Область техники, к которой относится изобретение.
Изобретение относится к системе электросвязи и предназначено для кодирования и декодирования речевого сигнала методом линейного предсказания при адаптивном распределении информационных ресурсов кодека (количества бит, выделяемых для кодирования текущего кадра речевого сигнала) по кодируемым параметрам.
Уровень техники.
Метод линейного предсказания речи принадлежит к классу методов преобразования речевого сигнала, использующих модель дискретного речевого сигнала в виде отклика линейной дискретной системы с переменными параметрами (голосового тракта) на соответствующий сигнал возбуждения (порождающий сигнал). Переменный характер состояния системы нацелен на повышение эффективности передачи речевого сигнала за счет доступной степени использования нестационарных свойств речи. Временной интервал постоянства параметров дискретной системы детерминирует длительность обрабатываемого кадра речи, выбирается в пределах интервала квазистационарности речевого сигнала (до 30 мс) и, как правило, является фиксированным. Анализатор речепреобразующего устройства выделяет из кадра речевого сигнала параметры состояния линейной системы и сигнала возбуждения, которые служат координатами вектора информационного обмена между кодером и декодером и позволяют синтезатору восстановить исходный сигнал с требуемой степенью верности.
Многовариантность определения, комбинирования и отображения параметров линейного предсказания и сигнала возбуждения является основной причиной разнообразия способов и устройств кодирования и декодирования речевого сигнала на основе метода линейного предсказания, доминирующего на современном этапе развития речепреобразующих устройств в диапазоне скоростей кодирования не более 16 кбит/с. Аналогом изобретения является способ преобразования речевого сигнала методом линейного предсказания с возбуждением от кода [Коротаев А.Г. Эффективный алгоритм кодирования речевого сигнала на скорости 4,8 кбит/с и ниже // Зарубежная электроника, 1996, №3, стр.52-68; Hayashi S., Kataoka A., Moriya T. 8 kbit/c short and medium delay speech codecs based on CELP coding // ETT, Vol.5, No.5, September-October 1994, pp. 49-56], заключающийся в идентификации синтезирующего фильтра кратковременного линейного предсказания с последующим выбором из фиксированных кодовых книг векторов стохастического и квазипериодического компонентов сигнала возбуждения и их масштабирующих коэффициентов, обеспечивающих синтез речевого кадра, максимально близкого к обрабатываемому по выбранной метрике. Выбор лучшего сигнала возбуждения осуществляется методом анализа через синтез. Информация о параметрах синтезирующего фильтра и сигнала возбуждения в виде двоичной кодовой комбинации передается по каналу связи. Декодирование сигнала заключается в формировании копии кадра цифрового речевого сигнала синтезирующим фильтром декодера, параметры и сигнал возбуждения которого определяются кодовой комбинацией, поступившей из канала связи. Недостатком способа является относительно низкое качество синтезированной речи, обусловленное, в числе прочих причин, невысокой степенью учета статистических характеристик кодируемых параметров. Известно устройство [Коротаев А.Г. Эффективный алгоритм кодирования речевого сигнала на скорости 4,8 кбит/с и ниже // Зарубежная электроника, 1996, №3, стр.52-68], реализующее этот способ.
Прототипом изобретения выбран способ преобразования речевого сигнала методом линейного предсказания с возбуждением от алгебраического кода и сопряженной структурой квантователя масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения (CS - ACELP) [Kataoka A., Hayashi S., Moriya Т., Kurihara S., Mano К. Basic algoritm of conjugate-structure algebraic CELP (CS - ASELP) speech coder // NTT Review, Vol. 8, No. 4, July 1996, pp. 24-29; Kataoka A., Hayashi S., Moriya Т., Ikedo J. LSP and gain quantization for CS - ACELP speech coder // NTT Review, Vol. 8, No. 4, July 1996, pp. 30-35; Kitawaki N. An 8-kbit/s speech coding method (CS - ASELP) standardized by ITU // NTT Review, Vol. 8, No. 4, July 1996, pp. 16-23], заключающийся в том, что методом анализа через синтез определяется набор квантованных параметров линейного предсказания кадра речи, обеспечивающий синтез кадра речевого сигнала, минимально отличающегося от оригинального. В качестве настраиваемой модели используется цифровой полюсный фильтр десятого порядка, коэффициенты которого, получаемые в результате процедуры идентификации, пересчитываются в вектор линейных спектральных частот  , подвергаемый непосредственному векторному квантованию. Квантованный вектор линейных спектральных частот
, подвергаемый непосредственному векторному квантованию. Квантованный вектор линейных спектральных частот 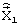 формирует частотную характеристику синтезирующего фильтра кратковременного линейного предсказания, используемого в процедуре анализа через синтез.
формирует частотную характеристику синтезирующего фильтра кратковременного линейного предсказания, используемого в процедуре анализа через синтез.
Сигнал возбуждения  , подаваемый на этот фильтр, непосредственно не определяется, представляется в виде линейной комбинации масштабированных стохастического и квазипериодического компонентов алгебраического типа и формируется на основании перебора возможных комбинаций кодовых векторов, содержащихся в кодовой книге стохастического компонента сигнала возбуждения, кодовой книге квазипериодического компонента сигнала возбуждения и кодовой книге векторов масштабирующих компонентов, имеющей сопряженную структуру. Выбор комбинации кодовых векторов, формирующих лучшую реализацию сигнала возбуждения, производится по минимуму взвешенной среднеквадратической ошибки между оригинальным и синтезированным кадрами речевого сигнала.
, подаваемый на этот фильтр, непосредственно не определяется, представляется в виде линейной комбинации масштабированных стохастического и квазипериодического компонентов алгебраического типа и формируется на основании перебора возможных комбинаций кодовых векторов, содержащихся в кодовой книге стохастического компонента сигнала возбуждения, кодовой книге квазипериодического компонента сигнала возбуждения и кодовой книге векторов масштабирующих компонентов, имеющей сопряженную структуру. Выбор комбинации кодовых векторов, формирующих лучшую реализацию сигнала возбуждения, производится по минимуму взвешенной среднеквадратической ошибки между оригинальным и синтезированным кадрами речевого сигнала.
