ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Данная заявка заявляет приоритет по предварительной заявке на патент США № 61/870933, поданной 28 августа 2013 г., предварительной заявке на патент США № 61/895959, поданной 25 октября 2013 г., и предварительной заявке на патент США № 61/908664, поданной 25 ноября 2013 г., каждая из которых полностью включена в данный документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Изобретение относится к обработке звуковых сигналов и, конкретнее, к усилению речевого содержимого звуковой программы относительно другого содержимого программы, при котором усиление речи является «гибридным» в том смысле, что оно включает усиление с кодированием формы сигнала (или относительно большее усиление с кодированием формы сигнала) при некоторых состояниях сигнала и усиление с параметрическим кодированием (или относительно большее усиление с параметрическим кодированием) при остальных состояниях сигнала. Другими аспектами являются кодирование, декодирование и представление звуковых программ, которые включают данные, подходящие для данного гибридного усиления речи.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
В кино и на телевидении диалог и повествование зачастую представлены вместе с другим неречевым звуком, таким как музыка, эффекты или атмосфера спортивных мероприятий. Во многих случаях речевые и неречевые звуки захватываются по отдельности и микшируются под управлением звукоинженера. Звукоинженер выбирает уровень речевого звука относительно уровня неречевого звука таким образом, чтобы он являлся подходящим для большинства слушателей. Однако, некоторые слушатели, например, с нарушением слуха, испытывают затруднения при понимании речевого содержимого звуковых программ (имеющих определенные инженером отношения микширования речевого звука к неречевому звуку) и предпочли бы, чтобы речь была микширована при более высоком относительном уровне.
Существует проблема, которая должна быть решена, состоящая в том, что данным слушателям необходимо предоставить возможность увеличения слышимости речевого содержимого звуковой программы относительно неречевого звукового содержимого.
Одним текущим подходом является предоставление слушателям двух высококачественных звуковых потоков. Один поток содержит звук первичного содержимого (главным образом речь), а другой содержит звук вторичного содержимого (остальную звуковую программу, которая исключает речь) и пользователю предоставлено управление над процессом микширования. К сожалению, данная схема является непрактичной, поскольку она не основана на текущей практике передачи полностью микшированной звуковой программы. Кроме того, она требует приблизительно вдвое большей полосы пропускания текущей вещательной практики, поскольку пользователю должны быть поданы два независимых звуковых потока, каждый из которых имеет вещательное качество.
Еще один способ усиления речи (называемый в данном документе усилением «с кодированием формы сигнала») описан в публикации заявки на патент США № 2010/0106507 A1, опубликованной 29 апреля 2010 г., закрепленной за Dolby Laboratories, Inc. и именующей автором изобретения Hannes Muesch. При усилении с кодированием формы сигнала отношение речевого звука к фоновому звуку (неречевому звуку) исходного звукового микширования речевого и неречевого содержимого (иногда называемого главным микшированием) увеличивается посредством добавления к главному микшированию версии сниженного качества (низкокачественной копии) чистого речевого сигнала, который был отправлен на приемник в дополнение к главному микшированию. Для уменьшения перегрузки полосы пропускания, низкокачественная копия, как правило, кодируется с очень низкой битовой скоростью передачи данных. Вследствие кодирования с низкой битовой скоростью передачи данных, артефакты кодирования связаны с низкокачественной копией и артефакты кодирования являются четко слышимыми при отдельных представлении и прослушивании низкокачественной копии. Таким образом, низкокачественная копия имеет неприемлемое качество при отдельном прослушивании. Усиление с кодированием формы сигнала предназначено для скрытия данных артефактов кодирования посредством добавления низкокачественной копии к главному микшированию только в тех случаях, когда уровень неречевых компонентов является высоким, так что артефакты кодирования маскируются неречевыми компонентами. Как будет подробно описано далее, ограничения данного подхода включают следующее: величина усиления речи, как правило, не может быть постоянной с течением времени и звуковые артефакты могут быть услышаны, если фоновые (неречевые) компоненты главного микширования являются слабыми или их амплитудно-частотный спектр существенно отличается от амплитудно-частотного спектра шума кодирования.
В соответствии с усилением с кодированием формы сигнала звуковая программа (для подачи на декодер для декодирования и последующего представления) кодируется в качестве битового потока, который включает низкокачественную копию речи (или ее кодированную версию) в качестве побочного потока главного микширования. Битовый поток может включать метаданные, указывающие на параметр масштабирования, который определяет величину усиления речи с кодированием формы сигнала, которое должно быть выполнено (т.е. параметр масштабирования определяет коэффициент масштабирования, который должен быть применен к низкокачественной копии речи перед масштабированием, при этом низкокачественная копия речи объединяется с главным микшированием, или максимальное значение такого коэффициента масштабирования, который гарантирует маскирование артефактов кодирования). Если текущее значение коэффициента масштабирования равняется нулю, декодер не выполняет усиление речи в отношении соответствующего сегмента главного микширования. Текущее значение параметра масштабирования (или текущее максимальное значение, которого он может достичь), как правило, определяется в кодере (поскольку оно, как правило, генерируется посредством вычислительно-трудоемкой психоакустической модели), но оно может быть сгенерировано в декодере. В последнем случае метаданные, указывающие на параметр масштабирования, не должны быть отправлены с кодера на декодер и вместо этого кодер может определить из главного микширования отношение мощности речевого содержимого микширования к мощности микширования и реализовать модель для определения текущего значения параметра масштабирования в ответ на текущее значение отношения мощностей.
Еще одним способом (называемым в данном документе усилением «с параметрическим кодированием») для усиления разборчивости речи при наличии постороннего звука (фонового звука) является сегментация исходной звуковой программы (как правило, звуковой дорожки) на частотно-временные мозаики и усиление мозаик в соответствии с отношением мощности (или уровня) их речевого и фонового содержимого для достижения усиления речевого компонента относительно фона. Основная идея данного подхода схожа с идеей, которая состоит в управляемом подавлении шума со спектральным вычитанием. В качестве яркого примера данного подхода, в котором полностью подавлены все мозаики с SNR (т.е. отношением мощности или уровня речевого компонента к мощности или уровню постороннего звукового содержимого) ниже предопределенного порогового значения, было показано предоставление надежных усилений разборчивости речи. При применении данного способа к вещанию отношение (SNR) речевого звука к фоновому звуку может быть получено посредством сравнивания исходного звукового микширования (речевого и неречевого содержимого) и речевого компонента микширования. Полученное SNR может быть затем преобразовано в подходящий набор параметров усиления, которые передаются в дополнение к исходному звуковому микшированию. На приемнике данные параметры могут быть (факультативно) применены к исходному звуковому микшированию для получения сигнала, указывающего на усиленную речь. Как будет подробно описано далее, усиление с параметрическим кодированием работает наилучшим образом, если речевой сигнал (речевой компонент микширования) преобладает над фоновым сигналом (неречевым компонентом микширования).
Для усиления с кодированием формы сигнала необходимо, чтобы низкокачественная копия речевого компонента поданной звуковой программы была доступна на приемнике. Для ограничения перегрузки данных, возникающей во время передачи данной копии в дополнение к главному звуковому микшированию, данная копия кодируется с очень низкой битовой скоростью передачи данных и имеет искажения кодирования. Данные искажения кодирования, вероятно, будут замаскированы исходным звуком, если уровень неречевых компонентов является высоким. При маскировании искажений кодирования полученное в результате качество усиленного звука будет очень хорошим.
Усиление с параметрическим кодированием основано на синтаксическом разборе сигнала главного звукового микширования на частотно-временные мозаики и применении подходящих усилений/ослаблений к каждой из данных мозаик. Скорость передачи данных, необходимая для передачи данных усилений на приемник, является низкой по сравнению со скоростью, необходимой в случае усиления с кодированием формы сигнала. Однако, вследствие ограниченной временно-спектральной разрешающей способности параметров, речь при микшировании с неречевым звуком не может быть обработана без параллельного воздействия на неречевой звук. Усиление с параметрическим кодированием речевого содержимого звукового микширования, следовательно, вносит модуляцию в неречевое содержимое микширования и данная модуляция («фоновая модуляция») может стать нежелательной при проигрывании микширования с усиленной речью. Фоновые модуляции, наиболее вероятно, будут нежелательными, если отношение речи к фону является очень низким.
Подходы, описанные в данном разделе, являются подходами, которые могут быть выполнены, но необязательно подходами, которые были ранее предложены или выполнены. Следовательно, если не указано иное, не следует предполагать, что любой из подходов, описанных в данном разделе, расценивается как известный уровень техники, только лишь вследствие их включения в данный раздел. Подобным образом, не следует предполагать, что проблемы, определенные относительно одного или более подходов, были учтены в известном уровне техники на основе данного раздела, если не указано иное.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Настоящее изобретение проиллюстрировано для примера, а не для ограничения, на фигурах прилагаемых графических материалов, на которых подобные позиционные обозначения относятся к одинаковым элементам, и на которых:
На фиг. 1 показана блок-диаграмма системы, выполненной с возможностью генерирования параметров предсказания для восстановления речевого содержимого одноканального сигнала микшированного содержимого (имеющего речевое и неречевое содержимое).
На фиг. 2 показана блок-диаграмма системы, выполненной с возможностью генерирования параметров предсказания для восстановления речевого содержимого многоканального сигнала микшированного содержимого (имеющего речевое и неречевое содержимое).
На фиг. 3 показана блок-диаграмма системы, включающей кодер, выполненный с возможностью выполнения варианта осуществления изобретения способа кодирования для генерирования кодированного звукового битового потока, указывающего на звуковую программу, и декодер, выполненный с возможностью декодирования и выполнения усиления речи (в соответствии с вариантом осуществления способа изобретения) в отношении кодированного звукового битового потока.
На фиг. 4 показана блок-диаграмма системы, выполненной с возможностью представления многоканального звукового сигнала микшированного содержимого, в том числе посредством выполнения в его отношении традиционного усиления речи.
На фиг. 5 показана блок-диаграмма системы, выполненной с возможностью представления многоканального звукового сигнала микшированного содержимого, в том числе посредством выполнения в его отношении традиционного усиления речи с параметрическим кодированием.
На фиг. 6 и на фиг. 6A показаны блок-диаграммы систем, выполненных с возможностью представления многоканального звукового сигнала микшированного содержимого, в том числе посредством выполнения в его отношении варианта осуществления способа изобретения усиления речи.
На фиг. 7 показана блок-диаграмма системы для выполнения варианта осуществления способа изобретения кодирования с использованием модели слухового маскирования;
На фиг. 8A и на фиг. 8B проиллюстрированы приведенные в качестве примера потоки процесса; и
На фиг. 9 проиллюстрирована приведенная в качестве примера аппаратная платформа, на которой может быть реализован компьютер или вычислительное устройство, как описано в данном документе.
ОПИСАНИЕ ПРИВЕДЕННЫХ В КАЧЕСТВЕ ПРИМЕРА ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
В данном документе описаны приведенные в качестве примера варианты осуществления, которые относятся к гибридному усилению речи с кодированием формы сигнала и параметрическим кодированием. В следующем описании в целях пояснения изложены многочисленные специфические подробности для предоставления полного понимания настоящего изобретения. Однако следует понимать, что настоящее изобретение может быть осуществлено без данных специфических подробностей. В других примерах хорошо известные структуры и устройства не описаны в исчерпывающих подробностях, во избежание ненужного перенасыщения, искажения смысла или запутывания содержания настоящего изобретения.
Приведенные в качестве примера варианты осуществления описаны в данном документе в соответствии со следующим планом:
1. ОБЩИЙ ОБЗОР
2. УСЛОВНЫЕ ОБОЗНАЧЕНИЯ И ТЕРМИНОЛОГИЯ
3. ГЕНЕРИРОВАНИЕ ПАРАМЕТРОВ ПРЕДСКАЗАНИЯ
4. ОПЕРАЦИИ УСИЛЕНИЯ РЕЧИ
5. ПРЕДСТАВЛЕНИЕ РЕЧИ
6. СРЕДНЕЕ/ПОБОЧНОЕ ПРЕДСТАВЛЕНИЕ
7. ПРИВЕДЕННЫЕ В КАЧЕСТВЕ ПРИМЕРА ПОТОКИ ПРОЦЕССА
8. МЕХАНИЗМЫ РЕАЛИЗАЦИИ – ОБЗОР АППАРАТНОГО ОБЕСПЕЧЕНИЯ
9. ЭКВИВАЛЕНТЫ, РАСШИРЕНИЯ, АЛЬТЕРНАТИВЫ И ПРОЧЕЕ
1. ОБЩИЙ ОБЗОР
Данный обзор представляет базовое описание некоторых аспектов варианта осуществления настоящего изобретения. Следует отметить, что данный обзор не является расширенным или исчерпывающим изложением аспектов варианта осуществления. Более того, следует отметить, что данный обзор не следует понимать, как определение каких-либо конкретных существенных аспектов или элементов варианта осуществления, а также ограничение какого-либо объема варианта осуществления в частности или изобретения в целом. Данный обзор представляет лишь некоторые идеи, которые относятся к приведенному в качестве примера варианту осуществления, в сокращенной и упрощенной форме, и он должен рассматриваться лишь как вводная часть для более подробного описания приведенных в качестве примера вариантов осуществления, которые следуют далее. Следует отметить, что, несмотря на то что в данном документе обсуждены отдельные варианты осуществления, любое сочетание вариантов осуществления и/или частичных вариантов осуществления, обсужденных в данном документе, может быть объединено для образования дополнительных вариантов осуществления.
Авторы изобретения осознали, что отдельные сильные и слабые стороны усиления с параметрическим кодированием и усиления с кодированием формы сигнала могут компенсировать друг друга, и, что традиционное усиление речи может быть по существу улучшено посредством способа гибридного усиления, который использует усиление с параметрическим кодированием (или смесь усиления с параметрическим кодированием и усиления с кодированием формы сигнала) при некоторых состояниях сигнала и усиление с кодированием формы сигнала (или отличную смесь усиления с параметрическим кодированием и усиления с кодированием формы сигнала) при остальных состояниях сигнала. Типичные варианты осуществления способа изобретения гибридного усиления предоставляют усиление речи с большей устойчивостью и лучшим качеством, чем может быть достигнуто либо посредством одного только усиления с параметрическим кодированием, либо посредством одного только усиления с кодированием формы сигнала.
В одном из классов вариантов осуществления способ изобретения включает следующие этапы: (a) прием битового потока, указывающего на звуковую программу, включающую речь, имеющую неусиленную форму сигнала и другое звуковое содержимое, при этом битовый поток включает: аудиоданные, указывающие на речь и другое звуковое содержимое, данные о форме сигнала, указывающие на версию сниженного качества речи (в случае чего аудиоданные генерируются посредством микширования речевых данных с неречевыми данными, при этом данные о форме сигнала, как правило, содержат меньшее количество битов, чем речевые данные), при этом версия сниженного качества имеет вторую форму сигнала, подобную (например, по меньшей мере по существу подобную) неусиленной форме сигнала, и версия сниженного качества будет иметь неприемлемое качество при отдельном прослушивании, и параметрические данные, при этом параметрические данные вместе с аудиоданными определяют параметрически составленную речь, и параметрически составленная речь является параметрически восстановленной версией речи, которая по меньшей мере по существу соответствует (например, имеет хорошее согласование с) речи; и (b) выполнение усиления речи в отношении битового потока в ответ на указатель смешивания, вследствие чего генерируются данные, указывающие на звуковую программу с усиленной речью, в том числе посредством сочетания аудиоданных с сочетанием низкокачественных речевых данных, определенных из данных о форме сигнала, и восстановленные речевые данные, при этом сочетание определяется указателем смешивания (например, сочетание имеет последовательность состояний, определенных последовательностью текущих значений указателя смешивания), восстановленные речевые данные генерируются в ответ на по меньшей мере некоторые из параметрических данных и по меньшей мере некоторые из аудиоданных, и звуковая программа с усиленной речью имеет менее слышимые артефакты усиления речи (например, артефакты усиления речи, которые замаскированы лучшим образом, и, следовательно, являются менее слышимыми во время представления и прослушивания звуковой программы с усиленной речью), чем звуковая программа с усиленной речью с одним только кодированием формы сигнала, определенная сочетанием лишь низкокачественных речевых данных (которые указывают на версию сниженного качества речи) с аудиоданными, или звуковая программа с усиленной речью с одним только параметрическим кодированием, определенная из параметрических данных и аудиоданных.
В данном документе «артефакт усиления речи» (или «артефакт кодирования усиления речи») обозначает искажение (как правило, измеримое искажение) звукового сигнала (указывающего на речевой сигнал и неречевой звуковой сигнал), вызванное представлением речевого сигнала (например, речевого сигнала с кодированием формы сигнала или параметрических данных вместе с сигналом микшированного содержимого).
В некоторых вариантах осуществления указатель смешивания (который может иметь последовательность значений, например, по одному значению для каждой из последовательностей сегментов битового потока) включен в битовый поток, принятый на этапе (a). Некоторые варианты осуществления включают этап генерирования указателя смешивания (например, в приемнике, который принимает и декодирует битовый поток) в ответ на битовый поток, принятый на этапе (a).
Следует понимать, что выражение «указатель смешивания» не обязательно должно предусматривать, чтобы указатель смешивания являлся одним параметром или значением (или последовательностью из одних параметров или значений) для каждого сегмента битового потока. Наоборот, предполагается, что в некоторых вариантах осуществления указатель смешивания (для сегмента битового потока) может являться набором из двух или более параметров или значений (например, параметром управления усилением с параметрическим кодированием и параметром управления усилением с кодированием формы сигнала для каждого сегмента) или последовательностью наборов из параметров или значений.
В некоторых вариантах осуществления указатель смешивания для каждого сегмента может являться последовательностью значений, указывающих на смешивание на полосу частот сегмента.
Данные о форме сигнала и параметрические данные не должны быть предоставлены для (например, включены в) каждого сегмента битового потока и как данные о форме сигнала, так и параметрические данные не должны быть использованы для выполнения усиления речи в отношении каждого сегмента битового потока. Например, в некоторых случаях по меньшей мере один сегмент может включать только данные о форме сигнала (и сочетание, определенное указателем смешивания для каждого такого сегмента, может состоять только из данных о форме сигнала) и по меньшей мере еще один сегмент может включать только параметрические данные (и сочетание, определенное указателем смешивания для каждого такого сегмента, может состоять только из восстановленных речевых данных).
Как правило, предполагается, что кодер генерирует битовый поток, в том числе посредством кодирования (например, сжатия) аудиоданных, но не посредством применения данного кодирования к данным о форме сигнала или параметрическим данным. Таким образом, при подаче битового потока на приемник, приемник, как правило, осуществляет синтаксический разбор битового потока для извлечения аудиоданных, данных о форме сигнала и параметрических данных (и указатель смешивания, если он подается в битовый поток), но декодирует только аудиоданные. Приемник, как правило, выполняет усиление речи в отношении декодированных аудиоданных (с использованием данных о форме сигнала и/или параметрических данных) без применения к данным о форме сигнала или параметрическим данным данного процесса декодирования, который применяется к аудиоданным.
Как правило, сочетание (указанное указателем смешивания) данных о форме сигнала и восстановленных речевых данных изменяется с течением времени, при этом каждое состояние сочетания относится к речевому и другому звуковому содержимому соответствующего сегмента битового потока. Указатель смешивания генерируется таким образом, что текущее состояние сочетания (данных о форме сигнала и восстановленных речевых данных) по меньшей мере частично определяется свойствами сигнала речевого и другого звукового содержимого (например, отношением мощности речевого содержимого и мощности другого звукового содержимого) в соответствии с сегментом битового потока. В некоторых вариантах осуществления указатель смешивания генерируется таким образом, что текущее состояние сочетания определяется свойствами сигнала речевого и другого звукового содержимого в соответствии с сегментом битового потока. В некоторых вариантах осуществления указатель смешивания генерируется таким образом, что текущее состояние сочетания определяется как свойствами сигнала речевого и другого звукового содержимого в соответствии с сегментом битового потока, так и количеством артефактов кодирования в данных о форме сигнала.
Этап (b) может включать этап выполнения усиления речи с кодированием формы сигнала посредством сочетания (например, микширования или смешивания) по меньшей мере некоторых из низкокачественных речевых данных с аудиоданными по меньшей мере одного сегмента битового потока и выполнения усиления речи с параметрическим кодированием посредством сочетания восстановленных речевых данных с аудиоданными по меньшей мере одного сегмента битового потока. Сочетание усиления речи с кодированием формы сигнала и усиления речи с параметрическим кодированием выполняется в отношении по меньшей мере одного сегмента битового потока посредством смешивания как низкокачественных речевых данных, так и параметрически составленной речи для сегмента с аудиоданными сегмента. При некоторых состояниях сигнала только одно (но не оба) из усиления речи с кодированием формы сигнала и усиления речи с параметрическим кодированием выполняется (в ответ на указатель смешивания) в отношении сегмента (или в отношении каждого из более чем одного сегментов) битового потока.
В данном документе выражение «SNR» (отношение сигнала к шуму) будет использовано для обозначения отношения мощности (или разницы в уровне) речевого содержимого сегмента звуковой программы (или всей программы) к мощности неречевого содержимого сегмента или программы, или отношения мощности речевого содержимого сегмента программы (или всей программы) к мощности всего (речевого и неречевого) содержимого сегмента или программы.
В одном из классов вариантов осуществления способ изобретения реализует временное переключение «вслепую» на основе SNR между усилением с параметрическим кодированием и усилением с кодированием формы сигнала сегментов звуковой программы. В данном контексте «вслепую» обозначает, что переключение не проводится перцепционно посредством сложной модели слухового маскирования (например, типа, описанного в данном документе), но проводится с использованием последовательности значений SNR (указателей смешивания), соответствующих сегментам программы. В одном варианте осуществления в данном классе усиление речи с гибридным кодированием достигается посредством временного переключения между усилением с параметрическим кодированием и усилением с кодированием формы сигнала, так что либо усиление с параметрическим кодированием, либо усиление с кодированием формы сигнала (но не как усиление с параметрическим кодированием, так и усиление с кодированием формы сигнала) выполняется в отношении каждого сегмента звуковой программы, в отношении которой выполняется усиление речи. Понимая, что усиление с кодированием формы сигнала наилучшим образом выполняется при условии низкого SNR (в отношении сегментов, имеющих низкие значения SNR) и усиление с параметрическим кодированием наилучшим образом выполняется при условии подходящего SNR (в отношении сегментов, имеющих высокие значения SNR), решение о переключении, как правило, основывается на отношении речевого звука (диалога) к остальному звуку в исходном звуковом микшировании.
Варианты осуществления, которые реализуют временное переключение «вслепую» на основе SNR, как правило, включают следующие этапы: сегментация неусиленного звукового сигнала (исходного звукового микширования) на последовательные временные промежутки (сегменты) и определение для каждого сегмента SNR между речевым содержимым и другим звуковым содержимым (или между речевым содержимым и всем звуковым содержимым) сегмента; и для каждого сегмента сравнивание SNR с пороговым значением и предоставление параметра управления усилением с параметрическим кодированием для сегмента (т.е. указатель смешивания для сегмента указывает, что должно быть выполнено усиление с параметрическим кодированием), если SNR превышает пороговое значение, или предоставление параметра управления усилением с кодированием формы сигнала для сегмента (т.е. указатель смешивания для сегмента указывает, что должно быть выполнено усиление с кодированием формы сигнала), если SNR не превышает пороговое значение. Как правило, неусиленный звуковой сигнал подается (например, передается) с параметрами управления, включенными в качестве метаданных, на приемник и приемник выполняет (в отношении каждого сегмента) тип усиления речи, указанный параметром управления для сегмента. Таким образом, приемник выполняет усиление с параметрическим кодированием в отношении каждого сегмента, для которого параметр управления является параметром управления усилением с параметрическим кодированием, и усиление с кодированием формы сигнала в отношении каждого сегмента, для которого параметр управления является параметром управления усилением с кодированием формы сигнала.
При готовности принять на себя расходы на передачу (с каждым сегментом исходного звукового микширования) как данных о форме сигнала (для реализации усиления речи с кодированием формы сигнала), так и параметров усиления с параметрическим кодированием с исходным (неусиленным) микшированием, более высокая степень усиления речи может быть достигнута посредством применения как усиления с кодированием формы сигнала, так и усиления с параметрическим кодированием к отдельным сегментам микширования. Таким образом, в одном из классов вариантов осуществления способ изобретения реализует временное смешивание «вслепую» на основе SNR усиления с параметрическим кодированием и усиления с кодированием формы сигнала сегментов звуковой программы. В данном контексте «вслепую» также обозначает, что переключение не проводится перцепционно посредством сложной модели слухового маскирования (например, типа, описанного в данном документе), но проводится с использованием последовательности значений SNR, соответствующих сегментам программы.
Варианты осуществления, которые реализуют временное смешивание «вслепую» на основе SNR, как правило, включают следующие этапы: сегментация неусиленного звукового сигнала (исходного звукового микширования) на последовательные временные промежутки (сегменты) и определение для каждого сегмента SNR между речевым содержимым и другим звуковым содержимым (или между речевым содержимым и всем звуковым содержимым) сегмента; и для каждого сегмента предоставление указателя управления смешиванием, при этом значение указателя управления смешиванием определяется (зависит от) SNR для сегмента.
