Предлагаемая группа изобретений относятся к компьютерным системам и, более конкретно, к системам и способам обработки индексной структуры для информационного поиска гипертекстовых документов.
Системы информационного поиска предназначены для выявления в большой совокупности (коллекции) электронных документов таких электронных документов, которые в наибольшей степени соответствуют информационной потребности пользователя, сформулированной в виде запроса к системе. Существуют различные способы формулировки запроса, например с помощью ключевых слов естественного языка, в виде текстового описания ситуации или вопроса. Если в результате поиска несколько документов удовлетворяют запросу пользователя, то результаты поиска упорядочиваются по убыванию степени соответствия документов запросу, то есть выполняется ранжирование по релевантности. Основными критериями оценки качества работы системы информационного поиска являются полнота результатов поиска, их точность, а также скорость обработки поискового запроса.
Система информационного поиска обычно включает в себя средство индексирования, которое идентифицирует и извлекает электронные документы из коллекции, строит на основе информации извлеченных документов их описания, которые помещает в индексную структуру данных. Индексная структура обычно организуется в виде обратного индекса (inverted index) слов естественного языка. Обратный индекс представляет собой структуру данных, реализуемую в виде хэш-таблицы или В-дерева (возможно, с некоторыми модификациями), хранящую информацию о проиндексированных документах. Как правило, в обратный индекс помещается информация о тех признаках документов, по которым предполагается осуществлять поиск. В качестве таких признаков могут выступать, например, слова естественного языка, а значениями является совокупность вхождений этих слов в конкретные электронные документы. Пользователь системы информационного поиска формулирует свою информационную потребность и заполняет поисковую форму, отображаемую на компьютерном дисплее. Сформулированный пользователем запрос передается системе поиска. Система поиска выполняет просмотр индексной базы данных на предмет записей, которые соответствуют запросу пользователя, формируя список результатов. Список результатов идентифицирует те электронные документы, которые, по мнению системы, удовлетворяют информационную потребность пользователя.
Известные машины поиска сортируют результата поиска на основе содержимого электронных документов, например на основе количества появлений слов запроса в каждом документе - RU 2383922. Также известны системы, использующие дополнительную информацию о запросе пользователя и о хранимых электронных документах с целью предоставления пользователю наиболее точных и полных результатов - RU 2383922, RU 2343537. В этих системах для определения электронных документов, в наибольшей степени соответствующих информационной потребности пользователя, применяются методы учета метаинформации о документах. В качестве метаинформации выступают сведения об авторах документа, дате публикации или обработки поисковой системой, информационном источнике, а также отдельные структурные элементы, такие как заголовок документа, сноски, ссылки на другие документы. При этом результаты поиска могут быть подвергнуты фильтрации по соответствующим метаданным, и документы, не соответствующие заданным значениям метаданных, исключаются из поисковой выдачи. Наряду с метаинформацией при поиске может быть учтена дополнительная информация, содержащаяся в тексте электронных документов: например, совместная встречаемость слов естественного языка, связи между словами, составляющими устойчивые словосочетания, и иные связи между сущностями, входящими в состав документа, - RU 2377645, RU 2388050. Для учета подобной информации она, наряду с метаданными, должна быть помещена в базу данных системы информационного поиска с целью обработки на этапе поиска.
Из вышесказанного следует, что в современных системах информационного поиска имеется тенденция к расширению возможностей формулировки поискового запроса, то есть пользователь не ограничивается только вводом ключевых слов, но и имеет возможность задавать метаинформацию, характеризующую целевые электронные документы. Кроме того, имеется потребность в обработке естественно-языковых запросов, сформулированных в виде описания некоторой ситуации или вопроса, и поиске электронных документов, содержащих близкие по смыслу ситуации или ответ на заданный вопрос. На решение указанной проблемы направлены предложенные способ и устройство семантического поиска электронных документов.
Соответственно, техническим результатом изобретения является повышение полноты и точности поиска электронных документов, которое достигается при использовании способа и системы семантического поиска электронных документов.
