Изобретение относится к области обработки данных при семантическом анализе текстовых данных и построении семантической модели документов.
Объем информации, которую приходится анализировать человеку, растет с каждым днем. В связи с этим возникает потребность в обогащении документов метаданными, позволяющими улучшить и увеличить скорость восприятия основной информации. Особо остро эта проблема ощутима при анализе текстовых документов. Изобретение позволяет решать широкий класс задач, относящихся к данному направлению. Ниже перечислены некоторые из этих задач.
Предлагаемое изобретение позволяет определять и подсвечивать ключевые термины текста. Это позволяет ускорить его чтение и улучшить понимание. При чтении больших текстовых документов или коллекции текстовых документов читателю достаточно взглянуть на ключевые слова, чтобы понять основное содержание текста и принять решение о необходимости более детального изучения.
В дополнение к этому, при помощи изобретения электронные тексты могут обогащаться гипертекстовыми ссылками на внешние электронные документы, содержащие более полное описание значений специфичных терминов. Это необходимо при ознакомлении с предметно-специфичной литературой, содержащей большое количество терминов, незнакомых читателю. Например, предложение "Настройка фортепиано заключается в согласовании звуков хроматического звукоряда между собой путем интервальной кварто-квинтовой темперации на семействе клавишно-струнных музыкальных инструментов", может быть не понятно человеку, не знакомому с предметной областью. Дополнительное описание значений терминов дает возможность понять смысл оригинального текста.
Кроме того, изобретение позволяет осуществлять помощь читателю при ознакомлении с иностранной литературой. Использование изобретения предоставляет возможность создания программных систем предлагающих более полную информацию о ключевых понятиях иностранного текста, в том числе описаний на родном языке читателя.
Предлагаемый способ выделения ключевых понятий и выбора близких к ним по смыслу, может быть применен в области информационного поиска. Одной из важнейших проблем современных информационно-поисковых систем (таких как Яндекс) является отсутствие прямой возможности поиска документов, содержащих только заранее известные значения многозначного запроса. Например, при использовании поискового запроса "платформа" из-за его многозначности будут получены документы из разных предметных областей (значениями могут быть "политическая платформа", "компьютерная платформа", "железнодорожная платформа" и т.д.). Для решения этой проблемы пользователю приходится уточнять запрос путем ввода дополнительного контекста в строку поиска.
Предложенное изобретение позволяет решить эту проблему, предоставив пользователю выбор значения или концепции для поиска. Информационно-поисковые системы, работающие со значениями терминов, относятся к области семантического поиска. На основе предлагаемого способа можно создавать системы семантического поиска. В таких системах документы будут ранжироваться с учетом семантической близости между значениями терминов запроса и значениями терминов в документах. Для этого производится автоматическое установление значения термина в заданном контексте. Данное изобретение также позволяет производить поиск в многоязычных коллекциях документов.
Кроме того, на основе данного изобретения возможно создание рекомендательных систем, которые будут находить и рекомендовать документы, значения чьих ключевых терминов семантически схожи с ключевыми понятиями текущего документа. Пользователю такой системы будет предложен мощный инструмент для изучения коллекции документов через навигацию по ней за счет гипертекстовых ссылок на рекомендуемые документы.
Также осуществление рекомендаций возможно для схожих коллекций документов. Этот вариант использования аналогичен предыдущему, но рекомендации происходят между коллекциями документов или документом и коллекцией документов. В этом случае коллекция характеризуется значениями ключевых слов входящих в нее документов.
Еще одной областью, где возможно применение данного изобретения, является область создания кратких описаний документов и коллекций документов, также известная как автоматическое аннотирование и реферирование документов. На основе предложенного способа можно создавать краткие описания документов и коллекций документов. Такие краткие описания позволят читателю быстро определить специфику документов. Краткие описания могут состоять из ключевых понятий документа, предложений, содержащих ключевые или близкие к ним понятия. Таким образом, краткие описания могут состоять из частей оригинального текста (коллекции текстов) или быть самостоятельными законченными документами, кратко отражающими основной смысл источников.
Предлагаемый способ может быть применен к задачам извлечения информации. Так, на основе предлагаемого способа возможно создание системы автоматического обогащения баз знаний новыми концепциями и связями между ними. Для расширения базы знаний новыми концепциями необходимо установить связи между ними и существующими в базе знаний концепциями. Предлагаемый способ позволяет легко устанавливать связи между новой концепцией и концепциями базы знаний, через анализ описания новой концепции. Это приложении более подробно описано ниже.
Изобретение может быть применено и в других областях, связанных с анализом естественного языка, таких как извлечение информации из документов, машинный перевод, дискурсивный анализ, анализ тональности текста, создание диалоговых и вопросно-ответных систем и т.д.
Заметим, что предложенный способ применим не только к текстовым документам и коллекциям документов, но и мультимедийным объектам, содержащим текстовые метаданные. Например, музыкальные композиции могут содержать в метаданных текстовое название, исполнителя, автора и т.п. Видеофайлы также могут содержать текстовое название, тип, имена режиссера и актеров (для фильмов). Таким образом, изобретение может быть применено к разнообразным типам электронных документов, содержащих текстовую информацию, в широком классе задач из области обработки естественного языка, информационного поиска и извлечения информации.
Наиболее близкие к предлагаемому способу идеи были высказаны в работах по созданию систем, позволяющих выделить в тексте ключевые слова и связать их со статьями Википедии. Способы, описанные в этих работах, состоят из двух частей: сначала выделяются ключевые термины, затем выделенные термины связываются со статьями Википедии.
Наиболее известными работами в данной области являются проект "Wikify!" и работа Дэвида Милна и Яна Виттена. В проекте "Wikify!" [Rada Mihalcea and Andras Csomai. 2007. Wikify!: linking documents to encyclopedic knowledge. In Proceedings of the sixteenth ACM conference on Conference on information and knowledge management (CIKM '07). ACM, New York, NY, USA, 233-242] авторы выделяют ключевые термины, связывают их со словарем Википедии и используют комбинацию заранее определенных правил и алгоритма машинного обучения для определения корректного значения. Так как поиск ключевых терминов осуществляется до определения значений терминов, то используются только признаки, не учитывающие семантические особенности текста. Это накладывает ограничения на точность алгоритмов.
Милн и Виттен в своей работе [David Milne and lan H.Witten. 2008. Learning to link with wikipedia. In Proceeding of the 17th ACM conference on Information and knowledge management (CIKM '08). ACM, New York, NY, USA, 509-518] улучшили результаты, предложив использовать более сложные алгоритмы классификации для выделения ключевых терминов и определения их значений. Так же, как и в предыдущей работе, Википедия использовалась как тренировочный корпус для алгоритмов. Однако как и в системе Wikify!, для определения ключевых терминов использовались только признаки, не учитывающие семантические особенности текста. Это накладывает ограничения на точность алгоритмов.
В патентной заявке [Andras Csomai, Rada Mihalcea. Method, System and Apparatus for Automatic Keyword Extraction. US patent 2010/0145678 A1], авторами которого являются авторы системы Wikify!, описывается способ определения ключевых слов. В патенте используются идеи, аналогичные представленным в работе [Rada Mihalcea and Andras Csomai. 2007. Wikify!: linking documents to encyclopedic knowledge. In Proceedings of the sixteenth ACM conference on Conference on information and knowledge management (CIKM '07). ACM, New York, NY, USA, 233-242]. Авторы определяют признаки, на основе которых с помощью комбинации алгоритмов выделяют ключевые слова текста. Описанный способ предлагается использовать для построения индексов для книг. Этот патент обладает недостатками систем, описанных выше (т.е. для определения ключевых терминов использовались только признаки, не учитывающие семантические особенности текста), и направлен на решение узкого круга задач.
Также в последнее время начали появляться работы, в которых решается аналогичная задача выделения ключевых слов и их связывания с внешним контекстом, но вместо Википедии используются Веб-сайты, содержащие открытые данные, связанные ссылками [Gabor Melli and Martin Ester. 2010. Supervised identification and linking of concept mentions to a domain-specific ontology. In Proceedings of the 19th ACM international conference on Information and knowledge management (CIKM '10). ACM, New York, NY, USA, 1717-1720. Delia Rusu, Blaz Fortuna and Dunja Miadenic. Automatically annotating text with linked open data. In Christian Bizer, Tom Heath, Tim Berners-Lee, and Michael Hausenblas, editors, 4th Linked Data on the Web Workshop (LDOW 2011), 20th World Wide Web Conference (WWW 2011), Hyderabad, India, 2011]. В этих работах предлагаются методы построения предметно-специфичных онтологии на основе специальных Веб-сайтов. В отличие от работ, использующих Википедию, получаемые онтологии имеют небольшой размер, поэтому для обработки текстов можно променять более ресурсоемкие алгоритмы. Из-за небольшого размера используемых онтологии в этих работах решалась только задача определения значения терминов, а задача поиска ключевых терминов не решалась.
