ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к способам пополнения электронных словников - списков терминов с метками.
УРОВЕНЬ ТЕХНИКИ
В некоторых задачах компьютерной обработки естественного языка автоматический анализ текста требует использования электронных словников терминов с метками, то есть списков слов, где каждому слову присвоена метка - категория, число и т.п.Такие словники используются, например, при классификации текстов, при этом метки словника могут, хотя бы частично, совпадать с названиями классов. Словники с числовыми метками могут использоваться в задачах регрессии.
[0001] Предыдущие исследования используют статичные электронные списки слов. Такие списки слов в некоторых случаях создаются вручную, их объемов недостаточно для обработки больших объемов данных. Пополнение таких списков при необходимости также производится вручную, что не всегда позволяет достигнуть требуемых размеров словника. В некоторых случаях также возникает необходимость пополнить списки терминами специальных областей, например, технической лексикой. Кроме того, язык меняется, появляются новые термины, в результате чего существующие списки устаревают, и может потребоваться их пополнение терминами, возникшими после их создания, например, лексикой интернет-общения. Все это в совокупности указывает на необходимость создания методов автоматического пополнения списков терминов с метками, называемых здесь электронными словниками.
[0002] Большинство известных методов не предусматривает введения весов для терминов словника. Таким образом, все термины считаются одинаково важными. Однако в случае с электронными словниками, пополненными автоматически, имеет смысл делать различие между словами, добавленными вручную, и словами, добавленными автоматически. Это может быть реализовано с помощью назначения терминам весов. Метод, описанный в статье "Интеллектуальный анализ блогосферы: возраст, пол и разнообразие самовыражения» (Mining the blogosphere: age, gender, and the varieties of self-expression), журнал First Monday, выпуск 12(9), 2007 г. (прототип) использует словники - списки терминов с метками для профилирования автора - определения пола, возраста, психологических характеристик автора текста. С помощью использования различных словников метод достигает высокой точности при решении задач определения пола и возраста автора. Возможным недостатком данного метода является невозможность использования взвешенных словников, так как терминам используемых в данном методе словников не назначаются веса. Кроме того, метод не предусматривает пополнения словников.
[0003] Другой метод, описанный в статье «Улучшая классификацию по полу авторов блогов» (Improving gender classification of blog authors), Труды международной конференции EMNLP 2010, наряду с другими характеристиками использует списки терминов с метками для классификации документов по полу автора. Списки содержат такие метки, как «Эмоции», «Семья», «Дом» и т.п. Метод не предусматривает пополнения использованного словника, а также словам не назначаются веса. [0004] Техническим результатом от использования предлагаемого изобретения является возможность более эффективного использования электронных словников - возможность назначения терминам осмысленных весов, автоматическое пополнение словников с помощью обучающего множества текстов и использование упомянутых словников в задачах анализа текста.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Заявленный технический результат достигается следующим образом.
