ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в общем относится к вычислительным системам, а более конкретно - к системам и способам обработки естественного языка.
УРОВЕНЬ ТЕХНИКИ
[0002] Автоматическая обработка документов (таких как изображения бумажных документов или различные электронные документы, включая тексты на естественном языке) может включать классификацию исходных документов путем соотнесения данного документа с одной или более категорий из определенного набора категорий.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более вариантами реализации настоящего изобретения, пример способа автоматического определения набора категорий для классификации документа может включать: создание множества признаков изображения путем обработки изображений из множества документов; создание множества признаков текста путем обработки текстов из множества документов; создание множества векторов признаков, таких, что каждый вектор признаков из множества векторов признаков включает как минимум что-то из следующего списка: подмножество множества признаков изображений и подмножество множества признаков текста; кластеризацию множества векторов признаков для получения множества кластеров; определение множества категорий документов, таких, что каждая категория документов из множества категорий документов определена соответствующим кластером признаков из множества кластеров признаков; и обучение классификатора для получения значения, отражающего степень связанности исходного документа с одной или более категорий документов из множества категорий документов.
[0004] В соответствии с одним или более вариантами реализации настоящего изобретения, пример системы автоматического определения набора категорий для классификации документа может включать запоминающее устройство и процессор, связанный с данным запоминающим устройством, причем процессор выполнен с возможностью: создания множества признаков изображения путем обработки изображений из множества документов; создания множества признаков текста путем обработки текстов из множества документов; создания множества векторов признаков, таких, что каждый вектор признаков из множества векторов признаков включает как минимум что-то из следующего списка: подмножество множества признаков изображений и подмножество множества признаков текста; кластеризацию множества векторов признаков для получения множества кластеров; определение множества категорий документов, таких, что каждая категория документов из множества категорий документов определена соответствующим кластером признаков из множества кластеров признаков; и обучение классификатора для получения значения, отражающего степень связанности исходного документа с одной или более категорий документов из множества категорий документов. [0005] В соответствии с одним или более вариантами реализации настоящего изобретения, пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их вычислительным устройством приводят к выполнению вычислительным устройством операций, включающих в себя: создание множества признаков изображения путем обработки изображений из множества документов; создание множества признаков текста путем обработки