Область техники, к которой относится изобретение
Настоящее изобретение относится к устройству векторного квантования, устройству векторного деквантования и способам квантования и деквантования для выполнения векторного квантования параметров LSP (линейных спектральных пар). В частности, настоящее изобретение относится к устройству векторного квантования, способу векторного деквантования и способам квантования и деквантования для выполнения векторного квантования параметров LSP, используемых в устройстве кодирования и декодирования речи, которое передает речевые сигналы в областях системы пакетной связи, представленной межсетевой связью, системы мобильной связи и т.д.
Обзор состояния техники
В области цифровой беспроводной связи, пакетной связи, представленной межсетевой связью и устройством хранения речи, методы кодирования и декодирования речевых сигналов имеют существенное значение для эффективного использования пропускной способности канала связи и средств хранения для радиоволн. В частности, базовым методом является метод кодирования и декодирования речи CELP (линейное предсказание с кодовым возбуждением).
Устройство CELP-кодирования речи кодирует входной речевой сигнал на основании предварительно сохраненных моделей речи. Конкретнее, устройство CELP-кодирования речи делит цифровой речевой сигнал на кадры с регулярными временными интервалами, например, кадры, приблизительно, от 10 до 20 мс, выполняет покадровый анализ речевого сигнала с линейным предсказанием, находит коэффициенты линейного предсказания («LPC´s») и остаточный вектор линейного предсказания и отдельно кодирует коэффициенты линейного предсказания и остаточный вектор линейного предсказания. В качестве способа кодирования коэффициентов линейного предсказания, обычно, преобразование коэффициентов линейного предсказания в параметры LSP и кодирование этих параметров LSP. Кроме того, в качестве способа кодирования параметров LSP часто применяют векторное квантование, выполняемое для параметров LSP. В данном случае, векторное квантование является способом выбора кодового вектора, максимально подобного вектору, являющемуся объектом квантования, из кодовой книги, содержащей множество репрезентативных векторов (т.е. кодовых векторов), и вывода индекса (кода), присвоенного выбранному кодовому вектору, в качестве результата квантования. При векторном квантовании размер кодовой книги определяют на основании количества информации, которая доступна. Например, когда векторное квантование выполняют с использованием количества информации, равного 8 битам, кодовую книгу можно сформировать с использованием 256 (=28) типов кодовых векторов.
Кроме того, чтобы сократить количество информации и объем вычислений при векторном квантовании, применяют различные методы, например многоступенчатое векторное квантование (MSVQ) и расщепленное векторное квантование (SVQ) (смотри непатентный документ 1). В данном случае, многоступенчатое векторное квантование является способом однократного выполнения векторного квантования вектора и, в дальнейшем, выполнения векторного квантования ошибки квантования, и расщепленное векторное квантование является способом квантования множества расщепленных векторов, полученных расщеплением вектора.
Кроме того, существует метод выполнения векторного квантования, подходящий для признаков LSP и дополнительно повышающий эффективность кодирования LSP соответствующим переключением кодовых книг для использования с целью векторного квантования на основании признаков речи, которые коррелируются с LSP´s, объекта квантования (например, информацией о вокализированной характеристике, невокализированной характеристике и режиме речи). Например, при масштабируемом кодировании, при использовании корреляции между широкополосными LSP´s (которые представляют собой LSP´s, получаемые из широкополосных сигналов) и узкополосными LSP´s (которые представляют собой LSP´s, получаемые из узкополосных сигналов), классификации узкополосных LSP´s по их признакам и переключении кодовых книг на первой ступени многоступенчатого векторного квантования на основании типов признаков узкополосных LSP´s (далее сокращенно именуемых «типами узкополосных LSP´s»), широкополосные LSP´s подвергают векторному квантованию (смотри патентный документ 1).
Непатентный документ 1: Allen Gersho, Robert M. Gray, в переводе Йосии и трех других переводчиков, «Vector Quantization and Information Compression», Corona Publishing Co., Ltd, 10 ноября 1998, страницы 524-531.
Патентный документ 1: Международная публикация №2006/030865.
Сущность изобретения
Задачи изобретения
При многоступенчатом векторном квантовании, описанном в патентном документе 1, векторное квантование на первой ступени выполняется с использованием кодовых книг, соответствующих типам узкополосных LSP´s, и поэтому дисперсия ошибок квантования при векторном квантовании на первой ступени изменяется от типа к типу узкополосных LSP´s. Однако на второй или последующей ступени применяется единственная общая кодовая книга, независимо от типов узкополосных LSP´s, и поэтому возникает проблема с тем, что точность векторного квантования на второй или последующей ступени является недостаточной.
Принимая во внимание вышеизложенное, целью настоящего изобретения является создание устройства векторного квантования, устройства векторного деквантования и способов квантования и деквантования для повышения точности квантования при векторном квантовании на второй или последующей ступени, при многоступенчатом векторном квантовании, при котором кодовые книги на первой ступени переключают на основании типов признаков, скоррелированных с вектором, являющимся объектом квантования.
Средства решения проблемы
Устройство векторного квантования в соответствии с настоящим изобретением использует конфигурацию, имеющую: секцию классификации, которая генерирует классификационную информацию, указывающую тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов; секцию выбора, которая выбирает одну первую кодовую книгу, ассоциированную с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов, соответственно; первую секцию квантования, которая получает первый код квантованием вектора, являющегося объектом квантования, с использованием множества первых кодовых векторов, формирующих выбранную первую кодовую книгу; кодовую книгу масштабных коэффициентов, содержащую масштабные коэффициенты, ассоциированные с множеством типов, соответственно; и вторую секцию квантования, которая имеет вторую кодовую книгу, содержащую множество вторых кодовых векторов, и получает второй код квантованием остаточного вектора между одним первым кодовым вектором, указанным первым кодом, и вектором, являющимся объектом квантования, с использованием вторых кодовых векторов и масштабного коэффициента, ассоциированного с классификационной информацией.
Устройство векторного деквантования в соответствии с настоящим изобретением использует конфигурацию, имеющую: секцию классификации, которая генерирует классификационную информацию, указывающую тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов; секцию демультиплексирования, которая демультиплексирует первый код, который является результатом квантования вектора, являющегося объектом квантования, на первой ступени, и второй код, который является результатом квантования вектора, являющегося объектом квантования, на второй ступени, из принятых кодированных данных; секцию выбора, которая выбирает одну первую кодовую книгу, ассоциированную с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов, соответственно; первую секцию деквантования, которая выбирает один первый кодовый вектор, ассоциированный с первым кодом, из выбранной первой кодовой книги; кодовую книгу масштабных коэффициентов, содержащую масштабные коэффициенты, ассоциированные с множеством типов, соответственно; и вторую секцию деквантования, которая выбирает один второй кодовый вектор, ассоциированный с вторым кодом, из второй кодовой книги, содержащей множество вторых кодовых векторов, и получает вектор, являющийся объектом квантования, с использованием одного второго кодового вектора, масштабного коэффициента, ассоциированного с классификационной информацией, и одного первого кодового вектора.
Способ векторного квантования в соответствии с настоящим изобретением содержит этапы: генерирования классификационной информации, указывающей тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов; выбор одной первой кодовой книги, ассоциированной с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов, соответственно; получение первого кода квантованием вектора, являющегося объектом квантования, с использованием множества первых кодовых векторов, формирующих выбранную первую кодовую книгу; и получение второго кода квантованием остаточного вектора между первым кодовым вектором, ассоциированным с первым кодом, и вектором, являющимся объектом квантования, с использованием множества вторых кодовых векторов, формирующих вторую кодовую книгу, и масштабного коэффициента, ассоциированного с классификационной информацией.
Способ векторного деквантования в соответствии с настоящим изобретением содержит этапы: генерирования классификационной информации, указывающей тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов; демультиплексирование первого кода, который является результатом квантования вектора, являющегося объектом квантования, на первой ступени, и второго кода, который является результатом квантования вектора, являющегося объектом квантования, на второй ступени, из принятых кодированных данных; выбор одной первой кодовой книги, ассоциированной с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов, соответственно; выбор одного первого кодового вектора, ассоциированного с первым кодом, из выбранной первой кодовой книги; и выбор одного второго кодового вектора, ассоциированного с вторым кодом, из второй кодовой книги, содержащей множество вторых кодовых векторов, и генерирование вектора, являющегося объектом квантования, с использованием одного второго кодового вектора, масштабного коэффициента, ассоциированного с классификационной информацией, и одного первого кодового вектора.
Полезный эффект изобретения
В соответствии с настоящим изобретением, при многоступенчатом векторном квантовании, при котором кодовые книги на первой ступени переключаются на основании типов признаков, коррелированных с вектором, являющимся объектом квантования, посредством выполнения векторного квантования на второй или последующей ступени с использованием масштабных коэффициентов, ассоциированных с вышеупомянутыми типами, можно повысить точность квантования при векторном квантовании на второй или последующей ступени.
Краткое описание чертежей
Фиг.1 - блок-схема, представляющая основные компоненты устройства векторного квантования LSP в соответствии с вариантом осуществления 1;
Фиг.2 - блок-схема, представляющая основные компоненты устройства векторного деквантования LSP в соответствии с вариантом осуществления 1;
Фиг.3 - блок-схема, представляющая основные компоненты устройства векторного квантования LSP в соответствии с вариантом осуществления 2;
Фиг.4 - блок-схема, представляющая основные компоненты устройства векторного квантования LSP в соответствии с вариантом осуществления 3;
Фиг.5 - блок-схема, представляющая основные компоненты устройства векторного деквантования LSP в соответствии с вариантом осуществления 3.
Наилучший вариант осуществления изобретения
Варианты осуществления настоящего изобретения подробно поясняются ниже со ссылкой на прилагаемые чертежи. В данном случае, примерные случаи поясняются ниже с использованием устройства векторного квантования LSP, устройства векторного деквантования LSP и способов квантования и деквантования, которые являются устройством векторного квантования, устройством векторного деквантования и способами квантования и деквантования в соответствии с настоящим изобретением.
Кроме того, примерные случаи поясняются ниже на вариантах осуществления настоящего изобретения, в которых широкополосные LSP´s применяются как объект векторного квантования в квантователе широкополосных LSP для масштабируемого кодирования, и кодовые книги, используемые для квантования на первой ступени, переключаются с использованием типов узкополосных LSP´s, коррелированных с объектом векторного квантования. Кроме того, равным образом, можно переключать кодовые книги, используемые для квантования на первой ступени с использованием квантованных узкополосных LSP´s (которые являются узкополосными LSP´s, предварительно квантованными квантователем (не показанным) узкополосных LSP), вместо узкополосных LSP´s. Кроме того, равным образом, можно преобразовывать квантованные узкополосные LSP´s в широкополосный формат и переключать кодовые книги, используемые для квантования на первой ступени с использованием преобразованных квантованных узкополосных LSP´s.
