Предлагаемый способ относится к вычислительной технике, а именно к информационно-поисковым и интеллектуальным системам, в частности к способам поиска информации в больших документальных базах данных.
Известен «Способ поиска информации в политематических массивах неструктурированных текстов» (патент RU 2266560 G06F от 28.04.2004), заключающийся в том, что терминам вектора запроса присваивают порядковые номера, осуществляют поиск с занесением в память компьютера номеров документов хотя бы с одним термином вектора запроса, заносят в память компьютера количество терминов, совпавших с терминами запроса, и порядковые номера совпавших терминов, сортируют в памяти компьютера документы по классам с равным количеством совпавших терминов. Технический результат достигается тем, что вводится новый критерий выдачи документов, позволяющий пользователю получать релевантные документы, наполненные новыми терминами, необходимыми для проведения дальнейших рекурсий. Эффективность способа при этом не зависит от того, на каком естественном языке написаны тексты в базе данных.
Существенные признаки аналога, общие с заявленным способом: терминам вектора запроса присваивают порядковые номера, поиск осуществляют с занесением в память компьютера номеров документов, в которых присутствует хотя бы один термин вектора запроса, заносят в память компьютера количество совпавших терминов с терминами запроса и порядковые номера совпавших терминов, в памяти компьютера документы сортируют по классам с равным количеством совпавших терминов.
Недостатком данного способа является то, что он многоитерационный и со временем будет улучшаться полнота, но уменьшаться точность поиска.
Известен «Способ синтеза самообучающейся системы извлечения знаний из текстовых документов для поисковых систем», осуществляющий поиск информации путем переформулирования пользовательского запроса и извлечения из текстов фраз, схожих с запросом, но синтаксически являющихися ответами на вопрос, поставленный пользователем (патент RU 2273879 G06F, G09B от 28.05.2002). Этот способ заключается: в обеспечении механизма самообучения в виде стохастически индексированной системы искусственного интеллекта, основанной на применении уникальных комбинаций двоичных сигналов стохастических индексов информации; в обеспечении автоматического обучения системы правилам грамматического и семантического анализа путем применения эквивалентных преобразований стохастически индексированных фрагментов текста, логического вывода и формирования из них связанных семантических структур и стохастического индексирования для представления в формате правил продукций; в выполнении морфологического анализа и стохастического индексирования лингвистических текстов в электронном виде с одновременным автоматическим обучением системы правилам морфологического анализа; в произведении морфологического и синтаксического анализа, а также стохастического индексирования текстовых документов по заданной теме в электронном виде на заданном языке с одновременным автоматическим обучением системы правилам синтаксического анализа; произведении семантического анализа стохастически индексированных текстовых документов по заданной теме в электронном виде с одновременным автоматическим обучением системы правилам семантического анализа; формировании запроса пользователя на естественном заданном языке и представлении его в электроном виде после стохастического индексирования в форме вопросительного предложения; преобразовании запроса пользователя в стохастически индексированном виде во множество новых запросов, эквивалентных исходному запросу; в осуществлении в соответствии с запросом пользователя предварительного выбора стохастически индексированных фрагментов текстовых документов в электронном виде, содержащих в совокупности все словосочетания преобразованного запроса; в формировании стохастически индексированной семантической структуры с использованием указанных фрагментов текстовых документов; в формировании краткого ответа системы на основе указанной структуры с помощью логического вывода, обеспечивающего связь стохастически индексированных элементов различных текстов и эквивалентного преобразования текста; в проверке релевантности полученного краткого ответа системы запросу путем формирования на его основе вопросительного предложения, сравнения полученного вопросительного предложения с запросом; в принятии решения о релевантности краткого ответа системы запросу и представлении его на заданном языке при идентичности полученного вопросительного предложения и запроса.
Существенные признаки, общие с заявленным способом: производят морфологический анализ, производят семантический анализ, формируют стохастически индексированную семантическую структуру на основе указанных фрагментов текстовых документов (в заявляемом способе - производят семантическое индексирование документов коллекции).
Недостатки способа: время отклика системы, описанной в данном способе, будет велико, так как трудоемок процесс извлечения информации из найденных документов.
