ОБЛАСТЬ ТЕХНИЧЕСКОГО ПРИМЕНЕНИЯ
Настоящее изобретение относится к способам аутентификации и верификации потоков данных. В частности, изобретение относится к вставке идентификаторов в такой поток данных, как битовый поток Dolby Pulse, AAC или HE AAC, и к аутентификации и верификации потока данных на основе этого идентификатора.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
В условиях возрастающего распространения систем цифрового телевидения и радио потоки данных, включающие, например, видеоданные и/или аудиоданные, транслируются все чаще. В дополнение к актуальному видео- и/или аудио-содержимому эти потоки данных также включают метаданные, которые позволяют, например, управлять громкостью и динамическим диапазоном программы на стороне приемника, а также управлять стереофоническим понижающим микшированием и другими свойствами.
В типичных сетевых сценариях видеокадры и/или аудиокадры и связанные с ними метаданные кодируются в системе головного узла сети вещания. Для этого могут использоваться различные схемы кодирования, такие как Dolby E, Dolby Digital, AAC, HE AAC, DTS или Dolby Pulse. Некоторые из этих схем кодирования, Dolby Pulse, AAC и HE AAC, в наибольшей степени и особенно хорошо подходят для передачи через различные средства передачи информации, такие как радио (например, FM-частотный диапазон, DVB/T, ATSC), скрученные медные провода (DSL), коаксиальные кабели (например, CATV) или оптические волокна. Приемник, например телевизор, радиоприемник, персональный компьютер или дополнительное внешнее устройство, содержит соответствующий декодер и создает декодированный медиапоток. Кроме того, приемник обычно предусматривает функции управления, которые инициируются посредством метаданных, сопровождающих видео- и/или аудиоданные.
Примеры схем кодирования/декодирования определены в стандарте ISO/IEC 14496-3 (2005) "Information technology - Coding of audio-visual objects - Part 3: Audio" ― для MPEG-4 AAC, и в стандарте ISO/IEC 13818-7 (2003) "Generic Coding of Moving Pictures and Associated Audio information - Part 7: Advanced Audio Coding (AAC)" ― для MPEG-2 AAC, которые ссылкой включаются в настоящее описание.
Известно несколько способов аутентификации и/или идентификации. Некоторые из них опираются на внедрение данных аутентификации и/или идентификации в кодированные мультимедийные данные. Эти способы известны также как «водяные знаки» и предназначаются, в основном, для защиты авторского права. Еще один способ аутентификации и/или идентификации ― это цифровая подпись, где отдельные данные аутентификации предусматриваются наряду с файлами данных, такими как файлы электронной почты, и используются в декодере для целей аутентификации и идентификации.
Для того чтобы приемник потоков данных был способен идентифицировать кодер потока данных, требуется наряду с потоком данных обеспечить средства аутентификации. Также может оказаться полезной проверка целостности потока данных. Кроме того, может оказаться полезным обеспечение корректной конфигурации приемника в отношении потока данных, который подвергается воспроизведению или обработке. Также может оказаться полезным допуск реализации дополнительных платных услуг или специальных функциональных возможностей для потоков данных, которые были надлежащим образом аутентифицированы и/или верифицированы. К этим и другим вопросам обращается настоящий патентный документ.
КРАТКОЕ ОПИСАНИЕ
Предлагаемый способ и система используют идентификатор, который может предусматриваться в виде метаданных в потоке данных. Указанные потоки данных, предпочтительно, представляют собой потоки данных, которые передаются через проводные или беспроводные средства передачи данных, однако потоки данных также могут быть предусмотрены на запоминающем устройстве, таком как CD, DVD или флеш-память. Идентификатор дает возможность декодеру на стороне приема проверять, является ли поток данных, который он принимает, происходящим из надежного кодера, т.е. от легального кодера на стороне передачи и/или кодирования. Эта верификация может быть особенно полезна в случае, когда декодер совместим с кодерами различного типа. Например, декодер Dolby Pulse может быть совместим с кодером HE-AAC version 2. В таком сценарии может потребоваться предоставление декодеру Dolby Pulse возможности обеспечивать некоторые нестандартные, или необязательные, возможности только в том случае, если сетевой трафик, т.е. потоки данных, происходит из соответствующих кодеров Dolby Pulse. При использовании указанного идентификатора декодер Dolby Pulse будет обладать способностью делать различие между потоком данных, или битовым потоком, который генерируется соответствующим кодером Dolby Pulse, и потоком данных, или битовым потоком, который генерируется любым произвольным кодером, совместимым с HE-AACv2. В этой связи, можно обеспечить то, что дополнительные возможности, например использование динамических метаданных, учитываются декодером только в том случае, если поток данных исходит из надежного кодера. Таким образом, может обеспечиваться корректное функционирование дополнительных возможностей.
Дополнительным преимуществом идентификатора является то, что он может предоставлять декодеру возможность проверки того, что битовый поток был получен корректным образом, а также того, что битовый поток не подвергался модификации или несанкционированному вмешательству в ходе передачи. Иными словами, идентификатор дает декодеру возможность проверки целостности принимаемого битового потока.
Кроме того, идентификатор может использоваться для того, чтобы гарантировать то, что в декодере задано правильное конфигурирование обработки, например воспроизведения, с целью надлежащего рендеринга медийного/мультимедийного сигнала. Например, указанное конфигурирование может быть направлено на частоту дискретизации, с которой воспроизводится медиасигнал. Конфигурирование также может быть направлено на конфигурирование каналов, например 2-канального стереофонического сигнала, другие настройки окружающего звука и т.д., которые будут использоваться при воспроизведении. Другая особенность конфигурирования может быть направлена на длину кадра, например 1024 кадров дискретных значений или 960 кадров дискретных значений в случае ААС, которая используется в конкретной схеме кодирования.
Помимо целей идентификации кодера и аутентификации, идентификатор может использоваться для проверки аутентичности полезной нагрузки потока данных. С этой целью идентификатор не должен легко подвергаться подделке, а манипуляции с защищенным сегментом должны быть идентифицируемыми. Кроме того, желательно, чтобы декодер определял аутентичность битового потока за относительно короткие промежутки времени. Предпочтительно, чтобы максимальное время, за которое декодер, или декодирующее устройство, способно идентифицировать подлинный битовый поток в потоковом режиме не превышало 1 секунду. Кроме того, сложность, вносимая верификацией идентификатора в декодере, должна поддерживаться на низком уровне, т.е. увеличение сложности декодера должно быть незначительным. Наконец, должны поддерживаться на низком уровне непроизводительные издержки при передаче, вносимые идентификатором.
Согласно одному из вариантов осуществления изобретения вышеупомянутые преимущества достигаются путем использования криптографической величины, или идентификатора, получаемой в соответствии с нижеописанным способом. Идентификатор может определяться в кодере путем применения односторонней функции к группе из одного или нескольких кадров данных. Кадр, как правило, включает данные, связанные с определенным сегментом аудиопотока и/или видеопотока, например с сегментом, включающим заданное количество дискретных значений медиапотока. Например, кадр аудиопотока может включать 1024 дискретных значений аудиоданных и соответствующие метаданные.
Как было упомянуто выше, для определения идентификатора определенное количество кадров группируется. Количество кадров в каждой группе может выбираться кодером и, как правило, заранее неизвестно декодеру. Односторонняя функция, предпочтительно, представляет собой криптографическую хэш-функцию HMAC-MD5 (хэш-код аутентификации сообщений), хотя вместо MD5 могут использоваться и другие хэш-функции, такие как SHA-1. Возможным критерием выбора подходящей криптографической хэш-функции может быть ее размер, который должен оставаться небольшим для того, чтобы уменьшить необходимые непроизводительные издержки при передаче. Размер криптографической хэш-функции, как правило, дается ее числом бит.
После того как идентификатор для группы кадров вычислен, например, с использованием процедуры HMAC-MD5, он может быть связан с кадром из следующей группы кадров, например вставлен в кадр из следующей группы кадров. В качестве примера идентификатор может быть записан в поле данных синтаксического элемента кадра. Предпочтительно, идентификатор вставляется в первый кадр следующей группы кадров. Это позволяет вычислить идентификатор в ходе операции за один проход без внесения дополнительного времени ожидания в кодер/декодер, что особенно полезно для передачи медиаданных в реальном времени. Поток данных, включающий идентификатор, затем может передаваться в соответствующие приемники/декодеры.
В приемнике вставленный идентификатор может использоваться в целях идентификации кодера, аутентификации, верификации и/или конфигурирования. Приемник, как правило, включает декодер, который может синхронизироваться с группой кадров, т.е. он может определять кадры, включающие идентификатор. На основе расстояния между двумя последовательными кадрами, которые включают идентификатор, можно определить количество кадров, приходящееся на группу кадров, которая использовалась для вычисления идентификатора. Иными словами, это может позволить декодеру определить длину группы кадров без уведомления из соответствующего кодера.
Декодер может вычислять идентификатор для принятой группы кадров. Идентификаторы, которые вычисляются на основе принятой группы кадров, могут быть названы идентификаторами верификации. Если предполагается, что идентификаторы вставляются в первый кадр из следующей группы кадров, то каждая группа кадров должна начинаться с первого кадра, который включает идентификатор для предыдущей группы кадров, и что она должна заканчиваться кадром, который непосредственно предшествует следующему кадру, который включает идентификатор для текущей группы кадров. Идентификатор верификации для текущей группы кадров может быть вычислен в соответствии с описанными выше способами.
На следующем этапе декодер может извлечь идентификатор, переданный кодером, из соответствующего кадра следующей группы кадров. И снова, если в кодере идентификаторы вставляются в первый кадр следующей группы кадров, то приемник также извлекает идентификатор из этого первого кадра. Этот идентификатор, извлеченный из потока данных, может сравниваться с идентификатором верификации, т.е. с идентификатором, который вычисляется декодером на основе принятого потока данных. Если оба идентификатора совпадают, декодер, как правило, может принять, что в ходе передачи ошибки не возникли, группа кадров принята незатронутой, группа кадров не была модифицирована в ходе передачи и группа кадров получена из надежного и/или легитимного кодера. Кроме того, если оба идентификатора совпадают, декодер может выбрать разблокирование одной или нескольких возможностей, зависящих от кодека, или улучшений, которые не были бы разрешены при декодировании произвольного битового потока. Например, дополнительные функции могут быть разрешены, если декодер идентифицирует битовый поток, специфичный для Dolby Pulse, в то время как указанные дополнительные функции не были бы доступны для стандартного кодированного битового потока HE-AAC 2-й версии. Тем не менее, декодеру может быть предоставлена возможность декодирования стандартного кодированного битового потока HE-AAC 2-й версии, однако без использования дополнительных функций.
Следует в дополнение отметить, что идентификатору может быть предоставлена возможность обеспечения установки в декодере конфигурации, соответствующей корректному декодированию и/или воспроизведению медиапотока. В этих случаях совпадение идентификатора верификации и переданного идентификатора должно указывать на то, что декодер использует корректные настройки конфигурации.
Если, с другой стороны, идентификаторы, т.е. идентификатор верификации и переданный идентификатор, не совпадают, то декодер будет знать, что в ходе передачи возникла ошибка, группа кадров не была принята незатронутой, группа кадров была модифицирована в ходе передачи или группа кадров передана не из надежного кодера. В этих случаях декодер может быть полностью заблокирован или, в альтернативном варианте, могут блокироваться специфические возможности или улучшения.
Следует отметить, что идентификатор также может использоваться для того, чтобы информировать декодер о том, что установлены неверные настройки конфигурации. В этих случаях несовпадение между идентификатором верификации и переданным идентификатором могут быть связаны с тем, что декодер использует неверные настройки конфигурации, даже если группа кадров была принята незатронутой и из надежного кодера. Может быть предусмотрено, что в этих случаях декодер может действовать для модификации настроек его конфигурации и для определения соответствующих идентификаторов верификации до тех пор, пока идентификатор верификации не будет совпадать с переданным идентификатором. Эта модификация может предоставлять декодеру возможность актуально устанавливать его конфигурацию в соответствии с требованиями принимаемого битового потока.
Ниже описаны различные особенности предлагаемого способа. В соответствии с первой особенностью, описывается способ кодирования потока данных, включающего ряд кадров данных. Потоки данных могут представлять собой потоки аудио-, видео- и/или других медийных и мультимедийных данных. В частности, потоки данных могут представлять собой потоки данных Dolby Pulse, AAC или HE-AAC. Потоки данных, как правило, упорядочены в кадры данных, которые включают определенное количество дискретных значений данных и покрывают определенный сегмент потока данных. Например, кадр может включать 1024 дискретных значений звукового сигнала, дискретизированного на частоте дискретизации 44,1 КГц, т.е. он покрывает сегмент, около, 23 мс. Следует отметить, что дискретные значения могут кодироваться с постоянными или переменными битовыми скоростями передачи данных, и фактическое количество бит в кадре может варьироваться.
