Уровень техники
Несмотря на огромные усилия поставщиков программного обеспечения, механизмы защиты программного обеспечения по-прежнему постоянно взламываются. Дополнительно, успешная атака одной копии зачастую может автоматически реплицироваться на другие копии. Например, если поставщик программного обеспечения распространяет оценочные версии части программного обеспечения, программа для взлома, которая удаляет ограничение по времени из одной копии, также может быть применена ко всем другим распространяемым копиям. Еще дополнительно, традиционные модели распространения предоставляют возможность серийных атак, которые быстро оказывают воздействие на тысячи пользователей.
Диверсификация - это концепция, которая может использоваться для того, чтобы повысить уровень безопасности программного обеспечения и предотвращать атаки. Тем не менее, методики диверсификации, разработанные для системы безопасности программного обеспечения, не всегда переносимы на защиту программного обеспечения, поскольку могут применяться различные правила. Например, большая часть диверсификации среды выполнения, введенной для безопасности, легко может быть отключена, когда у атакующего есть физический доступ к среде выполнения программ.
Как описано в данном документе, различные методики диверсификации для защиты программного обеспечения обеспечивают возобновляемую защиту в пространстве и времени, например, предоставляя каждому пользователю отдельную копию и обновляя защиту с помощью индивидуальных обновлений.
Сущность изобретения
Различные примерные методики используют виртуализацию для диверсификации кода и/или виртуальных машин (VM), чтобы таким образом улучшить защиту программного обеспечения. Например, компьютерно-реализованный способ включает в себя предоставление архитектуры набора команд (ISA), которая содержит признаки для того, чтобы формировать диверсифицированные копии программы, использование архитектуры набора команд, чтобы формировать диверсифицированные копии программы, и предоставление VM для выполнения одной из диверсифицированных копий программы. Различные другие примерные технологии также раскрыты.
Краткое описание чертежей
Неограничивающие и неисчерпывающие примеры описаны со ссылкой на прилагаемые чертежи:
Фиг. 1 - это схема системы и общей архитектуры, которая включает в себя уровень виртуализации в качестве пользовательской/измененной архитектуры набора команд (ISA) и/или виртуальной машины (VM).
Фиг. 2 - это блок-схема примерного способа, который включает в себя модуль безопасности, чтобы формировать пользовательский код и/или пользовательскую VM.
Фиг. 3 - это блок-схема примерного способа формирования пользовательской VM.
Фиг. 4 - это блок-схема примерного способа диверсификации функций в коде, чтобы сформировать пользовательский код.
Фиг. 5 - это схема примера, который относится к способу по фиг. 4.
Фиг. 6 - это блок-схема примерного способа диверсификации данных и/или структуры данных.
Фиг. 7 - это блок-схема различных инфраструктурных характеристик, которые могут быть использованы для диверсификации и защиты от несанкционированного вмешательства.
Фиг. 8 - это схема модели выполнения с характеристиками, которые могут быть использованы для диверсификации и защиты от несанкционированного вмешательства.
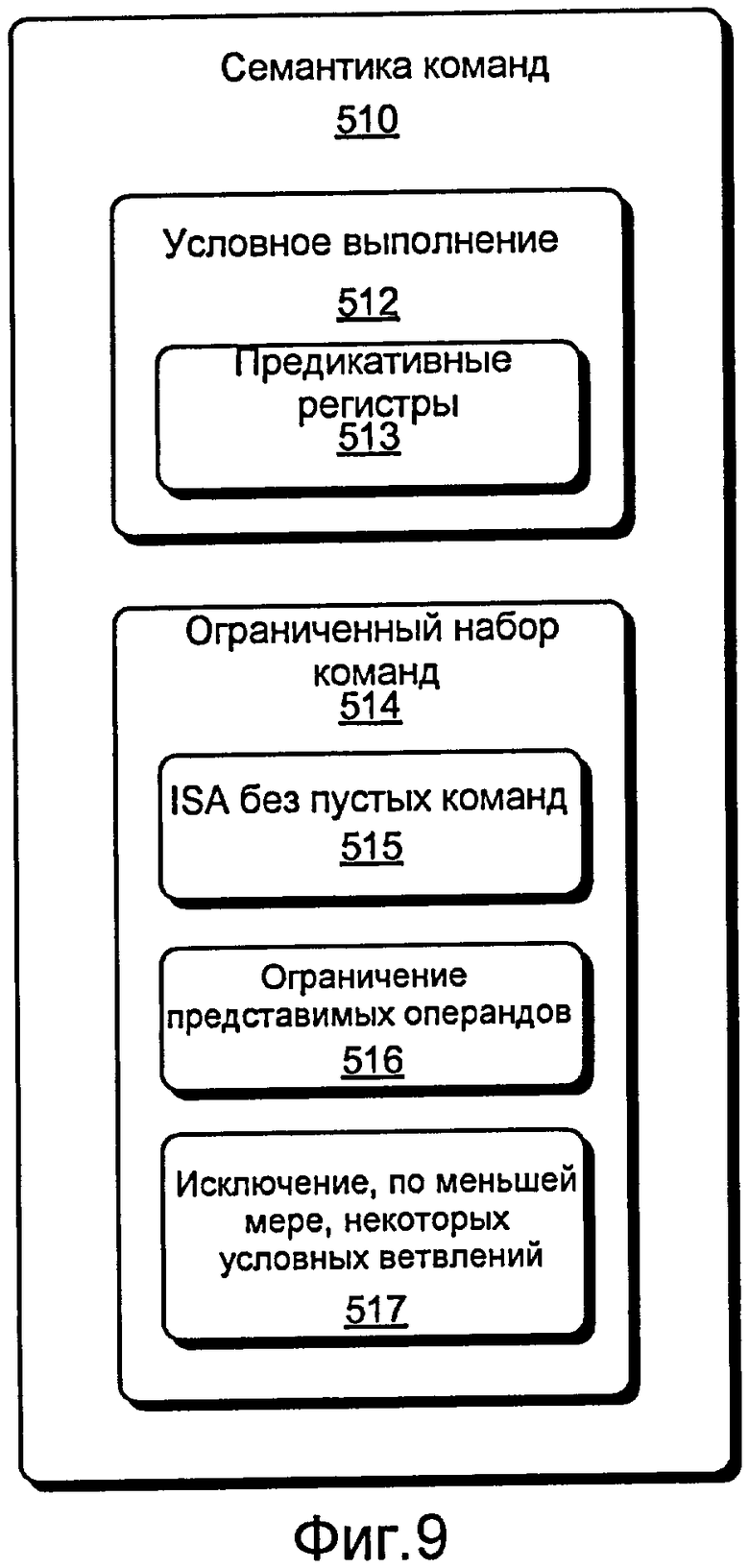
Фиг. 9 - это блок-схема различных подходов, которые могут быть применены к семантике команд для целей диверсификации и защиты от несанкционированного вмешательства.
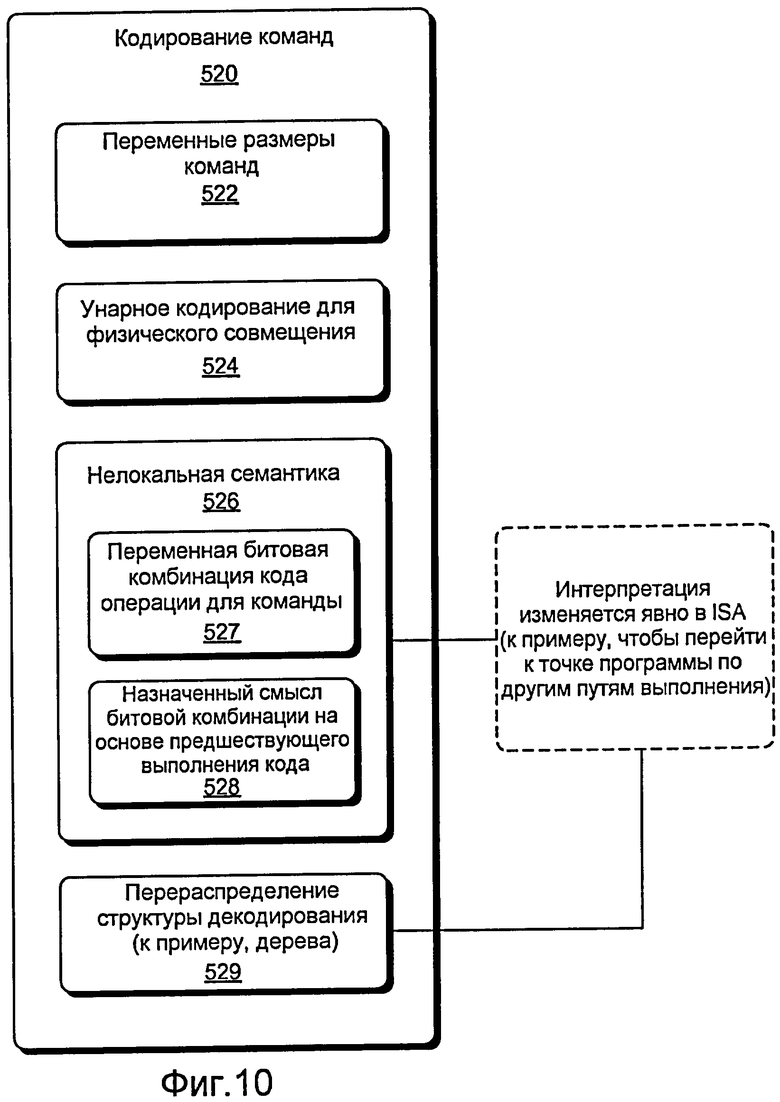
Фиг. 10 - это блок-схема различных подходов, которые могут быть применены к кодированию команд для целей диверсификации и защиты от несанкционированного вмешательства.
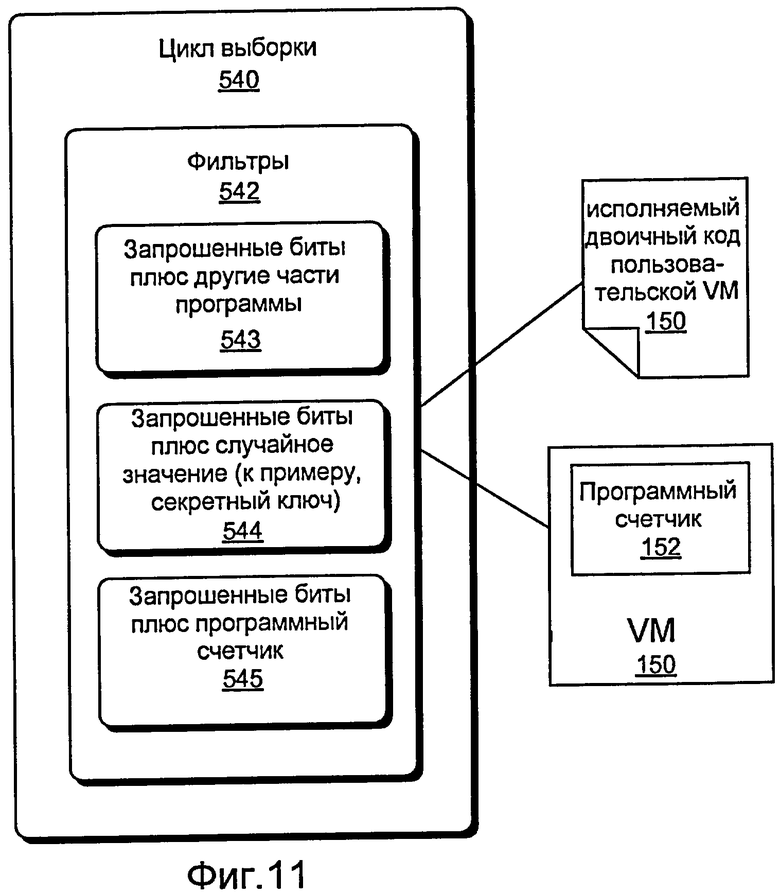
Фиг. 11 - это блок-схема различных подходов, которые могут быть применены к циклу выборки для целей диверсификации и защиты от несанкционированного вмешательства.
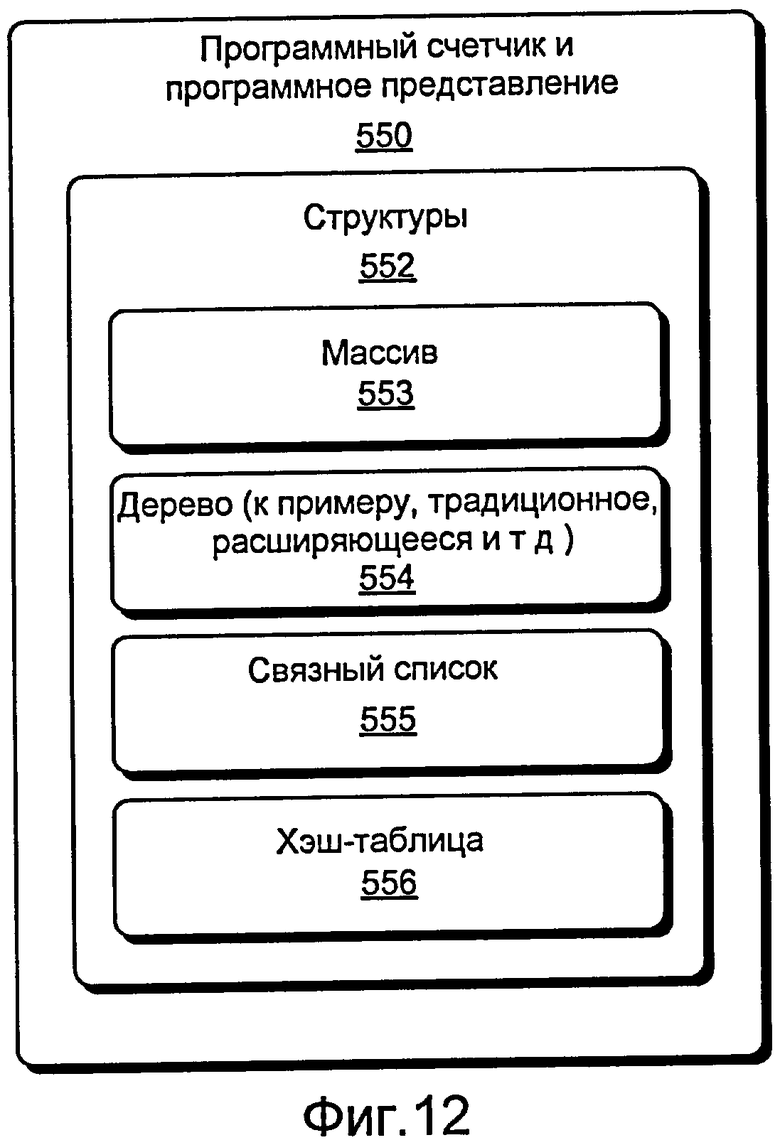
Фиг. 12 - это блок-схема различных подходов, которые могут быть применены к программному счетчику (PC) и/или программному представлению для целей диверсификации.
