Область техники, к которой относится изобретение
Настоящее изобретение относится к устройству обработки данных, способу управления устройством обработки данных и программе, которые сконфигурированы для установки имени документа для данных электронного документа, генерируемых при считывании исходного документа.
Уровень техники
До настоящего времени известен способ выполнения обработки распознавания символов (далее в этом документе называемый "OCR (Optical Character Recognition, Оптическое распознавание символов)") над данными электронного документа, генерируемыми при сканировании в устройстве обработки данных, например в цифровом многофункциональном периферийном устройстве (MFP) или в сканере. Кроме того, общеизвестным является способ установки строки символов, извлеченной при выполнении OCR, в качестве имени документа данных документа (см. PTL 1). Кроме того, известным является способ обеспечения возможности пользователю до выполнения OCR задавать тип языка (например, Японский, Английский и т.д., далее в этом документе называемый "тип языка") и выполнения OCR с использованием заданного типа языка. При выполнении OCR с использованием заданного типа языка точность распознавания символов во время OCR может быть увеличена.
Согласно другому примеру предшествующего уровня техники, в случае когда данные электронного документа, генерируемые при сканировании, отправлены по заданному адресу назначения, имя документа отправленных данных документа может быть отображено на экране "предыстория отправки" вместе с такими элементами, как отправитель и дата и время отправки. Такая практика отображения имени документа, установленного для данных документа, на цифровом MFP является обычной. В случае отображения символов имени документа и т.п. на цифровом MFP, символы обычно отображаются на типе языка, который был установлен с использованием установки типа языка в операционном блоке цифрового MFP.
Список литературы
Патентная литература
PTL 1: Выложенный японский патент № 9-134406
Сущность изобретения
Техническая задача
Имя документа данных документа, причем это имя документа является строкой символов, извлеченной посредством OCR и установленной в качестве имени документа с использованием способа согласно PTL 1, может быть отображено на цифровом MFP, как описано выше. Примером такого случая является отображение имени документа отправленных данных документа на экране "предыстория отправки". В этом случае коды символов, назначаемые символам, распознаваемым посредством OCR, в заданном типе языка, могут не быть назначены схеме кодирования символов типа языка, который установлен в установке типа языка в операционном блоке цифрового MFP.
Например, предположим случай, когда типом языка, заданным до выполнения OCR, является "Японский", и типом языка, установленным в установке типа языка в операционном блоке цифрового MFP является "Английский". В этом случае коды символов, извлеченных посредством OCR с типом языка Японский, включают в себя коды, которые не назначены схеме кодирования символов Английского языка (например, Windows-1252). Соответственно, когда пользователь пытается отобразить установленное имя документа на типе языка Английский на цифровом MFP, может иметь место искажение символов.
Искажение символов также имеет место, когда код символа, распознанного в заданном типе языка, является назначенным другому символу в схеме кодирования символов типа языка, установленного в установке типа языка в операционном блоке цифрового MFP.
Целью настоящего изобретения является обеспечение, ввиду вышеописанных проблем, средства для выполнения адекватной обработки, когда код символа, распознаваемого при обработке распознавания символов, не назначается схеме кодирования символов типа языка, который является установленным в установке типа языка в операционном блоке.
Решение задачи
Для достижения вышеописанной цели устройство обработки данных согласно настоящему изобретению включает в себя средство ввода для ввода данных документа, средство распознавания символов для выполнения над данными документа, введенными упомянутым средством ввода, распознавания символов с использованием заданного типа языка, средство установки имени документа для установки, в качестве, по меньшей мере, части имени документа данных документа, введенных упомянутым средством ввода, строки символов, распознанной упомянутым средством распознавания символов, средство отображения для отображения на операционном блоке имени документа, установленного упомянутым средством установки имени документа, и средство управления для предотвращения отображения упомянутым средством отображения имени документа, включающего в себя строку символов, установленную упомянутым средством установки имени документа, когда схема кодирования символов, задаваемая в случае, когда распознавание символов выполняется упомянутым средством распознавания символов, является схемой кодирования символов, несовместимой со схемой кодирования символов типа языка, который установлен в установке типа языка в операционном блоке.
Полезный эффект от изобретения
Согласно настоящему изобретению может быть предотвращено искажение символов, которое может иметь место, когда имя документа, состоящее из строки символов, полученной посредством распознавания символов в заданном типе языка, отображается на средстве отображения.
Краткое описание чертежей
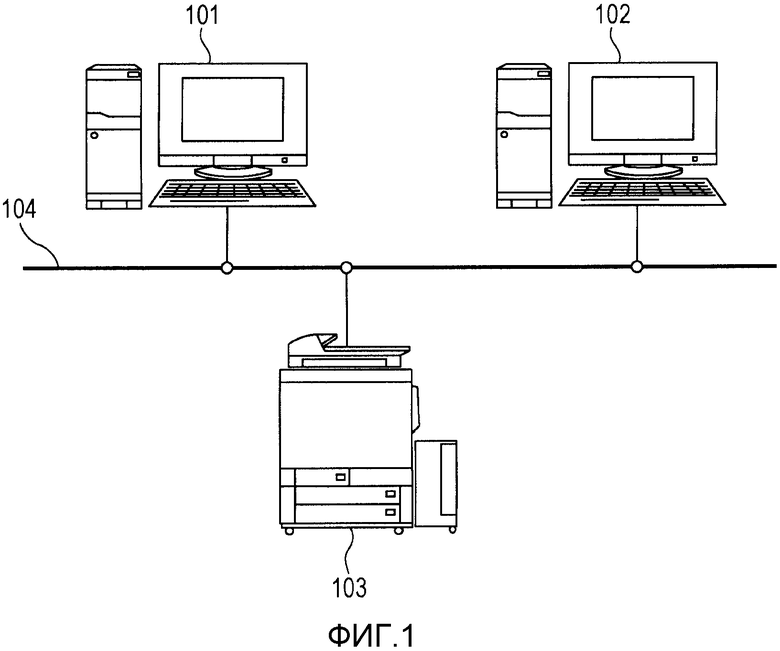
Фиг.1 - схема конфигурации системы, включающей в себя цифровое MFP, которое является примером устройства обработки данных.