Решаемая изобретением техническая задача состояла в создании способа построения семантической модели документа, используемой для обогащения документов дополнительной информацией, семантически связанной с основной темой (темами) документа (документов). При этом при построении семантической модели могли бы использоваться онтологии, построенные с использованием не только информационных источников (например, Википедия), содержащих открытые данные, связанные ссылками, но и любые другие доступные источники информации, содержащие текстовые описания объектов предметной области, не связанные ссылками, например, Веб-сайты компаний, электронные книги, специализированная документация и т.д. При этом значения терминов документа определялись бы не только исходя из лексических признаков, но и исходя из их семантической связи с документом.
Сущность изобретения состоит в том, что предложен способ построения семантической модели документа, по которому из информационных источников извлекают онтологию, в качестве информационных источников используют электронные ресурсы, содержащие описания отдельных объектов реального мира, как связанные гипертекстовыми ссылками, так и не содержащие гипертекстовых ссылок в описании, каждой концепции онтологии назначают идентификатор, по которому она может быть однозначно определена, в случае существования гипертекстовые ссылки между описаниями концепций преобразуют в связи между концепциями, при отсутствии структуры гипертекстовых ссылок их добавляют, анализируя описания и определяя значения терминов с помощью онтологии, извлеченных из гипертекстовых энциклопедий, и затем преобразуют в связи между концепциями, сохраняют уникальный идентификатор ресурса с оригинальным описанием концепции, для каждой концепции определяют не менее одного текстового представления, вычисляют частоту совместного использования каждого текстового представления концепции и информативность для каждого текстового представления, также определяют, какому естественному языку принадлежит текстовое представление, и сохраняют полученную информацию, получают текст анализируемого документа, осуществляют поиск терминов текста и их возможных значений путем сопоставления частей текста и текстовых представлений концепций из контролируемого словаря для каждого термина из его возможных значений, используя алгоритм разрешения лексической многозначности терминов, выбирают одно, которое считают значением термина, а затем концепции, соответствующие значениям терминов, ранжируют по важности к тексту, и наиболее важные концепции считают семантической моделью документа.
При этом в качестве алгоритма разрешения лексической многозначности терминов используют алгоритм, который выбирает наиболее часто употребляемое значение, для чего определяют частоту совместного использования обрабатываемого термина и всевозможных концепций, связанных с ним, после чего в качестве значения термина выбирают концепцию с наибольшей частотой использования термина и концепции.
Кроме того, в качестве алгоритма разрешения лексической многозначности терминов могут выбирать алгоритм, вычисляющий семантически наиболее связанную последовательность значений, по которому рассматривают всевозможные последовательности значений концепций для заданной последовательности терминов, для каждой возможной последовательности концепций вычисляют ее вес, как сумму весов уникальных попарных комбинаций концепций, входящих в последовательность концепций, а значениями терминов считают концепции, принадлежащие последовательности с наибольшим весом.
Кроме того, в качестве алгоритма разрешения лексической многозначности терминов могут выбирать алгоритм, основанный на машинном обучении с учителем, по которому для каждого термина вычисляют вектор признаков, на основании которого выбирают наиболее подходящее значение.
При этом в качестве признака вектора признаков выбирают информативность термина.
Кроме того, в качестве признака вектора признаков могут выбирать вероятность употребления термина t в данном значении mi, вычисляемую как 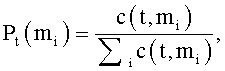
Кроме того, в качестве признака вектора признаков могут выбирать семантическую близость между концепцией и контекстом документа.
При этом в качестве контекста документа выбирают значения однозначных терминов.
Кроме того, в качестве признака вектора признаков выбирают сумму информативности каждого однозначного термина и семантической близости его значения ко всем другим концепциям из контекста документа.
При этом для определения структуры ссылок информационного источника, не содержащего гипертекстовых ссылок, извлекают онтологию из гипертекстовой энциклопедии, обогащают описание концепций информационного источника, не содержащего гипертекстовых ссылок, связями с существующей онтологией, извлеченной из гипертекстовой энциклопедии, расширяют контролируемый словарь существующей онтологии текстовыми представлениями всех концепций обрабатываемого информационного источника, не содержащего гипертекстовых ссылок, принимают частоту совместного использования этих концепций и их текстовых представлений равной 1 для каждой уникальной пары представление-концепция, повторяют операцию обогащения концепций обрабатываемого информационного источника, используя информативность, посчитанную через инвертированную документную частоту, таким образом, получают дополнительные ссылки между концепциями, извлеченными из информационного источника, не содержащего гипертекстовых ссылок, обновляют значение частоты совместного использования текстового представления и концепции на основе полученных ссылок.
При этом для ранжирования концепций по важности к документу строят семантический граф документа, состоящий из значений всех терминов документов и всевозможных взвешенных связей между ними, где вес связи равен семантической близости между концепциями, которые соединены связью, к семантическому графу применяют алгоритм кластеризации, группирующий семантически близкие концепции, затем концепции из наиболее весомых кластеров ранжируют по важности к документу, и наиболее важные концепции считают семантической моделью документа.
Кроме того, при извлечении онтологии вычисляют семантическую близость между концепциями, при этом для каждой концепции К составляют список концепций С, состоящий из концепций ci на которые у концепции К есть ссылка или с которых на концепцию К есть ссылка, вычисляют семантическую близость от текущей концепции К до каждой концепций ci∈C, сохраняют вычисленную семантическую близость между каждой парой концепций К и ci, а также соответствующие концепции К и ci, а для концепций, не входящих в список С, семантическую близость с концепцией К принимают равной нулю.
При этом ссылкой между концепциями назначают вес, выбирают пороговое значение для весов, а список концепций С составляют из концепций, на которые у концепции К есть ссылка с весом больше выбранного порогового значения или с которых на концепцию К есть ссылка с весом больше выбранного порогового значения.
Кроме того, онтологии могут извлекать из нескольких источников.
Кроме того, в качестве текста документа используют метаданные документа.
Таким образом, решение технической задачи стало возможным благодаря отличиям предлагаемого способа от способов, изложенных в известных работах, основные отличия состоят в следующем:
- известные способы определяют ключевые термины, а затем привязывают их к внешним источникам данных. В предлагаемом способе порядок обработки текстов обратный: сначала выделяются все термины и связываются с концепциями онтологии, извлеченной из внешних источников, а затем концепции ранжируются по важности к документу. Такой подход более сложен, так как необходимо определить значения всех терминов документа, но при этом позволяет принимать решения о принадлежности термина к ключевым на основе концептуальных знаний о документе, а не на основе текстовых признаков;
- данный способ предполагает построение семантической модели документа, которая, в частности, позволяет решать задачу обогащения текста ссылками на внешние источники;
- предлагаемый способ позволяет использовать намного больше информационных источников для построения онтологии. Так, кроме Википедии и Веб-сайтов, содержащих открытые данные, связанные ссылками, предлагается использовать любые доступные источники, содержащие текстовое описание объектов предметной области, в принципе не связанные гипертекстовыми ссылками: Веб-сайты компаний, электронные книги, специализированная документация и т.д.
- расширить круг решаемых задач.
Работа изобретения поясняется материалами, представленными на Фиг.1-Фиг.6.
На Фиг.1 представлена общая схема построения семантической модели документа.
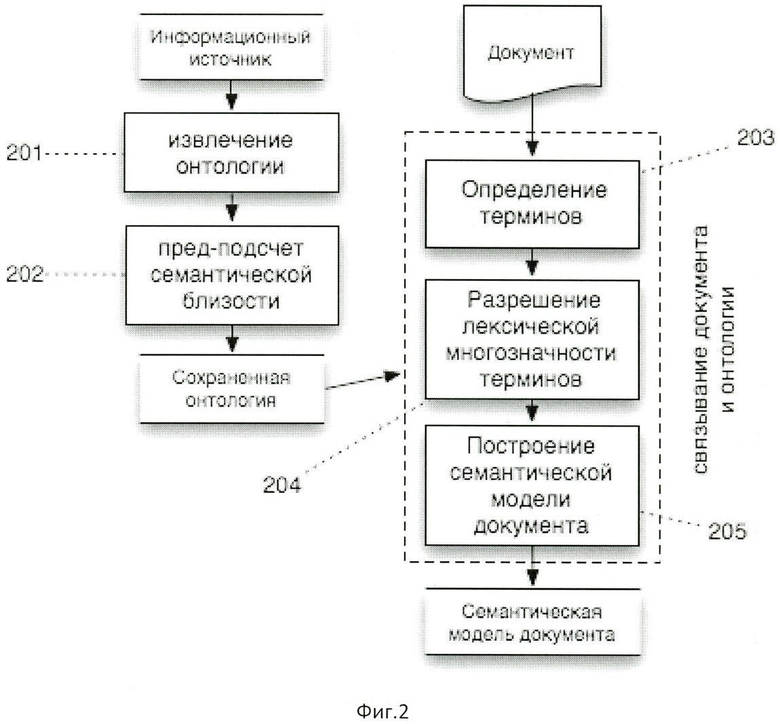
На Фиг.2 представлена общая схема построения семантической модели документа с предварительным подсчетом семантической близости.
