Настоящая заявка относится к области техники медицинской диагностики. Она находит особое применение в алгоритмах диагностики с применением компьютера (CADx) и алгоритмах классификации изображений. Однако она также найдет применение в других областях техники, в которых используется медицинская диагностика.
Один из типов системы CADx может оценивать вероятность злокачественности легочного узла, обнаруженного на снимке компьютерной томографии (CT). Однако в отличие от алгоритмов обнаружения с применением компьютера, которые полагаются исключительно на информацию изображения, чтобы локализовать возможные патологии, процесс принятия решения, связанный с оценкой злокачественности, типично включает объединение признаков, полученных без использования изображений. Анализ изображения снимка CT сам по себе редко является достаточным для оценки одиночного легочного узла. Важные исследования показали, что как диагностические оценки, так и восприятие радиологических признаков находятся под влиянием историй болезней пациентов. Конкретно для легочных узлов, исследования детально проанализировали степень, в которой факторы клинического риска модулируют статистическую вероятность злокачественности. Поэтому разработка алгоритмов диагностики с применением компьютера включила клинические признаки, чтобы дополнить информацию на изображениях.
Объединение разных типов данных, таких как, но не в качестве ограничения, клинических данных и данных, полученных с помощью изображений, имеет прямое отношение к способу, с помощью которого пользователь получает доступ к алгоритмам, и последовательности выполняемых действий, которая применяется при использовании системы. По причинам эффективности функционирования желательно выполнить столько вычислений диагностики с применением компьютера, сколько возможно, перед тем, как пользователь получит доступ к системе. Одной из проблем с современными диагностическими системами является то, что они неэффективны, потому что современные системы требуют, чтобы были введены все данные, независимо от того, необходимы ли эти данные на самом деле, чтобы провести диагностику. Поэтому желательно минимизировать количество информации, которую должен вводить пользователь, как например, путем минимизации или исключения ввода внешних клинических данных, которые не значительно изменят диагноз. Клиническая информация может быть взята из электронной медицинской карты. Однако поля данных могут отсутствовать или быть неполными, и информация может быть неизвестна. Другой проблемой с современными диагностическими системами является то, что им не хватает методик для оперирования отсутствующей или неполной клинической информацией. Поэтому желательно разработать вычисления, которые могут оценивать и представлять диапазон возможных результатов в пределах клинической информации, которая доступна.
Настоящая заявка предоставляет улучшенную систему и способ, который преодолевает вышеупомянутые и другие проблемы.
В соответствии с одним из аспектов, представлена система для выполнения диагностики с применением компьютера, используя данные медицинских изображений. Система выполняет медицинскую диагностику путем сравнения медицинских записей и вероятностей в базе данных с текущими данными изображений, чтобы предположить медицинский диагноз и представить вероятность того, что диагноз правильный. Если вероятность диагноза падает ниже порогового уровня, система рекомендует медицинскому пользователю вводить дополнительные клинические данные, чтобы предоставить больше информации на основании которой система может произвести медицинский диагноз с более высокой вероятностью правильности.
В соответствии с другим аспектом, представлен способ для выполнения диагностики с применением компьютера, используя данные медицинских изображений. Способ обеспечивает выполнение медицинской диагностики путем сравнения медицинских записей и вероятностей в базе данных с текущими данными изображений, чтобы предположить медицинский диагноз и рассчитать вероятность того, что диагноз правильный. Если вероятность диагноза падает ниже определенного порогового уровня, тогда способ обращается к медицинскому пользователю, чтобы получить дополнительные клинические данные, чтобы обеспечить большее основание информации, на основании которой может быть поставлен более точный и более определенный медицинский диагноз.
Дополнительное преимущество - это улучшенная эффективность для разбиения вычислений на меньшие компоненты для улучшений последовательности выполняемых действий. Не все данные извлекаются до того момента времени, когда эти данные необходимы. Нет необходимости извлекать данные до тех пор, пока данные не считаются необходимыми для пациента.
Дополнительное преимущество обеспечивается для оперирования отсутствующей или неполной клинической информацией.
Еще одно дополнительное преимущество - предоставление интерфейса и последовательности выполняемых операций системы, которая разделяет вычисления CADx на два или более этапов на основании доступности данных.
Еще одно дополнительное преимущество - предоставление вычислительного способа для объединения разных потоков данных, когда они становятся доступными.
Другие дополнительные преимущества и выгоды станут очевидны специалистам в данной области техники по мере прочтения и понимания нижеследующего подробного описания.
Настоящая заявка может быть осуществлена в различных компонентах и компоновках компонентов и в различных этапах и компоновках этапов. Чертежи представлены лишь в целях иллюстрации предпочтительных вариантов осуществления и не должны истолковываться, как ограничивающие настоящую заявку.
Фиг.1А иллюстрирует диагностический способ CADx;
Фиг.1В иллюстрирует диагностическую систему CADx;
Фиг.2 иллюстрирует подход для создания алгоритма для классификации;
Фиг.3 иллюстрирует обучающую методологию для классификатора;
Фиг.4 иллюстрирует другой подход для создания алгоритма для классификации;
Фиг.5 иллюстрирует другой классификатор, который объединяет множество;
Фиг.6 иллюстрирует способ, которым классификатор работает с новым и неизвестным случаем;
Фиг.7 иллюстрирует способ, которым байесовский анализ выполняет анализ риска;
Фиг.8 иллюстрирует экспериментальные результаты, подтверждающие концепцию;
Фиг.9 иллюстрирует схему расположения системы и взаимодействие между компонентами.
Со ссылкой на фиг.1А, способ 100 диагностики с применением компьютера включает алгоритм классификатора CADx, который оптимально работает на двух типах данных ('тип 1 данных' и 'тип 2 данных'). Клинические данные описывают аспекты истории болезни пациента, истории семьи, телосложения и образа жизни, включая такие элементы, как, но не в качестве ограничения, курение, предыдущие болезни и тому подобное. Данные изображений содержат рентгеновские лучи, снимки CT и любой другой тип получения медицинских изображений, применяемый к пациенту. Алгоритм CADx комбинирует данные изображений на изображениях CT (тип 1 данных в этом примере) с клиническими данными в клинических параметрах (рассматриваемый тип 2 данных в этом примере) пациента (например, состояние эмфиземы, состояние лимфатического узла).
Первый этап в способе содержит этап извлечения набора данных, связанных с пациентом, из базы 110 данных. Эти данные могут включать одну или более количественных переменных. Тип 1 данных извлекается вместо типа 2 данных, если, например, тип 1 данных легкодоступен, как в случае настоящего примера. Это извлечение предпочтительно происходит без взаимодействия с пользователем. Например, том CT грудного снимка (тип 1 данных в этом примере) извлекается автоматически из PACS (системы архивирования изображений и коммуникаций) больницы.
Следующий этап содержит применение алгоритма 120 CADx к данным типа 1 данных. Результат данных вычислений еще не представляет собой окончательный диагноз этапа алгоритма CADx. Это предпочтительно происходит без взаимодействия с пользователем. Например, этап 100 CADx запускает алгоритм обнаружения с применением компьютера, чтобы локализовать легочный узел на снимке, запускает алгоритм сегментации, чтобы определить границы легочного узла, обрабатывает изображение, чтобы извлечь из данных изображения набор числовых признаков, описывающих узел. Алгоритм классификации образов затем оценивает вероятность того, что этот узел злокачественный, исключительно на основании данных, полученных с помощью изображений.
