ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Данное изобретение относится к связыванию информационных записей о пациенте, хранимых в различных объектах.
УРОВЕНЬ ТЕХНИКИ
Обычно, пациенты могут пользоваться услугами множества поставщиков медицинских услуг, географически рассеянных во множественных местоположениях. В каждом местоположении, пациенту обычно дают свой идентификатор пациента. Этот идентификатор пациента может использоваться локально у данного поставщика медицинских услуг. Кроме того, данные одного пациента, такие как медицинские изображения и другая релевантная медицинская информация, распространяются по множественным местоположениям и помечаются различными локальными идентификаторами пациента. Чтобы иметь возможность извлечь данные пациента, хранимые где-либо еще, идентификаторы пациента совмещаются, и соответствующие записи о пациенте связываются вместе.
Со временем, средний объем данных, собираемых для пациента в контексте сложного заболевания, такого как рак, сильно увеличился. Например, для больных раком пациентов, имеющих рецидивы, большая часть истории болезни может быть релевантной для практикующего врача. В случае больных раком пациентов, имеющих рецидивы, релевантные связанные с раком эпизоды состояния здоровья могут возвращаться много лет. Сопутствующие заболевания часто также являются релевантными, так как они являются очень ограничивающим фактором в выборе лечения. Например, многие химиотерапевтические агенты являются кардиотоксичными, и чтобы выбрать правильное лечение, предшествующая информация, касающаяся сердечного заболевания, может быть важной. Очень маловероятно, что информация обо всех таких связанных со здоровьем эпизодах находится в системе одного учреждения. Однако, лечащий врач, наблюдающий пациента, должен быть способен извлечь все релевантные предшествующие эпизоды состояния здоровья из записи о пациенте, как связанные с раком, так и не связанные с раком, которые могут включать в себя много эпизодов и охватывать десятилетия.
Поток информации в запись о пациенте и из нее обычно канализируется через главный индекс пациента (MPI), который назначает уникальный номер медицинской записи (MRN) каждому пациенту некоторого объекта, когда существует единичная запись. Здесь, единичная запись содержит фактические данные пациента, поддерживаемые этим объектом. Это может быть электронная запись состояния здоровья пациента, запись о пациенте в радиологической информационной системе (RIS) и все другие данные пациента (такие как исследования, изображения, лабораторные данные), поддерживаемые этим объектом. Все элементы данных единичной записи могут быть связаны посредством локально назначенного идентификатора пациента (например, MRN). Для получения сведений о пациентах через распределенные источники данных, локальные идентификаторы в индивидуальных учреждениях совмещаются. Это в настоящее время осуществляется посредством построения главного индекса пациента для предприятия (EMPI), который обеспечивает взаимосвязь всех идентификаторов в больницах, которые являются частью предприятия. EMPI разрабатывается через интеграцию индивидуальных MPI источников. Обычно, интеграция достигается посредством сравнения демографических атрибутов, таких как имя/фамилия, пол, дата рождения, адрес и т.д. для создания идентификатора на уровне предприятия. Большинство существующих систем развертывают вероятностные алгоритмы, которые обычно сравнивают фиксированную запись с некоторым количеством кандидатов для совпадения, вычисляя для каждого кандидата отношение правдоподобия (взвешенную оценку), которое сравнивается с выбранными порогами принятия и отвергания. Результат используется для решения, связывать ли эти записи или нет. Когда решение не может быть принято автоматически (вычисленное правдоподобие попадает между двумя порогами), квалифицированному персоналу необходимо просмотреть или пометить потенциальные (рас)согласования перед тем, как они принимаются (или отвергаются). Просмотр вручную неопределенных совпадений помогает минимизировать ошибки связывания, так как они могут иметь далеко идущие последствия, в конечном счете, подвергая опасности здоровье пациента. Однако, представление большого количества записей для просмотра вручную является очень дорогим и может сделать все решение непрактичным.
Статья “Efficient Private Record Linkage” Mohamed Yakout и др., международная конференция IEEE по проектированию данных, 2009 г., с. 1283-1286, раскрывает протокол для конфиденциального связывания записей, которые не используют третью сторону. Этот протокол состоит из двух фаз. В фазе 1, формируются пары записей - кандидатов для согласования. В фазе 2, выполняется задача вычисления евклидова расстояния между каждой парой-кандидатом. Обе стороны участвуют в вычислениях евклидова расстояния без обнаружения первоначальных представлений их соответствующих записей.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Было бы выгодно иметь усовершенствованную систему для связывания соответствующих информационных записей о пациенте в различных объектах. Для лучшего обращения к этому делу, первый аспект данного изобретения обеспечивает систему, содержащую:
- множество объектов, имеющих соответствующие базы данных пациентов, содержащих информационные записи о пациентах, причем каждый объект имеет связанный с ним алгоритм идентификации пациентов для согласования соответствующих информационных записей об одном и том же пациенте в различных объектах; и
- подсистему связывания для поддержания множества связей первого объекта из множества объектов, причем эта подсистема связывания выполнена для связывания информационных записей о пациенте первого объекта с соответствующими информационными записями о пациенте других объектов, причем связь устанавливается, когда данная информационная запись о пациенте первого объекта совпадает с соответствующей информационной записью о пациенте другого объекта, на основе алгоритма идентификации пациентов первого объекта.
При связывании отдельных алгоритмов идентификации пациентов с различными объектами, эти объекты не должны иметь совпадающие единые стратегии идентификации пациента. Следовательно, гибкость связывания улучшается. Различные алгоритмы идентификации пациентов дают возможность объектам применять различные стратегии, касающиеся связывания записей о пациентах. Это может использоваться для сохранения связывания записей объектов автономным посредством осуществления возможности выбора объектами своих собственных алгоритмов идентификации пациентов.
Эти связи могут быть выполнены с возможностью обеспечения связи между локально назначенными идентификаторами одного и того же пациента в различных объектах. Информационные записи о пациенте в удаленном местоположении могут быть уникально определены посредством идентификатора пациента, приданного информационным записям о пациенте в этом удаленном местоположении. Кроме того, информационные записи о пациенте первого объекта могут также иметь уникальные идентификаторы пациента. Следовательно, связь между любой записью о пациенте первого объекта и любой записью о пациенте другого объекта может содержать идентификаторы пациента из двух информационных записей о пациенте. Это является подходящим способом установления связи. Кроме того, может быть включена идентификация другого объекта, так чтобы было ясно, к какому объекту принадлежит идентификатор пациента.
Эта система может содержать дополнительную подсистему связывания для поддержания дополнительного множества связей второго объекта из множества объектов, на основе алгоритма идентификации пациентов второго объекта. Это множество связей второго объекта является независимым от множества связей, генерируемого первым объектом. Оба объекта являются автономными относительно критерия, используемого в согласовании их информационных записей о пациенте с информационными записями о пациенте других объектов. Все же, эти объекты могут перекрестно связывать информационную запись о пациенте, если оба объекта решат создать связь между одной и той же парой информационных записей о пациенте.
Некоторый объект из множества объектов, например, первый объект, может быть выполнен с возможностью хранения локальной копии информации других объектов. В частности, этот объект может быть выполнен с возможностью хранения информации, которая используется алгоритмом идентификации пациентов этого объекта для согласования информационных записей о пациенте. Это уменьшает величину необходимой передачи данных, так как можно применить алгоритм идентификации пациентов с локально сохраненной информацией.
Эта система может содержать центральный репозиторий для хранения копии информации, используемой алгоритмами идентификации пациентов множества объектов для согласования информационных записей о пациенте. Это уменьшает величину необходимой памяти, так как какие-либо локальные копии этой информации не нужны.
