Область техники
Изобретение относится к средствам компьютерной безопасности, а более конкретно к средствам поиска и обнаружения электронных писем, содержащих спам.
Уровень техники
Спам - разновидность почтовой рассылки с целью рекламы (часто нежелательной) того или иного товара или услуги, а также с целью совершения мошеннических действий. Для рассылки спама в настоящий момент активно используются все возможные технические средства, в том числе прокси-серверы, бесплатные серверы электронной почты, допускающие автоматизацию отправки писем по электронной почте, и бот-сети. К спаму, кроме сообщений, передаваемых по электронной почте, относятся также и сообщения, передаваемые с помощью протоколов мгновенных сообщений в социальных сетях, блогах, сайтах знакомств, форумах, а также SMS- и MMS-сообщения.
Электронные письма, содержащие спам, являются серьезной проблемой в современном мире, так как уже достигают 70-90% от общего объема почтового трафика. Такое количество спама, отправленных по компьютерным сетям, вызывает существенные неудобства для пользователей электронной почты. В частности, спам вызывает ухудшение пропускной способности сетей, трату ресурсов системы обмена сообщениями и увеличение времени обработки электронных писем как пользователями, так и компьютерами. Таким образом, необходимо непрерывно бороться со спамом.
Для борьбы со спамом были разработаны различные механизмы, такие как черные списки отправителей, серые списки, требующие повторного обращения почтового сервера для отправки, методы контекстной фильтрации спама. Фильтрация спама, как правило, сосредоточена на анализе содержимого сообщения электронного письма, что может потребовать, во-первых, значительного времени анализа и, во-вторых, открытости анализируемой информации, что не допустимо в случае передачи информации без согласия пользователей. Возможны и случаи, когда письма могут содержать конфиденциальную информацию. Методы, основанные на фильтрации, как правило, требуют точного совпадения, чтобы обнаруживать и отличать письма, содержащие спам, от легитимных писем. Кроме того, массовая рассылка спама еще больше усугубляет проблему фильтрации.
Повысить эффективность фильтрации спама можно избегая обширного анализа содержимого каждого сообщения электронной почты или введения предварительного анализа. Однако современные технологии защиты от спама не обеспечивают эффективного механизма быстрого и статистически точного анализа заголовков электронной почты и символов, из которых состоят заголовки. Таким образом, необходимо иметь эффективный механизм для проведения быстрого анализа заголовков электронной почты либо наряду со стандартными механизмами фильтрации электронной почты, либо в качестве предварительного анализа для полного анализа содержимого во время фильтрации, либо даже в качестве автономного метода анализа краткого содержания некоторых новых форм спама со спамом.
Еще одна проблема современных средств борьбы со спамом связана с тем, что существует вероятность возникновения ошибки первого рода, т.е. ложного срабатывания. Ложным срабатыванием в данном случае является ситуация, когда легитимное письмо стала определяться как спам. В этом случае, в зависимости от настройки работы средств защиты письмо, кажущееся спамом, помещается в карантин или даже удаляется в автоматическом режиме без уведомления отправителя или получателя, что приводит к потере легитимных писем.
Кроме того, отправители писем, содержащих спам, также становятся все более изобретательными и стараются учитывать возможности решений для фильтрации спама. Поэтому в ряде случаев, чтобы избежать автоматического обнаружения спам маскируют, добавляя рандомизацию в содержимое электронных писем или данные, подобные легитимному письму.
Поэтому было бы полезно использовать анализ статистических данных по получаемым письмам клиентов, чтобы фактически превратить приемы маскирования спама отправителями спама в сторону обнаружения спама. В то же время, чтобы учесть интересы пользователей по конфиденциальности сообщений/информации, содержащиеся в письмах, необходимо выявлять письма, содержащие спам, без анализа текста, содержащегося в теле писем.
Поэтому существует потребность в создании решения, которое устраняло бы указанные недостатки и позволяло бы обеспечить более точное обнаружение спама. Настоящее изобретение позволяет решить указанные недостатки и задачи путем создания эвристических правил, позволяющих произвести проверку письма на наличие спама, при этом эвристическое правило позволяет произвести анализ последовательности полей заголовка электронного письма.
Раскрытие изобретения
Настоящее изобретение предлагает решение, нацеленное на развитие современных систем и способов, связанных с компьютерной безопасностью, а именно, с обнаружением писем, содержащих спам и получаемых по электронной почте. Заявленное изобретение позволят формировать эвристические правила для поиска и обнаружения писем, содержащих спам, на основании анализ статистических данных о получаемых электронных письмах клиентов. Статистические данные предварительно, до их анализа, преобразуются в определенный вид, который представляет данные для анализа в обезличенном виде. Таким образом, сообщения клиентов, содержащихся в письме, не используются в анализе, что обеспечивает конфиденциальность информации. Одной из особенностей заявленной технологии является то, что формируемое эвристическое правило позволяет произвести поиск и обнаружения письма, содержащего спам, за счет анализа структуры заголовка письма и частично тела письма, при этом анализа содержащегося сообщения в теле письма не производится. Для решения этой особенности формирование по крайней мере одного условия эвристического правила основано на анализе последовательностей полей заголовков электронных писем. Такое эвристическое правило позволяет улучшить качество обнаружения спам-писем, т.е. писем, содержащих спам.
Один технический результат настоящего изобретения заключается в повышении уровня обнаружения спам-писем за счет создания эвристических правил, содержащих по крайней мере условия для анализа последовательностей полей заголовков электронных писем, для поиска спам-писем на основании статистических данных по электронным письмам клиентов.
Другой технический результат настоящего изобретения заключается в автоматизации процесса создания эвристических правил для выявления спам-писем на основании статистических данных, полученных в обезличенном виде.
Еще один технический результат настоящего изобретения заключается расширение арсенала технических средств для поиска писем содержащих спам, за счет создания эвристических правил, содержащих по крайней мере условия для анализа последовательностей полей заголовков электронных писем.
В качестве одного варианта исполнения настоящего изобретения предлагается способ создания эвристического правила для выявления спам-писем, который содержит этапы, на которых: получают статистические данные по письмам клиентов, при этом статистические данные содержат по крайне мере информацию о последовательности полей в заголовке каждого письма и наличии ссылок в теле каждого письма; производят кластеризацию полученных статистических данных, где каждый кластер содержит сгруппированные по определенным типам данные, при этом формируют по крайней мере один кластер, который содержит сгруппированные по полям данные согласно полям из заголовков писем; выбирают по крайней мере одну наиболее встречаемую комбинацию групп в каждом сформированном кластере, которую преобразовывают в свертку, при этом по крайней мере одну наиболее встречаемую комбинацию группу формируют на основании информации о полях из заголовков писем; формируют по крайней мере одного регулярного выражения, объединяющего информацию о ссылках, содержащихся в письмах, которые соответствуют каждой сформированной свертке; создают эвристическое правило на основании объединения по крайней мере сформированной свертки, соответствующей последовательности полей в заголовке каждого письма, и одного регулярного выражения, соответствующего указанной свертке.
