Изобретение относится к решениям в области конверсии (преобразования) первых данных, имеющих первую структуру, во вторые данные, имеющие вторую структуру. В частности, заявленная группа изобретений относится к способу конверсии данных, устройству конверсии данных и системе конверсии данных, причем первые данные имеют первую табличную структуру, а вторые данные имеют вторую табличную структуру.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известны различные способы выполнения конверсии для различных структур данных.
Известен источник WO 2005/076155 А2, G06F 17/30, 18.08.2005, который описывает систему обработки данных, имеющую графический пользовательский интерфейс, которая позволяет преобразовать данные, имеющие первую структуру, в данные, имеющие вторую структуру.
Недостатком данного решения является то, что оно описывает систему, в которой осуществляется преобразование данных, не применимое для преобразования именно различных структур табличных данных, и не обеспечивает достаточной точности преобразования в случае несанкционированного воздействия на исходные данные.
Известны также различные конвертеры документов формата MS Excel в формат, поддерживаемый различными базами данных в зависимости от распознаваемого ими расширения (например, Конвертер данных MS Excel в АБДД Титул-2005,
http://www.titul2005.ru/imaqes/titulimg/manuals/Konverter iz Excel v BD Titul-2005.pdf). Однако данные приложения не позволяют достаточно широко применять конверсию данных, поскольку привязаны, как правило, к одному или нескольким конкретным форматам, а также не обеспечивают достаточной точности преобразования данных в случае несанкционированного воздействия на исходные данные
Известны также различные способы применения процедуры мэппинга, которая позволяет отображать позиции, содержащиеся в структуре одного каталога (исходного каталога), в структуру другого каталога (целевого каталога). Такие решения, например, раскрываются в источнике US 2006/0184539 А1, G06F 17/30, 17.08.2006, который описывает способ создания XBRL Instance Document, в котором один или более атрибутов XBRL таксономии ассоциированы с одним или более атрибутом бизнес-документа (в частности, документа MS Excel). Создание XBRL Instance Document осуществляется путем конверсии данных из исходной структуры в целевую структуру при помощи переноса данных из соответствующих ячеек исходной структуры в назначенные соответствующие ячейки конечной структуры.
Недостатком такого решения является то, что получаемый в результате конверсии документ может быть неточно отображен, за счет того что на стадии подготовки бизнес-документов для последующего извлечения их преобразования в ячейки табличной структуры бизнес-документов могут быть внесены неправомерные и недобросовестные изменения, нарушающие структуру таксономии при генерировании конечного документа.
Известно также решение, разработанное компанией Oracle, в частности, для управления созданием XBRL таксономии
(http://docs.oracle.com/cd/E17236 01/epm.1112/disclosure mgmt admin.pdf), данное решение также, как и предыдущее известное решение, описывает применения мэппинга для реализации конверсии формата данных, в частности MS Excel, в формат данных XBRL.
Однако также, как и предыдущее известное решение, данное решение не обеспечивает достаточной защищенности целевой структуры данных от несанкционированного воздействия на структуру данных исходного документа, что приводит к недостаточно точному, часто не пригодному результату конверсии.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Таким образом, задачей настоящего изобретения является обеспечение способа, устройства и системы, которые позволили бы с высокой точностью осуществлять конверсию данных, имеющих первую табличную структуру данных, в данные, имеющие вторую табличную структуру данных. Другой задачей настоящего изобретения является обеспечение способа, устройства и системы, которые бы обеспечили защищенность процедуры конверсии данных от воздействия на исходные данные.
Техническим результатом, на которое направлено заявленное решение, является повышение точности конверсии, а также обеспечение возможности применения данного способа для множества различных структур данных.
Варианты осуществления настоящего изобретения относятся к способам, устройствам, системам и машиночитаемому носителю данных для конверсии (преобразования) данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, при выполнении последовательных этапов, на которых:
1) идентифицируют данные, имеющие первую табличную структуру;
2) идентифицируют область обхода данных, имеющих первую табличную структуру;
3) совершают проход для каждой ячейки данных из упомянутой области обхода данных, при этом выполняются этапы, на которых:
4) формируют во внутренней базе данных для каждой ячейки данных буфер для идентифицированного контекста;
5) идентифицируют контекст для первой ячейки данных, для которой был совершен проход, причем до начала прохода для следующей ячейки данных идентифицированный контекст записывают в упомянутый буфер, причем с началом прохода для упомянутой следующей ячейки данных переносят идентифицированный для упомянутой первой ячейки данных контекст в упомянутый буфер для следующей ячейки данных;
6) идентифицируют контекст для упомянутой следующей ячейки данных, причем в случае когда идентифицированный контекст для данной ячейки отличается от упомянутого идентифицированного контекста, записанного в упомянутый буфер для данной ячейки данных, то идентифицированный контекст для данной ячейки данных заменяет идентифицированный контекст в буфере данной ячейки данных, причем над ним совершаются действия как над идентифицированным контекстом, указанные на этапе 5);
7) итеративно выполняют этапы 5) и 6) до тех пор, пока не будет совершен проход для каждой упомянутой ячейки данных из упомянутой области данных;
8) сериализуют полученную базу данных во внутренний формат данных XML;
9) применяют к полученному после процесса сериализации файлу XML шаблон таксономии, причем шаблон таксономии выбирается в зависимости от второй табличной структуры данных;
10) осуществляют конверсию полученного файла XML в данные, имеющие вторую табличную структуру, в соответствии с примененным к нему шаблоном таксономии.
Данная сущность предоставлена для того, чтобы представить ряд концепций в упрощенной форме, которые далее описываются в подробном описании. Данная сущность не предназначена для того, чтобы определить ключевые признаки или существенные признаки заявленного объекта изобретения, а также не предназначена для того, чтобы ее использовали в качестве вспомогательного средства при определении объема заявленного объекта изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Иллюстративные варианты осуществления настоящего изобретения описываются далее подробно со ссылкой на прилагаемые чертежи, которые включены в данный документ посредством ссылки и на которых:
фиг.1, 2 графически изображают примерный способ конверсии данных, имеющих первую структуру, в данные, имеющие вторую структуру, в соответствии с одним вариантом осуществления изобретения;
фиг.3 графически изображает примерное вычислительное устройство, пригодное для осуществления вариантов осуществления настоящего изобретения;
фиг.4 графически изображает примерную систему, пригодную для осуществления вариантов осуществления настоящего изобретения.
