Область техники, к которой относится изобретение
Настоящее изобретение относится к кодеру и соответствующему способу кодирования для кода коррекции ошибок, с использованием которого кодируют слова входных данных в кодовые слова. Кроме того, настоящее изобретение относится к передатчику и соответствующему способу передачи для широковещательной передачи данных в системе широковещательной передачи. Также, кроме того, настоящее изобретение относится к компьютерной программе для воплощения упомянутого способа передачи в компьютере. В конечном итоге, настоящее изобретение относится к системе широковещательной передачи, содержащей такой передатчик, и один или больше приемников для приема данных, передаваемых упомянутым передатчиком в режиме широковещательной передачи.
Настоящее изобретение, в частности, относится к кодеру LDPC, например, используемому в передатчике Цифровой системы широковещательной передачи (DVB), в которой используется мультиплексирование с ортогональным частотным разделением (OFDM). Кроме того, настоящее изобретение можно применять в других системах, в которых применяются такие же или аналогичные схемы кодирования LDPC для DVB.
Уровень техники
Параметры передачи известных систем широковещательной передачи таких, как системы широковещательной передачи в соответствии со стандартом DVB-T2 (стандарт цифровой наземной телевизионной системы широковещательной передачи второго поколения), обычно оптимизируют для фиксированного приема стационарными приемниками, например, используя антенны, установленные на крыше. В будущих системах широковещательной передачи, таких как будущий стандарт DVB-NGH (Портативная система DVB следующего поколения, которая в дальнейшем также называется NGH), мобильный приемник (на котором, в основном, фокусируется будущий стандарт) должен иметь возможность правильно принимать данные также в плохих ситуациях приема, например, несмотря на многолучевое распространение, эффект затухания и допплеровский сдвиг. Такие системы широковещательной передачи, в частности, характеризуются тем фактом, что обычно отсутствует канал обратной связи и отсутствует передача сигналов от приемников на передатчики.
Раскрытие изобретения
Цель настоящего изобретения состоит в том, чтобы обеспечить кодер и соответствующий способ кодирования, а также передатчик и соответствующий способ передачи для широковещательной передачи данных в системе широковещательной передачи, с помощью которых вероятность безошибочного приема/реконструкции данных мобильным приемником повышается по сравнению с передатчиками и способами передачи в известных системах широковещательной передачи, даже при плохих условиях приема. Кроме того, цель настоящего изобретения состоит в том, чтобы обеспечить возможность использования различных типов декодеров и приемников, но при этом обеспечить совместимость. Также, кроме того, цель настоящего изобретения состоит в том, чтобы предусмотреть компьютерную программу для воплощения упомянутого способа кодирования и системы широковещательной передачи.
В соответствии с аспектом настоящего изобретения предусмотрен кодер для кода с коррекцией ошибок, с помощью которого кодируют слова входных данных в кодовые слова, содержащий:
- вход кодера для приема входных слов данных, каждое из которых содержит первое количество Kldpc информационных символов,
- средство кодирования для кодирования входного слова данных в кодовое слово так, что кодовое слово содержит основную область кодового слова, включающую в себя область данных, и основную область четности со вторым количеством Nldpc-Kldpc основных символов четности, и вспомогательную область кодового слова, включающую в себя вспомогательную область четности с третьим количеством MIR вспомогательных символов четности,
при этом упомянутое средство кодирования выполнено с возможностью
i) генерирования упомянутой основной области кодового слова из входного слова данных в соответствии с первым кодом, в котором основной символ четности генерируют путем накопления информационного символа по адресу символов четности, определенному в соответствии с первым правилом генерирования адресов, и в котором Nldpc-Kldpc основных символов четности генерируют путем накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу у символа четности, в котором упомянутые адреса у символа четности определяют в соответствии с первым правилом генерирования адресов
y={x+m mod Gb×Qldpc}mod(Nldpc-Kldpc}, если x<Nldpc-Kldpc,
причем x обозначает адреса аккумулятора символа четности, соответствующие первому информационному символу группы размером Gb, и Qldpc представляет собой заранее определенную константу, зависимую от скорости основного кода,
и
ii) генерирования упомянутой области вспомогательного кодового слова из входного слова данных в соответствии со вторым кодом, в котором вспомогательный символ четности генерируют путем накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу у символа четности, в котором упомянутые адреса у символов четности определяют в соответствии со вторым правилом генерирования адресов
y=Nldpc-Kldpc+{x-(Nldpc-Kldpc)+m mod Ga×QIR}mod MIR, если x≥Nldpc-Kldpc,
причем x обозначает адреса аккумулятора символа четности, соответствующие первому информационному символу группы с размером Ga, и QIR представляет собой заранее определенную константу, зависимую от скорости кода, и в котором Ga=Gb=72, и
- выход кодера для вывода упомянутых кодовых слов.
В соответствии с дополнительным аспектом настоящего изобретения предусмотрен передатчик для широковещательной передачи данных в системе широковещательной передачи, содержащий:
- вход данных для приема по меньшей мере одного потока входных данных передатчика, сегментированных на входные слова данных,
- кодер, как определено выше, для кода с коррекцией ошибок для кодирования входных слов данных в кодовые слова,
- преобразователь данных для отображения кодовых слов на фреймы выходного потока данных передатчика, и
- модуль передатчика для передачи упомянутого выходного потока данных передатчика.
В соответствии с дополнительными аспектами настоящего изобретения предусмотрены соответствующий способ кодирования, способ передачи и компьютерная программа, содержащие средство программы, для обеспечения выполнения компьютером этапов упомянутого способа кодирования, когда упомянутая компьютерная программа выполняется в компьютере.
Предпочтительные варианты осуществления изобретения определены в зависимых пунктах формулы изобретения. Следует понимать, что заявленное устройство, заявленные способы и заявленная компьютерная программа имеют аналогичные и/или идентичные предпочтительные варианты осуществления, как и у заявленного кодера и как определено в зависимых пунктах формулы изобретения.
Настоящее изобретение основано на идее обеспечения возможности для мобильного приемника, например, приемника, установленного в автомобиле, или портативного приемника (например, мобильного телефона или КПК) в системе широковещательной передачи данных декодировать данные широковещательной передачи даже при плохих условиях канала передачи путем улучшения предусмотренных мер по коррекции ошибок. В частности, предложено обеспечить достаточную степень избыточности кодера для увеличения надежности кода. Упомянутая дополнительная избыточность обеспечивается передатчиком таким образом, что приемник может, но не обязательно, использовать ее, если прием или реконструкция (декодирование) принятых данных широковещательной передачи будут выполнены с ошибкой или могут быть выполнены только с недостаточным качеством. Оператор широковещательной передачи также имеет возможность выбирать из множества разных кодов и схем модуляции, находя, таким образом, компромисс между пропускной способностью и надежностью.
Для обеспечения того, чтобы приемник (например, существующий традиционный приемник), в частности его декодер, мог правильно декодировать принимаемые данные без какой-либо дополнительной избыточности, предусмотренной в соответствии с настоящим изобретением, первый код применяют с помощью кодера кода с коррекцией ошибок (обычно применяемая прямая коррекция ошибок) для генерирования основной области кодового слова для кодовых слов данных, предназначенных для передачи. Такой способ кодирования может представлять собой известный стандартный способ кодирования входных слов данных в кодовые слова, например кодирование с прямой коррекцией ошибок (FEC) такое, как применяется в DVB-T2, DVB-S2, DVB-C2 или в будущих передатчиках DVB-NGH (например, кодирование LDPC), то есть основная область кодового слова может соответствовать (“нормальному” коду с коррекцией ошибок) кодовому слову в соответствии со стандартом DVB-T2 (далее также называется T2). Кроме того, однако, предложено в соответствии с настоящим изобретением обеспечить возрастающую избыточность для декодера приемника путем генерирования вспомогательной области кодового слова из входных слов данных в соответствии со вторым кодом. “Весь” код, то есть код, в соответствии с которым генерируют “все” кодовое слово (содержащее основную область кодового слова и вспомогательную область кодового слова), таким образом, имеет более низкую скорость кода, чем у первого кода. Следовательно, упомянутый “весь” код, в частности упомянутая вспомогательная область кодового слова, обеспечивает более высокую надежность и обеспечивает (лучшее) декодирование, чем первый код, даже при плохих условиях приема.
Следовательно, в нормальных условиях приема декодер обычно (не должен) не использует вспомогательную область кодового слова вообще, а использует только основную область кодового слова для декодирования принимаемых данных. В ситуациях, когда декодер определяет, что декодирование принимаемых данных происходит с ошибкой или с недостаточным качеством, он использует часть или всю вспомогательную область кодового слова для лучшего декодирования принимаемых данных. Таким образом, основная область кодового слова может использоваться в том виде, как она есть, приемником/декодером, для декодирования, и вспомогательная область кодового слова должна использоваться только, если это действительно требуется для декодирования.
Кроме того, вспомогательная область кодового слова представляет дополнительную меру для улучшения возможности декодирования, в частности, для мобильных приемников, в случае плохих условий приема. Как основную область кодового слова, так и вспомогательную область кодового слова, отображают на выходной поток данных передатчика, используя соответствующий преобразователь данных передатчика, причем упомянутый выходной поток данных передатчика, в общем, сегментируют на фреймы. Например, структура фреймов применяется в соответствии с системой DVB-T2, используя фреймы T2 и фреймы FEF (расширенные фреймы будущего), которые можно использовать для транспортирования двух частей кодового слова соответствующим образом.
Предпочтительно, кодер и декодер применяют систематический код для генерирования упомянутых кодовых слов таким образом, что упомянутая основная область кодового слова содержит область данных, в частности входное слово данных, и основную область четности, и упомянутая вспомогательная область кодового слова содержит вспомогательную область четности. Например, основная область кодового слова может представлять собой комбинацию информационных символов (например, информационных битов или информационных байтов) входного слова данных и сгенерированных основных символов четности (например, основные биты или байты четности), упомянутая комбинация, представляющая основное кодовое слово в соответствии с первым кодом, который может быть декодирован декодером. В этом примере вспомогательная область кодового слова может содержать вспомогательные символы четности (например, вспомогательные биты или байты четности), упомянутая вспомогательная область кодового слова, представляющая вспомогательное кодовое слово второго кода, которая может использоваться для улучшения вероятности декодирования упомянутого первого кодового слова.
Кроме того, предпочтительно использовать упомянутую вспомогательную область кодового слова для обеспечения возможности использования добавочных дополнительных битов четности, для повышения надежности информации сигналов L1-Post в системе DVB-NGH. Более точно, код 4 k LDPC с кодовой скоростью (идентификатор) 1/2 используется как упомянутое основное кодовое слово четности для защиты данных L1-Post, где в зависимости от длины этих данных несколько его битов четности выкалывают. Концепция дополнительных кодов четности повторно использует эти выколотые биты, и их передают в другом фрейме NGH (предпочтительно в предыдущем фрейме). Однако если требуемое количество дополнительных битов четности превышает количество выколотых основных битов четности, остальные дополнительные биты могут быть взяты из вспомогательной области кодового слова.
Для генерирования упомянутых (основных и вспомогательных) символов четности упомянутых основной и вспомогательной области кодового слова используют аккумуляторы символов четности, как общеизвестно и применяется, например, в соответствии с DVB-T2 (ETSI EN 302755 V1.1.1 (2009-09) “Digital Video Broadcasting (DVB); Framing structure Channel Coding and Modulation for a Second Generation Digital Terrestrial Television Broadcasting System (DVB-T2)”), DVB-C2 (DVB BlueBook A138 “Digital Video Broadcasting (DVB); Frame structure channel coding and modulation for a second generation digital transmission system for cable systems (DVB-C2) or DVB-S2 (ETSI EN 302307 V1.2.1 (2009-08) “Digital Video Broadcasting (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other broadband satellite applications (DVB-S2)”). Для такого накопления символов четности используется правило генерирования адресов для определения адресов символов четности, по которым выполняют накопление информационных символов (“накопление”, в общем, также называется “кодированием”). Обычно, однако, используется только одно правило генерирования одного адреса, которое применяется для определения всех адресов четности основного кодового слова, что не должно исключать то, что больше правил генерирования адресов применяется для генерирования основного кода. В соответствии с настоящим изобретением, однако, разные правила генерирования адресов используют для генерирования основных символов четности и вспомогательных символов четности для получения требуемых свойств первого и второго кодов. В частности, второе правило генерирования адресов для получения каждого вспомогательного символа четности, для накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу y символа четности, в котором упомянутые адреса y символа четности, определенные в соответствии со вторым правилом генерирования адресов, могут быть представлены следующим образом
Nldpc-Kldpc+{x-(Nldpc-Kldpc)+m mod Ga×QIR}mod MIR, если x≥Nldpc-Kldpc,
при этом x обозначает адреса аккумулятора символа четности, соответствующие первому информационному символу группы размером Ga, и QIR представляет собой заранее определенную константу, зависящую от скорости вспомогательного кода, выбранную таким образом, что обеспечивается требуемая обратная совместимость кодов, как поясняется ниже. Таким образом, весь код также содержит первый код. Кроме того, второе правило генерирования адресов следует тому же поблочному (и квазицикличному) принципу кодирования (в группах длиной Ga), как во всех кодах LDPC для семейства стандартов DVB. В частности, обе группы могут иметь одинаковую длину.
Кодер и способ кодирования настоящего изобретения могут, в общем, применяться для расширения основного кода в расширенный код (имеющий более низкую скорость кода, чем у упомянутого основного кода), но в котором разные типы декодеров могут декодировать по меньшей мере основной код, то есть в котором обеспечивается обратная совместимость для традиционных декодеров, которые не могут декодировать расширенный код, а только основной код.
В соответствии с предпочтительным вариантом осуществления упомянутое средство кодирования выполнено с возможностью генерирования основного символа четности путем накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу у символа четности, в котором упомянутые адреса у символа четности определяют в соответствии с первым правилом генерирования адресов
{х+m mod Gb×Qldpc}mod(Nldpc-Kldpc), если x<Nldpc-Kldpc,
при этом x обозначает адреса аккумулятора символа четности, соответствующие первому информационному символу группы размером Gb, и Qldpc представляют собой заранее определенную константу, зависящую от скорости основного кода. Следовательно, в соответствии с этим вариантом осуществления применяют одно и то же правило генерирования адресов, которое определено для основной области четности кодового слова, которая обеспечивает для приемников возможность декодирования первого кода. Такое правило генерирования адресов описано, например, в заявке 2010 - 197393 на патент Японии, поданной 3 сентября 2010 г. под названием “Data processing apparatus and method”. Другое преимущество такой обратной совместимости состоит в том, что она упрощает декодирование нескольких входных потоков данных, которые либо кодированы с использованием правила основного кодирования или правила расширенного кодирования, которые выводят как основную, так и вспомогательные области кодового слова следующим образом: если возможно успешное декодирование основных областей кодового слова, декодер может использовать одну и ту же (основную) операцию декодирования. Только, если декодирование основного кода происходит неудачно, декодер должен изменить операцию декодирования в соответствии с расширенным кодом (и может игнорировать те входные потоки, которые кодированы только основным кодером).
В соответствии с дополнительным вариантом осуществления упомянутые размеры групп, используемые в упомянутом первом и втором правилах генерирования адресов, являются идентичными, то есть Ga=Gb. Предпочтительно выбирают размер группы равным 72 (в соответствии с генерированием кода LDPC в DVB). Таким образом, выполняют поблочное кодирование (или кодирование в группе) путем последовательного отбора групп G=Ga=Gb (предпочтительно = 72) информационных символов (предпочтительно, информационных битов) и кодирования их в символы четности. Таким образом, поддерживается квазициклическая структура как для основной области четности, так и для вспомогательной области четности, что обеспечивает возможность поблочного и, таким образом, более простого декодирования на основе упомянутых групп, имеющих фиксированный размер группы.
Предпочтительно упомянутое средство кодирования выполнено с возможностью поблочного генерирования упомянутых основных символов четности и упомянутых вспомогательных символов четности путем использования группы последовательных информационных символов, в котором каждый информационный символ i упомянутой группы последовательных информационных символов накапливают в наборе разных адресов у символов четности, в котором набор адресов символа четности, в котором накапливает первый информационный символ упомянутой группы, отбирают из заданной таблицы адресов, и в которой адреса символа, в которых накапливают последовательные информационные символы упомянутой группы, определяют из упомянутого набора адресов символа четности, в соответствии с упомянутым первым или упомянутым вторым правилом генерирования адресов, соответственно, и в котором отдельный набор адресов символа четности получают из упомянутой таблицы адресов для генерирования каждого нового блока основных символов четности и вспомогательных символов четности. Использование таких заданных таблиц адресов обеспечивает возможность предварительной оптимизации содержащихся в них адресов символа четности для каждой требуемой комбинации значений скорости данных, размеров Ga, Gb группы, заранее определенных констант Qldpc, QIR, зависящих от скорости кода, третьего количества вспомогательных символов MIR четности и длины основной области Nldpc кодового слова, таким образом, что получаемый код является как можно более сильным и позволяет корректировать столько ошибок, сколько возможно. Кроме того, адреса, предусмотренные в упомянутых таблицах адресов (номера которых являются действительными для групп Ga и Gb информационных символов), обеспечивают преимущество, состоящее в том, что эти правила генерирования адресов (и также таблиц адресов) можно сформулировать и эффективно сохранять, используя разумную величину пространства хранения в передатчике и в приемниках. В противном случае, правила генерирования адресов и таблицы адресов были бы намного большими и могли быть иметь чрезвычайно большой размер, если бы для каждого информационного символа требовалось бы предоставить адрес четности в таблице в явном виде.
В определенном предпочтительном варианте применения используются следующие значения параметров: MIR=Nldpc=4320, QIR=60, G=Ga=Gb=72. Кроме того, для идентификаторов скорости кода выбрано значение 1/2 и для параметра Qldpc=30. Как известно из стандартов DVB-T2 и DVB-S2, идентификаторы скорости кода не всегда идентичны действительной скорости кода (однако для выбранного кода идентификатор кода соответствует истинной скорости кода). Оптимизированные таблицы адресов, включающие в себя адреса символа четности для этих разных скоростей кода, и эти значения параметра определены в дополнительных зависимых пунктах формулы изобретения. Следовательно, в соответствии с такими вариантами осуществления средство кодирования выполнено с возможностью избирательного отбора нового ряда следующих таблиц адресов в качестве нового набора других адресов у символа четности для накопления новой группы последовательных информационных символов.
В то время как настоящее изобретение можно использовать, в общем, для расширения существующего кода, в предпочтительном варианте применения упомянутая основная область кодового слова предусмотрена для обычного декодирования и упомянутая вспомогательная область кодового слова предусмотрена как приращение избыточности, если регулярное декодирование кодового слова при использовании основной части кодового слова приводит к ошибкам.
В соответствии с предпочтительным вариантом осуществления передатчика преобразователь данных выполнен с возможностью отображения основной области кодового слова для кодового слова на другую область выходного потока данных передатчика, в частности на другой фрейм, чем вспомогательную область кодового слова того же кодового слова. Это обеспечивает преимущество, состоящее в том, что на вспомогательную область кодового слова могут не повлиять нарушения в канале, которые влияют на основную область кодового слова, такие как избирательное по времени затухание или пакетные шумы. В общем, амплитуда и фаза разных путей приема также зависят от положения приемника. Кроме того, в случае движущегося приемника, в частности, фаза сигналов разных каналов приема меняется, что приводит к избирательному по времени каналу. Изменения в направлении времени также могут иметь очень регулярную структуру, скорость изменения которой по оси времени пропорциональна относительной скорости приемника и передатчика и частоты передачи сигнала. Также другие нарушения, такие как импульсный шум, могут иметь регулярную структуру, например, вызванную частотой линейного цикла решетки мощности или пакетами других систем передачи данных, например, системы передачи данных GSM. Отображение основной части кодового слова, с одной стороны, и соответствующей вспомогательной части кодового слова, с другой стороны, на разные области выходного потока данных передатчика могут в таких ситуациях исключить влияние таких регулярных нарушений на все данные, относящиеся к определенной области кодового слова, и могут, таким образом, обеспечить правильное декодирование кодового слова в приемнике. Кроме того, как поясняется более подробно ниже, приемник может переключиться в режим ожидания во время передачи вспомогательной области данных, если упомянутая вспомогательная область данных не требуется для декодирования.