Способ пополнения электронного словника в компьютерной системе, заключающийся в том, что, по меньшей мере, один раз производят следующую последовательность действий:
- выявление терминов электронного словника в обучающем множестве;
- вычисление значения, по крайней мере, одного критерия выбора характеристик или одной функции от нескольких критериев для терминов обучающего множества
- извлечение терминов, для которых значение, по крайней мере, одного критерия выбора характеристик или функции от нескольких критериев попадает в заранее заданный промежуток значений;
- назначение терминам меток соответствующих электронных документов обучающего множества;
- добавление терминов в электронный словник.
При этом в предпочтительном варианте исполнения имеет место одно или несколько из нижеперечисленного:
- метки электронных документов обучающего множества предварительно преобразуют в формат меток электронного словника;
- выявление терминов включает извлечение обучающего подмножества электронных документов, содержащихся в обучаемом множестве и содержащих выявленные термины;
- обучающее подмножество сохраняется в электронном файле и/или оперативной памяти и/или в базе данных;
- набор меток обучающего множества и набора меток словника отличаются, и между ними установлено соответствие;
- метки представлены текстом;
- метки представлены вещественными числами;
- извлечение терминов из обучающего множества включает предварительную обработку текстов;
- предварительная обработка текстов может включать частеречную разметку и/или синтаксический анализ и/или семантический анализ и/или разрешение омонимии и неоднозначности и/или разрешение анафорических связей;
- словник является взвешенным словником;
- добавление терминов в словник включает назначение терминам весов;
- веса являются вещественными числами;
- извлечение терминов из обучающего множества включает применение, по крайней мере, одного критерия выбора характеристик;
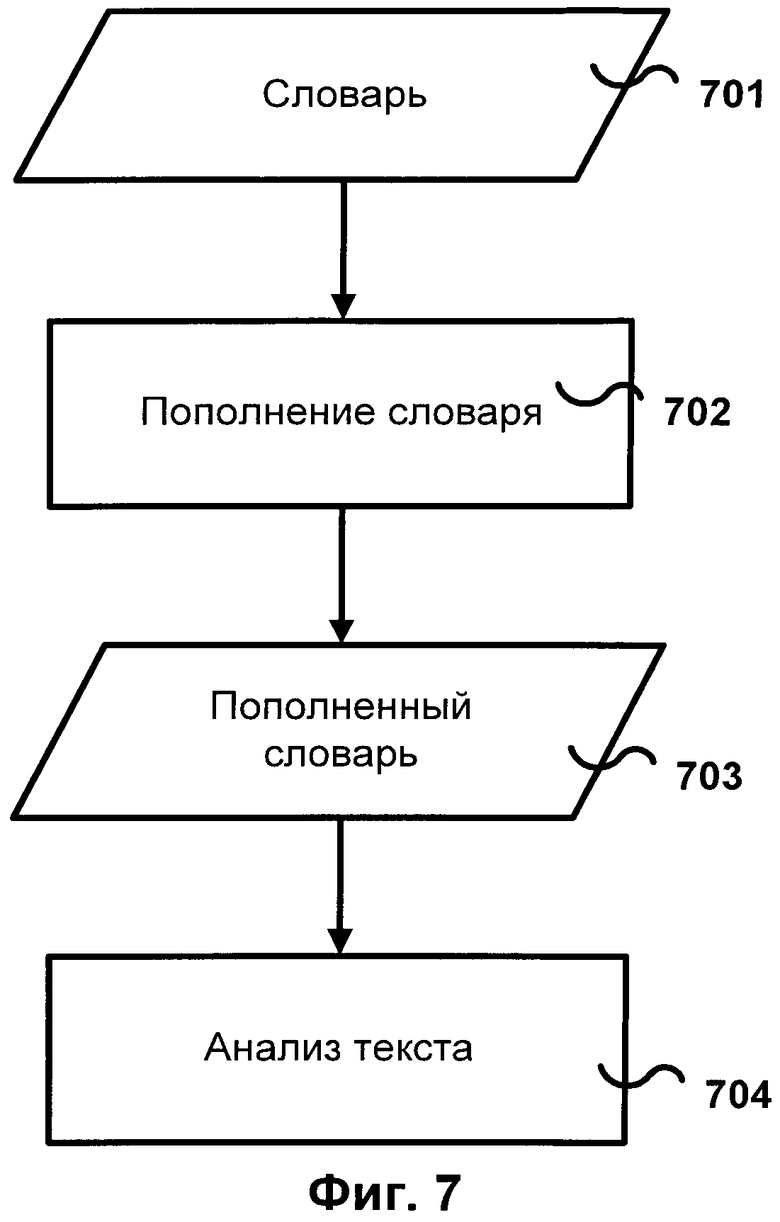
- извлечение терминов из обучающего множества включает применение комбинации критериев выбора характеристик;
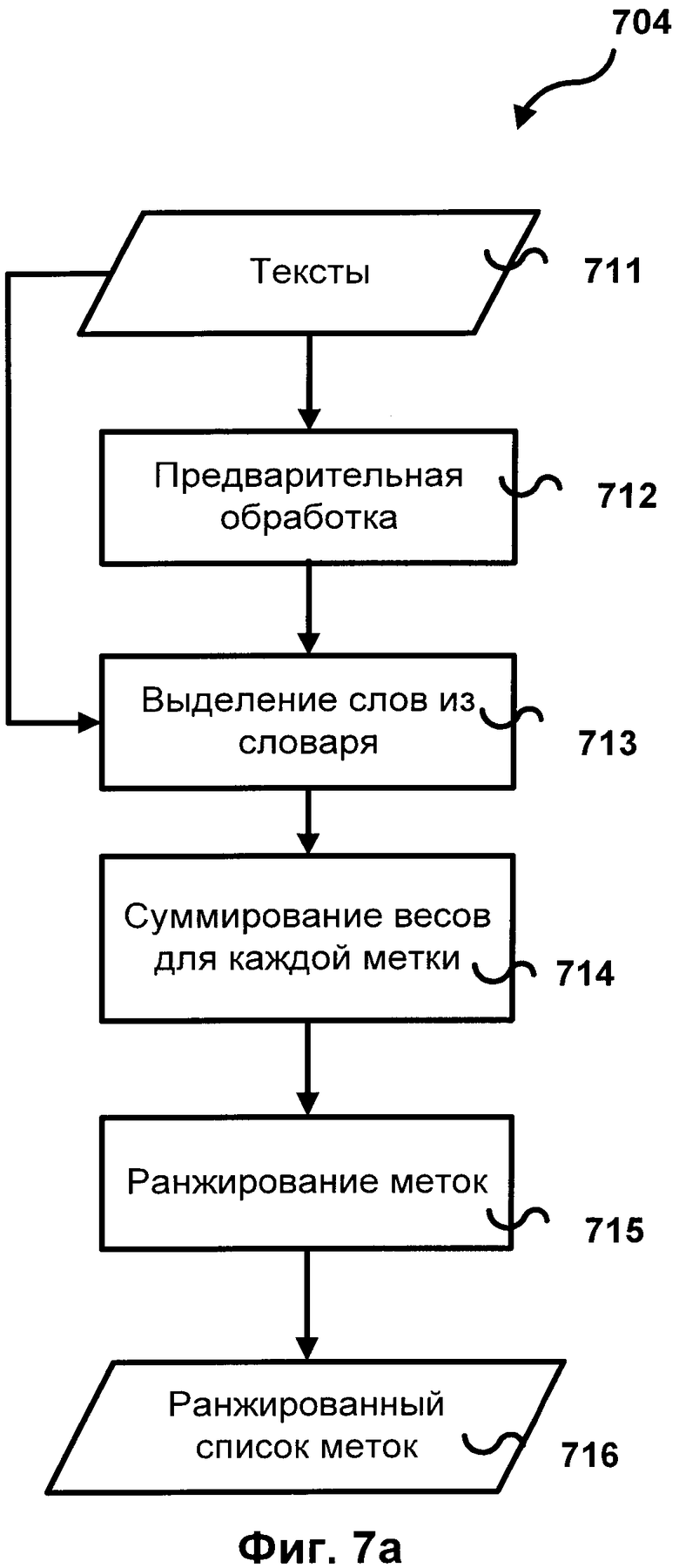
- извлечение терминов из обучающего множества включает подбор параметров;
- способ анализа текстов с использованием словника, заключающийся в том, что словник пополняется и документ анализируется с использованием пополненного словника;
- анализ текста является классификацией текстов.
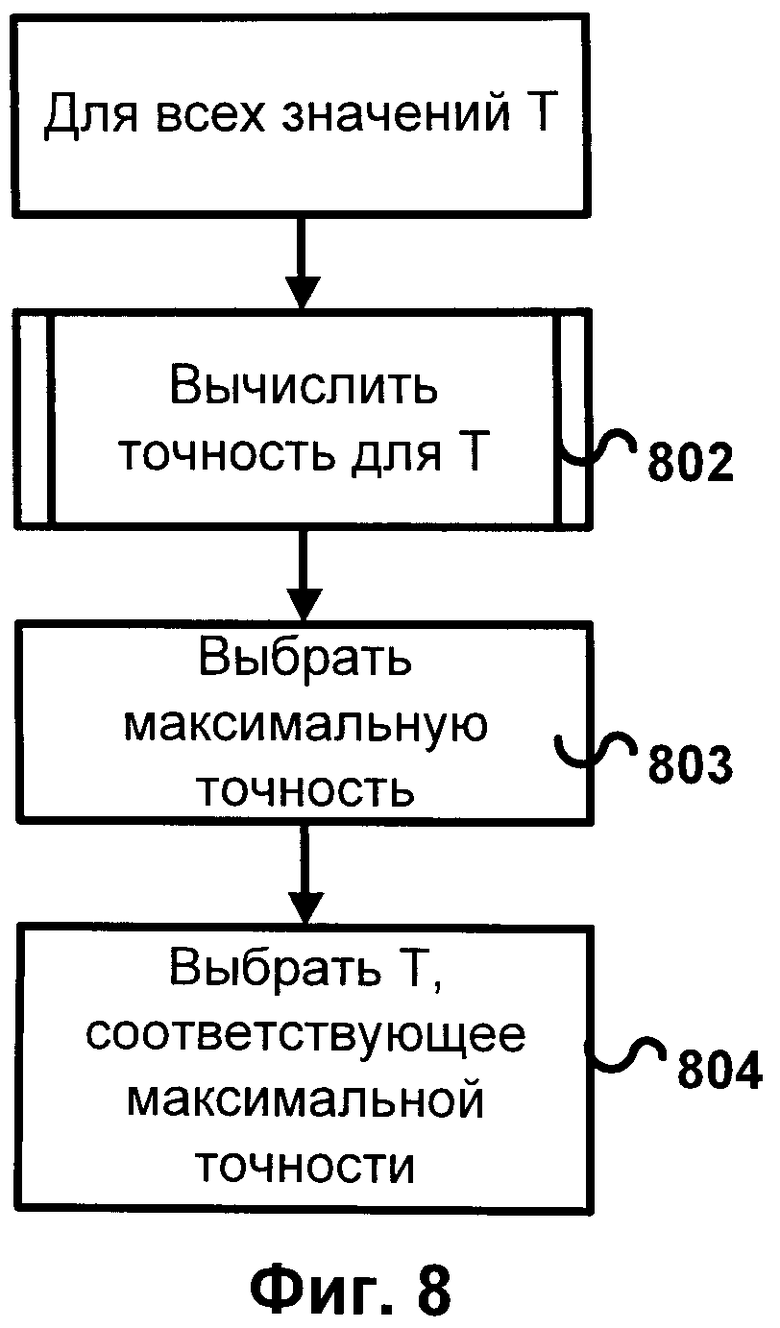
Для реализации способа используется система для распределения заданий между множеством вычислительных устройств, включающая: один или более процессоров, одно или более устройств памяти, программные инструкции для вычислительного устройства, записанные в одно или более устройств памяти, которые при выполнении на одном или более процессорах управляют системой для:
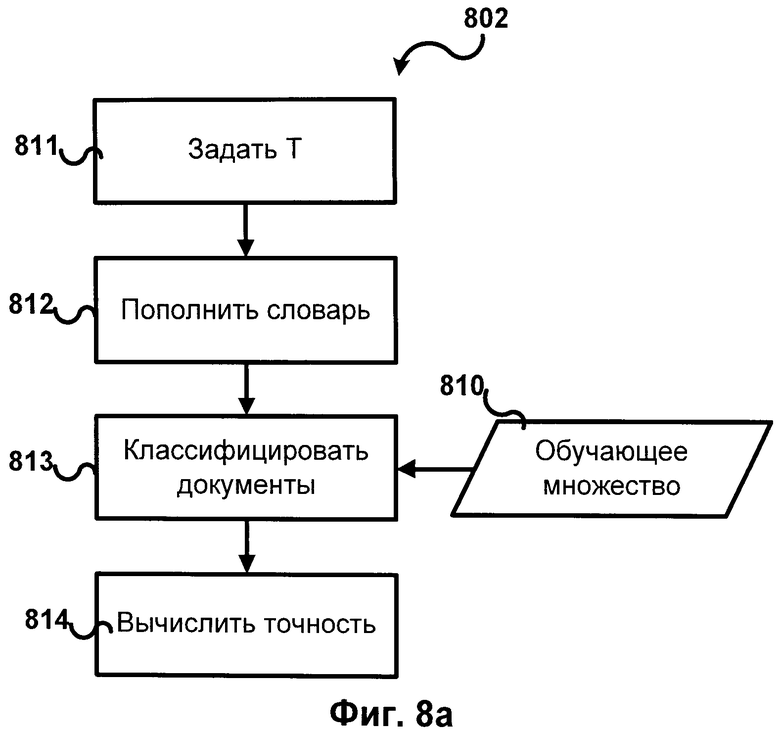
- выявления терминов электронного словника в обучающем множестве;
- вычисления значений, по крайней мере, одного критерия выбора характеристик или одной функции от нескольких критериев для терминов обучающего подмножества;
- извлечения из обучающего подмножества терминов, для которых значение, по крайней мере, одного критерия выбора характеристик или одной функции от нескольких критериев попадает в заранее заданный промежуток значений;
- сохранения извлеченных терминов в электронном файле оперативной памяти и/или в базе данных оперативной памяти;
