Настоящее изобретение относится к технологии целостности данных. В особенности, оно находит применение при идентификации отдельных пациентов и медицинских записей пациентов для передачи и совместного использования медицинской информации между различными лечебными учреждениями и будет описано с конкретными ссылками на нее. Однако оно также находит применение в других типах приложений для отображения данных, в которых есть интерес к целостности данных.
Пациенты обычно получают медицинское обслуживание от нескольких медицинских работников, многие из которых географически рассредоточены и расположены на нескольких участках. Использование нескольких медицинских работников приводит к тому, что отдельные пациенты получают несколько идентификаторов пациента, каждый идентификатор пациента частный для определенного медицинского работника. Данные пациента, такие как медицинские тесты, истории, отчеты докторов, медицинские изображения и другая соответствующая медицинская информация распространяются среди нескольких участков медицинских работников. Для того чтобы медицинскому работнику извлечь записи данных пациента, хранящиеся в нескольких участках медицинских работников, необходимо синхронизировать множество идентификаторов пациентов соответствующих медицинских работников и связать множество идентификаторов пациентов между собой.
Пациенты не всегда предоставляют информацию о своем имени унифицированно, например, без или со вторым инициалом, уменьшительное или полное имя, с или без суффикса, такого как младший, фамилия в замужестве или в девичестве и т.д. Не только адреса иногда предоставляются унифицированно, но и люди переезжают. Пациенты из одной и той же семьи могут иметь одинаковые имена, одинаковые адреса, а также одинаковую медицинскую информацию.
В настоящее время существует потребность в системе, способе и устройстве, которое дает возможность медицинским записям следовать за пациентами, по мере того как они перемещаются между несколькими медицинскими работниками.
Настоящее приложение предоставляет улучшенный способ, систему и устройство, которые преодолевают вышеуказанные и другие проблемы.
В соответствии с одним аспектом, предложен способ синхронизации пользовательских записей, который содержит назначение пользовательской записи уникального номера записи, затем извлечение демографической информации для пользовательской записи для отождествления демографической информации с демографической информацией из совокупности записей в других системах. Это используется для поиска записей, которые принадлежат тому же пользователю, а затем сравнить демографическую информацию пользовательской записи с по меньшей мере одной другой демографической информацией записи из совокупности записей в по меньшей мере одной другой системе для расчета отношения правдоподобия для каждой сравниваемой записи, последующего сравнения каждое отношение правдоподобия с определенным допустимым порогом и с определенным порогом отказа и, в конце концов, прикрепляет утверждение для сравненных пользовательских записей на основе по меньшей мере одного сравнения отношения правдоподобия.
В соответствии с другим аспектом предложено устройство для синхронизации пользовательских записей, которое включает в себя средства ввода для приема входной пользовательской записи и сопутствующих демографических данных, которые используют совокупность пользовательских записей и сопутствующие демографические данные. Также в его состав включены средства обработки для расчета уникального номера пользовательской записи из демографических данных с использованием вычислительных средств для сравнения по меньшей мере одних демографических данных пользовательской записи по меньшей мере одной пользовательской записи с другими демографическими данными записей из совокупности записей для того, чтобы рассчитать отношение правдоподобия для каждой сравниваемой записи. Затем вычислительные средства сравнивают каждое отношение правдоподобия с определенным допустимым порогом и порогом отказа, и выполняют одно из двух действий: либо отбрасывание по меньшей мере одной пользовательской записи, если отношение правдоподобия попадает ниже порога отказа; либо принятие по меньшей мере одной пользовательской записи, если отношение правдоподобия попадает выше допустимого порога; или определение по меньшей мере одной пользовательской записи для ручного рассмотрения, если отношение правдоподобия попадает между допустимым порогом и порогом отказа. Средства также создают запись в среде хранения данных, если по меньшей мере одна пользовательская запись была отброшена, принята или определена для ручного рассмотрения или записи, если учреждением сделано утверждение по поводу пары пользовательских записей.
В соответствии с другим аспектом изобретения предлагается способ синхронизации пользовательских медицинских записей, содержащий ввод записей пациента, извлечение множества записей пациентов из совокупности хранящихся записей пациентов, сравнение вводимой записи пациента с извлеченными записями пациента, расчет отношение правдоподобия из каждой пары сравниваемых записей, назначение утверждения об отказе в ответ на то, что отношение правдоподобия падает ниже порогового уровня отказа, назначение утверждения о принятии, в ответ на то, что отношение правдоподобия попадает в диапазон выше допустимого порогового уровня, и, в конечном счете, помещает запись в список исключений, если отношение правдоподобия попадает между допустимым порогом и порогом отказа.
Преимущество состоит в создании на основе демографических данных индекса, который будет таким же или похожим вне зависимости от процедуры оценки медицинского работника.
Дополнительным преимуществом является максимизация использования утверждений на этапе ручного рассмотрения, позволяющая одним учреждениям видеть утверждения, опубликованные другими учреждениями и при необходимости принимать их в расчет.
Дополнительные преимущества настоящего изобретения будут понятны обычным специалистам в области техники по мере чтения и понимания следующих подробных описаний.
Настоящее изобретение может принимать форму различных компонентов и набора компонентов и различных этапов и набора этапов. Рисунки только с целью иллюстрации предпочтительных реализаций и не должны толковаться как ограничивающие применение настоящего изобретения.
