Уровень техники
Системы управления взаимодействием с покупателями ("CRM") позволяют фирмам управлять связями с их покупателями, включая сбор, хранение и анализ информации о покупателях. Во многих CRM-системах электронная почта ("e-mail") является предпочтительным способом связи с покупателями. Когда электронная почта отправляется из CRM-системы покупателю, активность по отправке электронной почты создается в CRM-системе, чтобы отслеживать связь. Активность (действие) по отправке электронной почты может быть ассоциативно связана с заказом покупателя, номером счета покупателя или другим типом информации, которая уникально идентифицирует контекст сообщения электронной почты.
Когда покупатель отвечает на сообщение электронной почты, отправленное из CRM-системы, многие CRM-системы будут создавать новую ответную активность в электронной почте. Чтобы сгруппировать все связанные действия в электронной почте для конкретного контекста, необходимо идентифицировать сообщения электронной почты как CRM-связанные и, в таком случае, сопоставить каждое связанное ответное действие в электронной почте с другими уже существующими действиями в электронной почте. Таким образом, каждое ответное действие в электронной почте будет связано с тем же заказом покупателя, номером счета покупателя, что и оригинальные, уже существующие действия в электронной почте. Тогда может быть выполнен быстрый доступ ко всем сообщениям к и от покупателя с помощью только номера счета покупателя или заказа покупателя.
В прошлом использовалось несколько способов, чтобы идентифицировать ответные сообщения и сопоставлять ответные сообщения электронной почты с уже существующим сообщением электронной почты. Каждый из этих предыдущих способов, однако, страдает от существенных недостатков. В первом способе идентификатор потока сообщений электронной почты вставляется в заголовок x-mailer ("x-заголовок") каждого отправленного сообщения электронной почты. Если идентификатор потока присутствует в ответной электронной почте, он может использоваться, чтобы сопоставлять ответное сообщение электронной почты с первоначальным сообщением электронной почты. В то время как этот способ, в целом, подходит для сообщений электронной почты, отправленных по локальной вычислительной сети, этот способ, как правило, не работает для сообщений через Интернет. Причина в том, что многие Интернет-серверы электронной почты систематически удаляют x-заголовки из входящих и исходящих почтовых сообщений. Как результат, ответные сообщения электронной почты от этих систем не будут включать в себя первоначальный идентификатор потока, таким образом, делая сопоставление с помощью идентификатора потока невозможным.
Во втором способе код отслеживания помещается в строку темы, тело сообщения или другое поле отправленного сообщения электронной почты. Если код отслеживания присутствует в том же поле ответного сообщения, код отслеживания может использоваться, чтобы сопоставлять ответное сообщение с первоначально отправленным сообщением электронной почты. Однако использование кода отслеживания видится некоторыми организациями как неудобное в том, что часто требуется помещать код отслеживания в видимое поле электронной почты типа строки темы. Как результат, некоторые организации не склонны помещать такие данные в поля сообщений электронной почты, отправленных из их CRM-систем. Более того, код отслеживания, помещенный в поле темы или тело сообщения электронной почты, подвержен модификации или удалению, что делает идентификацию и сопоставление невозможными. Код отслеживания, помещенный в тело сообщения электронной почты, также может требовать значительной обработки, чтобы определять его местоположение, так как должно быть исследовано все тело сообщения электронной почты, чтобы найти местоположение кода отслеживания.
Относительно этих и других соображений предоставлено это открытие, сделанное в данном документе.
Сущность изобретения
В данном документе описываются технологии идентификации и сопоставления сообщений электронной почты. В аспектах, представленных на всем протяжении данного документа, входящие ответные сообщения электронной почты могут быть идентифицированы и сопоставлены со связанными уже существующими сообщениями электронной почты без необходимости использования x-заголовков, чтобы хранить идентификаторы потоков. Более того, входящие ответные сообщения могут также быть идентифицированы и сопоставлены со связанными сообщениями электронной почты или другими CRM-объектами без затребования отслеживающего кода или любого другого типа отслеживающих данных, которые должны помещаться в поля исходящих сообщений электронной почты.
Согласно одному аспекту, представленному в данном документе, входящие ответные сообщения электронной почты идентифицируются и сопоставляются со связанными сообщениями электронной почты с помощью содержимого полей электронной почты, которые не удаляются почтовыми серверами Интернета. Например, в одном осуществлении поля темы и получателя сообщений электронной почты, отправленных из или принятых в вычислительной системе, обрабатываются для использования в идентификации и сопоставлении входящих сообщений электронной почты. В частности, в одном варианте осуществления содержимое поля темы входящих и исходящих сообщений снабжается меткой. Посредством процесса снабжения меткой неучитываемые слова и выражения, обычно предшествующие полям темы (например, "Re:", "Fw:" и т.д.), удаляются. Уникальное хэш-значение, названное в данном документе хэш-значением темы, затем формируется для каждого из элементов в поле темы.
Адреса электронной почты, указанные в полях получателей каждого отправленного или принятого сообщения электронной почты, также обрабатываются. В частности, хэш-значение, упоминаемое в данном документе хэш-значением адреса, формируется для адресов электронной почты в каждом из полей получателей (например, "To:", "From:", "CC:", "Bcc:" и т.д.) отправленного или принятого сообщения электронной почты. Хэш-значения темы и хэш-значения адреса для каждого отправленного или принятого сообщения электронной почты затем сохраняются в базе данных, такой как база данных на языке структурированных запросов ("SQL"). В одном осуществлении в базу данных для каждого сообщения электронной почты вставляется запись, которая включает в себя идентификатор сообщения электронной почты вместе с хэш-значениями адреса и хэш-значениями темы, сформированными для сообщения электронной почты. Использование хэш-значений способом, представленным в данном документе, позволяет быстро идентифицировать связанные сообщения электронной почты, в то же время используя минимальный объем пространства хранения базы данных.
Когда входящее сообщение электронной почты принимается, данные, сохраненные в базе данных, используются, чтобы идентифицировать сообщение электронной почты как связанное с одним или более предшествующими сообщениями электронной почты и чтобы сопоставлять входящее сообщение электронной почты с одним или более сообщениями электронной почты, идентифицированными в базе данных. В частности, в одной реализации поле темы входящего сообщения электронной почты снабжается меткой и хэш-значения темы формируются для каждой из меток. Хэш-значения адреса затем формируются для адресов электронной почты каждого из получателей входящего сообщения электронной почты. После того как хэш-значения темы и хэш-значения адреса были сформированы для входящего сообщения электронной почты, эти значения сравниваются со значениями в базе данных, чтобы сопоставлять входящее сообщение электронной почты с одним или более связанными сообщениями электронной почты, идентифицированными в базе данных, или другими CRM-объектами.
В одном варианте осуществления входящее сообщение электронной почты идентифицируется как связанное с сообщением в базе данных или другим CRM-объектом посредством выполнения поиска в базе данных записей, сохраненных в ней, которые имеют, по меньшей мере, пороговое число хэш-значений адреса, которые совпадают с хэш-значениями адреса, сформированными для входящего сообщения электронной почты. После того как этот поиск был выполнен, входящее сообщение сопоставляется посредством идентификации возможных сообщений электронной почты, исследуя результаты для записей, имеющих второе пороговое число хэш-значений темы, которые совпадают с хэш-значениями темы, сформированными для входящего сообщения электронной почты. Согласно реализациям различные пороговые значения могут устанавливаться для того, чтобы улучшать вероятность точного сопоставления.