Вариант осуществления 1
На фиг.1 представлена блок-схема, представляющая основные компоненты устройства 100 векторного квантования LSP в соответствии с вариантом осуществления 1 настоящего изобретения. Ниже поясняется примерный случай, в котором входной вектор LSP квантуется методом многоступенчатого векторного квантования из трех ступеней в устройстве 100 векторного квантования LSP.
Как показано на фиг.1, устройство 100 векторного квантования LSP снабжено классификатором 101, коммутатором 102, первой кодовой книгой 103, сумматором 104, секцией 105 минимизации ошибок, секцией 106 определения масштабных коэффициентов, множительным устройством 107, второй кодовой книгой 108, сумматором 109, третьей кодовой книгой 110 и сумматором 111.
Классификатор 101 предварительно сохраняет классификационную кодовую книгу, сформированную множеством единиц классификационной информации, указывающей множество типов векторов узкополосных LSP, выбирает классификационную информацию, указывающую тип вектора широкополосных LSP объекта векторного квантования из классификационной кодовой книги, и выдает классификационную информацию в коммутатор 102 и секцию 106 определения масштабных коэффициентов. Более конкретно, классификатор 101 имеет встроенную классификационную кодовую книгу, сформированную кодовыми векторами, ассоциированными с различными типами векторов узкополосных LSP, и находит кодовый вектор, чтобы минимизировать квадратическую ошибку относительно входного вектора узкополосных LSP, посредством поиска в классификационной кодовой книге. Кроме того, классификатор 101 использует индекс кодового вектора, найденного поиском, в качестве классификационной информации, указывающей тип вектора LSP.
Коммутатор 102 выбирает из первой кодовой книги 103 одну кодовую подкнигу, ассоциированную с классификационной информацией, получаемой в качестве входных данных из классификатора 101, и подключает выход кодовой подкниги к сумматору 104.
Первая кодовая книга 103 предварительно сохраняет кодовые подкниги (CBa1-CBan), соответствующие типам узкополосных LSP´s. То есть, например, когда число типов узкополосных LSP´s равно n, число кодовых подкниг, формирующих первую кодовую книгу 103, равно n. Из множества первых кодовых векторов, формирующих первую кодовую книгу, первая кодовая книга 103 выдает первые кодовые вектора, назначенные обозначением из секции 105 минимизации ошибок, в коммутатор 102.
Сумматор 104 вычисляет разности между вектором широкополосных LSP, полученным в качестве входного объекта векторного квантования, и кодовыми векторами, полученными в качестве входных данных из коммутатора 102, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве первых остаточных векторов. Кроме того, из первых остаточных векторов, соответствующих всем первым кодовым векторам, сумматор 104 выдает в множительное устройство 107 один минимальный остаточный вектор, идентифицированный поиском в секции 105 минимизации ошибок.
Секция 105 минимизации ошибок использует результаты возведения в квадрат первых остаточных векторов, полученных в виде входных данных из сумматора 104, в качестве квадратических ошибок вектора широкополосных LSP и первых кодовых векторов, и находит первый кодовый вектор, чтобы минимизировать квадратическую ошибку, посредством поиска по первой кодовой книге. Аналогично, секция 105 минимизации квадратических ошибок использует результаты возведения в квадрат вторых остаточных векторов, полученных в виде входных данных из сумматора 109, в качестве квадратических ошибок первого остаточного вектора и вторых кодовых векторов, и находит второй кодовый вектор, чтобы минимизировать квадратическую ошибку, посредством поиска по второй кодовой книге. Аналогично, секция 105 минимизации квадратических ошибок использует результаты возведения в квадрат третьих остаточных векторов, полученных в виде входных данных из сумматора 111, в качестве квадратических ошибок второго остаточного вектора и третьих кодовых векторов, и находит третий кодовый вектор, чтобы минимизировать квадратическую ошибку, посредством поиска по третьей кодовой книге. Кроме того, секция 105 минимизации ошибок совместно кодирует индексы, присвоенные трем кодовым векторам, полученным поиском, и выдает результат как кодированные данные.
Секция 106 определения масштабных коэффициентов предварительно сохраняет кодовую книгу масштабных коэффициентов, сформированную масштабными коэффициентами, соответствующими типам узкополосных LSP векторов. Кроме того, секция 106 определения масштабных коэффициентов выбирает из кодовой книги масштабных коэффициентов, масштабный коэффициент соответствующей классификационной информации, полученной как входные данные из классификатора 101, и выдает величину, обратную выбранному масштабному коэффициенту, в множительное устройство 107. В данном случае, масштабный коэффициент может быть скаляром или вектором.
Множительное устройство 107 умножает первый остаточный вектор, полученный как входные данные от сумматора 104, на величину, обратную масштабному коэффициенту, полученному как входные данные из секции 106 определения масштабных коэффициентов, и выдает результат в сумматор 109.
Вторая кодовая книга (CBb) 108 сформирована множеством вторых кодовых векторов и выдает вторые кодовые вектора, назначенные обозначением из секции 105 минимизации ошибок, в сумматор 109.
Сумматор 109 вычисляет разности между первым остаточным вектором, который получен как входные данные из множительного устройства 107 и умножен на величину, обратную масштабному коэффициенту, и вторыми кодовыми векторами, полученными как входные данные из второй кодовой книги 108, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве вторых остаточных векторов. Кроме того, из вторых остаточных векторов, соответствующих всем вторым кодовым векторам, сумматор 109 выдает в сумматор 111 один минимальный второй остаточный вектор, идентифицированный поиском в секции 105 минимизации ошибок.
Третья кодовая книга 110 (CBc) сформирована множеством третьих кодовых векторов и выдает третьи кодовые вектора, назначенные обозначением из секции 105 минимизации ошибок, в сумматор 111.
Сумматор 111 вычисляет разность между вторым остаточным вектором, полученным в качестве входных данных из сумматора 109, и третьими кодовыми векторами, полученными в качестве входных данных из третьей кодовой книги 110, и выдает данные разности в секцию 105 минимизации ошибок в качестве третьих остаточных векторов.
Ниже поясняются операции, выполняемые устройством 100 векторного квантования LSP, с использованием примерного случая, в котором порядок векторов широкополосных LSP объектов квантования представляет собой R. Кроме того, в нижеследующем пояснении, вектора широкополосных LSP будут выражены в виде «LSP(i) (i=0, 1, …, R-1)».
Классификатор 101 имеет встроенную классификационную кодовую книгу, сформированную n кодовыми векторами, соответствующими n типам векторов узкополосных LSP, и, посредством поиска кодовых векторов, находит m-ный кодовый вектор, чтобы минимизировать квадратическую ошибку относительно входного вектора узкополосных LSP. Кроме того, классификатор 101 выдает m (1 ≤ m ≤ n) в коммутатор 102 и секцию 106 определения масштабных коэффициентов, в качестве классификационной информации.
Коммутатор 102 выбирает кодовую подкнигу CBam, соответствующую классификационной информации m, из первой кодовой книги 103 и подключает выход данной кодовой подкниги к сумматору 104.
Из первых кодовых векторов CODE_1(d1)(i) (d1=0, 1, …, D1-1, i=0, 1, …, R-1), формирующих CBam среди n кодовых подкниг CBa1-CBan, первая кодовая книга 103 выдает в коммутатор 102 первые кодовые вектора CODE_1(d1')(i) (i=0, 1, …, R-1), назначенные обозначением d1' из секции 105 минимизации ошибок. В данном случае, D1 представляет общее число кодовых векторов первой кодовой книги, и d1 представляет индекс первого кодового вектора. Кроме того, секция 105 минимизации ошибок последовательно назначает значения d1' от d1'=0 до d1'=D1-1, первой кодовой книге 103.
В соответствии со следующим уравнением 1, сумматор 104 вычисляет разности между вектором широкополосных LSP LSP(i) (i=0, 1, …, R-1), полученным в качестве входных объектов векторного квантования, и первыми кодовыми векторами CODE_1(d1')(i) (i=0, 1, …, R-1), полученными в качестве входных данных из первой кодовой книги 103, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве первых остаточных векторов Err_1(d1')(i) (i=0, 1, …, R-1). Кроме того, среди первых остаточных векторов Err_1(d1')(i) (i=0, 1, …, R-1), ассоциированных с d1'=0 до d1'=D1-1, сумматор 104 выдает минимальный первый остаточный вектор Err_1(d1_min)(i) (i=0, 1, …, R-1), идентифицированный посредством поиска в секции 105 минимизации ошибок, в множительное устройство 107.
[1]
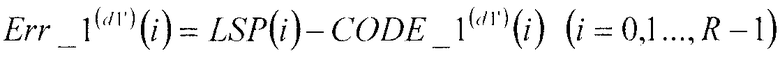 … (уравнение 1)
… (уравнение 1)
Секция 105 минимизации ошибок последовательно назначает значения d1 от d1'=0 до d1'=D1-1 первой кодовой книге 103 и относительно значений d1 от d1'=0 до d1'=D1-1 вычисляет квадратичные ошибки Err возведением в квадрат первых остаточных векторов Err_1(d1')(i) (i=0, 1, …, R-1), полученных в качестве входных данных из сумматора 104, в соответствии со следующим уравнением 2.
[2]
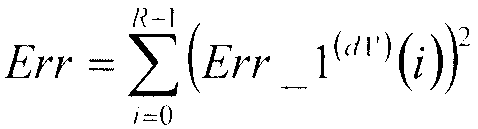 … (уравнение 2)
… (уравнение 2)
Секция 105 минимизации ошибок сохраняет индекс d1' первого кодового вектора, чтобы минимизировать квадратическую ошибку Err, в качестве первого индекса d1_min.
Секция 106 определения масштабных коэффициентов выбирает масштабный коэффициент Scale(m)(i) (i=0, 1, …, R-1), соответствующий классификационной информации m из кодовой книги масштабных коэффициентов, вычисляет величину, обратную масштабному коэффициенту, Rec_Scale(m)(i), в соответствии с нижеследующим уравнением 3 и выдает обратную величину в множительное устройство 107.
[3]
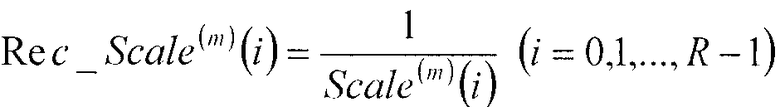 …(уравнение 3)
…(уравнение 3)
В соответствии с нижеследующим уравнением 4, множительное устройство 107 умножает первый остаточный вектор Err_1(d1_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из сумматора 104, на величину, обратную масштабному коэффициенту, Rec_Scale(m)(i), (i=0, 1, …, R-1), полученную в качестве входных данных из секции 106 определения масштабных коэффициентов, и выдает результат в сумматор 109.
[4]
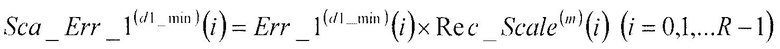 …(уравнение 4)
…(уравнение 4)
Из вторых кодовых векторов CODE_2(d2)(i) (d2=0, 1, …, D2-1, i=0, 1, …, R-1), формирующих кодовую книгу, вторая кодовая книга 108 выдает кодовые вектора CODE_2(d2')(i) (i=0, 1, …, R-1), назначенные обозначением d2' из секции 105 минимизации ошибок, в сумматор 109. В данном случае, D2 представляет общее число кодовых векторов второй кодовой книги, и d2 представляет индекс кодового вектора. Кроме того, секция 105 минимизации ошибок последовательно назначает значения d2' от d2'=0 до d2'=D2-1, во вторую кодовую книгу 108.
В соответствии с нижеследующим уравнением 5, сумматор 109 вычисляет разности между первым остаточным вектором, умноженным на величину, обратную масштабному коэффициенту Sca_Err_1(d1_min)(i) (i=0, 1, …, R-1), полученному в качестве входных данных из множительного устройства, и вторыми кодовыми векторами CODE_2(d2')(i) (i=0, 1, …, R-1), полученными в качестве входных данных из второй кодовой книги 108, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве вторых остаточных векторов Err_2(d2')(i) (i=0, 1, …, R-1). Кроме того, из вторых остаточных векторов Err_2(d2')(i) (i=0, 1, …, R-1), соответствующих значениям d2' от d2'=0 до d2'=D1-1, сумматор 109 выдает в сумматор 111 минимальный второй остаточный вектор Err_2(d2_min)(i) (i=0, 1, …, R-1), идентифицированный посредством поиска в секции 105 минимизации ошибок.
[5]
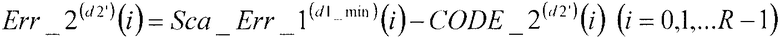 …(уравнение 5)
…(уравнение 5)
В данном случае, секция 105 минимизации ошибок последовательно назначает значения d2' от d2'=0 до d2'=D2-1 во вторую кодовую книгу 108, и, относительно значений d2' от d2'=0 до d2'=D2-1, вычисляет квадратичные ошибки Err возведением в квадрат вторых остаточных векторов Err_2(d2')(i) (i=0, 1, …, R-1), полученных в качестве входных данных из сумматора 109, в соответствии с нижеследующим уравнением 6.
[6]
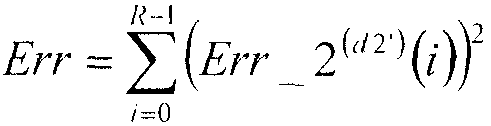 … (уравнение 6)
… (уравнение 6)
Секция 105 минимизации ошибок сохраняет индекс d2' второго кодового вектора, чтобы минимизировать квадратическую ошибку Err, в качестве второго индекса d2_min.
Из третьих кодовых векторов CODE_3(d3)(i) (d3=0, 1, …, D3-1, i=0, 1, …, R-1), формирующих кодовую книгу, третья кодовая книга 110 выдает третьи кодовые вектора CODE_3(d3')(i) (i=0, 1, …, R-1), назначенные обозначением d3' из секции 105 минимизации ошибок, в сумматор 111. В данном случае, D3 представляет общее число кодовых векторов третьей кодовой книги, и d3 представляет индекс кодового вектора. Кроме того, секция 105 минимизации ошибок последовательно назначает значения d3' от d3'=0 до d3'=D3-1, в третью кодовую книгу 110.
В соответствии с нижеследующим уравнением 7, сумматор 111 вычисляет разности между вторым остаточным вектором Err_2(d2_min)(i) (i=0, 1, …, R-1), полученным в качестве входных данных из сумматора 109, и кодовыми векторами CODE_3(d3')(i) (i=0, 1, …, R-1), полученными в качестве входных данных из третьей кодовой книги 110, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве третьих остаточных векторов Err_3(d3')(i) (i=0, 1, …, R-1).
[7]
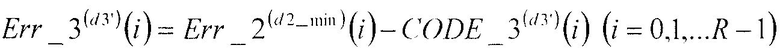 …(уравнение 7)
…(уравнение 7)
В данном случае, секция 105 минимизации ошибок последовательно назначает значения d3' от d3'=1 до d3'=D3-1 в третью кодовую книгу 110, и, относительно значений d3' от d3'=1 до d3'=D3-1, вычисляет квадратичные ошибки Err возведением в квадрат третьих остаточных векторов Err_3(d3')(i) (i=0, 1, …, R-1), полученных в качестве входных данных из сумматора 111, в соответствии с нижеследующим уравнением 8.
[8]
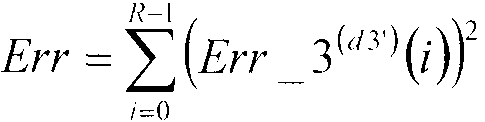 … (уравнение 8)
… (уравнение 8)
Затем секция 105 минимизации ошибок сохраняет индекс d3' третьего кодового вектора, чтобы минимизировать квадратическую ошибку Err, в качестве третьего индекса d3_min. Кроме того, секция 105 минимизации ошибок совместно кодирует первый индекс d1_min, второй индекс d2_min и третий индекс d3_min и выдает результат в виде закодированных данных.
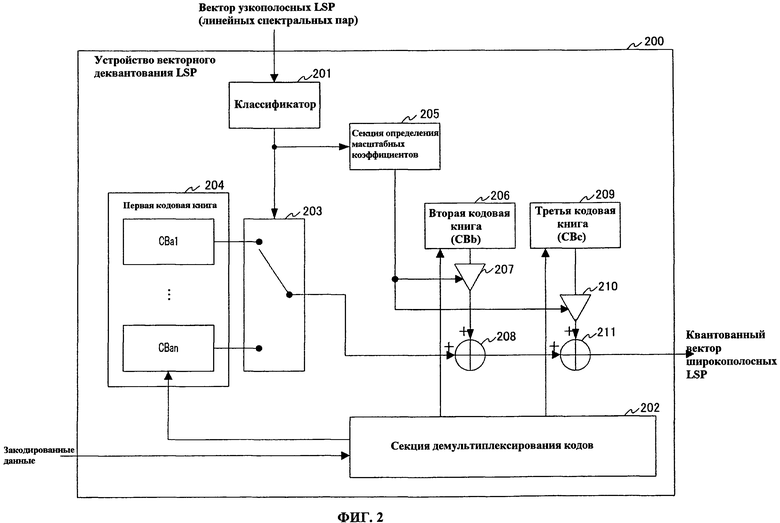
На фиг.2 изображена блок-схема, представляющая основные компоненты устройства 200 векторного деквантования LSP в соответствии с настоящим вариантом осуществления. Устройство 200 векторного деквантования LSP декодирует закодированные данные, выдаваемые из устройства 100 векторного квантования LSP, и генерирует квантованные вектора LSP.
Устройство 200 векторного деквантования LSP снабжено классификатором 201, секцией 202 демультиплексирования кодов, коммутатором 203, первой кодовой книгой 204, секцией 205 определения масштабных коэффициентов, второй кодовой книгой (CBb) 206, множительным устройством 207, сумматором 208, третьей кодовой книгой (CBc) 209, множительным устройством 210 и сумматором 211. В данном случае, первая кодовая книга 204 обеспечивает кодовые подкниги с таким же содержимым, как кодовые подкниги (CBa1-CBan) первой кодовой книги 103, и секция 205 определения масштабных коэффициентов обеспечивает кодовую книгу масштабных коэффициентов, имеющую такое же содержимое, как кодовая книга масштабных коэффициентов секции 106 определения масштабных коэффициентов. Кроме того, вторая кодовая книга 206 обеспечивает кодовую книгу, имеющую такое же содержимое, как кодовая книга второй кодовой книги 108, и третья кодовая книга 209 обеспечивает кодовую книгу, имеющую такое же содержимое, как кодовая книга третьей кодовой книги 110.
Классификатор 201 предварительно сохраняет классификационную кодовую книгу, сформированную множеством единиц классификационной информации, указывающей множество типов векторов узкополосных LSP, выбирает классификационную информацию, указывающую тип вектора широкополосных LSP объекта векторного квантования из классификационной кодовой книги и выдает классификационную информацию в коммутатор 203 и секцию 205 определения масштабных коэффициентов. Более конкретно, классификатор 201 имеет встроенную классификационную кодовую книгу, сформированную кодовыми векторами, соответствующими типам векторов узкополосных LSP, и находит кодовый вектор, чтобы минимизировать квадратическую ошибку относительно квантованного вектора узкополосных LSP, полученного в качестве входных данных из квантователя узкополосных LSP (не показанного), посредством поиска по классификационной кодовой книге. Кроме того, классификатор 201 использует индекс кодового вектора, найденного поиском, в качестве классификационной информации, указывающей тип вектора LSP.
Секция 202 демультиплексирования кодов демультиплексирует закодированные данные, передаваемые из устройства 100 векторного квантования LSP, на первый индекс, второй индекс и третий индекс. Кроме того, секция 202 демультиплексирования кодов направляет первый индекс в первую кодовую книгу 204, направляет второй индекс во вторую кодовую книгу 206 и направляет третий индекс в третью кодовую книгу 209.
Коммутатор 203 выбирает из первой кодовой книги 204 одну кодовую подкнигу (CBam), соответствующую классификационной информации, получаемой в качестве входных данных из классификатора 201, и подключает выход кодовой подкниги к сумматору 208.
Из множества первых кодовых векторов, формирующих первую кодовую книгу, первая кодовая книга 204 выдает в коммутатор 203 один первый кодовый вектор, соответствующий первому индексу, назначенному секцией 202 демультиплексирования кодов.
Из кодовой книги масштабных коэффициентов, секция 205 определения масштабных коэффициентов выбирает масштабный коэффициент, соответствующий классификационной информации, полученной в качестве входных данных из классификатора 201, и выдает масштабный коэффициент в множительное устройство 207 и множительное устройство 210.
Вторая кодовая книга 206 выдает один второй кодовый вектор, соответствующий второму индексу, назначенному секцией 202 демультиплексирования кодов, в множительное устройство 207.
Множительное устройство 207 умножает второй кодовый вектор, полученный в качестве входных данных из второй кодовой книги 206, на масштабный коэффициент, полученный в качестве входных данных из секции 205 определения масштабных коэффициентов, и выдает результат в сумматор 208.
Сумматор 208 суммирует второй кодовый вектор, умноженный на масштабный коэффициент, полученный в качестве входных данных из множительного устройства 207, и первый кодовый вектор, полученный в качестве входных данных из коммутатора 203, и выдает вектор, полученный в результате суммирования, в сумматор 211.
Третья кодовая книга 209 выдает один третий кодовый вектор, соответствующий третьему индексу, назначенному секцией 202 демультиплексирования кодов, в множительное устройство 210.
Множительное устройство 210 умножает третий кодовый вектор, полученный в качестве входных данных из третьей кодовой книги 209, на масштабный коэффициент, полученный в качестве входных данных из секции 205 определения масштабных коэффициентов, и выдает результат в сумматор 211.
Сумматор 211 суммирует третий кодовый вектор, умноженный на масштабный коэффициент, полученный в качестве входных данных из множительного устройства 210, и вектор, полученный в качестве входных данных из сумматора 208, и выдает вектор, полученный в результате суммирования, в качестве квантованного вектора широкополосных LSP.
