Изобретение относится к системам классификации документов и может использоваться в системах электронного документооборота, базах данных, автоматизированных системах, использующих метки конфиденциальности, где объектами доступа являются формализованные текстовые документы, субъектами - авторизованные пользователи, в условиях произвольного числа применяемых меток конфиденциальности.
Уровень техники
а) Описание аналогов
Известен аналог - способ автоматической классификации документов (Li Y., Jain A. "Classification of text documents", The Computer Journal 41, 8, pp. 537-546, 1998), заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления, на этапе обучения, по предъявленному набору классифицированных вручную документов, формируют набор классификационных признаков, а при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе, на основе простого байесовского классификационного критерия и классификационных признаков определяют принадлежность документа к информационной области [1].
Недостатками данного способа являются:
не позволяет классифицировать формализованные текстовые документы по меткам конфиденциальности;
не позволяет классифицировать авторизованных пользователей по меткам конфиденциальности.
Известен также аналог - способ автоматической классификации документов (Пат. 6327581 Соединенные Штаты Америки, МПК G06F 015/18. Methods and apparatus for building a support vector machine classifier [Текст] / CarltonJ.; заявитель и патентообладатель Microsoft Corporation. - №09/055477; заявл. 06.04.98; опубл. 04.12.01), заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления; на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе, на основе классификационного критерия SVM (SupportVectorMachines) и классификационных признаков определяют принадлежность документа к информационной области [2].
Недостатками данного способа являются:
не позволяет классифицировать формализованные текстовые документы по меткам конфиденциальности;
не позволяет классифицировать авторизованных пользователей по меткам конфиденциальности.
Известен также аналог - способ мультиклассовой классификации (Schapire R.E., Singer Y. "BoosTexter: A boosting-based system for text categorization". MachineLearning 39, 2/3, 2000, pp. 135-168), заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из информационной области [3].
Недостатками данного способа являются:
не позволяет классифицировать формализованные текстовые документы по меткам конфиденциальности;
не позволяет классифицировать авторизованных пользователей по меткам конфиденциальности.
Также известен аналог - способ автоматической классификации документов (Пат. 2254610 Российская Федерация, МПК G06F 17/30. Способ автоматической классификации документов [Текст] / Аграновский А.В., Арутюнян Р.Э., Хади Р.А., Телеснин Б.А.; заявитель и патентообладатель Государственное научное учреждение научно-исследовательский институт "СПЕЦВУЗАВТОМАТИКА". - №2003126907/09; заявл. 04.09.03; опубл. 20.06.05), заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в упомянутом документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из категорий [4]. Недостатками данного способа являются:
не позволяет классифицировать формализованные текстовые документы по меткам конфиденциальности;
не позволяет классифицировать авторизованных пользователей по меткам конфиденциальности.
Также известен аналог - способ автоматической классификации формализованных документов в системе электронного документооборота (Пат.2546555 Российская Федерация, МПК G06F 17/30. Способ автоматической классификации формализованных документов в системе электронного документооборота [Текст] / Носенко СВ., Королев И.Д., Поддубный М.И.; заявитель и патентообладатель Федеральное государственное казенное военное образовательное учреждение высшего профессионального образования «Военная академия связи имени Маршала Советского Союза С.М. Буденного» Министерства обороны Российской Федерации. - №2013155168/08; заявл. 11.12.2013; опубл. 10.04.2015), заключающийся в том, что определяют области формализованного документа для извлечения метаданных и информативной части, осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и тем самым формируют признаки документа: на этапе обучения по набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных; при классификации документа на основании полученных классификационных признаков с помощью базы данных принимают решение об относимости документа каждой из информационных областей, на этапе определения принадлежности документа каждой из информационной области используют априорную информацию о зависимостях категорий друг от друга [5].
Недостатками данного способа являются:
не позволяет классифицировать формализованные текстовые документы по меткам конфиденциальности;
не позволяет классифицировать авторизованных пользователей по меткам конфиденциальности.
б) Описание ближайшего аналога (прототипа)
Наиболее близким по технической сущности к предлагаемому является способ автоматической классификации конфиденциальных
формализованных документов в системе электронного документооборота, заключающийся в том, что определяют области формализованного документа для извлечения метаданных и информативной части, осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и тем самым формируют признаки документа, на этапе обучения по набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа на основании полученных классификационных признаков с помощью базы данных принимают решение об относимости документа к каждой из информационных областей и к каждой из меток конфиденциальности, заданных в информационной системе, на этапе определения принадлежности документа к каждой информационной области и метке конфиденциальности используют априорную информацию о зависимостях категорий друг от друга [6].
Недостатками данного способа являются:
не позволяет классифицировать формализованные текстовые документы по меткам конфиденциальности применительно к системам, в которых число меток конфиденциальности произвольно, что существенно затрудняет реализацию;
не позволяет классифицировать авторизованных пользователей по меткам конфиденциальности.
Раскрытие сущности изобретения
Целью настоящего изобретения является обеспечение автоматической классификации формализованных текстовых документов и авторизованных пользователей системы электронного документооборота по меткам конфиденциальности.