Способ 100 еще не получил данные типа 2 данных, чтобы завершить диагностику. Поэтому способ 100 тестирует разные предлагаемые возможные значения данных типа 2 данных (в этом случае, три разных возможных значения, представленные тремя разными стрелками), завершая вычисления CADx, используя эти тестовые значения во время операций, выполняемых этапами 130, 140, 150 операций. Если возможны N различных значений типа 2 данных, тогда вычисляются N результатов CADx, по одному для каждого тестового значения типа 2 данных. Например, алгоритм CADx настраивает вывод основанной на изображениях классификации на основании всех различных предлагаемых возможных комбинаций состояния эмфиземы и лимфатического узла. Так как они обе являются двоичными переменными (да/нет), возможны четыре различные комбинации. Как результат, теперь CADx имеет четыре возможных решения для вероятности злокачественности. Этот этап становится более сложным, если число возможных значений очень велико или если некоторые из переменных непрерывны. Эти выводы объединяются как вывод средством управляемого компьютером программного обеспечения и используются как ввод для устройства сравнения.
Этап 160 устройства сравнения средства управляемого компьютером программного обеспечения сравнивает N разных возможных результатов вычислений CADx или возможных решений для вероятности злокачественности и решает, находятся ли они в пределах предустановленного допустимого отклонения. Допустимое отклонение может быть установлено перед тем, как результат размещается в поле, или может быть установлено пользователем. Если возможные результаты CADx находятся в пределах предустановленного допустимого отклонения (то есть зная, что тип 2 данных не имеет значения, поэтому тип 1 данных был бы достаточным, чтобы поставить диагноз), тогда этап 190 отображения отображает для пользователя одно или более из следующего: среднее, медиану, диапазон или дисперсию результатов вычислений CADx. Результаты могут быть отображены графически. Например, для одного пациента алгоритм CADx обнаруживает, что четыре комбинации состояния эмфиземы и лимфатического узла выдают вероятности злокачественности 0,81, 0,83, 0,82, и 0,82 на шкале от 0 до 1. Так как они все очень близки по значению, то нет необходимости спрашивать у пользователя эти переменные или запрашивать вторую базу данных. Когда радиолог загружает случай, способ уже завершил все предшествующие этапы и предоставляет отчет о том, что алгоритм CADx оценивает вероятность злокачественности между 0,81-0,83.
Если возможные результаты вычислений CADx слишком разные (то есть зная, что тип 2 данных мог бы изменить диагноз и, следовательно, важно собрать эту информацию), тогда способ требует 170, чтобы пользователь представил важную клиническую информацию. Эта точная информация затем используется, чтобы идентифицировать, какой из N значений выводов CADx отобразить 180 пользователю. Например, для другого пациента алгоритм CADx обнаруживает, что четыре комбинации состояния эмфиземы и лимфатического узла выдают вероятности злокачественности 0,45, 0,65, 0,71, и 0,53 на шкале от 0 до 1. Четыре оценки такие разные, что тип 2 данных мог бы изменить диагноз. Когда радиолог загружает случай, способ уже завершил все предшествующие этапы, но сообщает радиологу о том, что необходима дополнительная информация (то есть тип 2 данных), чтобы завершить вычисления CADx. Состояние эмфиземы и лимфатического узла вводится вручную пользователем. На основании добавленного типа 2 данных, CADx выбирает одну из четырех вероятностей (например, 0,65) в качестве своей окончательной оценки. Этот окончательный результат отображается 180 пользователю.
Если запрашиваются дополнительные данные типа 2 данных, не являющиеся доступными, тогда N возможных результатов могут затем быть представлены пользователю вместе с оговоркой, что данных недостаточно, чтобы завершить вычисления. Например, для другого пациента состояние лимфатического узла недоступно, возможно потому что снимок не охватил необходимую анатомию. Поэтому радиолог вводит правильное состояние эмфиземы, но сообщает, что состояние лимфатического узла неизвестно. Используя данные эмфиземы, компьютер способен сузить диапазон возможных выводов с (0,45, 0,65, 0,71, 0,53) до (0,45, 0,53), но все еще не способен предсказать, вероятнее ли, что узел злокачественен (>0,50), или что он не злокачественен (<0,50). Таким образом, способ сообщает радиологу, что оценка вероятности рака у пациента - 0,45-0,53, но будут требоваться дополнительные данные, чтобы дополнительно сузить решение. Этот процесс может быть расширен иерархическим способом, прилагая дополнительные потоки данных, каждый с дополнительными тестовыми значениями и возможными решениями.
Алгоритм в пределах способа CADx, описанного выше, может быть использован, чтобы выполнить лежащие в основе вычисления. Изначальные вычисления типа 1 данных могут извлекать изображения, но не являются этапом классификации. Однако число клинических признаков велико, и множество возможных значений делает исчерпывающее тестирование всех возможных комбинаций непрактичным. Поэтому используются новые подходы, чтобы объединить клинические признаки и признаки изображений, способом, который напрямую дублирует последовательность выполняемых действий, описанных выше. Описание способов дается на основе примера применения легочной CADx и полагая, что тип 1 данных - данные изображений, а тип 2 данных - клинические данные. Однако способ следует рассматривать общим по отношению к любой классификационной задаче CADx, требующей многочисленных потоков данных.
В материалах настоящей заявки представлены три разных алгоритмических подхода для разделения на части данных, произведенных CADx: (A) Подход I выбора классификатора; (B) Подход II выбора классификатора; (C) байесовский анализ.
Способ, которым категориальные клинические данные преобразуются в числовую форму, совместимую с данными изображения. Преобразованные клинические данные затем обрабатываются эквивалентно относительно данных изображений во время выбора данных и обучения классификатора. Пример такого преобразования - схема кодирования 1-из-C. После этого кодирования не делается различий между данными, полученными из данных изображений или закодированных категориальных клинических переменных. Применение легочной CADx представляет новый способ для выполнения объединения этих данных.