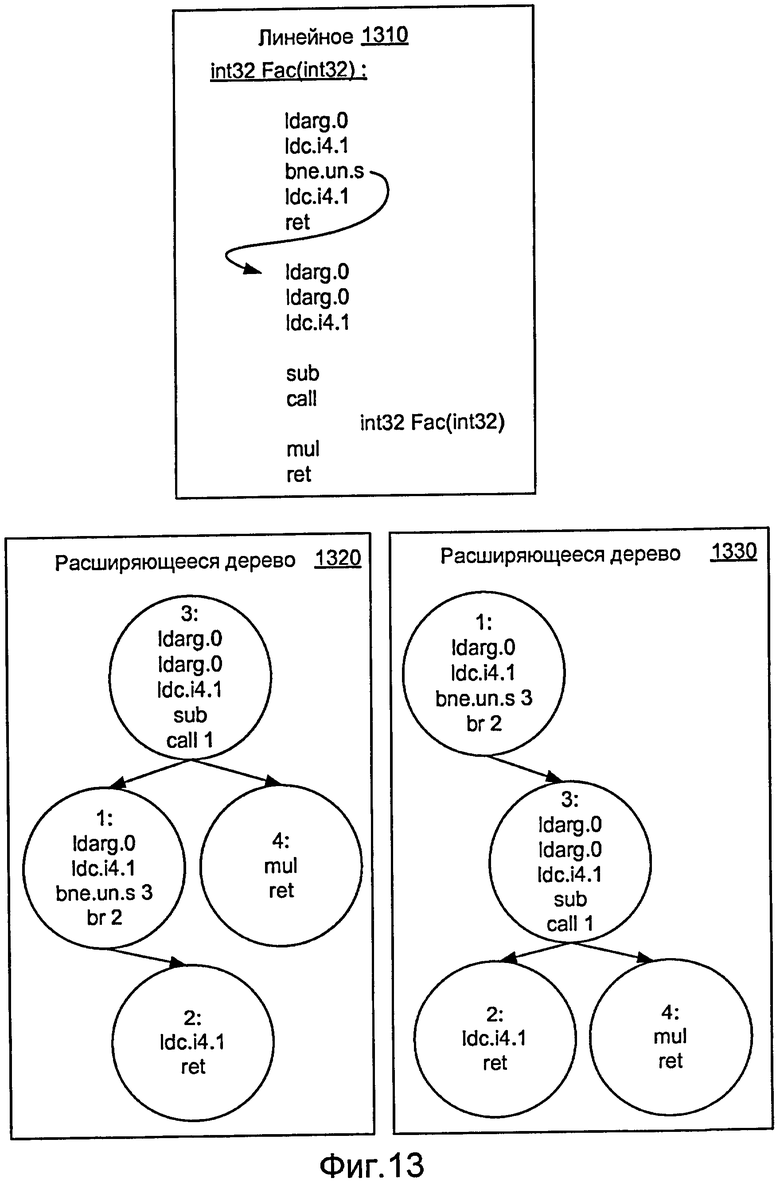
Фиг. 13 - это схема примера фрагмента кода в расходящемся дереве для целей диверсифицированной защиты от несанкционированного вмешательства.
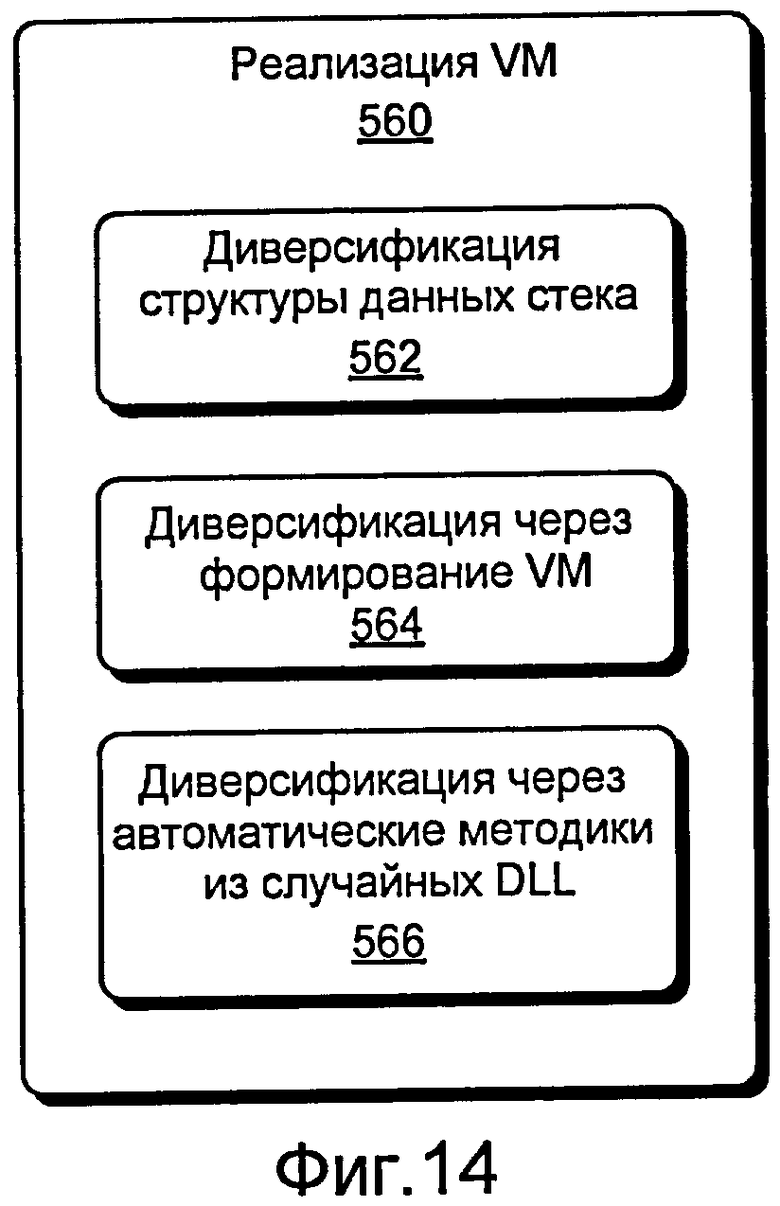
Фиг. 14 - это блок-схема различных подходов, которые могут быть применены к реализации виртуальной машины (VM) для целей диверсификации.
Фиг. 15 - это блок-схема примерного вычислительного устройства.
Подробное описание изобретения
Обзор
Примерные методики используют программно-реализованную систему безопасности для кода, который выполняется в виртуальной машине или другой машине, которой можно управлять (к примеру, работать конкретным способом). Различные примеры изменяют код, изменяют данные и/или изменяют работу виртуальной машины во взаимодействии, чтобы повышать уровень безопасности. Например, признаки, ассоциативно связанные с кодом, могут быть идентифицированы и использованы для того, чтобы диверсифицировать экземпляры кода. Различные примеры включают в себя использование пользовательской или измененной архитектуры набора команд (ISA), которая эмулируется поверх существующей архитектуры или измененной архитектуры. Если существующая архитектура включает в себя уровень виртуализации (к примеру, виртуальную машину или механизм среды выполнения, либо просто "среду выполнения"), примерный подход может добавлять еще один уровень виртуализации поверх существующего уровня виртуализации. Реализация различных методик может выполняться посредством использования пользовательской виртуальной машины, которая работает поверх базовой виртуальной машины, или посредством использования измененной виртуальной машины (к примеру, изменения базовой виртуальной машины). Для повышения уровня безопасности за счет производительности такой процесс может быть повторен итеративно, чтобы сформировать стек виртуальных машин, каждая из которых виртуализирует набор команд машины непосредственно под ней.
В отношении диверсификации, аналогия может быть проведена с генетической диверсификацией, где общие компоненты (к примеру, строительные блоки ДНК) собираются множеством способов, чтобы тем самым повысить диверсификацию видов. В свою очередь маловероятно, что вредоносный агент (к примеру, вирус) затронет всех членов генетически диверсифицированных видов. Также существует аналогия с некоторыми паразитами, где сотни генов могут создавать белки, которые смешиваются и сопоставляются. Такая диверсификация белков помогает этим паразитам избегать выявления посредством иммунной системы. Тем не менее, хотя генетическая диверсификация в видах зачастую ассоциативно связана с фенотипической диверсификацией (т.е. диверсификацией выражения или проявления), как описано в данном документе, диверсификация кода не должна менять приемы работы пользователей. Другими словами, при условии одних входных данных, все экземпляры диверсифицированного кода должны выполняться так, чтобы формировать один результат.
Рассмотрим следующие обобщенные уравнения:
генотип + среда = фенотип (1)
код/данные + машина = результат (2)
В уравнении 2 при использовании диверсифицированного кода и/или данных машина может быть пользовательской машиной или измененной либо управляемой машиной, которая обеспечивает то, что результат является практически таким же. Если используется виртуальная машина или виртуальные машины, базовые аппаратные средства и/или операционная система в типичном варианте остаются нетронутыми посредством примерных подходов к системе безопасности, описанной в данном документе; тем не менее, отметим, что эти подходы могут повышать вычислительную нагрузку.
Как описано в данном документе, диверсификация кода повышает уровень безопасности за счет предотвращения атак. Помимо этого, диверсификация кода позволяет предотвращать серийные атаки, поскольку маловероятно, что реплицирование успешной атаки на одном экземпляре кода будет успешным на "генетически" отличном экземпляре кода. Дополнительно, данные (или структура данных) могут быть диверсифицированы для того, чтобы повышать уровень безопасности. Еще дополнительно, примерные методики для диверсификации пользовательской или виртуальной машины могут быть использованы для того, чтобы повышать уровень безопасности с или без диверсификации кода и/или данных.
Хотя различные примеры ориентированы на формирование индивидуализированных байт-кодов из двоичного кода MSIL, различные примерные методики могут быть использованы для программ, выраженных на любом языке программирования, промежуточном языке, байт-коде или любым способом.
Как описано в данном документе, процесс виртуализации (к примеру, выполнения кода в виртуальной машине или виртуальной среде) упрощает (i) возможность создавать множество различных версий программы и (ii) возможность делать каждый экземпляр программы устойчивым к атаке. Различные примерные методики используют виртуализацию для того, чтобы эмулировать пользовательскую архитектуру набора команд (ISA) поверх портативной верифицируемой управляемой CLR-среды. Пользовательская среда выполнения или измененная среда выполнения может быть использована для того, чтобы эмулировать пользовательскую ISA, т.е. некоторым образом базовая среда выполнения должна иметь возможность управлять диверсификацией, вводимой через пользовательскую ISA.
Виртуализация предоставляет степени свободы, которые могут быть использованы в диверсификации. Например, архитектура набора команд (ISA) (к примеру и/или микроархитектура) в типичном варианте включает в себя (1) семантику команд, (2) кодирование команд, (3) кодирование кодов операции, (4) кодовое представление и программный счетчик, и (5) соответствующую внутреннюю реализацию виртуальной машины. При условии этих степеней свободы, различные примерные способы могут формировать множество диверсифицированных копий программы с любым из множества механизмов защиты.
Степени свободы, ассоциативно связанные с ISA, обеспечивают проектирование и выбор защищенных от несанкционированного вмешательства программ. Например, защита от несанкционированного вмешательства может быть результатом (1) задания локальных изменений более трудными за счет (a) переменной длины команд, (b) ограниченных наборов команд и содействия (c) физическому и (d) семантическому совмещению; (2) задания глобальных изменений более трудными вследствие всего вышеперечисленного и размывания границ между кодом, данными и адресами; (3) задания переменной семантики команд; и (4) постоянного перераспределения кода.
Более конкретные примеры включают в себя (i) рандомизацию семантики команд посредством конструирования команд через комбинацию младших команд; (ii) выбор семантики команд так, чтобы обеспечивать большее семантическое совмещение; (iii) отход от традиционного линейного представления кода к представлению кода как структуры данных, такой как самоадаптирующееся (расходящееся) двоичное дерево; (iv) назначение переменной длины кодам операций и операндам, чтобы усложнять дизассемблирование и затруднять локальные изменения; (v) ограничение набора команд, чтобы давать атакующим меньше вариантов при анализе и изменении кода; и (vi) задания переменной привязки между битовыми комбинациями, кодами операций и операндами. Некоторые из этих примеров подробнее описаны ниже. Подробное описание включает в себя в данный момент предполагаемый оптимальный режим.
Перед описанием различных подробностей, для целей контекста фиг. 1 иллюстрирует общую систему 100 и архитектуру 105, которая включает в себя виртуализацию. Архитектура 105 дополнительно показывает пользовательскую и/или измененную ISA и/или виртуальную машину во взаимосвязи с виртуальной машиной, упоминаемой как общеязыковая среда выполнения (CLR). CLR на фиг. 1 - это, к примеру, CLR, допускающая обработку кода на промежуточном языке, извлеченного из любого из множества языков объектно-ориентированного программирования (OOPL), отсюда термин "общая". Хотя фиг. 1 поясняется со ссылкой на инфраструктуру.NET™ (Microsoft Corp, Redmond, WA), примерные методики могут быть использованы с другими архитектурами.