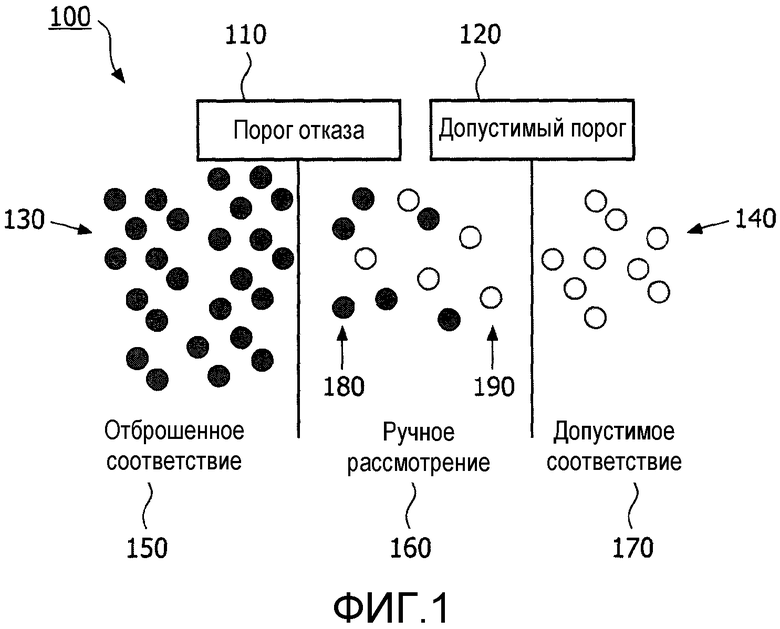
На фиг.1 показаны два пороговых значения для разделения трех итоговых значений в зависимости от соответствующей им записи.
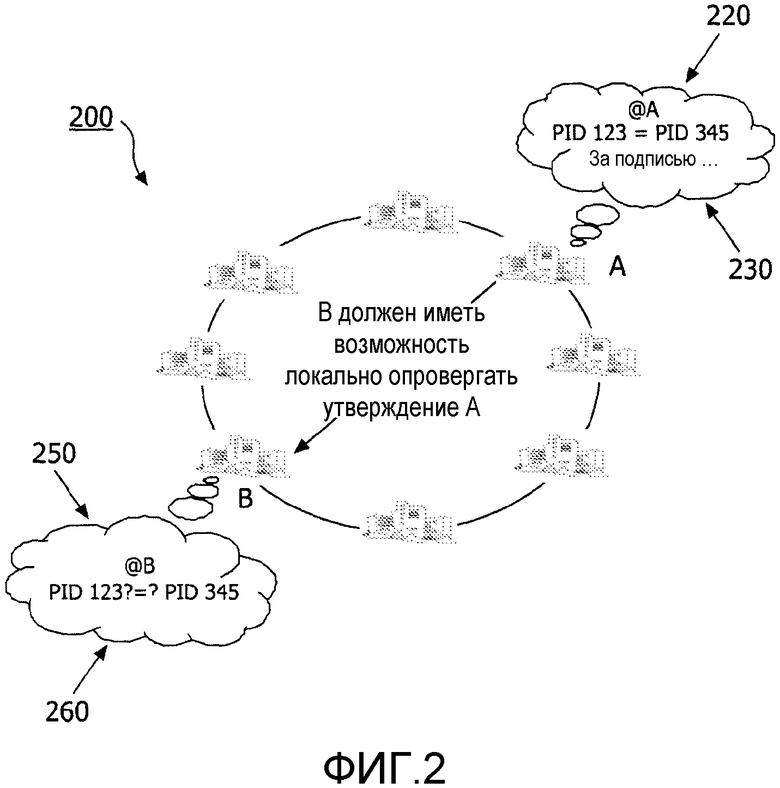
На фиг.2 показано принятие утверждения в неоднородной среде с независимыми учреждениями.
На фиг.3 показана система обработки утверждений для объединения, включающего в себя четыре участвующих организации.
