ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Данная заявка на изобретение заявляет приоритет предварительной заявки на патент США № 61/046271, поданной 18 апреля 2008, которая путем ссылки включается в данный документ во всей своей полноте.
УРОВЕНЬ ТЕХНИКИ
Данное изобретение, в общем, относится к обработке звуковых сигналов, а более конкретно, к улучшению четкости диалога и устной речи, в частности, в объемном развлекательном звуковом сопровождении.
Подходы, описанные в данном разделе документа, не представляют собой предшествующий уровень техники по отношению к формуле изобретения в данной заявке и не могут быть признаны как предшествующий уровень техники из-за включения в данный раздел, если только не указано обратное.
Современное развлекательное звуковое сопровождение с многочисленными одновременными звуковыми каналами (система объемного звука) предоставляет слушателям реалистичные звуковые окружения с эффектом погружения, имеющие колоссальное развлекательное значение. В таких окружениях многие звуковые элементы, такие как диалог, музыка и звуковые эффекты, представлены одновременно и конкурируют, отвлекая внимания слушателя. Для некоторых членов аудитории - особенно со сниженными слуховыми рецепторами или с замедленным когнитивным восприятием - диалог и устная речь могут быть трудны для понимания в течение некоторых частей программы, в которых представлены громкие конкурирующие звуковые элементы. В течение таких эпизодов для этих слушателей было бы полезно, если бы уровень конкурирующих звуков снизился.
Осознание того, что музыка и эффекты могут подавлять диалог, не ново, и было предложено несколько способов для исправления этой ситуации. Однако, как будет кратко изложено далее, эти предлагаемые способы либо несовместимы с современной практикой широковещательных передач, накладывают излишне высокую плату на всю индустрию развлечений, или и то и другое.
В производстве объемного звукового сопровождения в кино и на телевидении общепринятой практикой является размещение большей части диалога и устной речи только в один канал (центральный канал, его называют также речевым каналом). Обычно музыка, звуки окружающей среды и звуковые эффекты микшируются как в речевом, так и во всех остальных каналах (например, в Левом [L], Правом [R], Левом объемном [ls] и в Правом объемном [rs] каналах, их называют также неречевыми каналами). В результате этого речевой канал переносит большую часть речевого и значительное количество неречевого звукового сопровождения, содержащегося в звуковой программе, тогда как неречевые каналы переносят, преимущественно, неречевое звуковое сопровождение, но также могут переносить небольшое количество речи. Один простой подход к облегчению воспринимаемости диалога или устной речи в этих употребительных музыкальных смесях заключается в постоянном снижении уровня громкости всех неречевых каналов, относительно уровня громкости речевого канала, к примеру, на 6 dB. Этот подход простой и эффективный, и он практикуется в наши дни (например, система восстановления звука SRS [Sound Retrieval System] для чистоты диалога (Dialog Clarity) или модифицированные уравнения понижающего микширования в объемных декодерах). Однако он страдает, по меньшей мере, одним недостатком: постоянное ослабление неречевых каналов может до такой степени понизить уровень громкости спокойных звуков окружающей среды, которые не мешают восприятию речи, что их невозможно будет услышать. При ослаблении не мешающих звуков окружающей среды нарушается эстетический баланс передачи без какой-либо пользы для понимания речи слушателями.
Альтернативное решение описано в серии патентов авторов Vaudrey и Saunders (U.S. Patent № 7266501, U.S. Patent № 6772127, U.S. Patent № 6912501 и U.S. Patent № 6650755). Насколько понятно, их подход подразумевает модификацию содержания и распределения продукции. Согласно этой конфигурации, потребитель получает два различных звуковых сигнала. Первый из этих сигналов содержит “Главное содержание” звукового сопровождения. Во многих случаях этот сигнал всецело поглощается речью, но, по желанию продюсера продукции, он может содержать также и другие типы сигналов. Второй сигнал содержит "Вторичное содержание" звукового сопровождения, которое сложено из всех оставшихся звуковых элементов. Пользователю предоставлено управление относительными уровнями громкости этих двух сигналов либо посредством ручной настройки уровня громкости каждого из сигналов, либо посредством автоматической поддержки отношения мощностей, выбранного пользователем. Хотя эта конфигурация помогает ограничить излишнее ослабление не мешающих звуков окружающей среды, ее широкому распространению мешает несовместимость с устоявшимися способами производства и распределения продукции.
Другой пример способа управления относительными уровнями громкости речевого и неречевого звукового сопровождения был предложен автором Bennett в U.S. Application Publication No. 20070027682.
Все примеры на предшествующем уровне техники разделяют один общий недостаток: они не предоставляют никаких технических средств минимизации воздействия, которое оказывает повышение четкости диалога на систему звучания, подразумеваемую создателем программы, помимо других изъянов. Следовательно, объектом данного изобретения является предоставление технических средств для ограничения уровня громкости неречевых каналов в традиционно микшированной многоканальной развлекательной программе таким образом, чтобы речь оставалась понятной, в то время как поддерживалась бы также воспринимаемость неречевых звуковых компонент.
Таким образом, имеется потребность в улучшенных методиках поддержки воспринимаемости речи. Данное изобретение решает эти и другие проблемы посредством предоставления устройства и способа улучшения воспринимаемости речи в многоканальном звуковом сигнале.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Воплощения данного изобретения улучшают воспринимаемость речи. В одном воплощении данное изобретение включает в себя способ улучшения воспринимаемости речи в многоканальном звуковом сигнале. Этот способ включает в себя сравнение первой характеристики и второй характеристики многоканального звукового сигнала для генерации коэффициента ослабления. Эта первая характеристика соответствует первому каналу этого многоканального звукового сигнала, который содержит речевые и неречевые звуковые сигналы, а вторая характеристика соответствует второму каналу этого многоканального звукового сигнала, который, преимущественно, содержит неречевые звуковые сигналы. Этот способ дополнительно включает в себя корректировку этого ослабляющего коэффициента, согласно с оценкой вероятности речи, для генерации скорректированного ослабляющего коэффициента. Этот способ дополнительно включает в себя ослабление второго канала с использованием этого скорректированного ослабляющего коэффициента.