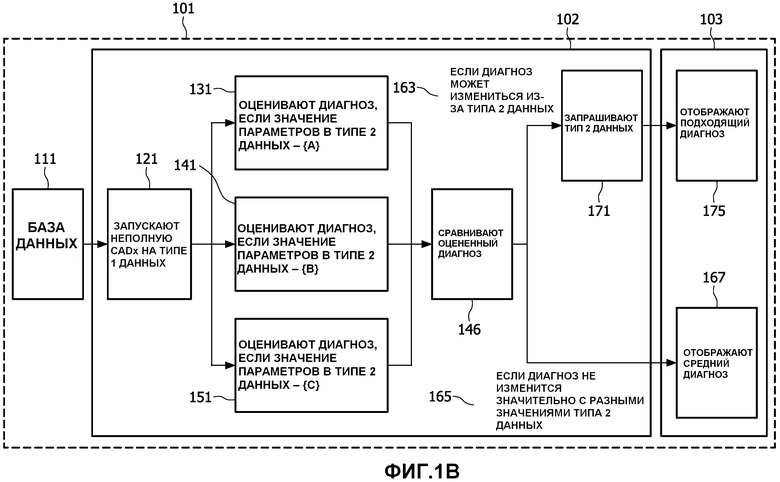
Со ссылкой на фиг.1B, представлена система 101 для объединения клинических данных и данных изображений в способе 100 диагностики с применением компьютера, которая включает управляемое компьютером устройство, включающее, но не в качестве ограничения, устройство хранения компьютерной базы данных, встроенное в память компьютера, терминал отображения вывода компьютера, клавиатуру для введения данных, интерфейс для импорта и извлечения данных и любые компоненты аппаратного обеспечения и программного обеспечения, необходимые для выполнения предложенной функции приложения. Система выполняет этапы способа 100, описанные на фиг.1. Система использует программное обеспечение, которое обрабатывает данные из базы 111 данных. Программное обеспечение запускается на процессоре 102, который реализует неполные данные в системе, основанной на алгоритме 121 CADx. Данные обрабатываются, используя процессор 102, который включает программное обеспечение, которое выполняет по меньшей мере одну из трех оценок 131, 141, 151, и затем перемещает эти созданные данные в устройство 146 сравнения.
Устройство сравнения использует средства управляемого компьютером программного обеспечения, чтобы оценить, значительно ли отличается диагноз, основанный на неполных данных, от оцененных диагнозов, созданных с использованием полных данных. Если неполные данные и данные диагнозов дополненных данных отличаются незначительно 165, тогда два результата, являющиеся средними двух результатов, представляются 167 процессором 102 и отображаются на средстве 103 вывода компьютера, таком как монитор. Однако если результаты разные 163, тогда выполняется запрос данных типа 2 данных 171 и диагноз представляется процессором 102 и отображается 175 на управляемом компьютером средстве 103 вывода.
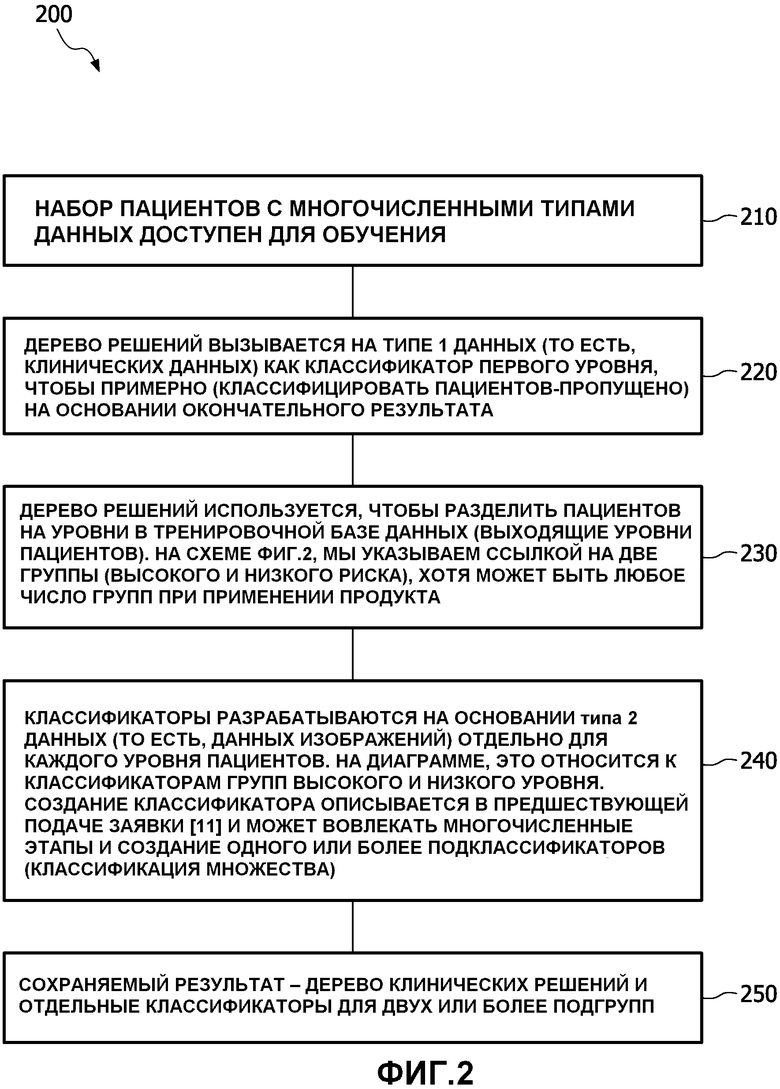
Со ссылкой на фиг.2, способ 200 (Подход I) выбора первого классификатора основывается на создании специфического классификатора(ов) для разных подгрупп пациентов. Способ разработки такого алгоритма начинается с этапа 210, в котором набор пациентов с многочисленными типами данных делают доступным для обучения. На следующем этапе 220, дерево решений вызывается на данных изображений типа 1 данных как классификатор первого уровня, чтобы примерно классифицировать пациентов на основании окончательного результата. Дерево решений затем используется на этапе 230, чтобы разделить пациентов на уровни в обучающей базе данных, также известной как выходящие уровни пациентов. Фиг.2 схематически 200 указывает на две группы, высокого риска и низкого риска, хотя при применении продукта может быть любое число групп. Классификаторы затем разрабатываются на этапе 240 на основании типа 2 данных клинических данных отдельно для каждого уровня пациентов. На диаграмме это указывает на классификаторы для групп высокого и низкого риска. Создание классификатора может вовлекать множество этапов и создание классификации из одного или более множеств подклассификаторов. На этапе 250 дерево клинических решений и отдельные классификаторы для двух или более подгрупп сохраняются как вывод.
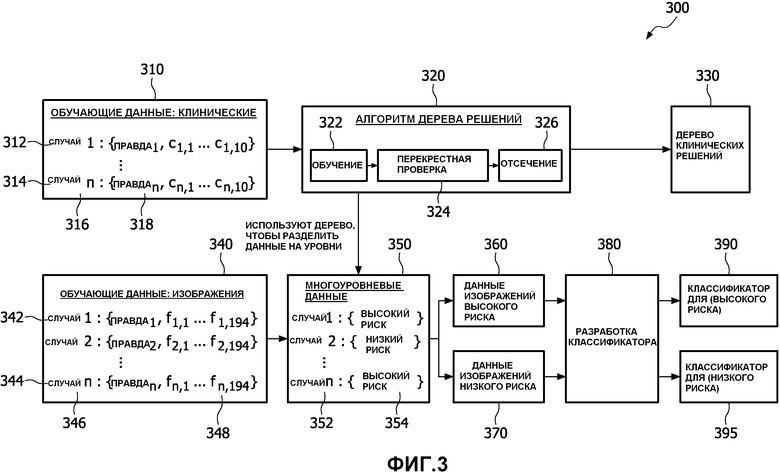
Со ссылкой на фиг.3, обучающая методология для выбора классификатора имеет цель создания специфических основанных на изображениях классификаторов для разных клинических групп 'риска'. Диаграмма на фиг.3 показывает, как клинические данные и данные изображений комбинируются, чтобы выполнить диагностику 300. Клинические данные 310 - это совокупность случаев, начиная с первого случая 312 и продолжая до заданных N случаев 314, где N - целое число, представляющее число случаев, с каждым индивидуальным случаем, представляющим конкретного пациента. Каждый случай содержит имя или идентификатор 316 пациента и ряд атрибутов 318, собранных о пациенте. Эти атрибуты включают, но не в качестве ограничения, курение и упражнения, или физические атрибуты, такие как, но не в качестве ограничения, рост и вес. Эти атрибуты также обязательно включают правду, связанную с диагнозом, о котором идет речь, например, но не в качестве ограничения, имеет ли пациент рак. Они вводятся в алгоритм 320 дерева решений, который включает модули для обучения 322 для создания новых ветвей дерева решений, средство 324 перекрестной проверки для проверки ветвей и средство 326 отсечения для удаления ветвей, которые больше не важны. Алгоритм 320 дерева решений используется, чтобы произвести или вывести дерево 330 клинических решений.