- назначения терминам меток соответствующих электронных документов обучающего множества;
- добавления терминов в электронный словник.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 иллюстрирует пример электронного словника для географической лексической вариации русского языка.
Фиг.1а иллюстрирует пример электронного словника тональности, где тональность задается текстовым значением.
Фиг.1б иллюстрирует пример электронного словника тональности, где тональность задается вещественным числом.
Фиг.2 является блок-схемой возможной реализации алгоритма, иллюстрирующего реализацию метода пополнения электронного словника.
Фиг.3 является блок-схемой возможной реализации алгоритма комбинации критериев выбора характеристик.
Фиг.4 является блок-схемой возможной реализации алгоритма, иллюстрирующего реализацию метода пополнения электронного словника на основе обучающего множества текстов, согласно данному изобретению.
Фиг.5 является блок-схемой возможной реализации алгоритма пополнения электронного словника с весами.
Фиг.6 является блок-схемой возможной реализации алгоритма формирования обучающего подмножества.
Фиг.7 является блок-схемой возможной реализации алгоритма пополнения словника как части алгоритма анализа текстов.
Фиг.7а является блок-схемой возможной реализации алгоритма анализа текста с использованием словника, пополненного согласно изобретению.
Фиг.8 является блок-схемой возможной реализации алгоритма подбора параметров.
Фиг.8а является блок-схемой возможной реализации алгоритма оценки точности при подборе параметров.
Фиг.9 иллюстрирует пример схемы аппаратного обеспечения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0005] Настоящее изобретение предназначено может быть реализовано на любом вычислительном средстве, способном воспринимать и обрабатывать текстовые данные. Это могут быть серверы, персональные компьютеры (ПК), переносные компьютеры (ноутбуки, нетбуки), компактные компьютеры (лаптопы), а также любые иные существующие или разрабатываемые, а также будущие вычислительные устройства.
[0006] Некоторые задачи обработки естественного языка предполагают использование списков слов, где каждое слово связано с некоторой категорией, областью или числом. Здесь набор слов, где каждое слово связано с некоторой категорией, областью или числом, мы называем словником или электронным словником. Настоящее изобретение является методом итеративного пополнения словника.
[0007] Словник может быть представлен, например, в виде набора именованных списков терминов. Например, словник региональной вариации языка может содержать слова, специфические для каждого географического региона, то есть каждое слово в таком словнике связано с географической зоной, являющейся в данном случае меткой. Все возможные метки представляют собой набор меток. Фиг.1 иллюстрирует пример части словника региональной вариации русского языка, словник представляет собой несколько списков слов 102, каждый из которых связан с категорией 101 из набора меток географических регионов распространения русского языка.
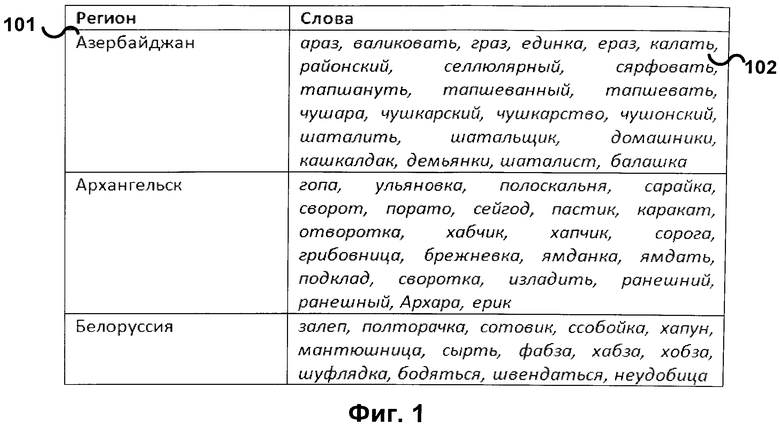
[0008] Фиг.1а иллюстрирует пример части словника тональности слов. Каждое слово 111 имеет метку тональности 112. В этом случае набор меток включает все возможные значения метки тональности. Для слов может также быть указана другая информация, например идентификатор 110 или грамматические характеристики.