В соответствии с другим предпочтительным вариантом осуществления передатчика упомянутый преобразователь данных выполнен с возможностью отображения основной области кодового слова для кодового слова на фрейм первого типа выходного потока данных передатчика, в частности на фрейм T2 выходного потока данных передатчика, в соответствии с системой широковещательной передачи DVB и для отображения вспомогательной области кодового слова соответствующего кодового слова на фрейм второго типа, расположенный между фреймами первого типа, выходного потока данных передатчика, в частности на фрейм FEF выходного потока данных передатчика, в соответствии с системой широковещательной передачи данных DVB. Это обеспечивает преимущество, состоящее в том, что стационарные приемники имеют доступ только к данным, переданным во фреймах первого типа, например, эти приемники в соответствии со стандартом DVB-T2 получают доступ только к данным, переданным во фреймах T2. Мобильные приемники, в общем, также получают доступ к данным, переданным во фреймах первого типа, которые также в соответствии с настоящим изобретением достаточны для правильного декодирования принятых кодовых слов и для воспроизведения кодированных слов данных. Однако если декодер определяет, что декодирование произошло с ошибкой или что декодированные данные имеют недостаточное качество, он может также затем обращаться к данным, то есть к вспомогательной области кодового слова, переданной во фреймах второго типа, и использовать эти дополнительные данные в качестве приращения избыточности, то есть использовать основную область кодового слова и (часть или всю) вспомогательную область кодового слова для декодирования, что, в конечном итоге, обеспечивает повышенную вероятность того, что данные будут декодированы корректно, поскольку комбинация основной области кодового слова и вспомогательной области кодового слова имеет более низкую скорость кода, чем у первого кода, в соответствии с которым было кодировано первое кодовое слово.
Такой вариант осуществления обеспечивает дополнительное преимущество, состоящее в том, что существующая структура фреймов, как определено в стандарте DVB-T2, может использоваться, например, таким образом, что стационарные приемники (в соответствии со стандартом DVB-T2) получают доступ только к данным, переданным во фреймах T2, и мобильные приемники получают доступ к данным, переданным во фреймах T2 и, если необходимо, в дополнение к вспомогательным областям кодового слова, переданным во фреймах FEF. Стационарные приемники, конечно, также могут использовать вспомогательные области кодового слова, переданные во фреймах FEF, если необходимо, но обычно игнорируют эти данные.
В предпочтительном варианте осуществления кодер содержит первый модуль кодирования для кодирования, в соответствии с упомянутым первым кодом, входного слова данных в основное кодовое слово, включая в себя упомянутую основную область кодового слова, и второй модуль кодирования для кодирования, в соответствии с упомянутым вторым кодом, входного слова данных во вспомогательное кодовое слово, включающее в себя упомянутую вспомогательную область кодового слова. Кроме того, преобразователь данных выполнен с возможностью отображения основного кодового слова на другую область выходного потока данных передатчика, в частности, на другой фрейм, чем вспомогательное кодовое слово. Следовательно, в соответствии с этим вариантом осуществления, уже существующий кодер, то есть первый модуль кодирования, можно использовать без каких-либо изменений, и просто добавляют второй кодер, то есть второй модуль кодирования, в который также подают входные слова данных, из которых генерируют вспомогательные кодовые слова, в соответствии со вторым кодом, который сам по себе может также иметь более низкую кодовую скорость, чем у первого кода, применяемого первым модулем кодирования, но который также имеет такую же или более высокую кодовую скорость.
Хотя обычно, как основные кодовые слова, так и вспомогательные кодовые слова можно отображать полностью на выходной поток данных передатчика в некоторых вариантах осуществления (в частности, если вспомогательные кодовые слова не только содержат вспомогательные биты четности, но также и область или полное входное слово данных и/или основную область основного кодового слова), достаточный для достижения требуемой цели, только вспомогательную область четности отображают на выходной поток данных передатчика в дополнение к основному кодовому слову. Приемник тогда использует в случае необходимости вспомогательную область четности как избыточность для декодирования принятого основного кодового слова, которое нельзя декодировать корректно.
Второй модуль кодирования может, кроме того, быть выполнен с возможностью кодирования в соответствии с упомянутым вторым кодом входного слова данных во вспомогательное кодовое слово, включая в себя упомянутую основную область кодового слова и упомянутую вспомогательную область кодового слова. Следовательно, основная область кодового слова представляет собой область, как основного кодового слова, так и вспомогательного кодового слова, но более не используется во вспомогательном кодовом слове, из которого, в основном, вспомогательную область четности вставляют в выходной поток данных передатчика. Такой вариант осуществления имеет преимущество, состоящее в том, что первый модуль кодирования может представлять собой (обычный) кодер известного приемника, например, приемника, в соответствии со стандартом DVB-Т2, который может, в общем, использоваться без изменений и в котором добавлен второй модуль кодирования, в соответствии с изобретением.
В качестве альтернативы, второй модуль кодирования может дополнительно быть выполнен с возможностью кодирования в соответствии с упомянутым вторым кодом входного слова данных во вспомогательное кодовое слово, включающее в себя только упомянутую вспомогательную область кодового слова. Такой модуль кодирования может быть легко добавлен к существующему кодеру и выполняет только минимальные требуемые этапы при воплощении настоящего изобретения на стороне передатчика.
В соответствии с альтернативным вариантом осуществления передатчика упомянутый кодер содержит один модуль кодирования для кодирования входного слова данных в кодовое слово, включающее в себя упомянутую основную область кодового слова и упомянутую вспомогательную область кодового слова, и в котором упомянутый преобразователь данных выполнен с возможностью отображения основной области кодового слова упомянутого кодового слова на другую область выходного потока данных передатчика, в частности на другой фрейм, чем вспомогательную область кодового слова упомянутого кодового слова. Такой вариант осуществления требует меньшей точности, поскольку только один процесс кодирования выполняют для генерирования кодовых слов, которые после этого разделяют на основную область кодового слова, с одной стороны, и вспомогательную область кодового слова, с другой стороны.
В соответствии с дополнительным вариантом осуществления упомянутый кодер выполнен с возможностью кодирования входных данных слов в кодовые слова, при этом кодовое слово содержит основную область кодового слова и вспомогательную область кодового слова, при этом упомянутая вспомогательная область кодового слова включает в себя по меньшей мере две вспомогательные подобласти кодового слова, упомянутая основная область кодового слова предусмотрена для обычного декодирования, а упомянутые по меньшей мере две вспомогательные подобласти кодового слова предусмотрены в качестве приращения избыточности, если при обычном декодировании кодового слова путем использования основной области кодового слова и при использовании меньшей избыточности возникает ошибка. Данный вариант осуществления обеспечивает преимущество, состоящее в том, что приемник может определять, какое количество дополнительного приращения избыточности требуется для правильного декодирования при выполнении обычного декодирования, то есть в случае, когда декодирование путем использования только основной области кодового слова приводит к ошибкам. Это обеспечивается путем кодирования входных слов данных таким образом, что генерируют две или более вспомогательные подобласти кодового слова (например, две или более групп вспомогательных символов четности), которые могут пошагово использоваться как такое приращение избыточности, то есть вспомогательные подобласти кодового слова генерируют таким образом, что не все подобласти требуются полностью для выполнения правильного декодирования принятого кодового слова, но одна или более из подобластей также достаточны для правильного декодирования. Однако если используется большее количество подобластей, скорость кода уменьшается и вероятность правильного декодирования повышается.
Таким образом, каждый приемник может самостоятельно определять (причем это определение может также изменяться время от времени), какое количество дополнительных последовательных приращений избыточности, то есть сколько этих по меньшей мере двух вспомогательных подобластей кодового слова должно использоваться для повышения качества декодирования, если необходимо. Следовательно, если дополнительно требуется только малая подобласть, другие подобласти вспомогательного кодового слова могут игнорироваться и даже могут не быть приняты или по меньшей мере могут не быть отображены вообще таким образом, что во время, когда эти другие вспомогательные подобласти кодового слова будут переданы, приемник может переключиться в режим ожидания, экономя энергию батареи и время обработки.
Данный вариант осуществления может быть дополнительно разработан таким образом, что преобразователь данных будет выполнен с возможностью отображения по меньшей мере двух вспомогательных подобластей кодового слова для кодового слова на упомянутый выходной поток данных передатчика таким образом, что подобласть вспомогательного кодового слова, используемая в качестве первого приращения избыточности, будет принята приемником после приема соответствующей основной области кодового слова, но до приема дополнительных вспомогательных подобластей кодового слова. Такой вариант осуществления обеспечивает то, что приемник можно переключать в режим ожидания после приема достаточного количества вспомогательных подобластей кодового слова для обеспечения правильного декодирования, если, как предложено, “наиболее полезные” вспомогательные подобласти кодового слова (например, наибольшие вспомогательные подобласти кодового слова) будут переданы первыми. В другом варианте осуществления вспомогательные подобласти кодового слова могут быть отображены на выходной поток передатчика таким образом, что первая малая вспомогательная подобласть кодового слова будет представлена, и что после этого будут предоставлены вспомогательные подобласти кодового слова с увеличением размера.
Последовательность подобластей вспомогательного кодового слова предпочтительно может быть выведена приемником из последовательности соответствующих основных областей кодового слова, переданных ранее, таким образом, что не требуется передача дополнительных сигналов для передачи сигналов последовательности вспомогательных подобластей кодового слова, например, последовательности вспомогательных подобластей кодового слова идентичны уже известной последовательности соответствующих основных областей кодового слова.
Кроме того, если во фреймах (например, T2 фреймах), которые предшествуют фрейму (например, фрейму FEF), содержащему вспомогательные подобласти кодового слова, содержатся данные из различных входных потоков данных передатчика (например, PLP), вспомогательные подобласти кодового слова могут быть сгруппированы таким образом, что, например, наибольшие или наименьшие подобласти всех вспомогательных областей кодового слова будут переданы первыми, и что после этого будут переданы дополнительные группы подобластей.
В общем, основные области кодового слова и вспомогательные области кодового слова отображают на выходной поток данных передатчика таким образом, что основная область кодового слова для кодового слова будет принята приемником перед тем, как будет принята соответствующая вспомогательная область кодового слова. В качестве альтернативы, однако, преобразователь данных выполнен с возможностью отображения основных областей кодового слова и вспомогательных областей кодового слова на фреймы выходного потока данных передатчика таким образом, что вспомогательная область кодового слова для кодового слова будет принята приемником до того, как будет принята соответствующая основная область кодового слова. Вспомогательные области кодового слова, таким образом, размещают в буфер в приемнике, используя соответствующий буфер. Если понятно, что декодирование соответствующего кодового слова на основе только основной области кодового слова было правильным, соответствующая вспомогательная область кодового слова (если имеется) может быть удалена из буфера. Даже если декодирование на основе основной области кодового слова не будет правильным, соответствующая вспомогательная область кодового слова уже будет доступна в буфере. Это обеспечивает преимущество, состоящее в том, что отсутствует или уменьшается время ожидания (для ожидания вспомогательной области четности, если декодирование было выполнено с ошибкой на основе основной области кодового слова), что особенно важно для уменьшения времени на переключение каналов и для мобильных приемников в случае внезапных искажений сигнала. Следовательно, данный вариант осуществления также обеспечивает преимущество, состоящее в том, что не возникает прерывание обслуживания (из-за ожидания приема вспомогательных областей кодового слова) в случае (например, внезапных) плохих условий приема основных областей кодового слова.
В соответствии с другим вариантом осуществления вход данных выполнен с возможностью приема по меньшей мере двух входных потоков данных передатчика, сегментированных во входные слова данных, и кодер выполнен с возможностью избирательного кодирования входного потока данных передатчика только в соответствии с первым кодом, в соответствии со вторым кодом или в соответствии с обоими кодами. Следовательно, в соответствии с этим вариантом осуществления передатчик, например, под управлением оператора системы для системы широковещательной передачи имеет свободу применения идеи настоящего изобретения, для обеспечения последовательного приращения избыточности в выходном потоке данных передатчика только для выбранных входных потоков данных передатчика, но чаще всего применяет его для всех входных потоков данных передатчика. Например, оператор системы может решить применять настоящее изобретение для потоков данных, которые предоставляют для приема как стационарным приемником, так и мобильным приемником, в то время как другие потоки данных, которые, в общем, должны быть приняты только стационарными приемниками, не будут обработаны в соответствии с настоящим изобретением, то есть вспомогательные области кодового слова не будут сгенерированы и переданы.
В общем поток выходных данных передатчика может быть передан передатчиком любого вида, например, имеющим только одну антенну или множество антенн, таких как, например, используются в системах MIMO (множество входов - множество выходов). В предпочтительном варианте осуществления, однако, преобразователь данных выполнен с возможностью отображения основных областей кодового слова для кодовых слов на первый выходной поток данных передатчика и для отображения вспомогательных областей кодового слова для кодовых слов на второй выходной поток данных передатчика, и модуль передатчика содержит предварительный кодер MIMO для предварительного кодирования MIMO упомянутых первого и второго выходных потоков данных и по меньшей мере две антенны, включающие в себя первую антенну и вторую антенну для передачи упомянутых предварительно кодированных MIMO первого и второго выходных потоков данных передатчика. Например, предварительный кодер MIMO выполнен с возможностью пространственного мультиплексирования таким образом, что первая антенна передает упомянутый первый выходной поток данных передатчика, и вторая антенна передает упомянутый второй выходной поток данных передатчика. В общем, однако, любой другой вариант осуществления предварительного кодирований MIMO (например, предварительное кодирование Аламоути) также может применяться для двух выходных потоков данных передатчика перед выводом их двумя или больше антеннами системы MIMO.
Приемник также может иметь только одну антенну или множество антенн, в котором, в общем, каждая антенна приемника принимает сигналы от всех антенн передатчика. Однако также возможно, чтобы, в общем, антенны приемника были настроены для приема сигналов только от первой антенны (то есть для приема первого выходного потока данных передатчика) и чтобы только в случае проблем с декодированием или ошибок антенны были дополнительно настроены для приема сигналов от второй антенны (для приема второго выходного потока данных передатчика). В соответствии с дополнительным вариантом осуществления возможно, чтобы приемник содержал одну антенну, которая настроена на первую антенну передатчика, и чтобы приемник содержал вторую антенну, которая настроена для приема сигналов от второй антенны передатчика, и чтобы сигналы, принятые второй антенной, оценивали только в случае необходимости.
В дополнительном варианте осуществления передатчик содержит модулятор, предназначенный для модуляции основной области кодового слова для кодового слова по-другому, чем вспомогательной области кодового слова того же кодового слова перед или после отображения кодовых слов на фреймы выходного потока данных передатчика. В общем, вспомогательная область кодового слова может быть передана в любых измерениях, которые являются ортогональными основной области кодового слова для кодового слова, таких как время, частота, пространство (MIMO) или код расширения. Термин “ортогональный” следует понимать, как общеизвестный в области кодирования и модуляции, то есть для обеспечения отдельных потоков данных (которые даже могут накладываться перед их разделением, такие как поднесущие OFDM и их соответствующие частичные спектры). Это обеспечивает преимущество, состоящее в том, что вспомогательная область кодового слова будет дополнительно защищена от нарушений, которые могут воздействовать на основную область кодового слова. Другая возможность состоит в использовании иерархической модуляции. В этом случае основная область кодового слова обращается к большому количеству надежных битов схемы модуляции, в то время как вспомогательная область кодового слова обращается к менее надежным битам.
Краткое описание чертежей
Эти и другие аспекты настоящего изобретения более подробно поясняются ниже со ссылкой на варианты осуществления, описанные ниже. На следующих чертежах:
на фиг.1 схематично показана блок-схема варианта осуществления передатчика в соответствии с настоящим изобретением,
на фиг.2 схематично показана блок-схема первого варианта осуществления кодера, используемого в передатчике,
на фиг.3 показана компоновка области данных, основной области четности и вспомогательной области четности в соответствии с настоящим изобретением,
на фиг.4 показан формат BBFrame в соответствии со стандартом DVB-T2,
на фиг.5 показан формат кодового слова FEC в соответствии со стандартом DVB-T2,
на фиг.6 показан формат кодового слова в соответствии с настоящим изобретением,
на фиг.7 показана схема, поясняющая структуру формирования фрейма DVB-T2,
на фиг.8 показана схема, поясняющая компоновку фреймов T2 и фреймов FEF в пределах суперфрейма в соответствии со стандартом DVB-T2,
на фиг.9 схематично показана блок-схема второго варианта осуществления кодера,
на фиг.10 схематично показана блок-схема третьего варианта осуществления кодера,
на фиг.11 показана компоновка вспомогательных областей четности в соответствии с настоящим изобретением,
на фиг.12 показано отображение PLP данных на фрейм Т2 в соответствии со стандартом DVB-T2,
на фиг.13 показано отображение сегментированных вспомогательных областей четности на кадр FEF,
на фиг.14 схематично показана блок-схема четвертого варианта осуществления кодера,
на фиг.15 схематично показана блок-схема приемника,
на фиг.16 схематично показана блок-схема первого варианта осуществления декодера, используемого в приемнике,
на фиг.17 схематично показана блок-схема второго варианта осуществления декодера,
на фиг.18 схематично показана блок-схема системы широковещательной передачи в соответствии с настоящим изобретением,
на фиг.19 показана схема, поясняющая генерирование битов кодового слова в соответствии с настоящим изобретением,
на фиг.20 показана структура фрейма передачи, используемая в соответствии с DAB,
на фиг.21 показана блок-схема другого варианта осуществления приемника,
на фиг.22 показана блок-схема другого варианта осуществления кодера в соответствии с настоящим изобретением,
на фиг.23 показана таблица адресов, зависимая от скорости кода для расширенного кода, используемого для генерирования битов четности в соответствии с настоящим изобретением,
на фиг.24 показана схема, поясняющая рабочую характеристику расширенного кода, предложенного в соответствии с настоящим изобретением,
на фиг.25 показана блок-схема другой системы передачи данных,
на фиг.26 показана блок-схема приемника, используемого в такой системе передачи данных, и
на фиг.27 показана расширенная матрица проверки на четность LDPC в соответствии с настоящим изобретением.
Осуществление изобретения
На фиг.1 показан пример блок-схемы передатчика 10 в соответствии с настоящим изобретением. Такой передатчик 10, например, может представлять собой OFDM кодированный передатчик (COFDM), который можно использовать для передачи видеоданных, изображений и аудиосигналов в соответствии со стандартом DVB-T2 (или будущим стандартом DVB-NGH) и в котором может использоваться изобретение. Упомянутые данные, предназначенные для передачи передатчиком 10, в общем, предоставляются, как по меньшей мере один входной поток I1, I2…, In данных передатчика, причем эти потоки данных, в общем, сегментированы на входные слова данных. Упомянутые входные потоки I1, I2…, In данных передатчика могут представлять собой один или больше (например, MPEG 2) транспортного потока (потоков) и/или один или больше общего потока (потоков), и данные могут переноситься в них в индивидуальных магистралях физического уровня PLP.
Из входа 12 данных, в котором может быть предварительно выполнена определенная входная обработка для входных потоков I1, I2…, In данных передатчика такая, как кодирование CRC (циклическая проверка избыточности), вставка заголовка BB (основной полосы пропускания), вставка заполнения и скремблирование BB, входные данные предоставляют на кодер 14, в котором входные слова данных из входных потоков I1, I2…, In данных передатчика кодируют в кодовые слова, как поясняется более подробно ниже. От кодера 14 кодированные данные затем предоставляют на преобразователь 16 данных для отображения генерируемых кодовых слов во фреймы выходного потока О данных передатчика, которые затем выводятся модулем 18 передатчика. В общем (но не в обязательно), модулятор 17 предусмотрен для модуляции данных перед выводом и передачей.
