Область изобретения
Изобретение относится к обработке сигналов в полосе звуковых частот и, в частности, к обработке сигналов в полосе звуковых частот в контексте кодирования звуковых объектов, такого как пространственное кодирование звукового объекта.
Предпосылки изобретения и прототип
В современных радиовещательных системах, таких как телевидение, при определенных обстоятельствах желательно не воспроизводить звуковые дорожки в том виде, как их спроектировал звукооператор, а скорее произвести специальные настройки, чтобы адресоваться к ограничениям, заданным во время представления (визуализации). Хорошо известная технология управления такими настройками при окончательном монтаже заключается в предоставлении соответствующих метаданных наряду со звуковыми дорожками.
Традиционные системы воспроизведения звука, например старые домашние телевизионные системы, состоят из одного громкоговорителя или пары стерео громкоговорителей. Более сложные многоканальные системы воспроизведения используют пять или даже больше громкоговорителей.
Если рассматриваются многоканальные системы воспроизведения, звукооператоры имеют намного больше свободы маневрирования при размещении единичных источников в двухмерной плоскости и поэтому могут также использовать более высокий динамический диапазон для полных звуковых дорожек, так как голос становится более внятным благодаря известному эффекту «коктейльной вечеринки».
Однако реалистические, высокодинамические звуки могут вызвать проблемы на традиционных системах воспроизведения. Могут существовать сценарии, где потребитель, возможно, не захочет получать этот высокий динамический сигнал, потому что он прослушивает контент в шумной окружающей среде (например, в едущем автомобиле или при использовании мобильной системы развлечений в полете), она или он носит слуховые устройства или она или он не хочет потревожить своих соседей (поздно вечером, например).
Кроме того, дикторы сталкиваются с той проблемой, что различные элементы одной программы (например, коммерческая реклама) могут быть на различных уровнях громкости из-за различных коэффициентов амплитуды, требующих регулирования уровня последовательных элементов.
В цепи классической вещательной передачи конечный пользователь получает уже микшированную звуковую дорожку. Любое дальнейшее управление на стороне приемника может быть сделано только в очень ограниченной форме. В настоящее время небольшой набор характеристик метаданных системы Долби позволяет пользователю изменять некоторые свойства звукового сигнала.
Обычно манипуляции, основанные на вышеупомянутых метаданных, осуществляются без какого бы то ни было частотного селективного распознавания, так как метаданные, традиционно приложенные к звуковому сигналу, не предоставляют достаточную информацию, чтобы сделать это.
Кроме того, можно управлять только целым звуковым потоком. К тому же, нельзя принять и выделить каждый звуковой объект внутри этого звукового потока. Это может быть неудовлетворительным, особенно в неподходящей окружающей среде прослушивания.
В полуночном режиме использующийся звуковой процессор не может отличить шумы окружения от диалога из-за недостатка управляющей информации. Поэтому в случае шумов высокого уровня (которые должны быть сжаты/ограничены по громкости) диалоги тоже будут управляться параллельно. Это могло бы повредить внятности речи.
Увеличение уровня диалога по сравнению с окружающим звуком помогает улучшить восприятие речи, особенно для прослушивания людьми с ослабленным слухом. Эта техника работает, только если звуковой сигнал действительно отделяется в диалоге и окружающих компонентах на стороне приемника помимо наличия информации о контроле качества. Если доступен только стерео сигнал понижающего микширования, никакое дальнейшее разделение больше не может быть применено для отдельного распознавания и управления речевой информацией. Современные способы осуществления понижающего микширования позволяют регулировать динамический стерео уровень для центрального и окружающих каналов. Но для любой отличной конфигурации громкоговорителя вместо стерео нет никакого реального указания от передатчика того, как микшировать с понижением конечный многоканальный звуковой источник. Только формула по умолчанию в декодере выполняет микширование сигнала точным образом.
Во всех описанных сценариях обычно существуют два различных подхода. Первый подход состоит в том, что при генерировании звукового сигнала, который будет передан, ряд звуковых объектов является микшированным с понижением до моно, стерео или многоканального сигнала. Сигнал, который должен быть передан пользователю этого сигнала посредством радиопередачи, посредством любого другого протокола передачи или посредством распределения на считываемом компьютером носителе данных, обычно имеет число каналов, меньшее чем число оригинальных звуковых объектов, которые были микшированы с понижением звукооператором, например, в студийном окружении. Кроме того, метаданные могут быть приложены, чтобы позволить несколько различных модификаций, но эти модификации могут быть применены только к целому переданному сигналу или, если переданный сигнал имеет несколько различных переданных каналов, к индивидуальным переданным каналам целиком. Поскольку, однако, такие переданные каналы всегда являются наложениями нескольких звуковых объектов, индивидуальное управление определенным звуковым объектом, в то время как следующий звуковой объект не управляется, вообще не возможно.
Другой подход состоит не в осуществлении понижающего микширования объекта, а в передаче сигналов звуковых объектов, поскольку они являются отдельными переданными каналами. Такой сценарий хорошо работает, когда число звуковых объектов небольшое. Когда, например, существует только пять звуковых объектов, тогда можно передать эти пять различных звуковых объектов отдельно друг от друга в пределах сценария 5.1. Метаданные могут быть связаны с теми каналами, которые указывают на определенную природу объекта/канала. Тогда, на стороне приемника, переданные каналы могут управляться, основываясь на переданных метаданных.
Неудобство этого подхода состоит в том, что он не является обратно-совместимым и работает хорошо только в контексте небольшого количества звуковых объектов. Когда число звуковых объектов увеличивается, также быстро увеличивается скорость передачи битов, требуемая для передачи всех объектов как отдельных определенных звуковых дорожек. Это увеличение скорости передачи битов особенно не полезно в контексте применения в радиопередачах.
Поэтому существующие подходы, эффективные относительно скорости передачи битов, не позволяют осуществлять индивидуальное управление отдельными звуковыми объектами. Такое индивидуальное управление доступно, только когда каждый объект будет передаваться отдельно. Этот подход, однако, не эффективен относительно скорости передачи битов и поэтому не подходит, конкретно, в сценариях радиопередач.
Задачей данного изобретения является обеспечение эффективной скорости передачи битов при гибком решении этих проблем.
Согласно первому аспекту данного изобретения это достигается посредством устройства для генерирования, по крайней мере, одного выходного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающего: процессор для обработки входного звукового сигнала, чтобы обеспечить объектное представление входного звукового сигнала, в котором, по крайней мере, два различных звуковых объекта отделены друг от друга, по крайней мере, два различных звуковых объекта доступны в качестве отдельных сигналов звуковых объектов и, по крайней мере, два различных звуковых объекта являются управляемыми независимо друг от друга; манипулятор объекта для управления сигналом звукового объекта или микшированным сигналом звукового объекта, по крайней мере, одного звукового объекта, основанного на объектно-ориентированных метаданных, относящихся, по крайней мере, к одному звуковому объекту, чтобы получить управляемый сигнал звукового объекта или управляемый микшированный сигнал звукового объекта, по крайней мере, для одного звукового объекта; и микшер объекта для микширования объектного представления посредством объединения управляемого звукового объекта с неизмененным звуковым объектом или с другим управляемым звуковым объектом, управляемым иначе, чем, по крайней мере, одним звуковым объектом.
Согласно второму аспекту данного изобретения это достигается посредством способа генерирования, по крайней мере, одного выходного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающего: обработку входного звукового сигнала, чтобы обеспечить объектное представление входного звукового сигнала, в котором, по крайней мере, два различных звуковых объекта отделены друг от друга, по крайней мере, два различных звуковых объекта доступны в качестве отдельных сигналов звуковых объектов и, по крайней мере, два различных звуковых объекта являются управляемыми независимо друг от друга; управление сигналом звукового объекта или микшированным сигналом звукового объекта, по крайней мере, одного звукового объекта, основанного на объектно-ориентированных метаданных, относящихся, по крайней мере, к одному звуковому объекту, чтобы получить управляемый сигнал звукового объекта или управляемый микшированный сигнал звукового объекта, по крайней мере, для одного звукового объекта; и микширование объектного представления посредством объединения управляемого звукового объекта с неизмененным звуковым объектом или с другим управляемым звуковым объектом, который управляется иначе, чем, по крайней мере, один звуковой объект.
Согласно третьему аспекту данного изобретения результат достигается посредством устройства для генерирования закодированного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающего: форматер потока данных для форматирования потока данных таким образом, чтобы поток данных включал сигнал понижающего микширования объекта, представляющего собой комбинацию, по крайней мере, двух различных звуковых объектов, и, в качестве дополнительной информации, метаданные, относящиеся, по крайней мере, к одному из различных звуковых объектов.
Согласно четвертому аспекту данного изобретения результат достигается посредством способа генерирования закодированного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающего: форматирование потока данных таким образом, чтобы поток данных включал сигнал понижающего микширования объекта, представляющий собой комбинацию, по крайней мере, двух различных звуковых объектов, и, в качестве дополнительной информация, метаданные, относящиеся, по крайней мере, к одному из различных звуковых объектов.
Дальнейшие аспекты данного изобретения относятся к компьютерным программам, реализующим изобретения на способы, и к считываемому компьютером носителю данных с сохраненным на нем сигналом понижающего микширования объекта и, в качестве дополнительной информации, параметрическими данными объекта и метаданными для одного или более звуковых объектов, включенных в сигнал понижающего микширования объекта.
Данное изобретение основывается на обнаружении того, что индивидуальное управление отдельными сигналами звуковых объектов или отдельными сериями микшированных сигналов звуковых объектов позволяет индивидуальную связанную с объектом обработку, основанную на связанных с объектом метаданных. Согласно данному изобретению результат управления не выходит непосредственно на громкоговоритель, но предоставляется микшеру объекта, который генерирует выходные сигналы для определенного сценария предоставления, где выходные сигналы генерируются наложением, по крайней мере, одного управляемого сигнала объекта или ряда микшированных сигналов объекта вместе с другими управляемыми сигналами объекта и/или неизмененным сигналом объекта. Естественно, нет необходимости управлять каждым объектом, но, в некоторых случаях, бывает достаточно управлять только одним объектом и не управлять последующим объектом множества звуковых объектов. Результатом операции микширования объекта является один или множество выходных звуковых сигналов, которые основываются на управляемых объектах. Эти выходные звуковые сигналы могут быть переданы громкоговорителям, или могут быть сохранены для дальнейшего использования, или могут даже быть переданы последующему приемнику в зависимости от определенного сценария применения.
Предпочтительно, чтобы входной сигнал в устройство управления/микширования, выполненное согласно изобретению, был сигналом понижающего микширования, сгенерированным посредством понижающего микширования множества сигналов звуковых объектов. Процесс понижающего микширования может контролироваться метаданными для каждого объекта индивидуально или может быть неконтролируемым, чтобы быть одинаковым для каждого объекта. В предыдущем случае управление объектом согласно метаданным является процессом индивидуального контролирования объекта и процессом микширования определенного объекта, в котором генерируется сигнал компонента громкоговорителя, представляющий этот объект. Предпочтительно, чтобы предоставлялись также пространственные параметры объекта, которые могут использоваться для реконструкции оригинальных сигналов посредством их приближенных версий, используя переданный сигнал понижающего микширования объекта. Тогда процессор для обработки входного звукового сигнала для обеспечения объектного представления входного звукового сигнала является эффективным для вычисления реконструированных версий оригинального звукового объекта, основанного на параметрических данных, где эти приближенные сигналы объекта могут затем индивидуально управляться объектно-ориентированными метаданными.
Предпочтительно, чтобы объектное представление (рендеринг) информации также предоставлялось там, где объектное представление информации включает информацию относительно предполагаемой звуковой установки воспроизведения и информацию относительно расположения индивидуальных звуковых объектов в пределах сценария воспроизведения. Определенные осуществления, однако, могут также работать без таких данных о местоположении объекта. Такие конфигурации являются, например, обеспечением стационарных положений объекта, которые могут быть прочно установлены или которые могут согласовываться между передатчиком и приемником для полной звуковой дорожки.