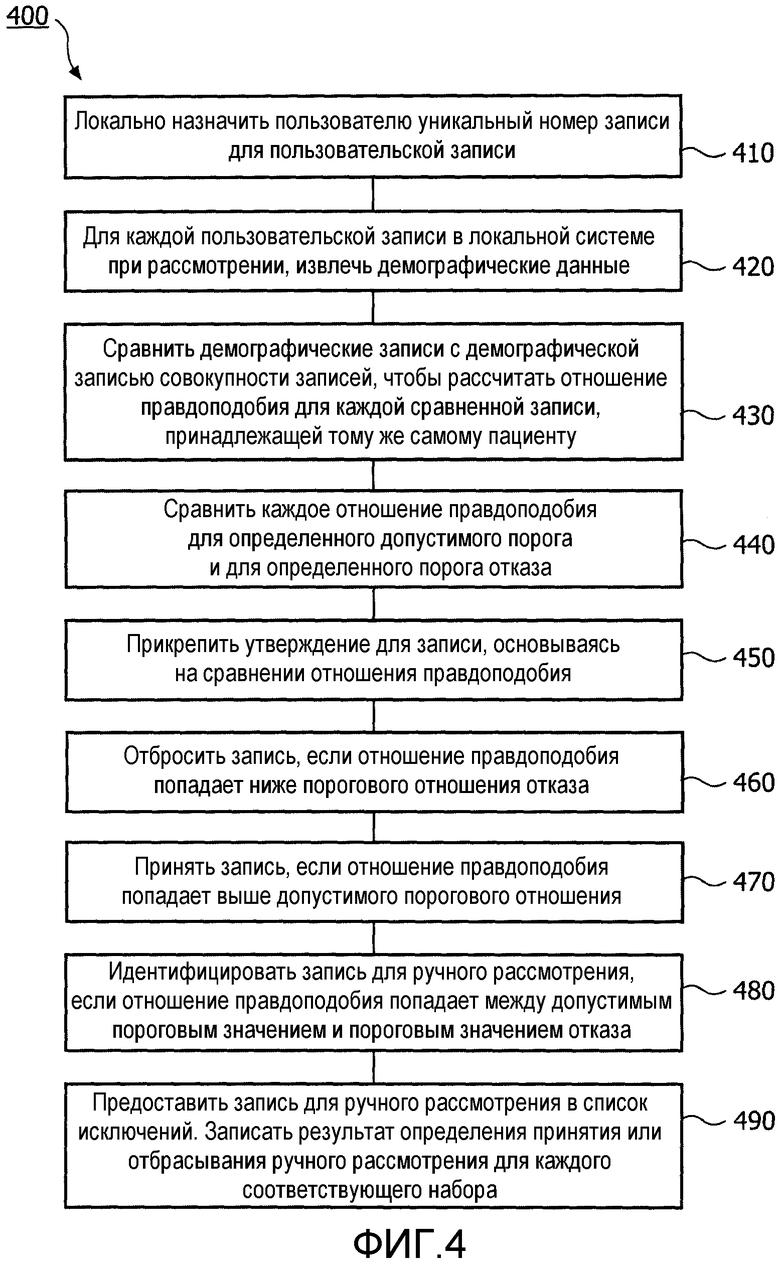
На фиг.4 представлена блок-схема, показывающая этапы способа.
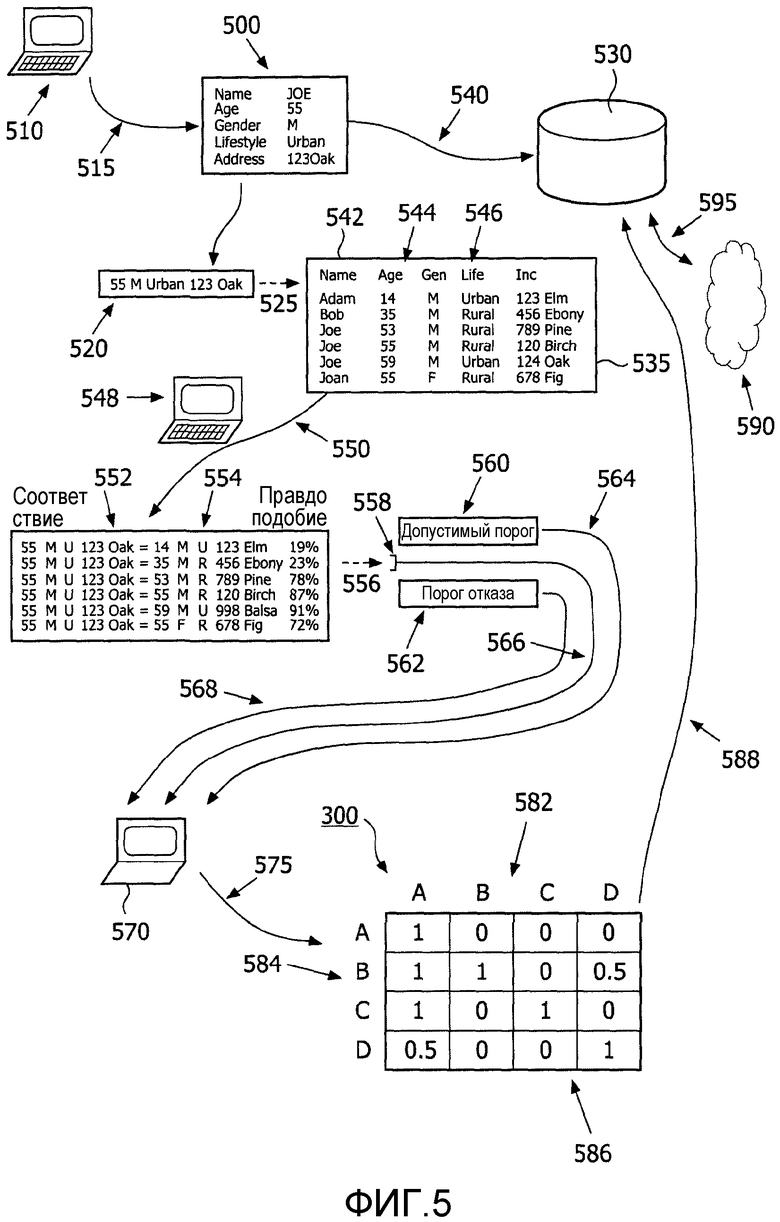
На фиг.5 представлена иллюстрация информационного потока, проходящего через устройство в реализации настоящего изобретения.