На фиг.2 представлен первый вариант 141 осуществления кодера 14, в соответствии с настоящим изобретением. Упомянутый вариант 141 осуществления кодера содержит два ответвления, то есть два модуля 20, 30 кодирования, на которые подают входной поток I1 данных передатчика, называемые магистралью физического уровня (PLP) в контексте DVB. За исключением перемежителей 27, 37 по времени, обработка предпочтительно выполняется для фиксированного уровня фрейма. Входной фрейм входного потока I1 данных передатчика, который будет рассмотрен в дальнейшем, как пример, обозначается, как BBFrame в контексте DVB.
Первый модуль 20 кодирования, то есть верхнее ответвление в данном варианте осуществления, соответствует цепочке кодирования с перемежением битов и модуляции (BICM), как описано в стандарте DVB-T2. Следовательно, он содержит блок 21 кодирования FEC для последовательного кодирования LDPC, перемежитель 22 битов, демультиплексор 23 для демультиплексирования битов в ячейки, преобразователь 24 совокупности сигналов для отображения ячеек для совокупностей сигналов в соответствии с отображением Грэя, модуль 25 для поворота совокупности сигналов и циклической Q-задержки, перемежитель 26 ячейки и перемежитель 27 времени. Функции и работа этих модулей 21-27 являются общеизвестными и, например, описаны в стандарте DVB-T2, который здесь представлен по ссылке, таким образом, что никакие дополнительные пояснения здесь не представлены.
Во второй модуль 30 кодирования, то есть в нижнее ответвление, также подают входной поток I1 данных передатчика в данном варианте осуществления. Блок 31 кодирования FEC, в общем, не идентичен блоку 21 кодирования FEC первого модуля 20 кодирования. В то время, как упомянутый блок 21 кодирования FEC прикрепляет биты четности к входным словам данных кодового слова LDPC, упомянутые биты четности LDPC, которые здесь, в общем, называются основной областью четности первого кода, блок 31 кодирования FEC генерирует дополнительную избыточность для повышения надежности общего кода канала, причем упомянутый общий код канала называется избыточностью как из блоков 21 кодирования FEC, так и из блоков 31 кодирования FEC. Другими словами, блок 31 кодирования FEC генерирует вспомогательные биты четности, которые могут в дополнение к основным битам четности, использоваться приемником для декодирования принимаемого кодового слова, как поясняется более подробно ниже.
Последовательные блоки 32-37, в общем, могут быть идентичными блокам 22-27 и, таким образом, могут быть приняты в соответствии со стандартом DVB-T2, но также могут быть отрегулированы в соответствии с конкретными обстоятельствами и потребностями второго модуля 30 кодирования. Применение перемежителя 37 по времени является необязательным, поскольку применение перемежения по времени в пределах только одного кадра вспомогательных битов четности уже охвачено перемежителем 36 ячейки. Однако применение перемежения по времени по более, чем одному фрейму вспомогательных данных четности позволяет обеспечить большее разнесение по времени.
В данном варианте осуществления вход двух блоков 21, 31 кодирования FEC идентичен, в частности, потоку I1* входных данных, который, по существу, соответствует входному потоку данных передатчика, но в котором к входным словам данных (BBFrames в контексте DVB) были добавлены биты четности кодового слова ВСН кодером 40 ВСН (как общеизвестно в области DVB). Следовательно, входной поток I1 данных уже был кодирован кодом ВСН, перед тем, как дальнейшее кодирование будет выполнено в кодерах 21 и 31 FEC. Следует, однако, отметить, что кодер 40, в общем, является несущественным элементом в настоящем изобретении. В определенном варианте применения кодер 40 может быть полностью исключен, может быть заменен другим кодером, или это исходное кодирование может представлять собой часть кодирования, выполняемого кодерами 21 и 31.
Кроме того, следует отметить, что ниже, в общем, упоминаются “биты” четности и “биты” входных данных. Та же идея, однако, также применима при использовании “байтов” четности и “байтов” входных данных или, в общем, “символов” четности и “символов” входных данных.
Выходные данные первого и второго модулей 20, 30 кодирования подают на преобразователь 16 данных, в общем, включающий в себя построитель фрейма, и, в случае необходимости, генератор OFDM. Преобразователь 16 данных и генератор OFDM, в общем, могут работать в соответствии со стандартом DVB-T2, который, в частности, представляет варианты осуществления этих блоков. Для отображения выходных данных первого и второго модулей 20, 30 кодирования, однако, существуют разные варианты осуществления, которые также более подробно поясняются ниже.
Со ссылкой на фиг.3 более подробно поясняется кодирование, выполняемое блоками 21 и 31 кодировании FEC. На фиг.3A показано первое кодовое слово Z1, которое представляет собой выходные данные блока 21 кодирования FEC. Упомянутое первое кодовое слово Z1 содержит область D данных, которая, в общем, соответствует входному слову данных блока 21 кодирования FEC и который в соответствии с данным вариантом осуществления содержит k входных битов s1, s2…, sk данных, и основная область Pb четности, содержащая в данном варианте осуществления m битов p1, p2…, pm четности. Такое первое кодовое слово Z1, в общем, соответствует в контексте DVB-T2 кодовому слову LDPC, принадлежащему коду C1 со скоростью R1=k/(k+m) кода, где k представляет собой количество s систематических битов (битов входных данных) и m представляет собой количество основных битов p четности. При использовании таких кодовых слов приемник, в частности стационарный приемник и/или мобильный приемник, на который слабо влияют нарушения, может декодировать входные данные, кодированные в нем.
Второе кодовое слово Z2, показанное на фиг.3B, принадлежит второму коду С2 с меньшей скоростью R2=k/(k+m+v)<R1 кода. Упомянутое второе кодовое слово Z2 содержит в дополнение к области D данных и основной области Pb четности, вспомогательной области Pa четности, v вспомогательных битов i1, i2…, iv четности. Упомянутая вспомогательная область Pa четности может использоваться приемником, например, в случае ошибок передачи, ошибок декодирования и/или недостаточного качества декодирования, как при последовательном приращении избыточности в дополнение к кодовому слову Z1, для декодирования. Следовательно, если первое кодовое слово Z1 не может быть декодировано правильно в приемнике, некоторые или все вспомогательные биты i1, i2…, iv четности могут использоваться для декодирования, в дополнение к первому кодовому слову Z1, для повышения вероятности правильного и безошибочного (или по меньшей мере повышенного качества) декодирования. С этой целью по меньшей мере вспомогательная область Pa четности также будет отображена на выходной поток данных передатчика для приема их, в конечном итоге, и использования в приемнике. Упомянутое отображение более подробно поясняется ниже.
Следовательно, комбинацию кодового слова Z1 и вспомогательной области Ра четности (второго кодового слова Z2) также можно рассматривать как “полное” кодовое слово “полного” кода, имеющего более низкую скорость кода, чем у первого кода кодового слова Z1, то есть кодовое слово Z1 можно рассматривать как основную область В кодового слова этого “полного” кодового слова, и вспомогательную область Ра четности можно рассматривать как вспомогательную область четности этого “полного” кодового слова. Здесь, в данном варианте осуществления, показанном на фиг.3, такое “полное” кодовое слово идентично кодовому слову Z2. Это, однако, не относится ко всем вариантам осуществления, как будет показано ниже.
В контексте DVB-T2 входной поток данных передатчика в кодер 14 обычно сегментируют на фреймы, называемые BBFrames, содержащие Kbch битов, как, например, представлено на фиг.4. Первое кодовое слово Z1 (в данном контексте), сгенерированное из него кодером 40 ВСН, и первый блок 21 кодирования, то есть в соответствии с кодированием, выполняемым в соответствии со стандартом DVB-T2, схематично представлены на фиг.5. Такое кодовое слово представляет собой стандартное кодовое слово FEC, содержащее (систематическую) входную область данных, которая сама содержит Kbch битов, поле которых следуют Nbch-Kbch битов четности кодера BCH, после которых следуют Nldpc-Kldpc битов четности кодера DPC. В общем, такое кодовое слово содержит Nldpc битов. Следовательно, основной код LDPC имеет скорость кода Re=Kldpc/Nldpc. Как представлено выше в пояснениях со ссылкой на фиг.3 и 4, Kldpc соответствует k (то есть области BBFRAME и BCHFEC рассматриваются, как входные слова D данных) и Nldpc соответствуют k+m (то есть область LDPCFEC рассматривается как основная область Pb четности).
Второй блок 31 кодирования содержит вспомогательные биты четности, предназначенные для использования как последовательное приращение избыточности, на основе его входных данных, которые, в общем, представляют собой те же, что и входные данные блока 21 кодирования FEC. В общем, имеются v вспомогательных битов четности, которые могут быть разделены на q подобластей (следует отметить, что в основном аспекте настоящего изобретения используется только одну подобласть). К подобластей имеют длину v(k). Таким образом, будет справедливым
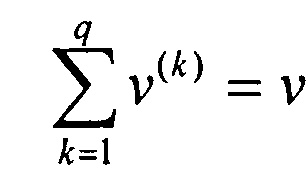 .
.
Если биты из первых x подобластей затем приложить к первому основному кодовому слову (Z1), генерируемому первым модулем 20 кодирования, и, в общем, принятому и оцененному приемником, генерируют вспомогательное кодовое слово (Z3*) “полного” кода, которое выводят из кодера с общей скоростью Rc* кода, равной
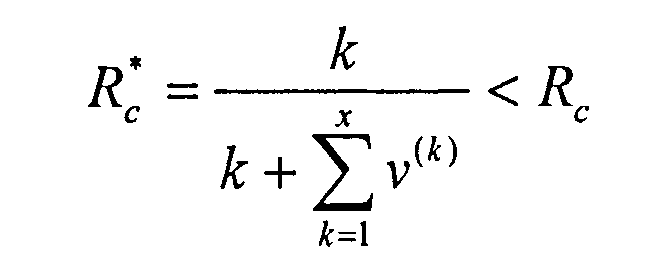
которая меньше, чем Rc, что означает, что этот общий код является более мощным.
На фиг.6 показан такой вариант осуществления кодового слова Z2 (в контексте DVT-T2), генерируемый вторым блоком 31 кодирования FEC, который в соответствии с этим вариантом осуществления также содержит кодирование ВСН и LDPC, но, кроме того, генерирует v вспомогательных битов четности для использования в случае необходимости в качестве последовательного приращения избыточности в приемнике.
Генерирование дополнительных битов четности LDPC, например, известного кода LDPC, и их использование в качестве последовательного приращения избыточности является общеизвестным, например, из публикации Kim J. et al. „Design of Rate-Compatible Irregular LDPC Codes for Incremental Redundancy Hybrid ARQ Systems”, ISIT 2006, Seattle, USA, July 9-14, 2006. Схема, иллюстрирующая такой “расширенный” код и его генерирование, показана на фиг.19. Здесь представлено, как каждый из битов основной области B кодового слова и вспомогательной области A четности генерируют из других, в частности всех “предыдущих”, битов в кодовом слове путем использования модулей 45 по модулю-2. Такой способ генерирования кодового слова обеспечивает то, что декодер может декодировать кодовое слово, используя только основную область B кодового слова или путем дополнительного использования одного или более вспомогательных битов четности вспомогательной области A четности. Ниже подробно поясняются конкретные способы генерирования битов четности LDPC в соответствии с предпочтительными вариантами осуществления настоящего изобретения.
Далее поясняется вариант осуществления преобразователя 16 данных. В общем, достаточно, чтобы первое кодовое слово (в общем, основная область B кодового слова), генерируемое первым модулем 20 кодирования, и вспомогательная область четности (в общем, вспомогательная область A кодового слова), генерируемая вторым модулем 30 кодирования для одного и того же входного слова данных, были отображены любым способом на фреймы выходного потока О данных передатчика. Другими словами, используя терминологию, представленную на фиг.3, для каждого входного слова данных соответствующую область D данных, основную область Pb четности и вспомогательную область Ра четности отображают на выходной поток О данных передатчика, в соответствии с настоящим изобретением. Предпочтительно, однако, преобразователь 16 данных выполнен таким образом, что область D данных и основная область Pb четности отображаются на разные области, например на другие фреймы, чем соответствующая вспомогательная область Pa четности того же кодового слова. Это обеспечивает преимущество, состоящее в том, что регулярные нарушения в канале, в общем, не будут влиять одновременно на область D данных и на основную область Pb четности, с одной стороны, и вспомогательную область Pa четности, с другой стороны.
Конкретный вариант осуществления для такой структуры отображения иллюстрируется со ссылкой на фиг.7 и 8. На фиг.7 иллюстрируется структура фреймов, применяемая в соответствии со стандартом DVB-T2. В частности, в соответствии с DVB-Т2, применяется структура суперфрейма, где каждый суперфрейм подразделяют на множество фреймов T2. После каждого заданного количества последовательных фреймов T2 область FEF (область будущего расширения фрейма) вставляют для будущего использования. Это также схематично представлено для структуры потока данных, показанной на фиг.8. При применении такой структуры формирования фреймов в передатчике 10, в соответствии с настоящим изобретением преобразователь 16 данных выполнен в одном варианте осуществления таким образом, что область данных и основная область четности кодового слова, которую также можно рассматривать как основную область B кодового слова и, в данном варианте осуществления, основное кодовое слово Z1 (см. фиг.3A), отображаются на фреймы T2 и, что вспомогательная область Ра четности (в общем, вспомогательная область A кодового слова) того же самого кодового слова (взятого из вспомогательного кодового слова Z2) отображается на область FEF, предпочтительно, область FEF, следующую рядом с фреймом (фреймами) T2, на который отображены соответствующие области D данных и основная область Pb четности.
Такое отображение обеспечивает преимущество, состоящее в том, что обычный приемник в соответствии со стандартом DVB-T2 просто игнорирует данные, передаваемые в областях FEF, и оценивают только данные, переданные во фреймах T2, как обычно. Мобильные приемники, однако, например, в соответствии с будущим стандартом DVB-NGH, на возможную способность декодирования и воспроизведения которых часто могут влиять нарушения, могут также обращаться к фреймам T2 и декодировать на первом этапе кодовые слова, встроенные в них. Кроме того, однако, в частности, в случае возникновения нарушений и полученных в результате ошибок декодирования, такие мобильные приемники обращаются к областям FEF и используют область или все вспомогательные данные четности, содержащиеся в них, для декодирования на втором этапе, кодовое слово принимают снова в соответствии с фреймом T2, как поясняется более подробно ниже.
В соответствии с еще одним, другим вариантом осуществления преобразователя 16 данных все данные, требуемые для декодирования мобильным приемником, передают в областях FEF, то есть полное кодовое слово, содержащее область D данных, основную область Pb четности и вспомогательную область Pa четности отображают на область FEF. Такие мобильные приемники, таким образом, игнорируют данные, содержавшиеся во фреймах T2, доступ к которым обеспечивается только стационарными приемниками, в частности приемниками в соответствии со стандартом DVB-T2.
Однако в такой ситуации вспомогательную область Pa четности предпочтительно модулируют по-другому, чем область D данных и основную область Pb четности. Предпочтительно вспомогательный код модуляции применяют для модуляции вспомогательных областей четности, упомянутый вспомогательный код модуляции является ортогональным основному коду модуляции, который используется для модуляции областей данных и основных областей четности, в общем, после отображения данных. Например, можно применять ортогональные время, частоту, пространство (MIMO) или код расширения. Другая возможность могла бы состоять в применении иерархической модуляции.
Конечно, могут быть представлены дополнительные варианты осуществления преобразователя 16 данных. Структура формирования фреймов, применяемая передатчиком 10, также может абсолютно другой, чем структура формирования фреймов, используемая в соответствии со стандартом DVB-T2, показанным на фиг.7 и 8. В общем, любая структура формирования фреймов, например вновь сформированная структура фреймов, может применяться, если только приемник имеет возможность обнаруживать или знать заранее, где искать область данных и различные области четности. Кроме того, в вариантах осуществления изобретения кодирование ВСН и LDPC не требуется, но можно применять другие коды (например, другие коды FEC).
Упрощенная блок-схема другого варианта осуществления кодера 142 и преобразователя 16 данных показана на фиг.9. В соответствии с этим вариантом осуществления кодер 142 содержит один модуль кодирования, с помощью которого кодируют входные слова данных, то есть с помощью которого генерируют как основные области Pb четности, так и вспомогательные области Ра четности. Другими словами, в упомянутом одном модуле кодирования кодера 142 генерируется полное кодовое слово Z2 (см. фиг.3B). Эти кодовые слова Z2 подают на преобразователь 16 данных, который разделяет вспомогательную область Ра четности и отображает ее на другую область выходного потока данных передатчика, чем область D данных, и основную область Pb четности. Для преобразователя 16 данных, в общем, существуют такие же варианты осуществления, как пояснялись выше.
Как показано на фиг.1 вход 12 данных может быть выполнен с возможностью не только принимать один входной поток данных передатчика, но и может, в общем, принимать множество n входных потоков данных передатчика, например множество n магистралей физического уровня. Кодер 14 может, в таком случае, однако, быть выполнен с возможностью выбора, кодирован ли входной поток данных передатчика, как обычно, то есть в соответствии с основным кодом и без генерирования каких-либо вспомогательных данных четности, или можно ли применять другой код, имеющий более низкую скорость кода, и должны ли быть сгенерированы вспомогательные данные четности для использования в качестве последовательного приращения избыточности приемником. Также возможно, что различные коды с разными (например, снижающимися) скоростями кода могут быть доступными для применения кодером таким образом, чтобы существовали даже более, чем две возможности. Какой код и какую скорость кода требуется применять, может быть предписано заранее, например, оператором передатчика или владельцем канала широковещательной передачи. Но выбор кода также может зависеть от вида данных, которые должны быть переданы. Например, аудиоданные могут быть кодированы с кодом, имеющим более высокую скорость кода, чем видеоданные, таким образом, что только для видеоданных генерируют такие вспомогательные данные четности или наоборот. В качестве другого примера любые ошибки декодирования могут быть приемлемыми при просмотре новостей, но могут быть неприемлемыми при просмотре кинофильма, для которого вспомогательные данные четности могут быть, таким образом, сгенерированы и переданы.
Еще один дополнительный вариант осуществления кодера 143 показан на фиг.10. Упомянутый кодер 143 выполнен таким образом, что он генерирует две или более вспомогательные подобласти Pa1, Pa2, Ра3 четности в дополнение к области данных D и основной области Pb четности, формируя, таким образом, кодовое слово Z3. Следовательно, сравнивая кодовые слова Z2 и Z3, вспомогательные подобласти Pa1, Pa2, Ра3 четности кодового слова Z3 можно рассматривать как сегменты вспомогательной области Ра четности кодового слова Z2, имеющие, в общем, идентичное содержание, хотя, в общем, вспомогательные подобласти Ра2 и Ра3 четности также могут представлять собой дополнительные вспомогательные области четности в дополнение к вспомогательной области Pa1 четности, которая (сама по себе) соответствует вспомогательной области Pa четности.
Эти вспомогательные подобласти Pa1, Ра2, Ра3 четности генерируют таким образом, что они могут быть шаг за шагом использованы декодером, как последовательное приращение избыточности. Другими словами, в общем, возможно декодировать кодовое слово путем использования только области D данных и основной области Pb четности (то есть основной области кодового слова). Если такое декодирование будет неудачным, первая вспомогательная подобласть Pa1 четности (то есть часть вспомогательной области кодового слова) может использоваться в дополнение к декодированию. Если это, в свою очередь, приведет к неудаче (или обеспечит недостаточное качество), может быть добавлена вторая вспомогательная подобласть Ра2 четности и так далее.
