Предлагаемый способ относится к сфере обработки и хранения больших объемов разнородных данных и может быть использован в системах управления базами данных для организации высокоэффективного поиска информации.
При обработке больших объемов данных значительную часть времени занимает поиск данных по указанным пользователем значениям (ключам поиска), особенно в случае необходимости располагать хранимые данные на внешних запоминающих устройствах, время доступа к данным на которых значительно превосходит время доступа в оперативной памяти. Затраты времени на поиск возрастают с ростом количества обрабатываемых документов: среднее время поиска требуемых данных при последовательном переборе равно T=T1*N/2, где T1 - время сравнения с ключом значения одного данного, что неприемлемо при больших объемах обрабатываемых данных.
Для минимизации времени поиска были предложены и реализованы более сложные, чем последовательная, схемы хранения данных: иерархическая (индексно-последовательная, индексно-прямая и др.), реляционная, постреляционная, объектная [1]. При возрастании сложности процедур поиска, что характерно для задач классификации, поиска новых знаний и аналогичных, рост значения среднего времени поиска приобретает нелинейный характер: время бинарного поиска равно T1*log2N, интерполяционного поиска - T1*log2log2N, где N - число хранимых элементов. При любом методе поиска, за исключением хеширования, время поиска в среде хранимых элементов является функцией их числа N. Хеширование, сокращая время поиска, также не может сделать его полностью независимым от числа хранимых элементов и их значений из-за необходимости разрешения коллизий и соответствующих временных затрат [2]. Для повышения скорости работы при поиске в текстовых документах выполняется предварительное индексирование текстов, причем затрачиваемое на построение индексов время во много раз превышает непосредственно требуемое для проведения поиска образца. Кроме того, при подготовке и использовании индексных структур резко возрастают и прочие затраты, в частности объемы памяти для хранения дополнительной поисковой информации.
В современных системах управления базами данных (СУБД), таких как Oracle, POSTGRES и ряда других, время поиска зависит от объема данных в базах данных (БД), т.к. при любом способе поиска (последовательный, хеш-поиск, В- и R-деревья) объем подлежащих анализу данных существенно превышает объем содержащихся в запросе.
Основным фактором, определяющим время поиска, является то, что количество используемых процессоров (каждый из которых последовательно реализует алгоритм поиска) на несколько порядков меньше числа обрабатываемых в ходе поиска объектов.
Аналогом предлагаемого способа поиска объектов может служить и способ формирования рекомендательного списка с использованием дактилоскопической базы данных, дактилоскопическая база данных и способ ее формирования [3].
Наиболее близким к предлагаемому является способ автоматизации архивного и складского учета на базе RFID-меток [4], принятый за прототип.
Способ-прототип позволяет ставить в соответствие каждому хранимому объекту номер метки, идентифицирующий содержащийся в хранимом объекте материал (авторы, год выпуска и т.п.), связывать материал с другими материалами в архиве по каким-либо признакам (одинаковые авторы, жанры и т.п.), что позволяет производить разнообразный поиск по хранимым материалам. Для осуществления поиска пользователь задает системе поиска параметры материала и активизирует функцию системы "Найти". Полученный запрос система поиска передает считывателю. Считыватель последовательно опрашивает RFIDы. При обнаружении в зоне видимости считывателя искомого материала считыватель выдает звуковой сигнал и данные о расположении найденного объекта.
Способ-прототип имеет следующие недостатки:
является узкоспециализированным, так как ориентирован на использование только в архивах и на складах;
при поступлении в хранилище каждый материал необходимо вручную снабдить RFIDом, сформировать уникальный идентификационный номер и связать с ним все необходимые атрибуты материала;
структура описания атрибутов материала, разработанная при организации хранилища, не может быть изменена;
ввиду того что ответ на запрос выдают только те RFIDы, которые находятся в рабочей зоне действия считывателя (не более 5 м), для полного обзора материалов пользователю необходимо обойти все хранилище.
Задачей предлагаемого способа является повышение скорости поиска данных при минимизации времени создания, ведения и реорганизации БД.
Для решения поставленной задачи в способе, включающем наличие дополнительного устройства для описания и поиска элемента - материала, объекта, хранимого в базе данных, согласно изобретению, используют адаптивные носители данных со средствами связи, позволяющие организовать «активную базу данных» с возможностью хранения объектов, имеющих различные типы и структуры; добавления объектов со структурами, ранее не встречавшимися в БД; автоматизации функций создания, ведения, изменения структуры и реорганизации самой БД хранимых объектов; самостоятельной организации связей хранимыми объектами друг с другом и с сервером БД; повышения защищенности хранимых объектов; обеспечения одновременного доступа к хранимым объектам.
