Область техники
Настоящее изобретение относится к области методов сжатия данных и, в частности, к способу и устройству для многоступенчатого квантования.
Уровень техники
С быстрым развитием технологий сжатия данных получило широкое применение векторное квантование. Векторное квантование (VQ) является эффективным методом сжатия данных, который выстраивает множество столбцов скалярных данных в вектор и выполняет общее квантование в векторном пространстве. В результате происходит сжатие данных без потери информации. Процедура VQ состоит в следующем: каждый кадр из k выборок формы волны сигнала или каждый набор параметров из k параметров выстраивается в вектор k-мерного евклидова пространства, после чего вектор “коллективно” квантуется. При квантовании вектора k-мерное бесконечное пространство делится на M областей с границами, и вектор входного сигнала сравнивается с этими границами и квантуется до центрального вектора области, границы которой имеют минимальное “расстояние” от вектора входного сигнала. Вычислительная сложность VQ в основном связана с поиском кодовой книги согласно определенному критерию меры искажения, и пространственная сложность в основном определяется размером используемого пространства кодовых книг. В общем случае чем больше пространство кодовой книги, тем большее требуется хранилище и тем выше вычислительная сложность поиска кодовой книги, хотя точность квантования также повышается.
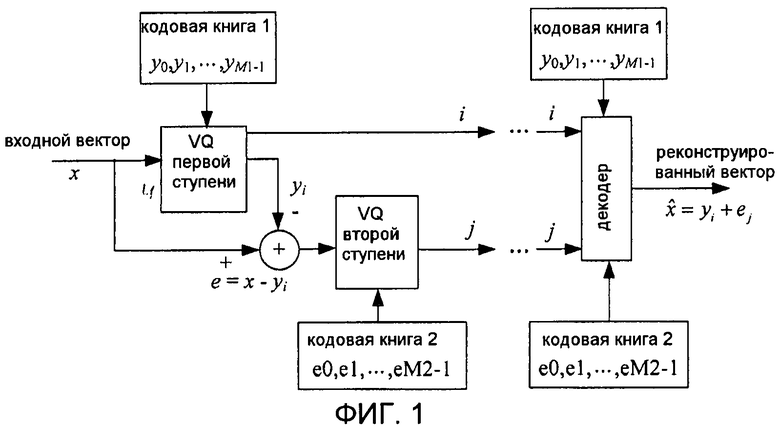
В настоящее время вычислительную сложность VQ обычно снижают с использованием многоступенчатого квантования или квантования разделенных кодовых книг. На фиг. 1 показана процедура двухступенчатого квантования, в которой входной вектор x проходит через VQ первой ступени с использованием кодовой книги 1 и VQ второй ступени с использованием кодовой книги 2. Хотя кодовые книги размером M1 и M2 используются на двух ступенях VQ соответственно, конечный эффект кодовой книги эквивалентен одноступенчатому VQ, имеющему размер M1*M2. Поэтому в отличие от системы одноступенчатого VQ количество вычислений для искажения и сравнения и необходимый объем памяти для хранения кодовых книг соответственно сокращаются с M1*M2 до M1+M2.
Метод квантования разделенных кодовых книг используется для снижения сложности поиска и хранения при квантовании многомерных векторов. Согласно этому способу вектор, который должен быть проквантован, разлагается на два или более подвекторов для квантования. Ниже описан пример разложения вектора на два подвектора. Предполагая, что входным вектором является 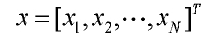 , используемой кодовой книгой является Y и длиной квантованного бита является L, получаем, что объемом памяти, необходимым для хранения кодовой книги Y, является
, используемой кодовой книгой является Y и длиной квантованного бита является L, получаем, что объемом памяти, необходимым для хранения кодовой книги Y, является 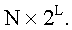 Если x разлагается на подвекторы
Если x разлагается на подвекторы 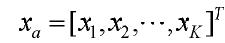 и
и 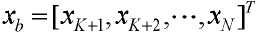 , то используемая кодовая книга разлагается на
, то используемая кодовая книга разлагается на 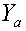 и
и 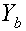 соответственно. Предполагая, что квантованный x
a имеет длину бита L
a и квантованный x
b имеет длину бита L
b, где
соответственно. Предполагая, что квантованный x
a имеет длину бита L
a и квантованный x
b имеет длину бита L
b, где 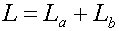 , объемом памяти, необходимым для хранения кодовой книги Y
a, является
, объемом памяти, необходимым для хранения кодовой книги Y
a, является 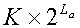 и объемом памяти, необходимым для хранения кодовой книги Y
b, является
и объемом памяти, необходимым для хранения кодовой книги Y
b, является 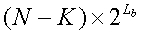 , и, таким образом, суммарный необходимый объем памяти значительно меньше, чем объем памяти
, и, таким образом, суммарный необходимый объем памяти значительно меньше, чем объем памяти 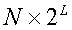 , необходимый для хранения кодовой книги Y. В частности, когда измерения x
a и x
b одинаковы и соответствующие пространственные составляющие имеют сходные статистические свойства, т.е. Y
a=Y
b, можно сэкономить больше места.
, необходимый для хранения кодовой книги Y. В частности, когда измерения x
a и x
b одинаковы и соответствующие пространственные составляющие имеют сходные статистические свойства, т.е. Y
a=Y
b, можно сэкономить больше места.
Согласно стандарту кодирования речи “conjugate-structure algebraic-code-excited linear prediction voice encoder” от Международного союза электросвязи (ITU) параметр спектра сигнала, т.е. Линейная Спектральная Частота (LSF), полученная в результате анализа Кодирования с Линейным Предсказанием (LPC), квантуется с использованием квантователя с предсказанием модели скользящего среднего (MA) четвертого порядка для предсказания коэффициентов LSF текущего кадра. Ошибка предсказания квантуется с использованием двухступенчатого VQ. Первая ступень предусматривает обработку десятимерного вектора с использованием кодовой книги L1 7-битовым кодом. Вторая ступень разлагает десять измерений на две 5-мерные кодовые книги L2 и L3, где L2 представляет пять младших измерений и L3 представляет пять старших измерений, и обе они используют 5-битовый код.
Однако, согласно стандарту кодирования речи “silence compression solution of conjugate-structure algebraic-code-excited linear prediction voice encoder” от ITU, VQ коэффициентов LSF шумового кадра осуществляется с использованием двухступенчатого квантования. На вход квантователя первой ступени поступает ошибка предсказания предсказателя, и ошибка квантования из первой ступени квантуется на второй ступени. Кодовая книга квантования первой ступени для шумового кадра является подмножеством кодовой книги первой ступени для речевого кадра, и кодовая книга квантования второй ступени для шумового кадра является подмножеством кодовой книги второй ступени для речевого кадра. Таким образом, две кодовые подкниги длиной в 16 битов можно обучать из двух кодовых книг длиной 32 бита, которые обе являются кодовыми книгами квантования второй ступени, и индексы кодовой книги хранятся в массиве.
В ходе реализации настоящего изобретения автор изобретения обнаруживает следующие недостатки уровня техники.
Когда вычислительная сложность процедуры VQ снижается с использованием способа многоступенчатого квантования, кодовые книги для квантования на каждой ступени не зависят друг от друга, и для каждой кодовой книги требуется соответствующее пространство кодовой книги. В результате растрачивается объем памяти и снижается эффективность использования ресурсов.
Сущность изобретения
Задачей настоящего изобретения является обеспечение способа и устройства многоступенчатого квантования, способных преодолеть недостатки уровня техники, а именно растрачивание объема памяти, вызванное независимыми кодовыми книгами каждой ступени квантования.