Из всех известных способов наиболее близким к заявляемому является «Система и метод поиска документов, основанные на контексте» (патент США №6633868). Выполняемый на вычислительных устройствах этот метод включает следующие существенные признаки:
- для каждого документа i из коллекции документов вычисляют матрицу D(i) взаимосвязей между словами, включающую статистику для пар слов из документа; вычисляют для каждого документа вектор частоты;
- генерируют контекстную базу данных, включающую матрицу С размерности N×N, где N - общее число уникальных слов в коллекции документов; матрицу С вычисляют из матриц взаимосвязей слов D(i) для всех документов;
- вычисляют поисковую матрицу S из поискового запроса и матрицы С;
- для каждого документа i вычисляют вес W(i) из поисковой матрицы S и матрицы взаимосвязей документа D(i);
- извлекают и выдают документы, отсортированные по весу W(i).
Кроме того, по этому методу взаимосвязь слов матрицы D(i) имеет развитие в зависимости от числа инцидентности пар, вычисление матрицы С включает добавление матрицы D(i) всех документов из коллекции документов, вычисление поисковой матрицы S включает выбранную колонкам векторов матрицу С, соответствующих ключевым словам поискового запроса, формирующих поисковую матрицу S из колонок векторов, вес W(i) вычисляют, включая поэлементное перемножение D(i) и S с последующим суммированием всех результирующих элементов.
Следующие существенные признаки прототипа являются общими с заявляемым способом: для формирования контекста предметной области строят контекст предметной области, для чего на вход системы подают тематическую коллекцию документов, после чего для каждого документа i из коллекции документов вычисляют матрицу оценок D(i) взаимосвязей между словами, далее суммируют D(i) в матрице контексте, а для обслуживания запроса поиска производят семантический анализ.
К недостаткам прототипа следует отнести пригодность его для небольших статей, так как существует квадратичная зависимость размера поисковых образов документов от количества слов в документе; кроме того, он не дает способа сокращения контекста, который без сокращения имеет размерность квадратичного порядка от общего числа уникальных слов в коллекции документов, что чрезвычайно велико, так как даже в тематической коллекции из 3000 документов уже может встретиться более 50000 уникальных слов, что составит 2,5 Гб, если приводить оценку взаимовстречаемости термов к 1 байту; у данного способа большая вычислительная трудоемкость, т.к необходимо сопоставить образу запроса все документы коллекции; при использовании прототипа происходит размывание границы искомых понятий, включенных в запрос пользователя, при сопоставлении образа документа - поисковому образу запроса - в результате могут быть найдены документы, в которых обсуждается близкая тема, но там не будет ни синонимов слов, ни самих слов из поискового запроса.
Задачей предлагаемого способа является: сокращение размера образов поисковых документов с квадратичной зависимости до линейной от количества уникальных слов в документе; сокращение размера контекста предметной области за счет фильтрации от шумовых элементов и сжатой формы записи; уменьшение вычислительной трудоемкости в процессе поиска - за счет отсева документов, не содержащих слова из пользовательского запроса; увеличение точности поиска - за счет введения двух оценок точности и полноты раскрытия понятия в тексте документа.
