Область техники
Данное изобретение относится к системам и способам защиты компьютерных устройств от нежелательных электронных сообщений на основе определения схожих сообщений и оценки их рейтинга.
Уровень техники
Компьютерные системы играют существенную роль в жизни современного человека. В современном обществе вряд ли кто-то сможет утверждать, что без труда сможет обходиться без персонального компьютера, ноутбука или карманного компьютера. Разнообразные компьютерные системы используются в работе, на производстве, в офисах. Огромная часть всей работы, выполняемой людьми, связана, так или иначе, с компьютерами.
Принимая в расчет всю значимость компьютерных систем в жизни людей для обеспечения ее привычного существования, повышается число злоумышленников, деятельность которых направлена на создание программных приложений, представляющих угрозу для компьютерных систем. Одним из наиболее распространенных примеров деятельности злоумышленников является организация рассылок спама. Спамом является анонимная незапрошенная массовая рассылка электронной почты. Разновидностью спама, которая в последнее время наращивает популярность, является SMS-рассылка сообщений, содержащих коммерческие и иные предложения, рассылаемые без согласия получателя. Спам, как правило, носит рекламный характер, поэтому в большей степени не представляет угрозу для компьютерных систем пользователей. Исключением является тот спам, который содержит вредоносный контент. Такие электронные сообщения, которые содержат вредоносные вложения, могут представлять угрозу данным, находящимся на компьютере.
Тем не менее, даже если нежелательные рассылки сообщений не являются вредоносными и носят только рекламный характер, они могут доставлять определенные неудобства. Одним из таких неудобств является «замусоривание» почты клиента, когда клиент может легко упустить нужное письмо в потоке многочисленных спам-писем. Кроме того, нежелательные сообщения занимают существенный объем трафика электронной почты, поскольку по статистике доля спама в почтовом трафике может составлять более 70%, согласно данным Лаборатории Касперского (http://www.securelist.com/en/analysis/204792249/Spam_in_September_2012). Все нежелательные сообщения, попадая на почтовый ящик, со временем накапливаются и заставляют тратить время на его очистку. Также стоит учитывать, что среди нежелательных сообщений встречаются сообщения, ведущие на фишинговые ресурсы, которые могут стать причиной кражи паролей и личных данных.
Перечисленные опасности и неудобства, связанные с нежелательными сообщениями, опровергая кажущуюся безвредность таких сообщений, указывают на необходимость создания подходов для защиты от деятельности распространителей спама. На текущий момент имеется множество подходов к обнаружению и блокированию нежелательных сообщений, каждый из которых имеет свои достоинства и недостатки. Самым распространенным подходом является проверка IP-адресов отправителей по черным спискам, где хранятся IP-адреса, с которых часто приходят нежелательные сообщения. Данный подход позволяет блокировать источник нежелательных сообщений, но недостатком является серьезный ущерб при ложных срабатываниях, когда в черный список попадает доверенный IP-адрес и полезная почта блокируется как спам. Использование такого подхода часто применяется в патентных заявках, посвященных обнаружению нежелательных сообщений, например, в американской заявке US 20110252472 А1, в которой по IP-адресу определяется рассылка нежелательных сообщений.
Другим часто используемым подходом, который применяется для обнаружения нежелательных сообщений, является фильтрация сообщений при помощи фильтра Байеса. Данный подход основан на обучении фильтра (предварительная стадия), при этом для различных слов в сообщении формируется вероятность того, что сообщение с данным словом является спамом. После этого производится определение вероятности принадлежности сообщения к спаму путем анализа всех его слов и сравнения полученного значения вероятности с пороговым значением, заданным заранее. Минусом данного подхода является низкий уровень обнаружения нежелательных сообщений, если пользователь получает сообщения, которые относятся к различным тематикам (в этом случае фильтр трудно обучить). Также данный подход трудно применим, когда анализируется входящий поток разнородных сообщений на корпоративном почтовом сервере, при этом поток состоит из сообщений для разных пользователей. В качестве примера применения фильтра Байеса для решения проблемы обнаружения нежелательных сообщений можно привести запатентованную технологию US 6732157 B1 определения спама с использованием вероятностного подхода, основанного на работе нескольких фильтров, в том числе фильтра Байеса. При этом результаты работы фильтров комбинируются при помощи логических операторов и операторов условий.
На сегодняшний момент все подходы, связанные с группировкой сообщений по различным критериям, влекут возникновение существенного числа ложных срабатываний, когда нежелательное сообщение попадает в группу легитимных сообщений или когда возникает обратная ситуация.
Данное изобретение позволяет снизить количество ложных срабатываний, возникающих в процессе обнаружения спама, и повысить защищенность от нежелательных сообщений.
Раскрытие изобретения
Техническим результатом данного изобретения является повышение качества обнаружения нежелательных электронных сообщений за счет кластеризации сообщений, определения рейтинга сообщений, соответствующего рейтингу кластера, и сравнения рейтинга сообщений со значением порогового рейтинга для нежелательных сообщений.
Настоящее изобретение представляет собой систему и способ определения нежелательных электронных сообщений. Способ определения нежелательных электронных сообщений, выполняющийся на компьютерной системе, заключается в том, что:
A) проводят предварительный анализ входящих сообщений для выявления, по меньшей мере, одного сообщения, которое не относится к легитимным и нежелательным сообщениям;
Б) формируют метаданные из проанализированного входящего электронного сообщения с помощью средства подготовки метаданных;
B) передают метаданные, сформированные из электронного сообщения, на средство кластеризации при помощи средства взаимодействия;
Г) определяют кластер, к которому относятся переданные метаданные, при помощи средства кластеризации;
Д) получают рейтинг кластера, к которому относятся переданные метаданные, при этом полученный рейтинг соответствует рейтингу электронного сообщения;
Е) передают рейтинг электронного сообщения на средство принятия решений;
Ж) определяют, основываясь на рейтинге электронного сообщения и установленном верхнем пороге, является ли сообщение нежелательным при помощи средства принятия решений.
В частном варианте исполнения метаданные, сформированные из сообщения, состоят, по меньшей мере, из набора хеш-сумм и IP-адреса отправителя.
В частном варианте исполнения набор хеш-сумм вычисляют, по меньшей мере, для данных, содержащихся в теле сообщения, путем предварительного разбиения данных на части и применения хеш-функции к каждой части.
В частном варианте исполнения входящие сообщения предварительно анализируют, по меньшей мере, с использованием белого и черного списков.
В частном варианте исполнения для проанализированных нежелательных сообщений формируют метаданные для помещения в кластеры средством кластеризации.
В частном варианте исполнения при помощи средства кластеризации фильтруют хеш-суммы подписей в сообщениях.
В частном варианте исполнения фильтрацию хеш-сумм подписей выполняют путем удаления из наборов хеш-сумм, по меньшей мере, тех из них, которые относятся к подписям отправителей.
В частном варианте исполнения при помощи средства кластеризации формируют кластеры, которые состоят из схожих наборов метаданных.
В частном варианте исполнения при помощи средства кластеризации формируют рейтинги для кластеров.
В частном варианте исполнения при помощи средства кластеризации хранят дерево кластеров, позволяющее определить, к какому кластеру относятся поступающие метаданные.
В частном варианте исполнения дерево кластеров формируют в виде многоуровневой структуры, на каждом уровне которой создаются узлы, состоящие из наиболее часто встречающихся в кластере хеш-сумм.
В частном варианте исполнения дерево кластеров обновляют после поступления новых метаданных.
В частном варианте исполнения кластер, к которому относятся метаданные, определяют путем вычисления степени схожести хеш-сумм в поступивших метаданных с хеш-суммами в одном из наборов в дереве кластеров.
В частном варианте исполнения вместе с рейтингом электронного сообщения на средство принятия решений для анализа передают значение, определяющее степень схожести хеш-сумм в поступивших метаданных с хеш-суммами в одном из наборов в дереве кластеров.
В частном варианте исполнения на средство кластеризации поступают нежелательные сообщения из ловушек сообщений для кластеризации.
В частном варианте исполнения рейтинг кластеров изменяют в сторону уменьшения при поступлении в кластер новых схожих наборов хеш-сумм, которые относятся к сообщениям, полученным от отправителей с разных IP-адресов.
В частном варианте исполнения сообщение, рейтинг которого находится между верхним порогом, соответствующим нежелательным сообщениям, и нижним порогом, соответствующим легитимным сообщениям, помещают в карантин на установленное время.
В частном варианте исполнения для сообщения повторно определяют рейтинг по истечении времени нахождения в карантине.
Система определения нежелательных электронных сообщений, взаимодействующая, по меньшей мере, с одним почтовым сервером клиента, который включает:
а) средство анализа сообщений, связанное со средством подготовки метаданных, при этом средство анализа сообщений предназначено для проведения предварительного анализа входящих электронных сообщений;
б) упомянутое средство подготовки метаданных, связанное со средством взаимодействия, при этом средство подготовки метаданных предназначено для формирования метаданных для входящего электронного сообщения, которое по результатам предварительного анализа не признано легитимным или нежелательным;
в) упомянутое средство взаимодействия, связанное со средством принятия решения и средством кластеризации системы определения рейтингов электронных сообщений, при этом средство взаимодействия предназначено для передачи метаданных сообщения на средство кластеризации и передачи рейтинга электронного сообщения, полученного от средства кластеризации в качестве ответа, на средство принятия решений;
г) упомянутое средство принятия решений, предназначенное для определения, основываясь на рейтинге электронного сообщения и установленном верхнем пороге, является ли сообщение нежелательным;
при этом система определения рейтингов электронных сообщений также включает:
I) упомянутое средство кластеризации, связанное со средством хранения кластеров, при этом средство кластеризации предназначено для определения кластера, к которому относятся метаданные, получения рейтинга кластера, который соответствует рейтингу электронного сообщения, и передаче рейтинга на средство взаимодействия на стороне почтового сервера клиента;
II) упомянутое средство хранения кластеров, предназначенное для хранения кластеров, состоящих из метаданных, объединенных по степени схожести.
В частном варианте исполнения метаданные для входящего электронного сообщения состоят, по меньшей мере, из набора хеш-сумм и IP-адреса отправителя.
В частном варианте исполнения набор хеш-сумм вычисляется, по меньшей мере, для данных, содержащихся в теле сообщения, путем предварительного разбиения данных на части и применения хеш-функции к каждой части.
В частном варианте исполнения средство кластеризации дополнительно предназначено для:
- формирования кластеров в средстве хранения кластеров;
- изменения рейтингов для кластеров;
- формирования дерева кластеров, позволяющего определить, к какому кластеру относятся поступающие метаданные. В частном варианте исполнения средство кластеризации определяет, к какому кластеру относятся метаданные путем определения степени схожести хеш-сумм в полученном наборе хеш-сумм с хеш-суммами в одном из наборов в анализируемом кластере.
