Область техники, к которой относится изобретение
Изобретение относится к области геоинформационной обработки данных.
Используемые термины
ГИС - геоинформационные системы;
СУБД - система управления базами данных;
Клиент-серверная СУБД - СУБД, использующая технологию «клиент-сервер»;
Технология «клиент-сервер» - вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг, называемыми серверами, и заказчиками услуг, называемыми клиентами.
База данных - информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств.
Терм - интуитивно определенное выражение формального языка (системы), являющееся формальным именем объекта или именем формы.
Объект - предмет, вещь, явление, на которые направлена деятельность, то, что подвергается какому-либо воздействию.
Уровень техники
Существуют различные городские ГИС, позволяющие ориентироваться в городском пространстве, получать информацию о расположении различных объектов, фирм, адресов и т.д.
Особенностью ГИС является то, что в них находится одновременно картографическая информация (информация о взаимном расположении объектов, их привязка к карте, дорожная сеть и т.д.) и семантическая часть (описание объектов, адреса, организации, кафе, рестораны, кинотеатры, маршруты, остановки). Городская ГИС является целостным объектом, т.е должна охватывать всю территорию в пределах городской черты с прилегающими городами-спутниками, дачными обществами и т.д. Эта территория охватывает большую площадь и содержит множество объектов, что подразумевает и большой объем данных, что не позволяет размещать полную базу на мобильном устройстве, потому что мобильные устройства ограничены по размеру хранимой информации и вычислительным возможностям. Поэтому существующие городские ГИС - Гугл.Карты, Яндекс.Карты и т.д размещаются на мобильных устройствах в виде клиента клиент-серверной СУБД.
Клиент-серверная СУБД позволяет обмениваться клиенту и серверу минимально необходимыми объемами информации. При этом основная вычислительная нагрузка ложится на сервер. Клиент может выполнять функции предварительной обработки перед передачей информации серверу, но в основном его функции заключаются в организации доступа пользователя к серверу.
В большинстве случаев клиент-серверная СУБД гораздо менее требовательна к пропускной способности компьютерной сети, особенно при выполнении операции поиска в базе данных по заданным пользователем параметрам, т.к. для поиска нет необходимости получать на клиент весь массив данных: клиент передает параметры запроса серверу, а сервер производит поиск по полученному запросу в локальной базе данных. Результат выполнения запроса, который обычно на несколько порядков меньше по объему, чем весь массив данных, возвращается клиенту, который обеспечивает отображение результата пользователю. Клиента, устанавливаемого на мобильном устройстве, и серверной части, которая размещается в центре обработки данных. Недостатком данной системы является обязательное подключение клиента к серверной части посредством сети Интернет с определенной шириной канала подключения, достаточной для передачи данных при обмене информацией с серверной частью. Соответственно, если нет подключения, то сервис становится недоступен.
Известны система и способ манипулирования данными, раскрытые в патенте на изобретение RU 2413984 «СИСТЕМЫ И СПОСОБЫ МАНИПУЛИРОВАНИЯ ДАННЫМИ В СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ». Изобретение относится к базам данных, в частности к системам и способам, облегчающим манипулирование данными на основе модели данных, и к безопасному осуществлению, связанному с системой хранения данных. Техническим результатом является облегчение манипулирования данными. Модель данных может представлять систему хранения данных так, что система хранения данных является файловой системой, основанной на базах данных. Компонента манипулирования данными может манипулировать данными, связанными с моделью данных, и внедрять по меньшей мере одно из ограничения и характеристики, чтобы гарантировать целостность такой системы. Кроме того, для обеспечения манипулирования данными в системе хранения данных может быть активизирована компонента интерфейса прикладного программирования (ИПП).
Раскрытое в патенте решение не обеспечивает высокой степени сжатия данных при упаковке и не подходит для использования ГИС на мобильных устройствах.
Известен способ, раскрытый в патенте RU 2166207 «СПОСОБ ИСПОЛЬЗОВАНИЯ ВСПОМОГАТЕЛЬНЫХ МАССИВОВ ДАННЫХ В ПРОЦЕССЕ ПРЕОБРАЗОВАНИЯ И/ИЛИ ВЕРИФИКАЦИИ КОМПЬЮТЕРНЫХ КОДОВ, ВЫПОЛНЕННЫХ В ВИДЕ СИМВОЛОВ, И СООТВЕТСТВУЮЩИХ ИМ ФРАГМЕНТОВ ИЗОБРАЖЕНИЯ». Изобретение относится к области электроники и предназначено, например, для использования вспомогательных массивов данных в процессе преобразования и/или верификации компьютерных кодов, выполненных в виде символов, и соответствующих им фрагментов изображения. Техническим результатом является снижение погрешности преобразования и/или верификации. Способ заключается в том, что производят выработку смысловых единиц распознаваемых фрагментов изображения, содержащих n составляющих их элементов, где n выбирают в пределах 1≤n≤103. В отобранных выборках выделяют подлежащие верификации совокупности их фрагментов изображения, содержащие n1 элементов, где n1 выбирают в пределах 1≤(n1+n)/n≤2. Осуществляют поиск во вспомогательном массиве данных смысловых единиц, отличающихся от выделенных совокупностей фрагментов изображения, с погрешностью s, выбираемой в пределах 0≤ε≤(αn1-1)/n1, где α - экспериментальный коэффициент в пределах 0,6≤α≤1,2, выбираемый в зависимости от частоты fi появления любой смысловой i-й единицы в допустимом множестве смысловых единиц, которую определяют как количество n2 повторений конкретной смысловой единицы, соотнесенное с общим количеством n3 смысловых единиц в допустимом множестве смысловых единиц. Выявляют в распознанных смысловых единицах элементы, которые не совпадают с эквивалентными им по месту расположения символами в смысловых единицах, найденных в процессе поиска, и производят их замену соответствующими им по месту расположения символами из найденных смысловых единиц. Формируют дополнительный массив динамических растровых эталонов компьютерных кодов элементов в составе распознаваемых смысловых единиц и с учетом предшествующих операций преобразуют вспомогательный массив данных до уменьшения итоговой погрешности ε3 способа, которую выбирают по отношению к промежуточной погрешности ε1 в пределах 1≤(ε1+e3)/ε1≤2.