Все вспомогательные подобласти Pa1, Ра2, Ра3 четности могут быть сгруппированы вместе и могут быть отображены на одну область выходного потока данных передатчика. Однако также возможно и предпочтительно распределять различные вспомогательные подобласти четности одного кодового слова Z3 так, что первая вспомогательная подобласть Pa1 будет принята перед второй вспомогательной подобластью Ра2 четности, которая, в свою очередь, будет принята перед третьей вспомогательной областью Ра3 четности. Это обеспечивает преимущество, состоящее в том, что приемник, который после использования первой вспомогательной подобласти четности может декодировать кодовое слово с достаточным качеством, может перейти в режим ожидания на период времени, в течение которого передают другие вспомогательные подобласти четности, которые больше не требуются и/или из других потоков данных, которые в настоящее время не требуется декодировать. Это обеспечивает определенную экономию энергии питания и меньшие объемы вычислений в приемнике.
Вариант осуществления компоновки вспомогательных подобластей четности различных входных фреймов (BBFrames, в общем, называемых входными словами данных) показан на фиг.11. Входные фреймы нумеруют в этом варианте осуществления, используя два индекса (е, f), где индекс е соответствует PLP_ID (номер PLP, также называемый здесь номером входного потока данных передатчика) и где f относится к входному фрейму (входное слово данных). Индекс е представляет собой участок набора S2, то есть наборов PLP, которые защищены дополнительным приращением избыточности. Предполагая, что передают n разных PLP, то есть е ∈ S1={1…, n}, S2 представляет собой поднабор S1 PLP, который защищен дополнительным последовательным приращением избыточности в соответствии с настоящим изобретением, поскольку, как упомянуто выше, не все PLP обязательно используют эту идею.
Таким образом, f-й входной фрейм е-ого PLP обозначен как Ie, f. Индекс f∈{1…, Fe}, где Fe представляет собой количество входных фреймов е-ого PLP, которые предшествуют FEF, начиная от конца предыдущего FEF. Следовательно, в одном варианте осуществления вспомогательные подобласти четности Pa1e, f вплоть до Paye, f могут быть отображены на фрейм FEF в последовательности, как показано на фиг.11, и могут принадлежать кодовым словам, отображенным на предыдущие T2 фреймы.
На фиг.12 иллюстрируется больше деталей компоновки данных в пределах фрейма T2 в соответствии со стандартом DVB-T2. PLP во фрейме T2 расположен в определенном порядке. После преамбул P1, P2 и после общих PLP передают PLP 1 типа без дополнительной нарезки, затем PLP 2 типа передают с дополнительной нарезкой. Оба PLP типа 1 и типа 2 имеют фиксированный порядок, который передают как сигналы в преамбуле P2. Это также подробно иллюстрируется в стандарте DVB-T2, пояснение которого представлено здесь по ссылке.
На фиг.13 показано предложение по размещению вспомогательных подобластей четности во фрейме FEF, которые выполнены аналогично компоновке PLP во фрейме T2. В этом варианте осуществления FEF также начинается с преамбулы P1, то есть символа OFDM, который выполнен с возможностью его использования для целей синхронизации (время, частота) для оценки канала и для передачи сигналов с наиболее важными параметрами передачи. Последующая (одна или больше) преамбула (преамбулы) P2 содержит (содержат) более подробную информацию о содержании FEF. Используя обозначение, пояснявшееся со ссылкой на фиг.11 и, предполагая, что существуют два PLP по три входных фрейма каждый, компоновка вспомогательных подобластей четности в FEF в данном варианте осуществления выполнена таким образом, что порядок разделенных вспомогательных подобластей четности выводят из нарезки/порядка фреймов T2, даже если не все PLP из фреймов T2 должны отображать вспомогательные подобласти четности на FEF. Таким образом, порядок вспомогательных подобластей четности не должен быть передан в виде сигнала в явном виде.
Вспомогательные области четности сортируют в области времени, в частности таким образом, что первую область Pa1e, f, например, более надежную область среди всех PLP, имеющую вспомогательные области четности, вставляют в начале FEF, то есть непосредственно после преамбул P1, P2. Вторая область Ра2 всех PLP со вспомогательными областями четности следует после этого и т.д. Как упомянуто выше, если основные кодовые слова не будут декодированы, выполняют оценку соответствующей первой области Pa1 FEF. Если приемник теперь может правильно декодировать общее кодовое слово без ошибки, он переходит в режим ожидания для экономии электроэнергии. В противном случае он дополнительно включает в себя вторую вспомогательную область Ра2 четности и т.д.
Следует отметить также, что FEF могут содержать информацию сигнала, например, в преамбуле или в заголовке ModCod, в отношении ссылки вспомогательных областей четности, используемых в FEF и PLP, отображенных на фреймы T2 (которые сами по себе остаются без изменения в данном варианте осуществления). Кроме того, другие данные также могут содержаться в FEF, например информация с низкой скоростью передачи битов для использования мобильным приемником.
На фиг.14 показан еще один, другой вариант осуществления 144 кодера в соответствии с настоящим изобретением. Аналогично варианту осуществления, показанному на фиг.2, кодер 144 содержит первый модуль 20 кодирования, предназначенный для кодирования в соответствии с упомянутым первым кодом входного слова данных в упомянутое основное кодовое слово Z1, как пояснялось выше. Кроме того, второй модуль 30а кодирования предусмотрен для кодирования в соответствии с упомянутым вторым кодом входного слова данных во вспомогательной области кодового слова (которая может рассматриваться, как вспомогательное кодовое слово Z4), содержащий только упомянутую вспомогательную область Ра четности. Следовательно, второй модуль 30а кодирования генерирует только данные, необходимые в конечном итоге для улучшения декодирования в декодере, если это требуется, но не генерирует другие области кодового слова, которые уже были сгенерированы первым модулем 20 кодирования.
На фиг.15 схематично показана блок-схема приемника 50, предназначенного для использования в системе широковещательной передачи, содержащей передатчик 10, как показано выше. Приемник 50, в частности, выполнен с возможностью использовать вспомогательную область четности (в общем, вспомогательную область кодового слова), как последовательное приращение избыточности, в случае ошибки или плохого качества декодирования.
Приемник 50 содержит вход 52 данных, предназначенный для приема входного потока О′ данных приемника, который, в общем, соответствует выходному потоку О данных передатчика, который был передан через канал широковещательной передачи системы широковещательной передачи с помощью передатчика и на который, таким образом, могли влиять нарушения, которые могли появиться в такой системе широковещательной передачи, в частности, в случае использования мобильных приемников, которые представляют собой основное применение настоящего изобретения на стороне приемника.
В случае необходимости предусмотрен демодулятор 53, который взаимосвязан с (необязательным) модулятором 17 передатчика 10 для демодуляции принятого входного потока О′ данных приемника. Обратный преобразователь 54 выполняет обратное отображение (в случае необходимости, демодулированных) входного потока О′ данных приемника, в частности по меньшей мере областей данных и основных областей четности (то есть основных областей кодового слова) кодовых слов, отображенных на входной поток О′ данных приемника, как более подробно поясняется ниже. Декодер 56 затем декодирует эти кодовые слова, используя основные области кодового слова в соответствии с тем же кодом, который применялся кодером 14 передатчика 10. В частности, в случае значительных нарушений в мобильных приемниках, например, из-за высокой скорости движения приемника, модуль 58 проверки предусмотрен в приемнике 50, с помощью которого проверяют, было ли декодирование выполнено правильно и/или с достаточным качеством, и/или ниже приемлемого уровня ошибки, как поясняется ниже. Если декодирование было выполнено без ошибок или с достаточным качеством, декодированные данные подают на модуль 60 вывода. На его выход может быть подан один или более выходных потоков I1′ I2, ′…, In′ данных приемника, которые должны в максимально возможной степени соответствовать входным потокам I1, I2…, In данных передатчика.
Если, однако, проверка, выполняемая модулем 58 проверки, показывает, что декодирование было выполнено с ошибкой, или что декодированные данные имеют недостаточное качество и, например, могут привести к получению выходного сигнала приемника с шумами (например, недостаточное качество изображения кинофильма), предусмотрен контур 62 обратной связи от модуля 58 проверки на обратный преобразователь 54 и/или на декодер 56 для использования вспомогательной области четности (в общем, вспомогательной области кодового слова) (полностью или частично) для улучшения качества декодирования. Следовательно, в такой ситуации обратный преобразователь 54 затем также выполняет обратное отображение вспомогательной области четности (полностью или части) из (в случае необходимости, демодулированного) входного потока О′ данных приемника. Используя такую дополнительную избыточность, декодер 56 снова декодирует принятые кодовые слова, но теперь применяет код, имеющий более низкую скорость кода, который, таким образом, обладает более высокой устойчивостью в отношении нарушений. Следовательно, существует высокая вероятность того, что качество декодирования будет лучше, чем раньше. В некоторых вариантах осуществления контур 62 обратной связи также предусмотрен от модуля 58 проверки на демодулятор 53, например, если декодером требуются вспомогательные области четности 56 от другого входного потока данных приемника, например, из данных, принимаемых другой антенной в приемнике MIMO или из другого канала (например, используя другую частоту).
После этого, снова может быть выполнена проверка модулем 58 проверки, если декодирование теперь было выполнено без ошибки или с достаточным качеством, и, в противном случае, еще дополнительная часть вспомогательной области четности может использоваться в другой итерации обратного отображение и декодирования. Если, с другой стороны, вся вспомогательная область четности кодового слова уже была полностью использована для декодирования, проверка также может быть исключена, и декодированные данные могут быть выведены непосредственно.
Аналогично, как и в кодере 14 передатчика 10, существуют различные варианты осуществления декодера 56 приемника 50. Первый вариант осуществления 561 декодера 56 схематично представлен на фиг.16. В соответствии с этим вариантом осуществления декодер 561 содержит первый модуль 70 декодирования и второй модуль 80 декодирования, аналогично, как и варианте осуществления кодера 141, представленном на фиг.2. Кроме того, дополнительный декодер 90 (например, декодер ВСН) предусмотрен для декодирования ВСН выхода декодера 561, если соответствующий передатчик, используемый в системе широковещательной передачи, применяет этап кодирования ВСН. Первый модуль 70 декодирования, в общем, соответствует модулю декодирования, используемому в приемниках, в соответствии со стандартом DVB-T2. Он содержит обратный перемежитель 71 по времени, обратный перемежитель 72 ячейки, удалитель 73 циклической задержки, обратный преобразователь 74 совокупности сигналов, обратный перемежитель 75 битов и первый блок 76 декодирования LDPC. Такой декодер, например, более подробно поясняется в документе A133 DVB, February 2009 “Implementation Guidelines for a Second Generation Digital Terrestrial Television Broadcasting System (DVB-T2)”, который здесь приведен по ссылке. В первый модуль 70 декодирования, таким образом, подают области D′ данных и основные области Pb' четности (в общем, основная область B′ кодового слова) после обратного отображения преобразователем 54 из принятого входного потока О′ данных приемника и декодируют, как обычно, эти кодовые слова.
Кроме того, в данном варианте осуществления декодера 561 предусмотрен второй модуль 80 декодирования, который, в основном, содержит те же элементы, в частности обратный перемежитель 81 по времени, обратный перемежитель 82 ячейки, удалитель 83 циклической задержки, обратный преобразователь 84 созвездия сигналов, обратный перемежитель 85 битов и второй блок 86 декодирования, функция которого идентична функции соответствующих элементов первого модуля 70 декодирования. Однако параметры этих блоков могут отличаться, если разные параметры применяют в кодере, например во втором модуле 30 кодирования (см. фиг.2). Второй модуль 80 декодирования, однако, предусмотрен в дополнение к областям D′ данных и основной области Pb′ четности с дополнительной вспомогательной областью Pa′ четности (в общем, вспомогательной областью A′ кодового слова) (полностью или частично) для декодирования кодовых слов с высокой надежностью, используя упомянутую вспомогательную область Pa′ четности, как информацию об избыточности. Следовательно, второй модуль 80 декодирования становится активным только в случае необходимости, например, если “поступает инструкция” от модуля 58 проверки через контур 62 обратной связи. В качестве альтернативы на второй модуль 80 декодирования подают только вспомогательную область A′ кодового слова.
Альтернативный вариант 562 осуществления декодера представлен на фиг.17. В соответствии с этим вариантом осуществления обратный преобразователь 54 получает доступ к T2 фреймам принятого входного потока данных О′ приемника для обратного отображения областей D′ данных и основных областей Pb′ данных из них и получает доступ к фреймам FEF для обратного отображения вспомогательных областей Pa′ четности из них, то есть обратный преобразователь 54 выполнен с возможностью связываться с преобразователем 16, как показано на фиг.9. Декодер 562, однако, содержит только один модуль декодирования, который одновременно выполнен с возможностью декодирования кодовых слов в соответствии с первым кодом (с более высокой скоростью кода) на основе только области D′ данных и основной области Pb′ четности и в соответствии со вторым кодом (с более низкой скоростью кода), используя информацию избыточности (частично ее или всю) вспомогательной области Pa′ четности, если необходимо.
Стандартный декодер LDPC, такой как, например, предусмотрен в DVB-T2, DVB-S2 в комбинации с приемником DVB-T2/S2, DVB-C2 или DVB-NGH, принимает на его входе кодовое слово (при нарушениях в канале передачи), а также информацию сигналов о скорости кода и длине кодовых слов (либо 16200, или 64800 битов и, возможно, также 4320 битов). На основе информации сигналов он применяет соответствующий алгоритм декодирования (обычно, так называемый, итеративный пропуск сообщений) на основе алгоритма с определенной реализацией кода и выводит оценку области данных.
То же относится к расширенному декодеру LDPC, включенному в декодер 56, в частности, расширенному декодеру 76 и 86 LDPC, которые принимают, кроме того, вспомогательную область кодового слова, в частности вспомогательные биты четности. Количество вспомогательных битов обычно передают с сигналами в дополнение к применяемой скорости кода и длине основной области кодового слова на декодер. Учитывая эти параметры, декодер 56 применяет соответствующий алгоритм декодирования на основе такого расширенного (или “всего”) кода.
Как упомянуто выше, в предпочтительном варианте осуществления обратный преобразователь и декодер предпочтительно выполнены с возможностью последовательного добавления большего количества частей (“подобластей”) вспомогательной области четности для улучшения декодирования. Предпочтительно, после того, как достаточное качество декодирования будет достигнуто, обратный преобразователь и декодер выполнены с возможностью перехода в режим ожидания, в то время как другие части (сегментированные; см., например, фиг.13) вспомогательных подобластей подают в принятый входной поток данных приемника, то есть эти дополнительные сегменты вспомогательных подобластей четности предпочтительно не будут обратно отображены и использованы для декодирования. Это, в частности, экономит электроэнергию в приемнике, что является особенно предпочтительным в случае мобильных приемников, в которых используется батарея в качестве источника питания.
Обобщенный декодер LDPC получает в качестве входных данных принятое кодовое слово (с или без дополнительных битов четности), а также информацию сигналов о скорости кодов и длине кодового слова. Последний, кроме того, неявно обновляется через контур 62 обратной связи, который передает сигналы, если (и так же в зависимости от количества) вспомогательные биты четности были прикреплены. В отличие от такого обобщенного декодера декодер LDPC в декодере 56 в соответствии с настоящим изобретением выводит его оценки для каждого бита кода (принятого) кодового слова C′, то есть оценку C” кодового слова C′. Предпочтительно побитные оценки выражены в виде логарифмических отношений вероятности (LLRs), магнитуда которых отражает надежность оценки.
Если модуль 58 проверки определяет, что оценка C”, вероятно, представляет собой переданное кодовое слово C, он выводит (жестко определенные) оценки области D′ данных и устанавливает флаг S в 1, что соответствует успешному декодированию. В противном случае, S=0, что передают по сигналам через контур 62 обратной связи для инициирования прикрепления в виде добавлений вспомогательных битов четности (все еще доступны). Индикатор E из модуля 58 проверки является необязательным и предоставляет оценку того, какое количество дополнительных вспомогательных подобластей четности все еще необходимо. В случае E>1, декодер 56 LDPC даже не должен пытаться декодировать следующее большее кодовое слово, но должен ожидать E дополнительных вспомогательных подобластей четности для повторного начала декодирования.
Критерии для успеха декодирования (S=1) представляют собой следующие:
a) В пределах максимального количества разрешенных этапов обработки декодера (обычно наложено максимальное количество итераций) находят достоверное кодовое слово C” (после жесткого решения).
b) Оценка области D′ данных (может быть выведена из оценки C” или даже включена в С” в случае систематического кода (как в DVB-T2)) может быть декодирована декодером ВСН. Следует отметить, что декодер ВСН также обладает определенными возможностями декодирования ошибок.
c) После декодирования ВСН поток I1′ должен соответствовать BBFrame, заголовок которого (BBHeader) защищен CRC. Если такая проверка будет успешной, вероятность того, что весь BBFrame является правильным, повышается.
d) Предпочтительно надежность всех LLR (логарифмических отношений вероятности) проверяют с помощью модуля 58 проверки. Это может быть выполнено путем усреднения магнитуд всех LLR, принадлежащих кодовому слову. Если такое среднее значение будет больше, чем определенное пороговое значение (что зависит от кода и должно быть определено), успешное декодирования весьма вероятно.
Если S=0, последний критерий (d) также предлагает оценку того, насколько ненадежным является кодовое слово (после декодирования). Предполагая, что следующие вспомогательные области кода имеют аналогичное качество, как и у предыдущего кодового слова, оценка E может быть сделана о том, какое количество дополнительных областей потребуется для успешного декодирования.
Следует отметить, что существуют два способа комбинирования предыдущего кодового слова (которое декодер не смог правильно декодировать) со вспомогательными областями кодового слова:
1) сохраняют предыдущее кодовое слово, которое было введено в декодер, и добавляют вспомогательную область кодового слова на его конце или
2) сохраняют конечную оценку C” декодера 56 LDPC (например, после того, как пройдет максимальное количество итераций) и добавляют вспомогательную область кодового слова на его конце.
В дополнение к вариантам осуществления, пояснявшимся выше, кодер передатчика также может быть выполнен таким образом, что вспомогательная область четности (в общем, вспомогательная область кодового слова) может не (только) содержать “реальную” информацию четности, но что он также может содержать повторение (части или всей) информации “основного” кодового слова, то есть (некоторые или все) биты области D данных и/или основной области Pb четности (то есть основной области кодового слова). Следовательно, в очень простом варианте осуществления вспомогательная область Ра четности просто содержит копию области D данных и/или основную область Pb четности. Это также улучшает декодирование, если основное кодовое слово будет нарушено, но вспомогательная область не будет (или будет в меньшей степени) нарушена. Кроме того, даже если как основная область кодового слова, так и вспомогательная область кодового слова будут нарушены, в результате использования обеих областей для декодирования, результат декодирования может быть улучшен, например, путем применения принципа мягкого комбинирования, например, путем улучшения мягких значений, полученных на первом этапе декодирования, используя только основную область кодового слова на втором этапе декодирования, используя, кроме того, вспомогательную область кодового слова.
Вариант осуществления системы широковещательной передачи в соответствии с настоящим изобретением схематично представлен на фиг.18. Система широковещательной передачи, в общем, содержит передатчик (Тх) 10 и один или больше приемников (Rx) 50a, 50b, 50c. Хотя обычно достаточно, чтобы передатчик 10 имел одну антенну для передачи выходного потока О данных передатчика, здесь в данном варианте осуществления в передатчике 10 предусмотрены две антенны 19a, 19b.
В первом режиме обе антенны можно использовать для одновременной передачи идентичного выходного потока О данных передатчика (или его модифицированного потока, например, в соответствии со схемой Аламоути по стандарту DVB-T2), например, для расширения зоны охвата.
В другом режиме, который, в частности, представлен на фиг.18, преобразователь 161 данных, предусмотренный в этом варианте осуществления передатчика 10, выполнен с возможностью генерирования двух выходных потоков O1 и O2 данных передатчика, в котором области D данных и основные области Pb четности кодовых слов (то есть основные области кодовых слов) отображают на первый выходной поток O1 данных передатчика и в котором вспомогательные области Pa четности кодовых слов (то есть вспомогательные области кодовых слов) отображают на второй выходной поток O2 данных передатчика. В данном варианте осуществления на первую антенну 19а затем может быть подан первый выходной поток O1 данных передатчика для передачи, и на вторую антенну 19b может быть подан второй выходной поток O2 данных передатчика для передачи. Например, во время передачи T2 фреймов передают только первый выходной поток O1 данных передатчика, в то время как во время передачи FEF передают оба выходных потока O1 и O2 данных передатчика.
В еще одном, другом режиме первый выходной поток O1 данных передатчика может быть передан с использованием антенны с горизонтальной поляризацией, в то время, как второй выходной поток 02 данных передатчика может быть передан с использованием антенны с вертикальной поляризацией или наоборот.
В случае необходимости предусмотрен предварительный кодер 162 MIMO, на который подают упомянутый первый и второй выходные потоки O1, O2 данных передатчика из преобразователя 161 данных для предварительного их кодирования в соответствии с любой схемой предварительного кодирования MIMO. Например, первый и второй выходные потоки O1, O2 данных передатчика могут быть пространственно мультиплексированы на предварительно кодированные выходные потоки O1*, O2* данных передатчика, которые затем передают, используя антенны 19а, 19b, или предварительное кодирование Аламоути может применяться к первому и второму выходным потокам O1, O2 данных передатчика. Предварительно кодированные выходные потоки O1*, O2* данных передатчика затем могут оба содержать смесь данных из первого и второго выходных потоков O1, O2 данных передатчика.
В этом варианте осуществления, представленном на фиг.18, в передатчике 10 предусмотрены две антенны 19а, 19b. Следует, однако, отметить, что передатчик, в частности передатчик MIMO, содержит больше, чем две антенны, в которые подают упомянутые предварительно кодированные выходные потоки O1* O2* данных передатчика для передачи.
Первый приемник 50а, имеющий одну антенну 61, может быть выполнен с возможностью приема только первого выходного потока O1 данных передатчика (как первый входной поток O1′ данных приемника), но не второго выходного потока O2 данных передатчика. Такой приемник 50а может представлять собой существующий, например, традиционный или стационарный приемник, который вообще не имеет возможности использования каких-либо вспомогательных областей четности. Например, если передатчик 10, в частности второй выходной поток O2 данных передатчика, направлен для приема мобильными приемниками в соответствии с новым стандартом, например стандартом DVB-NGH, приемник 50а мог бы представлять собой стационарный приемник в соответствии со стандартом DVB-T2.
Другой вариант осуществления приемника 5 Ob содержит две антенны 61a, 61b. В этом варианте осуществления первая антенна 61a выполнена с возможностью приема первого выходного потока O1 данных передатчика (в качестве первого входного потока O1′ данных приемника), и вторая антенна 61b выполнена с возможностью приема второго выходного потока O2 данных передатчика (в качестве второго входного потока O2′ данных приемника). Например, если две антенны 19а, 19b передатчика 10 используют разные каналы передачи, например частоты передачи, эти две антенны 61a, 61b приемника 50b могут быть выполнены с возможностью приема в одном и том же соответствующем канале передачи.
Третий вариант осуществления приемника 50c также имеет одну антенну 61, но выполнен с возможностью приема сигналов от обеих антенн 19а, 19b. Приемник 50c содержит средство для внутреннего разделения или разложения двух принимаемых входных потоков O1′, O2′ данных, соответственно.
Вариант осуществления приемника 50b, имеющего две отдельные антенны 61a, 61b, для раздельного приема разных выходных потоков O1, O2 данных передатчика, обеспечивает преимущество, состоящее в том, что вторая антенна 61b и последующее средство обработки в приемнике 50b требуется только активировать, если какие-либо вспомогательные области четности требуются в качестве последовательного приращения избыточности для улучшения декодирования. Это также справедливо для варианта осуществления передатчика, где второй выходной поток 02 данных передатчика не только содержит вспомогательные области четности, но также и области данных, и основные области четности кодовых слов. В последнем случае передача может быть выполнена еще более стабильно. Например, если канал передачи между антенной 19а передатчика и антенной 61a приемника будет нарушен, можно переключиться на другой канал передачи между антенной 19b передатчика и антенной 61b приемника. Преимущество более стабильной передачи также достигается с приемником 50c, который в последнем случае может переключаться между приемом первого или второго выходных потоков O1, O2 данных передатчика или который последовательно принимает оба выходных потока O1, O2 данных передатчика. Кроме того, такой вариант осуществления, в общем, также направлен на повышенную спектральную плотность.
Выше, в частности в отношении передатчика 10, были проиллюстрированы различные варианты осуществления, в частности того, как области данных, области четности и вспомогательные области четности отображают на выходной поток данных передатчика. Далее различные примеры были представлены в отношении структуры фреймов выходного потока данных передатчика. Следует понимать, что обратный преобразователь 54 данных приемника 50, конечно, соответствующим образом адаптирован для обратного отображения требуемых данных из входного потока данных приемника, то есть обратный преобразователь 54 знает определенную структуру фреймов и/или места положения, в которых соответствующие данные размещены во входном потоке данных приемника. Для обеспечения этого, в общем, применяются известные меры для передачи в виде сигналов этой информации на приемник из передатчика и/или для предварительной подписки на эту информацию, например в стандарте, и для обеспечения работы, соответственно, передатчиков и приемников.
Структура фреймов, применяемая в соответствии с настоящим изобретением, в общем, может быть выполнена так, чтобы она соответствовала структуре фреймов в соответствии с существующим стандартом, например, стандартом DVB-T2, таким образом, чтобы существующие приемники, в соответствии с этим стандартом, также могли принимать и обрабатывать такие потоки данных, даже если они не используют вспомогательную информацию четности, содержавшуюся в них, в качестве последовательного приращения избыточности. Однако структура фреймов может быть свободно выбрана и вновь сформирована в соответствии с конкретными потребностями системы широковещательной передачи.
В общем, настоящее изобретение можно применять во всех системах широковещательной передачи, в которых данные передают через канал. Например, изобретение можно применять в системе DAB, которая поясняется со ссылкой на фиг.20.
На фиг.20 показана структура фрейма передачи, как описано в стандарте DAB (ETS 300401 “Radio broadcasting systems; Digital Audio Broadcasting (DAB) to mobile, portable and fixed receivers”, May 1997, RE/JPT-OODAB-4). В системе передачи DAB скомбинированы три канала, в частности канал синхронизации, который используется внутри системы передачи для основных функций демодулятора (например, для синхронизации фрейма передачи), канал быстрой информации (FIC), который используется приемником для быстрого доступа к информации, который представляет собой канал передачи данных без перемежения по времени и который может быть подразделен на блоки быстрой информации (FIB), и канал основной услуги (MSC), который используется для передачи компонентов аудиоданных и услуги по передаче данных и который представляет собой канал передачи данных с перемежением по времени, разделенный на множество подканалов, которые кодированы индивидуально со сверткой.
MSC также можно рассматривать как составленный из общих кадров с перемежением (CIF), содержащих модули пропускной способности (CU), как наименьшие адресуемые модули. Каждый подканал MSC занимает целое число последовательных CU и может быть индивидуально кодирован со сверткой. Больше деталей в отношении структуры фрейма передачи и его содержания можно найти в цитируемых выше стандартах DAB, пояснение которых представлено здесь по ссылке.
В соответствии с настоящим изобретением один из подканалов, например SubCh a, может содержать основную версию кодового слова, тогда как один или больше из последующих подканалов, например SubCh b, содержит вспомогательную область кодового слова. Приемник теперь может обрабатывать SubCh a и в случае необходимости SubCh b для улучшения декодирования. Как показано в варианте осуществления, представленном выше, вспомогательная область кодового слова может быть дополнительно сегментирована на подобласти, каждую из которых передают в том же подканале или передают в различных подканалах. Это снова имеет преимущество, состоящее в том, что приемник может перейти в режим ожидания после успешного декодирования до тех пор, пока не будет передана следующая основная область кодового слова.
Будут ли и для какого канала будут предусмотрены вспомогательные биты четности, может быть передано в виде сигналов в канал быстрой информации (FIC). Поскольку этот канал, однако, является фиксированным и заранее определенным, сигналы предпочтительно могут быть переданы по другому подканалу, который содержит основную область кодового слова, например, во вновь определенном заголовке. Следовательно, приемники, модифицированные в соответствии с настоящим изобретением могут использовать эту дополнительную информацию. Кроме того, FIC может передавать сигнал, для приема которого предусмотрен подканал, используя все приемники DAB (традиционные приемники и приемники, в соответствии с настоящим изобретением), и эти подканалы декодируют (только) для приема приемниками в соответствии с настоящим изобретением.
Код коррекции ошибок, применяемый в DAB, представляет собой сверточный код. Различные скорости кода обычно достигаются в соответствии с DAB путем выкалывания исходного кода. Такой исходный код обычно имеет скорость кода 1/4, и в результате выкалывания определенных битов четности, получают более высокие скорости кода. Такие выколотые биты четности могли бы использоваться в качестве вспомогательных битов четности для предоставления последовательного приращения избыточности, в соответствии с настоящим изобретением. В качестве альтернативы также применим совершенно новый исходный код, из которого все скорости кода DAB могут быть получены путем выкалывания, и где выколотые биты используются в качестве вспомогательных битов четности в соответствии с настоящим изобретением.
На фиг.21 показана блок-схема другого варианта осуществления приемника 50d. В общем, основную область B кодового слова и вспомогательную область A кодового слова отображают с помощью передатчика на выходной поток O данных передатчика таким образом, что основную область кодового слова для кодового слова принимают с помощью приемника перед тем, как будет принята соответствующая вспомогательная область кодового слова. В качестве альтернативы, однако, преобразователь данных также может быть выполнен с возможностью отображения основной области B кодового слова и вспомогательной области A кодового слова на фреймы выходного потока данных передатчика таким образом, что вспомогательную область кодового слова для кодового слова принимают с помощью приемника перед тем, как будет принята соответствующая основная область кодового слова. Для варианта осуществления приемника 50d, показанного на фиг.21, следует принять, что передатчик выполнен таким образом.
В таком приемнике 50d обратный преобразователь 54d данных, таким образом, выполнен с возможностью обратного отображения (первых принятых) вспомогательных областей A′ кодового слова из входного потока O′ данных приемника, и перенаправления их в буфер 64. После этого (всякий раз при приеме) соответствующие основные области B′ кодового слова подвергают обратному отображению и направляют в кодер 56d для их декодирования. Если проверка в модуле 58d проверки показывает, что дополнительная избыточность должна использоваться для улучшенного декодирования, буфер 64 информируют через контур 62 обратной связи, что требуется предоставить размещенную в буфере вспомогательную область A′ кодового слова на декодер 56d, и декодер информируют о том, что требуется затем декодировать кодовое слово (теперь путем дополнительного использования (полного или частичного) вспомогательной области кодового слова. Если понятно, что декодирование соответствующего кодового слова выполнено правильно, вспомогательную область кодового слова, размещенную в буфере (если имеется), удаляют из буфера.
Вариант осуществления предоставляет преимущество, состоящее в том, что не возникает время ожидания (для ожидания вспомогательной области четности, если декодирование на основе основной области кодового слова было выполнено с ошибкой), что является особенно важным для уменьшения времени на переключение каналов или для мобильных приемников. Следовательно, такой вариант осуществления также обеспечивает преимущество, состоящее в том, что не возникает перерывов при предоставлении услуги (из-за ожидания приема вспомогательных областей кодового слова) в случае (например, внезапного возникновения) плохих условий приема основных областей кодового слова.
Далее, со ссылкой на фиг.5, 6, 19 и 22, поясняются предпочтительные варианты осуществления кодера, в соответствии с настоящим изобретением.
Как пояснялось выше, путем применения последовательного приращения избыточности (IR) определенные существующие коды LDPC для отрезка Nldpc FECFRAME (например, = 4320 или 16200) расширяют, таким образом, что новое кодовое слово состоит из оригинального кодового слова (основного FEC) и MIR (выше также называемого v) дополнительных (вспомогательных) битов четности, предназначенных для использования в качестве IR. Новая длина кодового слова, таким образом, составляет Nldpc, 1=Nldpc+MIR. Кодирование LDPC с IR можно рассматривать как один кодер со скоростью R1=Kldpc/Nldpc, 1 кода, где выход разделяют на основную часть FEC (“основная область Pb кодового слова”) и часть IR (“вспомогательная область Pa кодового слова”). Обе части могут рассматриваться как два ассоциированных PLP.
Взаимосвязь между исходным кодовым словом и расширенным кодовым словом можно видеть на фиг.5 и 6. На фиг.5 представлено обычное кодирование FEC в соответствии с, например DVB-T2, где вход в кодер LDPC со скоростью R0=Kldpc/Nldpc кода представляет собой выходные биты Kldpc кодера ВСН, в то время, как выход представляет собой систематическое кодовое слово с длительностью Nldpc. Последние Nldpc-Kldpc битов в данном кодовом слове представляют собой биты четности LDPC. Если PLP применяет IR, тогда используется расширенный кодер LDPC со скоростью кода R1=Kldpc/Nldpc, 1<R0, который имеет тот же вход, что и для обычного кодирования, но выходы Nldpc, 1=Nldpc+MIR битов, то есть количество битов четности LDPC увеличивается на Nldpc-Kldpc+MIR. Однако его первые Nldpc-Kldpc битов четности являются идентичными битам четности оригинального кодера LDPC со скоростью R0. Кодовое слово разделено на две области: первые биты Nldpc представляют собой основную часть FEC (то есть основную область четности), в то время как остальные биты MIR представляют собой часть IR (то есть вспомогательную область четности), предназначенную для использования в приемнике в случае необходимости в качестве IR.
Таким образом, обеспечивается то, что декодирование принятого кодового слова возможно (для хороших условий канала) со скоростью декодера R0, который учитывает только основную часть FEC, в то время как расширенное кодовое слово, состоящее как из основной части FEC, так и из части IR, позволяет выполнять декодирование со скоростью декодера R1.
Разделение одного FECFRAME, в котором используется IR, на основную часть FEC и часть IR, показанную на фиг.22, представляет только существенные элементы варианта 145 осуществления кодера 14 в соответствии с этими аспектами настоящего изобретения. Этот кодер 145 содержит вход кодера 1451 для приема входных слов D данных, каждое из которых содержит первое число Kldpc информационных символов 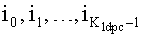
Кроме того, предусмотрен блок 1452 кодирования для кодирования входного слова данных в кодовое слово Z2 таким образом, что кодовое слово содержит основную область B кодового слова, включающую в себя область D данных и основную область Pb четности второго числа Nldpc-Kldpc основных символов четности 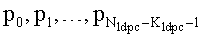
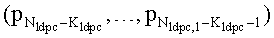
y={x+m mod Gb×Qldpc}mod(Nldpc-Kldpc) если x<Nldpc-Kldpc,
в котором x обозначает адреса аккумулятора символа четности, соответствующие первому информационному символу группы с размером Gb, и Qldpc представляет собой заранее определенную константу, зависимую от основной скорости кода.
Упомянутый модуль 1451 кодирования, с другой стороны, выполнен с возможностью генерирования упомянутой вспомогательной области A кодового слова из слова D входных данных в соответствии со вторым кодом, в котором вспомогательные символы четности генерируют путем накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу y символа четности, в котором упомянутые адреса у символа четности определяют в соответствии со вторым правилом генерирования адресов
y=Nldpc-Kldpc+{x-(Nldpc-Kldpc)+m mod Ga×QIR}mod MIR если x≥Nldpc-Kldpc,
где x обозначает адреса аккумулятора символа четности, соответствующие первому информационному символу группы с размером Ga, и QIR представляет собой заранее определенную константу, зависимую от скорости вспомогательного кода, и в которой Ga=Gb=72. Для такого генерирования предпочтительно используют таблицы адресов, которые сохранены в накопителе 1453 таблицы адресов.
Кроме того, кодер 145 содержит выход 1454 кодера для вывода упомянутых кодовых слов, который воплощен здесь как “последовательно-параллельный” преобразователь для разделения основной области B кодового слова и вспомогательной области A кодового слова для последующей независимой обработки. Конечно, выходной модуль может иметь простой последовательный выход для вывода полного кодового слова Z2, в том виде, как оно есть.
Кодированные биты обоих потоков дополнительно обрабатывают независимыми экземплярами перемежителей битов, частями демультиплексора и так далее, как представлено на фиг.2 для конкретного PLP. Таким образом, становится возможным увеличить надежность основной части FEC путем применения, например, созвездий сигналов QAM низкого порядка для этой части. Здесь следует отметить, что в соответствии с этим вариантом осуществления настоящего изобретения предпочтительно предусмотрен только один модуль кодирования (например, такой, как модуль 20 кодирования, показанный на фиг.2). Например, блок 1452 кодирования может воплощать оба блока 21 и 31 кодирования FEC, после которого следует один общий канал передачи с последующими элементами обработки или два отдельных канала последующих элементов обработки (как показано на фиг.2).
Планировщик выделяет пакеты основной части FEC в экземплярах более раннего времени, чем пакеты соответствующей части IR. Если приемник желает декодировать PLP, в котором используется IR, он должен демодулировать по меньшей мере основную часть FEC, которая соответствует выходу оригинального кодера со скоростью R0=Kldpc/Nldpc>R1. Если декодирование произойдет неудачно из-за несоответствующих условий канала (отношение сигнал-шум (SNR) падает ниже порогового значения оригинального кода), он может, кроме того, демодулировать часть IR, которая вместе с основной частью FEC строит кодовое слово с длиной Nldpc, 1. Однако декодер затем переключается на новую матрицу проверки на четность в соответствии с кодом со скоростью R1 кода (или меньше), где успешное декодирование происходит более вероятно, поскольку порог декодирования расширенного кода намного меньше, чем у исходного кода.
Следует отметить, что основное преимущество IR (по сравнению с применением низкой скорости R1 кода без IR на первом месте) состоит в том, что приемник может игнорировать часть IR до тех пор, пока она не потребуется. Если, например, R1=1/2*R0, при обычном подходе могла бы применяться скорость R1 кода с пределами пропускной способности данных с коэффициентом 2. Таким образом, вдвое больше пакетных ошибок должно быть обнаружено приемником для заданной скорости данных по сравнению со случаем, когда из-за предпочтительных условий капала передача могла бы быть возможной со скоростью R0 кода. Применяя, однако, IR, обеспечивается возможность перехода приемника в режим ожидания всякий раз, когда передают пакеты IR, если декодирование основной части FEC возможно и/или было успешным.
Количество битов IR должно быть таким же, как и сама длина FECFRAME, таким образом: MIR=Nldpc, в результате чего происходит разделение пополам исходной скорости кода, R1=1/2*R0. При практическом осуществлении, например, для использования в мобильных приемниках в соответствии с предстоящим стандартом DVB-NGH, IR используют для миникодов (Nldpc=4320) для идентификаторов кода: R0=1/2. Далее поясняется принцип изобретения, используя этот код (Nldpc=4320, идентификатор скорости кода R0=1/2).
Для каждого кода LDPC длиной Nldpc=4320 выводят расширенный код со скоростью R1=1/2*R0, далее обозначенный, как исходный код со скоростью R0. Расширенный кодер LDPC обрабатывает выход внешнего кодирования ВСН, 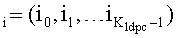
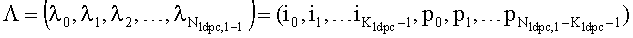
Далее процедура кодирования обеспечивает то, что первые биты расширенного кодового слова для i∈{0,…, Nldpc-Kldpc-1} являются такими же, как если бы использовали оригинальный код LDPC.