Обучающие данные для изображений 340 включают ряд случаев, начиная с первого случая 342 и продолжая до заданного N числа случаев 344, с каждым индивидуальным случаем, представляющим конкретного пациента. Случаи 342, 344 представляют тех же пациентов, что и случаи 312, 314. Каждый случай содержит имя или идентификацию 346 пациента, и ряд атрибутов 348, собранных о пациенте, и медицинские изображения пациента. Эти атрибуты также обязательно включают правду, связанную с диагнозом, о котором идет речь, например, но не в качестве ограничения, имеет ли пациент рак. Атрибуты дополнительно включают, но не в качестве ограничения, описательные признаки изображений и областей изображений, такие как, но не в качестве ограничения, описания контраста, текстуры, формы, интенсивности и изменений интенсивности. Эти случаи из обучающих данных для изображений 340 используются в комбинации с алгоритмом 320 дерева решений и клиническими данными 310, чтобы создать многоуровневые данные 350.
Многоуровневые данные 350 формируются, чтобы определить, представляет ли индивидуальный случай высокий риск 352 или низкий риск 354 обладания заданной болезнью или условием на основании того, вероятнее ли для человека со специфической историей здоровья иметь или не иметь заданную болезнь или условие, например, на основании информации, содержащейся в клинических данных 310. Человек с высокой вероятностью классифицируется как данные изображений высокого риска 360, в то время как человек с низкой вероятностью такой болезни классифицируется как низкий риск 370. Люди как высокого риска 360, так и низкого риска 370 анализируются средством 380 разработки классификатора. Классификатор 390 специфических изображений разрабатывается посредством 380 и вводимых обучающих данных 360, чтобы классифицировать пациентов высокого риска. Классификатор 395 специфических изображений разрабатывается посредством 380 и вводимых обучающих данных 370, чтобы классифицировать пациентов низкого риска.
Со ссылкой на фиг.4, выбор 400 (Подход II) второго классификатора представлен на основании выбора из одного или более классификаторов, которые оказываются хорошо работающими для разных подгрупп пациентов. На первом этапе 410 набор пациентов с множеством типов данных становится доступным для обучения. Затем на этапе 420 дерево решений вызывается на типе 1 данных (то есть клинических данных), как классификатор первого уровня, чтобы примерно классифицировать пациентов на основании окончательного результата. Дерево решений используется, чтобы разделить пациентов на уровни в обучающей базе данных на этапе 430. В способе 400 на фиг.4 мы указываем на эти две группы результатов пациентов как высокий риск и низкий риск, хотя это число может иметь любое значение. Большой набор возможных классификаторов разрабатывается на основании типа 2 данных (то есть клинических данных) на этапе 440, игнорируя любое разделение пациентов на уровни. Разнообразие в этих классификаторах может быть получено через придание случайного характера данным, используемым в обучении, и комбинирование одного или более алгоритмов выбора или классификатора. Каждый классификатор тестируется на этапе 450 на эффективность на обучающих данных (типе 2 данных).
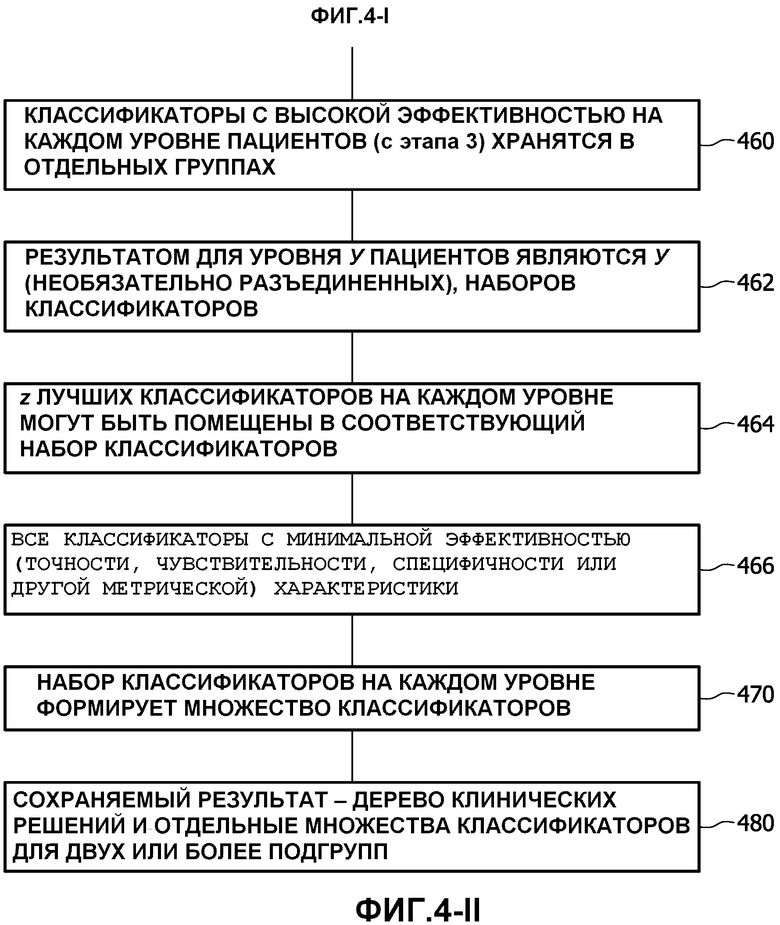
На этапе 460 те классификаторы, которые показали высокую эффективность на каждом уровне пациентов, сохраняются в отдельных группах. Результатом 462 для уровня у пациентов являются у, но необязательно разъединенных, наборов классификаторов. Любой из z лучших классификаторов 464 на каждом уровне может быть помещен в соответствующий набор классификаторов, или все классификаторы 466 с минимальной эффективностью на основании точности, чувствительности, специфичности или других метрических характеристик. Набор классификаторов в каждом уровне формирует множество классификаторов на этапе 470. На этапе 480 дерево клинических решений и отдельные множества классификаторов для двух или более подгрупп сохраняются как вывод.
Классификатор - это категоризация пациента на основании окончательного результата. Множество - это группа классификаторов, которые ранжируются на основании способности предсказывать. Вместе классификаторы во множестве способны предсказывать лучше и более точно, чем индивидуальные классификаторы.