Описанный способ не работает с ГИС и не обеспечивает высокой степени сжатия данных при упаковке.
Известен способ, раскрытый в патенте RU 2373569 «СПОСОБ ГЕНЕРАЦИИ БАЗ ДАННЫХ И БАЗ ЗНАНИЙ ДЛЯ СИСТЕМ ВЕРИФИКАЦИИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ РАСПРЕДЕЛЕННЫХ ВЫЧИСЛИТЕЛЬНЫХ КОМПЛЕКСОВ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ». Изобретение относится к средствам автоматизации обучения и научных исследований и может быть использовано в интерактивных системах автоматизации научно-исследовательских работ в процессе верификации программного обеспечения (ПО) распределенных вычислительных комплексов (РВК). Технический результат заключается в расширении функциональных возможностей процессов верификации ПО РВК. Предлагаемый способ и устройство для его реализации обеспечивают полную управляемость и наблюдаемость основных процессов проверки исходного кода ПО. При этом обеспечено совмещение процессов ввода и обработки исходного кода ПО по зависимым или независимым интерфейсным каналам, на основе использования сенсорных или механических манипуляторов рабочего места оператора ЭВМ, сетевых интерфейсов локальной или глобальной сети. Участки или точки уязвимости исходного кода ПО определяют на основе преобразования исходного кода ПО во внутреннее представление, которое хранят в виде баз данных и баз знаний, а точки или участки уязвимости исходного кода ПО определяют на основе автоматического составления и решения соответствующих систем уравнений.
Раскрытый в патенте способ не позволяет добиться высокой степени сжатия данных при упаковке и не предназначен для работы с ГИС.
Известен способ, раскрытый в патенте RU 2556425 «СПОСОБ АВТОМАТИЧЕСКОЙ ИТЕРАТИВНОЙ КЛАСТЕРИЗАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ, СПОСОБ ПОИСКА В СОВОКУПНОСТИ КЛАСТЕРИЗОВАННЫХ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ ДОКУМЕНТОВ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ». Изобретение относится к кластеризации документов по их семантической близости. Техническим результатом является упрощение и ускорение как обработки электронных документов, так и поиска в кластеризованной совокупности документов, релевантных поисковому запросу. В способе автоматической итеративной кластеризации электронных документов по семантической близости преобразуют каждый электронный документ в соответствующий многомерный вектор в многомерном пространстве, размерности которого определяются содержащимися в электронном документе термами. Находят меру близости полученного вектора к каждому из векторов уже имеющихся кластеров, объединяющих семантически близкие документы, обработанные ранее. Дополняют подлежащим обработке документом тот из кластеров, для которого найденная мера близости минимальна. Определяют для дополненного кластера его новый вектор. Принимают в качестве темы дополненного кластера название того из документов в данном кластере, для которого мера близости его вектора к определенному новому вектору минимальна. Таким образом, при поступлении новых электронных документов уже имеющиеся кластеры обрабатывают как отдельные документы, а не как множества документов.
Раскрытый в патенте способ не обеспечивает высокой степени сжатия данных при упаковке и не приспособлен для работы с ГИС.
Известен способ, раскрытый в патенте RU2501072 «РАСПРЕДЕЛЕННОЕ ХРАНЕНИЕ ВОССТАНАВЛИВАЕМЫХ ДАННЫХ». Изобретение относится к вычислительной технике. Технический результат заключается в увеличении надежности хранения данных. Способ замены отказавшего узла, хранящего распределенные данные, содержащий этапы, на которых: посредством первого узла хранения принимают первый набор квот, сгенерированный из файла данных, при этом каждая квота в первом наборе включает в себя линейную комбинацию частей файла данных наряду с набором коэффициентов, использованных для генерирования этой линейной комбинации; посредством первого узла хранения принимают указание нового узла хранения, заменяющего отказавший узел, при этом отказавший узел включает в себя второй набор квот, сгенерированный из файла данных; посредством первого узла хранения генерируют первую заменяющую квоту в качестве реакции на упомянутое указание, при этом первую заменяющую квоту генерируют путем умножения каждой квоты в первом наборе и набора коэффициентов на случайное масштабирующее значение и объединения умноженного первого набора квот и умноженного набора коэффициентов; и посредством первого узла хранения передают сгенерированную первую заменяющую квоту в новый узел хранения, при этом первая заменяющая квота и по меньшей мере одна другая заменяющая квота формируют второй набор квот в новом узле хранения, причем эта другая заменяющая квота генерируется вторым узлом хранения.
