Область техники, к которой относится изобретение
Настоящее изобретение относится к области информационных технологий, в частности к способу автоматизированного анализа выгрузок из баз данных.
Уровень техники
В настоящее время весьма остро стоит проблема так называемого перехвата данных. Такая проблема может встретиться в случае отслеживания документов, проходящих по сети компании, на предмет наличия в них конфиденциальной информации.
В настоящее время известно несколько систем или способов, позволяющих решить эту проблему.
Например, в заявке на патент США №20110066585 (опубл. 17.03.2011) раскрыт способ, в котором извлекают из неструктурированных данных структурированные в виде файла с текстом и, таким образом, на основе статистических данных об этом файле придают данным некоторую структуру, например, в виде таблицы. Этот способ имеет ограниченное применение, поскольку реализован только для выделения структурированных данных.
В заявке на патент Японии №2008257444 (опубл. 23.10.2008) раскрыт способ, который можно считать ближайшим аналогом настоящего изобретения, в котором выделяют в файле особенности за счет использования предписанных условий и вычисляют сходство между файлами путем сравнения этих особенностей. Этот способ имеет ограниченное применение и низкую эффективность при анализе перехваченных документов и соответственно требует длительного времени на обработку и имеет ограниченное применение.
Раскрытие изобретения
Таким образом, существует потребность в расширении арсенала технических средств за счет создания сравнительно быстрого и универсального способа автоматизированного анализа выгрузок из баз данных, с возможностью гибко настраивать параметры, при которых текущий анализируемый текст можно отнести к выгрузке из базы данных, который позволил бы выявлять в каком-либо документе информацию из заданной базы данных и который не имел бы недостатков относительно известных решений.
Для решения этой задачи и получения указанного технического результата в настоящем изобретении предложен способ автоматизированного анализа выгрузок из баз данных, заключающийся в том, что:
- преобразуют в заранее заданный формат все информационно-значимые ячейки эталонных выгрузок из базы данных с указанием их позиций в каждой выгрузке;
- задают именные условия, указывающие на взаимоотношения между ячейками в одной строке выгрузки;
- сохраняют преобразованные строки эталонных выгрузок на запоминающем устройстве;
- выявляют ячейки эталонных выгрузок в электронном файле анализируемого документа;
- составляют матрицу найденных ячеек;
- применяют заданные условия к матрице найденных ячеек;
- составляют список условий, которым соответствует матрица найденных ячеек;
- выносят вердикт на основании упомянутого списка условий.
Особенность способа по настоящему изобретению состоит в том, что исключают «стоп-слова» в анализируемом документе и в эталонной выгрузке.
Краткое описание чертежей
На Фиг.1 представлена блок-схема реализации способа автоматизированного анализа выгрузок из баз данных.
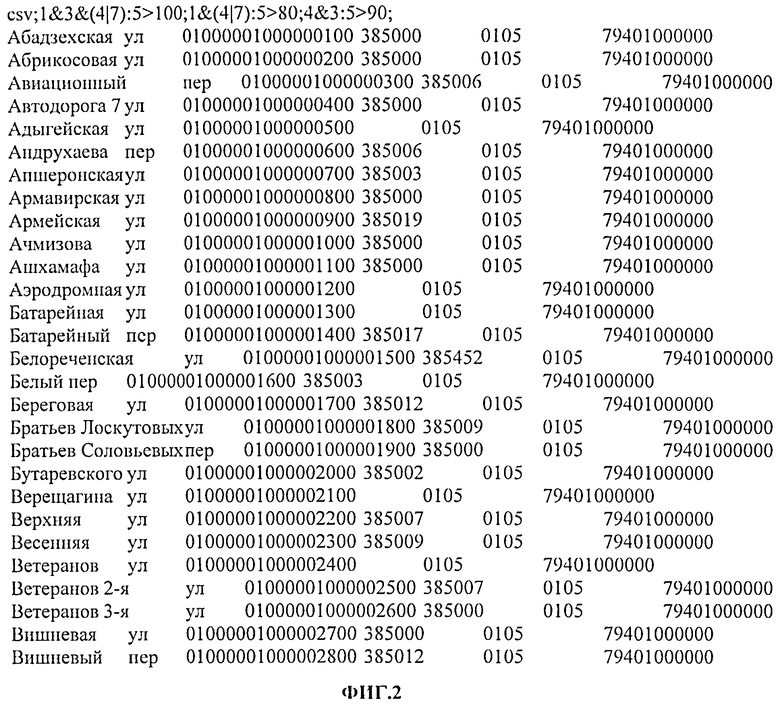
На Фиг.2 представлен пример эталонной выгрузки из базы данных, которая применяется в данном способе по настоящему изобретению.
