Область техники
Изобретение относится к средствам информационной безопасности, а более конкретно к способам выявления схожих электронных писем с использованием обученного спам-классификатора.
Уровень техники
Спам - массовая рассылка информации рекламного характера либо иного рода сообщений без согласия получателей. Лица, рассылающие подобные сообщения, получают списки адресатов спама всеми доступными способами, например, из краденых баз, открытых источников или просто случайным подбором. Для рассылки спама в настоящий момент активно используются все возможные технические средства, в том числе прокси-серверы, бесплатные почтовые серверы, допускающие автоматизацию отправки писем по электронной почте, а также зараженные компьютерные системы пользователей, из которых формируются бот-сети.
Электронные письма, содержащие спам, являются серьезной проблемой в современном мире, так как объем спама уже достигает 70-90% от общего объема почтового трафика. Такое количество спама, отправленного по компьютерным сетям, вызывает существенные неудобства для пользователей электронной почты. В частности, спам вызывает ухудшение пропускной способности сетей, трату ресурсов системы обмена сообщениями и увеличение времени обработки электронных писем как пользователями, так и компьютерами. Кроме того, упомянутый объем спама также снижает производительность серверов (как почтовых, так и магистральных, передающих трафик) и приводит к финансовым потерям (так называемая «ширина» канала оплачивается в зависимости от ее размера). Таким образом, необходимо непрерывно бороться со спамом.
Существуют различные подходы обнаружения спама: сигнатурный, эвристический и с использованием методов машинного обучения.
В сигнатурном подходе используются ловушки для спама. Письмо, попавшее в такую ловушку, автоматически считается спамом. Письмо разбирается на составные части, из подмножеств которых формируются сигнатуры. Сигнатуры позволяют детектировать на компьютерных системах пользователей и крупных почтовых серверах то, что было обнаружено в ловушках для спама. Плюсом такого подхода является практически нулевая вероятность возникновения ошибки первого рода, когда легитимное письмо определяется как спам. При эвристическом анализе эвристических сигнатур как таковых нет, но есть набор правил для выявления спама. Минусом упомянутых подходов обнаружения спама является их недостаточная обобщающая сила, следствием чего являются пропуски спам писем, то есть возникновение ошибки второго рода. При этом вклад человека в спам-защиту при сигнатурном и эвристическом анализе очень велик, так как автоматика без корректировки аналитиком зачастую формирует недостаточно общие детектирующие сигнатуры и правила. Более того, данные подходы имеют временной лаг. К примеру, между событием, когда письмо попадет в ловушку, и выпуском новой сигнатуры может пройти от нескольких минут до нескольких суток, в связи с чем существует проблема пропуска спам-писем, относящихся к «свежим» спам-рассылкам.
В рамках методов машинного обучения используется коллекция спам писем против коллекции не спам писем. Письма разбираются на части, из которых исключаются те части, что встречаются в обеих коллекциях. Остальные же части используются для обучения классификатора, что позволяет обнаруживать не только письма из спам-ловушек. Плюсом такого подхода является высокая обобщающая способность, что позволяет добиться минимального количества пропусков спам писем. Однако минусом данного подхода является высокая обобщающая способность, что позволяет добиться минимального количества пропусков спам писем. Однако минусом данного подхода является высокая вероятность возникновения ложных срабатываний.
Существуют решения, основанные на обобщении сигнатурного вердикта при помощи методов машинного обучения. К примеру, в публикации RU2019122433 описывается метод машинного обучения, в котором нейронная сеть на основании сигнатур, сформированных по данным в электронных письмах, вычисляет вероятность того, что письмо является спамом.
Однако зачастую для борьбы с распространением спама требуется не только определение вероятности спама. Также необходима кластеризация (выявление схожести) спам-писем для решения задач проактивной защиты от спама, выявления бот-сетей, посредством которых распространяется спам, создания более общих правил детектирования спама, а также удаления избыточных правил детектирования спама (например, когда для детектирования кластера спам-писем используется более одного правила детектирования).
Настоящее изобретение позволяет использовать обученную нейронную сеть, вычисляющую вероятность спама, для кластеризации спам-писем.
Раскрытие изобретения
Заявленное изобретение предназначено для кластеризации электронных писем.
Технический результат настоящего изобретения заключается в повышении точности, снижении погрешности вычислений и, соответственно, снижении ошибок кластеризации электронных писем с одновременным уменьшением корреляции между нейронами нейронной сети обученного классификатора.
Согласно одному из вариантов реализации предоставляется кластеризации электронных писем, являющихся спамом, который реализуется при помощи облачного сервиса и содержит этапы, на которых: выделяют по меньшей мере две характеристики из каждого полученного электронного письма; с использованием обученного классификатора, содержащего нейронную сеть, на основании характеристик писем определяют, является ли письмо спамом; вычисляют вектор признаков каждого электронного письма, которое является спамом, при этом вектор признаков вычисляется на последнем скрытом слое нейронной сети классификатора; формируют кластеры электронных писем, являющихся спамом, на основании схожести векторов признаков, вычисленных на последнем скрытом слое нейронной сети.
Согласно другому варианту реализации предоставляется способ, в котором характеристикой является по меньшей мере одно из: значение заголовка электронного письма, последовательность части заголовков электронного письма.
Согласно одному из частных вариантов реализации предоставляется способ, в котором классификатор обучен с сохранением ортогональности матриц нейронной сети.
Согласно одному из частных вариантов реализации предоставляется способ, в котором для сохранения ортогональности используют слой пакетной нормализации.
Согласно одному из частных вариантов реализации предоставляется способ, в котором для сохранения ортогональности используют исключающий слой.
Согласно одному из частных вариантов реализации предоставляется способ, в котором для сохранения ортогональности полносвязный слой умножают на гиперпараметр.
Согласно одному из частных вариантов реализации предоставляется способ, в котором для сохранения ортогональности в качестве функции активации используют гиперболический тангенс.
Согласно одному из частных вариантов реализации предоставляется способ, в котором для сохранения ортогональности функция потерь обеспечивает константную дисперсию нейронов.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 иллюстрирует один из вариантов архитектуры системы, реализующей способ признания электронного письма спамом.