Краткое описание чертежей
Предпочтительные осуществления данного изобретения далее обсуждаются в контексте приложенных чертежей, в которых:
фиг. 1 иллюстрирует предпочтительное осуществление устройства для генерирования, по крайней мере, одного выходного звукового сигнала;
фиг. 2 иллюстрирует предпочтительное исполнение процессора фиг. 1;
фиг. 3a иллюстрирует предпочтительное осуществление манипулятора для управления сигналами объекта;
фиг.3b иллюстрирует предпочтительное исполнение микшера объекта в контексте манипулятора, как проиллюстрировано на фиг. 3a;
фиг. 4 иллюстрирует конфигурацию процессора/манипулятора/микшера объекта в ситуации, в которой управление выполняется вслед за понижающим микшированием объекта, но до окончательного микширования объекта;
фиг. 5a иллюстрирует предпочтительное осуществление устройства для генерирования закодированного звукового сигнала;
фиг. 5b иллюстрирует сигнал передачи, имеющий понижающее микширование объекта, объектно-ориентированные метаданные и пространственные параметры объекта;
фиг.6 иллюстрирует карту, показывающую несколько звуковых объектов, идентифицированных в соответствии с определенной идентификацией, имеющих файл звукового объекта, и матрицу E объединенной информации о звуковом объекте;
фиг. 7 иллюстрирует объяснение матрицы E ковариации объекта фиг. 6;
фиг. 8 иллюстрирует матрицу понижающего микширования и звуковое кодирующее устройство объекта, управляемое матрицей D понижающего микширования;
фиг.9 иллюстрирует заданную матрицу визуализации А, которая обычно предоставляется пользователем, и пример определенного заданного воспроизводящего сценария;
фиг. 10 иллюстрирует предпочтительное осуществление устройства для генерирования, по крайней мере, одного выходного звукового сигнала в соответствии с дальнейшим аспектом данного изобретения;
фиг. 11a иллюстрирует дальнейшее осуществление;
фиг. 11b иллюстрирует еще один вариант осуществления;
фиг. 11c иллюстрирует дальнейшее осуществление;
фиг. 12a иллюстрирует примерный сценарий применения;
фиг. 12b иллюстрирует дальнейший примерный сценарий применения.
Детальное описание предпочтительных осуществлений
Чтобы разрешить вышеупомянутые проблемы, предпочтительный подход должен обеспечивать соответствующие метаданные наряду со звуковыми дорожками. Такие метаданные могут состоять из информации для управления следующими тремя факторами (три «классических» D):
• нормализация диалога;
• контроль динамического диапазона;
• понижающее микширование.
Такие звуковые метаданные помогают приемнику управлять полученным звуковым сигналом, основанным на настройках, выполненных слушателем. Чтобы отличить этот вид звуковых метаданных от других (например, описательные метаданные, такие как Автор, Название, …), обычно делается ссылка на «Метаданные системы Долби» (потому что они выполняются только системой Долби). В дальнейшем рассматривается только этот вид звуковых метаданных и называется просто «метаданные».
Звуковые метаданные являются дополнительной управляющей информацией, которая переносится наряду со звуковой программой и имеет существенную для приемника информацию о звуке. Метаданные предоставляют многие важные функции, включая контроль динамического диапазона для далеко неидеальной окружающей среды прослушивания, приведение в соответствие уровня программ, информацию о понижающем микшировании для воспроизведения многоканального звука через меньшее количество каналов громкоговорителя и другую информацию.
Метаданные обеспечивают инструменты, необходимые для звуковых программ, которые будут воспроизведены точно и мастерски во многих различных ситуациях прослушивания от полнофункциональных домашних театров до средств развлечения в полете, независимо от числа каналов громкоговорителя, качества оборудования воспроизведения или относительного уровня окружающих шумов.
В то время как инженер или поставщик контента заботятся об обеспечении звука самого высокого качества, возможного в рамках программы, они не имеют возможности контролировать обширный массив бытовой электроники или окружающей среды прослушивания, которые будут воспроизводить оригинальную звуковую дорожку. Метаданные предоставляют инженеру или поставщику контента возможность контролировать то, как их работа воспроизводится и воспринимается почти в любой мыслимой окружающей среде прослушивания.
Метаданные системы Долби являются специальным форматом для предоставления информации для управления этими тремя упомянутыми факторами.
Три самые важные функциональные возможности метаданных системы Долби:
• нормализация диалога для достижения долгосрочного среднего уровня диалога в пределах представления, часто состоящего из различных типов программы, таких как игровой фильм, коммерческая реклама и т.д.;
• контроль динамического диапазона, чтобы доставить большей части аудитории удовольствие приятным звуковым сжатием, но, в то же самое время, позволить каждому индивидуальному потребителю управлять динамикой звукового сигнала и регулировать сжатие для ее или его личной окружающей среды прослушивания;
• понижающее микширование для отображения звуков многоканального звукового сигнала до двух или одного канала в случае, если не доступно никакое многоканальное звуковое оборудование воспроизведения.
Метаданные системы Долби используются наряду с Цифровой системой Долби (AC-3) и системой Долби E. Формат звуковых метаданных системы-Долби-E, описанный в [16] Цифровой системы Долби (AC-3), предназначен для транслирования звука в дом посредством цифрового телевидения (высокого или стандартного разрешения), DVD или других носителей.
Цифровая система Долби может переносить все, что угодно, от одиночного звукового канала до полной программы с 5.1 каналами, включая метаданные. И в цифровом телевидении, и в DVD это часто используется для передачи стерео, а также полных 5.1 дискретных звуковых программ.
Система Долби E определенно предназначена для распределения многоканального звука в пределах профессиональной окружающей среды производства и распределения. В любое время до доставки потребителю, система Долби E является предпочтительным способом распределения многоканальных /мультипрограммных звуков с видео. Система Долби E может переносить до восьми дискретных звуковых каналов, скомпонованных в любое число индивидуальных программных конфигураций (включая метаданные для каждого) в пределах существующей двухканальной цифровой звуковой инфраструктуры. В отличие от Цифровой системы Долби, система Долби E может регулировать многие генерации кодировки/расшифровки и является синхронной с частотой видео кадров. Как и Цифровая система Долби, система Долби E переносит метаданные для каждой индивидуальной звуковой программы, закодированной в пределах потока данных. Использование системы Долби E позволяет расшифровывать, изменять и повторно кодировать получающийся звуковой поток данных без слышимой деградации. Поскольку поток системы Долби E синхронен с частотой видео кадров, он может быть маршрутизирован, переключен и отредактирован в профессиональной окружающей среде радиопередачи.
Кроме этого, средство предоставляется наряду с MPEG AAC для осуществления контроля динамического диапазона и управления генерированием понижающего микширования.
Чтобы регулировать исходный материал с переменными пиковыми уровнями, средними уровнями и динамическим диапазоном способом, минимизирующим изменчивость для потребителя, необходимо контролировать воспроизведенный уровень таким образом, чтобы, например, уровень диалога или средний музыкальный уровень устанавливался на контролируемый потребителем уровень при воспроизведении, независимо от того, как программа была создана. Дополнительно, не все потребители смогут слушать программы в хорошей (то есть с низким шумом) окружающей среде, без ограничения громкости звука при прослушивании. Автомобильная окружающая среда, например, имеет высокий уровень окружающего шума, и можно поэтому ожидать, что слушатель захочет уменьшить диапазон уровней, которые иначе были бы воспроизведены.
По обеим этим причинам контроль динамического диапазона должен быть доступным в пределах спецификации AAC (Advanced Audio Coding - усовершенствованное аудиокодирование). Чтобы достигнуть этого, необходимо сопровождать звук с пониженной скоростью передачи битов данными, используемыми для установки и контроля динамического диапазона пунктов программы. Этот контроль должен быть определен относительно контрольного уровня и в отношении к важным элементам программы, например диалогу.
Характеристики контроля динамического диапазона следующие:
1. Контроль динамического диапазона является полностью оптимальным. Поэтому при правильном синтаксисе не происходит изменение сложности для тех, кто не желает активизировать DRC (контроль соблюдения проектных норм).
2. Звуковые данные с пониженной скоростью передачи битов передаются с полным динамическим диапазоном исходного материала, с вспомогательными данными, чтобы способствовать контролю динамического диапазона.
3. Данные контроля динамического диапазона могут быть посланы на каждый фрейм, чтобы уменьшить до минимума время ожидания при установке коэффициентов усиления воспроизведения.
4. Данные контроля динамического диапазона посылаются посредством использования характеристики «элемент заполнения» (fill_element) AAC (формат усовершенствованного аудиокодирования).
5. Контрольный Уровень определяется как Полномасштабный.
6. Контрольный Уровень Программы передается, чтобы обеспечить равенство уровней воспроизведения различных источников и обеспечить ссылку, на которую может опираться контроль динамического диапазона. Именно эта характеристика исходного сигнала наиболее релевантна для субъективного впечатления от громкости программы, такого как уровень контента диалога программы или средний уровень музыкальной программы.
7. Контрольный Уровень Программы представляет тот уровень программы, который может быть воспроизведен при заданном уровне относительно Контрольного Уровня в аппаратных средствах потребителя, чтобы достигнуть равенства уровня воспроизведения. Относительно этого более тихие части программы могут быть усилены по уровню, а более громкие части программы могут быть ослаблены по уровню.
8. Контрольный Уровень Программы определяется в пределах диапазона от 0 до -31,75 децибел относительно Контрольного Уровня.
9. Контрольный Уровень Программы использует 7-битовое поле с шагом в 0,25 децибел.
10. Контроль динамического диапазона определяется в пределах диапазона ±31,75 децибел.
11. Контроль динамического диапазона использует 8-битовое поле (1 знак, 7 значений) с шагом в 0,25 децибел.
12. Контроль динамического диапазона может быть применен ко всем спектральным коэффициентам звукового канала или диапазонам частот как к единому объекту, или коэффициенты могут быть разделены на различные группы масштабных коэффициентов, каждый управляется отдельно отдельными наборами данных контроля динамического диапазона.
13. Контроль динамического диапазона может применяться ко всем каналам (стерео или многоканального битового потока) как к единому объекту или может быть разделен, при этом группы каналов будут управляться отдельно отдельными наборами данных контроля динамического диапазона.
14. Если предполагаемый набор данных контроля динамического диапазона отсутствует, должны использоваться полученные последними действительные значения.
15. Не все элементы данных контроля динамического диапазона посылаются каждый раз. Например, Контрольный Уровень Программы может посылаться в среднем только один раз каждые 200 миллисекунд.
16. Где необходимо, обнаружение/защита от ошибок обеспечивается Транспортным Уровнем (уровнем переноса).
17. Пользователю будет предоставлено средство для изменения степени контроля динамического диапазона, присутствующего в битовом потоке, который применяется к уровню сигнала.
Помимо возможности передать отдельные моно или стерео микшированные с понижением каналы в передаче с 5.1 каналами, AAC также позволяет автоматическое генерирование понижающего микширования от исходной дорожки с 5-ю каналами. Канал LFE должен быть опущен в этом случае.
Этот способ матричного понижающего микширования может управляться редактором звуковой дорожки с небольшим набором параметров, определяющих количество задних каналов, добавленных к понижающему микшированию.
Способ матричного понижающего микширования применяется только для микширования 3-передняя/2-задняя конфигурации громкоговорителя, программы с 5 каналами, до стерео или моно программы. Он не применяется ни к какой другой программе кроме 3/2 конфигурации.
В пределах MPEG предоставляются несколько средств для управления представлением звука (аудио рендерингом) на стороне приемника.
Типовая технология предоставляется языком описания сцены, например BIFS и LASeR. Обе технологии используются для воспроизведения аудиовизуальных элементов из разделенных закодированных объектов в сцену воспроизведения.
BIFS стандартизированы в [5] и LASeR - в [6].
MPEG-D главным образом имеет дело с (параметрическими) описаниями (то есть метаданными):
• чтобы генерировать многоканальный звук, основанный на звуковых представлениях понижающего микширования (MPEG Surround (объемного звучания)); и
• чтобы генерировать параметры MPEG Surround, основанные на звуковых объектах (MPEG Пространственное звуковое кодирование объекта).
MPEG Surround использует межканальные различия в уровне, фазе и когерентности, эквивалентные репликам ILD, ITD и IC, чтобы захватить пространственное изображение многоканального звукового сигнала относительно переданного сигнала понижающего микширования, и кодирует эти реплики в очень компактной форме таким образом, что реплики и переданный сигнал могут быть расшифрованы, чтобы синтезировать высококачественное многоканальное представление. MPEG Surround кодирующее устройство получает многоканальный звуковой сигнал, где N - число входных каналов (например, 5.1). Ключевой аспект процесса кодирования - то, что сигнал понижающего микширования, xt1 и xt2, который обычно бывает стерео (но может также быть моно), получается из многоканального входного сигнала и именно этот сигнал понижающего микширования сжимается для передачи по каналу, а не многоканальный сигнал. Кодирующее устройство может выгодно использовать процесс понижающего микширования таким образом, что оно создает точный эквивалент многоканального сигнала в моно или стерео понижающем микшировании, а также создает самую лучшую многоканальную расшифровку, основанную на понижающем микшировании и закодированных пространственных репликах. Альтернативно, понижающее микширование может поставляться внешне. MPEG Surround процесс кодирования независим от алгоритма сжатия, используемого для переданных каналов; это может быть любой из многих высокоэффективных алгоритмов сжатия, таких как MPEG-1 Слой III, MPEG-4 AAC или MPEG-4 Высокопроизводительной AAC, или это может быть даже PCM (ИКМ - импульсно-кодовая модуляция [сигнала]).