Технический результат достигается тем, что для формирования контекста предметной области вводят словарь, содержащий известные системе словоформы языка и позволяющий привести словоформу к нормализованной форме, пополняют его новыми словами из документов, матрицу оценок D(i) взаимосвязей между словами вычисляют на основании непосредственной близости терминов и логического деления текста на предложения и абзацы, а матрицу оценок D(i) суммируют в матрице контексте предметной области Cntxt, фильтруют матрицу Cntxt от шумовых элементов, обрезая шумовые элементы с малой неуникальной оценкой взаимовстречаемости, производят нормализацию строк матрицы Cntxt, сжимают контекст предметной области Cntxt, приводя его к виду в каждой строке <номер термина, оценка>, затем для формирования поискового индекса вносимым в поисковый индекс документам присваивают уникальные номера, формируют образы этих документов в виде перечисления для каждого уникального термина, используемого в документе, позиций употребления его словоформ, строят индекс встречаемости терминов в документах в виде перечисления для каждого уникального термина коллекции, в каких документах была встречена его словоформа, вычисляют оценки нахождения терминов в заголовках и присутствия терминов в текстах ссылок на данный документ и добавляют их в индекс встречаемости терминов в документах, вычисляют оценки точности и полноты раскрытия понятия и добавляют их в индекс встречаемости терминов в документах, затем представляют поисковый запрос в виде вектора, где каждому термину присваивают порядковый номер, производят морфологический анализ терминов запроса, используя словарь, получают номера терминов, осуществляют поиск, внося в память компьютера номера документов, в которых присутствуют хотя бы один термин вектора запроса, заносят в память компьютера количество совпавших терминов с терминами запроса и порядковые номера совпавших терминов, отбрасывают те документы, которые не содержат хотя бы одно не служебное слово из запросов пользователя, производят семантический анализ, вычисляя из запроса для существительных и устойчивых словосочетаний (с существительным) степень раскрытия понятия в найденных документах Rβ как функцию от оценок точности и полноты, оценивают соответствие поискового запроса найденным документам, вычисляя оценку W(i) как функцию от раскрытия понятий из запроса Rβ, близость и порядок слов из запроса, соответствия словоформам и запроса, нахождения слов в заголовке и присутствия ссылок на данный документ с текстом запроса, сортируют полученные документы по оценке W(i) и выдают пользователю найденные документы.
Для достижения технического результата в способе оценки степени раскрытия понятия в тексте, основанном на контексте, для поисковых систем, заключающемся в формировании контекста предметной области, для чего строят контекст предметной области, на вход системы подают тематическую коллекцию документов, для каждого документа i из коллекции документов вычисляют матрицу оценок D(i) взаимосвязей между словами, направляют матрицу оценок D(i) в контекст предметной области, суммируют D(i) в матрице контексте, для формирования контекста предметной области вводят словарь, содержащий известные системе словоформы языка и позволяющий привести словоформу к нормализованной форме, пополняют его новыми словами из документов, матрицу оценок D(i) взаимосвязей между словами вычисляют на основании непосредственной близости терминов и логического деления текста на предложения и абзацы, а матрицу оценок D(i) суммируют в матрице контексте предметной области Cntxt, фильтруют матрицу Cntxt от шумовых элементов, обрезая шумовые элементы с малой неуникальной оценкой взаимовстречаемости, производят нормализацию строк матрицы Cntxt, сжимают контекст предметной области Cntxt, приводя его к виду в каждой строке <номер термина, оценка>, затем для формирования поискового индекса вносимым в поисковый индекс документам присваивают уникальные номера, формируют образы этих документов в виде перечисления для каждого уникального термина, используемого в документе, позиций употребления его словоформ, строят индекс встречаемости терминов в документах в виде перечисления для каждого уникального термина коллекции, в каких документах была встречена его словоформа, вычисляют оценки нахождения терминов в заголовках и присутствия терминов в текстах ссылок на данный документ и добавляют их в индекс встречаемости терминов в документах, вычисляют оценки точности и полноты раскрытия понятия и добавляют их в индекс встречаемости терминов в документах, затем представляют поисковый запрос в виде вектора, где каждому термину присваивают порядковый номер, производят морфологический анализ терминов запроса, используя словарь, получают номера терминов, осуществляют поиск, внося в память компьютера номера документов, в которых присутствуют хотя бы один термин вектора запроса, заносят в память компьютера количество совпавших терминов с терминами запроса и порядковые номера совпавших терминов, отбрасывают те документы, которые не содержат хотя бы одно не служебное слово из запросов пользователя, производят семантический анализ, вычисляя из запроса для существительных и устойчивых словосочетаний (с существительным) степень раскрытия понятия в найденных документах Rβ как функцию от оценок точности и полноты, оценивают соответствие поискового запроса найденным документам, вычисляя оценку W(i) как функцию от раскрытия понятий из запроса Rβ, близость и порядок слов из запроса, соответствия словоформам и запроса, нахождения слов в заголовке и присутствия ссылок на данный документ с текстом запроса, сортируют полученные документы по оценке W(i) и выдают пользователю найденные документы.