Способ может включать этап группировки ряда из N последовательных кадров данных для формирования первого сообщения. Количество N последовательных кадров данных, как правило, выбирается в соответствии с соображениями непроизводительных издержек скорости передачи данных. Обычно непроизводительные издержки уменьшаются при увеличении количества N. N предпочтительно больше единицы. Типичные значения N составляют около 20. В предпочтительном варианте осуществления изобретения N может выбираться так, чтобы N последовательных кадров покрывали 0,5 секунд соответствующего сигнала при воспроизведении соответствующим декодером с соответствующей конфигурацией декодера. Следует отметить, что этап группировки может включать конкатенацию N последовательных кадров в их естественном, т.е. поточном, порядке.
На следующем этапе первое сообщение может группироваться с информацией о конфигурации для формирования второго сообщения. Указанная информация о конфигурации включает информацию вне потока данных, которая, как правило, относится к потоку данных, в частности, представляет собой информацию для рендеринга потока данных на стороне приемника. Информация о конфигурации может включать информацию, относящуюся к настройкам соответствующего приемника и/или декодера, который должен применяться для обработки потока данных. Поскольку указанная информация о конфигурации, как правило, не передается, или не включается, в поток данных, она также может называться внеполосными данными в противоположность потоку данных, который также может называться внутриполосными данными.
Информация о конфигурации может различными способами группироваться с первым сообщением. Она может конкатенироваться с первым сообщением, т.е. размещаться в начале и/или в конце первого сообщения. Информация о конфигурации также может размещаться в определенных положениях внутри первого сообщения, например между некоторыми или всеми последовательными кадрами.
Типичные примеры информации о конфигурации включают указатель частоты дискретизации, которая использовалась при дискретизации базового аналогового потока медиаданных. Информация о конфигурации также может включать указатель конфигурации каналов системы кодирования звукового сигнала, такую как монофоническая конфигурация каналов, 2-канальная стереофоническая конфигурация или 5.1-конфигурация окружающего звука. Информация о конфигурации также может включать указатель количества дискретных значений в кадре данных, например 960, 1024 или 2048 дискретных значений, приходящихся на кадр данных.
Также способ включает этап генерирования криптографической величины для первого и/или второго сообщения. Криптографическая величина также может называться идентификатором. Указанная криптографическая величина может генерироваться с использованием ключевого значения и криптографической хэш-функции. В частности, криптографическая величина может генерироваться путем вычисления значения HMAC-MD5 для первого и/или второго сообщения. Кроме того, генерирование криптографической величины может включать усечение значения HMAC-MD5, например усечение до 16, 24, 32, 48 или 64 бит. Это может оказаться полезным ввиду уменьшения требуемых непроизводительных издержек для криптографической величины в потоке данных.
Кроме того, способ включает вставку криптографической величины в поток данных после N последовательных кадров данных. Предпочтительно, криптографическая величина вставляется в первый кадр, следующий за N последовательными кадрами данных для того, чтобы позволить ее быстрое декодирование и аутентификацию и верификацию кодера в соответствующем декодере. Также может оказаться полезной вставка указателя синхронизации после N последовательных кадров данных, где указатель синхронизации указывает на вставку криптографической величины. Указанный указатель синхронизации может размещаться рядом с криптографической величиной, позволяя удобно извлекать криптографическую величину в соответствующем декодере.
В иллюстративном варианте осуществления изобретения поток данных представляет собой поток MPEG4-AAC или MPEG2-AAC, и криптографическая величина вставляется в виде элемента<DSE>потока данных. Указанный элемент<DSE>потока данных может вставляться в конец кадра перед элементом<TERM>. Кроме того, содержимое указанного элемента<DSE>потока данных, предпочтительно, может выравниваться по границе байта потока данных для того, чтобы упростить извлечение элемента<DSE>потока данных, в частности криптографической величины и/или указателя синхронизации в соответствующем декодере.
Следует отметить, что этап генерирования криптографической величины, предпочтительно, может выполняться итеративно на отдельных кадрах группы из N последовательных кадров. С этой целью для каждого из N последовательных кадров с использованием исходного состояния может генерироваться промежуточная криптографическая величина. Исходное состояние может представлять собой промежуточную криптографическую величину предыдущей итерации. Например, промежуточная криптографическая величина может генерироваться для первого кадра. Эта промежуточная криптографическая величина может затем использоваться в качестве исходного состояния для генерирования промежуточной криптографической величины второго кадра. Этот процесс повторяется до тех пор, пока не будет генерирована промежуточная криптографическая величина N-го кадра. Эта последняя промежуточная криптографическая величина, как правило, представляет собой криптографическую величину для группы из N последовательных кадров. Для того чтобы учесть информацию о конфигурации, исходное состояние первой итерации может представлять собой промежуточную криптографическую величину для информации о конфигурации.
В предпочтительном варианте осуществления изобретения криптографическая величина для блока из N последовательных кадров данных генерируется на блоке из N последовательных кадров данных, включающем криптографическую величину для предыдущего блока из N последовательных кадров данных. Таким образом, может быть генерирован поток взаимосвязанных криптографических величин.
Согласно другой особенности способ может включать этап взаимодействия с видео- и/или аудиокодером потока данных. Этот этап может быть реализован путем выполнения кодирования видео- и/или аудиосигнала, а также как генерирование криптографической величины интегрированным способом. В частности, взаимодействие между видео- и/или аудиокодером потока данных и генерированием криптографической величины может быть направлено на установку максимальной битовой скорости передачи данных для видео- и/или аудиокодера так, чтобы битовая скорость передачи данных потока данных, включающего криптографическую величину, не превышала заранее определенное значение. Это может оказаться особенно полезным, если базовый кодек потока данных устанавливает более высокий предел битовой скорости передачи данных для полного потока данных.
Согласно следующей особенности описан способ верификации потока данных в декодере и/или приемнике. Следует отметить, что описанные способы и системы могут применяться в контексте передаваемых потоков данных, а также потоков данных, предусматриваемых на носителе данных. Как описано выше, поток данных, как правило, включает ряд кадров данных и криптографическую величину, связанную рядом из N предшествующих последовательных кадров данных. Здесь следует обратиться к обсуждению, сделанному в данном документе, в особенности, в отношении возможных значений N и структуры потока данных и его кадров.
Способ включает этап извлечения N последовательных кадров данных для формирования первого сообщения. Способ также может включать этап определения значения N. Этот этап может выполняться в потоке данных, который включает ряд из N последовательных кадров данных и связанные с ним криптографические величины. Если N последовательных кадров данных назвать группой кадров, то указанный поток данных, как правило, включает ряд групп кадров и криптографические величины, связанные с каждой из групп кадров. В этих случаях, число N может быть определено как количество кадров между двумя последовательными криптографическими величинами.
Следует отметить, что текущая группа кадров, которая используется для вычисления второй криптографической величины, может включать криптографическую величину для предыдущей группы кадров. В альтернативном варианте, криптографическая величина для предыдущей группы кадров и любой связанный с ней указатель синхронизации и/или синтаксический элемент должен быть удален из текущей группы кадров перед вычислением второй криптографической величины. Последнее решение может оказаться предпочтительным с целью предупреждения изменений и отклонений от распространения при переходе от одной группы кадров к следующей.
Способ также может включать этап группирования первого сообщения с информацией о конфигурации с целью формирования второго сообщения, где информация о конфигурации, как правило, включает информацию вне потока данных, такую как информация для рендеринга потока данных. Этап группирования и различные особенности, относящиеся к информации о конфигурации, описаны выше. Эти особенности в равной мере применимы к декодеру.
Способ продолжается путем генерированием второй криптографической величины для первого и/или второго сообщения, путем извлечения криптографической величины из потока данных и сравнения криптографической величины со второй криптографической величиной. Вторая криптографическая величина также может называться криптографической величиной для верификации, или идентификатором верификации.
Следует отметить, что вторая криптографическая величина может генерироваться итеративным способом, как это описано в контексте генерирования криптографической величины.
В предпочтительном варианте осуществления изобретения криптографическая величина генерируется в соответствующем кодере и/или передатчике из N последовательных кадров данных и информации о конфигурации согласно способу, который соответствует способу, используемому для генерирования второй криптографической величины. Иными словами, способ генерирования криптографической величины в соответствующем кодере соответствует способу генерирования второй криптографической величины в декодере. В частности, криптографическая величина и вторая криптографическая величина генерируются с использованием уникального ключевого значения и/или уникальной криптографической хэш-функции.
Кроме того, набор N последовательных кадров, используемых для генерирования криптографической величины в кодере соответствует набору N последовательных кадров, используемых для генерирования второй криптографической величины в декодере. Как упоминалось выше, криптографическая величина и вторая криптографическая величина могут быть определены на наборе N последовательных кадров, которые включают, или которые не включают, криптографическую величину для предшествующего набора из N последовательных кадров. Аналогичное правило следует применять к кодеру и декодеру.
Даже если набор кадров, используемый в кодере и декодере, должен быть идентичным, следует отметить, что содержимое кадров в кодере и декодере может различаться, например, по причине модификаций, которым кадры подвергаются в ходе их передачи, или по причине ошибок на носителе потока данных.
В соответствии со следующей особенностью, способ может включать этап установки флага в случае, когда криптографическая величина соответствует второй криптографической величине и/или этап обеспечения визуальной индикации в приемнике и/или декодере, если флаг установлен. Аналогичным образом флаг и/или визуальная индикация может быть удален, если криптографическая величина не соответствует второй криптографической величине или если криптографическая величина не может быть извлечена из потока данных. Это может быть полезно для обеспечения пользователя декодера и зрителя/слушателя потока данных информацией об аутентичности потока данных.
Согласно другой особенности описан поток данных, включающий криптографическую величину, генерируемую и вставляемую в соответствии со способами, описанными в настоящем патентном документе.
Согласно другой особенности описан кодер, действующий для кодирования потока данных, включающего ряд кадров данных. Кодер действует для выполнения этапов способа, описанных в настоящем патентном документе. В частности, кодер может включать процессор, действующий на группу из количества N последовательных кадров данных с целью формирования первого сообщения; где N больше единицы; для группирования первого сообщения с информацией о конфигурации с целью формирования второго сообщения; где информация о конфигурации включает информацию вне потока данных, такую как информация для рендеринга потока данных; для генерирования криптографической величины для второго сообщения; и для вставки криптографической величины в поток данных, следующий за N последовательными кадрами данных.
Согласно следующей особенности описан декодер, действующий для верификации потока данных, включающего ряд кадров данных и криптографическую величину, связанную с количеством N предшествующих последовательных кадров данных, где N больше единицы. Декодер действует для выполнения этапов способа, описанных в настоящем патентном документе. В частности, декодер может включать процессор, действующий для извлечения N последовательных кадров данных с целью формирования первого сообщения; для группирования первого сообщения с информацией о конфигурации с целью формирования второго сообщения; где информация о конфигурации включает информацию для рендеринга потока данных; для генерирования второй криптографической величины для второго сообщения; для извлечения криптографической величины из потока данных; и для сравнения криптографической величины со второй криптографической величиной.
Согласно следующей особенности описана программа, реализованная программно. Программа, реализованная программно, адаптирована для исполнения на процессоре и для выполнения этапов способа, описанных в настоящем патентном документе, при осуществлении на вычислительном устройстве.
Согласно следующей особенности описан носитель данных. Носитель данных включает программу, реализованную программно, которая адаптирована для исполнения на процессоре и для выполнения этапов способа, описанных в настоящем патентном документе, при осуществлении на вычислительном устройстве.
Согласно следующей особенности описан компьютерный программный продукт. Компьютерный программный продукт включает исполняемые команды для выполнения этапов способа, описанных в настоящем патентном документе, при осуществлении на компьютере.
Согласно следующей особенности описано дополнительное внешнее устройство, переносное электронное устройство (например, мобильный телефон, PDA, смартфон и т.д.) или компьютер (например, настольный компьютер, ноутбук и т.д.), предназначенный для декодирования потока данных. Поток данных может включать звуковой сигнал. Дополнительное внешнее устройство, предпочтительно, включает декодер, соответствующий особенностям, описанным в настоящем патентном документе.
Согласно следующей особенности описана система вещания, предназначенная для передачи потока данных. Поток данных может включать звуковой сигнал. Система вещания, предпочтительно, включает кодер, соответствующий особенностям, описанным в настоящем патентном документе.
Согласно другой особенности описан способ конкатенации первого и второго битовых потоков в точке конкатенации. Каждый из двух битовых потоков может включать ряд кадров данных и криптографическую величину, связанную с заданным количеством кадров данных. Первый битовый поток может включать криптографическую величину для каждых N1 последовательных кадров, в то время как второй битовый поток может включать криптографическую величину для каждых N2 последовательных кадров. Числа N1 и N2 могут быть идентичны, т.е. оба битовых потока имеют одинаковый период криптографического повторения, или числа N1 и N2 могут быть различны, т.е. в битовых потоках могут быть различны количества кадров, после которых включены криптографические величины.
Способ конкатенации включает этап генерирования конкатенированного битового потока из первого и второго битовых потоков, где конкатенированный битовый поток включает, по меньшей мере, часть из ряда кадров данных из первого и второго битовых потоков. Иными словами, второй битовый поток или часть второго битового потока прикрепляется в точке конкатенации к первому битовому потоку или части первого битового потока.