Раскрываемый в патенте способ больше ориентирован на надежность хранения данных, а не на их сжатие.
Раскрытие изобретения
Задачей заявляемого изобретения является возможность размещения большого объема геоинформационных данных на мобильном электронном устройстве в автономном режиме работы.
При этом необходимо понимать, что размещение подобной ГИС на мобильном устройстве целесообразно только тогда, когда при плотной упаковке геоинформационных данных не нарушается целостность семантической информации.
Техническим результатом заявляемого изобретения является получение базы геоинформационных данных малого объема со степенью плотности до 10 байт на объект с сохранением структурных связей между объектами, позволяющее дальнейшее ее размещение на мобильном устройстве в автономном режиме работы.
Технический результат достигается за счет того, что данные об объекте собирают и вносят в систему, включающую в себя устройства ввода данных, устройства передачи информации, сервера индексирования, устройства хранения данных, устройства вывода данных, в полуавтоматическом режиме; внесенные данные разбивают на структурные блоки и обрабатывают на серверах индексирования; из полученного в результате этого упорядоченного проиндексированного массива удаляют дублирующую информацию; оставшуюся информацию подвергают пятиуровневой программной алгоритмической обработке с выстраиванием связей между объектами, включающую посимвольный уровень; словарный уровень; уровень морфологии языка; уровень связи термов и объектов; уровень объектов. После чего полученную информацию размещают на устройстве хранения данных, при этом размещенная на устройствах хранения данных полученная информация образует базы данных геоинформационных систем.
Особенностью способа является методика обработки ГИС-данных с удалением избыточной информации, ее уплотнением, упорядочиванием структуры поиска с адресацией в память устройства, что обеспечивает скорость обработки данных и сжатие базы в приемлемый объем.
Данное изобретение позволяет полностью разместить базу данных по технологии локальной СУБД (все части локальной СУБД размещаются на одном устройстве (смартфоне, ноутбуке, планшете, персональном компьютере) с минимальными требованиями к размеру занимаемого места, но используя все преимущества технологии клиент-сервер, как то - быстрая обработка запросов пользователя, полнота и релевантность полученных результатов.
Подробное описание осуществления способа преобразования данных геоинформационных систем.
Процесс преобразования происходит следующим образом.
ГИС-данные состоят из картографической информации и ее семантического наполнения, т.е. привязки к конкретным объектам, их описания и пространственных координат.
Данные разбиваются на структурные блоки и обрабатываются на серверах индексирования.
Обработка происходит по следующим принципам: выделяют такие типы объектов, как страна, область, район области, город, населенный пункт (кроме городов), район города, административный округ, место, остановка, станция метро, микрорайон, улица, адрес, здание, здание схлопнутое с единственным адресом, достопримечательность, группа геообъектов, дорога, перекресток, тип маршрута, маршрут, надрубрика, рубрика, атрибут, связь рубрики и атрибута, филиал, организация, описание адреса, организационно-правовая форма, описание организации, доп.описание организации, пользовательские запросы, города других проектов. При этом все упомянутые типы объектов образуют между собой сложную систему связей, представленную на чертеже. Эти связи могут быть как обязательными, так и необязательными. Так, например, «достопримечательность» находится в необязательных связях со «зданием», «зданием схлопнутым с единственным адресом», «группой геообъектов» и «городом». А «улица» находится в обязательных связях с «районом города», «микрорайоном», «населенным пунктом» и «городом», в то время как связь «улицы» и «перекрестка» является необязательной.
В результате обработки получается упорядоченный проиндексированный массив с многомерными связями в соответствии с разработанной структурой.
Из массива удаляется дублирующая информация. Например, если у организации 50 филиалов, то телефон центрального офиса можно получить по ссылке, и нет необходимости хранить его в описании каждого филиала.
Затем информация подвергается программной алгоритмической обработке с выстраиванием связей между объектами на приведенных ниже уровнях.
1) Посимвольный (побуквенный) уровень
Рассчитывают встречаемость символов во входных данных и сохраняют только разрешенные для данной конфигурации символы (предварительно создают базу данных символов, где каждый символ имеет код и множество свойств). Это позволяет отбросить ненужные языки.
2) Словарный уровень
Сохраняют словарь в виде сжатого префиксного дерева (подвид конечных автоматов). Этот подход дает эффективное сжатие текстов, а также возможность получить уникальный идентификатор для каждого слова.
3) Уровень морфологии языка
Для каждого слова языка хранится список лексем. Все лексемы разбивают на блоки, внутри блока информация о каждой лексеме и ее свойствах хранится как разница от предыдущего подобного блока. Это позволяет добиться сжатия данных и эффективного доступа к ним.
По номеру слова из словарного уровня каждой связки лексемы и набора морфологических свойств присваивают номер терма.
