Настоящее изобретение относится к аудиообработке и, в частности, к разложению аудиосигналов на различные компоненты, к примеру различные по восприятию компоненты.
Слуховая система человека воспринимает звук со всех направлений. Воспринимаемое слуховое (прилагательное "слуховой" обозначает то, что воспринимается, в то время как слово "звук" используется для того, чтобы описывать физические явления) окружение создает впечатление от акустических свойств окружающего пространства и возникающих звуковых событий. Слуховое впечатление, воспринимаемое в конкретном звуковом поле, может (по меньшей мере, частично) моделироваться с учетом трех различных типов сигналов на входах в уши: прямой звук, ранние отражения и рассеянные отражения. Эти сигналы способствуют формированию воспринимаемого слухового пространственного изображения.
Прямой звук обозначает волны каждого звукового события, которые первыми достигают слушателя непосредственно из источника звука без искажений. Это является характеристикой для источника звука и предоставляет наименее компрометируемую информацию относительно направления падения звукового события. Первичными метками для оценки направления источника звука в горизонтальной плоскости являются разности между входными сигналами в левое и правое ухо, а именно интерауральные разности времен (ITD) и интерауральные разности уровней (ILD). Затем множество отражений прямого звука поступают в уши из различных направлений и с различными относительными временными задержками и уровнями. С увеличением временной задержки, относительно прямого звука, плотность отражений возрастает до тех пор, пока они не составляют статистическую помеху.
Отраженный звук способствует восприятию расстояния и слуховому пространственному впечатлению, которое состоит, по меньшей мере, из двух компонентов: кажущаяся ширина источника (ASW) (другим общеупотребительным термином для ASW является объемность слышимости) и круговое охватывание слушателя (LEV). ASW задается как расширение кажущейся ширины источника звука и определяется главным образом посредством ранних латеральных отражений. LEV означает чувство охватывания звуком у слушателя и определяется главным образом посредством поздно поступающих отражений. Цель воспроизведения электроакустического стереофонического звука состоит в том, чтобы вызывать восприятие приятного слухового пространственного изображения. Это может иметь естественную или архитектурную природу (например, запись концерта в зале), либо это может быть звуковое поле, которое не является существующим в реальности (например, электроакустическая музыка).
Из области техники акустики концертных залов известно, что для того, чтобы получать субъективно приятное звуковое поле, важным является сильное чувство слухового пространственного впечатления, неотъемлемой частью которого является LEV. Интерес представляет способность компоновок громкоговорителей воспроизводить охватывающее звуковое поле посредством воспроизведения рассеянного звукового поля. В синтетическом звуковом поле невозможно воспроизводить все естественные отражения с использованием специализированных преобразователей. Это является, в частности, истинным для рассеянных поздних отражений. Свойства тактирования и уровней рассеянных отражений могут быть моделированы посредством использования "реверберированных" сигналов в качестве входных сигналов громкоговорителей. Если они достаточно декоррелированы, число и местоположение громкоговорителей, используемых для воспроизведения, определяет то, воспринимается или нет звуковое поле как рассеянное. Цель состоит в том, чтобы вызывать восприятие непрерывного, рассеянного звукового поля с использованием только дискретного числа преобразователей. Иными словами, создаются звуковые поля, где ни одно направление поступления звука не может быть оценено, и, в частности, не может быть локализован ни один преобразователь. Субъективная рассеянность синтетических звуковых полей может быть оценена в субъективных тестах.
Воспроизведение стереофонического звука нацелено на вызывание восприятия непрерывного звукового поля с использованием только дискретного числа преобразователей. Характеристиками, требуемыми в наибольшей степени, являются направленная устойчивость локализованных источников и реалистичное воспроизведение окружающего слухового окружения. Большая часть форматов, используемых сегодня для того, чтобы сохранять или транспортировать стереофонические записи, основана на канале. Каждый канал передает сигнал, который предназначен для воспроизведения по ассоциированному громкоговорителю в конкретной позиции. Конкретное слуховое изображение рассчитывается во время процесса записи или микширования. Это изображение точно воссоздается, если компоновка громкоговорителей, используемая для воспроизведения, напоминает целевую компоновку, для которой рассчитана запись.
Число подходящих каналов передачи и воспроизведения постоянно растет, и при появлении каждого нового формата звуковоспроизведения возникает потребность выполнять воспроизведение контента в традиционном формате в фактической системе воспроизведения. Алгоритмы повышающего микширования (с увеличением числа каналов) представляют собой решение для осуществления этой потребности за счет вычисления сигнала с большим числом каналов из традиционного сигнала. Ряд алгоритмов повышающего стереомикширования предложен в литературе, например, в работах Carlos Avendano и Jean-Marc Jot "A frequency-domain approach to multichannel upmix", Journal of the Audio Engineering Society, издание 52, № 7/8, стр. 740-749, 2004 год; Christof Faller "Multiple-loudspeaker playback of stereo signals", Journal of the Audio Engineering Society, издание 54, № 11, стр. 1051-1064, ноябрь 2006 года; John Usherand Jacob Benesty "Enhancement of spatial sound quality: A new reverberation-extraction audio upmixer", IEEE Transactions on Audio, Speech and Language Processing, издание 15, № 7, стр. 2141-2150, сентябрь 2007 года. Большинство этих алгоритмов основано на разложении на прямые/окружающие сигналы с последующим воспроизведением, адаптированным к целевой компоновке громкоговорителей.
Описанные разложения на прямые/окружающие сигналы не являются легко применимыми к многоканальным сигналам объемного звучания. Непросто сформулировать модель для сигналов и фильтрацию для того, чтобы получать из N аудиоканалов соответствующие N прямых звуковых и N окружающих звуковых каналов. Простая модель для сигналов, используемая в стереослучае (см., например, работу Christof Faller, "Multiple-loudspeaker playback of stereo signals", Journal of the Audio Engineering Society, издание 54, № 11, стр. 1051-1064, ноябрь 2006 года), при условии что прямой звук, который должен быть коррелирован между всеми каналами, не охватывает отношений разнесения между каналами, которые могут существовать между каналами сигналов объемного звучания.
Общая цель воспроизведения стереофонического звука состоит в том, чтобы вызывать восприятие непрерывного звукового поля с использованием только ограниченного числа каналов передачи и преобразователей. Два громкоговорителя являются минимальным требованием для пространственного воспроизведения звука. Современные потребительские системы зачастую предлагают большее число каналов воспроизведения. По существу, стереофонические сигналы (независимые от числа каналов) записываются или смешиваются таким образом, что для каждого источника прямой звук становится когерентным (=зависимым от) с числом каналов с конкретными направленными метками, и отраженные независимые звуки становятся числом каналов, определяющих метки для кажущейся ширины источника и кругового охватывания слушателя. Корректное восприятие целевого слухового изображения обычно является возможным только в идеальной точке наблюдения в компоновке для воспроизведения, для которой предназначена запись. Добавление дополнительных динамиков в данную компоновку громкоговорителей обычно обеспечивает более реалистичное восстановление/моделирование естественного звукового поля. Для того чтобы использовать в полной мере расширенную компоновку громкоговорителей, если входные сигналы предоставляются в другом формате, либо для того, чтобы обрабатывать различно воспринимаемые части входного сигнала, они должны быть отдельно доступными. Это подробное описание поясняет способ, чтобы разделять зависимые и независимые компоненты стереофонических записей, содержащих произвольное число нижеуказанных входных каналов.
Разложение аудиосигналов на различно воспринимаемые компоненты необходимо для высококачественной модификации сигналов, улучшения, адаптивного воспроизведения и перцепционного кодирования. Недавно предложен ряд способов, которые дают возможность обработки и/или извлечения различных по восприятию компонентов сигнала из двухканальных входных сигналов. Поскольку входные сигналы более чем с двумя каналами становятся все более распространенными, описанные обработки требуются также для многоканальных входных сигналов. Тем не менее, большинство принципов, описанных для двухканального входного сигнала, не могут быть легко переложены на работу с входными сигналами с произвольным числом каналов.
Если требуется выполнять анализ сигналов для прямых и окружающих частей, например, с помощью 5.1-канального сигнала объемного звучания, имеющего левый канал, центральный канал, правый канал, левый канал объемного звучания, правый канал объемного звучания и улучшение низких частот (сабвуфер), совсем не очевидно, как следует применять анализ прямых/окружающих сигналов. Можно вспомнить о сравнении каждой пары из шести каналов, приводящих к иерархической обработке, которая имеет, в конечном счете, до 15 различных операций сравнения. Затем, когда выполнены все из этих 15 операций сравнения, в которых каждый канал сравнивается с каждым другим каналом, следует определять то, как необходимо оценивать 15 результатов. Это отнимает много времени, результаты с трудом поддаются интерпретации и вследствие значительного объема ресурсов обработки не применимы, например, для вариантов применения для разделения на прямые/окружающие сигналы в реальном времени или, в общем, для разложений сигналов, которые могут быть, например, использованы в контексте повышающего микширования или любых других операций аудиообработки.
В работе M. M. Goodwin и J. M. Jot "Primary-ambient signal decomposition and vector-based localization for spatial audio coding and enhancement", в Proc. Of ICASSP 2007, 2007 год, анализ главных компонентов применяется к сигналам входного канала с тем, чтобы выполнять разложение на первичные (=прямые) и окружающие сигналы.
Модели, используемые в работах Christof Faller "Multiple-loudspeaker playback of stereo signals", Journal of the Audio Engineering Society, издание 54, № 11, стр. 1051-1064, ноябрь 2006 года, и C. Faller "A highly directive 2-capsule based microphone system", в Preprint 123rd Conv. Aud. Eng. Soc., октябрь 2007 года, предполагают декоррелированный или частично коррелированный рассеянный звук в стереосигналах и сигналах микрофонов соответственно. Они выводят фильтры для извлечения рассеянного/окружающего сигнала с учетом этого допущения. Эти подходы ограничены одно- и двухканальными аудиосигналами.
Дополнительным ссылочным материалом является C. Avendano и J.-M. Jot "A frequency-domain approach to multichannel upmix", Journal of the Audio Engineering Society, издание 52, № 7/8, стр. 740-749, 2004 год. Ссылочный материал M. M. Goodwin и J. M. Jot "Primary-ambient signal decomposition and vector-based localization for spatial audio coding and enhancement", в Proc. Of ICASSP 2007, 2007 год, содержит следующие комментарии по ссылочному материалу Avendano, Jot. Ссылочный материал предоставляет подход, который заключает в себе создание частотно-временной маски для того, чтобы извлекать окружающую часть из входного стереосигнала. Тем не менее, маска основана на взаимной корреляции между сигналами левого и правого каналов, так что этот подход не является сразу применимым к проблеме извлечения окружающей части из произвольного многоканального входного сигнала. Использование любого такого способа на основе корреляции для этого случая высшего порядка должно приводить к необходимости иерархического попарного корреляционного анализа, что влечет за собой значительные вычислительные затраты или некоторое альтернативное измерение многоканальной корреляции.
