Область техники
Изобретение относится к области информационных технологий, а именно к способу обработки данных в гибридных хранилищах, и может быть использовано для обработки и хранения данных в DLP (Data Loss Prevention) системах для возможности проведения ретроспективного анализа и обогащения информации о выявленных инцидентах.
Уровень техники
Традиционно в DLP системах использовались хранилища, основанные на реляционных СУБД, используемые для хранения и предоставления доступа к взаимосвязанным элементам информации. Реляционные базы данных основаны на реляционной модели - интуитивно понятном, наглядном табличном способе представления данных. Каждая строка, содержащая в таблице такой базы данных, представляет собой запись с уникальным идентификатором, который называют ключом. Столбцы таблицы имеют атрибуты данных, а каждая запись обычно содержит значение для каждого атрибута, что дает возможность устанавливать взаимосвязь между элементами данных.
Однако реляционная модель содержит ряд ограничений: недостаточная производительность при работе со сложно структурированными объектами и плохая адаптация для хранения больших блоков данных (объемных файлов). Также к недостаткам можно отнести относительно низкую скорость доступа и большой объем внешней памяти.
Наиболее современным и оптимальным форматом хранения данных в DLP системах являются гибридные хранилища с использованием реляционных СУБД и NoSQL (нереляционных БД) с целью использования лучших свойств каждой из файловых систем и объединения их в одну систему для улучшения производительности, устойчивости, возможностей резервного копирования.
Пример такого гибридного хранилища описан в патенте США US7870172B1 (опубликовано 201.01.11, МПК G06F12/00; G06F15/16; G06F17/30; G06F9/00; G06F9/44), которое выбрано за прототип настоящего изобретения, где раскрывается файловая система, имеющая формат гибридной файловой системы. Файловая система поддерживает определенные данные в двух форматах, тем самым определяя формат гибридной файловой системы. В одном примерном приложении первый формат имеет свойства, благоприятные для операций записи, например, формат файловой системы с журнальной структурой, тогда как второй формат имеет свойства, благоприятные для операций чтения, например, формат файловой системы на основе экстентов. Данные сохраняются в первом формате файловой системы, а затем асинхронно сохраняются во втором формате файловой системы. Данные, хранящиеся во втором формате файловой системы, также обновляются асинхронно.
Недостатком данного решения является повышенная сложность реализации файловой системы, отсутствие дедупликации, балансировки нагрузки и кластеризации на уровне хранилища, а также ограниченная масштабируемость.
Раскрытие сущности изобретения
Настоящее изобретение направлено на достижение технического результата, заключающегося в повышении быстродействия гибридного хранилища данных в DLP системах.
Заявленный технический результат обеспечивает способ обработки данных в гибридном хранилище, содержащий следующие этапы:
1) С помощью пользовательского интерфейса в части чтения данных формируется запрос на выборку данных, который передается на службу трансфера запросов;
2) Служба трансфера запросов обрабатывает запрос и разбивает на необходимые составляющие (атрибуты, оригиналы файлов, текстовые данные);
3) Выборка атрибутов происходит из конкретной БД конкретной СУБД, выборка текста происходит из конкретного индекса с конкретного сервера индексации, выборка оригинала файла происходит из конкретного Volume;
4) Ответ собирается службой трансфера запросов в единый результат и отображается в пользовательском интерфейсе.
Краткое описание чертежей
Заявляемое изобретение поясняется изображениями: Чертеж - Блок-схема способа обработки и хранения данных в гибридном хранилище.
Осуществление изобретения
Используемые термины в настоящем изобретении:
Сервер приложений - серверная часть клиент-серверной архитектуры комплекса разработчика, обеспечивающая прием и обработку входящих данных с различных источников (сетевого оборудования, прокси серверов, почтовых серверов, облачных сервисов хранения данных, агентов и прочих источников);
Пользовательский интерфейс - клиентская часть клиент-серверной архитектуры комплекса разработчика, обеспечивающая отображение администратору системы обработанных данных из СУБД, индексов и Volume, сохраненных с различных источников (сетевого оборудования, прокси серверов, почтовых серверов, облачных сервисов хранения данных, агентов и прочих источников);
Балансировка - метод распределения заданий между несколькими сетевыми устройствами (например, серверами) с целью оптимизации использования ресурсов, сокращения времени обслуживания запросов.