Длительность обрабатываемого кадра речевого сигнала составляет 10 мс, при этом вектор линейных спектральных частот определяется один раз на длительности кадра, а вектор сигнала возбуждения - дважды (один раз на длительности подкадра, равной 5 мс). В результате кодирования формируется кодовая комбинация двоичного мультипликативного кода
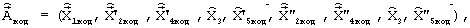
элементы которой содержат информацию о квантованном векторе линейных спектральных частот  , выбранных кодовых векторах квазипериодического компонента сигнала возбуждения на каждом из двух подкадров
, выбранных кодовых векторах квазипериодического компонента сигнала возбуждения на каждом из двух подкадров 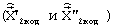 , стохастического компонента сигнала возбуждения на каждом из двух подкадров
, стохастического компонента сигнала возбуждения на каждом из двух подкадров 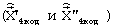 и масштабирующих коэффициентов на каждом из двух подкадров
и масштабирующих коэффициентов на каждом из двух подкадров 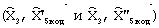 . Полученная кодовая комбинация имеет фиксированную структуру (для кодирования каждого информационного параметра выделяется постоянное количество бит), отображает обрабатываемый кадр речевого сигнала и поступает через канал связи (в неискаженном виде в случае идеального канала) к декодеру.
. Полученная кодовая комбинация имеет фиксированную структуру (для кодирования каждого информационного параметра выделяется постоянное количество бит), отображает обрабатываемый кадр речевого сигнала и поступает через канал связи (в неискаженном виде в случае идеального канала) к декодеру.
Декодирование заключается в формировании квантованных векторов 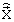 (один раз на длительности кадра) и
(один раз на длительности кадра) и 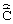 (два раза на длительности кадра) на основании полученной из канала связи информации с последующим синтезом кадра цифрового речевого сигнала полюсным фильтром, аналогичным используемому в процедуре анализа через синтез.
(два раза на длительности кадра) на основании полученной из канала связи информации с последующим синтезом кадра цифрового речевого сигнала полюсным фильтром, аналогичным используемому в процедуре анализа через синтез.
Недостатком данного способа является ограниченная степень учета характеристик текущего кадра речевого сигнала, проявляющаяся в фиксированном распределении информационных ресурсов кодека (количества бит, выделяемых для кодирования речевого кадра) по кодируемым параметрам в условиях инвариантности набора последних. Параметрическая степень адаптации кодирующей процедуры к характеристикам речи, используемая в рассматриваемом способе, ограничивает степень разрешения противоречия между нестационарным характером речевого сигнала и локально-стационарной моделью речеобразования, используемой в способе.
Прототипом изобретения выбрано устройство преобразования речевого сигнала методом линейного предсказания с возбуждением от алгебраического кода и сопряженной структурой квантователя масштабирующих коэффициентов компонентов сигнала возбуждения (CS - ACELP) [Kataoka А., Науаshi S., Moriya Т., Kurihara S., Mano K. Basic algoritm of conjugate-structure algebraic CELP (CS - ASELP) speech coder // NTT Review, Vol. 8, No. 4, July 1996, pp. 24-29; Kataoka A., Hayashi S., Moriya Т., Ikedo J. LSP and gain quantization for CS - ACELP speech coder // NTT Review, Vol. 8, No. 4, July 1996, pp. 30-35; Kitawaki N. An 8-kbit/s speech coding method (CS - ASELP) standardized by ITU // NTT Review, Vol. 8, No. 4, July 1996, pp. 16-23], изображенное на фиг.1 и реализующее способ, выбранный в качестве прототипа. Устройство состоит (фиг.1) из передающей части (кодера) и приемной части (декодера). Кодер прототипа содержит идентификатор фильтра кратковременного линейного предсказания (ИФКЛП) 1, фиксированный векторный квантователь параметров речевого сигнала (ФВК) 2 и устройство формирования кодовой комбинации (УФКК) 3, выход которого через канал связи соединен с декодером. Декодер прототипа содержит устройство разделения кодовой комбинации (УРКК) 4, фиксированный векторный деквантователь параметров речевого сигнала (ФВДК) 5 и фильтр синтеза кратковременного линейного предсказания (ФСКЛП) 6.
Структурная схема кодера прототипа изображена на фиг.2. Обрабатываемый кадр речевого сигнала 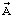 поступает на ИФКЛП 1, на выходе которого формируется вектор линейных спектральных частот
поступает на ИФКЛП 1, на выходе которого формируется вектор линейных спектральных частот  , поступающий на векторный квантователь линейных спектральных частот (ВКЛСЧ) 7. Результатом квантования является квантованный вектор линейных спектральных частот
, поступающий на векторный квантователь линейных спектральных частот (ВКЛСЧ) 7. Результатом квантования является квантованный вектор линейных спектральных частот  , формирующий частотную характеристику фильтра синтеза кратковременного линейного предсказания (ФСКЛП) 11, идентичного блоку 6. Реализации квантованного сигнала возбуждения
, формирующий частотную характеристику фильтра синтеза кратковременного линейного предсказания (ФСКЛП) 11, идентичного блоку 6. Реализации квантованного сигнала возбуждения  соответствующего каждому подкадру речевого сигнала и поступающего на второй вход ФСКЛП 11, формируются процедурой перебора на выходе сумматора, подключенного на выход кодовой книги векторов масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения (КК 3) 10, имеющей сопряженную структуру, и представляют собой линейные комбинации вида
соответствующего каждому подкадру речевого сигнала и поступающего на второй вход ФСКЛП 11, формируются процедурой перебора на выходе сумматора, подключенного на выход кодовой книги векторов масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения (КК 3) 10, имеющей сопряженную структуру, и представляют собой линейные комбинации вида
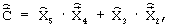
где  - кодовый вектор кодовой книги стохастического компонента сигнала возбуждения (КК 1) 8, отображающий остаток кратковременного и долговременного линейного предсказания подкадра речевого сигнала и имеющий единичную дисперсию;
- кодовый вектор кодовой книги стохастического компонента сигнала возбуждения (КК 1) 8, отображающий остаток кратковременного и долговременного линейного предсказания подкадра речевого сигнала и имеющий единичную дисперсию;
 - масштабирующий коэффициент кодового вектора
- масштабирующий коэффициент кодового вектора  ;
;
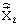 - кодовый вектор кодовой книги квазипериодического компонента сигнала возбуждения (КК 2) 9, отображающий квазипериодический компонент остатка кратковременного линейного предсказания подкадра речевого сигнала и имеющий единичную дисперсию;
- кодовый вектор кодовой книги квазипериодического компонента сигнала возбуждения (КК 2) 9, отображающий квазипериодический компонент остатка кратковременного линейного предсказания подкадра речевого сигнала и имеющий единичную дисперсию;
 - масштабирующий коэффициент кодового вектора
- масштабирующий коэффициент кодового вектора  .