Подробное описание изобретении
Настоящее изобретение может быть реализовано в любой вычислительной системе, например в персональном компьютере и т.п.
Способ автоматизированного анализа выгрузок из баз данных предназначен для осуществления защиты от утечек информации, хранящейся в защищаемой базе данных, а также для выявления информации не только в ячейках, но и о ее взаимном расположении. Например, просто числа, совпадающие с зарплатами сотрудников компании, но без текстового описания, несут мало информации. Однако, если в анализируемом тексте также присутствуют имена и фамилии из той же базы данных, то это, с высокой вероятностью, может оказаться утечкой информации из базы данных.
Способ автоматизированного анализа выгрузок из баз данных включает в себя несколько основных этапов. В одном из первоначальных этапов, прежде чем произвести автоматизированный анализ выгрузок из баз данных, необходимо подготовить эталонные данные для выгрузок, пример которых приведен на Фиг.2.
Выгрузкой из базы данных чаще всего является таблица, состоящая из одного или нескольких столбцов и одной или нескольких строк. Также стоит отметить тот факт, что в базах данных обычно хранится определенное количество служебной информации, которая недоступна обычному пользователю. Например, это может быть уникальный ключ, с помощью которого ссылаются на данную строку данной таблицы из других таблиц базы данных. Также некоторые выгрузки не являются прямым отображением базы данных, так как эти выгрузки формируются по определенным правилам. Например, зарплата сотрудников может вычисляться из ставок и коэффициентов в момент построения выгрузки. Поэтому очень важно правильно готовить эталонные выгрузки.
В способе по настоящему изобретению преобразуют в заранее заданный формат все информационно-значимые ячейки эталонных выгрузок из базы данных с указанием их позиций в каждой выгрузке и задают именные условия, указывающие на взаимоотношения между ячейками в одной строке выгрузки.
Каждая выгрузка состоит из набора ячеек, скомпонованных по строкам. Прежде всего, нужно выявить взаимосвязь между ячейками в одной строке. Это реализовано в связи с тем, что нет необходимости в защите данных только из одной ячейки, чаще всего данные становятся секретной информацией только в совокупности с данными из других ячеек данной выгрузки. Для описания таких взаимосвязей в настоящем изобретении введены именованные условия. Так как связи между ячейками могут быть многовариантными, а также с целью экономии ресурсов, именованных условий может быть несколько.
Непосредственно эталонные данные, относящиеся к эталонной выгрузке из базы данных, готовят следующим образом:
1. Каждая ячейка разбивается на слова либо числа (разделителем считаются все символы, кроме букв и цифр) (Фиг.1-2);
2. Из получившегося списка удаляются стоп-слова (Фиг.1-3);
3. Для каждого выделенного слова снимается HASH (Фиг.1-4);
4. Для полученных HASH значений записывается местоположение ячеек, в которых они встречаются (имя эталонной выгрузки, номер столбца, номер строки) (Фиг.1-5).
Преобразованные строки эталонной выгрузки, а также именованные условия сохраняют на запоминающем устройстве. В совокупности эти данные образуют цифровой отпечаток эталонной выгрузки из базы данных.
В именованных условиях должны быть заданы отношения между столбцами в одной строке. В простейшем случае это может быть условие присутствия в строке всех ячеек. Также в условии указывается минимальное число строк, при нахождении которого считается, что условие выполнено. Кроме того, задается рейтинг условия, чем выше рейтинг, тем более критичным считается условие. Сработавшее условие с наивысшим рейтингом останавливает анализ для текущего эталона. Рейтинг также является идентификатором условия.
