Уровень техники
Область техники, к которой относится изобретение
Некоторые варианты осуществления настоящего изобретения, в общем, относятся к беспроводной связи, а более конкретно к декодированию беспроводных передач.
Описание предшествующего уровня техники
Быстрое развитие услуг беспроводной связи, таких как широкополосный доступ в Интернет и потоковые мультимедийные приложения, приводит к возрастающей потребности в более высоких скоростях передачи данных. Совершенствование схем мультиплексирования, таких как мультиплексирование с ортогональным частотным разделением (OFDM) и множественный доступ с ортогональным частотным разделением (OFDMA), является важным для систем беспроводной связи следующего поколения. Это обусловлено тем фактом, что такие схемы могут предоставлять множество преимуществ, в том числе эффективность модуляции, эффективность использования спектра, гибкость (к примеру, обеспечение дифференцированного качества обслуживания) и сильную устойчивость к многолучевому распространению по сравнению с традиционными схемами модуляции с одной несущей.
OFDM- и OFDMA-системы зачастую используют сверточные кодеры в передающем устройстве, чтобы предусматривать коррекцию ошибок. При помощи сверточного кода m-битовая строка данных преобразуется в n битов, где m/n - это кодовая скорость. Декодеры, такие как декодеры Витерби, используются в приемном устройстве, чтобы декодировать принимаемые кодированные n битов, чтобы восстанавливать исходную m-битовую последовательность. Эта схема зачастую обеспечивает возможность корректного декодирования исходной m-битовой последовательности, даже если один или более из кодированных n битов не приняты корректно, тем самым приводя к уменьшению частоты ошибок по битам.
Тем не менее, при постоянно растущих требованиях к надежности и производительности беспроводных услуг, всегда имеется необходимость непрерывно уменьшать частоты ошибок по битам.
Раскрытие изобретения
Конкретные варианты осуществления обеспечивают способ для декодирования кодированных битов данных передачи по системе беспроводной связи для сообщения MAP. Способ, в общем, включает в себя формирование гипотезы, задающей набор битовых значений кодированных битов данных, на основе априорной информации, касающейся, по меньшей мере, одного из следующего: содержимое сообщения MAP и параметр связанной передачи, и декодирование передачи посредством исключения из рассмотрения наборов декодированных битов, которые являются не согласованными с заданными битовыми значениями, и выбора, в качестве вывода, декодированных битов, которые соответствуют битовым значениям, заданным посредством гипотезы.
Конкретные варианты осуществления обеспечивают приемное устройство для беспроводной связи, в общем, включающее в себя внешний приемный каскад для приема беспроводной передачи сообщения и формирования набора кодированных битов, механизм гипотез и декодер. Механизм гипотез выполнен с возможностью формировать одну или более гипотез, каждая из которых задает набор битовых значений кодированных битов данных, на основе априорной информации, касающейся сообщения. Декодер выполнен с возможностью декодировать кодированные биты посредством исключения из рассмотрения наборов декодированных битов, которые являются не согласованными с битовыми значениями, заданными посредством гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством одной из гипотез.
Конкретные варианты осуществления обеспечивают устройство для беспроводной связи. Устройство, в общем, включает в себя средство для приема беспроводной передачи сообщения и формирования набора кодированных битов, средство для формирования одной или более гипотез, каждая из которых задает набор битовых значений кодированных битов данных, на основе априорной информации, касающейся сообщения, и средство для декодирования кодированных битов посредством исключения из рассмотрения наборов декодированных битов, которые являются не согласованными с битовыми значениями, заданными посредством гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством одной из гипотез.
Конкретные варианты осуществления обеспечивают устройство мобильной связи, в общем, включающее в себя внешний приемный каскад для приема беспроводной передачи сообщения MAP и формирования набора кодированных битов, механизм гипотез и декодер. Механизм гипотез выполнен с возможностью формировать одну или более гипотез, каждая из которых задает набор битовых значений кодированных битов данных, на основе априорной информации, касающейся, по меньшей мере, одного из следующего: содержимое сообщения MAP или ранее декодированного сообщения MAP. Декодер выполнен с возможностью декодировать кодированные биты посредством исключения из рассмотрения наборов декодированных битов, которые являются не согласованными с битовыми значениями, заданными посредством гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством одной из гипотез.
Краткое описание чертежей
В качестве способа, которым вышеизложенные признаки настоящего изобретения могут подробно пониматься, более подробное описание изобретения, сущность которого вкратце приведена выше, может предоставляться в отношении некоторых вариантов осуществления, некоторые из которых проиллюстрированы на прилагаемых чертежах. Тем не менее, следует отметить, что прилагаемые чертежи иллюстрируют только некоторые варианты осуществления этого изобретения и, следовательно, не должны считаться ограничением его объема, и изобретение может признавать другие в равной мере эффективные варианты осуществления.
Фиг.1 иллюстрирует примерную беспроводную систему в соответствии с некоторым вариантом осуществления настоящего изобретения.
Фиг.2 - это блок-схема устройства беспроводной связи в соответствии с некоторым вариантом осуществления настоящего изобретения.
Фиг.3 иллюстрирует блок-схему приемного устройства и блок-схему передающего устройства в соответствии с некоторыми вариантами осуществления настоящего изобретения.
Фиг.4 иллюстрирует блок-схему априорного декодера в соответствии с некоторыми вариантами осуществления настоящего изобретения.
Фиг.5 иллюстрирует пример перехода состояния решетчатой схемы в соответствии с некоторым вариантом осуществления настоящего изобретения.
Фиг.6 и 6А являются блок-схемами последовательности операций примерных операций для априорного декодирования в соответствии с вариантом осуществления настоящего изобретения.
Фиг.7 иллюстрирует декодер по фиг.5 с примерными значениями битов априорной информации.
Фиг.8 иллюстрирует пример решетчатой схемы с полным набором трактов декодирования и набором трактов декодирования, который уменьшен на основе битов априорной информации, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
Фиг.9 иллюстрирует примерные результаты декодирования согласно первому набору априорной информации, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
Фиг.10 иллюстрирует примерные результаты декодирования согласно первому набору априорной информации, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
Фиг.11 является блок-схемой приемного устройства с априорным декодером и механизмом гипотез в соответствии с некоторыми вариантами осуществления настоящего изобретения.
Фиг.12 - это блок-схема механизма гипотез в соответствии с вариантом осуществления настоящего изобретения.
Фиг.13 иллюстрирует примерный формат сообщений, который может использоваться для того, чтобы формировать гипотезы декодирования на основе битов априорной информации.
Фиг.14A-14G иллюстрируют различные гипотезы декодирования на основе битов априорной информации.
Фиг.15 иллюстрирует примерные результаты декодирования для различных API-гипотез, в соответствии с некоторым вариантом осуществления настоящего изобретения.
Фиг.16 иллюстрирует примерные результаты декодирования для различных API-гипотез, в соответствии с некоторым вариантом осуществления настоящего изобретения.
Фиг.17 иллюстрирует примерные результаты декодирования для различных API-гипотез, в соответствии с вариантом осуществления настоящего изобретения.
Фиг.18 иллюстрирует примерное приемное устройство, допускающее параллельную оценку нескольких гипотез декодирования.
Фиг.19 иллюстрирует примерный процесс для параллельной оценки нескольких гипотез декодирования.
Фиг.20 иллюстрирует примерный декодер, допускающий параллельную оценку нескольких гипотез декодирования.
Фиг.21 иллюстрирует примерное приемное устройство, допускающее последовательную оценку нескольких гипотез декодирования.
Фиг.22 иллюстрирует примерный процесс для последовательной оценки нескольких гипотез декодирования.
Фиг.23 иллюстрирует примерный декодер, допускающий последовательную оценку нескольких гипотез декодирования.
Фиг.24 иллюстрирует примерное приемное устройство, допускающее итеративную оценку нескольких гипотез декодирования.
Фиг.25 иллюстрирует примерный процесс для итеративной оценки нескольких гипотез декодирования.
Фиг.26 иллюстрирует примерное приемное устройство, допускающее API-декодирование с гипотезой на основе сообщения DL-MAP.
Фиг.27 иллюстрирует примерный процесс для API-декодирования с гипотезой на основе сообщения DL-MAP.
Фиг.28 иллюстрирует примерный формат сообщения Normal (обычное) DL-MAP.
Фиг.29 иллюстрирует примерный процесс для API-декодирования сообщения Normal DL-MAP.
Фиг.30 иллюстрирует примерный формат сообщения Compressed (сжатое) DL-MAP.
Фиг.31 иллюстрирует примерный декодер, допускающий параллельную оценку гипотез Normal DL-MAP и Compressed DL-MAP.
Фиг.32 иллюстрирует примерный процесс для параллельной оценки гипотез Normal DL-MAP и Compressed DL-MAP.
Фиг.33 иллюстрирует примерное приемное устройство, допускающее API-декодирование с гипотезой на основе сообщения UL-MAP.
Фиг.34 иллюстрирует примерный формат сообщения UL-MAP.
Фиг.35 иллюстрирует примерный процесс для API-декодирования сообщения UL-MAP.
Фиг.36 иллюстрирует примерное приемное устройство, допускающее API-декодирование в базовой станции с гипотезами, касающимися сообщений BW-REQ и RNG-REQ.
Фиг.37 иллюстрирует примерный формат сообщения RNG-REQ.
Фиг.38 иллюстрирует примерный формат сообщения BW-REQ.
Фиг.39 иллюстрирует примерный процесс для API-декодирования сообщений BW-REQ и RNG-REQ.
Осуществление изобретения
Настоящее изобретение, в общем, предоставляет технологии и устройства для декодирования сверточно кодированных беспроводных передач с использованием априорной информации, касающейся передачи. Априорная информация может использоваться для того, чтобы эффективно уменьшать совокупность возможных декодированных потоков битов посредством исключения тех из них, которые включают в себя биты, которые являются несогласованными с априорной информацией. Посредством удаления этих "известных неправильных" трактов, которые приводят к ошибочным данным, декодированные частоты ошибок по битам могут снижаться в некоторых ситуациях.
При использовании в данном документе, термин "априорная информация", в общем, упоминается как информация, известная заранее, к примеру, информация, развивающаяся от известной или предполагаемой причины до обязательно связанного результата. Как подробнее описано ниже, примеры априорной информации, связанной с передачей, включают в себя известные информационные биты в определенных сообщениях. Примеры таких известных информационных битов включают в себя зарезервированные биты со значениями, указываемыми посредством стандарта, или биты, которые имеют известные или прогнозируемые значения на основе их значения в предыдущих передачах. Эти известные позиции битов и битовые значения (в данном документе называемые "API-значениями") могут использоваться в процессе декодирования для того, чтобы повышать производительность декодирования посредством исключения трактов, которые соответствуют значениям, которые отличаются от API-значений.
Примерная система беспроводной связи
Способы и устройства настоящего раскрытия сущности могут быть использованы в системе широкополосной беспроводной связи. Термин "широкополосный беспроводной" упоминается как технология, которая предоставляет доступ к беспроводным сетям, сетям телефонной связи, Интернету и/или сетям передачи данных в данной области.
WiMAX, который означает стандарт общемировой совместимости широкополосного беспроводного доступа, является основанной на стандартах широкополосной беспроводной технологией, которая предоставляет широкополосные соединения с высокой пропускной способностью на большие расстояния. Сегодня предусмотрено два основных варианта применения WiMAX: WiMAX для стационарных устройств и WiMAX для мобильных устройств. Варианты применения WiMAX для стационарных устройств, например, имеют тип "из точки к множеству точек" и обеспечивают широкополосный доступ в дома и офисы. WiMAX для мобильных устройств предлагает полную мобильность сотовых сетей на скоростях широкополосной передачи.
WiMAX для мобильных устройств основан на технологии OFDM (мультиплексирование с ортогональным частотным разделением) и OFDMA (множественный доступ с ортогональным частотным разделением). OFDM - это технология цифровой модуляции с несколькими несущими, которая с недавних пор нашла широкое применение во множестве систем связи с высокой скоростью передачи данных. В OFDM, поток передаваемых битов разделяется на несколько субпотоков с меньшей скоростью. Каждый субпоток модулируется с помощью одной из нескольких ортогональных поднесущих и отправляется по одному из множества параллельных подканалов. OFDMA - это технология множественного доступа, в которой пользователям назначаются поднесущие в различных временных квантах. OFDMA является гибкой технологией множественного доступа, которая может приспосабливать для множества пользователей различные приложения, скорости передачи данных и требования по качеству обслуживания.
Быстрое развитие технологий беспроводной связи по Интернету приводит к возрастающей потребности в высоких скоростях передачи данных в области техники услуг беспроводной связи. OFDM/OFDMA-системы сегодня рассматриваются как одна из наиболее перспективных исследовательских областей и как ключевая технология для следующего поколения беспроводной связи. Это обусловлено тем фактом, что схемы OFDM/OFDMA-модуляции могут предоставлять множество преимуществ, таких как эффективность модуляции, эффективность использования спектра, гибкость и сильная устойчивость к многолучевому распространению, по сравнению с традиционными схемами модуляции с одной несущей.
IEEE 802.16x является организацией-разработчиком новых стандартов, чтобы задавать радиоинтерфейс для систем на основе стандарта широкополосного беспроводного доступа (BWA) для стационарных и мобильных устройств. IEEE 802.16x приняла документ "IEEE P802.16-REVd/D5-2004" в мае 2004 года для BWA-систем для стационарных устройств и опубликовала документ "IEEE P802.16e/D12 Oct. 2005" в октябре 2005 года для BWA-систем для мобильных устройств. Эти два стандарта задали четыре различных физических уровня (PHY) и один уровень управления доступом к среде (MAC). Физический уровень OFDM и OFDMA из четырех физических уровней является самым популярным в областях BWA для стационарных и мобильных устройств, соответственно.
Примерное окружение
Фиг.1 иллюстрирует примерную систему, в которой варианты осуществления настоящего изобретения могут быть использованы для того, чтобы обрабатывать беспроводной сигнал от базовой станции 110 к мобильной станции 120. Базовая станция 110 может быть станцией беспроводной связи, установленной в стационарном местоположении, таком как вышка сотовой телефонной связи. Мобильная станция 120 может быть абонентским устройством (UE) любого подходящего типа, допускающим обмен данными с базовой станцией 110, к примеру, переносным сотовым телефоном или мобильным устройством другого типа.
Базовая станция 110 и мобильная станция 120 могут обмениваться данными с помощью одной или более антенн 112, 122 и с помощью любой подходящей технологии беспроводной связи с применением схем модуляции, такой как мультиплексирование с ортогональным частотным разделением (OFDM) и множественный доступ с ортогональным частотным разделением (OFDMA). Для некоторых вариантов осуществления обмен данными между базовой и мобильной станцией может быть частично или полностью совместим с множеством стандартов института инженеров по электронике и радиотехнике (IEEE), таких как семейство стандартов IEEE 802.16 (стандарт общемировой совместимости широкополосного беспроводного доступа - WiMAX) и 802.20 (стандарт широкополосного беспроводного доступа для мобильных устройств - MBWA).
В некоторых вариантах применения, базовая станция 110 может передавать данные в мобильную станцию по тому, что обычно упоминается как прямая линия связи, тогда как мобильная станция 120 передает данные в базовую станцию 120 по обратной линии связи. Как подробнее описано ниже, различные типы априорной информации могут быть доступными для передач по прямой и обратной линии связи. Эта априорная информация может включать в себя информацию, касающуюся синхронизации и содержимого определенных сообщений между базовой станцией 110 и мобильной станцией 120, которая может приводить к известности значения одного или более битов в передаче.
Технологии, описанные в данном документе, могут быть использованы при декодировании, выполняемом в базовой станции 110, мобильной станции 120 или в обеих из них. Как подробнее описано ниже, априорная информация о различных типах сообщений, передаваемых между базовой станцией 110 и 120, может использоваться для того, чтобы определять значение конкретных местоположений битов в передаче.
Фиг.2 иллюстрирует блок-схему примерных компонентов для одного варианта осуществления приемного устройства, допускающего прием передаваемых сигналов. Одна или более антенн 202 могут принимать передаваемые сигналы из передающего устройства и отправлять их в радиочастотный (RF) входной каскад 210. Входной RF-каскад 210 может включать в себя любые подходящие схемы для приема передаваемых сигналов и подготовки их для обработки цифровых сигналов, такие как автоматическая регулировка усиления (AGC), блок быстрого преобразования Фурье (FFT), модуль оценки канала и модуль оценки отношения "мощность-несущей-к-помехам-и-шуму" (CINR).
Сигналы из входного RF-каскада 210 могут затем отправляться в блок 220 обработки сигналов, который может содержать любые подходящие схемы для освобождения поднесущей, обратного преобразования сигналов и т.п. Выводом блока 220 обработки сигналов является набор кодированных битов. Кодированные биты перенаправляются в канальный декодер 230, который может декодировать кодированные биты с использованием априорной информации о соответствующей передаче.
Априорное декодирование
Фиг.3 является блок-схемой декодера 230, допускающего выполнение операций декодера на основе априорной информации в соответствии с вариантом осуществления настоящего изобретения. Хотя проиллюстрированный пример показывает схему декодирования по Витерби в качестве примера, технологии априорного декодирования, представленные в данном документе, также могут применяться к другим типам схем декодирования, таким как турбокодирование/декодирование, кодирование/декодирование на основе разреженного контроля по четности (LDPC), RS-кодирование/декодирование, BCH-кодирование/декодирование и различные другие схемы.
В случае схем, которые используют систематические коды, кодированные биты могут включать в себя систематические биты (информацию до кодирования) и биты четности (избыточные биты, являющиеся результатом кодирования). Схема API-декодирования может применяться к систематическим битам. Другими словами, значения API-битов могут включать в себя известные значения систематических битов на основе конкретных используемых систематических кодов. Чтобы применять API для систем с использованием систематических кодов, биты принимаемых данных могут заменяться (известными/прогнозированными) значениями API-битов во входном каскаде декодера. Таким образом, вероятность успешного декодирования может увеличиваться при использовании API для систематических декодеров.
Декодер 230 включает в себя модуль 232 показателей ветвления, логику 234 суммирования, сравнения и выбора (ACS) и модуль 236 обратного отслеживания (TB), чтобы формировать набор декодированных битов 246 из набора "мягко (или жестко)" кодированных/принимаемых битов 240. Модуль показателей ветвления, в общем, выполнен с возможностью вычислять показатели ветвления, которые представляют нормированные расстояния между принимаемым символом (набором битов) и символами в кодовом алфавите. ACS-модуль 234, в общем, компилирует данные показателей ветвления, чтобы формировать показатели для трактов декодирования (2K-1 трактов при условии длины кодового ограничения в K), и выбирает один из этих трактов декодирования в качестве оптимального. Результаты этих выборов записываются в запоминающее устройство модуля 236 обратного отслеживания, который восстанавливает тракт из сохраненных решений. Набор декодированных битов затем может быть сформирован на основе переходов восстановленного тракта.
Один или более из компонентов декодера могут управляться посредством набора API-битов 250, чтобы предотвращать выбор трактов декодирования, которые соответствуют битовым значениям, которые являются несогласованными с априорной информацией. Другими словами, API-биты 250 могут содержать достаточную информацию, чтобы задать конкретные значения ("0" или "1"), которые являются известными для определенных местоположений битов в последовательности декодируемых битов. Любая битовая строка, которая имеет значение, отличное от значения, задаваемого в API-битах 250, не является допустимой декодированной битовой строкой. Таким образом, декодер может удалять тракты декодирования, соответствующие этим недопустимым битовым строкам, из рассмотрения во время выбора тракта.
Как проиллюстрировано на фиг.4, для некоторых вариантов осуществления, ACS-модуль 234 может управляться посредством API-битов 250, чтобы исключать тракты декодирования, которые соответствуют недопустимым декодированным битовым строкам. Во время работы ACS, API-биты 250 могут использоваться для того, чтобы уменьшать конкретные переходы тракта декодирования, которые соответствуют кодированным битовым значениям, которые являются несогласованными с API-значениями.
API-биты 250, в общем, включают в себя достаточную информацию для того, чтобы идентифицировать один или более битов в декодированной битовой строке, которые имеют битовые значения, которые являются известными (или прогнозируемыми) на основе априорной информации, и, дополнительно, то, чему равны эти битовые значения. Фактический формат, в котором передается эта информация, может меняться в зависимости от различных вариантов осуществления и согласно фактическим схемам реализации.
Например, для некоторых вариантов осуществления, API-биты 250 могут включать в себя три типа информации: индикатор относительно позиций 252 битов, битовые значения 254 и, необязательно, биты 256 API-маски. Позиции 252 битов могут предоставлять индикатор относительно местоположений битов (в рамках кодированной последовательности), которые имеют известные значения, при этом битовые значения 254 обеспечивают фактические известные значения ("0" или "1") кодированного бита. Фиг.7, подробно описанная ниже, предоставляет иллюстрацию с примерными значениями для позиций битов, битовых значений и битов маски согласно этому формату.
Позиции 252 API-битов могут идентифицировать позиции битов, которые соответствуют позиции известного/прогнозированного кодированного бита в решетчатой структуре. Согласно одному варианту осуществления, позиции 252 API-битов могут явно идентифицировать позиции битов, которые имеют известные значения, при этом все другие позиции битов считаются "неизвестными". Соответствующее битовое значение "0" или "1" в битовых значениях 254 тем самым может использоваться для того, чтобы идентифицировать допустимые переходы в решетчатой структуре и эффективно удалять тракты декодирования, заключающие в себе недопустимые переходы.
Например, фиг.5 иллюстрирует пример перехода состояния решетчатой структуры с 3-битовыми состояниями. Проиллюстрированный пример предполагает кодовую скорость 1/2 и K=4 (с 3-битовым, K-1, регистром состояния). Сплошные стрелки задают переходы состояния, соответствующие входному биту "0", тогда как пунктирные стрелки задают переходы состояния, соответствующие входному биту "1". Согласно API-декодированию, переходы состояния, которые соответствуют входным битам, которые являются несогласованными с известными значениями, могут исключаться из рассмотрения, тем самым эффективно исключая все тракты, включающие в себя эти переходы, из конечного выбора.
В качестве примера, если известное значение API-бита для этого состояния равно "0", переходы состояния со сплошными линиями должны оцениваться, в то время как переходы состояния с пунктирными линиями не должны вычисляться, поскольку они являются частью недопустимых трактов, которые не должны рассматриваться для выбора. Как описано выше, эти переходы могут эффективно исключаться при следующем переходе посредством задания значения показателя состояния равным значению наихудшего случая. В дополнение к сокращению частоты ошибок по битам посредством исключения недопустимых трактов из выбора, исключение числа переходов на основе значений API-битов также может сокращать число вычислений в ACS-модуле.
Для некоторых вариантов осуществления маскирующая функция может быть реализована посредством использования битов 256 API-маски, чтобы идентифицировать позиции битов, значение API-бита которых должно игнорироваться. Такая маскирующая функция может быть полезной и добавлять гибкость, например, когда стандарт изменяется, приводя к тому, что ранее известное битовое значение становится неизвестным. Задание бита маски может предоставлять простой механизм, чтобы эффективно приспосабливать такие изменения. Маскирующая функция также может быть реализована посредством обработки позиций 252 API-битов так, чтобы удалять идентификационные данные позиции бита, которая более не имеет известного значения, тем самым предоставляя альтернативу изменению значения в значении битовой маски и/или вообще исключая необходимость значения битовой маски.
Фиг.6 иллюстрирует примерный процесс 600 для API-декодирования. Процесс начинается на этапе 602 посредством формирования гипотезы на основе априорной информации. На этапе 604 удаляются тракты декодирования, которые приводят к битовым значениям, не согласованным со значениями API-битов гипотезы. В завершение на этапе 606 декодирование выполняется на основе выбора одного из оставшихся трактов.
При использовании в данном документе термин "гипотеза", в общем, упоминается как конкретный набор API-битов, например, задающий позиции битов с известными значениями и задающий значения для этих битов. Как подробнее описано ниже, для некоторых вариантов осуществления, отдельная логика (упоминаемая в данном документе как "механизм гипотез") может предоставляться, чтобы формировать одну или более гипотез, например, на основе информации сообщений из MAC-процессора.
Фиг.7 иллюстрирует один пример гипотезы для 6-битового потока, применяемой к API-декодеру. Проиллюстрированная гипотеза задает, через значения позиций API-битов [1 2 3 5], что значения API-битов присутствуют в позициях битов 1, 2, 3 и 5 для использования при декодировании. Согласно проиллюстрированной схеме, соответствующие значения API-битов [1 0 1 1] задают, что битовые значения для битов в этих позициях следующие: бит 1=1, бит 2=0, бит 3=1 и бит 5=1. Для некоторых вариантов осуществления могут использоваться битовые значения API-маски [0 0 0 0], которые задают, что маскирующая функция не применяется ни к одному из битов. С другой стороны, чтобы исключать бит из API-декодирования, бит маски может задаваться, например, равным [0 0 0 1], чтобы маскировать позицию бита 5, приводя к фактическим битовым значениям [1 0 1 X].
Функциональность API-маски также может быть реализована посредством управления значениями позиций API-битов. В качестве примера, позиция бита 5 также может эффективно маскироваться посредством удаления 5 из значений позиций битов, приводя к значениям позиций битов [1 2 3], с соответствующими значениями API-битов [1 0 1]. В этой схеме позиции API-битов могут эффективно маскироваться без необходимости отдельной структуры данных для значений маски.
В альтернативной схеме могут использоваться только значения API-битов и соответствующие значения API-маски. В качестве примера, можно предположить, что все позиции в битовой последовательности используются для API-декодирования, например, по умолчанию или посредством специального индикатора относительно всех позиций битов в значении позиции API (к примеру, [1 2 3 4 5 6]). В любом случае, значения API-маски могут использоваться для того, чтобы идентифицировать позиции битов, которые не имеют соответствующих значений API-битов. Например, значение API-маски [0 0 0 1 0 1] может использоваться, где значения "1" задают, что значения API-битов, соответствующие позициям битов 4 и 6, должны игнорироваться, приводя к соответствующим значениям API-битов [1 0 1 X 1 X].
Фиг.8 иллюстрирует то, как значения API-битов гипотезы, показанной на фиг.7, могут применяться для того, чтобы сокращать число трактов декодирования, рассматриваемых в ходе декодирования. Верхняя схема 810 показывает все возможные тракты через схему, которые должны рассматриваться в традиционной схеме декодирования, которая предполагает, что все входные биты являются неизвестными. Как проиллюстрировано посредством нижней схемы 820, тем не менее, схема API-декодирования выполняет поиск в значительно сокращенном числе трактов, исключая число переходов трактов на основе использования известных значений API-битов.
Сокращение трактов на основе значений API-битов может поясняться посредством прохождения по схеме 820 слева направо. Известные API-значения для соответствующих переходов перечисляются наверху. Для первого перехода битовое значение - это известное "1", приводя к удалению переходов трактов, указанных сплошными линиями, соответствующих нулевому входному биту. Это приводит к переходам на узлы 100b, 101b, 110b и 111b состояния.
Второй переход соответствует известному битовому значению "0", приводя к удалению переходов трактов, указанных пунктирными линиями. Это приводит к переходам на узлы 010b и 011b состояния. Третий переход соответствует известному битовому значению "1", приводя к удалению переходов трактов, указанных сплошными линиями. Это приводит к переходам на один узел 101b состояния.
Битовое значение для четвертого перехода, тем не менее, является неизвестным. Следовательно, оба возможных тракта перехода оцениваются. Это приводит к переходам на узлы 010b и 110b состояния. Пятый переход соответствует известному битовому значению "1", приводя к удалению переходов трактов, указанных сплошными линиями. Это приводит к переходам на узлы 101b и 111b состояния. Битовое значение для шестого перехода снова является неизвестным. Следовательно, оба возможных тракта переходов оцениваются, приводя к переходам на узлы 010b и 110b состояния из узла 101b состояния и переходам на узлы 011b и 111b состояния из узла 111b состояния.
Показатели ветвления для этих оставшихся трактов могут оцениваться, чтобы выбирать оптимальный тракт и формировать соответствующий набор декодированных битов. Посредством исключения трактов декодирования, которые соответствуют недопустимым битовым последовательностям, частоты ошибок по битам/пакетам могут снижаться с использованием API-декодирования, причем большие снижения ожидаются в более зашумленных окружениях.
Фиг.9 является примерным графиком частоты ошибок по пакетам (PER) в зависимости от отношения "сигнал-шум" (SNR) для моделированного декодирования сообщения заголовка управления кадром (FCH)/префикса кадра нисходящей линии связи (DLFP) стандарта IEEE 802.16e. Этот тип сообщения содержит 24-битовую информацию. Из них 5 битов являются зарезервированными битами, которые должны быть заданы равными нулю согласно стандарту. В моделированном примере эти 5 зарезервированных битов используются в качестве априорной информации, с известными битовыми значениями в "0" в соответствующих местоположениях в 24-битовой строке. Моделирование также предполагает модуляцию и кодирование следующим образом: QPSK, TBCC (r=1/2), с коэффициентом повторения 4 и коэффициентом дублирования 2 и предполагает комбинирование с максимальным отношением для повторений (MRC) на приемной стороне (RX).
Как проиллюстрировано, схема API-декодирования демонстрирует повышенную производительность относительно традиционной схемы декодирования в AWGN-окружениях. Например, схема API-декодирования демонстрирует усиление примерно в 0,6 дБ при PER 10-2 в AWGN-канале по сравнению с традиционным декодированием (без учета API).
Фиг.10 является схемой, аналогичной фиг.9, но соответствующее моделирование предполагает как комбинирование с максимальным отношением для повторений (MRC), так и дублирование на приемной стороне (RX). Как проиллюстрировано, в этом примере, схема API-декодирования демонстрирует приблизительное усиление в 0,75 дБ при PER 10-2 в AWGN-канале по сравнению со случаем без схемы API-декодирования.
Механизм гипотез
Как описано выше, для некоторых вариантов осуществления, механизм гипотез может предоставляться, чтобы формировать "гипотезы", каждая из которых включает в себя набор значений API-битов, чтобы использовать при выполнении API-декодирования. В зависимости от конкретной реализации механизм гипотез может формировать одну гипотезу или несколько гипотез, которые могут отличаться тем, какие биты имеют известные значения, а также тем, чему равны эти известные значения битов. Оценка нескольких гипотез может быть полезной, например, когда имеется только ограниченное число допустимых битовых комбинаций для данной последовательности.
Фиг.11 иллюстрирует схему приемного устройства 1100, которое включает в себя API-декодер 230 и механизм 1110 гипотез. Как проиллюстрировано, механизм 1110 гипотез может принимать информацию, касающуюся сообщения от процессора 1120 управления доступом к среде (MAC), и формирует значения API-битов (гипотезу) для использования посредством API-декодера 230. API-декодер 230 начинает декодировать принимаемые мягко (или жестко) кодированные биты Rs с использованием значений API-битов, предоставленных посредством механизма 1110 гипотез. API-декодер 230 выводит декодированные биты Rd данных, которые доставляются в синтаксический анализатор 1130 сообщений.
Если синтаксический анализатор 1130 сообщений обнаруживает, что декодированные биты предназначены для данного типа сообщения, сообщение синтаксически анализируется и доставляется в процессор 1120 MAC (управление доступом к среде). MAC-процессор 1120 может выступать в качестве типа анализатора протоколов, анализирующего принимаемые данные, например, в попытке определять то, каким является следующий возможный тип сообщения, и то, какой должна быть синхронизация.
В качестве примера, MAC-процессор 1120 может распознавать первое входящее сообщение (или данные) как FCH/DLFP-сообщение, после которого следует преамбула нисходящей линии связи. В некоторых случаях, MAC-процессор 1120 может использовать определенную информацию из предыдущего кадра, например, чтобы определять кодовую скорость, длину сообщения или некоторый другой параметр. MAC-процессор 1120 может предоставлять эту информацию в механизм 1110 гипотез, который должен использовать ее для того, чтобы извлекать известные битовые значения (или прогнозированные битовые значения) для конкретных местоположений битов и формировать API-информацию, чтобы перенаправлять в API-декодер.
Фиг.12 иллюстрирует примерный механизм 1110 гипотез, который может использоваться для того, чтобы формировать гипотезы декодирования на основе априорной информации и информации сообщений, предоставленной посредством MAC-процессора 1120. Как проиллюстрировано, механизм гипотез принимает индикатор относительно типа сообщения и включает в себя логику 1210, чтобы извлекать соответствующее сообщение(я), обозначенное посредством типа сообщения, и формат сообщения(й) анализируется посредством логики 1220 формата.
Для некоторых вариантов осуществления, в дополнение к местоположениям битов с фиксированными/известными битовыми значениями (такими как зарезервированные биты, заданные равными известному значению согласно стандарту), гипотезы могут быть сформированы с помощью информации, которая является прогнозируемой. В качестве примера, битовая информация может быть прогнозируемой на основе значения из ранее принятого сообщения (к примеру, тип кодирования практически никогда не изменяется между сообщениями).
Таким образом, логика 1230 классификации может классифицировать битовую информацию в данном сообщении, по меньшей мере, на три категории: фиксированная информация, прогнозируемая информация и переменная информация. Фиксированная (известная) информация, в общем, упоминается как информация, которая является фиксированной, так что она является известной на 100% из начальной стадии или некоторых битовых значений, которые являются известными при некоторых условиях (к примеру, после проверки результатов декодирования связанных сообщений). Например, декодированные результаты сообщений, касающихся данных, которые должны быть декодированы, такие как сообщения или данные, о которых известно, что они размещаются перед данными, которые должны быть декодированы, могут анализироваться, и API-информация может извлекаться из проанализированных данных.
Прогнозируемая информация может включать в себя информацию, которая может быть прогнозируемой при определенных условиях или допущениях, так что она может предоставлять различные варианты значений или битовые комбинации для набора из одного или более битов. Различные варианты значений могут быть включены в различные гипотезы. Например, прогнозируемая информация может включать в себя определенную информацию, прогнозируемую при определенных условиях или допущениях, или информацию, которая является прогнозируемой после проверки результатов декодирования связанных сообщений.
Переменная информация, в общем, включает в себя информацию, которая является неизвестной или которую слишком трудно прогнозировать, так что она, в общем, не используется в качестве значений API-битов (к примеру, значения позиций API-битов для этих местоположений битов могут быть заданы равными "0"). После классификации информационных битов логика 1240 формирования гипотез по API и доставки API механизма гипотез может формировать набор или наборы значений API-битов (где каждый набор соответствует гипотезе) с помощью классифицированной информации. Например, логика 1240 может формировать строки из местоположений, битовых значений и масок API-битов, которые должны выводиться в декодер 230.
Схема API-декодирования, представленная в данном документе, может применяться к множеству различных типов сообщений. Например, API-декодирование может применяться к сообщениям (FCH)/префикса кадра нисходящей линии связи (DLFP), как описано ниже, обычным сообщениям MAP нисходящей линии связи (DL-MAP), сжатым сообщениям DL MAP, сообщениям MAP восходящей линии связи (UL-MAP), сообщениям запроса ширины полосы (BW-REQ), сообщениям запроса на выбор начального диапазона (IRNG-REQ) и т.д.
Сообщение 1300 заголовка управления кадром (FCH)/префикса кадра нисходящей линии связи (DLFP), как проиллюстрировано на фиг.13, предоставляет хороший пример различных битов информации, которая может быть классифицирована как фиксированная, прогнозируемая и переменная. Формат и содержимое FCH-сообщения задается в OFDMA-стандарте IEEE 802.16e. DLFP является содержимым FCH-канала. DLFP - это структура данных, передаваемая в начале каждого кадра, и она содержит информацию, касающуюся текущего кадра, и преобразуется в FCH. Следовательно, успешное декодирование DLFP очень важно для того, чтобы обрабатывать весь кадр. Классификация некоторых битов может изменяться со временем, например, после перехода из состояния начального обнаружения на обнаружение первого кадра сообщения.
В качестве примера, поле 1310 битовой карты включает в себя 6 битов, где каждый бит задает то, используется или нет соответствующая группа сообщений посредством сегмента. В состоянии начального обнаружения эти биты являются неизвестными. Тем не менее, после начального декодирования и идентификации сегмента сообщения, по меньшей мере, один из битов должен быть идентифицирован (к примеру, при условии, что первый бит группы сообщений используется, API-биты="1XXXXX"). Дополнительно, в обычном рабочем режиме мобильная станция может прогнозировать все 6 из битов при условии, что базовая станция отправляет битовую карту, идентичную битовой карте предыдущего кадра.
Как описано выше, биты зарезервированных полей 1320 и 1322 должны оставаться фиксированными до тех пор, пока в стандарт не вносятся изменения. В отличие от этого, 2 бита поля 1330 типа повторения трудно прогнозировать, и они могут изменяться между кадрами.
3-битовое поле 1340 типа кодирования может быть классифицировано по-разному и использовано для того, чтобы формировать ряд различных гипотез. Например, без наложения каких-либо условий на типы кодирования, 3-битовое поле может обрабатываться как переменное. Тем не менее, с помощью априорной информации некоторые из этих битов могут обрабатываться как фиксированные. Например, если известно, что текущая версия WiMAX поддерживает только два типа кодирования, TBCC(0b000) и CTC(0b010), первый и третий биты могут обрабатываться как известные битовые значения "0" (API-биты="0b0X0").
Хотя 8-битовое поле 1350 длины может варьироваться между кадрами, некоторые из битов могут быть классифицированы другими способами. В качестве примера, отсутствие наложения ограничения на все 8 битов поля длины должно быть переменным. Тем не менее, в большинстве случаев, длина DL-MAP составляет менее 2^7, так что MSB может быть прогнозирован как равный "0" (API-биты="0b0XXXXXXX"). Хотя это прогнозирование может не быть истинным, снижение достигаемой частоты ошибок по битам может перевешивать все потери производительности, обусловленные необходимостью повторно декодировать с помощью различной гипотезы. Более активные гипотезы также могут быть сформированы аналогичным образом, например, при условии, что длина составляет менее 2^6 (API-биты="0b00XXXXXX") или менее 2^4 (API-биты="0b0000XXXX").
Фиг.14A-14G иллюстрируют примеры нескольких гипотез API-декодирования для FCH/DLFP-сообщения на основе информации и возможных классификаций и предположений, описанных выше. Гипотезы упоминаются как имеющие различные уровни (L0-L6), которые, в общем, представляют то, насколько "активной" является гипотеза, на основе числа битов, которые обрабатываются как имеющие известные битовые значения.
Согласно фиг.14A, гипотеза L0 соответствует случаю отсутствия значений API-битов (отсутствия гипотезы), как в случае первого сообщения в каждом кадре. Другими словами, поскольку сообщение не декодировано, отсутствует информация сообщений, которая может использоваться для того, чтобы формировать API-значения.
Фиг.14B иллюстрирует гипотезу первого уровня (L1) только с зарезервированными битовыми значениями, используемыми в гипотезе.
Фиг.14C иллюстрирует гипотезу L2, которая включает в себя зарезервированные битовые значения плюс битовое значение битовой карты (группа сообщений, задаваемая в первом кадре), используемое в гипотезе.
Фиг.14D иллюстрирует гипотезу L3, которая, относительно гипотезы L2, добавляет оставшиеся битовые значения битовой карты, которые использованы в предыдущем кадре.
Фиг.14E иллюстрирует гипотезу L4, которая, относительно гипотезы L3, добавляет битовые значения поля кодирования, которые являются общими для поддерживаемых типов кодирования TBCC и CTC. Фиг.14F иллюстрирует гипотезу L5, которая, относительно гипотезы L4, добавляет верхние два бита поля длины на основе допущения, что длина составляет менее 2^6. Фиг.14G иллюстрирует гипотезу L6, которая, относительно гипотезы L5, добавляет еще два бита поля длины на основе допущения, что длина составляет менее 2^4.
Битовые значения для каждой из этих гипотез могут использоваться посредством API-декодера для того, чтобы сокращать число трактов декодирования, которые соответствуют ошибочным данным, способом, описанным выше. Конечно, гипотезы, показанные на фиг.14B-14G, являются только примерными. Дополнительно, хотя проиллюстрированные гипотезы постепенно становятся более активными и включают в себя большее число известных битовых значений, специалисты в данной области техники должны признавать, что другие гипотезы могут быть сформированы с использованием различных комбинаций битовых значений, показанных в этих примерах.
Как описано выше, значения API-битов согласно этим различным гипотезам могут использоваться посредством API-декодера для того, чтобы удалять тракты декодирования, которые соответствуют ошибочным данным. Поскольку различные гипотезы имеют различные значения API-битов, производительность декодирования может варьироваться между гипотезами. Фиг.15-17 показывают примерные графики, которые иллюстрируют варьирования производительности между различными гипотезами для различных каналов.
Фиг.15 показывает результаты моделирования API-декодирования для различных гипотез L0-L6 в канале аддитивного белого гауссова шума (AWGN). В моделировании предполагается, что все гипотезы являются корректными (другими словами, предполагается, что значения API-битов совпадают с фактическими кодированными битовыми значениями).
Как проиллюстрировано, гипотезы с большим количеством API-битов дают в результате лучшую производительность (уменьшенные частоты ошибок по битам). Фиг.16 показывает аналогичные результаты для API-декодирования при использовании различных гипотез для каналов ITU Ped-A и Ped-B. Фиг.17 показывает аналогичные результаты для API-декодирования при использовании различных гипотез для каналов ITU Veh-A и Veh-B.
Хотя вышеприведенное описание направлено на некоторые варианты осуществления настоящего изобретения, другие и дополнительные некоторые варианты осуществления изобретения могут быть разработаны без отступления от его объема, и его объем определяется посредством нижеприведенной формулы изобретения.
Способы обработки нескольких гипотез
Как пояснено выше, механизм гипотез формирует гипотезу битовых значений на основе как фиксированной, так и прогнозируемой априорной информации. Механизм гипотез может использовать прогнозируемую информацию, чтобы формировать несколько (Nc) гипотез посредством допущения различных комбинаций битовых значений. Чтобы повышать производительность, может быть желательным обрабатывать несколько гипотез. Соответственно, декодер может исследовать несколько доставляемых гипотез. Таким образом, число обработанных гипотез может равняться числу доставляемых гипотез Nc. Если имеется несколько обработанных гипотез, только самая точная гипотеза может выбираться.
В некоторых вариантах осуществления принимаемое сообщение может содержать поле контроля циклическим избыточным кодом (CRC). Для сообщений, в которых отсутствует CRC, критерии выбора могут быть основаны на накопленной вероятности (или накопленном расстоянии) на конечной стадии декодирования. Для сообщений, которые имеют CRC, критерии выбора могут быть основаны либо на результатах CRC-контроля, либо на накопленной вероятности.
Предусмотрено несколько способов, которые могут быть использованы для того, чтобы оценивать несколько гипотез. Эти способы могут включать в себя параллельную, последовательную и итеративную оценку. Чтобы реализовывать способ параллельной оценки, множество декодеров используется, где каждый декодер обрабатывает одну или более из Nc API-гипотез.
Напротив, последовательные и итеративные способы декодирования могут использовать один декодер, чтобы обрабатывать одну гипотезу за раз. При последовательном способе декодер обрабатывает все гипотезы в контуре, который имеет длину Nc, тогда как при итеративном способе декодер обрабатывает последовательность гипотез до тех пор, пока он не находит одну гипотезу, которая удовлетворяет заранее определенному пороговому значению критериев выбора.
В некоторых вариантах осуществления число гипотез может превышать число процессоров. В таких вариантах осуществления может быть использован гибридный способ, при котором каждый процессор работает параллельно, но каждый процессор оценивает несколько гипотез последовательно или итеративно.
Фиг.18 иллюстрирует схему приемного устройства, которая включает в себя параллельный API-декодер 1830 и механизм 1860 гипотез, который формирует несколько гипотез.
Как проиллюстрировано, механизм 1860 гипотез может формировать Nc различных гипотез, каждая из которых имеет различный набор значений API-битов API(1)-API(Nc), на основе информации сообщений, принимаемой из MAC-процессора. Механизм гипотез может формировать несколько гипотез, например, на основе различных предположений, используемых для того, чтобы прогнозировать битовые значения. Как описано выше, некоторые из гипотез могут считаться более активными, чем другие, например, на основе числа битовых значений, которые являются прогнозированными.
Декодер 1830 декодирует принимаемые биты Rs с использованием значений API-битов различных гипотез, фактически, многократно параллельно декодируя принимаемые биты посредством применения различных гипотез. После оценки нескольких гипотез декодер 1830 может выводить декодированные биты Rd данных, полученные с помощью гипотезы, определенной как наилучшая на основе некоторого типа критериев выбора.
Фиг.19 иллюстрирует примерный процесс 1900 для параллельной оценки нескольких гипотез. Процесс 1900 может описываться со ссылкой на фиг.20, где иллюстрируется примерный вариант осуществления параллельного декодера 1830, имеющего множество API-декодеров 2000, размещаемых параллельно.
Процесс начинается на этапе 1902 посредством формирования множества гипотез на основе априорной информации. На этапе 1904 каждая гипотеза может отправляться в один из декодеров 2000. Как проиллюстрировано на фиг.20, каждая гипотеза может включать в себя типы информации, описанные выше (к примеру, битовые значения, местоположения битов и/или битовые маски), которые должны использоваться посредством декодера при декодировании принимаемых битов Rs.
Каждый декодер выполняет API-декодирование на этапах 1906 и 1908 удаление трактов декодирования на основе значений API-битов соответствующей гипотезы и выбор из оставшихся трактов, чтобы формировать набор декодированных битов Rd. На этапе 1910 каждый декодер может формировать показатель качества (QA), который может использоваться для того, чтобы выбирать наилучшую гипотезу, например, в случае если декодированное сообщение не включает в себя CRC. Если сообщение фактически содержит CRC, отдельный показатель качества может формироваться или не формироваться. На этапе 1912 результаты декодирования из каждого декодера сравниваются, и на этапе 1914 результаты, полученные с помощью наилучшей гипотезы, выбираются.
Как проиллюстрировано на фиг.20, если декодируемое сообщение содержит CRC, результаты декодирования могут сравниваться посредством выполнения CRC-контроля с помощью CRC-логики 2020. CRC-логика 2020 может формировать вывод (Sx), идентифицирующий гипотезы с декодированными результатами, которые имеют совпадающий CRC. Вывод Sx может использоваться для того, чтобы управлять логикой 2030 выбора, которая выступает в качестве мультиплексора, чтобы выводить соответствующие декодированные результаты.
В качестве альтернативы CRC-контролю (к примеру, если декодированное сообщение не имеет CRC), показатель качества может использоваться для того, чтобы выбирать наилучшую гипотезу. Показателем качества может быть, например, значение вероятности или накопленного расстояния. Логика 2010 решений по ML может оценивать показатель качества из каждого декодера, формируя вывод (Sy), идентифицирующий гипотезу с декодированными результатами, которые имеют наилучший показатель качества (к примеру, наименьшее накопленное расстояние или наибольшую вероятность). Вывод Sy может использоваться для того, чтобы управлять логикой 2030 выбора, чтобы выводить соответствующие декодированные результаты.
Фиг.21 иллюстрирует схему приемного устройства, которая включает в себя последовательный API-декодер 2130 и механизм 2160 гипотез, который формирует несколько гипотез.
Как проиллюстрировано, механизм 2160 гипотез может формировать Nc различных гипотез и последовательно выводить эти гипотезы в декодер 2130, Например, как проиллюстрировано, механизм 2160 гипотез может выводить значения API-битов API(c) в декодер 2130, где c = от 1 до Nc.
Декодер 2130 декодирует принимаемые биты Rs с использованием значений API-битов различных гипотез, фактически, многократно последовательно декодируя принимаемые биты посредством применения различных гипотез. После оценки нескольких гипотез декодер 2130 может выводить декодированные биты Rd данных, полученные с помощью гипотезы, определенной как наилучшая на основе некоторого типа критериев выбора.
Фиг.22 иллюстрирует примерный процесс 2200 для последовательной оценки нескольких гипотез. Процесс 2200 может описываться со ссылкой на фиг.23, который иллюстрирует примерный вариант осуществления последовательного декодера 2130, имеющего один API-декодер 2300 для многократного последовательного декодирования набора принимаемых битов Rs на основе значений API-битов различных гипотез.
Процесс начинается, на этапе 2202, посредством формирования множества гипотез на основе априорной информации. На этапе 2204, одна из гипотез с битовыми значениями API(c) выбирается, чтобы отправляться в декодер 2130 для использования при декодировании принимаемых битов.
Декодер выполняет API-декодирование, на этапах 2206 и 2208, удаление трактов декодирования на основе значений API-битов и выбор 2330 из оставшихся трактов, чтобы формировать набор декодированных битов Rd. На этапе 2210, декодер может формировать показатель качества (QA) 2310, который может использоваться для того, чтобы выбирать наилучшую гипотезу, например, в случае если декодированное сообщение не включает в себя CRC 2320. Как описано выше, если сообщение фактически содержит CRC, отдельный показатель качества может формироваться или не формироваться. На этапе 2212, результаты декодирования и балльный показатель качества (если сформирован) сохраняются в запоминающем устройстве 2340 для последующей оценки.
Если имеются дополнительные гипотезы, как определено на этапе 2214, операции 2204-2212 повторяются. После того как процесс выполнен для каждой гипотезы, результаты гипотез сравниваются, на этапе 2216, и результаты, полученные с помощью наилучшей гипотезы, выбираются, на этапе 2218.
Как проиллюстрировано на фиг.23, результаты Rd(c) декодирования и показатель QA(c) качества, если сформирован, для каждой из гипотез могут извлекаться из запоминающего устройства 2340 и оцениваться, чтобы определять наилучшую гипотезу. Как проиллюстрировано, схема, аналогичная показанной на фиг.20, может использоваться для того, чтобы выводить идентификационные данные наилучшей гипотезы на основе CRC (Sx) и/или показателя качества (Sy), чтобы управлять логикой выбора так, чтобы выводить соответствующие декодированные результаты.
Фиг.24 иллюстрирует схему приемного устройства, которая включает в себя итеративный API-декодер 2430 и механизм 2460 гипотез, который формирует несколько гипотез.
Как и для механизма 2160 гипотез по фиг.21, механизм 2460 гипотез может формировать Nc различных гипотез и последовательно выводить эти гипотезы в декодер 2430. Как и для декодера 2130 по фиг.21, декодер 2430 может использовать один декодер 2470 для того, чтобы декодировать принимаемые биты Rs с использованием значений API-битов API(c) различных гипотез, фактически, многократно последовательно декодируя принимаемые биты посредством применения различных гипотез.
Однако вместо оценки каждой возможной гипотезы и сравнения выводимых результатов декодер 2430 может сравнивать результаты каждой гипотезы с пороговыми критериями выбора. После того как гипотеза оценена с результатами, которые удовлетворяют критериям выбора, соответствующие биты декодированных данных могут выводиться без оценки оставшихся гипотез.
Фиг.25 иллюстрирует примерный процесс 2500 для итеративной оценки нескольких гипотез. Процесс 2500 может выполняться, например, посредством компонентов, показанных на фиг.24.
Процесс начинается на этапе 2502 посредством формирования множества гипотез на основе априорной информации. На этапе 2504 одна из гипотез с битовыми значениями API(c) выбирается для выдачи в декодер 2430 для использования при декодировании принимаемых битов. Декодер выполняет API-декодирование на этапах 2506 и 2508, удаление трактов декодирования на основе значений API-битов и выбор из оставшихся трактов, чтобы формировать набор декодированных битов Rd.
Вместо ожидания до тех пор, пока все гипотезы не будут оценены, и сравнения результатов, как на фиг.22, результаты, полученные для выбранной гипотезы, оцениваются (в рамках контура) на этапах 2512. Как проиллюстрировано, декодер 2430 может включать в себя логику 2480, чтобы определять то, удовлетворяет или нет набор декодированных битов критериям выбора. Например, логика 2480 может выполнять CRC-контроль и/или сравнивать показатель качества с заранее определенным пороговым значением.
Если критерии выбора не удовлетворяются (к примеру, CRC-контроль не показывает соответствие или показатель качества падает ниже порогового значения), операции 2504-2512 могут повторяться, чтобы оценивать другую гипотезу. Тем не менее, если критерии выбора удовлетворяются, результаты, полученные с помощью текущей гипотезы, выбираются, на этапе 2514.
Порядок, в котором различные гипотезы оцениваются в этом итеративном подходе, может варьироваться. Например, для некоторых вариантов осуществления более активные гипотезы (с большим числом известных/прогнозированных битовых значений) могут оцениваться до менее активных гипотез. Для некоторых вариантов осуществления менее активные гипотезы могут оцениваться до более активных гипотез. Для некоторых вариантов осуществления некоторый другой тип критериев может использоваться для того, чтобы определять порядок, в котором гипотезы выбираются для оценки.
Специалистам в данной области техники должно быть понятно, что различные технологии для оценки нескольких гипотез могут варьироваться или в некоторых случаях комбинироваться. Например, как описано выше, параллельные и последовательные технологии могут комбинироваться, чтобы параллельно оценивать множество гипотез, когда имеется больше гипотез, чем параллельных декодеров.
Примерные сообщения для извлечения API-информации
Как указано выше, API-декодеры могут использовать априорную информацию, касающуюся последовательности, формата и/или содержимого различных типов сообщений, чтобы определять и/или прогнозировать битовые значения, чтобы уменьшать частоты ошибок по битам при декодировании передаваемых сообщений.
В качестве примера, согласно OFDMA-стандарту IEEE 802.16e, первой единицей данных в кадре является FCH (заголовок управления кадром), после которого следует Normal DL-MAP или Compressed DL-MAP и UL-MAP. Сообщения заголовка управления кадром (FCH), сообщения Downlink MAP (DL-MAP) и сообщения Uplink MAP (UL-MAP) являются примерами сообщений, которые могут использоваться для того, чтобы формировать гипотезы декодирования с известными значениями API-битов.
Как описано выше, FCH-сообщение типично содержит информацию длины и кодирования MAP, и различные допущения могут осуществляться по содержимому этой информации, например, на основе текущего стандарта, в настоящий момент поддерживаемого кодирования, а также допущений по длине MAP. Данные DL-MAP и UL-MAP типично обеспечивают данные, касающиеся выделения ресурсов, такие как выделение подканалов и субкадров и другая управляющая информация для кадров нисходящей линии связи и восходящей линии связи. Информация по формату и содержимому этих сообщений MAP может использоваться для того, чтобы формировать значения API-битов для декодирования этих сообщений.
Фиг.26 иллюстрирует схему приемного устройства, допускающего декодирование сообщения DL-MAP на основе априорной информации. Как проиллюстрировано, MAC-процессор 2650 может предоставлять информацию синхронизации и сообщений DL-MAP в механизм 2660 гипотез. Механизм 2660 гипотез может формировать набор значений API-битов на основе информации DL-MAP, чтобы управлять API-декодером 2630. В зависимости от варианта осуществления MAC-процессор может предоставлять непрерывную информацию синхронизации и DL-MAP (к примеру, каждый кадр) или может только обновлять эту информацию менее часто по мере того, как она изменяется.
MAC-процессор 2650 может анализировать ранее декодированные биты и проверять результаты из логики 2640 CRC-контроля и логики 2642 контроля HCS8 (последовательность контроля заголовков), чтобы определять то, присутствует или нет корректное сообщение DL-MAP, и предоставлять информацию индикаторов DL-MAP и синхронизацию, а также другую априорную информацию в механизм 2660 гипотез.
HCS8-логика может выполнять проверку 8-битового CRC для MAC-заголовка (к примеру, как задано согласно стандарту IEEE 802.16), предоставленного в сообщении Normal DL-MAP. Эта проверка предоставляет индикатор относительно того, декодирован или нет надлежащим образом, по меньшей мере, MAC-заголовок. Как подробнее описано ниже, в случае если полный CRC-контроль не завершается успешно (для всего сообщения Normal DL-MAP), удачный HCS8-контроль может обеспечивать использование информации в успешно декодированном MAC-заголовке для того, чтобы формировать значения API-битов, которые могут помогать при декодировании оставшейся части сообщения.
Вследствие различного формата и содержимого сообщения Normal DL-MAP и сообщения Compressed DL-MAP могут быть декодированы по-разному. В конкретных вариантах осуществления схема приемного устройства может иметь возможность формировать различный набор значений API-битов, чтобы декодировать соответствующее сообщение. Фиг.27 иллюстрирует примерный процесс для декодирования сообщений Normal и Compressed DL-MAP.
На этапе 2702 принимается индикатор относительно сообщения DL-MAP. Например, MAC-процессор может предоставлять этот индикатор на основе известной синхронизации последовательности сообщений, что сообщение DL-MAP является следующим в последовательности. На этапе 2704 выполняется определение в отношении того, является ли сообщение DL-MAP Normal или Compressed. Если сообщение DL-MAP является Normal, сообщение декодируется с использованием значений API-битов, сформированных для сообщения Normal DL-MAP, на этапе 2706. Если сообщение DL-MAP является Compressed, сообщение DL-MAP декодируется с использованием значений API-битов, сформированных для Compressed DL-MAP, на этапе 2708.
Хотя они показаны как отдельные этапы, которые являются взаимоисключающими в данных примерных процессах, в конкретных вариантах осуществления параллельные декодеры могут предоставляться для декодирования сообщений Normal и Compressed DL-MAP, обеспечивая начало декодирования даже до того, как тип сообщения DL-MAP станет известным. После декодирования должны использоваться только результаты декодирования для корректно декодированного типа, а остальные должны отбрасываться.
Одним из основных отличий между сообщениями Normal и Compressed DL-MAP является MAC-заголовок, предоставленный в сообщении Normal DL-MAP. Фиг.28 иллюстрирует полный формат сообщения Normal DL-MAP. Первая часть сообщения от начала MAC-заголовка до поля DlSymDur имеет фиксированную длину. После этой части фиксированной длины следуют несколько полей IE DL-MAP переменного размера и в завершение поле CRC32.
Таким образом, если сообщение может быть идентифицировано как сообщение Normal DL-MAP, можно формировать несколько значений API-битов. Например, многие поля MAC-заголовка устанавливаются равными определенным значениям на постоянной основе. Эти поля могут использоваться для того, чтобы формировать гипотезы для API-декодера на основе известных битовых значений. На фиг.28 поля, которые имеют фиксированные значения, указываются с помощью первой штриховки. Некоторые зарезервированные поля, отмеченные с помощью второй штриховки, также могут обрабатываться как известные битовые значения при условии, что стандарт, предписывающий значения для этих полей, не изменяется.