В частном варианте исполнения средство кластеризации выполнено с возможностью передачи для анализа вместе с рейтингом электронного сообщения на средство принятия решений значения, определяющего степень схожести хеш-сумм в поступивших метаданных с хеш-суммами в одном из наборов в дереве кластеров.
В частном варианте исполнения средство кластеризации изменяет в сторону уменьшения рейтинг кластера при поступлении схожих новых наборов хеш-сумм, которые относятся к сообщениям, полученным от отправителей с разными IP-адресами.
В частном варианте исполнения средство кластеризации формирует дерево кластеров в виде многоуровневой структуры, на каждом уровне которой создаются узлы, состоящие из наиболее часто встречающихся в кластере хеш-сумм.
В частном варианте исполнения средство кластеризации обновляет дерево кластеров после поступления новых метаданных.
В частном варианте исполнения упомянутая система содержит ловушки сообщений, связанные со средством хранения нежелательных сообщений, при этом ловушки сообщений предназначены для сбора рассылок нежелательных электронных сообщений и передаче их на средство хранения нежелательных сообщений.
В частном варианте исполнения упомянутая система содержит средство хранения нежелательных сообщений, связанное со средством кластеризации, при этом средство хранения нежелательных сообщений предназначено для хранения сообщений, полученных от ловушек сообщений.
В частном варианте исполнения средство кластеризации дополнительно предназначено для:
- вычисления наборов хеш-сумм для нежелательных сообщений, поступающих от ловушек сообщений;
- определения IP-адресов отправителей для нежелательных сообщений, поступающих от ловушек сообщений.
В частном варианте исполнения упомянутая система содержит средство хранения хеш-сумм подписей, связанное со средством кластеризации и предназначенное для хранения хеш-сумм подписей, которые необходимо отфильтровать до выполнения кластеризации.
В частном варианте исполнения средство кластеризации дополнительно предназначено для фильтрации хеш-сумм подписей при помощи средства хранения хеш-сумм подписей.
В частном варианте исполнения упомянутая система содержит средство хранения карантина, связанное со средством принятия решений, при этом средство хранения карантина предназначено для хранения в течение заданного времени сообщений, для которых рейтинг находится между верхним порогом, соответствующим нежелательным сообщениям, и нижним порогом, соответствующим легитимным сообщениям.
В частном варианте исполнения средство принятия решений повторно определяет рейтинг для сообщения по истечении времени нахождения в карантине.
В частном варианте исполнения упомянутая система содержит средство хранения черного списка, связанное со средством анализа сообщений, при этом средство хранения черного списка предназначено для хранения информации о нежелательных сообщениях.
В частном варианте исполнения упомянутая система содержит средство хранения белого списка, связанное со средством анализа сообщений, при этом средство хранения белого списка предназначено для хранения информации о легитимных сообщениях.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг.1 иллюстрирует схему системы определения рейтингов электронных сообщений.
Фиг.2 показывает часть схемы почтового сервера клиента.
Фиг.3 показывает внутреннее строение средства кластеризации системы определения рейтингов электронных сообщений.
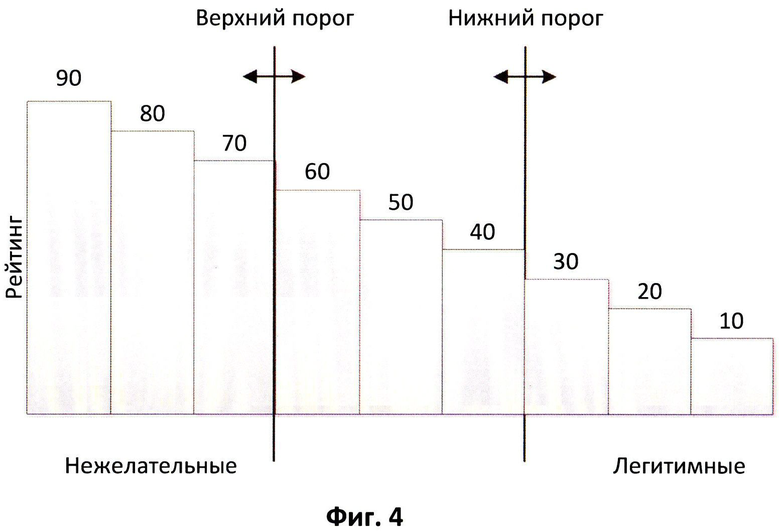
Фиг.4 иллюстрирует пример представления рейтингов сообщений и порогов.
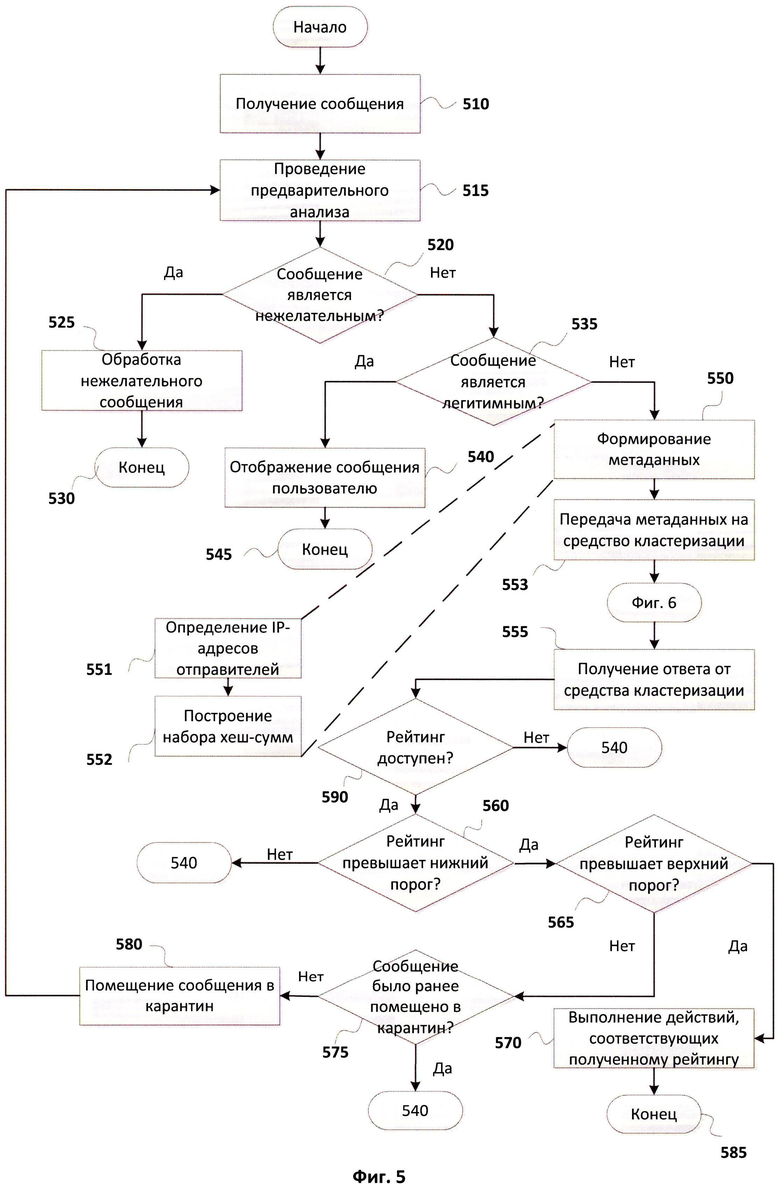
Фиг.5 показывает алгоритм обработки входящих сообщений, выполняемый на почтовом сервере клиента.
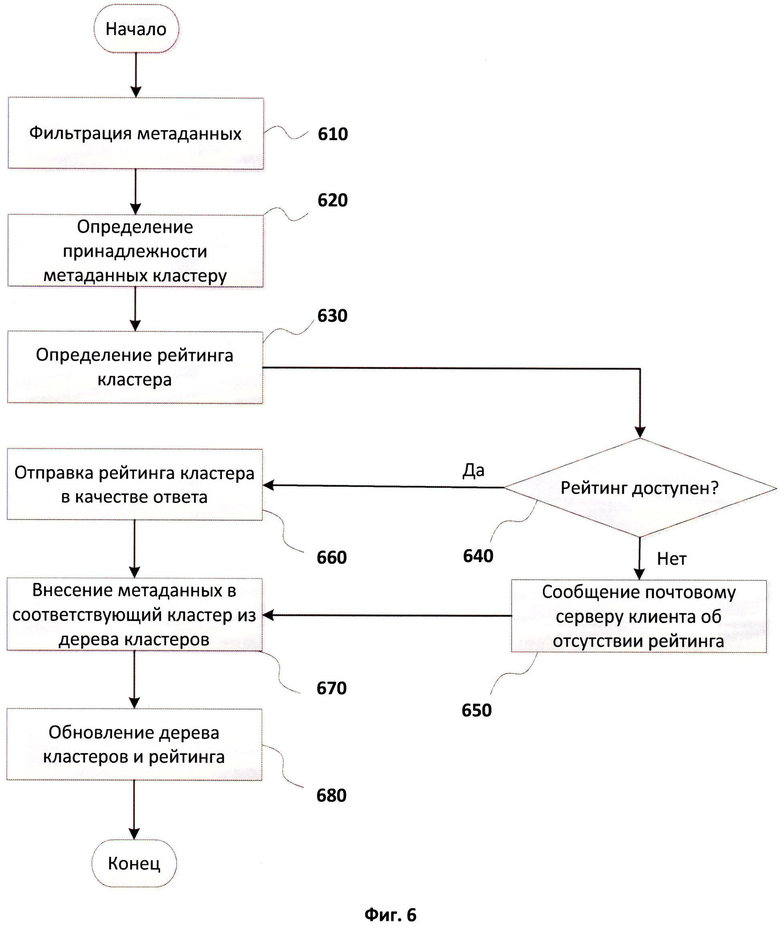
Фиг.6 иллюстрирует алгоритм определения рейтингов электронных сообщений.