Примеры условий для выгрузки, содержащей 5 столбцов и 1000 строк: 1&2&3&4&5:1000>100 - согласно этому условию в анализируемом документе должна присутствовать вся эталонная таблица. 1&(2|3):50>90 - это условие сработает, если в анализируемом тексте есть 50 или более строк из эталона, первая ячейка которых присутствует в анализируемом документе и также в этом документе присутствуют вторая или третья ячейка из данной строки. Далее перед началом автоматизированного анализа выгрузок из баз данных цифровые отпечатки эталонных выгрузок загружаются в память (Фиг.1-8). Согласно требованиям безопасности, тексты эталонных выгрузок не сохраняются, что позволяет предотвратить их несанкционированное чтение. Следующий этап настоящего изобретения заключается в том, что выявляют ячейки эталонных выгрузок в электронном файле анализируемого документа, таким образом, происходит анализ того, содержит ли электронный документ часть эталонной выгрузки или нет. Далее составляют матрицу найденных ячеек. Основной целью данного этапа является создание n-мерной матрицы, в которой каждая ячейка представляет собой проекцию ячейки эталонной выгрузки в бинарное поле. Если ячейка данной матрицы соответствует значению «истина», то это значит, что данная ячейка присутствует в анализируемом документе. Этап создания n-мерной матрицы найденных ячеек состоит из нескольких шагов:
1. Входной текст (Фиг.1-9) разбивается на слова и числа (разделителем считаются все символы, кроме букв и цифр), формируется вектор (Фиг.1-10);
2. Из полученного вектора удаляются стоп-слова и дубликаты, таким образом, получается вектор, состоящий из уникальных слов и чисел, принадлежащих анализируемому документу (Фиг.1-11);
3. От каждого элемента в векторе считается HASH сумма (Фиг.1-12);
4. Каждый HASH из полученного вектора ищется во внутреннем хранилище эталонных выгрузок (Фиг.1-13);
5. Каждая ячейка, где найден текущий HASH, помечается (Фиг.1-14);
6. Как только становится ясно, что все HASH значения в какой-либо ячейке присутствуют в анализируемом тексте, то соответствующая ячейка результирующей матрицы принимает значение «истина» (Фиг.1-15 и Фиг.1-16);
7. В результате получается n-мерная матрица с отмеченными ячейками (Фиг.1-17 и Фиг.1-18).
Количество измерений результирующей матрицы зависит от количества эталонных выгрузок.
Результатом дальнейшей реализации настоящего изобретения является список условий, которым удовлетворяет анализируемый документ, в котором применяют заданные условия к матрице найденных ячеек. Данный список получается следующим образом, n-мерная матрица раскладывается на двумерные матрицы (Фиг.1-19), каждая двумерная матрица - это представление одной эталонной выгрузки, к каждой строке каждой двумерной матрицы применяется каждое именованное условие (Фиг.1-20). Составляется список всех условий, которые сработали (Фиг.1-21), и выносится вердикт на основании упомянутого списка условий (Фиг.1-22). В частном случае осуществления изобретения перед началом работы из файла загружается список «стоп-слов». После разбиения текста на слова каждое полученное слово ищется в данном списке и если оно там присутствует, то его исключают.
Приведен пример реализации настоящего изобретения. На предприятии есть база данных, в этой базе данных кроме прочей информации хранится список клиентов со всеми их реквизитами. Для предприятия эти данные являются коммерческой тайной. Защитить предприятие от утечки этих данных можно несколькими способами, в том числе и анализом сетевого трафика выходящего за пределы локальной сети предприятия, в котором, например, список клиентов с реквизитами может быть передан как полностью, так и по частям. При этом упоминание клиентов может быть и вне контекста данного списка, например, в деловой переписке название организации и ее реквизиты могут встречаться в подписях писем сотрудников. Поэтому, кроме того, что нужно предотвратить утечку, также необходимо обеспечить минимальное количество ложноположительных срабатываний.
Для обеспечения подобного функционала и применяется способ автоматизированного анализа выгрузок из баз данных. Осуществляется способ следующим образом: данные о клиентах выгружаются в таблицу, таким образом, создается выгрузка из базы данных, для нее составляются логические условия, описывающие связи между столбцами, из полученных данных составляется эталонная выгрузка, которая передается в технологию анализа. Далее весь перехваченный исходящий трафик корпоративной сети передается для анализа. Если вердикт технологии положительный, то есть в перехваченном трафике присутствует часть эталонной выгрузки, удовлетворяющая заданным условиям, то данный трафик не передается вовне и об инциденте уведомляется офицер безопасности предприятия.
Таким образом, способ автоматизированного анализа выгрузок из баз данных по настоящему изобретению обеспечивает расширение арсенала технических средств и позволяет сравнительно быстро выявлять в каком-либо документе присутствие данных из эталонных выгрузок, преодолевая тем самым недостатки известных решений в виде ограниченности их применения.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЧЕСКОГО АНАЛИЗА ВЫГРУЗОК ИЗ БАЗ ДАННЫХ | 2024 |
|
RU2821442C1 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ЭТАЛОННЫХ ФОРМ | 2013 |
|
RU2581766C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ МАССИВОВ БИНАРНЫХ ДАННЫХ | 2015 |
|
RU2601191C1 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ТЕКСТОВЫХ ДОКУМЕНТОВ | 2011 |
|
RU2474870C1 |
| СПОСОБ И СИСТЕМА СТАТИЧЕСКОГО АНАЛИЗА ИСПОЛНЯЕМЫХ ФАЙЛОВ НА ОСНОВЕ ПРЕДИКТИВНЫХ МОДЕЛЕЙ | 2020 |
|
RU2759087C1 |
| Система предотвращения утечки информации и способ предотвращения утечки информации | 2024 |
|
RU2830388C1 |
| Способ организации поиска документов в прикладных базах неструктурированных данных и аппаратная версия двойной памяти для его осуществления | 2022 |
|
RU2792584C1 |
| Способ автоматизированного анализа векторных изображений | 2016 |
|
RU2633156C1 |
| Способ автоматизированного анализа растровых изображений | 2016 |
|
RU2633159C1 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
Изобретение относится к вычислительной технике. Технический результат заключается в защите информации, хранящейся в защищаемой базе данных, от утечек за счет автоматизированного анализа выгрузок из баз данных. Способ автоматизированного анализа выгрузок из баз данных, в котором преобразуют в заранее заданный формат все информационно-значимые ячейки эталонных выгрузок из базы данных с указанием их позиций в каждой выгрузке, задают именованные условия, указывающие на взаимоотношения между ячейками в одной строке выгрузки, сохраняют преобразованные строки эталонных выгрузок и именованные условия на запоминающем устройстве, выявляют ячейки эталонных выгрузок в электронном файле анализируемого документа, составляют матрицу найденных ячеек, применяют заданные именованные условия к матрице найденных ячеек, составляют список условий, которым соответствует матрица найденных ячеек, выносят вердикт о том, присутствует ли в анализируемом документе часть эталонной выгрузки, удовлетворяющей заданным именованным условиям. 1 з.п. ф-лы, 2 ил.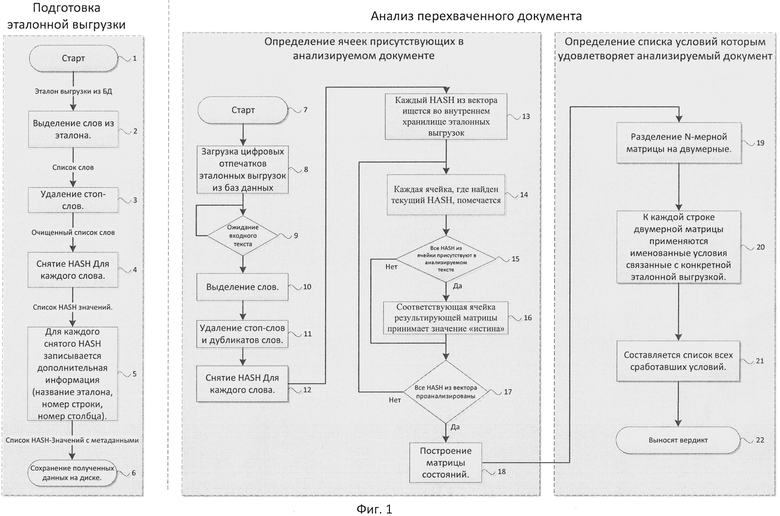
1. Способ автоматизированного анализа выгрузок из баз данных, заключающийся в том, что:
- преобразуют в заранее заданный формат все информационно-значимые ячейки эталонных выгрузок из базы данных с указанием их позиций в каждой выгрузке, причем каждая выгрузка состоит из набора ячеек, скомпонованных по строкам;
- задают именованные условия, указывающие на взаимоотношения между ячейками в одной строке выгрузки;
- сохраняют преобразованные строки эталонных выгрузок и именованные условия на запоминающем устройстве, причем в совокупности эти данные образуют цифровой отпечаток эталонной выгрузки из базы данных;
- выявляют ячейки эталонных выгрузок в электронном файле анализируемого документа;
- составляют матрицу найденных ячеек;
- применяют заданные именованные условия к матрице найденных ячеек;
- составляют список условий, которым соответствует матрица найденных ячеек;
- выносят вердикт о том, присутствует ли в анализируемом документе часть эталонной выгрузки, удовлетворяющей заданным именованным условиям на основании упомянутого списка условий.
2. Способ по п. 1, в котором исключают «стоп-слова» в анализируемом документе и в эталонной выгрузке.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| RU 2007114029 А, 27.10.2008 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| EA 007776 B1, 27.02.2007 | |||

