Настоящая заявка подана как частичное продолжение патентной заявки США 09/952,891 на «Устройство и способ для эффективной фильтрации и свертки данных информационного содержимого» от 29 октября 2001.
Настоящая патентная заявка связана с совместно поданной патентной заявкой США № - на «Способ и устройство для параллельного табличного преобразования с использованием SIMD-инструкций» от 30 июня 2003 и совместно поданной патентной заявкой США № - на «Способ и устройство для переупорядочивания данных между множеством регистров» от 30 июня 2003.
Область техники
Настоящее изобретение относится к области микропроцессоров и компьютерных систем. Более конкретно, настоящее изобретение относится к способу и устройству для тасования данных.
Предшествующий уровень техники
Компьютерные системы все в возрастающей степени проникают в жизнь современного общества. Возможности обработки компьютеров повысили эффективность и производительность труда работников в широком спектре профессий. Так как расходы на приобретение и получение в собственность компьютеров продолжает падать, все большее количество пользователей получают возможность пользоваться выгодами, обеспечиваемыми более новыми и более быстродействующими машинами. Кроме того, многие люди являются приверженцами использования дорожных компьютеров (ноутбуков) ввиду обеспечиваемой ими свободы использования. Мобильные компьютеры дают возможность пользователям простым способом переносить свои данные и работать с ними, когда они покидают место работы или совершают поездки. Этот сценарий хорошо знаком специалистам по маркетингу, должностным лицам корпораций и даже студентам.
По мере совершенствования технологии процессоров также генерируются обновленные коды программного обеспечения для исполнения на машинах с такими процессорами. Пользователи в общем случае ожидают и требуют более высоких показателей от своих компьютеров, независимо от типа используемого программного обеспечения. Один такой вопрос может возникнуть в связи с инструкциями и операциями, которые в текущий момент исполняются в процессоре. Некоторые типы операций требуют больше времени для вычисления ввиду сложности операций и/или типа требуемых схем. Это обеспечивает возможность оптимизации способа, которым исполняются некоторые сложные операции в процессоре.
Мультимедийные приложения способствуют развитию микропроцессоров в течение более десятка лет. Реально большинство компьютерных модернизаций в последние годы стимулировались мультимедийными приложениями. Эти модернизации преобладающим образом имели место в потребительских сегментах, хотя значительный прогресс также наблюдался в предпринимательском сегменте для достижения таких целей, как усовершенствование за счет занимательности обучения и коммуникации. Тем не менее будущие мультимедийные приложения потребуют еще более высоких вычислительных характеристик. В результате современный опыт в области персональных компьютеров будет еще более обогащен за счет аудиовизуальных эффектов, а также за счет большей простоты использования, и что еще более важно, вычисления будут интегрироваться с коммуникациями.
Соответственно, отображение изображений, а также воспроизведение аудио- и видеоданных, которые совместно определяются термином «контент» (информационное содержимое), становятся все более популярными приложениями для современных вычислительных устройств. Операции фильтрации и свертки являются некоторыми из наиболее общих операций, выполняемых над данными контента, такими как аудиоданные и видеоданные изображений. Такие операции являются интенсивными в вычислительном смысле, но обеспечивают высокий уровень параллелизма данных, который может быть использован посредством эффективной реализации с использованием различных устройств хранения данных, таких как, например, регистры с одним потоком команд и множеством потоков данных (SIMD-регистры). Ряд современных архитектур также требуют ненужных изменений типов данных, что минимизирует пропускную способность инструкции и значительно увеличивает число тактовых циклов, требуемых для упорядочения данных для арифметических операций.
Краткое описание чертежей
Настоящее изобретение иллюстрируется для примера, но не в качестве ограничения, на чертежах, на которых одинаковые ссылочные позиции обозначают сходные элементы и на которых представлено следующее:
Фиг.1А - блок-схема компьютерной системы, образованной процессором, который включает в себя исполнительные модули для исполнения инструкции тасования данных в соответствии с вариантом осуществления настоящего изобретения.
Фиг.1В - блок-схема другой приведенной для примера компьютерной системы в соответствии с вариантом осуществления настоящего изобретения.
Фиг.1С - блок-схема еще одной приведенной для примера компьютерной системы в соответствии с альтернативным вариантом осуществления настоящего изобретения.
Фиг.2 - блок-схема микроархитектуры для процессора в одном варианте осуществления, который включает в себя логические схемы для выполнения операций тасования данных в соответствии с настоящим изобретением.
Фиг.3А-С - иллюстрации масок тасования согласно различным вариантам осуществления настоящего изобретения.
Фиг.4А - иллюстрация представлений различных типов пакетных данных в мультимедийных регистрах в соответствии с вариантом осуществления настоящего изобретения.
Фиг.4В - иллюстрация типов пакетных данных в соответствии с альтернативным вариантом осуществления настоящего изобретения.
Фиг.4С - вариант осуществления формата кодирования операции (кода операции) для инструкции тасования.
Фиг.4D - иллюстрация альтернативного формата кодирования операции.
Фиг.4Е - иллюстрация другого альтернативного формата кодирования операции.
Фиг.5 - блок-схема варианта осуществления логики для выполнения операции тасования над операндом данных на основе маски тасования в соответствии с настоящим изобретением.
Фиг.6 - блок-схема варианта осуществления схемы для выполнения операции тасования данных в соответствии с настоящим изобретением.
Фиг.7 - иллюстрация операции тасования данных над элементами данных байтовой длины в соответствии с вариантом осуществления настоящего изобретения.
Фиг.8 - иллюстрация операции тасования данных над элементами данных с длиной слова в соответствии с другим вариантом осуществления настоящего изобретения.
Фиг.9 - блок-схема варианта осуществления способа тасования данных.
Фиг.10А-Н - иллюстрация операции алгоритма параллельного табличного преобразования с использованием SIMD-инструкций.
Фиг.11 - блок-схема варианта осуществления способа выполнения табличного преобразования с использованием SIMD-инструкций.
Фиг.12 - блок-схема другого варианта осуществления способа выполнения табличного преобразования.
Фиг.13А-С - иллюстрация алгоритма переупорядочения данных между множеством регистров.
Фиг.14 - блок-схема, иллюстрирующая вариант осуществления способа переупорядочения данных между множеством регистров.
Фиг.15А-К - иллюстрация алгоритма тасования данных между множеством регистров для генерирования перемеженных данных.
Фиг.16 - блок-схема, иллюстрирующая вариант осуществления способа тасования данных между множеством регистров для генерирования перемеженных данных.
Детальное описание
Раскрыты способ и устройство для тасования данных. Также описаны способ и устройство для параллельного табличного преобразования с использованием SIMD-инструкций. Также раскрыты способ и устройство для переупорядочения данных между множеством регистров. Представленные варианты осуществления описаны в контексте микропроцессора, но не ограничены этим. Хотя последующие варианты осуществления описаны со ссылкой на процессор, другие варианты осуществления применимы к другим типам интегральных схем и логических устройств. Те же методы и решения, соответствующие настоящему изобретению, могут быть легко применены к другим типам схем или полупроводниковых устройств, которые могут получать выгоду от более высокой пропускной способности конвейерной обработки и улучшенной производительности. Решения, согласно настоящему изобретению, применимы к любому процессору или машине, которая выполняет обработку данных. Однако настоящее изобретение не ограничивается процессорами или машинами, которые выполняют 256-битовые, 128-битовые, 64-битовые, 32-битовые или 16-битовые операции над данными, и может быть применено к любому процессору и машине, где требуется тасование данных.
В последующем описании в целях пояснения приводятся различные конкретные детали, чтобы более глубоко вникнуть в настоящее изобретение. Специалисту в данной области техники, однако, должно быть понятно, что эти конкретные детали не обязательны для реализации настоящего изобретения. В других случаях хорошо известные электрические структуры и схемы не раскрываются подробно, чтобы не затенять сущность изобретения несущественными деталями. Кроме того, в последующем описании приводятся примеры и на чертежах показываются различные примеры в целях иллюстрации. Однако эти примеры не должны толковаться в ограничительном смысле, поскольку они предназначены только для обеспечения примеров настоящего изобретения, но не представляют исчерпывающий перечень возможных вариантов реализации настоящего изобретения.
В варианте осуществления способы, соответствующие настоящему изобретению, воплощены в машиноисполняемых инструкциях. Инструкции могут использоваться для обеспечения того, чтобы универсальный или специализированный процессор, который запрограммирован этими инструкциями, выполнял этапы настоящего изобретения. Альтернативно, этапы настоящего изобретения могут выполняться конкретными компонентами аппаратных средств, которые содержат аппаратные логические средства для выполнения этих этапов, или любой комбинацией программируемых компьютерных компонентов и настраиваемых компонентов аппаратных средств.
Хотя приведенные ниже примеры описывают обработку и распределение инструкций в контексте исполнительных модулей и логических схем, друге варианты осуществления настоящего изобретения могут быть выполнены с помощью программного обеспечения. Настоящее изобретение может быть обеспечено как компьютерный программный продукт или программное обеспечение, что может включать в себя машину или машиночитаемый носитель с сохраненными на нем инструкциями, которые могут быть использованы для программирования компьютера (или иных электронных приборов) для выполнения процесса, соответствующего настоящему изобретению. Такое программное обеспечение может быть сохранено в памяти в системе. Аналогичным образом код может распространяться по сети или с помощью другого машиночитаемого носителя. Таким образом, машиночитаемый носитель может включать в себя любой механизм для хранения или передачи информации в форме, обеспечивающей возможность считывания машиной (например, компьютером), включая, без ограничения указанным, гибкие диски, оптические диски, компакт-диски (CD), ПЗУ на компакт-дисках (CD-ROM), магнитооптические диски, ПЗУ, ОЗУ, стираемое программируемое ПЗУ (СППЗУ), электронно-стираемое программируемое ПЗУ (ЭСППЗУ), магнитные или оптические карты, флэш-память, передачу через Интернет, электрическую, оптическую, акустическую или другие формы распространяющихся сигналов (например, несущие волны, инфракрасные сигналы, цифровые сигналы и т.д.) и тому подобное.
Соответственно, машиночитаемый носитель включает в себя любой тип среды передачи/машиночитаемого носителя, подходящий для хранения или передачи электронных инструкций или информации в форме, считываемой машиной (например, компьютером). Более того, настоящее изобретение может также предусматривать загрузку в виде компьютерного программного продукта. Как таковая программа может переноситься с удаленного компьютера (например, сервера) на запрашивающий компьютер (например, клиент). Перенос программы может осуществляться с помощью электрических, оптических, акустических или других форм распространяющихся сигналов, воплощенных в несущем колебании или другой среде распространения в коммуникационном канале (например, модем, сетевое соединение и тому подобное).
Кроме того, варианты осуществления структур интегральных схем в соответствии с настоящими изобретениями могут быть переданы или перенесены в электронной форме как база данных на магнитной ленте или ином машиночитаемом носителе. Например, электронная форма структуры интегральной схемы процессора в одном варианте осуществления может обрабатываться или изготавливаться на производстве для получения компьютерного компонента. В другом случае структура интегральной схемы в электронной форме может обрабатываться машиной для моделирования компьютерного компонента. Таким образом, топологии схем и/или структуры процессоров в некоторых вариантах осуществления могут распространяться посредством машиночитаемых носителей или воплощаться на них для изготовления схем или для моделирования интегральной схемы, модель которой при обработке машиной моделирует процессор. Машиночитаемый носитель также может хранить данные, представляющие предварительно заданные функции, в соответствии с настоящим изобретением в других вариантах осуществления.
В современных процессорах используется ряд различных исполнительных модулей для обработки и исполнения разнообразных кодов и инструкций. Не все инструкции создаются одинаковыми, так как некоторые обладают более высоким быстродействием выполнения, в то время как другие требуют огромного числа тактовых циклов. Чем более высокой является пропускная способность инструкций, тем лучше показатели процессора в целом. Таким образом, было бы предпочтительным, чтобы максимально больше инструкций имели максимально возможное быстродействие. Однако имеются некоторые инструкции, которые имеют более высокую сложность и требуют большего времени исполнения и больших ресурсов процессора. Например, имеются инструкции с плавающей запятой, операции загрузки/сохранения, перемещения данных и т.д.
По мере того как все больше компьютерных систем используется в Интернете и мультимедийных приложениях, со временем вводится дополнительная поддержка процессора. Например, целочисленные/с плавающей запятой SIMD-инструкции и потоковые SIMD-инструкции (SSE) представляют собой инструкции, которые сокращают общее число инструкций, требуемых для выполнения конкретной программной задачи. Эти инструкции могут повышать быстродействие выполнения программного обеспечения за счет параллельного осуществления операций над множеством элементов данных. В результате может быть обеспечен выигрыш по показателям в широком диапазоне приложений, включая обработку видео, речи, изображений/фотоснимков. Реализация SIMD-инструкций в микропроцессорах и аналогичных типах логических схем обычно связана с рядом вопросов. Кроме того, сложность SIMD-операций часто приводит к необходимости введения дополнительных схем для корректной обработки и манипулирования данными.
Варианты осуществления настоящего изобретения обеспечивают способ реализации упакованных байтовых инструкций тасования с возможностью сброса в нуль в качестве алгоритма, который использует SIMD-ориентированные аппаратные средства. В одном варианте осуществления алгоритм основан на принципе тасования данных из конкретного регистра или ячейки памяти на основе значений управляющей маски для каждой позиции элемента данных. Варианты осуществления упакованного байтового тасования могут использоваться для сокращения числа инструкций, требуемых во многих различных приложениях, которые предусматривают переупорядочение данных. Упакованные байтовые инструкции тасования могут также использоваться для любого приложения с не выровненными нагрузками. Варианты осуществления такой инструкции тасования могут быть использованы для фильтрации, чтобы упорядочить данные для обеспечения эффективных операций умножения-сложения. Аналогичным образом, упакованные инструкции тасования могу быть использованы в видео приложениях и в приложениях шифрования для упорядочения данных и малых таблиц преобразования. Такая инструкция может быть использована для смешивания данных из двух или более регистров. Таким образом, варианты осуществления упакованного тасования в соответствии с алгоритмом сброса в нуль, согласно настоящему изобретению, могут быть реализованы в процессе для поддержки SIMD-операций эффективным образом, без заметного ухудшения показателей в целом.
Варианты осуществления настоящего изобретения обеспечивают инструкцию тасования упакованных данных (PSHUFB) с возможностью сброса в нуль, для эффективного упорядочения и расположения данных любого размера. В одном варианте осуществления данные перетасовываются или переупорядочиваются в регистре с битовой гранулярностью. Операция битового тасования упорядочивает размеры данных, которые превышают байты, за счет поддержания относительного положения байтов в данных большего размера в процессе операции тасования. Кроме того, операция байтового тасования может изменить относительное положение данных в SIMD-регистре и может также дублировать данные. Эта PSHUFB-инструкция перетасовывает байты из первого регистра источника в соответствии с содержимым байтов управления тасованием во втором регистре источника. Хотя инструкция осуществляет перестановку данных, маска тасования не подвергается воздействию и остается неизменной в течение этой операции тасования в данном варианте осуществления. Мнемоника для одной реализации представляет следующее: «PSHUFB-регистр 1, регистр 2/память», при этом первый и второй операнды являются SIMD-регистрами. Однако регистр второго операнда может также быть заменен ячейкой памяти. Первый операнд включает в себя источник данных для тасования. Для этого варианта осуществления регистр для первого операнда также является регистром адресата. Варианты осуществления в соответствии с настоящим изобретением также включают в себя возможность установки выбранных байтов на нуль, в дополнение к изменению их позиции.
Второй операнд включает в себя набор байтов маски управления тасованием для обозначения шаблона тасования. Число битов, используемых для выбора элемента данных источника, равно логарифму по основанию два от числа элементов данных в операнде источника. Например, число байтов в варианте осуществления с 128-битовым регистром равно шестнадцати. Log216=4. То есть требуется четыре бита или полубайт. Индекс [3:0] в коде, представленном ниже, относится к четырем битам. Если старший бит (MSB), бит 7 в данном варианте осуществления, байта управления тасованием установлен, то постоянный нуль записывается в байт результата. Если младший полубайт байта I второго операнда, набор маски, содержит целое число J, то инструкция тасования обеспечивает то, что J-й байт первого регистра источника копируется в позицию I-го байта регистра адресата. Ниже приведен пример псевдокода для варианта осуществления упакованной операции байтового тасования над 128-битовыми операндами:
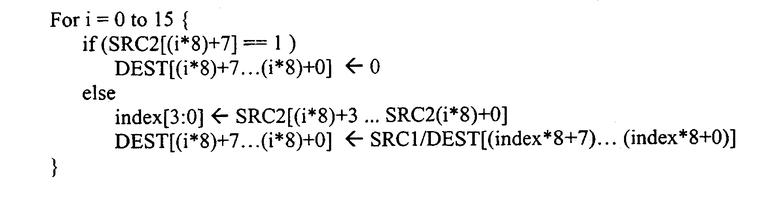
Аналогично, ниже приведен пример псевдокода для другого варианта осуществления упакованной операции байтового тасования над 64-битовыми операндами:
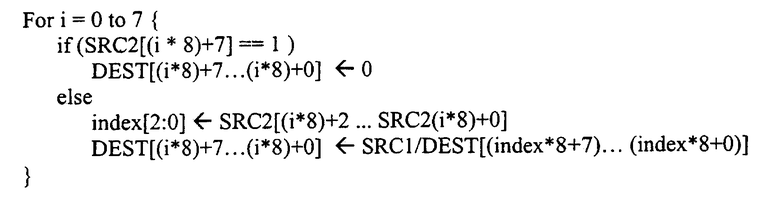
Заметим, что в этом варианте осуществления 64-битового регистра используются младшие три бита маски, так как имеется восемь байтов в 64-битовом регистре. Log28=3. Индекс [2:0] в коде, представленном выше, относится к трем битам. В альтернативных вариантах число битов в маске может изменяться для соответствия числу элементов данных, имеющихся в данных источника. Например, маска с младшими пятью битами необходима для выбора элемента данных в 256-битовом регистре.
В настоящее время является несколько затруднительным и трудоемким переупорядочивать данные в SIMD-регистре. Некоторые алгоритмы требуют больше инструкций для упорядочения данных для арифметических операций, чем действительное число инструкций для исполнения этих операций. Путем реализации вариантов осуществления упакованной инструкции байтового тасования в соответствии с настоящим изобретением можно существенным образом уменьшить число инструкций, требуемых для осуществления переупорядочивания данных. Например, один вариант осуществления упакованной инструкции байтового тасования может транслировать байт данных во все позиции 128-битового регистра. Трансляция данных в регистр часто используется в приложениях фильтрации, где один элемент данных умножается на много коэффициентов. Без такой инструкции байт данных должен был бы фильтроваться из его источника и сдвигаться в низшую байтовую позицию. Затем этот один байт должен был бы дублироваться сначала как байт, затем эти два байта должны дублироваться вновь для формирования двойного слова, и затем двойное слово должно дублироваться для формирования в итоге квадраслова. Все эти операции могут быть заменены одной упакованной инструкцией тасования.
Аналогичным образом реверсирование всех байтов в 128-битовом регистре, такое как переход между большим конечным и малым конечным форматами, может легко выполняться с помощью упакованной инструкции байтового тасования. В то время как даже эти довольно простые шаблоны требуют некоторого количества инструкций, если бы не использовалась упакованная инструкция тасования, комплексные или случайные шаблоны требуют намного больше неэффективных процедур инструкций. Наиболее простое решение для переупорядочения случайных байтов в SIMD-регистре заключается в записи их в буфер и затем использовании целочисленных байтовых считываний/записей для переупорядочения их и затем считывания их назад в SIMD-регистр. Вся эта обработка данных потребует длинной кодовой последовательности, в то время как может быть достаточной единственная упакованная инструкция тасования. Путем уменьшения требуемого числа инструкций можно значительно уменьшить число тактовых циклов, требуемых для формирования того же самого результата. Варианты осуществления настоящего изобретения также используют инструкции тасования для доступа к множеству значений в таблице с SIMD-инструкциями. Даже в случае, когда таблица имеет в два раза больший размер по сравнению с регистром, алгоритмы, соответствующие настоящему изобретению, позволяют осуществить доступ к элементам данных с более высокой скоростью, чем в случае одного элемента данных на инструкцию, как при целочисленных операциях.
На фиг.1А показана блок-схема примерной компьютерной системы с процессором, который содержит исполнительные модули для исполнения инструкции для тасования данных в соответствии с одним вариантом осуществления настоящего изобретения. Система 100 содержит компонент, такой как процессор 102, для использования исполнительных модулей, включая логику для выполнения алгоритмов тасования данных, в соответствии с настоящим изобретением, как в описанном варианте осуществления. Система 100 представляет системы обработки на основе микропроцессоров Pentium® III, Pentium® 4, Celeron®, XeonTM, Itanium®, XScaleTM и/или StrongARMTM, поставляемых компанией Intel Corporation (Santa Clara, California), хотя и другие системы (включая РС с другими микропроцессорами, рабочие станции, приставки и т.д.) также могут использоваться. В одном варианте осуществления приведенная в качестве образца система 100 может исполнять версию операционной системы WINDOWSTM, поставляемой компанией Microsoft Corporation (Redmond, Washington), хотя могут использоваться и другие операционные системы (например, UNIX, Linux), встроенное программное обеспечение и/или графические пользовательские интерфейсы. Таким образом, настоящее изобретение не ограничено какой-либо конкретной комбинацией схем аппаратных средств и программного обеспечения.