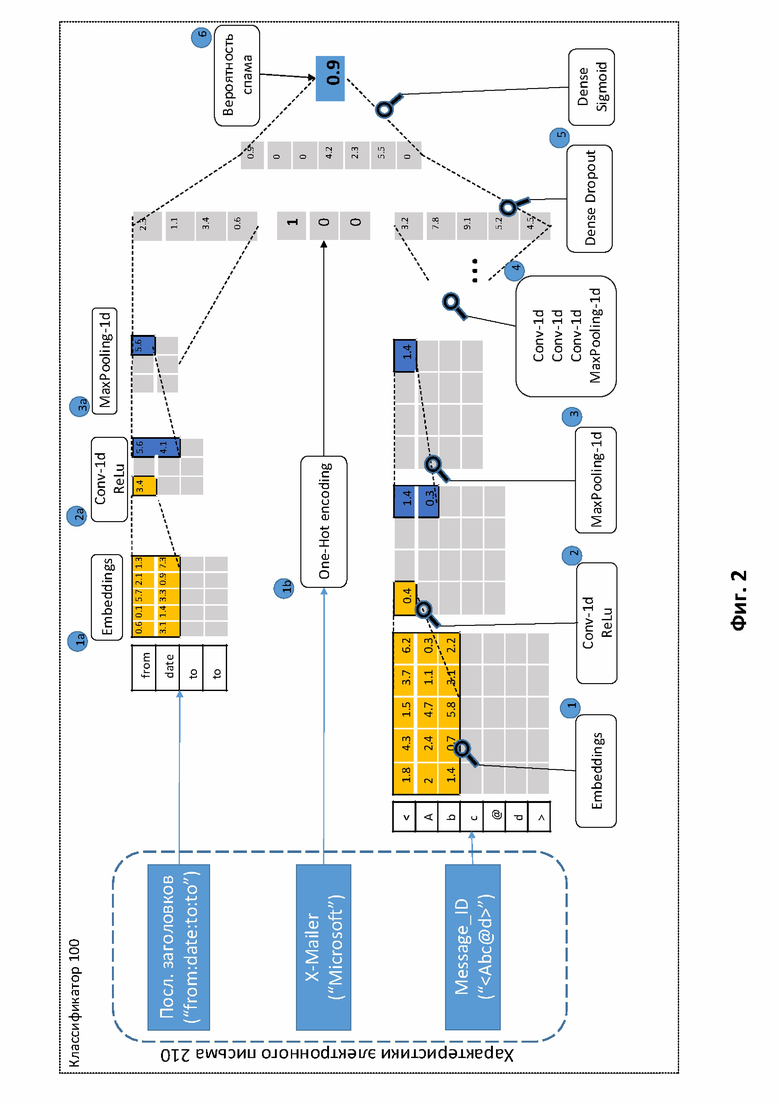
Фиг. 2 иллюстрирует пример анализа характеристик электронного письма при помощи классификатора.
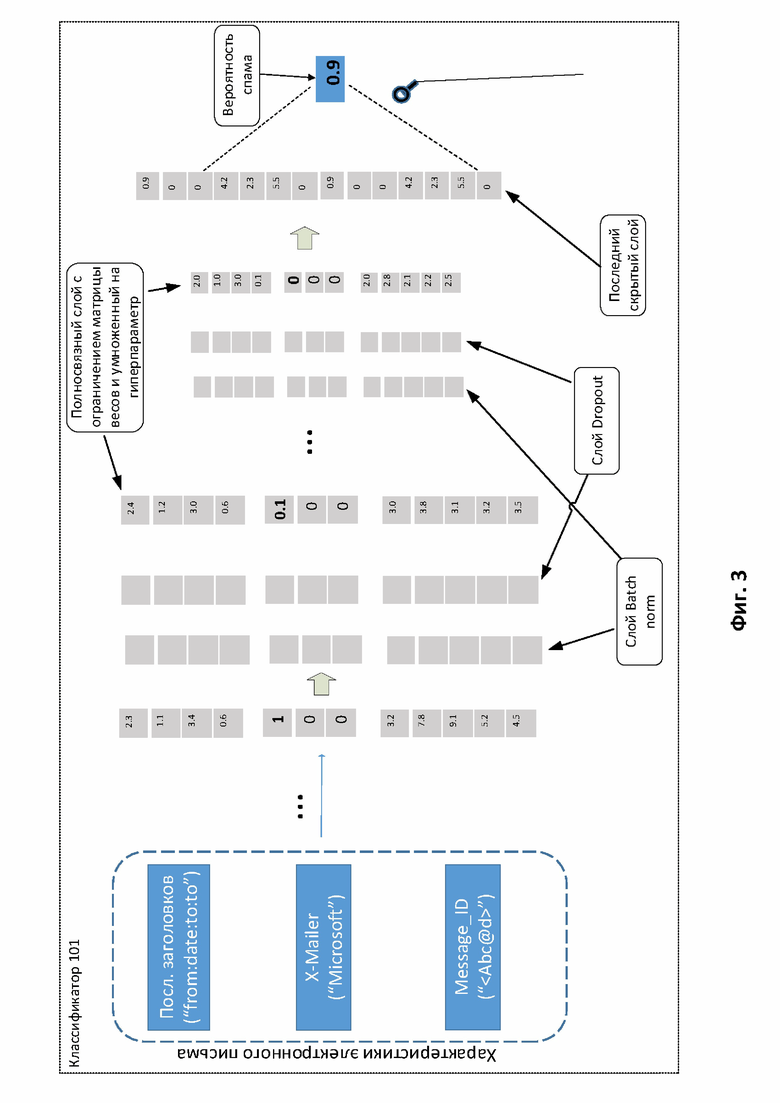
Фиг. 3 иллюстрирует пример обученного спам-классификатора для выявления схожих электронных писем.
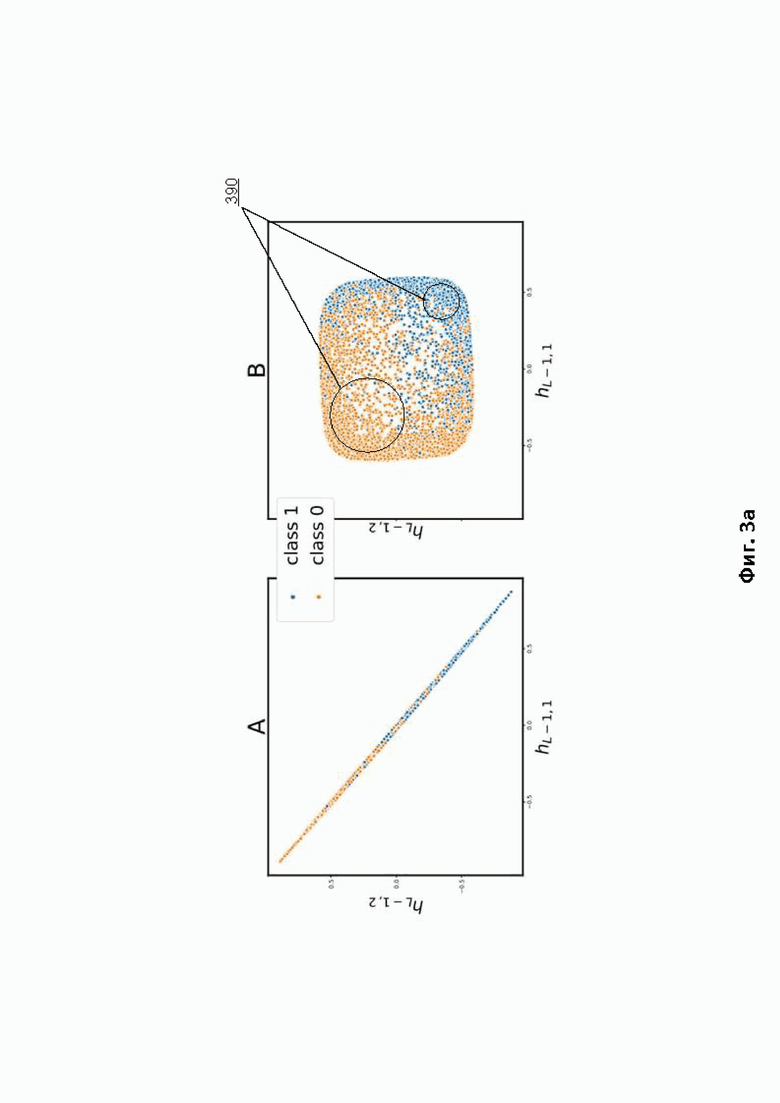
Фиг. 3а иллюстрирует пример кластеризации по признакам, которые сохраняет на последнем скрытом слое обученный спам-классификатор.