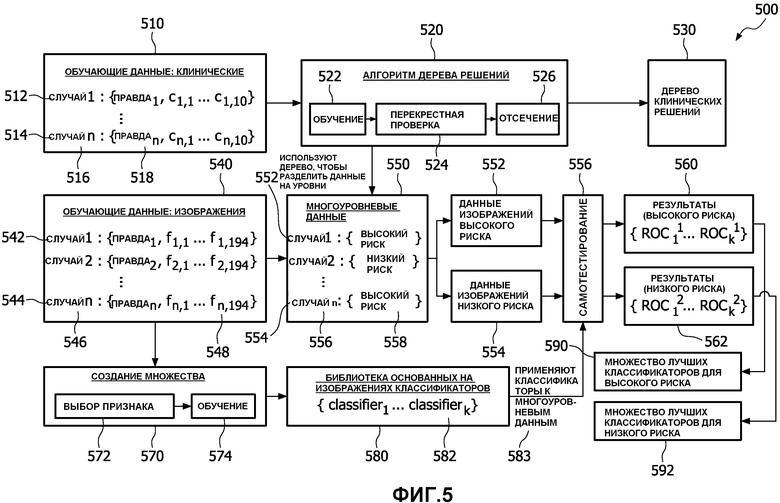
Со ссылкой на фиг.5, разрабатывается широкое множество основанных на изображениях классификаторов, и затем используют клинические данные, чтобы решить, какие классификаторы использовать для разных клинических групп 'риска'. Классификаторы, созданные таким образом, последовательно используются для диагностики с применением компьютера новых, ранее неизвестных пациентов 500. Способ, которым эти классификаторы применяются, тесно связан со способом, показанным на фиг.3. Клинические данные 510 - это совокупность случаев, начиная с первого случая 512 и продолжая до заданного N-го числа случаев 514, с каждым индивидуальным случаем, представляющим конкретного пациента. Каждый случай содержит имя или идентификатор 516 пациента и ряд атрибутов 518, собранных о пациенте. Атрибуты включают, но не в качестве ограничения, курение и упражнения, или физические атрибуты такие как, но не в качестве ограничения, рост и вес. Эти атрибуты также обязательно включают правду, связанную с диагнозом, о котором идет речь, например, но не в качестве ограничения, имеет ли пациент рак. К ним получает доступ алгоритм 520 дерева решений, который сам включает модули для обучения 522 для создания новых ветвей дерева решений, перекрестную проверку 524 для проверки ветвей и отсечение 526 для удаления ветвей, которые больше не важны. Алгоритм 520 дерева решений используется, чтобы произвести дерево 530 клинических решений.
Обучающие данные для изображений 540 включают ряд случаев, начиная с первого случая 542 и продолжая до заданного N-го случая 544, с каждым индивидуальным случаем, представляющим конкретного пациента. Случаи 542, 544 представляют тех же пациентов, что и случаи 512, 514. Каждый случай содержит имя или идентификатор 546 пациента и ряд атрибутов 548, собранных о пациенте, и медицинские изображения пациента. Эти атрибуты также обязательно включают правду, связанную с диагнозом, о котором идет речь, например, но не в качестве ограничения, имеет ли пациент рак. Атрибуты дополнительно включают, но не в качестве ограничения, описательные признаки изображений и областей изображений, такие как, но не в качестве ограничения, описания контраста, текстуры, формы, интенсивности и изменений интенсивности. Эти случаи используются в комбинации с алгоритмом 520 дерева решений, чтобы создать многоуровневые данные 550.
Многоуровневые данные 550 - это ряд из по меньшей мере одного случая 522 до N случаев 554, сформированных, чтобы определить, представляет ли индивидуальный случай высокий риск 556 или низкий риск 558 обладания заданной болезнью или условием на основании, вероятнее ли для человека со специфической историей здоровья иметь или не иметь заданную болезнь или условие, то есть на основании информации, содержащейся в клинических данных 510. Человек с высокой вероятностью классифицируется как данные изображений высокого риска 552, в то время как человек с низкой вероятностью такой болезни будет классифицироваться как низкий риск 554.
Обучающие данные 540 изображений также отправляются на модуль 570 множества, состоящий из части выбора признака 572 и части обучения 574. Это создание множества создает и сохраняет библиотеку 580 основанных на изображениях классификаторов, состоящую из множества классификаторов 582, которые способны связывать случаи 546 и их атрибуты 548 изображений с подходящим диагнозом. Эти классификаторы 582 затем применяются 583 в модуле 556 самотестирования данных. Люди как высокого риска 522, так и низкого риска 554 затем будут проанализированы самотестированием 556.
Впоследствии результат высокого риска - процессор 560 рабочей характеристической кривой приемника (ROC). Множество лучших классификаторов для высокого риска записывается в области 590 классификаторов высокого риска. Схожим образом результат низкого риска будет отправлен на ROC 562 результата низкого риска. Множество лучших классификаторов для низкого риска записывается в области 592 классификаторов низкого риска.
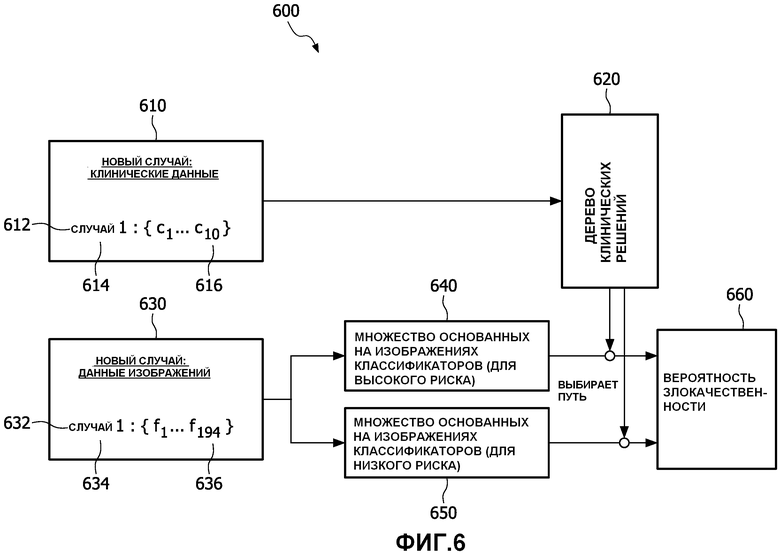
Фиг.6 показывает схему того, как система выбора классификатора будет работать над новыми, неизвестными случаями 600. Модуль клинических данных 610 новых случаев состоит из по меньшей мере одного нового случая 612, который состоит из имени 614 случая и ряда элементов 616. Этот случай отправляется на дерево 620 клинических решений, схожее с деревьями 330 и 530 клинических решений фиг.3 и 5 соответственно. Выбирается один из двух альтернативных путей.
Модуль данных 630 изображений новых случаев состоит из по меньшей мере одного нового случая 632, который состоит из имени 634 случая и ряда элементов 636. Этот по меньшей мере один новый случай представляет тех же людей, которые представлены в модуле клинических данных 610 новых случаев. Этот случай отправляется, чтобы быть классифицированным двумя альтернативными путями. На одном пути используется основанное на изображениях множество классификаторов для высокого риска 640. Это множество 640 классификаторов высокого риска схоже с вышеописанными модулями 390 и 590. На втором пути используется основанное на изображениях множество классификаторов для низкого риска 650. Это множество 650 классификаторов низкого риска схоже с вышеописанными модулями 392 и 592. Результат дерева клинических решений - использование путей, чтобы выбрать, какой путь активирован. Активный путь позволяет результату одного из двух результатов множества основанных на изображениях классификаторов (либо результату высокого риска, либо результату низкого риска) быть сохраненным в модуле 660 вероятности злокачественности.