Пример:
[сорока] Hash[405596]
Lexeme[17717] Props[0] Term[27202]
Lexeme[17718] Props[2] Term[27204]
Слово сорока может быть рассмотрено как сорока (птица в именительном падеже) и сорока (число в родительном падеже). 405596 - номер слова в словаре. 17717 и 17718 - две разные лексемы (птица и число). 0,2 - морфологические свойства. 27202 и 27204 - номера Термов.
4) Связи Термов и объектов
Для каждого Терма хранится список объектов, в которых он встречается, а также в каком названии (среди альтернативных) и в какой позиции в названии. Кроме того, признак значимости данного терма в названии объекта.
Пример:
TermId[27202]='сорока' Count[8]
5307869=[sn: 0 tp: 1 sign: Yes]
5326140=[sn: 0 tp: 1 sign: Yes]
6350461=[sn: 0 tp: 1 sign: Yes]
7353067=[sn: 0 tp: 2 sign: Yes]
7463828=[sn: 0 tp: 2 sign: Yes]
7707962=[sn: 0 tp: 1 sign: Yes]
7707974=[sn: 0 tp: 1 sign: Yes]
7707986=[sn: 0 tp: 1 sign: Yes]
TermId[27204]='сорока' Count[8]
5307869=[sn: 0 tp: 1 sign: Yes]
5326140=[sn: 0 tp: 1 sign: Yes]
6350461=[sn: 0 tp: 1 sign: Yes]
7353067=[sn: 0 tp: 2 sign: Yes]
7463828=[sn: 0 tp: 2 sign: Yes]
7707962=[sn: 0 tp: 1 sign: Yes]
7707974=[sn: 0 tp: 1 sign: Yes]
7707986=[sn: 0 tp: 1 sign: Yes]
Способ упаковки: выделяют связи, у которых набор свойств минимален и может быть сжат.Параметры отбора и сжатия выбирают так, чтобы максимальный процент связей подлежал сжатию (больше 90%).
5) Объекты
Для каждого объекта хранится набор признаков, указывающих на наличие определенных свойств. Если свойств у объекта нет, то ничего дополнительно не хранится.
Иерархические связи хранятся методом вложенных интервалов, что позволяет хранить их очень компактно, поскольку этот метод представляет из себя структуру данных, позволяющих быстро изменять значения в массиве и находить некоторые функции от элементов массива.
Идентификаторы хранятся в сжатом блочном виде. Идентификатор заменяется на номер блока и номер внутри блока. Это позволяет сжать идентификатор более чем в два раза. Идентификаторы разделены на 256 блоков и хранятся в следующем виде:
Номер блока (1 байт) + смещение в блоке (2 байта)
Это позволяет 8-байтовый идентификатор уместить в 3 байта.
Так же хранятся связи объектов между собой (как филиал связан с областью деятельности).
Обработка данных по заявляемому способу происходит следующим образом: Рассмотрим реализацию способа на примере г. Новосибирска. Изначальный объем данных г. Новосибирска 114 мегабайт, содержит 737579 объектов, 1149420 связей между ними, 930813 названий и альтернативных названий. В результате обработки предложенным в данном изобретении методом объем данных сокращается до 16 мегабайт без потери качества информации.
Выделяют блоки, позволяющие получить исчерпывающую информацию, описывающую объект и его взаимосвязи с другими объектами. Блоки выделяют следующих типов:
1) Геоданные
Страны, регионы, подрегионы, города, населенные пункты, городские административные округа, городские районы, микрорайоны, известные места на карте, улицы, дома, адреса.
Геоданные обладают следующими свойствами:
Идентификатор объекта, название, WGS84 картографическая информация в формате WKT, альтернативные названия, численная популярность объекта, иерархическая связь геообъекта с его родительским объектом, произвольные поля с дополнительной информацией об объекте.
R[street 141476222736736]
Text[Грибная]
Field[StreetClass][26005]
Geometry[LINESTRING(82.876291 55.088622,82.874596 55.090716,82.874538 55.090756,82.874445 55.09077)]
Parent[adm_div.settlement 141360258613345]
Parent[adm_div.city 141360258613345]
2) Блок данных с описанием сфер деятельности и групп товаров (онтология) Каждый объект имеет уникальный идентификатор, множество альтернативных
названий и множество ключевых слов, рассчитанную по статистике популярность объекта, связь с близкими по смыслу онтологическими объектами.
Пример:
R[attribute.2_9 70000201006748287]
Text[Шиномонтаж мототехники]
Synonym[мото{-}шиномонтаж]
Synonym[{-}шиномонтаж мотоциклов]
Synonym[Балансировка мотошины]
Synonym[{-}Шиномонтаж для мотоциклов]
Synonym[Мотошиномонтаж]
Adjacent[rubric 140857747447305]
Знаки {-} и {+} описывают важность слова в конкретном названии.
3) Блок данных с информацией об организациях и их филиалов.
У организаций и филиалов есть уникальный идентификатор, название и альтернативные названия, информация об организации (телефоны, веб сайты и т.п.), популярность, местоположение на карте, связь с адресом (блок данных 1), а также связи со сферами деятельности (блок данных 2).