Технический результат достигается тем, что вычислительным устройством определяют области формализованного документа для извлечения метаданных и информативной части, осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и формируют набор классификационных признаков: на этапе обучения по набору классифицированных вручную документов формируют систему предикатов идентификации метки конфиденциальности документа, сохраняют систему предикатов в базе данных; на этапе классификации документа на основании полученных классификационных признаков с помощью базы данных принимают решение об относимости документа каждой из меток конфиденциальности, отличающийся тем, что на основе меток конфиденциальности поступивших документов и прав доступа авторизованных пользователей системы к этим документам, извлекаемых из матрицы прав доступа, формируют набор классификационных признаков: на этапе обучения по набору классифицированных вручную авторизованных пользователей формируют систему предикатов идентификации их метки конфиденциальности и сохраняют систему предикатов в базе данных; на этапе классификации авторизованного пользователя получившийся набор классификационных признаков подставляют в систему предикатов, находящуюся в базе данных, по предикату, принявшему значение «истина», принимают решение об относимости авторизованного пользователя к одной из меток конфиденциальности.
Данный технический результат достигается за счет того, что осуществляют выделение характеристик одинаковых участков текста Z - реквизитов. При этом количество различных реквизитов формализованного документа ограничено [7], кроме того, некоторые из них не определяют индивидуальность формы документа (свойственные всем формам или не применяемые в данных условиях). Каждый реквизит выразим конечным предикатом PZ(T,L), где Т - конечное множество характеристик текста t, 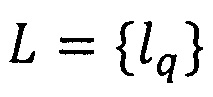 - множество ключевых слов
- множество ключевых слов 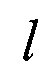 реквизита, где
реквизита, где 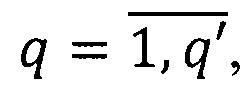 q' - количество всех используемых ключевых слов.
q' - количество всех используемых ключевых слов.
Правило построения предиката узнавания реквизита формализованного документа, выразится следующей формулой [8]:
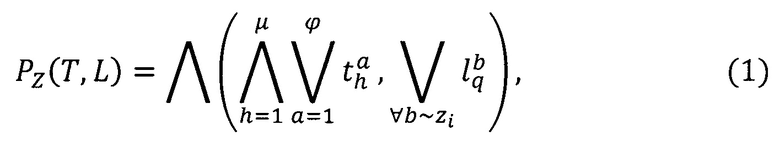
где 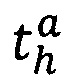 - предикат узнавания значения а h-той переменной текста;
- предикат узнавания значения а h-той переменной текста;
μ - количество переменных текста;
ϕ - величина алфавита h-той переменной текста;
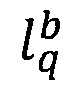 - предикат узнавания значения b ключевого слова q соответствующего i-той зоне.
- предикат узнавания значения b ключевого слова q соответствующего i-той зоне.
Форма документа выразится конечным предикатом PV(Z,L), где V={νj}, где 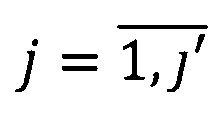 - множество форм документа; j' количество всех используемых форм документов, Z - множество реквизитов документа, n - количество всех реквизитов документов,
- множество форм документа; j' количество всех используемых форм документов, Z - множество реквизитов документа, n - количество всех реквизитов документов, 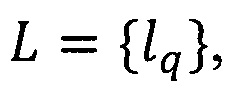 - множество ключевых слов, где
- множество ключевых слов, где 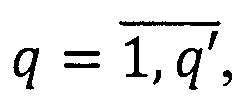 q' - количество всех используемых ключевых слов.
q' - количество всех используемых ключевых слов.
Правило построения предиката узнавания формы документа выразится следующей формулой [8]:
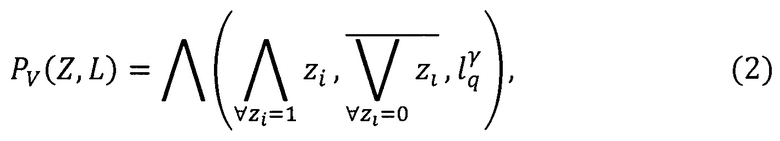
где 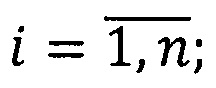 zi - предикат узнавания реквизита для j-той формы документа;
zi - предикат узнавания реквизита для j-той формы документа;
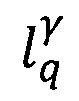 - предикат узнавания уникального значения γ ключевого слова q j-той формы документа.
- предикат узнавания уникального значения γ ключевого слова q j-той формы документа.
С использованием правил (1, 2) создаются системы предикатов идентификации реквизитов и форм документов.
Форма документа однозначно задает места расположения реквизитов документа, что позволяет классифицировать документы по форме документа и определяемой соответствующим реквизитом ограничения доступа.
Затем информативную часть документа (далее - текст) преобразуют из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в тексте в соответствии с частотами их появления и тем самым формируют предикаты идентификации признаков текста.
В режиме обучения по предъявленному набору классифицированных вручную текстов формируют систему предикатов идентификации признаков текста, где количество предикатов в системе предикатов определяется количеством областей информационной ответственности, на которые необходимо классифицировать документы (количество исполнителей в автоматизированной системе). Сохраняют предикаты в базе данных.
Правило построения предиката PU (W) узнавания информационной области U={uβ}, где 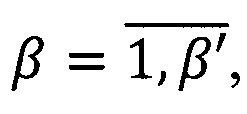 β' - количество областей информационной
β' - количество областей информационной
ответственности, выражается следующей формулой [8]:
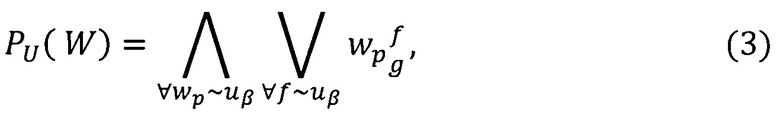
где W={wp} - множество значимых слов текстов, где 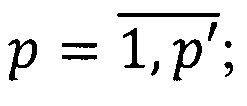
р' - количество значимых слов текстов;
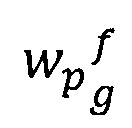 - предикат узнавания значения веса ƒ значимого слова wp, в тексте документа
- предикат узнавания значения веса ƒ значимого слова wp, в тексте документа 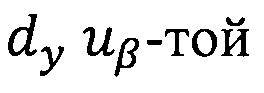 информационной области по g-тому значению веса слова.