Задача кодера состоит в том, чтобы определить Nldpc,1-Kldpc битов четности 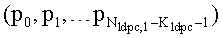
- Инициализируют все четности путем установки их в ноль, то есть 
- Накапливают первый информационный бит i0 в адресах битов четности, установленных в первой строке на фиг.23, представляющей таблицы адресов для предложенного миникода (Nldpc=4320) для идентификатора кода R0=1/2, для которого QIR=60, MIR=4320, Nldpc=4320, Qldpc=30, (все добавления находятся в GF (2)):
Следует отметить, что первые 19 адресов четности (все меньшие чем Nldpc-Kldpc=2160) являются такими же, как определено для кода 4k со скоростью 1/2, в то время как остальные адреса (все больше, чем или равные Nldpc-Kldpc=2160) соответствуют расширенному коду LDPC и записаны с использованием полужирного шрифта в таблицах адресов, представленных на фиг.23. Кроме того, следует отметить, что оригинальный код имеет длину Nldpc=4320 и имеет скорость кода 1/2, в то время, как расширенный код имеет длину Nldpc,1=Nldpc+MIR=2*4320=8640 и имеет скорость кода 1/4.
- Для следующих 71 информационных битов, im, m=1, 2 …, 71 накапливают im в адресах битов четности
[х+m mod 72×Qldpc}mod(Nldpc-Kldpc) если х<Nldpc-Kldpc,
(которое представляет собой первое правило генерирования адресов для оригинальных/основных значений четности), или
Nldpc-+{х-(Nldpc-Kldpc)+m mod Ga×QIR}mod MIR если x<Nldpc-Kldpc,
(которое представляет собой второе правило генерирования адресов для дополнительных IR/вспомогательных значений четности),
где x обозначает адреса аккумулятора бита четности, соответствующего первому биту i0, представленному в первой строке таблицы адресов (то есть, x∈{142, 150, …, 6181, 6186, 6192}, Qldpc представляет собой константу, зависящую от скорости кода, установленную для оригинальных кодов LDPC (в общем Qldpc=(Nldpc-Kldpc)/Gb=2160/72=30) стандартах DVB-T2 и DVB-C2, и QIR=MIR/72=4320/72=60. Для следующего набора Ga=Gb=72 информационных битов im, m=72, 2…, 2·72-1, вторая строка таблицы адресов определяет адреса x. В общем, адреса для информационного бита im заданы (m/72+1)-ой строкой таблицы адресов, где . обозначает операцию нижнего предела.
Пример для генерирования 51-ого информационного бита i50, то есть m=50, кратко поясняется ниже. Поскольку этот информационный символ (или информационный бит) все еще принадлежит первой группе с размером 72 бита, первая строка таблицы, показанной на фиг.23, все еще применима для адресов четности, то есть x∈{142, 150, …, 6181, 6186, 6192}. Информационный бит i50 накапливается по следующим адресам битов четности (все суммы представлены в GF (2)):
Рассмотри четыре примера:
- Первое уравнение из левого столбца (p1642=p1642 ⊕ i50): первый адрес x на фиг.23 представляет собой 142<Nldpc-Kldpc=2160; таким образом, используется первое правило генерирования: новый адрес для m=50, таким образом, представляет собой
{142+50 mod 72×Qldpc}mod(Nldpc)={142+50×30}mod 2160=1642.
- Последнее уравнение из левого столбца (p1457=p1457 ⊕ i50): 19-ый адрес x на фиг.23 представляет собой 2117<Nldpc-Kldpc=2160, таким образом, используется первое правило генерирования: новый адрес для m=50, таким образом, представляет собой
{2117+50 mod 72×Qldpc}mod(Nldpc-Kldpc)={2117+50×30}mod 2160=1457.
- Первое уравнение из правого столбца: p5536=p5536 ⊕ i50: 20-ый адрес x на фиг.23 представляет собой 2536>Nldpc-Kldpc=2160, таким образом, используется второе правило генерирования: новый адрес для m=50 так, что
2160+{2536-2160+50 mod 72×QIR}mod MIR=
=2160+{2536-2160+50×60}mod 4320=5536.
- Последнее уравнение из правого столбца (p4872=p4872 ⊕ i50): 25-ый адрес x на фиг.23 представляет собой 6192>Nldpc-Kldpc=2160, таким образом, используется второе правило генерирования: новый адрес для m=50, таким образом,
2160+{6192-2160+50 mod 72×QIR}mod MIR=
=2160+{6192-2160+50×60}mod 4320=4872
Следует отметить, что размер (также называется Ga) группы информационных битов, с которыми работают поблочно, также может отличаться от 72 и также может отличаться первым и вторым правилом генерирования адресов, но Kldpc всегда должно представлять собой число, кратное G. Соотношение между Gb и Qldpc представляет собой следующее: Qldpc=(Nldpc-Kldpc)/Gb и соотношение между Ga и QIR представляет собой: QIR=MIR/Ga.
Положения x, которые больше, чем или равны Nldpc-Kldpc, записаны цифрами представленными полужирным шрифтом в таблице адресов, показанной на фиг.23. Следует отметить, что только числа, представленные полужирным шрифтом, приводят к получению битов четности, используемых для вспомогательных областей кодового слова, в то время как остальные цифры генерируют значения четности для основной области кодового слова. Учитывая правило генерирования для разработки основной области кодового слова, адреса x для вспомогательных областей кодового слова оптимизируют таким образом, что расширенный FEC, включающий в себя как основную, так и вспомогательную области кодового слова, хорошо работает при очень низком значении SNR и позволяет получить минимизированный нижний уровень ошибки. Поиск соответствующих адресов включал в себя оптимизацию с использованием нескольких алгоритмов, включая в себя технологию диаграммы EXIT, средство уменьшения малого обхвата в коде LDPC и решения способов ограниченного квадратичного программирования.
Следует дополнительно отметить, что такой подход оставляет основную часть FEC как оригинальный код, и добавляет MIR большее количество проверок на четность, и поддерживает квазициклическую структуру LDPC как для основной части, так и для части IR. Однако квазициклическая структура прерывается после первых строк Nldpc-Kldpc матрицы проверки на четность. Но поскольку она представляет собой число, кратное 72 (а именно Qldpc), все еще можно применять поблочное декодирование на основе группы из 72 битов.
Аналогичным образом, для каждой группы Ga=Gb=72 новых информационных битов, используют новую строку из одной из представленных выше таблиц адресов (то есть таблиц адресов с требуемой скоростью данных) для поиска адресов аккумуляторов бита четности.
После того, как будут израсходованы все информационные биты, конечные биты четности получают следующим образом:
- Последовательно выполняют следующие операции, начиная с i=1.
pi=p1 ⊕ pi-1, i=1,2,…, Nldpc,1-Kldpc-1
- Конечное содержание pi, i=0,1, …, Nldpc,1-Kldpc равно биту pi четности.
Это означает, что все биты четности (основной и вспомогательный) дополнительно дифференцированно кодируют, то есть накапливают.
Следует отметить, что оригинальный код LDPC является квазицикличным, то есть первый столбец оригинальной матрицы проверки на четность LDPC повторяется во втором столбце, но с циклическим сдвигом на Qldpc битов (модуль (Nldpc-Kldpc)). Аналогичную квазицикличную структуру накладывали на дополнительные 1-цы расширенной матрицы LDPC путем сдвига на QIR. Однако циклический сдвиг выполняют только в нижней матрице расширения для матрицы проверки на четность, для предотвращения изменений в исходной матрице LDPC, как показано на фиг.27, представляющей расширенную матрицу проверки на четность LDPC в соответствии с настоящим изобретением.
Пример расширенного кода LDPC кратко поясняется ниже. Частоты ошибок бита и фрейма (BER и FER) в соответствии с характеристикой SNR и расширенным кодом LDPC для канала AWGN (без затухания) представлены на фиг.24. Оригинальный код (соответствующий основной области кодового слова) представляет собой миникод со скоростью R0=1/2 и длиной Nldpc=4320, расширенный код (состоящий из основной и вспомогательной области кодового слова) имеет скорость R1=1/4 кода. Пороговое значение декодирования (или предел отсечки) оригинального (4k) кода 1/2 составляет приблизительно -1,56 дБ. Расширенный код LDPC со скоростью кода R1=1/4 имеет свое пороговое значение на уровне -4,96 дБ. Количество имитируемых информационных битов составляло 1010.
Если SNR в приемнике превышает -1,56 дБ, он может декодировать оригинальный миникод со скоростью 1/2, который также соответствует основной части FEC расширенного кода LDPC. В этом случае частью IR можно пренебречь, что приводит к уменьшению мощности обработки с коэффициентом 2 (поскольку половина пакетов, принадлежащих этому PLP, поступает из части IR). Если SNR понижается, приемник может демодулировать часть IR и, таким образом, имеет запас дополнительных 3,4 дБ. Что касается усиления кодирования (различие в Eb/N0), оно соответствует усилению на 0,4 дБ, поскольку скорость кодирования уменьшена на половину.
Что касается расширенной матрицы проверки на четность LDPC, представляющей адреса бита четности для генерирования вспомогательных битов четности, необходимо отметить следующее. Каждая строка соответствует подгруппе из 72 информационных битов. Нормальные (представленные нежирным шрифтом) числа предназначены для генерирования оригинального кода, тогда как цифры, представленные полужирным шрифтом, предназначены для генерирования вспомогательных значений четности. Нумерация начинается с 0 (например, 142 соответствует 143-му биту четности). Конечное кодовое слово получают путем накопления всех значений четности. Максимальная степень переменного узла оригинального LDPC равна 19, в то время как максимальная степень переменного узла предложенного расширенного LDPC равна 25.
Для варианта применения с повышенной надежностью для передачи сигналов L1-Post в будущей системе DVB-NGH передатчик использует расширенный код, который формирует как основную, так и вспомогательную область кодового слова, то есть основную часть FEC и часть IR. В зависимости от длины данных сигналов L1-Post определенное количество основных битов четности FEC сокращают и выкалывают. Выколотые биты четности, а также заданное количество четности в части IR (вспомогательная область кодового слова) используют как дополнительные значения четности для повышения надежности. Эти дополнительные биты четности передают в предыдущем фрейме NGH, в то время как другие (невыколотые основные биты кодового слова) передают в текущем фрейме NGH. Приемник может сохранять дополнительные биты четности и использовать их в случае, когда основной код FEC не может быть декодирован. Если SNR находится на уровне намного выше порогового значения декодирования основного FEC, приемник может полностью игнорировать дополнительные биты четности для экономии электроэнергии.
Следует отметить, что также возможно разработать новые коды LDPC, которые могут быть разделены на основную часть FEC и часть IR. Поскольку часть FEC этих вновь разработанных кодов не обязательно должна соответствовать существующим (стандартизированным) кодам LDPC семейства DVB, получаемые в результате значения усиления кодирования части IR будут еще больше, чем коды, предложенные в соответствии с настоящим изобретением. Кроме того, также возможно расширить коды LDPC с разным количеством дополнительных битов четности MIR или разрешить больше, чем одну часть IR. Разделение на несколько частей IR могло бы обеспечить для приемника возможность оценки величины дополнительных областей четности, которые требуются для успешного декодирования.
Дополнительное значение избыточности, генерируемое в соответствии с настоящим изобретением, также может использоваться в другом сценарии для обеспечения возможности для мобильного приемника, например приемника, установленного в автомобиле, или портативного приемника (например, в мобильном телефоне или КПК) в системе широковещательной передачи декодировать данные широковещательной передачи, даже в тяжелых условиях канала передачи путем улучшения предусмотренных мер по коррекции ошибок. В частности, предложено обеспечить достаточную степень избыточности по запросу приемника для повышения надежности кода. Упомянутая дополнительная избыточность обеспечивается системой передачи данных после приема обратной связи от приемника, запрашивающей дополнительную избыточность. Упомянутую дополнительную избыточность, однако, не передают в режиме широковещательной передачи через систему широковещательной передачи, но передают через систему одноадресной передачи только запрашивающему приемнику. Этот приемник может использовать дополнительную избыточность для выполнения другого декодирования, ранее принятого (через систему широковещательной передачи) кодового слова. Следовательно, если прием или реконструкция (декодирование) принятых данных широковещательной передачи будет выполнено с ошибкой или может быть выполнено только с недостаточным качеством, приемник может повторить декодирование, используя в дополнение к ранее принятому кодовому слову запрашиваемую дополнительную избыточность.
Такой приемник, например, в соответствии с будущим стандартом DVB-NGH, может, например, быть включен в мобильный телефон, который также выполнен с возможностью приема данных из сетей одноадресной передачи, таких как мобильные системы передачи данных, например система передачи данных 3G (UMTS) или 4G (LTE), а так же из WLAN (беспроводная локальная вычислительная сеть), если точки доступа находятся в непосредственной близости. Дополнительная избыточность для ошибочно принятых или декодированных кодовых слов (термин “ошибочно” понимают не только, как означающий полностью ошибочный, но также и “с недостаточным качеством”) может быть получена из другой архитектуры (вертикальная передача мобильного терминала) в соответствии с настоящим изобретением, например, через сеть 3G, 4G или WLAN.
Таким образом, обычно для такого сценария несущественно, в соответствии с какой конкретной системой одноадресной передачи воплощен модуль запроса одноадресной передачи и модуль одноадресного приема. Обычно может использоваться любая система одноадресной передачи, например любая система (теле) коммуникаций для беспроводной передачи данных, и при этом также возможно, чтобы приемник мог быть воплощен с возможностью использования нескольких систем одноадресной передачи для предложенного запроса и приема дополнительной избыточности, например через систему одноадресной передачи, которая в настоящее время доступна в соответствующей ситуации. Кроме того, запрос и прием дополнительной избыточности также, в общем, могут быть выполнены через разные системы одноадресной передачи, но предпочтительно используется одна и та же система одноадресной передачи. Поскольку, в общем, одноадресная система передачи обеспечивает достаточное средство для коррекции ошибок и обнаружения, можно предположить, что передача вспомогательной области кодового слова будет выполнена без ошибки.
На фиг.25 схематично показана блок-схема системы передачи данных в соответствии с таким сценарием. Система содержит передатчик 10 широковещательной передачи, предназначенный для широковещательной передачи данных, приемник 50 для приема данных, переданных в режиме широковещательной передачи упомянутым передатчиком 10 широковещательной передачи, одноадресный передатчик 100 для передачи данных в системе одноадресной передачи и накопитель 150 данных, предназначенный для накопления данных, принятых из передатчика 10 широковещательной передачи. Как более подробно поясняется ниже, приемник 50 не только выполнен с возможностью принимать данные, переданные в режиме широковещательной передачи упомянутым передатчиком 10 широковещательной передачи, но он в определенной степени также выполнен с возможностью обмена данными с передатчиком 100 одноадресной передачи для обеспечения двунаправленного обмена данными, и также передатчик 100 одноадресной передачи выполнен с возможностью двунаправленного обмена данными с накопителем 150 данных. В конкретных вариантах осуществления дополнительный вспомогательный кодер 160 дополнительно предусмотрен для кодирования данных перед передачей на передатчик 100 одноадресной передачи. Далее различные элементы системы передачи данных поясняются отдельно для иллюстрации их функции и взаимосвязей, как предложено в соответствии с настоящим изобретением.
В такой системе передачи данных передатчик 10 широковещательной передачи и приемник 50, а также ссылка 200 между ними представляют собой часть системы широковещательной передачи, такой как система широковещательной передачи видеоданных в соответствии с любым стандартом DVB, в частности система беспроводной широковещательной передачи. Передатчик 100 одноадресной передачи и приемник 50, а также связь 300 между ними представляют собой часть системы одноадресной передачи, такой как система передачи данных в соответствии с любым стандартом системы передачи данных, в частности системы беспроводной передачи данных.
Связь 400 между передатчиком 10 широковещательной передачи и накопителем 150 данных может представлять собой часть системы широковещательной передачи таким образом, что данные, которые должны быть сохранены в накопителе 150 данных, получают с помощью накопителя 150 данных из сигнала широковещательной передачи. В качестве альтернативы эта связь 400 также может быть установлена с использованием отдельного канала передачи, например, проводной или беспроводной связи передачи, от передатчика 10 широковещательной передачи на накопитель 150 данных, который может, например, представлять собой сервер, расположенный рядом с передатчиком 10 широковещательной передачи.
Связь 500 между одноадресным передатчиком 100 и накопителем 150 данных, а также связь 600 между вспомогательным кодером 160 и одноадресным передатчиком 100 может представлять собой часть одноадресной системы передачи таким образом, что одноадресный передатчик 100 связывается с накопителем 150 данных и вспомогательным кодером 160 через ту же систему одноадресной передачи, которая используется для обмена данными с приемником 50. Связи 500, 600 и/или 700 между накопителем 150 данных, вспомогательным кодером 160 и/или одноадресным передатчиком 100 могут быть установлены с помощью любого средства передачи. Предпочтительно вспомогательный кодер 160 расположен в непосредственной близости к накопителю 150 данных таким образом, что проводная линия электропередачи является предпочтительным решением. Вспомогательный кодер 160, однако, может также представлять собой часть системы одноадресной передачи или даже часть одноадресного передатчика 100.
На фиг.26 схематично показана блок-схема приемника 50, предназначенного для использования в системе передачи данных, как показано на фиг.25. Приемник 50, в частности, выполнен с возможностью запроса вспомогательной области четности (в общем, вспомогательной области кодового слова) в качестве последовательного приращения избыточности в случае ошибочного декодирования или низкого его качества.
Приемник 50 содержит вход 52 данных, предназначенный для приема входного потока О′ данных приемника, который, в общем, соответствует выходному потоку О данных передатчика, который был передан через канал широковещательной передачи системы широковещательной передачи передатчиком 10 и на который, таким образом, могли повлиять нарушения, которые могут появиться в такой системе широковещательной передачи, в частности в случае использования мобильных приемников, которые представляют собой основное применение настоящего изобретения на стороне приемника.
В случае необходимости предусматривается демодулятор 53, который взаимосвязан с (необязательным) модулятором передатчика 10 для демодуляции принятого входного потока О′ данных приемника. Обратный преобразователь 54 выполняет обратное отображение (в случае необходимости демодулированного) входного потока О′ данных приемника, в частности по меньшей мере областей данных и основных областей четности (то есть основных областей кодового слова) для кодовых слов, отображенных на входной поток О′ данных приемника, как более подробно поясняется ниже. Декодер 56 затем декодирует эти кодовые слова, используя основные области кодового слова, в соответствии с тем же кодом, который применялся кодером передатчика 10. Как, в частности, в случае мобильных приемников серьезные нарушения, например, из-за высокой скорости движущегося приемника могут появляться в модуле 58 проверки, который предусмотрен в приемнике 50, с помощью которого проверяют, было ли выполнено декодирование правильно и/или с достаточным качеством, и/или ниже приемлемого уровня ошибок, как поясняется ниже. Если декодирование выполнено без ошибок или с достаточным качеством, декодированные данные подают в выходной модуль 60. Его выход может представлять собой один или более выходных потоков I1′ I2, ′…, In′ данных приемника, которые должны в максимально возможной степени соответствовать входных потокам I1, I2…, In данных передатчика. Если, однако, проверка, выполняемая модулем 58, показывает, что декодирование было выполнено с ошибкой или что декодируемые данные имеют недостаточное качество и могли бы, например, привести к зашумленному выходному сигналу приемника (например, недостаточное качество изображения кинофильма), боковой контур 62 предусмотрен от модуля 58 проверки на модуль 64 запроса одноадресной передачи для запроса вспомогательной области четности (в общем, вспомогательной области кодового слова) (полностью или частично) для улучшения качества декодирования.