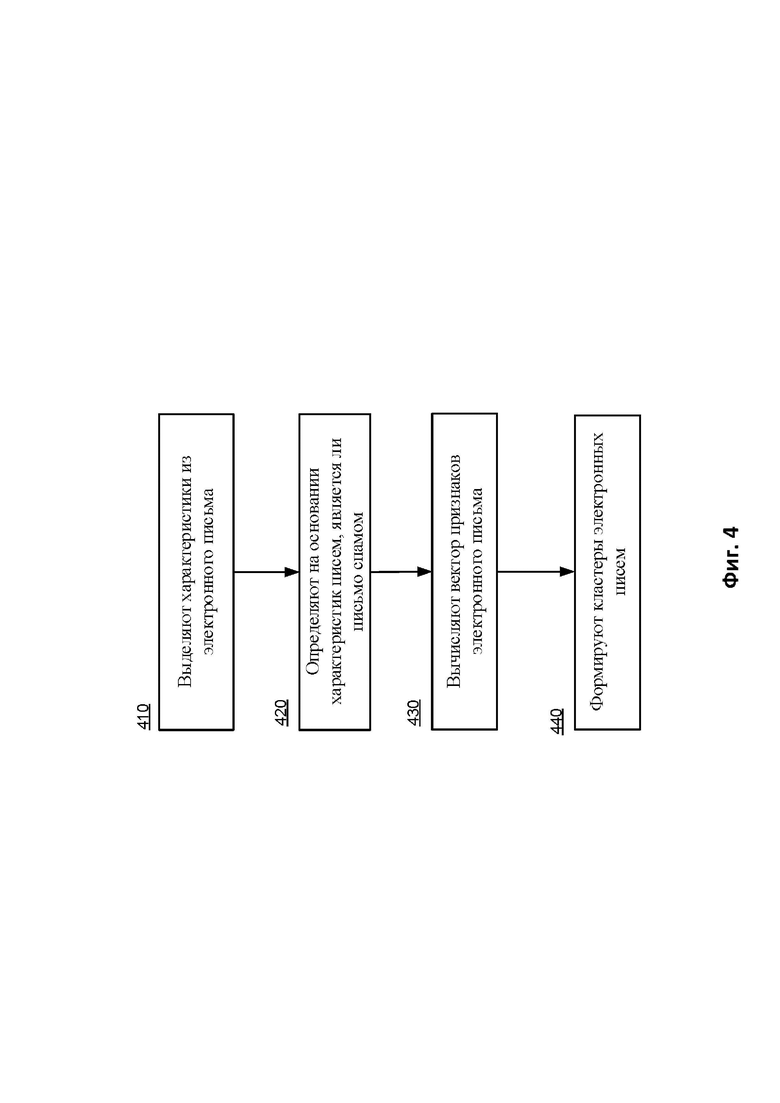
Фиг. 4 отображает способ кластеризации электронных писем, являющихся спамом, с использованием обученного спам-классификатора.
Фиг. 5 иллюстрирует пример компьютерной системы общего назначения, с помощью которого может быть реализовано заявленное изобретение.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено в приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Приведенное описание предназначено для помощи специалисту в области техники для исчерпывающего понимания изобретения, которое определяется только в объеме приложенной формулы.
Электронное письмо (далее также - письмо) имеет определенную структуру. Поэтому для формирования письма используются специальные программы, поддерживающие структуру электронной почты. Кроме тела (англ. body) письмо содержит заголовки (англ. header) (или поля) – это служебная информация, включающая в том числе информацию о маршруте прохождения писем. В заголовках представлены данные о том, когда, откуда и по какому маршруту пришло письмо, а также информация, добавляемая к письму различными служебными программами. При этом каждый заголовок определяется своим именем и значением. Значение заголовка представляет собой информацию, представленную в заранее заданном виде. Например, для заголовка, который содержит информацию об отправителе письма, в качестве имени служит «from», а значение будет иметь вид адреса электронной почты отправителя, например, username@domain.com.
Рассмотрим подробнее некоторые из заголовков, например, «Message_ID» и «X-mailer».
«Message_ID» – уникальный идентификатор письма, присваиваемый каждому письму чаще всего первым почтовым сервером, который встретится у него на пути. Обычно он имеет форму «имя@домен», где «имя» может быть любым (например, «a1B0!#»), зачастую ничего не значащим набором символов, а «домен» имя машины (например, «domen.ru»), присвоившей идентификатор. Иногда, но редко, «имя» включает в себя имя отправителя. Если структура идентификатора нарушена (пустая строка, нет знака @), вторая часть идентификатора не является реальным интернет-сайтом или структура, хотя и корректна, но не типична для подавляющего большинства почтовых сервисов, то письмо вероятно является подделкой (с целью выдать спам за обычное письмо).
«X-mailer» или «mailer_name» – свободное поле, в котором почтовая программа или сервис, с чей помощью было создано данное письмо, идентифицирует себя, например, «Outlook 2.2 Windows». Значение данного заголовка в совокупности с другими заголовками может указывать на принадлежность писем к спаму.
Как упоминалось выше, заголовки добавляются к письму по мере прохождения им маршрута от отправителя до получателя. Последовательности заголовков (части заголовков) также, как и значения некоторых отдельно взятых заголовков, могут быть использованы для отнесения писем к категории спама.
Ниже представлены примеры данных в формате «Последовательность заголовков; значение заголовка X-mailer; значение заголовка Message_ID» для спама и писем, не являющихся спамом.