Эта система может содержать подсистему инициализации для начальной установки множества связей по меньшей мере для одного из множества объектов, обработки по существу всех доступных информационных записей о пациенте данного объекта из множества объектов, по меньшей мере в такой степени, что эти доступные информационные записи о пациенте потенциально имеют соответствующие информационные записи о пациенте в других объектах. Таким образом, эти связи являются доступными одновременно, что может помочь избежать путаницы относительно того, существуют ли дополнительные данные для пациента или нет. Кроме того, можно избежать любых несогласованностей.
Подсистема связывания может быть выполнена для периодического обновления множества связей. Таким образом, это обновление может быть запланировано в свободные часы. Кроме того, сохраняется новейшее множество связей. Альтернативно или дополнительно, подсистема связывания может быть выполнена для обновления множества связей по требованию или каждый раз, когда новый идентификатор пациента генерируется в одном из объектов. Обновление по требованию обеспечивает гибкость. Обновление каждый раз, когда генерируется новый идентификатор пациента, позволяет поддерживать самые новейшие связи.
Алгоритм идентификации пациентов может быть основан на согласовании демографических данных пациента. Демографические данные пациента являются высоко полезными в различении между пациентами. Демографические данные могут включать в себя по меньшей мере одно из следующего: имя, адрес, номер социального обеспечения, персональный идентификационный номер, налоговый номер, возраст, дата рождения, пол. Другие типы данных не исключаются.
Алгоритм идентификации пациентов может включать в себя один или несколько порогов, которые являются специфическими для объекта, связанного с алгоритмом идентификации пациентов. Посредством различной установки порогов, объект может реализовать конкретную стратегию согласования пациентов.
Медицинская рабочая станция может быть частью некоторого объекта из множества объектов изложенной системы. Медицинская рабочая станция может содержать дисплей для отображения информации пациента из информационной записи о пациенте другого объекта, которая связана с информационной записью о пациенте объекта, содержащего эту рабочую станцию, причем это связывание выполняется подсистемой связывания.
Другой аспект изобретения обеспечивает способ связывания соответствующих информационных записей о пациенте в различных объектах, причем каждый объект имеет соответствующие базы данных пациентов, содержащие информационные записи о пациенте, причем каждый объект имеет связанный с ним алгоритм идентификации пациентов для согласования соответствующих информационных записей об одном и том же пациенте в различных объектах, причем этот способ предусматривает поддержание множества связей первого объекта из множества объектов, причем это множество связей связывает информационные записи о пациенте первого объекта с соответствующими информационными записями о пациенте других объектов, причем некоторая связь устанавливается, когда данная информационная запись о пациенте первого объекта согласуется с соответствующей информационной записью о пациенте другого объекта, на основе алгоритма идентификации пациентов первого объекта.
Другой аспект данного изобретения обеспечивает компьютерный программный продукт, содержащий команды для предписания процессорной системе выполнять изложенный способ.
Специалистам в данной области техники будет ясно, что два или несколько из вышеупомянутых вариантов осуществления, реализаций и/или аспектов изобретения могут быть скомбинированы любым способом, который считается полезным. Модификации и вариации устройства получения изображения, рабочей станции, системы и/или компьютерного программного продукта, которые соответствуют описанным модификациям и вариациям данной системы, могут быть осуществлены специалистом в данной области техники на основе данного описания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Эти и другие аспекты изобретения явствуют и будут объяснены со ссылкой на варианты осуществления, описанные далее. На чертежах,
Фиг.1 является схемой системы для связывания соответствующих информационных записей о пациенте, хранимых в различных объектах; и
Фиг.2 является блок-схемой последовательности операций способа связывания соответствующих информационных записей о пациенте в различных объектах.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Все более и более распространенным является то, что пациенты пользуются услугами множества поставщиков медицинских услуг, географически рассеянных во множественных местоположениях. Это может привести к ситуации, что пациенту обычно дают множество идентификаторов пациента, так как новый идентификатор пациента назначается пациенту каждый раз, когда он или она регистрируется в другом поставщике медицинских услуг. Кроме того, данные пациента, такие как медицинские изображения и другая релевантная медицинская информация пациента, собираются и сохраняются во множественных местоположениях. Однако, данные, собранные и хранимые в одном поставщике медицинских услуг, могут быть необходимы в другом поставщике медицинских услуг для целей диагностики или лечения. Для возможности извлечения данных пациента, хранимых где-либо еще, идентификаторы пациента в различных местоположениях могут быть совмещены и связаны вместе. Может быть выгодно, если это совмещение и/или связывание может быть выполнено без принятия стандартного идентификатора пациента в различных местоположениях.
В настоящее время это совмещение и/или связывание может быть достигнуто посредством использования алгоритмов согласования идентичности для связывания вместе записей в отдельных системах, которые принадлежат одному и тому же пациенту. Используемые в настоящее время подходы согласования идентичности, как вероятностные, так и управляемые с помощью правил, предполагают, что это согласование должно быть идентичным во всех местоположениях, и что единственный по федерации вид на результаты согласования является достаточным. Однако, на практике это необязательно имеет место. Автономные организации здравоохранения могут прийти к соглашению совместно использовать данные пациента, без обязательного соглашения на один и тот же вид относительно согласования записей о пациенте. Процесс согласования регулируется посредством координации непротиворечивости данных против полноты, и в системах предшествующего уровня техники, различные местоположения не способны выбирать различные компромиссные решения.
Известные подходы совмещения идентичности могут быть расширены путем разрешения различным организациям иметь различные алгоритмы согласования идентичности (также в отношении весов атрибутов и порогов), что может привести к различным распределениям, с адресацией к требованиям совмещения, происходящим из распределенного неоднородного окружения, в котором поставщики могут желать оставаться автономными и все же быть способными совместно использовать данные пациента.
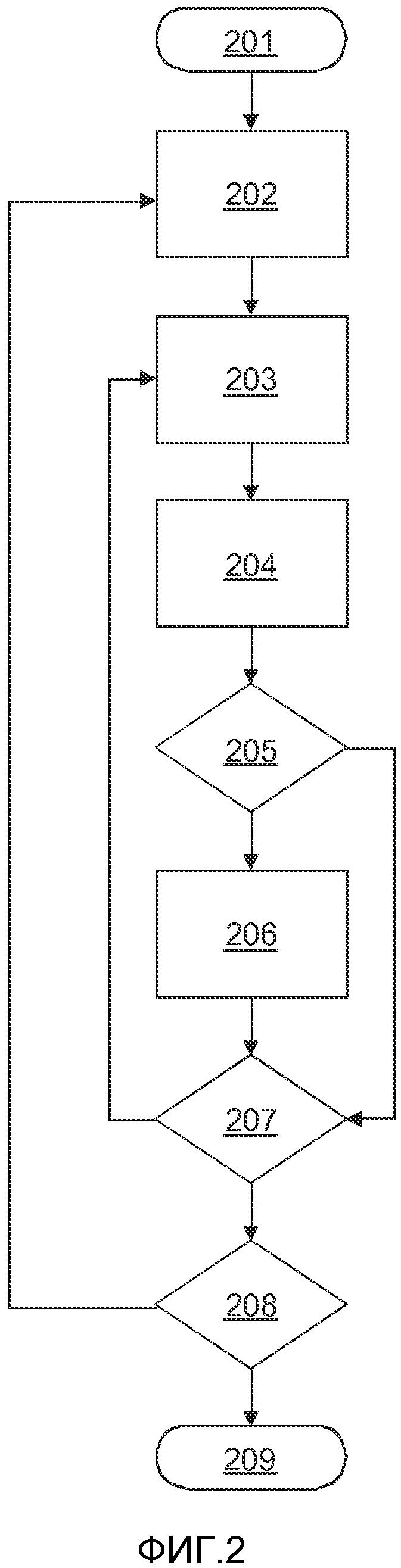
Фиг.1 иллюстрирует систему для связывания соответствующих информационных записей 19, 19а о пациенте, хранимых в различных объектах 1, 1а. Эта система содержит множество объектов 1, 1а. Такой объект может содержать множество компьютеров, подключенных через сеть. Объект может также содержать серверную систему, на которой была установлена система хранения данных пациентов. Эта система может, таким образом, содержать средство хранения, пользовательский интерфейс для управления системой, порт передачи данных, такой как сетевой порт, и/или подключение к глобальной сети. Различные объекты могут быть взаимосвязаны посредством глобальной сети. Глобальной сетью может быть Интернет. На чертеже, показаны два объекта 1, 1а для иллюстрации рабочего примера. Однако, возможно любое число объектов путем непосредственного расширения способов, описанных здесь. Кроме того, то, что описано здесь в качестве примера для одного из объектов 1 или 1а, может быть также применено к другим объектам в системе, включая объект 1 и/или 1а.
