Настоящее изобретение относится к кодированию, декодированию и обработке аудиосигналов, и в частности, к приведению уровня сигнала, подвергаемого частотно-временному преобразованию (или подвергаемого временно-частотному преобразованию), к динамическому диапазону соответствующего частотно-временного преобразователя (или временно-частотного преобразователя). Некоторые варианты осуществления настоящего изобретения относятся к приведению уровня сигнала, подвергаемого частотно-временному преобразованию (или подвергаемого временно-частотному преобразованию) к динамическому диапазону соответствующего преобразователя, реализованного на арифметике с фиксированной запятой или целочисленной арифметике. Дополнительные варианты осуществления настоящего изобретения относятся к предотвращению срезания для спектральных декодированных аудиосигналов, используя регулировку уровня во временной области совместно с дополнительной информацией.
Обработка аудиосигналов становится все более важной. Проблемы возникают, когда от современных кодеков воспринимаемого аудио требуется обеспечить удовлетворительное качество аудио при все более низких скоростях передачи битов.
В современных цепочках производства и доставки аудиоконтента доступный в цифровой форме оригинальный контент (поток PCM (поток с импульсно-кодовой модуляцией)) кодируется на стороне создания контента, например, профессиональным кодером AAC (Усовершенствованное аудиокодирование). Результирующий поток двоичных сигналов AAC затем становится доступным для покупки, например, посредством онлайн-магазина цифровых носителей. В редких случаях оказывается, что некоторые декодированные выборки PCM являются "срезанными", что означает, что две или более последовательные выборки достигли максимального уровня, который можно представить с помощью лежащего в основе битового разрешения (например, 16 битов) у равномерно квантованного представления с фиксированной запятой (например, модулированного в соответствии с PCM) для выходной формы сигнала. Это может приводить к слышимым артефактам (щелчки или кратковременное искажение). Хотя обычно на стороне кодера будут приложены усилия, чтобы предотвратить возникновение срезания на стороне декодера, тем не менее, срезание может возникать на стороне декодера по различным причинам, например разные реализации декодера, ошибки округления, ошибки передачи и т.п. Предполагая, что аудиосигнал на входе кодера ниже пороговой величины срезания, причины для срезания в современном кодере воспринимаемого аудио многочисленны. Прежде всего, аудиокодер применяет квантование к переданному сигналу, который доступен в виде разложения на частотные составляющие формы входного сигнала, чтобы уменьшить скорость передачи данных. Ошибки квантования в частотной области приводят к небольшим отклонениям амплитуды и фазы сигнала относительно исходной формы сигнала. Если амплитудные или фазовые ошибки конструктивно складываются, то результирующее положение во временной области временно может быть выше исходной формы сигнала. Во-вторых, способы параметрического кодирования (например, копирование спектральных полос, SBR) довольно грубо параметризуют мощность сигнала. Информация о фазе обычно пропускается. Следовательно, сигнал на стороне приемника восстанавливается только с правильной мощностью, но без сохранения формы сигнала. Сигналы с амплитудой, близкой к полной шкале, имеют тенденцию к срезанию.
Современные системы аудиокодирования предлагают возможность сообщать параметр уровня громкости (g1), предоставляя декодерам возможность регулировать громкость воспроизведения с помощью унифицированных уровней. Вообще, это могло бы приводить к срезанию, если аудиосигнал кодируется с достаточно высокими уровнями, и переданные коэффициенты нормализации предполагают увеличение уровней громкости. К тому же установившейся практикой при мастеринге аудиоконтента (в особенности музыки) является поднятие аудиосигналов до максимальных возможных значений, что приводит к срезанию аудиосигнала при крупном квантовании аудиокодеками.
Чтобы предотвратить срезание аудиосигналов, в качестве подходящего инструмента известны так называемые ограничители, чтобы ограничивать уровни аудиосигнала. Если входящий аудиосигнал превышает некоторую пороговую величину, то приводится в действие ограничитель и ослабляет аудиосигнал таким образом, что аудиосигнал на выходе не превышает заданный уровень. К сожалению, перед ограничителем необходим достаточный запас (в показателях динамического диапазона и/или битового разрешения).
Обычно любая нормализация громкости достигается в частотной области вместе с так называемым "управлением динамическим диапазоном" (DRC). Это дает возможность ровного смешивания в нормализации громкости, даже если коэффициент нормализации меняется от кадра к кадру из-за перекрытия гребенок фильтров.
Кроме того, из-за плохого квантования или параметрического описания любой кодированный аудиосигнал может попасть в срезание, если исходный аудиосигнал проходил мастеринг на уровнях возле пороговой величины срезания.
Как правило, в высокоэффективных устройствах цифровой обработки сигналов на основе арифметики с фиксированной запятой желательно поддерживать вычислительную сложность, использование памяти и энергопотребление как можно меньшими. По этой причине также желательно поддерживать длину слова у аудиовыборок как можно меньшей. Чтобы учесть любой возможный запас для срезания из-за нормализации громкости, потребовалось бы спроектировать гребенку фильтров, которая обычно является частью аудиокодера или декодера, с большей длиной слова.
Было бы желательно предоставить возможность ограничения сигнала без потери точности данных и/или без необходимости использования большей длины слова для гребенки фильтров декодера или гребенки фильтров кодера. В качестве альтернативы или дополнительно было бы желательно, если бы подходящий динамический диапазон сигнала, подвергаемого частотно-временному преобразованию или наоборот, можно было постоянно определять на покадровой основе для последовательных отрезков времени или "кадров" сигнала, чтобы уровень сигнала можно было регулировать таким образом, что текущий подходящий динамический диапазон помещается в динамический диапазон, предусмотренный преобразователем (преобразователем частотной области во временную или преобразователем временной области в частотную). Также было бы желательно выполнять такой сдвиг уровня с целью частотно-временного преобразования или временно-частотного преобразования практически "прозрачно" для других компонентов декодера или кодера. По меньшей мере одно из этих пожеланий и/или возможных дополнительных пожеланий выполняется декодером аудиосигнала по п. 1, кодером аудиосигнала по п. 14 и способом для декодирования кодированного представления аудиосигнала по п. 15.
Предоставляется декодер аудиосигнала для предоставления декодированного представления аудиосигнала на основе кодированного представления аудиосигнала. Декодер аудиосигнала содержит каскад предварительной обработки декодера, сконфигурированный для получения множества сигналов полосы частот из кодированного представления аудиосигнала. Декодер аудиосигнала дополнительно содержит модуль оценки срезания, сконфигурированный для анализа по меньшей мере одного из кодированного представления аудиосигнала, множества частотных сигналов и дополнительной информации касательно усиления сигналов полосы частот кодированного представления аудиосигнала в отношении того, предполагает (предполагают) ли кодированное представление аудиосигнала, множество частотных сигналов и/или дополнительная информация возможное срезание, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала. Когда дополнительная информация предполагает возможное срезание, текущий коэффициент сдвига уровня вызывает сдвиг информации о множестве сигналов полосы частот к самому младшему биту, чтобы получить запас в по меньшей мере одном самом старшем бите. Декодер аудиосигнала также содержит модуль сдвига уровня, сконфигурированный для сдвига уровней сигналов полосы частот в соответствии с коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем. Кроме того, декодер аудиосигнала содержит преобразователь частотной области во временную, сконфигурированный для преобразования сигналов полосы частот со сдвинутым уровнем в представление временной области. Декодер аудиосигнала дополнительно содержит компенсатор сдвига уровня, сконфигурированный для воздействия на представление временной области для по меньшей мере частичной компенсации сдвига уровня, примененного модулем сдвига уровня к сигналам полосы частот со сдвинутым уровнем, и для получения существенно компенсированного представления временной области.
Дополнительные варианты осуществления настоящего изобретения предоставляют кодер аудиосигнала, сконфигурированный для предоставления кодированного представления аудиосигнала на основе представления временной области входного аудиосигнала. Кодер аудиосигнала содержит модуль оценки срезания, сконфигурированный для анализа представления временной области входного аудиосигнала в отношении того, предполагается ли возможное срезание, чтобы определить текущий коэффициент сдвига уровня для представления входного сигнала. Когда предполагается возможное срезание, текущий коэффициент сдвига уровня вызывает сдвиг представления временной области входного аудиосигнала к самому младшему биту, чтобы получить запас в по меньшей мере одном самом старшем бите. Кодер аудиосигнала дополнительно содержит модуль сдвига уровня, сконфигурированный для сдвига уровня представления временной области входного аудиосигнала в соответствии с коэффициентом сдвига уровня для получения представления временной области со сдвинутым уровнем. Кроме того, кодер аудиосигнала содержит преобразователь временной области в частотную, сконфигурированный для преобразования представления временной области со сдвинутым уровнем в множество сигналов полосы частот. Кодер аудиосигнала также содержит компенсатор сдвига уровня, сконфигурированный для воздействия на множество сигналов полосы частот для по меньшей мере частичной компенсации сдвига уровня, примененного модулем сдвига уровня к представлению временной области со сдвинутым уровнем, и для получения множества существенно компенсированных сигналов полосы частот.
Дополнительные варианты осуществления настоящего изобретения предоставляют способ для декодирования кодированного представления аудиосигнала, чтобы получить декодированное представление аудиосигнала. Способ содержит предварительную обработку кодированного представления аудиосигнала, чтобы получить множество сигналов полосы частот. Способ дополнительно содержит анализ по меньшей мере одного из кодированного представления аудиосигнала, сигналов полосы частот и дополнительной информации касательно усиления сигналов полосы частот в отношении того, предполагается ли возможное срезание, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала. Когда предполагается возможное срезание, текущий коэффициент сдвига уровня вызывает сдвиг представления временной области входного аудиосигнала к самому младшему биту, чтобы получить запас в по меньшей мере одном самом старшем бите. Кроме того, способ содержит сдвиг уровней сигналов полосы частот в соответствии с коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем. Способ также содержит выполнение преобразования частотной области во временную для сигналов полосы частот в представление временной области. Способ дополнительно содержит воздействие на представление временной области для по меньшей мере частичной компенсации сдвига уровня, примененного к сигналам полосы частот со сдвинутым уровнем, и для получения существенно компенсированного представления временной области.
Кроме того, предоставляется компьютерная программа для реализации вышеописанных способов, когда исполняется на компьютере или процессоре сигналов.
Дополнительные варианты осуществления предоставляют декодер аудиосигнала для предоставления декодированного представления аудиосигнала на основе кодированного представления аудиосигнала. Декодер аудиосигнала содержит каскад предварительной обработки декодера, сконфигурированный для получения множества сигналов полосы частот из кодированного представления аудиосигнала. Декодер аудиосигнала дополнительно содержит модуль оценки срезания, сконфигурированный для анализа по меньшей мере одного из кодированного представления аудиосигнала, множества частотных сигналов и дополнительной информации касательно усиления сигналов полосы частот кодированного представления аудиосигнала, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала. Декодер аудиосигнала также содержит модуль сдвига уровня, сконфигурированный для сдвига уровней сигналов полосы частот в соответствии с коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем. Кроме того, декодер аудиосигнала содержит преобразователь частотной области во временную, сконфигурированный для преобразования сигналов полосы частот со сдвинутым уровнем в представление временной области. Декодер аудиосигнала дополнительно содержит компенсатор сдвига уровня, сконфигурированный для воздействия на представление временной области для по меньшей мере частичной компенсации сдвига уровня, примененного модулем сдвига уровня к сигналам полосы частот со сдвинутым уровнем, и для получения существенно компенсированного представления временной области.
Дополнительные варианты осуществления настоящего изобретения предоставляют кодер аудиосигнала, сконфигурированный для предоставления кодированного представления аудиосигнала на основе представления временной области входного аудиосигнала. Кодер аудиосигнала содержит модуль оценки срезания, сконфигурированный для анализа представления временной области входного аудиосигнала, чтобы определить текущий коэффициент сдвига уровня для представления входного сигнала. Кодер аудиосигнала дополнительно содержит модуль сдвига уровня, сконфигурированный для сдвига уровня представления временной области входного аудиосигнала в соответствии с коэффициентом сдвига уровня для получения представления временной области со сдвинутым уровнем. Кроме того, кодер аудиосигнала содержит преобразователь временной области в частотную, сконфигурированный для преобразования представления временной области со сдвинутым уровнем в множество сигналов полосы частот. Кодер аудиосигнала также содержит компенсатор сдвига уровня, сконфигурированный для воздействия на множество сигналов полосы частот для по меньшей мере частичной компенсации сдвига уровня, примененного модулем сдвига уровня к представлению временной области со сдвинутым уровнем, и для получения множества существенно компенсированных сигналов полосы частот.
Дополнительные варианты осуществления настоящего изобретения предоставляют способ для декодирования кодированного представления аудиосигнала, чтобы получить декодированное представление аудиосигнала. Способ содержит предварительную обработку кодированного представления аудиосигнала, чтобы получить множество сигналов полосы частот. Способ дополнительно содержит анализ по меньшей мере одного из кодированного представления аудиосигнала, сигналов полосы частот и дополнительной информации касательно усиления сигналов полосы частот, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала. Кроме того, способ содержит сдвиг уровней сигналов полосы частот в соответствии с коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем. Способ также содержит выполнение преобразования частотной области во временную для сигналов полосы частот в представление временной области. Способ дополнительно содержит воздействие на представление временной области для по меньшей мере частичной компенсации сдвига уровня, примененного к сигналам полосы частот со сдвинутым уровнем, и для получения существенно компенсированного представления временной области.
По меньшей мере некоторые из вариантов осуществления основываются на понимании, что можно без потери релевантной информации сдвинуть множество сигналов полосы частот в представлении частотной области с помощью некоторого коэффициента сдвига уровня в течение интервалов времени, в которых общий уровень громкости аудиосигнала довольно высокий. Точнее, релевантная информация в любом случае сдвигается в биты, которые, вероятно, содержат шум. Таким образом, может использоваться преобразователь частотной области во временную, имеющий ограниченную длину слова, даже если динамический диапазон сигналов полосы частот может быть больше поддерживаемого ограниченной длиной слова у преобразователя частотной области во временную. Другими словами, по меньшей мере некоторые варианты осуществления настоящего изобретения пользуются тем, что самый младший бит (биты) обычно не переносит никакой релевантной информации, хотя аудиосигнал довольно громкий, то есть релевантная информация с большей вероятностью содержится в самом старшем бите (битах). Сдвиг уровня, примененный к сигналам полосы частот со сдвинутым уровнем, также может обладать преимуществом снижения вероятности возникновения срезания в представлении временной области, где упомянутое срезание может происходить от конструктивного наложения одного или нескольких сигналов полосы частот в множестве сигналов полосы частот.
Эти догадки и результаты также применяются аналогичным образом к кодеру аудиосигнала и способу для кодирования исходного аудиосигнала, чтобы получить кодированное представление аудиосигнала.
Ниже подробнее описываются варианты осуществления настоящего изобретения со ссылкой на фигуры, на которых:
Фиг. 1 иллюстрирует кодер в соответствии с современным уровнем техники;
Фиг. 2 изображает декодер в соответствии с современным уровнем техники;
Фиг. 3 иллюстрирует другой кодер в соответствии с современным уровнем техники;
Фиг. 4 изображает еще один декодер в соответствии с современным уровнем техники;
Фиг. 5 показывает блок-схему декодера аудиосигнала в соответствии по меньшей мере с одним вариантом осуществления;
Фиг. 6 показывает блок-схему декодера аудиосигнала в соответствии по меньшей мере с еще одним вариантом осуществления;
Фиг. 7 показывает блок-схему, иллюстрирующую идею предложенного декодера аудиосигнала и предложенного способа для декодирования кодированного представления аудиосигнала в соответствии с вариантами осуществления;
Фиг. 8 – схематическая визуализация сдвига уровня, чтобы получить запас;
Фиг. 9 показывает блок-схему возможной регулировки формы перехода, которая может быть компонентом декодера или кодера аудиосигнала в соответствии по меньшей мере с некоторыми вариантами осуществления;
Фиг. 10 изображает блок оценки в соответствии с дополнительным вариантом осуществления, содержащий регулятор фильтра с предсказанием;
Фиг. 11 иллюстрирует устройство для формирования обратного потока данных;
Фиг. 12 иллюстрирует кодер в соответствии с современным уровнем техники;
Фиг. 13 изображает декодер в соответствии с современным уровнем техники;
Фиг. 14 иллюстрирует другой кодер в соответствии с современным уровнем техники; и
Фиг. 15 показывает блок-схему кодера аудиосигнала в соответствии по меньшей мере с одним вариантом осуществления; и
Фиг. 16 показывает блок-схему алгоритма способа для декодирования кодированного представления аудиосигнала в соответствии по меньшей мере с одним вариантом осуществления.
Обработка звуковых сигналов развилась во многих направлениях, и предметом многих исследований стало то, как эффективно кодировать и декодировать сигнал аудиоданных. Эффективное кодирование предусмотрено, например, в AAC MPEG (MPEG = Экспертная группа по движущимся изображениям; AAC = Усовершенствованное аудиокодирование). Некоторые аспекты AAC MPEG подробнее объясняются ниже в качестве введения к аудиокодированию и декодированию. Описание AAC MPEG нужно воспринимать только в качестве примера, так как описанные идеи с тем же успехом могут применяться к другим схемам аудиокодирования и декодирования.
В соответствии с AAC MPEG спектральные значения аудиосигнала кодируются с применением масштабных коэффициентов, квантования и кодовых книг, в частности, кодовых книг Хаффмана.
Перед тем, как проводится кодирование методом Хаффмана, кодер группирует множество кодируемых спектральных коэффициентов в разные разделы (спектральные коэффициенты получены от вышестоящих компонентов, например гребенки фильтров, психоакустической модели и квантователя, управляемого психоакустической моделью касательно порогов квантования и разрешений квантования). Для каждого раздела спектральных коэффициентов кодер выбирает кодовую книгу Хаффмана для кодирования методом Хаффмана. AAC MPEG предоставляет одиннадцать разных спектральных кодовых книг Хаффмана для кодирования спектральных данных, из которых кодер выбирает кодовую книгу, лучше всего подходящую для кодирования спектральных коэффициентов раздела. Кодер в качестве дополнительной информации предоставляет декодеру идентификатор кодовой книги, идентифицирующий кодовую книгу, используемую для кодирования методом Хаффмана спектральных коэффициентов раздела.