информационной области по g-тому значению веса слова.
Правило формирования системы предикатов узнавания метки конфиденциальности документа предполагает число информационных областей, сопоставимое с количеством применяемых меток конфиденциальности в системе [6]. Для реализации способа в более сложных информационных системах предлагается применять алгебру конечных предикатов.
С применением предложенной алгебры [9] представлено правило построения системы предикатов, не требующее дополнительных преобразований для любой информационной системы. Таким образом, правило построения предиката 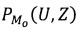 узнавания метки конфиденциальности М={mλ}, где
узнавания метки конфиденциальности М={mλ}, где 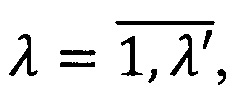 λ' - количество определенных в системе меток конфиденциальности выразится следующей формулой [10]:
λ' - количество определенных в системе меток конфиденциальности выразится следующей формулой [10]:
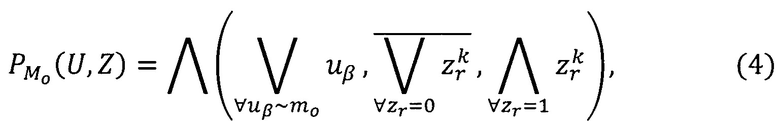
где 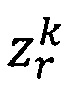 - предикат узнавания k-то значения r-ого реквизита;
- предикат узнавания k-то значения r-ого реквизита;
m0 - метка конфиденциальности объекта (документа dy), при этом mo ∈ М;
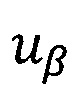 - предикат узнавания β-той области, где
- предикат узнавания β-той области, где 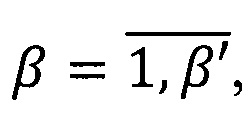 β' - количество информационных областей системы.
β' - количество информационных областей системы.
После определения меток конфиденциальности объектов информационной системы, классификатор переходит к этапу классификации конечного множества субъектов (авторизованных пользователей) S. На основании матрицы прав доступа и меток конфиденциальности формируется набор классификационных признаков, включающий метки конфиденциальности всех объектов, к которым имеет права доступа классифицируемый субъект (назовем эти объекты анализируемыми), текущую метку конфиденциальности классифицируемого субъекта, при наличии, и данные, предусмотренные политикой безопасности среды функционирования классификатора [11, 12].
Работа классификатора поясняется на примере системы электронного документооборота, в котором задано четыре метки конфиденциальности.
С целью разработки правила построения системы предикатов распознавания метки конфиденциальности субъектов введем множество переменных mo, 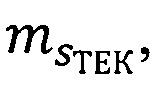 xs с величиной алфавитов 4, 4, 2 соответственно, где
xs с величиной алфавитов 4, 4, 2 соответственно, где
mo - метка конфиденциальности анализируемого объекта;
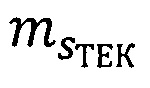 - текущая метка конфиденциальности классифицируемого субъекта;
- текущая метка конфиденциальности классифицируемого субъекта;
xs - условия безопасности классификации субъекта системы электронного документооборота.
Структуру используемых в данном примере признаков удобно представить в виде таблицы 1.
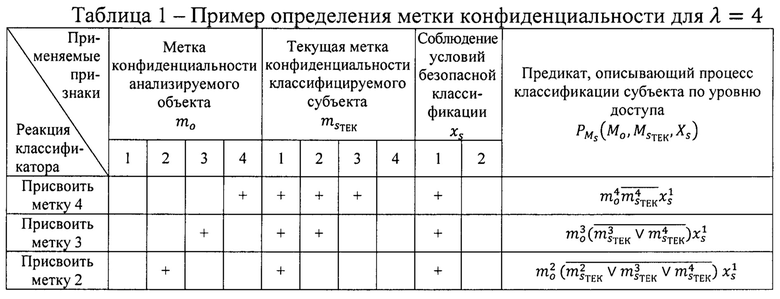

Однозначность и правильность классификации субъекта для λ=4 меток конфиденциальности доказаны прямым перебором. Доказательство является аналогичным для любой λ. При этом для реакции системы на присвоение метки проверяется не наличие необходимых условий, а отсутствие препятствующих, так как при анализе первого документа в потоке у субъекта отсутствует текущая метка классифицируемого субъекта [13].
Применяя алгебру конечных предикатов, составим систему предикатов определения метки конфиденциальности классифицируемого субъекта [9]:
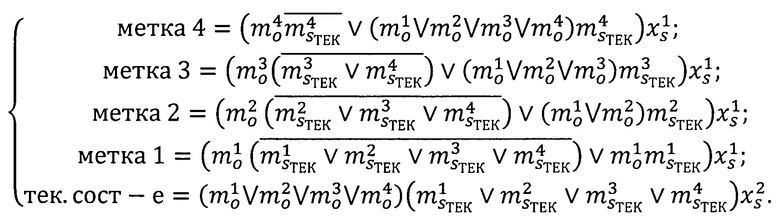
Наличие «дополнительного» предиката (сохранение текущего состояния), не свойственного для правил (1-4), является необходимостью. Он исключает постоянное срабатывание режима обучения при обнаружении нарушения политики безопасности, автоматически принимая априорно заданное решение. В заявленном способе это игнорирование потенциально опасного анализируемого объекта. Такой подход исключает завышение метки конфиденциальности субъекта.