Индексирование - процесс нормализации текстовой информации в вид, адаптированный для быстрого поиска;
Дедупликация - удаление либо запрет сохранения одинаковых объектов;
Атрибуты - свойства информации, описывающие ее, например, размер, дата, время, пользователь, отправитель, получатель, канал передачи, направление передачи, расширение и т.д.;
Volume - хранилище блоков данных оригиналов файлов, на которые они разбиваются, технически реализованное на стандартных системах хранения, например, SSHD, SSD и т.д.;
ПК - персональный компьютер;
Агенты - службы, устанавливаемые на компьютеры сети;
СУБД - система управления базами данных;
ПО - программное обеспечение, в частности DLP система.
Данное изобретение представляет из себя алгоритм обработки огромных массивов структурированных и не структурированных данных с производительностью существенно более высокой, чем обеспечивает любая из существующих реляционных СУБД.
Изобретение обеспечивает поддержку отказоустойчивости, кластеризации и балансировки нагрузки, ограниченную только суммой имеющихся характеристик технических средств. Также обеспечивает возможность бесшовного переноса, хранения и обработки части массива наименее активных данных на медленные и менее отказоустойчивые диски, тем самым освобождая место высокопроизводительных и отказоустойчивых дисков или дисковых массивов (RAID), необходимое для хранения актуального массива информации.
Функциональные характеристики изобретения:
- Хранение большого количества файлов (порядок - миллиарды файлов);
- Хранение большого объема (порядок - петабайты);
- Срок хранения (порядок - года);
- Отсутствие дублирующего хранения идентичных объектов;
- Объем хранения ограничен только объемом физического носителя;
- Отсутствие или незначительное влияние на скорость кол-ва/объема файлов;
- Возможность масштабирования.
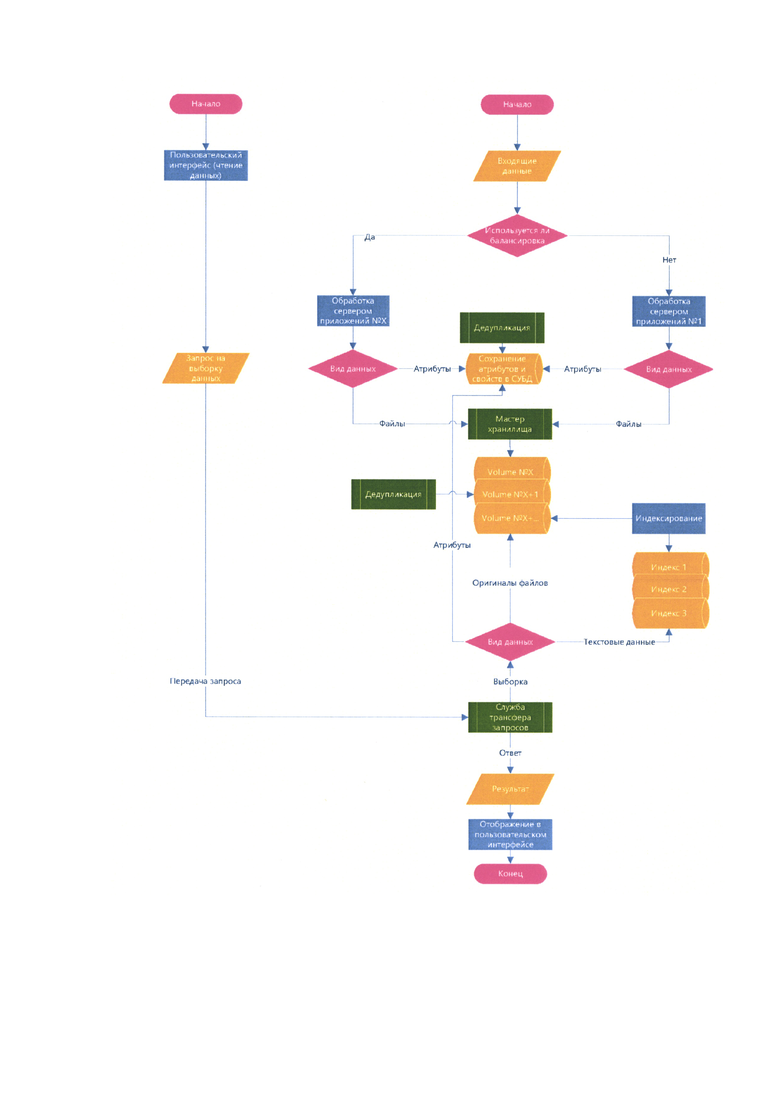
Как показано на чертеже, изобретение работает следующим образом:
Входящие данные передаются с одного или нескольких источников в гибридное хранилище - от агентов, установленных на рабочих станциях, от сетевого оборудования, от почтовых серверов и прочих источников.