Первый аспект этого изобретения основан на наблюдении, что речевой канал типичной развлекательной программы на протяжении значительной части этой программы переносит неречевой сигнал. Поэтому, согласно этому первому аспекту изобретения, маскировка речевого звукового сопровождения неречевым звуковым сопровождением может управляться посредством: (a) определения ослабления сигнала в неречевом канале, необходимого для того, чтобы предел отношения мощности сигнала в неречевом канале к мощности сигнала в речевом канале не превосходил заранее определенной пороговой величины, и (b) градуировки этого ослабления посредством коэффициента, который монотонно связан с оценкой вероятности того, что сигнал в речевом канале является речью, и (c) применения этого градуированного ослабления.
Второй аспект этого изобретения основан на наблюдении, что отношение мощности речевого сигнала к мощности маскирующего сигнала является плохим показателем для прогноза воспринимаемости речи. Поэтому, согласно этому второму аспекту изобретения, ослабление сигнала в неречевом канале, которое необходимо для поддержки заранее определенного уровня воспринимаемости речи, вычисляется посредством прогнозирования воспринимаемости речевого сигнала в присутствии неречевых сигналов посредством прогнозирующей модели воспринимаемости речи, основанной на психоакустике.
Третий аспект этого изобретения основан на наблюдениях, что, если ослаблению разрешить меняться в зависимости от частоты, то (a) заданный уровень воспринимаемости речи может быть достигнут посредством многих схем ослабления, и (b) различные схемы ослабления могут вырабатывать различные уровни интенсивности или отчетливости неречевого звукового сопровождения. Поэтому, согласно этому третьему аспекту изобретения, маскировка речевого звукового сопровождения неречевым звуковым сопровождением управляется посредством нахождения схемы ослабления, которая максимизирует интенсивность или некоторые другие показатели отчетливости неречевого звукового сопровождения при ограничении, что достигается заранее определенный уровень прогнозной воспринимаемости речи.
Воплощения данного изобретения могут быть осуществлены как способы или технологический процесс. Эти способы могут быть реализованы как электронная схема, как оборудование или программное обеспечение сопровождения или как комбинация вышеупомянутого. Электронная схема, обычно используемая для реализации этого технологического процесса, может представлять собой специализированную электронную схему (исполняющую только специфические задание) или общую электронную схему (запрограммированную для осуществления одного или нескольких конкретных заданий).
Следующее подробное описание и сопутствующие чертежи обеспечивают более хорошее понимание сущности и преимуществ данного изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
ФИГ.1 демонстрирует процессор сигналов, согласно одному воплощению данного изобретения.
ФИГ.2 демонстрирует процессор сигналов, согласно другому воплощению данного изобретения.
ФИГ.3 демонстрирует процессор сигналов, согласно другому воплощению данного изобретения.
ФИГ.4A и ФИГ.4B представляют собой структурные диаграммы, которые демонстрируют дополнительные вариации воплощений по чертежам 1-3.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Здесь описаны технические приемы для поддержки воспринимаемости речи. В последующем описании, с целью объяснения, приведены многочисленные примеры и конкретные технические подробности для предоставления полного понимания данного изобретения. Однако специалистам в данной области техники будет ясно, что данное изобретение, как это определено в формуле изобретения, может включать в себя некоторые или все признаки только этих примеров или в комбинации с другими признаками, описанными ниже, и может дополнительно включать в себя модификации или эквиваленты признаков и концепций, описанных в данном документе.
Различные способы и технологические процессы описываются ниже. То, что они описываются в определенном порядке, сделано в основном для облегчения изложения. Следует понимать, что конкретные этапы при желании могут быть осуществлены в другом порядке или параллельно, в зависимости от различных реализаций. Если некоторый конкретный этап должен предшествовать или следовать за другим этапом, это будет точно указано, если только это не ясно из контекста.
Принцип первого воплощения изобретения демонстрирует ФИГ.1. Ссылаясь теперь на ФИГ.1, принимается многоканальный сигнал, состоящий из речевого канала (101) и двух неречевых каналов (102 и 103). Мощности сигналов в каждом из этих каналов измеряются группой блоков оценки мощности (104, 105 и 106) и выражаются в логарифмической шкале [dB]. Эти блоки оценки мощности могут иметь механизм сглаживания, такой как интегратор утечек, с тем, чтобы результат измерения уровня мощности отражал уровень мощности, усредненный по длительности предложения или всего речевого эпизода. Этот уровень мощности в речевом канале вычитается из уровня мощности в каждом из неречевых каналов (посредством блоков суммирования 107 и 108), чтобы получить показатель разности уровней мощности между этими двумя типами сигналов. Контур сравнения 109 определяет для каждого неречевого канала количество dB, на которое этот неречевой канал должен быть ослаблен для того, чтобы его уровень мощности оставался, по меньшей мере, на ϑ dB ниже уровня мощности сигнала в речевом канале. (Символ "ϑ" обозначает переменную и на него также можно ссылаться как на букву тэта рукописного шрифта). Согласно одному воплощению, одной из реализаций этого является прибавление этой пороговой величины ϑ (которая хранится в электронном контуре 110) к разности уровней мощности (этот промежуточный результат называют допуском) с ограничением, чтобы этот результат был равен или меньше чем нуль (посредством блоков ограничения 111 и 112). Этот результат является приращением (или инвертированным ослаблением) в dB, которое должно быть применено к неречевым каналам для того, чтобы поддерживать уровень их мощности на ϑ dB ниже уровня мощности речевого канала. Подходящее значение величины ϑ составляет 15 dB. Это значение величины ϑ при желании может быть скорректировано в других воплощениях.