Объекты 1, 1а могут иметь соответствующие базы данных пациентов. Эти базы данных содержат информационные записи 3, 3а о пациенте. Например, информационные записи 3 о пациенте в базе данных объекта 1 могут содержать идентификатор пациента (ID), имя пациента (N), адрес пациента (А) и/или другую демографическую информацию (…). Кроме того, другие медицинские данные (DAT), такие как изображения и/или лабораторные результаты и/или информация о лекарственной терапии, могут храниться в отдельных записях 19, которые связаны с демографической информацией (N, A, …) посредством идентификатора пациента (ID). Альтернативно, эти дополнительные данные (DAT) могут также храниться в записи 3 о пациенте вместе с демографической информацией (N, A, …).
Объект 1 имеет связанный с ним алгоритм 4 идентификации пациентов. Этот алгоритм 4 идентификации пациентов может использоваться в процессе согласования соответствующих информационных записей об одном и том же пациенте в различных объектах. С этой целью, алгоритм 4 идентификации пациентов может содержать некоторое количество операций сравнения. Кроме того, алгоритм 4 идентификации пациентов может содержать одну или несколько оценок степени вероятности или правдоподобия, которые могут находиться в связи с вероятностью того, что две записи о пациенте совпадают. Результаты этих сравнений и/или оценок могут использоваться в связи с одним или несколькими пороговыми значениями 5. Эти пороговые значения 5 могут, например, определять минимальный уровень вероятности или подобия, необходимый для установления совпадения между двумя записями 3 и 3а о пациенте.
Эта система может дополнительно содержать подсистему 6, 6а связывания. Отдельные подсистемы 6, 6а связывания могут быть реализованы как независимые блоки в различных объектах 1, 1а, как показано на фиг.1. Однако это не является ограничением. В альтернативном примере, подсистема связывания может быть реализована как централизованная служба (не показана). Такая централизованная служба может быть выполнена для поддержания множества связей 7, 7а объектов 1, 1а, принимая во внимание соответствующие алгоритмы 4, 4а идентификации пациентов.
В примерной схеме организации фиг.1, подсистема 6 связывания объекта 1 выполнена для поддержания множества связей 7 объекта 1. Подсистема 6 связывания может связывать информационные записи 3 о пациенте объекта 1 с соответствующими информационными записями 3а о пациенте объекта 1а. Аналогично, подсистема 6 связывания может связывать информационные записи 3а о пациенте объекта 1 с соответствующими информационными записями о пациенте любого из других объектов (которые не показаны на фигуре). Связь может быть установлена, когда заданная информационная запись 3 о пациенте объекта 1 совпадает с соответствующей информационной записью 3а о пациенте другого объекта 1а, на основе алгоритма 4 идентификации пациентов объекта 1. Например, могут сравниваться соответствующие поля (N, A, …) информационных записей 3, 3а о пациенте; если они совпадают, может быть установлена связь. Если совпадение не совершенно, так как информационные записи 3, 3а о пациенте слегка различаются, то алгоритм 4 идентификации пациентов и его возможные пороги 5 могут представить стратегию того, устанавливать связь или нет. Следовательно, решение вопроса о том, устанавливать ли связь, может быть осуществлено автоматически, по меньшей мере в большинстве случаев. Алгоритм 4 идентификации пациентов может также привести к решению, что алгоритм 4 идентификации не способен осуществить конечное решение; в таком случае, человек-оператор может оценить эти данные и возможно получить исправление или какую-либо дополнительную релевантную информацию, например, путем опроса пациента. Такие решения алгоритма идентификации пациентов пересылаются в подсистему 6 связывания, которая действует соответственно, как это может быть в данном случае, посредством генерации связи 7 или помещения записей о пациенте в список для просмотра человеком-оператором.
Связи 7 могут обеспечить связь между локально назначенными идентификаторами одного и того же пациента в различных объектах. Например, связь 7 может содержать идентификатор (ID) из локальной информационной записи 3 о пациенте, хранимой объектом 1, и «удаленный» идентификатор (RID) из информационной записи 3а о пациенте другого объекта 1а. В случае если не гарантируется, что удаленный идентификатор (RID) является уникальным на множестве объектов, не гарантируется, что удаленный идентификатор (RID) уникально идентифицирует удаленную информационную запись 3а о пациенте. Следовательно, связь 7 может дополнительно содержать идентификатор (RLoc) другого объекта 1а, который хранит релевантную информационную запись 3а о пациенте, идентифицированную удаленным идентификатором (RID). Такой идентификатор (RLoc) объекта может содержать сетевое местоположение другого объекта 1a, например. Однако, может использоваться любой тип идентификатора. Слово «удаленный» используется здесь для удобства; оно не подразумевает какого-либо физического расстояния между объектами. Даже если эти идентификаторы являются уникальными на множестве объектов, идентификатор объекта (RLoc) может помочь сделать извлечение данных пациента более эффективным.
Альтернативно, связи 7 могут содержать гиперсвязь или унифицированный указатель ресурсов (URL), указывающий на соответствующую информационную запись о пациенте. В таком случае, идентификатор пациента, назначенный удаленным объектом 1а, может быть опущен в связи 7.
Как упоминалось выше, дополнительная подсистема 6а связывания объекта 1а может быть обеспечена для поддержания множества связей 7а объекта 1а, на основе алгоритма 4а идентификации пациентов объекта 1а. То же самое может быть сказано для других объектов, которые не изображены на фиг.1. Множества связей 7, 7а могут быть также обеспечены посредством центрального сервера (не показан), который может поддерживать множества связей 7, 7а объектов 1, 1а, на основе соответствующих алгоритмов 4, 4а идентификации пациентов.
Объект 1 может содержать память для хранения локальной копии 15 по меньшей мере части информационных записей 3а о пациенте по меньшей мере одного другого объекта 1а. Эта локальная копия может затем использоваться подсистемой 6 связывания и/или алгоритмом 4 идентификации пациентов, без необходимости переноса данных от другого объекта 1а по требованию. Следовательно, для этой цели необходимо хранить только информационные поля пациента, которые используются алгоритмом 4 идентификации пациентов для согласования информационных записей 3, 3а о пациенте.
Вместо локальных копий 15, 15а, система может содержать центральный репозиторий 17 для хранения копии информации, используемой алгоритмами идентификации пациентов множества объектов для согласования информационных записей о пациенте. Эта альтернатива была указана посредством пунктирных символов. Также можно использовать комбинацию локальных копий 15, 15а и центральный репозиторий 17.
