Настоящее изобретение относится к способам и системам классификации сердечных тонов, записанных от живого индивидуума, на классы, описывающие, присутствуют ли в сердечном тоне шумы по причине стеноза коронарной артерии.
Уровень техники
Заболевание коронарной артерии является отдельной наиболее распространенной причиной смерти от сердечно-сосудистых заболеваний в западном мире. Кровоснабжение сердечной мышцы происходит через коронарные артерии, и атеросклероз является наиболее распространенным патофизиологическим процессом, возникающим в коронарных артериях, дающим начало коронарной болезни сердца (CAD, КБС). Атеросклероз представляет собой процесс, в результате которого образуются бляшки внутри артерии, и, в связи с этим, кровоток может быть уменьшен или даже блокирован бляшкой. Постоянно работающее сердце требует непрерывного и эффективного кровоснабжения, чтобы работать должным образом. Дефекты в кровоснабжении могут быть очень тяжелыми и даже летальными. Постепенное уменьшения диаметра просвета или стеноз коронарной артерии сначала ограничивает резервный поток, затем уменьшает поток в покое и может, наконец, полностью окклюдировать сосуд.
Для клинических врачей и других профессионалов в области медицины существует потребность в измерении/обнаружении стеноза коронарной артерии для диагностики CAD. После того, как поставлен диагноз, можно начинать лечение.
В настоящее время существует несколько неинвазивных методик для измерения/обнаружения тяжести стеноза или его наличия в коронарной артерии. Это может быть выполнено с помощью магнитно-резонансной томографии (MPT, MPT), in vivo внутрисосудистого ультразвука (IVUS, ИВВУ) или оптической когерентной томографии (ОСТ, ОКТ). Однако все описанные выше методики довольно сложны и дороги для использования, и, в связи с этим, такое обследование предлагают только пациентам с особыми симптомами. Следствием является то, что при исследовании у большинства пациентов выявляют критический стеноз.
Клинические врачи и другие профессионалы в области медицины долгое время полагались на аускультационные звуки, такие как сердечно-сосудистые тоны, с тем, чтобы способствовать обнаружению и диагностике физиологических состояний. Например, клинический врач может использовать стетоскоп для контроля и записи сердечных тонов для обнаружения заболеваний сердечных клапанов. Кроме того, записанные сердечные тоны могут быть оцифрованы, сохранены и внесены в память в виде файлов данных для последующего анализа. Были разработаны устройства, которые применяют алгоритмы к записанным с помощью электронных средств аускультационным звукам. Одним примером является автоматизированное устройство, контролирующее кровяное давление. Другие примеры включают в себя системы анализа, которые пытаются автоматически регистрировать физиологические состояния на основании анализа аускультационных звуков. Например, в качестве одного возможного механизма для анализа аускультационных звуков и обеспечения автоматизированной диагностики или рекомендуемой диагностики обсуждали возможность применения искусственных нейронных сетей. Трудно обеспечить автоматизированное устройство для классификации аускультационных звуков в соответствии с коронарным стенозом с использованием данных обычных методик, поскольку очень трудно адаптировать данные методики для учета различий между людьми. Два различных человека могут по-разному влиять на аускультационные тоны, и аускультационные тоны двух пациентов могут быть различны даже при том, что оба человека страдают коронарным стенозом. Кроме того, часто трудно осуществить обычные методики способом, который может быть применен в реальном времени или псевдореальном времени для помощи клиническому врачу.
Множество клинических врачей для получения аускультационных звуков предпочитают использовать цифровой стетоскоп, поскольку они знакомы со стетоскопами, но качество аускультационных звуков, полученных цифровым стетоскопом очень часто низко по сравнению с аускультационными звуками, записанными более совершенными системами. Качество таких аускультационных звуков часто ухудшено, поскольку в ходе записи привносится побочный шум, например, вследствие трения между микрофоном и грудью пациента или по причине окружающего шума. Кроме того, очень хорошо знакомая ситуация, когда клинический врач делает запись аускультационного звука с использованием стетоскопа, поскольку расстояние между пациентом и клиническим врачом очень мало, и следствием является то, что аускультационная запись очень непродолжительна. В связи с этим, при использовании стетоскопа получают лишь небольшое количество данных, подходящих для проведения анализа заболевания коронарной артерии, и, в связи с этим, анализы, проводимые известными методиками, очень часто неправильны.
В US 5036857 раскрыты способ и система для неинвазивного обнаружения заболевания коронарной артерии. Способ содержит анализ диастолических сердечных тонов, обнаруженных в грудной полости пациента во время диастолической части сердечного цикла для идентифицирования низкоуровневой акустической компоненты, связанной с турбулентным кровотоком в частично окклюдированных коронарных артериях. Данные диастолические сердечные тоны моделируют с применением продвинутых технологий обработки сигналов, таких как авторегрессионный (AR, АР) способ, способ авторегрессионного скользящего усреднения (ARMA, АРСУ) и способ собственного вектора, которые позволяют надежно обозначить наличие такой акустической компоненты. Система включает в себя акустический преобразователь, устройство импульсного датчика, средство процессора сигналов и диагностический дисплей. Дополнительно система включает в себя контроллер для автоматического задания последовательности стадий сбора данных, анализа и вывода, в результате чего требуется минимальное взаимодействие с оператором. Данный способ и система анализируют уровень шума в диастолических сегментах, и диастолические сегменты с большим уровнем шума исключают и не используют в анализе низкоуровневых акустических компонент, связанных с турбулентным кровотоком в частично окклюдированных коронарных артериях. В связи с этим, для достижения точного анализа должно быть записано большое количество диастолических сегментов, и, в связи с этим, запись тонов должна быть очень длительной или повторена много раз. Это во многих клинических ситуациях невозможно, особенно при применении цифрового стетоскопа для записи сердечного тона.
Сущность изобретения
Целью настоящего изобретения является решение описанных выше проблем.
Она достигается с помощью способа классификации сердечно-сосудистого тона, записанного у живого индивидуума; указанный способ содержит этапы, на которых:
- идентифицируют диастолические и/или систолические сегменты указанного сердечно-сосудистого тона;
- разделяют, по меньшей мере, один из указанных идентифицированных диастолических и/или систолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент;
- извлекают из указанного первого подсегмента, по меньшей мере, первый параметр сигнала, характеризующий первое свойство указанного сердечно-сосудистого тона, извлекают из указанного второго подсегмента, по меньшей мере, второй параметр сигнала, характеризующего второе свойство указанного сердечно-сосудистого тона;
- классифицируют указанный сердечно-сосудистый тон с применением указанного, по меньшей мере, первого параметра сигнала и указанного, по меньшей мере, второго параметра сигнала многопараметрическим способом классификации.
Тем самым, обеспечивается очень устойчивый и простой способ, для которого требуется лишь малое количество данных сердечно-сосудистого тона для классификации тона. Следствием является то, что сердечно-сосудистые тоны могут быть классифицированы на основании кратковременной записи, которая очень удобна при записи тонов стетоскопом. Это достигнуто, поскольку диастолические и/или систолические сегменты сердечно-сосудистого тона разделены на подсегменты, и сердечно-сосудистый тон после этого классифицирован на основании параметров сигнала, извлеченных, по меньшей мере, из двух подсегментов из одного диастолического или систолического сегмента. Следствием является то, что классификация сердечно-сосудистого сигнала может быть основана только на подсегментах с хорошим отношением сигнал - шум; например, на подсегментах без трения или помех. В связи с этим, подсегменты с плохим отношением сигнал - шум могут быть исключены перед классификацией сердечно-сосудистого тона. Тем самым, требуется лишь малое количество записанного сердечно-сосудистого тона для достижения правильной классификации, поскольку лишь очень малая часть зарегистрированного сигнала должна быть исключена из-за шума. Сердечно-сосудистый тон, связанный с турбулентностью, содержит, по меньшей мере, две компоненты: широкополосную компоненту, вызванную турбулентным кровотоком, сталкивающимся с артериальной стенкой, и узкополосную компоненту, связанную с резонансной частотой стенки артерии. В связи с этим, необходимы различные переменные, описывающие различные свойства, для выполнения устойчивой классификации. Сердечно-сосудистый тон может дополнительно варьироваться от человека к человеку в связи с физическими различиями людей, например, структурой кости, толщиной грудной клетки, количеством жира и т.д. Настоящее изобретение устраняет данную вариацию за счет использования различных параметров сигнала при классификации сердечно-сосудистого тона. Например, могут быть использованы некоторые параметры сигнала от одного человека для значимой классификации сердечно-сосудистого тона, тогда как те же параметры сигнала от второго человека не подойдут для значимой классификации сердечно-сосудистого сигнала. Однако в данной ситуации могут быть использованы другие параметры сигнала для классификации сердечно-сосудистого тона от второго человека при применении способа в соответствии с настоящим изобретением. Дополнительно, некоторые параметры сигнала могут находиться под влиянием одного вида различий между людьми, и другие параметры сигнала могут находиться под влиянием других видов различий. В связи с этим, выбор множества различных параметров сигнала должен сделать способ классификации более устойчивым. Различные параметры сигнала описывают различные характеристики сердечно-сосудистого тона и, в связи с этим, должны быть некоррелированными, и, в связи с этим, должны предоставлять различную информацию сердечно-сосудистого тона. Различные параметры сигнала, например, могут представлять собой длительность диастолического сегмента сердечно-сосудистого тона, длительность систолического сердечно-сосудистого тона, наиболее преобладающую частотную компоненту тона, ширину полосы различных частотных компонент, энергию в двух частотных полосах, подвижность части сигнала, сложность сигнала, соотношение мощности между различными частями сигнала, например двумя различными сегментами или двумя различными частотными полосами, морфологические характеристики, такие как коэффициенты корреляции между различными сегментами или изменение амплитуды во времени, количество экстремальных точек в сигнале и т.д.. Способ может быть легко осуществлен в модуле процессора данных любого вида и, в связи с этим, например, интегрирован в программу, которую используют клинические врачи и доктора при классификации сердечно-сосудистого тона. Кроме того, способ может быть интегрирован в цифровой стетоскоп, и, в связи с этим, стетоскоп можно использовать для классификации сердечно-сосудистого тона пациента. Так как доктора и другие клинические врачи знакомы со стетоскопом, они могут быть легко обучены использованию стетоскопа для классификации сердечно-сосудистого тона. Результат состоит в том, что классификация может помочь доктору или другим клиническим врачам диагностировать, страдает ли пациент CAD.
Указанные, по меньшей мере, два параметра сигнала в другом варианте выполнения извлекают, по меньшей мере, из двух из указанного количества подсегментов. Тем самым, параметры сигнала, используемые в многопараметрическом способе классификации, могут быть извлечены из каждого из подсегментов, и затем можно было бы обеспечить большое количество того же вида параметров сигнала и использовать в многопараметрическом способе классификации. Это делает классификацию сердечно-сосудистого сигнала более устойчивой. Дополнительно, каждый подсегмент может быть классифицирован в многопараметрическом способе классификации.
По меньшей мере, первый параметр сигнала и/или, по меньшей мере, второй параметр сигнала в другом варианте выполнения извлекают как из указанного первого подсегмента, так и из указанного второго подсегмента. Тем самым, как первый, так и второй параметр сигнала могут быть извлечены из тех же под-подсегментов, и тогда сердечно-сосудистый сигнал может быть классифицирован на основании большого количества параметров сигнала, посредством чего увеличивается надежность классификации.
В другом варианте выполнения способ дополнительно содержит этап идентификации шумных подсегментов и исключения указанных шумных подсегментов до указанных этапов извлечения указанного первого параметра сигнала и/или извлечения указанного второго параметра сигнала. Шумные подсегменты тем самым могут быть исключены до извлечения параметров сигнала из подсегментов, и тем самым, качество извлеченных параметров сигнала будет существенно улучшено, потому что на характеристики тона, влияющие на параметры сигнала, не влияет шум. Шумные подсегменты, например, могут быть подсегментами с низким отношением сигнал-шум, как подсегменты с пиками от трения, подсегментами с шумом или подсегментами с физиологическим шумом, таким как шум дыхания. Шумные подсегменты могут быть идентифицированы по-разному, например, как подсегменты с амплитудой, распределением частоты или энергии, отличными от большинства подсегментов.
В другом варианте выполнения способ дополнительно содержит этап идентификации нестационарных подсегментов и этап исключения указанных нестационарных подсегментов до указанных этапов извлечения указанного первого параметра сигнала и/или извлечения указанного второго параметра сигнала. Тем самым, нестационарные подсегменты могут быть исключены перед извлечением параметров сигнала из подсегментов. Тем самым, можно учесть нестационарный тон в диастолическом сегменте, который часто имеет место, потому что кровоток в коронарной артерии не является постоянным во время диастолы, и, в связи с этим, шумы по причине стеноза должны быть нестационарными. Несколько способов обработки сигналов (например, модели AR), принимают условие стационарности моделируемого сигнала, и, в связи с этим, погрешность по причине нестабильности может быть преодолена путем разделения диастолического сегмента на подсегменты, поскольку можно предположить, что подсегменты в течение короткого промежутка времени являются стационарными. Поэтому точность параметров сигнала, извлеченных из моделей AR подсегментов должна быть более высокой.