Конкатенированный битовый поток включает криптографические величины, генерируемые и вставляемые в соответствии со способами, описанными в настоящем патентном документе. Преимущественно, криптографические величины в конкатенированном битовом потоке гладко покрывают точку конкатенации так, чтобы в приемнике/декодере не было заметно прерывание аутентичности битового потока. Это может достигаться путем генерирования в явном виде новых криптографических величин для конкатенированного битового потока после точки конкатенации.
Новые криптографические величины могут генерироваться, по меньшей мере, для некоторого количества последовательных кадров в секции конкатенированного битового потока, начинающейся в точке конкатенации. В некоторых случаях криптографические величины второго битового потока могут быть использованы повторно и скопированы в конкатенированный битовый поток после секции, в которую включены новые криптографические величины. Такое повторное использование применяется, в частности, тогда, когда криптографическая величина для предыдущей группы кадров, включенная в первый кадр следующей группы, не учитывается при вычислении криптографической величины следующей группы, и группы обрабатываются независимо, т.е. изменения в криптографических величинах не распространяются от одной группы к следующей.
Генерирование криптографических величин в явном виде в соответствии со способами, описанными в настоящем патентном документе может быть практически полезным на границах между первым битовым потоком и вторым битовым потоком, т.е. для конечных кадров первого битового потока и для первых кадров второго битового потока, включенных в конкатенированный битовый поток. В целом, при конкатенации двух битовых потоков количество финальных кадров первого битового потока, как правило, меньше или равно N1, и/или количество кадров, взятых из второго битового потока перед включением первой криптографической величины, как правило, меньше или равно N2. Иными словами, точка конкатенации, как правило, не располагается на границах групп первого и второго битового потоков.
Согласно одной из особенностей способа конкатенации или соединения новая криптографическая величина генерируется для конечных кадров первого битового потока и вставляется в следующий кадр конкатенированного битового потока, который представляет собой первый кадр, взятый из второго битового потока. Эта новая криптографическая величина считается «завершающей» первый битовый поток. Новые криптографические величины могут затем генерироваться для второго битового потока и включаться в соответствующие положения конкатенированного битового потока. Это особенно пригодно в тех случаях, когда без добавочной криптографической величины, вставленной в первый кадр, взятый из второго битового потока, количество кадров между последней криптографической величиной, генерируемой для кадров из первого битового потока, и первой криптографической величиной, генерируемой для кадров из второго битового потока, будет превышать максимальное количество, допускаемое системой.
В случае, если точка конкатенации не выровнена с группами кадров первого и второго битовых потоков, способ конкатенации может генерировать криптографическую величину для смешанной группы, включающей кадры, взятые из первого и второго битовых потоков. Как уже было упомянуто, криптографические величины, как правило, включаются в кадр, следующий за группой кадров, используемой для вычисления соответствующей криптографической величины.
Согласно следующей особенности описано устройство для конкатенации и/или головной узел сети вещания. Указанное устройство для конкатенации и/или головной узел сети вещания действует для конкатенации первого и второго битовых потоков, каждый из которых включает ряд кадров данных и криптографические величины, связанные с заданным количеством кадров данных. Устройство может включать декодер, содержащий любую комбинацию характерных признаков, описанных в настоящем патентном документе. Указанный декодер может использоваться для декодирования финальных кадров первого битового потока, первых кадров второго битового потока и связанных с ними криптографических величин. Устройство для конкатенации и/или головной узел сети вещания также может включать кодер, содержащий любую комбинацию характерных признаков, описанных в настоящем патентном документе. Кодер может использоваться для кодирования конечных кадров первого битового потока и первых кадров второго битового потока. Кроме того, устройство для конкатенации и/или головной узел сети вещания может включать блок перенаправления, предназначенный для перенаправления тех кадров и связанных с ними криптографических величин первого и второго битового потоков, которые не декодируются и не кодируются. Иными словами, блок продвижения может просто копировать, или перенаправлять, или переносить, кадры и связанные криптографические величины в конкатенированный битовый поток.
Следует отметить, что устройство для конкатенации также может действовать для декодирования и кодирования полных потоков данных, т.е. для декодирования криптографических величин входящего потока данных и для генерирования криптографических величин для исходящего потока данных. Это может быть полезно для того, чтобы генерировать непрерывную взаимосвязанность битового потока посредством криптографических величин. Фактически, ряд битовых потоков может декодироваться и конкатенированный битовый поток, включающий части битовых потоков из ряда, может кодироваться посредством непрерывно взаимосвязанных криптографических величин. Таким образом, приемник конкатенированного битового потока будет воспринимать конкатенированный битовый поток как битовый поток, происходящий из единичного кодера, заслуживающего доверия.
Также следует отметить, что для цели декодирования и/или кодирования битовых потоков, включающих криптографические величины, устройство для конкатенации может не испытывать необходимости в том, чтобы быть осведомленным о базовом кодеке потока данных. Например, устройство для конкатенации не нуждается в возможности выполнения декодирования/кодирования HE-AAC для того, чтобы извлекать и/или генерировать криптографические величины для потоков данных. В некоторых ситуациях, например, тогда, когда новая криптографическая величина вставляется в кадр, который ранее не содержал криптографическую величину, декодирование и последующее повторное кодирование потока данных может быть необходимо для создания в битовом потоке свободного места для новой криптографической величины, в частности, для удовлетворения требований битового потока.
Следует отметить, что способы и системы, включающие предпочтительные варианты осуществления изобретения в том виде, как они описаны в настоящем патентном документе, могут использоваться автономно или в комбинации с другими способами и системами, описанными в настоящем документе. Кроме того, все особенности способов и систем, описанных в настоящей патентной заявке, могут произвольно комбинироваться. В частности, характерные признаки пунктов формулы изобретения могут произвольным образом комбинироваться друг с другом. Также следует отметить, что может изменяться порядок этапов способа.
ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Ниже изобретение разъясняется на примерах с отсылкой к сопроводительным графическим материалам, где
Фиг. 1 ― иллюстративный способ определения идентификатора в соответствии с изобретением;
Фиг. 2a и 2b ― схемы последовательности операций иллюстративного способа генерирования идентификатора и его вставки в кодере;
Фиг. 3 ― схема последовательности операций на иллюстративных этапах аутентификации и верификации, предпринимаемых в декодере;
Фиг. 4 ― иллюстративный вариант осуществления кодера и декодера;
Фиг. 5 ― пример использования идентификатора в системе вещания; и
Фиг. 6 и 7 ― примеры конкатенации битовых потоков с целью формирования конкатенированного битового потока.
Нижеследующие варианты осуществления изобретения описаны на примерах и не ограничивают объем притязаний настоящего патентного документа. Изобретение будет описываться в контексте AAC (Advanced Audio Coding), в частности MPEG-2 AAC и MPEG-4 AAC. Следует отметить, однако, что изобретение также применимо к другим схемам кодирования медиасигналов, в частности к схемам кодирования аудиосигналов, видеосигналов и/или других мультимедийных сигналов. Кроме того, изобретение применимо к устройству для конкатенации, создающему комбинированный битовый поток из ряда кодеров.
Фиг. 1 иллюстрирует битовый поток 100 и способ определения идентификатора для этого битового потока 100. Примерами такого битового потока являются кодированные битовые видео- и/или аудиопотоки с базовым кодеком AAC, HE-AAC (High Efficiency - Advanced Audio Coding), Dolby Pulse, MPEG-4 AVC/H.264, MPEG-2 Video или MPEG-4 Video. Указанные кодеки и их формат определен, например, в описании стандарта ISO/TEC 14496-3 ― для MPEG-4 AAC, в описании стандарта ISO/IEC 13818-7 ― для MPEG-2 AAC, в описании стандарта ISO/IEC 14496-10 ― для MPEG-4 AVC/H.264, в описании стандарта ISO/IEC 13818-2 ― для MPEG-2 Video и в описании стандарта ISO/IEC 14496-2 ― для MPEG-4 Video. Эти описания ссылкой включаются в настоящее описание. В указанных кодеках потоки данных организованы в т.н. кадры, где кадры включают определенное количество дискретных значений медиасигнала. Различные кодеки могут использовать различные количества дискретных значений, приходящихся на кадр. Типичными примерами являются количества 960, 1024 или 2048 дискретных значений на кадр.
Помимо фактических медиаданных кадры также могут включать т.н. метаданные, которые могут нести дополнительную управляющую информацию, например относящуюся к громкости или динамическому диапазону программы.
На фиг. 1 показана последовательность кадров 101, 102, 103, …, 106. Ось времени проходит слева направо, поэтому кадр 101 обрабатывается перед кадром 106. Как описано выше, каждый кадр может включать медиаданные и дополнительные метаданные. Структура каждого кадра и возможные поля, или элементы, данных, которые может включать кадр, определяются базовой схемой кодирования. Например, кадр MPEG-4 AAC или кадр MPEG-2 AAC может включать аудиоданные для периода времени, содержащего 1024 или 960 дискретных значений, связанную информацию и другие данные. Синтаксис и структура кадра определены в разделах 4.4 и 4.5 вышеупомянутого описания стандарта ISO/IEC 14496-3 ― для MPEG-4 AAC, и в разделах 6 и 8 вышеупомянутого описания стандарта ISO/IEC 13818-7 ― для MPEG-2 AAC. Эти разделы ссылкой включаются в настоящее описание.
Кадр MPEG-4 AAC, или MPEG-2 AAC, может включать различные синтаксические элементы, такие как:
Элемент single_channel_element(), обозначаемый аббревиатурой SCE, который представляет собой синтаксический элемент битового потока, содержащего кодированные данные для единичного аудиоканала.
Элемент channel_pair_element(), обозначаемый аббревиатурой CPE, который представляет собой синтаксический элемент полезной нагрузки битового потока, содержащий кодированные данные для пары каналов.
Элемент coupling_channel_element(), обозначаемый аббревиатурой CСE, который представляет собой синтаксический элемент, содержащий кодированные аудиоданные для связанного канала.
Элемент lfe_channel_element(), обозначаемый аббревиатурой LFE, который представляет собой синтаксический элемент, содержащий канал увеличения низкой частоты дискретизации.
Элемент program_config_element(), обозначаемый аббревиатурой РСЕ, который представляет собой синтаксический элемент, который содержит данные о конфигурации программы.
Элемент fill_element(), обозначаемый аббревиатурой FIL, который представляет собой синтаксический элемент, который содержит данные о заполнении.
Элемент data_stream_element(), обозначаемый аббревиатурой DSE, который представляет собой синтаксический элемент, который содержит вспомогательные данные.
Синтаксический элемент TERM, указывающий конец блока необработанных данных или кадра.
Указанные синтаксические элементы используются в пределах кадра или блока необработанных данных с целью определения медиаданных и связанных с ними управляющих данных. Например, два кадра монофонического звукового сигнала могут быть определены посредством синтаксических элементов<SCE><TERM><SCE><TERM>. Два кадра стереофонического звукового сигнала могут быть определены синтаксическими элементами<CPE><TERM><CPE><TERM>. Два кадра 5.1-канального звукового сигнала могут быть определены синтаксическими элементами<SCE><CPE><CPE><LFE><TERM><SCE><CPE><CPE><LFE><TERM>.
Предлагаемый способ группирует определенное количество N таких кадров и, таким образом, формирует группы кадров 111, 112 и 113. На фиг. 1 показана полная группа кадров 112, включающая N=5 кадров от 103 до 105. Пять кадров группы кадров 112 конкатенируются с целью формирования первого сообщения.
Хэш-код аутентификации сообщения (HMAC) для первого сообщения можно определить, используя криптографическую хэш-функцию H(.) и «секретный» ключ К, который, как правило, заполняется справа дополнительными нулями до размера блока хэш-функции H(.). Пусть знак || обозначает конкатенацию, знак 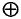 обозначает исключающее ИЛИ, а внешнее заполнение
обозначает исключающее ИЛИ, а внешнее заполнение 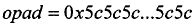 и внутреннее заполнение
и внутреннее заполнение 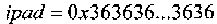 являются константами, имеющими длину размера блока хэш-функции H(.), тогда значение HMAC для первого сообщения можно записать как
являются константами, имеющими длину размера блока хэш-функции H(.), тогда значение HMAC для первого сообщения можно записать как
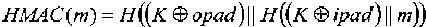 ,
,
где m - сообщение, также называемое в данном описании первым сообщением. Размер блока, используемый хэш-функциями MD5 или SHA-1, как правило, составляет 512 бит. Размер выходного сигнала операции HMAC является таким же, как у базовой хэш-функции, т.е. 128 бит - в случае MD5, и 160 бит - в случае SHA-1.
Значение HMAC для первого сообщения, т.е. значение HMAC конкатенированных кадров 103-105 группы кадров 112, можно использовать в качестве идентификатора группы кадров 112. Для того чтобы уменьшить длину идентификатора, значение НМАС можно усечь, например усечь до 16, 24, 32, 48 или 64 бит. Следует, однако, отметить, что указанная операция усечения, как правило, оказывает влияние на безопасность хэш-кода аутентификации сообщения. Поскольку идентификатор вставляется в поток данных, предлагаемый способ предпочтительно использует в качестве идентификатора усеченную версию значения HMAC.