При осуществлении предложенного способа семантического поиска электронных документов:
- формируют аппаратными средствами поисковой системы коллекцию электронных документов, каждый из которых обладает уникальным идентификатором (например, URI);
- выделяют метаинформацию о документах;
- электронные документы подвергают лингвистическому анализу;
- на основе проведенного анализа преобразуют коллекцию электронных документов поисковой системы в индексную структуру, организованную в виде инвертированного индекса слов естественного языка, содержащего информацию о вхождениях слов естественного языка в электронные документы, а также метаинформацию об электронных документах;
- выполняют анализ поискового запроса;
- выполняют поиск документов, содержащих слова поискового запроса;
- выполняют отбор документов, метаинформация которых соответствует метаинформации, заданной в запросе;
- осуществляют ранжирование документов по близости к поисковому запросу на основе сопоставления информации о вхождениях слов в документах и поисковом запросе;
- выдают в качестве результата идентификаторы электронных документов, ранжированные по степени близости к поисковому запросу.
Согласно предложенному способу индексная структура дополняется маркерами, предназначенными для хранения
- метаинформации электронных документов;
- информации о вхождениях слов естественного языка в электронные документы.
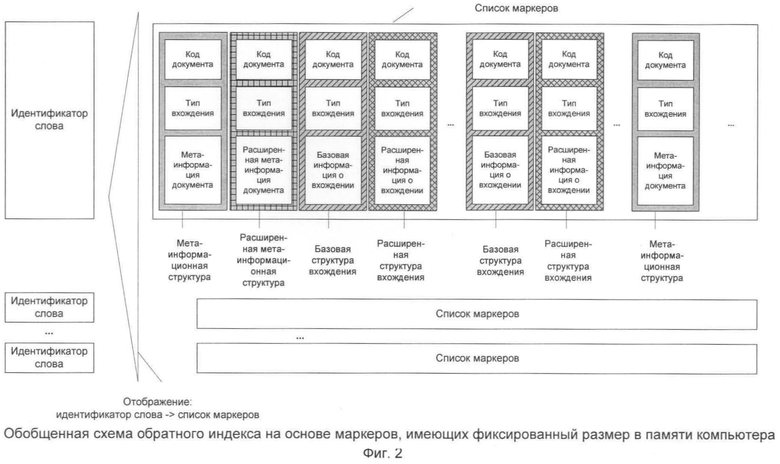
Под маркером понимается структура данных в обратном индексе, содержащая метаинформацию о документе или о вхождении некоторого слова в документ. В зависимости от своего типа маркер содержит набор полей, хранящих информацию о некотором документе или вхождении слова в документ. В обратном индексе маркеры хранятся в упорядоченных списках по следующему принципу: по номеру документа, а при совпадении номера документа - по типу и по смещению информационного вхождения слова в документ (по номеру предложения и по смещению в предложении), при совпадении смещений - по типу маркера. В памяти компьютера все маркеры вне зависимости от своего типа и конкретных значений хранимой информации имеют одинаковый фиксированный размер.
Для формирования маркеров, содержащих информацию о вхождениях слов естественного языка в электронные документы, выполняют лингвистический анализ указанных текстовых документов и помещают в маркеры информацию о
- позициях отдельных вхождений слов естественного языка в электронные документы,
- связях между вхождениями слов естественного языка в электронных документах, например семантических, синтаксических, кореферентных и др.,
- весовых коэффициентах слов естественного языка, входящих в электронные документы, и др.
При получении запроса на поиск электронных документов от пользователя поисковой системы выполняют лингвистический анализ запроса, производят выборку информации из обратного индекса и сопоставляют образ запроса с полученной информацией для определения степени соответствия запроса и найденных электронных документов; формируют и передают пользователю поисковой системы перечень идентификаторов электронных документов, ранжированных по релевантности.
Технический результат достигается за счет:
- сопоставления расширенной лингвистической информации о словах запроса и вхождениях слов в документы при оценке близости документов к поисковому запросу (например, сопоставление форм вхождений слов в тексты документов и запроса, сравнение значений синтаксем в документах и в запросе и т.п.);
- сопоставления метаинформации запроса и документов при информационном поиске документов и исключения из результатов документов, не удовлетворяющих критериям поиска по метаданным;
- эффективного хранения метаинформации о документах и информации о вхождениях слов в документы в индексной структуре в виде последовательностей маркеров фиксированного размера, что позволяет вычислительно эффективно производить выборку информации из индексной структуры и производить оценку близости документов к поисковому запросу.
Система семантического поиска электронных документов включает совокупность взаимосвязанных друг с другом модулей системы информационного поиска:
1) модуль формирования коллекции и выделения метаинформации электронных документов;
2) модуль хранения индексных структур электронных документов;
3) модуль формирования и выдачи пользователю поисковой системы перечня электронных документов, ранжированных по релевантности.