Подсистема 8 инициализации может быть обеспечена для начальной установки множества связей для объекта 1. Подобные подсистемы 8а инициализации могут быть обеспечены для других объектов 1а. Подсистема 8 инициализации может первоначально обработать по существу все доступные информационные записи 3 о пациенте объекта 1. Однако, информационные записи 3 о пациенте, для которых заранее известно, что нет соответствующих информационных записей о пациенте в других объектах, могут быть пропущены подсистемой 8 инициализации. Начальная обработка информационной записи 3 о пациенте может включать в себя оценивание подсистемой 6 связывания, в сопряжении с алгоритмом 4 идентификации пациентов, для установки множества связей 7 между локальными информационными записями 3 о пациенте и информационными записями 3а о пациенте, хранимыми в других объектах 1а.
Подсистема 6 связывания может быть выполнена для обновления множества связей 7 периодически, как, например, каждую ночь или каждый час (например, во время рабочих часов) или каждую неделю или каждый месяц. Альтернативно, или дополнительно, подсистема 6 связывания может быть выполнена для обновления множества связей по требованию или каждый раз, когда новый идентификатор пациента генерируется в одном из объектов. С этой целью, пользовательский интерфейс может быть обеспечен для представления требования или для создания новой информационной записи о пациенте, которая запустила бы генерацию нового идентификатора пациента. Такой пользовательский интерфейс может быть обеспечен через рабочую станцию 18.
Алгоритм 4 идентификации пациентов может быть основан на сравнении демографических данных пациента (N, A, …), хранимых в локальной информационной записи 3 о пациенте и в удаленной информационной записи 3а о пациенте. Например, этот алгоритм может содержать сравнение имени, адреса, номера социального обеспечения, персонального идентификационного номера, налогового номера, возраста, даты рождения и/или пола. Этот алгоритм может назначить различные веса (т.е. степени важности) различным типам демографической информации. Также, этот алгоритм может обрабатывать рассогласования между полями различным образом для различных видов полей. Все эти элементы алгоритма идентификации пациентов могут быть установлены различным образом для различных объектов 1, 1а. Например, алгоритм 4, 4а идентификации пациентов может включать в себя пороги, которые являются специфическими для объекта 1, 1а, связанного с алгоритмом 4, 4а идентификации пациентов.
Как упоминалось ранее, объект 1 может содержать медицинскую рабочую станцию 18. Кроме того, объект 1 может содержать различные рабочие станции с различными функциональными возможностями. Одна или несколько таких медицинских рабочих станций 18 могут содержать дисплей для отображения информации пациента из информационной записи 3а, 19а о пациенте другого объекта, которая связана с информационной записью 3 о пациенте объекта 1. Это связывание может быть воплощено посредством одной из связей во множестве связей 7, генерируемых подсистемой 6 связывания. Например, как только информационная запись 3 о пациенте объекта 1 была вызвана, рабочая станция 18 может отобразить по меньшей мере часть информации, хранимой в информационной записи 3 о пациенте. Кроме того, рабочая станция может отыскивать любые связи 7 для идентификатора пациента (ID) отображенной информационной записи 3 о пациенте. Если такая связь 7 найдена, дисплей может указать, что другая информация доступна для этого пациента от другого объекта. По выбору, дисплей может указать, в каком объекте расположена эта информация, на основе удаленного идентификатора или местоположения объекта (RLoc). Пользователь может быть задействован для запроса дополнительной информации. После приема такого запроса, рабочая станция 18 запускает запрос к удаленному объекту 1а на информационные записи 3а, 19а о пациенте, совпадающие с удаленным идентификатором пациента (RID). Рабочая станция 18 может затем отобразить список доступных элементов данных (DAT) в удаленном объекте 1а, как перечисленных в информационной записи 19а о пациенте для удаленного идентификатора пациента (RID). Например, информационная запись 19а о пациенте может содержать один или несколько результатов предшествующих исследований пациента, таких как CT сканирование, или рецепт. После запроса, или автоматически, рабочая станция может извлечь один или несколько элементов из дополнительных элементов данных (DAT), хранимых в удаленной записи 19а о пациенте. Таким образом, извлеченная информация может быть отображена на рабочей станции 18, или может быть подвергнута дополнительной обработке.
Будет ясно, что функциональные возможности некоторых элементов системы могут быть также представлены как стадии некоторого процесса. Фиг.2 иллюстрирует такой процесс связывания соответствующих информационных записей 3, 3а о пациенте в различных объектах 1, 1а. Каждый объект 1, 1а может иметь соответствующую базу данных пациентов, содержащую информационные записи 3, 3а о пациенте. Кроме того, каждый объект 1, 1а мог связать с ним алгоритм 4, 4а идентификации пациентов для согласования соответствующих информационных записей 3, 3а, 19, 19а об одном и том же пациенте в различных объектах 1, 1а. Этот способ может предусматривать стадию поддержания множества связей 7 объекта 1. Это множество связей 7 может связывать информационные записи 3, 19 о пациенте объекта 1 с соответствующими информационными записями 3а, 19а о пациенте другого объекта 1а. Этот способ может предусматривать стадию установления связи, когда данная информационная запись 3 о пациенте объекта 1 совпадает с соответствующей информационной записью 3а о пациенте объекта 1а, на основе алгоритма 4 идентификации пациентов объекта 1. Аналогично, этот способ может предусматривать поддержание такого множества связей для объекта 1а и для любых других объектов в системе. Этот способ может быть реализован как компьютерная программа, подходящая для выполнения на серверной системе.
Фиг.2 иллюстрирует примерный поток процесса связывания соответствующих информационных записей 3, 3а в различных объектах 1, 1а системы, описанной выше. Этот процесс может быть запущен на стадии 201, например, по истечении конкретного периода, или путем запроса вручную, или посредством добавления нового идентификатора пациента в системе. После того, как процесс был запущен, информационные записи 3 о пациенте могут быть обработаны одна за другой. На стадии 202, выбирается одна из этих информационных записей 3 о пациенте объекта 1. В случае, если запуск вызывается посредством добавления нового идентификатора пациента в системе, необходимо выбрать и обработать только информационную запись 3 о пациенте, соответствующую этому новому идентификатору пациента. На стадии 203, может быть выбран один из других объектов 1а в системе. На стадии 204, может быть проверено, имеет ли выбранный объект 1а информационную запись 3а о пациенте, информационные поля которой совпадают с информацией в выбранной информационной записи 3 о пациенте. На стадии 205, проверяется, была ли найдена на стадии 204 совпадающая информационная запись 3а о пациенте. Если на стадии 204 не была найдена совпадающая информационная запись 3а о пациенте, то процесс переходит к стадии 207. Если на стадии 204 была найдена совпадающая информационная запись 3а о пациенте, то на стадии 206, устанавливается связь между выбранной информационной записью 3 о пациенте и совпадающей информационной записью 3а о пациенте. Это может быть выполнено посредством сохранения пары, содержащей идентификатор пациента, найденный в выбранной информационной записи 3 о пациенте, и идентификатор пациента, найденный в совпадающей информационной записи 3а о пациенте. Идентификатор объекта, идентифицирующий выбранный другой объект 1а, может быть также сохранен вместе с идентификаторами пациента. На стадии 207, может быть проверено, были ли выбраны все объекты для выбранной в настоящее время информационной записи 3 о пациенте. Если нет, то следующий объект может быть выбран путем перехода к стадии 203. Если все объекты были выбраны для выбранной в настоящее время информационной записи 3 о пациенте, то на стадии 208 может быть проверено, были ли выбраны все локальные информационные записи 3 о пациенте. Если нет, то следующая информационная запись 3 о пациенте может быть выбрана путем перехода к стадии 202. Если да, то процесс может завершиться на стадии 209.