Для решения этой задачи вариант осуществления настоящего изобретения предусматривает способ многоступенчатого квантования, который включает в себя этапы, на которых:
получают опорную кодовую книгу согласно кодовой книге предыдущей ступени;
получают кодовую книгу текущей ступени согласно опорной кодовой книге и масштабному коэффициенту и
квантуют входной вектор с использованием кодовой книги текущей ступени.
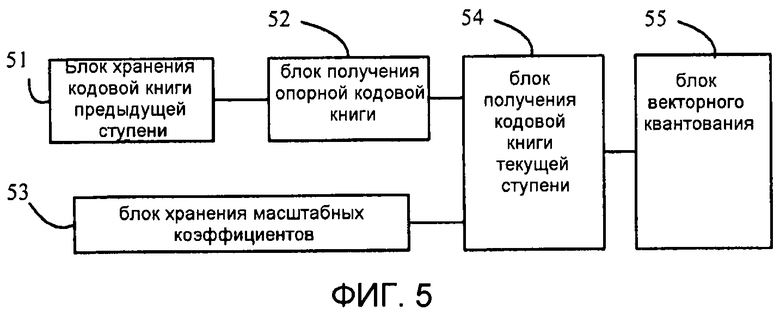
Другой вариант осуществления настоящего изобретения дополнительно предусматривает устройство многоступенчатого квантования, которое включает в себя:
блок хранения кодовой книги предыдущей ступени, выполненный с возможностью хранения кодовой книги предыдущей ступени или кодовых книг двух или более предыдущих ступеней;
блок получения опорной кодовой книги, выполненный с возможностью получения опорной кодовой книги согласно кодовой книге, хранящейся блоком хранения кодовой книги предыдущей ступени;
блок хранения масштабных коэффициентов, выполненный с возможностью хранения масштабного коэффициента;
блок получения кодовой книги текущей ступени, выполненный с возможностью получения кодовой книги текущей ступени согласно опорной кодовой книге, полученной блоком получения опорной кодовой книги, и масштабному коэффициенту, хранящемуся блоком хранения масштабных коэффициентов; и
блок векторного квантования, выполненный с возможностью квантования входного вектора с использованием кодовой книги текущей ступени, полученной блоком получения кодовой книги текущей ступени.
Варианты осуществления вышеописанных технических решений имеют следующие преимущества: кодовую книгу текущей ступени можно получить согласно кодовой книге предыдущей ступени, с использованием корреляции между кодовой книгой текущей ступени и кодовой книгой предыдущей ступени. В результате для кодовой книги текущей ступени не требуется пространство независимых кодовых книг, что позволяет экономить объем памяти и повышать эффективность использования ресурсов.
Краткое описание чертежей
Фиг. 1 является блок-схемой последовательности операций способа двухступенчатого квантования согласно уровню техники.
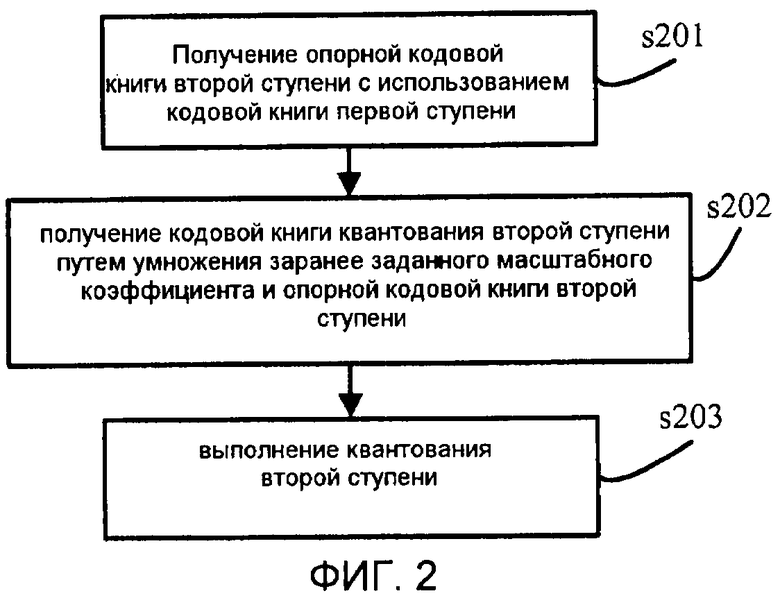
Фиг. 2 является блок-схемой последовательности операций способа двухступенчатого квантования согласно варианту осуществления настоящего изобретения.
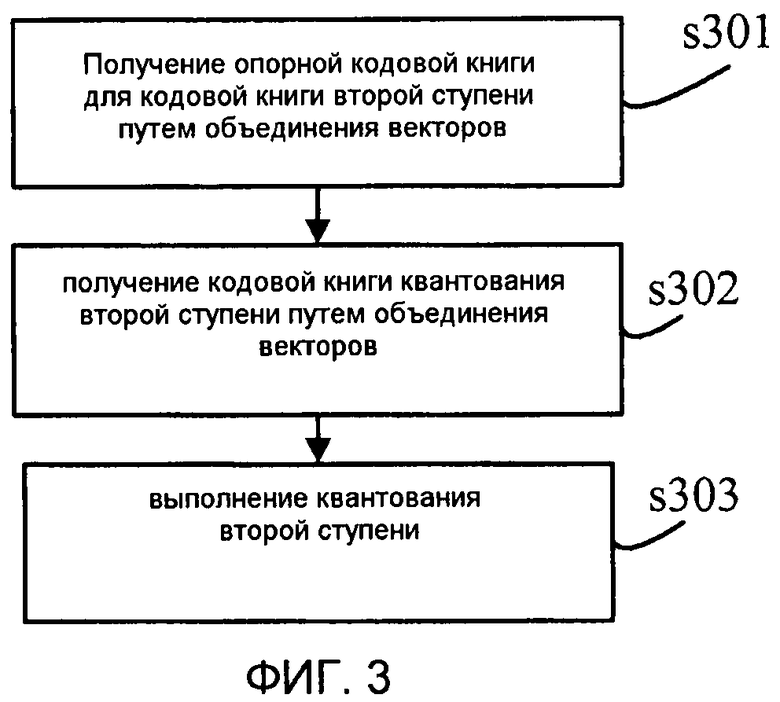
Фиг. 3 является блок-схемой последовательности операций способа двухступенчатого квантования согласно другому варианту осуществления настоящего изобретения.
Фиг. 4 является блок-схемой последовательности операций способа трехступенчатого квантования согласно варианту осуществления настоящего изобретения.
Фиг. 5 является блок-схемой многоступенчатого устройства согласно варианту осуществления настоящего изобретения.
Фиг. 6 является блок-схемой последовательности операций способа трехступенчатого квантования согласно другому варианту осуществления настоящего изобретения.
Фиг. 7 является блок-схемой многоступенчатого устройства согласно другому варианту осуществления настоящего изобретения.
Подробное описание
Ниже варианты осуществления настоящего изобретения будут дополнительно подробно описаны со ссылкой на примеры и чертежи.
При кодировании речи с линейным предсказанием необходимо выполнять векторное квантование параметров линейного предсказания. Примером является преобразование параметра линейного предсказания в 10-мерный параметр LSF путем двухступенчатого квантования.
На фиг. 2 показана блок-схема последовательности операций способа двухступенчатого квантования согласно варианту осуществления настоящего изобретения, который, в частности, включает в себя следующие этапы.
Сначала получают масштабный коэффициент (набор) γ, что можно делать следующим способом обучения.
γ можно получить путем обучения большого количества выборок, и простейший способ обучения можно реализовать путем сравнения радиуса векторного пространства ошибки квантования, полученного после квантования первой ступени, и радиуса входного векторного пространства квантования первой ступени. Предполагается, что имеется L выборок, каждая из которых является N-мерным вектором, и ошибкой квантования первой ступени является:
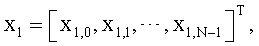
где 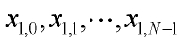 являются соответственно значениями ошибки квантования для каждого измерения вектора квантования предыдущей ступени.