Система 100 включает различные вычислительные устройства 101, 101', 102, 102', осуществляющие связь через сеть 103. Устройства 101, 101' могут быть клиентами (к примеру, PC, рабочими станциями, облегченными устройствами, интеллектуальными устройствами и т.д.), тогда как устройства 102, 102' являются серверами. Архитектура 105 показана с некоторыми линиями связи с устройством 101, сервером 102' и сетью 103.
Инфраструктура.NET™ имеет два основных компонента: общеязыковую среду выполнения (CLR) и библиотеку классов инфраструктуры.NET™. Они показаны как ассоциативно связанные с управляемыми приложениями. CLR - это виртуальная машина (VM) на основе инфраструктуры.NET™. CLR выступает в качестве агента, который управляет кодом во время выполнения, предоставляя базовые службы, такие как управление памятью, управление потоками и удаленное взаимодействие, при этом также активируя строгую защиту и другие формы точности кода, которые способствуют безопасности и отказоустойчивости. Концепция управления кодом является фундаментальным принципом CLR. Код, который предназначен для CLR, известен как управляемый код, тогда как код, который не предназначен для среды выполнения, известен как неуправляемый код (правая половина архитектуры).
В инфраструктуре.NET™ программы выполняются в управляемой среде выполнения, предоставляемой посредством CLR. CLR значительно повышает интерактивность среды выполнения между программами, переносимость, безопасность, простоту разработки, межъязыковую интеграцию и предоставляет основу для развитого набора библиотек классов. Каждый язык, предназначенный для CLR инфраструктуры.NET™, компилирует исходный код и создает метаданные и код промежуточного языка Microsoft® (MSIL). Хотя в различных примерах упоминается MSIL, различные примерные методики обеспечения безопасности могут быть использованы с другим языковым кодом. Например, различные методики могут быть использованы практически с любым низкоуровневым языком ассемблера (к примеру, любым кодом промежуточного языка (IL)). Различные методики могут быть использованы с байт-кодами, такими как байт-коды инфраструктуры JAVA™ (Sun Microsystem, Sunnyvale, CA).
В инфраструктуре.NET™ программный код в типичном варианте включает в себя информацию известную как "метаданные", или данные о данных. Метаданные зачастую включают в себя полную спецификацию к программе, в том числе все ее типы, за исключением фактической реализации каждой функции. Эти реализации сохраняются как MSIL, который является машинонезависимым кодом, который описывает команды программы. CLR может использовать этот план для того, чтобы активировать программу в среде выполнения.NET™, предоставляя услуги далеко за рамками того, что возможно при традиционном подходе, который базируется на компилировании кода непосредственно на языке ассемблера.
Библиотека классов, другой основной компонент инфраструктуры.NET™, - это полный объектно-ориентированный набор многократно используемых типов для того, чтобы разрабатывать приложения в пределах от традиционных приложений командной строки или графического пользовательского интерфейса (GUI) до приложений на основе последних новшеств, предоставляемых посредством ASP.NET, таких как веб-формы и XML-веб-службы.
Хотя CLR показана на стороне управляемого приложения в архитектуре 105, инфраструктура.NET может назначаться хостом посредством неуправляемых приложений, которые загружают CLR в свои процессы и инициируют выполнение управляемого кода, тем самым создавая программную среду, которая может применять управляемые и неуправляемые признаки. Инфраструктура.NET™ не только предоставляет несколько хостов среды выполнения, но также поддерживает разработку сторонних хостов среды выполнения.
Например, ASP.NET является хостом для среды выполнения (RT), чтобы предоставлять масштабируемую серверную среду для управляемого кода. ASP.NET работает напрямую со средой выполнения, чтобы разрешить ASP.NET-приложения и XML-веб-службы.
Приложение обозревателя Internet Explorer® (Microsoft Corp.) является примером неуправляемого приложения, который является хостом для среды выполнения (к примеру, в форме MIME-типа). Использование программного обеспечения Internet Explorer® для того, чтобы выступать в качестве хоста для среды выполнения, позволяет пользователю встраивать управляемые компоненты или элементы управления Windows Forms в HTML-документы. Задание хоста для среды выполнения таким образом делает возможным управляемый мобильный код (аналогично элементам управления Microsoft® ActiveX®), но со значительными усовершенствованиями, которые может предлагать только управляемый код, такими как полудоверенное выполнение и изолированное хранилище файлов.
Как описано в данном документе, управляемым кодом может быть любой код, который предназначен для среды выполнения (к примеру, виртуальной машины, механизма среды выполнения и т.д., где среда выполнения взаимодействует с базовой операционной системой (OS), в типичном варианте непосредственно ассоциативно связанной с управлением аппаратными средствами (HW)). В инфраструктуре.NET™ управляемый код предназначен для CLR и в типичном варианте включает в себя дополнительную информацию, известную как метаданные, которые описывают себя. Хотя и управляемый, и неуправляемый код может запускаться в CLR, управляемый код включает в себя информацию, которая позволяет CLR гарантировать, например, защищенное выполнение и функциональную совместимость.
Помимо управляемого кода, в архитектуре инфраструктуры.NET™ существуют управляемые данные. Некоторые языки.NET™ используют управляемые данные по умолчанию (к примеру, C#, Visual Basic.NET, JScript.NET), тогда как другие (к примеру, C++) не используют. Как и в случае с управляемым и неуправляемым кодом, использование управляемых и неуправляемых данных в приложениях.NET™ возможно (к примеру, данных, которые не собирают "мусор", а вместо этого анализируются посредством неуправляемого кода).
Программа или код в типичном варианте распространяется как переносимый исполняемый код (к примеру, PE). В.NET™ PE, первым блоком данных в оболочке PE является MSIL, который, как упоминалось выше, выглядит примерно как код на низкоуровневом языке ассемблера. MSIL традиционно является тем, что компилируется и выполняется в архитектуре.NET™. Вторым блоком данных в PE традиционно являются метаданные, и они описывают содержимое PE (к примеру, какие методы они предоставляют, какие параметры они берут и что они возвращают). Третий блок данных упоминается как манифест, который традиционно описывает то, какие другие компоненты требует исполняемый код для того, чтобы выполняться. Манифест также может содержать открытые ключи внешних компонентов, с тем чтобы CLR могла обеспечить то, что внешний компонент надлежащим образом идентифицируется (т.е. компонент, требуемый посредством исполняемого кода).
При запуске исполняемого кода.NET™ CLR может использовать оперативную (JIT) компиляцию. JIT-компиляция позволяет всему управляемому коду запускаться в собственном машинном языке системы, в которой он выполняется (OS/HW). Согласно JIT, по мере того как каждый метод в исполняемом коде вызывается, он компилируется в собственный код и, в зависимости от конфигурации, последующие вызовы в тот же метод не обязательно должны подвергаться такой же компиляции, что позволяет снижать затраты ресурсов (т.е. затраты ресурсов несутся только один раз на вызов метода). Хотя CLR предоставляет множество стандартных служб среды выполнения, управляемый код никогда не интерпретируется. Между тем, диспетчер памяти исключает возможности фрагментированной памяти и повышает локальность ссылок в памяти, чтобы дополнительно повысить производительность.
Ссылаясь снова на архитектуру 105, взаимосвязь CLR и библиотеки классов показана в отношении приложений и всей системы (к примеру, системы 100) и показывает то, как управляемый код работает в рамках более крупной архитектуры.
CLR управляет памятью, выполнением подпроцессов, выполнением кода, проверкой безопасности кода, компиляцией и другими системными службами. Эти признаки являются присущими управляемому коду, который запущен в CLR.
В отношении безопасности, управляемым компонентам могут присваиваться различные степени доверия, в зависимости от количества факторов, которые включают в себя свой источник (такой как Интернет, корпоративная сеть или локальный компьютер). Это означает, что управляемый компонент может иметь или не иметь возможности выполнять операции доступа к файлам, операции доступа к регистру или другие чувствительные функции, даже если он используется в том же активном приложении.
CLR может активировать систему безопасности доступа к коду. Например, пользователи могут доверять тому, чтобы исполняемый код, встроенный в веб-страницу, мог воспроизводить анимацию на экране или воспроизводить песню, но не мог осуществлять доступ к их личным данным, файловой системе или сети. Признаки обеспечения безопасности CLR, таким образом, могут предоставлять возможность легальному развертываемому через Интернет программному обеспечению обладать исключительно широкими техническими возможностями.
CLR также может активировать ошибкоустойчивость кода посредством реализации инфраструктуры строгой проверки типов и кода, называемую системой общего типа (CTS). CTS обеспечивает то, что весь управляемый код является самодокументируемым. Управляемый код может использовать больше управляемых типов и экземпляров, при этом строго активируя соответствие типов и защиту типов.
Управляемая среда CLR нацелена на то, чтобы устранять многие проблемы стандартного программного обеспечения. Например, CLR может автоматически обрабатывать структуру объектов и управлять ссылками на объекты, освобождая их, когда они более не используются. Это автоматическое управление памятью разрешает две наиболее стандартные ошибки приложений, утечку памяти и недопустимые ссылки на ячейку памяти. Функциональная совместимость между управляемым и неуправляемым кодом может позволять разработчикам продолжать использовать требуемые компоненты COM (модель компонентных объектов) и DLL (динамически подключаемые библиотеки).
CLR инфраструктуры.NET™ может размещаться в высокопроизводительных серверных приложениях, таких как Microsoft® SQL Server™ и Internet Information Services (IIS). Данная инфраструктура позволяет использование неуправляемого кода для записи бизнес-логики, при этом по-прежнему используя корпоративные серверы, которые поддерживают хостинг в среде выполнения.
Серверные приложения в управляемом домене реализуются через хосты среды выполнения. Неуправляемые приложения являются хостом для CLR, что позволяет пользовательскому управляемому коду контролировать режим работы сервера. Эта модель предоставляет признаки CLR и библиотеки классов при достижении производительности и масштабируемости хост-сервера.
Как уже упоминалось, различные примерные методики используют виртуализацию для того, чтобы эмулировать пользовательскую или модифицированную ISA поверх портативной верифицируемой управляемой CLR-среды. Это показано в архитектуре 105 посредством примерной пользовательской/измененной ISA и/или VM 107 (пунктирная дугообразная линия), которая размещается поверх границы CLR и пространства управляемых приложений (при этом различные примеры также поясняют неуправляемые приложения). Это подразумевает, что пользовательская/измененная ISA не мешает работе CLR и базовой среды или среды "хоста" (например, OS/HW). В то время как пользовательская ISA может предусмотреть элемент управления CLR или VM до степени, необходимой для того, чтобы реализовать различные признаки пользовательской ISA, различные примеры базируются на пользовательской VM, которая может быть измененной версией базовой VM (то есть модифицированной CLR). Следовательно, примерная архитектура может включать в себя отдельную модифицированную VM или несколько VM (например, пользовательскую VM поверх целевой VM). Чтобы повысить уровень безопасности за счет некоторого снижения производительности, множество VM может быть расположено в стеке таким образом, что все кроме самого низкого уровня VM виртуализируют набор команд VM непосредственно ниже.
На фиг. 1 стрелка указывает, например, где у обычной CLR есть уровень виртуализации с двумя типами VM1 и VM2 виртуализации поверх него, и другой пример, где традиционная CLR имеет два помещенных в стек уровня VM1 и VM3 виртуализации поверх него. В таких примерах базовая CLR может быть пользовательской или собственной CLR с признаками обеспечения безопасности, где дополнительные один или более уровней виртуализации дополнительно повышают уровень безопасности. Примерный способ включает в себя несколько размещенных в стеке VM, где каждая VM виртуализирует набор команд машины непосредственно ниже. При этом VM самого низкого уровня обычно виртуализирует операционную систему, которая управляет аппаратными средствами, в то время как другие VM более высокого уровня виртуализируют другую VM. Как указано на фиг. 1, различные компоновки возможны (например, две VM поверх VM, размещенные в стеке VM и т.д.). Подход с несколькими "пользовательскими" VM может быть рассмотрен как усиление виртуализации, чтобы получить дополнительный уровень безопасности за счет некоторого снижения производительности.
Ссылаясь снова на аналогию с генетикой и окружающей средой, генетика может рассматриваться статической, в то время как окружающая среда может рассматриваться динамической. Аналогично, различные основанные на диверсификации подходы к защите от несанкционированного вмешательства могут быть статическими и/или динамическими. В общем, статический подход диверсифицирует копии кода программы, в то время как динамический подход диверсифицирует работу нескольких VM или одной VM либо работу программы в среде выполнения. Таким образом, как описано в данном документе, различные примерные методики включают виртуализацию, которая работает статически, динамически и/или как статически (например, чтобы создать индивидуализированный программный код), так и динамически (например, чтобы изменить работу программы в среде выполнения).
Примерный способ может включать в себя предоставление архитектуры, которая включает в себя первый уровень виртуализации, и предоставление второго уровня виртуализации поверх первого уровня виртуализации, где второй уровень виртуализации выполнен с возможностью принимать диверсифицированную копию программы и обеспечивать выполнение программы, используя первый уровень виртуализации. Такой способ позволяет повысить уровень безопасности программного обеспечения через использование методик диверсификации, описанных в данном документе.
Примерный способ может включать в себя формирование индивидуализированных копий программного кода и предоставление виртуальной машины для выполнения индивидуализированной копии программного кода, причем виртуальная машина может изменять работу программы в среде выполнения. Такой способ позволяет повысить уровень безопасности программного обеспечения через использование методик диверсификации, описанных в данном документе.