Кроме того, предусмотрено несколько полей, которые также являются фиксированными на постоянной основе в ходе связи, но эти значения могут быть неизвестными, например, до тех пор, пока мобильная станция не решает ассоциироваться с базовой станцией. Эти поля, отмеченные с помощью третьей штриховки, могут обрабатываться как фиксированные поля для API-декодирования после синхронизации с базовой станцией.
Дополнительные битовые значения также могут быть определены на основе текущего значения и возможных будущих значений. Например, поле номера кадра (FrmNr) увеличивается монотонно на единицу каждый кадр, так что битовые значения могут быть прогнозируемыми по кадрам.
Хотя поле счетчика дескриптора канала нисходящей линии связи (DCD) (DcdCnt) не изменяется на каждый кадр, оно может иногда увеличиваться на единицу, чтобы задать изменение в конфигурации сообщения DCD. Следовательно, хотя может быть невозможным прогнозировать все биты, если текущее значение является известным, можно прогнозировать битовые значения на основе ограниченного числа битов DCDCnt, которые могут изменяться, если значение увеличивается на единицу. В качестве простого примера, для значения 0x2 (b'00000010') в предыдущем кадре, значение должно быть 0x2 или 0x3 (b'00000011) в следующем кадре, что означает то, что битовые значения этих 7 MSB являются прогнозируемыми (значения API-битов=b'0000001X').
Фиг.29 является блок-схемой последовательности операций примерного процесса 2900 для API-декодирования сообщения Normal DL-MAP, например, которое может выполняться посредством приемного устройства по фиг.26. Примерный процесс 2900 начинается на этапе 2902 посредством формирования гипотезы на основе API, касающейся сообщения Normal DL-MAP. Процесс может начинаться на границе кадра или после обнаружения допустимой преамбулы кадра. Например, MAC-процессор может обновлять и предоставлять информацию гипотез Normal DL-MAP в механизм гипотез Normal DL-MAP. В конкретных вариантах осуществления гипотеза Normal DL-MAP может сохранять самую свежую информацию так, что MAC-процессор не должен обновлять информацию, если она не изменена. Обновление и предоставление информации гипотез Normal DL-MAP может осуществляться в конце последовательности операций для следующего кадра.
API-декодирование выполняется на этапе 2904 и 2906 посредством удаления из рассмотрения трактов декодирования, которые являются несогласованными со значениями API-битов, и выбора из оставшихся трактов, чтобы формировать набор декодированных битов для сообщения. Например, API-декодер может начинать декодирование DL-MAP при временном смещении DL-MAP от границы кадра, которое заранее задается в стандарте.
На этапе 2908, CRC-контроль выполняется (для всего сообщения), чтобы определять то, декодировано или нет сообщение успешно. Например, вывод API-декодера отправляется в модуль CRC32-контроля, который сравнивает принимаемое значение CRC и вычисленное значение CRC, чтобы верифицировать сообщение DL-MAP. Если CRC-контроль завершается успешно, предполагается то, что сообщение декодировано корректно, и DL-MAP перенаправляется на этапе 2910.
В случае если CRC-контроль для полного сообщения является безуспешным, тем не менее, код контроля MAC-заголовков (HCS8) может проверяться на этапе 2912, чтобы проверить, декодирован или нет, по меньшей мере, MAC-заголовок успешно. Если HCS8-контроль завершается успешно, и текущий контур декодирования является "первым проходом", как определено на этапе 2916, информация гипотез может обновляться на этапе 2918, например, с использованием всех успешно декодированных полей MAC-заголовка, в дополнение к другим фиксированным/прогнозированным полям из оставшейся части сообщения Normal DL-MAP.
С помощью этой обновленной гипотезы с потенциально значительно большим числом известных битовых значений может быть осуществлена вторая попытка декодировать сообщение. Дополнительные биты могут приводить к успешному CRC-контролю на этапе 2908. Иначе, декодирование определяется как не завершенное успешно на этапе 2914.
В конкретных вариантах осуществления аналогичные операции API-декодирования могут выполняться на основе фиксированных, зарезервированных и прогнозированных битовых значений для сообщения Compressed DL-MAP.
Фиг.30 иллюстрирует формат сообщения Compressed DL-MAP. Первая часть сообщения, от начала сообщения до поля IeCnt, имеет фиксированную длину, после чего следуют несколько IE DL-MAP переменного размера и, в завершение, поле CRC32. После идентификации сообщения как сообщения Compressed DL-MAP (к примеру, посредством MAC-процессора) первые 3 бита сообщения, которые идентифицируют тип сообщения как индикатор Compressed MAP, являются известными и должны быть фиксированными (b'110'), как указано посредством первой штриховки.
Зарезервированное поле, указанное с помощью второй штриховки, также может считаться фиксированным и использоваться для API-декодирования, если стандарт не изменяет это поле в определенных целях. Как и для сообщения Normal DL-MAP, кроме того, предусмотрено несколько полей, которые также являются фиксированными на постоянной основе в ходе связи, но эти значения могут быть неизвестными, например, до тех пор, пока мобильная станция не решает ассоциироваться с базовой станцией. Эти поля, отмеченные с помощью третьей штриховки, могут обрабатываться как фиксированные поля для API-декодирования после синхронизации с базовой станцией.
Дополнительные битовые значения также могут быть определены на основе текущего значения и возможных будущих значений других полей, которые являются общими с Normal DL-MAP. Эти поля включают в себя поле номера кадра (FrmNr) и поле счетчика дескриптора канала нисходящей линии связи (DCD) (DcdCnt), как описано выше.
В конкретных вариантах осуществления логика декодирования может предоставляться, чтобы выбирать между типами сообщений Normal и Compressed DL-MAP. Хотя на основе последовательности сообщений может быть известным, что поступает DL-MAP, может быть неизвестным, является оно сообщением Normal или Compressed DL-MAP.
Фиг.31 иллюстрирует логику 3100 декодирования, которая включает в себя параллельные API-декодеры для параллельного декодирования сообщений Normal и Compressed DL-MAP. Фиг.32 иллюстрирует примерный процесс 3200 для параллельной обработки сообщений Normal и Compressed DL-MAP. Процесс 3200 может выполняться посредством компонентов, показанных на фиг.32.
Процесс 3200 начинается на этапе 3202 посредством формирования гипотез на основе априорной информации для Normal и Compressed DL-MAP. На этапе 3204 и 3206 API-декодирование выполняется параллельно с использованием гипотез Normal и Compressed DL-MAP. Как проиллюстрировано, декодер 3110 декодирует кодированные биты на основе значений API-битов Normal DL-MAP, тогда как декодер 3120 декодирует аналогичные кодированные биты на основе значений API-битов Compressed DL-MAP.
На этапе 3208 выполняется определение в отношении того, успешно или нет декодировано сообщение DL-MAP, с использованием любой из гипотезы Normal или Compressed DL-MAP. Если нет, декодирование не завершается успешно на этапе 3212. Иначе, DL-MAP выводится на этапе 3210, независимо от того, является сообщение DL-MAP Normal или Compressed.
Чтобы определять, завершено ли декодирование успешно или нет, и способствовать выбору между декодерами, логика 3130 выбора DL-MAP может предоставляться, чтобы верифицировать декодированные данные посредством выполнения CRC32- и/или HCS8-контроля. Если CRC-контроль завершается успешно для вывода из декодера 3120, сообщением является сообщение Compressed DL-MAP. Если CRC-контроль завершается успешно для вывода из декодера 3110, сообщением является сообщение Normal DL-MAP. Как описано выше, успешное частичное декодирование MAC-заголовка Normal DL-MAP, как указано посредством успешного HCS8-контроля, может использоваться для того, чтобы выполнять другую итерацию декодирования для Normal DL-MAP, если CRC-контроль не завершается успешно.
В качестве альтернативы параллельному подходу, описанному выше, DL-MAP также может быть декодировано с использованием последовательного подхода. Например, один API-декодер может быть использован для того, чтобы опробовать гипотезы Normal и Compressed DL-MAP последовательным способом. В качестве примера, гипотеза для Normal DL-MAP может быть опробована сначала, и если декодирование не завершается успешно, гипотеза для Compressed DL-MAP может использоваться. При использовании одного декодера может потребляться меньше энергии, чем в варианте осуществления с несколькими декодерами, описанном выше.
В конкретных вариантах осуществления, чтобы минимизировать число итераций, предыстория предыдущих типов DL-MAP может использоваться для того, чтобы прогнозировать тип DL-MAP текущего кадра. Другими словами, если последний тип сообщения DL-MAP - Compressed, значения API-битов, соответствующие типу Compressed DL-MAP, могут использоваться для декодирования. Если API-декодирование Compressed DL-MAP не завершается успешно, значения API-битов, соответствующие типу Normal DL-MAP, могут использоваться в последующей итерации декодирования.
Априорная информация, касающаяся формата и содержимого сообщения Uplink MAP (UL-MAP), также может использоваться, чтобы формировать значения API-битов и способствовать декодированию. Согласно OFDMA-стандартам IEEE 802.16e, задается то, что сообщение UL-MAP является первым MPDU в пакете, который направлен посредством первого информационного элемента (IE) DL-MAP трафика данных. Если как Compressed UL-MAP, так и Sub-DL-UL-MAP отсутствуют в кадре, мобильная станция типично может допускать, что первый MPDU первого пакета данных является сообщением UL-MAP, если некоторые условия удовлетворяются после синтаксического анализа DL-MAP. При использовании этой информации мобильная станция знает о том, какой тип сообщения должен выводиться посредством декодера в определенный момент, и может использовать известные значения сообщения в качестве априорной информации, чтобы повышать производительность декодирования на основе схемы API-декодирования.
Фиг.33 иллюстрирует схему приемного устройства, допускающего декодирование сообщения UL-MAP на основе априорной информации. Вследствие аналогичности формата между сообщениями DL-MAP и UL-MAP, схема приемного устройства может работать аналогично схеме приемного устройства по фиг.26, допускающего декодирование сообщений DL-MAP на основе априорной информации.
Как проиллюстрировано, MAC-процессор 3350 может предоставлять информацию синхронизации и сообщений UL-MAP в механизм 3360 гипотез. Механизм 3360 гипотез может формировать набор значений API-битов на основе информации UL-MAP, чтобы управлять API-декодером 3330. В зависимости от варианта осуществления процессор может предоставлять непрерывную информацию синхронизации и UL-MAP (к примеру, каждый кадр) или может только обновлять эту информацию менее часто по мере того, как она изменяется. Процессор 3350 может анализировать ранее декодированные биты и проверять результаты из логики 3340 CRC-контроля и логики 3342 HCS8-контроля, чтобы определять то, присутствует или нет корректное сообщение UL-MAP, и предоставлять информацию индикаторов UL-MAP и синхронизацию, а также другую априорную информацию в механизм 3360 гипотез.
Фиг.34 иллюстрирует формат сообщения UL-MAP. Первая часть сообщения, от начала MAC-заголовка до поля UlSymDur, имеет фиксированную длину. После этой части фиксированной длины следуют несколько полей IE UL-MAP переменного размера и, в завершение, поле CRC32.
Когда определено то, что сообщением является сообщение UL-MAP, многие поля части MAC-заголовка остаются равными фиксированным значениям. Данная известная информация по этим полям может использоваться для того, чтобы формировать значения API-битов для API-декодера. На чертеже поля, которые имеют фиксированные значения, указываются посредством первой штриховки. Некоторые зарезервированные поля, указанные посредством второй штриховки, также могут использоваться посредством API-декодера, если стандарт не изменяет битовые значения полей для определенной цели.
Предусмотрены также различные поля, которые имеют некоторые значения, которые могут быть прогнозированы на основе текущих рабочих параметров. В качестве примера, поле UcdCnt счетчика дескриптора канала восходящей линии связи (UCD) не должно изменяться в большинстве случаев, но может увеличиваться на единицу в определенный момент. Следовательно, в большинстве случаев число MSB не должно изменяться.
В качестве другого примера, максимальное значение определенных полей может быть определено после того, как мобильная станция ассоциирована с конкретной базовой станцией, и все полученные сетевые параметры, которые влияют на эти поля, являются известными. В качестве примера, когда ширина полосы радиочастот, длительность кадра и политика релевантности UL-MAP получены, максимальные значения для поля выделенного начального времени (AllocStartTime) и/или поля длительности символа восходящей линии связи (UlSymDur) могут вычисляться.
Чтобы иллюстрировать это, если текущая ширина полосы радиочастот составляет 5 МГц, а длительность кадра составляет 5 мс, максимальное значение AllocStartTime может составлять 0x1B58 или 0x36B0 согласно режиму релевантности MAP. Если максимальное значение составляет 0x36B0, то 18 MSB должны задаваться равными нулю. В качестве еще одной иллюстрации, если текущая ширина полосы радиочастот составляет 5 МГц, а длительность кадра составляет 5 мс, то максимальное значение UlSymDur составляет 0x15 согласно профилю WiMAX. Таким образом, первые 3 MSB (биты 7-5) должны задаваться равными нулю.
Фиг.35 иллюстрирует примерный процесс 3500 для декодирования сообщения UL-MAP. Процесс 3500 может начинаться, например, после декодирования DL-MAP, которое соответствует FCH. Как показано на фиг.33, MAC-процессор может обновлять и предоставлять гипотезу UL-MAP в UL-MAP для этого процесса.
Процесс 3500 начинается на этапе 3502 посредством формирования одной или более гипотез на основе априорной информации для UL-MAP. В зависимости от варианта осуществления, механизм гипотез UL-MAP может сохранять самую свежую информацию так, что MAC-процессор не должен обновлять информацию, если она не изменена. Обновление и предоставление гипотезы UL-MAP может осуществляться в конце последовательности операций для следующего кадра.
На этапе 3504 и 3506 API-декодер может начинать декодирование с помощью API UL-MAP, удаление трактов декодирования, которые являются несогласованными со значениями API-битов, и выбор из оставшихся трактов. API-декодер может начинать декодирование, например, при временном смещении UL-MAP, которое описывается в соответствующем IE DL-MAP, который находится в сообщении DL-MAP.
На этапе 3508 выполняется CRC-контроль для декодированного сообщения. Как проиллюстрировано на фиг.33, декодированные биты, выводимые из API-декодера, могут выводиться в логику CRC32-контроля, которая сравнивает принимаемое значение CRC и вычисленное значение CRC, чтобы верифицировать сообщение UL-MAP. Если CRC совпадают, успешно декодированный UL-MAP перенаправляется на этапе 3510.
Аналогично вышеописанному в отношении декодирования Normal DL-MAP, если CRC для всего сообщения не может быть верифицирован, но HCS8 для MAC-заголовка совпадает на этапе 3512, может выполняться другая итерация 3514 декодирования с обновленной гипотезой, сформированной на этапе 3518. Например, весь декодированный MAC-заголовок может использоваться как известные значения, в дополнение к другим фиксированным/прогнозным битовым значениям в оставшейся части сообщения UL-MAP. Если декодирование не завершается успешно даже после этой второй итерации декодирование может считаться неудачным на этапе 3514.
Примеры, описанные выше в отношении декодирования сообщений UL-MAP и DL-MAP, главным образом заключают в себе сообщения, которые традиционно передаются из базовой станции в мобильную станцию. Аналогичные операции API-декодирования типа также могут осуществляться в базовой станции при декодировании сообщений, передаваемых из мобильной станции (или другого типа передающего устройства).
Например, API-декодирование может применяться к сообщениям запроса диапазона (RNG-REQ) и запроса ширины полосы (BW-REQ) в соответствии с WiMAX. Операции API-декодирования с использованием битовых значений, сформированных на основе априорной информации о сообщениях RNG-REQ и BW-REQ, могут быть использованы для того, чтобы повышать производительность декодирования сообщений RNG-REQ и BW-REQ в базовой станции.
Согласно стандарту IEEE 802.16e, мобильная станция должна отправлять CDMA-коды в базовую станцию, чтобы запрашивать выделение ресурсов в восходящей линии связи так, что мобильная станция может отправлять сообщения RNG-REQ и/или BW-REQ. Базовая станция может выделять некоторый объем ресурсов в восходящей линии связи с использованием CDMA_Allocation_IE, который включен в UL-MAP.
Базовая станция знает, какое сообщение должно доставляться в выделенную область CDMA_Allocation_IE, до того как она фактически принимает сообщение. Это сообщение является сообщением RNG-REQ или сообщением BW-REQ. На основе этой информации базовая станция может выполнять API-декодирование с использованием гипотез с битовыми значениями, сформированными на основе априорной информации, касающейся сообщений RNG-REQ и BW-REQ.
Фиг.36 иллюстрирует схему приемного устройства, допускающего API-декодирование на основе априорной информации, касающейся сообщений RNG-REQ и BW-REQ. Как проиллюстрировано, MAC-планировщик 3650 может предоставлять информацию в MAC-процессор 3630, информацию CDMA_Allocation (к примеру, включающую в себя синхронизацию, область и ожидаемый тип сообщения). Процессор 3630 должен перенаправлять связанную информацию синхронизации и гипотез в механизм 3620 гипотез, который может извлекать известные битовые значения и формировать информацию гипотез для декодирования сообщения RNG-REQ и/или BW-REQ. Гипотезы RNG-REQ и BW-REQ могут оцениваться параллельным или последовательным способом, например, как описано выше в отношении гипотез Normal и Compressed DL-MAP.
Фиг.37 и 38 иллюстрируют форматы сообщений RNG-REQ и BW-REQ, из которых могут быть сформированы гипотезы. Согласно фиг.37, сообщение RNG-REQ начинается с 6-байтового общего MAC-заголовка. После MAC-заголовка следует 1-байтовый тип управляющего сообщения, после чего следует 1-байтовое зарезервированное поле, после чего следует несколько полей "тип-длина-значение" (TLV) и, в завершение, 32-битовый CRC. Из этих полей часть данной информации является фиксированной, а часть ее является прогнозируемой.
В качестве примера, 1-байтовый тип управляющего сообщения задается равным "4" для сообщений RNG-REQ, а 1-байтовое зарезервированное поле полностью состоит из нулей. Дополнительно, MAC-заголовок начинается с 1-битового типа заголовка, после чего следует 1-битовый код шифрования (EC), 6-битовое поле типа и 1-битовое поле Extended Sub0-header, которые состоят из одних нулей для сообщений RNG-REQ. После этих полей следует 1-битовый CRC-индикатор (CI), который равен 1 для RNG-REQ, после чего следует 2-битовое поле последовательности ключей шифрования (EKS), которое состоит из одних нулей, после чего следует 1-битовый зарезервированный бит, который равен нулю.
После этих полей следует поле длины, которое может быть, по меньшей мере, частично определено посредством ограничения длины TLV. Максимальная длина TLV может быть определена посредством накопления всех связанных с RNG-REQ длин TLV, как показано на фиг.37, что дает в результате 85 байтов согласно одной версии стандартов IEEE 802.16e. Таким образом, сообщение RNG-REQ не может превышать 97 байтов, в том числе MAC-заголовок и CRC32. Как результат, только младшие 8 битов поля длины требуются для того, чтобы представлять длину, и оставшиеся MSB равны нулю.
Все или часть 16-битового поля идентификатора подключения (CID) в MAC-заголовке также может быть прогнозирована, по меньшей мере, двумя способами. Во-первых, базовая станция имеет сведения о том, какой тип RNG-REQ должен отправляться через выделенную область UL, поскольку она диспетчеризует себя сама. Если эта область диспетчеризована для начального определения диапазона, CID должен быть нулем.
Во-вторых, если базовая станция не знает тип RNG-REQ (к примеру, поле CID может не быть нулем), базовая станция может использовать максимальное число мобильных станций, которое может поддерживать базовая станция. Поскольку стандарты типично предписывают то, что CID в RNG-REQ должен быть базовым CID, и диапазон базового CID должен быть между 1 и m (где m - это максимальное значение базового CID), максимальное значение поля CID является известным, что может давать возможность MSB быть известным. В качестве примера, если максимальное значение CID равно 255, только младшие 8 битов требуются, и оставшиеся MSB предположительно могут быть равны нулю.
