Область техники, к которой относится изобретение
Изобретение относится к медицине и предназначено для исследования функционального состояния голосовых складок. Изобретение также относится к информационным и сетевым технологиям, используемым в медицине, а именно, к электронной информационной системе, обеспечивающей формирование и визуальное отображение на экране терминального устройства индивида (пользователя) системы информации о состоянии его голосовых складок по параметрам голосового сигнала. Заявляемое изобретение представляет собой расширяемый, модифицируемый, модульный и интерактивный инструмент анализа и визуализации функционального состояния голосовых складок, предназначенный для информирования пользователя о текущем состоянии его голоса и вероятности наличия заболевания.
С помощью заявляемой системы пользователь может осуществлять мониторинг функционального состояния своих голосовых складок с целью ранней диагностики заболеваний гортани и своевременной профилактики хронических заболеваний, связанных с голосовыми складками, а также связанных с частью заболеваний верхних дыхательных путей, нервной системы и других заболеваний, маркером которых может являться изменение состояния голосовых складок.
Уровень техники
За 2008 год было диагностировано более 150 тыс.новых случаев рака гортани: более 8 тыс. - РФ, более 12 тыс. - США и более 28 тыс. в странах Евросоюза. Рак гортани стал причиной более чем 80 тыс. смертей. В течение многих лет остается стабильной поздняя диагностика заболевания (60-70% составляют III-IV стадии заболевания), в течении первого года после установления диагноза рака гортани умирают 32,8% больных. Существует еще множество заболеваний влияющих на голос. Около 5% населения имеют различные проблемы с голосом. К группе риска относятся: курильщики, педагоги, экскурсоводы, переводчики, диспетчеры, дикторы, артисты и т.д.
Заявляемые способ и система позволяют производить мониторинг функционального состояния голосовых складок и обратить внимание пользователя на необходимость дополнительного обследования. При этом для индивида технология реализована в простой и понятной форме, а вероятность заболевания оценивается по итогам простого речевого теста, который пользователь системы может пройти самостоятельно без привлечения специалиста-фониатра, вне клиники, в удобное для него время.
Из уровня техники известна диагностика заболеваний горла по итогам оценки изменений голоса, связанных с изменениями колебаний голосовых складок, которые приводят к изменению качества голоса, например, изменению голоса на хриплый, грубый и т.п. Причиной таких изменений могут быть нарушения процесса колебаний голосовых складок, которые возникают в результате наличия патологии, меняющей поведение складок при фонации.
Например, известны отдельные методы оценки вероятности заболеваний голосовых складок, основанные на записи голосового сигнала с последующим анализом, базирующемся на исследовании трека частоты основного тона голосового сигнала и получении различных параметров речи, описывающих функциональное состояние голосовых складок индивида. В их числе способ, основанный на исследовании случайных колебаний периода основного тона - эффект «Дрожания» (Jitter) («USE OF PERIODICITY AND JITTER AS SPEECH RECOGNITION FEATURES» D.L. Thomson and R. Chengalvarayan, Speech Processing Group Bell Labs, Lucent Technologies, Naperville, Illinois 60566, USA); способ, основанный на исследовании случайных колебаний амплитуды сигнала на соседних периодах основного тона - эффект «Мерцания» (Shimmer) («Voice Pathology Assessment based on a Dialogue System and Speech Analysis» R.B. Reilly, R. Moran, P. Lacy, Department of Electronic and Electrical Engineering, University College Dublin, Ireland); способ, основанный на исследовании турбулентного шума или уровня шума на периоде основного тона («Harmonics-to-noise ratio as an index of the degree of hoarseness» Yumoto E, Gould WJ, Baer T, J Acoust Soc Am. 1982 Jun; 71(6): 1544-9.)
Однако, несмотря на понимание основных механизмов воспроизведения звуков, оцениваемых критериев, описывающих голосовые условия, не всегда достаточно для получения достоверного результата, касающегося определения отклонений состояния голосовых складок от нормы.
Из уровня техники известны также решения, касающиеся диагностики состояния голосовых складок (клинической оценки голоса), основанные на получении серии изображений голосовых складок в процессе фонации с последующим анализом изображений и выявлением нарушений процесса колебаний голосовых складок (Yuling Yan, Kartini Ahmad, Melda Kunduk, Diane Bless. Analysis of Vocal-fold Vibrations from High-Speed Laryngeal Images Using a Hilbert Transform-Based Methodology, Journal of Voice, Volume 19, Issue 2, June 2005, Pages 161-175).
Однако имеющиеся инструментальные аналитические средства не обеспечивают эффективную обработку большого количества изображений и интерпретацию данных для получения достоверного результата о состоянии исследуемых голосовых складок.
Наиболее близким к заявляемому решению является система и метод анализа голоса для диагностики заболеваний голосовых складок (заявка US 2008/0300867, МПК: G10L 11/04), основанные на оценке количественных показателей вибрации голосовой складки посредством анализа записей изображений гортани, полученных с использованием эндоскопического оборудования во время воспроизведения речи, и анализа формы волны акустического сигнала, полученного с использованием звукозаписывающих устройств. При этом аналитическую обработку акустического сигнала осуществляют с использованием программно-аппаратных средств и методик расчета показателей, характеризующих в т.ч. эффект «Дрожания», эффект «Мерцания», уровень турбулентного шума.
Однако для проведения описанного диагностического исследования требуется присутствие врача специалиста и наличие специализированной техники, что значительно ограничивает сферу применения метода и допускает его использование только в рамках специализированных клиник.
Раскрытие изобретения
Задачей изобретения является создание новых способа и программно-аппаратного комплекса (системы) для оценки физиологических параметров звучания голосовых складок посредством обработки параметров функционального состояния голосовых складок и отображения этих результатов в наглядной и интуитивно-понятной форме.
Техническим результатом, на достижение которого направлено заявленное изобретение, является повышение достоверности определения риска какого-либо заболевания, симптомом которого является нарушение качества голоса (функционального состояния голосовых складок). При этом результаты визуализации показателей функционального состояния голосовых складок представляются в форме, доступной для восприятия лицом, не имеющим специальной медицинской подготовки. Показатели функционального состояния голосовых складок могут быть представлены в виде графических изображений или в комбинации с текстовой информацией, не требующих медицинского образования для понимания.
Поставленная задача решается тем, что аппаратно-программный комплекс (система) для определения риска развития заболеваний индивида по его голосу включает терминальное устройство индивида с расположенными в нем модулем записи голосового сигнала индивида, модулем управления записью голосового сигнала, выполненным с возможностью выбора частоты дискретизации и длительности записи голосового сигнала, вычислительным модулем, выполненным с возможностью перевода записанного голосового сигнала из аналогового в цифровой сигнал, модулем отображения информации на мониторе терминального устройства индивида, полученной с блока анализа голосового сигнала, выполненного с возможностью определения для записанного голосового сигнала, по крайней мере, одного параметра из группы, характеризующей эффект «Дрожания» (Jitter), и/или эффект «Мерцания» (Shimmer), и/или физиологические свойства голосовых складок, и/или уровень шума в голосовом сигнале, и параметр, характеризующий нелинейность голосового сигнала, с последующим построением вектора в N-мерном пространстве параметров голосового сигнала индивида, где N - количество используемых групп, и определением апостериорной вероятности принадлежности полученного вектора к предварительно сформированным в многомерном пространстве областям для нормы и патологии посредством вычисления функций плотности вероятности для нормы и патологии.
При наличии более одного параметра в группе, блок анализа голосового сигнала выполнен с возможностью формирования многомерного пространства для нормы и патологии с применением агрегирующих функций для каждой группы параметров.
Блок анализа голосового сигнала может быть расположен в терминальном устройстве индивида. В другом варианте исполнения блок анализа голосового сигнала может быть расположен на сервере удаленного доступа, при этом аппаратно-программный комплекс дополнительно содержит модуль подключения к сети Интернет, который расположен в терминальном устройстве индивида и выполнен с возможностью приема - передачи цифрового сигнала в блок анализа голосового сигнала.
Блок анализа голосового сигнала включает БД с функциями распределения плотности вероятности для голосовых сигналов в норме и патологии.
В качестве терминального устройства индивида используют мобильный телефон, смартфон, персональный компьютер, ноутбук, планшетный компьютер, а блок анализа голосового сигнала выполнен с возможностью вычисления параметров на платформах ×86, ×64, ARM, MIPS с использованием операционных систем: семейство Windows, Linux, MacOS, iOS, Android.
Вычислительный модуль выполнен с возможностью формирования голосового сигнала из записанной слитной речи посредством ее обработки путем выделения из слитной речи отдельных ударных гласных.
Поставленная задача решается также тем, что способ определения риска развития заболеваний индивида по его голосу с использованием аппаратно-программного комплекса включает запись голосового сигнала индивида, состоящего из набора гласных звуков, или формирование упомянутого голосового сигнала из записанной слитной речи, с последующим его анализом, включающим определение для записанного голосового сигнала, по крайней мере, одного параметра из группы, характеризующей эффект «Дрожания» (Jitter), и/или эффект «Мерцания» (Shimmer), и/или физиологические свойства голосовых складок, и/или уровень шума в голосовом сигнале и нелинейность голосового сигнала, с последующим построением вектора N-мерного пространства параметров голосового сигнала индивида, где N - количество используемых групп и вычислением апостериорной вероятности полученного вектора на принадлежность к предварительно сформированным многомерным пространствам для нормы и патологии посредством вычисления функции плотности вероятности для нормы и патологии, при этом формирование многомерного пространства для нормы и патологии при наличии более одного параметра в группе осуществляют с применением агрегирующих функций, которые вычисляют для каждой группы параметров.