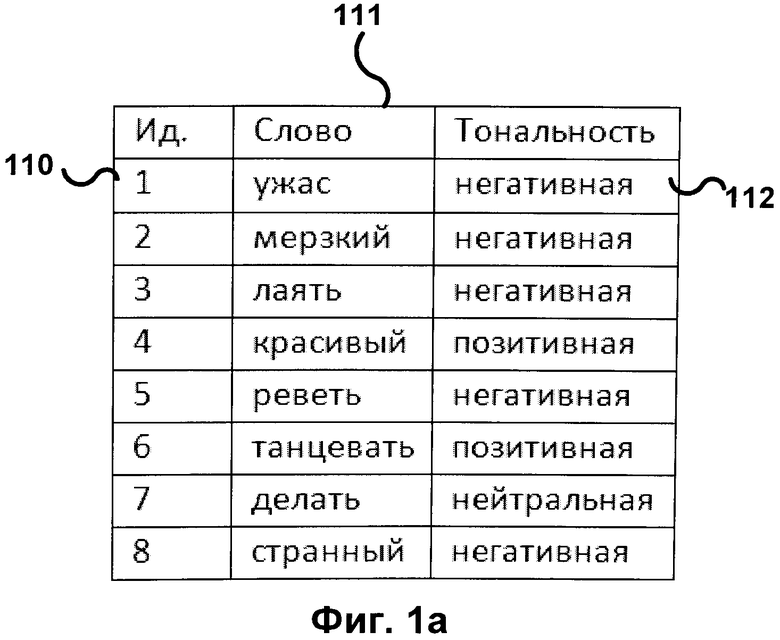
[0009] Фиг.1б иллюстрирует пример части словника тональности слов, где тональность слов представлена числовым значением. Каждое слово 121 имеет метку тональности 122, где отрицательные значения метки 122 соответствуют негативной тональности, а положительные - позитивной. Абсолютное значение метки тональности 122 может выражать степень окрашенности термина. В этом случае набор меток представляет собой область определения метки тональности, то есть все возможные числовые значения метки тональности. Для каждого слова 121 наряду с другими признаками также может быть указан идентификатор 120 и часть речи 123.
[0010] Словник может быть представлен как набор списков слов 101, связанных с метками 102. Словник также может быть представлен как список слов 111, 121, где каждое слово имеет метку 112, 122. Метки могут быть текстовыми 112 или числовыми 122. Кроме того, термины могут иметь метки, содержащие другую информацию, как, например, идентификатор 110, 120 или часть речи 123.
[0011] Такие словники могут быть использованы при классификации документов, и метки списков слов могут совпадать с названиями классов документов. В случае классификации по региональной вариации языка, где термины в словнике имеют метки географических регионов, классы в задаче классификации могут частично или полностью совпадать с метками словника, или между ними может быть установлено соответствие. Например, метки словника могут представлять собой названия населенных пунктов, в то время как классы в задаче классификации могут содержать области, республики и края. В этом случае классов будет меньше, чем меток, и необходимо соответствие между населенными пунктами и более крупными объектами.
[0012] В случае классификации по полу автора, где классами являются «мужской пол», «женский пол» и в некоторых случаях также «неизвестен», метки терминов словник могут не совпадать с метками классов. Например, термины словника могут иметь следующие метки «позитивная лексика», «негативная лексика», «радость», «грусть» и другие категории, наличие которых в тексте может указывать на пол автора текста, то есть уровень которых в текстах авторов женского пола существенного отличается от их уровня в текстах авторов мужского пола.
[0013] Изобретение представляет собой метод и систему автоматического итеративного пополнения словников с использованием обучающего множества текстов. Метод включает следующие шаги: по крайней мере один раз выполнить следующее: сформировать обучающее подмножество документов, выбрать слова из обучающего подмножества, добавить слова в словник с соответствующими метками.
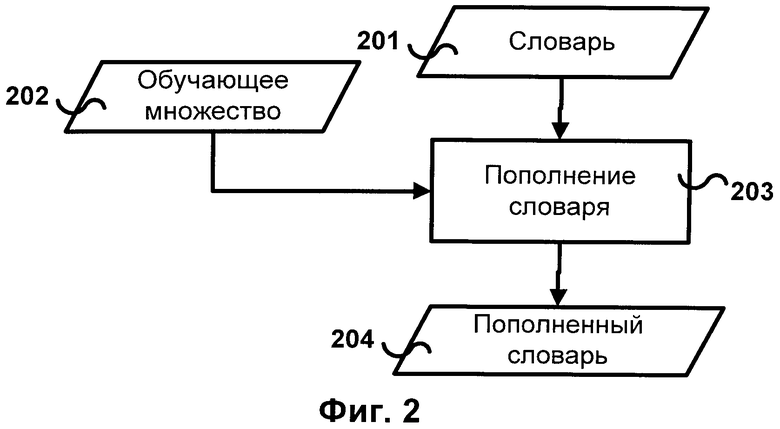
[0014] Фиг.2 иллюстрирует общую схему метода пополнения словника, согласно одной из возможных реализаций изобретения. Основные шаги метода следующие: словник 201 (итеративно) пополняется 203 с помощью обучающего множества 202. Результатом является пополненный словник 204.
[0015] В некоторых реализациях данного изобретения, требуется обучающее множество 202. Обучающее множество может быть представлено набором текстов с метками категорий или числовых значений. Набор меток обучающего множества, то есть множество всех возможных категорий обучающего множества, может совпадать с набором меток словника, то есть множеством всех возможных меток словника, или включать его; категории обучающего множества могут отличаться от категорий словника, в этом случае необходимо соответствие между ними. Например, словник может не содержать меток, а слова могут иметь идентификаторы, в то время как обучающее множество может быть размечено по темам, в этом случае должно быть представлено соответствие между идентификаторами слов и темами. Другим примером может быть случай, когда метками словника являются страны, а метками обучающего множества являются города. В этом случае необходимо соответствие между городами и странами.
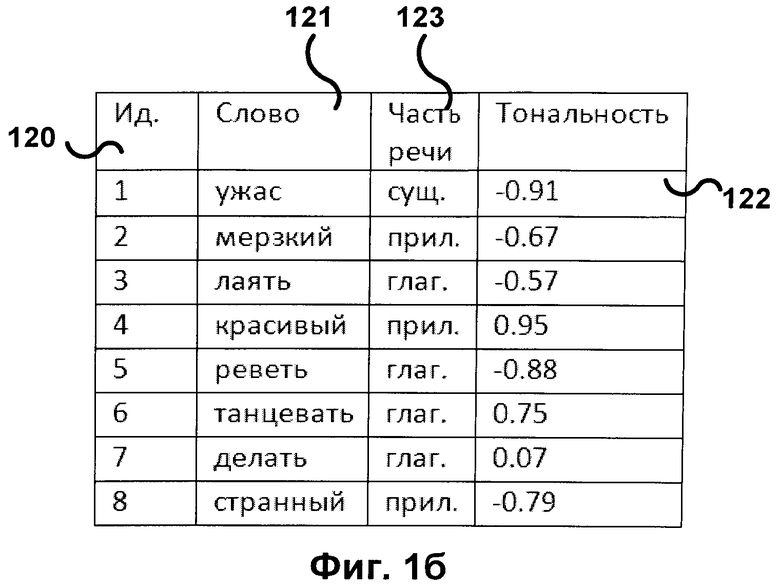
[0016] Если метки словника представлены числовыми значениями, например, вещественными числами от -1 до 1, а метки обучающего множества представлены вещественными числами от 0 до 10, то необходимо взаимно-однозначное соответствие между промежутками [0; 10] и [-1; 1], например,
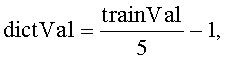
где dictVal - значение метки словника, a trainVal - значение метки обучающего множества.
[0017] Некоторые реализации настоящего изобретения могут включать методы выбора характеристик. Выбор характеристик - это процесс выявления характеристик, наиболее полезных для решения определенной задачи. Полезность характеристики оценивается с помощью критериев выбора характеристик. Такими критериями может быть, например, критерий, основанный на хи-квадрат статистике, оценивающей зависимость между классом и характеристикой.