Со ссылкой на фиг.1, вероятностный алгоритм, который сравнивает фиксированную запись с несколькими кандидатами на соответствие, рассчитывает для каждого кандидата отношение правдоподобия или взвешенный счет, который отдельно сравнивается с порогом 110 отказа или с допустимым порогом 120. Порог 110 отказа используется как основа для сравнения, используемого для того, чтобы решить падает ли запись ниже порога 110 отказа. Если отношение правдоподобия записи меньше, чем порог 110 отказа, запись отбрасывается 130 как несоответствующая 150 и запись не связывается. Допустимый порог 120 используется как основа для сравнения, используемая для того, чтобы решить какие записи превышают допустимый порог. Если отношение правдоподобия записи больше, чем допустимый 120 порог, запись 140 принимается как соответствующая 170 и запись связывается. Если запись больше чем порог 110 отказа, а также меньше допустимого порога 120, то рассчитанное отношение правдоподобия попадает между допустимым порогом и порогом отказа. Здесь запись может быть как отброшена 180, так и принята 190. Решение автоматически не принимается и отмечается флажком для ручного рассмотрения 160 квалифицированным персоналом. Ручное рассмотрение выполняется для того, чтобы определить, должна ли запись быть надлежащим образом отброшена 180 или принята 190 как соответствующая. Ручное рассмотрение 160 неточных соответствий является вопросом ключевой важности для того, чтобы минимизировать ошибки сопоставления, т.к. они могут иметь далеко идущие последствия, в конечном счете, подвергающие опасности здоровье пациента.
Т.к. медицинские работники или органы здравоохранения присоединятся или объединяются, общий доступ к записям пациентов может быть преимуществом. По существу, это может привести к тому, что базы данных нескольких медицинских работников будут содержать номера медицинских записей (MRN) для одного и того же пациента. Для каждого медицинского работника поток информации в запись и из записи пациента проходит через канал с первичным индексом пациента (MPI - master patient index), который связывает уникальный номер медицинской записи (MRN) с каждой сущностью пациента, когда существует уникальная запись. Для получения представления в масштабе предприятия по всем пациентам из распределенных источников данных вводится первичный индекс пациента по предприятию (EMPI). В общем случае, такая интеграция записей пациента достигается посредством сравнения демографических атрибутов, таких как имя/фамилия, пол, дата рождения, адрес и других демографических данных для создания EMPI как формы идентификатора пациента на уровне предприятия, который может обеспечивать возможность одному и тому же пациенту быть узнаваемым в записях, собранных в различных лечебных учреждениях различными медицинскими работниками. Такой идентификатор пациента на уровне предприятия редко основывается на едином идентификаторе, распределенном по различным структурам этого предприятия.
Вероятностный алгоритм может быть использован для сравнения фиксированных записей с несколькими кандидатами на соответствие, и для расчета для каждого кандидата отношения правдоподобия или взвешенный счет, который сравнивается с выбранными допустимым порогом и порогом отказа, как описано выше со ссылкой на фиг.1. Этот способ используется для определения вероятности того, что две различные записи в двух различных лечебных учреждениях представляют одного и того же пациента, и для того, чтобы решить, связывать ли эти записи или не связывать. Если решение не может быть принято автоматически, когда рассчитанное отношение правдоподобие попадает между двумя пороговыми значениями, квалифицированный персонал вручную просматривает или отмечает флажком потенциальные соответствия, перед тем как принять их, а также просматривает потенциальные несоответствия, перед тем как их отбросить. Ручное рассмотрение неоднозначных несоответствий очень важно для минимизации ошибок сопоставления, но в то же время трудоемко и, следовательно, дорого.
Для каждого лечебного учреждения поток информации в запись и из записи пациента проходит через канал с первичным индексом пациента (MPI), который связывает уникальный номер медицинской записи (MRN) с каждой сущностью пациента, когда существует уникальная запись. Для получения представления в масштабе предприятия по всем пациентам из распределенных источников данных вводится первичный индекс пациента по предприятию (EMPI). EMPI создается посредством интеграции отдельных MPI-индексов источников.
В настоящее время, если две записи связаны вручную или вручную заявлено, что они разные, то этот факт используется во всей системе как «истина одного обоснования». Проблемой такого подхода является то, что этап ручного приведения в соответствие принимает в качестве истинного отдельное авторитетное решение. Это решение может быть неприемлемо в другой независимой среде, где не существует авторитетного специалиста в масштабах предприятия, признаваемого на всех участках, и поэтому не существует одного источника истины. Стандарты в масштабах предприятия могут достигаться посредством использования утверждений.
Утверждение прикрепляется к паре записей для приведения в соответствие на основе сравнения отношения правдоподобия, устанавливающих, заслуживает ли доверия тот факт, что две записи принадлежат одному пациенту, или нет. Сопоставление записей на основе утверждений дает возможность всем принимающим участие участкам независимо принимать решение о том, принадлежит ли соответствующая запись, представленная к ручному рассмотрению в объединении медицинских работников, одному и тому же пациенту. Ни одно из решений по рассмотрению не принимается как истина одного глобального обоснования. Индивидуальные утверждения поддерживаются для каждого учреждения, выполняя функцию истины локального обоснования по отношению к учреждению, которое выпустило их, но не обязательно для других учреждений.
Со ссылкой на фиг.2 показана система 200, посредством которой две отдельные больницы А и В распределяют записи и вручную связывают две записи пациентов вместе как принадлежащие одному пациенту. Больница А, например, определяет 220, что две отдельные записи, например, устанавливаемые PID=123 и PID=345, соответственно (где PID - идентификатор пациента) находятся в соответствии, и делает утверждение 230 о том, что записи находятся в соответствии. Другое учреждение, больница В, имеет возможность выполнять 250 отдельное собственное ручное или автоматическое рассмотрение и делать утверждение 260 о том, что записи не находятся в соответствии, тем самым локально аннулируя утверждение 230, сделанное больницей А.