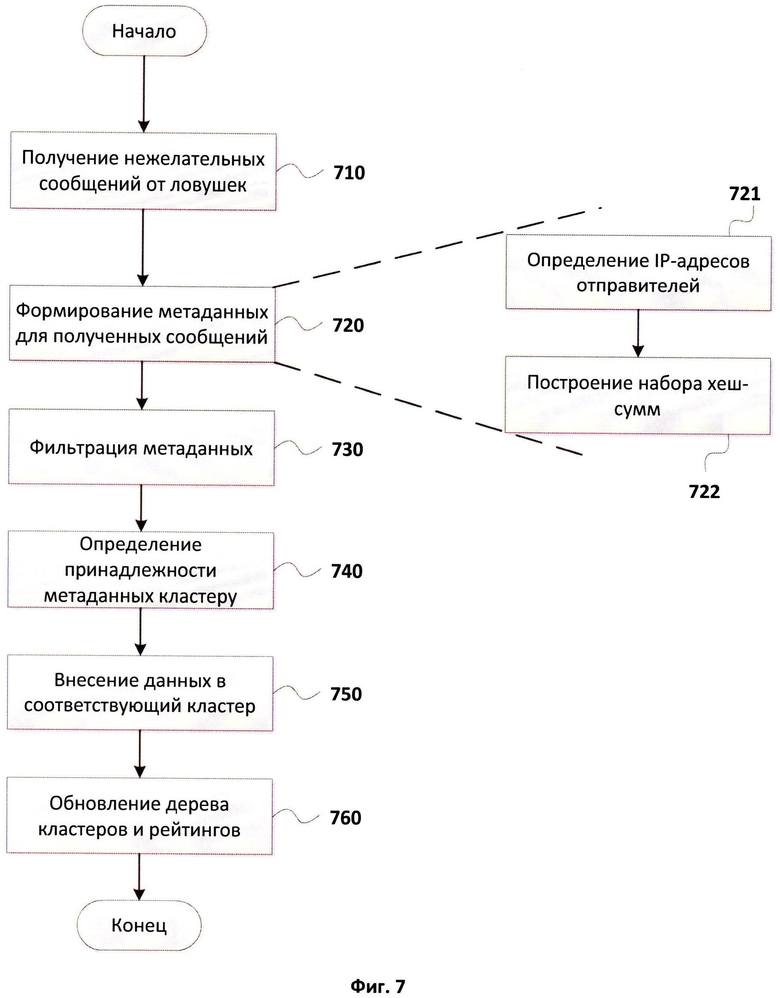
Фиг.7 иллюстрирует алгоритм обработки нежелательных входящих сообщений от ловушек сообщений.
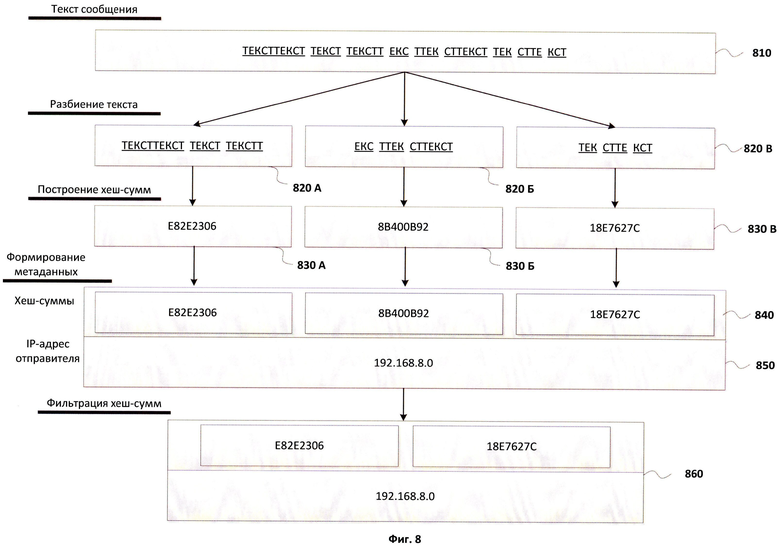
Фиг.8 отображает схему формирования метаданных из сообщений.
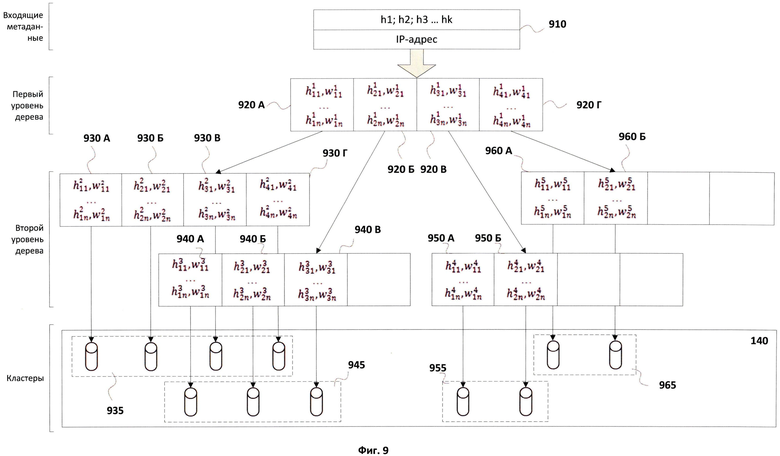
Фиг.9 отображает один из вариантов строения дерева индексов кластеров.
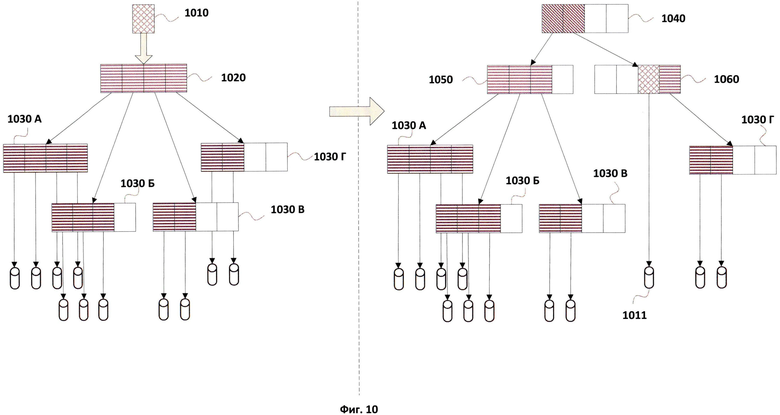
Фиг.10 показывает схему перестроения дерева индексов кластеров.
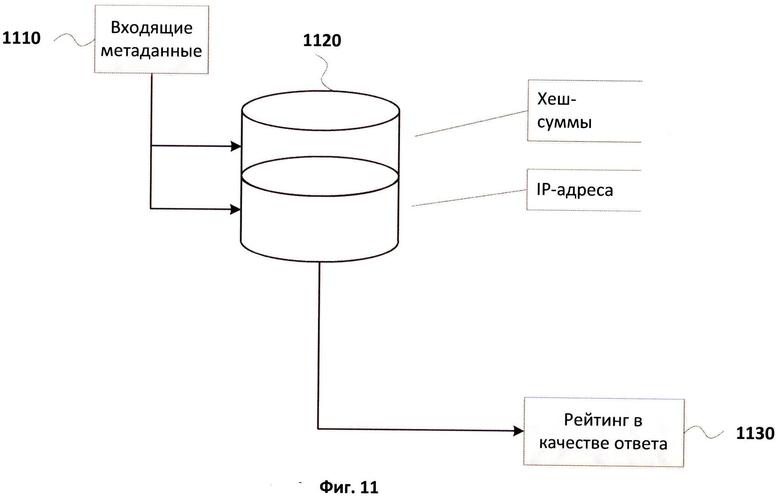
Фиг.11 иллюстрирует строение кластера.
Фиг.12 показывает пример компьютерного устройства общего назначения, на котором может быть реализовано описанное изобретение.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формулой.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
На Фиг.1 изображена схема системы определения рейтингов электронных сообщений. В основе описываемой системы лежит процесс кластеризации метаданных, которые подготавливаются системой определения рейтингов 100 из полученных сообщений. Метаданные сообщения представляют собой минимальную информацию о сообщении, необходимую для однозначного определения сообщения и его отправителя. В контексте текущего описания под метаданными понимается, по меньшей мере, набор хеш-сумм, полученных для сообщения, и IP-адрес отправителя сообщения. Такой набор, характеризующий сообщение, представляется достаточным, поскольку хеш-суммы характеризуют содержание сообщения, a IP-адрес несет информацию об отправителе. Поэтому может быть применен критерий отнесения сообщений к нежелательным, в соответствии с которым, если сообщения имеют схожее содержание, то есть схожие наборы хеш-сумм, но при этом достаточно большое количество IP-адресов отправителей разные, то анализируемые сообщения относятся к спамовой рассылке. При этом количество IP - адресов может задаваться в относительном выражении от общего количества IP-адресов для той или иной рассылки.
Кластеризация является важным этапом для определения принадлежности сообщения к спаму, однако не менее важным является этап определения рейтинга кластера, который указывает на то, метаданные каких сообщений хранятся в соответствующем кластере. После определения рейтинга кластера можно судить о том, является ли нежелательным сообщение, которое было отнесено к соответствующему кластеру. Рейтингом кластера в данном варианте реализации является числовое значение, которое может изменяться в установленном диапазоне, и служит критерием, определяющим категорию сообщений, метаданные которых находятся в кластере. Рейтинг кластера формируется и изменяется в процессе пополнения кластеров метаданными сообщений, а также после перестроения структуры дерева индексов кластеров (далее - дерево кластеров). Более подробно процесс формирования и изменения рейтингов кластеров будет рассмотрен далее.
В рамках описываемого варианта реализации изобретения системе определения рейтингов 100 отправляются данные из разных источников. В качестве одного из источников выступают ловушки сообщений 170, которые служат для предоставления нежелательных сообщений. В качестве ловушек сообщений могут использоваться заброшенные доменные имена, при этом сообщения, поступающие на заброшенные домены, будут пересылаться системе 100. Ловушки сообщений в частном варианте могут представлять собой множество разнообразных почтовых ящиков 170А…170N, обладающих разными электронными адресами, которые используются для сбора разнообразных рассылок нежелательных электронных сообщений. Для того чтобы обеспечить потоки входящих сообщений, электронные адреса ловушек преднамеренно распространяются на тех ресурсах, откуда отправителями спама потенциально могут собираться почтовые адреса для будущих спам-рассылок. Например, данные адреса могут быть преднамеренно оставлены при регистрации на различных порно-сайтах, интернет-магазинах с низким уровнем репутации, социальных сетях, тематических форумах и т.п. На ресурсы, на которых оставлены адреса ловушек, со временем начинают поступать разнообразные рассылки, которые перенаправляются системе определения рейтингов 100 и сохраняются в средстве 110 хранения нежелательных сообщений. При этом чем дольше ловушка сообщений существует, тем большее количество разнообразных сообщений она может собрать. Это связано, прежде всего, с тем, что адрес ловушки передается другим недобросовестным интернет-ресурсам, которые распространяют нежелательные сообщения, а также злоумышленникам, которые целенаправленно организуют спам-рассылки.
Сообщения из ловушек 170 поступают на систему определения рейтингов 100 по факту получения сообщения одной из ловушек. Все сообщения, поступающие от ловушек сообщений 170, сохраняются в средстве хранения нежелательных сообщений 110.