Следовательно, в такой ситуации модуль 64 одноадресного запроса передает запрос R через систему одноадресной передачи, то есть через одноадресный передатчик 100 системы передачи данных для получения соответствующей вспомогательной области четности (полностью или частично) для декодируемого с ошибками кодового слова из накопителя 150 данных. Запрос R включает в себя по меньшей мере идентификационную информацию кодового слова, полученного с ошибками. В то же время результат C” декодирования, представляющий собой результат декодирования кодового слова (или само кодовое слово C′) сохраняют в буфере (в общем, в модуле памяти данных) 66. Запрашиваемая вспомогательная область A′ кодового слова (или по меньшей мере его область или другие вспомогательные данные четности, которые можно использовать как последовательное приращение избыточности на дополнительном этапе декодирования, то есть которые были сгенерированы путем использования того же самого кода) принимают с помощью одноадресного приемника 68. Благодаря использованию такой дополнительной избыточности и данных, сохраненных в буфере 66, рекомбинатор 69 выполняет рекомбинацию этих данных таким образом, что декодер 56 затем снова декодирует принятые кодовые слова, но теперь применяет код, имеющий более низкую скорость кода, которая, таким образом, имеет более высокую устойчивость к нарушениям. Следовательно, существует большая вероятность того, что качество декодирования будет лучше, чем прежде.
После этого снова может быть выполнена проверка с помощью модуля 58 проверки, было ли декодирование теперь было выполнено без ошибки или с достаточным качеством, и, если нет, еще дополнительная часть вспомогательной области четности может быть запрошена и может использоваться в другой итерации декодирования. Если, с другой стороны, полная вспомогательная область четности кодового слова уже была полностью использована для декодирования, проверка также может быть исключена, и декодируемые данные могут быть выведены непосредственно.
Предпочтительно запрос R, переданный от модуля 64 одноадресного запроса, содержит только показатель, который вспомогательная область кодового слова запрашивает. Однако оценка E из модуля 58 проверки также может быть включена в запрос R, обозначающий величину последовательного приращения избыточности, которая требуется для обеспечения возможности лучшего декодирования кодового слова. Следовательно, на основе упомянутой оценки E полная вспомогательная область кодового слова не обязательно должна быть получена и передана через систему одноадресной передачи, но только то количество, которое было передано с помощью сигнала упомянутой оценки E, должно быть передано, экономя, таким образом, полосу пропускания и время передачи (и если вспомогательная область четности должна быть сгенерирована на лету во вспомогательном кодере 160, экономя также некоторое время, необходимое для кодирования).
Настоящее изобретение, таким образом, обеспечивает эффективную и простую для воплощения меру для улучшения надежности декодирования, в частности, для мобильных приемников в системе широковещательной передачи без какой-либо обратной связи от приемника на передатчик. Если структуру фрейма DVB-T2 поддерживают без изменения, и FEF содержат дополнительную избыточность, то есть вспомогательную область кодового слова, существуют, в основном, два аспекта, которые делают (мобильный) приемник или, в общем, любой приемник, использующий настоящее изобретение, более надежным для мобильного приема: i) последовательное приращение избыточности, как описано, и ii) FEF сами по себе со встроенным последовательным приращением избыточности, который может (и обычно будет) выбирать параметры передачи (например, OFDM), которые имеют лучшее поведение в мобильных каналах. Наиболее важные из них представляют собой меньшие размеры FFT и более высокую плотность пилотной структуры (относящуюся к FFT и к размерам защитного интервала). Конечно, данные последовательного приращения избыточности в FEF дополнительно могут быть защищены, используя схемы более низкой модуляции, другие глубины перемежения и т.д.
Глубина перемежителя по времени, выбранная в FEF, может, например, дополнять глубину перемежителя по времени фреймов T2. Если перемежитель по времени фреймов T2 приводит к ошибке (например, сигнал прерывается на заданное время (например, из-за туннеля и т.д.)), другие установки в перемежителе по времени FEF могут в лучшей степени быть приспособлены и обеспечивать общее правильное декодирование. Разные установки перемежителя по времени фрейма T2 и фрейма FEF, в общем, улучшают характеристики системы.
Приемник в соответствии с настоящим изобретением поэтому получает преимущества ввиду того факта, что в дополнение к основному приему T2 данные в FEF (то есть дополнительное последовательное приращение избыточности) являются более надежными в мобильных каналах. Другое основное преимущество предпочтительных вариантов осуществления настоящего изобретения состоит в том, что станции широковещательной передачи не обязаны передавать данные для мобильных приемников (например, NGH), а передают только последовательное приращение избыточности для обеспечения более надежного приема данных Т2 даже мобильным приемником. Таким образом, полоса пропускания передачи используется наиболее эффективно.
Изобретение было представлено и описано подробно на чертежах и в представленном выше описании, но такие иллюстрации и описание следует рассматривать как иллюстративные или примерные, а не как ограничительные. Изобретение не ограничено раскрытыми вариантами осуществления. Другие вариации раскрытых вариантов осуществления могут быть понятны и могут быть выполнены специалистами в данной области техники, выполняющими на практике заявленное изобретение, в результате изучения чертежей, раскрытия и приложенной формулы изобретения.
В пунктах формулы изобретения слово “содержащий” не исключает другие элементы или этапы, и неопределенный артикль “а” или “an” не исключает множественности. Один элемент или другой модуль могут выполнять функции нескольких элементов, перечисленных в пунктах формулы изобретения. Сам по себе факт, что некоторые определенные меры перечислены во взаимно разных зависимых пунктах формулы изобретения, не обозначает, что комбинация этих мер не может использоваться с преимуществом.
Компьютерная программа может быть сохранена/может распределяться на соответствующем носителе информации, таком как оптический носитель информации или твердотельный носитель информации, которые поставляются вместе или как часть других аппаратных средств, но также может распространяться в других формах, такой как через Интернет или другие проводные или беспроводные системы передачи данных.
Номера ссылочных позиций в формуле изобретения не следует рассматривать как ограничение объема.
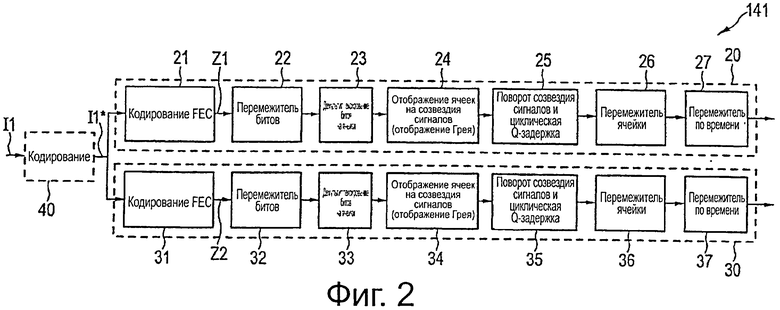
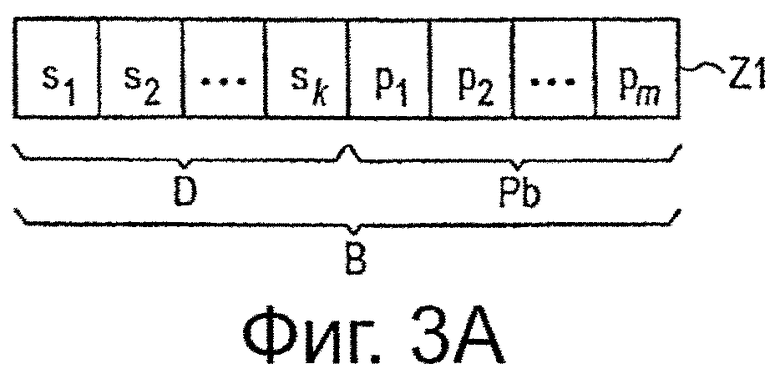
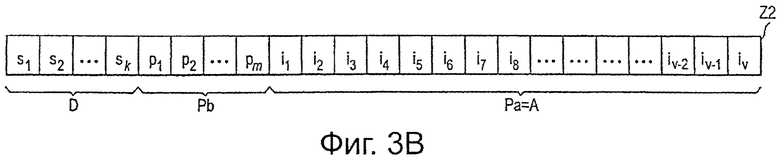
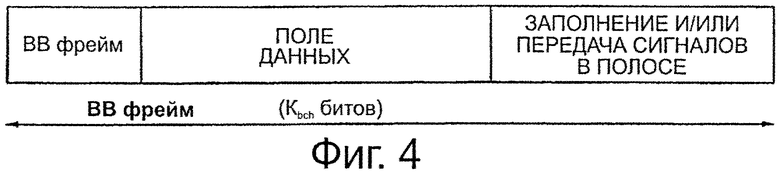
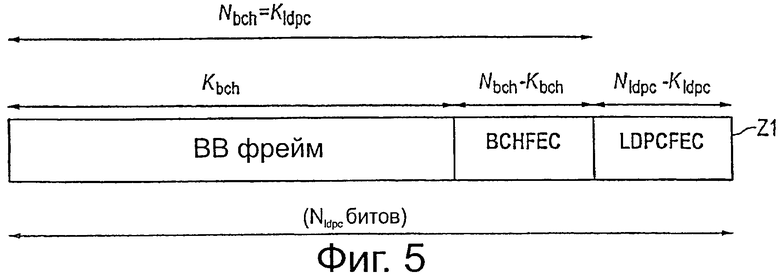
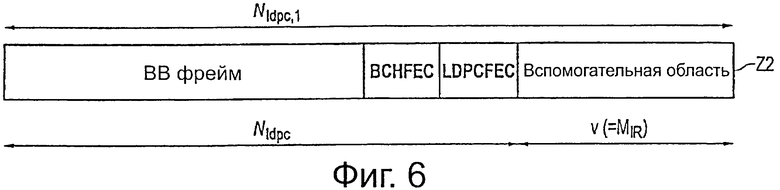
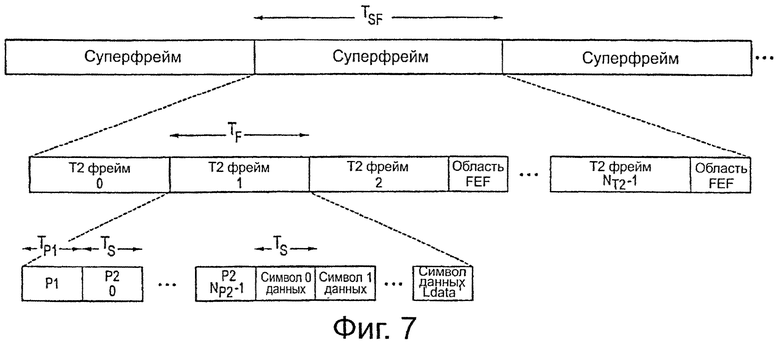

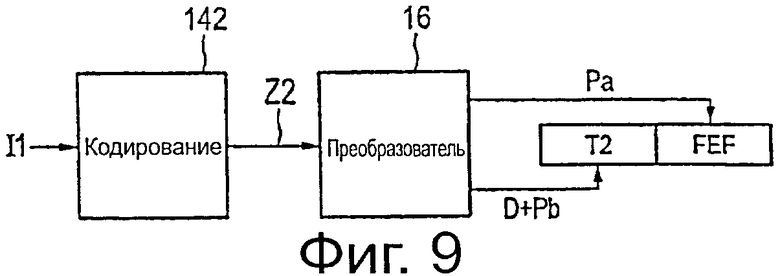
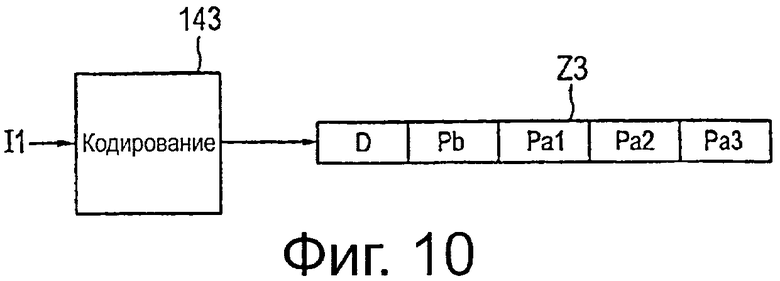
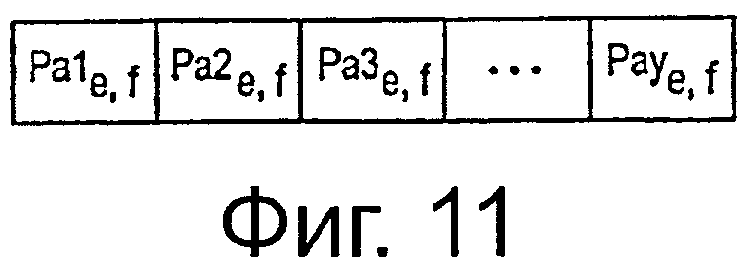
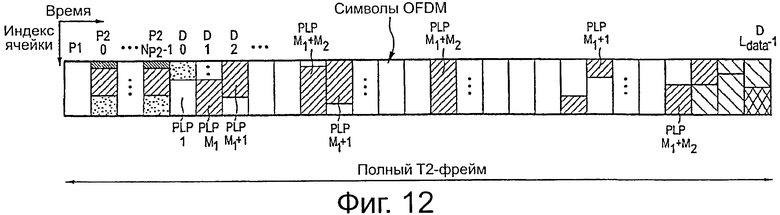

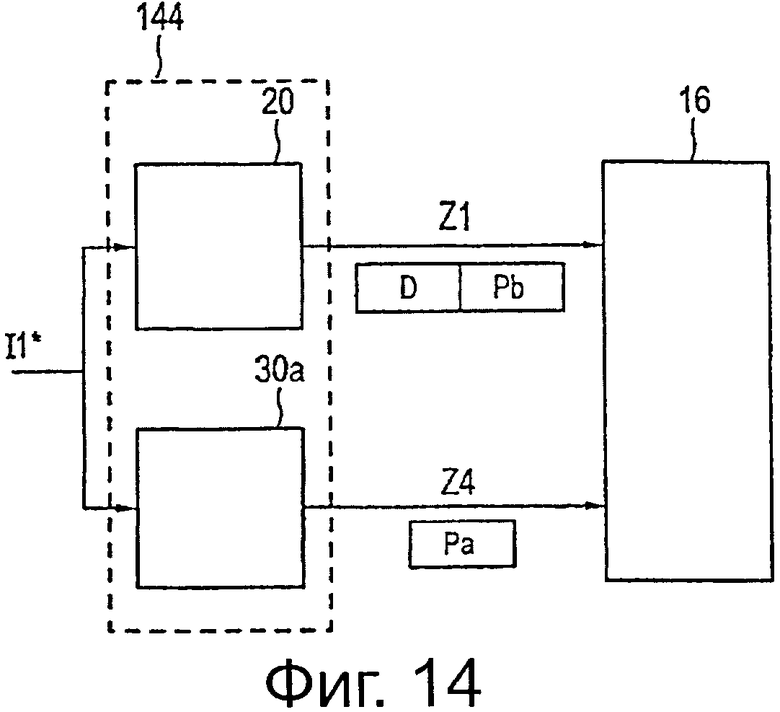
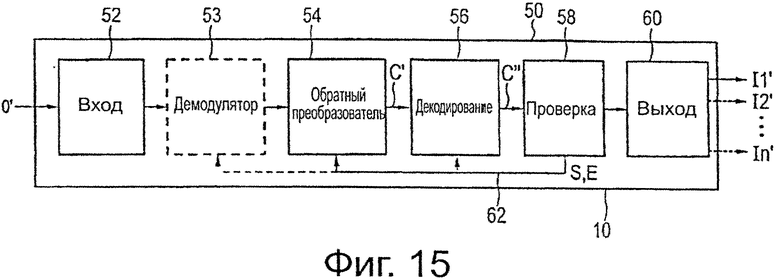
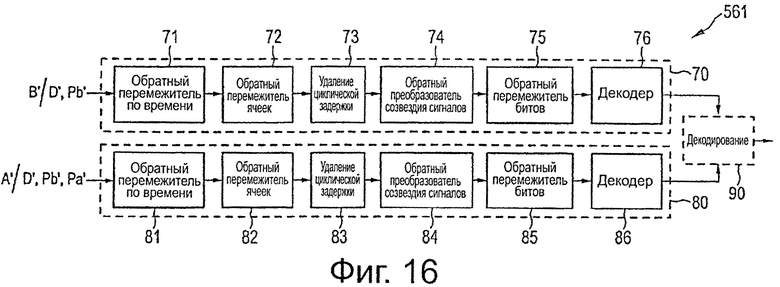
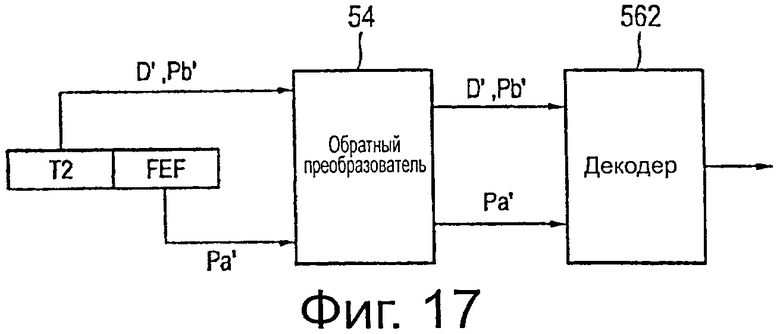
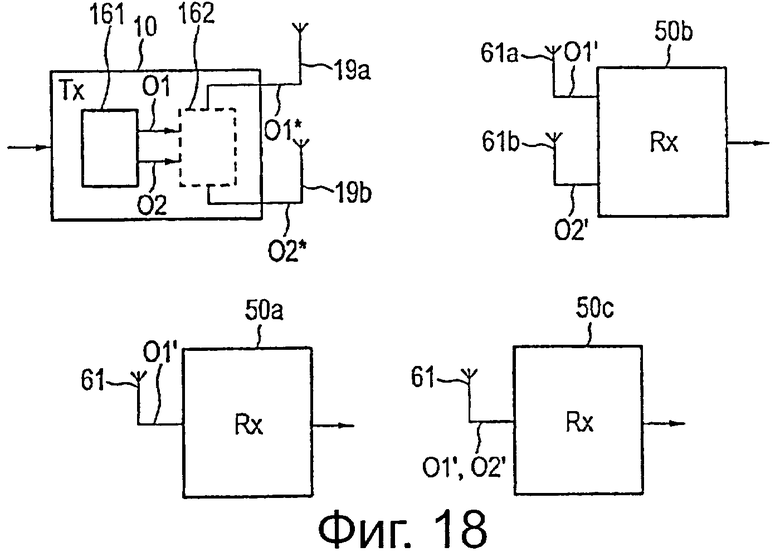
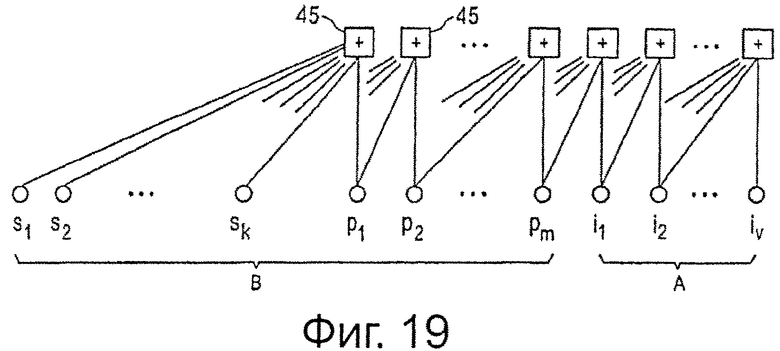
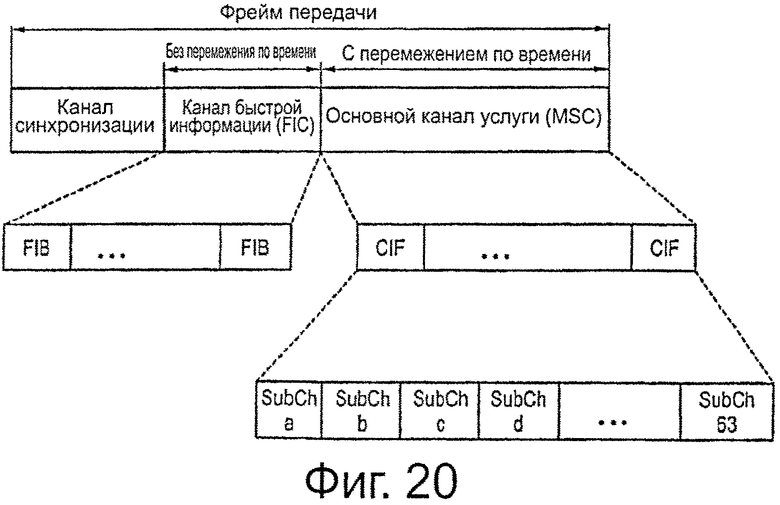
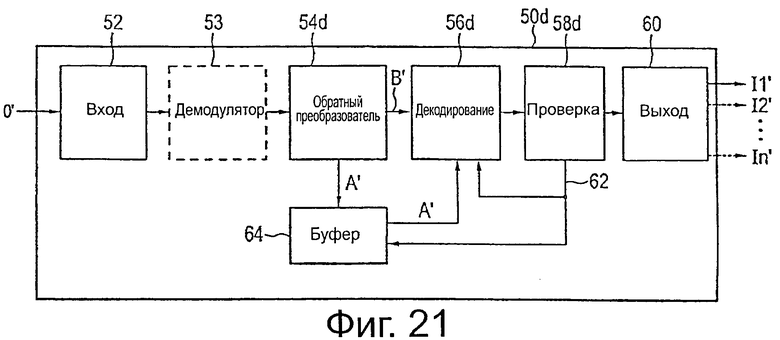
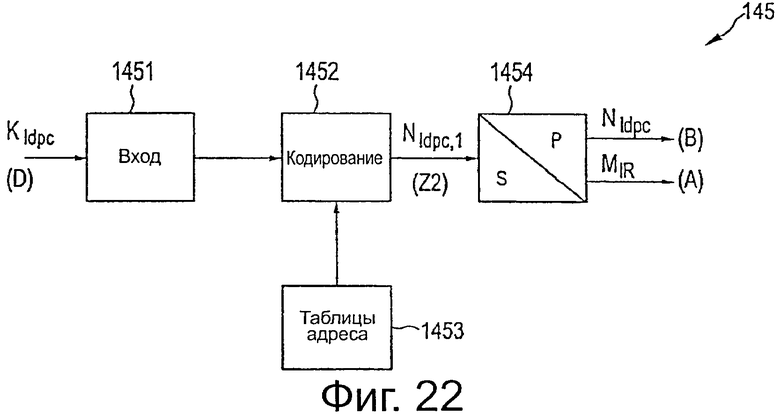
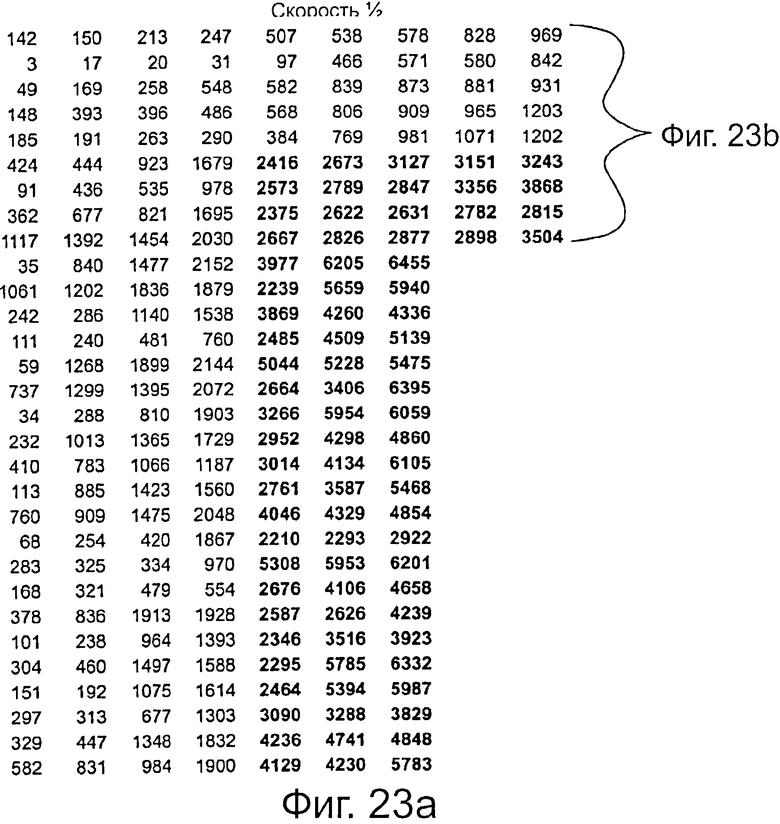

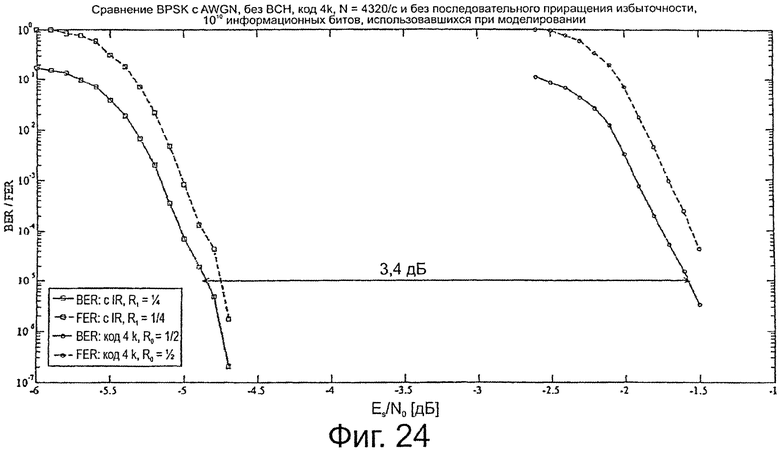
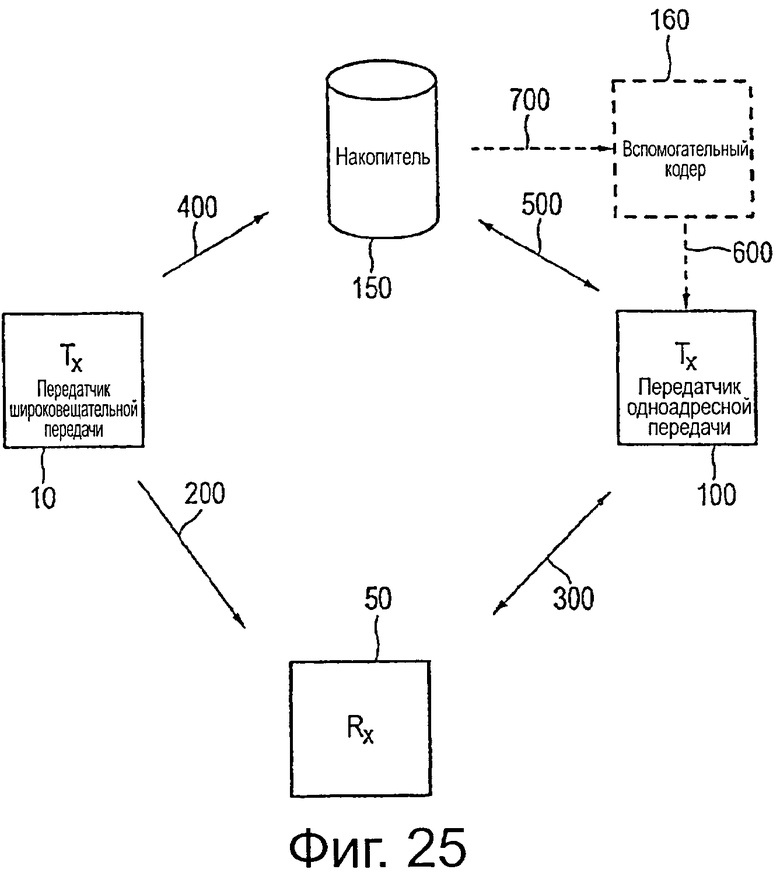
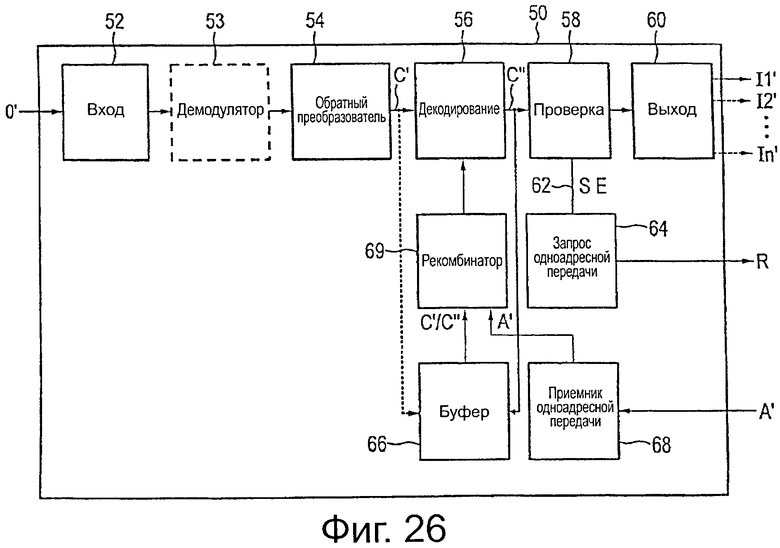
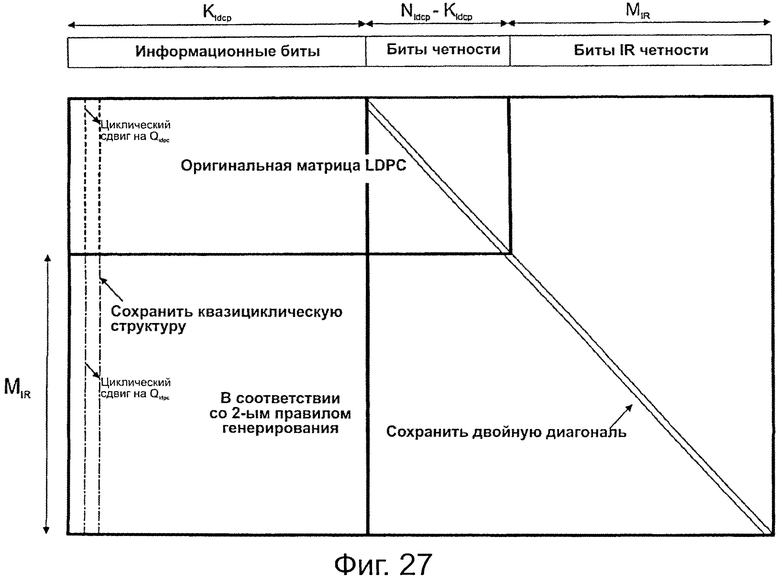
Изобретение относится к средствам кодирования с коррекцией ошибок. Технический результат заключается в повышении вероятности безошибочного приема/реконструкции данных приемником даже при плохих условиях приема. Кодируют входные слова (D) данных в кодовые слова (Z1, Z2), каждое из которых содержит первое число Kldpc информационных символов, средство (1452) кодирования для кодирования входного слова (D) данных в кодовое слово (Z1, Z2, Z3, Z4) так, что кодовое слово содержит основную область (B) кодового слова, включающую в себя область (D) данных и основную область (Pb) четности со вторым количеством Nldpc-Kldpc основных символов четности, и вспомогательную область (А) кодового слова, включающую в себя вспомогательную область (Pa) четности с третьим количеством MIR вспомогательных символов четности, и выход (1454) кодера для вывода упомянутых кодовых слов (Z1, Z2). 6 н. и 4 з.п. ф-лы, 26 ил.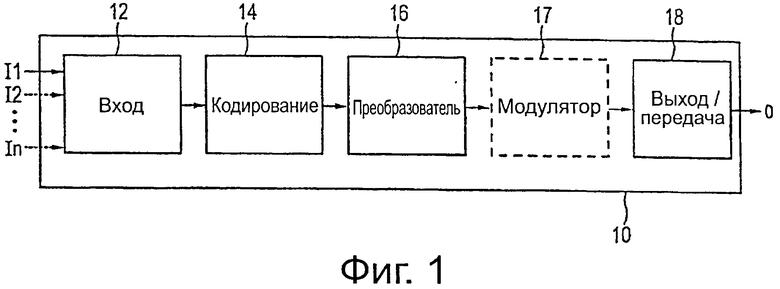