Входящие данные попадают в балансировщик, который в свою очередь перенаправляет их на конкретный сервер приложений согласно выбранным настройкам, и сохраняются на диск в виде сырой очереди.
Далее, в зависимости от типа данных (файлы или их атрибуты) происходит выбор их Volume, атрибуты сохраняются в СУБД в виде табличных данных, где каждый столбец содержит определенные атрибуты, а строка - отдельные записи. Файлы в свою очередь разбиваются на блоки данных и распределяются по определённым Volume с помощью мастера хранилища для ускорения обработки.
Хранилище как структура делится на 2 логические части - мастер хранилища и отдельные Volume хранилища.
Мастер выполняет роль администрирования, оценивает и регулирует нагрузку, занимается адресацией, назначает идентификаторы и сегментирует данные (т.к. в Volume хранятся не файлы как таковые, а блоки данных, на которые они разбиваются). Сегментация может происходить на разные Volume, то есть один файл может физически храниться на нескольких отдельных физических серверах в виде разрозненных блоков данных.
Volume могут:
- Быть расположенными как на нескольких отдельных серверах, так и на одном физическом сервере;
- Работать в режиме кластера нагрузки;
- Работать в режиме балансировщика;
- Производить запись или чтение по идентификатору блоков данных (в Volume нет ни структуры каталогов, ни файлов - там осуществляется “плоское” хранение блоков данных, из которых эти файлы состоят).
Индексирование текстов из оригинальных файлов происходит через обращение к Volume, далее индексатор решает в каком именно индексе будет сохранен результат в зависимости от типов данных, источников и других настроек.
С целью выявления одинаковых записей в Volume и СУБД выполняется дедупликация.
Как показано на чертеже, запрос на выборку данных обрабатывается следующим образом:
С помощью пользовательского интерфейса в части чтения данных формируется запрос на выборку данных, который передается на службу трансфера запросов.
Служба трансфера запросов обрабатывает его и разбивает на необходимые составляющие (атрибуты, оригиналы файлов, текстовые данные). Выборка атрибутов происходит из конкретной БД конкретной СУБД, выборка текста происходит из конкретного индекса с конкретного сервера индексации, выборка оригинала файла происходит из конкретного Volume.
Ответ собирается службой трансфера запросов в единый результат (где есть оригинал файла, его текстовое содержание из индекса и его атрибуты из БД) и отображается в пользовательском интерфейсе.
Так как гибридная файловая система хранит данные сразу и в СУБД, и в индексах, и в Volume, ей требуется отдельная служба, которая позволит пользователям бесшовно работать с выборками данных. При помощи пользовательского интерфейса задается необходимый запрос и выводится результат в одном окне - при этом, результат может быть собран с разных серверов СУБД, нескольких индексов и нескольких физических серверов с хранилищами. Для того чтобы пользователю этот процесс был незаметен и существует служба трансфера запросов.
Работа данной службы строится следующим образом:
1) При обращении к пользовательскому интерфейсу в части чтения данных происходит автоматическая передача первичного запроса со следующим наполнением (другими словами, происходит автоматическая подгрузка определенных данных с целью минимизации задержек):
- Список прав доступа к БД, индексах и хранилищах;
- Список серверов индексации;
- Список служб карантина (почты);
- Список серверов БД;
- Список цепочек индексов (с расположением по серверам индексации);
- Список БД (с расположением по СУБД и строками подключения);
- Список хранилищ (с расположением);
- Размеры отдельных индексов и хранилищ;
- Тип информации, хранящийся в БД, индексе или хранилище (почта, мессенджеры, аудиозаписи, файлы, загруженные в облака, скриншоты и прочее);
- Результат проверки учетной записи требованиям безопасности по SID;
- Лог ошибок.
2) При взаимодействии (выбор пользователем определённых настроек поиска) с пользовательским интерфейсом в части чтения данных происходит передача уточняющего запроса со следующим наполнением (другими словами, происходит автоматическая подгрузка определенных данных с целью минимизации задержек):
- Цепочка баз данных для конкретного канала обмена информации (корпоративная почта, мессенджеры и т.д.);
- Даты документов (файлов) в БД, индексах и хранилищах;
- Статистика использования лицензий ПО коннектором;
- Пользователи в БД, индексах и хранилищах (от каких пользователей поступали данные в гибридное хранилище);
- Разрешен ли объект для анализа (права доступа);
- Лицензирован ли объект (есть ли в лицензионном ключе ПО функция по его обработке);
- Имена доменов и рабочих групп.
3) Далее в пользовательском интерфейсе в части чтения данных передается конкретный запрос на поиск, а пользователь получает ответ со следующим наполнением:
- Атрибуты файлов;
- Атрибуты сообщений;
- Пользователи, группы в Microsoft Active Directory или рабочих группах;
- Идентификаторы пользователей в сторонних сервисах (получателей и отправителей);
- Имя ПК;
- IP, MAC, прочие адреса;
- Уникальные для канала передачи идентификаторы (для USB это будут пути к файлам, для скайпа - список контактов и т. Д.);
- Дата и время (события, отправки, получения, записи в систему и прочее);
- Текст файла или сообщения;
- Оригинал файла или сообщения.
В изобретении реализованы “цепочки” из индексов, Volume и БД, которые сегментируют данные в соответствии с настройками. Сегментация нужна для оптимизации хранения и ускорения поисковых выборок. Оптимизация хранения происходит за счет небольшого объема каждой отдельно взятой БД (т.к. любая СУБД теряет производительность при значительном росте объема отдельно взятой БД). Ускорение поисковых выборок происходит за счет двух факторов - небольшого объема отдельно взятой БД (в любой СУБД скорость выборки из БД меньшего размера быстрее, чем аналогичная выборка из БД большего размера), а так же “избирательного” поиска по БД, ведь ПО знает в каких СУБД и подключенным к ним БД поиск проводить бесполезно (т.к. там не содержатся события за выбранный период, по выбранным каналам защиты и прочее).
Изобретение может одновременно и бесшовно работать с несколькими СУБД сразу, более того, возможно работа с принципиально разными типами СУБД - в частности MS SQL и PostgreSQL\PostgresPRO. Например, сервер приложений может принимать поток данных и часть из них записывать в СУБД №1 в БД №1 - 12, а другую часть в СУБД №2 и в БД №13 - 22, при этом СУБД №1 это MS SQL, а СУБД №2 это PostgreSQL. Поиск информации проходит бесшовно, то есть поисковый запрос получает данные из любых разрозненных БД, индексов или хранилищ.
На крупных внедрениях у заказчиков могут быть подключены к одному ПО десятки СУБД (из-за территориальной распределенности и необходимости распределять высокую нагрузку) и сотен БД (т.к. каждая СУБД имеет свои БД под все виды данных ПО), а по прошествию некоторого времени работы ПО количество БД может исчисляться тысячами (вследствие автоматизированного сегментирования). Каждая БД и каждое хранилище может быть связано с одним или несколькими индексами, поэтому в изобретении и была добавлена столь развитая функция по обработке данных.