[0018] В статистике, тест хи-квадрат применяется для определения независимости двух событий, то есть события А и В независимы, если P(AB)=P(A)·P(B), т.е. P(A\B)=P(A) и P(B\A)=P(B). Для оценки полезности характеристики в задаче классификации, можно оценить независимость встречаемости характеристики и встречаемости класса. Например, для класса C и слова (в данном случае выступающего в качестве характеристики) w, все документы обучающего множества могут быть разделены на следующие четыре группы: Xw - документы класса C, в которых встречается w; Yw - документы, класс которых отличен от C, в которых встречается w; X - документы класса C, в которых не встречается w; Y документы, класс которых отличен от C, в которых не встречается w. Таким образом, общее число документов в обучающем множестве N=Xw+Yw+X+Y.
Тогда значение критерия хи-квадрат для выбора характеристик может быть вычислено по следующей формуле:
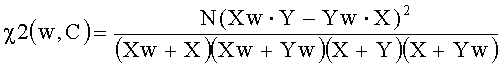
Таким образом, чем больше документов класса C содержат w и чем больше документов классов, отличных от C, не содержат w, тем выше значение хи-квадрат критерия выбора характеристик. С другой стороны, чем больше документов класса C, в которых не встречается w, и документов классов, отличных от C, в которых встречается w, тем ниже значение хи-квадрат критерия выбора характеристик.
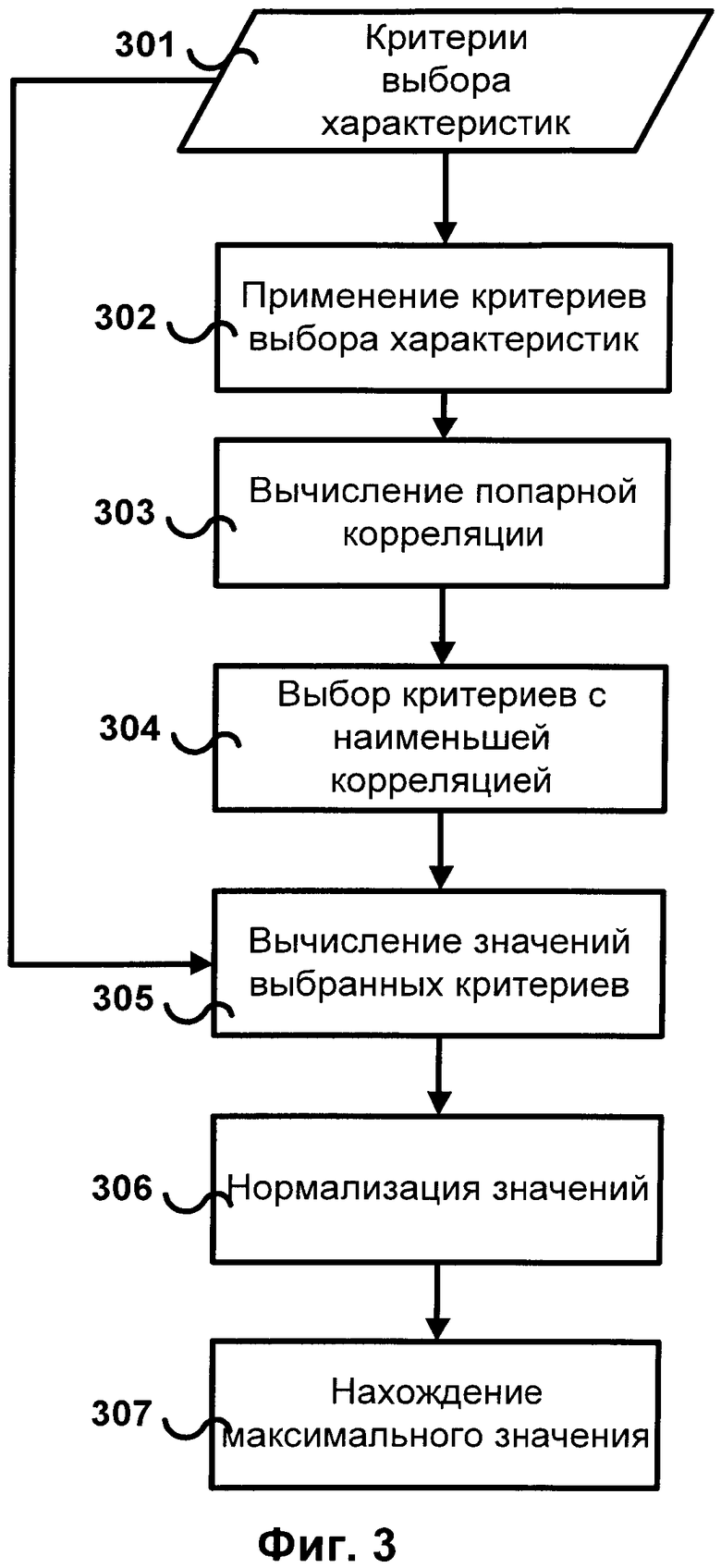
[0019] Некоторые реализации данного изобретения могут включать методы комбинации критериев выбора характеристик. Может учитываться несколько критериев выбора характеристик, затем может быть извлечено подмножество из двух и более критериев. Это может быть сделано посредством оценивания корреляции между значениями различных критериев и выбора наименее коррелирующих критериев, т.к. низкая корреляция может указывать на то, что критерии оценивают различные аспекты важности характеристик. Затем выбранные критерии вычисляются для каждого слова, полученные значения нормируются, и выбирается максимальное значение.
[0020] Фиг.3 иллюстрирует схему возможной реализации метода комбинации критериев выбора характеристик. Рассматривается набор критериев 301. Первым шагом является применение всех критериев к некоторым данным и получение наборов значений для всех критериев 302. Затем вычисляются попарные корреляции между критериями 303, то есть для каждой пары критериев X и Y, представленных своими значениями Х1,… Хn и Y1,… Yn соответственно, корреляция оценивается, например, с помощью коэффициента корреляции Пирсона, вычисляемого следующим образом:
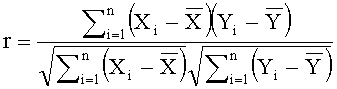
где 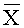
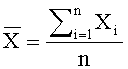
[0021] На третьем шаге, выделяются наименее коррелирующие критерии 304. Наименее коррелирующими критериями могут быть, как пары критериев с наименьшими значениями корреляции, так и пары критериев, корреляция которых достаточно мала, например, меньше некоторого порогового значения.
[0022] Затем на обучающем множестве 202 вычисляются значения выбранных критериев 305. Значения нормируются 306, таким образом, что все значения критериев оказываются в одном числовом промежутке, например [0;1]. Выбирается максимальное значение всех нормированных критериев 307. Это значение считается значением комбинации критериев.
[0023] В некоторых реализациях данного изобретения шаги 302-304, оценивающие корреляцию, могут быть опущены. При этом, имея набор критериев выбора характеристик 301, значения каждого критерия вычисляются 305, нормируются 306 и выбирается максимальное значение 307.