В некоторых вариантах осуществления способ включает этап определения (например, приема запроса на) общей величины («T») усиления речи и указатель управления смешиванием является параметром α для каждого сегмента, так что T = α Pw + (1-α)Pp, при этом Pw является усилением с кодированием формы сигнала для сегмента, которое произведет предопределенную общую величину усиления T при применении к неусиленному звуковому содержимому сегмента с использованием данных о форме сигнала, предоставленных для сегмента (при этом речевое содержимое сегмента имеет неусиленную форму сигнала, данные о форме сигнала для сегмента указывают на версию сниженного качества речевого содержимого сегмента, версия сниженного качества имеет форму сигнала, подобную (например, по меньшей мере по существу подобную) неусиленной форме сигнала, и версия сниженного качества речевого содержимого имеет неприемлемое качество при отдельных представлении и восприятии), и Pp является усилением с параметрическим кодированием, которое произведет предопределенную общую величину усиления T при применении к неусиленному звуковому содержимому сегмента с использованием параметрических данных, предоставленных для сегмента (при этом параметрические данные для сегмента с неусиленным звуковым содержимым сегмента определяют параметрическую восстановленную версию речевого содержимого сегмента). В некоторых вариантах осуществления указатель управления смешиванием для каждого из сегментов является набором данных параметров, включающим параметр для каждой полосы частот соответствующего сегмента.
При подаче (например, передаче) неусиленного звукового сигнала с параметрами управления в качестве метаданных на приемник, приемник может выполнить (в отношении каждого сегмента) гибридное усиление речи, указанное параметрами управления для сегмента. В качестве альтернативы приемник генерирует параметры управления из неусиленного звукового сигнала.
В некоторых вариантах осуществления приемник выполняет (в отношении каждого сегмента неусиленного звукового сигнала) сочетание усиления с параметрическим кодированием (равного величине, определенной усилением Pp, масштабированным на основе параметра α для сегмента) и усиления с кодированием формы сигнала (равного величине, определенной усилением Pw, масштабированным на основе значения (1 - α) для сегмента), так что сочетание усиления с параметрическим кодированием и усиления с кодированием формы сигнала генерирует предопределенную общую величину усиления:
T = α Pw + (1-α)Pp (1)
В еще одном классе вариантов осуществления сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении каждого сегмента звукового сигнала, определяется моделью слухового маскирования. В некоторых вариантах осуществления в данном классе оптимальное отношение смешивания для смеси усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении сегмента звуковой программы, использует наивысшую величину усиления с кодированием формы сигнала, которая лишь предотвращает слышимость шума кодирования. Следует понимать, что наличие шума кодирования в декодере всегда имеет вид статистической оценки и не может быть точно определено.
В некоторых вариантах осуществления в данном классе указатель смешивания для каждого сегмента аудиоданных указывает на сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении сегмента, и сочетание по меньшей мере частично равняется максимизирующему сочетанию с кодированием формы сигнала, определенному для сегмента моделью слухового маскирования, при этом максимизирующее сочетание с кодированием формы сигнала устанавливает наибольшую относительную величину усиления с кодированием формы сигнала, которая гарантирует, что шум кодирования (вследствие усиления с кодированием формы сигнала) в соответствующем сегменте звуковой программы с усиленной речью не будет являться нежелательно слышимым (например, будет являться неслышимым). В вариантах осуществления наибольшая относительная величина усиления с кодированием формы сигнала, которая гарантирует, что шум кодирования в сегменте звуковой программы с усиленной речью не будет являться нежелательно слышимым, является наибольшей относительной величиной, которая гарантирует, что сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено (в отношении соответствующего сегмента аудиоданных), генерирует предопределенную общую величину усиления речи для сегмента и/или (если артефакты усиления с параметрическим кодированием включены в оценку, выполняемую моделью слухового маскирования) артефакты кодирования (вследствие усиления с кодированием формы сигнала) могут являться слышимыми (если это является благоприятным) по сравнению с артефактами усиления с параметрическим кодированием (например, если слышимые артефакты кодирования (вследствие усиления с кодированием формы сигнала) являются менее слышимыми, чем слышимые артефакты усиления с параметрическим кодированием).
Вклад усиления с кодированием формы сигнала в гибридную схему кодирования изобретения может быть увеличен, при этом гарантируя, что шум кодирования не станет неприемлемо слышимым (например, не станет слышимым), посредством использования модели слухового маскирования для более точного предсказания того, каким образом шум кодирования в копии речи сниженного качества (которая должна быть использована для реализации усиления с кодированием формы сигнала) замаскирован звуковым микшированием главной программы, и для выбора отношения смешивания соответственно.
Данные варианты осуществления, которые используют модель слухового маскирования, включают следующие этапы: сегментация неусиленного звукового сигнала (исходного звукового микширования) на последовательные временные промежутки (сегменты) и предоставление копии сниженного качества речи в каждом сегменте (для использования в усилении с кодированием формы сигнала) и параметров усиления с параметрическим кодированием (для использования в усилении с параметрическим кодированием) для каждого сегмента; для каждого из сегментов использование модели слухового маскирования для определения максимальной величины усиления с кодированием формы сигнала, которая может быть применена без возникновения нежелательно слышимых артефактов кодирования; и генерирование указателя (для каждого сегмента неусиленного звукового сигнала) сочетания усиления с кодированием формы сигнала (равного величине, которая не превышает максимальную величину усиления с кодированием формы сигнала, определенного с использованием модели слухового маскирования для сегмента, и, которая по меньшей мере по существу соответствует максимальной величине усиления с кодированием формы сигнала, определенного с использованием модели слухового маскирования для сегмента) и усиления с параметрическим кодированием, так что сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием генерирует предопределенную общую величину усиления речи для сегмента.
В некоторых вариантах осуществления каждый указатель включен (например, посредством кодера) в битовый поток, который также включает кодированные аудиоданные, указывающие на неусиленный звуковой сигнал.
В некоторых вариантах осуществления неусиленный звуковой сигнал сегментируется на последовательные временные промежутки и каждый временной промежуток сегментируется на полосы частот, при этом для каждой полосы частот каждого временного промежутка модель слухового маскирования используется для определения максимальной величины усиления с кодированием формы сигнала, которое может быть применено без возникновения нежелательно слышимых артефактов кодирования, и указатель генерируется для каждой полосы частот каждого временного промежутка неусиленного звукового сигнала.
Факультативно, способ также включает этап выполнения (в отношении каждого сегмента неусиленного звукового сигнала) в ответ на указатель для каждого сегмента сочетания усиления с кодированием формы сигнала и усиления с параметрическим кодированием, определенного указателем, так что сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием генерирует предопределенную общую величину усиления речи для сегмента.
В некоторых вариантах осуществления звуковое содержимое кодируется в кодированный звуковой сигнал для эталонной конфигурации (или представления) звуковых каналов, такой как конфигурация объемного звука, конфигурация динамиков 5.1, конфигурация динамиков 7.1, конфигурация динамиков 7.2 и т.д. Эталонная конфигурация может содержать звуковые каналы, такие как стереоканалы, левый и правый передний канал, каналы объемного звука, каналы динамика, объектные каналы и т.д. Один или более из каналов, которые содержат речевое содержимое, могут не являться каналами представления средних/побочных (M/S) звуковых каналов. В данном контексте представление M/S звуковых каналов (или просто M/S представление) содержит по меньшей мере средний канал и побочный канал. В приведенном в качестве примера варианте осуществления средний канал представляет собой сумму левого и правого каналов (например, равновзвешенных и т.д.), тогда как побочный канал представляет собой разницу между левым и правым каналами, при этом левый и правый каналы могут считаться любым сочетанием двух каналов, например, переднего центрального и переднего левого каналов.
В некоторых вариантах осуществления речевое содержимое программы может быть микшировано с неречевым содержимым и может быть распределено по двум или более каналам, отличным от M/S, например, левому и правому каналам, левому и правому передним каналам и т.д., в эталонной конфигурации звуковых каналов. Речевое содержимое может, но не обязательно должно быть представлено на фантомном центре стереосодержимого, в котором речевое содержимое имеет одинаковую громкость в двух каналах, отличных от M/S, например, левом и правом каналах и т.д. Стереосодержимое может содержать неречевое содержимое, которое не обязательно должно иметь одинаковую громкость или даже присутствовать в обоих из двух каналов.
В соответствии с некоторыми подходами множество наборов данных управления каналами, отличными от M/S, параметров управления и т.д. для усиления речи, соответствующих множеству звуковых каналов, отличных от M/S, по которым распределено речевое содержимое, передается в качестве части общих аудиометаданных с аудиокодера на расположенные ниже по потоку аудиодекодеры. Каждый из множества наборов данных управления каналами, отличными от M/S, параметров управления и т.д. для усиления речи соответствует конкретному звуковому каналу множества звуковых каналов, отличных от M/S, по которым распределено речевое содержимое, и может быть использован расположенным ниже по потоку аудиодекодером для управления операциями усиления речи, относящимися к конкретному звуковому каналу. В данном контексте набор данных управления каналами, отличными от M/S, параметров управления и т.д. относится к данным управления, параметрам управления и т.д. для операций усиления речи в звуковом канале отличного от M/S представления, например, эталонной конфигурации, в которой кодируется звуковой сигнал, как описано в данном документе.
В некоторых вариантах осуществления метаданные усиления речи M/S каналов передаются в дополнение к или вместо одного или более наборов данных управления каналами, отличными от M/S, параметров управления и т.д. в качестве части аудиометаданных с аудиокодера на расположенные ниже по потоку аудиодекодеры. Метаданные усиления речи M/S каналов могут содержать один или более наборов данных управления M/S каналами, параметров управления и т.д. для усиления речи. В данном контексте набор данных управления M/S каналами, параметров управления и т.д. относится к данным управления, параметрам управления и т.д. для операций усиления речи в звуковом канале M/S представления. В некоторых вариантах осуществления метаданные усиления речи M/S каналов для усиления речи передаются аудиокодером на расположенные ниже по потоку аудиодекодеры с микшированным содержимым, кодированным в эталонной конфигурации звуковых каналов. В некоторых вариантах осуществления количество наборов данных управления M/S каналами, параметров управления и т.д. для усиления речи в метаданных усиления речи M/S каналов может быть меньше, чем количество множества звуковых каналов, отличных от M/S, в эталонном представлении звуковых каналов, по которым распределяется речевое содержимое в микшированном содержимом. В некоторых вариантах осуществления, даже если речевое содержимое в микшированном содержимом распределяется по двум или более звуковым каналам, отличным от M/S, например, левому и правому каналам т.д., в эталонной конфигурации звуковых каналов, только один набор данных управления M/S каналами, параметров управления и т.д. для усиления речи, например, соответствующий среднему каналу M/S представления, отправляется в качестве метаданных усиления речи M/S каналов с аудиокодера на расположенные ниже по потоку декодеры. Один набор данных управления M/S каналами, параметров управления и т.д. для усиления речи может быть использован для выполнения операций усиления речи для всех из двух или более звуковых каналов, отличных от M/S, например, левого и правого каналов и т.д. В некоторых вариантах осуществления матрицы преобразования между эталонной конфигурацией и M/S представлением могут быть использованы для выполнения операций усиления речи на основе данных управления M/S каналами, параметров управления и т.д. для усиления речи, как описано в данном документе.
Методы, описанные в данном документе, могут быть использованы в случае, если речевое содержимое панорамируется на фантомный центр левого и правого каналов, речевое содержимое не полностью панорамируется в центре (например, не имеет одинаковой громкости как на левом, так и на правом каналах и т.д.) и т.д. В примере данные методы могут быть использованы в случае, если большой процент (например, 70+%, 80+%, 90+% и т.д.) энергии речевого содержимого сосредоточен в центральном сигнале или центральном канале M/S представления. В еще одном примере (например, пространственные и т.д.) преобразования, такие как панорамирование, чередование и т.д., могут быть использованы для преобразования речевого содержимого, имеющего не одинаковую громкость, в эталонную конфигурацию, чтобы оно имело одинаковую или по существу одинаковую громкость в M/S конфигурации. Векторы представления, матрицы преобразования и т.д., представляющие панорамирование, чередование и т.д., могут быть использованы в качестве части или совместно с операциями усиления речи.
В некоторых вариантах осуществления (например, гибридном способе и т.д.) версия (например, версия сниженного качества и т.д.) речевого содержимого отправляется на расположенный ниже по потоку аудиодекодер в качестве либо только сигнала среднего канала, либо обоих сигналов среднего канала и побочного канала в M/S представлении наряду с микшированным содержимым, отправленным в эталонной конфигурации звуковых сигналов возможно с отличным от M/S представлением. В вариантах осуществления, в которых версия речевого содержимого отправляется на расположенный ниже по потоку аудиодекодер в качестве только сигнала среднего канала в M/S представлении, соответствующий вектор представления, который управляет (например, выполняет преобразование и т.д.) сигналом среднего канала для генерирования частей сигнала в одном или более каналах, отличных от M/S, конфигурации звуковых каналов, отличных от M/S, (например, эталонной конфигурации и т.д.) на основе сигнала среднего канала, также отправляется на расположенный ниже по потоку аудиодекодер.
В некоторых вариантах осуществления алгоритм усиления диалога/речи (например, в расположенном ниже по потоку аудиодекодере и т.д.), который реализует временное переключение «вслепую» на основе SNR между усилением с параметрическим кодированием (например, независимым от канала предсказанием диалога, многоканальным предсказанием диалога и т.д.) и усилением с кодированием формы сигнала сегментов звуковой программы, работает по меньшей мере частично в M/S представлении.
Методы, описанные в данном документе, которые реализуют операции усиления речи по меньшей мере частично в M/S представлении, могут быть использованы совместно с независимым от канала предсказанием (например, в среднем канале и т.д.), многоканальным предсказанием (например, в среднем канале и побочном канале и т.д.) и т.д. Данные методы могут быть также использованы для поддержания усиления речи для одного, двух или более диалогов одновременно. Ни одного, один или более дополнительных наборов параметров управления, данных управления и т.д., таких как параметры предсказания, усиления, векторы представления и т.д., могут быть предоставлены в кодированном звуковом сигнале в качестве части метаданных усиления речи M/S каналов для поддержания дополнительных диалогов.
В некоторых вариантах осуществления синтаксис кодированного звукового сигнала (например, выводимого из кодера и т.д.) поддерживает передачу M/S флага с расположенного выше по потоку аудиокодера на расположенные ниже по потоку аудиодекодеры. M/S флаг присутствует/устанавливается, если операции усиления речи должны быть выполнены по меньшей мере частично совместно с данными управления M/S каналами, параметрами управления и т.д., которые передаются вместе с M/S флагом. Например, если установлен M/S флаг, стереосигнал (например, из левого и правого каналов и т.д.) в каналах, отличных от M/S, может быть сначала преобразован принимающим аудиодекодером в средний канал и побочный канал M/S представления перед выполнением операций усиления речи M/S каналов с данными управления M/S каналами, параметрами управления и т.д. при приеме с M/S флагом в соответствии с одним или более алгоритмами усиления речи (например, независимым от канала предсказанием диалога, многоканальным предсказанием диалога, алгоритмом на основе формы сигнала, гибридным алгоритмом с кодированием формы сигнала и параметрическим кодированием и т.д.). После выполнения операций усиления речи M/S каналов сигналы с усиленной речью в M/S представлении могут быть преобразованы обратно в каналы, отличные от M/S.
В некоторых вариантах осуществления звуковая программа, речевое содержимое которой должно быть усилено в соответствии с изобретением, включает каналы динамика, но не включает никаких объектных каналов. В еще одних вариантах осуществления звуковая программа, речевое содержимое которой должно быть усилено в соответствии с изобретением, является звуковой программой на основе объекта (как правило, многоканальной звуковой программой на основе объекта), содержащей по меньшей мере один объектный канал, а также факультативно по меньшей мере один канал динамика.
Еще одним аспектом изобретения является система, включающая кодер, выполненный (например, запрограммированный) с возможностью выполнения любого варианта осуществления способа изобретения кодирования для генерирования битового потока, включающего кодированные аудиоданные, данные о форме сигнала и параметрические данные (а также факультативно указатель смешивания (например, данные, указывающие на смешивание) для каждого сегмента аудиоданных) в ответ на аудиоданные, указывающие на программу, включающую речевое и неречевое содержимое, и декодер, выполненный с возможностью синтаксического разбора битового потока для восстановления кодированных аудиоданных (а также факультативно каждого указателя смешивания) и декодирования кодированных аудиоданных для восстановления аудиоданных. В качестве альтернативы, декодер выполнен с возможностью генерирования указателя смешивания для каждого сегмента аудиоданных в ответ на восстановленные аудиоданные. Декодер выполнен с возможностью выполнения гибридного усиления речи в отношении восстановленных аудиоданных в ответ на каждый указатель смешивания.
Еще одним аспектом изобретения является декодер, выполненный с возможностью выполнения любого варианта осуществления способа изобретения. В еще одном классе вариантов осуществления изобретением является декодер, включающий буферную память (буфер), которая хранит (например, постоянно) по меньшей мере один сегмент (например, кадр) кодированного битового аудиопотока, который был сгенерирован любым вариантом осуществления способа изобретения.
Другие аспекты изобретения включают систему или устройство (например, кодер, декодер или процессор), выполненное (например, запрограммированное) с возможностью выполнения любого варианта осуществления способа изобретения, и машиночитаемый носитель (например, диск), в памяти которого хранится код, предназначенный для реализации любого варианта осуществления способа изобретения или его этапов. Например, система изобретения может являться или включать программируемый процессор общего назначения, процессор цифровой обработки сигналов или микропроцессор, запрограммированный с использованием программного обеспечения или программно-аппаратного обеспечения и/или иным образом выполненный с возможностью выполнения любого разнообразия операций в отношении данных, включая вариант осуществления способа изобретения или его этапы. Такой процессор общего назначения может являться или включать компьютерную систему, включающую устройство ввода, память и схему обработки, запрограммированную (и/или иным образом выполненную с возможностью) на выполнение варианта осуществления способа изобретения (или его этапов) в ответ на передаваемые на нее данные.
В некоторых вариантах осуществления механизмы, описанные в данном документе, образуют часть системы обработки медиаданных, включающей, помимо всего прочего: аудиовизуальное устройство, телевизор с плоским экраном, карманное устройство, игровой автомат, телевизор, систему домашнего кинотеатра, планшет, мобильное устройство, переносной компьютер, нетбук, сотовый радиотелефон, электронную книгу, терминал для производства платежей в месте совершения покупки, настольный компьютер, автоматизированное рабочее место, компьютерный информационный киоск, другие разнообразные типы терминалов и узлов обработки медиаданных и т.д.
Различные модификации предпочтительных вариантов осуществления и общие принципы и признаки, описанные в данном документе, будут очевидны специалистам в данной области техники. Таким образом, раскрытие не должно быть ограничено показанными вариантами осуществления, но должно соответствовать наиболее широкому объему в соответствии с принципами и признаками, описанными в данном документе.
2. УСЛОВНЫЕ ОБОЗНАЧЕНИЯ И ТЕРМИНОЛОГИЯ
Повсюду в данном раскрытии, включая формулу изобретения, термины «диалог» и «речь» взаимозаменяемо используются в качестве синонимов для обозначения содержимого звукового сигнала, воспринимаемого в виде общения между людьми (или персонажами в виртуальном мире).
Повсюду в данном раскрытии, включая формулу изобретения, выражение выполнения операции «в отношении» сигнала или данных (например, фильтрация, масштабирование, преобразование или применение усиления к сигналам или данным) используется в широком смысле для обозначения выполнения операции непосредственно в отношении сигнала или данных или в отношении обработанной версии сигнала или данных (например, в отношении версии сигнала, который был подвергнут предварительной фильтрации или предварительной обработке перед выполнением операции в его отношении).
Повсюду в данном раскрытии, включая формулу изобретения, выражение «система» используется в широком смысле для обозначения устройства, системы или подсистемы. Например, подсистема, которая реализует декодер, может называться системой декодера, и система, содержащая такую подсистему (например, система, которая генерирует Х выходных сигналов в ответ на ряд входных сигналов, в которой подсистема генерирует М входных сигналов, и остальные Х − М входные сигналы принимаются из внешнего источника), также может называться системой декодера.
Повсюду в данном раскрытии, включая формулу изобретения, термин «процессор» используется в широком смысле для обозначения системы или устройства, запрограммированного или иным образом выполненного (например, с использованием программного обеспечения или программно-аппаратного обеспечения) с возможностью выполнения операций в отношении данных (например, аудио или видео или других данных изображений). Примеры процессоров включают программируемую пользователем вентильную матрицу (или другую настраиваемую интегральную схему или набор микросхем), процессор цифровой обработки сигналов, запрограммированный и/или иным образом выполненный с возможностью выполнения конвейерной обработки в отношении аудио или других звуковых данных, программируемый процессор общего назначения или компьютер и программируемую микропроцессорную интегральную схему или набор микросхем.
Повсюду в данном раскрытии, включая формулу изобретения, выражения «аудиопроцессор» и «блок обработки аудиоданных» используются взаимозаменяемо и в широком смысле обозначают систему, выполненную с возможностью обработки аудиоданных. Примеры блоков обработки аудиоданных включают, помимо всего прочего, кодеры (например, транскодеры), декодеры, кодеки, системы предварительной обработки, системы последующей обработки и системы обработки битового потока (иногда называемые инструментами обработки битового потока).
Повсюду в данном раскрытии, включая формулу изобретения, выражение «метаданные» относится к отдельным и различным данным из соответствующих аудиоданных (звукового содержимого битового потока, который также включает метаданные). Метаданные связаны с аудиоданными и указывают по меньшей мере на один признак или характеристику аудиоданных (например, какой тип (типы) обработки уже был выполнен или должен быть выполнен в отношении аудиоданных, или траекторию объекта, указанного аудиоданными). Связь метаданных с аудиоданными является синхронной по времени. Таким образом, настоящие (принятые или обновленные совсем недавно) метаданные могут указывать, что соответствующие аудиоданные в данный момент имеют указанный признак и/или содержат результаты указанного типа обработки аудиоданных.
Повсюду в данном раскрытии, включая формулу изобретения, термин «соединяет» или «соединенный» используется для обозначения либо непосредственного, либо косвенного соединения. Таким образом, если первое устройство соединено со вторым устройством, данное соединение может быть осуществлено посредством непосредственного соединения или посредством косвенного соединения через другие устройства или соединения.
Повсюду в данном раскрытии, включая формулу изобретения, следующие выражения имеют следующие определения:
- динамик и громкоговоритель используются в качестве синонимов для обозначения любого звукоизлучающего преобразователя. Данное определение включает громкоговорители, реализованные в качестве множества преобразователей (например, низкочастотного громкоговорителя и высокочастотного громкоговорителя);
- сигнал, подаваемый на динамик: звуковой сигнал, который должен быть подан непосредственно на громкоговоритель, или звуковой сигнал, который должен быть последовательно подан на усилитель и громкоговоритель;
- канал (или «звуковой канал»): монофонический звуковой сигнал. Такой сигнал может быть, как правило, представлен таким образом, чтобы быть эквивалентным подаче сигнала непосредственно на громкоговоритель в необходимом или номинальном положении. Необходимое положение может являться статическим, как обычно бывает в случае с физическими громкоговорителями, или динамическим;
- звуковая программа: набор из одного или более звуковых каналов (по меньшей мере одного канала динамика и/или по меньшей мере одного объектного канала), а также факультативно связанные метаданные (например, метаданные, которые описывают необходимое представление звука в пространстве);
- канал динамика (или «канал сигнала, подаваемого на динамик»): звуковой канал, который связан с указанным громкоговорителем (в необходимом или номинальном положении) или с указанной зоной динамика в пределах определенной конфигурации динамика. Канал динамика представлен таким образом, чтобы быть эквивалентным подаче звукового сигнала непосредственно на указанный громкоговоритель (в необходимом или номинальном положении) или на динамик в указанной зоне динамика;
- объектный канал: звуковой канал, указывающий на звук, излучаемый источником звука (иногда называемый звуковым «объектом»). Как правило, объектный канал определяет параметрическое описание источника звука (например, метаданные, указывающие на параметрическое описание источника звука, включены в или предоставлены объектным каналом). Описание источника может определить звук, излучаемый источником (в зависимости от времени), кажущееся положение (например, трехмерные пространственные координаты) источника в зависимости от времени и факультативно по меньшей мере один дополнительный параметр (например, размер или ширину кажущегося источника), характеризующий источник;
- звуковая программа на основе объекта: звуковая программа, содержащая набор из одного или более объектных каналов (а также факультативно содержащая по меньшей мере один канал динамика), а также факультативно связанные метаданные (например, метаданные, указывающие на траекторию звукового объекта, который излучает звук, указанный объектным каналом, или метаданные, иным образом указывающие на необходимое представление звука в пространстве звука, указанного объектным каналом, или метаданные, указывающие на идентификацию по меньшей мере одного звукового объекта, который является источником звука, указанного объектным каналом); и
- представление: процесс преобразования звуковой программы в один или более сигналов, подаваемых на динамик, или процесс преобразования звуковой программы в один или более сигналов, подаваемых на динамик, и преобразования сигнала (сигналов), подаваемого на динамик, в звук с использованием одного или более громкоговорителей (в последнем случае представление в данном документе иногда называется представлением «посредством» громкоговорителя (громкоговорителей)). Звуковой канал может быть тривиально представлен («в» необходимом положении) посредством подачи сигнала непосредственно на физический громкоговоритель в необходимом положении, или один или более звуковых сигналов могут быть представлены с использованием одного из множества методов виртуализации, предназначенных для того, чтобы быть по существу эквивалентными (для слушателя) данному тривиальному представлению. В данном последнем случае каждый звуковой сигнал может быть преобразован в один или более сигналов, подаваемых на динамик, которые должны быть поданы на громкоговоритель (громкоговорители) в известных местоположениях, которые в целом отличаются от необходимого положения, так что звук, излучаемый громкоговорителем (громкоговорителями) в ответ на подаваемый сигнал (подаваемые сигналы), будет воспринят в качестве излучаемого из необходимого положения. Примеры данных методов виртуализации включают бинауральное представление через наушники (например, с использованием обработки Dolby Headphone, которая имитирует для носителя наушников количество каналов объемного звука до 7.1) и синтез волнового поля.
Варианты осуществления способов изобретения кодирования, декодирования и усиления речи и системы, выполненные с возможностью реализации способов, будут описаны со ссылкой на фиг. 3, фиг. 6 и фиг. 7.
3. ГЕНЕРИРОВАНИЕ ПАРАМЕТРОВ ПРЕДСКАЗАНИЯ
Для выполнения усиления речи (включая гибридное усиление речи в соответствии с вариантами осуществления изобретения) необходимо иметь доступ к речевому сигналу, который должен быть усилен. Если речевой сигнал недоступен (отдельно от микширования речевого и неречевого содержимого микшированного сигнала, который должен быть усилен) в то время, когда должно быть выполнено усиление речи, параметрические методы могут быть использованы для создания восстановления речи доступного микширования.
Один способ для параметрического восстановления речевого содержимого сигнала микшированного содержимого (указывающего на микширование речевого и неречевого содержимого) основан на восстановлении мощности речи в каждой частотно-временной мозаике сигнала и генерирует параметры в соответствии с:
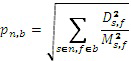 (2)
(2)
где pn,b является параметром (значением усиления речи с параметрическим кодированием) для мозаики, имеющей временной показатель n и показатель b полосы частот, значение Ds,f представляет собой речевой сигнал во временном интервале s и элементе f разрешения по частоте мозаики, значение Ms,f представляет собой сигнал микшированного содержимого в том же временном интервале и элементе разрешения по частоте мозаики, и осуществляется суммирование всех значений s и f во всех мозаиках. Параметры pn,b могут быть поданы (в качестве метаданных) вместе с самим сигналом микшированного содержимого для того, чтобы приемник мог восстановить речевое содержимое каждого сегмента сигнала микшированного содержимого.
Как показано на фиг. 1, каждый параметр pn,b может быть определен посредством выполнения преобразования из временной области в частотную область сигнала микшированного содержимого («микшированного звука»), речевое содержимое которого должно быть усилено, выполнения преобразования из временной области в частотную область речевого сигнала (речевого содержимого сигнала микшированного содержимого), суммирования энергии (каждой частотно-временной мозаики, имеющей временной показатель n и показатель b полосы частот речевого сигнала) всех временных интервалов и элементов разрешения по частоте в мозаике, суммирования энергии соответствующей частотно-временной мозаики сигнала микшированного содержимого всех временных интервалов и элементов разрешения по частоте в мозаике и разделения результата первого суммирования на результат второго суммирования для генерирования параметра pn,b для мозаики.
После умножения каждой частотно-временной мозаики сигнала микшированного содержимого на параметр pn,b для мозаики полученный в результате сигнал имеет такие же спектральные и временные огибающие, как и речевое содержимое сигнала микшированного содержимого.
Типичные звуковые программы, например, звуковые программы со стереоканалами или каналами 5.1, включают множество каналов динамика. Как правило, каждый канал (или каждый из поднабора каналов) указывает на речевое и неречевое содержимое и сигнал микшированного содержимого определяет каждый канал. Описанный способ параметрического восстановления речи может быть независимо применен к каждому каналу для восстановления речевого компонента всех каналов. Восстановленные речевые сигналы (по одному на каждый из каналов) могут быть добавлены к соответствующим сигналам канала микшированного содержимого с соответствующим усилением для каждого канала для достижения необходимого усиления речевого содержимого.
Сигналы (каналы) микшированного содержимого многоканальной программы могут быть представлены в качестве набора векторов сигнала, при этом каждый элемент вектора является совокупностью частотно-временных мозаик, соответствующих конкретному набору параметров, т.е. всем элементам (f) разрешения по частоте в полосе (b) параметров и временным интервалам (s) в кадре (n). Примером такого набора векторов для трехканального сигнала микшированного содержимого является следующее:
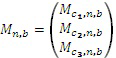 (3)
(3)
где ci обозначает канал. Пример предполагает три канала, но количество каналов является произвольной величиной.
Подобным образом, речевое содержимое многоканальной программы может быть представлено в качестве набора матриц 1 × 1 (при этом речевое содержимое содержит только один канал), Dn,b. Умножение каждого элемента матрицы сигнала микшированного содержимого на скалярное значение приведет к умножению каждого подэлемента на скалярное значение. Таким образом, восстановленное речевое значение для каждой мозаики получается посредством следующего вычисления
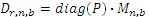 (4)
(4)
для каждого значения n и b, при этом P является матрицей, элементы которой являются параметрами предсказания. Восстановленная речь (для всех мозаик) может быть также выражена следующим образом:
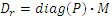 (5)
(5)
Содержимое во множестве каналов многоканального сигнала микшированного содержимого вызывает корреляции между каналами, которые могут быть использованы для осуществления лучшего предсказания речевого сигнала. Посредством использования предсказателя (например, традиционного типа) с минимальной среднеквадратичной ошибкой (MMSE) каналы могут быть объединены с параметрами предсказания для восстановления речевого содержимого с минимальной ошибкой в соответствии с критерием среднеквадратичной ошибки (MSE). Как показано на фиг. 2, предполагается, что трехканальный входной сигнал микшированного содержимого, такой как предсказатель MMSE (работающий в частотной области), несколько раз генерирует набор параметров pi предсказания (при этом показатель i равен 1, 2 или 3) в ответ на входной сигнал микшированного содержимого и один входной речевой сигнал, указывающий на речевое содержимое входного сигнала микшированного содержимого.
Речевое значение, восстановленное из мозаики каждого канала входного сигнала микшированного содержимого (при этом каждая мозаика имеет одинаковые показатели n и b), является линейным сочетанием содержимого (Mci, n,b) каждого канала (i = 1, 2 или 3) сигнала микшированного содержимого, управляемого весовым параметром для каждого канала. Данные весовые параметры являются параметрами pi предсказания для мозаик, имеющих одинаковые показатели n и b. Таким образом, речь, восстановленная из всех мозаик всех каналов сигнала микшированного содержимого, является следующей:
Dr = p1 ·Mc1 + p2 ·Mc2 + p3 ·Mc3 (6)
или в виде сигнальной матрицы:
Dr = PM (7)
Например, если речь связно присутствует во множестве каналов сигнала микшированного содержимого, тогда как фоновые (неречевые) звуки являются несвязанными между каналами, для аддитивного сочетания каналов предпочтительной будет энергия речи. В случае двух каналов это приведет к улучшенному на 3 дБ разделению речи по сравнению с независимым от канала восстановлением. В качестве еще одного примера, если речь присутствует в одном канале и фоновые звуки связно присутствуют во множестве каналов, тогда субтрактивное сочетание каналов (частично) устранит фоновые звуки, при этом речь будет сохранена.
В одном из классов вариантов осуществления способ изобретения включает следующие этапы: (a) прием битового потока, указывающего на звуковую программу, включающую речь, имеющую неусиленную форму сигнала и другое звуковое содержимое, при этом битовый поток включает: неусиленные аудиоданные, указывающие на речь и другое звуковое содержимое, данные о форме сигнала, указывающие на версию сниженного качества речи, при этом версия сниженного качества речи имеет вторую форму сигнала, подобную (например, по меньшей мере по существу подобную) неусиленной форме сигнала, и версия сниженного качества будет иметь неприемлемое качество при отдельном прослушивании, и параметрические данные, при этом параметрические данные вместе с неусиленными аудиоданными определяют параметрически составленную речь, и параметрически составленная речь является параметрически восстановленной версией речи, которая по меньшей мере по существу соответствует (например, имеет хорошее согласование с) речи; и (b) выполнение усиления речи в отношении битового потока в ответ на указатель смешивания, вследствие чего генерируются данные, указывающие на звуковую программу с усиленной речью, в том числе посредством сочетания неусиленных аудиоданных с сочетанием низкокачественных речевых данных, определенных из данных о форме сигнала, и восстановленные речевые данные, при этом сочетание определяется указателем смешивания (например, сочетание имеет последовательность состояний, определенных последовательностью текущих значений указателя смешивания), восстановленные речевые данные генерируются в ответ на по меньшей мере некоторые из параметрических данных и по меньшей мере некоторые из неусиленных аудиоданных, и звуковая программа с усиленной речью имеет менее слышимые артефакты кодирования усиления речи (например, артефакты кодирования усиления речи, которые замаскированы лучшим образом), чем звуковая программа с усиленной речью с одним только кодированием формы сигнала, определенная сочетанием лишь низкокачественных речевых данных с неусиленными аудиоданными, или звуковая программа с усиленной речью с одним только параметрическим кодированием, определенная параметрическими данными и неусиленными аудиоданными.
В некоторых вариантах осуществления указатель смешивания (который может иметь последовательность значений, например, по одному значению для каждой из последовательностей сегментов битового потока) включен в битовый поток, принятый на этапе (a). В других вариантах осуществления указатель смешивания генерируется (например, в приемнике, который принимает и декодирует битовый поток) в ответ на битовый поток.
Следует понимать, что выражение «указатель смешивания» не обязательно должно обозначать один параметр или значение (или последовательность из одних параметров или значений) для каждого сегмента битового потока. Наоборот, предполагается, что в некоторых вариантах осуществления указатель смешивания (для сегмента битового потока) может являться набором из двух или более параметров или значений (например, параметром управления усилением с параметрическим кодированием и параметром управления усилением с кодированием формы сигнала для каждого сегмента). В некоторых вариантах осуществления указатель смешивания для каждого сегмента может являться последовательностью значений, указывающих на смешивание на полосу частот сегмента.
Данные о форме сигнала и параметрические данные не должны быть предоставлены для (например, включены в) каждого сегмента битового потока или использованы для выполнения усиления речи в отношении каждого сегмента битового потока. Например, в некоторых случаях по меньшей мере один сегмент может включать только данные о форме сигнала (и сочетание, определенное указателем смешивания для каждого такого сегмента, может состоять только из данных о форме сигнала) и по меньшей мере еще один сегмент может включать только параметрические данные (и сочетание, определенное указателем смешивания для каждого такого сегмента, может состоять только из восстановленных речевых данных).
Предполагается, что в некоторых вариантах осуществления кодер генерирует битовый поток, в том числе посредством кодирования (например, сжатия) неусиленных аудиоданных, но не данных о форме сигнала или параметрических данных. Таким образом, при подаче битового потока на приемник, приемник осуществляет синтаксический разбор битового потока для извлечения неусиленных аудиоданных, данных о форме сигнала и параметрических данных (и указатель смешивания, если он подается в битовый поток), но декодирует только неусиленные аудиоданные. Приемник выполняет усиление речи в отношении декодированных неусиленных аудиоданных (с использованием данных о форме сигнала и/или параметрических данных) без применения к данным о форме сигнала или параметрическим данным данного процесса декодирования, который применяется к аудиоданным.
Как правило, сочетание (указанное указателем смешивания) данных о форме сигнала и восстановленных речевых данных изменяется с течением времени, при этом каждое состояние сочетания относится к речевому и другому звуковому содержимому соответствующего сегмента битового потока. Указатель смешивания генерируется таким образом, что текущее состояние сочетания (данных о форме сигнала и восстановленных речевых данных) определяется свойствами сигнала речевого и другого звукового содержимого (например, отношением мощности речевого содержимого и мощности другого звукового содержимого) в соответствии с сегментом битового потока.
Этап (b) может включать этап выполнения усиления речи с кодированием формы сигнала посредством сочетания (например, микширования или смешивания) по меньшей мере некоторых из низкокачественных речевых данных с неусиленными аудиоданными по меньшей мере одного сегмента битового потока и выполнения усиления речи с параметрическим кодированием посредством сочетания восстановленных речевых данных с неусиленными аудиоданными по меньшей мере одного сегмента битового потока. Сочетание усиления речи с кодированием формы сигнала и усиления речи с параметрическим кодированием выполняется в отношении по меньшей мере одного сегмента битового потока посредством смешивания как низкокачественных речевых данных, так и восстановленных речевых данных для сегмента с неусиленными аудиоданными сегмента. При некоторых состояниях сигнала только одно (но не оба) из усиления речи с кодированием формы сигнала и усиления речи с параметрическим кодированием выполняется (в ответ на указатель смешивания) в отношении сегмента (или в отношении каждого из более чем одного сегментов) битового потока.
4. ОПЕРАЦИИ УСИЛЕНИЯ РЕЧИ
В данном документе «SNR» (отношение сигнала к шуму) используется для обозначения отношения мощности (или уровня) речевого компонента (т.е. речевого содержимого) сегмента звуковой программы (или всей программы) к мощности неречевого компонента (т.е. неречевого содержимого) сегмента или программы, или к мощности всего (речевого и неречевого) содержимого сегмента или программы. В некоторых вариантах осуществления SNR получается из звукового сигнала (который должен быть подвержен усилению речи) и отдельного сигнала, указывающего на речевое содержимое звукового сигнала (например, низкокачественную копию речевого содержимого, которое было сгенерировано для использования в усилении с кодированием формы сигнала). В некоторых вариантах осуществления SNR получается из звукового сигнала (который должен быть подвержен усилению речи) и из параметрических данных (которые были сгенерированы для использования в усилении с параметрическим кодированием звукового сигнала).
В одном из классов вариантов осуществления способ изобретения реализует временное переключение «вслепую» на основе SNR между усилением с параметрическим кодированием и усилением с кодированием формы сигнала сегментов звуковой программы. В данном контексте «вслепую» обозначает, что переключение не проводится перцепционно посредством сложной модели слухового маскирования (например, типа, описанного в данном документе), но проводится с использованием последовательности значений SNR (указателей смешивания), соответствующих сегментам программы. В одном варианте осуществления в данном классе усиление речи с гибридным кодированием достигается посредством временного переключения между усилением с параметрическим кодированием и усилением с кодированием формы сигнала (в ответ на указатель смешивания, например, указатель смешивания, генерирующийся в подсистеме 29 кодера, показанного на фиг. 3, который указывает на то, что либо только усиление с параметрическим кодированием, либо только усиление с кодированием формы сигнала должно быть выполнено в отношении соответствующих аудиоданных), так что либо усиление с параметрическим кодированием, либо усиление с кодированием формы сигнала (но не как усиление с параметрическим кодированием, так и усиление с кодированием формы сигнала) выполняется в отношении каждого сегмента звуковой программы, в отношении которой выполняется усиление речи. Понимая, что усиление с кодированием формы сигнала наилучшим образом выполняется при условии низкого SNR (в отношении сегментов, имеющих низкие значения SNR) и усиление с параметрическим кодированием наилучшим образом выполняется при условии подходящего SNR (в отношении сегментов, имеющих высокие значения SNR), решение о переключении, как правило, основывается на отношении речевого звука (диалога) к остальному звуку в исходном звуковом микшировании.
Варианты осуществления, которые реализуют временное переключение «вслепую» на основе SNR, как правило, включают следующие этапы: сегментация неусиленного звукового сигнала (исходного звукового микширования) на последовательные временные промежутки (сегменты) и определение для каждого сегмента SNR между речевым содержимым и другим звуковым содержимым (или между речевым содержимым и всем звуковым содержимым) сегмента; и для каждого сегмента сравнивание SNR с пороговым значением и предоставление параметра управления усилением с параметрическим кодированием для сегмента (т.е. указатель смешивания для сегмента указывает, что должно быть выполнено усиление с параметрическим кодированием), если SNR превышает пороговое значение, или предоставление параметра управления усилением с кодированием формы сигнала для сегмента (т.е. указатель смешивания для сегмента указывает, что должно быть выполнено усиление с кодированием формы сигнала), если SNR не превышает пороговое значение.
При подаче (например, передаче) неусиленного звукового сигнала с параметрами управления, включенными в качестве метаданных, на приемник, приемник может выполнить (в отношении каждого сегмента) тип усиления речи, указанный параметром управления для сегмента. Таким образом, приемник выполняет усиление с параметрическим кодированием в отношении каждого сегмента, для которого параметр управления является параметром управления усилением с параметрическим кодированием, и усиление с кодированием формы сигнала в отношении каждого сегмента, для которого параметр управления является параметром управления усилением с кодированием формы сигнала.
При готовности принять на себя расходы на передачу (с каждым сегментом исходного звукового микширования) как данных о форме сигнала (для реализации усиления речи с кодированием формы сигнала), так и параметров усиления с параметрическим кодированием с исходным (неусиленным) микшированием, более высокая степень усиления речи может быть достигнута посредством применения как усиления с кодированием формы сигнала, так и усиления с параметрическим кодированием к отдельным сегментам микширования. Таким образом, в одном из классов вариантов осуществления способ изобретения реализует временное смешивание «вслепую» на основе SNR усиления с параметрическим кодированием и усиления с кодированием формы сигнала сегментов звуковой программы. В данном контексте «вслепую» также обозначает, что переключение не проводится перцепционно посредством сложной модели слухового маскирования (например, типа, описанного в данном документе), но проводится с использованием последовательности значений SNR, соответствующих сегментам программы.
Варианты осуществления, которые реализуют временное смешивание «вслепую» на основе SNR, как правило, включают следующие этапы: сегментация неусиленного звукового сигнала (исходного звукового микширования) на последовательные временные промежутки (сегменты) и определение для каждого сегмента SNR между речевым содержимым и другим звуковым содержимым (или между речевым содержимым и всем звуковым содержимым) сегмента; определение (например, прием запроса на) общей величины («T») усиления речи; и для каждого сегмента предоставление параметра управления смешиванием, при этом значение параметра управления смешиванием определяется (зависит от) SNR для сегмента.
Например, указатель смешивания для сегмента звуковой программы может являться параметром указателя смешивания (или набором параметров), сгенерированным в подсистеме 29 кодера, показанного на фиг. 3, для сегмента.
Указатель управления смешиванием может являться параметром α для каждого сегмента, так что T = α Pw + (1-α)Pp, при этом Pw является усилением с кодированием формы сигнала для сегмента, которое произведет предопределенную общую величину усиления T при применении к неусиленному звуковому содержимому сегмента с использованием данных о форме сигнала, предоставленных для сегмента (при этом речевое содержимое сегмента имеет неусиленную форму сигнала, данные о форме сигнала для сегмента указывают на версию сниженного качества речевого содержимого сегмента, версия сниженного качества имеет форму сигнала, подобную (например, по меньшей мере по существу подобную) неусиленной форме сигнала, и версия сниженного качества речевого содержимого имеет неприемлемое качество при отдельных представлении и восприятии), и Pp является усилением с параметрическим кодированием, которое произведет предопределенную общую величину усиления T при применении к неусиленному звуковому содержимому сегмента с использованием параметрических данных, предоставленных для сегмента (при этом параметрические данные для сегмента с неусиленным звуковым содержимым сегмента определяют параметрическую восстановленную версию речевого содержимого сегмента).
При подаче (например, передаче) неусиленного звукового сигнала с параметрами управления в качестве метаданных на приемник, приемник может выполнить (в отношении каждого сегмента) гибридное усиление речи, указанное параметрами управления для сегмента. В качестве альтернативы приемник генерирует параметры управления из неусиленного звукового сигнала.
В некоторых вариантах осуществления приемник выполняет (в отношении каждого сегмента неусиленного звукового сигнала) сочетание усиления Pp с параметрическим кодированием (масштабированного на основе параметра α для сегмента) и усиления Pw с кодированием формы сигнала (масштабированного на основе значения (1 - α) для сегмента), так что сочетание масштабированного усиления с параметрическим кодированием и масштабированного усиления с кодированием формы сигнала генерирует предопределенную общую величину усиления, как показано в выражении (1) (T = α Pw + (1-α)Pp).
Примером отношения между α и SNR для сегмента является следующее: α является неубывающей функцией SNR, диапазон α составляет от 0 до 1, α имеет значение 0, если SNR для сегмента меньше или равняется пороговому значению («SNR_poor»), и α имеет значение 1, если SNR больше или равняется большему пороговому значению («SNR_high»). Если SNR является подходящим, α имеет высокое значение, что приводит к большей доли усиления с параметрическим кодированием. Если SNR является низким, α имеет низкое значение, что приводит к большей доли усиления с кодированием формы сигнала. Расположение точек насыщения (SNR_poor и SNR_high) должно быть выбрано таким образом, чтобы соответствовать конкретным реализациям как алгоритмов усиления с кодированием формы сигнала, так и алгоритмов усиления с параметрическим кодированием.
В еще одном классе вариантов осуществления сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении каждого сегмента звукового сигнала, определяется моделью слухового маскирования. В некоторых вариантах осуществления в данном классе оптимальное отношение смешивания для смеси усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении сегмента звуковой программы, использует наивысшую величину усиления с кодированием формы сигнала, которое лишь предотвращает слышимость шума кодирования.
В вышеописанных вариантах осуществления смешивания «вслепую» на основе SNR отношение смешивания для сегмента получается из SNR и предполагается, что SNR указывает на емкость звукового микширования для маскирования шума кодирования в версии (копии) сниженного качества речи, которая должна быть использована для усиления с кодированием формы сигнала. Преимуществами подхода «вслепую» на основе SNR являются простота в реализации и низкая вычислительная нагрузка на кодер. Однако SNR является ненадежным предсказателем того, насколько хорошо будет замаскирован шум кодирования, и высокий предел надежности должен быть применен для гарантирования того, что шум кодирования будет всегда оставаться замаскированным. Это означает, что по меньшей мере некоторую часть времени уровень копии речи сниженного качества, которая смешивается, ниже, чем должен быть, или, если установлен более агрессивный предел, шум кодирования станет слышимым в течение некоторой части времени. Вклад усиления с кодированием формы сигнала в гибридную схему кодирования изобретения может быть увеличен, при этом гарантируя, что шум кодирования не станет слышимым, посредством использования модели слухового маскирования для более точного предсказания того, каким образом шум кодирования в копии речи сниженного качества замаскирован звуковым микшированием главной программы, и для выбора отношения смешивания соответственно.
Типичные варианты осуществления, которые используют модель слухового маскирования, включают следующие этапы: сегментация неусиленного звукового сигнала (исходного звукового микширования) на последовательные временные промежутки (сегменты) и предоставление копии сниженного качества речи в каждом сегменте (для использования в усилении с кодированием формы сигнала) и параметров усиления с параметрическим кодированием (для использования в усилении с параметрическим кодированием) для каждого сегмента; для каждого из сегментов использование модели слухового маскирования для определения максимальной величины усиления с кодированием формы сигнала, которая может быть применена без возникновения слышимых артефактов; и генерирование указателя смешивания (для каждого сегмента неусиленного звукового сигнала) сочетания усиления с кодированием формы сигнала (равного величине, которая не превышает максимальную величину усиления с кодированием формы сигнала, определенного с использованием модели слухового маскирования для сегмента, и, которая предпочтительно по меньшей мере по существу соответствует максимальной величине усиления с кодированием формы сигнала, определенного с использованием модели слухового маскирования для сегмента) и усиления с параметрическим кодированием, так что сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием генерирует предопределенную общую величину усиления речи для сегмента.
В некоторых вариантах осуществления каждый такой указатель смешивания включен (например, посредством кодера) в битовый поток, который также включает кодированные аудиоданные, указывающие на неусиленный звуковой сигнал. Например, подсистема 29 кодера 20, показанного на фиг. 3, может быть выполнена с возможностью генерирования данных указателей смешивания, и подсистема 28 кодера 20 может быть выполнена с возможностью включения указателей смешивания в битовый поток, который должен быть выведен из кодера 20. В качестве еще одного примера указатели смешивания могут быть сгенерированы (например, в подсистеме 13 кодера, показанного на фиг. 7) из параметров gmax(t), сгенерированных подсистемой 14 показанного на фиг. 7 кодера, и подсистема 13 показанного на фиг. 7 кодера может быть выполнена с возможностью включения указателей смешивания в битовый поток, который должен быть выведен из показанного на фиг. 7 кодера, (или подсистема 13 может включать в битовый поток, который должен быть выведен из показанного на фиг. 7 кодера, параметры gmax(t), сгенерированные подсистемой 14, и приемник, который принимает и осуществляет синтаксический разбор битового потока, может быть выполнен с возможностью генерирования указателей смешивания в ответ на параметры gmax(t)).
Факультативно, способ также включает этап выполнения (в отношении каждого сегмента неусиленного звукового сигнала) в ответ на указатель смешивания для каждого сегмента сочетания усиления с кодированием формы сигнала и усиления с параметрическим кодированием, определенного указателем смешивания, так что сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием генерирует предопределенную общую величину усиления речи для сегмента.
Пример варианта осуществления способа изобретения, который использует модель слухового маскирования, будет описан со ссылкой на фиг. 7. В данном примере микширование A(t) речевого и фонового звука (неусиленное звуковое микширование) определяется (в элементе 10, показанном на фиг. 7) и передается на модель слухового маскирования (реализованную элементом 11, показанным на фиг. 7), которая предсказывает пороговое значение Θ(f,t) маскирования для каждого сегмента неусиленного звукового микширования. Неусиленное звуковое микширование A(t) также предоставляется на элемент 13 кодирования для кодирования для передачи.
Пороговое значение маскирования, сгенерированное моделью, указывает в зависимости от частоты и времени на слуховое возбуждение, которое должен превысить любой сигнал для того, чтобы быть слышимым. Данные модели маскирования хорошо известны из уровня техники. Речевой компонент s(t) каждого сегмента неусиленного звукового микширования A(t) кодируется (в аудиокодеке 15 с низкой битовой скоростью) для генерирования копии s’(t) сниженного качества речевого содержимого сегмента. Копия s’(t) сниженного качества (которая содержит меньшее количество битов, чем исходная речь s(t)) может быть представлена в виде суммы исходной речи s(t) и шума кодирования n(t). Данный шум кодирования может быть отделен от копии сниженного качества для анализа посредством вычитания (в элементе 16) выровненного во времени речевого сигнала s(t) из копии сниженного качества. В качестве альтернативы, шум кодирования может быть доступен непосредственно с аудиокодека.
Шум n кодирования умножается в элементе 17 на коэффициент g(t) масштабирования и масштабированный шум кодирования передается на слуховую модель (реализованную элементом 18), которая предсказывает слуховое возбуждение N(f,t), сгенерированное масштабированным шумом кодирования. Данные модели возбуждения известны из уровня техники. На конечном этапе слуховое возбуждение N(f,t) сравнивается с предсказанным пороговым значением Θ(f,t) маскирования и обнаруживается (в элементе 14) наибольший коэффициент gmax(t) масштабирования, который гарантирует, что шум кодирования будет замаскирован, т.е. наибольшее значение g(t), которое гарантирует, что N(f,t) < Θ(f,t). Если слуховая модель является нелинейной, это может быть выполнено несколько раз (как показано на фиг. 2) посредством повторения значения g(t), примененного к шуму n(t) кодирования в элементе 17; если слуховая модель является линейной, это может быть выполнено на одном этапе упреждения. Полученный в результате коэффициент gmax(t) масштабирования является наибольшим коэффициентом масштабирования, который может быть применен к копии s’(t) речи сниженного качества перед ее добавлением в соответствующий сегмент неусиленного звукового микширования A(t) без артефактов кодирования в масштабированной копии речи сниженного качества, слышимых в микшировании масштабированной копии gmax(t)* s’(t) речи сниженного качества и неусиленном звуковом микшировании A(t).
На фиг. 7 система также включает элемент 12, который выполнен с возможностью генерирования (в ответ на неусиленное звуковое микширование A(t) и речь s(t)) параметров p(t) усиления с параметрическим кодированием для выполнения усиления речи с параметрическим кодированием в отношении каждого сегмента неусиленного звукового микширования.
Параметры p(t) усиления с параметрическим кодированием, а также копия s’(t) речи сниженного качества, сгенерированные в кодере 15, и коэффициент gmax(t), сгенерированный в элементе 14 для каждого сегмента звуковой программы, также передаются на элемент 13 кодирования. Элемент 13 генерирует кодированный битовый аудиопоток, указывающий на неусиленное звуковое микширование A(t), параметры p(t) усиления с параметрическим кодированием, копию s’(t) речи сниженного качества и коэффициент gmax(t) для каждого сегмента звуковой программы, и данный кодированный битовый аудиопоток может быть передан или иным образом подан на приемник.
В примере усиление речи выполнено (например, в приемнике, на который был подан кодированный выходной сигнал элемента 13) следующим образом в отношении каждого сегмента неусиленного звукового микширования A(t) для применения предопределенной (например, запрошенной) общей величины усиления T с использованием коэффициента gmax(t) масштабирования для сегмента. Кодированная звуковая программа декодируется для извлечения неусиленного звукового микширования A(t), параметров p(t) усиления с параметрическим кодированием, копии s’(t) речи сниженного качества и коэффициента gmax(t) для каждого сегмента звуковой программы. Для каждого сегмента усиление Pw с кодированием формы сигнала определяется в качестве усиления с кодированием формы сигнала, которое произведет предопределенную общую величину усиления T при применении к неусиленному звуковому содержимому сегмента с использованием копии s’(t) речи сниженного качества для сегмента, и усиление Pp с параметрическим кодированием определяется в качестве усиления с параметрическим кодированием, которое произведет предопределенную общую величину усиления T при применении к неусиленному звуковому содержимому сегмента с использованием параметрических данных, предоставленных для сегмента (при этом параметрические данные для сегмента с неусиленным звуковым содержимым сегмента определяют параметрически восстановленную версию речевого содержимого сегмента). Для каждого сегмента выполняется сочетание усиления с параметрическим кодированием (равного величине, масштабированной на основе параметра α2 для сегмента) и усиления с кодированием формы сигнала (равного величине, определенной значением α1 для сегмента), так что сочетание усиления с параметрическим кодированием и усиления с кодированием формы сигнала генерирует предопределенную общую величину усиления с использованием наибольшей величины усиления с кодированием формы сигнала, допускаемой моделью: T = (α1(Pw) + α2(Pp)), где коэффициент α1 является максимальным значением, которое не превышает gmax(t) для сегмента и обеспечивает получение указанного равенства T = (α1(Pw) + α2(Pp)), и параметр α2 является минимальным неотрицательным значением, которое обеспечивает получение указанного равенства T = (α1(Pw) + α2(Pp)).
В альтернативном варианте осуществления артефакты усиления с параметрическим кодированием включены в оценку (выполняемую моделью слухового маскирования) для того, чтобы артефакты кодирования (вследствие усиления с кодированием формы сигнала) стали более слышимыми, если это является благоприятным, чем артефакты усиления с параметрическим кодированием.
В вариациях показанного на фиг. 7 варианта осуществления (и вариантов осуществления, подобных показанному на фиг. 7, которые используют модель слухового маскирования), иногда называемого вариантами осуществления многополосного разделения, проводимого посредством слуховой модели, отношение между шумом N(f,t) кодирования усиления с кодированием формы сигнала в копии речи сниженного качества и пороговым значением Θ(f,t) маскирования может не являться равномерным среди всех полос частот. Например, спектральные характеристики шума кодирования усиления с кодированием формы сигнала могут являться такими, что в первом диапазоне частот шум маскирования почти превышает пороговое значение маскирования, тогда как во втором диапазоне частот шум маскирования намного ниже порогового значения маскирования. В показанном на фиг. 7 варианте осуществления максимальный вклад усиления с кодированием формы сигнала будет определен шумом кодирования в первом диапазоне частот, и максимальный коэффициент g масштабирования, который может быть применен к копии речи сниженного качества, определяется шумом кодирования и свойствами маскирования в первом диапазоне частот. Он меньше максимального коэффициента g масштабирования, который может быть применен, если определение максимального коэффициента масштабирования было основано только на втором диапазоне частот. Общая эффективность может быть улучшена, если принципы временного смешивания были применены отдельно в двух диапазонах частот.
В одной реализации многополосного разделения, проводимого посредством слуховой модели, неусиленный звуковой сигнал разделяется на M смежных неперекрывающихся полос частот и принципы временного смешивания (т.е. гибридное усиление речи со смесью усиления с кодированием формы сигнала и усиления с параметрическим кодированием в соответствии с вариантом осуществления изобретения) применяются независимо в каждой из M полос. Альтернативная реализация разделяет спектр на низкочастотную полосу ниже частоты fc среза и высокочастотную полосу выше частоты fc среза. Низкочастотная полоса всегда усиливается с использованием усиления с кодированием формы сигнала и высокочастотная полоса всегда усиливается с использованием усиления с параметрическим кодированием. Частота среза изменяется с течением времени и всегда выбирается таким образом, чтобы быть как можно более высокой в условиях ограничения, которое заключается в том, что шум кодирования усиления с кодированием формы сигнала при предопределенной общей величине усиления T речи ниже порогового значения маскирования. Другими словами, максимальная частота среза в любое время является следующей:
max(fc | T*N(f<fc,t) < Θ(f,t)) (8)
Варианты осуществления, описанные выше, предполагали, что средствами, доступными для предотвращения слышимости артефактов кодирования усиления с кодированием формы сигнала, является регулировка отношения смешивания (усиления с кодированием формы сигнала и усиления с параметрическим кодированием) или обратное масштабирование общей величины усиления. Альтернативой является управление величиной шума кодирования усиления с кодированием формы сигнала посредством переменного распределения битовой скорости для генерирования копии речи сниженного качества. В примере данного альтернативного варианта осуществления применяется постоянная базовая величина усиления с параметрическим кодированием и применяется дополнительное усиление с кодированием формы сигнала для достижения необходимой (предопределенной) величины общего усиления. Копия речи сниженного качества кодируется с переменной битовой скоростью и данная битовая скорость выбирается в качестве самой низкой битовой скорости, которая поддерживает шум кодирования усиления с кодированием формы сигнала ниже порогового значения маскирования усиленного основного звука с параметрическим кодированием.
В некоторых вариантах осуществления звуковая программа, речевое содержимое которой должно быть усилено в соответствии с изобретением, включает каналы динамика, но не включает никаких объектных каналов. В еще одних вариантах осуществления звуковая программа, речевое содержимое которой должно быть усилено в соответствии с изобретением, является звуковой программой на основе объекта (как правило, многоканальной звуковой программой на основе объекта), содержащей по меньшей мере один объектный канал, а также факультативно по меньшей мере один канал динамика.
Другие аспекты изобретения включают кодер, выполненный с возможностью выполнения любого варианта осуществления способа изобретения кодирования для генерирования кодированного звукового сигнала в ответ на входной звуковой сигнал (например, в ответ на аудиоданные, указывающие на многоканальный входной звуковой сигнал), декодер, выполненный с возможностью декодирования такого кодированного сигнала и выполнения усиления речи в отношении декодированного звукового содержимого, и систему, включающую такой кодер и такой декодер. Показанная на фиг. 3 система является примером такой системы.
Система, показанная на фиг. 3, включает кодер 20, который выполнен (например, запрограммирован) с возможностью выполнения варианта осуществления способа изобретения кодирования для генерирования кодированного звукового сигнала в ответ на аудиоданные, указывающие на звуковую программу. Как правило, программа является многоканальной звуковой программой. В некоторых вариантах осуществления многоканальная звуковая программа содержит только каналы динамика. В других вариантах осуществления многоканальная звуковая программа является звуковой программой на основе объекта, содержащей по меньшей мере один объектный канал, а также факультативно по меньшей мере один канал динамика.
Аудиоданные включают данные (определенные в качестве «микшированных звуковых» данных на фиг. 3), указывающие на микшированное звуковое содержимое (микширование речевого и неречевого содержимого), и данные (определенные в качестве «речевых» данных на фиг. 3), указывающие на речевое содержимое микшированного звукового содержимого.
Речевые данные подвергаются преобразованию из временной области в частотную (QMF) область на этапе 21 и полученные в результате компоненты QMF передаются на элемент 23 генерирования параметра усиления. Микшированные аудиоданные подвергаются преобразованию из временной области в частотную (QMF) область на этапе 22 и полученные в результате компоненты QMF передаются на элемент 23 и подсистему 27 кодирования.
Речевые данные также передаются на подсистему 25, которая выполнена с возможностью генерирования данных о форме сигнала (иногда называемых в данном документе копией речи «сниженного качества» или «низкокачественной» копией речи), указывающих на низкокачественную копию речевых данных, для использования в усилении речи с кодированием формы сигнала микшированного (речевого и неречевого) содержимого, определенного микшированными аудиоданными. Низкокачественная копия речи содержит меньшее количество битов, чем исходные речевые данные, и имеет неприемлемое качество при отдельных представлении и восприятии, и при представлении указывает на речь, имеющую форму сигнала, подобную (например, по меньшей мере по существу подобную) форме сигнала речи, указанной исходными речевыми данными. Способы реализации подсистемы 25 известны из уровня техники. Примерами являются речевые кодеры в режиме линейного предсказания (CELP) с кодовым возбуждением, такие как AMR и G729.1, или современные микшированные кодеры, такие как кодеры MPEG для унифицированного кодирования (USAC) речи и звука, как правило, работающие с низкой битовой скоростью (например, 20 кбит/с). В качестве альтернативы, могут быть использованы кодеры с частотной областью, примеры которых включают Siren (G722.1), MPEG 2 Layer II/III, MPEG AAC.
Гибридное усиление речи, выполняемое (например, в подсистеме 43 декодера 40) в соответствии с типичными вариантами осуществления изобретения, включает этап выполнения (в отношении данных о форме сигнала) обратного кодирования, выполняемого (например, в подсистеме 25 кодера 20) для генерирования данных о форме сигнала, для восстановления низкокачественной копии речевого содержимого микшированного звукового сигнала, который должен быть усилен. Восстановленная низкокачественная копия речи затем используется (вместе с параметрическими данными и данными, указывающими на микшированный звуковой сигнал) для выполнения остальных этапов усиления речи.
Элемент 23 выполнен с возможностью генерирования параметрических данных в ответ на данные, выводимые на этапах 21 и 22. Параметрические данные вместе с исходными микшированными аудиоданными определяют параметрически составленную речь, которая является параметрически восстановленной версией речи, указанной исходными речевыми данными (т.е. речевым содержимым микшированных аудиоданных). Параметрически восстановленная версия речи по меньшей мере по существу соответствует (например, имеет хорошее согласование с) речи, указанной исходными речевыми данными. Параметрические данные определяют набор параметров p(t) усиления с параметрическим кодированием для выполнения усиления речи с параметрическим кодированием в отношении неусиленного микшированного содержимого, определенного микшированными аудиоданными.
Элемент 29 генерирования указателя смешивания выполнен с возможностью генерирования указателя («BI») смешивания в ответ на данные, выводимые на этапах 21 и 22. Предполагается, что звуковая программа, указанная битовым потоком, выводимым из кодера 20, будет подвержена гибридному усилению речи (например, в декодере 40) для определения звуковой программы с усиленной речью, в том числе посредством сочетания неусиленных аудиоданных исходной программы с сочетанием низкокачественных речевых данных (определенных данными о форме сигнала) и параметрических данных. Указатель смешивания определяет данное сочетание (например, сочетание имеет последовательность состояний, определенных последовательностью текущих значений указателя смешивания), так что звуковая программа с усиленной речью имеет менее слышимые артефакты кодирования усиления речи (например, артефакты кодирования усиления речи, которые замаскированы лучшим образом), чем звуковая программа с усиленной речью с одним только кодированием формы сигнала, определенная сочетанием лишь низкокачественных речевых данных с неусиленными аудиоданными, или звуковая программа с усиленной речью с одним только параметрическим кодированием, определенная сочетанием лишь параметрически составленной речи с неусиленными данными.
В вариациях показанного на фиг. 3 варианта осуществления указатель смешивания, использующийся для обратного гибридного усиления речи, не генерируется в кодере изобретения (и не включен в битовый поток, выводимый из кодера), но вместо этого генерируется (например, в качестве вариации на приемнике 40) в ответ на битовый поток, выводимый из кодера (битовый поток которого не включает данных о форме сигнала и параметрических данных).
Следует понимать, что выражение «указатель смешивания» не обязательно должно обозначать один параметр или значение (или последовательность из одних параметров или значений) для каждого сегмента битового потока. Наоборот, предполагается, что в некоторых вариантах осуществления указатель смешивания (для сегмента битового потока) может являться набором из двух или более параметров или значений (например, параметром управления усилением с параметрическим кодированием и параметром управления усилением с кодированием формы сигнала для каждого сегмента).
Подсистема 27 кодирования генерирует кодированные аудиоданные, указывающие на звуковое содержимое микшированных аудиоданных (как правило, сжатую версию микшированных аудиоданных). Подсистема 27 кодирования, как правило, реализует обратное преобразование, выполняемое на этапе 22, а также другие операции кодирования.
Этап 28 форматирования предназначен для компоновки параметрических данных, выводимых из элемента 23, данных о форме сигнала, выводимых из элемента 25, указателя смешивания, генерируемого в элементе 29, и кодированных аудиоданных, выводимых из подсистемы 27, в кодированный битовый поток, указывающий на звуковую программу. Битовый поток (который может иметь формат E-AC-3 или AC-3 в некоторых реализациях) включает некодированные параметрические данные, данные о форме сигнала и указатель смешивания.
Кодированный битовый аудиопоток (кодированный звуковой сигнал), выводимый из кодера 20, подается на подсистему 30 подачи. Подсистема 30 подачи выполнена с возможностью сохранения кодированного звукового сигнала (например, с возможностью сохранения данных, указывающих на кодированный звуковой сигнал), генерируемого кодером 20, и/или с возможностью передачи кодированного звукового сигнала.
Декодер 40 соединен и выполнен (например, запрограммирован) с возможностью приема кодированного звукового сигнала от подсистемы 30 (например, посредством считывания или извлечения данных, указывающих на кодированный звуковой сигнал, из памяти в подсистеме 30 или посредством приема кодированного звукового сигнала, который был передан подсистемой 30) и с возможностью декодирования данных, указывающих на микшированное (речевое и неречевое) звуковое содержимое кодированного звукового сигнала и с возможностью выполнения гибридного усиления речи в отношении декодированного микшированого звукового содержимого. Декодер 40, как правило, выполнен с возможностью генерирования и вывода (например, на систему представления, не показанную на фиг. 3) декодированного звукового сигнала с усиленной речью, указывающего на версию с усиленной речью микшированого звукового содержимого, подаваемого на кодер 20. В качестве альтернативы он включает такую систему представления, которая соединена с возможностью приема выходного сигнала подсистемы 43.
Буфер 44 (буферная память) декодера 40 хранит (например, постоянно) по меньшей мере один сегмент (например, кадр) кодированного звукового сигнала (битового потока), принятого декодером 40. Во время обычной работы последовательность сегментов кодированного битового аудиопотока подается на буфер 44 и передается из буфера на этапе 41 деформатирования.
Этап 41 деформатирования (синтаксического разбора) декодера 40 предназначен для синтаксического разбора кодированного битового потока с подсистемы 30 подачи, извлечения из него параметрических данных (сгенерированных элементом 23 кодера 20), данных о форме сигнала (сгенерированных элементом 25 кодера 20), указателя смешивания (сгенерированного в элементе 29 кодера 20) и кодированных микшированных (речевых и неречевых) аудиоданных (сгенерированных в подсистеме 27 кодирования кодера 20).
Кодированные микшированные аудиоданные декодируются в подсистеме 42 декодирования декодера 40 и полученные в результате декодированные микшированные (речевые и неречевые) аудиоданные передаются на подсистему 43 гибридного усиления речи (и факультативно выводятся из декодера 40 без выполнения над ними усиления речи).
В ответ на данные управления (включающие указатель смешивания), извлеченные на этапе 41 из битового потока (или сгенерированные на этапе 41 в ответ на метаданные, включенные в битовый поток), и в ответ на параметрические данные и данные о форме сигнала, извлеченные на этапе 41, подсистема 43 усиления речи выполняет гибридное усиление речи в отношении декодированных микшированных (речевых и неречевых) аудиоданных от подсистемы 42 декодирования в соответствии с вариантом осуществления изобретения. Звуковой сигнал с усиленной речью, выводимый из подсистемы 43, указывает на версию с усиленной речью микшированого звукового содержимого, подаваемого на кодер 20.
В различных реализациях кодера 20, показанного на фиг. 3, подсистема 23 может генерировать любые из описанных примеров параметров pi предсказания для каждой мозаики каждого канала микшированного входного звукового сигнала для использования (например, в декодере 40) для восстановления речевого компонента декодированного микшированного звукового сигнала.
С использованием речевого сигнала, указывающего на речевое содержимое декодированного микшированного звукового сигнала (например, низкокачественную копию речи, сгенерированной подсистемой 25 кодера 20, или восстановление речевого содержимого, сгенерированного с использованием параметров pi предсказания, сгенерированных подсистемой 23 кодера 20), усиление речи может быть выполнено (например, в подсистеме 43 декодера 40, показанного на фиг. 3) посредством микширования речевого сигнала с декодированным микшированным звуковым сигналом. Посредством применения усиления к речи, которая должна быть добавлена (микширована), возможным является управление величиной усиления речи. Для усиления в 6 дБ речь может быть дополнена усилением в 0 дБ (при условии, что речь в микшировании с усиленной речью имеет такой же уровень, как и переданный или восстановленный речевой сигнал). Сигнал с усиленной речью является следующим:
Me = M + g∙Dr (9)
В некоторых вариантах осуществления для достижения усиления G усиления речи применяется следующее усиление при микшировании:
g = 10G/20 – 1 (10)
В случае независимого от канала восстановления речи микширование Me с усиленной речью получается следующим образом:
Me = M ∙ (1 + diag(P)∙ g) (11)
В вышеописанном примере вклад речи в каждый канал микшированного звукового сигнала восстанавливается с использованием одинакового количества энергии. Если речь была передана в качестве побочного сигнала (например, в качестве низкокачественной копии речевого содержимого микшированного звукового сигнала) или если речь восстанавливается с использованием множества каналов (например, с использованием предсказателя MMSE), для микширования усиления речи необходима информация о представлении речи для микширования речи с таким же распределением по различным каналам, как и речевой компонент, уже представленный в микшированном звуковом сигнале, который должен быть усилен.
Данная информация о представлении может быть предоставлена параметром ri представления для каждого канала, который может быть представлен в качестве вектора R представления, который имеет следующий вид
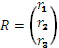 (12)
(12)
если присутствуют три канала. Микширование усиления речи является следующим:
Me = M + R∙g∙Dr (13)
В случае, если присутствует множество каналов и речь (которая должна быть микширована с каждым каналом микшированного звукового сигнала) восстанавливается с использованием параметров pi предсказания, предыдущее уравнение может быть записано следующим образом:
Me = M + R∙g∙P∙M = (I + R∙g∙P)∙M (14)
где I является матрицей тождественности.
5. ПРЕДСТАВЛЕНИЕ РЕЧИ
На фиг. 4 показана блок-диаграмма системы представления речи, которая реализует традиционное микширование усиления речи, имеющее следующий вид:
Me = M + R∙g∙Dr (15)
На фиг. 4 трехканальный микшированный звуковой сигнал, который должен быть усилен, находится в (или преобразуется в) частотной области. Частотные компоненты левого канала передаются во входной сигнал элемента 52 микширования, частотные компоненты центрального канала передаются во входной сигнал элемента 53 микширования и частотные компоненты правого канала передаются во входной сигнал элемента 54 микширования.
Речевой сигнал, который должен быть микширован с микшированным звуковым сигналом (для усиления последнего сигнала), может быть передан в качестве побочного сигнала (например, в качестве низкокачественной копии речевого содержимого микшированного звукового сигнала) или может быть восстановлен из параметров pi восстановления, передаваемых вместе с микшированным звуковым сигналом. Речевой сигнал указывается данными частотной области (например, он включает частотные компоненты, генерируемые посредством преобразования сигнала временной области в сигнал частотной области) и данные частотные компоненты передаются во входной сигнал элемента 51 микширования, в котором они умножаются на параметр g усиления.
Выходной сигнал элемента 51 передается на подсистему 50 представления. Также на подсистему 50 представления передаются параметры CLD (разности уровней каналов), CLD1 и CLD2, которые были переданы вместе с микшированным звуковым сигналом. Параметры CLD (для каждого сегмента микшированного звукового сигнала) описывают, каким образом речевой сигнал микшируется в каналы указанного сегмента микшированного содержимого звукового сигнала. CLD1 указывает на коэффициент панорамирования для одной пары каналов динамика (например, который определяет панорамирование речи между левым и центральным каналами), и CLD2 указывает на коэффициент панорамирования для другой пары каналов динамика (например, который определяет панорамирование речи между центральным и правым каналами). Таким образом, подсистема 50 представления передает (на элемент 52) данные, указывающие на R∙g∙Dr для левого канала (речевое содержимое, масштабированное на основе параметра усиления и параметра представления для левого канала), и эти данные суммируются с левым каналом микшированного звукового сигнала в элементе 52. Подсистема 50 представления передает (на элемент 53) данные, указывающие на R∙g∙Dr для центрального канала (речевое содержимое, масштабированное на основе параметра усиления и параметра представления для центрального канала), и эти данные суммируются с центральным каналом микшированного звукового сигнала в элементе 53. Подсистема 50 представления передает (на элемент 54) данные, указывающие на R∙g∙Dr для правого канала (речевое содержимое, масштабированное на основе параметра усиления и параметра представления для правого канала), и эти данные суммируются с правым каналом микшированного звукового сигнала в элементе 54.
Используются выходные каналы элементов 52, 53 и 54 соответственно для запуска левого динамика L, центрального динамика C и правого динамика «правый».
На фиг. 5 показана блок-диаграмма системы представления речи, которая реализует традиционное микширование усиления речи, имеющее следующий вид:
Me = M + R∙g∙P∙M = (I + R∙g∙P)∙M (16)
На фиг. 5 трехканальный микшированный звуковой сигнал, который должен быть усилен, находится в (или преобразуется в) частотной области. Частотные компоненты левого канала передаются во входной сигнал элемента 52 микширования, частотные компоненты центрального канала передаются во входной сигнал элемента 53 микширования и частотные компоненты правого канала передаются во входной сигнал элемента 54 микширования.
Речевой сигнал, который должен быть микширован с микшированным звуковым сигналом, восстанавливается (как указано) из параметров pi предсказания, переданных вместе с микшированным звуковым сигналом. Параметр p1 предсказания используется для восстановления речи из первого (левого) канала микшированного звукового сигнала, параметр p2 предсказания используется для восстановления речи из второго (центрального) канала микшированного звукового сигнала и параметр p3 предсказания используется для восстановления речи из третьего (правого) канала микшированного звукового сигнала. Речевой сигнал указывается данными частотной области и данные частотные компоненты передаются во входной сигнал элемента 51 микширования, в котором они умножаются на параметр g усиления.
Выходной сигнал элемента 51 передается на подсистему 55 представления. Также на подсистему представления передаются параметры CLD (разности уровней каналов), CLD1 и CLD2, которые были переданы вместе с микшированным звуковым сигналом. Параметры CLD (для каждого сегмента микшированного звукового сигнала) описывают, каким образом речевой сигнал микшируется в каналы указанного сегмента микшированного содержимого звукового сигнала. CLD1 указывает на коэффициент панорамирования для одной пары каналов динамика (например, который определяет панорамирование речи между левым и центральным каналами) и CLD2 указывает на коэффициент панорамирования для другой пары каналов динамика (например, который определяет панорамирование речи между центральным и правым каналами). Таким образом, подсистема 55 представления передает (на элемент 52) данные, указывающие на R∙g∙P∙M для левого канала (восстановленное речевое содержимое, микшированное с левым каналом микшированного звукового содержимого, масштабированное на основе параметра усиления и параметра представления для левого канала, микшированного с левым каналом микшированного звукового содержимого), и эти данные суммируются с левым каналом микшированного звукового сигнала в элементе 52. Подсистема 55 представления передает (на элемент 53) данные, указывающие на R∙g∙P∙M для центрального канала (восстановленное речевое содержимое, микшированное с центральным каналом микшированного звукового содержимого, масштабированное на основе параметра усиления и параметра представления для центрального канала), и эти данные суммируются с центральным каналом микшированного звукового сигнала в элементе 53. Подсистема 55 представления передает (на элемент 54) данные, указывающие на R∙g∙P∙M для правого канала (восстановленное речевое содержимое, микшированное с правым каналом микшированного звукового содержимого, масштабированное на основе параметра усиления и параметра представления для правого канала), и эти данные суммируются с правым каналом микшированного звукового сигнала в элементе 54.