Так как имеет место однозначное соответствие между показателем, выраженным в логарифмической шкале (dB), и тем же самым показателем, выраженным в линейной шкале, может быть изготовлен электронный контур, который эквивалентен ФИГ.1, в котором мощность, приращение и пороговая величина выражаются в линейной шкале. В этой реализации все разности уровней заменяются отношениями линейных оценок. В альтернативной реализации можно заменить этот показатель мощности показателем, который связан с силой сигнала, таким как абсолютная величина сигнала.
Следует упомянуть, что одним из важных признаков этого первого аспекта изобретения является градуировка полученного таким образом приращения посредством оценки, монотонно связанной с вероятностью того, что сигнал в речевом канале действительно является речью. Все еще ссылаясь на ФИГ.1, принимается управляющий сигнал (113) и умножается с приращениями (посредством блоков умножения 114 и 115). Эти градуированные приращения затем применяются к соответствующим неречевым каналам (посредством усилителей 116 и 117) для выработки модифицированных сигналов L' и R' (118 и 119). Управляющий сигнал (113) обычно является автоматически полученным показателем вероятности того, что сигнал в речевом канале является речью. Могут использоваться различные способы автоматического определения вероятности того, что сигнал является речью. Согласно одному воплощению, процессор 130 вероятности речи генерирует значение вероятности речи p (113) из информации в C канале 101. Один из примеров такого механизма описывается авторами Robinson и Vinton в "Automated Speech/Other Discrimination for Loudness Monitoring" (Audio Engineering Society, Preprint number 6437 of Convention 118, May 2005). В качестве альтернативы, этот управляющий сигнал (113) может быть создан вручную, например создателем программы, и передан вместе со звуковым сигналом конечному пользователю.
Специалисты в данной области техники без труда поймут, как эта конфигурация может быть распространена на любое количество входных каналов.
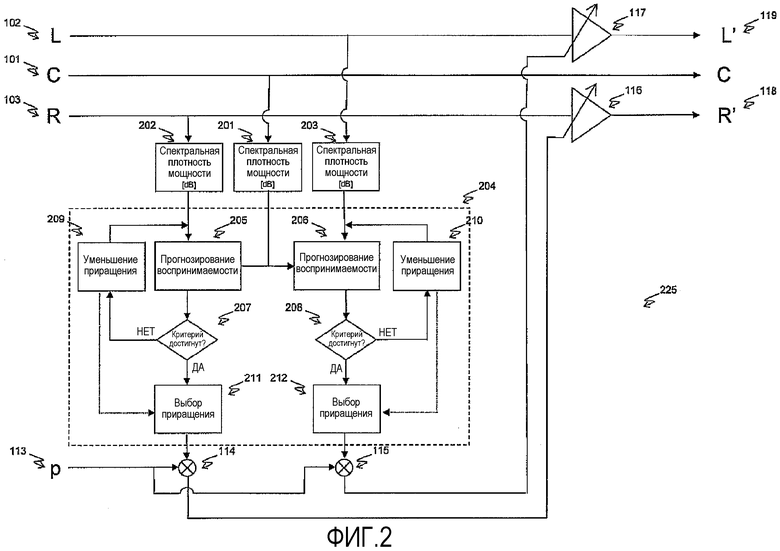
ФИГ.2 демонстрирует принцип второго аспекта изобретения. Ссылаясь теперь на ФИГ.2, принимается многоканальный сигнал, состоящий из речевого канала (101) и двух неречевых каналов (102 и 103). Мощности сигналов в каждом из этих каналов измеряются группой блоков оценки мощности (201, 202 и 203). В отличие от соответствующей группы блоков на ФИГ.1, эти блоки оценки мощности измеряют распределение мощности сигнала относительно частоты, что в результате дает спектр мощности, а не единственное число. Это спектральное разрешение спектра мощности идеально соответствует спектральному разрешению модели прогнозирования воспринимаемости речи (205 и 206, это пока еще не обсуждалось).
Эти два спектра мощности загружаются в контур 204 сравнения. Этот блок предназначен для определения ослабления, которое следует применить к каждому из неречевых каналов для обеспечения того, чтобы неречевой канал не уменьшил воспринимаемость речи сигнала в речевом канале до величины, которая меньше чем заранее определенный критерий. Это функциональное средство осуществляется посредством использования контуров прогнозирования воспринимаемости речи (205 и 206), которые прогнозируют воспринимаемость речи на основе спектров мощности речевого сигнала (201) и неречевых сигналов (202 и 203). Контуры 205 и 206 прогнозирования воспринимаемости речи могут реализовать подходящую модель прогнозирования воспринимаемости речи, в зависимости от выбранной архитектуры и выбора оптимальных соотношений. Примером этого является индекс воспринимаемости речи (Speech Intelligibility Index), подробно описанный в ANSI S3.5-1997 ("Methods for Calculation of the Speech Intelligibility Index"), и модель чувствительности распознавания речи (Speech Recognition Sensitivity model) авторов Muesch и Buus ("Using statistical decision theory to predict speech intelligibility. I. Model structure" Journal of the Acoustical Society of America, 2001, Vol 109, p 2896-2909). Ясно, что выходные данные модели прогнозирования воспринимаемости речи не имеют никакого смысла в случае, когда сигнал в речевых каналах является чем-то другим, отличным от речи. Несмотря на это, в последующем этот выходной результат модели прогнозирования воспринимаемости речи будет называться как прогнозная воспринимаемость речи. Отмеченная ошибка будет учтена в дальнейшей обработке посредством градуировки оценок приращения на выходе из контура 204 сравнения с параметром, который связан с вероятностью того, что сигнал является речью (113, это пока еще не обсуждалось).