В другом варианте исполнения способа дополнительно производят проверку каждой сформированной свертки на коллекции сверток, содержащей только свертки по легитимным письмам, при этом в случае совпадения сформированной свертки и свертки из коллекции сформированная свертка удаляется.
В еще одном варианте исполнения способа при создании эвристического правила устанавливают дополнительные условия на основании данных из статистически данных и связанных с письмами, на основании которых сформированы свертка и регулярное выражение.
В другом варианте исполнения способа получаемые статистические данные были получены на основании лексического анализа писем.
В еще одном варианте исполнения способа под наиболее встречаемой комбинацией понимается совокупность полей, которая объединяет наибольшее количество писем среди анализируемых.
В другом варианте исполнения способа для определения комбинации групп как наиболее встречаемой установлен порог от общего числа писем, по которым производится анализ статистических данных.
В еще одном варианте исполнения способа наиболее встречаемой комбинацией групп является каждая комбинация, которая объединяет не менее 90% писем, по которым были получены статистические данные.
В другом варианте исполнения способа в качестве свертки понимается по крайней мере MD5, хеш или гибкий хеш от найденной наиболее встречающейся комбинации групп.
В еще одном варианте исполнения способа формируют регулярные выражения по ссылкам согласно следующему принципу: разделяют каждую выявленную ссылку из статистических данных согласно установленным разделителям на сегменты; подсчитывают количество полученных сегментов для каждой ссылки; сравнивают ссылки между собой, у которых количество сегментов одинаково, по сегментно; и объединяют ссылки в регулярные выражения согласно длинам ссылок, при этом если сегменты одинаковые, то оставляют в неизмененном виде, если сегменты отличаются, то преобразуют в вид, в котором остаются только одинаковые значения.
В другом варианте исполнения способа кластеризация производится на основании алгоритма кластеризации данных «Density-based spatial clustering of applications with noise».
В качестве другого варианта исполнения предлагается система создания эвристических правил для выявления спам-писем, которая содержит: средство обработки данных, предназначенное для получения статистических данных по письмам клиентов в определенном виде, анализа полученных статистических данных, во время которого производит кластеризацию указанных данных, при этом по крайней мере один кластер содержит сгруппированные данные согласно выявленным из статистических данных полям из заголовков писем, и передачи информации о созданных кластерах средству создания сверток; средство создания сверток, предназначенное для выбора по крайней мере одной наиболее встречаемой комбинации групп в каждом сформированном кластере и преобразования найденной комбинации групп в свертку, которую предоставляет средству создания эвристических правил и информирует средство формирования регулярных выражений; средство формирования регулярных выражений, предназначенное для формирования регулярного выражения на основании анализа ссылок, содержащихся в письмах, которые соответствуют каждой свертке, которая была передана средству создания эвристического правила, и передачи регулярных выражений средству создания эвристических правил; средство создания эвристического правила, предназначенное для создание эвристических правил на основании по крайней мере определении соответствия между каждой полученной сверткой от средства создания сверток и регулярными выражениями, полученными от средства формирования регулярных выражений, с последующим их объединением.
В другом варианте исполнения системы под комбинацией групп понимается по крайней мере ряд полей из заголовков писем.
В еще одном варианте исполнения системы в качестве свертки понимается по крайней мере MD5, хеш или гибкий хеш от найденной наиболее встречающейся комбинации групп.
В другом варианте исполнения системы под наиболее встречаемой комбинацией понимается совокупность полей, которая объединяет наибольшее количество писем среди анализируемых.
В еще одном варианте исполнения системы для определения комбинации групп как наиболее встречаемой установлен порог от общего числа писем, по которым производится анализ статистических данных.
В другом варианте исполнения системы средство создание сверток дополнительно производит проверку сформированных сверток на коллекции сверток, относящихся к не спам письмам, где если свертка не соответствует указанной коллекции, то свертка передается средству создания эвристических правил.
В еще одном варианте исполнения системы коллекция сверток хранится в базе данных, которая взаимодействующую со средством создания сверток.
В другом варианте исполнения системы формирование регулярного выражения по ссылкам основано на: разделении каждой выявленной ссылки из статистических данных согласно установленным разделителям на сегменты; подсчете количества полученных сегментов для каждой ссылки; сравнении ссылок между собой, у которых количество сегментов одинаково, по сегментно; и объединении ссылок в регулярные выражения согласно длинам ссылок.
В еще одном варианте исполнения системы дополнительно средство создания эвристических правил формирует дополнительные условия для уменьшения ложного срабатывания.
В другом варианте исполнения системы дополнительные условия формируются на основании анализа статистических данных с учетом уже созданных основных условий.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
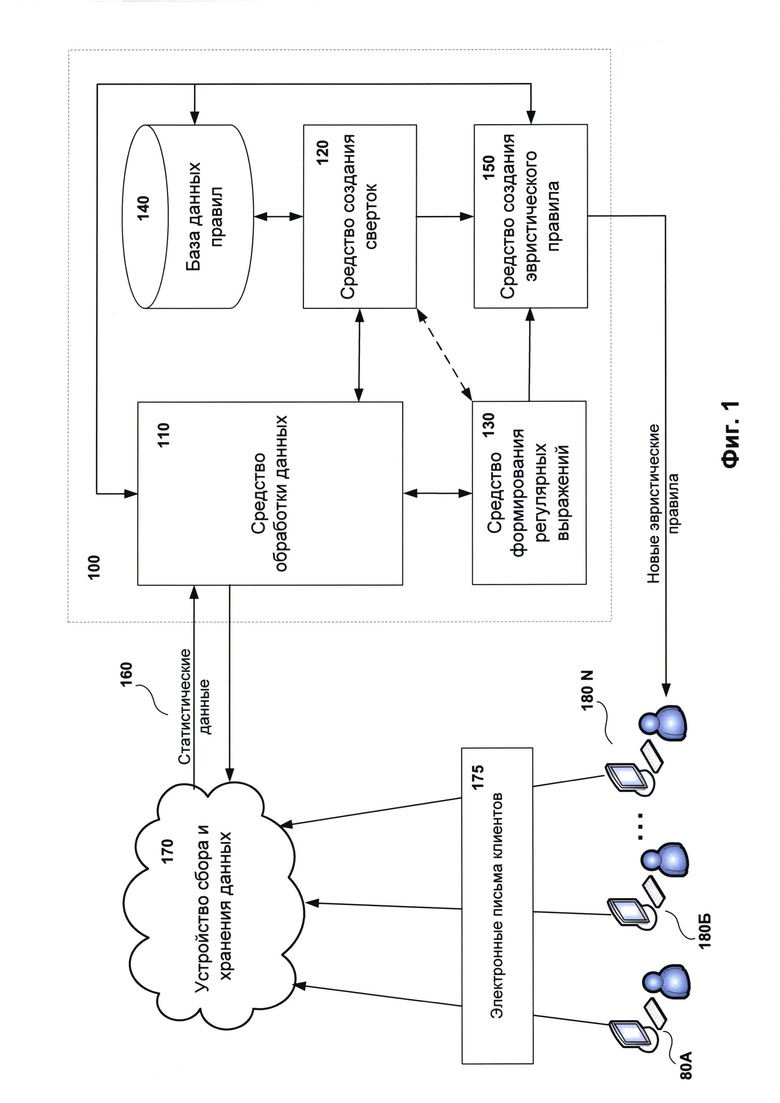
На Фиг. 1 схематично представлена система, выполненная с возможностью реализовать различные варианты осуществления настоящего изобретения.
