Изобретение относится к вычислительной технике и может быть использовано при расчетах, связанных с идентификацией текстовой информации в случаях определения ее автора.
Заявителям неизвестно о том, чтобы такая техническая задача решалась подобным образом. Это объясняется тем, что отсутствуют числовые методы содержательного анализа различных частей текстовой информации.
Техническим результатом заявленного решения является повышение уровня достоверности определения авторства текстовой информации и расширение арсенала технических средств. Это дает возможность принимать более объективные решения при защите авторских прав создателей текстовой информации.
Числовой содержательный анализ текстовой информации осуществляется следующим образом. Два отрывка текстовой информации можно сравнить путем сопоставления информации о вероятностях появления какой-либо буквы в двух различных отрывках. Среднее значение разности ΔPср между вероятностью появления i-й буквы отрывка «а» Pаi, и вероятностью появления j-й буквы отрывка «б» Pбj оценивается по следующей формуле:
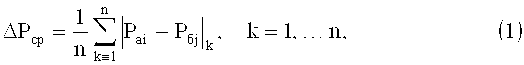
i=1, …, mаi, j=1, …, mбj,
где n - количество букв в алфавите
mаi - количество i-й буквы в отрывке «а»,
mбj - количество j-й буквы в отрывке «б».
Сравнивая величину ΔPср с допустимым значением ΔPд, можно сделать вывод о принадлежности двух отрывков «а» и «б» текстовой информации одному автору. Если ΔPср≤ΔPд, то отрывки «а» и «б» принадлежат одному автору. В противном случае (ΔPср>ΔPд) авторы этих отрывков различны.
Вероятности Pаi, и Pбj определяются по следующим формулам:
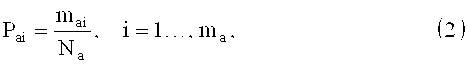
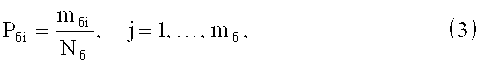
где Nа - общее количество букв в отрывке «а»,
Nб - общее количество букв в отрывке «б».
Для иллюстрации разработанного подхода целесообразно рассмотреть пример. В качестве объектов содержательного анализа можно использовать стихотворения Иосифа Бродского «Одиссей Телемаку» (отрывок «а») и «На смерть Жукова» (отрывок «б»).
Одиссей Телемаку
Мой Телемак,
Троянская война
окончена. Кто победил - не помню.
Должно быть, греки: столько мертвецов
вне дома бросить могут только греки…
И все-таки ведущая домой
дорога оказалась слишком длинной,
как будто Посейдон, пока мы там
теряли время, растянул пространство.
Мне неизвестно, где я нахожусь,
что передо мной. Какой-то грязный остров,
кусты, постройки, хрюканье свиней,
заросший сад, какая-то царица,
трава да камни… Милый Телемак,
все острова похожи друг на друга,
когда так долго странствуешь, и мозг
уже сбивается, считая волны,
глаз, засоренный горизонтом, плачет,
и водяное мясо застит слух.
Не помню я, чем кончилась война,
и сколько лет тебе сейчас, не помню.
Расти большой, мой Телемак, расти.
Лишь боги знают, свидимся ли снова.
Ты и сейчас уже не тот младенец,
перед которым я сдержал быков.
Когда б не Паламед, мы жили вместе.
Но, может быть, и прав он: без меня
ты от страстей Эдиповых избавлен,
и сны твои, мой Телемак, безгрешны.
На смерть Жукова
Вижу колонны замерших внуков,
гроб на лафете, лошади круп.
Ветер сюда не доносит мне звуков
русских военных плачущих труб.
Вижу в регалии убранный труп:
в смерть уезжает пламенный Жуков.
Воин, пред коим многие пали
стены, хоть меч был вражьих тупей,
блеском маневра о Ганнибале
напоминавший средь волжских степей.
Кончивший дни свои глухо, в опале,
как Велизарий или Помпей.
Сколько он пролил крови солдатской
в землю чужую! Что ж, горевал?
Вспомнил ли их, умирающий в штатской
белой кровати? Полный провал.
Что он ответит, встретившись в адской
области с ними? «Я воевал».
К правому делу Жуков десницы
больше уже не приложит в бою.
Спи! У истории русской страницы
хватит для тех, кто в пехотном строю
смело входили в чужие столицы,
но возвращались в страхе в свою.
Анализ этих текстов показывает, что общее количество букв в отрывке «a» Nа=745, a в отрывке «б» Nб=611. Количество букв в русском алфавите n=33. Количество i-й буквы mаi в отрывке «а» и j-й буквы mбj в отрывке «б» приведены в таблице 1, вероятности появления i-й буквы отрезка «а» Pаi, и i-й буквы отрезка «б» Pбj, определяемые по формулам, соответственно (2) и (3), представлены также в таблице 1.