Пространственное воспроизведение на основе импульсной характеристики (SIRR) (работа Juha Merimaa и Ville Pulkki "Spatial impulse response rendering", в Proc. of the 7th Int. Conf. on Digital Audio Effects (DAFx'04), 2004 год) оценивает прямой звук с направлением и рассеянный звук в импульсных характеристиках в B-формате. Во многом аналогично SIRR, направленное кодирование аудио (DirAC) (работа Ville Pulkki "Spatial sound reproduction with directional audio coding", Journal of the Audio Engineering Society, издание 55, № 6, стр. 503-516, июнь 2007 года), реализует аналогичный анализ прямого и рассеянного звука для непрерывных аудиосигналов в B-формате.
Подход, представленный в работе Julia Jakka "Binaural to Multichannel Audio Upmix", Ph.D. thesis, Master's Thesis, Helsinki University of Technology, 2005 год, описывает повышающее микширование с использованием бинауральных сигналов в качестве входного сигнала.
Ссылочный материал Boaz Rafaely "Spatially Optimal Wiener Filtering in the Reverberant Sound Field", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics 2001, 21-24 октября 2001 года, New Paltz, Нью-Йорк, описывает выведение фильтров Винера, которые являются пространственно оптимальными для реверберирующих звуковых полей. Обеспечивается применение к подавлению шумов в компоновке с двумя микрофонами в реверберационных помещениях. Оптимальные фильтры, которые выведены из пространственной корреляции рассеянных звуковых полей, захватывают локальный характер звуковых полей и, следовательно, имеют низший порядок и потенциально большую пространственную надежность, чем традиционные адаптивные фильтры подавления шумов в реверберационных помещениях. Представляются формулы для неограниченных и причинно ограниченных оптимальных фильтров, и примерное применение к улучшению речи с двумя микрофонами демонстрируется с использованием компьютерного моделирования.
Цель настоящего изобретения заключается в том, чтобы предоставлять усовершенствованный принцип для разложения входного сигнала.
Эта цель достигается посредством устройства для разложения входного сигнала по п. 1, способа разложения входного сигнала по п. 14 или компьютерной программы по п. 15.
Настоящее изобретение основано на том факте, что для разложения многоканального сигнала преимущественным является подход с условием не выполнять анализ относительно различных компонентов сигнала для самого входного сигнала, т.е. для сигнала, имеющего, по меньшей мере, три входных канала. Вместо этого многоканальный входной сигнал, имеющий, по меньшей мере, три входных канала, обрабатывается посредством понижающего микшера для понижающего микширования входного сигнала, чтобы получать микшированный с понижением сигнал. Микшированный с понижением сигнал имеет число каналов понижающего микширования, которое меньше числа входных каналов и предпочтительно равняется двум. Затем выполняется анализ входного сигнала для микшированного с понижением сигнала, а не для самого входного сигнала, и анализ приводит к получению результата анализа. Тем не менее, этот результат анализа не применяется к микшированному с понижением сигналу, а применяется к входному сигналу или, альтернативно, к сигналу, выведенному из входного сигнала, причем этот сигнал, выведенный из входного сигнала, может быть сигналом повышающего микширования или, в зависимости от числа каналов входных сигналов, также сигналом понижающего микширования, но этот сигнал, выведенный из входного сигнала, должен отличаться от микшированного с понижением сигнала, для которого выполнен анализ. Когда, например, рассматривается случай, в котором входной сигнал является 5.1-канальным сигналом, то сигнал понижающего микширования, для которого выполняется анализ, может быть понижающим стереомикшированием, имеющим два канала. Результаты анализа затем применяются непосредственно к входному сигналу 5.1, к более высокому повышающему микшированию, такому как выходной сигнал 7.1, или к многоканальному понижающему микшированию входного сигнала, имеющего, например, только три канала, которые представляют собой левый канал, центральный канал и правый канал, когда под рукой только трехканальное устройство для воспроизведения аудио. Тем не менее, в любом случае сигнал, для которого применяются результаты анализа посредством процессора сигналов, отличается от микшированного с понижением сигнала, для которого выполнен анализ, и типично имеет больше каналов, чем микшированный с понижением сигнал, для которого выполняется анализ относительно компонентов сигнала.
Так называемый "косвенный" анализ/обработка является возможным вследствие того факта, что можно предположить, что любые компоненты сигнала в отдельных входных каналах также возникают в микшированных с понижением каналах, поскольку понижающее микширование типично состоит из суммирования входных каналов различными способами. Одно простое понижающее микширование, например, заключается в том, что отдельные входные каналы взвешиваются по мере необходимости посредством правила понижающего микширования или матрицы понижающего микширования и затем суммируются после взвешивания. Альтернативное понижающее микширование состоит из фильтрации входных каналов с помощью определенных фильтров, таких как HRTF-фильтры, и понижающее микширование выполняется посредством использования фильтрованных сигналов, т.е. сигналов, фильтруемых посредством HRTF-фильтров, как известно в данной области техники. Для пятиканального входного сигнала требуется 10 HRTF-фильтров, и выходные сигналы HRTF-фильтров для левой части/левого уха суммируются, а выходные сигналы HRTF-фильтров для фильтров правых каналов суммируются для правого уха. Альтернативные понижающие микширования могут применяться для того, чтобы уменьшать число каналов, которые должны быть обработаны в анализаторе сигналов.
Следовательно, варианты осуществления настоящего изобретения описывают новый принцип для того, чтобы извлекать различные по восприятию компоненты из произвольных входных сигналов, посредством рассмотрения анализируемого сигнала в то время, когда результат анализа применяется к входному сигналу. Такой анализируемый сигнал может быть получен, например, посредством рассмотрения модели распространения сигналов каналов или громкоговорителей в уши. Это частично обусловлено тем фактом, что слуховая система человека также использует исключительно два сенсора (левое и правое ухо) для того, чтобы оценивать звуковые поля. Таким образом, извлечение различных по восприятию компонентов, по существу, сводится к рассмотрению анализируемого сигнала, который обозначается далее как понижающее микширование. В этом документе термин "понижающее микширование" используется для любой предварительной обработки многоканального сигнала, приводящей в результате к анализируемому сигналу (она может включать в себя, например, модель распространения, HRTF, BRIR, простое понижающее микширование на основе перекрестных коэффициентов).
Зная формат предоставленного входного сигнала и требуемых характеристик сигнала, который должен быть извлечен, могут быть заданы идеальные межканальные взаимосвязи для микшированного с понижением формата, и по сути, анализ этого анализируемого сигнала является достаточным для того, чтобы формировать весовую маску (или несколько весовых масок) для разложения многоканальных сигналов.
В варианте осуществления, многоканальная проблема упрощается посредством использования понижающего стереомикширования сигнала объемного звучания и применения анализа прямых/окружающих сигналов к понижающему микшированию. На основе результата, т.е. кратковременных оценок спектров мощности прямых и окружающих звуков, фильтры выводятся для разложения N-канального сигнала на N прямых звуковых и N окружающих звуковых каналов.
Настоящее изобретение является выгодным вследствие того факта, что анализ сигналов применяется для меньшего числа каналов, что существенно сокращает требуемое время обработки, так что идея изобретения может быть применена даже в вариантах применения для повышающего микширования или понижающего микширования либо любой другой операции обработки сигналов в реальном времени, при которой требуются различные компоненты, к примеру различные по восприятию компоненты сигнала.
Дополнительный полезный эффект настоящего изобретения состоит в том, что хотя выполняется понижающее микширование, выяснено, что это не ухудшает обнаруживаемость различных по восприятию компонентов во входном сигнале. Другими словами, даже когда микшируются с понижением входные каналы, тем не менее, отдельные компоненты сигнала могут быть разделены в значительной степени. Кроме того, понижающее микширование работает как некоторый "сбор" всех компонентов сигналов всех входных каналов в двух каналах, и один анализ, применяемый для этих "собранных" микшированных с понижением сигналов, предоставляет уникальный результат, который не должен более интерпретироваться и может непосредственно использоваться для обработки сигналов.
В предпочтительном варианте осуществления конкретная эффективность в целях разложения сигналов достигается, когда анализ сигналов выполняется на основе заранее вычисленной частотно-зависимой кривой подобия в качестве эталонной кривой. Термин "подобие" включает в себя корреляцию и когерентность, при этом, в строгом математическом смысле, корреляция вычисляется между двумя сигналами без дополнительного сдвига по времени, и когерентность вычисляется посредством сдвига двух сигналов по времени/фазе, так что сигналы имеют максимальную корреляцию, и фактическая корреляция по частоте затем вычисляется с применяемым сдвигом по времени/фазе. В этом тексте считается, что подобие, корреляция и когерентность означают одно и то же, т.е. количественную степень подобия между двумя сигналами, к примеру, когда более высокое абсолютное значение подобия означает, что два сигнала являются в большей степени подобными, а более низкое абсолютное значение подобия означает, что два сигнала являются в меньшей степени подобными.
Показано, что использование такой корреляционной кривой в качестве эталонной кривой обеспечивает очень эффективно реализуемый анализ, поскольку кривая может использоваться для простых операций сравнения и/или вычислений весовых коэффициентов. Использование заранее вычисленной частотно-зависимой корреляционной кривой позволяет выполнять только простые вычисления, а не более сложные операции фильтрации Винера. Кроме того, применение частотно-зависимой корреляционной кривой является в известной степени выгодным вследствие того факта, что проблема разрешается не со статистической точки зрения, а разрешается более аналитическим способом, поскольку вводится максимально возможный объем информации из текущей компоновки с тем, чтобы получать решение проблемы. Дополнительно, гибкость этой процедуры является очень высокой, поскольку эталонная кривая может быть получена посредством множества различных способов. Один способ заключается в том, чтобы фактически измерять два или более сигнала в определенной компоновке и затем вычислять корреляционную кривую по частоте из измеренных сигналов. Следовательно, можно излучать независимые сигналы из различных динамиков или сигналы, имеющие определенную степень зависимости, которая является заранее известной.
Другая предпочтительная альтернатива заключается в том, чтобы просто вычислять корреляционную кривую в соответствии с допущением относительно независимых сигналов. В этом случае сигналы фактически вообще не являются обязательными, поскольку результат является независимым от сигнала.
Разложение сигналов с использованием эталонной кривой для анализа сигналов может применяться для стереообработки, т.е. для разложения стереосигнала. Альтернативно, эта процедура также может быть реализована с помощью понижающего микшера для разложения многоканальных сигналов. Альтернативно, эта процедура также может быть реализована для многоканальных сигналов без использования понижающего микшера, когда предусмотрена попарная оценка сигналов иерархическим способом.
Предпочтительные варианты осуществления настоящего изобретения описаны далее со ссылками на прилагаемые чертежи, на которых:
Фиг.1 является блок-схемой для иллюстрации устройства для разложения входного сигнала с использованием понижающего микшера;