Как показано на фиг. 1, идентификатор 122 группы кадров 112 вставляется в кадр следующей группы кадров 113. Предпочтительно, идентификатор 122 вставляется в первый кадр 106 следующей группы кадров 113. Сходным образом, идентификатор 121 был определен для предшествующей группы кадров 111 и вставлен в первый кадр 103 группы кадров 112.
Следует отметить, что идентификатор 122 группы кадров 112 можно вычислить на основе первого сообщения m, которое включает идентификатор 121 предыдущей группы кадров 111, или его можно вычислить на основе первого сообщения m, которое не включает идентификатор 121 предыдущей группы кадров 111. В последнем случае, информацию, относящуюся к идентификатору 121, необходимо будет удалить из первого сообщения m перед определением идентификатора 122. Может потребоваться обеспечение того, чтобы кодер и декодер применяли один и тот же способ для определения первого сообщения m. В предпочтительном варианте осуществления изобретения идентификатор 122 определяется на основе первого сообщения m, которое включает идентификатор 121 предыдущей группы кадров 111. Таким образом, идентификаторы могут быть непрерывно взаимосвязаны и, соответственно, можно создать взаимосвязанный битовый поток, который нельзя модифицировать, например, путем модификации или замены некоторых групп кадров битового потока. Как следствие, можно обеспечить аутентичность полного потока данных, или битового потока. C другой стороны, по-прежнему обеспечивается возможность повторной синхронизации приемника на частично поврежденном битовом потоке, даже в том случае, когда идентификаторы взаимосвязаны.
В предпочтительном варианте осуществления изобретения идентификатор помещается в единичный элемент data_stream_element(), обозначаемый аббревиатурой<DSE>и определяемый в стандарте ISO/IEC 14496-3, таблица 4.10 - для MPEG-4 AAC, или определяемый в стандарте ISO/IEC 13818-7, таблица 24 - для MPEG-2 AAC, которые ссылкой включаются в настоящее описание. Для облегчения синхронизации декодера, кадр ААС должен включать только один элемент data_stream_element()<DSE>, несущий идентификатор, поэтому декодер может определять длину группы кадров как расстояние между двумя принятыми идентификаторами. Иными словами, кадр ААС может включать несколько элементов data_stream_element() <DSE>, но должен включать только один элемент data_stream_element() <DSE>, включающий идентификатор. В предпочтительном варианте осуществления изобретения положение<DSE>находится в конце кадра ААС непосредственно перед элементом<TERM>.
Для того чтобы позволить быстрое извлечение идентификатора, может использоваться функция DSE по выравниванию по границе байта. C этой целью DSE, как правило, включает поле, или бит, который указывает на то, что данные, включаемые в DSE, являются выровненными по границе байта. Это указывает декодеру на то, что фактические данные DSE начинаются на позиции бита в начале байта.
Битовый поток, или поток данных, может включать несколько элементов <DSE>. Для того чтобы иметь возможность отличать один элемент <DSE>от другого, каждый элемент<DSE>, как правило, включает метку element_instance_tag, определяемую для MPEG-4 AAC в стандарте ISO/EEC 14496-3, раздел 4.5.2.1.1, и для MPEG-2 AAC - в стандарте ISO/IEC 13818-7, раздел 8.2.2, при этом оба эти раздела ссылкой включаются в настоящее описание. Следует отметить, что значение метки element_instance_tag элемента data_stream_element(), включающего идентификатор, не ограничивается какой-либо конкретной величиной, т.е. применяются общие правила стандартов ISO/IEC. Иными словами, предпочтительно не существует специальных правил для метки element_instance_tag в элементе<DSE>, содержащем идентификатор, помимо тех, которые установлены для MPEG-4 AAC в документе стандарта ISO/IEC 14496-3, и для MPEG-2 AAC - в документе стандарта ISO/IEC 13818-7.
По аналогии с приведенными выше примерами возможных потоков данных, поток данных для 2-канальной аудиопрограммы может включать синтаксические элементы<CPE><FIL><DSE><TERM><CPE><FIL><DSE><TERM>.... 2-канальная аудиопрограмма с SBR (репликацией спектральных полос) может включать синтаксические элементы<CPE><SBR(CPE)><FIL><DSE><TERM><CPE><SBR(CPE)><FE><DSE><TERM>..., где<SBR(CPE)>- синтаксический элемент, специфичный для SBR. 5.1-канальная аудиопрограмма может быть составлена из синтаксических элементов<SCE><CPE><CPE><LFE><FIL><DSE><TERM><SCE><CPE><CPE><LFE><FIL><DSE><TERM>....
В предпочтительном варианте осуществления изобретения поле идентификатора, размещаемое в элементе<DSE>, может включать поле identifier_sync и поле identifier_value. Поле identifier_sync может использоваться для того, чтобы позволить быструю идентификацию на основании того, что данный конкретный элемент<DSE>включает идентификатор. Например, кодер может устанавливать заранее заданное значение этого поля, например, двоичный выходной сигнал, для указания того, что элемент<DSE>включает поле идентификатора. Декодер может использовать это поле для проверки доступности значения идентификатора. Иными словами, декодер информируется о том, что принятый поток данных включает идентификатор, который может быть использован с целью вышеописанной аутентификации, верификации и, возможно, конфигурирования.
В предпочтительном варианте осуществления изобретения поле identifier_value включает значение идентификатора, которое определено так, как это описано в настоящем документе. Это поле включает количество бит, требуемое для идентификатора, т.е. для усеченной версии значения НМАС. Как описано выше, идентификатор, как правило, покрывает N кадров ААС, где N>1, и каждый N-й кадр ААС включает идентификатор, т.е. он включает элемент<DSE>, который включает элемент идентификатора так, как это описано выше. Как правило, решение о количестве N покрываемых кадров ААС принимает кодер. Декодер способен определить эту величину по выраженному в кадрах расстоянию между двумя кадрами ААС, включающими соответствующие идентификаторы.
Как описано выше, идентификатор также может использоваться для обеспечения того, чтобы декодер использовал корректные настройки конфигурации. С этой целью идентификатор может генерироваться на основе расширенного сообщения, которое включает не только конкатенацию N последовательных кадров, но также включает и данные о конфигурации. Иными словами, первое сообщение, которое включает N последовательных кадров, как описано выше, также может включать данные о конфигурации. Указанные данные о конфигурации могут включать индекс samplingFrequencyIndex, т.е. указатель базовой частоты дискретизации звукового сигнала, индекс channelConfiguration, т.е. указатель используемой конфигурации каналов, и флаг frameLengthFIag, т.е. указатель используемой длины кадра. Также возможны и другие параметры конфигурации.
Эти параметры, т.е. (базовая) частота дискретизации ААС, или «samplingFrequencyIndex», конфигурация каналов и указатель длины ААС-преобразования, или "frameLengthFIag", могут использоваться для формирования слова configuration_word. Слово configuration_word также может включать заполняющие биты для того, чтобы привести его к заранее заданному размеру.
В предпочтительном варианте осуществления изобретения параметры "samplingFrequencyIndex" и "channelConfiguration" имеют тот же смысл и значение, что и одноименные элементы в "AudioSpecificConfig", описанные в соответствующем описании стандарта ISO/IEC (например, в разделе 1.6.2.1 стандарта ISO/IEC 14496-3). Параметр "frameLengthFIag" имеет тот же смысл и значение, что и одноименный элемент в "GASpecificConfig", описанный в соответствующем описании стандарта ISO/IEC (например, в разделе 4.4.1 и таблице 4.1 стандарта ISO/IEC 14496-3).
Слово configuration_word и N кадров ААС конкатенируются, давая сообщение m, которое также может называться вторым сообщением и которое включает слово configuration_word в дополнение к первому сообщению, которое включает конкатенацию N кадров ААС:
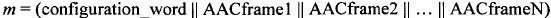 ;
;
где || обозначает конкатенацию. В приведенном выше примере слово configuration_word размещается перед первым сообщением. Следует отметить, что слово configuration_word также может размещаться и в других положениях, например в конце первого сообщения.
Аналогично описанному выше значение НМАС, например код HMAC-MD5, HMAC(m) по сообщению m вычисляется с использованием «секретного» ключа К. Ключ К может, например, представлять собой заданный код ASCII или любую другую секретную величину, а значение HMAC для сообщения m вычисляется с использованием вышеупомянутой формулы для НМАС.
Следует отметить, что значение HMAC для сообщения m может быть определено последовательно. Это означает, что на первом этапе может определяться значение НМАС для слова configuration_word. Это приводит к первому значению НМАС как исходному состоянию для определения значения НМАС для кадра 1 ААС. Выходным сигналом этой операции является второе значение НМАС для кадра 2 ААС, и т.д. В конечном счете, с использованием в качестве исходного состояния значения НМАС для кадра N-1 ААС определяется значение НМАС для кадра N ААС. Используя такое последовательное определение значения НМАС по всему сообщению m, т.е. по всей последовательности кадров и/или слову configuration_word, можно генерировать идентификатор без увеличения задержки, вносимой в битовый поток. Кроме того, требования к памяти для генерирования значения НМАС и/или идентификатора поддерживаются на низком уровне, поскольку необходимо хранение в памяти только текущего кадра битового потока и исходного состояния, т.е. 128-битной величины. Генерирование и хранение полного сообщения m не требуется.
Для того чтобы уменьшить непроизводительные издержки в битовом потоке, вызванные дополнительным идентификатором, значение НМАС усекается от 128 бит до уменьшенного количества бит путем отбрасывания наименее значимых бит. Например, значение НМАС "9el07d9d372bb6826bd81d3542a419d6" может быть усечено до "9el07d9d". Степень усечения, предпочтительно, выбирается как компромисс между безопасностью идентификатора и требуемыми непроизводительными издержками битовой скорости передачи данных. Возможные длины идентификатора могут, например, составлять 16, 24, 32, 48, 64, 80 или 96. Усеченное значение НМАС представляет собой идентификатор, который вставляется в поле identifier_value элемента DSE.
Ниже приводятся дополнительные подробности, относящиеся к процессу кодирования. Как уже упоминалось, именно кодер, как правило, принимает решение о количестве N кадров ААС, которые покрываются одним идентификатором. Например, может оказаться желательным обеспечить способность декодера синхронизироваться с длиной группы кадров в течение не более чем 1 секунды. Поскольку необходимо два идентификатора для того, чтобы декодер мог синхронизироваться с длиной группы кадров, которая задается количеством кадров между двумя кадрами, включающими идентификатор, необходимо обеспечить то, что декодер примет, по меньшей мере, два идентификатора в пределах требуемого интервала времени. Поэтому кодер должен выбрать значение N так, чтобы временное представление N кадров ААС не превышало или минимально превышало 0,5 секунд. Поскольку временное представление N кадров ААС зависит от выбранной (базовой) частоты дискретизации ААС, значение N, выбранное кодером, может изменяться в зависимости от выбранной (базовой) частоты дискретизации ААС.
Для того чтобы минимизировать непроизводительные издержки битовой скорости передачи данных, вносимые идентификатором, кодер может выбрать наибольшее значение N, удовлетворяющее ограничению, которое заключается в том, что временное представление N кадров ААС не должно превышать 0,5 секунд. В некоторых приложениях для временного представления N кадров ААС допустимо небольшое превышение 0,5 секунд. В этих приложениях кодер может выбирать значение N так, чтобы временное представление N кадров ААС было максимально возможно близким к 0,5 секунд, даже если это, в некоторых случаях, может приводить к временному представлению N кадров ААС, несколько превышающему 0,5 секунд. Непроизводительные издержки, которые вносятся передачей идентификатора, можно определить путем оценки соотношения между длиной элемента DSE, включающего идентификатор, и общей длиной группы кадров (в количестве бит).
Кроме того, рекомендуется выровнять ставку идентификатора с вставкой других конфигурационных элементов, таких как заголовок SBR. Это позволяет декодеру легко синхронизироваться с битовым потоком, а также позволяет принять все конфигурационные слова в ходе декодирования единичного кадра.
Следует отметить, что первый генерированный кадр ААС может содержать ложный идентификатор. Назначением первого идентификатора может являться передача декодеру сигнала о начале последовательности кадров ААС, включающих идентификаторы. Однако декодер может не оказаться в положении для выполнения аутентификации и верификации, поскольку идентификатор может не основываться на фактических медиаданных.
Как описывалось в отношении фиг. 1, первый вычисленный идентификатор покрывает кадры ААС от 1 до N и хранится в кадре N+1 ААС. Следующий идентификатор покрывает кадры ААС от N+1 до 2N и хранится в кадре 2N+1 ААС, и т.д.