Для осуществления вышеописанного способа работы система снабжена также модулем формирования маркеров, хранящих метаинформацию электронных документов; модулем лингвистического анализа текста на естественном языке и формирования маркеров, хранящих информацию о вхождениях слов естественного языка.
Предложенные способ и система поясняются чертежами.
Фиг.1 - схема взаимодействия рабочих модулей системы семантического поиска электронных документов.
Фиг.2 - обобщенная схема обратного индекса на основе маркеров, имеющих фиксированный размер в памяти компьютера.
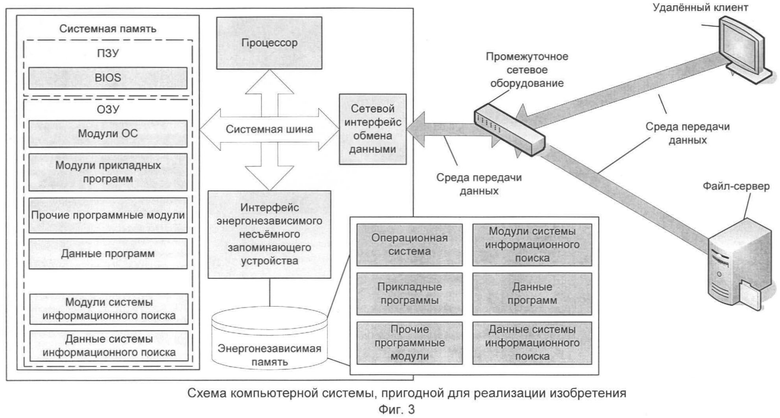
Фиг.3 - схема компьютерной системы, пригодной для реализации изобретения.
Система семантического поиска электронных документов состоит из аппаратных взаимосвязанных друг с другом модулей системы информационного поиска (фиг.1).
Модуль формирования коллекции и выделения метаинформации электронных документов 1 обеспечивает постоянное пополнение коллекции электронных документов из внешних информационных источников, например из Интернета. Указанный модуль 1 представляет собой совокупность распределенных серверов или один сервер, содержащий в участке памяти машинные команды, исполнение которых обеспечивает функциональность модуля 1, электронное представление документов.
Модуль хранения индексных структур электронных документов 2 представляет собой совокупность распределенных серверов или один сервер, содержащий в участке памяти машинные команды, исполнение которых обеспечивает функциональность модуля 2, а также хранящий индексные структуры электронных документов в участке памяти, который может располагаться как в оперативной памяти (оперативном запоминающем устройстве), так и на устройстве долговременного хранения информации (например, в виде файлов на жестких дисках).
Модуль формирования и выдачи пользователю поисковой системы перечня электронных документов, ранжированных по релевантности, 3 представляет собой совокупность распределенных серверов или один сервер, содержащий в участке памяти машинные команды, исполнение которых обеспечивает функциональность модуля 3. Модуль 3 позволяет пользователю сформировать поисковый запрос на естественном языке, задать метаинформацию, характеризующую интересующие пользователя документы. Модуль 3 использует функциональность модуля лингвистического анализа текста на естественном языке и формирования маркеров, хранящих информацию о вхождениях слов естественного языка для построения образа запроса. Модуль 3 использует функциональность модуля хранения индексных структур электронных документов 2 для выборки фрагментов индекса, соответствующих образу запроса, и осуществляет ранжирование результатов поиска путем определения близости запроса и электронных документов на основе сопоставления образа запроса и выбранных фрагментов индекса.
Модуль 4 формирования маркеров, хранящих метаинформацию электронных документов, представляет собой совокупность распределенных серверов или один сервер, содержащий в участке памяти машинные команды, исполнение которых обеспечивает функциональность модуля 4. Модуль 4 выделяет метаинформацию электронных документов и сохраняет ее в виде метаинформационных маркеров, которые помещаются в обратный индекс - передаются в модуль хранения индексных структур электронных документов 2.
Модуль лингвистического анализа текста на естественном языке и формирования маркеров, хранящих информацию о вхождениях слов естественного языка, 5 представляет собой совокупность распределенных серверов или один сервер, содержащий в участке памяти машинные команды, исполнение которых обеспечивает функциональность модуля 5. Модуль 5 используется для построения индексных структур, содержащих информацию о вхождениях слов естественного языка в тексты электронных документов. Указанные индексные структуры помещаются в модуль хранения индексных структур электронных документов 2. Модуль 5 также используется для построения образа запроса пользователя.