Общая черта моделей прогнозирования воспринимаемости речи состоит в том, что они дают прогноз либо на улучшение, либо на неизменность воспринимаемости речи в результате снижения уровня громкости неречевого сигнала. Продвигаясь по структурной схеме этапов технологического процесса по ФИГ.2, контуры 207 и 208 сравнения сравнивают прогнозную воспринимаемость речи с оценкой критерия. Если оценка уровня неречевого сигнала низкая, так что прогнозная воспринимаемость речи превосходит критерий, параметр приращения, который исходно установлен на 0 dB, извлекается из контуров 209 или 210 и предоставляется на контуры 211 и 212 как выходной результат контура 204 сравнения. Если критерий не достигнут, параметр приращения уменьшается на фиксированную величину и прогнозирование воспринимаемости речи повторяется. Подходящий размер шага для уменьшения приращения равен 1 dB. Описанный здесь итеративный процесс продолжается до тех пор, пока прогнозная воспринимаемость речи не достигнет или превзойдет величину критерия. Конечно возможно такое, что сигнал в речевом канале таков, что критерий воспринимаемости речи не может быть достигнут даже при отсутствии сигнала в неречевом канале. Примером такой ситуации служит речевой сигнал очень низкого уровня или с чрезвычайно ограниченной полосой частот. Если такое произошло, наступит момент, когда никакое дополнительное сокращение приращения, применяемого к неречевому каналу, не оказывает эффекта на прогнозную воспринимаемость речи, и критерий никогда не может быть достигнут. В таких условиях, петля, образованная из (205, 206), (207, 208) и (209, 210), продолжается бесконечно, и может быть применен дополнительный логический блок для разрыва этой петли. Одним из особенно простых примеров такого логического блока может служить подсчет числа итераций и выход из петли, как только будет превзойдено заранее определенное количество итераций.
Продвигаясь по структурной схеме этапов технологического процесса по ФИГ.2, управляющий сигнал p (113) принимается и умножается на приращения (посредством блоков умножения 114 и 115). Управляющий сигнал (113) обычно будет представлять собой автоматически произведенный показатель вероятности того, что сигнал в речевом канале является речью. Способы автоматического определения вероятности того, что сигнал является речью, известны per se и обсуждались в контексте ФИГ.1 (см. процессор 130 вероятности речи). Эти скорректированные приращения затем применяются к своим соответствующим неречевым каналам (посредством блоков усиления 116 и 117) для выработки модифицированных сигналов R' и L' (118 и 119).
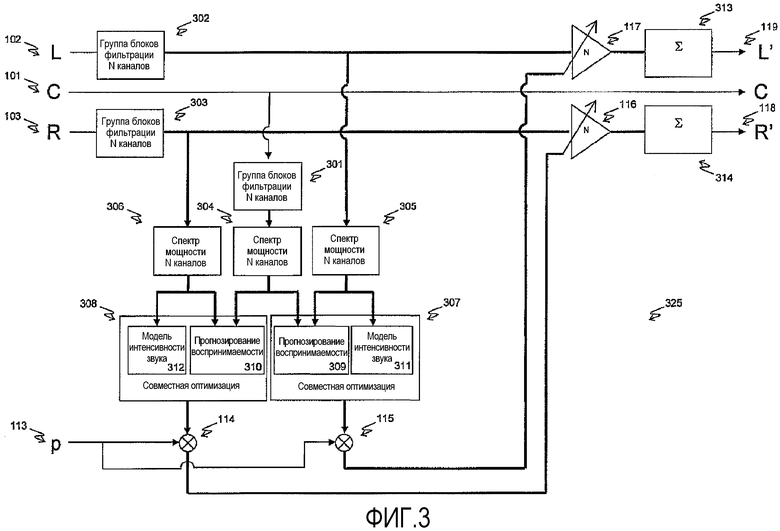
ФИГ.3 демонстрирует принцип третьего аспекта изобретения. Со ссылкой теперь на ФИГ.3, принимается многоканальный сигнал, состоящий из речевого канала (101) и двух неречевых каналов (102 и 103). Каждый из этих трех неречевых каналов разбивается на свои спектральные компоненты (посредством группы блоков 301, 302 и 303 фильтрации). Этот спектральный анализ может быть получен посредством N-канальной группы блоков фильтрации во временной области. Согласно одному воплощению, это разбиение диапазона частот группой блоков фильтрации на полосы частот в 1/3 октавы напоминает фильтрацию, которая, как предполагают, осуществляется внутри человеческого уха. Тот факт, что теперь сигнал состоит из N подсигналов, продемонстрирован посредством использования жирных линий. Процесс по ФИГ.3 может быть идентифицирован как разветвленный процесс (sidebranch process). Следуя по пути сигнала, каждый из этих N подсигналов, которые образуют неречевые каналы, градуируется посредством одним из членов множества из N оценок приращений (блоками усиления 116 и 117). Производство этих оценок приращений будет описано позднее. Далее, эти градуированные подсигналы воссоединяются в единый звуковой канал, это может быть сделано через простое суммирование (посредством контуров 313 и 314 суммирования). В качестве альтернативы, может быть использована группа фильтрующих блоков синтеза, которая соединена с группой фильтрующих блоков анализа. Результатом этого процесса являются модифицированные сигналы R' и L'(118 и 119).
Описывая теперь путь разветвленного процесса по ФИГ.3, каждое из выходных данных группы фильтрующих блоков отдается в распоряжение соответствующей группы из N блоков оценки (304, 305 и 306) мощности. Получившиеся в результате этого спектры служат в качестве входных данных для контуров (307 и 308) оптимизации, которые выдают в качестве выходных данных N-мерный вектор приращений. Эта оптимизация использует как контур (309 и 310) прогноза воспринимаемости речи, так и контур (311 и 312) вычисления интенсивности звука для нахождения вектора приращений, который максимизирует интенсивность звука в неречевом канале, при этом поддерживает заранее определенную оценку прогнозной воспринимаемости речи речевого сигнала. Подходящие модели для прогнозирования воспринимаемости речи обсуждались в связи с ФИГ.2. Контуры 311 и 312 вычисления интенсивности звука могут реализовать подходящую модель прогнозирования интенсивности звука, в зависимости от выбранной архитектуры и выбора оптимальных соотношений. Примерами подходящих моделей являются американский национальный стандарт (American National Standard) ANSI S3.4-2007 "Procedure for the Computation of Loudness of Steady Sounds" и немецкий стандарт (German standard) DIN 45631 "Berechnung des Lautstarkepegels und der Lautheit aus dem Gerauschspektrum".
