий такое состояние.
Когда во входном сигнале доминирует звукозапись, иная, чем речь, сигнал управления приводит пороговое значение расширения на высокие уровни, так что уровень входного сигнала имеет тенденцию быть ниже, чем пороговое значение расширения. В таком состоянии большинство составляющих сигнала не получают усиления. Фиг.3c изображает пример функции усиления, представляющий такое состояние.
Оценки мощности полосы из предыдущего обсуждения могут быть выведены посредством анализа выходных сигналов блока фильтров или выходного сигнала преобразования из временной области в частотную, такого как ДПФ (дискретное преобразование Фурье, DFT), МДКП (модифицированное дискретное косинусное преобразование) или вейвлет-преобразование. Оценки мощности также могут быть замещены показателями, которые имеют отношение к интенсивности сигнала, такими как среднее абсолютное значение сигнала, энергия Тиджера, или относящимися к восприятию показателями, такими как громкость. Кроме того, оценки мощности полосы могут сглаживаться во времени для регулирования скорости, с которой изменяется коэффициент усиления.
Согласно еще одному аспекту изобретения пороговое значение расширения, идеально, устанавливается так, чтобы, когда сигнал является речью, уровень сигнала был выше расширяющей области функции усиления, а когда сигнал является звукозаписью, иной, чем речь, уровень сигнала был ниже расширяющей области функции усиления. Как пояснено ниже, это может достигаться отслеживанием уровня неречевой звукозаписи и размещением порогового значения расширения относительно этого уровня.
Некоторые устройства отслеживания уровня устанавливают пороговое значение ниже, при этом такое нисходящее расширение (или схема автоматической регулировки громкости) применяется в качестве части системы шумоподавления, которая стремится проводить различие между желательной звукозаписью и нежелательным шумом, см., например, патенты US 3803357, 5263091, 5774557 и 6005953. В противоположность аспекты настоящего изобретения требуют проведения различий между речью, с одной стороны, и всеми остальными сигналами звукозаписи, такими как музыка и эффекты, с другой. Шум, отслеживаемый в предшествующем уровне техники, характеризуется временной или спектральной огибающими, которые пульсируют гораздо меньше, чем таковые у звукозаписи. Кроме того, шум часто имеет отличительные формы спектра, которые известны заранее. Такие проводящие различие характеристики используются устройствами отслеживания шума в предшествующем уровне техники. В противоположность аспекты настоящего изобретения отслеживают уровень неречевых сигналов звукозаписи. Во многих случаях такие неречевые сигналы звукозаписи демонстрируют пульсации в своей огибающей и спектральном профиле, которые, по меньшей мере, настолько же велики, как таковые у речевых сигналов звукозаписи. Следовательно, устройство отслеживания уровня, применяемое в настоящем изобретении, скорее требует анализа признаков сигнала, пригодных для разграничения между речевыми и неречевыми сигналами, чем между речью и шумом.
На Фиг.4 показано, каким образом коэффициент усиления повышения разборчивости речи в полосе частот может быть выведен из оценки мощности сигнала такой полосы. Представление ограниченного полосой сигнала 401 переправляется в блок оценки мощности или устройство 402 оценки («Оценка мощности»), которое формирует оценку мощности 403 сигнала в этой полосе частот. Такая оценка мощности сигнала проходит преобразование мощности в коэффициент усиления или функцию 404 преобразования («Кривая коэффициента усиления»), которая может иметь вид примера, проиллюстрированного на фиг.3a-c. Преобразование мощности в коэффициент усиления или функция 404 преобразования формирует коэффициент 403 усиления полосы, который может использоваться для модификации мощности сигнала в полосе (не показано).