текстов из множества документов; создание множества векторов признаков, таких, что каждый вектор признаков из множества векторов признаков включает как минимум что-то из следующего списка: подмножество множества признаков изображений и подмножество множества признаков текста; кластеризацию множества векторов признаков для получения множества кластеров; определение множества категорий документов, таких, что каждая категория документов из множества категорий документов определена соответствующим кластером признаков из множества кластеров признаков; и обучение классификатора для получения значения, отражающего степень связанности исходного документа с одной или более категорий документов из множества категорий документов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется на примерах, без каких бы то ни было ограничений; его сущность становится понятной при рассмотрении приведенного ниже подробного описания изобретения в сочетании с чертежами, при этом:
[0007] На Фиг. 1 схематически показан пример процесса автоматического определения набора категорий для классификации документов в соответствии с одним или более вариантами реализации настоящего изобретения;
[0008] На Фиг. 2 приведена блок-схема иллюстративного примера автоматического определения набора категорий для классификации документов в соответствии с одним или более вариантами реализации настоящего изобретения;
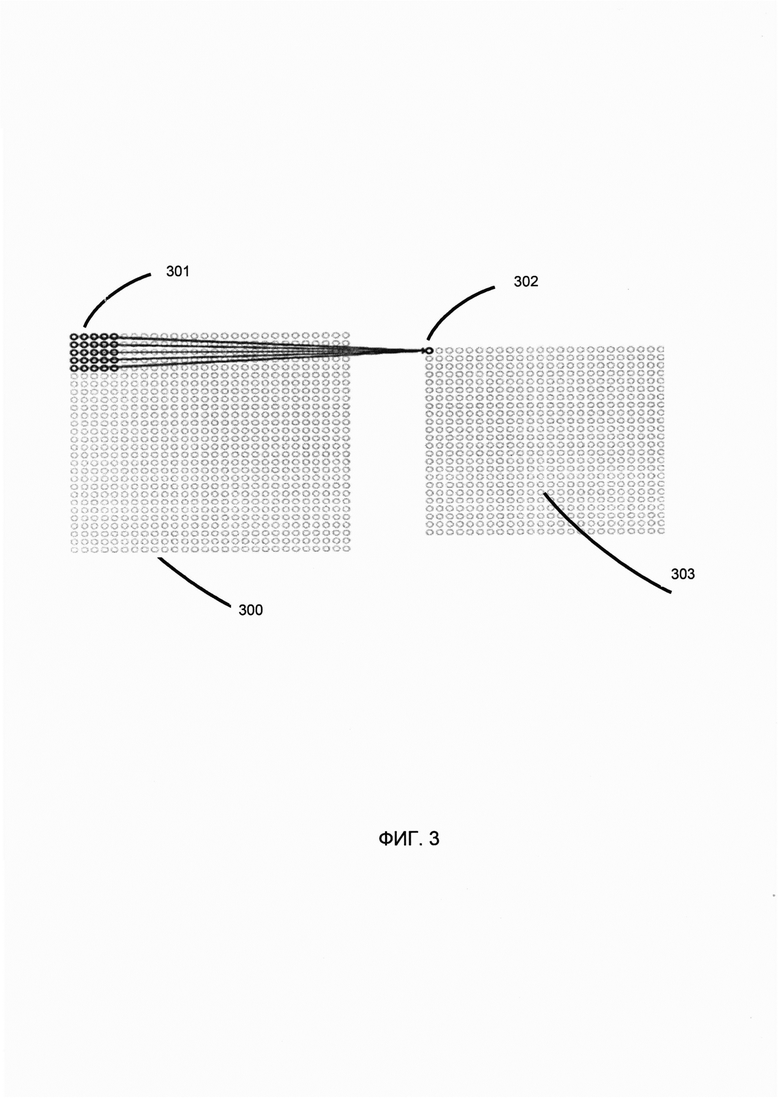
[0009] На Фиг. 3 схематически иллюстрируется работа сверточной нейронной сети (СНН) в соответствии с одним или более вариантами реализации настоящего изобретения;
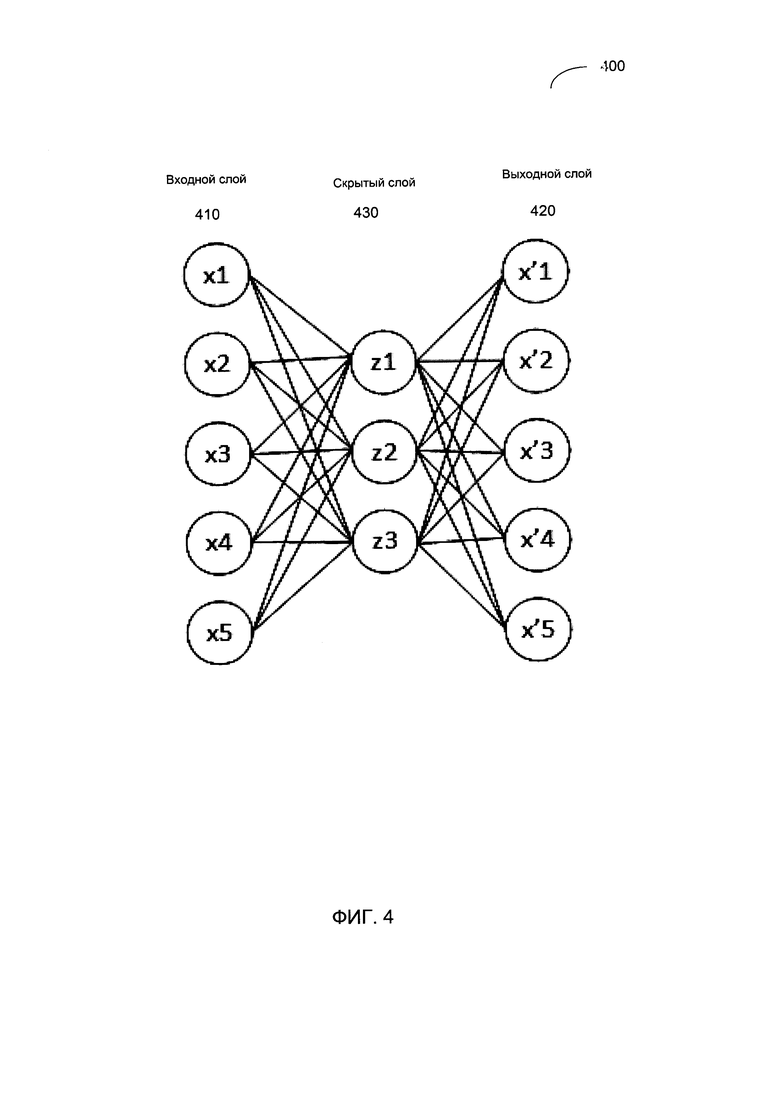
[00010] На Фиг. 4 схематически иллюстрируется структура примера автоэнкодера, работающего в соответствии с одним или более вариантами реализации настоящего изобретения;
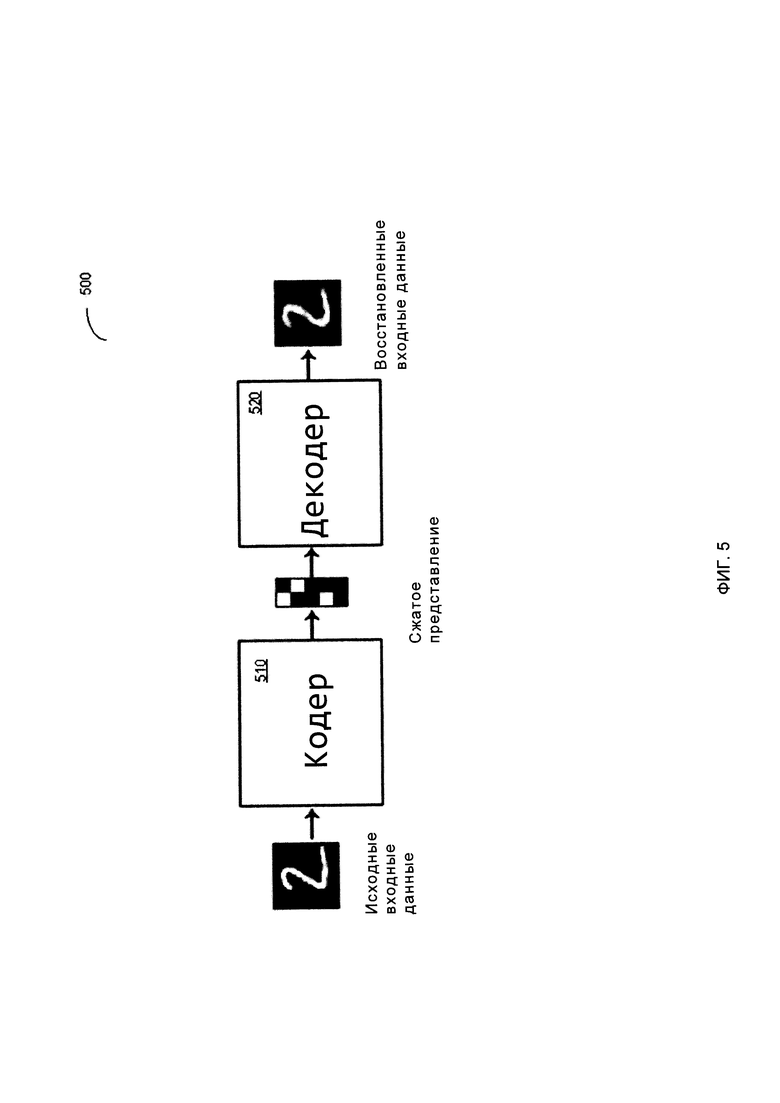
[00011] На Фиг. 5 схематически иллюстрируется работа примера автоэнкодера в
соответствии с одним или более вариантами реализации настоящего изобретения;
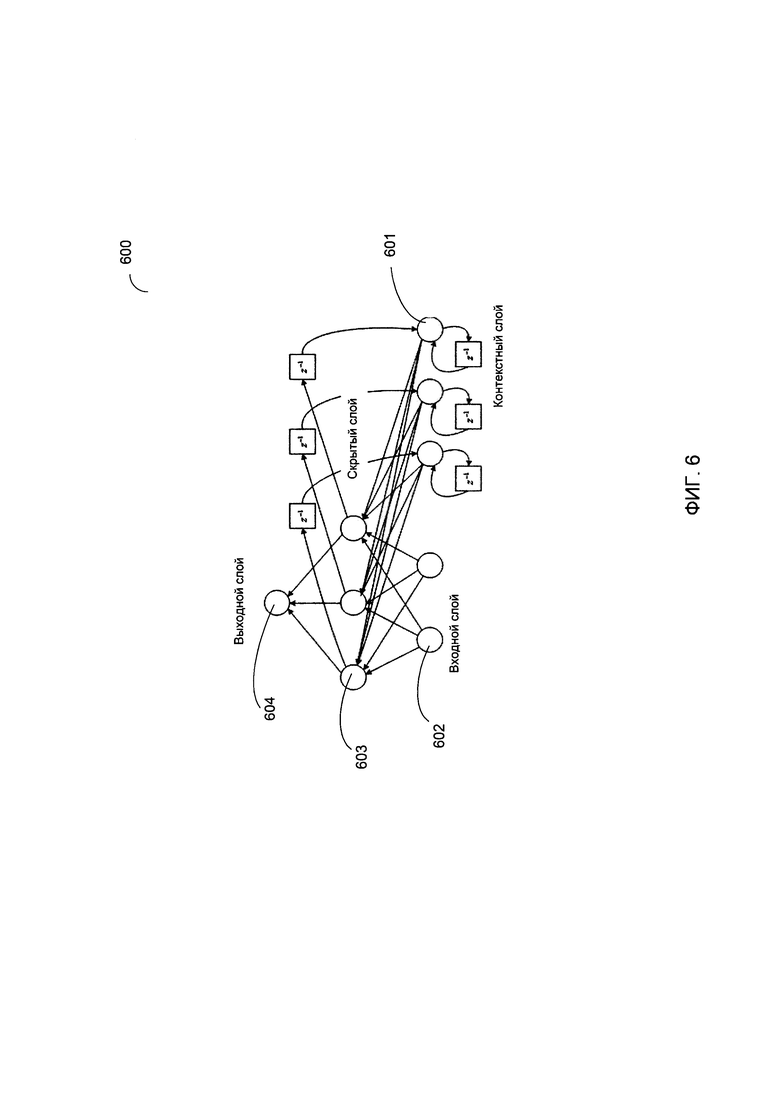
[00012] На Фиг. 6 схематически иллюстрируется структура примера рекуррентной нейронной сети, работающей в соответствии с одним или более вариантами реализации настоящего изобретения;
[00013] На Фиг. 7 схематически показано применение примера шаблона разметки документа к исходному документу в соответствии с одним или более вариантами реализации настоящего изобретения;
[00014] На Фиг. 8А-8С схематически показано применение метода главных компонент (РСА, Principal Component Analysis) для нормализации объединенных векторов признаков в соответствии с одним или более вариантами реализации настоящего изобретения;
[00015] На Фиг. 9 схематически показано использование автоэнкодера для нормализации объединенных векторов признаков в соответствии с одним или более вариантами реализации настоящего изобретения; и
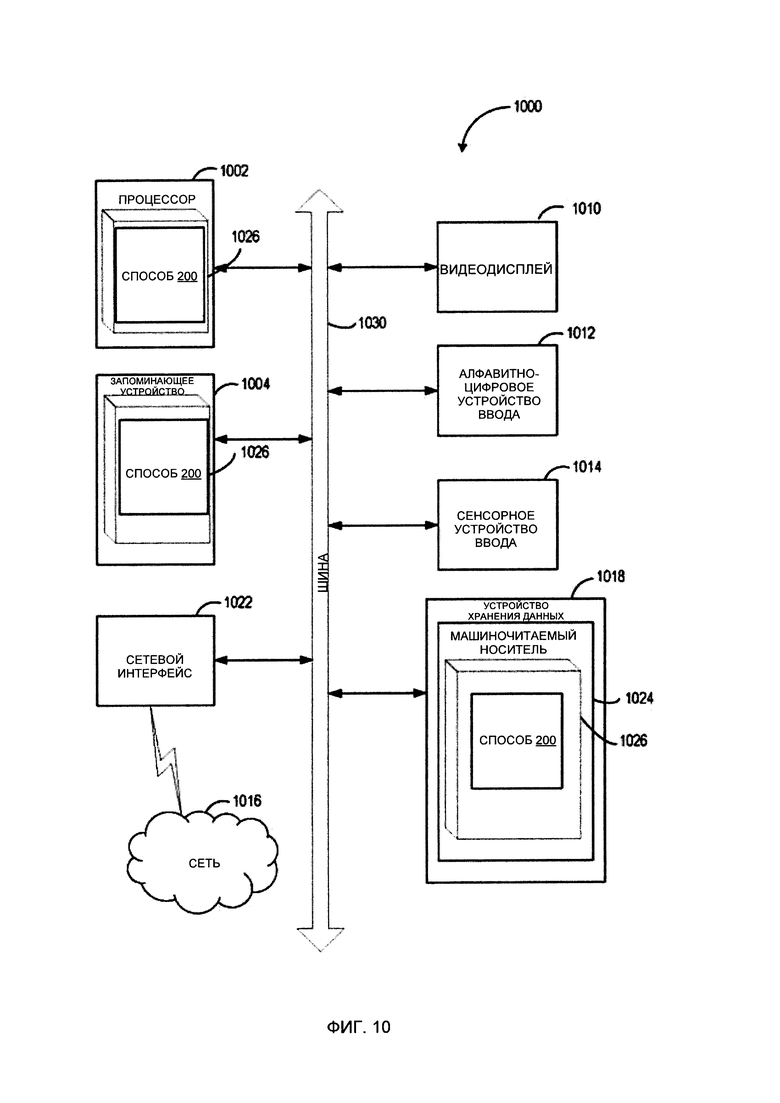
[00016] На Фиг. 10 показана схема примера вычислительной системы, реализующей методы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00017] В настоящем документе описываются способы и системы автоматического определения набора категорий для классификации документов.