Со ссылкой на фиг.7 представлен третий подход разделения задачи CADx на части посредством метода байесовского анализа 700. Здесь используется сущность ключевых важных уравнений байесовского анализа, чтобы анализировать факторы риска. Отношение правдоподобия болезни 710, обозначенное аббревиатурой LR 711, равно 750 формуле 760 чувствительности 764, деленной на единицу, минус специфичность 766. Вероятность 720 возникновения 722 равна 750 формуле 770 вероятности 774, деленной на значение 776 единицы, минус эта же вероятность 774. Последующая 730 вероятность болезни 732, такой как, но не в качестве ограничения, рак, равна 750 формуле 780 предыдущей вероятности рака 764, умноженной на последовательность отношений 766 правдоподобия, рассчитанную способом, схожим с отношением 711 правдоподобия. Вероятность болезни 740, такая как, но не в качестве ограничения, вероятность рака 742, равна 750 формуле 790 вероятности 792, деленной на вероятность 792, плюс один 794, где вероятность 792 рассчитывается схожим способом с рассчитанными выше вероятностями 722, 732.
В этом подходе к осуществлению настоящей заявки будет создана система CADx, основанная на признаках изображения. Эта основанная на изображениях система будет использоваться, чтобы сначала определить вероятность злокачественности неизвестного случая. Этот вывод основанной на изображениях CADx будет служить в качестве предварительной вероятности. Эта вероятность будет модулироваться на основании байесовского анализа клинических признаков. Как было описано ранее, будут выполняться тесты, чтобы увидеть, что байесовская модификация вероятностей влияет на результат окончательных вычислений. Пользователю будет рекомендовано ввести клиническую информацию только в том случае, если она будет считаться необходимой по результатам сравнительных расчетов.
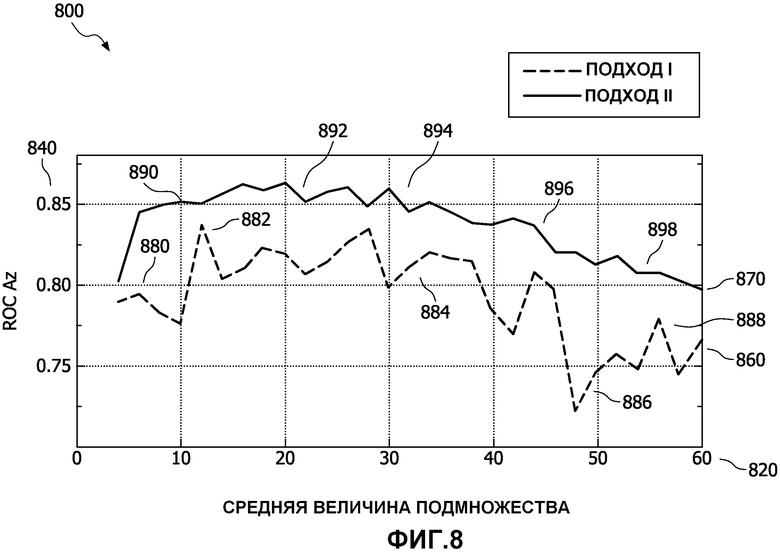
Со ссылкой на фиг.8 представлено подтверждение концепции систем 300, 500 выбора двух классификаторов при применении 800 легочной CADx. Рабочая характеристическая кривая приемника (ROC) содержит графическое построение для системы двоичного классификатора, сформированного путем построения графика с 1, минус специфичность по оси X и чувствительности по оси Y. Области под этой построенной кривой - Az и являются индексами точности. Значение 1,0 представляет совершенно точный тест, значение от 0,9 до 1 представляет отличный тест, значение от 0,8 до 0,9 представляет хороший тест, значение от 0,7 до 0,8 представляет справедливый тест, значение от 0,6 до 0,7 представляет плохой тест, и значение ниже 0,6 представляет провальный тест. ROC Az представляет область под кривой ROC, представляющую эти значения.
Подтверждающие концепцию тесты выполнялись, используя набор данных легочных узлов. Классификация выполнялась, используя множество произвольных подпространств линейных дискриминантных классификаторов.
Средняя величина подмножества отображается по оси X, увеличиваясь по величине до максимального значения 820 в 60. Ось Y содержит значение ROC Az, которое увеличивается до максимального значения 840 приблизительно в 0,9. График представляет два подхода. В первом 860 Подходе I, полученном способом 300, по мере того, как величина подмножества увеличивается, значение ROC Az постепенно увеличивается 880, достигает максимума 882, стабилизируется 884, начинает резко падать 886 и завершается выше самого низкого значения 888. Во втором 870 Подходе II, полученном способом 500, по мере того, как величина подмножества увеличивается, значение ROC Az постепенно увеличивается 890, стабилизируется 892, достигает максимума 894, постепенно падает 896 и завершается на своем самом низком значении 898. В целом значение ROC Az увеличивается для обоих Подходов I и II по мере того, как средняя величина подмножества увеличивается, пока величина подмножества не достигнет 30. Затем ROC Az начинает снижаться по мере того, как снижается величина подмножества. Показано, что Подход II 870 более точен, чем Подход I 860. Взаимосвязь Az с величиной подмножества находится в согласии с опубликованными ранее результатами, использующими традиционные способы множеств классификаторов. Поэтому мы полагаем, что способы, описанные в материалах настоящей заявки, могут соответствовать диагностической точности современных систем CADx, при этом давая выгоды улучшенной последовательности выполняемых операций и интерфейс, который хорошо подходит для клинического применения.
Изначальные тесты дополнительно выполнялись, чтобы продемонстрировать уместность предлагаемого подхода 700. Использующие исключение объектов по одному результаты CADx без клинических признаков были скомбинированы с информацией о возрасте пациента. Множество произвольных подпространств линейных дискриминантных классификаторов использовалось, чтобы создать основанный на изображениях классификатор, приводящий к результату Az в 0,861. Комбинирование этого с возрастом, используя байесовскую статистику, приводит к результату Az в 0,877. Эти результаты демонстрируют осуществимость и потенциал для этого байесовского подхода к объединению данных.