Спам:
1. "content-type:date:from:subject:to:message-id:";"none";" <i3mbd6v4vhjsdcmi-zu60opfkwplxb44x-37-6f8d@homesolrrebtes.icu>"
2. "content-type:date:from:subject:to:message-id:";"none";" <h5bds3kpswnk0ds0-oalwbjt3dtlcvhlv-2e-19550@homesolrrebtes.icu>"
3. "content-type:date:from:subject:to:message-id:";"none";" <yo8j0xsjsdrvxywv-ie41tpc7xle0b3no-26-c36d@homesolrrebtes.icu>"
4. "content-type:date:from:subject:to:message-id:";"none";" <7enbb9h6c2vapnhr-na5nlwg42raodhr7-2e-4febe@homesolrrebtes.icu>"
5. "message-id:from:to:subject:date:content-type:x-mailer:";" Microsoft Outlook Express 6.00.2900.2316";" <D2DDF9E326F6C73C33170DC81829D2DD@8II5L3SPI>"
6. "message-id:from:to:subject:date:content-type:x-mailer:";" Microsoft Outlook Express 6.00.2900.2180";" <D98EBBF7F3ECC2BFE8DD91958AA4D98E@L0773DI>"
7. "message-id:from:to:subject:date:content-type:x-mailer:";" Microsoft Outlook Express 6.00.2900.2180";" <F90CED31F818D024D130EC25C50DF90C@7TMANVQ>"
8. "message-id:from:to:subject:date:content-type:x-mailer:";" Microsoft Outlook Express 6.00.2900.5512";" <311476D62A53B48AAFCD6D91E80F3114@VX18OHGV>"
Не спам:
1. "content-type:date:from:subject:to:message-id:";"none";" <3c8b3b43089c02b53b882aa9ae67f010@acmomail3.emirates.net.ae>"
2. "content-type:date:from:subject:to:message-id:";"none";" <3c8b3b43089c02b53b882aa9ae67f010@acmomail3.emirates.net.ae>"
3. "content-type:date:from:subject:to:message-id:";"none";" <3c8b3b43089c02b53b882aa9ae67f010@acmomail3.emirates.net.ae>"
4. "content-type:date:from:subject:to:message-id:";"none";" <3c8b3b43089c02b53b882aa9ae67f010@acmomail3.emirates.net.ae>"
5. "from:to:subject:date:message-id:content-type:x-mailer:";" Microsoft Office Outlook 12.0";" <006b01d51986$06411be0$12c353a0$@domroese@evlka.de>"
6. "from:to:subject:date:message-id:content-type:x-mailer:";" Microsoft Outlook 15.0";" <!&!AAAAAAAAAAAYAAAAAAAAAEuD2rCFvsdIgBF3v59c6PrCgAAAEAAAAD+/2KYKE3pHiClPnnSDdSk"
7. "from:to:subject:date:message-id:content-type:x-mailer:";" Microsoft Outlook 15.0";" <!&!AAAAAAAAAAAYAAAAAAAAAEuD2rCFvsdIgBF3v59c6PrCgAAAEAAAAJCLHZRUOflDoROPaFfOwCk"
Глядя на примеры характеристик, взятых из писем, отнесенных к разным категориям, становится понятно, что человек будет долго выделять признаки из подобных данных, позволяющие идентифицировать спам, или может совершить ошибку при выделении признаков. Однако это может быть осуществлено с использованием методов машинного обучения, в частности, с использованием методов глубокого обучения, позволяющих обнаруживать зависимости, скрытые от человеческих глаз.
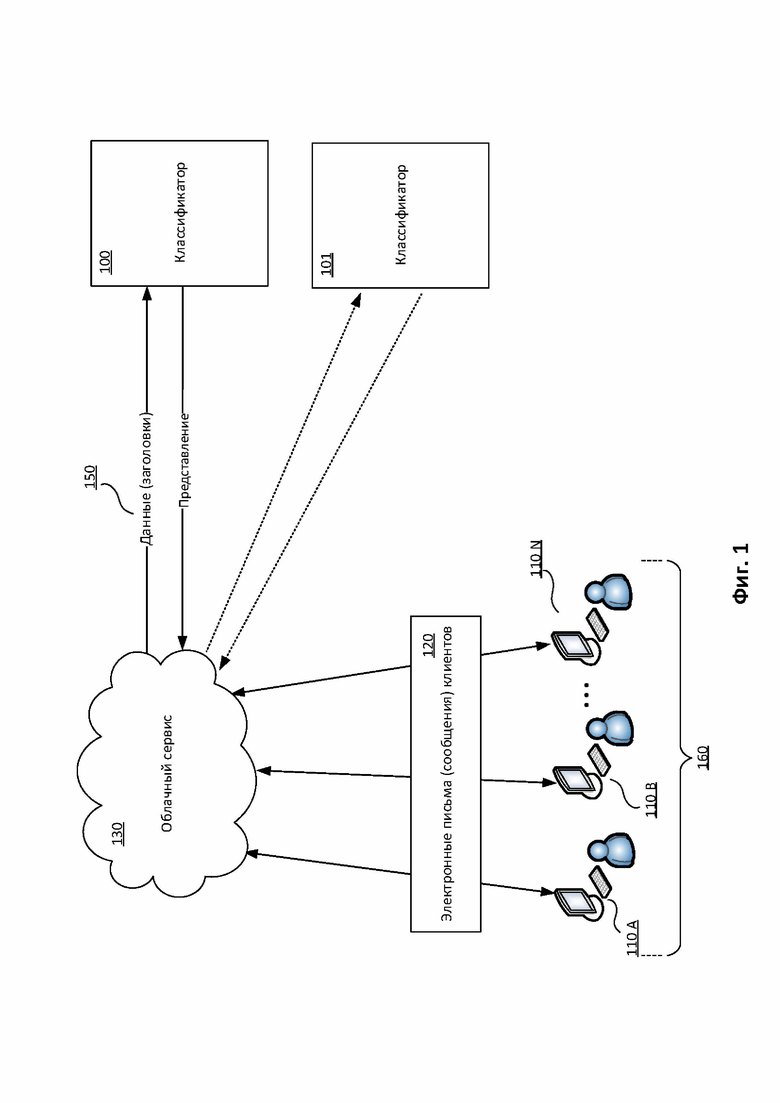
На Фиг. 1 представлен один из вариантов архитектуры системы, реализующей способ признания электронного письма спамом для множества компьютерных систем 160. Данная система включает в себя упомянутое множество компьютерных систем 160, классификатор 100 и облачный сервис 130, а также письма 120.
Облачный сервис 130 осуществляет сбор и хранение данных о письмах 120 с клиентов пользователей 110 А, 110 В, …, 110 N. Под облачным сервисом 130 в одном из вариантов реализации понимается техническое средство, содержащее систему, взаимодействующую с сетью информационной безопасности, например, с «Kaspersky Security Network» (сокр. KSN) компании АО «Лаборатория Касперского». В одном из вариантов реализации облачный сервис 130 - это техническое средство, которое может быть реализовано при помощи компьютерной системы, представленной на Фиг. 5. Под клиентами 110 А, 110 В, …, 110 N понимаются по крайней мере почтовые клиенты пользователей, установленные на каждой компьютерной системе из множества компьютерных систем 160, которое включает в себя как компьютеры пользователей, так и почтовые серверы. Стоит отметить, что собираемая облачным сервисом 130 информация не содержит информацию, относящуюся к пользователю, или информацию, однозначно идентифицирующую пользователя. Для этого часть информации обезличивается. Такой информацией являются сведения из тела письма, например, текстовые сообщения пользователей, и из заголовка письма, например, электронный адрес. Под обезличиванием понимается преобразование информации, например, с помощью свёрток, осуществляемых в том числе при помощи хэш-функций, ассиметричного шифрования и так далее. В частном варианте реализации система соответствует требованиям GDPR.
В рамках заявленного изобретения облачный сервис 130 собирает и хранит в исходном виде (не преобразованном) для каждого электронного письма с клиентов 110 А, 110 В, …, 110 N значения по меньшей мере заголовков «Message_ID» и «X-mailer», последовательность по меньшей мере части других и/или оставшихся заголовков, а также категорию письма («спам», «не спам»), выданную классификатором 100 (см. Фиг. 2), описание работы которого будет приведено ниже. Эти данные 150 передаются классификатору 100, который использует их в рамках методов машинного обучения, позволяющих принимать решение о том, является письмо спамом или нет.