РАСКРЫТИЕ АСПЕКТОВ ИЗОБРЕТЕНИЯ
Объект изобретения согласно вариантам осуществления настоящего изобретения описан с его особенностями в данном документе для соответствия предусмотренным требованиям. Тем не менее само описание не предназначено для ограничения объема данного патента. Скорее, следует исходить из того, что заявленный объект изобретения также может быть осуществлен другими способами таким образом, что будет включать в себя отличающиеся этапы или комбинации этапов, аналогичных этапам, описанным в данном документе, в сочетании с другими существующими и будущими технологиями.
В первом аспекте настоящее изобретение обеспечивает способ конверсии (преобразования) данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, при выполнении последовательных этапов, на которых:
1) идентифицируют данные, имеющие первую табличную структуру;
2) идентифицируют область обхода данных, имеющих первую табличную структуру;
3) совершают проход для каждой ячейки данных из упомянутой области обхода данных, при этом выполняются этапы, на которых:
4) формируют во внутренней базе данных для каждой ячейки данных буфер для идентифицированного контекста;
5) идентифицируют контекст для первой ячейки данных, для которой был совершен проход, причем до начала прохода для следующей ячейки данных идентифицированный контекст записывают в упомянутый буфер, причем с началом прохода для упомянутой следующей ячейки данных переносят идентифицированный для упомянутой первой ячейки данных контекст в упомянутый буфер для следующей ячейки данных;
6) идентифицируют контекст для упомянутой следующей ячейки данных, причем в случае когда идентифицированный контекст для данной ячейки отличается от упомянутого идентифицированного контекста, записанного в упомянутый буфер для данной ячейки данных, то идентифицированный контекст для данной ячейки данных заменяет идентифицированный контекст в буфере данной ячейки данных, причем над ним совершаются действия как над идентифицированным контекстом, указанные на этапе 5);
7) итеративно выполняют этапы 5) и 6) до тех пор, пока не будет совершен проход для каждой упомянутой ячейки данных из упомянутой области данных;
8) сериализуют полученную базу данных во внутренний формат данных XML;
9) применяют к полученному после процесса сериализации файлу XML шаблон таксономии, причем шаблон таксономии выбирается в зависимости от второй табличной структуры данных;
10) осуществляют конверсию полученного файла XML в данные, имеющие вторую табличную структуру, в соответствии с примененным к нему шаблоном таксономии. При этом данные, имеющие первую табличную структуру, могут быть, но не ограничиваться данными: данные формата MS Excel, табличные и содержащие табличные данные документы форматов MS Word, MS PowerPoint, Open Document Format for Office Applications (ODF), файлы формата PDF, содержащие поддающиеся точному распознаванию табличные формы, любые веб-формы, сканируемые печатные документы, имеющие табличные формы и любые другие табличные формы предоставления информации. Данные, имеющие вторую табличную структуру могут быть, но не ограничиваться, например, данными описываемыми языком деловой отчетности eXtensible Business Reporting Language (XBRL). Кроме того, на этапе идентификации области обхода данных может быть идентифицирована более чем одна область обхода данных. При этом проход может совершаться не для каждой ячейки данных из упомянутой области обхода данных, а только по тем ячейкам, которые не являются скрытыми. При этом существует возможность задать количество обходов упомянутой области данных на тот случай, если за один обход невозможно идентифицировать все необходимые атрибуты идентифицируемого контекста. При этом на этапе прохода для упомянутой ячейки данных существует возможность идентифицировать контекст, относящийся также и к ячейкам, граничащим и/или расположенным на расстоянии от упомянутой текущей ячейки данных. При этом на этапе обхода идентифицированной области данных идентификация контекста может быть осуществлена также и для ячеек из областей данных, расположенных за пределами упомянутой идентифицированной области обхода данных. При этом существует возможность записать совершенные действия в файл регистрации (журнал, лог-файл). Кроме того, существует возможность задать направление обхода указанной области данных: по столбцам, по строкам; как по столбцам, так и по строкам в течение одного обхода.
Во втором аспекте настоящее изобретение обеспечивает устройство для конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, которое может представлять собой, но не ограничиваться: персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон и тому подобное. Устройство обязательно содержит один или более процессоров, машиночитаемый носитель данных (память) и модули ввода/вывода (I/O). В качестве примера, а не ограничения машиночитаемый носитель данных может включать в себя оперативную память (RAM); постоянное запоминающее устройство (ROM); электрически стираемое программируемое постоянное запоминающее устройство (EEPROM); флэш-память или другие технологии памяти; CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для кодирования требуемой информации и к которому может быть осуществлен доступ посредством описываемого устройства. Память включает в себя носитель данных на основе запоминающего устройства компьютера в форме энергозависимой или энергонезависимой памяти или их комбинации. Примерные аппаратные устройства включают в себя твердотельную память, накопители на жестких дисках, накопители на оптических дисках и т.д. В памяти хранится примерная среда, в которой при помощи компьютерных команд или кодов, хранящихся в памяти устройства, может быть осуществлена процедура конверсии. Устройство содержит один или более процессоров, которые предназначены для выполнения компьютерных команд или кодов, хранящихся в памяти устройства с целью обеспечения выполнения процедуры конверсии. Модули I/O представляют собой, но не ограничиваются типичные и известные из уровня техники средства управления устройством: манипулятор типа «мышь», клавиатура, джойстик, тачпад, трекбол, электронное перо, стилус, сенсорный дисплей и тому подобное. Также модули I/O представляют собой, но не ограничиваются типичные и известные из уровня техники средства демонстрирования информации: монитор, проектор, принтер, графопостроитель и тому подобное. Компьютерные команды или коды, хранящиеся в памяти, предназначены для выполнения способа конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, и представляют собой, по меньшей мере, команды идентификации данных, имеющих первую табличную структуру; команды идентификации области обхода данных, имеющих первую табличную структуру; команды совершения прохода для каждой ячейки данных из упомянутой области