Фиг.2 является блок-схемой, иллюстрирующей реализацию устройства для разложения сигнала, имеющего, по меньшей мере, три входных канала, с использованием анализатора с заранее вычисленной частотно-зависимой корреляционной кривой в соответствии с дополнительным аспектом изобретения;
Фиг.3 иллюстрирует дополнительную предпочтительную реализацию настоящего изобретения при обработке в частотной области для понижающего микширования, анализа и обработки сигналов;
Фиг.4 иллюстрирует примерную заранее вычисленную частотно-зависимую корреляционную кривую для эталонной кривой для анализа, указываемой на фиг.1 или фиг.2;
Фиг.5 иллюстрирует блок-схему, иллюстрирующую последующую обработку для того, чтобы извлекать независимые компоненты;
Фиг.6 иллюстрирует дополнительную реализацию блок-схемы для последующей обработки, в которой извлекаются независимые рассеянные, независимые прямые и прямые компоненты;
Фиг.7 иллюстрирует блок-схему, реализующую понижающий микшер в качестве формирователя анализируемых сигналов;
Фиг.8 иллюстрирует блок-схему последовательности операций способа для указания предпочтительного способа обработки в анализаторе сигналов по фиг.1 или фиг.2;
Фиг.9А-9Е иллюстрируют различные заранее вычисленные частотно-зависимые корреляционные кривые, которые могут быть использованы в качестве эталонных кривых для нескольких различных компоновок с различными числами и позициями источников звука (к примеру, громкоговорителей);
Фиг.10 иллюстрирует блок-схему для иллюстрации другого варианта осуществления для оценки рассеянности, в котором рассеянные компоненты являются компонентами, которые должны быть разложены; и
Фиг.11A и 11B иллюстрируют примерные уравнения для применения анализа сигналов без частотно-зависимой корреляционной кривой, но с базированием на подходе на основе фильтрации Винера.
Фиг.1 иллюстрирует устройство для разложения входного сигнала 10, имеющего, по меньшей мере, три входных канала или, в общем, N входных каналов. Эти входные каналы вводятся в понижающий микшер 12 для понижающего микширования входного сигнала, чтобы получать микшированный с понижением сигнал 14, при этом понижающий микшер 12 выполнен с возможностью понижающего микширования так, что число каналов понижающего микширования микшированного с понижением сигнала 14, которое указывается посредством "m", составляет, по меньшей мере, два и меньше числа входных каналов входного сигнала 10. m каналов понижающего микширования вводятся в анализатор 16 для анализа микшированного с понижением сигнала, чтобы выводить результат 18 анализа. Результат 18 анализа вводится в процессор 20 сигналов, причем процессор сигналов выполнен с возможностью обработки входного сигнала 10 или сигнала, выведенного из входного сигнала посредством модуля 22 выведения сигналов с использованием результата анализа, при этом процессор 20 сигналов выполнен с возможностью применения результатов анализа к входным каналам или к каналам сигнала 24, выведенного из входного сигнала, чтобы получать разложенный сигнал 26.
В варианте осуществления, проиллюстрированном на фиг.1, число входных каналов составляет n, число каналов понижающего микширования составляет m, число выведенных каналов составляет l и число выходных каналов равно l, когда выведенный сигнал, а не входной сигнал обрабатывается посредством процессора сигналов. Альтернативно, когда модуля 22 выведения сигналов не существует, то входной сигнал обрабатывается непосредственно процессором сигналов, и в таком случае число каналов разложенного сигнала 26, указываемое посредством "l" на фиг.1, равно n. Следовательно, фиг.1 иллюстрирует два различных примера. Один пример не имеет модуля 22 выведения сигналов, и входной сигнал непосредственно применяется к процессору 20 сигналов. Другой пример заключается в том, что реализуется модуль 22 выведения сигналов, и после этого выведенный сигнал 24, а не входной сигнал 10 обрабатывается посредством процессора 20 сигналов. Модуль выведения сигналов, например, может быть микшером аудиоканалов, таким как повышающий микшер для формирования дополнительных выходных каналов. В этом случае l должно превышать n. В другом варианте осуществления модуль выведения сигналов может быть другим аудиопроцессором, который выполняет взвешивание, задержку или какую-либо еще обработку для входных каналов, и в этом случае число выходных каналов l модуля 22 выведения сигналов должно быть равно числу n входных каналов. В дополнительной реализации модуль выведения сигналов может быть понижающим микшером, который уменьшает число каналов от входного сигнала до выведенного сигнала. В этой реализации предпочтительно, чтобы число l по-прежнему превышало число m микшированных с понижением каналов, чтобы иметь одно из преимуществ настоящего изобретения, т.е. то, что анализ сигналов применяется к меньшему числу канальных сигналов.
Анализатор выполнен с возможностью анализировать микшированный с понижением сигнал относительно различных по восприятию компонентов. Эти различные по восприятию компоненты могут быть независимыми компонентами в отдельных каналах, с одной стороны, и зависимыми компонентами, с другой стороны. Альтернативные компоненты сигнала, которые должны быть проанализированы посредством настоящего изобретения, являются прямыми компонентами, с одной стороны, и окружающими компонентами, с другой стороны. Существует множество других компонентов, которые могут отделяться посредством настоящего изобретения, таких как речевые компоненты от музыкальных компонентов, компоненты шума от речевых компонентов, компоненты шума от музыкальных компонентов, компоненты высокочастотного шума относительно компонентов низкочастотного шума, в сигналах с несколькими высотами тона, компоненты, предоставляемые посредством различных инструментов, и т.д. Это обусловлено тем фактом, что существуют мощные инструментальные средства анализа, такие как фильтрация Винера, как пояснено в контексте фиг.11A, 11B, или другие процедуры анализа, такие как использование частотно-зависимой корреляционной кривой, как пояснено в контексте, например, фиг.8 в соответствии с настоящим изобретением.
Фиг.2 иллюстрирует другой аспект, в котором анализатор реализуется для использования заранее вычисленной частотно-зависимой корреляционной кривой 16. Таким образом, устройство для разложения сигнала 28, имеющего множество каналов, содержит анализатор 16 для анализа корреляции между двумя каналами анализируемого сигнала, идентичного входному сигналу или связанного с входным сигналом, например, посредством операции понижающего микширования, как проиллюстрировано в контексте фиг.1. Анализируемый сигнал, проанализированный посредством анализатора 16, имеет, по меньшей мере, два анализируемых канала, и анализатор 16 выполнен с возможностью использования заранее вычисленной частотно-зависимой корреляционной кривой в качестве эталонной кривой для того, чтобы определять результат 18 анализа. Процессор 20 сигналов может работать аналогично тому, что пояснено в контексте фиг.1, и выполнен с возможностью обработки анализируемого сигнала или сигнала, выведенного из анализируемого сигнала посредством модуля 22 выведения сигналов, причем модуль 22 выведения сигналов может быть реализован аналогично тому, что пояснено в контексте модуля 22 выведения сигналов по фиг.1. Альтернативно, процессор сигналов может обрабатывать сигнал, из которого выведен анализируемый сигнал, и обработка сигналов использует результат анализа для того, чтобы получать разложенный сигнал. Следовательно, в варианте осуществления по фиг.2 входной сигнал может быть идентичным анализируемому сигналу, и в этом случае анализируемый сигнал также может быть стереосигналом, имеющим всего два канала, как проиллюстрировано на фиг.2. Альтернативно, анализируемый сигнал может быть выведен из входного сигнала посредством любого вида обработки, такой как понижающее микширование, как описано в контексте фиг.1, либо посредством любой другой обработки, такой как повышающее микширование и т.п. Дополнительно, процессор 20 сигналов может быть полезным с целью применять обработку сигналов к сигналу, идентичному сигналу, введенному в анализатор, или процессор сигналов может применять обработку сигналов к сигналу, из которого выведен анализируемый сигнал, к примеру, как указано в контексте фиг.1, или процессор сигналов может применять обработку сигналов к сигналу, который выведен из анализируемого сигнала, к примеру, посредством повышающего микширования и т.п.
Следовательно, для процессора сигналов существуют различные возможности, и все эти возможности являются выгодными вследствие уникальной операции анализатора с использованием заранее вычисленной частотно-зависимой корреляционной кривой в качестве эталонной кривой для того, чтобы определять результат анализа.
Далее поясняются дополнительные варианты осуществления. Следует отметить, что, как пояснено в контексте фиг.2, рассматривается даже использование двухканального анализируемого сигнала (без понижающего микширования). Следовательно, настоящее изобретение, как пояснено в различных аспектах в контексте фиг.1 и фиг.2, которые могут быть использованы совместно или в качестве отдельных аспектов, понижающее микширование может быть обработано посредством анализатора, либо двухканальный сигнал, который, вероятно, не сформирован посредством понижающего микширования, может быть обработан посредством анализатора сигналов с использованием заранее вычисленной эталонной кривой. В этом контексте следует отметить, что последующее описание аспектов реализации может применяться к обоим аспектам, схематично проиллюстрированным на фиг.1 и фиг.2, даже когда некоторые признаки описываются только для одного аспекта, а не для обоих. Если, например, рассматривается фиг.3, становится очевидным, что признаки частотной области по фиг.3 описываются в контексте аспекта, проиллюстрированного на фиг.1, но очевидно, что частотно-временное преобразование, как описано ниже относительно фиг.3, и обратное преобразование также может применяться к реализации на фиг.2, которая не имеет понижающего микшера, но которая имеет указанный анализатор, который использует заранее вычисленную частотно-зависимую корреляционную кривую.
В частности, частотно-временной преобразователь должен быть размещен с возможностью преобразовывать анализируемый сигнал до того, как анализируемый сигнал вводится в анализатор, и преобразователь частота/время должен быть размещен на выходе процессора сигналов, чтобы преобразовывать обработанный сигнал обратно во временную область. Когда имеется модуль выведения сигналов, частотно-временной преобразователь может быть размещен на входе модуля выведения сигналов, так что модуль выведения сигналов, анализатор и процессор сигналов работают в частотной/поддиапазонной области. В этом контексте, частота и поддиапазон частот по существу означают часть в частоте частотного представления.
Кроме того, очевидно, что анализатор на фиг.1 может быть реализован многими различными способами, но этот анализатор в одном варианте осуществления также реализуется в качестве анализатора, поясненного на фиг.2, т.е. в качестве анализатора, который использует заранее вычисленную частотно-зависимую корреляционную кривую в качестве альтернативы фильтрации Винера или любому другому аналитическому способу.
Вариант осуществления по фиг.3 применяет процедуру понижающего микширования к произвольному входному сигналу, чтобы получать двухканальное представление. Выполняется анализ в частотно-временной области, и вычисляются весовые маски, которые умножаются на частотно-временное представление входного сигнала, как проиллюстрировано на фиг.3.
На чертеже T/F обозначает частотно-временное преобразование; обычно кратковременное преобразование Фурье (STFT). iT/F обозначает соответствующее обратное преобразование.  являются входными сигналами временной области, где n представляет собой временной индекс.
являются входными сигналами временной области, где n представляет собой временной индекс.  обозначают коэффициенты частотного разложения, где
обозначают коэффициенты частотного разложения, где  представляет собой временной индекс разложения, а i представляет собой частотный индекс разложения. являются двумя каналами микшированного с понижением сигнала.
представляет собой временной индекс разложения, а i представляет собой частотный индекс разложения. являются двумя каналами микшированного с понижением сигнала.