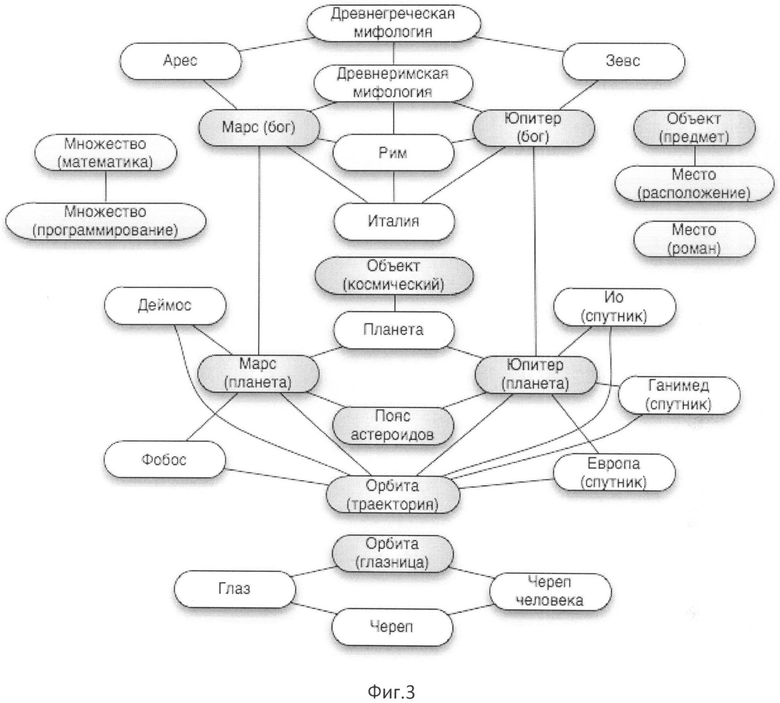
На Фиг.3 представлена модельная схема онтологии, которая может быть использована для построения семантической модели на примере документа, состоящего из одного предложения "Пояс астероидов расположен между орбитами Марса и Юпитера и является местом скопления множества объектов всевозможных размеров".
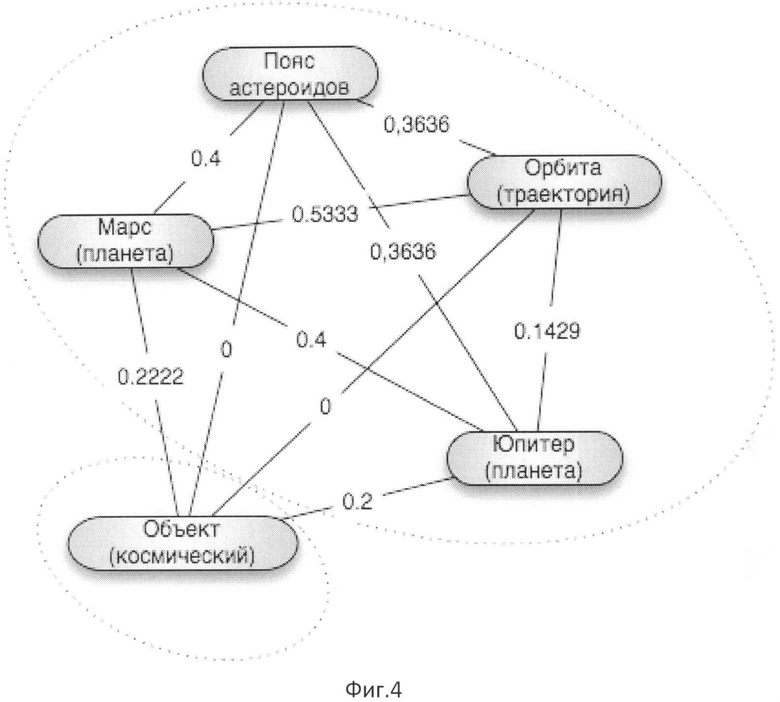
На Фиг.4 представлен Семантический граф для документа, состоящего из одного предложения "Пояс астероидов расположен между орбитами Марса и Юпитера и является местом скопления множества объектов всевозможных размеров".
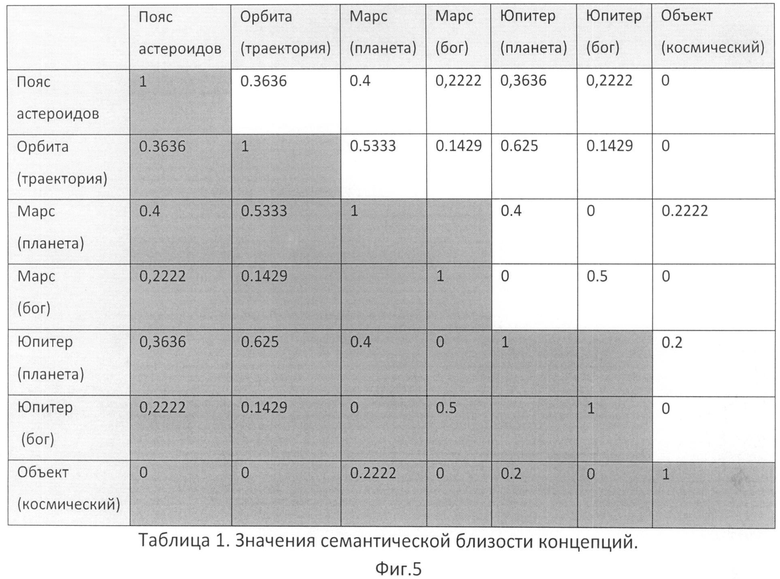
На Фиг.5 представлена Таблица значений семантической близости концепций.
На Фиг.6 представлена Таблица информативности текстовых репрезентаций.
Работа изобретения состоит из двух основных шагов, схематически представленных на Фиг.1. На первом шаге (101) из внешних информационных ресурсов извлекается онтология. На втором шаге (103-105) связывается текстовая информация документа с концепциями онтологии и строится семантическая модель документа.
Рассмотрим первый шаг предложенного способа: извлечение онтологии из внешних информационных источников. Источниками могут служить любые информационные ресурсы, которые содержат описания отдельных объектов предметной области. Далее при описании первого шага описывается структура онтологии, используемой в данном изобретении. После этого рассматривается процесс обработки различных информационных источников для извлечения онтологии с необходимой структурой.
Онтология состоит из концепций и связей между ними. Каждая концепция соответствует одному отдельному объекту предметной области. Связь между концепциями означает только то, что концепции некоторым образом взаимосвязаны. Наличие более сложной семантики связи возможно, но не обязательно для предлагаемого способа. Например, в онтологии, описывающей бизнес компании, производящей фототехнику, концепциями могут быть модели фотоаппаратов, используемые технологии ("система интеллектуальной автофокусировки") и т.д. Модели фотоаппаратов могут быть связаны с технологиями, которые в них используются и с другими моделями.
У каждой концепции имеется некоторый идентификатор, по которому концепция может быть однозначным образом найдена. Таким идентификатором может быть; (а) уникальное целое число, которое сопоставляется с концепцией при создании онтологии; (б) текстовое название концепции; или (в) любой другой способ однозначного нахождений концепции в онтологии, например, указатель в терминах языка программирования или первичный ключ в случае использования реляционной модели.
Каждая концепция обладает как минимум одним текстовым представлением. Текстовое представление - это слово или несколько слов, по которым можно идентифицировать концепцию (в отличие от идентификатора, возможно неоднозначно). Множество всех текстовых представлений представляет собой контролируемый словарь, который используется на этапе связывания документов и онтологии.
Если концепции соответствует несколько текстовых представлений, тогда эти представления будут являться синонимами по отношению друг к другу. Например, "Россия" и "Российская Федерация" являются текстовыми представлениями одной концепции.
Из-за особенностей естественного языка одно текстовое представления может быть связано с несколькими концепциями. Такие текстовые представления называются многозначными. Например, слово "платформа" может являться представлением концепций "политическая платформа", "компьютерная платформа", "железнодорожная платформа" и т.д.
Для осуществления связывания документа и онтологии необходимо знать частоту совместного использования текстового представления и концепции в заданной предметной области. Эта частота высчитывается на этапе построения онтологии, описанном ниже.
Также на этапе построения онтологии для каждого текстового представления вычисляется его информативность. Информативность - это числовая мера, отражающая степень важности текстового представления для предметной области. Способы вычисления информативности описаны также ниже.