Рассмотрим возможность осуществления предлагаемого способа на конкретном примере. Пусть дан документ из двух абзацев.
Геракл, в греческой мифологии герой. Геракл был сыном Зевса и смертной женщины Алкмены.
Имя «Геракл» скорее всего означает «прославленный Герой» или «благодаря Гере».
Вводят в систему словарь с известными системе словоформами русского языка, который позволяет привести словоформы к нормализованной форме.
Пополняют данный словарь новыми словами из исследуемого документа (при необходимости в случае отсутствия в словаре этих слов).
Все слова приводят к нормализованной форме, остаются только существительные, прилагательные и отглагольные:
Геракл, ... греческий, мифология, герой. Геракл ... сын Зевс ... смертный, женщина, Алкмена.
Имя Геракл ... означать прославленный Гера ... Гера.
Вначале выделяют пары терминов, которые стоят рядом и не разделены стоп-словами и знаками препинания. В контексте документа D(i) (где i=1 для данного конкретного примера) ставят им оценку за каждую встречу - 1 балл. Данные пары: греческий и мифология, мифология и герой, сын и Зевс, и т.д. После этого матрица D(1) будет выглядеть следующим образом:
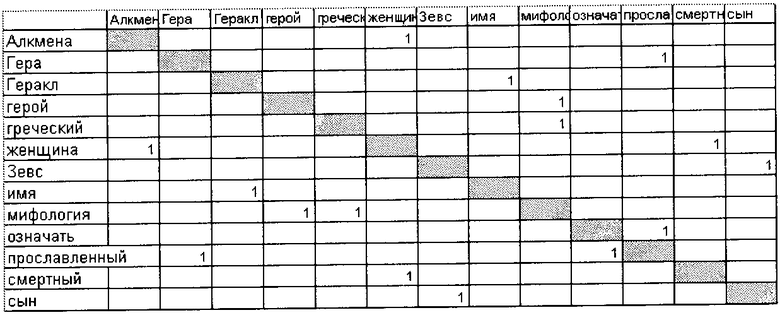
Ставят по 1 баллу терминам, хотя бы раз встретившимся в одном предложении. Для первого предложения по одному баллу добавится для пар:
Геракл и греческий, Геракл и мифология, Геракл и герой, греческий и мифология, греческий и герой, мифология и герой. Матрица D(1) после внесения оценок за встречаемость в предложении:
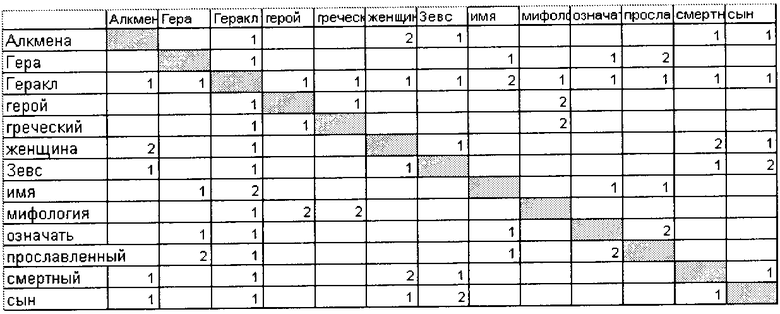
Ставят по 1 баллу терминам, хотя бы раз встретившимся в одном абзаце. Таким образом, для пары слов герой и Алкмена из первого абзаца, но находящихся в разных предложениях будет получен 1 балл. Матрица D(1) после внесения оценок за встречаемость в абзаце:
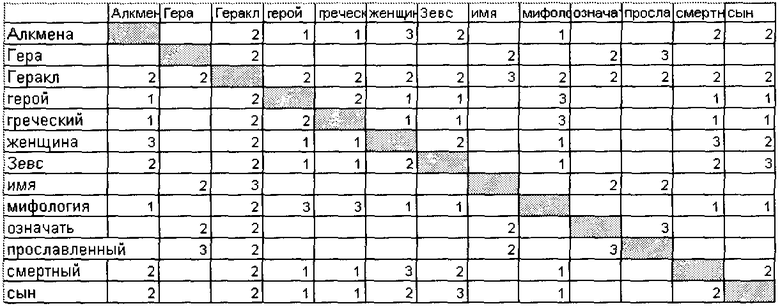
После этого полученную матрицу D(1) суммируют в матрицу контекста предметной области Cntxt (размерность данной матрицы будет больше, чем у D(i) ввиду того, что количество терминов, используемых внутри всей коллекции документов предметной области, больше, чем в одном документе). В матрице Cntxt в строках остаются только существительные и устойчивые словосочетания (с существительными).
