Технические решения по предлагаемому изобретению относятся к устройству и способу акустического эхоподавления, которые могут найти приложение, например, в управляемых „без рук" (хэндз-фри) системах телекоммуникации или других акустических системах многоканального звуковоспроизведения на основе параметрического представления пространственного звучания.
Акустическое эхо возникает в результате акустического взаимодействия или обратной связи между громкоговорителями и микрофонами средств телекоммуникации. В особенности, это явление выражено в устройствах с управлением без использования рук (хэндз-фри). Акустический сигнал, поступающий от громкоговорителя по цепи обратной связи, передается назад на дальний конец линии связи абоненту, который слышит собственную речь, звучащую с запозданием. Эхосигналы являются отвлекающим и весьма раздражающим фактором и могут быть причиной нарушения полноценной интерактивной дуплексной связи. В добавок, акустическое эхо может возбуждать паразитный гул и нестабильность акустического контура обратной связи. Из этого следует, что в системах полной двухсторонней дистанционной связи без ручного управления контроль над эхом необходим для устранения взаимовлияния между громкоговорителями и микрофонами.
Фиг.9 иллюстрирует общую постановку задачи контроля акустического эха. На приемном конце сигнал, исходящий из громкоговорителя, поступает в микрофон напрямую и по отраженным траекториям. Таким образом, микрофон улавливает не только речь на ближнем, передающем конце линии, но и эхосигнал, поступающий пользователю на дальнем конце по контуру обратной связи.
Выходной сигнал x(n) поступает на громкоговоритель 100, который преобразовывает электрический сигнал в звуковые колебания среды вокруг громкоговорителя 100. На фиг.9 дугообразным вектором показано как в микрофон 110 может попадать звук, генерируемый громкоговорителем 100, где y(n) обозначает сигнал обратной связи от громкоговорителя 100 к микрофону 110.
Помимо сигнала обратной связи y(n) микрофон 110 принимает дополнительный звуковой сигнал ~w(n), например голоса говорящего пользователя. Оба акустических сигнала улавливаются микрофоном 110 и в виде сигнала микрофона z(n) поступают на эхогаситель 120. Эхогаситель 120 одновременно получает сигнал громкоговорителя x(n). На выходе эхогасителя - в идеале - составляющая громкоговорителя x(n) должна быть удалена из зарегистрированного или микрофонного сигнала z(n).
Таким образом, фиг.9 отражает общую постановку задачи контроля акустического эхосигнала. Сигнал громкоговорителя x(n) возвращается в сигнал микрофона z(n). Процесс гашения эха удаляет такой эхосигнал, в идеале, пропуская нужный локальный сигнала ближнего, передающего конца w(n).
Контроль акустического эха представляет собой общепризнанную проблему, в силу чего были предложены различные методики его устранения [13]. Далее, кратко рассмотрим известные подходы к блокированию акустического эха (AES), например в [8, 9], где они более всего отвечают контексту решения проблемы передачи пространственного звука.
Для передачи или воспроизведения звуковых сигналов часто используют многоканальные системы. В подобных системах применяют для воспроизведения звука многокомпонентные громкоговорители, а для записи или передачи пространственного звучания - многочисленные микрофоны. Такие многоканальные системы используют, например, в телеконференцсвязи с пространственным звуком, где не только осуществляется обмен участников аудиосигналами, но и сохраняются пространственные параметры сценария звукопередачи [12]. В других системах пространственная информация может быть введена искусственно или изменена в интерактивном режиме [5].
Внесение в телекоммуникационные сценарии пространственного звучания требует эффективные средства представления многоканальных аудиосигналов, гарантирующие высокое качество звука. Надлежащим подходом к решению поставленной задачи представляется параметрическое пространственное аудиокодирование. Ниже предлагаем утилитарные подходы, основанные на концепции параметрического пространственного кодирования звука, имеющие особенное значение в контексте обмена информацией.
В то время как многоканальные системы, используемые, например, в вышеупомянутом пространственном аудиокодировании, обеспечивают эффективную и компактную по полосе частот передачу множества акустических сигналов, прямое введение приемов ослабления или подавления эхосигнала в подобные многоканальные системы потребует приложения таких приемов к каждому сигналу микрофона, включающему в себя каждый сигнал громкоговорителя как выход многоканальной системы. Это ведет к существенному, почти по экспоненте, росту вычислительной сложности, хотя бы только из-за большого числа сигналов микрофонов и/или громкоговорителей, требующих обработки. Соответственно, это потребует дополнительные затраты в силу увеличения энергозатрат, возрастания трудоемкости обработки данных и, в конечном счете, увеличит задержку.
Исходя из сказанного, техническая задача настоящего изобретения - представить устройство подавления акустического эхосигнала (акустический эхоподавитель) и фронтальное устройство (терминал) конференцсвязи, обеспечивающие более эффективное эхоподавление.
Поставленная цель достигается за счет устройства акустического эхоподавления по пункту 1 формулы изобретения, способа подавления акустического эхосигнала по п.8, терминала конференцсвязи по п.10, способа генерирования сигналов громкоговорителей и сигнала микрофона по п.14 или компьютерной программы по п.15.
Конструктивные решения по данному изобретению основаны на заключении, что эффективность подавления акустического эха возрастает в при условии выделения микшированного с понижением сигнала из входного сигнала, состоящего из микшированного с понижением сигнала и служебной параметрической информации, расчета коэффициентов пропускания адаптивного фильтра на основании сигнала понижающего микширования и сигнала микрофона или сигнала, производного от сигнала микрофона, и фильтрования микрофонного или производного от него сигнала, исходя из рассчитанных коэффициентов фильтрации. Другими словами, в случае многоканальной системы, основанной на даунмикс-сигнале и параметрической служебной информации, совместно составляющих входной многоканальный сигнал, подавление эха может осуществляться на базе микшированного с понижением сигнала (даунмикса).
Таким образом, используя вариант технического решения согласно предлагаемому изобретению, можно устранять акустическое эхо, исключив предварительную операцию декодирования входного сигнала в многоканальный сигнал. Благодаря этому можно значительно снизить вычислительную сложность, так как количество сигналов существенно уменьшается по сравнению с многоканальной системой, описанной выше. При применении компоновки в соответствии с настоящим изобретением акустическое эхо подавляется в даунмикс-сигнале как компоненте входного сигнала.
Другие версии реализации изобретения показывают, что эхоподавление может базироваться на опорных показателях спектральной плотности мощности, выведенных из полученного сигнала понижающего микширования и сигнала микрофона или сигнала, производного от сигнала микрофона. Произвольно в опорный спектр мощности, полученный из многоканального сигнала, может быть внесена задержка на величину, которая может быть определена, например, из корреляционного значения.
Следовательно, в терминал конференцсвязи, выполненный в соответствии с настоящим изобретением, введено не только устройство подавления акустического эха, решенное в соответствии с настоящим изобретением, но также многоканальный декодер и, по меньшей мере, один микрофонный блок, причем многоканальный декодер предназначен для декодирования сигнала понижающего микширования и служебной параметрической информации с преобразованием в множество сигналов громкоговорителей. По меньшей мере, один микрофонный блок предназначен для передачи сигнала микрофона на устройство подавления акустического эха. Кроме того, в конструктивном исполнении фронтальное устройство конференцсвязи включает в себя средства входного интерфейса для извлечения служебной параметрической информации, при этом многоканальный декодер имеет в своем составе повышающий микшер и процессор параметров. Процессор параметров выполнен с возможностью приема с входного интерфейса служебных параметрических данных и генерации управляющего сигнала повышающего микширования. Устройство повышающего микширования принимает с входного интерфейса микшированный с понижением сигнал, а от процессора параметров - сигнал управления повышающим микшированием, и на основе сигнала понижающего микширования и сигнала управления повышающим микшированием генерирует множество сигналов громкоговорителей. Из этого следует, что при реализации в соответствии с данным изобретением для подавителя акустического эха можно использовать входной интерфейс многоканального декодера, или многоканальный декодер и подавитель акустического эха могут иметь общий входной интерфейс.
Более того, в компоновку предлагаемого изобретения по желанию может быть включен соответствующий многоканальный кодер, предназначенный для кодирования множества входных аудиосигналов с последующим преобразованием в даунмикс-сигнал и сопровождающую его служебную параметрическую информацию, которые совокупно вмещают в себя множество входных аудиосигналов, одним из которых является микрофонный сигнал, по меньшей мере, от одного микрофонного блока. В этом случае подавитель акустического эха, включенный в схему терминала конференцсвязи, предусматривает получение сигнала понижающего микширования как производного от сигнала микрофона.
Формулируя иначе, ниже будет представлен подход, основанный на предлагаемом изобретении, обеспечивающий эффективное совмещение функций подавления акустического эхосигнала и параметрического кодирования пространственного звука.
Варианты конструктивных решений по данному изобретению описаны далее со ссылкой на прилагаемые фигуры.
Фиг.1 представляет собой принципиальную модульную схему фронтального устройства (терминала) конференцсвязи, включающего в себя устройство подавления (подавитель) акустического эха, в соответствии с настоящим изобретением; фиг.2 отображает общую компоновку параметрического кодера пространственного звука; фиг.3 отображает общую компоновку параметрического декодера пространственного звука; фиг.4 иллюстрирует алгоритм обработки сигналов, применяемый в декодерах стандарта MPEG Surround (MPS); фиг.5 отображает общую компоновку декодера пространственного кодирования аудиообъекта (SAOC); фиг.6А схематически отображает процесс перекодирования данных SAOC в данные MPS с помощью транскодера монофонического даунмикс-сигнала; фиг.6В схематически отображает процесс перекодирования данных SAOC в данные MPS с помощью транскодера стереофонического даунмикс-сигнала; фиг.7 отображает принципиальную модульную схему терминала конференцсвязи согласно настоящему изобретению, обеспечивающего реализацию выдвигаемого эффективного способа подавления акустического эха на основе сигнала понижающего микширования параметрических пространственных аудиокодеров; фиг.8 отображает принципиальную модульную схему реализации изобретения в форме терминала конференцсвязи, включающего в себя устройство подавления акустического эха, конструктивно решенное в соответствии с настоящим изобретением; фиг.9 схематически дает общую постановку проблемы контроля акустического эхосигнала.
Далее фиг.1-9 наглядно отображают варианты основных конструктивных и технологических решений по настоящему изобретению в контексте их детализации. Однако, прежде чем представить средства подавления акустического эха одноканального и многоканального аудиосигналов, рассмотрим вариант реализации изобретения в форме фронтального устройства (терминала) конференцсвязи, оснащенного устройством подавления акустического эха (эхоподавителем).
На фиг.1 представлена принципиальная модульная схема терминала конференцсвязи 200, содержащего в качестве основного компонента подавитель акустического эха (эхоподавитель) согласно изобретению. Акустический эхоподавитель 210 включает в себя вычислитель 220, устройство входного интерфейса 230 и адаптивный фильтр 240. Кроме того, терминал конференцсвязи 200 имеет в своем составе многоканальный декодер 250 с выходом на множество громкоговорителей 100, из которых для наглядности показаны четыре - 100-1,…, 100-4. Терминал конференцсвязи оснащен также микрофоном или микрофонным блоком 110.
Для большей детализации показан входной сигнал 300, несущий сигнал понижающего микширования (даунмикс-сигнала) 310 и служебную параметрическую информацию 320. В версии исполнения на фиг.1 устройство входного интерфейса 230 разделяет или извлекает из входного сигнала даунмикс-сигнал 310 и служебную параметрическую информацию 320. В варианте решения на фиг.1 устройство входного интерфейса 230 пересылает даунмикс-сигнал 310 в сопровождении служебной параметрической информации 320 на многоканальный декодер 250.
Многоканальный декодер 250 предназначен для декодирования даунмикс-сигнала 310 и служебной параметрической информации 320 с разложением на множество сигналов громкоговорителей 330, из которых для упрощения на фиг.1 обозначен только один. Каждый из громкоговорителей 100 сопряжен с соответствующим выходным каналом многоканального декодера 250, получает индивидуальный сигнал громкоговорителя 330 и реконструирует его в воспринимаемый на слух звуковой сигнал.
Вычислитель 220 соединен также с выходом даунмикс-канала 310 устройства входного интерфейса 230. Следовательно, вычислитель 220 предусматривает получение сигнала понижающего микширования 310. При этом, как показано на фиг.1, служебная параметрическая информация 320 входного сигнала 300 не поступает на вычислитель 220. Иначе говоря, реализация изобретения предусматривает возможность обработки вычислителем 220 только сигнала понижающего микширования из двух составляющих входного сигнала.
Выход микрофона 110 соединен с вычислителем 220 и адаптивным фильтром 240. Следовательно, вычислитель 220 может также напрямую снимать сигнал микрофона 340 с микрофона 110. Используя сигнал микрофона 340 и даунмикс-сигнал 310, вычислитель 220 рассчитывает коэффициенты пропускания адаптивного фильтра 240 и генерирует соответствующий сигнал 350, задающий коэффициент фильтрации адаптивному фильтру 240, который на основании полученных данных фильтрует поступающий сигнал микрофона 340. Адаптивный фильтр 240 генерирует на выходе очищенный от эха сигнал микрофона 340.
Другие особенности реализации вычислителя 220 будут рассмотрены ниже. Хотя устройство входного интерфейса 230 представлено на схеме фиг.1 как отдельный элемент акустического эхоподавителя 210, интерфейс 230 может быть включен в функции декодера 250 или может быть общим для декодера 250 и акустического эхоподавителя 210. Кроме того, возможна компоновка изобретения, при которой продуктом входного интерфейса 230 является только даунмикс-сигнал 310. В этом случае входной сигнал 300 будет поступать на многоканальный декодер 250, который, в свою очередь, включая в себя соответствующий интерфейс, будет раздельно извлекать даунмикс-сигнал 310 и служебную параметрическую информацию 320. Другими словами, акустический эхоподавитель 210 может включать в себя интерфейс 230 без обязательной экстракции параметрических протокольных данных, лишь с выделением сигнала понижающего микширования 310.
Оборудование, выполненное в соответствии с настоящим изобретением, воплощает в себе эффективный метод подавления акустического эхо-сигнала в многоканальных системах громкоговорящей связи с объемным звуком. Данный метод применим в случаях, когда сигналы объемного звука представлены сигналом понижающего микширования и сопутствующей служебной параметрической информацией или метаданными. Эти параметры несут информацию, необходимую для вычисления сигналов громкоговорителей на воспроизводящей стороне. Изобретение основано на заключении, что эхоподавление может быть применено непосредственно к получаемому микшированному с понижением (даунмикс-) сигналу вместо выполнения предварительного вычисления сигналов громкоговорителей перед подавлением в них акустического эха (AES). Подобно этому, составляющие эхосигнала могут быть блокированы в микшированном с понижением (даунмикс-) сигнале объемного звука, передаваемом на дальний конец линии связи. Данный подход, в целом, также более действенен, чем эхоподавление каждого из зарегистрированных сигналов микрофонов, фиксирующих все обозримое звуковое поле.
В дальнейшем к идентичным или подобным по своей структуре или функциям объектам, отображенным на схеме или фигуре более одного раза, применены общие условные обозначения. Например, на фиг.1 четыре громкоговорителя 100-1,…, 100-4 имеют индивидуальные условные обозначения, однако, при описании их основных или отличительных свойств как громкоговорителей используется ссылка „громкоговорители 100”.
Кроме того, для упрощения описания аналогичные или однотипные объекты отмечены одинаковыми или сходными условными обозначениями. При сравнении Фиг.1 и 9 можно видеть, что громкоговорители имеют одинаковое условное обозначение 100. Объекты, отмеченные одинаковыми или схожими условными обозначениями, могут быть реализованы аналогичным, подобным или отличным образом. В частности, определенные аппаратные версии требуют оснащения разными типами громкоговорителей 100, соответствующими разным видам звуковых сигналов, в то время как оборудование разного назначения может быть укомплектовано однотипными громкоговорителям. Следовательно, объекты, отмеченные одинаковыми или схожими условными обозначениями, могут быть тождественны или аналогичны.
Вместе с тем, следует заметить, что если фигура содержит более одного изображения некоторых объектов, это, как правило, сделано в целях наглядности. Отклонения по количеству могут быть как в сторону увеличения, так и в сторону уменьшения. Например, на фиг.1 показано четыре громкоговорителя 100-1,…, 100-4. В то же время, в различных конструктивных исполнениях может быть задействовано большее или меньшее количество громкоговорителей 100. Так, в компоновку систем формата „5.1" стандартно входят 5 громкоговорителя в комбинации с одним субвуфером.
Кратко рассмотрим общую концепцию подавления акустического эхосигнала. При этом, по существу, будет прослежена методика, описанная в [8, 9].
Как показано на фиг.9, микрофонный сигнал z(n) складывается из сигнала акустического эха y(n), возбуждаемого обратной связью сигнала громкоговорителя x(n), и сигнала ближнего конца w(n). Примем, что импульсная характеристика окружающего объема может быть выражена как комбинация прямой траектории, соответствующей задержке d отсчетов между сигналом громкоговорителя x(n) и сигналом микрофона z(n), и линейного фильтра gn, моделирующего акустические свойства помещения.
Тогда, сигнал микрофона z(n) может быть выражен как
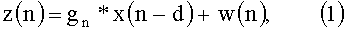
где * обозначает свертку. Представление уравнения (1) в области быстрого преобразования Фурье (БПФ) имеет вид

