Область техники
Изобретение относится к системам и способам тестирования надежности правил обнаружения программного обеспечения.
Уровень техники
Число вредоносного программного обеспечения растет каждый час, и антивирусным компаниям необходимо незамедлительно и адекватно реагировать на угрозы. Адекватная реакция на угрозу предполагает отсутствие ложных срабатываний, т.е. реакция должна быть такой, чтобы обезвредить угрозу и не затронуть безопасные файлы.
Реакцией на угрозу может быть, например, создание правила обнаружения подобной угрозы и последующего ее устранение. В качестве правила обнаружения в частном случае могут выступать сигнатуры, эвристические правила или хэш-суммы, т.е. способы которыми можно обнаружить целевые файлы из всего многообразия исследуемых файлов. После того как правило создано, это правило тестируют на предмет отсутствия ложных срабатываний. После тестирования правило начинает работать у пользователей, очень часто правило могут тестировать дополнительно еще и на стадии его активной работы у пользователя.
Так в патенте US 8280830 описывается система изменения правила обнаружения на основании предварительного тестирования созданного правила на коллекции безопасных файлов и вредоносных файлов.
Но коллекция безопасных файлов и вредоносных файлов, имеющаяся у производителей антивирусного программного обеспечения, не может покрыть все разнообразие файлов, встречающееся у пользователей, поэтому очень часто используется обратная связь от правила обнаружения, когда оно уже работает у пользователя. Антивирусное приложение, которое использует правило обнаружения, посылает разработчикам уведомления о том, на каких файлах сработало правило, и разработчики на своей стороне анализируют эту информацию. В патенте US 8356354 описывается система выпуска обновлений антивирусных баз, один из вариантов которой предполагает отправку антивирусным приложением разработчикам информации о файлах, на которых сработало правило, полученная информация анализируется на предмет ложных срабатываний указанного правила.
Но и совместное использование коллекции безопасных файлов и вредоносных файлов, с обратной связью от пользователей, не может гарантировать эффективность правила обнаружения, по причине неполноты коллекции и отсутствия возможности проверить правило на файлах, которые появятся в будущем, а также по причине того, что антивирусное программное обеспечение установлено не у каждого пользователя. Также существенный недостаток метода обратной связи, который используется сейчас, заключается в том, что, как правило, для обратной связи используется не сам файл, а контрольная сумма от файла, и если файл из коллекции будет хоть немного отличаться от файла, на котором сработало правило, контрольные суммы не совпадут и ложное срабатывание обнаружено не будет.
Вероятность ложных срабатываний возрастает в том случае, когда правило обнаружения создается не для одного, а для группы похожих файлов, и чем больше число файлов, для которых правило создается, тем выше будет вероятность ложного срабатывания, что также не учитывается ни одним из известных решений.
Хотя рассмотренные подходы направлены на решение определенных задач в области защиты от компьютерных угроз, они обладают недостатком - желаемое качество выбора надежных правил обнаружения (использование которых не повлечет за собой появление ложных срабатываний) не достигается. Настоящее изобретение позволяет более эффективно решить задачу выявления надежных правил обнаружения.
Раскрытие изобретения
Технический результат настоящего изобретения заключается в снижении числа ложных срабатываний правил обнаружения файлов путем определения надежности правила обнаружения, заключающейся в сравнении файлов отобранных правилом с известными файлами.
Способ признания надежности правила обнаружения файлов, в котором: выделяют из множества файлов, по меньшей мере, два подмножества файлов: подмножество А и подмножество Б на основании критерия; создают правило обнаружения файлов на основании, по меньшей мере, одного файла, принадлежащего подмножеству А; проверяют файлы из множества файлов, не входящие в подмножество А и подмножество Б, на срабатывание правила обнаружения; отбирают файлы из множества, на которых сработало правило обнаружения во время проверки; сравнивают отобранные файлы, по меньшей мере, с одним файлом, принадлежащим подмножеству А, и с файлами, принадлежащими подмножеству Б; признают правило обнаружения надежным, когда ни один из отобранных файлов в результате сравнения отобранных файлов, по меньшей мере, с одним файлом, принадлежащим подмножеству А, и с файлами, принадлежащими подмножеству Б, оказался не похож на файлы из подмножества Б, и отобранные файлы похожи на, по меньшей мере, один файл из подмножества А.