Технология MPEG Surround поддерживает очень эффективное параметрическое кодирование многоканальных звуковых сигналов. Идея MPEG SAOC (пространственное кодирование звукового объекта) состоит в том, чтобы применить аналогичные основные допущения вместе с аналогичным параметрическим представлением для очень эффективного параметрического кодирования индивидуальных звуковых объектов (дорожки). Дополнительно, включается функциональная возможность представления, чтобы в интерактивном режиме представлять звуковые объекты в акустической сцене для нескольких типов систем воспроизведения (1.0, 2.0, 5.0 для громкоговорителей или бинаурального для наушников). SAOC разработан, чтобы передать ряд звуковых объектов в объединенный моно или стерео сигнал понижающего микширования, чтобы позже обеспечить воспроизведение индивидуальных объектов в звуковой сцене, предоставленной в интерактивном режиме. С этой целью, SAOC кодирует Разность Уровней Объекта (OLD), Межобъектные перекрестные когерентности (IOC) и Разность Уровней Канала Понижающего микширования (DCLD) в параметрический битовый поток. SAOC декодер превращает SAOC параметрическое представление в MPEG Surround параметрическое представление, которое потом расшифровывается вместе с сигналом понижающего микширования посредством MPEG Surround декодера, чтобы произвести желательную звуковую сцену. Пользователь в интерактивном режиме управляет этим процессом, чтобы изменить представление звуковых объектов в получающейся звуковой сцене. Среди многочисленных вероятных применений SAOC далее перечислены несколько типичных сценариев.
Потребители могут создать личные интерактивные ремиксы, используя виртуальный микшерный пульт. Определенные инструменты могут быть, например, ослаблены для подыгрывания (как Караоке), оригинальный микс может быть изменен, чтобы удовлетворить личный вкус, уровень диалога в кинофильмах/радиопередачах может быть приспособлен для лучшей разборчивости речи и т.д.
Для интерактивных игр SAOC - это память и в вычислительном отношении эффективный способ воспроизведения саундтреков. Перемещение в виртуальной сцене отражается адаптацией объекта, воспроизводящего параметры. Сетевые игры со многими игроками извлекают выгоду из эффективности передачи, используя один поток SAOC, чтобы представить все звуковые объекты, которые являются внешними, на терминал определенного игрока.
В контексте этого применения термин «звуковой объект» также включает термин «основа», известный в сценариях производства звука. В частности, основы - индивидуальные компоненты микса, отдельно сохраненные (обычно на диске) в целях использования в ремиксах. Родственные основы обычно возвращаются из того же самого оригинального местоположения. Примером может быть основа барабана (включает все родственные барабану инструменты в миксе), вокальная основа (включает только речевые дорожки) или ритмическая основа (включает все ритмически связанные инструменты, такие как барабаны, гитара, клавиатура, …).
Современная телекоммуникационная инфраструктура является монофонической, и ее функциональные возможности могут быть расширены. Терминалы, оборудованные расширением SAOC, улавливают несколько звуковых источников (объектов) и производят монофонический сигнал понижающего микширования, который передается совместимым способом при использовании существующих (речевых) кодировщиков. Дополнительная информация может передаваться вложенным обратно совместимым способом. Традиционные терминалы продолжат производить монофонический вывод данных, в то время как SAOC-задействованные терминалы могут воспроизводить акустическую сцену и таким образом увеличивать разборчивость, пространственно разделяя различных говорящих субъектов («эффект коктейльной вечеринки»).
Краткий обзор реально доступных применений звуковых метаданных системы Долби описывается в следующем разделе.
Полуночный режим
Как упомянуто выше, могут существовать сценарии, где слушатель, возможно, не захочет получать высокий динамический сигнал. Поэтому слушатель может активизировать так называемый «полуночный режим» своего приемника. Тогда компрессор применяется к полному звуковому сигналу. Чтобы контролировать параметры этого компрессора, переданные метаданные оцениваются и применяются к полному звуковому сигналу.
Чистый звук
Другой сценарий - люди с ослабленным слухом, которые не хотят иметь высокодинамический окружающий шум, но хотят иметь довольно чистый сигнал, содержащий диалоги («Clean Audio» - чистый звук). Этот режим может также быть задействован, посредством использования метаданных.
В настоящее время предлагаемое решение определено в [15] - Приложение E. Баланс между главным стерео сигналом и дополнительным моно каналом, описывающим диалог, регулируется здесь индивидуальным набором параметров уровня. Предложенное решение, основанное на отдельном синтаксисе, называется дополнительным звуковым обслуживанием в DVB (цифровое видео- и телевещание).
Понижающее микширование
Существуют отдельные параметры метаданных, которые управляют L/R понижающим микшированием. Определенные параметры метаданных позволяют инженеру выбирать, как строится стерео понижающее микширование и какой стерео аналоговый сигнал предпочтителен. Здесь центральный и окружающий уровень понижающего микширования определяют окончательный баланс микширования сигнала понижающего микширования для каждого декодера.
Фиг. 1 иллюстрирует устройство для генерирования, по крайней мере, одного выходного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов в соответствии с предпочтительным осуществлением данного изобретения. Устройство фиг. 1 включает процессор 10 для обработки входного звукового сигнала 11 для обеспечения представления объекта 12 входного звукового сигнала, в котором, по крайней мере, два различных звуковых объекта отделены друг от друга, в котором, по крайней мере, два различных звуковых объекта доступны как отдельные звуковые сигналы объекта и в котором, по крайней мере, два различных звуковых объекта являются управляемыми независимо друг от друга.
Управление представлением объекта выполняется в манипуляторе объекта 13 для управления звуковым сигналом объекта или микшированным представлением звукового сигнала объекта, по крайней мере, одного звукового объекта, основанного на объектно-ориентированных метаданных 14, относящихся, по крайней мере, к одному звуковому объекту. Манипулятор звукового объекта 13 приспосабливается, чтобы получить управляемый звуковой сигнал объекта или управляемое микшированное звуковое представление сигнала объекта 15, по крайней мере, для одного звукового объекта.
Сигналы, генерированные манипулятором объекта, вводятся в микшер объекта 16 для микширования представления объекта посредством комбинирования управляемого звукового объекта с неизмененным звуковым объектом или с управляемым другим звуковым объектом, где управляемый другой звуковой объект управлялся другим способом, чем, по крайней мере, один звуковой объект. Результат микшера объекта включает один или более выходных звуковых сигналов 17a, 17b, 17c. Предпочтительно, чтобы один или более выходных сигналов 17a-17c разрабатывались для определенной установки представления, такой как моно установка представления, стерео установка представления, многоканальная установка представления, включающая три или более каналов, такая как установка объемного звучания, требующая, по крайней мере, пять или, по крайней мере, семь различных выходных звуковых сигналов.
Фиг. 2 иллюстрирует предпочтительную реализацию процессора 10 для обработки входного звукового сигнала. Предпочтительно, чтобы входной звуковой сигнал 11 реализовывался как объект понижающего микширования 11, полученный посредством микшера объекта понижающего микширования 101a фиг. 5a, который описан далее. В этой ситуации процессор дополнительно получает параметры объекта 18, такие как, например, генерируемые вычислителем параметров объекта 101b на фиг. 5a, как описано далее. Тогда процессор 10 находится в позиции для вычисления отдельных звуковых сигналов объекта 12. Число звуковых сигналов объекта 12 может быть больше, чем число каналов в объекте понижающего микширования 11. Объект понижающего микширования 11 может включать моно понижающее микширование, стерео понижающее микширование или даже понижающее микширование, имеющее больше чем два канала. Однако форматер потока данных процессор 12 может быть эффективным для генерирования большего количества звуковых сигналов объекта 12 по сравнению с числом индивидуальных сигналов в объекте понижающего микширования 11. Звуковые сигналы объекта, благодаря параметрической обработке, выполненной процессором 10, не являются точным воспроизведением оригинальных звуковых объектов, которые присутствовали прежде, чем было выполнено понижающее микширование объекта 11, но звуковые сигналы объекта являются приближенными версиями оригинальных звуковых объектов, где точность приближения зависит от вида алгоритма разделения, выполненного в процессоре 10, и, конечно, от точности переданных параметров. Предпочтительные параметры объекта - параметры, известные из кодирования пространственного звукового объекта, а предпочтительный алгоритм реконструкции для генерирования индивидуально разделенных звуковых сигналов объекта является алгоритмом реконструкции, выполненным в соответствии со стандартом кодирования пространственных звуковых объектов. Предпочтительное осуществление процессора 10 и параметры объекта будут впоследствии обсуждены в контексте фиг. 6-9.
Фиг. 3a и фиг. 3b совместно иллюстрируют исполнение, в котором выполняется управление объектом до понижающего микширования объекта для установки воспроизведения, в то время как фиг. 4 иллюстрирует дальнейшее исполнение, в котором понижающее микширование объекта выполняется до управления, а управление выполняется до заключительного процесса микширования объекта. Результат процесса фиг. 3a, 3b по сравнению с фиг. 4 является тем же самым, но управление объектом выполняется на различных уровнях в сценарии обработки. Когда управление звуковыми сигналами объекта является проблемой в контексте эффективности и вычислительных ресурсов, осуществление в соответствии с фиг. 3a, 3b является предпочтительным, так как управление звуковым сигналом должно быть выполнено только на одиночном звуковом сигнале, а не множестве звуковых сигналов, как на фиг. 4. В другом исполнении, в котором может быть требование о том, чтобы понижающее микширование объекта было выполнено посредством использования неизмененного сигнала объекта, предпочтительной является конфигурация фиг. 4, в которой управление выполняется вслед за понижающим микшированием объекта, но до заключительного микширования объекта, чтобы получить выходные сигналы для, например, левого канала L, центрального канала C или правого канала R.
Фиг. 3a иллюстрирует ситуацию, в которой процессор 10 фиг. 2 вырабатывает отдельные звуковые сигналы объекта. По крайней мере, один звуковой сигнал объекта, такой как сигнал для объекта 1, управляется манипулятором 13a, основанным на метаданных для этого объекта 1. В зависимости от исполнения, другие объекты, такие как объект 2, управляются также манипулятором 13b. Естественно, может возникнуть ситуация, в которой действительно существует объект, такой как объект 3, которым не управляют, но который, однако, генерируется посредством разделения объекта. Результатом обработки фиг. 3a, в примере фиг. 3a, являются два управляемых сигнала объекта и один неуправляемый сигнал.
Эти результаты вводятся в микшер объекта 16, который включает первую стадию микшера, исполненную как микшеры объекта понижающего микширования 19a, 19b, 19c, и который, кроме того, включает вторую стадию микшера объекта, исполненную устройствами 16a, 16b, 16c.
Первая стадия микшера объекта 16 включает, для каждого вывода данных фиг. 3a, микшер объекта понижающего микширования, такой как микшер объекта понижающего микширования 19a для вывода 1 фиг. 3a, микшер объекта понижающего микширования 19b для вывода 2 фиг. 3a, микшер объекта понижающего микширования 19c для вывода 3 фиг. 3a. Цель микшера объекта понижающего микширования 19a-19c состоит в том, чтобы «распределить» каждый объект на выходные каналы. Поэтому каждый микшер объекта понижающего микширования 19a, 19b, 19c имеет выход для левого составляющего сигнала L, центрального составляющего сигнала C и правого составляющего сигнала R. Таким образом, если, например, объект 1 был бы одиночным объектом, микшер понижающего микширования 19a был бы прямым микшером понижающего микширования, а вывод блока 19a был бы таким, как окончательный вывод L, C, R, обозначенный цифрами 17a, 17b, 17c. Микшеры объекта понижающего микширования 19a-19c предпочтительно получают информацию о рендеринге, обозначенную цифрой 30, где информация о рендеринге может описывать установку рендеринга, то есть, как в осуществлении фиг. 3e, существуют только три выходных громкоговорителя. Эти выводы - левый громкоговоритель L, центральный громкоговоритель C и правый громкоговоритель R. Если, например, установка рендеринга или установка воспроизведения включает сценарий 5.1, то каждый микшер объекта понижающего микширования имел бы шесть выходных каналов и там бы существовало шесть сумматоров так, чтобы был получен окончательный выходной сигнал для левого канала, окончательный выходной сигнал для правого канала, окончательный выходной сигнал для центрального канала, окончательный выходной сигнал для левого окружного канала, окончательный выходной сигнал для правого окружного канала и окончательный выходной сигнал для низкочастотного расширяющего (сабвуфер) канала.