Также изображен классификатор 101, который является измененным классификатором 100 и переназначен для кластеризации электронных писем. Классификатор 101 будет подробно рассмотрен при описании Фиг. 3.
На Фиг. 2 изображен пример анализа характеристик письма при помощи классификатора.
В заявке RU2019122433 подробно рассмотрено решение, основанное на классификации писем без анализа их содержания (non-content).
В основе упомянутого изобретения лежит спам классификатор 100, который основан на методах глубокого обучения (от англ. Deep learning). Модель машинного обучения, используемая в классификаторе 100, представляет собой результат, получаемый при обучении машинного алгоритма с помощью данных. После завершения обучения модель выдает выходные данные, когда в нее вводятся входные данные. Например, алгоритм выявления спама создает модель выявления спама. Затем, когда в модель выявления спама вводятся данные, она выдает результат выявления спама на основе тех данных, которые использовались для обучения модели.
На вход модели поступают характеристики письма 120, такие как значения заголовков Message_ID и X-mailer, а также последовательность иных упомянутых заголовков письма. Каждый из них проходит через несколько этапов выделения признаков (1-4), которые влияют на финальное решение классификатора 100. Рассмотрим пример осуществления преобразования для каждой из характеристик.
Message_ID. На первом этапе (1) каждый символ значения заголовка Message_ID отождествляется последовательностью чисел фиксированной длинны (например 90 символов), образуя матрицу размера 80x90.
На этапе (2) полученная матрица подается на вход одномерному сверточному слою (Conv-1d, от англ. 1D Convolution), при этом создаются 64 фильтра размера 5 (ReLu, от англ. Rectified Linear Unit), которые пошагово применяют к подпоследовательностям Message_ID для выделения из них закономерностей. Стоит отметить, что могут быть использованы более широкие фильтры, чтобы получить признаки из подпоследовательностей большей длины. Полученная матрица имеет размер 76x64.
Чтобы избежать случаев, когда небольшие изменения в Message_ID, например, смещение символов, могут кардинально изменить полученную матрицу (т.е. чтобы не образовывалась хаотичная система), на шаге (3) используется одномерный слой MaxPooling-1d (max-pooling - когда в уже известном сверточном слое матрица фильтра зафиксирована и является единичной, то есть умножение на нее никак не влияет на входные данные, а вместо суммирования всех результатов умножения входных данных по заданному условию просто выбирается максимальный элемент, то есть выбирается из всего окна элемент с наибольшей интенсивностью, при этом вместо функций максимум может быть другая арифметическая или даже более сложная функция). Данный слой берет максимум из значений в заданном окне (срезе слоя). В данном примере используется окно размера 5 с шагом равным 3 (каждый раз окно смещается на 3 элемента). Размер полученной матрицы равен 26x64.
Далее на этапе (4) последовательно применяются несколько одномерных сверточных слоев, каждый из которых имеет 64 фильтра размера 3, после чего применяется одномерный MaxPooling с размером окна равным 3 и с шагом 3.
Итоговая матрица размера 6x64 разворачивается в вектор фиксированной длины (в текущем варианте реализации, 445). То есть выполняется свёртка двумерной матрицы в одномерный вектор таким образом, чтобы сохранить все выявленные в матрице зависимости.
Последовательность заголовков. Обрабатывается аналогично Message_ID, за исключением количества слоев и входных данных. Вместо символов, как было для Message_ID, на этапе (1а) в последовательность чисел свёртываются названия заголовков. При этом свёртка может осуществляться любым известным из уровня техники способом, например, каждому слову ставится в соответствие некоторое число из заранее сформированного словаря, весь заголовок или отельные его лексемы сворачиваются с помощью хэш-функции, каждой букве заголовка ставится в соответствие своё число из заранее сформированного словаря и так далее.
Полученная матрица размера 10x20 на этапе (2a) поступает на вход одномерному свёрточному слою и далее на этапе (3a) одному слою MaxPooling. Итоговая матрица имеет размер 2x16 и разворачивается в вектор фиксированной длины (в текущем варианте реализации, 32).
X-Mailer. Поскольку значение заголовка X-Mailer является категориальной характеристикой электронного письма, то для векторного представления таких данных на этапе (1b) используется подход под названием унитарный код (по англ. One-hot Encoding) – двоичный код фиксированной длины, содержащий только одну 1 (прямой унитарный код) или только один 0 (обратный унитарный код). Таким образом для N возможно 2N разных вариантов кода, что соответствует 2N разным состояниям или характеристикам заголовка Длина кода определяется количеством кодируемых объектов, то есть каждому объекту соответствует отдельный разряд кода, а значение кода положением 1 или 0 в кодовом слове. Полученный вектор имеет размер 29 и состоит из нулей и одной единицы, которая показывает категорию X-Mailer.
Выделенные признаки для каждой характеристики объединяются и проходят еще несколько этапов преобразований на шаге (5) для того, чтобы учесть взаимосвязи между входными значениями. В приведенном примере сначала к ним применяется исключение (от англ. Dense Dropout), то есть метод регуляризации искусственных нейронных сетей, предназначенный для предотвращения переобучения сети. Суть метода заключается в том, что в процессе обучения выбирается слой, из которого случайным образом исключается определённое количество нейронов (например, 30%), которые не участвуют в дальнейших вычислениях. Затем после исключения используется функция активации (от англ. Dense Sigmoid), которая на выходе дает число, лежащее в пределах от 0 до 1. Выход классификатора 100 интерпретируется на этапе (6) как вероятность того, что письмо является спамом, или как степень схожести характеристик письма 120 с характеристиками спама. Числовой показатель на выходе сравнивается классификатором 100 с заранее установленным пороговым значением для принятия решения о признании письма 120 спамом.
На Фиг. 3 изображен пример обученного спам-классификатора для выявления схожих электронных писем.
Настоящее изобретение отличается от упомянутого тем, что позволяет выявлять схожие электронные письма с использованием обученного спам-классификатора 100, рассмотренного при описании Фиг. 2.
Стоит отметить, что в общем случае все классификаторы 100 на основе нейронных сетей обучаются следующим образом: на вход классификатора 100 поступают данные, веса слоев нейронной сети подстраиваются так, чтобы минимизировать потери (англ. loss) при неправильном принятии решений на основе наблюдаемых данных. Потери упомянутого при рассмотрении Фиг.2 классификатора 100 позволяют быстро выявлять «спам» / «не спам», учитывая структуры данных (технические заголовки писем).
Для решения задачи выявления схожих электронных писем с использованием обученного спам-классификатора 100 выполняют несколько преобразований, в результате которых нейронная сеть классификатора 101, (полученного из классификатора 100) позволяет решать задачу определения схожести писем и по-прежнему позволяет классифицировать объекта «спам» / «не спам».