На стороне декодера декодер анализирует принятую дополнительную информацию, чтобы определить, какая из множества спектральных кодовых книг Хаффмана использована для кодирования спектральных значений раздела. Декодер проводит декодирование методом Хаффмана на основе дополнительной информации о кодовой книге Хаффмана, применяемой для кодирования спектральных коэффициентов раздела, который декодеру нужно декодировать.
После декодирования методом Хаффмана в декодере получается множество квантованных спектральных значений. Декодер затем может провести обратное квантование, чтобы инвертировать неравномерное квантование, которое могло быть проведено кодером. С помощью этого в декодере получаются обратно-квантованные спектральные значения.
Однако обратно-квантованные спектральные значения все еще могут быть немасштабированными. Выведенные немасштабированные спектральные значения сгруппированы в масштабные диапазоны, при этом каждый масштабный диапазон имеет общий масштабный коэффициент. Масштабный коэффициент для каждого масштабного диапазона доступен декодеру в виде дополнительной информации, которая предоставлена кодером. Используя эту информацию, декодер умножает немасштабированные спектральные значения в масштабном диапазоне на их масштабный коэффициент. С помощью этого получаются масштабированные спектральные значения.
Теперь со ссылкой на фиг. 1–4 объясняется кодирование и декодирование спектральных значений в соответствии с современным уровнем техники.
Фиг. 1 иллюстрирует кодер в соответствии с современным уровнем техники. Кодер содержит гребенку 10 T/F-фильтров (временно-частотных) для преобразования аудиосигнала AS, который должен быть кодирован, из временной области в частотную область, чтобы получить аудиосигнал частотной области. Аудиосигнал частотной области вводится в блок 20 масштабных коэффициентов для определения масштабных коэффициентов. Блок 20 масштабных коэффициентов приспособлен для разделения спектральных коэффициентов аудиосигнала частотной области на несколько групп спектральных коэффициентов, называемых масштабными диапазонами, которые совместно используют один масштабный коэффициент. Масштабный коэффициент представляет собой значение усиления, используемое для изменения амплитуды всех спектральных коэффициентов в соответствующем масштабном диапазоне. Кроме того, блок 20 масштабных коэффициентов приспособлен для формирования и вывода немасштабированных спектральных коэффициентов аудиосигнала частотной области.
Кроме того, кодер на фиг. 1 содержит квантователь для квантования немасштабированных спектральных коэффициентов аудиосигнала частотной области. Квантователь 30 может быть квантователем с неравномерным шагом.
После квантования квантованные немасштабированные спектры аудиосигнала вводятся в кодер 40 Хаффмана для кодирования методом Хаффмана. Кодирование методом Хаффмана используется для уменьшения избыточности квантованного спектра аудиосигнала. Множество немасштабированных квантованных спектральных коэффициентов группируется в разделы. Хотя в MPEG-AAC предусмотрено одиннадцать возможных кодовых книг, все спектральные коэффициенты раздела кодируются одной и той же кодовой книгой Хаффмана.
Кодер выберет одну из одиннадцати возможных кодовых книг Хаффмана, которая особенно подходит для кодирования спектральных коэффициентов раздела. При этом выбор кодовой книги Хаффмана в кодере для конкретного раздела зависит от спектральных значений конкретного раздела. Кодированные методом Хаффмана спектральные коэффициенты затем можно передать декодеру вместе с дополнительной информацией, содержащей, например, информацию о кодовой книге Хаффмана, которая использована для кодирования раздела спектральных коэффициентов, масштабный коэффициент, который использован для конкретного масштабного диапазона, и т.п.
Два или четыре спектральных коэффициента кодируются кодовым словом в кодовой книге Хаффмана, применяемой для кодирования спектральных коэффициентов раздела методом Хаффмана. Кодер передает декодеру кодовые слова, представляющие кодированные спектральные коэффициенты, вместе с дополнительной информацией, содержащей длину раздела, а также информацию о кодовой книге Хаффмана, используемой для кодирования спектральных коэффициентов раздела.
В AAC MPEG предоставляется одиннадцать спектральных кодовых книг Хаффмана для кодирования спектральных данных аудиосигнала. Разные спектральные кодовые книги Хаффмана можно идентифицировать по их индексу кодовой книги (значение между 1 и 11). Размер кодовой книги Хаффмана указывает, сколько спектральных коэффициентов кодируется кодовым словом из рассматриваемой кодовой книги Хаффмана. В AAC MPEG размер кодовой книги Хаффмана равен либо 2, либо 4, указывая, что кодовое слово кодирует либо два, либо четыре спектральных значения аудиосигнала.
Однако разные кодовые книги Хаффмана также отличаются по другим свойствам. Например, максимальное абсолютное значение спектрального коэффициента, которое может кодировать кодовая книга Хаффмана, меняется от одной кодовой книги к другой и может быть равно, например, 1, 2, 4, 7, 12 или больше. Кроме того, рассматриваемая кодовая книга Хаффмана может быть приспособлена либо не приспособлена к кодированию значений со знаком.
Применяя кодирование методом Хаффмана, спектральные коэффициенты кодируются кодовыми словами разных длин. AAC MPEG предоставляет две разные кодовые книги Хаффмана, имеющие максимальное абсолютное значение 1, две разные кодовые книги Хаффмана, имеющие максимальное абсолютное значение 2, две разные кодовые книги Хаффмана, имеющие максимальное абсолютное значение 4, две разные кодовые книги Хаффмана, имеющие максимальное абсолютное значение 7, и две разные кодовые книги Хаффмана, имеющие максимальное абсолютное значение 12, где каждая кодовая книга Хаффмана представляет отдельную функцию распределение вероятностей. Кодер Хаффмана всегда будет выбирать кодовую книгу Хаффмана, которая лучше всего подходит для кодирования спектральных коэффициентов.
Фиг. 2 иллюстрирует декодер в соответствии с современным уровнем техники. Кодированные методом Хаффмана спектральные значения принимаются декодером 50 Хаффмана. Декодер 50 Хаффмана в качестве дополнительной информации также принимает информацию о кодовой книге Хаффмана, используемой для кодирования спектральных значений для каждого раздела спектральных значений. Затем декодер 50 Хаффмана выполняет декодирование методом Хаффмана для получения немасштабированных квантованных спектральных значений. Немасштабированные квантованные спектральные значения вводятся в обратный квантователь 60. Обратный квантователь выполняет обратное квантование для получения обратно-квантованных немасштабированных спектральных значений, которые вводятся в преобразователь 70 масштаба. Преобразователь 70 масштаба также принимает масштабные коэффициенты для каждого масштабного диапазона в качестве дополнительной информации. На основе принятых масштабных коэффициентов преобразователь 70 масштаба масштабирует немасштабированные обратно-квантованные спектральные значения, чтобы получить масштабированные обратно-квантованные спектральные значения. Затем гребенка 80 F/T-фильтров преобразует масштабированные обратно-квантованные спектральные значения аудиосигнала частотной области из частотной области во временную область, чтобы получить выборочные значения аудиосигнала временной области.
Фиг. 3 иллюстрирует кодер в соответствии с современным уровнем техники, отличающийся от кодера из фиг. 1 в том, что кодер из фиг. 3 дополнительно содержит блок TNS на стороне кодера (TNS = Временное ограничение шума). Временное ограничение шума может применяться для управления временной формой шума квантования путем проведения процесса фильтрации по отношению к частям спектральных данных аудиосигнала. Блок 15 TNS на стороне кодера проводит кодирование с линейным предсказанием (LPC) по отношению к спектральным коэффициентам кодируемого аудиосигнала частотной области. Результатом вычисления LPC, в числе прочего, являются коэффициенты отражения, также называемые коэффициентами PARCOR. Временное ограничение шума не используется, если эффективность [выигрыш] предсказания, которая также выводится с помощью вычисления LPC, не превышает некоторого порогового значения. Однако, если эффективность предсказания больше порогового значения, применяется временное ограничение шума. Блок TNS на стороне кодера удаляет все коэффициенты отражения, которые меньше некоторого порогового значения. Оставшиеся коэффициенты отражения преобразуются в коэффициенты линейного предсказания и используются в качестве коэффициентов фильтра ограничения шума в кодере. Затем блок TNS на стороне кодера выполняет операцию фильтрации над теми спектральными коэффициентами, для которых применяется TNS, чтобы получить обработанные спектральные коэффициенты аудиосигнала. Декодеру передается дополнительная информация, указывающая информацию TNS, например коэффициенты отражения (коэффициенты PARCOR).
Фиг. 4 иллюстрирует декодер в соответствии с современным уровнем техники, который отличается от проиллюстрированного на фиг. 2 декодера в том, что декодер из фиг. 4 к тому же содержит блок 75 TNS на стороне декодера. Блок TNS на стороне декодера принимает обратно-квантованные масштабированные спектры аудиосигнала, а также принимает информацию TNS, например, информацию, указывающую коэффициенты отражения (коэффициенты PARCOR). Блок 75 TNS на стороне декодера обрабатывает обратно-квантованные спектры аудиосигнала, чтобы получить обработанный обратно-квантованный спектр аудиосигнала.
Фиг. 5 показывает блок-схему декодера 100 аудиосигнала в соответствии по меньшей мере с одним вариантом осуществления настоящего изобретения. Декодер аудиосигнала сконфигурирован для приема кодированного представления аудиосигнала. Как правило, кодированное представление аудиосигнала сопровождается дополнительной информацией. Кодированное представление аудиосигнала вместе с дополнительной информацией может предоставляться в виде потока данных, который создан, например, кодером воспринимаемого аудио. Декодер 100 аудиосигнала дополнительно сконфигурирован для предоставления декодированного представления аудиосигнала, которое может быть идентично сигналу, обозначенному как "существенно компенсированное представление временной области" на фиг. 5, или может быть выведено из него с использованием последующей обработки.
Декодер 100 аудиосигнала содержит каскад 110 предварительной обработки декодера, который сконфигурирован для получения множества сигналов полосы частот из кодированного представления аудиосигнала. Например, каскад 110 предварительной обработки декодера может содержать распаковщик потока двоичных сигналов, если кодированное представление аудиосигнала и дополнительная информация содержатся в потоке двоичных сигналов. Некоторые стандарты аудиокодирования могут использовать изменяющиеся во времени разрешения, а также разные разрешения для множества сигналов полосы частот в зависимости от частотного диапазона, в котором кодированное представление аудиосигнала переносит релевантную информацию (высокое разрешение) или нерелевантную информацию (низкое разрешение или вообще отсутствие данных) в настоящее время. Это означает, что полоса частот, в которой кодированное представление аудиосигнала содержит в настоящее время большое количество релевантной информации, обычно кодируется с использованием довольно высокого разрешения (то есть, с использованием довольно большого количества битов) в течение того интервала времени, в отличие от сигнала полосы частот, который временно не переносит никакой информации или только очень мало информации. Может даже оказаться, что для некоторых сигналов полосы частот поток двоичных сигналов временно вообще не содержит данных или битов, потому что эти сигналы полосы частот не содержат никакой релевантной информации в течение соответствующего интервала времени. Поток двоичных сигналов, предоставленный в каскад 110 предварительной обработки декодера, обычно содержит информацию (например, как часть дополнительной информации), указывающую, какие сигналы полосы частот из множества сигналов полосы частот содержат данные для рассматриваемого в настоящее время интервала времени или "кадра", и соответствующее битовое разрешение.
Декодер 100 аудиосигнала дополнительно содержит модуль 120 оценки срезания, сконфигурированный для анализа дополнительной информации касательно усиления сигналов полосы частот кодированного представления аудиосигнала, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала. Некоторые стандарты кодирования воспринимаемого аудио используют индивидуальные масштабные коэффициенты для разных сигналов полосы частот в множестве сигналов полосы частот. Индивидуальные масштабные коэффициенты указывают для каждого сигнала полосы частот текущий диапазон амплитуд относительно других сигналов полосы частот. Для некоторых вариантов осуществления настоящего изобретения анализ этих масштабных коэффициентов дает возможность приблизительной оценки максимальной амплитуды, которая может возникать в соответствующем представлении временной области после того, как множество сигналов полосы частот преобразовано из частотной области во временную область. Эта информация может затем использоваться для определения, возможно ли возникновение срезания в представлении временной области для рассматриваемого интервала времени или "кадра" в отсутствие какой-либо подходящей обработки, которая предложена настоящим изобретением. Модуль 120 оценки срезания сконфигурирован для определения коэффициента сдвига уровня, который сдвигает все сигналы полосы частот в множестве сигналов полосы частот на одинаковую величину относительно уровня (например, относительно амплитуды сигнала или мощности сигнала). Коэффициент сдвига уровня может определяться индивидуально для каждого интервала времени (кадра), то есть коэффициент сдвига уровня изменяется во времени. Как правило, модуль 120 оценки срезания будет пытаться регулировать уровни у множества сигналов полосы частот на коэффициент сдвига, который является общим для всех сигналов полосы частот, таким образом, что вряд ли возникает срезание в представлении временной области, одновременно поддерживая разумный динамический диапазон для сигналов полосы частот. В качестве примера рассмотрим кадр кодированного представления аудиосигнала, в котором количество масштабных коэффициентов довольно большое. Модуль 120 оценки срезания теперь может рассмотреть наихудший случай, то есть возможные максимумы сигнала в множестве сигналов полосы частот конструктивно перекрываются или складываются, приводя к большой амплитуде в представлении временной области. Коэффициент сдвига уровня можно теперь определить как число, которое заставляет этот гипотетический максимум в представлении временной области находиться в нужном динамическом диапазоне, по возможности с учетом допустимого искажения. В соответствии по меньшей мере с некоторыми вариантами осуществления модулю 120 оценки срезания не нужно само кодированное представление аудиосигнала для оценки вероятности срезания в представлении временной области для рассматриваемого интервала времени или кадра. Причина в том, что по меньшей мере некоторые стандарты кодирования воспринимаемого аудио выбирают масштабные коэффициенты для сигналов полосы частот в множестве сигналов полосы частот в соответствии с наибольшей амплитудой, которую нужно кодировать в некотором сигнале полосы частот и рассматриваемом интервале времени. Другими словами, наибольшее значение, которое можно представить с помощью выбранного битового разрешения для имеющегося сигнала полосы частот, с очень большой вероятностью возникает по меньшей мере один раз в течение рассматриваемого интервала времени или кадра, обусловленное свойствами схемы кодирования. Используя это предположение, модуль 120 оценки срезания может сосредоточиться на оценивании дополнительной информации касательно усиления (усилений) сигналов полосы частот (например, упомянутого масштабного коэффициента и, возможно, дополнительных параметров), чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала и рассматриваемого интервала времени (кадра).
Декодер 100 аудиосигнала дополнительно содержит модуль 130 сдвига уровня, сконфигурированный для сдвига уровней сигналов полосы частот в соответствии с коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем.
Декодер 100 аудиосигнала дополнительно содержит преобразователь 140 частотной области во временную, сконфигурированный для преобразования сигналов полосы частот со сдвинутым уровнем в представление временной области. Преобразователь 140 частотной области во временную может быть, например, обратной гребенкой фильтров, обратным модифицированным дискретным косинусным преобразованием (обратным MDCT), обратным квадратурным зеркальным фильтром (обратным QMF). Для некоторых стандартов аудиокодирования преобразователь 140 частотной области во временную может конфигурироваться для поддержки организации окон из последовательных кадров, где два кадра перекрываются, например, на 50% их длительности.
Представление временной области, предоставленное преобразователем 140 частотной области во временную, предоставляется в компенсатор 150 сдвига уровня, который сконфигурирован для воздействия на представление временной области для по меньшей мере частичной компенсации сдвига уровня, примененного модулем 130 сдвига уровня к сигналам полосы частот со сдвинутым уровнем, и для получения существенно компенсированного представления временной области. Компенсатор 150 сдвига уровня дополнительно принимает коэффициент сдвига уровня от модуля 140 оценки срезания либо сигнал, выведенный из коэффициента сдвига уровня. Модуль 130 сдвига уровня и компенсатор 150 сдвига уровня обеспечивают соответственно регулировку усиления у сигналов полосы частот со сдвинутым уровнем и компенсацию регулировки усиления у представления временной области, где упомянутая регулировка усиления обходит преобразователь 140 частотной области во временную. Таким образом, сигналы полосы частот со сдвинутым уровнем и представление временной области можно привести к динамическому диапазону, предусмотренному преобразователем 140 частотной области во временную, который может быть ограничен из-за фиксированной длины слова и/или реализации преобразователя 140 на арифметике с фиксированной запятой. В частности, релевантный динамический диапазон сигналов полосы частот со сдвинутым уровнем и соответствующего представления временной области может иметь относительно высокие значения амплитуды или уровни мощности сигнала в течение относительно громких кадров. В отличие от этого, релевантный динамический диапазон сигнала полосы частот со сдвинутым уровнем, а следовательно, также у соответствующего представления временной области может иметь относительно небольшие значения амплитуды или значения мощности сигнала в течение относительно тихих кадров. В случае громких кадров информация, содержащаяся в младших битах двоичного представления сигналов полосы частот со сдвинутым уровнем, обычно может считаться незначительной по сравнению с информацией, которая содержится в старших битах. Как правило, коэффициент сдвига уровня является общим для всех сигналов полосы частот, что позволяет компенсировать сдвиг уровня, примененный к сигналам полосы частот со сдвинутым уровнем, даже после преобразователя 140 частотной области во временную. В отличие от предложенного коэффициента сдвига уровня, который определяется самим декодером 100 аудиосигнала, в потоке двоичных сигналов, который создан удаленным кодером аудиосигнала и предоставлен декодеру 100 аудиосигнала в качестве входа, содержится так называемый параметр глобального усиления. Кроме того, глобальное усиление применяется к множеству сигналов полосы частот между каскадом 110 предварительной обработки декодера и преобразователем 140 частотной области во временную. Как правило, глобальное усиление применяется к множеству сигналов полосы частот практически в том же месте в последовательности обработки сигналов, что и масштабные коэффициенты для разных сигналов полосы частот. Это означает, что для довольно громкого кадра сигналы полосы частот, предоставленные преобразователю 140 частотной области во временную, уже довольно громкие и поэтому могут вызвать срезание в соответствующем представлении временной области, потому что множество сигналов полосы частот не обеспечили достаточного запаса, если конструктивно складываются разные сигналы полосы частот, в силу этого приводя к довольно большой амплитуде сигнала в представлении временной области.