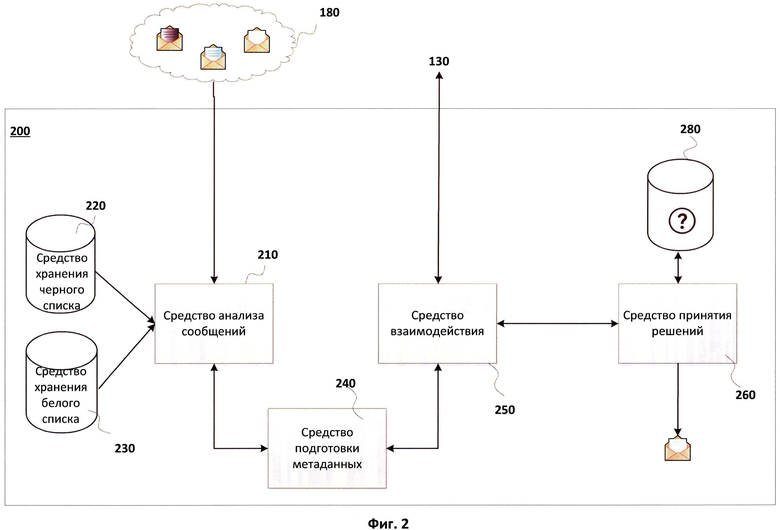
Система определения рейтингов 100, помимо ловушек сообщений, взаимодействует, по меньшей мере, с одним почтовым сервером клиента 200. В рамках данного описания для простоты будет рассматриваться один почтовый сервер клиента 200, но стоит указать, что таких серверов может быть несколько. Почтовый сервер клиента 200 содержит модули, необходимые для проведения анализа сообщений и осуществления взаимодействия с системой определения рейтингов сообщений.
На почтовый сервер поступают различные сообщения 180. Сразу после поступления сообщения анализируются средством 210 (будет подробно рассмотрено при описании Фиг.2) и по результатам анализа определяются нежелательные, легитимные сообщения и те сообщения, которые не относятся к первым двум категориям - они являются неизвестными. Нежелательные сообщения обрабатываются в соответствии с правилами клиента, в частности они могут быть удалены или помещены в специальную область для хранения нежелательных сообщений.
В одном из вариантов реализации системы нежелательные сообщения могут использоваться в процессе кластеризации. Сообщения могут передаваться на систему определения рейтингов 100, сохраняться в средстве хранения 110, после чего средство 130 выполнит их кластеризацию. В другом варианте нежелательные сообщения могут быть обработаны непосредственно на почтовом сервере клиента 200, для сообщений могут быть подготовлены метаданные, которые будут переданы на систему определения рейтингов 100, и при помощи средства кластеризации 130 будут отнесены к тому или иному кластеру.
Неизвестные сообщения могут включать как нежелательные, так и легитимные сообщения. Для определения того, к какой категории относятся неизвестные сообщения, они подлежат дополнительной проверке, которая осуществляется в несколько этапов. Сначала для таких сообщений формируются метаданные средством подготовки метаданных 240. После чего метаданные отправляются средству кластеризации 130, являющемуся центральным модулем системы определения рейтингов 100. По результатам обработки метаданных формируется ответ, который используется средством принятия решений 260 на почтовом сервере клиента 200 для определения, является ли письмо нежелательным или нет.
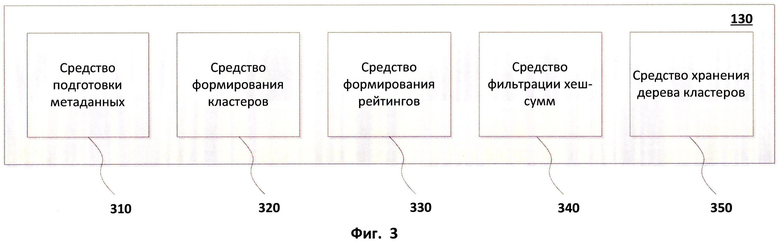
Ключевую роль в процессе создания кластеров выполняет средство кластеризации 130. Оно состоит из нескольких составных элементов, которые отображены на Фиг.3. Средство подготовки метаданных 310, входящее в средство кластеризации 130, предназначается для создания набора хеш-сумм для сообщений, а также получения IP - адресов отправителей. Алгоритмов для вычисления хеш-сумм существует большое количество, но в рамках данного изобретения алгоритм должен обеспечивать выполнение определенных требований, накладываемых на создаваемые хеш-суммы. В частности, хеш-суммы должны быть созданы так, чтобы при создании набора хеш-сумм для другого сообщения, которое отличается от первого незначительно, оба набора хеш-сумм обладали высокой степенью схожести, то есть в двух наборах должно быть количество совпадающих хеш-сумм выше установленного порога. Данное правило должно выполняться для обеспечения возможности определения близких по содержанию сообщений с незначительными отличиями, в том числе внесенными преднамеренно злоумышленниками для препятствования обнаружению сообщения с использованием точных шаблонов.
С другой стороны, хеш-суммы не должны быть построены так, чтобы два отличающихся сообщения обладали высоким числом совпадающих хеш-сумм. В таком случае высока вероятность возникновения ошибки, когда разные сообщения будут помещены в один кластер, при этом нежелательные сообщения могут смешаться с легитимными сообщениями, попав в один общий кластер. Более подробно процесс формирования хеш-сумм в качестве одного из вариантов реализации в рамках данного изобретения будет рассмотрен при описании схемы формирования метаданных, изображенной на Фиг.8.
С процессом формирования хеш-сумм из данных, находящихся в сообщении, связано также средство фильтрации хеш-сумм 340, которое также входит в состав средства кластеризации 130. Задачей средства фильтрации хеш-сумм 340 является определение хеш-сумм, которые необходимо отсеять предварительно, до выполнения процесса кластеризации. Такие хеш-суммы хранятся в средстве хранения хеш-сумм подписей 120 на стороне системы определения рейтингов 100. Выполнение предварительной фильтрации полученных средством 310 наборов хеш-сумм позволяет убирать те хеш-суммы, которые могут повлиять на возникновение ложных срабатываний. В качестве примера можно рассмотреть анализ сообщений, содержащих подписи. Подпись в сообщении может содержать имя отправителя, название компании, ссылку на веб-страницу и т.п. Поскольку подпись, как правило, добавляется к сообщению автоматически, то все сообщения от одного отправителя или группы отправителей будут обладать одними и теми же данными, которые если останутся неотфильтрованными, будут учтены в процессе формирования хеш-сумм и последующей кластеризации. Таким образом, степень сходства сообщений, обладающих похожими подписями, будет выше независимо от содержания сообщения. Данное обстоятельство может впоследствии отразиться на том, что по результатам анализа кластеров рассылка, состоящая из легитимных сообщений с похожими подписями, может быть определена как спам, поскольку она будет иметь массовый характер и поступать от различных отправителей. Чтобы избежать подобных ситуаций, средство 340 производит фильтрацию хеш-сумм, которые ухудшают полезную для анализа информативность полученного для сообщения набора хеш-сумм.
Информация, полученная после обработки сообщений, в виде хеш-сумм хранится в форме кластеров в средстве хранения кластеров 140. Кластеры формируются средством 320, которое входит в состав средства кластеризации 130. Кроме хеш-сумм, в средстве хранения 140 находятся IP-адреса отправителей соответствующих сообщений. IP-адреса устанавливаются при помощи средства подготовки метаданных 310 в составе средства кластеризации 130. Стоит отметить, что хеш-суммы вместе с IP-адресом составляют необходимую информацию о сообщении, которая образует метаданные для сообщения. Тем не менее, в общем случае может быть использована и другая дополнительная информация о сообщении.
С целью определения принадлежности набора хеш-сумм, характеризующего сообщение, конкретному кластеру в рамках данного изобретения используется принцип построения индексного дерева, содержащего характерные для каждого определенного кластера или группы кластеров хеш-суммы. Данное дерево кластеров формируется средством 320 и хранится в средстве 350 хранения дерева кластеров. В то же время сами кластеры в виде полных наборов хеш-сумм и IP-адресов хранятся на средстве хранения 140. При помещении новых данных в кластер с использованием дерева кластеров в средстве 350 средство 320 определяет подходящий кластер и сохраняет данные на средстве хранения 140 в найденный кластер. После добавления новых хеш-сумм дерево кластеров может перестраиваться средством 320. Более подробно механизм формирования и перестроения дерева кластеров будет описан далее при рассмотрении Фиг.9 и Фиг.10.
В составе средства кластеризации 130 осталось нерассмотренным только средство формирование рейтингов 330. Данное средство выполняет важную функцию в рамках данного изобретения, а именно определяет рейтинги для сформированных кластеров. Рейтинг кластера позволяет выяснить, какие сообщения в нем содержатся: являются ли сообщения нежелательными или не являются таковыми. Поэтому после определения, к какому кластеру принадлежит сообщение, данному сообщению присваивается рейтинг того кластера, который был определен.
Рейтинги кластеров могут меняться при добавлении новых метаданных в кластер. Основным критерием, который учитывается при формировании рейтинга кластера, является учет количества схожих наборов хеш-сумм с разными IP-адресами отправителей. Чем больше в кластер будет поступать схожих наборов хеш-сумм, полученных от разных отправителей, тем выше будет вероятность того, что данный кластер содержит хеш-суммы, относящиеся к нежелательным сообщениям, и рейтинг у кластера будет расти. Большое количество схожих хеш-сумм, относящихся к сообщению, отправленному с одного IP-адреса, будет означать, что данное сообщение не относится к нежелательным, что выразится в уменьшении рейтинга кластера.
В процессе изменения рейтингов кластеров могут быть учтены также источники, из которых были получены сообщения или метаданные сообщений. Например, при кластеризации сообщений, полученных из ловушек сообщений, рейтинг кластера, к которому метаданные сообщений будут отнесены, будет увеличиваться.
На Фиг.2 показана схема системы обработки входящих сообщений на почтовом сервере клиента, который осуществляет обработку входящих электронных сообщений 180. Сообщения 180, поступающие на сервер, в общем случае могут быть адресованы различным получателям, которые имеют электронный адрес, зарегистрированный на данном почтовом сервере клиента 200. На стороне сервера находятся черный и белый списки в средствах хранения 220 и 230 соответственно, списки используются при анализе входящих сообщений с целью обнаружения легитимных и нежелательных сообщений и их устранения из дальнейшего анализа. Данные списки содержат различную информацию, например в белом списке могут храниться легитимные IP-адреса. В черном списке, напротив, могут быть запрещенные адреса, которые были определены для блокирования сообщений, поступающих с этих адресов. Помимо этого, списки могут содержать контрольные суммы сообщений, характерные слова и другую информацию, позволяющую однозначно идентифицировать категорию сообщений. Обработку входящих сообщений осуществляет средство анализа сообщений 210.
После проведения предварительной обработки все входящие сообщения делятся на три группы: легитимные сообщения, которые становятся доступны получателю, нежелательные сообщения и неизвестные сообщения, которые не были отнесены к первым двум группам.
Сообщения в зависимости от группы, к которой они были отнесены, по-разному обрабатываются в дальнейшем.
Нежелательные сообщения в зависимости от варианта реализации системы могут быть обработаны различными способами. В одном из вариантов реализации системы нежелательные сообщения могут использоваться в процессе кластеризации. Сообщения могут передаваться на систему определения рейтингов 100, сохраняться в средстве хранения 110, после чего средство кластеризации 130 выполнит их кластеризацию. В другом варианте нежелательные сообщения могут быть обработаны непосредственно на почтовом сервере клиента 200, для сообщений могут быть подготовлены метаданные, которые будут переданы на систему определения рейтингов 100 и при помощи средства кластеризации 130 будут отнесены к тому или иному кластеру.
Процесс кластеризации нежелательных сообщений дает возможность, используя систему определения рейтингов 100, определять при помощи части рассылки нежелательных сообщений, обнаруженной стандартными средствами, другую часть той же рассылки нежелательных сообщений, которая не может быть обнаружена стандартными средствами обнаружения. Например, если средство анализа сообщений 210, обнаружив несколько одинаковых нежелательных сообщений, не обнаружит схожее, но немного измененное нежелательное сообщение, то такое сообщение будет обнаружено при помощи системы определения рейтингов 100. При этом метаданные нежелательных сообщений, обнаруженных стандартными средствами и в дальнейшем кластеризованных, будут необходимы для обнаружения схожих нежелательных сообщений при помощи системы определения рейтингов 100.
Основной же процесс, для реализации которого служит данное изобретение, связан с неизвестными сообщениями.
Когда средство анализа сообщений 210 не может достоверно определить при помощи доступных средств, к какой группе (к легитимным или нежелательным) относится сообщение, то сообщение получает промежуточный статус неизвестного сообщения. Группа неизвестных сообщений обрабатывается дополнительно, и по результатам обработки сообщения могут быть признаны нежелательными.
Неизвестные сообщения после средства анализа сообщений 210 отправляются на средство подготовки метаданных 240, где формируются метаданные, соответствующие поступившим сообщениям. Сформированные метаданные передаются при помощи средства взаимодействия 250 системе определения рейтинга 100 на средство кластеризации 130. Средство кластеризации 130 формирует метаданные и определяет, к какому кластеру они принадлежат, далее определятся рейтинг кластера, который отправляется обратно почтовому серверу клиента в качестве ответа. Если рейтинг кластера оказывается в пределах между верхним и нижним порогами, заданными на средстве принятия решений 260, то средство принятия решений 260 направляет сообщение в средство 280 на карантин, где сообщение находится в течение установленного промежутка времени, в ходе которого ожидается изменение рейтинга кластера, к которому относится сообщение. По истечении установленного времени сообщение из карантина подлежит повторной проверке. Система может быть реализована в одном из вариантов так, чтобы сообщение проверялось повторно несколько раз в течение времени нахождения в карантине. Время нахождения в карантине может быть также вычислено по результатам работы системы определения рейтингов, в частности может зависеть от скорости наполнения кластеров. Стоит отметить, что одно сообщение не может дважды быть помещено в карантин. После окончания времени нахождения в карантине, если письмо не признано нежелательным, оно отображается пользователю.
После получения ответа от средства кластеризации 130 в виде рейтинга кластера (который является рейтингом, характеризующим сообщение) средство взаимодействия 250 передает рейтинг сообщения средству принятия решения 260, которое играет роль конечного звена в процессе определения нежелательных сообщений. Средство 260 использует заданные значения верхнего и нижнего порогов для того, чтобы определить, является ли сообщение нежелательным. Схематично пороговые значения рейтинга отображены на Фиг.4. Данные значения могут изменяться автоматически после анализа полученных результатов фильтрации сообщений либо могут изменяться вручную, если имеется необходимость поменять требования к анализу электронных сообщений. Если полученный рейтинг сообщения не превышает нижнее пороговое значение рейтинга, то сообщение будет отнесено к легитимным и будет предоставлено получателю. Если будет превышен верхний порог, сообщение будет признано нежелательным, оно будет блокировано, либо будут применены правила, предусмотренные, в частности, политиками сервера. В одном из вариантов нежелательные сообщения передаются на систему определения рейтингов 100, сохраняются в средстве хранения 110, после чего средство кластеризации 130 выполняет их кластеризацию.
В другом варианте реализации нежелательные сообщения могут быть обработаны непосредственно на почтовом сервере клиента 200, для сообщений могут быть подготовлены метаданные, которые будут переданы на систему определения рейтингов 100 и при помощи средства кластеризации 130 будут отнесены к тому или иному кластеру.
Фиг.5 показывает алгоритм обработки входящих сообщений, выполняемый на почтовом сервере клиента. Алгоритм начинается с шага 510, на котором почтовый сервер клиента получает сообщение. На шаге 515 средство анализа сообщений 210 проводит предварительный анализ, по результатам которого делается вывод, является ли сообщение нежелательным, легитимным или неизвестным. При проведении анализа средство 210 использует стандартные средства обнаружения спама, которые заключаются, по меньшей мере, в проверке по черным и белым спискам, хранящимся в средствах хранения 220 и 230 соответственно. Если на шаге 520 по результатам анализа определяется, что сообщение является нежелательным, то такое сообщение на шаге 525 обрабатывается в соответствии с правилами обработки нежелательных сообщений. Сообщения передаются на систему определения рейтингов 100, сохраняются в средстве хранения 110, после чего средство кластеризации 130 выполняет их кластеризацию.
В другом варианте реализации нежелательные сообщения могут быть обработаны непосредственно на почтовом сервере клиента 200, для сообщений могут быть подготовлены метаданные, которые будут переданы на систему определения рейтингов 100 и при помощи средства кластеризации 130 будут отнесены к тому или иному кластеру. После чего работа на стороне почтового сервера клиента завершается на шаге 530.
Если на шаге 520 установлено, что полученное сообщение не является нежелательным, то следом, на шаге 535, проверяется с использованием доступных средств (по меньшей мере, с использованием белого списка), является ли сообщение легитимным. Легитимные сообщения отображаются получателю на шаге 540, после чего алгоритм завершается на шаге 545.
В качестве третьего варианта сообщение может быть не определено ни как нежелательное, ни как легитимное, то есть будет установлено, что сообщение является неизвестным. В таком случае выполняется формирование метаданных для сообщения на шаге 550 при помощи средства подготовки метаданных 240. С целью формирования метаданных определяется IP-адрес отправителя сообщения и строится набор хеш-сумм на шаге 551 и 552 соответственно. Метаданные содержат информацию, необходимую и достаточную для идентификации сообщения, вместе с тем данная информация не позволяет получить доступ к содержанию самого сообщения или восстановить по метаданным содержание сообщения, поэтому содержание сообщения остается конфиденциальным и доступным только для получателя, которому оно адресовано. Передача метаданных выполняется на шаге 553 средству кластеризации 130, где осуществляется их обработка, процесс выполнения которой будет более подробно рассмотрен на Фиг.6. Далее на шаге 555 средство взаимодействия 250 получает ответ от средства кластеризации, при этом ответ может содержать рейтинг сообщения либо не содержать его, если рейтинг недоступен. Рейтинг может быть недоступен в случае, если метаданные сообщения не были отнесены ни к одному из имеющихся кластеров и для них был создан новый кластер. При недоступности рейтинга на шаге 590 сообщение отображается пользователю.
Если на шаге 590 определяется, что рейтинг сообщения получен, то он используется на шаге 560 и 565 средством принятия решений 260, которое определяет, как соотносится полученный рейтинг с верхним и нижним порогами. Если рейтинг не превышает нижний порог, то сообщение отображается пользователю. Если рейтинг превышает верхний порог, то сообщение является нежелательным, и для этого сообщения на шаге 570 выполняются необходимые действия, например, предусмотренные правилами обработки нежелательных сообщений, описанным ранее. После чего алгоритм завершается на шаге 585.
В случае если рейтинг находится между нижним и верхним порогами и на шаге 575 установлено, что сообщение ранее не было в карантине, средство принятия решений 260 помещает сообщение в средство хранения карантина 280 на шаге 580. Сообщение помещается в карантин на заданное время, и по истечении времени нахождения в карантине сообщение передается на повторную проверку на шаг 515. В другом варианте реализации системы сообщение может быть несколько раз проверено в рамках времени нахождения в карантине. Повторная проверка спустя заданное время необходима, поскольку за это время могли измениться настройки средства анализа сообщений 210 на почтовом сервере клиента 200 и, что наиболее важно, мог измениться рейтинг для данного сообщения на системе определения рейтингов 100. Система может быть настроена так, что в одном из вариантов будет повторно проверяться только рейтинг для сообщения в карантине.
Почтовый сервер клиента может быть настроен таким образом, чтобы было задано оптимальное время нахождения сообщения в карантине, которого достаточно для изменения рейтинга и в то же время которое не будет влечь неудобств клиенту, связанных с задержкой отображения сообщений. Таким образом, помещая сообщения в карантин, появляется возможность снизить количество ложных срабатываний при определении нежелательных сообщений, если не удалось изначально определить сообщение как нежелательное или легитимное.
Из карантина сообщение не может повторно попасть в карантин. Поэтому при повторном анализе сообщения, если оно не отнесено средством анализа 210 к нежелательным, оно отображается клиенту на шаге 540, даже если рейтинг для него находится в интервале между верхним и нижним порогами.
Фиг.6 иллюстрирует алгоритм определения рейтингов электронных сообщений, выполняемый на стороне системы определения рейтингов. Как было отмечено ранее, для определения рейтинга сообщения метаданные, подготовленные для сообщения, передаются при помощи средства взаимодействия 250 средству кластеризации 130.
После получения метаданных сообщения средство фильтрации хеш-сумм 340, входящее в состав средства кластеризации 130, на шаге 610 проводит фильтрацию полученных хеш-сумм с использованием средства хранения 120. Завершив процесс фильтрации, на шаге 620 средство 320 формирования кластеров проводит поиск кластера, к которому относятся полученные метаданные, в средстве хранения дерева кластеров 350. Когда кластер определен, на шаге 630 определяется его рейтинг при помощи средства формирования рейтингов 330, а затем выполняется проверка доступности рейтинга. Рейтинг кластера может быть недоступен из-за недостаточного количества наборов метаданных в кластере. Если на шаге 640 определяется, что рейтинг кластера недоступен, то почтовому серверу клиента сообщается, что рейтинг для сообщения недоступен, на шаге 650. Если рейтинг доступен, то рейтинг кластера, к которому ранее были отнесены метаданные, отправляется в качестве ответа средством кластеризации 130 на средство взаимодействия почтового сервера клиента 250 на шаге 660. При этом метаданные сообщения сохраняются, они вносятся в соответствующий кластер в средстве хранения кластеров 140 на шаге 670, после чего проводится обновление дерева кластеров и соответствующих их рейтингов на шаге 680. Стоит отметить, что с целью снижения вычислительной нагрузки обновление и перестроение дерева кластеров, содержащегося в средстве хранения дерева кластеров 350, при помощи средства 320 на основе метаданных из средства хранения 140 и обновление рейтингов при помощи средства 330 может производиться не после каждого запроса, а периодически, спустя заданные интервалы времени, либо при поступлении установленного количества запросов от почтового сервера клиента.