Таким образом, правило построения предиката узнавания метки конфиденциальности субъектов 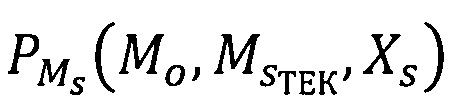 выражается формулой:
выражается формулой:
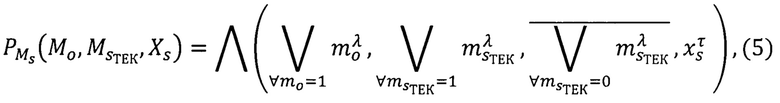
где 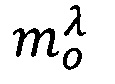 - предикат узнавания значения метки конфиденциальности Я анализируемого объекта dy;
- предикат узнавания значения метки конфиденциальности Я анализируемого объекта dy;
 - предикат узнавания текущей метки конфиденциальности λ классифицируемого субъекта s;
- предикат узнавания текущей метки конфиденциальности λ классифицируемого субъекта s;
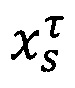 - предикат узнавания соблюдения условий τ безопасной классификации субъекта s.
- предикат узнавания соблюдения условий τ безопасной классификации субъекта s.
Условия безопасности классификации формулируются в рамках политики безопасности организации и могут существенно отличаться в зависимости от целей применения классификатора и ценности обрабатываемой в системе информации. Реализация политики безопасности в классифицируемой информационной системе требует отдельного исследования и в рамках предлагаемого способа ограничивается схемой безопасно-небезопасно.
В режиме обучения по предъявленному набору классифицированных вручную объектов и субъектов системы электронного документооборота, формируют системы предикатов идентификации их меток конфиденциальности. Количество предикатов в системе определяется: для объектов количеством меток конфиденциальности, заданных в информационной системе, для субъектов - количеством меток конфиденциальности +1. Сохраняют системы предикатов в базе данных.
В режиме работы системы на этапе классификации объектов (документов) осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова текста в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в тексте, получившиеся значения подставляют в систему предикатов (4), находящуюся в базе данных. По предикату, принявшему значение истинности «1», определяется область информационной ответственности и метка конфиденциальности классифицируемого объекта (документа).
При классификации субъектов информационной системы, для каждого из них формируется набор классификационных признаков. Данные признаки извлекаются из матрицы прав доступа и включают: набор множества анализируемых объектов, их метки конфиденциальности, текущие метки конфиденциальности классифицируемого субъекта (при наличии) и данные о политике безопасности. Определенный таким образом набор признаков подставляют в систему предикатов (5), находящуюся в базе данных. По предикату, принявшему значение истинности «1», определяется метка конфиденциальности классифицируемого субъекта.
При этом, в случае необходимости использования априорной информации о зависимостях меток конфиденциальности друг от друга используем алгебру конечных предикатов [9], позволяющую проводить полный спектр операций над логическими выражениями. Отметим, что данный способ предназначен для обработки машиночитаемых текстов на естественном языке.
Вес ƒ wp словоформы в тексте документа dy, рассчитывается по формуле:
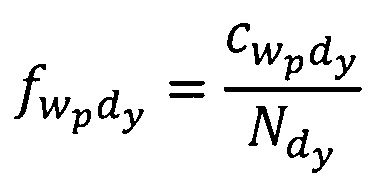
Здесь 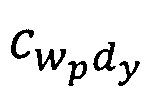 - количество раз, которое wp-я словоформа встречается в dy-м тексте документа,
- количество раз, которое wp-я словоформа встречается в dy-м тексте документа, 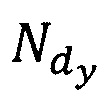 - общее количество словоформ в dy-m тексте документа.
- общее количество словоформ в dy-m тексте документа.
Документы для классификации могут быть представлены в различных форматах, допускающих выделение из них текстового содержания. Это могут быть текстовые файлы различных форматов, графические файлы с графическим представлением некоторого текста, звуковые файлы с записью речи и другие файлы, для которых существует механизм выделения из них текста, отражающего их содержание. Кроме того, классификатор должен иметь возможность извлечения информации из матрицы прав доступа независимо от ее реализации (свойства объекта, профиль субъекта или системная матрица).
Каждый объект (либо обучающий, либо подвергающийся классификации) предварительно проходит стадию первичной обработки, на которой производится определение формата документа и установление того, возможно ли извлечение текста из документа данного формата. В случае положительного решения производится извлечение текста из документа. После разбиения текста на слова происходит определение для каждого слова его базовой словоформы по одному из способов [14-17]. Наиболее часто для решения подобных задач используется алгоритм Портера, заключающийся в использовании специальных правил отсечения и замены окончаний слов.
Согласно предлагаемому способу каждый объект dy представляется декартовым произведением переменных из множеств Т×L×W, где для инициализации классификатора и построения классификационных признаков служит этап обучения классификатора. При этом должно быть задано множество обучающих документов, заранее вручную классифицированных по меткам конфиденциальности. После извлечения из них текстового содержания происходит построение словаря значимых слов. Словарь содержит базовые словоформы всех слов, встречающихся в обучающих документах.
При классификации документа в расчет берутся не все словоформы из словаря документов, а лишь те из них, которые входят в рабочий словарь классификатора данной метки конфиденциальности. В рабочий словарь классификатора включаются наиболее информативные словоформы с точки зрения определения принадлежности документа данной категории, не попавшие в стоп-словарь. Информативность словоформы wp для классификатора по информационной области uβ определяется по следующей формуле [18]:
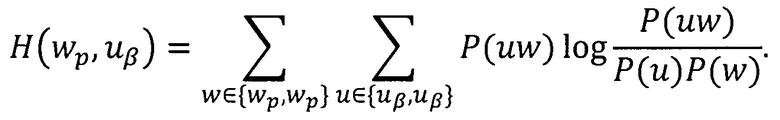
При этом устанавливается порог информативности ε; в рабочий словарь классификатора включаются все словоформы, не попавшие в стоп-словарь, информативность которых превышает этот порог. Стоп-словарь состоит из словоформ, частоты встречаемости которых во множестве обучающих документов превышают заранее установленный порог δ. При этом отсекаются слова, не несущие смысловой нагрузки, такие как предлоги, союзы, вводные и общие слова и т.д. Значения коэффициента δ, согласно данному способу, устанавливаются в пределах от 0,05 до 0,7 в зависимости от специфики использования способа. Значения порога информативности δ могут быть различны в различных условиях использования способа.
Однозначно определив область информационной ответственности, к которой относится документ по (3), используя извлеченные метаданные документа, а именно, определяющие его конфиденциальность реквизиты документа, полученные по (1), определяется соответствующая ему метка конфиденциальности. Для этого указанные значения подставляются в систему предикатов построенных по (4). По предикату, принявшему значение истинности «1», из списка определяется метка конфиденциальности.
Определив метки конфиденциальности объектов информационной системы, классификатор переходит к этапу классификации субъектов. Для этого наборы классификационных признаков для каждого анализируемого объекта, извлеченные из матрицы прав доступа, подставляются в систему предикатов. Система предикатов построена на этапе обучения по правилу (5) и находится в базе данных. После анализа всех объектов относительно классифицируемого субъекта по предикатам, принявшим значение истинности «1», определяется метка конфиденциальности.
Сопоставительный анализ заявляемого решения с прототипом показывает, что предлагаемый способ отличается от известного формированием на этапе обучения и применением на этапе классификации системы предикатов, строящейся по правилу (5). А так же усовершенствованным правилом (4).
Благодаря новой совокупности существенных признаков в способе реализована возможность обеспечения классификации субъектов системы электронного документооборота по меткам конфиденциальности.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обуславливающих тот же технический результат, который достигнут в заявленном способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Краткое описание чертежей
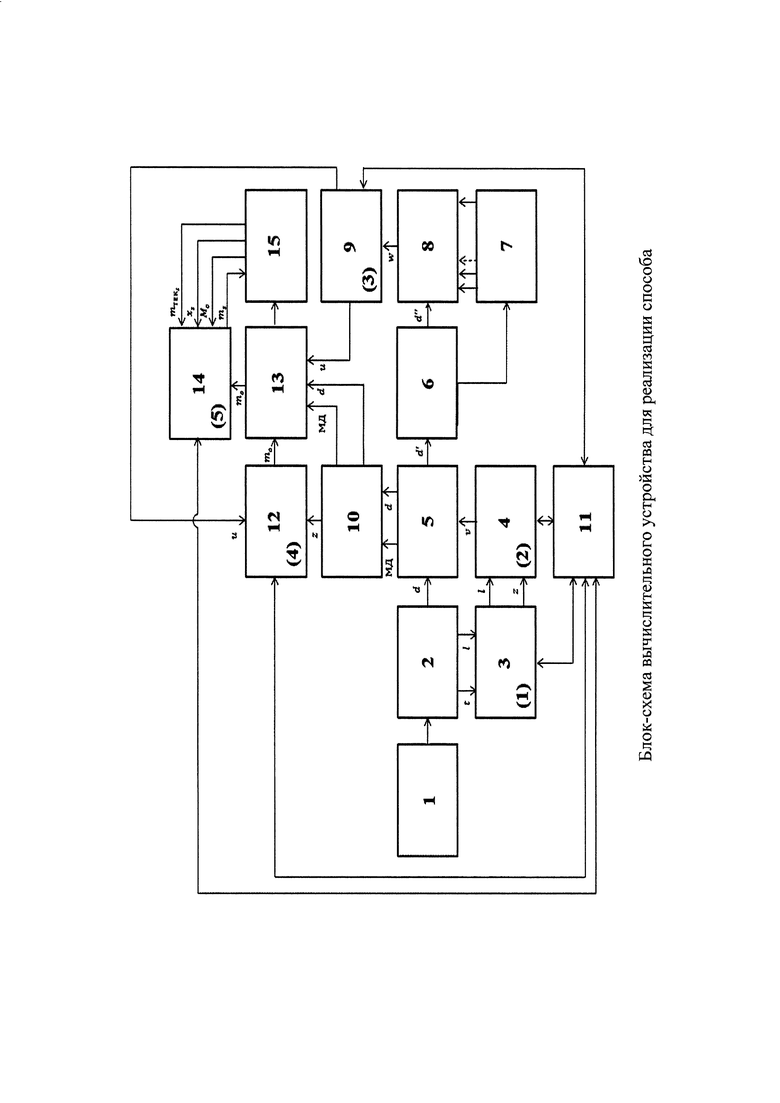
На фигуре представлена блок-схема вычислительного устройства для реализации способа.
Устройство для реализации способа состоит из блоков: источника документов 1, анализатора характеристик текста 2, распознавания реквизитов документа 3, распознавания формы документа 4, выделения метаданных 5, определения базовых словоформ 6, создания рабочего словаря 7, определение весов словоформ текста документа 8, распознавания области информационной ответственности 9, учета документа по метаданным 10, обучения 11, распознавания метки конфиденциальности объекта (документа) 12, адресации документа 13, распознавания метки конфиденциальности субъекта 14, загрузка в систему в соответствии с полученной классификацией 15. Осуществление изобретения
Автоматическая классификация формализованных текстовых документов и авторизованных пользователей системы электронного документооборота осуществляется следующим образом:
1. В режиме классификации.
На этапе классификации объектов (формализованных текстовых документов). При появлении в источнике документов 1 нового документа он поступает в блок 2, который выявляет значения характеристик текста t участков документа и ключевых слов 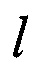 в них. Значения t и
в них. Значения t и  участков документа поступают в блок 3, где с помощью системы предикатов, построенных по правилу (1) распознаются реквизиты документа. Информация о распознанных реквизитах документа поступает в блок 4, где система предикатов, построенная по правилу (2) осуществляет распознавание формы документа.
участков документа поступают в блок 3, где с помощью системы предикатов, построенных по правилу (1) распознаются реквизиты документа. Информация о распознанных реквизитах документа поступает в блок 4, где система предикатов, построенная по правилу (2) осуществляет распознавание формы документа.
В блоке 5 из поступившего документа от блока 2, используя сведения об определенной форме документа из блока 4, которая однозначно задает места расположения значений реквизитов документа, выделяются требуемые значения реквизитов, которые являются метаданными документа. Документ и соответствующие ему метаданные поступают в блок 10, где документ учитывается по своим метаданным и организуется хранение его эталонной копии. Также однозначно определенная в блоке 5 информативная часть документа поступает в блок 6, где слова преобразуются в словоформы. Полученные в блоке 6 словоформы поступают в блок 7, где в процессе работы системы происходит создание рабочего словаря из значимых слов.
Полученные в блоке 6 словоформы поступают в блок 8, где производится расчет весов ƒ словоформ информативной части документа, попавших в рабочий словарь. Из блока 8 значения весов полученных словоформ поступают в блок 9, где происходит распознавание информационной области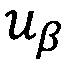 путем вычисления значений предикатов системы предикатов, построенной по правилу (3).
путем вычисления значений предикатов системы предикатов, построенной по правилу (3).
Из блока 10 документ поступает в блок 13, а метаданные - в блок 12 и 13. В блоке 12 на основе поступивших из блока 10 метаданных, а именно реквизитов документа, и значений полученных в блоке 9 на основе системы предикатов, построенной по правилу (4) определяется соответствующая классифицируемому документу метка конфиденциальности. В блоке 13 поступившему документу и метаданным из блока 10 на основе значений поступивших из блоков 12 и 9 присваиваются соответствующие информационным областям права доступа и метка конфиденциальности классифицируемого документа.
Далее через блок 15 происходит загрузка документа в информационную систему в соответствии с определенными классами, (прописывание прав доступа и меток конфиденциальности).
На этапе классификации субъектов (авторизованных пользователей). В блок 14 из блока 15 поступают данные об анализируемых объектах (метки конфиденциальности документов, к которым классифицируемый субъект имеет права доступа read, write; данные, характеризующие соблюдение политики безопасности) и текущая метка конфиденциальности классифицируемого субъекта. В блоке 14 на основе поступивших из блока 15 данных и системы предикатов, построенной по правилу (5), определяется соответствующая классифицируемому субъекту метка конфиденциальности.
Существует возможность корректировки меток
проклассифицированных субъектов при поступлении в систему новых документов. Тогда метка конфиденциальности анализируемого объекта поступает в блок 14 из блока 13.
Далее через блок 15 полученная в блоке 14 метка конфиденциальности загружается в информационную систему. 2. В режиме обучения.
Режим обучения системой используется в следующих случаях:
в случае невозможности распознавания системой предикатов реквизитов документа в блоке 3 по значениям переменных документа t и 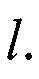 В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 3 или определяется реквизит документа «вручную»;
В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 3 или определяется реквизит документа «вручную»;
в случае невозможности распознавания системой предикатов формы документа в блоке 4 по значениям предикатов системы предикатов блока 3. В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 4 или определяется форма документа «вручную»;
в случае невозможности распознавания системой предикатов информационной области в блоке 9 по значениям весов значимых слов из рабочего словаря, извлеченных из информативной части документа. В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 9 или определяется информационная область документа «вручную»;
в случае невозможности распознавания системой предикатов метки конфиденциальности объекта в блоке 12 по значениям предикатов системы предикатов блока 9 и метаданным блока 10. В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 12 или определяется метка конфиденциальности «вручную»;
в случае невозможности распознавания системой предикатов метки конфиденциальности субъекта в блоке 14 по данным блока 15. В этом случае оператором системы через блок 11 вносятся изменения в систему предикатов блока 14 или определяется метка конфиденциальности «вручную».
Таким образом, способ позволяет классифицировать по меткам конфиденциальности не только объекты системы электронного документооборота (формализованные электронные текстовые документы), но и субъекты системы (авторизованных пользователей, исполнителей), чем достигается поставленный выше технический результат.
Источники информации:
1. Li Y., Jain A. "Classification of text documents", The Computer Journal 41, 8, pp. 537-546, 1998.
2. Пат.6327581 Соединенные Штаты Америки, МПК G 06 F 015/18.Methods and apparatus for building a support vector machine classifier [Текст] / CarltonJ.; заявитель и патентообладатель Microsoft Corporation. - №09/055477; заявл. 06.04.98; опубл. 04.12.01.