[00018] Автоматическая обработка документов (таких как изображения бумажных документов или различные электронные документы, включая тексты на естественном языке) может включать классификацию исходных документов путем соотнесения данного документа с одной или более категорий из определенного набора категорий.
[00019] Классификация документов может выполняться путем оценки одной или более функций классификации, также известных как «классификаторы», каждая из которых может быть представлена функцией признаков документа, которая отражает степень близости исходного документа с определенной категорией из определенного множества категорий. Таким образом, классификация документа может включать оценку множества классификаторов, соответствующих множеству категорий, и связывание документа с категорией, соответствующей оптимальному (максимальному или минимальному) значению из значений, выдаваемых классификаторами. В иллюстративном примере исходный документ может быть классифицирован по очевидным категориям верхнего уровня, таким как соглашения, фотографии, анкеты, сертификаты и т.д. В другом иллюстративном примере категории могут быть менее очевидными, например, одинаково структурированные документы, такие как счета, могут классифицироваться по наименованию продавца.
[00020] Значения параметров классификатора могут быть определены с помощью методов обучения с учителем, которые могут включать итеративную модификацию одного или более значений параметров на основе анализа обучающей выборки данных, содержащей документы с известными категориями классификации, для оптимизации выбранной функции соответствия (например, отражающей число документов в наборе проверочных данных, которые были правильно классифицированы с использованием определенных значений параметров классификатора, к общему числу текстов на естественном языке в наборе проверочных данных).
[00021] Фактически, количество доступных аннотированных документов, которые могут быть включены в обучающую выборку или набор проверочных данных, может быть относительно невелико, так как создание этих аннотированных документов может включать получение информации от пользователя, определяющего категорию классификации для каждого документа. Обучение с учителем на основе относительно небольших обучающих выборок и наборов проверочных данных может привести к малой эффективности классификаторов.
[00022] Кроме того, различные стандартные реализации требуют от пользователя точно определять множество категорий для классификации документов. Однако пользователь не всегда может быть в состоянии определить набор категорий, который наилучшим образом подойдет для последующего автоматического извлечения информации из обрабатываемых документов.
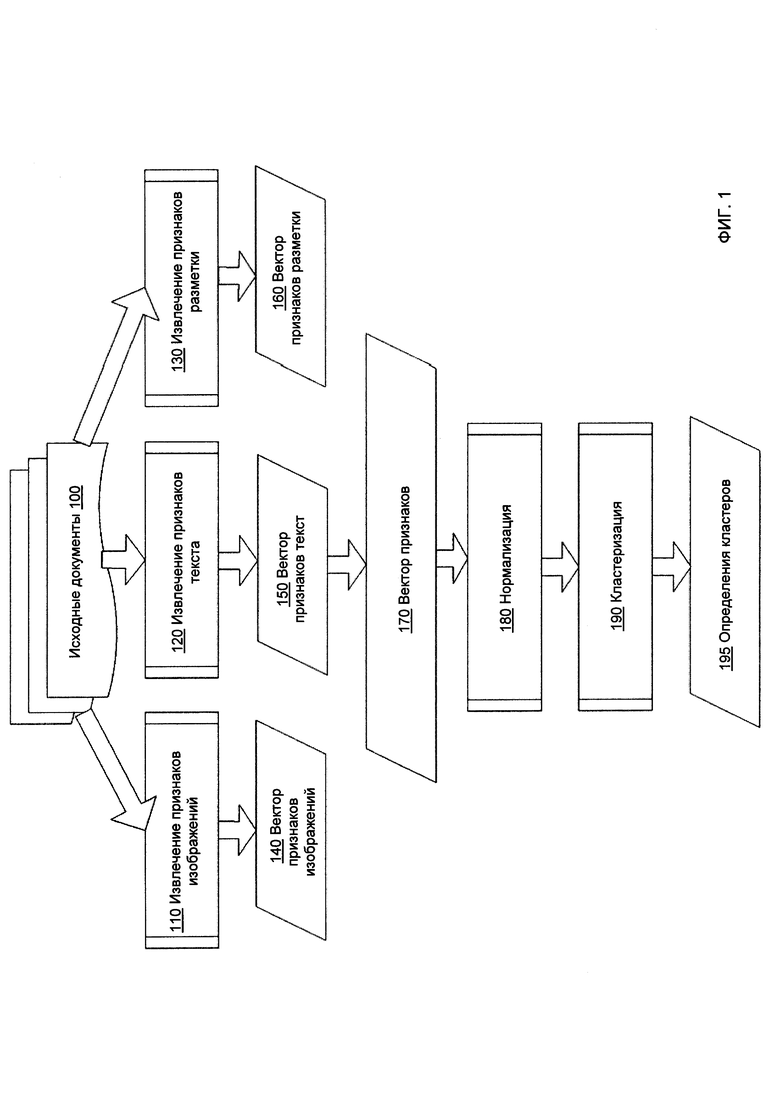
[00023] Таким образом, настоящее изобретение служит для устранения указанных выше и других недостатков известных способов классификации документов путем предоставления систем и способов автоматического определения набора категорий для классификации документов. Пример процесса автоматического определения набора категорий для классификации документов схематически показан на Фиг. 1. Как показано на Фиг. 1, исходные документы 100 поступают в функциональный модуль извлечения признаков изображений 110, функциональный модуль извлечения признаков текста 120 и функциональный модуль извлечения признаков разметки документа 130, которые обрабатывают каждый исходный документ для получения, соответственно, вектора признаков изображения 140, вектора признаков текста 150 и вектора признаков разметки документа 160. В настоящем документе термин «функциональный модуль» означает одну или более программ, выполняемых универсальным или специализированным устройством обработки данных для реализации указанной функциональности.
[00024] В иллюстративном примере функциональный модуль извлечения признаков изображения может быть реализован с помощью сверточной нейронной сети (CNN, Convolutional Neural Network). В другом иллюстративном примере функциональный модуль извлечения признаков изображения может быть реализован с помощью автоэнкодера. Функциональный модуль извлечения признаков текста может представлять текст каждого документа гистограммой, которая вычисляется по множеству кластеризованных эмбеддингов слов. Функциональный модуль извлечения признаков разметки документа может использовать для каждого исходного документа шаблон разметки документа, который содержит информацию о координатах, размерах и других атрибутах одного или более признаков разметки документа, для создания векторов признаков, кодирующих типы, размеры и другие атрибуты разметки документа, как более подробно описано ниже в этом документе.
[00025] Как минимум подмножества элементов вектора признаков изображения, вектора признаков текста и (или) вектора признаков разметки документа объединяются в вектор признаков 170, представляющий исходных документ, который затем может быть нормализован функциональным модулем нормализации 180 для подготовки вектора признаков для дальнейшей обработки (например, путем понижения размерности вектора, применения к вектору линейного преобразования и т.д.). Множество векторов признаков, соответствующее множеству исходных документов, затем передается функциональному модулю кластеризации 190. Категории документов, соответствующие определениям кластеров 195, создаваемые функциональным модулем кластеризации 190, могут использоваться для обучения одного или более классификаторов документов, что более подробно описано ниже в этом документе. Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, не с целью ограничения.
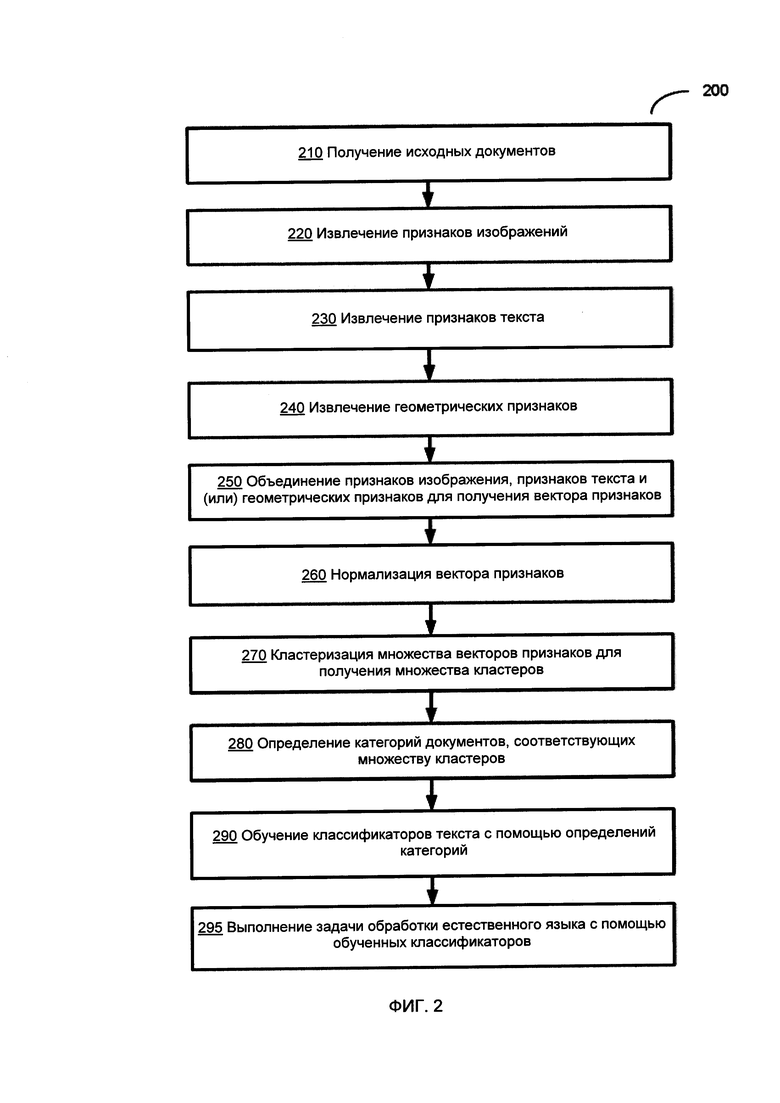
[00026] На Фиг. 2 приведена блок-схема иллюстративного примера способа автоматического определения набора категорий для классификации документов в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 200 и (или) каждая из его отдельных функций, программ, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы {например, вычислительной системы 1000 на Фиг. 10), реализующей этот способ. В некоторых реализациях способ 200 может быть реализован в одном потоке обработки. В качестве альтернативы способ 200 может быть реализован с помощью двух или более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций данного способа. В иллюстративном примере реализующие способ 200 потоки обработки могут быть синхронизированы (например, с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы реализующие способ 200 потоки обработки могут выполняться асинхронно по отношению друг к другу.