После того как возможные сообщения электронной почты были идентифицированы, входящее сообщение электронной почты сопоставляется с одним или более возможными сообщениями электронной почты. В одной реализации входящее сообщение электронной почты сопоставляется с самым последним модифицированным возможным сообщением электронной почты. Посредством сопоставления выполняется ассоциирование между входящим сообщением электронной почты и существующим сообщением электронной почты, идентифицированным в базе данных. Входящее сообщение электронной почты может также быть сопоставлено с другим типом CRM-объекта, таким как номер счета пользователя или заказ. Если кандидаты не идентифицированы, входящее сообщение электронной почты не сопоставляется с какими-либо сообщениями электронной почты, идентифицированными в базе данных. Входящее сообщение электронной почты может также быть сопоставлено с множеством существующих сообщений электронной почты для того, чтобы повторно создавать полный поток сообщений через множество сообщений электронной почты.
Вышеописанный предмет изучения может также быть реализован как управляемое компьютером устройство, компьютерный процесс, вычислительная система или изделие промышленного производства, такое как машиночитаемый носитель информации. Эти и различные другие признаки станут понятны из прочтения последующего подробного описания и просмотра ассоциированных чертежей.
Данная сущность предусмотрена для того, чтобы в упрощенной форме представить набор идей, которые дополнительно описываются ниже в подробном описании. Эта сущность не предназначена для того, чтобы идентифицировать ключевые признаки или важнейшие признаки заявляемого объекта изобретения, и не предназначена для того, чтобы использоваться в качестве ограничения области применения заявляемого объекта изобретения. Кроме того, заявленный объект изобретения не ограничен реализациями, которые решают любой или все недостатки, упомянутые в любой части этого раскрытия.
Краткое описание чертежей
Фиг.1 - это схема сети, показывающая иллюстративную сетевую вычислительную архитектуру и несколько компонентов программного обеспечения, предоставленных одним вариантом осуществления, описанным в данном документе;
фиг.2 - это блок-схема последовательности операций, показывающая иллюстративный процесс для обработки входящих и исходящих сообщений электронной почты, используемый в одном варианте осуществления, представленном в данном документе;
фиг.3 - это схема структуры данных, показывающая содержимое иллюстративного сообщения электронной почты и базы данных, используемых в одной реализации, описанной в данном документе;
фиг.4 - это блок-схема последовательности операций, показывающая процесс идентификации и сопоставления сообщения электронной почты с существующим сообщением электронной почты, используемый в одном варианте осуществления, представленном в данном документе;
фиг.5 - это схема архитектуры компьютера, показывающая иллюстративную архитектуру аппаратных средств, подходящую для реализации вычислительных систем, описанных со ссылкой на фиг.1-4.
Подробное описание
Следующее подробное описание направлено на технологии для идентификации и сопоставления сообщений электронной почты. Посредством вариантов осуществления, представленных в данном документе, входящее сообщение электронной почты может быть сопоставлено со связанным уже существующим сообщением электронной почты или со связанным CRM-объектом без использования отслеживающих меток или идентификаторов потока. В этом способе входящее сообщение электронной почты может быть сопоставлено со связанным сообщением электронной почты или CRM-объектом без помещения каких-либо данных в исходящие сообщения электронной почты.
Как будет описано более подробно ниже, реализации, представленные в данном документе, используют содержимое полей электронной почты, которые обычно не удаляются или модифицируются серверами электронной почты Интернета, чтобы идентифицировать и сопоставлять входящие сообщения электронной почты со связанными уже существующими сообщениями электронной почты или другими CRM-объектами. Согласно аспектам, представленным в данном документе, содержимое полей темы и получателей каждого сообщения электронной почты, отправленного из или принятого в вычислительной системе, хэшируется и сохраняется в базе данных. Когда входящее сообщение электронной почты принимается, содержимое полей темы и получателей входящего сообщения электронной почты также хэшируется. Вычисленные хэш-значения для входящего сообщения электронной почты затем сравниваются со значениями, сохраненными в базе данных, чтобы идентифицировать, существует ли достаточное ядро общего содержания и адресов получателя электронной почты, чтобы идентифицировать входящее сообщение электронной почты как связанное с одним или более сообщениями электронной почты, идентифицированными в базе данных. Если это так, входящее сообщение электронной почты сопоставляется со связанным сообщением электронной почты. Входящее сообщение электронной почты может также быть сопоставлено со связанным CRM-объектом подобным образом. Дополнительные детали, относящиеся к этому процессу, будут описаны ниже относительно фиг.1-5.
Хотя предмет изобретения, описанный в данном документе, представляется в общем контексте программных модулей, которые выполняются вместе с выполнением операционной системы и прикладных программ на компьютерной системе, специалисты в данной области техники должны признавать, что другие реализации могут быть осуществлены в комбинации с другими типами программных модулей. В общем, программные модули включают в себя алгоритмы, программы, компоненты, структуры данных и другие типы структур, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Более того, специалисты в данной области техники должны принимать во внимание, что предмет изобретения, описанный в данном документе, может быть реализован на практике с другими конфигурациями компьютерных систем, включающими в себя портативные устройства, многопроцессорные системы, основанную на микропроцессорах или программируемую бытовую электронную аппаратуру, миникомпьютеры, мейнфреймы и т.п.
В последующем подробном описании ссылки делаются на прилагаемые чертежи, которые составляют часть данного документа и в которых показаны посредством иллюстраций конкретные варианты осуществления или примеры. Обращаясь теперь к чертежам, на которых одинаковые номера представляют похожие элементы на протяжении нескольких чертежей, будут описаны аспекты вычислительной системы и методологии сопоставления сообщений электронной почты. В частности, фиг.1 - это схема архитектуры сети и программного обеспечения, которая предоставляет детали, касающиеся иллюстративного операционного окружения для вариантов осуществления, представленных в данном документе вместе с аспектами нескольких компонентов программного обеспечения, представленных в данном документе.
Иллюстративная вычислительная система, показанная на фиг.1, включает в себя CRM-систему 102. CRM-система 102 включает в себя компьютер 106 CRM-сервера, который выполняет CRM-приложение 108 и хранит ассоциированную CRM-базу 110 данных. CRM-система 102 предоставляет функциональность для управления взаимосвязями с деловыми клиентами, включающую в себя сбор, хранение и анализ информации о клиенте. Эти данные сохраняются CRM-приложением 108 в CRM-базе 110 данных. Клиентские данные, сохраненные в CRM-базе 110 данных, могут быть ассоциативно связаны с номером клиента, номером заказа или другим типом CRM-объекта. Согласно реализациям CRM-база 110 данных является базой данных на языке структурированных запросов SQL. Следует понимать, однако, что может использоваться любой тип технологии баз данных, чтобы реализовать CRM-базу 110 данных.
CRM-функциональность, представленная CRM-приложением 108, может быть доступна посредством использования приложения 104 веб-браузера, выполняющегося на компьютере 107 CRM-клиента. Таким образом, компьютер 107 CRM-клиента может использоваться, чтобы осуществлять доступ к функциональности, предоставленной CRM-приложением 108, для создания и просмотра информации о клиенте для связи с покупателями через CRM-систему 102 и для выполнения других связанных с CRM функций. CRM-система 102 использует электронную почту в качестве основного способа связи с покупателями.