Настоящее изобретение не ограничено компьютерными системами. Альтернативные варианты осуществления настоящего изобретения могут использоваться в других устройствах, таких как портативные устройства и встроенные приложения. Некоторые примеры портативных устройств включают в себя сотовые телефоны, устройства Интернет-протокола, цифровые камеры, персональные цифровые помощники (PDA) и карманные РС. Встроенные приложения могут включать в себя микроконтроллер, цифровой процессор сигналов (DSP), систему на микросхеме, сетевые компьютеры (NetPC), приставки, сетевые концентраторы, коммутаторы глобальной сети (WAN) или любую другую систему, которая выполняет целочисленные операции тасования над операндами. Кроме того, некоторые архитектуры реализованы для обеспечения возможности инструкциям работать над различными данными одновременно, чтобы улучшить эффективность мультимедийных приложений. По мере того как число типов и объем данных увеличиваются, компьютеры и их процессоры должны совершенствоваться, чтобы манипулировать данными более эффективными методами.
На фиг.1А показана блок-схема компьютерной системы 100, образованной процессором 102, который включает в себя один или более исполнительных модулей 108 для выполнения алгоритма тасования данных в соответствии с настоящим изобретением. Представленный вариант осуществления описан в контексте однопроцессорной системы рабочего стола или серверной системы, но альтернативные варианты осуществления могут быть включены в многопроцессорную систему. Система 100 является примером архитектуры концентратора. Компьютерная система 100 содержит процессор 102 для обработки сигналов данных. Процессор 102 может быть микропроцессором компьютера с полным набором команд (CICS), микропроцессором компьютера с сокращенным набором команд (RICS), микропроцессором с командными словами сверхбольшой длины (VLIW), процессором, реализующим комбинацию наборов инструкций, или любым другим процессорным устройством, например, таким как цифровой процессор сигналов. Процессор 102 связан с шиной 110 процессора, которая может передавать сигналы данных между процессором 102 и другими компонентами в системе 100. Элементы системы 100 выполняют свои обычные функции, хорошо известные специалистам в данной области техники.
В одном варианте осуществления процессор 102 содержит внутреннюю кэш-память 104 уровня 1 (L1). В зависимости от архитектуры процессор 102 может иметь один внутренний кэш или множество уровней внутреннего кэша. Альтернативно, в другом варианте осуществления кэш-память может содержаться вне процессора 102. Другие варианты осуществления могут также содержать комбинацию внутренних и внешних кэшей, в зависимости от конкретной реализации и потребностей. Регистровый файл 106 может сохранять различные типы данных в разных регистрах, включая целочисленные регистры, регистры с плавающей запятой, регистры статуса и регистры указателя инструкции.
Исполнительный модуль 108, включающий в себя логику для выполнения целочисленных операций и операций с числами с плавающей запятой, также содержится в процессоре 102. Процессор 102 также содержит ПЗУ микрокода (ucode), которое хранит микрокод для определенных макроинструкций. В этом варианте осуществления исполнительный модуль 108 содержит логику для обработки набора 109 упакованных инструкций. В одном варианте осуществления набор 109 упакованных инструкций включает в себя упакованную инструкцию тасования для организации данных. Путем включения набора 109 упакованных инструкций в набор инструкций универсального процессора 102 вместе со связанными схемами для исполнения инструкций операции, используемые множеством мультимедийных приложений, могут выполняться с использованием упакованных данных в универсальном процессоре 102. Таким образом, многие мультимедийные приложения могут выполняться с ускорением и более эффективно за счет использования полной ширины шины данных процессора для выполнения операций над упакованными данными. Это может исключить потребность в переносе малых блоков данных по шине данных процессора для выполнения одной или более операций над одним элементом данных в каждый данный момент времени.
Альтернативные варианты осуществления исполнительного модуля 108 также могут быть использованы в микроконтроллерах, встроенных процессорах, графических устройствах, DSP и логических схемах других типов. Система 100 содержит память 120. Память 120 может представлять собой динамическое ОЗУ (DRAM), статическое ОЗУ (SRAM), флэш-память или иное запоминающее устройство. Память 120 может сохранять инструкции и/или данные, представленные сигналами данных, которые могут исполняться процессором 102.
Микросхема 116 системной логики связана с процессорной шиной 110 и памятью 120. Микросхема 116 системной логики в представленном варианте осуществления представляет собой концентратор контроллера памяти (МСН). Процессор 102 может осуществлять информационный обмен с МСН 116 через процессорную шину 110. МСН 116 обеспечивает канал 118 памяти с большой шириной полосы для памяти 120 для хранения инструкций и данных и для хранения команд, данных и текстур графики. МСН 116 предназначен для направления сигналов данных между процессором 102, памятью 120 и другими компонентами в системе 100 и для переноса сигналов данных между процессорной шиной 110, памятью 120 и системой ввода/вывода (I/O) 122. В некоторых вариантах осуществления микросхема 116 системной логики может обеспечивать графический порт для связи с графическим контроллером 112. МСН 116 связан с памятью 120 через интерфейс 118 памяти. Графическая карта 112 связана с МСН 116 через межсоединение 114 ускоренного графического порта (AGP).
Система 100 использует специализированную шину 122 интерфейса концентратора для связи МСН 116 с концентратором контроллера I/O (ICH) 130. ICH 130 обеспечивает непосредственные соединения с некоторыми устройствами ввода/вывода через локальную шину ввода/вывода. Локальная шина ввода/вывода является высокоскоростной шиной ввода/вывода для соединения периферийных устройств с памятью 120, набором микросхем и процессором 102. Некоторыми примерами также являются аудио контроллер, концентратор программно-аппаратных средств (флэш-BIOS) 128, беспроводный приемопередатчик 126, память 124 данных, традиционный контроллер ввода/вывода, содержащий интерфейсы пользовательского ввода и клавиатуры, последовательный порт расширения, такой как порт универсальной последовательной шины (BUS), и сетевой контроллер 134. Устройство 124 хранения данных может содержать накопитель на жестком диске, накопитель на гибких дисках, устройство CD-ROM, устройство флэш-памяти или другие устройства массовой памяти.
В другом варианте осуществления системы исполнительный модуль для исполнения алгоритма с инструкцией тасования может использоваться с системой на микросхеме. Один вариант осуществления системы на микросхеме содержит процессор и память. Памятью для одной такой системы является флэш-память. Флэш-память может находиться на том же самом кристалле, что и процессор и другие системные компоненты. Дополнительно другие логические блоки, такие как контроллер памяти или графический контроллер, также могут находиться в системе на микросхеме.
На фиг.1В показан альтернативный вариант осуществления системы 140 обработки данных, которая реализует принципы настоящего изобретения. Один вариант осуществления системы 140 обработки данных представляет собой процессор приложений Intel®PCA (Архитектура персонального Интернет-клиента Intel®) с технологией IntelXScaleТМ, как представлено во Всемирной паутине по адресу developer.intel.com). Специалистам в данной области техники должно быть понятно, что описанные варианты осуществления могут быть использованы с альтернативными системами обработки без отклонения от объема изобретения.
Компьютерная система 140 содержит процессорное ядро 159, имеющее возможность выполнения SIMD-операций, включая тасование. В одном варианте осуществления процессорное ядро 159 представляет собой блок обработки с архитектурой любого типа, включая, без ограничения указанным, архитектуру типа SISC, RISC, VLIW. Процессорное ядро 159 содержит исполнительный блок 142, набор файловых регистров 145 и декодер 144. Процессорное ядро 159 также включает в себя дополнительные схемы (не показаны), которые не являются необходимыми для понимания настоящего изобретения. Исполнительный блок 142 используется для исполнения инструкций, принимаемых процессорным ядром 159. В дополнение к распознаванию типовых процессорных инструкций исполнительный блок 142 может распознавать инструкции в наборе 143 упакованных инструкций для выполнения операций над упакованными форматами данных. Набор 143 упакованных инструкций включает в себя инструкции для поддержки операций тасования, но может также включать в себя и другие упакованные инструкции. Исполнительный блок 142 связан с регистровым файлом 145 посредством внутренней шины. Регистровый файл 145 представляет область памяти на процессорном ядре 159 для хранения информации, включая данные. Как упомянуто выше, понятно, что область памяти, используемая для хранения пакетных данных, не является критичной. Исполнительный блок 142 связан с декодером 144. Декодер 144 используется для декодирования инструкций, принятых процессорным ядром 159, в управляющие сигналы и/или точки ввода в микрокод. В ответ на эти управляющие сигналы и/или точки ввода в микрокод исполнительный блок 142 выполняет соответствующие операции.
Процессорное ядро 159 связано с шиной 141 для информационного обмена с множеством других устройств системы, которые могут включать в себя, без ограничения указанным, например, управление синхронным динамическим ОЗУ (SDRAM), управление 147 статическим ОЗУ (SRAM), интерфейс 148 пакетной флэш-памяти, управление 149 картой памяти PCMCIA (Международной Ассоциацией производителей карт памяти для персональных компьютеров)/картой компактной флэш-памяти (CF), управление 150 жидкокристаллическим дисплеем, контроллер 151 прямого доступа к памяти (DMA), интерфейс 152 альтернативного "хозяина" шины (устройства управления передачей данных по шине). В одном варианте осуществления система 140 обработки данных может также содержать мост 154 ввода/вывода для коммуникации с различными устройствами ввода/вывода через шину 153 ввода/вывода. Такие устройства ввода/вывода могут включать в себя, без ограничения указанным, например, универсальный асинхронный приемник/передатчик (UART) 155, универсальную последовательную шину (USB) 156, беспроводный Bluetooth-UART 157 и интерфейс 158 расширения ввода/вывода.
Один вариант осуществления системы 140 обработки данных обеспечивает мобильные, сетевые и/или беспроводные коммуникации и процессорное ядро 159, имеющее возможность выполнения SIMD-операций, включая операцию тасования. Процессорное ядро 159 может быть запрограммировано в соответствии с различными алгоритмами обработки аудио, видео, формирования изображений и коммуникации, включая дискретные преобразования, такие как преобразования Уолша-Адамара, быстрое преобразование Фурье (БПФ) и дискретное косинусное преобразование (ДКП), и соответствующие им инверсные преобразования; методы сжатия/декомпрессии, такие как преобразование цветового пространства, оценивание движения в кодированном видео или компенсация движения в декодированном видео; функции модуляции/демодуляции, такие как импульсно-кодовая модуляция.
На фиг.1С показан еще один вариант осуществления системы обработки данных, обеспечивающий выполнение SIMD-операций тасования. В соответствии с другим вариантом осуществления система 160 обработки данных может содержать основной процессор 166, SIMD-сопроцессор 161, кэш-память 167 и систему 168 ввода/вывода. Система 168 ввода/вывода может быть дополнительно связана с беспроводным интерфейсом 169. SIMD-сопроцессор 161 может выполнять SIMD-операции, включая тасование данных. Процессорное ядро 170 может подходить для изготовления в одном или более технологических процессах, а также путем представления на машиночитаемом носителе с достаточной детализацией может способствовать облегчению изготовления всей или части системы 160 обработки, содержащей процессорное ядро 170.
В одном варианте осуществления SIMD-сопроцессор 161 содержит исполнительный блок 162 и набор файловых регистров 164. Один вариант осуществления основного процессора 166 содержит декодер 165 для распознавания инструкций из набора 163 инструкций, включая SIMD-инструкции тасования, для исполнения исполнительным блоком 162. В альтернативных вариантах осуществления SIMD-сопроцессор 161 также содержит, по меньшей мере, часть декодера 165В для декодирования инструкций из набора 163 инструкций. Процессорное ядро 170 также содержит дополнительные схемы (не показаны), которые не являются необходимыми для понимания настоящего изобретения.
В процессе работы основной процессор 166 исполняет поток инструкций по обработке данных, которые управляют операциями обработки данных общего типа, включая взаимодействия с кэш-памятью 167 и системой 168 ввода/вывода. В поток инструкций обработки данных введены инструкции SIMD-сопроцессора. Декодер 165 основного процессора 166 распознает эти инструкции SIMD-сопроцессора, как относящиеся к тому типу, который должен исполняться присоединенным SIMD-сопроцессором 161. Соответственно, основной процессор 166 выдает эти инструкции SIMD-сопроцессора (или управляющие сигналы, представляющие инструкции SIMD-сопроцессора) в шину 166 сопроцессора, откуда они принимаются любыми присоединенными SIMD-сопроцессорами. В этом случае SIMD-сопроцессор 161 будет принимать и исполнять любые принятые инструкции SIMD-сопроцессора, предназначенные для него.
Данные могут приниматься через беспроводный интерфейс 169 для обработки посредством инструкций SIMD-сопроцессора. Например, речевые передачи могут приниматься в форме цифрового сигнала, который может обрабатываться посредством инструкций SIMD-сопроцессора для восстановления выборок цифрового аудиосигнала, представляющих речевые передачи. В качестве другого примера сжатые аудио и/или видеоданные могут приниматься в форме цифрового битового потока, который может обрабатываться посредством инструкций SIMD-сопроцессора для восстановления выборок цифрового аудиосигнала и/или кадров движущегося видеоизображения. В одном варианте осуществления процессорного ядра 170 основной процессор 166 и SIMD-сопроцессор 161 интегрированы в единое процессорное ядро 170, содержащее исполнительный блок 162, набор регистровых файлов 164 и декодер 165 для распознавания инструкций из набора 163 инструкций, включая SIMD-инструкции тасования.
На фиг.2 показана блок-схема микроархитектуры для процессора 200 в одном варианте осуществления, который включает в себя логические схемы для выполнения операций тасования в соответствии с настоящим изобретением. Операция тасования также может упоминаться как операция тасования упакованных данных или как упакованная операция тасования, как описано выше. В одном варианте осуществления инструкции тасования инструкция может тасовать упакованные данные с байтовой гранулярностью. Эта инструкция может также упоминаться как PSHUFB или упакованный байт тасования. В других вариантах осуществления инструкция тасования может быть реализована для операции с элементами данных, имеющими размеры слова, двойного слова, квадраслова и т.д. Внутренний препроцессор 201 является частью процессора 200, который извлекает макроинструкции для исполнения и подготавливает их к последующему использованию в конвейерной обработке процессора. Препроцессор 201 в этом варианте осуществления включает в себя несколько блоков. Блок 226 выборки инструкций извлекает макроинструкции из памяти и вводит их в декодер 228 инструкций, который, в свою очередь, декодирует их в примитивы, называемые микроинструкциями или микрооперациями (также определяемые как micro op или uops), которые понятны машине для исполнения. Трассировочный кэш 230 принимает декодированные uops и компонует их в программно-упорядоченные последовательности или трассы в uop-очереди 234 для исполнения. Если трассировочный кэш 230 обнаруживает комплексную макроинструкцию, ПЗУ 232 микрокода обеспечивает uops, необходимые для завершения операции.
Многие макроинструкции преобразуются в одиночную микрооперацию, а другие требуют нескольких микроопераций для завершения полной операции. В этом варианте осуществления, если более четырех микроопераций требуется для завершения макроинструкции, то декодер 228 обращается к ПЗУ 232 микрокода для выполнения микроинструкции. В одном варианте осуществления упакованная инструкция тасования может быть декодирована в малое число микроопераций для обработки в декодере 228 инструкций. В другом варианте осуществления инструкция для алгоритма тасования упакованных данных может быть сохранена в ПЗУ 232 микрокода, если некоторое количество микроопераций требуется для выполнения операции. Трассировочный кэш 230 ссылается на программируемую логическую матрицу точек входа для определения корректного указателя микроинструкции для считывания последовательности микрокода для алгоритмов тасования в ПЗУ 232 микрокода. После того как ПЗУ 232 микрокода заканчивает установление последовательности выполнения микроинструкций для текущей макроинструкции, препроцессор 201 машины возобновляет выборку микроопераций из трассировочного кэша 230.
Некоторые SIMD и другие мультимедийные типы инструкций рассматриваются как комплексные инструкции. Большинство инструкций, связанных с плавающей запятой, являются, таким образом, комплексными инструкциями, Когда декодер 228 инструкций обнаруживает комплексную макроинструкцию, осуществляется обращение к ПЗУ 232 микрокода в соответствующей ячейке, чтобы извлечь последовательность микрокода для данной макроинструкции. Различные микрооперации, необходимые для выполнения данной микроинструкции, пересылаются в процессор 203 исполнения с изменением последовательности для исполнения в соответствующих исполнительных модулях, как целочисленных, так и с плавающей запятой.
Процессор 203 исполнения с изменением последовательности предназначен для подготовки микроинструкций для исполнения. Логика исполнения с изменением последовательности имеет ряд буферов для сглаживания и переупорядочения потока микроинструкций для оптимизации выполнения, по мере того как они проходят через конвейерную обработку и планируются для исполнения. Логика распределителя распределяет машинные буферы и ресурсы, требуемые каждой микрооперации (uop) для исполнения. Распределитель также назначает запись для каждой uop в одной из двух uop-очередей, одну для операций памяти и одну для операций вне памяти, перед планировщиками инструкций: планировщиком памяти, быстродействующим планировщиком 202, медленным/общим планировщиком 204 и простым планировщиком 204 с плавающей запятой. Планировщики 202, 204, 206 микроопераций определяют, когда микрооперация готова к исполнению, на основе готовности их зависимых источников операндов входных регистров и доступности ресурсов исполнения, требуемых микрооперациям для завершения их операции. Быстродействующий планировщик 202 в этом варианте осуществления может планировать на каждую половину основного тактового цикла, в то время как другие планировщики могут только планировать однократно на каждый тактовый цикл основного процессора. Планировщики проводят арбитраж по отношению к диспетчерским портам для планирования микроопераций для исполнения.
Регистровые файлы 208, 210 находятся между планировщиками 202, 204, 206 и исполнительными модулями 212, 214, 216, 218, 220, 222, 224 в исполнительном блоке 211. Имеется отдельный регистровый файл 208, 210 для целочисленных операций и операций с плавающей запятой соответственно. Каждый регистровый файл 208, 210 в данном варианте осуществления также включает в себя транзитную схему, которая может пропускать или пересылать только что полученные результаты, которые еще не были записаны в регистровый файл, в новые зависимые микрооперации. Целочисленный регистровый файл 208 и регистровый файл 210 с плавающей запятой также могут обмениваться данными друг с другом. В одном варианте осуществления целочисленный регистровый файл 208 разделен на два отдельных регистровых файла, один регистровый файл для 32 битов данных нижнего порядка и другой регистровый файл для 32 битов данных верхнего порядка. Регистровый файл 210 с плавающей запятой в одном варианте осуществления имеет 128-битовые записи, поскольку инструкции с плавающей запятой в типовом случае имеют операнды размером от 64 до 128 битов.
Исполнительный блок 211 содержит исполнительные модули 212, 214, 216, 218, 220, 222, 224, где инструкции исполняются в текущий момент. Эта секция содержит регистровые файлы 208, 210, которые сохраняют целочисленные и с плавающей запятой значения операндов данных, которые необходимо исполнять микроинструкциям. Процессор 200 в этом варианте осуществления содержит ряд исполнительных модулей: модуль генерации адреса (AGU) 212, AGU 214, быстродействующее арифметико-логическое устройство (ALU) 218, быстродействующее ALU 220, медленное ALU 222, модуль 224 перемещения с плавающей запятой. В данном варианте осуществления исполнительные модули 222, 224 исполняют операции с плавающей запятой MMX, SIMD, SSE. ALU 222 с плавающей запятой в данном варианте осуществления содержит делитель с плавающей запятой для исполнения микроопераций деления, извлечения квадратного корня и нахождения остатка. В вариантах осуществления настоящего изобретения любое действие, связанное со значением с плавающей запятой, осуществляется с помощью аппаратных средств с плавающей запятой. Например, преобразования между целочисленным форматом и форматом с плавающей запятой связано с использованием регистрового файла с плавающей запятой. Аналогичным образом операция деления с плавающей запятой осуществляется в делителе с плавающей запятой. С другой стороны, числа не с плавающей запятой и целые числа обрабатываются целочисленными ресурсами аппаратных средств. Простые очень частые арифметико-логические операции направляются в быстродействующие ALU 216, 218. Быстродействующие ALU 216, 218 в этом варианте осуществления могут исполнять быстродействующие операции с эффективным запаздыванием порядка половины такового цикла. В одном варианте осуществления большинство комплексных целочисленных операций направляются в медленное ALU 222, так как медленное ALU 222 включает в себя целочисленные исполнительные аппаратные средства для операций с большим запаздыванием, таких как умножение, сдвиги, флаговая логика и обработка ветвления. Операции загрузки/сохранения в памяти исполняются модулями AGU 212, 214. В этом варианте осуществления целочисленные ALU 216, 218, 220 описаны в контексте выполнения целочисленных операций над 64-битовыми операндами данных. В альтернативных вариантах осуществления ALU 216, 218, 220 могут быть реализованы для поддержки различного количества битов данных, включая 16, 32, 128, 256 и т.д. Аналогичным образом, модули 222, 224 с плавающей запятой могут быть реализованы для поддержки некоторого диапазона операндов, состоящих из разного количества битов. В одном варианте осуществления модули 222, 224 с плавающей запятой могут работать с 128-битовыми операндами упакованных данных в связи с SIMD и мультимедийными инструкциями.