В частности, сумматоры 16a, 16b, 16c приспособлены для объединения составляющих сигналов для соответствующего канала, которые были генерированы соответствующими микшерами объектов понижающего микширования. Эта комбинация, предпочтительно, является прямым поочередным дополнением образцов, но, в зависимости от исполнения, могут также применяться весовые коэффициенты. Кроме того, функциональные возможности фиг. 3a, 3b могут быть реализованы в частотной области или области поддиапазона так, чтобы элементы 19a-19c могли бы работать в частотной области и имелось бы некоторое преобразование частоты/времени до фактического вывода сигналов на громкоговорители в установке воспроизведения.
Фиг. 4 иллюстрирует альтернативное исполнение, в котором функциональные возможности элементов 19a, 19b, 19c, 16a, 16b, 16c подобны осуществлению фиг. 3b. Важно, однако, то, что управление, которое имело место на фиг. 3a до понижающего микширования объекта 19a, теперь происходит после понижающего микширования объекта 19a. Таким образом, управление, специфическое для объекта, которое контролируется метаданными для соответствующего объекта, производится в области понижающего микширования, то есть до фактического дополнения впоследствии управляемых составляющих сигналов. Когда фиг. 4 сравнивается с фиг. 1, становится ясно, что микшер объекта понижающего микширования 19a, 19b, 19c будет осуществлен в процессоре 10 и микшер объекта 16 будет включать сумматоры 16a, 16b, 16c. Когда исполняется фиг. 4 и микшеры объекта понижающего микширования являются частью процессора, тогда процессор получит, в дополнение к параметрам объекта 18 фиг. 1, информацию о рендеринге 30, то есть информацию относительно позиции каждого звукового объекта, информацию относительно установки рендеринга и дополнительную информацию в зависимости от обстоятельств.
Кроме того, управление может включать процесс понижающего микширования, осуществленный блоками 19a, 19b, 19c. В этом осуществлении манипулятор включает эти блоки, и дополнительные манипуляции могут иметь место, но не требуются в любом случае.
Фиг. 5a иллюстрирует осуществление на стороне кодирующего устройства, которое может генерировать поток данных, как схематично показано на фиг. 5b. В частности, фиг. 5a иллюстрирует устройство для генерирования закодированного звукового сигнала 50, представляющего наложение, по крайней мере, двух различных звуковых объектов. По существу, устройство фиг. 5a иллюстрирует форматер потока данных 51 для форматирования потока данных 50 так, чтобы поток данных включал сигнал объекта понижающего микширования 52, представляющего комбинацию, такую как взвешенная или невзвешенная комбинация, по крайней мере, двух звуковых объектов. Кроме того, поток данных 50 включает, в качестве дополнительной информации, связанные с объектом метаданные 53, относящиеся, по крайней мере, к одному из различных звуковых объектов. Предпочтительно, чтобы поток данных 50, кроме того, включал параметрические данные 54, которые являются селективными по времени и частоте и которые обеспечивают высококачественное разделение сигнала понижающего микширования объекта на несколько звуковых объектов, где этот процесс также называется процессом повышающего микширования объекта, который выполняется процессором 10 фиг. 1, как было объяснено ранее.
Сигнал понижающего микширования объекта 52 предпочтительно генерируется микшером объекта понижающего микширования 101a. Параметрические данные 54 предпочтительно генерируются вычислителем параметров объекта 101b, а метаданные селективных объектов 53 генерируются поставщиком метаданных селективных объектов 55. Поставщик метаданных селективных объектов может быть входом для получения метаданных в качестве произведенных генератором звука в студии звукозаписи или может быть данными, произведенными посредством анализа, связанного с объектом, который мог бы быть выполнен вслед за разделением объекта. В частности, поставщик метаданных селективных объектов может быть реализован, чтобы проанализировать выход объекта посредством процессора 10, чтобы, например, выяснить, является ли объект речевым объектом, звуковым объектом или объектом окружающего звука. Таким образом, речевой объект может быть проанализирован посредством некоторых известных алгоритмов речевого обнаружения, известных из речевого кодирования, и анализ селективных объектов может быть осуществлен, чтобы также обнаружить звуковые объекты, исходящие от инструментов. Такие звуковые объекты имеют высокую тональную природу и могут поэтому быть отличены от речевых объектов или объектов окружающих звуков. Объекты окружающих звуков будут иметь весьма шумную природу, отражающую фоновый звук, который обычно существует, например, в кинофильмах, где, например, фоновые шумы - это звуки транспортных средств или любые другие постоянные шумовые сигналы или непостоянные сигналы, имеющие широкополосный спектр, такой, какой производится, когда, например, в кино имеет место сцена со стрельбой.
Основываясь на этом анализе, можно усилить звуковой объект и ослабить другие объекты, чтобы выделить речь, поскольку это способствует улучшению понимания кинофильма плохо слышащими людьми или людьми преклонного возраста. Как установлено ранее, другие реализации включают предоставление метаданных определенного объекта, таких как идентификация объекта, и связанных с объектом данных звукооператором, производящим фактический сигнал понижающего микширования объекта на CD или DVD, такой как стерео понижающее микширование или понижающее микширование окружающего звука.
Фиг. 5d иллюстрирует примерный поток данных 50, который имеет, в качестве главной информации, моно, стерео или многоканальный объект понижающего микширования и который имеет, в качестве дополнительной информации, параметры объекта 54 и объектно-ориентированные метаданные 53, которые являются постоянными только в случае идентификации объектов, таких как речь или окружающие звуки, или которые являются переменными во времени в случае предоставления данных уровня, в качестве объектно-ориентированных метаданных, таких, какие требуются для полуночного режима. Предпочтительно, однако, чтобы объектно-ориентированные метаданные не предоставлялись частотно-селективным способом для сохранения скорости передачи данных.
Фиг. 6 иллюстрирует осуществление отображения звукового объекта, иллюстрирующее ряд объектов N. В примерном объяснении фиг. 6 каждый объект имеет ID (идентификатор) объекта, соответствующий файл звукового объекта и, что важно, информацию о параметрах звукового объекта, которая является, предпочтительно, информацией, касающейся мощности звукового объекта и межобъектной корреляции звукового объекта. В частности, информация о параметрах звукового объекта включает матрицу E ковариации объекта для каждого поддиапазона и для каждого временного интервала устойчивой связи.
Пример такой информации о параметрах звукового объекта матрицы E проиллюстрирован на фиг. 7. Диагональные элементы eii включают информацию об интенсивности или мощности звукового объекта i в соответствующем поддиапазоне и соответствующем временном интервале. Наконец, сигнал поддиапазона, представляющий определенный звуковой объект i, вводится в вычислитель интенсивности или мощности, который может, например, выполнять функцию автокорреляции (acf), чтобы получить значение e11 с или без нормализации. Альтернативно, мощность может быть вычислена как сумма квадратов сигнала на определенной длине (то есть векторное произведение: ss*). Функция автокорреляции (acf) может, в некотором смысле, описывать спектральное распределение мощности, но вследствие того что T(время)/F(частота)-преобразование для выбора частоты предпочтительно используется в любом случае, вычисление мощности может быть выполнено без функции автокорреляции (acf) для каждого поддиапазона отдельно. Таким образом, главные диагональные элементы матрицы E параметров звукового объекта указывают степень мощности звукового объекта в определенном поддиапазоне в определенном временном интервале устойчивой радиосвязи.
С другой стороны, недиагональный элемент eij указывает соответствующую меру корреляции между звуковыми объектами i, j в соответствующем поддиапазоне и временном интервале устойчивой радиосвязи. Из фиг. 7 ясно, что матрица E является, для реальных нормированных записей, симметричной относительно главной диагонали. Обычно эта матрица является эрмитовой матрицей. Элемент меры корреляции eij может быть вычислен, например, посредством взаимной корреляции двух сигналов поддиапазона соответствующих звуковых объектов так, чтобы была получена взаимная мера корреляции, которая может быть или не быть нормализована. Могут использоваться другие меры корреляции, которые не вычисляются посредством использования процедуры взаимной корреляции, а вычисляются другими способами определения корреляции между двумя сигналами. По практическим причинам все элементы матрицы E нормализуются так, чтобы они имели величины между 0 и 1, где 1 указывает максимальную мощность, или максимальную корреляцию, 0 указывает минимальную мощность (нулевая мощность) и -1 указывает минимальную (несовпадающую по фазе) корреляцию.
Матрица D понижающего микширования размера K×N, где K>1 определяет K канал сигнала понижающего микширования в форме матрицы с K рядами посредством матричного умножения
X=DS (2)
Фиг. 8 иллюстрирует пример матрицы D понижающего микширования, имеющей матричные элементы dij понижающего микширования. Такой элемент dij указывает, включается ли часть или целый объект j в сигнал понижающего микширования объекта i или нет. Когда, например, d12 равен нулю, это означает, что объект 2 не включен в сигнал понижающего микширования объекта 1. С другой стороны, значение d23, равное 1, указывает на то, что объект 3 полностью включен в сигнал понижающего микширования объекта 2.
Допустимы значения матричных элементов понижающего микширования между 0 и 1. В частности, значение 0,5 указывает на то, что определенный объект включается в сигнал понижающего микширования, но только с половиной его мощности. Таким образом, когда звуковой объект, такой как объект номер 4, одинаково распределяется по обоим каналам сигнала понижающего микширования, тогда d24 и d14 будут равны 0,5. Этот способ понижающего микширования является энергосберегающим процессом понижающего микширования, который предпочтителен для некоторых ситуаций. Альтернативно, однако, может также использоваться не энергосберегающее понижающее микширование, в котором целый звуковой объект вводится в левый канал понижающего микширования и правый канал понижающего микширования так, чтобы мощность этого звукового объекта была удвоена относительно других звуковых объектов в пределах сигнала понижающего микширования.
В нижних частях фиг. 8 дана схематическая диаграмма кодирующего устройства объекта 101 фиг. 1. В частности, кодирующее устройство объекта 101 включает две различных части 101a и 101b. Часть 101a - это микшер понижающего микширования, который предпочтительно выполняет взвешенную линейную комбинацию звуковых объектов 1, 2, …, N, и вторая часть кодирующего устройства объекта 101 - это вычислитель параметров звукового объекта 101b, который вычисляет информацию о параметрах звукового объекта, такую как матрица E для каждого временного интервала или поддиапазоны, чтобы предоставить информацию о мощности звука и корреляции, которая является параметрической информацией и может поэтому быть передана с низкой скоростью передачи битов или может быть сохранена, потребляя небольшое количество ресурсов памяти.
Контролируемая пользователем матрица A рендеринга объекта (матрица объектного представления) размера M×N определяет целевую визуализацию канала M звуковых объектов в форме матрицы с M рядами посредством матричного умножения
Y=AS (3)
Предполагается в ходе следующего дифференцирования, что M=2, поскольку основное внимание уделяется стерео визуализации. Предоставление начальной матрицы визуализации более чем на два канала и нормы понижающего микширования от этих нескольких каналов на два канала делает очевидным для квалифицированных специалистов получение соответствующей матрицы рендеринга A размера 2×N для стерео рендеринга. Для простоты также предполагается, что K=2, таким образом, объект понижающего микширования является также стерео сигналом. Случай понижающего микширования стерео объекта является, кроме того, самым важным частным случаем исходя из сценариев применения.
Фиг. 9 иллюстрирует детальное объяснение заданной матрицы рендеринга A. В зависимости от применения, заданная матрица рендеринга A может быть предоставлена пользователем. Пользователь может свободно указать, где виртуально должен быть расположен звуковой объект для установки воспроизведения. Достоинство концепции звукового объекта состоит в том, что информация о понижающем микшировании и информация о параметрах звукового объекта полностью независима от конкретной локализации звуковых объектов. Эта локализация звуковых объектов предоставляется пользователем в форме заданной информации рендеринга. Предпочтительно, чтобы заданная информация рендеринга могла быть осуществлена как заданная матрица рендеринга A, которая может быть в форме матрицы на фиг. 9. В частности, матрица рендеринга A имеет М линий и N колонок, где М равно числу каналов в выходном сигнале после рендеринга и где N равно числу звуковых объектов. М равно двум предпочтительным сценариям стерео рендеринга, но если выполняется рендеринг М каналов, то матрица A имеет М линий.
В частности, матричный элемент aij указывает на то, должна ли часть или целый объект j быть подвергнут рендерингу в конкретном выходном канале i или нет. Нижняя часть фиг. 9 дает простой пример заданной матрицы рендеринга сценария, в котором имеется шесть звуковых объектов AO1-AO6, где только первые пять звуковых объектов должны быть подвергнуты рендерингу в определенных позициях, а шестой звуковой объект вообще не должен быть подвергнут рендерингу.