В частном случае выделяют на основании критерия опасности файлов из множество файлов два подмножества файлов: подмножество А - подмножество вредоносных файлов и подмножество Б - подмножество безопасных файлов
В другом частном случае для сравнения файлов получают характеристики файлов.
Еще в одном частном случае файлы по результатам сравнения признают похожими, если степень сходства между файлами превышает установленный порог.
В частном случае степень сходства между файлами определяют на основании степени сходства характеристик файлов.
Система признания надежности правила обнаружения содержит:
средство кластеризации, предназначенное для выделения из множества файлов, по меньшей мере, два подмножества файлов: подмножество А и подмножество Б - на основании критерия и отбора файлов из множества, на которых сработало правило обнаружения во время проверки; средство создания правила, связанное со средством кластеризации и файловым хранилищем и предназначенное для создания правила обнаружения, по меньшей мере, для одного файла, принадлежащего подмножеству А; средство анализа, связанное с файловым хранилищем и средством создания правил, предназначенное для сравнения отобранных файлов, по меньшей мере, с одним файлом, принадлежащим подмножеству А, и с файлами, принадлежащими подмножеству Б, и признания правила обнаружения надежным, когда ни один из отобранных файлов в результате вышеуказанного сравнения оказался не похож на файлы из подмножества Б, и отобранные файлы похожи на, по меньшей мере, один файл из подмножества А.