На Фиг. 2 представлен пример получаемых данных по одному электронному письму от клиента, где данные соответствуют заголовку письма.
На Фиг. 3 представлен пример получаемых статистических данных, приведенных к определенному виду, по одному электронному письму.
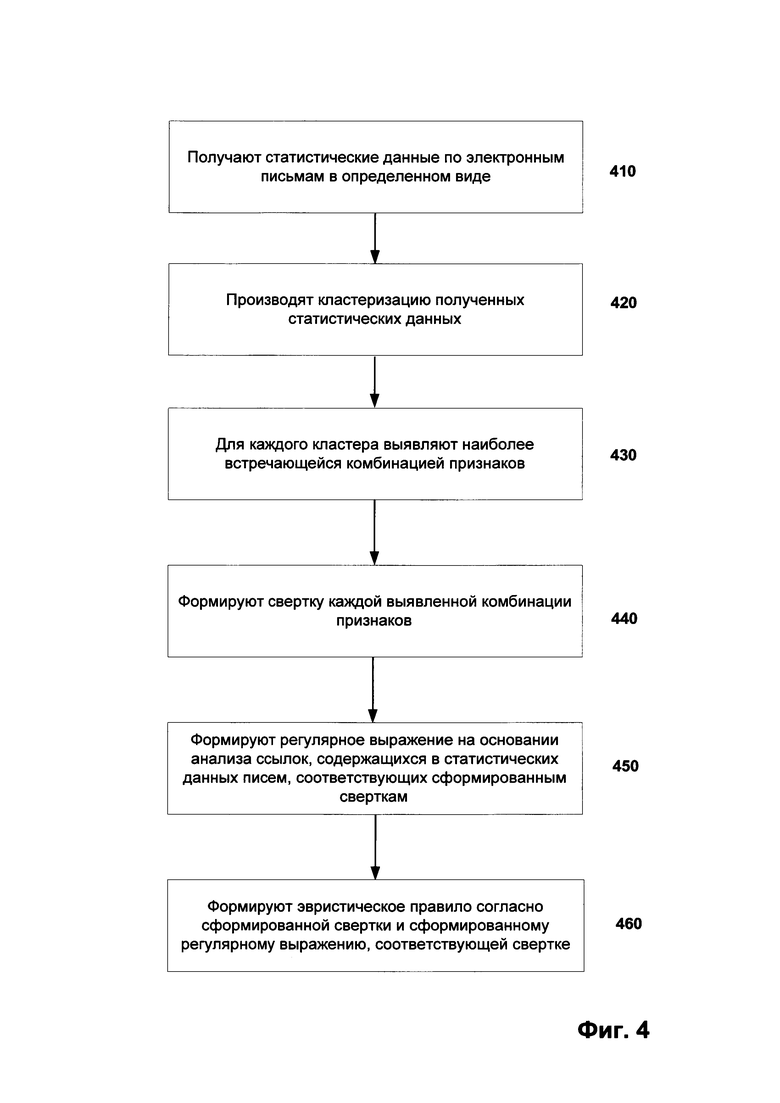
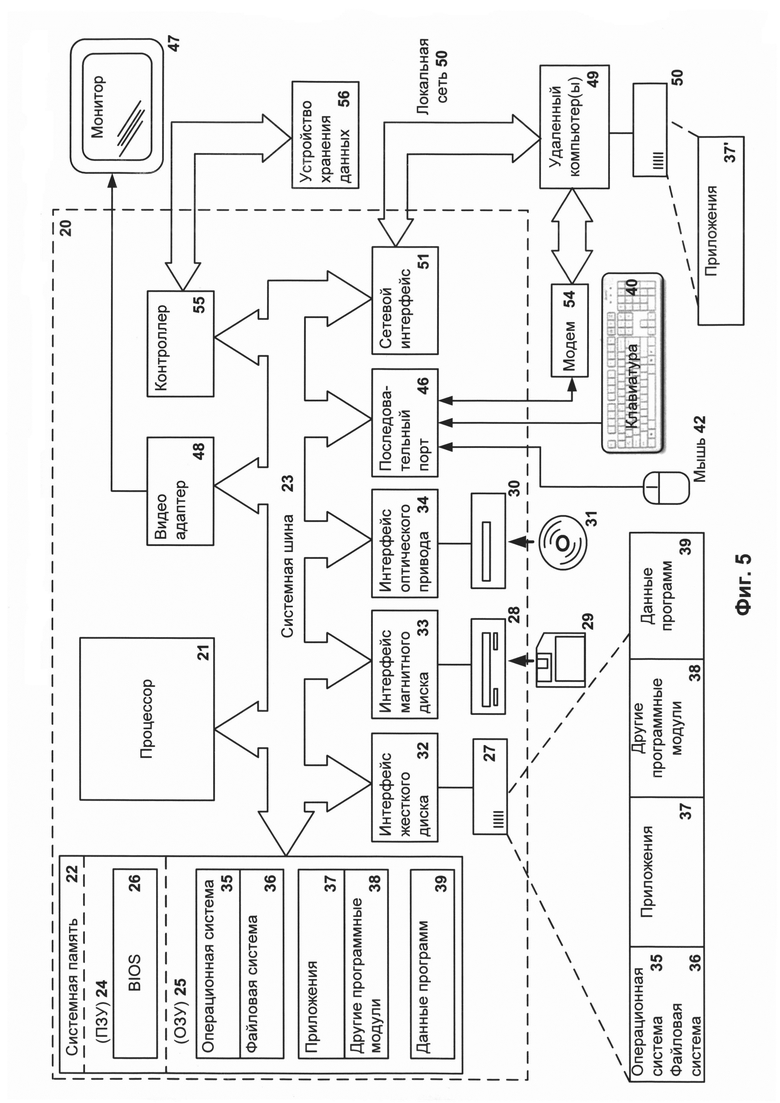
На Фиг. 4 показана блок-схема, схематично иллюстрирующая способ формирования эвристического правила для выявления писем, содержащих спам.
Фиг. 5 иллюстрирует пример компьютерной системы общего назначения, с помощью которого может быть реализовано заявленное изобретение.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Приведенное описание предназначено для помощи специалисту в области техники для исчерпывающего понимания изобретения, которое определяется только в объеме приложенной формулы.