являются соответственно значениями ошибки квантования для каждого измерения вектора квантования предыдущей ступени.
Кроме того, предполагается, что вектором квантования первой ступени является:
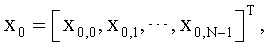
где, 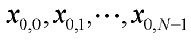 являются соответственно значениями каждого измерения вектора квантования предыдущей ступени.
являются соответственно значениями каждого измерения вектора квантования предыдущей ступени.
В этом случае масштабный коэффициент γ можно вычислять согласно следующему уравнению:

Альтернативно, оптимальное значение γ можно найти путем поиска согласно методу минимальной среднеквадратической ошибки (MMSE). В частности, диапазон от 0 до 2 делится на M частей, и пусть:
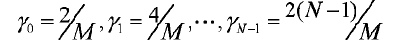
M значений γ умножаются на кодовую книгу Y1 предыдущей ступени для получения M новых кодовых книг:
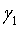 Y1,
Y1, 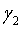 Y1,…,
Y1,…, 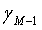 Y1
Y1
M кодовых книг соответственно используются для квантования векторов выборок. Если имеются L выборок, j-я новая кодовая книга используется для квантования каждого вектора выборок, для того чтобы искать оптимальную кодовую книгу для каждого вектора выборок и получать при этом минимально взвешенную ошибку 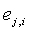 квантования. Предполагается, что суммой минимально взвешенных ошибок квантования всех выборок является:
квантования. Предполагается, что суммой минимально взвешенных ошибок квантования всех выборок является:
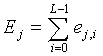
Каждая кодовая книга 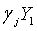 соответствует
соответствует 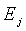 . Можно найти минимальное значение Emin для
. Можно найти минимальное значение Emin для 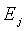 , и
, и 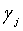 , соответствующий Emin, является значением оптимального вектора γ масштабирования. Если точность квантования недостаточно высока, диапазон (
, соответствующий Emin, является значением оптимального вектора γ масштабирования. Если точность квантования недостаточно высока, диапазон (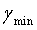 -1/N,
-1/N, 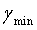 +1/N) можно дополнительно разделить на N частей, и оптимальный γ затем находят в N значениях γ. Эту процедуру можно неоднократно повторять до достижения необходимой точности.
+1/N) можно дополнительно разделить на N частей, и оптимальный γ затем находят в N значениях γ. Эту процедуру можно неоднократно повторять до достижения необходимой точности.
Выше описан случай только одного γ, и два или более γ также можно обучать и сохранять в массиве. Индексы γ можно квантовать с использованием n битов. В результате количество исходных кодовых книг увеличивается с коэффициентом 2n. При этом повышается адаптивность кодовых книг и может увеличиваться точность квантования.
На этапе s201 выполняется векторное квантование параметра линейного предсказания для кодирования речи с линейным предсказанием согласно существующему методу квантования для получения значения idx1 индекса, который представлен 7-битовым кодом. Таким образом, при VQ первой ступени кодовая книга квантования первой ступени предполагается равной 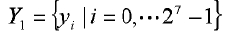 .
.
На этапе s202 кодовая книга квантования первой ступени используется при квантовании второй ступени как опорная кодовая книга:
Вектор 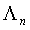 масштабных коэффициентов между кодовой книгой квантования второй ступени и кодовой книгой квантования первой ступени уже обучен, который можно квантовать с использованием n битов, т.е.
масштабных коэффициентов между кодовой книгой квантования второй ступени и кодовой книгой квантования первой ступени уже обучен, который можно квантовать с использованием n битов, т.е. 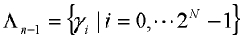 .
.
На основе вышеозначенного способа размером кодовой книги квантования второй ступени является 7+N битов, и кодовой книгой является:

Значения масштабных коэффициентов в ранее заданном наборе γ масштабных коэффициентов умножаются на кодовую книгу Y1 первой ступени, которая используется как опорная кодовая книга, для получения 2N-1 новых кодовых книг, т.е. γ0Y1, γ1Y1…γM-1Y1. Таким образом, получается набор кодовых книг из 2N-1 кодовых книг квантования второй ступени. Процесс переходит к этапу s203.
На этапе s203 векторы выборок квантуются с использованием соответствующей одной из 2N-1 кодовых книг, полученных на этапе s202. В частности, ошибку квантования первой ступени берут в качестве входного вектора квантования второй ступени и производят поиск по всем сгенерированным 2N кодовым книгам. Затем индекс idx 2 положения и индекс fidx положения берут в качестве выхода квантования второй ступени, причем индекс idx2 положения указывает положение вектора в кодовой книге, благодаря чему следующая взвешенная среднеквадратическая ошибка имеет минимальное значение; и индекс fidx положения указывает положение кодовой книги в наборе кодовых книг:
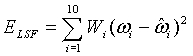
В ходе обратного квантования сначала находят обратно квантованный вектор первой ступени в кодовых книгах первой ступени с использованием индекса idx1 квантования первой ступени и представляют как Y1(idx1). Затем соответствующий масштабный коэффициент 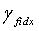 получают из набора γ масштабных коэффициентов.
получают из набора γ масштабных коэффициентов. 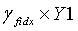 является кодовой книгой второй ступени, используемой в конце кодирования, таким образом, реконструированным вектором на второй ступени является
является кодовой книгой второй ступени, используемой в конце кодирования, таким образом, реконструированным вектором на второй ступени является 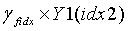 , и окончательным результатом обратного квантования является
, и окончательным результатом обратного квантования является 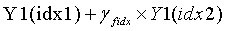 .
.
Согласно варианту осуществления кодовые книги текущей ступени можно получить согласно кодовым книгам предыдущей ступени, с использованием корреляции между кодовой книгой текущей ступени и кодовой книгой предыдущей ступени. В результате для кодовых книг текущей ступени не требуется пространство независимых кодовых книг, что позволяет экономить объем памяти и повышать эффективность использования ресурсов.
Здесь кодовые книги предыдущей ступени могут, в частности, включать в себя кодовую книгу предыдущей ступени или кодовые книги двух или более предыдущих ступеней. Различие в контенте, включенном в набор, не будет влиять на заявленный объем настоящего изобретения.
Фиг. 3 иллюстрирует способ двухступенчатого квантования согласно другому варианту осуществления настоящего изобретения, который, в частности, включает в себя следующие этапы.
На этапе s301 выполняют векторное квантование параметра линейного предсказания для кодирования речи с линейным предсказанием согласно существующему методу квантования для получения значения idx1 индекса, который представлен 7-битовым кодом. Таким образом, при VQ первой ступени кодовая книга квантования первой ступени предполагается равной 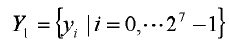 .
.
После квантования первой ступени дополнительно уменьшается динамический диапазон ошибки квантования. При этом векторы в кодовой книге предыдущей ступени можно объединять для уменьшения длины кодовой книги, что позволяет экономить биты. Например, K-битовые кодовые книги, которые часто используются, можно заранее выбирать из кодовых книг первой ступени 7 битов, и индексы K-битовых кодовых книг сохраняются в массиве, которые могут быть представлены в виде cb(i), i=0,1,…,2K-1. Индексы K битов из опорной кодовой книги Y2c для кодовой книги второй ступени.