Кроме того, для различных естественных языков представления одной концепции могут быть различны. Например, "кошка" и "cat" являются текстовыми представлениями одной концепции на русском и английском языках. Таким образом, онтология содержит информацию, какому естественному языку принадлежит текстовое представление.
Также при извлечении онтологии сохраняется ссылка на информационный ресурс с оригинальным описанием концепции. При создании практических приложений изобретения такие ссылки могут быть предоставлены читателю текста, обогащенного на основе предлагаемого способа, например в качестве ссылок на дополнительную информацию по теме документа.
Таким образом, для построения онтологии необходимо обладать следующей информацией:
- концепция и ее идентификатор,
- уникальный идентификатор информационного ресурса с оригинальным описанием концепции,
- связи между концепциями,
- текстовые представления концепций,
- частота совместного использования текстового представления и концепции,
- информативность текстового представления,
- язык текстового представления (при наличии многоязычной информации).
Рассмотрим процесс извлечения онтологии. Наиболее простыми для обработки информационными источниками являются гипертекстовые энциклопедии. Этот процесс известен и описан в [Rada Mihalcea and Andras Csomai. 2007. Wikify!: linking documents to encyclopedic knowledge. In Proceedings of the sixteenth ACM conference on Conference on information and knowledge management (CIKM '07). ACM, New York, NY, USA, 233-242.] и [David Milne and lan H.Witten. 2008. Learning to link with wikipedia. In Proceeding of the 17th ACM conference on Information and knowledge management (CIKM '08). ACM, New York, NY, USA, 509-518]. Гипертекстовая энциклопедия - совокупность информации, состоящая из объектов и описания этих объектов. Каждый объект представляет собой некоторую энциклопедическую статью, например, «Город Москва» или «Теорема Пифагора». Таким образом, каждый объект гипертекстовой энциклопедии становится концепцией онтологии. В качестве идентификатора концепции может быть использована информация, извлекаемая из энциклопедии, по которой можно однозначно определить концепцию, либо идентификатор может быть создан системой обработки онтологии, которая сама назначит его каждой концепции. Например, в открытой энциклопедии Википедии, каждая статья уже обладает уникальным идентификатором, который может быть использован в онтологии, извлеченной из этой энциклопедии. При извлечении онтологии также следует сохранить уникальный идентификатор ресурса (URL), по которому можно будет найти оригинальную страницу.
Описание объекта может содержать упоминания других объектов энциклопедии. В гипертекстовых энциклопедиях такие упоминания представляются в виде гипертекстовых ссылок на описания других объектов. Таким образом, каждый объект может иметь ссылки на другие объекты, где ссылка обозначает отношение взаимосвязи между двумя объектами: (i) тем объектом, который ссылается, и (ii) тем объектом, на который ссылаются при помощи ссылки. Эти ссылки определяют связи между концепциями. Например, из описания "Москва - [столица/Столица] [Российской Федерации/Россия]" можно понять что концепция "Москва" взаимосвязана с концепциями "Столица" и "Россия". В приведенном и будущих примерах гипертекстовые ссылки обозначаются квадратными скобками и состоят из двух частей, разделенных вертикальной чертой: текста, который видит пользователь ("столица", "Российской Федерации"), и объекта, на которые ведут ссылки ("Столица", "Россия"). Текст, видимый пользователем, называется подписью ссылки.
Для извлечения текстовых представлений и частотных характеристик, с ними связанных, будем использовать структуру ссылок, описанную выше. Будем считать подпись ссылки текстовым представлением концепции, на которую указывает ссылка. Так, в предыдущем примере "Российская Федерация" будет являться текстовым представлением концепции "Россия". В таком случае частота совместного использования текстового представления и концепции будет равна количеству ссылок, содержащих заданные текстовое представление и концепцию в качестве частей. Заметим, что в Википедии страницы перенаправлений, позволяющие задавать синонимы названия статьи, организуются как специальный случай гипертекстовый ссылки и обрабатываются аналогично.
Однако не все подписи стоит считать текстовыми представлениями и добавлять в онтологию. Например, в подписях могут содержаться слова с опечатками или несодержательные термины, представляющие интерес только в контексте (например, слово "этот"). Для фильтрации таких подписей предлагается использовать порог встречаемости, при преодолении которого подпись будет считаться текстовым представлением. Порог подбирается в зависимости от обрабатываемого ресурса. Так, для англоязычной Википедии порог рекомендуется задавать числом не больше 10.
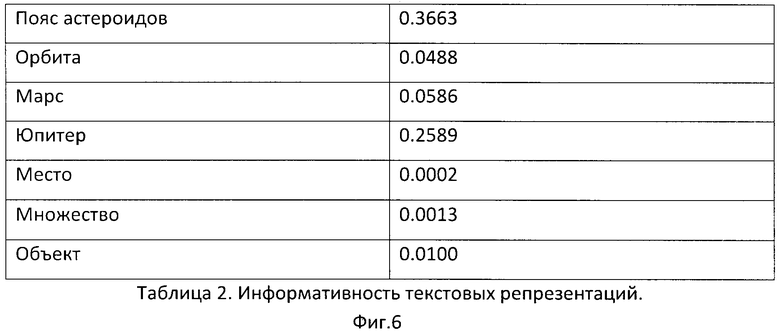
В гипертекстовых энциклопедиях принято использовать ссылки только для понятий, важных для понимания основного текста. Таким образом, информативность (степень важности) текстового представления можно оценить как отношение количества статей, где представление встретилось в качестве ссылки, к количеству статей, где представление встретилось вообще. Например, для термина "Пояс астероидов" информативность, вычисленная на основе Википедии, равна 0.3663, а информативность термина "База" равна 0.00468, что существенно ниже, так как термин многозначный и чаще предполагается, что его значение известно читателю, либо не существенно для описания.
Гипертекстовые энциклопедии обычно создаются для определенного языка, таким образом, язык текстового представления является языком энциклопедии. Заметим, что при создании многоязычных онтологии необходимо определять дубликаты концепций. Например, в Википедии для статьи "Россия" существует аналогичная статья на английском языке. Гипертекстовые энциклопедии содержат межъязыковые ссылки на аналоги статьи на других языках, которые представляют простой способ установления таких дубликатов. Существуют более сложные методы установления дубликатов, но они относятся к области машинного перевода и не рассматриваются в данном изобретении.
Помимо известного способа извлечения онтологии из гипертекстовых энциклопедий, в данном изобретении предлагается способ извлечения онтологии из других информационных источников, например из Вебсайтов, баз данных или электронных документов. Извлечение онтологии осуществимо, если из источника возможно выделить отдельные объекты и их описания. Например, Вебсайт с описанием новинок киноиндустрии может содержать отдельные страницы (или сегменты страниц) для описания фильмов и персональные страницы актеров, режиссеров и т.д.
Для таких источников каждый объект становится концепцией онтологии. Аналогично случаю гипертекстовой энциклопедии, идентификатор концепции определяется на основе доступной информации или задается автоматически системой обработки источника. Кроме того, сохраняется уникальный идентификатор ресурса с описанием. Если такого идентификатора для объекта не существует, например, если на одной странице содержится несколько объектов и их описаний, то сохраняется наиболее точный идентификатор более общего фрейма (в примере идентификатор страницы).
Извлечение текстовых представлений концепций осуществляется на основе описанных ниже правил, использующих структуру источника. Для Веб страниц текстовые представления могут содержаться в названии страницы, либо выделены специальными тэгами. Также могут быть использованы более сложные способы, учитывающие структурные и текстовые свойства документа. Например, могут использоваться алгоритмы машинного обучения, использующие в качестве признаков части речи слов, контекст из слов в окружении, присутствие заглавных букв и т.д. (Gabor Melli and Martin Ester. 2010. Supervised identification and linking of concept mentions to a domain-specific ontology. In Proceedings of the 19th ACM international conference on Information and knowledge management (CIKM '10). ACM, New York, NY, USA, 1717-1720.].
Определение связей между концепциями, производится на основе анализа их описаний. Если описания концепций имеют развитую ссылочную структуру, то извлечение остальной информации происходит образом, аналогичным обработке гипертекстовой энциклопедии.
В случай, когда описания не содержат ссылок, необходимы более сложные алгоритмы для построения связей между объектами. Данное изобретение может использоваться для решения этой задачи.
Сначала определим информативность текстового представления. Информативность текстового представления необходима на этапе определения связей между концепциями, однако в этом случае для ее определения нет возможности использовать ссылочную структуру. В таком случае степень важности текстового представления может быть определена с помощью меры обратной документной частоты термина, лексически совпадающего с текстовым представлением, которая известна из области информационного поиска [Дж Солтон. Динамические библиотечно-поисковые системы. М.: - Мир, 1979.]:
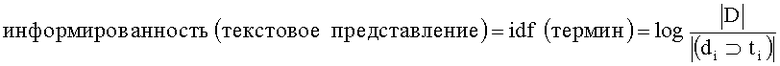
где |D| - количество обрабатываемых описаний, |(di⊃ti)| - количество описаний, в которых встречается термин ti.