Электронное письмо (далее также - письмо) имеет определенную структуру. Поэтому для написания письма используются специальные программы, поддерживающие структуру электронной почты. Структура письма состоит из двух частей: заголовка (от англ. header) и тела (от англ. body) письма. Заголовок в свою очередь содержит ряд полей (от англ. field), предназначенных для заполнения, при этом каждое поле определяется своим именем (заголовок поля) и значением. Под значением поля понимается какой-то вид информации. Например, для поля, которое предназначено для указания отправителя письма, в качестве имени (заголовка поля) служит «from», а значение будет иметь вид адреса электронной почты отправителя, например, username@kaspersky.com. Примерами других полей заголовка письма являются:
«Sender» - отправитель письма, обычно аналогично полю «From»;
«То» (Кому) - имя и электронный адрес получателя. Обязательное для заполнения поле;
«Subject» (Тема) - тема письма; является необязательным, но желательным для заполнения полем;
«Сс» (Копия, от англ. «CfrbonCopy») - адреса других абонентов, получающих копии сообщения;
«Date» - дата и время отправления сообщения;
«Reply-to» - электронные адреса, на которые отправляется ответ (они могут отличаться от адреса отправителя);
«Received» - различные Интернет-серверы, пересылавшие сообщение от отправителя к получателю;
«Subject» - содержание пересылаемого сообщения;
«Content-type» - формат составления передаваемого сообщения и кодировка, в которой создано письмо;
«Content-Transfer-Encoding» - способ передачи данных (7-ми, 8-ми битовое сообщение и др.);
«Message-ID» - уникальный идентификатор сообщения;
«Х-mailer» - программа передачи сообщений по электронной почте. Обычно размер письма не должен превышать некоторых значений, например,500 Кб или 2 Мб и т.д. Так, некоторые почтовые серверы не пересылают писем размером более 1 Мб.
На Фиг. 1 представлена примерная структурная схема системы формирования эвристических правил для обнаружения спам-писем 100. Система 100 содержит по крайней мере средство обработки данных 110, средство создания сверток 120, средство формирования регулярных выражений 130, базу данных правил 140 и средство создания эвристических правил 150. Система 100 формирует эвристические правила на основании обработки и анализа статистических данных 160, получаемых от устройства сбора и хранения данных 170.
Устройство сбора и хранения данных 170 в одном из вариантов реализации представляет собой «облачный» сервер, который производит сбор и хранение данных о письмах 175 клиентов 180A, 180Б…180N. Под «облачным» сервером, например, понимается техническое средство, содержащее систему Kaspersky Security Network (KSN) компании AO «Лаборатория Касперского». Под клиентами 180А, 180Б…180N понимаются по крайней мере почтовые клиенты пользователей, установленные на компьютерах пользователей, или почтовые серверы. Стоит отметить, что устройство 170 во время проведения сбора данных о письмах клиентов не собирает информацию, относящуюся к пользователю, или обезличивает ее, так чтобы информация не идентифицировалась. Такой информацией являются сведения из тела письма, например, текстовые сообщения пользователей, и из заголовка письма, например, электронный адрес. Под обезличиванием понимается преобразование информации, например, с помощью хеш-функций. Для этого каждый клиент 180 содержит агент (на показан на Фиг. 1), который перед отправкой устройству сбора и хранения данных 170 письма преобразовывает его. Пример преобразованной и передаваемой устройству 170 части информации по одному письму представлен Фиг. 2. Заголовок письма содержит ряд технических данных и поля заголовка, такие как: from, То, СС, Subject Message-ID и Content-Type, а также скрытые значения указанных полей. Хранение и передача системе 100 информации о собранных письмах производится в виде статистических данных 160. Устройство 170 формирует статистические данные по каждому письму еще одним преобразованием собираемых данных от клиентов. В одном из вариантов реализации статистические данные 160 формируются на основании преобразования собираемых писем клиентов с помощью лексического анализа. Пример такого преобразования представлен на Фиг. 3. На Фиг. 3 представлена информация, соответствующая заголовку одного электронного письма, при этом различные поля заголовка письма преобразованы в обезличенный вид и не содержат личной или персональной информации клиентов 180. Стоит отметить, что тело письма также будет преобразовано, и статистическая информация по телу письма будет содержать только сведения о содержащихся URL-адресах, различных шинглах (от англ. shingles), которые были сформированы на основании данных письма, и категории, присваиваемой письму. Под категорией понимается созданная внутренняя классификация писем, которая, например, содержит такие категории как: спам, не спам, возможно спам, возможно спам с элементами фишинга, возможно спам с подозрительными ссылками и так далее.
Средство обработки данных 110 получает указанные статистические данные 160 по электронным письмам и производит их первичный анализ. Первичный анализ заключается в выявлении различных признаков в каждом письме, где признаками по крайней мере являются: последовательность заголовков полей заголовка письма (на Фиг. 3 представлен как выделенный текст), URL-адреса (от англ. Uniform Resource Locator) из тела письма, различные идентификаторы (ID) и свертки (хеши, md5) от данных электронного письма и тому подобное. Далее средство 110 производит кластеризацию полученных статистических данных 160, во время которой формирует по крайней мере один кластер на основании выявленных данных. Каждый сформированный кластер содержит сгруппированные по определенным типам данных письма. Такими типами данных (признаками) являются по крайней мере заголовки полей и их значения.
В одном из вариантов реализации кластеризация статистических данных 160 производится на основании алгоритма кластеризации данных «Density-based spatial clustering of applications with noise (DBSCAN)».
В еще одном варианте реализации группирование по определенным типам данных писем заключается в формировании кластера по заголовкам полей, содержащихся в заголовке каждого письма. Так, например, группами по крайней мере для одного кластера являются следующие заголовки полей электронных писем: "hdr_seq2", "boundary_type", "mailer_niame", "msgid_type", "urlsQty", "content_type", "attach". Таким образом, электронное письмо, представленное в виде статистических данных на Фиг. 3, будет отнесено по крайней мере к одному кластеру, сформированному на основании следующих полей: "hdr_seq2", "from", "to", "subject", "date", "content-type", "x-mailer".
После формирования кластеров средство создания свертки 120 производит выбор по крайней мере одной наиболее встречаемой комбинации групп в каждом сформированном кластере и преобразует найденную комбинацию групп в свертку. Под комбинацией групп понимается по крайней мере ряд значений полей из заголовков писем. В качестве свертки понимается по крайней мере MD5, хеш или гибкий хеш от найденной комбинации групп. Под наиболее встречаемой комбинацией понимается совокупность полей, которая объединяет наибольшее количество писем среди анализируемых. При этом может быть задан порог количества писем, при преодолении которого каждая комбинация групп будет считаться как наиболее встречаемая. В этом случае будут далее проанализированы все комбинации групп, которые преодолели порог. Например, порог может быть установлен как 80% от общего числа писем. Стоит отметить, что в случае, когда ни одна комбинация групп не достигла указанного порога, будет выбрана комбинация групп, которая является наиболее близкой к установленному порогу.
В еще одном варианте реализации средство 110 может производить приоритизацию совокупностей групп, когда было сформировано более одной совокупности. Приоритизация позволяет в первую очередь сформировать эвристическое правило для часто встречаемых писем, содержащих спам. В качестве параметра приоритизации является, например, информация о присвоенных категориях писем, по которым получены статистические данные 160, или любая дополнительная информация, которая позволит оценить важность писем.
Рассмотрим пример поиска и формирования свертки на двух электронных письмах.