Фиг. 2а иллюстрирует схему последовательности операций процесса кодирования. На этапе 201 кодер инициализируется путем снабжения некоторым количеством N кадров, заключающихся в группе кадров. Кроме того, предусматривается ключ К. На следующем этапе 202 N кадров в группе кадров конкатенируются с целью создания первого сообщения. Затем на этапе 203 первое сообщение конкатенируется со словом конфигурации, давая второе сообщение. На этапе 204 определяется идентификатор в виде усеченной версии значения НМАС, вычисленного по второму сообщению. Этот идентификатор помещается в первый кадр следующей группы кадров (этап 205). Наконец, на этапе 206 выполняется передача группы кадров. Следует отметить, что переданная группа кадров содержит идентификатор группы кадров, переданной перед ней. Этапы 202―206 повторяются до тех пор, пока не будет передан полный поток данных.
Как уже упоминалось, описанный выше процесс может выполняться последовательным итеративным способом. Это означает, что идентификатор может определяться покадрово без необходимости в предварительной конкатенации N кадров и слова configuration_word и выполнении вычисления НМАС на этом полностью конкатенированном сообщении. Этот процесс проиллюстрирован на фиг. 2b. Итеративная процедура инициализируется на этапе 207 путем задания исходного состояния. Исходное состояние может представлять собой значение НМАС для слова configuration_word, которое хранится в 128 битах памяти. Затем значение НМАС может определяться для первого из N кадров (этап 208). Результирующее значение НМАС хранится в 128 битах памяти (этап 209) и используется в качестве исходного состояния для вычисления значения НМАС второго кадра (этап 208). Этот процесс повторяется до тех пор, пока не будет определено значение НМАС для N-го кадра, где значение НМАС для N-1-го кадра берется из 128 бит памяти и используется в качестве исходного состояния (этап 208). Идентификатор определяется как усеченная версия значения НМАС для N-го кадра (этап 210). В качестве альтернативы этапу 206, каждый кадр может отправляться непосредственно после обработки с целью вычисления значения НМАС без буферизации всей группы кадров. Идентификатор затем добавляется к N+1-му кадру и отправляется с этим кадром. Таким образом, этот кадр представляет собой первый кадр, который используется для итеративного вычисления значения НМАС для следующих N кадров. При использовании этого процесса процесс кодирования может выполняться покадрово с низкой задержкой, низкой вычислительной сложностью и низкими требованиями к памяти.
Ниже приведены дополнительные подробности, относящиеся к процессу декодирования. Как правило, декодер начинает с допущения того, что поток, который необходимо декодировать, не включает имеющий силу идентификатор. Т.е. указатель наличия имеющего силу идентификатора в битовом медиапотоке изначально устанавливается в значение «ложь» и, как правило, будет установлен в значение «истина» только при первом успешном приеме имеющего силу идентификатора. Это может показываться на приемнике, например, на дополнительном внешнем устройстве, посредством визуального индикатора, такого как LED, который указывает пользователю на то, что принятый битовый поток является аутентифицированным и имеющим силу битовым потоком. Как следствие, идентификатор может использоваться для указания пользователю качества принятого потока данных.
С другой стороны, если указатель на декодере установлен в значение «истина», но для более чем Nmax кадров отсутствует обновление в отношении идентификатора в битовом потоке, указатель может быть установлен в значение «ложь». Иными словами, декодер может быть осведомлен о максимальном значении N, например, Nmax, которое не должно превышаться. Если декодер не обнаруживает имеющий силу идентификатор для более чем Nmax кадров, то это указывает декодеру на то, что принятый битовый поток больше не происходит из легального кодера или что принятый битовый поток, возможно, был изменен. Как следствие, декодер устанавливает соответствующий указатель в значение «ложь». Это может приводить к тому, что визуальный индикатор, например LED, как правило, возвращается в исходное состояние.
Процедура декодирования идентификатора проиллюстрирована на фиг. 3 и может быть описана следующим образом:
• На этапе 300 декодер запускается и сбрасывает флаг "ID Verified".
• Затем на этапе 301 инициализируется (128-битное) состояние внутренней памяти.
• На этапе 303 декодер ожидает приема кадра (этап 302) и проверяет принятый кадр на наличие идентификатора битового потока. Наличие идентификатора в кадре может быть обнаружено посредством описанного выше поля identifier_sync. На этапе 307, если идентификатор был обнаружен на этапе 304, декодер извлекает identifier_value из соответствующего поля в<DSE>.
• Затем на этапе 308 путем усечения значения НМАС, содержащегося в 128-битном состоянии, генерируется идентификатор верификации.
• Декодер продолжает работу, сравнивая на этапе 309 идентификатор битового потока с идентификатором верификации. Если определяется, что два ID не равны (этап 310), на этапе 311 флаг "ID Verified" сбрасывается, указывая на то, что битовый поток не происходит из кодера, заслуживающего доверия. В случае идентичных ID на этапе 312 устанавливается флаг "ID Verified", указывающий на то, что идентификатор верифицирован и что битовый поток считается имеющим силу, поскольку он приходит из кодера, заслуживающего доверия. В этом случае могут быть разблокированы дополнительные функции декодера, и/или пользователь может быть проинформирован о состоянии верификации битового потока. В альтернативном варианте, некоторые функции могут блокироваться, если определено, что битовый поток не происходит из кодера, заслуживающего доверия, и/или пользователь может быть соответствующим образом проинформирован.
• Процесс декодирования продолжается на этапе 313 путем инициализации 128-битного состояния внутренней памяти.
• Затем на этапе 314 вычисляется 128-битное значение НМАС для текущего кадра, и на этапе 315 128-битное состояние внутренней памяти обновляется в соответствии с вычисленным значением НМАС. Затем декодер возвращается на этап 302 для ожидания приема следующего кадра.
• Если в указанном кадре отсутствует идентификатор (что определяется на этапе 304) декодер переходит на этап 305, где декодер определяет, присутствовал ли идентификатор в одном из последних Nmax кадров.
• В случае, если идентификатор отсутствовал в одном из последних Nmax кадров, декодер на этапе 306 сбрасывает флаг "ID verified", поскольку принято максимальное количество кадров Nmax, прошедшее без идентификатора. Декодер затем возвращается к этапу 302 для ожидания следующего кадра.
• Если идентификатор присутствует в одном из последних Nmax кадров, что определяется на этапе 305, декодер переходит на этап 314 для вычисления 128-битного значения НМАС для текущего кадра.
Как описано выше, декодер может определять идентификатор верификации в ходе последовательного итеративного процесса. Это означает, что обрабатывается только текущий кадр и нет необходимости вначале конкатенировать набор кадров для определения идентификатора верификации. Соответственно, декодирование идентификатора может выполняться с низкой задержкой, низкой вычислительной сложностью и низкими требованиями к памяти.
На фиг. 4 изображен иллюстративный вариант осуществления кодера 400 и декодера 410 потока данных. Аналоговый поток данных 405, например аудиопоток, преобразовывается в цифровой поток данных 406 с использованием аналого-цифрового преобразователя 402. Цифровой поток данных 406 кодируется с использованием аудиокодера 403, например Dolby E, Dolby Digital, AAC, HE AAC, DTS или Dolby Pulse. Аудиокодер 403, как правило, сегментирует цифровой поток данных 406 в кадры звукового сигнала и осуществляет сжатие данных. Кроме того, аудиокодер 403 может выполнять добавление метаданных. Выходной сигнал аудиокодера 403 представляет собой поток данных 407, включающий ряд кадров звукового сигнала. Затем поток данных 407 входит в дополнительный кодер 404 кадров, который добавляет к потоку данных 407 идентификаторы, или криптографические величины. Кодер 404 кадров функционирует в соответствии с особенностями, описанными в настоящем патентном документе. Следует отметить, что идентификаторы, как правило, определяются и добавляются последовательно, и, таким образом, каждый кадр, приходящий из аудиокодера 403, непосредственно обрабатывается кодером 404 кадров. Предпочтительно, аудиокодер 403 и кодер 404 кадров образуют объединенный кодер 401, который может быть реализован на процессоре цифровой обработки сигналов. Таким образом, особенности кодирования звукового сигнала и особенности генерирования идентификатора могут влиять друг на друга. В частности, в ходе кодирования аудиопотока может потребоваться учет дополнительных непроизводительных издержек, вызванных идентификатором. Это означает, что доступная битовая скорость передачи данных для битового аудиопотока может быть уменьшена. Подобное взаимодействие между аудиокодером и генерированием идентификатора может быть использована для соответствия общей ширине полосы пропускания и/или ограничению битовой скорости передачи данных в некоторых схемах кодирования, например в HE-AAC.
Объединенный кодер 401 выводит поток данных 408, включающий ряд групп кадров и связанные с ними идентификаторы. Поток данных 408, как правило, подается в связанный декодер и/или приемник 410 с использованием различных средств передачи данных и/или носителей данных. Он достигает декодера 410 в виде потока данных 418, который мог быть изменен относительно потока данных 408. Поток данных 418 входит в декодер 414 кадров, который выполняет верификацию и аутентификацию потока данных 418 в соответствии со способами и системами, описанными в настоящем патентном документе. Декодер 414 кадров выводит поток данных 417, который, как правило, соответствует потоку данных 418 без идентификаторов и соответствующего поля данных или синтаксических элементов. Поток данных 417 декодируется в аудиодекодере 413, где он распаковывается и где удаляются добавленные метаданные. Как описано, выше, декодирование кадров, как правило, выполняется последовательным итеративным способом, и, таким образом, обработка выполняется покадрово.
Также следует отметить, что различные компоненты декодирования/приема могут группироваться с целью формирования объединенного декодера. Например, декодер 414 кадров и аудиодекодер 413 могут образовывать объединенный декодер/приемник 411, который может реализовываться на процессоре цифровой обработки сигналов. Как описано выше, это может быть полезным для того, чтобы позволить осуществлять взаимодействия между аудиодекодером и верификацией идентификатора. В конечном счете, объединенный декодер/приемник 411 выводит поток данных 416, который преобразовывается в аналоговый звуковой сигнал 415 с использованием цифроаналогового преобразователя 412.
Следует отметить, что в настоящем документе термин «кодер» может относиться к полному кодеру 400, объединенному кодеру 401 или к кодеру 404 кадров. Термин «декодер» может относиться к полному декодеру 410, объединенному декодеру 411 или к декодеру 414 кадров. С другой стороны, т.н. «ненадежные кодеры» представляют собой кодеры, которые вообще не генерируют идентификатор или не генерируют идентификатор в соответствии со способами, описанными в настоящем документе.
Фиг. 5 иллюстрирует иллюстративную систему 500 вещания, которая включает головной узел 504 вещания. Головной узел 504 также включает устройство для конкатенации, или средства конкатенации, который действует для комбинирования битовых потоков 501, 502, 503, происходящих из различных кодеров. В системе радиовещания отличающиеся битовые потоки 501, 502, 503 могут представлять собой битовые аудиопотоки, которые, как правило, кодируются различными аудиокодерами. Битовые потоки 501, 502, 503 состоят из ряда кадров, которые представлены по-разному заштрихованными блоками. В иллюстрируемом примере битовый поток 501 включает пять кадров, битовый поток 502 включает четыре кадра, и битовый поток 503 включает шесть кадров. Устройство для конкатенации и/или головной узел 504 действует для комбинирования битовых потоков с целью создания объединенного битового потока 505. Как показано в примере, это комбинирование может осуществляться путем прикрепления битового потока 501 к битовому потоку 503 и путем прикрепления битового потока 502 к битовому потоку 501. Однако, что также показано на фиг. 5, может потребоваться выбрать только некоторые части оригинальных битовых потоков 501, 502 и 503, например только части битовых аудиопотоков. Как таковой комбинированный битовый поток 505 включает только два кадра битового потока 503, следующие за ними три кадра битового потока 501 и следующие за ними два кадра битового потока 502.
Оригинальные битовые потоки 501, 502, 503 могут включать идентификаторы, т.е. битовые потоки 501, 502, 503 могут происходить из надежных кодеров. Каждый из идентификаторов может основываться на различном количестве N кадров. Без отклонения от общности можно предположить, что идентификаторы битовых потоков 501 и 503 были определены для группы кадров, включающей два кадра. С другой стороны, битовый поток 502 не происходит из надежного кодера и поэтому не включает идентификатор.
Желательно, чтобы устройство для конкатенации и/или головной узел 504 транслировал битовый поток 505, который также включал бы идентификатор, если входящие битовые потоки 501 и 503 происходят из надежного кодера. Указанный идентификатор должен отправляться в битовом потоке 505 для всех частей битового потока 505, которые происходят из надежного кодера. С другой стороны, части битового потока 505, которые не происходят из надежного кодера, т.е. части, взятые из битового потока 502, не должны включать идентификатор.
Для того чтобы достичь этой цели, устройство для конкатенации может действовать, выполняя декодирование и/или кодирование идентификатора. Как показано на фиг. 5, первые два кадра исходящего битового потока 505 происходят из битового потока 503. Если эти два кадра соответствуют группе кадров, то идентификатор этой группы кадров может размещаться в третьем кадре битового потока 505. Это размещение описано в отношении фиг. 1. Если, с другой стороны, два кадра принадлежат различным группам кадров, то головной узел 504 может действовать для
• проверки того, является ли битовый поток 503 происходящим из надежного кодера; и
• генерирования нового идентификатора для исходящих кадров битового потока 503, т.е. для первых двух кадров битового потока 505.