В частном случае реализации системы средство кластеризации дополнительно предназначено для получения характеристик файлов.
В другом частном случае средство анализа дополнительно определяет степень сходства характеристик файлов.
В частном случае реализации системы средство анализа определяет степень сходства файлов на основании степени сходства характеристик.
Еще в одном частном случае средство анализа признает файлы похожими, если степень сходства файлов превышает установленный порог.
Краткое описание чертежей
Сопровождающие чертежи включены для обеспечения дополнительного понимания изобретения и составляют часть этого описания, показывают варианты осуществления изобретения и совместно с описанием служат для объяснения принципов изобретения.
Заявленное изобретение поясняется следующими чертежами, на которых:
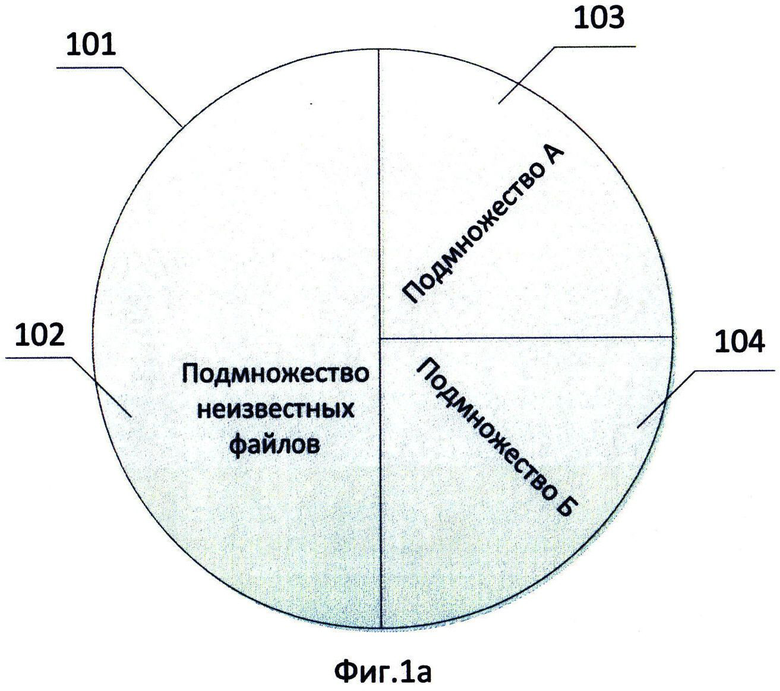
Фиг.1а, 1б показывают способ выделения подмножеств в множестве файлов;
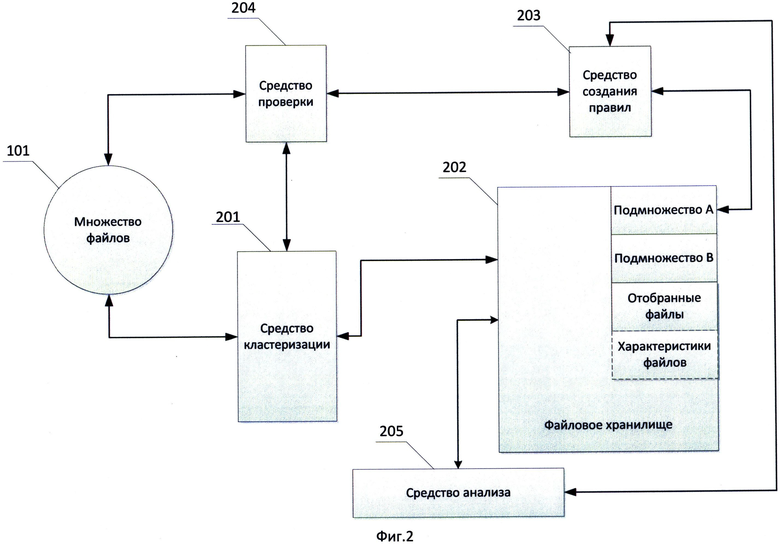
Фиг.2 показывает систему осуществления проверки надежности правила обнаружения;
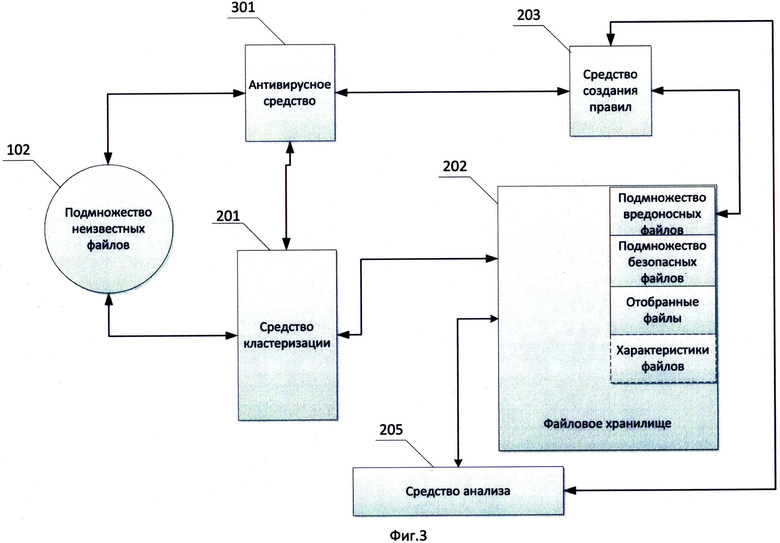
Фиг.3 показывает систему осуществления проверки надежности правила обнаружения вредоносного программного обеспечения;
Фиг.4 показывает пример компьютерной системы общего назначения.
Осуществление изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Приведенное описание предназначено для помощи специалисту в области техники для исчерпывающего понимания изобретения, которое определяется в объеме приложенной формулы.