В зависимости от имеющихся вычислительных ресурсов и наложенных ограничений, вид и сложность этих контуров (307, 308) оптимизации могут чрезвычайно сильно отличаться. Согласно одному воплощению используется итерационная многомерная оптимизация с ограничениями N свободных параметров. Каждый параметр представляет приращение, применяемое к каждой из полос частот в неречевом канале. Для нахождения максимума могут быть применены стандартные технические средства, такие как движение по пути наибольшего градиента в N-мерном пространстве. В другом воплощении, вычислительно менее требовательный подход ограничивает функциональные средства приращения-частота, как лежащие в малом множестве возможных функциональных средств приращения-частота, таком как множество различных спектральных градиентов или shelf-фильтров (super-hard extremely-low frequency). С такими дополнительными ограничениями задача оптимизации может быть сведена к малому количеству одномерных оптимизаций. Еще в одном воплощении осуществляется исчерпывающий поиск в очень маленьком множестве возможных функций приращения. Этот последний подход может оказаться особенно востребованным в приложениях в реальном времени, в которых требуется постоянная загрузка и скорость поиска.
Специалисты в данной области техники легко распознают дополнительные ограничения, которые могут быть наложены на оптимизацию, в соответствии с дополнительными воплощениями данного изобретения. Одним из примеров является ограничение, чтобы интенсивность звука модифицированного неречевого канала была не больше, чем интенсивность звука до модификации. Другой пример представляет собой ограничение на разности приращений между примыкающими полосами частот для того, чтобы ограничить возможности для временного искажения реконструирующей группой фильтрующих блоков (313, 314) или сократить возможности для нежелательных модификаций тембра. Желаемые ограничения зависят как от технической реализации группы блоков фильтрации, так и от выбора оптимальных соотношений между улучшением воспринимаемости речи и модификацией тембра. Для ясности демонстрации на ФИГ.3 эти ограничения опущены.
Продвигаясь по структурной схеме технологического процесса по ФИГ.3, принимается управляющий сигнал p (113) и умножается на приращения (посредством блоков умножения 114 и 115). Управляющий сигнал (113) обычно будет представлять собой автоматически произведенный показатель вероятности того, что сигнал в речевом канале является речью. Способы автоматического определения вероятности того, что сигнал является речью, обсуждались в связи с ФИГ.1 (см. процессор 130 вероятности речи). Эти скорректированные приращения затем применяются к своим соответствующим неречевым каналам (посредством блоков усиления 116 и 117), как это описано ранее.
ФИГ.4A и ФИГ.4B представляют собой структурные диаграммы, демонстрирующие вариации аспектов, показанных на ФИГ.1-3. Дополнительно, специалисты в данной области техники распознают несколько путей комбинирования элементов изобретения, описанных на чертежах 1-3.
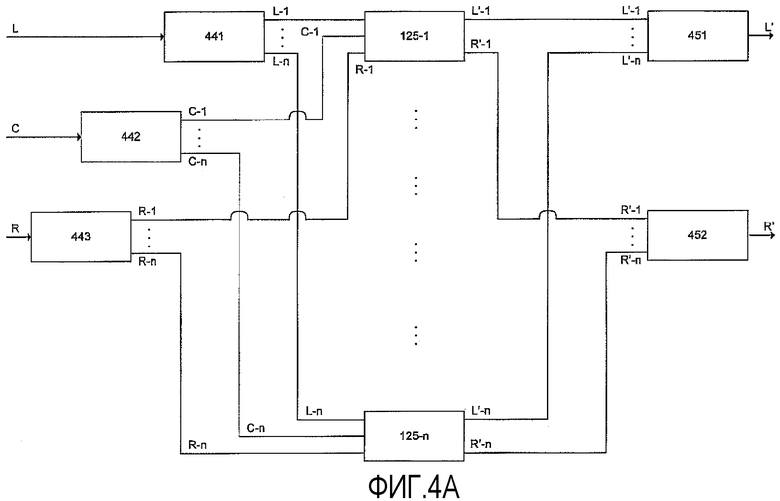
ФИГ.4A показывает, что конфигурация на ФИГ.1 также может быть применена к одной или нескольким подполосам частот сигналов L, C, и R. Более конкретно, каждый из этих сигналов L, C и R может быть пропущен через группу фильтрующих блоков (441, 442 и 443) для выработки трех множеств из n подполос полосы частот: {L1, L2, ..., Ln}, {C1, C2, ..., Cn} и {R1, R2, ..., Rn}. Подполосы, подходящие в пару, пропускаются в n экземпляров контура 125, продемонстрированного на ФИГ.1, и обработанные подсигналы рекомбинируются (посредством контуров суммирования 451 и 452). Для каждой из субполос могут быть выбраны отдельные пороговые величины ϑn. Хорошим выбором является множество, в котором ϑn пропорциональны среднему числу речевых тональных меток, переносимых в соответствующей области частот; то есть полосам на краях спектра частот приписываются меньшие пороговые величины, чем полосам, соответствующим доминирующим частотам речи. Эта реализация изобретения предлагает очень хороший выбор оптимальных соотношений между сложностью вычислений и производительностью системы.