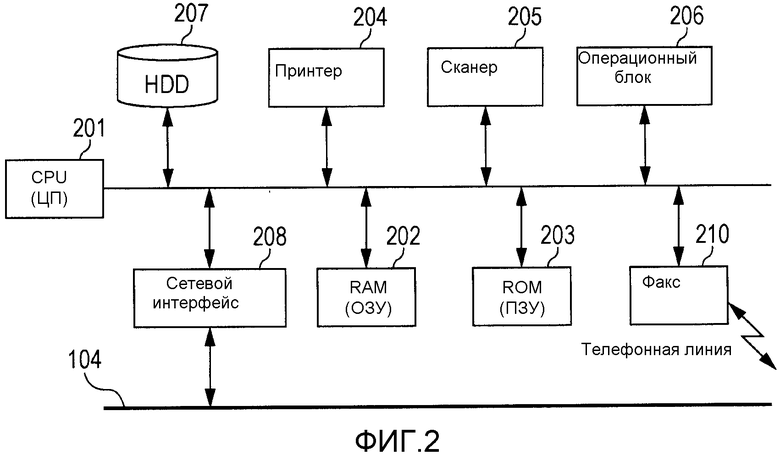
Фиг.2 - схема, иллюстрирующая конфигурацию аппаратного обеспечения цифрового MFP, изображенного на фиг.1.
Фиг.3 - схема, иллюстрирующая пример экрана для установки отправки, отображаемого на операционном блоке цифрового MFP, изображенного на фиг.1.
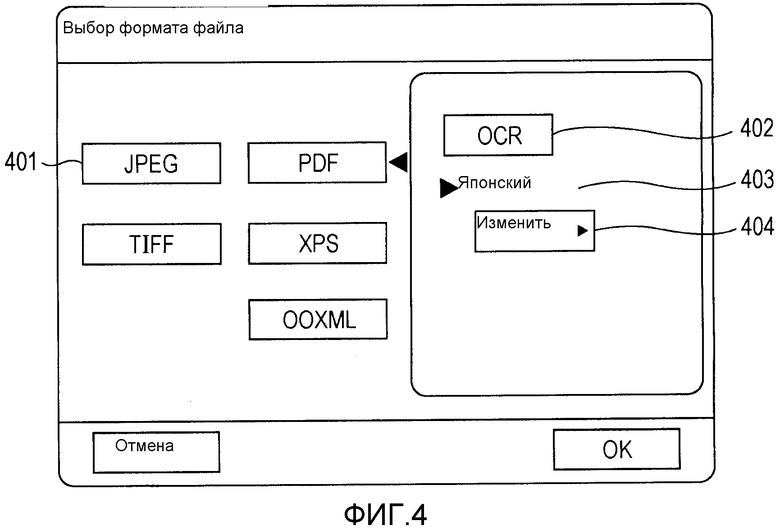
Фиг.4 - схема, иллюстрирующая пример экрана, используемого для выбора формата файла данных документа, которые должны быть отправлены.
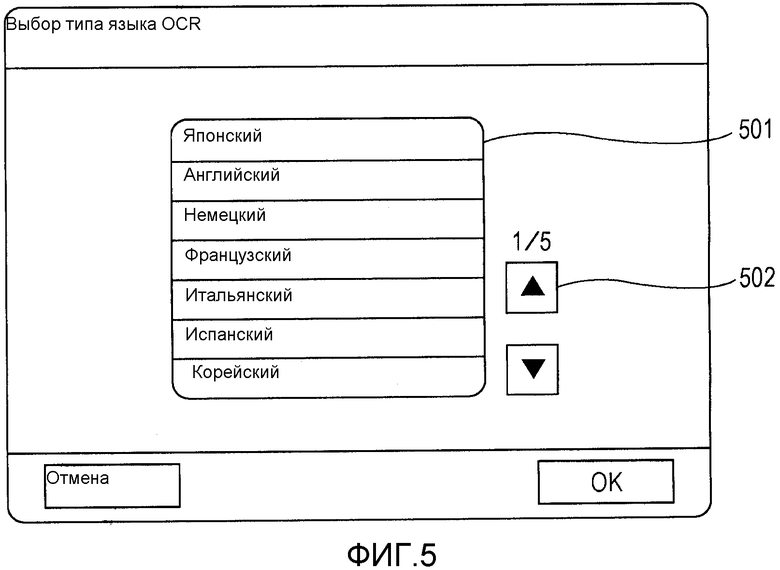
Фиг.5 - схема, иллюстрирующая пример экрана, используемого для выбора типа языка, который задается в случае выполнения OCR имени документа.
Фиг.6 включает в себя схемы, схематично изображающие соответствие между типами языка, которые устанавливаются в установке типа языка в операционном блоке, и схемами кодирования символов, и соответствие между типами языка, задаваемыми как исходное значение в случае выполнения OCR имени документа, и схемами кодирования символов.
Фиг.7 - блок-схема последовательности операций, иллюстрирующая процесс, исполняемый цифровым MFP, изображенным на фиг.1, после нажатия на кнопку "отправить" на экране для установки отправки, изображенном на фиг.3.
Фиг.8 - схема изображения, на которой изображена строка символов, распознанная во время OCR имени документа.
Фиг.9 - схема, иллюстрирующая пример экрана "предыстория отправки", отображаемого после нажатия на кнопку "предыстория отправки" на экране для установки отправки, изображенном на фиг.3.
Фиг.10 - схема, на которой изображена детализация экрана "предыстория отправки", изображенного на фиг.9.
Фиг.11 - блок-схема последовательности операций, подробно описывающая этап S711, изображенный на фиг.7, в первом варианте осуществления.
Фиг.12 - блок-схема последовательности операций, подробно описывающая этап S711, изображенный на фиг.7, во втором варианте осуществления.
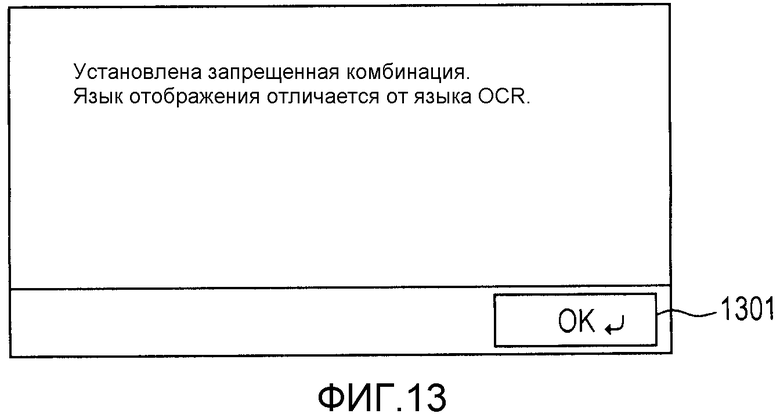
Фиг.13 - схема, иллюстрирующая пример экрана с предупреждением, отображаемого тогда, когда схема кодирования символов типа языка, который установлен в установке типа языка в операционном блоке, отличается от схемы кодирования символов типа языка в случае, когда выполняется OCR.