Специалисту в данной области техники будет ясно, что этот процесс и система могут быть применены к многомерным видеоданным, например, к двумерным (2-D), трехмерным (3-D) или четырехмерным (4-D) изображениям, полученным посредством различных средств получения изображений, таких как, но не ограниченных перечисленным, стандартное средство получения рентгеновских изображений, компьютерная томография (СТ), средство получения магнитно-резонансных изображений (MRI), ультразвук (US), позитронно-эмиссионная томография (РЕТ), однофотонная эмиссионная компьютерная томография (SPECT) и ядерная медицина (NM). Такие данные об изображениях могут быть связаны в качестве данных пациента (DAT) с идентификатором пациента (ID) в локальном объекте 1 или удаленном объекте 1а, посредством подходящей информационной записи 19 или 19а о пациенте. Данные пациента (DAT) могут также содержать лабораторные результаты или рецепты или диагнозы, например.
Число совпадений, автоматически отвергнутых, принятых или представленных для просмотра вручную, может зависеть как от весов, связанных с различными атрибутами во время сравнения, на основе которого может быть вычислено отношение правдоподобия, так и от выбранных порогов отвергания и принятия. По этой причине, оценивание соответствующих весов согласования, связанных с парами используемых атрибутов, и выбор подходящих порогов принятия и отвергания для автоматического согласования могут быть выполнены для улучшения реализации согласования идентичности.
Более высокий порог отвергания может вызвать большее количество потенциальных совпадений, подлежащих автоматическому отверганию, что означает, что процент истинных совпадений, которые отвергаются, является более высоким. В результате, релевантная информация пациента может быть потеряна. Когда эта информация является важной, как, например, аллергия на конкретное вещество, или предшествующий сердечный приступ для больного раком пациента, принимающего химиотерапию, ее потеря может серьезно подвергнуть опасности здоровье пациента. Более низкий порог принятия означает, что больше потенциальных совпадений автоматически принимается. В реальной жизни это означает, что информация пациента может быть согласована с не тем пациентом, и медицинское решение может быть основано на неверных данных. Этот второй тип ошибки также может угрожать жизни пациента.
Больницы могут выбрать различные компромиссные решения при обработке данных. Они могут выбрать преодоление риска потери части медицинской истории, когда они решают (повторно) провести все тесты, которые они считают необходимыми, или когда они имеют точный процесс опроса пациента на месте. В этом случае согласованность данных является более важной. С другой стороны, другие организации здравоохранения могут решить, что доступ к полным данным является существенным, и полагаются на практикующих врачей в отсеивании данных, которые не являются релевантными или считаются неверными.
В окружениях, где участвующие учреждения лишь слабо связаны и остаются автономными в их управлении, участвующие учреждения могут желать удерживать полный контроль над их данными и качеством процесса, который связан с их обработкой. Это означает, например, что если проверяющий служебный персонал в больнице А связывает две записи о пациенте вместе, то другое учреждение, скажем, больница В, должна все же быть способной осуществить свою собственную проверку этих двух записей и возможно (локально) аннулировать связь, созданную в А. Если больница В не способна сделать это, то она теряет свою автономию над своими данными и в принципе не может гарантировать согласованность данных. Как автономная организация, В не нуждается в рассмотрении и применении решений, принятых в А. То же самое должно сохраняться для автоматического согласования: каждое учреждение должно быть способно, применять свой собственный процесс согласования, как это имеет место для системы фиг.1 и процесса фиг.2, когда объектами являются компьютерные системы различных учреждений или больниц. Когда пара учреждений, А и В, решилась на идентичный процесс согласования, тот же самый процесс согласования не требуется при согласовании данных в учреждении С, так как С может иметь свой собственный процесс согласования.
В нижеследующем, будет описан неограничивающий случай использования. Рассмотрим два учреждения А и В. Как описано выше, каждое из них может применить свой собственный алгоритм согласования для связывания записей о пациенте, что приводит к отдельным множествам связей 7, 7а. Такое множество связей может быть названо регистрацией пациента (PR). Учреждения А и В используют одни и те же демографические атрибуты для согласования записей, но они назначают этим атрибутам различные веса WA1, …, WAn и WB1, …, WBn, соответственно. Они также используют различные пороги для автоматического принятия или отвергания совпадений. Это может привести к различиям в контенте их PR. Например, больница А согласовала запись, имеющую локальный идентификатор 115, с записью с удаленным идентификатором 371 в местоположении В, хотя местоположение В не рассмотрело эту связь. Местоположение В могло отвергнуть эту связь и поместить ее в список исключения с помощью проверки вручную. Аналогично, когда больница С добавлена к федерации, А и В могут использовать одни и те же алгоритмы для согласования их записей с записями в С, или различные алгоритмы.
Различные веса атрибутов могут использоваться различными объектами или учреждениями. Например, имя, которое является распространенным в некотором регионе, приняло бы другой вес согласования, чем очень не распространенное имя в этом регионе, и согласование между регионами может означать использование различных весов. Возраст 93 года имел бы более низкий вес согласования между двумя гериатрическими клиниками, чем при согласовании данных в двух больших университетских больницах. В нижеследующем, описывается неограничивающий примерный случай использования, включающий в себя сравнение демографической информации, собранной двумя записями в двух больницах А и В. Запись, хранимая в больнице А, содержит имя пациента “Jansen, Peter”, возраст “53”, адрес “Addr1” и пол «мужской», тогда как запись, хранимая в больнице В, содержит имя пациента “Janssen, Peter” (с двойным s), возраст 53, адрес “Addr2” и пол «мужской». Оба имени (Peter Jansen и Peter Janssen) довольно часто встречаются в Нидерландах. В зависимости от А и В решение, согласовать ли эти две записи, могло бы быть совершенно различным. Например, две больницы в Нидерландах имели бы низкие веса для этого имени, так как оба имени существуют, это довольно распространенные имена. Это могло бы вызвать автоматическое отвергание совпадения, так как адреса различны. Если бы возраст был 93 в обеих записях о пациенте, то вес совпадения увеличился бы для двух универсальных больниц, так как не так много их пациентов имели бы возраст 93, но не для двух гериатрических клиник, так как они имели бы более престарелых пациентов. Если бы А и В были двумя больницами во Франции, то вес нераспространенного имени был бы гораздо более высоким, и эти записи возможно были бы представлены для проверки вручную.
Может также иметь место то, что две организации здравоохранения предпринимают различные подходы, приводящие к различным согласованиям, относительно друг друга. Например, больница неотложной помощи обычно была бы меньше заинтересована в извлечении более старых не относящихся к ней данных из районной больницы, так как они имеют дело с неотложными случаями и повторно осуществляют большинство тестов; кроме того, когда пациент был переведен в больницу неотложной помощи, он наиболее вероятно приехал со всеми релевантными данными. Их процесс согласования был бы очень консервативным, нацеленным на малые списки исключения (которые необходимо проверить вручную), и имеющим высокий порог отвергания. С другой стороны, районная больница, возможно, нуждалась бы в доступе к информации об эпизоде неотложной помощи пациента, так как они собираются наблюдать этого пациента в будущем, так что они предпочли бы иметь больше, а не меньше, информации от удаленного местоположения.
Система, описанная здесь, может, вместо построения единственной глобальной регистрации пациентов (PR), содержащей все связи, рассматриваемые достоверными для всей федерации, строить собственные PR и поддерживать их для каждого учреждения, причем упомянутые PR, таким образом, служат как локальная фоновая истина относительно этого учреждения. Каждое учреждение может поддерживать свою собственную PR локально, или в общих службах федерации. Преимущества поддержания PR локально состоят в том, что не нужна глобальная связь для поиска PR, и что информация в PR является доступной, даже когда данное местоположение становится временно отключенным от федерации. Конечно, некоторый механизм может быть поставлен на место для обновления информации в PR, когда видны новые пациенты (это может осуществляться ежедневно, раз в неделю и т.д.).