 является вычисленным взвешиванием.
является вычисленным взвешиванием.  являются взвешенными частотными разложениями каждого канала. Hij(i) являются коэффициентами понижающего микширования, которые могут быть действительнозначными или комплекснозначными, и коэффициенты могут быть постоянными во времени или зависимыми от времени. Следовательно, коэффициенты понижающего микширования могут быть просто константами либо фильтрами, такими как HRTF-фильтры, реверберационные фильтры или аналогичные фильтры.
являются взвешенными частотными разложениями каждого канала. Hij(i) являются коэффициентами понижающего микширования, которые могут быть действительнозначными или комплекснозначными, и коэффициенты могут быть постоянными во времени или зависимыми от времени. Следовательно, коэффициенты понижающего микширования могут быть просто константами либо фильтрами, такими как HRTF-фильтры, реверберационные фильтры или аналогичные фильтры.



На фиг.3 проиллюстрирован случай применения идентичного взвешивания ко всем каналам.



 являются выходными сигналами временной области, содержащими извлеченные компоненты сигнала. (Входной сигнал может иметь произвольное число каналов (N), сформированных для произвольной целевой компоновки громкоговорителей для воспроизведения. Понижающее микширование может включать в себя HRTF, чтобы получать сигналы, поступающие в уши, моделирование фильтров слышимости и т.д. Понижающее микширование также может быть выполнено во временной области).
являются выходными сигналами временной области, содержащими извлеченные компоненты сигнала. (Входной сигнал может иметь произвольное число каналов (N), сформированных для произвольной целевой компоновки громкоговорителей для воспроизведения. Понижающее микширование может включать в себя HRTF, чтобы получать сигналы, поступающие в уши, моделирование фильтров слышимости и т.д. Понижающее микширование также может быть выполнено во временной области).
В варианте осуществления, вычисляется разность между эталонной корреляцией (В этом тексте, термин "корреляция" используется в качестве синонима для межканального подобия и в силу этого также может включать в себя оценки сдвигов по времени, для которых обычно используется термин "когерентность". Даже если оцениваются сдвиги во времени, результирующее значение может иметь знак. Обычно, когерентность задается как имеющая только положительные значения) в качестве функции от частоты ( ) и фактической корреляцией микшированного с понижением входного сигнала (
) и фактической корреляцией микшированного с понижением входного сигнала ( ). В зависимости от отклонения фактической кривой от эталонной кривой, вычисляется весовой коэффициент для каждого частотно-временного фрагмента, указывающий то, содержит он зависимые или независимые компоненты. Полученное частотно-временное взвешивание указывает независимые компоненты и может уже применяться к каждому каналу входного сигнала, чтобы давать в результате многоканальный сигнал (число каналов равно числу входных каналов), включающий в себя независимые части, которые могут восприниматься как различные или рассеянные.
). В зависимости от отклонения фактической кривой от эталонной кривой, вычисляется весовой коэффициент для каждого частотно-временного фрагмента, указывающий то, содержит он зависимые или независимые компоненты. Полученное частотно-временное взвешивание указывает независимые компоненты и может уже применяться к каждому каналу входного сигнала, чтобы давать в результате многоканальный сигнал (число каналов равно числу входных каналов), включающий в себя независимые части, которые могут восприниматься как различные или рассеянные.
Эталонная кривая может быть задана различными способами.
Примерами являются:
- Идеальная теоретическая эталонная кривая для идеализированного двух- или трехмерного рассеянного звукового поля, состоящего из независимых компонентов.
- Идеальная кривая, достижимая при эталонной целевой компоновке громкоговорителей для данного входного сигнала (например, стандартной стереокомпоновке с азимутальными углами (±30°) или стандартной пятиканальной компоновке согласно ITU-R BS.775 с азимутальными углами (0°, ±30°, ±110°).
- Идеальная кривая для фактической текущей компоновки громкоговорителей (Фактические позиции могут измеряться или быть известны через пользовательский ввод. Эталонная кривая может быть вычислена при допущении воспроизведения независимых сигналов по данным громкоговорителям).
- Фактическая частотно-зависимая кратковременная мощность каждого входного канала может быть включена в вычисление эталонной кривой.
При наличии частотно-зависимой эталонной кривой (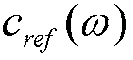 ) может быть задано верхнее пороговое значение (
) может быть задано верхнее пороговое значение (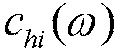 ) и нижнее пороговое значение (
) и нижнее пороговое значение ( ) (см. фиг.4). Пороговые кривые могут совпадать с эталонной кривой (
) (см. фиг.4). Пороговые кривые могут совпадать с эталонной кривой ( ) или задаваться при допущении пороговых значений обнаруживаемости, либо они могут быть выведены эвристически.
) или задаваться при допущении пороговых значений обнаруживаемости, либо они могут быть выведены эвристически.
Если отклонение фактической кривой от эталонной кривой находится в пределах границ, заданных посредством пороговых значений, фактический элемент выборки получает взвешивание, указывающее независимые компоненты. Выше верхнего порогового значения или ниже нижнего порогового значения элемент выборки указывается как зависимый. Этот индикатор может быть двоичным или постепенным (т.е. соответствующим функции на основе мягкого решения). В частности, если верхнее и нижнее пороговое значение совпадает с эталонной кривой, применяемое взвешивание непосредственно связано с отклонением от эталонной кривой.
Со ссылкой на фиг.3, ссылка с номером 32 иллюстрирует частотно-временной преобразователь, который может быть реализован как кратковременное преобразование Фурье или как любой вид гребенки фильтров, формирующей подполосные сигналы, такой как QMF-гребенка фильтров и т.п. Независимо от подробной реализации частотно-временного преобразователя 32, выводом частотно-временного преобразователя для каждого входного канала xi является спектр для каждого периода времени входного сигнала. Следовательно, частотно-временной процессор 32 может быть реализован с возможностью всегда принимать блок входных выборок отдельного сигнала канала и вычислять частотное представление, к примеру FFT-спектр, имеющий спектральные линии, идущие от нижней частоты к верхней частоте. Затем для следующего блока времени выполняется идентичная процедура, так что в конечном счете последовательность кратковременных спектров вычисляется для каждого сигнала входного канала. Определенный частотный диапазон определенного спектра, связанного с определенным блоком входных выборок входного канала, называется "частотно-временным фрагментом", и предпочтительно анализ в анализаторе 16 выполняется на основе этих частотно-временных фрагментов. Следовательно, анализатор принимает, в качестве входного сигнала для одного частотно-временного фрагмента, спектральное значение на первой частоте для определенного блока входных выборок первого канала D1 понижающего микширования и принимает значение для идентичной частоты и идентичного блока (во времени) второго канала D2 понижающего микширования.
Затем, что касается примера, проиллюстрированного на фиг.8, анализатор 16 выполнен с возможностью определения (80) значения корреляции между двумя входными каналами в расчете на каждый поддиапазон частот и временным блоком, т.е. значения корреляции для частотно-временного фрагмента. Затем анализатор 16 извлекает, в варианте осуществления, проиллюстрированном относительно фиг.2 или фиг.4, значение корреляции (82) для соответствующей подполосы частот из эталонной корреляционной кривой. Когда, например, поддиапазон частот является поддиапазоном частот, указываемым как 40 на фиг.4, то этап 82 приводит к значению 41, указывающему корреляцию от -1 до +1, и значение 41 в таком случае представляет собой извлеченное значение корреляции. Затем, на этапе 83, результат для поддиапазона частот с использованием определенного значения корреляции из этапа 80 и извлеченного значения корреляции 41, полученного на этапе 82, обрабатывается посредством выполнения сравнения и последующего нахождения решения либо трактуется посредством вычисления фактической разности. Результат может быть, как пояснено выше, двоичным результатом, сообщающим, что фактический частотно-временной фрагмент, рассматриваемый в сигнале понижающего микширования/анализируемом сигнале, имеет независимые компоненты. Это решение находится, когда фактически определенное значение корреляции (на этапе 80) равно эталонному значению корреляции или достаточно близко к эталонному значению корреляции.
Тем не менее, когда определяется то, что определенное значение корреляции указывает более высокую абсолютную корреляцию, чем эталонное значение корреляции, то определяется то, что рассматриваемый частотно-временной фрагмент содержит зависимые компоненты. Следовательно, когда корреляция частотно-временного фрагмента сигнала понижающего микширования или анализируемого сигнала указывает более высокое абсолютное значение корреляции, чем эталонная кривая, то можно сказать, что компоненты в этом частотно-временном фрагменте зависят друг от друга. Тем не менее, когда корреляция указывается как очень близкая к эталонной кривой, то можно сказать, что компоненты являются независимыми. Зависимые компоненты могут принимать первое взвешенное значение, к примеру 1, и независимые компоненты могут принимать второе взвешенное значение, к примеру 0. Предпочтительно, как проиллюстрировано на фиг.4, высокие и низкие пороговые значения, которые разнесены от эталонной линии, используются для того, чтобы предоставлять лучший результат, что подходит больше, чем использование одной только эталонной кривой.
Кроме того, относительно фиг.4 следует отметить, что корреляция может варьироваться от -1 до +1. Корреляция, имеющая знак минус, дополнительно указывает сдвиг фаз в 180° между сигналами. Следовательно, также могут применяться другие корреляции, охватывающие только от 0 до 1, в которых отрицательная часть корреляции просто задается положительной. В этой процедуре в таком случае можно игнорировать сдвиг по времени или сдвиг фаз в целях определения корреляции.
Альтернативный способ вычисления результата состоит в том, чтобы фактически вычислять расстояние между значением корреляции, определенным на этапе 80, и извлеченным значением корреляции, полученным на этапе 82, и затем определять показатель от 0 до 1 в качестве весового коэффициента на основе расстояния. Хотя первая альтернатива (1) на фиг.8 приводит только к значениям 0 или 1, вариант (2) приводит к значениям от 0 до 1 и, в некоторых реализациях, является предпочтительным.
Процессор 20 сигналов на фиг.3 проиллюстрирован в качестве умножителей, и результаты анализа представляют собой просто определенный весовой коэффициент, который перенаправляется из анализатора в процессор сигналов, как проиллюстрировано в 84 на фиг.8, а затем применяется к соответствующему частотно-временному фрагменту входного сигнала 10. Когда, например, фактически рассматриваемый спектр является 20-м спектром в последовательности спектров и когда фактически рассматриваемый элемент разрешения по частоте является пятым элементом разрешения по частоте этого 20-го спектра, то частотно-временной фрагмент может указываться как (20, 5), где первое число указывает номер блока во времени, а второе число указывает элемент разрешения по частоте в этом спектре. Затем результат анализа для частотно-временного фрагмента (20, 5) применяется к соответствующему частотно-временному фрагменту (20, 5) каждого канала входного сигнала на фиг.3 или, когда реализуется модуль выведения сигналов, как проиллюстрировано на фиг.1, к соответствующему частотно-временному фрагменту каждого канала выведенного сигнала.
Далее подробнее поясняется вычисление эталонной кривой. Для настоящего изобретения, тем не менее, по существу, не важно, как выведена эталонная кривая. Это может быть произвольная кривая или, например, значения в таблице поиска, указывающие идеальную или требуемую взаимосвязь входных сигналов xj в сигнале D понижающего микширования либо (и в контексте фиг.2) в анализируемом сигнале. Следующее выведение является примерным.
Физическое рассеяние звукового поля может быть оценено посредством способа, представленного посредством работы Cook и др. (Richard K. Cook, R. V. Waterhouse, R. D. Berendt, Seymour Edelman и Jr. M.C. Thompson "Measurement of correlation coefficients in reverberant sound fields", Journal Of The Acoustical Society Of America, издание 27, № 6, стр. 1072-1077, ноябрь 1955 года), с использованием коэффициента (r) корреляции звукового давления в установившемся состоянии плоских волн в двух пространственно разделенных точках, как проиллюстрировано в следующем уравнении (4):
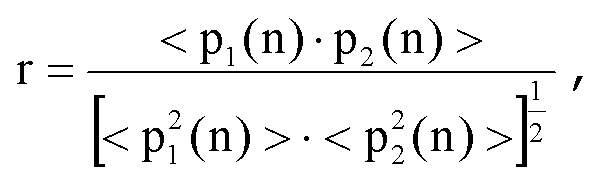
где  и
и  являются измерениями звукового давления в двух точках, n является временным индексом и < > обозначает усреднение во времени. В звуковом поле в установившемся состоянии могут быть выведены следующие взаимосвязи:
являются измерениями звукового давления в двух точках, n является временным индексом и < > обозначает усреднение во времени. В звуковом поле в установившемся состоянии могут быть выведены следующие взаимосвязи:
 (5)
(5)
 (6)
(6)
(для двумерных звуковых полей)
где d является расстоянием между двумя точками измерения, а  является волновым числом, причем λ представляет собой длину волны. (Физическая эталонная кривая r(k,d) уже может быть использована в качестве
является волновым числом, причем λ представляет собой длину волны. (Физическая эталонная кривая r(k,d) уже может быть использована в качестве  для последующей обработки.)
для последующей обработки.)
Показателем воспринимаемой рассеянности звукового поля является коэффициент интерауральной взаимной корреляции ( ), измеряемый в звуковом поле. Измерение подразумевает, что радиус между датчиками давления (соответственно, ушами) является фиксированным. При включении этого ограничения r становится функцией от частоты с угловой частотой
), измеряемый в звуковом поле. Измерение подразумевает, что радиус между датчиками давления (соответственно, ушами) является фиксированным. При включении этого ограничения r становится функцией от частоты с угловой частотой  , где c является скоростью звука в воздушной среде. Кроме того, сигналы давления отличаются от ранее рассматриваемых сигналов свободного поля вследствие эффектов отражения, дифракции и отклонения, вызываемых посредством ушных раковин, головы и торса слушателя. Эти эффекты, существенные для пространственного слухового восприятия, описываются посредством передаточных функций восприятия звука человеком (HRTF). С учетом этих воздействий результирующие сигналы давления на входах в уши представляют собой
, где c является скоростью звука в воздушной среде. Кроме того, сигналы давления отличаются от ранее рассматриваемых сигналов свободного поля вследствие эффектов отражения, дифракции и отклонения, вызываемых посредством ушных раковин, головы и торса слушателя. Эти эффекты, существенные для пространственного слухового восприятия, описываются посредством передаточных функций восприятия звука человеком (HRTF). С учетом этих воздействий результирующие сигналы давления на входах в уши представляют собой  и
и  . Для вычисления могут быть использованы измеряемые HRTF-данные, либо могут быть получены аппроксимации посредством использования аналитической модели (например, в работе Richard O. Duda и William L. Martens "Range dependence of the response of the spherical head model", Journal Of The Acoustical Society Of America, издание 104, № 5, стр. 3048-3058, ноябрь 1998 года).
. Для вычисления могут быть использованы измеряемые HRTF-данные, либо могут быть получены аппроксимации посредством использования аналитической модели (например, в работе Richard O. Duda и William L. Martens "Range dependence of the response of the spherical head model", Journal Of The Acoustical Society Of America, издание 104, № 5, стр. 3048-3058, ноябрь 1998 года).
Поскольку слуховая система человека выступает в качестве анализатора частоты с ограниченной частотной избирательностью, дополнительно может быть включена эта частотная избирательность. Слуховые фильтры предположительно имеют характер изменения, аналогичный перекрывающимся полосовым фильтрам. В нижеприведенном примерном пояснении, подход на основе критических полос частот используется для того, чтобы аппроксимировать эти перекрывающиеся полосы пропускания фильтра посредством фильтров с прямоугольной характеристикой. Эквивалентная прямоугольная полоса пропускания (ERB) может вычисляться как функция от центральной частоты (работа R Brian. Glasberg и Brian C. J. Moore "Derivation of auditory filter shapes from notched-noise data", Hearing Research, издание 47, стр. 103-138, 1990 год). С учетом того, что бинауральная обработка выполняется после слуховой фильтрации, должно быть вычислено для отдельных частотных каналов, давая в результате следующие частотно-зависимые сигналы давления:
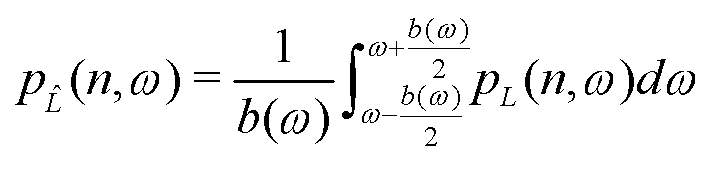