В матрице Cntxt производят поэлементное суммирование оценок для соответствующих пар терминов. Так как в данном примере анализируют только один документ, то матрица Cntxt будет сформирована из рассмотренной выше матрицы D(1).
После добавления всех контекстов документов в матрицу Cntxt производят фильтрацию и нормализацию.
Убирают шумовые элементы в Cntxt. Для данного примера, ввиду малочисленности выборки, актуально убрать только пары с минимальной оценкой встречаемости (с оценкой 1). Для больших контекстов убирают все элементы с минимальными оценками, пока не будет нарушена целочисленная непрерывность оценки (например, если у понятия было встречено 15 терминов с оценкой 1, 4 термина с оценкой 2, 2 термина с оценкой 1, 1 термин с оценкой 3, 1 термин с оценкой 5, 1 термин с оценкой 7 и т.д.; мы видим разрыв в ряде натуральных чисел оценки на 4-х; таким образом все термины с оценками ниже 4 будут отброшены). Выбранный способ фильтрации позволяет увеличить степень разреженности матрицы Cntxt с увеличением размерности матрицы Cntxt. После фильтрации матрица Cntxt (предполагаем, что коллекция состояла из одного документа, рассмотренного выше) будет выглядеть следующим образом:
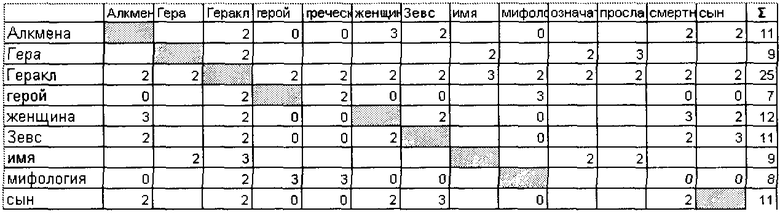
Далее проводят нормализацию векторов контекстов для понятий, разделив оценки в строке на сумму оценок в строке. После нормализации Cntxt примет вид:
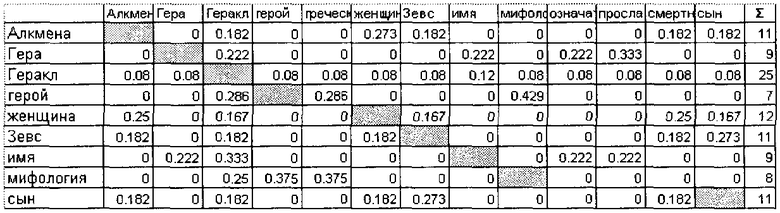
В связи с высокой степенью разреженности матрицы в памяти компьютера будет удобно представить матрицу в виде отсортированного списка терминов с оценками для каждого из понятий. Например, для понятия «Алкмена» будет создан вектор из 5 элементов:
<женщина, 0.273>, <Геракл, 0.182>, <3евс, 0.182>, <смерть, 0.182>, <сын, 0.182>
Данный вектор описывает контекст, в котором в тематической коллекции документов наиболее часто встречается понятие «Алкмена». Наибольшая связь у понятия «Алкмена» с термином «женщина».
Рассмотрим пример формирования поискового индекса на статье из краткого мифологического словаря:
Геракл (у римлян Геркулес) - в древнегреческой мифологии величайший герой, сын Зевса, совершивший множество подвигов; после смерти вознесен на Олимп и принят в сонм бессмертных богов.
В поисковом индексе документов присваивают приведенной статье индекс 1. Формируют образ этого документа в виде перечисления для каждого уникального термина, используемого в документе, позиций употребления его словоформ. При подсчете позиций учитывают все слова русского языка (в том числе и стоп-слова). Для приведенной в качестве примера статьи для термина «Геракл» будет записана одна позиция: 1.