Данный способ обработки данных в гибридном хранилище можно разделить на следующие этапы:
1) С помощью пользовательского интерфейса в части чтения данных формируется запрос на выборку данных, который передается на службу трансфера запросов;
2) Служба трансфера запросов обрабатывает запрос и разбивает на необходимые составляющие (атрибуты, оригиналы файлов, текстовые данные);
3) Выборка атрибутов происходит из конкретной БД конкретной СУБД, выборка текста происходит из конкретного индекса с конкретного сервера индексации, выборка оригинала файла происходит из конкретных Volume;
4) Ответ собирается службой трансфера запросов в единый результат (где есть оригинал файла, его текстовое содержание из индекса и его атрибуты из БД) и отображается в пользовательском интерфейсе.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ извлечения информации и корпоративная система поиска информации | 2019 |
|
RU2729224C2 |
| СПОСОБ И СИСТЕМА ГРАНУЛЯРНОГО ВОССТАНОВЛЕНИЯ РЕЗЕРВНОЙ КОПИИ БАЗЫ ДАННЫХ | 2024 |
|
RU2825077C1 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ПАРТИЦИОНИРОВАННЫХ ВИТРИН ДАННЫХ, СОДЕРЖАЩИХ ГЕОДАННЫЕ, И ИХ ИСПОЛЬЗОВАНИЯ В ПРОЦЕССЕ ЭКСПЛУАТАЦИИ ХРАНИЛИЩА ДАННЫХ | 2023 |
|
RU2811359C1 |
| Система и способ перехвата файловых потоков | 2023 |
|
RU2816551C1 |
| СПОСОБ ПРЕДОСТАВЛЕНИЯ ПОЛЬЗОВАТЕЛЯМ МОБИЛЬНЫХ УСТРОЙСТВ ЭЛЕКТРОННОЙ СВЯЗИ АКТУАЛЬНОЙ КОММЕРЧЕСКОЙ ИНФОРМАЦИИ НА АЛЬТЕРНАТИВНОЙ ОСНОВЕ (ВАРИАНТЫ) И ИНФОРМАЦИОННАЯ СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ (ВАРИАНТЫ) | 2003 |
|
RU2254611C2 |
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МЕТАДАННЫМИ В ВЫСОКОНАГРУЖЕННЫХ ОБЛАЧНЫХ СРЕДАХ | 2024 |
|
RU2829567C1 |
| ИНТЕЛЛЕКТУАЛЬНОЕ ИНДЕКСИРОВАНИЕ КОНТЕЙНЕРА И ПОИСК В НЕМ | 2006 |
|
RU2417419C2 |
| СИСТЕМА АВТОМАТИЗИРОВАННОГО МОНИТОРИНГА И КОНТРОЛЯ ПРОМЫШЛЕННОЙ БЕЗОПАСНОСТИ ГИДРОТЕХНИЧЕСКИХ СООРУЖЕНИЙ | 2021 |
|
RU2772447C1 |
| СИСТЕМА АГРЕГИРОВАНИЯ И ИНДЕКСАЦИИ ДАННЫХ ДЛЯ ИХ ВЫВОДА ПОЛЬЗОВАТЕЛЮ | 2022 |
|
RU2811451C2 |
Изобретение относится к области информационных технологий и может быть использовано для обработки и хранения данных в DLP (Data Loss Prevention) системах для возможности проведения ретроспективного анализа и обогащения информации о выявленных инцидентах. Техническим результатом является повышение быстродействия осуществления поиска. Способ содержит этапы, на которых с помощью пользовательского интерфейса в части чтения данных формируется запрос на выборку данных, который передается на службу трансфера запросов, служба трансфера запросов обрабатывает запрос и разбивает на необходимые составляющие, включающие атрибуты, оригиналы