.
Для выбора лучшей реализации сигнала возбуждения  в состав кодера прототипа включена система анализа через синтез, состоящая из ФСКЛП 11, сумматора 12, взвешивающего фильтра восприятия (ВФВ) 13 и определителя минимального искажения (ОМИ) 14. Перечисленные блоки системы анализа через синтез совместно с блоками 7, 8, 9 и 10 являются составными элементами ФВК 2. На выходе сумматора 12 формируется вектор разности оригинального и синтезированного подкадров речевого сигнала
в состав кодера прототипа включена система анализа через синтез, состоящая из ФСКЛП 11, сумматора 12, взвешивающего фильтра восприятия (ВФВ) 13 и определителя минимального искажения (ОМИ) 14. Перечисленные блоки системы анализа через синтез совместно с блоками 7, 8, 9 и 10 являются составными элементами ФВК 2. На выходе сумматора 12 формируется вектор разности оригинального и синтезированного подкадров речевого сигнала  (для первого подкадра) или
(для первого подкадра) или  (для второго подкадра), который подвергается процедуре частотного взвешивания в ВФВ 13 с расчетом взвешенного вектора разности
(для второго подкадра), который подвергается процедуре частотного взвешивания в ВФВ 13 с расчетом взвешенного вектора разности 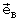 , после чего в ОМИ 14 производится расчет взвешенной среднеквадратичной ошибки (ВСКО) между оригинальным речевым подкадром и подкадрами синтезированного речевого сигнала, полученными от каждой реализации сигнала возбуждения. По критерию минимума ВСКО формируется команда выбора лучших кодовых векторов (КВЛКВ), поступающая на блоки 8, 9 и 10. Информация о выбранных векторах кодовых книг
, после чего в ОМИ 14 производится расчет взвешенной среднеквадратичной ошибки (ВСКО) между оригинальным речевым подкадром и подкадрами синтезированного речевого сигнала, полученными от каждой реализации сигнала возбуждения. По критерию минимума ВСКО формируется команда выбора лучших кодовых векторов (КВЛКВ), поступающая на блоки 8, 9 и 10. Информация о выбранных векторах кодовых книг 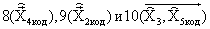 на обоих подкадрах совместно с информацией о векторе
на обоих подкадрах совместно с информацией о векторе 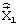
 поступает на УФКК 3, с выхода которого кодовая комбинация
поступает на УФКК 3, с выхода которого кодовая комбинация 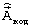 поступает в канал связи.
поступает в канал связи.
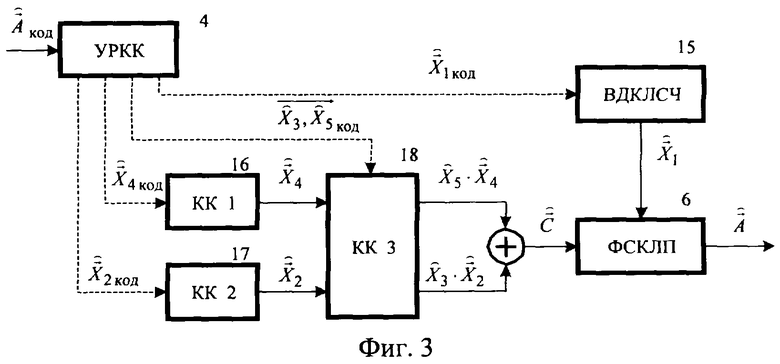
Структурная схема декодера прототипа изображена на фиг.3. Кодовая комбинация 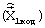 , поступающая из канала связи на вход декодера, в УРКК 4 разделяется на элементы
, поступающая из канала связи на вход декодера, в УРКК 4 разделяется на элементы 
 которые определяют векторы, формируемые один раз на длительности кадра векторным деквантователем линейных спектральных частот (ВДКЛСЧ) 15 и дважды на длительности кадра кодовой книгой квазипериодического компонента сигнала возбуждения (КК 2) 17, кодовой книгой стохастического компонента сигнала возбуждения (КК 1) 16 и кодовой книгой векторов масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения (КК 3) 18. На входы ФСКЛП 6 поступают вектор линейных спектральных частот
которые определяют векторы, формируемые один раз на длительности кадра векторным деквантователем линейных спектральных частот (ВДКЛСЧ) 15 и дважды на длительности кадра кодовой книгой квазипериодического компонента сигнала возбуждения (КК 2) 17, кодовой книгой стохастического компонента сигнала возбуждения (КК 1) 16 и кодовой книгой векторов масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения (КК 3) 18. На входы ФСКЛП 6 поступают вектор линейных спектральных частот 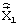 , детерминирующий частотную характеристику фильтра, и вектор сигнала возбуждения
, детерминирующий частотную характеристику фильтра, и вектор сигнала возбуждения 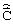 , обеспечивающие формирование подкадров кадра синтезированного речевого сигнала
, обеспечивающие формирование подкадров кадра синтезированного речевого сигнала  идентичного (в случае идеального канала связи) кадру речевого сигнала на выходе ФСКЛП 11. Блоки 15, 16, 17 и 18 являются составными элементами ФВДК 5.