В другом варианте выполнения способа, по меньшей мере, часть указанного первого подсегмента перекрывается, по меньшей мере, с частью указанного второго подсегмента. Перекрытие сегментов гарантирует, что при излечении параметров сигнала и классификации сердечно-сосудистого тона использовали максимально возможную часть диастолического/систолического сегмента, потому что сигнальные части без шума могли быть исключены вместе с подсегментами, содержащими короткий шумовой пик. Однако данные части сигнала должны быть включены в перекрывающийся сегмент, и, таким образом, при извлечении параметров сигнала и классификации сердечно-сосудистого тона используют большую часть сердечно-сосудистого тона.
Этап классификации сердечно-сосудистого тона содержит в другом варианте выполнения этап вычисления среднего значения указанного первого параметра сигнала и/или указанного, по меньшей мере, второго параметра сигнала, извлеченных из, по меньшей мере, двух из указанного количества подсегментов, и с применением указанного среднего значения в указанном многопараметрическом способе классификации. Затем параметры сигнала, используемые в способе классификации, могут быть рассчитаны, как среднее значение параметров сигнала из большого количества подсегментов, и тогда погрешности по причине случайного шума уменьшаются. Среднее значение может быть дополнительно рассчитано путем присваивания различных весовых коэффициентов различным подсегментам, например, так, что подсегментам в начале диастолического сегмента присваивают более высокие весовые коэффициенты, чем подсегментам в конце диастолического сегмента. Тем самым, началу диастолического сегмента, в котором шумы по причине стеноза слышны лучше, можно присваивать более высокие весовые коэффициенты при классификации сердечно-сосудистого тона.
Этап классификации сердечно-сосудистого тона включает в другом варианте выполнения этап классификации, по меньшей мере, одного из указанного количества подсегментов первого параметра сигнала и указанного второго параметра сигнала в указанном многопараметрическом способе классификации, где как указанный первый параметр сигнала, так и указанный второй параметр сигнала извлекают из указанного, по меньшей мере, одного из указанного количества подсегментов, и этап классификации указанного сердечно-сосудистого тона на основании указанной классификации указанного, по меньшей мере, одного из указанного количества подсегментов. Затем сердечно-сосудистый тон может быть классифицирован на основании большого количества классифицированных подсегментов, и, тем самым, можно определить вероятность того, что классификация является правильной. Сердечно-сосудистый тон можно, например, считать правильным, если, например, 99 процентов подсегментов были единообразно классифицированы.
В другом варианте выполнения способ дополнительно содержит этап моделирования, по меньшей мере, одного из указанного количества подсегментов и извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала из указанной модели. Преимущество с применением моделей состоит в том, что модели могут улучшать свойства сигналов, например, при использовании функции огибающей или авторегрессивной модели. Кроме того, модели упростили бы и оптимизировали бы процесс вычисления, когда способ осуществляют в процессоре.
В другом варианте выполнения способа, указанный первый параметр сигнала и/или указанный второй параметр сигнала представляет собой параметр уровня частоты, описывающий свойство уровня частоты, по меньшей мере, одной частотной компоненты, по меньшей мере, в одном из указанного количества подсегментов. Параметр уровня частоты очень полезен при классификации сердечно-сосудистых тонов, поскольку шумы по причине стеноза обычно имеют преобладающую частотную компоненту между 200-1200 Гц, и когда наиболее мощная частотная компонента находится в данном диапазоне, это является хорошим показателем наличия шумов по причине стеноза. Свойство уровня частоты может также определять отношение между энергией в различных частотных полосах.
В другом варианте выполнения способа указанный первый параметр сигнала и/или указанный второй параметр сигнала представляет собой параметр сложности, описывающий сложность, по меньшей мере, одного из указанного количества подсегментов. Сложность сердечно-сосудистого тона, например, может быть определена количеством собственных функций, используемых для моделирования сигнала, поскольку, чем больше собственных функций необходимо для моделирования сигнала, тем сложнее сигнал. Сложность сердечно-сосудистого тона обычно сохраняется, и на нее не влияют различия от пациента к пациенту. Некоторые собственные функции могут быть ослаблены по-разному от человека к человеку, но они редко полностью устраняются из сердечно-сосудистого тона, и, в связи с этим, сложность сохраняется.
По меньшей мере, один из указанных идентифицированных диастолических и/или систолических сегментов в другом варианте выполнения разделен, по меньшей мере, на 8 подсегментов. Тем самым улучшается точность классификации сердечно-сосудистого тона, поскольку среднее значение статистически улучшено пропорционально квадратному корню количества образцов. Следствием является то, что для классификации тона необходима более кратковременная запись сердечно-сосудистого тона.
Изобретение дополнительно относится к системе для классификации сердечно-сосудистого тона, записанного от живого индивидуума, указанная система включает в себя:
- средство обработки для идентификации диастолических и/или систолических сегментов указанного сердечно-сосудистого тона;
- средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных диастолических и/или систолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент;
- средство обработки для извлечения из указанного первого подсегмента, по меньшей мере, первого параметра сигнала, характеризующего первое свойство указанного сердечно-сосудистого тона, и средство обработки для извлечения из указанного второго подсегмента, по меньшей мере, второго параметра сигнала, характеризующего второе свойство указанного сердечно-сосудистого тона;
- средство обработки для классификации указанного сердечно-сосудистого тона с применением указанного, по меньшей мере, первого параметра сигнала и указанного, по меньшей мере, второго параметра сигнала в многопараметрическом способе классификации;
- средство обработки для классификации указанного сердечно-сосудистого тона с применением указанных, по меньшей мере, двух параметров сигнала с использованием многопараметрического способа классификации.
Тем самым, может быть создана система для классификации сердечно-сосудистого тона, и тем самым достигают те же преимущества, что описаны выше.
Средство обработки для извлечения указанного первого параметра сигнала и/или указанное средство обработки для извлечения указанного второго параметра сигнала находится в другом варианте выполнения, адаптированном для извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала из, по меньшей мере, одного из указанного количества подсегментов. Тем самым достигаются те же преимущества, что описаны выше.
В другом варианте выполнения система дополнительно содержит средство обработки для идентификации шумных подсегментов и средство обработки для исключения указанных шумных подсегментов до извлечения указанного первого параметра сигнала и/или извлечения указанного второго параметра сигнала. Тем самым достигаются те же преимущества, что описаны выше.
В другом варианте выполнения система дополнительно содержит средство обработки для идентификации нестационарных подсегментов и средство обработки для исключения указанных нестационарных подсегментов до извлечения указанного первого параметра сигнала и/или извлечения указанного второго параметра сигнала.
Средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных диастолических и/или систолических сегментов на множество подсегментов в другом варианте выполнения, адаптировано с помощью перекрытия, по меньшей мере, части указанного первого подсегмента, по меньшей мере, частью указанного второго подсегмента. Тем самым достигаются те же преимущества, что описаны выше.
Средство обработки для классификации указанного сердечно-сосудистого тона в другом варианте выполнения адаптировано для вычисления среднего значения указанного первого параметра сигнала и/или указанного, по меньшей мере, второго параметра сигнала, извлеченного, по меньшей мере, из одного из указанного количества подсегментов, и использования указанного среднего значения в указанном многопараметрическом способе классификации. Тем самым достигаются те же преимущества, что описаны выше.
Средство классификации указанного сердечно-сосудистого тона в другом варианте выполнения адаптировано для классификации, по меньшей мере, одного из указанного количества подсегментов с использованием указанного первого параметра сигнала и указанного второго параметра сигнала в указанном многопараметрическом способе классификации и классификации указанного сердечно-сосудистого тона на основании указанной классификации указанных, по меньшей мере, одного из указанного количества подсегментов. Тем самым достигаются те же преимущества, что описаны выше.
В другом варианте выполнения система содержит средство обработки для моделирования указанного, по меньшей мере, одного из указанного количества подсегментов, средство обработки для извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала из указанной модели. Тем самым достигаются те же преимущества, что описаны выше.
Средство обработки для извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала в другом варианте выполнения адаптировано для извлечения, по меньшей мере, одного параметра уровня частоты, описывающего свойство уровня частоты, по меньшей мере, одной частотной компоненты, по меньшей мере, одного из указанного количества подсегментов. Тем самым достигаются те же преимущества, что описаны выше.
Обработка, извлекающая указанный первый параметр сигнала и/или указанный второй параметр сигнала в другом варианте выполнения адаптирована для извлечения, по меньшей мере, одного параметра сложности, описывающего сложность, по меньшей мере, одного из указанного количества подсегментов. Тем самым достигаются те же преимущества, что описаны выше.
Средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных диастолических и/или систолических сегментов на множество подсегментов в другом варианте выполнения адаптировано для разделения, по меньшей мере, одного из указанных идентифицированных диастолических и/или систолических сегментов, по меньшей мере, на 8 подсегментов.
Изобретение дополнительно относится к машиночитаемому носителю с сохраненными на нем инструкциями для осуществления модулем обработки выполнения способа, как описано выше. Тем самым достигаются те же преимущества, что описаны выше.
Изобретение дополнительно относится к стетоскопу, содержащему средство записи, адаптированное для записи сердечно-сосудистого тона от живого индивидуума, средство накопления, адаптированное для сохранения указанного записанного сердечно-сосудистого тона, машиночитаемый носитель и модуль обработки, указанный машиночитаемый носитель содержит сохраненные на нем инструкции для осуществления указанным модулем обработки выполнения способа, как описано выше, и, таким образом, классификации указанного записанного сердечно-сосудистого тона. Тем самым, способ в соответствии с настоящим изобретением может быть осуществлен в стетоскопе, и достигаются те же преимущества, что описаны выше.
Изобретение дополнительно относится к серверному устройству, связанному с сетью передачи данных, содержащей средство приема, адаптированное для получения сердечно-сосудистого тона, записанного от живого индивидуума, через указанную сеть передачи данных, средство накопления, адаптированное для сохранения указанного записанного сердечно-сосудистого тона в машиночитаемом носителе, и модуль обработки, причем указанный машиночитаемый носитель содержит сохраненные на нем инструкции для осуществления указанным модулем обработки способа, как описано выше, и, таким образом, классификации указанного полученного сердечно-сосудистого тона. Тем самым способ в соответствии с настоящим изобретением может быть осуществлен в серверном устройстве, связанном с сетью передачи данных. Затем серверное устройство может выполнять описанный выше способ, и могут быть достигнуты описанные выше преимущества.
В другом варианте выполнения серверного устройства, указанное средство приема дополнительно адаптировано для получения указанного сердечно-сосудистого тона от устройства клиента, связанного с указанной сетью передачи данных. Тем самым, клинический врач/доктор может отправить сердечно-сосудистый звук в серверное устройство с применением устройства клиента, такого как портативный компьютер. После этого серверное устройство может классифицировать полученный сердечно-сосудистый тон. Тем самым достигаются описанные выше преимущества.
В другом варианте выполнения серверного устройства серверное устройство дополнительно содержит средство отправки указанной классификации указанного сердечно-сосудистого тона, по меньшей мере, в один модуль клиента, связанный с указанной сетью передачи данных. Тем самым, результат классификации можно отправить обратно в устройство клиента, и, в связи с этим, клинический врач/ доктор может получить результат классификации. Тем самым, достигаются описанные выше преимущества.