Для определения ссылочной структуры необходимо выполнить следующие шаги:
1. извлечь онтологию из гипертекстовой энциклопедии, например Википедии;
2. обогатить описание концепций обрабатываемого информационного источника связями с существующей онтологией;
3. расширить контролируемый словарь существующей онтологии текстовыми представлениями всех концепций обрабатываемого информационного источника;
4. принять частоту совместного использования текстового представления и новой концепции, равной 1 для каждой уникальной пары представление-концепция;
5. повторить операцию обогащения концепций обрабатываемого информационного источника. Здесь необходимо использовать информативность, посчитанную через инвертированную документную частоту. При этом появятся дополнительные ссылки между самими концепциями (см. процесс обработки текста, описанный ниже);
6. обновить значение частоты совместного использования текстового представления и концепции на основе информации из полученных ссылок.
Использование онтологии, извлеченной из гипертекстовой энциклопедии, для построения новой онтологии необходимо из-за многозначности терминов языка. Данное изобретение позволяет определять значение термина в заданном контексте. Таким образом, использование известной онтологии позволит разрешить многозначность терминов в описаниях новых концепций.
Некоторые информационные источники содержат перевод информации на различные языки. Для таких источников необходимо при обработке сохранять язык текстового представления.
Результатом описанных выше операций будет служить одна онтология, извлеченная из нескольких информационных источников. Однако для некоторых приложений полезно различать онтологии, построенные на основе разных информационных источников. Для этого каждой концепции добавляется дополнительный атрибут, указывающий, из какого источника была извлечена концепция, и при обработке документов, обращаются к этому атрибуту для получения информации об источнике.
Прежде чем перейти к процессу обработки текстов, введем понятие семантической близости между концепциями, которое будет использоваться в дальнейшем.
Семантической близостью будем называть отображение f:X×X→R, ставящее в соответствие паре концепций x и y действительное число и обладающее следующими свойствами:
- 0≤f(x,y)≤1,
- f(x,y)=1 ⇔ x=y.
Известные методы нахождения семантической близости можно разделить на два класса:
- методы, определяющие близость над текстовыми полями и
- методы, использующие ссылочную структуру онтологии.
К первому классу относятся методы, используемые в информационном поиске, для сравнения текстовых документов. Наиболее известным методом является представление документа через векторную модель: каждому слову во всех документах назначается вес, затем документы представляются как векторы в n-мерном пространстве всевозможных слов и по некоторой математической мере вычисляется близость между полученными векторами. Вес слова в документе может быть определен как
вес=tf*idf
где tf - количество вхождений слова в документ, idf - обратная документная частота, описанная выше. Тогда вес каждого слова будет задавать координату вектора документа в соответствующем измерении. Для вычисления близости между векторами часто используется косинусная мера между ними:
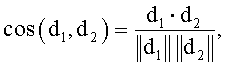
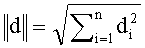
Таким образом, близость между концепциями может быть определена как близость между их описаниями.
Однако чаще используются меры из второго класса. Эти меры в свою очередь могут быть разделены на локальные и глобальные. Локальные методы определяют близость между концепциями А и В как нормализованное количество общих соседей N(X):
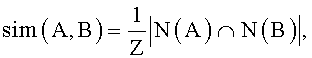
где Z - коэффициент нормализации, 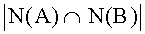
Наиболее известными локальными методами являются
- косинусная мера: 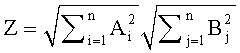
- коэффициент Дайса: 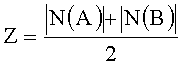
- коэффициент Жаккара: 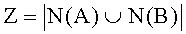
Для того чтобы данные меры удовлетворяли второму свойству определения семантической близости, будем считать, что каждая концепция онтологии обладает ссылкой на саму себя. Тогда близость между концепциями без связей с другими концепциями будет равна 1, только если эти концепции совпадают, и 0 во всех других случаях.
Заметим, что указанные меры определяются над множествами и не могут учитывать семантику ссылок. Для устранения этого недостатка в диссертации Турдакова Д.Ю. было предложено взвешивать ссылки различного типа, а меры близости обобщить на случай взвешенных ссылок с помощью теории нечетких множеств [Турдаков Д.Ю. Методы и программные средства разрешения лексической многозначности на основе сетей документов. Диссертация, Москва, 2010].
Наиболее известным из глобальных методов является мера "SimRank". Основная предпосылка этой модели формулируется так: "два объекта похожи, если на них ссылаются похожие объекты". Поскольку данная предпосылка формулирует понятие похожести через саму себя, то базовой предпосылкой в модели SimRank служит утверждение: "каждый объект считается максимально похожим на себя самого", т.е. имеющим с самим собой значение похожести, равное единице.
Заметим, что глобальные методы имеют более высокую вычислительную сложность и могут быть применены только к небольшим онтологиям. Поэтому для предложенного способа рекомендуется использовать локальные методы.
Кроме приведенного выше известного определения семантической близости данное изобретение предлагает обобщение для вычисления семантической близости между множествами концепций. Для этого множества представляются в виде обобщенной концепции, которая соединена с соседями всех входящих в нее концепций:
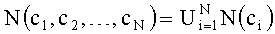
то есть множество соседей обобщенной концепции состоит из объединения множеств всех непосредственных соседей концепций, входящих в обобщенную.
Вычисление семантической близости - частая операция при обработке текста. Поэтому в данном изобретении предлагается сделать дополнительный (не обязательный) шаг при построении онтологии и заранее вычислить близость между концепциями (Фиг.2. 202). Однако посчитать заранее семантическую близость между всеми концепциями достаточно большой онтологии, например, извлеченной из Википедии, не представляется возможным. Википедия содержит описание более 3.5 миллионов понятий, причем все понятия сильно связаны. Это означает, что для хранения понадобится несколько терабайт данных, и, при существующем уровне техники, - несколько машинолет для подсчета. Поэтому в данном изобретении предлагается несколько эвристик, позволяющих произвести предварительный подсчет для подмножества терминов, и использовать только эти значения при обработке текстов.
- Для онтологии, не хранящей типы ссылок производить подсчет семантической близости только для концепций, имеющих прямую ссылку.
- Для онтологии хранящих семантику ссылки назначить веса ссылок в зависимости от их типа и вычислять семантическую близость только для ссылок с весами больше некоторого порога. Порог и веса ссылок подбираются таким образом, чтобы найти компромисс между количеством значений семантической близости для предварительного подсчета и качеством определения значений терминов.
Данные эвристики позволяют заранее определить семантическую близость без существенной потери качества при обработке текстов.
Предварительный подсчет семантической близости выполняется для всех пар концепций, между которыми есть ссылка, определяемая с помощью перечисленных выше эвристик. Предварительный подсчет семантической близости осуществляется следующим образом:
Для каждой концепции К
- получают список соседних концепций С, на которые у концепции К есть ссылка или с которых на концепцию К есть ссылка,
- вычисляют семантическую близость от текущей концепции К до всех соседних концепций ci∈С,
- для каждой концепции ci из С сохраняют вычисленную семантическую близость между парой концепций К и ci, а также соответствующие концепции K и ci.
Если значение семантической близости посчитано заранее, то при обработке текстов ее сохраненные значения будут извлекаться из онтологии. Если же предподсчет семантической близости не производился, то она будет вычисляться по запросу.
Перейдем ко второму шагу предлагаемого способа: связыванию документа и онтологии. Будем называть термином слово или несколько идущих подряд слов текста. Целью этого шага является поиск однозначного соответствия между терминами и концепциями онтологии. Такие концепции будем называть значениями терминов. Таким образом, цель можно переформулировать как поиск терминов в тексте и определение их значений.
Для Нахождения терминов в тексте и определение их значений необходимо сделать три шага (Фиг.1):
- На первом шаге определяют всевозможные связи между терминами и концепциями (103).
- На втором шаге разрешается лексическая многозначность терминов (104).
- На третьем шаге строится семантическая модель документа (105).
Процесс поиска терминов (103) состоит в сопоставлении частей текста и текстовых представлений присутствующих в контролируемом словаре. Наиболее простым и эффективным способом является поиск полностью совпадающих строк. Также известны методы, использующие частичное совпадение, но эти методы могут применяться только для небольших онтологии, так как обладают значительно большей вычислительной сложностью.
Рассмотрим метод, основанный на присутствии термина в словаре. Так как перебор всевозможных частей текста неэффективен, приведем несколько эвристик, позволяющих ускорить этот процесс.
1. Так как в контролируемом словаре содержаться только слова или последовательности слов, имеет смысл разбить текст на слова и проверять на присутствие в словаре только части текста, состоящие из слов.