Способность больницы В опровергать утверждение, сделанное больницей А, является преимуществом настоящего изобретения. Если больница В, 240, не была бы способна опровергать утверждение больницы А, то больница В потеряла бы независимость своих собственных данных и, по существу, не могла бы обеспечивать целостность данных. Например, ошибка, сделанная больницей А при рассмотрении, заставила бы больницу В, если бы больница В не могла опровергнуть утверждение, сделанное больницей А, стать ответственной за ошибку больницы А без возможности влиять на итог соответствия. Однако как независимой организации больнице В не нужно учитывать и применять решения, сделанные больницей А.
В некоторых, имеющихся в настоящее время решениях по сопоставлению записей, если две записи связаны вручную или вручную заявлены как различные, этот факт используется в качестве «истины одного обоснования» во всей системе. Например, соответствие записи, примененное в рамках однородных настроек в масштабах предприятия, где распределенные участки со своими собственными схемами идентификации становятся частью одного большего «виртуального» предприятия, например, посредством присоединений или слияний. Подход «истины одного обоснования» к ручному рассмотрению в таких условиях работает хорошо, потому что степень доверия, установившегося среди участвующих сторон, обычно достаточно высока, и поэтому результаты ручного рассмотрения без сомнений принимаются всеми сторонами.
Модель полного доверия, которая существенно предполагается в подходе «истины одного обоснования», не применяется для всех сред, в которых должны распределятся данные пациента. В особенности в средах, в которых принимающие участие учреждения неопределенно связаны и остаются независимыми в своем управлении, решение с только одним обоснованием истины по отношению к ручному рассмотрению соответствия может вызвать проблемы. Некоторые из возникающих региональных организаций информации о здоровье (RHIO) представляют такие распределенные независимые среды. В них участвующие учреждения удерживают полный контроль на своими данными и над процессом качества, связанным с их обработкой.
Со ссылкой на фиг.3, система 300 обработки утверждений показана в сценарии, в котором независимые решения и решения о связи не принимаются на уровне всего предприятия, где уровень масштаба предприятия или уровень объединения ссылается на два или более медицинских учреждения, использующих настоящее изобретение. Система масштаба предприятия, которая обрабатывает реестр пациентов 310 (PR) масштаба предприятия и хранит данные в глобальной базе данных 315, формирует список исключений 320 в масштабе предприятия с потенциальными соответствиями для ручного рассмотрения. Каждый ввод данных в глобальный список исключений 320 содержит множество локальных идентификаторов пациента, ссылающихся на множество записей, с которыми они потенциально находятся в соответствии, где содержимое записей используется для определения соответствия, а идентификаторы используются для ссылки на определенные записи, используемые в процессе определения утверждения о соответствии. Система 300 также содержит список 330 утверждений, который включает в себя список утверждений о соответствии или несоответствии записей, представленных идентификаторами пациентов, и при каждом вводе данных в этот список 330 утверждений указывается медицинское учреждение, которое сделало утверждение. В системе также указывается дополнительная информация, такая как пользователь, который сделал утверждение, метка времени, когда было сделано утверждение. Записи, потенциально находящиеся в соответствии в списке 320 исключений в масштабе предприятия, сравниваются с утверждениями о соответствиях или несоответствиях в списке 330 утверждений для идентификации одинаковых, потенциально находящихся в соответствии записей в обоих списках: списке 330 утверждений и списке 320 исключений в масштабах предприятия. При рассмотрении исключений вместе с соответствующей частью списка 320 исключений в масштабах предприятия список 330 утверждений предоставляется руководству локальных участков 335, 385. Список 320 исключений в масштабе предприятия вместе с уже существующим списком 330 утверждений распределяется 325, 395 к участвующим учреждениям 340, 370, принимая в расчет локально релевантную информацию, такую как разделение/распределение списка 330 утверждений, который определяется локально известными идентификаторами пациентов. Эта локальная информация хранится в локальном реестре пациентов или базе данных 345, 375. Каждый участок затем продолжает разрешение своего локального списка 350, 380 исключений посредством выполнения утверждений 365 о соответствиях и несоответствиях. Эти утверждения 365 затем проходят обратно 355 в список 320 исключений в масштабах предприятия, в котором утверждения, указывающие на то, что в отдельных учреждениях 340, 370 предоставленные утверждения 365 составляют истину локального обоснования. Представленные к рассмотрению утверждения 365 также распространяются или добавляются в локальные списки 350, 380 исключений тех медицинских утверждений, чьи списки 350, 380 исключений включают в себя запись пациента, о которой было сделано утверждение 365. Когда списки 360, 390 утверждений локально разрешаются каждым участком 340, 370, записи в локальных списках 350, 380 исключений, уже имеющие утверждения с различных участков, с этого момента времени считаются соответствующими или несоответствующими для этого участка. Эти записи не будут снова отправляться на этот участок с новым локальным списком исключений.
Медицинские учреждения рассматривают свои собственные списки локальных исключений, а также соответствующие списки утверждений, когда идентификаторы пациентов различных медицинских организаций, участвующих в системе, связываются между собой.
Медицинским учреждениям также необходимо рассматривать исключения в процессе нормальной работы системы каждый раз, когда новые данные, относящиеся к этому участку, добавляются в глобальный список исключений. Элементы добавляются в глобальный список исключений в процессе работы системы, когда регистрируются новые пациенты, а алгоритм приведения в соответствие идентичности генерирует исключение для возможного соответствия, в случае которого необходимо регулярно рассматривать список исключений.
