Область техники, к которой относится изобретение
Изобретение относится к области цифровых вычислений и обработки данных, а именно к автоматизированному сравнению массивов бинарных данных, и может быть использовано при разработке новых и совершенствовании существующих систем проведения анализа и контроля информационных объектов.
Уровень техники
Известен способ определения степени сходства документов, описанный в патенте US 5909677 A от 18 июня 1996 г., заключающийся в представлении документа, написанного на естественном языке, в виде набора последовательностей, полученных разбиением текста на слова или группы слов, применении хэш-функций к полученным последовательностям и сравнении результатов между собой для получения оценки сходства. Существенным недостатком данного способа является низкая точность оценки сходства массивов бинарных данных.
Также известен способ обнаружения дубликатов файлов, описанный в патенте US 8015162 B2 от 4 августа 2006 г., заключающийся в сравнении результатов хэширования последовательностей, полученных разбиением текста на слова или группы слов, с результатами хэширования документов, доступных в сети, для поиска полных или частичных дубликатов. Недостатком данного способа является низкая точность оценки сходства массивов бинарных данных.
Наиболее близким по технической сущности и выполняемым функциям аналогом (прототипом) к заявляемому является "Способ автоматизированного анализа текстовых документов" (патент РФ №2474870, G06F 17/00, 18.11.2011), заключающийся в том, что сначала преобразуют в заранее заданный формат все электронные файлы эталонных документов, выделяя в каждом из них осмысленные фрагменты, именуемые клаузами, и сохраняют преобразованные электронные файлы эталонных документов в базе данных, преобразуют каждый электронный файл анализируемого документа в заранее заданный формат, выявляют совпадение выделенных клауз в электронном файле анализируемого документа с выделенными клаузами в электронных файлах эталонных документов, подсчитывают относительное число клауз в электронном файле анализируемого документа, совпавших с соответствующими клаузами каждого из электронных файлов эталонных документов, сравнивают найденные относительные числа совпадений с заранее заданным пороговым значением для выявления наличия в электронном файле анализируемого документа отрывков текста какого-либо из эталонных документов.
Характерной особенностью способа-прототипа является возможность обработки и сравнения документов в виде массивов бинарных данных, при этом используются пары рассчитанных значений хэш-функции последовательности и ее позиции в массиве, где под позицией понимается указание на начало данной последовательности, отсчитанное от конца массива. Недостатком способа-прототипа является низкая точность оценки сходства массивов бинарных данных, обусловленная использованием всего одной хэш-функции и случайным выбором ее значений в каждом документе.
Раскрытие изобретения
Задачей изобретения является разработка способа идентификации массивов бинарных данных, позволяющего повысить точность оценки сходства массивов бинарных данных. Эта задача решается тем, что способ идентификации массивов бинарных данных, заключающийся в том, что преобразуют в заранее заданный формат все электронные файлы эталонных документов; сохраняют преобразованные электронные файлы эталонных документов в базе данных; преобразуют каждый электронный файл анализируемого документа в заранее заданный формат; выявляют совпадение идентификационных данных; сравнивают найденные относительные числа совпадений с заранее заданным пороговым значением, согласно изобретению дополнен следующими операциями: разбивают последовательность бинарных данных на подблоки заданной длины с перекрытием на один символ данных; формируют набор независимых хэш-функций путем использования списка неповторяющихся начальных значений параметров хэш-функции; выбирают идентификационные данные путем вычисления значений независимых хэш-функций от подблоков заданной длины и выбора подблоков с минимальным значением хэш-функции; получают наборы идентификационных данных HL, состоящие из последовательно расположенных минимальных значений для каждой хэш-функции, в виде набора идентификационных данных анализируемых документов и получают такие же наборы идентификационных данных HLi для эталонных документов, после чего выявляют совпадения между этими наборами.