2. Термин не может пересекать границы предложений, поэтому необходимо искать термин только в рамках одного предложения.
3. В подавляющем большинстве случаев текстовые представления концепций являются группами имени существительного (или существительными в случае одного слова). Поэтому для ускорения обработки рекомендуется определить части речи слов и не рассматривать комбинации, не являющиеся группами имени существительного. Эта эвристика также поможет увеличить точность нахождения терминов, разрешив морфологическую многозначность (например, в русском языке наречие «стекло» не будет рассматриваться как существительное «стекло», для английского глагол «cause» не будет рассматриваться как существительное «cause»).
4. Так как слова могут находиться в различных формах, то необходимо хранить возможные формы слов в контролируемом словаре. Для уменьшения объема памяти и увеличения скорости обработки, рекомендуется с помощью алгоритмов лемматизации преобразовать все слова к начальной форме, например существительные - к единственному числу, именительному падежу в случае русского языка, и к единственному числу в случае английского языка. Для этих же целей имеет смысл преобразовать все буквы к единому регистру, в составных терминах убрать пробельные символы и знаки препинания. В этом случае такому же преобразованию подлежат все слова в контролируемом словаре. Например, текстовое представление "Пояс астероидов" преобразуется в "поясастероид".
5. Для составных терминов, содержащих в качестве своих частей другие термины, имеет смысл рассматривать только самый длинный термин. Например, для термина "Пояс астероидов", можно не рассматривать слово "Пояс" в отдельности.
После того, как присутствующие в контролируемом словаре термины найдены, будем считать соответствующие им концепции возможными значениями терминов. Следующим шагом будет являться выбор из возможных концепций одной, которая будет считаться значением термина. Задача определения значений терминов относится к области разрешения лексической многозначности. Важнейшие результаты в данной области основаны на последних достижениях в области машинного обучения.
Машинное обучение - подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться. Выделяют обучение с учителем и обучение без учителя. В случае обучения с учителем, алгоритм генерирует функцию, которая связывает входные данные с выходными определенным образом (задача классификации). В качестве обучающих данных даны примеры связи входных данных с выходными желаемым образом. В случае обучения без учителя, алгоритм действует как агент, моделирующий набор входных данных, не имея доступа к предварительно размеченным примерам. Оба типа алгоритмов используют понятие признака. Признаки - индивидуальные измеримые свойства наблюдаемого феномена, которые используются для создания его численного представления (например, семантическая близость между обрабатываемой концепцией и значением предыдущего термина).
Рассмотрим некоторые существующие алгоритмы определения значений, которые могут быть использованы в данном изобретении. Наиболее простым способом является выбор наиболее часто употребляемого значения. Для этого находим частоту совместного использования обрабатываемого термина и всевозможных концепций, связанных с ним. После этого в качестве значения выбираем концепцию с наибольшей частотой. Этот алгоритм всегда выбирает одно и то же значение для фиксированного термина, вне зависимости от контекста, поэтому имеет невысокую точность.
Другим подходом является алгоритм, вычисляющий семантически наиболее связанную последовательность значений. Рассмотрим всевозможные последовательности значений для заданной последовательности терминов. Для каждой возможной последовательности концепций необходимо вычислить ее вес. Вес последовательности вычисляется, как сумма весов уникальных попарных комбинаций концепций, входящих в нее. Значениями терминов будут являться концепции последовательности с наибольшим весом. Пример использования описан ниже.
Два описанных алгоритма являются крайними случаями, не учитывающими важную информацию о тексте. Поэтому наилучшие результаты показывают алгоритмы, основанные на машинном обучении с учителем. Для каждого термина вычисляется вектор признаков, на основании которого алгоритм выбирает наиболее подходящее значение. Признаками могут служить
- информативность термина
- вероятность употребления термина t в данном значении mi, вычисляемая как 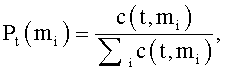
- Семантическая близость между концепцией и контекстом. Контекстом могут служить уже определенные значения, например значения однозначных терминов.
- Качество контекста, определенное как сумма информативности каждого однозначного термина и семантической близости его значения ко всем другим концепциям из контекста.
- а также другие признаки.
В качестве обучающих данных для алгоритма машинного обучения может использоваться текст, размеченный экспертами. Однако разметка текста - это ресурсоемкая операция, поэтому в качестве обучающего множества можно использовать документы из источника для построения онтологии.
Еще одним важным замечанием является то, что не всегда значение термина содержится в онтологии. Для определения такой ситуации добавим к списку концепций соответствующих каждому термину специальную концепцию, означающую отсутствие правильного значения в онтологии. Тогда описанный выше алгоритм машинного обучения будет определять такие случаи. Однако для этого потребуется специальный тренировочный набор, содержащий такие случаи. Заметим, что с помощью такого корпуса можно обучить алгоритм, который будет определять присутствие значения термина в онтологии. Такой алгоритм можно комбинировать и с простыми алгоритмами определения значений, описанными выше. Частным случаем такого алгоритма является фильтрация терминов с информативностью ниже некоторого порога. Последний подход описан в литературе [Rada Mihalcea and Andras Csomai. 2007. Wikify!: linking documents to encyclopedic knowledge. In Proceedings of the sixteenth ACM conference on Conference on information and knowledge management (CIKM '07). ACM, New York, NY, USA, 233-242; и David Milne and lan H.Witten. 2008. Learning to link with wikipedia. In Proceeding of the 17th ACM conference on Information and knowledge management (CIKM '08). ACM, New York, NY, USA, 509-518].
На завершающем шаге предлагаемого способа строится семантическая модель документа (Фиг.1. 105). В простейшем случае семантическая модель документа представляет собой список всех значений терминов. Такая модель может быть полезна, если документ содержит малое количество терминов, и как следствие, все они важны. Однако для больших документов необходимо определять наиболее значимые концепции.
Способ определения наиболее значимых концепций состоит из следующих шагов:
- На первом шаге выделяется основная тема (темы) документа. В больших документах часто присутствует одна или небольшое количество основных тем и множество дополнительных описаний. Например, документ с описанием некоторого события может, кроме терминов, непосредственно относящихся к событию, содержать термины с описанием времени и места, где данное событие произошло. Другим случаем, где важно понимать основную тему, является обработка зашумленных документов. Например, при обработке Веб-страниц иногда сложно отделить основной текст от вспомогательных элементов, таких как меню и т.д.
Для выделения основной темы предлагается сгруппировать семантически близкие значения, и после этого выделить основную группу (группы). Для исполнения этой идеи построим полный взвешенный семантический граф документа, где узлами будут значения терминов, а ребра будут иметь вес, равный семантической близости между концепциями в соответствующих узлах. К построенному графу применим алгоритм кластеризации. Алгоритмы кластеризации относятся к алгоритмам машинного обучения без учителя и позволяют разделить граф на группы таким образом, чтобы внутри группы были сильные связи, а между группами были только слабые связи.
Далее каждой группе назначается вес. Вес может состоять из комбинации нескольких параметров группы. В качестве примера, можно использовать информативности группы, то есть сумму информативностей всех терминов, чьи значения присутствуют в группе.
Далее выбирается группа или несколько групп с наибольшим весом. Количество групп может определяться эвристически, например, браться все группы с весом больше некоторого порога, либо автоматически через анализ перепадов между весами групп. В качестве примера можно брать все группы с весом не менее 75% от наибольшего веса для всех групп.
Выделенные группы будут содержать значения, описывающие основные темы документа. Будем считать эти значения кандидатами в ключевые.
- На втором шаге из значений-кандидатов выбираются ключевые. Для этого все значения-кандидаты взвешиваются и сортируются по убыванию веса. Ключевыми концепциями выбираются N наиболее весомых, где параметр N подбирается эвристически. Для взвешивания концепций могут использоваться различные комбинации их параметров. Например, весом может быть произведение
- среднего количества слов во всех текстовых представлениях концепции, которые встретились в качестве термина документа,
- частоты встречаемости концепции в документе и
- максимума информативности для всех текстовых представлений концепции, встретившихся в качестве термина в документе.
Имея построенную семантическую модель документа с выделенными концепциями можно легко реализовать, приложения, описанные выше. Например, для задачи обогащения документа можно считать ключевыми те термины, чьи значения являются ключевыми. Вычисляя близость между документами, как семантическую близость между их моделями можно строить системы семантического поиска и семантические рекомендательные системы.
Рассмотрим процесс построения семантической модели на примере документа, состоящего из одного предложения "Пояс астероидов расположен между орбитами Марса и Юпитера и является местом скопления множества объектов всевозможных размеров" и онтологии, изображенной на Фиг.3.
1. Определим термины текста, которым могут соответствовать концепции.
2.1 Разбиваем входящий текст на лексемы: "Пояс", "астероидов", "расположен", "между", "орбитами", "Марса", "и", "Юпитера", "и", "является", "местом", "скопления", "множества", "объектов", "всевозможных", "размеров".
2.2. Применяем алгоритм для нахождения леммы каждого слова: "пояс", "астероид", "расположенный", "между", "орбита", "Марс", "и", "Юпитер", "и", "являться", "место", "скопление", "множество", "объект", "всевозможный", "размер".
2.3. Применяем жадный алгоритм для поиска терминов в словаре. Для этого просматриваем последовательности лексем, состоящие не более чем из пяти слов (n=5), и проверяем их на присутствие в контролируемом словаре. Каждое слово в словаре должно находиться в нормальной форме, чтобы по последовательности "пояс"+"астероид" можно было найти "пояс астероидов". Таким образом, находим термины "Пояс астероидов", "Орбита", "Марс", "Юпитер", "Место", "Множество", "Объект". Заметим, что термины "скопление" и "размер" не были найдены, так как не присутствуют в онтологии.
2.4. Для каждого термина получаем множество концепций, которые связаны с текстовыми репрезентациями из словаря: "Пояс астероидов", "Орбита (траектория)", "Орбита (глазница)", "Марс (планета)", "Марс (бог)", "Юпитер (планета)", "Юпитер (бог)", "Место (расположение)", "Место (роман)", "Множество (математика)", "Множество (программирование)", "Объект (предмет), "Объект (космический)".
2. Определим значения терминов. Для этого необходимо каждому термину сопоставить только одну из возможных концепцию.
2.1. На первом шаге произведем фильтрацию терминов с информативностью ниже некоторого порога. Порог подбирается в зависимости от онтологии. Для данной онтологии выберем порог, равный 0.003. Информативность терминов представлена в таблице на Фиг.6. На основании алгоритма фильтрации термины "Множество" и "Место" и соответствующие им концепции исключаются из дальнейшей обработки. Заметим, что таким образом мы избежали ошибки определения значения термина "Множество", так как его общеупотребительное неопределенно-количественное значение "много" не присутствует в онтологии.
2.2. Следующим шагом определим значения оставшихся терминов. В данном примере покажем, как для вычисления значения концепций применять алгоритм, вычисляющий семантически наиболее связанную последовательность. Для этого для каждой возможной последовательности необходимо вычислить ее вес. Вес последовательности вычисляется как сумма весов уникальных попарных комбинаций концепций, входящих в нее. Веса семантической близости между концепциями данного примера показаны на Фиг.5 в таблице значений семантической близости концепций (близость концепций, представленных в таблице, и концепций "Орбита (глазница)" и "Объект (предмет)" нулевая, поэтому они не представлены в таблице с целью экономии места). В данном примере семантическая близость вычисляется через меру Дайса. Близость между концепциями вычисляется как удвоенное количество общих соседей, деленное на сумму всех соседей. Например, для концепций "Пояс астероидов" и "Орбита (траектория)" общими соседями являются "Марс (планета)" и "Юпитер (планета)". У концепции "Пояс астероидов" 3 соседних концепции (учитывая ссылку на себя), у "Орбиты (траектория)" - 8 соседей. Таким образом, семантическая близость равна 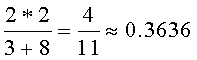
вес1=0.3636+0.4+0.3636+0+0.5333+0.635+0+0.4+0.2222+0.2=3.1177.
Для всех остальных последовательностей вес будет меньше. Например, для последовательности "Пояс астероидов", "Орбита (траектория)", "Марс (бог)", "Юпитер (бог)", "Объект (космический)"
вес2=0.3636+0.2222+0.2222+0+0.1429+0.1429+0+0.5+0=1.5938<вес1.
Таким образом, определяются значения терминов.
3. На третьем шаге строим полный взвешенный граф, где узлами служат значения, найденные на предыдущем шаге, а вес ребер равен семантической близости между узлами. Заметим, что семантическую близость между узлами мы вычислили на предыдущем шаге. Семантический граф для данного примера представлен на Фиг.4.
4. Вычислим ключевые слова для данного документа. Для этого с помощью алгоритма кластеризации определим список кандидатов. Не будем вдаваться в подробности работы алгоритмов кластеризации, однако заметим, что все концепции, за исключением концепции "Объект (космический)", имеют ненулевую семантическую близость между собой. Алгоритм кластеризации найдет один кластер, содержащий все эти концепции, а принадлежность концепции "Объект (космический)" к этому кластеру будет зависеть от алгоритма. В данном примере, будем считать, что "Объект (космический)" был отнесен к другому кластеру. Выберем один кластер с наибольшим весом. Вес кластера будем вычислять как сумму информативностей терминов, чьи значения входят в него. Несложно понять, что таким кластером будет кластер, содержащий концепции "Пояс астероидов", "Орбита (траектория)", "Марс (планета)", "Юпитер (планета)". Таким образом, список кандидатов будет содержать только эти значения.
5. Произведем ранжирование концепций по значимости. Будем определять вес как произведение следующих трех величин:
- среднего количества слов во всех текстовых репрезентациях концепции, которые встретились в качестве термина документа,
- частоты встречаемости концепции в документе и
- максимуму информативности для всех текстовых репрезентаций концепции, встретившихся в качестве термина в документе.
Информативность текстовых репрезентаций представлена в таблице на Фиг.6.
Таким образом, вес концепций в порядке убывания будет следующим:
вес("Пояс астероидов")=2*1*0.3663=0.7326
вес("Юпитер (планета)")=1*1*0.2589=0.2589
вес("Марс (планета)")=1*1*0.0586=0.0586
вес("Орбита (траектория)")=1*1*0.0488=0.0488
6. Ключевыми будут являться первые n концепций, где n задается эвристически в зависимости от задачи. Выберем в данном примере значение n=3. Тогда ключевыми будут считаться концепции "Пояс астероидов", "Марс (планета)", "Юпитер (планета)".
В дальнейшем легко определить ключевые слова в исходном тексте. Ключевыми будут считаться все текстовые репрезентации ключевых концепций, то есть "Пояс астероидов", "Марса" и "Юпитера".
Так, основываясь на предложенном подходе легко создавать приложения для помощи чтения документов, подсветив ключевые термины или обогатив исходный текст гиперссылками с ключевых слов на описание концепций.
Также очевидно применение изобретения в области построения семантических информационно-поисковых систем. Если позволить пользователю указывать системе, какое именно значение термина он ищет, то можно обрабатывать только те документы, семантическая модель которых содержит это значение. Для обеспечения большей полноты поиска, можно также искать документы, содержащие близкие по значению концепции в семантической модели.
Применение изобретения в области рекомендательных систем заключается в рекомендации документов, чьи семантические модели наиболее близки к модели текущего документа. Близость между моделями может вычисляться как классическими способами (через нормализованное пересечение множеств), так и через введенное в данном изобретении обобщение семантической близости для множества концепций.
Кроме того, аналогичную технику можно применять для рекомендации коллекций документов. В данном случае коллекция документов интерпретируется как обобщенный документ, содержащий семантические модели документов входящих в нее. Рассмотрим данное применение на примере Веб журналов. Пусть пользователя интересуют сообщения в одном Веб журнале. Чтобы порекомендовать Веб журналы, в которых пишется о семантически близких вещах, необходимо сравнить сообщения журналов и найти наиболее близкие. Применяя предложенный способ можно считать, что Веб журнал является обобщенным документом с семантической моделью, состоящей из моделей всех сообщений. Тогда, применяя метод для рекомендации документов, получим рекомендации для Веб журналов.