[00027] На шаге 210 вычислительная система, реализующая способ, может получать множество документов (например, представленных изображениями документов и текстами, полученными при применении методов оптического распознавания символов (OCR) к изображениям документов). Каждый исходных документ может обрабатываться путем выполнения операций, описанных ниже в этом документе, со ссылкой на шаги 220-260.
[00028] На шаге 220 вычислительная система может извлекать признаки изображения документа. В различных иллюстративных примерах извлечение признака изображения может включать применение к каждому изображению исходного документа сверточной нейронной сети (CNN, Convolution Neural Network) или автоэнкодера.
[00029] Результат работы CNN представлен в виде вектора, каждый элемент которого описывает степень связанности изображения исходного документа с классом, определяемым по индексу элемента в выходном векторе, и может быть использован для предварительного обучения CNN на обучающей выборке данных, которая содержит множество изображений с известной классификацией. При использовании способа 200 после предварительного обучения CNN вектор признаков изображения может быть получен с выхода одной или более сверточных и (или) субдискретизирующих слоев CNN, как более подробно описано ниже в этом документе.
[00030] CNN представляет собой вычислительную модель, основанную на многоэтапном алгоритме, который применяет набор заранее определенных функциональных преобразований ко множеству исходных данных (например, пикселей изображения), а затем использует преобразованные данные для выполнения распознавания образов. CNN может быть реализована в виде искусственной нейронной сети с прямой связью, в которой схема соединений между нейронами подобна тому, как организована зрительная зона коры головного мозга животных. Отдельные нейроны коры откликаются на раздражение в ограниченной области пространства, известной под названием рецептивного поля. Рецептивные поля различных нейронов частично перекрываются, образуя поле зрения. Отклик отдельного нейрона на входной сигнал в его рецептивном поле может быть аппроксимирован математически операцией свертки, которая включает применение сверточного фильтра (то есть матрицы) к каждому элементу изображения, представленному одним или более пикселями.
[00031] В иллюстративном примере CNN может содержать несколько слоев, в том числе слои свертки, нелинейные слои (например, реализуемые блоками линейной ректификации (ReLU, rectified linear units)), субдискретизирующие слои и слои классификации (полносвязные). Сверточный слой может извлекать признаки из исходного изображения, применяя один или более обучаемых фильтров пиксельного уровня к исходному изображению. Как схематично представлено на Фиг. 3, фильтр 301 пиксельного уровня может быть представлен матрицей целых значений, производящей свертку по всей площади исходного изображения 300 для вычисления скалярных произведений между значениями фильтра 301 и исходного изображения 300 в каждом пространственном положении, создавая таким образом карту признаков 303, представляющих собой отклики фильтра в каждом пространственном положении 302 исходного изображения.
[00032] К карте признаков, созданной сверточным слоем, могут применяться нелинейные операции. В иллюстративном примере нелинейные операции могут быть представлены блоком линейной ректификации (ReLU, rectified linear unit), который заменяет нулями все отрицательные значения пикселей на карте признаков. В различных других реализациях нелинейные операции могут быть представлены функцией гиперболического тангенса, сигмоидной функцией или другой подходящей нелинейной функцией.
[00033] Субдискретизирующий слой может выполнять подвыборку для получения карты признаков с пониженным разрешением, которая будет содержать наиболее актуальную информацию. Подвыборка может включать усреднение и (или) определение максимального значения групп пикселей.
[00034] В некоторых вариантах реализации сверточные, нелинейные и субдискретизирующие слои могут применяться к исходному изображению несколько раз, прежде чем результат будет передан в классифицирующий (полносвязный) слой. Совместно эти слои извлекают полезные признаки из исходного изображения, вводят нелинейность и снижают разрешение изображения, делая признаки менее чувствительными к масштабированию, искажениям и мелким трансформациям исходного изображения. Результат сверточного и (или) субдискретизирующего слоя представляет собой вектор признаков изображения, который используется в последующих операциях по способу 200.
[00035] Результат работы классифицирующего слоя, который представлен в виде вектора, каждый элемент которого описывает степень связанности изображения исходного документа с классом, определяемым по индексу элемента в выходном векторе, и может быть использован для предварительного обучения CNN. В иллюстративном примере классифицирующий слой может быть представлен искусственной нейронной сетью, содержащей множество нейронов. Каждый нейрон получает свои исходные данные от других нейронов или из внешнего источника и генерирует результат, применяя функцию активации к сумме взвешенных исходных данных и полученному при обучении значению смещения. Нейронная сеть может содержать множество нейронов, расположенных по слоям, включая входной слой, один или более скрытых слоев и выходной слой. Нейроны соседних слоев соединены взвешенными ребрами. Термин «полносвязный» означает, что каждый нейрон предыдущего слоя соединен с каждым нейроном следующего слоя.
[00036] Веса ребер определяются на этапе обучения сети на базе обучающей выборки данных, которая содержит множество изображений с известной классификацией. В иллюстративном примере все веса ребер инициализируются случайными значениями. Нейронная сеть активируется в ответ на любые исходные данные из набора данных для обучения. Наблюдаемый результат работы нейронной сети сравнивается с ожидаемым результатом работы, включенным в обучающую выборку данных, и ошибка распространяется назад на предыдущие слои нейронной сети, в которых веса соответственно корректируются. Этот процесс может повторяться, пока ошибка в результатах не станет ниже заранее определенного порогового значения.
[00037] Как было указано выше в этом документе, извлечение признаков изображения может также выполняться автоэнкодером. На Фиг. 4 схематически иллюстрируется структура примера автоэнкодера, работающего в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 4, автоэнкодер 400 может быть представлен нейронной нерекуррентной сетью прямого распространения, содержащей входной слой 410, выходной слой 420 и один или более скрытых слоев 430, соединяющих входной слой 410 с выходным слоем 420. Выходной слой 420 может иметь то же количество узлов, что и входной слой 410, так что сеть 400 может быть обучена в ходе обучения без учителя восстанавливать собственные входные данные.
[00038] На Фиг. 5 схематически иллюстрируется работа примера автоэнкодера в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 5, пример автоэнкодера 500 может содержать этап энкодера 510 и этап декодера 520. Этап энкодера 510 автоэнкодера может получать входной вектор х и отображать его на скрытое представление z, размерность которого значительно ниже, чем размерность входного вектора:
[00039] z=σ(Wx+b),
где σ - функция активации, которая может быть представлена сигмоидной функцией или блоком линейной ректификации,
W - матрица весов, и
b - вектор смещения.
[00040] Этап декодера 520 автоэнкодера может отображать скрытое представление z на восстановленный вектор х', имеющий ту же размерность, что и входной вектор х:
[00041] X'=σ' (W'z+b').
[00042] Автоэнкодер можно обучить сводить к минимуму ошибку восстановления:
[00043] L(х, х')=||х-х'||2=||х-σ'(W'(σ(Wx+b))+b')||2,
[00044] где х может быть усреднено по обучающей выборке данных.
[00045] Поскольку размерность скрытого слоя значительно ниже размерности входного и выходного слоев, автоэнкодер сжимает входной вектор в входном слое, а затем восстанавливает его в выходном слое, таким образом обнаруживая некоторые внутренние или скрытые признаки входной выборки данных.
[00046] Обучение автоэнкодера без учителя может включать, для каждого входного вектора х, выполнение прохода с прямой передачей сигнала для получения выхода x', измерение ошибки выхода, описываемой функцией потерь L(х, х'),и обратное распространение ошибки выхода по сети для обновления размерности скрытого слоя, весов и (или) параметров функции активации. В иллюстративном примере функция потерь может быть представлена бинарной функцией перекрестной энтропии. Процесс обучения может повторяться, пока ошибка выхода не станет ниже заранее определенного порогового значения.
[00047] Рассмотрим снова Фиг. 2, на шаге 230 вычислительная система может извлекать признаки текста. Текст документа можно получить, например, применив методы OCR к изображению документа. В некоторых вариантах реализации извлечение признаков текста может представлять текст каждого исходного документа гистограммой, которая вычисляется по множеству кластеризованных эмбеддингов слов. «Эмбединг слов» в настоящем документе относится к вектору действительных чисел, которые могут быть получены, например, нейронной сетью, реализующей математическое преобразование из пространства с одним измерением на слово в непрерывное пространство вектора со значительно большей размерностью.