Используются выходные каналы элементов 52, 53 и 54 соответственно для запуска левого динамика L, центрального динамика C и правого динамика «правый».
Параметры CLD (разности уровней каналов) традиционно передаются вместе с сигналами канала динамика (например, для определения отношений между уровнями, при которых должны быть представлены различные каналы). Они по-новому используются в некоторых вариантах осуществления изобретения (например, для панорамирования усиленной речи между каналами динамика звуковой программы с усиленной речью).
В типичных вариантах осуществления параметры ri представления являются (или указывают на) коэффициентами повышающего микширования речи, описывающими, каким образом речевой сигнал микшируется в каналы микшированного звукового сигнала, который должен быть усилен. Данные коэффициенты могут быть эффективно переданы на усилитель речи с использованием параметров (CLD) разности уровней каналов. Один параметр CLD указывает на коэффициенты панорамирования для двух динамиков. Например,
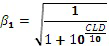 (17)
(17)
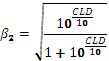 (18)
(18)
где β1 указывает на усиление для сигнала, подаваемого на динамик, для первого динамика, и β2 указывает на усиление для сигнала, подаваемого на динамик, для второго динамика во время панорамирования. Если CLD = 0, панорамирование полностью выполняется в отношении первого динамика, тогда как, если CLD стремится к бесконечности, панорамирование полностью выполняется в отношении второго динамика. Если CLD определены в области дБ, ограниченного количества уровней квантования может быть достаточно для описания панорамирования.
С использованием двух CLD может быть определено панорамирование в пределах трех динамиков. CLD могут быть получены из коэффициентов представления следующим образом:
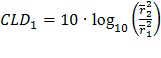 (19)
(19)
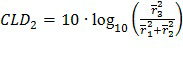 (20)
(20)
где 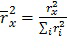 являются нормированными коэффициентами представления, так что
являются нормированными коэффициентами представления, так что
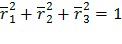 (21)
(21)
Затем коэффициенты представления могут быть восстановлены из CLD следующим образом:
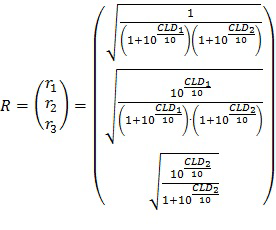 (22)
(22)
Как отмечалось в других местах в данном документе, усиление речи с кодированием формы сигнала использует низкокачественную копию речевого содержимого сигнала микшированного содержимого, который должен быть усилен. Низкокачественная копия, как правило, кодируется с низкой битовой скоростью и передается в качестве побочного сигнала вместе с сигналом микшированного содержимого и, следовательно, низкокачественная копия, как правило, содержит значительные артефакты кодирования. Таким образом, усиление речи с кодированием формы сигнала предоставляет хорошую эффективность усиления речи в ситуациях с низким SNR (т.е. низким отношением между речью и всеми другими звуками, указанными сигналом микшированного содержимого) и, как правило, предоставляет низкую эффективность (т.е. приводит к нежелательным слышимым артефактам кодирования) в ситуациях с высоким SNR.
И наоборот, если речевое содержимое (сигнала микшированного содержимого, который должен быть усилен) выделяется (например, предоставляется в качестве единственного содержимого центрального канала многоканального сигнала микшированного содержимого) или сигнал микшированного содержимого иным образом имеет высокое SNR, усиление речи с параметрическим кодированием предоставляет хорошую эффективность усиления речи.
Следовательно, усиление речи с кодированием формы сигнала и усиление речи с параметрическим кодированием имеют дополняющую друг друга эффективность. На основе свойств сигнала, речевое содержимое которого должно быть усилено, класс вариантов осуществления изобретения смешивает два способа для улучшения их эффективностей.
На фиг. 6 показана блок-диаграмма системы представления речи в данном классе вариантов осуществления, которая выполнена с возможностью выполнения гибридного усиления речи. В одной реализации подсистема 43 кодера 40, показанного на фиг. 3, реализует показанную на фиг. 6 систему (за исключением трех динамиков, показанных на фиг. 6). Гибридное усиление (микширование) речи может быть описано следующим образом:
Me = R∙g1∙Dr + (I + R∙g2∙P)∙M (23)
где R∙g1∙Dr является усилением речи с кодированием формы сигнала типа, реализованного традиционной показанной на фиг. 4 системой, R∙g2 ∙P∙M является усилением речи с параметрическим кодированием типа, реализованного традиционной показанной на фиг. 5 системой, и параметры g1 и g2 управляют общим усилением усиления и балансом между двумя способами усиления речи. Пример определения параметров g1 и g2 представлен далее:
g1 = αc ∙ (10G/20 – 1) (24)
g2 = (1 - αc ) ∙ (10G/20 – 1) (25)
где параметр αc определяет баланс между способами усиления речи с параметрическим кодированием и усиления речи с кодированием формы. Если αc = 1, тогда используется только низкокачественная копия речи для усиления речи с кодированием формы сигнала. Режим усиления с параметрическим кодированием полностью способствует усилению, если αc = 0. Значения αc между 0 и 1 смешивают два способа. В некоторых реализациях αc является широкополосным параметром (применяющимся ко всем полосам частот аудиоданных). Те же принципы могут быть применены в рамках отдельных полос частот, так что смешивание оптимизировано в зависимости от частоты с использованием отличного значения параметра αc для каждой полосы частот.
На фиг. 6 трехканальный микшированный звуковой сигнал, который должен быть усилен, находится в (или преобразуется в) частотной области. Частотные компоненты левого канала передаются во входной сигнал элемента 65 микширования, частотные компоненты центрального канала передаются во входной сигнал элемента 66 микширования, и частотные компоненты правого канала передаются во входной сигнал элемента 67 микширования.
Речевой сигнал, который должен быть микширован с микшированным звуковым сигналом (для усиления последнего сигнала), включает низкокачественную копию (определенную в качестве «речи» на фиг. 6) речевого содержимого микшированного звукового сигнала, который был сгенерирован из данных о форме сигнала, переданных (в соответствии с усилением речи с кодированием формы сигнала) вместе с микшированным звуковым сигналом (например, в качестве побочного сигнала), и восстановленный речевой сигнал (выводимый из элемента 68 восстановления речи с параметрическим кодированием, показанным на фиг. 6), который восстанавливается из микшированного звукового сигнала и параметров pi предсказания, переданных (в соответствии с усилением речи с параметрическим кодированием) вместе с микшированным звуковым сигналом. Речевой сигнал указан данными частотной области (например, он содержит частотные компоненты, сгенерированные посредством преобразования сигнала временной области в сигнал частотной области). Частотные компоненты низкокачественной копии речи передаются во входной сигнал элемента 61 микширования, в котором они умножаются на параметр g2 усиления. Частотные компоненты параметрически восстановленного речевого сигнала передаются из выходного сигнала элемента 68 на входной сигнал элемента 62 микширования, в котором они умножаются на параметр g1 усиления. В альтернативных вариантах осуществления микширование, выполненное для реализации усиления речи, выполняется во временной области, нежели в частотной области, как в показанном на фиг. 6 варианте осуществления.
Выходные сигналы элементов 61 и 62 суммируются элементом 63 суммирования для генерирования речевого сигнала, который должен быть микширован с микшированным звуковым сигналом, и данный речевой сигнал передается из выходного сигнала элемента 63 на подсистему 64 представления. Также на подсистему 64 представления передаются параметры CLD (разности уровней каналов), CLD1 и CLD2, которые были переданы вместе с микшированным звуковым сигналом. Параметры CLD (для каждого сегмента микшированного звукового сигнала) описывают, каким образом речевой сигнал микшируется в каналы указанного сегмента микшированного содержимого звукового сигнала. CLD1 указывает на коэффициент панорамирования для одной пары каналов динамика (например, который определяет панорамирование речи между левым и центральным каналами), и CLD2 указывает на коэффициент панорамирования для другой пары каналов динамика (например, который определяет панорамирование речи между центральным и правым каналами). Таким образом, подсистема 64 представления передает (на элемент 52) данные, указывающие на R∙g1∙Dr + (R∙g2∙P)∙M для левого канала (восстановленное речевое содержимое, микшированное с левым каналом микшированного звукового содержимого, масштабированное на основе параметра усиления и параметра представления для левого канала, микшированного с левым каналом микшированного звукового содержимого), и эти данные суммируются с левым каналом микшированного звукового сигнала в элементе 52. Подсистема 64 представления передает (на элемент 53) данные, указывающие на R∙g1∙Dr + (R∙g2∙P)∙M для центрального канала (восстановленное речевое содержимое, микшированное с центральным каналом микшированного звукового содержимого, масштабированное на основе параметра усиления и параметра представления для центрального канала), и эти данные суммируются с центральным каналом микшированного звукового сигнала в элементе 53. Подсистема 64 представления передает (на элемент 54) данные, указывающие на R∙g1∙Dr + (R∙g2∙P)∙M для правого канала (восстановленное речевое содержимое, микшированное с правым каналом микшированного звукового содержимого, масштабированное на основе параметра усиления и параметра представления для правого канала), и эти данные суммируются с правым каналом микшированного звукового сигнала в элементе 54.
Используются выходные каналы элементов 52, 53 и 54 соответственно для запуска левого динамика L, центрального динамика C и правого динамика «правый».
Показанная на фиг. 6 система может реализовать временное переключение на основе SNR, если параметр αc ограничен либо значением αc = 0, либо значением αc = 1. Такая реализация является особенно полезной в ситуациях с сильно ограниченной битовой скоростью, в которых либо данные низкокачественной копии речи могут быть отправлены, либо параметрические данные могут быть отправлены, но не те и другие. Например, в одной такой реализации низкокачественная копия речи передается вместе с микшированным звуковым сигналом (например, в качестве побочного сигнала) только в сегменты, для которых αc = 1, и параметры pi предсказания передаются вместе с микшированным звуковым сигналом (например, в качестве побочного сигнала) только в сегменты, для которых αc = 0.
Переключатель (реализованный элементами 61 и 62 данной реализации, показанной на фиг. 6) определяет, должно ли быть выполнено усиление с кодированием формы сигнала или усиление с параметрическим кодированием в отношении каждого сегмента, на основе отношения (SNR) между речью и всем остальным звуковым содержимым в сегменте (данное отношение в свою очередь определяет значение αc). Такая реализация может использовать пороговое значение SNR для принятия решения о том, какой способ выбрать:
 (26)
(26)
где τ является пороговым значением (например, τ может равняться 0).
Некоторые реализации, показанные на фиг. 6, используют гистерезиз для предотвращения быстрого переменного переключения между режимами усиления с кодированием формы сигнала и усиления с параметрическим кодированием, если SNR находится в пределах порогового значения для нескольких кадров.
Показанная на фиг. 6 система может реализовать временное смешивание на основе SNR, если параметр αc может иметь любое действительное значение в диапазоне от 0 до 1 включительно.
Одна реализация показанной на фиг. 6 системы использует два целевых значения τ1 и τ2 (SNR сегмента микшированного звукового сигнала, который должен быть усилен), за пределами которых один способ (либо усиления с кодированием формы сигнала, либо усиление с параметрическим кодированием) всегда предусматривает предоставление наилучшей эффективности. Между данными целевыми значениями используется интерполяция для определения значения параметра αc для сегмента. Например, линейная интерполяция может быть использована для определения значения параметра αc для сегмента:
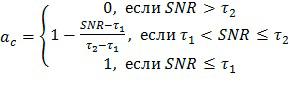 (27)
(27)
В качестве альтернативы, могут быть использованы другие подходящие схемы интерполяции. Если SNR является недоступным, во многих реализациях могут быть использованы параметры предсказания для предоставления приблизительного значения SNR.
В еще одном классе вариантов осуществления сочетание усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении каждого сегмента звукового сигнала, определяется моделью слухового маскирования. В типичных вариантах осуществления в данном классе оптимальное отношение смешивания для смеси усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении сегмента звуковой программы, использует наивысшую величину усиления с кодированием формы сигнала, которое лишь предотвращает слышимость шума кодирования. Пример варианта осуществления способа изобретения, который использует модель слухового маскирования, описан в данном документе со ссылкой на фиг. 7.
В более общем смысле, следующие рассмотрения относятся к вариантам осуществления, в которых модель слухового маскирования используется для определения сочетания (например, смеси) усиления с кодированием формы сигнала и усиления с параметрическим кодированием, которое должно быть выполнено в отношении каждого сегмента звукового сигнала. В данных вариантах осуществления данные, указывающие на микширование речевого и фонового звука A(t), которое называется неусиленным звуковым микшированием, предоставляются и обрабатываются в соответствии с моделью слухового маскирования (например, моделью, реализованной элементом 11, показанным на фиг. 7). Модель предсказывает пороговое значение Θ(f,t) маскирования для каждого сегмента неусиленного звукового микширования. Пороговое значение маскирования каждой частотно-временной мозаики неусиленного звукового микширования, имеющего временной показатель n и показатель b полосы частот, может быть обозначено как Θn,b.
Для кадра n и полосы b пороговое значение Θn,b маскирования указывает на то, какая величина искажения может быть добавлена, не будучи при этом слышимой. Пусть будет ошибкой кодирования (т.е. шумом квантования) низкокачественной копии речи (которая должна быть использована для усиления с кодированием формы сигнала) и будет параметрической ошибкой предсказания.
Некоторые варианты осуществления в данном классе реализуют резкое переключение на способ (усиление с кодированием формы сигнала или усиление с параметрическим кодированием), который наилучшим образом маскируется неусиленным содержимым звукового микширования:
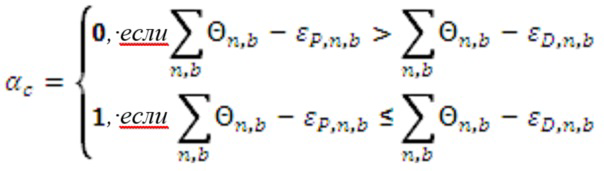 (28)
(28)
Во многих практических ситуациях точная параметрическая ошибка предсказания может не являться доступной в момент генерирования параметров усиления речи, поскольку они могут быть сгенерированы перед кодированием неусиленного микшированного микширования. В частности, схемы параметрического кодирования могут иметь значительное влияние на ошибку параметрического восстановления речи из каналов микшированного содержимого.
Следовательно, некоторые альтернативные варианты осуществления смешивают усиление речи с параметрическим кодированием (с усилением с кодированием формы сигнала), если артефакты кодирования в низкокачественной копии речи (которые должны быть использованы для усиления с кодированием формы сигнала) не замаскированы микшированным содержимым:
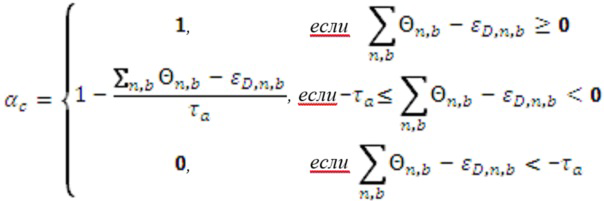 (29)
(29)
где τa является пороговым значением искажения, за пределами которого применяется только усиление с параметрическим кодированием. Данное решение начинает смешивание усиления с кодированием формы сигнала и усиления с параметрическим кодированием, если общее искажение превышает общий потенциал маскирования. На практике это означает, что искажения уже были услышаны. Следовательно, может быть использовано второе пороговое значение с более высоким значением, чем 0. В качестве альтернативы, могут быть использованы условия, при которых лучше сосредоточиться на незамаскированных частотно-временных мозаиках, нежели на поведении в среднем.
Подобным образом, данный подход может быть объединен с правилом смешивания на основе SNR, если искажения (артефакты кодирования) в низкокачественной копии речи (которая должна быть использована для усиления с кодированием формы сигнала) являются слишком высокими. Преимуществом данного подхода является то, что в случаях очень низкого SNR режим усиления с параметрическим кодированием не используется, поскольку он производит большее количество слышимого шума, чем искажения низкокачественной копии речи.
В еще одном варианте осуществления тип усиления речи, выполняемого для некоторых частотно-временных мозаик, отличается от типа, определенного приведенными в качестве примера вышеописанными схемами (или подобными схемами), если спектральный провал обнаруживается в каждой такой частотно-временной мозаике. Спектральные провалы могут быть обнаружены, например, посредством оценки энергии в соответствующей мозаике во время параметрического восстановления, тогда как энергия равняется 0 в низкокачественной копии речи (которая должна быть использована для усиления с кодированием формы сигнала). Если данная энергия превышает пороговое значение, она может считаться соответствующим звуком. В данных случаях для мозаики может быть установлен параметр αc, равный 0 (или в зависимости от SNR параметр αc для мозаики может быть смещен в сторону 0).
В некоторых вариантах осуществления кодер изобретения работает в любом выбранном из следующих режимов:
1. Независимый от канала параметрический режим – В данном режиме набор параметров передается для каждого канала, который содержит речь. С использованием данных параметров декодер, который принимает кодированную звуковую программу, может выполнить усиление речи с параметрическим кодированием в отношении программы для усиления речи в данных каналах на произвольную величину. Приведенная в качестве примера битовая скорость для передачи набора параметров составляет 0,75 – 2,25 кбит/с.
2. Многоканальное предсказание речи – В данном режиме множество каналов микшированного содержимого объединяется в линейное сочетание для предсказания речевого сигнала. Набор параметров передается для каждого канала. С использованием данных параметров декодер, который принимает кодированную звуковую программу, может выполнить усиление речи с параметрическим кодированием в отношении программы. Дополнительные позиционные данные передаются вместе с кодированной звуковой программой для обеспечения представления усиленной речи обратно в микширование. Приведенная в качестве примера битовая скорость для передачи набора параметров и позиционных данных составляет 1,5 – 6,75 кбит/с на диалог.
3. Речь с кодированием формы сигнала – В данном режиме низкокачественная копия речевого содержимого звуковой программы передается отдельно любыми подходящими средствами параллельно с обычным звуковым содержимым (например, в качестве отдельного подпотока). Декодер, который принимает кодированную звуковую программу, может выполнять усиление речи с кодированием формы сигнала в отношении программы посредством микширования отдельной низкокачественной копии речевого содержимого с главным микшированием. Микширование низкокачественной копии речи с усилением в 0 дБ, как правило, усилит речь на 6 дБ, поскольку амплитуда удваивается. Для данного режима также передаются позиционные данные, так что речевой сигнал должным образом распределяется по соответствующим каналам. Приведенная в качестве примера битовая скорость для передачи низкокачественной копии речи и позиционных данных превышает 20 кбит/с на диалог.
4. Гибридный режим с параметрическим кодированием и кодированием формы сигнала – В данном режиме как низкокачественная копия речевого содержимого звуковой программы (для использования при выполнении усиления речи с кодированием формы сигнала в отношении программы), так и набор параметров для каждого содержащего речь канала (для использования при выполнении усиления речи с параметрическим кодированием в отношении программы) передаются параллельно с неусиленным микшированным (речевым и неречевым) звуковым содержимым программы. При снижении битовой скорости для низкокачественной копии речи станет слышно большее количество артефактов кодирования в данном сигнале и уменьшится полоса пропускания, необходимая для передачи. Также передается указатель смешивания, который определяет сочетание усиления речи с кодированием формы сигнала и усиления речи с параметрическим кодированием, которое должно быть выполнено в отношении каждого сегмента программы, с использованием низкокачественной копии речи и набора параметров. На приемнике гибридное усиление речи выполняется в отношении программы, в том числе посредством выполнения сочетания усиления речи с кодированием формы сигнала и усиления речи с параметрическим кодированием, определенного указателем смешивания, таким образом, генерируя данные, указывающие на звуковую программу с усиленной речью. И снова, позиционные данные также передаются вместе с неусиленным микшированным звуковым содержимым программы для указания того, где следует представить речевой сигнал. Преимуществом данного подхода является то, что сложность необходимого приемника/декодера может быть снижена, если приемник/декодер отбрасывает низкокачественную копию речи и применяет только набор параметров для выполнения усиления с параметрическим кодированием. Приведенная в качестве примера битовая скорость для передачи низкокачественной копии речи, набора параметров, указателя смешивания и позиционных данных составляет 8 – 24 кбит/с на диалог.
По практическим соображениям усиление усиления речи может быть ограничено диапазоном 0 – 12 дБ. Кодер может быть реализован с возможностью дополнительного снижения верхнего ограничения данного диапазона посредством поля битового потока. В некоторых вариантах осуществления синтаксис кодированной программы (выводимой из кодера) будет поддерживать множество одновременных усиливаемых диалогов (в дополнение к неречевому содержимому программы), так что каждый диалог может быть отдельно восстановлен и представлен. В данных вариантах осуществления в последних режимах усиления речи для одновременных диалогов (из множества источников в различных пространственных положениях) будут представлены в одном положении.
В некоторых вариантах осуществления, в которых кодированная звуковая программа является звуковой программой на основе объекта, один или более (из максимального общего количества) кластеров объекта могут быть выбраны для усиления речи. Пары значений CLD могут быть включены в кодированную программу для использования системой представления и усиления речи для панорамирования усиленной речи между кластерами объекта. Подобным образом, в некоторых вариантах осуществления, в которых кодированная звуковая программа включает каналы динамика в традиционном формате 5.1, один или более передних каналов динамика могут быть выбраны для усиления речи.
Еще одним аспектом изобретения является способ (например, способ, выполняющийся декодером 40, показанным на фиг. 3) декодирования и выполнения гибридного усиления речи в отношении кодированного звукового сигнала, который был сгенерирован в соответствии с вариантом осуществления способа изобретения кодирования.
Изобретение может быть реализовано в аппаратном обеспечении, программно-аппаратном обеспечении или программном обеспечении, или их сочетании (например, в качестве программируемой логической матрицы). Если не указано иное, алгоритмы или процессы, включенные в качестве части изобретения, по существу не относятся к какому-либо конкретному компьютеру или другому устройству. В частности, различные машины общего назначения могут быть использованы вместе с программами, написанными в соответствии с идеями в данном документе, или удобнее может быть сконструировать более специализированное устройство (например, интегральные схемы) для выполнения необходимых этапов способа. Таким образом, изобретение может быть реализовано в одной или более компьютерных программах, исполняющихся на одной или более программируемых компьютерных системах (например, компьютерной системе, которая реализует кодер 20, показанный на фиг. 3, или кодер, показанный на фиг. 7, или декодер 40, показанный на фиг. 3), каждая из которых включает по меньшей мере один процессор, по меньшей мере одну систему хранения данных (включая энергозависимую и энергонезависимую память и/или запоминающие элементы), по меньшей мере одно устройство или порт ввода и по меньшей мере одно устройство или порт вывода. Программный код применяется к входным данным для выполнения функций, описанных в данном документе, и генерирования выходной информации. Выходная информация известным способом применяется к одному или более устройствам вывода.
Каждая такая программа может быть реализована на любом необходимом языке программирования (включая машинный язык, язык ассемблера, высокоуровневый процедурный язык, логический язык или объектно-ориентированный язык программирования) для установки связи с компьютерной системой. В любом случае язык может являться компилируемым или интерпретируемым языком.
Например, при реализации посредством последовательностей компьютерных программных команд, различные функции и этапы вариантов осуществления изобретения могут быть реализованы многопотоковыми последовательностями программных команд, запущенными на подходящем аппаратном обеспечении цифровой обработки сигналов, в случае чего различные устройства, этапы и функции вариантов осуществления могут соответствовать частям программных команд.
Каждая такая компьютерная программа предпочтительно сохраняется на или загружается на носители данных или запоминающее устройство (например, твердотельную память или носители, или магнитные или оптические носители), считывающееся программируемым компьютером общего или специального назначения, для настройки и работы компьютера при чтении носителей данных или запоминающего устройства компьютерной системой для выполнения процедур, описанных в данном документе. Система изобретения может быть также реализована в качестве машиночитаемого носителя данных, оснащенного (т.е. содержащего) компьютерной программой, при этом оснащенный таким образом носитель данных вынуждает компьютерную систему работать указанным и предопределенным образом для выполнения функций, описанных в данном документе.
Был описан ряд вариантов осуществления изобретения. Тем не менее, следует понимать, что различные модификации могут быть осуществлены без отступления от сущности и объема настоящего изобретения. В свете вышеизложенных идей возможны многочисленные модификации и изменения настоящего изобретения. Следует понимать, что в рамах объема прилагаемой формулы изобретения изобретение может быть применено на практике иным образом, отличным от конкретно описанного в данном документе.
6. СРЕДНЕЕ/ПОБОЧНОЕ ПРЕДСТАВЛЕНИЕ
Операции усиления речи, как описано в данном документе, могут быть выполнены аудиодекодером на основе по меньшей мере частично данных управления, параметров управления и т.д. в M/S представлении. Данные управления, параметры управления и т.д. в M/S представлении могут быть сгенерированы расположенным выше по потоку аудиокодером и извлечены аудиодекодером из кодированного звукового сигнала, сгенерированного расположенным выше по потоку аудиокодером.