Оценка 403 мощности сигнала также переправляется в устройство или функцию 406 («Блок отслеживания уровня»), которая отслеживает уровень всех составляющих сигнала в полосе, которые не являются речевыми. Блок 406 отслеживания уровня может включать в себя схему или функцию 407 удержания минимума утечки («Удержание минимума») с адаптивной скоростью утечки. Эта скорость утечки регулируется постоянной 408 времени, которая имеет тенденцию быть низкой, когда в мощности сигнала доминирует речь, и высокой, когда в мощности сигнала доминирует звукозапись, иная, чем речь. Постоянная 408 времени может выводиться из информации, содержащейся в оценке мощности 403 сигнала в полосе. Более точно, постоянная времени может монотонно зависеть от энергии огибающей сигнала полосы в диапазоне частот между 4 и 8 Гц. Такой признак может выделяться надлежащим образом настроенным полосовым фильтром или функцией 409 фильтрации («Полоса пропускания»). Выходной сигнал полосы 409 пропускания может соотноситься с постоянной 408 времени передаточной функцией 410 («Мощность в постоянную времени»). Оценка уровня неречевых составляющих 411, которая формируется блоком 406 отслеживания, является входным сигналом в преобразование или функцию преобразования («Мощность в пороговое значение расширения»), которая устанавливает отношение оценки уровня фона к пороговому значению 414 расширения. Комбинация блока 406 отслеживания уровня, преобразования 412 и нисходящего расширения (отличающегося степенью 305 расширения) соответствует VAD 108 по фиг.1a и 1b.
Преобразование 412 может быть простым сложением, то есть порог 306 расширения может быть фиксированным количеством децибелов над оцененным уровнем неречевой звукозаписи 411. В качестве альтернативы, преобразование 412, которое устанавливает отношение оцененного уровня 411 фона с порогом 306 расширения, может зависеть от независимой оценки правдоподобия широкополосного сигнала, являющегося речью 413. Таким образом, когда оценка 413 указывает высокое правдоподобие сигнала, являющегося речью, порог 306 расширения уменьшается. Наоборот, когда оценка 413 указывает низкое правдоподобие сигнала, являющегося речью, порог 306 расширения увеличивается. Оценка 413 правдоподобия речи может выводиться из одиночного признака сигнала или из комбинации признаков сигнала, которые отличают речь от других сигналов. Она соответствует выходному сигналу 109 из SVO 107 на фиг.1a и 1b. Пригодные признаки сигнала и способы их обработки для получения оценки правдоподобия 413 речи известны специалистам в данной области техники. Примеры описаны в патентах US 6785645 и 6570991, а также в заявке US 20040044525 на выдачу патента и в ссылках, содержащихся в них.
Следующие патенты, заявки на патенты и публикации настоящим включены в состав настоящей заявки посредством ссылки, каждая во всей своей полноте:
US 3803357; Сакс, 9 апреля 1974 года, Шумовой фильтр;
US 5263091; Уолтер младший, 16 ноября 1993 года, Интеллектуальная автоматическая пороговая схема;
US 5388185; Терри и другие, 7 февраля 1995 года, Система для адаптивной обработки телефонных речевых сигналов;
US 5539806; Аллен и другие, 23 июля 1996 года, Способ для выбора потребителем улучшения телефонного звука;
US 5774557; Слейтер, 30 июня 1998 года, Схема автоматической регулировки громкости микрофона с автоматическим слежением для систем внутренней связи летательного аппарата;
US 6005953; Штулфельнер, 21 декабря 1999, Схемная компоновка для улучшения отношения сигнал/шум;
US 6061431; Кнапп и другие, 9 мая 2000 года, Способ для компенсации потери слуха в системах телефонии на основании идентификации номера телефона;
US 6570991; Ширер и другие, 27 мая 2003 года, Системы различения речи/музыки по многим признакам;
US 6,785,645; Кхалил и другие, 31 августа 2004 года, Классификатор речи и музыки реального времени;
US 6,914,988; Ирвен и другие, 5 июля 2005 года, Устройство воспроизведения звукозаписи;
US 2004/0044525 на выдачу патента США; Винтон, Марк Стюарт и другие, 4 марта 2004 года, Регулирование громкости речи в сигналах, которые содержат речь и другие типы материала звукозаписи;
«Регулирование динамического диапазона посредством метаданных» («Dynamic Range Control via Metadata») от Чарлза К. Робинсона и Кеннета Гундри, Конвенционное периодическое издание 5028, 107ой съезд общества звукотехники, Нью-Йорк, 24-27 сентября 1999 года.