где k - показатель времени блока, а m - коэффициент частотности. Xd(k, m) определяется как вариант задержанного сигнала громкоговорителя в области БПФ. Первый член правой части уравнения (2) выражает составляющие эха Y(k, m), где
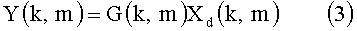
Следующий шаг в обсуждении темы подавления акустического эхосигнала затрагивает БПФ как представление сигналов в спектральной области. Однако очевидно, что наряду с этим данная концепция может иметь любое иное частотно-подполосовое представление.
Акустический эхосигнал глушат, модулируя амплитуду БПФ сигнала микрофона Z(k, m), сохраняя его фазу неизменной. Это может быть выражено

где H(k, m) действительный положительный коэффициент ослабления. В дальнейшем ссылка на H(k, m) означает обращение к эхоподавляющему фильтру (ЭПФ/ESF).
Утилитарный подход к фильтру эхоподавления H(k, m) опирается на метод параметрического спектрального вычитания, как представлено в [7]:

где α, β, и γ выражают расчетные параметры управления эхоподавлением.
Номинальные значения β и γ находятся в пределах 2, а для α в некоторых случаях выбирается значение, противоположное γ. Другими словами, при выборе типичных значений β=2 и γ=2 величина α чаще всего выбирается как 0,5 (=1/2).
Спектральная плотность мощности эхо-сигнала может быть оценена посредством

где 

Или же может быть использован комплексный подход на основе спектра, исходя из
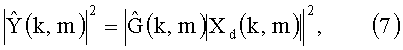
Следует обратить внимание на то, что на практике функция передачи мощности эхо-сигнала 

Одна из методик расчета фильтра оценивания эхо-сигнала (EEF) была предложена в [8]. Если предположить, что пользователь на передающем конце молчит, согласно уравнению (2) подразумевается, что EEF может быть рассчитан в соответствии с
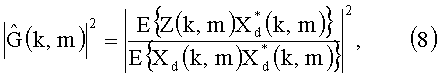
где * обозначает комплексно-сопряженный оператор, а E{…} выражает ожидаемый оператор. Оператор математического ожидания может быть аппроксимирован посредством плавающего среднего значения его аргумента.
Описанная выше процедура эффективно оценивает передаточную функцию пути прохождения эха, а ее амплитуда берется для получения действительного EEF. При резком фазовом переходе, как, например, при изменении траектории эха, смещении по времени и т.п., полученная оценка EEF должна быть вновь приведена к соответствию. Чтобы сделать уравнение (8) нечувствительным к изменениям фазы, его необходимо преобразовать для расчета из значений спектральной плотности мощности, а не из сложных спектров [6]:
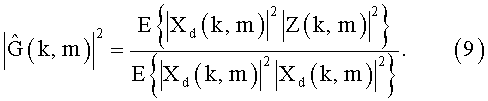
В [6] показано, что (9) дает отклонение в оценке. В связи с этим в [6] предложен другой подход к оценке фильтра EEF, а именно, вычисление


Тогда фильтры EEF оценивают аналогично уравнению (9), но на основании флуктуирующих спектров громкоговорителя и микрофона:

Важно обратить внимание на то, что флуктуирующие спектральные плотности мощности используют только для оценки
Величина задержки d может быть вычислена с использованием квадратичной функции когерентности в отношении спектров мощности громкоговорителя и микрофона, следуя

Вообще, в последующем для каждого шага по частоте m может быть выбрана разная задержка d. Тем не менее, здесь принята одна общая величина задержки для всех частот. В силу этого выигрыш от предсказания эха ωd(k) определяется в данном случае как среднее значение Гd(k, m) на частоту

где М указывает количество шагов частотной дискретизации. Тогда d выбирают таким образом, чтобы усиление предсказания эха было максимизировано, т.е.