Предлагаемый способ организации баз данных использует объектно-ориентированный подход [5, 6] к процессам создания, обработки, хранения и реорганизации разнородных данных. Он реализуется посредством использования адаптивных носителей данных, содержащих специализированные процессоры доступа к объекту (в которые могут загружаться методы и процедуры, реализующие реакции объектов на события) и активно участвующих в указанных выше процессах [7-9].
Способ базируется на сети ЭВМ, имеющих различную специализацию, что позволяет реализовать адаптируемый носитель данных и, как следствие, автоматизировать функции создания, ведения и реорганизации БД. Использование радиоканалов для связи ЭВМ в предлагаемой сети позволяет осуществлять практически одновременный доступ ко всем данным.
На нижнем уровне иерархии для инкапсуляции работы с хранимым данным (далее - объектом) используются ЭВМ (в дальнейшем - ЭВМ объекта), имеющие в своем составе:
энергонезависимое ОЗУ для хранения данных объекта;
процессор с ПЗУ и перепрограммируемой памятью для хранения программ;
приемопередающее устройство [10], на базе которого возможно реализовать локальную сеть ЭВМ [11].
На средних уровнях иерархии (число уровней и количество ЭВМ на уровнях зависят от конкретной реализации СУБД, в простейшем случае средний уровень может отсутствовать) используются ЭВМ с приемопередающими устройствами. Эти ЭВМ осуществляют функции концентрации и предварительной обработки массива выбранных данных (в дальнейшем - ЭВМ-концентратор). Программное обеспечение (ПО) этих ЭВМ отличается от ПО ЭВМ объекта, так как у них имеются более развитые программные и аппаратные средства обмена данными.
На верхнем уровне находится сервер СУБД (в дальнейшем - ЭВМ-сервер). Сервер осуществляет функции управления БД, анализ запросов пользователей, прием данных от ЭВМ-концентраторов и отображение результатов поиска.
Предлагаемый способ осуществляется следующей последовательностью операций.
Пользователь на пользовательском терминале формирует запрос к БД, который поступает на сервер СУБД.
Получив запрос, сервер БД осуществляет обработку и анализ запроса, на выделенной частоте доводит его содержание до ЭВМ-концентраторов (при их отсутствии в простейшем случае запрос передается непосредственно ЭВМ объектов);
ЭВМ-концентраторы по получении запроса одновременно обрабатывают его с учетом значений параметров запроса и обобщенных характеристик объектов, хранящихся в подчиненных ЭВМ объектов.
При наличии готового ответа ЭВМ-концентраторы выдают его на сервер БД.
При необходимости ЭВМ-концентраторы транслируют запрос всем подчиненным ЭВМ объектов.
Получив запрос, ЭВМ объектов с помощью процедур-методов объектов обрабатывают его и передают ответ ЭВМ-концентратору.
Получив ответы, ЭВМ-концентратор осуществляет необходимую обработку и отправляет обобщенный результат на ЭВМ-сервер.
Получив ответы от ЭВМ-концентраторов, ЭВМ-сервер завершает обработку запроса и передает окончательный результат на терминал пользователя.
Таким образом, предлагаемый способ позволяет практически одновременно осуществлять доступ ко всем объектам БД. Кроме того, предлагаемый способ позволяет сократить время работы процедур управления БД (создание, удаление, коррекция данных хранимых объектов) и повысить защищенность БД, так как:
физически разделены области памяти данных хранимых объектов и процедур управления БД и обработки запросов;
правила доступа к каждому объекту могут быть прописаны непосредственно в ПО ЭВМ соответствующего объекта [12].
Предлагаемый способ организации БД является адаптивным, поскольку методы объектов могут модифицироваться в процессе работы по команде ЭВМ-сервера БД, что позволяет в процессе обработки объектов объединять их в иерархические структуры и осуществлять реорганизацию БД. При этом анализ полей хранимых объектов в процессе поиска осуществляется самими ЭВМ объектов, что позволяет объектам БД играть активную роль в процессе поиска.
В зависимости от количества объектов и отношений между ними возможны разные варианты структуры БД.
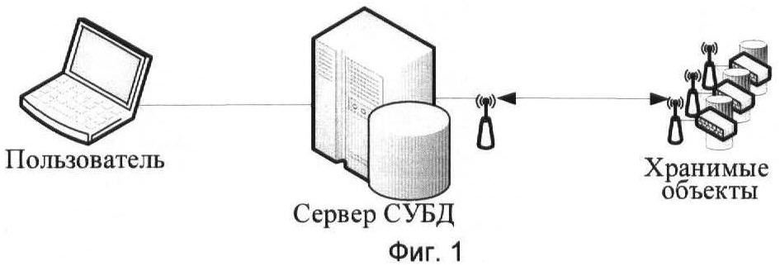
1. В простейшем случае ЭВМ-концентраторы не требуются, и сеть БД имеет двухуровневая структуру, вид которой приведен на фиг.1.