Краткое описание чертежей
На фиг.1 изображен график типичного сердечного тона,
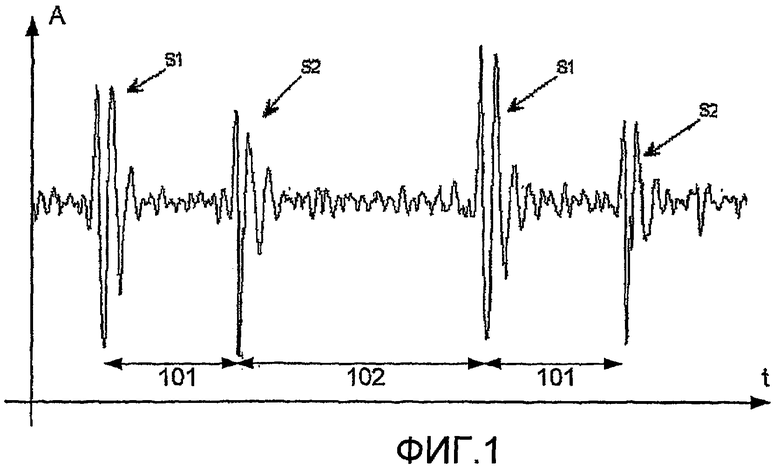
на фиг.2 изображена гидродинамическая модель артериального стеноза,
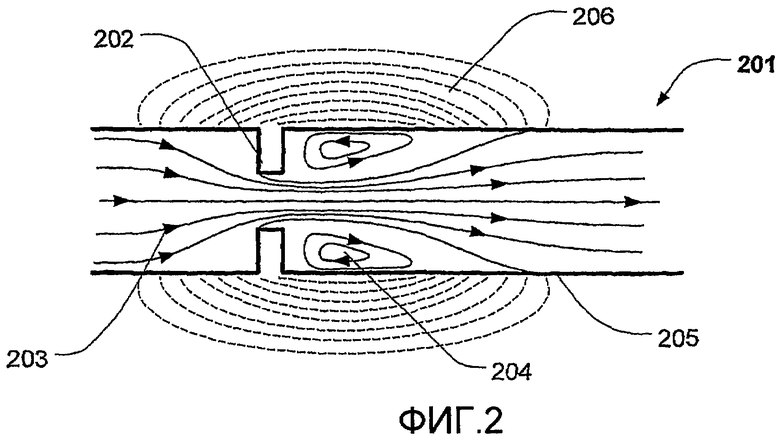
на фиг.3 представлен краткий обзор в форме блок-схемы способа в соответствии с настоящим изобретением,
на фиг.4 изображен вариант выполнения системы в соответствии с настоящим изобретением,
на фиг.5 изображен другой вариант выполнения способа в соответствии с настоящим изобретением,
на фиг.6 изображена схема работы способа сегментации,
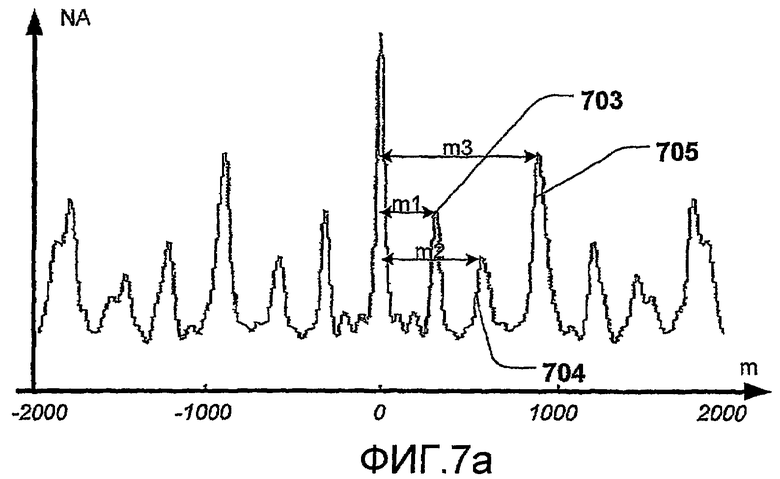
на фиг.7 изображена, для сердечного тона, зависимость между автокорреляцией огибающей сердечного цикла и сердечным циклом,
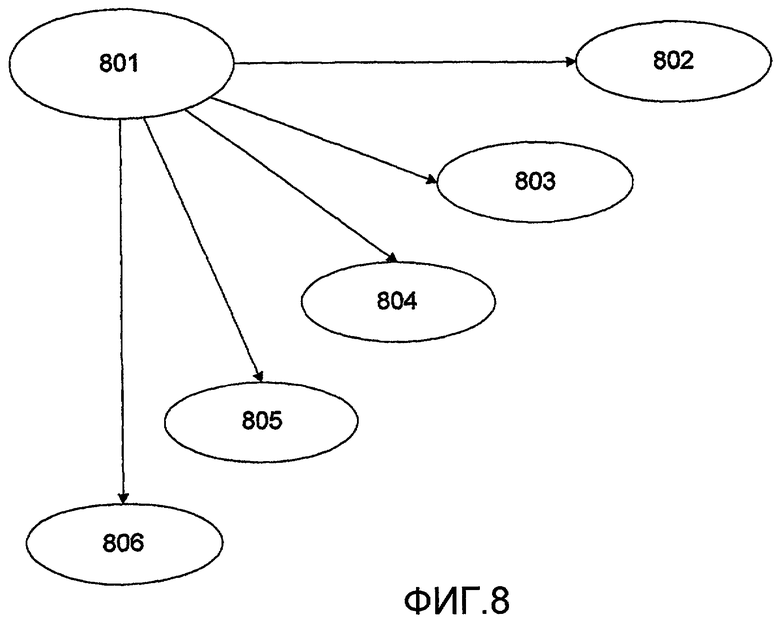
на фиг.8 изображена реализация байесовой сетки, используемой для вычисления вероятности тона, представляющего собой тон S1, S2 и шум,
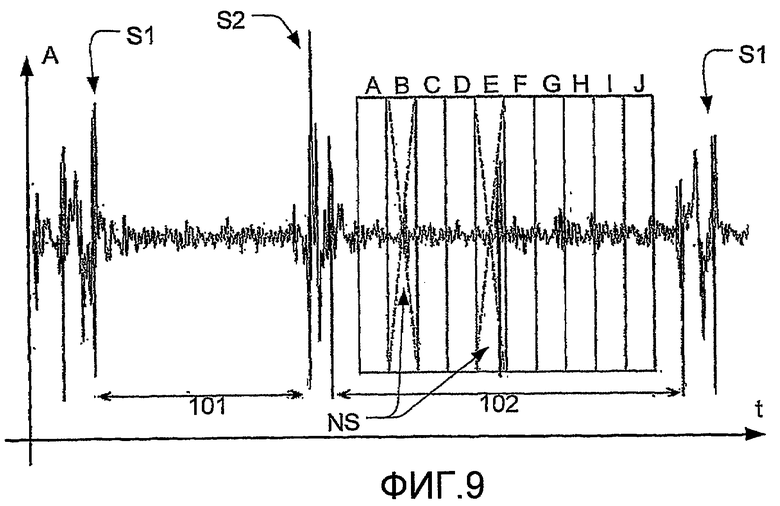
на фиг.9 изображено, как диастолический сегмент разделяют на множество последовательных подсегментов,
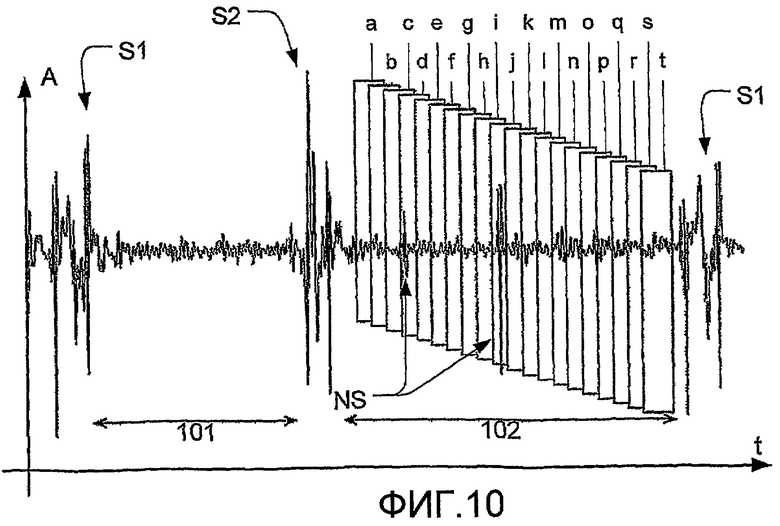
на фиг.10 изображено, как диастолический сегмент разделяют на перекрывающиеся подсегменты,
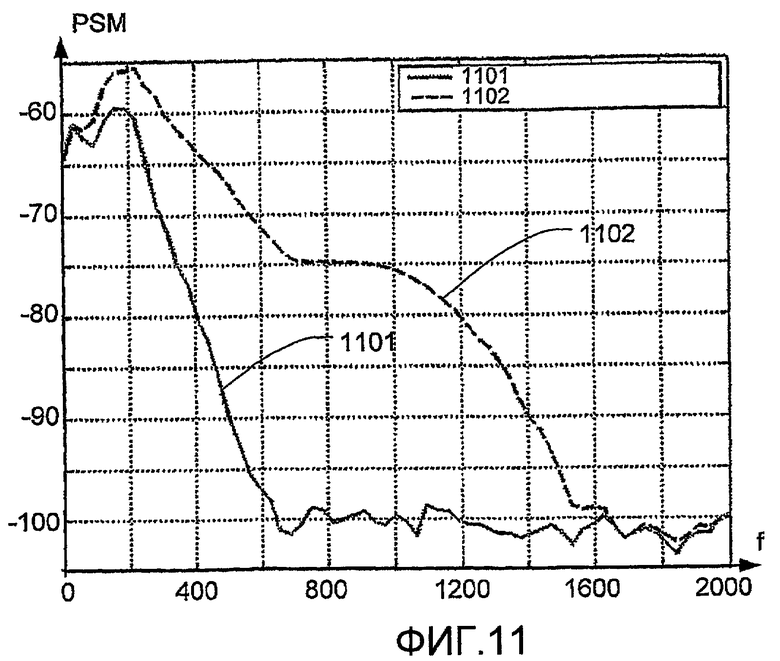
на фиг.11 изображена кривая спектральной плотности мощности (PSD, СПМ) для диастолы, изображенной на фиг.9.
Подробное описание изобретения
На фиг.1 изображен график типичного сердечного тона, записанного стетоскопом, и показана амплитуда (А) звукового давления на оси у и время (t) на оси x. Сердечные тоны отражают явления в сердечном цикле: замедление тока крови, турбулентность кровотока и закрытие клапанов. Закрытие клапанов обычно представлено двумя различными сердечными тонами, первым (S1) и вторым (S2) сердечным тоном. На фигуре изображены первый и второй сердечные тоны, и S1 отмечает начало систолы (101), которая представляет собой часть сердечного цикла, в котором сердечная мышца сокращается, заставляя кровь поступать в главные кровеносные сосуды, и конец диастолы, которая представляет собой часть сердечного цикла, во время которого сердечная мышца расслабляется и расширяется. Во время диастолы (102), кровь заполняет сердечные камеры. Продолжительность систолических сегментов практически постоянна вблизи 300 мс для здоровых индивидуумов. При условии пульса 60 ударов в минуту, продолжительность сердечного цикла составляет в среднем одну секунду, и продолжительность диастолы составляет 700 мс. Однако продолжительность диастолы не является постоянной, а варьируется в зависимости от пульса индивида. Кроме того, меньшие вариации продолжительности диастолы привносятся по причине невральных регуляций и эффектов дыхания.
На фиг.2 изображена гидродинамическая модель артериального стеноза и показана артерия (201) со стенозированным поражением (202). Стрелки (203) показывают кровоток через артерию. Когда кровь с высокой скоростью выходит из стенозированного поражения (202) возникают вихри (204). Данные вихри сталкиваются с артериальной стенкой (205) и преобразуются в вибрации давления, которые заставляют артерии вибрировать на их резонансных частотах. Результатом является то, что генерируются и исходят от артериальной стенки звуковые волны в форме шумов (206) с частотой, соответствующей резонансным частотам артериальной стенки. Резонансные частоты в артериальном сегменте увеличены, если присутствует стеноз, и значения их частоты зависят от диаметра стенозированного сегмента в сравнении с диаметром артерии. С увеличением тяжести стеноза резонансная частота также повышается. Резонансная частота частично закупоренной стенозированной артерии с наибольшей вероятностью находится в диапазоне между 200 Гц и 1100 Гц. Интенсивность вихревых флуктуаций зависит от кровотока так, что шумы от левых коронарных артерий наиболее интенсивны во время диастолы, когда кровоток через данные артерии наиболее высокий. Шумы от правых коронарных артерий наиболее интенсивны во время диастолы, если стеноз имеет место в ветвях правой коронарной артерии, снабжающей правосторонние полости, тогда как шум с наибольшей вероятностью будет систолическим от ветвей правой коронарной артерии, подающей артериальную кровь к левому желудочку. Интенсивность шумов не только зависит от кровотока, но также и от частотного содержания шума. Высокочастотные шумы сильнее подавляются стенкой грудной клетки по сравнению с низкими частотами. Шумы, вызванные артериальными вибрациями, влияют на график сердечного тона, записанного, например, стетоскопом.