где пределы интегрирования задаются посредством пределов критической полосы частот согласно фактической центральной частоте ω. Коэффициенты 1/b(ω) могут использоваться или не использоваться в уравнениях (7) и (8).
Если одно из измерений звукового давления выполняется с опережением или задержкой на частотно-независимую разность времен, когерентность сигналов может быть оценена. Слуховая система человека имеет возможность использовать такое свойство временного совмещения. Обычно, интерауральная когерентность вычисляется в пределах ±1 мс. В зависимости от доступной вычислительной мощности, вычисления могут быть реализованы с использованием только значения нулевого запаздывания (для низкой сложности) или когерентности с временным опережением и задержкой (если высокая сложность является возможной). Далее не проводится различие между обоими случаями.
Идеальный характер изменения достигается при условии идеального рассеянного звукового поля, которое может быть идеализировано в качестве волнового поля, которое состоит из в равной степени сильных, некоррелированных плоских волн, распространяющихся во всех направлениях (т.е. наложения бесконечного числа распространяющихся плоских волн со случайными соотношениями фаз и равномерно распределенными направлениями распространения). Сигнал, испускаемый посредством громкоговорителя, может считаться плоской волной для слушателя, расположенного достаточно далеко. Это допущение плоской волны является общим в стереофоническом воспроизведении по громкоговорителям. Таким образом, синтетическое звуковое поле, воспроизведенное посредством громкоговорителей, сформировано из составляющих плоских волн из ограниченного числа направлений.
При входном сигнале с N каналов, сформированных для воспроизведения в компоновке с позициями  громкоговорителей. (В случае только горизонтальной компоновки для воспроизведения, li указывает азимутальный угол. В общем случае, li=(азимут, высота) указывает позицию громкоговорителя относительно головы слушателя. Если текущая компоновка в помещении для прослушивания отличается от эталонной компоновки, li альтернативно может представлять позиции громкоговорителей фактической компоновки для воспроизведения). С помощью этой информации эталонная кривая
громкоговорителей. (В случае только горизонтальной компоновки для воспроизведения, li указывает азимутальный угол. В общем случае, li=(азимут, высота) указывает позицию громкоговорителя относительно головы слушателя. Если текущая компоновка в помещении для прослушивания отличается от эталонной компоновки, li альтернативно может представлять позиции громкоговорителей фактической компоновки для воспроизведения). С помощью этой информации эталонная кривая  интерауральной когерентности для моделирования на основе рассеянного поля может быть вычислена для этой компоновки при допущении, что в каждый громкоговоритель подаются независимые сигналы. Мощность сигнала, образуемая за счет доли от каждого входного канала в каждом частотно-временном фрагменте, может быть включена в вычисление эталонной кривой. В примерной реализации используется в качестве
интерауральной когерентности для моделирования на основе рассеянного поля может быть вычислена для этой компоновки при допущении, что в каждый громкоговоритель подаются независимые сигналы. Мощность сигнала, образуемая за счет доли от каждого входного канала в каждом частотно-временном фрагменте, может быть включена в вычисление эталонной кривой. В примерной реализации используется в качестве 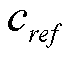
Различные эталонные кривые в качестве примеров для частотно-зависимых эталонных кривых или корреляционных кривых проиллюстрированы на фиг.9А-9Е для различного числа источников звука в различных позициях источников звука и различных ориентациях головы, как указано на чертежах.
Далее подробнее поясняется вычисление результатов анализа, как пояснено в контексте фиг.8, на основе эталонных кривых.
Цель состоит в том, чтобы выводить взвешивание, которое равняется 1, если корреляция каналов понижающего микширования равна вычисленной эталонной корреляции в соответствии с допущением относительно независимых сигналов, воспроизводимых из всех громкоговорителей. Если корреляция понижающего микширования равняется +1 или -1, выведенное взвешивание должно быть 0, что указывает то, что независимые компоненты не присутствуют. Между этими крайними случаями взвешивание должно представлять обоснованный переход между индикатором как независимого (W=1) или абсолютно зависимого (W=0).
При эталонной корреляционной кривой (ω) и оценке корреляции/когерентности фактического входного сигнала, воспроизведенного по фактической компоновке для воспроизведения ((csig(ω)), является корреляцией относительно когерентности понижающего микширования, может быть вычислено отклонение csig(ω) от (ω). Это отклонение (возможно включающее в себя верхнее и нижнее пороговое значение) отображается на диапазон [0; 1], чтобы получать взвешивание (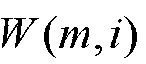 ), которое применяется ко всем входным каналам с тем, чтобы разделять независимые компоненты.
), которое применяется ко всем входным каналам с тем, чтобы разделять независимые компоненты.
Следующий пример иллюстрирует возможное отображение, когда пороговые значения соответствуют эталонной кривой:
Амплитуда отклонения (обозначается как  ) фактической кривой
) фактической кривой  от эталонной задается следующим образом:
от эталонной задается следующим образом:
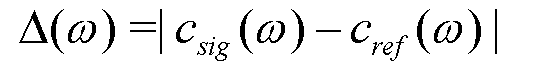