Значение поля длины каждого TLV фиксируется посредством стандартов, за исключением типа TLV 21. К сожалению, без сведений о типе может быть невозможным использовать значение длины как гипотезу. Тем не менее, если делается допущение, что поле типа данной гипотезы является корректным, соответствующие TLV-биты могут использоваться. Битовые значения полей длины TLV могут использоваться в различных гипотезах, например, оцениваться во второй или дополнительных итерациях, если CRC32 сообщения является некорректным.
Согласно сообщению BW-REQ по фиг.38, этот формат сообщений имеет только 6 байтов. Однако первые 4 бита из них имеют фиксированные значения, и они могут использоваться в качестве априорной информации. В конкретных вариантах осуществления отдельные декодеры могут предоставляться, чтобы обеспечивать возможность параллельных операций API-декодирования с использованием гипотез RNG-REQ и BW-REQ, аналогично операциям декодирования с использованием гипотез Normal и Compressed DL-MAP, описанным выше. Альтернативно, такие гипотезы могут оцениваться последовательным способом.
Фиг.39 является блок-схемой последовательности операций примерного процесса 3900 для API-декодирования сообщений RNG-REQ и BW-REQ, который может выполняться, например, посредством приемного устройства базовой станции по фиг.36.
Процесс 3900 начинается на этапе 3902 посредством отправки CDMA_ALLOCATION_IE, чтобы выделять некоторый объем ресурсов в подключении по восходящей линии связи с мобильной станцией. На этапе 3903 информация выделения CDMA предоставляется в процессор 3660, и процессор 3660 предоставляет в механизм гипотез информацию типов сообщений, синхронизации и гипотез, 3904, и на этапе 3906 формируются гипотезы BW_REQ и RNG_REQ. В конкретных вариантах осуществления информация гипотез может храниться в механизме гипотез и обновляться только тогда, когда изменяется (к примеру, посредством MAC-процессора).
На этапе 3908 базовая станция ожидает сигнала восходящей линии связи в области CDMA_ALLOCATION. Сигнал восходящей линии связи в области CDMA_ALLOCATION принимается на этапе 3910. На этапе 3912 выполняется определение в отношении того, соответствует сигнал сообщению RNG_REQ или сообщению BW_REQ.
Если сигнал соответствует сообщению RNG_REQ, как определено на этапе 3912, сигнал декодируется с использованием гипотезы RNG_REQ на этапе 3914. Если CRC декодированного сигнала проверяется как удачный, как определено на этапе 3916, декодирование является удачным, что может задаваться тем или иным образом на этапе 3918.
Даже если CRC не завершается успешно, возможно, что заголовок декодирован надлежащим образом, что определяется посредством HCS-контроля на этапе 3920. Если HCS-контроль не завершается успешно, заголовок не декодирован надлежащим образом, и декодирование не завершается успешно на этапе 3926.
Однако если HCS-контроль завершается успешно (задает, что MAC-заголовок декодирован надлежащим образом), и он является первым контуром декодирования, как определено на этапе 3922, гипотеза может обновляться, чтобы отражать это, на этапе 3924. Операции декодирования могут выполняться повторно с обновленной гипотезой (включающей в себя MAC-заголовок в дополнение к другим значениям API-битов). Например, MAC-процессор может обновлять информацию гипотез, предоставленную в механизм гипотез.
Если CRC повторно не завершается успешно после API-декодирования с этой дополнительной информацией гипотез, но HCS-контроль повторно является удачным, MAC-процессор может пытаться декодировать с использованием более упреждающего допущения для TLV-элементов. Например, во втором контуре декодирования (после API-декодирования с битами заголовка), как определено на этапе 3928, MAC-процессор может делать TLV-допущения на этапе 3930. В качестве примера, если поля типа предполагаются как корректные, большинство полей длины может использоваться в качестве априорной информации согласно стандарту. В конкретных вариантах осуществления может иметься предел, сколько итераций декодирования разрешается. Например, если CRC повторно не завершается успешно после этого более активного декодирования на основе TLV-допущений, то декодирование безуспешно на этапе 3932, даже если HCS совпадает.
Ссылаясь снова на этап 3912, если сигнал соответствует сообщению BW_REQ, сигнал декодируется с использованием гипотезы BW_REQ на этапе 3940. Сообщение BW_REQ имеет только значение HCS и не имеет CRC. Следовательно, если проверка HCS декодированного сигнала успешна на этапе 3942, то декодирование является успешным (3944). Если HCS-контроль не завершается успешно, декодирование не завершается успешно на этапе 3946.
Посредством выполнения API-декодирования в базовой станции, например, с помощью гипотез, описанных в данном документе, производительность декодирования сообщений RNG-REQ и BW-REQ в базовой станции может повышаться.
Различные операции способов, описанных выше, могут выполняться посредством различных аппаратных и/или программных компонентов и/или модулей, соответствующих блокам "средство плюс функция", проиллюстрированным на чертежах. Например, блоки 600-606, проиллюстрированные на фиг.6, соответствуют блокам "средство плюс функция" 600A-606A, проиллюстрированным на фиг.6A. Если обобщить, когда предусмотрены способы, проиллюстрированные на чертежах, имеющие соответствующие эквивалентные чертежи "средство плюс функция", функциональные блоки соответствуют блокам "средство плюс функция" с аналогичной нумерацией.