1. Кодер кодирования с коррекцией ошибок для кодирования слов (D) входных данных в кодовые слова (Z1, Z2), содержащий:
вход (1451) кодера, выполненный с возможностью приема входных слов (D) данных, каждое из которых содержит первое количество Kldpc информационных символов,
средство (1452) кодирования, выполненное с возможностью кодирования входного слова (D) данных в кодовое слово (Z1, Z2, Z3, Z4) так, что кодовое слово содержит основную область (В) кодового слова, включающую в себя область (D) данных и основную область (Pb) четности со вторым количеством Nldpc-Kldpc основных символов четности и вспомогательную область (А) кодового слова, включающую в себя вспомогательную область (Ра) четности с третьим количеством MIR вспомогательных символов четности,
при этом упомянутое средство (14) кодирования выполнено с возможностью
генерирования упомянутой основной области (В) кодового слова из входного слова (D) данных в соответствии с первым кодом, причем основной символ четности генерируют посредством накопления информационного символа по адресу символа четности, определенному в соответствии с первым правилом генерирования адресов, а Nldpc-Kldpc основных символов четности генерируют посредством накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу y символа четности, при этом упомянутые адреса y символа четности определяют в соответствии с первым правилом генерирования адресов
y={х+m mod Gb×Qldpc}mod(Nldpc-Kldpc), если x<Nldpc-Kldpc,
при этом x указывает адрес накопителя символа четности, соответствующего первому информационному символу группы размером Gb, в Qldpc - заранее определенная константа, зависящая от скорости основного кода, и
генерирования упомянутой области (А) вспомогательного кодового слова из входного слова (D) данных в соответствии со вторым кодом, причем вспомогательный символ четности генерируют посредством накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу y символа четности, а упомянутые адреса y символов четности определяют в соответствии со вторым правилом генерирования адресов
y=Nldpc-Kldpc+{x-(Nldpc-Kldpc)+m mod Ga× QIR}mod MIR, если x≥Nldpc-Kldpc,
при этом x указывает адрес накопителя символа четности, соответствующего первому информационному символу группы размером Ga, a QIR - заранее определенная константа, зависящая от скорости кода, причем Ga=Gb=72, и
выход (1454) кодера, выполненный с возможностью вывода упомянутых кодовых слов (Z1, Z2).
2. Кодер по п.1,
в котором упомянутое средство (1452) кодирования выполнено с возможностью поблочного генерирования упомянутых основных символов четности и упомянутых вспомогательных символов четности посредством использования группы последовательных информационных символов,
характеризующийся тем, что выполнен с возможностью накопления каждого информационного символа i упомянутой группы последовательных информационных символов в наборе разных адресов y символа четности,
отбора набора адресов символа четности, для накопления первого информационного символа упомянутой группы, из заданной таблицы адресов,
определения адресов символа, для накопления последовательных информационных символов упомянутой группы, из упомянутого набора адресов символа четности в соответствии с упомянутым первым или упомянутым вторым правилом генерирования адресов, соответственно, и
получения отдельного набора адресов символа четности из упомянутой таблицы адресов для генерирования каждого нового блока основных символов четности и вспомогательных символов четности.
3. Кодер по п.2,
в котором упомянутое средство (1452) кодирования выполнено с возможностью последовательного отбора новой строки следующей таблицы адресов в качестве нового набора отличающихся адресов y символа четности для накопления новой группы последовательных информационных символов, при этом упомянутая таблица адресов для QIR=60, MIR=4320, Nldpc=4320, Qldpc=30 и идентификатора скорости кода, равного ½, представляет собой


4. Кодер по п.1,
в котором упомянутое средство (1452) кодирования выполнено с возможностью накопления основных символов четности и вспомогательных символов четности, в частности всех основных символов четности и всех вспомогательных символов четности.
5. Кодер по п.1,
в котором упомянутая основная область кодового слова (B) обеспечивается для обычного декодирования, а упомянутая вспомогательная область (A) кодового слова обеспечивается в качестве последовательного приращения избыточности, при выполнении, с ошибкой, обычного декодирования кодового слова, осуществляемого с использованием основной области (B) кодового слова.
6. Способ кодирования кода с коррекцией ошибок для кодирования входных слов (D) данных в кодовые слова (Z1, Z2), содержащий этапы, на которых:
принимают входные слова (D) данных, каждое из которых содержит первое количество Kldpc информационных символов,
кодируют входное слово (D) данных в кодовое слово (Z1, Z2, Z3, Z4) так, что кодовое слово содержит основную область (B) кодового слова, включающую в себя область (D) данных и основную область (Pb) четности со вторым количеством Nldpc-Kldpc основных символов четности, и вспомогательную область (A) кодового слова, включающую в себя вспомогательную область (Pa) четности с третьим количеством MIR вспомогательных символов четности,
генерируют упомянутую основную область (В) кодового слова из входного слова (D) данных в соответствии с первым кодом, при этом генерируют основной символ четности посредством накопления информационного символа в адресе символа четности, определенном в соответствии с первым правилом генерирования адресов и генерируют Nldpc-Kldpc основных символов четности посредством накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу y символа четности, причем определяют упомянутые адреса y символа четности определяют в соответствии с первым правилом генерирования адресов
y={х+m mod Gb×Qldpc}mod(Nldpc-Kldpc), если x<Nldpc-Kldpc,
при этом x указывает адрес накопителя символа четности, соответствующего первому информационному символу группы размером Gb, a Qldpc - заранее определенная константа, зависящая от скорости основного кода,
генерируют упомянутую вспомогательную область (A) кодового слова из входного слова (D) данных в соответствии со вторым кодом, при этом генерируют вспомогательный символ четности посредством накопления информационного символа в положении m, m=0…, Kldpc-1 по адресу y символа четности, причем определяют упомянутые адреса y символа четности в соответствии со вторым правилом генерирования адресов
y=Nldpc-Kldpc+{х+m mod Ga×QIR}mod MIR, если x≥Nldpc-Kldpc,
при этом x указывает адрес накопителя символа четности, соответствующего первому информационному символу группы размером Ga, и QIR - заранее определенная константа, зависящая от скорости вспомогательного кода, причем Ga=Gb=72, и
выводят упомянутые кодовые слова (Z1, Z2).
7. Носитель информации, хранящий компьютерную программу, содержащую средство программного кода, вызывающее, при выполнении на компьютере, осуществление компьютером этапов кодирования и отображения по способу п.6.
8. Передатчик широковещательной передачи данных в системе широковещательной передачи, содержащий:
вход данных для приема по меньшей мере одного потока (I1, I2,…, In) входных данных передатчика, сегментированных на входные слова (D) данных,
кодер (14, 141, 142, 143, 144, 145) для кодирования в коде с коррекцией ошибок входных слов (D) данных в кодовые слова (Z1, Z2) по любому из пп.1-5,
преобразователь (16) данных для отображения кодовых слов (Z1, Z2) на фреймы выходного потока (О) данных передатчика, и
модуль (18) передатчика для передачи упомянутого выходного потока (О) данных передатчика.
9. Способ передачи для широковещательной передачи данных в системе широковещательной передачи данных, содержащий этапы, на которых:
принимают по меньшей мере один входной поток данных (I1, I2…, In) передатчика, сегментированный во входные слова (D) данных,
выполняют способ кодирования кода с коррекцией ошибок для кодирования входных слов (D) данных в кодовые слова (Z1, Z2) в соответствии с п.6,
отображают кодовые слова (Z1, Z2) во фреймы выходного потока (О) данных передатчика, и
передают упомянутый выходной поток (О) данных передатчика.
10. Система широковещательной передачи, содержащая передатчик по п.8 и один или более приемников для приема данных, передаваемых упомянутым передатчиком в режиме широковещательной передачи.
| JP 2010197393 A, 09.09.2010 |