Локальные местоположения могут выбрать применение отличающегося процесса согласования для каждого другого местоположения в федерации (алгоритм, веса и пороги). Результат согласования может содержать множество связей, которые соединяют записи о пациенте в локальной системе с записями о пациенте в другом местоположении. Компьютерная система в таком местоположении может быть объектом системы, описанной выше.
Вместо построения общей PR в масштабах федерации, каждая локальная PR может хранить для каждого идентификатора пациента, известного локально, все идентификаторы записей, согласованных как принадлежащих этому пациенту в других местоположениях, вместе с идентификаторами местоположений, владеющих этими записями. Поскольку согласование достоверно только для локального местоположения, тот факт, что связи были получены через различные процессы согласования, не влияет на согласованность данных. Локальная система имеет автономию выбора того, какие данные следует извлечь из других местоположений без необходимости принятия во внимание решений согласования в этих местоположениях. Местоположение А может решить связать собственную запись с PID=123 с записью с PID=456 в местоположении В, а не с записью с PID=789 в местоположении С. Тот факт, что местоположение В могло связать PID=456 с PID=789 не имеет отношения к решению в А.
Общий объем данных, хранимых в локальных PR, может быть больше, чем объем данных, который мог бы храниться в единственной глобальной PR, но каждая локальная PR может быть значительно меньшей, чем глобальная PR, так как она нуждается в хранении данных, касающихся только пациентов, известных в локальном местоположении. В настоящее время, в среднем менее 20% пациентов имеют данные в более чем одном местоположении, так что и процент записей, которые хранятся в PR в более, чем одном местоположении, может быть ниже 20%. Этот процент является лишь примером. Он может различаться от ситуации к ситуации и может флуктуировать во времени.
Кроме того, каждое местоположение может поддерживать базу данных, содержащую демографические данные, используемые для согласования для всех удаленных местоположений (или по меньшей мере некоторых из удаленных местоположений, например, наиболее важных местоположений) в федерации. Если вместо построения PR в каждом местоположении, все эти отдельные PR поддерживаются в общем местоположении, которое может быть названо местоположением служб федерации, может быть подготовлена единственная база данных демографии, содержащая все релевантные демографические данные (т.е. данные, используемые для согласования) для всех местоположений. Альтернативно, некоторый объект может запрашивать базы данных других объектов отдельно. Регистрация пациентов (PR) может регистрировать данные, которые необходимы для связывания локальных идентификаторов пациента с удаленными идентификаторами пациента.
В нижеследующем предполагается, что каждое местоположение поддерживает свою PR. Однако, то, что описано ниже, может быть приспособлено специалистом к случаю центральной PR и к случаю индивидуального запрашивания других объектов. Когда новая запись для ранее не известного пациента добавляется в местоположении А, может быть создана новая запись в локальной PR, первоначально имеющая только новый локальный PID, и по желанию также локально известные демографические данные этого пациента. Далее, на основе демографических данных нового пациента все потенциально релевантные демографические данные могут быть извлечены из каждого другого местоположения, и может быть выполнен соответствующий алгоритм согласования. Когда локальные демографические данные хранятся в PR, текущее местоположение может согласовать свои демографические данные нового пациента непосредственно по отношению к демографическим данным в каждом удаленном PR, и нет необходимости запрашивать удаленные системы. В качестве альтернативы локальное местоположение может послать информацию о демографических данных в удаленное местоположение и попросить это местоположение обеспечить все потенциальные согласования с демографическими данными в своей PR. Далее, локальное местоположение может выполнить алгоритм согласования на данных, возвращенных от удаленного местоположения, и сохранить во вводимых в PR данных нового пациента в локальном местоположении все удаленные идентификаторы, рассматриваемые как согласования (совпадения), и идентификатор удаленного местоположения, владеющего ими.
Поскольку связи согласования могут быть специфическими для каждого местоположения, когда запись о новом пациенте вводится в местоположении А, и выполняется согласование, удаленные местоположения не будут автоматически знать о новых вводимых данных. Также, локально установленные связи могут не быть релевантными для них и могут быть не приняты. Однако, местоположения могут нуждаться в знании всех записей, введенных в других местоположениях в федерации, так как они могут совпадать с собственными записями и обеспечивать релевантную информацию. Это может быть достигнуто посредством уведомления каждым местоположением А всех других местоположений, когда создана новая запись о пациенте, и новый идентификатор назначен ей. Это может быть эффективно осуществлено, когда местоположение А выполняет согласование своей идентичности для данных в каждом удаленном местоположении. Когда местоположение А высылает демографические данные для нового пациента в местоположение В и запрашивает демографические данные потенциально совпадающих записей, локально назначенный идентификатор новой записи может быть также послан. Таким образом, на основе принятых демографических данных, местоположение В может также согласовать новую запись в местоположении А по отношению к записям в своей собственной PR (в местоположении В), и когда оно находит совпадение с собственной записью (которая является вводимыми данными в его PR), добавить идентификатор пациента, принятый от А и ссылку на А в локальные вводимые данные. Для каждой введенной новой записи, может быть единственная стадия передачи между локальным местоположением и всеми другими местоположениями в федерации, во время которой обмениваются демографические данные и/или идентификаторы пациента. После этого новая запись может быть согласована по отношению к существующим записям в каждом местоположении.
Таким образом, все PR могут быть новейшими, когда новые записи добавляются в локальные местоположения, даже хотя процессы согласования являются локальными для каждого местоположения.
Нижеследующее описывает процесс, включающий построение и обновление PR. Предполагается, что имеется N местоположений (где местоположение соответствует объекту системы, описанной выше).
1. Каждое местоположение может построить свою собственную начальную PR сразу же, подобно большому хлопку, или более постепенно, согласно следующим стадиям:
а. Извлечь и сохранить демографические данные (например, имя, возраст, пол, адрес) и идентификаторы для пациентов в других N-1 местоположениях. Эта информация может также использоваться во время обычной работы, так что она может быть сохранена в демографической базе данных.
b. Согласовать демографические данные пациентов в собственном местоположении по отношению к демографическим данным пациентов в удаленных местоположениях, с использованием собственных алгоритмов, весов и порогов для согласования (все они могут быть различными для каждой пары местоположений).
с. Сохранить в собственной PR пары записей, идентифицированных как автоматические совпадения, например, как триплеты (тройки) (локальный идентификатор пациента, идентификатор удаленного местоположения, удаленный идентификатор пациента). Другая релевантная информация, такая как временная метка, может быть также сохранена.
d. Построить список исключений для просмотра вручную с парами записей, которые не могли бы быть автоматически согласованы или отклонены (т.е. попадают между двумя порогами).
е. Дать возможность оператору просмотреть список исключений и добавить пару записей, заявленных как совпадения, в PR.
2. Каждое местоположение может выполнять следующие стадии во время обычной работы:
а. Когда новый пациент регистрируется в локальном местоположении, выполнить согласование для ее или его демографических данных по отношению к записям в демографической базе данных.
b. Когда найдены совпадения, триплет (локальный идентификатор пациента, идентификатор удаленного местоположения, удаленный идентификатор пациента) добавляется к PR.
с. Когда найдено потенциальное совпадение (между двумя порогами), этот триплет добавляется в список исключений для просмотра вручную.
d. Периодически (например, один раз в день, один раз в неделю):
i. Извлекать релевантные демографические данные для пациентов, зарегистрированных в других местоположениях. Согласовывать собственные демографические данные пациента по отношению к демографическим данным вновь извлеченных удаленных пациентов.
ii. Когда найдено совпадение, триплет (локальный идентификатор пациента, идентификатор удаленного местоположения, удаленный идентификатор пациента) добавляется к PR.
iii. Когда найдено потенциальное совпадение (между двумя порогами), этот триплет добавляется в список исключений для просмотра вручную.
iv. Сохранить вновь извлеченные демографические данные в демографической базе данных.