R[org 141274359267329]
Text[АФИНА ПАЛЛАДА, туристическое агентство]
Weight[79]
Field[] [АФИНАПАЛЛАДА]
Field[HasWebsite][True]
Feature[rubric 140857747439888]
Feature[rubric 140857747440016]
Feature[rubric 140857747461731]
Feature[rubric 140857747550003]
Feature[rubric 140857747464724]
Feature[name_description 1]
R[branch 141265769355742]
Weight[79]
Field[CityCenterDistance][0.00677777302069148]
Field[FlampRating][21.1373]
Field[HasPhone] [True]
Field[HasPhoto][True]
Field[Phone] [+73 832222666;+73 832226522;+73 832222297]
Point[82.914323 55.032533]
Parent[org 141274359267329]
Feature[address 141669496262772]
Feature[building 141373143 520923]
4) Прочие данные.
Вспомогательные данные. Это конфигурация поиска для конкретного города, настройка приоритетов данных для конкретных условий, например, по поиску «кафе» выдают все организации общепита.
Погрешность в пространственном поиске (сколько метров может быть погрешность), настройки словарного поиска (какие возможны словари, какие допустимы ошибки), языковые настройки, настройки страны.
Данную информацию структурируют, удаляют всю излишнюю информацию (дублирующие, повторяющиеся объекты).
В результате обработки предложенным способом получают сжатую структурированную информацию, позволяющую эффективно работать с поисковыми запросами, выдавая наиболее релевантные результаты.
Описание второго объекта изобретения
Для реализации предложенного способа преобразования данных ГИС требуется определенная специально запрограммированная система. Поэтому вторым объектом заявляемого изобретения является система для реализации способа преобразования данных ГИС, каждая часть из которой предназначена для определенного этапа заявляемого способа преобразования данных.
Известна система, раскрытая в патенте на изобретение №2606877 «СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ В ИСПОЛНЯЕМОЙ НА КОМПЬЮТЕРЕ СИСТЕМЕ»: Исполняемая на компьютере система для обработки запроса пользовательского устройства на обработку части пользовательских данных, включающая в себя:
сервер, содержащий процессор, который обладает пространством пользователя и пространством ядра, процессор выполнен с возможностью осуществлять:
получение запроса пользовательского устройства на обработку части пользовательских данных от пользовательского устройства;
при получении запроса пользовательского устройства осуществлять считывание части пользовательских данных из базы данных на сервере;
выделение на процессоре пространства для определения среды «песочницы», среда «песочницы» определяется набором команд пространства ядра процессора для выполнения обработки части пользовательских данных;
изолирование процессора в среде «песочницы» от пространства пользователя для того, чтобы изолированно выполнить запрос пользовательского устройства с помощью набора команд пространства ядра;
обработку части пользовательских данных процессором в среде «песочницы»;
деизолирование среды «песочницы» из пространства пользователя путем вывода указания на обработанную часть пользовательских данных; и
запись указания на обработанную часть пользовательских данных в пространство пользователя процессора.
Раскрытая в патенте совокупность устройств не позволяет реализовать способ преобразования данных, являющийся первым пунктом заявляемого изобретения.
Известно техническое решение, раскрытое в патенте на полезную модель №94361 «СИСТЕМА ДЛЯ ОБРАБОТКИ ДАННЫХ ПРОЦЕССА ИННОВАЦИОННОЙ ДЕЯТЕЛЬНОСТИ В ОБЛАСТИ ВОДОСНАБЖЕНИЯ»: Система для обработки данных процесса инновационной деятельности в области водоснабжения, содержащая последовательно соединенные устройство ввода, персональный компьютер, включающий вычислительный модуль, интерфейс и устройство долговременной памяти в составе блока ячеек финансово-экономической информации и блока ячеек проектно-строительных данных, соединенное интерфейсом с входом и выходом вычислительного устройства, причем персональный компьютер соединен с регистрирующим устройством, отличающаяся тем, что в ее состав включены регистры состояния информации о параметрах инновационного договора.
Раскрытая в патенте совокупность устройств не позволяет реализовать способ преобразования данных, являющийся первым пунктом заявляемого изобретения.
Известно техническое решение, раскрытое в патенте на полезную модель №53794 «АВТОМАТИЗИРОВАННАЯ СИСТЕМА СБОРА И ОБРАБОТКИ ДАННЫХ О КЛИЕНТАХ»: Автоматизированная система сбора и обработки данных о клиентах, включающая устройство хранения данных, содержащее полные данные о клиентах, и множество компьютерных устройств пользователей, отличающееся тем, что в систему дополнительно включены первое компьютерное устройство, предназначенное для интеграции с внешними системами и обеспечения формирования и доставки сообщений системам и пользователям, второе компьютерное устройство, обеспечивающее управление бизнес процессом обслуживания клиентов, а устройство хранения данных дополнительно содержит базу данных с каталогом продуктов, при этом компьютерные устройства пользователей соединены с первым компьютерным устройством, предназначенным для интеграции с внешними системами и обеспечения формирования и доставки сообщений системам и пользователям, которое соединено со вторым компьютерным устройством, обеспечивающим управление бизнес процессами обслуживания клиентов, в свою очередь соединенным с устройством хранения данных.
Раскрытая в патенте совокупность устройств не позволяет реализовать способ преобразования данных, являющийся первым пунктом заявляемого изобретения.