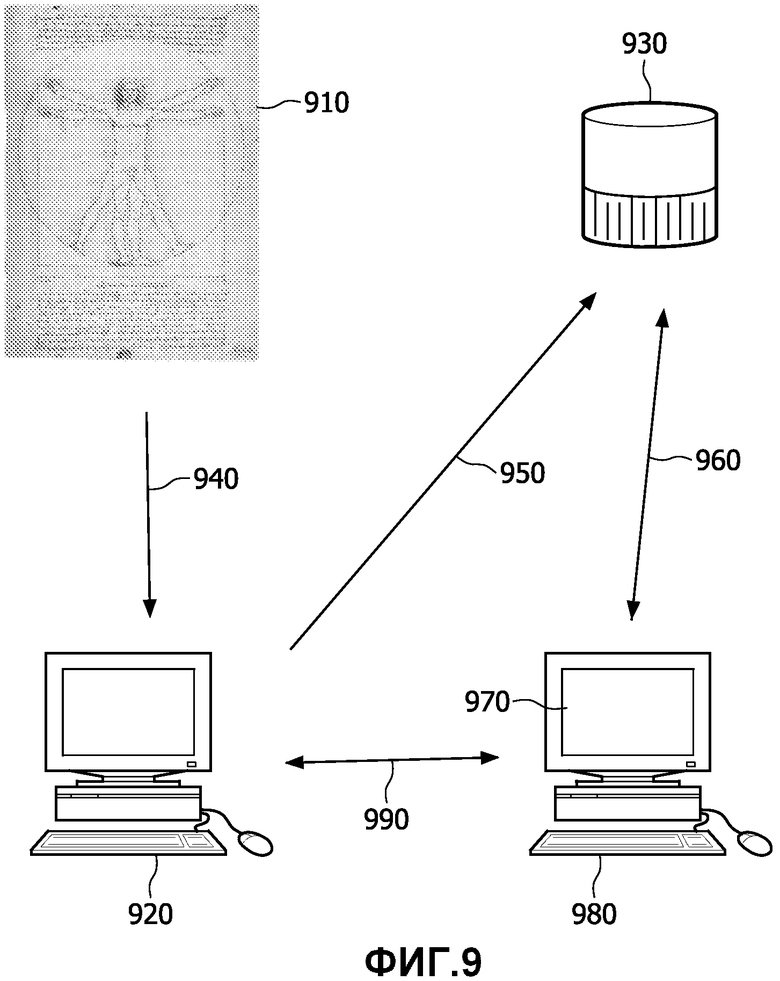
Со ссылкой на фиг.9, система использует медицинское изображение 910, которое вводится в управляемую компьютером систему 920 для обработки. Механизм решений, осуществляемый в управляемой компьютером системе 920, получает доступ к системе основанного на компьютере классификатора из базы 930 данных диагностики с применением компьютера. Система классификатора выполняется на управляемой компьютером системе 920, чтобы вычислить частичный диагноз на основании данных 910 изображений, а далее вычислить потенциальные полные диагнозы на основании возможных клинических данных. Механизм решений решает на основании этих диагнозов, требуются ли дополнительные клинические данные. Если требуется, запрос на дополнительные клинические данные отправляется на механизм 980 интерфейса с терминалом 970 отображения, который запрашивает у оператора дополнительную информацию. В случае доступности эта дополнительная информация затем отправляется механизму решений, чтобы вычислить окончательный диагноз. Затем этот диагноз отправляется на терминал 970 отображения компьютера. В качестве альтернативы, если оператор не способен предоставить дополнительную информацию или если механизм решений решает, что дополнительные данные не требуются, тогда могут быть отображены частичные результаты или возможные диагнозы, вычисленные механизмом решений, на терминале 970 отображения компьютера. Результаты вычислений затем сохраняются в базе 930 данных решений. Между механизмом решений управляемой компьютером системы 920 и механизмом 980 интерфейса может осуществляться взаимодействие. В качестве альтернативы, как механизм решений, так и механизм 980 интерфейса могут существовать в одном и том же компьютерном устройстве.
Ключевые применения в здравоохранении включают системы поддержки основанных на изображениях клинических решений в конкретных системах диагностики с применением компьютера и системах поддержки клинических решений (CDS) для терапии, которая может быть интегрирована в системы получения медицинских изображений, рабочих станциях получения изображений, системах мониторинга пациентов и информационных технологиях здравоохранения. Системы CDS специфической основанной на изображениях диагностики с применением компьютера и терапии включают, но не в качестве ограничения, системы для рака легких, рака груди, рака толстой кишки, рака простаты, основанные на CT, магнитно-резонансной томографии (МРТ), ультразвука, позитронной эмиссионной томографии (ПЭТ) или однофотонной эмиссионной компьютерной томографии (SPECT). Интеграция может вовлекать использование настоящей заявки в радиологических рабочих станциях (например, PMW, Philips Extended Brilliance™ Workstation) или PACS (например, iSite™).
Настоящая заявка была описана со ссылкой на предпочтительные варианты осуществления. Модификации и изменения могут возникнуть по мере прочтения и понимания предшествующего подробного описания. Подразумевается, что настоящая заявка будет истолкована как содержащая все такие модификации и изменения в той мере, в которой они имеют место в объеме прилагающихся пунктов формулы изобретения или их эквивалентов.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ ВЫБОРА ПРИЗНАКОВ, ИСПОЛЬЗУЮЩИЕ ОСНОВАННЫЕ НА ГРУППЕ КЛАССИФИКАТОРОВ ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ | 2007 |
|
RU2477524C2 |
| СПОСОБ И СИСТЕМА КОМПЬЮТЕРНОЙ СТРАТИФИКАЦИИ ПАЦИЕНТОВ НА ОСНОВЕ СЛОЖНОСТИ СЛУЧАЕВ ЗАБОЛЕВАНИЙ | 2015 |
|
RU2687760C2 |
| СПОСОБ РАННЕЙ ДИАГНОСТИКИ ХРОНИЧЕСКИХ ЗАБОЛЕВАНИЙ ПАЦИЕНТА, ОСНОВАННЫЙ НА КЛАСТЕРНОМ АНАЛИЗЕ БОЛЬШИХ ДАННЫХ | 2021 |
|
RU2800315C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ИДЕНТИФИКАЦИИ ПАЦИЕНТОВ С УМЕРЕННЫМИ КОГНИТИВНЫМИ НАРУШЕНИЯМИ С РИСКОМ ПЕРЕХОДА В БОЛЕЗНЬ АЛЬЦГЕЙМЕРА | 2011 |
|
RU2603601C2 |
| Способ экспресс-оценки изменений легочной ткани при COVID-19 без применения компьютерной томографии органов грудной клетки | 2020 |
|
RU2742429C1 |
| СИСТЕМЫ И СПОСОБЫ ПОДДЕРЖКИ КЛИНИЧЕСКИХ РЕШЕНИЙ | 2010 |
|
RU2543563C2 |
| СПОСОБ И СИСТЕМА ПОДДЕРЖКИ ПРИНЯТИЯ ВРАЧЕБНЫХ РЕШЕНИЙ НА ОСНОВАНИИ ГИБРИДНОЙ МОДЕЛИ ДИАГНОСТИКИ, ПРОГНОЗИРОВАНИЯ РИСКОВ ОСЛОЖНЕНИЙ, ПОСТАНОВКИ КЛИНИЧЕСКОГО ДИАГНОЗА, ПРОВЕДЕНИЯ ДИФФЕРЕНЦИАЛЬНОЙ ДИАГНОСТИКИ И ОПРЕДЕЛЕНИЯ ТАКТИКИ ВЕДЕНИЯ ПАЦИЕНТА | 2023 |
|
RU2828464C1 |
| НАПРАВЛЯЕМАЯ КЛИНИЦИСТОМ КОМПЬЮТЕРНАЯ ДИАГНОСТИКА НА БАЗЕ ПРИМЕРОВ | 2007 |
|
RU2459244C2 |
| СПОСОБ ПОСТРОЕНИЯ ЕДИНОГО ИНФОРМАЦИОННОГО ПРОСТРАНСТВА ДЛЯ ПРАКТИЧЕСКОГО ВРАЧА | 2004 |
|
RU2299470C2 |
| СПОСОБ ДИАГНОСТИКИ БОЛЕЗНИ АЛЬЦГЕЙМЕРА | 2024 |
|
RU2837964C1 |


Изобретение относится к медицинской диагностике, а именно к алгоритмам диагностики с применением компьютера и алгоритмам классификации изображений. Технический результат - предоставление интерфейса и последовательности выполняемых операций системы, которая разделяет вычисления CADx на этапы на основании доступности данных. Система для предоставления интерактивного анализа медицинских изображений с применением компьютера содержит: процессор изображений, сконфигурированный для обработки данных медицинских изображений; механизм решений, сконфигурированный для формирования предварительного диагностического результата на основании только данных обработанного медицинского изображения и для вычисления возможных диагностических результатов на основании возможных значений для недоступных клинических данных; механизм интерфейса для запрашивания и приема клинических данных; терминал отображения, сконфигурированный для отображения результатов анализа с применением компьютера. 4 н. и 9 з.п. ф-лы, 11 ил.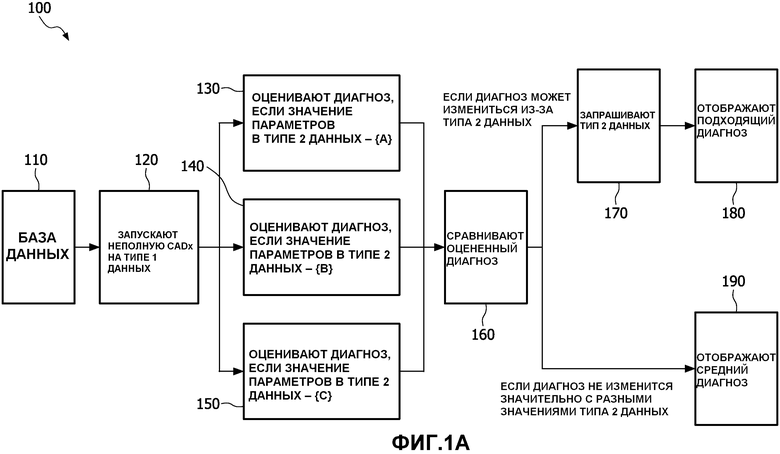