Предположим, что одно письмо (M1) содержит последовательность полей заголовка письма, состоящую из шести полей: F1, F2, F8, F9, и F20, где F - соответствует заголовку поля, а число указывает на тип поля в определенной классификации. Классификация полей за рамками изобретения и является входным параметром. Например, F1 соответствует полю "from", а F2 - "to", F8 - "x-mailer", F9 - "сс" и F20 - "message-id". Другое письмо (М2) содержит следующие поля: F1, F3, F5, F8, F9, F15 и F20. Для каждого письма свертка является уникальной и формируется на основании каждой последовательности. Например, для последовательности F1F2F8F9F20 письма M1 формируется свертка (хеш) - md5 (from:to:x-mailer:message-id:cc), которая будет иметь следующий вид: "c72c4c829a3863d1056634d3a306871f".
В одном из вариантов реализации при кластеризации N-ого количества писем, например, сотен тысяч, возможно формирование сверток от других сверток, которые были в свою очередь сформированы от наиболее встречаемых групп, с целью обхвата наибольшего количества анализируемых писем. Например, было проанализировано 10000 писем, из которых 2000 писем были объединены в группу 1 на основании следующих значений полей: F1:A1, F2:A2, F8:A8, F11:A11 (т.е. эти заголовки встречаются во всех 2000 писем) и 7500 писем были объединены в группу 2 на основании следующих заголовков полей: F1:A1, F5:A5, F9:A9. Соответственно, для группы 1 была сформирована свертка «hash 1», а для группы 2 - свертка «hash 2». После чего была сформирована еще одна свертка путем объединения двух созданных сверток (хешей), где указанная свертка является гибким хешем.
В еще одном варианте реализации изобретения, когда ни одна совокупность групп кластера не достигла указанного порога, возможно объединение нескольких совокупностей для преодоления установленного порога. Например, будут объединены две или три свертки через знак «или». В этом случае далее по тексту такое объединение также будет соответствовать признаку «свертка».
Далее средство 120 производит первичную проверку каждой выбранной свертки на коллекции сверток, принадлежащих к письмам, не содержащим спам, т.е. легитимным письмам. Стоит отметить, что первичная проверка может являться как одним из основных этапов формирования эвристического правила, так и необязательным, а дополнительным. Коллекция таких сверток хранится в базе данных 140. В случае совпадения выбранной свертки со сверткой из упомянутой коллекции выбранная свертка удаляется из дальнейшего процесса формирования эвристического правила. В противном случае, если выбранная свертка не совпала ни с одной сверткой из упомянутой коллекции, то свертка передается средству создания эвристического правила 150, где свертка будет являться одним из обязательных условий, и средство 120 информирует средство формирования регулярного выражения 130 о передаче указанных данных. Если же первичная проверка не производилась, то считается что каждая свертка не совпадает ни с одной сверткой из упомянутой коллекции.
В одном из вариантов реализации база данных 140 содержит по крайней мере набор сверток, соответствующий легитимным письмам, и набор сверток, соответствующий письмам, содержащих спам, а также набор гибких сверток для тех и других типов писем.
Средство формирования регулярного выражения 130 производит формирование регулярного выражения на основании анализа ссылок, содержащихся в электронных письмах, которые соответствуют каждой свертке, которая была передана средству создания эвристического правила 150. Для этого из полученных статистических данных каждого упомянутого письма выявляются данные, содержащие информацию о ссылках (URL адресах). URL-адрес - от англ. Uniform Resource Locator, уникальный идентификатор ресурса, расположенного в информационной сети, например сети Интернет. Регулярное выражение (англ. regular expressions) является еще одним обязательным условий для формирования эвристического правила Регулярное выражение представляет собой строку, задающую правило поиска указанных ссылок.
В одном из вариантов реализации средство 130 формирует регулярное выражение следующим образом.
На первом этапе средство 130 разделяет каждую ссылку, выявленную и: статистических данных, на сегменты согласно разделителям, содержащимся в ссылке. Под разделителями понимаются следующие знаки: деление - '/', точка - '.' и символ '@'. Дальше средство 130 определяет длину каждой ссылки путем подсчета количества сегментов, полученных после указанного разделения. Например, для ссылки (URL-адреса) http://app.ingos.ru/email/road_rules/?utm_source=newsletter&utm_medium=email&utm_campaign=digest_02_2019_feb&utm_content=road_rules&email=username@kaspersky.com будет произведено деление на восемь сегментов, где первый сегмент - «арр», второй сегмент - «ingos», третий сегмент - «ru», четвертый сегмент - «email», пятый сегмент - «road_rules», шестой сегмент - «?utm_source=newsletter&utm_medium=email&utm_campaign=digest_02_2019_feb&utm_content=road_rules&email=username», седьмой сегмент - «kaspersky» и восьмой сегмент - «com». Таким образом, для указанной ссылки длина равна восьми.
На втором этапе средство 130 сравнивает ссылки одинаковой длины и: различных писем между собой по сегментам для формирования регулярных выражений, соответствующих ссылкам определенной длины. Стоит отметить что письма соответствуют одному и тому же кластеру, из которого была сформирована ранее свертка средством 120. Сегменты сравниваются согласно их порядку, т.е. при сравнении ссылок одинаковой длины сравниваются первый сегмент первой ссылке из одного письма с первым сегментом первой ссылки другого письма и так далее. Если сегменты совпадают, то набор символов регулярного выражения для такого сегмента будет полностью соответствовать указанному сегменту в неизменном виде. В противном случае, если сегменты различны, сегмент регулярного выражения будет иметь вид [х]+, где х - диапазон, который содержит символы, которые содержатся в обоих сегментах. Таким образом, при сравнении ссылок одинаковой длины различных писем в результате получается N-oe количество регулярных выражений.
На третьем этапе средство 130 сравнивает регулярные выражения между собой. Сравнение производится так же, как и на предыдущем этапе, а именно, сравниваются только регулярные выражения, соответствующие ссылкам одинаковой длины, по принципу, чем более общее регулярное выражение, тем больший приоритет оно имеет. Таким образом, менее общее регулярное выражение удаляется из дальнейшего анализа. В итоге, формируется список, содержащий по одному регулярному выражению, соответствующее ссылкам на каждую длину ссылок.
После формирования списка регулярных выражений средство 130 передает его средству создания эвристических правил 150.
Средство создания эвристических правил 150 производит создание эвристических правил на основании полученных данных от средства создания сверток 120 и средства формирования регулярных выражений 130. Средство 150 определяет соответствие между каждой полученной сверткой от средства 120 и регулярными выражениями, полученными от средства 150. После определения их соответствия объединяет их в эвристическое правило вида:
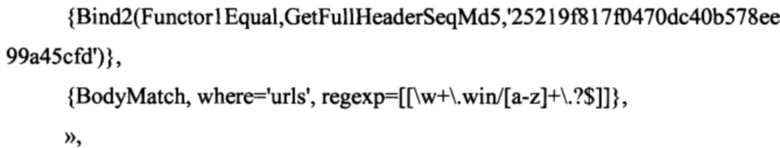
где каждое правило содержит по крайней мере два указанных обязательных условия, при этом первое соответствует свертке от последовательности полей заголовка письма, а второе - регулярному выражению, соответствующему ссылкам по определенной длине.