идентичного (в случае идеального канала связи) кадру речевого сигнала на выходе ФСКЛП 11. Блоки 15, 16, 17 и 18 являются составными элементами ФВДК 5.
Недостатком устройства является неэффективное использование информационных ресурсов (а следовательно - пропускной способности канала связи) по причине невысокой степени учета статистических характеристик кодируемых параметров речи.
Сущность изобретения.
Предлагаемый способ преобразования речевого сигнала решает задачу повышения качества речевого сигнала, синтезируемого методом линейного предсказания, без увеличения скорости кодирования.
Указанный технический результат достигается тем, что известный способ преобразования речевого сигнала методом линейного предсказания с возбуждением от алгебраического кода и сопряженной структурой квантователя масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения дополняется процедурой акустико-фонетической классификации обрабатываемых кадров речевого сигнала на четыре непересекающиеся класса (кадры отсутствия речи, кадры вокализованной речи, кадры невокализованной речи, переходные кадры к вокализованной речи), используемой в качестве управляющей процедуры адаптивного распределения информационных ресурсов. Такой подход повышает степень адаптации процедур кодирования и декодирования от параметрической до структурной и позволяет использовать различия в статистических характеристиках кодируемых параметров речевого сигнала в указанных классах речевых кадров, выделяя биты на кодирование параметров пропорционально их информативности в данном классе речевых кадров. Процедура акустико-фонетической классификации выполняется одновременно с процедурой идентификации настраиваемой модели (цифрового полюсного фильтра), что предотвращает нежелательное возрастание алгоритмической временной задержки на обработку речевого кадра, являющейся критическим параметром для осуществления телефонного обмена в режиме реального времени. Классификационное решение h (номер класса обрабатываемого речевого кадра) является дополнительным параметром информационного обмена между кодером и декодером, в результате чего кодовая комбинация двоичного мультипликативного кода имеет вид

без изменения ее разрядности (без изменения скорости кодирования речевого сигнала). Кодирование параметра h требует выделения двух бит кодовой комбинации, остальные информационные ресурсы адаптивно распределяются по кодируемым параметрам, что обуславливает переход от используемых фиксированных векторных квантования и деквантования кодируемых параметров речевого сигнала к классифицированным векторным квантованию и деквантованию [Спутниковое телевидение. Новые методы передачи. Под редакцией Харатишвили Н.Г. - М.: Радио и связь, 1993. - стр.175-199] с четырьмя режимами функционирования. Обучение квантователей и деквантователей для каждого класса речевых кадров производится по обучающим выборкам, сформированным на основе речевых кадров, принадлежащих к данному классу.
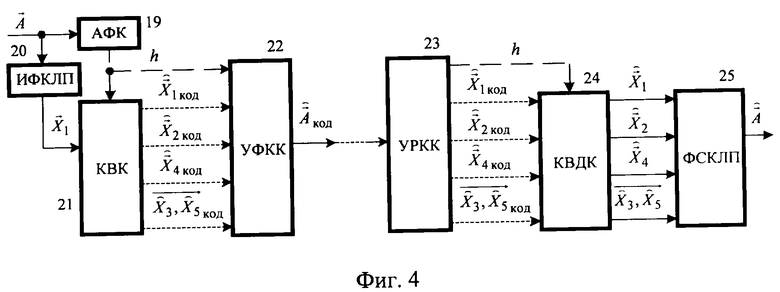
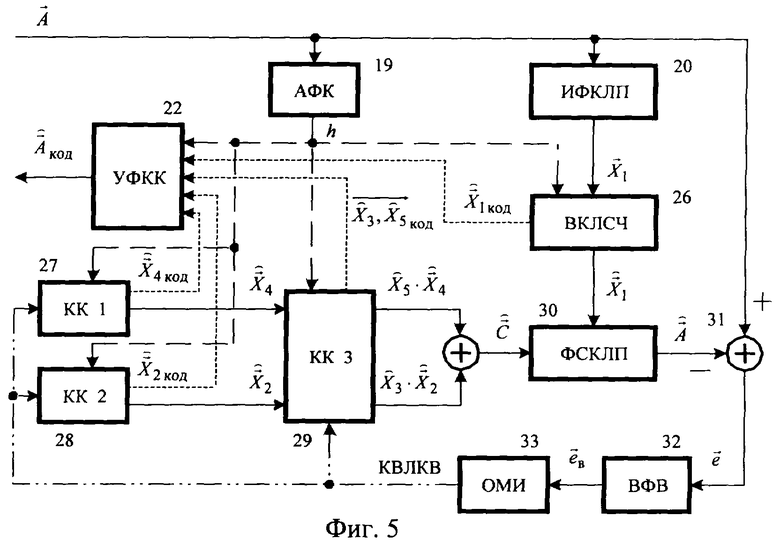
Предлагаемое устройство предназначено для осуществления предлагаемого способа в целом. Повышение качества речевого сигнала без увеличения скорости кодирования достигается тем, что известное устройство преобразования речевого сигнала методом линейного предсказания с возбуждением от алгебраического кода и сопряженной структурой квантователя масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения дополняется акустико-фонетическим классификатором (АФК) 19 (фиг.4, 5), вместо ФВК 2 и ФВДК 5 используются классифицированный векторный квантователь (KBК) 21 и классифицированный векторный деквантователь (КВДК) 24. На вход АФК 19 поступает обрабатываемый кадр речевого сигнала 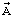 , с его выхода классификационное решение h (h=1,2,3,4), определяющее принадлежность обрабатываемого кадра к одному из четырех непересекающихся классов (кадрам отсутствия речи, кадрам вокализованной речи, кадрам невокализованной речи, переходным кадрам к вокализованной речи), поступает на устройство формирования кодовой комбинации (УФКК) 22 и на квантующие устройства КВК 21: векторный квантователь линейных спектральных частот (ВКЛСЧ) 26, кодовую книгу стохастического компонента сигнала возбуждения (КК 1) 27, кодовую книгу квазипериодического компонента сигнала возбуждения (КК 2) 28 и кодовую книгу векторов масштабирующих коэффициентов компонентов сигнала возбуждения (КК 3) 29. УФКК 22 отличается от УФКК 3 тем, что использует четыре варианта структуры формируемой кодовой комбинации