Предложенный подход, схематически проиллюстрированный на фиг. 5, который реализуется, например, декодером 100 аудиосигнала, допускает ограничение сигнала без потери точности данных или использования большей длины слова для гребенок фильтров декодера (например, преобразователя 140 частотной области во временную).
Чтобы решить проблему ограниченной длины слова у гребенок фильтров, нормализацию громкости как источник возможного срезания можно переместить в обработку во временной области. Это позволяет реализовать гребенку 140 фильтров с исходной длиной слова или уменьшенной длиной слова по сравнению с реализацией, где нормализация громкости выполняется в рамках обработки в частотной области. Чтобы выполнить ровное смешивание значений усиления, может выполняться регулировка формы перехода, которая будет объясняться ниже применительно к фиг. 9.
Кроме того, аудиовыборки в потоке двоичных сигналов обычно квантуются с меньшей точностью, нежели восстановленный аудиосигнал. Это предусматривает некоторый запас в гребенке 140 фильтров. Декодер 100 выводит некоторую оценку из другого параметра p потока двоичных сигналов (например, коэффициента глобального усиления), и если возможно срезание выходного сигнала, то применяет сдвиг уровня (g2), чтобы избежать срезания в гребенке 140 фильтров. Этот сдвиг уровня сигнализируется во временную область для надлежащий компенсации компенсатором 150 сдвига уровня. Если не предполагается никакого срезания, то аудиосигнал остается без изменений, и поэтому способ не теряет в точности.
Модуль оценки срезания может дополнительно конфигурироваться для определения вероятности срезания на основе дополнительной информации и/или для определения текущего коэффициента сдвига уровня на основе вероятности срезания. Даже если вероятность срезания указывает лишь тенденцию, а не установленный факт, она может предоставить полезную информацию касательно коэффициента сдвига уровня, который можно разумно применить к множеству сигналов полосы частот для заданного кадра кодированного представления аудиосигнала. Определение вероятности срезания может быть относительно простым в плане вычислительной сложности или затрат и по сравнению с преобразованием частотной области во временную, выполняемым преобразователем 140 частотной области во временную.
Дополнительная информация может содержать по меньшей мере одно из коэффициента глобального усиления для множества сигналов полосы частот и множества масштабных коэффициентов. Каждый масштабный коэффициент может соответствовать одному или нескольким сигналам полосы частот в множестве сигналов полосы частот. Коэффициент глобального усиления и/или множество масштабных коэффициентов уже предоставляют полезную информацию касательно уровня громкости текущего кадра, который нужно преобразовать во временную область с помощью преобразователя 140.
В соответствии по меньшей мере с некоторыми вариантами осуществления каскад 110 предварительной обработки декодера может конфигурироваться для получения множества сигналов полосы частот в виде множества последовательных кадров. Модуль 120 оценки срезания может конфигурироваться для определения текущего коэффициента сдвига уровня для текущего кадра. Другими словами, декодер 100 аудиосигнала может конфигурироваться для динамического определения изменяющихся коэффициентов сдвига уровня для разных кадров кодированного представления аудиосигнала, например, в зависимости от изменяющегося уровня громкости в последовательных кадрах.
Декодированное представление аудиосигнала может определяться на основе существенно компенсированного представления временной области. Например, декодер 100 аудиосигнала может дополнительно содержать ограничитель временной области после компенсатора 150 сдвига уровня. В соответствии с некоторыми вариантами осуществления компенсатор 150 сдвига уровня может быть частью такого ограничителя временной области.
В соответствии с дополнительными вариантами осуществления дополнительная информация касательно усиления сигналов полосы частот может содержать множество связанных с полосой частот коэффициентов усиления.
Каскад 110 предварительной обработки декодера может содержать обратный квантователь, сконфигурированный для переквантования каждого сигнала полосы частот, используя специфический для полосы частот индикатор квантования из множества специфических для полос частот индикаторов квантования. В частности, разные сигналы полосы частот могут быть квантованы с использованием разных разрешений квантования (или битовых разрешений) с помощью кодера аудиосигнала, который создал кодированное представление аудиосигнала и соответствующую дополнительную информацию. Поэтому разные специфические для полос частот индикаторы квантования могут предоставлять информацию об амплитудном разрешении для различных сигналов полосы частот в зависимости от необходимого амплитудного разрешения для того конкретного сигнала полосы частот, определенного ранее кодером аудиосигнала. Множество специфических для полос частот индикаторов квантования может быть частью дополнительной информации, предоставленной каскаду 110 предварительной обработки декодера, и может предоставлять дополнительную информацию для использования в модуле 120 оценки срезания для определения коэффициента сдвига уровня.
Модуль 120 оценки срезания может дополнительно конфигурироваться для анализа дополнительной информации на предмет того, предполагает ли дополнительная информация возможное срезание в представлении временной области. Такой результат затем интерпретировался бы, что самый младший бит (LSB) не содержит никакой релевантной информации. В этом случае сдвиг уровня, примененный модулем 130 сдвига уровня, может сдвинуть информацию к самому младшему биту, чтобы путем освобождения самого старшего бита (LSB) получить некоторый запас в самом старшем бите, который может понадобиться для разрешения временной области, если два или более сигналов полосы частот конструктивно складываются. Эту идею также можно распространить на n самых младших битов и n самых старших битов.
Модуль 120 оценки срезания может конфигурироваться для учета шума квантования. Например, при AAC-декодировании "глобальное усиление" и "масштабные диапазоны" используются для нормализации аудио/поддиапазона. В результате релевантная информация по каждому (спектральному) значению сдвигается к MSB, тогда как LSB пренебрегают при квантовании. После переквантования в декодере LSB обычно содержал (содержит) только шум. Если значения "глобального усиления" и "масштабного диапазона" (p) предполагают возможное срезание после восстановления гребенкой 140 фильтров, то разумно предположить, что LSB не содержал никакой информации. С помощью предложенного способа декодер 100 сдвигает информацию также в эти биты, чтобы получить некоторый запас с MSB. Это не вызывает практически никакой потери информации.
Предложенное устройство (декодер или кодер аудиосигнала) и способы дают возможность предотвращения срезания для аудиодекодеров/кодеров, не расходуя гребенку фильтров высокого разрешения на необходимый запас. Это обычно менее затратно в показателях требований к памяти и вычислительной сложности, нежели выполнение/реализация гребенки фильтров с более высоким разрешением.
Фиг. 6 показывает блок-схему декодера 100 аудиосигнала в соответствии с дополнительными вариантами осуществления настоящего изобретения. Декодер 100 аудиосигнала содержит обратный квантователь 210 (Q-1), который сконфигурирован для приема кодированного представления аудиосигнала, а также, как правило, дополнительной информации или части дополнительной информации. В некоторых вариантах осуществления обратный квантователь 210 может содержать распаковщик потока двоичных сигналов, сконфигурированный для распаковки потока двоичных сигналов, который содержит кодированное представление аудиосигнала и дополнительную информацию, например, в виде пакетов данных, где каждый пакет данных может соответствовать некоторому количеству кадров кодированного представления аудиосигнала. Как объяснялось выше, в кодированном представлении аудиосигнала и в каждом кадре каждая полоса частот может иметь собственное, индивидуальное разрешение квантования. Таким образом, полосы частот, которые временно требуют относительно точного квантования, чтобы правильно представить части аудиосигнала в упомянутых полосах частот, может иметь такое высокое разрешение квантования. С другой стороны, полосы частот, которые в течение данного кадра не содержат никакой информации или только небольшое количество, можно квантовать с использованием более грубого квантования, посредством этого экономя информационные биты. Обратный квантователь 210 может конфигурироваться для приведения различных полос частот, которые квантованы с использованием индивидуальных и изменяющихся во времени разрешений квантования, к общему разрешению квантования. Общее разрешение квантования может быть, например, разрешением, предусмотренным арифметическим представлением с фиксированной запятой, которое используется декодером 100 аудиосигнала внутри для вычислений и обработки. Например, декодер 100 аудиосигнала может использовать внутри 16-битовое или 24-битовое представление с фиксированной запятой. Дополнительная информация, предоставленная обратному квантователю 210, может содержать информацию касательно разных разрешений квантования для множества сигналов полосы частот для каждого нового кадра. Обратный квантователь 210 можно рассматривать как частный случай каскада 110 предварительной обработки декодера, изображенного на фиг. 5.
Модуль 120 оценки срезания, показанный на фиг. 6, аналогичен модулю 120 оценки срезания на фиг. 5.
Декодер 100 аудиосигнала дополнительно содержит модуль 230 сдвига уровня, которыйподключается к выходу обратного квантователя 210. Модуль 230 сдвига уровня, кроме того, принимает дополнительную информацию или часть дополнительной информации, а также коэффициент сдвига уровня, который динамически определяется модулем 120 оценки срезания, то есть для каждого интервала времени или кадра коэффициент сдвига уровня может предполагать разное значение. Коэффициент сдвига уровня последовательно применяется к множеству сигналов полосы частот с использованием множества умножителей или масштабирующих элементов 231, 232, и 233. Может случиться так, что некоторые из сигналов полосы частот относительно сильные при выходе из обратного квантователя 210, возможно, уже с использованием их соответствующих MSB. Когда эти сильные сигналы полосы частот складываются в преобразователе 140 частотной области во временную, может наблюдаться перегрузка в представлении временной области, выведенном преобразователем 140 частотной области во временную. Коэффициент сдвига уровня, определенный модулем 120 оценки срезания и примененный масштабирующими элементами 231, 232, 233, позволяет выборочно (то есть с учетом текущей дополнительной информации) уменьшать уровни сигналов полосы частот, чтобы перегрузка в представлении временной области возникала с меньшей вероятностью. Модуль 230 сдвига уровня дополнительно содержит второе множество умножителей или масштабирующих элементов 236, 237, 238, сконфигурированных для применения специфических для полос частот масштабных коэффициентов к соответствующим полосам частот. Дополнительная информация может содержать M масштабных коэффициентов. Модуль 230 сдвига уровня предоставляет множество сигналов полосы частот со сдвинутым уровнем преобразователю 140 частотной области во временную, который сконфигурирован для преобразования сигналов полосы частот со сдвинутым уровнем в представление временной области.
Декодер 100 аудиосигнала из фиг. 6 дополнительно содержит компенсатор 150 сдвига уровня, который в изображенном варианте осуществления содержит дополнительный умножитель или масштабирующий элемент 250 и вычислитель 252 обратной величины. Вычислитель 252 обратной величины принимает коэффициент сдвига уровня и определяет обратную величину (1/x) коэффициента сдвига уровня. Обратная величина коэффициента сдвига уровня перенаправляется в дополнительный масштабирующий элемент 250, где она умножается на представление временной области, чтобы создать существенно компенсированное представление временной области. В качестве альтернативны умножителям или масштабирующим элементам 231, 232, 233 и 252 также можно использовать аддитивные/субтрактивные элементы для применения коэффициента сдвига уровня к множеству сигналов полосы частот и к представлению временной области.
При желании декодер 100 аудиосигнала на фиг. 6 дополнительно содержит элемент 260 последующей обработки, подключенный к выходу компенсатора 150 сдвига уровня. Например, элемент 260 последующей обработки может содержать ограничитель временной области, обладающий неизменной характеристикой, чтобы уменьшать или удалять любое срезание, которое все же может присутствовать в существенно компенсированном представлении временной области, несмотря на предоставление модуля 230 сдвига уровня и компенсатора 150 сдвига уровня. Выход необязательного элемента 260 последующей обработки предоставляет декодированное представление аудиосигнала. Если необязательный элемент 260 последующей обработки отсутствует, то декодированное представление аудиосигнала может быть доступно на выходе компенсатора 150 сдвига уровня.
Фиг. 7 показывает блок-схему декодера 100 аудиосигнала в соответствии с дополнительными возможными вариантами осуществления настоящего изобретения. Обратный квантователь/декодер 310 потока двоичных сигналов сконфигурирован для обработки входящего потока двоичных сигналов и выведения из него следующей информации: множества сигналов X1(f) полосы частот, параметров p потока двоичных сигналов и глобального усиления g1. Параметры p потока двоичных сигналов могут содержать масштабные коэффициенты для полос частот и/или глобального усиления g1.
Параметры p потока двоичных сигналов предоставляются модулю 320 оценки срезания, который выводит масштабный коэффициент 1/g2 из параметров p потока двоичных сигналов. Масштабный коэффициент 1/g2 вводится в модуль 330 сдвига уровня, который в изображенном варианте осуществления также реализует управление динамическим диапазоном (DRC). Модуль 330 сдвига уровня дополнительно может принимать параметры p потока двоичных сигналов или их часть для применения масштабных коэффициентов к множеству сигналов полосы частот. Модуль 330 сдвига уровня выводит множество сигналов X2(f) полосы частот со сдвинутым уровнем в обратную гребенку 340 фильтров, которая обеспечивает преобразование частотной области во временную. На выходе обратной гребенки 340 фильтров предоставляется представление X3(t) временной области для передачи в компенсатор 350 сдвига уровня. Компенсатор 350 сдвига уровня является умножителем или масштабирующим элементом, как в изображенном на фиг. 6 варианте осуществления. Компенсатор 350 сдвига уровня является частью последующей обработки 360 во временной области для высокоточной обработки, например, поддерживающей большую длину слова, нежели обратная гребенка 340 фильтров. Например, обратная гребенка фильтров может иметь длину слова в 16 битов, а высокоточная обработка, выполняемая с помощью последующей обработки во временной области, может выполняться с использованием 20 битов. В качестве другого примера длиной слова у обратной гребенки 340 фильтров может быть 24 бита, а длиной слова у высокоточной обработки может быть 30 битов. В любом случае количество битов не должно рассматриваться в качестве ограничения объема настоящего патента/заявки на патент, пока не указано явно. Последующая обработка 360 во временной области выводит декодированное представление X4(t) аудиосигнала.
Примененный сдвиг g2 усиления передается дальше в реализацию 360 ограничителя для компенсации. Ограничитель 362 можно реализовать с высокой точностью.
Если модуль 320 оценки срезания не оценивает никакого срезания, то аудиовыборки остаются практически без изменений, то есть как будто не выполнено никакого сдвига уровня и никакой компенсации сдвига уровня.
Модуль оценки срезания предоставляет обратную величину g2 коэффициента 1/g2 сдвига уровня в объединитель 328, где она объединяется с глобальным усилением g1 для получения объединенного усиления g3.
Декодер 100 аудиосигнала дополнительно содержит регулировку 370 формы перехода, которая сконфигурирован для обеспечения плавных переходов, когда объединенное усиление g3 резко меняется от предыдущего кадра к текущему кадру (или от текущего кадра к последующему кадру). Регулятор 370 формы перехода может конфигурироваться для перекрестного затухания текущего коэффициента сдвига уровня и последующего коэффициента сдвига уровня, чтобы получить коэффициент g4 сдвига уровня с перекрестным затуханием для использования компенсатором 350 сдвига уровня. Чтобы предусмотреть плавный переход изменяющихся коэффициентов усиления, нужно выполнить регулировку формы перехода. Этот инструмент создает вектор коэффициентов g4(t) усиления (один коэффициент для каждой выборки соответствующего аудиосигнала). Чтобы имитировать такую же характеристику регулировки усиления, какую дала бы обработка сигнала частотной области, нужно использовать одинаковые переходные окна W из гребенки 340 фильтров. Один кадр охватывает множество выборок. Объединенный коэффициент g3 усиления обычно является постоянным в течение одного кадра. Переходное окно W обычно имеет длину в один кадр и предоставляет разные значения окна для каждой выборки в кадре (например, первый полупериод косинуса). Подробности касательно одной возможной реализации регулировки формы перехода предоставляются на фиг. 9 и в соответствующем описании ниже.
Фиг. 8 схематически иллюстрирует результат сдвига уровня, примененного к множеству сигналов полосы частот. Аудиосигнал (например, каждый из множества сигналов полосы частот) можно представить с использованием 16-битового разрешения, что символически изображено прямоугольником 402. Прямоугольник 404 схематически иллюстрирует то, как биты 16-битового разрешения применяются для представления квантованной выборки в одном из сигналов полосы частот, предоставленных каскадом 110 предварительной обработки декодера. Видно, что квантованная выборка может использовать некоторое количество битов, начиная с самого старшего бита (MSB) и до последнего бита, используемого для квантованной выборки. Оставшиеся биты до самого младшего бита (LSB) содержат только шум квантования. Это можно объяснить тем, что для текущего кадра соответствующий сигнал полосы частот был представлен в потоке двоичных сигналов лишь уменьшенным количеством битов (<16 битов). Даже если использовалось полное битовое разрешение в 16 битов в потоке двоичных сигналов для текущего кадра и для соответствующей полосы частот, самый младший бит обычно содержал бы значительное количество шума квантования.
Прямоугольник 406 на фиг. 8 схематически иллюстрирует результат сдвигания уровня у сигнала полосы частот. Так как можно предположить, что содержимым самого младшего бита (битов) является значительное количество шума квантования, квантованную выборку можно сдвинуть к самому младшему биту практически без потери релевантной информации. Этого можно достичь путем простого сдвигания битов вниз ("правый сдвиг") или путем фактического пересчета двоичного представления. В обоих случаях коэффициент сдвига уровня можно запомнить для более поздней компенсации примененного сдвига уровня (например, посредством компенсатора 150 или 350 сдвига уровня). Сдвиг уровня приводит к дополнительному запасу в самом старшем бите (битах).