Когда сообщение 112 электронной почты отправляется из CRM-системы 102 компьютеру 116 покупателя, копия отправленного сообщения 112 электронной почты создается в CRM-базе 110 данных, чтобы отслеживать связь. Копия отправленного сообщения 112 электронной почты может быть ассоциирована с клиентским заказом, номером счета покупателя или другим типом CRM-объекта, который уникально идентифицирует контекст сообщения электронной почты. Как будет описано более подробно ниже, данные, содержащиеся в сообщении 112 электронной почты, отправленном из CRM-системы 102, также обрабатываются и сохраняются в CRM-базе 110 данных для использования в идентификации связанных сообщений и сопоставлении этих сообщений со связанными уже существующими сообщениями электронной почты, идентифицированными в CRM-базе 110 данных. Детали, касающиеся этого процесса, предоставлены ниже относительно фиг.2-4.
Покупатели принимают сообщения электронной почты от CRM-приложения 108 с помощью клиентского приложения 118 электронной почты, выполняющегося на компьютере 116 покупателя. Покупатели могут также принимать такие сообщения электронной почты посредством использования прикладной программы веб-браузера и размещенной в веб-сети почтовой службы. В ответ на прием сообщения 112 электронной почты покупатель может использовать клиентское приложение 118 электронной почты или размещенную в веб-сети почтовую службу, чтобы передавать ответное сообщение 114 электронной почты CRM-системе 102. Например, покупатель может передавать ответное сообщение 114 электронной почты, чтобы узнать о заказе, который он разместил.
Когда CRM-приложение 108 принимает ответное сообщение 114 электронной почты, выполняется попытка идентифицировать сообщение как связанное с CRM и, если это так, сопоставить ответное сообщение 114 со связанным сообщением электронной почты, идентифицированным в CRM-базе 110 данных, таким как сообщение 112 электронной почты. Как будет описано более подробно ниже, содержимое различных полей, содержащихся во входящем ответном сообщении 114 электронной почты, анализируется и сравнивается с данными, сохраненными в CRM-базе 110 данных для других сообщений электронной почты, чтобы идентифицировать и сопоставить ответное сообщение 114 электронной почты с уже существующим связанным сообщением электронной почты. Дополнительно, после того как ответное сообщение 114 электронной почты было правильно сопоставлено со связанным сообщением 112 электронной почты, данные, содержащиеся в ответном сообщении 114 электронной почты, также обрабатываются и сохраняются в CRM-базе 110 данных для использования в сопоставлении будущих входящих сообщений электронной почты. Идентифицируя и сопоставляя все связанные сообщения электронной почты таким образом, все связанные сообщения для покупателя могут быть ассоциативно связаны и доступны вместе. Детали, касающиеся различных процессов, предусмотренных в данном документе, для идентификации и сопоставления сообщений электронной почты в CRM-системе 102, обсуждаются ниже со ссылкой на фиг.2-4.
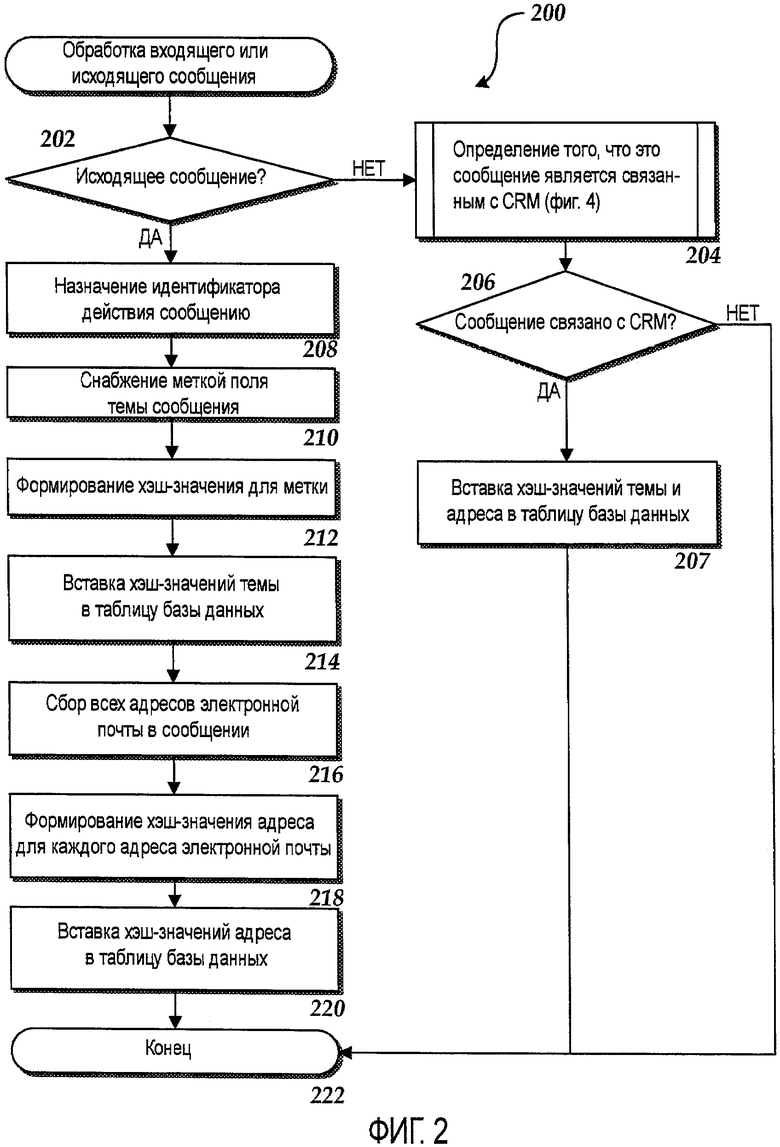
Обращаясь теперь к фиг.2, дополнительные детали будут предоставлены относительно вариантов осуществления, представленных в данном документе, для идентификации и сопоставления сообщений электронной почты. В частности, фиг.2 является блок-схемой, показывающей алгоритм 200, который иллюстрирует аспекты работы CRM-приложения 108 для обработки входящих и исходящих сообщений электронной почты в одной реализации, описанной в данном документе. Как описано кратко выше, CRM-приложение 108 обрабатывает содержимое нескольких полей сообщений электронной почты, отправленных из и принятых в CRM-системе 102, для использования в сопоставлении входящих сообщений электронной почты с сообщениями электронной почты, сохраненными в CRM-базе 110 данных. Фиг.2 показывает один иллюстративный вариант осуществления, используемый CRM-приложением 108 для выполнения этой обработки. Фиг.2 будет описана совместно с фиг.3, которая иллюстрирует содержимое иллюстративного сообщения 112 электронной почты и аспекты CRM-базы 110 данных.