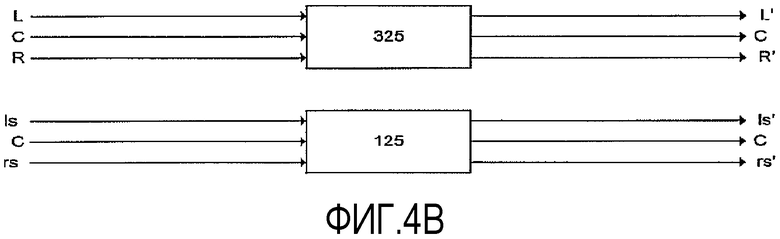
ФИГ.4B показывает другой вариант. Например, для снижения вычислительной нагрузки может быть улучшен типичный объемный звуковой сигнал с пятью каналами (C, L, R, ls и rs) посредством обработки сигналов L и R в соответствии с контуром 325, показанном на ФИГ.3, и сигналов ls и rs, которые обычно менее мощные, чем сигналы L и R, в соответствии с контуром 125, показанном на ФИГ.1.
В описаниях, приведенных выше, используются термины "речь" (или речевое звуковое сопровождение или речевой канал или речевой сигнал) и "не речь" (или неречевое звуковое сопровождение или неречевой канал или неречевой сигнал). Квалифицированный специалист в данной области техники поймет, что эти термины в большей мере используются для того, чтобы установить различие, а в меньшей мере для того, чтобы абсолютно описать содержание этих каналов. Например, в сцене фильма в ресторане, речевой канал преимущественно может нести в себе диалог за одним столом, а неречевые каналы могут нести в себе диалоги за другими столами (таким образом, оба канала несут "речь", как использовал бы этот термин не профессионал). Тем не менее, определенные воплощения данного изобретения направлены на ослабление именно диалогов за другими столами.
РЕАЛИЗАЦИИ ИЗОБРЕТЕНИЯ
Это изобретение может быть реализовано в виде оборудования или программного обеспечения сопровождения, или в виде комбинации и того, и другого (например, программируемые матрицы логических элементов). Если точно не указано, алгоритмы, включенные в состав изобретения, по существу не относятся к какому-либо конкретному компьютеру или другому устройству. В частности, могут быть использованы различные компьютеры общего пользования с программами, написанными в соответствии с тем, что объяснено в данном документе, или может оказаться более удобным сконструировать специализированное устройство (например, интегральную схему) для осуществления требуемых этапов способа.
Итак, это изобретение может быть реализовано в виде одной или нескольких компьютерных программ, исполняемых на одной или нескольких программируемых компьютерных системах, каждая из которых содержит, по меньшей мере, один процессор, по меньшей мере, одну систему хранения данных (включая долговременную и недолговременную память и/или элементы хранения данных), по меньшей мере, одно устройство ввода или порт ввода и, по меньшей мере, одно устройство вывода или порт вывода. Программный код применяет входные данные для осуществления функциональных средств, описанных здесь, и генерирует выходную информацию. Эта выходная информация, известным образом, направляется к одному или нескольким устройствам выхода.
Каждая такая программа может быть реализована на любом желаемом компьютерном языке (включая машинные, ассемблерные или процедурные, логические или объектно-ориентированные языки программирования) для работы с компьютерной системой. В любом случае, язык может быть транслируемым или интерпретируемым языком программирования.
Каждая такая компьютерная программа предпочтительно хранится в среде или устройстве хранения информации или загружается туда (например, твердотельная память или среда, или магнитная или оптическая среда), считываемая программируемым компьютером (специализированным или общего пользования), для настройки и функционирования этого компьютера после того, как компьютерная программа обратится к среде или устройству хранения информации для осуществления описанных здесь процедур. Может также быть рассмотрена реализация этой системы изобретения как читаемая компьютером среда хранения информации, оснащенная компьютерной программой, при этом среда хранения информации, настроенная таким образом, заставляет эту компьютерную систему функционировать специальным и заранее определенным образом для осуществления функциональных средств, описанных здесь.
Описание, приведенное выше, демонстрирует различные воплощения данного изобретения вместе с примерами того, как может быть реализовано данное изобретение. Примеры и воплощения, приведенные выше, не следует воспринимать как единственно возможные воплощения, и они представлены для демонстрации гибкости и преимущества данного изобретения, как это определено в последующей формуле изобретения. На основе раскрытия сущности изобретения, приведенного выше, и следующей формулы изобретения, специалистам в данной области техники будут ясны другие конфигурации, воплощения, реализации изобретения и их эквиваленты, которые могут быть использованы без отхода от духа и буквы этого изобретения, как это определено в формуле изобретения.