Фиг.1 - Простейшая двухуровневая структура «Активной базы данных».
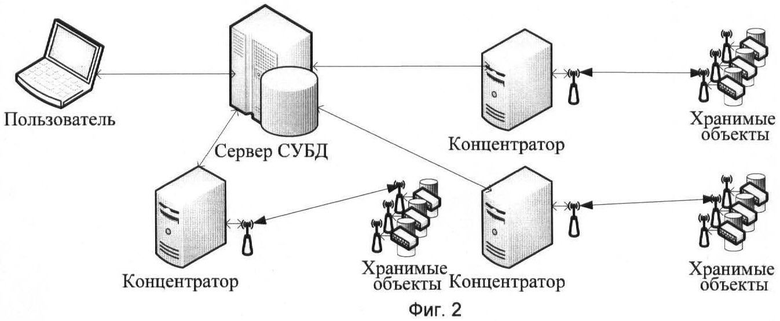
2. При использовании ЭВМ-концентраторов возможно выполнение ими функций предварительной обработки собранной информации, например осуществление сбора статистики, с последующей передачей ЭВМ-серверу итогового результата обработки запроса. В этом случае структура сети принимает вид, приведенный на фиг.2.
Фиг.2 - Трехуровневая структура «Активной базы данных».
3. При наличии множественных связей между объектами возникает необходимость обмена информацией между ЭВМ объектов для формирования информационных связей между объектами в соответствии с семантикой информации объектов и описанием отношений между ними, реализуемых в процедурах-методах объектов. В этом случае ЭВМ-концентраторы не только обрабатывают запросы, но и изменяют связи между ЭВМ объектов. При наличии технической возможности реализуем более сложный вариант изменения ПО как ЭВМ объектов, так и ЭВМ-концентраторов по командам, получаемым с ЭВМ-сервера (архитектуру которого в этом случае целесообразно сделать многопроцессорной и масштабируемой). Это позволяет формировать списки данных в виде цепочек объектов (они в отличие от современных БД могут иметь разную структуру), инкапсулированных в ЭВМ объектов, то есть осуществлять предварительную сортировку и группирование объектов с соответствующим отображением характеристик группы объектов на ЭВМ-концентраторе. Структура сети принимает вид, приведенный на фиг.3.
Фиг.3 - Сетевая структура «Активной базы данных».
Процедуры добавления данных в БД сводятся к физическому размещению новых носителей в пределах зоны хранения данных.
Областью применения предлагаемых «активных баз данных» являются все области вычислений, предназначенные для административных, коммерческих, финансовых, управленческих, надзорных, диагностических или прогностических целей, для которых характерно наличие большого объема данных и высокая интенсивность запросов к БД.
Предполагается, что максимальный эффект изобретение может дать при моделировании сложных систем, содержащих множество компонентов, на вычислительных системах, в которых нецелесообразно или невозможно отвлечение вычислительных и аппаратных ресурсов на организацию и актуализацию базы данных, а также в случае, когда для моделируемых процессов характерен интенсивный обмен данными.
Предлагаемая организация поиска может использоваться не только для СУБД, но и в любом хранилище данных, содержащем отдельные объекты. При данном подходе не требуется наличия метаданных, поскольку описание структур хранимых объектов содержится в программных компонентах самих объектов, а в описании явных взаимосвязей между различными типами объектов, обычно фиксируемом в виде логической структуры связанных таблиц, вообще нет необходимости.
Предлагаемый способ, в случае реализации, позволит существенно повысить эффективность поиска, т.к. максимальное время поиска будет определяться не числом обрабатываемых объектов, а временем распространения электромагнитной волны до наиболее физически удаленного хранимого объекта и максимальным из времен обработки запроса ЭВМ, инкапсулирующих работу с хранимыми объектами.
В качестве ЭВМ объектов в настоящее время предлагается микроконтроллер общего применения NXP LPC1102 на базе процессора Cortex-М0 [13]. В качестве ЭВМ-концентраторов могут быть использованы микрокомпьютеры на основе более мощных микропроцессоров.
Максимальный эффект от предлагаемого способа будет достигнут при минимизации времени передачи запроса, что может быть достигнуто применением нанотехнологий, позволяющих объединить ЭВМ, память, хранящую данные объекта, и приемопередатчик в одном устройстве.
Источники информации
1. Карпова Т. Базы данных. Модели, разработка, реализация. СПб.: «Питер», 2001.
2. Кнут Д. Искусство программирования для ЭВМ, т.3. Сортировка и поиск. М.: «Мир», 1978.
3. Пат. РФ 2410749, G06K 9/00 (2006.01).