В одном из вариантов реализации средство 150 при создании эвристического правила дополнительно к указанным условиям формирует дополнительные условия. Дополнительные условия формируются также на основании статистических данных 160 с учетом уже созданных основных условий. Так, например, одно из дополнительных условий может быть создано на основании анализа по крайней мере одного поля заголовка, которое содержится в последовательности полей заголовка письма, на основании которой сформирована свертка для первого условия эвристического правила. Другое дополнительное условие может быть создано на основании анализа полученных данных из тела письма, например, URL-адресов. Формирование каждого дополнительного условия производится аналогично формированию первого условия, а именно, свертке. Для этого средство 150 взаимодействует со средством 110. Так, будет выбран один тип поля заголовка письма, для которого производится группирование по кластерам согласно значениям, указанным в соответствующем поле из анализируемых писем. Например, если письмо содержит поле "Content-Type" или поле "X-mailer", то на основании анализа значений каждого поля, указанных в анализируемых письмах, производится группирование, позволяющее сформировать при создании эвристического правила дополнительные условия оценки письма на наличие спама (пример представлен ниже). В другом варианте формирования дополнительного условия может быть произведен анализ тела письма. Например, анализ заключается в определении количества в теле каждого письма содержащихся ссылок (URL-адресов). Так производится подсчет максимального и минимального количества ссылок в анализируемых письмах, которые соответствуют кластеру, из которого сформирована свертка для обязательного условия. Согласно подсчету, формируется дополнительное условие для эвристического правила. Таким образом, формирование дополнительных условий позволяет минимизировать вероятность ложного срабатывания во время исполнения созданного эвристического правила.
В предпочтительном варианте реализации выбор признаков для формирования дополнительных условий производится таким образом, чтобы информация о них содержалась во всех письмах, соответствующих свертке. Предположим, что на основании признаков из указанных выше примеров были сформированы дополнительные условия для эвристического правила. Тогда эвристическое правило может иметь вид:

где первое условие говорит о том, что свертка от последовательности полей заголовка письма должна соответствовать указанной Md5, второе условие говорит о том, что письмо должно содержать один URL-адрес, третье условие - говорит о том, что в поле «Content-type» отсутствует boundary, четвертое условие говорит о том, что в письме отсутствует поле «Х-mailer», а пятое условие говорит о том, что содержащийся в письме URL-адрес подпадает под указанное регулярное выражение.
Таким образом, средство 150 сформирует по одному правилу для каждого ранее созданного регулярного выражения.
После создания эвристических правил средство 150 дополнительно может произвести их проверку на дополнительных коллекциях легитимных писем. Если эвристическое правило не сработает на проверяемых коллекциях, то оно будет направлено клиентам 180. В противном случае, если эвристическое правило сработает, то оно будет удалено.
В еще одном варианте реализации средство 150 производит оценку созданных правил с целью выявления по крайней мере одного эвристического правила, которое покрывает наибольшее количество писем из кластера. Оценка основана на сравнении созданных правил между собой согласно следующему подходу:
- если правила описаны одним и тем же регулярным выражением, то условия правил объединяются в одно правило через знак «или»;
- если правила описаны разными регулярными выражениями, но при этом другие условия совпадают, вплоть до одного, то определяется наиболее предпочтительное регулярное выражение, где наиболее предпочтительным регулярным выражением будет являться то, которое будет удовлетворять критерию - покрытие N% писем в кластере и более строгая форма регулярного выражения, при этом размер покрытия является наиболее важным критерием. Например, если правило с более строгим регулярным выражением описывает меньше, чем 90% писем от другого правила, то это правило станет менее предпочтительным, чем другое правило и соответственно будет выбрано правила с менее строгим регулярным выражением.
Таким образом, менее предпочтительное правило удаляется, а более предпочтительное правило сравнивается с остальными, что приводит к тому, что остается по крайней мере одно эвристическое правило, которое наиболее полно описывает большую часть кластера, на основании которого сформирована свертка (хеш) в правиле средством 120 и само правило. После чего может быть произведена проверка правила на коллекции легитимных писем.
Стоит отметить, что средство 120 и средство 130 производят обмен информацией во время выполнения назначений в случае необходимости, например, для передачи данных о готовых свертках для кластеров и передачи данных, связанных с информацией для формирования регулярных выражений.
В одном из вариантов реализации система 100 является частью устройства сбора и хранения данных 170 и, соответственно, производит анализ статистических данных и формирования эвристических правил в рамка устройства 170.
В еще одном варианте реализации система 100 производит автоматическое выявление события, которое указывает на потребность создания эвристического правила для выявления рассылаемых спам-писем. Такими событиями являются по крайней мере события, указывающие на сбор определенного объема статистических данных 160, определение ложного срабатывания эвристического правила на устройствах клиентов 180, необходимость пересчета одного из ранее созданных кластеров и другие. Для этого система отслеживает наличие таких событий от устройств клиентов 180 самостоятельно, либо через устройство сбора и хранения данных 170. Далее система 100 либо запрашивает необходимые данные для создания эвристических правил, либо получает данные параллельно с выявленным событием.
На Фиг. 4 представлен способ формирования эвристических правил для выявления спам-писем. Способ реализуется с помощью средств системы 100. Предположим, что система 100 получило событие, которое указывает на потребность создания эвристического правила для поиска и выявления спам-писем.
Для этого на этапе 410 с помощью средства 110 получают статистические данные 160 от устройства хранения данных 170. Статистические данные 160 представлены в определенном виде, в частности содержат информацию об электронном письме в обезличенном виде, т.е. так чтобы информация клиента 180 и о клиенте не была определена. Пример таких статистических данных для одного письма представлен на Фиг. 3. На Фиг. 3 представлены данные, содержащие информацию о письме, в частности о из заголовка письма, при этом часть данных обезличены и представлены в виде, например, хешей.
На этапе 420 с помощью средства обработки данных 110 производят кластеризацию полученных статистических данных, во время которой формируют по крайней мере один кластер. Каждый кластер содержит сгруппированные по определенным типам данные писем. Одним из типов данных, согласно которому формируются кластеры, являются заголовки полей, соответствующие заголовку каждого письма. Для этого на этапе 420 производится анализ полученных статистических данных, во время которого выявляется по крайней мере последовательность заголовков полей для каждого письма. После чего формируются кластеры согласно полям из выявленных последовательностей. Для формирования кластеров используется наиболее предпочтительный алгоритм кластеризации данных, который выбирает опытным путем, например, алгоритм DBSCAN. Пример формирования кластеров представлен при описании Фиг. 1.
На этапе 430 с помощью средства 120 выбирают по крайней мере одну наиболее встречаемую комбинацию групп в каждом сформированном кластере и преобразуют найденную комбинацию в свертку на этапе 440. Под комбинацией групп понимается по крайней мере ряд наиболее встречаемых полей заголовка из анализируемых писем. Под наиболее встречаемой комбинацией понимается совокупность полей, которая объединяет наибольшее количество писем среди анализируемых. В качестве свертки понимается по крайней мере MD5, хеш или гибкий хеш от найденной комбинации групп. В частном случае для определения наиболее встречаемой комбинации групп может служить заданный порог от общего количества анализируемых чисел.
В частном случае реализации на дополнительном этапе 445 (не представлен на Фиг. 4) производят первичную проверку каждой свертки на коллекции сверток, содержащей только свертки по легитимным (не спам) письмам, при этом в случае совпадения сформированной свертки и свертки из коллекции сформированная свертка удаляется из дальнейшего процесса формирования эвристического правила. В противном случае, если свертка не соответствует ни одной свертки из коллекции сверток, то переходя к этапу 440.
На этапе 450 с помощью средства 130 производят формирование регулярных выражений на основании анализа ссылок, содержащихся в статистических данных писем, которые соответствуют сформированным на этапе 440 сверткам. Принцип формирования регулярных выражений раскрывается при описании Фиг. 1.
На этапе 460 с помощью средства 150 создают по крайней мере одно эвристическое правило на основании каждой сформированной свертки и регулярных выражений. Каждое эвристическое правило формируется путем объединения по крайней мере одной свертки и регулярного выражения, соответствующего указанной свертки, которые были сформированы ранее. Соответствие определяется с помощью статистических данных, на основании которых были сформированы свертка и регулярное выражение. Таким образом, будет сформировано по одному эвристическому правилу для каждого ранее созданного регулярного выражения. Далее произведут оценку созданных правил с целью выявления по крайней мере одного эвристического правила, которое объединяет наибольшее количество писем, соответствующих кластеру, для которого были сформированы эвристические правила. Оценку производят путем сравнения правил между собой. В результате чего останется одно эвристическое правило, которое наиболее полно описывает кластер.
В частном случае реализации дополнительно эвристическое правило может содержать и дополнительные условия, которые также формируются на основании полученных статистических данных 160 с учетом уже созданных основных условий.
В частном случае реализации дополнительно эвристическое правило будет проверено на коллекции легитимных писем и, в случае несоответствия ни одному письму, эвристическое правило направят клиентам 180 с помощью системы 100.
Фиг. 5 представляет пример компьютерной системы 20 общего назначения, которая может быть использована как компьютер клиента (например, персональный компьютер) или сервера. Компьютерная система 20 содержит центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами компьютерной системы 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Компьютерная система 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных компьютерной системы 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Компьютерная система 20 способна работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа компьютерной системы 20, представленного на Фиг. 5. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях компьютерная система (персональный компьютер) 20 подключена к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обнаружения мошеннического письма, относящегося к категории внутренних ВЕС-атак | 2021 |
|
RU2766539C1 |
| Система и способ классификации писем электронной почты | 2024 |
|
RU2828611C1 |
| Способ кластеризации электронных писем, являющихся спамом | 2021 |
|
RU2769633C1 |
| Способ классификации писем электронной почты и система, его реализующая | 2024 |
|
RU2828610C1 |
| Система утилизации спама | 2021 |
|
RU2787308C1 |
| СИСТЕМА И СПОСОБ ОПРЕДЕЛЕНИЯ РЕЙТИНГА ЭЛЕКТРОННЫХ СООБЩЕНИЙ ДЛЯ БОРЬБЫ СО СПАМОМ | 2013 |
|
RU2541123C1 |
| Способ признания письма спамом через анти-спам карантин | 2019 |
|
RU2750643C2 |
| СИСТЕМА И СПОСОБ ИСКЛЮЧЕНИЯ ШИНГЛОВ ОТ НЕЗНАЧИМЫХ ЧАСТЕЙ ИЗ СООБЩЕНИЯ ПРИ ФИЛЬТРАЦИИ СПАМА | 2013 |
|
RU2583713C2 |
| Система и способ определения похожих файлов | 2015 |
|
RU2614561C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |


Изобретение относится к средствам формирования эвристических правил для поиска и обнаружения спам-писем на основании анализа статистических данных о получаемых электронных письмах клиентов. Технический результат заключается в повышении точности обнаружения спама. Статистические данные предварительно, до их анализа, преобразуются в определенный вид, который представляет данные для анализа в обезличенном виде. Таким образом, сообщения клиентов, содержащихся в письме, не используются в анализе, что обеспечивает конфиденциальность информации. Особенность заявленного изобретения заключается в формировании эвристических правил на основании анализа последовательности расположения полей в заголовках писем и создании регулярных выражений для ссылок, содержащихся в указанных письмах. 2 н. и 18 з.п. ф-лы, 5 ил.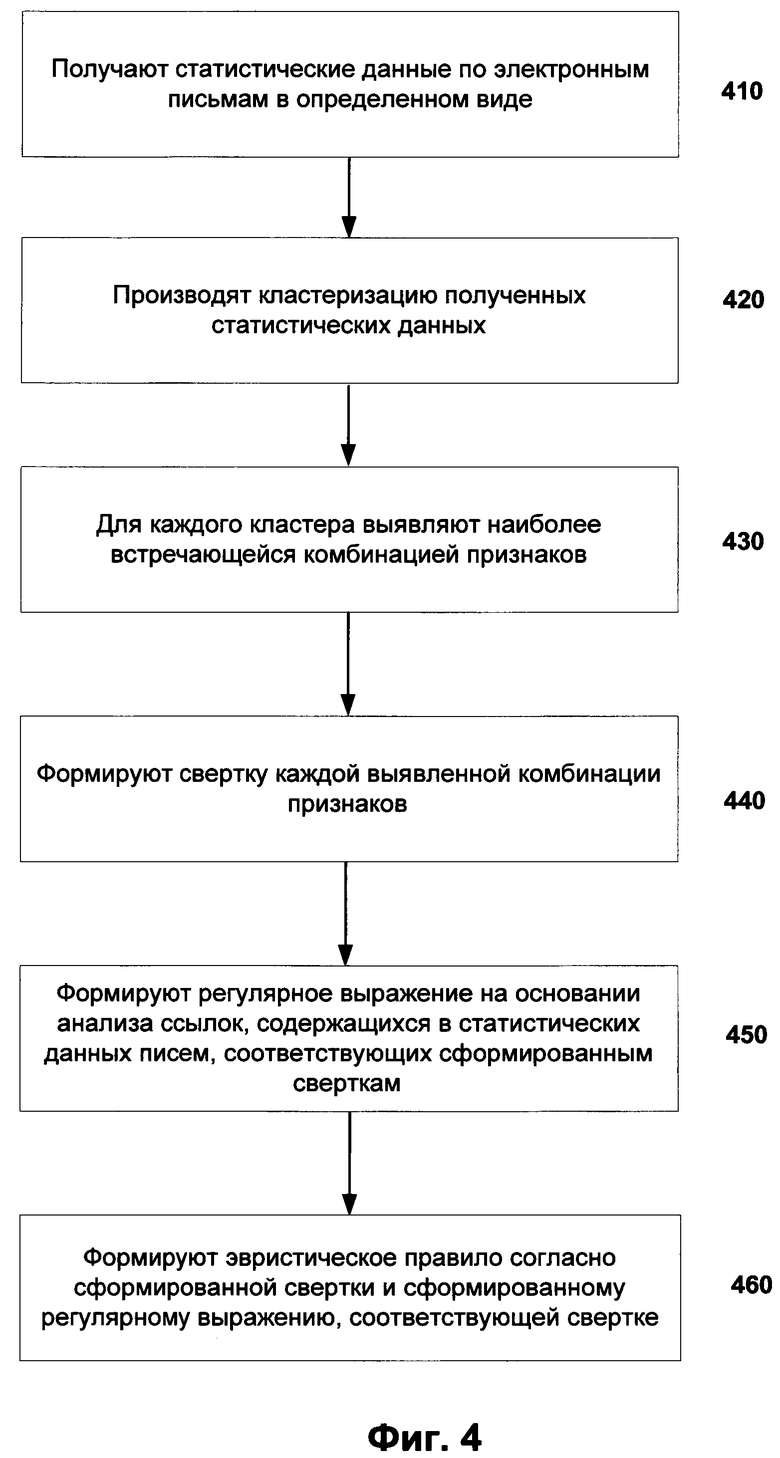
1. Способ создания эвристического правила для выявления спам-писем, который содержит этапы, на которых:
а. получают статистические данные по письмам клиентов, при этом статистические данные содержат по крайне мере информацию о последовательности полей в заголовке каждого письма и наличии ссылок в теле каждого письма;
б. производят кластеризацию полученных статистических данных, где каждый кластер содержит сгруппированные по определенным типам данные, при этом формируют по крайней мере один кластер, который содержит сгруппированные по полям данные согласно полям из заголовков писем;
в. выбирают по крайней мере одну наиболее встречаемую комбинацию групп в каждом сформированном кластере, которую преобразовывают в свертку, при этом по крайней мере одну наиболее встречаемую комбинацию группу формируют на основании информации о полях из заголовков писем;
г. формируют по крайней мере одно регулярное выражение, объединяющее информацию о ссылках, содержащихся в письмах, которые соответствуют каждой сформированной свертке;
д. создают эвристическое правило на основании объединения по крайней мере сформированной свертки, соответствующей последовательности полей в заголовке каждого письма, и одного регулярного выражения, соответствующего указанной свертке.
2. Способ по п. 1, в котором дополнительно производят проверку каждой сформированной свертки на коллекции сверток, содержащей только свертки по легитимным письмам, при этом в случае совпадения сформированной свертки и свертки из коллекции сформированная свертка удаляется.
3. Способ по п. 1, в котором при создании эвристического правила устанавливают дополнительные условия на основании данных из статистически данных и связанных с письмами, на основании которых сформированы свертка и регулярное выражение.
4. Способ по п. 1, в котором получаемые статистические данные были получены на основании лексического анализа писем.
5. Способ по п. 1, в котором под наиболее встречаемой комбинацией понимается совокупность полей, которая объединяет наибольшее количество писем среди анализируемых.
6. Способ по п. 1, в котором для определения комбинации групп как наиболее встречаемой установлен порог от общего числа писем, по которым производится анализ статистических данных.
7. Способ по п. 6, в котором наиболее встречаемой комбинацией групп является каждая комбинация, которая объединяет не менее 90% писем, по которым были получены статистические данные.
8. Способ по п. 1, в котором в качестве свертки понимается по крайней мере MD5, хеш или гибкий хеш от найденной наиболее встречающейся комбинации групп.
9. Способ по п. 1, в котором формируют регулярные выражения по ссылкам согласно следующему принципу:
а. разделяют каждую выявленную ссылку из статистических данных согласно установленным разделителям на сегменты,
б. подсчитывают количество полученных сегментов для каждой ссылки,
в. сравнивают ссылки между собой, у которых количество сегментов одинаково, посегментно, и
г. объединяют ссылки в регулярные выражения согласно длинам ссылок, при этом если сегменты одинаковые, то оставляют в неизмененном виде, если сегменты отличаются, то преобразуют в вид, в котором остаются только одинаковые значения.
10. Способ по п. 1, в котором кластеризация производится на основании алгоритма кластеризации данных «Density-based spatial clustering of applications with noise».
11. Система создания эвристических правил для выявления спам-писем, которая содержит:
а. средство обработки данных, предназначенное для:
i. получения статистических данных по письмам клиентов в определенном виде;
ii. анализа полученных статистических данных, во время которого производит кластеризацию указанных данных, при этом по крайней мере один кластер содержит сгруппированные данные согласно выявленным из статистических данных полям из заголовков писем;
iii. передачи информации о созданных кластерах средству создания сверток;
б. средство создания сверток, предназначенное для выбора по крайней мере одной наиболее встречаемой комбинации групп в каждом сформированном кластере и преобразования найденной комбинации групп в свертку, которую предоставляет средству создания эвристических правил и информирует средство формирования регулярных выражений;
в. средство формирования регулярных выражений, предназначенное для формирования регулярного выражения на основании анализа ссылок, содержащихся в письмах, которые соответствуют каждой свертке, которая была передана средству создания эвристического правила, и передачи регулярных выражений средству создания эвристических правил;
г. средство создания эвристического правила, предназначенное для создания эвристических правил на основании по крайней мере определения соответствия между каждой полученной сверткой от средства создания сверток и регулярными выражениями, полученными от средства формирования регулярных выражений, с последующим их объединением.
12. Система по п. 11, в которой под комбинацией групп понимается по крайней мере ряд полей из заголовков писем.
13. Система по п. 11, в которой в качестве свертки понимается по крайней мере MD5, хеш или гибкий хеш от найденной наиболее встречающейся комбинации групп.
14. Система по п. 11, в которой под наиболее встречаемой комбинацией понимается совокупность полей, которая объединяет наибольшее количество писем среди анализируемых.
15. Система по п. 11, в которой для определения комбинации групп как наиболее встречаемой установлен порог от общего числа писем, по которым производится анализ статистических данных.
16. Система по п. 15, в которой средство создание сверток дополнительно производит проверку сформированных сверток на коллекции сверток, относящихся к не спам письмам, где если свертка не соответствует указанной коллекции, то свертка передается средству создания эвристических правил.
17. Система по п. 16, в которой коллекция сверток хранится в базе данных, которая взаимодействует со средством создания сверток.
18. Система по п. 11, в которой формирование регулярного выражения по ссылкам основано на:
а. разделении каждой выявленной ссылки из статистических данных согласно установленным разделителям на сегменты,
б. подсчете количества полученных сегментов для каждой ссылки,
в. сравнении ссылок между собой, у которых количество сегментов одинаково, посегментно, и
г. объединении ссылок в регулярные выражения согласно длинам ссылок.
19. Система по п. 11, в которой дополнительно средство создания эвристических правил формирует дополнительные условия для уменьшения ложного срабатывания.
20. Система по п. 19, в которой дополнительные условия формируются на основании анализа статистических данных с учетом уже созданных основных условий.
| US 7899866 B1, 01.03.2011 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Передвижная обжигательная камера для обжига кирпича | 1949 |
|
SU85247A1 |
| СИСТЕМА И СПОСОБ ИСКЛЮЧЕНИЯ ШИНГЛОВ ОТ НЕЗНАЧИМЫХ ЧАСТЕЙ ИЗ СООБЩЕНИЯ ПРИ ФИЛЬТРАЦИИ СПАМА | 2013 |
|
RU2583713C2 |