Известно техническое решение, раскрытое в патенте на полезную модель №50695 «СИСТЕМА ХРАНЕНИЯ И ОБРАБОТКИ ДАННЫХ»: Система хранения и обработки данных, содержащая первую подсистему, включающую в себя по меньшей мере один компьютер, хранящую массив графической информации об объектах, расположенных на поверхности Земли, и массив семантической информации об упомянутых объектах, при этом информация о каждом объекте в одном из упомянутых массивов связана с соответствующей информацией об этом же объекте из другого массива посредством базы данных графосемантической информации, реализованной на сервере первой подсистемы, модуль сверки и контроля, выполненный с возможностью автоматического обновления информации об объектах в базе данных графосемантической информации при внесении любых изменений в информацию по меньшей мере об одном объекте по меньшей мере в одном из упомянутых массивов, и вторую подсистему, реализованную на основе по меньшей мере одного компьютера, связанного с первой подсистемой по компьютерной сети, содержащую базу данных, причем система выполнена с возможностью поддержания информации в базе данных второй подсистемы, совпадающей с информацией в базе данных графосемантической информации первой подсистемы, посредством выполнения в оперативном режиме обновления информации в базе данных второй подсистемы с помощью передачи данных из первой подсистемы во вторую подсистему.
Раскрытая в патенте совокупность устройств не позволяет реализовать способ преобразования данных, являющийся первым пунктом заявляемого изобретения.
Задачей заявляемой системы является возможность реализации на ней способа преобразования данных ГИС, являющегося первым объектом данного изобретения.
Техническим результатом системы является возможность реализации на системе способа преобразования данных ГИС, являющегося первым объектом данного изобретения.
Технический результат достигается за счет того, что в систему объединены устройства ввода данных, устройства передачи информации, сервера индексирования, устройства хранения данных и устройства вывода данных.
Система работает следующим образом
Система включает в себя устройства ввода (клавиатуры, сканеры, компьютерные мыши, сенсорные экраны и т.д.), устройства передачи данных (модемы, Bluetooth-адаптеры, Wi-Fi-адаптеры и т.д.), сервера индексирования, устройства хранения данных (жесткие диски, карты памяти и т.д.), устройства вывода данных (мониторы, принтеры, проекторы и т.д.). При этом устройства ввода данных и устройства передачи информации выполнены с возможностью сбора и внесения данных об объектах в систему в полуавтоматическом режиме; сервера индексирования выполнены с возможностью осуществления внесения данных, разбивания данных на структурные блоки и обработки, удаления избыточной информации и последующей программной алгоритмической обработки данных с выстраиванием связей между объектами; устройства хранения данных выполнены с возможностью размещения базы данных ГИС.
Устройства ввода данных и устройства передачи данных служат для сбора и внесения данных об объектах в систему в полуавтоматическом режиме.
На серверах индексирования внесенные данные разбивают на структурные блоки и обрабатывают, удаляют избыточную информацию и подвергают данные программной алгоритмической обработке с выстраиванием связей между объектами.
На устройствах хранения данных размещаются полученные таким образом базы данных ГИС.
А устройства вывода служат для возможности взаимодействия конечного пользователя с базой данных ГИС.
Третьим объектом настоящего изобретения является способ обработки поискового запроса, обращенного к базе данных, сформированной по способу преобразования данных ГИС, являющемуся первым объектом заявляемого изобретения.
Известен способ поиска, раскрытый в патенте на изобретение №2451329 «КОНТЕКСТНО-ЗАВИСИМЫЕ ПОИСКИ И ФУНКЦИОНАЛЬНЫЕ ВОЗМОЖНОСТИ ДЛЯ ПРИЛОЖЕНИЙ НЕМЕДЛЕННОЙ ПЕРЕДАЧИ ТЕКСТОВЫХ СООБЩЕНИЙ»: Способ поиска релевантной информации, реализуемый, по меньшей мере частично, компьютером, содержащий:
выделение одного или более ключевых слов или фраз в диалоге немедленного обмена текстовыми сообщениями;
прием пользовательского выбора упомянутых одного или более ключевых слов или фраз; и
в ответ на упомянутый прием, представление пользовательского интерфейса, который отображает контекстуально релевантные материал или функциональные возможности, которые относятся к выбранным одному или нескольким ключевым словам или фразам, при этом пользовательский интерфейс включает в себя совместно используемую часть поиска, которая включает в себя область поиска для приема поисковых терминов для дополнительного уточнения отображенных контекстуально релевантных материала или функциональных возможностей, которые относятся к выбранным одному или более ключевым словам или фразам, прием поискового термина в области поиска от первого участника в диалоге немедленного обмена текстовыми сообщениями, отображение результатов поиска принятого поискового термина для просмотра первым участником и по меньшей мере вторым участником в диалоге немедленного обмена текстовыми сообщениями, чтобы позволить первому и второму участникам совместно взаимодействовать с результатами поиска.
Данный способ поиска не подходит для обработки поисковых запросов, обращенных к базе данных, сформированной по способу, являющемуся первым объектом заявляемого изобретения.