В целом предложенные система и способ могут быть реализованы на широком классе компьютерных систем, например на портативных компьютерах, на мультипроцессорных вычислительных системах, а также на распределенных вычислительных системах, в которых задачи выполняются удаленными компьютерами под управлением одного или нескольких процессоров (фиг.3). В распределенных компьютерных системах программные модули могут находиться на устройствах хранения данных как локальных, так и удаленным компьютером и загружаться в оперативную память непосредственно через сетевой интерфейс.
При работе системы, так же как и при работе известных поисковых систем, формируют аппаратными средствами поисковой системы соответствующую коллекцию электронных документов, каждый из которых обладает уникальным идентификатором (например, URL-адресом). Затем преобразуют коллекцию электронных документов поисковой системы в индексную структуру, организованную в виде инвертированного индекса слов естественного языка, а на этапе поиска выполняют поиск и анализ метаинформации о словах естественного языка в указанных документах.
Индексную структуру дополняют маркерами, хранящими метаинформацию (заголовок, сведения об авторах, дате публикации, формате документа и др.). Такие маркеры, содержащие базовую метаинформацию об электронном документе, помещаются в упорядоченный список маркеров, соответствующий каждому слову, входящему в электронный документ, помещаемый в индекс (фиг.2).
В ходе лингвистического анализа электронного документа определяют:
- смещение вхождения слова от начала текста;
- номер предложения, в котором находится вхождение;
- смещение в словах от начала предложения, в котором находится вхождение;
- вес вхождения - действительное число, определяющее информационную значимость вхождения в тексте документа;
- тег языка HTML или иную метку, соответствующую вхождению;
- ассоциативные, синтаксические и семантические связи вхождения слова с другими вхождениями слов в текст.
После лингвистического анализа документов дополняют индексную структуру маркерами, хранящими информацию, полученную в ходе лингвистического анализа. При этом, если часть информации, связанной с вхождением слова в документ, отсутствует (например, синтаксические или семантические связи), то соответственный маркер не помещается в индекс. Это способствует уменьшению размеров занимаемой памяти индексами поисковой системы.
Схема организации данных в виде упорядоченных последовательностей маркеров в обратном индексе позволяет реализовать в системе семантического поиска эффективные алгоритмы индексирования, поиска и ранжирования электронных документов.
После получения запроса поиск электронных документов от пользователя поисковой системы формируют и передают пользователю поисковой системы перечень электронных документов, ранжированных по релевантности. Одновременное использование маркеров, хранящих в индексной структуре результаты лингвистического анализа метаданных документов, повышает качество проведения информационного поиска электронных документов.
Таким образом, предложен способ и система, отличающиеся от известных прототипов:
- методами хранения и использования метаинформации электронных документов в индексных структурах в памяти компьютера;
- методами хранения и использования лингвистической информации о вхождениях слов в электронные документы в индексных структурах в памяти компьютера;
- методами извлечения информации из индексных структур и ее сопоставления с пользовательскими запросами.