В качестве альтернативы уравнению (15) оценка величины задержки сможет быть выполнена также относительно флуктуирующих спектров, то есть - на основании уравнений (10), (11).
Обратим внимание, что на практике математическое ожидание E{…}, использованное в производных выше, может потребовать замещение соответствующими кратковременными или плавающими средними значениями. В качестве примера рассмотрим

Кратковременная средняя величина 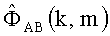

Коэффициент αavg определяет степень сглаживания во времени и может быть скорректирован с учетом любого требования.
Дальше мы рассмотрим, как подавление акустического эхосигнала (AES) в одиночном канале, описанное в предшествующей части, может быть применено для многоканального AES.
Пусть в виде X1(k, m) будет представлен сигнал громкоговорителя l в области БПФ. Совокупная спектральная плотность мощности всех каналов громкоговорителей тогда рассчитывается путем сложения спектральных плотностей мощности индивидуальных сигналов громкоговорителей:

где L обозначает количество каналов громкоговорителей.
И наоборот, общий спектр мощности сигналов громкоговорителей может быть вычислен суммированием спектров каждого сигнала громкоговорителя с последующим получением квадрата величины объединенного спектра:
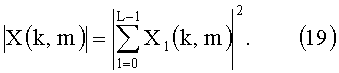
Аналогичным образом вычисляют совокупную спектральную плотность мощности микрофонных каналов, выполняя

где Zp(k, m) отображает сигнал микрофона p, а P указывает количество микрофонов.
Как и в случае с сигналами громкоговорителей, объединенный спектр мощности микрофонов может быть альтернативно вычислен согласно
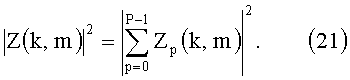
Модель вычисления спектральной плотности мощности эхо-сигнала аналогична уравнению (2), если допустить статистическую независимость сигналов громкоговорителей и сигналов передающего конца:
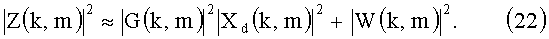
где для многоканального варианта спектры мощности 

Для расчета фильтра оценивания эхосигнала 
Тогда действительное эхоподавление осуществляется для каждого сигнала микрофона отдельно, но с использованием одинаковых фильтров эхокомпенсации для каждого канала микрофона:
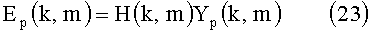
для p=0, 1,…, P-1.
Данный раздел посвящен обзору основных алгоритмов параметрического представления пространственного аудиосигнала и параметрического пространственного аудиокодирования. В этой связи обсудим такие форматы, как кодирование направленного звука (DirAC) [12], MPEG Surround (MPS) [1], пространственное кодирование аудиообъекта (SAOC) стандарта MPEG [5]. Прежде, чем углубиться в специфику разновидностей кодеков, рассмотрим, устройство кодера/декодера, которое является общим для всех методик, обсуждаемых здесь.
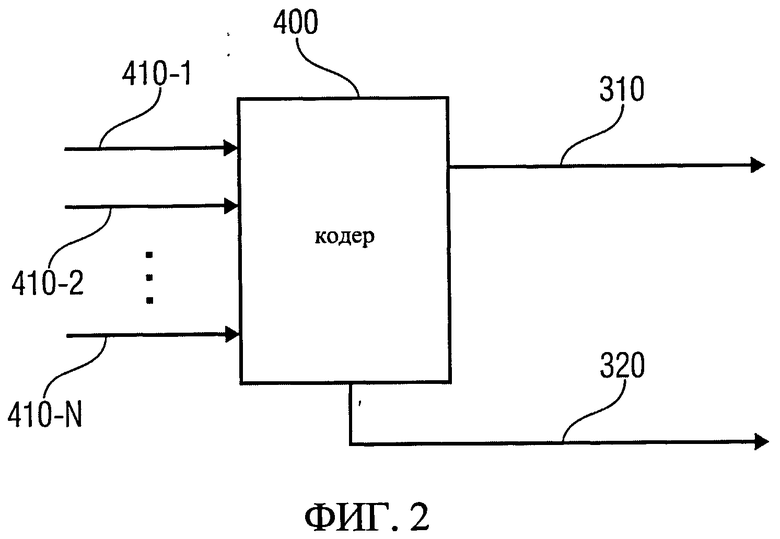
Общая схема параметрического кодера пространственного звука изображена на фиг.2. Фиг.2 отображает многоканальный или параметрический пространственный аудиокодер 400. Кодер принимает на входе множественные аудиосигналы и генерирует на выходе микшированный с понижением (даунмикс) сигнал одного или более каналов и сопутствующей служебной параметрической информации. Для большей детализации уточним, что многоканальный кодер 400 получает множество входных сигналов 410-1,…, 410-N, которые, в принципе, могут представлять собой любые акустические сигналы. На базе множества входных сигналов 410 кодер 400 формирует их представление в виде даунмикс-сигнала 310, сопровождаемого служебной параметрической информацией 320.
Во многих случаях и в различных реализациях многоканальный кодер 400 в подобной компоновке не является беспроигрышным вариантом решения.
Входными данными кодера являются многочисленные звуковые каналы. В зависимости от принятого на практике подхода к кодированию такие звуковые входные каналы могут представлять собой микрофонные сигналы [12], сигналы аудиорепродукторов [10] или сигналы так называемых пространственных аудиообъектов [5]. Выходной сигнал кодера состоит из сигнала понижающего микширования 310 и соответствующих протокольных данных 320. Сигнал, полученный понижающим микшированием, несет в себе один или более аудиоканалов. Протокольные данные содержат параметрические метаданные, представляющие слышимое звуковое поле, соотношение различных входных каналов или взаимную ориентацию аудиообъектов. Выходные данные кодера, или комбинация даунмикс-сигнала и служебной информации, далее будут именоваться пространственным аудиопотоком или пространственным представлением звука.
Общая схема соответствующего параметрического декодера пространственного звука изображена на фиг.3. Фиг.3 отображает (многоканальный) декодер 250, который получает на входе даунмикс-сигнал 310 и соответствующую служебную параметрическую информацию 320. Многоканальный декодер 250 генерирует на выходе множество выходных сигналов 420-1,…, 420-N, которые могут представлять собой, например, сигналы громкоговорителя (скажем, сигналы громкоговорителя 330, как на фиг.1) в соответствии с желаемой конфигурацией воспроизведения. На схеме видно, что декодер принимает на входе пространственный аудиопоток. Исходя из сигнала понижающего микширования и метаданных, содержащихся в служебной информации, декодер рассчитывает сигналы громкоговорителей в соответствии с заданной конфигурацией воспроизведения. Типичные уставки динамиков громкоговорителей приведены, например, в [1].
Примером схемы параметрического пространственного аудиокодирования служит направленное аудиокодирование, называемое также DirAC. В DirAC параметрическое представление акустического пространства осуществляется в поддиапазонах частот с учетом направления источника (DOA) и свойств рассеяния звука. Следовательно, этот метод учитывает только особенности слуха человека. Концепция DirAC основывается на предпосылке, что интерауральные (межушные) временные интервалы (ITD) и интерауральное различие уровней (ILD) воспринимаются надлежащим образом, если правильно воссоздано направление источников в звуковом поле. Соответственно, допускается, что интерауральная когерентность (IC) воспринимается естественно, если корректно воспроизведена диффузность акустического поля. Благодаря этому стороне воспроизведения требуются только параметры направленности и рассеяния, а также микрофонный моносигнал для воспроизведения звука с характеристиками, соответствующими восприятию человеком пространственного звучания с определенного места слушателя при использовании некоего набора динамиков.
В DirAC необходимые параметры (т.е. DOA φ(k, m) звука и диффузности Ψ(k, m) в каждой полосе частот) оценивают через энергетический анализ звукового поля [12] на основе микрофонных сигналов В-формата (Би-формата). Би-форматные микрофонные сигналы обычно состоят из всенаправленного сигнала W(k, m) и двух дипольных сигналов (Ux(k, m), Uy(k, m)), соответствующих направлениям по осям X, Y декартовой системы координат. Сигналы В-формата могут быть измерены напрямую с использованием, например, микрофонов звукового поля [2]. И наоборот, комплект всенаправленных микрофонов может быть задействован для генерации требуемых би-форматных сигналов [11].
На стороне воспроизведения (декодера), разнообразные сигналы громкоговорителей рассчитываются на базе сигнала монофонического понижающего микширования (монодаунмикс-сигнала) и параметров направления и рассеяния. Сигналы громкоговорителей формируются из компонент сигнала, соответствующих прямому звуку и диффузному звуку, соответственно. Так, например, сигнал канала громкоговорителя p может быть вычислен, следуя

где Ψ(k, m) выражает диффузность частотной подполосы и временной индекс k блока. Усиление панорамирования gp(k, m) зависит как от DOA звука φ(k, m), так и от расположения громкоговорителя p относительно предполагаемого места нахождения слушателя. Оператор Dp{…} соответствует декоррелятору. Декоррелятор применяют к сигналу понижающего микширования W(k, m), вычисляя сигнал громкоговорителя p.
Из сказанного следует, что микрофонные сигналы (формата В или от набора всенаправленных микрофонов) представляют собой входные данные кодера DirAC 400. Выходные данные кодера представляют собой сигнал понижающего микширования W(k, т) и параметры направленности φ(k, m) и диффузности (Ψ (k, m)) в качестве служебной информации.
Соответственно, декодер 250 на входе принимает даунмикс-сигнал W(k, m) и служебную параметрическую информацию в виде φ(k, m) и Ψ(k, m) как данные для расчета сигналов громкоговорителей согласно (24).
Формат MPEG Surround (MPS) обеспечивает действенный подход к высококачественному пространственному кодированию звука [10]. С полной спецификацией формата MPS можно ознакомиться в [1]. В последующем мы не будем подробно рассматривать формат MPS, а обратимся к тем его моментам, которые имеют значение в контексте конструктивных решений по представленному изобретению.
В кодекс MPS за основу принято то, что с перцептуальной точки зрения многоканальные аудиосигналы типично содержат значительную избыточность по разным каналам громкоговорителей. Кодер MPS получает на входе множество сигналов громкоговорителей, в котором заранее должна быть известна соответствующая пространственная конфигурация динамиков. Исходя из этих входных сигналов, кодер MPS 400 рассчитывает пространственные параметры в частотных поддиапазонах, такие как межканальная разность уровней (CLD) двух каналов, межканальная корреляция (ICC) двух каналов и коэффициенты предсказания канала (СРС), используемые для предсказания третьего канала на базе двух других каналов. Из этих пространственных параметров затем выводится текущая протокольная информация 320 формата MPS. В добавок, кодер 400 рассчитывает микшированный с понижением сигнал, который может состоять из одного или более аудиоканалов.
В монофоническом варианте даунмикс-сигнал B(k, m), естественно, содержит только один канал B(k, m), тогда как в стереоварианте микшированный с понижением сигнал может иметь вид:
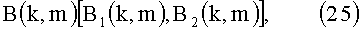
где, например, B1(k, m) соответствует каналу левого динамика, a B2(k, m) - каналу правого динамика в общей стереоконфигурации акустических систем.
Декодер MPS 250 получает на входе даунмикс-сигнал и служебную параметрическую информацию и вычисляет сигналы громкоговорителей 330, 420 для их заданной конфигурации. Фиг.4 иллюстрирует общую схему технологической цепочки обработки декодером формата MPEG Surround стереофонических сигналов.
На фиг.4 дана схема декодера MPEG Surround 250. На декодер 250 поступают даунмикс-сигнал 310 и служебная параметрическая информация [320]. Даунмикс-сигнал 310 заключает в себе каналы даунмикс-сигнала B1(k, m) и B2(k, m), которые соответствуют каналам левого и правого громкоговорителей стандартной стереокомпоновки.
С помощью матрицы предварительного микширования 450 (Mi) эти два канала даунмикс-сигнала 310 преобразуются в вектор промежуточного сигнала V(k, m). Элементы составляющих вектора промежуточного сигнала V(k, m) далее поступают для декорреляции во множество декорреляторов 460-1,…, 460-Р. Сигналы, сгенерированные декорреляторами 460 вместе с недекоррелированными сигналами или компонентами вектора промежуточного сигнала V(k, m), образуют второй вектор промежуточного сигнала R(k, m), который, в свою очередь, поступает в матрицу последующего микширования 470 (М2). Матрица постмикширования 470 формирует на выходе множество сигналов громкоговорителей 330-1,…, 330-Р, которые представляют выходные сигналы 420 декодера, как показано на фиг.3.
Далее, декодер 250 включает в свой состав параметрический процессор 480, в который поступает служебная параметрическая информация 320. Параметрический процессор 480 сопряжен как с матрицей предмикширования 450, так и с матрицей постмикширования 470. Процессор параметров 480 предусматривает получение служебной параметрической информации 320 и формирование соответствующих матричных элементов, подлежащих обработке матрицами предварительного 450 и последующего 470 микширования. С целью интенсификации такой обработки параметрический процессор 480 соединен с обеими матрицами - предмикширования 450 и постмикширования 470.
Как следует из фиг.4, процесс декодирования может быть записан в матричном представлении:


Согласно [1] M1(k, m) обозначает матрицу предварительного микширования 450, а M2(k, m) - матрицу последующего микширования 470. Обратим внимание, что элементы M1(k, m) и M2(k, m) находятся в зависимости от служебной пространственной информации и топологии аудиорепродукторов, которые могут быть заданы процессором параметров 480.
Как видно на фиг.4, отношение векторов промежуточного сигнала V(k, m) и R(k, m) выглядит следующим образом: одна часть элементов вектора сигнала Vp(k, m) остается неизменной (Rp(k, m)=Vp(k, m)), в то время как другие компоненты R(k, m) являются декоррелированными модификациями соответствующих элементов V(k, m), т.е. Rl(k, m)=Dl{(k, m)}, где Dl{(k, m)} описывает оператор декоррелятора. Элементы вектора сигнала X(k, m) соответствуют многоканальным сигналам громкоговорителей Xp{k, m), участвующим в воспроизведении.
Следует заметить, что кодек MPS предполагает в качестве входного потока каналы громкоговорителей, тогда как системы телеконференцсвязи принимают на входе зафиксированные микрофонные сигналы. Возможен вариант, при котором входной сигнал микрофона будет преобразован в соответствующие каналы громкоговорителей до применения формата MPS для создания делаемого эффективного пространственного представления зафиксированного звука. Это может быть вариант простого использования множества направленных микрофонов, размещенных так, что расчет каналов громкоговорителей будет выполняться непосредственно путем комбинирования входных сигналов микрофонов. Или же, для расчета каналов громкоговорителей может быть применена методика DirAC, состоящая в подключении напрямую кодера DirAC и декодера DirAC, как описано в предыдущем разделе.
Формат SAOC пространственного кодирования аудиообъектов основан на принципе отображении сложной звуковой сцены посредством ряда одиночных объектов, сопровождаемых соответствующим описанием сцены. Для обеспечения эффективности воплощения поставленной цели SAOC задействует средства, близкие с форматом MPS [5]. Как и ранее, мы примем во внимание только те элементы алгоритма SAOC, которые вписываются в контекст рассматриваемого изобретения. Более подробные сведения можно найти, например, в [5].
Общая схема кодера SAOC показана на фиг.2, где входные сигналы 410 соответствуют аудиообъектам. На основе этих входных сигналов 410 кодер SAOC 400 выполняет расчет даунмикс-сигнала 310 (моно или стерео) в сочетании с соответствующей служебной параметрической информацией 320, отображающей соотношение различных аудиообъектов в данной звуковой сцене. Как и в MPS, эти параметры высчитываются для временного индекса каждого блока и для каждой частотной подполосы. Эти параметры включают в себя разность уровней объектов (OLD), межобъектную кросскогерентность (IOC), величины энергии объектов (NRG) и др., а также расчеты и показатели, относящиеся к понижающему микшированию [5].
Декодер SAOC 250 получает на входе даунмикс-сигнал 310 вместе с сопутствующей информацией 320 и выводит сигналы каналов громкоговорителей желаемой конфигурации. Кроме того, SAOC-декодер использует заимствованный у кодека MPS механизм рендеринга (звукоотображения) для конечного оформления сигналов громкоговорителей. В дополнение следует отметить, что кроме протокольных данных, генерируемых кодером SAOC 400, декодер SAOC 250 в качестве входного массива для обработки и получения конечного выходного сигнала принимает параметры конфигурации акустических систем для аудиорендеринга или иную интерактивную информацию для управления специфическими аудиообъектами. Это проиллюстрировано на фиг.5.
Фиг.5 отображает общую компоновку декодера SAOC 250 для пространственного кодирования аудиообъекта. На декодер SAOC 250 подается даунмикс-сигнал 310 в сопровождении служебной параметрической информации 320. Дополнительно SAOC-декодер 250 получает параметры рендеринга или интерактивную информацию 490. Как описано выше, декодер SAOC 250 получает сигнал понижающего микширования 310, служебную параметрическую информацию 320, а также параметры рендеринга / интерактивные данные 490, которые использует для генерации совокупности сигналов громкоговорителей 330-1,…, 330-N. Эти сигналы подаются на выход декодера SAOC 250.
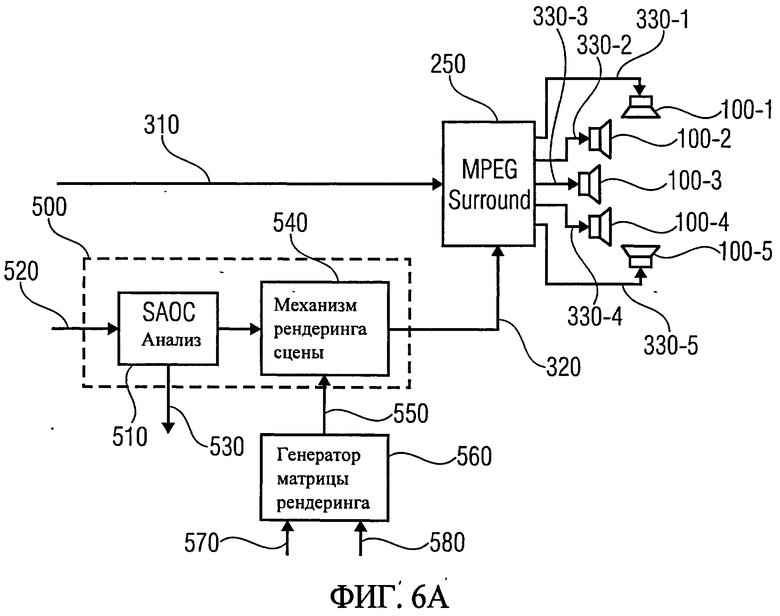
Теперь рассмотрим случаи применение декодера SAOC для обработки монофонического даунмикс-сигнала (монодаунмикса) и стереофонического даунмикс-сигнала (стереодаунмикса), соответственно. Согласно [5] компоновка декодера SAOC, отображенная на фиг.6А, предназначена для монодаунмикса, и на фиг.6В - для стереодаунмикса.
На фиг.6А дана более глубокая детализация транскодера монофонического понижающего микширования, который согласно [5] может использоваться как преобразователь кода SAOC-MPS. Система, изображенная на фиг.6А, включает в себя декодер MPEG Surround 250, на который подаются даунмикс-сигнал 310 и битстрим MPEG Surround, несущий служебную параметрическую информацию 320. В компоновке, представленной на фиг.6А, декодер MPEG Surround 250 обеспечивает на выходе, по меньшей мере, пять сигналов громкоговорителей 330-1,…, 330-5. В качестве опции декодер формата MPEG Surround 250 может дополнительно генерировать на выходе, например, сигналы динамика низких и сверхнизких частот (субвуфера). Однако на фиг.6А субвуферная акустическая система для упрощения не показана, но отображены динамики 100-1,…, 100-5 каждого из соответствующих сигналов громкоговорителей 330.
В то время как битовый поток понижающего микширования 310 поступает на декодер MPEG Surround 250 напрямую, служебная параметрическая информация 320 подготавливается преобразователем кода SAOC-MPS 500, включающим в свой состав синтаксический анализатор SAOC 510, который в качестве входного сигнала 520 принимает битстрим SAOC. Синтаксический анализатор SAOC 510 в качестве одного из своих выходных сигналов формирует данные по группе объектов 530.
Далее данные анализатора SAOC 510 поступают на устройство рендеринга сцены 540, где обрабатываются на базе матрицы аудиорендеринга (звукоотображения) 550, полученной от генератора матрицы рендеринга 560, с формированием в результате сопроводительной служебной информации 320 для декодера MPEG Surround 250. Следовательно, устройство рендеринга сцены 540 и его выходной поток, протокольные данные 320 которого поступают в декодер MPEG Surround 250, также являются функциональными составляющими транскодера 500.
Генератор матрицы рендеринга 560 конструирует матрицу аудиорендеринга 550 на основе полученных данных о построении звукоотображения 570 и о точках размещения объектов 580.
Декодирование монодаунмикс-сигнала состоит в перекодировании данных протокола SAOC в данные протокола MPS 520, исходя из позиций объектов 580 и конфигурации акустических систем 570 при воспроизведении. Сформированная таким образом служебная информация в формате MPS 320 вводится в MPS-декодер 250 вместе с монодаунмикс-сигналом SAOC 310. Так как микшированный с понижением моносигнал 310 остается неизмененным, сигналы громкоговорителей также могут быть рассчитаны по уравнениям (26), (27), где матрица предмикширования M1(k, m) и матрица постмикширования M1(k, m) определены с помощью преобразователя кода SAOC-MPS.
На фиг.6В показан преобразователь кода SAOC-MPS 500, аналогичный кодопреобразователю 500 на фиг.6А, соответственно, делается ссылка на описание, данное выше. Тем не менее, основное отличие системы и транскодера 500 заключается в том, что на фиг.6В обрабатываемый даунмикс-сигнал 310 является стереофоническим. Следовательно, декодер MPEG Surround 250 на фиг.6В отличается от соответствующего декодера MPEG Surround на фиг.6А тем, что даунмикс-сигнал 310 имеет два канала, в силу чего декодер 250 рассчитан на генерацию сигналов громкоговорителей 330 на базе служебной информации 320 и сигнала понижающего стереомикширования (стереодаунмикс-сигнала) 310.
Система на фиг.6В имеет и иные различия с системой на фиг.6А. Транскодер 500 включает в себя также перекодировщик сигнала понижающего микширования (даунмикс-сигнала) 590, принимающий исходный даунмикс-сигнал 310' и получающий от устройства рендеринга сцены 540 управляющую информацию 600. Таким образом, перекодировщик даунмикс-сигнала 590 предназначен для формирования даунмикс-сигнала 310, на основе управляющей информации 600 и оригинального или входящего даунмикс-сигнала 310'.
В стереоварианте даунмикс-сигнал SAOC 310' может не соответствовать параметрам входного сигнала MPS-декодера. Например, в такой ситуации, когда составляющие сигнала одного объекта присутствуют только в левом канале стереодаунмикс-сигнала SAOC 310', тогда как в процессе микширования в формате MPS он должен быть представлен в правой полусфере [5]. Далее, как изображено на фиг.6В, даунмикс-сигнал SAOC 310', прежде чем станет входным сигналом MPS-декодера 250, должен пройти обработку так называемым перекодировщиком даунмикс-сигнала 590.
Специфика этой стадии обработки диктуется текущей служебной информацией SAOC 520 и конфигурацией воспроизведения 570. Очевидно, что взаимозависимость между перекодированным даунмикс-сигналом 310 и каналами воспроизведения громкоговорителей 330 также может быть выражена уравнениями (26), (27).
Следует обратить внимание на то, что кодек SAOC рассчитан на преобразование входных сигналов, соответствующих группе аудиообъектов, в то время как в системах телеконференцсвязи на вход, как правило, поступают зафиксированные микрофонные сигналы. Преобразование входного микрофонного сигнала в соответствующее многомерное представление акустического объекта может быть целесообразным до введения формата SAOC для задания желаемого эффективного объемного отображения записанного звука. Как один из возможных подходов к выделению разнообразных аудиообъектов во входном сигнале группы микрофонов в [3] предложен алгоритм разделения источников вслепую. Методы разделения источников вслепую, опираясь на входные микрофонные сигналы, используют статистическую независимость различных аудиообъектов для формирования соответствующих аудиосигналов. В тех случаях, когда стереометрия размещения микрофонной группы известна заранее, может быть сформулирована дополнительная пространственная информация относительно звуковых объектов [4].
Следует отметить, что исключительно в целях упрощения предлагаемого описания информация и сигналы, несущие такую информацию, были помечены одинаковыми условными обозначениями. Кроме этого, сигналы и линии передачи данных, по которым проходят эти сигналы, также были обозначены одинаково. В зависимости от конкретного конструктивного решения по настоящему изобретению обмен данными между различными элементами или объектами может производиться посредством сигналов, передаваемых напрямую по линиям передачи или через устройства памяти, ячейки памяти или иные промежуточные звенья (например, „защелки"), соединяющие между собой соответствующие элементы или объекты. Например, в случае реализации на базе процессора, информация может сохраняться в ассоциированном ЗУ. В силу этого, информация, отдельные данные и сигналы допускают синонимичное обращение к ним.
Теперь, опираясь на рассмотренные в предыдущих разделах подходы к подавлению акустического эхосигнала и параметрическому кодированию пространственного звука, представим способ эффективного интегрирования акустического эхоподавления (AES) в структуру пространственного аудиокодера/декодера для применения в телекоммуникации с объемным звуком согласно настоящему изобретению.
Базовая структура предлагаемого подхода представлена на фиг.7. На фиг.7 дана схема терминала конференцсвязи 200, реализованного в соответствии с данным изобретением, где подавление акустического эха основано на сигналах понижающего микширования параметрических кодеров пространственного звука.
Терминал конференцсвязи 200, как показано на фиг.7, включает в себя акустический эхоподавитель 210, оснащенный в соответствии с изобретением средством входного интерфейса 230, которое сопряжено с эхогасителем или эхоподавителем 700, куда поступает даунмикс-сигнал 310 как составляющая входного сигнала 300, принимаемого через средство входного интерфейса 230. В варианте решения на фиг.7 служебная параметрическая информация 320, также выделяемая средством входного интерфейса 230 как составляющая входного сигнала 300, на эхоподавитель 700 не поступает.
Даунмикс-сигнал 310 и служебная параметрическая информация 320 передаются на многоканальный декодер 250 с выходом на множество громкоговорителей 100-1,…, 100-N. Декодер 220 обеспечивает каждый из громкоговорителей 100 соответствующим сигналом громкоговорителя 330-1,…, 330-N.
Кроме того, терминал конференцсвязи 200 включает в себя множество микрофонов 110-1,…, 110-K, обеспечивающих терминал конференцсвязи 200 входными акустическими сигналами. Громкоговорители 100, в свою очередь, обеспечивают озвучивание соответствующего выходного акустического сигнала. Микрофоны 110 соединены с препроцессором 710 и далее - с кодером 400 генерирующим микшированный с понижением сигнал (даунмикс-сигнал) 720 и служебную параметрическую информацию 730, сопровождающую предварительно обработанные сигналы 340 микрофонов 110. Эхоподавитель 700 подключен к кодеру 400 для приема очередного даунмикс-сигнала 720 в сопровождении очередной служебной информации 730. На выходе устройство эхоподавления 700 выдает модифицированный сигнал понижающего микширования 740 в сопровождении служебной параметрической информации 730, которая проходит через эхоподавитель 700 без изменения.
Устройство эхоподавления 700, которое более детально рассматривается в контексте фиг.8, имеет в своем составе вычислитель 220 и адаптивный фильтр 240, как было показано на фиг.1.
Здесь внимание уделено прикладным вопросам пространственной звукопередачи, предполагающей представление многомерного звучания аудиосцен на дальнем и ближнем концах связи посредством пространственных аудиопотоков, транслируемых между различными абонентами. Поскольку при воспроизведении панорамного звука через множество акустических систем часто важно выполнение действий без использования рук (хэндз-фри), целесообразным может быть применение аудиоэхоподавителя AES 210, устраняющего раздражающее эхо на выходе декодера ближнего (передающего) конца. В отличие от описанных выше методик, где аудиоэхоподавление (AES) осуществлялось на базе сигналов громкоговорителей, мы предлагаем подавлять эхо-сигнал исключительно на основе даунмикс-сигнала 310 пространственного аудиопотка 300, получаемого с дальнего (принимающего) конца. В силу того, что количество каналов понижающего микширования, как правило, намного меньше количества сигналов громкоговорителей, участвующих в воссоздании звука, предлагаемый способ значительно более эффективен по степени сложности. Акустическое эхоподавление (AES) может быть применено или к микрофонным сигналам ближнего конца, или - с еще большей эффективностью - к сигналу понижающего микширования на выходе кодера ближнего конца, как показано на фиг.7.
Прежде чем приступить к детализации устройства эхоподавления 700 в компоновке, представленной на фиг.8, ниже подробнее рассмотрим процесс или способ, предлагаемый настоящим изобретением.
Сначала рассчитывают опорную спектральную плотность мощности (RPS) сигналов воспроизведения P(k, m), исходя из даунмикс-сигнала 310, входящего в состав полученного пространственного аудиопотока. В общем случае N-канального сигнала понижающего микширования B(k, m)=[B1(k, m), Bi(k, m),…, BN(k, m)] это можно выполнить согласно линейной комбинации

И наоборот, линейная комбинация может быть рассчитана по сложным спектрам каналов понижающего микширования
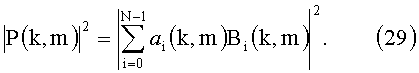
Весовые коэффициенты Ai(k, m) могут быть использованы для управления составляющими различных каналов понижающего микширования в RPS.
Применение разновесовых каналов может быть выигрышным, например, при пространственном кодировании аудиообъектов SAOC. Если параметры аудиоэхоподавления в сигнале понижающего микширования SAOC будут рассчитаны до применения к нему транскодера (см. фиг.6(b)), то моделирование изменяющегося во времени поведения транскодера даунмикс-сигнала с помощью фильтра оценивания эхо-сигнала может быть пропущено, поскольку такое поведение уже предписывается найденным опорным значением спектральной плотности мощности.
Для частного случая монодаунмикс-сигнала справедлив простой выбор RPS, равной спектральной плотности мощности даунмикс-сигнала, т.е. 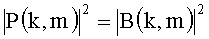
Другими словами, коэффициенты взвешивания ai(k, m) выбирают по одному на каждый канал понижающего микширования в составе даунмикс-сигнала 310.
По аналогии с уравнениями (28), (29) вычисляем Q(k, m) RPS зарегистрированных сигналов, исходя из K-канального сигнала понижающего микширования A(k, m)=[A1(k, m), Ai(k, m),…АК(k, m)} кодера передающей стороны:

И наоборот, линейная комбинация может быть рассчитана по сложным спектрам каналов понижающего микширования
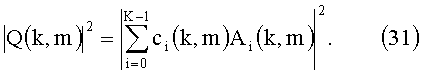
Весовые коэффициенты ci(k, m) могут быть использованы для регулирования составляющих различных каналов понижающего микширования в относительном спектре мощности RPS. В случае монодаунмикс-сигнала (ci(k,m)), как и раньше, мы можем просто использовать 
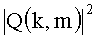