Промышленная применимость
Изобретение может быть реализовано аппаратным или программным обеспечением либо комбинацией обоих (например, на программируемых логических матрицах). Если не указан иной способ действий, алгоритмы, включенные в состав в качестве части изобретения, по своей природе не имеют отношения к какому бы то ни было конкретному компьютеру или другому устройству. В частности, различные машины общего применения могут использоваться с программами, написанными в соответствии с доктринами, приведенными в материалах настоящей заявки, или может быть более удобным сконструировать более специализированное устройство (например, интегральные схемы) для выполнения требуемых этапов способа. Таким образом, изобретение может быть реализовано в одной или более компьютерных программах, выполняющихся в одной или более программируемых компьютерных системах, каждая из которых содержит, по меньшей мере, один процессор, по меньшей мере одну систему хранения данных (в том числе энергозависимую и энергонезависимую память и/или запоминающие элементы), по меньшей мере, одно устройство или порт ввода и, по меньшей мере, одно устройство или порт вывода. Управляющая программа применяется к входным данным для выполнения функций, описанных в материалах настоящей заявки, и формирует выходную информацию. Выходная информация подводится к одному или более устройствам вывода известным образом.
Каждая такая программа может быть реализована на любом желательном компьютерном языке (включая машинные, компоновочные или высокоуровневые процедурные, логические или объектно-ориентированные языки программирования) для обмена информацией с компьютерной системой. В любом случае язык может быть компилируемым или интерпретируемым языком.
Каждая такая компьютерная программа предпочтительно хранится на или загружается на запоминающие носители или устройство (например, твердотельную память или носители либо магнитные или оптические носители), читаемые программируемым компьютером общего или специального назначения, для конфигурирования и управления компьютером, когда запоминающие носители или устройство считываются компьютерной системой, чтобы выполнять процедуры, описанные в материалах настоящей заявки. Обладающая признаками изобретения система также может считаться реализуемой в качестве машинно-читаемого запоминающего носителя, сконфигурированного компьютерной программой, где запоминающий носитель, сконфигурированный таким образом, побуждает компьютерную систему работать специфичным и предопределенным образом для выполнения функций, описанных в материалах настоящей заявки.
Было описано некоторое количество вариантов осуществления изобретения. Тем не менее будет понятно, что различные модификации могут быть произведены, не выходя из сущности и объема изобретения. Например, некоторые из этапов, описанных в материалах настоящей заявки, могут быть не зависящими от очередности и таким образом могут выполняться в очередности, отличной от той, которая описана.
Изобретение относится к обработке сигналов звукозаписи, в частности к повышению разборчивости звукозаписи развлекательных программ, таких как телевизионная звукозапись. Техническим результатом является улучшение ясности и разборчивости речи, такой как звукозапись диалогов и повествовательного изложения. Указанный результат достигается тем, что в ответ на одно или более управляющих воздействий обрабатывают звукозапись развлекательных программ: изменяют уровень сигнала звукозаписи в каждой из множества полос частот в соответствии с характеристикой коэффициента усиления, которая соотносит уровень сигнала полосы с коэффициентом усиления. Далее формируют управляющий сигнал для изменения характеристики коэффициента усиления в каждой полосе частот: определяют в одной широкой полосе частот отрезки времени звукозаписи развлекательных программ (а) как речевые или неречевые либо (b) как вероятно являющиеся речевыми или неречевыми, получают в каждой из множества полос частот величину пульсаций уровней речи, отслеживают в каждой из множества полос частот минимум уровня звукозаписи в полосе, при этом время отклика отслеживания является реагирующим на величину пульсаций уровней речи, преобразуют отслеживаемые минимумы в каждой полосе в соответствующий адаптивный пороговый уровень и смещают каждый соответствующий адаптивный пороговый уровень по результату определения для формирования управляющего сигнала для каждой полосы частот. 6 н. и 24 з.п. ф-лы, 7 ил.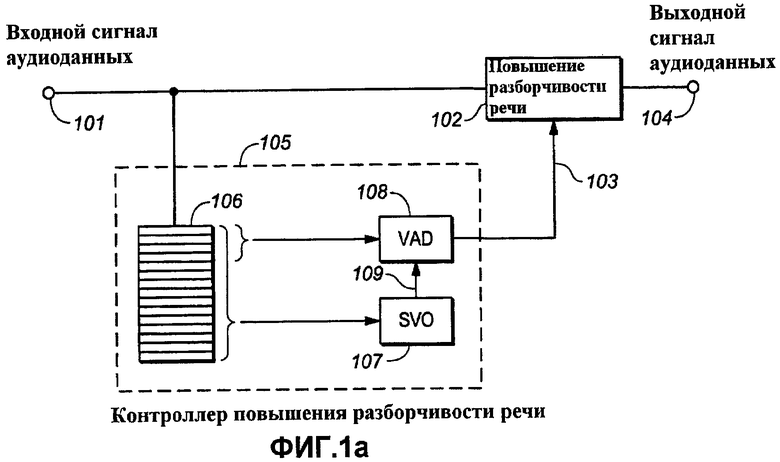