При использовании в данном документе, термин "определение" охватывает широкий спектр действий. Например, "определение" может включать в себя расчет, вычисление, обработку, извлечение, получение сведений, поиск (к примеру, поиск в таблице, базе данных или другой структуре данных), обнаружение и т.п. Также, "определение" может включать в себя прием (к примеру, прием информации), осуществление доступа (к примеру, осуществление доступа к данным в запоминающем устройстве) и т.п. Также, "определение" может включать в себя разрешение, отбор, выбор, установление и т.п.
Информация и сигналы могут быть представлены с помощью любой из множества различных технологий и методов. Например, данные, инструкции, команды, информация, сигналы и т.п., которые могут упоминаться по всему описанию выше, могут быть представлены посредством напряжений, токов, электромагнитных волн, магнитных полей или частиц, оптических полей или частиц либо любой комбинации вышеозначенного.
Различные иллюстративные логические блоки, модули и схемы, описанные в связи с настоящим раскрытием сущности, могут быть реализованы или выполнены с помощью процессора общего назначения, процессора цифровых сигналов (DSP), специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA) или другого программируемого логического устройства, дискретного логического элемента или транзисторной логики, дискретных аппаратных компонентов либо любой комбинации вышеозначенного, предназначенной для выполнения описанных в данном документе функций. Процессором общего назначения может быть микропроцессор, но в альтернативном варианте, процессором может быть любой доступный процессор, контроллер, микроконтроллер или конечный автомат. Процессор также может быть реализован как комбинация вычислительных устройств, например, комбинация DSP и микропроцессора, множество микропроцессоров, один или более микропроцессоров вместе с ядром DSP либо любая другая подобная конфигурация.
Этапы способа или алгоритма, описанные в связи с изобретением, могут быть реализованы непосредственно в аппаратных средствах, в программном модуле, приводимом в исполнение посредством процессора, либо в комбинации вышеозначенного. Программный модуль может находиться в любой форме носителя хранения, который известен в области техники. Некоторые примеры носителей хранения, которые могут быть использованы, включают в себя RAM-память, флеш-память, ROM-память, EPROM-память, EEPROM-память, регистры, жесткий диск, съемный диск, CD-ROM и т.д. Программный модуль может содержать одну инструкцию или много инструкций и может быть распределен по нескольким различным сегментам кода, среди различных программ и среди множества носителей хранения. Примерный носитель хранения может быть связан с процессором так, что процессор может считывать информацию с и записывать информацию на носитель хранения. В альтернативном варианте, носитель хранения данных может быть встроен в процессор.
Способы, раскрытые в данном документе, содержат один или более этапов или действий для осуществления описанного способа. Этапы и/или действия способа могут меняться друг с другом без отступления от объема формулы изобретения. Другими словами, если конкретный порядок этапов или действий не задается, порядок и/или использование конкретных этапов и/или действий может модифицироваться без отступления от объема формулы изобретения.
Описанные функции могут быть реализованы в аппаратных средствах, программном обеспечении, микропрограммном обеспечении или в любой комбинации вышеозначенного. При реализации в программном обеспечении функции могут сохраняться как одна или более инструкций на машиночитаемом носителе. Носителями хранения могут быть любые доступные носители, к которым можно осуществлять доступ посредством компьютера. В качестве примера, а не ограничения, эти машиночитаемые носители могут содержать RAM, ROM, EEPROM, CD-ROM или другое запоминающее устройство на оптических дисках, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, либо любой другой носитель, который может быть использован, чтобы переносить или сохранять требуемый программный код в форме инструкций или структур данных, к которым можно осуществлять доступ посредством компьютера. Диск (disk) и диск (disc) при использовании в данном документе включают в себя компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), гибкий диск и диск Blu-Ray®, при этом диски (disk) обычно воспроизводят данные магнитным способом, тогда как диски (disc) обычно воспроизводят данные оптически с помощью лазеров.
Программное обеспечение или инструкции также могут передаваться по среде передачи. Например, если программное обеспечение передается с веб-узла, сервера или другого удаленного источника с помощью коаксиального кабеля, оптоволоконного кабеля, "витой пары", цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасные, радиопередающие и микроволновые среды, то коаксиальный кабель, оптоволоконный кабель, "витая пара", DSL или беспроводные технологии, такие как инфракрасные, радиопередающие и микроволновые среды, включены в определение носителя.
Дополнительно, следует принимать во внимание, что модули и/или другие соответствующие средства для выполнения способов и технологий, описанных в данном документе, таких как проиллюстрированные на чертежах, могут быть загружены и/или иначе получены посредством мобильного устройства (устройства мобильной связи) и/или базовой станции при соответствующих условиях. Например, такое устройство может быть связано с сервером, чтобы упрощать передачу средства для осуществления способов, описанных в данном документе. Альтернативно, различные способы, описанные в данном документе, могут предоставляться через средство хранения (к примеру, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), физический носитель хранения данных, такой как компакт-диск (CD) или гибкий диск и т.д.), так что устройство мобильной связи и/или базовая станция может получать различные способы при подключении или предоставлении средства хранения для устройства. Кроме того, любая другая подходящая технология для предоставления способов и технологий, описанных в данном документе, для устройства может быть использована.