Описание вариантов осуществления
Далее в этом документе со ссылкой на чертежи описываются варианты осуществления настоящего изобретения.
Первый вариант осуществления
Фиг.1 является схемой, иллюстрирующей конфигурацию всей системы согласно этому варианту осуществления. В этой системе цифровое MFP 103, которое является примером устройства обработки данных, сервер 101 совместного использования файлов и почтовый сервер 102, которые являются примерами внешнего устройства, являются связанными друг с другом через сеть 104. Цифровой MFP 103 имеет различные функции обработки изображения, например функцию считывания изображения, функцию отправки изображения и функцию формирования (печати) изображения. Сервер 101 совместного использования файлов является компьютером, функционирующим как файловый сервер, который управляет файлами в сети 104 согласно протоколу совместного использования файлов, например SMB или WebDAV. Почтовый сервер 102 является компьютером, который отправляет и принимает почту согласно протоколу электронной почты, например SMTP или POP.
В этом варианте осуществления приведено описание примера, в котором данные электронного документа, генерируемые при сканировании оригинального документа с использованием цифрового MFP 103, отправляют в виде файла на сервер 101 совместного использования файлов согласно протоколу, например SMB, или отправляют на почтовый сервер 102 посредством присоединения к электронной почте.
Фиг.2 является схемой, иллюстрирующей конфигурацию аппаратного обеспечения цифрового MFP 103, изображенного на фиг.1. Цифровое MFP 103 включает в себя CPU (ЦП) 201, который управляет всем устройством, и RAM (ОЗУ) 202, которое обеспечивает рабочую область для CPU 201. Системные программы и прикладные программы хранятся в ROM (ПЗУ) 203. Приложения, хранящиеся в ROM 203, включают в себя приложение для выполнения OCR на данных документа, введенных через сканер 205, и извлечения строки символов.
Кроме того, цифровое MFP 103 включает в себя сканер 205, который считывает изображение исходного документа, и принтер 204, который печатает изображение на основе данных документа, введенных из сканера 205, или данных, введенных через сетевой интерфейс 208. Кроме того, цифровое MFP 103 включает в себя HDD 207, на котором хранятся данные, различные параметры установки и данные документа. Кроме того, цифровое MFP 103 включает в себя операционный блок 206 (сенсорную панель и т.п.), в котором устройство ввода для приема операции от пользователя и устройство отображения для отображения экрана для операции, отображаемого для обеспечения возможности функционирования устройства ввода, являются объединенными. Экран для операции, отображаемый на операционном блоке 206, отображается на основе данных экрана для операции, хранящихся в ROM 203. Данные экрана для операции хранятся в ROM 203 или HDD 207 в блоках типов языка, описанных ниже. Когда пользователь выбирает любой из типов языка через операционный блок 206, данные экрана для операции, соответствующие типу языка, считываются и отображаются на операционном блоке 206.
Кроме того, цифровое MFP 103 включает в себя сетевой интерфейс 208, который выполняет сетевую связь с сервером 101 совместного использования файлов, почтовым сервером 102 и другими внешними устройствами.
Фиг.3 является схемой, иллюстрирующей пример экрана для установки отправки, отображаемого на операционном блоке 206, изображенном на фиг.2. В результате обеспечения команды для считывания исходного документа и для отправки данных документа с использованием экрана для установки отправки, изображенного на фиг.3, цифровое MFP 103 отправляет данные электронного документа, сгенерированные посредством сканирования сканером 205, на сервер 101 совместного использования файлов и т.п. через сеть 104.
После нажатия кнопки 302 "адресная книга", данные адресной книги, хранящиеся в HDD 207, считываются и выбираются, и затем на экране 301 "адрес назначения" отображаются адреса назначения для данных документа. При выборе любого из "факс", "файл" и "электронная почта" с использованием кнопки 303 "новый адрес назначения" и произвольном вводе адреса назначения с использованием операционного блока 206 пользователь может отправлять данные документа даже по адресу назначения, включенному в данные адресной книги, которые не хранятся в HDD 207. Адрес назначения, который устанавливают при нажатии на кнопку 303 "новый адрес назначения", отображается на экране 301 "адрес назначения", как и в случае, когда установка выполняется с использованием кнопки 302 "адресная книга".
Кнопка 304 установки разрешения обеспечивает возможность установки разрешения (например, 200 точек на дюйм) для документа, который должен быть отсканирован.
После нажатия на «OCR 306 имени документа» (также называемое OCR названия) установка OCR имени документа становится активной. После того как установка стала активной, цифровое MFP 103 выполняет OCR (Оптическое распознавание символов) в отношении данных электронного документа, сгенерированных посредством сканирования. Далее цифровое MFP 103 извлекает строку символов из данных документа и устанавливает имя документа, включающее в себя извлеченную строку символов, для данных документа.
Нажатие на кнопку 305 "формат файла" вызывает отображение экрана для выбора формата файла, изображенного на фиг.4.
На фиг.4 изображен экран, который отображается после нажатия на кнопку 305 "формат файла", изображенную на фиг.3, и который используется для выбора формата файла данных документа. Может быть выбран один из форматов файла, перечисленных в «формате файла» 401 (JPEG, TIFF, PDF, XPS и OOXML). После нажатия на кнопку OK на экране, изображенном на фиг.4, установленное значение сохраняется в RAM 202. После нажатия на кнопку "отмена" установленное значение становится недействительным.
Когда в «формате файла» 401 выбирается формат файла, совместимый с OCR, то есть любой формат файла из PDF, XPS и OOXML, отображается всплывающий экран, изображенный на правой стороне экрана, изображенного на фиг.4. На всплывающем экране отображаются кнопка 402 установки OCR для установки того, должно ли выполняться OCR (распознавание символов), тип 403 языка OCR, указывающий тип языка (тип языка), используемого во время OCR, и кнопка 404 "изменить" для изменения типа 403 языка OCR. После нажатия на кнопку 402 установки OCR выполняется OCR с типом языка, отображенным в типе 403 языка OCR, в отношении данных электронного документа, сгенерированных посредством сканирования. В этом варианте осуществления в типе 403 языка OCR в качестве исходного значения устанавливается тип языка, идентичный типу языка, который установлен в установке типа языка в операционном блоке 206. В примере, иллюстрированном на фиг.4, типом языка, который установлен в установке типа языка в операционном блоке 206, является Английский. Соответственно, в типе 403 языка OCR в качестве исходного значения также устанавливается Английский. Однако тип языка, который установлен в установке типа языка в операционном блоке 206, не всегда может быть установлен как тип языка для OCR. В случае типа языка, который может быть установлен как тип языка, установленный в установке типа языка в операционном блоке 206, но который не может быть установлен как язык OCR, в качестве исходного значения типа языка для OCR устанавливается другой тип языка.