Число N, используемое для генерирования идентификатора на исходящем битовом потоке 505, необязательно должно быть равным числу N, используемому для генерирования идентификатора на исходящих битовых потоках 501 и 503. Это можно рассмотреть в контексте битового потока 501, для которого только три кадра включаются в исходящий битовый поток 505. Первый идентификатор может генерироваться для первых двух кадров, в то время как второй идентификатор может генерироваться для третьего кадра. Иными словами, N может быть равно двум для первых двух кадров, и N может быть равно единице для третьего кадра. Поэтому, в общем, можно утверждать, что N может изменяться в пределах битового потока 505. Это связано с тем, что N может определяться в декодере независимо. Предпочтительно, число N, используемое для исходящего битового потока 505 меньше или равно числу N, используемому для входящих битовых потоков 501 и 503.
Кроме того, следует отметить, что входящий битовый поток 502 не включает идентификатор, т.е. битовый поток 502 не происходит из надежного кодера. Соответственно, устройство для конкатенации и/или головной узел не предусматривает в битовом потоке 505 идентификатор для кадров, происходящих из битового потока 502. Как уже было описано выше, декодер, как правило, действует для обнаружения отсутствия идентификатора в битовом потоке 505. Если количество кадров, не включающих идентификатор, превышает заранее заданное максимальное количество Nmax, то декодер, как правило, будет обнаруживать, что битовый поток 505 больше не является происходящим из надежного кодера.
Как показано в примере по фиг. 5, битовый поток 505 слагается из частей, которые происходят из надежного кодера, и других частей, которые не происходят из надежного кодера. Соответственно, битовый поток 505 может включать части, которые включают имеющий силу идентификатор, и другие части, которые не включают имеющий силу идентификатор. Устройство для конкатенации и/или головной узел 504 может действовать для
• обнаружения входящих битовых потоков, включающих идентификатор;
• перенаправления битового потока, включающего идентификатор, как исходящего битового потока;
• аутентификации входящего битового потока на основе идентификатора; и
• кодирования битового потока посредством нового идентификатора.
Иными словами, устройство для конкатенации и/или головной узел 504 может включать функции кодера и/или декодера, описанные в настоящем патентном документе. Т.е. устройство для конкатенации и/или головной узел 504 может функционировать в качестве декодера при приеме входящего битового потока, и оно может функционировать в качестве кодера при генерировании исходящего битового потока. Кроме того, оно может действовать для перенаправления битового потока, включающего идентификатор, без выполнения аутентификации и повторного кодирования. Операция перенаправления может выполняться для непрерывной передачи одного и того же битового потока, в то время как декодирование и повторное кодирование, предпочтительно, могут использоваться на границах между битовыми потоками из различных кодеров. Используя операцию перенаправления, можно снизить вычислительную нагрузку на устройство для конкатенации и/или головной узел 504.
Следует отметить, что операция перенаправления может использоваться в тех случаях, когда идентификатор предшествующей группы кадров не оказывает влияния на значение идентификатора текущей группы кадров. В этих случаях группу кадров и связанный с ней идентификатор можно рассматривать как независимый логический объект, который может быть непосредственно перенаправлен в исходящий битовый поток. С другой стороны, если используются непрерывные взаимосвязанные идентификаторы, где идентификатор текущей группы кадров зависит от идентификатора предыдущей группы кадров, то устройство для конкатенации, предпочтительно, будет повторно кодировать весь битовый поток для того, чтобы генерировать для исходящего битового потока поток непрерывно взаимосвязанных идентификаторов. Это может гарантировать то, что неуполномоченная сторона не будет иметь возможность замены сегментов исходящего битового потока.
Следует отметить, что в большинстве случаев повторное кодирование устройством для конкатенации ограничивается только генерированием новых идентификаторов. Сам по себе битовый поток, т.е., в особенности, битовый поток кодирования звукового сигнала, как правило, не затрагивается. Соответственно, повторное кодирование битового потока может выполняться с низкой вычислительной сложностью. Однако если криптографическая величина вставляется в кадр, который предварительно не содержал криптографическую величину, может возникнуть необходимость в выполнении повторного кодирования звукового сигнала.
Фиг. 6 также иллюстрирует конкатенацию входящих битовых потоков 1―4 в исходящий конкатенированный битовый поток для предпочтительного варианта осуществления изобретения. В иллюстрируемом примере входящий битовый поток 1 образует группы из 4 кадров для генерирования криптографических величин. Угловые стрелки под битовым потоком иллюстрируют то, что криптографическая величина группы кадров вставляется в первый кадр следующей группы. Кадры, в которые вставлены криптографические величины, на фигуре заштрихованы. Группы кадров входящего битового потока 2 включают 6 кадров, и группы кадров входящего битового потока 3 включают 5 кадров. Входящий битовый поток 4 не содержит криптографических величин и не является верифицированным и заслуживающим доверия.
Вертикальные линии на фигуре указывают точки конкатенации. Как видно из фигуры, исходящий битовый поток включает первую секцию I, соответствующую входящему битовому потоку 1, вторую секцию II, соответствующую входящему битовому потоку 2, третью секцию III, соответствующую входящему битовому потоку 3, и четвертую секцию IV, соответствующую входящему битовому потоку 4, где секции конкатенированы в точках конкатенации. Перед первой точкой конкатенации входящий битовый поток 1, включающий криптографические величины, может быть скопирован в конкатенированный битовый поток. Однако первая криптографическая величина в секции II нуждается в повторном вычислении, поскольку из-за конкатенации она относится к иным кадрам данных, чем соответствующая криптографическая величина битового потока 2. Подробнее, эта криптографическая величина основывается на 5 кадрах: одном, принадлежащем входящему битовому потоку 1 (перед точкой конкатенации), и четырех ― принадлежащих входящему потоку 2 (после точки конкатенации). Повторное вычисление криптографических величин указано стрелками над битовым потоком и изменением штриховки. По причине распространения изменения в первой повторно вычисленной криптографической величине на конкатенированный битовый поток, следующие криптографические величины битового потока 2 также должны вычисляться повторно.
Во второй точке конкатенации выбранный битовый поток изменяется от 2 к 3. Криптографическая величина первого кадра битового потока III повторно вычисляется на основе предыдущих 6 кадров битового потока 2. В следующей точке конкатенации выбирается ненадежный битовый поток 4, и в секцию IV конкатенированного потока криптографические величины не вставляются. В альтернативном варианте, криптографическая величина может генерироваться для конечных кадров битового потока 3, скопированного в конкатенированный битовый поток, для того чтобы правильно указывать окончание заслуживающей доверия секции конкатенированного битового потока. Эта дополнительная криптографическая величина, предпочтительно, вставляется в первый кадр секции IV, что показано на фигуре пунктирной окружностью. В зависимости от требований битовой скорости передачи данных может возникать необходимость повторного кодирования этого кадра с целью создания свободного места для вставки дополнительной криптографической величины.
Фиг. 7 иллюстрирует другой пример конкатенации входящих битовых потоков 1 и 2 в исходящий битовый поток. Здесь точка конкатенации находится в первом битовом потоке прямо перед кадром, несущим криптографическую величину, и во втором битовом потоке ― сразу после кадра, несущего криптографическую величину. Если взять положения криптографических величин из первого и второго битовых потоков, то в результате в конкатенированном битовом потоке может возникнуть большой разрыв между криптографическими величинами. Расстояние между криптографическими величинами в данной секции конкатенированного битового потока может превысить максимальное значение Nmax, приемлемое для декодера, без указания потери доверия в битовом потоке. Поэтому предпочтительной является вставка дополнительной криптографической величины в точке конкатенации, например, в первый кадр второго битового потока, и, таким образом, количество кадров в группах не будет превышать Nmax. И снова, в зависимости от требований битовой скорости передачи данных, может возникнуть необходимость в повторном кодировании этого кадра с целью создания свободного места для вставки в битовый поток дополнительной криптографической величины. Следует отметить, что криптографическая величина в данном случае может быть скопирована из первого кадра битового потока 1 после точки конкатенации, поскольку дополнительная криптографическая величина в конкатенированном битовом потоке относится к тем же 6 кадрам битового потока 1. Содержание данных кадра, в который включается дополнительная криптографическая величина, однако, принадлежит битовому потоку 2 (точнее, оно соответствует первому кадру битового потока 2 после точки конкатенации).
Настоящий документ описывает способ и систему, которые позволяют вводить идентификатор, или криптографическую величину, в поток данных. Идентификатор может использоваться для аутентификации и верификации потока данных. Кроме того, идентификатор может использоваться для обеспечения правильной настройки конфигурации декодера для потока данных, который воспроизводится или обрабатывается. В частности, способ и система добавляют к битовому потоку HE AAC дополнительные данные, т.е. идентификатор, который аутентифицирует этот битовый поток как происходящий из легального кодера или передатчика. Эта аутентификация может указывать приемнику на то, что битовый поток HE AAC придерживается определенной спецификации и/или определенного стандарта качества. Предпочтительно, идентификатор получается путем вычисления HMAC-MD5.
Способ и система могут использоваться для аутентификации мультимедийных файлов и мультимедийных потоков, а также они могут обнаруживать конкатенацию нескольких защищенных потоков без разрыва аутентификации в целом. Это означает, что на соответствие проверяется не только полный поток, но и набор последовательных кадров. Эта проверка поддерживает типичные сценарии вещания, т.е. т.н. «конкатенацию», где часто для создания фактического выходного потока устройство переключается между различными кодерами битового потока. Кроме того, способ и система могут также использоваться для защиты внутриполосной и внешнеполосной информации, где внутриполосная информация, как правило, включает медиаданные и связанные с ними метаданные, а внешнеполосная информация, как правило, включает данные о конфигурации. Таким образом, способ и система позволяют управлять и/или обнаруживать корректное воспроизведение и/или декодирование мультимедийного потока.
Способ и система, описанные в настоящем документе, могут быть реализованы как программное обеспечение, встроенное программное обеспечение и/или аппаратное обеспечение. Некоторые компоненты могут быть реализованы, например, как программное обеспечение, запускаемое на процессоре цифровой обработки сигналов или микропроцессоре. Другие компоненты могут быть реализованы, например, как аппаратное обеспечение или как специализированные интегральные схемы. Сигналы, заключаемые в описанных способах и системах, могут храниться на носителях, таких как оперативная память или оптические носители данных. Они могут передаваться по сетям, таким как радиосети, спутниковые сети, беспроводные сети, или проводные сети, например Интернет. Типичными устройствами, использующими способ и систему, описанные в настоящем документе, являются дополнительные внешние устройства или другое оборудование на территории пользователя, которое декодирует звуковые сигналы. На стороне кодирования способ и система могут использоваться на вещательных станциях, например в аудио- и видеосистемах головных узлов вещания.