Далее строят индекс встречаемости терминов в документах в виде перечисления для каждого уникального термина коллекции, в каких документах была встречена его словоформа. Например, для термина «Геракл» будет одна запись о встрече данного термина в документе 1.
После этого вычисляют оценку нахождения терминов в текстах ссылок на данный документ. Т.к. в предлагаемом примере нет ссылок на рассматриваемый документ из других документов, то для всех терминов эта оценка будет равна 0.
Затем вычисляют оценки точности и полноты. Рассмотрим пример получения оценок точности и полноты раскрытия контекста термина «Геракл» в приведенной статье. Добавим все полученные оценки в поисковый индекс. Для термина «Геракл» запись будет выглядеть следующим образом:
Геракл: встречается в документе 1, оценка за присутствие в заголовке - 0, оценка за присутствие в тексте ссылок 0, оценка точности раскрытия понятия - 0,2036, оценка полноты раскрытия понятия - 0,32.
Из контекста внутри словарной статьи присутствуют следующие элементы: <герой, 0.08>, <3евс, 0.08>, <мифология, 0.08>, <сын, 0.08>.
Контекст термина t раскрываемый на участке текста ψ't=4*0.08=0.32.
Полный контекст термина t ψt=1 (т.к. пользуемся нормализованным вектором контекста).
Количество терминов, содержащихся в области текста, в которой раскрывается контекст термина t обозначим ϕt.=11 (Позиция первого слова «Геракл» - 1, позиция последнего слова из контекста «Зевс» 11) Нормализующую величину, обозначающую среднюю величина энциклопедической статьи, в которой может быть раскрыт смысл понятия обозначим θ. Этот параметр выбирается эмпирически в зависимости от тематически и размера коллекции. В данном примере примем его равным 15. ϕ't - нормализованная величина размера текста в терминах, которая равна 1 при ϕt<=θ и равна ϕt/θ при ϕt>θ.
Таким образом, точность раскрытия понятия в словарной статье:
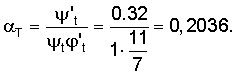
Контекст термина t раскрываемый внутри всего документа ψ''t=0.32 (т.к. предполагаем, что на странице кроме словарной статьи больше ничего не находится).
Полнота раскрытия понятия будет равна:
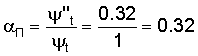
Рассмотрим обработку поискового запроса пользователя. Предположим, что пользователь ввел в строку запроса «О Геракле».
Представляют поисковый запрос в виде вектора, где каждому термину присваивают порядковый номер. «О» - получит номер 1, «Геракле» - получит номер 2.
Далее производят морфологический анализ терминов запроса, используя словарь. Получаем номера нормализованных форм в словаре для двух слов из запроса. По номерам нормализованных форм из словаря извлекают информацию о частях речи. «О» - предлог, а следовательно служебная часть речи. «Геракле» - существительное, приведется к нормализованному виду «Геракл».
По поисковому индексу встречаемости терминов в документах находят все документы, в которых присутствует термин «Геракл». В итоге получают список из одного документа с номером 1, в котором встречен термин «Геракл». Найденный документ содержит все не служебные слова из запроса пользователя.
Вычисляют степень раскрытия понятия в найденных документах Rβ как функцию от оценок точности и полноты. Отдадим приоритет точности. Пусть β=0,9. Тогда:
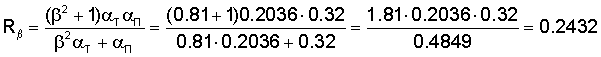
В общем случае оценка соответствия поискового запроса найденным документам W(i) зависит от Rβ, от оценки ω (значение от 0 до 1, зависит от близости и порядка слов из запроса, соответствия словоформам и запроса), оценки λ (значение от 0 до 1, зависит от количества употреблений термина в заголовках и от важности заголовков), оценки μ (значение от 0 до 1, зависит от количества ссылок на данный документ с термином в тексте ссылки). Один из возможных вариантов функции W(i):
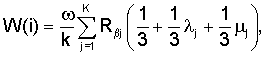
где k - число неслужебных терминов из пользовательского запроса.