В этом варианте осуществления планировщики 202, 204, 206 микроопераций диспетчеризуют зависимые операции, прежде чем исходная нагрузка завершит исполнение. Поскольку микрооперации опережающим образом планируются и исполняются в процессоре 200, процессор 200 также включает в себя логику для обработки пропусков в памяти. Если загрузка данных пропущена в кэше данных, то могут быть зависимые текущие операции в конвейерной обработке, которые вышли из планировщика с временно некорректными данными. Соответствующий ответный механизм отслеживает и повторно исполняет такое использование некорректных данных. Необходимо повторять только зависимые операции, а независимые операции разрешается завершить. Планировщики и ответный механизм в одном варианте осуществления процессора также предназначены для перехвата последовательностей инструкций для операций тасования.
Термин «регистры» используется в настоящем документе для обозначения встроенных ячеек памяти процессора, которые используются как часть макроинструкций для идентификации операндов. Иными словами, упоминаемые регистры представляют собой регистры, которые видимы вне процессора (с точки зрения программиста). Однако регистры в одном варианте осуществления не должны ограничиваться в своем смысловом значении конкретным типом схем. Наоборот, регистры в варианте осуществления должны только иметь возможность хранить и обеспечивать данные и выполнять функции, описанные в настоящем документе. Описанные регистры могут быть реализованы схемами в процессоре с использованием любого числа различных методов, таких как специализированные физические регистры, динамически распределяемые физические регистры с использованием переименования регистров, комбинации специализированных и динамически распределяемых регистров и т.д. В одном варианте целочисленные регистры хранят 32-битовые целочисленные данные. Регистровый файл в одном варианте осуществления также содержит восемь мультимедийных SIMD-регистров для упакованных данных. Для описания, приведенного ниже, регистры понимаются как регистры данных, предназначенные для хранения упакованных данных, такие как 64-битовые ММХЕТМ-регистры (также называемые в некоторых случаях «mm-регистрами») в микропроцессорах, реализованных по ММХ-технологии, компании Intel Corporation (Santa Clara, California). Эти ММХ-регистры, доступные как в целочисленном варианте, так и в варианте с плавающей запятой, могут использоваться с элементами упакованных данных, которые сопровождают SIMD и SSE-инструкции. Аналогичным образом 128-битовые ХХМ-регистры, относящиеся к SSE2-технологии, также могут использоваться для хранения таких операндов упакованных данных. В этом варианте осуществления при хранении упакованных данных и целочисленных данных регистрам не требуется поводить различия между двумя типами данных.
В примерах, приведенных на следующих чертежах, описан ряд операндов данных. Для простоты исходные сегменты данных источника обозначены, начиная с буквы А, по алфавиту, где А относится к низшему адресу, а Z - к высшему адресу. Таким образом, А может первоначально соответствовать адресу 0, В - адресу 1, С - адресу 3 и т.д. В принципе, операция тасования, как в случае тасования упакованных байтов в одном варианте осуществления, связана с тасованием сегментов данных из первого операнда и переупорядочением одного или более из элементов данных источника в шаблон, определенный набором масок во втором операнде. Таким образом, тасование может циклически изменить или полностью переупорядочить часть или все из элементов данных в любой желательный порядок. Кроме того, любой конкретный элемент данных или ряд элементов данных могут дублироваться или транслироваться в результат. Варианты осуществления инструкции тасования в соответствии с настоящим изобретением включают в себя функцию сброса в нуль, причем маска для каждого конкретного элемента данных может обеспечить то, что позиция элемента данных будет обнулена в полученном результате.
На фиг.3А-С приведены иллюстрации масок тасования в соответствии с различными вариантами осуществления настоящего изобретения. В данном примере показан операнд 310 упакованных данных, содержащий множество отдельных элементов 311, 312, 313, 314 данных. Упакованный операнд 310 данного примера описан в контексте операнда упакованных данных, как содержащий набор масок для указания шаблона тасования для соответствующих элементов упакованных данных другого операнда. Таким образом, маска в каждом из элементов 311, 312, 313, 314 данных упакованного операнда 310 обозначает содержимое в соответствующей позиции элемента данных результата. Например, элемент 311 данных соответствует позиции самого левого элемента данных. Маска в элементе 311 данных предназначена для указания того, что данные должны тасоваться или помещаться в позицию самого левого элемента данных результата для операции тасования. Аналогичным образом элемент 312 данных соответствует позиции второго слева элемента данных. Маска в элементе 312 данных предназначена для указания того, что данные должны тасоваться или помещаться в позицию второго слева элемента данных результата. Для данного варианта осуществления каждый из элементов данных в упакованном операнде, содержащем маски тасования, имеет взаимно однозначное соответствие с позицией элемента данных в упакованном результате.
На фиг.3А элемент 312 данных используется для описания содержимого приведенной для примера маски тасования в одном варианте осуществления. Маска 318 тасования в одном варианте осуществления содержит три части: поле 315 «флаг установки в нуль», поле 316 «зарезервировано» и поле 317 «биты выбора». Поле 315 «флаг установки в нуль» предназначено для индикации, должна ли позиция элемента данных результата, указанная представленной маской, быть обнулена или, иными словами, заменена значением нуля («0»). В одном варианте осуществления поле «флаг установки в нуль» является преобладающим, причем если поле 315 «флаг установки в нуль» установлено, то остальные поля в маске 318 игнорируются, и позиция элемента данных результата заполняется «0». Поле 316 «зарезервировано» включает в себя один или более битов, которые могут использоваться или не использоваться в альтернативных вариантах осуществления, или могут резервироваться для дальнейшего или специального использования. Поле 317 «биты выбора» маски 318 тасования предназначено для указания источника данных для соответствующей позиции элемента данных в упакованном результате.
В одном варианте осуществления инструкции тасования упакованных данных один операнд содержит набор масок, а другой операнд содержит набор упакованных элементов данных. Оба операнда имеют одинаковый размер. В зависимости от числа элементов данных в операнде требуется переменное число битов выбора для выбора индивидуального элемента данных из второго операнда упакованных данных для помещения в упакованный результат. Например, для 28-битового операнда источника упакованных байтов необходимы, по меньшей мере, четыре бита выбора, так как для выбора доступны 16 байтовых элементов данных. На основе значения, указанного битами выбора маски, соответствующий элемент данных помещается в соответствующую позицию элемента данных для данной маски. Например, маска 318 элемента 312 данных соответствует позиции второго слева элемента данных. Если биты 317 выбора этой маски 318 содержат значение «Х», то элемент данных из позиции «Х» элемента данных в операнде исходных данных переставляется в позицию второго слева элемента данных в результате. Но если поле 315 «флаг установки в нуль» установлено, то позиция второго слева элемента данных в результате заменяется на «0», и указание битов 317 выбора игнорируется.
На фиг.3В иллюстрируется структура маски 328 для варианта осуществления, в котором используются элементы данных байтового размера и 128-битовые упакованные операнды. Для данного варианта осуществления поле 325 «установка в нуль» состоит из бита 7, а поле 327 «выбор» состоит из битов с 3 по 0, поскольку имеется 16 возможных вариантов выбора элементов данных. Биты с 6 по 4 не используются в этом варианте осуществления и остаются в поле 326 «зарезервировано». В другом варианте осуществления число битов, используемых в поле 327 «выбор», может быть увеличено, как это необходимо, с учетом числа возможных вариантов выбора элементов данных, доступных в операнде исходных данных.
На фиг.3С показана структура маски 338 для другого варианта осуществления, в котором используются элементы данных байтового размера и 128-битовые упакованные операнды, а также множество источников элементов данных. Маска 338 в данном варианте осуществления содержит поле 335 «установка в нуль», поле 336 «выбор источника» и поле 337 «выбор». Поле 335 «установка в нуль» и поле 337 «выбор» функционируют аналогично описанному выше. Поле 336 «выбор источника» в данном варианте осуществления предназначено для указания того, из какого источника данных должен быть получен операнд данных, определенный битами выбора. Например, может быть использован тот же самый набор масок с множеством источников данных, таких как множество мультимедийных регистров. Каждому мультимедийному регистру источника присвоено числовое значение, и значение в поле 336 «выбор источника» указывает на один из этих регистров источников. В зависимости от содержимого поля 336 «выбор источника», выбираемый элемент данных выбирается из соответствующего источника данных для помещения в соответствующую позицию элемента данных в упакованном результате.
На фиг.4А показаны представления различных типов упакованных данных в мультимедийных регистрах в соответствии с одним вариантом осуществления настоящего изобретения. Фиг.4А иллюстрирует типы данных для упакованного байта 410, упакованного слова 420, упакованного двойного слова 430 для 128-битовых операндов. Формат 410 упакованного байта в этом примере имеет длину 128 битов и содержит 16 элементов данных упакованного байта. Байт определен здесь как 8 битов данных. Информация для каждого байтового элемента данных сохранена в битах с 7 по 0 для байта 0, в битах с 15 по 8 для байта 1, в битах с 23 по 16 для байта 2 и, наконец, в битах с 120 по 127 для байта 15. Таким образом, все имеющиеся биты используются в этом регистре. Эта конфигурация хранения повышает эффективность хранения процессора. Кроме того, при доступе к 16 элементам данных одна операция может теперь выполняться над 16 элементами данных параллельно.
В общем случае, элемент данных является отдельным фрагментом данных, который сохранен в операнде (одном регистре или ячейке памяти), причем другие элементы данных имеют ту же длину. В последовательностях упакованных данных, относящихся к SSE2-технологии, число элементов данных, сохраненных в операнде (ХММ-регистре или ячейке памяти), равно 128 битам, деленным на длину в битах отдельного элемента данных. Аналогичным образом в последовательностях упакованных данных, относящихся к ММХ и SSE-технологии, число элементов данных, сохраненных в операнде (ХММ-регистре или ячейке памяти), равно 64 битам, деленным на длину в битах отдельного элемента данных. Формат 420 упакованного слова в данном примере имеет длину 128 битов и содержит 8 элементов данных упакованного слова. Каждое упакованное слово содержит 16 битов информации. Формат 430 упакованного двойного слова по фиг.4А имеет длину 128 битов и содержит 4 элемента данных упакованного двойного слова. Каждое упакованное двойное слово содержит 32 бита информации. Упакованное квадраслово имеет длину 128 битов и содержит два элемента данных упакованного квадраслова.
Фиг.4В иллюстрирует альтернативные форматы внутрирегистрового хранения данных. Каждые упакованные данные могут включать в себя более одного независимого элемента данных. Показаны три формата упакованных данных: упакованный половинный 441, упакованный одиночный 442 и упакованный двойной 443. В одном варианте осуществления упакованный половинный 441, упакованный одиночный 442 и упакованный двойной 443 содержат элементы данных с фиксированной запятой. В альтернативном варианте осуществления один или более из упакованного половинного 441, упакованного одиночного 442 и упакованного двойного 443 могут содержать элементы данных с плавающей запятой. В одном альтернативном варианте осуществления упакованный половинный 441 имеет 128-битовую длину и содержит восемь 16-битовых элементов данных. В одном варианте осуществления упакованный одиночный 442 имеет 128-битовую длину и содержит четыре 32-битовых элемента данных. В одном варианте осуществления, упакованный двойной 443 имеет 128-битовую длину и содержит два 64-битовых элемента данных. Понятно, что такие форматы упакованных данных могут быть дополнительно распространены на другие длины регистров, например, из 96 битов, 160 битов, 192 битов, 224 битов, 256 битов и более.
На фиг.4С иллюстрируется вариант осуществления формат 460 кодирования операции (opcode), имеющий 32 или более битов, и режимы адресации операнда для регистра/памяти в соответствии с типом формата opcode, описанным в публикации "IA-32 Intel Architecture Software Developer's Manual Volume 2: Instruction Set Reference", доступной от Intel Corporation (Santa Clara, CA) во Всемирной паутине (www) по адресу intel.com/design/litcentr. Тип операции тасования может быть кодирован одним или более полями 461 и 462. Может быть идентифицировано до двух местоположений операнда на инструкцию, включая до двух идентификаторов 464 и 465 операнда источника. В одном варианте осуществления инструкции тасования идентификатор 466 операнда адресата тот же, что и идентификатор 464 операнда источника. В альтернативном варианте идентификатор 466 операнда адресата тот же, что и идентификатор 465 операнда источника. Поэтому в вариантах осуществления операции тасования один из операторов источника, идентифицированных идентификаторами 464 и 465 операнда источника, переписывается результатами операций тасования. В одном варианте осуществления операции тасования идентификаторы 464 и 465 операнда источника могут быть использованы для идентификации 64-битовых операндов источника и адресата.
На фиг.4D показан другой альтернативный формат 470 кодирования операции (opcode), имеющий 40 или более битов. Opcode-формат 470 соответствует opcode-формату 460 и содержит факультативный префиксный байт 478. Тип операции тасования может быть кодирован одним или более полями 478, 471 и 472. До двух местоположений операндов на инструкцию может идентифицироваться идентификаторами 474 и 475 операнда источника и префиксным байтом 478. В одном варианте осуществления инструкции тасования префиксный байт 478 может использоваться для идентификации 128-битовых операндов источника и адресата. В одном варианте осуществления инструкции тасования идентификатор 476 операнда адресата является тем же самым, что и идентификатор 474 операнда источника. В альтернативном варианте осуществления идентификатор 476 операнда адресата является тем же самым, что и идентификатор 475 операнда источника. Поэтому в вариантах осуществления операций тасования один из операндов источника, идентифицированный идентификаторами 474 и 475 операнда источника, перезаписывается результатами операций тасования. Opcode-форматы 460 и 470 обеспечивают возможность адресации типа регистр к регистру, память к регистру, регистр памятью, регистр регистром, регистр посредником, регистр к памяти, как это определено частично MOD-полями 463 и 473 и факультативными байтами коэффициента масштабирования основания и смещения.
Согласно фиг.4Е в некоторых альтернативных вариантах осуществления 64-битовые арифметические SIMD-операции могут выполняться посредством инструкции обработки данных сопроцессора (CDP). Opcode-формат 480 изображает одну такую CDP-инструкцию, имеющую поля 482 и 489 CDP-opcode. Тип CDP-инструкции в альтернативных вариантах осуществления операций тасования может кодироваться одним или более из полей 483, 484, 487 и 488. До трех местоположений операндов на инструкцию может идентифицироваться, включая до двух идентификаторов 485 и 490 операнда источника и один идентификатор 486 операнда адресата. Один вариант осуществления сопроцессора может осуществлять обработку 8-, 16-, 32- и 64-битовых значений. В одном варианте осуществления операция тасования выполняется над элементами данных с плавающей запятой и целочисленными элементами данных. В некоторых вариантах осуществления операция тасования может выполняться условно, с использованием поля 481 условия. Для некоторых инструкций тасования размеры данных источника могут кодироваться полем 483. В некоторых вариантах осуществления операции тасования над SIMD-полями может выполняться определение состояний нуля (Z), отрицательного значения (N), переноса (C), переполнения (V). Для некоторых инструкций тип насыщения может кодироваться в поле 484.
На фиг.5 показана блок-схема варианта выполнения логики для выполнения операции тасования над операндом данных на основе маски тасования в соответствии с настоящим изобретением. Инструкция (PSHUFB) для операции тасования с функцией установки в нуль для этого варианта начинается с двумя сегментами информации: первым (маской) операндом 510 и вторым (данными) операндом 520. Для последующего описания MASK, DATA и RESULTANT, в общем случае, упоминаются как операнды или блоки данных, но не ограничиваются как таковые и также включают в себя регистры, регистровые файлы и ячейки памяти. В одном варианте осуществления PSHUFB-инструкция тасования декодируется в одну микрооперацию. В альтернативном варианте осуществления инструкция может декодироваться в переменное число микроопераций для выполнения операции тасования над операндами данных. Например, операнды 510, 520 являются 128-битовыми сегментами информации, сохраненными в регистре/памяти источника, имеющих элементы данных байтового размера. В одном варианте осуществления операнды 510, 520 содержатся в 128-битовых SIMD-регистрах, таких как 128-битовые SSE2 XMM-регистры. Однако один или оба из операндов 510, 520 также могут быть загружены из ячейки памяти. В одном варианте осуществления RESULTANT 540 также является SSE2 или XMM-регистром данных. Кроме того, RESULTANT 540 может также быть тем же самым регистром или ячейкой памяти, что и один из операндов источника. В зависимости от конкретной реализации операнды и регистры могут иметь размер 32, 64 и 256 битов и содержать элементы данных с размером слова, двойного слова или квадраслова. Первый операнд 510 в этом примере состоит из набора из 16 масок (в шестнадцатеричном формате): 0х0Е, 0х0А, 0х09, 0х8F, 0x02, 0x0E, 0x06, 0x06, 0x06, 0xF0, 0x04, 0x08, 0x08, 0x06, 0x0D и 0x00. Каждая отдельная маска должна определять содержимое соответствующей ей позиции элемента данных в результате 540.
Второй операнд 520 состоит из 16 сегментов данных: P, O, N, M, L, K, J, I, H, G, F, E, D, C, B и A. Каждый сегмент данных во втором операнде 520 также обозначен значением позиции элемента данных в шестнадцатеричном формате. Сегменты данных здесь имеют одинаковую длину и содержат каждый один байт (8 битов) данных. Если бы каждый элемент данных был словом (16 битов), двойным словом (32 бита) или квадрасловом (64 бита), то 128-битовые операнды имели бы, соответственно, восемь элементов данных длиной в слово, четыре элемента данных длиной в двойное слово или два элемента данных длиной в квадраслово. Однако в другом варианте осуществления настоящего изобретения могут использоваться другие размеры операндов и сегментов данных. Варианты осуществления настоящего изобретения не ограничиваются операндами данных, сегментами данных или величинами сдвигов конкретной длины, а могут использовать соответствующую длину для каждой реализации.
Операнды 510, 520 могут находиться как в регистре, так и в ячейке памяти, или файловом регистре, или их комбинации. Операнды 510, 520 данных посылаются в логику 530 тасования исполнительного модуля в процессоре вместе с инструкцией тасования. К моменту, когда инструкция тасования попадает в исполнительный модуль, инструкция должна быть декодирована ранее, в процессе конвейерной обработки процессора. Таким образом, инструкция тасования может быть в форме микрооперации (uop) или в некотором другом декодированном формате. Для данного варианта осуществления два операнда 510, 520 данных принимаются в логике 530 тасования. Логика 530 тасования выбирает элементы данных из операнда 520 данных на основе значений в операнде 510 маски и упорядочивает/перетасовывает выбранные элементы данных в соответствующие позиции в результате 540. Логика 530 тасования также обнуляет заданные позиции элементов данных в результате 540, как задано. Здесь результат 540 содержит 16 сегментов данных: O, K, J, '0', C, O, G, G, F, '0', E, I, I, G, N и A.
Операция логики 530 тасования описана здесь в связи с несколькими элементами данных. Маска тасования для позиции крайнего слева элемента данных в операнде 510 маски есть 0х0Е. Логика 530 тасования интерпретирует различные поля маски, описанные выше со ссылкой на фиг.3А-С. В этом случае поле «установка в нуль» не установлено. Поле выбора, содержащее младшие четыре бита или полубайт, имеет шестнадцатеричное значение 'E'. Логика 530 тасования перетасовывает данные О в позиции '0xE' элемента данных операнда 520 данных в позицию крайнего слева элемента данных результата 540. Аналогичным образом маска тасования для позиции второго слева элемента данных в операнде 510 маски есть 0х0А. Логика 530 тасования интерпретирует маску для данной позиции. Это поле выбора имеет шестнадцатеричное значение 'А'. Логика 530 тасования копирует данные К в позиции '0xE' элемента данных операнда 520 данных в позицию второго слева элемента данных результата 540.
Логика 530 тасования в данном варианте осуществления также поддерживает функцию «сброс в нуль» инструкции тасования. Маска тасования в позиции четвертого элемента данных слева для операнда 510 маски есть 0Х8F. Логика 530 тасования распознает, что поле «установка в нуль» установлено, что указывается значением '1' в бите 8 маски. В ответ директива «сброс в нуль» переопределяет поле выбора, и логика 530 тасования игнорирует шестнадцатеричное значение 'F' в поле выбора данной маски. '0' помещается в соответствующую позицию четвертого элемента данных слева в результате 540. В данном варианте осуществления логика 530 тасования оценивает поле «установка в нуль» и поле выбора для каждой маски и не заботится о других битах, которые могут существовать помимо этих полей в маске, таких как зарезервированные биты и поле выбора источника. Эта обработка масок тасования и тасования данных повторяется для всего набора масок в операнде 510 маски. В одном варианте осуществления все маски обрабатываются параллельно. В другом варианте осуществления определенная часть набора масок и элементов данных может обрабатываться одновременно совместно.
В вариантах осуществления представленной инструкции тасования элементы данных в операнде могут переупорядочиваться различными путями. Кроме того, некоторые данные из конкретного элемента данных могут повторяться в множестве позиций элементов данных или даже транслироваться в каждую позицию. Например, четвертая и пятая маски обе имеют шестнадцатеричное значение 0х08. В результате данные I в позиции 0х8 элемента данных операнда 520 данных перемещаются в четвертую и пятую позиции справа результата 540. С учетом функции установки в нуль варианты осуществления инструкции тасования могут принудительно установить любую из позиций элементов данных в результате 540 в '0'.