, с его выхода классификационное решение h (h=1,2,3,4), определяющее принадлежность обрабатываемого кадра к одному из четырех непересекающихся классов (кадрам отсутствия речи, кадрам вокализованной речи, кадрам невокализованной речи, переходным кадрам к вокализованной речи), поступает на устройство формирования кодовой комбинации (УФКК) 22 и на квантующие устройства КВК 21: векторный квантователь линейных спектральных частот (ВКЛСЧ) 26, кодовую книгу стохастического компонента сигнала возбуждения (КК 1) 27, кодовую книгу квазипериодического компонента сигнала возбуждения (КК 2) 28 и кодовую книгу векторов масштабирующих коэффициентов компонентов сигнала возбуждения (КК 3) 29. УФКК 22 отличается от УФКК 3 тем, что использует четыре варианта структуры формируемой кодовой комбинации 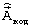 , при этом два бита во всех режимах выделяются на кодирование классификационного решения h, остальные биты без увеличения общей разрядности кодовой комбинации адаптивно распределяются по кодируемым параметрам речевого сигнала в зависимости от значения h.
, при этом два бита во всех режимах выделяются на кодирование классификационного решения h, остальные биты без увеличения общей разрядности кодовой комбинации адаптивно распределяются по кодируемым параметрам речевого сигнала в зависимости от значения h.
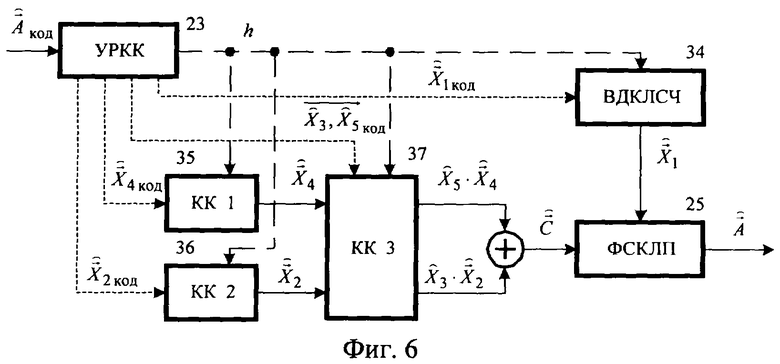
Устройство разделения кодовой комбинации (УРКК) 23 (фиг.4, 6) отличается от УРКК 4 тем, что, в зависимости от классифицированного решения h, содержащегося в поступающей из канала связи кодовой комбинации, использует один из четырех вариантов разделения, отличающихся числом бит, выделенных на каждый из кодируемых параметров. С выхода УРКК 23 классификационное решение h поступает на управляющие входы элементов КВДК 24: векторный деквантователь линейных спектральных частот (ВДКЛСЧ) 34, кодовую книгу стохастического компонента сигнала возбуждения (КК 1) 35, кодовую книгу квазипериодического компонента сигнала возбуждения (КК 2) 36 и кодовую книгу векторов масштабирующих коэффициентов компонентов сигнала возбуждения (КК 3) 37.
Блоки 26, 27, 28, 29, 34, 35, 36, 37 отличаются от блоков 7, 8, 9, 10, 15, 16, 17 и 18 соответственно наличием четырех вариантов кодовых книг (четырех режимов работы), обученных на основе обучающих выборок, сформированных использованием кадров речевого сигнала, принадлежащих конкретному классу речевых кадров. Режим работы этих блоков определяется классификационным решением h.
Перечень фигур схем.
На фиг.1 представлена структурная схема устройства преобразования речевого сигнала на основе метода линейного предсказания с фиксированным распределением информационных ресурсов (прототип); на фиг.2 - структурная схема кодера речевого сигнала устройства прототипа; на фиг.3 - структурная схема декодера речевого сигнала устройства прототипа; на фиг.4 - структурная схема предлагаемого устройства преобразования речевого сигнала на основе метода линейного предсказания с адаптивным распределением информационных ресурсов, с помощью которого реализуется предлагаемый способ; на фиг.5 - структурная схема кодера речевого сигнала предлагаемого устройства; на фиг.6 - структурная схема декодера речевого сигнала предлагаемого устройства; на фиг.7 - структурная схема акустико-фонетического классификатора кодера речевого сигнала предлагаемого устройства, на фиг.8 - блок-схема алгоритма акустико-фонетической классификации кадров речевого сигнала.
Сведения, подтверждающие возможность осуществления изобретения.
Предлагаемый способ преобразования речевого сигнала осуществляют следующим образом. В процедуры кодирования и декодирования речевого сигнала вводят процедуру акустико-фонетической классификации обрабатываемого кадра речевого сигнала, принятое классификационное решение h используют в качестве управляющего параметра адаптивного распределения информационных ресурсов, определяющего варианты осуществления классифицированных векторных квантования и деквантования кодируемых параметров речевого кадра. Такой подход позволяет использовать отдельные варианты квантования и деквантования речевых кадров для каждого класса, характеризующиеся различным распределением информационных ресурсов по кодируемым параметрам, определяемым степенью значимости каждого из кодируемых параметров для качественного представления речевых кадров данного класса (обеспечивающим максимальное качество синтезируемых кадров данного класса). Дополнительные затраты двух бит кодовой комбинации компенсируются значительным увеличением качества квантованного представления каждого из четырех классов речевых кадров, в результате чего достигается повышение качества речевого сигнала, синтезируемого методом линейного предсказания без увеличения скорости кодирования.