[00048] В одном из иллюстративных примеров заранее определенное множество эмбедингов, построенное на основе большого корпуса слов, может быть кластеризовано в относительно небольшое количество кластеров (например, 256 кластеров) с использованием выбранной метрики кластеризации. Гистограмма, представляющая исходный текст, может быть инициализирована нулевыми значениями во всех столбцах гистограммы, так что каждый столбец соответствует соответствующему кластеру из множества заранее определенных кластеров. Таким образом, для каждого слова в исходном тексте определен его вектор контекста и выявлен кластер, ближайший к вектору контекста для выбранной метрики кластеризации. Столбец гистограммы, соответствующий выявленному кластеру, увеличивается на заранее определенное число. Результат работы шага 230, таким образом, может быть представлен вектором, каждый элемент которого содержит число, хранящееся в столбце гистограммы, имеющем индекс, эквивалентный индексу элемента вектора. С другой стороны, результат работы вектора 230 может быть представлен вектором значений частоты использования слов - обратной частоты документа (TF-IDF, Term Frequency - Inverse Document Frequency), вычисленным на множестве кластеров.
[00049] Частота использования слов (TF, Term Frequency) представляет собой частоту встречаемости данного слова (или вектора контекста, представляющего слово) в документе:
[00050] 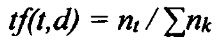
где t - это идентификатор слова,
d - идентификатор документа,
nt - количество появлений слова t в документе d, и
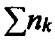 - общее количество слов в документе d.
- общее количество слов в документе d.
[00051] Обратная частота документа (IDF, Inverse Document Frequency) определяется как логарифмическое отношение количества текстов в корпусе к количеству документов, содержащих данное слово:
[00052] idƒ(t, D)=log [|D| / |{di ∈D|t∈di}|]
где D - идентификатор текстового корпуса,
|D| - количество документов в корпусе, и
{di ∈ D\t∈di} - количество документов в корпусе D, содержащих слово t.
[00053] Таким образом, TF-IDF можно определить как произведение частоты использования слов (TF, Term Frequency) и обратной частоты документа (IDF, Inverse Document Frequency):
tƒ-idƒ(t, d, D)=tƒ(t, d)*idƒ(t, D)
[00054] TF-IDF будет давать большие значения для слов, которые чаще встречаются в одном документе, чем в других документах корпуса.
[00055] Как было указано выше в этом документе, каждое слово исходного документа может быть представлено кластером в заранее определенном множестве кластеров, так, что кластер, представляющий слово, является ближайшим по выбранной метрике кластеризации к вектору контекста, соответствующего слову исходного документа. Таким образом, в приведенном выше вычислении значений TF-IDF слова можно заменить на кластеры из заранее определенного множества кластеров. Результат работы шага 230, следовательно, может быть представлен вектором, каждый элемент которого содержит значение TF-IDF кластера, выбранного по индексу, эквивалентный индексу элемента вектора. Соответственно, текстовый корпус может быть представлен матрицей, в каждой ячейке которой хранится значение TF-IDF кластера, определяемого индексом столбца, в документе, определяемом индексом строки.
[00056] В некоторых вариантах реализации изобретения векторы контекста, представляющие слова, могут быть созданы с помощью рекуррентной нейронной сети. Рекуррентные нейронные сети в состоянии хранить состояние сети, отражающее информацию об исходных данных, обрабатываемых сетью, таким образом позволяя сети использовать свое внутреннее состояние для обработки последующих исходных данных. Как схематически показано на Фиг. 6, рекуррентная нейронная сеть 600 получает исходный вектор от входного слоя 602, обрабатывает исходный вектор в скрытых слоях 603, сохраняет состояние сети в слое контекста 601 и создает выходной вектор на выходном слое 604. Состояние сети, которое сохраняется в слое контекста 601, может затем использоваться для обработки последующих исходных векторов. В различных иллюстративных примерах извлечение векторов контекста может включать подачу на вход рекуррентной нейронной сети 600 последовательностей слов исходного текста, групп слов (например, предложений или абзацев) или последовательностей отдельных символов. Последующая возможность вычисления векторов контекста, соответствующих последовательностям отдельных символов, может быть особенно полезна в ситуациях, когда исходных текст, полученный с помощью применения методов OCR к изображению исходного документа, может страдать от множества ошибок распознавания и таким образом содержать относительно большое количество групп символов, которые не являются словарными словами.
[00057] Еще раз рассмотрим Фиг. 2, на шаге 240 вычислительная система может обрабатывать каждый исходный документ для получения признаков разметки документа. В некоторых вариантах реализации признаки разметки документа могут извлекаться, исходя из предоставленной пользователем разметки, которая может графически выделять некоторые элементы, фрагменты или отдельные слова, например, подчеркиванием, подсветкой, обводкой, помещением в ограниченную рамку и т.д. В различных иллюстративных примерах разметка может графически выделять логотип, заголовок или подзаголовок документа и т.д. Таким образом, признаки разметки документа могут представлять информацию о выделяемом пользователем тексте, включая его координаты в тексте и его представление эмбедингами или векторами контекста.
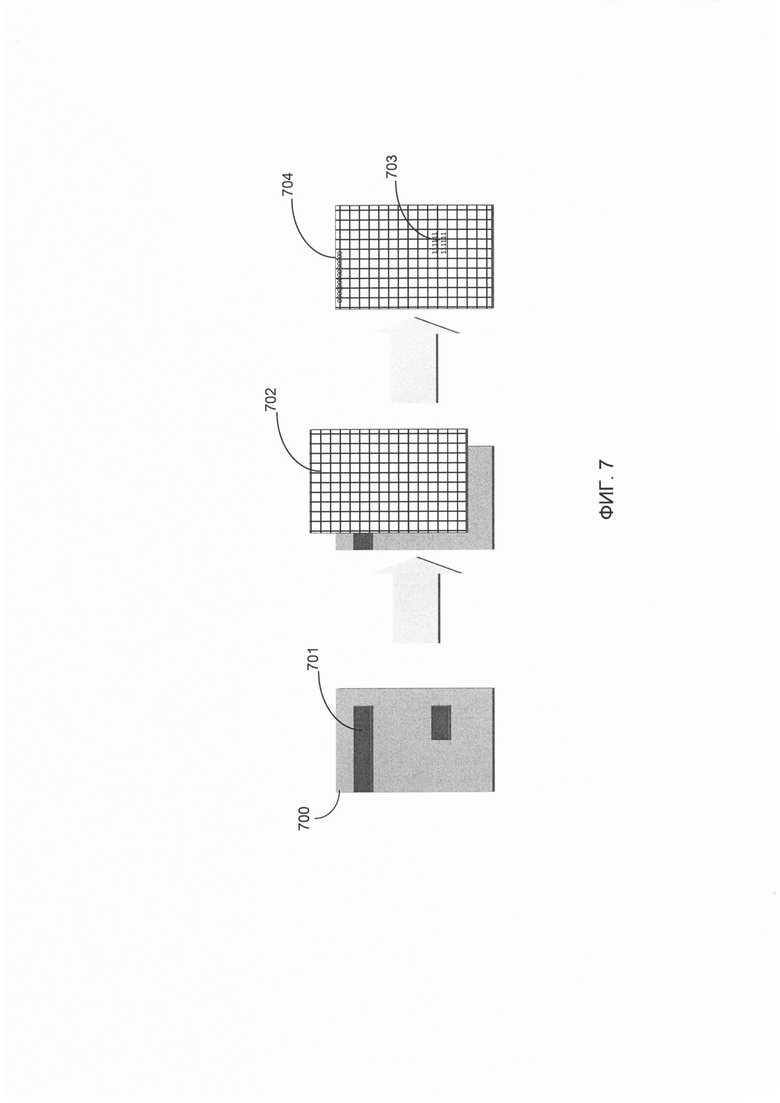
[00058] В некоторых вариантах осуществления признаки разметки документа могут отражать наличие или отсутствие отдельных графических элементов исходного документа, например, заранее определенных фрагментов изображений (таких как логотипы), заранее определенных слов или групп слов, штрих-кодов, границ документа, графических разделителей и т.д. Как схематично показано на Фиг. 7, шаблон разметки документа 702, который содержит определения координат, размеры и другие атрибуты параметров разметки одного или более документа, может быть сравнен с исходным документом 700, содержащим признаки разметки документа 701, для получения векторов признаков 703 и 704, кодирующих типы, размеры и другие атрибуты признаков разметки документа, определенные в шаблоне и обнаруживаемые в исходном документе. В некоторых вариантах осуществления с исходным документом могут последовательно сравниваться множественные шаблоны разметки документа для извлечения нескольких наборов признаков разметки документа.
[00059] Еще раз рассмотрим Фиг. 2, на шаге 250 вычислительная система может для каждого исходного документа объединять как минимум подмножества элементов вектора признаков изображения, вектора признаков текста и (или) вектора признаков разметки документа для получения вектора признаков, представляющего исходный документ. В некоторых вариантах осуществления вектор признаков может также содержать морфологические, лексические, синтаксические, семантические и (или) другие признаки исходного документа.