В режиме усиления с параметрическим кодированием, в котором речевое содержимое (например, один или более диалогов и т.д.) предсказывается из микшированного содержимого, операции усиления речи могут быть в целом представлены в виде одной матрицы H, как показано в следующем выражении:
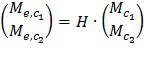 (30)
(30)
где левая сторона (LHS) представляет сигнал микшированного содержимого с усиленной речью, сгенерированный операциями усиления речи, как представлено матрицей H, применяемой к исходному сигналу микшированного содержимого на правой стороне (RHS).
В целях иллюстрации каждый сигнал микшированного содержимого с усиленной речью (например, LHS выражения (30) и т.д.) и исходный сигнал микшированного содержимого (например, исходный сигнал микшированного содержимого, к которому применяется H в выражении (30) и т.д.) содержит два компонентных сигнала, имеющих микшированное содержимое с усиленной речью и исходное микшированное содержимое в двух каналах c1 и c2 соответственно. Два канала c1 и c2 могут являться звуковыми каналами, отличными от M/S, (например, левым передним каналом, правым передним каналом и т.д.) на основе отличного от M/S представления. Следует отметить, что в различных вариантах осуществления каждый сигнал микшированного содержимого с усиленной речью и исходный сигнал микшированного содержимого может дополнительно содержать компонентные сигналы, имеющие неречевое содержимое в каналах (например, каналах объемного звука, канале низкочастотных эффектов и т.д.), которые отличаются от двух каналов c1 и c2, отличных от M/S. Следует также отметить, что в различных вариантах осуществления каждый сигнал микшированного содержимого с усиленной речью и исходный сигнал микшированного содержимого может с некоторой вероятностью содержать компонентные сигналы, имеющие речевое содержимое в одном, двух, как проиллюстрировано в выражении (30), или более чем двух каналах. Речевое содержимое, как описано в данном документе, может содержать один, два или более диалогов.
В некоторых вариантах осуществления операции усиления речи, как представлено матрицей H в выражении (30), могут быть использованы (например, под управлением правила смешивания на основе SNR и т.д.) для временных промежутков (сегментов) микшированного содержимого с относительно высокими значениями SNR между речевым содержимым и другим (например, неречевым и т.д.) содержимым в микшированном содержимом.
Матрица H может быть переписана/расширена в качестве продукта матрицы HMS, представляющей операции усиления в M/S представлении, умножена с правой стороны на матрицу прямого преобразования от отличного от M/S представления до M/S представления и умножена с левой стороны на обратную (которая содержит коэффициент, равный 1/2) матрицу прямого преобразования, как показано в следующем выражении:
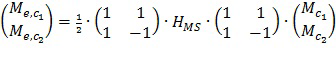 (31)
(31)
где приведенная в качестве примера матрица преобразования с правой стороны матрицы HMS определяет сигнал микшированного содержимого среднего канала в M/S представлении в качестве суммы двух сигналов микшированного содержимого в двух каналах c1 и c2 и определяет сигнал микшированного содержимого побочного канала в M/S представлении в качестве разницы между двумя сигналами микшированного содержимого в двух каналах c1 и c2 на основе матрицы прямого преобразования. Следует отметить, что в различных вариантах осуществления другие матрицы преобразования (например, присваивающие различные весовые коэффициенты различным каналам, отличным от M/S, и т.д.), отличные от приведенных в качестве примера матриц преобразования, показанных в выражении (31), могут быть также использованы для преобразования сигналов микшированного содержимого из одного представления в другое представление. Например, для усиления диалога, который представлен не в фантомном центре, а панорамирован между двумя сигналами с неравными весовыми коэффициентами λ1 и λ2. Матрицы M/S преобразования могут быть модифицированы для минимизации энергии компонента диалога в побочном сигнале, как показано в следующем выражении:
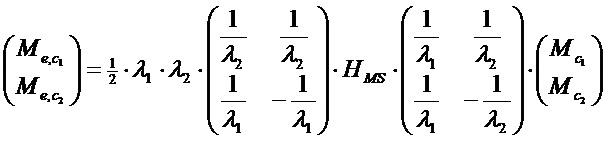
В приведенном в качестве примера варианте осуществления матрица HMS, представляющая операции усиления в M/S представлении, может быть определена в качестве диагонализированной (например, эрмитовой и т.д.) матрицы, как показано в следующем выражении:
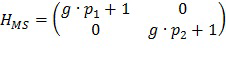 (32)
(32)
где p1 и p2 представляют собой параметры предсказания среднего канала и побочного канала соответственно. Каждый из параметров p1 и p2 предсказания может содержать изменяющийся во времени набор параметров предсказания для частотно-временных мозаик соответствующего сигнала микшированного содержимого в M/S представлении, который должен быть использован для восстановления речевого содержимого из сигнала микшированного содержимого. Параметр g усиления соответствует усилению G усиления речи, например, как показано в выражении (10).
В некоторых вариантах осуществления операции усиления речи в M/S представлении выполняются в режиме независимого от канала усиления с параметрическим кодированием. В некоторых вариантах осуществления операции усиления речи в M/S представлении выполняются с использованием предсказанного речевого содержимого как в сигнале среднего канала, так и в сигнале побочного канала или с использованием предсказанного речевого содержимого только в сигнале среднего канала. В целях иллюстрации операции усиления речи в M/S представлении выполняются с использованием сигнала микшированного содержимого только в среднем канале, как показано в следующем выражении:
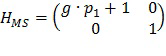 (33)
(33)
где параметр p1 предсказания содержит один набор параметров предсказания для частотно-временных мозаик сигнала микшированного содержимого в среднем канале M/S представления, который должен быть использован для восстановления речевого содержимого из сигнала микшированного содержимого только в среднем канале.
На основе диагонализированной матрицы HMS, приведенной в выражении (33), операции усиления речи в режиме усиления с параметрическим кодированием, как представлено выражением (31), могут быть дополнительно сокращены до следующего выражения, которое предоставляет подробный пример матрицы H в выражении (30):
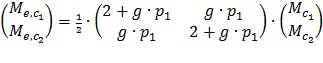 (34)
(34)
В режиме гибридного усиления с кодированием формы сигнала и параметрическим кодированием операции усиления речи могут быть представлены в M/S представлении с использованием следующих представленных в качестве примера выражений:
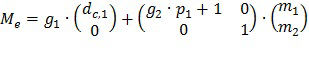 (35)
(35)
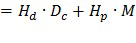
где m1 и m2 обозначают сигнал микшированного содержимого среднего канала (например, сумму сигналов микшированного содержимого в каналах, отличных от M/S, таких как левый и правый передние каналы, и т.д.) и сигнал микшированного содержимого побочного канала (например, разницу между сигналами микшированного содержимого в каналах, отличных от M/S, таких как левый и правый передние каналы, и т.д.) соответственно в векторе M сигнала микшированного содержимого. Сигнал dc,1 обозначает аналоговый сигнал диалога среднего канала (например, кодированные формы сигналов, представляющие версию сниженного качества диалога в микшированном содержимом, и т.д.) в векторе Dc сигнала диалога M/S представления. Матрица Hd представляет операции усиления речи в M/S представлении на основе сигнала dc,1 диалога в среднем канале M/S представления и может содержать только один элемент матрицы в строке 1 и столбце 1 (1х1). Матрица Hp представляет операции усиления речи в M/S представлении на основе восстановленного диалога с использованием параметра p1 предсказания для среднего канала M/S представления. В некоторых вариантах осуществления параметры g1 и g2 усиления вместе (например, после соответствующего применения к аналоговому сигналу диалога и восстановленному диалогу и т.д.) соответствуют усилению G усиления речи, например, как показано в выражениях (23) и (24). В частности, параметр g1 применяется в операциях усиления речи с кодированием формы сигнала, относящихся к сигналу dc,1 диалога в среднем канале M/S представления, тогда как параметр g2 применяется в операциях усиления речи с параметрическим кодированием, относящихся к сигналам m1 и m2 микшированного содержимого в среднем канале и побочном канале M/S представления. Параметры g1 и g2 управляют общим усилением усиления и балансом между двумя способами усиления речи.
В отличном от M/S представлении операции усиления речи, соответствующие операциям, представленным посредством выражения (35), могут быть представлены следующими выражениями:
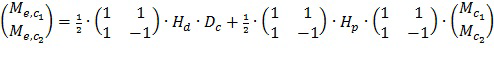 (36)
(36)
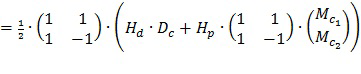
где сигналы m1 и m2 микшированного содержимого в M/S представлении, как показано в выражении (35), заменены сигналами Mc1 и Mc2 микшированного содержимого в каналах, отличных от M/S, умноженными с левой стороны на матрицу прямого преобразования между отличным от M/S представлением и M/S представлением. Матрица обратного преобразования (с коэффициентом, равным ½) в выражении (36) преобразовывает сигналы микшированного содержимого с усиленной речью в M/S представлении, как показано в выражении (35), обратно в сигналы микшированного содержимого с усиленной речью в отличном от M/S представлении (например, левом и правом передних каналах и т.д.).
В качестве дополнения, факультативно или в качестве альтернативы, в некоторых вариантах осуществления, в которых после операций усиления речи не выполняется последующая обработка на основе QMF, некоторые или все операции усиления речи (например, как представлено Hd, Hp, преобразованиями и т.д.), которые объединяют содержимое с усиленной речью на основе сигнала dc,1 диалога и микшированное содержимое с усиленной речью на основе восстановленного диалога посредством предсказания, могут быть выполнены после банка синтезирующих фильтров QMF во временной области в целях обеспечения эффективности.
Параметр предсказания, использующийся для восстановления/предсказания речевого содержимого из сигнала микшированного содержимого в одном из или как в среднем канале, так и побочном канале M/S представления, может быть сгенерирован на основе одного из одного или более способов генерирования параметра предсказания, включая, помимо всего прочего, любое из следующего: способы предсказания независимого от канала диалога, как показано на фиг. 1, способы предсказания многоканального диалога, как показано на фиг. 2, и т.д. В некоторых вариантах осуществления по меньшей мере один из способов генерирования параметра предсказания может быть основан на MMSE, градиентном спуске, одном или более других способах оптимизации и т.д.
В некоторых вариантах осуществления способ временного переключения «вслепую» на основе SNR, как обсуждалось ранее, может быть использован между данными усиления с параметрическим кодированием (например, относящимися к содержимому с усиленной речью на основе сигнала dc,1 диалога, и т.д.) и усилением с кодированием формы сигнала (например, относящимся к микшированному содержимому с усиленной речью на основе восстановленного диалога посредством предсказания и т.д.) сегментов звуковой программы в M/S представлении.
В некоторых вариантах осуществления сочетание (например, указанное указателем смешивания, обсужденным ранее, сочетание g1 и g2 в выражении (35) и т.д.) данных о форме сигнала (например, относящихся к содержимому с усиленной речью на основе сигнала dc,1 диалога, и т.д) и данных восстановленной речи (например, относящихся к микшированному содержимому с усиленной речью на основе восстановленного диалога посредством предсказания и т.д.) в M/S представлении меняется со временем, при этом каждое состояние сочетания относится к речевому и другому звуковому содержимому соответствующего сегмента битового потока, который содержит данные о форме сигнала и микшированное содержимое, использующееся в восстановлении речевых данных. Указатель смешивания генерируется таким образом, что текущее состояние сочетания (данных о форме сигнала и восстановленных речевых данных) определяется свойствами сигнала речевого и другого звукового содержимого (например, отношением SNR мощности речевого содержимого и мощности другого звукового содержимого и т.д.) в соответствии с сегментом программы. Указатель смешивания для сегмента звуковой программы может являться параметром указателя смешивания (или набором параметров), сгенерированным в подсистеме 29 кодера, показанного на фиг. 3, для сегмента. Модель слухового маскирования, как обсуждалось ранее, может быть использована для более точного предсказания того, каким образом шумы кодирования в копии речи сниженного качества в векторе Dc сигнала диалога замаскированы звуковым микшированием главной программы, и для выбора отношения смешивания соответственно.
Подсистема 28 кодера 20, показанного на фиг. 3, может быть выполнена с возможностью включения указателей смешивания, относящихся к операциям усиления речи M/S каналов, в битовый поток в качестве части метаданных усиления речи M/S каналов, которые должны быть выведены из кодера 20. Указатели смешивания, относящиеся к операциям усиления речи M/S каналов, могут быть сгенерированы (например, в подсистеме 13 кодера, показанного на фиг. 7) из коэффициентов gmax(t) масштабирования, относящихся к артефактам кодирования в сигнале Dc диалога и т.д. Коэффициенты gmax(t) масштабирования могут быть сгенерированы подсистемой 14 показанного на фиг. 7 кодера. Подсистема 13 показанного на фиг. 7 кодера может быть выполнена с возможностью включения указателей смешивания в битовый поток, который должен быть выведен из показанного на фиг. 7 кодера. В качестве дополнения, факультативно или в качестве альтернативы, подсистема 13 может включать в битовый поток, который должен быть выведен из показанного на фиг. 7 кодера, коэффициенты gmax(t) масштабирования, сгенерированные подсистемой 14.
В некоторых вариантах осуществления неусиленное звуковое микширование A(t), сгенерированное операцией 10, показанной на фиг. 7, представляет (например, временные сегменты и т.д.) вектор сигнала микшированного содержимого в эталонной конфигурации звуковых каналов. Параметры p(t) усиления с параметрическим кодированием, сгенерированные элементом 12, показанным на фиг. 7, представляют по меньшей мере часть метаданных усиления речи M/S каналов для выполнения усиления речи с параметрическим кодированием в M/S представлении в отношении каждого сегмента вектора сигнала микшированного содержимого. В некоторых вариантах осуществления копия s’(t) речи сниженного качества, сгенерированная кодером 15, показанным на фиг. 7, представляет вектор сигнала диалога в M/S представлении (например, с сигналом диалога среднего канала, сигналом диалога побочного канала и т.д.).
В некоторых вариантах осуществления элемент 14, показанный на фиг. 7, генерирует коэффициенты gmax(t) масштабирования и предоставляет их на элемент 13 кодирования. В некоторых вариантах осуществления элемент 13 генерирует кодированный битовый аудиопоток, указывающий на (например, неусиленный и т.д.) вектор сигнала микшированного содержимого в эталонной конфигурации звуковых каналов, метаданные усиления речи M/S каналов, вектор сигнала диалога в M/S представлении, если необходимо, и коэффициенты gmax(t) масштабирования, если необходимо, для каждого сегмента звуковой программы и данный кодированный битовый аудиопоток может быть передан или иным образом подан на приемник.
При подаче (например, передаче) неусиленного звукового сигнала в отличном от M/S представлении с метаданными усиления речи M/S каналов на приемник, приемник может преобразовать каждый сегмент неусиленного звукового сигнала в M/S представлении и выполнить операции усиления речи M/S каналов, указанные метаданными усиления речи M/S каналов для сегмента. Вектор сигнала диалога в M/S представлении для сегмента программы может быть предоставлен вместе с вектором неусиленного сигнала микшированного содержимого в отличном от M/S представлении, если операции усиления речи для сегмента должны быть выполнены в режиме гибридного усиления речи или в режиме усиления с кодированием формы сигнала. Если необходимо, приемник, который принимает и осуществляет синтаксический разбор битового потока, может быть выполнен с возможностью генерирования указателей смешивания в ответ на коэффициенты gmax(t) масштабирования и определения параметров g1 и g2 усиления в выражении (35).
В некоторых вариантах осуществления операции усиления речи выполняются по меньшей мере частично в M/S представлении в приемнике, на который был подан кодированный выходной сигнал элемента 13. В примере параметры g1 и g2 усиления в выражении (35), соответствующие предопределенной (например, запрошенной) общей величине усиления, могут быть применены к каждому сегменту неусиленного сигнала микшированного содержимого на основе по меньшей мере частично указателей смешивания, синтаксически разобранных из битового потока, принятого приемником. В еще одном примере параметры g1 и g2 усиления в выражении (35), соответствующие предопределенной (например, запрошенной) общей величине усиления, могут быть применены к каждому сегменту неусиленного сигнала микшированного содержимого на основе по меньшей мере частично указателей смешивания, как определено коэффициентами gmax(t) масштабирования для сегмента, синтаксически разобранных из битового потока, принятого приемником.
В некоторых вариантах осуществления элемент 23 кодера 20, показанного на фиг. 3, выполнен с возможностью генерирования параметрических данных, включающих метаданные усиления речи M/S каналов (например, параметры предсказания для восстановления содержимого диалога/речевого содержимого из микшированного содержимого в среднем канале и/или в побочном канале и т.д.), в ответ на данные, выводимые на этапах 21 и 22. В некоторых вариантах осуществления элемент 29 генерирования указателя смешивания кодера 20, показанного на фиг. 3, выполнен с возможностью генерирования указателя («BI») смешивания для определения сочетания содержимого с параметрически усиленной речью (например, с параметром g1 усиления и т.д.) и содержимого с усиленной речью на основе формы сигнала (например, с параметром g1 усиления и т.д.) в ответ на данные, выводимые на этапах 21 и 22.
В вариациях показанного на фиг. 3 варианта осуществления указатель смешивания, использующийся для гибридного усиления речи M/S каналов, не генерируется в кодере (и не включен в битовый поток, выводимый из кодера), но вместо этого генерируется (например, в качестве вариации на приемнике 40) в ответ на битовый поток, выводимый из кодера (битовый поток которого не включает данных о форме сигнала в M/S каналах и метаданных усиления речи M/S каналов).
Декодер 40 соединен и выполнен (например, запрограммирован) с возможностью приема кодированного звукового сигнала с подсистемы 30 (например, посредством считывания или извлечения данных, указывающих на кодированный звуковой сигнал, из памяти в подсистеме 30 или посредством приема кодированного звукового сигнала, который был передан подсистемой 30) и с возможностью декодирования данных, указывающих на вектор сигнала микшированного (речевого и неречевого) содержимого в эталонной конфигурации звуковых каналов, из кодированного звукового сигнала и с возможностью выполнения операций усиления речи по меньшей мере частично в M/S представлении в отношении декодированного микшированного содержимого в эталонной конфигурации звуковых каналов. Декодер 40 может быть выполнен с возможностью генерирования и вывода (например, на систему представления и т.д.) декодированного звукового сигнала с усиленной речью, указывающего на микшированное содержимое с усиленной речью.
В некоторых вариантах осуществления некоторые или все системы представления, показанные на фиг. 4 - фиг. 6, могут быть выполнены с возможностью представления микшированного содержимого с усиленной речью, сгенерированного операциями усиления речи M/S каналов, по меньшей мере некоторые из которых являются операциями, выполненными в M/S представлении. На фиг. 6A проиллюстрирована приведенная в качестве примера система представления, выполненная с возможностью выполнения операций усиления речи, как представлено в выражении (35).
Система представления, показанная на фиг. 6A, может быть выполнена с возможностью выполнения операций усиления речи с параметрическим кодированием в ответ на определение того, что по меньшей мере один параметр (например, g2 в выражении (35) и т.д.) усиления, использующийся в операциях усиления речи с параметрическим кодированием, не равняется нулю (например, в режиме гибридного усиления, в режиме усиления с параметрическим кодированием и т.д.). Например, при таком определении подсистема 68A, показанная на фиг. 6A, может быть выполнена с возможностью выполнения преобразования вектора сигнала микшированного содержимого («микшированного звука (T/F)»), который распределен по каналам, отличным от M/S, для генерирования соответствующего вектора сигнала микшированного содержимого, который распределен по M/S каналам. Данное преобразование может использовать матрицу прямого преобразования при необходимости. Параметры (например, p1, p2 и т.д.) предсказания, параметры (например, g2 в выражении (35) и т.д.) усиления для операций усиления с параметрическим кодированием могут быть применены для предсказания речевого содержимого из вектора сигнала микшированного содержимого M/S каналов и усиления предсказанного речевого содержимого.
Система представления, показанная на фиг. 6A, может быть выполнена с возможностью выполнения операций усиления речи с кодированием формы сигнала в ответ на определение того, что по меньшей мере один параметр (например, g1 в выражении (35) и т.д.) усиления, использующийся в операциях усиления речи с кодированием формы сигнала, не равняется нулю (например, в режиме гибридного усиления, в режиме усиления с кодированием формы сигнала и т.д.). Например, при таком определении подсистема представления, показанная на фиг. 6A, может быть выполнена с возможностью приема/извлечения из принятого кодированного звукового сигнала вектора сигнала диалога (например, с версией сниженного качества речевого содержимого, присутствующего в векторе сигнала микшированного содержимого), который распределен по M/S каналам. Параметры (например, g1 в выражении (35) и т.д.) усиления для операций усиления с кодированием формы сигнала могут быть применены для усиления речевого содержимого, представленного вектором сигнала диалога M/S каналов. Определяемое пользователем усиление (G) усиления может быть использовано для получения параметров g1 и g2 усиления с использованием параметра смешивания, который может или не может присутствовать в битовом потоке. В некоторых вариантах осуществления параметр смешивания, который должен быть использован вместе с определяемым пользователем усилением (G) усиления для получения параметров g1 и g2 усиления, может быть извлечен из метаданных в принятом кодированном звуковом сигнале. В некоторых других вариантах осуществления такой параметр смешивания может быть не извлечен из метаданных в принятом кодированном звуковом сигнале, а скорее может быть получен принимающим кодером на основе звукового содержимого в принятом кодированном звуковом сигнале.
В некоторых вариантах осуществления сочетание усиленного речевого содержания с параметрическим кодированием и усиленного речевого содержания с кодированием формы сигнала в M/S представлении передается или вводится в подсистему 64A, показанную на фиг. 6A. Подсистема 64A, показанная на фиг. 6, может быть выполнена с возможностью выполнения преобразования сочетания усиленного речевого содержимого, которое распределено по M/S каналам, для генерирования вектора сигнала усиленного речевого содержимого, который распределен по каналам, отличным от M/S. Данное преобразование может использовать матрицу обратного преобразования при необходимости. Вектор сигнала усиленного речевого содержимого каналов, отличных от M/S, может быть объединен с вектором сигнала микшированного содержимого («микшированным звуком (T/F)»), который распределен по каналам, отличным от M/S, для генерирования вектора сигнала микшированного содержимого с усиленной речью.
В некоторых вариантах осуществления синтаксис кодированного звукового сигнала (например, выводимого из кодера 20, показанного на фиг. 3, и т.д.) поддерживает передачу M/S флага с расположенного выше по потоку аудиокодера (например, кодера 20, показанного на фиг. 3, и т.д.) на расположенные ниже по потоку аудиодекодеры (например, декодер 40, показанный на фиг. 3, и т.д.). M/S флаг представлен/установлен аудиокодером (например, элементом 23 в кодере 20, показанном на фиг. 3, и т.д.), если операции усиления речи должны быть выполнены принимающим аудиодекодером (например, декодером 40, показанным на фиг. 3, и т.д.) по меньшей мере частично вместе с данными управления M/S каналами, параметрами управления и т.д., которые передаются вместе с M/S флагом. Например, если установлен M/S флаг, стереосигнал (например, из левого и правого каналов и т.д.) в каналах, отличных от M/S, может быть сначала преобразован принимающим аудиодекодером (например, декодером 40, показанным на фиг. 3, и т.д.) в средний канал и побочный канал M/S представления перед выполнением операций усиления речи M/S каналов с данными управления M/S каналами, параметрами управления и т.д. при приеме с M/S флагом в соответствии с одним или более алгоритмами усиления речи (например, независимым от канала предсказанием диалога, многоканальным предсказанием диалога, алгоритмом на основе формы сигнала, гибридным алгоритмом с кодированием формы сигнала и параметрическим кодированием и т.д.). В принимающем аудиодекодере (например, декодере 40, показанном на фиг. 3, и т.д.) после выполнения операций усиления речи M/S каналов сигналы с усиленной речью в M/S представлении могут быть преобразованы обратно в каналы, отличные от M/S.
В некоторых вариантах осуществления метаданные усиления речи, сгенерированные аудиокодером (например, кодером 20, показанным на фиг. 3, элементом 23 кодера 20, показанного на фиг. 3 и т.д.), как описано в данном документе, могут содержать один или более специальных флагов для указания наличия одного или более наборов данных управления усилением речи, параметров управления и т.д. для одного или более различных типов операций усиления речи. Один или более наборов данных управления усилением речи, параметров управления и т.д. для одного или более различных типов операций усиления речи могут включать, помимо всего прочего, набор данных управления M/S каналами, параметров управления и т.д. в качестве метаданных усиления речи M/S каналов. Метаданные усиления речи могут также включать флаг предпочтения для указания того, какой тип операций усиления речи (например, операций усиления речи M/S каналов, операций усиления речи каналов, отличных от M/S, и т.д.) является предпочтительным для звукового содержимого, речь которого должна быть усилена. Метаданные усиления речи могут быть поданы на расположенный ниже по потоку декодер (например, декодер 40, показанный на фиг. 3, и т.д.) в качестве части метаданных, поданных в кодированном звуковом сигнале, который включает микшированное звуковое содержимое, кодированное для эталонной конфигурации звуковых каналов, отличных от M/S. В некоторых вариантах осуществления только метаданные усиления речи M/S каналов, но не метаданные усиления речи каналов, отличных от M/S, включены в кодированный звуковой сигнал.
В качестве дополнения, факультативно или в качестве альтернативы, аудиодекодер (например, декодер 40, показанный на фиг. 3, и т.д.) может быть выполнен с возможностью определения и выполнения конкретного типа (например, усиления речи M/S каналов, усиления речи каналов, отличных от M/S, и т.д.) операций усиления речи на основе одного или более коэффициентов. Данные коэффициенты могут включать, помимо всего прочего: один или более пользовательских вводов данных, которые указывают на предпочтение конкретного выбранного пользователем типа операции усиления речи, пользовательских вводов данных, которые указывают на предпочтение выбранного системой типа операций усиления речи, возможности конкретной конфигурации звуковых каналов, управление которой осуществляется аудиодекодером, доступность метаданных усиления речи для конкретного типа операции усиления речи, любой генерируемый кодером флаг предпочтения для типа операции усиления речи и т.д. В некоторых вариантах осуществления аудиодекодер может реализовать одно или более правил старшинства, может потребовать дополнительного пользовательского ввода данных и т.д. для определения конкретного типа операции усиления речи, если данные коэффициенты противоречат друг другу.
7. ПРИВЕДЕННЫЕ В КАЧЕСТВЕ ПРИМЕРА ПОТОКИ ПРОЦЕССА
На фиг. 8A и на фиг. 8B проиллюстрированы приведенные в качестве примера потоки процесса. В некоторых вариантах осуществления одно или более вычислительных устройств или узлов в системе обработки медиаданных могут выполнять данный поток процесса.
На фиг. 8A проиллюстрирован приведенный в качестве примера поток процесса, который может быть реализован аудиокодером (например, кодером 20, показанным на фиг. 3), как описано в данном документе. В блоке 802, показанном на фиг. 8A, аудиокодер принимает микшированное звуковое содержимое, имеющее микширование речевого содержимого и неречевого звукового содержимого, в исходном представлении звуковых каналов, которое распределяется по множеству звуковых каналов исходного представления звуковых каналов.
В блоке 804 аудиокодер преобразовывает одну или более частей микшированного звукового содержимого, которые распределены по одному или более каналам, отличным от средних/побочных (M/S), во множестве звуковых каналов исходного представления звуковых каналов, в одну или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов, которые распределены по одному или более M/S каналам представления M/S звуковых каналов.
В блоке 806 аудиокодер определяет метаданные усиления речи M/S каналов для одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов.
В блоке 808 аудиокодер генерирует звуковой сигнал, который содержит микшированное звуковое содержимое в исходном представлении звуковых каналов и метаданные усиления речи M/S каналов для одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов.
В варианте осуществления аудиокодер дополнительно выполнен с возможностью выполнения: генерирования версии речевого содержимого в представлении M/S звуковых каналов, отделенной от микшированного звукового содержимого; и вывода звукового сигнала, кодированного с использованием версии речевого содержимого в представлении M/S звуковых каналов.
В варианте осуществления аудиокодер дополнительно выполнен с возможностью выполнения: генерирования данных, указывающих на смешивание, которые позволяют принимающему аудиодекодеру применять усиление речи к микшированному звуковому содержимому с конкретным количественным сочетанием усиления речи с кодированием формы сигнала на основе версии речевого содержимого в представлении M/S звуковых каналов и усиления речи с параметрическим кодированием на основе восстановленной версии речевого содержимого в представлении M/S звуковых каналов; и вывода звукового сигнала, кодированного с использованием данных, указывающих на смешивание.
В варианте осуществления аудиокодер дополнительно выполнен с возможностью предотвращения кодирования одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов в качестве части звукового сигнала.
На фиг. 8B проиллюстрирован приведенный в качестве примера поток процесса, который может быть реализован аудиодекодером (например, декодером 40, показанным на фиг. 3), как описано в данном документе. В блоке 822, показанном на фиг. 8B, аудиодекодер принимает звуковой сигнал, который содержит микшированное звуковое содержимое в исходном представлении звуковых каналов и метаданные усиления речи средних/побочных (M/S) каналов.
В блоке 824, показанном на фиг. 8B, аудиодекодер преобразовывает одну или более частей микшированного звукового содержимого, которые распределены по одному, двум или более каналам, отличным от M/S, во множестве звуковых каналов исходного представления звуковых каналов, в одну или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов, которые распределены по одному или более M/S каналам представления M/S звуковых каналов.
В блоке 826, показанном на фиг. 8B, аудиодекодер выполняет одну или более операций усиления речи M/S каналов на основе метаданных усиления речи M/S каналов в отношении одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов для генерирования одной или более частей усиленного речевого содержимого в M/S представлении.
В блоке 828, показанном на фиг. 8B, аудиодекодер объединяет одну или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов с одним или более усиленными речевыми содержимыми в M/S представлении для генерирования одной или более частей микшированного звукового содержимого с усиленной речью в M/S представлении.
В варианте осуществления аудиодекодер дополнительно выполнен с возможностью обратного преобразования одной или более частей микшированного звукового содержимого с усиленной речью в M/S представлении в одну или более частей микшированного звукового содержимого с усиленной речью в исходном представлении звуковых каналов.
В варианте осуществления аудиодекодер дополнительно выполнен с возможностью выполнения: извлечения версии речевого содержимого в представлении M/S звуковых каналов, отделенной от микшированного звукового содержимого из звукового сигнала; и выполнения одной или более операций усиления речи на основе метаданных усиления речи M/S каналов в отношении одной или более частей версии речевого содержимого в представлении M/S звуковых каналов для генерирования одной или более вторых частей усиленного речевого содержимого в представлении M/S звуковых каналов.
В варианте осуществления аудиодекодер дополнительно выполнен с возможностью выполнения: определения данных, указывающих на смешивание, для усиления речи; и генерирования на основе данных, указывающих на смешивание, для усиления речи конкретного количественного сочетания усиления речи с кодированием формы сигнала на основе версии речевого содержимого в представлении M/S звуковых каналов и усиления речи с параметрическим кодированием на основе восстановленной версии речевого содержимого в представлении M/S звуковых каналов.
В варианте осуществления данные, указывающие на смешивание, генерируются на основе по меньшей мере частично одного или более значений SNR для одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов. Одно или более значений SNR представляют одно или более отношений мощности речевого содержимого и неречевого звукового содержимого одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов или отношений мощности речевого содержимого и общего звукового содержимого одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов.
В варианте осуществления конкретное количественное сочетание усиления речи с кодированием формы сигнала на основе версии речевого содержимого в представлении M/S звуковых каналов и усиления речи с параметрическим кодированием на основе восстановленной версии речевого содержимого в представлении M/S звуковых каналов определяется моделью слухового маскирования, в которой усиление речи с кодированием формы сигнала на основе версии речевого содержимого в представлении M/S звуковых каналов представляет собой наибольшую относительную величину усиления речи во множестве сочетаний усилений речи с кодированием формы сигнала и усиления речи с параметрическим кодированием, которая гарантирует, что шум кодирования не будет нежелательно слышимым в выходной звуковой программе с усиленной речью.
В варианте осуществления по меньшей мере часть метаданных усиления речи M/S каналов позволяет принимающему аудиодекодеру восстанавливать версию речевого содержимого в M/S представлении из микшированного звукового содержимого в исходном представлении звуковых каналов.
В варианте осуществления метаданные усиления речи M/S каналов содержат метаданные, относящиеся к одной или более операциям усиления речи с кодированием формы сигнала в представлении M/S звуковых каналов или операциям усиления речи с параметрическим кодированием в M/S звуковом канале.
В варианте осуществления исходное представление звуковых каналов содержит звуковые каналы, относящиеся к динамикам объемного звучания. В варианте осуществления один или более каналов, отличных от M/S, исходного представления звуковых каналов содержат один или более центральных каналов, левых каналов или правых каналов, при этом один или более M/S каналов представления M/S звуковых каналов содержат один или более средних каналов или побочных каналов.
В варианте осуществления метаданные усиления речи M/S каналов содержат один набор метаданных усиления речи, относящихся к среднему каналу представления M/S звуковых каналов. В варианте осуществления метаданные усиления речи M/S каналов представляют собой часть всех аудиометаданных, кодированных в звуковом сигнале. В варианте осуществления аудиометаданные, кодированные в звуковом сигнале, содержат поле данных для указания наличия метаданных усиления речи M/S каналов. В варианте осуществления звуковой сигнал является частью аудиовизуального сигнала.
В варианте осуществления устройство, содержащее процессор, выполнено с возможностью выполнения любого способа, как описано в данном документе.
В варианте осуществления постоянный машиночитаемый носитель данных, содержащий программные команды, которые при исполнении одним или более процессорами вызывают выполнение любого способа, как описано в данном документе. Следует отметить, что, несмотря на то что в данном документе обсуждены отдельные варианты осуществления, любое сочетание вариантов осуществления и/или частичных вариантов осуществления, обсужденных в данном документе, может быть объединено для образования дополнительных вариантов осуществления.
8. МЕХАНИЗМЫ РЕАЛИЗАЦИИ – ОБЗОР АППАРАТНОГО ОБЕСПЕЧЕНИЯ
В соответствии с одним вариантом осуществления методы, описанные в данном документе, реализуются одним или более вычислительными устройствами специального назначения. Вычислительные устройства специального назначения могут быть реализованы на аппаратном уровне для выполнения методов или могут включать цифровые электронные устройства, такие как одна или более специализированных интегральных схем (ASIC) или программируемых пользователем вентильных матриц (FPGA), которые постоянно программируются для выполнения методов, или могут включать один или более аппаратных процессоров общего назначения, программируемых для выполнения методов в соответствии с программными командами в программно-аппаратном обеспечении, памяти, другом запоминающем устройстве или их сочетании. Данные вычислительные устройства специального назначения могут также сочетать заказную аппаратно-реализованную логику, ASIC или FPGA с программированием по индивидуальному заказу для осуществления методов. Вычислительные устройства специального назначения могут являться настольными компьютерными системами, портативными компьютерными системами, карманными устройствами, сетевыми устройствами или любым другим устройством, которое включает аппаратно-реализованную и/или программную логику для реализации методов.
Например, на фиг. 9 показана блок-диаграмма, которая иллюстрирует компьютерную систему 900, на которой может быть реализован вариант осуществления изобретения. Компьютерная система 900 включает шину 902 или другой механизм связи для передачи информации и аппаратный процессор 904, соединенный с шиной 902 для обработки информации. Аппаратный процессор 904 может являться, например, микропроцессором общего назначения.
Компьютерная система 900 также включает основную память 906, такую как оперативное запоминающее устройство (RAM) или другое динамическое запоминающее устройство, соединенную с шиной 902 для хранения информации и команд, которые должны быть исполнены процессором 904. Основная память 906 также может быть использована для хранения временных переменных или другой промежуточной информации во время исполнения команд, которые должны быть исполнены процессором 904. Данные команды при хранении в постоянных носителях данных, доступных для процессора 904, превращают компьютерную систему 900 в машину специального назначения, которая зависит от устройств, для выполнения операций, указанных в командах.
Компьютерная система 900 также включает постоянное запоминающее устройство (ROM) 908 или другое статическое запоминающее устройство, соединенное с шиной 902, для хранения статических информации и команд для процессора 904. Запоминающее устройство 910, такое как магнитный диск или оптический диск, предоставлено и соединено с шиной 902 для хранения информации и команд.
Компьютерная система 900 может быть соединена посредством шины 902 с дисплеем 912, таким как жидкокристаллический дисплей (LCD), для отображения информации пользователю компьютера. Устройство 914 ввода, содержащее буквенно-цифровые и другие клавиши, соединено с шиной 902 для передачи информации и выборов команд на процессор 904. Другим типом пользовательского устройства ввода является устройство 916 управления курсором, такое как мышь, шаровой манипулятор или клавиши направления курсора для передачи информации о направлении и выборов команд на процессор 904 и для управления перемещением курсора на дисплее 912. Данное устройство ввода, как правило, имеет две степени свободы в двух осях, первой оси (например, x) и второй оси (например, y), что позволяет устройству определять положения на плоскости.
Компьютерная система 900 может реализовать методы, описанные в данном документе, с использованием зависящей от устройств аппаратно-реализованной логики, одной или более ASIC или FPGA, программно-аппаратной и/или программной логики, что в сочетании с компьютерной системой обеспечивает или программирует компьютерную систему 900 для функционирования в качестве машины специального назначения. В соответствии с одним вариантом осуществления методы в данном документе выполняются компьютерной системой 900 в ответ на исполнение процессором 904 одной или более последовательностей одной или более команд, содержащихся в основной памяти 906. Данные команды могут быть считаны в основную память 906 с другого носителя данных, такого как запоминающее устройство 910. Исполнение последовательностей команд, содержащихся в основной памяти 906, приводит к выполнению процессором 904 этапов процесса, описанных в данном документе. В альтернативных вариантах осуществления аппаратно-реализованная схема может быть использована вместо или в сочетании с программными командами.
Термин «носители данных» в данном контексте относится к любым постоянным носителям, которые хранят данные и/или команды, которые приводят к работе машины специфическим образом. Данные носители данных могут содержать энергонезависимые носители и/или энергозависимые носители. Энергонезависимые носители включают, например, оптические или магнитные диски, такие как запоминающее устройство 910. Энергозависимые носители включают динамическую память, такую как основная память 906. Общие формы носителей данных включают, например, дискету, гибкий диск, жесткий диск, твердотельный накопитель, магнитную ленту или любой другой магнитный носитель данных, CD-ROM, любой другой оптический носитель данных, любой физический носитель со схемами отверстий, RAM, PROM и EPROM, FLASH-EPROM, NVRAM, любую другую интегральную схему памяти или картридж памяти.
Носители данных отличаются от средств передачи данных, но могут быть использованы совместно с ними. Средства передачи данных участвует в передаче информации между носителями данных. Например, средства передачи данных включают коаксиальные кабели, медный провод и оптоволоконные кабели, включая провода, которые содержат шину 902. Средства передачи данных могут также принимать форму акустических или световых волн, таких, которые генерируются во время радиоволновой и инфракрасной передач данных.
Различные формы носителей могут быть включены в передачу одной или более последовательностей одной или более команд на процессор 904 для исполнения. Например, команды могут быть сначала переданы на магнитный диск или твердотельный накопитель удаленного компьютера. Удаленный компьютер может загрузить команды в свою динамическую память и отправить команды через телефонную линию с использованием модема. Модем, установленный локально с компьютерной системой 900, может принимать данные на телефонную линию и использовать инфракрасный передатчик для преобразования данных в инфракрасный сигнал. Инфракрасный детектор может принимать данные, содержащиеся в инфракрасном сигнале, и соответствующая схема может передать данные на шину 902. Шина 902 передает данные на основную память 906, из которой процессор 904 извлекает и исполняет команды. Команды, принятые основной памятью 906, могут быть факультативно сохранены на запоминающем устройстве 910 либо перед, либо после исполнения процессором 904.
Компьютерная система 900 также включает интерфейс 918 связи, соединенный с шиной 902. Интерфейс 918 связи предоставляет двустороннюю передачу данных, соединенную с сетевой линией 920 связи, которая соединена с локальной сетью 922. Например, интерфейс 918 связи может являться картой цифровой сети (ISDN) с интегрированными службами, кабельным модемом, спутниковым модемом или модемом для предоставления соединения передачи данных с соответствующим типом телефонной линии. В качестве еще одного примера интерфейс 918 связи может являться картой локальной сети (LAN) для предоставления соединения передачи данных с совместимой LAN. Беспроводные линии связи могут быть также реализованы. В любой такой реализации интерфейс 918 связи отправляет и принимает электрические, электромагнитные или оптические сигналы, которые содержат потоки цифровых данных, представляющие различные типы информации.
Сетевая линия 920 связи, как правило, обеспечивает передачу данных через одну или более сетей на другие устройства передачи данных. Например, сетевая линия 920 связи может обеспечить соединение через локальную сеть 922 с главным компьютером 924 или с оборудованием передачи данных, работающим посредством Интернет-провайдера (ISP) 926. ISP 926 в свою очередь предоставляет службы передачи данных через глобальную сеть передачи пакетных данных, которая в наше время обычно называется сетью «Интернет» 928. Как локальная сеть 922, так и сеть Интернет 928 используют электрические, электромагнитные или оптические сигналы, которые содержат потоки цифровых данных. Сигналы через различные сети и сигналы на сетевую линию 920 связи и через интерфейс 918 связи, которые передают цифровые данные на и с компьютерной системы 900, являются приведенными в качестве примера формами средств передачи данных.
Компьютерная система 900 может отправлять сообщения и принимать данные, включая программный код, через сеть (сети), сетевую линию 920 связи и интерфейс 918 связи. На примере сети Интернет сервер 930 может передавать запрашиваемый код для прикладной программы через сеть Интернет 928, ISP 926, локальную сеть 922 и интерфейс 918 связи.
Принятый код может быть исполнен процессором 904 после его приема и/или сохранен на запоминающем устройстве 910 или другом энергонезависимом запоминающем устройстве для последующего исполнения.
9. ЭКВИВАЛЕНТЫ, РАСШИРЕНИЯ, АЛЬТЕРНАТИВЫ И ПРОЧЕЕ
В вышеизложенном описании варианты осуществления изобретения были описаны со ссылкой на многочисленные специфические подробности, которые могут изменяться от реализации к реализации. Таким образом, единственным и исключительным показателем того, чем является изобретение, и, того, чем является изобретение, по мнению заявителей, является формула изобретения, которая вытекает из данной заявки, в конкретной форме, в которой представлена данная формула изобретения, включая любое последующее исправление. Любые определения, изложенные в данном документе в прямой форме для терминов, содержащихся в данной формуле изобретения, должны обуславливать значение, в котором данные термины используются в формуле изобретения. Следовательно, никакое ограничение, элемент, свойство, признак, преимущество или атрибут, который не изложен в прямой форме в формуле изобретения, не должен никоим образом ограничивать объем данной формулы изобретения. Описание и графические материалы соответственно должны рассматриваться скорее в пояснительном, а не ограничительном смысле.
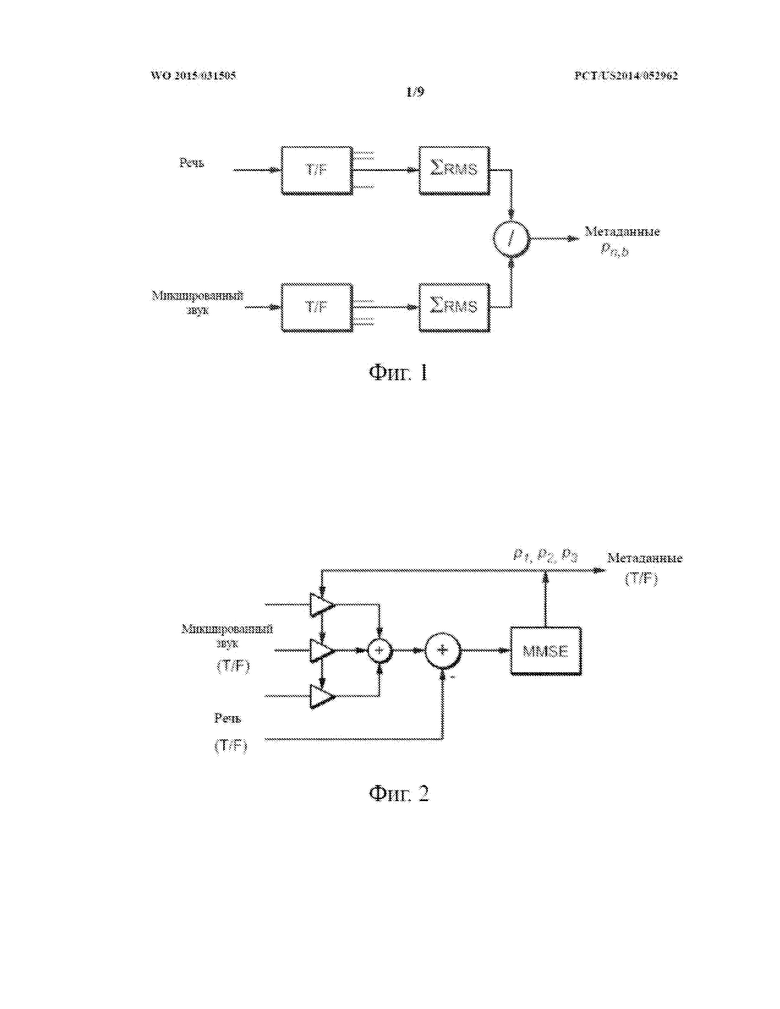
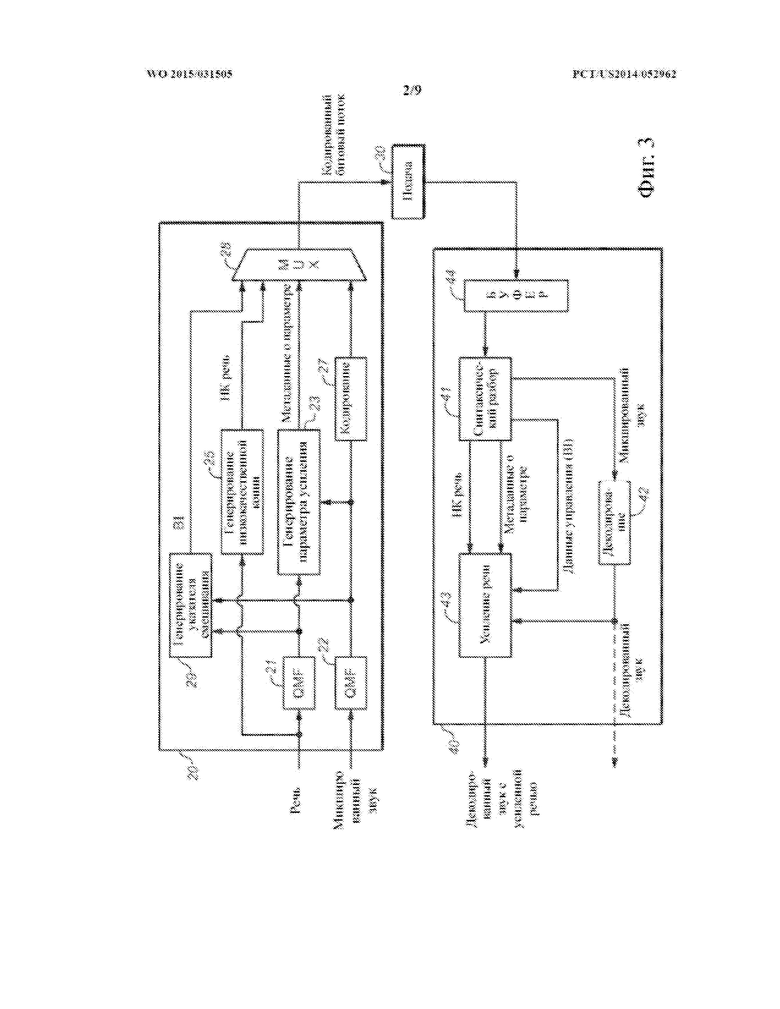
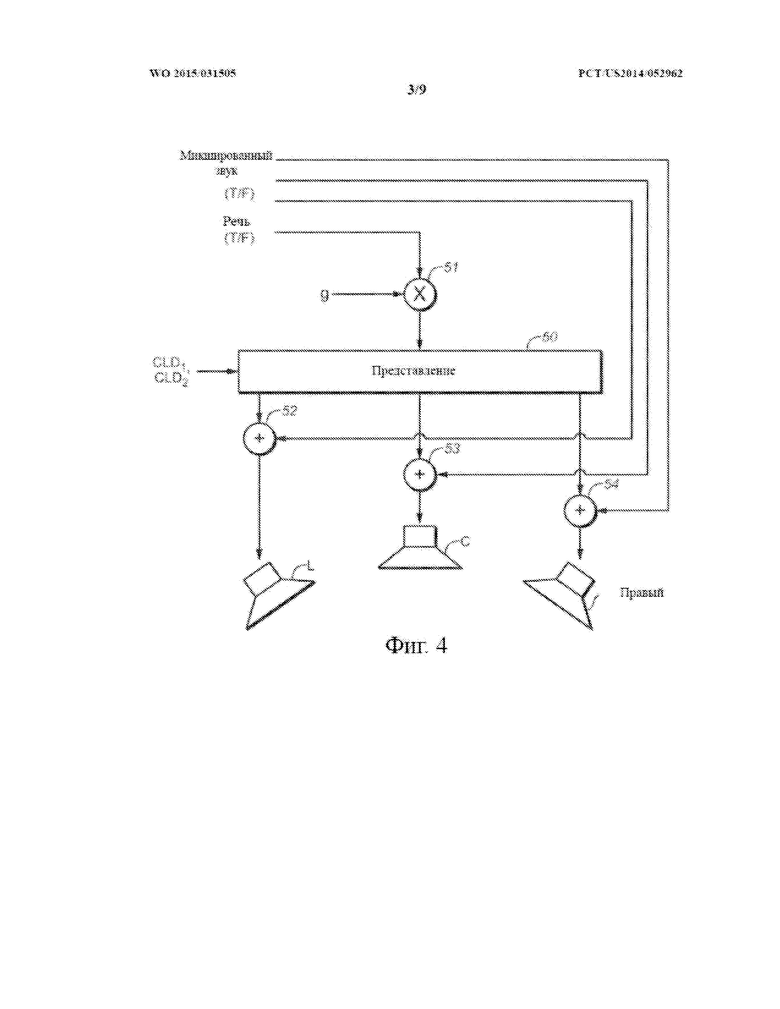
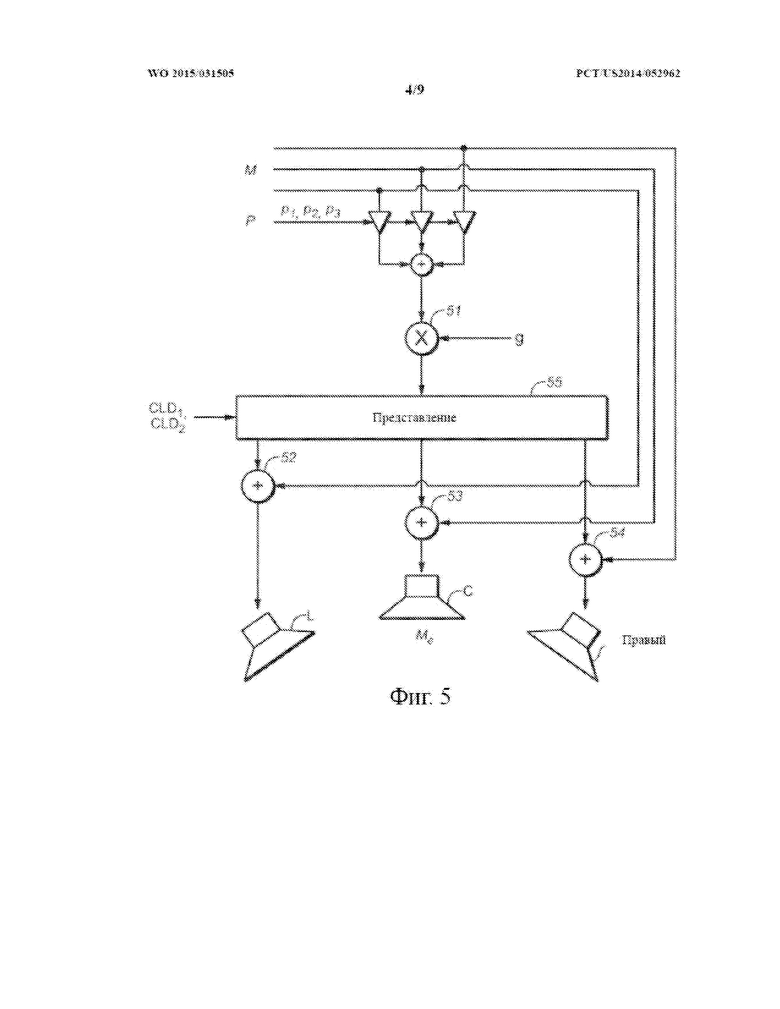
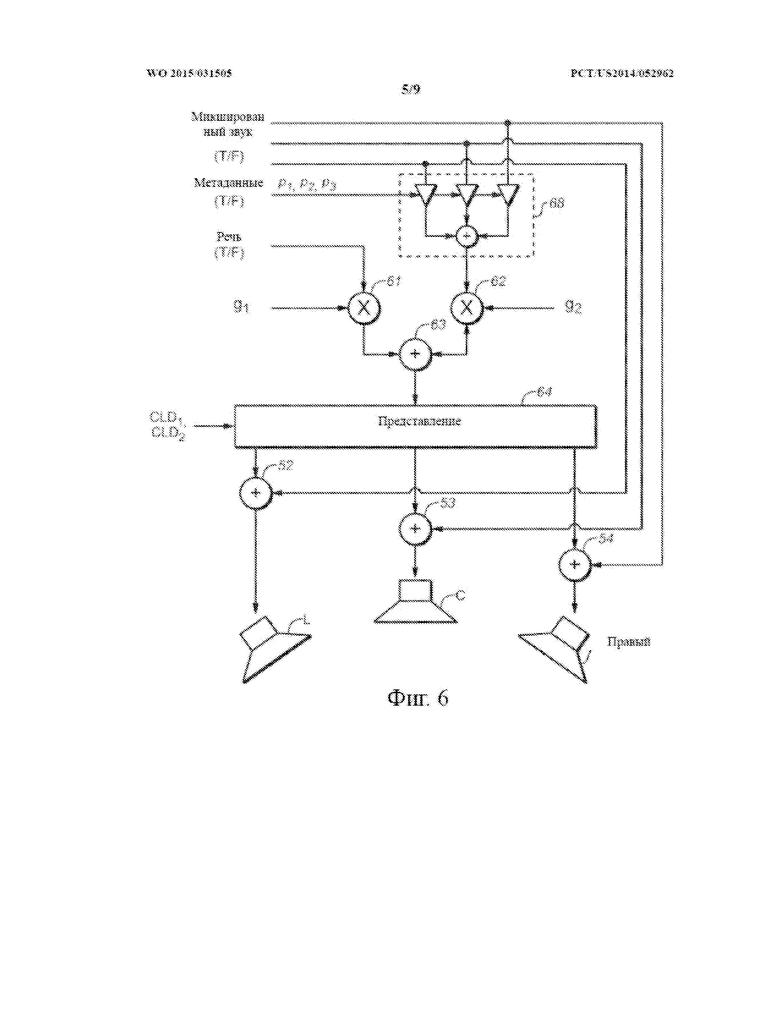
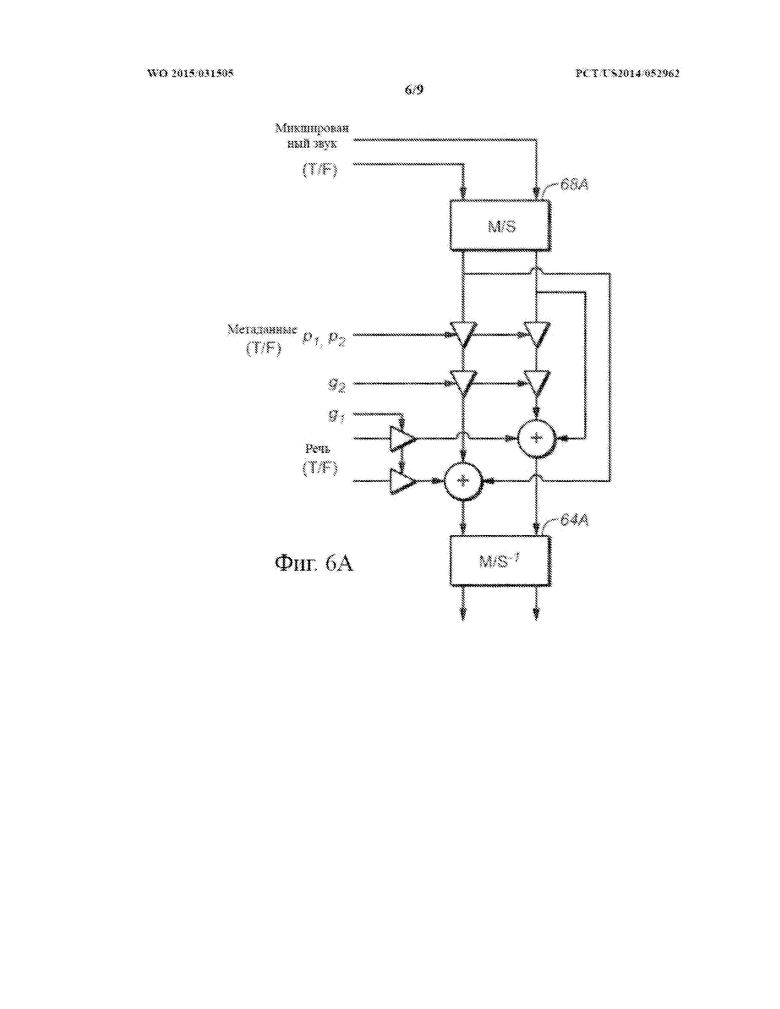
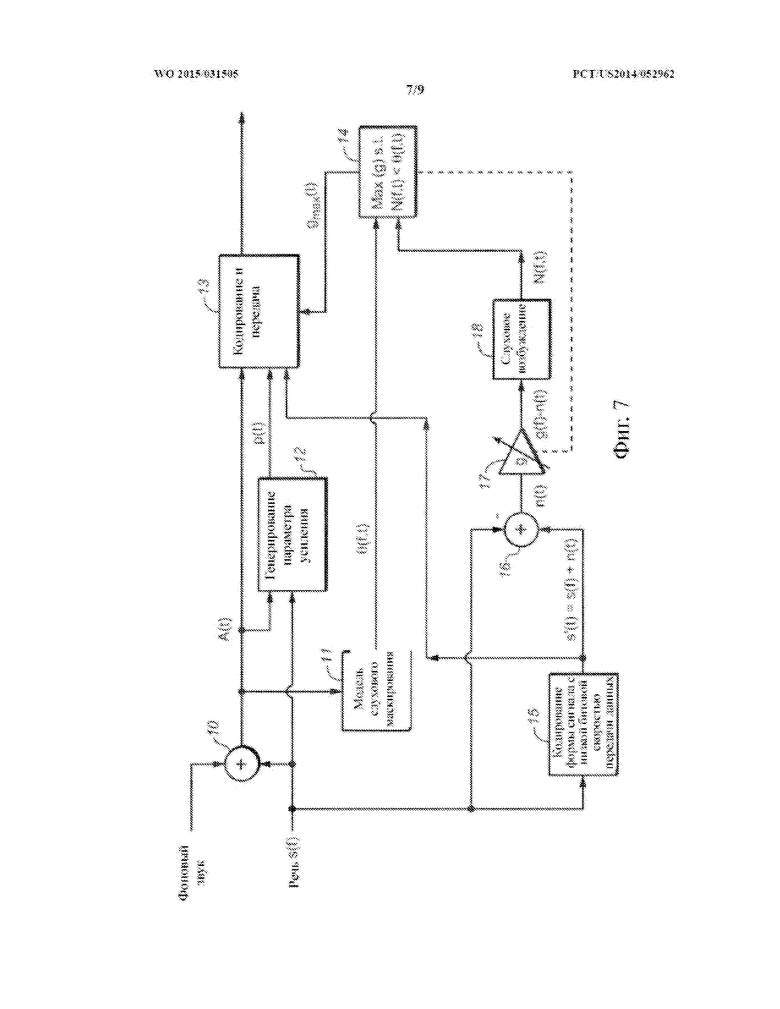
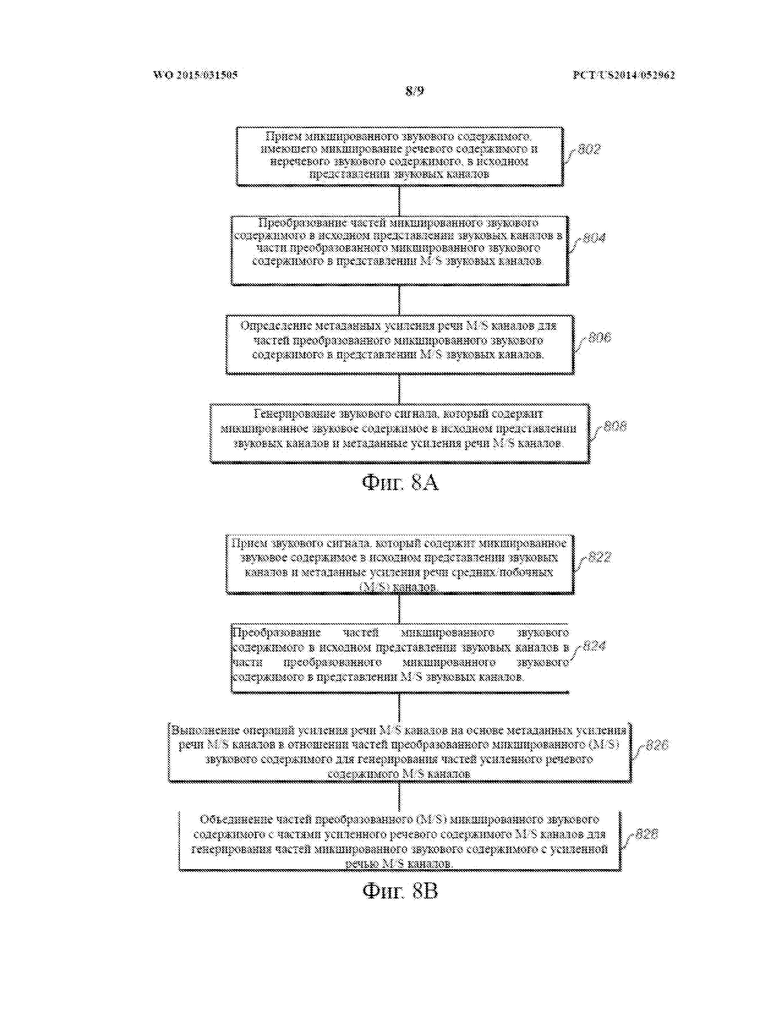
Изобретение относится к средствам для гибридного усиления речи. Технический результат заключается в повышении слышимости речевого содержимого звукового сигнала относительно неречевого звукового содержимого. Предлагаемый способ гибридного усиления речи использует усиление с параметрическим кодированием при некоторых состояниях сигнала и усиление с кодированием формы сигнала при остальных состояниях сигнала. Другими аспектами являются способы генерирования битового потока, указывающего на звуковую программу, включающую речевое и другое содержимое, так что гибридное усиление речи может быть выполнено в отношении программы, декодер, включающий буфер, который хранит по меньшей мере один сегмент кодированного битового аудиопотока, сгенерированного любым вариантом осуществления способа изобретения, и система или устройство, выполненное с возможностью выполнения любого варианта осуществления способа изобретения. По меньшей мере некоторые из операций усиления речи выполнены принимающим аудиодекодером с использованием метаданных усиления речи средних/побочных каналов, сгенерированных расположенным выше по потоку аудиокодером. 8 н. и 29 з.п. ф-лы, 11 ил.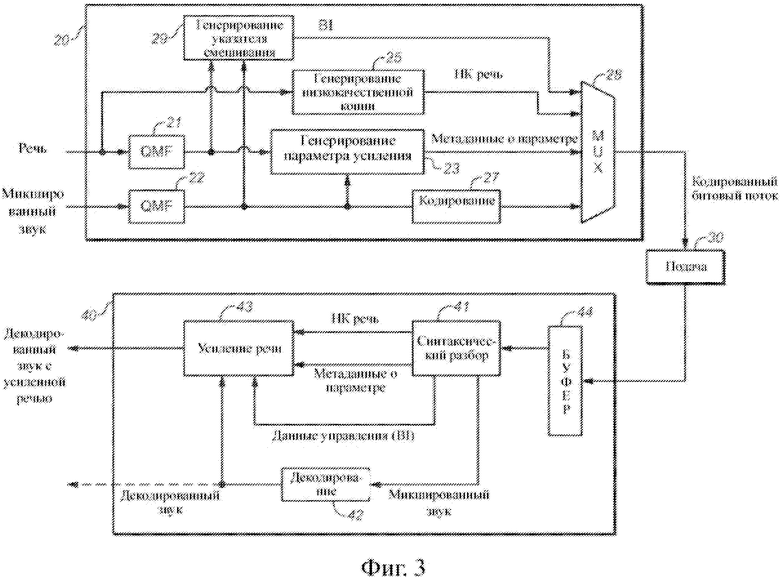
1. Способ кодирования речевого сигнала, включающий:
прием микшированного звукового содержимого в исходном представлении звуковых каналов, которое распределено по множеству звуковых каналов исходного представления звуковых каналов, при этом микшированное звуковое содержимое содержит микширование речевого содержимого и неречевого звукового содержимого;
преобразование одной или более частей микшированного звукового содержимого, которые распределены по двум или более каналам, отличным от средних/побочных (отличным от M/S), во множестве звуковых каналов исходного представления звуковых каналов, в одну или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов, которые распределены по одному или более каналам представления M/S звуковых каналов, при этом представление M/S звуковых каналов содержит по меньшей мере средний канал и побочный канал, при этом средний канал представляет собой взвешенную или невзвешенную сумму двух каналов исходного представления звуковых каналов и при этом побочный канал представляет взвешенную или невзвешенную разность двух каналов исходного представления звуковых каналов;
определение метаданных для усиления речи одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов; и
генерирование звукового сигнала, который содержит микшированное звуковое содержимое и метаданные для усиления речи одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов;
при этом способ выполняют посредством одного или более вычислительных устройств.
2. Способ по п. 1, отличающийся тем, что микшированное звуковое содержимое находится в представлении звуковых каналов, отличных от M/S.
3. Способ по любому из предыдущих пунктов, отличающийся тем, что дополнительно включает:
генерирование версии речевого содержимого в представлении M/S звуковых каналов, отделенной от микшированного звукового содержимого; и
вывод звукового сигнала, кодированного с использованием версии речевого содержимого в представлении M/S звуковых каналов.
4. Способ по п. 3, отличающийся тем, что дополнительно включает:
генерирование данных, указывающих на смешивание, указывающих на конкретное количественное сочетание первого и второго типов усиления речи, подлежащего генерированию принимающим аудиодекодером, при этом первый тип усиления речи представляет собой усиление речи на основе версии речевого содержимого в представлении M/S звуковых каналов и при этом второй тип усиления речи представляет собой усиление речи с параметрическим кодированием на основе восстановленной версии речевого содержимого в представлении M/S звуковых каналов; и
вывод звукового сигнала, кодированного с использованием данных, указывающих на смешивание.
5. Способ по п. 4, отличающийся тем, что по меньшей мере часть метаданных для усиления речи позволяет принимающему аудиодекодеру восстанавливать восстановленную версию речевого содержимого в M/S представлении из микшированного звукового содержимого в исходном представлении звуковых каналов.
6. Способ по п. 4, отличающийся тем, что данные, указывающие на смешивание, генерируются на основе по меньшей мере частично одного или более значений SNR для одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов, при этом одно или более значений SNR представляют одно или более отношений мощности речевого содержимого и неречевого звукового содержимого одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов или отношений мощности речевого содержимого и общего звукового содержимого одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов.
7. Способ по п. 4, отличающийся тем, что конкретное количественное сочетание первого и второго типов усиления речи определяется моделью слухового маскирования, в которой первый тип усиления речи представляет наибольшую относительную величину усиления речи во множестве сочетаний усилений речи во множестве сочетаний первого и второго типов усиления речи, которая гарантирует, что шум кодирования не будет нежелательно слышимым в выходной звуковой программе с усиленной речью.
8. Способ по п. 1, отличающийся тем, что по меньшей мере часть метаданных для усиления речи позволяет принимающему аудиодекодеру восстанавливать версию речевого содержимого в M/S представлении из микшированного звукового содержимого в исходном представлении звуковых каналов.
9. Способ по п. 1, отличающийся тем, что метаданные для усиления речи содержат метаданные, относящиеся к одной или более операциям усиления речи в представлении M/S звуковых каналов на основе версии речевого содержимого или операциям усиления речи с параметрическим кодированием в представлении M/S звуковых каналов.
10. Способ по п. 1, отличающийся тем, что исходное представление звуковых каналов содержит звуковые каналы, относящиеся к динамикам объемного звучания.
11. Способ по п. 1, отличающийся тем, что два или более каналов, отличных от M/S, исходного представления звуковых каналов содержат два или более центральных каналов, левых каналов или правых каналов; и при этом один или более M/S каналов представления M/S звуковых каналов содержат один или более средних каналов или побочных каналов.
12. Способ по п. 1, отличающийся тем, что метаданные для усиления речи содержат один набор метаданных усиления речи, относящихся к среднему каналу представления M/S звуковых каналов.
13. Способ по п. 1, отличающийся тем, что дополнительно включает предотвращение кодирования одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов в качестве части звукового сигнала.
14. Способ по п. 1, отличающийся тем, что метаданные для усиления речи представляют собой часть всех аудиометаданных, кодированных в звуковом сигнале.
15. Способ по п. 1, отличающийся тем, что аудиометаданные, кодированные в звуковом сигнале, содержат поле данных для указания наличия метаданных для усиления речи.
16. Способ по п. 1, отличающийся тем, что звуковой сигнал является частью аудиовизуального сигнала.
17. Способ усиления речевого сигнала, включающий:
прием звукового сигнала, который содержит микшированное звуковое содержимое в исходном представлении звуковых каналов и метаданные для усиления речи, при этом микшированное звуковое содержимое имеет микширование речевого содержимого и неречевого звукового содержимого;
преобразование одной или более частей микшированного звукового содержимого, которые распределены по двум или более каналам, отличным от M/S, во множестве звуковых каналов исходного представления звуковых каналов, в одну или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов, которые распределены по одному или более M/S каналам представления M/S звуковых каналов, при этом представление M/S звуковых каналов содержит по меньшей мере средний канал и побочный канал, при этом средний канал представляет собой взвешенную или невзвешенную сумму двух каналов исходного представления звуковых каналов и при этом побочный канал представляет собой взвешенную или невзвешенную разность двух каналов исходного представления звуковых каналов;
выполнение одной или более операций усиления речи на основе метаданных усиления речи в отношении одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов для генерирования одной или более частей усиленного речевого содержимого в M/S представлении;
объединение одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов с одной или более частями улучшенного речевого содержимого в M/S представлении для генерирования одной или более частей микшированного звукового содержимого с усиленной речью в M/S представлении;
при этом способ выполняют посредством одного или более вычислительных устройств.
18. Способ по п. 17, отличающийся тем, что этапы преобразования, выполнения и объединения реализуют в одной операции, которую выполняют в отношении одной или более частей микшированного звукового содержимого, которые распределяются по двум или более каналам, отличным от M/S, во множестве звуковых каналов исходного представления звуковых каналов.
19. Способ по любому из пп. 17-18, отличающийся тем, что дополнительно включает обратное преобразование одной или более частей микшированного звукового содержимого с усиленной речью в M/S представлении в одну или более частей микшированного звукового содержимого с усиленной речью в исходном представлении звуковых каналов.
20. Способ по п. 17, отличающийся тем, что дополнительно включает:
извлечение версии речевого содержимого в представлении M/S звуковых каналов, отделенной от микшированного звукового содержимого из звукового сигнала; и
выполнение одной или более операций усиления речи на основе по меньшей мере части метаданных для усиления речи в отношении одной или более частей версии речевого содержимого в представлении M/S звуковых каналов для генерирования одной или более вторых частей усиленного речевого содержимого в представлении M/S звуковых каналов.
21. Способ по п. 20, отличающийся тем, что дополнительно включает:
определение данных, указывающих на смешивание, для усиления речи;
генерирование на основе данных, указывающих на смешивание, для усиления речи конкретного количественного сочетания двух типов усиления речи, при этом первый тип усиления речи основан на версии речевого содержимого в представлении M/S звуковых каналов и второй тип усиления речи представляет собой усиление речи с параметрическим кодированием на основе восстановленной версии речевого содержимого в представлении M/S звуковых каналов.
22. Способ по п. 21, отличающийся тем, что данные, указывающие на смешивание, генерируются одним из следующего: расположенным выше по потоку аудиокодером, который генерирует звуковой сигнал, или принимающим аудиодекодером, который принимает звуковой сигнал, на основе по меньшей мере частично одного или более значений SNR для одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов, при этом одно или более значений SNR представляют одно или более отношений мощности речевого содержимого и неречевого звукового содержимого одной или более частей преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов или отношений мощности речевого содержимого и общего звукового содержимого одной или более частей одного из следующего: преобразованного микшированного звукового содержимого в представлении M/S звуковых каналов или микшированного звукового содержимого в исходном представлении звуковых каналов.
23. Способ по любому из пп. 21-22, отличающийся тем, что конкретное количественное сочетание двух типов усиления речи определяется моделью слухового маскирования как произведено одним из следующего: расположенным выше по потоку аудиокодером, который генерирует звуковой сигнал, или принимающим аудиодекодером, который принимает звуковой сигнал, в котором первый тип усиления речи представляет наибольшую относительную величину усиления речи во множестве сочетаний усилений речи во множестве сочетаний первого и второго типов усиления речи, которая гарантирует, что шум кодирования не будет нежелательно слышимым в выходной звуковой программе с усиленной речью.
24. Способ по п. 17, отличающийся тем, что по меньшей мере часть метаданных для усиления речи позволяет принимающему аудиодекодеру восстанавливать версию речевого содержимого в M/S представлении из микшированного звукового содержимого в исходном представлении звуковых каналов.
25. Способ по п. 17, отличающийся тем, что метаданные для усиления речи содержат метаданные, относящиеся к одной или более операциям усиления речи в представлении M/S звуковых каналов на основе версии речевого содержимого или операциям усиления речи с параметрическим кодированием в представлении M/S звуковых каналов.
26. Способ по п. 17, отличающийся тем, что исходное представление звуковых каналов содержит звуковые каналы, относящиеся к динамикам объемного звучания.
27. Способ по п. 17, отличающийся тем, что два или более каналов, отличных от M/S, исходного представления звуковых каналов содержат один или более центральных каналов, левых каналов или правых каналов; и при этом один или более M/S каналов представления M/S звуковых каналов содержат один или более средних каналов или побочных каналов.
28. Способ по п. 17, отличающийся тем, что метаданные для усиления речи содержат один набор метаданных усиления речи, относящихся к среднему каналу представления M/S звуковых каналов.
29. Способ по п. 17, отличающийся тем, что метаданные для усиления речи представляют собой часть всех аудиометаданных, кодированных в звуковом сигнале.
30. Способ по п. 17, отличающийся тем, что аудиометаданные, кодированные в звуковом сигнале, содержат поле данных для указания наличия метаданных для усиления речи.
31. Способ по п. 17, отличающийся тем, что звуковой сигнал является частью аудиовизуального сигнала.
32. Система обработки медиаданных, выполненная с возможностью выполнения способа по любому из пп. 1-16.
33. Устройство, содержащее процессор и выполненное с возможностью выполнения способа по любому из пп. 1-16.
34. Постоянный машиночитаемый носитель данных, содержащий программные команды, которые при исполнении одним или более процессорами приводят к выполнению способа по любому из пп. 1-16.
35. Система обработки медиаданных, выполненная с возможностью выполнения способа по любому из пп. 17-31.
36. Устройство, содержащее процессор и выполненное с возможностью выполнения способа по любому из пп. 17-31.
37. Постоянный машиночитаемый носитель данных, содержащий программные команды, которые при исполнении одним или более процессорами приводят к выполнению способа по любому из пп. 17-31.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 7080007 B2, 18.07.2006 | |||
| US 7231344 B2, 12.06.2007 | |||
| US 7844452 B2, 20.11.2010 | |||
| УСТРОЙСТВО И СПОСОБ ДЛЯ ГЕНЕРАЦИИ МНОГОКАНАЛЬНОГО СИГНАЛА, ИСПОЛЬЗУЮЩИЕ ОБРАБОТКУ ГОЛОСОВОГО СИГНАЛА | 2008 |
|
RU2461144C2 |