3. Schapire R.E., Singer Y. "BoosTexter: A boosting-based system for text categorization". MachineLearning 39, 2/3, 2000, pp. 135-168.
4. Пат.2254610 Российская Федерация, МПК G 06 F 17/30. Способ автоматической классификации документов [Текст] / Аграновский А.В., Арутюнян Р.Э., Хади Р.А., Телеснин Б.А.; заявитель и патентообладатель Государственное научное учреждение научно-исследовательский институт "СПЕЦВУЗАВТОМАТЖА". - №2003126907/09; заявл. 04.09.03; опубл. 20.06.05.
5. Пат. 2546555 Российская Федерация, МПК G06F 17/30. Способ автоматической классификации формализованных документов в системе электронного документооборота [Текст] / Носенко СВ., Королев И.Д., Поддубный М.И.; заявитель и патентообладатель Федеральное государственное казенное военное образовательное учреждение высшего профессионального образования «Военная академия связи имени Маршала Советского Союза С.М. Буденного» Министерства обороны Российской Федерации. - №2013155168/08; заявл. 11.12.2013; опубл. 10.04.2015.
6. Заявка на изобретение №2015152418 от 07.12.2015. Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота [Текст] / Поддубный М.И., Королев И.Д., Носенко СВ.; заявитель и патентообладатель Федеральное государственное казенное военное образовательное учреждение высшего профессионального образования «Краснодарское высшее военное училище имени генерала армии С.М. Штеменко» Министерства обороны Российской Федерации - №2015152418; заявл. 07.12.2015; опубл. 13.06.2017 Бюл. №17.
7. ГОСТ Р 6.30-2003. Унифицированные системы документации. Унифицированная система организационно-распорядительной документации. Требования к оформлению документов: утв. и введ. в действие Постановлением Госстандарта России от 3.03.2003 №65 - ст. - М.: Стандартинформ, 2007 г. - 17 с.
8. Королев И.Д. Подходы к оперативной идентификации формализованных электронных документов в автоматизированных делопроизводствах / И.Д. Королев, СВ. Носенко // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета (Научный журнал КубГАУ) [Электронный ресурс]. - Краснодар: КубГАУ, 2013. - №08(092). - IDA [article ID]: 0921308074. -Режим доступа: http://ej.kubagro.ru/2013/08/pdf/74.pdf, 0,875 у.п.л.
9. М.Ф. Бондаренко, Ю.П. Шабанов-Кушнаренко. Об алгебре конечных предикатов. [Текст] // Научно-технический журнал «Бионика интеллекта». ХНУРЭ, г. Харьков, Украина - 2011 №3(77).
10. Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота / Д.В. Малышев, И.Н. Шайков, М.И. Поддубный, И.Д. Королев // Телекоммуникации.: ежемес. произв., информ.-аналит. и учеб.-метод, ж-л, г. Москва: МГТУ им. Баумана, 2016 №8. - С. 18-22.
11. «Руководящий документ. Автоматизированные системы. Защита от несанкционированного доступа к информации. Классификация автоматизированных систем и требования по защите информации» (утв. решением Гостехкомиссии России от 30.03.1992).
12. «Руководящий документ. Средства вычислительной техники. Защита от несанкционированного доступа к информации. Показатели защищенности от несанкционированного доступа к информации» (утв. решением Гостехкомиссии России 30.03.1992).
13. Методика автоматической классификации сущностей системы электронного документооборота по меткам конфиденциальности // Интернет-журнал «Технологии техносферной безопасности» (Научный журнал Академии Государственной противопожарной службы) [Электронный ресурс]. - М.: 2016. - №6(70). - ISSN 2071-7342. - режим доступа http://agps-2006/narod.ru//ttb/2016-6/29-06-16.ttb.pdf.
14. Porter M.F. "An algorithm for suffix stripping", Program, Vol. 14, No. 3, 1980, pp. 130-137.
15. Пат.2096825 Российская Федерация, МПК G06F 17/00, G06F 17/30. Устройство обработки информации для информационного поиска [Текст] / Ковалев М.В., Виргунов И.В., Наймушин И.А., Четверов В.В; заявитель и патентообладатель Общество с ограниченной ответственностью "Информбюро". - №96119820/09; заявл. 14.10.96; опубл. 20.11.97, Бюл. №14.
16. Пат. 6308149 Соединенные Штаты Америки, МПК G06F 17/27. Grouping words with equivalent substrings by automatic clustering based on suffix relationships [Текст] / Gaussier E., Grefenstette G., Chanod J.-P.; заявитель и патентообладатель Xerox Corporation. - №09/213309; заявл. 16.12.98; опубл. 23.10.01.
17. Пат. 6430557 Соединенные Штаты Америки, МПК G06F 017/30; G06F 017/27; G06F 017/21. Identifying a group of words using modified query words obtained from successive suffix relationships [Текст] / Gaussier E., Grefenstette G., Chanod J.-P.; заявитель и патентообладатель Xerox Corporation. - №09/212662; заявл. 16.12.98; опубл. 06.08.02.
18. Craven M., DiPasquo D., Freitag D. et al. "Learning to construct knowledge bases from the World Wide Web", Artificial Intelligence, Vol. 118(1-2), 2000, pp. 69-113.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота | 2015 |
|
RU2647640C2 |
| Способ автоматической классификации электронных документов в системе электронного документооборота с автоматическим формированием электронных дел | 2019 |
|
RU2726931C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА С АВТОМАТИЧЕСКИМ ФОРМИРОВАНИЕМ РЕКВИЗИТА РЕЗОЛЮЦИИ РУКОВОДИТЕЛЯ | 2018 |
|
RU2692972C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ЭЛЕКТРОННЫХ ГРАФИЧЕСКИХ И ТЕКСТОВЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА С АВТОМАТИЧЕСКИМ ФОРМИРОВАНИЕМ ЭЛЕКТРОННЫХ ДЕЛ | 2020 |
|
RU2759887C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2013 |
|
RU2546555C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ДОКУМЕНТОВ | 2003 |
|
RU2254610C2 |
| СПОСОБ КЛАССИФИКАЦИИ ДОКУМЕНТОВ ПО КАТЕГОРИЯМ | 2012 |
|
RU2491622C1 |
| Способ классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных | 2024 |
|
RU2834318C1 |
| КЛАССИФИКАЦИЯ ДОКУМЕНТОВ ПО УРОВНЯМ КОНФИДЕНЦИАЛЬНОСТИ | 2019 |
|
RU2732850C1 |
| СПОСОБ ПОТОКОВОЙ ОБРАБОТКИ ТЕКСТОВЫХ СООБЩЕНИЙ | 2003 |
|
RU2251148C1 |
Изобретение относится к вычислительной технике. Технический результат – обеспечение автоматической классификации формализованных текстовых документов и авторизованных пользователей системы электронного документооборота по меткам конфиденциальности. Способ включает: извлечение метаданных и информативной части документа, преобразование документа из формата хранения в текст, преобразование слов в словоформы, отбрасывание незначимых слов, подсчет весов слов, формирование набора классификационных признаков, при этом на этапе обучения по набору классифицированных документов формируют систему предикатов идентификации метки конфиденциальности документа; на этапе классификации документа на основании признаков принимают решение об относимости документа каждой из меток конфиденциальности, на этапе обучения по набору классифицированных вручную авторизованных пользователей формируют систему предикатов идентификации их метки конфиденциальности, причем на основе меток конфиденциальности поступивших документов и прав доступа авторизованных пользователей системы к этим документам формируют набор классификационных признаков. 1 ил., 1 табл.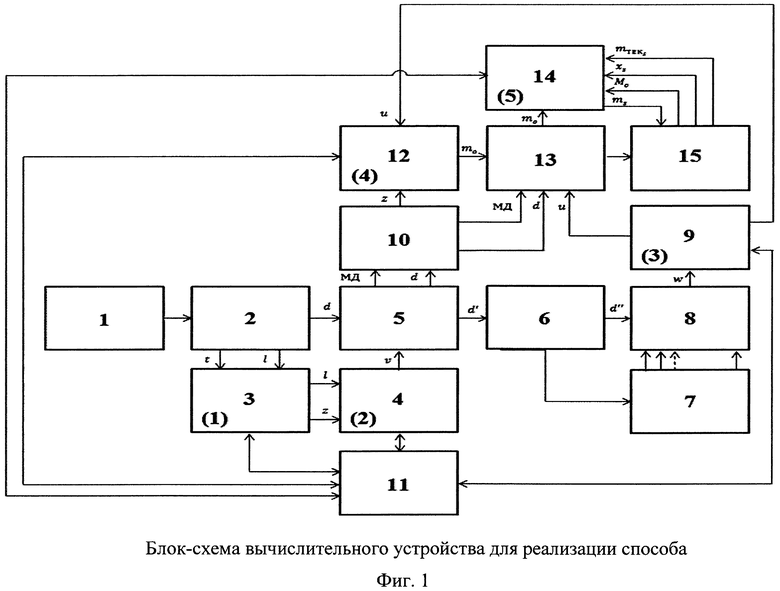
Способ автоматической классификации формализованных текстовых документов и авторизованных пользователей системы электронного документооборота, заключающийся в том, что вычислительным устройством определяют области формализованного документа для извлечения метаданных и информативной части, осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и формируют набор классификационных признаков: на этапе обучения по набору классифицированных вручную документов формируют систему предикатов идентификации метки конфиденциальности документа, сохраняют систему предикатов в базе данных; на этапе классификации документа на основании полученных классификационных признаков с помощью базы данных принимают решение об относимости документа каждой из меток конфиденциальности, отличающийся тем, что на основе меток конфиденциальности поступивших документов и прав доступа авторизованных пользователей системы к этим документам, извлекаемых из матрицы прав доступа, формируют набор классификационных признаков: на этапе обучения по набору классифицированных вручную авторизованных пользователей формируют систему предикатов идентификации их метки конфиденциальности и сохраняют систему предикатов в базе данных; на этапе классификации авторизованного пользователя получившийся набор классификационных признаков подставляют в систему предикатов, находящуюся в базе данных, по предикату, принявшему значение «истина», принимают решение об относимости авторизованного пользователя к одной из меток конфиденциальности.
| Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота | 2015 |
|
RU2647640C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ТЕКСТОВЫХ ДОКУМЕНТОВ | 2011 |
|
RU2474870C1 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| КЛАССИФИКАЦИЯ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МНОГОУРОВНЕВЫХ СИГНАТУР ТЕКСТА | 2014 |
|
RU2632408C2 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В МАССИВЕ ТЕКСТОВ | 2008 |
|
RU2392660C2 |
| US 6446061 B1, 03.09.2002 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