4. Keytex RFID Document Registration System. Автоматизация архивного и складского учета. Учет книг, аудиофондов и фондов видеотек с применением RFID-меток. http://www.keytex.ru/index.php?page=products_view&id=2.
5. Дарахвелидзе П.Г., Марков Е.П. Программирование в Delphi 7. СПб.: БХВ-Петербург, 2004.
6. Гайсарян С.С. Объектно-ориентированный подход. Центр Информационных Технологий, http://citforum.ru/programming/oop_rsis/glava1.shtml:
7. RFID в Мэдисонской публичной библиотеке для обеспечения сохранности экземпляров и ускорения обслуживания клиентов. http://rfid-and-wms.blogspot.com, 25.03.10. Статья взята с сайта 28.03.2010.
8. RFID решения для библиотек. http://elementstore.ru/rfid/. Статья взята с сайта 28.03.2010.
9. Борн Д. Будущее RFID-меток - интеллектуальные задачи http://www.3dnews.ru/tags/RFID, 18.08.2009, со ссылкой на http://www.newscientist.com.
10. Э.Регис. Самый маленький радиоприемник в мире. В мире науки, май, 2009 (по сообщениям сайта www.SciAm.com/nanoradio).
11. В.Atakan, Ozgur В.Atakan. Carbon Nanotube-Based Nanoscale Ad Hoc Networks. - IEEE Communication Magazine, June 2010, p.129-135.
12. Буслов С.Д. Управление параметрами контроля доступа с использованием прикладного программного обеспечения. Информация и безопасность: науч. изд. - Воронеж: 2009. - Вып.3. - Стр.457-460.
13. Баранова С. NXP LPC1102 - самый маленький микроконтроллер http://f1cd.ru/news/pc/1404/, 27.04.2010.
Изобретение относится к сфере обработки и хранения больших объемов разнородных данных и может быть использовано в системах управления базами данных (БД) для организации высокоэффективного поиска информации. Технический результат - повышение скорости поиска данных при минимизации времени создания, ведения и реорганизации БД. Для этого в способе повышения скорости поиска данных используют адаптивные носители данных со средствами связи, позволяющие организовать «активную базу данных» с возможностью хранения объектов, имеющих различные типы и структуры; добавления объектов со структурами, ранее не встречавшимися в БД; автоматизации функций создания, ведения, изменения структуры и реорганизации самой БД хранимых объектов; самостоятельной организации связей хранимыми объектами друг с другом и с сервером БД; повышения защищенности хранимых объектов; обеспечения одновременного доступа к хранимым объектам. 3 ил.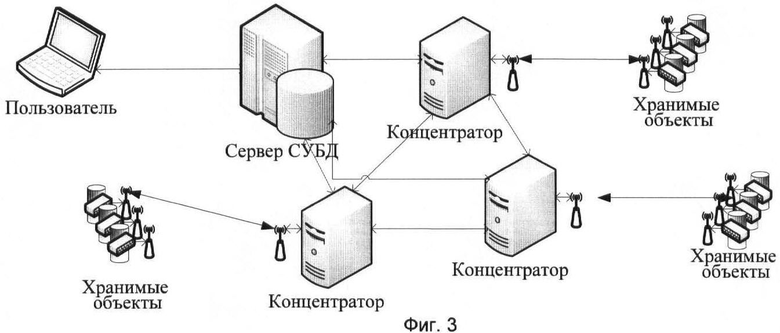
Способ поиска данных с использованием адаптивных носителей данных, включающий наличие дополнительного устройства для описания и поиска элемента - материала, объекта - хранимого в базе данных, отличающийся тем, что используют адаптивные носители данных со средствами связи, позволяющие организовать «активную базу данных» с возможностью:
хранения объектов, имеющих различные типы и структуры;
добавления объектов со структурами, ранее не встречавшимися в БД;
автоматизации функций создания, ведения, изменения структуры и реорганизации самой БД хранимых объектов;
самостоятельной организации связей хранимыми объектами друг с другом и с сервером БД;
повышения защищенности хранимых объектов;
обеспечения одновременного доступа к хранимым объектам.
| СИСТЕМА И СПОСОБ ДЛЯ ПРЕДСТАВЛЕНИЯ ЭЛЕМЕНТОВ, СОХРАНЕННЫХ НА КОМПЬЮТЕРЕ | 2004 |
|
RU2377647C2 |
| CN 102043836 A, 04.05.2011 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СИНХРОНИЗАЦИИ ТОГО, КАК ДАННЫЕ СОХРАНЯЮТСЯ В РАЗЛИЧНЫХ ХРАНИЛИЩАХ ДАННЫХ | 2003 |
|
RU2337398C2 |
| Способ получения спеканием пористых антифрикционных сплавов | 1936 |
|
SU50695A1 |