Ниже поясняются операции устройства 200 векторного деквантования LSP.
Классификатор 201 имеет встроенную классификационную кодовую книгу, сформированную n кодовыми векторами, соответствующими n типам векторов узкополосных LSP, и находит m-ный кодовый вектор, чтобы минимизировать квадратическую ошибку относительно квантованного вектора узкополосных LSP, полученного в качестве входных данных из квантователя (не показанного) узкополосных LSP, посредством поиска кодовых векторов. Классификатор 201 выдает m (1 ≤ m ≤ n) в коммутатор 203 и секцию 205 определения масштабных коэффициентов, в качестве классификационной информации.
Секция 202 демультиплексирования кодов демультиплексирует закодированные данные, передаваемые из устройства 100 векторного квантования LSP, на первый индекс d1_min, второй индекс d2_min и третий индекс d3_min. Кроме того, секция 202 демультиплексирования кодов направляет первый индекс d1_min в первую кодовую книгу 204, направляет второй индекс d2_min во вторую кодовую книгу 206 и направляет третий индекс d3_min в третью кодовую книгу 209.
Коммутатор 203 выбирает из первой кодовой книги 204 кодовую подкнигу CBam, соответствующую классификационной информации m, полученной в качестве входных данных из классификатора 201, и подключает выход кодовой подкниги к сумматору 208.
Из первых кодовых векторов CODE_1(d1)(i) (d1=0, 1, …, D1-1, i=0, 1, …, R-1), формирующих кодовую подкнигу CBam, первая кодовая книга 204 выдает в коммутатор 203 первый кодовый вектор CODE_1(d1_min)(i) (i=0, 1, …, R-1), назначенный обозначением d1_min из секции 202 демультиплексирования кодов.
Секция 205 определения масштабных коэффициентов выбирает масштабный коэффициент Scale(m)(i) (i=0, 1, …, R-1), соответствующий классификационной информации m, полученной в качестве входных данных из классификатора 201, из кодовой книги масштабных коэффициентов и выдает масштабный коэффициент в множительное устройство 207 и множительное устройство 210.
Из вторых кодовых векторов CODE_2(d2)(i) (d2=0, 1, …, D2-1, i=0, 1, …, R-1), формирующих вторую кодовую книгу, вторая кодовая книга 206 выдает в множительное устройство 207 второй кодовый вектор CODE_2(d2_min)(i) (i=0, 1, …, R-1), назначенный обозначением d2_min из секции 202 демультиплексирования кодов.
Множительное устройство 207 умножает второй кодовый вектор CODE_2(d2_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из второй кодовой книги 206, на масштабный коэффициент Scale(m)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из секции 205 определения масштабных коэффициентов, в соответствии с нижеследующим уравнением 9 и выдает результат в сумматор 208.
[9]
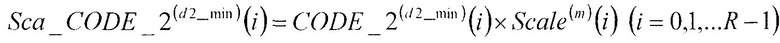 …(уравнение 9)
…(уравнение 9)
В соответствии с нижеследующим уравнением 10, сумматор 208 суммирует первый кодовый вектор CODE_1(d1_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из первой кодовой книги 204, и второй кодовый вектор CODE_2(d2_min)(i) (i=0, 1, …, R-1), умноженный на масштабный коэффициент, полученный в качестве входных данных из множительного устройства 207, и выдает вектор TMP(i) (i=0, 1, …, R-1), являющийся результатом суммирования, в сумматор 211.
[10]
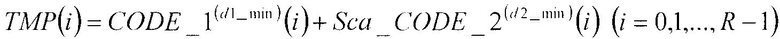 … (уравнение 10)
… (уравнение 10)
Из третьих кодовых векторов CODE_3(d3)(i) (d3=0, 1, …, D3-1, i=0, 1, …, R-1), формирующих кодовую книгу, третья кодовая книга 209 выдает третий кодовый вектор CODE_3(d3_min)(i) (i=0, 1, …, R-1), назначенный обозначением d3_min из секции 202 демультиплексирования кодов, в множительное устройство 210.
В соответствии с нижеследующим уравнением 11, множительное устройство 210 умножает третий кодовый вектор CODE_3(d3_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из третьей кодовой книги 209, на масштабный коэффициент Scale(m)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из секции 205 определения масштабных коэффициентов, и выдает результат в сумматор 211.
[11]
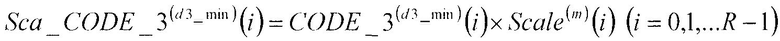 …(уравнение 11)
…(уравнение 11)
В соответствии с нижеследующим уравнением 12, сумматор 211 суммирует вектор TMP(i) (i=0, 1, …, R-1), полученный в качестве входных данных из сумматора 208, и третий кодовый вектор, умноженный на масштабный коэффициент Sca_CODE_3(d3_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из множительного устройства 210, и выдает вектор Q_LSP(i) (i=0, 1, …, R-1), являющийся результатом суммирования, в качестве квантованного вектора широкополосных LSP.
[12]
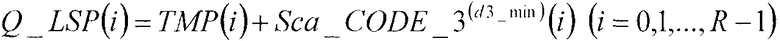 … (уравнение 12)
… (уравнение 12)
Первые кодовые книги, вторые кодовые книги, третьи кодовые книги и кодовые книги масштабных коэффициентов, которые используются в устройстве 100 векторного квантования LSP и устройстве 200 векторного деквантования LSP, предварительно обеспечивают посредством обучения. Способ обучения данных кодовых книг поясняется ниже в качестве примера.
Чтобы собрать первую кодовую книгу, обеспечиваемую в первой кодовой книге 103 и первой кодовой книге 204 посредством обучения, сначала подготавливают большое число (например, V) векторов LSP из большого числа речевых данных для обучения. Затем, группировкой V векторов LSP по типам (т.е. группировкой по n типам) и вычислением D1 первых кодовых векторов CODE_1(d1)(i) (d1=0, 1, …, D1-1, i=0, 1, …, R-1), с использованием векторов LSP каждой группы в соответствии с обучающими алгоритмами, например, алгоритмом LBG (Линде-Бузо-Грея), генерируют n кодовых подкниг.
Чтобы собрать вторую кодовую книгу, обеспечиваемую во второй кодовой книге 108 и второй кодовой книге 206 посредством обучения, собирают V первых остаточных векторов Err_1(d1_min)(i) (i=0, 1, …, R-1), выдаваемых из сумматора 104, посредством выполнения векторного квантования на первой ступени с использованием первой кодовой книги, созданной вышеописанным способом. Затем, посредством вычисления D2 вторых кодовых векторов CODE_2(d2)(i) (d2=0, 1, …, D1-1, i=0, 1, …, R-1) с использованием V первых остаточных векторов Err_1(d1_min)(i) (i=0, 1, …, R-1), в соответствии с алгоритмом обучения, например, алгоритмом LBG, генерируют вторую кодовую книгу.
Чтобы собрать третью кодовую книгу, обеспечиваемую в третьей кодовой книге 110 и третьей кодовой книге 209 посредством обучения, собирают V вторых остаточных векторов Err_2(d2_min)(i) (i=0, 1, …, R-1), выдаваемых из сумматора 109, посредством выполнения векторного квантования на первой и второй ступенях с использованием первой и второй кодовых книг, созданных вышеописанными способами. Затем, посредством вычисления D3 третьих кодовых векторов CODE_3(d3)(i) (d3=0, 1, …, D1-1, i=0, 1, …, R-1) с использованием V вторых остаточных векторов Err_2(d2_min)(i) (i=0, 1, …, R-1), в соответствии с алгоритмом обучения, например алгоритмом LBG, генерируют третью кодовую книгу. В данном случае, кодовую книгу масштабных коэффициентов еще не создают, и, следовательно, множительное устройство 107 не работает, и выходные данные сумматора 104 принимаются без изменений в качестве входных данных в сумматоре 109.
Чтобы собрать кодовую книгу масштабных коэффициентов, обеспеченную в секции 106 определения масштабных коэффициентов и секции 205 определения масштабных коэффициентов посредством обучения, когда значение масштабного коэффициента равно α, посредством выполнения векторного квантования на ступенях с первой по третью с использованием кодовых книг с первой по третью, созданных вышеописанными способами, вычисляют V квантованных LSP. Затем вычисляют среднее значение спектральных искажений (или кепстральных искажений) между V векторами LSP и V квантованными векторами LSP, получаемыми в качестве входных данных. В данном случае, существенным требованием является постепенное изменение значения α в диапазоне, например, 0,8-1,2, вычисление спектральных искажений, соответственно связанных со значениями α, и использование значения α, чтобы минимизировать спектральное искажение в качестве масштабного коэффициента. Посредством определения значения α для каждого типа векторов узкополосных LSP определяют масштабный коэффициент, соответствующий каждому типу, так что кодовую книгу масштабных коэффициентов создают с использованием этих масштабных коэффициентов. Кроме того, когда масштабный коэффициент является вектором, существенным требованием является выполнение обучения, как описано выше, для каждого элемента вектора.
Таким образом, в соответствии с настоящим вариантом осуществления, при многоступенчатом векторном квантовании, в котором кодовые книги для векторного квантования на первой ступени переключаются на основании типов векторов узкополосных LSP, коррелированных с векторами широкополосных LSP, и статистическая дисперсия ошибок векторного квантования (т.е. первых остаточных векторов) на первой ступени различается между типами, квантованный остаточный вектор на первой ступени умножается на масштабный коэффициент, соответствующий результату классификации вектора узкополосных LSP, так что можно изменять дисперсию векторов объектов векторного квантования на второй и третьей ступенях в соответствии со статистической дисперсией ошибок векторного квантования на первой ступени и, следовательно, повышать точность квантования векторов широкополосных LSP.
Кроме того, в устройстве векторного деквантования, путем получения, в качестве входных данных, закодированных данных векторов широкополосных LSP, сформированных способом квантования с повышенной точностью квантования, и посредством выполнения векторного деквантования можно генерировать точно квантованные вектора широкополосных LSP. Кроме того, при применении данного устройства векторного деквантования в устройстве декодирования речи можно декодировать речь с использованием точно квантованных векторов широкополосных LSP, и поэтому можно получать декодированную речь высокого качества.
Кроме того, хотя выше описан примерный случай с использованием настоящего варианта осуществления, в котором масштабные коэффициенты, формирующие кодовую книгу масштабных коэффициентов, обеспеченную в секции 106 определения масштабных коэффициентов и секции 205 определения масштабных коэффициентов, ассоциированы с типами векторов узкополосных LSP, настоящее изобретение не ограничено этим, и масштабные коэффициенты, формирующие кодовую книгу масштабных коэффициентов, обеспеченную в секции 106 определения масштабных коэффициентов и секции 205 определения масштабных коэффициентов, могут ассоциироваться с типами, классифицирующими признаки речи. В данном случае, классификатор 101 получает параметры, представляющие признак речи, в качестве входной информации признака речи, вместо вектора узкополосных LSP и выводит тип признака речи, соответствующего информации о признаке речи, получаемой в качестве входных данных, в коммутатор 102 и секцию 106 определения масштабных коэффициентов, в качестве классификационной информации. Когда настоящее изобретение применяют в кодирующем устройстве, которое переключает тип кодера согласно признакам, например, вокализированной характеристике и невокализированной характеристике речи, как, например, в VMR-WB (многорежимном широкополосном речевом кодеке с переменной скоростью), информацию о типе кодера можно использовать в неизменном виде, как количество признаков речи.