При решении задачи определения схожести писем 120 были определены несколько видов потери информации внутри классификатора 100. Первый вид потери информации, приводящий к снижению точности, повышению погрешности вычислений и, соответственно, ошибок, – корреляция данных внутри нейронной сети. В общем случае есть скрытое представление объектов (вектор), в котором коррелируют признаки объектов. Коррелирование признаков объектов (в настоящем изобретении – писем 120) ведет к тому, что нейронная сеть несколько раз учитывает одну и ту же информацию. Это происходит потому, что рассмотренная при описании Фиг. 2 нейронная сеть постепенно сужается (в результирующий вектор), в результате ей не нужно хранить всю информацию о письме 120, нужно лишь вычислить, письмо 120 – это спам или не спам. Поэтому необходимо добиться того, чтобы нейроны сети были некоррелируемыми. Для этого в классификаторе 101 все упомянутые при описании Фиг. 2 матрицы инициализируются ортогонально. Ортогональность – необходимое свойство, чтобы избавиться от корреляции. Второй вид потери информации – корреляция данных на обучении классификатора 101. Поэтому после обеспечения ортогональности на инициализации матриц необходимо поддерживать ортогональность на обучении классификатора 101. В общем случае для этого изменяется функция потерь (англ. loss function), при этом добавляются дополнительные условия, которые штрафуют нейронную сеть, чтобы она сохраняла ортогональность для уменьшения корреляции между нейронами сети.
Таким образом, после операций сверток, когда характеристики письма 120 объединяются в один входной вектор в классификаторе 101, классификатор 101 дополнительно преобразуется следующим образом. Для каждого скрытого полносвязного слоя в классификаторе 101:
1. Добавляется слой пакетной нормализации (англ. Modified Batch-Normalization), который необходим, чтобы получить нулевое математическое ожидание и одинаковую дисперсию компонент вектора (слоя). В одном из вариантов реализации упомянутый слой вычисляется, как:
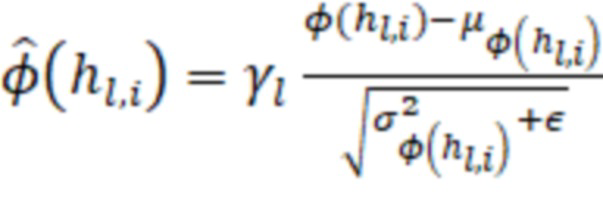 , где:
, где:
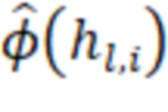 – матрица, описывающая скрытый слой l;
– матрица, описывающая скрытый слой l;
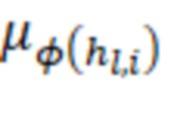 – математическое ожидание пакета;
– математическое ожидание пакета;
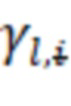 – гамма-параметр сжатия нормализованной величины;
– гамма-параметр сжатия нормализованной величины;
 – дисперсия пакета;
– дисперсия пакета;
∈ – константа для вычислительной устойчивости.
Математическое ожидание пакета должно быть равно нулю. Бета-параметр исключается из расчетов, так как является обучаемым, при его наличии математическое ожидание не будет равняться нулю. Гамма-параметры для каждого слоя выбираются одинаковые, чтобы дисперсия также была одинаковая.
2. Добавляется исключающий слой или дропаут (англ. dropout) для уменьшения корреляции между нейронами. В результате практического эксперимента было установлено, что функция активации не линейна и может образовывать дополнительную корреляцию в нейронной сети. Самым эффективным с точки зрения производительности (необходимого времени на вычисление вердикта) является дропаут, который обеспечивает равновероятное исключение некоторого процента (например, 20%) случайных нейронов (находящихся как в скрытых, так и видимых слоях) на разных итерациях во время обучения нейронной сети.
3. Изменяется полносвязный слой (Dense на графике архитектуры) с ограничением на ортогональность матрицы весов. Это необходимо, чтобы предотвратить возникновение корреляции после преобразования. Размер слоя не должен превышать размерность входного вектора. При этом ортогональность матрицы может добиваться несколькими способами, например, матрица поворота задается через углы Эйлера. Эти углы могут быть ограничены определенным диапазоном, то есть можно наложить ограничение на элементы матрицы, например, на размер чисел.
4. Полносвязный слой умножается на гиперпараметр (параметр, который устанавливается перед обучением, например, размер вектора или еще что-то, что описывает базу их модели), отвечающий за норму векторов матрицы преобразования (данный шаг необходим для дополнительной регуляризации с целью предотвращения переобучения).
5. Используется функция активации (в общем случае - гиперболический тангенс). Стоит отметить, что функция активации в нейронных сетях может вносить дополнительную корреляцию, потому что выполняет свертку данных с частичной потерей информации.
С помощью метода случайной проекции (англ. random projection) - метода, используемого для уменьшения размерности множества точек, лежащих в евклидовом пространстве, возможно получить оценку снизу на размер вектора представления (последний скрытый слой классификатора 101). Метод позволяет выполнить перевод множества точек N-мерного пространства в множество точек (N-M) мерного пространства. Например, для последнего скрытого слоя классификаторе 101 устанавливает ширину слоя (количество нейронов) как минимум:
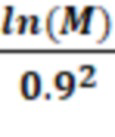 , где M - объем (количество писем) обучающей выборки, но не превышая размер предыдущего слоя.
, где M - объем (количество писем) обучающей выборки, но не превышая размер предыдущего слоя.
Например, ширина последнего скрытого слоя для выборки, состоящей из 140 миллионов писем, равна: 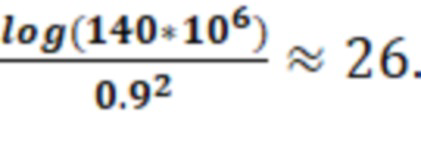
Для выявления схожести при применении классификатора 101 не используется обратный проход – градиент. В результате для векторизации данных градиент не рассчитывается, а используется последний скрытый слой сети. Так, в результате практических испытаний, градиентный спуск, например, позволяет получить размерность вектора порядка 50 тысяч элементов. Вектор, получаемый в результате описанных выше действий, имеет размерность ~ 25 элементов, что существенно (на порядки) ускоряет скорость вычислений классификатором 101.
Для обучения классификатора 101 используется следующая функция потерь, рассчитываемая из ранее полученной функции потерь (данный процесс является итерационным):
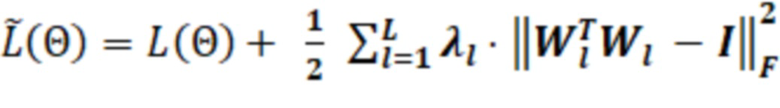 ,
,
где:
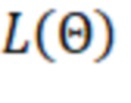 – функция потерь – величина ошибки гипотезы на событиях
– функция потерь – величина ошибки гипотезы на событиях 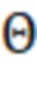 ,
,
 – матрица весов,
– матрица весов,
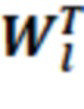 – транспонированная матрица ,
– транспонированная матрица ,
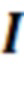 – единичная матрица.
– единичная матрица.