На Фиг.1б изображен способ работы данного изобретения. Существует множество файлов 101, изображенное на Фиг.1а, в которое в частном случае входит все многообразие существующих файлов. В этом множестве выделяют подмножество известных файлов. Файлы множества, не относящиеся к подмножеству известных файлов, считают подмножеством неизвестных файлов 102. Под известными файлами, в частном случае, можно понимать файлы, характеристики которых известны, и, используя эти характеристики, подмножество известных файлов разделяют на, по меньшей мере, два подмножества: подмножество А 103 и подмножество Б 104 - на этапе 105. Например, такими подмножествами могут быть подмножества вредоносных и безопасных файлов (критерий - опасность), исполняемых и неисполняемых (критерий - способ использования), файлов сценария и файлов РЕ-формата (критерий - тип файла) и т.д. Также для разделения можно использовать несколько критериев и сформировать подмножество из файлов, удовлетворяющих одновременно нескольким критериям. Из подмножества А 103 подмножества известных файлов выделяют группу файлов, для этой группы файлов на этапе 106 создается правило обнаружения. Правило обнаружения в частном случае представляет собой некоторый логический механизм, оперирующий совокупностью характеристик файлов, на основании которого отбирают из множества файлов только интересующие файлы. Файлы из подмножества неизвестных файлов 102 отбираются во время проверки подмножества неизвестных файлов на срабатывание правила на этапе 107. Прежде, чем признать правило работоспособным, не создающим ложные срабатывания, его тестируют, проверяют на эффективность и надежность. Под эффективностью правила обнаружения понимают отсутствие в ходе работы правила появления ошибок первого рода, под надежностью правила обнаружения понимают отсутствие ошибок второго рода. Под ошибками первого рода понимают несрабатывание правила обнаружения на файле, на котором оно должно срабатывать, а под ошибками второго рода - срабатывание правила на файле, на котором оно срабатывать не должно. После запуска проверки на этапе 108 из подмножества неизвестных файлов 102 отбирают файлы, на которых сработало правило. На основании отобранных файлов определяют надежность правила обнаружения.
Для осуществления тестирования получают характеристики отобранных файлов. В частном случае для файлов РЕ формата такими характеристиками могут быть: размер файла, размер образа файла, количество секций файла, API функции (application programming interface) файла, RVA(Related Virtual Address) секций файла, RVA точки входа, взаимное расположение объектов таблицы директорий, частотные характеристики символов (в том числе печатных), множество строк файла и их количество, информационная энтропия начала и конца секции, виртуальный размер секции, физический размер секции, использованный при создании файла компилятор, тип подсистемы (NATIVE, WINDOWS_GUI, WINDOWS_CUI, OS2_CUI, POSIX_CUI, NATIVE_WINDOWS, WINDOWS_CE_GUI), характеристики файла из COFF заголовка (Common Object File Format), расположение объектов таблицы директорий по секциям файла и т.д. Также характеристиками файла в частном случае являются правила обнаружения, отличные от описываемого правила, которые также срабатывают на файле.
Полученные характеристики используются при сравнении отобранных файлов с файлами из подмножества известных файлов и сравнении отобранных файлов между собой. Отобранные файлы сравниваются, по меньшей мере, с одним файлом из подмножества А 103 на этапе 109, в частном случае таким файлом может быть искомый файл, для которого создавали правило обнаружения. Данное сравнение проводят для того, чтобы оценить однородность файлов, на которых сработало правило обнаружения, и определить похожесть отобранных файлов на файлы из подмножества А 103. Далее на этапе 110 сравнивают отобранные файлы с файлами из подмножества Б 104, для того, чтобы исключить пересечение отобранных файлов с файлами из подмножества Б. Для сравнений в частном случае реализации используются разные характеристики. Если по результатам сравнения отобранные файлы оказались похожи на файлы из подмножества А 103 и не похожи на файлы из подмножества Б 104, то правило обнаружения признают надежным на этапе 112. Если отобранные файлы не похожи на файлы из подмножества А или отобранные файлы похожи на файлы из подмножества Б, то правило обнаружения на этапе 111 признают ненадежным. Файлы при сравнении считаются похожими, если степень сходства между файлами превышает установленный порог. Степень сходства между файлами определяют на основании степени сходства характеристик файлов. В частном случае реализации степень сходства между файлами определяют на основании степени сходства данных, хранящихся в файлах. В другом частном случае реализации степень сходства файлов определяют на основании степени сходства функционала файлов. В частном случае реализации в качестве функционала файла рассматривается журнал вызовов API-функций операционной системы при эмуляции исполнения файла. В частном случае реализации изобретения степень сходства определяют в соответствии с мерой Дайса, в другом частном случае реализации степень сходства определяют в соответствии с одной из метрик: Хэмминга, Левенштейна, Жаккара.