Будет ясно, что изобретение также применимо к компьютерным программам, особенно к компьютерным программам на или в носителе, приспособленном для проведения изобретения в практику. Эта программа может быть в форме исходного кода, объектного кода, кода, промежуточного между исходным и объектным кодом, как, например, в частично компилированной форме, или в любой другой форме, подходящей для использования в реализации способа согласно изобретению. Также будет ясно, что такая программа может иметь много различных архитектурных конструкций. Например, программный код, реализующий функциональность способа или системы согласно изобретению, может быть подразделен на одну или несколько подпрограмм. Много различных способов распределения функциональности среди этих подпрограмм будут очевидны для специалиста. Эти подпрограммы могут храниться вместе в одном выполняемом файле для образования автономной программы. Такой выполняемый файл может содержать выполняемые компьютером команды, например, команды процессора и/или команды интерпретатора (например, команды Java-интерпретатора). Альтернативно, одна или несколько или все из этих подпрограмм могут храниться по меньшей мере в одном внешнем библиотечном файле и могут быть связаны с основной программой либо статически, либо динамически, например, во время выполнения. Основная программа содержит по меньшей мере одно обращение по меньшей мере к одной из подпрограмм. Эти подпрограммы могут также содержать функциональные обращения друг к другу. Вариант осуществления, относящийся к компьютерному программному продукту, содержит выполняемые компьютером команды, соответствующие каждой стадии обработки по меньшей мере одного из способов, изложенных здесь. Эти команды могут быть подразделены на подпрограммы и/или храниться в одном или нескольких файлах, которые могут быть связаны статически или динамически. Другой вариант осуществления, относящийся к компьютерному программному продукту, содержит выполняемые компьютером команды, соответствующие каждому средству по меньшей мере из одной из систем и/или продуктов, изложенных здесь. Эти команды могут быть подразделены на подпрограммы и/или храниться в одном или нескольких файлах, которые могут быть связаны статически или динамически.
Носителем компьютерной программы может быть любой объект или устройство, способное нести эту программу. Например, носитель может включать в себя носитель данных, такой как ПЗУ, например, CD ROM или полупроводниковое ПЗУ, или магнитный записывающий носитель, например, флоппи-диск или жесткий диск. Кроме того, этим носителем может быть передаваемый носитель, такой как электрический или оптический сигнал, который может быть передан через электрический или оптический провод или посредством радио или других средств. Когда программа воплощена в таком сигнале, этот носитель может быть составлен посредством такого провода или другого устройства или средства. Альтернативно, носителем может быть интегральная схема, в которой внедрена эта программа, причем эта интегральная схема приспособлена для выполнения, или использования в выполнении, релевантного способа.
Следует отметить, что вышеупомянутые варианты осуществления иллюстрируют, а не ограничивают изобретение, и что специалисты в данной области техники смогут сконструировать много альтернативных вариантов осуществления, не выходя за рамки объема прилагаемой формулы изобретения. В формуле изобретения, любые ссылки, заключенные в скобки, не будут истолковываться как ограничивающие данный пункт формулы изобретения. Использование глагола «содержит» и его сопряжений не исключает присутствия элементов или стадий, отличных от элементов и стадий, заявляемых в пункте формулы изобретения. Использование единственного числа для элемента не исключает присутствия множества таких элементов. Изобретение может быть реализовано посредством аппаратного обеспечения, содержащего несколько отдельных элементов, и посредством соответствующим образом запрограммированного компьютера. В пункте устройства, перечисляющего несколько средств, несколько из этих средств могут быть воплощены посредством одного и того же элемента аппаратного обеспечения. Простой факт, что некоторые меры излагаются во взаимно различных зависимых пунктах формулы изобретения, не указывает, что комбинация таких мер не может быть с выгодой использована.
Изобретение относится к связыванию соответствующих информационных записей о пациентах. Техническим результатом является повышение достоверности связывания соответствующих информационных записей о пациентах. Множество объектов имеет соответствующие базы данных пациентов, содержащие информационные записи о пациентах. Каждый объект имеет связанный с ним алгоритм идентификации пациентов для согласования соответствующих информационных записей об одном и том же пациенте в различных объектах. Подсистема связывания поддерживает множество связей первого объекта из множества объектов. Подсистема связывания выполнена для связывания информационных записей о пациенте первого объекта с соответствующими информационными записями о пациенте других объектов. Связь устанавливается, когда данная информационная запись о пациенте первого объекта согласуется с соответствующей информационной записью о пациенте другого объекта на основе алгоритма идентификации пациентов первого объекта. Эти связи обеспечивают связь между локально назначенными идентификаторами одного и того же пациента в различных объектах. 4 н. и 10 з.п. ф-лы, 2 ил.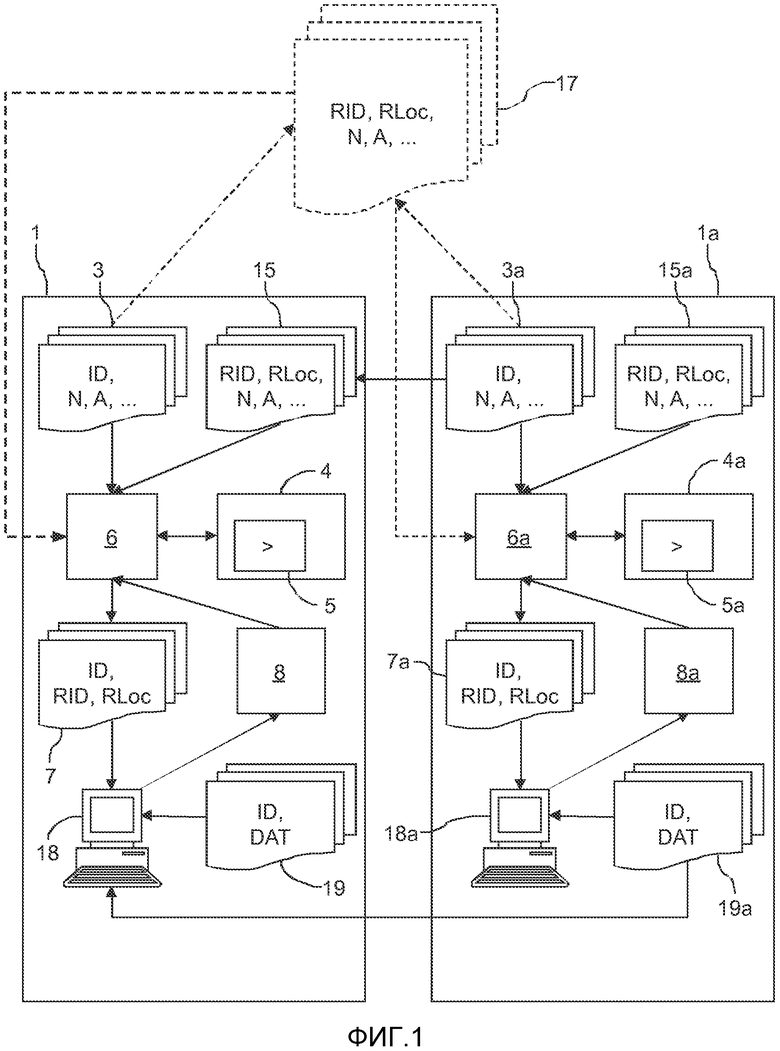
1. Система для связывания соответствующих информационных записей о пациенте, хранимых в различных объектах, содержащая:
- множество объектов (1, 1а), при этом каждый из объектов имеет
одну или более базу данных пациентов, содержащих информационные записи (3, 3а) о пациенте,
специфический для объекта алгоритм (4, 4а) идентификации пациентов для согласования информационных записей (3, 3а) о пациенте, расположенных в этом объекте из множества объектов (1, 1а), с информационными записями (3, 3а) об одном и том же пациенте, расположенными в других объектах из множества объектов; и
- подсистему (6) связывания для поддержания множества связей (7) между этим объектом (1) и другими объектами из множества объектов (1, 1а), в которой каждая связь из множества связей представляет специфическое для объекта согласование,
причем подсистема (6) связывания первого объекта из множества объектов выполнена с возможностью связывания информационных записей (3) о пациенте одного и того же пациента, расположенных в первом объекте (1), с соответствующими информационными записями (3а) о пациенте одного и того же пациента, расположенными во втором объекте из множества объектов (1а), путем создания первой связи из множества связей первого объекта в ответ на специфический для первого объекта алгоритм идентификации пациента первого объекта, согласующий информационную запись о пациенте одного и того же пациента, расположенную в первом объекте, с соответствующей информационной записью о пациенте одного и того же пациента, расположенной во втором объекте,
причем подсистема связывания второго объекта из множества объектов связывает информационные записи о пациенте одного и того же пациента, расположенные во втором объекте, с соответствующими информационными записями о пациенте одного и того же пациента, расположенными в первом объекте из множества объектов путем создания первой связи из множества связей второго объекта в ответ на специфический для второго объекта алгоритм идентификации пациента второго объекта, согласующий информационную запись о пациенте одного и того же пациента, расположенную во втором объекте, с соответствующей информационной записью о пациенте одного и того же пациента, расположенной в первом объекте,
причем специфический для первого объекта алгоритм идентификации пациента и специфический для второго объекта алгоритм идентификации пациента являются различными, и
первая связь первого объекта и первая связь второго объекта являются различными связями.