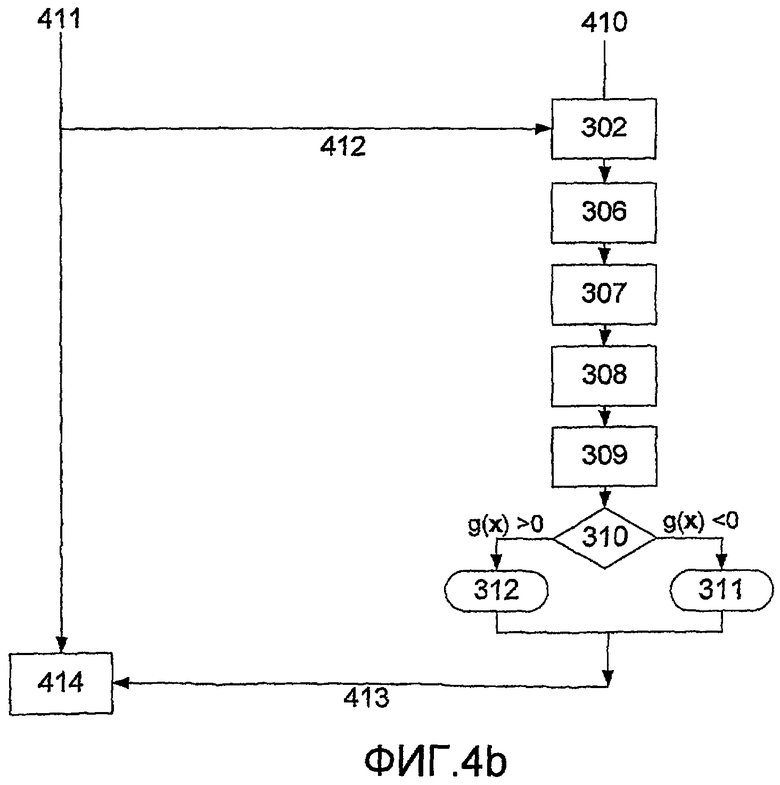
На фиг.3 изображен краткий обзор в форме блок-схемы способа в соответствии с настоящим изобретением. Способ, например, может быть осуществлен в виде программного обеспечения, запущенного на компьютере или на микроконтроллере, встроенном в стетоскоп. Коротко говоря, способ начинается с инициализации (301), получения тестового сигнала (302), разделения тестового сигнала на значимые сегменты (306), фильтрации значимых сегментов (307); расчета/разработки модели сигнала (308) в значимых сегментах; извлечения различных параметров из сигнала и модели (309), выполнения анализа сигнала (310) с использованием извлеченных параметров и классификации значимых сегментов на две группы: одну, указывающую на то, что сигнал содержит шумы по причине стеноза (311), и одну, указывающую на то, что сигнал не содержит шумов по причине стеноза (312).
После того, как способ был инициализирован (301), способ получает тестовый сигнал (302) в виде файла данных (303). Тестовый сигнал должен представлять собой сердечный тон от человека (304), записанный и оцифрованный в файл данных, например цифровым стетоскопом (305). Тестовый сигнал должен быть схожим с сердечным тоном, изображенным на фиг.1; однако продолжительность тестового сигнала обычно в 5-15 раз больше, чем у сигнала, показанного на фиг.1. Как только тестовый сигнал будет получен (302), проводят сегментацию (306) для обнаружения и разделения тестового сигнала на сегменты. Процесс сегментации обычно должен обнаружить сердечные тоны S1 и S2 и после этого разделить тестовый сигнал на систолические и диастолические части. После этого тестовый сигнал фильтруют (307), и процесс фильтрации включает авторегрессивный фильтр, который уменьшает белый шум в сигнале, и полосовой фильтр, который пропускает только частоты между 450-1100 Гц. Тестовый сигнал после этого должен содержать частоты, вызванные вибрациями артериальной стенки, когда в артерии присутствует стеноз. Авторегрессивный фильтр может быть выполнен в виде фильтра Калмана, который является мощным алгоритмом оценки прошлых, настоящих и будущих состояний, и он может делать это даже когда точная природа моделируемой системы не известна. Это является желательной особенностью в настоящей заявке для уменьшения эффектов шума, так как точное содержание шума не известно. Фильтр Калмана первого порядка может уменьшить влияние белого шума и сгладить запись шумного сердечного тона для дальнейшей обработки. Полосовой фильтр может быть выполнен в виде фильтра волнового пакета. В другом варианте выполнения фильтр Калмана исключен для упрощения реализации способа, например, в микропроцессоре и дополнительного уменьшения количества вычислений, выполненных микропроцессором.
Когда сигнал отфильтрован (307), для дальнейшего анализа выбирают значимые сегменты. В одном варианте выполнения для дальнейшего анализа выбрана часть диастолического сегмента, поскольку шум по причине стеноза с наибольшей вероятностью будет слышимым в диастолическом сегменте, и диастолические сегменты в другом варианте выполнения также разделяют на множество подсегментов для устранения шума, например, по причине трения между микрофоном и грудной клеткой пациента (см. фиг.5).
После этого рассчитывают/разрабатывают математическую модель сигнала в выбранном сегменте (308) с использованием выбранного сердечного тона в файле данных. Модель используют для извлечения параметров, которые характеризуют тон в сегменте и которые можно использовать для категоризации, присутствуют ли в сегменте тона шумы по причине стеноза. В настоящем варианте выполнения для моделирования сигнала используют авторегрессивную полюсную параметрическую оценку (AR-модель (АР-модель)). В AR-модели выбранный звуковой сигнал у из файла данных моделируют в виде линейной комбинации М прошлых значений сигнала и настоящего ввода u под управлением процессом генерирования звука. Модель может быть описана следующим Уравнением:
[3.1]
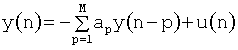 ,
,
где М представляет порядок модели, Аp - коэффициенты AR и n - номер образца. Коэффициенты AR определяют через автокорреляцию и путем минимизации погрешности, связанной с моделью.
Модель AR в данном варианте выполнения используют для извлечения частотных параметров, описывающих сердечный тон. Предпочтительной является модель второго порядка М=2, поскольку она производит лучшее разделение между частотными параметрами, извлеченными из сердечного тона с присутствующими шумами, и частотными параметрами, извлеченными из сердечного тона с присутствующими шумами.
После этого извлекают различные параметры сигнала (309) из дискретизированного сигнала и модели AR с применением технологии обработки сигналов. Некоторые параметры сигнала могут быть извлечены из выбранных сегментов или подсегментов. Каждый параметр сигнала характеризует сердечный тон в выбранных сегментах/подсегментах и, в связи с этим, может быть использован для классификации сердечно-сосудистого тона, например, присутствуют ли в сердечном тоне шумы по причине стеноза.
Параметры сигнала, например, могут представлять собой частотный параметр, описывающий свойство в области частоты, по меньшей мере, части сердечно-сосудистого тона, и частотный параметр может быть использован в качестве параметра в многопараметрическом способе классификации, описанном ниже. Частотные параметры являются очень хорошими параметрами для классификации, присутствуют ли в сердечно-сосудистом тоне шумы по причине стеноза, поскольку стеноз изменяет частотные компоненты сердечно-сосудистого тона. Частотный параметр, например, может представлять собой параметр уровня частоты, описывающий свойство уровня частоты, по меньшей мере, части указанного сердечно-сосудистого тона. Шумы обычно изменяют уровень частоты сердечно-сосудистого тона, и, путем использования параметров, описывающих уровень частоты тона, может быть достигнута устойчивая классификация сердечно-сосудистого тона. Свойства уровня частоты также могут характеризовать наиболее мощную частотную компоненту, по меньшей мере, части указанного сердечно-сосудистого тона. Данный параметр является очень полезным параметром, поскольку шумы по причине стеноза обычно имеют преобладающую частотную компоненту между 200-1200 Гц. И если наиболее мощная частотная компонента находится в данном диапазоне, это представляет собой хороший показатель в отношении наличия шумов по причине стеноза. Частотный параметр также может представлять собой параметр ширины полосы частот, описывающий свойство ширины полосы частот, по меньшей мере, части указанного сердечно-сосудистого тона. Преимущество с применением свойства ширины полосы частот сердечно-сосудистого тона состоит в том, что шумы часто имеют ограниченную ширину полосы частот, и, в связи с этим, параметр ширины полосы частот должен быть хорошим показателем того, присутствуют ли в сердечно-сосудистом тоне шумы по причине стеноза. Свойства ширины полосы частот, например, могут характеризовать ширину полосы наиболее мощной частотной компоненты.
Параметры сигнала также могут представлять собой параметры времени, описывающие свойства в области времени, по меньшей мере, части указанного сердечно-сосудистого тона. При использовании как временных, так и частотных параметров достигается очень устойчивая классификация сердечно-сосудистого тона, так как временные и частотные свойства часто некоррелированы. Параметр времени, например, может характеризовать подвижность, по меньшей мере, части указанного сердечно-сосудистого тона. Подвижность является хорошим показателем того, присутствуют ли в сердечно-сосудистом тоне шумы по причине стеноза. Подвижность описывает дисперсию тона, и так как шумы вызывают большую дисперсию тона, подвижность должна быть хорошим показателем.
Параметрами сигнала, используемыми в настоящем варианте выполнения, являются количество экстремальных точек на длину сигнала TP (ЭТ); подвижность сигнала MB (ПО); магнитуда полюса РМ (МП); нормализованная частота AR-пика NF (НЧ); и спектральное соотношение AR, SR (СС).
Количество экстремальных точек TP извлекают из цифрового сигнала в области времени, и его находят путем вычисления числа перегибов, осуществляемых сигналом в области времени за единицу времени. Это может быть проделано путем определения количества локальных максимумов в интервале времени. Таким образом:
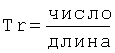
[3.2]
Подвижность MB извлекают из выбранного сигнала в домене времени и находят путем вычисления дисперсии σy, сигнала в области времени и дисперсии первой производной сигнала, σy ,. После этого подвижность находят по формуле:
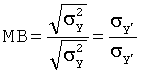
[3.3]
Магнитуду полюсов PM находят путем преобразования AR-модели в z-домен и вычисления магнитуды полюсов в z-домене, описанном AR-спектром.
Нормализованная AR пиковая частота NF основана на предположении, что шумы по причине стеноза с большей вероятностью будут найдены в диастолическом сегменте, чем в систолическом сегменте. NF находят путем вычисления угла полюсов в AR-спектре в z-плоскости и преобразования его в частоту как диастолического сегмента, так и систолического сегмента. Если абсолютная разность между ними меньше, чем 25 Гц, что типично в случаях, когда шумы по причине стеноза не присутствуют, то 25 Гц вычитают из диастолической пиковой частоты. Если средняя диастолическая частота более, чем на 50 Гц, превышает среднюю систолическую пиковую частоту, что типично для случая, когда присутствуют шумы по причине стеноза, тогда 25 Гц прибавляют к средней пиковой диастолической частоте.
Спектральное соотношение AR, SR находят путем вычисления соотношения энергии в диапазоне частот 200-500 Гц к энергии в диапазоне частот 500-1000 Гц диастолического сегмента.
После этого извлеченные параметры используют в многопараметрической дискриминантной функции для классификации, содержит ли сегмент тона шумы по причине стеноза (310). В данном варианте выполнения для классификации сегментов тона используют линейную дискриминантную функцию. Линейная дискриминантная функция объединяет взвешенные характеристики в дискриминантный балл g(х) и может быть описана следующим образом:
g(x)=w1x1,+w2x2+w3x3+…+wkxk+w10=wTx+w0,
[3.4]
где x представляет собой характеристический вектор, состоящий из извлеченных параметров, k представляет количество характеристик, i представляет классы, и w представляет собой весовой вектор, в котором хранятся дискриминантные коэффициенты. В случае, когда должны быть разделены только два класса, используют одну дискриминантную функцию. Классификатор двух классов называют дихотомическим преобразователем сигнала. Дихотомический преобразователь сигнала обычно классифицирует характеристический вектор с границей принятия решения g(x)=0 (ввиду константы w0). Если дискриминантный балл g(x) больше нуля, сегмент присваивают классу 1, в противном случае его присваивают классу 2. Поскольку g представляет собой линейную функцию g(x)=0, она определяет поверхность принятия решения гиперплоскости, разделяя многомерное пространство на два половинчатых подпространства. Дискриминантный балл g(x) представляет собой алгебраическое расстояние до гиперплоскости. Дискриминантная функция должна быть обучена для нахождения значений весовых коэффициентов, w, и осуществления безопасной и устойчивой классификации сегментов тона. Процедура обучения дискриминанта должна быть выполнена до использования системы, и целью процедуры является нахождение оптимальных значений весовых коэффициентов w так, чтобы гиперплоскость оптимально разделяла характеристические векторы. Процедуру обучения в одном варианте выполнения выполняют при использовании 18 тестируемых тонов, записанных у 18 тестируемых людей, где девять тестируемых людей имеют коронарный стеноз и девять тестируемых людей не имеют коронарного стеноза. Процедуру обучения дискриминанта выполняют при использовании статистического программного обеспечения SPSS v.12.0 для Windows (SPSS inc., Чикаго, Иллинойс, США). Отмеченные выше параметры извлекают из 18 обучающих тонов и используют в качестве статистических входных данных для программы. Полученный дискриминант может представлять собой:
g(x)=164.709МВ-0.061NF-78.027РМ+27,188SR+91.878TP+33,712
[3.5],
где MB представляет собой подвижность сигнала, NF - AR - пиковую частоту, РМ - магнитуду полюсов, SR спектральное соотношение AR и TP - количество экстремальных точек.
Если результат дискриминантной функции больше нуля (g(x)>0), тогда сегмент тона не содержит шумов по причине стеноза (312). С другой стороны, если дискриминантная функция меньше нуля (g(x)<0), тогда сегмент тона содержит шумы по причине стеноза (311).
Дискриминантная функция может быть легко подстроена специалистом в данной области техники так, чтобы она включала дополнительные или меньшее количество параметров с целью разработки правильной дискриминантной функции, которую можно использовать для классификации сердечного тона. Дополнительные параметры могут, например, представлять собой: сложность, CP, цифрового сигнала в домене времени. Данный параметр основан на отношении подвижности первой производной сигнала к подвижности самого сигнала, где y'' представляет собой вторую производную отфильтрованного сигнала сердечного тона. Мера сложности относительно чувствительна к шумным сигналам, так как она основана на второй производной.
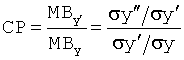
[3.6]
Можно использовать другие меры сложности сигнала, например, приближенную энтропию, спектральную энтропию или внедрение собственного пространственного спектр.
Дополнительно, в дискриминантной функции можно извлекать и использовать частоту AR-пиков (PF, ЧП). Частоту AR-пиков можно находить, вычисляя угол полюсов AR в z-плоскости.
Дополнительно, из различных сегментов с функцией спектральной плотности мощности (PSD, СПМ) можно извлекать отношение мощностей (PR, ОМ). PSD можно рассчитывать при помощи дискретного преобразования Фурье. Отношение мощностей можно извлекать из PSD, как отношение энергии между 150-350 Гц к энергии между 350 и 1000 Гц.
Параметры, используемые в дискриминантной функции можно извлекать из различных сегментов сердечного тона, например, из множества различных диастолических сегментов, где множество параметров извлекают из каждого диастолического сегмента. После этого можно рассчитать и использовать в качестве входных данных в дискриминантной функции среднее значение каждого параметра.
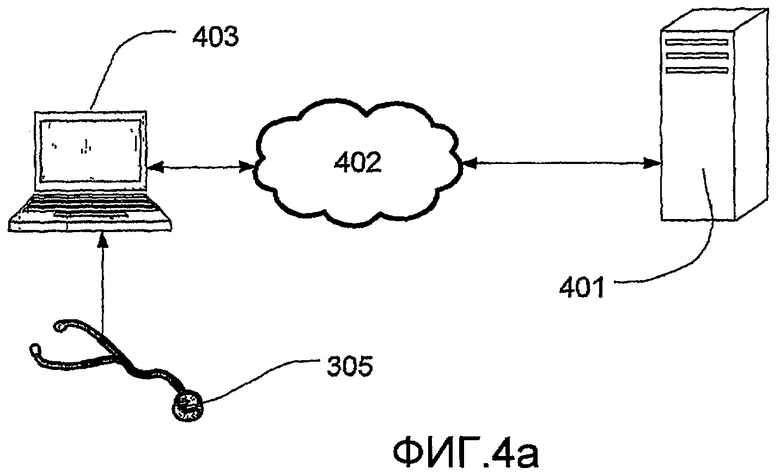
На фиг.4а изображен вариант выполнения системы в соответствии с настоящим изобретением, в котором серверное устройство (401) запрограммировано для осуществления способа, описанного на фиг.3. Кроме того, серверное устройство связано с сетью (402), например, сетью Интернет, и адаптировано для получения и анализа сердечного тона по запросу. Клинические врачи или другие профессионалы в области медицины могут записывать сердечный тон от пациента цифровым стетоскопом (305) и, после того, передавать оцифрованный сердечный тон в персональный компьютер (403). Клинический врач может после этого послать запрос серверному устройству для анализа сердечного тона. Как только серверное устройство проанализирует сердечный тон, результат автоматически посылают обратно клиническому врачу. На фиг.4b изображена блок-схема процесса и сообщения между персональным компьютером (403) и серверным устройством. Слева представлена сторона клиента (410) и справа представлена сторона серверного устройства (411). Сначала клиент отправляет сердечный тон в цифровой форме на серверное устройство (412). После этого станция выполняет способ, изображенный на фиг.3, и отправляет (413) результат анализа обратно клиенту, где он выводится на экран (414) клиническому врачу. После этого, клинический врач может оценить результат для выбора правильного лечения пациента.
Система в соответствии с настоящим изобретением также может быть осуществлена как функционально полный цифровой стетоскоп. В связи с этим, стетоскоп автоматически осуществляет анализ, описанный на фиг.3, когда записан сердечный тон. Это означает, что способ, описанный на фиг.3, необходимо реализовать в средстве обработки стетоскопа, и результат анализа, например, может быть выведен на небольшой жидкокристаллический экран, интегрированный в стетоскоп. Преимущество данного варианта выполнения состоит в том, что большинство клинических врачей знакомы с цифровым стетоскопом и, в связи с этим, могут легко научиться использовать стетоскоп для диагностики наличия коронарного стеноза у пациента.
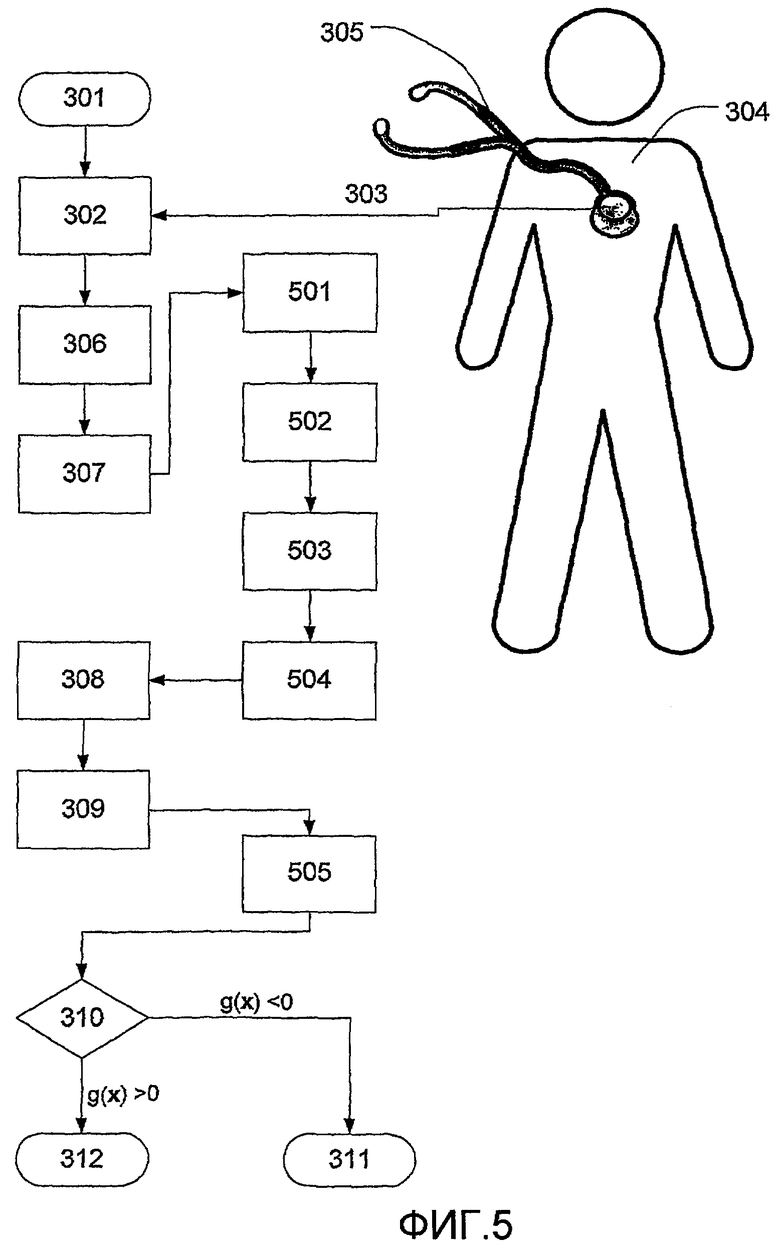
На фиг.5 изображен другой вариант выполнения способа, описанного на фиг.3. Когда сигнал был отфильтрован (307), значимые сегменты, такие как систолические и/или диастолические сегменты, идентифицируют (501) и после этого значимые сегменты разделяют на подсегменты (502). Шумные подсегменты на этапе (503) идентифицируют и исключают, и нестационарные подсегменты на этапе (504) также идентифицируют и исключают. В одном варианте выполнения часть диастолического сегмента выбирают для дальнейшего анализа, поскольку шум по причине стеноза с наибольшей вероятностью различим в диастолическом сегменте. В данном варианте выполнения диастолический сегмент, содержащий звуки дыхания исключают на этапе (501). Это делают путем вычисления уровня энергии диастолического сегмента в полосе частот 200-440 Гц и сравнения данного уровня энергии с медианным уровнем энергии всего диастолического сегмента. Диастолический сегмент должен быть исключен, если уровень энергии частотной полосы 200-440 Гц в 1,1 раза больше уровня энергии во всем диастолическом сегменте.
После этого остальные диастолические сегменты на этапе (502) разделяют на множество подсегментов, и на фиг.9 и 10 изображено, как диастолический сегмент может быть разделен на подсегменты. На фиг.9 и 10 изображен график типичного сердечного тона, записанного стетоскопом, и показана амплитуда (А) звукового давления на оси у и время (t) на оси х. На фигуре изображен первый сердечный тон (S1), второй сердечный тон (S2), систолический сегмент (101) и диастолический сегмент (102). В диастолический сегмент были привнесены два коротких шумовых импульса (NS, ШИ). На фиг.9 изображено, как диастолический сегмент (102) разделен на множество последовательных подсегментов (А, В, С, D, Е, F, G, H, I, J). Каждый подсегмент используют в классификации сердечно-сосудистого тона на этапе (309) и (310); однако шумные сегменты (В) и (Е) из-за коротких шумовых импульсов (NS) исключены на этапе (503) и, в связи с этим, не используются при классификации сердечно-сосудистого тона.
На фиг.10 изображено, как диастолический сегмент (102)
разделен на перекрывающиеся подсегменты (а, b, с … t).
Можно видеть, что, по меньшей мере, часть сегмента (b) перекрывается, по меньшей мере, с частью сегмента (а) и другая часть сегмента (b) перекрывается, по меньшей мере, с частью сегмента (с). Остальные сегменты накладываются друг на друга аналогичным образом. Следствием этого является то, что можно использовать большую величину диастолического сегмента при классификации сердечно-сосудистого тона на этапе (309) и (310). Сегмент (j) исключают из-за короткого шумового импульса (NS), но последняя часть сегмента (j) не содержит шума, потому что продолжительность подсегмента (j) больше, чем продолжительность шумового импульса. Следствием этого является то, что звук, подходящий для классификации сердечно-сосудистого тона был бы исключен при исключении сегмента (j). Однако часть сегмента (j) без шумовых импульсов использовали бы в классификации, как часть сегмента (k), так как сегмент (j) и сегмент (k) перекрываются друг с другом. В связи с этим, перекрытие сегментов гарантирует, что в способе классификации диастолический сегмент использовали бы в максимально возможной степени.
Импульсы от трения часто содержат высокую энергию, которая делает их преобладающими над сигнальными параметрами, извлеченными на этапе (309). Пример того, как импульсы от трения преобладали бы и влияли бы на значение параметра сигнала, извлеченного на этапе (309), изображен на фиг.11. На фиг.11 изображена кривая спектральной плотности мощности (PSD) для диастолы, изображенной на фиг.9, где величины спектра мощности (PSM) в дБ с (1101) и без (1102) исключения подсегментов, содержащих импульсы от трения, построены, как функция частоты (f) в Гц. Оба графика PSD сделаны путем сегментирования сигнала на подсегменты, как изображено на фиг.9, с последующим вычислением спектра мощности от каждого подсегмента и затем вычислением PSD путем усреднения PSD для каждого подсегмента. Разница между данными двумя графиками (1101) и (1102) состоит в том, что 2 подсегмента (В, Е), содержащие импульсы от трения (см. фиг.9), были удалены перед вычислением среднего значения PSD, изображенного сплошной линией (1101). Как было отмечено, импульсы трения сильно влияют на PSD в области частот 200-1600 Гц. В связи с этим, удаление коротких подсегментов с шумом высокой энергии может уменьшить влияние шума, генерируемого ручным стетоскопом.
Короткая продолжительность подсегментов гарантирует, что исключают лишь локальные части сигнала. Анализ записей сердечного тона от 20 пациентов показал, что лишь 44 из 138 диастол (32%) включали сегмент продолжительностью 256 мс без шума высокой энергии. Это указывает на то, что способы, такие как способы предшествующего уровня техники с использованием одного фиксированного 256 мс окна от каждой диастолы, должны отклонить 68% зарегистрированных диастол и, таким образом, нуждаются в более чем в 3 раза более длительных записях, чем настоящий способ, чтобы иметь возможность проанализировать то же количество диастол.
В настоящем варианте выполнения продолжительность подсегментов составляет 37,5 мс, но в других вариантах выполнения продолжительность может быть меньше или больше, чем 37,5 мс, и они также могут перекрываться, как изображено на фиг.10. Одним преимуществом более коротких сегментов является более высокое разрешение в области времени, и одно преимущество более длинных сегментов часто заключается в лучшей точности параметров, рассчитанных из настоящего подсегмента.
Шумные подсегменты идентифицируют и исключают на этапе (503) через статистический анализ подсегментов. Шумные подсегменты представляют собой подсегменты с низким отношением сигнал - шум, как подсегменты с импульсами трения, подсегменты с фоновым шумом или подсегменты с физиологическим шумом, таким как шум от дыхания. Шумные подсегменты могут быть идентифицированы по-разному, например: шумные подсегменты могут быть идентифицированы как подсегменты с амплитудой, частотой или распределением энергии, отличным от большинства подсегментов.
В настоящем варианте выполнения рассчитывают дисперсию сигнала во всех подсегментах и затем исключают подсегменты с дисперсией большей, чем 1,3 медианной дисперсии всех подсегментов. В других вариантах выполнения шумные подсегменты можно идентифицировать путем фильтрации сигнала на множество полос частот и вычисления дисперсии полос частот в каждом подсегменте. Подсегменты, в которых дисперсия одной или более полос частот больше, чем дисперсия полос частот в остальных подсегментах, считают шумными.
После этого, на этапе (504) нестационарные подсегменты удаляют для уменьшения влияния нестационарности. Кровоток в коронарной артерии не является постоянным во время диастолы, и, в связи этим, шумы по причине стеноза не были бы стационарными; однако несколько способов обработки сигналов, таких как AR-модели, предполагают, что стационарность сигнала смоделирована. Преимущество с применением коротких подсегментов состоит в том, что сигнал за короткое время может быть принят стационарным. В настоящем варианте выполнения это проделано путем разделения подсегмента на под-подсегменты с продолжительностью 3,75 мс, или 30 образцов, с последующим вычислением дисперсии каждого под-подсегмента. Таким образом, создают контур дисперсии в течение подсегмента. Затем рассчитывают контур дисперсии, и подсегмент удаляют, если контур дисперсии больше 1.
На данном этапе было исключено множество подсегментов для удаления шумных и нестационарных подсегментов. Это обычно должно приводить к 30-100 подсегментам от приблизительно 10-секундной сердечно-сосудистой записи.
После этого остальные подсегменты используют на этапе (308) и (309), как представлено на фиг.3, для извлечения параметров сигнала, описывающих различные свойства сердечно-сосудистого сигнала. После этого рассчитывают медиану каждого параметра с применением значения параметра сигнала от каждого подсегмента (505). После этого медиану каждого параметра используют в многопараметрической дискриминантной функции, как представлено на фиг.3. В данном варианте выполнения используют следующие параметры сигнала: подвижность, соотношение энергий и амплитуда полюса 3 полюсов в модели AR порядка 6. Вычисление параметра сигнала как среднего значения параметров сигнала от множества подсегментов уменьшает влияние случайного шума, так как точность среднего значения статистически улучшается как квадратный корень количества образцов.
С тем чтобы проиллюстрировать разницу между вычислением параметров сигнала от одного сегмента каждой диастолы и с применением множества подсегментов от всех диастол, для обоих способов рассчитывают параметр PR сигнала. При анализе записи с использованием одного 256 мс окна для каждой диастолы среднее значение PR, рассчитанное по более, чем 9 диастолам, составляет 0,484, и 95% доверительный интервал среднего значения составляет ±0,0134 (рассчитан из среднеквадратической погрешности, умноженной на 1,96). Однако если ту же запись анализировали настоящим способом с применением 50 коротких подсегментов, 95% доверительный интервал среднего значения составляет лишь ±0,0064. Для достижения такого же узкого доверительного интервала с использованием единственного сегмента от каждой диастолы необходимо 39 диастол, и, таким образом, необходимы очень длительные записи.
Остальные подсегменты в другом варианте выполнения используют с целью извлечения параметров сигнала, описывающих различные свойства сердечно-сосудистого сигнала, и, после этого, параметры сигнала от каждого подсегмента используют в многопараметрической дискриминантной функции, создающей дискриминантный балл, связанный с каждым подсегментом. Затем рассчитывают конечный дискриминантный балл как медиану баллов, связанных с каждым подсегментом.
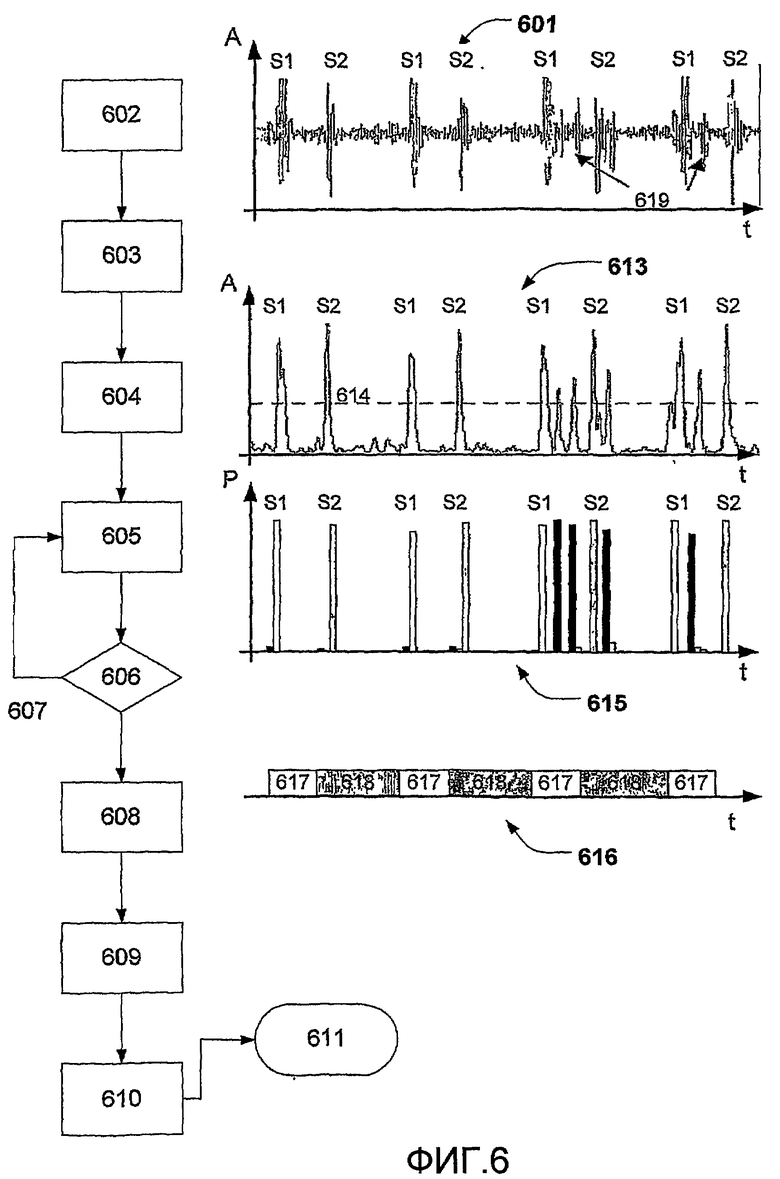
На фиг.6 изображена схема операции способа сегментации (306) в соответствии с настоящим изобретением, используемая для автоматического разделения сердечного тона (601) на подсегменты. Сердечный тон (601) записан стетоскопом, и сигнал оцифрован для цифровой обработки сигнала. На графике показана амплитуда (А) интенсивности звука как функция времени (t). Сердечные тоны отражают явления в сердечном цикле; замедление крови, турбулентность кровотока и закрытия клапанов. Закрытие клапанов обычно представлено двумя различными сердечными тонами, первым (S1) и вторым (S2) сердечным тоном. Первый и второй сердечные тоны изображены на фигуре, и (S1) отмечает начало систолы, которая представляет собой часть сердечного цикла, в котором сердечная мышца сокращается, заставляя кровь поступать в главные кровеносные сосуды, и конец диастолы, которая является частью сердечного цикла, во время которого сердечная мышца расслабляется и расширяется. Во время диастолы кровь заполняет сердечные камеры.
Целью способа сегментации является классификация записанного сердечного тона на систолические, диастолические и шумовые сегменты. Изображенный способ включает этапы подавления шума (602) с последующим созданием огибающей (603). Подавление шума может быть осуществлено с помощью фильтра высоких частот с последующим удалением шумовых импульсов трения с высокой амплитудой по причине внешнего шума из-за движения стетоскопа во время записи и, после этого, фильтра низких частот. Целью создания огибающей является усиление тренда сигнала. Огибающую в данном варианте выполнения, получают путем вычисления энергии Шеннона сигнала:
se(n)=-x(n)2·logx(n)2,
где x представляет собой сигнал, и se представляет собой энергию Шеннона. Компонентам с высокой амплитудой в сигнале присвоены более высокие весовые коэффициенты, чем компонентам с низкой амплитудой, при вычислении энергии Шеннона. Огибающая (613) сердечного тона (601), рассчитанная с использованием энергии Шеннона, показана на фигуре (613), и можно заметить, что здесь сердечные тоны S1 и S2 усилены.
Для классификации обнаруженных тонов в систолических сегментах, диастолических сегментах и шумовых компонентах, на основании продолжительности интервала с обеих сторон сердечных тонов S1 и S2, необходимо знать, какая длительность интервалов между S1 и S2. В связи с этим, продолжительности сердечных циклов (систолических и диастолических интервалов) извлекают из автокорреляции огибающей (604). Этот процесс подробно показан на фиг.7.
Затем выбираемые S1 и S2 обнаруживают (605) с использованием временных интервалов, извлеченных выше, и порога (614) на огибающей (613). Для уменьшения количества обнаруженных шумовых импульсов на выбираемые сегменты накладывают минимальное условие, которое эффективно удаляет некоторые из ошибочно обнаруженных шумовых импульсов. В некоторых записях существует большая разница между интенсивностью тонов S1 и S2. Это приводит к проблеме, так как некоторые из тонов с низкой интенсивностью могут быть пропущены порогом. В результате способ сегментации выполняет тест на пропускание тонов S1 и S2 (606). Если может быть определено, что некоторые сегменты пропущены, процедуру применения порога повторяют (607) с применением более низких локальных порогов.
Как только сигнал был разделен на сегменты, как описано выше, затем извлекают параметры интервалов, и параметры частот для каждого сегмента (608). Параметры помогают в классификации тонов на систолические сегменты и диастолические сегменты.
Параметры интервалов представляют собой четыре булевых параметра, извлеченные для каждого тона, путем сравнения длительности с предыдущим тоном и со следующим тоном, где интервалы времени извлекают с применением автокорреляций. Параметрами являются:
- AfterDia: Является истинным, если за тоном следует диастолический тон после периода, соответствующего продолжительности диастолы,
- AfterSys: Является истинным, если за тоном следует диастолический тон после периода, соответствующего продолжительности систолы,
- BeforeDia: Является истинным, если тон следует за диастолическим тоном после периода, соответствующего продолжительности диастолы,
- BeforeSys: Является истинным, если тон следует за диастолическим тоном после периода, соответствующего продолжительности систолы.
Частотный параметр разделяет тоны на низкочастотные и высокочастотные тоны путем вычисления медианной частоты тона. Он является полезной информацией, поскольку ожидается, что первый сердечный тон является низкочастотным тоном, и ожидается, что второй сердечный тон является высокочастотным тоном.
Параметры разбивают на байесову сеть, в которой вычисляют вероятность того, что сегмент представляет собой S1, S2 и шумовой тон (609). На фигуре изображена гистограмма (615) вероятности, рассчитанной для каждого тона в сердечном сигнале (601). Каждый тон обычно должен иметь преобладающую вероятность, указывающую тип (S1, S2 или шум) тона. Таким образом, все тоны классифицированы на S1, S2 и шумовые тоны. Однако вероятность данных трех типов в некоторых случаях должна быть более или менее равной, и в таких случаях невозможно классифицировать тон на S1, S2 или шумовой тон с использованием байесовой сети.
Вероятности используют на последнем этапе (610) для разделения и верификации сердечного сигнала на систолические и диастолические сегменты. Это проделано с использованием положения идентифицированных тонов S1 и S2 для маркировки начала систолического и диастолического сегмента тона соответственно.