При условии, что корреляция/когерентность ограничена рамками [-1; +1], максимально возможное отклонение в направлении +1 или -1 для каждой частоты задается следующим образом:


Взвешивание для каждой частоты тем самым получается из

С учетом временной зависимости и ограниченного частотного разрешения частотного разложения, взвешенные значения выводятся следующим образом (Здесь приводится общий случай эталонной кривой, которая может изменяться во времени. Независимая от времени эталонная кривая (т.е.  ) также возможна):
) также возможна):


Такая обработка может быть выполнена при частотном разложении с частотными коэффициентами, сгруппированными в обусловленные восприятием поддиапазона частот по причинам вычислительной сложности, а также для того, чтобы получать фильтры с меньшими импульсными характеристиками. Кроме того, могут применяться сглаживающие фильтры, и могут применяться функции сжатия (т.е. искажение взвешивания требуемым способом, дополнительное введение минимальных и/или максимальных взвешенных значений).
Фиг.5 иллюстрирует дополнительную реализацию настоящего изобретения, в которой понижающий микшер реализуется с использованием HRTF-фильтров и слуховых фильтров, как проиллюстрировано. Кроме того, фиг.5 дополнительно иллюстрирует, что результатами анализа, выведенными посредством анализатора 16, являются весовые коэффициенты для каждого частотно-временного элемента разрешения, и процессор 20 сигналов проиллюстрирован в качестве модуля выведения для выведения независимых компонентов. В таком случае вывод процессора 20 снова составляет N каналов, но каждый канал теперь включает в себя только независимые компоненты и более не включает в себя зависимые компоненты. В этой реализации, анализатор должен вычислять взвешивания, так что в первой реализации по фиг.8 независимый компонент должен принимать взвешенное значение 1, а зависимый компонент должен принимать взвешенное значение 0. В таком случае, частотно-временные фрагменты в исходных N каналах, обработанных посредством процессора 20, которые имеют зависимые компоненты, должны задаваться равными 0.
В другой альтернативе, если существуют взвешенные значения от 0 до 1 на фиг.8, анализатор должен вычислять взвешивание таким образом, что частотно-временной фрагмент, имеющий небольшое расстояние до эталонной кривой, должен принимать высокое значение (более близкое к 1), а частотно-временной фрагмент, имеющий большое расстояние до эталонной кривой, должен принимать небольшой весовой коэффициент (более близкий к 0). В последующем проиллюстрированном взвешивании, например, на фиг.3 в 20, независимые компоненты затем должны быть усилены, в то время как зависимые компоненты должны быть ослаблены.
Тем не менее, когда процессор 20 сигналов реализован не для извлечения независимых компонентов, а для извлечения зависимых компонентов, то взвешивания должны назначаться наоборот, так что, когда взвешивание выполняется в умножителях 20, проиллюстрированных на фиг.3, независимые компоненты ослабляются, а зависимые компоненты усиливаются. Следовательно, каждый процессор сигналов может применяться для извлечения компонентов сигнала, поскольку определение фактически извлеченных компонентов сигнала выполняется посредством фактического назначения взвешенных значений.
Фиг.6 иллюстрирует дополнительную реализацию идеи изобретения, но теперь в другой реализации процессора 20. В варианте осуществления фиг.6 процессор 20 реализуется для извлечения независимых рассеянных частей, независимых прямых частей и прямых частей/компонентов по существу.
Чтобы получать, из разделенных независимых компонентов ( ), части, способствующие восприятию охватывающего /окружающего звукового поля, должны учитываться дополнительные ограничения. Одно такое ограничение может представлять собой допущение, что охватывающий окружающий звук является в равной степени сильным из каждого направления. Таким образом, например, минимальная энергия каждого частотно-временного фрагмента в каждом канале независимых звуковых сигналов может быть извлечена, чтобы получать охватывающий окружающий сигнал (который дополнительно может обрабатываться, чтобы получать более высокое число окружающих каналов). Пример:
), части, способствующие восприятию охватывающего /окружающего звукового поля, должны учитываться дополнительные ограничения. Одно такое ограничение может представлять собой допущение, что охватывающий окружающий звук является в равной степени сильным из каждого направления. Таким образом, например, минимальная энергия каждого частотно-временного фрагмента в каждом канале независимых звуковых сигналов может быть извлечена, чтобы получать охватывающий окружающий сигнал (который дополнительно может обрабатываться, чтобы получать более высокое число окружающих каналов). Пример:
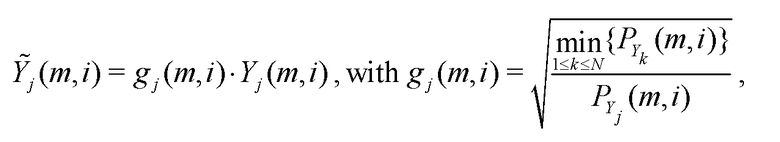

где 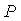 обозначает кратковременную оценку мощности. (Этот пример показывает простейший случай. Один очевидный исключительный случай, в котором он неприменим - это когда один из каналов включает в себя приостановки сигналов, в ходе которых входная мощность этого канала должна быть очень низкой или нулевой).
обозначает кратковременную оценку мощности. (Этот пример показывает простейший случай. Один очевидный исключительный случай, в котором он неприменим - это когда один из каналов включает в себя приостановки сигналов, в ходе которых входная мощность этого канала должна быть очень низкой или нулевой).
В некоторых случаях преимущественным является то, чтобы извлекать равные энергетические части всех входных каналов и вычислять взвешивание с использованием только извлеченных спектров.