файлов, текстовые данные; выборка атрибутов происходит из конкретной БД конкретной СУБД, выборка текста происходит из конкретного индекса с конкретного сервера индексации, выборка оригинала файла происходит из конкретных Volume; ответ собирается службой трансфера запросов в единый результат, где есть оригинал файла, его текстовое содержание из индекса и его атрибуты из БД, и отображается в пользовательском интерфейсе. 1 ил.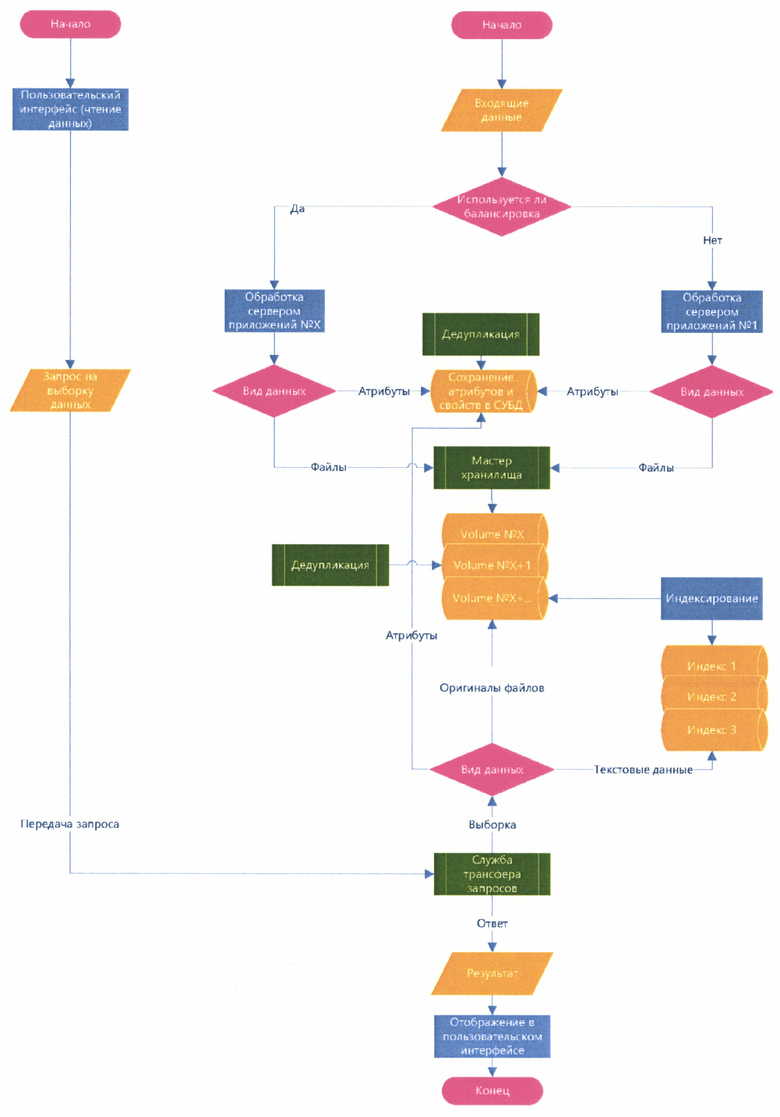
Способ обработки данных в гибридном хранилище, содержащий следующие этапы:
1) с помощью пользовательского интерфейса в части чтения данных формируется запрос на выборку данных, который передается на службу трансфера запросов, при этом происходит автоматическая передача первичного запроса от / на службу трансфера запросов, имеющего наполнение, в котором содержится:
- список прав доступа к БД, индексах и хранилищах;
- список серверов индексации;
- список служб карантина (почты);
- список серверов БД;
- список цепочек индексов с расположением по серверам индексации;
- список БД с расположением по СУБД и строками подключения;
- список хранилищ с расположением;
- размеры отдельных индексов и хранилищ;
- тип информации, хранящийся в БД, индексе или хранилище;
- результат проверки учетной записи требованиям безопасности по SID;
- лог ошибок,
и передача уточняющего запроса от / на службу трансфера запросов, имеющего наполнение, в котором содержится:
- цепочка баз данных для конкретного канала обмена информации;
- даты документов (файлов) в БД, индексах и хранилищах;
- статистика использования лицензий ПО коннектором;
- пользователи в БД, индексах и хранилищах (от каких пользователей поступали данные в гибридное хранилище);
- разрешен ли объект для анализа (права доступа);
- лицензирован ли объект (есть ли в лицензионном ключе ПО функция по его обработке);
- имена доменов и рабочих групп;
2) служба трансфера запросов обрабатывает запрос и разбивает на необходимые составляющие (атрибуты, оригиналы файлов, текстовые данные);
3) выборка атрибутов происходит из конкретной БД конкретной СУБД, выборка текста происходит из конкретного индекса с конкретного сервера индексации, выборка оригинала файла происходит из конкретных Volume;
4) ответ собирается службой трансфера запросов в единый результат (где есть оригинал файла, его текстовое содержание из индекса и его атрибуты из БД) и отображается в пользовательском интерфейсе.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 7870172 B1, 11.01.2011 | |||
| US 20190361779 A1, 28.11.2019 | |||
| Способ извлечения информации и корпоративная система поиска информации | 2019 |
|
RU2729224C2 |