Изобретение относится к вычислительной технике. Технический результат заключается в улучшении слышимости речи в многоканальном звуковом сигнале. Способ поддержки воспринимаемости речи в многоканальном звуковом сигнале, в котором сравнивают первую характеристику и вторую характеристику многоканального звукового сигнала для формирования коэффициента ослабления, причем первая характеристика соответствует первому каналу многоканального звукового сигнала, который содержит речевой звук и неречевой звук, причем вторая характеристика соответствует второму каналу многоканального звукового сигнала, который содержит преимущественно неречевой звук; корректируют коэффициент усиления, применяемый ко второму спектру мощности, пока прогнозированная разборчивость речи не удовлетворит критерию; и используют скорректированный коэффициент усиления в качестве коэффициента ослабления, как только прогнозированная разборчивость речи удовлетворит критерию; корректируют коэффициент ослабления в соответствии со значением вероятности речи для формирования скорректированного коэффициента ослабления; и ослабляют второй канал с использованием скорректированного коэффициента ослабления. 4 н. и 10 з.п. ф-лы, 5 ил.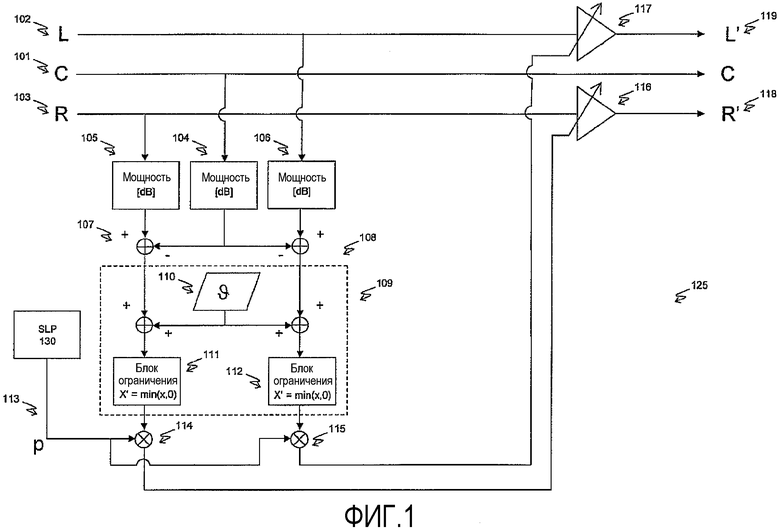
1. Способ поддержки воспринимаемости речи в многоканальном звуковом сигнале, при этом упомянутый способ содержит следующие этапы:
сравнивают первую характеристику и вторую характеристику многоканального звукового сигнала для формирования коэффициента ослабления, причем первая характеристика соответствует первому каналу многоканального звукового сигнала, который содержит речевой звук и неречевой звук, причем первая характеристика соответствует первому спектру мощности сигнала в первом канале, причем вторая характеристика соответствует второму каналу многоканального звукового сигнала, который содержит преимущественно неречевой звук, и причем вторая характеристика соответствует второму спектру мощности сигнала во втором канале, причем сравнение первой характеристики и второй характеристики содержит следующие операции:
выполняют прогнозирование разборчивости речи на основании первого спектра мощности и второго спектра мощности для формирования прогнозированной разборчивости речи;
корректируют коэффициент усиления, применяемый ко второму спектру мощности, пока прогнозированная разборчивость речи не удовлетворит критерию; и
используют скорректированный коэффициент усиления в качестве коэффициента ослабления, как только прогнозированная разборчивость речи удовлетворит критерию;
корректируют коэффициент ослабления в соответствии со значением вероятности речи для формирования скорректированного коэффициента ослабления; и
ослабляют второй канал с использованием скорректированного коэффициента ослабления.
2. Способ по п.1, дополнительно содержащий следующий этап:
обрабатывают многоканальный звуковой сигнал для формирования первой характеристики и второй характеристики.
3. Способ по п.1, дополнительно содержащий следующий этап:
обрабатывают первый канал для формирования значения вероятности речи.
4. Способ по п.1, в котором второй канал является одним из множества вторых каналов, при этом вторая характеристика является одной из множества вторых характеристик, причем коэффициент ослабления является одним из множества коэффициентов ослабления, и причем скорректированный коэффициент ослабления является одним из множества скорректированных коэффициентов ослабления, причем способ дополнительно содержит следующие этапы:
сравнивают первую характеристику и множество вторых характеристик для формирования множества коэффициентов ослабления;
корректируют множество коэффициентов ослабления в соответствии со значением вероятности речи для формирования множества скорректированных коэффициентов ослабления; и
ослабляют множество вторых каналов с использованием множества скорректированных коэффициентов ослабления.
5. Способ по п.1, в котором многоканальный звуковой сигнал содержит третий канал, который содержит преимущественно неречевой звук, при этом способ дополнительно содержит следующие этапы:
сравнивают первую характеристику и третью характеристику для формирования дополнительного коэффициента ослабления, причем третья характеристика соответствует третьему каналу;
корректируют дополнительный коэффициент ослабления в соответствии со значением вероятности речи для формирования скорректированного дополнительного коэффициента ослабления; и
ослабляют третий канал с использованием скорректированного коэффициента ослабления.
6. Способ по п.1, в котором второй спектр мощности содержит множество частотных полос, при этом этап сравнения первой характеристики и второй характеристики дополнительно содержит выполнение вычисления уровня громкости на основании второго спектра мощности для формирования вычисленного уровня громкости; причем этап коррекции коэффициента усиления дополнительно содержит коррекцию множества коэффициентов усиления, применяемых, соответственно, к каждой частотной полосе второго спектра мощности, пока прогнозированная разборчивость речи не удовлетворит критерию разборчивости речи и вычисленный уровень громкости не удовлетворит критерию уровня громкости; и причем этап использования коэффициента усиления содержит использование множества скорректированных коэффициентов усиления в качестве коэффициента ослабления для каждой частотной полосы, соответственно, как только прогнозированная разборчивость речи удовлетворит критерию разборчивости речи и вычисленный уровень громкости удовлетворит критерию уровня громкости.
7. Устройство поддержки воспринимаемости речи в многоканальном звуковом сигнале, содержащее схему для улучшения слышимости речи в многоканальном звуковом сигнале, при этом устройство содержит:
схему сравнения, которая выполнена с возможностью сравнения первой характеристики и второй характеристики многоканального звукового сигнала для формирования коэффициента ослабления, причем первая характеристика соответствует первому каналу многоканального звукового сигнала, который содержит речевой звук и неречевой звук, причем первая характеристика соответствует первому спектру мощности сигнала в первом канале, причем вторая характеристика соответствует второму каналу многоканального звукового сигнала, который содержит преимущественно неречевой звук, и причем вторая характеристика соответствует второму спектру мощности сигнала во втором канале, причем схема сравнения содержит:
схему прогнозирования разборчивости речи, которая выполнена с возможностью прогнозирования разборчивости речи на основании первого спектра мощности и второго спектра мощности для формирования прогнозированной разборчивости речи;
схему коррекции коэффициента усиления, которая выполнена с возможностью коррекции коэффициента усиления, применяемого ко второму спектру мощности, пока прогнозированная разборчивость речи не удовлетворит критерию; и
схему выбора коэффициента усиления, которая выполнена с возможностью выбора скорректированного коэффициента усиления в качестве коэффициента ослабления, как только прогнозированная разборчивость речи удовлетворит критерию;
умножитель, который выполнен с возможностью коррекции коэффициента ослабления в соответствии со значением вероятности речи, для формирования скорректированного коэффициента ослабления; и
усилитель, который выполнен с возможностью ослабления второго канала с использованием скорректированного коэффициента ослабления.