Извлеченные зависимые (которые, например, могут быть выведены как Ydependent=Yj(m,i)-Xj(m,i)) части могут быть использованы для того, чтобы обнаруживать канальные зависимости и таким образом оценивать направленные метки, внутренне присущие вследствие входного сигнала, обеспечивая возможность дополнительных процессов, таких как, например, повторное панорамирование.
Фиг.7 иллюстрирует разновидность общего принципа. N-канальный входной сигнал подается в формирователь анализируемых сигналов (ASG). Формирование M-канального анализируемого сигнала может, например, включать в себя модель распространения из каналов/громкоговорителей в уши или другие способы, обозначаемые в качестве понижающего микширования в этом документе. Индикатор относительно различных компонентов основан на анализируемом сигнале. Маски, указывающие различные компоненты, применяются к входным сигналам (извлечение A/извлечение D (20a, 20b)). Взвешенные входные сигналы дополнительно могут обрабатываться (постобработка A/постобработка D (70a, 70b), чтобы давать в результате выходные сигналы с конкретным символом, причем в этом примере обозначения "A" и "D" выбраны так, что они указывают то, что компоненты, которые должны быть извлечены, могут быть "окружающими" и "прямыми звуковыми".
Далее описывается фиг.10. Стационарные звуковые поля называются рассеянными, если направленное распределение звуковой энергии не зависит от направления. Направленное распределение энергии может быть оценено посредством измерения всех направлений с использованием остронаправленного микрофона. В акустике помещений реверберирующее звуковое поле в замкнутом пространстве зачастую моделируется в качестве рассеянного поля. Рассеянное звуковое поле может быть идеализировано в качестве волнового поля, которое состоит из в равной степени сильных, некоррелированных плоских волн, распространяющихся во всех направлениях. Такое звуковое поле является изотропным и гомогенным.
Если равномерность распределения энергии представляет отдельный интерес, коэффициент корреляции "точка-точка"

звуковых давлений p1(t) и p2(t) в установившемся состоянии в двух пространственно разделенных точках может быть использован для того, чтобы оценивать физическое рассеяние звукового поля. Для допущенных идеальных трехмерных и двумерных рассеянных звуковых полей в установившемся состоянии, наведенных посредством синусоидального источника, могут быть выведены следующие взаимосвязи:

и

где 
При условии нахождения слушателя в звуковом поле измерения звукового давления задаются посредством сигналов pl(t) и pr(t), поступающих в уши. Таким образом, допущенное расстояние d между точками измерения является фиксированным, и r становится функцией только от частоты при 
Оценка рассеянности основана на сравнении моделированных меток с предполагаемыми эталонными метками в рассеянном поле. Это сравнение подчинено ограничениям человеческого слуха. В слуховой системе бинауральная обработка выполняется для слуховой периферии, состоящей из внешнего уха, среднего уха и внутреннего уха. Эффекты внешнего уха, которые не аппроксимируются посредством сферической модели (например, форма ушных раковин, слуховой канал), и эффекты среднего уха не рассматриваются. Спектральная избирательность внутреннего уха моделируется в качестве гребенки перекрывающихся полосовых фильтров (обозначаемых слуховыми фильтрами на фиг.10). Подход на основе критических полос частот используется для того, чтобы аппроксимировать эти перекрывающиеся полосы пропускания фильтра посредством фильтров с прямоугольной характеристикой. Эквивалентная прямоугольная полоса пропускания (ERB) вычисляется как функция от центральной частоты в соответствии со следующим:

Предполагается, что слуховая система человека допускает выполнение временного совмещения для того, чтобы обнаруживать когерентные компоненты сигнала, и этот взаимно-корреляционный анализ используется для оценки времени совмещения (соответствующий ITD) при присутствии сложных звуков. Приблизительно вплоть до 1-1,5 кГц, сдвиги по времени несущего сигнала оцениваются с использованием взаимной корреляции форм сигналов, тогда как на верхних частотах взаимная корреляция огибающих становится релевантной меткой. Далее, это различие не проводится. Оценка интерауральной когерентности (IC) моделируется в качестве максимального абсолютного значения нормализованной функции интерауральной взаимной корреляции:
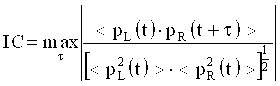
Некоторые модели бинаурального восприятия рассматривают проводимый анализ на основе интерауральной взаимной корреляции. Поскольку рассматриваются стационарные сигналы, зависимость от времени не принимается во внимание. Для того чтобы моделировать влияние обработки на основе критических полос частот, частотно-зависимая нормализованная взаимно-корреляционная функция вычисляется следующим образом:

где A является взаимно-корреляционной функцией в расчете на критическую полосу частот, а B и C являются автокорреляционными функциями в расчете на критическую полосу частот. Их взаимосвязь с частотной областью посредством полосового взаимного спектра и полосовых автоспектров может формулироваться следующим образом:



где L(f) и R(f) являются преобразованиями Фурье сигналов, поступающих в уши, 
Если сигналы из двух или более источников под различными углами накладываются, вызываются колеблющиеся ILD- и ITD-метки. Такие изменения ILD и ITD в качестве функции от времени и/или частоты могут формировать объемность. Тем не менее, в долговременном среднем, не должно быть ILD и ITD в рассеянном звуковом поле. Средняя ITD в нуль означает, что корреляция между сигналами не может быть увеличена посредством временного совмещения. ILD в принципе могут оцениваться в пределах полного диапазона звуковых частот. Поскольку голова не составляет препятствия на низких частотах, ILD являются самыми эффективными на средних и высоких частотах.
Далее поясняются фиг.11A и 11B для того, чтобы иллюстрировать альтернативную реализацию анализатора без использования эталонной кривой, как пояснено в контексте фиг.10 или фиг.4.
Кратковременное преобразование Фурье (STFT) применяется к входным аудиоканалам объемного звучания, давая в результате кратковременные спектры 





На основе стереосигнала понижающего микширования фильтры WD и WA вычисляются для получения оценок прямых и окружающих звуковых сигналов объемного звучания в уравнении (2) и (3).
При допущении, что окружающий звуковой сигнал декоррелируется между всеми входными каналами, коэффициенты понижающего микширования выбраны таким образом, что это допущение также применяется для каналов понижающего микширования. Таким образом, можно сформулировать модель для сигналов понижающего микширования в уравнении 4.
D1 и D2 представляют коррелированные STFT-спектры непосредственного звука, а A1 и A2 представляют декоррелированный окружающий звук. Дополнительно предполагается, что прямой звук и окружающий звук в каждом канале являются взаимно декоррелированными.
Оценка непосредственного звука, в отношении метода наименьших квадратов, достигается посредством применения фильтра Винера к исходному сигналу объемного звучания, чтобы подавлять окружающую часть. Чтобы вывести один фильтр, который может применяться ко всем входным каналам, прямые компоненты в понижающем микшировании оцениваются с использованием идентичного фильтра для левого и правого каналов согласно уравнению (5).
Объединенная функция среднеквадратической ошибки для этой оценки задается посредством уравнения (6).

Функция ошибок (6) минимизируется посредством обнуления ее производной. Результирующий фильтр для оценки непосредственного звука находится в уравнении 8.
Аналогично, фильтр оценки для окружающего звука может быть выведен согласно уравнению 9.
Далее, выводятся оценки для PD и PA, требуемые для вычисления WD и WA. Взаимная корреляция понижающего микширования задается посредством уравнения 10, в котором с учетом модели для сигналов понижающего микширования (4) задается ссылка на (11).
Дополнительно, при условии, что окружающие компоненты в понижающем микшировании имеют идентичную входную мощность левого и правого каналов понижающего микширования, можно записывать уравнение 12.
При подстановке уравнения 12 в последнюю строку уравнения 10 и рассмотрении уравнения 13 получается уравнение (14) и (15).
Как пояснено в контексте фиг.4, формирование эталонных кривых для минимальной корреляции может предполагаться посредством размещения двух или более различных источников звука в компоновке для воспроизведения и посредством размещения головы слушателя в определенной позиции в этой компоновке для воспроизведения. Затем полностью независимые сигналы излучаются посредством различных громкоговорителей. Для компоновки с двумя динамиками два канала должны быть полностью декоррелированы с корреляцией, равной 0, в случае если отсутствуют результирующие взаимные микширования. Тем не менее, эти результирующие взаимные микширования возникают вследствие перекрестного связывания от левой стороны к правой стороне слуховой системы человека, и другие перекрестные связывания также возникают вследствие ревербераций в помещении и т.д. Следовательно, результирующие эталонные кривые, как проиллюстрировано на фиг.4 или на фиг.9А-9D, не всегда равны 0, а имеют значения, в частности, отличающиеся от 0, хотя эталонные сигналы, предполагаемые в этом сценарии, являются полностью независимыми. Тем не менее, важно понимать, что эти сигналы фактически не требуются. Также достаточно предположить полную независимость между двумя или более сигналами при вычислении эталонной кривой. В этом контексте, тем не менее, следует отметить, что другие эталонные кривые могут быть вычислены для других сценариев, например, с использованием или допущением сигналов, которые не являются полностью независимыми, а имеют определенную, но заранее известную зависимость или степень зависимости между собой. Когда вычисляется эта другая эталонная кривая, интерпретация или предоставление весовых коэффициентов должно отличаться относительно эталонной кривой, в которой допускаются полностью независимые сигналы.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока, или элемента, или признака соответствующего устройства.
Изобретенный разложенный сигнал может быть сохранен на цифровом носителе хранения данных или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные на нем электронно-читаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат невременный носитель хранения данных, имеющий электронно-читаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт запущен на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретенного способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа запущена на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто примерными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и признаков, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных признаков, представленных посредством описания и пояснения вариантов осуществления в данном документе.