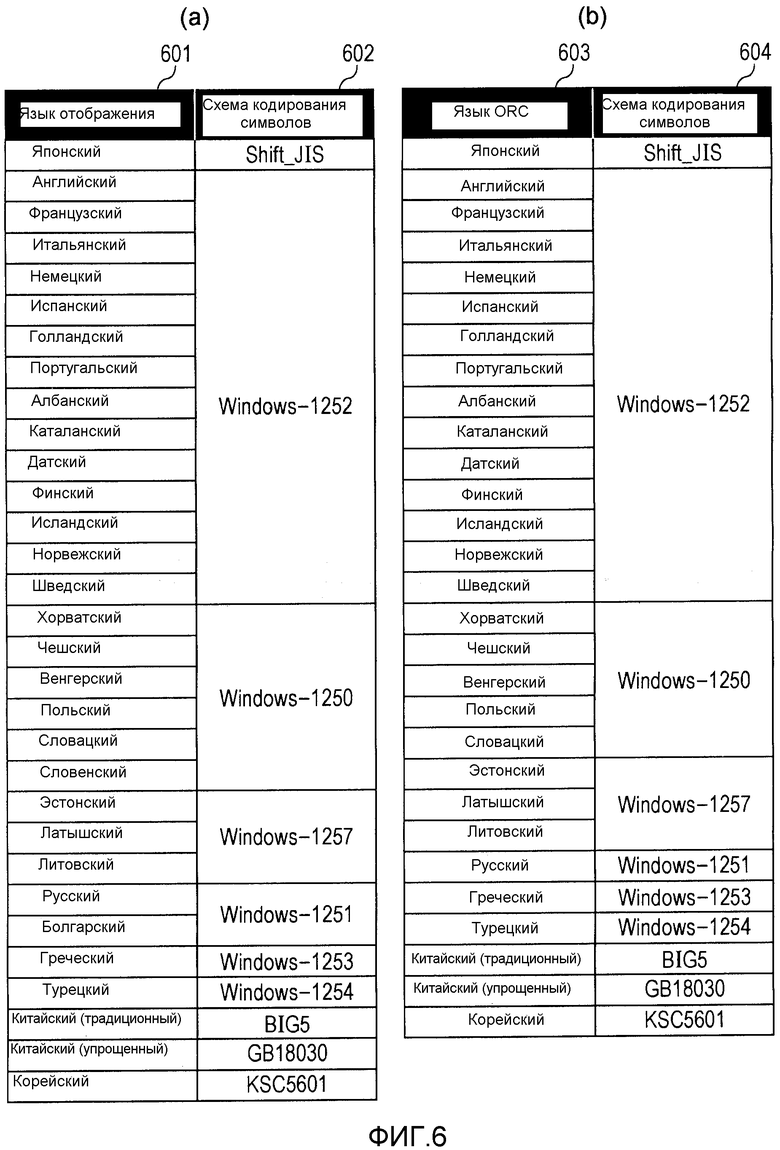
На фиг.6 схематично изображено соответствие между типами языка и схемами кодирования символов типов языка. Информация об отдельных записях, изображенных на фиг.6, хранится в HDD 207.
На фиг.6(a) изображено соответствие между типом языка, используемым для отображения на экране операционного блока 206 (далее в этом документе называемым "тип 601 языка отображения"), и схемой 602 кодирования символов типа 601 языка отображения. На фиг.6(b) изображено соответствие между языком, заданным до выполнения OCR (далее в этом документе называемым "тип 603 языка OCR"), и схемой 604 кодирования символов типа 603 языка OCR. Тип 601 языка отображения является типом языка, который может быть отображен на операционном блоке 206 цифровым MFP 103. На операционном блоке 206 отображается экран согласно типу языка, который устанавливается пользователем из списка типа 601 языка отображения на экране установки типа языка, который не изображен. Иллюстративные экраны по фиг.3-5 являются экранами установки типа языка, которые не изображены, на которых в качестве типа языка отображения установлен "Японский".
Когда тип 601 языка отображения установлен на "Японский", типом 603 языка OCR, устанавливаемым как исходное значение, является "Японский". Когда тип 601 языка отображения установлен на "Английский", типом 603 языка OCR, устанавливаемым как исходное значение, является "Английский".
Возвращаясь к фиг.4, с использованием кнопки 404 "изменить" тип 403 языка OCR, установленный как исходное значение на фиг.4, может быть изменен. Нажатие на кнопку 404 "изменить" вызывает отображение экрана, изображенного на фиг.5.
На фиг.5 иллюстрируется пример экрана, используемого для выбора типа языка OCR. Из HDD 207 считывается список типов языка OCR, совместимых с цифровым MFP 103, и отображается в поле 501. Когда пользователь выбирает требуемый тип языка в качестве типа языка OCR и нажимает на кнопку OK, цифровое MFP 103 сохраняет значение, установленное на экране, изображенном на фиг.5, в RAM 202.
После того как на экранах, изображенных на фиг.3-5, были выполнены вышеописанные установки и была нажата кнопка 307 "отправить", изображенная на фиг.3, запускается процесс по блок-схеме последовательности операций, изображенной на фиг.7, и цифровое MFP 103 отправляет данные документа согласно вышеописанным установкам.