Фиг.7 иллюстрирует алгоритм обработки нежелательных входящих сообщений от ловушек сообщений. Данный алгоритм описывает последовательность действий, совершаемых системой определения рейтингов сообщений при обработке нежелательных сообщений, которые поступают от ловушек сообщений на шаге 710. После получения сообщений они сохраняются в средстве хранения 110 и средство кластеризации на шаге 720 создает метаданные для полученных сообщений. Процесс формирования метаданных состоит из шага 721 определения IP-адреса отправителя сообщения и шага 722 построения набора хеш-сумм для сообщения. На шаге 730 проводится процесс фильтрации метаданных путем удаления из наборов хеш-сумм подписей при использовании средства хранения 120. Завершив процесс фильтрации, на шаге 740 средство 320 формирования кластеров проводит поиск кластера, к которому относятся полученные метаданные, в средстве хранения дерева кластеров 350. После этого метаданные сохраняются на сервере, они вносятся в соответствующий кластер в средстве хранения кластеров 140 на шаге 750, далее проводится обновление дерева кластеров и соответствующих рейтингов на шаге 760, после чего алгоритм завершается.
Фиг.8 отображает схему формирования метаданных из сообщений. Для простоты рассматривается процесс получения метаданных для текстового сообщения, которое не содержит вложенных объектов. Но следует отметить, что для сообщений, содержащих вложенные объекты, процесс создания метаданных может быть выполнен аналогичным образом, при этом в зависимости от типа вложенного объекта могут быть использованы различные алгоритмы получения хеш-сумм. Из текстового сообщения извлекается текст 810, содержащийся в теле письма. Текст разбивается на фрагменты 820А-820В, из которых после строятся хеш-суммы 830А-830В с использованием хеш-функции.
После процесса построения хеш-сумм к хеш-суммам 840 добавляется IP-адрес отправителя сообщения 850, после чего полученные метаданные перед процессом кластеризации и определения рейтинга подлежат фильтрации. После фильтрации получившиеся метаданные 860 подлежат кластеризации.
Набор получившихся хеш-сумм 830А-830В может содержать элементы, которые будут вносить негативный эффект в процесс кластеризации, к таким элементам могут быть отнесены хеш-суммы, которые получены из фрагментов текста, часто встречающихся как в легитимных сообщениях, так и в нежелательных, а также часто повторяющихся элементов, которые могут быть восприняты как характерные элементы, свойственные спаму. Например, в легитимных сообщениях часто используются подписи отправителей, с указанием места работы, должности, ссылками на сайты, телефонами и т.п. Часто к тексту сообщения добавляются текстовые элементы, сообщающие тип устройства, с которого было отправлено сообщение (например, текст «Sent from mobile device»), или почтовые ресурсы, с использованием которых сообщение было отправлено (например, название почтового сервиса или социальной сети). Описанные элементы могут встречаться в сообщениях, отправленных различными пользователями с разных IP-адресов, поэтому такие сообщения могут быть классифицированы как рассылка спама, хотя таковыми не являются. Кроме того, сообщения, содержащие одинаковые подписи, будут обладать большей степенью схожести, и вероятность попадания в один кластер у таких сообщений будет выше независимо от содержания сообщений.
Для снижения вероятности появления ошибок, вызванных описанными особенностями, в одном из вариантов реализации после построения набора хеш-сумм производится фильтрация хеш-сумм при помощи средства фильтрации 340 и средства хранения 120, содержащего известные хеш-суммы, которые не должны учитываться при кластеризации. В одном из вариантов реализации также возможно дополнительно выполнять фильтрацию текста на этапе его разбиения до формирования хеш-сумм. При этом, кроме подписей, могут также быть отфильтрованы другие малоинформативные элементы, свойственные всем сообщениям, например текст приветствия в начале сообщений.
Использование процесса кластеризации позволяет разделить сообщения по степени схожести на кластеры, с использованием получившегося разбиения становится возможным определить рейтинг для кластера, а значит, для всех метаданных, находящихся в нем, и для сообщений, которые соответствуют этим метаданным. Рейтинг кластера отождествляется с рейтингом сообщений, метаданные которых содержатся в кластере, и позволяет сделать однозначный вывод о том, является ли сообщение нежелательным или нет. На Фиг.9 изображен один из вариантов строения дерева индекса кластеров, который предпочтителен для описываемого технического решения.
Дерево индекса кластеров образуется при помощи средства кластеризации 130, которое выполняет кластеризацию поступающих метаданных 910, состоящих, по меньшей мере, из набора хеш-сумм {h1; h2…hk} и IP-адреса отправителя сообщения, которое характеризуется набором хеш-сумм {h1; h2…hk}. Дерево кластеров служит для того, чтобы найти кластер, к которому относятся поступающие метаданные, то есть набор хеш-сумм после прохождения по уровням дерева в конце получит указатель на кластер в средстве хранения кластеров 140, куда и будет помещен.
Дерево кластеров строится на основе наборов хеш-сумм, имеющихся в средстве хранения 140. Дерево состоит из уровней и узлов. На Фиг.9 изображены два уровня: первый уровень состоит из одного узла, включающего наборы 920А-920Г, второй уровень состоит из четырех узлов, включающих наборы 930А-930Г, 940А-940В, 950А-950Б, 960А-960Б. В зависимости от количества наборов хеш-сумм в средстве 140 и степени их схожести уровней может быть существенно больше. Каждый уровень состоит из узлов, каждый узел, в свою очередь, состоит из фиксированного количества наборов значений (hi, wi). В описываемом варианте строения древа максимальное число наборов значений (hi, wi) для любого узла равно четырем, однако в общем случае их число может быть иным. Узел первого уровня состоит из наборов 920А, 920Б, 920В, 920Г. Каждый набор значений (hi, wi) содержит n пар, состоящих из значений наиболее встречающихся хеш-сумм hi и весовых коэффициентов wi, соответствующих данным значениям, к примеру, набор значений 920А первого уровня состоит из следующих n пар: 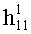
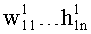
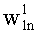
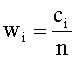
где ci - количество раз, которое hi встречается в кластере. При этом выполняется неравенство:
w1≥w2>…≥wN
Таким образом, первый уровень создается на основе анализа всех имеющихся хеш-сумм, находящихся в средстве хранения кластеров 140, с выбором наиболее часто встречающихся хеш-сумм, взятых для формирования дерева кластеров. Каждый набор значений (hi, wi) содержит ссылку на узел следующего уровня либо указывает непосредственно на кластер в средстве хранения 140, если дно дерева достигнуто.
Следующий уровень состоит из аналогичных узлов, но для данного уровня каждый набор значений 930А-930Г, 940А-940В, 950А-950Б и 960А-960Б определяется не из всех хеш-сумм, находящихся в средстве хранения кластеров 140, а только из части, которая включает группу кластеров, соответствующих тому или иному узлу. Например, для узла, содержащего наборы 930А-930Г, наиболее часто встречающиеся значения хеш-сумм будут определяться не из всех хеш-сумм, хранящихся в средстве 140, а только из части 935. Аналогично для наборов 940А-940В, 950А-950Б и 960А-960Б будут использоваться части 945, 955 и 965 соответственно. Для определения наборов значений (hi, wi) для каждого узла всех уровней используется алгоритм, который был описан для первого уровня.
Некоторые узлы могут иметь вакантные места, которые в определенные моменты времени не заполнены наборами (hi, wi). На Фиг.9 изображено дерево кластеров, у которого на втором уровне заполнен до предела только один узел, состоящий из наборов 930А-930Г. Такие вакантные места могут появляться, например, когда дерево еще не до конца наполнено либо после завершения процесса перестроения дерева. С поступлением новых метаданных дерево будет наполняться хеш-суммами и его узлы будут заполняться.
Таким образом, каждый узел дерева состоит из наборов значений (hi, wi), которые содержат наиболее часто встречающиеся хеш-суммы hi, но на первом уровне содержатся наиболее встречающиеся хеш-суммы для всего средства хранения 140, а на других уровнях - для соответствующих частей. Поэтому, спускаясь вниз по дереву кластеров, проводится пошаговое приближение поступившего набора хеш-сумм к наиболее подходящему кластеру.
Подходящий кластер определяется по степени схожести между поступившим набором хеш-сумм {h1; h2…hk} из метаданных 910 и имеющимися наборами в дереве кластеров, которая определяется Формулой 2:
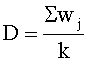
При этом суммирование ведется по всем Wj, соответствующим хеш-суммам в дереве кластеров, с которыми совпали хеш-суммы во входящем наборе {h1; h2…hk}. Чем больше значение D, тем больше входящий набор соответствует кластеру. Также значение D должно быть выше заданного порогового значения Т. Значение Т является границей кластера, оно показывает минимальную степень схожести, которой должны обладать наборы хеш-сумм, относящиеся к кластеру.
После получения новых метаданных значение D вычисляется для каждого из четырех наборов 920А-920Г узла первого уровня, после чего определяется один из них, для которого полученное значение D оказалось наибольшим и которое превосходит пороговое значение Т, например набор 920Г. Далее выполняется переход на второй уровень к тому узлу, на который ссылается набор 920Г. Далее в соответствии с переходом вычисляются значения D для наборов 960А и 960Б, и выбирается наибольшее из них, которое превосходит пороговое значение Т. Так определяется кластер, к которому относятся полученные метаданные и куда они будут помещены. Если метаданные не отнесены ни к одному из имеющихся кластеров, то создается новый кластер, при этом сообщение, которому соответствуют метаданные, будет признано легитимным.
В одном из вариантов реализации в качестве ответа на средство взаимодействия может передаваться значение D вместе с рейтингом кластера. Данное значение будет участвовать в анализе, проводимом средством принятия решений 260, и позволит улучшить точность определения нежелательных сообщений.