В нижней строке таблицы 1 размещены величины модуля разности |Pаi-Pбj|.
Сумма этих величин равна 0,334, среднее значение разности ΔPср между вероятностью появления i-й буквы отрывка «а» Pаi и вероятностью появления i-й буквы отрывка «б» Pбj оценивается по формуле (1):
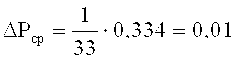
Если принять допустимое значение этой вероятности ΔPд=0,02, то можно делать вывод о том, что отрывки «а» и «б» принадлежат одному автору.
Технический результат достигается тем, что устройство для содержательного анализа текстовой информации содержит первую и вторую группы входных регистров, состоящие из n элементов, с первого по четвертый входные регистры, первую и вторую группы блоков деления, состоящие из n элементов, группу блоков вычитания по модулю, состоящую из n элементов, накопительный сумматор, блок деления, блок сравнения, блок индикации, генератор тактовых импульсов и распределитель импульсов (РИ), тактовый вход которого соединен с выходом генератора тактовых импульсов, первый выход РИ - с входами записи первой и второй групп входных регистров, а также с входами записи первого, второго, третьего и четвертого входных регистров, второй выход - с входами считывания первой и второй групп входных регистров, а также первого и второго входных регистров, третий и четвертый выходы - с входами считывания соответственно третьего и четвертого входных регистров, информационные входы с первого по n-й элементов первой группы входных регистров являются входом задания исходной информации, на которые поступают значения mаi, характеризующие количество i-й буквы в отрывке «а», информационные входы с первого по n-й элементов второй группы входных регистров являются входом задания исходной информации, на которые поступают значения mбj, характеризующие количество j-й буквы в отрывке «б», информационные входы с первого по четвертый входных регистров являются входами задания исходной информации, на которые поступают соответственно значение Νа, характеризующее общее количество букв отрывка «а», значение Νб, характеризующее общее количество букв в отрывке «б», значение n, характеризующее количество букв в алфавите, значение ΔPд, характеризующее величину допустимого значения средней разности между вероятностью появления i-й буквы отрывка «а» и вероятностью появления j-й буквы в отрывке «б», выходы, с первого по n-й, элементов первой и второй групп входных регистров соединены с входами делимого каждого соответствующего элемента соответственно первой и второй групп блоков деления, входы делителя которых подключены к выходам соответственно первого и второго входных регистров, а выходы - соответственно к выходам уменьшаемого и к входам вычитаемого группы блоков вычитания по модулю, выходы которых соединены с входами, с первого по n-й, накопительного сумматора, выход которого подключен к входу делимого блока деления, вход делителя которого соединен с выходом третьего входного регистра, а выход - с информационным входом блока сравнения, пороговый вход которого подключен к выходу четвертого входного регистра, а выход - к входу блока индикации.
На фиг. 1 представлена функциональная схема устройства для содержательного анализа текстовой информации (для ликвидации громоздкости связи между РИ и управляющими входами соответствующих блоков показаны не полностью, а обозначены путем нумерации входов и выходов); на фиг. 2 изображена циклограмма работы заявленного устройства (на оси ординат обозначены номера входов РИ, а по оси абсцисс - число тактов), причем длительность различных вычислительных операций (сложение и вычитание - один такт, деление - двенадцать тактов) в верхней части фиг. 2.
Устройство для содержательного анализа текстовой информации (фиг. 1) содержит первую 1 и вторую 2 группы входных регистров, каждая из которых состоит из n элементов, первый 3, второй 4, третий 5 и четвертый 6 входные регистры, первую 7 и вторую 8 группы блоков деления, каждая из которых состоит из n элементов, группу 9 блоков вычитания по модулю, состоящую из n элементов, накопительный сумматор 10, блок 11 деления, блок 12 сравнения, блок 13 индикации, генератор 14 тактовых импульсов и распределитель 15 импульсов.
Устройство для содержательного анализа текстовой информации работает следующим образом. На информационные входы с первого по n-й элементов первой группы 1 входных регистров (фиг. 1) засылаются соответственно величины mа1, …mаi, …mаn, а на информационные входы с первого по n-й элементов второй группы 2 входных регистров подаются соответственно значения mб1, …mбi, …mбn.
На информационные входы первого 3, второго 4, третьего 5 и четвертого 6 входных регистров направляются соответственно величины Nа, Nб, n и ΔPд. При этом управляющий сигнал на входы записи всех элементов этих групп входных регистров и входных регистров подается с первого выхода РИ 15, темп работы которого задается генератором 14 тактовых импульсов.
По сигналу со второго выхода РИ 15 на входы считывания первой 1 и второй 2 групп входных регистров величины mаi и mбj с их выходов засылаются на входы делимого соответственно первой 7 и второй 8 групп блоков деления. На входы делителя этих групп направляются по сигналу со второго выхода РИ 15 с выходов соответственно первого 3 и второго 4 входных регистров значения Nа и Nб. С выходов первой 7 и второй 8 групп блоков деления величины Pаi, и Pбj, определяемые по формулам (2) и (3), поступают соответственно на входы уменьшаемого и входы вычитаемого группы 9 блоков вычитания по модулю. С выходов этой группы величины |Pаi-Pбj|k засылаются на входы накопительного сумматора 10, с выхода которого значение 
Если ΔPср≤ΔPд (отрывки «а» и «б» принадлежат одному автору) на выходе блока 12 сравнения появится сигнал, который приведет к загоранию блока 13 индукции. В противном случае, когда ΔPср>ΔPд сигнала на выходе блока 12 сравнения не будет и блок 13 индукции не засветится, это будет свидетельствовать о том, что отрывки «а» и «б» принадлежат разным авторам. Порядок функционирования блоков устройства представлен на циклограмме его работы (фиг. 2).
Таким образом, технический результат достигается не за счет математического аппарата, а за счет технических средств (блоков и элементов), упомянутых в процессе описания работы устройства, осуществляющего повышение уровня достоверности определения авторства текстовой информации и расширение арсенала технических средств.
Промышленная применимость изобретения обосновывается тем, что оно может быть использовано в разных областях (отраслях) при расчетах, связанных с идентификацией текстовой информации в случаях определения ее автора с целью принятия объективных решений при защите авторских прав создателей текстовой информации.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ ПРЕДПОЧТИТЕЛЬНОГО УРОВНЯ УНИФИКАЦИИ ТЕХНИЧЕСКИХ СИСТЕМ | 2013 |
|
RU2519049C1 |
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ ЭКОНОМИЧЕСКОЙ ЭФФЕКТИВНОСТИ ПРОЦЕССА УПРАВЛЕНИЯ СЛОЖНЫМИ СИСТЕМАМИ | 2014 |
|
RU2541859C1 |
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ ЭФФЕКТИВНОСТИ | 2006 |
|
RU2306598C1 |
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ ФУНКЦИИ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН И ЕЕ ТОЛЕРАНТНЫХ ГРАНИЦ ПО МАЛЫМ ВЫБОРКАМ | 2014 |
|
RU2553120C1 |
| УСТРОЙСТВО ДЛЯ ТЕХНИКО-ЭКОНОМИЧЕСКОЙ ОЦЕНКИ ВЫПОЛНЕНИЯ НАУЧНО-ИССЛЕДОВАТЕЛЬСКИХ И ОПЫТНО-КОНСТРУКТОРСКИХ РАБОТ | 2011 |
|
RU2470365C1 |
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ КАЧЕСТВА ОБУЧЕНИЯ РАБОТЕ С КОМПЬЮТЕРОМ | 2007 |
|
RU2330323C1 |
| УСТРОЙСТВО ДЛЯ КОЛИЧЕСТВЕННОЙ ОЦЕНКИ КАЧЕСТВЕННОГО ПОКАЗАТЕЛЯ | 2011 |
|
RU2448364C1 |
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ ВЫПОЛНЕНИЯ НАУЧНО-ИССЛЕДОВАТЕЛЬСКИХ И ОПЫТНО-КОНСТРУКТОРСКИХ РАБОТ | 2009 |
|
RU2410750C1 |
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ И СРАВНЕНИЯ ЭФФЕКТИВНОСТИ ФУНКЦИОНИРОВАНИЯ ОДНОТИПНЫХ ОРГАНИЗАЦИЙ | 2008 |
|
RU2363042C1 |
| УСТРОЙСТВО ДЛЯ ОЦЕНКИ ПРЕДПОЧТИТЕЛЬНОГО УРОВНЯ УНИФИКАЦИИ ТЕХНИЧЕСКИХ СИСТЕМ | 2010 |
|
RU2427900C1 |

Изобретение относится к вычислительной технике, а именно к идентификации текстовой информации в случаях определения ее автора. Технический результат - повышение уровня достоверности определения авторства текстовой информации. Устройство содержит группы входных регистров, входные регистры группы блоков деления, группу блоков вычитания по модулю, накопительный сумматор, блок деления, блок сравнения, блок индикации, генератор тактовых импульсов и распределитель импульсов. 2 ил., 1 табл.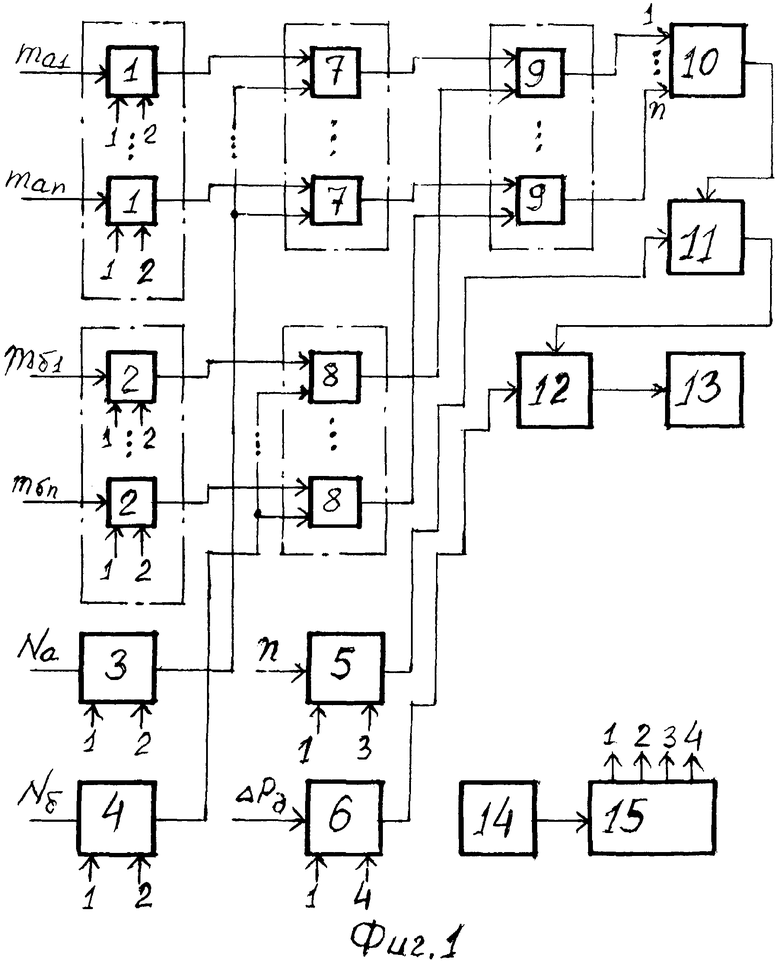
Устройство для содержательного анализа текстовой информации, содержащее первую и вторую группы входных регистров, состоящие из n элементов, с первого по четвертый входные регистры, первую и вторую группы блоков деления, состоящие из n элементов, группу блоков вычитания по модулю, состоящую из n элементов, накопительный сумматор, блок деления, блок сравнения, блок индикации, генератор тактовых импульсов и распределитель импульсов (РИ), тактовый вход которого соединен с выходом генератора тактовых импульсов, первый выход РИ - с входами записи первой и второй групп входных регистров, а также с входами записи первого, второго, третьего и четвертого входных регистров, второй выход - с входами считывания первой и второй групп входных регистров, а также первого и второго входных регистров, третий и четвертый выходы - с входами считывания соответственно третьего и четвертого входных регистров, информационные входы с первого по n-й элементов первой группы входных регистров являются входом задания исходной информации, на которые поступают значения mаi, характеризующие количество i-й буквы в отрывке «а», информационные входы с первого по n-й элементов второй группы входных регистров являются входом задания исходной информации, на которые поступают значения mбj, характеризующие количество j-й буквы в отрывке «б», информационные входы с первого по четвертый входных регистров являются входами задания исходной информации, на которые поступают соответственно значение Νа, характеризующее общее количество букв отрывка «а», значение Νб, характеризующее общее количество букв в отрывке «б», значение n, характеризующее количество букв в алфавите, значение ΔP∂, характеризующее величину допустимого значения средней разности между вероятностью появления i-й буквы отрывка «а» и вероятностью появления j-й буквы в отрывке «б», выходы, с первого по n-й, элементов первой и второй групп входных регистров соединены с входами делимого каждого соответствующего элемента соответственно первой и второй групп блоков деления, входы делителя которых подключены к выходам соответственно первого и второго входных регистров, а выходы - соответственно к выходам уменьшаемого и к входам вычитаемого группы блоков вычитания по модулю, выходы которых соединены с входами, с первого по n-й, накопительного сумматора, выход которого подключен к входу делимого блока деления, вход делителя которого соединен с выходом третьего входного регистра, а выход - с информационным входом блока сравнения, пороговый вход которого подключен к выходу четвертого входного регистра, а выход - к входу блока индикации.
| Аппарат для замера уровней жидкостей в скважинах | 1941 |
|
SU62263A1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ПРОИЗВЕДЕНИЙ ЖИВОПИСИ НА ПРЕДМЕТ ИХ АВТОРСТВА | 2007 |
|
RU2333613C1 |
| Мяльно-трепальный станок для обработки тресты лубовых растений | 1922 |
|
SU200A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |