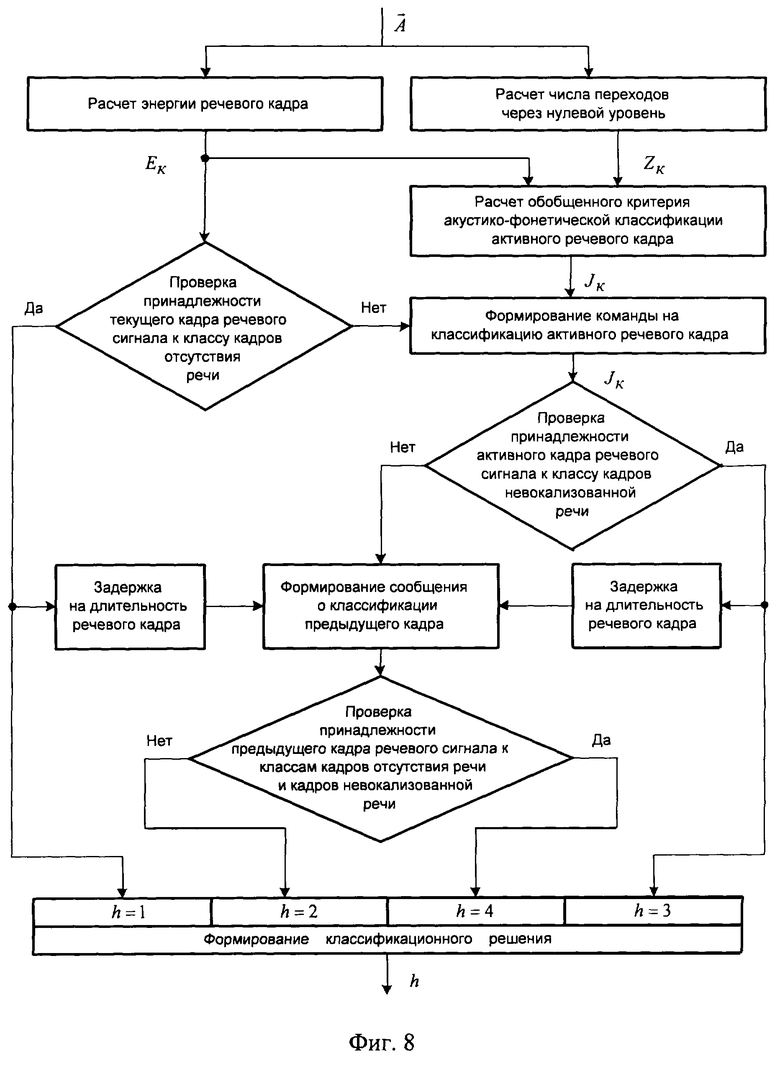
Акустико-фонетическая классификация речевых кадров осуществляется на основе процедур анализа речи на акустическом и фонетическом уровнях. В качестве классификационного критерия принадлежности кадра речевого сигнала к классу кадров отсутствия речи используется энергия речевого кадра Еk. Для принятия решения о принадлежности кадра активного речевого сигнала к классу кадров невокализованной речи используется обобщенный критерий Jk, учитывающий энергию речевого кадра Еk и число переходов через нуль Zk. К классу переходных кадров относятся начальные кадры вокализованных сегментов речевого сигнала.
Предлагаемое устройство (фиг.4) состоит из передающей части (кодера) и приемной части (декодера). Кодер содержит акустико-фонетический классификатор (АФК) 19, идентификатор фильтра кратковременного линейного предсказания (ИФКЛП) 20, классифицированный векторный квантователь параметров речевого сигнала (KBК) 21 и устройство формирования кодовой комбинации (УФКК) 22, выход которого через канал связи соединен с декодером. Декодер предлагаемого устройства содержит устройство разделения кодовой комбинации (УРКК) 23, классифицированный векторный деквантователь параметров речевого сигнала (КВДК) 24 и фильтр синтеза кратковременного линейного предсказания (ФСКЛП) 25.
Структурная схема кодера изображена на фиг.5. Выход АФК 19 соединен с УФКК 22 и управляющими входами элементов КВК: векторного квантователя линейных спектральных частот (ВКЛСЧ) 26, кодовой книги стохастического компонента сигнала возбуждения (КК 1) 27, кодовой книги квазипериодического компонента сигнала возбуждения (КК 2) 28 и кодовой книги векторов масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения (КК 3) 29. Блоки 26, 27, 28 и 29 имеют четыре варианта функционирования в зависимости от одного из четырех возможных значений сигнала на выходе АФК. Выход ИФКЛП 20 является входом ВКЛСЧ 26, выход которого соединен со входом фильтра синтеза кратковременного линейного предсказания (ФСКЛП) 30, идентичного блоку 25. Выходы КК 1 и КК 2 являются входами КК 3, выходы которого соединены с входами сумматора, формирующего сигнал возбуждения 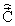 . Выход сумматора соединен со вторым входом ФСКЛП 30. На входы сумматора 31 поступают сигнал со входа кодера и инвертированный сигнал с выхода ФСКЛП 30, выход сумматора соединен с входом взвешивающего фильтра восприятия (ВФВ) 32. Выход ВФВ 32 является входом определителя минимального искажения (ОМИ) 33, выход которого соединен с управляющими входами блоков 27, 28, 29. Вторые выходы блоков 26, 27, 28 и 29 являются входами УФКК 22. Выход УФКК 22 является выходом кодера предлагаемого устройства.