В зависимости от конкретной реализации каждая маска тасования может быть использована для указания содержимого отдельной позиции элемента данных в результате. В данном примере каждая отдельная маска тасования байтовой длины соответствует позиции элемента данных байтовой длины в результате 540. В другом варианте осуществления могут использоваться комбинации множества масок для совместного указания блоков элементов данных. Например, маски длиной два байта могут быть использованы вместе для обозначения элемента данных длиной в слово. Маски тасования не ограничены байтовой длиной и могут иметь любой другой размер, необходимый для конкретной реализации. Аналогичным образом элементы данных и позиции элементов данных могут иметь другую гранулярность, отличную от байтовой.
На фиг.6 показана блок-схема варианта осуществления схемы 600 для выполнения операции тасования данных в соответствии с настоящим изобретением. Схема в этом варианте осуществления содержит мультиплексирующую структуру для выбора корректного результирующего байта из первого операнда источника на основе декодирования маски тасования второго операнда. Операнд данных источника здесь содержит верхние элементы упакованных данных и нижние элементы упакованных данных. Мультиплексирующая структура в этом варианте осуществления относительно проще, чем другие мультиплексирующие структуры, используемые для реализации других упакованных инструкций. В результате мультиплексирующая структура в этом варианте осуществления не вводит никакого нового критического пути синхронизации. Схема 600 в этом варианте осуществления содержит блок масок тасования, блоки для хранения нижних/верхних элементов упакованных данных из операндов источников, первое множество (8:1) мультиплексоров для первоначального выбора элементов данных, другое множество (3:1) мультиплексоров для первоначального выбора верхних и нижних элементов данных, логику выбора мультиплексоров и обнуления и множество управляющих сигналов. Для простоты на фиг.6 показано ограниченное число (8:1) и (3:1) мультиплексоров, которые представлены многоточиями. Однако их функции сходны с функциями показанных на чертеже и поясняются ниже.
В процессе операции тасования в данном примере в схеме 600 обработки тасования принимается два операнда: первый операнд с набором элементов упакованных данных и второй операнд с набором масок тасования. Маски тасования подаются в блоке 602 масок тасования. Набор масок тасования декодируется в блоке 604 логики выбора мультиплексора и обнуления для генерирования сигналов выбора (SELECT A 606, SELECT B 608, SELECT C 610) и сигнала (ZERO) 611 установки в нуль. Эти сигналы используются для управления операцией мультиплексоров для восстановления в единое целое результата 632.
В данном примере операнд маски и операнд данных оба имеют длину 128 битов и каждый скомпонован из 16 байтовых сегментов данных. Значение N, как показано для различных сигналов, в данном случае равно 16. В этом варианте осуществления элементы данных разделены на набор нижних и верхних элементов упакованных данных, причем каждый набор содержит 8 элементов данных. Это позволяет использовать меньшие (8:1) мультиплексоры в процессе выбора элементов данных вместо (16:1) мультиплексоров. Эти наборы верхних и нижних элементов упакованных данных хранятся, соответственно, в верхней и нижней областях 612, 622 хранения. Начиная с нижнего набора данных, каждый из 8 элементов данных посылается на первый набор из 16 отдельных (8:1) мультиплексоров 618А-D через набор линий, таких как линии 614 маршрутизации. Каждый из 16 (8:1) мультиплексоров 618А-D управляется одним из N сигналов 606 SELECT A. В зависимости от значения этого сигнала 606 SELECT A соответствующий мультиплексор должен выдать один из 8 нижних элементов 614 данных для последующей обработки. Имеется 16 (8:1) мультиплексоров для набора нижних элементов упакованных данных, так как можно перемещать любой из нижних элементов данных в любую из 16 позиций элементов данных результата. Каждый из (8:1) мультиплексоров соответствует одной из 16 позиций элементов данных результата. Аналогичным образом имеется 16 (8:1) мультиплексоров для набора верхних элементов упакованных данных. 8 элементов данных посылаются на второй набор из 16 (8:1) мультиплексоров 624А-D. Каждый из 16 (8:1) мультиплексоров 624А-D управляется одним из N сигналов 608 SELECT В. В зависимости от значения этого сигнала 608 SELECT В соответствующий (8:1) мультиплексор должен выдать один из 8 верхних элементов 616 данных для последующей обработки.
Каждый из 16 (3:1) мультиплексоров 628А-D соответствует позиции элемента данных в результате 632. 16 выходных сигналов 620А-D с 16 мультиплексоров 618А-D нижних элементов данных маршрутизируются к набору из 16 (3:1) мультиплексоров 628А-D выбора верхних/нижних элементов данных, как и выходные сигналы 626А-D с мультиплексоров 624А-D верхних данных. Каждый из этих (3:1) мультиплексоров 628А-D получает свои сигналы SELECT C 610 и ZERO 611 из логики 604 выбора мультиплексора и обнуления. Значение сигнала SELECT C 610 для данного (3:1) мультиплексора предназначено для указания, следует ли этому мультиплексору вывести выбранный операнд данных из набора нижних данных или из набора верхних данных. Управляющий сигнал ZERO 611 для каждого (3:1) мультиплексора предназначен для указания, следует ли этому мультиплексору установить свой выходной сигнал в нуль ('0'). Для данного варианта осуществления управляющий сигнал ZERO 611 переопределяет выбор, осуществленный сигналом SELECT C 610, и принудительно выдает в результат 632 '0' для соответствующей позиции элемента данных.
Например, (3:1) мультиплексор 628А принимает выбранный нижний элемент данных 620А из (8:1) мультиплексора 624А для данной позиции элемента данных. Сигнал SELECT C 610 управляет тем, какой из элементов данных переместить на его выходе 630А в позицию элемента данных, обеспечиваемую в результате 632. Однако если сигнал ZERO 611, подаваемый на мультиплексор 628А, является активным, указывая, что маска тасования для данного элемента данных устанавливает, что требуется '0', то на выходе 630А мультиплексора устанавливается '0', и ни один из входных сигналов 620А, 626А не используется. Результат 632 операции тасования состоит из выходных сигналов 630А-D (3:1) мультиплексоров 628А-D, причем каждый из этих выходных сигналов соответствует конкретной позиции элементов данных и представляет собой либо элемент данных, либо '0'. В этом примере каждый выходной сигнал (3:1) мультиплексора имеет байтовый размер, и результат является блоком данных, состоящим из 16 упакованных байтов данных.
Фиг.7 иллюстрирует операцию тасования данных над элементами данных байтового размера в соответствии с одним вариантом осуществления настоящего изобретения. Это пример инструкции "PSHUFB DATA, MASK". Заметим, что старший бит масок тасования для байтовых позиций 0х6 и 0хС маски MASK 701 установлен таким образом, чтобы результирующие данные в результате 741 для этих позиций были нулевыми. В этом примере данные организованы в устройстве 721 хранения данных адресата, которое в одном варианте осуществления является также устройством 721 хранения данных источника, ввиду набора масок 701, которые определяют адрес, в котором соответствующие элементы данных из операнда 721 источника должны сохраняться в регистре 741 адресата. Два операнда источника, маска 701 и данные 721, содержат каждый 16 элементов упакованных данных в данном примере, как и результат 741. В этом варианте осуществления каждый из используемых элементов данных имеет размер, равный восьми битам или байту. Таким образом, блоки данных маски 701, данных 721 и результата 741 имеют длину 128 битов каждый. Кроме того, эти блоки данных могут находиться в памяти или в регистрах. В одном варианте осуществления конфигурация масок основана на желательной операции обработки данных, которая может включать в себя, например, операцию фильтрации или операцию свертки.
Как показано на фиг.7, операнд 701 маски содержит элементы данных с масками тасования: 0х0Е 702, 0х0А 703, 0х09 704, 0х08F 705, 0x02 706, 0x0E 707, 0x06 708, 0x06 709, 0x05 710, 0xF0 711, 0x04 712, 0x08 713, 0x08 714, 0x06 715, 0x0D 716, 0x00 717. Аналогичным образом, операнд 721 данных включает в себя элементы данных источника: P 722, O 723, N 724, M 725, L 726, K 727, J 728, I 729, H 730, G 731, F 732, E 733, D 734, C 735, B 736, A 737. В представлениях сегментов данных на фиг.7 позиция элемента данных также указана под данными как шестнадцатеричное значение. Соответственно, упакованная операция тасования выполняется с маской 701 и данными 721. С использованием набора масок 701 тасования обработка данных 721 может выполняться параллельно.
Когда каждая из масок тасования элементов данных оценивается, соответствующие данные из указанного элемента данных или '0' перемещаются в соответствующую позицию элемента данных для данной конкретной маски тасования. Например, крайняя правая маска 717 тасования имеет значение 0х00, которое декодируется для указания данных из позиции 0х0 операнда данных источника. В ответ данные А из позиции 0х0 данных копируются в крайнюю правую позицию результата 741. Аналогичным образом, вторая справа маска 716 тасования имеет значение 0х0D, которое декодируется как 0хD. В ответ данные N из позиции 0хD данных копируются во вторую справа позицию результата 741.
Четвертая позиция слева элемента данных в результате 741 есть '0'. Это относится к значению 0х8F в маске тасования для данной позиции элемента данных. В этом варианте осуществления бит 7 байта маски тасования является указателем «установки в нуль» или «сброса в нуль». Если это поле установлено, то соответствующая позиция элемента данных в результате заполняется значением '0', вместо данных из операнда 721 данных источника. Аналогичным образом седьмая позиция справа в результате 741 имеет значение '0'. Это обусловлено значением 0хF0 маски тасования для позиции этого элемента данных в маске 701. Заметим, что не все биты в маске тасования могут быть использованы в некоторых вариантах осуществления. В этом варианте осуществления нижний полубайт или четыре бита маски тасования достаточны для выбора любого из 16 возможных элементов данных в операнде 721 данных источника. Так как бит 7 является полем «установка в нуль», три других бита остаются неиспользуемыми и могут быть зарезервированы или игнорируются в некоторых вариантах осуществления. Для этого варианта осуществления поле «установка в нуль» управляет и переопределяет выбор элемента данных, как указано в нижнем полубайте маски тасования. В обоих этих случаях четвертой позиции слева элемента данных и седьмой позиции справа значение 0х80 маски тасования, где установлен флаг «установка в нуль» в бите 7, может также вызвать заполнение значением '0' соответствующей позиции элемента данных результата.
Как показано на фиг.7, стрелки иллюстрируют тасование элементов данных для масок тасования в маске 701. В зависимости от конкретного набора масок тасования один или более элементов данных источника могут не появляться в результате 741. В некоторых случаях один или более '0' могут также появляться в различных позициях элементов данных в результате 741. Если маски тасования конфигурированы для трансляции одного или конкретной группы элементов данных, данные для этих элементов данных могут повторяться как выбранный шаблон в результате. Варианты осуществления настоящего изобретения не ограничены какими-либо конкретными конфигурациями или шаблонами масок тасования.
Как отмечено выше, регистр данных источника также используется в качестве регистра хранения данных адресата в данном варианте осуществления, тем самым сокращая число требуемых регистров. Хотя данные 721 источника при этом переопределяются, набор масок 701 тасования не изменяется и доступен для последующего обращения. Переопределенные данные в устройстве хранения данных источника могут быть перезагружены из памяти или другого регистра. В другом варианте осуществления множество регистров могут быть использованы в качестве устройства хранения данных источника, причем их соответствующие данные организованы в устройстве хранения данных адресата, как это необходимо.
На фиг.8 иллюстрируется операция тасования данных над элементами данных длиной в слово, в соответствии с другим вариантом осуществления настоящего изобретения. Общее описание этого примера в некоторой степени сходно с описанием примера на фиг.7. Однако в данном сценарии элементы данных операнда 821 данных и результат 831 имеют длину слова. Для данного варианта осуществления слова элементов данных обрабатываются как пары байтов элементов данных, так как маски тасования в операнде 8021 имеют размер байта. Таким образом, пара байтов маски тасования используется для определения каждой позиции слова элемента данных. Но в другом варианте осуществления маски тасования могут также иметь гранулярность слова и описывать позиции элементов данных, имеющих размер слова, в результате.
Операнд 801 маски содержит элементы данных байтовой длины с масками тасования: 0х03 802, 0х02 803, 0х08F 804, 0x0E 805, 0х83 806, 0х82 807, 0x0D 808, 0x0С 809, 0x05 810, 0x04 811, 0х0В 812, 0х0А 813, 0x0D 814, 0х0С 815, 0х01 816, 0x00 817. Операнд 821 данных включает в себя элементы данных источника: Н 822, G 823, F 824, E 825, D 826, C 827, B 828, A 829. В представлениях сегментов данных на фиг.8 позиция элемента данных также указана под данными как шестнадцатеричное значение. Как показано на фиг.8, каждый из элементов данных длиной в слово в операнде 821 данных имеет адреса позиций данных, которые он занимает, соответствующие двум позициям байтового размера. Например, данные Н 822 занимают позиции данных 0xF и 0xE элементов данных байтового размера.
Упакованная операция тасования выполняется с маской 801 и данными 821. Стрелки на фиг.8 иллюстрируют тасование элементов данных для масок тасования в маске 801. Кода каждая из масок тасования элементов данных оценивается, соответствующие данные из указанного элемента данных операнда 821 данных или '0' перемещаются в соответствующую позицию элемента данных в результате 831 для данной конкретной маски тасования. В этом варианте осуществления маски тасования байтового размера работают парами, чтобы указывать элементы данных размером в слово. Например, две крайние слева маски 0х03 802, 0х02 803 в операнде 801 маски вместе соответствуют крайней слева позиции 832 элемента данных длиной в слово результата 831. В операции тасования два байта данных или одно слово данных в байтовых позициях 0х03 802, 0х02 803 элемента данных, что в этом случае соответствует данным В 828, упорядочиваются в две крайних слева позиции 832 элемента данных размером в байт в результате 831.
Кроме того, маски тасования могут также конфигурироваться для установки элемента данных размером в слово в '0' в результате, как показано масками 0х83 806 и 0х82 807 тасования для третьей позиции 834 элемента данных размером в слово в результате 831. Маски 0х83 806 и 0х82 807 имеют установленные поля «установка в нуль». Хотя два байта масок тасования здесь объединяются в пары, могут быть реализованы различные объединения в пары для упорядочения четырех байтов вместе, например, в виде квадраслова или восьми байтов вместе для формирования двойного квадраслова. Аналогичным образом объединения в пары не ограничены последовательными масками тасования конкретных байтов. В другом варианте осуществления маски тасования размером в слово могут быть использованы для указания элементов данных размером в слово.
На фиг.9 представлена блок-схема, иллюстрирующая один вариант осуществления способа тасования данных. Значение L длины в общем виде используется здесь для представления длины операндов и блоков данных. В зависимости от конкретного варианта осуществления L может использоваться для обозначения размера в терминах числа сегментов данных, битов, байтов и т.д. В блоке 910 первый операнд упакованных данных длиной L принимается для использования в операции тасования. Набор длиной L из масок тасования длиной М, указывающих шаблон тасования, принимается в блоке 920. В этом примере L равно 128 битам и М равно 8 битам или байту. В другом варианте осуществления L и М могут иметь другие значения, например 256 и 16 соответственно. В блоке 930 выполняется операция тасования, причем элементы данных из операнда данных тасуются для упорядочения в результат в соответствии шаблоном тасования.
Детальные подробности тасования в блоке 930 в данном варианте осуществления далее описаны в аспекте того, что происходит для каждой позиции элемента данных. В одном варианте осуществления тасование для всех позиций элементов данных упакованного результата обрабатывается параллельно. В другом варианте осуществления определенная часть масок может одновременно обрабатываться совместно. В блоке 932 проверяется, установлен ли флаг нуля. Этот флаг нуля относится к полю «установка/сброс в нуль» каждой маски тасования. Если флаг нуля определен как установленный в блоке 932, то позиция элемента данных результата, соответствующая этой конкретной маске тасования, устанавливается в '0'. Если флаг нуля определен как установленный в блоке 932, то данные из элемента данных источника, указываемого маской тасования, помещаются в позицию элемента данных адресата для результата, соответствующую этой конкретной маске тасования.
В настоящее время таблицы преобразования, использующие целочисленные инструкции, требуют большого числа инструкций. Еще большее число инструкций требуется на преобразование, если целочисленные операции используются для доступа к алгоритмам, реализованным с SIMD-инструкциями. Однако за счет использования вариантов осуществления инструкции тасования упакованных байтов отсчет инструкции и время исполнения существенным образом сокращаются. Например, можно обращаться к 16 байтам данных в процессе табличного преобразования с использованием одной инструкции, если размер таблицы равен 16 байтам и менее. 11 SIMD-инструкций может быть использовано для преобразования табличных данных для таблицы размером в пределах от 17 до 32 байтов. 32 SIMD-инструкции необходимы, если размер таблицы находится в пределах от 33 до 64 байтов.
Имеются некоторые приложения с параллелизмом данных, который не может быть реализован SIMD-инструкциями ввиду использования их таблиц преобразования. Алгоритмы квантования и деблокирования в методе сжатия видео H.26L являются примером алгоритма, который использует малые таблицы преобразования, которые не согласуются со 128-битовым регистром. В некоторых случаях таблицы преобразования, используемые этими алгоритмами, имеют малый размер. Если таблица согласуется с одним регистром, то операция табличного преобразования может быть выполнена с использованием одной упакованной инструкции тасования. Но если требование пространства памяти, предъявляемое к таблице, превышает размер одного регистра, то варианты осуществления упакованной инструкции могут работать с использованием другого алгоритма. Один вариант осуществления метода обработки таблиц с увеличенными размерами предусматривает разделение таблицы на секции, каждая из которых равна емкости регистра, и доступ к каждой из этих секций таблиц с использованием инструкции тасования. Инструкция тасования использует ту же самую последовательность управления тасованием для доступа к каждой секции таблицы. В результате параллельное табличное преобразование может быть реализовано в этих случаях с инструкциями тасования упакованных байтов, тем самым позволяя использовать SIMD-инструкции для повышения эффективности алгоритма. Варианты осуществления настоящего изобретения могут способствовать повышению эффективности и сокращению числа обращений к памяти, необходимых для алгоритмов, которые используют малые таблицы преобразования. Другие варианты осуществления также позволяют обращаться к множеству элементов таблицы преобразования с использованием SIMD-инструкций. Инструкция тасования упакованного байта в соответствии с настоящим изобретением обеспечивает эффективную реализацию SIMD-инструкций, вместо менее эффективного целочисленного воплощения алгоритмов, которые используют малые таблицы преобразования. Этот вариант осуществления настоящего изобретения демонстрирует, каким образом осуществить доступ к данным из таблицы, которая требует пространства памяти, большего, чем одиночный регистр. В этом примере регистры содержат различные сегменты таблицы.
Фиг.10А-Н иллюстрируют операцию параллельного алгоритма табличного преобразования с использованием SIMD-инструкций. Пример, описанный со ссылками на фиг.10А-Н, предусматривает преобразование данных с использованием множества таблиц, причем некоторые выбранные элементы данных, как определено в наборе масок, перетасовываются из этих многих таблиц в объединенный блок данных результата. Приведенное ниже описание поясняется в контексте упакованных операций, в частности, упакованной инструкции тасования, как раскрыто выше. Операция тасования в данном примере переопределяет табличные данные источника в регистре. Если таблица должна повторно использоваться, следуя операции преобразования, то табличные данные должны копироваться в другой регистр, прежде чем операция будет выполняться, так что другая загрузка не требуется. В альтернативном варианте осуществления операция тасования использует три отдельных регистра или ячейки памяти: два источника и один адресат. Адрес в альтернативном варианте осуществления представляет собой регистр или ячейку памяти, которые отличаются от любого из операндов источника. Таким образом, табличные данные источника не переопределяются и могут быть повторно использованы. В этом примере табличные данные обрабатываются как поступающие из отличающихся частей большой таблицы. Например, «нижние табличные данные» 1021 соответствуют нижней адресной области таблицы, а «верхние табличные данные» 1051 - верхней адресной части таблицы. Варианты осуществления настоящего изобретения не являются ограничительными, что касается того, откуда могут браться табличные данные. Блоки 1021, 1051 данных могут быть смежными, далеко разнесенными и даже перекрывающимися. Аналогичным образом табличные данные могут также быть из разных таблиц данных или различных источников памяти. Также очевидно, что такое табличное преобразование и объединение данных может выполняться над данными из множества таблиц. Например, вместо различных частей одной и той же таблицы «нижние табличные данные» 1021 могут быть из первой таблицы, а «верхние табличные данные» 1051 - из второй таблицы.
Фиг.10А иллюстрирует тасование упакованных данных первого набора элементов данных из таблицы на основе набора масок тасования. Первый набор элементов данных группируется как операнд под именем «нижние табличные данные» 1021. Маска MASK 1001 и «нижние табличные данные» 1021 содержат каждые в данном примере по 16 элементов. Операция тасования с использованием MASK 1001 и «нижних табличных данных» 1021 дает результат в виде промежуточного результата TEMP RESULTANT A 1041. Нижняя часть маски управления тасованием выбирает элемент данных в регистре. Число битов, требуемых для выбора элемента данных, есть число элементов данных регистра в log2. Например, если емкость регистра равна 128 битам и тип данных представляет собой байты, то число элементов данных регистра равно 16. В этом случае четыре бита необходимы для выбора элемента данных. Фиг.10В иллюстрирует тасование упакованных данных второго набора элементов данных из таблицы на основе того же набора масок тасования, показанного на фиг.10А. Второй набор элементов данных группируется как операнд под именем «верхние табличные данные» 1051. «Верхние табличные данные» 1051 также содержат в данном примере 16 элементов. Операция тасования с использованием маски MASK 1001 и «верхних табличных данных» 1051 дает результат в виде промежуточного результата TEMP RESULTANT B 1042.