Следует понимать, что логические операции, описанные в данном документе, реализованы (1) как последовательность машинореализованных действий или программных модулей, выполняющихся в вычислительной системе, и/или (2) как взаимосвязанные машинные логические схемы или модули схем в вычислительной системе. Эта реализация зависит от требований к производительности и других требований к вычислительной системе. Соответственно, логические операции, описанные в данном документе, упоминаются по-разному как операции, структурные устройства, действия или модули. Эти операции, структурные устройства, действия и модули могут быть осуществлены в программном обеспечении, в микропрограммном обеспечении, в специализированной цифровой логике и в любой их комбинации. Также следует понимать, что больше или меньше операций может выполняться, чем показано на чертежах и описано в данном документе. Эти операции могут также быть выполнены в другом порядке, чем описано в данном документе относительно различных чертежей.
Как кратко обсуждено выше, CRM-приложение 108 обрабатывает каждое сообщение электронной почты, отправленное или принятое в CRM-системе 102. Фиг.3 показывает иллюстративное сообщение 112 электронной почты, которое было отправлено CRM-приложением 108. Как показано на фиг.3, сообщение 112 электронной почты включает в себя ряд полей 302A-302D. В частности, сообщение 112 электронной почты включает в себя три поля 302A-302C получателей. Поля 302A-302C получателей используются, чтобы хранить адреса электронной почты для получателей сообщения 112 электронной почты. Например, поле 302A "from:" ("от кого:") хранит адрес 304A электронной почты, поле 302B "to:" ("кому:") хранит адреса 304B и 304C электронной почты и поле 302C "cc:" ("копия:") хранит адрес 304D электронной почты. Следует понимать, что адрес электронной почты может иметь дополнительные поля получателей, не показанные на фиг.3.
Сообщение 112 электронной почты также включает в себя поле 302D темы и поле 308 тела сообщения. Поле 302D темы используется, чтобы хранить буквенно-цифровую тему для сообщения 112 электронной почты. Поле 308 тела сообщения используется, чтобы хранить основное тело сообщения 112 электронной почты. В примерном сообщении 112 электронной почты, показанном на фиг.3, поле 308 тела хранит сообщение для покупателя, касающееся отправки заказа. Как будет описано подробно ниже, CRM-приложение 108 обрабатывает содержимое полей 302A-302D, чтобы сформировать данные для использования в идентификации и сопоставлении входящих сообщений электронной почты с сообщениями электронной почты, идентифицированными в CRM-базе 110 данных. Следует понимать, что хотя иллюстративное сообщение 112 электронной почты, показанное на фиг.3, является исходящим сообщением электронной почты, отправляемым из CRM-системы 102, процесс, описанный относительно фиг.2, выполняется относительно как входящих, так и исходящих сообщений.
Алгоритм 200 начинается на этапе 202, где выполняется определение относительно того, обрабатывается ли сообщение, входящее в CRM-приложение 108, или сообщение, исходящее от CRM-приложения 108. Если обрабатывается исходящее сообщение, алгоритм 200 переходит от этапа 202 к этапу 208. Если обрабатывается входящее сообщение, алгоритм 200 переходит от этапа 202 к этапу 204, описанному ниже.
На этапе 208 CRM-приложение 108 назначает сообщению 112 электронной почты идентификатор 310 действия ("ID действия"). ID 310 действия уникально идентифицирует контекст сообщения 112 электронной почты. Например, ID 310 действия может использоваться, чтобы сопоставлять сообщение 112 электронной почты с другими связанными сообщениями электронной почты, со связанным счетом покупателя или номером заказа, или с другим типом CRM-объекта. В случае исходящего сообщения 112 электронной почты идентификатор 310 действия известен CRM-приложению 108.
От этапа 208 алгоритм 200 переходит к этапу 210, где CRM-приложение 108 помечает содержимое поля 302D темы сообщения 112 электронной почты. В одной реализации все управляющие слова предварительно определенного формата в поле 302D темы игнорируются. Например, любое слово или фраза, которая заканчивается двоеточием, могут быть игнорированы. Это позволяет выполнять быстрое удаление фраз, обычно добавляемых в поля тем электронной почты (например, "Re:", "Fw:" и т.д.). Альтернативно, список слов, которые должны быть удалены из поля темы, может быть принят во внимание, чтобы определять, какие слова должны быть удалены. Этот список может настраиваться администратором, как, например, добавление новых слов или удаление слов из списка. Оставшееся содержимое затем лексически анализируется, чтобы идентифицировать словесные метки, содержащиеся в поле 302D темы. Например, посредством применения процесса снабжения метками к иллюстративному содержимому поля 302D темы, показанного на фиг.3, метки 306A-306D будут идентифицированы.
После того как метки 306A-306D, содержащиеся в поле 302D темы, были идентифицированы, алгоритм 200 продолжается на этапе 212, где формируется хэш-значение для каждой из меток 306A-306D. Хэш-значения для меток 306A-306D называются в данном документе хэш-значениями 318 темы. Например, в примере, показанном на фиг.3, хэш-значение 318A темы формируется для метки 306A, хэш-значение 318B темы формируется для метки 306B, хэш-значение 318C темы формируется для метки 306C и хэш-значение 318D темы формируется для метки 306D. Следует понимать, что может использоваться любая подходящая хэш-функция, чтобы сформировать хэш-значения 316 темы. В вариантах осуществления хэш-функция формирует защищенные хэши из секретного ключа. Также могут использоваться фиксированные, компактные хэши.
От этапа 218 алгоритм 200 переходит к этапу 214, где хэш-значения 316 темы вставляются в хэш-запись 322 электронной почты в хэш-таблице 320 электронной почты, сохраненной в CRM-базе 110 данных. Хэш-таблица 320 электронной почты включает в себя хэш-запись 322 электронной почты для каждого входящего и исходящего сообщения электронной почты и, как будет описано более подробно, используется, чтобы сопоставлять входящие сообщения электронной почты с уже существующими связанными сообщениями, идентифицированными в CRM-базе 110 данных. Каждая хэш-запись 322 электронной почты также включает в себя ID 310 действия для соответствующего сообщения электронной почты и одно или более хэш-значений 314 адресов. Формирование хэш-значений 314 адресов описано ниже.
От этапа 214 алгоритм 200 переходит к этапу 216, где собираются адреса электронной почты в каждом из полей 302A-302D получателей. Алгоритм 200 затем продолжается на этапе 218, где хэш-значение формируется для каждого из собранных адресов электронной почты. Эти хэш-значения упоминаются в данном документе как хэш-значения 312 адресов. Для иллюстративного сообщения 112 электронной почты, показанного на фиг.3, хэш-значение 314A адреса формируется из адреса 304A электронной почты, хэш-значение 314B адреса формируется из адреса 304B электронной почты, хэш-значение 314C адреса формируется из адреса 304C электронной почты и хэш-значение 314D адреса формируется из адреса 304D электронной почты. Может использоваться любая подходящая хэш-функция, чтобы сформировать хэш-значения 312 адресов из адресов 304A-304D электронной почты.
От этапа 218 алгоритм 200 переходит к этапу 220, где хэш-значения 312 адресов вставляются в соответствующую хэш-запись 322 электронной почты в хэш-таблице 320 электронной почты. Следует понимать, что процессы, показанные на этапах 208-220 на фиг.2 и описанные выше, повторяются для каждого сообщения электронной почты, которое передается из CRM-системы 102. Таким образом, хэш-запись 322 электронной почты создается для каждого исходящего сообщения электронной почты. Как будет описано более подробно ниже относительно фиг.4, CRM-приложение 108 использует содержимое хэш-записей 322 электронной почты, чтобы сопоставлять входящие сообщения с уже существующими сообщениями электронной почты, идентифицированными в CRM-базе 110 данных. От этапа 220 алгоритм 200 переходит к этапу 222, где он заканчивается.
Если на этапе 202 определяется, что обрабатывается исходящее сообщение от CRM-приложения 108, алгоритм 200 переходит от этапа 202 к этапу 204. На этапе 204 выполняется определение относительно того, является ли входящее сообщение электронной почты связанным с CRM, и, если так, оно сопоставляется с одним или более существующими сообщениями электронной почты. Иллюстративный процесс будет описан ниже со ссылкой на фиг.4 для идентификации сообщения электронной почты как связанного с CRM и для сопоставления входящего сообщения электронной почты с одним или более уже существующими связанными сообщениями электронной почты, идентифицированными в CRM-базе 110 данных.
Если входящее сообщение идентифицировано как связанное с CRM, алгоритм 200 переходит от этапа 206 к этапу 207, где хэш-значения темы и хэш-значения адресов для входящего сообщения электронной почты сохраняются в базе 110 данных. Алгоритм 200 переходит от этапа 207 к этапу 222, где он заканчивается. Если входящее сообщение электронной почты не является связанным с CRM, входящее сообщение игнорируется. Алгоритм 200, следовательно, переходит непосредственно от этапа 206 к этапу 222, где он заканчивается.
Возвращаясь теперь к фиг.4, будет описан алгоритм 400, который иллюстрирует один иллюстративный процесс, выполняемый CRM-приложением 108 для сопоставления входящего сообщения электронной почты с уже существующим связанным сообщением электронной почты, идентифицированным в CRM-базе 110 данных. Алгоритм 400 начинается с этапа 402, где поле темы входящего сообщения электронной почты, которое должно быть сопоставлено, помечается способом, описанным выше относительно фиг.2. Алгоритм 400 затем переходит к этапу 404, где хэш-значение 316 темы вычисляется для сформированных меток тем же способом, что и описанный выше относительно фиг.2.
От этапа 404 алгоритм 400 переходит к этапу 406, где собираются все адреса электронной почты в каждом из полей получателей входящего сообщения электронной почты. Алгоритм 400 затем продолжается на этапе 408, где хэш-значение 312 адреса формируется для каждого из собранных адресов электронной почты. От этапа 408 алгоритм 400 переходит к этапу 410.
На этапе 410 CRM-приложение 108 выполняет поиск в хэш-таблице 320 электронной почты. В частности, поиск в хэш-таблице 320 электронной почты выполняется, чтобы найти хэш-записи 322 электронной почты, сохраненные в ней, которые имеют, по меньшей мере, предварительно определенное число (названное в данном документе "N") хэш-значений 318 адресов, которые соответствуют хэш-значениям адресов, вычисленным для входящего сообщения электронной почты. Алгоритм 400 затем продолжается на этапе 412, где результаты поиска, выполненного на этапе 410, исследуются на предмет каких-либо хэш-записей 322 электронной почты, которые имеют, по меньшей мере, предварительно определенное число (названное в данном документе "X") хэш-значений 318 темы, которые соответствуют хэш-значениям темы, вычисленным для входящего сообщения электронной почты. Следует понимать, что посредством поисков, выполненных на этапах 412 и 414, находятся сообщения электронной почты, идентифицированные в CRM-базе 110 данных, которые имеют, по меньшей мере, N хэш-значений адресов и X хэш-значений темы подобных входящему сообщению электронной почты. Сообщения электронной почты могут упоминаться в данном документе как электронные почтовые сообщения-кандидаты для сопоставления.
От этапа 412 алгоритм 400 переходит к этапу 414, где результаты поиска, выполненного на этапах 410 и 412, исследуются на предмет каких-либо записей, которые имеют не больше чем предварительно определенное число (упоминаемое в данном документе как "C") хэш-значений темы. Устраняя потенциальные электронные почтовые сообщения-кандидаты для сопоставления, которые имеют больше чем C хэш-значений темы, можно избежать излишних совпадений. Следует понимать, что хотя в данном документе они описаны как отдельные этапы, поиски, описанные выше относительно этапов 410, 412 и 414, могут быть выполнены с помощью одного поискового SQL-запроса. Следует также понимать, что N, X и C могут модифицироваться, чтобы улучшать точность алгоритма сопоставления, описанного в данном документе.
От этапа 414 алгоритм 400 переходит к этапу 416, где выполняется определение относительно того, не получены ли в качестве результатов поисков, выполненных на этапах 410, 412, 414, электронные почтовые сообщения-кандидатов для сопоставления (т.е. совпадающие хэш-записи электронной почты не были возвращены). Если кандидаты не были идентифицированы, входящее сообщение электронной почты рассматривается как не связанное с сообщениями электронной почты, идентифицированными в хэш-таблице 320 электронной почты. Алгоритм 400, следовательно, переходит от этапа 416 к этапу 420, где может быть предоставлено указание о том, что входящее сообщение электронной почты не связано с действиями CRM-системы 102. Если один или более кандидатов были идентифицированы, алгоритм 400 переходит от этапа 416 к этапу 418.
На этапе 418 выполняется определение относительно того, было ли идентифицировано более чем одно электронное почтовое сообщение-кандидат, во время поисков, выполняемых на этапах 410, 412 и 414. Если был найден только один кандидат, алгоритм 400 переходит к этапу 422, где входящее сообщение электронной почты сопоставляется с сообщением электронной почты, на которое ссылается совпадающая хэш-запись 322 электронной почты. Это может быть выполнено, например, посредством назначения входящему сообщению электронной почты того же идентификатора 310 действия, что и содержащийся в совпадающей хэш-записи 322 электронной почты. Если было идентифицировано больше чем один кандидат, алгоритм 400 переходит от этапа 418 к этапу 424, где входящее сообщение электронной почты сопоставляется с самым недавним модифицированным сообщением электронной почты, на которое ссылаются совпадающие хэш-записи электронной почты (т.е. самый последний модифицированный кандидат). От этапов 420, 422 и 424 алгоритм 400 переходит к этапу 426, где он заканчивается.
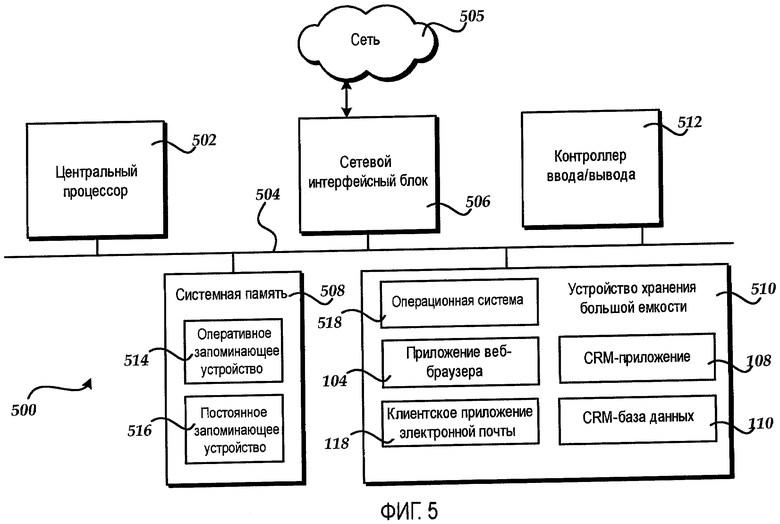
Обращаясь теперь к фиг.5, иллюстративная архитектура компьютера 500, способного выполнять компоненты программного обеспечения, описанные выше со ссылкой на фиг.1-4, будет описана. Архитектура компьютера, показанная на фиг.5, иллюстрирует традиционный настольный, портативный или серверный компьютер и может использоваться, чтобы осуществлять любую из компьютерных систем, описанных в данном документе.
Архитектура компьютера, показанная на фиг.5, включает в себя центральный процессор 502 ("CPU"), системную память 508, включающую в себя оперативное запоминающее устройство 514 ("RAM") и постоянное запоминающее устройство ("ROM") 516, и системную шину 504, которая связывает память с CPU 502. Базовая система ввода/вывода, содержащая базовые процедуры, которые помогают передавать информацию между элементами в компьютере 500, как, например, во время начальной загрузки, хранится в ROM 516. Компьютер 500 дополнительно включает в себя устройство 510 хранения большой емкости для хранения операционной системы 518, прикладных программ и других программных модулей, которые будут описаны более подробно ниже.
Устройство 510 хранения большой емкости подключено к CPU 502 посредством контроллера устройства хранения большой емкости (не показан), подключенного к шине 504. Устройство 510 хранения большой емкости и ассоциированные с ним машиночитаемые носители обеспечивают энергонезависимое хранилище для компьютера 500. Хотя описание машиночитаемых носителей, содержащееся в данном документе, ссылается на устройство хранения большой емкости, такое как жесткий диск, накопитель CD-ROM, следует понимать, что машиночитаемые носители могут быть любыми доступными носителями, к которым можно осуществлять доступ посредством компьютера 500.
В качестве примера, но не ограничения, машиночитаемые носители могут включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Например, машиночитаемые носители включают в себя (но не только) память по технологии RAM, ROM, EPROM, EEPROM, флэш-памяти или другой твердотельной технологии, CD-ROM, универсальный цифровой диск (DVD), HD-DVD, BLU-RAY или другое оптическое запоминающее устройство, магнитные кассеты, магнитную ленту, магнитный диск или другие магнитные устройства хранения, либо любой другой носитель, который может быть использован для того, чтобы хранить требуемую информацию, и к которому можно осуществлять доступ с помощью компьютера 500.
Согласно различным вариантам осуществления компьютер 500 работает в сетевом окружении, используя логические соединения с удаленными компьютерами по сети, такой как сеть 505. Персональный компьютер 500 может подключаться к сети 505 через сетевой интерфейсный модуль 506, подключенный к шине 504. Следует принимать во внимание, что сетевой интерфейсный блок 506 может также использоваться для подключения к другим типам сетей и удаленным компьютерным системам. Компьютер 500 может также включать в себя контроллер 512 ввода/вывода для приема и обработки входных данных от ряда других устройств, включающих в себя клавиатуру, мышь или электронное перо (не показано на фиг.5). Аналогично, контроллер ввода-вывода может предоставлять вывод на экран дисплея, принтер или другой тип устройства вывода (также не показано на фиг.5).
Как кратко упомянуто выше, ряд программных модулей и файлов данных могут храниться в устройстве 510 хранения большой емкости и RAM 514 компьютера 500, в том числе операционная система, подходящая для управления работой соединенного в сеть настольного, переносного или серверного компьютера. Устройство 510 хранения большой емкости и RAM 514 может также хранить один или более программных модулей. В частности, устройство 510 хранения большой емкости и RAM 514 могут хранить прикладную программу 104 веб-браузера, программу 118 клиентского приложения электронной почты, CRM-приложение 108 и CRM-базу 110 данных, каждое из которых было описано выше со ссылками на фиг.1-4. Другие программные модули также могут быть сохранены в устройстве 510 хранения большой емкости и использоваться компьютером 500.
Согласно другим вариантам осуществления CRM-приложение 108 может предоставлять пользовательский интерфейс, доступный через приложение 104 веб-браузера, для корректировки ошибочного сопоставления. Например, если CRM-приложение 108 некорректно сопоставило входящее сообщение электронной почты с несвязанным сообщением электронной почты или CRM-объектом, пользователь будет иметь возможность скорректировать ошибочное сопоставление через пользовательский интерфейс посредством сопоставления входящего сообщения электронной почты со связанным сообщением электронной почты или CRM-объектом. Согласно другим аспектам пользовательский интерфейс может отображать уровень конфиденциальности для каждого сопоставления, выполненного CRM-приложением 108. Если уровень конфиденциальности выше некоего предварительно определенного порогового значения, пользователю может быть не разрешено модифицировать сопоставление. Согласно другим вариантам осуществления пользователю может быть разрешено добавлять сопоставление там, где CRM-приложение 108 его не обнаружило. Альтернативно, если сообщение идентифицировано как связанное с CRM, но соответствующим образом не сопоставлено, ссылка для сообщения не будет создана.
Следует понимать, что хотя различные процессы, представленные здесь, были описаны как выполняемые CRM-приложением 108, другие типы программ, выполняющихся в других типах вычислительных систем, могут выполнять эти процессы. Например, в другой реализации функциональность, предоставленная в данном документе, для идентификации и сопоставления сообщений электронной почты, может быть объединена в клиентское приложение 118 электронной почты. Посредством объединения этой функциональности клиентское приложение 118 электронной почты может ассоциировать связанные сообщения электронной почты друг с другом и отображать связанные сообщения согласно потокам. Функциональность, описанная в данном документе, может также использоваться в веб-системе электронной почты или другом типе системы электронной почты.
Также следует понимать, что реализации, описанные в данном документе, предоставлены для большей безопасности, чем предшествующие решения, которые использовали отслеживающие метки. При использовании предыдущих решений отслеживающие метки могут быть спрогнозированы и подделаны пользователем-злоумышленником. При использовании реализаций, представленных в данном документе, тема и получатели должны достаточно близко совпадать для сообщений электронной почты, которые должны быть идентифицированы и сопоставлены с таким же контекстом. Пользователю-злоумышленнику будет очень трудно атаковать процесс, описанный в данном документе. Более того, также следует понимать, что предыдущие решения, которые используют отслеживающие метки, требуют принятия решения в момент, когда сообщение электронной почты отправляется, относительно того, будет ли отслеживаться электронная почта. При использовании процессов, представленных в данном документе, решение может быть принято позднее, и сопоставление может все еще предоставляться для последующих ответных сообщений.
На основе упомянутого выше следует понимать, что в данном документе предоставлены технологии идентификации и сопоставления сообщений электронной почты. Хотя предмет изобретения, представленный в данном документе, описан на языке, конкретном для компьютерных структурных признаков, методологических действий и машиночитаемых носителей, следует понимать, что изобретение, заданное в прилагаемой формуле изобретения, не обязательно ограничено конкретными признаками, действиями или носителями, описанными в данном документе. Наоборот, описанные в данном документе характерные признаки, действия и носители раскрываются как примерные формы реализации формулы изобретения.
Предмет изобретения, описанный выше, предоставляется только в качестве иллюстрации и не должен считаться ограничивающим. Различные модификации и изменения могут быть выполнены в предмет изобретения, описанный в данном документе, без следования примерным вариантам осуществления и применения, проиллюстрированным и описанным, и без отступления от истинной сущности и объема настоящего изобретения, которые изложены в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ВЫЯВЛЕНИЯ НЕЗНАЧАЩИХ ЛЕКСИЧЕСКИХ ЕДИНИЦ В ТЕКСТОВОМ СООБЩЕНИИ И КОМПЬЮТЕР | 2014 |
|
RU2580424C1 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| ЭЛЕКТРОННАЯ СЕРТИФИКАЦИЯ, ИНДЕНТИФИКАЦИЯ И ПЕРЕДАЧА ИНФОРМАЦИИ С ИСПОЛЬЗОВАНИЕМ КОДИРОВАННЫХ ГРАФИЧЕСКИХ ИЗОБРАЖЕНИЙ | 2008 |
|
RU2494455C2 |
| КОНТУР ОБРАТНОЙ СВЯЗИ ДЛЯ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОЙ РАССЫЛКИ | 2004 |
|
RU2331913C2 |
| СЕРВЕР И СПОСОБ ОБРАБОТКИ ЭЛЕКТРОННЫХ СООБЩЕНИЙ (ВАРИАНТЫ) | 2014 |
|
RU2580434C2 |
| РЕКОМЕНДАТЕЛЬНАЯ СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ ЕЮ | 2012 |
|
RU2609072C2 |
| ФИНАНСОВЫЕ ТРАНЗАКЦИИ С ОПЛАТОЙ ПЕРЕДАЧИ И ПРИЕМА СООБЩЕНИЙ | 2005 |
|
RU2380754C2 |
| ЭЛЕКТРОННОЕ УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ ЭЛЕКТРОННОГО СООБЩЕНИЯ | 2014 |
|
RU2608880C2 |
| ФРЕЙМВОРК ПРИЕМА ВИДЕО ДЛЯ ПЛАТФОРМЫ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2720536C1 |
| СЛУЖБА РЕПУТАЦИИ КОНТЕНТА НА ОСНОВЕ ДЕКЛАРАЦИИ | 2011 |
|
RU2573760C2 |


Изобретение относится к области идентификации и сопоставления сообщений электронной почты. Техническим результатом является повышение эффективности обработки сообщений электронной почты. Содержимое полей темы и получателей сообщений электронной почты, принятых в и отправленных из вычислительной системы, хэшируются и сохраняются в базе данных. Когда входящее сообщение электронной почты принимается в вычислительной системе, содержимое его полей темы и получателей также хэшируется. Затем выполняется поиск в базе данных, чтобы найти сообщения электронной почты, идентифицированные в базе данных, которые имеют достаточное число хэш-значений темы и адреса, которые совпадают с хэш-значениями темы и адреса, сформированными для входящего сообщения электронной почты, так что сообщения могут быть сопоставлены. Сопоставление выполняется между входящим сообщением электронной почты и наиболее совпадающим сообщением электронной почты, найденным во время поиска в базе данных. 4 н. и 16 з.п. ф-лы, 5 ил.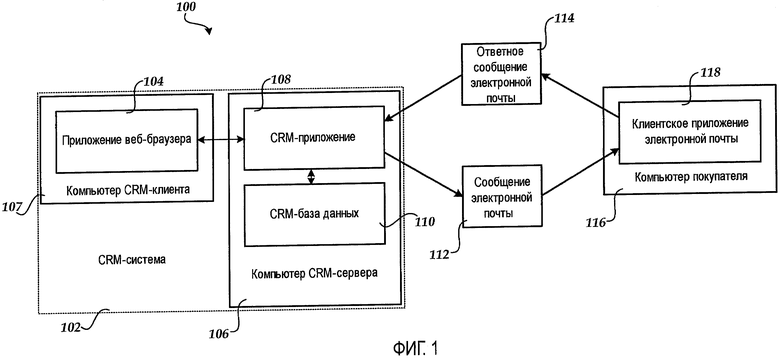
1. Способ идентификации и сопоставления входящего сообщения (114) электронной почты с предыдущим сообщением (112) электронной почты, указанным в базе (110) данных, причем способ содержит этапы, на которых:
принимают входящее сообщение (114) электронной почты;
в ответ на прием входящего сообщения (114) электронной почты определяют, связано ли входящее сообщение электронной почты с предыдущим сообщением электронной почты в базе (110) данных;
в ответ на определение, что входящее сообщение (114) электронной почты связано с предыдущим сообщением электронной почты в базе (110) данных, определяют, достаточно ли совпадают данные, сохраненные в первом поле (302A) и втором поле (302D) входящего сообщения (114) электронной почты с данными, сохраненными в базе (110) данных для соответствующего первого поля и второго поля предыдущего сообщения (112) электронной почты, чтобы сопоставить входящее сообщение (114) электронной почты с предыдущим сообщением (112) электронной почты, и сопоставляют входящее сообщение (114) электронной почты с предыдущим сообщением (112) электронной почты в ответ на определение, что данные, сохраненные в первом и втором полях входящего сообщения (114) электронной почты, достаточно совпадают с данными, сохраненными в базе (110) данных для соответствующих первого и второго полей предыдущего сообщения (112) электронной почты.
2. Способ по п.1, дополнительно содержащий этапы, на которых:
идентифицируют данные, сохраненные в первом и втором полях предыдущего сообщения электронной почты; и
сохраняют хэш-значения в базе данных для данных, сохраненных в первом и втором полях предыдущего сообщения электронной почты.
3. Способ по п.1, в котором первое поле содержит поле темы и в котором второе поле содержит поле получателя.
4. Машиночитаемый носитель информации, имеющий машиноисполняемые инструкции, сохраненные на нем, которые, когда выполняются компьютером, инструктируют компьютеру выполнять способ по п.1.
5. Способ идентификации и сопоставления входящего сообщения (114) электронной почты (e-mail) с одним из множества сообщений (112) электронной почты, принятых в или отправленных из вычислительной системы (102), каждое из множества сообщений (112) электронной почты имеет содержимое, сохраненное в поле (302D) темы, и идентифицирует одного или более получателей посредством адреса (304) электронной почты, причем способ содержит этапы, на которых:
идентифицируют одну или более меток (306) для содержимого в поле (302D) темы множества сообщений электронной почты;
формируют хэш-значение (318) темы для каждой из меток (316);
формируют хэш-значение (314) адреса для каждого из адресов (304) электронной почты получателей множества сообщений электронной почты;
сохраняют хэш-значения (318) темы и хэш-значения (314) адреса в базе (110) данных;
принимают входящее сообщение (114) электронной почты; и
в ответ на прием входящего сообщения (114) электронной почты сопоставляют входящее сообщение (114) электронной почты с одним из множества сообщений электронной почты с помощью хэш-значений (318) темы и хэш-значений (314) адреса, сохраненных в базе (110) данных.
6. Способ по п.5, в котором сопоставление входящего сообщения электронной почты с одним из множества сообщений электронной почты с помощью хэш-значений темы и хэш-значений адреса, сохраненных в базе данных, содержит этапы, на которых:
идентифицируют одну или более меток для содержимого в поле темы входящего сообщения электронной почты;
формируют хэш-значение темы для каждой из меток для содержимого в поле темы входящего сообщения электронной почты;
формируют хэш-значение адреса для каждого из адресов электронной почты получателей входящего сообщения электронной почты; и
сопоставляют входящее сообщение электронной почты с одним из множества сообщений электронной почты с помощью хэш-значений темы и хэш-значений адреса, сформированных для входящего сообщения электронной почты, и хэш-значений темы и хэш-значений адреса, сохраненных в базе данных.
7. Способ по п.6, в котором сохранение хэш-значений темы и хэш-значений адреса в базе данных содержит этап, на котором сохраняют запись в базе данных для каждого из множества сообщений электронной почты, каждая запись содержит идентификатор для сообщения электронной почты, хэш-значения темы для сообщения электронной почты и хэш-значения адреса для сообщения электронной почты.
8. Способ по п.7, в котором сопоставление входящего сообщения электронной почты с одним из множества сообщений электронной почты с помощью хэш-значений темы и хэш-значений адреса, сформированных для входящего сообщения электронной почты, и хэш-значений темы и хэш-значений адреса, сохраненных в базе данных, содержит этапы, на которых:
выполняют поиск в базе данных записей, сохраненных в ней, имеющих, по меньшей мере, первое пороговое число хэш-значений адреса, которые совпадают с хэш-значениями адреса, сформированными для входящего сообщения электронной почты;
идентифицируют ноль или более сообщений-кандидатов электронной почты посредством исследования результатов поиска в базе данных записей, имеющих, по меньшей мере, второе пороговое число хэш-значений темы, которые совпадают с хэш-значениями темы, сформированными для входящего сообщения электронной почты; и
сопоставляют входящие сообщения электронной почты с одним из сообщений-кандидатов электронной почты.
9. Способ по п.8, дополнительно содержащий перед сопоставлением входящего сообщения электронной почты с самым последним модифицированным сообщением-кандидатом электронной почты этап, на котором:
удаляют из сообщений-кандидатов электронной почты любое сообщение электронной почты, имеющее более чем третье пороговое значение итоговых хэш-значений адреса и хэш-значений темы.
10. Способ по п.9, в котором сопоставление входящего сообщения электронной почты с одним из сообщений-кандидатов электронной почты содержит этап, на котором сопоставляют входящее сообщение электронной почты с самым последним модифицированным одним из сообщений-кандидатов электронной почты.
11. Способ по п.10, дополнительно содержащий этап, на котором предоставляют указание о том, что входящее сообщение электронной почты не связано с каким-либо из множества сообщений электронной почты, в ответ на определение того, что присутствует ноль сообщений-кандидатов электронной почты.
12. Способ по п.11, при этом база данных содержит базу данных на языке структурированных запросов (SQL).
13. Машиночитаемый носитель информации, имеющий машиноисполняемые инструкции, сохраненные на нем, которые, когда выполняются компьютером, инструктируют компьютеру:
принимать входящее сообщение (114) электронной почты, имеющее поле (302D) темы и одно или более полей (302A) адреса, каждое поле адреса имеет один или более адресов (304) получателей электронной почты, сохраненных в них;
в ответ на прием входящего сообщения (114) электронной почты снабжать поле (302D) темы входящего сообщения (114) электронной почты одной или более метками (306), чтобы сформировать хэш-значение (318) темы для каждой из меток (306) и сформировать хэш-значение (314) адреса для каждого из адресов (304) получателей электронной почты; и
идентифицировать входящее сообщение (114) электронной почты как связанное с уже существующим сообщением (112) электронной почты с помощью хэш-значений (318) темы и хэш-значений (314) адреса; и
в ответ на идентификацию сообщения (114) электронной почты как связанного с уже существующим сообщением (112) электронной почты сопоставлять входящее сообщение (114) электронной почты с уже существующим сообщением (112) электронной почты с помощью хэш-значений (318) темы и хэш-значений (314) адреса.
14. Машиночитаемый носитель информации по п.13, имеющий дополнительные машиноисполняемые инструкции, сохраненные на нем, которые, когда выполняются компьютером, инструктируют компьютеру:
формировать хэш-значения темы и хэш-значения адреса для множества сообщений электронной почты, принятых в или переданных из компьютера; и
сохранять хэш-значения темы и хэш-значения адреса для множества сообщений электронной почты, принятых в или переданных из компьютера, в базе данных.
15. Машиночитаемый носитель информации по п.14, при этом сохранение хэш-значений темы и хэш-значений адреса для сообщений электронной почты, принятых в или переданных компьютером, в базе данных, содержит этап, на котором сохраняют запись в базе данных для каждого из множества сообщений электронной почты, каждая запись содержит идентификатор для сообщения электронной почты, хэш-значения темы для сообщения электронной почты и хэш-значения адреса для сообщения электронной почты.
16. Машиночитаемый носитель информации по п.15, при этом сопоставление входящего сообщения электронной почты с уже существующим сообщением электронной почты с помощью хэш-значений темы и хэш-значений адреса содержит этап, на котором сопоставляют входящее сообщение электронной почты с одним из множества сообщений электронной почты с помощью хэш-значений темы и хэш-значений адреса, сформированных для входящего сообщения электронной почты, и хэш-значений темы и хэш-значений адреса, сохраненных в базе данных.
17. Машиночитаемый носитель информации по п.16, при этом сопоставление входящего сообщения электронной почты с одним из множества сообщений электронной почты с помощью хэш-значений темы и хэш-значений адреса, сформированных для входящего сообщения электронной почты, и хэш-значений темы и хэш-значений адреса, сохраненных в базе данных, содержит этапы, на которых:
выполняют поиск в базе данных записей, сохраненных в ней, имеющих, по меньшей мере, первое пороговое число хэш-значений адреса, которые совпадают с хэш-значениями адреса, сформированными для входящего сообщения электронной почты;
идентифицируют ноль или более сообщений-кандидатов электронной почты посредством исследования результатов поиска в базе данных записей, имеющих, по меньшей мере, второе пороговое число хэш-значений темы, которые совпадают с хэш-значениями темы, сформированными для входящего сообщения электронной почты; и
сопоставляют входящие сообщения электронной почты с одним из сообщений-кандидатов электронной почты.
18. Машиночитаемый носитель информации по п.17, имеющий дополнительные машиноисполняемые инструкции, сохраненные на нем, которые инструктируют компьютеру удалять из сообщений-кандидатов электронной почты любое сообщение электронной почты, имеющее более чем третье пороговое значение итоговых хэш-значений адреса и хэш-значений темы, перед сопоставлением входящего сообщения электронной почты с самым последним модифицированным сообщением-кандидатом электронной почты.
19. Машиночитаемый носитель информации по п.18, при этом сопоставление входящего сообщения электронной почты с одним из сообщений-кандидатов электронной почты содержит этап, на котором сопоставляют входящее сообщение электронной почты с самым последним модифицированным одним из сообщений-кандидатов электронной почты.
20. Машиночитаемый носитель информации по п.19, при этом база данных содержит базу данных на языке структурированных запросов (SQL).
| WO 2004032439 A1, 15.04.2004 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Масляный выключатель высокого напряжения | 1937 |
|
SU54446A1 |