обхода данных; команды формирования во внутренней базе данных для каждой ячейки данных буфера для идентифицированного контекста; команды идентификации контекста для первой ячейки данных, для которой была совершена команда прохода, причем до начала выполнения команд прохода для следующей ячейки данных выполняются команды записи идентифицированного контекста в упомянутый буфер, причем с началом выполнения команд прохода для упомянутой следующей ячейки данных выполняются команды переноса идентифицированного для упомянутой первой ячейки данных контекста в упомянутый буфер для следующей ячейки данных; команды идентификации контекста для упомянутой следующей ячейки данных, команды перезаписи для случаев, когда идентифицированный контекст для данной ячейки отличается от упомянутого идентифицированного контекста, записанного в упомянутый буфер для данной ячейки данных, и при выполнении этих команд идентифицированный контекст для данной ячейки данных заменяет идентифицированный контекст в буфере данной ячейки данных; команды итеративного выполнения команд идентификации контекста до тех пор, пока не будут выполнены команды прохода для каждой упомянутой ячейки данных из упомянутой области данных; команды формирования внутренней базы данных; команды сериализации полученной базы данных во внутренний формат данных XML; команды применения к полученному после процесса сериализации файлу XML шаблона таксономии, причем применяется команда выбора шаблона таксономии в зависимости от второй табличной структуры данных. При этом данные, имеющие первую табличную структуру, могут быть, но не ограничиваться данными: данные формата MS Excel, табличные и содержащие табличные данные документы форматов MS Word, MS PowerPoint, Open Document Format for Office Applications (ODF), файлы формата PDF, содержащие поддающиеся точному распознаванию табличные формы, любые веб-формы, сканируемые печатные документы, имеющие табличные формы и любые другие табличные формы предоставления информации. Данные, имеющие вторую табличную структуру, могут быть, но не ограничиваться данными, например, описываемыми языком деловой отчетности extensible Business Reporting Language (XBRL). Кроме того, могут быть команды, осуществляющие при выполнении команд идентификации области обхода данных идентификацию более чем одной области обхода данных. При этом команды прохода могут совершаться не для каждой ячейки данных из упомянутой области обхода данных, а только для тех ячеек, которые не являются скрытыми. При этом могут быть команды, которые осуществляют возможность задать количество команд обхода упомянутой области данных, на тот случай, если за выполнение одной команды обхода невозможно идентифицировать все необходимые атрибуты идентифицируемого контекста. При этом при выполнении команд прохода для упомянутой ячейки данных существуют команды идентификации контекста, относящегося также и к ячейкам, граничащим и/или расположенным на расстоянии от упомянутой текущей ячейки данных. При этом при выполнении команд обхода идентифицированной области данных команды идентификации контекста могут быть осуществлены также и для ячеек из областей данных, расположенных за пределами упомянутой идентифицированной области обхода данных. При этом существуют команды записи выполненных команд в файл регистрации (журнал, лог-файл). Кроме того, существуют команды, которые задают направление обхода указанной области данных: по столбцам, по строкам; как по столбцам, так и по строкам в течение выполнения одной команды обхода.
Несмотря на то что в примерном варианте осуществления изобретения перечисленные компьютерные команды написаны на языке JAVA, не следует считать, что данный пример осуществления изобретения ограничивает написание перечисленных компьютерных команд только данным языком программирования. В действительности перечисленные команды могут быть написаны на любом известном или вновь созданном языке программирования.
В третьем аспекте настоящее изобретение обеспечивает устройство для конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, имеющее в своем составе один или более процессоров, память, модули I/O и отличающееся тем, что содержит блок идентификации, который осуществляет идентификацию данных, имеющих первую табличную структуру, идентификацию области обхода данных, при этом может быть осуществлена идентификация более чем одной области обхода данных, блок анализа и сбора данных, который осуществляет проход для каждой ячейки данных из упомянутой области данных или только для тех ячеек данных из упомянутой области данных, которые не являются скрытыми, формирует во внутренней базе данных для каждой ячейки данных буфер для идентифицированного контекста, осуществляет идентификацию контекста для первой ячейки данных, для которой был совершен проход, причем до начала осуществления прохода для следующей ячейки данных, блок сбора и анализа данных записывает идентифицированный контекст в упомянутый буфер, а с началом осуществления прохода для упомянутой следующей ячейки данных блок сбора и анализа данных переносит идентифицированный для упомянутой первой ячейки данных контекст в упомянутый буфер для следующей ячейки данных, осуществляет идентификацию контекста для упомянутой следующей ячейки данных, причем в случае когда идентифицированный контекст для данной ячейки отличается от упомянутого идентифицированного контекста, записанного в упомянутый буфер для данной ячейки данных, блок сбора и анализа данных заменяет идентифицированный контекст в буфере данной ячейки данных на идентифицированный контекст для данной ячейки данных и обеспечивает выполнение перечисленных действий для данной ячейки данных, осуществляет итеративное выполнение перечисленных действий с идентифицированным контекстом до тех пор, пока не будет осуществлен проход для каждой ячейки данных из упомянутой области обхода данных, при этом блок сбора и анализа данных дополнительно может осуществлять идентификацию контекста, относящегося также и к ячейкам, граничащим и/или расположенным на расстоянии от упомянутой текущей ячейки данных, осуществлять идентификацию контекста также и для ячеек из областей данных, расположенных за пределами упомянутой идентифицированной области обхода данных, осуществлять запись совершенных действий в файл регистрации (журнал, лог-файл), указывать направление обхода упомянутой области обхода данных: по столбцам, по строкам и как по столбцам, так и по строкам. При этом устройство также содержит блок конверсии, который осуществляет сериализацию полученной блоком сбора и анализа данных базы данных во внутренний формат данных XML, выбирает шаблон таксономии в зависимости от второй табличной структуры данных и осуществляет применение шаблона таксономии к полученному путем сериализации файлу XML.