Для удобства пользовательские и измененные ISA упоминаются в данном документе как пользовательские ISA. Пользовательские ISA могут использоваться для того, чтобы создавать набор отличных копий (или "версий") программы со следующими свойствами: (i) у каждой копии в наборе есть надлежащий уровень защиты от несанкционированного вмешательства, и (ii) трудно перенацелить текущую атаку против одной копии так, чтобы она работала против другой копии. Много вариантов приводят к большому пространству семантически эквивалентных программ, которые могут быть созданы. Подход может полагать, что все это пространство обеспечивает большую диверсификацию, или, альтернативно, подход может рассматривать только части этого пространства, которые, как полагают или как доказано, являются более защищенными от несанкционированного вмешательства, чем другие части.
Свойства защиты от несанкционированного вмешательства включают в себя: (i) недопущение статического анализа программы; (ii) недопущение динамического анализа программы; (iii) недопущение локальных изменений; и (iv) недопущение глобальных изменений. Первые два тесно связаны с проблемой маскировки структуры, в то время как последние два более ориентированы на защиту от несанкционированного вмешательства. Тем не менее, интеллектуальное несанкционированное вмешательство требует, по меньшей мере, определенной степени понимания программы, которое обычно получается из анализа статического двоичного кода, анализа выполняющегося исполняемого кода или комбинации и/или повторения двух предыдущих методик.
Существуют различные ISA, к примеру, CISC, RISC и недавно созданный байт-код Java™ и управляемый MSIL. Тем не менее, последние два элемента имеют тенденцию легче анализироваться по ряду причин. Во-первых, двоичные коды в типичном варианте не выполняются непосредственно на аппаратных средствах, а должны быть эмулированы или переведены на собственный машинный код перед выполнением. Чтобы обеспечить это, границы между кодом и данными должны быть известны, и не может быть никакой путаницы между постоянными данными и перемещаемыми адресами. Это, конечно, подпадает под преимущество мобильности. Помимо мобильности, принципы проектирования включают в себя поддержку управления памятью с контролем типов и проверяемости. Чтобы гарантировать проверяемость, арифметика указателя запрещена, поток команд управления ограничен и т.д. Чтобы предоставить управление памятью с контролем типов, большой объем информации о типах объектов должен сообщаться в среду выполнения.
Все эти принципы проектирования привели к двоичным кодам, которые просто анализировать посредством среды выполнения, но в равной степени просто анализировать и атакующему. Это привело к созданию декомпиляторов и для Java™, и для управляемых двоичных кодов MSIL.
Вообще, существует тенденция, при которой принципы проектирования ISA все более и более конфликтуют с принципами проектирования, которые должны упрощать защиту программного обеспечения.
Как описано в данном документе, примерная методика для того, чтобы противостоять этой тенденции, добавляет дополнительный уровень виртуализации (или необязательно, множество дополнительных уровней виртуализации). Более конкретно, виртуализация может использоваться для того, чтобы эмулировать пользовательскую ISA поверх портативной проверяемой управляемой среды выполнения. Рассмотрим следующую конструкцию: (i) написание эмулятора (к примеру, пользовательской виртуальной машины) для среды, которая выполняется поверх CLR; (ii) взятие двоичного представления двоичного кода и добавление его в качестве данных к эмулятору; и (iii) задание эмуляции начала главной процедуры в точке входа исходного исполняемого кода. При условии этой конструкции результатом является управляемый, переносимый и проверяемый двоичный код. Кроме того, он защищен в такой же степени, как и машинный двоичный код, поскольку атакующий машинного двоичного кода легко может взять машинный двоичный код и следовать вышеописанной конструкции.
Вообще, для двоичных кодов опыт и интуиция показывают, что средний двоичный код IA32 намного более сложен для понимания и манипулирования, чем средний управляемый двоичный код. Некоторые основные причины включают в себя (i) переменную длину команды; (ii) отсутствие четкого различия между кодом и данными; и (iii) отсутствие четкого различия между постоянными данными и перемещаемыми адресами. Поскольку команды (код операций + операнды) могут иметь переменную длину (например, 1-17 байтов), команды должны быть только совмещенными по байтам и могут быть смешаны с данными заполнения или обычными данными в IA32, дизассемблеры могут легко рассинхронизироваться. Так как нет явного разделения между кодом и данными, и то, и другое может считываться и записываться прозрачно и использоваться взаимозаменяемо. Это обеспечивает самоизменяющийся код, признак, который известен вследствие трудности его анализа и введения в заблуждение атакующих.
Признак, что двоичное представление кода может легко быть прочитано, использовался для того, чтобы предоставить механизмы самопроверки, в то время как отсутствие ограничений на поток команд управления предоставило такие методики, как выравнивание потока команд управления и совмещение команд.
Тот факт, что адреса могут быть вычислены и что их нельзя легко отличить от обычных данных, усложняет несанкционированное вмешательство в двоичные коды. Например, атакующий может выполнять только локальные изменения, поскольку у него нет достаточной информации, чтобы перераспределить весь двоичный код. Такие наблюдения могут быть использованы для того, чтобы сформировать примерную пользовательскую ISA, которая оказывается трудной для анализа ISA. Эта ISA позволяет повышать безопасность.
В то время как примерные методики могут включать самоизменяющийся код в ISA и/или управлять выравниванием потока команд управления и/или совмещением команд, конкретные примеры, поясненные в данном документе, включают в себя предоставление переменной длины команд и использование двоичного представления частей программы для повышения защиты от несанкционированного вмешательства, которое может рассматриваться как связанное с некоторыми механизмами самопроверки.
Программное обеспечение зачастую знает вещи, которые оно не хочет совместно использовать без надлежащего контроля. Например, пробные версии могут содержать функциональные возможности, чтобы выполнить данную задачу, но ограничение по времени позволяет предотвратить их использование в течение слишком долгого времени. В цифровых контейнерах программное обеспечение часто используется для того, чтобы предоставить контролируемый доступ к содержимому. Мобильные агенты могут содержать криптографические ключи, которые должны остаться секретными.
Чтобы предотвращать атаки, примерные подходы включают в себя (i) задание программы различной для различных установок; (ii) задание программы различной во времени через индивидуальные обновления; и (iii) задание программы различной для каждого выполнения через рандомизацию во время выполнения.
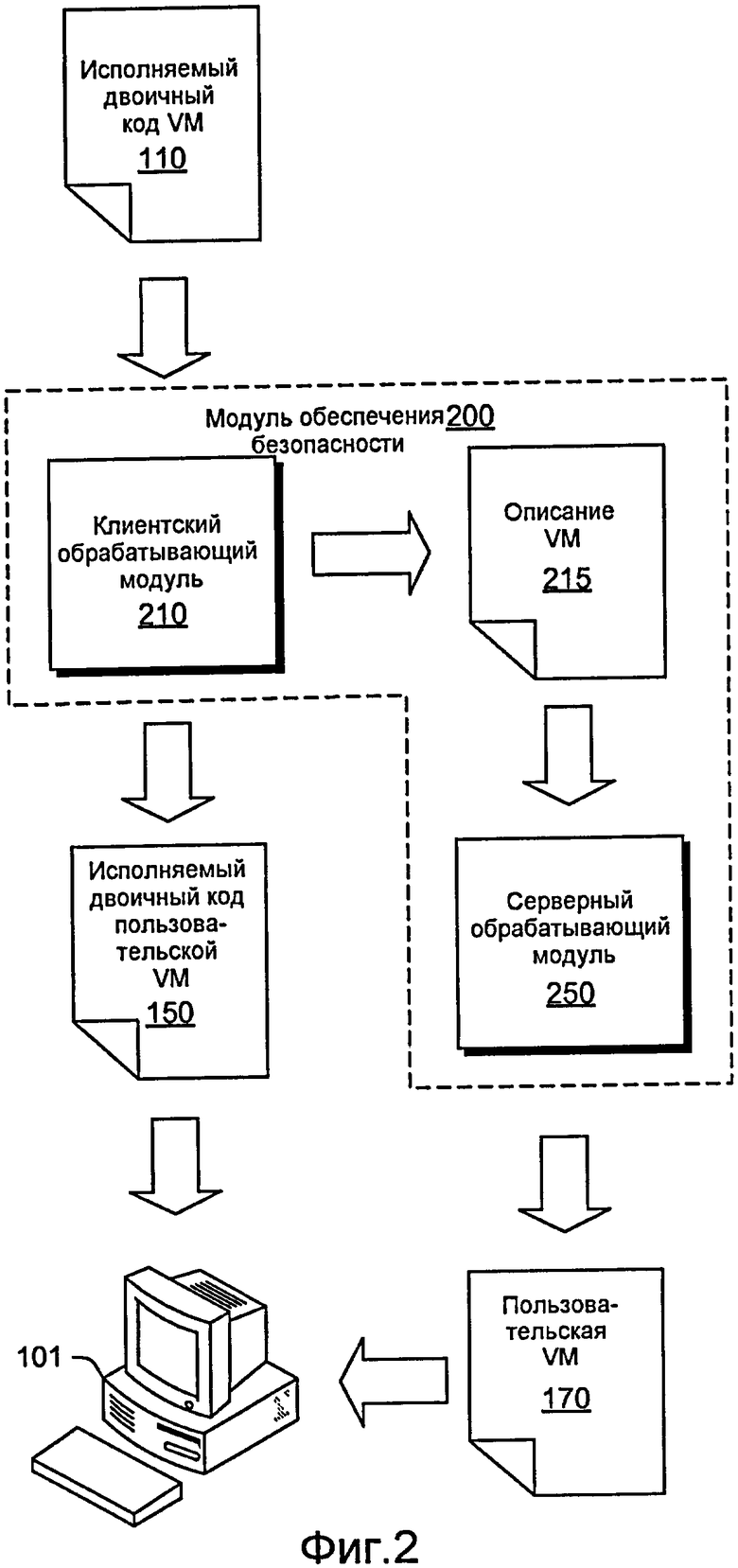
Фиг. 2 иллюстрирует примерный модуль 200 безопасности, реализованный совместно с инфраструктурой, которая запускает переносимые исполняемые файлы на виртуальной машине. Модуль 200 безопасности включает в себя клиентский обрабатывающий модуль 210 и серверный обрабатывающий модуль 250. Клиентский обрабатывающий модуль 210 считывает исполняемый двоичный файл 110, который предназначается для VM, и создает пользовательский исполняемый двоичный файл 150, который предназначается для измененной версии исходной целевой VM или пользовательской VM. В любом случае клиентский обрабатывающий модуль 210 может использовать файл 110, чтобы определять информацию об исходной целевой VM, например, описание 115 VM. Серверный обрабатывающий модуль 250 может использовать описание 215 VM, чтобы сформировать код, DLL и т.д. для пользовательской VM 170. Например, обычная VM может быть поставлена как совместно используемая библиотека или DLL (к примеру, "собственная" библиотека), и такие методики могут использоваться для пользовательской VM, при этом, если VM работает поверх VM, специфические особенности базовой VM могут учитываться в форме и/или характеристиках пользовательской VM. Для удобства термин "пользовательская" в применении к VM может включать в себя измененную VM (например, измененную версию кода исходной целевой VM).
В примере, ориентированном на инфраструктуру.NET™, клиентский обрабатывающий модуль 210 считывает управляемые двоичные коды 110 MSIL, запускается несколько раз поверх кода, чтобы определить его ISA, и создает XML-описание 215 из его целевой VM. Как только ISA была определена, модуль 210 может перезаписать исходный двоичный код в пользовательский язык 150 байт-кода.
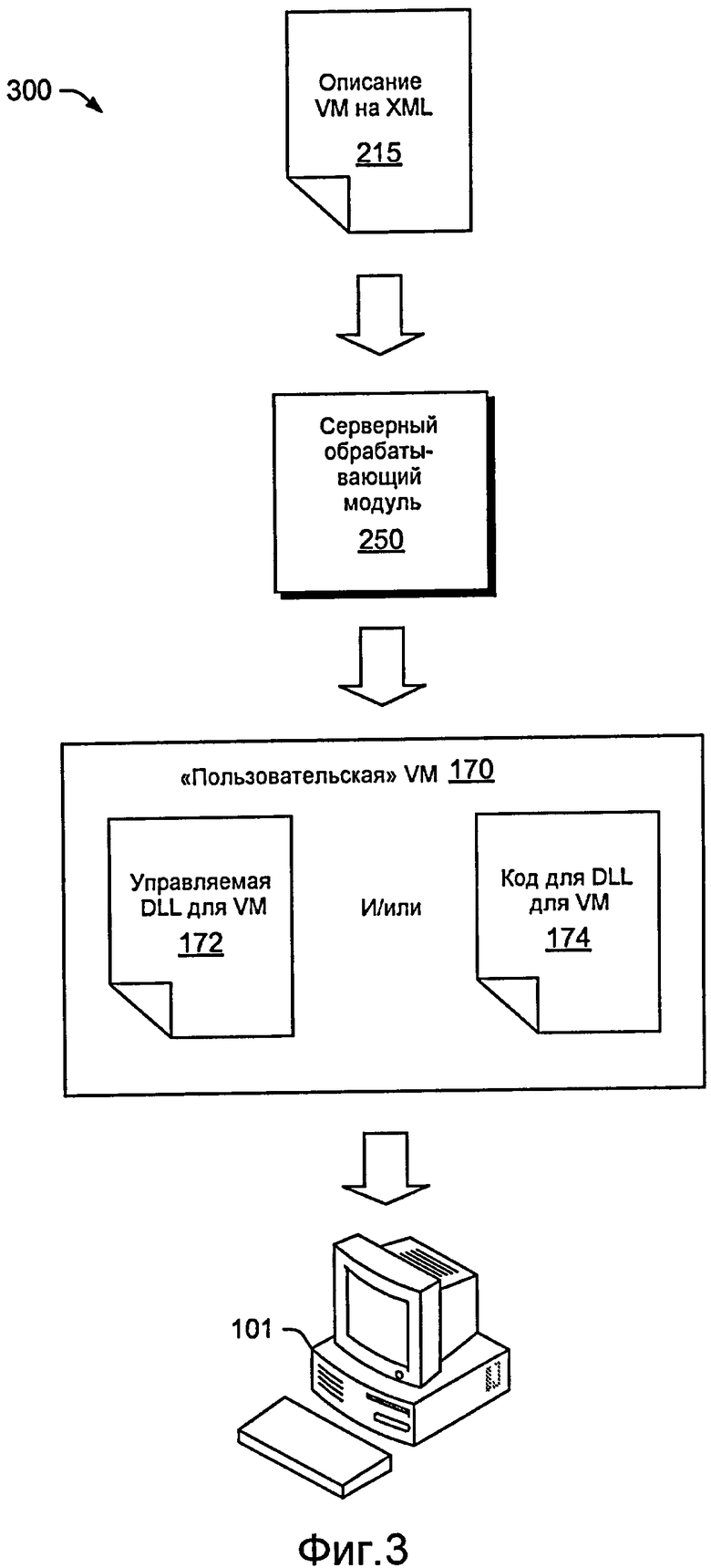
Фиг. 3 иллюстрирует примерный способ 300, в котором серверный обрабатывающий модуль 250 считывает XML-описание 215 и создает управляемую DLL для пользовательской VM 172. Разделение на серверную часть и клиентскую часть немного искусственно, но оно предоставляет более модульное проектирование и может облегчить отладку. Например, серверному обрабатывающему модулю 250 может быть проинструктировано вывести код 174 C# вместо непосредственного компилирования DLL (см., к примеру, 172). Код 174 затем может быть проанализирован и отлажен отдельно.