Конечным результатом способа (611) являются начало и окончание всех идентифицированных систол и диастол. В связи с этим, может быть создана "последовательность" (616) из сменяющих друг друга систол (617) и диастол (618). Как только систолы и диастолы будут идентифицированы, их можно использовать в дополнительной обработке данных, например, извлекать дополнительные параметры из данных сегментов и, после этого, использовать параметры для классификации медицинского состояния записанного сердечного тона.
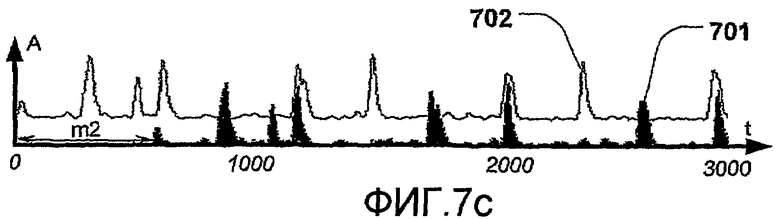
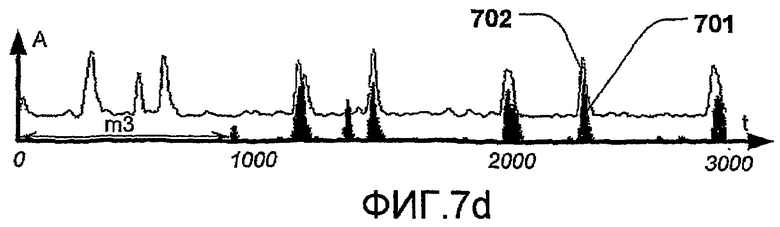
На фиг.7 изображена зависимость между автокорреляцией огибающей и сердечным циклом, и каким образом интервалы между сердечными тонами S1 и S2 могут быть найдены из автокорреляции.
На фиг.7а изображена автокорреляция огибающей с нормализованной автокорреляцией на оси у (NA) и смещением (m) сдвинутой огибающей на оси х.
На фиг.7b изображено смещение (m1), когда сдвинутая огибающая (701) смещена на продолжительность систолы, соответствующую несдвинутой огибающей (702). На оси у показана амплитуда (А) огибающей и на оси x - время (t). S1 в смещенной огибающей умножены на S2 в несмещенных огибающих, результатом чего является первый пик (703), который виден в автокорреляции.
На фиг.7с изображено смещение (m2), когда сдвинутая огибающая (701) смещена на продолжительность диастолы, соответствующую несдвинутой огибающей (702). Смещенные S2 умножены на S1 в несдвинутой огибающей, результатом чего является второй пик (704), который виден в автокорреляции.
На фиг.7d изображено смещение (m3), когда сдвинутая огибающая (701) смещена на продолжительность сердечного цикла, соответствующую несдвинутой огибающей (702). S1 в смещенной огибающей умножены на S1 в несдвинутой огибающей, и S2 в смещенной огибающей умножены на S2 в несдвинутой огибающей. Когда это происходит, в автокорреляции создается преобладающий пик (705).
В связи с этим, интервал между сердечными тонами может быть найден путем измерения интервала между пиками в автокорреляции, как описано выше.
На фиг.8 изображена реализация байесовой сети, используемой, для вычисления вероятности того, что тон является S1, S2 и шумовым тоном на этапе (809). Фундаментальным понятием в байесовой сети является условная вероятность и апостериорная вероятность. Условная вероятность описывает вероятность события а при условии события b.
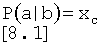
Если приведенное выше Уравнение описывает начальную условную вероятность, апостериорная вероятность будет:
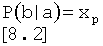
В соответствии с правилом Байеса между апостериорной вероятностью и условной вероятностью существует следующее соотношение:
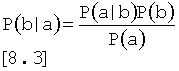 ,
,
где P(a) представляет собой априорную вероятность для события а, и Р (b) представляет собой априорную вероятность для события b. Уравнение [8.3] описывает лишь соотношение между одним родительским элементом и одним дочерним элементом, но поскольку событие а может представлять собой комбинацию нескольких явлений {а1, а2, …, аn}, Уравнение может быть расширено до:
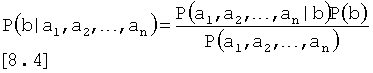
Поскольку целью является нахождение вероятности для различных состояний b, когда a1 и а2 известны, P(a1, а2, …, аn) является лишь константой нормализации k, и [7.4] может быть упрощено до:
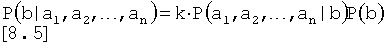
Если дочерние события {а1, а2, …, аn) условно независимы, Уравнение [8.5] может быть обобщено до:
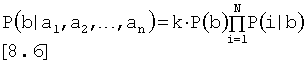 ,
,
где N равно количеству известных событий а. Уравнение [8.6] полезно при определении вероятности явления b, если состояния всех событий а известны и если все события условно независимы. Байесову сеть, основанную на Уравнении [8.6], называют наивной байесовой сетью, поскольку для нее требуется условная независимость дочерних элементов.
Задачей байесовой сети является оценка типа каждого обнаруженного тона, выше порога обнаружения. Для каждого из данных тонов рассчитана апостериорная вероятность того, что является тоном S1, тоном S2 или шумовой компонентой, и байесова сеть создана с применением одного родительского элемента и пяти дочерних элементов. Родительский элемент представляет собой тон выше порога огибающей (801), и дочерние элементы представляют собой пять параметров, описанных выше: Frequency (частота) (802), AfterSys (803), AfterDia (804), BeforeSys (805) и BeforeDia (806). При определении апостериорной вероятности для типа конкретного тона, априорная вероятность для различных состояний типа тона P(S) и условные вероятности должны быть известны, то есть условные вероятности, что "AfterSys" находятся в данном состоянии, когда S представляет собой данный тип Р(AfterSys|S). Данная апостериорная вероятность требует определения P(S), Р(AfterSys|S), Р(AfterDia|S), Р(BeforeSys|S), Р(BeforeDia|S) и Р(Frequency|S) прежде, чем Уравнение [8.6] может быть использовано для вычисления апостериорной вероятности того, что тон представляет собой конкретный тип тона.
Априорная вероятность того, что тон является S1, S2 или шумовой компонентой, изменяется между записями. В оптимальной записи, в которой не обнаружены никакие шумовые компоненты, априорная вероятность для шума равна нулю, P(S=Шум)=0. Если дело обстоит таким образом, и обнаружено равное количество S1 и S2, априорная вероятность того, что обнаруженный тон представляет собой S1, равна 50%, и аналогично для S2. В связи с этим, Р(S=S1)=Р(S=S2)=0,5, если Р (S=шум)=0. Однако, данное оптимальное условие не может быть принято для реальных сигналов, и шумовые тоны будут обнаружены. Это увеличивает априорную вероятность того, что данный тон является шумом.
Точная вероятность того, что обнаруженный тон является шумом, P(S=шум) может быть определена, если известно количество обнаруженных шумовых тонов, Nшум, и общее количество обнаруженных тонов Nтон. Например, если известно, что обнаружено четыре шумовых тона, Nшум=4, и общее количество обнаруженных тонов равно 20, вероятность того, что исследуемый тон является шумовым тоном составляет Р(S=Шум)=4/20. Однако, в большинстве сигналов Nшум не известно, и, в связи с этим, необходима оценка Nшум, и эта оценка может быть основана на уже доступной информации, так как продолжительность сердечного цикла известна из автокорреляции огибающей (804). В связи с этим, может быть рассчитано ожидаемое количество сердечных циклов в одной записи путем деления длительности записи на длительность сердечных циклов. В связи с этим, количество S1 и S2 в записи в два раза больше количества сердечных циклов при регистрации. В связи с этим, априорная вероятность типа тона будет представлять собой:
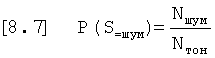
и априорная вероятность того, что обнаруженный тон является S1 или S2:
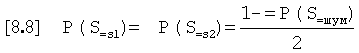
Условная вероятность того, что за S1 следует тон S2 после интервала, соответствующего продолжительности систолы, Р (AfterSys|S=S1), зависит от нескольких факторов. За тонами S1 обычно следуют тоны S2 после интервала с продолжительностью, равной систоле. Также могут встречаться отклонения от этого, например, когда S1 представляет собой последний тон в записи, или если S2 отсутствует, поскольку он не обнаружен порогом. Также может встречаться, что обнаружен слабый (ниже порога) S2, поскольку в окне допуска возникает шум, связанный с данными тонами. Таким образом, вероятность того, что "AfterSys" является ложным, если тон представляет собой тон S1, может быть рассчитана как

где "EndSound" представляет собой событие, описывающее, что тон является последним тоном в записи. "SingleSound" описывает, что за S1 не следует S2, поскольку следующий тон S2 не обнаружен по причине амплитуды ниже порога. "NoiseInWin" описывает возникновение шума в окне, в котором ожидался тон S2. Условная вероятность того, что "AfterSys" является истинным при условии, что исследованный тон является тоном S1, задается формулой:
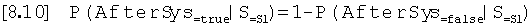
Если исследованный тон является тоном S2, маловероятно, что какой-либо тон встречается после интервала, соответствующего продолжительности систолы, так как следующий тон S1 встречается после продолжительности диастолы. Исключением является случай, когда шумовой тон встречается в окне Р(NoiseInWin) или если продолжительности систолы и диастолы равны. Если продолжительность диастолы равна продолжительности систолы, тон S1, который следует за тоном S2 после продолжительности диастолы, возникает как в окне допуска систолы, так и в окне допуска диастолы. Это случается когда у индивидуума высокая частота сердечных сокращений. Вероятность того, что тон встречается в обоих окнах допуска (перекрытие) равна степени перекрытия между окнами допуска систолы и диастолы. Данную вероятность называют Р(Перекрытие). В связи с этим, условная вероятность того, что тон возникает в окне после продолжительности систолы, если исследованный тон является тоном S2, равна:

Условная вероятность того, что тон не возникает после продолжительности систолы, если исследованный тон представляет собой S2, противоположна условной вероятности того, что он возникает:
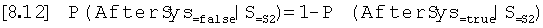
Условная вероятность того, что за обнаруженным шумовым тоном следует другой тон после продолжительности систолы, основана на вероятности того, что тон любого вида присутствует в сегменте с длиной используемого окна допуска. Она может быть оценена из отношения продолжительности окна допуска, умноженного на количество обнаруженных тонов, минус один, к продолжительности записи.
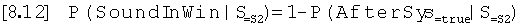
Условная вероятность того, что за обнаруженным шумовым тоном следует другой тон после продолжительности систолы, Р(AfterSys|S=Шум), основана на вероятности того, что тон любого вида присутствует в сегменте с длиной используемого окна допуска. Она может быть оценена из отношения продолжительности окна допуска, умноженного на количество обнаруженных тонов, минус один, к продолжительности записи. В связи с этим, условная вероятность того, что за шумовым тоном следует другой тон после продолжительности систолы, равна:
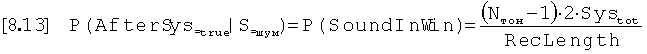 ,
,
где Nтон представляет собой количество тонов в записи, Systot представляет собой продолжительность систолы, и RecLength представляет собой продолжительность записи. Условная вероятность того, что за шумом не следует другой тон после интервала систолы, противоположна:
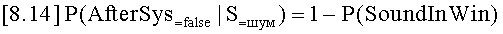
Условные вероятности для Р(AfterDia|S), Р(BeforeSys|S) и Р(BeforeDia|S) основаны на тех же предположениях, что и используемые для определения Р(AfterSys|S). Данные условные вероятности могут быть найдены в таблицах 1-5, представленных ниже:
Предварительно было обнаружено, что частотный параметр классифицировал 86% тонов S1 как низкочастотные и 80% тонов S2 как высокочастотные. 85% всех шумовых тонов были классифицированы как высокочастотные. Данную информацию использовали в качестве условных вероятностей между частотным параметром Р (Frequency|S):
Когда все условные вероятности будут найдены, Уравнение [8.6] используется байесовой сетью для вычисления апостериорных вероятностей для всех обнаруженных тонов. Данным путем для каждого тона рассчитывают три вероятности, которые отражают, с какой вероятностью настоящий тон принадлежит к данному типу.
Следует отметить, что описанные выше варианты выполнения скорее иллюстрируют, чем ограничивают изобретение, и что специалисты в данной области техники могут предложить множество альтернативных вариантов выполнения, не отступая от объема приложенной формулы изобретения.