[0024] Фиг.4 иллюстрирует схему алгоритма пополнения словника 203. Сначала для пополнения словника 401 выделяется обучающее подмножество 402 обучающего множества 202. Затем для каждого w 411 и каждого С 412, где w 411 - слово, представляющее термин словника 401, а C 412 - метка класса обучающего множества 202, 403, вычисляется функция выбора характеристик Fsf 412. Функция выбора характеристик Fsf 412 может вычисляться как значение критерия выбора характеристик или значение комбинации критериев выбора характеристик (пример на Фиг.3). Затем выбираются 404 термины w, для которых значение Fsf превышает пороговое значение T 414; эти термины добавляются 405 в словник 401.
[0025] В некоторых реализациях данного изобретения терминам словника могут назначаться веса. Веса могут отражать то, насколько достоверно наличие метки у данного слова или вероятность того, что данное слово в некотором контексте может быть помечено данной меткой.
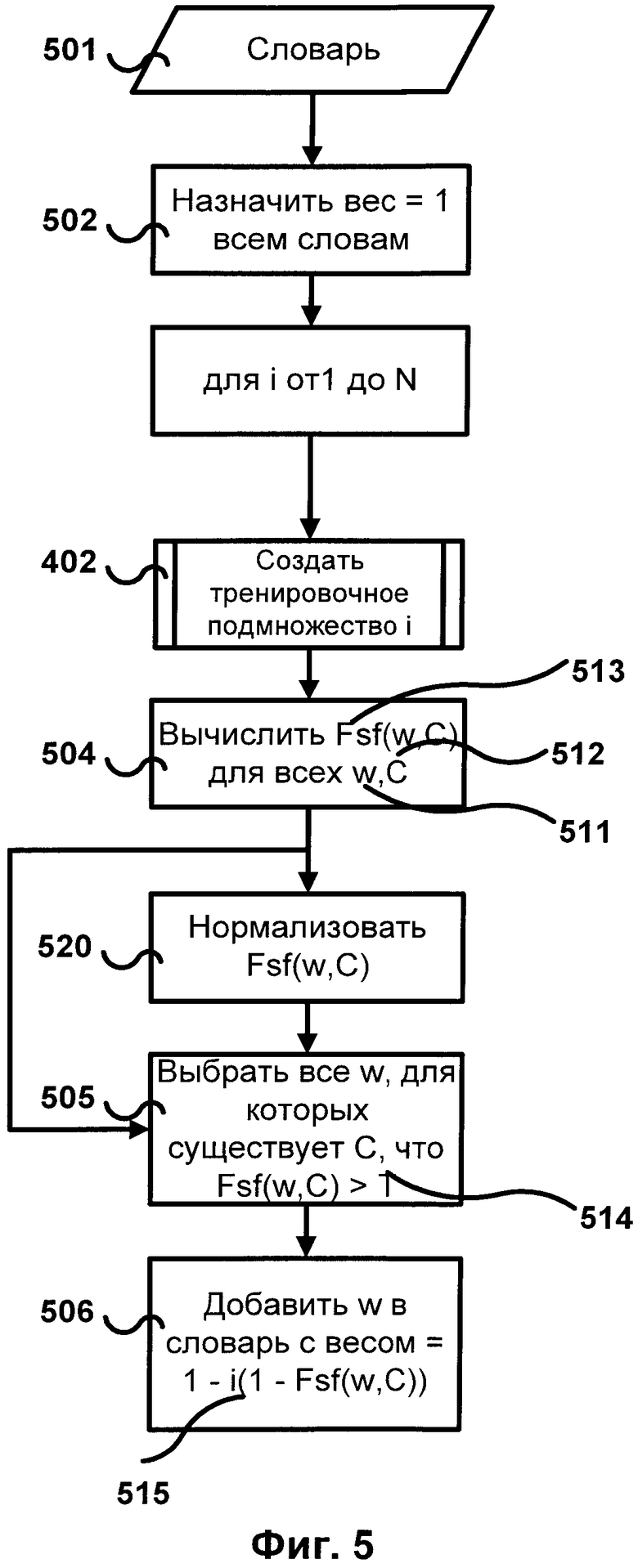
[0026] Фиг.5 иллюстрирует пример метода, в котором терминам словника назначаются веса. Все слова, изначально находящиеся в словнике 501, возможно добавленные вручную, получают максимально возможный вес 502, в данном примере максимально возможный вес равен 1. Затем итеративно повторяется следующее: формируется обучающее подмножество - подмножество документов обучающего множества, содержащих слова из словника 402; для всех слов w 511 в обучающем подмножестве и всех меток классов C 512 вычисляется функция выбора характеристик Fsf(w,C) 513 как значение критерия выбора характеристик или комбинации критериев выбора характеристик (пример на Фиг.3) 504; значения критерия (комбинации критериев) опционально могут быть нормированы 520, так чтобы их значения находились в промежутке между 0 и 1 или другими заданными числовыми значениями; выбираются слова, для которых значение критерия (комбинации критериев) выше порогового значения T 514 или заданного количества, процента всех слов 505; каждое из выбранных слов добавляется в словник 506 с весом 515, прямо пропорциональным значению Fsf(w,C) 513 и обратно пропорциональным номеру итерации (чем больше номер итерации, тем менее достоверны метки терминов).
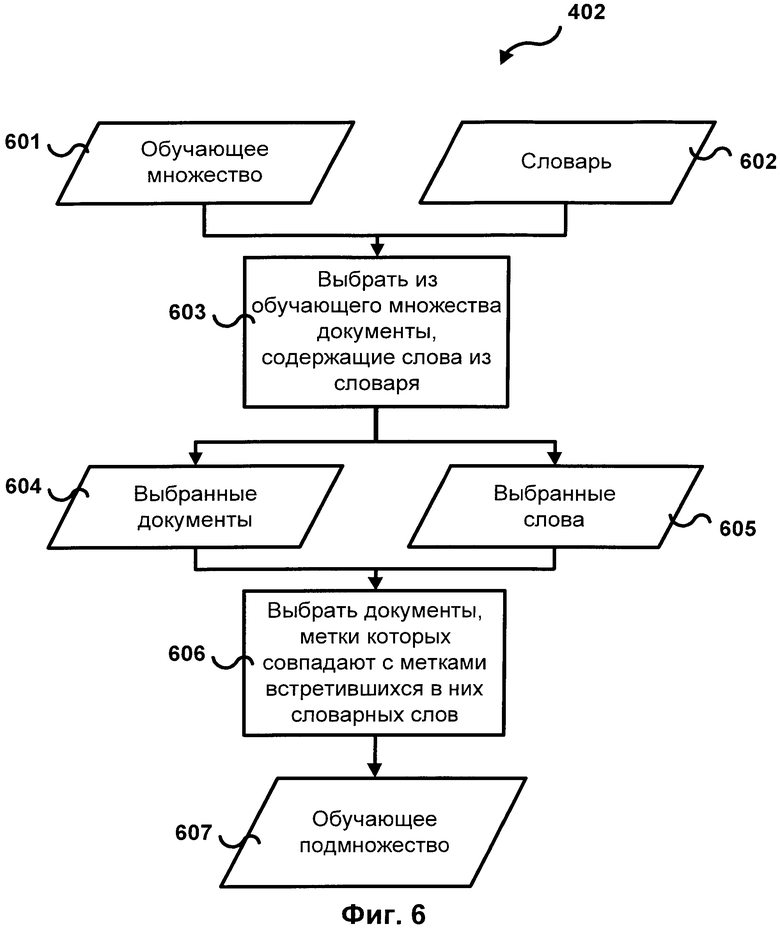
[0027] Фиг.6 иллюстрирует схему одной из реализаций метода создания обучающего подножества 402. Сначала из обучающего множества 601 выбираются документы 603, содержащие слова из словника 602. Затем документ из отобранных документов 604, содержащих слова 605 из словника, выбирается в том случае, если его метка совпадает с меткой по крайней мере одного слова из словника 604, содержащегося в этом документе. Все выбранные документы добавляются в обучающее подмножество 607.