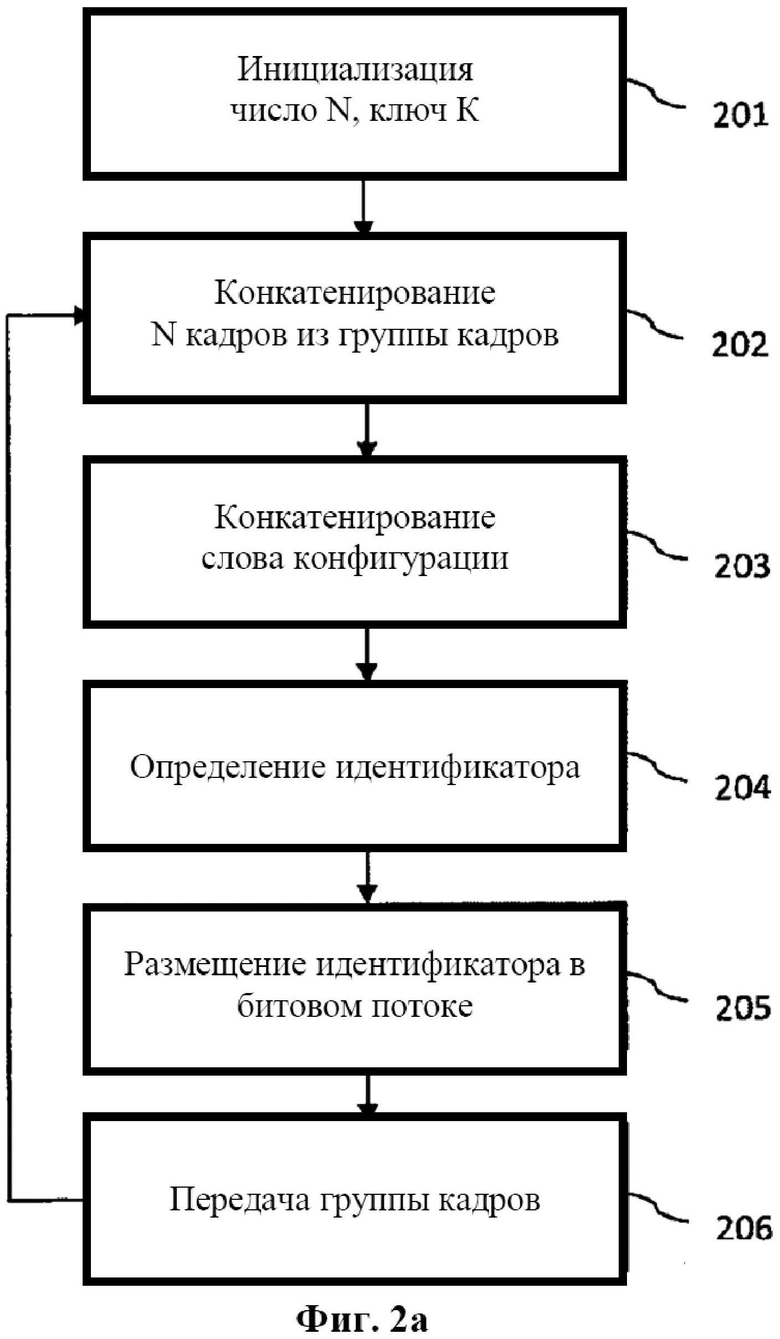
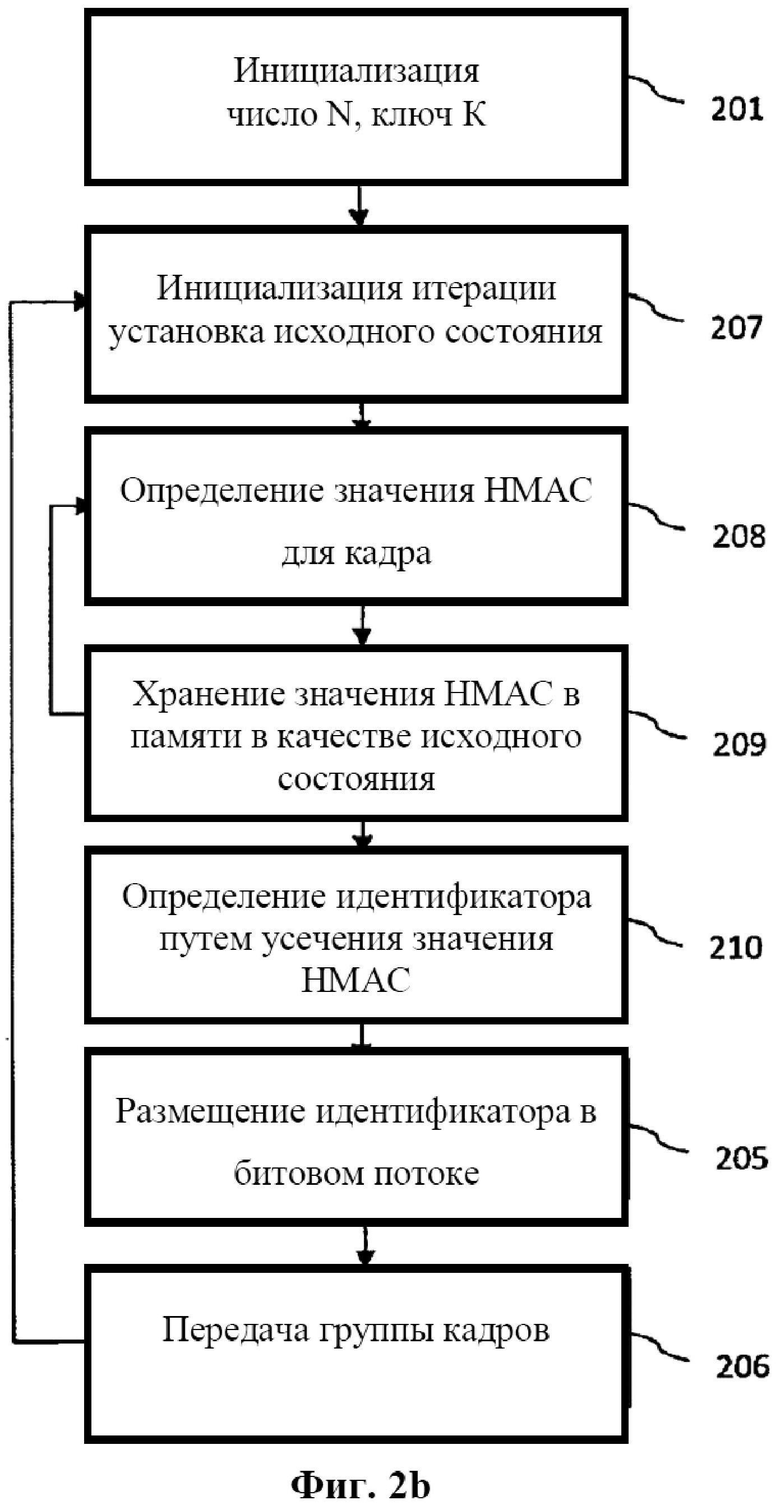
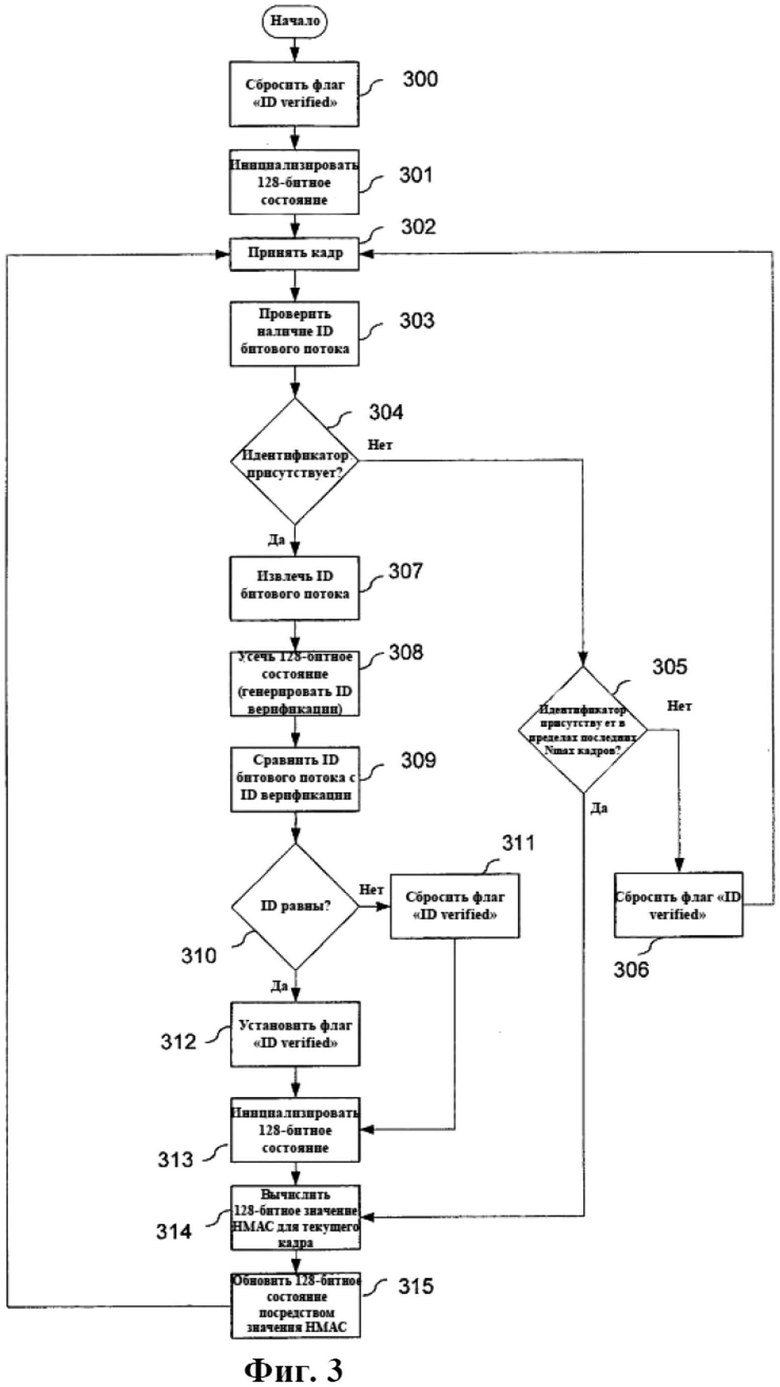
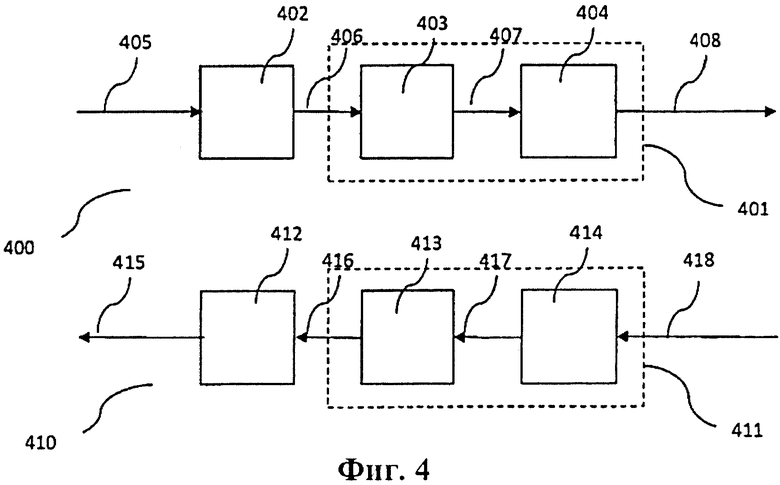
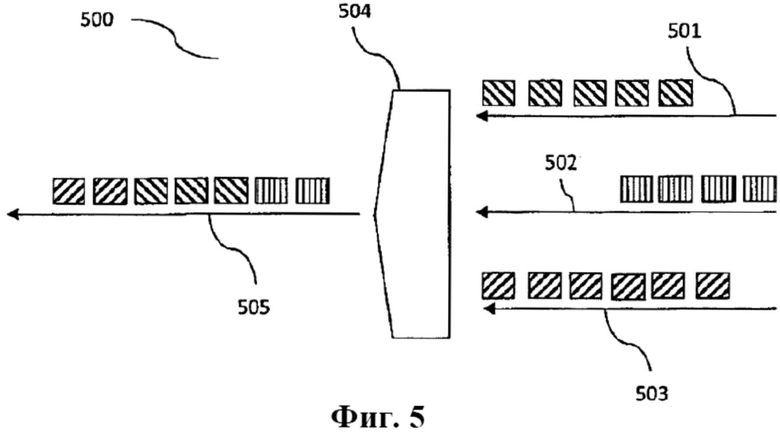
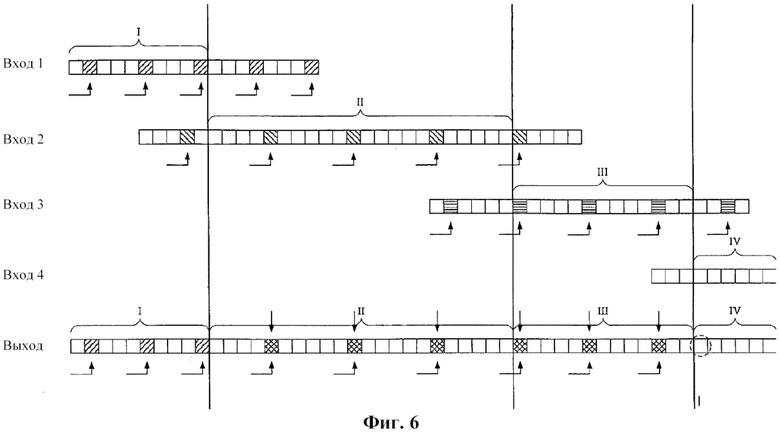
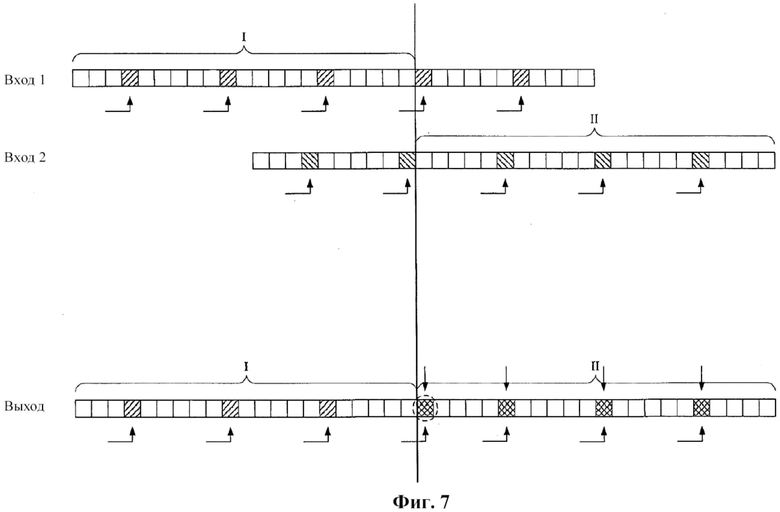
Настоящее изобретение относится к технологиям аутентификации потоков данных, а именно к вставке идентификаторов в такой поток данных, как битовый поток Dolby Pulse, AAC или HE AAC, и к аутентификации и верификации потока данных на основе указанных идентификаторов. Технический результат заключается в обеспечении способности делать различие между потоком данных, или битовым потоком, или битовым потоком, который генерируется соответствующим кодером Dolby Pulse, и потоком данных, или битовым потоком, который генерируется любым произвольным кодером, совместимым с HE-AACv2. Технический результат достигается за счет создания способа и системы для декодирования потока данных, включающего ряд кадров данных, где способ включает этап генерирования криптографической величины для блока из N последовательных кадров данных и информации о конфигурации, отличающийся тем, что информация о конфигурации включает информацию для рендеринга потока данных; затем способ вставляет криптографическую величину в поток данных, следующий за N последовательными кадрами данных. 12 н. и 26 з.п. ф-лы, 8 ил.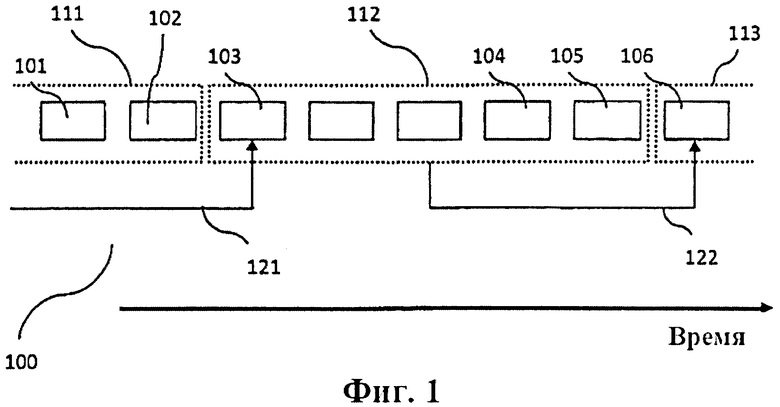
1. Способ кодирования потока данных, включающего ряд кадров данных, где способ включает этапы, на которых
- генерируют криптографическую величину для блока из N последовательных кадров данных из ряда кадров данных и информации о конфигурации с использованием криптографической хэш-функции; где информация о конфигурации включает информацию для рендеринга потока данных; и
- осуществляют вставку криптографической величины в кадр потока данных, следующий за N последовательными кадрами данных; и
- осуществляют генерирование промежуточной криптографической величины для каждого из N последовательных кадров блока с использованием исходного состояния; где исходное состояние представляет собой промежуточную криптографическую величину предыдущего кадра блока; и где исходное состояние первого кадра блока представляет собой промежуточную криптографическую величину для информации о конфигурации, и где криптографическая величина представляет собой промежуточную криптографическую величину N-го кадра блока.