Фиг. 9 схематически иллюстрирует возможную реализацию регулировки 370 формы перехода, показанной на фиг. 7. Регулятор 370 формы перехода может содержать запоминающее устройство 371 для предыдущего коэффициента сдвига уровня, первый организатор 372 окон, сконфигурированный для формирования первого множества разделенных на окна выборок путем применения формы окна к текущему коэффициенту сдвига уровня, второй организатор 376 окон, сконфигурированный для формирования второго множества разделенных на окна выборок путем применения предыдущей формы окна к предыдущему коэффициенту сдвига уровня, предоставленному запоминающим устройством 371, и объединитель 379 выборок, сконфигурированный для объединения взаимно соответствующих разделенных на окна выборок из первого множества разделенных на окна выборок и второго множества разделенных на окна выборок, чтобы получить множество объединенных выборок. Первый организатор 372 окон содержит поставщика 373 формы окна и умножитель 374. Второй организатор 376 окон содержит поставщика 377 предыдущей формы окна и дополнительный умножитель 378. Умножитель 374 и дополнительный умножитель 378 выводят векторы по времени. В случае первого организатора 372 окон каждый векторный элемент соответствует умножению текущего объединенного коэффициента g3(t) усиления (постоянного в течение текущего кадра) на текущую форму окна, предоставленную поставщиком 373 формы окна. В случае второго организатора 376 окон каждый векторный элемент соответствует умножению предыдущего объединенного коэффициента g3(t–T) усиления (постоянного в течение предыдущего кадра) на предыдущую форму окна, предоставленную поставщиком 377 предыдущей формы окна.
В соответствии с вариантом осуществления, схематически проиллюстрированным на фиг. 9, коэффициент усиления из предыдущего кадра нужно умножить на "вторую половину" окна в гребенке 340 фильтров, тогда как фактический коэффициент усиления умножается на "первую половину" окна в последовательности. Эти два вектора можно сложить, чтобы образовать один вектор g4(t) усиления для поэлементного умножения на аудиосигнал X3(t) (см. фиг. 7).
Формы окон могут сообщаться с помощью дополнительной информации w от гребенки 340 фильтров, если необходимо.
Форма окна и предыдущая форма окна также могут использоваться преобразователем 340 частотной области во временную, чтобы одна и та же форма окна и предыдущая форма окна использовались для преобразования сигналов полосы частот со сдвинутым уровнем в представление временной области и для организации окон текущего коэффициента сдвига уровня и предыдущего коэффициента сдвига уровня.
Текущий коэффициент сдвига уровня может быть действительным для текущего кадра множества сигналов полосы частот. Предыдущий коэффициент сдвига уровня может быть действительным для предыдущего кадра множества сигналов полосы частот. Текущий кадр и предыдущий кадр могут перекрываться, например, на 50%.
Регулировка 370 формы перехода может конфигурироваться для объединения предыдущего коэффициента сдвига уровня со второй частью предыдущей формы окна, получая в результате последовательность коэффициентов предыдущего кадра. Регулировка 370 формы перехода может дополнительно конфигурироваться для объединения текущего коэффициента сдвига уровня с первой частью текущей формы окна, получая в результате последовательность коэффициентов текущего кадра. Последовательность коэффициентов сдвига уровня с перекрестным затуханием может определяться на основе последовательности коэффициентов предыдущего кадра и последовательности коэффициентов текущего кадра.
Предложенный подход не обязательно ограничивается декодерами, также кодеры могли бы иметь регулировку усиления или ограничитель совместно с гребенкой фильтров, которые могли бы извлечь пользу из предложенного способа.
Фиг. 10 иллюстрирует, как соединяются каскад 110 предварительной обработки декодера и модуль 120 оценки срезания. Каскад 110 предварительной обработки декодера соответствует определителю 1110 кодовой книги или содержит его. Модуль 120 оценки срезания содержит блок 1120 оценки. Определитель 1110 кодовой книги приспособлен для определения кодовой книги в качестве идентифицированной кодовой книги из множества кодовых книг, где аудиосигнал кодирован с применением идентифицированной кодовой книги. Блок 1120 оценки приспособлен для выведения значения уровня, например, значения энергии, значения амплитуды или значения громкости, ассоциированного с идентифицированной кодовой книгой, в качестве выведенного значения уровня. Кроме того, блок 1120 оценки приспособлен для оценивания оценки уровня аудиосигнала, например оценки энергии, оценки амплитуды или оценки громкости, с использованием выведенного значения уровня. Например, определитель 1110 кодовой книги может определить кодовую книгу, которая использована кодером для кодирования аудиосигнала, путем приема дополнительной информации, переданной вместе с кодированным аудиосигналом. В частности, дополнительная информация может содержать информацию, идентифицирующую кодовую книгу, используемую для кодирования рассматриваемого раздела аудиосигнала. Такая информация может, например, передаваться от кодера декодеру в виде числа, идентифицирующего кодовую книгу Хаффмана, используемую для кодирования рассматриваемого раздела аудиосигнала.
Фиг. 11 иллюстрирует блок оценки в соответствии с вариантом осуществления. Блок оценки содержит блок 1210 выведения значения уровня и масштабирующий блок 1220. Блок выведения значения уровня приспособлен для выведения значения уровня, ассоциированного с идентифицированной кодовой книгой, то есть кодовой книгой, которая использовалась кодером для кодирования спектральных данных, путем поиска значения уровня в запоминающем устройстве, путем запроса значения уровня из локальной базы данных или путем запроса значения уровня, ассоциированного с идентифицированной кодовой книгой, из удаленного компьютера. В варианте осуществления значение уровня, которое ищется или запрашивается блоком выведения значения уровня, может быть средним значением уровня, которое указывает средний уровень кодированного немасштабированного спектрального значения, кодированного с использованием идентифицированной кодовой книги.
При этом выведенное значение уровня не вычисляется из фактических спектральных значений, а вместо этого используется среднее значение уровня, которое зависит только от применяемой кодовой книги. Как объяснено раньше, кодер обычно приспособлен для выбора кодовой книги из множества кодовых книг, которая лучше всего подходит для кодирования соответствующих спектральных данных некоторого раздела аудиосигнала. Поскольку кодовые книги отличаются, например, в части их максимального абсолютного значения, которое можно кодировать, то среднее значение, которое кодируется кодовой книгой Хаффмана, отличается от одной кодовой книги к другой, и поэтому среднее значение уровня у кодированного спектрального коэффициента, кодированного конкретной кодовой книгой, также отличается от одной кодовой книги к другой.
Таким образом, в соответствии с вариантом осуществления среднее значение уровня для кодирования спектрального коэффициента аудиосигнала, применяющего конкретную кодовую книгу Хаффмана, может определяться для каждой кодовой книги Хаффмана и может, например, сохраняться в запоминающем устройстве, базе данных или на удаленном компьютере. Тогда блоку выведения значения уровня нужно просто искать или запросить значение уровня, ассоциированное с идентифицированной кодовой книгой, которая применялась для кодирования спектральных данных, чтобы получить выведенное значение уровня, ассоциированное с идентифицированной кодовой книгой.
Однако нужно принять во внимание, что кодовые книги Хаффмана часто применяются для кодирования немасштабированных спектральных значений, как в случае AAC MPEG. Тогда следует учитывать масштабирование, когда проводится оценка уровня. Поэтому блок оценки из фиг. 11 также содержит масштабирующий блок 1220. Масштабирующий блок приспособлен для выведения масштабного коэффициента, относящегося к кодированному аудиосигналу или к части кодированного аудиосигнала, в качестве выведенного масштабного коэффициента. Например, по отношению к декодеру масштабирующий блок 1220 будет определять масштабный коэффициент для каждого масштабного диапазона. Например, масштабирующий блок 1220 может принять информацию о масштабном коэффициенте масштабного диапазона путем приема дополнительной информации, переданной от кодера декодеру. Масштабирующий блок 1220, кроме того, приспособлен для определения масштабированного значения уровня на основе масштабного коэффициента и выведенного значения уровня.
В варианте осуществления, где выведенное значение уровня является выведенным значением энергии, масштабирующий блок приспособлен для применения выведенного масштабного коэффициента к выведенному значению энергии, чтобы получить масштабированное значение уровня, путем умножения выведенного значения энергии на квадрат выведенного масштабного коэффициента.
В другом варианте осуществления, где выведенное значение уровня является выведенным значением амплитуды, масштабирующий блок приспособлен для применения выведенного масштабного коэффициента к выведенному значению амплитуды, чтобы получить масштабированное значение уровня, путем умножения выведенного значения амплитуды на выведенный масштабный коэффициент.
В дополнительном варианте осуществления, в котором выведенное значение уровня является выведенным значением громкости, масштабирующий блок 1220 приспособлен для применения выведенного масштабного коэффициента к выведенному значению громкости, чтобы получить масштабированное значение уровня, путем умножения выведенного значения громкости на куб выведенного масштабного коэффициента. Существуют альтернативные способы вычисления громкости, например с помощью показателя степени 3/2. Как правило, масштабные коэффициенты нужно преобразовывать в область громкости, когда выведенное значение уровня является значением громкости.
Эти варианты осуществления принимают во внимание, что значение энергии определяется на основе квадрата спектральных коэффициентов аудиосигнала, что значение амплитуды определяется на основе абсолютных значений спектральных коэффициентов аудиосигнала, и что значение громкости определяется на основе спектральных коэффициентов аудиосигнала, которые преобразованы в область громкости.
Блок оценки приспособлен для оценивания оценки уровня аудиосигнала с использованием масштабированного значения уровня. В варианте осуществления из фиг. 11 блок оценки приспособлен для вывода масштабированного значения уровня в качестве оценки уровня. В этом случае никакая постобработка масштабированного значения уровня не проводится. Однако, как проиллюстрировано в варианте осуществления из фиг. 12, блок оценки также может быть приспособлен для проведения постобработки. Поэтому блок оценки из фиг. 12 содержит постпроцессор 1230 для постобработки одного или нескольких масштабированных значений уровня для оценивания оценки уровня. Например, оценка уровня в блоке оценки может определяться постпроцессором 1230 путем определения среднего значения у множества масштабированных значений уровня. Это усредненное значение блок оценки может вывести в качестве оценки уровня.
В отличие от представленных вариантов осуществления подход из современного уровня техники для оценивания, например, энергии одного масштабного диапазона состоял бы в выполнении декодирования методом Хаффмана и обратного квантования для всех спектральных значений и вычисления энергии путем суммирования квадрата всех обратно-квантованных спектральных значений.
Однако в предложенных вариантах осуществления этот сложный в вычислительном отношении процесс из современного уровня техники заменяется оценкой среднего уровня, который зависит только от масштабного коэффициента и используемой кодовой книги, а не от фактических квантованных значений.
Варианты осуществления настоящего изобретения применяют тот факт, что кодовая книга Хаффмана спроектирована для обеспечения оптимального кодирования, следуя специальной статистике. Это означает, что кодовая книга спроектирована в соответствии с вероятностью данных, например, спектральных линий AAC-ELD (AAC-ELD = Усовершенствованное аудиокодирование – Улучшенная малая задержка). Этот процесс можно обратить, чтобы получить вероятность данных в соответствии с кодовой книгой. Вероятность каждой записи данных внутри кодовой книги (индекс) задается длиной кодового слова. Например,
p (индекс)=2^-длина(кодовое слово)
то есть
p (индекс)=2-длина(кодовое слово)
где p(индекс) – вероятность записи данных (индекса) внутри кодовой книги.
На основе этого можно заранее вычислить и сохранить предполагаемый уровень следующим образом: каждый индекс представляет последовательность целочисленных значений (x), например, спектральных линий, где длина последовательности зависит от размера кодовой книги, например, 2 или 4 для AAC-ELD.
Фиг. 13a и 13b иллюстрируют способ для формирования значения уровня, например значения энергии, значения амплитуды или значения громкости, ассоциированного с кодовой книгой, в соответствии с вариантом осуществления. Способ содержит:
Определение последовательности числовых значений, ассоциированных с кодовым словом в кодовой книге для каждого кодового слова в кодовой книге (этап 1310). Как объяснено раньше, кодовая книга кодирует последовательность числовых значений, например, 2 или 4 числовых значения, с помощью кодового слова в кодовой книге. Кодовая книга содержит множество кодовых книг для кодирования множества последовательностей числовых значений. Последовательность числовых значений, которая определяется, является последовательностью числовых значений, которая кодируется рассматриваемым кодовым словом в кодовой книге. Этап 1310 проводится для каждого кодового слова в кодовой книге. Например, если кодовая книга содержит 81 кодовое слово, то на этапе 1310 определяется 81 последовательность числовых значений.
На этапе 1320 определяется обратно-квантованная последовательность числовых значений для каждого кодового слова в кодовой книге путем применения обратного квантователя к числовым значениям в последовательности числовых значений кодового слова для каждого кодового слова в кодовой книге. Как объяснено раньше, кодер, как правило, может применять квантование при кодировании спектральных значений аудиосигнала, например, неравномерное квантование. В результате это квантование нужно инвертировать на стороне декодера.
Потом на этапе 1330 последовательность значений уровня определяется для каждого кодового слова в кодовой книге.
Если значение энергии нужно сформировать в качестве значения уровня кодовой книги, то определяется последовательность значений энергии для каждого кодового слова, и вычисляется квадрат каждого значения в обратно-квантованной последовательности числовых значений для каждого кодового слова в кодовой книге.
Однако, если значение амплитуды нужно сформировать в качестве значения уровня кодовой книги, то определяется последовательность значений амплитуды для каждого кодового слова, и вычисляется абсолютная величина каждого значения в обратно-квантованной последовательности числовых значений для каждого кодового слова в кодовой книге.
Однако, если значение громкости нужно сформировать в качестве значения уровня кодовой книги, то определяется последовательность значений громкости для каждого кодового слова, и вычисляется куб каждого значения в обратно-квантованной последовательности числовых значений для каждого кодового слова в кодовой книге. Существуют альтернативные способы вычисления громкости, например с помощью показателя степени 3/2. Как правило, значения в обратно-квантованной последовательности числовых значений нужно преобразовывать в область громкости, когда значение громкости нужно сформировать в качестве значения уровня кодовой книги.
Потом на этапе 1340 суммарное значение уровня для каждого кодового слова в кодовой книге вычисляется путем суммирования значений в последовательности значений уровня для каждого кодового слова в кодовой книге.
Затем на этапе 1350 взвешенное по вероятности суммарное значение уровня определяется для каждого кодового слова в кодовой книге путем умножения суммарного значения уровня кодового слова на значение вероятности, ассоциированное с кодовым словом, для каждого кодового слова в кодовой книге. При этом учитывается, что некоторые из последовательностей числовых значений, например, последовательности спектральных коэффициентов, не будут появляться так же часто, как другие последовательности спектральных коэффициентов. Значение вероятности, ассоциированное с кодовым словом, учитывает это. Такое значение вероятности можно вывести из длины кодового слова, так как кодовые слова, которые появляются с большей вероятностью, кодируются с использованием кодовых слов, имеющих меньшую длину, тогда как другие кодовые слова, которые появляются с меньшей вероятностью, будут кодироваться с использованием кодовых слов, имеющих большую длину, когда применяется кодирование методом Хаффмана.
На этапе 1360 будет определяться усредненное, взвешенное по вероятности суммарное значение уровня для каждого кодового слова в кодовой книге путем деления взвешенного по вероятности суммарного значения уровня кодового слова на значение размера, ассоциированное с кодовой книгой, для каждого кодового слова в кодовой книге. Значение размера указывает количество спектральных значений, которые кодируются кодовым словом в кодовой книге. С помощью этого определяется усредненное, взвешенное по вероятности суммарное значение уровня, которое представляет значение уровня (взвешенное по вероятности) для спектрального коэффициента, который кодируется кодовым словом.
Затем на этапе 1370 значение уровня в кодовой книге вычисляется путем суммирования усредненных, взвешенных по вероятности суммарных значений уровня у всех кодовых слов.
Нужно отметить, что такое формирование значения уровня нужно выполнять только один раз для кодовой книги. Если определяется значение уровня в кодовой книге, то это значение можно просто искать и использовать, например, с помощью устройства для оценки уровня в соответствии с описанными выше вариантами осуществления.
Ниже представляется способ для формирования значения энергии, ассоциированного с кодовой книгой, в соответствии с вариантом осуществления. Чтобы оценить предполагаемое значение энергии данных, кодированных с помощью заданной кодовой книги, следующие этапы нужно выполнять только один раз для каждого индекса в кодовой книге:
A) применить обратный квантователь к целочисленным значениям в последовательности (например, AAC-ELD: x^(4/3))
B) вычислить энергию путем возведения каждого значения последовательности из A) в квадрат
C) составить сумму последовательности из B)
D) умножить C) на заданную вероятность индекса
E) поделить на размер кодовой книги, чтобы получить предполагаемую энергию в расчете на спектральную линию.
В конечном счете все значения, вычисленные этапом E), нужно суммировать для получения предполагаемой энергии полной кодовой книги.
После того, как результат этих этапов сохраняется в таблицу, оцененные значения энергии можно просто искать на основе индекса кодовой книги, то есть в зависимости от того, какая кодовая книга используется. Фактические спектральные значения для этой оценки не нужно декодировать методом Хаффмана.
Чтобы оценить общую энергию спектральных данных полного аудиокадра, нужно принять во внимание масштабный коэффициент. Масштабный коэффициент можно извлечь из потока двоичных сигналов без значительной сложности. Масштабный коэффициент можно изменить перед применением к предполагаемой энергии, например, можно вычислить квадрат используемого масштабного коэффициента. Предполагаемая энергия тогда умножается на квадрат используемого масштабного коэффициента.
В соответствии с вышеописанными вариантами осуществления спектральный уровень для каждого масштабного диапазона может оцениваться без декодирования спектральных значений, кодированных методом Хаффмана. Оценки уровня могут использоваться для идентификации потоков с низким уровнем, например с малой мощностью, которые обычно не приводят к срезанию. Поэтому можно избежать полного декодирования таких потоков.
В соответствии с вариантом осуществления устройство для оценки уровня дополнительно содержит запоминающее устройство или базу данных, имеющие сохраненное в них множество записанных значений уровня кодовой книги, указывающих значение уровня, ассоциируемое с кодовой книгой, где каждая из множества кодовых книг имеет ассоциированное с ней записанное значение уровня кодовой книги, сохраненное в запоминающем устройстве или базе данных. Кроме того, блок выведения значения уровня сконфигурирован для выведения значения уровня, ассоциированного с идентифицированной кодовой книгой, путем выведения записанного значения уровня кодовой книги, ассоциированного с идентифицированной кодовой книгой, из запоминающего устройства или из базы данных.
Уровень, оцененный в соответствии с вышеописанными вариантами осуществления, может меняться, если в кодеке применяется этап дополнительной обработки в виде предсказания, такого как фильтрация с предсказанием, например, для фильтрации TNS (Временное ограничение шума) в AAC-ELD. Здесь коэффициенты предсказания передаются внутри потока двоичных сигналов, например, в виде коэффициентов PARCOR для TNS.
Фиг. 14 иллюстрирует вариант осуществления, в котором блок оценки дополнительно содержит регулятор 1240 фильтра с предсказанием. Регулятор фильтра с предсказанием приспособлен для выведения одного или нескольких коэффициентов фильтра с предсказанием, относящихся к кодированному аудиосигналу или к части кодированного аудиосигнала, в качестве выведенных коэффициентов фильтра с предсказанием. Кроме того, регулятор фильтра с предсказанием приспособлен для получения отрегулированного значения уровня у фильтра с предсказанием на основе коэффициентов фильтра с предсказанием и выведенного значения уровня. Кроме того, блок оценки приспособлен для оценивания оценки уровня аудиосигнала с использованием отрегулированного значения уровня у фильтра с предсказанием.
В варианте осуществления коэффициенты PARCOR для TNS используются в качестве коэффициентов фильтра с предсказанием. Эффективность предсказания у процесса фильтрации может весьма эффективно определяться из тех коэффициентов. Что касается TNS, то эффективность предсказания может вычисляться в соответствии с формулой: эффективность=1/prod(1-parcor.^2).
Например, если нужно принять в расчет 3 коэффициента PARCOR, например parcor1, parcor2 и parcor3, то усиление вычисляется в соответствии с формулой:
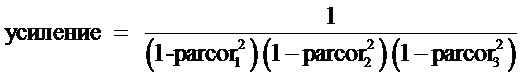
Для n коэффициентов PARCOR parcor1, parcor2, … parcorn применяется следующая формула:
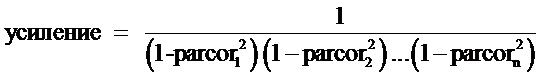
Это означает, что усиление аудиосигнала посредством фильтрации может оцениваться без применения самой операции фильтрации.
Фиг. 15 показывает блок-схему кодера 1500, который реализует предложенную регулировку усиления, которая "обходит" гребенку фильтров. Кодер 1500 аудиосигнала сконфигурирован для предоставления кодированного представления аудиосигнала на основе представления временной области входного аудиосигнала. Представление временной области может быть, например, входным аудиосигналом с импульсно-кодовой модуляцией.
Кодер аудиосигнала содержит модуль 1520 оценки срезания, сконфигурированный для анализа представления временной области входного аудиосигнала, чтобы определить текущий коэффициент сдвига уровня для представления входного сигнала. Кодер аудиосигнала дополнительно содержит схему 1530 сдвига уровня, сконфигурированный для сдвига уровня представления временной области входного аудиосигнала в соответствии с коэффициентом сдвига уровня для получения представления временной области со сдвинутым уровнем. Преобразователь 1540 временной области в частотную (например, гребенка фильтров, такая как гребенка квадратурных зеркальных фильтров, модифицированное дискретное косинусное преобразование и т.п.) сконфигурирован для преобразования представления временной области со сдвинутым уровнем в множество сигналов полосы частот. Кодер 1500 аудиосигнала также содержит компенсатор 1550 сдвига уровня, сконфигурированный для воздействия на множество сигналов полосы частот для по меньшей мере частичной компенсации сдвига уровня, примененного модулем 1530 сдвига уровня к представлению временной области со сдвинутым уровнем, и для получения множества существенно компенсированных сигналов полосы частот.
Кодер 1500 аудиосигнала может дополнительно содержать компонент 1510 распределения битов/шума, квантователя и кодирования и психоакустическую модель 1508. Психоакустическая модель 1508 определяет переменные по времени-частоте пороги маскирования (и/или индивидуальные для полосы частот и индивидуальные для кадра разрешения квантования, и масштабные коэффициенты) на основе входного аудиосигнала PCM для использования компонентом 1510 распределения битов/шума, квантователя и кодирования. Подробности касательно одной возможной реализации психоакустической модели и других аспектов кодирования воспринимаемого аудио можно найти, например, в международных стандартах ISO/IEC 11172-3 и ISO/IEC 13818-3. Компонент 1510 распределения битов/шума, квантователя и кодирования сконфигурирован для квантования множества сигналов полосы частот в соответствии с их индивидуальными для полосы частот и индивидуальными для кадра разрешениями квантования и предоставления этих данных блоку 1505 форматирования потока двоичных сигналов, который выводит кодированный поток двоичных сигналов для предоставления одному или нескольким декодерам аудиосигнала. Компонент 1510 распределения битов/шума, квантователя и кодирования может конфигурироваться для определения дополнительной информации в дополнение к множеству квантованных частотных сигналов. Эта дополнительная информация также может предоставляться блоку 1505 форматирования потока двоичных сигналов для включения в поток двоичных сигналов.
Фиг. 16 показывает блок-схему алгоритма способа для декодирования кодированного представления аудиосигнала, чтобы получить декодированное представление аудиосигнала. Способ содержит этап 1602 предварительной обработки кодированного представления аудиосигнала, чтобы получить множество сигналов полосы частот. В частности, предварительная обработка может содержать распаковку потока двоичных сигналов на данные, соответствующие последовательным кадрам, и переквантование (обратное квантование) связанных с полосой частот данных в соответствии со специфическими для полос частот разрешениями квантования, чтобы получить множество сигналов полосы частот.
На этапе 1604 способа для декодирования анализируется дополнительная информация касательно усиления сигналов полосы частот, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала. Усиление относительно сигналов полосы частот может быть индивидуальным для каждого сигнала полосы частот (например, масштабные коэффициенты, известные в некоторых схемах кодирования воспринимаемого аудио, или аналогичные параметры) либо общим для всех сигналов полосы частот (например, глобальное усиление, известное в некоторых схемах кодирования воспринимаемого аудио). Анализ дополнительной информации дает возможность сбора информации о громкости кодированного аудиосигнала в течение рассматриваемого кадра. Громкость, в свою очередь, может указывать тенденцию к срезанию у декодированного представления аудиосигнала. Коэффициент сдвига уровня обычно определяется как значение, которое препятствует такому срезанию, сохраняя при этом релевантный динамический диапазон и/или релевантное информационное содержание у (всех) сигналов полосы частот.
Способ для декодирования дополнительно содержит этап 1606 сдвига уровней сигнала полосы частот в соответствии с коэффициентом сдвига уровня. Если сигналы полосы частот сдвигаются к более низкому уровню, то сдвиг уровня создает некоторый дополнительный запас в самом старшем бите (битах) двоичного представления сигналов полосы частот. Этот дополнительный запас может быть необходим при преобразовании множества сигналов полосы частот из частотной области во временную область, чтобы получить представление временной области, что выполняется на последующем этапе 1608. В частности, дополнительный запас снижает угрозу срезания у представления временной области, если некоторые из сигналов полосы частот находятся рядом с верхним пределом относительно их амплитуды и/или мощности. В результате преобразование частотной области во временную может выполняться с использованием относительно небольшой длины слова.
Способ для декодирования также содержит этап 1609 воздействия на представление временной области для по меньшей мере частичной компенсации сдвига уровня, примененного к сигналам полосы частот со сдвинутым уровнем. Впоследствии получается существенно компенсированное временное представление.
Соответственно, способ для декодирования кодированного представления аудиосигнала в декодированное представление аудиосигнала содержит:
- предварительную обработку кодированного представления аудиосигнала, чтобы получить множество сигналов полосы частот;
- анализ дополнительной информации касательно усиления сигналов полосы частот, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала;
- сдвиг уровней сигналов полосы частот в соответствии с коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем;
- выполнение преобразования частотной области во временную для сигналов полосы частот в представление временной области; и
- воздействие на представление временной области для по меньшей мере частичной компенсации сдвига уровня, примененного к сигналам полосы частот со сдвинутым уровнем, и для получения существенно компенсированного представления временной области.
В соответствии с дополнительными аспектами анализ дополнительной информации может содержать: определение вероятности срезания на основе дополнительной информации и определение текущего коэффициента сдвига уровня на основе вероятности срезания.
В соответствии с дополнительными аспектами дополнительная информация может содержать по меньшей мере одно из коэффициента глобального усиления для множества сигналов полосы частот и множества масштабных коэффициентов, причем каждый масштабный коэффициент соответствует одному сигналу полосы частот из множества сигналов полосы частот.
В соответствии с дополнительными аспектами предварительная обработка кодированного представления аудиосигнала может содержать получение множества сигналов полосы частот в виде множества последовательных кадров, а анализ дополнительной информации может содержать определение текущего коэффициента сдвига уровня для текущего кадра.
В соответствии с дополнительными аспектами декодированное представление аудиосигнала может определяться на основе существенно компенсированного представления временной области.
В соответствии с дополнительными аспектами способ может дополнительно содержать: применение характеристики ограничителя временной области после воздействия на представление временной области для по меньшей мере частичной компенсации сдвига уровня.
В соответствии с дополнительными аспектами дополнительная информация касательно усиления сигналов полосы частот может содержать множество связанных с полосой частот коэффициентов усиления.
В соответствии с дополнительными аспектами предварительная обработка кодированного аудиосигнала может содержать переквантование каждого сигнала полосы частот с использованием специфического для полосы частот индикатора квантования из множества специфических для полос частот индикаторов квантования.
В соответствии с дополнительными аспектами способ может дополнительно содержать выполнение регулировки формы перехода, при этом регулировка формы перехода содержит: перекрестное затухание текущего коэффициента сдвига уровня и последующего коэффициента сдвига уровня, чтобы получить коэффициент сдвига уровня с перекрестным затуханием для использования во время действия по меньшей мере частичной компенсации сдвига уровня.
В соответствии с дополнительными аспектами регулировка формы перехода может дополнительно содержать:
- временное сохранение предыдущего коэффициента сдвига уровня,
- формирование первого множества разделенных на окна выборок путем применения формы окна к текущему коэффициенту сдвига уровня,
- формирование второго множества разделенных на окна выборок путем применения предыдущей формы окна к предыдущему коэффициенту сдвига уровня, предоставленному действием временного сохранения предыдущего коэффициента сдвига уровня, и
- объединение взаимно соответствующих разделенных на окна выборок из первого множества разделенных на окна выборок и второго множества разделенных на окна выборок, чтобы получить множество объединенных выборок.
В соответствии с дополнительными аспектами форма окна и предыдущая форма окна также могут использоваться преобразованием частотной области во временную, чтобы одна и та же форма окна и предыдущая форма окна использовались для преобразования сигналов полосы частот со сдвинутым уровнем в представление временной области и для организации окон текущего коэффициента сдвига уровня и предыдущего коэффициента сдвига уровня.
В соответствии с дополнительными аспектами текущий коэффициент сдвига уровня может быть действительным для текущего кадра множества сигналов полосы частот, где предыдущий коэффициент сдвига уровня может быть действительным для предыдущего кадра множества сигналов полосы частот, и где текущий кадр и предыдущий кадр могут перекрываться. Регулировка формы перехода может конфигурироваться
- для объединения предыдущего коэффициента сдвига уровня со второй частью предыдущей формы окна, получая в результате последовательность коэффициентов предыдущего кадра,
- для объединения текущего коэффициента сдвига уровня с первой частью текущей формы окна, получая в результате последовательность коэффициентов текущего кадра, и
- для определения последовательности коэффициентасдвига уровня с перекрестным затуханием на основе последовательности коэффициентов предыдущего кадра и последовательности коэффициентов текущего кадра.
В соответствии с дополнительными аспектами анализ дополнительной информации может выполняться на предмет того, предполагает ли дополнительная информация возможное срезание в представлении временной области, что означает, что самый младший бит не содержит никакой релевантной информации, и в этом случае сдвиг уровня сдвигает информацию к самому младшему биту, чтобы получить некоторый запас в самом старшем бите путем освобождения самого старшего бита.
В соответствии с дополнительными аспектами может предоставляться компьютерная программа для реализации способа для декодирования или способа для кодирования, когда компьютерная программа исполняется на компьютере или процессоре сигналов.
Хотя некоторые аспекты описаны применительно к устройству, понято, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. По аналогии аспекты, описанные применительно к этапу способа, также представляют собой описание соответствующего блока или элемента либо признака соответствующего устройства.
Патентоспособный разложенный сигнал может храниться на цифровом носителе информации или может передаваться по передающей среде, например беспроводной передающей среде или проводной передающей среде, такой как Интернет.
В зависимости от некоторых требований к реализации варианты осуществления изобретения можно реализовать в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя информации, например дискеты, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные на нем электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой так, что выполняется соответствующий способ.
Некоторые варианты осуществления в соответствии с изобретением содержат долговременный носитель информации, имеющий электронно считываемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой так, что выполняется один из способов, описанных в этом документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код действует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может храниться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в этом документе способов, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления патентоспособного способа поэтому является компьютерной программой, имеющей программный код для выполнения одного из описанных в этом документе способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления патентоспособных способов поэтому является носителем информации (или цифровым носителем информации, или машиночитаемым носителем), содержащим записанную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления патентоспособного способа поэтому является потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в этом документе. Поток данных или последовательность сигналов могут конфигурироваться, например, для передачи по соединению передачи данных, например через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированные или приспособленные для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в этом документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнить один из способов, описанных в этом документе. Как правило, способы предпочтительно выполняются любым аппаратным устройством.