[0028] Фиг.7 иллюстрирует схему алгоритма анализа текста с пополнением словника, согласно одной из реализаций изобретения. Словник 701 пополняется 702, с помощью описанного метода пополнения словника, затем пополненный словник 703 используется для анализа текстов 704. Анализ текстов 704 может быть, например, классификацией - распределением текстов по заранее заданным категориям, или ранжированием текстов.
[0029] Фиг.7а иллюстрирует схему метода анализа текста 704 с использованием взвешенного словника, пополненного согласно описанному методу, а именно схему метода ранжирования возможных меток (категорий) для данного документа. Тексты 711 опционально проходят предварительную обработку 712, затем документы 711 представляются только словами, содержащимися в словнике, 713. Для каждой метки суммируются веса всех терминов с этой меткой 714. Затем метки ранжируются 715 согласно значению суммы весов. Результатом является ранжированный список меток 716. Затем тексту может быть присвоена метка, имеющая наивысший ранг, или могут учитываться несколько категорий с наиболее высоким рангом.
[0030] Одной из возможных реализаций изобретения является использование пополненных словников для классификации документов согласно географической лексической вариации языка. Другими словами, цель такой классификации назначить документу категорию - географический регион - согласно лексической вариации языка его автора. Такая задача может быть решена с использованием словника региональной лексики, созданного вручную, - каждое слово в словнике имеет одну или несколько географических меток, согласно регионам его распространения (см. пример на Фиг.1). Такие словники обычно создаются вручную и имеют сравнительно небольшой размер, при этом, их неавтоматическое пополнение оказывается трудоемким. Подобные словники могут быть расширены автоматически с помощью обучающего множества, согласно одной из реализации данного изобретения. В задаче классификации документов согласно географической лексической вариации языка обучающее множество должно быть размечено по географическим зонам (набор меток обучающего множества содержит географические объекты). Например, блоги, для которых указан родной город автора, могут быть использованы как обучающее множество.
[0031] В некоторых реализациях данного изобретения может быть необходим подбор параметров алгоритма. В частности пороговое значение Т 414, 514 функции выбора характеристик Fsf(w,C) 412, 513 может быть подобрано. Например, если значения функции выбора характеристик Fsf(w,C) 412, 513 находятся между 0 и 1, возможные пороговые значения для подбора могут быть следующими: [0; 0.1; 0.2; 0.3; 0.4; 0.5; 0.6; 0.7; 0.8; 0.9] (где 0 соответствует случаю, в котором пороговое значение не используется). Возможные пороговые значения тестируются на размеченных тренировочных данных, лучшее значение затем используется в алгоритме.
[0032] Фиг.8 иллюстрирует схему метода подбора порогового значения, согласно одному или нескольким реализациям данного изобретения. Пороговое значение подбирается in vivo, то есть его качество оценивается в рамках более широкой задачи. Сначала оценивается точность анализа текста при использовании каждого возможного порогового значения 802. Затем выбирается случай, когда точность максимальна 803. И выбирается пороговое значение, соответствующее максимальному качеству работы метода 804. Это значение 804 затем может использоваться в методе пополнения словника, согласно одной или нескольким реализациям данного изобретения.
[0033] Фиг.8А иллюстрирует схему метода оценки качества работы метода 802 для заданного порогового значения. Т присваивается конкретное значение 811. Затем словник расширяется 812 с заданным 811 значением Т, согласно одной из реализаций данного изобретения (пример на Фиг.4 или Фиг.5). Затем документы из тренировочного множества 810 классифицируются, например, согласно методу, схема которого представлена на Фиг.7, где документу назначается метка с максимальным рангом. Затем оценивается качество работы метода 814. Качество работы метода может оцениваться, например, как процент правильно назначенных меток; или как функция полноты (recall) и точности (precision).
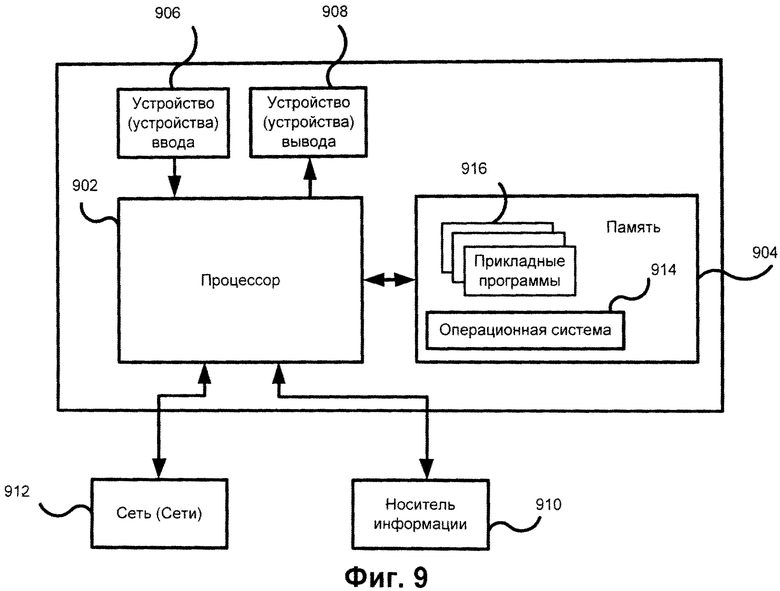
[0034] На Фиг.9 приведен возможный пример вычислительного средства 900, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 900 включает в себя, по крайней мере, один процессор 902, соединенный с памятью 904. Процессор 902 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер. Память 904 может представлять собой оперативную память (ОЗУ), а также содержать любые другие типы и виды памяти, в частности, устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например жесткие диски и т.д. Кроме того, может считаться, что память 904 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 900, например кэш-память в процессоре 902, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 910.
[0035] Вычислительное средство 900 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 900 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 908 (например, жидкокристаллический дисплей). Вычислительное средство 900 также может иметь одно или более постоянных запоминающих устройств 910, например, привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 900 может иметь интерфейс с одной или более сетями 912, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные со всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 900 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 902 и каждым из компонентов 904, 906, 908, 910 и 912.
[0036] Вычислительное средство 900 работает под управлением операционной системы 914 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 916.
[0037] Вообще программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт, либо их комбинацию.