Следует понимать, что формула изобретения не ограничена точной конфигурацией и компонентами, проиллюстрированными выше. Различные модификации, изменения и варьирования могут осуществляться в компоновке, работе и подробностях способов и устройств, описанных выше, без отступления от объема формулы изобретения.
Хотя вышеприведенное описание направлено на варианты осуществления настоящего изобретения, другие и дополнительные варианты осуществления изобретения могут быть разработаны без отступления от его объема, и его объем определяется посредством нижеприведенной формулы изобретения.
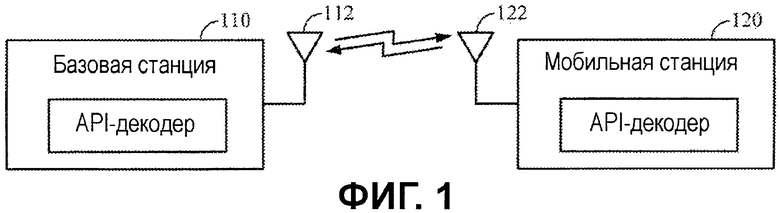
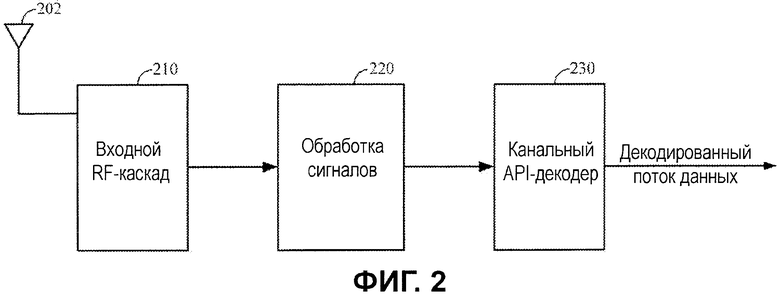
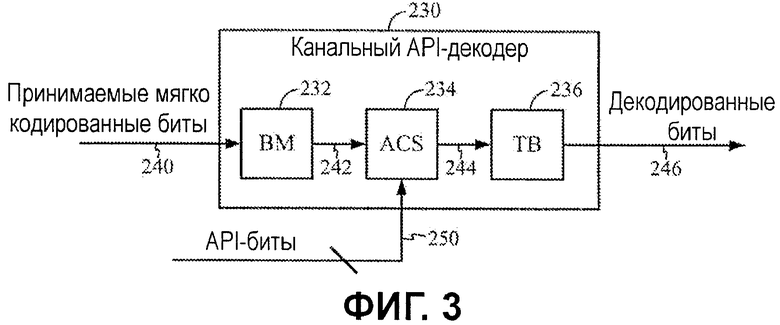
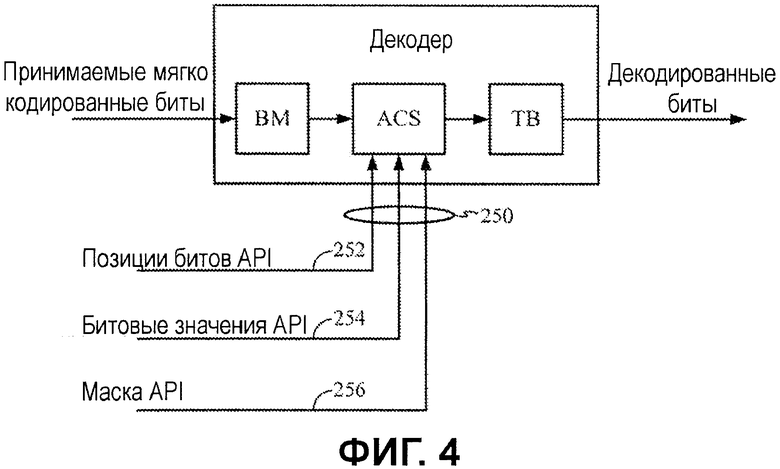
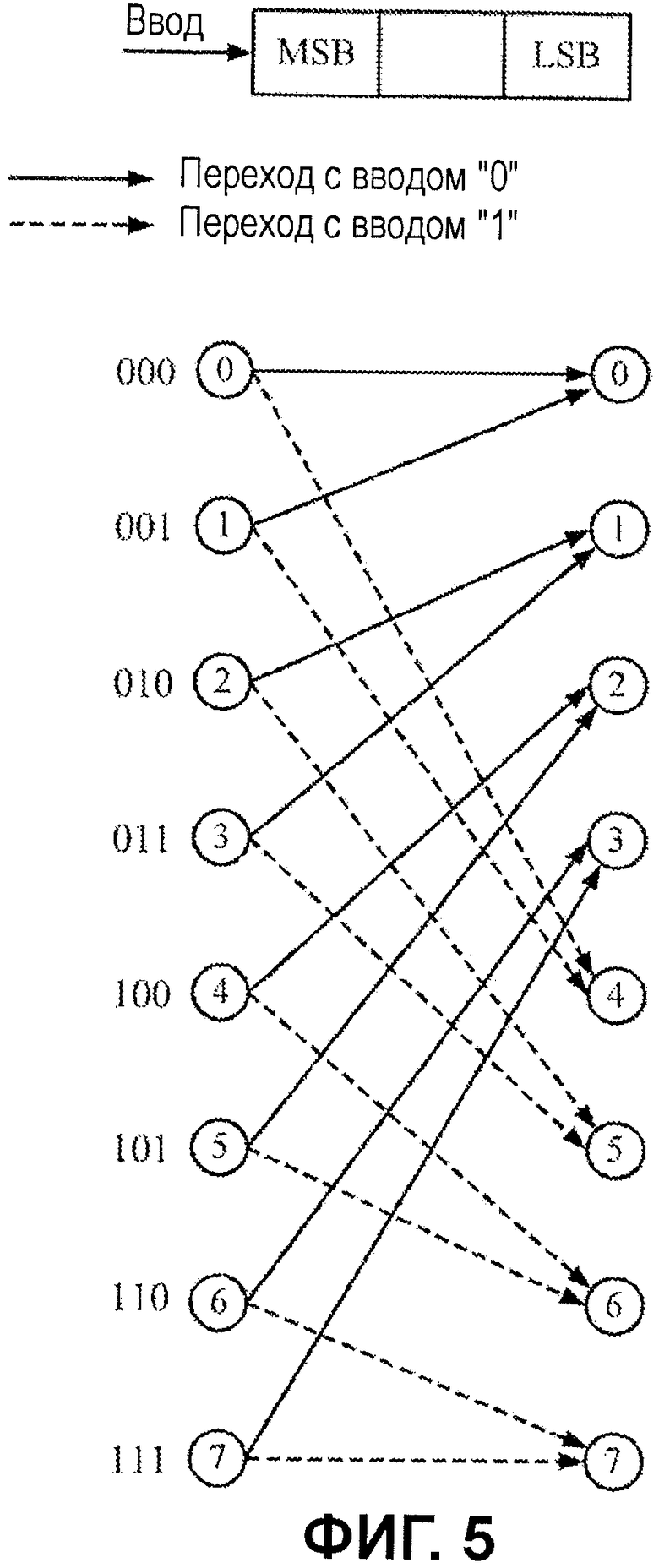
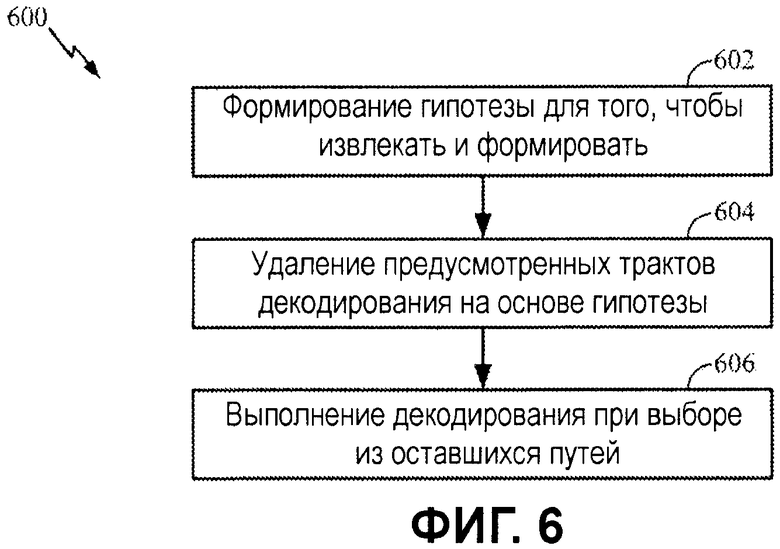
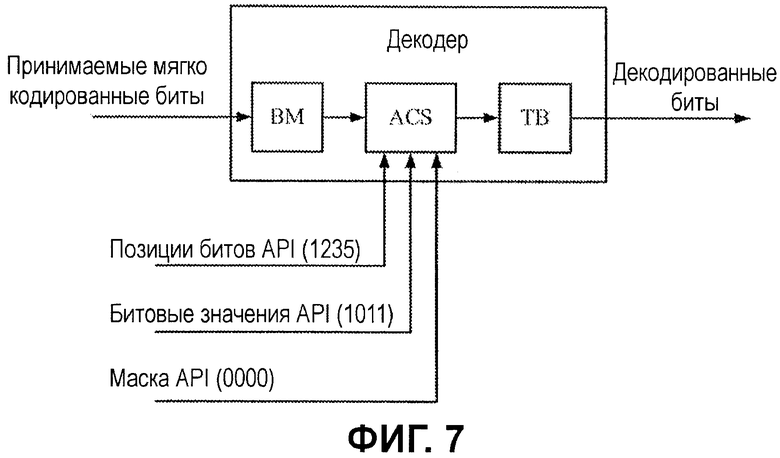
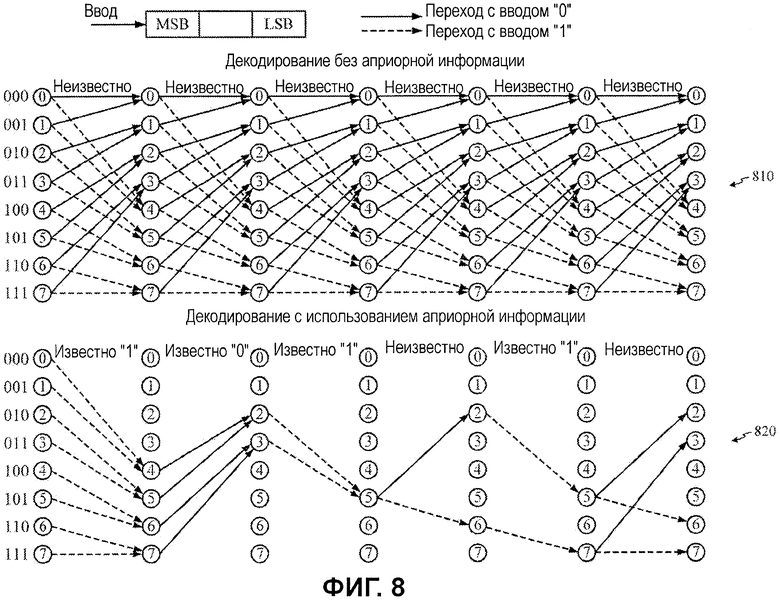
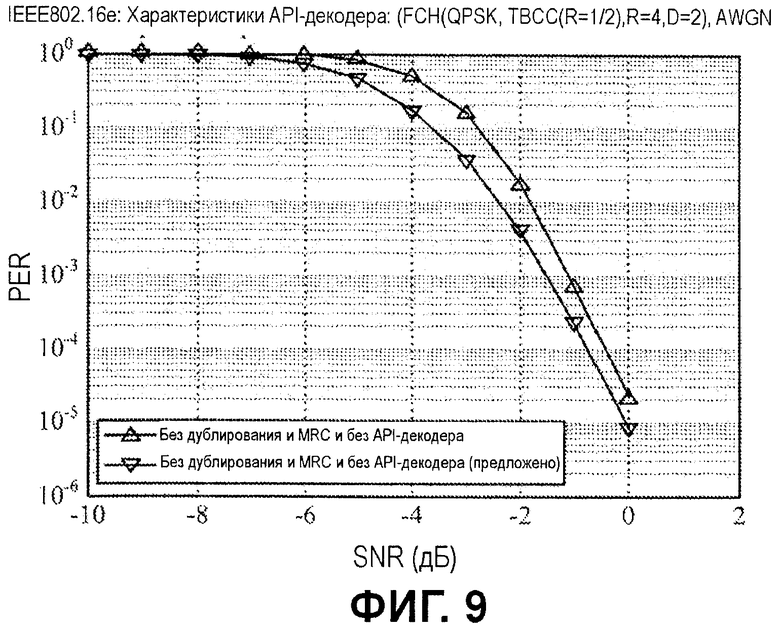
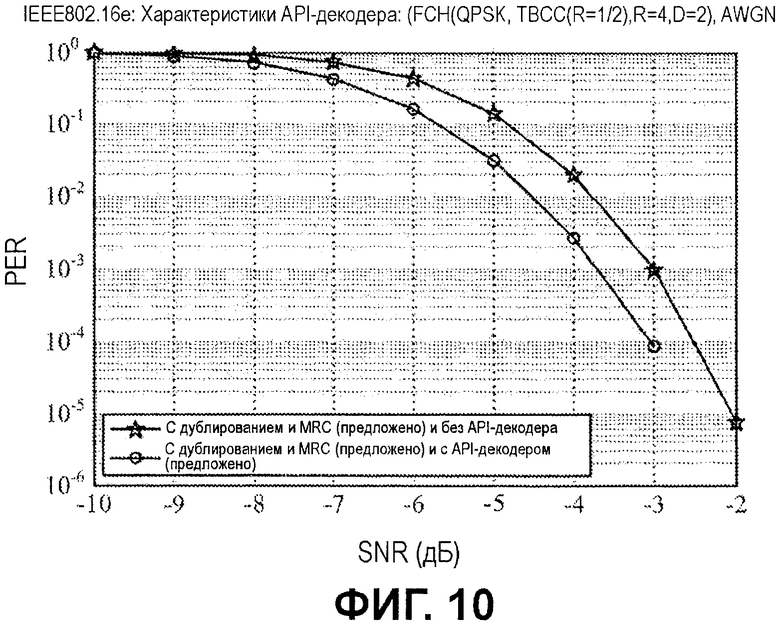
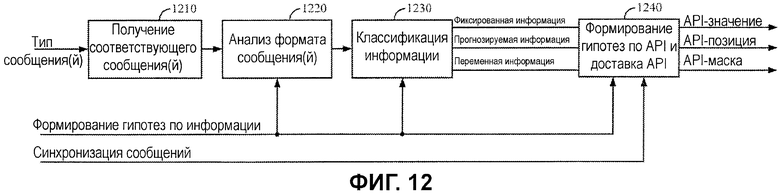
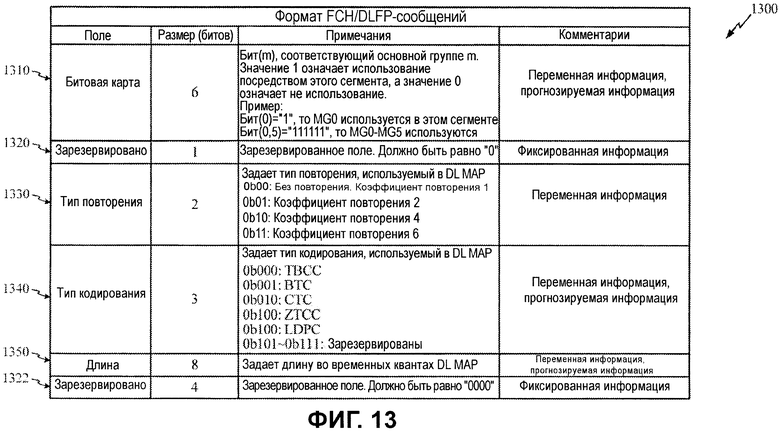
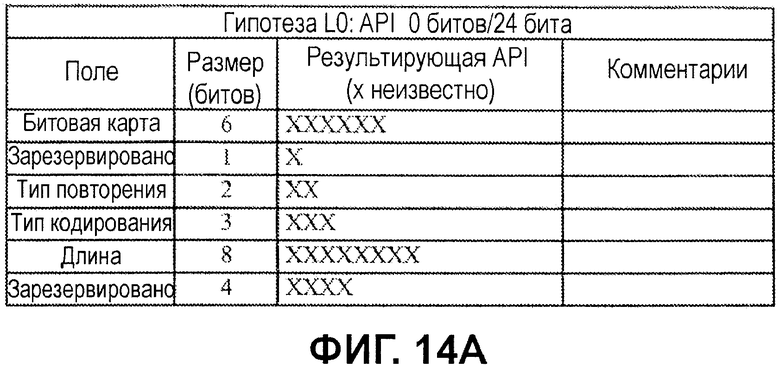
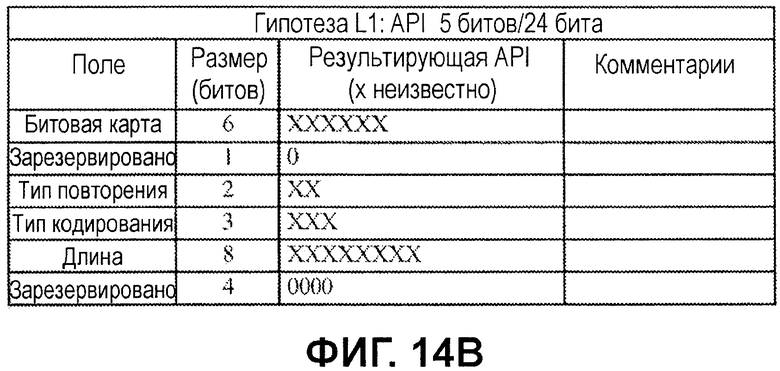


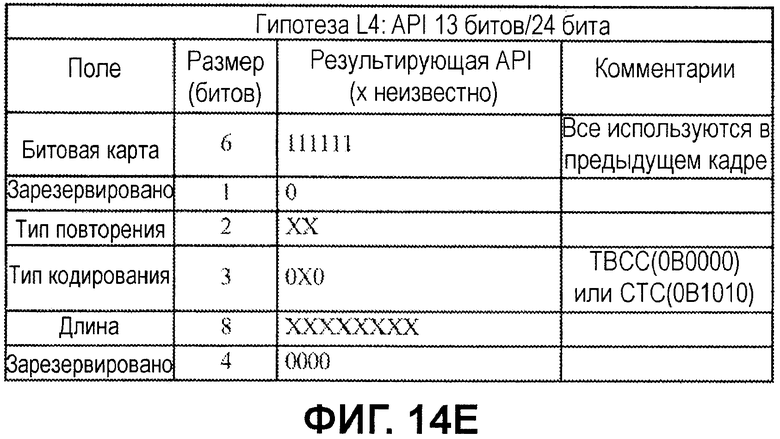


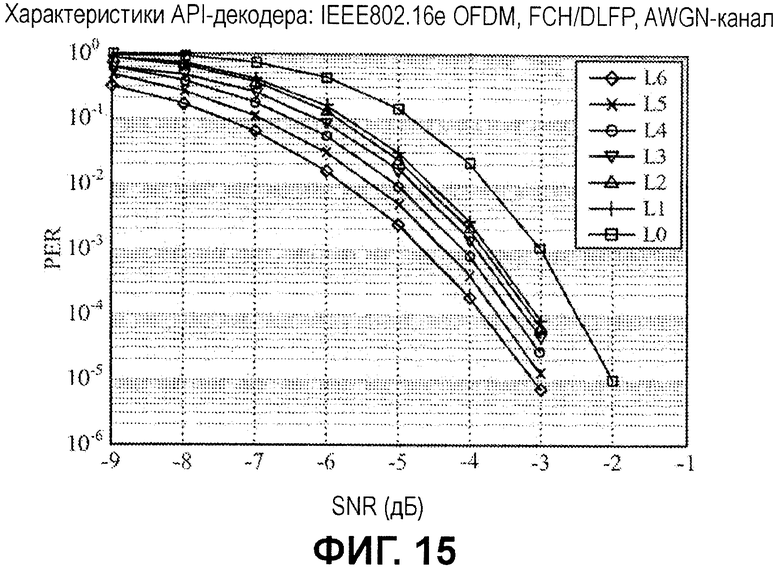
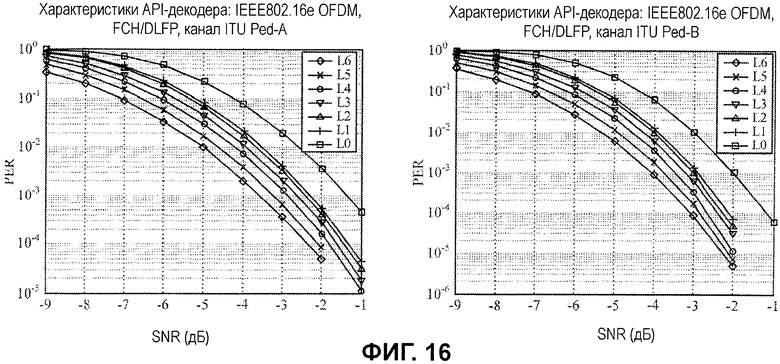
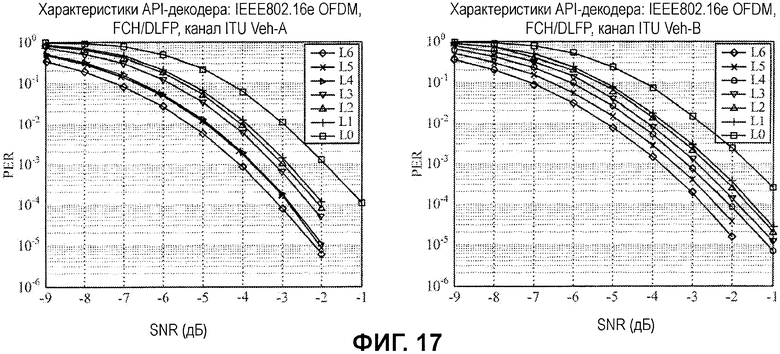
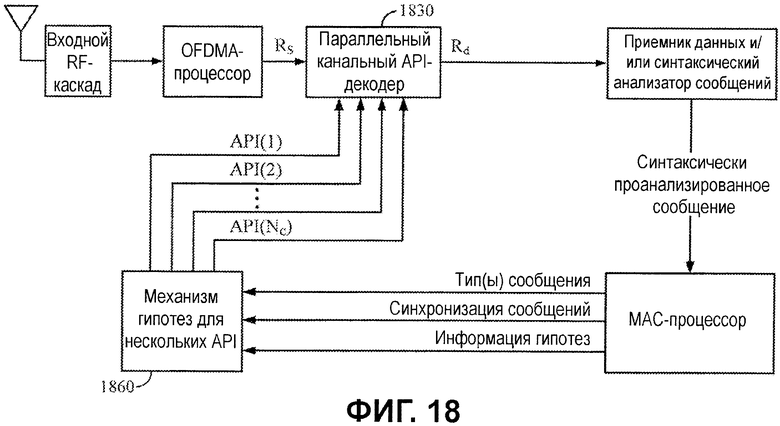
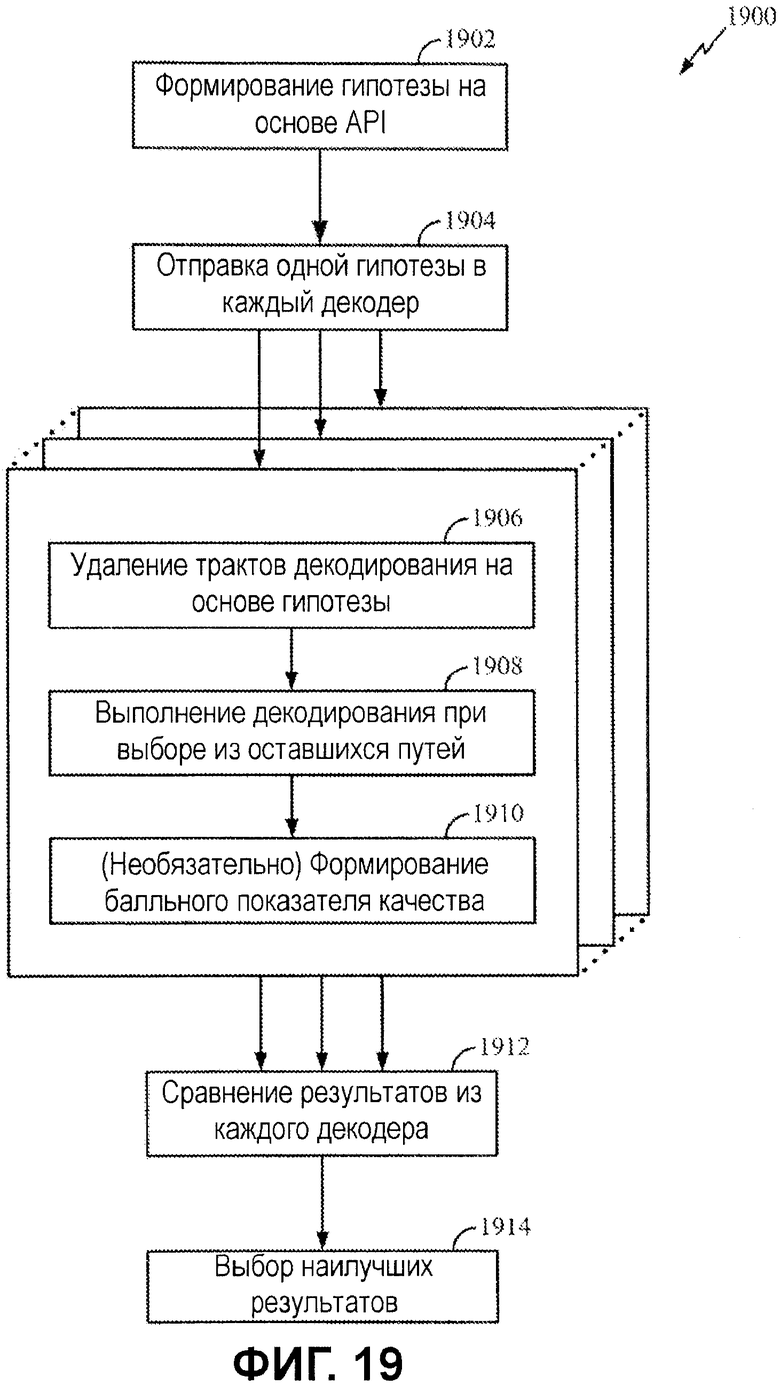
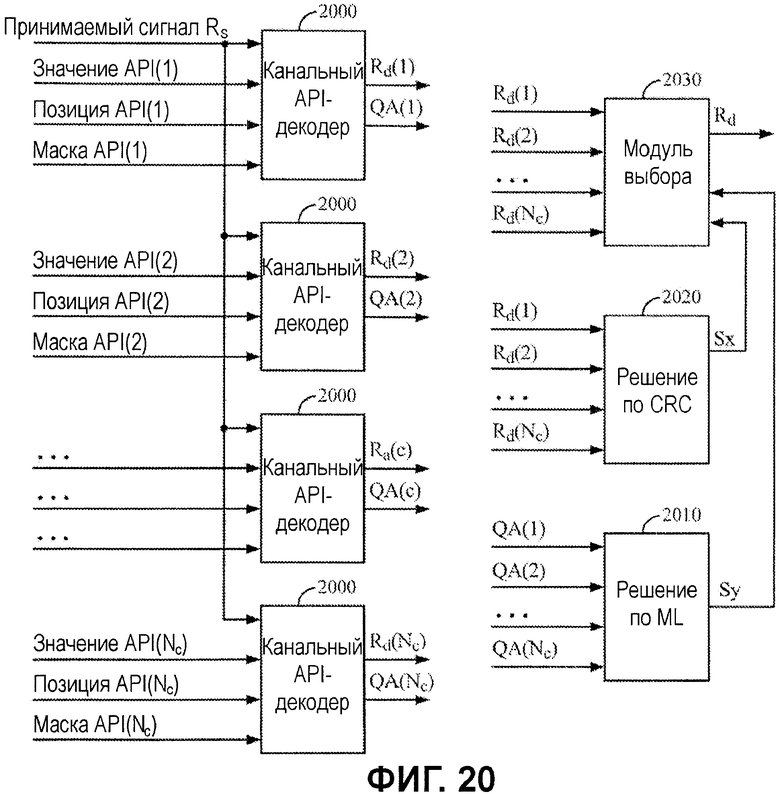
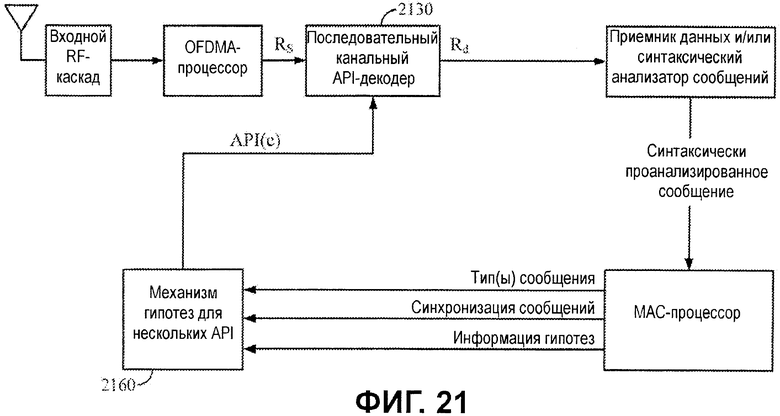
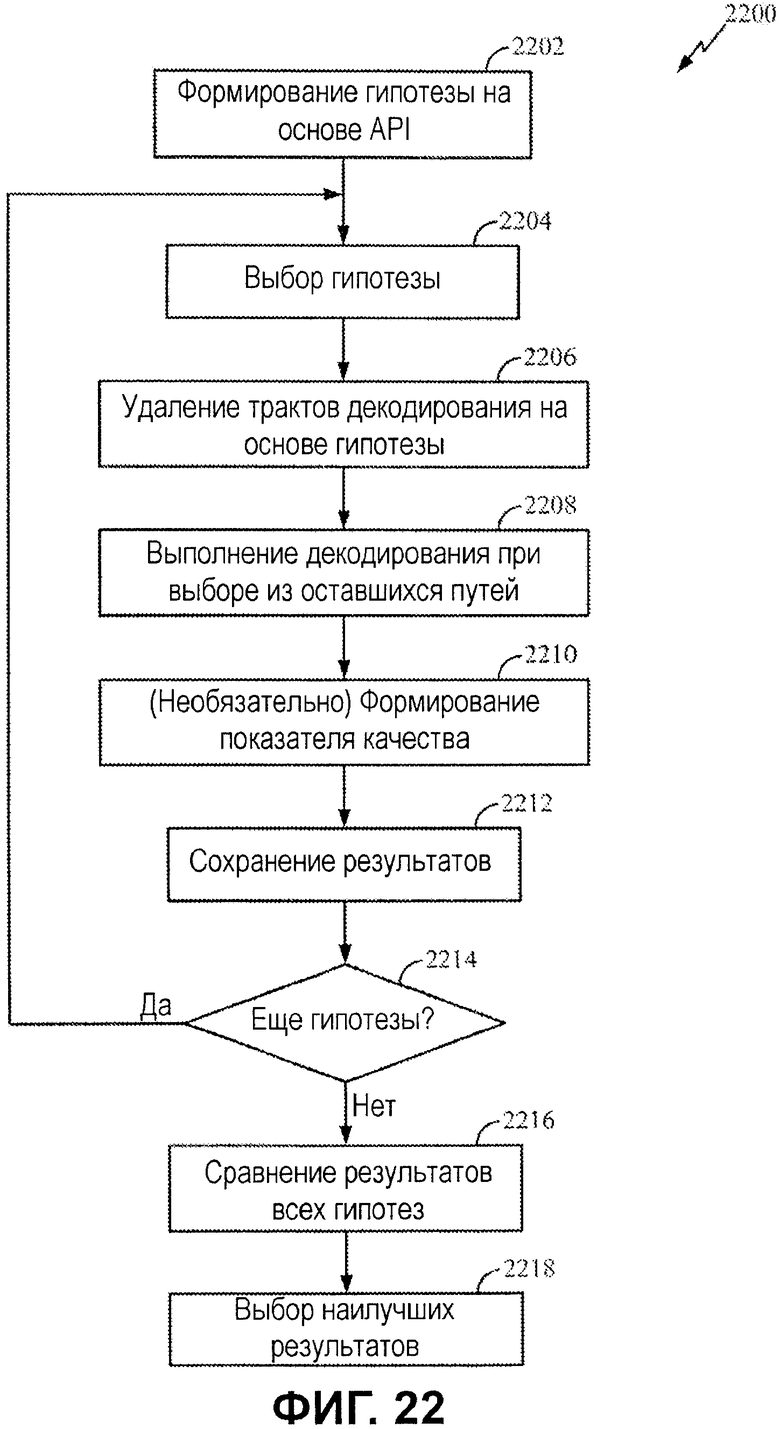

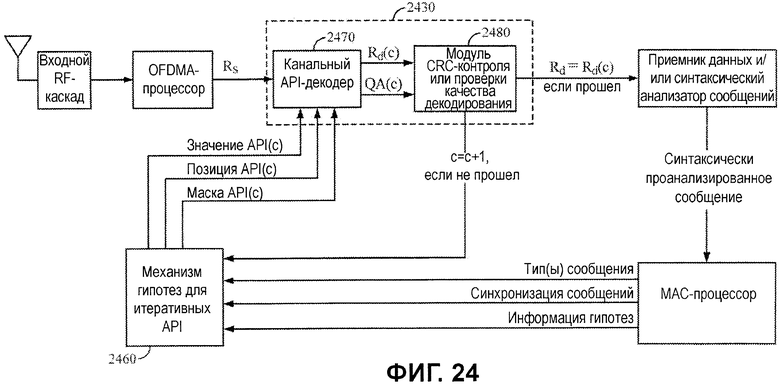
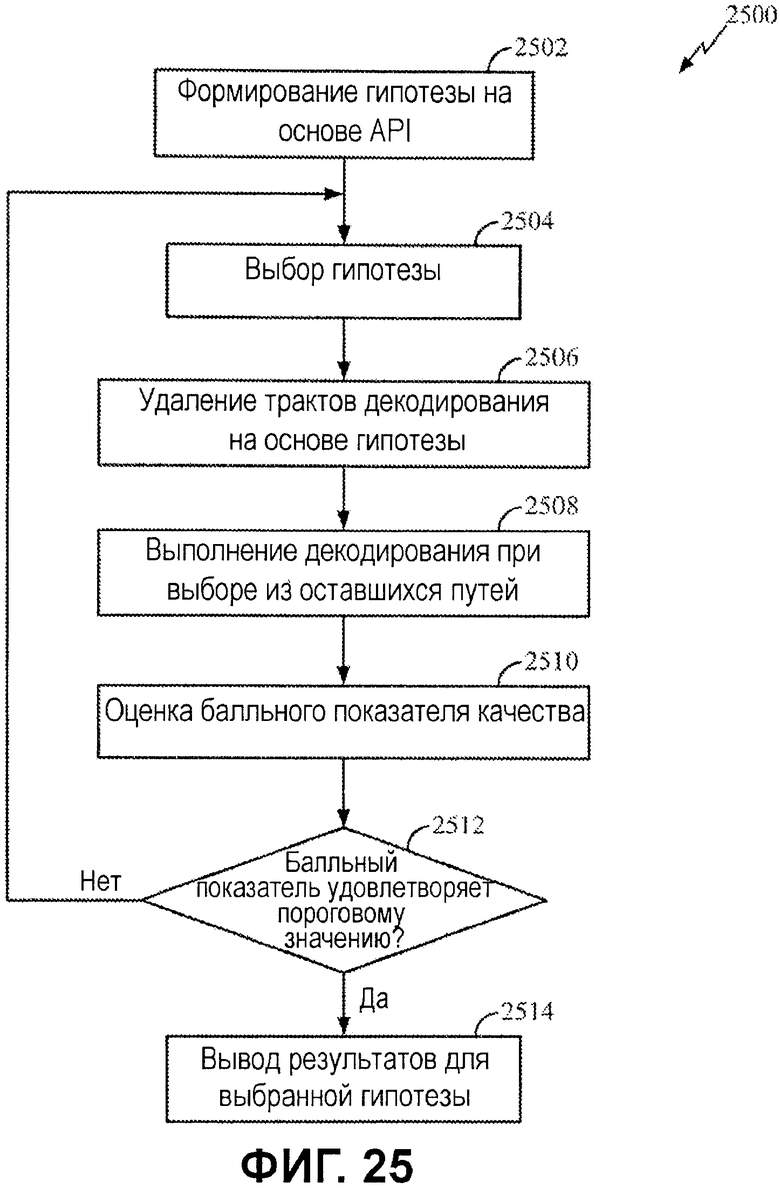
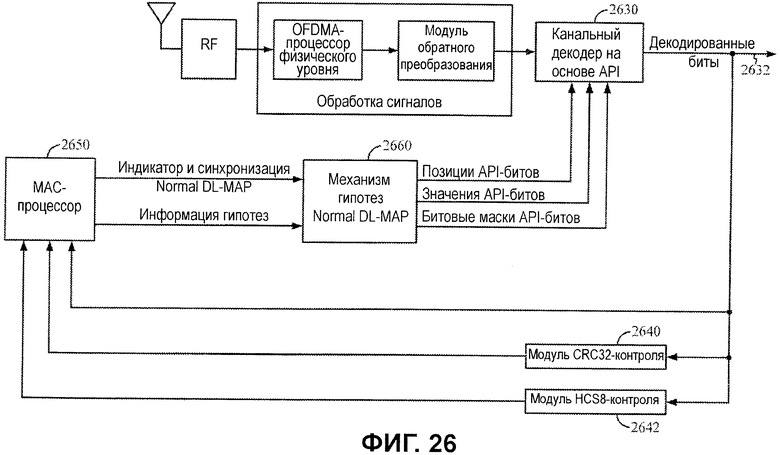
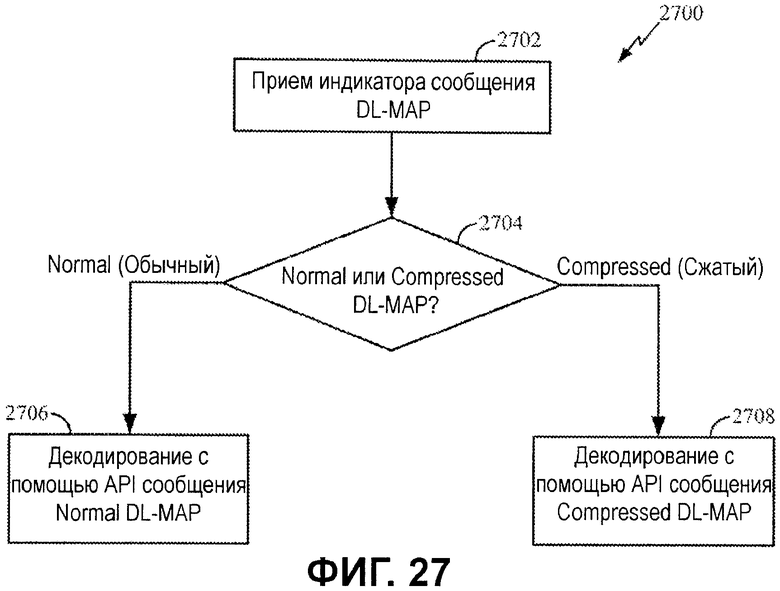
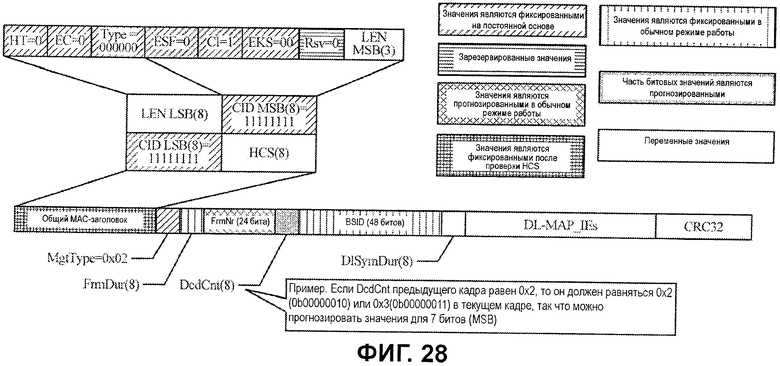
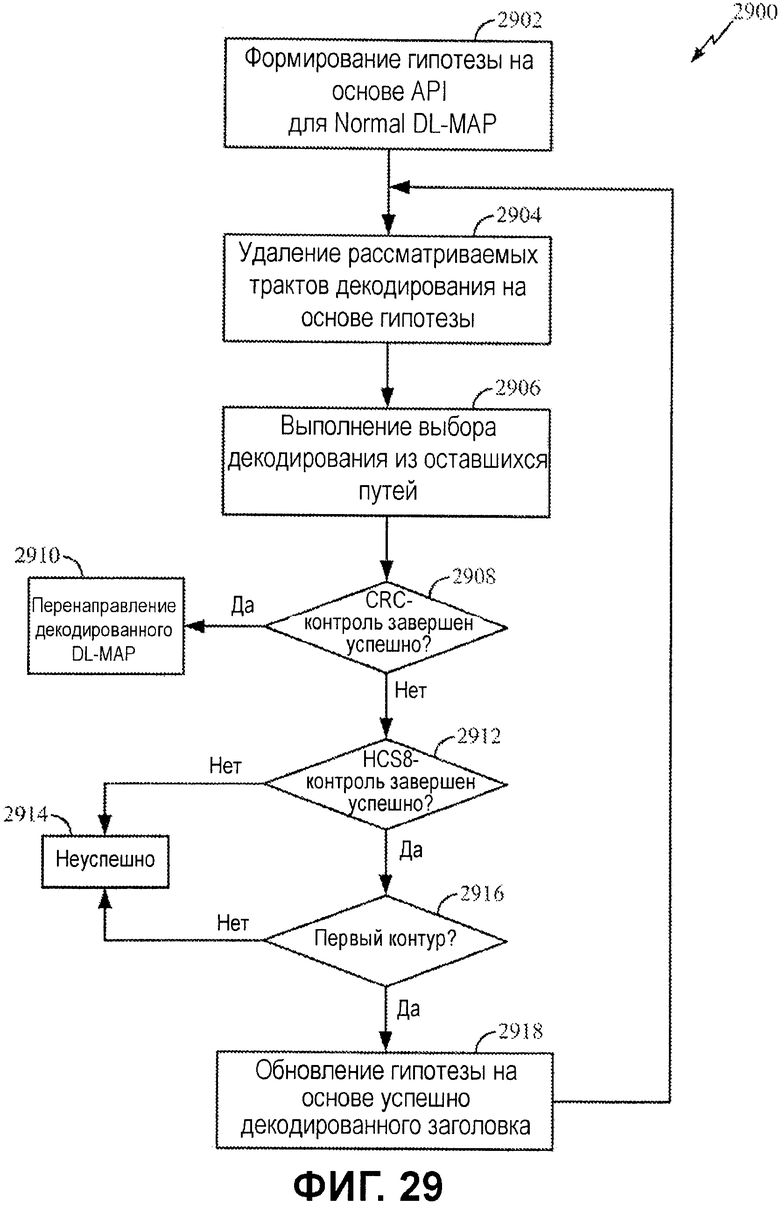
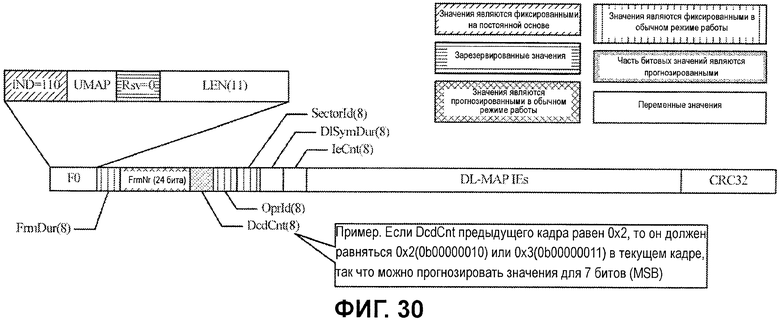
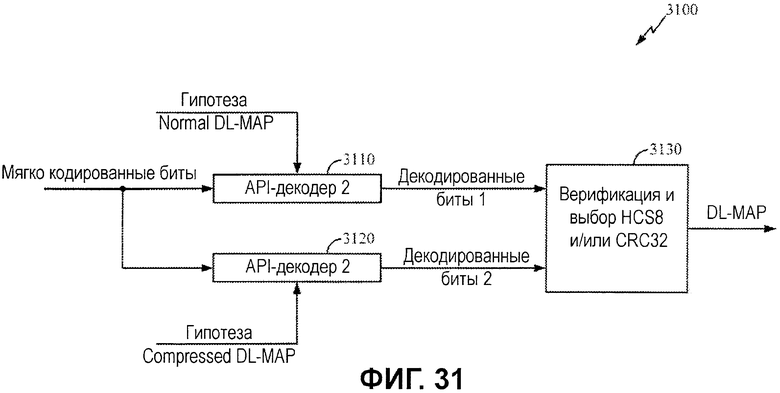
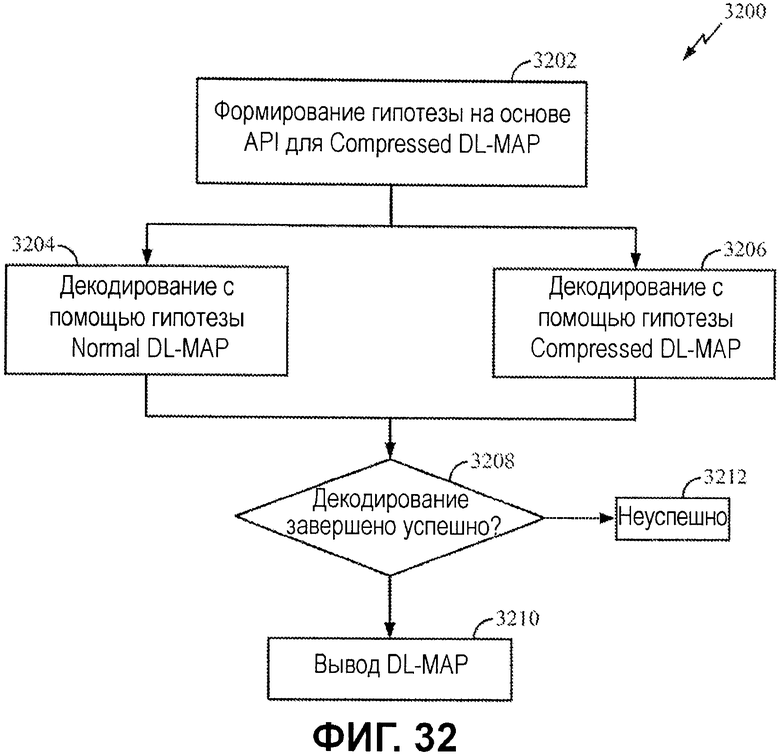
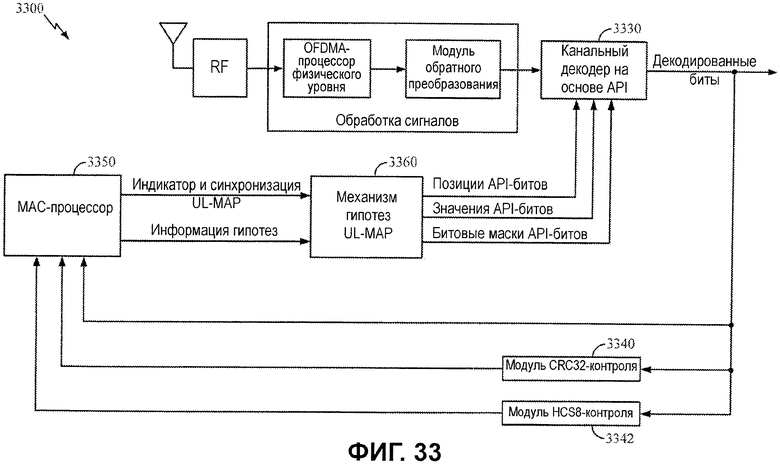
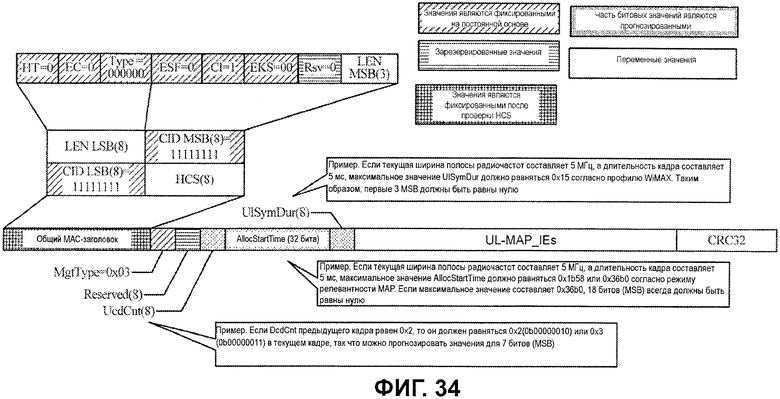
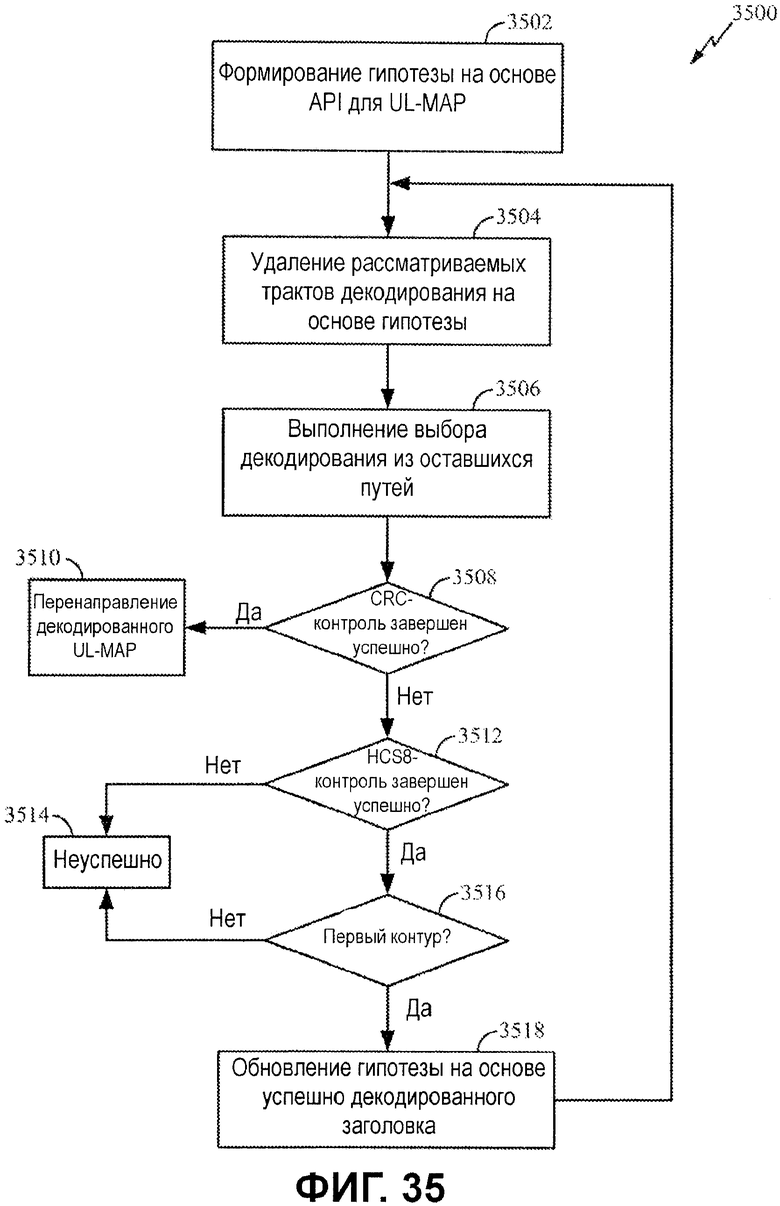
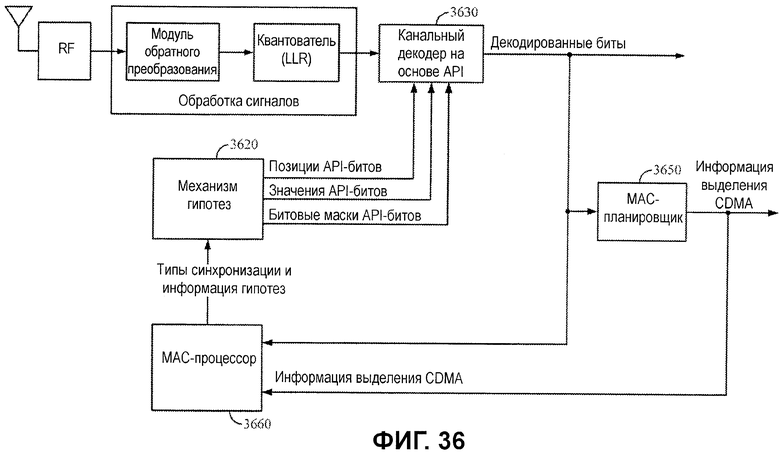
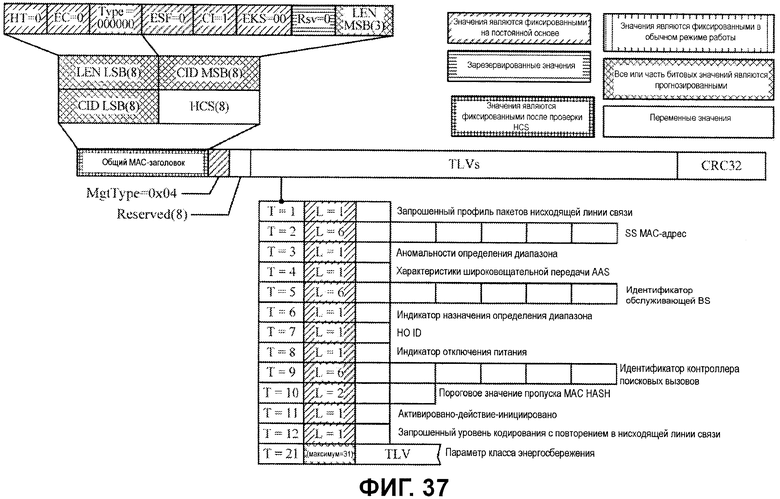
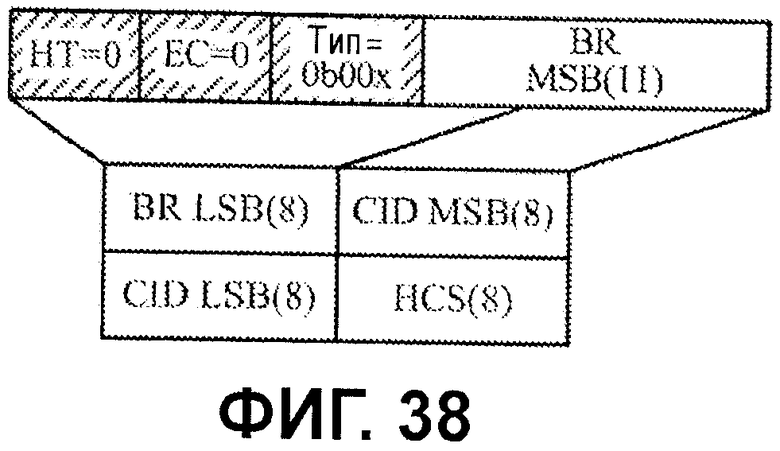
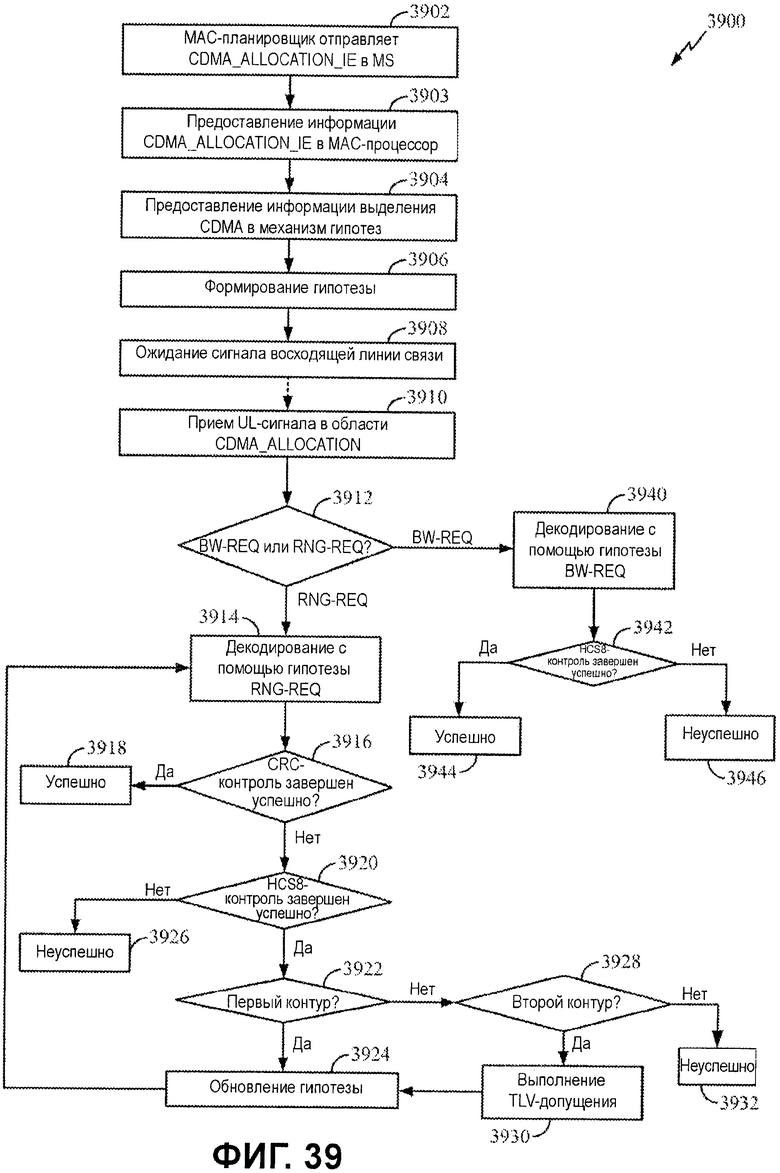
Изобретение относится к беспроводной связи, а более конкретно к декодированию беспроводных передач. Техническим результатом является уменьшение частоты ошибок по битам за счет исключения из рассмотрения наборов декодированных битов, которые являются не согласованными с битовыми значениями, заданными посредством гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством одной из гипотез. Способ включает в себя формирование гипотезы, задающей набор битовых значений кодированных битов данных, на основе априорной информации, касающейся, по меньшей мере, одного из следующего: содержимое сообщения MAP и параметр связанной передачи, и декодирование передачи посредством исключения из рассмотрения наборов декодированных битов, которые являются не согласованными с заданными битовыми значениями, и выбора, в качестве вывода, декодированных битов, которые соответствуют битовым значениям, заданным посредством гипотезы. 3 н. и 12 з.п. ф-лы, 46 ил.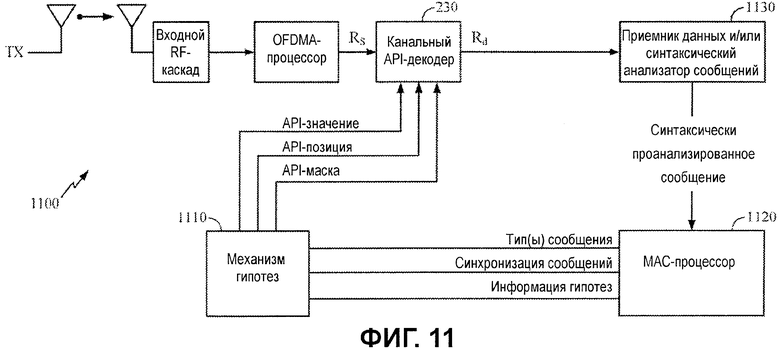
1. Способ декодирования кодированных битов данных передачи сообщения беспроводной связи, содержащий этапы, на которых:
- формируют гипотезу, задающую набор битовых значений кодированных битов данных, на основе априорной информации, касающейся, по меньшей мере, одного из содержимого сообщения подсистемы мобильных приложений (MAP) и параметра связанной передачи;
- декодируют передачу посредством исключения из рассмотрения наборов декодированных битов, которые являются несогласованными с заданными битовыми значениями, и выбора, в качестве вывода, декодированных битов, которые соответствуют битовым значениям, заданным посредством гипотезы;
- определяют, что сообщение не декодировано успешно;
- определяют, что МАС-заголовок сообщения декодирован успешно;
- обновляют гипотезу, чтобы задать битовые значения успешно декодированного МАС-заголовка; и
- повторно декодируют передачу посредством исключения из рассмотрения наборов декодированных битов, которые являются несогласованными с заданными битовыми значениями, и выбора, в качестве вывода, декодированных битов, которые соответствуют битовым значениям, заданным посредством гипотезы.
2. Способ по п.1, в котором сообщение MAP содержит, по меньшей мере, одно из обычного сообщения подсистемы мобильных приложений нисходящей линии связи (Normal DL-MAP), сжатого сообщения подсистемы мобильных приложений нисходящей линии связи (Compressed DL-MAP), сообщения подсистемы мобильных приложений восходящей линии связи (UL-MAP), сообщения запроса диапазона (RNG-REQ) и сообщения запроса ширины полосы (BW-REQ).
3. Способ по п.1, в котором формирование гипотезы содержит этап, на котором:
- задают одно или более битовых значений на основе значения, которое является фиксированным на постоянной основе согласно стандарту.
4. Способ по п.1, в котором формирование гипотезы содержит этап, на котором:
- задают одно или более битовых значений на основе значения поля в ранее декодированном сообщении MAP и числа битов, которые предположительно должны изменяться при текущей декодированной передаче.
5. Способ по п.4, в котором значение поля предположительно должно монотонно увеличиваться.
6. Способ по п.4, в котором значение поля предположительно не должно изменяться во время работы.
7. Способ по п.1, в котором:
- сообщением MAP является сообщение подсистемы мобильных приложений восходящей линии связи (UL-MAP); и
- формирование гипотезы содержит этап, на котором задают одно или более битовых значений на основе значения поля в сообщении MAP, определенном, по меньшей мере частично, посредством ширины полосы радиочастот и длительности кадра.
8. Способ по п.1, в котором:
- сообщением является сообщение запроса диапазона (RNG-REQ); и
- формирование гипотезы содержит этап, на котором задают одно или более битовых значений на основе значения, которое является фиксированным согласно стандарту, при условии, что некоторые из принимаемых полей являются корректными.
9. Устройство для беспроводной связи, содержащее:
- средство для приема беспроводной передачи сообщения и формирования набора кодированных битов;
- средство для формирования одной или более гипотез, каждая из которых задает набор битовых значений кодированных битов данных, на основе априорной информации, касающейся сообщения;
- средство для декодирования кодированных битов посредством исключения из рассмотрения наборов декодированных битов, которые являются несогласованными с битовыми значениями, заданными посредством гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством одной из гипотез;
- средство для определения того, что сообщение не декодировано успешно, но МАС-заголовок сообщения декодирован успешно;
- средство для сигнализации средству для формирования гипотез для обновления гипотез, чтобы задать битовые значения, соответствующие успешно декодированному МАС-заголовку; и
- средство для сигнализации средству для декодирования, чтобы декодировать кодированные биты посредством исключения из рассмотрения наборов декодированных битов, которые являются несогласованными с битовыми значениями, заданными посредством обновленных гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством обновленных гипотез.
10. Устройство по п.9, в котором:
- сообщение содержит, по меньшей мере, одно из сообщения запроса диапазона (RNG-REQ) и сообщения запроса ширины полосы (BW-REQ); и
средство для формирования одной или более гипотез конфигурировано для формирования, по меньшей мере, одной гипотезы, задающей битовые значения, соответствующие сообщению RNG-REQ, и, по меньшей мере, одной гипотезы, задающей битовые значения, соответствующие сообщению BW-REQ.
11. Устройство по п.9, в котором сообщение содержит, по меньшей мере, одно из сообщения подсистемы мобильных приложений восходящей линии связи (UL-MAP), обычного сообщения подсистемы мобильных приложений (Normal DL-MAP) и сжатого сообщения подсистемы мобильных приложений (Compressed DL-MAP).
12. Устройство по п.11, в котором средство для формирования гипотез конфигурировано для формирования, по меньшей мере, одной гипотезы, задающей битовые значения, соответствующие сообщению Normal DL-MAP, и, по меньшей мере, одной гипотезы, задающей битовые значения, соответствующие сообщению Compressed DL-MAP.
13. Машиночитаемый носитель, содержащий набор сохраненных на нем инструкций для беспроводной связи, причем набор инструкций выполняется посредством одного или более процессоров, и набор инструкций содержит:
- инструкции для приема беспроводной передачи сообщения и формирования набора кодированных битов;
- инструкции для формирования одной или более гипотез, каждая из которых задает набор битовых значений кодированных битов данных, на основе априорной информации, касающейся сообщения;
- инструкции для декодирования кодированных битов посредством исключения из рассмотрения наборов декодированных битов, которые являются несогласованными с битовыми значениями, заданными посредством гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством одной из гипотез;
- инструкции для определения того, что сообщение не декодировано успешно, но МАС-заголовок сообщения декодирован успешно;
- инструкции для сигнализации инструкций для формирования гипотез, чтобы обновлять гипотезы, чтобы задать битовые значения, соответствующие успешно декодированному МАС-заголовку; и
- инструкции для сигнализации инструкций для декодирования, чтобы декодировать кодированные биты посредством исключения из рассмотрения наборов декодированных битов, которые являются несогласованными с битовыми значениями, заданными посредством обновленных гипотез, и выбора, в качестве вывода, декодированных битов, согласованных с битовыми значениями, заданными посредством обновленных гипотез.
14. Машиночитаемый носитель по п.13, в котором:
- сообщение содержит, по меньшей мере, одно из сообщения запроса диапазона (RNG-REQ) и сообщения запроса ширины полосы (BW-Req); и
- инструкции для формирования одной или более гипотез конфигурированы, чтобы формировать, по меньшей мере, одну гипотезу, задающую битовые значения, соответствующие сообщению RNG-REQ, и, по меньшей мере, одну гипотезу, задающую битовые значения, соответствующие сообщению BW-REQ.
15. Машиночитаемый носитель по п.13, в котором сообщение содержит, по меньшей мере, одно из сообщения подсистемы мобильных приложений восходящей линии связи (UL-MAP), обычного сообщения подсистемы мобильных приложений нисходящей линии связи (Normal DL-MAP) и сжатого сообщения подсистемы мобильных приложений нисходящей линии связи (Compressed DL-MAP).
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| ПАРАЛЛЕЛЬНЫЙ КАСКАДНЫЙ СВЕРТОЧНЫЙ КОД С КОНЕЧНОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ БИТОВ И ДЕКОДЕР ДЛЯ ТАКОГО КОДА | 1997 |
|
RU2187196C2 |
| ОПТИМАЛЬНЫЙ ДЕКОДЕР ПРОГРАММИРУЕМЫХ ВЫХОДНЫХ ДАННЫХ ДЛЯ РЕШЕТЧАТЫХ КОДОВ С КОНЕЧНОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ БИТОВ | 1997 |
|
RU2179367C2 |