Относительно звукового объекта AO1, пользователь хочет, чтобы рендеринг этого звукового объекта реализовывался в левой стороне сценария воспроизведения. Поэтому этот объект размещается в позиции левого громкоговорителя в (виртуальном) помещении воспроизведения, результаты чего в первой колонке матрицы визуализации А должны быть обозначены (10). Относительно второго звукового объекта, a22 - 1, и a12 - 0, это означает, что рендеринг второго звукового объекта должен быть осуществлен на правой стороне.
Звуковой объект 3 должен быть подвергнут рендерингу посередине, между левым громкоговорителем и правым громкоговорителем, так, чтобы 50% уровня или сигнала этого звукового объекта входили в левый канал и 50% уровня или сигнала входили в правый канал, чтобы соответствующая третья колонка заданной матрицы рендеринга A была (0,5 длины 0,5).
Аналогично, любое размещение между левым громкоговорителем и правым громкоговорителем может быть указано заданной матрицей рендеринга. Относительно звукового объекта 4, размещение больше на правой стороне, так как матричный элемент a24 больше, чем a14. Аналогично, рендеринг пятого звукового объекта AO5 осуществляется так, чтобы быть больше на левом громкоговорителе, как обозначено элементами a15 и a25 заданной матрицы рендеринга. Заданная матрица рендеринга А дополнительно позволяет вообще не выполнять операцию рендеринга определенного звукового объекта. Это примерно проиллюстрировано шестой колонкой заданной матрицы рендеринга, имеющей нулевые элементы.
Впоследствии предпочтительное осуществление данного изобретения описывается со ссылкой на фиг. 10.
Предпочтительно, чтобы способы, известные из SAOC (Пространственное Звуковое Кодирование Объекта), разделяли один звуковой сигнал на различные части. Эти части могут быть, например, различными звуковыми объектами, но можно этим не ограничиваться.
Если метаданные передаются для каждой одиночной части звукового сигнала, это позволяет регулировать только некоторые из компонентов сигнала, в то время как другие части останутся неизменными или даже могли бы быть изменены другими метаданными.
Это может быть сделано для различных звуковых объектов, а также и для индивидуальных спектральных диапазонов.
Параметры для разделения объекта являются классическими или даже новыми метаданными (усиление, сжатие, уровень, …) для каждого индивидуального звукового объекта. Эти данные предпочтительно передаются.
Блок обработки декодера реализуется на двух различных стадиях: на первой стадии параметры разделения объекта используются для генерирования (10) индивидуальных звуковых объектов. На второй стадии процессорный блок 13 имеет множество элементов, где каждый элемент - для индивидуального объекта. Здесь должны применяться метаданные конкретного объекта. В конце процесса, происходящего в декодере, все индивидуальные объекты снова объединяются (16) в один единственный звуковой сигнал. Дополнительно, контроллер оригинального и управляемого сигналов 20 (dry/wet контроллер) может обеспечить плавное микширование наплывом между оригинальным и управляемым сигналом, чтобы предоставить конечному пользователю простую возможность найти собственную предпочтительную настройку.
В зависимости от конкретного исполнения фиг. 10 иллюстрирует два аспекта. В основном аспекте связанные с объектом метаданные только указывают на описание объекта для конкретного объекта. Предпочтительно, чтобы описание объекта было связано с ID (идентификатором) объекта как обозначено цифрой 21 на фиг. 10. Поэтому объектно-ориентированные метаданные для верхнего объекта, управляемого устройством 13a, являются только информацией о том, что этот объект - «речевой» объект. Объектно-ориентированные метаданные для другого объекта, обработанного устройством 13b, имеют информацию о том, что этот второй объект - объект объемного звучания.
Этих основных связанных с объектом метаданных для обоих объектов может быть достаточно для того, чтобы осуществить расширенный чистый звуковой режим, в котором речевой объект усиливается, а объект окружающего звука ослабляется или, короче говоря, речевой объект усиливается относительно объекта окружающего звука, или объект окружающего звука ослабляется относительно речевого объекта. Пользователь, однако, может предпочтительно осуществлять различные режимы обработки на стороне приемника/декодера, который может быть запрограммирован через вход управления режимами. Эти различные режимы могут быть режимом уровня диалога, режимом сжатия, режимом понижающего микширования, расширенным полуночным режимом, расширенным чистым звуковым режимом, режимом динамического понижающего микширования, режимом катализированного повышающего микширования, режимом для перемещения объектов и т.д.
В зависимости от исполнения, различные способы требуют различных объектно-ориентированных метаданных в дополнение к основной информации, указывающей вид или характер объекта, такого как речь или окружающий звук. В полуночном режиме, в котором динамический диапазон звукового сигнала должен быть сжат, предпочтительно, чтобы для каждого объекта, такого как речевой объект и окружающий объект, либо фактический уровень, либо заданный уровень для полуночного режима был предоставлен в качестве метаданных. Когда предоставлен фактический уровень объекта, тогда приемник должен вычислить заданный уровень для полуночного режима. Однако когда предоставлен заданный относительный уровень, тогда обработка на стороне декодера/приемника уменьшается.
В этом исполнении каждый объект имеет зависящую от времени объектно-ориентированную последовательность информации об уровне, которая используется приемником, чтобы сжать динамический диапазон так, чтобы разность уровней в пределах одиночного объекта была уменьшена. Это автоматически приводит к получению заключительного звукового сигнала, в котором разность уровней время от времени уменьшается, как того требует исполнение полуночного режима. Для чистых звуковых применений может быть предоставлен также заданный уровень для речевого объекта. Тогда окружающий объект может быть установлен на ноль или почти на ноль, чтобы лучше подчеркнуть речевой объект в пределах звука, генерированного определенной установкой громкоговорителя. В высококачественном воспроизведении, которое является обратным полуночному режиму, может быть расширен динамический диапазон объекта или динамический диапазон различия между объектами. В этом исполнении предпочтительно обеспечить заданные уровни усиления объекта, так как эти заданные уровни гарантируют то, что в конце получается звук, который создается художественным звукооператором в звуковой студии и поэтому имеет более высокое качество по сравнению с автоматической настройкой или настройкой, определяемой пользователем.
В другом исполнении, в котором объектно-ориентированные метаданные касаются улучшенного понижающего микширования, управление объектом включает понижающее микширование, отличающееся от того, которое предназначено для определенных установок рендеринга. Тогда объектно-ориентированные метаданные вводятся в блоки 19a-19c микшера понижающего микширования объекта на фиг. 3b или фиг. 4. В этом исполнении манипулятор может включать блоки 19a-19c, когда индивидуальное понижающее микширование объекта выполняется в зависимости от установки рендеринга. В частности, блоки 19a-19c понижающего микширования объекта могут быть установлены отлично друг от друга. В этом случае, речевой объект может быть введен только в центральный канал, а не в левый или правый канал, в зависимости от конфигурации канала. Тогда блоки микшера понижающего микширования 19a-19c могут иметь различное число выходов компонентов сигнала. Понижающее микширование также может быть осуществлено динамически.
Дополнительно, может также предоставляться информация о направленном повышающем микшировании и информация для перемещения объектов.
Ниже дается краткое изложение предпочтительных способов предоставления метаданных и применения метаданных определенного объекта.
Звуковые объекты могут разделяться не идеально, как в типичном SOAC применении. Для управления звуком может быть достаточным иметь «маску» объектов, а не полное разделение.
Это может привести к меньшему количеству/более грубым параметрам для разделения объекта.
Для применения режима, называемого «полуночным режимом», звукоинженер должен определить все параметры метаданных независимо для каждого объекта, производя, например, постоянный объем диалога и управляемый шум окружения («расширенный полуночный режим»).
Это может быть также полезно для людей, носящих слуховые аппараты («расширенный чистый звук»).
Новые сценарии понижающего микширования: различные разделенные объекты могут рассматриваться по-разному для каждой определенной ситуации понижающего микширования. Например, сигнал с 5.1 каналами должен быть микширован с понижением для домашней телевизионной стерео системы, а другой приемник имеет только моно систему воспроизведения. Поэтому различные объекты могут рассматриваться по-разному (и все это контролируется звукооператором во время производства благодаря метаданным, предоставленным звукооператором).
Предпочтительно также понижающее микширование до 3.0 и т.д.
Произведенное понижающее микширование не будет определяться постоянным основным параметром (набор), но оно может быть сгенерировано из переменных во времени зависящих от объекта параметров. Посредством новых объектно-ориентированных метаданных можно также выполнить направленное повышающее микширование.
Объекты могут быть размещены в различных позициях, например, чтобы сделать пространственное изображение более широким, когда окружение ослаблено. Это поможет улучшить отчетливость речи для плохо слышащих людей.
Предложенный в этой работе способ расширяет существующее понятие метаданных, осуществленное и главным образом используемое в Кодер-декодерах системы Долби. Теперь можно применить известное понятие метаданных не только к целому звуковому потоку, но и к извлеченным объектам в пределах этого потока. Это предоставляет звуковым инженерам и операторам намного больше возможности для маневра, обеспечивает большие диапазоны регулирования и поэтому лучшее качество звука и большее удовольствие для слушателей.
Фиг. 12a, 12b иллюстрируют различные сценарии применения концепции изобретения. В классическом сценарии существует телевизионная трансляция спортивных соревнований, где присутствует обстановка стадиона во всех 5.1 каналах и где канал громкоговорителя отображается на центральном канале. Эта «отображение» может быть выполнено прямым добавлением канала громкоговорителя к центральному каналу, предназначенному для этих 5.1 каналов, несущих обстановку стадиона. Теперь способ согласно изобретению позволяет иметь такой центральный канал в звуковом описании обстановки стадиона. Тогда процесс добавления смешивает центральный канал из обстановки стадиона и громкоговоритель. Генерируя параметры объекта для громкоговорителя и центральный канал из обстановки стадиона, данное изобретение позволяет разделять эти два звуковых объекта на стороне декодера и позволяет усиливать или ослаблять громкоговоритель или центральный канала из обстановки стадиона. Дальнейший сценарий предполагает наличие двух громкоговорителей. Такая ситуация может возникнуть, когда два человека комментируют один и тот же футбольный матч. В частности, когда имеются два диктора, которые говорят одновременно, может быть полезным иметь этих двух дикторов в качестве отдельных объектов и, дополнительно, сделать так, чтобы эти два диктора были отделены от каналов обстановки стадиона. В таком применении эти 5.1 каналов и два канала громкоговорителя могут обрабатываться как восемь различных звуковых объектов или семь различных звуковых объектов, когда низкочастотным каналом расширения (канал сабвуфера) пренебрегают. Так как инфраструктура прямого распределения приспособлена к 5.1 каналам звукового сигнала, семь (или восемь) объектов могут быть микшированы с понижением в 5.1 каналов сигнала понижающего микширования, и параметры объекта могут быть предоставлены в дополнение к 5.1 каналам понижающего микширования так, чтобы на стороне приемника объекты могли быть снова разделены, и благодаря тому что объектно-ориентированные метаданные будут идентифицировать дикторские объекты из объектов обстановки стадиона, обработка конкретного объекта возможна до того, как заключительное понижающее микширование 5.1 каналов посредством микшера объектов имеет место на стороне приемника.
В этом сценарии можно было также иметь первый объект, включающий первого диктора, второй объект, включающий второго диктора, и третий объект, включающий полную обстановку стадиона.
Впоследствии различные исполнения сценариев объектно-ориентированного понижающего микширования обсуждаются в контексте фиг. 11a-11c.
Когда, например, звук, генерированный посредством сценариев фиг. 12a или 12b, должен быть воспроизведен на обычной 5.1 системе воспроизведения, тогда вложенный поток метаданных может быть проигнорирован и полученный поток может проигрываться, как он есть. Когда, однако, воспроизведение должно производиться на установках стерео громкоговорителя, должно иметь место понижающее микширование от 5.1 до стерео. Если окружающие каналы были добавлены непосредственно к левому/правому, модераторы могут быть на уровне, который является слишком низким. Поэтому предпочтительно снизить уровень обстановки до или после понижающего микширования до того, как объект регулятора будет (заново) добавлен.
Люди с ослабленным слухом могут захотеть снизить уровень обстановки, чтобы улучшить разборчивость речи, все еще разделяя оба громкоговорителя на левый/правый, что известно как «эффект коктейльной вечеринки», где человек слышит свое имя и затем концентрируется в направлении, откуда услышал свое имя. Эта концентрация на конкретном направлении будет, с психоакустической точки зрения, ослаблять звук, поступающий из других направлений. Поэтому точное местоположение определенного объекта, такое как нахождение громкоговорителя слева или справа или одновременно слева или справа так, чтобы громкоговоритель появился в середине между левым или правым, могло бы улучшить разборчивость. И наконец, входной звуковой поток предпочтительно разделяется на отдельные объекты, где объекты должны быть ранжированы в метаданных в зависимости от того, важен объект или менее важен. Тогда разность уровней между ними может быть отрегулирована в соответствии с метаданными, или позиция объекта может быть перемещена, чтобы улучшить разборчивость в соответствии с метаданными.