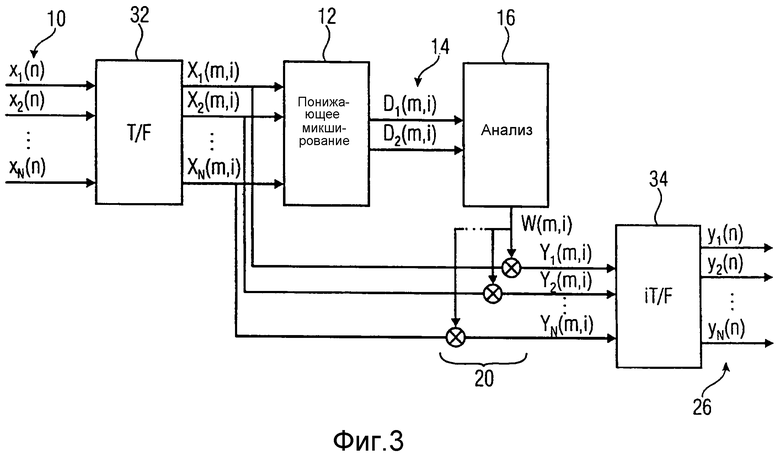


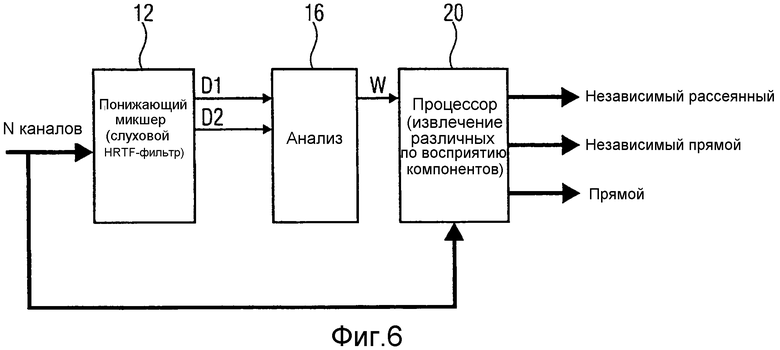
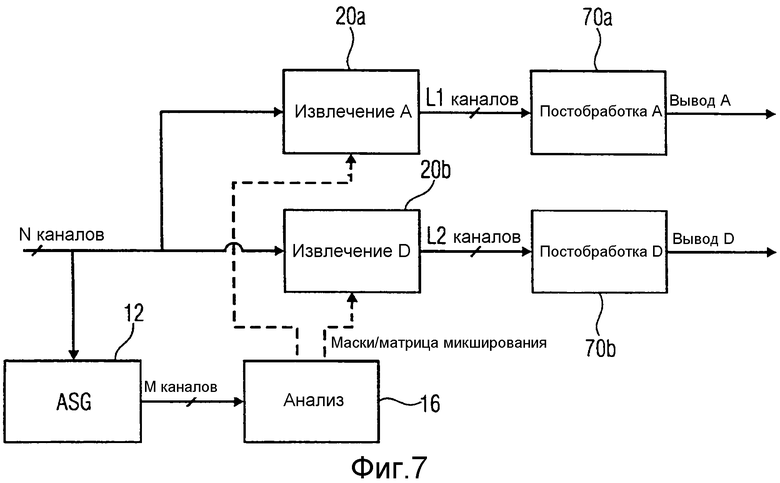



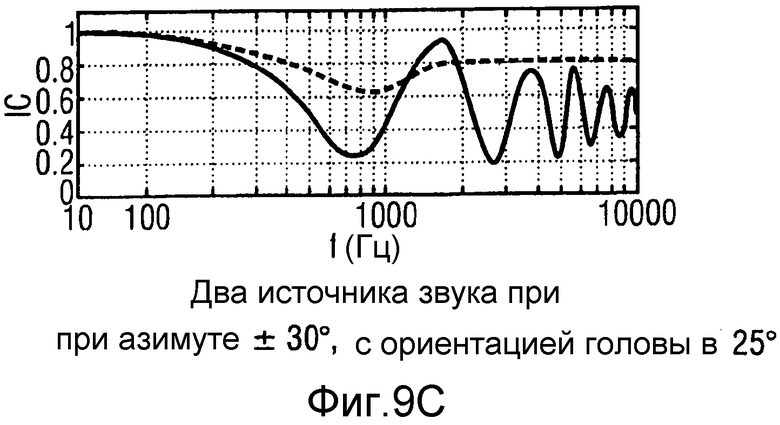





Изобретение относится к аудиообработке и, в частности, к разложению аудиосигналов на различные компоненты. Технический результат - повышение точности воспроизведения стереофонического звука. Для этого устройство для разложения входного сигнала, имеющего, по меньшей мере, три входных канала, содержит понижающий микшер для понижающего микширования входного сигнала, чтобы получать микшированный с понижением сигнал, имеющий меньшее число каналов, анализатор для анализа микшированного с понижением сигнала, чтобы выводить результат анализа, который перенаправляется в процессор сигналов для обработки входного сигнала или сигнала, выведенного из входного сигнала, чтобы получать разложенный сигнал. 3 н. и 12 н.п. ф-лы, 16 ил.
1. Устройство для разложения входного сигнала (10), имеющего по меньшей мере три входных канала, содержащее:
- понижающий микшер (12) для понижающего микширования входного сигнала, чтобы получать сигнал понижающего микширования, при этом понижающий микшер (12) выполнен с возможностью понижающего микширования, так что число каналов понижающего микширования сигнала (14) понижающего микширования составляет по меньшей мере 2 и меньше от числа входных каналов;
- анализатор (16) для анализа сигнала понижающего микширования, чтобы выводить результат (18) анализа; и
- процессор (20) сигналов для обработки входного сигнала (10) или сигнала (24), выведенного из входного сигнала с использованием результата (18) анализа, при этом процессор (20) сигналов выполнен с возможностью применения результата анализа к входным каналам входного сигнала или каналам сигнала, выведенного из входного сигнала, чтобы получать разложенный сигнал (26), при этом сигнал, выведенный из входного сигнала, отличается от сигнала понижающего микширования.
2. Устройство по п. 1, дополнительно содержащее частотно-временной преобразователь (32) для преобразования входных каналов во временную последовательность частотных представлений канала, причем каждое частотное представление входного канала имеет множество поддиапазонов частот, или в котором понижающий микшер (12) содержит частотно-временной преобразователь для преобразования сигнала понижающего микширования,
- при этом анализатор (16) выполнен с возможностью формирования результата (18) анализа для отдельных поддиапазонов частот, и
- при этом процессор (20) сигналов выполнен с возможностью применения отдельных результатов анализа к соответствующим поддиапазонам частот входного сигнала или сигнала, выведенного из входного сигнала.
3. Устройство по п. 1, в котором анализатор (16) выполнен с возможностью формировать, в качестве результата анализа, весовые коэффициенты (W(m, i)), и
- при этом процессор (20) сигналов выполнен с возможностью применения весовых коэффициентов к входному сигналу или сигналу, выведенному из входного сигнала, посредством взвешивания с помощью весовых коэффициентов.
4. Устройство по п. 1, в котором понижающий микшер выполнен с возможностью суммирования взвешенных или невзвешенных входных каналов в соответствии с правилом понижающего микширования, заданным таким образом, что по меньшей мере два канала понижающего микширования отличаются друг от друга.
5. Устройство по п. 1, в котором понижающий микшер (12) выполнен с возможностью фильтрации входного сигнала (10) с использованием фильтров на основе импульсных характеристик помещения, фильтров на основе бинауральных импульсных характеристик помещения (BRIR) или фильтров на основе HRTF.
6. Устройство по п. 1, в котором процессор (20) выполнен с возможностью применения фильтра Винера к входному сигналу или сигналу, выведенному из входного сигнала, и в котором анализатор (16) выполнен с возможностью вычисления фильтра Винера с использованием значений математического ожидания, выведенных из каналов понижающего микширования.
7. Устройство по одному из предшествующих пунктов, дополнительно содержащее модуль (22) выведения сигналов для выведения сигнала из входного сигнала так, что сигнал, выведенный из входного сигнала, имеет отличное число каналов по сравнению с сигналом понижающего микширования или входным сигналом.
8. Устройство по п. 1, в котором анализатор (20) выполнен с возможностью использования предварительно сохраненной частотно-зависимой кривой подобия, указывающей частотно-зависимое подобие между двумя сигналами, формируемыми посредством заранее известных эталонных сигналов.
9. Устройство по п. 1, в котором анализатор выполнен с возможностью использования предварительно сохраненной частотно-зависимой кривой подобия, указывающей частотно-зависимое подобие между двумя или более сигналами в позиции слушателя при допущении, что сигналы имеют известную характеристику подобия и что сигналы могут испускаться посредством громкоговорителей в известных позициях громкоговорителей.
10. Устройство по п. 1, в котором анализатор выполнен с возможностью вычислять зависимую от сигнала частотно-зависимую кривую подобия с использованием частотно-зависимой кратковременной мощности входных каналов.
11. Устройство по п. 8, в котором анализатор (16) выполнен с возможностью вычислять подобие канала понижающего микширования в поддиапазоне частот (80), сравнивать результат оценки подобия с подобием, указываемым посредством эталонной кривой (82, 83), и формировать весовой коэффициент на основе результата сжатия в качестве результата анализа, или
- вычислять расстояние между соответствующим результатом и подобием, указываемым посредством эталонной кривой для идентичного поддиапазона частот, и дополнительно вычислять весовой коэффициент на основе расстояния в качестве результата анализа.
12. Устройство по п. 1, в котором анализатор (16) выполнен с возможностью анализировать каналы понижающего микширования в поддиапазонах частот, определенных посредством частотного разрешения человеческого уха.
13. Устройство по п. 1, в котором анализатор (16) выполнен с возможностью анализировать сигнал понижающего микширования, чтобы формировать результат анализа, обеспечивающий разложение на прямые и окружающие части, и
- при этом процессор (20) сигналов выполнен с возможностью извлечения прямой части или окружающей части с использованием результата анализа.
14. Способ разложения входного сигнала (10), имеющего по меньшей мере три входных канала, содержащий этапы, на которых:
- микшируют с понижением (12) входной сигнал, чтобы получать сигнал понижающего микширования, так что число каналов понижающего микширования сигнала (14) понижающего микширования составляет по меньшей мере 2 и меньше от числа входных каналов;
- анализируют (16) сигнал понижающего микширования, чтобы выводить результат (18) анализа; и
- обрабатывают (20) входной сигнал (10) или сигнал (24), выведенный из входного сигнала, с использованием результата (18) анализа, при этом результат анализа применяется к входным каналам входного сигнала или каналам сигнала, выведенного из входного сигнала, чтобы получать разложенный сигнал (26), при этом сигнал, выведенный из входного сигнала, отличается от сигнала понижающего микширования.
15. Машиночитаемый носитель, содержащий записанную на нем компьютерную программу для осуществления способа по п. 14, когда компьютерная программа выполняется посредством компьютера или процессора.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СМЕШИВАНИЯ АУДИОПОТОКА И НОСИТЕЛЬ ИНФОРМАЦИИ | 2003 |
|
RU2315371C2 |
| АУДИОКОДИРОВАНИЕ | 2003 |
|
RU2363116C2 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 6694027 B1, 17.02.2004 | |||
| US 6052658 A1, 18.04.2000 | |||