. Выход сумматора соединен со вторым входом ФСКЛП 30. На входы сумматора 31 поступают сигнал со входа кодера и инвертированный сигнал с выхода ФСКЛП 30, выход сумматора соединен с входом взвешивающего фильтра восприятия (ВФВ) 32. Выход ВФВ 32 является входом определителя минимального искажения (ОМИ) 33, выход которого соединен с управляющими входами блоков 27, 28, 29. Вторые выходы блоков 26, 27, 28 и 29 являются входами УФКК 22. Выход УФКК 22 является выходом кодера предлагаемого устройства.
Структурная схема декодера изображена на фиг.6. Сигналы с выхода УРКК 23 поступают на управляющие и информационные входы элементов КВДК: векторного деквантователя линейных спектральных частот (ВДКЛСЧ) 34, кодовой книги стохастического компонента сигнала возбуждения (КК 1) 35, кодовой книги квазипериодического компонента сигнала возбуждения (КК 2) 36 и кодовой книги векторов масштабирующих коэффициентов стохастического и квазипериодического компонентов сигнала возбуждения (КК 3) 37. Блоки 34, 35, 36 и 37 имеют четыре варианта функционирования в зависимости от одного из четырех возможных значений сигнала h на выходе АФК. Выходы блоков 35 и 36 соединены с входами блока 37, выходы которого соединены с входами сумматора, формирующего сигнал возбуждения  . Выход сумматора соединен со входом ФСКЛП 25, на второй вход которого поступает сигнал с ВДКЛСЧ 34. Выход блока 25 является выходом декодера предлагаемого устройства.
. Выход сумматора соединен со входом ФСКЛП 25, на второй вход которого поступает сигнал с ВДКЛСЧ 34. Выход блока 25 является выходом декодера предлагаемого устройства.
Акустико-фонетический классификатор 19 содержит (фиг.7) определитель энергии (ОЭ) 38 и определитель числа переходов через нуль (ОЧПЧН) 39, на входы которых одновременно поступает обрабатываемый сигнал. Выходы блоков 38 и 39 соединены со входами определителя кадров невокализованной речи (ОКНР) 41, кроме того, выход ОЭ 38 является входом определителя кадров пауз (ОКП) 40. На вход определителя кадров вокализованной речи и переходных кадров (ОКВР и ПК) 42 поступают сигналы с двух выходов ОКНР 41 и с выхода ОКП 40. Входы формирователя классификационных решений (ФКР) 43 соединены с двумя выходами блока 42, выходами блоков 40 и 41. Выход ФКР 43 является выходом АФК.
Предлагаемое устройство выполняет покадровую обработку речевого сигнала. На вход кодера подается текущий кадр 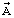 речевого сигнала, представленный в формате линейной импульсно-кодовой модуляции. Результатом параметрического кодирования на основе метода линейного предсказания с адаптивным распределением информационных ресурсов является двоичная кодовая комбинация
речевого сигнала, представленный в формате линейной импульсно-кодовой модуляции. Результатом параметрического кодирования на основе метода линейного предсказания с адаптивным распределением информационных ресурсов является двоичная кодовая комбинация 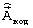 , поступающая с выхода кодера в канал связи. На выходе декодера формируется кадр синтезированного речевого сигнала
, поступающая с выхода кодера в канал связи. На выходе декодера формируется кадр синтезированного речевого сигнала  , соответствующего исходному кадру
, соответствующего исходному кадру  .
.
Предлагаемое устройство работает следующим образом. Обрабатываемый кадр речевого сигнала поступает одновременно на АКФ 19 и ИФКЛП 20, где производятся акустико-фонетическая классификация речевого кадра и идентификация фильтра кратковременного линейного предсказания соответственно. Алгоритм акустико-фонетической классификации кадров речевого сигнала представлен блок-схемой на фиг.8. Обрабатываемый кадр 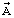 речевого сигнала одновременно анализируется на величину энергии Еk и число переходов через нуль Zk. По величине энергии кадра принимается классификационное решение первого уровня "кадр отсутствия речи (кадр паузы, h=1) - кадр активной речи". В случае принятия решения о кадре отсутствия речи классификационная процедура завершается. В противном случае рассчитывается обобщенный критерий
речевого сигнала одновременно анализируется на величину энергии Еk и число переходов через нуль Zk. По величине энергии кадра принимается классификационное решение первого уровня "кадр отсутствия речи (кадр паузы, h=1) - кадр активной речи". В случае принятия решения о кадре отсутствия речи классификационная процедура завершается. В противном случае рассчитывается обобщенный критерий 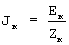 , на основании которого принимается классификационное решение второго уровня "кадр невокализованной речи (h=3) - кадр вокализованной речи или переходной кадр". В случае принятия решения о кадре невокализованной речи классификационная процедура завершается. В противном случае на основании сравнения текущего решения с классификационным решением по предыдущему речевому кадру принимается классификационное решение третьего уровня "кадр вокализованной речи (h=2) - переходной кадр (h=4)". На этом процедура классификации завершается. Выделение переходных кадров, характеризующихся наиболее широким диапазоном изменения значений кодируемых параметров, в отдельный класс позволяет повысить точность их квантования, что оказывает значительное влияние на качество синтезируемой речи.
, на основании которого принимается классификационное решение второго уровня "кадр невокализованной речи (h=3) - кадр вокализованной речи или переходной кадр". В случае принятия решения о кадре невокализованной речи классификационная процедура завершается. В противном случае на основании сравнения текущего решения с классификационным решением по предыдущему речевому кадру принимается классификационное решение третьего уровня "кадр вокализованной речи (h=2) - переходной кадр (h=4)". На этом процедура классификации завершается. Выделение переходных кадров, характеризующихся наиболее широким диапазоном изменения значений кодируемых параметров, в отдельный класс позволяет повысить точность их квантования, что оказывает значительное влияние на качество синтезируемой речи.
Классификационное решение h детерминирует режим функционирования УФКК 22 и текущее состояние ВКЛСЧ 26, блоков 27, 28 и 29, адаптируя, тем самым, распределение информационных ресурсов устройства под характеристики обрабатываемого кадра речевого сигнала. ВКЛСЧ 26 выполняет векторное квантование вектора линейных спектральных частот  , являющегося результатом процедуры идентификации в блоке 20, с выхода ВКЛСЧ 26 квантованный вектор
, являющегося результатом процедуры идентификации в блоке 20, с выхода ВКЛСЧ 26 квантованный вектор 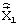 поступает на ФСКЛП 30, фиксируя его состояние на временной интервал, равный длительности обрабатываемого кадра. Перебор кодовых векторов, содержащихся в кодовых книгах 27, 28, 29, приводит к формированию множества возможных реализаций сигнала возбуждения
поступает на ФСКЛП 30, фиксируя его состояние на временной интервал, равный длительности обрабатываемого кадра. Перебор кодовых векторов, содержащихся в кодовых книгах 27, 28, 29, приводит к формированию множества возможных реализаций сигнала возбуждения  поочередно для обоих подкадров речевого сигнала. На выходе ФСКЛП 30 поочередно формируются множества реализации подкадров квантованного речевого кадра
поочередно для обоих подкадров речевого сигнала. На выходе ФСКЛП 30 поочередно формируются множества реализации подкадров квантованного речевого кадра  . На выходе сумматора 31 формируется множество векторов
. На выходе сумматора 31 формируется множество векторов  ошибок квантования подкадров, на выходе ВФВ 32 - множество векторов
ошибок квантования подкадров, на выходе ВФВ 32 - множество векторов 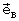 взвешенных ошибок квантования подкадров, которое в ОМИ 33 пересчитывается во множество взвешенных среднеквадратических ошибок (ВСКО).
взвешенных ошибок квантования подкадров, которое в ОМИ 33 пересчитывается во множество взвешенных среднеквадратических ошибок (ВСКО).
По минимальной из полученных ВСКО в ОМИ 33 принимается решение о лучшей комбинации кодовых векторов, которое в виде команды КВЛКВ поступает на блоки 27, 28, 29. С выхода этих блоков по окончании обработки каждого подкадра информация о лучших комбинациях кодовых векторов поступает на УФКК 22, где она объединяется с информацией о классификационном решении h и информацией о векторе 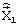 . На выходе УФКК 22 формируется кодовая комбинация
. На выходе УФКК 22 формируется кодовая комбинация

поступающая в канал связи, а из него - на вход УРКК 23. Классификационное решение h, выделенное в УРКК 23 из  , детерминирует режим разделения кодовой комбинации в УРКК 23 и состояние ВДКЛСЧ 34, блоков 35, 36 и 37, адаптируя, тем самым, распределение информационных ресурсов устройства под характеристики обрабатываемого кадра речевого сигнала.
, детерминирует режим разделения кодовой комбинации в УРКК 23 и состояние ВДКЛСЧ 34, блоков 35, 36 и 37, адаптируя, тем самым, распределение информационных ресурсов устройства под характеристики обрабатываемого кадра речевого сигнала.
Элемент  комбинации мультипликативного кода, содержащий информацию о квантованном векторе линейных спектральных частот, поступает на вход ВДКЛСЧ 34, на выходе которого формируется вектор
комбинации мультипликативного кода, содержащий информацию о квантованном векторе линейных спектральных частот, поступает на вход ВДКЛСЧ 34, на выходе которого формируется вектор  , идентичный вектору на выходе ВКЛСЧ 26. Элементы комбинации мультипликативного кода, содержащие информацию о лучших кодовых векторах первого подкадра
, идентичный вектору на выходе ВКЛСЧ 26. Элементы комбинации мультипликативного кода, содержащие информацию о лучших кодовых векторах первого подкадра 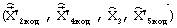 и второго подкадра
и второго подкадра
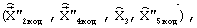 поступают на блоки 36, 35 и 37, в результате чего на выходе сумматора, включенного между блоками 37 и 25, формируется сигнал возбуждения, идентичный сигналу на входе ФСКЛП 30. ФСКЛП 25 идентичен ФСКЛП 30. На выходе ФСКЛП 25 формируется кадр
поступают на блоки 36, 35 и 37, в результате чего на выходе сумматора, включенного между блоками 37 и 25, формируется сигнал возбуждения, идентичный сигналу на входе ФСКЛП 30. ФСКЛП 25 идентичен ФСКЛП 30. На выходе ФСКЛП 25 формируется кадр  синтезированного речевого сигнала, идентичный кадру речевого сигнала на выходе ФСКЛП 30 и являющийся наиболее близким к обрабатываемому кадру
синтезированного речевого сигнала, идентичный кадру речевого сигнала на выходе ФСКЛП 30 и являющийся наиболее близким к обрабатываемому кадру  по критерию ВСКО.
по критерию ВСКО.
Приведенные сведения показывают, что средства, воплощающие изобретения при их осуществлении, способны обеспечить более качественную передачу речи за счет адаптивного распределения информационных ресурсов устройства преобразования речевого сигнала, использующего метод линейного предсказания.


Изобретение относится к электросвязи. Его использование для кодирования и декодирования речевого сигнала методом линейного предсказания при адаптивном распределении информационных ресурсов кодека обеспечивает достижение технического результата в виде повышения качества синтезируемого сигнала без увеличения скорости кодирования. Этот результат достигается за счёт использования акустико-фонетической классификации обрабатываемых кадров речевого сигнала на четыре непересекающихся класса – отсутствие речи, вокализованная речь, невокализованная речь и переход к вокализованной речи. Эта классификация выполняется одновременно с идентификацией фильтра кратковременного линейного предсказания, и по ее результатам информационные ресурсы адаптивно распределяются по кодируемым параметрам. Классификационное решение включают в структуру кодовой комбинации для передачи по каналу связи и используют для определения режимов векторных квантователя и деквантователя, обученных для каждого класса речевых кадров. 2 с. и 2 з.п. ф-лы, 8 ил.