В четвертом аспекте настоящее изобретение обеспечивает систему для конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру. Примерная система для конверсии данных включает в себя сеть. Сеть может включать в себя, но не ограничиваться одну или более локальных сетей (LAN) и/или глобальных сетей (WAN). Такие сетеобразующие среды обычно используются в офисах, корпоративных компьютерных сетях, внутрикорпоративных сетях и Интернете. Соответственно, упомянутая сеть далее дополнительно не описывается. Примерная система для конверсии данных дополнительно включает в себя базу данных и множество устройств для конверсии данных, которые представляют собой одни из устройств, или их комбинацию, описанные во втором и/или третьем аспектах настоящего изобретения, которые, соответственно, дополнительно не описываются. Примерная система для конверсии данных дополнительно содержит серверное вычислительное устройство, которое сохраняет и содействует манипуляции компьютерными командами или кодами, описанными во втором аспекте настоящего изобретения, которые, соответственно, дополнительно не описываются.
В пятом аспекте настоящее изобретение обеспечивает машиночитаемый носитель данных, содержащий код программы, который побуждает процессор и/или процессоры выполнять действия по способу, описанному в первом аспекте настоящего изобретения, и который, соответственно, дополнительно не описывается. В качестве примера, а не ограничения, машиночитаемый носитель данных может включать в себя оперативную память (RAM); постоянное запоминающее устройство (ROM); электрически стираемое программируемое постоянное запоминающее устройство (EEPROM); флэш-память или другие технологии памяти; CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для кодирования требуемой информации и к которому может быть осуществлен доступ посредством устройства, описываемого во втором, третьем и четвертом аспектах настоящего изобретения, которое, соответственно, дополнительно не описывается.
ДЕТАЛЬНОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Описанное в данном разделе возможное осуществление аспектов настоящего изобретения представлено на примере конверсии (преобразования) данных формата Microsoft Excel в данные формата XBRL Instance Document. Несмотря на то что дальнейшее детальное описание чертежей составлено в отношении этих двух форматов, способа конверсии, устройства и системы для конверсии указанных форматов необходимо отметить, что в действительности ни один из вариантов осуществления аспектов настоящего изобретения не ограничивается конверсией данных формата Microsoft Excel в данные формата XBRL Instance Document. Вместо данных формата Microsoft Excel могут быть использованы, но не ограничиваться, любые данные, имеющие табличную структуру, например: данные формата MS Excel, табличные и содержащие табличные данные документы форматов MS Word, MS PowerPoint, Open Document Format for Office Applications (ODF), файлы формата PDF, содержащие поддающиеся точному распознаванию табличные формы, любые веб-формы, сканируемые печатные документы, имеющие табличные формы и любые другие табличные формы предоставления информации. Вместо целевых данных формата XBRL Instance Document могут быть использованы, но не ограничиваться, любые данные, имеющие табличную структуру, например, данные, описываемые языком деловой отчетности extensible Business Reporting Language (XBRL). Ячейки данных документа формата Microsoft Excel, составленного для отчетности, например по энергетическому предприятию, типично содержат, но не ограничиваются в этом, данные, представляющие собой показатели и аналитики. Показатели представляют собой, например, объем отпуска тепловой энергии за отчетный месяц (год, время), стоимость отпущенной тепловой энергии за отчетный месяц (год, время), степень износа, фонд заработной платы основного персонала. Аналитики представляют собой, например, регионы, категории потребителей, виды топлива, уровни напряжения. При конверсии эти данные должны быть помещены в соответствующие ячейки данных формата XBRL.
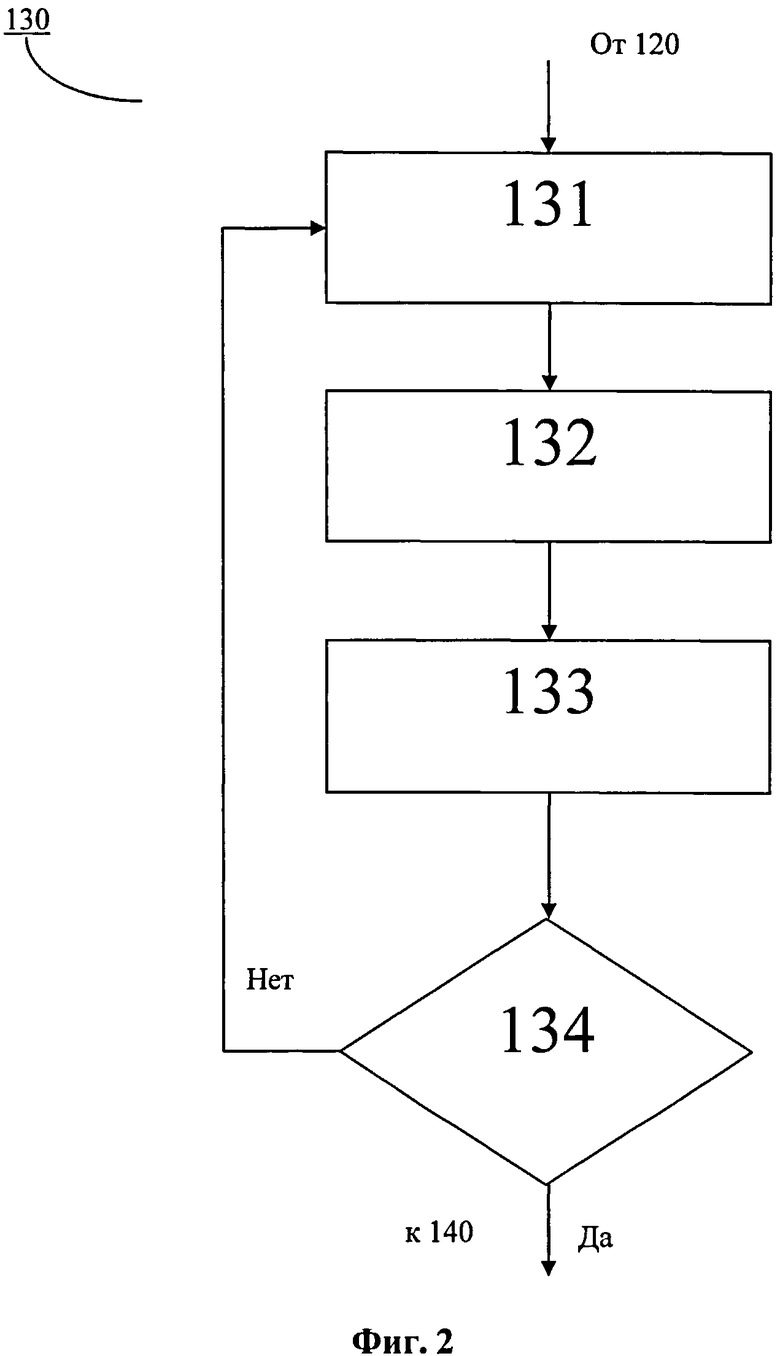
На фиг.1 показан примерный вариант осуществления способа конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру. В качестве примера, а не ограничения, описывается способ конверсии данных формата Microsoft Excel в данные формата XBRL Instance Document. На этапе 110 идентификации данных осуществляется идентификация данных, имеющих первую табличную структуру, а именно идентификация данных формата Microsoft Excel. На этапе 120 идентификации области обхода данных осуществляется идентификация (выбор) области данных из области данных формата Microsoft Excel. В данном примерном варианте осуществления способа область обхода данных может быть задана отдельными ячейками, строками, столбцами. Дополнительно может быть выбрано множество областей обхода данных и направление обхода области: по строкам, по столбцам, по строкам и столбцам. Этап 130 сбора и анализа данных дополнительно показан на фиг.2.