[00060] На шаге 260 вычислительная система может нормализовать вектор признаков, то есть подготовить его к дальнейшей обработке. В некоторых вариантах осуществления вектор признаков может нормализовываться с помощью метода главных компонент (РСА, Principal Component Analysis), который представляет собой статистическую процедуру, использующую ортогональное преобразование для преобразования множества наблюдений возможно коррелирующих переменных в набор значений линейно некоррелирующих между собой переменных, которые называются главными компонентами. РСА, таким образом, может рассматриваться как процесс подгонки n-размерного эллипсоида под данные, где каждая ось эллипсоида соответствует главной компоненте.
[00061] РСА математически определяется как ортогональное линейное преобразование, которое преобразует данные к новой системе координат таким образом, что наибольшая дисперсия по одной из проекций данных лежит на первой оси (именуемой первой главной компонентой), вторая по величине дисперсия - на второй оси, и так далее. Это преобразование определено таким образом, что первая главная компонента имеет наибольшую возможную дисперсию (то есть, имеет максимально возможную для данных дисперсию), и каждая последующая компонента ортогональна предыдущим компонентам и имеет наибольшую возможную дисперсию.
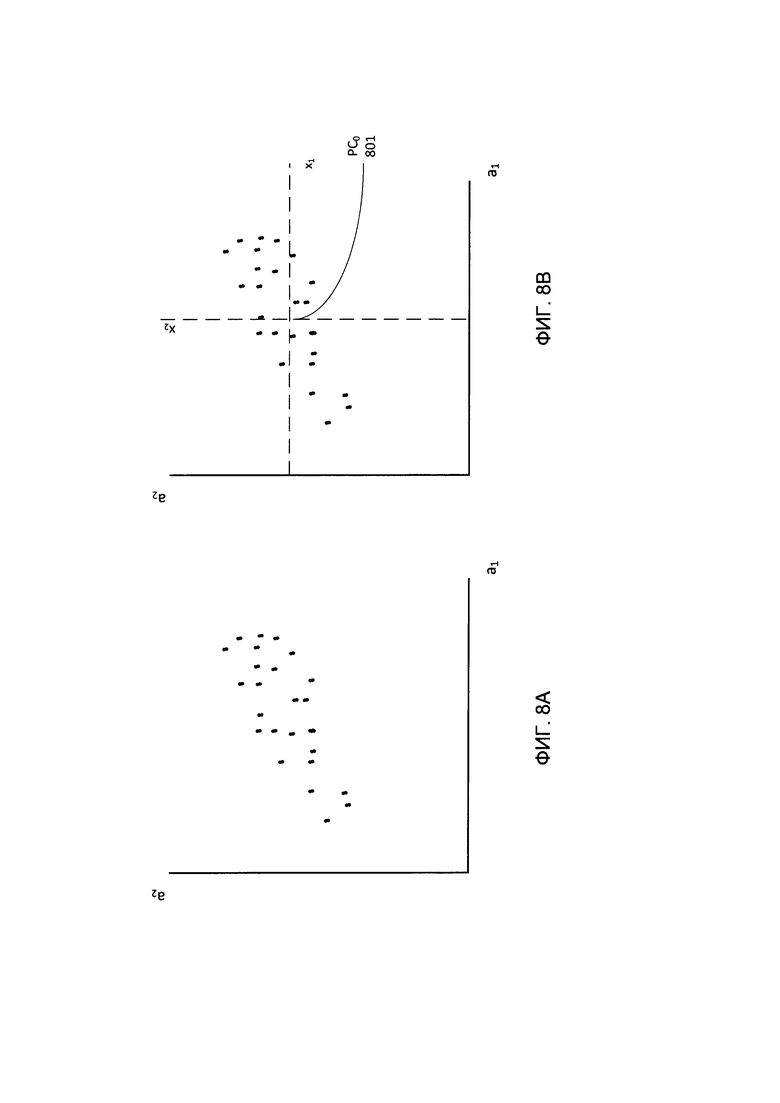
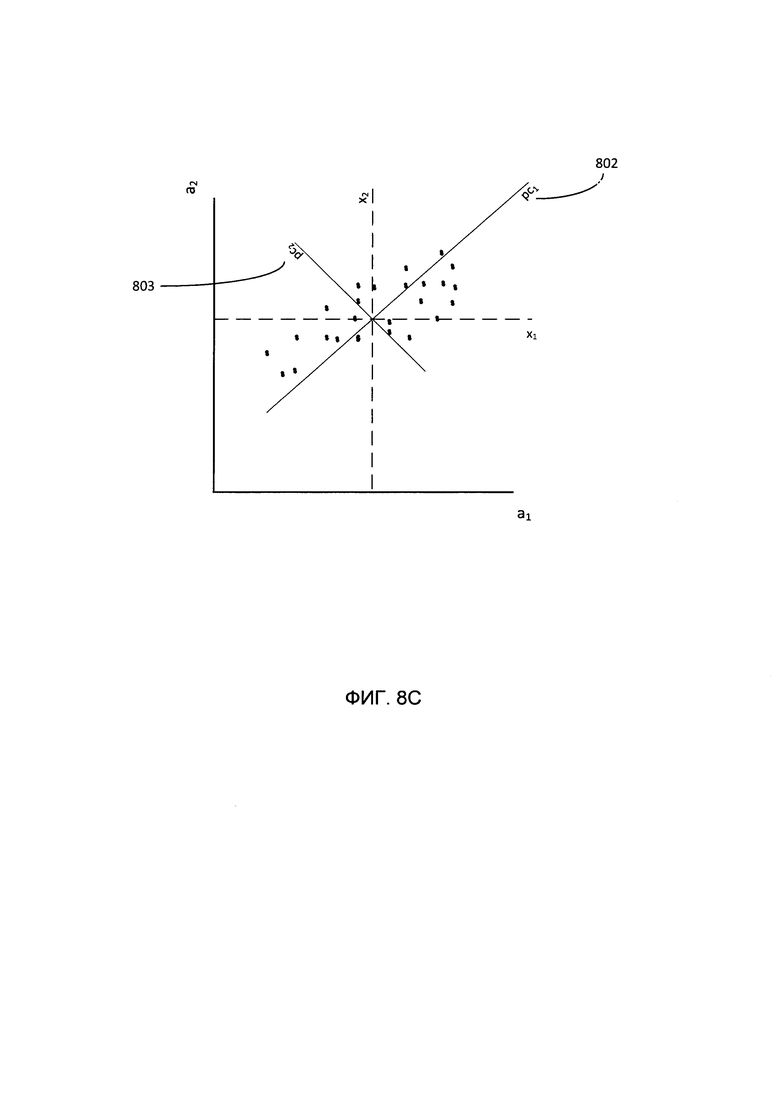
[00062] Таким образом, РСА обеспечивает уменьшение размерности исходных векторов без потери большей части полезной информации. Как схематически показано на Фиг. 8А-8В, выполнение РСА включает выявление значений РС0, PC1 и РС2 таким образом, чтобы значения векторов имели максимально возможную дисперсию. На Фиг. 8А-8С исходное множество двухмерных векторов проиллюстрировано облаком точек в двумерном пространстве. Этот способ может включать выявление центра облака, которое становится новой точкой начала координат РС0 (801). Затем выявляется ось, соответствующая направлению максимальной дисперсии данных, которая становится первой главной компонентой PC1 (802). И наконец, выявляется другая ось РС2 (803), которая перпендикулярна первой оси, чтобы отражать оставшуюся дисперсию данных. Таким образом, размерность вектора исходных данных уменьшается.
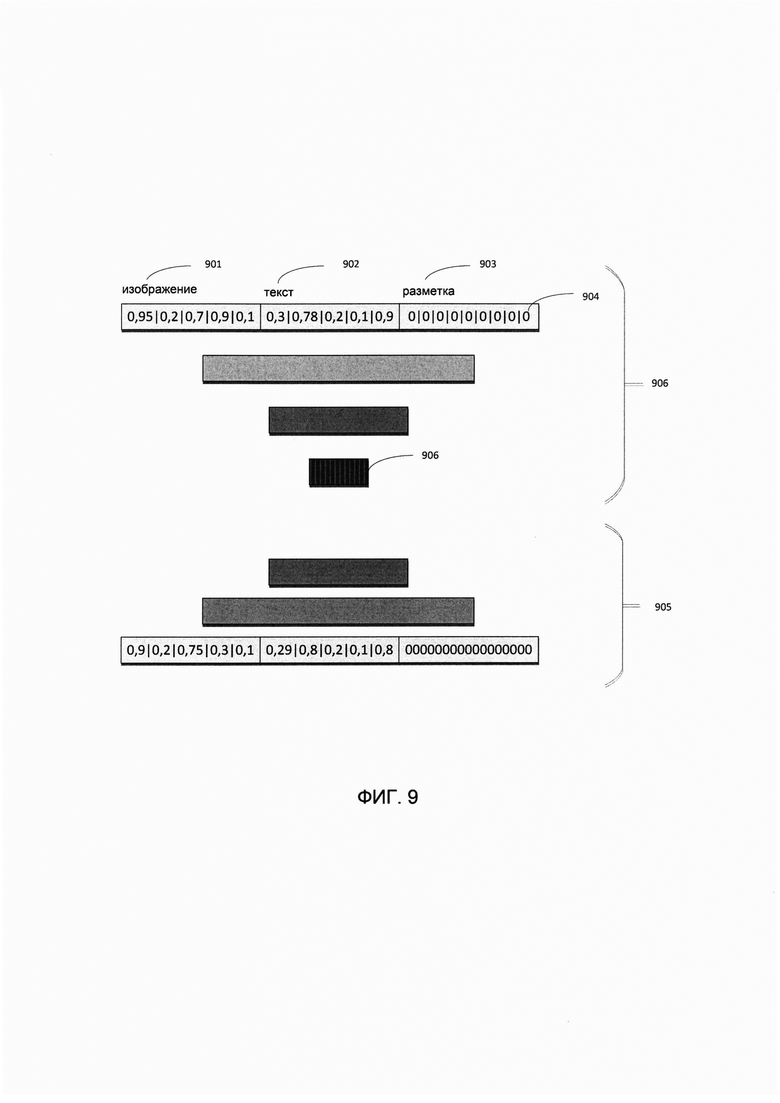
[00063] Вместо этого, как схематически показано на Фиг. 9, вектор признаков может быть нормализован с помощью автоэнкодера, на вход которого поступает объединенный вектор признаков изображений 901, признаков текста 902 и признаков разметки 903. Если какой-то набор признаков в объединенном векторе отсутствует, соответствующие элементы вектора могут быть заполнены нулями 904. Выходной слой 905 используется для предварительного обучения автоэнкодера. После завершения предварительного обучения нормализованное представление исходного вектора признаков можно получить из промежуточного слоя 906.
[00064] Вместо этого вектор признаков может быть нормализован и другими способами, например, такими как латентно-семантический анализ (LSA, Latent Semantic Analysis), вероятностный латентно-семантический анализ (PLSA, Probabilistic Latent Semantic Analysis) или распределение хи-квадрат.
[00065] Еще раз рассмотрим Фиг. 2, на шаге 270 вычислительная система может создать множество кластеров признаков, кластеризуя набор нормализованных векторов признаков, извлеченных из множества исходных документов. В одном из иллюстративных примеров кластеризация может быть выполнена методом K-средних, который включает деление п наблюдений на к кластеров, при котором каждое наблюдение принадлежит к кластеру с ближайшим средним, выступая в качестве прототипа кластера. Таким образом, кластеризация может включать случайный выбор центров кластеров и итеративное связывание векторов признаков с ближайшими кластерами с повторным вычислением центров кластеров по мере формирования кластеров.
[00066] Вместо этого для кластеризации множества нормализованных векторов свойств могут использоваться другие способы кластеризации, такие как пространственная кластеризация на основе плотности для приложений с шумами (DBSCAN, Density-Based Spatial Clustering of Applications with Noise).
[00067] Еще раз рассмотрим Фиг. 2, на шаге 280 вычислительная система может создать множество категорий документов, такое, что каждая категория документа определяется соответствующим кластером признаков из множества кластеров признаков. Другими словами, каждая категория документов должна включать документы, наиболее близкие по выбранной метрике кластеризации к соответствующему кластеру признаков.
[00068] На шаге 290 вычислительная система может использовать категории классификации документов, полученные в результате выполнения шага 280, для обучения одного или более классификаторов с целью получения значения, отражающего степень связанности исходного документа с одной или более категориями документов из множества категорий документов. В некоторых вариантах реализации этот классификатор может быть представлен классификатором машины опорных векторов (SVM, Support Vector Machine), классификатором градиентного бустинга (GBoost, Gradient Boost), или классификатором радиальной базисной функции (RBF, Radial Basis Function). Обучение классификатора может включать итеративное определение значений определенных параметров классификатора, который будет оптимизировать выбранную функцию соответствия. В одном из иллюстративных примеров функция соответствия может отражать число текстов на естественном языке в проверочном наборе данных, которые должны быть правильно классифицированы при использовании определенных значений параметров классификатора. В одном из иллюстративных примеров функция приспособленности может быть представлена F-мерой, которая определяется как взвешенное среднее гармоническое точности и полноты проверки:
[00069] F=2*P*R/(P+R),
где Р - количество правильных положительных результатов, деленное на количество всех положительных результатов, и
R - количество правильных положительных результатов, деленное на количество положительных результатов, которое должно быть получено.
[00070] На шаге 295 вычислительная система может использовать обученный классификатор для выполнения одной или более операций или задач обработки естественного языка. К примерам задач обработки естественного языка относятся выявление семантических сходств, ранжирование результатов поиска, определение авторства текста, фильтрация спама, выбор текстов для контекстной рекламы и т.д. После завершения операций, указанных на шаге 295, выполнение способа может быть завершено.
[00071] На Фиг. 10 показан иллюстративный пример вычислительной системы 1000, которая может исполнять набор команд, которые вызывают выполнение вычислительной системой любого одного или более способов настоящего изобретения. Вычислительная система может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система может работать в качестве сервера или клиента в сетевой среде «клиент/сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB, set-top box), карманным ПК (PDA, Personal Digital Assistant), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или более наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[00072] Пример вычислительной системы 1000 включает процессор 1002, основное запоминающее устройство 1004 (например, постоянное запоминающее устройство (ROM, read-only memory) или динамическое оперативное запоминающее устройство (DRAM, dynamic random access memory)) и устройство хранения данных 1018, которые взаимодействуют друг с другом по шине.
[00073] Процессор 1002 может быть представлен одной или более универсальными вычислительными системами например, микропроцессором, центральным процессором и т.д. В частности, процессор 1002 может представлять собой микропроцессор с полным набором команд (CISC, complex instruction set computing), микропроцессор с сокращенным набором команд (RISC, reduced instruction set computing), микропроцессор с командными словами сверхбольшой длины (VLIW, very long instruction word), процессор, реализующий другой набор команд или процессоры, реализующие комбинацию наборов команд. Процессор 1002 также может представлять собой одну или более вычислительных систем специального назначения, например заказную интегральную микросхему (ASIC, application specific integrated circuit), программируемую пользователем вентильную матрицу (FPGA, field programmable gate array), процессор цифровых сигналов (DSP, digital signal processor), сетевой процессор и т.п. Процессор 1002 реализован с возможностью выполнения команд 1026 для осуществления рассмотренных в настоящем документе операций и функций.
[00074] Вычислительная система 1000 может дополнительно включать устройство сетевого интерфейса 1022, устройство визуального отображения 1010, устройство ввода символов 1012 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 1014.
[00075] Устройство хранения данных 1018 может содержать машиночитаемый носитель данных 1024, в котором хранится один или более наборов команд 1026 и в котором реализованы одна или более методик или функций, рассмотренных в настоящем документе. Команды 1026 также могут находиться полностью или по меньшей мере частично в основном запоминающем устройстве 1004 и/или в процессоре 1002 во время выполнения их в вычислительной системе 1000, при этом оперативное запоминающее устройство 1004 и процессор 1002 также представляют собой машиночитаемый носитель данных. Команды 1026 дополнительно могут передаваться или приниматься по сети 1016 через устройство сетевого интерфейса 1022.
[00076] В некоторых вариантах реализации изобретения набор команд 1026 может содержать команды способа 200 автоматического определения набора категорий для классификации документов в соответствии с одним или более вариантами реализации настоящего изобретения. Несмотря на то, что машиночитаемый носитель данных 1024 показан в примере на Фиг. 10 в виде одного носителя, термин «машиночитаемый носитель» следует понимать в широком смысле, подразумевающем один носитель или несколько носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как включающий любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[00077] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00078] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00079] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, «алгоритмом» называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. «Операции» подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать, и выполнять с ними другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00080] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если явно не указано обратное, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «определение», «изменение» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в регистрах и устройствах памяти вычислительной системы, в другие данные, также представленные в виде физических величин в устройствах памяти или регистрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00081] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[00082] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого, область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.