1. Способ повышения разборчивости речи в звукозаписи развлекательных программ, содержащий этапы, на которых
обрабатывают в ответ на одно или более управляющих воздействий звукозапись развлекательных программ для улучшения ясности и разборчивости участков речи в звукозаписи развлекательных программ, при этом обработка включает в себя этапы, на которых
изменяют уровень сигнала звукозаписи развлекательных программ в каждой из множества полос частот в соответствии с характеристикой коэффициента усиления, которая соотносит уровень сигнала полосы с коэффициентом усиления, и
формируют управляющий сигнал для изменения характеристики коэффициента усиления в каждой полосе частот, при этом формирование включает в себя этапы, на которых
определяют отрезки времени звукозаписи развлекательных программ (а) как речевые или неречевые, либо (b) как вероятно являющиеся речевыми или неречевыми, при этом определение производится в одной широкой полосе частот,
получают, в каждой из упомянутого множества полос частот величину пульсаций уровней речи,
отслеживают в каждой из множества полос частот, минимум уровня звукозаписи в полосе, при этом время отклика отслеживания является реагирующим на величину пульсаций уровней речи,
преобразуют отслеживаемые минимумы в каждой полосе в соответствующий адаптивный пороговый уровень, и
смещают каждый соответствующий адаптивный пороговый уровень по результату определения для формирования управляющего сигнала для каждой полосы частот.
2. Способ по п.1, в котором имеют доступ к временной эволюции звукозаписи развлекательных программ до и после момента обработки, и при формировании управляющего воздействия реагируют на, по меньшей мере, некоторую звукозапись после момента обработки.
3. Способ по п.1, в котором обработку осуществляют в соответствии с одним или более параметрами обработки.
4. Способ по п.3, в котором настройка одного или более параметров зависит от звукозаписи развлекательной программы, так чтобы показатель разборчивости речи обработанной звукозаписи был максимизирован или форсирован выше требуемого порогового уровня.
5. Способ по п.4, в котором звукозаписи развлекательных программ содержат многочисленные каналы звукозаписи, в которых один канал является речевым, а один или более других каналов являются неречевыми, при этом показатель разборчивости речи основан на уровне речевого канала и уровне в одном или более других каналах.
6. Способ по п.5, в котором показатель разборчивости речи также основан на уровне шума в среде прослушивания, в которой воспроизводится обработанная звукозапись.
7. Способ по п.3, в котором настройка одного или более параметров зависит от одного или более долгосрочных дескрипторов звукозаписи развлекательных программ.
8. Способ по п.7, в котором долгосрочный дескриптор является средним уровнем диалога звукозаписи развлекательной программы.
9. Способ по п.7, в котором долгосрочный дескриптор является оценкой обработки, уже примененной к звукозаписи развлекательной программы.
10. Способ по п.3, в котором настраивают один или более параметров в соответствии с предписывающей формулой, при этом предписывающая формула соотносит остроту слуха слушателя или группы слушателей с одним или более из этих параметров.
11. Способ по п.3, в котором настраивают один или более параметров в соответствии с предпочтениями одного или более слушателей.
12. Способ по п.1, в котором при обработке обеспечивают управление динамическим диапазоном, динамическое выравнивание, спектральное уточнение, смещение частот, выделение речи, шумоподавление или другие действия по повышению разборчивости речи.
13. Способ по п.12, в котором управление динамическим диапазоном обеспечивают функцией сжатия/расширения динамического диапазона.