Известен способ поиска, раскрытый в патенте на изобретение №2393536 «СПОСОБ УНИФИЦИРОВАННОЙ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ИНФОРМАЦИИ, ОБЕСПЕЧИВАЮЩИЙ В РАМКАХ ОДНОЙ ФОРМАЛЬНОЙ МОДЕЛИ ПРЕДСТАВЛЕНИЕ, КОНТРОЛЬ СЕМАНТИЧЕСКОЙ ПРАВИЛЬНОСТИ, ПОИСК И ИДЕНТИФИКАЦИЮ ОПИСАНИЙ ОБЪЕКТОВ»: Способ унифицированной семантической обработки информации, обеспечивающий в рамках одной формальной модели представление, контроль семантической правильности, поиск и идентификацию описаний объектов, заключающийся в том, что преобразуют последовательности данных, чисел, в частности слов или лексем или, по меньшей мере, одну последовательность, представляющую собой описание некоторого объекта, ситуации, процесса или явления, в частности поисковый запрос, сформированный на пользовательском компьютере, коммуникаторе или мобильном телефоне, в сигналы, пригодные для машинной обработки, используют сигналы цифровых измерительных устройств или аналоговых измерительных устройств, снабженных аналого-цифровыми преобразователями, которые подключены к компьютеру, коммуникатору или мобильному телефону, формируют описание объекта, ситуации, процесса или явления для обращения к базе данных в системе хранения и обработки информации, производят сопоставление наборов описаний объектов или текущего описания с набором описаний, совмещающее различные процессы обработки данных: поиск, идентификация, пополнение, обнаружение и диагностика ошибок, проводят анализ получаемых результатов с расширенной интерпретацией одинаковости, производят поиск-идентификацию объектов путем совмещения выбора похожих описаний и отсева заведомо неподходящих, рассматривают наборы описаний, в каждый момент времени их идентичность текущему описанию определяется количественной мерой оценки совпадающих значений всех либо некоторых признаков текущего описания, реализуют поиск-идентификацию объектов, пополнение наборов их описаний, пополнение набора признаков, обнаружение и диагностику ошибок как циклическое выполнение в определенном порядке действий по обработке набора описаний объектов и поступающей по одному из каналов связи от одного из входных устройств последовательности сигналов - текущего описания, используют данные из описания в зависимости от текущего состояния для поиска-идентификации, пополнения, обнаружения и диагностики ошибок, используют для обрабатываемых наборов описаний простые или составные ключи, предназначенные для повышения скорости сопоставления, динамически пополняют набор признаков, с помощью которых дается описание объектов, и на основании которого осуществляют сопоставление.
Данный способ поиска не подходит для обработки поисковых запросов, обращенных к базе данных, сформированной по способу, являющемуся первым объектом заявляемого изобретения.
Известен способ поиска, раскрытый в патенте на изобретение №2365984 «ПОИСК ПРОИЗВОЛЬНОГО ТЕКСТА И ПОИСК ПО АТРИБУТАМ В ДАННЫХ ЭЛЕКТРОННОГО РУКОВОДСТВА ПО ПРОГРАММАМ»: Способ поиска данных в электронном руководстве по программам (ЭРП), содержащий этапы:
принимают текстовую поисковую цепочку,
нормализуют текстовую поисковую цепочку, причем нормализация включает в себя удаление или преобразование символов в текстовой поисковой цепочке так, чтобы получить доступные для поиска элементы, разделяют доступные для поиска элементы на текстовые элементы и элементы-атрибуты,
выполняют поиск в данных ЭРП для каждого текстового элемента и каждого элемента-атрибута, и
выполняют одну из операций: объединение, ранжирование и фильтрацию результатов поиска для отображения программ, удовлетворяющих поисковой цепочке.
Данный способ поиска не подходит для обработки поисковых запросов, обращенных к базе данных, сформированной по способу, являющемуся первым объектом заявляемого изобретения.
Технический результат заключается в обработке поисковых запросов по специальному алгоритму для баз геоинформационных данных, сформированных по способу, являющемуся первым объектом заявляемого изобретения.
Поскольку при реализации способа сжатия данных, представляющего собой первый объект настоящего изобретения, формируется особая база данных с определенной системой хранения в ней информации, то и для обработки поисковых запросов в ней требуется специальный алгоритм.
Способ поиска данных по базе данных, расположенной на устройстве хранения данных и формируемой по способу преобразования данных геоинформационных систем по п. 1, заключающийся в том, что:
Вводят поисковый запрос, обрабатывают его на символьном уровне (нормализуют);
Разбивают его на токены (сегментируют);
Распознают телефоны и адреса;
Выполняют словарный поиск с исправлением ошибок (словарный уровень); Преобразуют найденные в запросе слова в Термы при помощи морфологических данных;
Находят объекты, в которых встречаются термы, при помощи связей термов и объектов;
Находят все связи между найденными объектами и всеми остальными объектами;
Среди множества найденных объектов путем определения различных параметров степени совпадения с запросом и вероятности того, что требуется именно этот объект, рассчитанной на базе статистики использования поиска, выделяют самые релевантные и выдают их как конечный результат, а наименее релевантные отбрасывают.
Таким образом, использование настоящего изобретения позволяет обрабатывать большие массивы данных и достигнуть при сжатии плотности до 10 байт на объект с сохранением структурных связей между объектами, что позволяет в дальнейшем проводить быстрый и эффективный поиск по сформированной базе данных.