Группа изобретений относится к области медицины. Варианты способов содержат этапы: идентифицируют систолические или диастолические сегменты сердечно-сосудистого тона; разделяют один из идентифицированных систолических или диастолических сегментов на множество подсегментов, содержащих первый подсегмент и второй подсегмент; идентифицируют шумные подсегменты и исключают шумные подсегменты; извлекают из первого подсегмента первый параметр сигнала, характеризующий первое свойство сердечнососудистого тона, извлекают из второго подсегмента второй параметр сигнала, характеризующий второе свойство сердечно-сосудистого тона; классифицируют сердечно-сосудистый тон с применением первого параметра сигнала и второго параметра сигнала многопараметрическим способом классификации. Варианты системы содержат: средство обработки для идентификации диастолических или систолических сегментов сердечно-сосудистого тона; средство обработки для разделения сегментов на множество подсегментов; средство обработки для идентификации шумных подсегментов; средство обработки для исключения шумных подсегментов; средство обработки для извлечения из первого подсегмента первого параметра сигнала и средство обработки для извлечения из второго подсегмента второго параметра сигнала; средство обработки для классификации сердечно-сосудистого тона. Стетоскоп, содержит: средство записи, средство накопления, машиночитаемый носитель и модуль обработки. Машиночитаемый носитель содержит сохраненные в нем инструкции для осуществления модулем обработки выполнения вариантов способа и классификации записанного сердечно-сосудистого тона. Серверное устройство связано с сетью передачи данных и содержит: средство приема, средство накопления, машиночитаемый носитель и модуль обработки. Применение данной системы изобретений позволит улучшить качество извлеченных параметров сигнала при прохождении сигнала из коронарных артерий. 7 н. и 24 з.п. ф-лы, 11 ил., 5 табл.
1. Способ классификации сердечно-сосудистого тона, записанного от живого индивидуума, содержащий этапы, на которых: идентифицируют диастолические сегменты указанного сердечно-сосудистого тона; разделяют, по меньшей мере, один из указанных идентифицированных диастолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент; идентифицируют шумные подсегменты и исключают указанные шумные подсегменты; извлекают из указанного первого подсегмента, по меньшей мере, первый параметр сигнала, характеризующий первое свойство указанного сердечно-сосудистого тона, извлекают из указанного второго подсегмента, по меньшей мере, второй параметр сигнала, характеризующий второе свойство указанного сердечно-сосудистого тона; классифицируют указанный сердечно-сосудистый тон с применением указанного, по меньшей мере, первого параметра сигнала и указанного, по меньшей мере, второго параметра сигнала многопараметрическим способом классификации.
2. Способ по п.1, в котором дополнительно идентифицируют систолические сегменты указанного сердечно-сосудистого тона и разделяют, по меньшей мере, один из указанных дополнительно идентифицированных систолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент.
3. Способ классификации сердечно-сосудистого тона, записанного от живого индивидуума, содержащий этапы, на которых: идентифицируют систолические сегменты указанного сердечно-сосудистого тона; разделяют, по меньшей мере, один из указанных идентифицированных систолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент; идентифицируют шумные подсегменты и исключают указанные шумные подсегменты; извлекают из указанного первого подсегмента, по меньшей мере, первый параметр сигнала, характеризующий первое свойство указанного сердечно-сосудистого тона, извлекают из указанного второго подсегмента, по меньшей мере, второй параметр сигнала, характеризующий второе свойство указанного сердечно-сосудистого тона; классифицируют указанный сердечно-сосудистый тон с применением указанного, по меньшей мере, первого параметра сигнала и указанного, по меньшей мере, второго параметра сигнала многопараметрическим способом классификации.
4. Способ по п.3, в котором дополнительно идентифицируют диастолические сегменты указанного сердечно-сосудистого тона и разделяют, по меньшей мере, один из указанных дополнительно идентифицированных диастолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент.
5. Способ по любому из пп.1-4, в котором указанный, по меньшей мере, первый параметр сигнала и/или указанный, по меньшей мере, второй параметр сигнала извлекают из, по меньшей мере, двух из указанного множества подсегментов.
6. Способ по любому из пп.1-4, в котором указанный способ дополнительно содержит этапы, на которых: идентифицируют нестационарные подсегменты и исключают указанные нестационарные подсегменты до указанных этапов извлечения указанного первого параметра сигнала и/или извлечения указанного второго параметра сигнала.
7. Способ по любому из пп.1-4, в котором, по меньшей мере, часть указанного первого подсегмента перекрывается, по меньшей мере, с частью указанного второго подсегмента.
8. Способ по любому из пп.1-4, в котором указанный этап классификации указанного сердечно-сосудистого тона содержит этап, на котором: вычисляют среднее значение указанного первого параметра сигнала и/или указанного, по меньшей мере, второго параметра сигнала, извлеченного из, по меньшей мере, двух из указанного множества подсегментов, и используют указанное среднее значение в указанном многопараметрическом способе классификации.
9. Способ по любому из пп.1-4, в котором указанный этап классификации указанного сердечно-сосудистого тона содержит этапы, на которых: классифицируют, по меньшей мере, один из указанного множества подсегментов с применением указанного первого параметра сигнала и указанного второго параметра сигнала в указанном многопараметрическом способе классификации, в котором как указанный первый параметр сигнала, так и указанный второй параметр сигнала извлекают из указанного, по меньшей мере, одного из указанного множества подсегментов, классифицируют указанный сердечно-сосудистый тон на основании указанной классификации указанного, по меньшей мере, одного из указанного множества подсегментов.
10. Способ по любому из пп.1-4, в котором указанный способ дополнительно содержит этапы моделирования, по меньшей мере, одного из указанного множества подсегментов и извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала из указанной модели.
11. Способ по любому из пп.1-4, в котором указанный первый параметр сигнала и/или указанный второй параметр сигнала представляет собой параметр уровня частоты, описывающий свойство уровня частоты, по меньшей мере, одной частотной компоненты, по меньшей мере, одного из указанного множества подсегментов.
12. Способ по любому из пп.1-4, в котором указанный первый параметр сигнала и/или указанный второй параметр сигнала представляют собой параметры сложности, описывающие сложность, по меньшей мере, одного из указанного множества подсегментов.
13. Способ по любому из пп.1-4, в котором, по меньшей мере, один из указанных идентифицированных диастолических и/или систолических сегментов разделен, по меньшей мере, на 8 подсегментов.
14. Система для классификации сердечно-сосудистого тона, записанного от живого индивидуума, содержащая: средство обработки для идентификации диастолических сегментов указанного сердечно-сосудистого тона; средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных диастолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент; средство обработки для идентификации шумных подсегментов; средство обработки для исключения указанных шумных подсегментов; средство обработки для извлечения из указанного первого подсегмента, по меньшей мере, первого параметра сигнала, характеризующего первое свойство указанного сердечно-сосудистого тона, и средство обработки для извлечения из указанного второго подсегмента, по меньшей мере, второго параметра сигнала, характеризующего второе свойство указанного сердечно-сосудистого тона; средство обработки для классификации указанного сердечно-сосудистого тона с применением указанного, по меньшей мере, первого параметра сигнала и указанного, по меньшей мере, второго параметра сигнала в многопараметрическом способе классификации.
15. Система по п.14, которая дополнительно содержит средство обработки для идентификации систолических сегментов указанного сердечно-сосудистого тона и средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных систолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент.
16. Система для классификации сердечно-сосудистого тона, записанного от живого индивидуума, содержащая: средство обработки для идентификации систолических сегментов указанного сердечно-сосудистого тона; средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных систолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент; средство обработки для идентификации шумных подсегментов; средство обработки для исключения указанных шумных подсегментов; средство обработки для извлечения из указанного первого подсегмента, по меньшей мере, первого параметра сигнала, характеризующего первое свойство указанного сердечно-сосудистого тона, и средство обработки для извлечения из указанного второго подсегмента, по меньшей мере, второго параметра сигнала, характеризующего второе свойство указанного сердечно-сосудистого тона; средство обработки для классификации указанного сердечно-сосудистого тона с применением указанного, по меньшей мере, первого параметра сигнала и указанного, по меньшей мере, второго параметра сигнала в многопараметрическом способе классификации.
17. Система по п.16, в которой система дополнительно содержит средство обработки для идентификации диастолических сегментов указанного сердечно-сосудистого тона и средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных диастолических сегментов на множество подсегментов, содержащих, по меньшей мере, первый подсегмент и, по меньшей мере, второй подсегмент.
18. Система по любому из пп.14-17, в которой указанное средство обработки для извлечения указанного первого параметра сигнала и/или указанное средство обработки для извлечения указанного второго параметра сигнала выполнено с возможностью извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала из, по меньшей мере, одного из указанного множества подсегментов.
19. Система по любому из пп.14-17, которая дополнительно содержит: средство обработки для идентификации нестационарных подсегментов и средство обработки для исключения указанных нестационарных подсегментов до извлечения указанного первого параметра сигнала и/или извлечения указанного второго параметра сигнала.
20. Система по любому из пп.14-17, в которой указанное средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных диастолических и/или систолических сегментов на множество подсегментов выполнено с возможностью перекрытия, по меньшей мере, части указанного первого подсегмента, по меньшей мере, с частью указанного второго подсегмента.
21. Система по любому из пп.14-17, в которой указанное средство обработки для классификации указанного сердечно-сосудистого тона выполнено с возможностью вычисления среднего значения указанного первого параметра сигнала и/или указанного, по меньшей мере, второго параметра сигнала, извлеченного, по меньшей мере, из двух из указанного множества подсегментов, и применения указанного среднего значения в указанном многопараметрическом способе классификации.
22. Система по любому из пп.14-17, в которой указанное средство для классификации указанного сердечно-сосудистого тона выполнено с возможностью классификации, по меньшей мере, одного из указанного множества подсегментов, применения указанного первого параметра сигнала и указанного второго параметра сигнала в указанном многопараметрическом способе классификации и классификации указанного сердечно-сосудистого тона на основании указанной классификации указанного, по меньшей мере, одного из указанного множества подсегментов.
23. Система по любому из пп.14-17, которая дополнительно содержит средство обработки для моделирования, по меньшей мере, одного из указанного множества подсегментов и средство обработки для извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала из указанной модели.
24. Система по любому из пп.14-17, в которой указанное средство обработки для извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала выполнено с возможностью извлечения, по меньшей мере, одного параметра уровня частоты, описывающего свойство уровня частоты, по меньшей мере, одной частотной компоненты, по меньшей мере, одного из указанного множества подсегментов.
25. Система по любому из пп.14-17, в которой указанное средство обработки для извлечения указанного первого параметра сигнала и/или указанного второго параметра сигнала выполнено с возможностью извлечения, по меньшей мере, одного параметра сложности, описывающего сложность, по меньшей мере, одного из указанного множества подсегментов.
26. Система по любому из пп.14-17, в которой указанное средство обработки для разделения, по меньшей мере, одного из указанных идентифицированных диастолических и/или систолических сегментов на множество подсегментов выполнено с возможностью разделения, по меньшей мере, одного из указанных идентифицированных диастолических и/или систолических сегментов, по меньшей мере, на 8 подсегментов.
27. Машиночитаемый носитель, содержащий сохраненные на нем инструкции для осуществления модулем обработки выполнения способа по пп.1-13.
28. Стетоскоп, содержащий: средство записи, выполненное с возможностью записи сердечно-сосудистого тона от живого индивидуума, средство накопления, выполненное с возможностью сохранения указанного записанного сердечно-сосудистого тона, машиночитаемый носитель и модуль обработки, при этом указанный машиночитаемый носитель содержит сохраненные в нем инструкции для осуществления модулем обработки выполнения способа по пп.1-13 и, таким образом, классификации указанного записанного сердечно-сосудистого тона.
29. Серверное устройство, связанное с сетью передачи данных, содержащее: средство приема, выполненное с возможностью получения сердечно-сосудистого тона, записанного от живого индивидуума через указанную сеть передачи данных, средство накопления, выполненное с возможностью сохранения указанного полученного сердечно-сосудистого тона, машиночитаемый носитель и модуль обработки, при этом указанный машиночитаемый носитель содержит сохраненные в нем инструкции для осуществления модулем обработки выполнения способа по пп.1-13 и, таким образом, классификации указанного полученного сердечно-сосудистого тона.
30. Серверное устройство по п.29, в котором указанное средство приема дополнительно выполнено с возможностью получения указанного сердечно-сосудистого тона от клиента, связанного с указанной сетью передачи данных.
31. Серверное устройство по любому из пп.29-30, в котором указанное серверное устройство дополнительно содержит средство для отправки указанной классификации указанного сердечно-сосудистого тона, по меньшей мере, одному модулю клиента, связанному с указанной сетью передачи данных.
| DE 3732122 А1, 06.04.1989 | |||
| SU 1317708 А1, 15.03.1988 | |||
| US 2004260188 А1, 23.12.2004 | |||
| Устройство для составления развозочных маршрутов | 1973 |
|
SU525124A1 |
| US 2005090755 А1, 28.04.2005 | |||
| US 2002099286 A1, 25.07.2002 | |||
| WANG, PING, et al | |||
| Phonocardiography Signal Analysis Method Using a Modified Hidden Markov Model Annals of Biomedical Engineering, Volume 35, Number 3, March 2007, pp.367-374(8) (Реферат). | |||