2. Способ по п. 1, отличающийся тем, что криптографическую величину вставляют в элемент <DSE> потока данных; где элемент <DSE> потока данных представляет собой синтаксический элемент кадра потока данных; и где поток данных представляет собой поток MPEG4-AAC или MPEG2-AAC.
3. Способ по п. 1, отличающийся тем, что количество кадров N больше единицы.
4. Способ по п. 1, отличающийся тем, что кадры данных представляют собой видео- или аудиокадры.
5. Способ по п. 1, отличающийся тем, что кадры данных представляют собой кадры AAC или HE-AAC.
6. Способ по п. 1, отличающийся тем, что информация о конфигурации включает, по меньшей мере, один из следующих указателей:
- указатель частоты дискретизации;
- указатель конфигурации каналов системы кодирования звукового сигнала;
- указатель количества дискретных значений в кадре данных.
7. Способ по п. 1, отличающийся тем, что криптографическую величину генерируют с использованием ключевой величины.
8. Способ по п. 7, отличающийся тем, что этап генерирования криптографической величины включает
- вычисление значения HMAC-MD5 для блока из N последовательных кадров данных и информации о конфигурации.
9. Способ по п. 8, отличающийся тем, что этап генерирования криптографической величины включает
- усечение значения HMAC-MD5 для получения криптографической величины.
10. Способ по п. 9, отличающийся тем, что значение HMAC-MD5 усекается до 16, 24, 32, 48, 64, 80, 96 или 112 бит.
11. Способ по п.1, отличающийся тем, что криптографическую величину для блока из N последовательных кадров данных вставляют в следующий кадр данных потока данных, следующий за блоком из N последовательных кадров данных.
12. Способ по п. 1, отличающийся тем, что дополнительно включает этап, на котором
- вставляют указатель синхронизации после блока из N последовательных кадров данных, где указатель синхронизации указывает на то, что криптографическая величина была вставлена.
13. Способ по п. 1, отличающийся тем, что элемент <DSE> потока данных вставляют в конец кадра перед элементом <TERM>.
14. Способ по п. 1, отличающийся тем, что содержимое элемента <DSE> потока данных выровнено по границе байта потока данных.
15. Способ по п. 1, отличающийся тем, что этапы генерирования и вставки криптографической величины повторяют для ряда блоков из N последовательных кадров данных.
16. Способ по п. 1, отличающийся тем, что включает этап, на котором
- выбирают N таким образом, чтобы блок из N последовательных кадров максимально возможно близко покрывал заранее определенную длительность соответствующего сигнала при воспроизведении в соответствующей конфигурации.
17. Способ по п. 16, отличающийся тем, что включает этап, на котором
- выбирают N таким образом, чтобы заранее определенная длительность не была превышена.
18. Способ по одному из пп.16 или 17, отличающийся тем, что заранее определенная длительность составляет 0,5 секунд.
19. Способ по п.4, отличающийся тем, что дополнительно включает этап, на котором
- осуществляют взаимодействие с видео- и/или аудиокодером потока данных.
20. Способ по п. 19,отличающийся тем, что на этапе взаимодействия с видео- и/или аудиокодером потока данных осуществляют
- установку для видео- и/или аудиокодера такой максимальной битовой скорости передачи данных, чтобы указанная битовая скорость передачи данных для потока данных, включающего криптографическую величину, не превышала заранее определенное значение.
21. Способ декодирования для верификации потока данных в декодере, где поток данных включает ряд кадров данных и криптографическую величину, связанную с блоком из N последовательных кадров данных, где способ включает этапы, на которых
- генерируют вторую криптографическую величину для блока из N последовательных кадров данных и информации о конфигурации с использованием криптографической хэш-функции; где информация о конфигурации включает информацию для рендеринга данных; где генерирование второй криптографической величины включает генерирование промежуточной криптографической величины для каждого из N последовательных кадров с использованием исходного состояния; где исходное состояние представляет собой промежуточную вторую криптографическую величину предыдущего кадра блока; где исходное состояние первого кадра блока представляет собой промежуточную вторую криптографическую величину для информации о конфигурации; где вторая криптографическая величина представляет собой промежуточную криптографическую величину N-го кадра блока;
- извлекают криптографическую величину из потока данных; и
- сравнивают криптографическую величину со второй криптографической величиной для верификации потока данных.
22. Способ по п. 21, отличающийся тем, что поток данных представляет собой поток MPEG4-AAC или MPEG2-AAC; где криптографическая величина извлекается из элемента <DSE> потока данных; и где элемент <DSE> потока данных представляет собой синтаксический элемент кадра потока данных.
23. Способ по п. 21, отличающийся тем, что поток данных включает ряд блоков из N последовательных кадров данных и связанных с ними криптографических величин, и где способ дополнительно включает этап, на котором
- определяют число N как количества кадров между двумя последовательными криптографическими величинами.
24. Способ по п. 21, отличающийся тем, что криптографическую величину генерируют в соответствующем кодере из N последовательных кадров данных и информации о конфигурации согласно способу, который соответствует способу, используемому для генерирования второй криптографической величины.
25. Способ по п. 24, отличающийся тем, что
- криптографическую величину и вторую криптографическую величину генерируют с использованием уникального ключевого значения и уникальной криптографической хэш-функции.
26. Способ по одному из п.п. 21-25, отличающийся тем, что дополнительно включает этапы, на которых
- устанавливают флаг в случае, когда криптографическая величина соответствует второй криптографической величине; и
- обеспечивают визуальную индикацию, если флаг установлен.
27. Способ по п. 21, отличающийся тем, что дополнительно включает этап, на котором
- осуществляют сброс флага, если криптографическая величина не соответствует второй криптографической величине или если криптографическая величина не может быть извлечена из потока данных.
28. Кодер для кодирования потока данных, включающего ряд кадров данных, где кодер содержит процессор, действующий для:
- генерирования криптографической величины для блока из N последовательных кадров данных из ряда кадров данных и информации о конфигурации с использованием криптографической хэш-функции; где информация о конфигурации включает информацию для рендеринга потока данных;
- вставки криптографической величины в кадр потока данных, следующий за N последовательными кадрами данных; и
- генерирования промежуточной криптографической величины для каждого из N последовательных кадров блока с использованием исходного состояния; где исходное состояние представляет собой промежуточную криптографическую величину предыдущего кадра блока; и где исходное состояние первого кадра блока представляет собой промежуточную криптографическую величину для информации о конфигурации, и где криптографическая величина представляет собой промежуточную криптографическую величину N-го кадра блока.
29. Декодер для верификации потока данных, включающего ряд кадров данных и криптографическую величину, связанную с блоком из N последовательных кадров данных, где декодер содержит процессор, действующий для:
- генерирования второй криптографической величины для блока из N последовательных кадров данных и информации о конфигурации с использованием криптографической хэш-функции; где информация о конфигурации включает информацию для рендеринга данных; где генерирование второй криптографической величины включает генерирование промежуточной криптографической величины для каждого из N последовательных кадров с использованием исходного состояния; где исходное состояние представляет собой промежуточную вторую криптографическую величину предыдущего кадра блока; где исходное состояние первого кадра блока представляет собой промежуточную вторую криптографическую величину для информации о конфигурации; где вторая криптографическая величина представляет собой промежуточную криптографическую величину N-го кадра блока;
- извлечения криптографической величины из кадра потока данных; и
- сравнения криптографической величины со второй криптографической величиной для верификации потока данных.
30. Носитель данных, который включает программу, реализованную программно, адаптированную для исполнения на процессоре и для выполнения этапов способа по одному из пп. 1-20 при осуществлении на вычислительном устройстве.
31. Носитель данных, который включает программу, реализованную программно, адаптированную для исполнения на процессоре и для выполнения этапов способа по одному из пп. 21-27 при осуществлении на вычислительном устройстве.
32. Внешнее дополнительное устройство, предназначенное для декодирования принятого потока данных, включающего звуковой сигнал, где внешнее дополнительное устройство включает декодер по п. 29, предназначенный для верификации принятого потока данных.
33. Переносное электронное устройство, предназначенное для декодирования принятого потока данных, включающего звуковой сигнал, где переносное электронное устройство включает декодер по п. 29, предназначенный для верификации принятого потока данных.
34. Компьютер, предназначенный для декодирования принятого потока данных, включающего звуковой сигнал; где компьютер включает декодер по п. 29, предназначенный для верификации принятого потока данных.
35. Система вещания, предназначенная для передачи потока данных, включающего звуковой сигнал; где система вещания включает кодер по п. 28.
36. Способ конкатенации первого и второго битовых потоков, каждый из которых включает ряд кадров данных и криптографическую величину, связанную с заданным количеством кадров данных, где способ включает этап, на котором
- генерируют конкатенированный битовый поток из первого и второго битовых потоков, где конкатенированный битовый поток включает, по меньшей мере, часть ряда кадров данных из первого и второго битовых потоков и включает криптографическую величину, генерируемую и вставляемую в соответствии со способом по одному из пп. 1-20.
37. Устройство для конкатенации, действующее для конкатенации первого и второго битовых потоков, каждый из которых включает ряд кадров данных и криптографические величины, связанные с заданным количеством кадров данных, где устройство для конкатенации содержит
- кодер по п. 28, предназначенный для кодирования последних кадров первого битового потока и первых кадров второго битового потока.
38. Устройство для конкатенации по п. 37, отличающееся тем, что дополнительно содержит:
- декодер по п. 29, предназначенный для верификации последних кадров первого битового потока, первых кадров второго битового потока и связанных с ними криптографических величин; и
блок управления, который разблокирует кодер для вставки криптографических величин в конкатенированный битовый поток только в том случае, если соответствующий первый и второй битовые потоки аутентифицированы.
| СПОСОБЫ И СИСТЕМЫ ДЛЯ КРИПТОГРАФИЧЕСКОЙ ЗАЩИТЫ ОХРАНЯЕМОГО СОДЕРЖИМОГО | 2002 |
|
RU2308077C2 |
| ОБНАРУЖЕНИЕ ВОДЯНОГО ЗНАКА | 2005 |
|
RU2351013C2 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ очистки сернокислого электролита меднения | 1989 |
|
SU1652383A1 |