Изобретение относится к геоинформационной обработке данных. Техническим результатом является сжатие большого объема данных. Способ преобразования данных геоинформационных систем (ГИС), заключающийся в том, что данные об объекте собирают и вносят в систему, включающую в себя устройства ввода данных, устройства передачи информации, сервера индексирования, устройства хранения данных, устройства вывода данных, в полуавтоматическом режиме; внесенные данные разбивают на структурные блоки и обрабатывают на серверах индексирования; из полученного в результате этого упорядоченного проиндексированного массива удаляют дублирующую информацию; оставшуюся информацию подвергают пятиуровневой программной алгоритмической обработке с выстраиванием связей между объектами, включающей посимвольный уровень; словарный уровень; уровень морфологии языка; уровень связи термов и объектов; уровень объектов,. после чего полученную информацию размещают на устройстве хранения данных, при этом размещенная на устройствах хранения данных полученная информация образует базы данных геоинформационных систем. 3 н. и 2 з.п. ф-лы, 1 ил.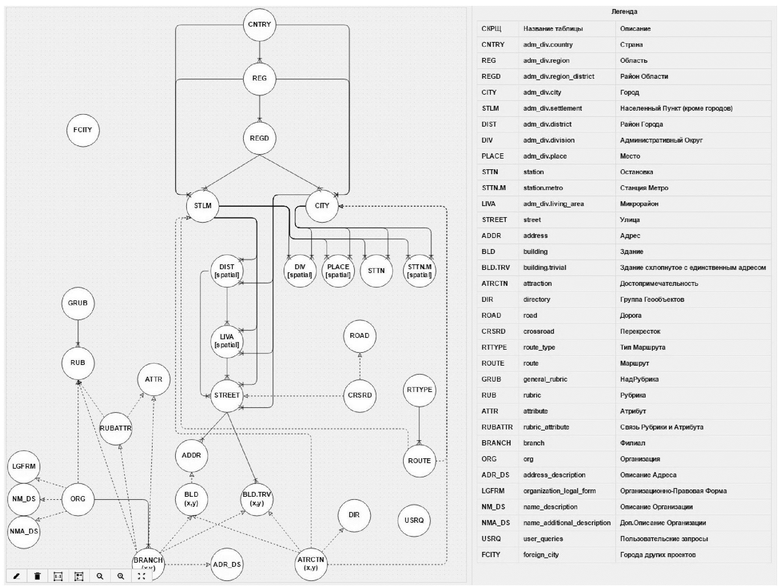
1. Способ преобразования данных геоинформационных систем (ГИС), заключающийся в том, что:
- данные об объекте собирают и вносят в систему, включающую в себя устройства ввода данных, устройства передачи информации, сервера индексирования, устройства хранения данных, устройства вывода данных, в полуавтоматическом режиме;
- внесенные данные разбивают на структурные блоки и обрабатывают на серверах индексирования;
- из полученного в результате этого упорядоченного проиндексированного массива удаляют дублирующую информацию;
- оставшуюся информацию подвергают пятиуровневой программной алгоритмической обработке с выстраиванием связей между объектами, включающей посимвольный уровень; словарный уровень; уровень морфологии языка; уровень связи термов и объектов; уровень объектов.
- после чего полученную информацию размещают на устройстве хранения данных, при этом размещенная на устройствах хранения данных полученная информация образует базы данных геоинформационных систем.
2. Способ по п. 1, в котором связи между объектами выстраиваются по крайней мере на пяти уровнях: посимвольном, словарном, морфологическом, уровне связей термов и объектов, уровне объектов.
3. Система, включающая в себя устройства ввода данных, устройства передачи информации, сервера индексирования, устройства хранения данных, устройства вывода данных, отличающаяся тем, что она может реализовать способ преобразования данных геоинформационных систем по п. 1, при этом устройства ввода данных и устройства передачи информации выполнены с возможностью сбора и внесения данных об объектах в систему в полуавтоматическом режиме; сервера индексирования выполнены с возможностью осуществления внесения данных, разбивания данных на структурные блоки и обработки, удаления избыточной информации и последующей программной алгоритмической обработки данных с выстраиванием связей между объектами; устройства хранения данных выполнены с возможностью размещения базы данных ГИС.
4. Способ поиска данных по базе данных, расположенной на устройстве хранения данных и формируемой по способу преобразования данных геоинформационных систем по п. 1, заключающийся в том, что:
- вводят поисковый запрос;
- обрабатывают его на посимвольном уровне;
- разбирают на токены;
- программными средствами распознают телефоны и адреса;
- выполняют словарный поиск с исправлением ошибок;
- при помощи морфологических данных преобразовывают найденные в запросе слова в термы;
- при помощи связей термов и объектов находят объекты, в которых встречаются термы;
- находят связи между найденными объектами и прочими объектами;
- выделяют наиболее релевантные из найденных результатов;
- выводят выделенные результаты в качестве конечного результата поискового запроса.
5. Способ по п. 4, в котором на словарном уровне словарь сохраняется в виде сжатого префиксного дерева (подвид конечных автоматов).
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Свая с уширенным основанием | 1950 |
|
SU92976A1 |