Вышеописанные варианты осуществления являются всего лишь пояснительными для принципов настоящего изобретения. Подразумевается, что модификации и изменения компоновок и подробностей, описанных в этом документе, будут очевидны другим специалистам в данной области техники. Поэтому есть намерение ограничиться только объемом предстоящей формулы изобретения, а не определенными подробностями, представленными посредством описания и объяснения вариантов осуществления в этом документе.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕЙ ДИСКРЕТИЗАЦИИ ИЛИ ИНТЕРПОЛЯЦИИ МАСШТАБНЫХ ПАРАМЕТРОВ | 2018 |
|
RU2762301C2 |
| СИСТЕМА ОБРАБОТКИ АУДИО | 2014 |
|
RU2625444C2 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР И СВЯЗАННЫЕ СПОСОБЫ ОБРАБОТКИ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ С ИСПОЛЬЗОВАНИЕМ КОМПЛЕКСНОГО ПРЕДСКАЗАНИЯ | 2011 |
|
RU2577195C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
| КОДИРОВАНИЕ ИНФОРМАЦИИ БЕЗ ПОТЕРЬ С ГАРАНТИРОВАННОЙ МАКСИМАЛЬНОЙ БИТОВОЙ СКОРОСТЬЮ | 2006 |
|
RU2367087C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
| СПОСОБ КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ ИНДЕКСОВ КОДОВОЙ КНИГИ ДЛЯ КВАНТОВАННОГО СПЕКТРА МДКП В МАСШТАБИРУЕМЫХ РЕЧЕВЫХ И АУДИОКОДЕКАХ | 2008 |
|
RU2437172C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ С ПОМОЩЬЮ КОМПАКТНЫХ КОДОВЫХ КНИГ | 2006 |
|
RU2379832C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2456682C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2019 |
|
RU2793725C2 |
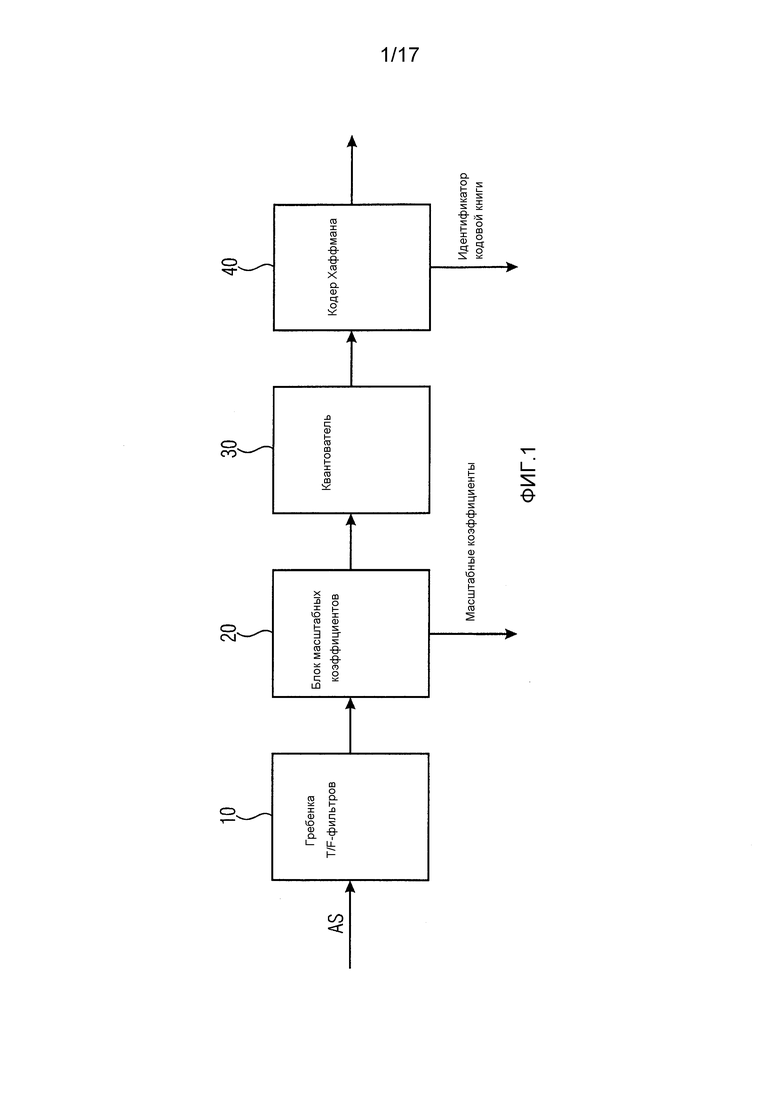
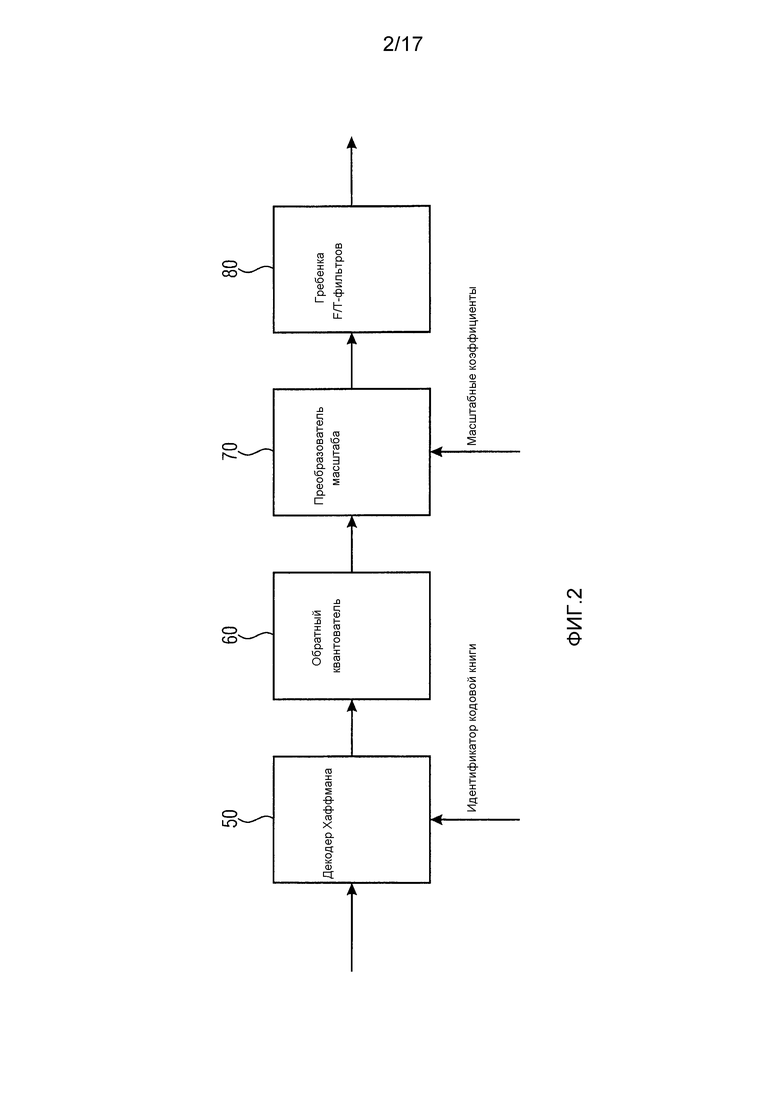
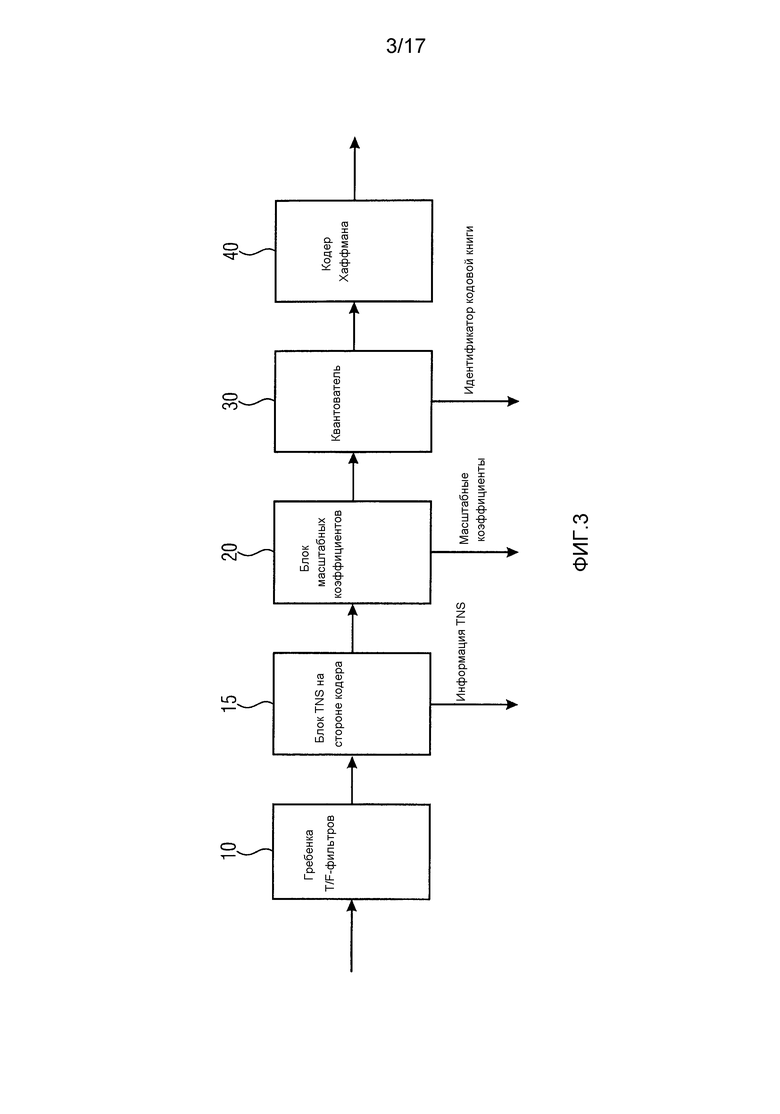
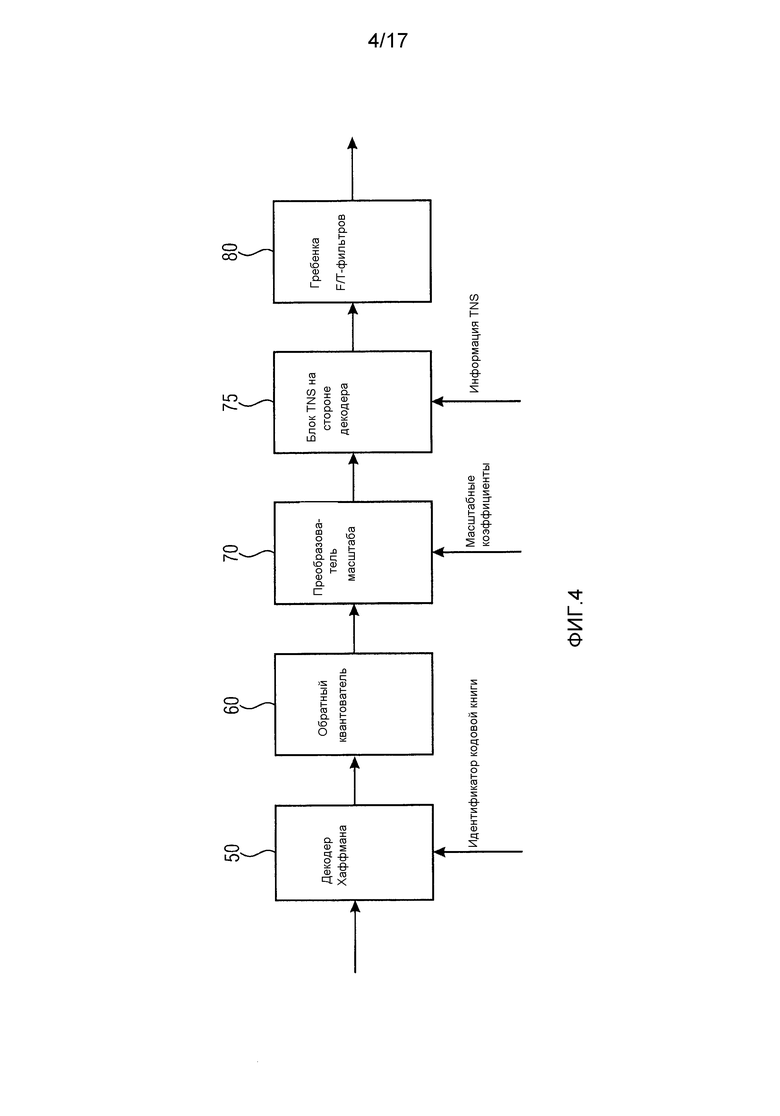
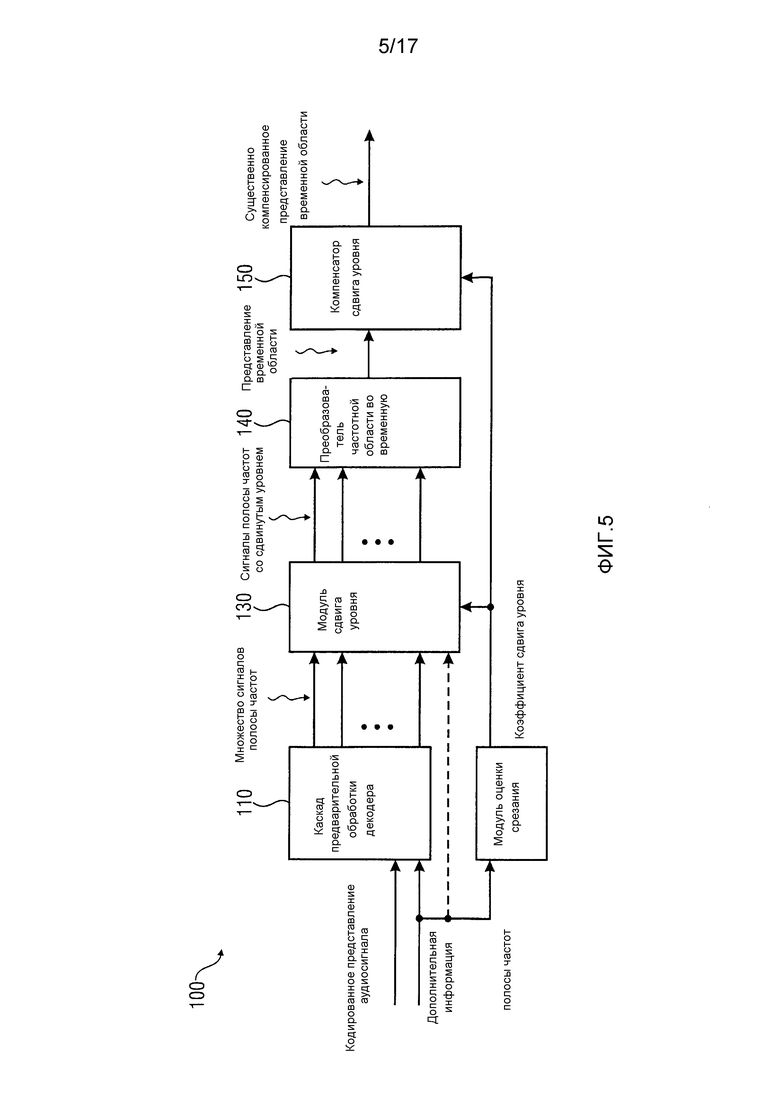
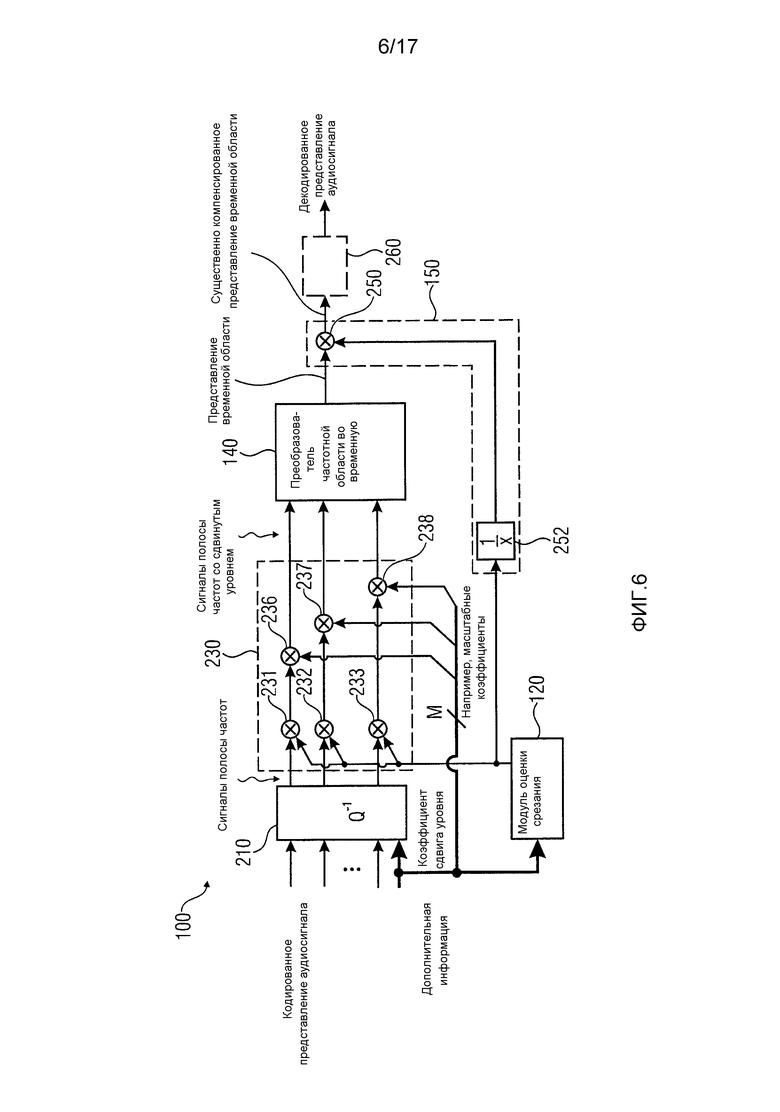
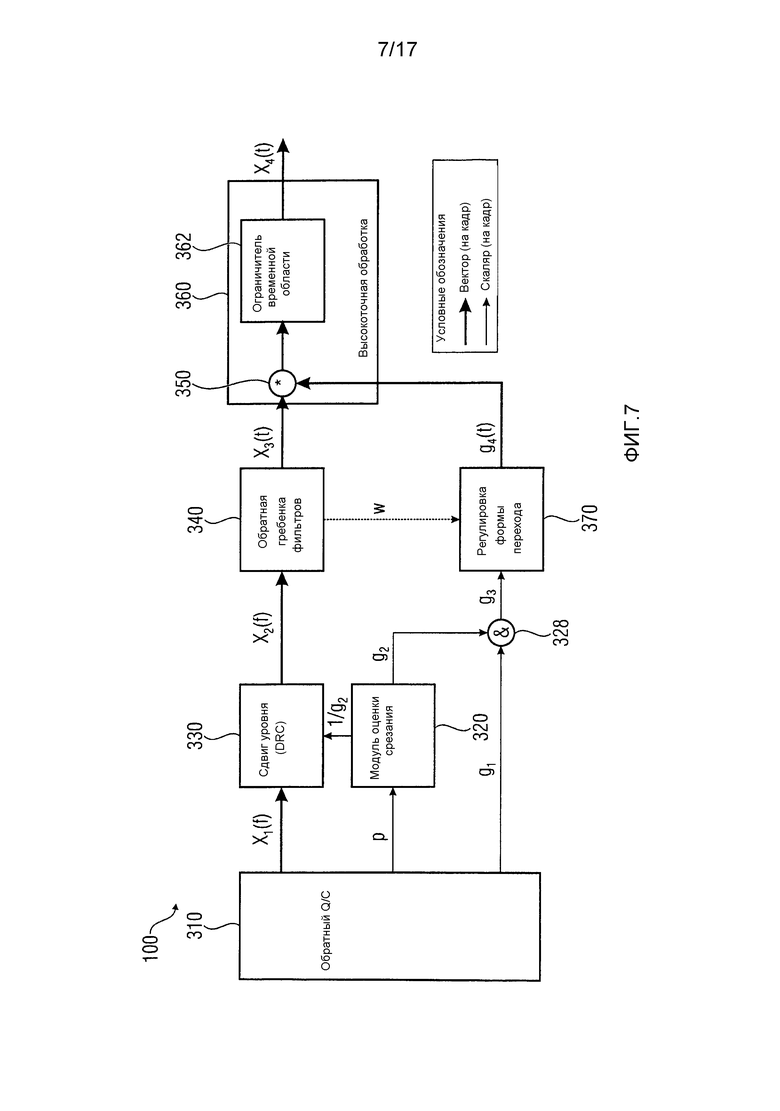
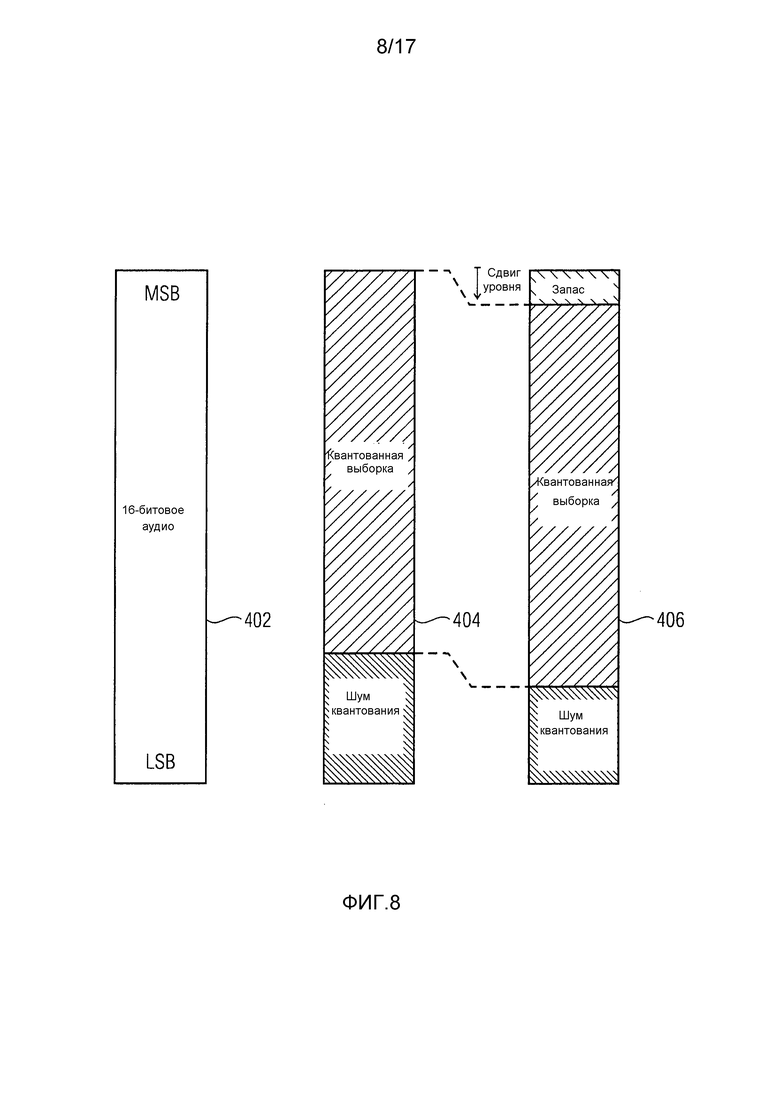
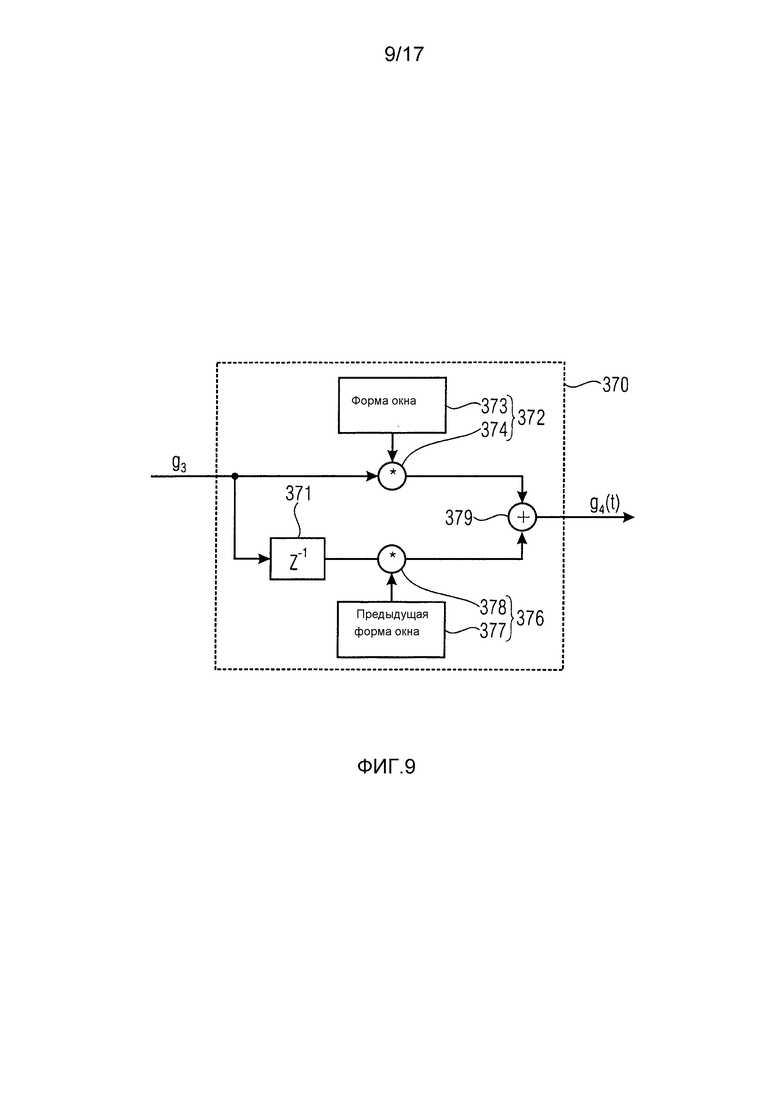
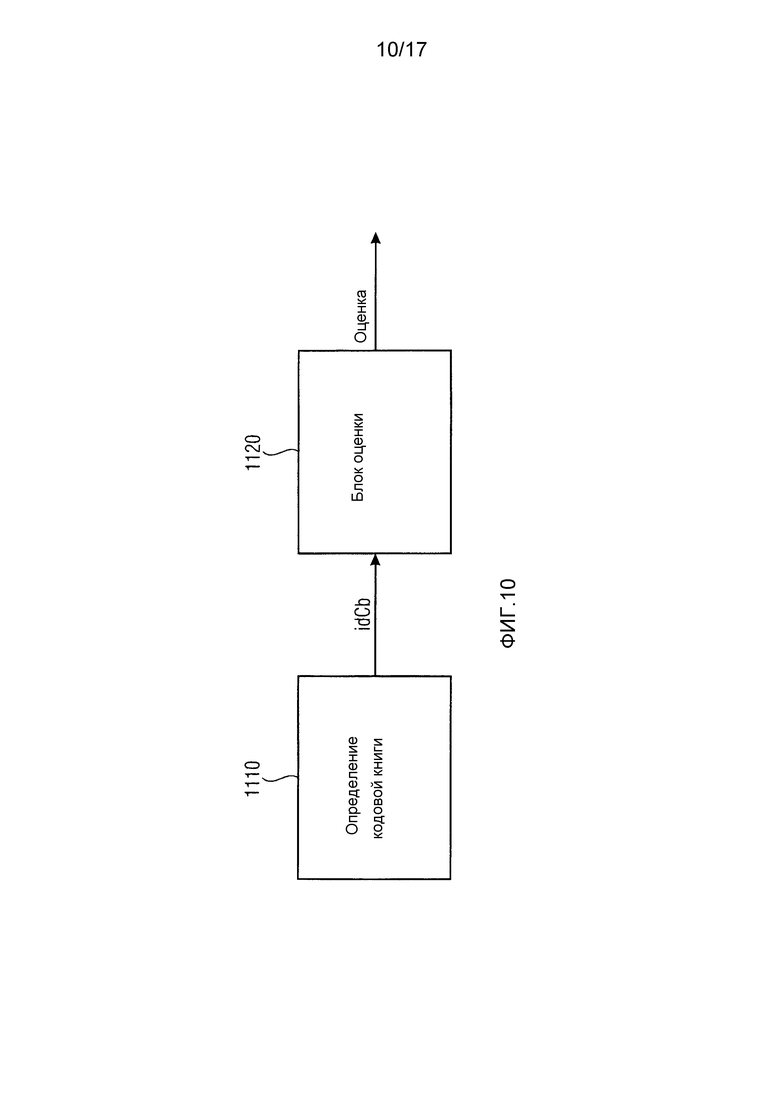
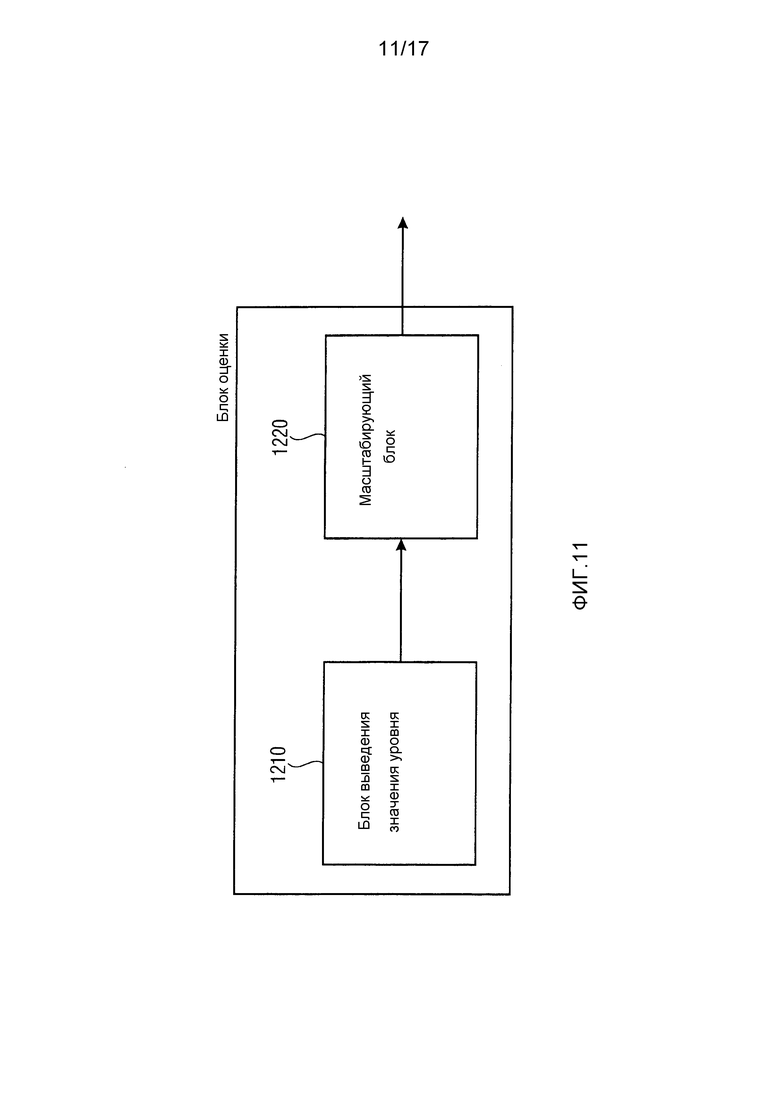
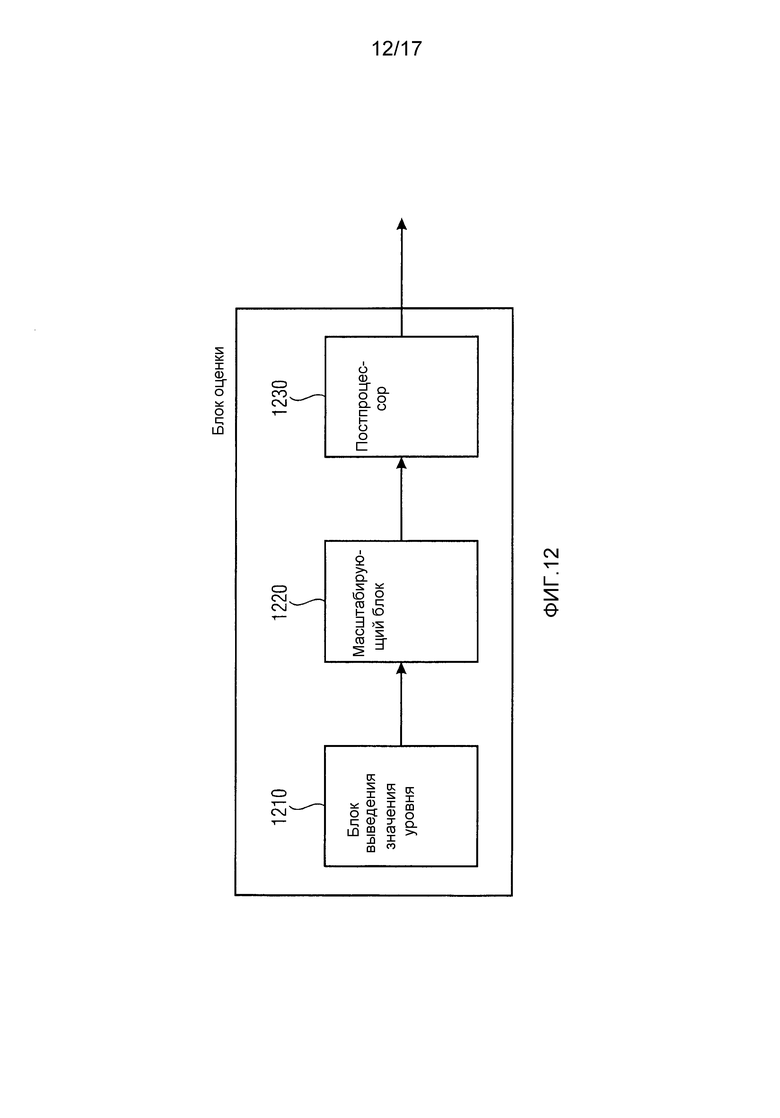
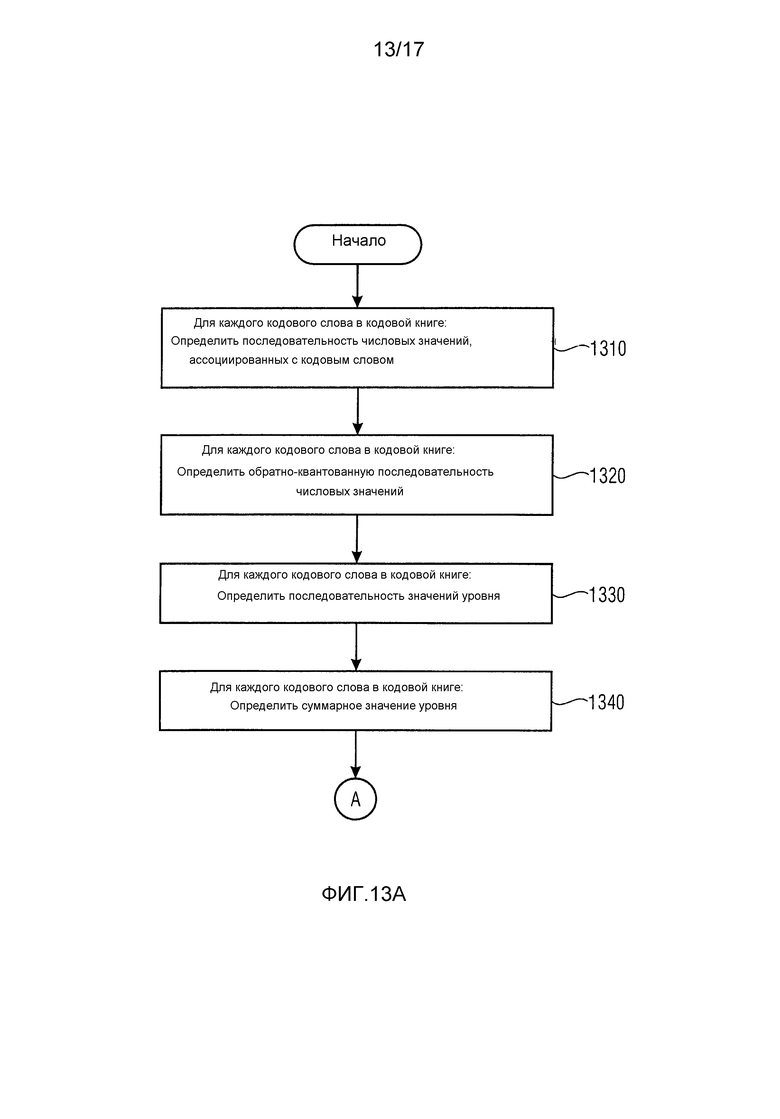
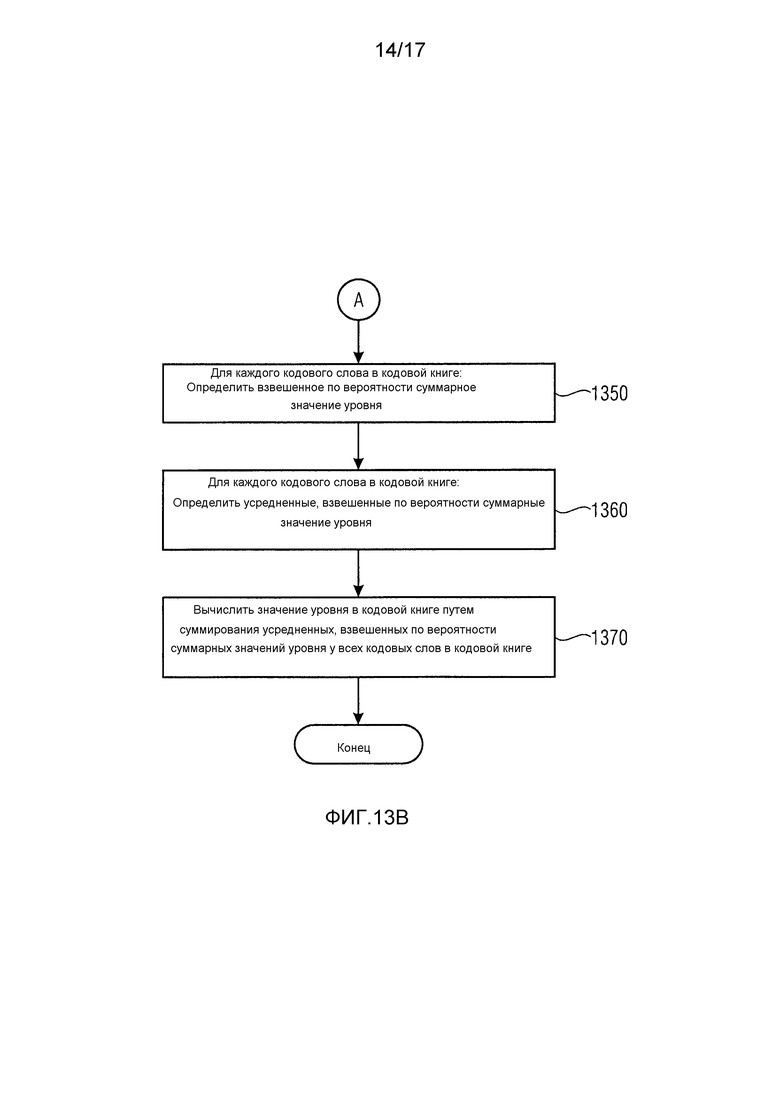
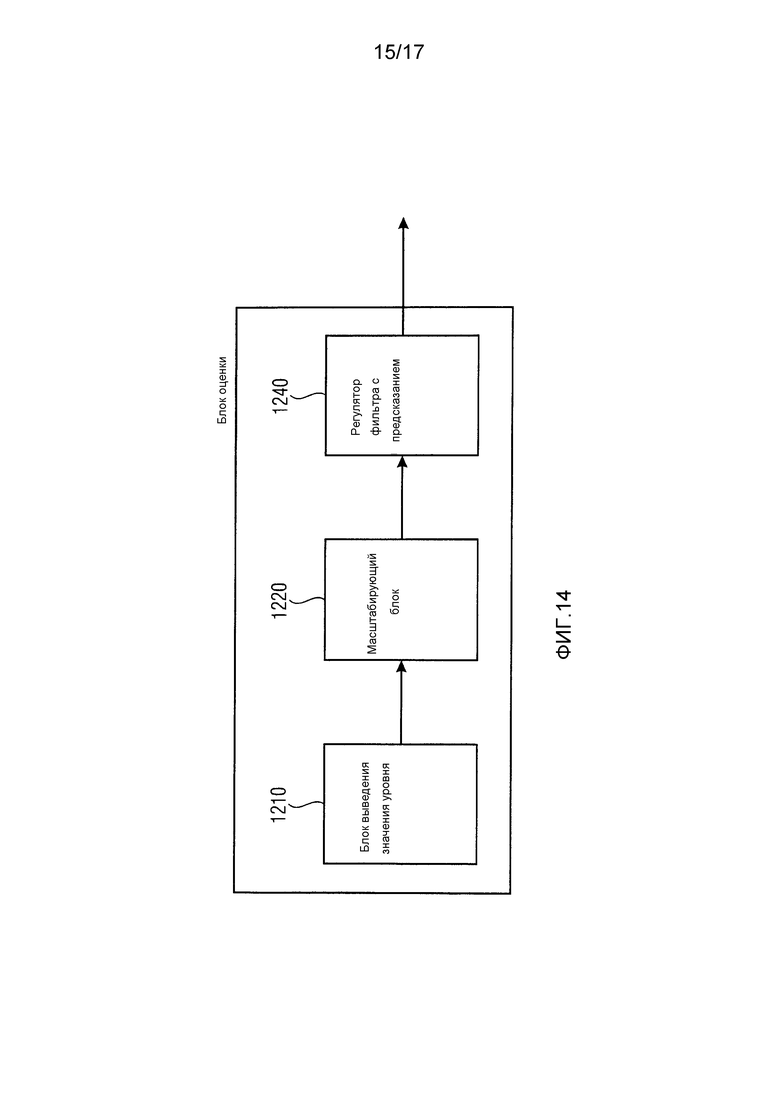
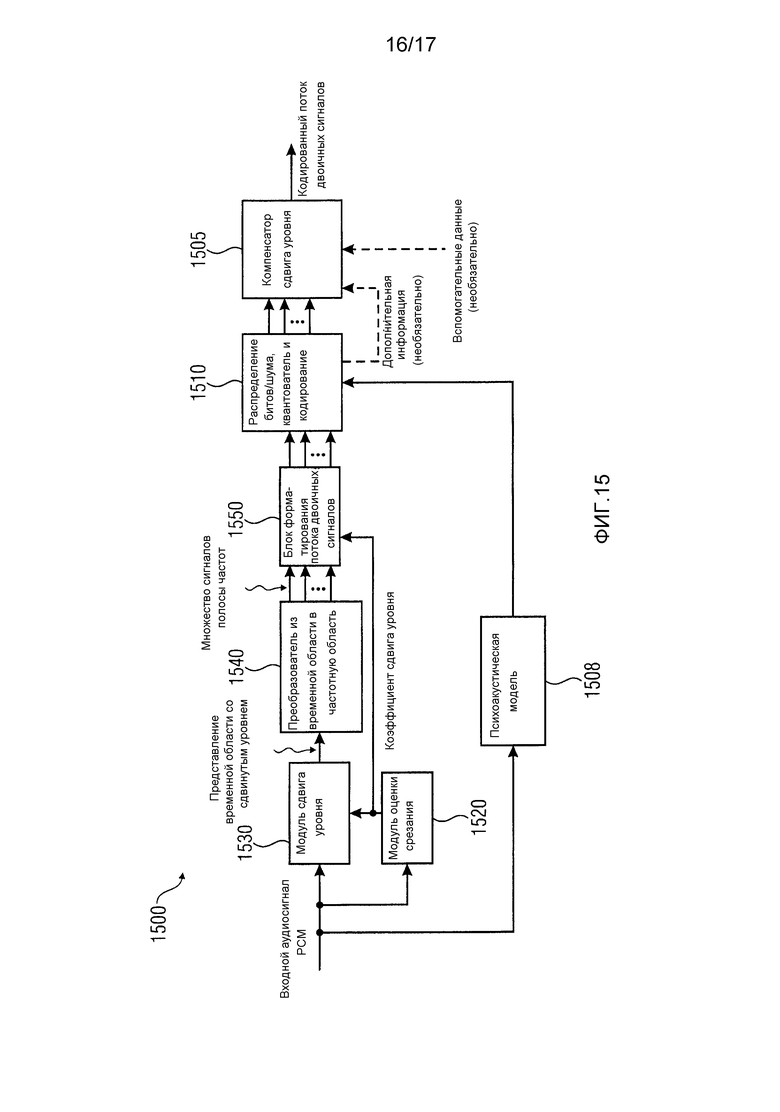
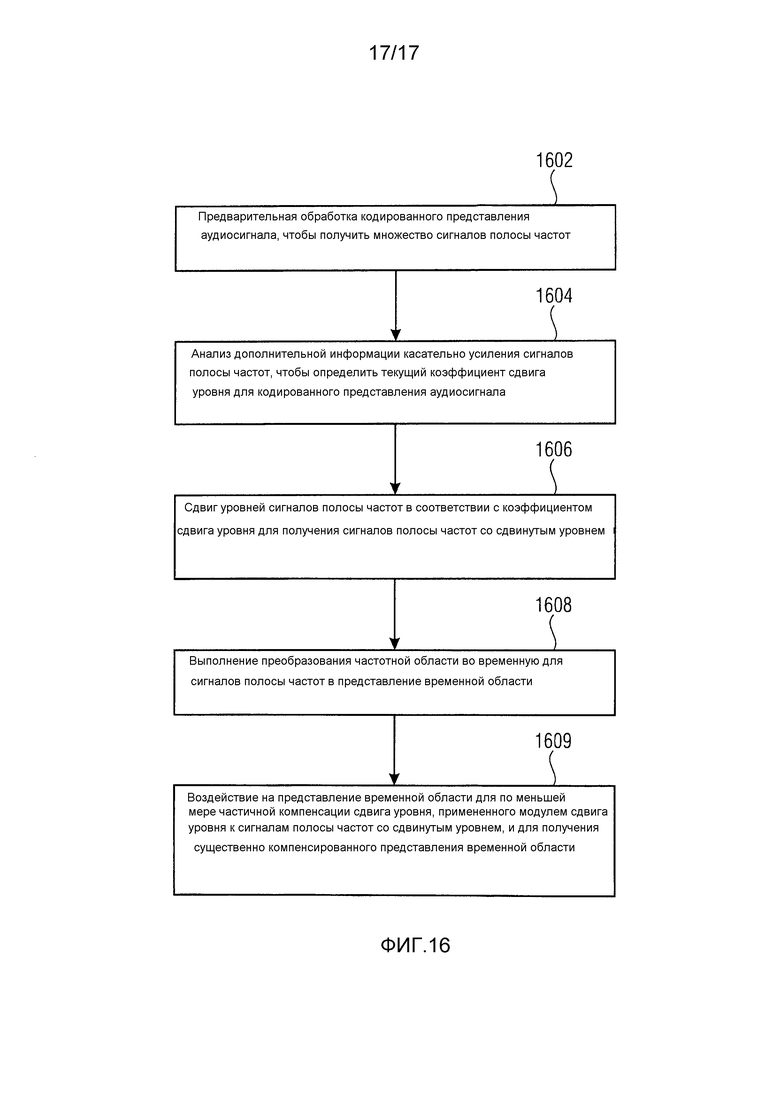
Изобретение относится к кодированию, декодированию и обработке аудиосигналов. Технический результат – возможность регулировки уровня сигнала в динамическом диапазоне без потери точности данных. Декодер аудиосигнала для предоставления декодированного представления аудиосигнала на основе кодированного представления аудиосигнала содержит каскад предварительной обработки декодера для получения множества сигналов полосы частот из кодированного представления аудиосигнала, модуль оценки срезания, модуль сдвига уровня, преобразователь частотной области во временную и компенсатор сдвига уровня. Модуль оценки срезания анализирует кодированное представление аудиосигнала и/или дополнительную информацию касательно усиления сигналов полосы частот для определения текущего коэффициента сдвига уровня. Модуль сдвига уровня сдвигает уровни сигналов полосы частот в соответствии с коэффициентом сдвига уровня. Преобразователь частотной области во временную преобразует сигналы полосы частот со сдвинутым уровнем в представление временной области. Компенсатор сдвига уровня воздействует на представление временной области для частичной компенсации соответствующего сдвига уровня и для получения существенно компенсированного представления временной области. 4 н. и 12 з.п. ф-лы, 17 ил.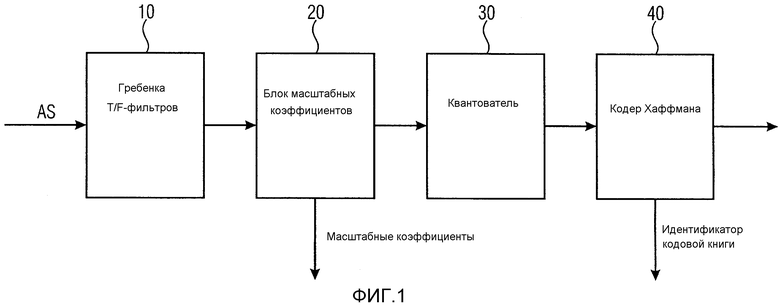
1. Декодер аудиосигнала (100), сконфигурированный для предоставления декодированного представления аудиосигнала на основе кодированного представления аудиосигнала, при этом декодер аудиосигнала содержит:
каскад предварительной обработки декодера (110), сконфигурированный для получения множества сигналов полосы частот из кодированного представления аудиосигнала;
модуль оценки ограничения (120), сконфигурированный для анализа дополнительной информации касательно усиления сигналов полосы частот кодированного представления аудиосигнала в отношении того, предполагает ли дополнительная информация возможное ограничение, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала, при этом, когда дополнительная информация предполагает возможное ограничение, текущий коэффициент сдвига уровня вызывает сдвиг информации о множестве сигналов полосы частот к самому младшему биту, чтобы получить запас в по меньшей мере одном самом старшем бите;
модуль сдвига уровня (130), сконфигурированный для сдвига уровней сигналов полосы частот в соответствии с текущим коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем;
преобразователь из частотной области во временную (140), сконфигурированный для преобразования сигналов полосы частот со сдвинутым уровнем в представление во временной области; и
компенсатор сдвига уровня (150), сконфигурированный для воздействия на представление во временной области для по меньшей мере частичной компенсации сдвига уровня, примененного модулем сдвига уровня (130) к сигналам полосы частот со сдвигаемым уровнем, и для получения по существу компенсированного представления во временной области.
2. Декодер аудиосигнала (100) по п. 1, в котором модуль оценки ограничения (120) дополнительно сконфигурирован для определения вероятности ограничения на основе по меньшей мере одного из дополнительной информации и кодированного представления аудиосигнала, и для определения текущего коэффициента сдвига уровня на основе вероятности ограничения.
3. Декодер аудиосигнала (100) по п. 1, в котором дополнительная информация содержит по меньшей мере одно из коэффициента глобального усиления для множества сигналов полосы частот и множества масштабных коэффициентов, причем каждый масштабный коэффициент соответствует одному сигналу полосы частот или одной группе сигналов полосы частот в множестве сигналов полосы частот.
4. Декодер аудиосигнала (100) по п. 1, в котором каскад предварительной обработки декодера (110) сконфигурирован для получения множества сигналов полосы частот в виде множества последовательных кадров, и в котором модуль оценки ограничения (120) сконфигурирован для определения текущего коэффициента сдвига уровня для текущего кадра.
5. Декодер аудиосигнала (100) по п. 1, в котором декодированное представление аудиосигнала определяется на основе по существу компенсированного представления во временной области.
6. Декодер аудиосигнала (100) по п. 1, дополнительно содержащий ограничитель временной области после компенсатора сдвига уровня (150).
7. Декодер аудиосигнала (100) по п. 1, в котором дополнительная информация касательно усиления сигналов полосы частот содержит множество связанных с полосой частот коэффициентов усиления.
8. Декодер аудиосигнала (100) по п. 1, в котором каскад предварительной обработки декодера (110) содержит обратный квантователь, сконфигурированный для переквантования каждого сигнала полосы частот с использованием специфического для полосы частот индикатора квантования из множества специфических для полос частот индикаторов квантования.
9. Декодер аудиосигнала (100) по п. 1, дополнительно содержащий регулятор формы перехода, сконфигурированный для осуществления плавного перехода между текущим коэффициентом сдвига уровня и последующим коэффициентом сдвига уровня, чтобы получить коэффициент сдвига уровня с плавным переходом для использования компенсатором сдвига уровня (150).
10. Декодер аудиосигнала (100) по п. 9, в котором регулятор формы перехода содержит запоминающее устройство (371) для предыдущего коэффициента сдвига уровня, первый организатор окон (372), сконфигурированный для формирования первого множества разделенных на окна выборок путем применения формы окна к текущему коэффициенту сдвига уровня, второй организатор окон (376), сконфигурированный для формирования второго множества разделенных на окна выборок путем применения предыдущей формы окна к предыдущему коэффициенту сдвига уровня, предоставленному запоминающим устройством (371), и объединитель выборок (379), сконфигурированный для объединения взаимно соответствующих разделенных на окна выборок из первого множества разделенных на окна выборок и второго множества разделенных на окна выборок, чтобы получить множество объединенных выборок.
11. Декодер аудиосигнала (100) по п. 10,
в котором текущий коэффициент сдвига уровня действителен для текущего кадра множества сигналов полосы частот, в котором предыдущий коэффициент сдвига уровня действителен для предыдущего кадра множества сигналов полосы частот и в котором текущий кадр и предыдущий кадр перекрываются;
в котором регулировка формы перехода сконфигурирована для
объединения предыдущего коэффициента сдвига уровня со второй частью предыдущей формы окна, получая в результате последовательность коэффициентов предыдущего кадра,
объединения текущего коэффициента сдвига уровня с первой частью текущей формы окна, получая в результате последовательность коэффициентов текущего кадра, и
определения последовательности коэффициента сдвига уровня с плавным переходом на основе последовательности коэффициентов предыдущего кадра и последовательности коэффициентов текущего кадра.