Поскольку тот же набор масок тасования использовался как для «нижних табличных данных» 1021, так и для «верхних табличных данных» 1051, то их соответствующие результаты 1041, 1042 имеют сходным образом позиционированные данные, но из данных разных источников. Например, крайняя слева позиция данных обоих результатов 1041, 1042 имеет данные из элемента данных 0хЕ 1023, 1053 соответствующих источников 1021, 1051 данных. Фиг.10С иллюстрирует логическую упакованную операцию «И» с использованием фильтра 1043 выбора и набора масок тасования MASK 1001. Фильтр выбора в данном случае представляет собой фильтр для различения того, какая из масок тасования в MASK 1001 относится к первым табличным данным 1021, и какая - ко вторым табличным данным 1051. Маски тасования в этом варианте осуществления используют поле выбора источника «выбор источника» 336, как описано выше со ссылкой на фиг.3С. Младшие биты байта управления тасованием используются для выбора позиции элемента данных в регистре, а старшие биты, исключая самый старший бит, используются для выбора сегмента таблицы. В этом варианте осуществления биты непосредственно выше и рядом с используемыми для выбора данных выбирают секцию таблицы. Фильтр выбора 1043 применяет 0Х10 ко всем маскам тасования в MASK 1001 для выделения поля выбора источника из масок тасования. Упакованная операция «И» дает «маску выбора таблицы» 1044 для указания того, какая позиция элемента данных в конечном результате должна быть из первого набора данных 1021 или второго набора данных 1051.
Число битов для выбора секции таблицы равно числу секций таблицы в log2. Например, в случае размеров таблицы от 17 до 32 байтов, с 16-байтовыми регистрами, младшие 4 бита выбирают данные и пятый бит выбирает секцию таблицы. Здесь выбор источника использует младший бит второго полубайта, бит 4, из каждой маски тасования для указания источника данных, так как имеется два источника данных 1021 и 1051. К секции таблицы с индексами от 0 до 15 осуществляется доступ инструкции упакованного тасования по фиг.10А. К секции таблицы с индексами от 16 до 31 осуществляется доступ инструкции упакованного тасования по фиг.10В. Поле, которое осуществляет выбор таблицы, является отдельным от байтов/индексов управления тасованием, согласно фиг.10С. В реализациях с большим числом источников данных дополнительные биты могут потребоваться для полей выбора источника. В случае 32-байтовой таблицы байты 0х00 - 0х0F управления тасованием будут выбирать табличные элементы от 0 до 15 в первой секции таблицы, и байты 0х10 - 0х1F управления тасованием будут выбирать табличные элементы от 16 до 31 во второй секции таблицы. Например, рассмотрим случай, когда байт управления тасованием определен как 0Х19. Битовое представление 0х19 есть 0001 1001. Младшие четыре бита 1001 выбирают девятый байт (отсчитывая от 0), и пятый бит, который установлен в 1, выбирает вторую таблицу из двух таблиц. Пятый бит, равный 0, выбрал бы первую таблицу.
Маска для выбора значений данных, обращение к которой осуществляется из первой секции таблицы с индексами от 0 до 15, вычисляется с помощью операции «сравнения-определения равенства» для данного варианта осуществления на фиг.10D путем выбора байтов управления тасованием, у которых пятый бит равен нулю. Фиг.10D иллюстрирует упакованную операцию «сравнения-определения равенства» нижнего фильтра 1045 и «маски выбора таблицы» 1044. Маска выбора нижней таблицы, сформированная на фиг.10D, для первой секции таблицы выбирает элементы данных, к которым имеется доступ из первой секции таблицы с использованием другой упакованной операции тасования. Нижний фильтр 1045 в этом примере является маской для извлечения или выделения позиций элементов данных, указанных масками тасования, как поступающих из первого набора 1021 данных. Если поле выбора источника есть '0' в данном варианте осуществления изобретения, то источником данных должна быть «нижняя таблица данных» 1021. Операция «сравнения-определения равенства» дает «маску выбора нижней таблицы» 1046 с значениями 0хFF для позиций элементов данных, которые имеют значение выбора источника '0'.
Маска для выбора значений данных, к которым обращаются из второй секции таблицы с индексами от 16 до 31 вычисляется с помощью операции «сравнения-определения равенства» по фиг.10Е путем выбора байтов управления тасованием, у которых пятый бит равен единице. Фиг.10Е иллюстрирует сходную операцию «сравнения-определения равенства» верхнего фильтра 1047 и «маски выбора таблицы» 1044. Маска выбора верхней таблицы, сформированная на фиг.10Е, для второй секции таблицы выбирает элементы данных, к которым имеется доступ из второй секции таблицы с использованием упакованной операции тасования. Верхний фильтр 1047 является маской для извлечения позиций элементов данных, указанных полями выбора источника маски тасования, как поступающих из второго набора 1051 данных. Если поле выбора источника есть '1' в данном варианте осуществления изобретения, то источником данных должна быть «верхняя таблица данных» 1051. Операция «сравнения-определения равенства» дает «маску выбора верхней таблицы» 1048 с значениями 0хFF для позиций элементов данных, которые имеют значение выбора источника '1'.
Элементы данных, выбранные из двух секций таблицы, объединяются, как показано на фиг.10F. На фиг.10F показана упакованная операция «И» над «маской выбора нижней таблицы» 1046 и промежуточным результатом А 1041. Упакованная операция «И» отфильтровывает выбранные перетасованные элементы данных из первого набора 1021 данных для маски 1046, которая основана на полях выбора источника. Например, поле выбора источника в маске 1002 тасования для крайней слева позиции элемента данных имеет значение '0', как показано в «маске выбора таблицы» 1044. Соответственно, «маска выбора нижней таблицы» 1046 имеет значение 0хFF в этой позиции. Операция «И», согласно фиг.10F, между 0хFF и данными в крайней слева позиции элемента данных приводит к переносу данных О в «выбранные данные нижней таблицы» 1049. С другой стороны, поле выбора источника в маске 1004 тасования для третьей позиции элемента данных слева имеет значение '1' для указания того, что данные поступают от источника, иного, чем первый набор 1021 данных. Соответственно «маска выбора нижней таблицы» 1046 имеет значение 0х00 в этой позиции. Операция «И» в данном случае не пропускает данные J в «выбранные данные нижней таблицы» 1049, и эта позиция остается пустой, т.е.0х00.
Аналогичная упакованная операция «И» над «маской выбора верхней таблицы» 1048 и промежуточным результатом В 1042, как показано на фиг.10G. Упакованная операция «И» отфильтровывает выбранные перетасованные элементы данных из второго набора 1051 данных для маски 1048. В отличие от упакованной операции «И», описанной со ссылкой на фиг.10F, маска 1048 позволяет данным, указанным полями выбора источника как поступающие из второго набора данных, проходить в «выбранные данные верхней таблицы» 1050, в то время как другие позиции элементов данных остаются пустыми.
Фиг.10Н иллюстрирует объединение выбранных данных из первого набора данных и из второго набора данных. Упакованная логическая операция «ИЛИ» выполняется над «выбранными данными нижней таблицы» 1049 и «выбранными данными верхней таблицы» 1050 для получения «объединенных данных выбранной таблицы» 1070, что представляет желательный результат параллельного алгоритма табличного преобразования в данном примере. В альтернативном варианте осуществления упакованная операция сложения, предназначенная для сложения «выбранных данных нижней таблицы» 1049 и «выбранных данных верхней таблицы» 1050 может также обеспечить получение «объединенных данных выбранной таблицы» 1070. Как показано на фиг.10Н, либо «выбранные данные нижней таблицы» 1049, либо «выбранные данные верхней таблицы» 1050 имеют значение 0х00 для конкретной позиции данных в этом варианте осуществления. Это объясняется тем, что другой операнд, который не имеет значение 0х00, должен содержать желательные табличные данные, выбранные из соответствующего источника. Здесь крайняя слева позиция элемента данных в результате 1070 есть 0, что представляет собой перетасованные данные 1041 из первого набора 1021 данных. Аналогичным образом, третья позиция слева элемента данных в результате 1070 есть Z, что представляет собой перетасованные данные 1042 из второго набора 1051 данных.
Способ табличного преобразования данных в таблицах с завышенным размером в этом приведенном для примера варианте осуществления может быть сведен, в основном, к следующим операциям. Во-первых, данные копируются или загружаются в регистры. Табличные значения из каждой секции таблицы оцениваются посредством упакованной операции тасования. Поля выбора источника, которые идентифицируют секцию таблицы, выделяются из масок тасования. Выполняются операции «сравнение-определение равенства» над полями выбора источника с номером секции таблицы, чтобы определить, какие секции таблицы являются соответствующими источниками для перетасовываемых элементов данных. Операция «сравнение-определение равенства» обеспечивает маски для дополнительной фильтрации желательных перетасовываемых элементов данных для каждой секции таблицы. Желательные элементы данных из соответствующих секций таблицы объединяются вместе для формирования конечного результата табличного преобразования.
На фиг.11 показана блок-схема, иллюстрирующая вариант осуществления способа выполнения табличного преобразования с использованием SIMD-инструкций. Описываемый поток операций в основном соответствует методу, представленному на фиг.10А-Н, но как таковой не ограничивается этим. Некоторые из этих операций могут также выполняться в другом порядке или с использованием других типов SIMD-инструкций. В блоке 1102 принимается набор масок тасования, указывающий шаблон тасования. Эти маски тасования также включают в себя поля источника для указания того, из какой таблицы или источника следует тасовать элементы данных, чтобы получить желательный результат. В блоке 1104 загружаются элементы данных из первой части таблицы или первого набора данных. Элементы данных первой части перетасовываются в соответствии с шаблоном тасования блока 1102 в блоке 1106. Элементы данных для второй части таблицы или второго набора данных загружаются в блоке 1108. Элементы данных второй части перетасовываются в соответствии с шаблоном тасования блока 1102 в блоке 1110. В блоке 1112 варианты выбора таблиц отфильтровываются из масок тасования. Варианты выбора таблиц в этом варианте осуществления используют поля выбора источника, которые указывают, из какого источника поступают элементы данных. В блоке 1114 маска выбора таблицы генерируется для перетасовываемых данных из первой части таблицы. Маска выбора таблицы генерируется для перетасовываемых данных из второй части таблицы в блоке 1116. Эти маски выбора таблиц должны отфильтровывать желательные перетасовываемые элементы данных для конкретных позиций элементов данных из соответствующих источников табличных данных.
В блоке 1118 элементы данных выбираются из перетасовываемых данных первой части таблицы в соответствии с маской выбора таблицы блока 1114 для первой части таблицы. Элементы данных выбираются в блоке 1120 из перетасовываемых данных второй части таблицы в соответствии с маской выбора таблицы блока 1116 для второй части таблицы. Перетасовываемые элементы данных, выбранные из первой части таблицы в блоке 1118 и из второй части таблицы в блоке 1120, объединяются вместе в блоке 1122 для получения объединенных табличных данных. Объединенные табличные данные в одном варианте осуществления включают в себя элементы данных, перетасовываемые как из первых табличных данных, так и из вторых табличных данных. В другом варианте осуществления объединенные табличные данные могут включать в себя данные, преобразуемые из более чем двух табличных источников или областей памяти.
На фиг.12 показана блок-схема, иллюстрирующая другой вариант осуществления способа выполнения табличного преобразования. В блоке 1202 загружается таблица, имеющая множество элементов данных. В блоке 1204 определяется, подходит ли таблица для одного регистра. Если таблица подходит для одного регистра, то табличное преобразование выполняется с помощью операции тасования в блоке 1216. Если данные не помещаются в один регистр, то табличное преобразование должно выполняться с помощью операций тасования для каждой релевантной части таблицы в блоке 1206. Логическая упакованная операция «И» выполняется для получения битов или поля, которые выбирают часть таблицы или источник данных. Операция «сравнение-определение равенства» в блоке 1210 создает маску для выбора табличных данных из релевантных частей таблицы для просмотра. В блоке 1212 логическая операция «И» используется для просмотра и выбора элементов данных из секций таблицы. Логическая операция «ИЛИ» объединяет выбранные данные в блоке 1214 для получения желательных данных табличного преобразования.
Один вариант осуществления упакованной инструкции тасования реализован в виде алгоритма для переупорядочивания данных между множеством регистров с использованием функции сброса в нуль. Целью операции смешивания является объединение содержимого двух или более SIMD-регистров в один SIMD-регистр в выбранной конфигурации, в которой позиции данных в результате отличаются от их исходных позиций в операндах источника. Выбранные элементы данных сначала перемещаются в желательные позиции результата, а невыбранные элементы данных устанавливаются в нуль. Позиции, в которые были перемещены выбранные элементы данных, для одного регистра устанавливаются в нуль для других регистров. Вследствие этого один из регистров результата может содержать ненулевой элемент данных в заданной позиции элемента данных. Следующая общая последовательность инструкций может быть использована для смешивания данных из двух операндов:
Тасование упакованных байтов DATA А, MASK А;
Тасование упакованных байтов DATA В, MASK В;
Упакованная логическая операция «ИЛИ» RESULTANT А, RESULTANT В.
Операнды DATA А и DATA В содержат элементы, которые должны быть переупорядочены или установлены в нуль. Операнды MASK А и MASK В содержат байты управления тасованием, которые определяют, куда элементы данных должны быть перемещены и какие элементы данных должны быть установлены в нуль. В данном варианте осуществления элементы данных в позициях адресата, не установленных в нуль посредством MASK А, устанавливаются в нуль посредством MASK В, и позиции адресата, не установленные в нуль посредством MASK В, устанавливаются в нуль посредством MASK А. Фиг.13А-С иллюстрируют алгоритм для переупорядочивания данных между множеством регистров. В этом примере элементы данных из двух источников данных или регистров 1304, 1310 перетасовываются вместе в перемеженный блок 1314 данных. Блоки данных, включающие маски 1302, 1308, данные 1304, 1310 источников и результаты 1306, 1312, 1314, в этом примере имеют каждый длину 128 битов и состоят из элементов данных размером 16 байтов. Однако альтернативные варианты осуществления могут включать в себя блоки данных другой длины, имеющие элементы данных разных размеров.
На фиг.13А показана первая операция тасования упакованных данных первой маски MASK A 1302 над первым операндом данных источника DATA A 1304. В этом примере желательный перемеженный результат 1314 должен включать в себя перемеженный шаблон одного элемента данных из первого источника 1304 данных и другой элемент данных из второго источника 1310 данных. В этом примере пятый байт DATA А 1304 должен перемежаться с 12-м байтом DATA В 1310. MASK A 1302 включает в себя повторяющийся шаблон 0х80 и 0х05 в этом варианте осуществления. Значение 0х80 в этом варианте осуществления имеет установленное поле «установка в нуль», причем соответствующая позиция элемента данных заполнена '0'. Значение 0х05 указывает, что соответствующая позиция элемента данных для данной маски тасования должна быть образована данными F1 из элемента данных 0х5 из DATA А 1304. По существу, шаблон тасования в MASK A 1302 упорядочивает и повторяет данные F1 в каждой другой позиции элемента данных результата. Здесь данные F1 представляют собой одиночный фрагмент данных, который должен перетасовываться из DATA А 1304. В альтернативных вариантах осуществления могут перетасовываться данные из различного числа элементов данных источников. Эти варианты осуществления не ограничены шаблонами, использующими одиночный фрагмент данных или какой-либо конкретный шаблон. Комбинации шаблонов масок могут использовать возможности самых разных видов. Стрелки на фиг.13А показывают тасование элементов данных для масок тасования MASK A 1302. RESULTANT A 1306 этой операции тасования состоит, таким образом, из '0' и F1 для шаблона маски 1302.
Фиг.13В иллюстрирует вторую операцию тасования упакованных данных с использованием второй маски MASK В 1308 вместе с вторым операндом данных источника DATA В 1310. MASK В 1308 включает в себя повторяющийся шаблон из 0x0C и 0x80. Значение 0х80 обуславливает то, что соответствующая позиция данных для этой маски тасования получает '0'. Значение 0хС0 обуславливает то, что позиция элемента данных результата, соответствующая данной маске тасования, обеспечивается данными М2 из элемента 0хС данных из DATA В 1310. Шаблон тасования MASK В 1308 обеспечивает данные М2 для любой другой позиции элемента данных результата. Стрелки на фиг.13В иллюстрируют тасование элементов данных для набора масок тасования в MASK В 1308. Результат RESULTANT B 1312 этой операции тасования, таким образом, состоит из комбинации '0' и М2 для шаблона 1308 тасования.
Фиг.13С иллюстрирует объединение перетасованных данных RESULTANT A 1306 и RESULTANT B 1312 для получения перемеженного результата INTERLEAVED RESULTANT 1314. Объединение выполняется посредством упакованной логической операции «ИЛИ». Комбинация '0' в RESULTANT A 1306 и RESULTANT B 1312 обеспечивает возможность перемежения значений 1314 данных М2 и F1. Например, в крайней слева позиции элемента данных логическая операция «ИЛИ» для '0' и М2 приводит к получению М2 в крайней слева позиции элемента данных результата 1314. Аналогичным образом в крайней справа позиции элемента данных логическая операция «ИЛИ» для F1 и '0' приводит к получению F1 в крайней справа позиции элемента данных результата 1314. Таким образом, данные из множества регистров или ячеек памяти могут быть переупорядочены в требуемую комбинацию.
На фиг.14 показана блок-схема, иллюстрирующая вариант осуществления способа переупорядочения данных между множеством регистров. Данные загружаются из первого регистра или ячейки памяти в блоке 1402. Данные первого регистра перетасовываются в блоке 1404 на основе первого набора масок тасования. В блоке 1406 данные загружаются из второго регистра или ячейки памяти. Эти данные второго регистра перетасовываются в блоке 1408 в соответствии с вторым набором масок тасования. Перетасованные данные из первого и второго регистров объединяются в блоке 1410 с помощью логической операции «ИЛИ» для получения перемеженного блока данных с данными из первого и второго регистров.
На фиг.15А-К показан алгоритм тасования данных между множеством регистров для генерации перемеженных данных. Это пример приложения, относящегося к перемежению цветовых данных плоского изображения. Данные изображения часто обрабатываются в отдельных цветовых плоскостях, и затем эти плоскости перемежаются для отображения изображения. Алгоритм, описанный ниже, демонстрирует перемежение для данных красной плоскости, зеленой плоскости и синей плоскости, как это используется форматами изображения, такими как битовые образы. Возможны многочисленные цветовые пространства и шаблоны перемежения. Как таковой данный подход может просто распространяться на другие цветовые пространства и форматы. Этот пример реализует часто используемую обработку изображения соответственно процессу формата данных, в котором данные красной (R) плоскости, зеленой (G) плоскости и синей (В) плоскости перемежаются в RGB-формат. Этот пример иллюстрирует, каким образом функция сброса в нуль, согласно настоящему изобретению, существенным образом сокращает доступы к памяти.
Данные из трех источников объединяются вместе способом перемежения. Более конкретно, данные относятся к пиксельным цветовым данным. Например, цветовые данные для каждого пикселя могут включать в себя информацию из источников красного (R), зеленого (G), синего (В) цвета. Путем объединения цветовой информации RGB-данные могут оцениваться для обеспечения желательного цвета для конкретного пикселя. Здесь красные цветовые данные содержатся в операнде DATA A 1512, зеленые цветовые данные содержатся в операнде DATA В 1514, и синие цветовые данные - в операнде DATA С 1516. Эта конфигурация может существовать в графических системах или системах памяти, где данные для каждого отдельного цвета сохраняются вместе или накапливаются отдельно как потоковые данные. Чтобы использовать эту информацию в воссоздании или отображении желательного изображения, пиксельные данные должны упорядочиваться в RGB-шаблон, где все данные для конкретного пикселя сгруппированы вместе.
В этом варианте осуществления набор масок, имеющих предварительно определенные шаблоны, используется при перемежении RGB-данных. На фиг.15А показан набор масок: MASK A 1502, имеющая первый шаблон, MASK В 1504, имеющая второй шаблон, и MASK С 1506, имеющая третий шаблон. Данные из каждого регистра должны быть разнесены на три байта, так что они могут быть перемежены с данными из двух других регистров. Байты контроля с шестнадцатеричными значениями 0х80 имеют старший бит, установленный так, что соответствующий байт сбрасывается в нуль инструкцией тасования упакованных байтов. В каждой из этих масок каждая третья маска тасования может выбрать элемент данных для тасования, в то время как две принимающие участие в процессе маски тасования имеют значения 0х80. Значение 0х80 указывает, что поля «установка в нуль» в масках для этих соответствующих позиций элементов данных установлены. Таким образом, '0' должен быть помещен в позиции элементов данных, связанных с этой маской. В этом примере шаблоны масок должны, в принципе, отделять элементы данных для каждого цвета, чтобы выполнить перемежение. Например, если MASK A 1502 применяется к операнду данных в операции тасования, то MASK A 1502 вызывает тасование шести элементов данных (0х0, 0х1, 0х2, 0х3, 0х4, 0х5) по отдельности, с промежутками в два элемента данных между каждым элементом данных. Аналогично, MASK В 1504 предназначена для тасования по отдельности элементов данных соответственно 0х0, 0х1, 0х2, 0х3, 0х4. MASK С 1506 предназначена для тасования по отдельности элементов данных соответственно 0х0, 0х1, 0х2, 0х3, 0х4.
Заметим, что в данной реализации маска тасования для каждой конкретной перекрывающейся позиции элемента данных имеет два установленных поля «установка в нуль», причем одна маска тасования указывает элемент данных. Например, ссылаясь на крайнюю справа позицию элемента данных для трех наборов масок, значениями масок являются 0х00, 0х80 и 0х80 для MASK A 1502, MASK В 1504 и MASK С 1506 соответственно. Таким образом, только маска тасования 0х00 для MASK A 1502 будет определять данные для этой позиции. Маски в этом варианте осуществления имеют такой шаблон, что перетасованные данные можно легко объединить для формирования перемеженного блока RGB-данных.
Фиг.15В иллюстрирует блоки данных, которые должны подвергаться процедуре перемежения: DATA A 1512, DATA В 1514 и DATA С 1516. В данном варианте осуществления каждый набор данных имеет запись данных с цветовой информацией для 16 пиксельных позиций. Например, R0 - красные цветовые данные для пикселя 0 и G15 - зеленые цветовые данные для пикселя 15. Шестнадцатеричные значения в каждом показанном элементе данных представляют номер позиции этого элемента данных. Цветовые данные (DATA A 1512, DATA В 1514, DATA С 1516) могут копироваться в другие регистры, так что данные не перезаписываются операцией тасования и могут повторно использоваться без другой операции загрузки. В примере, соответствующем данному варианту осуществления, необходимы три прохода с использованием трех масок 1512, 1514, 1516 для завершения перемежения пиксельных данных. Для других реализаций и других объемов данных число проходов и операций тасования может изменяться по мере необходимости.
На фиг.15С показан блок данных результата MASKED DATA A 1522 для упакованной операции тасования над красными пиксельными данными DATA A 1512 с использованием первого шаблона тасования MASK A 1502. В ответ на MASK A 1502 красные пиксельные данные упорядочиваются в каждую третью позицию элемента данных. Аналогичным образом на фиг.15D показан блок данных результата MASKED DATA В 1524 для упакованной операции тасования над зелеными пиксельными данными DATA В 1514 с использованием второго шаблона тасования MASK В 1504. На фиг.15Е показан блок данных результата MASKED DATA С 1526 для упакованной операции тасования над синими пиксельными данными DATA С 1516 с использованием третьего шаблона тасования MASK С 1506. Для шаблонов масок в этом варианте осуществления блоки данных результата, получаемые из этих операций тасования, обеспечивают элементы данных, которые чередуются таким образом, что один из элементов данных имеет данные, в то время как два имеют '0'. Например, крайняя слева позиция элемента данных этих результатов 1522, 1524, 1526 содержит соответственно R5, '0', '0'. В следующей позиции элемента данных представлены пиксельные данные для другого одного из RGB-цветов. Таким образом, при их объединении реализуется группирование RGB-типа.
В этом варианте осуществления вышеупомянутые перетасованные данные для красных цветовых данных и зеленых цветовых данных сначала объединяются вместе с использованием упакованной логической операции «ИЛИ». На фиг.15F показаны данные результата INTERLEAVED A&B DATA 1530 упакованной логической операции «ИЛИ» над MASKED DATA А 1522 и MASKED DATA В 1524. Перетасованные синие цветовые данные затем объединяются вместе с перемеженными красными и зелеными цветовыми данными с помощью другой упакованной логической операции «ИЛИ». На фиг.15G показан новый результат INTERLEAVED A,В&С DATA 1532 упакованной логической операции «ИЛИ» над MASKED DATA С 1526 и MASKED DATA А&B 1530. Таким образом, блок данных результата, показанный на фиг.15G, содержит перемеженные RGB-данные для первых пяти пикселей и части шестого пикселя. Последующие итерации алгоритма в этом варианте осуществления дадут перемеженные RGB-данные для остальных из 16 пикселей.
В данный момент для одной трети данных в DATA A 1512, DATA В 1514 и DATA С 1516 выполнено перемежение. Для обработки остальных данных в этих регистрах могут быть использованы два метода. Другой набор байтов управления тасованием может быть использован для упорядочения данных, подлежащих перемежению, или данные в DATA A 1512, DATA В 1514 и DATA С 1516 могут быть сдвинуты вправо, так что маски тасования 1502, 1504 и 1506 могут быть использованы вновь. В описанных вариантах реализации данные сдвигаются, чтобы избежать обращений к памяти, необходимых для загрузки дополнительных байтов управления тасованием. Без этих операций сдвига в этом варианте осуществления потребовалось бы девять наборов байтов управления вместо трех (MASK A 1502, MASK В 1504, MASK С 1506). Этот вариант осуществления может также применяться в архитектурах, где имеется ограниченное число регистров, и обращения к памяти являются длинными.
В альтернативных вариантах осуществления, где имеется большое число регистров, поддержание всех или большого числа наборов масок в регистрах для исключения операций сдвига может оказаться более эффективным. Кроме того, в архитектуре с множеством регистров и исполнительных модулей все операции тасования могут выполняться, не ожидая выполнения сдвига. Например, процессор с исполнением в измененной последовательности с девятью модулями тасования и девятью наборами масок может выполнять девять операций тасования параллельно. В вышеописанных вариантах осуществления данные должны сдвигаться, прежде чем маски смогут быть повторно применены.
Элементы данных в исходных цветовых данных DATA A 1512, DATA В 1514 и DATA С 1516 сдвигаются в соответствии с числом элементов данных, уже обработанных для данного конкретного цвета. В этом примере данные для шести пикселей уже обработаны для красного цвета, так что элементы данных для операнда DATA A 1512 красных цветовых данных сдвигаются вправо на шесть позиций элементов данных. Аналогичным образом данные для пяти пикселей уже обработаны для зеленого и синего цветов, поэтому элементы данных для операнда DATA В 1514 зеленых цветовых данных и для операнда DATA С 1516 синих цветовых данных сдвигаются вправо на пять элементов данных каждый. Сдвинутые данные источника показаны как DATA A' 1546, DATA В' 1542 и DATA С' 1544 соответственно для красного, зеленого и синего цветов на фиг.15Н.
Операции тасования и логического «ИЛИ», как описано выше со ссылками на фиг.15А-G, повторяются с использованием этих сдвинутых данных. Последующие упакованные операции тасования над DATA A' 1546, DATA В' 1542 и DATA С' 1544 вместе с MASK A 1502, MASK В 1504, MASK С 1506 соответственно в комбинации с упакованными логическими операциями «ИЛИ» над тремя упакованными результатами тасования обеспечивают перемеженные RGB-данные для других четырех пикселей и частей двух других. Эти данные результата INTERLEAVED A',В'&С' DATA 1548 показаны на фиг.15I. Заметим, что крайние справа два элемента данных относятся к шестому пикселю, для которого уже имелись красные цветовые данные R2, упорядоченные согласно первому перемеженному набору 1532 данных. Исходные пиксельные цветовые данные вновь сдвигаются на соответствующее число позиций на результаты обработки при втором проходе. Здесь данные для пяти дополнительных пикселей обработаны для красного и синего цветов, так что элементы данных для операнда DATA A' 1546 красных цветовых данных и для операнда DATA С' 1544 синих цветовых данных сдвигаются вправо на пять позиций элементов данных. Данные для шести пикселей обработаны для зеленого цвета, так что элементы данных для операнда DATA В' 1542 красных цветовых данных сдвигаются вправо на шесть позиций. Сдвинутые данные для этого третьего прохода показаны на фиг.15J. Повторение упакованных операций тасования и логического «ИЛИ» применяется к DATA C" 1552, DATA A" 1554 и DATA B" 1556. Перемеженные RGB-данные результата для последних 16 пикселей показаны на фиг.15J как INTERLEAVED A", B" DATA 1558. Крайний справа элемент данных с В10 относится к 11-му пикселю, который уже имеет свои зеленые цветовые данные G190 и красные цветовые данные R10, упорядоченные согласно второму перемеженному набору 1548 данных. Таким образом, посредством ряда упакованных тасований с использованием набора шаблонов масок и упакованных логических операций «ИЛИ» данные из множества источников 1512, 1514, 1516 могут быть объединены и переупорядочены вместе желательным образом для дальнейшего использования или обработки подобно этим результатам 1532, 1548, 1558.
На фиг.16 показана блок-схема одного варианта осуществления способа тасования данных между множеством регистров для генерации перемеженных данных. Например, варианты осуществления настоящего способа могут быть применены к генерации перемеженных пиксельных данных, как пояснено со ссылками на фиг.15А-К. Хотя настоящее изобретение описано в контексте трех источников данных или плоскостей данных, другие варианты осуществления могут работать с двумя или более плоскостями данных. Эти плоскости данных могут включать в себя цветовые данные для одного или более кадров изображений. В блоке 1602 данные кадра для множества пикселей доступны в качестве индивидуальных цветовых данных из разных плоскостей. Данные в первой плоскости соответствуют красному цвету, данные во второй плоскости - зеленому, и данные в третьей плоскости - синему. В блоке 1604 загружается набор масок с шаблонами управления тасованием (М1, М2 и М3). Эти шаблоны управления тасованием определяют шаблоны тасования и упорядочение данных для выполнения перемежения цветов. В зависимости от реализации любое число шаблонов тасования может использоваться для генерации желательной конфигурации данных.
В блоке 1606 для каждой плоскости данных выбирается соответствующий шаблон управления. В этом варианте осуществления шаблон управления выбирается на основе того, какой порядок цветовых данных желателен и какая итерация выполняется в текущий момент. Данные кадра из первого набора данных, для красного цвета, перетасовываются с использованием первого шаблона управления тасованием в блоке 1608, чтобы получить перетасованные красные цветовые данные. Второй набор данных, для зеленого цвета, перетасовывается с использованием второго шаблона управления тасованием в блоке 1610, чтобы получить перетасованные зеленые цветовые данные. Третий набор данных, для синего цвета, перетасовывается с использованием третьего шаблона управления тасованием в блоке 1612, чтобы получить перетасованные синие цветовые данные. Хотя в этом варианте осуществления три маски и их шаблоны управления тасованием отличаются друг от друга, маска и ее шаблон управления тасованием могут быть использованы более чем для одного набора данных на каждой итерации. Кроме того, некоторые маски могут быть использованы более часто, чем другие.
В блоке 1614 перетасованные данные блоков 1608, 1610, 1612 для трех наборов данных объединяются вместе для формирования перемеженного результата для данного прохода. Например, результат первого прохода может представлять собой перемеженные данные 1532, как показано на фиг.15G, причем RGB-данные для каждого пикселя сгруппированы вместе в виде набора. В блоке 1616 делается проверка для определения, имеются ли еще данные кадра, загруженные в регистры для тасования. Если нет, то в блоке 1620 проверяется, имеются ли еще данные из трех плоскостей данных, подлежащих перемежению. Если нет, то способ завершен. Если в блоке 1620 определено, что имеются еще данные упомянутых плоскостей, то процесс возвращается к блоку 1602 для загрузки других данных кадра для тасования.
Если определение в блоке 1616 истинно, то данные кадра в каждой плоскости цветовых данных сдвигаются на предварительно заданный отсчет, который соответствует тому, какой шаблон маски был применен к набору данных для данного конкретного цвета в последнем проходе. Например, в соответствии с примером первого прохода на фиг.15G красные, зеленые и синие цветовые данные в первой, второй и третьей плоскостях сдвинуты на шесть, пять и пять позиций соответственно. В зависимости от реализации шаблон тасования, выбранный для каждых цветовых данных, может различаться при каждом проходе, или может повторно использоваться тот же самый шаблон. В процессе второго прохода в одном варианте осуществления три маски из первой итерации поворачиваются таким образом, что данные первой плоскости теперь образуют пару с третьей маской, данные второй плоскости образуют пару с первой маской, и данные третьей плоскости образуют пару с третьей маской. Этот поворот масок обеспечивает возможность надлежащей непрерывности перемеженных RGB-данных от одного прохода к следующему, как показано на фиг.15G и 15I. Тасование и объединение продолжаются, как в первом проходе. Если желательны третья и последующие итерации, то шаблоны масок тасования в этом варианте осуществления продолжают поворачиваться для различных плоскостей данных, чтобы сформировать перемеженные в большей степени RGB-данные.
Варианты осуществления алгоритмов, использующих упакованные инструкции тасования, в соответствии с настоящим изобретением могут также улучшить характеристики процессора и системы при существующих ресурсах аппаратных средств. Но по мере совершенствования технологии варианты осуществления настоящего изобретения при объединении с большим объемом ресурсов аппаратных средств и более быстродействующими и более эффективными логическими схемами могут иметь даже более глубокое влияние на повышение производительности. Так, эффективный вариант осуществления упакованной инструкции тасования, имеющий байтовую гранулярность и опцию сброса в нуль, может иметь различное и более сильное влияние на поколения процессоров. Простое добавление большего количества ресурсов в современные архитектуры процессоров не гарантирует усовершенствования, обеспечивающего более высокую производительность. При поддержании эффективности приложений, подобных варианту осуществления с параллельной таблицей преобразования и упакованной инструкцией байтового тасования (PSHUFB) возможны более существенные усовершенствования, приводящие к повышению производительности.
Хотя приведенные выше примеры описаны в общем контексте 128-битовых аппаратных/регистровых/операндов для упрощения описания, в других вариантах осуществления для выполнения упакованных операций тасования могут использоваться 64- или 128-битовые аппаратные/регистровые/операнды, параллельное табличное преобразование и переупорядочение данных в множестве регистров. Кроме того, варианты осуществления изобретения не ограничены конкретными аппаратными средствами или типами технологии, такими как MMX/SSE/SSE2-технологии, а могут быть использованы с другими SIMD-реализациями и другими методами манипулирования графическими данными.
В приведенном выше описании изобретение пояснено со ссылкой на приведенные для примера конкретные варианты осуществления. Однако очевидно, что различные модификации и изменения могут быть осуществлены без отклонения от сущности и объема изобретения, как представлено в формуле изобретения. Соответственно, описание и чертежи должны рассматриваться не в ограничительном смысле, а только как иллюстративные.
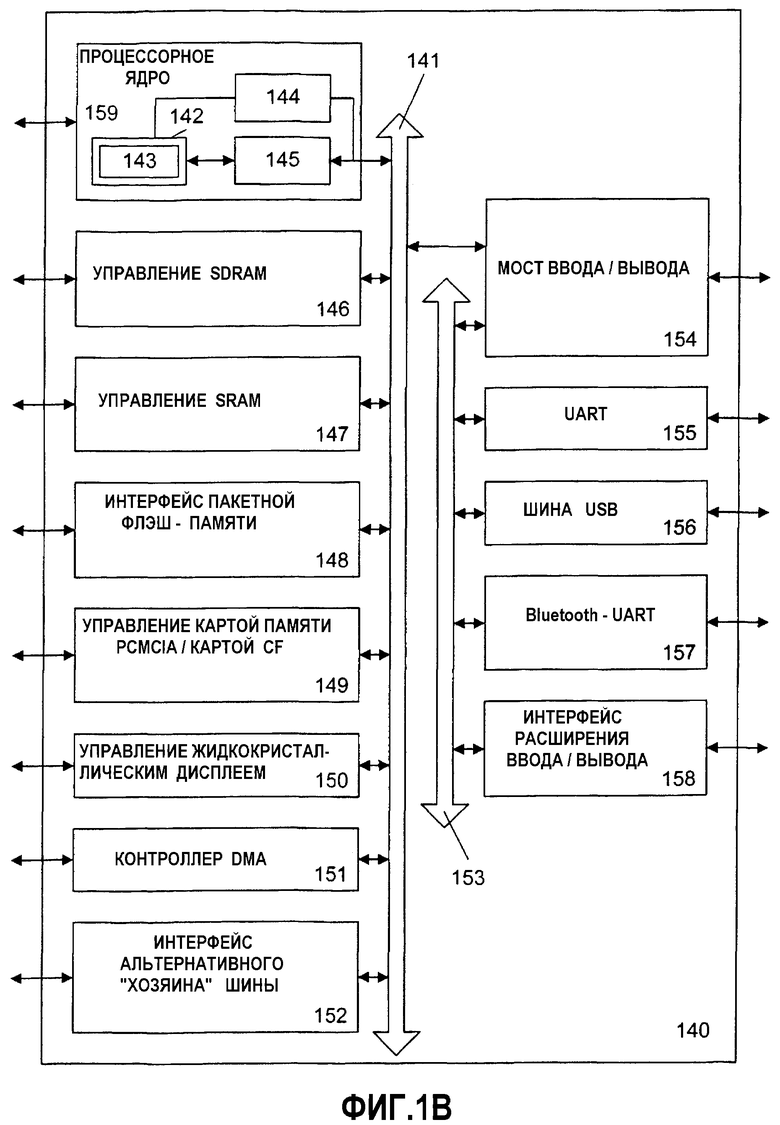
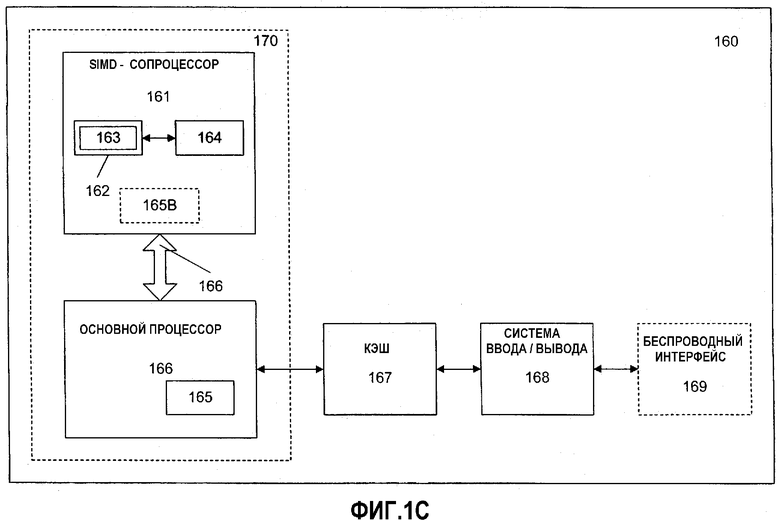
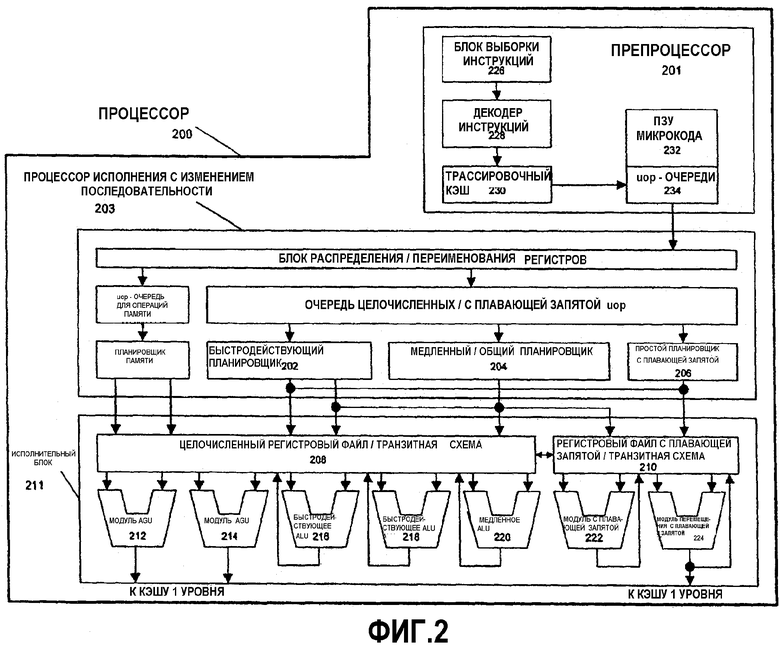
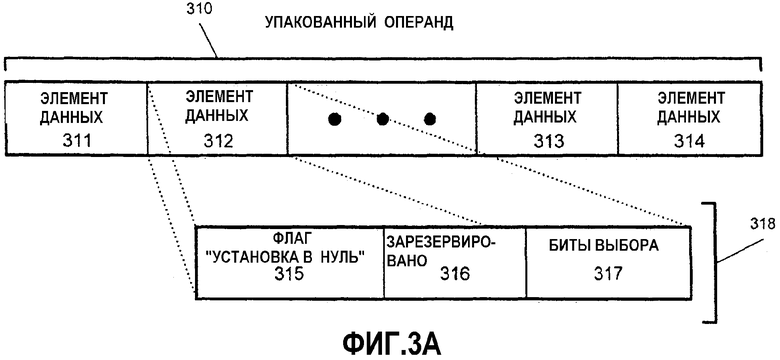
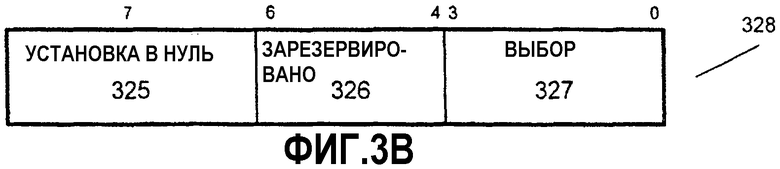
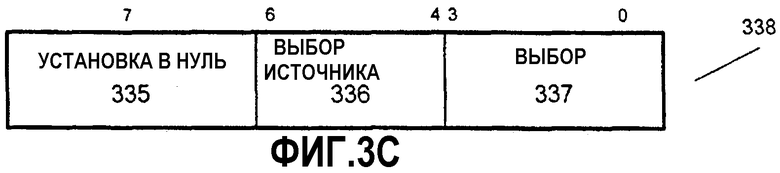
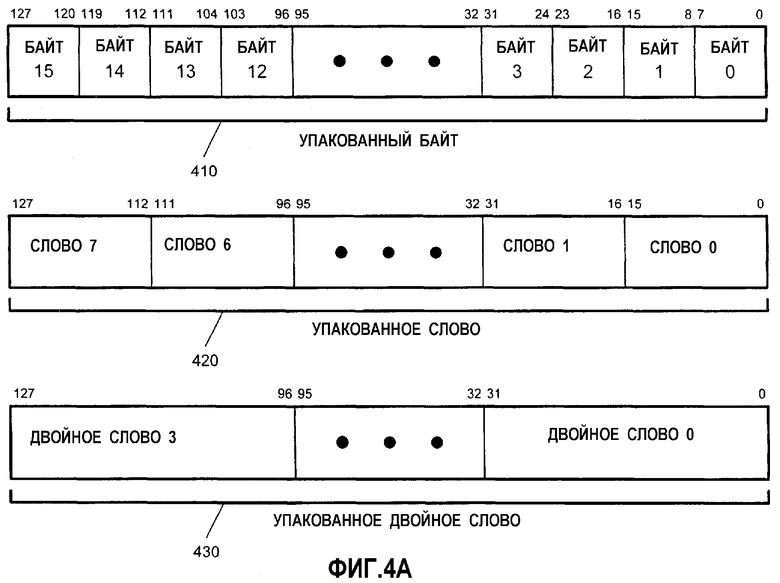
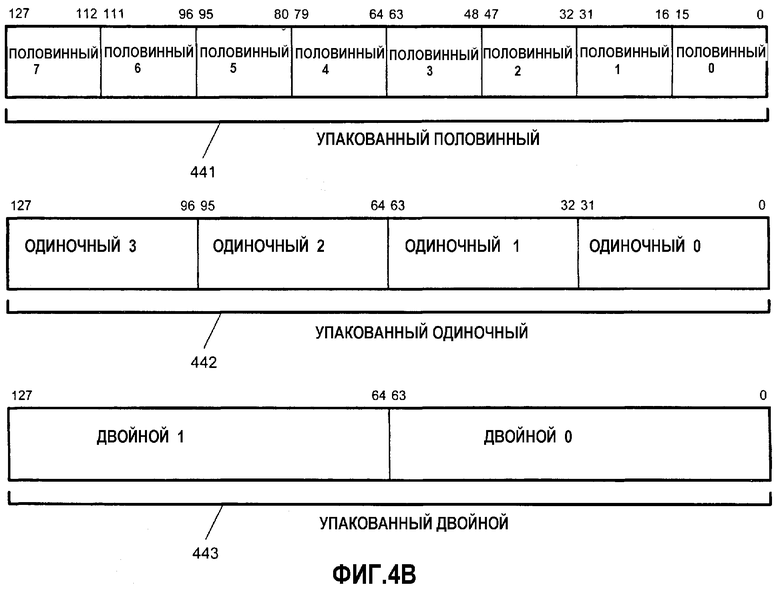
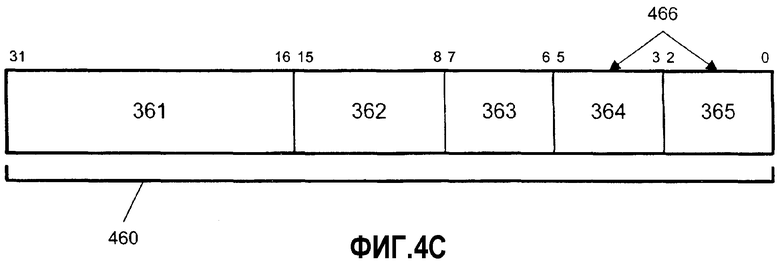
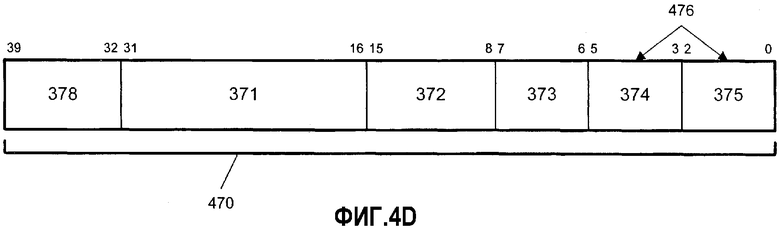
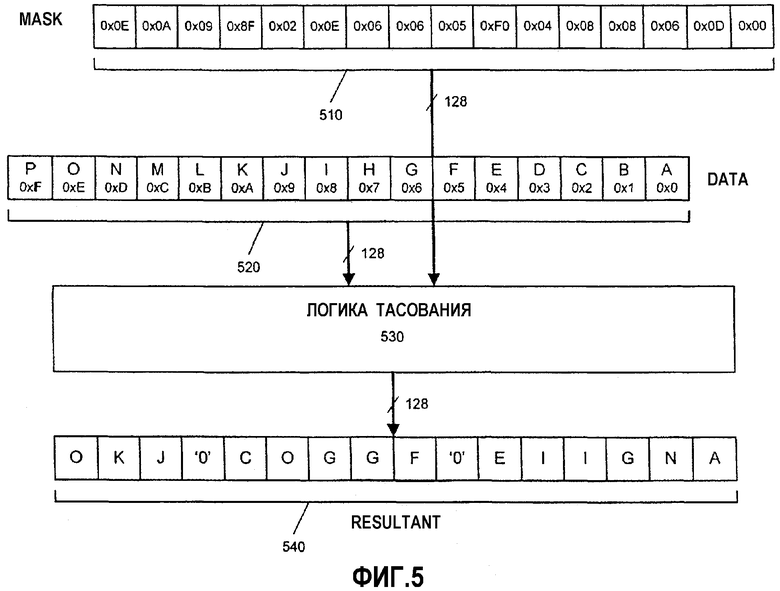
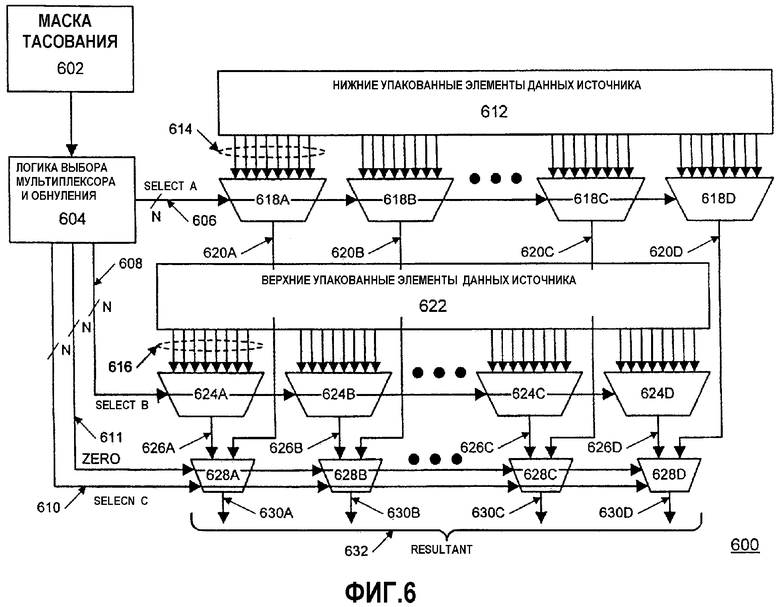
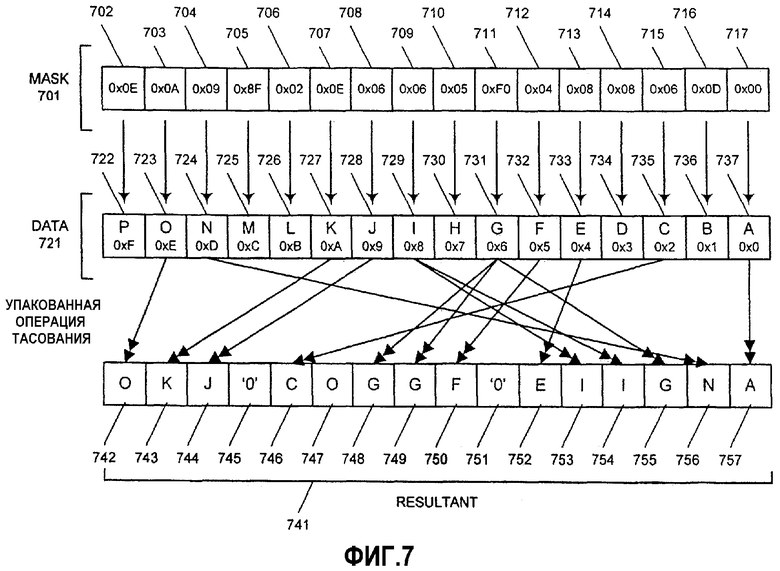
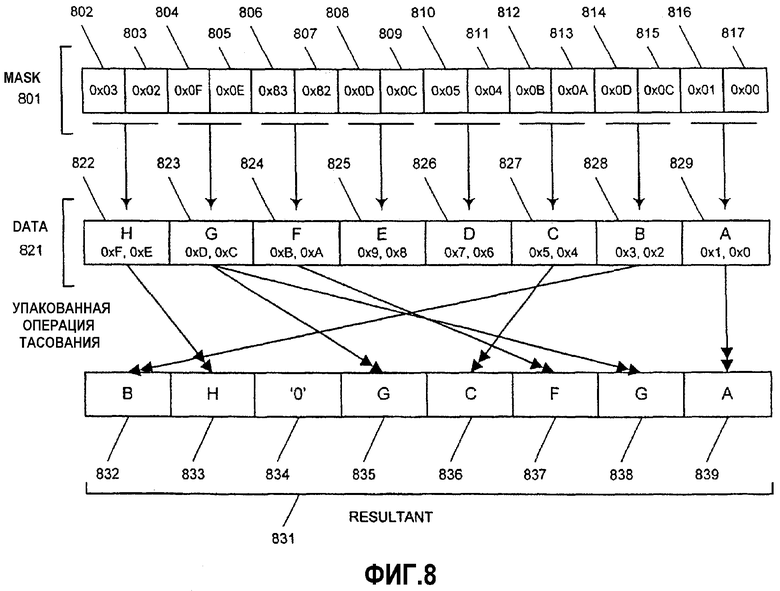
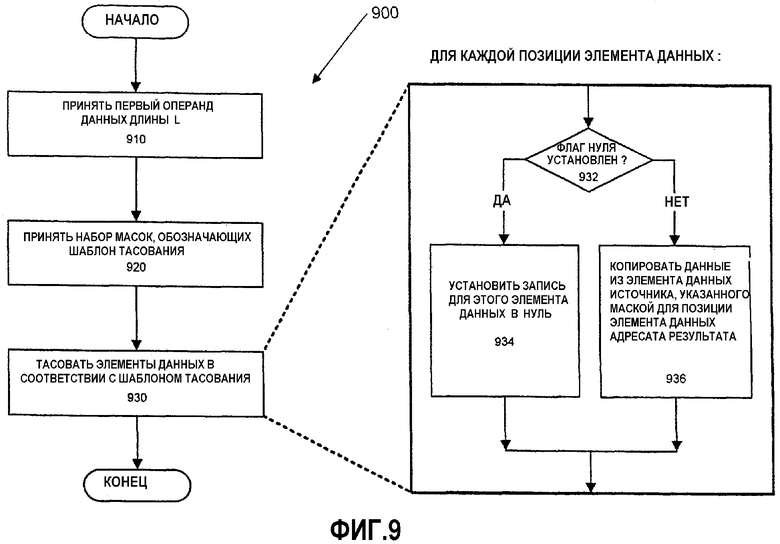
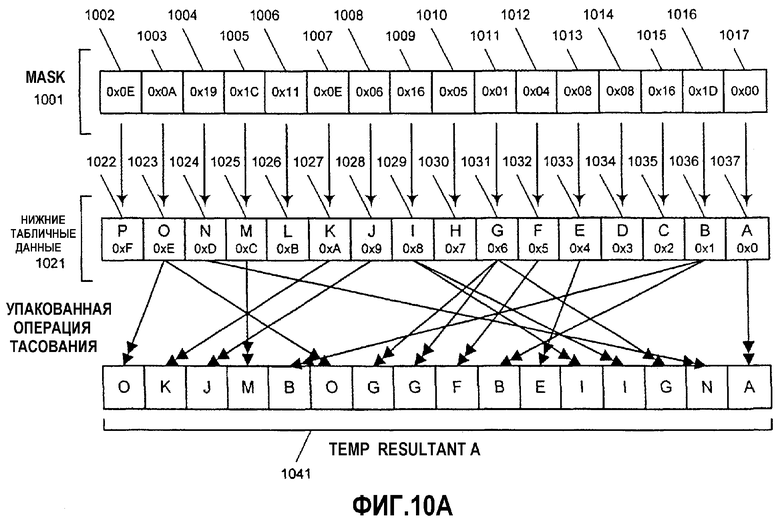
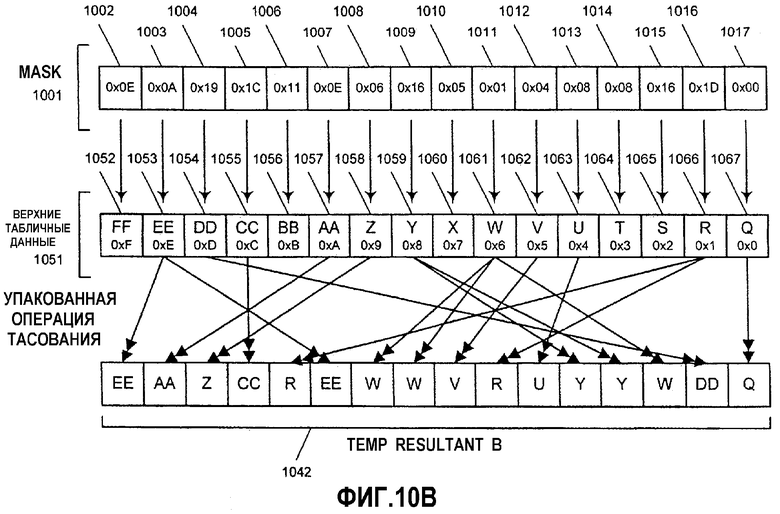
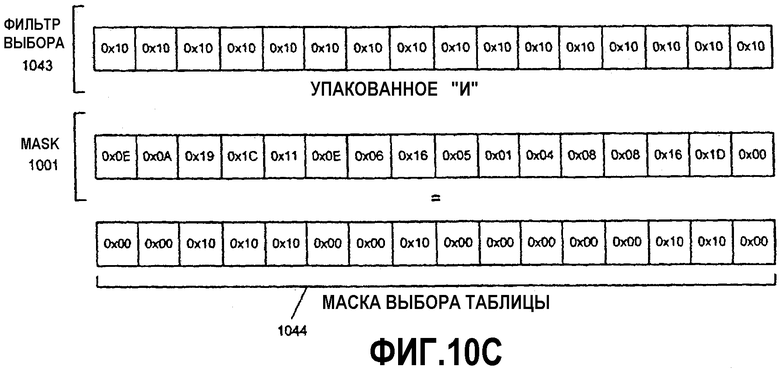
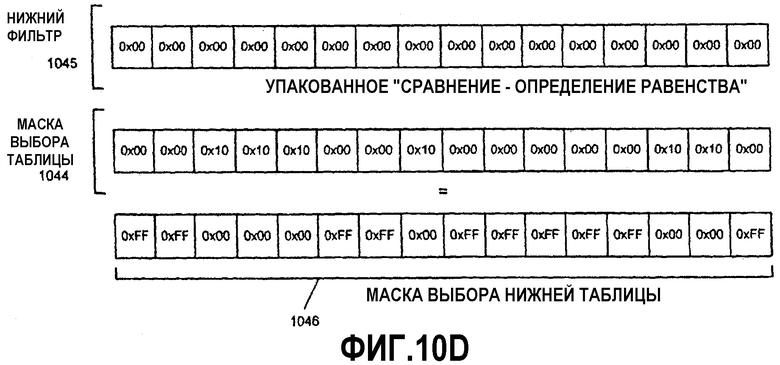
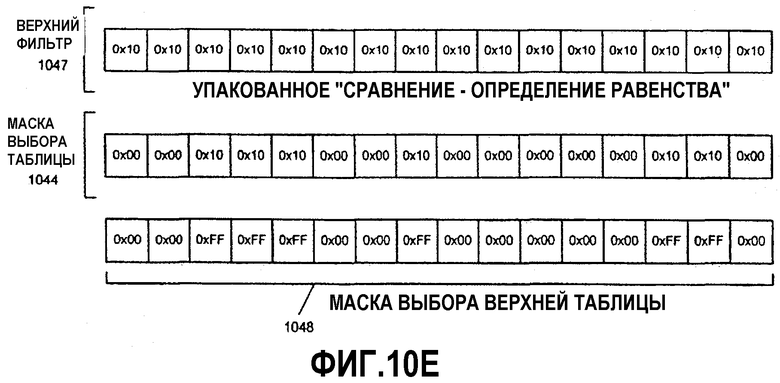
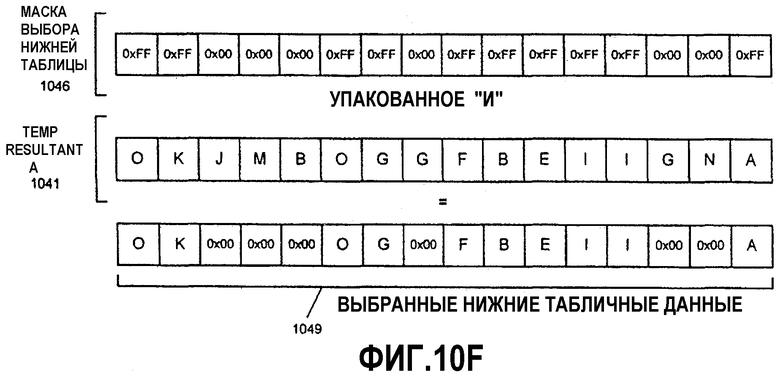
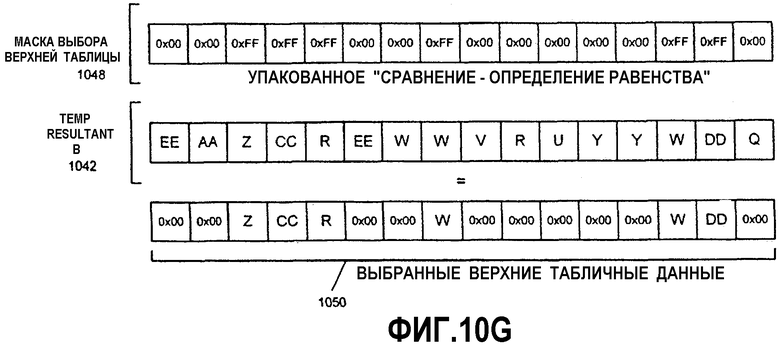
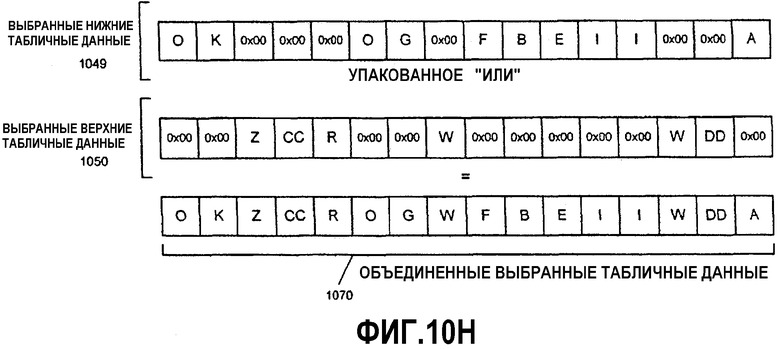
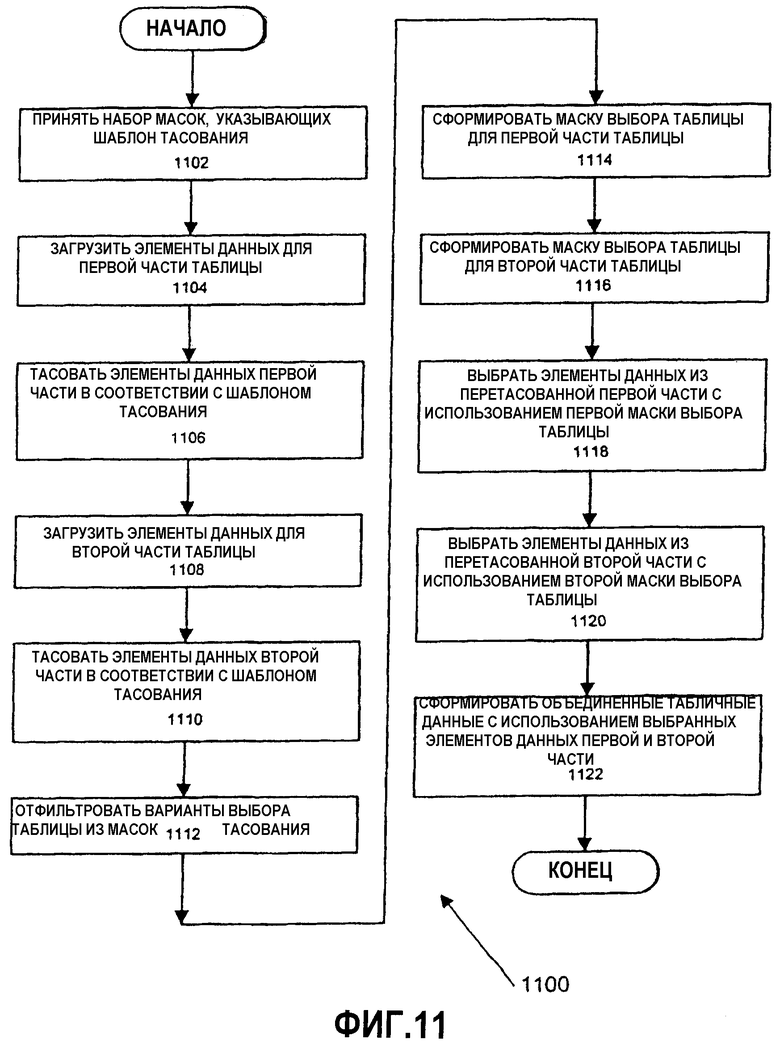
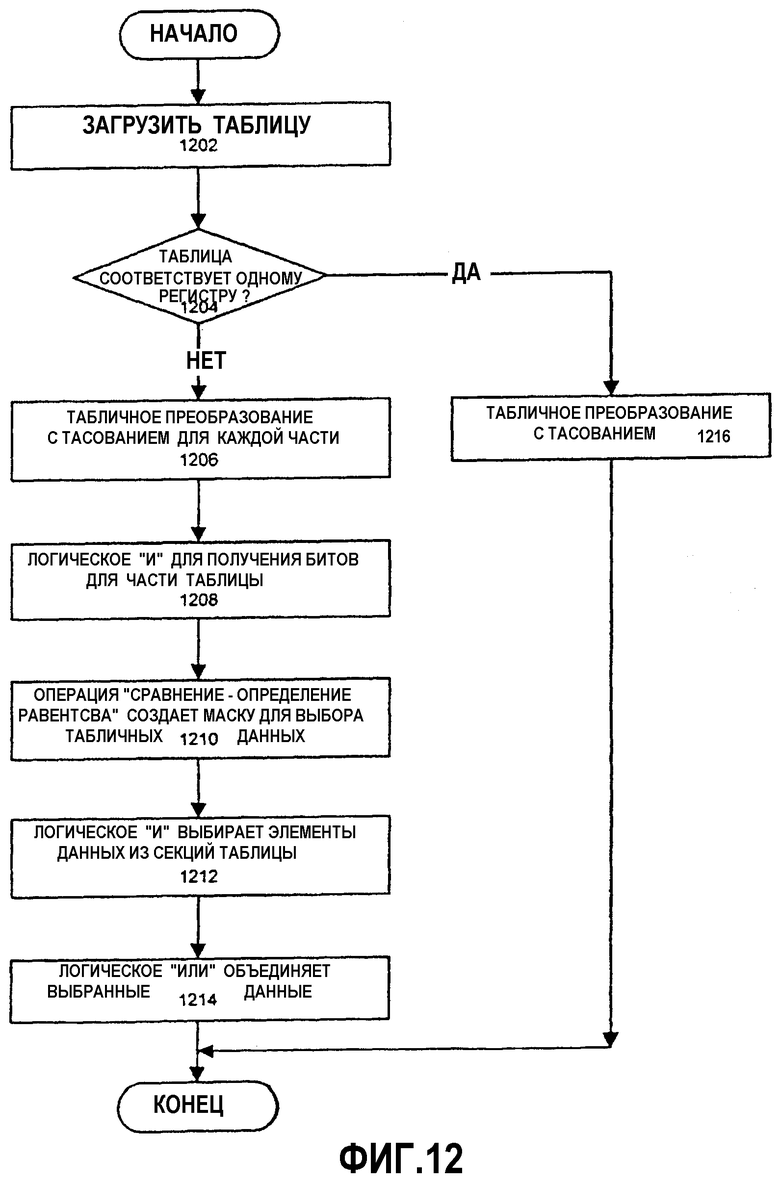
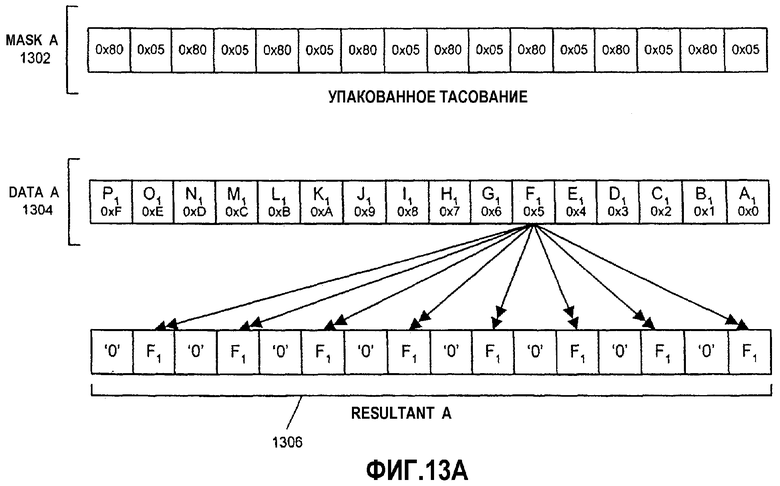
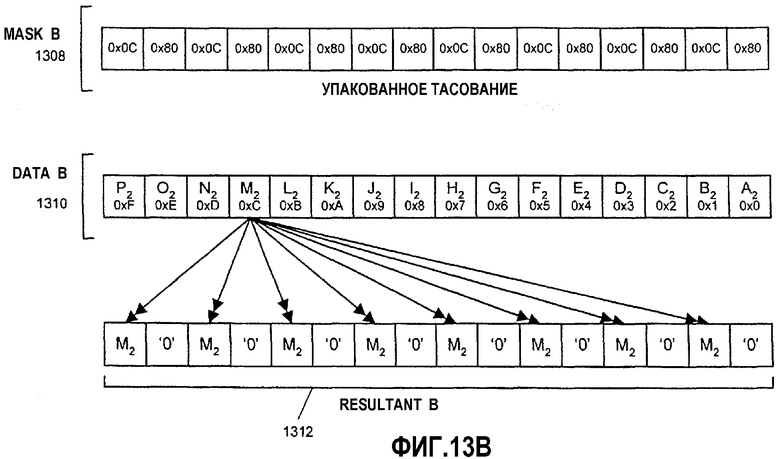
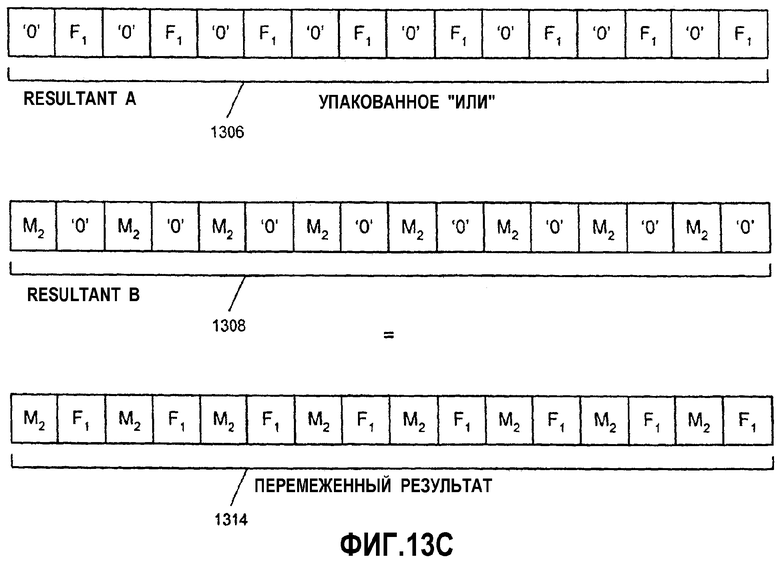
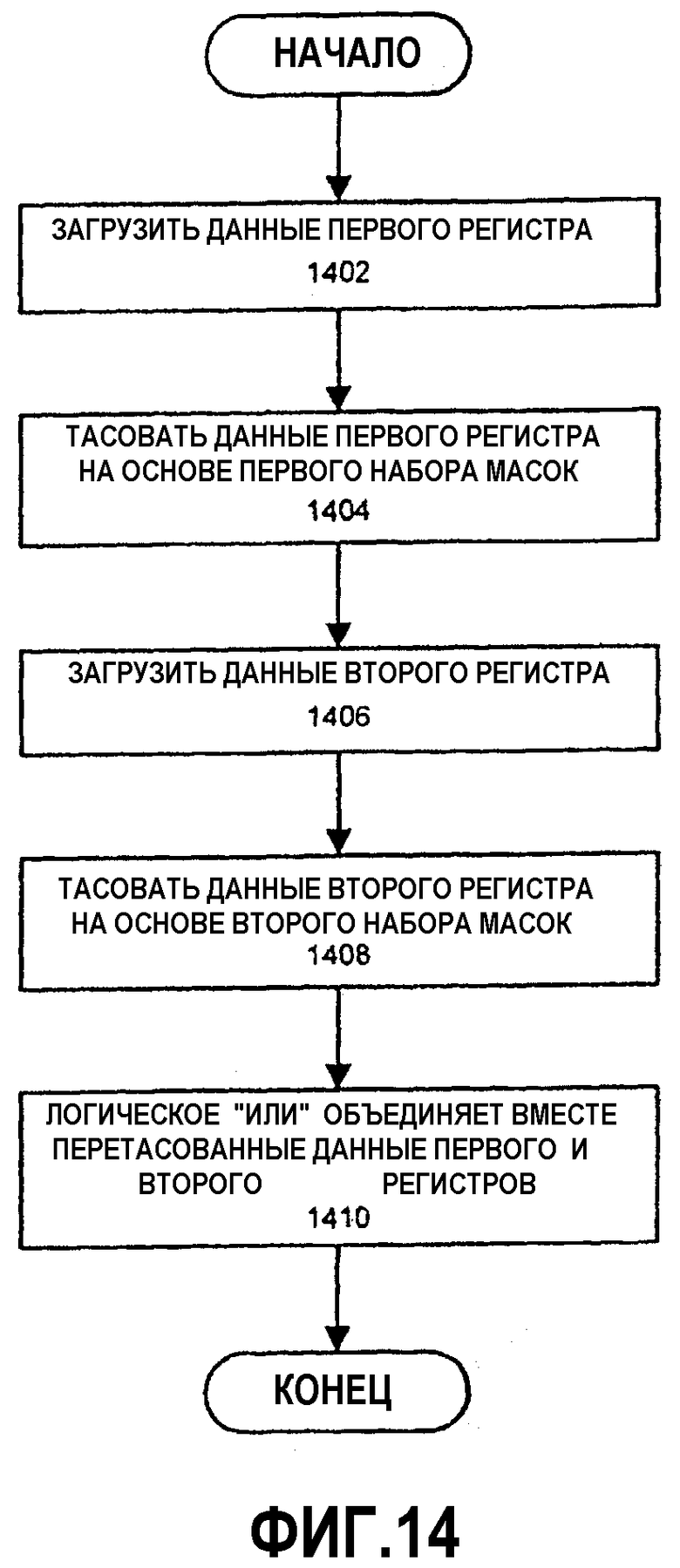
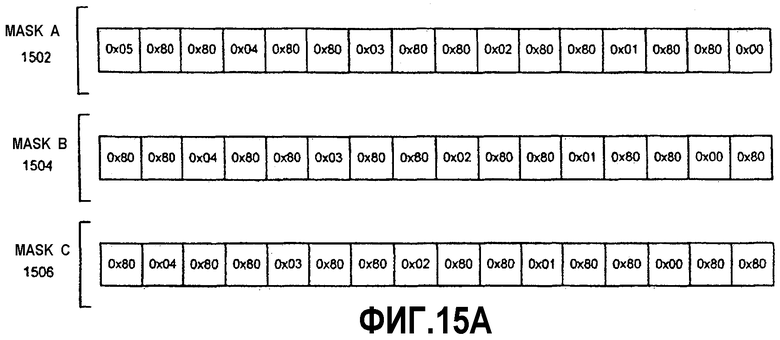
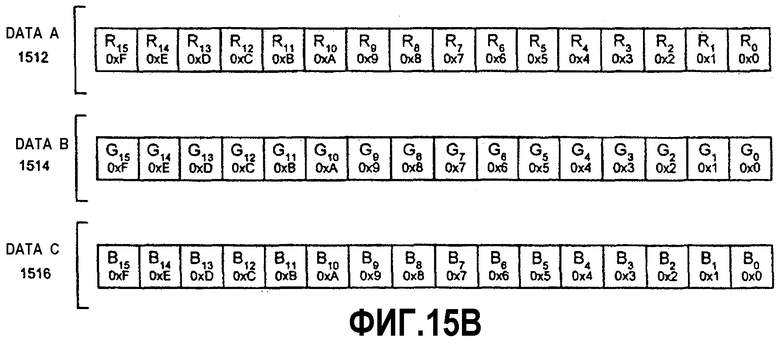





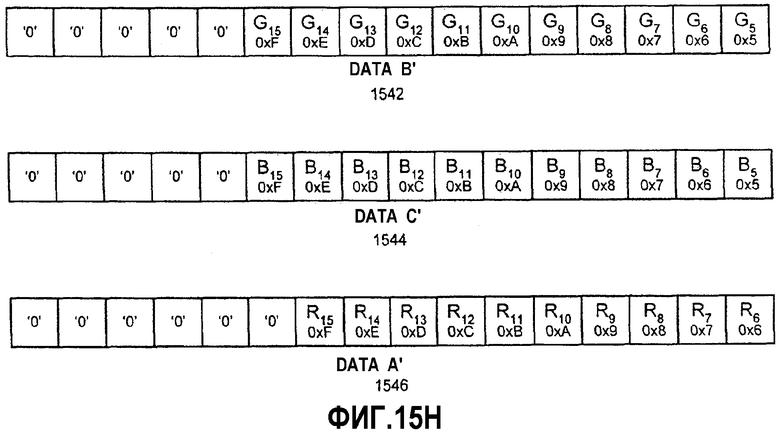
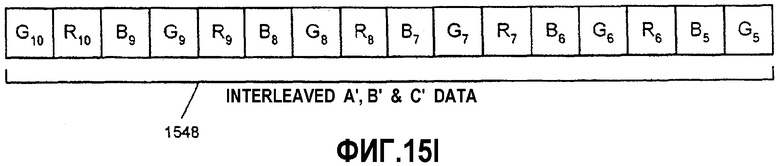
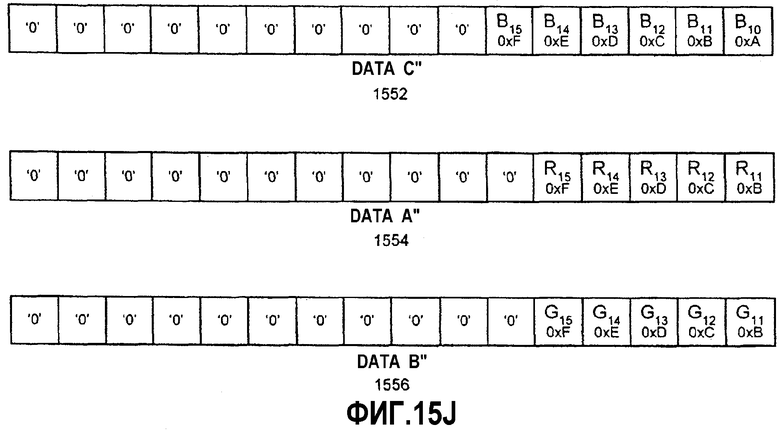
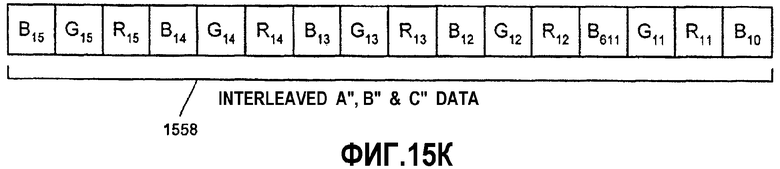
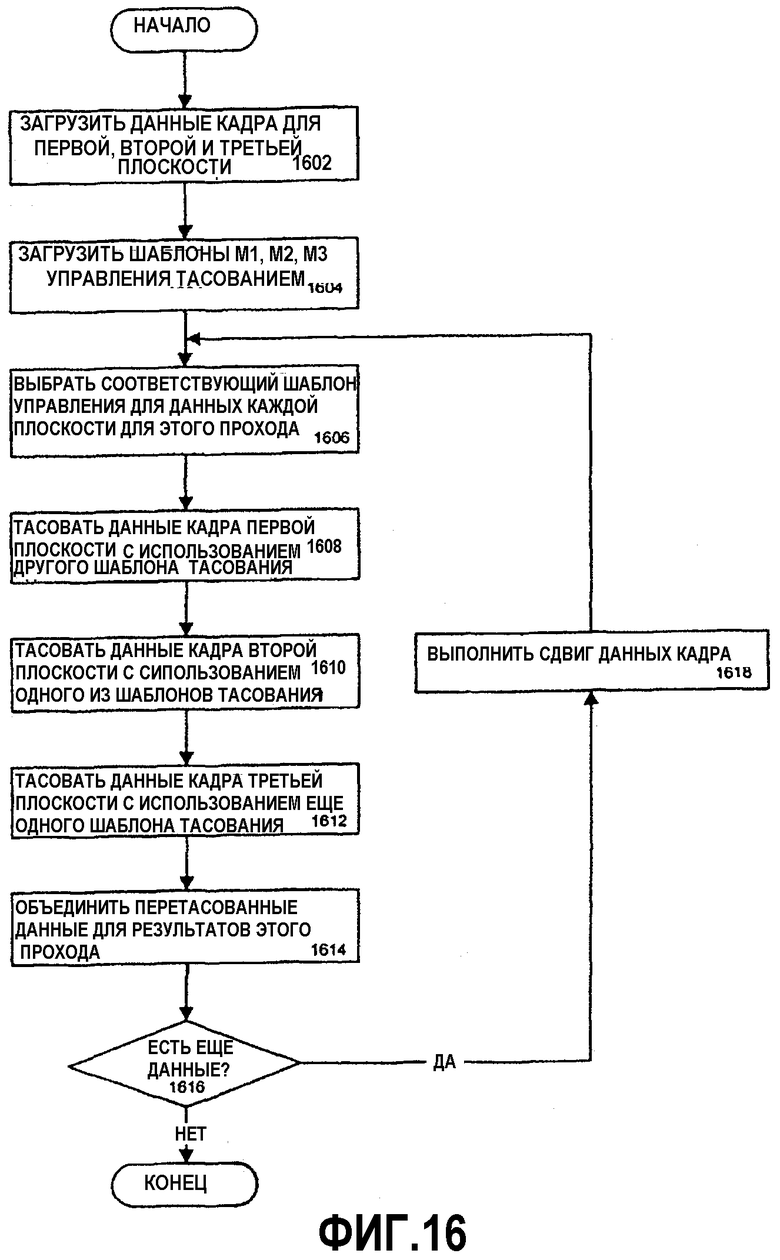
Изобретение относится к области микропроцессоров и компьютерных систем. Технический результат изобретения заключается в улучшении характеристик процессора и повышении его производительности. Технический результат достигается за счет того, что согласно инструкции тасования принимают первый операнд, содержащий набор из L элементов данных, и второй операнд, содержащий набор из L масок тасования, причем каждая из масок тасования включает в себя поле «сброс в нуль» и поле выбора, для каждой маски тасования если поле «сброс в нуль» маски тасования не установлено, то перемещают данные, указанные полем выбора маски тасования, из элемента данных первого операнда в ассоциированный элемент данных результата, и если поле «сброс в нуль» маски тасования установлено, то помещают нуль в ассоциированный элемент данных результата. 8 н. и 46 з.п. ф-лы, 16 ил.
| US 6041404 А, 21.03.2000 | |||
| СИСТЕМА ВРЕМЕННОГО ЗАПОМИНАНИЯ ИНФОРМАЦИИ | 1991 |
|
RU2138845C1 |
| КОНТРОЛЛЕР ПАМЯТИ, КОТОРЫЙ ВЫПОЛНЯЕТ КОМАНДЫ СЧИТЫВАНИЯ И ЗАПИСИ НЕ В ПОРЯДКЕ ПРОСТОЙ ОЧЕРЕДИ | 1996 |
|
RU2157562C2 |
| US 5784709 A, 21.07.1998 | |||
| US 6088795 A, 11.07.2000. | |||