Также возможно создание кратких описаний документов. Они могут состоять из ключевых терминов, либо предложений или параграфов, содержащих ключевые термины, либо использоваться более сложные техники из области автоматического аннотирования и реферирования, где в качестве признаков будут использоваться знания о ключевых терминах и их значениях.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КЛАССИФИКАЦИИ ТЕКСТОВ, ПОЛУЧЕННЫХ В РЕЗУЛЬТАТЕ РАСПОЗНАВАНИЯ РЕЧИ | 2016 |
|
RU2628897C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ ОНТОЛОГИЧЕСКИХ МОДЕЛЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2596599C2 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ СЕМАНТИЧЕСКИХ СЛОВАРЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2584457C1 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ВЫБОРА ЗНАЧИМЫХ ЭЛЕМЕНТОВ СТРАНИЦЫ С НЕЯВНЫМ УКАЗАНИЕМ КООРДИНАТ ДЛЯ ИДЕНТИФИКАЦИИ И ПРОСМОТРА РЕЛЕВАНТНОЙ ИНФОРМАЦИИ | 2015 |
|
RU2708790C2 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
Изобретение относится к области обработки данных при семантическом анализе текстовых данных и построении семантической модели документов. Техническим результатом является обеспечение возможности обогащения документов метаданными, позволяющими улучшить и увеличить скорость восприятия основной информации, а также обеспечение возможности определять и подсвечивать ключевые термины текста, что позволяет ускорить его чтение и улучшить понимание. Способ построения семантической модели документа состоит из двух основных шагов. На первом из внешних информационных ресурсов, которые содержат описания отдельных объектов предметной области, извлекают онтологию. На втором - связывают текстовую информацию документа с концепциями онтологии и строят семантическую модель документа. В качестве информационных источников используют электронные ресурсы как связанные, так и не связанные структурой гипертекстовых ссылок. Технический результат, в частности, достигается за счет того, что сначала выделяют все термины документа и связывают их с концепциями онтологии таким образом, чтобы каждому термину соответствовала единственная концепция, являющаяся его значением, а затем значения терминов ранжируются по важности к документу. 14 з.п. ф-лы, 6 ил.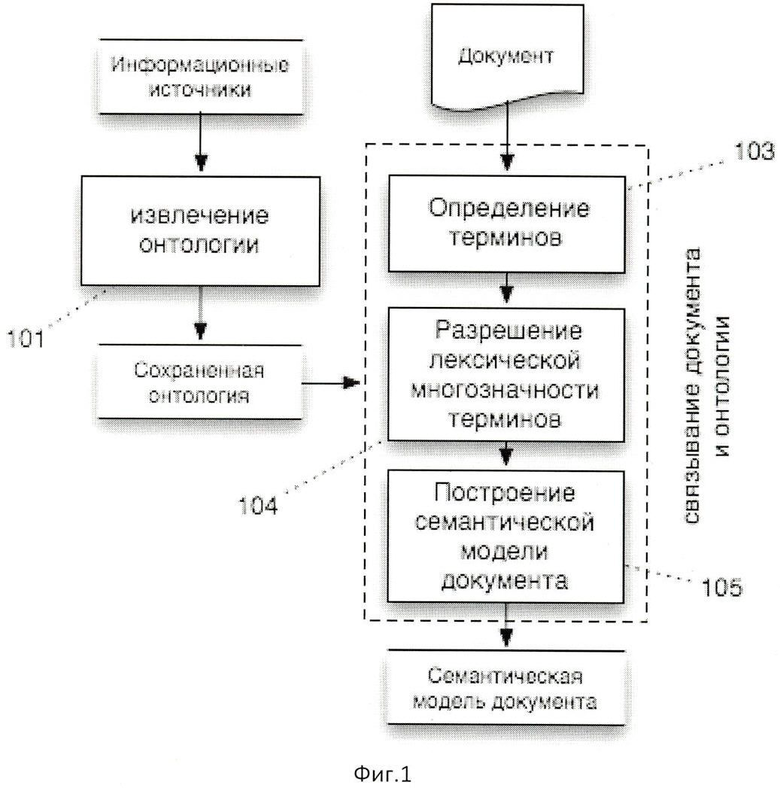
1. Способ построения семантической модели документа, по которому из информационных источников извлекают онтологию, в качестве информационных источников используют электронные ресурсы, содержащие описания отдельных объектов реального мира, как связанные гипертекстовыми ссылками, так и не содержащие гипертекстовых ссылок в описании, каждой концепции онтологии назначают идентификатор, по которому она может быть однозначно определена, в случае существования гипертекстовые ссылки между описаниями концепций преобразуют в связи между концепциями, при отсутствии структуры гипертекстовых ссылок их добавляют, анализируя описания и определяя значения терминов с помощью онтологии, извлеченных из гипертекстовых энциклопедий, и затем преобразуют в связи между концепциями, сохраняют уникальный идентификатор ресурса с оригинальным описанием концепции, для каждой концепции определяют не менее одного текстового представления, вычисляют частоту совместного использования каждого текстового представления концепции и информативность для каждого текстового представления, также определяют, какому естественному языку принадлежит текстовое представление, и сохраняют полученную информацию, получают текст анализируемого документа, осуществляют поиск терминов текста и их возможных значений, путем сопоставления частей текста и текстовых представлений концепций из контролируемого словаря, для каждого термина из его возможных значений, используя алгоритм разрешения лексической многозначности терминов, выбирают одно, которое считают значением термина, а затем концепции, соответствующие значениям терминов, ранжируют по важности к тексту, и наиболее важные концепции считают семантической моделью документа.
2. Способ по п.1, отличающийся тем, что в качестве алгоритма разрешения лексической многозначности терминов используют алгоритм, который выбирает наиболее часто употребляемое значение, для чего определяют частоту совместного использования обрабатываемого термина и всевозможных концепций, связанных с ним, после чего в качестве значения термина выбирают концепцию с наибольшей частотой использования термина и концепции.
3. Способ по п.1, отличающийся тем, что в качестве алгоритма разрешения лексической многозначности терминов выбирают алгоритм, вычисляющий семантически наиболее связанную последовательность значений, по которому рассматривают всевозможные последовательности значений концепций для заданной последовательности терминов, для каждой возможной последовательности концепций вычисляют ее вес, как сумму весов уникальных попарных комбинаций концепций, входящих в последовательность концепций, а значениями терминов считают концепции, принадлежащие последовательности с наибольшим весом.
4. Способ по п.1, отличающийся тем, что в качестве алгоритма разрешения лексической многозначности терминов выбирают алгоритм, основанный на машинном обучении с учителем, по которому для каждого термина вычисляют вектор признаков, на основании которого выбирают наиболее подходящее значение.
5. Способ по п.4, отличающийся тем, что в качестве признака выбирают информативность термина.
6. Способ по п.4, отличающийся тем, что в качестве признака выбирают вероятность употребления термина t в данном значении mi, вычисляемую как 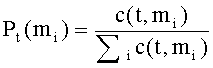
7. Способ по п.4, отличающийся тем, что в качестве признака выбирают семантическую близость между концепцией и контекстом документа.
8. Способ по п.7, отличающийся тем, что в качестве контекста документа выбирают значения однозначных терминов.
9. Способ по п.4, отличающийся тем, что в качестве признака выбирают сумму информативности каждого однозначного термина и семантической близости его значения ко всем другим концепциям из контекста документа.
10. Способ по п.1, отличающийся тем, что для определения структуры ссылок информационного источника, не содержащего гипертекстовых ссылок, извлекают онтологию из гипертекстовой энциклопедии, обогащают описание концепций информационного источника, не содержащего гипертекстовых ссылок, связями с существующей онтологией, извлеченной из гипертекстовой энциклопедии, расширяют контролируемый словарь существующей онтологии текстовыми представлениями всех концепций обрабатываемого информационного источника, не содержащего гипертекстовых ссылок, принимают частоту совместного использования этих концепций и их текстовых представлений равной 1 для каждой уникальной пары представление-концепция, повторяют операцию обогащения концепций обрабатываемого информационного источника, используя информативность, посчитанную через инвертированную документную частоту, таким образом, получают дополнительные ссылки между концепциями, извлеченными из информационного источника, не содержащего гипертекстовых ссылок, обновляют значение частоты совместного использования текстового представления и концепции на основе полученных ссылок.
11. Способ по п.1, отличающийся тем, что для ранжирования концепций по важности к документу строят семантический граф документа, состоящий из значений всех терминов документов и всевозможных взвешенных связей между ними, где вес связи равен семантической близости между концепциями, которые соединены связью, к семантическому графу применяют алгоритм кластеризации, группирующий семантически близкие концепции, затем концепции из наиболее весомых кластеров ранжируют по важности к документу, и наиболее важные концепции считают семантической моделью документа.
12. Способ по п.1, отличающийся тем, что при извлечении онтологии вычисляют семантическую близость между концепциями, при этом для каждой концепции К составляют список концепций С, состоящий из концепций ci, на которые у концепции К есть ссылка или с которых на концепцию К есть ссылка, вычисляют семантическую близость от текущей концепции К до каждой концепций ci∈С, сохраняют вычисленную семантическую близость между каждой парой концепций К и ci, а также соответствующие концепции К и ci, а для концепций не входящих в список С, семантическую близость с концепцией К принимают равной нулю.
13. Способ по п.12, отличающийся тем, что ссылкам между концепциями назначают веса, выбирают пороговое значение для весов, а список концепций С составляют из концепций, на которые у концепции К есть ссылка с весом больше выбранного порогового значения или с которых на концепцию К есть ссылка с весом больше выбранного порогового значения.
14. Способ по п.1, отличающийся тем, что онтологии извлекают из нескольких источников.
15. Способ по п.1, отличающийся тем, что в качестве текста документа используют метаданные документа.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 7734623 B2, 08.06.2010 | |||
| Химический огнетушитель | 1927 |
|
SU8675A1 |
| СПОСОБ И СИСТЕМА СОПОСТАВЛЕНИЯ ОПЕРАЦИЙ СЕМАНТИЧЕСКИМ МЕТКАМ В ЭЛЕКТРОННЫХ ДОКУМЕНТАХ | 2003 |
|
RU2328034C2 |