Чтобы достичь этой цели, метаданные применяются не к переданному сигналу, а метаданные применяются к одиночным разделяемым звуковым объектам до или после понижающего микширования объекта в зависимости от обстоятельств. Теперь данное изобретение не требует больше того, чтобы объекты были ограничены пространственными каналами так, чтобы этими каналами можно было управлять индивидуально. Вместо этого, концепция изобретения объектно-ориентированных метаданных не требует того, чтобы имелся определенный объект в определенном канале, но объекты могут микшироваться с понижением до нескольких каналов и могут все еще управляться индивидуально.
Фиг. 11a иллюстрирует дальнейшее исполнение предпочтительного осуществления. Микшер понижающего микширования объекта 16 генерирует m выходных каналов из k×n входных каналов, где k - число объектов и где n каналов генерируются на объект. Фиг. 11a соответствует сценарию фиг. 3a, 3b, где управление 13a, 13b, 13c имеет место до понижающего микширования объекта.
Фиг. 11a, кроме того, включает манипуляторы уровня 19d, 19e, 19f, которые могут быть исполнены без контроля метаданных. Альтернативно, однако, эти манипуляторы уровня могут также контролироваться объектно-ориентированными метаданными так, чтобы модификация уровня, осуществленная блоками 19d-19f, была также частью манипулятора объекта 13 фиг. 1. То же самое верно для процессов понижающего микширования 19a, 19b, 19c, когда эти процессы понижающего микширования контролируются объектно-ориентированными метаданными. Этот случай, однако, не проиллюстрирован на фиг. 11a, но также может быть осуществлен, когда объектно-ориентированные метаданные также отправлены блокам понижающего микширования 19a-19c. В последнем случае эти блоки также были бы частью объектного манипулятора 13 на фиг. 11a, а остальные функциональные возможности микшера объекта 16 осуществляются комбинацией в виде выходного канала компонентов сигналов управляемого объекта для соответствующих выходных каналов. Фиг. 11a, кроме того, включает функциональные возможности нормализации диалога 25, которые могут быть осуществлены посредством обычных метаданных, так как эта нормализация диалога имеет место в не области объекта, а в области выходного канала.
Фиг. 11b иллюстрирует исполнение объектно-ориентированного 5.1-стерео-понижающего микширования. Здесь понижающее микширование выполняется перед управлением, и поэтому фиг. 11b соответствует сценарию фиг. 4. Модификация уровня 13a, 13b выполняется объектно-ориентированными метаданными, где, например, верхняя ветвь соответствует речевому объекту и более низкая ветвь соответствует окружающему объекту или, для примера в фиг. 12a, 12b, верхний переход (ветвь) соответствует одному или обоим громкоговорителям, а нижний переход соответствует всей окружающей информации. Тогда блоки манипулятора уровня 13a, 13b управляли бы обоими объектами, основанными на установленных параметрах так, чтобы объектно-ориентированные метаданные были точной идентификацией объектов, а манипуляторы уровня 13a, 13b могли бы также управлять уровнями, основанными на заданных уровнях, предоставленных метаданными 14, или основанными на фактических уровнях, предоставленных метаданными 14. Поэтому чтобы генерировать стерео понижающее микширование для многоканального входа, формула понижающего микширования применяется для каждого объекта и объекты взвешиваются данным уровнем до их повторного микширования снова до выходного сигнала.
Для чистых звуковых применений, как показано на фиг. 11c, уровень значимости передается в качестве метаданных, чтобы дать возможность уменьшить менее значимые компоненты сигнала. Тогда другой переход (ветвь) соответствовал бы компонентам значимости, которые усиливаются, в то время как нижний переход (ветвь) мог бы соответствовать менее значимым компонентам, которые могут быть ослаблены. То, как выполняется определенное ослабление и/или усиление различных объектов, может быть фиксированно установлено приемником, но может также контролироваться, кроме того, объектно-ориентированными метаданными, как это исполняется посредством контроля оригинального и управляемого сигналов (dry/wet контроля) 14 на фиг. 11c.
Обычно динамический контроль диапазона может исполняться в области объекта, который реализуется подобно исполнению AAC-динамического контроля диапазона как многополосного сжатия. Объектно-ориентированные метаданные могут даже быть частотно- селективными данными так, чтобы исполнялось частотно-селективное сжатие, которое подобно исполнению эквалайзера.
Как было сказано ранее, нормализация диалога предпочтительно выполняется вслед за понижающим микшированием, то есть в сигнале понижающего микширования. Понижающее микширование должно, в общем, быть в состоянии обработать объекты k с n входными каналами в m выходные каналы.
Не всегда бывает важно разделить объекты на дискретные объекты. Может быть достаточно «снять маску» с компонентов сигнала, которые подлежат управлению. Это подобно редактированию масок в обработке изображения. Тогда генерализованный «объект» является наложением нескольких оригинальных объектов, где это наложение включает число объектов, меньшее, чем общее число оригинальных объектов. Все объекты снова складываются на заключительной стадии. Разделенные одиночные объекты не представляют никакого интереса, и для некоторых объектов значение уровня может быть установлено на 0, что соответствует высоким отрицательным числом децибел, когда определенный объект должен быть удален полностью, как в караоке, где может существовать заинтересованность в полном удалении голосового объекта так, чтобы певец караоке мог добавить свой собственный вокал к оставшимся инструментальным объектам.
Другие предпочтительные применения изобретения, как было сказано ранее, являются расширенным полуночным режимом, где динамический диапазон одиночных объектов может быть уменьшен, или режимом высокой точности, где динамический диапазон объектов расширен. В этом контексте переданный сигнал может быть сжат, и предполагается инвертирование этого сжатия. Особо предпочтительно, когда имеет место применение нормализации диалога для полного сигнала в качестве выхода на громкоговорители, но нелинейное ослабление/усиление для различных объектов полезно, когда установлена нормализация диалога. В дополнение к параметрическим данным для отделения различных звуковых объектов от сигнала понижающего микширования объекта, предпочтительно передать, для каждого объекта и суммарного сигнала в дополнение к классическим метаданным, связанным с суммарным сигналом, значения уровня для понижающего микширования, значения значимости, указывающие уровень значимости для чистого звука, идентификацию объекта, фактические абсолютные или относительные уровни в качестве переменной во времени информации или абсолютные или относительные заданные уровни в качестве переменной во времени информации и т.д.
Описанные осуществления являются только иллюстративными для принципов данного изобретения. Подразумевается, что модификации и изменения компоновки и деталей, описанных здесь, будут очевидны для других специалистов в этой области. Поэтому мы намереваемся ограничиться только областью пунктов формулы изобретения, а не специфическими деталями, представленными здесь посредством описания и объяснения осуществлений. В зависимости от определенных требований к реализации предложенных способов, они могут быть реализованы в аппаратных средствах или в программном обеспечении. Исполнение может быть реализовано посредством использования цифрового носителя данных, в частности DVD или компакт-диска, имеющего сохраненные на нем электронно-считываемые управляющие сигналы, которые взаимодействуют с программируемыми компьютерными системами таким образом, что реализуются способы по изобретению. В общем, данное изобретение является поэтому компьютерным программным продуктом с управляющей программой, сохраненным на машиночитаемом носителе, управляющая программа вводится в действие, чтобы реализовать способы, когда компьютерный программный продукт запущен на компьютере. Другими словами, способы по изобретению являются поэтому компьютерной программой, имеющей управляющую программу для реализации, по крайней мере, одного из изобретательных способов, когда компьютерная программа запущена на компьютере.
Источники информации
1. ISO/IEC 13818-7: MPEG-2 (Типовое кодирование кинофильмов и связанной звуковой информации) - Часть 7: Усовершенствованное Звуковое Кодирование (AAC).
2. ISO/IEC 23003-1: MPEG-D (звуковые технологии MPEG) - Часть 1: MPEG Surround (окружающий).
3. ISO/IEC 23003-2: MPEG-D (звуковые технологии MPEG) - Часть 2: Пространственное Кодирование Звукового Объекта (SAOC).
4. ISO/IEC 13818-7: MPEG-2 (Типовое кодирование кинофильмов и связанной звуковой информации) - Часть 7: Улучшенное Звуковое Кодирование (AAC).
5. ISO/IEC 14496-11: MPEG 4 (Кодирование аудиовизуальных объектов) - Часть 11: Описание Сцены и Движок Приложения (BIFS).
6. ISO/IEC 14496-: MPEG 4 (Кодирование аудиовизуальных объектов) - Часть 20: Облегченное Прикладное Представление Сцены (LASeR) и Простой Формат Агрегирования (SAF).
7. http:/www.dolby.com/assets/pdf/techlibrary/17. AllMetadata.pdf.
8. http:/www.dolby.com/assets/pdf/tech_library/18_Metadata. Guide.pdf.
9. Краусс, Курт; Реден, Джонас; Шилдбах, Вульфганг: Транскодирование Коэффициентов Динамического Контроля Диапазона и Других Метаданных в MPEG-4 HE AA, AES Соглашение 123, октябрь 2007, стр.7217.
10. Робинсон, Чарльз Кв., Гандри, Кеннет: Динамический Контроль Диапазона посредством Метаданных, AES Соглашение 102, сентябрь 1999, стр.5028.
11. Система Долби, «Стандарты и Инструкции для Создания Цифровой системы Долби и Битовых потоков системы Долби E», Выпуск 3.
14. Технологии кодирования/система Долби, «Система Долби E /Решение проблемы Транскодера Метаданных aacPlus для aacPlus Многоканального Цифрового Видео- и Телевещания (DVB)», V1.1.0.
15. ETSI TS101154: Цифровое Видео- и Телевещание (DVB), V1.8.1.
16. SMPTE RDD 6-2008: Описание и Справочник по Использованию Последовательного Битового Потока Звуковых Метаданных системы Долби.