Кроме того, хотя выше описан примерный случай с использованием настоящего варианта осуществления, в котором секция 106 определения масштабных коэффициентов выдает величины, обратные масштабным коэффициентам, ассоциированным с типами, получаемыми в качестве входных данных из классификатора 101, настоящее изобретение не ограничено этим, и, равным образом, возможно предварительное вычисление величин, обратных масштабным коэффициентам, и сохранение вычисленных величин, обратных масштабным коэффициентам, в кодовой книге масштабных коэффициентов.
Кроме того, хотя выше описан примерный случай с использованием настоящего варианта осуществления, в котором выполняется трехступенчатое векторное квантование для векторов LSP, настоящее изобретение не ограничено этим и, равным образом, применимо к случаю векторного квантования в две ступени или к случаю векторного квантования в четыре или более ступени.
Кроме того, хотя выше описан случай с использованием настоящего варианта осуществления, в котором выполняется многоступенчатое векторное квантование в три ступени для векторов LSP, настоящее изобретение не ограничено этим и, равным образом, применимо к случаю, когда векторное квантование выполняется вместе с расщепленным векторным квантованием.
Кроме того, хотя выше описан случай с использованием настоящего варианта осуществления, в котором в качестве объектов квантования используются вектора широкополосных LSP, объект квантования не ограничен этим, и, равным образом, возможно использование векторов, отличающихся от векторов широкополосных LSP.
Кроме того, хотя выше описан случай с использованием настоящего варианта осуществления, в котором устройство 200 векторного деквантования LSP декодирует закодированные данные, выдаваемые из устройства 100 векторного квантования LSP, настоящее изобретение не ограничено этим, и нет необходимости указывать, что устройство 200 векторного деквантования LSP может получать и декодировать закодированные данные, пока закодированные данные имеют формат, который можно декодировать устройством 200 векторного деквантования LSP.
Вариант осуществления 2
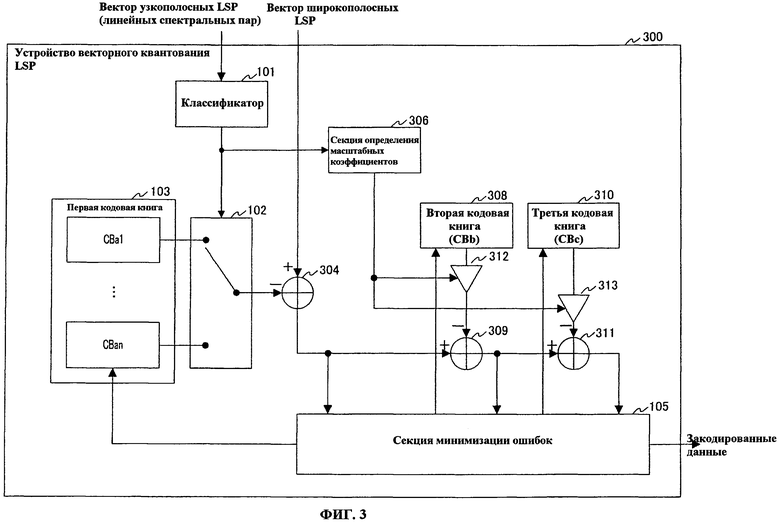
На фиг.3 показана блок-схема, представляющая основные компоненты устройства 300 векторного квантования LSP в соответствии с вариантом осуществления 2 настоящего изобретения. Кроме того, устройство 300 векторного квантования LSP имеет такую же базовую конфигурацию, как устройство 100 векторного квантования LSP (смотри фиг.1), показанное в варианте осуществления 1, и одинаковым компонентам будут присвоены одинаковые ссылочные номера и их описания будут отсутствовать.
Устройство 300 векторного квантования LSP снабжено классификатором 101, коммутатором 102, первой кодовой книгой 103, сумматором 304, секцией 105 минимизации ошибок, секцией 306 определения масштабных коэффициентов, второй кодовой книгой 308, сумматором 309, третьей кодовой книгой 310, сумматором 311, множительным устройством 312 и множительным устройством 313.
Сумматор 304 вычисляет разности между вектором широкополосных LSP, получаемым извне в качестве входного объекта векторного квантования, и первыми кодовыми векторами, полученными в качестве входных данных из коммутатора 102, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве первых остаточных векторов. Кроме того, из первых остаточных векторов, соответствующих всем первым кодовым векторам, сумматор 304 выдает один минимальный первый остаточный вектор, идентифицированный поиском в секции 105 минимизации ошибок, в сумматор 309.
Секция 306 определения масштабных коэффициентов предварительно сохраняет кодовую книгу масштабных коэффициентов, сформированную масштабными коэффициентами, соответствующими типам векторов узкополосных LSP. Секция 306 определения масштабных коэффициентов выдает масштабный коэффициент, соответствующий классификационной информации, полученной в качестве входных данных из классификатора 101, в множительное устройство 312 и множительное устройство 313. В данном случае, масштабный коэффициент может быть скаляром или вектором.
Вторая кодовая книга (CBb) 308 сформирована множеством вторых кодовых векторов и выдает вторые кодовые вектора, назначенные обозначением из секции 105 минимизации ошибок, в множительное устройство 312.
Третья кодовая книга (CBc) 310 сформирована множеством третьих кодовых векторов и выдает третьи кодовые вектора, назначенные обозначением из секции 105 минимизации ошибок, в множительное устройство 313.
Множительное устройство 312 умножает вторые кодовые вектора, полученные в качестве входных данных из второй кодовой книги 308, на масштабный коэффициент, полученный в качестве входных данных из секции 306 определения масштабных коэффициентов, и выдает результаты в сумматор 309.
Сумматор 309 вычисляет разности между первым остаточным вектором, полученным в качестве входных данных из сумматора 304, и вторыми кодовыми векторами, умноженными на масштабный коэффициент, полученный в качестве входных данных из множительного устройства 312, и выдает данные разности в секцию 105 минимизации ошибок в качестве вторых остаточных векторов. Кроме того, из вторых остаточных векторов, соответствующих всем вторым кодовым векторам, сумматор 309 выдает один минимальный второй остаточный вектор, идентифицированный поиском в секции 105 минимизации ошибок, в сумматор 311.
Множительное устройство 313 умножает третьи кодовые вектора, полученные в качестве входных данных из третьей кодовой книги 310, на масштабный коэффициент, полученный в качестве входных данных из секции 306 определения масштабных коэффициентов, и выдает результаты в сумматор 311.
Сумматор 311 вычисляет разности между вторым остаточным вектором, полученным в качестве входных данных из сумматора 309, и третьими кодовыми векторами, умноженными на масштабный коэффициент, полученный в качестве входных данных из множительного устройства 313, и выдает эти разности в секцию 105 минимизации ошибок в качестве третьих остаточных векторов.
Ниже поясняются операции, выполняемые устройством 300 векторного квантования LSP, с использованием примерного случая, в котором порядок векторов LSP объектов квантования равен R. Кроме того, в нижеследующем пояснении, вектора LSP будут выражены через «LSP(i) (i=0, 1, …, R-1)».
В соответствии со следующим уравнением 13, сумматор 304 вычисляет разности между вектором LSP(i) (i=0, 1, …, R-1) широкополосных LSP и первыми кодовыми векторами CODE_1(d1')(i) (i=0, 1, …, R-1), полученными в качестве входных данных из первой кодовой книги 103, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве первых остаточных векторов Err_1(d1')(i) (i=0, 1, …, R-1). Кроме того, из первых остаточных векторов Err_1(d1')(i) (i=0, 1, …, R-1), соответствующих d1' от d1'=0 до d1'=D1-1, сумматор 304 выдает минимальный первый остаточный вектор Err_1(d1_min)(i) (i=0, 1, …, R-1), идентифицированный посредством поиска в секции 105 минимизации ошибок, в множительное устройство 309.
[13]
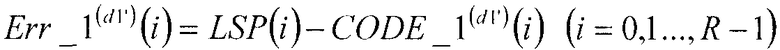 … (уравнение 13)
… (уравнение 13)
Секция 306 определения масштабных коэффициентов выбирает масштабный коэффициент Scale(m)(i) (i=0, 1, …, R-1), соответствующий классификационной информации m из кодовой книги масштабных коэффициентов, и выдает масштабный коэффициент в множительное устройство 312 и множительное устройство 313.
Из вторых кодовых векторов CODE_2(d2)(i) (d2=0, 1, …, D2-1, i=0, 1, …, R-1), формирующих кодовую книгу, вторая кодовая книга 308 выдает кодовые вектора CODE_2(d2')(i) (i=0, 1, …, R-1), назначенные обозначением d2' из секции 105 минимизации ошибок, в множительное устройство 312. В данном случае, D2 представляет общее число кодовых векторов второй кодовой книги, и d2 представляет индекс кодового вектора. Кроме того, секция 105 минимизации ошибок последовательно назначает значения d2' от d2'=0 до d2'=D2-1, во вторую кодовую книгу 308.
В соответствии с нижеследующим уравнением 14, множительное устройство 312 умножает вторые вектора CODE_2(d2')(i) (i=0, 1, …, R-1), полученные в качестве входных данных из второй кодовой книги 308, на масштабный коэффициент Scale(m)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из секции 306 определения масштабных коэффициентов, и выдает результаты в сумматор 309.
[14]
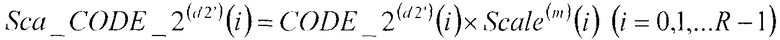 …(уравнение 14)
…(уравнение 14)
В соответствии с нижеследующим уравнением 15, сумматор 309 вычисляет разности между первым остаточным вектором Err_1(d1_min)(i) (i=0, 1, …, R-1), полученным в качестве входных данных из сумматора 304, и вторыми кодовыми векторами, умноженными на масштабный коэффициент Sca_CODE_2(d2')(i) (i=0, 1, …, R-1), полученный в качестве входных данных из множительного устройства 312, и выдает эти разности в секцию 105 минимизации ошибок, в качестве вторых остаточных векторов Err_2(d2')(i) (i=0, 1, …, R-1). Кроме того, из вторых остаточных векторов Err_2(d2')(i) (i=0, 1, …, R-1), соответствующих d2' от d2'=0 до d2'=D1-1, сумматор 309 выдает минимальный второй остаточный вектор Err_2(d2_min)(i) (i=0, 1, …, R-1), идентифицированный посредством поиска в секции 105 минимизации ошибок, в сумматор 311.
[15]
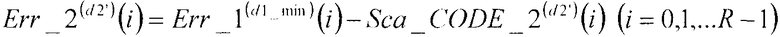 …(уравнение 15)
…(уравнение 15)
Из третьих кодовых векторов CODE_3(d3)(i) (d3=0, 1, …, D3-1, i=0, 1, …, R-1), формирующих кодовую книгу, третья кодовая книга 310 выдает кодовые вектора CODE_3(d3')(i) (i=0, 1, …, R-1), назначенные обозначением d3' из секции 105 минимизации ошибок, в множительное устройство 313. В данном случае, D3 представляет общее число кодовых векторов третьей кодовой книги, и d3 представляет индекс кодового вектора. Кроме того, секция 105 минимизации ошибок последовательно назначает значения d3' от d3'=0 до d3'=D3-1, в третью кодовую книгу 310.
В соответствии с нижеследующим уравнением 16, множительное устройство 313 умножает третьи кодовые вектора CODE_3(d3')(i) (i=0, 1, …, R-1), полученные в качестве входных данных из третьей кодовой книги 310, на масштабный коэффициент Scale(m)(i) (i=0, 1, R-1), полученный в качестве входных данных из секции 306 определения масштабных коэффициентов, и выдает результаты в сумматор 311.
[16]
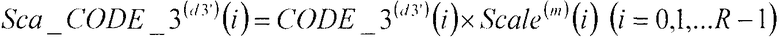 … (уравнение 16)
… (уравнение 16)
В соответствии с нижеследующим уравнением 17, сумматор 311 вычисляет разности между вторым остаточным вектором Err_2(d2_min)(i) (i=0, 1, …, R-1), полученным в качестве входных данных из сумматора 309, и третьими кодовыми векторами, умноженными на масштабный коэффициент Sca_CODE_3(d3')(i) (i=0, 1, …, R-1), полученный в качестве входных данных из множительного устройства 313, и выдает эти разности в секцию 105 минимизации ошибок в качестве третьих остаточных векторов Err_3(d3')(i) (i=0, 1, …, R-1).
Таким образом, в соответствии с настоящим вариантом осуществления, при многоступенчатом векторном квантовании, в котором кодовые книги для векторного квантования на первой ступени переключаются на основании типов векторов узкополосных LSP, коррелированных с векторами широкополосных LSP, и статистическая дисперсия ошибок векторного квантования (т.е. первых остаточных векторов) на первой ступени различается между типами, вторая кодовая книга, используемая для векторного квантования на второй и третьей ступенях, и кодовые вектора второй кодовой книги умножаются на масштабный коэффициент, соответствующий результату классификации вектора узкополосных LSP, так что можно изменять дисперсию векторов объектов векторного квантования на второй и третьей ступенях в соответствии со статистической дисперсией ошибок векторного квантования на первой ступени и, следовательно, повышать точность квантования векторов широкополосных LSP.
Кроме того, вторая кодовая книга 308 в соответствии с настоящим вариантом осуществления может иметь такое же содержимое, как вторая кодовая книга 108 в соответствии с вариантом осуществления 1, и третья кодовая книга 310 в соответствии с настоящим вариантом осуществления может иметь такое же содержимое, как третья кодовая книга 110 в соответствии с вариантом осуществления 1. Кроме того, секция 306 определения масштабных коэффициентов в соответствии с настоящим вариантом осуществления может обеспечить кодовую книгу, имеющую такое же содержимое, как кодовая книга масштабных коэффициентов, обеспеченная в секции 106 определения масштабных коэффициентов в соответствии с вариантом осуществления 1.
Вариант осуществления 3
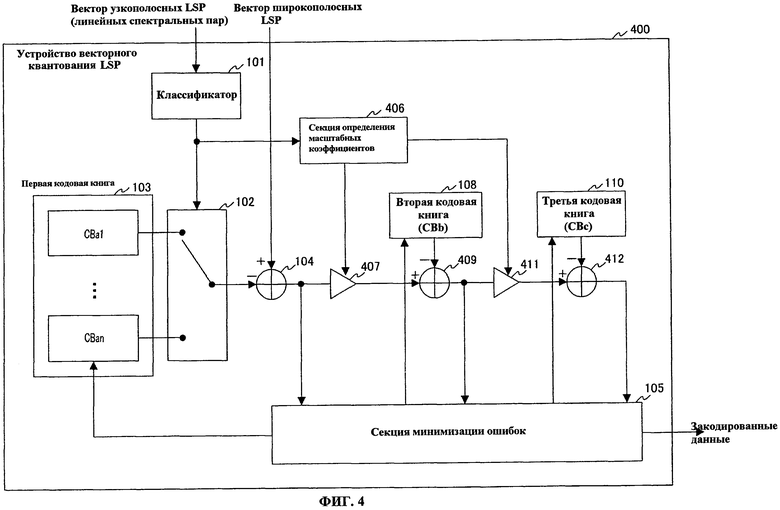
На фиг.4 показана блок-схема, представляющая основные компоненты устройства 400 векторного квантования LSP в соответствии с вариантом осуществления 3 настоящего изобретения. В данном случае, устройство 400 векторного квантования LSP имеет такую же базовую конфигурацию, как устройство 100 векторного квантования LSP (смотри фиг.1), и одинаковым компонентам будут присвоены одинаковые ссылочные номера, и их описания будут отсутствовать.
Устройство 400 векторного квантования LSP снабжено классификатором 101, коммутатором 102, первой кодовой книгой 103, сумматором 104, секцией 105 минимизации ошибок, секцией 106 определения масштабных коэффициентов, множительным устройством 407, второй кодовой книгой 108, сумматором 409, третьей кодовой книгой 110, сумматором 412 и множительным устройством 411.
Секция 406 определения масштабных коэффициентов предварительно сохраняет кодовую книгу масштабных коэффициентов, сформированную масштабными коэффициентами, соответствующими типам векторов узкополосных LSP. Секция 406 определения масштабных коэффициентов определяет масштабные коэффициенты, соответствующие классификационной информации, получаемой в качестве входных данных из классификатора 101. В данном случае, масштабные коэффициенты формируются масштабным коэффициентом, на который умножается первый остаточный вектор, выдаваемый из сумматора 104 (т.е. первым масштабным коэффициентом), и масштабным коэффициентом, на который умножается первый остаточный вектор, выдаваемый из сумматора 409 (т.е. вторым масштабным коэффициентом). Затем секция 406 определения масштабных коэффициентов выдает первый масштабный коэффициент в множительное устройство 407 и выдает второй масштабный коэффициент в множительное устройство 411. Таким образом, посредством предварительной подготовки масштабных коэффициентов, подходящих для ступеней многоступенчатого векторного квантования, можно выполнять более детальную адаптивную настройку кодовых книг.
Множительное устройство 407 умножает первый остаточный вектор, полученный в качестве входных данных из сумматора 104, на величину, обратную первому масштабному коэффициенту, выдаваемому из секции 406 определения масштабных коэффициентов, и выдает результат в сумматор 409.
Сумматор 409 вычисляет разности между первым остаточным вектором, умноженным на величину, обратную масштабному коэффициенту, полученному в качестве входных данных из множительного устройства 407, и вторыми кодовыми векторами, полученными в качестве входных данных из второй кодовой книги 108, и выдает упомянутые разности в секцию 105 минимизации ошибок, в качестве вторых остаточных векторов. Кроме того, из вторых остаточных векторов, соответствующих всем вторым кодовым векторам, сумматор 409 выдает один минимальный второй остаточный вектор, идентифицированный посредством поиска в секции 105 минимизации ошибок, в множительное устройство 411.
Множительное устройство 411 умножает второй остаточный вектор, полученный в качестве входных данных из сумматора 409, на величину, обратную второму масштабному коэффициенту, полученному в качестве входных данных из секции 406 определения масштабных коэффициентов, и выдает результат в сумматор 412.
Сумматор 412 вычисляет разности между вторым остаточным вектором, умноженным на величину, обратную масштабному коэффициенту, полученному в качестве входных данных из множительного устройства 411, и третьими кодовыми векторами, полученными в качестве входных данных из третьей кодовой книги 110, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве третьих остаточных векторов.
Ниже поясняются операции, выполняемые устройством 400 векторного квантования LSP, с использованием примерного случая, в котором порядок векторов LSP объектов квантования равен R. Кроме того, в нижеследующем пояснении, вектора LSP будут выражены в виде «LSP(i) (i=0, 1, …, R-1)».
Секция 406 определения масштабных коэффициентов выбирает первый масштабный коэффициент Scale_1(m)(i) (i=0, 1, …, R-1) и второй масштабный коэффициент Scale_2(m)(i) (i=0, 1, …, R-1), соответствующие классификационной информации m из кодовой книги масштабных коэффициентов, вычисляет величину, обратную первому масштабному коэффициенту Scale_1(m)(i) (i=0, 1, …, R-1), в соответствии со следующим уравнением 17 и выдает обратную величину в множительное устройство 407, и вычисляет величину, обратную второму масштабному коэффициенту Scale_2(m)(i) (i=0, 1, …, R-1), в соответствии со следующим уравнением 18 и выдает обратную величину в множительное устройство 411.
[17]
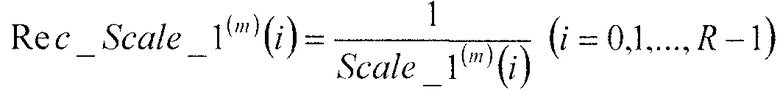 … (уравнение 17)
… (уравнение 17)
[18]
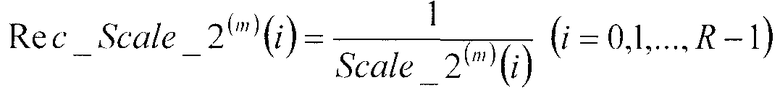 … (уравнение 18)
… (уравнение 18)
В данном случае, хотя выше описан случай, в котором выбираются масштабные коэффициенты и затем вычисляются их обратные величины посредством вычисления величин, обратных масштабным коэффициентам, заранее и сохранения их в кодовой книге масштабных коэффициентов, можно исключить операции вычисления величин, обратных масштабным коэффициентам. Даже в данном случае настоящее изобретение может обеспечивать такой же эффект, как выше.
В соответствии с нижеследующим уравнением 19, множительное устройство 407 умножает первый остаточный вектор Err_1(d1_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из сумматора 104, на величину, обратную первому масштабному коэффициенту, Rec_Scale_1(m)(i), (i=0, 1, …, R-1), полученную в качестве входных данных из секции 406 определения масштабных коэффициентов, и выдает результат в сумматор 409.
[19]
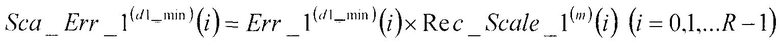 (уравнение 19)
(уравнение 19)
В соответствии с нижеследующим уравнением 20, сумматор 409 вычисляет разности между первым остаточным вектором, умноженным на величину, обратную первому масштабному коэффициенту, Sca_Err_1(d1_min)(i) (i=0, 1, …, R-1), полученную в качестве входных данных из множительного устройства 407, и вторыми кодовыми векторами CODE_2(d2')(i) (i=0, 1, …, R-1), полученными в качестве входных данных из второй кодовой книги 108, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве вторых остаточных векторов Err_2(d2')(i) (i=0, 1, …, R-1). Далее, из вторых остаточных векторов Err_2(d2')(i) (i=0, 1, …, R-1), соответствующих значениям d2' от d2'=0 до d2'=D1-1, сумматор 409 выдает минимальный второй остаточный вектор Err_2(d2_min)(i) (i=0, 1, …, R-1), идентифицированный посредством поиска в секции 105 минимизации ошибок, в множительное устройство 411.
[20]
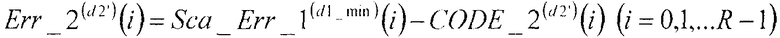 …(уравнение 20)
…(уравнение 20)
В соответствии с нижеследующим уравнением 21, множительное устройство 411 умножает второй остаточный вектор Err_2(d2_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из сумматора 409, на величину, обратную второму масштабному коэффициенту, Rec_Scale_2(m)(i) (i=0, 1, …, R-1), полученную в качестве входных данных из секции 406 определения масштабных коэффициентов, и выдает результат в сумматор 412.
[21]
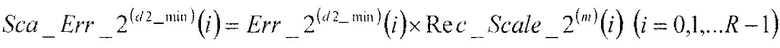 (уравнение 21)
(уравнение 21)
В соответствии с нижеследующим уравнением 22, сумматор 412 вычисляет разности между вторым остаточным вектором, умноженным на величину, обратную второму масштабному коэффициенту, Sca_Err_2(d2_min)(i) (i=0, 1, …, R-1), полученную в качестве входных данных из множительного устройства 411, и третьими кодовыми векторами CODE_3(d3')(i) (i=0, 1, …, R-1), полученными в качестве входных данных из третьей кодовой книги 110, и выдает упомянутые разности в секцию 105 минимизации ошибок в качестве третьих остаточных векторов Err_3(d3')(i) (i=0, 1, …, R-1).
[22]
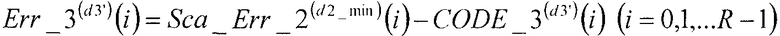 …(уравнение 22)
…(уравнение 22)
Таким образом, в соответствии с настоящим вариантом осуществления, при многоступенчатом векторном квантовании, в котором кодовые книги для векторного квантования на первой ступени переключаются на основании типов векторов узкополосных LSP, коррелированных с векторами широкополосных LSP, и статистическая дисперсия ошибок векторного квантования (т.е. первых остаточных векторов) на первой ступени различается между типами, вторая кодовая книга, используемая для векторного квантования на второй и третьей ступенях, и кодовые вектора третьей кодовой книги умножаются на масштабные коэффициенты, соответствующие результату классификации вектора узкополосных LSP, так что можно изменять дисперсию векторов объектов векторного квантования на второй и третьей ступенях в соответствии со статистической дисперсией ошибок векторного квантования на первой ступени и, следовательно, повышать точность квантования векторов широкополосных LSP. В данном случае, посредством раздельной подготовки масштабного коэффициента, используемого на второй ступени, и масштабного коэффициента, используемого на третьей ступени, создается возможность более детальной адаптации.
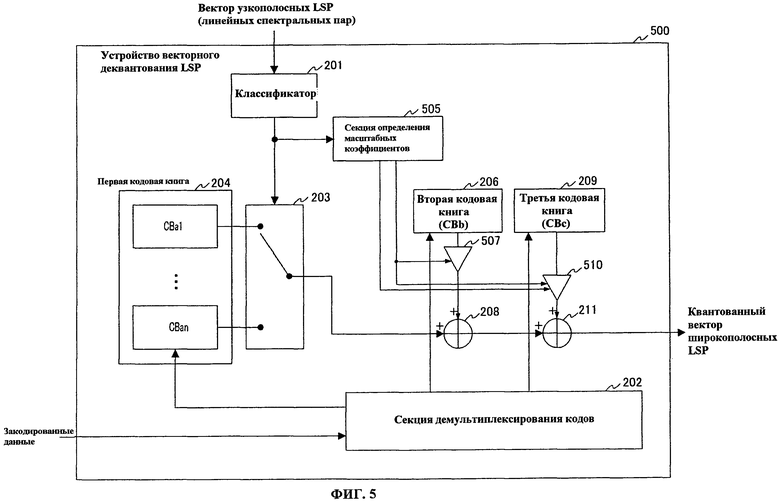
На фиг.5 изображена блок-схема, представляющая основные компоненты устройства 500 векторного деквантования LSP в соответствии с настоящим вариантом осуществления. Устройство 500 векторного деквантования LSP декодирует закодированные данные, выдаваемые из устройства 400 векторного квантования LSP, и генерирует квантованные вектора LSP. Кроме того, устройство 500 векторного деквантования LSP имеет такую же базовую конфигурацию, как устройство 200 векторного деквантования LSP (смотри фиг.2), показанное в варианте осуществления 1, и одинаковым компонентам присвоены одинаковые ссылочные номера, и их пояснения опущены.
Устройство 500 векторного деквантования LSP снабжено классификатором 201, секцией 202 демультиплексирования кодов, коммутатором 203, первой кодовой книгой 204, секцией 505 определения масштабных коэффициентов, второй кодовой книгой (CBb) 206, множительным устройством 507, сумматором 208, третьей кодовой книгой (CBc) 209, множительным устройством 510 и сумматором 211. В данном случае, первая кодовая книга 204 обеспечивает кодовые подкниги, имеющие такое же содержимое, как кодовые подкниги (CBa1-CBan) первой кодовой книги 103, и секция 505 определения масштабных коэффициентов обеспечивает кодовую книгу масштабных коэффициентов, имеющую такое же содержимое, как кодовая книга масштабных коэффициентов секции 406 определения масштабных коэффициентов. Кроме того, вторая кодовая книга 206 обеспечивает кодовую книгу с таким же содержимым, как кодовая книга второй кодовой книги 108, и третья кодовая книга 209 обеспечивает кодовую книгу, имеющую такое же содержимое, как кодовая книга третьей кодовой книги 110.
Из кодовой книги масштабных коэффициентов секция 505 определения масштабных коэффициентов выбирает первый масштабный коэффициент Scale_1(m)(i) (i=0, 1, …, R-1) и второй масштабный коэффициент Scale_2(m)(i) (i=0, 1, …, R-1), соответствующие классификационной информации m, полученной в качестве входных данных из классификатора 201, выдает первый масштабный коэффициент Scale_1(m)(i) (i=0, 1, …, R-1) в множительное устройство 507 и множительное устройство 510 и выдает второй масштабный коэффициент Scale_2(m)(i) (i=0, 1, …, R-1) в множительное устройство 510.
В соответствии с нижеследующим уравнением 23, множительное устройство 507 перемножает второй кодовый вектор CODE_2(d2_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из второй кодовой книги 206, и первый масштабный коэффициент Scale_1(m)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из секции 505 определения масштабных коэффициентов, и выдает результат в сумматор 208.
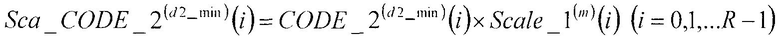
(уравнение 23)
В соответствии с нижеследующим уравнением 24, множительное устройство 510 умножает третий кодовый вектор CODE_3(d3_min)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из третьей кодовой книги 209, на первый масштабный коэффициент Scale_1(m)(i) (i=0, 1, …, R-1) и второй масштабный коэффициент Scale_2(m)(i) (i=0, 1, …, R-1), полученный в качестве входных данных из секции 505 определения масштабных коэффициентов, и выдает результат в сумматор 211.
[24]
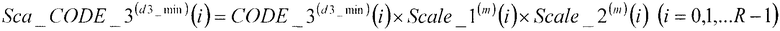
(уравнение 24)
Таким образом, в соответствии с настоящим вариантом осуществления устройство векторного деквантования LSP получает в качестве входных данных и выполняет векторное деквантование закодированных данных векторов широкополосных LSP, сгенерированные способом квантования с повышенной точностью квантирования, что можно генерировать точно квантованные вектора широкополосных LSP. Кроме того, при применении упомянутого устройства векторного деквантования в устройстве декодирования речи, речь можно декодировать с использованием точно квантованных векторов широкополосных LSP таким образом, что можно получать декодированную речь высокого качества.
Кроме того, хотя выше описан случай, в котором устройство 500 векторного деквантования LSP декодирует закодированные данные, выдаваемые из устройства 400 векторного квантования LSP, настоящее изобретение не ограничено этим, и нет необходимости указывать, что устройство 500 векторного деквантования LSP может получать и декодировать закодированные данные, пока закодированные данные в форме, которая может быть декодирована устройством 400 векторного деквантования LSP.
Варианты осуществления настоящего изобретения описаны выше.
Кроме того, устройство векторного квантования, устройство векторного деквантования и способы векторного квантования и векторного деквантования в соответствии с настоящим изобретением не ограничены вышеописанными вариантами осуществления и могут быть реализованы с разными изменениями.
Например, хотя устройство векторного квантования, устройство векторного деквантования и способы векторного квантования и векторного деквантования описаны выше в вариантах осуществления, предназначенных для речевых сигналов, упомянутые устройства и способы, равным образом, применимы к аудиосигналам и т.д.
LSP можно также именовать «LSF (линейной спектральной частотой)» и LSP можно понимать как LSF. Кроме того, когда вместо LSP квантуются ISP (спектральные пары иммитансов) в качестве спектральных параметров, LSP можно понимать как ISP, и в настоящих вариантах осуществления можно применять устройства квантования/деквантования ISP. Когда вместо LSP квантуется ISF (спектральная частота иммитанса) в качестве спектральных параметров, LSP можно понимать как ISF, и в настоящих вариантах осуществления можно применять устройства квантования/деквантования ISF.
Кроме того, устройство векторного квантования, устройство векторного деквантования и способы векторного квантования и векторного деквантования в соответствии с настоящим изобретением можно применять в устройстве CELP-кодирования и устройстве CELP-декодирования, которые кодируют и декодируют речевые сигналы, аудиосигналы и т.д. Например, в случае, когда устройство векторного квантования LSP в соответствии с настоящим изобретением применяют в устройстве CELP-кодирования речи, в устройстве CELP-кодирования, устройство 100 векторного квантования LSP в соответствии с настоящим изобретением обеспечивается в секции квантования LSP, которая: получает в виде входных данных и выполняет обработку методом квантования LSP, преобразованного из коэффициентов линейного предсказания, полученных выполнением анализа входного сигнала методом линейного предсказания, выдает квантованный LSP в синтезирующий фильтр; и выдает код квантованного LSP, указывающий квантованный LSP как закодированные данные. Тем самым, можно повышать точность векторного квантования так, что, равным образом, можно повышать качество речи после декодирования. Аналогично, в случае, когда устройство векторного деквантования LSP в соответствии с настоящим изобретением применяют в устройстве CELP-декодирования речи, в устройстве CELP-декодирования, при обеспечении устройства 200 векторного деквантования LSP в соответствии с настоящим изобретением в секции деквантования LSP, которая декодирует квантованный LSP из кода квантованного LSP, полученного демультиплексированием полученных мультиплексированных закодированных данных, и выдает декодированный квантованный LSP в синтезирующий фильтр, можно обеспечить эффект, подобный вышеописанному.
Устройство векторного квантования и устройство векторного деквантования в соответствии с настоящим изобретением можно устанавливать на оконечном устройстве связи в системе мобильной связи, которая передает речь, аудиоданные и т.п., и поэтому можно обеспечить оконечное устройство связи, имеющее такой же функциональный эффект, который описан выше.
Хотя выше, на примере вышеприведенных вариантов осуществления, описан случай, в котором настоящее изобретение реализовано аппаратными средствами, настоящее изобретение можно реализовать программными средствами. Например, посредством описания способа векторного квантования и способа векторного деквантования в соответствии с настоящим изобретением на языке программирования, сохранения упомянутой программы в памяти и обеспечения исполнения упомянутой программы секцией обработки информации, можно реализовать такую же функцию, как в устройстве векторного квантования и устройстве векторного деквантования в соответствии с настоящим изобретением.
Кроме того, каждый функциональный блок, применяемый в описании каждого из вышеупомянутых вариантов осуществления можно, обычно, реализовать в виде БИС (большой интегральной схемы), образованной интегральной схемой, которые могут представлять собой отдельные микросхемы или частично, или целиком содержаться на одной микросхеме.
В данном случае применяется термин «БИС», однако, возможно также применение как «ИС» (интегральная схема), «системная БИС», «суперБИС» или «ультраБИС», в зависимости от различия степеней интеграции.
Кроме того, способ схемной интеграции не ограничен БИС, и возможна также реализация с использованием специализированных схем или универсальных процессоров. После изготовления БИС, возможно также использование FPGA (программируемая пользователем вентильная матрица) или реконфигурируемого процессора, в котором можно реконфигурировать соединения и настройки схемных ячеек в БИС.
Далее, если появляется технология интегральных схем, заменяющая БИС в результате развития полупроводниковой технологии или модификации другой технологии, то, разумеется, можно также выполнять интеграцию функциональных блоков с применением упомянутой технологии. Применима также биотехнология.
Содержания японской патентной заявки №2007-266922, поданной 12 октября 2007 г., и японской патентной заявки №2007-285602, поданной 1 ноября 2007 г., включая описания, чертежи и рефераты, целиком включены в настоящую заявку путем отсылки.
Промышленная применимость
Устройство векторного квантования, устройство векторного деквантования и способы векторного квантования и векторного деквантования в соответствии с настоящим изобретением применимы в таких областях, как кодирование речи и декодирование речи.
Изобретение относится к устройствам векторного квантования и деквантования для выполнения векторного квантования параметров LSP, используемых в устройстве кодирования/декодирования речи, которое передает речевые сигналы в областях системы пакетной связи. Технический результат заключается в повышении точности квантования на второй и последующей ступени векторного квантования. Устройство содержит секцию классификации, которая классифицирует тип признака, секцию выбора, которая выбирает первую кодовую книгу, ассоциированную с типом признака, первую секцию квантования, которая получает первый код квантования вектора, кодовую книгу масштабных коэффициентов, содержащую масштабные коэффициенты, ассоциированные с типами признаков, и вторую секцию квантования, которая содержит вторую кодовую книгу, имеющую вторые кодовые вектора, и получает второй код с использованием вторых кодовых векторов и масштабного коэффициента, ассоциированного с типом признака. Способ, описывающий работу устройства. 4 н. и 5 з.п. ф-лы, 5 ил.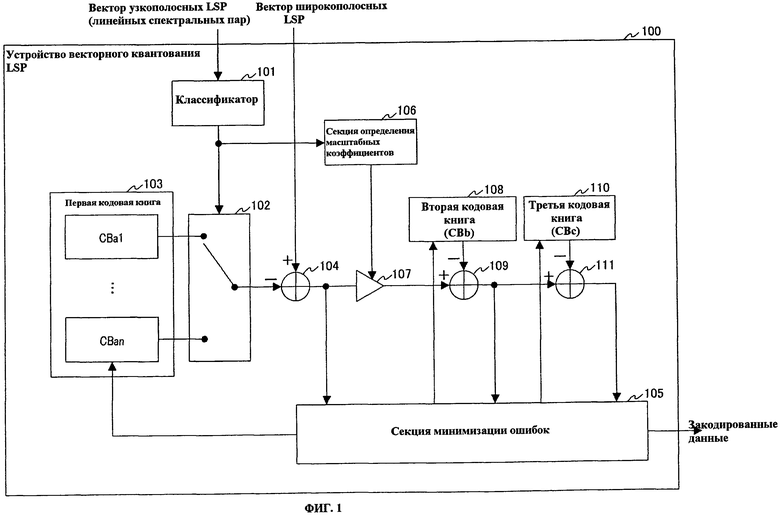
1. Устройство векторного квантования, содержащее:
секцию классификации, которая генерирует классификационную информацию, указывающую тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов;
секцию выбора, которая выбирает одну первую кодовую книгу, ассоциированную с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов соответственно;
первую секцию квантования, которая получает первый код квантованием вектора, являющегося объектом квантования, с использованием множества первых кодовых векторов, формирующих выбранную первую кодовую книгу;
кодовую книгу масштабных коэффициентов, содержащую масштабные коэффициенты, ассоциированные с множеством типов соответственно; и
вторую секцию квантования, которая имеет вторую кодовую книгу, содержащую множество вторых кодовых векторов, и получает второй код квантованием остаточного вектора между одним первым кодовым вектором, указанным первым кодом, и вектором, являющимся объектом квантования, с использованием вторых кодовых векторов и масштабного коэффициента, ассоциированного с классификационной информацией.
2. Устройство векторного квантования по п.1, дополнительно содержащее множительную секцию, которая получает вектор умножения посредством умножения остаточного вектора на величину, обратную масштабному коэффициенту, ассоциированному с классификационной информацией,
при этом вторая секция квантования квантует вектор умножения с использованием множества вторых кодовых векторов.
3. Устройство векторного квантования по п.1, дополнительно содержащее множительную секцию, которая получает множество векторов умножения посредством умножения каждого из множества вторых кодовых векторов на масштабный коэффициент, ассоциированный с классификационной информацией,
при этом вторая секция квантования квантует остаточный вектор с использованием множества векторов умножения.
4. Устройство векторного квантования по п.1, дополнительно содержащее третью секцию квантования, которая имеет третью кодовую книгу, содержащую множество третьих кодовых векторов, и получает третий код квантованием второго остаточного вектора между одним вторым кодовым вектором, указанным вторым кодом, и остаточным вектором, с использованием третьих кодовых векторов и масштабного коэффициента, ассоциированного с классификационной информацией.
5. Устройство векторного квантования по п.4, дополнительно содержащее вторую множительную секцию, которая получает второй вектор умножения посредством умножения второго остаточного вектора на величину, обратную масштабному коэффициенту, ассоциированному с классификационной информацией,
при этом третья секция квантования квантует второй вектор умножения с использованием множества третьих кодовых векторов.
6. Устройство векторного квантования по п.4, дополнительно содержащее вторую множительную секцию, которая получает множество вторых векторов умножения посредством умножения каждого из множества третьих кодовых векторов на масштабный коэффициент, ассоциированный с классификационной информацией,
при этом третья секция квантования квантует второй остаточный вектор с использованием множества вторых векторов умножения.
7. Устройство векторного деквантования, содержащее:
секцию классификации, которая генерирует классификационную информацию, указывающую тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов;
секцию демультиплексирования, которая демультиплексирует первый код, который является результатом квантования вектора, являющегося объектом квантования, на первой ступени, и второй код, который является результатом квантования вектора, являющегося объектом квантования, на второй ступени, из принятых закодированных данных;
секцию выбора, которая выбирает одну первую кодовую книгу, ассоциированную с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов соответственно;
первую секцию деквантования, которая выбирает один первый кодовый вектор, ассоциированный с первым кодом, из выбранной первой кодовой книги;
кодовую книгу масштабных коэффициентов, содержащую масштабные коэффициенты, ассоциированные с множеством типов соответственно; и
вторую секцию деквантования, которая выбирает один второй кодовый вектор, ассоциированный с вторым кодом, из второй кодовой книги, содержащей множество вторых кодовых векторов, и получает вектор, являющийся объектом квантования, с использованием одного второго кодового вектора, масштабного коэффициента, ассоциированного с классификационной информацией, и одного первого кодового вектора.
8. Способ векторного квантования, содержащий следующие этапы:
генерирования классификационной информации, указывающей тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов;
выбор одной первой кодовой книги, ассоциированной с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов соответственно;
получение первого кода квантованием вектора, являющегося объектом квантования, с использованием множества первых кодовых векторов, формирующих выбранную первую кодовую книгу; и
получение второго кода квантованием остаточного вектора между первым кодовым вектором, ассоциированным с первым кодом, и вектором, являющимся объектом квантования, с использованием множества вторых кодовых векторов, формирующих вторую кодовую книгу, и масштабного коэффициента, ассоциированного с классификационной информацией.
9. Способ векторного деквантования, содержащий следующие этапы:
генерирования классификационной информации, указывающей тип признака, коррелированного с вектором, являющимся объектом квантования, среди множества типов;
демультиплексирование первого кода, который является результатом квантования вектора, являющегося объектом квантования, на первой ступени, и второго кода, который является результатом квантования вектора, являющегося объектом квантования, на второй ступени, из принятых закодированных данных;
выбор одной первой кодовой книги, ассоциированной с классификационной информацией, из множества первых кодовых книг, ассоциированных с множеством типов соответственно;
выбор одного первого кодового вектора, ассоциированного с первым кодом, из выбранной первой кодовой книги; и
выбор одного второго кодового вектора, ассоциированного с вторым кодом, из второй кодовой книги, содержащей множество вторых кодовых векторов, и генерирование вектора, являющегося объектом квантования, с использованием одного второго кодового вектора, масштабного коэффициента, ассоциированного с классификационной информацией, и одного первого кодового вектора.
| RU 2005123381 А, 20.01.2006 | |||
| СПОСОБ И УСТРОЙСТВО ПРЕОБРАЗОВАНИЯ РЕЧЕВОГО СИГНАЛА МЕТОДОМ ЛИНЕЙНОГО ПРЕДСКАЗАНИЯ С АДАПТИВНЫМ РАСПРЕДЕЛЕНИЕМ ИНФОРМАЦИОННЫХ РЕСУРСОВ | 2003 |
|
RU2248619C2 |
| US 20070112564 A1, 17.05.2007 | |||
| WO 2006030865 A1, 23.03.2006 | |||
| WO 2006062202 A1, 15.06.2006. | |||