Список утверждений, содержащий уже сделанные другими медицинскими учреждениями утверждения относительно записей, которые необходимо оценить, может помочь локальным участкам принять решение о связывании записей, но он не является источником истины. Локальный участок делает свои собственные утверждения, которые отправляются обратно в реестр 310 пациентов и хранятся в глобальном списке 330 утверждений как истинные для данного участка.
Со ссылкой на фиг.4 представляется последовательность этапов способа 400 выполнения настоящего приложения. Этап или средства 410 назначают пользовательской записи уникальный номер записи. Затем этап или средства 420 извлекают демографические данные для определенной пользовательской записи из рассматриваемой системы для того, чтобы эту определенную пользовательскую запись привести в соответствие с демографическими данными из других систем в организации для поиска записей, принадлежащих тому же самому пациенту. Затем этап или средства 430 сравнивают демографические данные пользовательской записи с демографическими данными из совокупности записей для расчета отношения правдоподобия для каждой сравниваемой записи. Далее, этап или средства 440 сравнивают каждое отношение правдоподобия для определения допустимого порога и порога отказа. Затем этап или средства 450 на основании сравнения отношения правдоподобия прикрепляют к записи утверждение. Далее, этап или средства 460 отбрасывают запись, если отношение правдоподобия оказывается ниже порогового отношения отказа. Затем этап или средство 470 принимает запись, если отношение правдоподобия превышает допустимое пороговое отношение. Затем этап или средство 480 устанавливают запись для ручного рассмотрения, если значение отношения правдоподобия попадает между допустимым порогом и порогом отказа. Затем этап или средство 490 помещает записи для ручного рассмотрения в список исключений и распределяет этот список соответствующим учреждениям и записывает определение результатов принятия или отбрасывания, выполненных посредством ручного рассмотрения в каждом соответствующем учреждении.
Проблема идентичности пациента в объединенной среде в отсутствие общего глобального идентификатора является ключевым вопросом, в котором решение такого ключевого вопроса считается предпосылкой к возможности сформировать и развернуть решение в виде объединенной системы архивации и передачи изображений (PACS). Настоящее изобретение направлено на фазу ручного рассмотрения процесса приведения в соответствие в контексте независимой среды.
Со ссылкой на фиг.5 описано 500 взаимодействие данных с устройством в рамках действующей компьютерной среды. Используя средство 510 ввода с использованием входного устройства, такого как, но не ограничиваясь, компьютерный терминал 510, вводится 515 запись. Введенные записи постоянно хранятся в любом типе формата или в предварительно определенном формате 520. Запись будет также содержать демографические данные, такие как, но не ограничиваемые, возраст, поло, национальность, городской или сельский образ жизни, адрес, номер телефона и тому подобные. Введенные демографические данные записи передаются 535 в базу данных 530. Демографические данные 540 будут использоваться в качестве указателя 525. Этот указатель 525 будет использоваться для поиска 552 совокупности ранее введенных записей 550, извлеченных 535 из базы данных 530. Поиск будет продолжаться по одной записи единовременно или в той последовательности, в которой введены, или упорядочено, как, но не ограничиваясь, упорядочивание в алфавитном порядке. Такой поиск будет пытаться найти соответствие в демографических данных только что введенных новых записей 520 и демографических данных записей 550 в существующей базе данных 530 на основании того, как близко демографические данные в нововведенной записи 520 соответствуют демографическим данным отдельных записей 550 в базе данных 530. Такой поиск выполняется с использованием средств программного обеспечения, обеспечиваемых в действующей компьютерной среде 560 и исполняемой процессором. Из этого соответствия 562 рассчитывается отношение правдоподобия 564. Отношение правдоподобия 564 сравнивается 566 с определенным допустимым порогом 570 и с определенным порогом отказа 572, производя один из следующих трех результатов. Если отношение правдоподобия 564 больше чем или равно допустимому порогу 570, то значение принимается как соответствующее и делается положительное утверждение о том, что это соответствие 576. Если отношение правдоподобия 564 меньше чем или равно значению порога отказа 572, то значение отбрасывается как несоответствующее и делается отрицательное утверждение о несоответствии 578. Если отношение меньше, чем допустимый порог 570, и также больше, чем порог отказа 572, то запись помечается флагом 574 и запись будет помещена в список исключений. Записи в этом списке исключений будут представлены к ручному рассмотрению. Такое ручное рассмотрение может включать в себя определение того, что соответствие между двумя записями, помещенными в список исключений, должно быть принято или отброшено, и прикрепление утверждения к паре записей. Это утверждение должно быть введено вручную в компьютер 580. Список исключений может также помещаться в компьютер. Каждый участок, хранящий одну из записей, независимо добавляет утверждение о том, принадлежат ли две записи одному и тому же пациенту или нет. Это определение становится основой для утверждения. Как только такое определение сделано, делается утверждение о принятии или отбрасывании, и это утверждение 585 хранится в базе данных 530 системы. Утверждения, записанные в базу данных, могут быть распространены другим пользователям 595 с помощью подключения базы данных 530 утверждений к сети 590.