1. Система для предоставления интерактивного анализа медицинских изображений с применением компьютера, содержащая:
процессор (910) изображений, сконфигурированный для обработки данных (940) медицинских изображений;
механизм (920) решений, сконфигурированный для формирования предварительного диагностического результата на основании только данных обработанного медицинского изображения и
вычисления возможных диагностических результатов на основании возможных значений для недоступных клинических данных;
механизм (980) интерфейса для запрашивания и приема клинических данных;
причем механизм (920) решений дополнительно сконфигурирован для:
определения того, какие из недоступных клинических данных влияют на предварительный диагностический результат больше, чем пороговое значение, основанное на возможных диагностических результатах;
приема дополнительных клинических данных, соответствующих определенным клиническим данным с использованием механизма (980) интерфейса, и
фильтрации возможных диагностических результатов на основе принятых клинических данных, причем результаты включают в себя отфильтрованные диагностические результаты,
терминал (970) отображения, сконфигурированный для отображения результатов анализа с применением компьютера.
2. Система по п.1, дополнительно включающая в себя базу (930) данных предыдущих диагнозов, их сопроводительные вероятности (960) и алгоритмы классификаторов для оценки вероятности болезни на основании только имеющихся данных изображений или данных изображений с клиническими данными.
3. Система по п.1, в которой механизм решений (920) дополнительно сконфигурирован для отображения среднего диагноза на терминале (970) отображения и определения (160), какие недоступные клинические данные необходимы, чтобы поставить определенный диагноз (660).
4. Система по п.1, в которой клинические данные содержат по меньшей мере одну медицинскую карту, историю болезни, историю семьи, физические параметры и демографические данные.
5. Система по п.1, в которой по меньшей мере одно из данных изображений и клинических данных используется, чтобы разделить данные на уровни, как имеющие высокий риск или низкий риск конкретной болезни (350).
6. Система по п.2, в которой база (930) данных случаев используется, чтобы определить по меньшей мере один из факторов риска, создать библиотеку основанных на изображениях классификаторов и получить множество.
7. Система по п.1, в которой механизм (920) решений дополнительно сконфигурирован для:
определения первой вероятности болезни на основании доступных данных изображений и доступных клинических данных;
определения вторых вероятностей болезни на основании диапазона возможных значений для недоступных клинических данных;
сравнения первой и вторых вероятностей для определения, какие недоступные данные повлияют на вероятности больше, чем пороговое значение.
8. Способ предоставления интерактивного анализа медицинских изображений с применением компьютера, в котором:
обрабатывают данные (940) медицинских изображений;
формируют предварительный диагностический результат на основании только данных обработанного медицинского изображения;
вычисляют возможные диагностические результаты на основании возможных значений для недоступных клинических данных;
определяют, какие из недоступных клинических данных влияют на предварительный диагностический результат больше, чем пороговое значение, основанное на возможных диагностических результатах;
принимают дополнительные клинические данные, соответствующие определенным клиническим данным с использованием механизма (980) интерфейса, и
выполняют фильтрацию возможных диагностических результатов на основе принятых клинических данных, причем результаты включают в себя отфильтрованные диагностические результаты;
отображают результаты анализа с применением компьютера.
9. Способ по п.8, в котором дополнительно:
оценивают вероятность болезни на основании только имеющихся данных изображений или данных изображений с клиническими данными, причем оценку выполняют с использованием базы (930) данных предыдущих диагнозов, их сопроводительных вероятностей (960) и алгоритмов классификаторов.
10. Способ по любому из пп.8 или 9, в котором дополнительно
отображают средний диагноз и
определяют (160), какие недоступные клинические данные необходимы, чтобы поставить определенный диагноз.
11. Способ по любому из пп.8 или 9, в котором дополнительно
определяют первую вероятность болезни на основании доступных данных изображений и доступных клинических данных;
определяют вторые вероятности болезни на основании диапазона возможных значений для недоступных клинических данных;
сравнивают первую и вторые вероятности для определения, какие недоступные данные повлияют на вероятности больше, чем пороговое значение.
12. Система для диагностики с применением компьютера (CADx), содержащая:
процессор (920) запрограммированный, чтобы выполнять способ по любому из пп.8-11; и
дисплей (970), который отображает отфильтрованные диагностические результаты.
13. Компьютерное программируемое средство, содержащее компьютерную программу, которая, будучи загруженной в компьютер, управляет компьютером, чтобы он выполнял способ по любому из пп.8-11.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОМПЬЮТЕРНОЙ ТЕПЛОВИЗИОННОЙ ДИАГНОСТИКИ В СТОМАТОЛОГИИ | 2005 |
|
RU2282392C1 |