После помещения новых метаданных в кластеры в средстве хранения 140 общее количество встречающихся одинаковых хеш-сумм в кластере будет меняться, что, в свою очередь, повлечет изменение весовых коэффициентов wi и, как следствие, изменение структуры узлов дерева. В частности, узлы дерева могут содержать другие хеш-суммы или в другой последовательности, поскольку изменилось количество этих хеш-сумм в соответствующем кластере. В идеальном исполнении после добавления новых метаданных в кластер дерево кластеров должно обновляться, но данный процесс влечет потребление больших вычислительных ресурсов, поскольку каждый раз придется заново проводить расчет всех весовых коэффициентов wi по Формуле 1. Однако в качестве одного из вариантов реализации можно отказаться от постоянного обновления дерева кластеров при добавлении новых метаданных, если новые метаданные не будут вносить существенного изменения в содержание дерева. Например, если кластеры содержат тысячи наборов хеш-сумм, то добавление одного нового набора не внесет существенную погрешность, как если бы кластеры содержали десятки хеш-сумм. Во втором случае погрешность может иметь существенную величину. Поэтому с учетом размеров кластеров можно варьировать критерий обновления индексного дерева. То есть если кластеры имеют небольшой размер (содержат немного данных), обновление дерева можно проводить после каждой записи нового набора хеш-сумм, и при этом увеличение нагрузки на вычислительную систему будет незначительной из-за малого обрабатываемого объема данных. Если кластеры имеют большой объем, то производить обновление дерева можно после получения заданного количества новых метаданных 910, при этом количество может быть выбрано оптимально, чтобы снизить нагрузку и одновременно сохранить значение погрешности из-за отсутствия обновления на допустимом уровне.
Другая ситуация, которая может возникнуть при кластеризации метаданных с использованием дерева кластеров, заключается в отсутствии превышения порогового значения Т при расчете значения D, определяющего степень схожести между входящим набором хеш-сумм {h1; h2…hk} из метаданных 910 и имеющимися наборами в дереве кластеров. Такая ситуация может возникнуть на любом уровне дерева кластеров. При этом стоит отметить, что в общем случае значение Т не обязательно должно быть одинаковым для всех элементов дерева, оно может отличаться в зависимости от уровня дерева или даже узла.
При возникновении упомянутой ситуации, когда значение Т не достигается ни для одного набора значений (hi, wi) заданного узла дерева, возможно несколько вариантов поведения средства кластеризации 130. В случае если заданный узел имеет незаполненные наборами (hi, wi) области, что имеет место на втором уровне дерева на Фиг.9 для всех узлов, кроме узла, состоящего из наборов 930А-930Г, соответствующие свободные области будут заполняться и участвовать наравне с ранее заполненными в процессе кластеризации. При этом будет создан новый кластер в средстве хранения 140, который соответствует новому набору (hi, wi).
Поскольку количество наборов значений (hi, wi) для каждого узла дерева ограничено и фиксировано, когда все наборы заполнены и возникает ситуация, при которой значение Т не достигается ни для одного набора значений (hi, wi) заданного узла дерева, дерево будет перестроено путем деления узла, который будет подробно описан со ссылкой на Фиг.10.
На Фиг.10 схематично показан процесс перестроения дерева кластеров, при котором возникает деление одного узла 1020 на два независимых узла 1050 и 1060 с образованием нового уровня, состоящего из узла 1040.
На Фиг.10 проиллюстрирован пример разделения узла первого уровня при поступлении новых метаданных 1010, содержащих набор хеш-сумм, для которого рассчитанная величина D для каждого набора значений узла 1020 оказалась ниже установленного порогового значения Т. При этом все области узла 1020 заполнены. Для разделения узла вначале создается новый кластер 1011, куда записываются полученные метаданные 1010, для нового кластера вычисляется набор значений (hi, wi). После создания нового набора значений (hi, wi) вычисляется степень схожести нового набора и других наборов узла 1020 по Формуле 3:
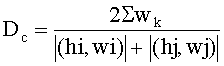
где суммирование ведется по всем весовым коэффициентам wk из обоих наборов значений (hi, wi) и (hj, wj), для которых имеются совпадающие хэш-суммы, a |(hi, wi)| и |(hj, wj)| - количество элементов в соответствующих наборах значений. Чем меньше Dc, тем менее схожи наборы значений и соответствующие кластеры. По полученным значениям Dc определяются наименее пересекающиеся наборы, которые помещаются в два разных узла 1050 и 1060. Оставшиеся наборы распределяются в получившиеся узлы дерева с учетом степени схожести по отношению к распределенным наименее пересекающимся наборам. Таким образом, из одного узла 1020 на первом уровне формируется два узла - 1050 и 1060 на втором уровне, при этом формируется новый уровень, состоящий из узла 1040. Наборы значений (hi, wi) для нового родительского узла 1040 на первом уровне могут быть получены на основании соответствующих значений из узлов 1050 и 1060 путем расчета по Формуле 1.
Обратный процесс объединения узлов или наборов значений также возможен в рамках данной модели построения дерева кластеров. Процесс объединения может проводиться, например, в случае обновления дерева кластеров. В основе процесса объединения лежит определение степени схожести Dc наборов значений (hi, wi) и (hj, wj) одного или нескольких узлов в рамках одного уровня дерева. Значения Dc рассчитываются по Формуле 3, указанной ранее. Если полученные значения Dc превосходят установленный порог Тс, то соответствующие наборы (hi, wi) и (hj, wj) близки и соответствующие им кластеры также близки. Если наборы (hi, wi) и (hj, wj) содержатся в рамках одного узла, то они объединяются. Получившийся объединенный набор значений пересчитывается по Формуле 1. Если наборы (hi, wi) и (hj, wj) находятся в разных узлах, то до помещения в какой-либо узел предварительно необходимо определить, к какому узлу объединенный набор будет более близок. Это можно определить также при помощи Формулы 3, установив близость к наименее схожим наборам двух узлов.
На Фиг.11 показана схема строения кластера 1120 в средстве хранения кластеров 140. Каждый кластер содержит в себе наборы хеш-сумм, IP-адреса отправителей сообщений, которые соответствуют наборам хеш-сумм. Рейтинги кластеров хранятся в средстве формирования рейтингов 330 для каждого кластера. Когда с использованием дерева кластеров определяется кластер, к которому относятся метаданные 1110, они записываются в соответствующий кластер 1120, то есть сохраняется набор хеш-сумм и IP-адрес. После чего определяется рейтинг кластера. Рейтинг 1130 сообщается в качестве ответа почтовому серверу клиента, который принимает решение в отношении сообщения, основываясь на полученном рейтинге.
Рейтинги кластеров могут меняться при добавлении новых метаданных в кластер. Основным критерием, который учитывается при формировании рейтинга кластера, является учет количества схожих наборов хеш-сумм с разными IP-адресами отправителей. Чем больше в кластер будет поступать схожих наборов хеш-сумм, полученных от разных отправителей, тем выше будет вероятность того, что данный кластер содержит хеш-суммы, относящиеся к нежелательным сообщениям, и рейтинг у кластера будет расти. Большое количество схожих хеш-сумм, относящихся к сообщению, отправленному с одного IP-адреса, будет означать, что данное сообщение не относится к нежелательным, что выразится в уменьшении рейтинга кластера.
В процессе изменения рейтингов кластеров могут быть учтены также источники, из которых были получены сообщения или метаданные сообщений. Например, при кластеризации сообщений, полученных из ловушек сообщений, рейтинг кластера, к которому метаданные сообщений будут отнесены, будет увеличиваться.
В одном из вариантов реализации системы предусматривается участие специалиста, который будет участвовать в процессе формирования кластеров, давая заключения о нежелательности сообщений до помещения метаданных сообщений в кластеры. Подобные заключения будут влиять на формирование рейтинга кластеров.
Фиг.12 представляет пример компьютерного устройства общего назначения, на котором может быть реализовано описанное изобретение. Компьютерное устройство общего назначения, персональный компьютер или сервер 20 содержит центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая, в свою очередь, память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20, в свою очередь, содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс привода магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.).
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35 и дополнительные программные приложения 37, другие программные модули 38 и программные данные 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который, в свою очередь, подсоединен к системной шине, но могут быть подключены иным способом, например при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например колонки, принтер и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг.12. В вычислительной сети могут присутствовать также и другие устройства, например маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 51 и глобальную вычислительную сеть (WAN) 52. Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN- сетях персональный компьютер 20 подключен к локальной сети 51 через сетевой адаптер или сетевой интерфейс 53. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью 52, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В соответствии с описанием компоненты, этапы исполнения, структуры данных, описанные выше, могут быть выполнены, используя различные типы операционных систем, компьютерных платформ, программ.
В заключение следует отметить, что приведенные в описании сведения являются только примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ классификации писем электронной почты | 2024 |
|
RU2828611C1 |
| Способ классификации писем электронной почты и система, его реализующая | 2024 |
|
RU2828610C1 |
| Система и способ формирования эвристических правил для выявления писем, содержащих спам | 2019 |
|
RU2710739C1 |
| КОНТУР ОБРАТНОЙ СВЯЗИ ДЛЯ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОЙ РАССЫЛКИ | 2004 |
|
RU2331913C2 |
| Способ кластеризации электронных писем, являющихся спамом | 2021 |
|
RU2769633C1 |
| СИСТЕМА И СПОСОБ ЗАЩИТЫ ОТ НЕЛЕГАЛЬНОГО ИСПОЛЬЗОВАНИЯ ОБЛАЧНЫХ ИНФРАСТРУКТУР | 2012 |
|
RU2536663C2 |
| Система утилизации спама | 2021 |
|
RU2787308C1 |
| СИСТЕМА И СПОСОБ ИСКЛЮЧЕНИЯ ШИНГЛОВ ОТ НЕЗНАЧИМЫХ ЧАСТЕЙ ИЗ СООБЩЕНИЯ ПРИ ФИЛЬТРАЦИИ СПАМА | 2013 |
|
RU2583713C2 |
| Способ формирования сигнатуры нежелательного электронного сообщения | 2021 |
|
RU2776924C1 |
| Способ обнаружения мошеннического письма, относящегося к категории внутренних ВЕС-атак | 2021 |
|
RU2766539C1 |
Изобретение относится к способу и системе определения нежелательных электронных сообщений. Технический результат заключается в повышении защищенности от нежелательных сообщений. В способе проводят предварительный анализ входящих сообщений для выявления, по меньшей мере, одного сообщения, не относящегося к легитимным и нежелательным сообщениям, формируют метаданные, состоящие из набора хеш-сумм и IP-адреса отправителя для выявленного входящего электронного сообщения, с помощью средства подготовки метаданных, передают метаданные, сформированные из электронного сообщения, на средство кластеризации при помощи средства взаимодействия, определяют кластер, к которому относятся переданные метаданные, при помощи средства кластеризации, получают рейтинг кластера, к которому относятся переданные метаданные, при этом полученный рейтинг соответствует рейтингу электронного сообщения и имеет прямую зависимость от количества различных IP-адресов отправителей, соответствующих метаданным в данном кластере, передают рейтинг электронного сообщения на средство принятия решений, определяют, основываясь на рейтинге электронного сообщения и установленном верхнем пороге, является ли сообщение нежелательным при помощи средства принятия решений. 2 н. и 30 з.п. ф-лы, 12 ил.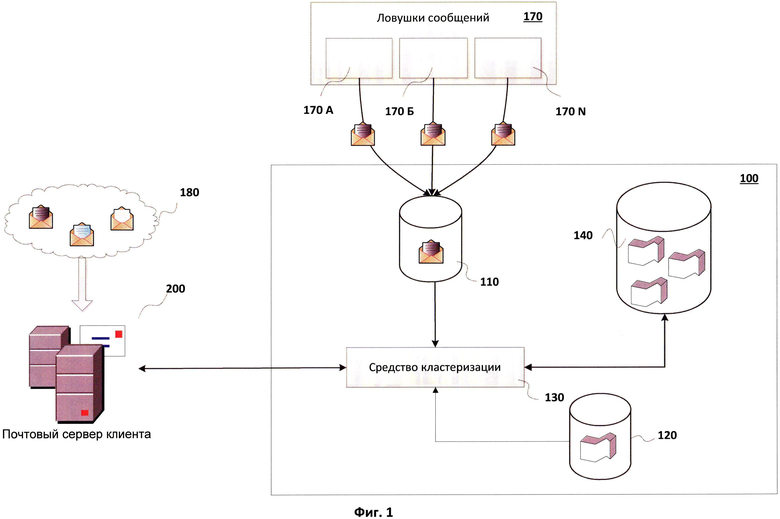
1. Способ определения нежелательных электронных сообщений, выполняющийся на компьютерной системе, заключается в том, что:
A) проводят предварительный анализ входящих сообщений для выявления, по меньшей мере, одного сообщения, которое не относится к легитимным и нежелательным сообщениям;
Б) формируют метаданные, состоящие, по меньшей мере, из набора хеш-сумм и IP-адреса отправителя, для выявленного входящего электронного сообщения, которое не относится к легитимным и нежелательным сообщениям, с помощью средства подготовки метаданных;
B) передают метаданные, сформированные из электронного сообщения, на средство кластеризации при помощи средства взаимодействия;
Г) определяют кластер, к которому относятся переданные метаданные, при помощи средства кластеризации;
Д) получают рейтинг кластера, к которому относятся переданные метаданные, при этом полученный рейтинг соответствует рейтингу электронного сообщения и имеет прямую зависимость от количества различных IP-адресов отправителей, соответствующих метаданным в данном кластере;
Е) передают рейтинг электронного сообщения на средство принятия решений;
Ж) определяют, основываясь на рейтинге электронного сообщения и установленном верхнем пороге, является ли сообщение нежелательным при помощи средства принятия решений.
2. Способ по п. 1, в котором набор хеш-сумм вычисляют, по меньшей мере, для данных, содержащихся в теле сообщения, путем предварительного разбиения данных на части и применения хеш-функции к каждой части.
3. Способ по п. 1, в котором входящие сообщения предварительно анализируют, по меньшей мере, с использованием белого и черного списков.
4. Способ по п. 1, в котором для проанализированных нежелательных сообщений формируют метаданные для помещения в кластеры средством кластеризации.
5. Способ по п. 1, в котором при помощи средства кластеризации фильтруют хеш-суммы подписей в сообщениях для снижения вероятности появления ошибок кластеризации.
6. Способ по п. 5, в котором фильтрацию хеш-сумм подписей выполняют путем удаления из наборов хеш-сумм, по меньшей мере, тех из них, которые относятся к подписям отправителей.
7. Способ по п. 1, в котором при помощи средства кластеризации формируют кластеры, которые состоят из схожих наборов метаданных.
8. Способ по п. 1, в котором при помощи средства кластеризации формируют рейтинги для кластеров.
9. Способ по п. 1, в котором при помощи средства кластеризации хранят дерево кластеров, позволяющее определить, к какому кластеру относятся поступающие метаданные.
10. Способ по п. 9, в котором дерево кластеров формируют в виде многоуровневой структуры, на каждом уровне которой создаются узлы, состоящие из наиболее часто встречающихся в кластере хеш-сумм.
11. Способ по п. 9, в котором дерево кластеров обновляют после поступления новых метаданных.
12. Способ по п. 9, в котором кластер, к которому относятся метаданные, определяют путем вычисления степени схожести хеш-сумм в поступивших метаданных с хеш-суммами в одном из наборов в дереве кластеров.
13. Способ по п. 12, в котором вместе с рейтингом электронного сообщения на средство принятия решений для анализа передают значение, определяющее степень схожести хеш-сумм в поступивших метаданных с хеш-суммами в одном из наборов в дереве кластеров.
14. Способ по п. 1, в котором на средство кластеризации поступают нежелательные сообщения из ловушек сообщений для кластеризации.
15. Способ по п. 1, в котором сообщение, рейтинг которого находится между верхним порогом, соответствующим нежелательным сообщениям, и нижним порогом, соответствующим легитимным сообщениям, помещают в карантин на установленное время.
16. Способ по п. 15, в котором для сообщения повторно определяют рейтинг по истечении времени нахождения в карантине.
17. Система определения нежелательных электронных сообщений, взаимодействующая, по меньшей мере, с одним почтовым сервером клиента, который включает:
а) средство анализа сообщений, связанное со средством подготовки метаданных, при этом средство анализа сообщений предназначено для проведения предварительного анализа входящих электронных сообщений для выявления, по меньшей мере, одного сообщения, которое не относится к легитимным и нежелательным сообщениям;
б) упомянутое средство подготовки метаданных, связанное со средством взаимодействия, при этом средство подготовки метаданных предназначено для формирования метаданных, состоящих, по меньшей мере, из набора хеш-сумм и IP-адреса отправителя, для выявленного электронного сообщения, которое по результатам предварительного анализа не признано легитимным или нежелательным;
в) упомянутое средство взаимодействия, связанное со средством принятия решения и средством кластеризации системы определения рейтингов электронных сообщений, при этом средство взаимодействия предназначено для передачи метаданных сообщения на средство кластеризации и передачи рейтинга электронного сообщения, полученного от средства кластеризации в качестве ответа, на средство принятия решений;
г) упомянутое средство принятия решений, предназначенное для определения, основываясь на рейтинге электронного сообщения и установленном верхнем пороге, является ли сообщение нежелательным;
при этом система определения рейтингов электронных сообщений также включает:
I) упомянутое средство кластеризации, связанное со средством хранения кластеров, при этом средство кластеризации предназначено для определения кластера, к которому относятся метаданные, получения рейтинга кластера, который соответствует рейтингу электронного сообщения и имеет прямую зависимость от количества различных IP-адресов отправителей соответствующих метаданным в данном кластере, и передачи рейтинга на средство взаимодействия на стороне почтового сервера клиента;
II) упомянутое средство хранения кластеров, предназначенное для хранения кластеров, состоящих из метаданных, объединенных по степени схожести.
18. Система по п. 17, в которой набор хеш-сумм вычисляется, по меньшей мере, для данных, содержащихся в теле сообщения, путем предварительного разбиения данных на части и применения хеш-функции к каждой части.
19. Система по п. 17, в которой средство кластеризации дополнительно предназначено для:
- формирования кластеров в средстве хранения кластеров;
- изменения рейтингов для кластеров;
- формирования дерева кластеров, позволяющего определить, к какому кластеру относятся поступающие метаданные.
20. Система по п. 17, в которой средство кластеризации определяет, к какому кластеру относятся метаданные путем определения степени схожести хеш-сумм в полученном наборе хеш-сумм с хеш-суммами в одном из наборов в анализируемом кластере.
21. Система по п. 20, в которой средство кластеризации выполнено с возможностью передачи для анализа вместе с рейтингом электронного сообщения на средство принятия решений значения, определяющего степень схожести хеш-сумм в поступивших метаданных с хеш-суммами в одном из наборов в дереве кластеров.
22. Система по п. 19, в которой средство кластеризации формирует дерево кластеров в виде многоуровневой структуры, на каждом уровне которой создаются узлы, состоящие из наиболее часто встречающихся в кластере хеш-сумм.
23. Система по п. 19, в которой средство кластеризации обновляет дерево кластеров после поступления новых метаданных.
24. Система по п. 17, которая содержит ловушки сообщений, связанные со средством хранения нежелательных сообщений, при этом ловушки сообщений предназначены для сбора рассылок нежелательных электронных сообщений и передачи их на средство хранения нежелательных сообщений.
25. Система по п. 24, которая содержит средство хранения нежелательных сообщений, связанное со средством кластеризации, при этом средство хранения нежелательных сообщений предназначено для хранения сообщений, полученных от ловушек сообщений.
26. Система по п. 25, в которой средство кластеризации дополнительно предназначено для:
- вычисления наборов хеш-сумм для нежелательных сообщений, поступающих от ловушек сообщений;
- определения IP-адресов отправителей для нежелательных сообщений, поступающих от ловушек сообщений.
27. Система по п. 17, которая содержит средство хранения хеш-сумм подписей, связанное со средством кластеризации и предназначенное для хранения хеш-сумм подписей, которые необходимо отфильтровать до выполнения кластеризации.
28. Система по п. 27, в которой средство кластеризации дополнительно предназначено для фильтрации хеш-сумм подписей при помощи средства хранения хеш-сумм подписей для снижения вероятности появления ошибок кластеризации.
29. Система по п. 17, которая содержит средство хранения карантина, связанное со средством принятия решений, при этом средство хранения карантина предназначено для хранения в течение заданного времени сообщений, для которых рейтинг находится между верхним порогом, соответствующим нежелательным сообщениям, и нижним порогом, соответствующим легитимным сообщениям.
30. Система по п. 29, в которой средство принятия решений повторно определяет рейтинг для сообщения по истечении времени нахождения в карантине.
31. Система по п. 17, которая содержит средство хранения черного списка, связанное со средством анализа сообщений, при этом средство хранения черного списка предназначено для хранения информации о нежелательных сообщениях.
32. Система по п. 17, которая содержит средство хранения белого списка, связанное со средством анализа сообщений, при этом средство хранения белого списка предназначено для хранения информации о легитимных сообщениях.
| US 20090307771 A1, 10.12.2009 | |||
| US 20060168006 A1, 27.07.2006 | |||
| US 20050060643 A1, 17.03.2005 | |||
| US 20060095521 A1, 04.05.2006 | |||
| КОНТУР ОБРАТНОЙ СВЯЗИ ДЛЯ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОЙ РАССЫЛКИ | 2004 |
|
RU2331913C2 |