На этапе s302 вектор масштабных коэффициентов между кодовой книгой квантования второй ступени и кодовой книгой квантования первой ступени уже обучен, который можно квантовать с использованием N битов, т.е. 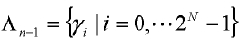 . На основе вышеозначенного способа размером кодовой книги квантования второй ступени является K+N битов, и кодовой книгой является:
. На основе вышеозначенного способа размером кодовой книги квантования второй ступени является K+N битов, и кодовой книгой является:

Длину кодовой книги можно дополнительно уменьшить. K-битовые кодовые книги, которые часто используются, выбирают из кодовых книг первой ступени 7 битов, и индексы наиболее часто используемых K-битовых кодовых книг сохраняются в массиве, которые могут быть представлены в виде cb(i), i=0,1,…,2K-1. Таким образом, результатом квантования второй ступени является K+N битов. Удаляют наименее часто используемую кодовую книгу; в результате, квантование не сопровождается большими потерями, в то время как количество квантованных битов сокращается.
На этапе s303 ошибку квантования первой ступени берут как целевой вектор, осуществляют поиск среди вышеупомянутых 2N кодовых книг на предмет наилучшего вектора кода, который обеспечивает минимальную взвешенную среднеквадратическую ошибку (MSE), что показано следующим уравнением, и индекс найденного вектора кода рассматривается как выход квантования второй ступени.
где Wi является весовым коэффициентом. Результат выхода квантования имеет две части, одной из которых является индекс idx2 положения, указывающий положение вектора кодовой книги в кодовой книге, и другой частью является индекс fidx, указывающий положение масштабного коэффициента в векторе масштабных коэффициентов.
В ходе обратного квантования сначала находят обратно квантованный вектор первой ступени в кодовой книге первой ступени с использованием индекса idx1 квантования первой ступени и представляют как Y1(idx1). Затем соответствующий масштабный коэффициент 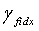 получают из набора γ масштабных коэффициентов.
получают из набора γ масштабных коэффициентов. 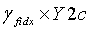 является кодовой книгой второй ступени, используемой в конце кодирования, таким образом, реконструированным вектором на второй ступени является
является кодовой книгой второй ступени, используемой в конце кодирования, таким образом, реконструированным вектором на второй ступени является 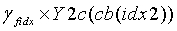 , и окончательным результатом обратного квантования является
, и окончательным результатом обратного квантования является 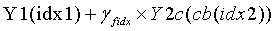 .
.
Согласно варианту осуществления кодовую книгу текущей ступени можно получить согласно кодовой книге предыдущей ступени, с использованием корреляции между кодовой книгой текущей ступени и кодовой книгой предыдущей ступени. В результате для кодовой книги текущей ступени не требуется пространство независимых кодовых книг, что позволяет экономить объем памяти и повышать эффективность использования ресурсов.
Фиг. 4 иллюстрирует способ трехступенчатого квантования согласно другому варианту осуществления настоящего изобретения. Согласно варианту осуществления вектор, который должен быть проквантован, является 10-мерным, схемы квантования для первых двух ступеней используют независимые кодовые книги, и схема квантования для третьей ступени основана на этом варианте осуществления. В частности, процедура включает в себя этапы, на которых:
процедуру обучения набора масштабных коэффициентов выполняют заранее:
γ получают путем обучения большого количества выборок, и простейший способ обучения можно реализовать путем сравнения радиуса векторного пространства ошибки квантования, полученного после квантования первой ступени, и радиуса векторного пространства квантования первой ступени. Предполагается, что имеется L выборок, каждая из которых является N-мерным вектором, и ошибкой квантования первой ступени является:
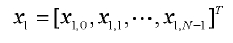
Кроме того, предполагается, что вектором квантования первой ступени является:
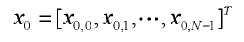
Таким образом, масштабный коэффициент γ вычисляется согласно следующему уравнению:
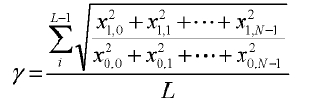
Альтернативно, оптимальное значение γ можно найти путем поиска согласно методу MMSE. В частности, диапазон от 0 до 2 делится на M частей, и пусть:
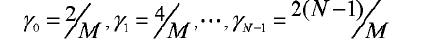
M из этих значений γ умножаются на кодовую книгу Y1 предыдущей ступени для получения M новых кодовых книг:
Y1, Y1,…, Y1
M кодовых книг соответственно используются для квантования векторов выборок. Если имеются L выборок, j-я новая кодовая книга используется для квантования каждого вектора выборок, для того чтобы искать оптимальную кодовую книгу для каждого вектора выборок и получать при этом минимально взвешенную ошибку квантования. Предполагается, что суммой минимально взвешенных ошибок квантования всех выборок является:
Каждая кодовая книга 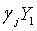 соответствует
соответствует 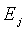 , минимальное значение Emin можно найти из
, минимальное значение Emin можно найти из 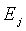 , и
, и 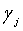 , соответствующий Emin, является значением оптимального вектора масштабирования. Если точность квантования недостаточно высока, диапазон (
, соответствующий Emin, является значением оптимального вектора масштабирования. Если точность квантования недостаточно высока, диапазон (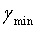 -1/N,
-1/N, 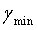 +1/N) можно дополнительно разделить на N частей, и оптимальное значение можно найти в N значениях γ. Эту процедуру можно неоднократно повторять до достижения необходимой точности.
+1/N) можно дополнительно разделить на N частей, и оптимальное значение можно найти в N значениях γ. Эту процедуру можно неоднократно повторять до достижения необходимой точности.
Выше описан случай только одного γ, и два или более γ также можно обучать и сохранять в массиве, и индексы γ можно квантовать с использованием n битов. В этом случае количество исходных кодовых книг увеличивается с коэффициентом 2n. При этом повышается адаптивность кодовых книг и может увеличиваться точность квантования.
Процедура трехступенчатого квантования
На этапе s401 ищут в кодовой книге первой ступени входной вектор, который должен быть проквантован, согласно способу минимально взвешенной среднеквадратической ошибки, для получения индекса idx1 положения, указывающего положение кодового вектора в кодовой книге.
где Wi является весовым коэффициентом.
На этапе s402 ошибку квантования первой ступени берут в качестве входного вектора квантования второй ступени и квантование с разложением используют для разложения кодовой книги второй ступени на две 5-мерные кодовые книги 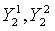 . Квантование выполняется для старших 5 измерений и младших 5 измерений соответственно по аналогии с этапом s301, и их результатами квантования являются соответственно два индекса
. Квантование выполняется для старших 5 измерений и младших 5 измерений соответственно по аналогии с этапом s301, и их результатами квантования являются соответственно два индекса 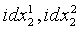 положения.
положения.
На этапе s403 ошибки квантования для старших и младших пяти измерений соответственно вычисляются как вектор квантования третьей ступени.
На этапе s404 две разделенные кодовые книги квантования второй ступени берут в качестве опорных кодовых книг двух разделенных кодовых книг квантования третьей ступени. Масштабный коэффициент в массиве масштабных коэффициентов берут в качестве коэффициента опорных кодовых книг, получая, таким образом, пару наборов кодовых книг. Длиной кодовой таблицы масштабных коэффициентов является 2N, и, таким образом, 2N пар вновь полученных разделенных кодовых книг соответственно равны 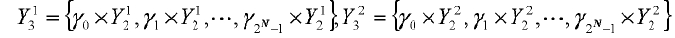 .
.