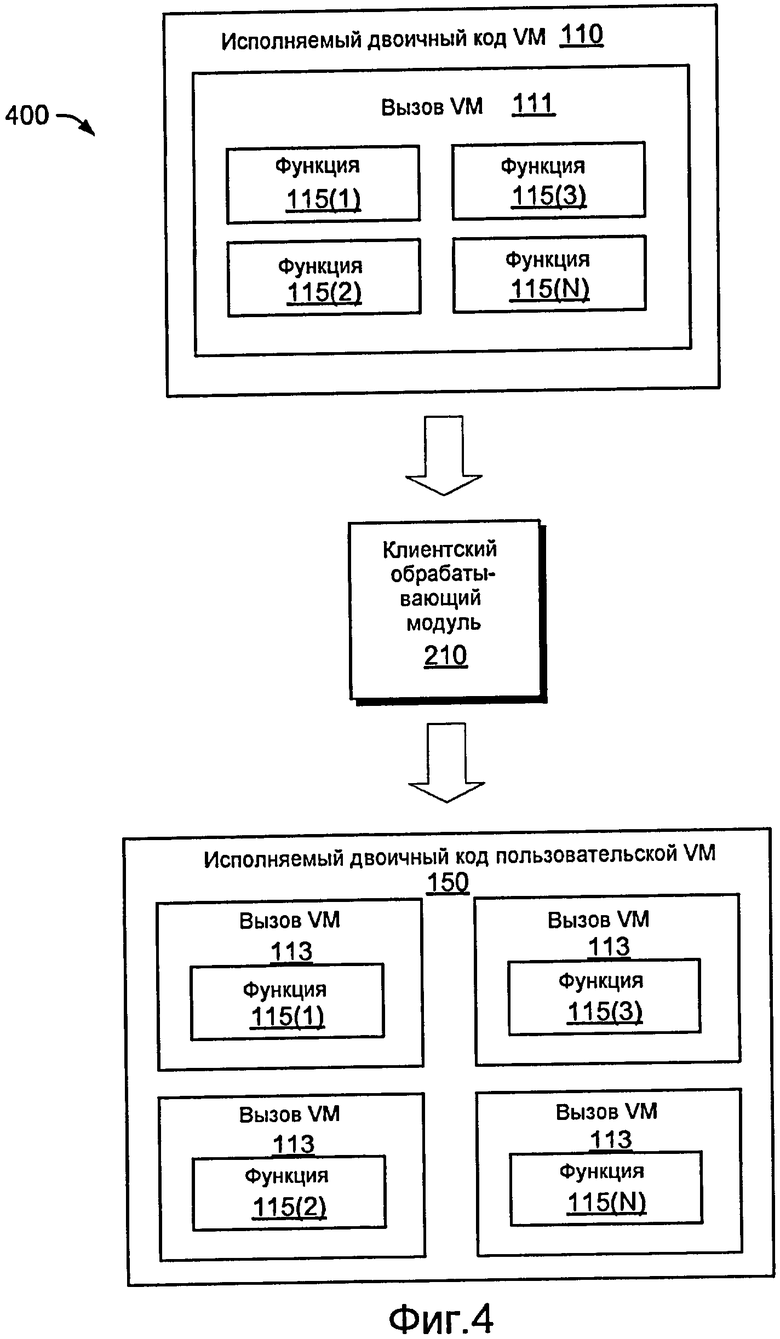
Фиг. 4 иллюстрирует примерный способ 400, где различные части исходного двоичного кода сохранены. Более конкретно, исходный исполняемый двоичный код 110 VM включает в себя оболочку 111 функций 115(1)-(N) и клиентский обрабатывающий модуль 210, перезаписывает каждую функцию 115(1)-(N) в оболочку 113, которая вызывает VM, передавая необходимые аргументы. В этом примере все аргументы можно передать в массиве объектов. Для функций instance способ 400 также включает в себя указатель this. Поскольку способ 400 оперирует со всеми функциями, чтобы поместить каждую как отдельную структуру, клиентский обрабатывающий модуль 210 может также предусматривать прохождение идентификации точки входа каждой функции. Кроме того, клиентский обрабатывающий модуль 210 может предоставлять признаки, чтобы гарантировать то, что возвращенный объект приведен к типу возвращаемого значения исходной функции, при необходимости.
Фиг. 5 подробнее иллюстрирует конкретную реализацию способа 400. В этом примере клиентский обрабатывающий модуль 210 конвертировал функции в заглушки, используя оболочку, которая вызывает VM. Более конкретно, функция foo заключена в оболочку с помощью вызова InvokeVM.
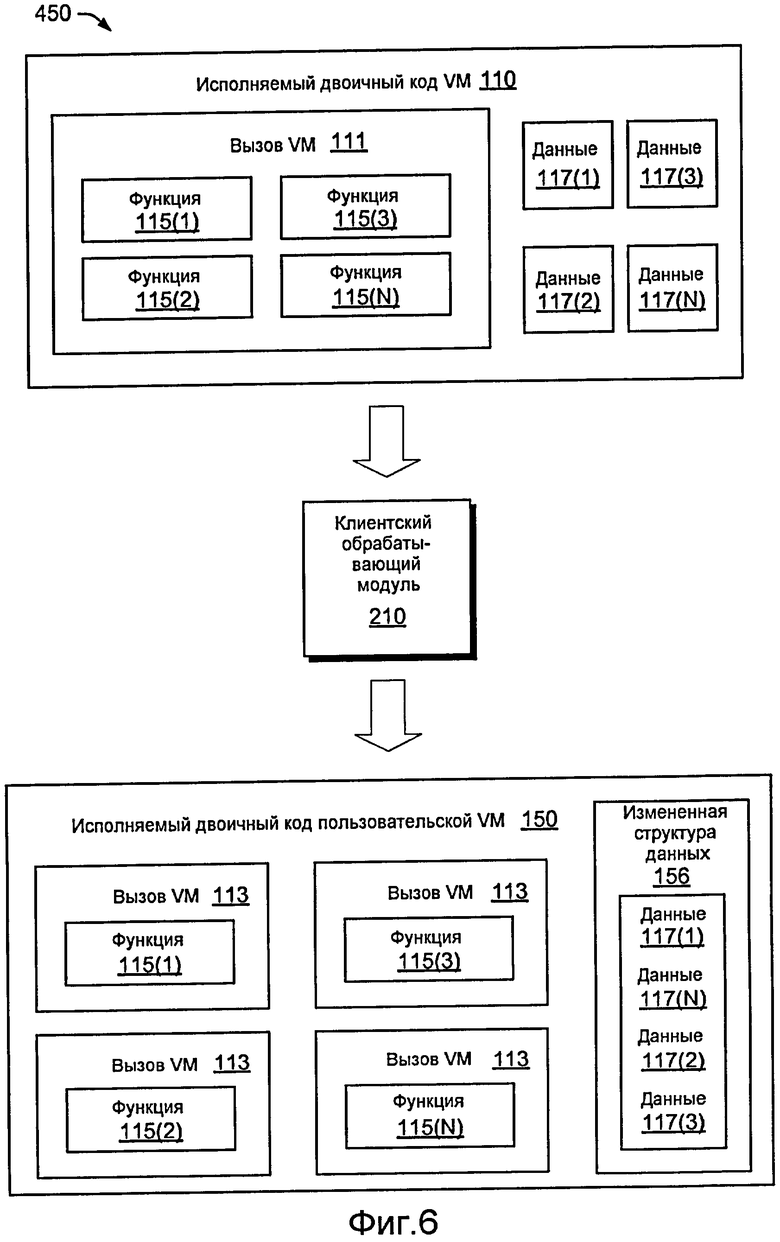
Как уже упоминалось, данные или структура данных могут предоставлять средство для диверсификации. Фиг. 6 показывает примерный способ 450, где примерный клиентский обрабатывающий модуль 210 принимает двоичный код 110 с данными 117(1)-(N) в исходной структуре данных и выводит пользовательский двоичный код 150 с данными 117(1)-(N) в измененной или пользовательской структуре 156 данных. В то время как способ 450 также демонстрирует заключение в оболочку функций 115(1)-(N), примерный способ позволяет формировать пользовательский двоичный код посредством диверсификации кода, диверсификации данных и/или диверсификации кода и данных. Фраза "диверсификация данных" может включать в себя диверсификацию данных и диверсификацию, основанную на структуре данных.
Примерные способы, которые включают в себя перезаписывание исходной программы на основе функций, имеют преимущество только в том, что такие вещи, как сборка мусора, не становятся проблемой, поскольку структуры данных все еще рассматриваются как находящиеся в исходной программе. Если методики применяются для маскировки структуры, диверсификации и повышения степени защиты данных от несанкционированного вмешательства, изменения могут предусматривать такие задачи, как сборка мусора.
Фиг. 1-6, описанные выше, иллюстрируют то, как виртуализация может использоваться для повышения уровня безопасности. Более конкретно, клиентский обрабатывающий модуль может использоваться, чтобы формировать пользовательский двоичный код, а серверная обработка может использоваться, чтобы формировать пользовательскую VM, чтобы выполнить пользовательский двоичный код. Фиг. 7-14, описанные ниже, иллюстрируют, как специальные признаки ISA и/или VM могут использоваться для повышения уровня безопасности через диверсификацию.
Относительно управляемого кода и различных примерных методик, представленных в данном документе, выбор между управляемым MSIL для CLR и байт-кодом Java™ для среды исполнения Java (JRE) в некоторой степени произволен, поскольку различные примерные методики могут быть переданы из.NET ™ в домен Java™. Далее, методики для того, чтобы маскировать структуру байт-кода Java™, могут быть применены к управляемым двоичным кодам MSIL. Нижеследующее пояснение ориентировано прежде всего на примерные методики, которые вытекают из "добавленного" или пользовательского уровня виртуализации. Автоматизированная диверсификация распространяемых копий, например, через Интернет-распространение постоянно получает признание. Следовательно, дополнительное введение любой из примерных методик все более и более экономически ценно.
Различные примерные методики могут представлять защиту автоматически в точке, где взаимодействие с человеком больше не требуется. Теоретически возможно сформировать неуправляемое число диверсифицированных семантически эквивалентных программ. Рассмотрим программу с 300 командами и выберем для каждой команды то, следует ли вставлять перед ней команду NOP/NOOP (пустая команда). Это приводит к 2300 различным семантически эквивалентным программам, и 2300 больше, чем 1087, предполагаемое число частиц во вселенной.
Тем не менее, уникальность не обязательно достаточна, поскольку результирующие программы должны быть достаточно диверсифицированными для того, чтобы усложнить отображение информации, полученной от одного экземпляра, на другой экземпляр. Кроме того, результирующие программы предпочтительно должны быть нетривиальными, чтобы нарушить их защиту. Хотя необоснованно ожидать, что кообласть различных примерных методик диверсификации должна включать в себя каждую семантически эквивалентную программу, цель может быть установлена, чтобы максимизировать кообласть элемента диверсификации, поскольку, чем больше пространство, тем более простым становится получение внутренне отличных программ.
Примерный подход начинается с существующей реализации семантики, а не с семантики непосредственно. Через ряд параметризуемых трансформаций получаются отличные версии. В различных нижеприведенных примерах идентифицирован ряд компонентов ISA, которые могут быть индивидуализированы независимо.