14. Способ повышения разборчивости речи в звукозаписи развлекательных программ, содержащий этапы, на которых
обрабатывают, в ответ на один или более управляющих сигналов, звукозапись развлекательной программы, для улучшения ясности и разборчивости участков речи звукозаписи развлекательных программ, при этом обработка включает в себя этапы, на которых
изменяют уровень сигнала звукозаписи развлекательной программы в каждой из множества полос частот в соответствии с характеристикой коэффициента усиления, которая соотносит уровень сигнала полосы с коэффициентом усиления, и
формируют управляющий сигнал для изменения характеристики коэффициента усиления в каждой полосе частот, при этом формирование включает в себя этапы, на которых
принимают результаты определения отрезков времени звукозаписи развлекательных программ как (а) речевые или неречевые, либо (b) как вероятно являющиеся речевыми или неречевыми, при этом, результаты определения касаются одной широкой полосы частот,
получают, в каждой из множества полос частот, величину пульсаций уровней речи,
отслеживают в каждой из множества полос частот минимум уровня звукозаписи в полосе, при этом время отклика отслеживания является реагирующим на величину пульсаций уровней речи,
преобразуют отслеживаемые минимумы в каждой полосе в соответствующий адаптивный пороговый уровень, и
смещают каждый соответствующий адаптивный пороговый уровень по результату определения для выработки управляющего воздействия для каждой полосы.
15. Способ по п.14, в котором имеют доступ к временной эволюции звукозаписи развлекательных программ до и после момента обработки, и при формировании управляющего воздействия реагируют на, по меньшей мере, некоторую звукозапись после момента обработки.
16. Способ по п.14, в котором обработку осуществляют в соответствии с одним или более параметров обработки.
17. Способ по п.16, в котором настройка одного или более параметров зависит от звукозаписи развлекательной программы, так чтобы показатель разборчивости речи обработанной звукозаписи был максимизирован или форсирован выше требуемого порогового уровня.
18. Способ по п.17, в котором звукозаписи развлекательных программ содержат многочисленные каналы звукозаписи, в которых один канал является речевым, а один или более других каналов являются неречевыми, при этом показатель разборчивости речи основан на уровне речевого канала и уровне в одном или более других каналов.
19. Способ по п.18, в котором показатель разборчивости речи также основан на уровне шума в среде прослушивания, в которой воспроизводится обработанная звукозапись.
20. Способ по п.16, в котором настройка одного или более параметров зависит от одного или более долгосрочных дескрипторов звукозаписи развлекательных программ.
21. Способ по п.20, в котором долгосрочный дескриптор является средним уровнем диалога звукозаписи развлекательной программы.
22. Способ по п.20, в котором долгосрочный дескриптор является оценкой обработки, уже примененной к звукозаписи развлекательной программы.
23. Способ по п.16, в котором настраивают один или более параметров в соответствии с предписывающей формулой, при этом
предписывающая формула соотносит остроту слуха слушателя или группы слушателей с одним или более из этих параметров.
24. Способ по п.16, в котором настраивают один или более параметров в соответствии с предпочтениями одного или более слушателей.
25. Способ по п.14, в котором при обработке обеспечивают управление динамическим диапазоном, динамическое выравнивание, спектральное уточнение, смещение частот, выделение речи, шумоподавление или другие действия по повышению разборчивости речи.
26. Способ по п.25, в котором управление динамическим диапазоном обеспечивают функцией сжатия/расширения динамического диапазона.
27. Устройство повышения разборчивости речи в звукозаписи развлекательных программ, содержащее средство для выполнения способа по п.1.
28. Устройство повышения разборчивости речи в звукозаписи развлекательных программ, содержащее средство для выполнения способа по п.14.
29. Машиночитаемый носитель с сохраненной на нем компьютерной программой, предназначенной для побуждения компьютера выполнять способ по п.1.
30. Машиночитаемый носитель с сохраненной на нем компьютерной программой, предназначенной для побуждения компьютера выполнять способ по п.14.
| US 6198830 B1, 06.03.2001 | |||
| WO 2005052913 A2, 09.06.2005 | |||
| US 2003198357 A1, 23.10.2003 | |||
| US 4672669 A, 09.06.1987 | |||
| US 6813490 B1, 02.11.2004 | |||
| СПОСОБ И СИСТЕМА УСИЛЕНИЯ РЕЧЕВОГО СИГНАЛА В СЕТИ СВЯЗИ | 1994 |
|
RU2142675C1 |
| СПОСОБ ИЗМЕРЕНИЯ РАЗБОРЧИВОСТИ РЕЧИ | 2005 |
|
RU2284585C1 |