На Фиг.2 изображена система, которая использует описанный выше способ. Система работает с множеством файлов 101, которое включает все многообразие существующих файлов. С множеством связано средство кластеризации 201, при этом средство кластеризации 201 осуществляет выделение подмножества А 103 и подмножества Б 104 из множества файлов 101 по выбранному критерию, и в частном случае реализации получает характеристики файлов. Выделенные подмножества файлов размещают в файловом хранилище 202. Средство создания правил 203 создает правило обнаружения для группы файлов из подмножества А. Созданное правило используется средством проверки 204 для проверки множества файлов на срабатывание правила обнаружения. Средство проверки 204 передает средству кластеризации 201 информацию о файлах, на которых сработало правило обнаружения. Средство кластеризации 201 отбирает указанные файлы, и отобранные файлы размещаются в файловом хранилище 202. Средство анализа 205 сравнивает отобранные файлы с файлами, принадлежащими подмножеству А и подмножеству Б, и сравнивает отобранные файлы, по меньшей мере, с одним файлом, для обнаружения которого создали правило обнаружения. Далее средство анализа 205 осуществляет проверку надежности правила обнаружения на основании выполненного сравнения. Если в результате сравнения отобранные файлы оказались не похожи ни на один файл из подмножества Б и похожи на файлы, для которых создавалось правило обнаружения, то средство анализа признает правило обнаружения надежным.
В частном случае реализации средство кластеризации 201 используют для получения характеристик файлов, а файловое хранилище 202 хранит полученные характеристики файлов.
В частном случае средство анализа 205 для сравнения файлов определяет степень сходства между файлами на основании степени сходства характеристик файлов.
На Фиг.3 изображена система проверки надежности правила обнаружения вредоносного программного обеспечения. Имеется некоторое подмножество вредоносных файлов и безопасных файлов. Из подмножества вредоносных файлов выбирают файлы, для которых необходимо создать правило обнаружения. Например, это могут быть файлы из одного семейства вредоносного программного обеспечения, файлы, упакованные одним упаковщиком, при этом использование данного упаковщика характерно только для вредоносных файлов и т.д. Средство создания правила обнаружения 203 создает правило обнаружения для выбранных файлов. Правило обнаружения используется в работе антивирусного средства 301. Средство создания правил 203 передает антивирусному средству 301 правило для проверки подмножества неизвестных файлов. Подмножество неизвестных файлов 102 может храниться в локальном файловом хранилище либо может быть распределено по удаленным средствам хранения, например, персональным компьютерам пользователей. Антивирусное средство 301 проверяет на срабатывание правила обнаружения подмножество неизвестных файлов 102. Антивирусное средство 301 передает средству кластеризации 201 информацию о файлах, на которых сработало правило, средство кластеризации 201 отбирает указанные файлы и сохраняет их в файловом хранилище 202. Средство кластеризации 201 получает характеристики отобранных файлов. Далее средство анализа 205 сравнивает отобранные файлы с файлами из подмножества вредоносных файлов, определяя степени сходства характеристик сравниваемых файлов. Из подмножества вредоносных файлов для сравнения в частном случае выбирают файлы, для которых создавалось правило обнаружения. Для сравниваемых файлов средство анализа 205 подсчитывает степень сходства выбранных характеристик, если степень сходства превышает установленный порог, то файлы считают похожими. Если