[0038] Настоящее описание излагает основной изобретательский замысел авторов, который не может быть ограничен теми аппаратными устройствами, которые упоминались ранее. Следует отметить, что аппаратные устройства, прежде всего, предназначены для решения узкой задачи. С течением времени и с развитием технического прогресса такая задача усложняется или эволюционирует. Появляются новые средства, которые способны выполнить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не чисто технической реализации на некой элементной базе.
| название | год | авторы | номер документа |
|---|---|---|---|
| МЕТОД ПОСТРОЕНИЯ И ОБНАРУЖЕНИЯ ТЕМАТИЧЕСКОЙ СТРУКТУРЫ КОРПУСА | 2013 |
|
RU2583716C2 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2657173C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ТЕКСТОВЫХ ДОКУМЕНТОВ И АВТОРИЗОВАННЫХ ПОЛЬЗОВАТЕЛЕЙ СИСТЕМЫ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2017 |
|
RU2692043C2 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ И СОЗДАНИЕ ОТЧЕТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2635257C1 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2681356C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА С АВТОМАТИЧЕСКИМ ФОРМИРОВАНИЕМ РЕКВИЗИТА РЕЗОЛЮЦИИ РУКОВОДИТЕЛЯ | 2018 |
|
RU2692972C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ПОМОЩЬЮ КОМБИНАЦИИ КЛАССИФИКАТОРОВ | 2017 |
|
RU2679988C1 |
Изобретение относится к способам пополнения электронных словников - списков терминов с метками. Техническим результатом является повышение эффективности использования электронных словников в задачах анализа текста за счет обеспечения возможности назначения терминам осмысленных весов и автоматического пополнения словников с помощью обучающего множества текстов. В способе пополнения словника из обучающего множества электронных документов с помощью вычислительной машины (персонального компьютера, сервера и пр.) формируют обучающее подмножество, тексты всех электронных документов которого содержат термины словника. К словам, встречающимся в обучающем подмножестве, применяют критерии выбора характеристик. Выбранным с помощью критериев словам назначают метки, выбранным словам опционально назначают веса. Выбранные слова добавляют в словник с соответствующими метками (и весами). 2 н. и 14 з.п. ф-лы, 13 ил.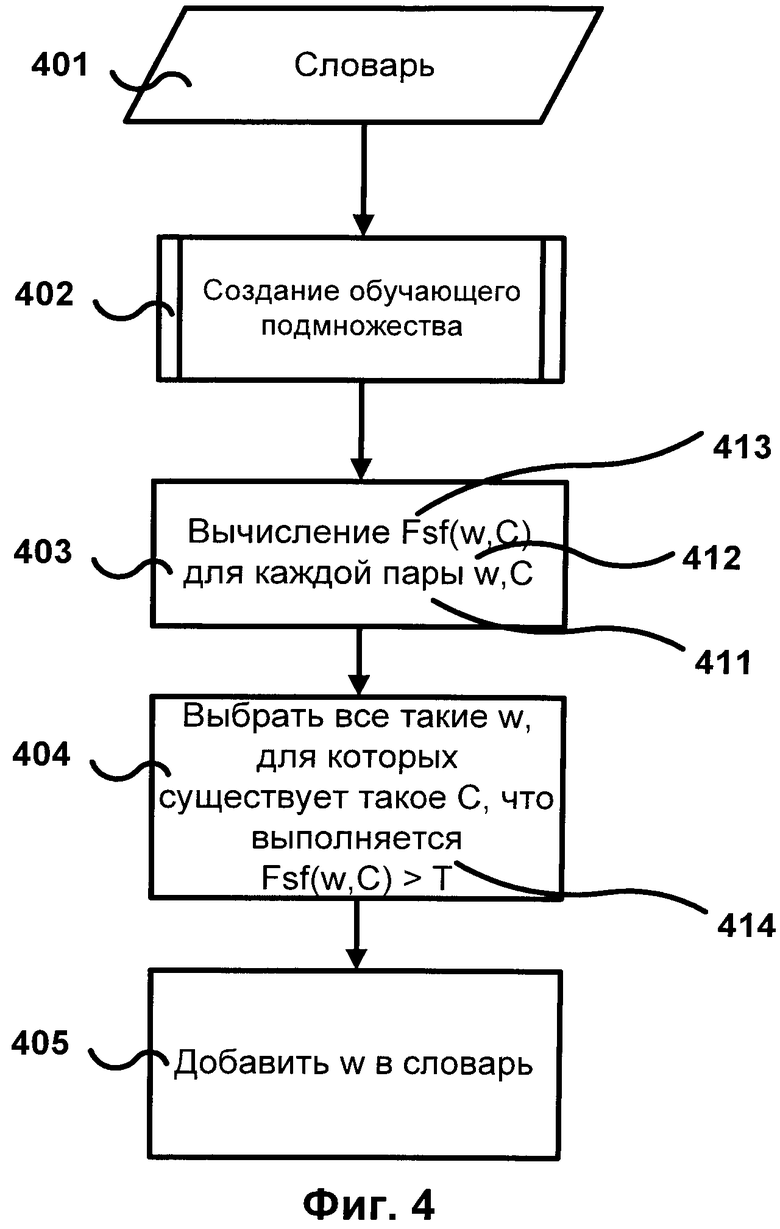
1. Способ пополнения электронного словника в компьютерной системе, заключающийся в том, что, по меньшей мере, один раз производят следующую последовательность действий:
- выявление терминов электронного словника в обучающем множестве;
- вычисление значения, по крайней мере, одного критерия выбора характеристик или одной функции от нескольких критериев для терминов обучающего множества;
- извлечение терминов, для которых значение, по крайней мере, одного критерия выбора характеристик или функции от нескольких критериев попадает в заранее заданный промежуток значений;
- назначение терминам меток соответствующих электронных документов обучающего множества;
- добавление терминов в электронный словник.
2. Способ по п. 1, где метки электронных документов обучающего множества предварительно преобразуют в формат меток электронного словника.
3. Способ по п. 1, где выявление терминов включает извлечение обучающего подмножества электронных документов, содержащихся в обучаемом множестве и содержащих выявленные термины.
4. Способ по п. 3, где обучающее подмножество сохраняют в электронном файле и/или оперативной памяти и/или в базе данных.
5. Способ по п. 1, где набор меток обучающего множества и набор меток словника отличаются, и между ними установлено соответствие.
6. Способ по п. 1, где метки представлены текстом.
7. Способ по п. 1, где метки представлены вещественными числами.
8. Способ по п. 1, где извлечение терминов из обучающего множества включает предварительную обработку текстов.
9. Способ по п. 8, где предварительная обработка текстов может включать частеречную разметку и/или синтаксический анализ и/или семантический анализ и/или разрешение омонимии и неоднозначности и/или разрешение анафорических связей.
10. Способ по п. 1, где словник является взвешенным словником.
11. Способ по п. 1, где добавление терминов в словник включает назначение терминам весов.
12. Способ по п. 11, где веса являются вещественными числами.
13. Способ по п. 1, где извлечение терминов из обучающего множества включает применение, по крайней мере, одного критерия выбора характеристик.
14. Способ по п. 1, где извлечение терминов из обучающего множества включает применение комбинации критериев выбора характеристик.
15. Способ по п. 1, где извлечение терминов из обучающего множества включает подбор параметров.
16. Система пополнения электронного словника вычислительным устройством, включающая: один или более процессоров, одно или более устройств памяти, программные инструкции для вычислительного устройства, записанные в одно или более устройств памяти, которые при выполнении на одном или более процессорах управляют системой для:
- выявления терминов электронного словника в обучающем множестве;
- вычисления значения, по крайней мере, одного критерия выбора характеристик или одной функции от нескольких критериев для терминов обучающего множества;
- извлечения терминов, для которых значение, по крайней мере, одного критерия выбора характеристик или функции от нескольких критериев попадает в заранее заданный промежуток значений;
- назначения терминам меток соответствующих электронных документов обучающего множества;
- добавления терминов в электронный словник.
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 6493713 B1, 10.12.2002 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |