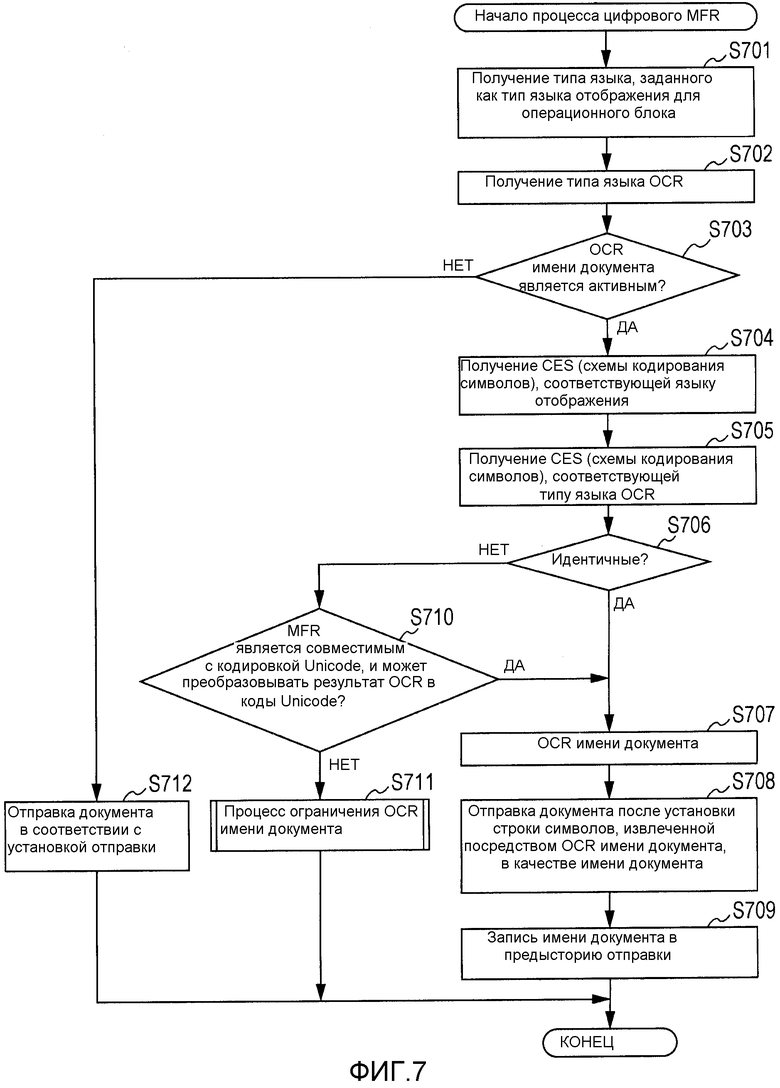
Фиг.7 является блок-схемой последовательности операций, иллюстрирующей процесс цифрового MFP 103 согласно этому варианту осуществления. Программа для исполнения отдельных этапов в блок-схеме последовательности операций, изображенной на фиг.7, хранится в HDD 207. Эта программа загружается в RAM 202 и исполняется CPU 201.
На этапе S701 CPU 201 получает тип языка отображения, заданный как тип языка отображения для операционного блока 206. Например, когда отображаются экраны, изображенные на фиг.3-5 (экраны, на которых символы отображаются на английском языке), получают информацию об "английском языке" как о типе языка отображения.
Если выполнена такая установка, что в отношении данных документа должно быть выполнено OCR, то на этапе S702 получают задание типа языка OCR. Например, если в типе 403 языка OCR задано "Японский", как на экране, изображенном на фиг.4, то в качестве типа языка OCR получают "Японский". В случае выполнения OCR, OCR выполняется с использованием типа языка, полученного на этапе S702. Соответственно, точность распознавания символов может быть увеличена по сравнению со случаем, когда до выполнения OCR тип языка не задается.
На этапе S703 CPU 201 определяет, должна ли строка символов, распознанная в OCR, быть установлена как имя документа (должно ли быть выполнено OCR имени документа). А именно, если установка OCR 306 имени документа по фиг.3 установлена на ON (ВКЛ) и если установка OCR (распознавание символов) по фиг.4 установлена на ВКЛ, то CPU 201 определяет выполнение OCR имени документа. Если установка OCR 306 имени документа установлена на OFF (ВЫКЛ) или если установка OCR 306 имени документа установлена на ВКЛ и установка кнопки 402 установки OCR установлена на ВЫКЛ, то CPU 201 определяет невыполнение OCR имени документа. Если CPU 201 определяет невыполнение OCR имени документа (НЕТ на этапе S703), то процесс переходит к этапу S712, и выполняется обычная обработка отправки. Если CPU 201 определяет выполнение OCR имени документа (ДА на этапе S703), то процесс переходит к этапу S704.
На этапе S704 CPU 201 получает из таблицы, изображенной на фиг.6(a), схему кодирования символов, соответствующую типу языка отображения, принятому на этапе S701. Например, если в качестве типа языка отображения установлено "Английский", как на экранах, изображенных на фиг.3-5, то CPU 201 получает из таблицы, изображенной на фиг.6(a), схему Windows 1252 кодирования символов.
На этапе S705 CPU 201 получает из таблицы, изображенной на фиг.6(b), схему кодирования символов типа языка, заданного как тип 403 языка OCR. Например, если в качестве типа языка OCR задано "Японский", как на экране, изображенном на фиг.4, то CPU 201 получает из таблицы, изображенной на фиг.6(b), схему Shift_JIS кодирования символов.
На этапе S706 CPU 201 сравнивает схему кодирования символов (также называемую схемой кодирования), полученную на этапе S704, со схемой кодирования символов, полученной на этапе S705, и определяет, являются ли обе схемы кодирования символов идентичными. Если на этапе S706 определено, что эти схемы кодирования символов являются идентичными (ДА на этапе S706), то CPU 201 выполняет OCR в отношении данных документа (S707). После этого CPU 201 устанавливает, в качестве имени документа часть строки символов, извлеченной в результате OCR, для данных документа и отправляет данные документа в устройство, указанное адресом назначения (S708).
На этапе S706 схема кодирования символов типа языка отображения и схема кодирования символов типа языка OCR не обязательно должны быть полностью идентичными. На этапе S706 может быть выполнено определение "ДА", если схема кодирования символов типа языка OCR и схема кодирования символов типа языка отображения являются совместимыми друг с другом. Например, символ, описанный в коде ASCII, может быть правильно отображен без искажения символов, даже когда этот символ отображается с использованием схемы Shift_JIS кодирования символов. Соответственно, ASCII является схемой кодирования символов, которая является совместимой с Shift_JIS.
На этапе S706 схема кодирования символов типа языка отображения сравнивается со схемой кодирования символов типа языка OCR. Однако для выполнения более упрощенного управления, вместо сравнения схем кодирования символов могут сравниваться друг с другом типы языка. В случае сравнения друг с другом типов языка, когда типом языка отображения является "Английский" и типом языка OCR является "Французский", например, на этапе S706 выполняется определение "НЕТ", несмотря на то, что обе схемы кодирования символов являются идентичными (Windows 1252), и выполняется процесс ограничения OCR имени документа. С выполнением более упрощенного процесса сравнения может быть предотвращено искажение символов в результате сравнения типа языка отображения с типом языка OCR.
На этапе S709 CPU 201 записывает имя документа, установленное на этапе S708, в HDD 207, причем это имя документа используется как часть информации предыстории отправки.
На фиг.8 иллюстрируется изображение исходного документа, на котором напечатана строка символов, которая должна быть извлечена, когда на этапе S707 выполняется OCR имени документа.
После того как в результате OCR извлекается строка символов, находящаяся в области 801, изображенной на фиг.8, для данных документа, полученных посредством сканирования, устанавливается имя документа "СОВЕЩАНИЕ", и данные документа отправляются. Кроме того, когда отображаются экраны "предыстория отправки", изображенные на фиг.9 и фиг.10, которые будут описаны ниже, отображается строка символов "ИМЯ ДОКУМЕНТА: СОВЕЩАНИЕ".
На фиг.9 иллюстрируется пример экрана "предыстория отправки". Экран, изображенный на фиг.9, отображается после нажатия на кнопку 308 "предыстория отправки", изображенную на фиг.3. При нажатии на "подробная информация" 902 после выбора одного элемента из списка 901 в предыстории отправки отображается подробная информация предыстории отправки, изображенная на фиг.10. Элементы 1001, которые могут быть отображены как подробная информация предыстории отправки, включают в себя время начала отправки, время окончания отправки, адрес назначения, имя документа и объем отправляемой информации. На фиг.10 изображена подробная информация предыстории отправки о процессе отправки данных документа, на которых выполняется OCR имени документа, когда сканируется изображение исходного документа, изображенное на фиг.8.
Этап S710 является процессом, который выполняется, если на этапе S706 определено, что схема кодирования символов типа языка отображения отличается от схемы кодирования символов типа 403 языка OCR. На этапе S710 CPU 201 определяет то, может ли цифровое MFP 103 отображать символы на операционном блоке 206 с использованием кодов символов, совместимых с кодировкой Unicode, и преобразовывать результат OCR в коды символов, совместимые с кодировкой Unicode. Если CPU 201 определяет, что цифровое MFP 103 может отображать символы на операционном блоке 206 с использованием кодов символов, совместимых с кодировкой Unicode, и преобразовывать результат OCR в коды символов, совместимые с кодировкой Unicode (ДА на этапе S710), то процесс переходит к этапу S707. Если CPU 201 определяет, что цифровое MFP 103 не может отображать символы, совместимые с кодировкой Unicode, на операционном блоке 206, или не может преобразовывать результат OCR в коды символов, совместимые с кодировкой Unicode (НЕТ на этапе S710), то на этапе S711 процесс переходит к процессу ограничения OCR имени документа.
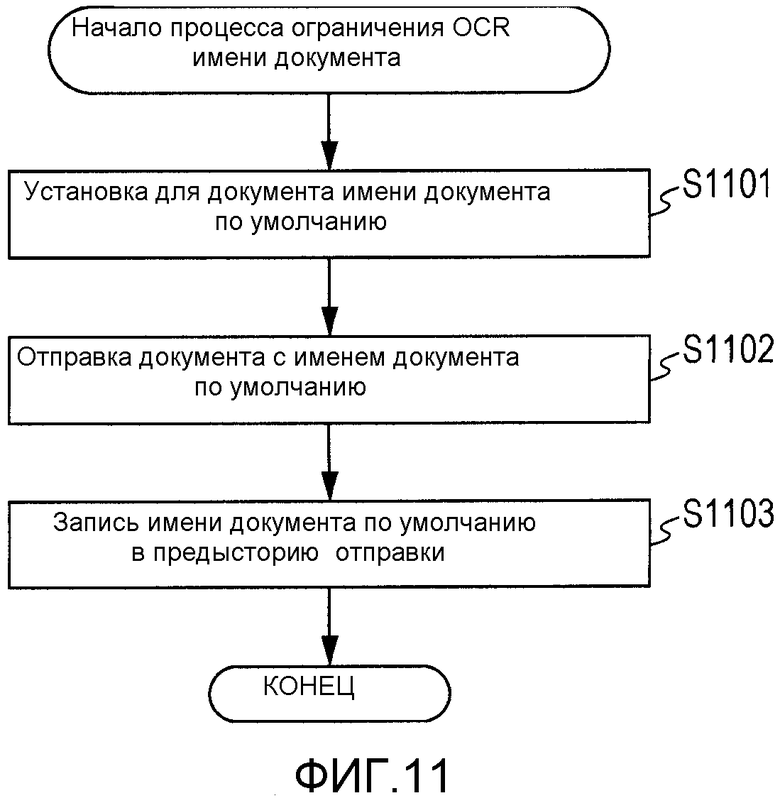
Со ссылкой на фиг.11 подробно описывается процесс, выполняемый на этапе S711.
Фиг.11 является блок-схемой последовательности операций, подробно иллюстрирующей процесс, выполняемый на этапе S711 по фиг.7. На этапе S1101 CPU 201 выполняет OCR в отношении данных электронного документа, полученных посредством сканирования, но не устанавливает строку символов, распознанную во время OCR, в качестве имени документа. Для документа в качестве имени документа устанавливается имя документа по умолчанию (то есть имя документа, которое устанавливается, когда OCR имени документа устанавливается на "ВЫКЛ."). Далее, на этапе S1102, CPU 201 отправляет данные документа, для которых было установлено имя документа по умолчанию. После этого, на этапе S1103, CPU 201 записывает в HDD 207 имя документа по умолчанию как предысторию отправки и завершает процесс по этой блок-схеме последовательности операций. Имя документа по умолчанию является именем документа, которое не вызывает искажение символов и которое устанавливается согласно предопределенному правилу в цифровом MFP 103. В этом варианте осуществления, например, устанавливается имя документа "год, месяц, дата, час, минута и секунда (например, 20101001170023)", описанное в коде ASCII.
В качестве альтернативы, может быть установлено имя документа в схеме кодирования символов, которая установлена в установке типа языка в операционном блоке 206. В этом случае, если в операционном блоке 206 в установке типа языка установлено Английский, то в качестве имени документа устанавливается, например, строка символов согласно схеме Windows 1252 кодирования символов.
В случае отображения предыстории отправки данных документа, отправляемых на этапе S1102, на экране предыстории отправки, изображенном на фиг.10, отправляют данные документа с установкой для них имени документа по умолчанию, вместо установленного для них результата OCR. Соответственно, имя документа, соответствующее схеме кодирования символов, в котором может иметь место искажение символов, не отображается на операционном блоке 206.
Во время установки на этапе S1101 имени документа по умолчанию на операционном блоке 206 может быть отображено предупреждающее сообщение, например, "установка OCR имени документа отменена".
Согласно этому варианту осуществления, когда схема кодирования символов типа языка отображения, который устанавливается на экране установки типа языка (не изображен) операционного блока 206, отличается от схемы кодирования символов типа 403 языка OCR, то OCR имени документа не выполняется, если даже установка OCR имени документа является активной. Соответственно, строка символов, извлеченная в результате OCR, не устанавливается как имя документа. Вместо этого данные документа отправляются с установкой для них имени документа по умолчанию. В результате может быть предотвращено искажение символов имени документа, которое устанавливается для данных документа, которое должно быть отправлено с отображением его на экране "предыстория отправки".
В этом варианте осуществления, на этапе S706 определяется, являются ли схема кодирования символов типа языка отображения и схема кодирования символов типа языка OCR одинаковыми или разными. Однако, согласно модификации, вместо выполнения вышеописанного процесса определения на этапе S706 может быть определено, назначены ли коды символов, распознанных во время OCR имени документа, схеме кодирования символов типа языка отображения, полученной на этапе S704.
В этом варианте осуществления, когда схема кодирования символов, соответствующая типу языка отображения, который используется для отображения экрана на операционном блоке 206, отличается от схемы кодирования символов, соответствующей типу 403 языка OCR, результат OCR не используется как имя документа, а для данных документа устанавливается имя документа по умолчанию. Однако, согласно модификации, результат OCR устанавливается как имя документа, но это установленное имя документа не записывается в предысторию отправки. Соответственно, вышеописанная задача, то есть отображение имени документа, которое может вызывать искажение символов на операционном блоке 206, может быть решена.
Например, на этапе S1101, для данных документа в качестве имени документа устанавливается строка символов, полученная посредством OCR имени документа (а не имя документа по умолчанию). На этапе S1102, отправляются данные документа с именем документа, которое было установлено посредством OCR имени документа. Далее, на этапе S1103, выполняется управление для предотвращения записи в HDD 207 информации об имени документа, которое было установлено посредством OCR имени документа.
Второй вариант осуществления
Согласно первому варианту осуществления, когда схема кодирования символов типа языка отображения отличается от схемы кодирования символов типа языка OCR, OCR имени документа не выполняется, и данные документа отправляются после установки для них имени документа по умолчанию. Согласно второму варианту осуществления, отправка данных документа не выполняется, посредством чего предотвращается отправка данных документа, для которых имя документа было установлено не в соответствии с командой, обеспеченной пользователем.
Второй вариант осуществления совпадает с вышеописанным первым вариантом осуществления в отношении фиг.1-7, и, соответственно, их описание опущено.
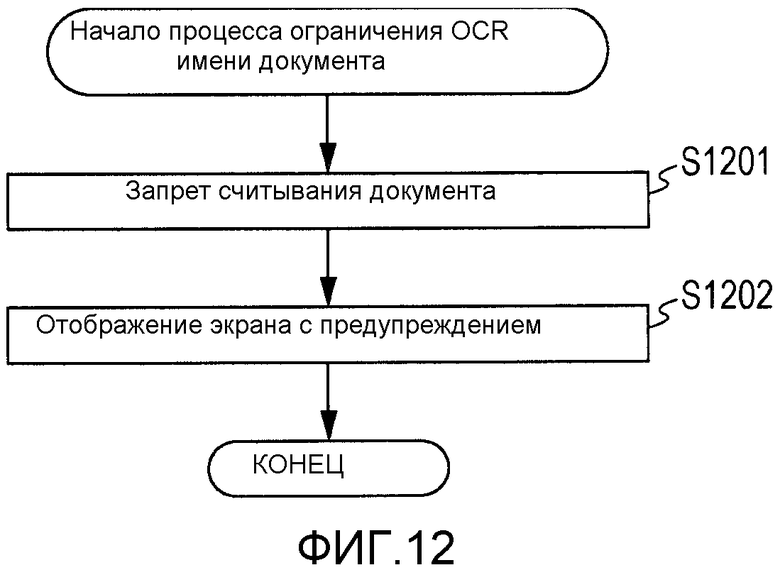
Фиг.12 является блок-схемой последовательности операций, подробно описывающей этап S711 по фиг.7 согласно второму варианту осуществления.
На этапе S1201, CPU 201 прекращает процесс считывания на основе установок, принятых на экранах, изображенных на фиг.3-5. На этапе S1202, CPU 201 отображает экран с предупреждением, изображенный на фиг.13, на операционном блоке 206. В результате, CPU выполняет управление для предотвращения исполнения процесса отправки, если даже нажата кнопка 307 "отправить".
Согласно этому варианту осуществления, когда схема кодирования символов типа языка отображения отличается от схемы кодирования символов типа языка OCR, исполнение процесса отправки данных документа запрещается. Соответственно, может быть предотвращено отображение искаженного имени документа на экране предыстории отправки, а также может быть предотвращена отправка данных документа с именем документа, которое было установлено не в соответствии с командой, обеспеченной пользователем. Кроме того, для уведомления пользователя об упомянутом факте может отображаться экран с предупреждением.
Другие варианты осуществления
Настоящее изобретение также может быть реализовано посредством выполнения следующего процесса, то есть процесса доставки программного обеспечения (программы), которое реализует функции вышеописанных вариантов осуществления, в систему или устройство через сеть или различные типы носителей информации, и считывания и исполнения упомянутой программы компьютером (или CPU, MPU и т.п.) упомянутой системы или упомянутого устройства.
Настоящее изобретение не ограничивается вышеописанными вариантами осуществления, и могут быть сделаны различные изменения и модификации, не отходя от существа и объема настоящего изобретения. Соответственно, для раскрытия объема настоящего изобретения прилагается нижеследующая Формула изобретения.
Список ссылочных позиций
101 сервер совместного использования файлов
102 почтовый сервер
103 цифровое MFP
201 CPU (ЦП)
202 RAM (ОЗУ)
203 ROM(ПЗУ)
204 принтер
205 сканер
206 операционный блок
208 сетевой интерфейс



Изобретение относится к устройству обработки данных, способу управления таким устройством и машиночитаемому носителю информации. Техническим результатом является предотвращение неправильного отображения на экране имени документа, когда язык для отображения и язык распознавания, используемый во время распознавания для имени документа, установлены разными. Изобретение отличается наличием: средства установки имени документа для установки имени документа, которое включает в себя строку символов, которая распознается на основе данных документа, для данных документа, которые генерируются средством считывания, и средства управления для управления тем, как средство установки имени документа устанавливает имя документа, если язык, задаваемый средством задания языка распознавания символов, и язык, задаваемый средством задания языка отображения, являются разными. 3 н. и 8 з.п. ф-лы, 13 ил.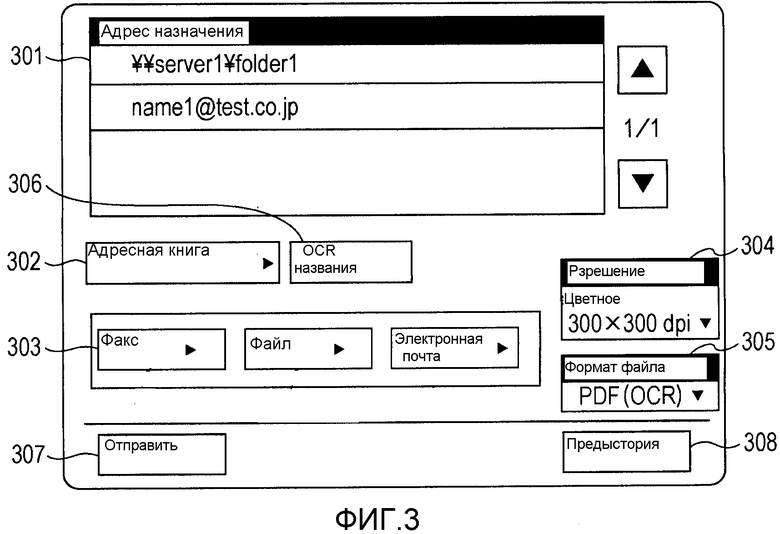
1. Устройство обработки данных, содержащее:
средство ввода для ввода данных документа,
средство распознавания символов для выполнения в отношении
данных документа, введенных упомянутым средством ввода, распознавания символов на основе первого типа языка,
средство установки имени документа для установки имени документа, включающего в себя строку символов, распознанную упомянутым средством распознавания символов, для данных документа, введенных упомянутым средством ввода,
средство отображения для отображения имени документа, установленного упомянутым средством установки имени документа, в соответствии со вторым типом языка, и
средство управления для предотвращения отображения упомянутым средством отображения имени документа, включающего в себя строку символов, установленную упомянутым средством установки имени документа, когда коды символов первого типа языка являются несовместимыми с кодами символов второго типа языка.
2. Устройство обработки данных по п. 1, в котором средство управления запрещает средству установки имени документа устанавливать имя документа, включающее в себя упомянутую строку символов, посредством чего предотвращается отображение имени документа, включающего в себя упомянутую строку символов.
3. Устройство обработки данных по п. 1, в котором средство управления выполняет управление так, что средство установки имени документа устанавливает имя документа, включающее в себя строку символов второго типа языка, посредством чего предотвращается отображение упомянутым средством отображения имени документа, включающего в себя строку символов, распознанную упомянутым средством распознавания символов.
4. Устройство обработки данных по п. 1, в котором средство управления выполняет управление так, что средство установки имени документа устанавливает имя документа в коде ASCII, посредством чего предотвращается отображение упомянутым средством отображения имени документа, включающего в себя строку символов, распознанную упомянутым средством распознавания символов.
5. Устройство обработки данных по п. 1, дополнительно содержащее средство отправки для отправки данных документа, введенных упомянутым средством ввода, во внешнее устройство.
6. Устройство обработки данных по п. 5, в котором средство отображения отображает упомянутое имя документа в предыстории отправки в случае, когда упомянутое средство отправки отправило данные документа.
7. Устройство обработки данных по п. 1, в котором первый тип языка вводится пользователем.
8. Устройство обработки данных по п. 1, в котором средство отображения отображает имя документа, когда коды символов первого типа языка являются совместимыми с кодами символов второго типа языка.
9. Устройство обработки данных по п. 1, в котором средство отображения отображает имя документа, когда первый тип языка является идентичным второму типу языка.
10. Способ управления устройством обработки данных, содержащий:
этап ввода, состоящий из ввода с использованием средства ввода данных документа,
этап распознавания символов, состоящий из выполнения, с использованием средства распознавания символов, в отношении данных документа, введенных упомянутым средством ввода, распознавания символов на основе первого типа языка,
этап установки имени документа, состоящий из установки имени документа, включающего в себя строку символов, распознанную упомянутым средством распознавания символов,
этап отображения, состоящий из отображения имени документа, установленного на этапе установки имени документа, в соответствии со вторым типом языка, и
этап управления, состоящий из предотвращения отображения имени документа, включающего в себя строку символов, установленную на этапе установки имени документа, когда коды символов первого типа языка являются несовместимыми с кодами символов второго типа языка.
11. Машиночитаемый носитель информации, на котором хранится машиночитаемая программа, причем упомянутая программа содержит исполняемые компьютером коды для выполнения способа обработки данных устройством передачи данных, причем этот способ обработки данных содержит:
этап ввода, состоящий из ввода, с использованием средства ввода, данных документа,
этап распознавания символов, состоящий из выполнения, с использованием средства распознавания символов, в отношении данных документа, введенных упомянутым средством ввода, распознавания символов на основе первого типа языка,
этап установки имени документа, состоящий из установки имени документа, включающего в себя строку символов, распознанную упомянутым средством распознавания символов,
этап отображения, состоящий из отображения имени документа, установленного на этапе установки имени документа, в соответствии со вторым типом языка, и
этап управления, состоящий из предотвращения отображения имени документа, включающего в себя строку символов, установленную на этапе установки имени документа, когда коды символов первого типа языка являются несовместимыми с кодами символов второго типа языка.
| EP 0762730 A2, 12.03.1997 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ И СРЕДСТВО ДЛЯ МОБИЛЬНОГО ЗАХВАТА, ОБРАБОТКИ, ХРАНЕНИЯ И ПЕРЕДАЧИ ТЕКСТА И СМЕШАННОЙ ИНФОРМАЦИИ, СОДЕРЖАЩЕЙ ЗНАКИ И ИЗОБРАЖЕНИЯ | 2001 |
|
RU2287183C2 |
| СПОСОБ ВОСПРОИЗВЕДЕНИЯ ИНФОРМАЦИИ, СПОСОБ ВВОДА/ВЫВОДА ИНФОРМАЦИИ, УСТРОЙСТВО ВОСПРОИЗВЕДЕНИЯ ИНФОРМАЦИИ, ПОРТАТИВНОЕ УСТРОЙСТВО ВВОДА/ВЫВОДА ИНФОРМАЦИИ И ЭЛЕКТРОННАЯ ИГРУШКА, В КОТОРОЙ ИСПОЛЬЗОВАН ТОЧЕЧНЫЙ РАСТР | 2003 |
|
RU2349956C2 |