8. Устройство по п.7, в котором второй спектр мощности содержит множество частотных полос, и при этом схема сравнения дополнительно содержит:
схему вычисления уровня громкости, которая выполнена с возможностью выполнения вычисления уровня громкости на основании второго спектра мощности, для формирования вычисленного уровня громкости; и
схему оптимизации, которая выполнена с возможностью коррекции множества коэффициентов усиления, применяемых, соответственно, к каждой частотной полосе второго спектра мощности, пока прогнозированная разборчивость речи не удовлетворит критерию разборчивости речи и вычисленный уровень громкости не удовлетворит критерию уровня громкости, и которая использует множество скорректированных коэффициентов усиления в качестве коэффициента ослабления для каждой частотной полосы, соответственно, как только прогнозированная разборчивость речи удовлетворит критерию разборчивости речи и вычисленный уровень громкости удовлетворит критерию уровня громкости.
9. Устройство по п.7, дополнительно содержащее:
первый вычислитель спектральной плотности мощности, который выполнен с возможностью вычисления первого спектра мощности первого канала; и
второй вычислитель спектральной плотности мощности, который выполнен с возможностью вычисления второго спектра мощности второго канала.
10. Устройство по п.7, дополнительно содержащее:
первый набор фильтров, который выполнен с возможностью разбиения первого канала на первое множество спектральных составляющих;
первый набор блоков оценки мощности, который выполнен с возможностью вычисления первого спектра мощности по первому множеству спектральных составляющих;
второй набор фильтров, который выполнен с возможностью разбиения второго канала на второе множество спектральных составляющих; и
второй набор блоков оценки мощности, который выполнен с возможностью вычисления второго спектра мощности по второму множеству спектральных составляющих.
11. Устройство по п.7, дополнительно содержащее:
процессор определения речи, который выполнен с возможностью обработки первого канала, для формирования значения вероятности речи.
12. Носитель записи, содержащий компьютерную программу для улучшения слышимости речи в многоканальном звуковом сигнале, при этом компьютерная программа управляет устройством для выполнения обработки, содержащей:
сравнение первой характеристики и второй характеристики многоканального звукового сигнала для формирования коэффициента ослабления, причем первая характеристика соответствует первому каналу многоканального звукового сигнала, который содержит речевой звук и неречевой звук, причем первая характеристика соответствует первому спектру мощности сигнала в первом канале, причем вторая характеристика соответствует второму каналу многоканального звукового сигнала, который содержит преимущественно неречевой звук, и причем вторая характеристика соответствует второму спектру мощности сигнала во втором канале, причем сравнение содержит:
выполнение прогнозирования разборчивости речи на основании первого спектра мощности и второго спектра мощности для формирования прогнозированной разборчивости речи;
коррекцию коэффициента усиления, применяемого ко второму спектру мощности, пока прогнозированная разборчивость речи не удовлетворит критерию; и
использование скорректированного коэффициента усиления в качестве коэффициента ослабления, как только прогнозированная разборчивость речи удовлетворит критерию;
коррекцию коэффициента ослабления в соответствии со значением вероятности речи для формирования скорректированного коэффициента ослабления; и
ослабление второго канала с использованием скорректированного коэффициента ослабления.
13. Устройство поддержки воспринимаемости речи в многоканальном звуковом сигнале, при этом устройство содержит:
средство для сравнения первой характеристики и второй характеристики многоканального звукового сигнала для формирования коэффициента ослабления, причем первая характеристика соответствует первому каналу многоканального звукового сигнала, который содержит речевой звук и неречевой звук, причем первая характеристика соответствует первому спектру мощности сигнала в первом канале, причем вторая характеристика соответствует второму каналу многоканального звукового сигнала, который содержит преимущественно неречевой звук, и причем вторая характеристика соответствует второму спектру мощности сигнала во втором канале, причем средство для сравнения содержит:
средство для выполнения прогнозирования разборчивости речи на основании первого спектра мощности и второго спектра мощности для формирования прогнозированной разборчивости речи;
средство для коррекции коэффициента усиления, применяемого ко второму спектру мощности, пока прогнозированная разборчивость речи не удовлетворит критерию; и
средство для использования скорректированного коэффициента усиления в качестве коэффициента ослабления, как только прогнозированная разборчивость речи удовлетворит критерию;
средство для коррекции коэффициента ослабления в соответствии со значением вероятности речи для формирования скорректированного коэффициента ослабления; и
средство для ослабления второго канала с использованием скорректированного коэффициента ослабления.
14. Устройство по п.13, в котором второй спектр мощности содержит множество частотных полос, при этом средство для сравнения дополнительно содержит средство для выполнения вычисления уровня громкости на основании второго спектра мощности, для формирования вычисленного уровня громкости; причем средство для коррекции коэффициента усиления соответствует средству для коррекции множества коэффициентов усиления, применяемых, соответственно, к каждой частотной полосе второго спектра мощности, пока прогнозированная разборчивость речи не удовлетворит критерию разборчивости речи, и вычисленный уровень громкости не удовлетворит критерию уровня громкости; и средство для использования коэффициента усиления соответствует средству для использования множества скорректированных коэффициентов усиления в качестве коэффициента ослабления для каждой частотной полосы, соответственно, как только прогнозированная разборчивость речи удовлетворит критерию разборчивости речи и вычисленный уровень громкости удовлетворит критерию уровня громкости.
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 7050966 B2, 23.05.2006 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Вихретоковый толщиномер диэлектрических покрытий | 1984 |
|
SU1191814A1 |
| СПОСОБ ПОДАВЛЕНИЯ ШУМА В ИНФОРМАЦИОННОМ СИГНАЛЕ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2206960C1 |