Приведенная функция потерь позволяет получить ортогональные матрицы весов в каждом полносвязном слое после сверток в классификаторе 101 после использования dropout и подхода пакетной нормализации, при этом соблюдается константная дисперсия для всех признаков (нейронов). В процессе обучения классификатора 101 штрафуется нейронная сеть, то есть модифицируются веса таким образом, чтобы обученная модель проводила кластеризацию данных на иные кластеры с большей вероятностью, чем на текущие кластеры. Матрица, умноженная на транспонированную матрицу, равна единичной матрице – это условие ортогональности. Классификатор 101 использует матрицу весов, транспонирует ее, домножает на матрицу весов и вычитает единичную матрицу. После чего вычисляет норму. В случае полного выполнения свойства ортогональности, результирующая матрица нулевая, классификатор 101 ничего не прибавляет к потерям. Если результирующая матрица отлична от единичной матрицы, свойство ортогональности не выполняется, норма ненулевая, норма прибавляется к штрафу. После этого применяется функция штрафа, чтобы то, что сеть вычисляет, соответствовало реальному объекту. Задача обучения нейронной сети – снизить штрафы, то есть свести к минимуму как количество изменений весов, так и их относительные значения. Например, подобрать веса нейронной сети так, чтобы штрафы были минимальными, тем самым минимизировать потери. В общем случае в начале обучения веса случайные, потери значительные. Сеть делает первую итерацию, в результате обучения снижает потери. И повторяет шаги обучения для минимизации потерь.
На Фиг. 3а предоставлен пример кластеризации по признакам, которые сохраняет на последнем скрытом слое классификатор 100 (множество «А») и классификатор 101 (множество «В»). При этом class 0 – не спам, class 1 – спам. Очевидно, что при использовании множества «В» возможно выделение кластеров 390 для кластеризации писем 120. Множество «А» практически полностью соответствует линейной вероятностной оценке (признаки линейно зависимы) и не пригодно для кластеризации.
Таким образом, после получения письма 120 из него облачным сервисом 130 выделяются заголовки и передаются в классификатор 101 (см. Фиг. 1). Обученный классификатор 101 используется облачным сервисом 130 для сравнения писем 120 путем вычисления расстояний между письмами 120, при этом облачный сервис 130 для вычисления расстояний использует последний скрытый слой классификатора 101. Кроме того, на последнем слое классификатор 101 по-прежнему вычисляет вердикт, является ли письмо 120 спамом или нет. Тот вектор признаков, который получился на последнем скрытом слое сети, облачный сервис 130 использует для формирования кластеров писем 120, в общем случае используя косинусное расстояние при сравнении писем 120. Если оно меньше порогового значения, то письма 120 считаются схожими. Из схожих писем облачный сервис 130 формирует кластеры.
Примеры использования классификатора 101 для выявления схожих писем 120 и формирования кластеров писем 120 описаны ниже.
В одном из примеров реализации облачный сервис 130 сравнивает вектор признаков (например, с помощью упомянутого косинусного расстояния или иным известным из уровня техники способом) с известным спамом и выявляет схожесть, формируя кластеры писем 120 на основании схожести писем 120. Сформированные кластеры писем 120 позволяют выявлять бот-сети, а именно облачный сервис 130 выявляет IP-адреса серверов, с которых были отправлены схожие письма 120. Кроме того, в случае повторной отправки схожих писем 120 адреса бот-сетей могут быть дополнены или скорректированы.
В другом примере реализации облачный сервис 130 сравнивает вектор признаков письма 120 с векторами признаков других писем 120, находящихся в карантине (проактивная анти-спам защита). В случае, если письма схожи, облачный сервис 130 принимает решение, основываясь, например, на количестве схожих писем.
В еще одном примере реализации облачный сервис 130 проверяет, есть ли группы писем 120, которые не определяются как спам полностью (часть писем группы определяется как спам, другая часть – не как спам). Например, есть кластер схожих писем 120, выявленный с использованием классификатора 101, но две трети определяются облачным сервисом 130 как спам, а треть - нет. В случае нахождения подобных кластеров писем 120 необходимо делать аудит правил детектирования спама облачным сервисом 130.
В еще одном примере реализации облачный сервис 130 проверяет, есть ли схожие рассылки писем 120, выявленные классификатором 101 как один кластер, но описанные несколькими правилами. Если есть, необходимо проверить возможность описания подобных рассылок одним правилом, но более общим для детектирования.
Фиг. 4 отображает способ кластеризации электронных писем, являющихся спамом, с использованием обученного спам-классификатора.
В общем случае способ кластеризации электронных писем, реализуется при помощи облачного сервиса 130.
На начальном этапе 410 выделяют по меньшей мере две характеристики из каждого полученного электронного письма 120. Характеристикой электронного письма 120 является по меньшей мере одно из:
- значение заголовка электронного письма 120,
- последовательность части заголовков электронного письма 120.
Более подробно характеристики электронных писем 120 рассмотрены при описании Фиг. 2.
На этапе 420 с использованием классификатора 101, содержащего нейронную сеть, на основании характеристик писем 120 определяют, является ли письмо спамом. В общем случае классификатор 101 обучен с сохранением ортогональности матриц нейронной сети. В одном из вариантов реализации для сохранения ортогональности матриц нейронной сети используют слой пакетной нормализации. В другом варианте реализации для сохранения ортогональности используют исключающий слой. В еще одном из вариантов реализации сохранения ортогональности полносвязный слой умножают на гиперпараметр. В еще одном из вариантов реализации для сохранения ортогональности в качестве функции активации используют гиперболический тангенс. В еще одном из вариантов реализации для сохранения ортогональности функция потерь обеспечивает константную дисперсию нейронов. Более подробно сохранение ортогональности рассмотрено при описании Фиг. 3.
На этапе 430 вычисляют вектор признаков каждого электронного письма 120, которое является спамом, при этом вектор признаков вычисляется на последнем скрытом слое нейронной сети классификатора 101.
На этапе 440 формируют кластеры электронных писем 120, являющихся спамом, на основании схожести векторов признаков, вычисленных на последнем скрытом слое нейронной сети классификатора 101.