На фиг.2 показан примерный вариант осуществления этапа 130 сбора и анализа данных в способе конверсии данных. На этапе 131 формирования буфера для каждой ячейки данных из идентифицированной на этапе 120 области обхода данных во внутренней базе данных компьютерного приложения, выполняемого посредством устройства или системы для конверсии данных, подробно описанных во втором, третьем и четвертом аспектах настоящего изобретения, и которые будут более подробно описаны далее, формируется буфер, в который на этапе 132 идентификации контекста текущей ячейки и до начала этапа 133 идентификации контекста следующей ячейки записывается идентифицированный на этапе 132 контекст. С началом этапа 133 идентификации контекста следующей ячейки контекст, идентифицированный на этапе 132 переносят в буфер, сформированный для следующей ячейки данных. Далее на этапе 133 идентификации контекста осуществляют идентификацию контекста для следующей ячейки данных, причем в случае когда идентифицированный на этапе 133 контекст отличается от записанного до начала этапа 133 в текущий буфер контекста, то этот идентифицированный контекст заменяет записанный ранее контекст, и далее с этим контекстом осуществляются те же действия, что были осуществлены с идентифицированным на этапе 132 контекстом, т.е. каждая следующая ячейка становится текущей ячейкой и способ повторяется. На этапе 134 итерации осуществляется повторение этапов 132, 133 до тех пор, пока не будет совершен проход для каждой ячейки данных. Дополнительно, во время выполнения этапа 130 сбора и анализа данных проход может совершаться не для каждой ячейки данных из области данных, указанной на этапе 120 (см. фиг.1). Например, ячейки, которые являются «скрытыми» могут не идентифицироваться, как ячейки, содержащие контекст, подлежащий идентификации. Дополнительно, на этапах 132 и 133 идентификации контекста может быть идентифицирован контекст, относящийся также и к ячейкам, граничащим и/или расположенным на расстоянии от текущей ячейки данных, и для ячеек из областей данных, расположенных за пределами упомянутой идентифицированной области обхода данных. Процедура записи изменившегося идентифицированного контекста на этапе 133 идентификации контекста вместо прежнего идентифицированного контекста, хранящегося в буфере текущей ячейки, позволяет упростить XML-описание конвертера. Если в отчете единица измерения, аналитика или показатель действует на всю строку, то достаточно задать их только один раз для всей строки. В свою очередь это позволяет осуществлять более точную и эффективную конверсию данных в требуемый формат из-за меньшего объема конвертируемых данных. После завершения этапа 130 сбора и анализа данных (см. фиг.1), способ переходит к этапу 140 сериализации, на котором полученную базу данных сериализуют в формат данных XML, тем самым получая файл формата XML. На этапе 150 таксономии выбирается шаблон таксономии, соответствующий целевой табличной структуре данных. В описываемом примерном варианте осуществления одного аспекта настоящего изобретения таким шаблоном таксономии является типичный шаблон XBRL-таксономии, подходящий для применения к полученному файлу формата XML. В отличие от шаблона мэппинга шаблон таксономии применяется к сформированному файлу формата XML, что позволяет обеспечить высокую точность конверсии данных. На этапе 160 конверсии происходит конверсия файла формата XML, к которому на этапе 150 таксономии был применен шаблон таксономии, которая заключается в том, что содержащиеся в файле XML данные, имеющие соответствующие атрибуты, записывают в соответствующие ячейки шаблона XBRL, тем самым обеспечивается достаточная точность конверсии данных, даже если исходные данные были несанкционированно изменены.