2. Система по п. 1, в которой эти связи обеспечивают связь между локально назначенными идентификаторами (ID, RID) одного и того же пациента в различных объектах (1, 1а).
3. Система по п. 1, в которой подсистема связывания второго объекта связывает информационные записи о пациенте одного и того же пациента, расположенные во втором объекте, с соответствующими информационными записями о пациенте одного и того же пациента, расположенными в третьем объекте из множества объектов, путем создания второй связи из множества связей второго объекта в ответ на специфический для второго объекта алгоритм идентификации пациента второго объекта, согласующий информационную запись о пациенте одного и того же пациента, расположенную во втором объекте, с соответствующей информационной записью о пациенте одного и того же пациента, расположенной в третьем объекте,
причем подсистема связывания первого объекта связывает информационные записи о пациенте одного и того же пациента, расположенные в первом объекте, с соответствующими информационными записями о пациенте одного и того же пациента, расположенными в третьем объекте из множества объектов, путем создания второй связи из множества связей первого объекта в ответ на специфический для первого объекта алгоритм идентификации пациента первого объекта, согласующий информационную запись о пациенте одного и того же пациента, расположенную в первом объекте, с соответствующей информационной записью о пациенте одного и того же пациента, расположенной в третьем объекте, и
первая и вторая связи первого объекта являются различными связями, первая и вторая связи второго объекта являются различными связями, и вторая связь первого объекта и вторая связь второго объекта являются различными связями.
4. Система по п. 1, в которой первый объект выполнен с возможностью хранения локальной копии (15) по меньшей мере части информационных записей о пациенте одного и того же пациента, расположенной во втором объекте, и специфический для объекта алгоритм идентификации пациентов использует локально сохраненную копию для согласования информационных записей о пациенте из второго объекта.
5. Система по п. 1, дополнительно содержащая центральный репозиторий (17) для хранения копии информации (3, 3а), используемой специфическими для объекта алгоритмами (4, 4а) идентификации пациентов каждого из множества объектов (1, 1а) для согласования информационных записей (3, 3а) о пациенте согласно каждому из множества объектов.
6. Система по п. 1, содержащая подсистему (8) инициализации для начальной установки множества связей (7) для первого объекта, обработки по существу всех доступных информационных записей (3) о пациенте первого объекта и соответствующих информационных записей о пациенте, полученных первым объектом, для каждого другого объекта из множества объектов, причем каждая связь из множества связей представляет связь с информационной записью о пациенте в соответствующем объекте.
7. Система по п. 1, в которой каждая связь является единственным соответствием между объектом и удаленным объектом и включает в себя локальный идентификатор пациента, удаленный идентификатор объекта и удаленный идентификатор пациента.
8. Система по п. 1, в которой подсистема (6) связывания первого объекта выполнена с возможностью обновления множества связей первого объекта по требованию или каждый раз, когда новый идентификатор (ID, RID) пациента генерируется в одном из объектов (1, 1а).
9. Система по п. 1, в которой специфический для объекта алгоритм идентификации пациентов первого объекта и специфический для объекта алгоритм идентификации пациентов второго объекта выполнены с возможностью согласования демографических данных пациента различно посредством по меньшей мере одного из атрибута и веса атрибута.
10. Система по п. 9, в которой атрибуты демографических данных включают в себя по меньшей мере одно из следующего: имя, адрес, номер социального обеспечения, персональный идентификационный номер, налоговый номер, возраст, дата рождения, пол.
11. Система по п. 1, в которой алгоритм идентификации пациентов включает в себя пороги для по меньшей мере одного из принятия или отвергания согласования, которые являются специфическими для объекта, связанного с алгоритмом идентификации пациентов.
12. Медицинская рабочая станция (18), которая является частью первого объекта системы по п. 1, причем эта медицинская рабочая станция содержит дисплей для отображения информации пациента из информационной записи о пациенте по меньшей мере второго объекта, которая связана с информационной записью о пациенте первого объекта.
13. Реализуемый компьютером способ связывания соответствующих информационных записей о пациенте в множестве объектов, причем каждый объект имеет соответствующие базы данных пациентов, содержащие информационные записи о пациенте, причем каждый объект имеет связанный с ним алгоритм идентификации пациентов для согласования соответствующих информационных записей об одном и том же пациенте в различных объектах, причем способ предусматривает
поддержание первого множества связей первого объекта из множества объектов, причем это первое множество связей связывает информационные записи о пациенте первого объекта с соответствующими информационными записями о пациенте других объектов, причем первая связь первого множества связей устанавливается (206), когда данная информационная запись о пациенте первого объекта согласуется (204) с соответствующей информационной записью о пациенте другого объекта, на основе алгоритма идентификации пациентов первого объекта, причем каждая связь из множества связей представляет специфическую для объекта связь с соответствующей информационной записью о пациенте другого объекта из множества объектов, и каждая связь сохранена в памяти компьютера,
поддержание второго множества связей второго объекта из множества объектов, причем это второе множество связей связывает информационные записи о пациенте второго объекта с соответствующими информационными записями о пациенте других объектов, причем вторая связь второго множества связей устанавливается, когда данная информационная запись о пациенте второго объекта согласуется с соответствующей информационной записью о пациенте другого объекта, на основе алгоритма идентификации пациентов второго объекта, причем первый алгоритм идентификации пациента первого объекта создает первую связь, и второй алгоритм идентификации пациента создает вторую связь, причем первый алгоритм идентификации пациента первого объекта и второй алгоритм идентификации пациента второго объекта являются различными, и
первая связь и вторая связь являются различными связями.
14. Машиночитаемый носитель, имеющий компьютерный программный продукт, содержащий команды для предписания процессорной системе выполнять способ по п. 13.
| US20060287890 A1, 21.12.2006 | |||
| US6523019 B1, 18.02.2013 | |||
| WO03021485 A2, 13.03.2003 | |||
| ИНФОРМАЦИОННО-АНАЛИТИЧЕСКАЯ СИСТЕМА В ОБЛАСТИ ТЕЛЕМЕДИЦИНЫ | 2003 |
|
RU2251965C2 |
| Реле времени | 1938 |
|
SU54445A1 |