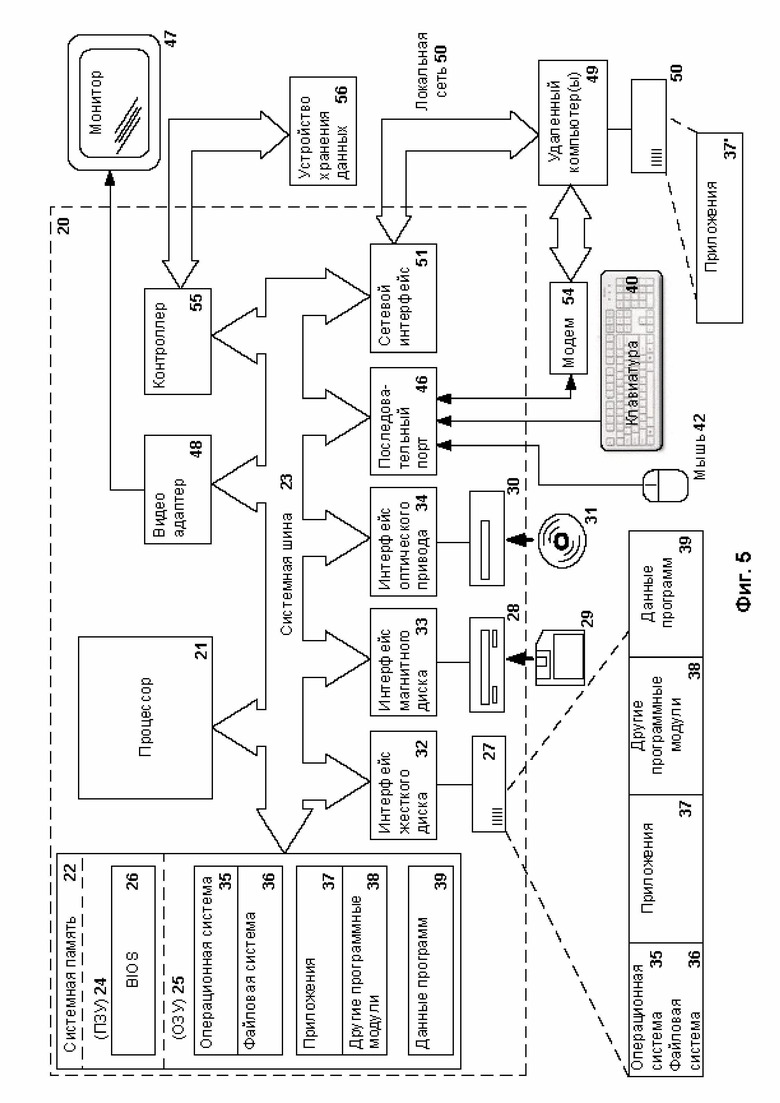
Фиг. 5 представляет пример компьютерной системы 20 общего назначения, которая может быть использована как компьютер клиента (например, персональный компьютер) или сервера. Компьютерная система 20 содержит центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами компьютерной системы 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Компьютерная система 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных компьютерной системы 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Компьютерная система 20 способна работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа компьютерной системы 20, представленного на Фиг. 5. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях компьютерная система (персональный компьютер) 20 подключена к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ формирования сигнатуры нежелательного электронного сообщения | 2021 |
|
RU2776924C1 |
| Способ признания письма спамом через анти-спам карантин | 2019 |
|
RU2750643C2 |
| Способ определения фишингового электронного сообщения | 2020 |
|
RU2790330C2 |
| Система и способ классификации писем электронной почты | 2024 |
|
RU2828611C1 |
| Способ классификации писем электронной почты и система, его реализующая | 2024 |
|
RU2828610C1 |
| Способ обнаружения мошеннического письма, относящегося к категории внутренних ВЕС-атак | 2021 |
|
RU2766539C1 |
| Система и способ формирования эвристических правил для выявления писем, содержащих спам | 2019 |
|
RU2710739C1 |
| Система и способ определения правила классификации события на терминальном устройстве пользователя | 2020 |
|
RU2772404C2 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| Система и способ ограничения получения электронных сообщений от отправителя массовой рассылки спама | 2021 |
|
RU2787303C1 |
Настоящее изобретение относится к области вычислительной техники для кластеризации электронных писем. Технический результат настоящего изобретения заключается в повышении точности, снижении погрешности вычислений и, соответственно, снижении ошибок кластеризации электронных писем с одновременным уменьшением корреляции между нейронами нейронной сети обученного классификатора. Технический результат достигается путем использования способа, в котором: выделяют характеристики из электронного письма; определяют на основании характеристик писем, является ли письмо спамом; вычисляют вектор признаков электронного письма; формируют кластеры электронных писем на основании схожести векторов признаков. 7 з.п. ф-лы, 6 ил.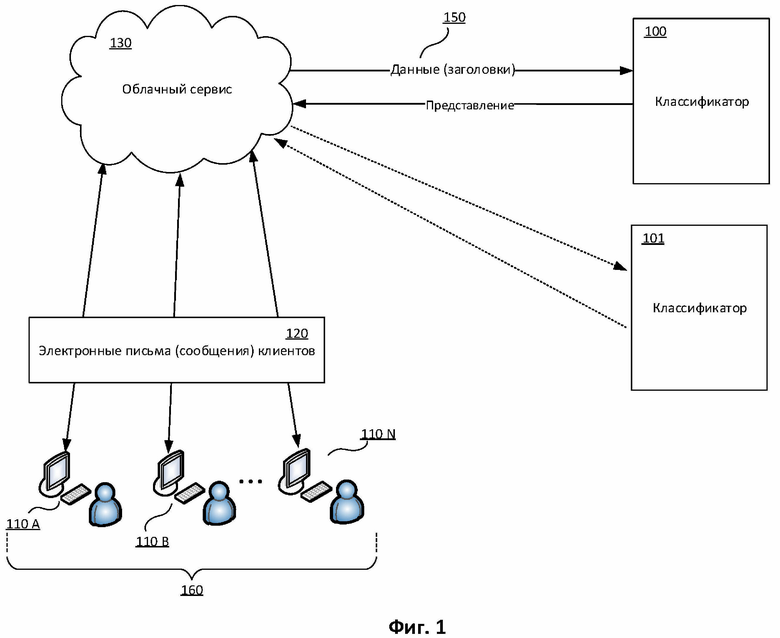
1. Способ кластеризации электронных писем, являющихся спамом, который реализуется при помощи облачного сервиса и содержит этапы, на которых:
а. выделяют по меньшей мере две характеристики из каждого полученного электронного письма;
б. с использованием обученного классификатора, содержащего нейронную сеть, на основании характеристик писем определяют, является ли письмо спамом, где обученный классификатор выполнен с возможностью вычисления расстояний между письмами посредством последнего скрытого слоя нейронной сети классификатора, где на последнем слое классификатор вычисляет вердикт, является ли письмо спамом или нет;
в. вычисляют вектор признаков каждого электронного письма, которое является спамом, при этом вектор признаков вычисляется на последнем скрытом слое нейронной сети классификатора;
г. формируют кластеры электронных писем, являющихся спамом, на основании схожести векторов признаков, вычисленных на последнем скрытом слое нейронной сети, при этом формирование кластеров писем выполняется посредством использования косинусного расстояния при сравнении писем, где упомянутые кластеры формируются в случае, если косинусное расстояние меньше порогового значения, а сформированные кластеры писем обеспечивают выявление бот-сетей посредством выявления IP-адреса серверов, с которых были отправлены схожие письма.
2. Способ по п. 1, в котором характеристикой является по меньшей мере одно из:
- значения заголовка электронного письма,
- последовательности части заголовков электронного письма.
3. Способ по п. 1, в котором классификатор обучен с сохранением ортогональности матриц нейронной сети.
4. Способ по п. 3, в котором для сохранения ортогональности используют слой пакетной нормализации.
5. Способ по п. 3, в котором для сохранения ортогональности используют исключающий слой.
6. Способ по п. 3, в котором для сохранения ортогональности полносвязный слой умножают на гиперпараметр.
7. Способ по п. 3, в котором для сохранения ортогональности в качестве функции активации используют гиперболический тангенс.
8. Способ по п. 3, в котором для сохранения ортогональности функция потерь обеспечивает константную дисперсию нейронов.
| US 8131655 B1, 06.03.2012 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 8065379 B1, 22.11.2011 | |||
| US 7680886 B1, 16.03.2010 | |||
| Способ признания письма спамом через анти-спам карантин | 2019 |
|
RU2750643C2 |