Изобретение относится к области вычислительной техники. Техническим результатом является обеспечение классификации документов. Раскрыт способ классификации документов, включающий создание вычислительной системой множества признаков изображений путем обработки изображений из множества документов; создание множества признаков одного или более текстов путем обработки текстов из множества документов; создание множества векторов признаков, таких, что каждый вектор признаков из множества векторов признаков включает по меньшей мере одно из следующего: подмножество множества признаков изображений и подмножество множества признаков текста; кластеризацию множества векторов признаков для получения множества кластеров; определение множества категорий документов, таких, что каждая категория документов из множества категорий документов определена соответствующим кластером признаков из множества кластеров признаков; обучение классификатора для получения одного или более значений, отражающих степень связанности одного или более исходных документов с одной или более категорией документов из множества категорий документов; и применение обученного классификатора для классификации одного или более документов с учетом указанных полученных одного или более значений. 3 н. и 17 з.п. ф-лы, 12 ил.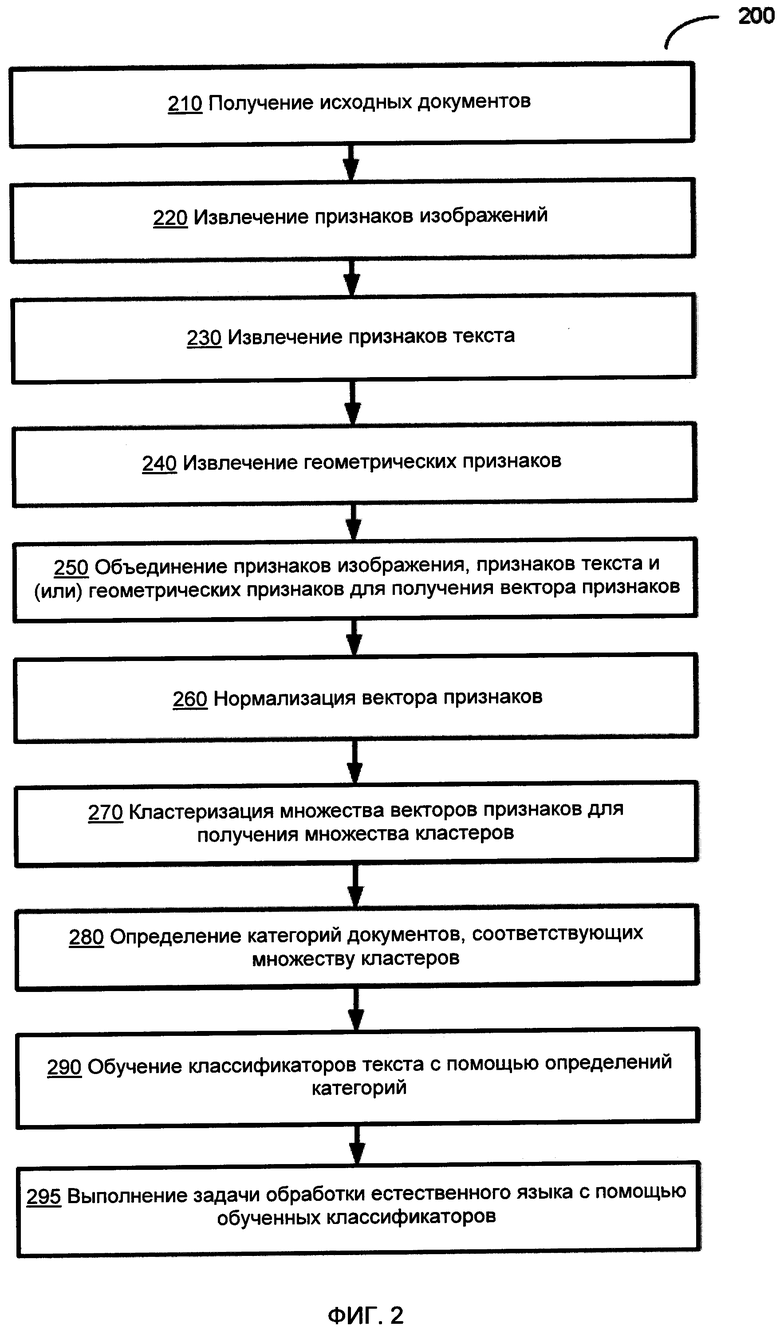
1. Способ классификации документов, включающий:
создание вычислительной системой множества признаков изображений путем обработки изображений из множества документов;
создание множества признаков одного или более текстов путем обработки текстов из множества документов;
создание множества векторов признаков, таких, что каждый вектор признаков из множества векторов признаков включает по меньшей мере одно из следующего:
подмножество множества признаков изображений и подмножество множества признаков текста;
кластеризацию множества векторов признаков для получения множества кластеров;
определение множества категорий документов, таких, что каждая категория документов из множества категорий документов определена соответствующим кластером признаков из множества кластеров признаков;
обучение классификатора для получения одного или более значений, отражающих степень связанности одного или более исходных документов с одной или более категорией документов из множества категорий документов; и
применение обученного классификатора для классификации одного или более документов с учетом указанных полученных одного или более значений.
2. Способ по п. 1, дополнительно включающий:
создание множества признаков разметки документа путем обработки множества документов, таких, что каждый вектор признаков из множества векторов признаков дополнительно включает по меньшей мере одно подмножество множества признаков разметки документа.
3. Способ по п. 1, отличающийся тем, что создание множества векторов признаков дополнительно включает:
нормализацию множества векторов признаков.
4. Способ по п. 1, отличающийся тем, что создание множества признаков изображений дополнительно включает:
обработку множества изображений документов с помощью сверточной нейронной сети; и
получение множества признаков изображения с одного или более скрытых слоев сверточной нейронной сети.
5. Способ по п. 1, отличающийся тем, что создание множества признаков изображений дополнительно включает:
обработку множества изображений документов с помощью автоэнкодера.
6. Способ по п. 1, отличающийся тем, что создание множества векторов признаков текста дополнительно включает:
получение множества векторов контекста, представляющих текст документа; и
связывание каждого вектора контекста из множества векторов контекста с кластером из заранее определенного множества кластеров признаков текста.
7. Способ по п. 1, отличающийся тем, что создание множества векторов признаков дополнительно включает:
объединение по меньшей мере одного подмножества множества признаков изображения и по меньшей мере одного подмножества множества признаков текста.
8. Способ по п. 1, отличающийся тем, что кластеризация множества векторов признаков дополнительно включает:
разделение множества векторов признаков на множество кластеров, так что каждый вектор признаков принадлежит к кластеру с ближайшим средним значением.
9. Способ по п. 1, дополнительно включающий:
использование классификатора для выполнения задачи обработки естественного языка, представленного текстами документов.
10. Система классификации документов, включающая:
запоминающее устройство;
процессор, связанный с данным запоминающим устройством, причем этот процессор выполнен с возможностью
создавать множество признаков изображений путем обработки изображений из множества документов;
создавать множество признаков одного или более текстов путем обработки текстов из множества документов;
создавать множество векторов признаков, таких, что каждый вектор признаков из множества векторов признаков включает по меньшей мере одно из следующего: подмножество множества признаков изображений и подмножество множества признаков текста;
кластеризовать множество векторов признаков для получения множества кластеров;
определять множество категорий документов, таких, что каждая категория документов из множества категорий документов определена соответствующим кластером признаков из множества кластеров признаков;
обучать классификатор для получения одного или более значений, отражающих степень связанности одного или более исходных документов с одной или более категорией документов из множества категорий документов; и
применять обученный классификатор для классификации одного или более документов с учетом указанных полученных одного или более значений.
11. Система по п. 10, отличающаяся тем, что процессор дополнительно имеет возможность
создавать множество признаков разметки документа путем обработки множества документов, таких, что каждый вектор признаков из множества векторов признаков дополнительно включает по меньшей мере одно подмножество множества признаков разметки документа.
12. Система по п. 11, отличающаяся тем, что создание множества векторов признаков изображений дополнительно включает:
обработку множества изображений документов с помощью сверточной нейронной сети; и
получение множества признаков изображения с одного или более скрытых слоев сверточной нейронной сети.
13. Система по п. 10, отличающаяся тем, что создание множества векторов признаков текста дополнительно включает:
получение множества векторов контекста, представляющих текст документа; и
связывание каждого вектора контекста из множества векторов контекста с кластером из заранее определенного множества кластеров признаков текста.
14. Система по п. 10, отличающаяся тем, что получение множества векторов признаков дополнительно включает:
объединение по меньшей мере подмножества множества признаков изображения и по меньшей мере подмножества множества признаков текста.
15. Система по п. 11, дополнительно включающая:
использование классификатора для выполнения задачи обработки естественного языка, представленного текстами документов.
16. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при их исполнении вычислительной системой побуждают вычислительную систему
создавать множество признаков изображений путем обработки изображений из множества документов;
создавать множество признаков одного или более текстов путем обработки текстов из множества документов;
создавать множество векторов признаков, таких, что каждый вектор признаков из множества векторов признаков включает по меньшей мере одно из следующего: подмножество множества признаков изображений и подмножество множества признаков текста;
кластеризовать множество векторов признаков для получения множества кластеров;
определять множество категорий документов, таких, что каждая категория документов из множества категорий документов определена соответствующим кластером признаков из множества кластеров признаков;
обучать классификатор для получения одного или более значений, отражающих степень связанности одного или более исходных документов с одной или более категорией документов из множества категорий документов; и
применять обученный классификатор для классификации одного или более документов с учетом указанных полученных одного или более значений.
17. Постоянный машиночитаемый носитель данных по п. 16, дополнительно включающий исполняемые команды, которые при их исполнении вычислительной системой побуждают вычислительную систему
создавать множество признаков разметки документа путем обработки множества документов, таких, что каждый вектор признаков из множества векторов признаков дополнительно включает по меньшей мере одно подмножество множества признаков разметки документа.
18. Постоянный машиночитаемый носитель данных по п. 16, отличающийся тем, что создание множества признаков изображений дополнительно включает:
обработку множества изображений документов с помощью сверточной нейронной сети; и
получение множества признаков изображения с одного или более скрытых слоев сверточной нейронной сети.
19. Постоянный машиночитаемый носитель данных по п. 16, отличающийся тем, что создание множества векторов признаков дополнительно включает:
объединение по меньшей мере одного подмножества множества признаков изображения и по меньшей мере одного подмножества множества признаков текста.
20. Постоянный машиночитаемый носитель данных по п. 16, также включающий:
использование классификатора для выполнения задачи обработки естественного языка, представленного текстами документов.
| US 6055540 A, 25.04.2000 | |||
| US 6094653 A, 25.07.2000 | |||
| US 7047236 B2, 16.05.2006 | |||
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ДОКУМЕНТОВ | 2003 |
|
RU2254610C2 |