Запись голосового сигнала индивида осуществляют с использованием микрофона, при этом записанный сигнал направляют в блок анализа голосового сигнала, расположенный в терминальном устройстве индивида и/или на удаленном сервере.
Анализ голосового сигнала индивида осуществляют с использованием программно-аппаратного комплекса, выполненного на платформах ×86, ×64, ARM, MIPS с использованием семейств операционных систем: Windows, Linux, MacOS, iOS, Android.
Формирование голосового сигнала из записанной слитной речи осуществляют на вычислительном модуле терминального устройства индивида посредством ее обработки путем выделения из слитной речи отдельных ударных гласных.
При записи голосового сигнала индивида, состоящего из набора гласных звуков, количество гласных звуков выбирают не менее двух, один из которых - закрытый, второй - открытый, при этом продолжительность гласных звуков - не менее пяти секунд.
При формировании голосового сигнала из записанной слитной речи, суммарная длительность гласного звука в наборе, составленная из выделенных фрагментов из слитной речи, составляет не менее 10 с.
Агрегирующие функции определяют с использованием метода главных компонент.
Для получения N-мерного пространства используют функцию распределения плотности вероятности.
Формирование N-мерных пространств для нормы и патологии осуществляют с использованием баз данных звуковых сигналов голосов индивидов в норме и патологии, соответственно.
Запись голосового сигнала индивида производят в виде звуковой волны формата импульсно - кодовой модуляции, «Моно», с частотой дискретизации не меньше чем 16 кГц.
В способе предусмотрена повторная запись голосового сигнала индивида и ее анализ с получением параметров, которые сравнивают с ранее полученными параметрами с определением уровня отклонения, по которому судят о динамике вероятности заболевания голосовых складок индивида.
Параметры эффекта «Дрожания» (Jitter) получают посредством определения из записанного голосового сигнала трека частоты основного тона с последующим анализом колебаний частоты основного тона. Параметры эффекта «Мерцания» (Shimmer) получают посредством определения трека максимальных амплитуд на периодах основного тона с последующим анализом колебаний амплитудных характеристик сигнала. Параметры, характеризующие физиологические свойства голосовых складок получают посредством обратной фильтрации голосового сигнала с последующим анализом сигнала остатка. Параметры уровня шума в голосовом сигнале определяют на интервалах основного тона. Параметры, характеризующие нелинейность голосового сигнала получают посредством построения фазового пространства голосового сигнала.
При этом в качестве параметров, характеризующих эффект «Дрожания», используют усредненное абсолютное значение эффекта «Дрожания» (Mean absolute Jitter), и/или стандартное отклонение частоты основного тона (Standard deviation of FO contour), и/или голосовой диапазон частот (Phonatory frequency Range), и/или фактор возмущения частоты основного тона (Pitch perturbation Factor), и/или относительное значение эффекта «Дрожания», выраженное в % (Jitter (%)), и/или коэффициент колебания частоты основного тона (Pitch Perturbation Quotient), и/или сглаженный коэффициент возмущения частоты основного тона (Smoothed Pitch Perturbation Quotient), и/или относительное среднее колебание частоты основного тона (Relative Average Perturbation). В качестве параметров, характеризующих эффект «Дрожания», дополнительно используют кратковременное изменение эффекта «Дрожания» (Short term Jitter Estimation).
В качестве параметров, характеризующих эффект «Мерцания», используют относительное значение эффекта «Мерцания», выраженное в % (Shimmer (%)), и/или абсолютное значение эффекта «Мерцания» (Mean absolute shimmer), и/или стандартное отклонение амплитуды (Standard deviation of Amp contour), и/или фактор возмущения амплитуды (Amplitude Perturbation Factor), и/или значение эффекта «Мерцания», выраженное в децибелах (Shimmer (dB)), и/или колебания амплитуды относительно среднего (Amplitude Relative Average Perturbation), и/или коэффициент колебания амплитуды (Amplitude Perturbation Quotient), и/или сглаженный коэффициент колебания амплитуды (Smoothed Amplitude Perturbation Quotient).
В качестве параметров, характеризующих уровень шума на интервалах основного тона, используют параметр характеризующий уровень турбулентного шума на периоде основного тона (Turbulent noise index (TNI)), и/или параметр, характеризующий степень схлопывания голосовых складок (Soft phonation index (SPI)), и/или показатель уровня шума относительно уровня вокализированной компоненты (Voice turbulence index (VTI)), и/или отношение гармонической компоненты сигнала к негармонической компоненте (Harmonic to Noise Ratio (HNR)), и/или отношение энергии возбуждения к энергии шума (Glottal to Noise Excitation Ratio (GNER)). Дополнительно в качестве параметров используют уровень турбулентного шума (Glottal to Noise Distribution Ratio), который определяют в следующим образом: на вход подают сигнал в формате импульсно -кодовой модуляции, «Моно», с частотой дискретизации 16кГц, у которого определяют трек частоты основного тона, после этого производят обратную фильтрацию входного сигнала (вычисление сигнала остатка), затем производят вычисление кохлеарного спектра сигнала остатка, осуществляют взвешивание спектральной энергии сигнала остатка в диапазоне от 1,5 кГц до 2 кГц с использованием средней энергии в данном диапазоне частот, затем осуществляют взвешивание спектральной энергии сигнала остатка в диапазоне частоты основного тона с использованием средней энергии в диапазоне от минимальной частоты основного тона до максимальной частоты основного тона, по итогам полученных значений определяют отношение взвешенных энергий и получают распределение энергетического отношения посредством построения гистограммы.
Для определения параметров, характеризующих нелинейность голосового сигнала, используют метод энтропии Шеннона, и/или метод энтропии Ренье, и/или значение первого минимума информационной функции (Value of First Minimum of Mutual Information Function), и/или показатель периодичности сигнала (Recurrent period density entropy); и/или показатель получаемый в результате анализа сигнала с исключением внутреннего тренда (Detrended Fluctuation Analysis), и/или показатель получаемый в результате анализа сигнала методом Теккен-Трейлера (Taken's Estimator), и/или показатель получаемый в результате эмпирической декомпозиции сигнала на уровни (Empirical Mode Decomposition Excitations Ratios).
Для определения физиологических свойства голосовых складок используют параметры, характеризующие массу и жесткость в одномассовой модели голосовых складок, коэффициент открытия голосовой щели (Glottis Quotient) и/или показатель возбуждения голосовых складок (Vocal Fold Excitation Ratios).
Краткое описание чертежей
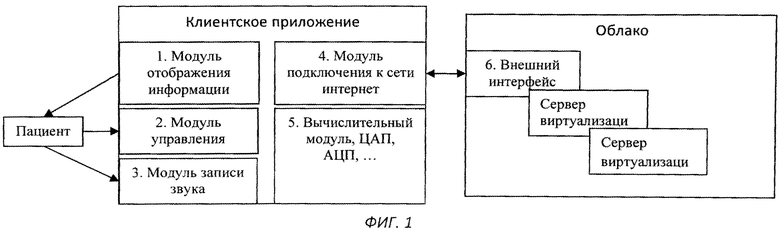
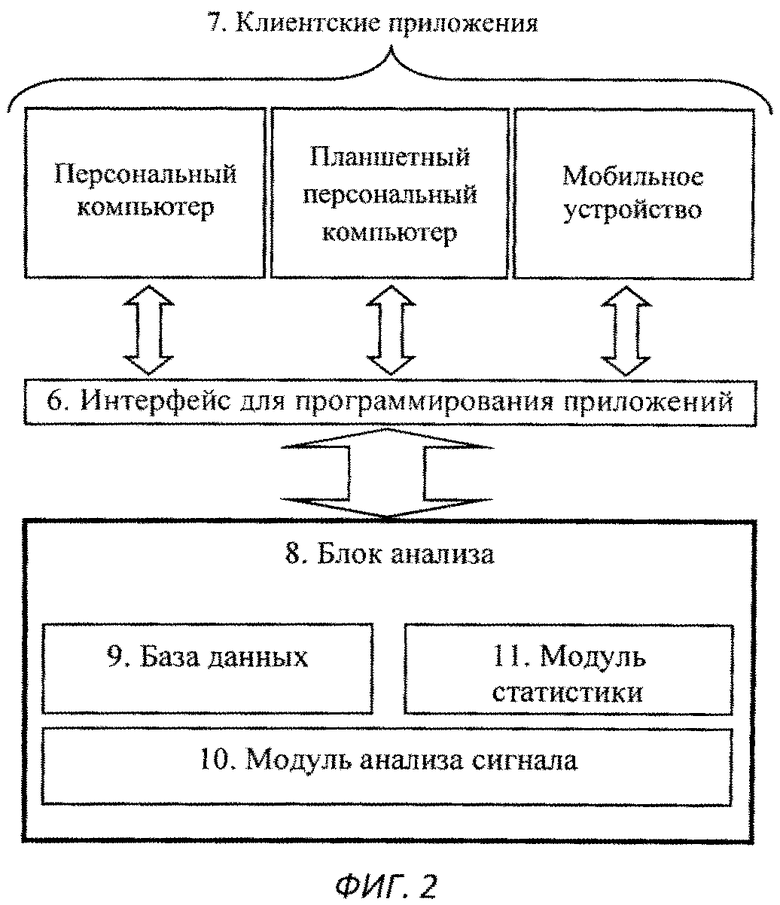
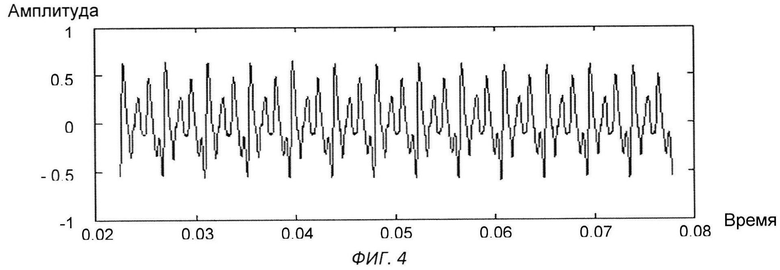
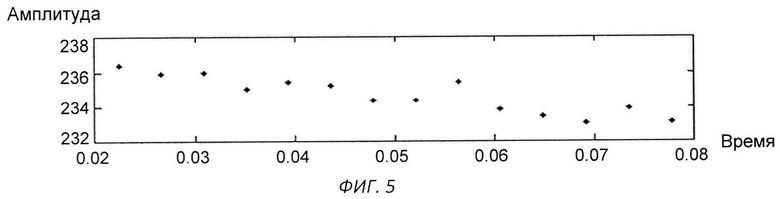
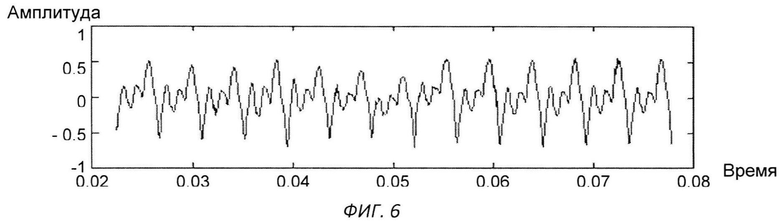
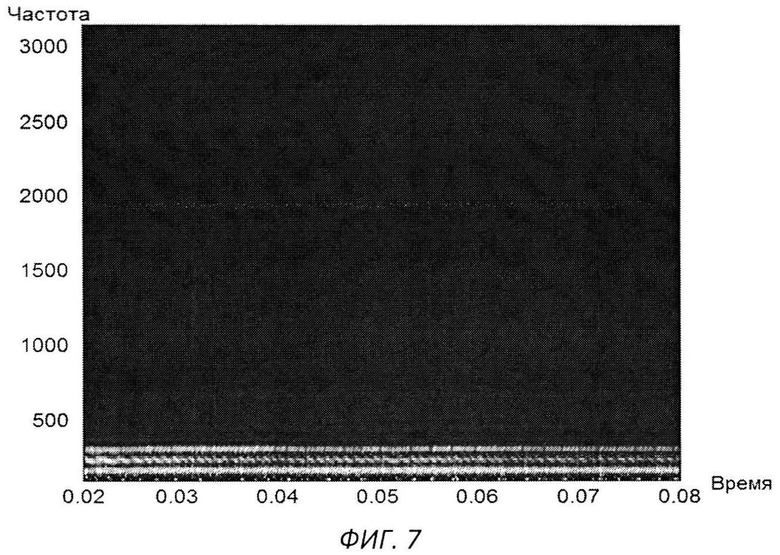
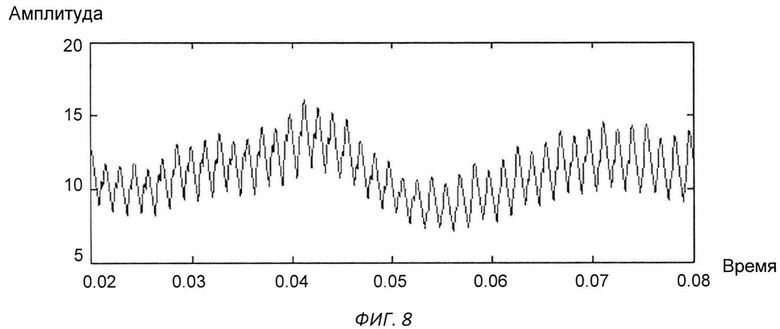
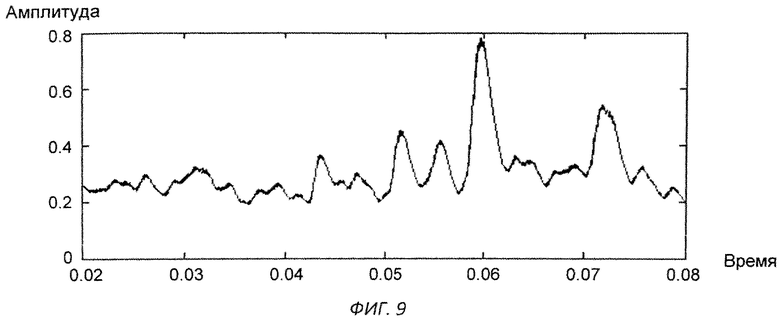
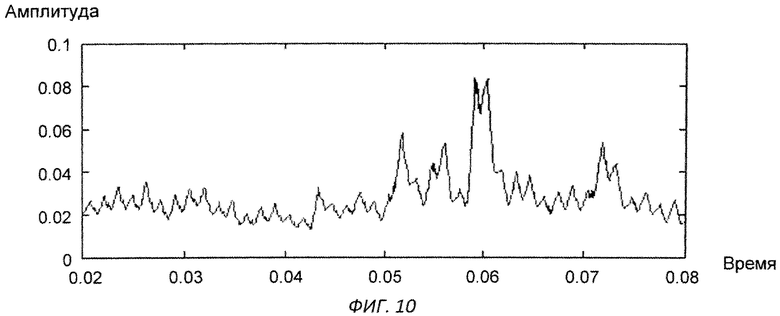
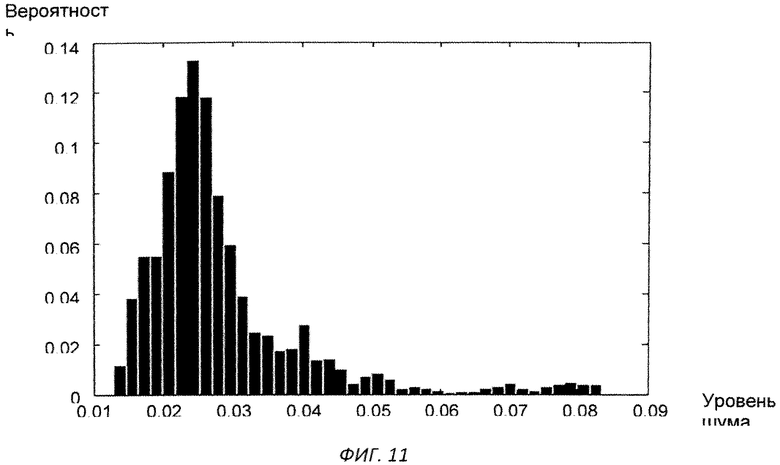
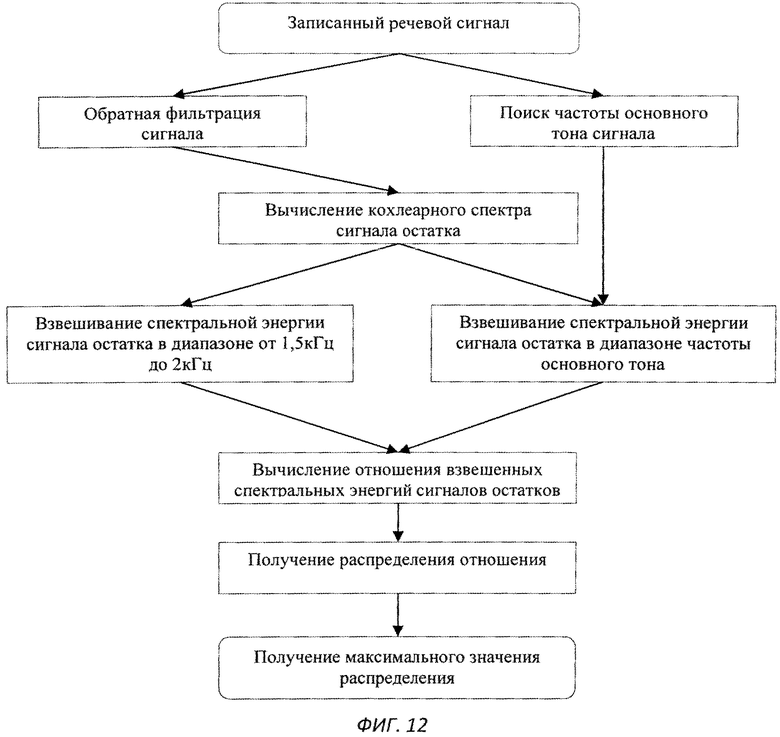
Изобретение поясняется чертежами, где на фиг.1 представлен вариант архитектуры аппаратного комплекса заявляемой системы, согласно которому, блок анализа расположен в облачной инфраструктуре, на фиг.2 представлена блок-схема реализации системы, на фиг.3 схематично представлен алгоритм процесса обучения системы, на фиг.4-11 представлены результаты этапов определения уровня турбулентного шума голосового источника в частности, на фиг.4 представлен фрагмент речевого сигнала, на фиг.5 представлен трек частоты основного тона, на фиг.6 представлен сигнал - остаток, на фиг.7 - кохлеарный спектр сигнала остатка, на фиг.8 - взвешенная энергия сигнала остатка в диапазоне 1.5-2.5 кГц, на фиг.9 представлена взвешенная энергия сигнала остатка в диапазоне от минимальной до максимальной частоты основного тона голосового сигнала, на фиг.10 - отношение взвешенных энергий, представленных на фиг.9 и фиг.8, на фиг.11 представлена спектрограмма распределения уровня шума, на фиг.12 представлена блок-схема алгоритма вычисления уровня турбулентного шума голосового источника, на фиг.13 схематично представлен алгоритм реализации блока анализа заявляемого способа, на фиг.14-15 представлена схема отображения результатов оценки вероятности наличия заболеваний голосовых складок на терминальном устройстве пользователя, в частности на фиг.14 показан вариант отображения информации в виде приращения параметров относительно предыдущего теста, на фиг.15 представлен вариант отображения информации в виде абсолютных значений параметров, на фиг.16 схематично представлена информация, выводимая модулем отображения информации перед началом тестирования индивида, на фиг.17 - перед началом записи гласного звука, на фиг.18 после записи всех гласных звуков.
Осуществление изобретения
В настоящем изобретении использована следующая терминология.
База данных - представленная в объективной форме на цифровом носителе совокупность самостоятельных материалов, систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ).
Импульсно-кодовая модуляция (ИКМ, англ. Pulse Code Modulation, PCM) - используется для оцифровки аналоговых сигналов. Практически все виды аналоговых данных (видео, голос, музыка, данные телеметрии, виртуальные миры) допускают применение ИКМ.
Моно формат - формат одноканальной записи звука.
Способ диагностики заболевания голосовых складок может быть реализован с помощью системы, представленной на Фиг.1-2. Система содержит следующие модули: 1 - модуль отображения информации; 2 - модуль управления; 3 - модуль записи звука (голосового сигнала индивида); 4 - модуль подключения к сети; 5 - вычислительный модуль, включающий в себя процессорное устройство и все необходимые подсистемы для полноценного функционирования блоков 1-4; 6 - внешний интерфейс к «облачному» сервису, включающему в себя набор серверов и виртуальных машин, выполненных на базе платформы ×32, ×64, ARM, поддерживающих следующие семейства операционных систем: Windows, Linux, MacOS, iOS, Android.
В случае если модуль 5 клиентского приложения выполнен на платформах ×32, ×64, ARM, с поддержкой семейств операционных систем Windows, Linux, MacOS, iOS, Android - то возможна полная установка программного обеспечения, реализующего алгоритм заявляемого способа (см. фиг.2), в данный модуль, что исключает потребность в облачном сервисе и модуле 4.
Модули 1-5 могут быть реализованы на базе любых устройств с данными функциями, в т.ч. персональных терминальных устройств индивида, например, мобильного телефона, смартфона, персонального компьютера, ноутбука, планшетного компьютера и т.д.
Система содержит клиентское приложение 7 (см. фиг.2), реализующее графический интерфейс для взаимодействия с пользователем; внешний интерфейс 6, в случае облачной архитектуры в качестве интерфейса может быть использован удаленный сервис; блок анализа 8, состоящий из трех основных элементов: модуля 9, представляющего собой базу данных, содержащую функции плотности распределения вероятности для голосов в норме (характеризующихся отсутствием каких-либо заболеваний голосовых складок) и патологии (характеризующихся наличием функционального или органического расстройства голосовых складок), модуля анализа сигнала 10, производящего вычисление параметров сигнала с целью последующей классификации сигнала; модуля статистики 11, производящего классификацию сигнала по полученным из модуля анализа 10 параметрам на вероятность нормы/патологии. В случае если аппаратное обеспечение клиентского приложения удовлетворяет предъявляемым выше требованиям, то блок 8 может быть встроен в клиентское приложение.
Способ осуществляют следующим образом.
Программный модуль, реализующий алгоритм заявляемого способа, загружают в персональное устройство индивида, например, телефон или в облачный сервис, например, Microsoft Windows Azure. При этом блок анализа 8 записанного сигнала, реализующего аналитическую часть заявляемого способа, может быть встроен как в терминальное устройство индивида, так и может быть расположен в удаленном доступе, например, на сервере организации, обслуживающей терминальные устройства через сеть Интернет.
Пользователь запускает программный модуль и производит запись голосового сигнала с целью его последующего анализа аппаратно-программным комплексом. При этом терминальное устройство должно поддерживать формат записи голосового сигнала, с частотой дискретизации 16 кГц.
В случае если система работает в режиме анализа слитной речи, то производится выделение гласных сегментов речи, например, методом, описанным в («Анализ и автоматическая сегментация речевого сигнала», А. Цыплихин, диссертация кандидата технических наук, 2006). При этом для оценки вероятности заболевания необходимо накопить суммарную длительность сегментов порядка 10 секунд для каждого типа гласного.
В случае если система работает в режиме анализа продолжительных сигналов, необходимо чтобы длина голосовой записи была порядка 5 секунд для каждого типа гласного.
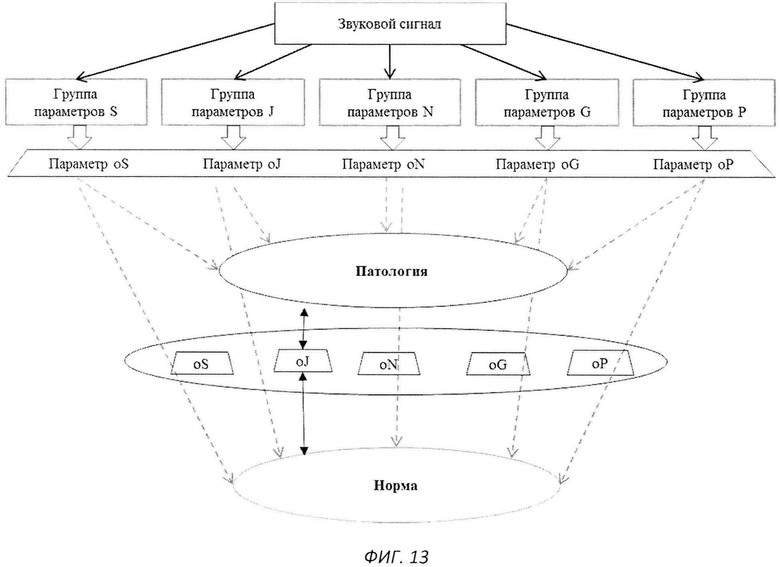
На следующем этапе посредством сети Интернет или внутренней памяти (в случае если вычислительный модуль установлен на терминальном устройстве), производят передачу записанных сигналов в блок анализа данных, где осуществляют анализ полученного сигнала по алгоритму, представленному на фиг.13. На первом этапе анализа входящий звуковой сигнал подвергают предварительному анализу, на котором определяют сигнал остаток, трек частоты основного тона и трек амплитуд сигнала на периодах основного тона (метод определения более подробно представлен ниже), на основании которых вычисляют группы параметров характеризующие: эффект «Дрожания», и/или эффект «Мерцания», и/или уровень турбулентного шума в голосовом сигнале, и/или физиологические свойства голосовых складок и нелинейность голосового сигнала. Далее представлено описание процесса эксплуатации системы с использованием пяти групп параметров.
На втором этапе на основе данных, полученных при обучении системы (алгоритм обучения см. ниже) и представляющих собой базы данных функций плотности вероятности для голосов в норме и патологии, и коэффициенты для вычисления главных компонент, производят вычисление главной компоненты для каждой из групп параметров. При этом вычисление функций распределения плотности вероятности производят на этапе обучения системы, который является предварительным этапом перед тиражированием системы (программно-аппаратного комплекса) по схеме, представленной на фиг.3.
Для каждой входящей записи голосового сигнала получают пятимерный вектор {oS, oJ, oN, oG, oP} где, oS - главная компонента для параметров, характеризующих эффект «Мерцания» (S), oJ - главная компонента для параметров, характеризующих эффект «Дрожания» (J), oN - главная компонента для параметров, характеризующих уровень турбулентного шума (N), oG - главная компонента для параметров, характеризующих параметры голосового источника (G), oP - главная компонента для параметров, характеризующих нелинейность процесса фонации (P).
На следующем шаге производят вычисление апостериорной вероятности принадлежности полученного пятимерного вектора к функции распределения плотности вероятности для голосов в норме и к функции распределения плотности вероятности для голосов в патологии. Данная мера может быть рассчитана, например, с помощью метода, описанного в литературе («The Optimality of Naive Bayes», H. Zhang, American Association for Artificial Intelligence, 2004); (Caruana, R.; Niculescu-Mizil, A. (2006). "An empirical comparison of supervised learning algorithms". Proceedings of the 23rd international conference on Machine learning).
Вероятность наличия патологии голосовых складок можно вычислить, например, с помощью алгоритма логистической регрессии (Hosmer, David W.; Lemeshow, Stanley (2000). Applied Logistic Regression (2nd ed.). Wiley), предварительно проведя совместное обучение системы и данного алгоритма.
Итоговую информацию, содержащую данные, полученные после анализа голосового сигнала, отображают на терминальном устройстве пользователя. Данные могут быть представлены в виде индикаторов, отображающих функциональное состояние голосовых складок и качества голоса. При этом поочередно отображают абсолютное значение параметра (см. фиг.16) и его приращение по сравнению с предыдущим значением (см. фиг.15). В качестве выводимых параметров используют: главную компоненту группы параметров, описывающих эффект «Мерцания», которую отображают как параметр с названием «стабильность дыхания»; главную компоненту группы параметров, описывающих эффект «Дрожания», которую отображают с названием «Дрожание голоса», главную компоненту группы параметров, описывающих уровень турбулентного шума, которую отображают с названием «Осиплость голоса», главную компоненту группы параметров, описывающих нелинейность процесса колебаний, которую отображают с названием «Гармония голоса», вероятность наличия патологии голосовых складок индивида, которую отображают с названием «Вероятность наличия патологии».
Обучение системы.
Целью процесса обучения системы является выделение главных компонент для каждой из групп параметров и получение значений функций плотности распределения вероятности для голосов в норме и патологии. Обучение системы производят на существующей базе данных голосов в норме и патологии. При этом база данных должна удовлетворять следующим условиям:
1. База данных должна включать запись голоса индивида, представленную в виде звуковой волны формата ИКМ, «Моно», с частотой дискретизации не меньше, чем 16кГц; также база данных может содержать записи в формате, который может быть конвертирован в требуемый формат без потери данных, например: *.wav, *.nsp, и т.д.
2. В базе данных должны присутствовать данные о том, к какой категории относится запись голоса индивида: норма/патология; данные о поле индивида: муж/жен;
частота дискретизации, с которой произведена запись голоса; данные о том, к какому звуку относится запись голоса: /а:/, /о:/, /i:/, /u:/.
В изобретении могут быть использованы как имеющиеся на рынке базы данных, например. The Disordered Voice Database of Massachusetts Eye and Ear Infirmary (MEEI) Voice and Speech Lab (http://www.kavelemetrics.com/index.php?option=com_product& Itemid=3&controller=product&task=learn_more&cid%5B%5D=52), так и базы данных, сформированные отдельно при наличии вышеперечисленных критериев.
На первом этапе процесса обучения (см. фиг.3) для каждой голосовой записи сигнала производят предварительный анализ (подробное описание которого представлено ниже), после чего вычисляют параметры, относящиеся к той или иной группе, характеризующей: эффект «Дрожания», и/или эффект «Мерцания», и/или уровень турбулентного шума в голосовом сигнале, и/или физиологические свойства голосовых складок и нелинейность голосового сигнала. Далее представлено описание процесса обучения с использованием пяти групп параметров. При этом достоверный результат оценки вероятности риска заболевания голосовых складок может быть получен при использовании меньшего количества групп параметров (от двух до пяти), характеризующих перечисленные выше эффекты (которые используют как при обучении системы, так и в процессе реализации способа).
На втором этапе процесса обучения с помощью метода главных компонент («А Tutorial on Principal Component Analysis», J. Shiens, Center for Neural Science, New York University New York City, NY 10003-6603 and Systems Newobiology Laboratory, Salk Institute for Biological Studies La Jolla, CA 92037) выделяют главные компоненты для каждой из групп параметров (см. фиг.3), таким образом для каждой голосовой записи сигнала получают пятимерный вектор главных компонент {oS, oj, oN, oG, oP} где, oS - главная компонента для параметров, характеризующих эффект «Мерцания»(S), oJ - главная компонента для параметров, характеризующих эффект «Дрожания»(J), oN - главная компонента для параметров, характеризующих уровень турбулентного шума (N), oG - главная компонента для параметров, характеризующих параметры голосового источника (G), oP - главная компонента для параметров, характеризующих нелинейность процесса фонации (P).
На третьем этапе производят построение функции плотности вероятности (http://en.wikipedia.org/wiki/Probability density function) для полученных векторов, относящихся к голосам в норме и функции плотности вероятности для полученных векторов, относящихся к голосам в патологии.
Предварительный анализ голосового сигнала.
Большинство параметров, получаемых из голосового сигнала (фиг.4) с целью описания текущего состояния голоса, базируются на треке частоты основного тона (фиг.5).
При этом определение частоты основного тона может быть реализовано по известным методикам: L.R. Rabiner, M.J. Cheng, A.E. Rosenberg и С.A. McGonegal, «A comparative perfomance study of several pitch detection algorithms,» IEEE Trans. Audio Electroacoust., pp.399-417, 1976; D. Gerhard, «Pitch extraction and fundamental frequency: history and current techniques,» University of Regina, Saskatchewan, Canada, 2003; A. De Cheveigne, «International Conference on Acoustics,» в Pitch perception models from origins to today, Kyoto, 2004; V.N. Sorokin и V.P. Trifonenkov, «Autocorrelational Analysis of Speech Signal,» т.3, №42, 1996.
Изобретение может быть реализовано с использованием следующих алгоритмов:
- Алгоритмы, основанные на анализе сигнала во временной области: ITU G.726 («ITU Recommendation G.726,» [В Интернете]. http://www.itu.int/rec/T-REC-G.726/en.), YIN (A. De Cheveigne и Н. Kawahara, «YIN, a fundamental frequency estimator for speech and music,» JASA, №111, pp.1917-1930, 2002), TWIN (А. И. Цыплихин, «Анализ импульсов голосового источника,» Акустический журнал, т.53, pp.119-133, 2007).
- Алгоритмы, основанные на анализе сигнала в спектральной области: REPS, DASH (Т. Nakatani и Т. Irino, «Robust and accurate fundamental frequency estimation based on dominant harmonic components,» JASA, т.116, №6, pp.3690-3700, 2004), TEMPO (Н. Kawahara, I. Masuda-Kasuse и А. De Cheveigne, «Restructuring speech representations a pitch-adaptive time-frequency smoothing and instantaneous-frequency-based FO exctraction: Possible role of repetitive structure in sounds,» Speech Communication, т.29, №3-4, pp.187-207, 1999).
Учитывая зависимость точности вычисления параметров от точности вычисления трека частоты основного тона, целесообразно использовать группу алгоритмов, основанных на анализе сигнала во временной области.
Для расчета группы параметров эффекта «Мерцания» предварительно вычисляют трек максимальных амплитуд сигнала на периодах основного тона. Один из возможных методов выделения трека максимальных амплитуд сигнала описан в TWIN (А.И. Цыплихин, «Анализ импульсов голосового источника,» Акустический журнал, т.53, pp.119-133,2007.)
Также на этапе предварительного анализа сигнала производят вычисление сигнала остатка (фиг.6) («Начальные условия в задаче идентификации голосового источника», В.Н. Сорокин, А.А. Тананыкин, Информационные процессы. Том 10, №1, стр.1-10), путем обратной фильтрации исходного сигнала (D. Wong, J. Markel, A. Gray, "Least Squares Glottal Inverse Filtering from the Acoustic Speech Waveform", IEEE Trans. Acoust., Speech, Signal Process., vol. ASSP-27, No 4, pp.350-355, 1979).
Определение параметров эффекта «Дрожания».
Основные параметры эффекта «Дрожания» базируются на треке частоты основного тона и могут быть вычислены с помощью формул, представленных в Таблице 1.
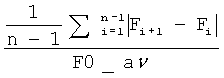
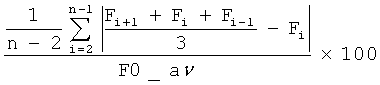
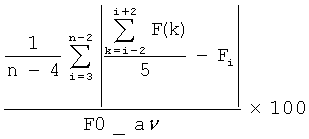
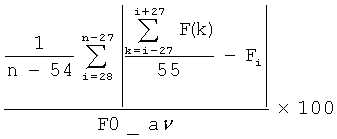
Fi - частота основного тона с i-м номером, полученная из трека частоты основного тона, F0_av - средняя частота основного тона на всем треке частоты основного тона.
В качестве дополнительного параметра может быть использован параметр, определяющий кратковременное изменение эффекта «Дрожания» (Short term Jitter Estimation), методика вычисления которого представлена в «Voice Pathology Detection Based on Short-Term Jitter Estimations in Running Speech», M. Vasilakis, Y. Stylianou, Folia Phoniatr Logop 509-T1.
Определение параметров эффекта «Мерцания».
Голосовые складки человека в большинстве случаев способны генерировать звуковой сигнал, амплитуда которого будет постоянной. Исключением является слитная речь, где помимо всего прочего, на амплитуду будут влиять эмоциональные и артикуляторные аспекты. Однако даже в случае слитной речи изменение амплитуды на гласных звуках будет происходить монотонно. Случайные колебания амплитуды сигнала служат признаком патологии и называются эффектом «Мерцания». В Таблице 2 представлены параметры, которые отобраны для использования в заявляемом способе.
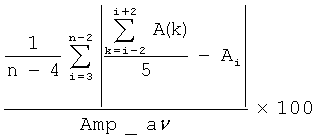
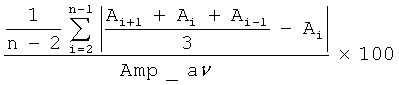
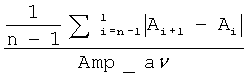
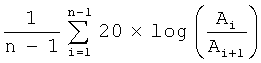
Ai - максимальная амплитуда сигнала на i-м периоде основного тона, 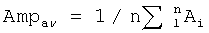
Все параметры, для оценки эффекта «Мерцания», вычисляют по треку максимальных амплитуд сигнала, синхронному с треком частоты основного тона.
Определение параметров турбулентного шума.
Уровень шума определяет качество сигнала и голоса в целом, в частности, наличие хрипов и осиплости голоса. Уровень шума в сигнале является хорошим показателем для определения наличия патологии гортани. В изобретении предлагается использовать один или несколько из следующих параметров, позволяющих характеризовать уровень шума в сигнале.
Параметр, характеризующий уровень турбулентного шума на периоде основного тона (Turbulent noise index (TNI)):
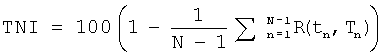
где N - длина трека основного тона, R(tn,Tn) - нормализованная автокорреляционная функция. Параметр TNI может быть определен, например, по методике, представленной в Р. Mitev и S. Hadjitodorov, «A method for turbulent noise estimation in voiced signal,» Med Biol Eng Comput., т.38, №6, pp.625-631, 2000; «SOFTWARE INSTRUCTION MANUAL Multi-Dimensional Voice Program (MDVP) Model 5105», KayPentax.
Параметр, характеризующий степень схлопывания голосовых складок (Soft phonation index (SPI)) - определяется отношением гармонической энергии в частотном диапазоне от 70Hz до 1600Hz к гармонической энергии в частотном диапазоне от 1600Hz до 4500Hz (S. An Xue, «Effects of aging on selected acoustic voice parameters: preliminary normative data and educational implications» 2001; «SOFTWARE INSTRUCTION MANUAL Multi-Dimensional Voice Program (MDVP) Model 5105», KayPentax).
Показатель уровня шума относительно уровня вокализированной компоненты (Voice turbulence index (VTI)) - параметр, характеризующийся средним отношением негармонической энергии сигнала в частотном диапазоне от 2800Hz до 5800Hz к гармонической энергии в частотном диапазоне от 70Hz до 4500Hz. При этом уровень гармонической энергии необходимо вычислять в области с минимальным уровнем колебания частоты гармоник, амплитуды сигнала и минимальной энергией субгармонической составляющей сигнала. Определение данного параметра может быть реализовано по методике, представленной в следующих источниках информации: S. An Xue, «Effects of aging on selected acoustic voice parameters: preliminary normative data and educational implications» 2001; V.D. Nicola, M.I. Fiorella, D.A. Spinelli и R. Fiorella, «Acoustic analysis of voice in patients treated by reconstructive subtotal laryngectomy. Evaluation and critical review» ACTA OTORHINOLARYNGOL, т.26, pp.56-68, 2006; «SOFTWARE INSTRUCTION MANUAL Multi-Dimensional Voice Program (MDVP) Model 5105», KayPentax.
Отношение гармонической компоненты сигнала к негармонической компоненте (Harmonic to Noise Ratio (HNR)) - параметр, который характеризует относительный уровень шума в речевом сигнале. Способы определения данного параметра представлены в следующих материалах: L.L. Oiler, «Analysis of voice signals for the harmonic-to-noise crossover frequency,» UPC Barselona, 2008; К. Shama, A. Krishna и N.U. Cholayya, «Study of harmonics to noise ratio and critical-band energy spectrum of speech as acoustic indicators of laryngeal and voice pathology,» EURASIP Journal on Advances Signal Processing, 2007; Q. Yingyong, «Temporal and spectral estimations of harmonic to noise ratio in human voice signal,» JASA, т.102, №1, pp.537-543, 1997; L. Girin, «14th European Signal Processing Conference (EUSIPCO 2006),» в Theoretical and experimental bases of a new method for accurate separation of harmonic and noise components of speech signals, Florence, Italy, 2006; P. Boersma, «Accurate short-term analysis of the fundamental frequncy and the harmonic to 17 noise ratio of sampled sound,» Proceedings, т.17, pp.97-110, 1993; E. Yumoto и W. J. Gould, «Harmonics to noise ratio as an index of the degree ofhoarseness,» JASA, т.71, №6, pp.1544-1550, 1982; С. Ferrer, E. Gonzalez, H. Hemandez-Diaz, D. Torres и A. del Toro, «Removing the influence of shimmer in the calculation of harmonic noise ratios using ensemble-averages in voice signals,» EURASIP Journal on Advances in Signal Processing, 2009.
Отношение энергии возбуждения к энергии шума (Glottal to Noise Excitation Ratio (GNER)) - параметр, характеризующий качество речевого сигнала. Параметр рассчитывается как максимальный коэффициент корреляции между Гильбертовыми огибающими речевого сигнала в различных частотных диапазонах. («Glottal-to-Noise Excitation Ratio - a New Measure for Describing Pathological Voices», D. Michaelis, T. Gramss, H.W. Strube).
Уровень турбулентного шума голосового источника - параметр характеризует отношение энергии голосового источника к энергии турбулентного шума. Алгоритм вычисления параметра представлен на фиг.12. На вход терминального модуля индивида подают голосовой сигнал, с частотой дискретизации 16 кГц (фиг.4). После чего производят поиск трека частоты основного тона входного сигнала (фиг.5) и путем обратной фильтрации получают сигнал остаток, фиг.6. По сигналу остатку вычисляют кохлеарный спектр (фиг.7) методом, описанным в «An Efficient Implementation of the Patterson-Holdsworth Auditory Filter Bank», M. Slaney, Apple Computer Technical Report #35 Perception Group-Advanced Technology Group.Производят взвешивание спектральной энергии сигнала остатка в диапазоне от 1,5 кГц до 2 кГц с использованием средней энергии в данном диапазоне частот (фиг.8), а также взвешивание спектральной энергии сигнала остатка в диапазоне частоты основного тона с использованием средней энергии в диапазоне от минимальной частоты основного тона до максимальной частоты основного тона (фиг.9). После чего берут отношение взвешенных энергий, полученных в пунктах выше (фиг.10), и вычисляют распределение энергетического отношения путем построения гистограммы (фиг.11). В качестве результирующего параметра берут максимальное значение в функции распределения отношения энергий, полученной на предыдущем этапе.
Определение параметров характеризующих нелинейность процесса фонации (нелинейность голосового сигнала).
В качестве параметров, характеризующих нелинейность процесса фонации, могут быть использованы следующие параметры:
Показатель периодичности сигнала (Recurrent period density entropy) - параметр, который вычисляется на основе фазового пространства сигнала и характеризует периодичность сигнала. Определение данного параметра может быть реализовано по методике, представленной в «NONLINEAR, BIOPHYSICALLY-INFORMED SPEECH PATHOLOGY DETECTION» Max Little, Patrick McSharryab, Irene Moroza and Stephen Robertsb Mathematical Institute, Engineering Science, Oxford University, UK
Показатель, получаемый в результате анализа сигнала с исключением внутреннего тренда (Den-ended Fluctuation Analysis) может быть определен по методике, представленной в «NONLINEAR, BIOPHYSICALLY-INFORMED SPEECH PATHOLOGY DETECTION» Max Little, Patrick McSharryab, Irene Moroza and Stephen Robertsb Mathematical Institute, Engineering Science, Oxford University, UK.
Значение первого минимума информационной функции (Value of First Minimum of Mutual Information) - параметр, характеризующий смещение фазы сигнала на 180°. Определение данного параметра может быть реализовано по методике, представленной в «Information Function Characterization of Healthy and Pathological Voice Through Measures Based on Nonlinear Dynamics» Patricia Henrfquez, Jesus B. Alonso, Miguel A. Ferrer, Carlos M. Travieso, Juan I. Godino-Llorente, and Fernando Diaz-de-Maria.
Показатель, получаемый в результате анализа сигнала методом Теккен (Taken's Estimator) - характеризует корреляционную размерность сигнала. Определение данного параметра может быть реализовано по методике, представленной в «Information Function Characterization of Healthy and Pathological Voice Through Measures Based on Nonlinear Dynamics» Patricia Henrfquez, Jesus B. Alonso, Miguel A. Ferrer, Carlos M. Travieso, Juan I. Godino-Llorente, and Femando Diaz-de-Maria.
Энтропия Шеннона (Shannon Entropy) - мера неопределенности или непредсказуемости сигнала. Определение данного параметра может быть реализовано по методике, представленной в «Information Function Characterization of Healthy and Pathological Voice Through Measures Based on Nonlinear Dynamics» Patricia Henrfquez, Jesus B. Alonso, Miguel A. Ferrer, Carlos M. Travieso, Juan I. Godino-Llorente, and Fernando Diaz-de-Maria.
Энтропия Ренье (Renyi Entropies) - параметр, определяющий количественное разнообразие неопределенности сигнала. Определение данного параметра может быть реализовано по методике, представленной в «Information Function Characterization of Healthy and Pathological Voice Through Measures Based on Nonlinear Dynamics» Patricia Henriquez, Jesus В. Alonso, Miguel A. Ferrer, Carlos M. Travieso, Juan I. Godino-Llorente, and Femando Diaz-de-Maria.
Определение параметров голосового источника
Коэффициент открытия голосовой щели (Glottis Quotient) характеризует случайные изменения периода, на котором голосовая щель находится в открытом состоянии. Определение данного параметра может быть реализовано по методике, представленной в Journal of the Royal Society Interface Electronic Supplementary Material, «Nonlinear speech analysis algorithms mapped to a standard metric achieve clinically useful quantification of average Parkinson's disease symptom severity» Athanasios Tsanasa, Max A. Little, Patrick E. McSharry, Lorraine 0. Ramige.
Показатель возбуждения голосовых складок (Vocal Fold Excitation Ratios) характеризует уровень энергии импульсов голосового источника в сравнении с уровнем турбулентного шума. Определение данного параметра может быть реализовано по методике, представленной в Journal of the Royal Society Interface Electronic Supplementary Material, «Nonlinear speech analysis algorithms mapped to a standard metric achieve clinically useful quantification of average Parkinson's disease symptom severity» Athanasios Tsanasa, Max A. Little, Patrick E. McSharry, Lorraine O. Ramige.
Параметры одномассовой модели голосовых складок - параметры, характеризующие массу и жесткость голосовых складок. Данные параметры могут быть получены по методу, описанному в Р. Gomez-Vilda, R. Fernandez-Baillo, V. Rodllar-Biarge, V.N. lluis, A. Alvarez-Marquina, L.M. Mazaira-Femandez, R. Martinez-Olalla и J.I. Godino-Llorente, «Glottal source biomedical signature for voice pathology detection,» Speech Communication, 2008.
Пример выполнения
Заявляемая система была изготовлена на базе облачного сервиса Windows Azure, смартфона Nokia Lumia 800 (http://allnokia.ru/catalog/nokia-Lumia+800/) с модулем 7, встроенным в смартфон и модулями 6, 8, встроенными в облачный сервис.
Пользователь производит запуск системы нажатием соответствующей кнопки на смартфоне. Система выводит информацию о процессе тестирования и предоставляет пользователю возможность начать тестирование посредством нажатия кнопки «Начать тестирование» (см. фиг.17). После нажатия кнопки «Начать тестирование» система выводит в качестве текста гласный звук /а:/ и предоставляет пользователю возможность начать запись отображенного гласного звука (см. фиг.18). После нажатия кнопки «Запись» пользователь произносит данный звук до тех пор, пока система не разблокирует кнопку «Запись» и не поменяет информацию о звуке, который необходимо произнести пользователю. По описанному выше алгоритму пользователь продолжает запись всех необходимых звуков (/о:/, /i:/, /u:/). После чего пользователь нажимает кнопку «Далее» (см. фиг.18), тем самым осуществляя передачу всех записанных файлов в модуль анализа.
В случае если в системе используется вариант анализа слитной речи, то производится фоновый запуск системы, которая активируется, например, в момент телефонного звонка индивида. Терминальное устройство индивида производит запись голосового сигнала, после чего осуществляется его сегментация с выделением участков гласных звуков. При достижении суммарной длительности по 10 секунд для каждого гласного звука терминальное устройство производит передачу данных в модуль анализа.
Модуль анализа принимает все голосовые сигналы, записанные пользователем, которые, либо записаны на терминальном устройстве в требуемом формате, либо преобразованы вычислительным модулем терминального устройства к формату одноканального сигнала с частотой 16 кГц (см. фиг.4). Модуль анализа производит предварительный анализ каждого полученного сигнала, в ходе которого вычисляет трек частоты основного тона (см. фиг.5), трек максимальных амплитуд сигнала на периодах основного тона и сигнал остаток (см. фиг.6). После чего по полученным данным производят расчет следующих параметров: Колебание амплитуды относительно среднего, рассчитанное на трех периодах основного тона, Колебание амплитуды относительно среднего, рассчитанное на пяти периодах основного тона. Колебание амплитуды относительно среднего, рассчитанное на одиннадцати периодах основного тона, Относительное значение эффекта «Мерцания», выраженное в %, Параметр, характеризующий степень схлопывания голосовых складок. Показатель уровня шума относительно уровня вокализированной компоненты. Параметр, характеризующий уровень турбулентного шума на периоде основного тона. Отношение гармонической компоненты сигнала к негармонической компоненте. Отношение энергии возбуждения к энергии шума. Относительное значение эффекта «Дрожания», выраженное в %, Коэффициент колебания частоты основного тона, вычисленный для трех периодов основного тона. Коэффициент колебания частоты основного тона, вычисленный для пяти периодов основного тона, Коэффициент колебания частоты основного тона, вычисленный для одиннадцати периодов основного тона. Энтропия Шеннона, Энтропия Ренье, Показатель, получаемый в результате анализа сигнала с исключением внутреннего тренда. Показатель периодичности сигнала.
Используя коэффициенты (Таблица 3), полученные в ходе обучения для каждой из групп параметров, модуль анализа выделяет главные компоненты: oS=31,83; oJ=12,53;
oN=ll,07; oP=0,22; По полученным значениям главных компонент вычисляют вектор {31,83; 12,53; 11,07; 0,22} и функции плотности распределения для голосов в норме и патологии. После чего модуль анализа производит определение вероятности наличия патологии голосовых складок у индивида. Полученная вероятность риска какого-либо заболевания у индивида по настоящему примеру составила 5,2%.
Модуль анализа передает результирующие данные терминальному устройству индивида, где производится их отображение индивиду в понятной и легко интерпретируемой форме (см. фиг.14-15). Используя предоставленные системой данные, индивид делает вывод, что состояние голосовых складок приближено к норме и нет необходимости посещения врача-специалиста.
Преимущества заявляемой технологии
Заявляемые способ и система для реализации способа позволяют производить мониторинг функционального состояния голосовых складок индивида в любое удобное для него время, при этом не требуют присутствия врача специалиста и дают возможность проходить регулярные «скрининг» обследования с целью определения изменений в голосе индивида. Такой подход позволяет экономить средства и время индивида, при этом увеличивая вероятность раннего обнаружения патологий голосовых складок или других заболеваний, маркером которых может являться изменение состояния голосовых складок.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ консервативного лечения хронического отечно-полипозного ларингита | 2021 |
|
RU2758136C1 |
| Способ лечения гипотонусной дисфонии у пациентов пожилой возрастной группы | 2020 |
|
RU2738574C1 |
| Способ лечения узелков голосовых складок у профессиональных вокалистов | 2020 |
|
RU2730940C1 |
| Способ консервативного лечения хронического катарального ларингита | 2023 |
|
RU2813037C1 |
| СПОСОБ ЛЕЧЕНИЯ ОБОСТРЕНИЙ ХРОНИЧЕСКОГО ЛАРИНГИТА | 2011 |
|
RU2510757C2 |
| Способ лечения бамбуковых узелков голосовых складок | 2022 |
|
RU2786954C1 |
| СПОСОБ ЛЕЧЕНИЯ ОСТРЫХ И ОБОСТРЕНИЙ ХРОНИЧЕСКОГО ЛАРИНГИТА | 2011 |
|
RU2474431C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ИЗМЕНЕНИЙ ГОЛОСОВОЙ ФУНКЦИИ ЧЕЛОВЕКА | 2014 |
|
RU2598051C2 |
| Способ лечения хронического гиперпластического ларингита с применением сеансов фотодинамической терапии | 2023 |
|
RU2806971C1 |
| СПОСОБ ХИРУРГИЧЕСКОГО ЛЕЧЕНИЯ ПАПИЛЛОМАТОЗА ГОЛОСОВЫХ СКЛАДОК | 2015 |
|
RU2604940C1 |


Изобретение относится к медицине и предназначено для исследования функционального состояния голосовых складок. Техническим результатом является повышение точности диагностики состояния здоровья индивида по параметрам голосового сигнала. Комплекс содержит: терминальное устройство индивида с расположенными в нем модулем записи голосового сигнала индивида, модулем управления записью голосового сигнала, выполненным с возможностью выбора частоты дискретизации и длительности записи голосового сигнала, вычислительным модулем, выполненным с возможностью перевода записанного голосового сигнала из аналогового в цифровой сигнал, модулем отображения информации на мониторе терминального устройства индивида, полученной с блока анализа голосового сигнала, выполненного с возможностью определения для записанного голосового сигнала параметра, характеризующего нелинейность голосового сигнала, и по крайней мере одного параметра из группы,
характеризующей эффект «Дрожания» (Jitter), и/или эффект «Мерцания» (Shimmer), и/или физиологические свойства голосовых складок, и/или уровень шума в голосовом сигнале, с последующим построением вектора в N-мерном пространстве параметров голосового сигнала индивида. 2 н. и 28 з.п. ф-лы, 18 ил., 3 табл.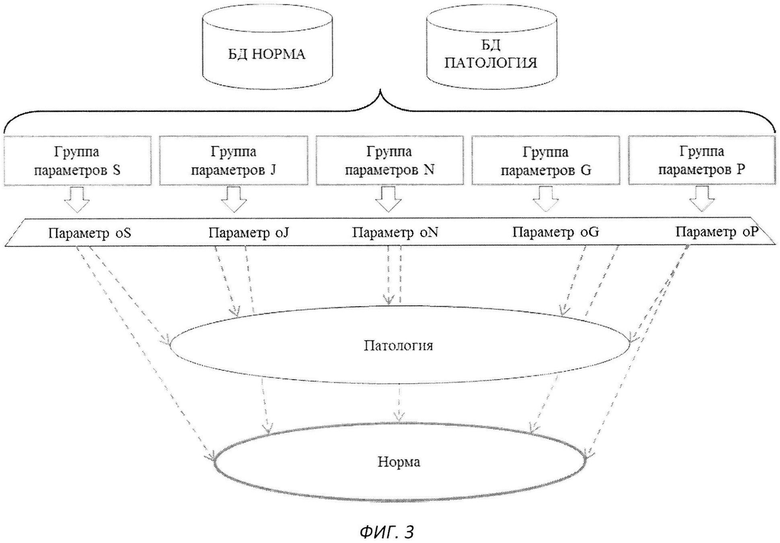
1. Аппаратно-программный комплекс для определения риска развития заболеваний индивида по его голосу, включающий терминальное устройство индивида с расположенными в нем модулем записи голосового сигнала индивида, модулем управления записью голосового сигнала, выполненным с возможностью выбора частоты дискретизации и длительности записи голосового сигнала, вычислительным модулем, выполненным с возможностью перевода записанного голосового сигнала из аналогового в цифровой сигнал, модулем отображения информации на мониторе терминального устройства индивида, полученной с блока анализа голосового сигнала, выполненного с возможностью определения для записанного голосового сигнала параметра, характеризующего нелинейность голосового сигнала, и по крайней мере одного параметра из группы, характеризующей эффект «Дрожания» (Jitter), и/или эффект «Мерцания» (Shimmer), и/или физиологические свойства голосовых складок, и/или уровень шума в голосовом сигнале, с последующим построением вектора в N-мерном пространстве параметров голосового сигнала индивида, где N - количество используемых групп, и определением апостериорной вероятности принадлежности полученного вектора к предварительно сформированным в многомерном пространстве областям для нормы и патологии посредством вычисления функций плотности вероятности для нормы и патологии.
2. Аппаратно-программный комплекс по п.1. характеризующийся тем, что при наличии более одного параметра в группе блок анализа голосового сигнала выполнен с возможностью формирования многомерного пространства для нормы и патологии с применением агрегирующих функций для каждой группы параметров.
3. Аппаратно-программный комплекс по п.1, характеризующийся тем, что блок анализа голосового сигнала расположен в терминальном устройстве индивида.
4. Аппаратно-программный комплекс по п.1, характеризующийся тем, что он содержит сервер удаленного доступа и модуль подключения к сети Интернет, который расположен в терминальном устройстве индивида и выполнен с возможностью приема-передачи цифрового сигнала в блок анализа голосового сигнала, который расположен на сервере удаленного доступа.
5. Аппаратно-программный комплекс по п.1, характеризующийся тем, что блок анализа голосового сигнала включает базу данных с функциями распределения плотности вероятности для голосовых сигналов в норме и патологии.
6. Аппаратно-программный комплекс по п.1, характеризующийся тем, что в качестве терминального устройства индивида используют мобильный телефон, смартфон, персональный компьютер, ноутбук, планшетный компьютер, а блок анализа голосового сигнала выполнен с возможностью вычисления параметров на платформах х86, х64, ARM, MIPS с использованием операционных систем: семейство Windows, Linux, MacOS, iOS, Android.
7. Аппаратно-программный комплекс по п.1, характеризующийся тем, что вычислительный модуль выполнен с возможностью формирования голосового сигнала из записанной слитной речи посредством ее обработки путем выделения из слитной речи отдельных ударных гласных.
8. Способ определения риска развития заболеваний индивида по его голосу с использованием аппаратно-программного комплекса по п.1, включающий запись голосового сигнала индивида, состоящего из набора гласных звуков, или формирование упомянутого голосового сигнала из записанной слитной речи, с последующим его анализом, включающим определение для записанного голосового сигнала параметра, характеризующего нелинейность голосового сигнала, и по крайней мере одного параметра из группы, характеризующей эффект «Дрожания» (Jitter), и/или эффект «Мерцания» (Shimmer), и/или физиологические свойства голосовых складок, и/или уровень шума в голосовом сигнале, с последующим построением вектора N-мерного пространства параметров голосового сигнала индивида, где N - количество используемых групп, и вычислением апостериорной вероятности полученного вектора на принадлежность к предварительно сформированным многомерным пространствам для нормы и патологии посредством вычисления функции плотности вероятности для нормы и патологии, при этом формирование многомерного пространства для нормы и патологии при наличии более одного параметра в группе осуществляют с применением агрегирующих функций, которые вычисляют для каждой группы параметров.
9. Способ по п.8, характеризующийся тем, что запись голосового сигнала индивида осуществляют с использованием микрофона, при этом записанный сигнал направляют в блок анализа голосового сигнала, расположенный в терминальном устройстве индивида и/или на удаленном сервере.
10. Способ по п.8, характеризующийся тем, что анализ голосового сигнала индивида осуществляют с использованием программно-аппаратного комплекса, выполненного на платформах х86, х64, ARM, MIPS с использованием семейств операционных систем: Windows, Linux, MacOS, iOS, Android.
11. Способ по п.8, характеризующийся тем, что формирование голосового сигнала из записанной слитной речи осуществляют на вычислительном модуле терминального устройства индивида посредством ее обработки путем выделения из слитной речи отдельных ударных гласных.
12. Способ по п.8, характеризующийся тем, что при записи голосового сигнала индивида, состоящего из набора гласных звуков, количество гласных звуков выбирают не менее двух, один из которых - закрытый, второй - открытый, при этом продолжительность гласных звуков - не менее пяти секунд.
13. Способ по п.8, характеризующийся тем, что при формировании голосового сигнала из записанной слитной речи суммарная длительность гласного звука в наборе, составленная из выделенных фрагментов слитной речи, составляет не менее 10 с.
14. Способ по п.8, характеризующийся тем, что параметры «Jitter» эффекта получают посредством определения из записанного голосового сигнала трека частоты основного тона с последующим анализом колебаний частоты основного тона.
15. Способ по п.8, характеризующийся тем, что параметры «Shimmer» эффекта получают посредством определения трека максимальных амплитуд на периодах основного тона с последующим анализом колебаний амплитудных характеристик сигнала.
16. Способ по п.8, характеризующийся тем, что параметры, характеризующие физиологические свойства голосовых складок, получают посредством обратной фильтрации голосового сигнала с последующим анализом сигнала остатка.
17. Способ по п.8, характеризующийся тем, что параметры уровня шума в голосовом сигнале определяют на интервалах основного тона.
18. Способ по п.8, характеризующийся тем, что параметры, характеризующие нелинейность голосового сигнала, получают посредством построения фазового пространства голосового сигнала.
19. Способ по п.8, характеризующийся тем, что агрегирующие функции определяют с использованием метода главных компонент.
20. Способ по п.8, характеризующийся тем, что для получения N-мерного пространства используют функцию распределения плотности вероятности.
21. Способ по п.8, характеризующийся тем, что формирование N-мерных пространств для нормы и патологии осуществляют с использованием баз данных звуковых сигналов голосов индивидов в норме и патологии соответственно.
22. Способ по п.8, характеризующийся тем, что запись голосового сигнала индивида производят в виде звуковой волны формата импульсно-кодовой модуляции, «Моно», с частотой дискретизации не меньше чем 16 кГц.
23. Способ по п.8, характеризующийся тем, что осуществляют повторную запись голосового сигнала индивида и ее анализ с получением параметров, которые сравнивают с ранее полученными параметрами с определением уровня отклонения, по которому судят о динамике вероятности заболевания голосовых складок индивида.
24. Способ по п.8, характеризующийся тем, что в качестве параметров, характеризующих эффект «Дрожания», используют усреднённое абсолютное значение эффекта «Дрожания» (Mean absolute Jitter), и/или стандартное отклонение частоты основного тона (Standard deviation of FO contour), и/или голосовой диапазон частот (Phonatory frequency Range), и/или фактор возмущения частоты основного тона (Pitch perturbation Factor), и/или относительное значение эффекта «Дрожания», выраженное в % (Jitter (%)), и/или коэффициент колебания частоты основного тона (Pitch Perturbation Quotient), и/или сглаженный коэффициент возмущения частоты основного тона (Smoothed Pitch Perturbation Quotient), и/или относительное среднее колебание частоты основного тона (Relative Average Perturbation).
25. Способ по п.24, характеризующийся тем, что в качестве параметров, характеризующих эффект «Дрожания», дополнительно используют кратковременное изменение эффекта «Дрожания» (Short term Jitter Estimation).
26. Способ по п.8, характеризующийся тем, что в качестве параметров, характеризующих эффект «Мерцания», используют относительное значение эффекта «Мерцания», выраженное в % (Shimmer (%)), и/или абсолютное значение эффекта «Мерцания» (Mean absolute shimmer), и/или стандартное отклонение амплитуды (Standard deviation of Amp contour), и/или фактор возмущения амплитуды (Amplitude Perturbation Factor), и/или значение эффекта «Мерцания», выраженное в децибелах (Shimmer (dB)), и/или колебания амплитуды относительно среднего (Amplitude Relative Average Perturbation), и/или коэффициент колебания амплитуды (Amplitude Perturbation Quotient), и/или сглаженный коэффициент колебания амплитуды (Smoothed Amplitude Perturbation Quotient).
27. Способ по п.8, характеризующийся тем, что в качестве параметров, характеризующих уровень шума на интервалах основного тона, используют параметр, характеризующий уровень турбулентного шума на периоде основного тона (Turbulent noise index (TNI)), и/или параметр, характеризующий степень схлопывания голосовых складок (Soft phonation index (SPI)), и/или показатель уровня шума относительно уровня вокализированной компоненты (Voice turbulence index (VTI)), и/или отношение гармонической компоненты сигнала к негармонической компоненте (Harmonic to Noise Ratio (HNR)), и/или отношение энергии возбуждения к энергии шума (Glottal to Noise Excitation Ratio (GNER)).
28. Способ по п.8, характеризующийся тем, что дополнительно в качестве параметров используют уровень турбулентного шума (Glottal to Noise Distribution Ratio), который определяют следующим образом: на вход подают сигнал в формате импульсно-кодовой модуляции, «Моно», с частотой дискретизации 16 кГц, у которого определяют трек частоты основного тона, после этого производят обратную фильтрацию входного сигнала (вычисление сигнала остатка), затем производят вычисление кохлеарного спектра сигнала остатка, осуществляют взвешивание спектральной энергии сигнала остатка в диапазоне от 1,5 кГц до 2 кГц с использованием средней энергии в данном диапазоне частот, затем осуществляют взвешивание спектральной энергии сигнала остатка в диапазоне частоты основного тона с использованием средней энергии в диапазоне от минимальной частоты основного тона до максимальной частоты основного тона, по итогам полученных значений определяют отношение взвешенных энергий и получают распределение энергетического отношения посредством построения гистограммы.
29. Способ по п.8, характеризующийся тем, что для определения параметров, характеризующих нелинейность голосового сигнала, используют метод энтропии Шеннона, и/или метод энтропии Ренье, и/или значение первого минимума информационной функции (Value of First Minimum of Mutual Information Function), и/или показатель периодичности сигнала (Recurrent period density entropy); и/или показатель, получаемый в результате анализа сигнала с исключением внутреннего тренда (Detrendcd Fluctuation Analysis), и/или показатель, получаемый в результате анализа сигнала методом Теккен-Трейлера (Taken's Estimator), и/или показатель, получаемый в результате эмпирической декомпозиции сигнала на уровни (Empirical Mode Decomposition Kxcitalions Ratios).
30. Способ по п.8, характеризующийся тем, что для определения физиологических свойств голосовых складок используют параметры, характеризующие массу и жесткость в одномассовой модели голосовых складок, коэффициент открытия голосовой щели (Glottis Quotient) и/или показатель возбуждения голосовых складок (Vocal Fold Excitation Ratios).
| US20120220899 A1, 30.08.2012 | |||
| US20080300867 A1, 04.12.2008 | |||
| WO2008054162 A1, 08.05.2008 | |||
| СПОСОБ ИССЛЕДОВАНИЯ ФУНКЦИОНАЛЬНОГО СОСТОЯНИЯ ГОЛОСОВЫХ СКЛАДОК | 2006 |
|
RU2313280C1 |