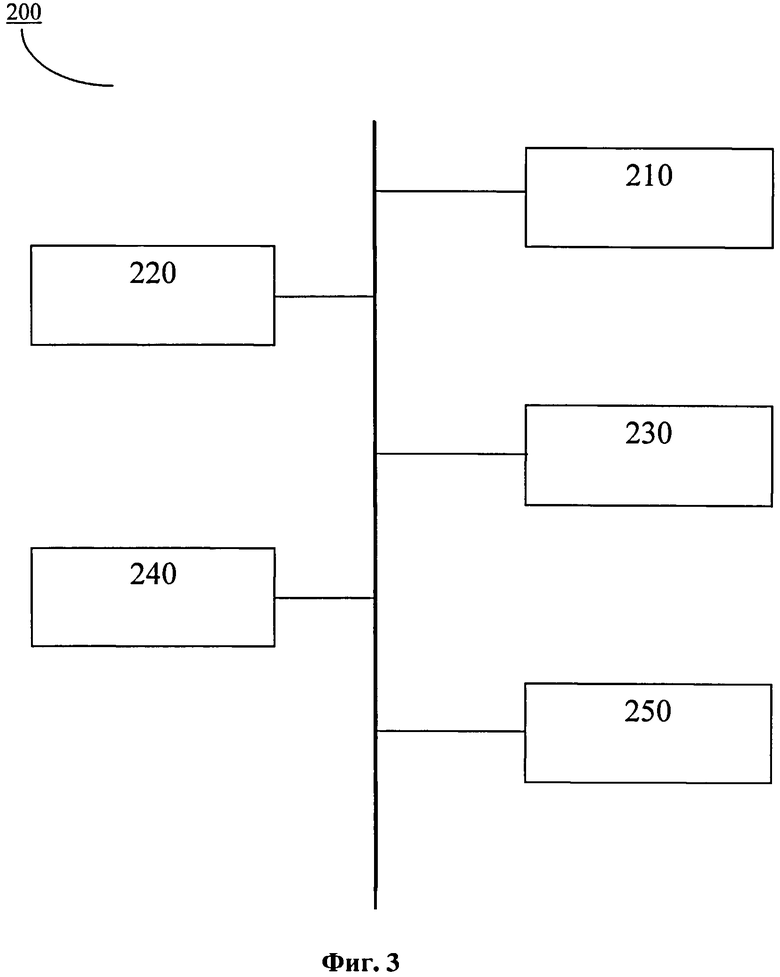
На фиг.3 изображено примерное осуществление одного из второго или третьего аспекта осуществления настоящего изобретения, а именно устройства 200 для конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, которое может представлять собой, но не ограничиваться: персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон и тому подобное. Устройство выполнено с возможностью доступа в сеть и обязательно содержит один или более процессоров 210, машиночитаемый носитель данных (память) 220, модули ввода/вывода (I/O) 230 и порты ввода/вывода (I/O) 240. В качестве примера, а не ограничения, машиночитаемый носитель данных 220 может включать в себя оперативную память (RAM); постоянное запоминающее устройство (ROM); электрически стираемое программируемое постоянное запоминающее устройство (EEPROM); флэш-память или другие технологии памяти; CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для кодирования требуемой информации и к которому может быть осуществлен доступ посредством описываемого устройства. Память 220 включает в себя носитель данных на основе запоминающего устройства компьютера в форме энергозависимой или энергонезависимой памяти или их комбинации. Примерные исполнения аппаратных устройств памяти включают в себя твердотельную память, накопители на жестких дисках, накопители на оптических дисках и т.д. В памяти хранится примерная среда 250, в которой при помощи компьютерных команд или кодов, хранящихся в памяти 220 устройства, может быть осуществлена процедура конверсии. Устройство содержит один или более процессоров 210, которые предназначены для выполнения компьютерных команд или кодов, хранящихся в памяти устройства с целью обеспечения выполнения процедуры конверсии. Модули I/O 230 представляют собой, но не ограничиваются, типичные и известные из уровня техники средства управления устройством: манипулятор типа «мышь», клавиатура, джойстик, тачпад, трекбол, электронное перо, стилус, сенсорный дисплей и тому подобное. Также модули I/O 230 представляют собой, но не ограничиваются типичные и известные из уровня техники средства представления демонстрирования и воспроизведения информации: монитор, проектор, принтер, графопостроитель и тому подобное. Порты 240 I/O позволяют логически соединять вычислительное устройство 200 с другими устройствами, включая модули (240) I/O, которые могут быть как встроенными, так и внешними. Компьютерные команды представляют собой команды, описанные во втором аспекте осуществления настоящего изобретения, и, соответственно, дополнительно не описываются. В одном аспекте осуществления настоящего изобретения устройство 200 представляет собой в качестве примера, а не ограничения, персональный компьютер пользователя. Данный персональный компьютер имеет операционную среду 250, которая в качестве примера, а не ограничения представляет собой операционную систему семейства Windows. Кроме того, устройство содержит память, выполненную в одном из перечисленных вариантов осуществления, в которой хранится компьютерное приложение, представляющее собой набор перечисленных во втором аспекте настоящего изобретения компьютерных команд или кодов, которыми может манипулировать пользователь. Процедура конверсии осуществляется посредством этого приложения путем выбора исходных данных, имеющих первую структуру, в качестве примера, а не ограничения этими данными могут быть файлы формата Microsoft Excel. В данном примерном варианте осуществления изобретения пользователь сам задает область обхода данных, которую необходимо конвертировать, сам определяет количество обходов, сам задает направления обходов, сам задает параметры, характеризующие процесс сбора и анализа данных. Однако необходимо отметить, что пользователь также имеет возможность создать шаблон конверсии (сценарий конверсии) либо он может быть сгенерирован автоматически с помощью компьютерного приложения или блока генерирования сценария конверсии по заданным параметрам.
На фиг.4 представлено примерное исполнение системы 300 для конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, которая содержит устройство 200 для конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, сеть 310, один или несколько серверов 320 и базу данных 330. Сеть 310 может включать в себя, но не ограничиваясь этим, одну или более локальных сетей (LAN) и/или глобальных сетей (WAN) или может представлять собой сеть Интернет или Интранет, может также представлять собой виртуальную частную сеть (VPN) и тому подобное. Система 300 включает в себя упомянутое устройство 200 для конверсии данных. Устройство 200 для конверсии данных, как было указано выше, применяется для выполнения конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру. В примерном варианте осуществления устройство 200 для конверсии данных представляет собой устройство 200 для конверсии данных, которое было описано ранее со ссылкой на фиг.3. Дополнительно система 300 включает в себя сервер 320, который может представлять собой, также как и устройство 200 для конверсии данных: персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон и тому подобное.
Сервер 320, также как и устройство 200, может представлять собой, но не ограничиваясь: суперкомпьютер, персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон и тому подобное. Сервер 320 обеспечивает регулирование обменом данных в системе 300, а также обеспечивает обработку данных при условии подключения к нему более чем одного устройства 200 для конверсии данных или когда устройство 200 для конверсии данных представляет собой тонкий клиент (thin client), и все вычислительные мощности по обеспечению выполнения процедуры конверсии данных расположены на сервере 320. В этом случае обеспечение выполнение процедуры конверсии осуществляется сервером 320 со ссылкой на фиг.1-3. Сервер 320 также имеет возможность обеспечивать виртуальную вычислительную среду (Virtual Machine) для обеспечения взаимодействия между устройством 200 для конверсии и базой данных 330 (БД). БД 330 может представлять собой, но не ограничиваясь: иерархическую БД, сетевую БД, реляционную БД, объектную БД, объектно-ориентированную БД, объектно-реляционную БД, пространственную БД и тому подобное. БД 330 хранит данные в памяти, которая может представлять собой, но не ограничиваясь: постоянное запоминающее устройство (ROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), флэш-память, CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для хранения требуемой информации и к которому может быть осуществлен доступ посредством устройства 200 для конверсии данных и сервера 320. БД 330 служит для хранения данных, представляющих собой: исходные данные первой табличной структуры, шаблоны таксономии, данные, собранные на этапе 130 сбора или анализа данных, подробно описанном со ссылкой на фиг.1 или с помощью блока сбора и анализа данных, описанном в третьем аспекте осуществления настоящего изобретения, во время выполнения процедуры конверсии данных из одной табличной структуры в другую, данные файла регистрации (журнал, лог-файл), данные, полученные после выполнения процедуры конверсии, соответствующие второй табличной структуре данных, и тому подобное.

Группа изобретений относится к области конверсии данных, причем первые данные имеют первую табличную структуру, вторые данные имеют вторую табличную структуру. Техническим результатом является повышение точности, а также обеспечение возможности применения данного способа для множества различных структур данных. Способ содержит этапы, на которых: 1) идентифицируют данные, имеющие первую табличную структуру; 2) идентифицируют область обхода данных; 3) совершают проход для каждой ячейки данных из упомянутой области обхода данных, при этом: 4) формируют во внутренней базе данных для каждой ячейки данных буфер для идентифицированного контекста; 5) идентифицируют контекст для первой ячейки данных; 6) идентифицируют контекст для следующей ячейки данных; 7) итеративно выполняют этапы 5) и 6) до тех пор, пока не будет совершен проход для каждой упомянутой ячейки данных из упомянутой области данных; 8) сериализуют полученную базу данных во внутренний формат данных XML; 9) применяют к полученному файлу XML шаблон таксономии, причем шаблон таксономии выбирается в зависимости от второй табличной структуры данных; 10) осуществляют конверсию полученного файла XML в данные, имеющие вторую табличную структуру, в соответствии с примененным к нему шаблоном таксономии. 4 н. и 30 з.п. ф-лы, 4 ил.
1. Способ конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, заключающийся в выполнении этапов, на которых:
1) идентифицируют данные, имеющие первую табличную структуру;
2) идентифицируют область обхода данных, имеющих первую табличную структуру;
3) совершают проход для каждой ячейки данных из упомянутой области обхода данных, при этом выполняются этапы, на которых:
4) формируют во внутренней базе данных для каждой ячейки данных буфер для идентифицированного контекста;
5) идентифицируют контекст для первой ячейки данных, для которой был совершен проход, причем до начала прохода для следующей ячейки данных идентифицированный контекст записывают в упомянутый буфер, причем с началом прохода для упомянутой следующей ячейки данных переносят идентифицированный для упомянутой первой ячейки данных контекст в упомянутый буфер для следующей ячейки данных;
6) идентифицируют контекст для упомянутой следующей ячейки данных, причем в случае когда идентифицированный контекст для данной ячейки отличается от упомянутого идентифицированного контекста, записанного в упомянутый буфер для данной ячейки данных, то идентифицированный контекст для данной ячейки данных заменяет идентифицированный контекст в буфере данной ячейки данных, причем над ним совершаются действия как над идентифицированным контекстом, указанные на этапе 5);
7) итеративно выполняют этапы 5) и 6) до тех пор, пока не будет совершен проход для каждой упомянутой ячейки данных из упомянутой области данных;
8) сериализуют полученную базу данных во внутренний формат данных Extensible Markup Language (XML);
9) применяют к полученному после процесса сериализации файлу XML шаблон таксономии, причем шаблон таксономии выбирается в зависимости от второй табличной структуры данных;
10) осуществляют конверсию полученного файла XML в данные, имеющие вторую табличную структуру, в соответствии с примененным к нему шаблоном таксономии.
2. Способ по п.1, отличающийся тем, что данные, имеющие первую табличную структуру, представляют собой, например, документы формата MS Excel, табличные и содержащие табличные данные документы форматов MS Word, MS PowerPoint, Open Document Format for Office Applications (ODF), PDF, веб-формы.
3. Способ по п.1, отличающийся тем, что данные, имеющие вторую табличную структуру, представляют собой данные формата Extensible Business Reporting Language (XBRL).
4. Способ по п.1, отличающийся тем, что на этапе идентификации области обхода данных может быть идентифицирована более чем одна область обхода данных.
5. Способ по п.1, отличающийся тем, что совершают проход не для каждой ячейки данных из упомянутой области обхода данных.
6. Способ по п.1, отличающийся тем, что указывают количество обходов указанной области данных.
7. Способ по п.1, отличающийся тем, что на этапе прохода для упомянутой ячейки данных идентифицируют контекст, относящийся также и к ячейкам, граничащим и/или расположенным на расстоянии от упомянутой текущей ячейки данных.
8. Способ по п.1, отличающийся тем, что на этапе обхода идентифицированной области данных идентификация контекста происходит также и для ячеек из областей данных, расположенных за пределами упомянутой идентифицированной области обхода данных.
9. Способ по п.1, отличающийся тем, что выполнение этапов записывают в файл регистрации.
10. Способ по п.1, отличающийся тем, что указывают направление обхода указанной области данных.
11. Способ по п.10, отличающийся тем, что направление обхода совершается по столбцам.
12. Способ по п.10, отличающийся тем, что направление обхода совершается по строкам.
13. Способ по п.10, отличающийся тем, что направление обхода совершается как по столбцам, так и по строкам.
14. Устройство для выполнения конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, содержащее, по меньшей мере:
один или более процессоров;
модули ввода/вывода (I/O);
порты I/O; и
память, содержащую код программы, который при выполнении побуждает процессор и/или процессоры выполнять действия, представляющие собой этапы, на которых:
1) идентифицируют данные, имеющие первую табличную структуру;
2) идентифицируют область обхода данных, имеющих первую табличную структуру;
3) совершают проход для каждой ячейки данных из упомянутой области обхода данных, при этом выполняются этапы, на которых:
4) формируют во внутренней базе данных для каждой ячейки данных буфер для идентифицированного контекста;
5) идентифицируют контекст для первой ячейки данных, для которой был совершен проход, причем до начала прохода для следующей ячейки данных идентифицированный контекст записывают в упомянутый буфер, причем с началом прохода для упомянутой следующей ячейки данных переносят идентифицированный для упомянутой первой ячейки данных контекст в упомянутый буфер для следующей ячейки данных;
6) идентифицируют контекст для упомянутой следующей ячейки данных, причем в случае, когда идентифицированный контекст для данной ячейки отличается от упомянутого идентифицированного контекста, записанного в упомянутый буфер для данной ячейки данных, то идентифицированный контекст для данной ячейки данных заменяет идентифицированный контекст в буфере данной ячейки данных, причем над ним совершаются действия как над идентифицированным контекстом, указанные на этапе 5);
7) итеративно выполняют этапы 5) и 6) до тех пор, пока не будет совершен проход для каждой упомянутой ячейки данных из упомянутой области данных;
8) сериализуют полученную базу данных во внутренний формат данных XML;
9) применяют к полученному после процесса сериализации файлу XML шаблон таксономии, причем шаблон таксономии выбирается в зависимости от второй табличной структуры данных;
10) осуществляют конверсию полученного файла XML в данные, имеющие вторую табличную структуру, в соответствии с примененным к нему шаблоном таксономии.
15. Устройство по п.14, отличающееся тем, что данные, имеющие первую табличную структуру, представляют собой, например, документы формата MS Excel, табличные и содержащие табличные данные документы форматов MS Word, MS PowerPoint, ODF, PDF, веб-формы.
16. Устройство по п.14, отличающееся тем, что данные, имеющие вторую табличную структуру, представляют собой данные формата XBRL.
17. Устройство по п.14, отличающееся тем, что на этапе идентификации области обхода данных может быть идентифицирована более чем одна область обхода данных.
18. Устройство по п.14, отличающееся тем, что на этапе совершения прохода совершается проход не для каждой ячейки данных из упомянутой области обхода данных.
19. Устройство по п.14, отличающееся тем, что оно выполнено с возможностью указывать количество обходов указанной области данных.
20. Устройство по п.14, отличающееся тем, что на этапе прохода для упомянутой ячейки данных идентифицируется контекст, относящийся также и к ячейкам, граничащим и/или расположенным на расстоянии от упомянутой текущей ячейки данных.
21. Устройство по п.14, отличающееся тем, что на этапе обхода идентифицированной области данных идентификация контекста происходит также и для ячеек из областей данных, расположенных за пределами упомянутой идентифицированной области обхода данных.
22. Устройство по п.14, отличающееся тем, что выполнение этапов записывается в файл регистрации.
23. Устройство по п.14, отличающееся тем, что оно выполнено с возможностью указать направление обхода указанной области данных.
24. Устройство по п.23, отличающееся тем, что направление обхода совершается по столбцам.
25. Устройство по п.23, отличающееся тем, что направление обхода совершается по строкам.
26. Устройство по п.23, отличающееся тем, что направление обхода совершается как по столбцам, так и по строкам.
27. Система для выполнения конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, содержащая, по меньшей мере:
множество устройств для выполнения конверсии данных, имеющих первую табличную структуру, в данные, имеющие вторую табличную структуру, выполненных в виде устройств по любому из пп.14-26;
один или несколько серверов, обеспечивающих регулирование обменом данных в системе;
базу данных, предназначенную для хранения данных, выполненную с возможностью взаимодействия с упомянутыми устройствами для выполнения конверсии и одним или несколькими серверами;
сеть, обеспечивающую взаимодействие упомянутых устройств для выполнения конверсии, одного или нескольких серверов и базы данных.
28. Система по п.27, отличающаяся тем, что конверсия данных выполняется одним или несколькими серверами, а упомянутые устройства для выполнения конверсии данных представляют собой тонкий клиент.
29. Система по п.27, отличающаяся тем, что данные первой табличной структуры и второй табличной структуры хранятся в упомянутой базе данных и запрашиваются упомянутыми устройствами для выполнения конверсии перед началом конверсии.
30. Система по п.28, отличающаяся тем, что данные первой табличной структуры и второй табличной структуры хранятся в упомянутой базе данных и запрашиваются упомянутыми серверами перед началом конверсии.
31. Система по п.27, в которой упомянутые серверы регулируют обмен данными с упомянутыми устройствами для выполнения конверсии данных посредством виртуальной машины.
32. Система по п.27, в которой организация упомянутой базы данных может представлять собой одну из: иерархическую, сетевую, реляционную, объектную, объектно-ориентированную, объектно-реляционную, пространственную.
33. Система по п.27, в которой упомянутая сеть представляет собой одно из: локальную сеть (LAN), глобальную сеть (WAN), Интернет, Интранет, виртуальную частную сеть (VPN).
34. Машиночитаемый носитель данных, содержащий код программы, который при выполнении побуждает процессор и/или процессоры выполнять действия способа по любому из пп.1-13.
| WO 2005076155 A2, 18.08.2005 | |||
| US 2006184539 A1, 17.08.2006 | |||
| US 2013018923 A1, 17.01.2013 | |||
| СИСТЕМА И СПОСОБ ВЗАИМНОГО ПРЕОБРАЗОВАНИЯ ПРОГРАММНЫХ ОБЪЕКТОВ И ДОКУМЕНТОВ НА БАЗЕ ЭЛЕМЕНТОВ СТРУКТУРИРОВАННОГО ЯЗЫКА | 2001 |
|
RU2287181C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРЕОБРАЗОВАНИЯ ИЕРАРХИЧЕСКОЙ СТРУКТУРЫ ДАННЫХ НА ОСНОВЕ СХЕМЫ В ПЛОСКУЮ СТРУКТУРУ ДАННЫХ | 2004 |
|
RU2378690C2 |