Например, введенная запись в настоящем примере предназначена для Джоу, 55 лет, мужчина, городской житель. Сравнение с записью в базе данных Адама, 14 лет, мужчина, городской житель, произведет низкое в 19% отношение правдоподобия соответствия из-за значительного рассогласования по возрасту и адресу между двумя сравниваемыми записями. Если пороговое отношение отказа было бы 20%, то эта запись с отношением 19% была бы ниже 20% порога отказа и была бы отброшена. Эти две сравниваемые записи возможно не для одного и того же человека.
Другое сравнение, на этот раз введенной записи Джоу, 55 лет, мужчина, городской житель, с записью из базы данных о другом Джоу, которому 59 лет, мужской, городской житель, произведет более высокое отношение правдоподобия в 91%, из-за того, что эти две записи в намного более близком соответствии с точки зрения возраста, пола и образа жизни. Если бы пороговое отношение для принятия было бы 90%, то эта запись с отношением правдоподобия была бы выше допустимого отношения в 90% и была бы принята как соответствующая. Эти две сравниваемые записи вероятны для одного и того же человека.
Сравнение с записью для Джоан, 55 лет, женский, сельский житель, произведет отношение правдоподобия равное 72%. Так как эти 72% выше 20% порога отказа и также ниже 90% допустимого порога, эта запись помещается в список исключений и отмечается флагом для ручного рассмотрения. Только ручное рассмотрение может определить, для одного ли человека эти записи.
Каждый демографический фактор может быть, но без необходимости, в равной степени взвешен. Например, адрес индивида может существенно измениться за короткий период времени. Поэтому эта демографическая информация должна быть взвешена для того, чтобы быть менее важной, чем другая, более стабильная, менее предрасположенная к изменениям демографическая информация. Демографической информации, которая редко или никогда не изменяется, такая как пол или национальность, нужно дать больший вес, потому что эта демографическая информация может быть более надежна как индикатор определенного человека. В настоящем примере, это объяснит, почему отношение правдоподобия между Джоу 55 мужчина, городской житель, 123 Оак и Джоу 59, мужчина, городской житель, 998 Бальса составляет 91%, не смотря на различие адресов двух индивидов. Здесь сходство в возрасте, поле, образе жизни взвешено больше, чем адрес.
Вышеописанный процесс выполняется на одном или более компьютерах или системах компьютеров. Компьютерные программы для выполнения этапов могут храниться на материальном считываемом компьютером носителе, таком как диск, память компьютера или подобное.
Множество медицинских работников могут обмениваться информацией и рассматривать оценки медицинских записей пациентов друг друга при определении отношения правдоподобия, показывающего, что две записи, предоставленные для ручного рассмотрения, принадлежат одному и тому же пациенту.
Настоящее заявка описана со ссылкой на предпочтительные воплощения. Модификации и изменения могут появиться у прочих по мере чтения и понимания предшествующего подробного описания. Оно предназначено для того, чтобы настоящая заявка была создана, как включающая в себя все такие модификации и изменения в такой мере, в которой они попадают в объем прилагаемой формулы изобретения или ее эквивалентны.
Изобретение относится к области синхронизации записей в медицинской среде. Техническим результатом является обеспечение интегрирования двух и более источников данных посредством уникального номера записи в корпоративном реестре. В способе назначают уникальный номер записи пользовательской записи; сравнивают демографическую информацию пользовательской записи с по меньшей мере одной демографической информацией другой записи в совокупности записей из по меньшей мере одного другого источника данных для расчета отношения правдоподобия для каждой сравниваемой записи; сравнивают каждое отношение правдоподобия с заданным порогом допустимости и с заданным порогом отказа, при этом идентифицируют пользовательские записи для ручного рассмотрения, если отношение правдоподобия попадает между порогом допустимости и порогом отказа; прикрепляют утверждение для сравненных пользовательских записей на основе сравнения по меньшей мере одного отношения правдоподобия; и размещают пользовательские записи, для которых должно быть выполнено ручное рассмотрение, в списке исключений и распределяют список исключений на каждый источник данных. 4 н. и 11 з.п. ф-лы, 5 ил.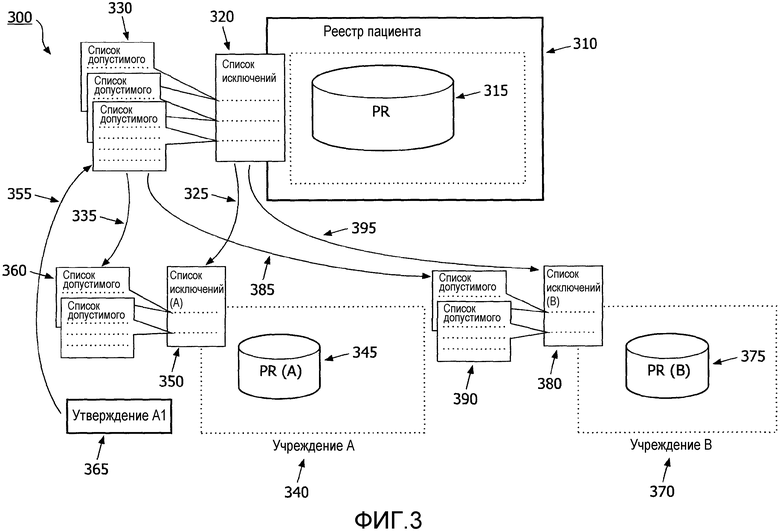
1. Способ синхронизации пользовательских записей, содержащий этапы, на которых:
назначают уникальный номер записи пользовательской записи (410);
извлекают демографическую информацию пользовательской записи для сопоставления упомянутой демографической информации с демографической информацией в совокупности записей из других источников данных, чтобы найти записи, которые принадлежат одному и тому же пользователю (420);
сравнивают демографическую информацию пользовательской записи с по меньшей мере одной демографической информацией другой записи в совокупности записей из по меньшей мере одного другого источника данных для расчета отношения правдоподобия для каждой сравниваемой записи (430);
сравнивают каждое отношение правдоподобия с заданным порогом допустимости и с заданным порогом отказа (440), при этом сравнение включает в себя:
отбрасывание сравненных пользовательских записей, если отношение правдоподобия попадает ниже отношения порога отказа;
принятие сравненных пользовательских записей, если отношение правдоподобия превышает пороговое отношение допустимости; и
идентификацию пользовательских записей для ручного рассмотрения, если отношение правдоподобия попадает между порогом допустимости и порогом отказа;
прикрепляют утверждение для сравненных пользовательских записей на основе сравнения по меньшей мере одного отношения правдоподобия (450); и
размещают пользовательские записи, для которых должно быть выполнено ручное рассмотрение, в списке исключений и распределяют список исключений на каждый источник данных.
2. Способ по п.1, в котором утверждения прикрепляются только для записей, идентифицированных для ручного рассмотрения, и утверждения сравненных записей поддерживаются для каждого источника данных.
3. Способ по любому одному из пп.1 и 2, в котором утверждения поддерживаются в глобальном списке исключений и каждый источник данных получает локально поддерживаемый лист; и
назначенный уникальный номер записи является уникальным для центрального хранилища и для других источников данных.
4. Способ по п.1, дополнительно включающий в себя этап, на котором:
после того как выполняется ручное рассмотрение записи для одного из других источников данных, вводят и записывают решение о принятии или отказе для одного из других источников данных и соответствующее утверждение (490) в списки утверждений.
5. Способ по п.1, дополнительно включающий в себя этап, на котором создают положительное утверждение в ответ на решение о принятии записи, о котором положительное утверждение предполагает, что две сравниваемые записи относятся к одному и тому же пользователю; или создают отрицательное утверждение в ответ на решение об отбрасывании записи, о котором отрицательное утверждение предполагает, что две сравниваемые записи не относятся к одному и тому же пользователю.
6. Способ по п.1, в котором утверждения хранятся в по меньшей мере одном из центрального хранилища и других источников данных.
7. Способ по п.1, в котором этап, на котором принимают решение о принятии или отбрасывании, выполняется для каждого другого источника данных и дополнительно включает в себя уведомление пользователей других источников данных, когда два других источника данных делают конфликтующие утверждения об общей записи.
8. Способ по п.1, в котором утверждения об общей записи включают в себя по меньшей мере один из других источников данных, соответствующий сделанному утверждению, лицо, которое сделало утверждение, и временную метку.
9. Способ по п.1, в котором записи, которые рассмотрены вручную, помещаются в группу списков особых исключений центрального хранилища и в один список особых исключений другого источника данных.
10. Способ по п.1, в котором пользователи являются медицинскими пациентами, получающими медицинские услуги в одном или более из множества медицинских учреждений, и другой источник данных соответствует медицинскому учреждению, и пользовательские записи являются медицинскими записями.
11. Считываемый компьютером носитель, запрограммированный программным обеспечением, которое при исполнении процессором выполняет способ по любому из пп.1-10.
12. Система синхронизации пользовательских записей, включающая в себя один или более процессоров, запрограммированных на выполнение способа по любому из пп.1-10.
13. Устройство для синхронизации пользовательских записей, содержащее:
средства (510) ввода для получения входящей пользовательской записи (520) и сопутствующих демографических данных;
совокупность (550) пользовательских записей и сопутствующие демографические данные;
средства (525) обработки для расчета уникального номера (540) пользовательской записи из демографических данных в центральном хранилище, и уникальный номер записи является уникальным для центрального хранилища и для других источников данных;
вычислительные средства (560) для сравнения по меньшей мере одних демографических данных по меньшей мере одной пользовательской записи с демографическими данными другой записи в совокупности записей из других источников данных для расчета отношения правдоподобия (555) для каждой сравниваемой записи;
вычислительные средства (566) для сравнения каждого отношения правдоподобия с заданным порогом допустимости (570) и с заданным порогом отказа (572) и выполнения одного из:
отбрасывания по меньшей мере одной пользовательской записи (578), если отношение правдоподобия меньше порога отказа; и
принятия по меньшей мере одной пользовательской записи (576), если отношение правдоподобия превышает порог допустимости; и
идентификации по меньшей мере одной пользовательской записи для ручного рассмотрения (574), если отношение правдоподобия попадает между порогом допустимости и порогом отказа; и
средства для записи в среду хранения данных (530) того, была ли по меньшей мере одна пользовательская запись отброшена, принята или идентифицирована для ручного рассмотрения, и записи о том, было ли сделано пользователями по меньшей мере одного источника данных утверждение относительно пары пользовательских записей.
14. Устройство по п.13, в котором утверждение определяется положительным, если две сравниваемые записи определены как относящиеся к одному и тому же пациенту, и утверждение определяется отрицательным, если две сравниваемые записи определены как не относящиеся к одному и тому же пользователю.
15. Устройство по п.13, в котором пользователь по меньшей мере одного источника данных уведомляется, если сделаны два конфликтующих утверждения по поводу одной записи из двух различных источников данных.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |