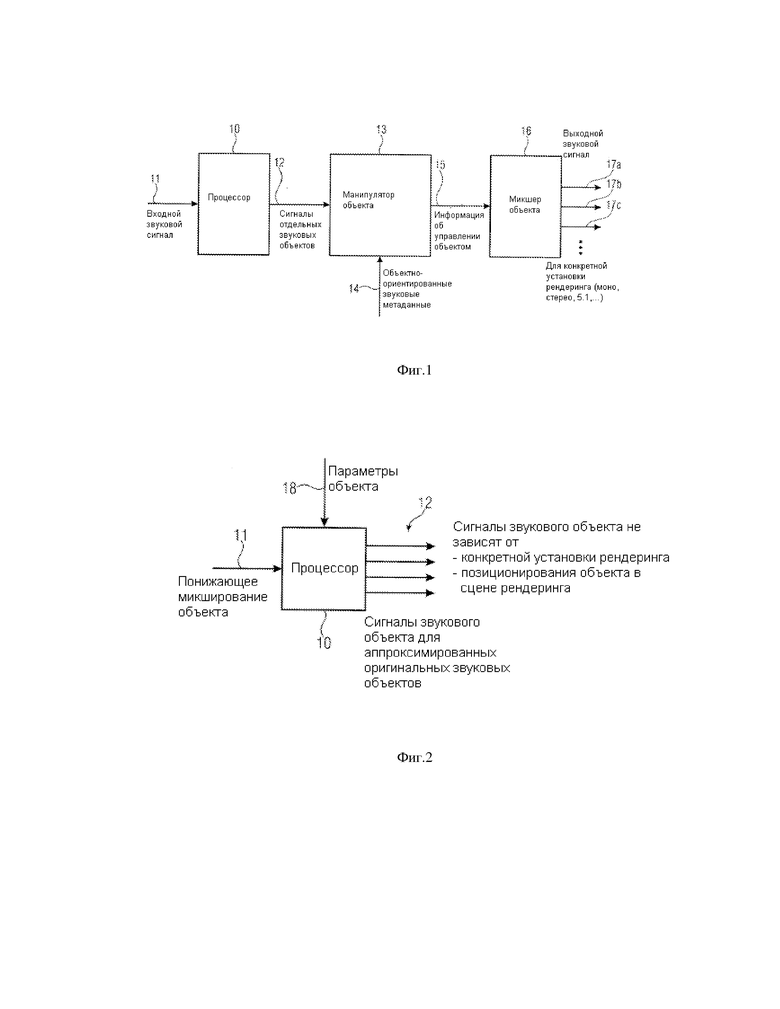
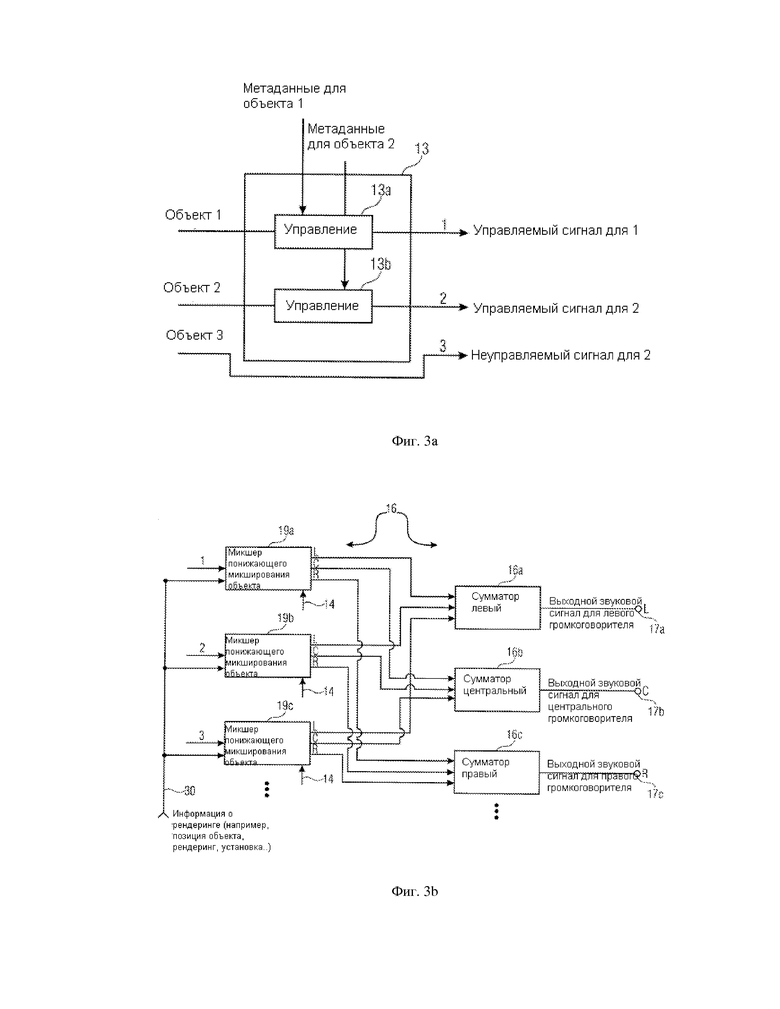
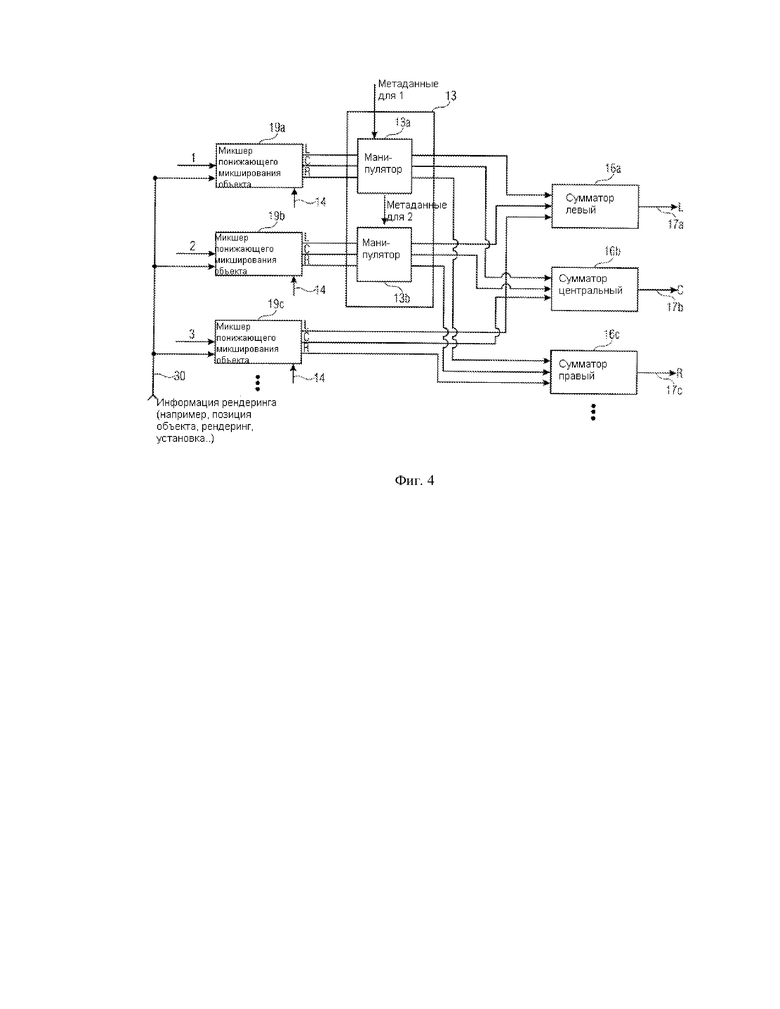
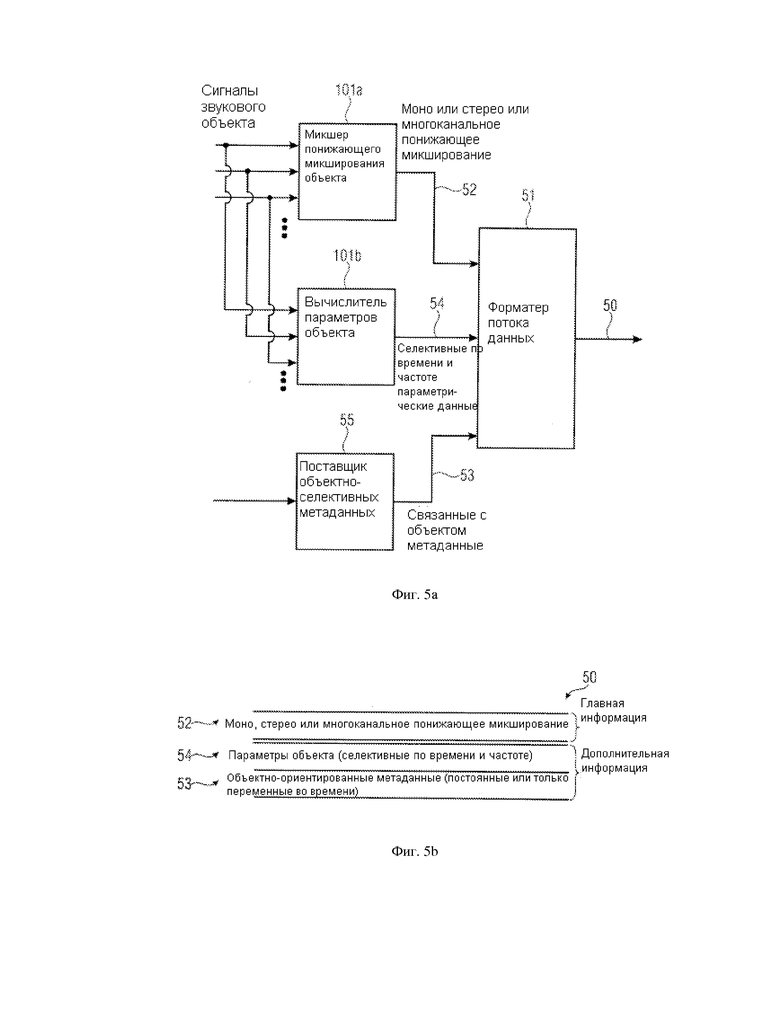


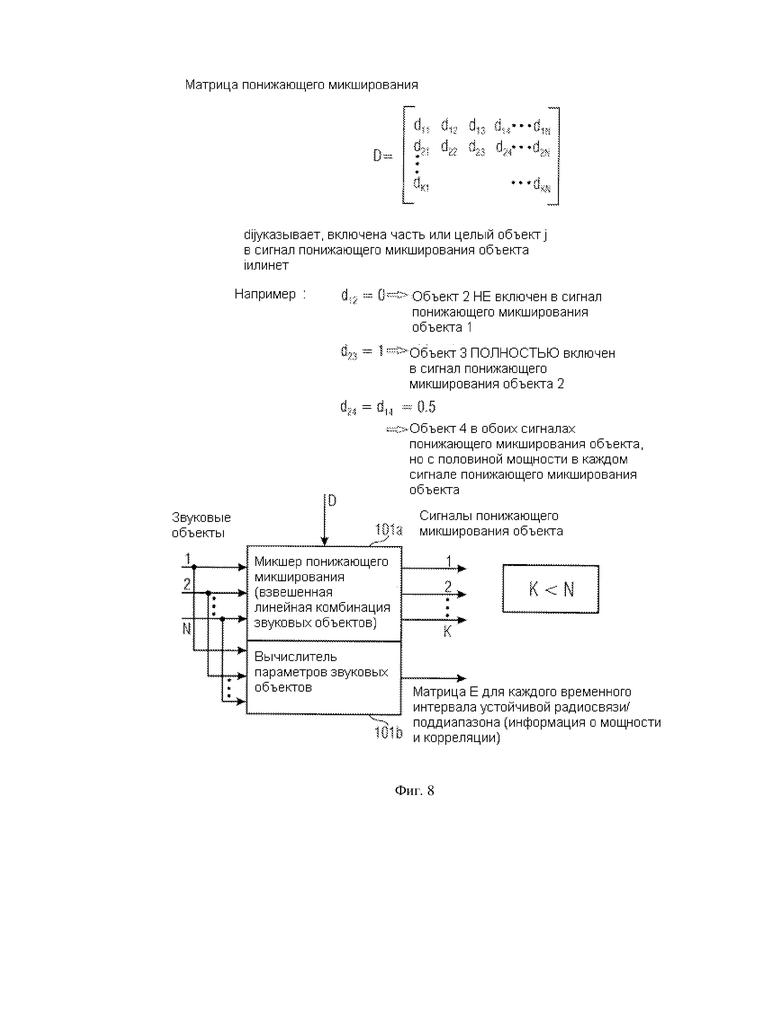

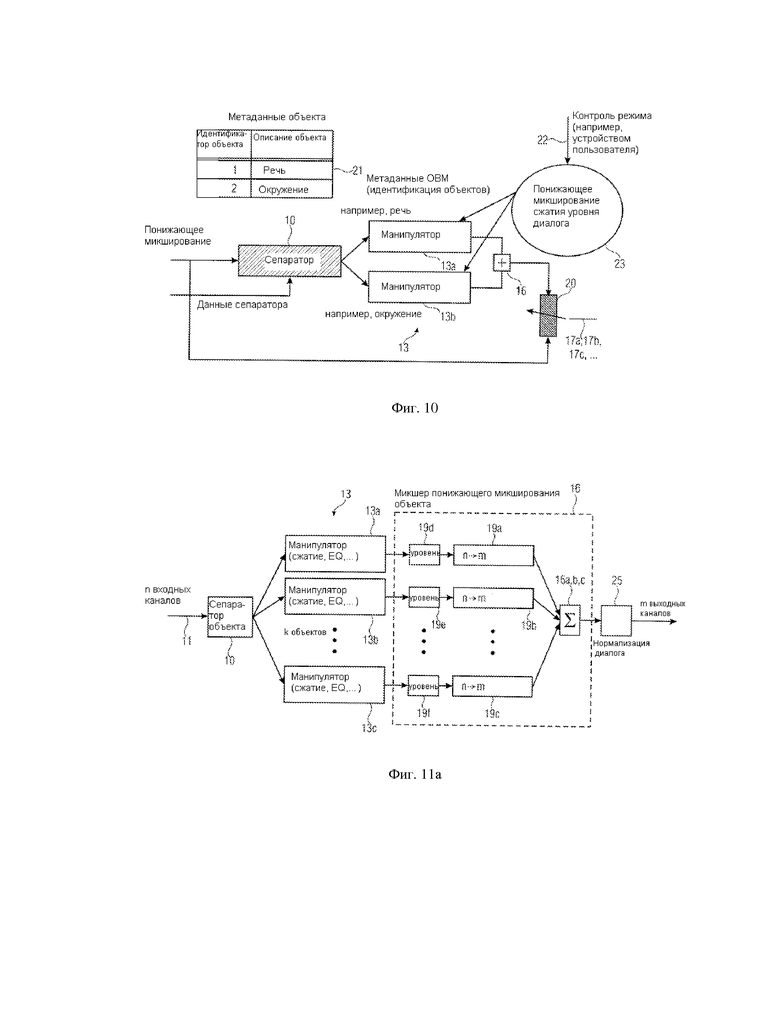
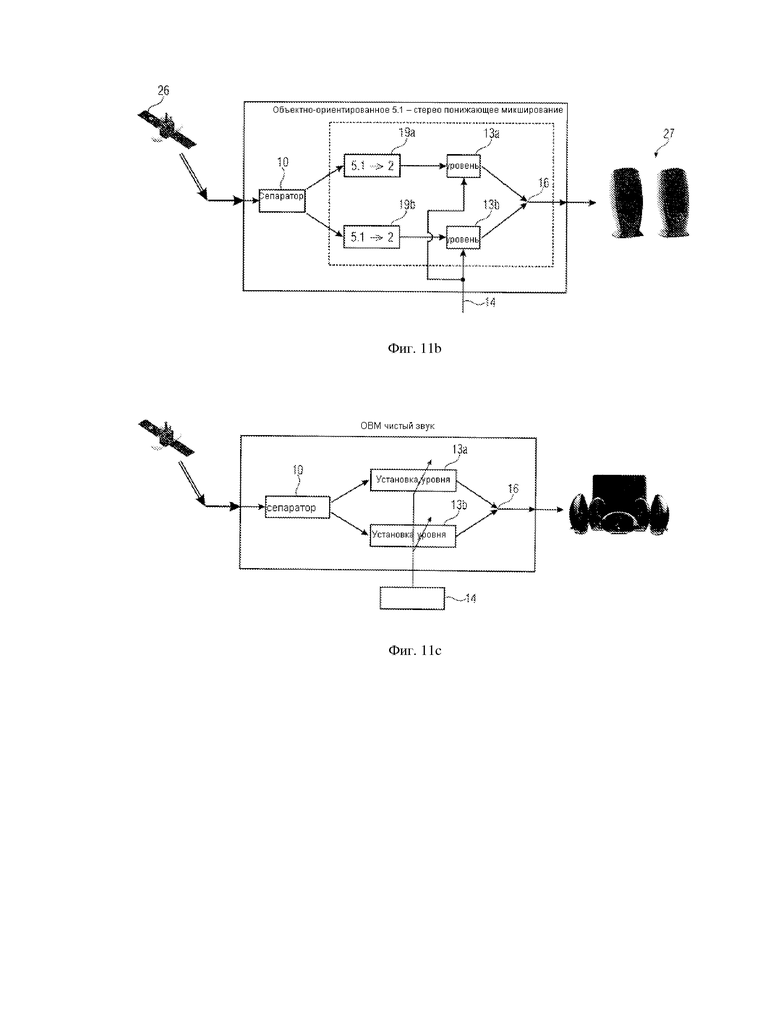
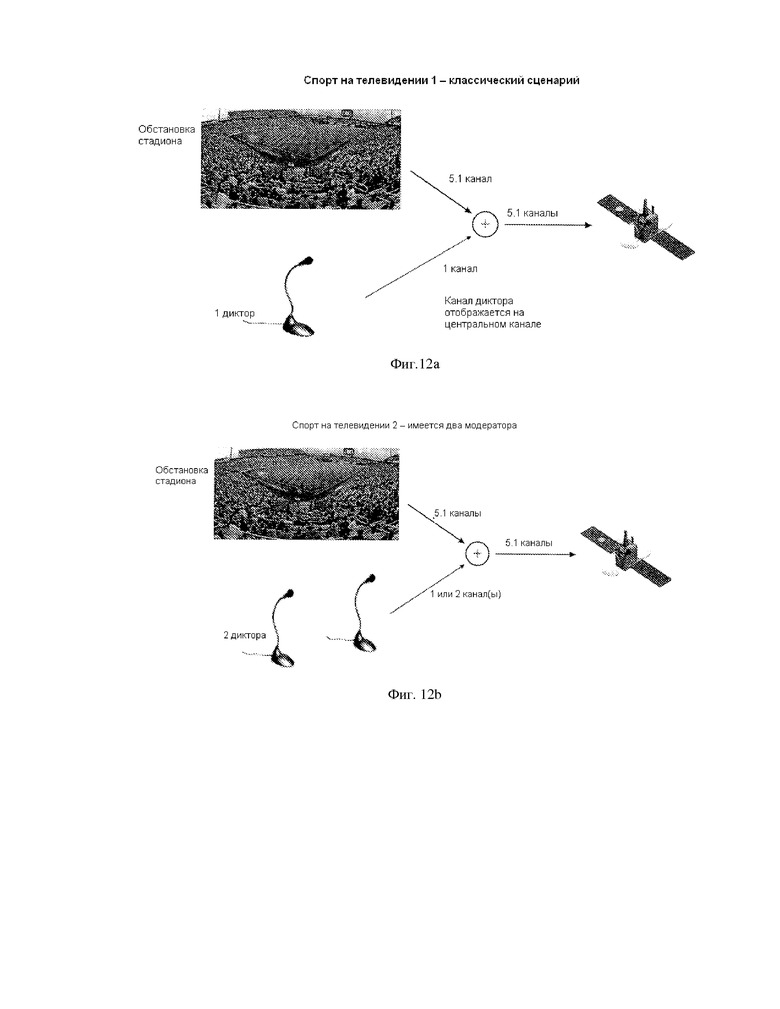
Изобретение относится к обработке звуковых сигналов. Технический результат изобретения заключается в повышении скорости передачи сигналов. Устройство для генерирования, по крайней мере, одного выходного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включает процессор для обработки входного звукового сигнала для обеспечения объектного представления входного звукового сигнала, где это объектное представление может быть сгенерировано параметрически управляемым приближением оригинальных объектов посредством использования сигнала понижающего микширования объекта. Манипулятор объекта индивидуально управляет объектами, используя объектно-ориентированные звуковые метаданные, относящиеся к индивидуальным звуковым объектам, чтобы получить управляемые звуковые объекты. Управляемые звуковые объекты микшируются посредством использования микшера объекта для того, чтобы, в конце концов, получить выходной звуковой сигнал, имеющий одно или многоканальные сигналы в зависимости от конкретной установки рендеринга. 6 н. и 6 з.п. ф-лы, 17 ил.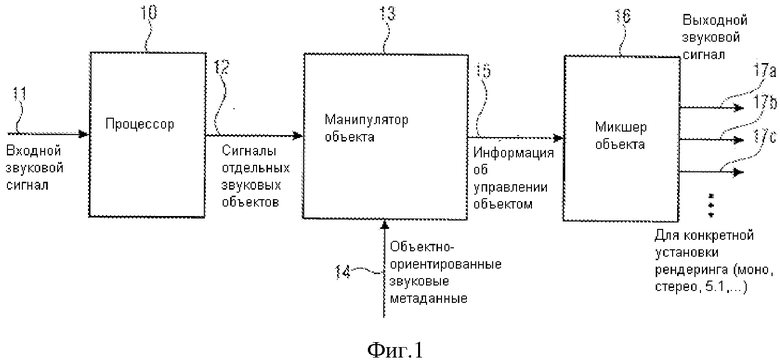
1. Устройство для генерирования, по крайней мере, одного звукового выходного сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающее процессор для обработки звукового входного сигнала, позволяющий обеспечить объектное представление звукового входного сигнала, в котором, по крайней мере, два различных звуковых объекта отделены друг от друга, по крайней мере, два различных звуковых объекта доступны в качестве отдельных сигналов звуковых объектов и, по крайней мере, два различных звуковых объекта являются управляемыми независимо друг от друга; манипулятор объекта для управления сигналом звукового объекта или микшированным сигналом звукового объекта, по крайней мере, одного звукового объекта, основанного на объектно-ориентированных звуковых метаданных, относящихся, по крайней мере, к одному звуковому объекту, позволяющий получить управляемый сигнал звукового объекта или управляемый микшированный сигнал звукового объекта, по крайней мере, для одного звукового объекта; и микшер объекта для микширования объектного представления посредством комбинирования управляемого звукового объекта с неизмененным звуковым объектом или с другим управляемым звуковым объектом, которым управляют иначе, чем, по крайней мере, одним звуковым объектом.
2. Устройство по п. 1, в котором входной звуковой сигнал является микшированным с понижением представлением множества оригинальных звуковых объектов и включает, в качестве дополнительной информации, объектно-ориентированные метаданные, имеющие информацию относительно одного или более звуковых объектов, включенных в микшированное с понижением представление, и в котором манипулятор объекта приспособлен, чтобы извлечь объектно-ориентированные метаданные из входного звукового сигнала.
3. Устройство по п. 1, в котором манипулятор объекта приспособлен, чтобы управлять каждым множеством сигналов компонентов объекта тем же самым способом, основанным на метаданных для объекта, чтобы получить сигналы компонентов объекта для звукового объекта, и в котором микшер объекта приспособлен, чтобы добавить сигналы компонентов объекта от других объектов к тому же самому выходному каналу, чтобы получить выходной звуковой сигнал для выходного канала.
4. Устройство по п. 1 дополнительно включает микшер выходного сигнала для микширования выходного звукового сигнала, который был получен, основываясь на управлении, по крайней мере, одним звуковым объектом, и соответствующего выходного звукового сигнала, полученного без управления, по крайней мере, одним звуковым объектом.
5. Устройство по п. 1, в котором метаданные включают информацию относительно усиления, сжатия, уровня, установки понижающего микширования или характеристик, специфических для данного объекта, и где манипулятор объекта приспособлен, чтобы управлять объектом или другими объектами, основанными на метаданных для осуществления, способом, предназначенным для конкретного объекта, полуночного режима, высокоточного режима, режима чистого звука, нормализации диалога, заданного управления понижающим микшированием, динамического понижающего микширования, управляемого повышающего микширования, перемещения речевых объектов или ослабления объекта окружения.