все отобранные файлы признаются похожими на файлы из подмножества вредоносных файлов, средство анализа продолжает сравнение, сравнивая отобранные файлы с подмножеством безопасных файлов, при этом набор характеристик файлов, которые используют для сравнения в частном случае отличен от набора использовавшегося при сравнении отобраных файлов с файлами из подмножества вредоносных файлов. Если в результате сравнения ни один из отобранных файлов оказывается не похож ни на один файл из подмножества безопасных файлов, то средство анализа 205 признает трестируемое правило обнаружения надежным
Фиг.4 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26 содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг.4. В вычислительной сети могут присутствовать также и другие устройства, например маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОЦЕНКИ НАДЕЖНОСТИ ПРАВИЛА КАТЕГОРИЗАЦИИ | 2013 |
|
RU2587429C2 |
| СИСТЕМА И СПОСОБ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ОБНАРУЖЕНИЯ НЕИЗВЕСТНЫХ ВРЕДОНОСНЫХ ОБЪЕКТОВ | 2010 |
|
RU2454714C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |
| Система и способ определения похожих файлов | 2015 |
|
RU2614561C1 |
| Система и способ двухэтапной классификации файлов | 2018 |
|
RU2708356C1 |
| Система и способ снижения количества ложных срабатываний классифицирующих алгоритмов | 2018 |
|
RU2706883C1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ НАПРАВЛЕННЫХ АТАК НА КОРПОРАТИВНУЮ ИНФРАСТРУКТУРУ | 2013 |
|
RU2587426C2 |
| СПОСОБ АВТОМАТИЧЕСКОГО ФОРМИРОВАНИЯ ЭВРИСТИЧЕСКИХ АЛГОРИТМОВ ПОИСКА ВРЕДОНОСНЫХ ОБЪЕКТОВ | 2012 |
|
RU2510530C1 |
| СИСТЕМА И СПОСОБ ОПРЕДЕЛЕНИЯ СТАТУСА НЕИЗВЕСТНОГО ПРИЛОЖЕНИЯ | 2014 |
|
RU2580053C2 |
| Система и способ создания антивирусной записи | 2018 |
|
RU2697954C2 |
Изобретение относится к информационной безопасности. Технический результат заключается в снижении числа ложных срабатываний правил обнаружения файлов. Способ признания надежности правила обнаружения файлов, в котором выделяют из множества существующих файлов подмножество известных файлов, разделяют выделенное подмножество известных файлов на подмножества безопасных и вредоносных файлов; создают правило обнаружения файлов на основании, по меньшей мере, одного известного файла из подмножества вредоносных файлов; проверяют неизвестные файлы из множества существующих файлов; признают правило обнаружения надежным, когда степень сходства ни одного из отобранных неизвестных файлов с известными файлами из подмножества безопасных файлов не превышает установленный порог сходства и степень сходства отобранных неизвестных файлов с, по меньшей мере, одним файлом из подмножества вредоносных файлов превышает установленный порог сходства. 2 н.п. ф-лы, 5 ил.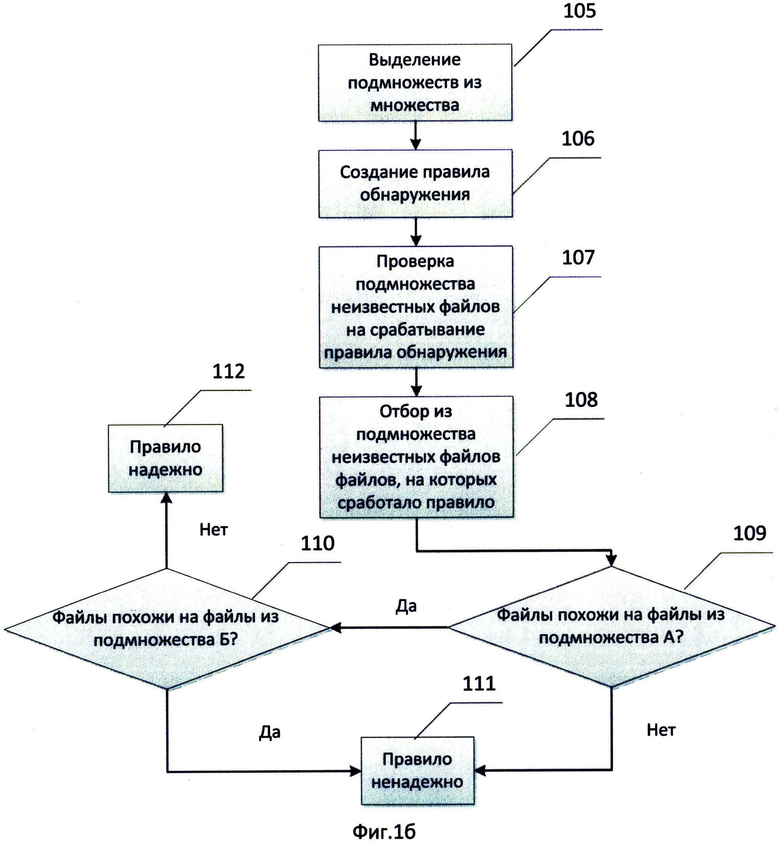
1. Способ признания надежности правила обнаружения файлов, в котором:
а) выделяют из множества существующих файлов подмножество известных файлов, где известными являются файлы характеристика опасности, на основании которой осуществляется выделение, известна;
б) разделяют выделенное подмножество известных файлов на основании значения характеристики опасности по критерию опасности на два подмножества: подмножество безопасных файлов и подмножество вредоносных файлов;
в) создают правило обнаружения файлов на основании, по меньшей мере, одного известного файла, принадлежащего подмножеству вредоносных файлов;
г) проверяют неизвестные файлы из множества существующих файлов, не входящие в подмножества известных файлов: подмножество вредоносных файлов и подмножество безопасных файлов, на срабатывание правила обнаружения, где неизвестными файлами являются файлы, характеристика опасности для которых неизвестна;