Т.к. в тексте статьи нет предлога «о» и словоформы «Геракле», то оценка дается только за присутствие термина «Геракл», без совпадения словоформы ω=0.333. Один из вариантов общего вида формулы для вычисления ω:

где m - общее число слов в пользовательском запросе,
l - число не служебных слов,
swl - число служебных слов,
presence(j) - булевская функция, возвращающая 1, если слово j присутствует в тексте документа,
sw_presence(j) - булевская функция, возвращающая 1, если служебное слово j присутствует в тексте документа,
order(j) - булевская функция, возвращающая 1, если слово j стоит в тексте документа перед словом j+1, т.е. в той же последовательности, что и в поисковом запросе относительно соседних слов и возвращает 0, в случае когда позиция не соответствует,
distance(j) - функция, возвращающая расстояние между словами j и j+1 из пользовательского запроса; в случае когда два слова стоят рядом, то расстояние равно 1, если слово отсутствует, то функция вернет бесконечно большое значение,
form(j) - булевская функция, возвращающая 1, если данное неслужебное слово j стоит в тексте документа в той же форме, что и в пользовательском запросе.
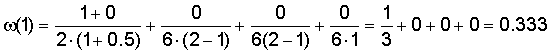
Из поискового индекса встречаемости терминов в документах известно, что для документа оценки нахождения слов в заголовке λ=0 (нет в статье заголовка с термином («Геракл»), оценка присутствия ссылок на данный документ с текстом запроса μ=0 (нет ссылок с термином «Геракл»).
Вычисляют W(i) для документа 1 (k=1, т.к. в запросе только одно не служебное слово):
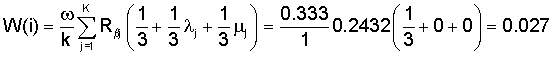
Полученные документы сортируют по оценке W(i) и выдаются пользователю в отсортированном виде.
Предлагается новый способ информационного поиска с линейной, а не квадратичной, зависимостью размера образов поисковых документов от количества уникальных терминов в документе; сокращение размера контекста предметной области за счет фильтрации шума и сжатия формы записи; уменьшение вычислительной трудоемкости в процессе поиска за счет отсева документов, не содержащих слова из пользовательского запроса и вынесения основных вычислительных операций на этап индексирования; увеличение точности поиска за счет использования оценок точности и полноты раскрытия понятия в тексте документа; предоставляется возможность объединять найденные документы в группы за счет соотношения оценок точности и полноты.
Использование данного способа обеспечивает возможность автоматического формирования знаний о предметной области путем извлечения их из коллекции текстовых документов и интеллектуальную обработку запросов пользователя с целью получения документов, в которых наиболее раскрыто значение искомого понятия. Этот результат достигается благодаря обеспечению механизма самообучения в виде автоматического формирования контекстов; производят морфологический и синтаксический анализ коллекции текстовых документов по заданной теме для формирования контекста предметной области; формируется поисковый индекс, содержащий оценки точности и полноты раскрытия понятия для каждого из документов на основании контекстов; находят оценку релевантности документов как соотношение между параметрами точности и полноты в зависимости от предпочтений пользователя.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| СПОСОБ ПОСТРОЕНИЯ СЕМАНТИЧЕСКОЙ МОДЕЛИ ДОКУМЕНТА | 2011 |
|
RU2487403C1 |
| СПОСОБ КЛАСТЕРИЗАЦИИ РЕЗУЛЬТАТОВ ПОИСКА В ЗАВИСИМОСТИ ОТ СЕМАНТИКИ | 2014 |
|
RU2564629C1 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В МАССИВЕ ТЕКСТОВ | 2008 |
|
RU2392660C2 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОГО ПОИСКА ЭЛЕКТРОННЫХ ДОКУМЕНТОВ | 2011 |
|
RU2473119C1 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ АНАЛИТИЧЕСКОЙ ВОПРОСНО-ОТВЕТНОЙ СИСТЕМЫ С ИЗВЛЕЧЕНИЕМ ЗНАНИЙ ИЗ ТЕКСТОВ | 2007 |
|
RU2345416C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
Изобретение относится к информационно-поисковым и интеллектуальным системам, в частности к способам поиска информации в больших документальных базах данных. Изобретение позволяет сократить размер образов поисковых документов с квадратичной зависимости до линейной от количества уникальных терминов в документе; сократить размер контекста предметной области; уменьшить вычислительную трудоемкость; увеличить точность поиска. Вычисляют матрицу оценок взаимосвязей между словами, суммируют ее в матрицу контекста предметной области, фильтруют матрицу контекста от шумовых элементов, формируют образ вносимых в поисковый индекс документов в виде перечисления для каждого уникального термина, используемого в документе, строят индекс встречаемости терминов в документах, вычисляют оценки точности и полноты раскрытия понятия и добавляют их в индекс встречаемости. Представляют поисковый запрос, вносят в память компьютера номера документов, в которых присутствует хотя бы один термин из запроса, вычисляют из запроса степень раскрытия понятия в найденных документах как функцию от оценок точности и полноты, вычисляют оценку W(i) как функцию от раскрытия понятия из запроса, близости и порядка слов из запроса, соответствия словоформам и запроса, сортируют полученные документ по оценке W(i) и выдают пользователю найденные документы.
