ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[1] Настоящее решение относится к системе и способу выявления незначащих лексических единиц в тексте сообщения электронной почты.
УРОВЕНЬ ТЕХНИКИ
[2] В современных компьютерных технологиях, использование электронной почты получило широкое распространение. Пользователи сервисов электронной почты зачастую получают более десятка сообщений электронной почты в день. Некоторые пользователи получают более сотни сообщений электронной почты в день.
[3] Как правило, при составлении сообщения электронной почты, отправитель заполняет поле «Тема», где он может кратко указать содержание сообщения электронной почты. Поле «тема» позволяет получателю быстрее ориентироваться в массиве полученных сообщений электронной почты, а также сразу же по получении сообщения электронной почты составить себе представление о его важности. Например, пользователь может, не открывая сообщение электронной почты, сразу же оценить как неважное сообщение с темой «Беспрецедентные скидки на чемоданы!» и, напротив, оценить как важное сообщение с темой «Внимание, изменилось расписание Вашего рейса».
[4] В некоторых случаях, однако, поле «тема» сообщения электронной почты может быть недостаточным для определения важности сообщения электронной почты. Так может быть в случае, когда тема сообщения сформулирована автором нечетко, либо когда пользователь получает множество сообщений электронной почты со схожими темами. В таких случаях, полезной может оказаться функция просмотра нескольких первых строк сообщения электронной почты. Например, почтовый клиент Microsoft Outlook™ позволяет осуществлять просмотр первых трех строк сообщений в главном окне.
[5] В некоторых случаях, показ нескольких первых строк также не дает возможности определить важность письма. Например, так может быть, если первые строки содержат обращение и общие вводные фразы. Такие незначащие слова и фразы могут не давать хорошего представления о сути сообщения.
[6] Таким образом, в то время как существующие обычные компьютерные системы являются приемлемыми, улучшение таких систем, тем не менее, возможно.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[7] Целью настоящего решения является устранение или смягчение по меньшей мере некоторых из неудобств, присутствующих на существующем уровне техники.
[8] В соответствии с вариантами осуществления настоящего решения, предусматривается способ компьютерной обработки предназначенного пользователю входящего текстового сообщения, включающего в себя значащие и незначащие лексические единицы, способ включающий: (i) осуществление синтаксического анализа текстового сообщения для определения по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы; (ii) осуществление первой проверки по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из первой базы данных лексических единиц, где первая база данных сформирована в результате синтаксического анализа предыдущих текстовых сообщений, предназначенных пользователю; (iii) осуществление второй проверки указанного по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из второй базы данных незначащих лексических единиц, где вторая база данных сформирована в результате синтаксического анализа предыдущих текстовых сообщений, предназначенных группе пользователей из множества пользователей; (iv) в ответ на положительный результат любой из: первой проверки и второй проверки, определение кандидата в незначащие лексические единицы в качестве незначащей лексической единицы.
[9] В некоторых вариантах осуществления, способ включает формирование реферата текстового сообщения, причем реферат сформирован таким образом, что незначащие лексические единицы отсутствуют в реферате текстового сообщения.
[10] В некоторых вариантах осуществления, реферат текстового сообщения содержит по меньшей мере одну фразу, имеющую смысловое значение.
[11] В некоторых вариантах осуществления, реферат текстового сообщения является рефератом наиболее значимой части текстового сообщения.
[12] В некоторых вариантах осуществления, текстовое сообщение является сообщением электронной почты, и в котором наиболее значимая часть данного сообщения электронной почты определяется как наиболее значимый логический блок HTML кода из множества логических блоков HTML кода, содержащих текст.
[13] В некоторых вариантах осуществления, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, размер которого превышает размер текста любого другого логического блока HTML кода данного сообщения электронной почты.
[14] В некоторых вариантах осуществления, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, причем текст наиболее значимого логического блока HTML кода содержит наибольшее количество значащих лексических единиц по сравнению с текстами любого другого логического блока HTML кода данного сообщения электронной почты.
[15] В некоторых вариантах осуществления, реферат текстового сообщения является рефератом предопределенного количества абзацев в начале текстового сообщения.
[16] В некоторых вариантах осуществления, группа пользователей представляет собой все множество пользователей.
[17] В некоторых вариантах осуществления, способ включает получение входящего текстового сообщения.
[18] В некоторых вариантах осуществления, лексической единицей является любое из: (i) слово, (ii) словосочетание, (iii) предложение, (iv) абзац.
[19] В вариантах осуществления, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы является определением по меньшей мере одной лексической единицы, имеющей смысловое значение.
[20] В некоторых вариантах осуществления, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы осуществляется на основе синтаксического анализа одного из: (i) всего текста, содержащегося в текстовом сообщении, и (ii) фрагмента текста, содержащегося в текстовом сообщении, причем фрагмент текста, содержащийся в тексте сообщения, включает в себя предопределенное количество абзацев.
[21] В некоторых вариантах осуществления, осуществление синтаксического анализа текстового сообщения включает в себя анализ языка разметки текстового сообщения.
[22] В некоторых вариантах осуществления, анализ языка разметки текстового сообщения включает анализ по меньшей мере одного, выбранного из: вида шрифта, размера шрифта, начертания шрифта, знаков препинания, специальных знаков.
[23] В некоторых вариантах осуществления, способ включает определение контрольной суммы лексической единицы.
[24] В некоторых вариантах осуществления, контрольная сумма лексической единицы является одним из: контрольным элементом и комбинацией контрольных элементов, причем контрольным элементом является любой элемент, выбранный из: количество символов, количество букв, количество заглавных букв, количество прописных букв, количество пробелов, количество цифр в лексической единице, количество специальных знаков в лексической единице, количество слов в лексической единице, размер лексической единицы, выраженный в единицах обработки и хранения информации.
[25] В некоторых вариантах осуществления, сопоставление кандидата в незначащие лексические единицы с незначащими лексическими единицами из любой из: первой базы данных лексических единиц и второй базы данных лексических единиц, осуществляется путем сопоставления, по меньшей мере по одному предопределенному параметру, кандидата в незначащие лексические единицы с незначащими лексическими единицами из любой из: первой базы и второй базы данных лексических единиц.
[26] В вариантах осуществления, предопределенный параметр, по которому осуществляется сопоставление, является одним из: контрольной суммой и комбинацией отдельных контрольных элементов, входящих в состав контрольной суммы лексической единицы.
[27] В некоторых вариантах, результат любой из: первой проверки и второй проверки, является положительным в случае, когда сопоставление по меньшей мере по одному предопределенному параметру выявляет одно из: частичное совпадение по указанному по меньшей мере одному предопределенному параметру, причем степень совпадения превышает предустановленный порог совпадения, и полное совпадение по указанному по меньшей мере одному предопределенному параметру.
[28] В некоторых вариантах, способ включает, перед осуществлением синтаксического анализа текстового сообщения, создание по меньшей мере одной из: первой базы данных и второй базы данных.
[29] Другим объектом настоящего решения является компьютер. Компьютер включает в себя процессор. Конфигурация процессора настроена таким образом, чтобы компьютер мог: (i) осуществлять синтаксический анализ текстового сообщения для определения по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы; (ii) осуществлять первую проверку по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из первой базы данных лексических единиц, где первая база данных сформирована в результате синтаксического анализа предыдущих текстовых сообщений, предназначенных пользователю; (iii) осуществлять вторую проверку указанного по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из второй базы данных незначащих лексических единиц, где вторая база данных сформирована в результате синтаксического анализа предыдущих текстовых сообщений, предназначенных группе пользователей из множества пользователей; (iv) в ответ на положительный результат любой из: первой проверки и второй проверки, определять кандидата в незначащие лексические единицы в качестве незначащей лексической единицы.
[30] В некоторых вариантах компьютера, конфигурация процессора настроена таким образом, чтобы компьютер мог осуществлять формирование реферата текстового сообщения, причем реферат текстового сообщения сформирован таким образом, что незначащие лексические единицы отсутствуют в реферате текстового сообщения.
[31] В некоторых вариантах воплощения компьютера, реферат текстового сообщения содержит по меньшей мере одну фразу, имеющую смысловое значение.
[32] В некоторых вариантах воплощения компьютера, реферат текстового сообщения является рефератом наиболее значимой части текстового сообщения.
[33] В некоторых вариантах воплощения компьютера, текстовое сообщение является сообщением электронной почты, в котором наиболее значимая часть данного сообщения электронной почты определяется как наиболее значимый логический блок HTML кода из множества логических блоков HTML кода, содержащих текст.
[34] В некоторых вариантах воплощения компьютера, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, размер которого превышает размер текста любого другого логического блока HTML кода данного сообщения электронной почты.
[35] В некоторых вариантах воплощения компьютера, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, причем текст наиболее значимого логического блока HTML кода содержит наибольшее количество значащих лексических единиц по сравнению с текстами любого другого логического блока HTML кода данного сообщения электронной почты.
[36] В некоторых вариантах, реферат текстового сообщения является рефератом предопределенного количества абзацев в начале текстового сообщения.
[37] В некоторых вариантах воплощения компьютера, группа пользователей представляет собой все множество пользователей.
[38] В некоторых вариантах воплощения компьютера, конфигурация процессора настроена таким образом, чтобы компьютер мог осуществлять получение входящего текстового сообщения.
[39] В некоторых вариантах воплощения компьютера, лексической единицей является любое из: (i) слово, (i) словосочетание, (iii) предложение, (iv) абзац.
[40] В некоторых вариантах, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы является определением по меньшей мере одной лексической единицы, имеющей смысловое значение.
[41] В некоторых вариантах, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы осуществляется на основе синтаксического анализа одного из: (i) всего текста, содержащегося в текстовом сообщении, и (ii) фрагмента текста, содержащегося в текстовом сообщении.
[42] В некоторых вариантах, осуществление синтаксического анализа сообщения электронной почты включает анализ языка разметки сообщения электронной почты.
[43] В некоторых вариантах воплощения компьютера, анализ языка разметки текстового сообщения включает анализ по меньшей мере одного, выбранного из: вида шрифта, размера шрифта, начертания шрифта, знаков препинания, специальных знаков.
[44] В некоторых вариантах воплощения компьютера, конфигурация процессора настроена таким образом, чтобы компьютер мог осуществлять определение контрольной суммы лексической единицы.
[45] В некоторых вариантах, контрольная сумма лексической единицы является одним из: контрольным элементом и комбинацией контрольных элементов, контрольным элементом является любой элемент, выбранный из: количество символов в лексической единице, количество букв в лексической единице, количество заглавных букв в лексической единице, количество прописных букв в лексической единице, количество пробелов в лексической единице, количество цифр в лексической единице, количество специальных знаков в лексической единице, количество слов в лексической единице, размер лексической единицы, выраженный в единицах обработки и хранения информации.
[46] В некоторых вариантах, сопоставление кандидата в незначащие лексические единицы с незначащими лексическими единицами из любой из: первой базы данных лексических единиц и второй базы данных лексических единиц, осуществляется путем сопоставления, по меньшей мере по одному предопределенному параметру, кандидата в незначащие лексические единицы с незначащими лексическими единицами из любой из: первой базы данных лексических единиц и второй базы данных лексических единиц.
[47] В некоторых вариантах, предопределенный параметр, по которому осуществляется сопоставление, является одним из: контрольной суммой и комбинацией отдельных контрольных элементов, входящих в состав контрольной суммы лексической единицы.
[48] В некоторых вариантах, результат любой из: первой проверки и второй проверки, является положительным в случае, когда сопоставление по меньшей мере по одному предопределенному параметру выявляет одно из: частичное совпадение по указанному по меньшей мере одному предопределенному параметру, причем степень совпадения превышает предустановленный порог совпадения, и полное совпадение по указанному по меньшей мере одному предопределенному параметру.
[49] В некоторых вариантах воплощения компьютера, конфигурация процессора настроена таким образом, чтобы компьютер мог осуществлять, перед осуществлением синтаксического анализа текстового сообщения, создание по меньшей мере одной из: первой базы данных и второй базы данных.
[50] Еще одним объектом настоящего решения является реализованный на компьютере способ выявления незначащих лексических единиц в текстовом сообщении. Способ включает: (i) осуществление синтаксического анализа текстового сообщения для определения меньшей мере одной лексической единицы в качестве первого кандидата в незначащие лексические единицы; (ii) определение контрольной суммы первого кандидата в незначащие лексические единицы; (iii) сопоставление, по первому критерию, первого кандидата в незначащие лексические единицы с незначащими лексическими единицами из множества лексических единиц, содержащихся в базе данных лексических единиц, где сопоставлением по первому критерию является сопоставление контрольной суммы первого кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц; (iv) определение первого кандидата в незначащие лексические единицы в качестве незначащей лексической единицы, если база данных лексических единиц содержит в себе по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме первого кандидата в незначащие лексические единицы.
[51] В некоторых вариантах осуществления, если в базе данных лексических единиц отсутствует незначащая лексическая единица, контрольная сумма которой соответствует контрольной сумме первого кандидата в незначащие лексические единицы, способ дополнительно включает: (i) разбиение первого кандидата в лексические единицы на по меньшей мере две более мелкие лексические единицы и определение по меньшей мере одной более мелкой лексической единицы в качестве второго кандидата в незначащие лексические единицы; (ii) определение контрольной суммы второго кандидата в незначащие лексические единицы; (iii) сопоставление, по второму критерию, второго кандидата в незначащие лексические единицы с незначащими лексическими единицами, содержащимися в базе данных лексических единиц, где сопоставлением по второму критерию является сопоставление контрольной суммы второго кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц; (iv) определение второго кандидата в незначащие лексические единицы в качестве незначащей лексической единицы, если база данных лексических единиц содержит в себе по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме второго кандидата в незначащие лексические единицы
[52] В некоторых вариантах осуществления, первый кандидат в незначащие лексические единицы является абзацем, и второй кандидат в незначащие лексические единицы является предложением из этого абзаца.
[53] В некоторых вариантах, контрольная сумма включает в себя совокупность контрольных элементов.
[54] В некоторых вариантах осуществления, контрольным элементом является любой элемент, выбранный из: количество символов в лексической единице, количество букв в лексической единице, количество заглавных букв в лексической единице, количество прописных букв в лексической единице, количество пробелов в лексической единице, количество цифр в лексической единице, количество специальных знаков в лексической единице, количество слов в лексической единице, размер лексической единицы, выраженный в единицах обработки и хранения информации.
[55] В некоторых вариантах осуществления, сопоставление по первому критерию осуществляется по первому набору контрольных элементов, и сопоставление по второму критерию осуществляется по второму набору контрольных элементов.
[56] В некоторых вариантах осуществления, первый набор контрольных элементов и второй набор контрольных элементов идентичны.
[57] В некоторых вариантах осуществления, контрольные суммы считаются соответствующими в случае идентичности контрольных сумм.
[58] В некоторых вариантах осуществления, когда сопоставление выявляет различие контрольных сумм, способ дополнительно включает: проверку степени различия контрольных сумм, и признание контрольных сумм соответствующими, когда степень различия находится в пределах предустановленной допустимой амплитуды различия.
[59] В некоторых вариантах, степень различия определяется в отношении каждого из контрольных элементов, включенных в состав контрольной суммы, и амплитуда различия установлена для каждого из контрольных элементов.
[60] В некоторых вариантах, когда база данных лексических единиц содержит по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме кандидата в незначащие лексические единицы, способ включает в себя осуществление познакового сравнения кандидата в незначащие лексические единицы с этой по меньшей мере одной незначащей лексической единицей и, когда определение кандидата в незначащие лексические единицы в качестве незначащей лексической единицы осуществляется в ответ на совпадение последовательности символов кандидата в незначащие лексические единицы с последовательностью символов этой по меньшей мере одной незначащей лексической единицей.
[61] В некоторых вариантах, лексическая единица из множества лексических единиц, содержащихся в базе данных лексических единиц, является незначащей, если ее весовое значение превышает предопределенное пороговое значение.
[62] В некоторых вариантах, база данных лексических единиц сформирована на основе множества лексических единиц, встречающихся во множестве текстовых сообщений, и весовое значение каждой лексической единицы прямо пропорционально частотности данной лексической единицы во множества лексических единиц, встречающихся в указанном множестве текстовых сообщений.
[63] В некоторых вариантах, осуществление синтаксического анализа текстового сообщения включает в себя анализ языка разметки текстового сообщения.
[64] В некоторых вариантах, анализ языка разметки текстового сообщения включает в себя анализ по меньшей мере одного, выбранного из: структуры текстового сообщения, вида, размера, начертания шрифта, знаков препинания, специальных знаков.
[65] В некоторых вариантах осуществления, осуществление синтаксического анализа текстового сообщения является синтаксическим анализом предопределенного количества абзацев в начале текстового сообщения.
[66] В некоторых вариантах текстовое сообщение является сообщением электронной почты.
[67] В некоторых вариантах, текстовое сообщение является сообщением электронной почты, и осуществление синтаксического анализа сообщения электронной почты является синтаксическим анализом наиболее значимой части сообщения электронной почты.
[68] В некоторых вариантах осуществления, наиболее значимая часть сообщения электронной почты определяется как наиболее значимый логический блок HTML кода из множества логических блоков HTML кода, содержащих текст.
[69] В некоторых вариантах, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, размер которого превышает размер текста любого другого логического блока HTML кода данного сообщения электронной почты.
[70] В некоторых вариантах осуществления, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, причем текст наиболее значимого логического блока HTML кода содержит наибольшее количество значащих лексических единиц по сравнению с текстами любого другого логического блока HTML кода данного сообщения электронной почты.
[71] В некоторых вариантах осуществления, лексической единицей является любое из: (i) слово, (ii) словосочетание, (iii) предложение, (iv) абзац.
[72] В некоторых вариантах, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы является определением по меньшей мере одной лексической единицы, имеющей смысловое значение.
[73] В некоторых вариантах, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы осуществляется на основе синтаксического анализа одного из: (i) всего текста, содержащегося в текстовом сообщении, и (ii) фрагмента текста, содержащегося в текстовом сообщении.
[74] В некоторых вариантах осуществления, способ дополнительно включает получение текстового сообщения.
[75] В некоторых вариантах осуществления, уникальная контрольная сумма является идентификатором уникальной лексической единицы.
[76] Еще одним объектом решения является компьютер. Компьютер включает в себя процессор. Конфигурация процессора настроена таким образом, чтобы компьютер мог: (i) осуществлять синтаксический анализ текстового сообщения; (ii) определять по меньшей мере одну лексическую единицу в качестве первого кандидата в незначащие лексические единицы; (iii) определять контрольную сумму первого кандидата в незначащие лексические единицы; (iv) сопоставлять, по первому критерию, первого кандидата в незначащие лексические единицы с незначащими лексическими единицами из множества лексических единиц, содержащихся в базе данных лексических единиц, где сопоставлением по первому критерию является сопоставление контрольной суммы первого кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц; (v) определять первого кандидата в незначащие лексические единицы в качестве незначащей лексической единицы, если база данных лексических единиц содержит по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме первого кандидата в незначащие лексические единицы.
[77] В некоторых воплощениях, если в базе данных лексических единиц отсутствует незначащая лексическая единица, контрольная сумма которой соответствует контрольной сумме первого кандидата в незначащие лексические единицы, компьютер дополнительно осуществляет: (i) разбиение первого кандидата в лексические единицы на по меньшей мере две более мелкие лексические единицы и определение по меньшей мере одной более мелкой лексической единицы в качестве второго кандидата в незначащие лексические единицы; (ii) определение контрольной суммы второго кандидата в незначащие лексические единицы; (iii) сопоставление, по второму критерию, второго кандидата в незначащие лексические единицы с незначащими лексическими единицами, содержащимися в базе данных лексических единиц, где сопоставлением по второму критерию является сопоставление контрольной суммы второго кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц; (iv) определение второго кандидата в незначащие лексические единицы в качестве незначащей лексической единицы, если база данных лексических единиц содержит в себе по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме второго кандидата в незначащие лексические единицы.
[78] В некоторых воплощениях, первый кандидат в незначащие лексические единицы является абзацем, и второй кандидат в незначащие лексические единицы является предложением из этого абзаца.
[79] В некоторых воплощениях, контрольная сумма включает в себя совокупность контрольных элементов.
[80] В некоторых воплощениях, контрольным элементом является любой элемент, выбранный из: количество символов в лексической единице, количество букв в лексической единице, количество заглавных букв в лексической единице, количество прописных букв в лексической единице, количество пробелов в лексической единице, количество цифр в лексической единице, количество специальных знаков в лексической единице, количество слов в лексической единице, размер лексической единицы, выраженный в единицах обработки и хранения информации.
[81] В некоторых воплощениях, сопоставление по первому критерию осуществляется по первому набору контрольных элементов, и сопоставление по второму критерию осуществляется по второму набору контрольных элементов.
[82] В некоторых воплощениях, первый набор контрольных элементов и второй набор контрольных элементов идентичны.
[83] В некоторых воплощениях, контрольные суммы считаются соответствующими в случае идентичности контрольных сумм.
[84] В некоторых воплощениях, когда сопоставление выявляет различие контрольных сумм, процессор дополнительно осуществляет: проверку степени различия контрольных сумм, и признание контрольных сумм соответствующими, когда степень различия находится в пределах предустановленной допустимой амплитуды различия.
[85] В некоторых воплощениях, степень различия определяется в отношении каждого из контрольных элементов, включенных в состав контрольной суммы, и амплитуда различия установлена для каждого из контрольных элементов, включенных в состав контрольной суммы.
[86] В некоторых воплощениях, когда база данных лексических единиц содержит в себе по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме кандидата в незначащие лексические единицы, конфигурация процессора настроена таким образом, чтобы компьютер мог дополнительно осуществлять познаковое сравнение кандидата в незначащие лексические единицы с этой по меньшей мере одной незначащей лексической единицей и определять кандидата в незначащие лексические единицы в качестве незначащей лексической единицы в ответ на совпадение последовательности символов кандидата в незначащие лексические единицы с последовательностью символов этой по меньшей мере одной незначащей лексической единицы.
[87] В некоторых воплощениях, лексическая единица из множества лексических единиц, содержащихся в базе данных лексических единиц, является незначащей, если ее весовое значение превышает предопределенное пороговое значение.
[88] В некоторых воплощениях, база данных лексических единиц сформирована на основе множества лексических единиц, встречающихся во множестве текстовых сообщений, и в котором весовое значение каждой лексической единицы прямо пропорционально частотности данной лексической единицы во множества лексических единиц, встречающихся в указанном множестве текстовых сообщений.
[89] В некоторых воплощениях, осуществление синтаксического анализа текстового сообщения включает в себя анализ языка разметки текстового сообщения.
[90] В некоторых воплощениях, анализ языка разметки текстового сообщения включает в себя анализ по меньшей мере одного, выбранного из: структуры текстового сообщения, вида шрифта, размера шрифта, начертания шрифта, знаков препинания, специальных знаков.
[91] В некоторых воплощениях настоящей технологии, осуществление синтаксического анализа текстового сообщения является синтаксическим анализом предопределенного количества абзацев в начале текстового сообщения.
[92] В некоторых воплощениях, текстовое сообщение является сообщением электронной почты.
[93] В некоторых воплощениях, текстовое сообщение является сообщением электронной почты, и в котором осуществление синтаксического анализа сообщения электронной почты является синтаксическим анализом наиболее значимой части сообщения электронной почты.
[94] В некоторых воплощениях, наиболее значимая часть сообщения электронной почты определяется как наиболее значимый логический блок HTML кода из множества логических блоков HTML кода, содержащих текст.
[95] В некоторых воплощениях, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, размер которого превышает размер текста любого другого логического блока HTML кода данного сообщения электронной почты.
[96] В некоторых воплощениях, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, причем текст наиболее значимого логического блока HTML кода содержит наибольшее количество значащих лексических единиц по сравнению с текстами любого другого логического блока HTML кода данного сообщения электронной почты.
[97] В некоторых воплощениях, лексической единицей является любое из: (i) слово, (ii) словосочетание, (iii) предложение, (iii) абзац.
[98] В некоторых воплощениях, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы является определением по меньшей мере одной лексической единицы, имеющей смысловое значение.
[99] В некоторых воплощениях, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы осуществляется на основе синтаксического анализа одного из: (i) всего текста, содержащегося в текстовом сообщении, и (ii) фрагмента текста, содержащегося в текстовом сообщении.
[100] В некоторых воплощениях, компьютер дополнительно осуществляет получение текстового сообщения.
[101] В некоторых воплощениях, уникальная контрольная сумма является идентификатором уникальной лексической единицы.
[102] В контексте описания, «сервер» представляет собой программу, выполняемую на соответствующем оборудовании и способную осуществлять прием запросов (например, подаваемых клиентскими устройствами), передаваемых по сети, и выполнять эти запросы или обеспечивать их выполнение. Оборудование может представлять собой один компьютер или одну компьютерную систему, однако ни одно, ни другое не является обязательным в отношении предлагаемой технологии. В данном контексте выражение «по меньшей мере один сервер» не означает, что каждая задача (например, предусмотренная принятыми инструкциями или запросами) или какая-либо конкретная задача будет принята, выполнена или ее выполнение будет обеспечено тем же самым сервером (то есть тем же самым программным обеспечением и/или оборудованием); предполагается, что прием и передача, выполнение или обеспечение выполнения любой задачи или запроса либо обработка результатов задачи или запроса может осуществлять любое число компонентов программного обеспечения или устройств и все эти компоненты программного обеспечения или оборудования могут быть представлены одним сервером или несколькими серверами, причем термин «сервер» охватывает оба указанных варианта.
[103] В контексте описания, «клиентское устройство» представляет собой любое компьютерное оборудование, обеспечивающее возможность выполнения программного обеспечения, предназначенного для решения требуемой задачи. В контексте настоящего описания, термин «клиентское устройство» в основном ассоциируется с пользователем клиентского устройства. Некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные компьютеры, переносные компьютеры, нетбуки и т.д.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте тот факт, что устройство функционирует в качестве клиентского устройства, не исключает возможности его функционирования в качестве сервера для других клиентских устройств. Использование выражения «клиентское устройство» не препятствует применению нескольких клиентских и/или электронных устройств в процессе приема и передачи, выполнения или обеспечения выполнения задачи либо запроса или обработки результатов задачи или запроса либо этапов способа, представленного в настоящем описании.
[104] В контексте описания, термин «сообщение электронной почты» включает в себя файл, содержащий текст, формируемый отправителем и предназначенный для передачи одному или нескольким получателям посредством электронной почты. Сообщение электронной почты является разновидностью текстового сообщения.
[105] В контексте описания, «исходный код» представляет собой текст компьютерной программы на каком-либо языке программирования или языке разметки, который может быть прочтен человеком. В обобщенном смысле исходный код представляет собой любые входные данные для транслятора. Исходный код транслируется в исполняемый код до запуска программы при помощи компилятора, или может исполняться сразу при помощи интерпретатора.
[106] В контексте описания, термин «информация» включает в себя информацию любого характера или типа, которая может быть записана в базе данных. Таким образом, информация охватывает, среди прочего, аудиовизуальную информацию (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные местоположения, числовые данные и т.д.), текстовую информацию (высказывания, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы и т.д.
[107] В контексте описания, термин «компонент программного обеспечения» охватывает программное обеспечение (соответствующее конкретному оборудованию), которое является одновременно необходимым и достаточным для выполнения конкретной указанной функции (функций).
[108] В настоящем описании выражение «носитель информации, предназначенный для использования компьютером» (также кратко именуемый «носитель информации») охватывает носители любого характера и типа, в том числе оперативные запоминающие устройства, постоянные запоминающие устройства, диски (компакт-диски, DVD-диски, гибкие диски, жесткие диски и т.д.), USB-ключи, твердотельные накопители, ленточные накопители и т.д.
[109] В контексте описания, «база данных» представляет собой любой структурированный набор данных, независимо от конкретной структуры, программы управления базой данных или оборудования, на котором осуществляется хранение данных, реализована память или иным способом обеспечивается возможность использования данных. База данных может быть реализована на том же оборудовании, что и процесс, осуществляющий хранение или использование информации, записанной в базе данных, или на отдельном оборудовании, таком как выделенный сервер или множество серверов.
[110] В настоящем описании «модуль анализа сообщений» (парсер, parser) представляет собой программу или часть программы, выполняемую на соответствующем оборудовании и способную осуществлять синтаксический анализа текста. В некоторых воплощениях настоящей технологии, модуль анализа сообщений способен также осуществлять структурный анализа текста. Оборудование может представлять собой один компьютер или одну компьютерную систему, однако ни одно, ни другое не является обязательным в отношении предлагаемой технологии. В данном контексте выражение «модуль анализа сообщений» не означает, что каждая задача (например, предусмотренная принятыми инструкциями или запросами) или какая-либо конкретная задача будет принята, выполнена или ее выполнение будет обеспечено тем же самым программным обеспечением и/или оборудованием; предполагается, что выполнение любой задачи или запроса либо обработка результатов задачи или запроса может осуществлять любое число компонентов программного обеспечения или устройств.
[111] В настоящем описании термин «лексическая единица» может представлять собой принятое в естественном языке слово, фразу, устойчивое словосочетание, предложение, абзац, аббревиатуру, символ, дату, сокращение, в том числе общепринятое, лексически значимый компонент сложного слова, а также эквивалентные им кодовые или символические обозначения искусственного языка. Лексическая единица может быть представлена в тексте сообщения электронной почты цифрами, буквами, иероглифами, специальными знаками, либо составлена из них.
[112] В настоящем описании слова «первый», «второй», «третий» и т.д. используются только в качестве описательных элементов для целей разделения существительных, отличающихся друг от друга, а не с целью определения какого-либо конкретного соотношения между указанными существительными. Таким образом, например, следует понимать, что термины «первая база данных» и «третий сервер» не означают введения конкретной последовательности, типа, хронологии, иерархии или ранжирования (например) конкретного сервера или нескольких серверов, а их использование (само по себе) не означает, что в какой-либо конкретной ситуации должен обязательно существовать какой-либо «второй сервер». Кроме того, как указано в данном описании относительно других примеров осуществления технологии, ссылка на «первый» элемент и «второй» элемент не означает, что два элемента не могут представлять собой в реальном мире фактически один и тот же элемент. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой один компонент программного обеспечения и (или) оборудования, а в других ситуациях могут быть реализованы на различном программном обеспечении и (или) оборудовании.
[113] Каждый из вариантов имеет по меньшей мере одну из вышеупомянутых целей и/или один из вышеупомянутых аспектов, но не обязательно все их.
[114] Дополнительные и/или альтернативные особенности, цели, аспекты и преимущества станут очевидны из нижеследующего описания, сопровождающих чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[115] Для лучшего понимания настоящего решения, а также других особенностей, предлагается обратиться к нижеследующему описанию, которым следует пользоваться совместно с прилагаемыми чертежами, на которых:
[116] Фиг. 1 является схематическим изображением варианта воплощения сетевой компьютерной системы 100, реализованной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем.
[117] Фиг. 2 является изображением текста сообщения 200 электронной почты, направленного пользователем 141, изображенным на Фиг. 1, пользователю 121, изображенному на Фиг. 1.
[118] Фиг. 3 является изображением фрагмента веб-интерфейса 300 сервиса электронной почты (существующий уровень техники).
[119] Фиг. 4 является изображением фрагмента веб-интерфейса 400 сервиса электронной почты, реализованного в соответствии с вариантами осуществления.
[120] Фиг. 5 является блок-диаграммой способа 500, выполняемого на почтовом сервере 102, изображенном на Фиг. 1, выполняемого в соответствии с вариантами осуществления.
[121] Фиг. 6 и Фиг. 7 являются блок-диаграммой способа 600, выполняемого на почтовом сервере 102, изображенном на Фиг. 1, выполняемого в соответствии с вариантами осуществления.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[122] На Фиг. 1 изображена принципиальная схема сетевой компьютерной системы 100, компоненты которой находятся в связи друг с другом посредством сети 112 передачи данных.
[123] Важно иметь в виду, что сетевая компьютерная система 100 представлена как наглядный вариант осуществления. Таким образом, нижеследующее описание должно рассматриваться исключительно как описание наглядных примеров. Это описание не предназначено для определения объема или установления границ настоящего решения. Некоторые полезные примеры модификаций сетевой компьютерной системы 100 также могут быть охвачены нижеследующим описанием. Целью этого описания является исключительно оказание помощи в понимании, а не определение объема и границ настоящего решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным способом осуществления этого элемента. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что сетевая компьютерная система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления будут обладать гораздо большей сложностью.
[124] Сетевая компьютерная система 100 включает в себя почтовый сервер 102.
[125] Почтовый сервер 102 может представлять собой обычный компьютерный сервер. В примере варианта осуществления, почтовый сервер 102 представляет собой сервер Dell PowerEdge, на котором используется операционная система Microsoft™ Windows Server.
[126] Излишне говорить, что почтовый сервер 102 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления почтовый сервер 102 является одиночным сервером. В других вариантах осуществления функциональность почтового сервера 102 может быть разделена, и может выполняться с помощью нескольких серверов.
[127] В целом, варианты осуществления почтового сервера 102 хорошо известны в данной области техники. Таким образом, достаточно отметить, что почтовый сервер 102 содержит, среди прочего, интерфейс сетевой связи (не изображен) для двусторонней связи по сети 112 передачи данных; и процессор (не изображен), соединенный с интерфейсом сетевой связи, который выполнен с возможностью выполнять различные процедуры, включая те, что описаны ниже. С этой целью процессор может сохранять или иметь доступ к машиночитаемым инструкциям, выполнение которых инициирует процессор, и выполнять различные описанные здесь процедуры.
[128] К задачам почтового сервера 102 относятся прием сообщений электронной почты, предназначенных пользователю 121, их хранение, и передача их из почтового ящика пользователю 121.
[129] Почтовый сервис может быть реализован любым известным способом.
[130] В альтернативных воплощениях, в качестве неограничивающего примера, сетевая компьютерная система 100 может включать в себя вместо почтового сервера 102 либо дополнительно к почтовому серверу 102, сервер обработки мгновенных сообщений («Instant Messages)), «IМ») либо сервер обработки SMS сообщений, либо иной сервер обработки текстовых сообщений.
[131] Почтовый сервер 102 соединен с сетью 112 передачи данных через линию связи (не пронумерована).
[132] Почтовый сервер 102 включает в себя носитель информации 104, который может использоваться почтовым сервером 102. В принципе, данный носитель информации 104 может быть носителем абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д, а также их комбинации.
[133] Носитель информации 104 почтового сервера 102 предназначен для хранения модуля почтового сервиса (не изображен), включающего в себя почтовые ящики пользователей, в том числе почтовый ящик пользователя 121, сообщения электронной почты, в том числе сообщения электронной почты, предназначенные пользователю 121, а также сообщения электронной почты, предназначенные другим пользователям, и машиночитаемые инструкции, обеспечивающие работу сервисов и различных модулей.
[134] При этом почтовые ящики представляют собой часть дискового пространства, выделяемого на носителе информации 104 для хранения сообщений электронной почты пользователей, в том числе пользователя 121, где на указанной части дискового пространства почтовый ящик хранится как обычный каталог файловой системы. При этом сообщения электронной почты представляют собой файлы данных, находящиеся в данном каталоге файловой системы.
[135] Носитель информации предназначен также для хранения модуля 106 анализа сообщений.
[136] Модуль 106 анализа сообщений представляет собой программу или часть программы, выполняемую на соответствующем оборудовании и способную осуществлять синтаксический и структурный анализа текста. Оборудование для модуля 106 анализа сообщений может представлять собой один компьютер или одну компьютерную систему, однако ни одно, ни другое не является обязательным.
[137] В данном контексте, использование термина «модуль 106 анализа сообщений» не означает, что каждая задача (например, предусмотренная принятыми инструкциями или запросами) или какая-либо конкретная задача будет принята, выполнена или ее выполнение будет обеспечено тем же самым программным обеспечением и/или оборудованием; предполагается, что выполнение любой задачи или запроса либо обработка результатов задачи или запроса может осуществлять любое число компонентов программного обеспечения или устройств.
[138] Под синтаксическим анализом может пониматься процесс сопоставления линейной последовательности лексем текста с его формальной грамматикой. Синтаксический анализ осуществляется модулем 106 анализа сообщений в целях определения значащих и незначащих лексических единиц, содержащихся в текстовых сообщениях, каковыми в данном воплощении являются сообщения электронной почты. В альтернативных воплощениях, текстовыми сообщениями могут быть мгновенные сообщения, SMS сообщения, и другие.
[139] Незначащими лексическими единицами могут являться лексические единицы, не несущие существенной смысловой нагрузки. Например, это могут быть обращения, вводные слова, формулы вежливости, адреса отправителей и тому подобное. Напротив, значащие лексические единицы могут нести существенное смысловое значение.
[140] В некоторых воплощениях настоящей технологии, синтаксический анализ осуществляется модулем 106 анализа сообщений в целях определения значащих и незначащих лексических единиц, содержащихся в сообщениях электронной почты, таким образом, что значащие и незначащие лексические единицы имеют смысловое значение.
[141] Другими словами, лексическая единица в данном воплощении может представлять собой логически относительно завершенное значение и нести самостоятельную смысловую нагрузку. Например, текст «Конвенция о гражданско-правовых аспектах международного похищения детей», являющийся фрагментом текста «Заказанный вами текст документа "Конвенция о гражданско-правовых аспектах международного похищения детей" [рус, англ.] (Заключена в г. Гааге 25.10.1980) находится в приложенном файле.», может являться лексической единицей, имеющей смысловое значение. Напротив, потенциально возможная лексическая единица «вами» или «аспектах международного» не имеет смыслового значения.
[142] В некоторых воплощениях, синтаксический анализ может представлять собой или включать в себя анализ исходного кода сообщений электронной почты. Анализ исходного кода сообщений электронной почты может включать в себя, в качестве неограничивающего примера, анализ разметки сообщений электронной почты. Синтаксический анализ может осуществляться для определения типов сообщений электронной почты, выявления шаблонов сообщений электронной почты, а также для определения лексических единиц, в том числе с целью их дальнейшей проверки в качестве кандидатов в значимые и незначимые лексические единицы.
[143] В некоторых воплощениях, анализ разметки сообщений электронной почты, дополнительно или в качестве альтернативы, может включать в себя анализ размера шрифта. Так, например, части текста, напечатанные шрифтом разного размера, потенциально могут считаться разными лексическими единицами.
[144] В некоторых воплощениях, анализ разметки сообщений электронной почты может включать в себя анализ начертания шрифта. Например, словосочетание, выделенное курсивом, жирным шрифтом, подчеркиванием, может потенциально считаться одной лексической единицей.
[145] В некоторых воплощениях, анализ разметки сообщений электронной почты может включать в себя анализ знаков препинания. Например, в некоторых воплощениях отдельные слова не являются одной лексической единицей, если между ними стоит точка. Напротив, в некоторых воплощениях, последовательность слов может считаться одной логической единицей, если эта последовательность заключена в кавычки и не превышает определенного количества слов. В альтернативных воплощениях, каждое предложение может считаться отдельной лексической единицей.
[146] В некоторых воплощениях, анализ разметки сообщений электронной почты может включать анализ специальных знаков. Например, такими знаками могут быть знак абзаца, знак табуляции, знак разрыва страницы, и так далее. В некоторых воплощениях некоторые из таких специальных знаков могут являться признаками того, что разделенные ими слова, цифры и так далее, не являются единой лексической единицей. Напротив, знак «@» может свидетельствовать, что прилегающие к нему до и после буквы, цифры и некоторые другие специальные знаки (точка, тире, нижнее подчеркивание) являются единой лексической единицей (в данном примере - адресом электронной почты).
[147] В некоторых воплощениях, модуль 106 анализа сообщений может обрабатывать и систематизировать результаты синтаксического анализа одного сообщения электронной почты, и/или определенной группы сообщений электронной почты, и/или всей совокупности сообщений электронной почты, поступающей в адрес пользователей, имеющих аккаунт электронной почты на почтовом сервере 102.
[148] Дополнительно или альтернативно, в некоторых воплощениях, модуль 106 анализа сообщений может обрабатывать и систематизировать результаты синтаксического анализа одного сообщения электронной почты, и/или определенной группы сообщений электронной почты, и/или всей совокупности сообщений электронной почты, подготовленных и/или отправленных пользователями, имеющими аккаунт электронной почты на почтовом сервере 102. В качестве неограничивающего примера систематизации лексических единиц, модуль 106 анализа сообщений может группировать идентичные лексические единицы в группы, и затем определять количество лексических единиц в каждой группе лексических единиц.
[149] Модуль 106 анализа сообщений может также определить общее количество лексических единиц во всех сообщениях электронной почты, предназначенных пользователю 121.
[150] Модуль 106 анализа сообщений может также определить общее количество лексических единиц во всех сообщениях электронной почты, предназначенных всем пользователям.
[151] Модуль 106 анализа сообщений может также определить общее количество лексических единиц во всех сообщениях электронной почты, предназначенных определенным группам пользователей. Такими группами могут быть группы пользователей, сформированные по каким-либо признакам. В качестве неограничивающих примеров, группы пользователей могут быть сформированы по критерию возраста, пола, места нахождения пользователя, временной зоны пользователя, типа используемого клиентского устройства. Соответствующие сведения о возрасте, поле, месте нахождения, типе клиентского устройства могут быть получены из любых доступных источников. В качестве неограничивающих примеров, такими источниками могут быть данные из аккаунта почтовой службы (возраст, пол, регион, и другие), IP-адрес (регион), данные, формируемые почтовым агентом, установленным на клиентском устройстве.
[152] Модуль 106 анализа сообщений может также определить общее количество лексических единиц во всех сообщениях электронной почты, направленных отправителем определенного типа всем пользователям или группе пользователей. Типы отправителей, в качестве примера, но не ограничения, могут включать в себя: кредитно-финансовые учреждения (например, банки, сберегательные кассы, кредитные кооперативы), страховые компании, онлайн-магазины, сайты по продаже билетов (например, по продаже авиабилетов, железнодорожных билетов, театральных касс, и тому подобное), социальные сети (например, Фейсбук™, Твиттер™, ЛинкедИн™, Вконтаке™, Одноклассники™).
[153] Модуль 106 анализа сообщений может также определить типы сообщений определенного отправителя. Типы сообщений определенного отправителя могут определяться, в качестве неограничивающего примера, когда отправитель осуществляет рассылку значительного количества стандартизированных сообщений с использованием различных шаблонов. Например, в качестве неограничивающего примера, это могут быть сообщения различного типа, направляемые социальной сетью Фейсбук™.
[154] В отношении стандартизированных сообщений отправителей, осуществляющих массовые рассылки сообщений электронной почты, модуль 106 анализа сообщений электронной почты может дополнительно или альтернативно осуществлять следующие операции: получение множества сообщений определенного отправителя сообщений электронной почты, предназначенных множеству пользователей электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102; осуществление синтаксического анализа указанного множества сообщений электронной почты указанного определенного отправителя и определение типов сообщений электронной почты указанного определенного отправителя; разбиение сообщений электронной почты указанного определенного отправителя на абзацы; включение множества абзацев в базу данных 108 лексических единиц и/или в базу данных 110 лексических единиц, причем каждый из множества указанных абзацев ассоциирован с идентификатором данного определенного отправителя и с идентификатором по меньшей мере одного типа сообщения указанного определенного отправителя.
[155] Затем, когда пользователю 121 поступает сообщение электронной почты от такого определенного отправителя, модуль 106 анализа сообщений электронной почты может осуществлять: получение сообщения электронной почты определенного отправителя, осуществляющего массовую рассылку; определение типа указанного сообщения электронной почты данного отправителя; синтаксический анализ сообщения электронной почты и разбиение тела сообщения электронной почты на множество абзацев; проверка по меньшей мере одного абзаца по меньшей мере по одной базе данных лексических единиц, является ли данный абзац значимым для данного типа сообщения электронной почты данного отправителя.
[156] Затем модуль 106 анализа сообщений может вычислить весовое значение лексических единиц.
[157] Вычисление весового значения лексической единицы может выполняться в отношении всего массива сообщений электронной почты, направляемых пользователю 121. В этом случае расчет может осуществляться по первой формуле:
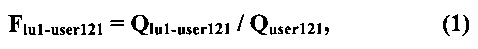
где
 - весовое значение первой лексической единицы во всем массиве сообщений электронной почты, направляемых пользователю 121,
- весовое значение первой лексической единицы во всем массиве сообщений электронной почты, направляемых пользователю 121,
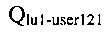 - количество употреблений первой лексической единицы во всем массиве сообщений электронной почты, направляемых пользователю 121, и
- количество употреблений первой лексической единицы во всем массиве сообщений электронной почты, направляемых пользователю 121, и
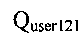 - общее количество лексических единиц во всем массиве сообщений электронной почты, направляемых пользователю 121.
- общее количество лексических единиц во всем массиве сообщений электронной почты, направляемых пользователю 121.
[158] Вычисление весового значения лексической единицы может выполняться модулем 106 анализа сообщений также в отношении всего массива сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102. В этом случае расчет может осуществляться по второй формуле:
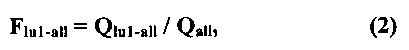
где
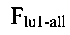 - весовое значение первой лексической единицы во всем массиве сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102,
- весовое значение первой лексической единицы во всем массиве сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102,
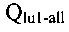 - количество употреблений первой лексической единицы во всем массиве сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102, и
- количество употреблений первой лексической единицы во всем массиве сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102, и
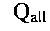 - общее количество лексических единиц во всем массиве сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102.
- общее количество лексических единиц во всем массиве сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102.
[159] Альтернативно или дополнительно, весовое значение лексических единиц может вычисляться модулем 106 анализа сообщений отдельно в отношении одного из: 1) либо различных типов отправителей; 2) либо различных групп получателей, 3) в отношении данного типа сообщения данного массового отправителя, 4) различных комбинаций различных типов отправителей и различных групп получателей, отдельно получателя 121, и/или всего множества получателей.
[160] Альтернативно или дополнительно, при вычислении весового значения лексических единиц, модуль 106 анализа сообщений может принимать в расчет не полные тексты сообщений электронной почты, а только несколько абзацев каждого из сообщений электронной почты. Максимальное количество таких абзацев может быть предопределено. В случае, если какое-либо сообщение электронной почты содержит меньшее количество абзацев, чем указанное предопределенное число абзацев, при вычислении весового значения лексических единиц может использоваться полный текст такого сообщения электронной почты.
[161] Альтернативно или дополнительно, при вычислении весового значения лексических единиц, модуль 106 анализа сообщений может принимать в расчет не полные тексты сообщений электронной почты, а только несколько первых, считая от начала, абзацев каждого из сообщений электронной почты. Максимальное количество таких первых абзацев может быть предопределено. В случае, если какое-либо сообщение электронной почты содержит меньшее количество абзацев, чем указанное предопределенное число первых абзацев, при вычислении весового значения лексических единиц может использоваться полный текст такого сообщения электронной почты.
[162] Альтернативно или дополнительно, при вычислении весового значения лексических единиц, модуль 106 анализа сообщений может принимать в расчет не полныетексты сообщений электронной почты, а наиболее значимые части сообщений электронной почты, как это описано ниже.
[163] Таким образом, в некоторых воплощениях настоящей технологии весовое значение одной и той же лексической единицы может быть различной в зависимости от того, по отношению к какому массиву сообщений электронной почты весовое значение вычисляется, и в зависимости от того, вычисляется ли весовое значение в отношении полных текстов сообщений электронной почты, либо в отношении фрагментов сообщений электронной почты, а также в зависимости от того, в отношении каких именно фрагментов вычислялось весовое значение.
[164] Весовое значение лексических единиц может использоваться при построении различных баз данных лексических единиц и при принятии решения о том, следует ли считать ту или иную лексическую единицу значащей или незначащей в той или иной базе данных.
[165] В некоторых воплощениях, модуль 106 анализа сообщений может определять контрольную сумму лексических единиц. В данном воплощении, контрольная сумма лексической единицы представляет собой совокупность следующих контрольных элементов: количество слов, количество букв, количество цифр, количество точек в лексической единице, количество запятых в лексической единице.
[166] В альтернативных воплощениях, в качестве неограничивающего примера, контрольная сумма лексической единицы может определяться как размер соответствующей лексической единицы, выраженный в байтах. В альтернативных воплощениях, контрольная сумма лексической единицы может определяться комбинация любых возможных контрольных элементов, таких как количество символов, количество букв, количество заглавных букв, количество прописных букв, количество пробелов, количество цифр в лексической единице, количество специальных знаков в лексической единице, количество слов в лексической единице, размер лексической единицы, выраженный в единицах обработки и хранения информации, и других.
[167] В некоторых воплощениях, модуль 106 анализа сообщений может индексировать лексические единицы.
[168] В данном воплощении, модуль 106 анализа сообщений может дополнительно осуществлять структурный анализ сообщения электронной почты.
[169] В данном воплощении, под структурным анализом следует понимать процесс анализа структуры сообщения электронной почты. Анализ структуры сообщения электронной почты в данном воплощении производится путем анализа HTML-разметки сообщения электронной почты. Такой анализ позволяет выявлять логические блоки HTML кода, содержащие текст. Такими блоками, например, могут быть крупные блоки текста, содержащие текст таблицы, содержащие текст ячейки таблиц, текстовые абзацы и другое. При анализе разметки сообщения электронной почты могут использоваться различные теги, например, <div align=″?″></di> (теги используемые для форматирования блоков текста), <table></table> (теги таблицы), <td></td> (теги, определяющие ячейку в таблице), <р></р>(теги абзаца), и другие.
[170] Модуль 106 анализа сообщений находится во взаимодействии с первой базой данных 108 лексических единиц.
[171] Первая база данных 108 лексических единиц представляет собой структурированный набор данных, включающих в себя лексические единицы. Первая база данных 108 лексических единиц реализована на том же оборудовании, что и процесс, осуществляющий хранение или использование информации, записанной в первой базе данных 108. Однако, как будет понятно специалистам в данной области, первая база данных 108 лексических единиц может быть реализована также на отдельном оборудовании, таком как выделенный сервер или множество серверов.
[172] В данном воплощении, первая база данных 108 лексических единиц является базой данных, сформированной в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных пользователю 121 и полученных пользователем 121 в течение всего периода существования аккаунта пользователя 121 на почтовом сервере 102. В альтернативных воплощениях, первая база данных 108 лексических единиц может быть сформирована в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных пользователю 121 и полученных им в определенный период времени, например, за предшествующий год. Как будет понятно специалистам в данной сфере, данный период может быть любым, как более одного года, так и менее одного года.
[173] Каждая из множества лексических единиц, содержащихся в первой базе данных 108 лексических единиц, может быть отмечена как значащая лексическая единица или как незначащая лексическая единица.
[174] В альтернативных воплощениях, значащие лексические единицы и незначащие лексические единицы могут храниться в одной и той же базе данных с указанием их весового значения, либо с указанием различных весовых значений, рассчитанных по различным критериям, как это будет описано ниже. Таким образом, определение того, является ли лексическая единица значащей или незначащей, может осуществляться непосредственно в момент обращения к базе данных путем сравнения определенного соответствующего весового значения соответствующих лексических единиц с соответствующим предопределенным пороговым значением. Так, некоторых вариантах осуществления, лексическая единица из множества лексических единиц, содержащихся в базе данных лексических единиц, является незначащей, если ее весовое значение превышает предопределенное пороговое значение. Поскольку и весовое значение лексической единицы, и предопределенное пороговое значение содержатся в базе данных, становится возможным определить, непосредственно в момент обращения к базе данных, является ли лексическая единица значимой или незначимой.
[175] В альтернативных воплощениях, значащие лексические единицы и незначащие лексические единицы могут храниться в раздельных базах данных. В других альтернативных воплощениях, база данных может хранить только незначащие лексические единицы.
[176] Лексические единицы, содержащиеся в первой базе данных 108 лексических единиц, могут быть ассоциированы с их весовым значением, рассчитанным по первой формуле, то есть весовым значением в расчете по отношению ко во всему массиву сообщений электронной почты, направленных пользователю 121 за весь период существования аккаунта пользователя 121 на почтовом сервере 102. В альтернативных воплощениях, лексические единицы, содержащиеся в первой базе данных 108 лексических единиц, могут быть ассоциированы с их весовым значением, рассчитанным по первой формуле, то есть весовым значением в расчете по отношению ко во всему массиву сообщений электронной почты, направленных пользователю 121 за предопределенный предшествующий период.
[177] Модуль 106 анализа сообщений также находится во взаимодействии со второй базой данных 110 лексических единиц.
[178] Вторая база данных 110 лексических единиц, как и первая база данных 108 лексических единиц, представляет собой структурированный набор данных, включающих в себя лексические единицы. Вторая база данных 110 лексических единиц реализована на том же оборудовании, что и процесс, осуществляющий хранение или использование информации, записанной в базе данных. Однако, как будет понятно специалистам в данной области, вторая база данных 110 лексических единиц, как и первая база данных 108 лексических единиц, может быть реализована также на отдельном оборудовании, таком как выделенный сервер или множество серверов.
[179] В данном воплощении, вторая база данных 110 лексических единиц является базой данных, сформированной в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102, и полученные этими пользователями в течение всего периода существования их аккаунтов. В альтернативных воплощениях, вторая база данных 110 лексических единиц может быть сформирована в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102, и полученные этими пользователями в течение предшествующего года. Как будет понятно специалистам в данной сфере, данный период может быть любым, как более одного года, так и менее одного года.
[180] Каждая из множества лексических единиц, содержащихся во второй базе данных 110 лексических единиц, может быть отмечена как значащая лексическая единица или как незначащая лексическая единица. В альтернативных воплощениях, значащие лексические единицы и незначащие лексические единицы могут храниться в раздельных базах данных. В других альтернативных воплощениях, база данных может хранить только незначащие лексические единицы.
[181] Во второй базе данных 110 лексических единиц содержится информация о весовом значении лексических единиц, рассчитанном по второй формуле, то есть о весовом значении в расчете по отношению ко во всему массиву сообщений электронной почты, направляемых всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102. В данном воплощении, при расчете берутся все сообщения электронной почты, полученные каждым из пользователей, почтовые аккаунты которых расположены на почтовом сервере 102, за весь период пользования ими их аккаунтами. В альтернативных воплощениях, в расчет могут браться только сообщения электронной почты, полученные за предшествующий год. Как будет понятно специалистам в данной сфере, данный период может быть любым, как более одного года, так и менее одного года.
[182] Говоря о почтовом сервере 102 в целом, важно иметь в виду, что различные воплощения почтового сервера 102 даны исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления воплощения почтовых серверов, которые могут использоваться для реализации настоящего решения.
[183] Почтовый сервер 102 соединен с сетью 112 передачи данных через линию связи (не пронумерована). В некоторых вариантах осуществления сеть 112 передачи данных связи может представлять собой Интернет. В других вариантах осуществления, сеть 112 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[184] Реализация линии связи не ограничена, и будет зависеть от того, какие устройства присоединены к сети 112 передачи данных. В качестве примера, но не ограничения, подключение почтового сервера 102 к сети 112 передачи данных может быть осуществлено по проводной связи (соединение на основе сети Ethernet).
[185] Через сеть передачи данных 112, почтовый сервер 112 соединен с первым клиентским устройством 122.
[186] Первое клиентское устройство 122 обычно связано с пользователем 121. Пользователем 121 является лицо, чей аккаунт электронной почты размещен на почтовом сервере 102.
[187] Следует отметить, что тот факт, что первое клиентское устройство 122 связано с пользователем 121, не подразумевает какого-либо конкретного режима работы.
[188] Изображенное на Фиг. 1 первое клиентское устройство 122 реализовано в виде персонального компьютера Dell™ Precision Т1700 МТ CA033PT170011RUWS с процессором Intel® Xeon™, частота процессора: 3300 МГц, с видеокартой nVIDIA Quadro К2000, с установленной и действующей операционной системой Windows 7 Pro 64-bit. Однако, как будет понятно специалистам в данной сфере, варианты первого клиентского устройства 122 конкретно не ограничены. В качестве первого клиентского устройства 122 могут использоваться, например, персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (мобильные телефоны, смартфоны, планшеты и т.п.), и другое оборудование.
[189] Первое клиентское устройство 122 включает в себя носитель информации 124, реализованный как жесткий диск объемом 500 Гб. Однако, как будет понятно специалистам в данной сфере, данный носитель информации 124 может быть реализован как носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д, а также их комбинации.
[190] Носитель информации 124 может сохранять файлы пользователя и программные инструкции. В частности, носитель информации 124 может хранить программное обеспечение, реализующее функции браузера 126. В общем случае, целью браузера 126 является предоставление возможности пользователю 121 подключаться к почтовому серверу 102 и получать и принимать сообщения электронной почты с помощью веб-интерфейса, и показывать получаемые и отправляемые сообщения электронной почты на дисплее 128. В первом клиентском устройстве 122 браузер 126 реализован как мобильный браузер Яндекс™. Однако, как будет понятно специалистам в данной сфере, реализация браузера 126 никак конкретно не ограничена. В качестве неограничивающих примеров, такими браузерами могут быть Яндекс™ браузер, Google Chrome™, Internet Explorer™, различные мобильные поисковые приложения, и так далее. Важно иметь в виду, что любое другое коммерчески доступное или собственное приложение может быть использовано для реализации вариантов осуществления.
[191] Первое клиентское устройство 122 включает в себя также дисплей 128, являющийся монитором Монитор Dell™ Е2214Н 2214-7803, диагональ 21,5′′, с разрешением 1920×1080, позволяющий представлять видеоинформацию пользователю 121. Таким образом, пользователь 121 имеет возможность видеть на дисплее 128 в интерфейса браузера 126 первого клиентского устройства 122 различные объекты, входящие и исходящие сообщения электронной почты, а также рефераты входящих сообщений электронной почты.
[192] Через сеть передачи данных 112, почтовый сервер 112 соединен также со вторым клиентским устройством 132.
[193] Второе клиентское устройство 132 обычно связано с пользователем 131. В данном примере, пользователь 121 является частным лицом, которое использует свой аккаунт электронной почты в личных целях и отправляет с данного аккаунта в основном сообщения электронной почты личного характера. Структура и характерные особенности сообщений электронной почты личного характера может отличаться от структуры и характерных особенностей других типов сообщений электронной почты (например, от сообщений электронной почты, содержащих, например, электронные билеты, рекламные объявления о скидках). Таким образом, машинные методы обработки и анализа сообщений электронной почты, осуществляемые модулем 106 анализа сообщений почтового сервера 102, могут идентифицировать и классифицировать сообщения, направляемые пользователем 131 пользователю 121, как личные сообщения.
[194] Пользователь 131 может быть отправителем сообщений электронной почты, предназначенной различным получателям, в том числе пользователю 121 и/или иным получателям, имеющим аккаунт электронной почты на почтовом сервере 102 либо на любом ином почтовом сервере.
[195] Почтовый аккаунт пользователя 131 может быть размещен на любом почтовом сервере, подходящем для этого, в том числе может быть на почтовом сервере 102.
[196] Следует отметить, что тот факт, что второе клиентское устройство 132 связано с пользователем 131, не подразумевает какого-либо конкретного режима работы.
[197] Для отправки сообщений электронной почты, пользователь 131 использует второе клиентское устройство 132, реализованное в виде в виде смартфона Apple™ iPhone 5S с установленной на нем и действующей операционной системой iOS 7, с Bluetooth, Wi-Fi, 3G, LTE, системой позиционирования GPS. Однако, как будет понятно специалистам в данной сфере, варианты второго клиентского устройства 132 конкретно не ограничены. В качестве второго клиентского устройства 132 могут использоваться, например, персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (мобильные телефоны, смартфоны, планшеты и т.п.) и другое оборудование.
[198] Второе клиентское устройство 132 включает в себя носитель информации 134, реализованный как жесткий диск объемом 500 Гб. Однако, как будет понятно специалистам в данной сфере, данный носитель информации 134 второго клиентского устройства 132 может быть реализован как носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д., а также их комбинации.
[199] Носитель информации 134 второго клиентского устройства 132 может сохранять файлы пользователя и программные инструкции. В частности, носитель информации 134 второго клиентского устройства 132 может хранить программное обеспечение, реализующее функции почтового клиента 136. В общем случае, целью почтового клиента 136 является предоставление возможности пользователю 131 подключаться к почтовому серверу (каковым может быть, в некоторых ситуациях, почтовый сервер 102) и получать и принимать сообщения электронной почты в интерфейсе почтового клиента 136, и показывать получаемые и отправляемые сообщения электронной почты на дисплее 138. Почтовый клиент 136 реализован на втором клиентском устройстве 132 как Triage™. Однако, как будет понятно специалисту в данной сфере, реализация почтового клиента 136 конкретно никак не ограничена. В качестве неограничивающих примеров, такими почтовыми клиентами могут быть Mailbox™, Evomail™, Dispatch™, Inky Mail™, Seed™, myMail™, Boxer™ и другие. Кроме того, в альтернативных воплощениях, функции почтового клиента, - то есть отправку и прием сообщений, показ на дисплее 138 сообщений электронной почты, - могут быть выполнены с помощью веб-браузера. Это может быть выполнено с помощью любого веб-браузера, например Яндекс™ браузера, Google Chrome™, Internet Explorer™, и так далее. Важно иметь в виду, что любое другое коммерчески доступное или собственное приложение может быть использовано для реализации вариантов осуществления.
[200] Второе клиентское устройство 132 включает в себя также дисплей 128, являющийся сенсорным экраном 4′′, с разрешением 640×1136, позволяющий представлять видеоинформацию пользователю 131, а также который может использоваться как устройство ввода информации. Таким образом, пользователь 131 имеет возможность видеть на дисплее 128 в интерфейсе браузера 126 второго клиентского устройства 132 различные объекты, входящие и исходящие сообщения электронной почты, а также рефераты входящих сообщений электронной почты.
[201] Через сеть передачи данных 112, почтовый сервер 112 соединен также с третьим клиентским устройством 142.
[202] Третье клиентское устройство 142 обычно связано с пользователем 141.
[203] В данном примере, пользователь 141 является сотрудником маркетинговой компании, который использует аккаунт электронной почты в целях, определенных клиентами данной маркетинговой компании. Таким образом, пользователь 141 третьего может рассылать множество сообщений электронной почты с клиентского устройства 142, которые могут быть по определенным признакам классифицированы и распределены в условные группы. Например, рассылаемые пользователем 141 с клиентского устройства 142 различные сообщения электронной почты могут быть классифицированы как рекламные сообщения, и/или информационные сообщения, и/или транзакционные сообщения, и/или персональные уведомления, и так далее. Классификация сообщений может быть осуществлена с помощью анализа как содержания соответствующих сообщений по ключевым словам, специфическим терминам, так и путем анализа кода сообщений электронной почты, например, особенностей разметки, выявление использования определенных HTML-шаблонов, и тому подобное.
[204] HTML-шаблон может представлять собой макет сообщения, включающий в себя готовое HTML-форматирование, задающее дизайн и расположение всех элементов оформления. Машинные методы обработки и анализа сообщений электронной почты, осуществляемые модулем 106 анализа сообщений почтового сервера 102, могут идентифицировать и классифицировать сообщения, направляемые пользователем 141 с клиентского устройства 142 пользователю 121, как рекламные сообщения, и/или информационные сообщения, и/или транзакционные сообщения, и/или персональные уведомления, и так далее. Машинные методы обработки и анализа сообщений электронной почты, осуществляемые модулем 106 анализа сообщений почтового сервера 102, могут идентифицировать в таком сообщении электронной почты логические блоки HTML кода, в том числе такие блоки HTML код, которые содержат текст.
[205] Пользователь 141 может быть отправителем сообщений электронной почты, предназначенной различным получателям, в том числе пользователю 121 и/или иным получателям, имеющим аккаунт электронной почты на почтовом сервере 102 либо на любом ином почтовом сервере.
[206] Почтовый аккаунт пользователя 141 может быть размещен на любом почтовом сервере, подходящем для этого, в том числе он может быть на почтовом сервере 102.
[207] Следует отметить, что тот факт, что третье клиентское устройство 142 связано с пользователем 141, не подразумевает какого-либо конкретного режима работы.
[208] Так же, как и первое и второе клиентские устройства 122 и 132, третье клиентское устройство 142 включает в себя носитель информации (не изображен). На третьем клиентском устройстве 142 может быть установлен веб-браузер и/или почтовый клиент (не изображен). Третье клиентское устройство 142 может также включать в себя дисплей (не изображен). Как будет понятно специалистам в данной сфере, варианты третьего клиентского устройства 142 конкретно не ограничены и хорошо известны специалистам в данной сфере. В качестве третьего клиентского устройства 142 могут использоваться, например, персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (мобильные телефоны, смартфоны, планшеты и т.п.), и другое оборудование. По этой причине третье клиентское устройство 142 не будет описано в подробностях.
[209] Как будет понятно специалистам в данной области техники, количество пользователей, направляющих сообщения электронной почты пользователю 121 и другим пользователям, чьи аккаунты расположены на почтовом сервере 102, будет значительно больше, нежели два пользователя 131 и 141.
[210] Как будет понятно специалистам в данной области техники, количество клиентских устройств, с которых направляются сообщения электронной почты пользователю 121 и другим пользователям, чьи аккаунты расположены на почтовом сервере 102, будет значительно больше, нежели два клиентских устройства 132 и 142.
[211] В альтернативных воплощениях, первое клиентское устройство 122, второе клиентское устройство 132 и третье клиентское устройство 142 могут быть реализованы таким образом, чтобы обеспечивать отправку иных текстовых сообщений, нежели сообщения электронной почты. Так, например, первое клиентское устройство 122, второе клиентское устройство 132 и третье клиентское устройство 142 могут быть реализованы как мобильные телефоны, позволяющие осуществление отправки и приема SMS сообщений, а также осуществлять синтаксический анализ текстовых сообщений.
[212] Фиг. 2 является изображением текста сообщения электронной почты 200, направленного пользователем 141 с клиентского устройства 142, изображенным на Фиг. 1, пользователю 121, изображенному на Фиг. 1.
[213] Сообщение 200 электронной почты включает в себя адрес 202 электронной почты отправителя. Отправителем сообщения 200 электронной почты в данном примере является пользователь 141.
[214] Сообщение 200 электронной почты также включает в себя имя 202 (John Smith) и адрес электронной почты получателя (johnsmith@company.com). Получателем сообщения 200 электронной почты в данном примере является пользователь 121.
[215] Сообщение 200 электронной почты включает в себя также тему 204 сообщения электронной почты 200. Темой 204 сообщения электронной почты 200 в данном случае является «Moscow, 11 November 2014: Open Innovations Conference)).
[216] Ниже строки, содержащей тему 204 сообщения электронной почты 200, следует тело сообщения электронной почты (не пронумеровано). В теле сообщения электронной почты содержатся изображения и текст. В частности, в теле сообщения электронной почты 200 содержатся фрагменты текста 206, 208, 210, 212 и 214, которые, в качестве неограничивающих примеров, могут, с точки зрения HTML-структуры сообщения 200 электронной почты, представлять собой отдельные абзацы и/или отдельные таблицы и/или отдельные ячейки таблицы.
[217] Фиг. 3 является изображением фрагмента веб-интерфейса 300 сервиса электронной почты пользователя 121, в котором вкладка 302 «Inbox», то есть вкладка входящих сообщений, является активной. Фиг. 3 представляет собой изображение фрагмента веб-интерфейса 300 сервиса электронной почты, как это может быть реализовано на существующем уровне техники.
[218] Как видно из фрагмента веб-интерфейса 300 сервиса электронной почты, пользователь 121 получил сообщение 200 электронной почты, представленное на Фиг. 2, от пользователя 141, представленного на Фиг. 1. В веб интерфейсе 300 отображается строка 304, включающая в себя адрес 201 электронной почты отправителя. Отправителем сообщения 200 электронной почты в данном примере является пользователь 141.
[219] Строка 304 включает в себя также тему 204 сообщения электронной почты 200.
[220] Строка 304 включает в себя также реферат 310 входящего сообщения электронной почты 200 «Moscow, Russia», что является текстом первой строки фрагмента текста 206, расположенного в самом начале тела сообщения 200 электронной почты. Реферат 310 входящего сообщения электронной почты 200 представляет собой реферат, включающий в себя любые лексические единицы - как потенциально значащие, так и потенциально незначащие. Реферат 310 входящего сообщения электронной почты сформирован без осуществления анализа HTML-структуры сообщения 200 электронной почты, а также без осуществления лексического анализа сообщения 200 электронной почты в целом, и без осуществления лексического анализа текстов, расположенных в логических блоках HTML кода сообщения 200 электронной почты.
[221] Фиг. 4 является изображением фрагмента веб-интерфейса 400 сервиса электронной почты пользователя 121, в котором вкладка 402 «Inbox», то есть вкладка входящих сообщений, является активной. Фиг. 4 представляет собой изображение фрагмента веб-интерфейса 400 сервиса электронной почты, реализованного в соответствии с одним из неограничивающих воплощений настоящей технологии.
[222] Как видно из фрагмента веб-интерфейса 400 сервиса электронной почты, пользователь 121 получил сообщение 200 электронной почты от пользователя 141 с клиентского устройства 142. В веб интерфейсе 400 отображается строка 404, включающая в себя адрес 201 электронной почты отправителя. Отправителем сообщения 200 электронной почты в данном примере является пользователь 141.
[223] Строка 404 включает в себя также тему 204 сообщения электронной почты 200.
[224] Строка 404 включает в себя также реферат 410 входящего сообщения электронной почты 200 «Early bird registration fees available)), что является частью фрагмента текста 212, расположенного в середине сообщения 200 электронной почты. Реферат 410 входящего сообщения электронной почты 200 представляет собой реферат, включающий в себя значащие лексические единицы. Реферат 410 входящего сообщения электронной сформирован с осуществлением анализа HTML-структуры сообщения 200 электронной почты, а также с осуществлением лексического анализа текстов, расположенных в логических блоках HTML кода сообщения 200 электронной почты.
[225] Фиг. 5 является блок-диаграммой способа 500, выполняемого на почтовом сервере 102, изображенном на Фиг. 1, и выполненного в соответствии с вариантами осуществления. Способ 500 является способом компьютерной обработки предназначенного пользователю входящего тестового сообщения, и в данном воплощении - сообщения 200 электронной почты, включающего в себя текст, включающий в себя значащие и незначащие лексические единицы.
[226] В вариантах осуществления способ 500 может выполняться на сервере 102, изображенном на Фиг. 1. Для этого почтовый сервер 102 включает в себя носитель информации 104, хранящий машиночитаемые инструкции, при выполнении которых сервер 102 выполняет этапы способа 500. Однако, как это будет понятно специалистам в данной области техники, метод 500 может быть осуществлен на других серверах.
[227] В данном воплощении, описанном в блок-диаграмме способа 500, почтовый сервер 102 получает от множества отправителей сервисов электронной почты сообщения, предназначенные различным пользователям, в том числе пользователю 121.
[228] Этап 502 - осуществление синтаксического анализа сообщения 200 электронной почты и определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы.
[229] Способ 500 начинается на этапе 502, на котором почтовый сервер 102, изображенный на Фиг. 1, осуществляет синтаксический анализ сообщения 200 электронной почты. Синтаксический анализ осуществляется модулем 106 анализа сообщений в целях определения значащих и незначащих лексических единиц, содержащихся в сообщении 200 электронной почты.
[230] В данном воплощении, осуществление синтаксического анализа сообщения 200 электронной почты включает в себя анализ языка разметки сообщения 200 электронной почты. Так, в данном воплощении, анализ языка разметки сообщения 200 электронной почты включает в себя анализ видов, размеров, начертаний шрифтов, знаков препинания и специальных знаков.
[231] При осуществлении анализа знаков препинания и специальных знаков, могут быть выявлены предложения, которые потенциально могут являться лексическими единицами. Кроме того, выявление предложений может служить основой для дальнейшего анализа с использованием анализа вида шрифтов и анализа размеров и начертаний шрифтов. Признаками конца и начала предложения могут служить как знаки препинания (например, точка, восклицательный знак, многоточие и другие), так и специальные знаки (например, знак абзаца, знак табуляции, знак разрыва страницы, и другие).
[232] При осуществлении анализа вида шрифтов, осуществляется проверка шрифтов, которыми написаны различные части текста. Такой анализ может использоваться для определения лексических единиц. Тот факт, что две части текста написаны разным шрифтом, может свидетельствовать о том, что эти две части текста не являются единой лексической единицей.
[233] При осуществлении анализа размеров и начертаний шрифтов, могут быть выявлены части предложения, в которых отдельные его части написаны шрифтами разных размеров, либо шрифтами с разным начертанием (например, с использованием курсива и/или с выделением жирным), либо с сочетанием первого и второго. Такой анализ может позволить идентифицировать выделенные части предложения как лексические единицы.
[234] В данном воплощении, осуществление синтаксического анализа сообщения 200 электронной почты включает в себя осуществление синтаксического анализа наиболее значимой части сообщения 200 электронной почты, и не включает в себя осуществление синтаксического анализа других частей сообщения 200 электронной почты. В альтернативных воплощениях, осуществление синтаксического анализа сообщения 200 электронной почты может осуществляться по всему тексту сообщения электронной почты, либо по его отдельным частям (например, по первым трем абзацам, либо по первым двум абзацам после абзаца с обращением, либо части для анализа могут быть выбраны по любому иному критерию).
[235] Определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы
[236] Определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы может являться результатом осуществления синтаксического анализа сообщения 200 электронной почты.
[237] Лексической единицей может являться отдельное слово в любой его форме. Например, лексической единицей может являться слово «Привет».
[238] Лексической единицей может являться также отдельное предложение. Например, лексической единицей может быть предложение «Ваш заказ доставлен».
[239] Лексической единицей может являться словосочетание в пределах предложения. Например, в предложении «Ваш заказ доставлен; для получения посылки обратитесь в почтовое отделение по нижеуказанному адресу.», отдельной лексической единицей может являться словосочетание «Ваш заказ доставлен».
[240] Лексической единицей может являться абзац в пределах сообщения электронной почты.
[241] В данном воплощении, лексические единицы могут иметь смысловое значение. Так, например, вышеприведенные лексические единицы имеют смысловое значение, то есть могут рассматриваться как некие завершенные единицы информации. Однако, в альтернативных воплощениях, лексические единицы не обязательно несут смысловое значение. Это могут быть, например, сочетания слов, которые сами по себе, в отрыве от других слов и сочетаний слов, могут не являться завершенными единицами информации.
[242] Определение лексических единиц, имеющих смысловое значение, может осуществляться с помощью синтаксического анализа сообщения 200 электронной почты.
[243] В данном воплощении, как это было отмечено, осуществление синтаксического анализа включает в себя анализ разметки сообщения 200 электронной почты.
[244] В альтернативных вариантах воплощения, определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы может осуществляться с использованием иных методов. Например, для определения лексической единицы, помимо собственно анализа разметки сообщения 200 электронной почты, может производиться дополнительная проверка на наличие в первой строке слов, характерных для обращения (например, «Уважаемый», «Добрый день», «Привет» и другие). Наличие таких ключевых слов в совокупности с определенными моделями разметки могут использоваться для определения лексических единиц.
[245] Затем метод 500 переходит к этапу 506.
[246] Этап 506 - осуществление первой проверки по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из первой базы данных 108 лексических единиц.
[247] На этапе 506 осуществляется первая проверка по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из первой базы данных 108 лексических единиц. В данном воплощении, первая база данных 108 лексических единиц является базой данных, сформированной в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных пользователю 121 и полученных пользователем 121 в течение всего периода существования аккаунта пользователя 121 на почтовом сервере 102. В альтернативных воплощениях, первая база данных 108 лексических единиц может быть сформирована в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных пользователю 121 и полученных им в определенный период времени, например, за предшествующий год. Как будет понятно специалистам в данной сфере, данный период может быть любым, как более одного года, так и менее одного года.
[248] В данном воплощении, каждая из множества лексических единиц, содержащихся в первой базе данных 108 лексических единиц, отмечена как значащая лексическая единица или как незначащая лексическая единица. Сопоставление кандидатов в незначащие лексические единицы будет осуществляться с незначащими лексическими единицами. Наличие же значащих лексических единиц в первой базе данных 108 может быть обусловлено тем, что весовое значение всех лексических единиц в первой базе данных 108 может изменяться в сторону увеличения или уменьшения по мере поступления новых сообщений и по мере их анализа. Соответственно, наличие значащих лексических единиц в первой базе данных 108 может быть необходимо для расчета и перерасчета весового значения этих лексических единиц, и при преодолении весового значения предопределенного порогового значения, значимая лексическая единица, содержащаяся в первой базе данных 108, может стать незначимой лексической единицей.
[249] Таким образом, осуществление первой проверки по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из первой базы данных 108 лексических единиц позволяет определить значимость или незначимость того или иного кандидата в незначащие лексические единицы по отношению к базе данных, сформированной в отношении всей совокупности сообщений электронной почты, предназначенных пользователю 121. Таким образом, речь идет об определении значимости или незначимости лексических единиц для данного конкретного пользователя 121.
[250] В данном воплощении, сопоставление кандидата в незначащие лексические единицы с незначащими лексическими единицами из первой базы данных 108 лексических единиц осуществляется путем сопоставления, по предопределенному параметру, кандидата в незначащие лексические единицы с незначащими лексическими единицами из первой базы данных 108 лексических единиц.
[251] В данном воплощении, таким параметром последовательность символов в кандидате в незначащие лексические единицы и в лексических единицах, содержащихся в первой базе данных 108 лексических единиц. Другими словами, осуществляется посимвольное сравнение кандидата в незначащие лексические единицы с незначащими лексическими единицами из первой базы данных 108 лексических единиц.
[252] В некоторых воплощениях, кандидаты в незначащие лексические единицы, а также лексические единицы в первой базе данных 108 лексических единиц могут иметь контрольные суммы. Эти контрольные суммы могут быть рассчитаны предварительно и выражены, например, в байтах. В отношении кандидатов в лексические единицы, а также лексических единиц в первой базе данных 108 лексических единиц, имеющих контрольные суммы, проверка может проводиться в два этапа. На первом этапе, контрольная сумма кандидата в незначащие лексические единицы сравнивается с контрольными суммами лексических единиц, содержащихся в первой базе данных 108 лексических единиц. Если контрольная сумма кандидата в лексические единицы совпадает с контрольной суммой любой из незначащих единиц, содержащихся в первой базе данных 108 лексических единиц, то в некоторых воплощениях кандидат сразу определяется как незначащая лексическая единица. В альтернативных вариантах воплощения, если совпадение выявлено, то способ переходит к дополнительному этапу, где происходит верификация путем посимвольного сравнения кандидата в незначащие лексические единицы с лексической единицей, содержащейся в первой базе данных 108 лексических единиц, и чья контрольная сумма совпадает с контрольной суммой кандидата в незначащие лексические единицы.
[253] На этапе 508, по результатам проверки принимается одно из двух решений. В случае, если результат проверки положительный (шаг 510), то есть когда проверка показывает, что кандидат в незначащие лексические единицы идентичен какой-либо незначащей лексической единице, содержащейся в базе данных 108 лексических единиц, способ переходит к шагу 522, где кандидат в незначащие лексические единицы определяется как незначащая лексическая единица. Признание кандидата в незначащие лексические единицы незначащей лексической единицей имеет своим последствием то, что в дальнейшем, при формировании реферата сообщения 200 электронной почты, данная лексическая единица не будет в него включена. Затем способ 500 завершается.
[254] Если на этапе 508 проверка дает отрицательный результат (этап 512), то есть когда проверка показывает, что кандидат в незначащие лексические единицы отличен от любой из незначащих лексических единиц, содержащихся в базе данных 108 лексических единиц, способ переходит к этапу 514.
[255] Этап 514 - осуществление второй проверки указанного по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из второй базы данных 110 лексических единиц.
[256] На этапе 514 осуществляется вторая проверка по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из второй базы данных 110 лексических единиц. В данном воплощении, вторая база данных 110 лексических единиц является базой данных, сформированной в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102, и полученные этими пользователями в течение всего периода существования их аккаунтов. В альтернативных воплощениях, вторая база данных 110 лексических единиц может быть сформирована в результате синтаксического анализа совокупности всех сообщений электронной почты, предназначенных всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102, и полученные этими пользователями в течение за предшествующего года. Как будет понятно специалистам в данной сфере, данный период может быть любым, как более одного года, так и менее одного года.
[257] В данном воплощении, каждая из множества лексических единиц, содержащихся во второй базе данных 110 лексических единиц, отмечена как значащая лексическая единица или как незначащая лексическая единица. Сопоставление кандидатов в незначащие лексические единицы будет осуществляться с незначащими лексическими единицами. Наличие же значащих лексических единиц во второй базе данных 110 может быть обусловлено тем, что весовое значение всех лексических единиц во второй базе данных 110 может изменяться в сторону увеличения или уменьшения по мере поступления новых сообщений и по мере их анализа. Соответственно, наличие значащих лексических единиц во второй базе данных 110 может быть необходимо для расчета и перерасчета весового значения этих лексических единиц, и при преодолении весового значения предопределенного порогового значения, значимая лексическая единица, содержащаяся во второй базе данных 110, может стать незначимой лексической единицей.
[258] Таким образом, осуществление второй проверки по меньшей мере одного кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из второй базы данных 110 лексических единиц позволяет определить значимость или незначимость того или иного кандидата в незначащие лексические единицы по отношению к базе данных, сформированной в отношении всей совокупности сообщений электронной почты, предназначенных всем пользователям электронной почты, почтовые аккаунты которых расположены на почтовом сервере 102, и полученные этими пользователями в течение всего периода существования их аккаунтов. Таким образом, речь идет об определении значимости или незначимости лексических единиц для группы пользователей, а не специфически для пользователя 121.
[259] В данном воплощении, сопоставление кандидата в незначащие лексические единицы с незначащими лексическими единицами из второй базы данных 110 лексических единиц осуществляется путем сопоставления, по предопределенному параметру, кандидата в незначащие лексические единицы с незначащими лексическими единицами из второй базы данных 110 лексических единиц.
[260] В данном воплощении, таким параметром последовательность символов в кандидате в незначащие лексические единицы и в лексических единицах, содержащихся во второй базе данных 110 лексических единиц. Другими словами, осуществляется посимвольное сравнение кандидата в незначащие лексические единицы с незначащими лексическими единицами из второй базы данных 110 лексических единиц.
[261] В некоторых воплощениях, кандидаты в незначащие лексические единицы, а также лексические единицы во второй базе данных 110 лексических единиц могут иметь контрольные суммы. Эти контрольные суммы могут быть рассчитаны предварительно и выражены, например, в байтах. В отношении кандидатов в лексические единицы, а также лексических единиц во второй базе данных 110 лексических единиц, имеющих контрольные суммы, проверка может проводиться в два этапа. На первом этапе, контрольная сумма кандидата в незначащие лексические единицы сравнивается с контрольными суммами лексических единиц, содержащихся во второй базе данных 110 лексических единиц. Если контрольная сумма кандидата в лексические единицы совпадает с контрольной суммой любой из незначащих единиц, содержащихся во второй базе данных 110 лексических единиц, то в некоторых воплощениях кандидат сразу определяется как незначащая лексическая единица. В альтернативных вариантах воплощения, если совпадение выявлено, то способ переходит к дополнительному этапу, где происходит верификация путем посимвольного сравнения кандидата в незначащие лексические единицы с лексической единицей, содержащейся во второй базе данных 110 лексических единиц, и чья контрольная сумма совпадает с контрольной суммой кандидата в незначащие лексические единицы.
[262] На этапе 516, по результатам проверки принимается одно из двух решений. В случае, если результат проверки положительный (шаг 518), то есть когда проверка показывает, что кандидат в незначащие лексические единицы идентичен какой-либо незначащей лексической единице, содержащейся во второй базе данных 110 лексических единиц, способ переходит к шагу 522, где кандидат в незначащие лексические единицы определяется как незначащая лексическая единица. Признание кандидата в незначащие лексические единицы незначащей лексической единицей имеет своим последствием то, что в дальнейшем, при формировании реферата сообщения 200 электронной почты, данная лексическая единица не будет в него включена. Затем способ 500 завершается.
[263] Если на этапе 516 проверка дает отрицательный результат (этап 520), то есть когда проверка показывает, что кандидат в незначащие лексические единицы отличен от любой из незначащих лексических единиц, содержащихся во второй базе данных 110 лексических единиц, способ переходит к шагу 524, и кандидат в незначащие лексические единицы определяется как значащая лексическая единица. Признание кандидата в незначащие лексические единицы значащей лексической единицей имеет своим последствием то, что в дальнейшем, при формировании реферата сообщения 200 электронной почты, данная лексическая единица может быть в него включена.
[264] Затем способ 500 завершается.
[265] Как было отмечено выше, способ 500 компьютерной обработки предназначенного пользователю входящего сообщения электронной почты, включающего в себя текст, выполняется с целью определить незначащие лексические единицы во всем сообщении электронной почты, либо в некоторой части сообщения электронной почты. В отношении той части текста сообщения 200 электронной почты, в отношении которой осуществлялось определение незначащих лексических единиц, может быть сформирован реферат, в котором не содержится незначащих лексических единиц. Другими словами, реферат может содержать только значащие лексические единицы.
[266] В некоторых воплощениях настоящей технологии, способ включает в себя формирование реферата 410 сообщения 200 электронной почты, причем реферат 410 сообщения 200 электронной почты сформирован таким образом, что незначащие лексические единицы отсутствуют в реферате 410 сообщения 200 электронной почты.
[267] В некоторых воплощениях, способ включает в себя формирование реферата 410 части сообщения 200 электронной почты, причем реферат 410 части сообщения 200 электронной почты сформирован таким образом, что незначащие лексические единицы отсутствуют в реферате 410 части сообщения 200 электронной почты. Реферат сообщения 200 электронной почты может являться рефератом предопределенного количества абзацев в начале сообщения электронной почты.
[268] В некоторых воплощениях, формирование реферата 410 части сообщения 200 электронной почты является формированием реферата наиболее значимой части сообщения электронной почты. В качестве неограничивающего примера, наиболее значимая часть сообщения 200 электронной почты может быть определена как наиболее значимый логический блок HTML кода из множества логических блоков HTML кода, содержащих текст. Логические блоки HTML кода могут быть определены модулем 106 анализа сообщений почтового сервера 102.
[269] В некоторых воплощениях, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, размер которого превышает размер текста любого другого логического блока HTML кода данного сообщения электронной почты. Размер текста может определяться по количеству знаков, включая или исключая знаки препинания и пробелы.
[270] В некоторых воплощениях, наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, причем текст наиболее значимого логического блока HTML кода содержит наибольшее количество значащих лексических единиц по сравнению с текстами любого другого логического блока HTML кода данного сообщения электронной почты. Значащие лексические единицы могут быть определены модулем 106 анализа сообщений почтового сервера 102.
[271] Фиг. 6 и Фиг. 7 являются блок-диаграммой способа 600, выполняемого на почтовом сервере 102, изображенном на Фиг. 1, и выполненного в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Способ 600 представляет собой реализованный на компьютере двухуровневый способ выявления незначащих лексических единиц в текстовом сообщении. В данном воплощении, текстовым сообщением является сообщение электронной почты 200.
[272] Способ 600 может быть осуществлен для осуществления проверки по любой базе данных лексических единиц. Так, проверка может быть проведена по первой базе данных 108 лексических единиц, и/или по второй базе данных 110 лексических единиц, и/или третьей базе данных лексических единиц (не изображена), которая может быть создана, и так далее.
[273] В вариантах осуществления способ 600 может выполняться на почтовом сервере 102, изображенном на Фиг. 1. Для этого почтовый сервер 102 включает в себя носитель информации 104, хранящий машиночитаемые инструкции, при выполнении которых почтовый сервер 102 выполняет этапы способа 600. Однако, как это будет понятно специалистам в данной области техники, метод 600 может быть осуществлен на других серверах.
[274] В данном воплощении, описанном в блок-диаграмме способа 600, почтовый сервер 102 получает от множества отправителей сервисов электронной почты сообщения, предназначенные различным пользователям, в том числе пользователю 121.
[275] Этап 602 - осуществление синтаксического анализа сообщения 200 электронной почты.
[276] Способ 600 начинается на этапе 602, на котором почтовый сервер 102, изображенный на Фиг. 1, осуществляет синтаксический анализ сообщения 200 электронной почты. Синтаксический анализ осуществляется модулем 106 анализа сообщений в целях определения значащих и незначащих лексических единиц, содержащихся в сообщении 200 электронной почты.
[277] В данном воплощении, осуществление синтаксического анализа сообщения 200 электронной почты включает в себя анализ языка разметки сообщения 200 электронной почты. Так, в данном воплощении, анализ языка разметки сообщения 200 электронной почты включает в себя анализ HTML тегов сообщения электронной почты.
[278] При осуществлении анализа HTML тегов сообщения электронной почты, модуль 106 анализа сообщений выявляет блоки сообщений, содержащие текст, с использованием тегов, обозначающих начало и конец текстовых блоков, абзацев, ячеек таблиц.
[279] В альтернативных воплощениях, анализ языка разметки текстового сообщения может включать в себя анализ видов шрифтов, размеров шрифтов, начертаний шрифтов, знаков препинания и специальных знаков.
[280] При осуществлении анализа знаков препинания и специальных знаков, могут быть выявлены предложения, которые потенциально сами могут являться лексическими единицами. Кроме того, выявление предложений может служить основой для дальнейшего анализа с использованием анализа вида шрифтов и анализа размеров шрифтов и начертаний шрифтов. Признаками конца и начала предложения могут служить как знаки препинания (например, точка, восклицательный знак, многоточие и другие), так и специальные знаки (например, знак абзаца, знак табуляции, знак разрыва страницы, и другие).
[281] При осуществлении анализа вида шрифтов, осуществляется проверка шрифтов, которыми написаны различные части текста. Такой анализ может использоваться для определения лексических единиц. Тот факт, что две части текста написаны разным шрифтом, может свидетельствовать о том, что эти две части текста не являются единой лексической единицей.
[282] При осуществлении анализа размеров шрифтов и начертаний шрифтов, могут быть выявлены части предложения, в которых отдельные его части написаны шрифтами разных размеров, либо шрифтами с разным начертанием (например, с использованием курсива и/или с выделением жирным), либо с сочетанием первого и второго. Такой анализ может позволить идентифицировать выделенные части предложения как лексические единицы.
[283] В данном воплощении, осуществляется синтаксический анализа всего текста сообщения 200 электронной почты. В альтернативных воплощениях, осуществление синтаксического анализа текстового сообщения может осуществляться по всему тексту сообщения, либо по его отдельным частям (например, по первым трем абзацам, либо по первым двум абзацам после абзаца с обращением, либо части для анализа могут быть выбраны по любому иному критерию), либо ограничиваться синтаксическим анализом наиболее значимой части текстового сообщения.
[284] В некоторых воплощениях, способ может дополнительно включать получение входящего сообщения 200 электронной почты, то есть поступление сообщения электронной почты 200 на почтовый сервер 102.
[285] Определение по меньшей мере одной лексической единицы в качестве первого кандидата в незначащие лексические единицы.
[286] Определение по меньшей мере одной лексической единицы в качестве первого кандидата в незначащие лексические единицы может являться результатом осуществления синтаксического анализа сообщения 200 электронной почты. Этап 606 может осуществляться так же, как и описанный выше этап 502, и поэтому не будет описан в подробностях.
[287] В данном примере, на этапе 602 модуль 106 анализа сообщений выбрал в качестве первого кандидата в незначащие лексические единицы фрагмент текста, представляющий собой целый абзац (не изображен), состоящий из двух предложений (не изображены).
[288] Затем метод 600 переходит к этапу 606.
[289] Этап 606 - определение контрольной суммы первого кандидата в незначащие лексические единицы.
[290] На этапе 606 осуществляется определение контрольной суммы первого кандидата в незначащие лексические единицы. Под контрольной суммой первого кандидата в незначащие лексические единицы, который сам является лексической единицей, может пониматься любая количественная характеристика, объективно характеризующая лексическую единицу.
[291] В данном воплощении, контрольная сумма первого кандидата в незначащие лексические единицы представляет собой совокупность следующих контрольных элементов: количество слов в контрольной единице, количество букв в лексической единице, количество цифр в лексической единице, количество точек в лексической единице, количество запятых в лексической единице. Модуль 106 анализа сообщений определил, что первый кандидат в незначащие лексические единицы содержит 44 слова, 268 букв, 9 цифр, две точки и две запятые.
[292] В альтернативных воплощениях, контрольная сумма первого кандидата в незначащие лексические единицы может представлять собой совокупность любых контрольных элементов, в том числе следующих: количество символов, количество букв, количество заглавных букв, количество прописных букв, количество пробелов в лексической единице, количество цифр в лексической единице, количество специальных знаков в лексической единице, количество слов в лексической единице, размер лексической единицы, выраженный в единицах обработки и хранения информации.
[293] Для определения контрольного элемента первого кандидата в незначащие лексические единицы, выраженного в единицах обработки и хранения информации, например в байтах, модуль 106 анализа сообщений производит оценку соответствующего неформатированного текста, представляющего лексическую единицу, являющуюся первым кандидатом в незначащие лексические единицы. Как будет понятно специалистам в данной области техники, выбор конкретного способа оценки не имеет принципиального значения. Другими словами, возможно применение различных способов. При этом однажды выбранный способ должен применяться последовательно с тем, чтобы при расчете контрольных элементов двух и более идентичных лексических единиц, выраженных в единицах обработки и хранения информации, эти контрольные элементы были тождественными.
[294] Затем метод 600 переходит к этапу 608.
[295] Этап 608 - сопоставление, по первому критерию, первого кандидата в незначащие лексические единицы с лексическими единицами, содержащимися в базе данных лексических единиц.
[296] На этапе 608 осуществляется сопоставление по первому критерию первого кандидата в незначащие лексические единицы с незначащими лексическими единицами из множества лексических единиц, содержащихся в базе данных лексических единиц, где сопоставлением является сопоставление контрольной суммы первого кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся во второй базе данных 110 лексических единиц.
[297] В данном воплощении, сопоставление контрольных сумм по первому критерию представляет собой сопоставление по первому набору контрольных элементов, а именно, по следующим пяти контрольным элементам, содержащимся в базе данных 110 в отношении каждой лексической единицы: 1) по количеству слов в контрольной единице, 2) по количеству букв в лексической единице, 3) по количество цифр в лексической единице, 4) по количеству точек в лексической единице, 5) по количеству запятых в лексической единице. В альтернативных неограничивающих вариантах воплощения технологии, сопоставление контрольных сумм по первому критерию может представлять собой сравнение хеш-кода кандидата в незначимые лексические единицы с хеш-кодом незначимых лексических единиц во второй базе данных 110.
[298] На данном этапе, модуль анализа 106 анализа сообщений проверяет, имеются ли в базе данных 110 лексических единиц такие незначащие лексические единицы, контрольная сумма которых соответствует контрольной сумме первого кандидата в незначащие лексические единицы.
[299] В данном воплощении, контрольная сумма первого кандидата в незначащие лексические единицы соответствует контрольной сумме незначимой лексической единицы, содержащейся в базе данных 110, если (а) эти две контрольные суммы идентичны, либо (б) эти две контрольные суммы не идентичны, но степень различия незначительна, т.е. находится в пределах предустановленной допустимой амплитуды различия.
[300] На этапе 610 осуществляется проверка на предмет идентичности контрольных сумм.
[301] Чтобы две контрольные суммы были идентичными, необходимо, чтобы все контрольные элементы, входящие в первый набор контрольных элементов, полностью совпали. Это значит, в данном примере, что у обоих - у первого кандидата в незначащие лексические единицы и у незначащей лексической единицы из базы данных 110, контрольные элементы были следующими: 44 слова, 268 букв, 9 цифр, две точки и две запятые.
[302] Если такое точное совпадение выявлено (этап 612), то метод 600 переходит на этап 626, где кандидат в незначащие лексические единицы определяется в качестве незначащей лексической единицы.
[303] Если такое точное совпадение не выявлено (этап 614), то метод 600 переходит на этап 618, где осуществляется проверка степени различия контрольных сумм. В данном воплощении, степень различия определяется в отношении каждого из контрольных элементов, включенных в состав контрольной суммы, и амплитуда различия установлена для каждого из контрольных элементов, включенных в состав контрольной суммы. В данном примере, амплитуда установлена как максимально допустимая степень отклонения, выражаемая в коэффициентах допустимого отклонения, применяемых по отношению к контрольным элементам, содержащимся в базе данных 110 лексических единиц. В данном примере, коэффициенты допустимого отклонения установлены равными: 0,018 для слов; 0,01 для букв; 0,5 для цифр; 0 для точек; 0 для запятых. После применения коэффициентов допустимого отклонения, все полученные значения округляются в большую сторону.
[304] Например, допустим, что в базе данных 110 лексических единиц имеется незначащая лексическая единица, чья контрольная сумма включает в себя следующие контрольные элементы: 43 слова, 265 букв, 9 цифр, две точки и одну запятую. Применив указанные коэффициенты, можно увидеть, что контрольная сумма первого кандидата в незначащие лексические единицы будет соответствовать контрольной сумме указанной незначащей лексической единицы, если каждый из следующих элементов будет находиться в пределах следующих параметров:
- количество слов - от 42 до 44 (допустимое отклонение от 43 слов рассчитывается как 43×0,018=0,774, и 0,774 округляется в большую сторону до одного, то есть допустимое отклонение равно +/- 1);
- количество букв - от 262 до 268 (допустимое отклонение +/- 3);
- количество точек - 2 (допустимое отклонение +/- 0);
- количество запятых - 2 (допустимое отклонение +/- 0);
В этом случае, сопоставление степени расхождения на этапе 618 покажет, что расхождение находится в пределах допустимого отклонения (этап 620), контрольные суммы этой незначащей лексической единицы и первого кандидата в незначащие лексические единицы будут считаться соответствующими, поскольку параметры контрольных элементов первого кандидата будут находиться в пределах амплитуды допустимого расхождения. В этом случае первый кандидат в незначащие лексические единицы определяется в качестве незначащей лексической единицы (этап.626).
[305] Как было указано выше, после осуществления любого из этапов 612 и 620, кандидат в незначащие лексические единицы определяется в качестве незначащей лексической единицы (этап 626).
[306] Признание кандидата в незначащие лексические единицы незначащей лексической единицей имеет своим последствием то, что в дальнейшем, при формировании реферата сообщения 200 электронной почты, данная лексическая единица не будет в него включена. Затем способ 600 завершается.
[307] Если в предыдущем примере расхождение хотя бы по одному из контрольных элементов превысило бы допустимую амплитуду, контрольные суммы первого кандидата в незначащие лексические единицы и незначащей лексической единицы из базы данных 110 лексических единиц не считались бы соответствующими (этап 622), и в этом случае первый кандидат в незначащие лексические единицы не был бы определен в качестве незначащей лексической единицы. В этом случае, метод 600 переходит на этап 628.
[308] Этап 628 - разбиение первого кандидата в незначимые лексические единицы на по меньшей мере две более мелкие лексические единицы и определение по меньшей мере одной более мелкой лексической единицы в качестве второго кандидата в незначащие лексические единицы.
[309] На этапе 628 осуществляется разбиение первого кандидата в лексические единицы по меньшей мере на две более мелкие лексические единицы и определение по меньшей мере одной более мелкой лексической единицы в качестве второго кандидата в незначащие лексические единицы.
[310] Разбиение первого кандидата в лексические единицы на по меньшей мере две более мелкие лексические единицы осуществляется модулем 106 анализа сообщений путем осуществления синтаксического анализа первого кандидата в незначимые лексические единицы, как если бы первый кандидат в незначимые лексические единицы был бы полным текстовым сообщением.
[311] В данном воплощении, первый кандидат в незначимые лексические единицы, являющийся в данном воплощении абзацем, разбивается на более мелкие незначимые единицы, которые могут быть предложениями.
[312] В данном примере, первый кандидат в незначащие лексические единицы, представляющий собой абзац, состоящий из двух предложений, разбивается на две более мелкие незначащие лексические единицы, каждая из которых является предложением в составе этого абзаца.
[313] В альтернативных воплощениях, первый кандидат в незначащие лексические единицы разбивается на две, либо на большее количество более мелких лексических единиц, причем такими более мелкими лексическими единицами могут быть принятые в естественном языке слова, фразы, устойчивые словосочетания, предложения, аббревиатуры, символы, даты, сокращения, в том числе общепринятые, лексически значимые компоненты сложных слов, а также эквивалентные им кодовые или символические обозначения искусственного языка, и тому подобное.
[314] Далее, метод 630 переходит на этап 630.
[315] Этап 630 - определение контрольной суммы второго кандидата в незначащие лексические единицы.
[316] На этапе 630 осуществляется определение контрольной суммы второго кандидата в незначащие лексические единицы. Под контрольной суммой второго кандидата в незначащие лексические единицы, который сам является лексической единицей, может пониматься любая количественная характеристика, объективно характеризующая лексическую единицу.
[317] В данном воплощении, контрольная второго кандидата в незначащие лексические единицы представляет собой совокупность следующих контрольных элементов: количество слов в контрольной единице, количество букв в лексической единице, количество цифр в лексической единице, количество точек в лексической единице, количество запятых в лексической единице. Модуль 106 анализа сообщений определил, что второй кандидат в незначащие лексические единицы содержит 19 слов, 92 буквы, 6 цифр, одну точку и две запятые.
[318] В альтернативных воплощениях, контрольная сумма второго кандидата в незначащие лексические единицы может представлять собой совокупность любых контрольных элементов, в том числе следующих: количество символов в лексической единице, количество букв в лексической единице, количество заглавных букв в лексической единице, количество прописных букв в лексической единице, количество пробелов в лексической единице, количество цифр в лексической единице, количество специальных знаков в лексической единице, количество слов в лексической единице, размер лексической единицы, выраженный в единицах обработки и хранения информации.
[319] Этап 632 - сопоставление, по второму критерию, второго кандидата в незначащие лексические единицы с незначащими лексическими единицами, содержащимися в базе данных 110 лексических единиц.
[320] На этапе 632, модуль 106 анализа сообщений осуществляет сопоставление, по второму критерию, второго кандидата в незначащие лексические единицы с незначащими лексическими единицами, содержащимися в базе данных 110 лексических единиц, причем сопоставлением по второму критерию является сопоставление контрольной суммы второго кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц.
[321] В данном воплощении, сопоставление контрольных сумм по второму критерию представляет собой сопоставление по в набору контрольных элементов, а именно, по следующим пяти контрольным элементам, содержащимся в базе данных 110 в отношении каждой лексической единицы: 1) по количеству слов в контрольной единице, 2) по количеству букв в лексической единице, 3) по количество цифр в лексической единице, 4) по количеству точек в лексической единице, 5) по количеству запятых в лексической единице. Таким образом, мы можем видеть, что в данном воплощении первый набор контрольных элементов и второй набор контрольных элементов идентичны. В альтернативных воплощениях, первый набор и второй набор контрольных элементов могут различаться. В альтернативных вариантах, сопоставление контрольных сумм по первому критерию может представлять собой сравнение хеш-кода кандидата в незначимые лексические единицы с хеш-кодом незначимых лексических единиц во второй базе данных 110.
[322] На данном этапе, модуль анализа 106 анализа сообщений проверяет, имеются ли в базе данных 110 лексических единиц такие незначащие лексические единицы, контрольная сумма которых соответствует контрольной сумме второго кандидата в незначащие лексические единицы.
[323] В данном воплощении, контрольная сумма второго кандидата в незначащие лексические единицы соответствует контрольной сумме незначимой лексической единицы, содержащейся в базе данных 110, если (а) эти две контрольные суммы идентичны, либо (б) эти две контрольные суммы не идентичны, но степень различия незначительна, то есть находится в пределах предустановленной допустимой амплитуды различия.
[324] На этапе 634 осуществляется проверка на предмет идентичности контрольных сумм. Чтобы две контрольные суммы были идентичными, необходимо, чтобы все контрольные элементы, входящие в первый набор контрольных элементов, полностью совпали. Это значит, в данном примере, что у обоих - у второго кандидата в незначащие лексические единицы и у незначащей лексической единицы из базы данных 110, контрольные элементы были следующими: 19 слов, 92 буквы, 6 цифр, одна точка и две запятые.
[325] Если такое точное совпадение выявлено (этап 632), то метод 600 переходит на этап 648, где кандидат в незначащие лексические единицы определяется в качестве незначащей лексической единицы. При этом метод 600 завершается.
[326] Если такое точное совпадение не выявлено (этап 638), то метод 600 переходит на этап 640, где осуществляется проверка степени различия контрольных сумм. В данном воплощении, степень различия определяется в отношении каждого из контрольных элементов, включенных в состав контрольной суммы, и амплитуда различия установлена для каждого из контрольных элементов, включенных в состав контрольной суммы. В данном примере, амплитуда установлена как максимально допустимая степень отклонения, выражаемая в коэффициентах допустимого отклонения, применяемых по отношению к контрольным элементам, содержащимся в базе данных 110 лексических единиц. В данном примере, коэффициенты допустимого отклонения установлены равными: 0,018 для слов; 0,01 для букв; 0,5 для цифр; 0 для точек; 0 для запятых. После применения коэффициентов допустимого отклонения, все полученные значения округляются в большую сторону. Соответственно, все расчеты производятся так же, как было описано выше применительно к проверке степени различия контрольных сумм первого кандидата в незначащие лексические единицы с незначащей лексической единицей из базы данных 110 лексических единиц.
[327] В этом случае, сопоставление степени расхождения на этапе 638 покажет, что расхождение находится в пределах допустимого отклонения (этап 646), контрольные суммы этой незначащей лексической единицы и первого кандидата в незначащие лексические единицы будут считаться соответствующими, поскольку параметры контрольных элементов первого кандидата будут находиться в пределах амплитуды допустимого расхождения. В этом случае второй кандидат в незначащие лексические единицы определяется в качестве незначащей лексической единицы (этап.648).
[328] Если в предыдущем примере расхождение хотя бы по одному из контрольных элементов превысило бы допустимую амплитуду, контрольные суммы второго кандидата в незначащие лексические единицы и незначащей лексической единицы из базы данных 110 лексических единиц не считались бы соответствующими (этап 642), и в этом случае второй кандидат в незначащие лексические единицы был бы определен в качестве значащей лексической единицы (этап 644).
[329] Затем способ 600 завершается.
[330] Признание любого кандидата в незначащие лексические единицы (как первого, так и второго) незначащей лексической единицей имеет своим последствием то, что в дальнейшем, при формировании реферата сообщения 200 электронной почты, данные лексические единицы не будут в него включены. Затем способ 600 завершается.
[331] Признание первого кандидата в незначащие лексические единицы или второго кандидата в незначащие лексические единицы значащей лексической единицей имеет своим последствием то, что в дальнейшем, при формировании реферата сообщения 200 электронной почты, соответствующая лексическая единица может быть в него включена.
[332] В рамках настоящего описания следует понимать, что везде, где указано получение данных от любого клиентского устройства и/или от любого почтового сервера, и/или от любого другого сервера, может использоваться получение электронного или иного сигнала от соответствующего клиентского устройства (сервера, почтового сервера), а отображение на экране устройства может быть реализовано как подача сигнала экрану, в котором содержится определенная информация, которая в дальнейшем может быть интерпретирована определенными образами и по меньшей мере частично отображена на экране клиентского устройства. Подача и получение сигнала не везде указаны в рамках настоящего описания для упрощения изложения и облегчения понимания настоящего решения. Сигналы могут передаваться оптическими методами (по волоконно-оптической связи, например), электронными методами (по проводной или беспроводной связи), механическими методами (передача давления, температуры и/или других физических параметров посредством которых возможна передача сигнала).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБРАБОТКИ СООБЩЕНИЙ ЭЛЕКТРОННОЙ ПОЧТЫ, СОДЕРЖАЩИХ ЦИТИРУЕМЫЙ ТЕКСТ, И КОМПЬЮТЕР, ИСПОЛЬЗУЕМЫЙ В НЕМ | 2014 |
|
RU2682038C2 |
| Способ автоматизированного анализа текста и подбора релевантных рекомендаций по улучшению его читабельности | 2021 |
|
RU2769427C1 |
| СИСТЕМА И СПОСОБЫ ДЛЯ ОБНАРУЖЕНИЯ СЕТЕВОГО МОШЕННИЧЕСТВА | 2017 |
|
RU2744671C2 |
| УСТРОЙСТВА, СПОСОБЫ И СИСТЕМЫ ТОКЕНИЗАЦИИ КОНФИДЕНЦИАЛЬНОСТИ ПЛАТЕЖЕЙ | 2012 |
|
RU2602394C2 |
| УСТРОЙСТВА, СПОСОБЫ И СИСТЕМЫ ОБЕСПЕЧЕНИЯ ДИНАМИЧЕСКОЙ КНОПКИ ОФОРМЛЕНИЯ ЗАКАЗА | 2015 |
|
RU2666301C2 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |
| СИСТЕМА ОТОБРАЖЕНИЯ ПОЧТОВЫХ ВЛОЖЕНИЙ НА СТРАНИЦЕ ВЕБ-ПОЧТЫ | 2013 |
|
RU2595533C2 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ОРФАННЫХ ВЫСКАЗЫВАНИЙ | 2015 |
|
RU2699399C2 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |
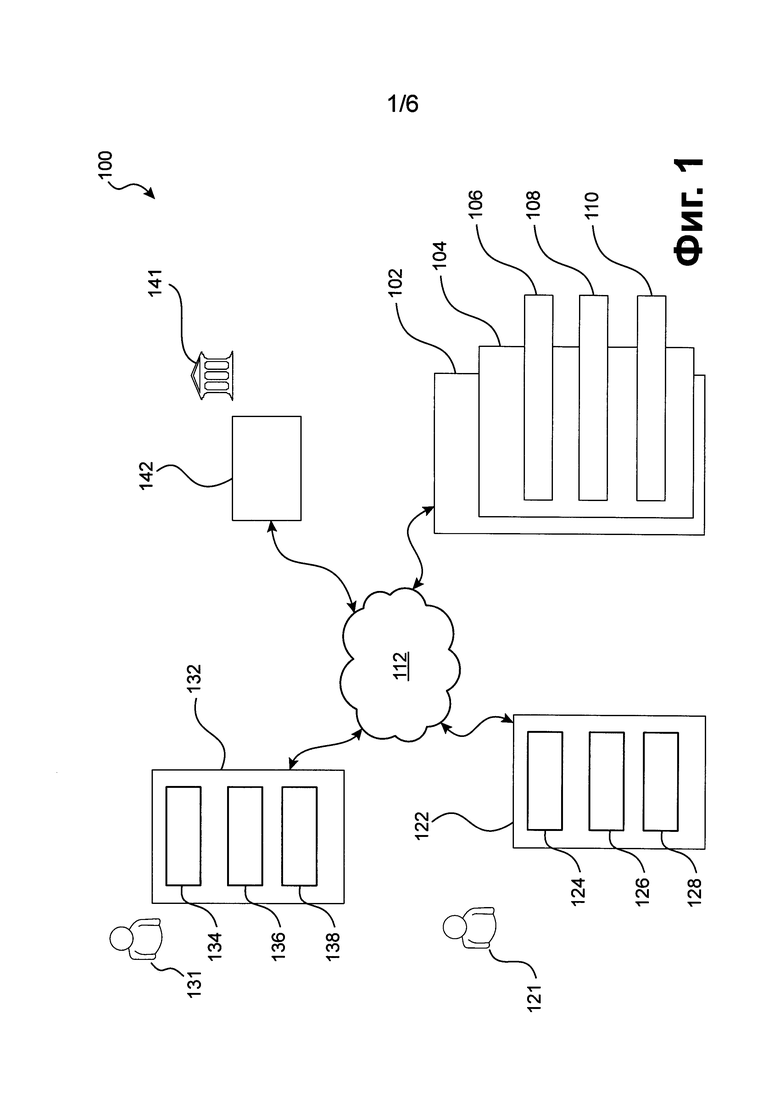
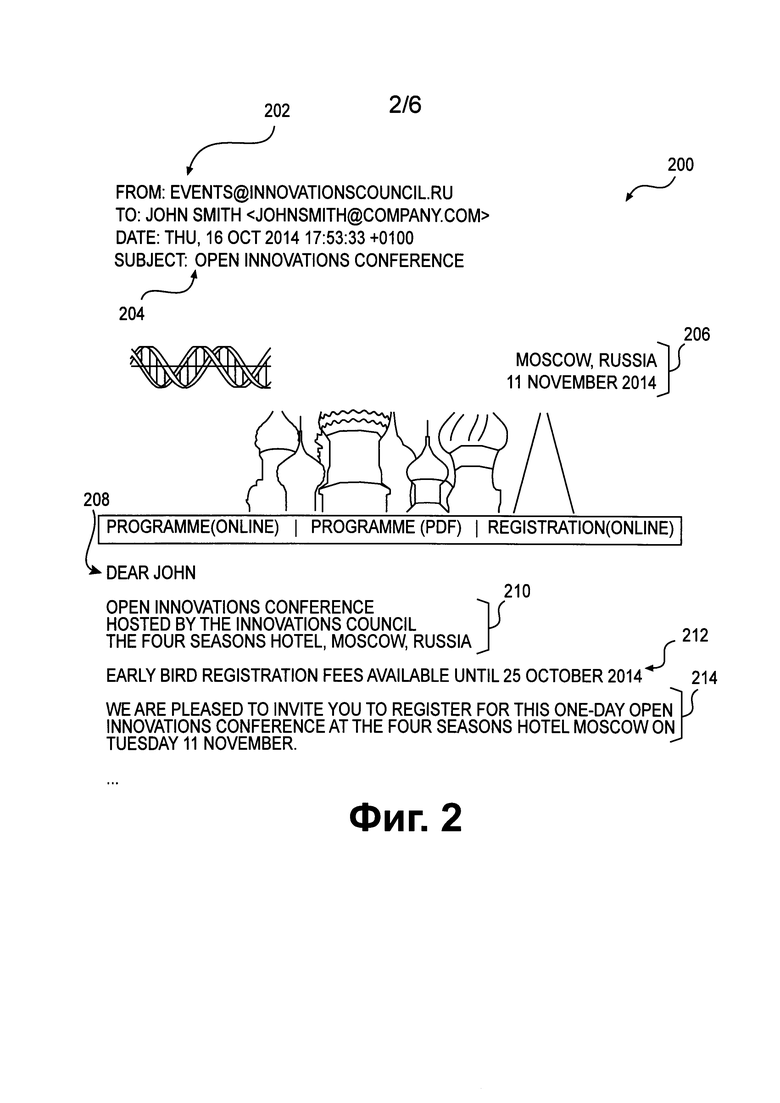
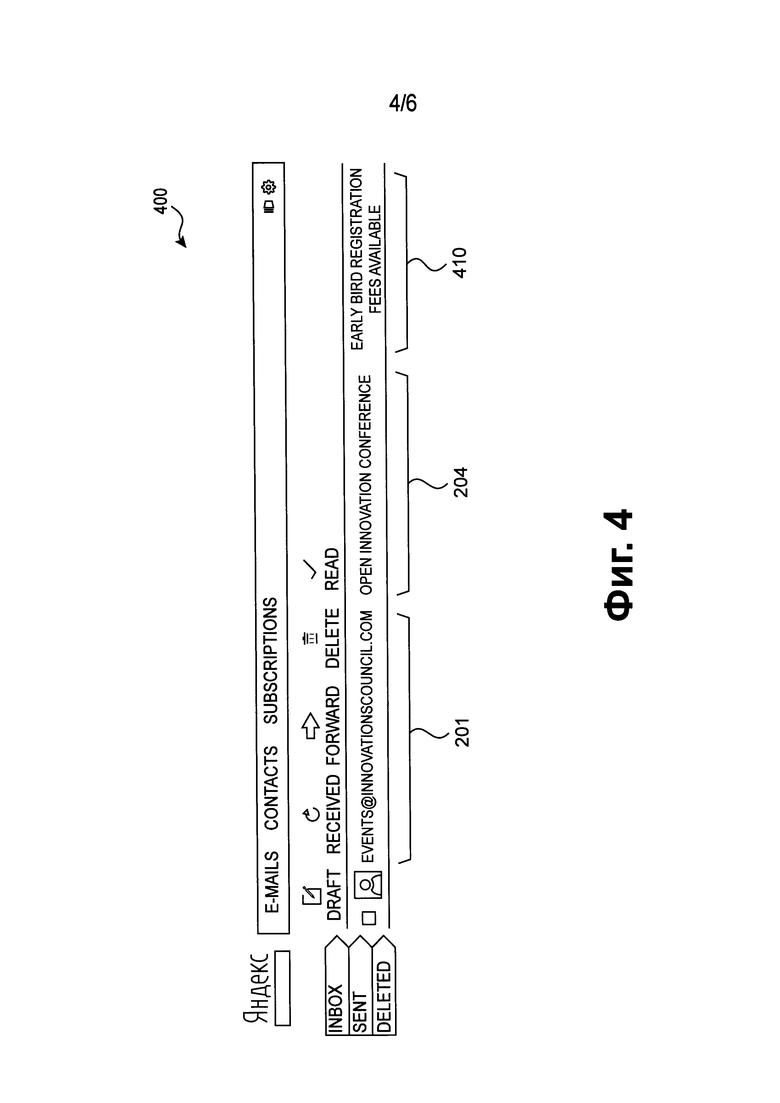
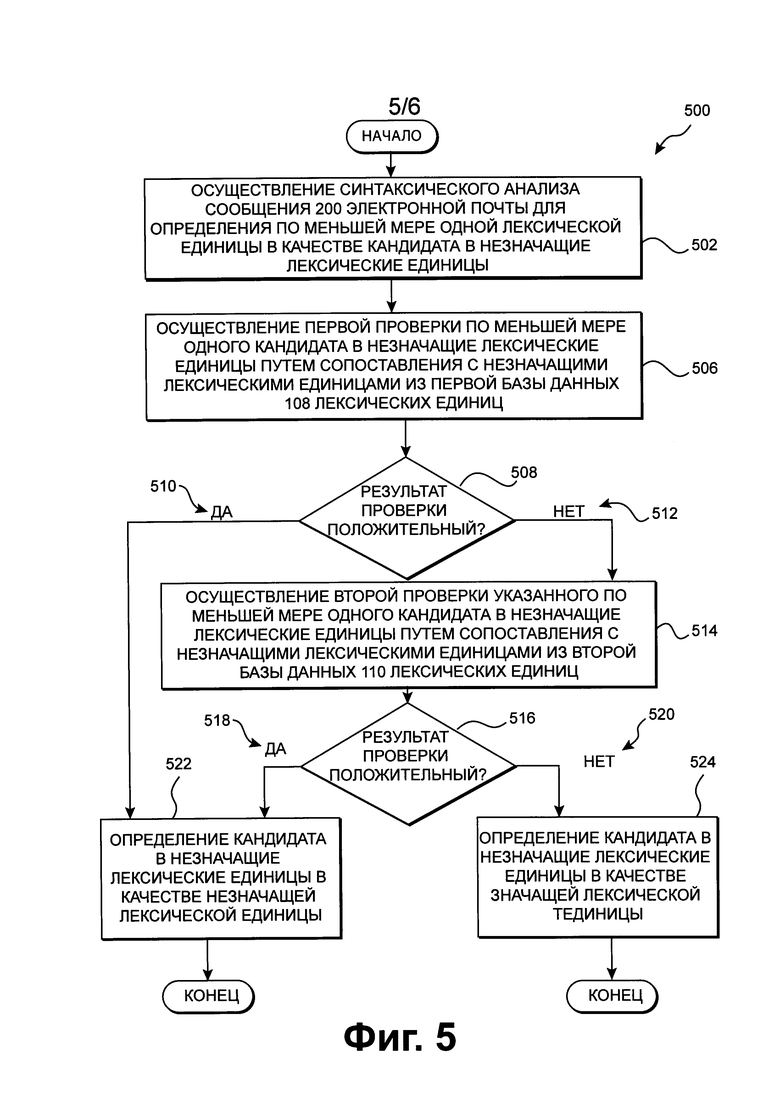
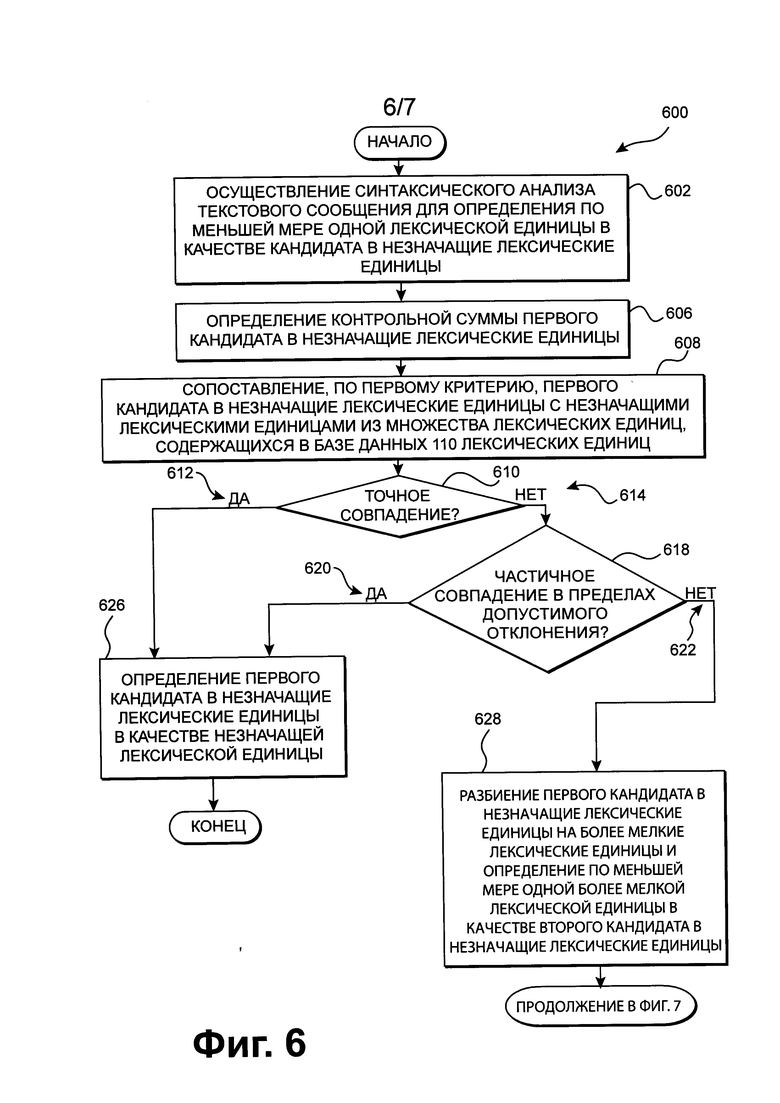
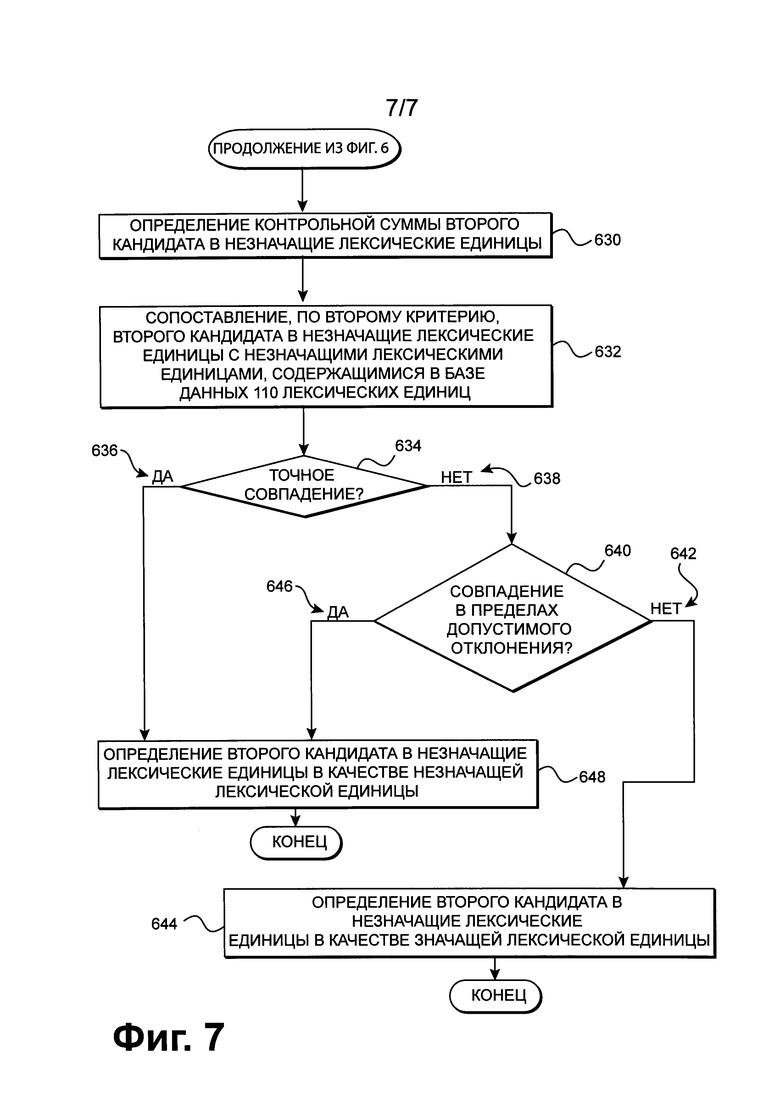
Изобретение относится к системам обработки предназначенного пользователю входящего сообщения электронной почты. Технический результат заключается в обеспечении возможности выявления незначащих лексических единиц в тексте сообщения электронной почты. Такой результат достигается тем, что осуществляют синтаксический анализ сообщения электронной почты для определения лексической единицы в качестве кандидата в незначащие лексические единицы; осуществляют первую и вторую проверки кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из первой и из второй базы данных лексических единиц, где первая база данных сформирована в результате синтаксического анализа предыдущих сообщений электронной почты, предназначенных пользователю, а вторая база данных сформирована в результате синтаксического анализа предыдущих сообщений электронной почты, предназначенных группе пользователей из множества пользователей. В ответ на положительный результат любой из первой проверки и второй проверки определяют кандидата в незначащие лексические единицы в качестве незначащей лексической единицы. 2 н. и 50 з.п. ф-лы, 7 ил.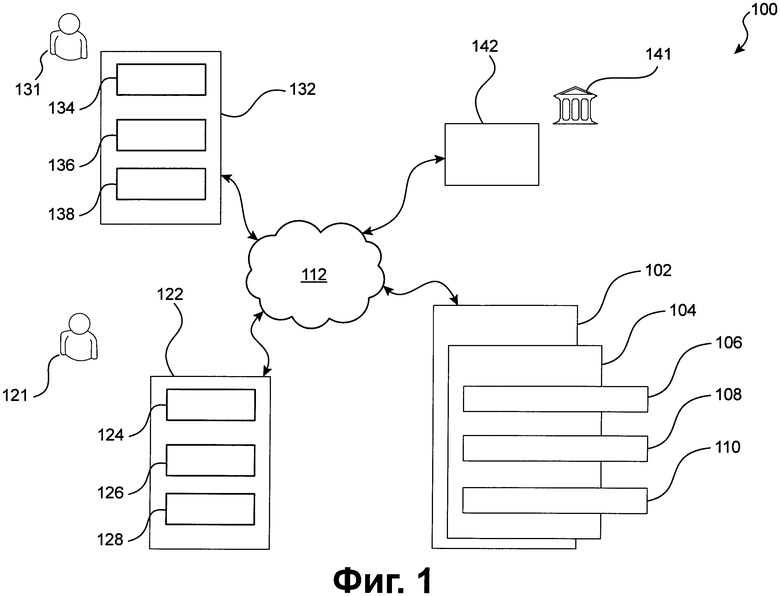
1. Способ выявления незначащих лексических единиц в текстовом сообщении, включающий:
(i) определение по меньшей мере одной лексической единицы в качестве первого кандидата в незначащие лексические единицы посредством синтаксического анализа текстового сообщения;
(ii) определение контрольной суммы первого кандидата в незначащие лексические единицы;
(iii) сопоставление первого кандидата в незначащие лексические единицы с незначащими лексическими единицами из группы лексических единиц, содержащихся в базе данных лексических единиц, по первому критерию, представляющему собой сопоставление контрольной суммы первого кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц;
(iv) определение первого кандидата в незначащие лексические единицы в качестве незначащей лексической единицы при наличии в базе данных лексических единиц по меньшей мере одной незначащей лексической единицы, имеющей контрольную сумму, соответствующую контрольной сумме первого кандидата в незначащие лексические единицы.
2. Способ по п. 1, в котором при отсутствии в базе данных лексических единиц незначащей лексической единицы, имеющей контрольную сумму, соответствующую контрольной сумме первого кандидата в незначащие лексические единицы, осуществляют:
(i) разбиение первого кандидата по меньшей мере на две более мелкие лексические единицы и определение по меньшей мере одной более мелкой лексической единицы в качестве второго кандидата в незначащие лексические единицы;
(ii) определение контрольной суммы второго кандидата в незначащие лексические единицы;
(iii) сопоставление второго кандидата в незначащие лексические единицы с незначащими лексическими единицами, содержащимися в базе данных лексических единиц, по второму критерию, представляющему сопоставление контрольной суммы второго кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц;
(iv) определение второго кандидата в незначащие лексические единицы в качестве незначащей лексической единицы при наличии в базе данных лексических единиц по меньшей мере одной незначащей лексической единицы, имеющей контрольную сумму, соответствующую контрольной сумме второго кандидата в незначащие лексические единицы.
3. Способ по п. 2, в котором в качестве первого кандидата в незначащие лексические единицы используют абзац, а в качестве второго кандидата в незначащие лексические единицы используют предложение из этого абзаца.
4. Способ по любому из пп. 1-3, в котором в качестве контрольной суммы используют совокупность контрольных элементов.
5. Способ по п. 4, в котором в качестве контрольного элемента используют любой элемент, выбранный из: количества символов в лексической единице, количества букв в лексической единице, количества заглавных букв в лексической единице, количества прописных букв в лексической единице, количества пробелов в лексической единице, количества цифр в лексической единице, количества специальных знаков в лексической единице, количества слов в лексической единице, размера лексической единицы, выраженного в единицах обработки и хранения информации.
6. Способ по п. 4, в котором сопоставление по первому критерию осуществляют по первому набору контрольных элементов, а сопоставление по второму критерию осуществляют по второму набору контрольных элементов.
7. Способ по п. 6, в котором используют идентичные первый и второй наборы контрольных элементов.
8. Способ по п. 1, в котором определяют соответствие контрольных сумм при их идентичности.
9. Способ по п. 1, в котором при различии контрольных сумм осуществляют проверку степени различия контрольных сумм и определяют контрольные суммы соответствующими при степени различия, находящейся в пределах предустановленной допустимой амплитуды различия.
10. Способ по п. 9, в котором степень различия определяют в отношении каждого из контрольных элементов, включенных в состав контрольной суммы, а амплитуда различия установлена для каждого из контрольных элементов, включенных в состав контрольной суммы.
11. Способ по п. 1, в котором при наличии в базе данных лексических единиц по меньшей мере одной незначащей лексической единицы, имеющей контрольную сумму, соответствующую контрольной сумме кандидата в незначащие лексические единицы, осуществляют познаковое сравнение кандидата в незначащие лексические единицы с этой по меньшей мере одной незначащей лексической единицей и определяют кандидата в незначащие лексические единицы в качестве незначащей лексической единицы при совпадении последовательности символов кандидата в незначащие лексические единицы с последовательностью символов этой по меньшей мере одной незначащей лексической единицы.
12. Способ по п. 1, в котором лексическую единицу из группы лексических единиц, содержащихся в базе данных лексических единиц, определяют в качестве незначащей лексической единицы при ее весовом значении, превышающем предопределенное пороговое значение.
13. Способ по п. 12, в котором базу данных лексических единиц формируют на основе множества лексических единиц, встречающихся во множестве текстовых сообщений, а весовое значение каждой лексической единицы прямо пропорционально частотности данной лексической единицы во множестве лексических единиц, встречающихся в указанном множестве сообщений.
14. Способ по п. 1, в котором при синтаксическом анализе текстового сообщения осуществляют анализ языка разметки текстового сообщения.
15. Способ по п. 14, в котором анализ языка разметки текстового сообщения осуществляют посредством анализа по меньшей мере одного, выбранного из: структуры текстового сообщения, вида шрифта, размера шрифта, начертания шрифта, знаков препинания, специальных знаков.
16. Способ по п. 1, в котором осуществляют синтаксический анализ текстового сообщения предопределенного количества абзацев в начале текстового сообщения.
17. Способ по п. 1, в котором в качестве текстового сообщения используют сообщение электронной почты.
18. Способ по п. 17, в котором осуществляют синтаксический анализ наиболее значимой части сообщения электронной почты.
19. Способ по п. 18, в котором наиболее значимую часть сообщения электронной почты определяют как наиболее значимый логический блок HTML кода из множества логических блоков HTML кода, содержащих текст.
20. Способ по п. 19, в котором используют в качестве наиболее значимого логического блока HTML кода блок HTML кода, содержащий текст, размер которого превышает размер текста любого другого логического блока HTML кода данного сообщения электронной почты.
21. Способ по п. 19, в котором в качестве наиболее значимого логического блока HTML кода используют блок HTML кода, содержащий текст с наибольшим количеством значащих лексических единиц по сравнению с текстами любого другого логического блока HTML кода данного сообщения электронной почты.
22. Способ по п. 1, в котором в качестве лексической единицы используют любое из: слово, словосочетание, предложение, абзац.
23. Способ по п. 1, в котором определяют по меньшей мере одну лексическую единицу в качестве кандидата в незначащие лексические единицы с определением по меньшей мере одной лексической единицы, имеющей смысловое значение.
24. Способ по п. 1, в котором определяют по меньшей мере одну лексическую единицу в качестве кандидата в незначащие лексические единицы на основе синтаксического анализа одного из: всего текста, содержащегося в текстовом сообщении, и фрагмента текста, содержащегося в текстовом сообщении.
25. Способ по п. 1, в котором получают текстовое сообщение.
26. Способ по п. 1, в котором используют контрольную сумму, представляющую собой уникальный идентификатор лексической единицы.
27. Компьютер, включающий процессор, выполненный с возможностью:
(i) осуществления синтаксического анализа текстового сообщения для определения по меньшей мере одной лексической единицы в качестве первого кандидата в незначащие лексические единицы;
(ii) определение контрольной суммы первого кандидата в незначащие лексические единицы;
(iii) сопоставление, по первому критерию, первого кандидата в незначащие лексические единицы с незначащими лексическими единицами из множества лексических единиц, содержащихся в базе данных лексических единиц, где сопоставлением по первому критерию является сопоставление контрольной суммы первого кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц;
(iv) определение первого кандидата в незначащие лексические единицы в качестве незначащей лексической единицы, если база данных лексических единиц содержит по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме первого кандидата в незначащие лексические единицы.
28. Компьютер по п. 27, в котором процессор выполнен с возможностью при отсутствии в базе данных лексических единиц незначащей лексической единицы, имеющей контрольную сумму, соответствующую контрольной сумме первого кандидата в незначащие лексические единицы:
(i) разбиения первого кандидата в лексические единицы на по меньшей мере две более мелкие лексические единицы и определение по меньшей мере одной более мелкой лексической единицы в качестве второго кандидата в незначащие лексические единицы;
(ii) определения контрольной суммы второго кандидата в незначащие лексические единицы;
(iii) сопоставления, по второму критерию, второго кандидата в незначащие лексические единицы с незначащими лексическими единицами, содержащимися в базе данных лексических единиц, где сопоставлением по второму критерию является сопоставление контрольной суммы второго кандидата в незначащие лексические единицы с контрольными суммами незначащих лексических единиц, содержащихся в базе данных лексических единиц;
(iv) определения второго кандидата в незначащие лексические единицы в качестве незначащей лексической единицы, если база данных лексических единиц содержит в себе по меньшей мере одну незначащую лексическую единицу, имеющую контрольную сумму, соответствующую контрольной сумме второго кандидата в незначащие лексические единицы.
29. Компьютер по п. 28, в котором первый кандидат в незначащие лексические единицы является абзацем, а второй кандидат в незначащие лексические единицы является предложением из этого абзаца.
30. Компьютер по любому из пп. 27-29, в котором контрольная сумма включает в себя совокупность контрольных элементов.
31. Компьютер по п. 30, в котором контрольным элементом является любой элемент, выбранный из: количества символов в лексической единице, количества букв в лексической единице, количества заглавных букв в лексической единице, количества прописных букв в лексической единице, количества пробелов в лексической единице, количества цифр в лексической единице, количества специальных знаков в лексической единице, количества слов в лексической единице, размера лексической единицы, выраженного в единицах обработки и хранения информации.
32. Компьютер по п. 30, в котором процессор выполнен с возможностью сопоставления по первому критерию по первому набору контрольных элементов и сопоставления по второму критерию по второму набору контрольных элементов.
33. Компьютер по п. 32, в котором первый набор контрольных элементов и второй набор контрольных элементов идентичны.
34. Компьютер по п. 27, в котором процессор выполнен с возможностью установления соответствия контрольных сумм при идентичности контрольных сумм.
35. Компьютер по п. 27, в котором при выявлении различия контрольных сумм процессор выполнен с возможностью проверки степени различия контрольных сумм и признания контрольных сумм соответствующими, когда степень различия находится в пределах предустановленной допустимой амплитуды различия.
36. Компьютер по п. 35, в котором процессор выполнен с возможностью определения степени различия в отношении каждого из контрольных элементов, включенных в состав контрольной суммы, и установки амплитуды различия для каждого из контрольных элементов, включенных в состав контрольной суммы.
37. Компьютер по п. 27, в котором процессор выполнен с возможностью при наличии в базе данных лексических единиц по меньшей мере одной незначащей лексической единицы, имеющей контрольную сумму, соответствующую контрольной сумме кандидата в незначащие лексические единицы, осуществления познакового сравнения кандидата в незначащие лексические единицы с этой по меньшей мере одной незначащей лексической единицей и определения кандидата в незначащие лексические единицы в качестве незначащей лексической единицы при совпадении последовательности символов кандидата в незначащие лексические единицы с последовательностью символов этой по меньшей мере одной незначащей лексической единицы.
38. Компьютер по п. 27, в котором лексическая единица из множества лексических единиц, содержащихся в базе данных лексических единиц, является незначащей, если ее весовое значение превышает предопределенное пороговое значение.
39. Компьютер по п. 38, в котором база данных лексических единиц сформирована на основе множества лексических единиц, встречающихся во множестве текстовых сообщений, и в котором весовое значение каждой лексической единицы прямо пропорционально частотности данной лексической единицы во множестве лексических единиц, встречающихся в указанном множестве сообщений.
40. Компьютер по п. 27, в котором процессор выполнен с возможностью синтаксического анализа текстового сообщения посредством анализа языка разметки текстового сообщения.
41. Компьютер по п. 40, в котором анализ языка разметки текстового сообщения включает анализ по меньшей мере одного из: структуры текстового сообщения, вида, размера, начертания шрифта, знаков препинания и специальных знаков.
42. Компьютер по п. 27, в котором осуществление синтаксического анализа текстового сообщения является синтаксическим анализом предопределенного количества абзацев в начале текстового сообщения.
43. Компьютер по п. 27, в котором текстовое сообщение является сообщением электронной почты.
44. Компьютер по п. 27, в котором текстовое сообщение является сообщением электронной почты и в котором осуществление синтаксического анализа сообщения электронной почты является синтаксическим анализом наиболее значимой части сообщения электронной почты.
45. Компьютер по п. 44, в котором наиболее значимая часть сообщения электронной почты определяется как наиболее значимый логический блок HTML кода из множества логических блоков HTML кода, содержащих текст.
46. Компьютер по п. 45, в котором наиболее значимым логическим блоком HTML кода является блок, содержащий текст, размер которого превышает размер текста любого другого логического блока данного сообщения электронной почты.
47. Компьютер по п. 46, в котором наиболее значимым логическим блоком HTML кода является блок HTML кода, содержащий текст, причем текст наиболее значимого логического блока HTML кода содержит наибольшее количество значащих лексических единиц по сравнению с текстами любого другого логического блока HTML кода данного сообщения электронной почты.
48. Компьютер по п. 27, в котором лексической единицей является любое из: слово, словосочетание, предложение, абзац.
49. Компьютер по п. 27, в котором определение по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы является определением по меньшей мере одной лексической единицы, имеющей смысловое значение.
50. Компьютер по п. 27, в котором процессор выполнен с возможностью определения по меньшей мере одной лексической единицы в качестве кандидата в незначащие лексические единицы на основе синтаксического анализа одного из: всего текста, содержащегося в текстовом сообщении, и фрагмента текста, содержащегося в текстовом сообщении.
51. Компьютер по п. 27, в котором процессор выполнен с возможностью получения текстового сообщения.
52. Компьютер по п. 27, в котором уникальная контрольная сумма является идентификатором уникальной лексической единицы.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 6137911 A, 24.10.2000 | |||
| ПЕРЕЧНИ И ПРИЗНАКИ ИСТОЧНИКОВ/АДРЕСАТОВ ДЛЯ ПРЕДОТВРАЩЕНИЯ НЕЖЕЛАТЕЛЬНЫХ ПОЧТОВЫХ СООБЩЕНИЙ | 2004 |
|
RU2378692C2 |