При этом под хэш-функцией понимается функция, получающая на вход строку переменной длины и преобразующая ее в строку фиксированной, обычно меньшей длины (Брюс Шнайер "Прикладная криптография. Протоколы, алгоритмы, исходные тексты на языке Си". - М.: Триумф, 2002, раздел 2.4). В отличие от использования одной хэш-функции, применение набора независимых хэш-функций обеспечивает равновероятность выбора подблоков бинарных данных для анализируемого и эталонного документов (электронный документ "Несколько простых хеш-функций и их свойства", http://habrahabr.ru/post/219139/). Перекрытие подблоков бинарных данных осуществляют для того, чтобы оценка сходства не зависела от позиции и размера подблоков в последовательности бинарных данных, что непосредственно влияет на точность оценки их сходства (Andrew Tridgell "Efficient Algorithms for Sorting and Synchronization", 02.1999, раздел 3).
Перечисленные существенные признаки в совокупности обеспечивают повышение точности оценки сходства массивов бинарных данных.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного способа идентификации массивов бинарных данных, отсутствуют. Следовательно, заявленное изобретение соответствует условию патентоспособности "новизна".
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного способа, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения преобразований на решение задачи изобретения. Следовательно, заявленное изобретение соответствует условию патентоспособности "изобретательский уровень".
"Промышленная применимость" способа обусловлена наличием элементной базы, на основе которой могут быть выполнены устройства, реализующие данный способ с достижением указанного в изобретении назначения.
Краткое описание чертежей
Заявленный способ поясняется чертежами, на которых показано:
фиг. 1 - функциональная схема способа идентификации массивов бинарных данных;
фиг. 2 - график точности оценки сходства массивов бинарных данных.
Осуществление способа
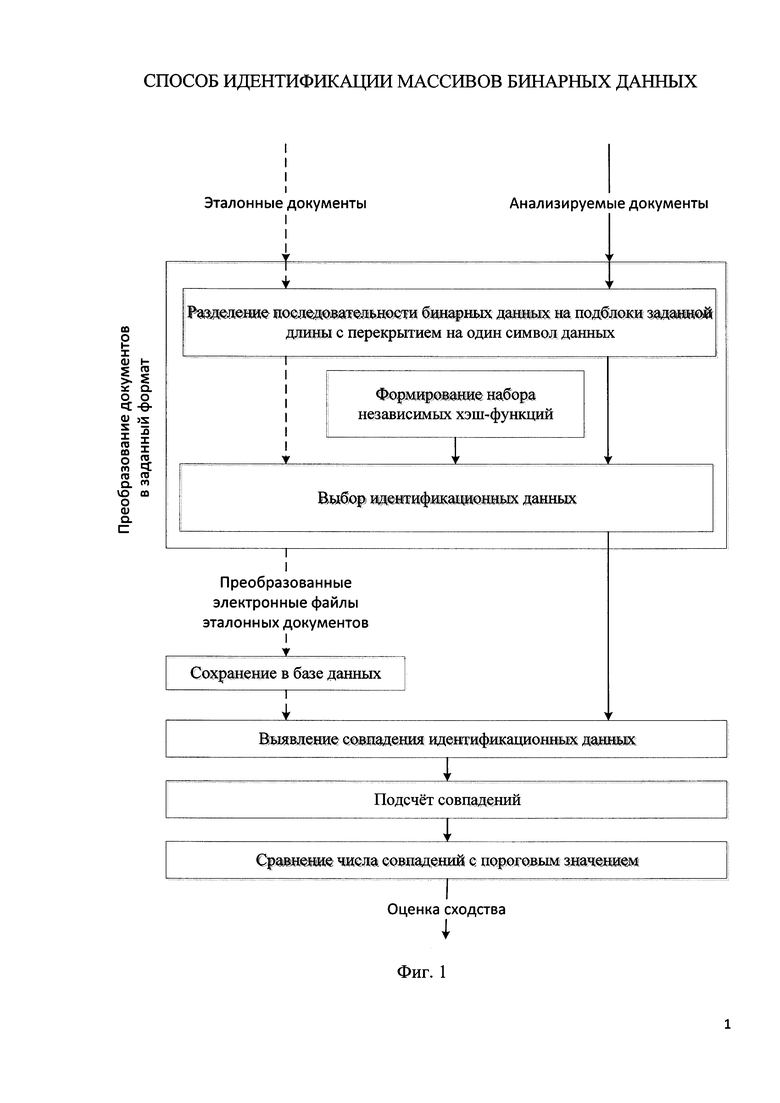
Заявленный способ поясняется функциональной схемой (фиг. 1), где сначала считывают эталонные и анализируемые документы из ячеек долговременной памяти в ячейки оперативной памяти подблоками заданного размера W, после считывания каждого подблока позиция для считывания следующего подблока увеличивается на 1 от начала документа. Таким образом, в ячейках оперативной памяти осуществляется разбиение последовательности бинарных данных сравниваемых документов на подблоки заданной длины с перекрытием на один символ данных.
Набор из L независимых хэш-функций формируют с помощью полинома hi=a i·x+b mod P, где i изменяется от 1 до L, коэффициенты а х различны для каждой сгенерированной хэш-функции и считываются из ячеек долговременной памяти, в которых хранится список неповторяющихся начальных значений параметров хэш-функции, а P - наиболее близкое к максимальному четырехбайтному значению ячейки памяти простое число, которое также считывают из ячеек долговременной памяти. Таким образом обеспечивается формирование L различных независимых преобразователей входных данных, хранящихся в оперативной памяти, с фиксированным размером выходных данных.
Выбор идентификационных данных осуществляется следующим образом:
- бинарные данные в ячейках оперативной памяти, соответствующие подблокам заданного размера W, модифицируют L раз для каждого подблока отдельно с использованием набора сформированных независимых хэш-функций;
- при каждой модификации данных полученные значения хэш-функций сохраняют в ячейках долговременной памяти;
- полученные значения хэш-функций измеряют и сравнивают между собой для выбора минимального значения каждой хэш-функции hi;
- полученный набор идентификационных данных HL, состоящий из последовательно расположенных минимальных значений для каждой хэш-функции из сформированного набора, сохраняют в ячейках долговременной памяти. При этом ячейки долговременной памяти для хранения идентификационных данных эталонных документов организованы в виде базы данных.
Для выявления совпадения идентификационных данных последовательно сравнивают полученный набор идентификационных данных HL для анализируемого документа с наборами идентификационных данных эталонных документов, для чего:
- считывают из ячеек долговременной памяти вычисленное значение HL для анализируемого документа;
- последовательно считывают из ячеек долговременной памяти базы данных каждый набор идентификационных данных эталонных документов HLi, где i изменяется от 1 до K, где K - количество эталонных документов;
- последовательно для каждого считанного набора идентификационных данных проверяют равенство HL и HLi.
Подсчет относительного числа идентификационных данных в электронном файле анализируемого документа, совпавших с соответствующими идентификационными данными каждого из электронных файлов эталонных документов осуществляется следующим образом:
- последовательно для каждого считанного набора идентификационных данных измеряют di - количество одинаковых значений хэш-функций между наборами идентификационных данных HL и HLi;
- последовательно вычисляют нормированное значение оценки сходства массивов бинарных данных Ri=(L-di)/L.
Для сравнения найденного относительного числа совпадений с пороговым значением вычисляют индекс i наиболее похожего набора идентификационных данных, для которого оценка сходства R=max(Ri). Результатом идентификации считают индекс i наиболее похожего эталонного документа и оценка сходства набора идентификационных данных R. При низкой оценке степени сходства, определяющейся заданными граничными условиями, идентификацию считают неуспешной, т.к. анализируемый документ не соответствует ни одному из эталонных.