д) отбирают неизвестные файлы, на которых сработало правило обнаружения во время проверки, из множества существующих файлов и получают характеристики неизвестных и известных файлов, где характеристиками, по меньшей мере, являются последовательность вызова API функций в файлах и строки в файлах;
е) сравнивают отобранные неизвестные файлы с известными файлами из подмножеств известных файлов: подмножеством вредоносных файлов и подмножеством безопасных файлов, где сравнение осуществляется путем сравнения полученных характеристик файлов;
ж) получают в результате сравнения степень сходства неизвестных отобранных файлов с известными файлами из подмножеств известных файлов, где степень сходства файлов есть степень сходства полученных характеристик отобранных неизвестных файлов с характеристиками известных файлов;
з) устанавливают порог сходства, где порог некоторое числовое значение степени сходства;
и) признают правило обнаружения надежным, когда степень сходства ни одного из отобранных неизвестных файлов с известными файлами из подмножества безопасных файлов не превышает установленный порог сходства, и степень сходства отобранных неизвестных файлов с, по меньшей мере, одним файлом из подмножества вредоносных файлов превышает установленный порог сходства.
2. Система признания надежности правила обнаружения содержит: а) средство кластеризации, предназначенное для:
выделения из множества существующих файлов подмножества известных файлов, где известными являются файлы характеристика опасности, на основании которой осуществляется выделение, известна;
разделения выделенного подмножества известных файлов на основании значения характеристики опасности по критерию опасности на два подмножества: подмножество безопасных файлов и подмножество вредоносных файлов;
отбора неизвестных файлов, на которых сработало правило обнаружения во время проверки, из множества существующих файлов и получения характеристики неизвестных и известных файлов, где характеристиками, по меньшей мере, являются последовательность вызова API функций в файлах и строки в файлах;
б) средство создания правила, связанное со средством кластеризации и файловым хранилищем и предназначенное для создания правила обнаружения файлов на основании, по меньшей мере, одного известного файла, принадлежащего подмножеству вредоносных файлов.
в) средство анализа, связанное с файловым хранилищем и средством создания правил, предназначенное для:
сравнения отобранных неизвестных файлов с известными файлами из подмножеств известных файлов: подмножества вредоносных файлов и подмножества безопасных файлов, где сравнение осуществляется путем сравнения полученных характеристик файлов;
получения в результате сравнения степени сходства неизвестных отобранных файлов с известными файлами из подмножеств известных файлов, где степень сходства файлов есть степень сходства полученных характеристик отобранных неизвестных файлов с характеристиками известных файлов;
установления порога сходства, где порог некоторое числовое значение степени сходства.
признания правила обнаружения надежным, когда степень сходства ни одного из отобранных неизвестных файлов с известными файлами из подмножества безопасных файлов не превышает установленный порог сходства, и степень сходства отобранных неизвестных файлов с, по меньшей мере, одним файлом из подмножества вредоносных файлов превышает установленный порог сходства.
| СПОСОБ ВОЗДЕЙСТВИЯ НА ОРГАНИЗМ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1995 |
|
RU2182458C2 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление к раскройно-ленточной машине для разрезки полотна на тесьму | 1950 |
|
SU92551A1 |