6. Устройство для генерирования закодированного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающее форматер потока данных для форматирования потока данных таким образом, чтобы поток данных включал сигнал понижающего микширования объекта, представляющий комбинацию, по крайней мере, двух других звуковых объектов, и, в качестве дополнительной информации, метаданные, относящиеся, по крайней мере, к одному из других звуковых объектов, при этом метаданные включают информацию относительно сжатия, усиления, установок понижающего микширования, информацию о том, является ли объект речевым, звуковым или объемным, или информацию о ранжировании объектов, где указывается, что первый объект более важен, чем второй объект, и вычислитель параметров для вычисления параметрических данных для приближения, по крайней мере, двух различных звуковых объектов.
7. Устройство по п. 6, в котором форматер потока данных предназначен, чтобы дополнительно ввести в поток данных, в качестве дополнительной информации, параметрические данные, обеспечивающие приближение, по крайней мере, двух различных звуковых объектов.
8. Устройство по п. 6, дополнительно включающее микшер понижающего микширования для понижающего микширования, по крайней мере, двух различных звуковых объектов, чтобы получить сигнал понижающего микширования, и вход для метаданных, индивидуально касающихся, по крайней мере, двух различных звуковых объектов.
9. Способ генерирования, по крайней мере, одного выходного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающий обработку входного звукового сигнала для обеспечения объектного представления входного звукового сигнала, в котором, по крайней мере, два различных звуковых объекта отделены друг от друга, по крайней мере, два различных звуковых объекта доступны как отдельные сигналы звукового объекта и, по крайней мере, два различных звуковых объекта являются управляемыми независимо друг от друга; управление сигналом звукового объекта или микшированным сигналом звукового объекта, по крайней мере, одного звукового объекта, основанного на объектно-ориентированных звуковых метаданных, относящихся, по крайней мере, к одному звуковому объекту, чтобы получить управляемый сигнал звукового объекта или управляемый микшированный сигнал звукового объекта, по крайней мере, для одного звукового объекта; и микширование объектного представления посредством комбинирования управляемого звукового объекта с неизмененным звуковым объектом или с управляемым другим звуковым объектом, который управляется иным способом, чем, по крайней мере, один звуковой объект.
10. Способ генерирования закодированного звукового сигнала, представляющего наложение, по крайней мере, двух различных звуковых объектов, включающий форматирование потока данных таким образом, чтобы поток данных включал сигнал понижающего микширования объекта, представляющий комбинацию, по крайней мере, двух различных звуковых объектов, и, в качестве дополнительной информации, метаданные, относящиеся, по крайней мере, к одному из других звуковых объектов, при этом метаданные включают информацию относительно сжатия, усиления, установок понижающего микширования, информацию о том, является ли объект речевым, звуковым или объемным, или информацию о ранжировании объектов, где указывается, что первый объект более важен, чем второй объект, и вычисления параметрических данных для приближения, по крайней мере, двух различных звуковых объектов.
11. Машиночитаемый носитель, хранящий компьютерную программу для реализации, будучи выполненной на компьютере, способа генерирования, по крайней мере, одного выходного звукового сигнала по п. 9.
12. Машиночитаемый носитель, хранящий компьютерную программу для реализации, будучи выполненной на компьютере, способа генерирования закодированного звукового сигнала по п. 10.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 5479564 A, 26.12.1995 | |||
| RU 2006139082 A, 20.05.2008 | |||
| Способ получения древесной массы | 1984 |
|
SU1234484A1 |