Способ оценки степени раскрытия понятия в тексте, основанный на контексте, для поисковых систем, заключающийся в формировании контекста предметной области, для чего строят контекст предметной области, на вход системы подают тематическую коллекцию документов, для каждого документа i из коллекции документов вычисляют матрицу оценок D(i) взаимосвязей между словами, направляют матрицу оценок D(i) в контекст предметной области, суммируют D(i) в матрице контексте, отличающийся тем, что для формирования контекста предметной области вводят словарь, содержащий известные системе словоформы языка и позволяющий привести словоформу к нормализованной форме, пополняют его новыми словами из документов, матрицу оценок D(i) взаимосвязей между словами вычисляют на основании непосредственной близости терминов и логического деления текста на предложения и абзацы, а матрицу оценок D(i) суммируют в матрице контекста предметной области Cntxt, фильтруют матрицу Cntxt от шумовых элементов, обрезая шумовые элементы с малой неуникальной оценкой взаимовстречаемости, производят нормализацию строк матрицы Cntxt, сжимают контекст предметной области Cntxt, приводя его к виду в каждой строке <номер термина, оценка>, затем для формирования поискового индекса вносимым в поисковый индекс документам присваивают уникальные номера, формируют образы этих документов в виде перечисления для каждого уникального термина, используемого в документе, позиций употребления его словоформ, строят индекс встречаемости терминов в документах в виде перечисления для каждого уникального термина коллекции, в каких документах была встречена его словоформа, вычисляют оценки нахождения терминов в заголовках и присутствия терминов в текстах ссылок на данный документ и добавляют их в индекс встречаемости терминов в документах, вычисляют оценки точности и полноты раскрытия понятия и добавляют их в индекс встречаемости терминов в документах, затем представляют поисковый запрос в виде вектора, где каждому термину присваивают порядковый номер, производят морфологический анализ терминов запроса, используя словарь, получают номера терминов, осуществляют поиск, внося в память компьютера номера документов, в которых присутствуют хотя бы один термин вектора запроса, заносят в память компьютера количество совпавших терминов с терминами запроса и порядковые номера совпавших терминов, отбрасывают те документы, которые не содержат хотя бы одно не служебное слово из запросов пользователя, производят семантический анализ, вычисляя из запроса для существительных и устойчивых словосочетаний (с существительным) степень раскрытия понятия в найденных документах Rβ как функцию от оценок точности и полноты, оценивают соответствие поискового запроса найденным документам, вычисляя оценку W(i) как функцию от раскрытия понятий из запроса Rβ, близости и порядка слов из запроса, соответствия словоформам и запроса, нахождения слов в заголовке и присутствия ссылок на данный документ с текстом запроса, сортируют полученные документы по оценке W(i) и выдают пользователю найденные документы.
| US 6633868 B1, 14.10.2003 | |||
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В ПОЛИТЕМАТИЧЕСКИХ МАССИВАХ НЕСТРУКТУРИРОВАННЫХ ТЕКСТОВ | 2004 |
|
RU2266560C1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