На этапе s405 осуществляют поиск соответствующих наборов кодовых книг для старших пяти и младших пяти измерений вектора квантования третьей ступени соответственно. Результатами квантования третьей ступени являются положения 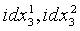 в соответствующих кодовых книгах, каждое из которых указывает вектор, который обеспечивает минимальную сумму взвешенных среднеквадратических ошибок для старших и младших 5 измерений и индекс fidx соответствующего масштабного коэффициента, которые являются:
в соответствующих кодовых книгах, каждое из которых указывает вектор, который обеспечивает минимальную сумму взвешенных среднеквадратических ошибок для старших и младших 5 измерений и индекс fidx соответствующего масштабного коэффициента, которые являются:
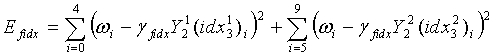
В ходе обратного квантования сначала находят обратно квантованный вектор первой ступени в кодовой книге первой ступени с использованием индекса idx1 квантования первой ступени и представляют как Y1(idx1). Затем разделенные подвекторы 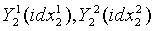 обратного квантования второй ступени соответственно реконструируются из двух разделенных кодовых подкниг второй ступени, с использованием соответствующих индексов
обратного квантования второй ступени соответственно реконструируются из двух разделенных кодовых подкниг второй ступени, с использованием соответствующих индексов 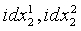 квантования второй ступени. После этого соответствующий масштабный коэффициент
квантования второй ступени. После этого соответствующий масштабный коэффициент 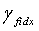 получают из набора γ масштабных коэффициентов с использованием индекса масштабного коэффициента квантования третьей ступени. Если
получают из набора γ масштабных коэффициентов с использованием индекса масштабного коэффициента квантования третьей ступени. Если 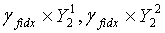 являются двумя разделенными кодовыми подкнигами кодовой книги третьей ступени, используемой в конце кодирования, то реконструированными подвекторами третьей ступени являются соответственно
являются двумя разделенными кодовыми подкнигами кодовой книги третьей ступени, используемой в конце кодирования, то реконструированными подвекторами третьей ступени являются соответственно 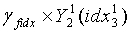 ,
,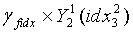 , и окончательным результатом обратного квантования является:
, и окончательным результатом обратного квантования является:
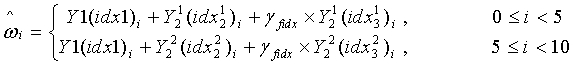
Согласно варианту осуществления кодовую книгу текущей ступени можно получить согласно кодовой книге предыдущей ступени, с использованием корреляции между кодовой книгой текущей ступени и кодовой книгой предыдущей ступени. В результате для кодовой книги текущей ступени не требуется пространство независимых кодовых книг, что позволяет экономить объем памяти и повышать эффективность использования ресурсов.
На фиг. 5 показано устройство многоступенчатого квантования согласно варианту осуществления настоящего изобретения, которое включает в себя блок 51 хранения кодовой книги предыдущей ступени, блок 52 получения опорной кодовой книги, блок 53 хранения масштабных коэффициентов, блок 54 получения кодовой книги текущей ступени и блок 55 векторного квантования.
Блок 51 хранения кодовой книги предыдущей ступени подключен к блоку 52 получения опорной кодовой книги. Блок 54 получения кодовой книги текущей ступени подключен к блоку 52 получения опорной кодовой книги, блоку 53 хранения масштабных коэффициентов и блоку 55 векторного квантования соответственно.
Блок 51 хранения кодовой книги предыдущей ступени выполнен с возможностью хранения кодовой книги предыдущей ступени или кодовых книг двух или более предыдущих ступеней.
Блок 52 получения опорной кодовой книги выполнен с возможностью получения опорной кодовой книги согласно кодовой книге, хранящейся в блоке 51 хранения кодовой книги предыдущей ступени, который, в частности, выполнен с возможностью:
получать опорную кодовую книгу согласно кодовой книге предыдущей ступени, хранящейся в блоке 51 хранения кодовой книги предыдущей ступени; или
получать опорную кодовую книгу согласно кодовой книге, выбранной из кодовой книги предыдущей ступени или кодовых книг двух или более предыдущих ступеней, хранящихся в блоке 51 хранения кодовой книги предыдущей ступени; или
объединять векторы в кодовой книге предыдущей ступени, хранящейся в блоке 51 хранения кодовой книги предыдущей ступени, для генерации опорной кодовой книги.
Блок 53 хранения масштабных коэффициентов выполнен с возможностью хранения масштабного коэффициента, который можно получить предварительным обучением.
Блок 54 получения кодовой книги текущей ступени выполнен с возможностью получения кодовой книги текущей ступени согласно опорной кодовой книге, полученной блоком 52 получения опорной кодовой книги и масштабному коэффициенту, хранящемуся блоком 53 хранения масштабных коэффициентов.
Блок 55 векторного квантования выполнен с возможностью квантования входного вектора с использованием кодовой книги текущей ступени, полученной блоком 54 получения кодовой книги текущей ступени.
На фиг. 6 показан другой способ трехступенчатого квантования согласно варианту осуществления настоящего изобретения. В этом варианте осуществления требуется квантовать параметр спектра и параметр энергии. В общем случае для квантования спектра необходимо многоступенчатое квантование для согласования с требованием к точности квантования, тогда как для квантования энергии достаточно лишь одноступенчатого квантования для согласования с требованием к точности квантования. Предполагается, что параметр энергии уже квантован, и результатом квантования является idx_E. Дополнительно предполагается, что вектор спектра, который должен быть проквантован, является 10-мерным, схема квантования для первых двух ступеней использует независимые кодовые книги и схема квантования для третьей ступени основана на настоящем изобретении. Масштабный коэффициент, используемый для третьей ступени, по-прежнему можно получать из кодовой таблицы масштабных коэффициентов, тогда как индексы масштабных коэффициентов больше не кодируются и не передаются. Вместо этого индексы квантования предыдущей ступени (для тех же или других векторов, которые должны быть проквантованы) можно напрямую отображать для получения масштабного коэффициента для квантования третьей ступени вектора, который должен быть проквантован. В частности, процедура включает в себя следующие этапы.
Процедуру обучения набора масштабных коэффициентов выполняют заранее:
Оптимальное значение γ можно найти путем поиска согласно способу MMSE. В частности, диапазон от 0 до 2 делится на M частей, и пусть:
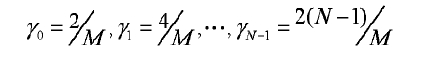
M из этих значений γ умножаются на кодовую книгу Y1 предыдущей ступени для получения M новых кодовых книг:
Y1, Y1,…, Y1
M кодовых книг соответственно используются для квантования векторов выборок. Если имеются L выборок, j-я новая кодовая книга используется для квантования каждого вектора выборок, для того чтобы искать оптимальную кодовую книгу для каждого вектора выборок и получать при этом минимально взвешенную ошибку квантования. Предполагается, что суммой минимально взвешенных ошибок квантования всех выборок является:
Каждая кодовая книга 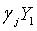 соответствует
соответствует 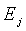 , минимальное значение Emin находят из
, минимальное значение Emin находят из 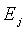 , и
, и 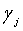 , соответствующий Emin, является значением оптимального вектора γ масштабирования. Если точность квантования недостаточно высока, диапазон (
, соответствующий Emin, является значением оптимального вектора γ масштабирования. Если точность квантования недостаточно высока, диапазон (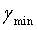 -1/N,
-1/N, 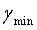 +1/N) можно дополнительно разделить на N частей, и оптимальное значение затем находят в N значениях γ. Эту процедуру можно неоднократно повторять до достижения необходимой точности.
+1/N) можно дополнительно разделить на N частей, и оптимальное значение затем находят в N значениях γ. Эту процедуру можно неоднократно повторять до достижения необходимой точности.
Вышеописанную процедуру обучения можно использовать для обучения двух или более масштабных коэффициентов, которые можно сохранять в массиве масштабных коэффициентов. Длиной массива масштабных коэффициентов является 2n. Если оптимальный масштабный коэффициент подлежит поиску и кодированию из массива 2n масштабных коэффициентов с использованием способа, описанного в варианте 2 осуществления, вычислительная сложность оказывается слишком высокой. При этом необходимы дополнительные биты кода для передачи индексов масштабных коэффициентов. Для преодоления этих проблем в этом варианте осуществления предложен усовершенствованный способ квантования с низкой сложностью и без дополнительных битов.
Процедура трехступенчатого квантования в конце кодирования
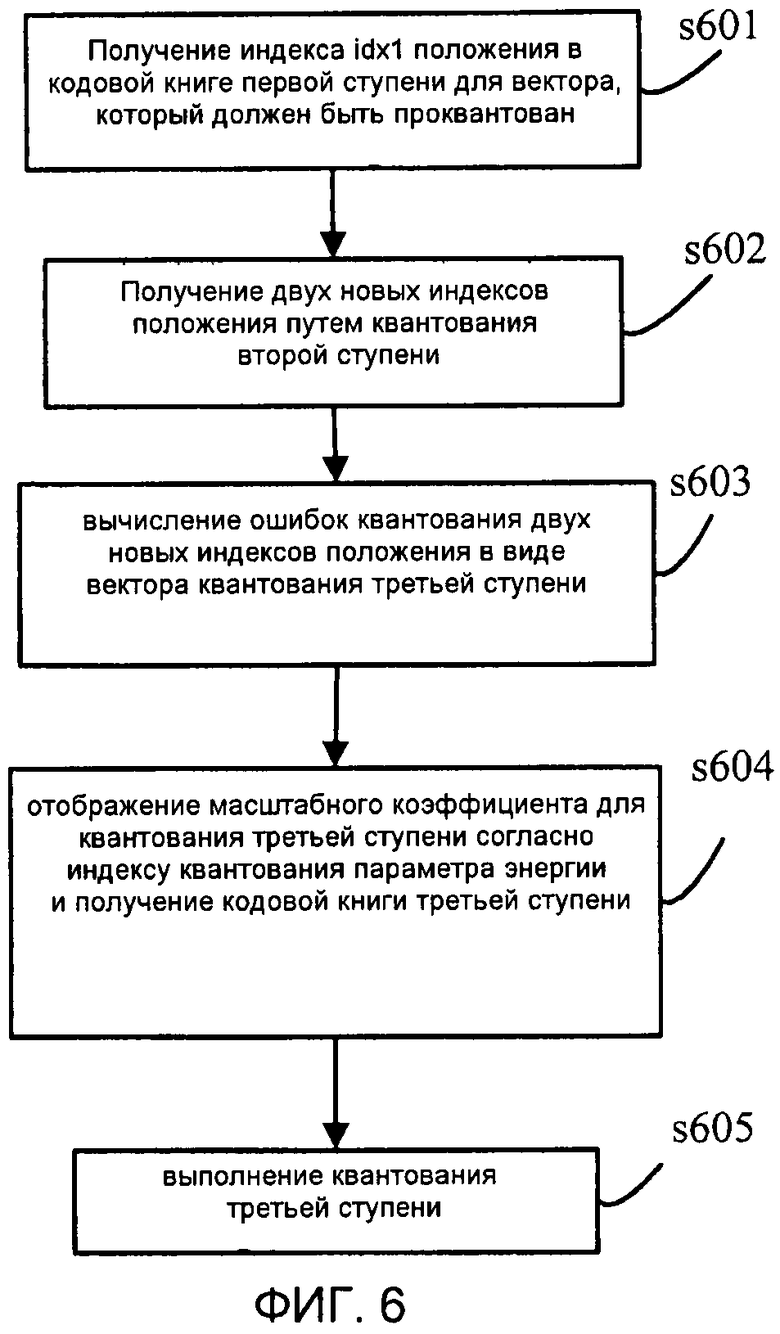
На этапе s601 ищут в кодовой книге первой ступени входной вектор, который должен быть проквантован, согласно критерию минимально взвешенной среднеквадратической ошибки, для того чтобы получать индекс idx1 положения кодового вектора в кодовой книге.
где Wi является весовым коэффициентом.
На этапе s602 ошибку квантования первой ступени берут в качестве вектора квантования второй ступени и квантование с разложением используют для разложения кодовой книги второй ступени на две 5-мерные кодовые книги 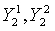 . Квантование выполняется для старших 5 измерений и младших 5 измерений соответственно по аналогии с этапом s301, и их результатами квантования являются соответственно два индекса
. Квантование выполняется для старших 5 измерений и младших 5 измерений соответственно по аналогии с этапом s301, и их результатами квантования являются соответственно два индекса 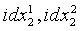 положения.
положения.
На этапе s603 ошибки квантования для старших и младших пяти измерений соответственно вычисляются как вектор квантования третьей ступени.
На этапе s604 при квантовании индексы масштабных коэффициентов можно получить путем поиска по всему массиву масштабных коэффициентов, как описано выше. Кроме того, индексы масштабных коэффициентов также можно находить путем битового отображения результата квантования предыдущей ступени. На этом этапе масштабный коэффициент квантования третьей ступени можно получить путем битового отображения старших n битов индекса idx_E квантования для энергии, и, таким образом, можно получить кодовую книгу третьей ступени. Предполагая, что idx_E содержит всего m битов, n старших битов получаются согласно 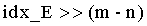 , где знак '>>' указывает операцию сдвига вправо. Таким образом, отображенным масштабным коэффициентом третьей ступени является
, где знак '>>' указывает операцию сдвига вправо. Таким образом, отображенным масштабным коэффициентом третьей ступени является 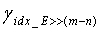 . Соответственно, кодовыми книгами третьей ступени старших и младших 5 измерений соответственно являются
. Соответственно, кодовыми книгами третьей ступени старших и младших 5 измерений соответственно являются
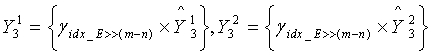 ,
,
где 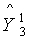 ,
, 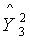 являются опорными кодовыми книгами кодовой книги третьей ступени и могут представлять собой кодовую книгу квантования второй ступени или кодовую подкнигу кодовой книги первой ступени.
являются опорными кодовыми книгами кодовой книги третьей ступени и могут представлять собой кодовую книгу квантования второй ступени или кодовую подкнигу кодовой книги первой ступени.
На этапе s605 ищут кодовую книгу третьей ступени для старших и младших пяти измерений вектора квантования третьей ступени соответственно. Таким образом, получают положения 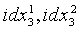 векторов, которые имеют минимальную сумму взвешенных среднеквадратических ошибок с соответствующими старшими и младшими пятью базисными подвекторами в кодовой книге. Положения являются результатом квантования третьей ступени:
векторов, которые имеют минимальную сумму взвешенных среднеквадратических ошибок с соответствующими старшими и младшими пятью базисными подвекторами в кодовой книге. Положения являются результатом квантования третьей ступени:
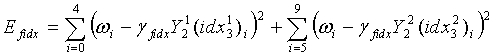
В ходе обратного квантования в конце декодирования сначала находят обратно квантованный вектор первой ступени в кодовой книге первой ступени с использованием индекса idx1 квантования первой ступени и представляют как Y1(idx1). Затем разделенные подвекторы, представленные как 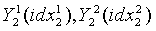 , обратного квантования второй ступени соответственно реконструируются из двух разделенных кодовых подкниг второй ступени, с использованием соответствующих индексов
, обратного квантования второй ступени соответственно реконструируются из двух разделенных кодовых подкниг второй ступени, с использованием соответствующих индексов 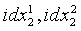 квантования второй ступени. После этого масштабный коэффициент
квантования второй ступени. После этого масштабный коэффициент 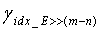 третьей ступени получают из набора γ масштабных коэффициентов с использованием индекса квантования энергии. Если
третьей ступени получают из набора γ масштабных коэффициентов с использованием индекса квантования энергии. Если 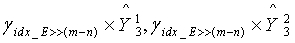 являются двумя разделенными кодовыми подкнигами кодовой книги третьей ступени, используемой в конце кодирования, то реконструированными векторами третьей ступени соответственно являются
являются двумя разделенными кодовыми подкнигами кодовой книги третьей ступени, используемой в конце кодирования, то реконструированными векторами третьей ступени соответственно являются 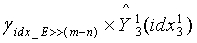 ,
,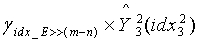 , и окончательным результатом обратного квантования является:
, и окончательным результатом обратного квантования является:
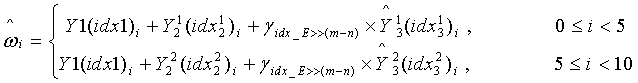
Согласно варианту осуществления кодовую книгу текущей ступени можно получить согласно кодовой книге предыдущей ступени, с использованием корреляции между кодовой книгой текущей ступени и кодовой книгой предыдущей ступени. В результате для кодовой книги текущей ступени не требуется пространство независимых кодовых книг, что позволяет экономить объем памяти и повышать эффективность использования ресурсов. Кроме того, применяется способ, согласно которому масштабный коэффициент получают путем отображения известных результатов квантования. Это позволяет экономить вычислительную мощность при поиске масштабного коэффициента и кодировании битов для индексов масштабных коэффициентов. Таким образом, дополнительно повышается эффективность квантования.
Кроме того, в конкретном применении варианта осуществления, кроме результата квантования параметра энергии, можно получать масштабный коэффициент путем отображения индекса квантования предыдущей ступени (первой или второй ступени) для параметра спектра, который должен быть проквантован. Таким образом, даже в отсутствие результата для других параметров вектор, который должен быть проквантован, все же можно улучшать с использованием решения настоящего изобретения.
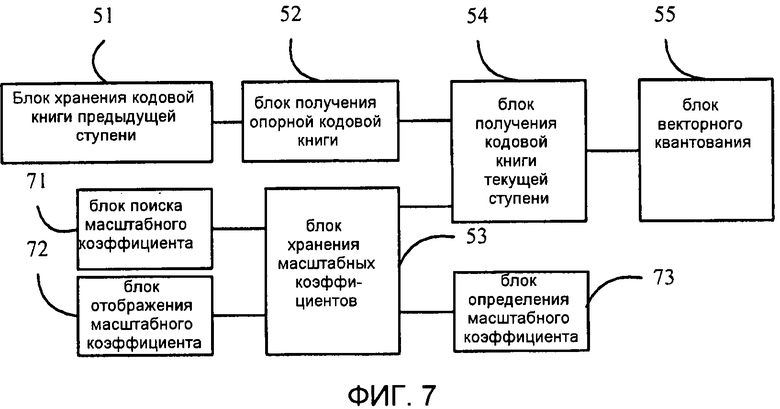
Как показано на фиг. 7, устройство многоступенчатого квантования, согласно варианту осуществления настоящего изобретения, может дополнительно включать в себя блок 71 поиска масштабного коэффициента, или блок 72 отображения масштабного коэффициента, или блок 73 определения масштабного коэффициента. В частности:
блок 71 поиска масштабного коэффициента выполнен с возможностью получения масштабного коэффициента путем поиска по всему массиву масштабных коэффициентов и передачи масштабного коэффициента на блок 53 хранения масштабных коэффициентов;
блок 72 отображения масштабного коэффициента выполнен с возможностью получения масштабного коэффициента путем битового отображения результата квантования предыдущей ступени и передачи масштабного коэффициента на блок 53 хранения масштабных коэффициентов; и
блок 73 определения масштабного коэффициента выполнен с возможностью определения масштабного коэффициента согласно ошибке квантования предыдущей ступени и вектору квантования предыдущей ступени и передачи масштабного коэффициента на блок 53 хранения масштабных коэффициентов.
Согласно варианту осуществления кодовую книгу текущей ступени можно получить согласно кодовой книге предыдущей ступени, с использованием корреляции между кодовой книгой текущей ступени и кодовой книгой предыдущей ступени. В результате для кодовой книги текущей ступени не требуется пространство независимых кодовых книг, что позволяет экономить объем памяти и повышать эффективность использования ресурсов.
Из описания вариантов осуществления специалисты в данной области техники могут понять, что изобретение можно реализовать в виде программного обеспечения в сочетании с необходимой общей аппаратной платформой или только в виде оборудования; хотя в большинстве случаев предпочтительнее первая реализация. Исходя из этого, техническое решение изобретения, позволяющее усовершенствовать уровень техники, можно воплотить в программном продукте. Компьютерный программный продукт хранится на носителе информации и включает в себя некоторые инструкции, которые предписывают вычислительному устройству (например, персональному компьютеру, серверу или сетевому устройству) исполнять способ, описанный вариантами осуществления изобретения.
Вышеприведенное описание раскрывает лишь предпочтительные варианты осуществления изобретения. Заметим, что на основе описания изобретения специалисты в данной области техники могут предложить различные модификации, эквивалентные замены и усовершенствования, не выходящие за рамки объема изобретения.
Изобретение относится к области методов сжатия данных, в частности к способу и устройству для многоступенчатого квантования. Техническим результатом является экономия объема памяти и повышение эффективности использования ресурсов. Указанный результат достигается тем, что в способе многоступенчатого квантования получают опорную кодовую книгу согласно кодовой книге предыдущей ступени, получают кодовую книгу текущей ступени согласно опорной кодовой книге и масштабному коэффициенту и квантуют входной вектор с использованием кодовой книги текущей ступени. 2 н. и 9 з.п. ф-лы, 7 ил.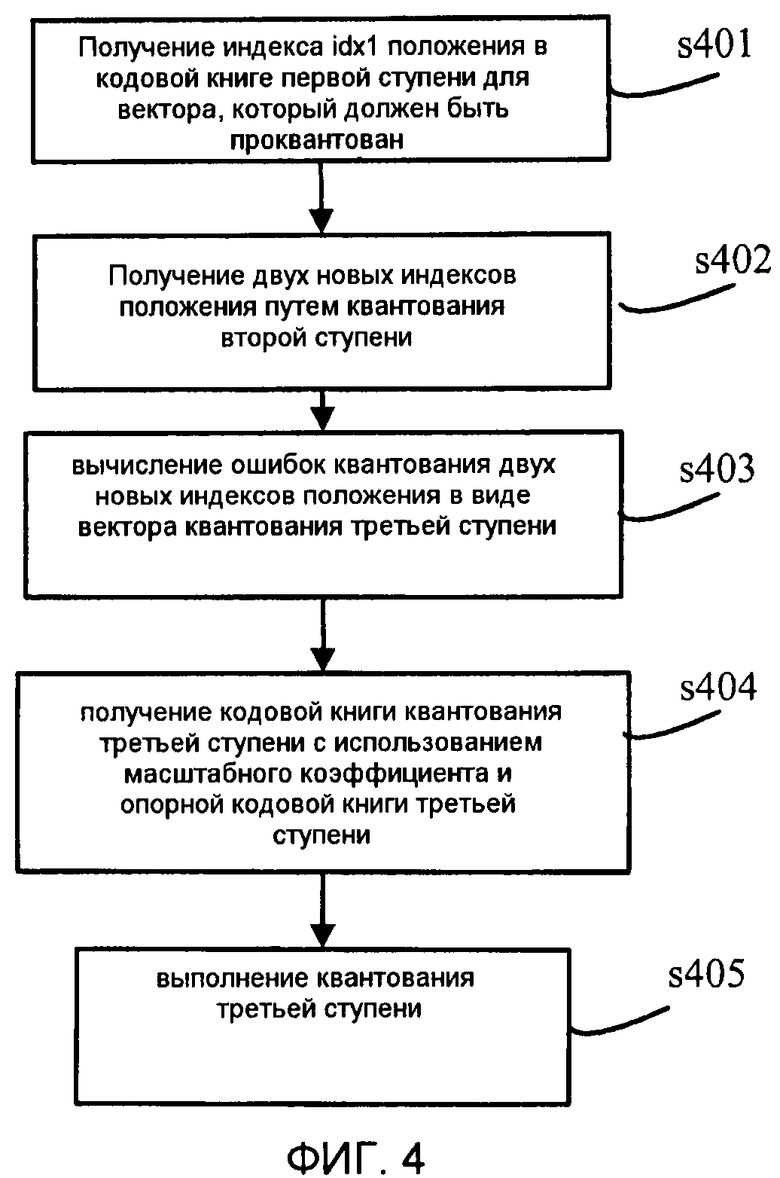
1. Способ многоступенчатого квантования, содержащий этапы, на которых:
получают опорную кодовую книгу согласно кодовой книге предыдущей ступени,
получают кодовую книгу текущей ступени согласно опорной кодовой книге и масштабному коэффициенту, и
квантуют входной вектор с использованием кодовой книги текущей ступени.
2. Многоступенчатое квантование по п.1, в котором этап получения опорной кодовой книги согласно кодовой книге предыдущей ступени содержит этапы, на которых:
получают опорную кодовую книгу согласно кодовой книге предыдущей ступени, или
получают опорную кодовую книгу согласно кодовой книге, выбранной из кодовой книги предыдущей ступени или кодовых книг двух или более предыдущих ступеней, или
объединяют векторы в кодовой книге предыдущей ступени для генерации опорной кодовой книги.
3. Многоступенчатое квантование по п.1, в котором масштабный коэффициент определяют согласно ошибке квантования предыдущей ступени и вектору квантования предыдущей ступени.
4. Многоступенчатое квантование по п.3, в котором, когда ошибкой квантования предыдущей ступени является x1=[x1,0, x1,1, …, x1,N-1]T, и входным вектором квантования предыдущей ступени является x0=[x0,0, x0,1, …, x0,N-1]T, масштабный коэффициент получают с использованием уравнения:
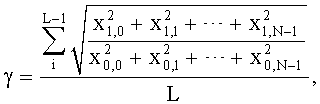
где L является количеством выборок, N является размерностью вектора, x1,0, x1,1, …, x1,N-1 являются соответственно значениями ошибки квантования для каждого измерения вектора квантования предыдущей ступени, и x0,0, x0,1, …, x0,N-1 являются соответственно значениями каждого измерения вектора квантования предыдущей ступени.
5. Многоступенчатое квантование по п.3, в котором масштабный коэффициент получают следующим образом:
делят 0 до 2 на М частей и получают М значений γ согласно уравнению
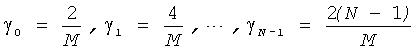 ,
,
получают М новых кодовых книг γ0Y1, γ1Y1, … γM-1Y1 согласно М значениям γ и кодовой книге Y1 предыдущей ступени,
квантуют вектор выборок с использованием М новых кодовых книг и получают для каждой кодовой книги сумму Ej минимально взвешенных ошибок квантования всех выборок с использованием уравнения
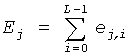 ,
,
где L является количеством выборок и ej,i является минимально взвешенной ошибкой квантования, и
получают оптимальный масштабный коэффициент γ согласно Ej, соответствующий каждой кодовой книге.
6. Многоступенчатое квантование по любому одному из пп.3-5, в котором, когда имеется множество масштабных коэффициентов, масштабные коэффициенты хранят в массиве и квантуют индексы масштабных коэффициентов.
7. Многоступенчатое квантование по п.6, в котором, при квантовании, индексы масштабных коэффициентов находят путем поиска по всему массиву масштабных коэффициентов или путем битового отображения результата квантования предыдущей ступени.
8. Многоступенчатое квантование по п.7, в котором результат квантования предыдущей ступени содержит результат квантования параметра энергии, который должен быть проквантован в текущий момент, или результат квантования параметра спектра.
9. Устройство многоступенчатого квантования, содержащее:
блок хранения кодовой книги предыдущей ступени, выполненный с возможностью хранения кодовой книги предыдущей ступени или кодовых книг двух или более предыдущих ступеней,
блок получения опорной кодовой книги, выполненный с возможностью получения опорной кодовой книги согласно кодовой(ым) книге(ам), хранящейся(имся) блоком хранения кодовой книги предыдущей ступени,
блок хранения масштабных коэффициентов, выполненный с возможностью хранения масштабного коэффициента,
блок получения кодовой книги текущей ступени, выполненный с возможностью получения кодовой книги текущей ступени согласно опорной кодовой книге, полученной блоком получения опорной кодовой книги, и масштабному коэффициенту, хранящемуся блоком хранения масштабных коэффициентов, и
блок векторного квантования, выполненный с возможностью квантования входного вектора с использованием кодовой книги текущей ступени, полученной блоком получения кодовой книги текущей ступени.
10. Устройство многоступенчатого квантования по п.9, в котором блок получения опорной кодовой книги, в частности, выполнен с возможностью:
получать опорную кодовую книгу согласно кодовой книге предыдущей ступени, хранящейся блоком хранения кодовой книги предыдущей ступени, или
получать опорную кодовую книгу согласно кодовой книге, выбранной из кодовой книги предыдущей ступени или кодовых книг двух или более предыдущих ступеней, хранящейся(ихся) блоком хранения кодовой книги предыдущей ступени, или
объединять векторы в кодовой книге предыдущей ступени, хранящейся блоком хранения кодовой книги предыдущей ступени для генерации опорной кодовой книги.
11. Устройство многоступенчатого квантования по п.9 или 10, дополнительно содержащее:
блок поиска масштабного коэффициента, выполненный с возможностью получения масштабного коэффициента путем поиска в массиве масштабных коэффициентов и передачи масштабного коэффициента на блок хранения масштабных коэффициентов, и/или
блок отображения масштабного коэффициента, выполненный с возможностью получения масштабного коэффициента путем битового отображения результата квантования предыдущей ступени и передачи масштабного коэффициента на блок хранения масштабных коэффициентов, и/или
блок определения масштабного коэффициента, выполненный с возможностью определения масштабного коэффициента согласно ошибке квантования предыдущей ступени и вектору квантования предыдущей ступени и передачи масштабного коэффициента на блок хранения масштабных коэффициентов.
| ЕР 1353323 А1, 15.10.2003 | |||
| СПОСОБ РЕСТАВРАЦИИ ЖЕВАТЕЛЬНЫХ ГРУПП ЗУБОВ ПРИ ПОЛНОМ ОТСУТСТВИИ КОРОНКОВОЙ ЧАСТИ С ПРИМЕНЕНИЕМ АРМИРУЮЩЕГО СЕТОЧНОГО КОЛЬЦА | 2003 |
|
RU2238696C1 |
| ЕР 1760694 А2, 07.03.2007 | |||
| US 5023910 А, 11.06.1991 | |||
| Устройство для загрузки дозировочных бункеров сыпучим материалом | 1991 |
|
SU1791116A1 |
| US 6952671 B1, 04.10.2005 | |||
| WO 00/11657 A1, 02.03.2000 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| JP 11143499 A, 28.05.1999 | |||
| КВАНТОВАНИЕ КОЭФФИЦИЕНТОВ УСИЛЕНИЯ ДЛЯ РЕЧЕВОГО КОДЕРА ЛИНЕЙНОГО ПРОГНОЗИРОВАНИЯ С КОДОВЫМ ВОЗБУЖДЕНИЕМ | 2001 |
|
RU2257556C2 |