Предложенная группа изобретений относится к средствам автоматизированного информационного поиска и обеспечивает высокую полноту и точность информационного поиска. Техническим результатом является повышение полноты и точности поиска электронных документов. Предложенный способ семантического поиска электронных документов включает дополнение индексной структуры электронного документа маркерами, занимающими одинаковый и фиксированный размер в компьютерной памяти, хранящими в зависимости от своего типа как метаинформацию электронных документов, так и информацию о вхождениях слов естественного языка в электронные документы, полученную с помощью лингвистического анализа. Предложенная система семантического поиска электронных документов включает соответствующие модули: модуль формирования коллекции и выделения метаинформации электронных документов, модуль хранения индексных структур электронных документов, модуль формирования и выдачи пользователю поисковой системы перечня электронных документов, ранжированных по релевантности, модуль формирования маркеров, хранящих метаинформацию электронных документов, модуль лингвистического анализа текста на естественном языке и формирования маркеров, хранящих информацию о вхождениях слов естественного языка. 2 н. и 2 з.п. ф-лы, 3 ил.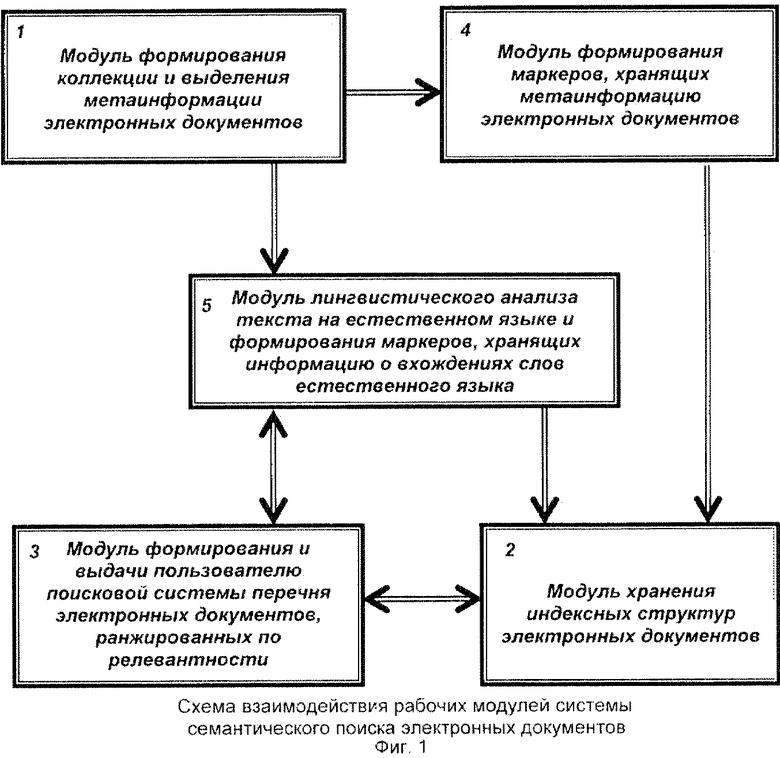
1. Способ семантического поиска электронных документов, при котором формируют аппаратными средствами поисковой системы коллекцию электронных документов, каждый из которых обладает уникальным идентификатором;
выделяют метаинформацию электронных документов;
извлекают тексты электронных документов из их электронного представления;
выполняют лингвистический анализ текстов электронных документов;
формируют инвертированный индекс слов естественного языка с привоением каждой лексеме соответствующего списка маркеров различных типов, занимающих одинаковый и фиксированный размер в компьютерной памяти и содержащих, в зависимости от своего типа, для каждого электронного документа, в тексте которого присутствует хотя бы одно вхождение лексемы:
метаинформацию об электронном документе,
информацию о вхождении слова в электронный документ для каждого вхождения;
получают запрос на поиск электронных документов от пользователя поисковой системы, содержащий фразу или предложение на естественном языке, а также метаинформацию документов, интересующих пользователя;
осуществляют выборку информации из инвертированного индекса соответственно словам и метаинформации запроса;
формируют и передают пользователю поисковой системы перечень идентификаторов найденных электронных документов.
2. Способ по п.1, отличающийся тем, что присваиваемые маркеры содержат дополнительную метаинформацию об электронном документе.
3. Способ по п.1, отличающийся тем, что присваиваемые маркеры содержат дополнительную информацию о вхождении слова в электронный документ.
4. Система семантического поиска электронных документов, включающая совокупность взаимосвязанных друг с другом модулей системы информационного поиска:
модуль формирования коллекции и выделения метаинформации электронных документов;
модуль хранения индексных структур электронных документов;
модуль формирования и выдачи пользователю поисковой системы перечня электронных документов, ранжированных по релевантности;
модуль формирования маркеров, хранящих метаинформацию электронных документов;
модуль лингвистического анализа текста на естественном языке и формирования маркеров, хранящих информацию о вхождениях слов естественного языка.
| КОМПЬЮТЕРНЫЙ ПОИСК С ПОМОЩЬЮ АССОЦИАТИВНЫХ СВЯЗЕЙ | 2004 |
|
RU2343537C2 |
| Губин М.В | |||
| «Модели и методы представления текстового документа в системах информационного поиска», диссертация, 2005 г., найдена в Интернете 06.06.2012 по адресу url: http://maxgubin.com/articles/thesis.pdf | |||
| СПОСОБ УНИФИЦИРОВАННОЙ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ИНФОРМАЦИИ, ОБЕСПЕЧИВАЮЩИЙ В РАМКАХ ОДНОЙ ФОРМАЛЬНОЙ МОДЕЛИ ПРЕДСТАВЛЕНИЕ, КОНТРОЛЬ СЕМАНТИЧЕСКОЙ ПРАВИЛЬНОСТИ, ПОИСК И ИДЕНТИФИКАЦИЮ ОПИСАНИЙ ОБЪЕКТОВ | 2008 |
|
RU2393536C2 |
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |