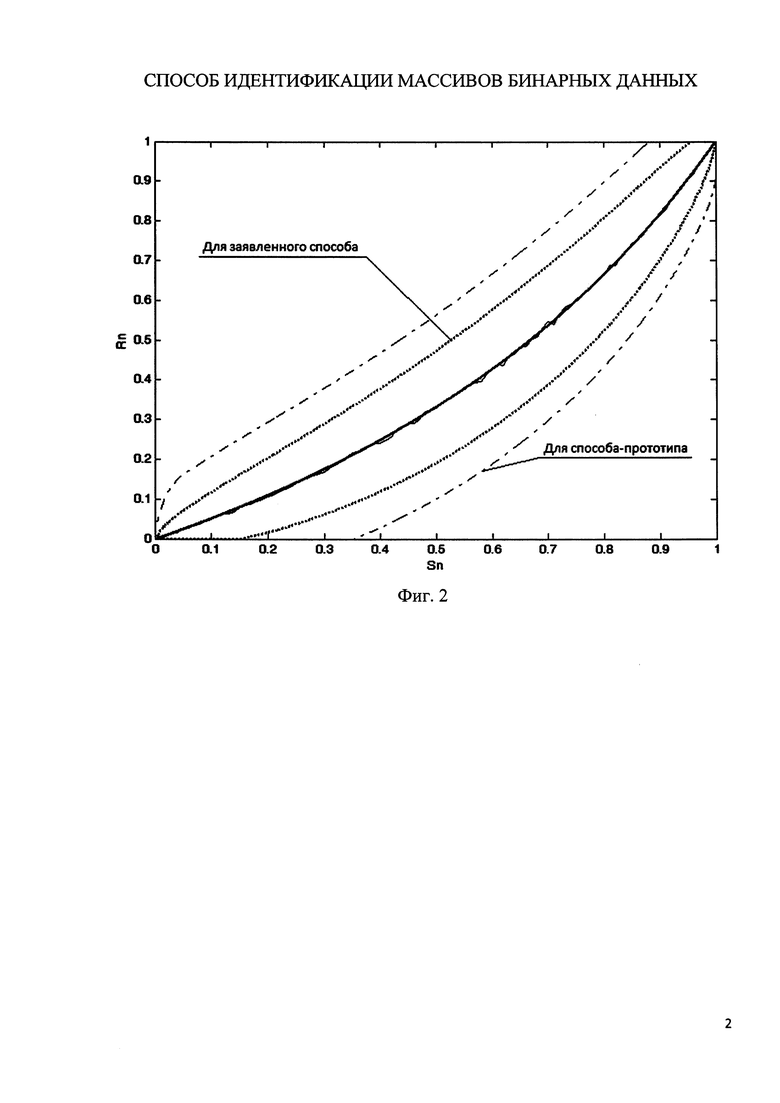
Осуществление задачи изобретения по повышению точности оценки сходства массивов бинарных данных может быть представлено в виде графика (фиг. 2) сравнения результатов экспериментов для заявленного способа и способа-прототипа. При этом по оси абсцисс показаны нормированные значения количества изменений между эталонным и анализируемым документом, по оси ординат - нормированное значение оценки сходства. Из графика видно, что при 10000 экспериментах в среде MatLAB с различными документами и различной степенью изменений Sn между ними средневыборочное значение полученной оценки степени сходства Rn для заявленного способа и способа-прототипа совпадает, однако дисперсия оценки заявленного способа при L=100 существенно меньше и оценка сходства имеет точность 3σ, где 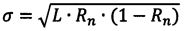 .
.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ТЕКСТОВЫХ ДОКУМЕНТОВ | 2011 |
|
RU2474870C1 |
| Способ хеширования файлов для быстрого поиска дубликатов | 2024 |
|
RU2825549C1 |
| Рекомендательная система подбора персонала с использованием машинного обучения и с понижением размерности многомерных данных и способ подбора персонала с использованием машинного обучения и с понижением размерности многомерных данных | 2019 |
|
RU2711717C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2761066C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2804029C2 |
| СПОСОБ И СИСТЕМА ИЕРАРХИЧНОГО КОНТРОЛЯ ЦЕЛОСТНОСТИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ | 2023 |
|
RU2805339C1 |
| Способ автоматизированного анализа векторных изображений | 2016 |
|
RU2633156C1 |
| СПОСОБ КОНТРОЛЯ И ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ | 2017 |
|
RU2680739C1 |
| Способы и вычислительное устройство для определения того, является ли знак подлинным | 2015 |
|
RU2648582C1 |
Изобретение относится к обработке данных. Технический результат заключается в повышении точности оценки сходства массивов бинарных данных. В способе идентификации массивов бинарных данных осуществляют автоматизированное сравнение массивов бинарных данных путем получения наборов идентификационных данных, состоящих из последовательно расположенных минимальных значений для каждой хэш-функции в виде набора идентификационных данных анализируемых документов, а также получения наборов идентификационных данных для эталонных документов, с выявлением совпадений между этими наборами. 2 ил.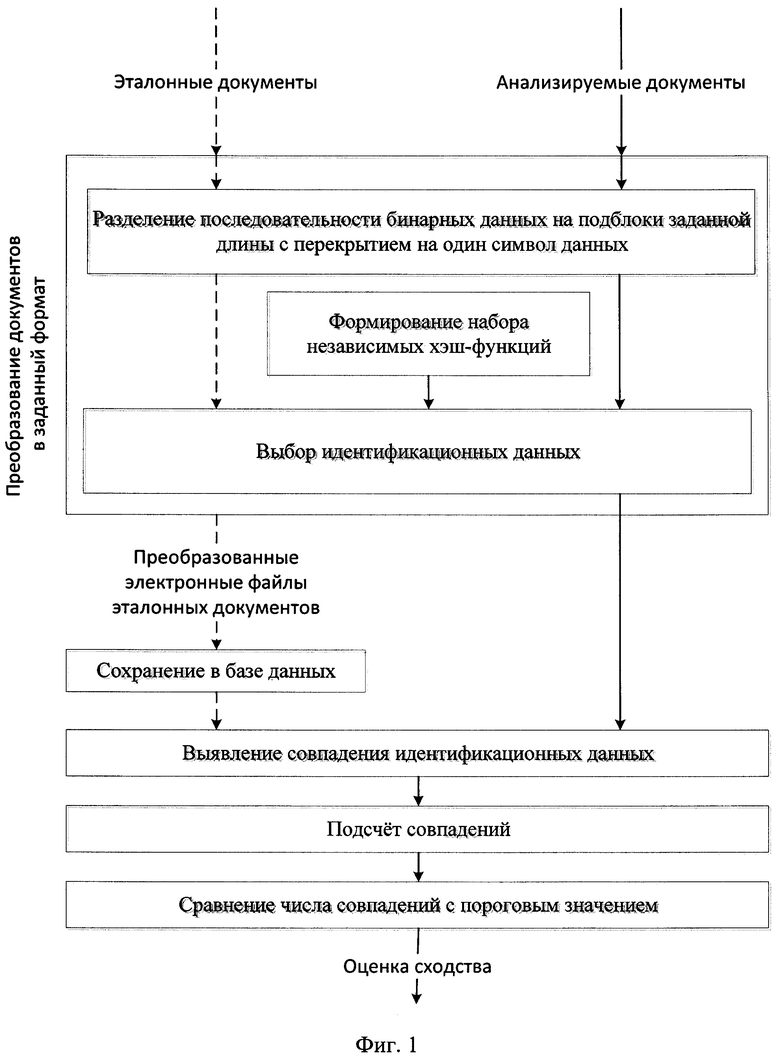
Способ идентификации массивов бинарных данных, заключающийся в том, что преобразуют в заранее заданный формат все электронные файлы эталонных документов; сохраняют преобразованные электронные файлы эталонных документов в базе данных; преобразуют каждый электронный файл анализируемого документа в заранее заданный формат; выявляют совпадение идентификационных данных; сравнивают найденные относительные числа совпадений с пороговым значением, отличающийся тем, что при преобразовании в заданный формат разбивают последовательность бинарных данных на подблоки заданной длины с перекрытием на один символ данных, формируют набор независимых хэш-функций путем использования списка неповторяющихся начальных значений параметров хэш-функции, выбирают идентификационные данные путем вычисления значений независимых хэш-функций от подблоков заданной длины и выбора подблоков с минимальным значением хэш-функции, получают наборы идентификационных данных HL, состоящие из последовательно расположенных минимальных значений для каждой хэш-функции, в виде набора идентификационных данных анализируемых документов и получают такие же наборы идентификационных данных HLi для эталонных документов, после чего выявляют совпадения между этими наборами.
| СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ТЕКСТОВЫХ ДОКУМЕНТОВ | 2011 |
|
RU2474870C1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