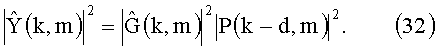
По аналогии с описанным выше показатель 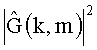
Такая оценка дальше используется для задания фильтра эхоподавления (ЭПФ/ESF), например, подобно (5):

где α, β и γ выражают расчетные параметры управления эффективностью эхоподавления. Номинальные характеристики α, β и γ даны выше.
Устранение эхо-помех в итоге достигается умножением каналов исходного даунмикса, поступающего от кодера ближнего конца, на показатель ЭПФ

Расчет EEF может основываться на корреляции с RPS в соответствии с
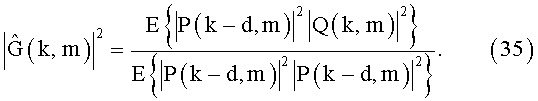
И наоборот, фильтр EEF может быть рассчитан с использованием временных флуктуации RPS, то есть по аналогии с (12):
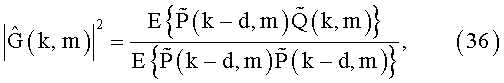
где временные флуктуации относительных спектральных плотностей мощности RPS вычисляют, следуя
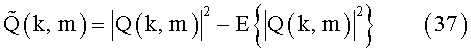
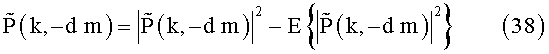
Величина задержки d может быть определена аналогично (13) с подстановкой вместо сигналов громкоговорителей и микрофонов X(k, m) и Z(k, m) нужных значений RPS P(k, m) и Q(k, m), соответственно.
Следует заметить, что чаще всего нет значимого фазового соотношения между сигналами понижающего микширования A(k, m) и B(k, m). Это обусловлено тем, что их фазы взаимосвязаны не только по частотной характеристике окружающего пространства, но и весьма неравномерным по времени формированием сигналов громкоговорителей на основе даунмикса и пространственной служебной информации. Из этого следует, что подходы с использованием фазовых характеристик для расчета EEF (или задержки), например (8), не подходят для эхоблокировки, основанной на даунмикс-сигналах.
Те же доводы можно привести в пользу применения к микшированным с понижением сигналам механизма компенсации эха линейной адаптивной фильтрацией. Такие адаптивные фильтры предусматривают моделирование и отслеживание высокой временной вариативности, возникающей вследствие преобразования даунмикс-сигнала в каналы акустических динамиков.
На фиг.8 представлена принципиальная модульная схема терминала конференцсвязи 200, реализованного согласно настоящему изобретению аналогично решению на фиг.1. Соответственно, ссылка одновременно делается на описание фиг.1.
Терминал конференцсвязи 200 согласно конструктивному решению изобретения включает в себя акустический эхоподавитель 210, в который, в свою очередь, входит вычислитель 220, выполняющий, в основном, функции, аналогичные описанным в контексте фиг.1. Далее обратимся к более подробному обсуждению.
Терминал конференцсвязи 200 включает в себя также средство входного интерфейса 230 и адаптивный фильтр 240. Кроме того, фронтальное устройство конференцсвязи 200 имеет в своем составе многоканальный декодер 250, имеющий выход на множество громкоговорителей 100-1,…, 100-N. Далее, в компоновку конференц-терминала 200 включен соответствующий кодер или многоканальный кодер 400, сопряженный на входе с множеством микрофонов 110-1,…, 110-K.
Входной сигнал 300 поступает на устройство входного интерфейса 230 с дальнего (приемного) конца коммуникационного мэйнфрейма, в структуру которого входит фронтальный процессор 200. В аппаратной версии на фиг.8 средство входного интерфейса 230 выделяет даунмикс-сигнал 310 и служебную параметрическую информацию 320 из входного сигнала и пересылает их в качестве входных сигналов но многоканальный декодер 250. В многоканальном декодере 250 эти два сигнала -понижающего микширования 310 и служебной параметрической информации 320 -преобразуются в множество соответствующих сигналов громкоговорителей 330, которые затем подаются на расчетные громкоговорители 100. Для упрощения на схеме промаркирован только первый сигнал громкоговорителя 330-1.
Декодер 250 в варианте решения на фиг.8 включает в свой состав повышающий микшер 705 и параметрический процессор 480. Повышающий микшер 705 соединен со средством входного интерфейса 230, получая от него даунмикс-сигнал 310. Аналогично со средством входного интерфейса 230 соединен параметрический процессор 480, который, однако, принимает от него служебную параметрическую информацию 320. Устройство повышающего микширования 705 и параметрический процессор 480 сопряжены таким образом, что управляющая информация повышающего микширования 707, экстрагированная из служебной параметрической информации 320, может быть направлена повышающему микшеру 705. Повышающий микшер 705 соединен также с громкоговорителями 100.
Рабочей функцией повышающего микшера 705 является формирование сигналов громкоговорителей 330 из сигнала понижающего микширования 310 с использованием управляющей информации повышающего микширования 707, извлеченной из служебной параметрической информации 320. Для каждого из N (N - целое число) громкоговорителей 100-1,…, 100-N повышающий микшер 705 генерирует индивидуальный сигнал громкоговорителя 330.
Как пояснялось выше, декодер 250 может в качестве опции включать в себя интерфейс, выполняющий извлечение служебной информации 320 и даунмикс-сигнала 310 и передачи их на параметрический процессор 480 и повышающий микшер 705, соответственно, в том случае, если средство входного интерфейса 230 не используется совместно декодером 250 и акустическим эхоподавителем 210.
Как уже было сказано в контексте фиг.1, выход средства входного интерфейса 230 сопряжен с вычислителем 220 для введения в вычислитель 220 даунмикс-сигнала 310. Говоря иначе, вычислитель 220 предназначен для приема даунмикс-сигнала 310.
Перед детализацией внутреннего устройства вычислителя 220 следует обратить внимание на то, что микрофоны 110 обеспечивают соответствующее количество K. (K - целое число) микрофонных сигналов 340, из которых на фиг.8 промаркирован только первый сигнал микрофона 340-1, поступающий в многоканальный кодер 400.
На основании принятых микрофонных сигналов 340 многоканальный кодер 400 генерирует новый микшированный с понижением сигнал 720 и новый сигнал служебной параметрической информации 730. В то время как новая служебная параметрическая информация 730 передается на выход системы конференц-связи 200, новый сигнал понижающего микширования 720 поступает одновременно на вычислитель 220 и адаптивный фильтр 240. Одновременно вычислитель 220 передает сигнал, задающий коэффициент фильтрации 350, на адаптивный фильтр 240, на базе чего выполняется фильтрация даунмикс-сигнала 720 с получением модифицированного микшированного с понижением сигнала 740 на выходе адаптивного фильтра 240. Модифицированный микшированный с понижением сигнал 740 представляет собой очищенную от эха версию вновь принимаемого даунмикс-сигнала 720. Благодаря этому на стороне приема нового даунмикс-сигнала 720 и очередной служебной параметрической информации 730 может быть реконструирована очищенная от эха версия сигналов микрофонов 110.
Схемотехника вычислителя 220 обеспечивает передачу даунмикс-сигналов 310 от средства входного интерфейса 230 к первому генератору относительной спектральной плотности мощности 800, предназначенному для генерации ранее описанной относительной спектральной плотности мощности, допустим, в соответствии с уравнениями (28) и (29). Выход первого генератора опорного энергетического спектра 800 соединен с контуром задержки 810 как опцией, предназначенной для задержки входного сигнала на величину задержки d. Контур задержки 810 далее имеет выход на вычислитель оценки эхо-сигнала 820, который может, например, рассчитать ожидаемое эхо по уравнению (38). Выход вычислителя оценки эхо-сигнала 820 соединен последовательно с генератором фильтра эхоподавления 830, который генерирует или оценивает фильтр эхоподавления согласно уравнению (33). На выходе генератора фильтра эхоподавления 830 формируется сигнал 350, задающий коэффициент пропускания адаптивного фильтра 240.
Очередной микшированный с понижением сигнал 720, сгенерированный кодером 400, поступает в генератор фильтра эхоподавления 830, если в этот контур включен второй генератор опорного спектра мощности 840, или подается на второй генератор опорного спектра мощности 840. При необходимости для этих целей в акустический эхоподавитель 210 произвольно может быть добавлен входной интерфейс экстракции вновь поступающего микшированного с понижением сигнала 720.
Второй генератор опорного энергетического спектра 840 имеет выход на генератор коэффициентов фильтрации ожидаемого эха, который, в свою очередь сопряжен с вычислителем оценки эхо-сигнала 820 для введения в него коэффициентов фильтрации ожидаемого эха согласно уравнению (35) или (36). В случае, если генератор коэффициентов фильтрации ожидаемого эха 850 выполняет вычислительные операции на базе уравнения (36), то между ним и выходами контура задержки 810 и второго генератора опорного спектра мощности 840 в качестве опции встраивают, соответственно, первый и второй компенсаторы временных колебаний 860, 870. Два указанных компенсатора временных колебаний 860, 870 могут предусматривать также последующее вычисление скорректированных опорных спектральных плотностей мощности на базе уравнений (37) и (38), соответственно. Тогда генератор коэффициентов фильтрации ожидаемого эха 850 может использовать модифицированные опорные спектры мощности для выполнения действий на основе уравнения (36).
Следует заметить, что контур задержки 810 является не обязательным, но часто полезным компонентом. Величины задержки сможет быть найдена с помощью расчетов в соответствии с уравнениями (13), (14) и (15). Детализируя техническое решение изобретения, в него логически можно ввести вычислитель когерентности 880, вход которого будет подключен к выходу первого генератора опорного спектра мощности 800. Кроме этого, вычислитель когерентности 880 может быть соединен с выходом второго генератора опорного спектра мощности 840 для получения от него соответствующего показателя опорной спектральной плотности мощности.
Например, исходя из уравнения (13), но используя два опорных энергетических спектра, полученных от двух генераторов опорной спектральной плотности мощности 800, 840, вычислитель когерентности 880 может генерировать значения функции когерентности в соответствии с уравнением (13) для передачи на вычислитель выигрыша усиления предсказания эха 890, который оценивает выигрыш от предсказания эха ωd(k) согласно или на базе уравнения (14). Далее, выход вычислителя усиления предсказания эха соединен с входом оптимизатора 900, который может выполнять функцию оптимизации величины задержки d согласно уравнению (15). Для ввода в контур задержки 810 величины задержки d он соединен с оптимизатором 900. Логично, что в подобной ситуации контур задержки предусматривает задержку входного сигнала (здесь - первой опорной спектральной плотности мощности) на величину задержки d.
Для отображения полной компоновки на фиг.8 показан эхоподавитель 700, который включает в себя вычислитель 220 и адаптивный фильтр 240, о чем говорилось в контексте фиг.7.
В завершение этого раздела мы представляем практические варианты описанного выше метода эхоподавления на основе сигнала понижающего микширования.
На базе уравнения (32) можно получить вариант

где сложный опорный спектр воспроизводимых сигналов P(k, m) рассчитывается относительно сложных спектров каналов понижающего микширования, то есть - в соответствии с
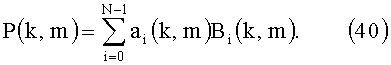
Уравнение (40) вытекает из (29) при исключении расчета амплитуды.
Разновидностью подхода к подавлению акустического эха является его реализация не на базе каналов понижающего микширования, что выражено через (34), а на базе входных микрофонных сигналов.
Из обсуждения следует, что различные варианты исполнения данного изобретения выполняют общие для всех функции, такие как:
1. Получение первого параметрического представления пространственного звука, состоящего из микшированного с понижением сигнала (даунмикса) в сопровождении служебной информации, который используется для генерирования многоканальных сигналов громкоговорителей.
2. Получение второго параметрического представления пространственного звука, состоящего из даунмикса в сопровождении служебной информации, выведенные из зафиксированных микрофонных сигналов.
3. Вычисление опорной (контрольной) спектральной плотности мощности первого и второго сигналов понижающего микширования.
4. Расчет фильтра оценивания эхо-сигнала для определения составляющих эхосигнала в опорном спектре мощности второго микшированного с понижением сигнала.
5. Расчет эхоподавляющего фильтра из характеристик опорного спектра мощности первого даунмикс-сигнала, опорного спектра мощности второго даунмикс-сигнала и фильтра оценивания эхо-сигнала с целью удаления эхо-составляющих из микшированного с понижением сигнала второго пространственного представления звука.
В зависимости от целей практического приложения методы данного изобретения технически могут быть решены как в виде аппаратных средств, так и в виде программного обеспечения. Средой реализации могут быть цифровые носители данных, такие как диск, CD или DVD, содержащие электронно считываемый управляющий сигнал, исполняемый программируемым компьютером или процессором с целью осуществления способов, предложенных в изобретении. В силу этого, реализация настоящего изобретения, в общем смысле, представляет собой компьютерный программный продукт, где код программы, хранящийся на машиночитаемом носителе, обеспечивает осуществление изобретенного способа, если данный компьютерный программный продукт используется с применением компьютера или процессора. Другими словами, варианты осуществления относящихся к изобретению способов представляют собой компьютерную программу с присвоенным ей кодом программы, обеспечивающим реализацию, по меньшей мере, одного из способов, вводимых изобретением, при условии, что компьютерная программа будет выполняться с применением компьютера или процессора. Процессор может быть задействован в конфигурации компьютера, чип-карты, смарт-карты, специализированной интегральной микросхемы (ASIC) или других разновидностей интегральных схем.
Более того, данное изобретение может быть аппаратно решено на базе дискретных электротехнических или электронных элементов, интегральных микросхем или их комбинации.
Таким образом, реализации описываемого изобретения позволяют контролировать акустическое эхо при воспроизведении параметрического пространственного аудиосигнала.
Как показало предшествующее обсуждение, представленные конструктивные решения могут являться примерами осуществления эффективного способа подавления акустических эхо-сигналов в многоканальных системах громкоговорящей связи с пространственным звуком.
Предлагаемые методы применимы в случаях, когда сигналы объемного звука представлены сигналом понижающего микширования и сопутствующей служебной параметрической информацией или метаданными. Осуществление изобретения строится на применении эхоподавления непосредственно к принимаемому микшированному с понижением сигналу вместо предварительного точного расчета сигналов громкоговорителей перед активизацией их акустического эхоподавления. Таким же образом подавление составляющих эхосигнала может быть применено к даунмиксу пространственного аудиосигнала, который должен быть передан на дальний конец линии связи.
Использованные условные обозначения
100 громкоговоритель (акустический динамик)
110 микрофон
120 эхогаситель
200 фронтальное устройство (терминал) конференц-связи
210 подавитель акустического эха
220 вычислитель
230 средство входного интерфейса
240 адаптивный фильтр
250 многоканальный декодер
300 входной сигнал
310 микшированный с понижением сигнал (сигнал понижающего микширования; даунмикс-сигнал)
320 служебная параметрическая информация (параметрические протокольные данные)
330 сигнал громкоговорителя
340 микрофонный сигнал
350 сигнал с коэффициентом фильтрации (сигнал, задающий коэффициент пропускания фильтра)
360 выходной сигнал
400 многоканальный кодер
410 входной сигнал
420 выходной сигнал
450 матрица предварительного микширования (матрица предмикширования)
460 декоррелятор
470 матрица последующего микширования (матрица постмикширования)
480 параметрический процессор
490 данные воспроизведения/взаимодействия
500 транскодер (преобразователь кода; кодопреобразователь; перекодировщик)
510 анализатор (синтаксиса) SAOC (пространственного кодирования аудиообъекта)
520 битстрим SAOC
530 количество (аудио-) объектов
540 устройство рендеринга сцены
550 матрица (аудио-) рендеринга
560 генератор матрицы рендеринга
570 конфигурация воспроизведения (построение звукоотображения)
580 положение (аудио-) объекта
590 транскодер даунмикса
600 управляющая информация
700 эхоподавитель
710 процессор
720 новый даунмикс-сигнал
730 новая служебная параметрическая информация
740 модифицированный даунмикс
800 первый генератор опорной спектральной плотности мощности (опорного спектра мощности; опорного энергетического спектра)
810 контур задержки
820 вычислитель оценки эхосигнала
830 генератор фильтра эхоподавления
840 второй генератор опорной спектральной плотности мощности (см. 800)
850 генератор коэффициентов фильтрации ожидаемого эха
860 первый компенсатор временных колебаний
870 второй компенсатор временных колебаний
880 вычислитель когерентности
890 вычислитель выигрыша от предсказания эха (вычислитель усиления предсказания эха)
900 оптимизатор
Список литературы
[1] ISO/IEC 23003-1:2007. Information technology - MPEG Audio technologies - Part 1: MPEG Surround. International Standards Organization, Geneva, Switzerland, 2007.
[2] E.Benjamin and T.Chen. The native B-format microphone: Part I. In 119th AES Convention, Paper 6621, New York, Oct. 2005.
[3] H.Buchner, R.Aichner, and W.Kellermann. A generalization of blind source separation algorithms for convolutive mixtures based on second order statistics. IEEE trans. on Speech and Audio Processing, 13(1): 120-134, Jan. 2005.
[4] H.Buchner, R.Aichner, J.Stenglein, H.Teutsch, and W.Kellermann. Simultaneous localization of multiple sound sources using blind adaptive MIMO filtering. In Proc. IEEE Int. Conf on Acoustics, Speech, and Signal Processing (ICASSP), Philadelphia, March 2005.
[5] J.Engdegard, B.Resch, C.Falch, O.Hellmuth, J.Hilpert, A.Hoelzer, L.Terentiev, J.Breebaart, J.Koppens, E.Schuijers, and W.Oomen. Spatial audio object coding (SAOC) - the upcoming MPEG standard on parametric object based audio coding. In 124th AES Convention, Paper 7377, Amsterdam, May 2008.
[6] A.Favrot et. al. Acoustic echo control based on temporal fluctuations of short-time spectra. In Proc. Intl. Works, on Acoust. Echo and Noise Control (IWAENC), Seattle, Sept. 2008, submitted.
[7] W.Etter and G.S.Moschytz. Noise reduction by noise-adaptive spectral magnitude expansion. J. Audio Eng. Soc., 42:341-349, May 1994.
[8] С.Faller and С.Toumery. Estimating the delay and coloration effect of the acoustic echo path for low complexity echo suppression. In Proc. Intl. Works, on Acoust. Echo and Noise Control (IWAENC), Sept. 2005.
[9] A.Favrot, C.Faller, M.Kallinger, F.Kuech, and M.Schmidt. Acoustic echo control based on temporal fluctuations of short-time spectra. In Proc. Intl. Works, on Acoust. Echo and Noise Control (I WAENC), Sept. 2008.
[10] Jilrgen Herre, Kristofer Kjorling, Jeroen Breebaart, Christof Faller, Sascha Disch, Heiko Pumhagen, Jeroen Koppens, Johannes Hilpert, Jonas Roden, Wemer Oomen, Karsten Linzmeier, and Kok Seng Chong. MPEG Surround - The ISO / MPEG Standard for efficient and compatible multichannel audio coding. J. Audio Eng. Soc., 56(11):932-955, Nov. 2008.
[11] J. Merimaa. Applications of a 3-D microphone array. In 112th AES Convention, Paper 5501, Munich, May 2002.
[12] V. Pulkki. Spatial sound reproduction with directional audio coding. J. Audio Eng. Soc., 55(6):503-516, June 2007.
[13] G.Schmidt and E.Hansler. Acoustic echo and noise control: a practical approach. Hoboken: Wiley, 2004.







Изобретение относится к средствам подавления акустического эха. Технический результат заключается в снижении вычислительной сложности и увеличении эффективности процесса подавления акустического эха. Акустический эхоподавитель включает в себя средство входного интерфейса (230) для извлечения даунмикс-сигнала (310) из входного сигнала (300), содержащего даунмикс (310) и служебную параметрическую информацию (320), которые в совокупности представляют многоканальный сигнал; также включает в себя вычислитель (220) для расчета коэффициентов пропускания адаптивного фильтра (240) на основе даунмикс-сигнала (310) и микрофонного сигнала (340) или сигнала, производного от микрофонного сигнала; и адаптивный фильтр (240) микрофонного сигнала (340) или сигнала, производного от микрофонного сигнала, использующий заданные ему коэффициенты пропускания для подавления эха, возбуждаемого многоканальным сигналом в микрофонном сигнале (340). 6 н.з. и 9 з.п. ф-лы, 10 ил.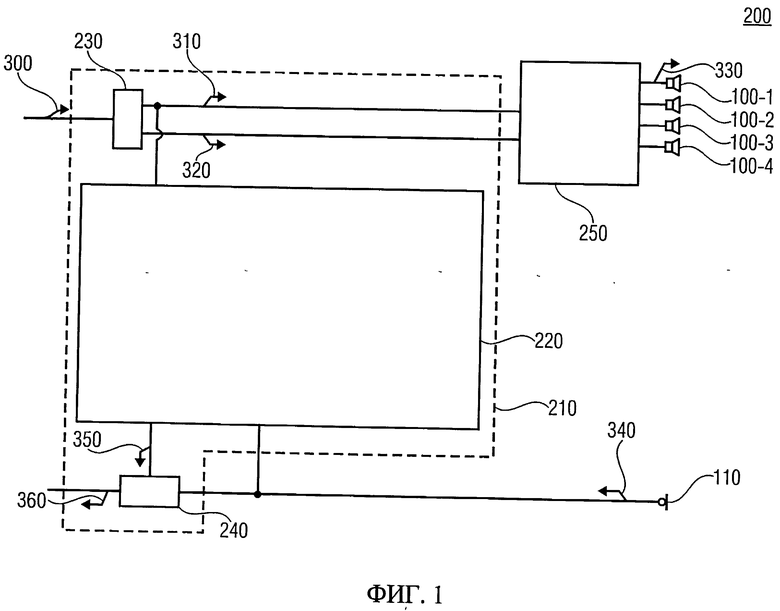
1. Подавитель акустического эха (210), включающий средство входного интерфейса (230), обеспечивающее извлечение микшированного с понижением сигнала - даунмикс-сигнала (310) из входного сигнала (300), который, в целом, состоит из даунмикс-сигнала (310) и служебной параметрической информации (320), совокупно представляющих собой многоканальный сигнал, содержащий, по меньшей мере, дополнительные каналы или большее число каналов, чем содержится в даунмикс-сигнале; вычислитель (220), предназначенный для расчета коэффициентов пропускания (350) адаптивного фильтра (240) на основе принятых вычислителем (220) даунмикс-сигнала (310), сигнала микрофона (340) или сигнала, производного от сигнала микрофона (720); адаптивный фильтр (240), предназначенный для получения от вычислителя (220) коэффициентов фильтрации (350) и их использования для фильтрации сигнала микрофона (340) или сигнала, производного от сигнала микрофона (720), для подавления эха, возбуждаемого многоканальным сигналом в сигнале микрофона (340), в котором вычислитель (220) предназначен для расчёта коэффициентов фильтрации (350) путем определения первого показателя опорной спектральной плотности мощности на основании микшированного с понижением сигнала (310), путем определения второго показателя опорной спектральной плотности мощности на основании сигнала микрофона (340) или сигнала, производного от сигнала микрофона (720), путем определения коэффициентов фильтрации ожидаемого эха на основании первого и второго показателей опорной спектральной плотности мощности, путем определения ожидаемого эхо-сигнала на основании первого показателя опорной спектральной плотности мощности и коэффициентов фильтрации ожидаемого эха и путем определения коэффициентов фильтрации (350) на основании коэффициентов фильтрации ожидаемого эха и второго показателя опорной спектральной плотности мощности.
2. Подавитель акустического эха (210) по п. 1, в котором вычислитель (220) предназначен для расчета первого опорного спектра мощности на основании
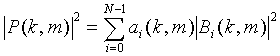
или
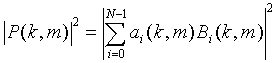
где  - первый показатель опорной спектральной плотности мощности, ai(k, m) - весовой коэффициент,
- первый показатель опорной спектральной плотности мощности, ai(k, m) - весовой коэффициент,  - i-ный канал микшированного с понижением сигнала (310), где N - количество каналов в микшированном с понижением сигнале (310), причем N - больше или равно 1, где k - временной индекс блока и m - коэффициент частотности.
- i-ный канал микшированного с понижением сигнала (310), где N - количество каналов в микшированном с понижением сигнале (310), причем N - больше или равно 1, где k - временной индекс блока и m - коэффициент частотности.
3. Подавитель акустического эха (210) по п. 1, в котором вычислитель (220) предназначен для расчета второго опорного спектра мощности на основании

или
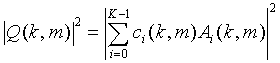
где 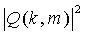 - второй опорный спектр мощности, ci(k, m) - весовой коэффициент,
- второй опорный спектр мощности, ci(k, m) - весовой коэффициент,  - i-ный канал микшированного с понижением сигнала (720), где К - количество каналов в микшированном с понижением сигнале (720), причем К - больше или равно 1, где k - временной индекс блока и m - коэффициент частотности.
- i-ный канал микшированного с понижением сигнала (720), где К - количество каналов в микшированном с понижением сигнале (720), причем К - больше или равно 1, где k - временной индекс блока и m - коэффициент частотности.
4. Подавитель акустического эха (210) по п. 1, в котором вычислитель (220), кроме названного, предназначен для расчета коэффициентов фильтрации ожидаемого эха и оценки эхо-сигнала, исходя из первого опорного показателя спектральной плотности мощности в версии с задержкой на некую величину задержки.
5. Подавитель акустического эха (210) по п. 4, в котором вычислитель (220) предназначен также для определения величины задержки путем нахождения корреляционного значения для множества возможных величин задержек, путем нахождения значения выигрыша от предсказания эха для множества возможных величин задержек и путем нахождения значения множества возможных величин задержек как величины задержки с максимальным значением среди установленных значений выигрыша от предсказания эха.
6. Подавитель акустического эха (210) по п. 1, в котором вычислитель (220) предусматривает возможность вычисления первого модифицированного спектра мощности на основании первого опорного показателя спектральной плотности мощности путем вычитания среднего значения первой опорной спектральной плотности мощности; в котором вычислитель (220) предусматривает возможность вычисления второго модифицированного спектра мощности на основании второго опорного показателя спектральной плотности мощности путем вычитания второго среднего значения второй опорной спектральной плотности мощности; и в котором вычислитель (220) предусматривает возможность вычисления коэффициентов фильтрации ожидаемого эха на основании первого и второго модифицированных показателей спектральной плотности мощности.
7. Способ подавления акустического эхо-сигнала, включающий в себя: извлечение микшированного с понижением сигнала (310) из входного сигнала (300), состоящего из микшированного с понижением сигнала (310) и служебной параметрической информации (320), где микшированный с понижением сигнал (310) и служебная параметрическая информация (320) совокупно представляют многоканальный сигнал, содержащий, по меньшей мере, дополнительные каналы или число каналов, большее, чем количество каналов в микшированном с понижением сигнале; вычисление коэффициентов пропускания фильтра (350) для адаптивной фильтрации на основе микшированного с понижением сигнала и сигнала микрофона или сигнала, производного от сигнала микрофона; путем определения первого показателя опорной спектральной плотности мощности на основании микшированного с понижением сигнала (310), путем определения второго показателя опорной спектральной плотности мощности на основании сигнала микрофона (340) или сигнала, производного от сигнала микрофона (720), путем определения коэффициентов фильтрации ожидаемого эха на основании первого и второго показателей опорной спектральной плотности мощности, путем определения ожидаемого эхо-сигнала на основании первого показателя опорной спектральной плотности мощности и коэффициентов фильтрации ожидаемого эха и путем определения коэффициентов фильтрации (350) на основании коэффициентов фильтрации ожидаемого эха и второго показателя опорной спектральной плотности мощности; адаптивную фильтрацию микрофонного сигнала (340) или сигнала, производного от микрофонного сигнала (720), исходя из коэффициентов фильтрации, с целью подавления эха, возбуждаемого многоканальным сигналом в микрофонном сигнале (340).
8. Способ по п. 7, включающий в себя, кроме того, декодирование микшированного с понижением сигнала (310) и служебной параметрической информации (320) с преобразованием в совокупное множество сигналов громкоговорителей (330).
9. Терминал конференц-связи (200), включающий акустический эхоподавитель (210) по любому из пп. 1 - 6; многоканальный декодер (250); не менее одного микрофонного блока (110), в составе которого многоканальный декодер (250) предназначен для декодирования микшированного с понижением сигнала (310) и служебной параметрической информации (320) с преобразованием в множество сигналов громкоговорителей (330); в котором, по меньшей мере, один микрофонный блок (110) обеспечивает микрофонный сигнал (340).
10. Терминал по п. 9, в котором средство входного интерфейса (230) предназначено для дальнейшего извлечения служебной параметрической информации (320); в составе которого многоканальный декодер (250) включает в себя повышающий микшер (705) и параметрический процессор (480), где параметрический процессор (480) выполнен с возможностью приема служебной параметрической информации (320) от средства входного интерфейса (230) и с возможностью генерации сигнала, управляющего повышающим микшированием (707), и где повышающий микшер (705) выполнен с возможностью приема микшированного с понижением сигнала (310) от средства входного интерфейса (230) и приема сигнала управления повышающим микшированием от параметрического процессора и выполнен с возможностью генерации множества сигналов громкоговорителя (330) на основе микшированного с понижением сигнала (310) и управляющего сигнала повышающего микшера (707).
11. Терминал по п. 9, имеющий в своем составе, кроме указанного, многоканальный кодер (400), предназначенный для кодирования множества входных звуковых сигналов (340; 410) с преобразованием в новый микшированный с понижением сигнал (720) и новую служебную параметрическую информацию (730), которые в совокупности представляют множество входных аудиосигналов, из которых микрофонный сигнал (340) от, по меньшей мере, одного микрофонного блока (110) содержится в множестве входных аудиосигналов; имеющий также в своем составе подавитель акустического эха (210), выполненный с возможностью приема нового микшированного с понижением сигнала (720) как сигнала, производного от микрофонного сигнала.
12. Терминал по п. 10, включающий в свой состав множество микрофонных блоков (110), обеспечивающих множество входных звуковых сигналов (330; 410).
13. Способ генерации множества сигналов громкоговорителей (330) и сигналов микрофонов (340), включающий в себя: способ подавления (210) акустического эха по п. 7; этап многоканального декодирования (250); этап приема микрофонного сигнала (340), причем на этапе многоканального декодирования (250) микшированный с понижением сигнал (310) и служебную параметрическую информацию (320) декодируют с получением множества сигналов громкоговорителей (330).
14. Машиночитаемый носитель информации с записанной на нем компьютерной программой для осуществления способа по п. 7 при условии ее выполнения с использованием процессора.
15. Машиночитаемый носитель информации с записанной на нем компьютерной программой для осуществления способа по п. 13 при условии ее выполнения с использованием процессора.
| WO 2003061344 A3, 24.07.2013 | |||
| RU 2010131421 A, 12.01.2009 | |||
| СЕТЕВОЙ ЭХОПОДАВИТЕЛЬ | 1993 |
|
RU2109408C1 |
| RU 2000120915 A, 20.08.2002 | |||
| ИЗМЕРЕНИЕ СХОДИМОСТИ АДАПТИВНЫХ ФИЛЬТРОВ | 1996 |
|
RU2180984C2 |