12. Декодер аудиосигнала (100) по п. 1, в котором модуль оценки ограничения (120) сконфигурирован для анализа по меньшей мере одного из кодированного представления аудиосигнала и дополнительной информации на предмет того, предполагает ли по меньшей мере одно из кодированного представления аудиосигнала и дополнительной информации возможное ограничение в представлении во временной области, что означает, что самый младший бит не содержит никакой релевантной информации, и в этом случае сдвиг уровня, применяемый модулем сдвига уровня, сдвигает информацию к самому младшему биту, чтобы получить некоторый запас в самом старшем бите путем освобождения самого старшего бита.
13. Декодер аудиосигнала (100) по п. 1, в котором модуль оценки ограничения (120) содержит:
определитель кодовой книги (1110) для определения кодовой книги в качестве идентифицированной кодовой книги из множества кодовых книг, где кодированное представление аудиосигнала кодировано с применением идентифицированной кодовой книги, и
блок оценки (1120), сконфигурированный для выведения значения уровня, ассоциированного с идентифицированной кодовой книгой, в качестве выведенного значения уровня, и для получения оценки уровня аудиосигнала с использованием выведенного значения уровня.
14. Кодер аудиосигнала, сконфигурированный для предоставления кодированного представления аудиосигнала на основе представления во временной области входного аудиосигнала, при этом кодер аудиосигнала содержит:
модуль оценки ограничения, сконфигурированный для анализа представления во временной области входного аудиосигнала в отношении того, предполагается ли возможное ограничение, чтобы определить текущий коэффициент сдвига уровня для представления входного сигнала, при этом, когда возможное ограничение предполагается, текущий коэффициент сдвига уровня вызывает сдвиг представления во временной области входного аудиосигнала к самому младшему биту, чтобы получить запас в по меньшей мере одном самом старшем бите;
модуль сдвига уровня, сконфигурированный для сдвига уровня представления во временной области входного аудиосигнала в соответствии с текущим коэффициентом сдвига уровня для получения представления во временной области со сдвинутым уровнем;
преобразователь из временной области в частотную, сконфигурированный для преобразования представления во временной области со сдвинутым уровнем в множество сигналов полосы частот; и
компенсатор сдвига уровня, сконфигурированный для воздействия на множество сигналов полосы частот для по меньшей мере частичной компенсации сдвига уровня, примененного модулем сдвига уровня к представлению во временной области со сдвигаемым уровнем, и для получения множества по существу компенсированных сигналов полосы частот.
15. Способ для декодирования кодированного представления аудиосигнала и для предоставления соответствующего декодированного представления аудиосигнала, содержащий этапы, на которых:
предварительно обрабатывают кодированное представление аудиосигнала, чтобы получить множество сигналов полосы частот;
анализируют дополнительную информацию касательно усиления сигналов полосы частот в отношении того, предполагает ли дополнительная информация возможное ограничение, чтобы определить текущий коэффициент сдвига уровня для кодированного представления аудиосигнала, при этом, когда дополнительная информация предполагает возможное ограничение, текущий коэффициент сдвига уровня вызывает сдвиг информации о множестве сигналов полосы частот к самому младшему биту, чтобы получить запас в по меньшей мере одном самом старшем бите;
сдвигают уровни сигналов полосы частот в соответствии с коэффициентом сдвига уровня для получения сигналов полосы частот со сдвинутым уровнем;
выполняют преобразование из частотной области во временную для сигналов полосы частот в представление во временной области; и
воздействуют на представление во временной области для по меньшей мере частичной компенсации сдвига уровня, примененного к сигналам полосы частот со сдвигаемым уровнем, и для получения по существу компенсированного представления во временной области.
16. Физический носитель данных, хранящий компьютерную программу для предписания компьютеру выполнить способ по п. 15.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| АДАПТИВНОЕ ОСТАТОЧНОЕ АУДИОКОДИРОВАНИЕ | 2006 |
|
RU2380766C2 |
| УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ СИГНАЛА, ИМЕЮЩЕГО ПОСЛЕДОВАТЕЛЬНОСТЬ ДИСКРЕТНЫХ ЗНАЧЕНИЙ | 2004 |
|
RU2325708C2 |
| КОДИРОВАНИЕ СИГНАЛА С ИСПОЛЬЗОВАНИЕМ КОДИРОВАНИЯ С РЕГУЛЯРИЗАЦИЕЙ ОСНОВНЫХ ТОНОВ И БЕЗ РЕГУЛЯРИЗАЦИИ ОСНОВНЫХ ТОНОВ | 2011 |
|
RU2470384C1 |
| US 6651040 B1, 18.11.2003 | |||
| US 6289309 B1, 11.09.2001 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |