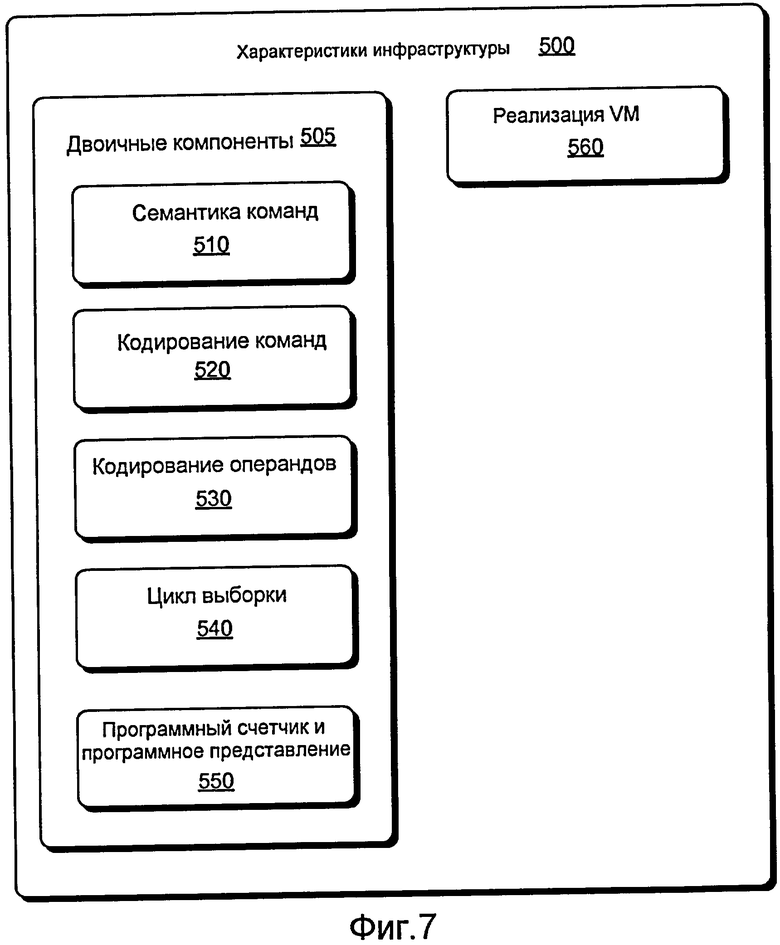
Фиг. 7 иллюстрирует примерные характеристики 500 инфраструктуры, сгруппированные как двоичные компоненты 505 и компонент 560 реализации VM. Двоичные компоненты 505 включают семантику 510 команд, кодирование 520 команд, кодирование 530 операндов, цикл 540 выборки и программный счетчик (PC) и программное представление 550. Эти компоненты могут быть индивидуализированы ортогональным способом, пока интерфейсы соблюдаются. Компонентов 505 достаточно для того, чтобы сформировать двоичный код на пользовательском языке байт-кода, то есть определить примерную пользовательскую ISA. Кроме того, диверсификация может осуществиться посредством диверсификации целевой VM или пользовательской VM (см., к примеру, компонент 560 реализации VM).
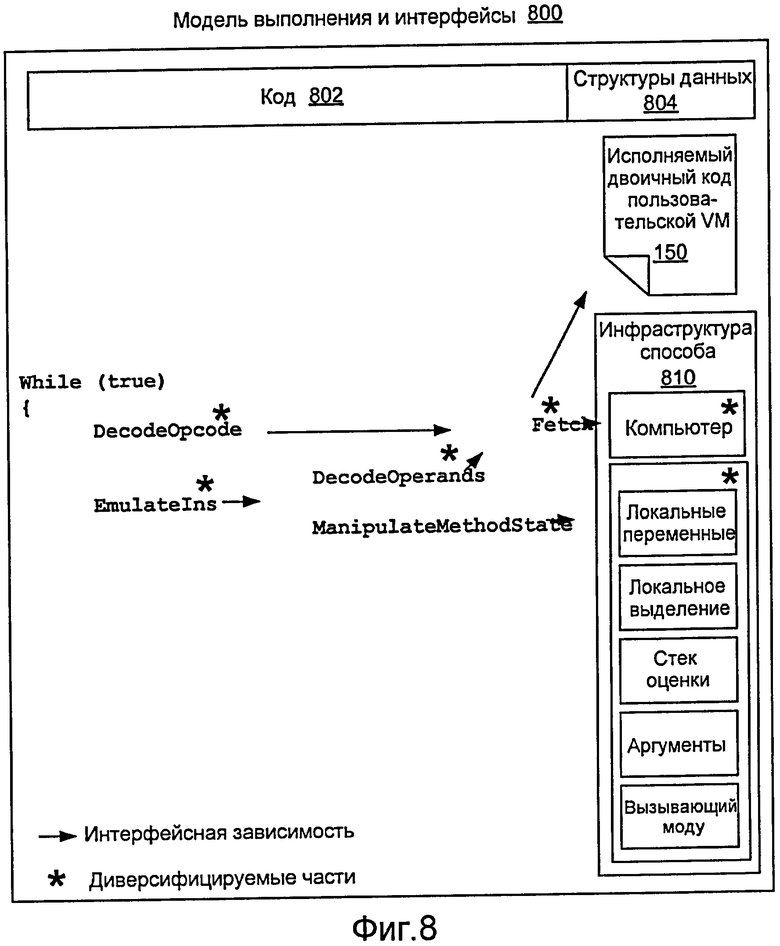
Фиг. 8 показывает модель и интерфейсы 800 выполнения. Модель 800 включает в себя код 802, структуру 804 данных, инфраструктуру 810 способа и пользовательский двоичный код 150. На фиг. 8 стрелки представляют интерфейсные зависимости, и звездочки представляют некоторые диверсифицируемые части. Примерный подход, который использует такую модель, предусматривает модульное проектирование и независимую разработку.
Согласно модели 800 и инфраструктуре 500, диверсификация может включать в себя (i) рандомизацию семантики команд посредством конструирования команд через комбинацию младших команд, (ii) выбор семантики команд так, чтобы обеспечивать большее семантическое совмещение, (iii) отход от традиционного линейного представления кода к представлению кода как структуры данных, такой как самоадаптирующееся (расходящееся) двоичное дерево; (iv) назначение переменной длины кодам операций и операндам, чтобы усложнять дизассемблирование и затруднять локальные изменения; (v) ограничение набора команд, чтобы давать атакующим меньше вариантов при анализе и изменении кода; и (vi) задание переменной привязки между битовыми комбинациями, кодами операций и операндами.
Код 802 на фиг. 8 дает высокоуровневое общее представление механизма исполнения команд, основанного на цикле "выборка-исполнение". Основные внутренние структуры данных VM показаны как инфраструктура 810 способа. Как уже упоминалось, стрелки указывают интерфейсную зависимость. Например, DecodeOpcode, как ожидается, может извлечь число битов.
Фиг. 9 иллюстрирует семантику 510 команд по фиг. 5 и некоторые признаки, которые могут использоваться для диверсификации. Понятие микроопераций может предоставлять возможность диверсификации семантики команд. Например, команда на пользовательском языке байт-кода (например, на пользовательскую ISA) может быть любой последовательностью заранее определенного набора микроопераций. Для MSIL набор микроопераций в настоящий момент включает в себя проверяемые команды MSIL и многие дополнительные команды для того, чтобы (i) передавать метаинформацию, требуемую для надлежащего выполнения, и (ii) активировать дополнительные признаки, такие как изменение семантики (подробнее описанное ниже).
Это можно сравнить с понятием микроопераций (µops) в микроархитектуре P6. Каждая команда IA32 транслируется в последовательность операций (ops), которые затем выполняются конвейером. Это также можно сравнить с супероператорами. Супероператоры - это операции виртуальной машины, автоматически синтезируемые из комбинаций младших операций, чтобы избежать затрат ресурсов в расчете на операцию и уменьшить размер исполняемого кода.
Примерный способ может включать в себя предоставление заглушек, чтобы эмулировать каждую из микроопераций, и они могут быть конкатенированы, чтобы эмулировать более выразительные команды на пользовательском языке байт-кода (например, пользовательской ISA), при этом многие функции эмуляции могут в значительной степени базироваться на отражении.
Рассмотрим пример, используя следующие команды MSIL (сложение, загрузка аргумента и загрузка константы) и их заглушки эмуляции (которые упрощены):
Idarg Int32:
EvaluationStack.Push (
ArgsIn.Peek(getArgSpec(insNr) );
Idc Int32:
EvaluationStack.Push (
getInt32Spec(insNr));
add:
EvaluationStack.Push (
(Int32)EvaluationStack.Pop() +
(Int32)EvaluationStack.Pop());
Допустим, что во время фазы выбора команды мы хотим создать пользовательскую команду байт-кода со следующей семантикой:
CustomIns n i: загрузить n-й аргумент, загрузить константу i и сложить эти два значения.
Эта команда затем назначается case-выражению (к примеру, 1) в большом switch-выражении. Case-выражение является конкатенацией различных заглушек эмуляции микроопераций:
switch(insNr) {
…
case 1:
//Конкатенация заглушек
break;
}
Относительно защиты от несанкционированного вмешательства, отсутствие сведений о семантике команды усложняет понимание программы, в противоположность наличию руководства, в котором указана семантика. Чтобы перейти на один уровень далее, пользовательская ISA защиты от несанкционированного вмешательства может выбрать семантику команды как придерживающуюся некоторого принципа(ов) проектирования.
Ссылаясь снова на фиг. 9, условное выполнение 512 может использоваться, необязательно совместно с предикатными регистрами 513, чтобы повысить степень защиты от несанкционированного вмешательства. Условное выполнение может дополнительно способствовать объединению немного отличающихся фрагментов кода. При наличии условного выполнения командам могут предшествовать предикативные регистры. Если предикативному регистру присвоено значение "ложный", команда интерпретируется как пустая команда (отсутствие операции), иначе команда эмулируется. Используя этот подход, регистры устанавливаются на или вдоль других выполняемых ветвей, чтобы иметь возможность выполнить немного отличающиеся фрагменты кода.
Примерный способ может включать в себя предоставление последовательностей кода a, b, c и a, d, c в двух различных контекстах в исходной программе и последующее "объединение" кода в a, [p1]b, [p2]d, c, где p1 присвоено значение "истинный", а p2 присвоено значение "ложный", чтобы выполнить код в первом контексте и, наоборот, чтобы выполнить код во втором контексте. В результате настройки одного или более предикативных регистров по-разному, различные фрагменты кода могут быть выполнены (например, a, b, пустая команда, c и a, пустая команда, d, c).
Ограниченный набор 514 команд может использоваться, чтобы повысить степень защиты от несанкционированного вмешательства. Например, в пользовательской ISA могут отсутствовать пустые команды 515, она может ограничивать представимые операнды 516 и/или исключать, по меньшей мере, некоторые условные ветви 517. Другой подход может приспособить пользовательскую VM к конкретной программе(ам); таким образом, примерный подход может гарантировать, что VM может только эмулировать операции, которые требуются в соответствии с этой программой.
Ссылаясь снова на пользовательскую ISA без пустых команд 515, этот подход учитывает общую методику атаки, которая удаляет "нежелательные" функциональные возможности (например, проверка лицензии или уменьшение здоровья раненного персонажа игры) посредством записывания поверх таких функциональных возможностей пустых команд. Во многих случаях едва ли есть причина включать пустую команду в пользовательскую ISA, а отсутствие этой команды усложнит попытку атакующего дополнить нежелательный код.
Относительно ограничения представимых операндов 516, статистические данные показывают, что, например, из целочисленных литералов приблизительно из 600 программ Java™ (в совокупности 1,4 миллиона строк) 80% находятся между 0-99, 95% находятся между 0 и 999, и 92% являются степенями двух или степенями двух плюс или минус 1. Таким образом, примерная пользовательская ISA может ограничить число представимых операндов, снова ограничивая свободу атаки.
Другой примерный подход может изменять или ограничивать использование, по меньшей мере, некоторых условных ветвей 517. Например, обычно есть две версии для каждого условия: "ветвление, если условие установлено, и ветвление, если условие не установлено". Так как использование двух ветвей избыточно, пользовательская ISA может включить код перезаписи так, чтобы только одна версия использовалась, а ее ответная часть не включалась в ISA. Эта примерная методика может быть полезной, например, когда проверка лицензии ветвится в зависимости от условий согласно допустимости регистрационного номера: она предотвратит простое инвертирование условия ветвления посредством атакующего.
Фиг. 10 иллюстрирует блок 520 кодирования команд по фиг. 5 с различными аспектами кодирования команд, которые могут быть использованы для диверсификации. Более конкретно, аспекты включают в себя переменные размеры 522 команд, унарное кодирование для физического совмещения 524, нелокальную семантику 526 и перераспределение структуры 529 декодирования.
После того как семантика команд определена, существует потребность в том, чтобы определить кодирование кодом операций для этих команд. Размер всех кодов операций для традиционных архитектур обычно является постоянным или только немного переменным. Например, коды операций MSIL обычно составляют один байт, со значением перехода (0xfe), чтобы предоставить двухбайтные коды операций для менее частых команд. Ограниченная вариативность облегчает быстрый поиск через табличную интерпретацию. Тем не менее, обобщая, любой префиксный код (ни одно из кодовых слов не является префиксом любого другого кодового слова) предусматривает однозначную интерпретацию.
В своей самой общей форме, декодирование кодов операций к семантике может выполняться через пересечение двоичного дерева. Декодирование обычно начинается в корневом узле; когда 0 бит считан, выполняется перемещение к левому дочернему узлу; когда 1 бит считан, выполняется перемещение к правому дочернему узлу. Когда концевой узел достигнут, код операции успешно декодирован (например, рассмотрим концевой узел, который содержит ссылку на case-выражение, эмулирующее семантику команд).
Если пользовательская ISA позволяет произвольные размеры кодов операций без запрещенных кодов операций, число возможных кодирований для n команд задается следующим уравнением:
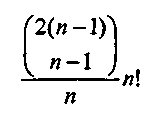 (3)
(3)
В уравнении 3 дробь представляет число плоских двоичных деревьев с n листьями (число Каталана), в то время как факториал представляет назначение кодов операций листьям. Если фиксированные размеры кодов операций выбраны с самым коротким возможным кодированием, то есть log2(n) битов, это может вводить запрещенные коды операций. В этом случае, число возможных кодирований задается следующим представлением (уравнение 4):
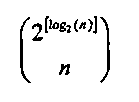 (4)
(4)
Еще много возможностей возникает, если пользовательская ISA разрешает запрещенные коды операций по причинам, отличным от минимального фиксированного размера кодов операций. Тем не менее, это может увеличить размер двоичного кода, записанного в пользовательской ISA, не предлагая преимуществ.
В различных примерах, представленных в данном документе, направленных на инфраструктуру.NET™ (например, MSIL), могут поддерживаться следующие режимы: (i) коды операций фиксированной длины с табличным поиском; (ii) многоуровневое табличное кодирование, чтобы обеспечить немного варьирующиеся размеры команд (коды перехода используются для более длинных кодов операций), и (iii) коды операций произвольной длины с пересечением двоичного дерева для декодирования. Эти режимы можно применять к другим инфраструктурам надлежащим образом.
Относительно защиты от несанкционированного вмешательства, так же отсутствие сведений по отображению битовых последовательностей на семантику представляет кривую изучения для атакующего, например, по сравнению с наличием такой информации в руководстве. Ряд дополнительных подходов существует для того, чтобы выбрать отображение таким образом, чтобы оно учитывало свойства защиты от несанкционированного вмешательства.
Как уже упоминалось, блок 520 кодирования команд по фиг. 10 включает в себя подход 522 переменного размера команд. Например, пользовательская ISA может водить даже большее варьирование в длину кодов операций, чем разрешено в двоичном коде CISC. Переменные размеры команд также могут использоваться для того, чтобы сделать локальные изменения более сложными. Вообще, старшая команда не может просто заменить младшую команду, потому что она перезапишет следующую команду. Пользовательская ISA также может гарантировать, что младшие команды без передачи управления не могут заменить старшие команды. Например, это может быть достигнуто посредством обеспечения того, что такие команды не могут быть дополнены, чтобы позволить потоку команд управления перейти к следующей команде.
Рассмотрим код или ISA с 64 командами, где каждой из команд может быть назначен уникальный размер в диапазоне битов (например, приблизительно от 64 битов до приблизительно 127 битов). Очевидно, что старшие команды не умещаются в пространство младших команд. Дополнительно, младшие команды умещаются в пространство старших команд. Все же, когда управление передается следующему биту, нет доступных команд для того, чтобы дополнить оставшиеся биты пустыми командами, чтобы обеспечить то, что управление переходит к следующей команде. Следовательно, согласно этой схеме полезно делать команды передачи управления самыми длинными, чтобы не допустить перехода атакующего в другую позицию, где он может делать то, что хочет.
Блок 520 кодирования команд также включает в себя подход 524 унарного кодирования, чтобы добиться, например, физического совмещения. Подход унарного кодирования может усложнять программу за счет увеличения или максимизации физического совмещения. Например, такой подход может иметь возможность "перепрыгнуть" в середину другой команды и начать декодирование другой команды. Этот подход может быть упрощен посредством выбора оптимального кодирования. Например, унарное кодирование может использоваться для того, чтобы закодировать коды операций (0, 01, 001,..., 0631). В этом примере есть хороший шанс, что будет найдена другая команда при перепрыгивании на один бит после начала команды:
1: add (сложение)
01: mul (умножение)
001: sub (вычитание)
0001: div (деление)
Выше четырем командам назначен код операции с помощью унарного кодирования. В этом примере, если декодирование начинается со второго бита команды деления (div), открывается команда вычитания (sub). Аналогично, рассматривая последний бит деления, команда вычитания и умножения (mul) раскрывает команду сложения.
Другой подход для пользовательской ISA, связанный с кодированием команд, использует нелокальную семантику 526. Наличие уникального языка байт-кодов для каждой распространяемой копии воздвигает существенный барьер против атакующих.
Вообще, для ISA нет доступной документации по: (i) отображению битовых комбинаций на команды; (ii) семантике команд; (iii) отображению битовых комбинаций на операнды; (iv) представлению структур данных; и т.д. Тем не менее, такие отображения или представления в конечном счете могут быть изучены атакующим через статический или динамический анализ. Чтобы предотвращать атаки, пользовательская ISA может использовать нелокальную семантику 524 для того, чтобы обеспечить, что битовая комбинация имеет различное значение вдоль различных выполняемых ветвей.
Программа в двоичном представлении - это последовательность только 1 и 0, которым дается смысл процессором. Значение между битовыми комбинациями и интерпретацией обычно фиксируется ISA. В традиционных архитектурах, если код операции определенной команды представлен заданной битовой комбинацией, эта комбинация является постоянной для всех двоичных кодов во всех местах. Пользовательская ISA может сделать любую конкретную битовую комбинацию переменной, при этом не все битовые комбинации команд должны быть сделаны переменными, чтобы воздвигнуть существенный барьер против атаки. Следовательно, блок 526 нелокальной семантики включает в себя блок 527 переменной битовой комбинации, например, для кода операции команды.
В пользовательской ISA битовой комбинации может назначаться смысл только в зависимости от ранее выполненного кода. Чтобы сделать интерпретацию зависимой от ранее выполненного кода, в зависимости от (полностью указанного) ввода, пользовательская ISA может разрешить переход к точке программы по другим выполняемым ветвям. Тем не менее, такая пользовательская ISA по-прежнему может захотеть управлять интерпретацией битов в данной точке программы. Чтобы приспособить эту вариативность, пользовательская ISA может сделать изменения интерпретации явными, а не неявными в качестве побочного эффекта какого-либо другого события. Следовательно, блок 526 нелокальной семантики включает в себя подход с блоком 528 битовых комбинаций, например, чтобы назначать смысл на основе предшествующего выполнения кода. Дополнительно, блок 526 нелокальной семантики связывается с изменениями интерпретации, явными в пользовательской ISA, например, чтобы переходить к точке программы вдоль других выполняемых ветвей.
Примерный способ включает в себя формирование диверсифицированных копий программы с помощью кодирования команд, чтобы перераспределить структуру декодирования, чтобы таким образом разрешить переход к точке в программе вдоль двух или более выполняемых ветвей, при этом назначенный смысл битовой комбинации в точке зависит от выполняемой ветви до точки. Например, этот способ может назначать смысл на основе предшествующего выполнения кода, которое может отличаться для различных выполняемых ветвей.
Пользовательская ISA может стремиться не ограничивать сложность относительно получения среды выполнения в конкретном состоянии интерпретации. Другими словами, такой подход может обеспечивать то, что если переход к точке программы из различных выполняемых ветвей в различных состояниях интерпретации разрешен, может быть относительно просто мигрировать в одно целевое состояние интерпретации независимо от того, какими могут быть различные состояния интерпретации.
Конкретный подход влечет за собой перераспределение структуры 529. Например, изменение интерпретации может быть эквивалентным именно перераспределению дерева декодирования. Принимая во внимание предыдущие наблюдения, пользовательская ISA может разрешать только ограниченную форму диверсификации. С этой целью, у пользовательской ISA может быть выбранный уровень, на котором могут быть перемещены поддеревья (или другие подструктуры). Такой вариант является компромиссом между тем, сколько различных интерпретаций возможно, и насколько просто перейти к фиксируемой интерпретации из набора возможно отличающихся состояний интерпретации.
В примере рассмотрим выбор третьего уровня структуры дерева. Предположим, что самый короткий код операции составляет 3 бита, это дает 8! состояний интерпретации, при этом любое состояние интерпретации достижимо самое большее за 8 микроопераций. Такой подход может быть применен к набору микроопераций MSIL. Например, рассмотрим следующие микрооперации:
Swap(UInt3 position1, UInt3 position2), которая меняет местами узлы в положении position1 и position2, и
Set(UInt3 label, UInt3 position), которая меняет местами узел с меткой (везде, где это возможно) и узел в положении position.
В случае табличной интерпретации это реализуется как табличная интерпретация с двумя уровнями. Первый уровень может ссылаться на другие таблицы, которые могут быть переставлены.
В вышеприведенном примере микрооперации в значительной степени соответствуют командам MSIL, а типы операнда в значительной степени соответствуют типам операндов MSIL. Заглушки эмуляции микроопераций, которые используют операнды, используют вызовы функции для обеспечения того, что кодирование кодов операций могло диверсифицироваться ортогонально. Такие обратные вызовы, помимо прочего, передают аргумент insNr, идентифицирующий пользовательскую команду VM, из которой он вызван (см., например, пример семантики 510 команд). Это дает возможность кодирования операндов по-разному для различных пользовательских команд VM. Отметим, что из-за конкатенации заглушек произвольное число операндов может следовать коду операции. Таким образом, подход для кодирования 530 операнда может включать в себя эти методики. Следовательно, аналогичные подходы для диверсификации кодирования кодов операций могут быть сделаны в отношении кодирования команд.
Диверсификация цикла выборки может считаться "искусственной" формой диверсификации. Фиг. 11 иллюстрирует блок 540 цикла выборки как включающий в себя различные подходы, которые используют "фильтры" 542. Основной "непользовательский" цикл выборки просто получает ряд битов от пользовательского двоичного кода байт-кода, в зависимости от текущего программного счетчика (PC). Тем не менее, использование одного или более фильтров 542 предусматривает пользовательский цикл выборки, что повышает степень защиты от несанкционированного вмешательства. Такой фильтр или фильтры могут преобразовывать фактические биты в двоичном коде в биты, которые будут интерпретироваться посредством VM.
Фильтры 542 цикла выборки могут добавлять сложность посредством комбинирования одного или более запрошенных битов с другой информацией. Например, фактически запрошенные биты могут быть комбинированы с другими частями программы 543. Таким образом, программа становится более взаимозависимой, поскольку изменение одной части программы может также влиять на другие части. Другие подходы фильтров включают в себя фильтр, который комбинирует один или более битов со случайным значением 544 (к примеру, извлеченным из секретного ключа), и фильтр, который комбинирует один или более битов с программным счетчиком (PC) 545, чтобы усложнить методики сопоставления комбинаций.
Наиболее традиционным представлением кода является линейная последовательность байтов. При таком подходе программный счетчик (PC) просто указывает на следующий байт для выполнения, и передачи управления в типичном варианте определяют байт, с которого продолжать выполнение, как относительное смещение или абсолютный адрес. Это, по существу, может рассматриваться как структура, которая представляет код как массив байтов.
Фиг. 12 иллюстрирует программный счетчик и блок 550 представления программы, наряду с различными структурными подходами, включая массив 553, дерево 554, связный список 555 и хэш-таблицу 556. Пользовательская ISA может представлять код как расходящееся дерево, к примеру, расходящиеся деревья 1320 и 1330 по фиг. 13. Хотя код может быть представлен как расходящееся дерево, примерный подход для пользовательской ISA альтернативно или дополнительно может представлять данные в расходящемся дереве или другой выбранной структуре, чтобы повысить уровень безопасности. В общем, такие подходы могут предусматривать более легкую диверсификацию, чем традиционное линейное представление (см., например, линейный подход 1310 по фиг. 13).
У расходящихся деревьев есть ряд преимуществ. Они являются самоуравновешивающимися, что дает возможность автоматического перемещения кода. Кроме того, они почти оптимальны в отношении амортизированной стоимости для произвольных последовательностей. Наконец, недавно вызванные узлы имеют тенденцию быть около корня дерева, что дает возможность частичного усиления пространственной и временной локализации, существующей в большинстве исполняемых кодов.
Из-за свойства самоуравновешивания фрагмент кода может быть во многих различных ячейках памяти, в зависимости от выполняемой ветви, которая привела к конкретному фрагменту кода. Фрагменты кода могут перемещаться до тех пор, пока есть способ ссылаться на них для передач потока команд управления, и так, чтобы они могли быть извлечены, когда управление передано им. Примерный структурный подход использует ключи узлов в расходящемся дереве, где передачи управления указывают ключ узла, к которому должно быть передано управление. В таком примере требуется, чтобы целевыми объектами потока элемента управления были узлы (т.е. невозможно легко перепрыгнуть в середину кода, содержавшегося в рамках узла). На практике это означает, что выполнение запускает новый узел для каждого базового блока. Пути передачи управления могут быть обработаны посредством задания всего потока команд управления явным. В этом примере все целевым объекты потока команд управления могут быть указаны как ключи узла, содержащего объектный код. Дополнительно, размер кода в узле может быть постоянным. Еще дополнительно, если узел является слишком маленьким для того, чтобы содержать весь базовый блок, он может выйти за пределы к другому узлу и продолжить выполнение там.
Фиг. 13 иллюстрирует примерный подход использования расходящихся деревьев 1320, 1330 для данного линейного подхода 1310 для функции факториала Fac. Когда, например, функция Fac вызывается первый раз, узел с ключом 1 указывается ссылкой и просачивается к корню, как показано в части (2). Еще одной вещью, которую стоит отметить в этом примере, является то, что вызовы больше не должны указывать функциональную подпись, поскольку этот код не подлежит верификации.
Если данная методика реализуется в простом варианте, то только указатели перемещаются, и фактический код останется в том же самом месте "кучи". Чтобы дополнительно усложнить это, явный обмен фактическим содержимым (примитивных типов) узлов может выполняться, или альтернативно, выделение нового кодового буфера может осуществляться наряду с копированием кодового буфера в выделенное пространство, возможно с повторным кодированием и/или с другим дополнением "мусором".
Ссылаясь снова на характеристики 500 инфраструктуры по фиг. 7, примерные подходы могут применяться к реализации 560 VM. Некоторые подходы показаны на фиг. 12. Для данной внутренней реализации стек оценки не определяется на основе ISA (например, рассмотрим компоненты 505). В этом примере заглушки эмуляции для микроопераций могут базироваться только на интерфейсе, который поддерживает многие операции, например, pop и push. Примерный подход для внутренней реализации структуры 562 данных стека представляет независимую диверсификацию, например, через массив, связный список и т.д. Примерный подход необязательно может предоставлять ряд различных реализаций таких интерфейсов.
Другой подход стремится диверсифицировать формирование 564 VM. Например, как только параметры для вышеупомянутых указанных форм диверсификации полностью заданы, примерная серверная обработка может комбинировать кодовые фрагменты из различных местоположений с некоторым автоматически сгенерированным кодом, чтобы ассемблировать управляемое представление C# для реализации пользовательской VM. Альтернативно, примерная серверная обработка может выводить непосредственно DLL.
Другой примерный подход влечет за собой диверсификацию DLL 566, например, с помощью рандомизированных версий существующих преобразований кода из различных областей, например, оптимизации программного обеспечения, маскировки структуры программного обеспечения, диверсификации программного обеспечения (подходы не на основе виртуализации) и т.д.
Хотя различные примерные методики, поясненные в данном документе, в общем, представляют некоторые дополнительные затраты, в которые включается цифровое управление правами, секретная информация (например, государственная тайна, секреты фирмы и т.д.), лицензии, и т.д., то эти дополнительные затраты могут быть допущены при условии повышенного уровня безопасности, вводимого через диверсификацию. В таких случаях методики диверсификации можно применять к типичным целевым областям и не применять к признакам среды выполнения, которые требуют определенной степени одновременного выполнения или выполнения "в реальном времени". Например, диверсификация может быть применена к коду, ассоциативно связанному с цифровым управлением правами, а не к ассоциативно связанному коду, который требует некоторой формы подтверждения цифровых прав до выполнения.
Виртуализация раскрывает широкий диапазон возможностей и для диверсификации, и для защиты от несанкционированного вмешательства. Управление средой выполнения предоставляет существенные рычаги, чтобы усложнить задачу атакующего. Хотя различные примеры ссылаются на конкретную инфраструктуру для защиты программного обеспечения на основе концепции виртуализации, различные подходы также идентифицированы, в которых диверсификация и/или признаки защиты от несанкционированного вмешательства могут быть введены большей частью независимым способом. Может быть использована модульная разработка и/или развертывание.
Фиг. 15 иллюстрирует примерное вычислительное устройство 1500, которое может использоваться для того, чтобы реализовать различные примерные компоненты, а также в формировании примерной системы. Например, серверы и клиенты системы по фиг. 1 могут включать в себя различные признаки устройства 1500.
В своей самой базовой конфигурации вычислительное устройство 1500 в типичном варианте включает в себя, по меньшей мере, один блок 1502 обработки и системную память 1504. В зависимости от точной конфигурации и типа вычислительного устройства, системную память 1504 может быть энергозависимой (например, RAM), энергонезависимой (например, ROM, флэш-память и т.д.) или какой-либо комбинацией двух этих вариантов. Системная память 1504 обычно включает в себя операционную систему 1505, один или более программных модулей 806 и может включать в себя программные данные 1507. Операционная система 1506 включает в себя основанную на компоненте инфраструктуру 1520, которая поддерживает компоненты (включая свойства и события), объекты, наследование, полиморфизм, отражение и предоставляет объектно-ориентированный основанный на компонентах интерфейс прикладного программирования (API), например, интерфейс.NET™ Framework, созданный Microsoft Corporation, Редмонд, Вашингтон. Операционная система 1505 также включает в себя примерную инфраструктуру 1600, например, но не только, примерную инфраструктуру с пользовательской ISA и/или пользовательской VM. Далее, вычислительное устройство 1500 может включать в себя программный модуль для формирования пользовательской ISA и/или пользовательской VM. Еще дополнительно, вычислительное устройство 1500 может включать в себя программный модуль для тестирования пользовательской ISA и/или пользовательской VM. Вычислительное устройство 1500 может включать в себя программный модуль для формирования пользовательского кода и/или пользовательской VM, чтобы, по меньшей мере, частично выполнять пользовательский код. Устройство 1500 имеет самую базовую конфигурацию, разграниченную пунктирной линией 1508. Так же, терминал может иметь меньше компонентов, но будет взаимодействовать с вычислительным устройством, у которого может быть такая базовая конфигурация.
Вычислительное устройство 1500 может иметь дополнительные признаки или функциональность. Например, вычислительное устройство 1500 также может включать в себя дополнительные устройства хранения (съемные и/или несъемные), такие как, например, магнитные диски, оптические диски или лента. Такое дополнительное хранилище проиллюстрировано на фиг. 15 посредством съемного хранилища 1509 и несъемного хранилища 1510. Компьютерные носители хранения могут включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией хранения информации, такой как компьютерночитаемые команды, структуры данных, программные модули или другие данные. Системная память 1504, съемное хранилище 1509 и несъемное хранилище 1510 являются примерами компьютерных носителей хранения. Компьютерные носители хранения включают в себя, но не только, RAM, ROM, EEPROM, флэш-память или другую технологию памяти, CD-ROM, универсальные цифровые диски (DVD) или другое оптическое хранилище, магнитные кассеты, магнитную ленту, хранилища на магнитных дисках или другие магнитные устройства хранения, либо любой другой носитель, который может быть использован, чтобы хранить требуемую информацию, и к которому может осуществлять доступ вычислительное устройство 1500. Любые такие компьютерные носители хранения могут быть частью устройства 1500. Вычислительное устройство 1500 также может иметь устройство(а) 1512 ввода, такое как клавиатура, мышь, перо, устройство речевого ввода, устройство сенсорного ввода и т.д. Устройство(а) 1514 вывода, такое как дисплей, громкоговорители, принтер и т.д., также может быть включено. Эти устройства хорошо известны в данной области техники, и нет необходимости подробно пояснять их в данном документе.
Вычислительное 1500 устройство также может содержать соединения 1516 связи, которые позволяют устройству обмениваться данными с другими вычислительными устройствами 1518, например, по сети (например, рассмотрим вышеупомянутую веб- или Интернет-сеть 103). Соединения 1516 связи являются одним примером среды связи. Среда связи в типичном варианте может воплощать компьютерночитаемые команды, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущая волна или другой транспортный механизм, и включает в себя любую среду для доставки информации. Термин "модулированный сигнал данных" означает сигнал, который имеет одну или более из его характеристик, установленных или измененных таким образом, чтобы кодировать информацию в сигнале. Для примера, но не в качестве ограничения, среда связи включает в себя проводную среду, такую как проводная сеть или прямое проводное соединение, и беспроводную среду, такую как акустическая среда, радиочастотная, инфракрасная и другая беспроводная среда. Термин "компьютерночитаемые носители" при использовании в данном документе включает в себя как носители хранения, так и среды связи.
Хотя предмет изобретения описан на языке, характерном для структурных признаков и/или методологических действий, следует понимать, что предмет изобретения, заданный в прилагаемой формуле изобретения, не обязательно ограничен характерными признаками или действиями, описанными выше. Скорее, характерные признаки и действия, описанные выше, раскрываются как примерные формы реализации формулы изобретения.


Изобретение относится к области защиты программного обеспечения от несанкционированного вмешательства. Техническим результатом является улучшение защиты программного обеспечения. Компьютерно-реализуемый способ включает в себя предоставление архитектуры набора команд (ISA), которая содержит признаки для формирования диверсифицированных копий программы, использование архитектуры набора команд для формирования диверсифицированных копий программы и предоставление виртуальной машины для выполнения одной из диверсифицированных копий программы. Различные примерные способы, устройства, системы и т.д. используют виртуализацию для диверсификации кода и/или виртуальных машин, чтобы таким образом повысить уровень безопасности программного обеспечения. 3 н. и 7 з.п. ф-лы, 15 ил.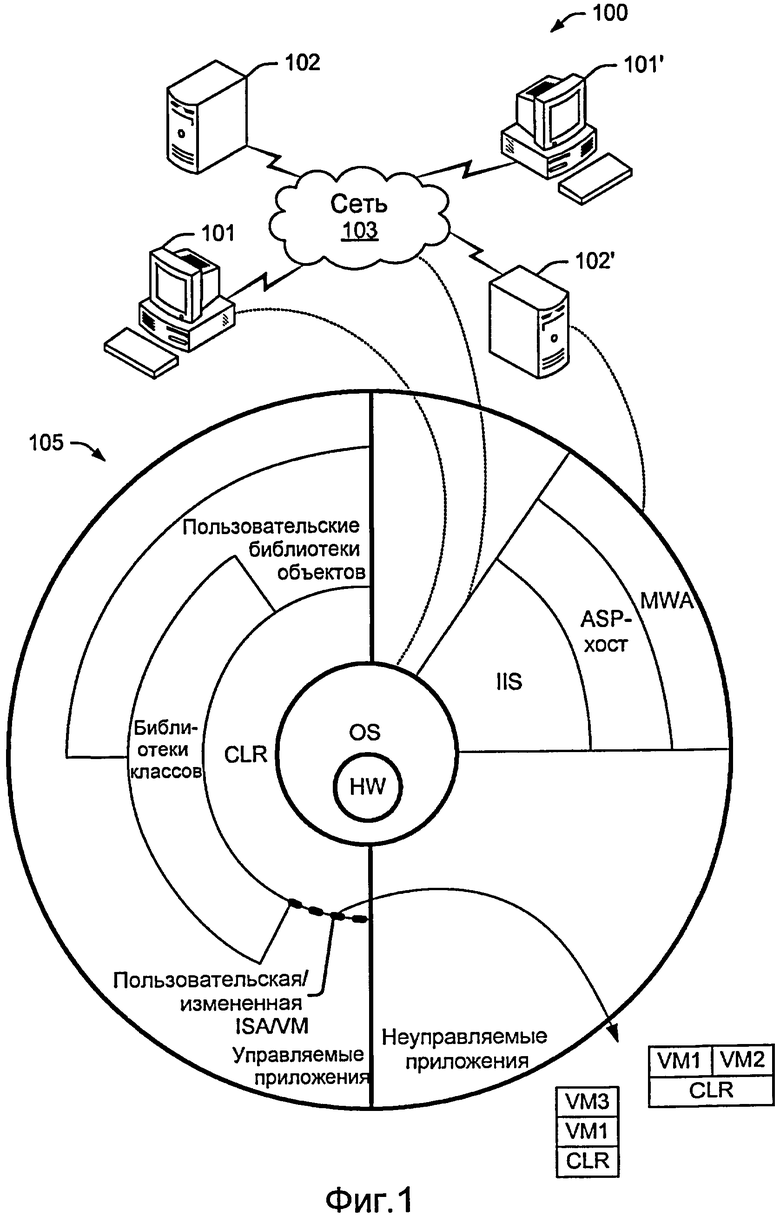
1. Компьютерно реализуемый способ диверсификации кода, содержащий этапы, на которых:
предоставляют архитектуру набора команд, которая включает в себя признаки для формирования диверсифицированных копий программы, которая задает виртуальную машину;
используют эту архитектуру набора команд для формирования диверсифицированных копий программы, при этом каждая диверсифицированная копия программы формируется таким образом, чтобы она предназначалась для ассоциированной модифицированной версии виртуальной машины; и
формируют ассоциированную модифицированную версию виртуальной машины для исполнения одной из диверсифицированных копий программы.
2. Способ по п.1, в котором при формировании ассоциированной модифицированной версии виртуальной машины формируют динамически подключаемую библиотеку (DLL) виртуальной машины.
3. Способ по п.1, в котором признаки для формирования диверсифицированных копий программы содержат семантику команд, которая предусматривает условное исполнение, используя предикативные регистры.
4. Способ по п.1, в котором признаки для формирования диверсифицированных копий программы содержат семантику команд с ограниченным набором команд, причем, в необязательном порядке, ограниченный набор команд не включает в себя команду "пустая операция", причем, в необязательном порядке, ограниченный набор команд имеет ограниченное представление операндов и причем, в необязательном порядке, ограниченный набор команд ограничивает, по меньшей мере, некоторые условные ветвления.
5. Способ по п.1, в котором признаки для формирования диверсифицированных копий программы содержат кодирование команд для переменных размеров команд, причем, в необязательном порядке, признаки для формирования диверсифицированных копий программы содержат кодирование команд для назначения кода операций с помощью унарного кодирования, чтобы представлять физическое совмещение, причем, в необязательном порядке, признаки для формирования диверсифицированных копий программы содержат кодирование команд для того, чтобы представить переменную битовую комбинацию для кода операции для команды, причем, в необязательном порядке, признаки для формирования диверсифицированных копий программы содержат кодирование команд для того, чтобы назначать битовую комбинацию на основе предшествующего исполнения кода операции, и причем, в необязательном порядке, признаки для формирования диверсифицированных копий программы содержат кодирование команд для того, чтобы перераспределить структуру декодирования, чтобы таким образом разрешить переход к точке в программе по двум или больше путям исполнения, при этом назначаемое смысловое значение битовой комбинации в точке зависит от пути исполнения до точки.
6. Способ по п.1, в котором признаки для формирования диверсифицированных копий программы содержат один или более фильтров цикла выборки, причем, в необязательном порядке, один или более фильтров цикла выборки содержат фильтр, который добавляет информацию к запрошенному биту или битам кода, причем, в необязательном порядке, эта информация содержит случайное значение, причем, в необязательном порядке, эта информация содержит значение программного счетчика или информацию, основывающуюся по меньшей мере частично на значении программного счетчика.
7. Способ по п.1, в котором признаки для формирования диверсифицированных копий программы содержат по меньшей мере одну структуру, выбранную из группы, состоящей из расходящихся деревьев, связных списков и хэш-таблиц, чтобы представлять эту программу.
8. Компьютерно реализуемый способ диверсификации кода, содержащий этапы, на которых:
анализируют код для определения виртуальной машины, для которой предназначен этот код;
модифицируют виртуальную машину для получения модифицированной виртуальной машины;
формируют диверсифицированную виртуальную машину, которая основывается по меньшей мере частично на модифицированной виртуальной машине;
формируют диверсифицированный код, который предназначен для диверсифицированной виртуальной машины и основывается по меньшей мере частично на упомянутом коде; и
исполняют диверсифицированный код с использованием диверсифицированной виртуальной машины.
9. Способ повышения уровня защиты программного обеспечения, содержащий этапы, на которых:
предоставляют базовую виртуальную машину, которая виртуализирует операционную систему, которая управляет аппаратными средствами;
принимают программу, которая задает целевую виртуальную машину;
модифицируют эту программу, чтобы создать диверсифицированную копию данной программы, которая предназначена для модифицированной версии целевой виртуальной машины;
предоставляют эту диверсифицированную копию программы пользовательской виртуальной машине, которая виртуализирует набор команд базовой виртуальной машины, при этом модифицированная версия целевой виртуальной машины основывается на пользовательской виртуальной машине; и
исполняют диверсифицированную копию программы посредством пользовательской виртуальной машины.
10. Способ по п.9, дополнительно содержащий этапы, на которых:
формируют индивидуализированные копии программного кода и предоставляют виртуальную машину для исполнения индивидуализированной копии программного кода, при этом виртуальная машина может изменять работу программы в процессе исполнения.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| RU 2004128233 A, 10.03.2006. | |||

